Спосіб розподілу програми користувача для комп’ютерної системи
Номер патенту: 103535
Опубліковано: 25.10.2013
Автори: Яковлєв Юрій Сергійович, Єлісєєва Олена Володимирівна, Сергієнко Іван Васильович, Палагін Олександр Васильович, Боюн Віталій Петрович












Формула / Реферат
1. Спосіб розподілу програми користувача для комп'ютерної системи, який включає перетворення початкових кодів програми в проміжні коди, розділення проміжних кодів на множину кодів задач, генерацію інформації про відносини серед множини задач на основі даних в задачах і перетворення кожної задачі в об'єктну програму, яку передають до множини процесорів комп'ютерної системи, який відрізняється тим, що спочатку за допомогою хост-машини формують багаторівневу модель розподілу кодів програми користувача, потім формують блок послідовності дій, який використовують для кожного і-го поточного рівня розподілу, в межах цього блока визначають можливість розділення програми користувача на незалежні за даними задачі або частини задач, потім для і-го рівня розподілу формують вхідний керуючий пакет розподілу, аналізують та структурують інформацію про параметри комп'ютерної системи та про параметри програми користувача та її частин, на основі цієї інформації формують базу поточних значень, які запам'ятовують в електронній пам'яті, потім формують послідовність сигналів кодів мікропрограм для розподілу на поточному рівні, виконують розділення кодів програми користувача або її задач на незалежні за даними коди частин і розподіляють їх між процесорами комп'ютерної системи стосовно сформованої моделі розподілу для і-го поточного рівня, використовуючи критерій відповідності системи команд цих процесорів наборам операцій програми користувача вибраного рівня розподілу, далі після визначення тривалості обробки машинних команд кожної із задач перевіряють баланс завантаження процесорів комп'ютерної системи кодами програми користувача, які присутні в моделі розподілу поточного і-го рівня, і за наявності балансу генерують для поточного рівня коди вихідного пакету, інакше коректують розподіл шляхом укрупнення або подрібнення отриманих задач програми користувача або їх частин, далі на кінцевому рівні розподілу кожну частину програми, яка призначена на попередньому рівні, розділяють на програмні модулі, які розподіляють між всіма процесорами, що входять в набір моделі розподілу кінцевого рівня, при цьому виконують послідовність дій стосовно блока послідовності дій за виключенням того, що використовують модель розподілу, а також формують послідовність кодів мікропрограм, коди полів керуючого вхідного та вихідного пакетів для кінцевого рівня розподілу, при цьому як критерій розділення кодів програмних частин на коди модулів програми використовують час виконання модулів на кожному процесорі, які присутні в моделі розподілу цього рівня, і зв'язки за даними, далі за результатами розподілу на всіх рівнях, за даними кодів вихідних пакетів формують групи кодів задач програми користувача, які не мають зв'язків між собою за даними, при цьому послідовність виконання кодів груп визначають на підставі зв'язків між задачами в різних групах згідно з порядком зв'язків даних програми користувача, аналізують всі отримані задачі, щоб визначити наявність таких груп, після цього перетворюють ці програмні групи в об'єктні програми, які передають до відповідних процесорів комп'ютерної системи, а також до хост-машини, формують та передають до комп'ютерної системи та хост-машини коди вихідних керуючих пакетів, аналогічних вихідним пакетам для і-го рівня розподілу, з відповідними індексами і ознаками та їх значеннями для груп, що визначає розділені по процесорах вихідні команди, дані та керуючу інформацію, які необхідні для паралельного виконання кодів програми користувача на комп'ютерній системі та на хост-машині.
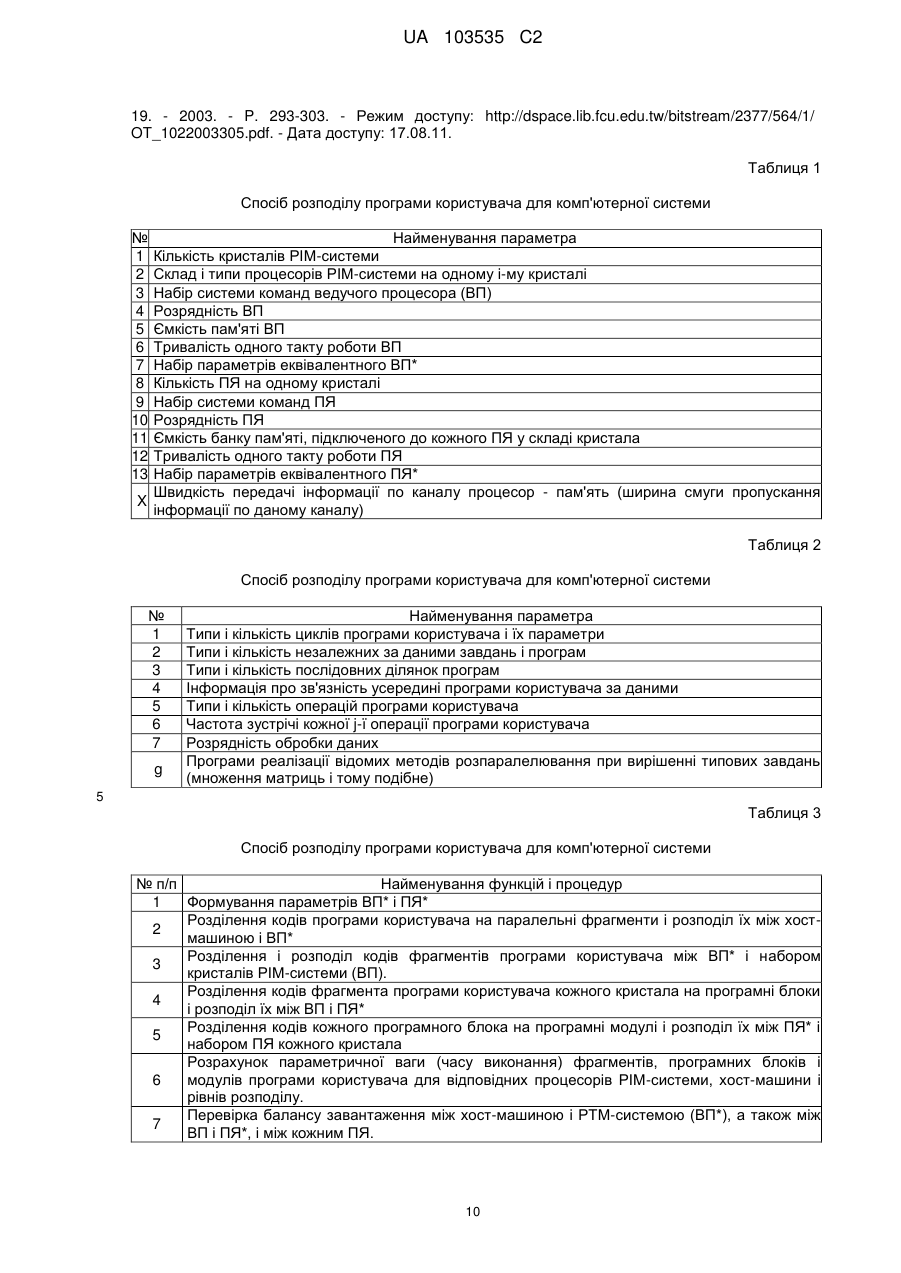
2. Спосіб за п. 1, який відрізняється тим, що у вхідний керуючій пакет, який формують до кожного рівня розподілу, включають коди полів, що містять код і-го рівня розподілу програми користувача; а також стосовно рівня розподілу - код ідентифікатора параметрів програми користувача або її задачі, частини, модуля; код ідентифікатора параметрів комп'ютерної системи; код ідентифікатора адреси програми користувача або її задачі, частини, модуля; код запуску системи на обробку програми користувача або її задачі, частини, модуля; код інсталяції або деінсталяції програми користувача або її задачі, частини, модуля; код ознаки ініціалізації програми користувача або її задачі, частини, модуля; код ідентифікатора наявності посилань, який включає: код ідентифікатора таблиці посилань; код ознаки наявності посилань на стандартні методи розпаралелювання; код ознаки наявності посилань на інші програмні блоки; код ідентифікатора джерела посилань програми користувача або її задачі, частини, модуля; код ідентифікатора приймача посилань програми користувача або її задачі, частини, модуля; код повідомлення про зміну посилань в таблиці посилань; код ідентифікатора початкового посилання на обробку.
