Скорочення контексту для контекстно-адаптивного бінарного арифметичного кодування
Номер патенту: 109507
Опубліковано: 25.08.2015
Автори: Соле Рохальс Хоель, Карчєвіч Марта, Чіень Вей-Цзюн







Формула / Реферат
1. Спосіб кодування відеоданих, який містить:
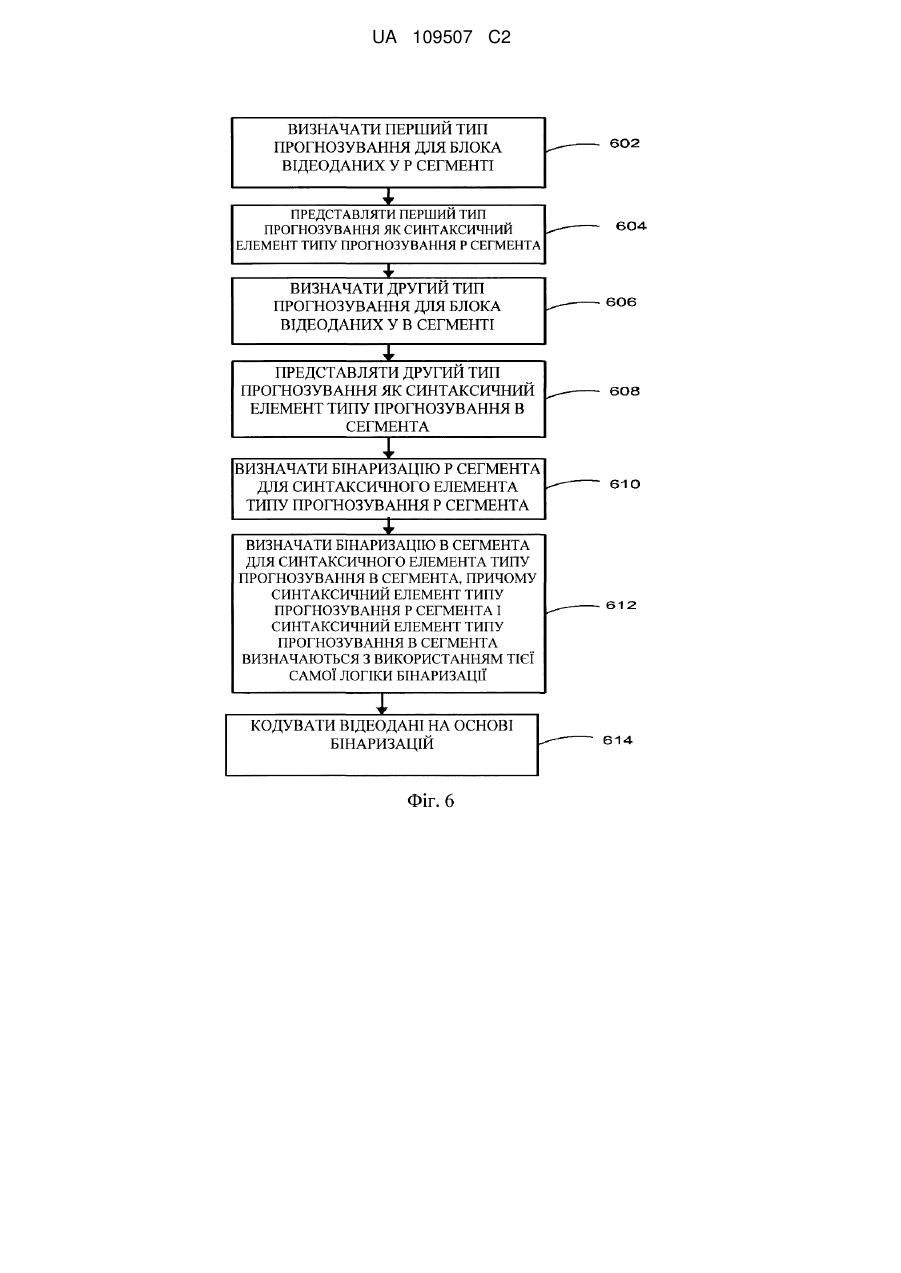
визначення першого типу прогнозування для блока відеоданих у Р сегменті;
представлення першого типу прогнозування як синтаксичного елемента типу прогнозування Р сегмента;
визначення другого типу прогнозування для блока відеоданих у В сегменті;
представлення другого типу прогнозування як синтаксичного елемента типу прогнозування В сегмента;
визначення бінаризації Р сегмента для синтаксичного елемента типу прогнозування Р сегмента;
визначення бінаризації В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації; і
кодування відеоданих на основі бінаризацій синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента.
2. Спосіб за п. 1, в якому кодування відеоданих включає в себе: бінаризацію синтаксичного елемента типу прогнозування Р сегмента з визначеною бінаризацією Р сегмента;
бінаризацію синтаксичного елемента типу прогнозування В сегмента з визначеною бінаризацією В сегмента;
застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування Р сегмента; і
застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування В сегмента.
3. Спосіб за п. 1, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
4. Спосіб за п. 3, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
5. Спосіб за п. 3, в якому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
6. Спосіб декодування відеоданих, який включає в себе:
відображення бінаризованого синтаксичного елемента типу прогнозування Р сегмента на тип прогнозування з використанням відображення бінаризації для блока відеоданих у Р сегменті;
відображення бінаризованого синтаксичного елемента типу прогнозування В сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у В сегменті; і
декодування відеоданих на основі відображених типів прогнозування.
7. Спосіб за п. 6, який додатково містить:
прийом підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування Р сегмента, який вказує тип прогнозування для блока відеоданих у Р сегменті; і
прийом підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування В сегмента, який вказує тип прогнозування для блока відеоданих у В сегменті;
причому декодування відеоданих додатково містить:
декодування синтаксичного елемента типу прогнозування Р сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування Р сегмента; і
декодування синтаксичного елемента типу прогнозування В сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування В сегмента.
8. Спосіб за п. 6, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
9. Спосіб за п. 8, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
10. Спосіб за п. 8, в якому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
11. Пристрій, сконфігурований для кодування відеоданих, який містить:
засіб для визначення першого типу прогнозування для блока відеоданих у Р сегменті;
засіб для представлення першого типу прогнозування як синтаксичного елемента типу прогнозування Р сегмента;
засіб для визначення другого типу прогнозування для блока відеоданих у В сегменті;
засіб для представлення другого типу прогнозування як синтаксичного елемента типу прогнозування В сегмента;
засіб для визначення бінаризації Р сегмента для синтаксичного елемента типу прогнозування Р сегмента;
засіб для визначення бінаризації В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації; і
засіб для кодування відеоданих на основі бінаризацій синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента.
12. Пристрій за п. 11, в якому засіб для кодування відеоданих включає в себе:
засіб для бінаризації синтаксичного елемента типу прогнозування Р сегмента з визначеною бінаризацією Р сегмента;
засіб для бінаризації синтаксичного елемента типу прогнозування В сегмента з визначеною бінаризацією В сегмента;
засіб для застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування Р сегмента; і
засіб для застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування В сегмента.
13. Пристрій за п. 11, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
14. Пристрій за п. 13, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
15. Пристрій за п. 13, в якому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
16. Пристрій, сконфігурований для декодування відеоданих, який включає в себе:
засіб для відображення бінаризованого синтаксичного елемента типу прогнозування Р сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у Р сегменті;
засіб для відображення бінаризованого синтаксичного елемента типу прогнозування В сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у В сегменті; і
засіб для декодування відеоданих на основі відображених типів прогнозування.
17. Пристрій за п. 16, який додатково містить:
засіб для прийому підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування Р сегмента, який вказує тип прогнозування для блока відеоданих у Р сегменті; і
засіб для прийому підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування В сегмента, який вказує тип прогнозування для блока відеоданих у В сегменті;
причому засіб для декодування відеоданих додатково містить:
засіб для декодування синтаксичного елемента типу прогнозування Р сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування Р сегмента; і
засіб для декодування синтаксичного елемента типу прогнозування В сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування В сегмента.
18. Пристрій за п. 16, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
19. Пристрій за п. 18, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
20. Пристрій за п. 18, в якому тип розділення включає в себе одне з симетричних розділень та асиметричних розділень.
21. Пристрій, сконфігурований для кодування відеоданих, який містить: відеокодер, сконфігурований для:
визначення першого типу прогнозування для блока відеоданих у Р сегменті;
представлення першого типу прогнозування як синтаксичного елемента типу прогнозування Р сегмента;
визначення другого типу прогнозування для блока відеоданих у В сегменті;
представлення другого типу прогнозування як синтаксичного елемента типу прогнозування В сегмента;
визначення бінаризації Р сегмента для синтаксичного елемента типу прогнозування Р сегмента;
визначення бінаризації В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації; і
кодування відеоданих на основі бінаризацій синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента.
22. Пристрій за п. 21, в якому відеокодер додатково сконфігурований для:
бінаризації синтаксичного елемента типу прогнозування Р сегмента з визначеною бінаризацією Р сегмента;
бінаризації синтаксичного елемента типу прогнозування В сегмента з визначеною бінаризацією В сегмента;
застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування Р сегмента; і
застосування контекстно-адаптивного бінарного арифметичного кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування В сегмента.
23. Пристрій за п. 21, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
24. Пристрій за п. 23, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
25. Пристрій за п. 23, в якому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
26. Пристрій, сконфігурований для декодування відеоданих, який включає в себе:
відеодекодер, сконфігурований для:
відображення бінаризованого синтаксичного елемента типу прогнозування Р сегмента на тип прогнозування з використанням відображення бінаризації для блока відеоданих у Р сегменті;
відображення бінаризованого синтаксичного елемента типу прогнозування В сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у В сегменті; і
декодування відеоданих на основі відображених типів прогнозування.
27. Пристрій за п. 26, в якому відеодекодер додатково сконфігурований для:
прийому підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування Р сегмента, який вказує тип прогнозування для блока відеоданих у Р сегменті; і
прийому підданого контекстно-адаптивному бінарному арифметичному кодуванню синтаксичного елемента типу прогнозування В сегмента, який вказує тип прогнозування для блока відеоданих у В сегменті;
декодування синтаксичного елемента типу прогнозування Р сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування Р сегмента; і
декодування синтаксичного елемента типу прогнозування В сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування В сегмента.
