Синтаксичні розширення високого рівня для високоефективного відеокодування







Формула / Реферат
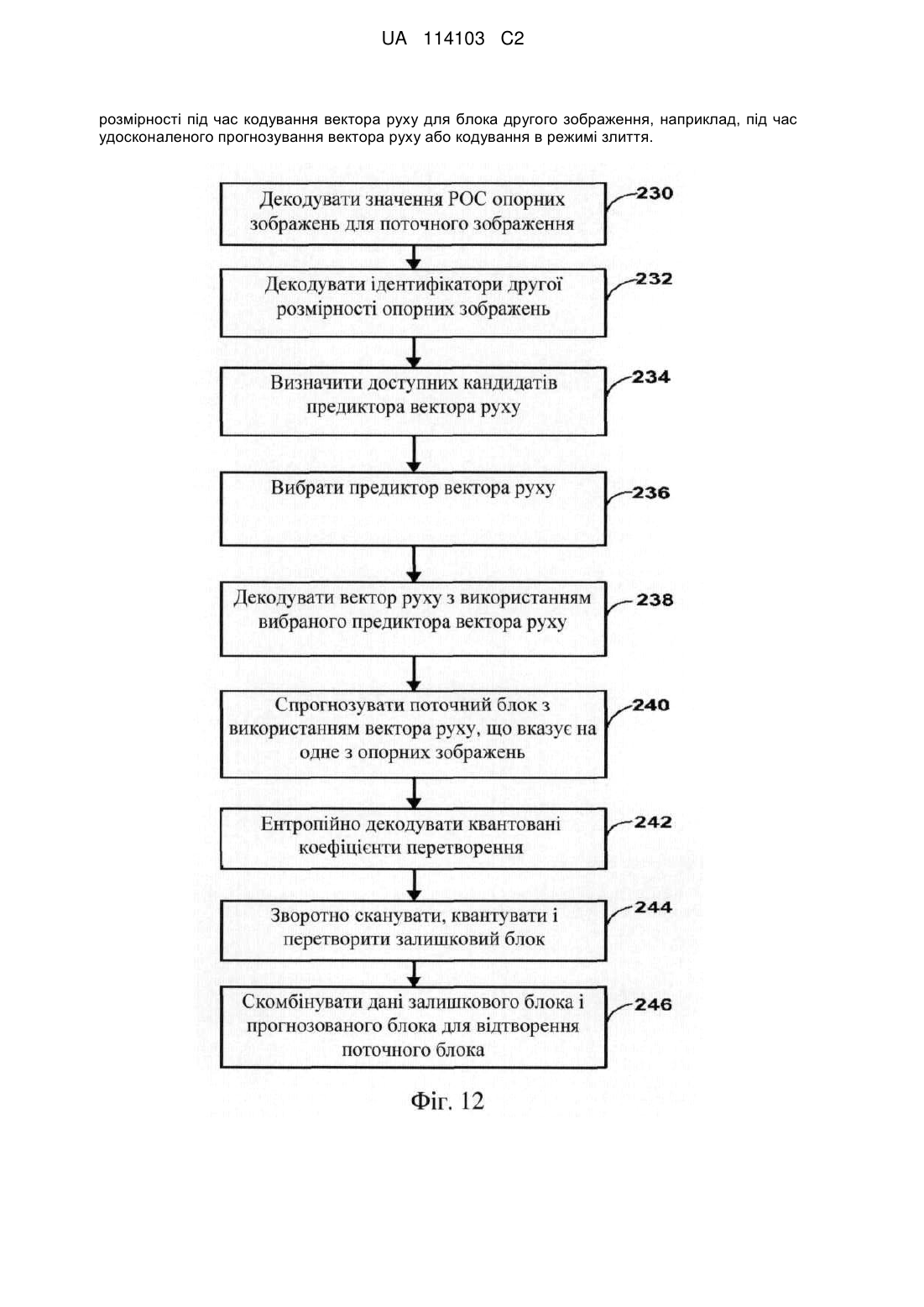
1. Спосіб декодування відеоданих, який включає:
декодування даних другого зображення, що стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих;
декодування даних другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення;
декодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення; і
заборону прогнозування вектора руху між першим вектором руху першого блока другого зображення і другим вектором руху другого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і при цьому другий вектор руху посилається на довгострокове опорне зображення.
2. Спосіб за п. 1, у якому кодування другого зображення включає: ідентифікацію першого зображення з використанням значення РОС і ідентифікатора зображення другої розмірності; і
декодування щонайменше частини другого зображення відносно першого зображення.
3. Спосіб за п. 2, у якому ідентифікація першого зображення включає ідентифікацію першого зображення під час декодування вектора руху для блока другого зображення, при цьому кодування вектора руху містить кодування вектора руху згідно з щонайменше одним з удосконаленого прогнозування вектора руху (AMVP), часового прогнозування вектора руху (TMVP) і режиму злиття.
4. Спосіб за п. 1, який додатково включає:
дозвіл прогнозування між першим короткостроковим вектором руху другого зображення і другим короткостроковим вектором руху другого зображення; і
масштабування щонайменше одного з першого короткострокового вектора руху і другого короткострокового вектора руху на основі значення РОС для першого короткострокового опорного зображення, на яке посилається перший короткостроковий вектор руху, і значення РОС для другого короткострокового опорного зображення, на яке посилається другий короткостроковий вектор руху.
5. Спосіб за п. 1, який додатково включає декодування значення, яке вказує, чи містить третє зображення відеоданих довгострокове опорне зображення, при цьому значення, яке вказує, чи містить третє зображення довгострокове опорне зображення, додатково вказує, чи використовується третє зображення для міжвидового прогнозування.
6. Спосіб за п. 1, який додатково включає декодування, відповідно до розширення базової специфікації відеокодування, третього зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення.
7. Спосіб за п. 6, який додатково включає, до декодування третього зображення, маркування всіх міжвидових опорних зображень, у тому числі перше зображення, як довгострокових опорних зображень.
8. Спосіб за п. 7, який додатково включає:
збереження статусу для кожного з міжвидових опорних зображень для третього зображення, при цьому статус містить одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, до маркування міжвидових опорних зображень як довгострокових опорних зображень, при цьому міжвидові опорні зображення містять у собі перше зображення; і, після кодування другого зображення, встановлення нових статусів для кожного з міжвидових опорних зображень на основі збережених статусів.
9. Спосіб за п. 6, у якому базова специфікація відеокодування містить базову специфікацію Високоефективного Відеокодування (HEVC), і в якому розширення базової специфікації відеокодування містить одне з розширення Масштабованого Відеокодування (SCV) для базової специфікації HEVC і розширення Багатовидового Відеокодування (MVC) для базової специфікації HEVC.
10. Спосіб за п. 6, у якому ідентифікатор зображення другої розмірності містить щонайменше один з ідентифікатора виду для виду, що включає в себе перше зображення, індексу порядку виду для виду, що включає в себе перше зображення, комбінації індексу порядку виду і прапора глибини, ідентифікатора рівня для рівня масштабованого відеокодування (SCV), що включає в себе перше зображення, і загального ідентифікатора рівня.
11. Спосіб за п. 6, який додатково включає, після декодування третього зображення, маркування кожного міжвидового опорного зображення як одного з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання.
12. Спосіб за п. 11, який додатково включає:
після маркування міжвидового опорного зображення як довгострокового опорного зображення, призначення міжвидовому опорному зображенню нового значення РОС, що у даний момент є невикористовуваним; і,
після декодування другого зображення, відновлення вихідного значення РОС для міжвидового опорного зображення.
13. Спосіб за п. 12, у якому вихідне значення РОС містить значення РОС першого зображення.
14. Спосіб кодування відеоданих, який включає:
кодування даних другого зображення, що стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих;
кодування даних другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення;
кодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення; і
заборону прогнозування вектора руху між першим вектором руху першого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і другим вектором руху другого блока другого зображення, при цьому другий вектор руху посилається на довгострокове опорне зображення.
15. Спосіб за п. 14, який додатково включає:
ідентифікацію першого зображення з використанням значення РОС і ідентифікатора зображення другої розмірності; і
кодування щонайменше частини другого зображення відносно першого зображення.
16. Спосіб за п. 15, у якому ідентифікація першого зображення містить ідентифікацію першого зображення під час кодування вектора руху для блока другого зображення, при цьому кодування вектора руху містить кодування вектора руху згідно з щонайменше одним з удосконаленого прогнозування вектора руху (AMVP), часового прогнозування вектора руху (TMVP) і режиму злиття.
17. Спосіб за п. 14, який додатково включає:
дозвіл прогнозування між першим короткостроковим вектором руху другого зображення і другим короткостроковим вектором руху другого зображення; і
масштабування щонайменше одного з першого короткострокового вектора руху і другого короткострокового вектора руху на основі значення РОС для першого короткострокового опорного зображення, на яке посилається перший короткостроковий вектор руху, і значення РОС для другого короткострокового опорного зображення, на яке посилається другий короткостроковий вектор руху.
18. Спосіб за п. 14, у якому ідентифікатор зображення другої розмірності містить щонайменше один з ідентифікатора виду для виду, що включає в себе перше зображення, індексу порядку виду для виду, що включає в себе перше зображення, комбінації індексу порядку виду і прапора глибини, ідентифікатора рівня для рівня масштабованого відеокодування (SCV), що включає в себе перше зображення, і загального ідентифікатора рівня.
19. Спосіб за п. 14, який додатково включає кодування значення, яке вказує, чи містить третє зображення відеоданих довгострокове опорне зображення, при цьому значення, яке вказує, чи містить третє зображення довгострокове опорне зображення, додатково вказує, чи використовується третє зображення для міжвидового прогнозування.
20. Спосіб за п. 14, який додатково включає кодування, відповідно до розширення базової специфікації відеокодування, третього зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення.
21. Спосіб за п. 20, який додатково включає, до кодування третього зображення, маркування всіх міжвидових опорних зображень як довгострокових опорних зображень.
22. Спосіб за п. 21, який додатково включає:
збереження статусу для кожного з міжвидових опорних зображень, при цьому статус містить одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, до маркування міжвидових опорних зображень як довгострокових опорних зображень; і,
після кодування другого зображення, встановлення нових статусів для кожного з міжвидових опорних зображень на основі збережених статусів.