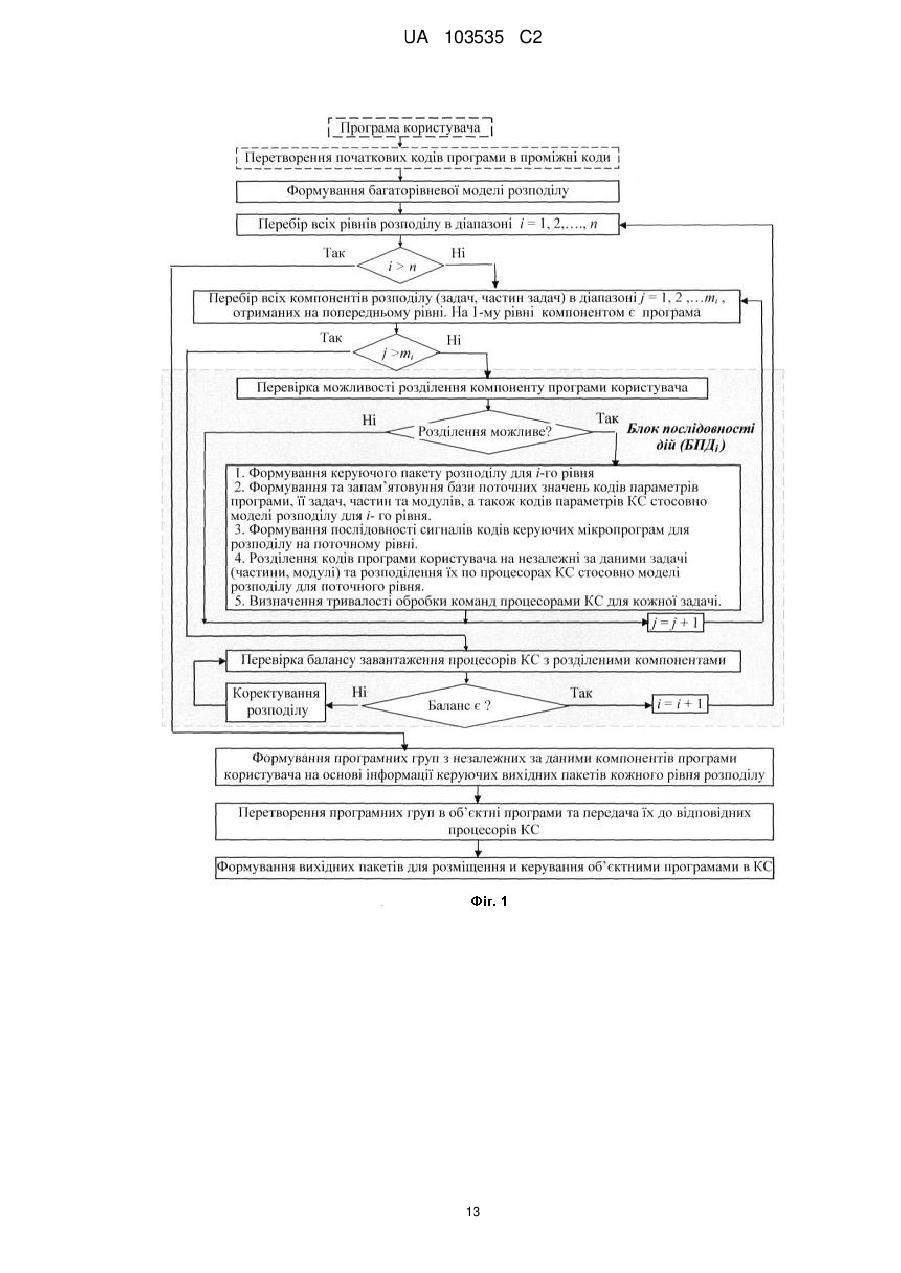
3. Спосіб за п. 1, який відрізняється тим, що у вихідні пакети, які формують після кожного рівня розподілу на і-ому рівні програми користувача, включають коди полів, що містять код рівня розподілу програми користувача; а також стосовно рівня розподілу - код ідентифікатора адресів задач програми користувача або їх частин та модулів після розділення; код ідентифікатора апаратних блоків, до яких направлено задачі програми користувача або їх частини та модулі; код інсталяції або деінсталяції задач програми користувача або їх частин та модулів; код типу обробки розподіленої програми користувача; код ідентифікатора адресів груп з паралельними задачами або частинами, або модулями програми користувача; код ідентифікатора посилань між групами програми користувача; код ідентифікатора адресів груп джерел посилань; код ідентифікатора адресів груп, які приймають посилання; код ознаки повідомлення від комп'ютерної системи про виконання групи; код ознаки повідомлення про зміну зв'язків між групами; код ознаки відповіді комп'ютерної системи про виконання обробки; код ідентифікатора адреси наступного вихідного пакету; вільне поле.
Текст
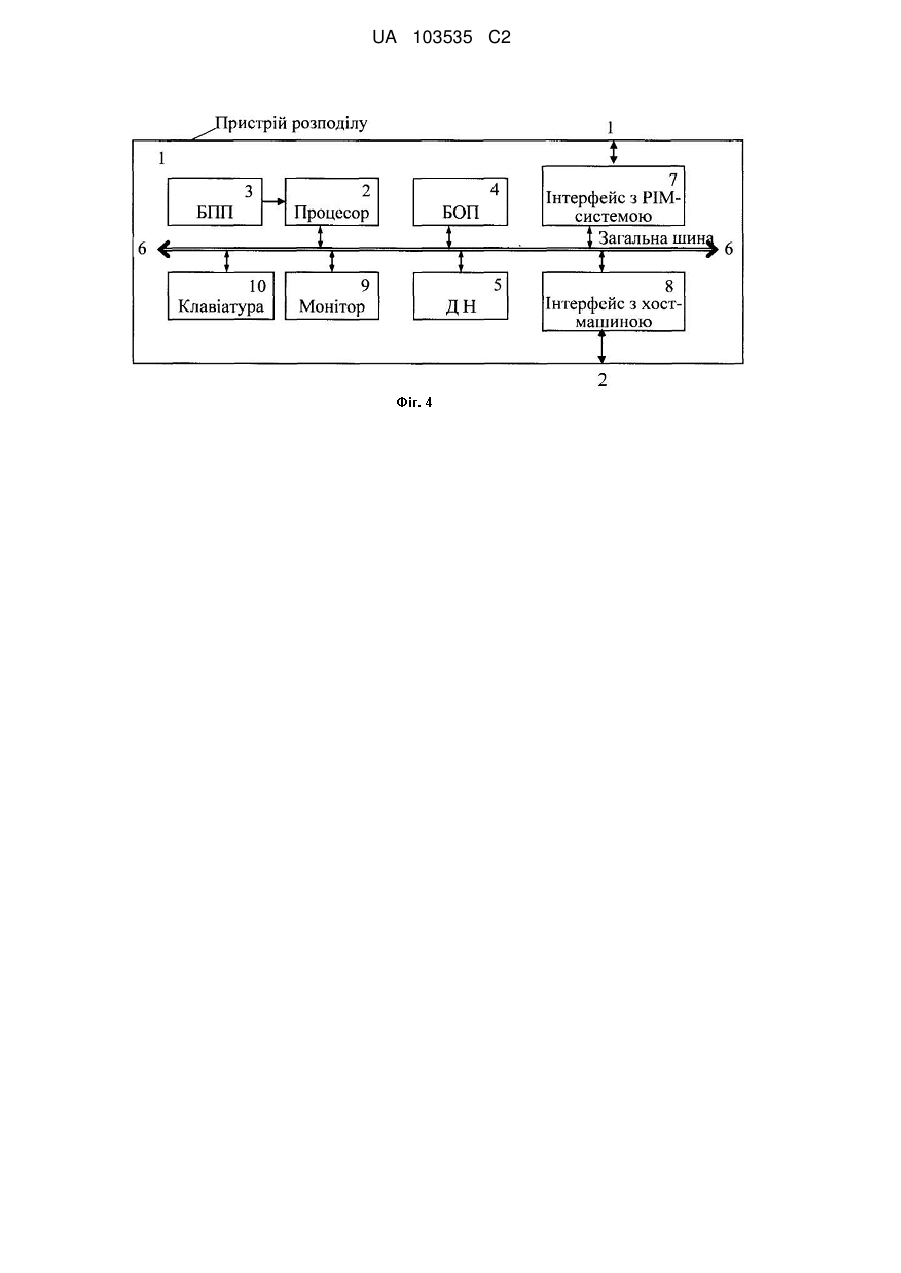
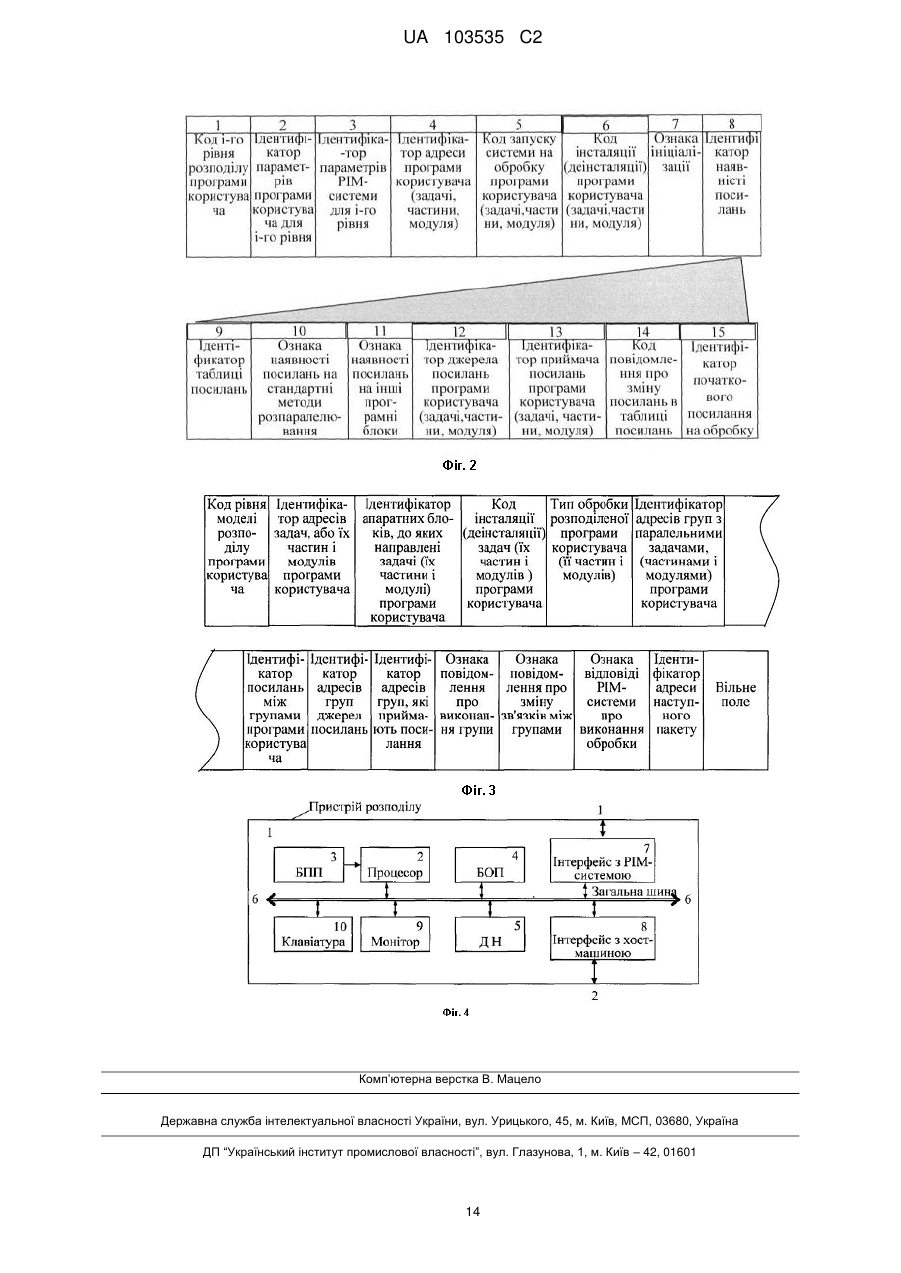
Реферат: Винахід належить до області обчислювальної техніки, зокрема, до розподілених гетерогенних комп'ютерних систем, зокрема, систем типу "Процесор - в - пам'яті ("Processor-in-memory" або до РІМ-систем). В способі за допомогою обчислювальної техніки формують багаторівневу модель процесу розподілу, відповідну початкову інформацію та відповідні керуючи пакети. Для реалізації розподілу на кожному рівні використовують послідовність кодів мікропрограм, що забезпечує використання способу розподілу до різних апаратно-програмних платформ. В основу винаходу поставлено задачу удосконалення способу розподілу програми користувача для паралельного виконання з метою спрощення процесу розподілу, зменшення його загального часу, підвищення функціональних можливостей та якості розпаралелювання програми користувача для виконання на комп'ютерній системі. UA 103535 C2 (12) UA 103535 C2 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 Винахід належить до області обчислювальної техніки, зокрема - до розподілених гетерогенних комп'ютерних систем з різноманітними процесорами, наприклад, кластерних систем з прискорювачами обчислень, систем типу "Процесор - в - пам'яті ("Processor-in-memory" або РІМ-систем) та ін. Особливості архітектурно-структурної організації РІМ-систем забезпечують в порівнянні з КС з класичною архітектурою при однакових рівнях технології створення елементної бази істотно менший час реалізації одних і тих самих програм користувача (на порядок і більш) при менших значеннях параметрів споживаної потужності, габаритів і ваги [1]. Реалізація програми користувача РІМ-систем особливо ефективна при вирішенні складних задач, які можуть бути розпаралелені на різних рівнях ієрархічної структури засобів обробки і зберігання інформації при масовому зверненні до пам'яті. Це задачі обробки зображень, управління літальними апаратами і космічними об'єктами, завдання обробки радарних сигналів і ін. Тому далі розглядатимемо запропонований спосіб розподілу програми користувача стосовно РІМ-систем, беручи до уваги, що запропонований спосіб може бути використаний для гетерогенних розподілених систем іншого типу, оскільки РІМ-система, що розглядається тут, містить множину РІМ-пристроїв, кожен з яких виконано на одному кристалі (чипі), на якому ведучий процесор (ВП) можна приймати за вузловий процесор одного вузла кластера, а процесорні ядра (ПЯ), які підключені до ВП і розміщені на тому ж кристалі, можна приймати за процесорні елементи цього кластера [1]. Множина таких РІМ-пристроїв (чипів) утворює розподілену кластерну систему, сполучену міжчиповою комутаційною схемою. Така кластерна система, виходячи з принципів побудови РІМ-систем, є гетерогенною, оскільки ВП за своїми параметрами і системою команд істотно відрізняється від ПЯ, які орієнтовано на виконання простих, але масових операцій при масовому зверненні до пам'яті. РІМ - пристрої, які сполучено за допомогою комутаційної схеми, підключені до хост-машини (перший рівень ієрархії), а кристал (чип) кожного РІМ - пристрою, на якому розміщено ведучий процесор разом з пам'яттю утворюють другий рівень ієрархії. Множина ПЯ, до кожного з яких підключено банк пам'яті (БП), утворює третій рівень ієрархії. Взаємодію компонентів в таких системах виконують за принципами передачі повідомлення, основною структурною одиницею якого є керуючий пакет. Процес розпаралелювання кодів складних програм користувача для таких систем є вельми трудомістким. Його, як правило, виконують на супер-ЕОМ, витрачаючи при цьому час і ресурси, які можуть суттєво перевищувати час і ресурси, необхідні безпосередньо для реалізації програми користувача. Це, в основному, відбувається через те, що відомі способи розподілу програм користувача по процесорах складних комп'ютерних систем, і в першу чергу РІМ-систем, не враховують особливості їх архітектурно-структурної організації, наприклад, гетерогенність, і тим самим не використовують повною мірою можливості систем такого класу. Тому створення нового способу розподілу програм користувача для гетерогенних розподілених систем, який в максимальному ступеню враховує особливості їх архітектурно - структурної організації і тим самим дозволяє істотно зменшити час розподілу програм користувача та істотно поліпшити технічні характеристики системи, є актуальним завданням. Відомі система і спосіб для розподілу програм серед взаємодіючих процесорів (див. пат. США "System and method for the distribution of a program among cooperating processors" № 7765536, 27.07.2010). Винахід присвячений розподілу програм користувача серед процесорів, який засновано на застосуванні спеціальної програми розподілу Veil, що включає множину стратегій розподілу. Ця програма для кожної стратегії аналізує початковий текст програми, цикли початкового тексту, розміри даних і типи, щоб підготувати ряд дистрибутивних спроб, за допомогою чого виконують розподіл програм користувача згідно кожної стратегії та оцінку результатів, щоб визначити кращу стратегію і з її допомогою виконати оптимальний розподіл програм користувача по процесорах. Недоліками такого способу є: - Висока трудомісткість і великий час реалізації розпаралелювання цільової програми (програми користувача), оскільки вибір робочої (кращої) стратегії паралелізму виконується тільки після виконання всіх наявних стратегій розпаралелювання програми користувача і оцінки їх тимчасових параметрів за наслідками виконання, зокрема - часу обчислювального процесу і часу розриву між надходженням програм (або частини програми) і відповідних даних. - Необхідність використання для кожного процесора великої ємкості пам'яті унаслідок копіювання програми користувача (або її частин) в пам'ять кожного з n процесорів, а також розміщення в пам'яті кожного процесора відповідного підпотоку даних, отриманого в результаті демультиплексування всього потоку даних. Відомий також спосіб розподілу програми користувача для РІМ-системи, який описано в [2]. Спосіб засновано на застосуванні двох'ярусної моделі РІМ-системи (хост-машина ↔ ведучий процесор) і програмної системи SAGE (Statement-Analysis-Grouping-Evaluation), яка містить 1 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 набір послідовно виконуваних програм, за допомогою якого виконують аналіз програми користувача, операторне розбиття програми користувача, конструювання вагового графа WPG (Weight Partition Dependence Graph), оцінку часу виконання фрагментів програм для кожного комп'ютера, генерування фронту реалізації паралельних фрагментів програми користувача (груп), визначення плану виконання програми користувача і генерування відповідних завдань (підпрограм або пакетів) ведучим процесорам і хост-машині. До недоліків способу відносяться: Даний спосіб є обмеженим за функціональними можливостями, оскільки розглядає обмежену модель і відповідно процес розподілу програми користувача тільки між хост-машиною і одного ВП. Не дивлячись на обмежену модель, процес розподілу програми користувача для РІМ-системи згідно способу є дуже трудомістким і займає велику кількість часу, оскільки включає більше 20 послідовно виконуваних великих програмних блоків, кожен з яких включає велику кількість переборів і підпрограм з великою кількістю операцій. Як основну одиницю аналізу початкової програми користувача використовують оператори в циклі (застосовано операторний метод розбиття), Через складність операторного методу розглядають тільки оператори усередині