28. Пристрій за п. 26, в якому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
29. Пристрій за п. 28, в якому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
30. Пристрій за п. 28, в якому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
31. Зчитуваний комп'ютером носій зберігання даних, що зберігає інструкції, які при виконанні спонукають один або більше процесорів кодувати відеодані, щоб:
визначати перший тип прогнозування для блока відеоданих у Р сегменті;
представляти перший тип прогнозування як синтаксичний елемент типу прогнозування Р сегмента;
визначати другий тип прогнозування для блока відеоданих у В сегменті;
представляти другий тип прогнозування як синтаксичний елемент типу прогнозування В сегмента;
визначати бінаризацію Р сегмента для синтаксичного елемента типу прогнозування Р сегмента;
визначати бінаризацію В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації; і
кодувати відеодані на основі бінаризацій синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента.
32. Зчитуваний комп'ютером носій зберігання даних за п. 31, причому інструкції додатково спонукають один або більше процесорів:
бінаризувати синтаксичний елемент типу прогнозування Р сегмента з визначеною бінаризацією Р сегмента;
бінаризувати синтаксичний елемент типу прогнозування В сегмента з визначеною бінаризацією В сегмента;
застосовувати контекстно-адаптивне бінарне арифметичне кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування Р сегмента; і
застосовувати контекстно-адаптивне бінарне арифметичне кодування (САВАС) до бінаризованого синтаксичного елемента типу прогнозування В сегмента.
33. Зчитуваний комп'ютером носій зберігання даних за п. 31, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
34. Зчитуваний комп'ютером носій зберігання даних за п. 33, причому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
35. Зчитуваний комп'ютером носій зберігання даних за п. 33, причому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
36. Зчитуваний комп'ютером носій зберігання даних, що зберігає інструкції, які при виконанні спонукають один або більше процесорів декодувати відеодані, щоб:
відображати бінаризований синтаксичний елемент типу прогнозування Р сегмента на тип прогнозування з використанням відображення бінаризації для блока відеоданих у Р сегменті;
відображати бінаризований синтаксичний елемент типу прогнозування В сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у В сегменті; і
декодувати відеодані на основі відображених типів прогнозування.
37. Зчитуваний комп'ютером носій зберігання даних за п. 36, причому інструкції додатково спонукають один або більше процесорів:
приймати підданий контекстно-адаптивному бінарному арифметичному кодуванню синтаксичний елемент типу прогнозування Р сегмента, який вказує тип прогнозування для блока відеоданих у Р сегменті;
приймати підданий контекстно-адаптивному бінарному арифметичному кодуванню синтаксичний елемент типу прогнозування В сегмента, який вказує тип прогнозування для блока відеоданих у В сегменті;
декодувати синтаксичний елемент типу прогнозування Р сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування Р сегмента; і
декодувати синтаксичний елемент типу прогнозування В сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування В сегмента.
38. Зчитуваний комп'ютером носій зберігання даних за п. 36, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення.
39. Зчитуваний комп'ютером носій зберігання даних за п. 38, причому режим прогнозування включає в себе одне з інтерпрогнозування та інтрапрогнозування.
40. Зчитуваний комп'ютером носій зберігання даних за п. 38, причому тип розділення включає в себе одне із симетричних розділень та асиметричних розділень.
Текст
Реферат: На фіг. 6 представлена блок-схема, що ілюструє приклад способу відеокодування згідно з даним розкриттям. Спосіб за фіг. 6 може бути реалізований відеокодером 20. Відеокодер 20 може бути сконфігурований, щоб визначати перший тип прогнозування для блока відеоданих у Р сегменті (602) і представляти перший тип прогнозування як синтаксичний елемент типу прогнозування Р сегмента (604). Відеокодер 20 може бути додатково сконфігурований, щоб визначати другий тип прогнозування для блока відеоданих у В сегменті (606) і представляти другий тип прогнозування як синтаксичний елемент типу прогнозування В сегмента (608). Синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначають режим прогнозування і тип розділення. Режим прогнозування може включати в себе одне з інтер-прогнозування та інтра-прогнозування. Тип розділення може включати в себе одне із симетричних розділень та асиметричних розділень. Відеокодер 20 може бути додатково сконфігурований, щоб визначати бінаризацію Р сегмента для синтаксичного елемента типу прогнозування Р сегмента (610) і визначати бінаризацію В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації (612). Відеокодер 20 може потім кодувати відеодані на основі бінаризації синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента (614). UA 109507 C2 (12) UA 109507 C2 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дана заявка заявляє пріоритет попередньої заявки США 61/557325, поданої 8 листопада 2011 р., і попередньої заявки США 61/561911, поданої 20 листопада 2011 р., обидві з яких включені в цей документ як посилання у всій їх повноті. Галузь техніки Даний винахід відноситься до кодування відео і, зокрема, контекстно-адаптивного бінарного арифметичного кодування (CABAC), що використовується в кодуванні відео. Попередній рівень техніки Можливості цифрового відео можуть бути включені в широкий діапазон пристроїв, включаючи цифрові телевізори, системи цифрового прямого мовлення, бездротові системи мовлення, персональні цифрові помічники (PDA), портативні або настільні комп'ютери, планшетні комп'ютери, електронні книги, цифрові камери, цифрові записуючі пристрої, цифрові медіаплеєри, ігрові відеопристрої, ігрові приставки, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої відеотелеконференцій, пристрої потокового відео і тому подібне. Цифрові відеопристрої реалізовують технології стиснення відео, такі як ті, що описані в стандартах, визначених MPEG-2, MPEG-4, ITU-T H.263, ITU-Т H.264/MPEG-4, частина 10, Розширене кодування відео (AVC), стандарт Високоефективного кодування відео (HEVC), що знаходиться в цей час в стадії розробки, і розширення таких стандартів. Відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію більш ефективно шляхом реалізації таких методів стиснення відео. Методи стиснення відео виконують просторове (всередині зображення, інтра-) прогнозування і/або часове (між зображеннями, інтер-) прогнозування для скорочення або усунення надмірності, властивої відеопослідовностями. Для блокового кодування відео відеослайс (тобто відеозображення або частина відеозображення) може бути розділений на блоки відео, які також можуть згадуватися як блоки дерева, одиниці кодування (CU) і/або вузли кодування. Блоки відео в інтра-кодованому (I) слайсі (сегменті) зображення кодуються з використанням просторового прогнозування відносно опорних вибірок у сусідніх блоках в тому самому зображенні. Блоки відео в інтер-кодованому (Р або В) сегменті зображення можуть використовувати просторове прогнозування відносно опорних вибірок у сусідніх блоках в тому самому зображенні або часове прогнозування відносно опорних вибірок в інших опорних зображеннях. Зображення можуть згадуватися як кадри, і опорні зображення можуть згадуватися як опорні кадри. Просторове або часове прогнозування призводить в результаті до блока прогнозування для блока, що підлягає кодуванню. Залишкові дані представляють піксельні різниці між вихідним блоком, що підлягає кодуванню, і блоком прогнозування. Інтер-кодований блок кодується відповідно до вектора руху, який вказує на блок опорних вибірок, утворюючих блок прогнозування, і залишковими даними, які вказують різницю між кодованим блоком і блоком прогнозування. Інтра-кодований блок кодується відповідно до режиму інтра-кодування і залишкових даних. Для подальшого стиснення залишкові дані можуть бути перетворені з піксельної ділянки в ділянку перетворення, призводячи в результаті до залишкових коефіцієнтів перетворення, які потім можуть бути квантовані. Квантовані коефіцієнти перетворення, спочатку впорядковані в двомірний масив, можуть скануватися, щоб сформувати одномірний вектор коефіцієнтів перетворення, і ентропійне кодування може бути застосоване для досягнення ще більшого стиснення. Суть винаходу Загалом, це розкриття описує методи для контекстно-адаптивного бінарного арифметичного кодування (CABAC) в процесі відеокодування. Зокрема, це розкриття пропонує скорочення кількості контекстів CABAC, що використовуються для одного або декількох синтаксичних елементів, необмежувальні приклади яких включають pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag та coeff_abs_level_greater2_flag. Модифікації можуть скоротити до 56 контекстів з нехтувано малими змінами ефективності кодування. Скорочення контексту для синтаксичних елементів, що пропонуються, можуть бути використані окремо або в будь-якій комбінації. В одному прикладі здійснення розкриття спосіб кодування відео може включати в себе визначення першого типу прогнозування для блока відеоданих у Р слайсі (сегменті), представлення першого типу прогнозування як синтаксичний елемент типу прогнозування Р сегмента, визначення другого типу прогнозування для блока відеоданих у В сегменті, представлення другого типу прогнозування як синтаксичний елемент типу прогнозування В сегмента, визначення бінаризації Р сегмента для синтаксичного елемента типу прогнозування Р сегмента, визначення бінаризації В сегмента для синтаксичного елемента типу прогнозування В сегмента, при цьому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний 1 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації, і кодування відеоданих на основі бінаризації синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента. В іншому прикладі даного розкриття спосіб декодування відео може включати в себе відображення бінаризованого синтаксичного елемента типу прогнозування Р сегмента на тип прогнозування, використовуючи відображення бінаризації для блока відеоданих у Р сегменті, відображення бінаризованого синтаксичного елемента типу прогнозування В сегмента на тип прогнозування, використовуючи відображення бінаризації для блока відеоданих у В сегменті, і декодування