23. Спосіб за п. 20, у якому базова специфікація відеокодування містить базову специфікацію Високоефективного Відеокодування (HEVC), і в якому розширення базової специфікації відеокодування містить одне з розширення Масштабованого Відеокодування (SCV) для базової специфікації HEVC і розширення Багатовидового Відеокодування (MVC) для базової специфікації HEVC.
24. Спосіб за п. 14, який додатково включає, після кодування третього зображення, маркування кожного міжвидового опорного зображення як одного з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання.
25. Спосіб за п. 24, який додатково включає:
після маркування міжвидового опорного зображення як довгострокового опорного зображення, призначення міжвидовому опорному зображенню нового значення РОС, що у даний момент є невикористовуваним; і,
після кодування другого зображення, відновлення вихідного значення РОС для міжвидового опорного зображення.
26. Спосіб за п. 25, у якому вихідне значення РОС містить значення РОС другого зображення.
27. Пристрій декодування відеоданих, який містить відеодекодер, виконаний з можливістю декодувати дані другого зображення, що стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих, декодувати дані другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення, декодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення, і забороняти прогнозування вектора руху між першим вектором руху першого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і другим вектором руху другого блока другого зображення, при цьому другий вектор руху посилається на довгострокове опорне зображення.
28. Пристрій за п. 27, у якому відеодекодер виконаний з можливістю ідентифікувати перше зображення з використанням значення РОС і ідентифікатора зображення другої розмірності і декодувати щонайменше частину другого зображення відносно першого зображення.
29. Пристрій за п. 28, у якому відеодекодер виконаний з можливістю ідентифікувати перше зображення під час кодування вектора руху для блока другого зображення, і в якому відеодекодер виконаний з можливістю декодувати вектор руху згідно з щонайменше одним з удосконаленого прогнозування вектора руху (AMVP), часового прогнозування вектора руху (TMVP) і режиму злиття.
30. Пристрій за п. 27, у якому відеодекодер виконаний з можливістю дозволяти прогнозування між першим короткостроковим вектором руху другого зображення і другим короткостроковим вектором руху другого зображення і масштабувати щонайменше один з першого короткострокового вектора руху і другого короткострокового вектора руху на основі значення РОС для першого короткострокового опорного зображення, на яке посилається перший короткостроковий вектор руху, і значення РОС для другого короткострокового опорного зображення, на яке посилається другий короткостроковий вектор руху.
31. Пристрій за п. 27, у якому ідентифікатор зображення другої розмірності містить щонайменше один з ідентифікатора виду для виду, що включає в себе перше зображення, індексу порядку виду для виду, що включає в себе перше зображення, комбінації індексу порядку виду і прапора глибини, ідентифікатора рівня для рівня масштабованого відеокодування (SCV), що включає в себе перше зображення, і загального ідентифікатора рівня.
32. Пристрій за п. 27, у якому відеодекодер виконаний з можливістю декодувати значення, яке вказує, чи містить третє зображення відеоданих довгострокове опорне зображення, при цьому значення, яке вказує, чи містить третє зображення довгострокове опорне зображення, додатково вказує, чи використовується третє зображення для міжвидового прогнозування.
33. Пристрій за п. 27, у якому відеодекодер додатково виконаний з можливістю декодувати, відповідно до розширення базової специфікації відеокодування, третє зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення.
34. Пристрій за п. 33, у якому відеодекодер виконаний з можливістю маркувати всі міжвидові опорні зображення для третього зображення, у тому числі перше зображення, як довгострокові опорні зображення, до декодування третього зображення, зберігати статус для кожного з міжвидових опорних зображень, при цьому статус містить одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, до маркування міжвидових опорних зображень як довгострокових опорних зображень, і, після декодування третього зображення, установлювати нові статуси для кожного з міжвидових опорних зображень на основі збережених статусів.
35. Пристрій за п. 33, у якому відеодекодер додатково виконаний з можливістю маркувати кожне міжвидове опорне зображення для третього зображення, у тому числі перше зображення, як одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, після декодування третього зображення, призначати кожному з міжвидових опорних зображень нове значення РОС, що у даний момент є невикористовуваним, після маркування міжвидового опорного зображення як довгострокового опорного зображення, і відновлювати вихідне значення РОС для міжвидового опорного зображення, після кодування другого зображення.
36. Пристрій за п. 27, у якому пристрій містить щонайменше одне з:
інтегральної схеми;
мікропроцесора; і
бездротового пристрою зв'язку, що містить у собі відеодекодер.
37. Пристрій кодування відеоданих, який містить відеокодер, виконаний з можливістю кодувати дані другого зображення, що стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих, кодувати дані другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення, кодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення, і забороняти прогнозування вектора руху між першим вектором руху першого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і другим вектором руху другого блока другого зображення, при цьому другий вектор руху посилається на довгострокове опорне зображення.
38. Пристрій за п. 37, у якому відеокодер виконаний з можливістю ідентифікувати перше зображення з використанням значення РОС і ідентифікатора зображення другої розмірності і кодувати щонайменше частину другого зображення відносно першого зображення.
39. Пристрій за п. 38, у якому відеокодер виконаний з можливістю ідентифікувати перше зображення під час кодування вектора руху для блока другого зображення, і в якому відеокодер виконаний з можливістю кодувати вектор руху згідно з щонайменше одним з удосконаленого прогнозування вектора руху (AMVP), часового прогнозування вектора руху (TMVP) і режиму злиття.
40. Пристрій за п. 37, у якому відеокодер виконаний з можливістю дозволяти прогнозування між першим короткостроковим вектором руху другого зображення і другим короткостроковим вектором руху другого зображення і масштабувати щонайменше один з першого короткострокового вектора руху і другого короткострокового вектора руху на основі значення РОС для першого короткострокового опорного зображення, на яке посилається перший короткостроковий вектор руху, і значення РОС для другого короткострокового опорного зображення, на яке посилається другий короткостроковий вектор руху.
41. Пристрій за п. 37, у якому ідентифікатор зображення другої розмірності містить щонайменше один з ідентифікатора виду для виду, що включає в себе перше зображення, індексу порядку виду для виду, що включає в себе перше зображення, комбінації індексу порядку виду і прапора глибини, ідентифікатора рівня для рівня масштабованого відеокодування (SCV), що включає в себе перше зображення, і загального ідентифікатора рівня.
42. Пристрій за п. 37, у якому відеокодер виконаний з можливістю кодувати значення, яке вказує, чи містить третє зображення відеоданих довгострокове опорне зображення, при цьому значення, яке вказує, чи містить третє зображення довгострокове опорне зображення, додатково вказує, чи використовується третє зображення для міжвидового прогнозування.
43. Пристрій за п. 37, у якому відеокодер додатково виконаний з можливістю кодувати, відповідно до розширення базової специфікації відеокодування, третє зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення.
44. Пристрій за п. 43, у якому відеокодер виконаний з можливістю маркувати всі міжвидові опорні зображення для третього зображення, що включають у себе перше зображення, як довгострокові опорні зображення, до кодування третього зображення, зберігати статус для кожного з міжвидових опорних зображень, при цьому статус містить одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, до маркування міжвидових опорних зображень як довгострокових опорних зображень, і, після кодування третього зображення, установлювати нові статуси для кожного з міжвидових опорних зображень на основі збережених статусів.
45. Пристрій за п. 43, у якому відеокодер додатково виконаний з можливістю маркувати кожне міжвидове опорне зображення для третього зображення, у тому числі перше зображення, як одне з довгострокового опорного зображення, короткострокового опорного зображення і невикористовуваного для посилання, після кодування третього зображення, призначати кожному з міжвидових опорних зображень нове значення РОС, що у даний момент є невикористовуваним, після маркування міжвидового опорного зображення як довгострокового опорного зображення, і відновлювати вихідне значення РОС для міжвидового опорного зображення, після кодування другого зображення.
46. Пристрій кодування відеоданих, який містить:
засіб для кодування даних другого зображення, які стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих;
засіб для кодування даних другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення;
засіб для кодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення; і
засіб для заборони прогнозування вектора руху між першим вектором руху першого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і другим вектором руху другого блока другого зображення, при цьому другий вектор руху посилається на довгострокове опорне зображення.
47. Зчитуваний комп'ютером носій даних, на якому зберігаються інструкції, що, при їхньому виконанні, спонукають процесор:
декодувати дані другого зображення, що стосуються значення рахунка порядку зображення (РОС) для першого зображення відеоданих;
декодувати дані другого зображення, що стосуються ідентифікатора зображення другої розмірності для першого зображення;
декодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення; і
забороняти прогнозування вектора руху між першим вектором руху першого блока другого зображення, при цьому перший вектор руху посилається на короткострокове опорне зображення, і другим вектором руху другого блока другого зображення, при цьому другий вектор руху посилається на довгострокове опорне зображення.