циклів, і виявляють залежності по даним тільки для деяких конструкцій програми користувача (для ідеально вкладених циклів), при цьому інші конструкції не розглядають, що також указує на обмежені функціональні можливості способу. Крім того, такий спосіб розподілу не може бути використано для виконання розподілу програм користувача, які розроблено для реалізації з використанням інших апаратнопрограмних платформ. Відомі також інші способи розподілу програм користувача (див. патент США "System for managing distribution of programs". № 7437723, 14.10.2008). Технічні рішення, які запропоновані в патенті, за своїм призначенням повинні полегшувати управління розподілом програм за наявності залежності посилань між програмами на різних комп'ютерах, а також управління для розподілу і видалення програми користувача. Систему розподілу виконано у вигляді комплексу програм, які розміщені на двох комп'ютерах, зв'язаних між собою мережевими засобами, між якими в процесі розподілу виконуються численні пересилки складних структур даних (пакетів) з метою їх аналізу і обробки. Це істотно ускладнює і збільшує трудомісткість процесу розподілу програм користувача. Крім того, втручання менеджера (оператора, користувача) в процес розподілу програми користувача на найбільш важливих ділянках алгоритму його реалізації, також збільшує кількість ітерацій і час реалізації алгоритму розподілу для досягнення поставлених цілей, оскільки рішення можуть ухвалюватися не достатньо обґрунтовано. Так менеджер перевіряє залежні програми користувача і апаратуру, на яких розміщені ці програми, визначає пакет передачі програми користувача як предмет обробки і блок завдання як адресат видачі, визначає зміст обробки і передачу пакету програми користувача, вибирає посилання адресів, які повинні бути збережені, а також комбінацію ідентифікатора програми користувача і ідентифікатора блока для програми користувача, які будуть видалені і визначає умови видалення програми користувача ("стерти", "не стирати", "змінити"), на які система реагує відповідним чином. Найбільш близьким до пропонованого способу по технічній суті і вирішуваному завданню є спосіб розподілу програми користувача (див. патент США "Program parallelizing apparatus capable of optimizing processing time". № 5452461 (A), 19.09.1995), який включає послідовність наступних кроків: перетворення початкової програми в проміжні коди; ділення проміжних кодів на множину задач; генерація інформації про відносини, що показують послідовні відносини для задач серед множини задач на основі даних операндів в задачах; розповсюдження множини задач до множини рівнів, отриманих діленням повної тривалості обробки часовими точками синхронізації, що вказують часовий послідовний порядок; призначення задач, які розподілені на кожному з рівнів, на процесори в багатопроцесорній системі; визначення тривалості обробки машинних команд, складових кожної з задач; перетворення задач в об'єктні програми, які будуть оброблені множиною процесорів. При цьому за допомогою програмних засобів розпаралелювання програм згідно винаходу можливо генерувати з високою швидкістю початкову програму в об'єктну програму, здатну оброблятися паралельно множиною процесорів, складових багатопроцесорної системи, яка включає механізм комунікації для міжпроцесорної комунікації і механізм синхронізації, щоб обробка виконувалася паралельно серед процесорів через координацію в багатопроцесорній системі, і призначення об'єктних програм на процесори. Запропоновані засоби планування задачі наділені функцією генерувати інформацію зв'язків задачі для скріплення в одну задачу тих задач, які можуть зменшити після їх об'єднання кількість часу координації або очікування обробки, яка повинна бути виконана засобами 2 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 синхронізації і, отже, часу, потрібного для того, щоб виконати паралельну обробку в багатопроцесорній системі. До недоліків способу-прототипу відносяться: Початкове планування задач для паралельної обробки вимагає розрахунку часу реалізації кожної задачі, а для кожної ітерації низхідному і висхідному переміщенням по рівнях задач при їх величезній кількості визначається загальний час реалізації всього алгоритму. Це призводить до великих витрат обчислювальних ресурсів і ресурсів пам'яті тим паче, що при цьому повинні формуватися і розміщуватися в пам'яті множина таблиць, наприклад, реєстраційна таблиця завдань, таблиця міжзадачних послідовних відносин і ін. Крім того, при переміщенні задач виникає складна проблема синхронізації процесорів як усередині кожної групи процесорів, так і між такими групами, що також ускладнює управління всім процесом розпаралелювання. Апарат розподілення стосовно третьої реалізації винаходу має велику кількість компіляторів різного типу: керований компілятор проблемно-орієнтованої мови, паралельний компілятор, два компілятори операційно-орієнтованої мови, язиковий компілятор, векторний компілятор, компілятор з розподіленими функціями. Тим самим спосіб і алгоритм розпаралелювання є проблемно-орієнтованими, і для розпаралелювання конкретних початкових програм потрібна розробка і використання конкретного типу компілятора, що збільшує вартість розробки і скорочує область застосування пропонованих методів розпаралелювання. Спосіб розподілення програми користувача стосовно четвертої реалізації винаходу орієнтовано на використання спільно з розподіленою комп'ютерною системою, яка відрізняється від класичного варіанту архітектурно-структурної організації наявністю розширеного каналу зв'язку з процесорами разом зі схемами управління шинами і для кожного процесору наявністю механізму паралельної обробки, Тим самим можна зробити висновок, що для інших комп'ютерних систем, зокрема для кластерних або РІМ-систем цей метод є мало ефективним. В основу винаходу, який пропонується, покладено технічну задачу створення способу розподілу кодів програми користувача для паралельного виконання на розподіленій гетерогенній комп'ютерній системі, у тому числі - РІМ-системі, який дозволить зменшити загальний час розпаралелювання за рахунок використання запропонованої багаторівневої моделі розподілу, цілеспрямованого початкового розподілу кодів програми користувача з використанням критеріїв відповідності системи команд процесорів комп'ютерної системи (РІМсистеми) наборам операцій програми користувача на кожному рівні розподілу, що істотно скорочує кількість ітерацій розподілу, а також за рахунок перевірки і при необхідності коректування на кожному рівні результатів розподілу. При цьому знижується трудомісткість, вартість розробки і використання програми розподілу в цілому за рахунок використання на всіх рівнях однотипних програм розділення програми користувача на складові її компоненти (коди задач, програмних частин, програмних модулів) і розподілу їх по процесорах КС (РІМ-системи). При цьому розширюється область запропонованого способу розподілу кодів програми користувача на різні апаратно-програмні платформи за рахунок використання мікропрограмного принципу формування процесу розподілу для кожного рівня. Впровадження запропонованого способу розподілу кодів програми користувача забезпечує також додатково позитивний ефект в частині підвищення продуктивності КС за рахунок розпаралелювання на всіх рівнях обробки інформації, перевірки і, при необхідності, коректування на кожному рівні розподілу рівномірності завантаження всіх процесорів корисною (обчислювальною) роботою. Позитивний ефект запропонованого способу розподілу програми користувач досягається тим, що у способі максимально враховують наступні особливості архітектурно-структурної організації цього класу машин: По-перше: багаторівневий спосіб розподілу кодів програми користувача відповідає багаторівневої організації засобів обробки і зберігання інформації в РІМ-системі: процесор хостмашини ↔ ВП ↔ ПЯ; пам'ять хост-машини ↔ пам'ять ВП ↔ пам'ять ПЯ. По-друге: приймається до уваги гетерогенність системи, на який має бути виконано програму користувача, для цього при розподілі програми використовують нові критерії розподілу - відповідність на кожному рівні систем команд процесорів РІМ-системи наборам операцій програми (стосовно рівня - задачі, модуля) користувача. По-третє: приймається до уваги однотипність РІМ-пристроїв (чипів), які складають РІМсистему, та однотипність множини ПЯ в межах кожного чипу. Це дозволяє спростити моделі розподілу на кожному рівні таким чином: РІМ-система містить однакові РІМ-пристрої, кожен з яких виконано на одному кристалі (чипі) і сполучено з іншими чипами за допомогою міжчипової комутаційної схеми. Проте, разом з хостмашиною сукупність таких РІМ-пристроїв, складових РІМ-системи, утворює