відеоданих, основуючись на відображених типах прогнозування. В іншому прикладі даного розкриття спосіб кодування відеоданих включає в себе визначення типу розділення для режиму прогнозування для блока відеоданих, кодування структурного елемента типу розділення синтаксичного елемента типу прогнозування для блока відеоданих з використанням CABAC з одним контекстом, причому цей один контекст є тим самим для будь-якого типу розділення, і кодування структурного елемента розміру розділення синтаксичного елемента типу прогнозування для блока відеоданих з використанням CABAC в режимі обходу. В іншому прикладі даного розкриття спосіб декодування відеоданих містить прийом синтаксичного елемента типу прогнозування для блока відеоданих, які були кодовані з використанням CABAC, причому синтаксичний елемент типу прогнозування включає в себе структурний елемент типу розділення, що представляє тип розділення, і структурний елемент розміру розділення, що представляє розмір розділення, декодування структурного елемента типу розділення синтаксичного елемента типу прогнозування з використанням контекстноадаптивного бінарного арифметичного кодування з одним контекстом, причому цей один контекст є тим самим для будь-якого типу розділення, і декодування структурного елемента типу розділення синтаксичного елемента типу прогнозування з використанням CABAC в режимі обходу. В іншому прикладі даного розкриття спосіб кодування відеоданих включає в себе кодування прапора кодованого блока кольоровості Cb для блока відеоданих з використанням CABAC, причому кодування прапора кодованого блока кольоровості Cb включає в себе використання набору контекстів, що включає в себе один або більше контекстів як частину CABAC, і кодування прапора кодованого блока кольоровості Cr з використанням CABAC, причому кодування прапора кодованого блокакольоровості Cr містить використання того самого набору контекстів, що і для прапора кодованого блока кольоровості Cb, як частину CABAC. Дане розкриття також описує вищезгадані способи в термінах пристроїв, сконфігурованих для виконання цих способів, а також в термінах зчитуваного комп'ютером носія для зберігання інструкцій, які, при їх виконанні, спонукають один або більше процесорів виконувати ці способи. Деталі одного або декількох прикладів наведені на прикладених кресленнях і в описі нижче. Інші ознаки, цілі та переваги будуть очевидні з опису і креслень і з формули винаходу. Короткий опис креслень На фіг. 1 представлена блок-схема, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати методи, описані в даному розкритті. На фіг. 2 представлена блок-схема, що ілюструє зразковий відеокодер, який може реалізувати способи, описані в даному розкритті. На фіг. 3 представлена блок-схема, що ілюструє зразковий відеодекодер, який може реалізувати способи, описані в даному розкритті. На фіг. 4 показане концептуальне креслення, що демонструє як квадратні, так і неквадратні типи розділення. На фіг. 5 показане концептуальне креслення, що демонструє асиметричні типи розділення. На фіг. 6 представлена блок-схема послідовності операцій, що ілюструє приклад способу кодування відео згідно з даним розкриттям. На фіг. 7 представлена блок-схема послідовності операцій, що ілюструє приклад способу декодування відео згідно з даним розкриттям. На фіг. 8 представлена блок-схема послідовності операцій, що ілюструє приклад способу кодування відео згідно з даним розкриттям. На фіг. 9 представлена блок-схема послідовності операцій, що ілюструє приклад способу декодування відео згідно з даним розкриттям. На фіг. 10 представлена блок-схема послідовності операцій, що ілюструє приклад способу кодування відео згідно з даним розкриттям. Докладний опис 2 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дане розкриття описує способи кодування даних, таких як відеодані. Зокрема, в даному розкритті описуються способи, які можуть сприяти ефективному кодуванню відеоданих з використанням процесів контекстно-адаптивного ентропійного кодування. Зокрема, в даному розкритті пропонується скорочення кількості контекстів CABAC, що використовуються для кодування синтаксичних елементів, таких як pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag та coeff_abs_level_greater2_flag. Модифікації скорочують до 56 контекстів з нехтувано малими змінами ефективності кодування. Дане розкриття описує кодування відео для цілей ілюстрації. Однак способи, описані в даному описі, також можуть бути застосовні до кодування інших типів даних. На фіг. 1 представлена блок-схема, що ілюструє приклад системи 10 кодування і декодування відео, яка може бути сконфігурована, щоб використовувати методи контекстноадаптивного бінарного арифметичного кодування (CABAC) відповідно до прикладів даного розкриття. Як показано на фіг. 1, система 10 включає в себе пристрій-джерело 12, який передає кодоване відео до пристрою-одержувача 14 через канал 16 зв'язку. Кодовані відеодані можуть також зберігатися на носії 34 зберігання даних або файловому сервері 36, і пристрій-одержувач 14 може звертатися до них за бажанням. При зберіганні на носії зберігання даних або файловому сервері відеокодер 20 може надати кодовані відеодані іншому пристрою, такому як мережний інтерфейс, компакт-диск (CD), програматор або пристрій обладнання штампування Blu-Ray або цифрового відеодиска (DVD) або інші пристрої, для зберігання кодованих відеоданих на носії зберігання даних. Крім того, пристрій, окремий від відеодекодера 30, такий як мережний інтерфейс, CD або DVD зчитувач або тому подібне, може витягувати кодовані відеодані з носія зберігання даних і надавати витягнуті дані на відеодекодер 30. Пристрій-джерело 12 і пристрій-одержувач 14 можуть включати в себе будь-який з широкого спектра пристроїв, включаючи настільні комп'ютери, ноутбуки (тобто портативні комп'ютери), планшетні комп'ютери, телевізійні приставки, телефонні апарати, такі як так звані смартфони, телевізори, камери, пристрої відображення, цифрові медіаплеєри, ігрові консолі або тому подібне. У багатьох випадках такі пристрої можуть бути оснащені для бездротового зв'язку. Таким чином, канал 16 зв'язку може містити бездротовий канал, дротовий канал або комбінацію дротових і бездротових каналів, придатних для передачі кодованих відеоданих. Аналогічно файловий сервер 36 може бути доступний для пристрою-одержувача 14 через будь-яке стандартне з'єднання передачі даних, в тому числі Інтернет-з'єднання. Це може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем і або поєднання того і іншого, яке підходить для доступу до кодованих відеоданих, що зберігаються на файловому сервері. Методи САВАС, відповідно до прикладів даного розкриття, можуть бути застосовані до кодування відео для підтримки будь-якого з множини мультимедійних додатків, таких як ефірне телевізійне мовлення, передачі кабельного телебачення, передачі супутникового телебачення, передачі потокового відео, наприклад, через Інтернет, кодування цифрового відео для зберігання на носії даних, декодування цифрового відео, збереженого на носії даних, або інших додатків. У деяких прикладах система 10 може бути сконфігурована для підтримки односторонніх або двосторонніх передач відео для підтримки таких додатків, як потокове відео, відтворення відео, відеомовлення і/або відеотелефонія. У прикладі за фіг. 1 пристрій-джерело 12 включає в себе джерело 18 відео, відеокодер 20, модулятор/демодулятор 22 і передавач 24. У пристрої-джерелі 12 джерело 18 відео може включати в себе джерело, таке як пристрій захоплення відео, наприклад, відеокамеру, відеоархіви, що містять раніше захоплене відео, інтерфейс відеоканалу для прийому відео від постачальника відеоконтенту і/або систему комп'ютерної графіки для генерації даних комп'ютерної графіки як вихідного відео або комбінацію таких джерел. Як один приклад, якщо джерело 18 відео являє собою відеокамеру, пристрій-джерело 12 і пристрій-одержувач 14 можуть утворювати так звані камери-телефони або відеотелефони. Однак способи, описані в даному розкритті, можуть застосовуватися до кодування відео загалом і можуть бути застосовані до бездротових і/або дротових додатків або додатку, в якому кодовані відеодані збережені на локальному диску. Захоплене, заздалегідь захоплене відео або відео, що генерується комп'ютером, може кодуватися за допомогою відеокодера 20. Кодована інформація відео може модулюватися за допомогою модему 22 відповідно до стандарту зв'язку, наприклад, протоколу бездротового зв'язку, і передаватися до пристрою-одержувача 14 за допомогою передавача 24. Модем 22 може включати в себе різні змішувачі, фільтри, підсилювачі та інші компоненти, призначені для модуляції сигналу. Передавач 24 може включати в себе схеми, призначені для передачі даних, в тому числі підсилювачі, фільтри і одну або більше антен. 3 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 Захоплене, заздалегідь захоплене відео або відео, що генерується комп'ютером, яке кодується за допомогою відеокодера 20, також може зберігатися на носії 34 зберігання даних або файловому сервері 36 для подальшого споживання. Носій 34 зберігання даних може включати Blu-Ray диски, DVD-диски, CD-ROM, флеш-пам'ять або будь-який інший підходящий цифровий носій зберігання даних для зберігання кодованого відео. Кодоване відео, збережене на носії 34 зберігання даних, може потім бути доступним для пристрою-одержувача 14 для декодування і відтворення. Хоча це не показано на фіг. 1, в деяких прикладах носій 34 зберігання даних і/або файловий сервер 36 може зберігати вихідний сигнал передавача 24. Файловий сервер 36 може бути будь-яким типом сервера, здатним зберігати кодоване відео і передавати це кодоване відео до пристрою-одержувача 14. Зразкові файлові сервери включають в себе веб-сервер (наприклад, для веб-сайта), FTP-сервер, пристрої зберігання, зв'язані з мережею (NAS), локальний диск або будь-який інший тип пристрою, здатного зберігати кодовані відеодані і передавати їх до пристрою-одержувача. Передача кодованих відеоданих з файлового сервера 36 може бути потоковою передачею, передачею завантаження або поєднанням того і іншого. Файловий сервер 36 може бути доступним для пристроюодержувача 14 через будь-яке стандартне з'єднання передачі даних, в тому числі Інтернетз'єднання. Це може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем, Ethernet, USB і або поєднання того і іншого, яке підходить для доступу до кодованих відеоданих, що зберігаються на файловому сервері. Пристрій-одержувач 