Текст
Реферат: В одному прикладі, пристрій містить у собі відеокодер, виконаний з можливістю кодувати значення рахунка порядку зображення (РОС) для першого зображення відеоданих, кодувати ідентифікатор зображення другої розмірності для першого зображення і кодувати, відповідно до базової специфікації відеокодування або розширення базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. Відеокодер може містити відеокодер і відеодекодер. Ідентифікатор зображення другої розмірності може містити, наприклад, ідентифікатор виду, індекс порядку виду, ідентифікатор рівня або інший подібний ідентифікатор. Відеокодер може кодувати значення РОС і ідентифікатор зображення другої UA 114103 C2 (12) UA 114103 C2 розмірності під час кодування вектора руху для блока другого зображення, наприклад, під час удосконаленого прогнозування вектора руху або кодування в режимі злиття. UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дана заявка заявляє пріоритет заявки на патент США №61/611,959, поданої 16 березня 2012 року, заявки на патент США №61/624,990, поданої 16 квітня 2012 року, заявки на патент США №61/658,344, поданої 11 червня 2012 року, заявки на патент США №61/663,484, поданої 22 червня 2012 року, і заявки на патент США №61/746,476, поданої 27 грудня 2012 року, зміст яких повністю включений в дану заявку за допомогою посилання. Галузь техніки, до якої належить винахід Дане розкриття стосується кодування відео. Рівень техніки Можливості цифрового відео можуть бути включені в широкий ряд пристроїв, включаючи цифрові телевізори, цифрові системи прямого мовлення, бездротові системи мовлення, персональні цифрові помічники (PDA), портативні або настільні комп'ютери, планшети, пристрої для читання електронних книг, цифрові камери, цифрові записуючі пристрої, цифрові медіапрогравачі, пристрої відеоігор, ігрові відеоприставки, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої для відео телеконференції, пристрої потокового відео тощо. Цифрові відеопристрої здійснюють способи відеокодування, як, наприклад, описані в стандартах, визначених MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, частина 10, Просунуте кодування (AVC) відеосигналу, стандарт Високоефективного Відеокодування (HEVC), що знаходиться в розробці в даний час, і розширення цих стандартів. Відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію ефективніше шляхом здійснення подібних способів відеокодування. Способи відеокодування містять у собі просторове (із внутрішнім (intra-) кодуванням) прогнозування і/або часове (із зовнішнім (inter-) кодуванням) прогнозування для скорочення або усунення надмірності, властивої для послідовностей відеокадрів. Для кодування відео на основі блоків, відеослайс (наприклад, відеокадр або частина відеокадру) може бути розділений на відеоблоки, які також називають деревоподібними блоками, елементами (одиницями) (CU) кодування і/або вузлами кодування. Відеоблоки у внутрішньо-кодованому (I) слайсі зображення кодуються з використанням просторового прогнозування відносно опорних відліків у сусідніх блоках у тому ж зображенні. Відеоблоки у зовнішньокодованому (Р або В) слайсі можуть використовувати просторове прогнозування відносно опорних відліків у сусідніх блоках у тому ж зображенні або часове прогнозування відносно опорних відліків в інших опорних зображеннях. Зображення можна також називати кадрами, а опорні зображення можна називати опорними кадрами. Просторове або часове прогнозування має своїм результатом прогнозуючий блок для блока, який повинен бути кодований. Залишкові дані являють собою різниці пікселів між вихідним блоком, який повинен бути кодований, і прогнозуючим блоком. Зовнішньокодований блок кодується відповідно до вектора руху, що вказує на блок опорних відліків, які формують прогнозуючий блок, і залишковими даними, які вказують різницю між закодованим блоком і прогнозуючим блоком. Внутрішньокодований блок кодується відповідно до режиму внутрішнього кодування і залишкових даних. Для додаткового стиснення залишкові дані можуть бути перетворені з області пікселів в область перетворення, що приведе до залишкових коефіцієнтів перетворення, які потім можуть бути квантовані. Квантовані коефіцієнти перетворення, початково розміщені в двовимірному масиві, можуть бути скановані для відтворення одновимірного вектора коефіцієнтів перетворення, і може бути застосоване ентропійне кодування для досягнення ще більшого стиснення. Розкриття винаходу Загалом, дане розкриття описує різні способи підтримки розширень стандартів кодування, як, наприклад, Стандарт Високоефективного Відеокодування, що розвивається (HEVC), зі зміною тільки синтаксису високого рівня. Наприклад, дане розкриття описує способи як у базовій специфікації HEVC, так і в розширеннях HEVC багатовидового відеокодека і/або тривимірного (3D) відеокодека, де базовий вид порівнянний з базовою специфікацією HEVC. Загалом, "базова специфікація відеокодування" може відповідати специфікації відеокодування, що використовується для кодування двовимірних, однорівневих відеоданих. Розширення базової специфікації відеокодування можуть розширювати можливості базової специфікації відеокодування, щоб дозволити 3D і/або багаторівневе відеокодування. Базова специфікація HEVC являє собою приклад базової специфікації відеокодування, у той час як розширення MVC і SVC до базової специфікації HEVC являють собою приклади розширень базової специфікації відеокодування. В одному прикладі, спосіб включає в себе декодування значення рахунка порядку зображення (POC) для першого зображення відеоданих, декодування ідентифікатора 1 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 зображення другої розмірності для першого зображення і декодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. Ідентифікатор зображення другої розмірності може додатково бути спрощений до типу зображення, наприклад, чи є зображення довгостроковим або короткостроковим зображенням, або чи має зображення, якщо воно опорне зображення, те ж значення рахунка порядку зображення (POC), що і зображення, яке посилається на нього. При формуванні кандидатів векторів руху із сусідніх блоків, кандидат може вважатися недоступним, коли він має ідентифікатор зображення другої розмірності, відмінний від такого у вектора руху, який повинен бути прогнозований, ідентифікатор зображення другої розмірності якого - це зображення, на яке вказує цей вектор руху, і ідентифіковане індексом цільового посилання. В іншому прикладі, спосіб включає в себе кодування значення рахунка порядку зображення (POC) для першого зображення відеоданих, кодування ідентифікатора зображення другої розмірності для першого зображення і кодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, пристрій містить у собі відеодекодер, виконаний з можливістю декодувати значення рахунка порядку зображення (POC) для першого зображення відеоданих, декодувати ідентифікатор зображення другої розмірності для першого зображення і декодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, пристрій містить у собі відеокодер, виконаний з можливістю кодувати значення рахунка порядку зображення (POC) для першого зображення відеоданих, кодувати ідентифікатор зображення другої розмірності для першого зображення і кодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, пристрій містить у собі засіб декодування значення рахунка порядку зображення (POC) для першого зображення відеоданих, засіб декодування ідентифікатора зображення другої розмірності для першого зображення і засіб декодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, пристрій містить у собі засіб для кодування значення рахунка порядку зображення (POC) для першого зображення відеоданих, засіб для кодування ідентифікатора зображення другої розмірності для першого зображення і засіб для кодування, відповідно до базової специфікації відеокодування, другого зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, зчитуваний комп'ютером носій даних, на якому зберігаються інструкції, які, при їхньому виконанні, спонукають процесор декодуватизначення рахунка порядку зображення (POC) для першого зображення відеоданих, декодувати ідентифікатор зображення другої розмірності для першого зображення і декодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. В іншому прикладі, зчитуваний комп'ютером носій даних, на якому зберігаються інструкції, які, при їхньому виконанні, спонукають процесор кодувати значення рахунка порядку зображення (POC) для першого зображення відеоданих, кодувати ідентифікатор зображення другої розмірності для першого зображення і кодувати, відповідно до базової специфікації відеокодування, друге зображення на основі, щонайменше частково, значення РОС і ідентифікатора зображення другої розмірності першого зображення. Деталі одного або декількох прикладів вказані в супровідних кресленнях і наступному описі. Інші особливості, цілі і переваги будуть очевидні з опису і креслень, а також з формули винаходу. Короткий опис креслень Фіг. 1 є блоковою діаграмою, яка зображує приклад системи кодування і декодування відео, що може використовувати способи кодування відеоданих відповідно до синтаксичного розширення високого рівня стандарту відеокодування. Фіг. 2 є блоковою діаграмою, яка зображує приклад відеокодера, що може здійснювати способи кодування відеоданих відповідно до синтаксичного розширення високого рівня стандарту відеокодування. 2 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 Фіг. 3 є блоковою діаграмою, яка зображує приклад відеодекодера, що може здійснювати способи кодування відеоданих відповідно до синтаксичного розширення високого рівня стандарту відеокодування. Фіг. 4 є концептуальною діаграмою, яка зображує приклад моделі прогнозування MVC. Фіг. 5-9 є концептуальними діаграмами, які зображують потенційні проблеми, які повинні бути переборені для досягнення тільки синтаксичного розширення високого рівня HEVC. Фіг. 10 є концептуальною діаграмою, яка зображує приклад групи сусідніх блоків для поточного блока для використання в прогнозуванні вектора руху. Фіг. 11 є блок-схемою, яка зображує приклад способу кодування відеоданих, відповідно до способів даного розкриття. Фіг. 12 є блок-схемою, яка зображує приклад способу декодування відеоданих, відповідно до способів даного розкриття. Детальний опис Загалом, дане розкриття описує різні способи підтримки розширень стандартів кодування, як, наприклад, Стандарт Високоефективного Відеокодування, що розвивається (HEVC), зі зміною тільки синтаксису (HLS) високого рівня. Наприклад, дане розкриття описує способи як у базовій специфікації HEVC, так і в розширеннях HEVC багатовидового Відеокодування (MVC) і/або кодування тривимірного відеосигналу (3DV), де базовий вид порівнянний з базовою специфікацією HEVC. Дане розкриття описує конкретні способи, які забезпечують профіль тільки синтаксису високого рівня в специфікації розширення HEVC. Термін "міжвидовий" у контексті MVC\3DV може бути замінений на "міжрівневий" у контексті Масштабованого Відеокодування (SCV). Тобто, хоча опис цих способів первинно фокусується на "міжвидовому" кодуванні, ті ж або подібні ідеї можна застосувати до "міжрівневих" опорних зображень для