гетерогенну 3 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 систему, оскільки функціональні можливості і системи команд хост-машини і РІМ-системи істотно відрізняються. Тому формують модель першого рівня розподілу програми користувача у вигляді: процесор хост-машини ↔ еквівалентний ведучий процесор (ВП екв ). При цьому як систему команд ВПекв приймають систему команд одного РІМ-пристрою (бо всі вони однакові), ємкість пам'яті приймають рівній сумі ємкостей всіх РІМ-пристроїв, а за тривалість такту роботи ВПекв приймають тривалість такту одного ВП, поділену на кількість ВП у складі РІМ-системи, враховуючи можливість їх одночасної роботи. При цьому як критерій розділення кодів програми користувача на коди задач використовують критерій відповідності системи команд хост-машини та ВПекв наборам операцій відповідних задач для кожного РІМ-пристрою. Кожен РІМ-пристрій, виконаний на одному кристалі (чипі), є гетерогенним, оскільки містить ВП разом з пам'яттю і множину ПЯ, кожен з яких підключений до свого банку пам'яті і сполучений з ВП. При цьому, згідно принципам організації РІМ-пристрою, як ВП використовують процесор з розширеними в порівнянні з ПЯ функціональними можливостями і розширеною системою команд, яку орієнтовано на виконання складних операцій. Як ПЯ використовують спрощений процесор зі скороченою системою команд, яку орієнтовано на виконання простих, але масових операцій типу додавання, віднімання, зсуву і ін. при масовому зверненні до пам'яті за операндами. Тому формують модель другого рівня розподілу програми користувача у вигляді: ВП ↔ еквівалентне процесорне ядро (ПЯ екв). При цьому за систему команд ПЯекв приймають систему команд одного ПЯ (оскільки всі ПЯ на кристалі - однакові), ємкість пам'яті приймають рівній сумі ємкостей всіх банків пам'яті одного чипу, а за тривалість такту роботи ПЯекв приймають тривалість такту одного ПЯ, поділену на кількість ПЯ у складі РІМ-пристрою (чипу), враховуючи можливість їх одночасноїроботи усередині одного кристалу. При цьому враховуються обмеження на скорочений набір команд ПЯ і ємкість кожного банку пам'яті, підключеного до ПЯ на цьому ж кристалі. Таке положення пояснюється тенденцією розмістити на одному кристалі з ВП і з пам'яттю максимально можливу кількість ПЯ для найбільшого розпаралелювання програмних частин програми користувача. Модель розподілу програми користувача на третьому (кінцевому) рівні стосовно РІМсистеми формують у вигляді: ПЯекв ↔ множина ПЯ зі своїми власними параметрами. При розподілі програми користувача стосовно запропонованого способу спочатку формують багаторівневу модель розподілу кодів програми користувача, потім формують блок послідовності дій (БПДі), якій використовують для кожного і-го поточного рівня розподілу, в межах цього блока визначають можливість розділення програми користувача на незалежні за даними задачі (фіг. 1). Потім для і-го рівня розподілу формують вхідний керуючий пакет розподілу (фіг. 2), аналізують та структурують інформацію про параметри комп'ютерної системи (таблиця 1), та про параметри програми користувача та її частин (таблиця 2), на основі цієї інформації формують бази поточних значень, які запам'ятовують в електронній пам'яті, потім формують послідовність сигналів кодів мікропрограм для розподілу на поточному рівні, виконують розділення кодів програми користувача або її задач на незалежні за даними коди частин і розподіляють їх між процесорами КС стосовно сформованої моделі розподілу для і-го поточного рівня, використовуючи критерій відповідності системи команд цих процесорів наборам операцій програми користувача вибраного рівня розподілу. Далі після визначення тривалості обробки машинних команд кожної із задач перевіряють баланс завантаження процесорів КС кодами програми користувача, які присутні в моделі розподілу поточного і-го рівня, і за наявності балансу генерують для поточного рівня коди керуючого вихідного пакету, який запам'ятовують в електронній пам'яті. При відсутності балансу коректують розподіл шляхом укрупнення або подрібнення отриманих задач або їх частин. Далі на кінцевому рівні розподілу кожну частину програми, яку призначено на попередньому рівні, розділяють на програмні модулі, які розподіляють поміж усіма процесорами, що входять в набір моделі розподілу кінцевого рівня, при цьому виконують послідовність дій стосовно БПД і за виключенням того, що використовують модель розподілу, а також формують послідовність кодів мікропрограм, коди полів керуючого вхідного та вихідного пакетів для кінцевого рівня розподілу. При цьому як критерій розділення кодів програмних блоків на коди модулів програми використовують час виконання на кожному процесорі, які присутні в моделі розподілу цього рівня, і зв'язки за даними. Далі за результатами розподілу на всіх рівнях, за даними кодів вихідних пакетів формують групи кодів задач програми користувача, які не мають зв'язків між собою за даними, при цьому послідовність виконання кодів груп визначають на підставі зв'язків між задачами в різних групах згідно порядку зв'язків даних програми користувача, аналізують всі отримані задачі, щоб визначити наявність таких груп, після цього перетворюють ці програмні групи в об'єктні програми, які передають до відповідних процесорів комп'ютерної системи, а також до хост-машини, формують та передають до комп'ютерної системи та хост-машини коди 4 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 вихідних керуючих пакетів, аналогічних вихідним пакетам для і-го рівня розподілу, з відповідними індексами і ознаками та їх значеннями для груп, що визначають розділені по процесорах вихідні команди, дані та керуючу інформацію, які необхідні для паралельного виконання кодів програми користувача на комп'ютерній системі та на хост-машині. При цьому на кожному поточному рівні формують таблицю кодів параметрів КС, до якої включають тип і кількість процесорів, системи команд процесорів, тривалість виконання кожної команди відповідним процесором (таблиця 1), а також формують таблицю кодів параметрів програми користувача та її частин, до якої включають типи циклів та їх параметри, тип і кількість операцій кожного типу (таблиця 2). У вхідний керуючий пакет (фіг. 2), який формують до кожного рівня розподілу, включають коди полів, що містять код і-го рівня розподілу програми користувача, а також стосовно рівня розподілу - код ідентифікатора параметрів програми користувача або її задачі, частини, модуля, код ідентифікатора параметрів комп'ютерноїсистеми; код ідентифікатора адреси програми користувача або її задачі, частини, модуля; код запуску системи на обробку програми користувача або її задачі, частини, модуля; код інсталяції (деінсталяції) програми користувача або її задачі, частини, модуля; код ознаки ініціалізації програми користувача або її задачі, частини, модуля; код ідентифікатора наявності посилань, який включає: код ідентифікатора таблиці посилань; код ознаки наявності посилань на стандартні методи розпаралелювання; код ознаки наявності посилань на інші програмні блоки; код ідентифікатора джерела посилань програми користувача або її задачі, частини, модуля; код ідентифікатора приймача посилань програми користувача або її задачі, частини, модуля; код повідомлення про зміну посилань в таблиці посилань; код ідентифікатора початкового посилання на обробку. У вихідні пакети (Фіг. 3), які формують після кожного рівня розподілу на і-ому рівні програми користувача, включають коди полів, що містять код рівня розподілу програми користувача, а також стосовно рівня розподілу - код ідентифікатора адресів задач програми користувача або їх частин та модулів після розділення; код ідентифікатора апаратних блоків, до яких направлено задачі програми користувача або їх частини та модулі; код інсталяції (деінсталяції) задач програми користувача або їх частин та модулів; код типу обробки розподіленої програми користувача; код ідентифікатора адресів груп з паралельними задачами або частинами, або модулями програми користувача; код ідентифікатора посилань між групами програми користувача; код ідентифікатора адресів груп джерел посилань; код ідентифікатора адресів груп, які приймають посилання; код ознаки повідомлення від комп'ютерної системи про виконання групи; код ознаки повідомлення про зміну зв'язків між групами; код ознаки відповіді комп'ютерної системи про виконання обробки; код ідентифікатора адреси наступного вихідного пакету; вільне поле. На фіг. 1 наведено узагальнену блок-схему багаторівневої стратегії розподілу кодів програми користувача. На фіг. 2 наведено узагальнену структуру вхідного керуючого пакету. На фіг. 3 наведено узагальнену структуру вихідного пакету, що відображає результати багаторівневої стратегії розподілу. На фіг. 4 наведено блок-схему пристрою для здійснення запропонованого способу розподілу кодів програми користувача. Блок-схема пристрою розподілу 1 для здійснення запропонованого способу розподілу кодів програми користувача містить (фіг. 4): 2 - процесор, призначений для обробки інформації, необхідної для процедур розділення кодів програм користувача і розподілу кодів отриманих задач і їх частин між процесорами РІМсистеми, а також для формування проміжних і кінцевих таблиць, відповідних запитів до блоків постійної пам'яті 3, оперативної пам'яті 4 та дискового накопичувача 5. Функціонування процесора на різних рівнях розподілу програми користувача визначається відповідною кожному рівню моделлю стратегії, що представлено на вході процесора у вигляді сформованої послідовності кодів відповідних мікрокоманд, які поступають з виходів блока 3. Основні функції і процедури процесора представлені в табл. 3. 