Статистичне кодування коефіцієнтів, використовуючи об’єднану контекстну модель
Номер патенту: 106937
Опубліковано: 27.10.2014
Автори: Джоши Раджан Л., Соле Рохальс Хоель, Карчевіч Марта







Формула / Реферат
1. Спосіб кодування даних відео, який включає:
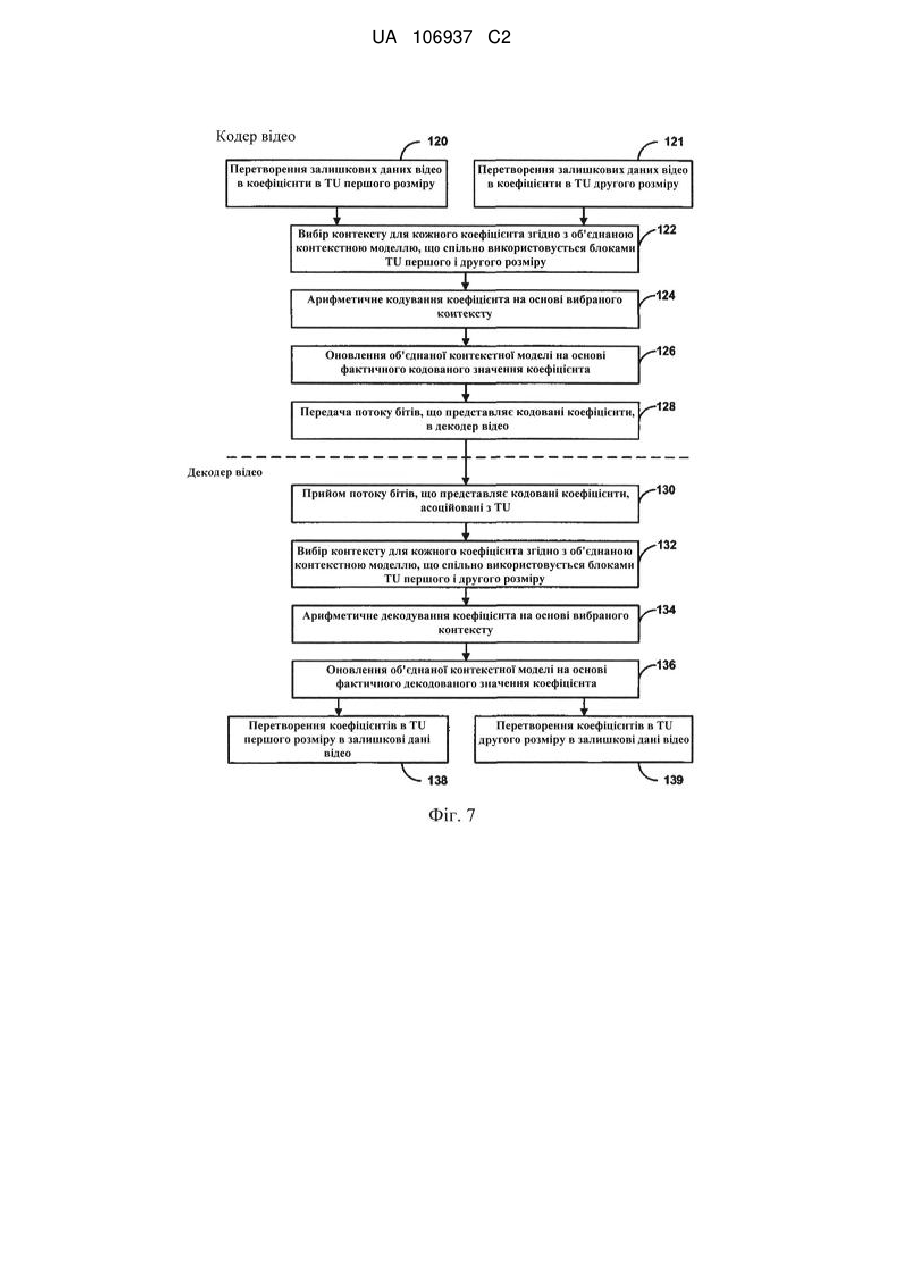
підтримування об'єднаної контекстної моделі, що використовується спільно першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, що включає в себе множину блоків коефіцієнтів перетворення;
вибір контекстів для компонентів карти значущості для згаданих коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю; і
статистичне кодування згаданих компонентів карти значущості, асоційованих із згаданим одним з блоків перетворення, на основі вибраних контекстів.
2. Спосіб за п. 1, в якому вибір контекстів для компонентів карти значущості для згаданих коефіцієнтів перетворення згідно із об'єднаною контекстною моделлю містить:
призначення контексту в об'єднаній контекстній моделі заданому одному з компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення; і
визначення оцінки ймовірності для значення згаданого заданого одного з компонентів карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі, і
оновлення оцінки ймовірності, асоційованої з призначеним контекстом в об'єднаній контекстній моделі, на основі фактичних кодованих значень компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір.
3. Спосіб за п. 1, в якому спосіб включає спосіб декодування даних відео, який додатково включає:
прийом потоку бітів, який представляє кодовану карту значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибір контекстів для згаданих компонентів кодованої карти значущості згідно із об'єднаною контекстною моделлю; і
статистичне декодування згаданих компонентів згаданої кодованої карти значущості для згаданих коефіцієнтів перетворення одного зі згаданих блоків перетворення на основі вибраних контекстів.
4. Спосіб за п. 3, який додатково включає зворотне перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення.
5. Спосіб за п. 1, в якому спосіб включає спосіб декодування даних відео, який додатково включає:
перетворення залишкових піксельних значень в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибір контекстів для згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення згідно із об'єднаною контекстною моделлю; і
статистичне кодування згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів.
6. Спосіб за п. 1, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16.
7. Спосіб за п. 1, в якому вибір контекстів згідно із об'єднаною контекстною моделлю містить:
призначення контексту в об'єднаній контекстній моделі першому компоненту першої карти значущості для коефіцієнтів перетворення першого блока перетворення, який має перший розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого першого блока перетворення;
визначення оцінки ймовірності для значення згаданого першого компонента першої карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі;
оновлення оцінки ймовірності, асоційованої з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичного кодованого значення згаданого першого компонента першої карти значущості, асоційованого з першим блоком перетворення;
призначення того ж самого контексту в об'єднаній контекстній моделі другому компоненту другої карти значущості для згаданих коефіцієнтів перетворення другого блока перетворення, який має другий розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого другого блока перетворення;
визначення оцінки ймовірності для значення згаданого другого компонента другої карти значущості, асоційованого з тим же самим призначеним контекстом в об'єднаній контекстній моделі; і
оновлення оцінки ймовірності, асоційованої з одним і тим же призначеним контекстом в об'єднаній контекстній моделі, на основі фактичного закодованого значення згаданого другого компонента другої карти значущості, асоційованого з другим блоком перетворення.
8. Пристрій кодування відео, який містить:
пам'ять, яка зберігає об'єднану контекстну модель, спільно використовувану першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, який включає в себе множину блоків коефіцієнтів перетворення; і
процесор, який конфігурується, щоб підтримувати об'єднану контекстну модель, вибирати контексти для компонентів карти значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю, і статистично кодувати згадані компоненти карти значущості, асоційовані з одним з блоків перетворення на основі вибраних контекстів.
9. Пристрій кодування відео за п. 8, в якому процесор сконфігурований для:
призначення контексту в об'єднаній контекстній моделі заданому одному зі згаданих компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення; і
визначення оцінки ймовірності для значення згаданого заданого одного з компонентів карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі, і
оновлення оцінки ймовірності, асоційованої з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір.
10. Пристрій кодування відео за п. 8, в якому пристрій кодування відео містить пристрій декодування відео, причому процесор сконфігурований для:
прийому потоку бітів, який представляє кодовану карту значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибору контекстів для згаданих компонентів кодованої карти значущості, згідно із об'єднаною контекстною моделлю; і
статистичного декодування згаданих компонентів кодованої карти значущості для згаданих коефіцієнтів перетворення одного зі згаданих блоків перетворення на основі вибраних контекстів.
11. Пристрій кодування відео за п. 10, в якому процесор сконфігурований для зворотного перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення.
12. Пристрій кодування відео за п. 8, в якому пристрій кодування відео містить процесор для кодування відео, причому процесор сконфігурований для:
перетворення залишкових піксельних значень в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибору контекстів для згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення згаданого одного з блоків перетворення згідно із об'єднаною контекстною моделлю; і
статистичного кодування згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів.
13. Пристрій кодування відео за п. 8, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16.
14. Пристрій кодування відео за п. 8, в якому процесор сконфігурований для:
призначення контексту в об'єднаній контекстній моделі перших компонентів першої карти значущості для коефіцієнтів перетворення першого блока перетворення, який має перший розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого першого блока перетворення;
визначення оцінки ймовірності для значення згаданого першого компонента згаданої першої карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі;
оновлення оцінки ймовірності, асоційованої з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичного кодованого значення згаданого першого компонента першої карти значущості, асоційованого з першим блоком перетворення;
призначення того ж самого контексту в об'єднаній контекстній моделі другому компоненту другої карти значущості для згаданих коефіцієнтів перетворення згаданого другого блока перетворення, який має другий розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого другого блока перетворення;
визначення оцінки ймовірності для значення другого компонента другої карти значущості, асоційованого з тим же самим призначеним контекстом в об'єднаній контекстній моделі; і
оновлення оцінки ймовірності, асоційованої з одним і тим же призначеним контекстом в об'єднаній контекстній моделі, на основі фактичного закодованого значення згаданого другого компонента другої карти значущості, асоційованого з другим блоком перетворення.
15. Пристрій кодування відео, який містить:
засіб для підтримки об'єднаної контекстної моделі, що використовується спільно першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, що включає в себе множину блоків коефіцієнтів перетворення;
засіб для вибору контекстів для компонентів карти значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю; і
засіб для статистичного кодування компонентів карти значущості, асоційованих із згаданим одним з блоків перетворення, на основі вибраних контекстів.
16. Пристрій кодування відео за п. 15, який додатково містить:
засіб для призначення контексту в об'єднаній контекстній моделі заданому одному з компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення;
засіб для визначення оцінки ймовірності для значення згаданого заданого одного зі згаданих компонентів карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі; і
засіб для оновлення оцінки ймовірності, асоційованої з призначеним контекстом в об'єднаній контекстній моделі, на основі фактичних кодованих значень згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір.
17. Пристрій кодування відео за п. 15, в якому пристрій кодування відео містить пристрій декодування відео, який додатково містить:
засіб для прийому потоку бітів, який представляє кодовану карту значущості для згаданих коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
засіб для вибору контекстів для компонентів кодованої карти значущості коефіцієнтів згідно із об'єднаною контекстною моделлю; і
засіб для статистичного декодування згаданих компонентів кодованої карти значущості для згаданих коефіцієнтів перетворення одного зі згаданих блоків перетворення на основі вибраних контекстів.
18. Пристрій кодування відео за п. 17, який додатково містить засіб для зворотного перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення.
19. Пристрій кодування відео за п. 15, в якому пристрій кодування відео містить пристрій кодування відео, який додатково містить:
засіб для перетворення залишкових піксельних значень в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
засіб для вибору контекстів для згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення згідно із об'єднаною контекстною моделлю; і
засіб для статистичного кодування компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів.
20. Пристрій кодування відео за п. 15, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16.
21. Зчитуваний комп'ютером носій, що містить інструкції для кодування даних відео, які, коли виконуються, змушують процесор:
підтримувати об'єднану контекстну модель, спільно використовувану першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, який включає в себе множину блоків коефіцієнтів перетворення;
вибирати контексти для компонентів карти значущості для згаданих коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю; і
статистично кодувати компоненти карти значущості, асоційовані з одним з блоків перетворення, на основі вибраних контекстів.
22. Зчитуваний комп'ютером носій за п. 21, який додатково містить інструкції, які змушують процесор:
призначати контекст в об'єднаній контекстній моделі заданому одному з компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення;
визначати оцінку ймовірності для значення згаданого заданого одного зі згаданих компонентів карти значущості, асоційованих з призначеним контекстом, в об'єднаній контекстній моделі; і
оновлювати оцінку ймовірності, асоційовану з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичних кодованих значень згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір.
23. Зчитуваний комп'ютером носій за п. 21, в якому інструкція містить інструкції для декодування даних відео, який додатково містить інструкції, які змушують процесор:
приймати потік бітів, який представляє кодовану карту значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибирати контексти для згаданих компонентів кодованої карти значущості коефіцієнтів згідно з об'єднаною контекстною моделлю; і
статистично декодувати згадані компоненти кодованої карти значущості для згаданих коефіцієнтів перетворення для одного зі згаданих блоків перетворення на основі вибраних контекстів.
24. Зчитуваний комп'ютером носій за п. 23, який додатково містить інструкції, які змушують процесор виконувати зворотнє перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення.
25. Зчитуваний комп'ютером носій за п. 21, в якому інструкції містять інструкції для кодування даних відео, який додатково містить інструкції, які змушують процесор:
перетворювати залишкові піксельні значення в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір;
вибирати контексти для згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення згаданого одного з блоків перетворення згідно з об'єднаною контекстною моделлю; і
статистично кодувати згадані компоненти карти значущості для згаданих коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів.
26. Зчитуваний комп'ютером носій за п. 21, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16.