розширення тільки HLS SVC HEVC. Фіг. 1 є блоковою діаграмою, яка зображує приклад системи 10 кодування і декодування відео, що може використовувати способи кодування відеоданих відповідно тільки до синтаксичного розширення високого рівня стандарту відеокодування. Як зображено на Фіг. 1, система 10 містить у собі пристрій-джерело 12, що забезпечує закодовані відеодані, які повинні бути декодовані пізніше пристроєм-адресатом 14. Більш конкретно, пристрій-джерело 12 забезпечує відеодані пристрою-адресату 14 по зчитуваному комп'ютером носію 16. Пристрійджерело 12 і пристрій-адресат 14 можуть містити будь-який із широкого діапазону пристроїв, включаючи настільні комп'ютери, ноутбуки (тобто, портативні комп'ютери), планшетні комп'ютери, телевізійні приставки, телефонні трубки, як, наприклад, так звані "смартфони", так звані "смартпади", телевізори, камери, пристрої відображення, цифрові медіаплеєри, ігрові відеоприставки, пристрій потокового відео або тому подібне. У деяких випадках, пристрійджерело 12 і пристрій-адресат 14 можуть бути обладнані для бездротового зв'язку. Пристрій-адресат 14 може приймати закодовані відеодані, які повинні бути декодовані, по зчитуваному комп'ютером носію 16. Зчитуваний комп'ютером носій 16 може містити будь-який тип носія або пристрою, здатного переміщувати закодовані відеодані від пристрою-джерела 12 до пристрою-адресата 14. В одному прикладі, зчитуваний комп'ютером носій 16 може містити носій зв'язку для дозволу пристрою-джерелу 12 передавати закодовані відеодані прямо пристрою-адресату 14 у реальному часі. Закодовані відеодані можуть бути модульовані відповідно до стандарту зв'язку, як, наприклад, протокол бездротового зв'язку, і передані пристрою-адресату 14. Носій зв'язку може містити будь-який бездротовий або дротовий носій зв'язку, як, наприклад, радіочастотний (RF) спектр або одна або кілька фізичних ліній передачі. Носій зв'язку може формувати частину пакетної мережі, як, наприклад, локальна мережа, регіональна мережа або глобальна мережа, як, наприклад, Інтернет. Носій зв'язку може містити в собі роутери, перемикачі, базові станції або будь-яке інше обладнання, яке може бути використане для посилення зв'язку від пристрою-джерела 12 до пристрою-адресата 14. У деяких прикладах, закодовані дані можуть бути виведені від вихідного інтерфейсу 22 пристрою збереження. Подібним чином, доступ до закодованих даних може бути здійснений від пристрою збереження за допомогою вхідного інтерфейсу. Пристрій збереження може містити в собі будь-який з різноманітних розподілених носіїв даних або носіїв даних локального доступу, як, наприклад, накопичувач на твердих дисках, диски Blu-ray, DVD, CD-ROM, флеш-пам'ять, енергозалежний або енергонезалежний запам'ятовуючий пристрій, або будь-які інші придатні цифрові носії даних для збереження закодованих відеоданих. У додатковому прикладі, пристрій збереження може відповідати файловому серверу або іншому проміжному пристрою збереження, який може зберігати закодоване відео, сформоване пристроєм-джерелом 12. Пристрій-адресат 14 може здійснювати доступ до збережених відеоданих у пристрої 3 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 збереження по потоковій передачі або завантаженню даних. Файловий сервер може бути будьяким типом сервера, здатним зберігати закодовані відеодані і передавати ці закодовані відеодані пристрою-адресату 14. Приклади файлових серверів містять у собі веб-сервер (наприклад, для веб-сайту), сервер FTP, пристрої мережевого сховища (NAS) даних або накопичувач на локальному диску. Пристрій-адресат 14 може здійснювати доступ до закодованих відеоданих по будь-якому стандартному з'єднанню даних, включаючи інтернетз'єднання. Це може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем і так далі) або їхню комбінацію, що підходить для доступу до закодованих відеоданих, які зберігаються на файловому сервері. Передача закодованих відеоданих від пристрою збереження може бути потоковою передачею, передачею завантаження або їх комбінацією. Способи даного розкриття необов'язково обмежені бездротовими застосуваннями або налаштуваннями. Способи можуть бути застосовані до кодування відео для підтримки будьякого з різноманітних мультимедійних застосувань, як, наприклад, ефірні телевізійні широкомовні передачі, кабельні телевізійні передачі, супутникові телевізійні передачі, потокові передачі відеосигналу по інтернету, як, наприклад, динамічна адаптивна потокова передача по HTTP (DASH), цифровий відеосигнал, який закодований на носії даних, декодування цифрового відеосигналу, що зберігається на носії даних, або інші застосування. У деяких прикладах, система 10 може бути виконана з можливістю підтримувати односторонню або двосторонню передачу відеосигналу для підтримки таких застосувань, як потокова передача відеосигналу, відтворення відеосигналу, широкомовна передача відеосигналу і/або відеотелефонія. У прикладі на Фіг. 1, пристрій-джерело 12 містить у собі джерело 18 відео, відеокодер 20 і вихідний інтерфейс 22. Пристрій-адресат 14 містить у собі вхідний інтерфейс 28, відеодекодер 30 і пристрій 32 відображення. Відповідно до даного розкриття, відеокодер 20 пристроюджерела 12 може бути виконаний з можливістю застосовувати способи кодування відеоданих відповідно тільки до синтаксичного розширення високого рівня стандарту відеокодування. В інших прикладах, пристрій-джерело й пристрій-адресат можуть містити в собі інші компоненти або установки. Наприклад, пристрій-джерело 12 може приймати відеодані від зовнішнього джерела 18 відео, як, наприклад, зовнішня камера. Подібним чином, пристрій-адресат 14 може взаємодіяти з зовнішнім пристроєм відображення, замість того, щоб містити в собі інтегрований пристрій відображення. Зображена система 10 на Фіг. 1 є лише прикладом. Способи кодування відеоданих відповідно тільки до синтаксичного розширення високого рівня стандарту відеокодування можуть бути виконані будь-яким цифровим пристроєм кодування і/або декодування відео. Хоча, загалом, способи даного винаходу виконуються пристроєм відеокодування, способи можуть також бути виконані відеокодером/декодером, як правило, який називається "CODEC". Більше того, способи даного розкриття можуть також бути виконані пристроєм попередньої обробки відеосигналу. Пристрій-джерело 12 і пристрій-адресат 14 є лише прикладами таких пристроїв кодування, у яких пристрій 12 формує закодовані відеодані для передачі пристрою-адресату 14. У деяких прикладах, пристрої 12, 14 можуть функціонувати по суті симетричним чином, так що кожен з пристроїв 12, 14 містить у собі компоненти кодування і декодування відео. Отже, система 10 може підтримувати односторонню або двосторонню передачу між відеопристроями 12, 14, наприклад, для потокового відео, відтворення відеосигналу, широкомовної передачі відеосигналу або відеотелефонії. Джерело 18 відео пристрою-джерела 12 може містити в собі пристрій захоплення відеосигналу, як, наприклад, відеокамера, відеоархів, що містить раніше захоплене відео, і/або інтерфейс подачі відео для прийому відео від провайдера відеовмісту. Як додаткова альтернатива, джерело 18 відео може формувати дані комп'ютерної графіки як вихідне відео, або комбінацію відео в реальному часі, архівоване відео і сформоване комп'ютером відео. У деяких випадках, якщо джерелом 18 відео є відеокамера, то пристрій-джерело 12 і пристрійадресат 14 можуть формувати так звані камерофони або відеофони. Однак, як згадано вище, способи, описані в даному винаході, можуть бути застосовні до кодування відео загалом і можуть бути застосовні в бездротових і/або дротових застосуваннях. У будь-якому випадку, захоплене, попередньо захоплене або сформоване комп'ютером відео може бути закодоване відеокодером 20. Закодована відеоінформація потім може бути виведена вихідним інтерфейсом 22 на зчитуваний комп'ютером носій 16. Зчитуваний комп'ютером носій 16 може містити в собі енергозалежні носії, як, наприклад, бездротова широкомовна або дротова мережева передача, або носії даних (тобто, енергонезалежні носії даних), як, наприклад, накопичувач на твердих дисках, флеш-пам'ять, компакт-диск, цифровий відеодиск, диск Blu-ray або інші зчитувані комп'ютером носії даних. У 4 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 деяких прикладах, мережевий сервер (не зображений) може приймати закодовані відеодані від пристрою-джерела 12 і забезпечувати закодовані відеодані пристрою-адресату 14, наприклад, по мережевій передачі. Подібним чином, обчислювальний пристрій блока відтворення носія, як, наприклад, блока маркування диска, може приймати закодовані відеодані від пристроюджерела 12 і виробляти диск, що містить закодовані відеодані. Отже, зчитуваний комп'ютером носій 16 можна розуміти як такий, що включає в себе один або декілька зчитуваних комп'ютером носіїв різних форм, у різних прикладах. Вхідний інтерфейс 28 пристрою-адресата 14 приймає інформацію від зчитуваного комп'ютером носія даних 16. Інформація зчитуваного комп'ютером носія даних 16 може містити в собі синтаксичну інформацію, визначену відеокодером 20, що також використовується відеодекодером 30, що містить у собі синтаксичні елементи, які описують характеристики і/або обробні блоки й інші закодовані елементи, наприклад, GOP. Пристрій 32 відображення відображає закодовані відеодані користувачу і може містити будь-який з різноманітних пристроїв, як, наприклад, катодно-променева трубка (CRT), рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світлодіодах (OLED) або інший тип пристрою відображення. Відеокодер 20 і відеодекодер 30 можуть функціонувати відповідно до стандарту відеокодування, як, наприклад, стандарт Високоефективного Відеокодування (HEVC), що знаходиться в розробці в даний час, і можуть відповідати тестовій моделі (HM) HEVC. Остання робоча версія HEVC, яка називається "Робоча версія 7 HEVC" або "WD7", описана в документі JCTVC-I1003, Бросс і інші, "Робоча версія 7 текстової специфікації високоефективного Відеокодування (HEVC)», Спільна експертна група (JCT-VC) по кодуванню відео ITU-T SG16 WP3 і ISO/IEC JTC1/SC29/WG11, 9-а зустріч: Женева, Швейцарія, з 27 квітня 2012 року по 7 травня 2012 року, що, за станом на 22 червня 2012 року, можна завантажити з http://phenix.itsudparis.eu/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-I1003-v3.zip. Як відзначено вище, дане розкриття містить у собі способи розширення HEVC з використанням синтаксису високого рівня. Відповідно, відеокодер 20 і відеодекодер 30 можуть функціонувати відповідно до версії HEVC, розширеної з використанням синтаксису високого рівня. Альтернативно, відеокодер 20 і відеодекодер 30 можуть функціонувати відповідно до інших приватних або промислових стандартів, як, наприклад, стандарт ITU-T H.264, який альтернативно називається MPEG-4, Частина 10, Просунуте кодування (AVC) відеосигналу, або розширеннями таких стандартів. Знову ж, ці розширення можуть бути досягнуті з використанням синтаксису високого рівня. Способи даного винаходу, однак, не обмежені будь-яким конкретним стандартом кодування. Інші приклади стандартів відеокодування містять у собі MPEG-2 ITU-T і H.263. Хоча це не зображено на Фіг. 1, у деяких аспектах відеокодер 20 