14 в прикладі за фіг. 1 включає в себе приймач 26, модем 28, відеодекодер 30 і пристрій 32 відображення. Приймач 26 пристрою-одержувача 14 приймає інформацію по каналу 16, і модем 28 демодулює інформацію для одержання демодульованого потоку бітів для відеодекодера 30. Інформація, що передається через канал 16, може включати в себе різну синтаксичну інформацію, що генерується відеокодером 20, для використання відеодекодером 30 при декодуванні відеоданих. Такий синтаксис також може бути включений в кодовані відеодані, збережені на носії 34 зберігання даних або файловому сервері 36. Кожний з відеокодера 20 і відеодекодера 30 може бути частиною відповідного кодера-декодера (кодека), який здатний кодувати або декодувати відеодані. Пристрій 32 відображення може бути вбудованим або зовнішнім по відношенню до пристрою-одержувача 14. У деяких прикладах пристрій-одержувач 14 може включати в себе вбудований пристрій відображення, а також може бути сконфігурований для взаємодії із зовнішнім пристроєм відображення. В інших прикладах пристрій-одержувач 14 може бути пристроєм відображення. Загалом, пристрій 32 відображення відображає декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, таких як рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світловипромінюваних діодах (OLED) або інший тип пристрою відображення. У прикладі на фіг. 1 канал 16 зв'язку може містити будь-яке дротове або бездротове середовище зв'язку, наприклад, радіочастотний (РЧ) спектр або одну або декількох фізичних ліній передачі, або будь-яку комбінацію бездротових і дротових середовищ передачі. Канал 16 зв'язку може бути частиною пакетної мережі, наприклад, локальної мережі, мережі широкого охоплення або глобальної мережі, такої як Інтернет. Канал 16 зв'язку звичайно являє собою будь-яке підходяще середовище зв'язку або набір різних середовищ зв'язку для передачі відеоданих від пристрою-джерела 12 до пристрою-одержувача 14, включаючи будь-яку підходящу комбінацію дротових або бездротових середовищ передачі. Канал 16 зв'язку може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути корисним для забезпечення зв'язку від пристрою-джерела 12 до пристроюодержувача 14. Відеокодер 20 і відеодекодер 30 можуть працювати відповідно до стандарту стиснення відео, такого як стандарт Високоефективного кодування відео (HEVC), що знаходиться в цей час на стадії розробки Об'єднаної спільної групи з кодування відео (JCT-VC) ITU-Т, Групи експертів з кодування відео (VCEG) і ISO/IEC Групи експертів з рухомого зображення (MPEG). Недавній проект стандарту HEVC, який називається "HEVC робочий проект 6" або "WD6", описується в документі JCTVC-H1003, Bross et al., "High efficiency video coding (HEVC) text specification draft 6", Об'єднаної спільної групи з кодування відео (JCT-VC) ITU-T SGI 6 WP3 та ISO/IEC JTC1/SC29/WG11, 8-е засідання: Сан-Хосе, Каліфорнія, США, лютий 2012 р., який за станом на 1 червня 2012 року можна скачати з http://phenix.intevry.fr/jct/doc_end_user/documents/8_San%20Jose/wg11/JCTVC-1003-v22.zip. Крім того, відеокодер 20 і відеодекодер 30 можуть діяти відповідно до інших пропрієтарних або промислових стандартів, таких як стандарт ITU-T H.264, який альтернативно називається MPEG-4, частина 10, Розширене кодування відео (AVC), або розширення таких стандартів. 4 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 Методи даного розкриття, однак, не обмежуються яким-небудь конкретним стандартом кодування. Інші приклади включають MPEG-2 та ITU-T H.263. Хоча це не показане на фіг. 1, в деяких аспектах відеокодер 20 і відеодекодер 30 можуть, кожний, бути інтегрований з аудіокодером і декодером і можуть включати в себе відповідні блоки MUX-DEMUX або інші апаратні засоби і програмне забезпечення для обробки кодування аудіо і відео в загальному потоці даних або окремих потоках даних. Якщо застосовно, в деяких прикладах блоки MUX-DEMUX можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Відеокодер 20 і відеодекодер 30, кожний, може бути реалізований як будь-яка з множини підходящих схем кодера, таких як один або більше мікропроцесорів, цифрові сигнальні процесори (DSP), спеціалізовані інтегральні схеми (ASIC), програмовані вентильні матриці (FPGA), дискретна логіка, програмне забезпечення, апаратні засоби, програмно-апаратні засоби або будь-які їх комбінації. Коли технології реалізовані частково в програмному забезпеченні, пристрій може зберігати інструкції для програмного забезпечення на підходящому постійному зчитуваному комп'ютером носії і виконувати інструкції в апаратних засобах з використанням одного або більше процесорів для виконання методів даного розкриття. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або більше кодерів або декодерів, кожний з яких може бути інтегрований як частина комбінованого кодера/декодера (кодека) у відповідному пристрої. Відеокодер 20 може реалізовувати будь-який або всі методи даного розкриття для CABAC в процесі кодування відео. Крім того, відеодекодер 30 може здійснювати деякі або всі з цих методів для CABAC в процесі кодування відео. Пристрій кодування відео, як описано в даному розкритті, може відноситися до відеокодера або відеодекодера. Аналогічним чином блок кодування відео може відноситися до відеокодера або відеодекодера. Крім того, кодування відео може відноситися до кодування відео або декодування відео. В одному прикладі даного розкриття відеокодер 20 може бути сконфігурований, щоб визначати перший тип прогнозування для блока відеоданих у Р сегменті, представляти перший тип прогнозування як синтаксичний елемент типу прогнозування Р сегмента, визначати другий тип прогнозування для блока відеоданих у В сегменті, представляти другий тип прогнозування як синтаксичний елемент типу прогнозування В сегмента, визначати бінаризацію Р сегмента для синтаксичного елемента типу прогнозування Р сегмента, визначати бінаризацію В сегмента для синтаксичного елемента типу прогнозування В сегмента, при цьому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації, і кодувати відеодані на основі бінаризації синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента. В іншому прикладі даного розкриття відеодекодер 30 може бути сконфігурований, щоб відображати бінаризований синтаксичний елемент типу прогнозування Р сегмента на тип прогнозування, використовуючи відображення бінаризації для блока відеоданих у Р сегменті, відображати бінаризований синтаксичний елемент типу прогнозування В сегмента на тип прогнозування, використовуючи те саме відображення бінаризації для блока відеоданих у В сегменті, і декодувати відеодані, основуючись на відображених типах прогнозування. В іншому прикладі даного розкриття відеокодер 20 може бути сконфігурований, щоб визначати тип розділення для режиму прогнозування для блока відеоданих, кодувати структурний елемент типу розділення синтаксичного елемента типу прогнозування для блока відеоданих з використанням CABAC з одним контекстом, причому цей один контекст є тим самим для будь-якого типу розділення, і кодувати структурний елемент розміру розділення синтаксичного елемента типу прогнозування для блока відеоданих з використанням CABAC в режимі обходу. В іншому прикладі даного розкриття відеодекодер 30 може бути сконфігурований, щоб приймати синтаксичний елемент типу прогнозування для блока відеоданих, які були кодовані з використанням CABAC, причому синтаксичний елемент типу прогнозування включає в себе структурний елемент типу розділення, що представляє тип розділення, і структурний елемент розміру розділення, що представляє розмір розділення, декодувати структурний елемент типу розділення синтаксичного елемента типу прогнозування з використанням САВАС з одним контекстом, причому цей один контекст є тим самим для будь-якого типу розділення, і декодувати структурний елемент розміру розділення синтаксичного елемента типу прогнозування з використанням CABAC в режимі обходу. В іншому прикладі даного розкриття, як відеокодер 20, так і відеодекодер 30 можуть бути сконфігуровані, щоб кодувати прапор кодованого блока кольоровості Cb для блока відеоданих з 5 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 використанням CABAC, причому кодування прапора кодованого блока кольоровості Cb включає в себе використання набору контекстів, що включає в себе один або більше контекстів як частину CABAC, і кодувати прапор кодованого блока кольоровості Cr з використанням CABAC, причому кодування прапора кодованого блока кольоровості Cr містить використання того самого набору контекстів, що і для прапора кодованого блока кольоровості Cb, як частину CABAC. JCT-VC працює над розвитком стандарту HEVC. Зусилля HEVC стандартизації базуються на моделі пристрою кодування, що розвивається відео, яка називається тестовою моделлю HEVC (HM). HM передбачає декілька додаткових можливостей пристроїв кодування відео відносно існуючих пристроїв відповідно, наприклад, до ITU-Т H.264/AVC. Наприклад, в той час як H.264 забезпечує дев'ять режимів кодування з інтра-прогнозуванням, HM може забезпечити тридцять три режими кодування з інтра-прогнозуванням. У наступному розділі будуть більш детально описані деякі аспекти HM. Загалом, робоча модель HM описує, що відеокадр або зображення може бути розділено на послідовність блоків дерева або найбільших одиниць кодування (LCU), які включають в себе вибірки як яскравості, так і кольоровості. Блок дерева має мету, подібну до такої макроблока стандарту H.264. Сегмент (слайс) включає в себе ряд послідовних блоків дерева в порядку кодування. Відеокадр або зображення може бути розділено на один або більше сегментів. Кожний блок дерева може бути розділений на одиниці кодування (CU) відповідно до квадродерева. Наприклад, блок дерева, як кореневий вузол квадродерева, може бути розділений на чотири дочірніх вузли, а кожний дочірній вузол, в свою чергу, може бути батьківським вузлом і може бути розділений на наступні чотири дочірніх вузли. Остаточний, нероздільний дочірній вузол, як вузол листа квадродерева, включає в себе вузол кодування, тобто блок кодованого відео. Дані синтаксису, зв'язані з кодованим бітовим потоком, можуть визначати максимальну кількість разів розбиття блока дерева, а також можуть визначати мінімальний розмір вузлів кодування. CU включає в себе вузол кодування і одиниці прогнозування (PU) і одиниці перетворення (TU), зв'язані з вузлом кодування. Розмір CU звичайно відповідає розміру вузла кодування і звичайно повинен бути