Текст
Реферат: Даний винахід описує способи для виконання статистичного кодування і декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Наприклад, об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. Виконання статистичного кодування, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, може зменшити об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності, і зменшити обчислювальні витрати підтримування моделей контексту. В одному прикладі об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір, з коефіцієнтами, обнуленими для генерування блока коефіцієнтів, що залишилися, який має другий розмір, і перетворення блоків, які мають другий розмір. В іншому прикладі об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір, і блоками перетворення, які мають другий розмір. UA 106937 C2 (12) UA 106937 C2 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 Галузь техніки Даний винахід стосується кодування відео і, більш конкретно, статистичного кодування для кодування відео. Рівень техніки Цифрові можливості відео можуть бути вбудовані у широкий діапазон пристроїв, включаючи цифрові телевізори, цифрові системи прямого мовлення, бездротові системи мовлення, персональні цифрові помічники (PDA), ноутбуки або настільні комп'ютери, цифрові камери, цифрові пристрої запису, цифрові медіа програвачі, відеоігрові пристрої, відеоігрові консолі, стільникові або супутникові радіотелефони, пристрої організації відео телеконференцій, тощо. Цифрове відео пристрої реалізують способи стиснення відео, такі як описані в стандартах, визначених MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Частина 10, Вдосконалене кодування відео (AVC), або стандарт кодування відео високої ефективності (HEVC), що знаходиться в стадії становлення, і розширення таких стандартів. Способи стиснення відео виконують просторове прогнозування і/або часове прогнозування, щоб зменшити або видалити надмірність, властиву послідовностям відео. Для основаного на блоках кодування відео, кадр відео або вирізка можуть бути розділені в блоки відео або блоки кодування (CU). CU може бути далі розділені в один або більше блоків прогнозування (PU), щоб визначити прогнозуючі дані відео для CU. Способи стиснення відео можуть також розділити CU в один або більше блоків перетворення (TU) блоків залишкових даних відео, які представляють різницю між блоком відео, який повинен бути закодований, і прогнозуючими даними відео. Лінійні перетворення, такі як двовимірне дискретне косинусне перетворення (DCT), можуть бути застосовані до TU, щоб перетворити блоки залишкових даних відео з піксельної ділянки в частотну ділянку, щоб досягнути подальшого стиснення. Після перетворення коефіцієнти перетворення в TU можуть бути далі стиснуті за допомогою квантування. Після квантування модуль статистичного кодування може застосовувати зигзагоподібний перегляд або інший порядок перегляду, асоційований з розміром TU, щоб переглянути двовимірну множину коефіцієнтів в TU, щоб сформувати перетворений в послідовну форму вектор, який може бути статистично кодований. Модуль статистичного кодування потім статистично кодує перетворений в послідовну форму вектор коефіцієнтів. Наприклад, модуль статистичного кодування може виконати контекстно-адаптивне кодування із змінною довжиною коду (CAVLC), контекстно-адаптивне двійкове арифметичне кодування (CABAC), або інший спосіб статистичного кодування. У випадку контекстно-адаптивного статистичного кодування модуль статистичного кодування може вибрати контексти для кожного з коефіцієнтів у TU згідно з контекстною моделлю, асоційованою з розміром TU. Коефіцієнти можуть потім бути статистично закодовані на основі вибраних контекстів. Суть винаходу В цілому даний винахід описує способи для виконання статистичного кодування і декодування коефіцієнтів перетворення, асоційованого з блоком залишкових даних відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Наприклад, об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. У деяких випадках більше ніж два розміри блоків перетворення можуть спільно використовувати одну і ту саму об'єднану контекстну модель. Як один приклад, об'єднана контекстна модель може бути об'єднаною контекстною моделлю карти значущості для блока перетворення. В інших прикладах об'єднана контекстна модель може бути асоційована з іншою інформацією кодування або елементами синтаксису. У стандарті кодування відео з високою ефективністю (HEVC), що знаходиться в стадії становлення, блок кодування (CU) може включати в себе один або більше блоків перетворення (TU), які включають в себе залишкові дані відео для перетворення. Додаткові розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео, але також і призвели до збільшеної пам'яті та обчислювальних вимог для підтримки контекстної моделі для кожного з додаткових розмірів блока перетворення. Виконання статистичного кодування, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, може зменшити об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності на пристроях кодування і декодування відео, і зменшити обчислювальні витрати підтримки контекстних моделей на пристроях кодування і декодування відео. У деяких прикладах способи можуть також зменшити вимоги проміжної буферизації для великих розмірів блока перетворення при виконанні двовимірних перетворень. У цьому випадку способи включають в себе обнулення, тобто, встановлення значень в нуль, піднабору більш 1 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 високочастотних коефіцієнтів перетворення, включених в блок перетворення першого розміру після застосування кожного напрямку двовимірного перетворення, щоб згенерувати блок коефіцієнтів, що залишилися. У цьому прикладі об'єднана контекстна модель для статистичного кодування може бути спільно використана між блоком перетворення, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоком перетворення, що спочатку має другий розмір. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. В інших прикладах об'єднана контекстна модель для статистичного кодування може бути спільно використана між блоком перетворення, який має перший розмір, і блоком перетворення, який має другий розмір. В одному прикладі винахід описує спосіб декодування даних відео, який містить підтримку об'єднаної контекстної моделі, що спільно використовується блоком перетворення, який має перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні. Спосіб також включає в себе вибір контекстів для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру згідно з об'єднаною контекстною моделлю, і статистичне кодування коефіцієнтів, асоційованих з блоком перетворення згідно з процесом кодування на основі вибраних контекстів. В іншому прикладі винахід описує пристрій кодування відео, що містить пам'ять, яка зберігає об'єднану контекстну модель, що спільно використовується блоком перетворення, який має перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні. Пристрій кодування відео далі включає в себе процесор, що конфігурується, щоб підтримувати об'єднану контекстну модель, вибирати контексти для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру, згідно з об'єднаною контекстною моделлю, і статистично кодувати коефіцієнти, асоційовані з блоком перетворення, згідно з процесом кодування, на основі вибраних контекстів. В іншому прикладі винахід описує пристрій кодування відео, який містить засіб для підтримки об'єднаної контекстної моделі, що спільно використовується блоком перетворення, який має перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні. Пристрій кодування відео також містить засіб для вибору контекстів для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру згідно з об'єднаною контекстною моделлю, і засіб для статистичного кодування коефіцієнтів, асоційованих з цим блоком перетворення, згідно з процесом кодування на основі вибраних контекстів. В іншому прикладі винахід описує зчитуваний комп'ютером носій, що містить інструкції для кодування даних відео, які, коли виконуються, змушують процесор підтримувати об'єднану контекстну модель, що спільно використовується блоком перетворення, який має перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні. Інструкції також змушують процесор вибирати контексти для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру згідно з об'єднаною контекстною моделлю, і статистично кодувати коефіцієнти, асоційовані з цим блоком перетворення, згідно з процесом кодування на основі вибраних контекстів. В іншому прикладі винахід описує спосіб кодування даних відео, який містить підтримку об'єднаної контекстної моделі, що спільно використовується блоком перетворення, який має перший розмір, і блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні. Спосіб також включає в себе вибір контекстів для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру і другого розміру, згідно з об'єднаною контекстною моделлю, і статистичне кодування коефіцієнтів блока перетворення згідно з процесом кодування на основі вибраних контекстів. У додатковому прикладі винахід описує пристрій кодування відео, що містить пам'ять, яка зберігає об'єднану контекстну модель, що спільно використовується блоком перетворення, який має перший розмір, і блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні, і процесор, що конфігурується, щоб підтримувати об'єднану контекстну модель, вибирати контексти для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру і другого розміру згідно з об'єднаною контекстною моделлю, і 2 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 статистично кодувати коефіцієнти блока перетворення згідно з процесом кодування на основі вибраних контекстів. У подальшому прикладі винахід описує пристрій кодування відео, який містить засіб для підтримування об'єднаної контекстної моделі, що спільно використовується блоком перетворення, який має перший розмір, і блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні. Пристрій кодування відео також включає в себе засіб для вибору контекстів для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру і другого розміру згідно з об'єднаною контекстною моделлю, і засіб для статистичного кодування коефіцієнтів блока перетворення згідно з процесом кодування на основі вибраних контекстів. В іншому прикладі винахід описує зчитуваний комп'ютером носій, що містить інструкції для кодування даних відео, які, коли виконуються, змушують процесор підтримувати об'єднану контекстну модель, що спільно використовується блоком перетворення, який має перший розмір, і блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір є різними, вибирати контексти для коефіцієнтів, асоційованих з блоком перетворення, який має один з першого розміру і другого розміру згідно з об'єднаною контекстною моделлю, і статистично кодувати коефіцієнти блока перетворення згідно з процесом кодування на основі вибраних контекстів. Короткий опис креслень Фіг. 1 є блок-схемою, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати способи для виконання статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Фіг. 2 є блок-схемою, що ілюструє зразковий кодер відео, який може реалізувати способи для статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Фіг. 3A та 3B - концептуальні діаграми, що відповідно ілюструють квадратні та прямокутні ділянки блоків коефіцієнтів, що залишилися, які мають другий розмір, з блока перетворення, який має перший розмір. Фіг. 4 є блок-схемою, що ілюструє зразковий декодер відео, який може реалізувати способи для статистичного декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Фіг. 5 є блок-схемою, що ілюструє зразковий модуль статистичного кодування, що конфігурується, щоб вибрати контексти для коефіцієнтів відео згідно з об'єднаною контекстною моделлю. Фіг. 6 є блок-схемою, що ілюструє зразковий модуль статистичного декодування, що конфігурується, щоб вибрати контексти для коефіцієнтів відео згідно з об'єднаною контекстною моделлю. Фіг. 7 є послідовністю операцій, що ілюструє зразкову операцію статистичного кодування і статистичного декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір. Фіг. 8 є послідовністю операцій, що ілюструє зразкову операцію статистичного кодування і декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між першим блоком перетворення, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і другим блоком перетворення, який має другий розмір. Докладний опис В цілому цей винахід описує способи для виконання статистичного кодування і декодування коефіцієнтів перетворення, асоційованих з блоком залишкових даних відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Наприклад, об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. У стандарті кодування відео з високою ефективністю (HEVC), що знаходиться в стадії становлення, блок кодування (CU) може включати в себе один або більше блоків перетворення (TU), які включають в себе залишкові дані відео. До перетворення залишкові дані відео включають в себе залишкові піксельні значення в просторовій ділянці. Після перетворення залишкові дані відео включають в себе залишкові коефіцієнти перетворення в ділянці перетворення. Додаткові розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео, але також призвело до збільшення пам'яті та обчислювальних вимог, щоб підтримувати контекстні 3 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 моделі для кожного з додаткових розмірів блока перетворення. Виконання статистичного кодування, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, може зменшити об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності на пристроях кодування і декодування відео, і зменшити обчислювальні витрати підтримки контекстних моделей на пристроях кодування і декодування відео. У деяких прикладах способи можуть також зменшити вимоги проміжної буферизації для більш крупних розмірів блоків перетворення при виконанні двовимірних перетворень. Способи включають в себе обнулення, тобто, встановлення значень в нуль, піднабору більш високочастотних коефіцієнтів перетворення, включених в блок перетворення першого розміру, після того як кожний напрямок двовимірного перетворення було застосовано, щоб генерувати блок коефіцієнтів, що залишилися. Пристрої кодування і декодування відео можуть потім буферизувати скорочену кількість коефіцієнтів між застосуванням кожного напрямку, тобто, рядки і стовпці, двовимірного перетворення. Коли більш високочастотні коефіцієнти обнулені з блока перетворення, який має перший розмір, коефіцієнти, включені в блок коефіцієнтів, що залишилися, мають аналогічну імовірнісну статистику, що і коефіцієнти, включені в блок перетворення початково другого розміру. У цьому випадку об'єднана контекстна модель для статистичного кодування може бути спільно використана між блоками перетворення, які мають перший розмір, з коефіцієнтами, обнуленими для генерування блока коефіцієнтів, що залишилися, і блоками перетворення, які спочатку мають другий розмір. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. В інших випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює третьому розміру, відмінному і від першого розміру і від другого розміру. В інших прикладах коефіцієнти, включені в перший блок перетворення, який має перший розмір, можуть мати подібну статистику імовірності, як і коефіцієнти, включені у другий блок перетворення другого розміру навіть без обнулення більш високочастотних коефіцієнтів в межах першого блока перетворення. Це можливе тому, що більш високочастотні коефіцієнти можуть представляти такі маленькі залишкові дані відео, що вплив на імовірнісну статистику сусідніх коефіцієнтів для статистичного кодування незначний. У цьому випадку об'єднана контекстна модель для статистичного кодування може бути спільно використана між блоками перетворення, які мають перший розмір, і блоками перетворення, які мають другий розмір. Фіг. 1 є блок-схемою, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати способи для виконання статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Як показано на Фіг. 1, система 10 включає в себе вихідний пристрій 12, який може зберігати кодоване відео і/або передавати кодоване відео на пристрій-адресат 14 через комунікаційний канал 16. Вихідний пристрій 12 і пристрій-адресат 14 можуть не обов'язково брати участь в активному зв'язку в реальному часі один з одним. У деяких випадках вихідний пристрій 12 може зберігати кодовані дані відео на носій даних, до якого пристрій-адресат 14 може одержати доступ при необхідності за допомогою звернення до диска, або може зберегти кодовані дані відео на файл-сервер, до якого пристрій-адресат 14 може одержати доступ при необхідності за допомогою потокової передачі. Вихідний пристрій 12 і пристрій-адресат 14 можуть містити будь-який з широкого діапазону пристроїв. У деяких випадках вихідний пристрій 12 і пристрій-адресат 14 можуть містити пристрої бездротового зв'язку, які можуть обмінюватися інформацією відео по комунікаційному каналу 16, коли комунікаційний канал 16 є бездротовим. Однак, способи згідно з даним винаходом, які стосуються статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, не обов'язково обмежені бездротовими додатками або параметрами настройки. Наприклад, ці способи можуть належати до ефірного телевізійного мовлення, передач кабельного телебачення, передач супутникового телебачення, передач відео по Інтернет, кодованого цифрового відео, яке закодоване на носій даних, або інших сценаріїв. Відповідно, комунікаційний канал 16 може містити будь-яку комбінацію бездротових або дротових носіїв, прийнятних для передачі кодованих даних відео, і пристрої 12, 14 можуть містити будь-який з множини пристроїв з дротовими або бездротовими носіями, такими як мобільні телефони, смартфони, цифрові медіа-програвачі, телевізійні приставки, телевізори, дисплеї, настільні комп'ютери, портативні комп'ютери, планшетні комп'ютери, ігрові консолі, портативні ігрові пристрої або подібне. У прикладі згідно з Фіг. 1 вихідний пристрій 12 включає в себе джерело 18 відео, кодер 20 відео, модулятор/демодулятор (модем) 22 і передавач 24. Пристрій-адресат 14 включає в себе приймач 26, модем 28, декодер 30 відео і пристрій 32 відображення. В інших прикладах 4 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 вихідний пристрій і пристрій-адресат можуть включати в себе інші компоненти або компонування. Наприклад, вихідний пристрій 12 може приймати дані відео від зовнішнього джерела 18 відео, такого як зовнішня камера, запам'ятовуючий пристрій відео, джерело комп'ютерної графіки або подібне. Аналогічно, пристрій-адресат 14 може з'єднуватися із зовнішнім пристроєм відображення, замість включення інтегрованого пристрою відображення. Ілюстрована система 10 згідно з фіг. 1 є просто одним прикладом. В інших прикладах будьякий цифровий пристрій кодування і/або декодування відео може виконувати розкриті способи для статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Способи можуть бути також виконані кодером/декодером відео, який звичайно називається "кодеком". Крім того, способи згідно з даним винаходом можуть бути також виконані передпроцесором відео. Вихідний пристрій 12 і пристрій-адресат 14 є просто прикладами таких пристроїв кодування, в яких вихідний пристрій 12 генерує кодовані дані відео для передачі на пристрій-адресат 14. У деяких прикладах пристрої 12, 14 можуть працювати по суті симетричним чином таким чином, що кожний з пристроїв 12, 14 включають в себе компоненти