3 - блок постійної пам'яті (БПП) для зберігання кодів мікропрограм для розподілу кодів програм користувача на різних рівнях. 4 - блок оперативної пам'яті (БОП), призначений для тимчасового зберігання інформації, отриманої в результаті виконання процесором арифметичних і логічних операцій, зокрема - для тимчасового зберігання сформованих таблиць різного призначення. 5 - дисковий накопичувач (ДН) для зберігання програми, за допомогою якої формують моделі розподілу кодів програми користувача кожного рівня, бази даних, призначеної для зберігання кодів параметрів РІМ-системи згідно табл. 1, кодів параметрів програми користувача 5 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 60 згідно таблиця 2, кодів даних і команд, що поступають від хост-машини, інформації про зв'язність компонентів програми користувача за даними, кодів вхідних керуючих пакетів та вихідних пакетів, що відображають результати розподілення програми користувача на різних рівнях, а також іншої інформації, необхідної для роботи системи розподілення кодів програм користувача. 6 - загальна шина типу РСІ або PCI-Express, за допомогою якої зв'язані між собою основні вузли і блоки пристрою. 7 - блок інтерфейсу для зв'язку пристрою розподілу з РІМ-системою видає в РІМ-систему інформацію, що відображає результати розподілу кодів між процесорами РІМ-системи, а також приймає від РІМ-системи службову інформацію, зокрема - про закінчення процесів обробки інформації кодів розподілених задач, частин задач і модулів програми користувача процесорами. 8 - блок інтерфейсу пристрою розподілу для зв'язку з хост-машиною реалізує зв'язок пристрою розподілу кодів програми користувача з хост-машиною, приймаючи коди даних, команд і керуючого пакету від хост-машини і направляючи в хост-машину сформовані для хостмашини коди пакетів інформації, що відображають результати розподілу програми користувача між хост-машиною і РІМ-пристроями. 9 і 10 - монітор та клавіатура для відображення та введення-виводу різноманітної інформації при взаємодії користувача з пристроєм розподілу 1. При цьому виходи постійного блока пам'яті 3 кодів мікропрограм сполучені з входами процесора 2, входи-виходи якого підключені до загальної шини 6. Входи-виходи блока оперативної пам'яті 4, дискового накопичувача 5, перші входи-виходи інтерфейсу з РІМсистемою 7, перші входи-виходи інтерфейсу з хост-машиною 8, входи-виходи монітора 9 і входи-виходи клавіатури 10 також підключені до загальної шини 6. При цьому другі входивиходи блока інтерфейсу з РІМ-системою 7 підключені до відповідних перших входів-виходів пристрою розподілу програми користувача 1, другі входи-виходи якого сполучені з другими входами-виходами блока інтерфейсу з хост-машиною. Спосіб розподілу програми користувача для паралельного виконання на РІМ-системі здійснюють за допомогою описаного пристрою 1 таким чином. Перед запуском процесу розподілу кодів програми користувача за допомогою засобів обчислювальної техніки, наприклад, за допомогою хост-машини, готують початкову інформацію. Для цього будують модель стратегії розподілу кодів програми користувача, яку представляють у вигляді послідовності кодів для кожного рівня розподілу та запам'ятовують в блоці 5 пристрою 1. При цьому на першому рівні модель стратегії розподілу програми користувача виглядає так: процесор хост-машини ↔ еквівалентний ведучий процесор (ВП*) РІМ-системи". Параметри ВП* формують, як наведено вище, на основі параметрів одного ВП, розміщеного на кристалі РІМпристрою, і кількості РІМ-пристроїв N, які входять до складу РІМ-системи. Таке представлення моделі є допустимим, оскільки всі РІМ-пристрої РІМ-системи є однаковими, а хост-машина безпосередньо зв'язана з ВП кожного РІМ-пристрою. Блок-схему стратегії розподілу наведено на фіг. 1. Також за допомогою процесору 2 аналізують та структурують параметри РІМ-системи, параметри програми користувача, які для аналізу передають з блока 5 через загальну шину 6 в блок 4 та формують з цієї інформації відповідні набори параметрів, які запам'ятовують в дисковому накопичувачу 5. Перелік основних параметрів цих наборів наведено в таблиці 1 і таблиці 2. Крім того, за допомогою процесору 2, якій використовує специфічну програму з блока 5, формують керуючий пакет спочатку для першого рівня розподілу. Узагальнену структуру такого пакету для трьох рівнів розподілу стосовно РІМ-системи наведено на фіг. 2. Керуючий пакет розміщують в БОП 4, а решту всієї початкової інформації розміщують в дисковому накопичувачу 5 (фіг. 4) на додаток до іншої, розміщеної там інформації, серед якої доцільно виділити: безпосередньо програму користувача, яку необхідно розпаралелювати, інформацію про зв'язність компонентів програми користувача за даними, програми, що відображають моделі стратегії розподілу програми користувача на кожному з трьох рівнів розподілу, програму для лексичного аналізу програми користувача і її фрагментів та ін. Програму моделі розподілу першого рівня представляють у вигляді кодів програмного блока стратегії розподілу програми користувача, який розміщують в пам'яті дискового накопичувача 5, при цьому набори кодів всіх параметрів, включаючи параметри зв'язності по даним, представляють в базі даних, яку також розміщують в пам'яті дискового накопичувача 5 пристрою розподілу 1. При розділенні кодів програми користувача у відповідності з моделлю першого рівня перевага віддається розділенню на крупні фрагменти-задачі, де кожна задача призначена для 6 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 самостійної реалізації на окремому РІМ-пристрої. Розділення роблять так, щоб взаємозв'язок по даним між цими задачами здійснювався, в основному, підсумковими значеннями результатів їх реалізації. Процес розподілу кодів програми користувача на першому рівні на незалежні за даними задачі починають з того, що формують блок послідовності дій (БПД,), якій використовують для всіх рівнів розподілу. У межах цього блока спочатку перевіряють можливості розподілу, що здійснюють за допомогою процесору 2 і відповідної програми, яка перед початком розподілу розміщена в дисковому накопичувачі 5. Для цього виконують аналіз програми користувача, в результаті якого може бути виявлено два варіанти реалізації процедур розпаралелювання (фіг. 1): 1. Коди програми користувача не підлягають подальшому розділенню на коди задач або їх частини, тобто відсутні цикли, стандартні функції, які розпаралелюють стандартними методами, відсутні послідовні ділянки програми, що реалізовують набір послідовних операцій, які можна представити у вигляді функцій, що підлягають при обчисленні розпаралелюванню і інші відомі ознаки. 