квадратної форми. Розмір CU може знаходитися в діапазоні від 8 × 8 пікселів до розміру блока дерева максимально з 64 × 64 пікселів або більше. Кожна CU може містити одну або більше PU і одну або більше TU. Дані синтаксису, асоційовані з CU, можуть описувати, наприклад, розділення CU на одну або більше PU. Режими розділення можуть відрізнятися залежно від того, чи пропускається CU, або кодована в прямому режимі, кодована в режимі інтра-прогнозування або кодована в режимі інтер-прогнозування. PU можуть бути розділені, щоб бути в неквадратній формі. Дані синтаксису, асоційовані з CU, також можуть описувати, наприклад, розділення CU на одну або більше TU відповідно до квадродерева. TU може бути квадратної або неквадратної форми. Новий стандарт HEVC допускає перетворення відповідно до TU, які можуть бути різними для різних CU. TU звичайно мають розмір залежно від розміру PU в межах даної CU, визначеної для розділеної LCU, хоча це може не завжди мати місце. TU, як правило, такого самого розміру або менше, ніж PU. У деяких прикладах залишкові вибірки, що відповідають СU, можуть бути розділені на більш дрібні одиниці, використовуючи структуру квадродерева, відому як "залишкове квадродерево" (RQT). Листові вузли RQT можуть згадуватися як одиниці перетворення (TU). Піксельні різницеві значення, зв'язані з TU, можуть бути перетворені для одержання коефіцієнтів перетворення, які можуть бути квантовані. Загалом, PU належить до даних, що відносяться до процесу прогнозування. Наприклад, коли PU є кодованою в інтра-режимі, PU може включати дані, що описують режим інтрапрогнозування для PU. Як інший приклад, коли PU кодована в інтер-режимі, PU може включати дані, що визначають вектор руху для PU. Дані, що визначають вектор руху для PU, можуть описувати, наприклад, горизонтальну складову вектора руху, вертикальну складову вектора руху, розрізнення для вектора руху (наприклад, точність в одну чверть пікселя або точність в одну восьму пікселя), опорне зображення, на яке вказує вектор руху, і/або список опорних зображень (наприклад, список 0, список 1 або список С) для вектора руху. Загалом, TU використовується для процесів перетворення і квантування. Дана CU, що має одну або більше PU, може також включати в себе одну або більше одиниць перетворення (TU). Після прогнозування відеокодер 20 може обчислити залишкові значення з блока відео, ідентифікованого вузлом кодування, відповідно до PU. Вузол кодування потім оновлюється для посилання на залишкові значення замість вихідного блока відео. Залишкові значення містять піксельні різницеві значення, які можуть перетворюватися в коефіцієнти перетворення, квантуватися і скануватися з використанням перетворень та іншої інформації перетворення, 6 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 визначеної в TU, щоб створити перетворені в послідовну форму коефіцієнти перетворення для ентропійного кодування. Вузол кодування може бути в черговий раз оновлений, щоб посилатися на ці перетворені в послідовну форму коефіцієнти перетворення. Дане розкриття звичайно використовує термін "блок відео", щоб посилатися на вузол кодування CU. У деяких конкретних випадках дане розкриття може також використовувати термін "блок відео", щоб посилатися на блок дерева, тобто LCU або СU, яка включає в себе вузол кодування і PU і TU. Відеопослідовність звичайно включає в себе ряд відеокадрів або зображень. Група зображень (GOP) звичайно включає в себе послідовність з одного або більше відеозображень. GOP може включати синтаксичні дані в заголовку GOP, заголовку одного або більше зображень або в іншому місці, яке описує ряд зображень, включених в GOP. Кожний сегмент зображення може включати синтаксичні дані сегмента, які описують режим кодування для відповідного сегмента. Відеокодер 20 звичайно працює на блоках відео в окремих сегментах відео для кодування відеоданих. Блок відео може відповідати вузлу кодування всередині CU. Блоки відео можуть мати фіксовані або змінні розміри і можуть відрізнятися за розміром відповідно до заданого стандарту кодування. Як приклад HM підтримує прогнозування в різних розмірах PU. У припущенні, що розмір визначеної CU рівний 2Nx2N, HM підтримує інтра-прогнозування в PU розмірів 2Nx2N або NxN та інтер-прогнозування в симетричних PU розмірів 2Nx2N, 2NxN, Nx2N або NxN. HM також підтримує асиметричне розділення для інтер-прогнозування в PU розмірів 2NxnU, 2NxnD, nLx2N та nRx2N. В асиметричному розділенні один напрямок СU не розділяється, а інший напрямок розділяється на 25 % та 75 %. Частина СU, що відповідає 25 % розділенню, означається за допомогою "n" з подальшою вказівкою "вгору", "вниз", "ліворуч" або "праворуч". Так, наприклад, "2NxnU" відноситься до 2Nx2N CU, яка розділена горизонтально з 2Nx0,5 N PU зверху і 2Nx1,5 N PU знизу. На фіг. 4 показана концептуальна діаграма, що демонструє як квадратні, так і неквадратні типи розділення для інтра-прогнозування та інтер-прогнозування. Розділення 102 є розділенням 2Nx2N і може бути використане як для інтра-прогнозування, так і для інтер-прогнозування. Розділення 104 є розділенням NxN і може бути використане як для інтра-прогнозування, так і для інтер-прогнозування. Розділення 106 є розділенням 2NxN і в цей час використовується в HEVC для інтер-прогнозування. Розділення 108 є розділенням Nx2N і в цей час використовується в HEVC для інтер-прогнозування. На фіг. 5 представлена концептуальна діаграма, що показує асиметричні типи розділення. Розділення 110 є розділенням 2NxnU і в цей час використовується в HEVC для інтерпрогнозування. Розділення 112 є розділенням 2NxnD і в цей час використовується в HEVC для інтер-прогнозування. Розділення 114 є розділенням nLx2N і в цей час використовується в HEVC для інтер-прогнозування. Розділення 116 є розділенням nRx2N і в цей час використовується в HEVC для інтер-прогнозування. У цьому описі "NxN" та "N на N" можуть використовуватися взаємозамінним чином для позначення розмірів у пікселях блока відео по вертикалі і горизонталі, наприклад, 16 × 16 пікселів або 16 на 16 пікселів. Загалом, 16 × 16 блок буде мати 16 пікселів у вертикальному напрямку (у=16) та 16 пікселів у горизонтальному напрямку (х=16). Аналогічно блок NxN, в загальному вигляді, має N пікселів у вертикальному напрямку і N пікселів в горизонтальному напрямку, де N являє собою ненегативне ціле число. Пікселі в блоці можуть бути впорядковані в рядки і стовпці. Крім того, блоки не обов'язково повинні мати однакове число пікселів у горизонтальному напрямку і у вертикальному напрямку. Наприклад, блоки можуть містити NхM пікселів, де М не обов'язково дорівнює N. Після кодування з інтра-прогнозуванням або інтер-прогнозуванням з використанням PU для CU відеокодер 20 може обчислити залишкові дані, до яких застосовуються перетворення, вказані за допомогою TU в PU. Залишкові дані можуть відповідати різниці в пікселях між пікселями некодованого зображення і значеннями прогнозування, що відповідають CU. Відеокодер 20 може формувати залишкові дані для СU, а потім перетворювати залишкові дані для одержання коефіцієнтів перетворення. Після будь-яких перетворень, щоб сформувати коефіцієнти перетворення, відеокодер 20 може виконувати квантування коефіцієнтів перетворення. Квантування, загалом, відноситься до процесу, в якому коефіцієнти перетворення квантуються, щоб по можливості зменшити обсяг даних, що використовуються для представлення коефіцієнтів, забезпечуючи подальше стиснення. Процес квантування може зменшити бітову глибину, асоційовану з деякими або усіма коефіцієнтами. Наприклад, n-бітове значення можна округлити вниз до m-бітового значення під час квантування, де n більше, ніж m. 7 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 У деяких прикладах відеокодер 20 може використовувати зумовлений порядок сканування для сканування квантованих коефіцієнтів перетворення для одержання перетвореного в послідовну форму вектора, який може ентропійно кодуватися. В інших прикладах відеокодер 20 може виконувати адаптивне сканування. Після сканування квантованих коефіцієнтів перетворення, щоб сформувати одномірний вектор, відеокодер 20 може ентропійно кодувати одномірний вектор, наприклад, відповідно до контекстно-адаптивного кодування змінної довжини (CAVLC), контекстно-адаптивного бінарного арифметичного кодування (CABAC), основаного на синтаксисі контекстно-адаптивного бінарного арифметичного кодування (SBAC), ентропійного кодування з розділенням інтервалу імовірності (PIPE) або іншим методом ентропійного кодування. Відеокодер 20 може також ентропійно кодувати синтаксичні елементи, асоційовані з кодованими відеоданими для використання відеодекодером 30 в декодування відеоданих. Для виконання CABAC відеокодер 20 може призначити контекст в контекстній моделі для символу, що підлягає передачі. Контекст може відноситися, наприклад, до того, чи є сусідні значення символу ненульовими, чи ні. Для виконання CAVLC відеокодер 20 може вибрати код змінної довжини для символу, що підлягає передачі. Кодові слова в VLC можуть бути сконструйовані так, що відносно більш короткі коди відповідають більш імовірним символам, в той час як більш довгі коди відповідають менш імовірним символам. Таким чином, використання VLC може досягати економії в бітах в порівнянні, наприклад, з використанням кодових слів однакової довжини для кожного символу, що підлягає передачі. Визначення імовірності може бути основане на контексті, призначеному символу. Дане розкриття відноситься до способів для ентропійних кодерів контекстно-адаптивного бінарного арифметичного кодування (CABAC) або інших ентропійних кодерів, таких як ентропійне кодування з розділенням інтервалу імовірності (PIPE) або зв'язаних кодерів. Арифметичне кодування є формою ентропійного кодування, що використовується в багатьох алгоритмах стиснення, які мають високу ефективність кодування, оскільки воно здатне відображати символи на кодові слова нецілочисельної довжини. Прикладом алгоритму арифметичного кодування є основане на контексті бінарне арифметичне кодування (CABAC), що використовується в H.264/AVC. Загалом, кодування символів даних за допомогою CABAC включає в себе один або більше з наступних етапів: (1) Бінаризація: Якщо символ, що підлягає кодуванню, не є бінарним значенням, він відображається на послідовності так званих "структурних елементів". Кожний структурний елемент може мати значення "0" або "1". (2) Призначення контексту: Кожному структурному елементу (в звичайному