кодування і декодування відео. Отже, система 10 може підтримувати однонаправлену або двонаправлену передачу відео між відео пристроями 12, 14, наприклад, для потокової передачі відео, відтворення відео, бездротового мовлення відео або відео телефонії. Джерело 18 відео з вихідного пристрою 12 може включати в себе пристрій захоплення відео, такий як відео камера, відео архів, що містить раніше захоплене відео, і/або подачу відео від постачальника відео контенту. Як інша альтернатива, джерело 18 відео може генерувати основані на комп'ютерній графіці дані як вихідне відео, або комбінація відео в реальному часі, архівоване відео і відео, що генерується комп'ютером. У деяких випадках, якщо джерело 18 відео є відео камерою, вихідний пристрій 12 і пристрій-адресат 14 можуть формувати так звані камерофони або відео телефони. Як згадано вище, однак, способи, описані в даному винаході, можуть бути застосовними до кодування відео взагалі, і можуть бути застосовані до бездротових і/або дротових додатків. У кожному випадку захоплене, заздалегідь захоплене або відео, що генерується комп'ютером, може бути закодоване кодером 20 відео. Закодована інформація відео може потім модулюватися модемом 22 згідно зі стандартом зв'язку, і передана на пристрій-адресат 14 через передавач 24. Модем 22 може включати в себе різні змішувачі, фільтри, підсилювачі або інші компоненти, розроблені для модуляції сигналу. Передавач 24 може включати в себе схеми, розроблені для передачі даних, включаючи підсилювачі, фільтри і одну або більше антен. Відповідно до даного винаходу кодер 20 відео з вихідного пристрою 12 може бути сконфігурований, щоб застосовувати способи для статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Блок кодування (CU) кадру відео, який повинен бути закодований, може включати в себе один або більше блоків перетворення (TU), які включають в себе залишкові дані відео. До перетворення залишкові дані відео включають в себе залишкові піксельні значення в просторовій ділянці. Після перетворення залишкові дані відео включають в себе залишкові коефіцієнти перетворення в перетвореній ділянці. Кодер 20 відео може підтримувати об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, і вибирати контексти для коефіцієнтів, асоційованих з одним з перетворених блоків згідно з об'єднаною контекстною моделлю. Кодер 20 відео може потім статистично кодувати коефіцієнти на основі вибраних контекстів. Як приклад об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. В інших прикладах більш ніж два розміри блоків перетворення можуть спільно використовувати одну і ту саму об'єднану контекстну модель. Крім того, два або більше розмірів блоків перетворення можуть спільно використовувати деякі або всі з контекстних моделей для блоків TU. В одному випадку об'єднана контекстна модель може бути об'єднаною контекстною моделлю карти значущості для TU. В інших випадках об'єднана контекстна модель може бути асоційована з іншою інформацією кодування або елементами синтаксису. Ці способи тому можуть зменшити об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності на кодері 20 відео і зменшити обчислювальні витрати підтримки контекстних моделей на кодері 20 відео. В одному прикладі кодер 20 відео може обнуляти, тобто, встановлювати значення, що дорівнюють нулю, більш високочастотний піднабір коефіцієнтів перетворення, включених в блок перетворення першого розміру, після того як кожний напрямок двовимірного перетворення застосований, щоб генерувати блок коефіцієнтів, що залишилися. У цьому випадку способи можуть зменшити кількість коефіцієнтів, які повинні бути буферизовані між застосуванням кожного напрямку, тобто, рядки і стовпці, двовимірного перетворення. Коли високочастотні коефіцієнти обнуляються з блока перетворення, коефіцієнти, включені в блок коефіцієнтів, що 5 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 залишилися, мають аналогічну імовірнісну статистику, що і коефіцієнти, включені в блок перетворення початково другого розміру. У цьому прикладі кодер 20 відео може підтримувати об'єднану контекстну модель, що спільно використовується блоками перетворення, які мають перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоками перетворення, які мають другий розмір, і вибирати контексти для коефіцієнтів блока перетворення одного з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру, згідно з об'єднаною контекстною моделлю. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. В інших випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює третьому розміру, відмінному і від першого розміру і від другого розміру. В іншому прикладі коефіцієнти, включені в перший блок перетворення, який має перший розмір, може мати подібну статистику імовірності, що і коефіцієнти, включені у другий блок перетворення, який має другий розмір, навіть без обнулення високочастотних коефіцієнти в межах першого блока перетворення. Це можливе, оскільки високочастотні коефіцієнти можуть представляти такі маленькі залишкові дані відео, що вплив на імовірнісну статистику сусідніх коефіцієнтів для статистичного кодування незначний. У цьому прикладі кодер 20 відео може підтримувати об'єднану контекстну модель, що спільно використовується блоками перетворення, які мають перший розмір і другий розмір, і вибирати контексти для коефіцієнтів у блоці перетворення одного з першого і другого розміру згідно з об'єднаною контекстною моделлю. У деяких випадках тільки високочастотні коефіцієнти в межах перетворених блоків першого розміру і другого розміру можуть спільно використовувати об'єднану контекстну модель. Низькочастотні коефіцієнти, наприклад, компоненти DC і сусідні коефіцієнти, в перетворенні першого розміру можуть використовувати відмінну контекстну модель, ніж низькочастотні коефіцієнти в перетворенні другого розміру. Приймач 26 з пристрою-адресата 14 приймає інформацію по каналу 16, і модем 28 демодулює цю інформацію. Інформація, передана по каналу 16, може включати в себе інформацію синтаксису, визначену кодером 20 відео, яка також використовується декодером 30 відео, яка включає в себе елементи синтаксису, які описують характеристики і/або обробку блоків кодування (CU), блоків прогнозування (PU), блоків перетворення (TU) або інші одиниці кодованого відео, наприклад, вирізок відео, кадрів відео, і послідовностей відео або груп картинок (GOP). Пристрій 32 відображення відображає декодовані дані відео користувачу, і може містити будь-яку множину пристроїв відображення, таких як електронно-променева трубка (CRT), рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світловипромінюючих діодах (OLED), або інший тип пристрою відображення. Відповідно до даного винаходу декодер 30 відео з пристрою-адресата 14 може бути сконфігурований, щоб застосовувати способи статистичного декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Блок CU кадру відео, який повинен бути декодований, може включати в себе один або більше блоків TU, які включають в себе залишкові дані відео до і після перетворення. Декодер 30 відео може підтримувати об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, і вибирати контексти для коефіцієнтів, асоційованих з одним з перетворених блоків, згідно з об'єднаною контекстною моделлю. Декодер 30 відео може потім статистично декодувати коефіцієнти на основі вибраних контекстів. Як приклад об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. Як описано вище, в інших прикладах більше ніж два розміри блоків перетворення можуть спільно використовувати одну і ту саму об'єднану контекстну модель. Крім того, два або більше розмірів блоків перетворення можуть спільно використовувати деякі або всі контекстні моделі для блоків TU. В одному випадку об'єднана контекстна модель може бути об'єднаною контекстною моделлю карти значущості для TU. В інших випадках об'єднана контекстна модель може бути асоційована з іншою інформацією кодування або елементами синтаксису. Ці способи тому можуть зменшувати об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності на декодері 30 відео, і зменшити обчислювальні витрати на підтримку контекстних моделей на декодері 30 відео. В одному прикладі декодер 30 відео може прийняти потік бітів, який представляє кодовані коефіцієнти, асоційовані з блоком коефіцієнтів, що залишилися, і обнулені коефіцієнти від блока перетворення, який має перший розмір. Коли високочастотні коефіцієнти є обнуленими з блока перетворення, коефіцієнти, включені в блок коефіцієнтів, що залишилися, мають аналогічну імовірнісну статистику, що і коефіцієнти, включені в блок перетворення початково другого розміру. У цьому прикладі декодер 30 відео може підтримувати об'єднану контекстну модель, 6 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 що спільно використовується блоками перетворення, які мають перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і блоками перетворення, які мають другий розмір, і вибирати контексти для кодованих коефіцієнтів, асоційованих з блоком перетворення одного з першого розміру з блоком коефіцієнтів, що залишилися, і другого розміру, згідно з об'єднаною контекстною моделлю. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. В інших випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює третьому розміру, відмінному і від першого розміру і від другого розміру. В іншому прикладі декодер 30 відео може прийняти потік бітів, який представляє кодовані коефіцієнти, асоційовані з блоком перетворення, що має один з першого розміру і другого розміру. Коефіцієнти, включені в перший блок перетворення, який має перший розмір, можуть мати подібну статистику імовірності, що і коефіцієнти, включені у другий блок перетворення другого розміру, навіть без обнулення високочастотних коефіцієнтів у межах першого блока перетворення. У цьому прикладі декодер 30 відео може підтримувати об'єднану контекстну модель, що спільно використовується блоками перетворення, які мають перший розмір і другий розмір, і вибирати контексти для кодованих коефіцієнтів, асоційованих з блоком перетворення одного з першого і другого розміру, згідно з об'єднаною контекстною моделлю. У деяких випадках тільки високочастотні коефіцієнти в межах перетворених блоків першого розміру і другого розміру можуть спільно використовувати об'єднану контекстну модель. Низькочастотні коефіцієнти, наприклад, компоненти DC і сусідні коефіцієнти, в перетворенні першого розміру можуть використовувати відмінну контекстну модель, ніж низькочастотні коефіцієнти в перетворенні другого розміру. У прикладі на Фіг. 1 комунікаційний канал 16 може містити будь-який з бездротового або дротового носія зв'язку, такого як радіочастотний (RF, РЧ) спектр або одна або більше фізичних ліній передачі, або будь-яку комбінацію бездротового і дротового носія. Комунікаційний канал 16 може формувати частину основаної на пакетній передачі мережі, такої як локальна мережа, широкомасштабна мережа, або глобальна мережа, така як Інтернет. Комунікаційний канал 16 звичайно являє собою будь-який прийнятний комунікаційний носій, або колекцію різних комунікаційних носіїв, для того, щоб передати дані відео від вихідного пристрою 12 на пристрійадресат 14, включаючи будь-яку прийнятну комбінацію дротового або бездротового носія. Комунікаційний канал 16 може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути використане, щоб полегшити передачу від вихідного пристрою 12 на пристрій-адресат 14. Як описано вище, в деяких випадках вихідний пристрій 12 і пристрій-адресат 14 можуть не брати участь в активному зв'язку в реальному часі через комунікаційний канал 16. Наприклад, вихідний пристрій 12 може замість цього зберегти кодовані дані відео на носій даних, до якого пристрій-адресат 14 може одержати доступ при необхідності за допомогою доступу до диска, або зберегти кодовані дані відео в файл-сервер, до якого пристрій-адресат 14 може одержати доступ при необхідності за допомогою потокової передачі. Кодер 20 відео і декодер 30 відео можуть працювати згідно зі стандартом стиснення відео, таким як стандарт кодування відео з високою ефективністю (HEVC) такий, що знаходиться в стадії становлення, або стандарт ITU-T H.264, який альтернативно називається MPEG-4, Частина 10, Вдосконалене кодування відео (AVC). Способи з даного винаходу, однак, не обмежені ніяким конкретним стандартом кодування. Інші приклади включають в себе MPEG-2 та ITU-T H.263. Хоча не показано на Фіг. 1, в деяких аспектах кодер 20 відео і декодер 30 відео може бути кожний інтегровані з кодером і декодером аудіо, і можуть включати в себе відповідні блоки MU×-DEMU× (мультиплексування-демультиплексування), або інше апаратне забезпечення і програмне забезпечення, щоб обробляти кодування і аудіо і відео в загальному потоку даних або окремих потоках даних. Якщо застосовно, блоки MU×-DEMU× можуть відповідати протоколу ITU H.223 мультиплексора або іншим протоколам, таким як протокол дейтаграм користувача (UDP). Зусилля по стандартизації HEVC основані на моделі пристрою кодування відео, що називається Тестова Модель HEVC (HM). HM передбачає декілька додаткових можливостей пристрою кодування відео відносно існуючих пристроїв, згідно з, наприклад, ITU-T H.264/AVC. HM посилається на блок даних відео як блок кодування (CU). Дані синтаксису в межах потоку бітів можуть визначати найбільший блок кодування (LCU), який є найбільшим блоком кодування в термінах кількості пікселів. В цілому, CU має аналогічне призначення до макроблока стандарту H.264, за винятком того, що CU не має різниці в розмірах. Таким чином, CU може бути розділений в під-CU. В цілому, посилання в даному винаході на CU можуть належати до найбільшого блока кодування картинки або під-CU в LCU. LCU може бути розділений на під-CU, і кожний під-CU може бути далі розділений в під-CU. Дані синтаксису для потоку бітів можуть 7 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 визначити максимальну кількість разів, скільки LCU може бути розділений, що називається глибиною CU. Відповідно, потік бітів може також визначити найменший блок кодування (SCU). CU, яка далі не розділена (тобто, листовий вузол LCU) може включати в себе один або більше блоків прогнозування (PU). В цілому, PU представляє весь або частину відповідного CU, і включає в себе дані для витягання опорної вибірки для PU. Наприклад, коли PU є закодованим у внутрішньому режимі, PU може включати в себе дані, що описують режим внутрішнього прогнозування для PU. Як інший приклад, коли PU є закодованим у зовнішньому режимі, PU може включати в себе дані, що визначають вектор руху для PU. Дані, що визначають вектор руху, можуть описувати, наприклад, горизонтальний компонент вектора руху, вертикальний компонент вектора руху, розрізнення для вектора руху (наприклад, точність в півпікселя, точність в чверть пікселя, або точність в одну восьму пікселя), опорний кадр, на який вектор руху вказує, і/або список опорних кадрів (наприклад, Список 0 або Список 1) для вектора руху. Дані для CU, що визначають PU(s), можуть також описувати, наприклад, фрагментування CU в один або більше блоків PU. Режими фрагментування можуть відрізнятися між тим, чи є CU пропущеним або кодованим в прямому режимі, кодованим в режимі внутрішнього прогнозування, або кодованим в режимі зовнішнього прогнозування. CU, що має один або більше PU, може також включати в себе один або більше блоків перетворення (TU). Дотримуючись прогнозування, використовуючи PU, кодер відео може обчислити залишкові значення для частини CU, що відповідає PU. Залишкові значення, включені в блоки TU, відповідають значенням піксельної різниці, які можуть бути перетворені в коефіцієнти перетворення, потім квантовані і скановані, щоб сформувати перетворені в послідовну форму коефіцієнти перетворення для статистичного кодування. TU не обов'язково обмежений розміром PU. Таким чином, блоки TU можуть бути більшими або меншими, ніж відповідний PU для одного і того самого CU. У деяких прикладах максимальний розмір TU може бути розміром відповідного CU. Даний винахід використовує термін "блок відео", щоб звертатися до будь-якого з CU, PU або TU. Кодер 20 відео і декодер 30 відео кожний може бути реалізований як будь-яке з множини прийнятних схем кодера, таких як один або більше мікропроцесорів, цифрових сигнальних процесорів (DSP), спеціалізованих інтегральних схем (ASIC), програмованих користувачем вентильних матриць (FPGA), дискретної логіки, програмного забезпечення, апаратного забезпечення, програмно-апаратних засобів або будь-яких їх комбінацій. Кожний кодер 20 відео і декодер 30 відео може бути включений в один або більше кодерів або декодерів, будь-який з яких може бути інтегрований як частина об'єднаного кодера/декодера (кодека) у відповідну камеру, комп'ютер, мобільний пристрій, пристрій абонента, пристрій мовлення, телевізійну приставку, сервер або подібне. Послідовність відео або група картинок (GOP, ГК) звичайно включають в себе ряд кадрів відео. GOP може включати дані синтаксису в заголовок GOP, заголовок одного або більше кадрів у GOP, або в інше місце, які описують кількість кадрів, включених в GOP. Кожний кадр може включати в себе дані синтаксису кадру, які описують режим кодування для відповідного кадру. Кодер 20 відео звичайно оперує над блоками відео в межах індивідуальних кадрів відео, щоб закодувати дані відео. Блок відео може відповідати CU або PU в CU. Блок відео може мати фіксований або змінний розміри, і може відрізнятися за розміром згідно з вказаним стандартом кодування. Кожний кадр відео може включати в себе множину вирізок. Кожна вирізка може включати в себе множину CU, які можуть включати в себе один або більше PU. Як приклад Тестова Модель HEVC (HM) підтримує прогнозування в CU різних розмірів. Розмір LCU може бути визначений за допомогою інформації синтаксису. Передбачаючи, що розмір конкретного CU що дорівнює 2N×2N, HM підтримує внутрішнє прогнозування в розмірах 2N×2N або N×N, і зовнішнє прогнозування в симетричних розмірах 2N×2N, 2N×N, N×2N або N×N. HM також підтримує асиметричне розділення для зовнішнього прогнозування для 2N×nU, 2N×nD, nL×2N та nR×2N. В асиметричному розділенні один напрямок CU не розділяється, в той час як інший напрямок розділяється на 25 % та 75 %. Частина CU, що відповідає 25 %-ому розділенню, позначається "n" з супровідною індикацією "Верхній", "Нижній", "Лівий" або "Правий". Таким чином, наприклад, "2N×nU" належить до 2N×2N CU, який розділений горизонтально з 2N×0.5 N PU зверху і 2N×1.5 N PU внизу. У даному винаході "N×N" та "N на N" може використовуватися взаємозамінно, щоб належати до піксельних вимірювань блока відео (наприклад, CU, PU або TU) в термінах вертикальних і горизонтальних вимірювань, наприклад, 16×16 пікселі або 16 на 16 пікселів. Блок 16×16 буде мати 16 пікселів у вертикальному напрямку (у=16) і 16 пікселів в горизонтальному напрямку (х=16). Аналогічно, блок N×N має N пікселів у вертикальному напрямку і N пікселів в горизонтальному напрямку, де N представляє ненегативне цілочисельне значення. Пікселі в 8 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 блоці можуть бути розміщені в рядках і стовпцях. Крім того, блоки не обов'язково повинні мати ту саму кількість пікселів у горизонтальному напрямку, як у вертикальному напрямку. Наприклад, блоки можуть містити прямокутні ділянки з пікселями N×M, де М не обов'язково дорівнює N. Після кодування з внутрішнім прогнозуванням або зовнішнім прогнозуванням, щоб сформувати PU для CU, кодер 20 відео може обчислити