і відеодекодер 30 можуть бути інтегровані з аудіокодером і декодером і можуть містити в собі відповідні елементи MUX-DEMUX або інші технічні засоби або програмне забезпечення для керування кодуванням аудіо і відео в загальному потоці даних або окремих потоках даних. Якщо це застосовно, то елементи MUX-DEMUX можуть відповідати протоколу мультиплексування ITU H.223 або іншим протоколам, як, наприклад, протокол (UDP) користувацької дейтаграми. Стандарт ITU-T H.264/MPEG-4 (AVC) був сформульований Експертною групою (VCEG) кодування відео ITU-T разом з Експертною групою (MPEG) по рухомому зображенню ISO/IEC як продукт колективного партнерства, відомого як Об'єднана команда (JVT) по кодуванню відео. У деяких аспектах, способи, описані в даному розкритті, можуть бути застосовані до пристроїв, що загалом відповідають стандарту Н.264. Стандарт Н.264 описаний у Рекомендації Н.264 ITU-T, Просунуте відеокодування для загальних аудіовізуальних послуг, дослідницькою групою ITU-T, від березня 2005 року, і в даному документі може називатися стандарт Н.264 або специфікація Н.264, або стандарт H.264/AVC, або специфікація. Об'єднана команда (JVT) по кодуванню відео продовжує роботу над розширеннями H.264/MPEG-4 AVC. Відеокодер 20 і відеодекодер 30 можуть бути здійснені як будь-яка з різноманітних придатних схем пристрою кодування, як, наприклад, один або кілька мікропроцесорів, цифрові сигнальні процесори (DSP), спеціалізовані інтегральні схеми (ASIC), програмовані користувачем вентильні матриці (FPGA), дискретна логіка, програмне забезпечення, технічні засоби, програмно-апаратні засоби або будь-яка їхня комбінація. Коли способи здійснені частково в програмному забезпеченні, пристрій може зберігати інструкції для програмного забезпечення на придатному, енергонезалежному зчитуваному комп'ютером носії і виконувати інструкції в технічних засобах з використанням одного або декількох процесорів для виконання способів даного розкриття. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або кілька пристроїв кодування або пристроїв декодування, будь-який з яких може бути інтегрований як частина комбінованого кодера/декодера (CODEC) у відповідному пристрої. 5 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 JCT-VC розробляє стандарт HEVC. Зусилля по стандартизації HEVC основані на моделі пристрою відеокодування, яка розвивається, що називається Тестовою моделлю (НМ) HEVC. НМ надає кілька додаткових можливостей пристроїв відеокодування відносно існуючих пристроїв, відповідно, наприклад, до ITU-T H.264/AVC. Наприклад, у той час як Н.264 забезпечує дев'ять режимів кодування з внутрішнім прогнозуванням, НМ може забезпечувати тридцять три режими кодування з внутрішнім прогнозуванням. Загалом, робоча модель НМ описує, що відеокадр або зображення може бути розділений на послідовність деревоподібних блоків або найбільших елементів (LCU) кодування, що містять у собі відліки яскравості і кольоровості. Синтаксичні дані усередині бітового потоку можуть визначати розмір LCU, що є найбільшим елементом кодування у сенсі числа пікселів. Слайс містить у собі число послідовних деревоподібних блоків у порядку кодування. Вдеокадр або зображення може бути розділене на один або декілька слайсів. Кожен деревоподібний блок може бути розбитий на елементи (CU) кодування, відповідно до дерева квадратів. Загалом, структура даних дерева квадратів містить у собі один вузол на CU, з кореневим вузлом, що відповідає деревоподібному блоку. Якщо CU розбитий на чотири під-CU, то вузол, що відповідає CU, містить у собі чотири кінцеві вузли, кожний з яких відповідає одному з під-CU. Кожен вузол структури даних дерева квадратів може забезпечувати синтаксичні дані відповідному CU. Наприклад, вузол у дереві квадратів може містити в собі прапор розділення, який вказує, чи розділений CU, що відповідає вузлу, на під-CU. Синтаксичні елементи CU можуть бути визначені рекурсивно і можуть залежати від того, чи розділений CU на під-CU. Якщо CU не розділений додатково, він називається кінцевим CU. У даному розкритті, чотири під-CU кінцевого CU будуть також називатися кінцевими CU, навіть якщо немає чіткого розділення вихідного кінцевого CU. Наприклад, якщо CU розміру 16×16 не розділений додатково, чотири під-CU 8×8 будуть також називатися кінцевими CU, хоча CU 16×16 ніколи не був розділений. CU має ту ж мету, що і макроблок стандарту Н.264, за винятком того, що CU не має відмінності в розмірі. Наприклад, деревоподібний блок може бути розділений на чотири дочірні вузли (які також називаються під-CU), і кожен дочірній вузол, у свою чергу, може бути батьківським вузлом і бути розділений на інші чотири дочірні вузли. Останній, не розділений дочірній вузол, який називається кінцевим вузлом дерева квадратів, містить вузол кодування, який також називається кінцевим CU. Синтаксичні дані, зв'язані з закодованим бітовим потоком, можуть визначати кількість разів, що дерево квадратів може бути розділене, що називається максимальною глибиною CU, і може також визначати мінімальний розмір вузлів кодування. Відповідно, бітовий потік може також визначати найменший елемент (SCU) кодування. Дане розкриття використовує термін "блок" для посилання на будь-який з CU, PU або TU, у контексті HEVC, або подібні структури даних у контексті інших стандартів (наприклад, макроблоки і їхні підблоки в H.264/AVC). CU містить у собі вузол кодування, елементи (PU) прогнозування й елементи (TU) перетворення, зв'язані з вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен бути квадратним за формою. Розмір CU може варіюватися від 8×8 пікселів до розміру дерева квадратів, максимально 64×64 пікселів або більше. Кожен СU може містити один або декілька PU і один або декілька ТU. Синтаксичні дані, зв'язані з CU, можуть описувати, наприклад, розділення CU на один або декілька PU. Режими розділення можуть відрізнятися залежно від того, чи є CU закодованим у режимі пропуску або прямому режимі, закодованим у режимі внутрішнього прогнозування або закодованим у режимі зовнішнього прогнозування. PU може бути розділений так, що за формою він не квадратний. Синтаксичні дані, зв'язані з CU, можуть також описувати, наприклад, розділення CU на один або декілька TU, відповідно до дерева квадратів. TU може бути квадратної або неквадратної (наприклад, прямокутної) форми. Стандарт HEVC допускає перетворення, відповідно до TU, що можуть відрізнятися для різних CU. TU, як правило, мають розмір на основі розміру PU усередині заданого CU, визначеного для розділеного LCU, хоча це не завжди може бути так. TU, як правило, мають той же розмір або менший, ніж PU. У деяких прикладах, залишкові відліки, що відповідають CU, можуть бути підрозділені на менші елементи з використанням структури дерева квадратів, відомої як "залишкове дерево (RQT) квадратів". Кінцеві вузли RQT можуть називатися елементами (TU) перетворення. Значення різниці пікселів, зв'язані з TU, можуть бути перетворені для відтворення коефіцієнтів перетворення, що можуть бути квантовані. Кінцевий CU може містити в собі один або кілька елементів (PU) прогнозування. Загалом, PU являє собою просторову область, що відповідає усім або частині відповідних CU, і може містити в собі дані для витягування опорного відліку для PU. Більше того, PU містить у собі дані, що стосуються прогнозування. Наприклад, коли PU закодований у внутрішньому режимі, дані 6 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 для PU можуть бути включені в залишкове дерево (RQT) квадратів, що може містити в собі дані, які описують режим внутрішнього прогнозування для TU, що відповідає PU. Як інший приклад, коли PU закодований у зовнішньому режимі, PU може містити в собі дані, які визначають один або кілька векторів руху для PU. Дані, що визначають вектор руху для PU, можуть описувати, наприклад, горизонтальну компоненту вектора руху, вертикальну компоненту вектора руху, розрізнення вектора руху (наприклад, з точністю до однієї четвертої пікселя або з точністю до однієї восьмої пікселя), опорне зображення, на яке указує вектор руху, і/або список опорних зображень (наприклад, Список 0, Список 1, або Список С) для вектора руху. Кінцевий CU, що має один або декілька PU, може також містити в собі один або кілька елементів (TU) перетворення. Елементи перетворення можуть бути визначені з використанням RQT (який також називається структурою дерева квадратів TU), як описано вище. Наприклад, прапор розділення може вказувати, чи розділений кінцевий CU на чотири елементи перетворення. Потім, кожен елемент перетворення може бути додатково розділений на додаткові під-TU. Коли TU не розділений додатково, він може називатися кінцевим TU. Загалом, для внутрішнього кодування, усі кінцеві TU, що належать кінцевому CU, мають однаковий режим внутрішнього прогнозування. Тобто, однаковий режим внутрішнього прогнозування, загалом, застосовується для обчислення прогнозованих значень для всіх TU кінцевого CU. Для внутрішнього кодування, відеокодер може обчислювати залишкове значення для кожного кінцевого TU з використанням режиму внутрішнього прогнозування, як різницю між частиною CU, що відповідає TU, і вихідним блоком. TU необов'язково обмежений розміром PU. Таким чином, TU можуть бути більші або менші, ніж PU. Для внутрішнього кодування, PU може бути розташований разом з відповідним кінцевим TU для того ж CU. У деяких прикладах, максимальний розмір кінцевого TU може відповідати розміру відповідного кінцевого CU. Більше того, TU кінцевих CU можуть також бути зв'язані з відповідними структурами даних дерева квадратів, які називаються залишковими деревами (RQT) квадратів. Тобто, кінцевий CU може містити в собі дерево квадратів, що вказує, як кінцевий CU розділений на TU. Кореневий вузол дерева квадратів TU, загалом, відповідає кінцевому CU, у той час як кореневий вузол дерева квадратів CU, загалом, відповідає деревоподібному блоку (або LCU). TU RQT, які не розділені, називаються кінцевими TU. Загалом, дане розкриття використовує терміни CU і TU для посилання на кінцевий CU і кінцевий TU, відповідно, якщо тільки не вказане інше. Відеопослідовність, як правило, містить у собі ряд відеокадрів або зображень. Група (GOP) зображень, загалом, містить ряд з одного або декількох зображень. GOP може містити в собі синтаксичні дані в заголовку GOP, заголовку одного або декількох зображень або в іншому місці, що описує кількість зображень, включених у GOP. Кожен слайс зображення може містити в собі синтаксичні дані слайса, що описують режим кодування для відповідного слайса. Відеокодер 20, як правило, функціонує з відеоблоками усередині окремих відеослайсів, щоб закодувати відеодані. Відеоблок може відповідати вузлу кодування усередині CU. Відеоблоки можуть мати фіксовані або змінювані розміри і можуть відрізнятися в розмірах відповідно до конкретного стандарту кодування. Як приклад, НМ підтримує прогнозування в різних розмірах PU. Припустимо, що розмір конкретного CU дорівнює 2N×2N, тоді НМ підтримує внутрішнє прогнозування в розмірах PU 2N×2N або N×N, і зовнішнє прогнозування в симетричних розмірах PU 2N×2N, 2N×N, N×2N або N×N. НМ також підтримує асиметричне розділення для зовнішнього прогнозування в розмірах PU 2NnU, 