режимі) призначається контекст. Контекстна модель визначає, як розраховується контекст для даного структурного елемента на основі інформації, доступної для структурного елемента, такої як значення раніше кодованих символів або кількість структурних елементів. (3) Кодування структурних елементів: Структурні елементи кодуються арифметичним кодером. Для кодування структурного елемента арифметичний кодер вимагає як вхід імовірність значення структурного елемента, тобто імовірність того, що значення структурного елемента дорівнює "0", і імовірність того, що значення структурного елемента дорівнює "1". (Оцінена) імовірність кожного контексту представлена цілим числом, що називається "станом контексту". Кожний контекст має стан, і, таким чином, стан (тобто оцінена імовірність) є тим самим для структурних елементів, призначених одному контексту, і відрізняється між контекстами. (4) Оновлення стану: Імовірність (стан) для вибраного контексту оновлюється на основі фактичного кодованого значення структурного елемента (наприклад, якщо значення структурного елемента було "1", імовірність "1" збільшується). Потрібно зазначити, що ентропійне кодування з розділенням інтервалу імовірності (PIPE) використовує принципи, аналогічні принципам арифметичного кодування, і, таким чином, може також використовувати метод даного розкриття. CABAC в H.264/AVC і HEVC використовує стани, і кожний стан неявно зв'язаний з імовірністю. Існують варіанти CABAC, в яких імовірність символу ("0" або "1") використовується безпосередньо, тобто імовірність (або її цілочисельна версія) є станом. Наприклад, такі варіанти САВАС описані в "Description of video coding technology proposal by France Telecom, st NTT, NTT DOCOMO, Panasonic and Technicolor", JCTVC-A114, 1 JCT-VC Meeting, Dresden, DE, квітень 2010 р., далі згадується як "JCTVC-A114", і A. Alshin and E. Alshina, "Multi-parameter th probability update for САВАС", JCTVC-F254, 6 JCT-VC Meeting, Torino, IT, липень 2011 р., далі згадується як "JCTVC-F254". 8 UA 109507 C2 5 10 15 20 25 30 35 40 45 50 55 60 У даному розкритті запропоноване скорочення кількості бінаризацій і/або контекстів, що використовуються в CABAC. Зокрема, дане розкриття пропонує методи, які можуть знизити кількість контекстів, що використовуються в CABAC, на величину до 56. З числом на 56 менше контекстів експериментальні результати показують, 0,00 %, 0,01 % та -0,13 % зміни частоти спотворення бітів (BD) у високоефективному інтра-режимі тільки, довільному доступі і тестових умовах малої затримки відповідно. Таким чином, скорочення в кількості необхідних контекстів знижує потреби в зберіганні як в кодері, так і декодері без істотного впливу на ефективність кодування. У даному розкритті запропоноване скорочення кількості контекстів CABAC, що використовуються для синтаксичних елементів pred_typ, merge_idx, inert_pred_flag, ref_idx_lx, cbf_cb, cbf_cr, coeff_abs_level_greater1_flag та coeff_abs_level_greater2_flag. Модифікації скорочують до 56 контекстів з нехтувано малими змінами в ефективності кодування. Запропоновані скорочення контексту для синтаксичних елементів, наведених вище, можуть бути використані окремо або в будь-якій комбінації. Синтаксичний елемент pred_type включає в себе режим прогнозування (pred_mode_flag) і тип розділення (part_mode) для кожної одиниці кодування. Синтаксичний елемент pred_mode_flag, рівний 0, визначає, що поточна одиниця кодування кодована в режимі інтерпрогнозування. Синтаксичний елемент pred_mode_flag, рівний 1, вказує, що поточна одиниця кодування кодована в режимі інтра-прогнозування. Синтаксичний елемент part_mode визначає режим розділення поточної одиниці кодування. Синтаксичний елемент merge_jdx[х0][y0] визначає індекси кандидатів злиття списку кандидатів злиття, де х0, у0 визначають місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування, що розглядається, відносно верхньої лівої вибірки яскравості зображення. Коли merge_jdx[х0][y0] відсутній, то робиться висновок, що він дорівнює 0. Список кандидатів злиття є списком сусідніх одиниць кодування з поточними одиницями, з яких інформація про рух може бути скопійована. Синтаксичний елемент inter_pred_flag[х0][y0] визначає, чи використовується монопрогнозування або бі-прогнозування для поточної одиниці прогнозування. Індекси масиву х0, у0 визначають місцеположення (х0, у0) верхньої-лівої вибірки яскравості блока прогнозування, що розглядається, відносно верхньої-лівої вибірки яскравості зображення. Синтаксичний елемент ref_idx_lx відноситься до конкретного опорного зображення всередині списку опорних зображень. Синтаксичні елементи cbf_cb, cbf_cr вказують, чи містять блоки перетворення кольоровості (Cb та Cr, відповідно) ненульові коефіцієнти перетворення. Синтаксичний елемент cbf_cb[х0][y0][trafoDepth], рівний 1, визначає, що блок перетворення Cb містить один або більше рівнів коефіцієнтів перетворення, не рівних 0. Індекси масиву х0, у0 вказують місцеположення (х0, у0) верхньої-лівої вибірки яскравості блока перетворення, що розглядається, відносно верхньої-лівої вибірки яскравості зображення. Індекс масиву trafoDepth вказує поточний рівень підрозділу одиниці кодування на блоки з метою кодування перетворення. Індекс масиву trafoDepth рівний 0 для блоків, які відповідають одиницям кодування. Коли cbf_cb[х0][y0][trafoDepth] не присутній, і режимом прогнозування є не інтра-прогнозування, значення cbf_cb[х0][y0][trafoDepth] виводиться як рівне 0. Синтаксичний елемент cbf_cr[х0][y0][trafoDepth], рівний 1, вказує, що блок перетворення Cr містить один або більше рівнів коефіцієнтів перетворення, не рівних 0. Індекси масиву х0, у0 вказують місцеположення (х0, у0) верхньої-лівої вибірки яскравості блока перетворення, що розглядається, відносно верхньої-лівої вибірки яскравості зображення. Індекс масиву trafoDepth вказує поточний рівень підрозділу одиниці кодування на блоки з метою кодування перетворення. Індекс масиву trafoDepth рівний 0 для блоків, які відповідають одиницям кодування. Коли cbf_cr[х0][y0][trafoDepth] не присутній, і режимом прогнозування не є інтрапрогнозування, значення cbf_cr[х0][y0][trafoDepth] виводиться рівним 0. Синтаксичний елемент coeff_abs_level_greater1_flag[n] вказує для позиції n сканування, чи є рівні коефіцієнтів перетворення більше, ніж 1. Коли coeff_abs_level_greater1_flag[n] не присутній, то робиться висновок, що він дорівнює 0. Синтаксичний елемент coeff_abs_level_greater2_flag [n] вказує для позиції n сканування, чи є рівні коефіцієнтів перетворення більше, ніж 2. Коли coeff_abs_level_greater2_flag[n] не присутній, робиться висновок, що він дорівнює 0. В одній пропозиції для HEVC різні бінаризації за синтаксичним елементом pred_type використовуються в Р та В сегментах, як показано в таблиці 1. Дане розкриття пропонує використовувати ті самі бінаризації для Р та В сегментів. Приклади наведені в таблицях 2-4. Таблиця 5 показує вплив ефективності кодування на Р сегмент в стандартних умовах 9 UA 109507 C2 тестування (див., наприклад, F. Bossen, "Common test conditions and software reference configurations", JCTVC-F900). Таблиця 1 Бінаризація для pred_type в одній пропозиції для HEVC Тип Значення Режим сегмента pred_type прогнозування Ι P B 5 10 15 20 25 30 0 1 0 1 2 4 5 6 7 3 4 5 0 1 2 4 5 6 7 3 4 5 MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA Режим розділення PART_2Nx2N PART_NxN PART_2Nx2N PART_2NxN PART_Nx2N PART_2NxnU PART_2NxnD PART_nLx2N PART_nRx2N PART_NxN PART_2Nx2N PART_NxN PART_2Nx2N PART_2NxN PART_Nx2N PART_2NxnU PART_2NxnD PART_nLx2N PART_nRx2N PART_NxN PART_2Nx2N PART_NxN Рядок структурного елемента cLog2CUSize = = Log2Min CUSize cLog2CUSize cLog2CUSize = = 3 Log2Min cLog2CUSize 3 CUSize !inter_44_enabled_flag inter_44_enabled_flag (1) (2) (3) 1 1 0 0 01 01 01 0 011 0 01 0 01 0 0011 0 00 0 001 0 0100 0 0101 0 00100 0 00101 0 000 1 11 11 10 10 1 1 1 011 01 01 0011 001 001 0100 0101 00100 00101 0001 000 000 0 0000 0 000 1 0000 1 Як видно з таблиці 1, I сегменти (наприклад, сегменти, які включають тільки блоки інтрапрогнозування) включають в себе два різних типи прогнозування (pred_type). Один рядок структурного елемента (бінаризація) використовується для блока інтра-прогнозування з типом розділення 2Nx2N, а інший рядок структурного елемента використовується для блока інтрапрогнозування з типом розділення NxN. Як показано в таблиці 1, рядок структурного елемента, що використовується для I сегментів, не залежить від розміру CU. Для Р та В сегментів, в таблиці 1, різні рядки структурного елемента використовуються для кожного значення pred_type. Знову значення pred_type залежить як від режиму прогнозування (інтер-прогнозування або інтра-прогнозування), так і використовуваного типу розділення. Для Р та В сегментів фактичний використовуваний рядок структурного елемента додатково залежить від розміру кодованої CU і від того, чи підтримується інтер-прогнозування для розміру 4 × 4 блока. Перший стовпець під рядком структурного елемента застосовується для ситуації, коли логарифмічна функція розміру CU кодованої СU перевищує логарифмічну функцію мінімально допустимого розміру CU. Згідно з одним прикладом в HEVC, перший стовпець рядків структурного елемента використовується, якщо cLog2CUSize > Log2MinCUsize. Логарифмічна функція використовується для створення меншого числа, так що може бути використаний менший послідовний індекс. Якщо логарифмічна функція від розміру CU кодованої CU еквівалентна логарифмічній функції мінімально допустимого розміру CU (тобто cLog2CUSize == Log2MinCUSize), то один зі стовпців 2 та 3 під рядком структурного елемента в таблиці 1 використовується для вибору бінаризації. Стовпець 2 використовується, коли логарифмічна функція від розміру CU кодованої CU еквівалентна 3, і інтер-прогнозування для 4 × 4 СU не підтримується (тобто cLog2CUSize == 3 &&! inter_4 × 4_enabled_flag). Стовпець 3 використовується, коли логарифмічна функція від розміру CU для кодованої СU більше, ніж 3, або коли інтер-прогнозування для 4 × 4 CU підтримується (тобто cLog2CUSize > 3|| inter_4 × 4_enabled_flag). У таблиці 2 нижче показані приклади бінаризації, де Р та В сегменти використовують ті самі рядки структурного елемента, відповідно до одного або більше прикладів, описаних в даному розкритті. Як показано в таблиці 2, Р сегменти використовують ті самі бінаризації, що використовуються для В сегментів у таблиці 1. Таким чином, немає необхідності зберігати і 10 UA 109507 C2 використовувати окремий набір контекстів для Р та В сегментів. Таким чином, загальна кількість контекстів, необхідних для кодування синтаксичного елемента pred_type, знижується. Крім того, тільки одне відображення (замість двох) між логікою рядка структурного елемента (показано в стовпцях (1)-(3)) і фактичним рядком структурного елемента повинне бути збережене. 