залишкові дані, щоб сформувати один або більше блоків TU для CU. Залишкові дані можуть відповідати піксельним різницям між пікселями незакодованої картинки і значеннями прогнозування PU в CU. Кодер 20 відео може сформувати один або більше блоків TU, що включають в себе залишкові дані для CU. Кодер 20 відео може потім перетворити блоки TU. До застосування перетворення, такого як дискретне косинусне перетворення (DCT), цілочисельне перетворення, вейвлет перетворення, або концептуально подібне перетворення, блоки TU в CU можуть містити залишкові дані відео, що містять значення піксельної різниці в піксельній ділянці. Після застосування перетворення блоки TU можуть містити коефіцієнти перетворення, які представляють залишкові дані відео в частотній ділянці. Після будь-яких перетворень для формування коефіцієнтів перетворення може бути виконано квантування коефіцієнтів перетворення. Квантування в цілому належить до процесу, в якому коефіцієнти перетворення квантуються, щоб можливо зменшити кількість даних, що використовуються для представлення коефіцієнтів. Процес квантування може зменшити глибину в бітах, асоційовану з деякими або всіма коефіцієнтами. Наприклад, значення n-бітів може бути округлене в менший бік до бітового значення m-бітів під час квантування, де n більше ніж m. Кодер 20 відео може застосувати зигзагоподібний перегляд, горизонтальний перегляд, вертикальний перегляд або інший порядок перегляду, асоційований з розміром TU, щоб сканувати (переглянути) квантовані коефіцієнти перетворення, щоб сформувати перетворений в послідовну форму вектор, який може бути статистично кодований. У деяких прикладах кодер 20 відео може використовувати заздалегідь заданий порядок перегляду, щоб переглянути квантовані коефіцієнти перетворення. В інших прикладах кодер 20 відео може виконати адаптивний перегляд (сканування). Після перегляду квантованих коефіцієнтів перетворення, щоб сформувати одновимірний вектор, кодер 20 відео може статистично кодувати одновимірний вектор, наприклад, згідно з контекстно-адаптивним кодуванням із змінною довжиною коду (CAVLC), контекстно-адаптивним двійковим арифметичним кодуванням (CABAC), або іншим методом статистичного кодування. Щоб виконати контекстно-адаптивне статистичне кодування, кодер 20 відео повинен призначити контекст на кожний коефіцієнт згідно з контекстною моделлю, яка може належати до, наприклад, того, чи є значення сусідніх коефіцієнтів відмінними від нуля. Кодер 20 відео потім визначає процес кодування для цього коефіцієнта, асоційованого з призначеним контекстом в контекстній моделі. Звичайно, кодер 20 відео повинен підтримувати окремі контекстні моделі для кожного з різних розмірів блоків TU, що підтримуються реалізованим стандартом стиснення відео. Для стандарту HEVC додаткові розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео, але додаткові розміри TU також призводять до збільшеної пам'яті і обчислювальних вимог, щоб підтримувати контекстні моделі для кожного з додаткових розмірів блока перетворення. Відповідно до способів даного винаходу, щоб виконати контекстно-адаптивне статистичне кодування, кодер 20 відео може вибрати контексти для коефіцієнтів згідно з об'єднаною контекстною моделлю, що спільно використовується між блоками TU різних розмірів. Більш конкретно, кодер 20 відео може призначити контекст в об'єднаній контекстній моделі заданому коефіцієнту блока TU на основі значень раніше кодованих сусідніх коефіцієнтів цього TU. Призначений контекст вибирають на основі критеріїв, визначених об'єднаною контекстною моделлю, що спільно використовується за допомогою TU. Кодер 20 відео може визначити процес кодування для коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі. Кодер 20 відео потім статистично кодує цей коефіцієнт на основі визначеної оцінки імовірності. Наприклад, у випадку CABAC кодер 20 відео може визначити оцінку імовірності для значення (наприклад, 0 або 1) коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі. Кодер 20 відео потім оновлює оцінку імовірності, асоційовану з призначеним контекстом в об'єднаній контекстній моделі, на основі фактично кодованого значення коефіцієнта. Як приклад кодер 20 відео може вибрати контексти, використовуючи одну і ту саму об'єднану контекстну модель для коефіцієнтів, асоційованих або з блоком коефіцієнтів, що 9 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 залишилися, в межах першого блока перетворення, що спочатку має перший розмір, або з другим блоком перетворення, що спочатку має другий розмір. Крім того, кодер 20 відео може оновити оцінки імовірності, асоційовані з вибраними контекстами в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів або блока коефіцієнтів, що залишилися, в межах першого блока перетворення початково першого розміру, або другого блока перетворення початково другого розміру. Як інший приклад, кодер 20 відео може вибрати контексти, використовуючи одну і ту саму об'єднану контекстну модель для коефіцієнтів, асоційованих або з першим блоком перетворення, який має перший розмір, або з другим блоком перетворення, який має другий розмір. У цьому випадку кодер 20 відео може потім оновити оцінки імовірності, асоційовані з вибраними контекстами в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів або першого блока перетворення першого розміру або другого блока перетворення другого розміру. У будь-якому випадку спільно використовуючи об'єднану контекстну модель між двома або більше розмірами блока перетворення, можна зменшити об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності в кодері 20 відео. Крім того, спільне використання об'єднаної контекстної моделі може також зменшити обчислювальні витрати підтримки контекстних моделей на кодері 20 відео, включаючи переустановлення всієї контекстної моделі на початку вирізки відео. Кодер 20 відео може також статистично кодувати елементи синтаксису, що вказують інформацію прогнозування. Наприклад, кодер 20 відео може статистично кодувати елементи синтаксису, що вказують інформацію блока відео, що включає розміри блоків CU, PU та TU, інформацію вектора руху для прогнозування у внутрішньому режимі, і інформацію карти значущих коефіцієнтів, тобто, карти одиниць і нулів, що вказують позицію значущих коефіцієнтів, для CABAC. Декодер 30 відео може працювати способом, по суті симетричним такому кодера 20 відео. Фіг. 2 є блок-схемою, що ілюструє зразковий кодер відео, який може реалізувати способи для статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. Кодер 20 відео може виконувати внутрішнє і зовнішнє кодування блоків кодування в межах кадрів відео. Внутрішнє кодування покладається на просторове прогнозування, щоб зменшити або видалити просторову надмірність у відео в межах заданого кадру відео. Зовнішнє кодування покладається на часове прогнозування, щоб зменшити або видалити часову надмірність у відео в межах суміжних кадрів послідовності відео. Внутрішній режим (I режим) може належати до будь-якого з декількох просторово-основаних режимів стиснення. Зовнішні режими, такі як однонаправлене прогнозування (Р-режим), двонаправлене прогнозування (Врежим), або узагальнене прогнозування Р/В (режим GPB) можуть належати до будь-якого з декількох час-основаних режимів стиснення. У прикладі на Фіг. 2 кодер 20 відео включає в себе модуль 38 вибору режиму, модуль 40 прогнозування, модуль 50 підсумовування, модуль 52 перетворення, модуль 54 квантування, модуль 56 статистичного кодування і пам'ять 64 опорних кадрів. Модуль 40 прогнозування включає в себе модуль 42 оцінки руху, модуль 44 компенсації руху і модуль 46 внутрішнього прогнозування. Для реконструкції блока відео кодер 20 відео також включає в себе модуль 58 зворотного квантування, модуль 60 зворотного перетворення і модуль 62 підсумовування. Фільтр видалення блоковості або інші контурні фільтри, такий адаптивний контурний фільтр (ALF) і адаптивне зміщення вирізки (SAO) (не показаний на Фіг. 2) можуть бути також включені, щоб фільтрувати межі блока, щоб видалити артефакти блоковості зображення з реконструйованого відео. Якщо бажано, фільтр видалення блоковості звичайно може фільтрувати вихідний сигнал модуля 62 підсумовування. Як показано на Фіг. 2, кодер 20 відео приймає блок відео в межах кадру відео або вирізки, які повинні бути кодовані. Кадр або вирізка можуть бути розділені на множинні блоки відео або CU. Модуль 38 вибору режиму може вибрати один з режимів кодування, внутрішній або зовнішній, для блока відео на основі результатів помилки. Модуль 40 прогнозування потім видає отримуваний внутрішньо або зовнішньо кодований блок прогнозування до модуля 50 підсумовування, щоб згенерувати залишкові дані блока, і до модуля 62 підсумовування, щоб відновити (реконструювати) кодований блок для використання як опорного блока в опорному кадрі. Модуль 46 внутрішнього прогнозування в модулі 40 прогнозування виконує кодування з внутрішнім прогнозуванням блока відео відносно одного або більше сусідніх блоків у тому самому кадрі, що і блок відео, який повинен бути кодований. Модуль 42 оцінки руху і модуль 44 компенсації руху в модулі 40 прогнозування виконують кодування із зовнішнім прогнозуванням блока відео відносно одного або більше опорних блоків у одному або більше опорних кадрах, 10 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 збережених в пам'яті 64 опорних кадрів. Модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути високо інтегровані, але ілюстровані окремо в концептуальних цілях. Оцінка руху, виконана модулем 42 оцінки руху, є процесом генерування векторів руху, які оцінюють рух для блоків відео. Вектор руху, наприклад, може указати зміщення блока відео або PU в межах поточного кадру відео відносно опорного блока або PU в межах опорного кадру. Опорний блок є блоком, який виявлений як близько відповідний блоку відео або PU, який повинен бути закодований, в термінах піксельної різниці, яка може бути визначена за допомогою суми абсолютної різниці (SAD), суми різниці квадратів (SSD), або іншими метриками різниці. Модуль 42 оцінки руху посилає обчислений вектор руху в модуль 44 компенсації руху. Компенсація руху, виконана модулем 44 компенсації руху, може залучити вибірку або генерування блока прогнозування на основі вектора руху, визначеного за допомогою оцінки руху. Кодер 20 відео формує залишковий блок відео, віднімаючи блок прогнозування з блока відео, що кодується. Модуль 50 підсумовування представляє компонент або компоненти, які виконують цю операцію віднімання. Модуль 44 компенсації руху може генерувати елементи синтаксису, визначені для представлення інформації прогнозування на одному або більше з рівня послідовності відео, рівня кадру відео, рівня вирізки відео, рівня CU відео, або рівня PU відео. Наприклад, модуль 44 компенсації руху може генерувати елементи синтаксису, що вказують інформацію блока відео, включаючи розміри CU, PU та TU, і інформацію вектора руху для прогнозування у внутрішньому режимі. Після того, як кодер 20 відео сформував залишковий блок відео за допомогою віднімання блока прогнозування з поточного блока відео, модуль 52 перетворення може сформувати один або більше блоків TU із залишкового блока. Модуль 52 перетворення застосовує перетворення, таке як дискретне косинусне перетворення (DCT), цілочисельне перетворення, вейвлет перетворення або концептуально подібне перетворення, до TU, щоб сформувати блок відео, що містить залишкові коефіцієнти перетворення. Перетворення може перетворювати залишковий блок з піксельної ділянки в ділянку перетворення, таку як частотна ділянка. Більш конкретно, до застосування перетворення TU може містити залишкові дані відео в піксельній ділянці, і після застосування перетворення TU може містити коефіцієнти перетворення, які представляють залишкові дані відео в частотній ділянці. У деяких прикладах модуль 52 перетворення може містити двовимірне роздільне перетворення. Модуль 52 перетворення може застосовувати двовимірне перетворення до TU за допомогою спочатку застосування одновимірного перетворення до рядків залишкових даних відео в блоці TU, тобто, в першому напрямку, і потім застосування одновимірного перетворення до стовпців залишкових даних відео в блоці TU, тобто, у другому напрямку, або навпаки. Як один приклад, TU може містити 32×32 TU. Модуль 52 перетворення може спочатку застосувати одновимірне 32-точкове перетворення до кожного рядка піксельних даних в TU, щоб згенерувати 32×32 TU проміжних коефіцієнтів перетворення, і по-друге застосувати 32-точкове одновимірне перетворення до кожного стовпця проміжних коефіцієнтів перетворення в TU, щоб генерувати 32×32 TU коефіцієнтів перетворення. Після застосування одновимірного перетворення в першому напрямку до залишкових відео даних в TU, кодер 20 відео буферизує проміжні коефіцієнти перетворення для застосування одновимірного перетворення у другому напрямку. Як описано вище, в стандарті HEVC великі розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео. Великі розміри TU, однак, також призведуть до збільшених вимог проміжної буферизації для двовимірного перетворення. Наприклад, у випадку 32×32 TU, кодер 20 відео повинен буферизувати 1024 проміжних коефіцієнтів перетворення після одновимірного перетворення в першому напрямку. Щоб зменшити вимоги проміжної буферизації для великих розмірів TU, способи, описані в даному винаході, включають в себе обнулення високочастотного піднабору коефіцієнтів перетворення, включених в TU першого розміру, після того як кожний напрямок двовимірного перетворення було застосоване. Таким чином, модуль 52 перетворення може генерувати блок коефіцієнтів, що залишилися, в блоці TU, який має другий розмір, менший ніж перший розмір TU. Процес обнулення містить встановлення значень піднабору коефіцієнтів перетворення в блоці TU, що дорівнюють нулю. Коефіцієнти перетворення, які є обнуленими, не обчислюються або відхиляються; замість цього, обнулені коефіцієнти перетворення просто встановлюються такими, що дорівнюють нулю і не мають ніякого значення для збереження або кодування. Згідно з даним винаходом обнулені коефіцієнти перетворення звичайно є більш високочастотними коефіцієнтами перетворення відносно більш низькочастотних коефіцієнтів перетворення, що 11 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 залишилися, в TU. Високочастотні коефіцієнти перетворення представляють залишкові дані відео, які звичайно відповідають дуже маленьким піксельним різницям між блоком відео, який повинен бути закодований, і блоком прогнозування. Високочастотні коефіцієнти перетворення тому можуть містити такі маленькі залишкові дані відео, що встановлення цих значень такими, що дорівнюють нулю, має незначний вплив на якість декодованого відео. Як приклад модуль 52 перетворення може застосовувати одновимірне перетворення в першому напрямку, наприклад, порядково, до залишкових відео даних в 32×32 TU та обнуляти половину проміжних коефіцієнтів перетворення, одержаних з перетворення. Кодеру 20 відео потім тільки потрібно буферизувати половину проміжних коефіцієнтів перетворення, що залишилася. Модуль 52 перетворення може потім застосувати одновимірне перетворення у другому напрямку, наприклад, по стовпцях, до проміжних коефіцієнтів перетворення, що залишилися, в 32×32 TU і знов обнулити половину коефіцієнтів перетворення, що залишилася, одержаних з перетворення. Таким чином, модуль 52 перетворення може генерувати блок коефіцієнтів значущих коефіцієнтів, що залишилися, що мають розмір 16×16 в блоці TU початково розміру 32×32. У прикладі, описаному вище, модуль 52 перетворення був сконфігурований, щоб згенерувати 16×16 блок коефіцієнтів, що залишилися, тобто, одну чверть первинного розміру TU. В інших випадках модуль 52 перетворення може бути сконфігурований, щоб генерувати блок коефіцієнтів, що залишилися, який має відмінний розмір, за допомогою обнулення більшого або меншого відсотка коефіцієнтів залежно від вимог складності кодування для процесу кодування. Крім того, в деяких випадках модуль 52 перетворення може бути сконфігурований, щоб генерувати блок коефіцієнтів, що залишилися, який має прямокутну ділянку. У цьому випадку способи забезпечують подальше скорочення вимог проміжної буферизації за допомогою спочатку застосування одновимірного перетворення в напрямку більш короткого боку (тобто, менше коефіцієнтів перетворення, що залишилися) прямокутної ділянки. Таким чином, кодер 20 відео може буферизувати менше, ніж половину проміжних коефіцієнтів перетворення до застосування одновимірного перетворення в напрямку більш довгого боку прямокутної ділянки. Процеси обнулення блоків коефіцієнтів, що залишилися, і для квадратної і для прямокутної ділянки описані більш детально з посиланнями на фіг. 3A та 3B. Модуль 52 перетворення може послати коефіцієнти перетворення, що одержуються, до модуля 54 квантування. Модуль 54 квантування квантує коефіцієнти перетворення, щоб далі зменшити швидкість передачі (частоту проходження) бітів. Процес квантування може зменшити глибину в бітах, асоційовану з деякими або всіма коефіцієнтами. Ступінь квантування може бути змінений за допомогою регулювання параметра квантування. Модуль 56 статистичного кодування або модуль 54 квантування може потім виконувати перегляд TU, що включає в себе квантовані коефіцієнти перетворення. Модуль 56 статистичного кодування може застосувати зигзагоподібний перегляд, або інший порядок перегляду, асоційований з розміром TU, щоб переглянути квантовані коефіцієнти перетворення, щоб сформувати перетворений в послідовну форму вектор, який може бути статистично кодований. В одному прикладі, в якому коефіцієнти TU початково першого розміру були обнулені, щоб згенерувати блок коефіцієнтів, що залишилися, який має другий розмір, модуль 56 статистичного кодування може переглянути коефіцієнти, що залишилися, використовуючи порядок перегляду відносно TU другого розміру. У цьому випадку модуль 56 статистичного кодування може застосувати порядок перегляду 16×16 до блока коефіцієнтів, що залишилися, який має розмір 16×16 в блоці TU початково розміру 32×32. В іншому прикладі, в якому коефіцієнти TU початково першого розміру були обнулені, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, модуль 56 статистичного кодування може переглянути коефіцієнти, що залишилися, використовуючи порядок перегляду відносно TU першого розміру, який був змінений, щоб пропустити коефіцієнти TU, не включені в блок коефіцієнтів, що залишилися. У цьому випадку блок статистичного кодування може застосувати порядок перегляду 32×32 до блока коефіцієнтів, що залишилися, який має розмір 16×16, пропускаючи всі обнулені коефіцієнти в блоці TU початково розміру 32×32. Після перегляду квантованих коефіцієнтів перетворення, щоб сформувати одновимірний вектор, модуль 56 статистичного кодування статистично кодує вектор квантованих коефіцієнтів перетворення. Наприклад, модуль 56 статистичного кодування може виконати контекстноадаптивне статистичне кодування, таке як CABAC, CAVLC, або інший спосіб статистичного кодування. Після статистичного кодування за допомогою модуля 56 статистичного кодування кодований потік бітів може бути переданий до відео декодеру, такого як декодер 30 відео, або заархівований для більш пізньої передачі або витягання. 