2NnD, nL2N і nR2N. При асиметричному розділенні, один напрямок CU не розділяється, у той час як інший напрямок розділяється на 25 % і 75 %. Частина CU, що відповідає 25 % розділення, указується "n", за яким йде вказівка "Зверху", "Знизу", "Ліворуч" або "Праворуч". Таким чином, наприклад, "2NnU" стосується 2N2N CU, який розділений горизонтально з 2N0,5N PU зверху і 2N1,5N PU знизу. У даному розкритті, "NN" і "N на N" можуть бути використані взаємозамінно для посилання на піксельні розміри відеоблока відносно вертикальних і горизонтальних розмірів, наприклад, 1616 пікселів або 16 на 16 пікселів. Загалом, блок 1616 має 16 пікселів у вертикальному напрямку (у=16) і 16 пікселів у горизонтальному напрямку (х=16). Подібним чином, блок NN, загалом, має N пікселів у вертикальному напрямку і N пікселів у горизонтальному напрямку, де N являє собою ненегативне ціле значення. Пікселі в блоці можуть бути упорядковані в ряди і стовпці. Більше того, блоки необов'язково повинні мати однакове число пікселів у горизонтальному напрямку, а також у вертикальному напрямку. Наприклад, блоки можуть містити NM пікселів, де М необов'язково дорівнює N. Слідом за кодуванням із внутрішнім прогнозуванням або зовнішнім прогнозуванням з використанням PU CU, відеокодер 20 може обчислювати залишкові дані для TU CU. PU можуть містити синтаксичні дані, які описують спосіб або режим формування прогнозних піксельних 7 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 даних у просторовому домені (який також називається піксельним доменом), і TU можуть містити коефіцієнти в домені перетворення слідом за застосуванням перетворення, наприклад, дискретного косинусного перетворення (DCT), цілочисельного перетворення, хвильового перетворення або концептуально схожого перетворення до залишкових відеоданих. Залишкові дані можуть відповідати різницям пікселів між пікселями незакодованого зображення і значеннями прогнозування, що відповідають PU. Відеокодер 20 може формувати TU, що включають у себе залишкові дані для CU, а потім перетворювати TU для відтворення коефіцієнтів перетворення для CU. Слідом за будь-якими перетвореннями для відтворення коефіцієнтів перетворення, відеокодер 20 може виконувати квантування коефіцієнтів перетворення. Квантування, загалом, стосується процесу, у якому коефіцієнти перетворення кантуються для можливого скорочення кількості даних, використовуваних для представлення коефіцієнтів, що забезпечує додатковий стиснення. Процес квантування може скоротити глибину бітів, зв'язану з деякими або всіма коефіцієнтами. Наприклад, значення n-бітів може бути округлене до значення m-бітів під час квантування, де n більше, ніж m. Слідом за квантуванням, відеокодер може сканувати коефіцієнти перетворення, виробляючи одновимірний вектор із двовимірної матриці, що включає в себе квантовані коефіцієнти перетворення. Сканування може бути задумане так, щоб розмістити коефіцієнти з високою енергією (і, отже, з низькою частотою) у передній частині масиву і розмістити коефіцієнти з низькою енергією (і, отже, з високою частотою) у задній частині масиву. У деяких прикладах, відеокодер 20 може використовувати попередньо заданий порядок сканування для сканування квантованих коефіцієнтів перетворення для відтворення упорядкованого вектора, який можна ентропійно закодувати. В інших прикладах, відеокодер 20 може виконувати адаптивне сканування. Після сканування квантованих коефіцієнтів перетворення для формування одновимірного вектора, відеокодер 20 може ентропійно кодувати одновимірний вектор, наприклад, відповідно до контекстно-залежного адаптивного кодування зі змінною довжиною кодового слова (CAVLC), контекстно-залежним адаптивним двійковим арифметичним кодуванням (САВАС), синтаксичним контекстно-залежним адаптивним двійковим арифметичним кодуванням (SBAC), ентропійним кодуванням (PIPE) з розділенням інтервалів імовірності або іншою методологією ентропійного кодування. Відеокодер 20 може також ентропійно кодувати синтаксичні елементи, зв'язані з закодованими відеоданими для використання відеодекодером 30 при декодуванні відеоданих. Для виконання САВАС, відеокодер 20 може призначати контекст усередині контекстної моделі символу, який повинен бути переданий. Контекст може стосуватися, наприклад, того, чи є сусідні значення символу ненульовими чи ні. Для виконання САVLС, відеокодер 20 може вибирати змінну довжину кодового слова для символу, який повинен бути переданий. Кодові слова в VLC можуть бути побудовані так, що відносно коротші коди відповідають найбільш ймовірним символам, у той час як довші коди відповідають менш ймовірним символам. Таким чином, за допомогою використання VLC можна домогтися збереження бітів у порівнянні, наприклад, з використанням кодових слів однакової довжини для кожного символу, який повинен бути переданий. Визначення імовірності може бути основане на контексті, призначеному символу. Відеокодер 20 може додатково відправляти синтаксичні дані, як, наприклад, синтаксичні дані на основі блока, синтаксичні дані на основі кадру і синтаксичні дані на основі GOP, відеодекодеру 30, наприклад, у заголовку кадру, заголовку блока, заголовку слайса або заголовку GOP. Синтаксичні дані GOP можуть описувати число кадрів у відповідній GOP, і синтаксичні дані кадру можуть указувати режим кодування/прогнозування, використовуваний для кодування відповідного кадру. Загалом, дане розкриття описує різні приклади рішень для дозволу тільки синтаксичного розширення високого рівня (HLS) стандарту відеокодування, як, наприклад, HEVC. Наприклад, ці способи можуть бути використані для розробки розширення тільки-HLS для профілю HEVC, як, наприклад, MVC або SVC. Різні приклади описані далі. Необхідно розуміти, що різні приклади описані окремо, а елементи будь-яких або всіх прикладів можуть бути скомбіновані в будь-якій комбінації. У першому прикладі змін у поточній базовій специфікації HEVC немає. У розширенні HEVC, зображення (наприклад, компонента виду) може бути ідентифіковане по двох якостях: його значенню рахунка порядку зображення (POC) і ідентифікатору зображення другої розмірності, наприклад, значенню view_id (яке може ідентифікувати вид, у якому зображення представлене). Відеокодеру 20 може знадобитися вказати компоненту виду, яка повинна бути використана для міжвидового прогнозування, як довгострокове опорне зображення. 8 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 В другому прикладі, змін у поточній базовій специфікації HEVC немає. У розширенні HEVC, можуть бути застосовані наступні зміни. Зображення (наприклад, компонента виду) може бути ідентифіковане по двох якостях: значенню РОС і ідентифікатору зображення другої розмірності, наприклад, view_id. В другому прикладі, процес маркування додаткового зображення може бути виконаний відразу до кодування поточної компоненти виду, для маркування всіх міжвидових опорних зображень як довгострокових опорних зображень. Інший процес маркування зображення може бути виконаний відразу після кодування поточної компоненти виду для маркування кожного міжвидового опорного зображення як або довгострокового, короткострокового або "невикористовуваного для посилання", що є тим же, що його попередній статус маркування до того, як була закодована поточна компонента виду. У третьому прикладі, способи другого приклада використовуються і доповнюються, як описано далі. На додаток до способів другого приклада, для кожного міжвидового опорного зображення, після того, як воно марковано як довгострокове опорне зображення, його значення РОС відображається в нове значення POC, що не еквівалентно значенню РОС будь-якого існуючого опорного зображення. Після декодування поточної компоненти виду, для кожного міжвидового опорного зображення, його значення РОС відображається назад у вихідне значення РОС, яке дорівнює поточній компоненті виду. Наприклад, поточна компонента виду може належати виду 3 (припустимо, що ідентифікатор виду дорівнює індексу порядку виду) і може мати значення РОС, яке дорівнює 5. Два міжвидових опорних зображення можуть мати свої значення РОС (які дорівнюють 5), конвертовані, наприклад, у 1025 і 2053. Після декодування поточної компоненти виду, значення РОС міжвидових зображень можуть бути назад конвертовані в 5. У четвертому прикладі, способи другого або третього прикладів можуть бути використані і доповнені, як описано далі. На додаток до способів першого приклада або другого приклада, як вказано вище, у базовій специфікації HEVC, додатковий прийом може бути використаний для заборони прогнозування між будь-яким вектором руху, що стосується короткострокового зображення, і іншим вектором руху, що стосується довгострокових зображень, особливо, під час удосконаленого прогнозування вектора руху (AMVP). У п'ятому прикладі, у розширенні HEVC, зображення може бути ідентифіковане по двох якостях: значенню РОС і ідентифікатору зображення другої розмірності, наприклад, view_id. У базовій специфікації HEVC, одна або кілька наступних прив'язок можуть бути додані (окремо або в комбінації). В одному прикладі (який називається приклад 5.1), при ідентифікації опорного зображення під час AMVP і режиму злиття, ідентифікація зображення другої розмірності, наприклад, індекс порядку виду, може бути використана разом з РОС. У контексті двовимірного 2D декодування відео в базовій специфікації HEVC, ідентифікація зображення другої розмірності завжди може вважатися (установлюватися) такою, що дорівнює 0. В іншому прикладі (приклад 5.2), прогнозування між часовим вектором руху і міжвидовим вектором руху забороняється під час AMVP (включаючи часове прогнозування вектора руху (TMVP)). Якість вектора руху може бути визначена за допомогою зв'язаного опорного індексу, що ідентифікує опорне зображення і те, як на опорне зображення посилається зображення, що містить вектор руху, наприклад, як на довгострокове опорне зображення, короткострокове опорне зображення, або міжвидове опорне зображення. В іншому прикладі (приклад 5.3), прогнозування між часовим короткостроковим вектором руху і часовим довгостроковим вектором руху може бути заборонене (наприклад, явно або неявно). В іншому прикладі (приклад 5.4), прогнозування між часовим короткостроковим вектором руху і часовим довгостроковим вектором руху може бути дозволене (наприклад, явно або неявно). В іншому прикладі (приклад 5.5), прогнозування між векторами руху, що посилаються на два різні міжвидові опорні зображення, може бути заборонене (наприклад, явно або неявно). Два міжвидових опорних зображення можна розглядати як мають різні типи, якщо значення ідентифікаторів зображення другої розмірності для них є різними. В іншому прикладі (приклад 5.6), прогнозування між векторами руху, що посилаються на два різні міжвидові опорні зображення, може бути дозволене (наприклад, явно або неявно). В іншому прикладі (приклад 5.7), прогнозування між векторами руху, що посилаються на довгострокове зображення і міжвидове зображення, може бути дозволене (наприклад, явно або неявно). В іншому прикладі (приклад 5.8), прогнозування між векторами руху, що посилаються на довгострокове зображення і міжвидове зображення, може бути заборонене (наприклад, явно або неявно). У будь-якому