2. Коди програми користувача може бути розділено на коди програмних задач згідно вказаним в п. 1 і іншим відомим ознакам і може бути розпаралелено. У другому випадку процес розподілу кодів програми користувача починають з розшифровки за допомогою процесору 2 коду першого поля керуючого пакету, розміщеного в блоці 4, який вказує, що коди параметрів і коди ідентифікаторів параметрів всіх полів пакету відносяться до першого рівня розподілу програми користувача. Керуючі сигнали, які отримано після розшифровки цього коду, через загальну шину 6 і відповідні входи-виходи блока 3 безпосередньо направляють в блок 3, який видає коди мікрокоманд відповідно для першого рівню розподілу. Одночасно з отриманням послідовності кодів мікропрограм, процесор 2 через його входи-виходи і загальну шину 6 виставляє запити до бази даних, яку розміщено на дисковому накопичувачу 5, з метою отримання кодів параметрів РІМ-системи, параметрів програми користувача, що відносяться тільки до першого рівня розподілу, а також інформації про зв'язність за даними. Ці параметри зчитують з бази даних на основі значень кодів ідентифікаторів другого і третього полів керуючого пакету (фіг. 2), які розшифровані за допомогою процесору 2. Отримані в результаті сигнали використовують для структуризації, формування з них відповідних таблиць, які запам'ятовують в блоці 4, вхід-вихід пристрою 4 передають для тимчасового зберігання в оперативний запам'ятовуючий пристрій 4. Далі за допомогою процесору 2 розшифровують код шостого поля керуючого пакету і за наявності коду інсталяції виконують інсталяцію програм шляхом розміщення всіх необхідних програмних файлів у відповідних місцях пам'яті програм користувача пристрою розподілу 1. Крім того, блок процесор 2 аналізує код сьомого поля керуючого пакету і за наявності коду ознаки ініціалізації привласнюють початкові значення змінним. При цьому процесор 2 формує запит в пристрій 5 для читання з відповідних таблиць і формування списку операцій програми користувача і списку команд РІМ-системи для першого рівня розподілу. Цю інформацію представляють у вигляді файлів: код ідентифікатора програми користувача, список операцій програми користувача; код ідентифікатора процесора хост-машини, список кодів команд хостмашини, код ідентифікатора процесора ВП* РІМ-пристрою, список команд ВП*, який рівний списку команд одного ВП. Ці файли записують в блок 4 по ланцюгу: входи-виходи блока 5, загальна шина 6, відповідні входи-виходи блока 4. Формують та по цьому ж ланцюгу записують в блок 4 файл, який містить інформацію про кількість ітерацій для кожного циклу, що входить в програму користувача, а також файл з описом залежності за даними. При формуванні файлу залежності за даними використовують значення кодів полів посилань 8 - 14 керуючого пакету (фіг. 2.), які аналізують за допомогою блока 2, і отриману при цьому інформацію передають з перших входів-виходів блока 2 через загальну шину 6 на відповідні входи-виходи блока 4, для зберігання на час виконання процесу розподілу кодів програми користувача. Далі за допомогою процесора 2 у відповідності з послідовністю кодів мікрокоманд для першого рівня розподілу, яка поступає з виходів блока 3 на відповідні входи процесора 2, виконують розподіл задач програми користувача між хост-машиною і еквівалентним ВП* РІМсистеми. Для цього за допомогою процесору 2 та програми, яка розміщена в блоці 5, виконують лексичний аналіз тексту програми користувача, який використовують для подальшого визначення можливості виконання задач програми користувача за допомогою хост-машини і за допомогою РІМ-системи, а також виконують для них по відповідним формулам розрахунки ваги (часу реалізації) задач програми користувача. В процесі аналізу виділяють операції задач програми користувача і записують в пристрій 4 в таблицю операцій. 7 UA 103535 C2 На підставі таблиці операцій задачі програми користувача обчислюють вагу задачі для процесора хост-машини і ВП* за формулою: n W ХОСТ i qi , (1) i1 5 де n - кількість записів в таблиці операцій задачі програми користувача, i - час виконання процесором хост-машини і-тої операції, qi - скільки разів і-та операція може бути виконана в даній задачі програми користувача. Вагу задачі для еквівалентного процесора ВП* РІМ-системи обчислюють за аналогічною формулою: WВП 10 15 20 25 30 35 40 45 50 55 m j j , (2) j1 де m - кількість записів в таблиці операцій задачі програми користувача, j - час виконання команди за допомогою ВП* РІМ-системи, яка відповідає j-ї операції, j - скільки разів j-а операція може бути виконана в даній задачі програми користувача. Результати обчислень запам'ятовують в блоці пам'яті 4. Таку процедуру визначення часу виконання задачі виконують аналітично для всіх задач програми користувача, які були виділені для хост-машини і окремо для ВП* РІМ-системи. Далі розподіляють набір кодів задач між хост-машиною і ВП*. При цьому набір кодів задач, отриманий для ВП*, розподіляють між однаковими ВП усіх РІМ-пристроїв одним з відомих методів, наприклад, методом пошуку незалежних задач, і перевіряють баланс завантаження (час виконання кожної задачі) для процесора хост-машини і ВП* РІМ-системи. Якщо є баланс завантаження, то переходять на другий рівень розподілу програми користувача, при цьому записують в блок 5 результати розподілу на першому рівні, при цьому формують набір кодів задач програми користувача для хост-машини і відповідний набір кодів задач для ВП кожного РІМ-пристрою РІМ-системи з відповідними кодами атрибутів (ідентифікаторів), які вказують на їх приналежність до апаратних засобів. Всю цю інформацію також представляють у вигляді кодів вихідного пакету за наслідками розподілу на першому рівні. Узагальнену (для трьох рівнів) структуру вихідного пакету для РІМ-системи наведено на фіг. 3. Якщо баланс завантаження процесора хост-машини і ВП* РІМ-системи відсутній, то виконують коректування розподілу початкових задач методом їх укрупнення або розділення на складові частини, і процес розподілу задач програми користувача повторюють за тим же сценарієм. На другому рівні виконують розподіл виділених на першому рівні кодів задач для кожного РІМ-пристрою РІМ-системи. Оскільки всі РІМ-пристрої РІМ-системи однакові, то можна вважати, що процеси розподілу для всіх РІМ-пристроїв виконують за одним і тим самим сценарієм. Для реалізації розподілу на другому рівні, на якому кожну задачу програми, призначену на другому рівні для кожного РІМ-пристрою, розділяють на програмні частини, виконують ту ж саму послідовність дій, як і для першого рівня, використовуючи БПДі за наступним виключенням. Процес розподілу також починають з перевірки можливості розподілу, але кодів задач програми користувача на незалежні за даними програмні частини (фіг. 1). І якщо така можливість є, використовують послідовність кодів мікропрограм для другого рівня розподілу, коди полів керуючого вхідного та вихідного пакетів заміняють на відповідні коди полів для другого рівня згідно фіг. 2, фіг. 3. Формують основні параметри еквівалентного процесорного ядра (ПЯ*) для одного РІМ-пристрою та модель "один ВП - еквівалентний ПЯ*". При цьому як критерій розділення кодів задачі на коди програмних частин використовують критерій відповідності системи команд ВП і еквівалентного процесорного ядра ПЯ* наборам операцій відповідних програмних частин для кожного РІМ-пристрою. Оскільки всі ПЯ в наборі ПЯ* РІМпристрою однакові, то за систему команд ПЯ* приймають систему команд одного ПЯ, ємкість пам'яті ПЯ* приймають рівною сумарній ємкості пам'яті, підключеної до всіх ПЯ РІМ-пристрою, а як час виконання будь-якої команди ПЯ* приймають час виконання цієї команди одним ПЯ, поділений на кількість ПЯ в наборі ПЯ*, враховуючи одночасну їх роботу. Керуючий пакет розміщують в пам'яті 4, а решта всієї початкової інформації вже знаходиться в блоці оперативної пам'яті 4 і дисковій пам'яті 5 (фіг. 4.) пристрою розподілу 1, зокрема: у пристрої 4 знаходяться коди задач програми користувача і коди їх параметрів, розподілені на першому рівні; на дисковому накопичувані 5 знаходиться програма, що відображає модель стратегії розподілу програми користувача на другому рівні розподілу, у базі даних дискового накопичувана 5 розміщені коди наборів параметрів програми користувача і 8 UA 103535 C2 5 10 15 20 25 30 35 40 45 50 55 РІМ-пристроїв РІМ-системи, параметри зв'язності задач за даними та інша інформація, яка необхідна для розподілу на цьому рівні. Далі послідовність процесу розподілу кодів на третьому (для РІМ-системи на кінцевому) рівні аналогічна послідовності процесу розподілу кодів програми користувача на першому рівні, однак при цьому кожну частину програми, яка призначена на попередньому рівні, розділяють на програмні модулі, які розподіляють між всіма процесорами, що входять в набір моделі розподілу кінцевого рівня. При цьому також використовують блок послідовності дій БПД і, в межах якого виконують послідовність дій стосовно послідовності дій цього блока за виключенням того, що використовують модель розподілу, а також формують послідовність кодів мікропрограм, коди полів керуючого вхідного та вихідного пакетів для кінцевого рівня розподілу. Як критерій розділення кодів програмних частин на коди модулів програми використовують час виконання модулів на кожному процесорі, які присутні в моделі розподілу цього рівня, і зв'язки за даними. Час виконання обчислюють за допомогою процесору 2 за виразом (2) з відповідними індексами та їх значенням для кінцевого рівня розподілу. Результат записують в блок пам'яті 4 за ланцюгом: вхід-вихід блока 2, загальна шина 6 - вхід-вихід блока 4. За результатами розподілу на всіх рівнях, за даними вихідних керуючих пакетів, які на даний час розміщені в блоці 4, за допомогою процесора 2 та з використанням програми в дисковому накопичувану 5, формують групи задач, програми користувача, які