12 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 Щоб виконати контекстно-адаптивне статистичне кодування, модуль 56 статистичного кодування призначає контекст на кожний коефіцієнт згідно з контекстною моделлю, яка може відноситися, наприклад, до того, чи є значення сусідніх коефіцієнтів відмінними від нуля. Модуль 56 статистичного кодування також визначає процес кодування для коефіцієнта, асоційованого з призначеним контекстом в контекстній моделі. Модуль 56 статистичного кодування потім статистично кодує коефіцієнти на основі призначених контекстів. Наприклад, у випадку CABAC модуль 56 статистичного кодування може визначити оцінку імовірності для значення (наприклад, 0 або 1) коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі. Модуль 56 статистичного кодування потім оновлює оцінку імовірності, асоційовану з призначеним контекстом в контекстній моделі, на основі фактично кодованого значення цього коефіцієнта. Звичайно кодер 20 відео підтримує окремі контекстні моделі для кожного з різних розмірів блоків TU, що підтримуються реалізованим стандартом стиснення відео. Для стандарту HEVC додаткові розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео, але ці додаткові розміри TU також призводять до збільшеної пам'яті та обчислювальних вимог, щоб підтримувати контекстну модель для кожного з додаткових розмірів блока перетворення. У деяких випадках великі розміри TU можуть використовувати більше контекстів, які можуть призвести до збільшеної пам'яті та обчислювальної вимоги, щоб підтримувати збільшене число контекстів для великих розмірів TU. Згідно зі способами даного винаходу модуль 56 статистичного кодування може бути сконфігурований, щоб виконувати статистичне кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Ці способи головним чином описуються відносно способу статистичного кодування CABAC. У деяких випадках, однак, ці способи можуть бути також застосовані до інших контекстно-адаптивних способів статистичного кодування. Спільне використання об'єднаної контекстної моделі між двома або більше розмірами блоків перетворення може зменшити об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності на кодері 20 відео. Крім того, спільне використання об'єднаної контекстної моделі може також зменшити обчислювальні витрати підтримки контекстних моделей на кодері 20 відео, включаючи скидання всіх контекстних моделей на початку вирізки відео. У випадку CABAC ці способи можуть також зменшити витрати обчислення безперервного оновлення оцінок імовірності моделей контексту на основі фактичних кодованих значень коефіцієнтів. Відповідно до даного винаходу модуль 56 статистичного кодування може підтримувати об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, і вибирати контексти для коефіцієнтів, асоційованих з одним з перетворених блоків згідно з об'єднаною контекстною моделлю. Модуль 56 статистичного кодування може потім статистично кодувати значущі коефіцієнти в межах перетворених блоків на основі вибраних контекстів. Як приклад об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. У деяких випадках більше ніж два розміри блоків перетворення можуть спільно використати одну і ту саму об'єднану контекстну модель. В одному прикладі об'єднана контекстна модель може бути об'єднаною контекстною моделлю карт значущості для блоків перетворення. В інших прикладах об'єднана контекстна модель може бути асоційована з іншою інформацією кодування або елементами синтаксису. Процес кодування CABAC, що використовує об'єднані контекстні моделі, описаний більш детально з посиланнями на фіг. 5. В одному прикладі модуль 56 статистичного кодування може підтримувати об'єднану контекстну модель, що спільно використовується за допомогою блока TU, який має перший розмір, з коефіцієнтами, які є обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і TU, що спочатку має другий розмір. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. Наприклад, коли високочастотні коефіцієнти є обнуленими з TU першого розміру, коефіцієнти, включені в блок коефіцієнтів другого розміру, що залишилися, мають аналогічну статистику імовірності, що і коефіцієнти, включені в TU початково другого розміру. У цьому випадку, коли блок коефіцієнтів другого розміру, що залишилися, згенерований за допомогою обнулення коефіцієнтів TU початково першого розміру, модуль 56 статистичного кодування може вибрати контексти для коефіцієнтів блока коефіцієнтів, що залишилися згідно з об'єднаною контекстною моделлю. Модуль 56 статистичного кодування потім статистично кодує значущі коефіцієнти в блоці коефіцієнтів, що залишилися, на основі вибраних контекстів. У випадку CABAC модуль 56 статистичного 13 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодування також оновлює оцінки імовірності, асоційовані з вибраними контекстами в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів. В іншому прикладі модуль 56 статистичного кодування може підтримувати об'єднану контекстну модель, що спільно використовується першим TU, який має перший розмір, і другим TU, який має другий розмір. У деяких випадках коефіцієнти, включені в перший TU, який має перший розмір, можуть мати аналогічну статистику імовірності, що і коефіцієнти, включені у другий TU, який має другий розмір, навіть без обнулення високочастотних коефіцієнтів в першому TU. Це можливе, оскільки високочастотні коефіцієнти можуть представляти такі маленькі залишкові дані відео, що вплив на імовірнісну статистику сусідніх коефіцієнтів для статистичного кодування є незначним. У цьому прикладі модуль 56 статистичного кодування може вибрати контексти для коефіцієнтів в блоці TU з одного з першого і другого розміру згідно з об'єднаною контекстною моделлю. Модуль 56 статистичного кодування потім статистично кодує значущі коефіцієнти в блоці TU на основі вибраних контекстів. У випадку CABAC модуль 56 статистичного кодування може потім оновити оцінки імовірності, асоційовані з вибраними контекстами в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів. Модуль 56 статистичного кодування може також статистично кодувати елементи синтаксису, що вказують вектори руху та іншу інформацію прогнозування для відео блока, що кодується. Наприклад, модуль 56 статистичного кодування може статистично кодувати елементи синтаксису, що вказують карту значущості, тобто, карту одиниць і нулів, що вказують позицію значущих коефіцієнтів в TU, використовуючи способи, описані в даному винаході. Модуль 56 статистичного кодування може також конструювати інформацію заголовка, яка включає в себе відповідні елементи синтаксису, що генеруються модулем 44 компенсації руху, для передачі в закодованому потоку бітів. Кодер 20 відео може статистично кодувати елементи синтаксису, що вказують інформацію блока відео, включаючи розміри блоків CU, PU та TU, і інформацію вектора руху для прогнозування у внутрішньому режимі. Для статистичного кодування елементів синтаксису модуль 56 статистичного кодування може виконати CABAC за допомогою бінаризації елементів синтаксису в один або більше двійкових бітів і вибору контекстів для кожного біта згідно з контекстною моделлю. Модуль 58 зворотного квантування і модуль 60 зворотного перетворення застосовують зворотне квантування і зворотне перетворення, відповідно, щоб реконструювати залишковий блок в піксельній ділянці для більш пізнього використання як опорний блок опорного кадру. Модуль 62 підсумовування підсумовує реконструйований залишковий блок в прогнозуючий блок, що генерується модулем 44 компенсації руху, щоб сформувати опорний блок для зберігання в пам'яті 64 опорних кадрів. Опорний блок може використовуватися модулем 42 оцінки руху і модулем 44 компенсації руху як опорний блок, щоб внутрішньо передбачити блок в подальшому кадрі відео. Фіг. 3A та 3B є концептуальними діаграмами, що відповідно ілюструють квадратні і прямокутні ділянки блоків коефіцієнтів, що залишилися, які мають другий розмір в блоці перетворення, який має перший розмір. На концептуальних ілюстраціях на Фіг. 3A та 3B різні прямокутники представляють коефіцієнти перетворення в блоці TU після застосування перетворення. Коефіцієнти в межах відмічених штрихуванням ділянок містять коефіцієнти перетворення, що залишилися, а коефіцієнти, не включені у відмічені штрихуванням ділянки (тобто, білий або затемнені прямокутники), містять коефіцієнти, які були обнулені під час двовимірного перетворення. Як описано вище, способи згідно з даним винаходом зменшують вимоги проміжної буферизації для великих розмірів TU, наприклад, 32×32 аж до 128×128, за допомогою обнулення високочастотного піднабору коефіцієнтів перетворення, включених в TU першого розміру, після кожного напрямку двовимірного перетворення. Таким чином, модуль 52 перетворення згідно з Фіг. 2 може генерувати блок коефіцієнтів, що залишилися в блоці TU, який має другий розмір, менший ніж перший розмір TU. Процес обнулення містить встановлення значень піднабору коефіцієнтів перетворення в блоці TU такими, що дорівнюють нулю. Коефіцієнти перетворення, які є обнуленими, не обчислюються або відхиляються; замість цього обнулені коефіцієнти перетворення просто встановлюються такими, що дорівнюють нулю і не мають ніякого значення для збереження або кодування. Згідно з даним винаходом обнулені коефіцієнти перетворення є високочастотними коефіцієнтами перетворення відносно коефіцієнтів перетворення, що залишилися в TU. Високочастотні коефіцієнти перетворення представляють залишкові дані відео, які відповідають дуже маленьким піксельним різницям між блоком відео, який повинен бути закодований, і блоком прогнозування. Високочастотні коефіцієнти перетворення тому може містити такі 14 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 маленькі залишкові дані відео, що встановлення цих значень такими, що дорівнюють нулю, має незначний вплив на якість декодованого відео. Фіг. 3A ілюструють TU 70, який має перший розмір 16×16, і блок 74 коефіцієнтів, що залишилися, який має остаточну квадратну ділянку другого розміру 8×8 в блоці TU 70. Розмір і форма блока 74 коефіцієнтів, що залишилися, може бути вибрана на основі вимог складності кодування для процесу кодування. У цьому прикладі модуль 52 перетворення згідно з фіг. 2 може бути сконфігурований, щоб генерувати блок 74 коефіцієнтів, що залишилися, з квадратною ділянкою розміром 8×8 в блоці TU 70 початково розміру 16×16. Щоб згенерувати блок 74 коефіцієнтів, що залишилися, модуль 52 перетворення може обнулити половину більш високочастотних коефіцієнтів після застосування кожного напрямку, тобто, рядків і стовпців, двовимірного перетворення. В інших випадках модуль 52 перетворення може бути сконфігурований обнуляти більший або менший піднабір коефіцієнтів залежно від вимог складності кодування для процесу кодування. Спочатку модуль 52 перетворення може застосовувати одновимірне перетворення до рядків залишкових даних відео в TU 70, і обнуляти піднабір (в цьому випадку половину) проміжних коефіцієнтів перетворення, одержаних з перетворення. В ілюстрованому прикладі на Фіг. 3A проміжні коефіцієнти перетворення, що залишилися, включені в блок 73 проміжних коефіцієнтів (тобто, затемнені блоки в TU 70), що залишилися, які мають прямокутну ділянку 16×8, що дорівнює половині вихідного розміру 16×16 в TU 70. Обнулений піднабір (тобто, білі блоки в TU 70) можуть включати в себе коефіцієнти зі значеннями частоти, які вищі, ніж коефіцієнти в межах блока 73 проміжних коефіцієнтів, що залишилися, з TU 70. В ілюстрованому прикладі, модуль 52 перетворення обнулює половину коефіцієнтів з 8 найвищими значеннями частоти в кожному рядку TU 70. Цей процес обнулення призводить до блока 73 проміжних коефіцієнтів, що залишилися, з прямокутною ділянкою 16×8 в блоці TU 70. В інших прикладах ділянка блока 73 проміжних коефіцієнтів, що залишилися, може мати інший розмір або форму. Модуль 52 перетворення може обнуляти половину коефіцієнтів з найвищими значеннями частоти серед всіх коефіцієнтів в TU 70 16×16. Цей процес обнулення може призвести до збереженого проміжного блока коефіцієнтів з трикутною ділянкою у верхньому лівому кутку в TU 70. За допомогою обнулення половини проміжних коефіцієнтів перетворення, одержаних з перетворення в першому напрямку, кодеру 20 відео тільки потрібно буферизувати коефіцієнти в межах блока 73 проміжних коефіцієнтів, що залишилися, раніше, ніж застосувати перетворення у другому напрямку. Коефіцієнти в межах обнуленого піднабору (тобто, білі блоки в TU 70) не мають ніякого значення для збереження, перетворення або кодування. Таким чином, ці способи можуть зменшити вимоги проміжної буферизації при виконанні двовимірних перетворень. Це може бути особливо корисно для великих розмірів блока перетворення, наприклад, 32×32 аж до 128×128, які були запропоновані для стандарту HEVC. Після буферизації модуль 52 перетворення може потім застосувати одновимірне перетворення до стовпців проміжних коефіцієнтів перетворення, що залишилися, в блоці 73 проміжних коефіцієнтів, що залишилися, і обнулити піднабір (в цьому випадку половину), коефіцієнтів перетворення, одержаних з перетворення. В ілюстрованому прикладі на Фіг. 3A коефіцієнти перетворення, що залишилися, включені в блок 74 коефіцієнтів (тобто, відмічені штрихуванням блоки в TU 70), що залишилися, які мають квадратну ділянку розміром 8×8, що дорівнює одній четвертій вихідного розміру 16×16 в TU 70. Обнулений піднабір (тобто, не відмічені штрихуванням квадрати в блоці 73 проміжних коефіцієнтів, що залишилися) може включати в себе коефіцієнти зі значеннями частоти, які вище, ніж коефіцієнти в блоці 74 коефіцієнтів, що залишилися, з TU 70. В ілюстрованому прикладі модуль 52 перетворення обнулює половину коефіцієнтів з 8 найвищими значеннями частоти в кожному стовпці блока 73 проміжних коефіцієнтів, що залишилися. В інших прикладах модуль 52 перетворення може обнуляти половину коефіцієнтів з найвищими значеннями частоти серед всіх коефіцієнтів в блоці 73 проміжних коефіцієнтів 16×8, що залишилися. У будь-якому випадку процес обнулення призводить до блока 74 коефіцієнтів, що залишилися, з квадратною ділянкою 8×8 в блоці TU 70. Фіг. 3B ілюструє TU 76, який має перший розмір 16×16 і блок 78 коефіцієнтів, що залишилися, який має остаточну прямокутну ділянку другого розміру 4×16 в блоці TU 76. Розмір і форма блока 78 коефіцієнтів, що залишилися, може бути вибрана на основі вимоги складності кодування для процесу кодування. Більш конкретно, остаточна прямокутна ділянка блока 78 коефіцієнтів, що залишилися, може бути вибрана на основі щонайменше одного з режиму внутрішнього кодування, шаблона перегляду і позиції останнього значущого коефіцієнта для блока 78 коефіцієнтів, що залишилися. В ілюстрованому прикладі на Фіг. 3B модуль 52 перетворення може бути сконфігурований, щоб генерувати блок 78 коефіцієнтів, що залишилися, з прямокутною ділянкою розміром 4×16 в 15 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 блоці TU 76 початково розміру 16×16. Модуль 52 перетворення може спочатку бути застосований до TU 76 в напрямку коротшого боку (наприклад, стовпців) остаточної прямокутної ділянки блока 78 коефіцієнтів, що залишилися. Щоб генерувати блок 78 коефіцієнтів, що залишилися, блок 52 перетворення може обнулити три чверті коефіцієнтів після застосування двовимірного перетворення в першому напрямку (наприклад, стовпців). В інших випадках модуль 52 перетворення може бути сконфігурований для обнулення більшого або меншого піднабору коефіцієнтів залежно від вимог складності кодування для процесу кодування. Коли прямокутна ділянка вибрана для блока коефіцієнтів, що залишилися, способи можуть забезпечити подальше скорочення вимог проміжної буферизації за допомогою спочатку застосування одновимірного перетворення в напрямку коротшого боку (тобто, менше коефіцієнтів перетворення, що залишилися) прямокутної ділянки. Таким чином, кодер 20 відео може буферизувати менше ніж половину проміжних коефіцієнтів перетворення до застосування одновимірного перетворення в напрямку більш довгого боку прямокутної ділянки. В ілюстрованому прикладі на Фіг. 3B, висота (Н) остаточної прямокутної ділянки блока 78 коефіцієнтів, що залишилися, менше, ніж ширина (W) прямокутної ділянки, таким чином менше проміжних коефіцієнтів перетворення буде збережено у вертикальному напрямку. Модуль 52 перетворення може тому спочатку застосувати перетворення до стовпців TU 76 таким чином, що кодер 20 відео може буферизувати менше, ніж половину (в цьому випадку одну чверть) проміжних коефіцієнтів перетворення перед застосуванням перетворення до рядків TU 76. Більш конкретно, модуль 52 перетворення може застосувати одновимірне перетворення до стовпців залишкових даних відео в TU 76, і обнулити піднабір (в цьому випадку три чверті) проміжних коефіцієнтів перетворення, одержаних з перетворення. В ілюстрованому прикладі на Фіг. 3B, проміжні коефіцієнти перетворення, що залишилися, включені в блок 77 проміжних коефіцієнтів (тобто, затемнені блоки в TU 76), що залишилися, які мають прямокутну ділянку 4×16, що дорівнює одній чверті вихідного розміру 16×16 в TU 76. Обнулений піднабір (тобто, білі блоки в TU 76) може включати в себе коефіцієнти зі значеннями частоти, які вище, ніж коефіцієнти в блоці 77 проміжних коефіцієнтів, що залишилися, з TU 76. В ілюстрованому прикладі модуль 52 перетворення обнулює три чверті коефіцієнтів з 12 найвищими значеннями частоти в кожному стовпці в TU 76. Ці процес обнулення призводить до блока 77 проміжних коефіцієнтів, що залишилися, з прямокутною ділянкою 4×16 в блоці TU 76. За допомогою обнулення трьох чвертей проміжних коефіцієнтів перетворення, одержаних з перетворення в першому напрямку, кодеру 20 відео тільки потрібно буферизувати коефіцієнти в блоці 77 проміжних коефіцієнтів, що залишилися, перш ніж застосувати перетворення у другому напрямку. Коефіцієнти в межах обнуленого піднабору (тобто, білі блоки в TU 76) не мають ніякого значення для збереження, перетворення або кодування. Таким чином, ці способи можуть зменшити вимоги проміжної буферизації при виконанні двовимірних перетворень. Це може бути особливо корисно для великих розмірів блока перетворення, наприклад, 32×32 аж до 128×128, які були запропоновані для стандарту HEVC. Після буферизації модуль 52 перетворення може потім застосувати одновимірне перетворення до рядків коефіцієнтів в блоці 77 проміжних коефіцієнтів, що залишилися. У цьому прикладі модуль 52 перетворення може не обнуляти будь-який з коефіцієнтів перетворення, одержаних з перетворення, оскільки TU 76 вже був обнулений до однієї чверті первинного розміру 16×16. В ілюстрованому прикладі на Фіг. 3В коефіцієнти перетворення, що залишилися, включені в блок 78 коефіцієнтів (тобто, відмічені штрихуванням блоки в TU 76), що залишилися, які мають ту саму прямокутну ділянку 4×16, що і блок 77 проміжних коефіцієнтів, що залишилися. Процес обнулення призводить до блока 78 коефіцієнтів, що залишилися, з прямокутною ділянкою 4×16 в блоці TU 70. Фіг. 4 є блок-схемою, що ілюструє зразковий декодер відео, який може реалізувати способи для статистичного декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель. У прикладі на Фіг. 4 декодер 30 відео включає в себе модуль 80 статистичного декодування, модуль 81 прогнозування, модуль 86 зворотного квантування, модуль 88 зворотного перетворення, модуль 90 підсумовування і пам'ять 92 опорних кадрів. Модуль 81 прогнозування включає в себе модуль 82 компенсації руху і модуль 84 внутрішнього прогнозування. Декодер 30 відео, в деяких прикладах, може виконати прохід декодування, загалом зворотний до проходження кодування, описаного відносно кодера 20 відео (Фіг. 2). Під час процесу декодування декодер 30 відео