з вищевказаних прикладів, прогнозування між двома векторами руху, що посилаються на два різні часові короткострокові опорні зображення, може завжди бути дозволено, і масштабування з одного в інше на основі значень РОС може бути дозволене. Додатково або альтернативно, у будь-якому з вищевказаних прикладів, прогнозування між 9 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 векторами руху, що посилаються на два різні довгострокові зображення, може бути заборонене. Конкретні деталі різних прикладів, описаних вище, обговорюються більш докладно далі. Загалом, дане розкриття посилається на "вектор руху" або "дані вектора руху" як включають у себе опорний індекс (тобто, покажчик на опорне зображення) і х- і у-координати самого вектора руху. Обидва вектор руху диспаратності і часовий вектор руху можуть, загалом, називатися "векторами руху". Опорне зображення, що відповідає опорному індексу, може називатися опорним зображенням, на яке посилається вектор руху. Якщо вектор руху посилається на опорне зображення іншого виду, він називається вектор руху диспаратності. Часовий вектор руху може бути короткостроковим часовим вектором руху ("короткостроковий вектор руху") або довгостроковим часовим вектором руху ("довгостроковий вектор руху"). Наприклад, вектор руху є короткостроковим, якщо він посилається на короткострокове опорне зображення, у той час як вектор руху є довгостроковим, якщо він посилається на довгострокове опорне зображення. Необхідно відзначити, що якщо не вказане інше, вектор руху диспаратності і довгостроковий вектор руху, загалом, описують різні категорії векторів руху, наприклад, для міжвидового прогнозування і часового внутрішньовидового прогнозування, відповідно. Короткострокове і довгострокове опорні зображення являють собою приклади часових опорних зображень. Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю ідентифікувати опорне зображення з буфера (DPB) декодованих зображень, який може бути здійснений як пам'ять опорних зображень. Процес ідентифікації опорного зображення з DPB може бути використаний у будь-якому із прикладів способів, описаних у даному розкритті. Процес ідентифікації опорного зображення з DPB може бути використаний для наступних цілей у специфікації розширення HEVC: створення групи опорних зображень, створення списку опорних зображень і/або маркування опорних зображень. Компонента виду, компонента виду текстури, компонента виду глибини або масштабований рівень (наприклад, з конкретною комбінацією dependency_id і quality_id) можуть бути ідентифіковані за допомогою значення рахунка порядку зображення (POC) і інформації ідентифікації зображення другої розмірності. Інформація ідентифікації зображення другої розмірності може містити в собі одне або декілька з наступних: ID виду (view_id) у багатовидовому контексті; індекс порядку виду в багатовидовому контексті; у 3DV (багатовидовий із глибиною) контексті, комбінацію індексу порядку виду і depth_flag (який вказує, чи є поточний компонент виду текстурою або глибиною), наприклад, індекс порядку виду, помножений на два, плюс значення depth_flag; у контексті SVC, ID рівня (в оточенні масштабованого кодування, наприклад, у SVC на основі AVC, ID рівня може дорівнювати dependency_id, помноженому на 16, плюс quality_id); або загальний ID рівня (layer_id), наприклад, значення reserved_one_5bits мінус 1, причому reserved_one_5bits вказана в базовій специфікації HEVC. Необхідно відзначити, що загальний ID рівня може застосовуватися в змішаному 3DV (багатовидовий із глибиною) і масштабованому сценаріях. Вищевказані приклади можуть застосовуватися до будь-якого багаторівневого кодеку, включаючи масштабований відеокодек, за допомогою, наприклад, розгляду кожного рівня як виду. Іншими словами, для багатовидового відеокодування, різні види можуть бути розглянуті як окремі рівні. У деяких сценаріях, базовий рівень або залежний вид можуть мати багато представлень, наприклад, унаслідок використання різних фільтрів підвищувальної дискретизації/згладжування, або унаслідок факту використання зображення із синтезованим видом для прогнозування; таким чином, у місцерозташуванні одного виду, можуть бути два зображення, готові для використання, де одне є звичайним відновленим залежним зображенням виду, а інше є зображенням із синтезованим видом, обидва мають однаковий view_id або індекс порядку виду. У такому випадку, може бути використана ідентифікація зображення третьої розмірності. Відеокодер 20 і відеодекодер 30 також можуть бути виконані з можливістю ідентифікувати опорне зображення зі списку опорних зображень. Буфер (DPB) опорних зображень може бути організований у списки опорних зображень, наприклад, RefPicList0, який містить у собі потенційні опорні зображення, що мають значення РОС менше, ніж значення РОС поточного зображення, і RefPicList1, що містить у собі потенційні опорні зображення, що мають значення РОС більше, ніж значення РОС поточного зображення. Способи ідентифікації опорного зображення зі списку опорних зображень використовуються як прив'язка для поточної базової специфікації HEVC. Визначені функції можуть бути використані багато разів відеокодером або відеодекодером під час AMVP і режиму злиття. Компонента виду, компонента виду текстури, компонента виду глибини або масштабований рівень (наприклад, з конкретною комбінацією dependency_id і quality_id) можуть бути ідентифіковані за допомогою значення РОС і інформації ідентифікації зображення другої 10 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 розмірності, що може бути однією з наступних: індекс порядку виду в багатовидовому або 3DV контексті. Функція viewOldx (pic) повертає індекс порядку виду для виду, до якого належить зображення, ідентифіковане як "pic". Ця функція повертає 0 для будь-якої компонента виду, компоненти виду текстури або компоненти виду глибини базового виду; ID виду (view_id); у контексті 3DV, комбінацію індексу порядку виду і depth_flag (яка вказує, чи є поточний компонент виду текстурою або глибиною): індекс порядку виду, помножений на 2, плюс значення depth_flag; у контексті SVC, ID рівня (в оточенні масштабованого кодування, наприклад, SVC на основі AVC, ID рівня може бути дорівнює dependency_id, помноженому на 16, плюс quality_id); або загального ID рівня (layer_id), наприклад, значення reserved_one_5bits мінус 1, причому reserved_one_5bits вказаний у базовій специфікації HEVC. Функція layerId (pic) повертає layer_id зображення pic. LayerId (pic) повертає 0 для будь-якої компоненти виду (текстури) базового виду. LayerId (pic) повертає 0 для будь-якого зображення (або представлення рівня) базового рівня SVC. Необхідно відзначити, що загальний ID рівня може застосовуватися в змішаному 3DV (багатовидовий із глибиною) і масштабованому сценаріях. У деяких сценаріях, базовий рівень або залежний вид можуть мати множину представлень, наприклад, унаслідок використання різних фільтрів підвищувальної дискретизації/згладжування, або внаслідок факту використання зображення із синтезованим видом для прогнозування; таким чином, у місцерозташуванні одного виду, можуть бути два зображення, готових для використання: одне є звичайним відновленим залежним зображенням виду, а інше є зображенням із синтезованим видом, обидва мають однаковий view_id або індекс порядку виду. У такому випадку, може бути використана ідентифікація зображення третьої розмірності. Одна або декілька з вищезгаданих ідентифікацій зображень другої розмірності і/або третьої розмірності може бути визначена за допомогою функції AddPicId (pic). Відеокодер 20 і відеодекодер 30 можуть також бути виконані з можливістю ідентифікувати тип запису в списку опорних зображень. Це може бути використано як прив'язка для поточної базової специфікації HEVC. Будь-яка або всі функції, визначені нижче, можуть бути використані багато разів відеокодером 20 і/або відеодекодером 30 під час AMVP і/або режиму злиття. Будьяка або усі з наступних прикладів способів можуть бути використані для ідентифікації типу запису в списку опорних зображень. В одному прикладі, функція "RefPicType (pic)» повертає 0, якщо зображення pic є часовим опорним зображенням, і повертає 1, якщо зображення pic не є часовим опорним зображенням. В іншому прикладі, функція RefPicType (pic) повертає 0, якщо зображення має той же РОС, що і поточне зображення, і повертає 1, якщо зображення має РОС, відмінний від РОС поточного зображення. В іншому прикладі, результатів прикладів, описаних вище, можна досягти за допомогу заміщення використання функції RefPicType (pic) просто на перевірку того, чи дорівнює РОС "pic" (аргумент функції) РОС поточного зображення. У деяких прикладах, міжвидове опорне зображення може бути промарковане як "невикористовуване для посилання". Міжвидове опорне зображення може бути промарковане як "невикористовуване для посилання". Для спрощення, таке зображення називається неопорним зображенням у базовій специфікації HEVC. У деяких прикладах, зображення, марковане як "використовуване для довгострокового посилання" або "використовуване для короткострокового посилання", може називатися опорним зображенням у базовій специфікації HEVC. У деяких прикладах, функція RefPicType (pic) повертає 0, якщо зображення марковане як "використовуване для довгострокового посилання" або "використовуване для короткострокового посилання", і повертає 1, якщо зображення марковане як "невикористовуване для посилання". Додатково, у деяких прикладах, у розширенні HEVC, компонента виду, відразу після її декодування, може бути маркована як "невикористовувана для посилання", незалежно від значення синтаксичного елемента nal_ref_flag. Після того, як весь елемент доступу закодований, компоненти виду елемента доступу можуть бути марковані як "використовувані для короткострокового посилання" або "використовувані для довгострокового посилання", якщо nal_ref_flag справжній. Альтернативно, компонента виду може бути промаркована тільки як "використовувана для короткострокового посилання" або "використовувана для довгострокового посилання", якщо це включено в набір опорних зображень (RPS) наступного компонента виду в порядку декодування в тому ж виді, відразу після того, як витягнутий RPS для наступної компоненти виду. Додатково, у базовій специфікації HEVC, поточне зображення, відразу після його декодування, може бути марковане як "невикористовуване для посилання". У деяких прикладах, RefPicType (picX, refIdx, LX) повертає значення RefPicType (pic) у той час, коли picX є поточним зображенням, причому pic є опорним зображенням з індексом refIdx зі списку LX опорних зображень зображення picX. 11 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 Відносно приклада, що згадується вище як "четвертий приклад", відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю дозволяти прогнозування між довгостроковими опорними зображеннями без масштабування під час AMVP і TMVP. Відносно AMVP, відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати модифікований процес витягування кандидатів предиктора вектора руху (MVP). Введення в процес можуть містити в собі місцерозташування (хР, уР) яскравості, що указує верхній лівий відлік яскравості поточного елемента прогнозування відносно верхнього лівого відліку поточного зображення, змінні, що вказують ширину і висоту елемента прогнозування для яскравості, nPSW і nPSH, і опорний індекс refIdxLX (де Х дорівнює 0 або 1) розділення поточного елемента прогнозування. Виведення процесу можуть містити в собі (де N заміщений або на А, або на В, де А відповідає сусіднім кандидатам ліворуч, а В відповідає сусіднім кандидатам зверху, як зображено в прикладі на Фіг. 10) вектори mvLXN руху сусідніх елементів прогнозування і прапори availableFlagLXN доступності сусідніх елементів прогнозування. Змінна isScaledFlagLX, де Х дорівнює 0 або 1, може вважатися такою, що дорівнює 1 або 0. Відеокодер 20 і відеодекодер 30 можуть витягати вектор mvLXA руху і прапор availableFlagLXA доступності в наступному порядку етапів в одному прикладі, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. Нехай набір із двох місцерозташувань відліку буде (xA k, yAk), де k=0, 1, що вказує місцерозташування відліку, де xAk=xP-1, yAo=yP+nPSH і yA1=yA0-MinPuSize. Набір місцерозташувань відліку (xAk, yAk) являє собою місцерозташування відліку безпосередньо з лівої сторони лівої межі розділення і її продовженої лінії. 