не мають зв'язків між собою за даними стосовно інформації про зв'язки, яка розміщена в блоці 5. Перебирають всі отримані задачі, щоб визначити наявність таких груп. При цьому послідовність виконання груп визначають на підставі зв'язків між задачами в різних групах згідно порядку зв'язків даних програми користувача. Після цього, за допомогою процесору 2 з використанням спеціальної програми, яка розміщена в блоці 5, перетворюють ці програмні групи в об'єктні програми, які через інтерфейс 7 передають через перший вхід-вихід пристрою розподілу 1 до стосовних процесорів РІМ-системи, а також через інтерфейс 8 і другий вхід-вихід пристрою розподілу 1 до хост-машини. Одночасно формують вихідні керуючі пакети з відповідними ознаками для груп, , аналогічно пакету на фіг. 3, які запам'ятовують в блоці 5 та через треті та четверті входи-виходи пристрою розподілу 1 з третіх входів-виходів інтерфейсів 7 і 8 передають відповідно до РІМсистеми та хост-машини, що визначає розділені по процесорах вихідні команди, дані та керуючу інформацію, які необхідні для паралельного виконання кодів програми користувача на комп'ютерній системі та на хост-машині. Таким чином, запропонований спосіб розподілу програми користувача для паралельного виконання на комп'ютерній системі забезпечує широкі функціональні можливості розподілу кодів програм користувача і зменшує загальний час її розпаралелювання за рахунок використання запропонованої багаторівневої моделі розподілу, яка відображає багаторівневу архітектурно-структурну організацію комп'ютерної системи, цілеспрямованого початкового розподілу кодів програми користувача з використанням критеріїв відповідності системи команд процесорів РІМ-системи наборам операцій програми користувача на кожному рівні розподілу, що істотно скорочує кількість ітерацій розподілу, а також за рахунок перевірки і при необхідності коректування на кожному рівні результатів розподілу. Крім того, запропонований спосіб розподілу кодів програм користувача знижує трудомісткість, вартість розробки програми розподілу в цілому за рахунок використання на всіх рівнях розподілу однотипного блока послідовності дій (БПДі) при розділенні програми користувача на складові компоненти (задачі, частини задач, програмні модулі) і розподіли їх по процесорах (див. фіг. 1) а також розширює область застосування запропонованого способу і пристрою розподілу на різні апаратно-програмні платформи за рахунок використання мікропрограмного принципу формування процесу розподілу для кожного рівня. Впровадження запропонованого способу і системи розподілу програми користувача забезпечує також додатково позитивний ефект в частині підвищення продуктивності комп'ютерної системи за рахунок глибокого розпаралелювання на всіх рівнях ієрархічної організації засобів обробки і зберігання інформації, перевірки і при необхідності коректування на кожному рівні розподілу рівномірності завантаження всіх процесорів корисною (обчислювальною) роботою. Перелік використаних джерел інформації: 1. Яковлев Ю.С. Однокристальные компьютерные системы высокой производительности. Особенности архитектурно-структурной организации и внутренних процессов: монография / Ю.С. Яковлев. - Винница: ВНТУ, 2009. - 294 с. 2. Slo-Li Chu. Exploiting Application Parallelism for Processor-in-Memory Architecture / Slo-Li Chu, Tsung-Chuan Huang // Proc. of National Computer Symposium, Taiwan, 2003, December 18 9 UA 103535 C2 19. - 2003. - P. 293-303. - Режим доступу: http://dspace.lib.fcu.edu.tw/bitstream/2377/564/1/ OT_1022003305.pdf. - Дата доступу: 17.08.11. Таблиця 1 Спосіб розподілу програми користувача для комп'ютерної системи № 1 2 3 4 5 6 7 8 9 10 11 12 13 Найменування параметра Кількість кристалів РІМ-системи Склад і типи процесорів РІМ-системи на одному і-му кристалі Набір системи команд ведучого процесора (ВП) Розрядність ВП Ємкість пам'яті ВП Тривалість одного такту роботи ВП Набір параметрів еквівалентного ВП* Кількість ПЯ на одному кристалі Набір системи команд ПЯ Розрядність ПЯ Ємкість банку пам'яті, підключеного до кожного ПЯ у складі кристала Тривалість одного такту роботи ПЯ Набір параметрів еквівалентного ПЯ* Швидкість передачі інформації по каналу процесор - пам'ять (ширина смуги пропускання X інформації по даному каналу) Таблиця 2 Спосіб розподілу програми користувача для комп'ютерної системи № 1 2 3 4 5 6 7 g Найменування параметра Типи і кількість циклів програми користувача і їх параметри Типи і кількість незалежних за даними завдань і програм Типи і кількість послідовних ділянок програм Інформація про зв'язність усередині програми користувача за даними Типи і кількість операцій програми користувача Частота зустрічі кожної j-ї операції програми користувача Розрядність обробки даних Програми реалізації відомих методів розпаралелювання при вирішенні типових завдань (множення матриць і тому подібне) 5 Таблиця 3 Спосіб розподілу програми користувача для комп'ютерної системи № п/п Найменування функцій і процедур 1 Формування параметрів ВП* і ПЯ* Розділення кодів програми користувача на паралельні фрагменти і розподіл їх між хост2 машиною і ВП* Розділення і розподіл кодів фрагментів програми користувача між ВП* і набором 3 кристалів РІМ-системи (ВП). Розділення кодів фрагмента програми користувача кожного кристала на програмні блоки 4 і розподіл їх між ВП і ПЯ* Розділення кодів кожного програмного блока на програмні модулі і розподіл їх між ПЯ* і 5 набором ПЯ кожного кристала Розрахунок параметричної ваги (часу виконання) фрагментів, програмних блоків і 6 модулів програми користувача для відповідних процесорів РІМ-системи, хост-машини і рівнів розподілу. Перевірка балансу завантаження між хост-машиною і РТМ-системою (ВП*), а також між 7 ВП і ПЯ*, і між кожним ПЯ. 10 UA 103535 C2 8 9 10 11 12 q Перерозподіл кодів програми користувача за відсутності балансу завантаження процесорів Формування кодів таблиць при розподілі програми користувача на даний момент часу: таблиць параметричної ваги фрагментів, програмних блоків і модулів програми користувача, таблиць балансу завантаження ВП і ПЯ, таблиць відповідності системи команд ВП, системи команд ПЯ відповідним наборам операцій для кожного рівня розподілу програми користувача, таблиці зв'язності за даними і іншої поточної інформації. Формування пакетів, що відображають результати розподілу програми користувача на кожному рівні і передача їх в хост-машину і РІМ-систему Перетворення послідовних ділянок програм в паралельні (за наявності такої можливості) Управління умовами переходу при реалізації алгоритмів розділення і розподілу програм користувача Формування запитів до БД і пам'яті для запису і читання інформації ФОРМУЛА ВИНАХОДУ 5 10 15 20 25 30 35 40 45 1. Спосіб розподілу програми користувача для комп'ютерної системи, який включає перетворення початкових кодів програми в проміжні коди, розділення проміжних кодів на множину кодів задач, генерацію інформації про відносини серед множини задач на основі даних в задачах і перетворення кожної задачі в об'єктну програму, яку передають до множини процесорів комп'ютерної системи, який відрізняється тим, що спочатку за допомогою хостмашини формують багаторівневу модель розподілу кодів програми користувача, потім формують блок послідовності дій, який використовують для кожного і-го поточного рівня розподілу, в межах цього блока визначають можливість розділення програми користувача на незалежні за даними задачі або частини задач, потім для і-го рівня розподілу формують вхідний керуючий пакет розподілу, аналізують та структурують інформацію про параметри комп'ютерної системи та про параметри програми користувача та її частин, на основі цієї інформації формують базу поточних значень, які запам'ятовують в електронній пам'яті, потім формують послідовність сигналів кодів мікропрограм для розподілу на поточному рівні, виконують розділення кодів програми користувача або її задач на незалежні за даними коди частин і розподіляють їх між процесорами комп'ютерної системи стосовно сформованої моделі розподілу для і-го поточного рівня, використовуючи критерій відповідності системи команд цих процесорів наборам операцій програми користувача вибраного рівня розподілу, далі після визначення тривалості обробки машинних команд кожної із задач перевіряють баланс завантаження процесорів комп'ютерної системи кодами програми користувача, які присутні в моделі розподілу поточного і-го рівня, і за наявності балансу генерують для поточного рівня коди вихідного пакету, інакше коректують розподіл шляхом укрупнення або подрібнення отриманих задач програми користувача або їх частин, далі на кінцевому рівні розподілу кожну частину програми, яка призначена на попередньому рівні, розділяють