приймає кодований потік бітів відео, який представляє кодовані кадри відео або вирізки та елементи синтаксису, які представляють інформацію кодування з кодера 20 відео. Модуль 80 статистичного декодування статистично декодує потік двійкових сигналів, щоб генерувати квантовані коефіцієнти перетворення в межах 16 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 TU. Наприклад, модуль 80 статистичного декодування може виконати контекстно-адаптивне статистичне декодування, таке як CABAC, CAVLC або інший спосіб статистичного кодування. Модуль 80 статистичного декодування також статистично декодує елементи синтаксису, включаючи карту значущості, тобто, карту одиниць і нулів, що вказують позицію значущих коефіцієнтів в TU, використовуючи способи, описані в даному винаході. Модуль 80 статистичного декодування може також статистично декодувати вектори руху та інші елементи синтаксису прогнозування. Щоб виконати контекстно-адаптивне статистичне декодування, модуль 80 статистичного декодування призначає контекст на кожний кодований коефіцієнт, представлений в потоку бітів, згідно з контекстною моделлю, яка може належить до того, наприклад, чи є значення раніше декодованих сусідніх коефіцієнтів відмінними від нуля. Модуль 80 статистичного декодування також визначає процес кодування для кодованого коефіцієнта, асоційованого з призначеним контекстом в контекстній моделі. Модуль 80 статистичного декодування потім статистично декодує коефіцієнти на основі призначених контекстів. У випадку CABAC модуль 80 статистичного декодування визначає оцінку імовірності для значення (наприклад, 0 або 1) кодованого коефіцієнта, асоційованого з призначеним контекстом в контекстній моделі. Модуль 80 статистичного декодування потім оновлює оцінку імовірності, асоційовану з призначеним контекстом в контекстній моделі, на основі фактичного декодованого значення цього коефіцієнта. Звичайно декодер 30 відео повинен підтримувати окремі контекстні моделі для кожного з різних розмірів блоків TU, що підтримуються за допомогою реалізованого стандарту стиснення відео. Для стандарту HEVC додаткові розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео, але додаткові розміри TU також призводять до збільшеної пам'яті та обчислювальних вимог, щоб підтримувати контекстну модель для кожного з додаткових розмірів блока перетворення. Згідно зі способами даного винаходу модуль 80 статистичного декодування може бути сконфігурований, щоб виконувати статистичне декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Способи головним чином описані відносно статистичного декодування способу CABAC. У деяких випадках, однак, способи можуть бути також застосовані до інших контекстно-адаптивних способів статистичного кодування. Спільне використання об'єднаної контекстної моделі між двома або більше розмірами блоків перетворення може зменшити об'єм пам'яті, необхідної, щоб зберегти контексти та імовірності на декодері 30 відео. Крім того, спільне використання об'єднаної контекстної моделі може також зменшити обчислювальні витрати підтримки контекстних моделей на декодері 30 відео, включаючи встановлення у вихідний стан всіх контекстних моделей на початку вирізки відео. У випадку CABAC ці способи можуть також зменшити витрати обчислень оцінок імовірності моделей контексту, що безперервно оновляються, на основі фактичних кодованих значень коефіцієнтів. Відповідно до даного винаходу модуль 80 статистичного декодування може підтримувати об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, і вибирати контексти для коефіцієнтів, асоційованих з одним з блоків перетворення, згідно з об'єднаною контекстною моделлю. Модуль 80 статистичного декодування може потім статистично декодувати значущі коефіцієнти, асоційовані з блоками перетворення, на основі вибраних контекстів. Як приклад об'єднана контекстна модель може бути спільно використана між блоками перетворення, які мають перший розмір 32×32, і блоками перетворення, які мають другий розмір 16×16. У деяких випадках більше ніж два розміри блоків перетворення можуть спільно використовувати одну і ту саму об'єднану контекстну модель. В одному прикладі об'єднана контекстна модель може бути об'єднаною контекстною моделлю карт значущості для блоків перетворення. В інших прикладах об'єднана контекстна модель може бути асоційована з іншою інформацією кодування або елементами синтаксису. Процес декодування CABAC, що використовує об'єднану контекстну модель, описаний більш детально з посиланнями на фіг. 6. В одному прикладі модуль 80 статистичного декодування може підтримувати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, і TU, що спочатку має другий розмір. У деяких випадках блок коефіцієнтів, що залишилися, може мати розмір, що дорівнює другому розміру. Наприклад, в цьому випадку модуль 80 статистичного декодування може вибрати контексти для коефіцієнтів блока коефіцієнтів, що залишилися, який має другий розмір, в блоці TU, що спочатку має перший розмір, згідно з об'єднаною контекстною моделлю. Модуль 80 статистичного декодування потім арифметично декодує кодовані значущі 17 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 коефіцієнти в блок коефіцієнтів, що залишилися, в блоці TU, який має перший розмір, на основі вибраних контекстів. У випадку CABAC модуль 80 статистичного декодування також оновлює оцінки імовірності, асоційовані з вибраними контекстами, в об'єднаній контекстній моделі, на основі фактичних декодованих значень коефіцієнтів. В іншому прикладі модуль 80 статистичного декодування може підтримувати об'єднану контекстну модель, що спільно використовується першим TU, який має перший розмір, і другим TU, який має другий розмір. У цьому прикладі модуль 80 статистичного декодування може вибрати контексти для кодованих коефіцієнтів, асоційованих з TU одного з першого і другого розміру згідно з об'єднаною контекстною моделлю. Модуль 80 статистичного декодування потім статистично декодує кодовані значущі коефіцієнти в TU на основі вибраних контекстів. У випадку CABAC модуль 80 статистичного декодування може потім оновити оцінки імовірності, асоційовані з вибраними контекстами, в об'єднаній контекстній моделі на основі фактичних декодованих значень коефіцієнтів. У будь-якому випадку модуль 80 статистичного декодування направляє квантовані декодовані коефіцієнти перетворення в блоках TU або першого розміру або другого розміру до модуля 86 зворотного квантування. Модуль 86 зворотного квантування зворотно квантує, тобто, деквантує, квантовані коефіцієнти перетворення, декодовані в блоки TU, за допомогою модуля 80 статистичного декодування, як описано вище. Зворотний процес квантування може включати в себе використання параметра квантування QP, обчисленого кодером 20 відео для кожного блока відео або CU, щоб визначити ступінь квантування і, аналогічно, ступінь зворотного квантування, яка повинна бути застосована. Модуль 88 зворотного перетворення застосовує зворотне перетворення, наприклад, зворотне DCT, зворотне цілочисельне перетворення, зворотне вейвлет перетворення, або концептуально подібний процес зворотного перетворення до коефіцієнтів перетворення в межах блоків TU, щоб сформувати залишкові дані відео в піксельній ділянці. У деяких прикладах модуль 88 зворотного перетворення може містити двовимірне роздільне перетворення. Модуль 88 зворотного перетворення може застосувати двовимірне перетворення до TU за допомогою спочатку застосування одновимірного зворотного перетворення до рядків коефіцієнтів перетворення в блоці TU, і потім застосувати одновимірне зворотне перетворення до стовпців коефіцієнтів перетворення в блоці TU, або навпаки. Після застосування одновимірного зворотного перетворення в першому напрямку до коефіцієнтів перетворення в TU декодер 30 відео буферизує проміжні залишкові дані для застосування одновимірного зворотного перетворення у другому напрямку. Як описано вище, в стандарті HEVC великі розміри блока перетворення, наприклад, 32×32 аж до 128×128, були запропоновані, щоб поліпшити ефективність кодування відео. Великі розміри TU, однак, також призведуть до збільшених вимог проміжної буферизації для двовимірних перетворень. Щоб зменшити вимоги проміжної буферизації для великих розмірів TU, способи, описані в даному винаході, можуть включати в себе обнулення високочастотного піднабору коефіцієнтів перетворення, включених в TU, кодером 20 відео згідно з фіг. 2. Обнулені коефіцієнти перетворення в блоці TU просто встановлюються такими, що дорівнюють нулю і не мають ніякого значення для збереження, перетворення або кодування. Модуль 80 статистичного декодування тому приймає кодований потік бітів, який представляє кодовані коефіцієнти, асоційовані з блоком коефіцієнтів, що залишилися, який має другий розмір в блоці TU, який спочатку має перший розмір. Модуль 80 статистичного декодування декодує коефіцієнти в блок коефіцієнтів, що залишилися, в блоці TU, який має перший розмір. TU тоді включає в себе коефіцієнти в блоці коефіцієнтів другого розміру, що залишилися, і нулі, які представляють коефіцієнти, що залишилися, в межах цього TU. Таким чином, процес обнулення коефіцієнтів перетворення в кодері 20 відео може також зменшити вимоги до проміжної буферизації для великих розмірів TU при виконанні зворотного перетворення в декодері 30 відео. Як приклад модуль 88 зворотного перетворення може застосувати одновимірне зворотне перетворення в першому напрямку, наприклад, порядково, до коефіцієнтів перетворення блоці коефіцієнтів, що залишилися, який має розмір 16×16 в блоці TU, який має розмір 32×32. Після зворотного перетворення рядка декодеру 30 відео може тільки потребуватися буферизувати проміжні залишкові дані, перетворені з коефіцієнтів в блоці коефіцієнтів, що залишилися, який містить тільки половину TU, тобто коефіцієнти 32×16. Модуль 88 зворотного перетворення може потім застосувати одновимірне зворотне перетворення у другому напрямку, наприклад, по стовпцях, до проміжних залишкових даних в TU. Таким чином, модуль 88 зворотного перетворення може генерувати TU первинного розміру 32×32 за допомогою включення залишкових даних в блок коефіцієнтів, що залишилися, який 18 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 має розмір 16×16, і додавання нулів для представлення залишкових даних, що залишилися, в TU. Модуль 80 статистичного декодування також передає декодовані вектори руху та інші елементи синтаксису прогнозування до модуля 81 прогнозування. Декодер 30 відео може прийняти елементи синтаксису на рівні блока прогнозування відео, рівні блока кодування відео, рівні вирізки відео, рівні кадру відео і/або рівні послідовності відео. Коли кадр відео кодується як внутрішньо кодований кадр, модуль 84 внутрішнього прогнозування з модуля 81 прогнозування генерують дані прогнози для блоків відео поточного кадру відео на основі даних від раніше декодованих блоків поточного кадру. Коли кадр відео кодується як зовні кодований кадр, модуль 82 компенсації руху з модуля 81 прогнозування формує блоки прогнозування для блоків відео поточного кадру відео на основі декодованих векторів руху, прийнятих від модуля 80 статистичного декодування. Блоки прогнозування можуть генеруватися відносно одного або більше опорних блоків опорного кадру, збережених в пам'яті 92 опорних кадрів. Модуль 82 компенсації руху визначає інформацію прогнозування для блока відео, який повинен бути декодований, за допомогою синтаксичного аналізу векторів руху та іншого синтаксису прогнозування, і використовує інформацію прогнозування, щоб генерувати блоки прогнозування для поточного декодованого блока відео. Наприклад, модуль 82 компенсації руху використовує деякі з прийнятих елементів синтаксису, щоб визначити розміри блоків CU, що використовуються для кодування поточного кадру, розділення інформації, яка описує, як кожний CU кадру розділений, режими, що вказують, як кожне розділення кодується (наприклад, за допомогою внутрішнього або зовнішнього прогнозування), тип вирізки зовнішнього прогнозування (наприклад, В вирізка, Р вирізка, або вирізка GPB), команди побудови списку опорних кадрів, інтерполяційні фільтри, що відносяться до опорних кадрів, вектори руху для кожного блока кадру відео, значення параметрів відео, асоційованих з векторами руху, і іншу інформацію, щоб декодувати поточний кадр відео. Декодер 30 відео формує декодований блок відео за допомогою підсумовування залишкових блоків від модуля 88 зворотного перетворення з відповідними блоками прогнозування, що генеруються модулем 82 компенсації руху. Модуль 90 підсумовування представляє компонент або компоненти, які виконують цю операцію підсумовування. Якщо бажано, фільтр видалення блоковості також може бути застосований, щоб фільтрувати декодовані блоки, щоб видалити артефакти блоковості на квадрати. Декодовані блоки відео потім зберігаються в опорних кадрах в пам'яті 92 опорних кадрів, яка забезпечує опорні блоки опорних кадрів для подальшої компенсації руху. Пам'ять 92 опорних кадрів також формує декодоване відео для представлення на пристрої відображення, такому як пристрій 32 відображення згідно з фіг. 1. Фіг. 5 є блок-схемою, що ілюструє приклад модуля 56 статистичного кодування згідно з фіг. 2, сконфігурованого, щоб вибрати контексти для коефіцієнтів відео згідно з об'єднаною контекстною моделлю. Модуль 56 статистичного кодування включає в себе модуль 94 контекстного моделювання, модуль 99 арифметичного кодування і сховище 98 об'єднаної контекстної моделі. Як описано вище, способи згідно з даним винаходом направлені на виконання статистичного кодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Зокрема, способи описані тут відносно процесу кодування CABAC. Модуль 56 статистичного кодування підтримує об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, в сховищі 98 об'єднаної контекстної моделі. Як один приклад, сховище 98 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб згенерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, що спочатку має другий розмір. Як інший приклад, сховище 98 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, і TU, який має другий розмір. У деяких випадках перший розмір може містити 32×32, і другий розмір може містити 16×16. Модуль 94 контекстного моделювання приймає коефіцієнти перетворення, асоційовані з TU або першого розміру або другого розміру, які були скановані, у вектор для статистичного кодування. Модуль 94 контекстного моделювання потім призначає контекст на кожний з коефіцієнтів TU на основі значень раніше кодованих сусідніх коефіцієнтів у TU згідно з об'єднаною контекстною моделлю. Більш конкретно, модуль 94 контекстного моделювання може призначити контексти згідно з тим, чи є значення раніше кодованих сусідніх коефіцієнтів відмінними від нуля. Призначений контекст може посилатися на індекс контексту, наприклад, контекст (i), де i=0, 1, 2…, N, в об'єднаній контекстній моделі. 19 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 Після того, як контекст призначений коефіцієнту, модуль 94 контекстного моделювання може визначити оцінку імовірності для значення (наприклад, 0 або 1) коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі. Кожний різний індекс контексту асоційований з оцінкою імовірності для значення коефіцієнта з цим індексом контексту. Оцінка імовірності, виконана для CABAC за допомогою модуля 94 контекстного моделювання, може бути основана на керованому таблицею модулі оцінки, що використовує кінцевий автомат (FSM). Для кожного контексту FSM підтримує асоційовану оцінку імовірності, відстежуючи минулі значення контексту і забезпечуючи поточний стан як найкращу оцінку імовірності того, що заданий коефіцієнт має значення 0 або 1. Наприклад, якщо стани імовірності змінюються від 0 до 127, стан 0 може означати, що імовірність коефіцієнта, який має значення 0, що дорівнює 0,9999, і стан 127 може означати, що імовірність коефіцієнта, який має значення 0, що дорівнює 0,0001. Модуль 99 арифметичного кодування арифметично кодує коефіцієнт на основі визначеної оцінки імовірності коефіцієнта, асоційованого з призначеним контекстом. Таким чином, модуль 99 арифметичного кодування генерує кодований потік бітів, який представляє арифметично кодовані коефіцієнти, асоційовані з TU або першого розміру або другого розміру, згідно з об'єднаною контекстною моделлю. Після кодування модуль 99 арифметичного кодування подає фактичне кодоване значення коефіцієнта назад до модуля 94 контекстного моделювання, щоб оновити оцінку імовірності, асоційовану з призначеним контекстом в об'єднаній контекстній моделі, в сховищі 98 об'єднаної контекстної моделі. Модуль 94 контекстного моделювання виконує оновлення імовірності для призначеного контексту в об'єднаній контекстній моделі, переходячи між станами імовірності. Наприклад, якщо фактичне кодоване значення коефіцієнта дорівнює 0, то імовірність, що значення коефіцієнта дорівнює 0, може бути збільшена, переходячи до більш низького стану. За допомогою безперервного оновлення оцінок імовірності об'єднаної контекстної моделі, щоб відобразити фактичні кодовані значення коефіцієнтів, оцінки імовірності для майбутніх коефіцієнтів, призначених на ті самі контексти в об'єднаній контекстній моделі, можуть бути більш точними і призвести до подальшого зменшеного кодування бітів модулем 99 арифметичного кодування. У першому прикладі сховище 98 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, що спочатку має другий розмір. Наприклад, сховище 98 об'єднаної контекстної моделі може зберегти об'єднану контекстну модель, що спільно використовується блоками коефіцієнтів, що залишилися, які мають розмір 16×16 в блоках TU, що спочатку мають розмір 32×32, і TU, що спочатку мають розмір 16×16. Перший коефіцієнт в блоці коефіцієнтів розміру 16×16, що залишилися, в першому TU розміром 32×32 може бути призначеним контекстом (5) в об'єднаній контекстній моделі, що спільно використовується блоком TU розміром 32×32 з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів розміру 16×16, що залишилися, і TU розміром 16×16. Модуль 94 контекстного моделювання потім визначає оцінку імовірності для значення першого коефіцієнта, асоційованого з призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного закодованого значення першого коефіцієнта. Другому коефіцієнту у другому TU розміром 16×16 можна також призначити той самий контекст (5) в об'єднаній контекстній моделі, що і коефіцієнт в блоці коефіцієнтів, що залишилися, в першому TU. Модуль 94 контекстного моделювання потім визначає оцінку імовірності для значення другого коефіцієнта, асоційованого з тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного закодованого значення другого коефіцієнта. У другому прикладі сховище 98 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, і блоком TU, який має другий розмір. Наприклад, сховище 98 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоками TU, які мають розміри 32×32 та 16×16. Перший коефіцієнт в першому TU розміром 32×32 може бути призначеним контекстом (5) в об'єднаній контекстній моделі, що спільно використовується блоками TU розміром 32×32 та 16×16. Модуль 94 контекстного моделювання потім визначає оцінку імовірності для значення першого коефіцієнта, асоційованого з призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з призначеним 20 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 контекстом (5) в об'єднаній контекстній моделі, на основі фактичного закодованого значення першого коефіцієнта. Другому