5 Таблиця 2 Бінаризація для pred_type в одному прикладі даного розкриття Тип сегмента Значення pred_type Режим прогнозування Режим розділення Ι 0 1 0 1 2 4 5 6 7 3 4 5 MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA PART_2Nx2N PART_NxN PART_2Nx2N PART_2NxN PART_Nx2N PART_2NxnU PART_2NxnD PART_nLx2N PART_nRx2N PART_NxN PART_2Nx2N PART_NxN P або В 10 15 20 25 30 35 40 Рядок структурного елемента cLog2CUSize = = Log2Min CUSize cLog2CUSize cLog2CUSize = = 3 cLog2CUSize 3 Log2Min CUSize !inter_44_enabled_flag inter_44_enabled_flag (1) (2) (3) 1 1 0 0 1 1 1 011 01 01 0011 001 001 0100 0101 00100 00101 0001 000 000 0 0000 0 000 1 0000 1 У таблиці 3 нижче показаний інший приклад бінаризації для pred_type. У цьому прикладі В сегменти використовують ті самі бінаризації, що і Р сегменти з таблиці 1. Таблиця 4 нижче показує додатковий приклад, де Р сегменти і В сегменти використовують ті самі бінаризації. Таблиці 2-4 призначені тільки для того, щоб показати приклади загальних бінаризацій між Р та В сегментами. Будь-які бінаризації або правила бінаризації можуть бути використані так, що синтаксичні елементи pred_type для Р та В сегментів спільно використовують ті самі бінаризації. Відеокодер 20 і відеодекодер 30 можуть зберігати ті самі правила відображення і таблиці відображення (наприклад, як показано в таблицях 2-4) для використання з Р та В сегментами. Кодування і декодування CABAC можуть бути застосовані до синтаксичного елемента pred_type з використанням цих відображень. Таким чином, відеокодер 20 може бути сконфігурований, щоб визначати перший тип прогнозування для блока відеоданих у Р сегменті, представляти перший тип прогнозування як синтаксичний елемент типу прогнозування Р сегмента, визначати другий тип прогнозування для блока відеоданих у В сегменті, представляти другий тип прогнозування як синтаксичний елемент типу прогнозування В сегмента, визначати бінаризацію Р сегмента для синтаксичного елемента типу прогнозування Р сегмента, визначати бінаризацію В сегмента для синтаксичного елемента типу прогнозування В сегмента, причому синтаксичний елемент типу прогнозування Р сегмента і синтаксичний елемент типу прогнозування В сегмента визначаються з використанням тієї самої логіки бінаризації, і кодувати відеодані на основі бінаризацій синтаксичного елемента типу прогнозування Р сегмента і синтаксичного елемента типу прогнозування В сегмента. Відеокодер 20 може бути додатково сконфігурований для бінаризації синтаксичного елемента типу прогнозування Р сегмента з визначеною бінаризацією Р сегмента, бінаризації синтаксичного елемента типу прогнозування В сегмента з визначеною бінаризацією В сегмента, застосування контекстно-адаптивного бінарного арифметичного кодування (CABAC) до бінаризованого синтаксичного елемента типу прогнозування Р сегмента і застосування контекстно-адаптивного бінарного арифметичного кодування (CABAC) до бінаризованого синтаксичного елемента типу прогнозування В сегмента. Аналогічним чином відеодекодер 30 може бути сконфігурований для відображення бінаризованого синтаксичного елемента типу прогнозування Р сегмента на тип прогнозування з використанням відображення бінаризації для блока відеоданих у Р сегменті, відображення бінаризованого синтаксичного елемента типу прогнозування В сегмента на тип прогнозування з використанням того самого відображення бінаризації для блока відеоданих у В сегменті і декодування відеоданих на основі відображених типів прогнозування. Відеодекодер 30 може бути додатково сконфігурований, щоб приймати підданий контекстноадаптивному бінарному арифметичному кодуванню синтаксичний елемент типу прогнозування Р сегмента, який вказує тип прогнозування для блока відеоданих у Р сегменті, приймати 11 UA 109507 C2 5 підданий контекстно-адаптивному бінарному арифметичному кодуванню синтаксичний елемент типу прогнозування В сегмента, який вказує тип прогнозування для блока відеоданих у В сегменті, декодувати синтаксичний елемент типу прогнозування Р сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування Р сегмента, і декодувати синтаксичний елемент типу прогнозування В сегмента, щоб сформувати бінаризований синтаксичний елемент типу прогнозування В сегмента. Таблиця 3 Бінаризація для pred_type в іншому прикладі даного розкриття Тип сегмента Значення pred_type Режим прогнозування Режим розділення Ι 0 1 0 1 2 4 5 6 7 3 4 5 MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA PART_2Nx2N PART_NxN PART_2Nx2N PART_2NxN PART_Nx2N PART_2NxnU PART_2NxnD PART_nLx2N PART_nRx2N PART_NxN PART_2Nx2N PART_NxN P або В Рядок структурного елемента cLog2CUSize = = Log2Min CUSize cLog2CUSize cLog2CUSize = = 3 cLog2CUSize 3 Log2Min CUSize !inter_44_enabled_flag inter_44_enabled_flag (1) (2) (3) 1 1 0 0 01 01 01 0 011 0 01 0 01 0 0011 0 00 0 001 0 0100 0 0101 0 00100 0 00101 0 000 1 11 11 10 10 Таблиця 4 Бінаризація для pred_type в іншому прикладі даного розкриття Тип сегмента Значення pred_type Режим прогнозування Режим розділення Ι 0 1 0 1 2 4 5 6 7 3 4 5 MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA MODE_INTRA PART_2Nx2N PART_NxN PART_2Nx2N PART_2NxN PART_Nx2N PART_2NxnU PART_2NxnD PART_nLx2N PART_nRx2N PART_NxN PART_2Nx2N PART_NxN P або В 10 15 Рядок структурного елемента cLog2CUSize = = Log2Min CUSize cLog2CUSize cLog2CUSize = = 3 cLog2CUSize 3 Log2Min CUSize !inter_44_enabled_flag inter_44_enabled_flag (1) (2) (3) 1 1 0 0 1 1 1 011 01 01 001 00 001 0100 0101 0000 0001 000 000 000 0 0000 0 000 1 0000 1 Таблиця 5 нижче показує продуктивність кодування з використанням загальної бінаризації для Р та В сегментів, показаних в таблиці 2. Як можна бачити з таблиці 5, незначна ефективність кодування втрачається (або не втрачається взагалі) при використанні загальних бінаризацій. HE (висока ефективність) низької затримки Р є загальною тестовою умовою для бінаризацій однонаправлено прогнозованих (Р) сегментів. Класи A-E представляють різні розрізнення кадрів. Клас А відповідає розрізненню 2kх4k. Клас В відповідає розрізненню 1920 × 1080. Клас С відповідає розрізненню WVGA. Клас D відповідає розрізненню WQVGA. Клас Е відповідає розрізненню 720P. Зміна від 0,1 до 0,2 відсотка при тестовій умові НЕ низької затримки Р, як правило, вважається незначною. 20 12 UA 109507 C2 Таблиця 5 Продуктивність кодування для єдиної бінаризації за pred_type частота BD Клас A Клас B Клас C Клас D Клас E Всього код. Т[%] декод. Т [%] 5 10 15 20 HЕ низької затримки P U Y 0,02 % 0,01 % -0,02 % 0,02 % 0,01 % 0,16 % 0,05 % -0,10 % 0,03 % 0,04 % V 0,26 % -0,12 % -0,12 % 0,05 % 0,03 % Опційно ті самі бінаризації (не обмежуючись таблицями 2-4) для типу прогнозування (включає розмір прогнозування і/або режим прогнозування) можуть бути спільно використані в двох і більше різних типах сегментів інтер- прогнозування. Сегменти інтер-прогнозування можуть включати в себе, без обмеження вказаним: а. Р сегмент: сегмент підтримує тільки однонаправлене прогнозування руху; b. В сегмент: сегмент підтримує однонаправлене і двонаправлене прогнозування руху; с. У кодуванні відео, що масштабується: поліпшений шар може спільно використовувати ті самі бінаризації з базовим шаром; d. У багатовидовому кодуванні: різні види (представлення) можуть спільно використовувати ті самі бінаризації. Коли підтримується асиметричне розділення, чотири контексти, порівну розділені на два набори контекстів, використовуються для CABAC на останніх двох структурних елементах для сигналізації синтаксичного елемента pred_type для асиметричних розділень (тобто PART_2NxnU, PART_2NxnD, PAPT_nLx2N, PART_nRx2N). Залежно від того, чи виконане розділення в горизонтальному напрямку або вертикальному напрямку, застосовується один набір контекстів. Передостанній структурний елемент (тобто структурний елемент типу розділення; part_mode) визначає, чи має поточна CU симетричні розділення або асиметричні розділення. Останній структурний елемент (тобто структурний елемент розміру розділення; part_mode) визначає, чи є розміром першого розділення одна чверть або три чверті від розміру CU. Таблиця 6 показує приклад контекстів передостаннього (тип розділення) і останнього (розмір розділення) для синтаксичного елемента pred_type. Таблиця 6 Контексти для останніх двох структурних елементів синтаксичного елемента pred_type Структурний елемент Тип розділення (симетричний або асиметричний) Розмір розділення (перше розділення дорівнює ¼ CU або ¾ CU) Контекст Набір 1 контекстів (2 контексти, один для вертикального розділення, 1 для горизонтального розділення) Набір 2 контекстів (2 контексти, один для ¼ CU і один для ¾ CU) 25 30 Дане розкриття пропонує використовувати один контекст для передостаннього структурного елемента (тобто структурного елемента типу розділення) і використовувати режим обходу на останньому структурному елементі (тобто структурному елементі розміру розділення). У результаті, число контекстів зменшується з 4 до 1. Таблиця 7 показує приклад контексту, що використовується згідно з даним прикладом даного розкриття. Таблиця 8 показує продуктивність кодування, зв'язану із змінами, що пропонуються. Висока ефективність (НЕ) довільного доступу є тестовою умовою з кадрами довільного доступу. НЕ низької затримки В є тестовою умовою, яка допускає двонаправлене прогнозування. 