на програмні модулі, які розподіляють між всіма процесорами, що входять в набір моделі розподілу кінцевого рівня, при цьому виконують послідовність дій стосовно блока послідовності дій за виключенням того, що використовують модель розподілу, а також формують послідовність кодів мікропрограм, коди полів керуючого вхідного та вихідного пакетів для кінцевого рівня розподілу, при цьому як критерій розділення кодів програмних частин на коди модулів програми використовують час виконання модулів на кожному процесорі, які присутні в моделі розподілу цього рівня, і зв'язки за даними, далі за результатами розподілу на всіх рівнях, за даними кодів вихідних пакетів формують групи кодів задач програми користувача, які не мають зв'язків між собою за даними, при цьому послідовність виконання кодів груп визначають на підставі зв'язків між задачами в різних групах згідно з порядком зв'язків даних програми користувача, аналізують всі отримані задачі, щоб визначити наявність таких груп, після цього перетворюють ці програмні групи в об'єктні програми, які передають до відповідних процесорів комп'ютерної системи, а також до хост-машини, формують та передають до комп'ютерної системи та хост-машини коди вихідних керуючих пакетів, аналогічних вихідним пакетам для і-го рівня розподілу, з відповідними індексами і ознаками та їх значеннями для груп, що визначає розділені по процесорах вихідні команди, дані та керуючу інформацію, які необхідні для паралельного виконання кодів програми користувача на комп'ютерній системі та на хост-машині. 2. Спосіб за п. 1, який відрізняється тим, що у вхідний керуючий пакет, який формують до кожного рівня розподілу, включають коди полів, що містять код і-го рівня розподілу програми користувача; а також стосовно рівня розподілу - код ідентифікатора параметрів програми 11 UA 103535 C2 5 10 15 20 користувача або її задачі, частини, модуля; код ідентифікатора параметрів комп'ютерної системи; код ідентифікатора адреси програми користувача або її задачі, частини, модуля; код запуску системи на обробку програми користувача або її задачі, частини, модуля; код інсталяції або деінсталяції програми користувача або її задачі, частини, модуля; код ознаки ініціалізації програми користувача або її задачі, частини, модуля; код ідентифікатора наявності посилань, який включає: код ідентифікатора таблиці посилань; код ознаки наявності посилань на стандартні методи розпаралелювання; код ознаки наявності посилань на інші програмні блоки; код ідентифікатора джерела посилань програми користувача або її задачі, частини, модуля; код ідентифікатора приймача посилань програми користувача або її задачі, частини, модуля; код повідомлення про зміну посилань в таблиці посилань; код ідентифікатора початкового посилання на обробку. 3. Спосіб за п. 1, який відрізняється тим, що у вихідні пакети, які формують після кожного рівня розподілу на і-ому рівні програми користувача, включають коди полів, що містять код рівня розподілу програми користувача; а також стосовно рівня розподілу - код ідентифікатора адресів задач програми користувача або їх частин та модулів після розділення; код ідентифікатора апаратних блоків, до яких направлено задачі програми користувача або їх частини та модулі; код інсталяції або деінсталяції задач програми користувача або їх частин та модулів; код типу обробки розподіленої програми користувача; код ідентифікатора адресів груп з паралельними задачами або частинами, або модулями програми користувача; код ідентифікатора посилань між групами програми користувача; код ідентифікатора адресів груп джерел посилань; код ідентифікатора адресів груп, які приймають посилання; код ознаки повідомлення від комп'ютерної системи про виконання групи; код ознаки повідомлення про зміну зв'язків між групами; код ознаки відповіді комп'ютерної системи про виконання обробки; код ідентифікатора адреси наступного вихідного пакету; вільне поле. 12 UA 103535 C2 13 UA 103535 C2 Комп’ютерна верстка В. Мацело Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 14
ДивитисяДодаткова інформація
Автори англійськоюSerhiienko Ivan Vasyliovych, Palahin Oleksandr Vasyliovych, Boiun Vitalii Petrovych, Yakovliev Yurii Serhiyovych, Yeliseieva Olena Volodymyrivna
Автори російськоюСергиенко Иван Васильевич, Палагин Александр Васильевич, Боюн Виталий Петрович, Яковлев Юрий Сергеевич, Елисеева Елена Владимировна
МПК / Мітки
Мітки: системі, програми, користувача, розподілу, комп'ютерної, спосіб
Код посилання
<a href="https://ua.patents.su/16-103535-sposib-rozpodilu-programi-koristuvacha-dlya-kompyuterno-sistemi.html" target="_blank" rel="follow" title="База патентів України">Спосіб розподілу програми користувача для комп’ютерної системи</a>
Спосіб розподілу програми користувача для комп’ютерної системи

Номер патенту: 71719
Опубліковано: 25.07.2012
Автори: Сергієнко Іван Васильович, Єлісєєва Олена Володимирівна, Палагін Олександр Васильович, Яковлєв Юрій Сергійович, Боюн Віталій Петрович
Мітки: системі, комп'ютерної, користувача, програми, спосіб, розподілу
Формула / Реферат:
1. Спосіб розподілу програми користувача для комп'ютерної системи, що включає перетворення початкових кодів програми в проміжні коди, розділення проміжних кодів на множину кодів задач, генерацію інформації про відносини серед множини задач на основі даних в задачах і перетворення кожної задачі в об'єктну програму, яку передають до множини процесорів комп'ютерної системи, який відрізняється тим, що спочатку формують багаторівневу модель...
Система для розподілу програми користувача

Номер патенту: 73423
Опубліковано: 25.09.2012
Автори: Боюн Віталій Петрович, Єлісєєва Олена Володимирівна, Яковлєв Юрій Сергійович, Палагін Олександр Васильович, Сергієнко Іван Васильович
Мітки: програми, система, розподілу, користувача
Формула / Реферат:
Система для розподілу програми користувача, що містить процесор, оперативну пам'ять, накопичувач, інтерфейс користувача, перші входи-виходи яких підключені до загальної шини, яка відрізняється тим, що до складу системи введені блок управління, блок пам'яті мікропрограм, блок пам'яті таблиць, логічний блок, блок розподілу, блок проміжної інформації, блок буферної пам'яті, інтерфейс з хост-машиною, інтерфейс з робочою системою, при цьому...
Система збору, обробки та ідентифікації даних про користувача програми лояльності

Номер патенту: 82007
Опубліковано: 10.07.2013
Автор: Таран Вадим Олександрович
МПК: G06K 9/62, G06Q 20/00
Мітки: система, обробки, лояльності, збору, ідентифікації, даних, програми, користувача
Формула / Реферат:
1. Система збору, обробки та ідентифікації даних про користувача програми лояльності, що містить центральний сервер, який з'єднаний за допомогою щонайменше одного каналу зв'язку з множиною терміналів, які розташовані в торгових точках та забезпечені пристроями зчитування інформації з дисконтних карток, причому центральний сервер містить модуль збору та обробки інформації, модуль нарахування знижок та/або бонусів та базу даних відомостей про...
Спосіб захисту даних доступу користувача системи

Номер патенту: 9534
Опубліковано: 17.10.2005
Автор: Слободянюк Максим Едуардович
МПК: H03K 19/20, G06F 9/40, G06Q 10/00
Мітки: даних, доступу, спосіб, захисту, користувача, системі
Формула / Реферат:
Спосіб захисту даних доступу користувача системи, який відрізняється тим, що системою генерують дані доступу користувача до системи, системою передають ідентифікатори користувачу додатком до генеральної угоди, ідентифікатори поодинці пропускають через функцію хешування, вихідні значення ідентифікаторів складають, складене вихідне значення пропускають через інший (або той же) алгоритм функції хешування, системою обчислюють результат, значення...
Соска-пустушка (варіанти) і спосіб підтримки правильної зубощелепної системи користувача

Номер патенту: 86001
Опубліковано: 25.03.2009
Автор: Бергерсен Ерл О.
МПК: A61J 17/00
Мітки: системі, зубощелепної, правильної, варіанти, користувача, спосіб, підтримки, соска-пустушка
Формула / Реферат:
1. Соска-пустушка, призначена для носіння у роті користувача, яка містить захисний диск, що має, по суті, плоский корпус, і виступ, прикріплений до захисного диска, при цьому вказаний виступ має перший і другий кінець, розташований навпроти першого кінця, перший і другий кінці виступу направлені до задньої частини ротової порожнини користувача при носінні соски-пустушки у роті користувача, причому виступ має, по суті, U-подібну форму, а...
Попередній патент: Пакувальний матеріал, що містить намагнічувані ділянки
Наступний патент: Пристрій для визначення параметрів явища фотосинтезу хлорофілу у листках рослин
Випадковий патент: Ливарний сплав алюмінію, що містить магній та кремній