коефіцієнту у другому TU розміром 16×16 можна також призначити той самий контекст (5) в об'єднаній контекстній моделі, що і коефіцієнту в першому TU. Модуль 94 контекстного моделювання потім визначає оцінку імовірності для значення другого коефіцієнта, асоційованого з тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного закодованого значення другого коефіцієнта. Фіг. 6 є блок-схемою, що ілюструє приклад модуля 80 статистичного декодування, сконфігурованого, щоб вибрати контексти для коефіцієнтів відео згідно з об'єднаною контекстною моделлю. Модуль 80 статистичного декодування включає в себе модуль 102 арифметичного кодування, модуль 104 контекстного моделювання і сховище 106 об'єднаної контекстної моделі. Як описано вище, способи згідно з даним винаходом направлені на виконання статистичного декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри. Зокрема, способи описані тут відносно процесу декодування CABAC. Модуль 80 статистичного декодування може працювати способом, по суті зворотним такому для модуля 56 статистичного кодування згідно з фіг. 5. Модуль 80 статистичного декодування підтримує об'єднану контекстну модель, що спільно використовується між блоками перетворення, які мають різні розміри, в сховищі 106 об'єднаної контекстної моделі. Об'єднана контекстна модель, збережена в сховищі 106 об'єднаної контекстної моделі, по суті подібна до об'єднаної контекстної моделі, збереженої в сховищі 98 об'єднаної контекстної моделі в модулі 56 статистичного кодування згідно з фіг. 5. Як один приклад, сховище 106 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, що спочатку має другий розмір. Як інший приклад, сховище 106 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, і TU, який має другий розмір. У деяких випадках перший розмір може містити 32×32, і другий розмір може містити 16×16. Модуль 102 арифметичного декодування приймає закодований потік бітів, який представляє закодовані коефіцієнти перетворення, асоційовані з блоком TU або першого розміру або другого розміру. Модуль 102 арифметичного декодування декодує перший коефіцієнт, включений в бітовий потік. Модуль 104 контекстного моделювання потім призначає контекст на подальший кодований коефіцієнт, включений в бітовий потік, на основі значення першого декодованого коефіцієнта. Аналогічним чином модуль 104 контекстного моделювання призначає контекст на кожний з кодованих коефіцієнтів, включених в бітовий потік, на основі значень раніше декодованих сусідніх коефіцієнтів TU згідно з об'єднаною контекстною моделлю. Більш конкретно, модуль 104 контекстного моделювання може призначити контексти згідно з тим, чи є значення раніше декодованих сусідніх коефіцієнтів відмінними від нуля. Призначений контекст може належати до індексу контексту в об'єднаній контекстній моделі. Після того, як контекст призначений кодованому коефіцієнту, модуль 104 контекстного моделювання може визначити оцінку імовірності для значення (наприклад, 0 або 1) кодованого коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі. Кожний різний індекс контексту асоційований з оцінкою імовірності. Модуль 104 контекстного моделювання подає визначену оцінку імовірності кодованого коефіцієнта назад до модуля 102 арифметичного декодування. Модуль 102 арифметичного декодування потім арифметично декодує кодований коефіцієнт на основі визначеної оцінки імовірності коефіцієнта, асоційованого з призначеним контекстом. Таким чином, модуль 102 арифметичного декодування генерує декодовані коефіцієнти перетворення в TU або першого розміру або другого розміру згідно з об'єднаною контекстною моделлю. Після декодування модуль 102 арифметичного декодування подає фактичне декодоване значення коефіцієнта до модуля 104 контекстного моделювання, щоб оновити оцінку імовірності, асоційовану з призначеним контекстом в об'єднаній контекстній моделі в сховищі 106 об'єднаної контекстної моделі. За допомогою безперервного оновлення оцінок імовірності об'єднаної контекстної моделі, щоб відобразити фактичні декодовані значення коефіцієнтів, оцінки імовірності для майбутніх коефіцієнтів, призначені на одні і ті самі контексти в об'єднаній контекстній моделі, можуть бути більш точними і призвести до подальшого зменшеного декодування бітів за допомогою модуля 102 арифметичного декодування. 21 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 У першому прикладі сховище 106 об'єднаної контекстної моделі може зберегти об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, що спочатку має другий розмір. Наприклад, сховище 106 об'єднаної контекстної моделі може зберегти об'єднану контекстну модель, що спільно використовується блоком коефіцієнтів, що залишилися, який має розмір 16×16 в блоці TU, що спочатку має розмір 32×32, і TU, що спочатку має розмір 16×16. Перший кодований коефіцієнт, асоційований з блоком коефіцієнтів розміром 16×16, що залишилися, в першому TU розміром 32×32, може бути призначеним контекстом (5) в об'єднаній контекстній моделі, що спільно використовується блоком TU розміром 32×32 з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має розмір 16×16, і TU розміром 16×16. Модуль 104 контекстного моделювання потім визначає оцінку імовірності для значення першого кодованого коефіцієнта, асоційованого з призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного декодованого значення першого коефіцієнта. Другому закодованому коефіцієнту, асоційованому з другою блоком TU розміром 16×16, може бути призначений той самий контекст (5) в об'єднаній контекстній моделі, що і перший кодований коефіцієнт, асоційований з блоком коефіцієнтів, що залишилися, в першому TU. Модуль 104 контекстного моделювання потім визначає оцінку імовірності для значення другого кодованого коефіцієнта, асоційованого з одним і тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з одним і тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного декодованого значення другого коефіцієнта. У другому прикладі сховище 106 об'єднаної контекстної моделі може зберегти об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, і блоком TU, який має другий розмір. Наприклад, сховище 106 об'єднаної контекстної моделі може зберігати об'єднану контекстну модель, що спільно використовується блоками TU, які мають розміри 32×32 та 16×16. Перший кодований коефіцієнт, асоційований з першим блоком TU розміром 32×32, може мати призначений контекст (5) в об'єднаній контекстній моделі, що спільно використовується блоком TU розміром 32×32, і блоком TU розміром 16×16. Модуль 104 контекстного моделювання потім визначає оцінку імовірності для значення першого кодованого коефіцієнта, асоційованого з призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного декодованого значення першого коефіцієнта. Другому кодованому коефіцієнту, асоційованому з другим блоком TU розміром 16×16, може бути призначений той самий контекст (5) в об'єднаній контекстній моделі, що і перший кодований коефіцієнт, асоційований з першим блоком TU. Модуль 104 контекстного моделювання потім визначає оцінку імовірності для значення другого кодованого коефіцієнта, асоційованого з одним і тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, і оновлює оцінку імовірності, асоційовану з одним і тим самим призначеним контекстом (5) в об'єднаній контекстній моделі, на основі фактичного декодованого значення другого коефіцієнта. Фіг. 7 є послідовністю операцій, що ілюструє зразкову операцію статистичного кодування і декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір. Ілюстрована операція описана відносно модуля 56 статистичного кодування згідно з фіг. 5 в кодері 20 відео згідно з фіг. 2 і модуля 80 статистичного декодування згідно з фіг. 6 в декодері 30 відео згідно з фіг. 3, хоча інші пристрої можуть реалізувати подібні способи. В ілюстрованій операції модуль 56 статистичного кодування в кодері 20 відео і модуль 80 статистичного кодування в декодері 30 відео можуть підтримувати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір, і блоком TU, який має другий розмір. У цьому випадку коефіцієнти, включені в перший TU, який має перший розмір, наприклад, 32×32, можуть мати аналогічну статистику імовірності, що і коефіцієнти, включені у другий TU другого розміру, наприклад, 16×16, навіть без обнулення високочастотних коефіцієнтів в першому TU. Це може бути можливе, коли високочастотні коефіцієнти представляють такі маленькі залишкові дані відео, що вплив на імовірнісну статистику сусідніх коефіцієнтів для статистичного кодування незначний. В одному випадку кодер 20 відео може використовувати модуль 52 перетворення, щоб перетворити залишкові дані відео в коефіцієнти перетворення в блоці TU, який має перший розмір (120). В іншому випадку кодер 20 відео може використовувати модуль 52 перетворення, 22 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 щоб перетворити залишкові дані відео в коефіцієнти перетворення в блоці TU, який має другий розмір (121). Незалежно від того, чи має TU перший розмір або другий розмір, способи згідно з даним винаходом дозволяють модулю 56 статистичного кодування статистично кодувати коефіцієнти в блоці TU згідно з однією і тією самою об'єднаною контекстною моделлю. Ці способи тому зменшують об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності на кодері 20 відео, і зменшити обчислювальні витрати підтримки контекстних моделей на кодері 20 відео. Модуль 94 контекстного моделювання в модулі 56 статистичного кодування вибирає контекст для кожного коефіцієнта в блоці TU згідно з об'єднаною контекстною моделлю, що спільно використовується блоками TU, які мають і перший розмір і другий розмір (122). Більш конкретно, модуль 94 контекстного моделювання призначає контекст на заданий коефіцієнт блока TU на основі значень раніше кодованих сусідніх коефіцієнтів цього блока TU згідно з об'єднаною контекстною моделлю. Модуль 94 контекстного моделювання потім може визначити оцінку імовірності для значення (наприклад, 0 або 1) коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі в сховищі 98 об'єднаної контекстної моделі. Модуль 99 арифметичного кодування потім арифметично кодує цей коефіцієнт на основі вибраного контексту для цього коефіцієнта (124). Після кодування модуль 99 арифметичного кодування подає фактичні кодовані значення коефіцієнтів назад до модуля 94 контекстного моделювання. Модуль 94 контекстного моделювання може потім оновити оцінку імовірності об'єднаної контекстної моделі на основі фактичних кодованих значень коефіцієнтів в блоці TU або першого розміру або другого розміру (126). Кодер 20 відео передає потік бітів, що представляє кодовані коефіцієнти, асоційовані з блоком TU або першого розміру або другого розміру, до декодера 30 відео (128). Декодер 30 відео може прийняти потік бітів, який представляє кодовані коефіцієнти, асоційовані з блоком TU, який має або перший розмір або другий розмір (130). Незалежно від того, чи має TU перший розмір або другий розмір, способи згідно з даним винаходом дозволяють модулю 80 статистичного декодування статистично декодувати коефіцієнти, асоційовані з блоком TU, на основі однієї і тієї самої об'єднаної контекстної моделі. Ці способи тому можуть зменшити об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності на декодері 30 відео, і зменшити обчислювальні витрати підтримки контекстних моделей на декодері 30 відео. Модуль 104 контекстного моделювання в модулі 80 статистичного декодування вибирає контекст для кожного кодованого коефіцієнта, асоційованого з блоком TU, згідно з об'єднаною контекстною моделлю, що спільно використовується блоками TU, які мають і перший розмір і другий розмір (132). Більш конкретно, модуль 104 контекстного моделювання може призначити контекст на подальший кодований коефіцієнт, асоційований з блоком TU, на основі значень раніше декодованих сусідніх коефіцієнтів TU згідно з об'єднаною контекстною моделлю. Модуль 104 контекстного моделювання потім може визначити оцінку імовірності для значення (наприклад, 0 або 1) кодованого коефіцієнта, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі в сховищі 106 об'єднаної контекстної моделі. Модуль 104 контекстного моделювання подає визначену оцінку імовірності, асоційовану з вибраним контекстом для кодованого коефіцієнта, назад до модуля 102 арифметичного декодування. Модуль 102 арифметичного декодування потім арифметично декодує кодований коефіцієнт в блок TU або першого розміру або другого розміру на основі вибраного контексту (134). Після декодування, модуль 102 арифметичного декодування подає фактичні декодовані значення коефіцієнтів до модуля 104 контекстного моделювання. Модуль 104 контекстного моделювання може потім оновити оцінку імовірності об'єднаної контекстної моделі на основі фактичних декодованих значень коефіцієнтів у блоці TU або першого розміру або другого розміру (136). В одному випадку декодер 30 відео може використовувати модуль 88 зворотного перетворення для зворотного перетворення коефіцієнтів в блоці TU, який має перший розмір, в залишкові дані відео (138). В іншому випадку декодер 30 відео може використовувати модуль 88 зворотного перетворення для зворотного перетворення коефіцієнтів в блоці TU, що має другий розмір, в залишкові дані відео (139). Фіг. 8 є послідовністю операцій, що ілюструє зразкову операцію статистичного кодування і декодування коефіцієнтів відео, використовуючи об'єднану контекстну модель, що спільно використовується між першим блоком перетворення, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і другим блоком перетворення, який має другий розмір. Ілюстрована операція описана відносно модуля 56 статистичного кодування згідно з фіг. 4 в кодері 20 відео згідно з фіг. 2 і модуля 80 23 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 статистичного декодування згідно з фіг. 5 в декодері 30 відео згідно з фіг. 3, хоча інші пристрої можуть реалізувати подібні способи. В ілюстрованій операції модуль 56 статистичного кодування в кодері 20 відео і модуль 80 статистичного кодування в декодері 30 відео можуть підтримувати об'єднану контекстну модель, що спільно використовується блоком TU, який має перший розмір з коефіцієнтом, обнуленим, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, який має другий розмір. У цьому випадку коефіцієнти, включені в блок коефіцієнтів, що залишилися, який має другий розмір, наприклад, 16×16, в першому блоці TU, який має перший розмір, наприклад, 32×32, може мати аналогічну статистику імовірності, що і коефіцієнти, включені у другий TU другого розміру, наприклад, 16×16. В одному випадку кодер 20 відео може використовувати модуль 52 перетворення, щоб перетворити залишкові дані відео в коефіцієнти перетворення в блоці TU, який має перший розмір (140). Кодер 20 відео обнулює піднабір коефіцієнтів, включених в перший TU після перетворення, для генерування блока коефіцієнтів, що залишилися, який має другий розмір в першому TU (141). Піднабір обнулених коефіцієнтів перетворення звичайно включає в себе високочастотні коефіцієнти перетворення відносно коефіцієнтів у блоці коефіцієнтів, що залишилися. Високочастотні коефіцієнти перетворення можуть містити такі маленькі залишкові дані відео, що встановлення цих значень такими, що дорівнюють нулю, має незначний вплив на якість декодованого відео. В іншому випадку кодер 20 відео може використовувати модуль 52 перетворення, щоб перетворити залишкові дані відео в коефіцієнти перетворення в блоці TU, який має другий розмір (142). Незалежно від того, чи має TU початково перший розмір або другий розмір, способи згідно з даним винаходом дозволяють модулю 56 статистичного кодування статистично кодувати коефіцієнти, що залишилися, в блоці TU згідно з однією і тією самою об'єднаною контекстною моделлю. Ці способи тому зменшують об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності на кодері 20 відео і зменшити обчислювальні витрати підтримки контекстних моделей на кодері 20 відео. Модуль 94 контекстного моделювання в модулі 56 статистичного кодування вибирає контекст для кожного коефіцієнта, що залишився, в блоці TU згідно з об'єднаною контекстною моделлю, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими до другого розміру, і блоком TU, який має другий розмір (144). Більш конкретно, модуль 94 контекстного моделювання призначає контекст на заданий коефіцієнт в блоці коефіцієнтів першого блока, що залишилися, TU на основі значень раніше кодованих сусідніх коефіцієнтів блока коефіцієнтів, що залишилися, згідно з об'єднаною контекстною моделлю. Модуль 94 контекстного моделювання потім може визначити оцінку імовірності для значення (наприклад, 0 або 1) коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі, в сховищі 98 об'єднаної контекстної моделі. Модуль 99 арифметичного кодування потім арифметично кодує цей коефіцієнт на основі вибраного контексту для коефіцієнта (146). Після кодування модуль 99 арифметичного кодування подає фактичні кодовані значення коефіцієнтів назад до модуля 94 контекстного моделювання. Модуль 94 контекстного моделювання може потім оновити оцінку імовірності об'єднаної контекстної моделі на основі фактичних кодованих значень коефіцієнтів в блоці коефіцієнтів другого розміру, що залишилися, в блоці TU першого розміру, або TU початково другого розміру (148). Кодер 20 відео передає потік бітів, що представляє кодовані коефіцієнти, асоційовані з блоком коефіцієнтів, що залишилися в блоці TU першого розміру, або блоком TU другого розміру, до декодера 30 відео (150). Декодер 30 відео може прийняти потік бітів, який представляє кодовані коефіцієнти, асоційовані з блоком коефіцієнтів другого розміру, що залишилися, в блоці TU першого розміру, або блоком TU початково другого розміру (152). Незалежно від того, чи має TU перший розмір або другий розмір, способи згідно з даним винаходом дозволяють модулю 80 статистичного декодування статистично декодувати коефіцієнти, асоційовані з блоком TU на основі однієї і тієї самої об'єднаної контекстної моделі. Ці способи тому зменшують об'єм пам'яті, необхідної, щоб зберігати контексти та імовірності на декодері 30 відео, і зменшити обчислювальні витрати підтримки контекстних моделей на декодері 30 відео. Модуль 104 контекстного моделювання в модулі 80 статистичного декодування вибирає контекст для кожного коефіцієнта, асоційованого з блоком TU згідно з об'єднаною контекстною моделлю, що спільно використовується блоком TU, який має перший розмір, з коефіцієнтами, обнуленими, щоб генерувати блок коефіцієнтів, що залишилися, який має другий розмір, і блоком TU, який має другий розмір (154). Більш конкретно, модуль 104 контекстного 24 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 60 моделювання може призначити контекст на подальший кодований коефіцієнт, асоційований з блоком коефіцієнтів, що залишилися, першого TU на основі значень раніше декодованих сусідніх коефіцієнтів блока коефіцієнтів, що залишилися, згідно з об'єднаною контекстною моделлю. Модуль 104 контекстного моделювання потім може визначити оцінку імовірності для значення (наприклад, 0 або 1) кодованого коефіцієнта, асоційованого з призначеним контекстом в об'єднаній контекстній моделі, в сховищі 106 об'єднаної контекстної моделі. Модуль 104 контекстного моделювання подає визначену імовірність, асоційовану з вибраним контекстом для кодованого коефіцієнта, назад до модуля 102 арифметичного декодування. Модуль 102 арифметичного декодування потім арифметично декодує кодований коефіцієнт в блок