13 UA 109507 C2 Таблиця 7 Контексти для останніх двох структурних елементів синтаксичного елемента pred_type відповідно до прикладу даного розкриття Структурний елемент Тип розділення (симетричний або асиметричний) Розмір розділення (перше розділення дорівнює ¼ CU або ¾ CU) Контекст Набір 1 контекстів (1 контекст) Режим обходу (жодного контексту) Таблиця 8 Продуктивність кодування запропонованого способу для pred_type Частота BD Клас A Клас B Клас C Клас D Клас E Всього код. Т[%] декод. Т [%] 5 10 15 20 25 30 35 Y НЕ всіх інтра U V НЕ довільного доступу Y U V 0,03 % -0,17 % -0,29 % 0,02 % -0,03 % 0,04 % -0,01 % -0,03 % -0,02 % 0,01 % 0,07 % -0,05 % 0,01 % -0,04 % -0,07 % HЕ низької затримки В Y U V 0,01 % -0,01 % 0,01 % 0,00 % 0,00 % 0,00 % -0,03 % 0,06 % 0,30 % 0,06 % 0,24 % 0,02 % 0,03 % 0,39 % 0,01 % Таким чином, згідно з цим прикладом, відеокодер 20 може бути сконфігурований, щоб визначати тип розділення для режиму прогнозування для блока відеоданих, кодувати структурний елемент типу розділення синтаксичного елемента типу прогнозування для блока відеоданих з використанням контекстно-адаптивного бінарного арифметичного кодування з одним контекстом, причому один контекст є однаковим для будь-якого типу розділення, і кодувати структурний елемент розміру розділення синтаксису типу прогнозування для блока відеоданих з використанням контекстно-адаптивного бінарного арифметичного кодування в режимі обходу. Крім того, згідно з цим прикладом, відеодекодер 30 може бути сконфігурований, щоб приймати синтаксичний елемента типу прогнозування для блока відеоданих, який був кодований з використанням контекстно-адаптивного бінарного арифметичного кодування (CABAC), причому синтаксичний елемент типу прогнозування включає в себе структурний елемент типу розділення, що представляє тип розділення, і структурний елемент розміру розділення, що представляє розмір розділення, декодувати структурний елемент типу розділення синтаксичного елемента типу прогнозування з використанням контекстноадаптивного бінарного арифметичного кодування з одним контекстом, причому один контекст є однаковим для будь-якого типу розділення, і декодувати структурний елемент розміру розділення синтаксису типу прогнозування для блока відеоданих з використанням контекстноадаптивного бінарного арифметичного кодування в режимі обходу. В іншому прикладі при кодуванні прямокутного типу розділення режим обходу або один контекст може бути використаний для структурного елемента, який вказує, чи є режимом розділення PART_nLx2N або PART_nRx2N, або ж режимом є PART_2NxnU, PART_2NxnD. Використання режиму обходу або одного контексту застосовне, тому що імовірність будь-якого режиму розділення, що використовується, близька до 50 %. Також опційно режим обходу або один контекст може бути використаний для структурного елемента, який вказує, чи є режим симетричним розділенням або асиметричним розділенням. Наступний приклад даного розкриття відноситься до сигналізації в режимі "злиття" інтерпрогнозування. У режимі злиття кодер інструктує декодер, через сигналізацію бітового потоку синтаксису прогнозування, копіювати вектор руху, опорний індекс (що ідентифікує опорне зображення, в даному списку опорних зображень, на яке вказує вектор руху) і напрямок прогнозування руху (яке ідентифікує список опорних зображень (Список 0 або Список 1), тобто з точки зору того, чи передує у часі опорний кадр або йде за поточним кадром) від вибраного вектора руху-кандидата для поточної частини зображення, яке повинне кодуватися. Це 14 UA 109507 C2 5 10 15 виконується за допомогою сигналізації в бітовому потоці індексу в список векторів рухукандидатів, що ідентифікує вибраний вектор руху-кандидат (тобто конкретний кандидат просторового прогнозувальника вектора руху (MVP) або кандидат часового MVP). Таким чином, в режимі злиття синтаксис прогнозування може включати в себе прапор, що ідентифікує режим (в цьому випадку режим злиття), та індекс (merge_idx), що ідентифікує вибраний вектор руху-кандидат. У деяких випадках вектор руху-кандидат буде в причинній частині по відношенню до поточної частини. Тобто вектор руху-кандидат буду вже декодованим декодером. Таким чином, декодер вже прийняв і/або визначив вектор руху, опорний індекс і напрямок руху прогнозування для причинної частини. Таким чином, декодер може просто витягнути вектор руху, опорний індекс і напрямок прогнозування руху, асоційовані з причинною частиною, з пам'яті і скопіювати ці значення як інформацію руху для поточної частини. Для відновлення блока в режимі злиття декодер одержує блок прогнозування, використовуючи одержану інформацію руху для поточної частини, і додає залишкові дані до блока прогнозування для відновлення кодованого блока. У HM4.0 один з п'яти кандидатів злиття сигналізується, коли поточна PU знаходиться в режимі злиття. Зрізаний унарний код використовується для представлення синтаксичного елемента merge_idx. В одній пропозиції для HEVC, для CABAC, кожний структурний елемент використовує один контекст. Дане розкриття пропонує використовувати один контекст повторно в усіх чотирьох структурних елементах, як показано в таблиці 9. 20 Таблиця 9 Контексти для останніх двох структурних елементів синтаксичного елемента pred_type Структурний елемент Структурний елемент 0-3 для merge_idx Контекст Набір 1 контексту (той самий контекст для всіх структурних елементів) Таблиця 10 показує продуктивність кодування, зв'язану з цим прикладом. Таблиця 10 Продуктивність кодування запропонованого способу для merge_idx Частота BD Клас A Клас B Клас C Клас D Клас E Всього код. Т[%] декод. Т [%] 25 30 35 Y НЕ всіх інтра U V НЕ довільного доступу Y U V 0,00 % -0,20 % -0,07 % 0,01 % 0,03 % 0,03 % 0,00 % 0,04 % 0,00 % 0,03 % 0,07 % 0,05 % 0,01 % -0,05 % -0,02 % HЕ низької затримки В Y U V 0,01 % 0,00 % 0,05 % -0,04 % -0,01 % -0,08 % -0,08 % -0,24 % 0,08 % -0,09 % -0,22 % -0,09 % 0,44 % 0,78 % 0,17 % Опційно більш ніж один контекст може бути використаний в кодуванні індексу злиття, при цьому деякі структурні елементи спільно використовують той самий контекст, і деякі структурні елементи використовують різні контексти. Як один приклад тільки послідовні структурні елементи (bin) спільно використовують той самий контекст. Наприклад, bin2 та bin3 можуть спільно використовувати один контекст; bin2 та bin4 не можуть спільно використовувати один і той самий контекст, якщо тільки bin3 також не використовує цей контекст. Як інший приклад припустимо, що загальна кількість структурних елементів індексу злиття дорівнює N (перший структурний елемент є bin0, останній структурний елемент є bin N-1). Y порогів, thresi, i=1,…, у, використовуються для визначення контексту, що спільно використовується в кодуванні індексу злиття. У цьому прикладі наступні правила вказують, як контексти спільно використовуються між структурними елементами: 1. 0
ДивитисяДодаткова інформація
Назва патенту англійськоюContext reduction for context adaptive binary arithmetic coding
Автори англійськоюChien, Wei-Jung, Sole Rojals, Joel, Karczewicz, Marta
Автори російськоюЧиэнь Вэй-Цзюн, Соле Рохальс Хоэль, Карчевич Марта
МПК / Мітки
Мітки: скорочення, бінарного, контекстно-адаптивного, кодування, контексту, арифметичного
Код посилання
<a href="https://ua.patents.su/42-109507-skorochennya-kontekstu-dlya-kontekstno-adaptivnogo-binarnogo-arifmetichnogo-koduvannya.html" target="_blank" rel="follow" title="База патентів України">Скорочення контексту для контекстно-адаптивного бінарного арифметичного кодування</a>
Скорочення кількості контекстів для контекстно-адаптивного бінарного арифметичного кодування

Номер патенту: 109506
Опубліковано: 25.08.2015
Автори: Карчєвіч Марта, Чіень Вей-Цзюн, Соле Рохальс Хоель
Мітки: бінарного, кількості, скорочення, контекстно-адаптивного, контекстів, кодування, арифметичного
Формула / Реферат:
1. Спосіб кодування відеоданих, що включає:вибір контексту з одного або більше контекстів на основі глибини перетворення одиниці перетворення, асоційованої з блоком відеоданих;кодування прапора кодованого блока кольоровості Сb для блока відеоданих з використанням контекстно-адаптивного бінарного арифметичного кодування (САВАС) і вибраного контексту, причому кодування прапора кодованого блока кольоровості Сb включає використання...
Синтаксичний аналізатор контекстно-вільних граматик

Номер патенту: 37162
Опубліковано: 16.04.2001
Автори: Жихарев Володимир Якович, Дергачова Наталія Володимирівна, Чумаченко Ігор Володимирович
МПК: G06F 17/27
Мітки: синтаксичний, аналізатор, контекстно-вільних, граматик
Формула / Реферат:
1. Синтаксичний аналізатор контекстовільних граматик, який містить керуючий вхід, двійковий лічильник, n шин початкових даних, перший і другий елементи “АБО”, елемент “І”, вхід “Скидання”, n блоків аналізу, кожен з яких має три входи, чотири виходи та інформаційний вхід, елемент “АБО-НІ”, вихід результату аналізу, причому і-а шина початкових даних з’єднана з інформаційними входами і-го блока аналізу (і = 1...n), вхід “Скидання” з’єднаний з...
Ефективне за пам’яттю моделювання контексту

Номер патенту: 108698
Опубліковано: 25.05.2015
Автори: Чіень Вей-Цзюн, Ван Сянлінь, Карчевіч Марта
МПК: H04N 7/00, H04N 19/96, H04N 19/70, H04N 19/13
Мітки: контексту, моделювання, пам'яттю, ефективне
Формула / Реферат:
1. Спосіб кодування відеоданих, причому спосіб включає:визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформаціі включає визначення контекстної інформації на основі глибини...
Спосіб адаптивного контекстно-граматичного стискання текстових повідомлень

Номер патенту: 90653
Опубліковано: 25.05.2010
Автори: Ісаєва Олеся Володимирівна, Чернега Віктор Степанович
МПК: H03M 7/30, G06F 11/00, G10L 19/00
Мітки: текстових, повідомлень, стискання, спосіб, контекстно-граматичного, адаптивного
Формула / Реферат:
Спосіб адаптивного контекстно-граматичного стискання текстових повідомлень, заснований на підрахунку на кожному кроці стискання кількості появи символів у вхідному тексту, зв'язаних з поточними контекстами різних порядків, обчисленні сумарних оцінок імовірностей появи символів у відповідних контекстах, наступного множення цих оцінок на вагові коефіцієнти відповідних контекстів та присвоєнні символам тексту кодових комбінацій у відповідності...
Спосіб стиснення відеоданих без втрат на основі методу одномірного поліадичного кодування

Номер патенту: 75322
Опубліковано: 26.11.2012
Автори: Корольова Наталія Анатоліївна, Сідченко Сергій Олександрович, Остроумов Борис Володимирович, Ларін Володимир Валерійович, Баранник Володимир Вікторович, Яковенко Олександр Васильович
МПК: H03M 13/31
Мітки: поліадичного, спосіб, основі, втрат, стиснення, методу, одномірного, кодування, відеоданих
Формула / Реферат:
Спосіб стиснення відеоданих без втрат на основі методу одномірного поліадичного кодування, який відрізняється тим, що формується інтегрований код на базі згортки вихідних елементів з ваговими коефіцієнтами для стовбців масиву відеоданих, які розглядаються як числа з обмеженими та нерівномірними значеннями підстав.
Попередній патент: Скорочення кількості контекстів для контекстно-адаптивного бінарного арифметичного кодування
Наступний патент: Спосіб виготовлення суміші відновленого заліза і шлаку
Випадковий патент: Комбінований симетруючий пристрій