коефіцієнтів, що залишилися, в блоці TU першого розміру, або TU другого розміру на основі вибраного контексту (156). Після декодування модуль 102 арифметичного декодування подає фактичні декодовані значення коефіцієнтів до модуля 104 контекстного моделювання. Модуль 104 контекстного моделювання може потім оновити оцінку імовірності об'єднаної контекстної моделі на основі фактичних декодованих значень коефіцієнтів у блоці коефіцієнтів другого розміру, що залишилися, в блоці TU першого розміру, або блоці TU початково другого розміру (158). В одному випадку декодер 30 відео може використовувати модуль 88 зворотного перетворення для зворотного перетворення коефіцієнтів блока коефіцієнтів, що залишилися, який має другий розмір в блоці TU, який має перший розмір, в залишкові дані відео (160). Таким чином, модуль 88 зворотного перетворення може генерувати TU, який має перший розмір, за допомогою включення залишкових даних блока коефіцієнтів, що залишилися, який має другий розмір, і додавання нулів, що представляють залишкові дані, що залишилися, в TU. В іншому випадку декодер 30 відео може використовувати модуль 88 зворотного перетворення для зворотного перетворення коефіцієнтів у блоці TU, який має другий розмір, в залишкові дані відео (162). В одному або більше прикладах описані функції можуть бути реалізовані в апаратному забезпеченні, програмному забезпеченні, програмно-апаратних засобах, або будь-якій їх комбінації. Якщо реалізовано в програмному забезпеченні, ці функції можуть бути збережені на або передані, як одна або більше інструкцій або код, за допомогою зчитуваного комп'ютером носія і виконані основаним на апаратному забезпеченні блоком обробки. Зчитуваний комп'ютером носій може включати в себе зчитуваний комп'ютером носій даних, який відповідає матеріальному носію, такому як запам'ятовуючий носій даних, або комунікаційний носій, що включає в себе будь-який носій, який полегшує передачу комп'ютерної програми від одного місця до іншого, наприклад, згідно з протоколом зв'язку. У цьому способі зчитуваний комп'ютером носій в цілому може відповідати (1) матеріальному зчитуваному комп'ютером носій даних, який є нечасовим, або (2) комунікаційному носію, такому як сигнал або несуча. Запам'ятовуючим носієм даних може бути будь-який доступний носій, до якого можуть одержати доступ один або більше комп'ютерів або один або більше процесорів, щоб витягнути інструкції, код і/або структури даних для реалізації способів, описаних в даному винаході. Комп'ютерний програмний продукт може включати в себе зчитуваний комп'ютером носій. За допомогою прикладу, а не обмеження, такі зчитувані комп'ютером носії даних можуть містити RAM, ROM, EEPROM, CD-ROM або інший запам'ятовуючий пристрій на оптичних дисках, запам'ятовуючий пристрій на магнітних дисках, або інші магнітні пристрої зберігання, флеш-пам'ять, або будь-який інший носій, який може використовуватися, щоб зберігати бажаний код програми в формі інструкцій або структур даних, і до якого може одержати доступ комп'ютер. Крім того, будь-яке з'єднання належно називають зчитуваним комп'ютером носієм. Наприклад, якщо інструкції передані від вебсайту, сервера, або іншого віддаленого джерела, що використовує коаксіальний кабель, волоконно-оптичний кабель, виту пару, цифрову абонентську лінію (DSL), або бездротові технології, такі як інфрачервоне, радіо і мікрохивильове випромінювання, то цей коаксіальний кабель, волоконно-оптичний кабель, вита пара, DSL, або бездротові технології, такі як інфрачервоне, радіо і мікрохивильове випромінювання включаються у визначення носія. Треба мати на увазі, однак, що зчитувані комп'ютером носії даних і запам'ятовуючі пристрої даних не включають в себе з'єднання, несучі, сигнали, або інші тимчасові носії, але замість цього спрямовані на нетимчасові, матеріальні носії даних. Диск і диск, як використовується тут, включають в себе компакт-диск (CD), лазерний диск, оптичний диск, цифровий універсальний диск (DVD), дискета і диск Blu-ray, де диски (disks) звичайно відтворюють дані магнітним чином, в той час як диски (dicks) звичайно відтворюють дані оптично за допомогою лазерів. Комбінації вищезазначеного повинні також бути включені в рамки зчитуваного комп'ютером носія. Інструкції можуть бути виконані одним або більше процесорами, такими як один або більше цифрових сигнальних процесорів (DSP), мікропроцесори загального призначення, 25 UA 106937 C2 5 10 15 20 25 30 35 40 45 спеціалізовані інтегральні схеми (ASIC), програмовані користувачем логічні матриці (FPGA), або інші еквівалентні інтегральні або дискретні логічні схеми. Відповідно, термін "процесор", як використовується тут, може належати до будь-якої попередньої структури або будь-якої іншої структури, прийнятної для реалізації способів, описаних тут. Крім того, в деяких аспектах функціональні можливості, описані тут, можуть бути забезпечені в спеціалізованому апаратному забезпеченні і/або програмних модулях, сконфігурованих для кодування і декодування, або вбудовані в об'єднаний кодек. Крім того, способи можуть бути повністю реалізовані в одній або більше схемах або логічних елементах. Способи згідно з даним винаходом можуть бути реалізовані в широкій різноманітності пристроїв або пристроїв, включаючи бездротову телефонну трубку, інтегральну схему (IC) або набір IC (наприклад, мікропроцесорний набір). Різні компоненти, модулі, або блоки описані в даному винаході, щоб підкреслити функціональні аспекти пристроїв, що конфігуруються, щоб виконувати розкриті способи, але не обов'язково вимагати реалізації різними блоками апаратного забезпечення. Замість цього, як описано вище, різні блоки можуть бути об'єднані в блок апаратного забезпечення кодека або забезпечені колекцією взаємодіючих блоків апаратного забезпечення, включаючи один або більше процесорів, як описано вище, в з'єднанні з прийнятним програмним забезпеченням і/або програмно-апаратними засобами. Посилальні позиції 10 система 12 вихідний пристрій 14 пристрій-адресат 16 комунікаційний канал 18 джерело відео 20 кодер відео 22 модулятор/демодулятор (модем) 24 передавач 26 приймач 28 модем 30 декодер відео 32 пристрій відображення 38 модуль вибору режиму 40, 81 модуль прогнозування 42 модуль оцінки руху 44, 82 модуль компенсації руху 46, 84 модуль внутрішнього прогнозування 50 модуль підсумовування 52 модуль перетворення 54 модуль квантування 56, 80 модуль статистичного кодування 58, 86 модуль зворотного квантування 60, 88 модуль зворотного перетворення 62, 90 модуль підсумовування 64, 92 пам'ять опорних кадрів 70, 76 TU 73, 77 блок проміжних коефіцієнтів 74, 78 блок коефіцієнтів 94, 104 модуль контекстного моделювання 98,106 сховище об'єднаної контекстної моделі 99, 102 модуль арифметичного кодування 50 ФОРМУЛА ВИНАХОДУ 55 1. Спосіб кодування даних відео, який включає: підтримування об'єднаної контекстної моделі, що використовується спільно першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, що включає в себе множину блоків коефіцієнтів перетворення; 26 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 вибір контекстів для компонентів карти значущості для згаданих коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю; і статистичне кодування згаданих компонентів карти значущості, асоційованих із згаданим одним з блоків перетворення, на основі вибраних контекстів. 2. Спосіб за п. 1, в якому вибір контекстів для компонентів карти значущості для згаданих коефіцієнтів перетворення згідно із об'єднаною контекстною моделлю містить: призначення контексту в об'єднаній контекстній моделі заданому одному з компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення; і визначення оцінки ймовірності для значення згаданого заданого одного з компонентів карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі, і оновлення оцінки ймовірності, асоційованої з призначеним контекстом в об'єднаній контекстній моделі, на основі фактичних кодованих значень компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір. 3. Спосіб за п. 1, в якому спосіб включає спосіб декодування даних відео, який додатково включає: прийом потоку бітів, який представляє кодовану карту значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір; вибір контекстів для згаданих компонентів кодованої карти значущості згідно із об'єднаною контекстною моделлю; і статистичне декодування згаданих компонентів згаданої кодованої карти значущості для згаданих коефіцієнтів перетворення одного зі згаданих блоків перетворення на основі вибраних контекстів. 4. Спосіб за п. 3, який додатково включає зворотне перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення. 5. Спосіб за п. 1, в якому спосіб включає спосіб декодування даних відео, який додатково включає: перетворення залишкових піксельних значень в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір; вибір контекстів для згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення згідно із об'єднаною контекстною моделлю; і статистичне кодування згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів. 6. Спосіб за п. 1, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16. 7. Спосіб за п. 1, в якому вибір контекстів згідно із об'єднаною контекстною моделлю містить: призначення контексту в об'єднаній контекстній моделі першому компоненту першої карти значущості для коефіцієнтів перетворення першого блока перетворення, який має перший розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого першого блока перетворення; визначення оцінки ймовірності для значення згаданого першого компонента першої карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі; оновлення оцінки ймовірності, асоційованої з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичного кодованого значення згаданого першого компонента першої карти значущості, асоційованого з першим блоком перетворення; призначення того ж самого контексту в об'єднаній контекстній моделі другому компоненту другої карти значущості для згаданих коефіцієнтів перетворення другого блока перетворення, який має другий розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого другого блока перетворення; визначення оцінки ймовірності для значення згаданого другого компонента другої карти значущості, асоційованого з тим же самим призначеним контекстом в об'єднаній контекстній моделі; і 27 UA 106937 C2 5 10 15 20 25 30 35 40 45 50 55 оновлення оцінки ймовірності, асоційованої з одним і тим же призначеним контекстом в об'єднаній контекстній моделі, на основі фактичного закодованого значення згаданого другого компонента другої карти значущості, асоційованого з другим блоком перетворення. 8. Пристрій кодування відео, який містить: пам'ять, яка зберігає об'єднану контекстну модель, спільно використовувану першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, в якому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, який включає в себе множину блоків коефіцієнтів перетворення; і процесор, який конфігурується, щоб підтримувати об'єднану контекстну модель, вибирати контексти для компонентів карти значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення або другого блока перетворення, згідно із об'єднаною контекстною моделлю, і статистично кодувати згадані компоненти карти значущості, асоційовані з одним з блоків перетворення на основі вибраних контекстів. 9. Пристрій кодування відео за п. 8, в якому процесор сконфігурований для: призначення контексту в об'єднаній контекстній моделі заданому одному зі згаданих компонентів карти значущості на основі значень раніше кодованих сусідніх коефіцієнтів згаданого одного з блоків перетворення; і визначення оцінки ймовірності для значення згаданого заданого одного з компонентів карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі, і оновлення оцінки ймовірності, асоційованої з призначеним контекстом, в об'єднаній контекстній моделі, на основі фактичних кодованих значень коефіцієнтів згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення першого блока перетворення, який має перший розмір, і другого блока перетворення, який має другий розмір. 10. Пристрій кодування відео за п. 8, в якому пристрій кодування відео містить пристрій декодування відео, причому процесор сконфігурований для: прийому потоку бітів, який представляє кодовану карту значущості для коефіцієнтів перетворення, асоційованих з одним з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір; вибору контекстів для згаданих компонентів кодованої карти значущості, згідно із об'єднаною контекстною моделлю; і статистичного декодування згаданих компонентів кодованої карти значущості для згаданих коефіцієнтів перетворення одного зі згаданих блоків перетворення на основі вибраних контекстів. 11. Пристрій кодування відео за п. 10, в якому процесор сконфігурований для зворотного перетворення згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення одного з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір, в залишкові піксельні значення. 12. Пристрій кодування відео за п. 8, в якому пристрій кодування відео містить процесор для кодування відео, причому процесор сконфігурований для: перетворення залишкових піксельних значень в коефіцієнти перетворення в одному з першого блока перетворення, який має перший розмір, або другого блока перетворення, який має другий розмір; вибору контекстів для згаданих компонентів карти значущості для згаданих коефіцієнтів перетворення згаданого одного з блоків перетворення згідно із об'єднаною контекстною моделлю; і статистичного кодування згаданих компонентів карти значущості для коефіцієнтів перетворення згаданого одного з блоків перетворення на основі вибраних контекстів. 13. Пристрій кодування відео за п. 8, в якому перший блок перетворення першого розміру містить блок перетворення 32×32, і в якому другий блок перетворення другого розміру містить блок перетворення 16×16. 14. Пристрій кодування відео за п. 8, в якому процесор сконфігурований для: призначення контексту в об'єднаній контекстній моделі перших компонентів першої карти значущості для коефіцієнтів перетворення першого блока перетворення, який має перший розмір, на основі значень раніше кодованих сусідніх коефіцієнтів згаданого першого блока перетворення; визначення оцінки ймовірності для значення згаданого першого компонента згаданої першої карти значущості, асоційованого з призначеним контекстом, в об'єднаній контекстній моделі; 28
ДивитисяДодаткова інформація
Назва патенту англійськоюEntropy coding coefficients using a joint context model
Автори англійськоюSole Rojals, Joel, Joshi, Rajan L., Karczewicz, Marta
Автори російськоюСоле Рохальс Хоель, Джоши Раджан Л., Карчевич Марта
МПК / Мітки
МПК: H04N 7/00
Мітки: контекстну, кодування, коефіцієнтів, модель, статистичне, використовуючи, об'єднану
Код посилання
<a href="https://ua.patents.su/38-106937-statistichne-koduvannya-koeficiehntiv-vikoristovuyuchi-obehdnanu-kontekstnu-model.html" target="_blank" rel="follow" title="База патентів України">Статистичне кодування коефіцієнтів, використовуючи об’єднану контекстну модель</a>
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 106704
Опубліковано: 25.09.2014
Автори: Соле Рохальс Хоель, Карчевіч Марта, Джоши Раджан Лаксман
МПК: H04N 19/00
Мітки: відео, коефіцієнтів, кодування, перетворення
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео, в процесі кодування відео, причому спосіб включає:компонування блока коефіцієнтів перетворення в один або більше піднаборів коефіцієнтів перетворення на основі порядку сканування;кодування першої частини рівнів коефіцієнтів перетворення в кожному піднаборі, причому перша частина рівнів включає в себе щонайменше значущість коефіцієнтів...
Пристрій для розподілу та кодування інформаційного ресурсу в мультисервісних мережах

Номер патенту: 91075
Опубліковано: 25.06.2014
Автори: Рябуха Юрій Миколайович, Королюк Наталія Олександрівна, Красноруцький Андрій Олександрович, Лазебнік Сергій Володимирович, Третяк В'ячеслав Федорович, Ширяєв Андрій Володимирович, Романенко Ігор Володимирович, Баранник Володимир Вікторович, Голубничий Дмитро Юрійович, Власов Андрій Володимирович
МПК: G06F 15/00
Мітки: мережах, пристрій, інформаційного, кодування, мультисервісних, ресурсу, розподілу
Формула / Реферат:
Пристрій для розподілу та кодування інформаційного ресурсу в мультисервісних мережах, який містить блок сортування даних, блок управління систолічним процесором, обчислювальний пристрій, в якому кожен процесорний елемент містить блок регістрів, арифметичний обчислювач, який працює за алгоритмом МАХ (вибір максимального значення довжини шляху в графі за вагою функціоналу на основі принципу оптимізації за напрямком) і блок ідентифікації,...
Пристрій для динамічного кодування та захисту інформаційного ресурсу в інфокомунікаційних системах

Номер патенту: 91198
Опубліковано: 25.06.2014
Автори: Голубничий Дмитро Юрійович, Рябуха Юрій Миколайович, Бойко Юлія Петрівна, Юдін Олександр Костянтинович, Сєвєрінов Олександр Васильович, Власов Андрій Володимирович, Баранник Володимир Вікторович, Королюк Наталія Олександрівна, Ширяєв Андрій Володимирович, Третяк В'ячеслав Федорович
МПК: G06F 15/00, G06F 17/00
Мітки: інформаційного, захисту, ресурсу, системах, кодування, інфокомунікаційних, динамічного, пристрій
Формула / Реферат:
Пристрій для динамічного кодування та захисту інформаційного ресурсу в інфокомунікаційних системах, який містить блок управління систолічним процесором, обчислювальний пристрій формування вектора шляху та модуль пам'яті, який відрізняється тим, що введено блок сортування даних по убуванню значень коефіцієнтів в функціоналі та в обчислювальний пристрій, в якому кожен процесорний елемент містить блок регістрів, введено арифметичний обчислювач,...
Пристрій для вивчення кодування цифрових сигналів

Номер патенту: 87526
Опубліковано: 10.02.2014
Автори: Сендульський Микола Володимирович, Полянська Аріна Петрівна, Паун Олександр Штефанович
МПК: G06F 5/00, H03M 1/00, G09B 9/00
Мітки: сигналів, пристрій, вивчення, кодування, цифрових
Формула / Реферат:
Пристрій для вивчення кодування цифрових сигналів, який містить блок задавача двійкового коду, інформаційні виходи якого з'єднані з інформаційними входами блока перетворювачів кодів, групи виходів якого з'єднані з групами входів блока візуальної індикації, який відрізняється тим, що додатково містить блок задавача коду виду коду цифрового сигналу, виходи якого з'єднані з входами блока перетворювачів кодів, блок візуальної індикації...
Пристрій для обчислення коефіцієнтів фур’є

Номер патенту: 53130
Опубліковано: 15.01.2003
Автор: Волинець Віктор Іванович
МПК: G06F 17/14
Мітки: пристрій, обчислення, коефіцієнтів, фур'є
Формула / Реферат:
1. Пристрій для обчислення коефіцієнтів Фур'є, що містить два вхідних регістри, чотири блоки множення, шість підсумовуючих блоків, два проміжних регістри, чотири блоки зсуву, чотири блоки округлення та блок керування зсувами, вихід якого підключений до керуючих входів з першого по четвертий блоків зсуву та є виходом значення коефіцієнта масштабування операндів пристрою, інформаційні входи першого та другого вхідних регістрів підключені до...
Попередній патент: Фільтр з внутрішнім згладжуванням для кодування відео
Наступний патент: Скануючий пристрій та спосіб візуалізації шляхом зворотного розсіювання з застосуванням пучка променів
Випадковий патент: Спосіб застосування регуляторів росту рослин нового покоління для передпосівної обробки насіння озимої пшениці в умовах лісостепу західного