2. Нехай прапор availableFlagLXA доступності буде спочатку вважатися таким, що дорівнює 0, і обидві компоненти mvLXA вважатися такими, що дорівнюють 0. 3. Коли одна або декілька з наступних умов істинні, змінна isScaledFlagLX вважатися такою, що дорівнює 1, у даному прикладі. - елемент прогнозування, що покриває місцерозташування (xA0, yA0) яскравості доступний [Ed. (Ред.) (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA. - елемент прогнозування, що покриває місцерозташування (xA1, yA1) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA. 4. Для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), де xA1, yA1, наступне застосовується повторно доти, поки availableFlagLXA не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і опорний індекс refIdxLX[xAk][yAk] дорівнює опорному індексу refIdxLX поточного елемента прогнозування, то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListA вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xAk][yAk] (де Y=!X) дорівнює 1, і PicOrderCnt(RefPicListY[refIdxLY[xAk][yAk]]) дорівнює PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListA вважається таким, що дорівнює ListY, і mvLXA вважається таким, що дорівнює mvLXA. 5. Коли availableFlagLXA дорівнює 0, то для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), де yA1=yA0MinPuSize, наступне застосовується повторно, поки availableFlagLXA не дорівнює 1, у даному прикладі: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і RefPicListX[refIdxLX] і refPicList[refIdxLX[xAk][yAk]] обидва є довгостроковими опорними зображеннями або обидва є короткостроковими опорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xA k][yAk], а ListА вважається таким, що дорівнює ListХ. 12 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xAk][yAk]] обидва є довгостроковими опорними зображеннями або обидва є короткостроковими опорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, а вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, і обидва RefPicListА[refIdxLА] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXA витягають, як вказано нижче (де позначення 8-### стосується розділів поточної робочої версії HEVC, тобто, WD7). tx=(16384+(Abs(td)>>1))/td (8-126) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127) mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListA[refIdxA])) (8-129) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-130) Відеокодер 20 і відеодекодер 30 можуть виконані з можливістю витягати вектор mvLXB руху і прапор availableFlagLXB доступності в наступному порядку етапів в одному прикладі, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. Нехай набір із трьох місцерозташувань відліку буде (xВk, yВk), де k=0, 1, 2, що вказує місцерозташування відліку, де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, хВ2=хP-MinPuSize і yВk=yР-1. Набір місцерозташувань відліку (xВk, yВk) являє собою місцерозташування відліку безпосередньо з верхньої сторони межі розділення зверху і її продовженої лінії. [Ed. (BB): Визначити MinPuSize у SPS, але витягування повинне залежати від використання прапора AMP] 2. Коли уР-1 менше, ніж ((yC>>Log2CtbSize)3)3)&1)*7 (8-131), xB1=(xB1>>3)3)&1)*7 (8-132), xB2=(xB2>>3)3)&1)*7 (8-133). 3. Нехай прапор availableFlagLXВ доступності буде спочатку вважатися таким, що дорівнює 0, і обидві компоненти mvLXВ вважатися такими, що дорівнюють 0. 4. Для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де хВ0=xP+nPSW, xB1=xB0-MinPuSize і xB2=xPMinPuSize, то наступне застосовується повторно доти, поки availableFlagLXВ не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і опорний індекс refIdxLX[xВk][yВk] дорівнює опорному індексу refIdxLX поточного елемента прогнозування, то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВ k, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і PicOrderCnt(RefPicListY[refIdxLY[xВk][yВk]]) дорівнює PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. 5. Коли isScaledFlagLX дорівнює 0 і availableFlagLXB дорівнює 1, то mvLXA вважається таким, що дорівнює mvLXB, refIdxA вважається таким, що дорівнює refIdxB, і availableFlagLXA вважається таким, що дорівнює 1. 6. Коли isScaledFlagLX дорівнює 0, то availableFlagLXB вважається таким, що дорівнює 0 і для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, і xВ2=xPMinPuSize, наступне застосовується повторно, поки availableFlagLXВ не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і RefPicListX[refIdxLX] і RefPicListX[refIdxLX[xВk][yВk]] обидва є довгостроковими опорними зображеннями або обидва є короткостроковими опорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору 13 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВ k][yВk], а ListВ вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xВk][yВk]] обидва є довгостроковими опорними зображеннями або обидва є короткостроковими опорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, а вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. - Коли availableFlagLXВ дорівнює 1, PicOrderCnt(RefPicListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]), і RefPicListВ[refIdxLВ] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXВ витягають, як вказано нижче (де позначення 8-### стосується розділів поточної робочої версії HEVC). tx = (16384+(Abs(td)>>1))/td (8-134) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135) mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor * mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicList[refIdxB])) (8-137) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-138). Відеокодер 20 і відеодекодер 30 можуть також бути виконані з можливістю виконувати модифікований процес витягування для часового прогнозування вектора руху (TMVP) для кодування векторів руху блоків сигналу яскравості. В одному прикладі, введення в цей процес містять у собі місцерозташування (хР, уР) яскравості, що указує верхній лівий відлік яскравості поточного елемента прогнозування відносно верхнього лівого відліку поточного зображення, змінні, що вказують ширину і висоту елемента прогнозування для яскравості, nPSW і nPSH, і опорний індекс розділення refIdxLX (де Х дорівнює 0 або 1) поточного елемента прогнозування. Виведення цього процесу можуть містити в собі прогнозування mvLXCol вектора руху і прапор availableFlagLXCol доступності. В одному прикладі, відеокодер 20 і відеодекодер 30 можуть виконувати функцію RefPicOrderCnt(picX, refIdx, LX), що повертає рахунок PicOrderCntVal порядку зображення опорного зображення з індексом refIdx зі списку LX опорних зображень зображення рісХ. Ця функція може бути визначена, як вказано далі, де (8-141) і подібні посилання в цьому описі стосуються розділів HEVC WD7: RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] зображення PicX) (8-141) Залежно від значень slice_type, collocated_from_10_flag і collocated_ref_idx, змінна colPic, що визначає зображення, яке містить суміщене розділення, може бути витягнута наступним чином: - Якщо slice_type дорівнює В і collocated_from_10_flag дорівнює 0, то змінна colPic визначає зображення, що містить суміщене розділення, як визначено RefPicList1[collocated_ref_idx]. - Інакше, (slice_type дорівнює В і collocated_from_10_flag дорівнює 1 або slice_type дорівнює Р), змінна colPic визначає зображення, що містить суміщене розділення, як вказано RefPicList0 [collocated_ref_idx]. Змінна colPu і її положення (xPCol, yPCol) можуть бути витягнуті з використанням наступного порядку етапів: 1. Змінна colPu може бути витягнута наступним чином yPRb=yP+nPSH (8-139) - Якщо (yP>>Log2CtbSize) дорівнює (yPRb>>Log2CtbSize), то горизонтальний компонент правого нижнього положення яскравості поточного елемента прогнозування визначається так xPRB=xP+nPSW (8-140) і змінна colPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPRb>>4) 4) Log2CtbSize) не дорівнює (yPRB>>Log2CtbSize)), colPu маркується як "недоступна". 2. Коли colPU кодується в режимі внутрішнього прогнозування, або colPu промаркована як "недоступна", то застосовується наступне. - Центральне положення яскравості поточного елемента прогнозування визначається так xPCtr=(xP+(nPSW>>1) (8-141) yPCtr=(yP+(nPSH>>1) (8-142) 14 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 - Змінна ColPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPCtr>>4) 4) 1))/td (8-144) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145) mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol) * ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-148). У вищевказаному прикладі, приступність суміщеного блока, використовуваного під час TMVP, також може залежати від типу опорного зображення (наприклад, чи є зображення довгостроковим або короткостроковим опорним зображенням) для суміщеного блока. Тобто, навіть коли правий нижній блок для TMVP доступний (після етапу 1 у підпункті), то нижній правий блок може додатково вважатися недоступним, якщо вектор руху в блоці посилається на тип зображення (короткостроковий або довгостроковий), що відрізняється від типу цільового 15 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 опорного зображення. Подібним чином, центральний блок може додатково бути використаний для TMVP. Наприклад, відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати предиктор вектора руху для вектора руху яскравості, відповідно до наступного докладного прикладу. Введення в цей процес, здійснювані відеокодером 20 і відеодекодером 30, можуть містити в собі: - місцерозташування (xP, yP) яскравості, що визначає верхній лівий відлік яскравості поточного елемента прогнозування відносно верхнього лівого відліку поточного зображення, - змінні, які визначають ширину і висоту елемента прогнозування для яскравості, nPSW і NPSH, - опорний індекс розділення refIdxLX (де Х дорівнює 0 або 1) поточного елемента прогнозування. Виведення цього процесу можуть містити в собі: - прогнозування mvLXCol вектора руху, - прапор availableFlagLXCol доступності. Функція RefPicOrderCnt(picX, refIdx, LX), при виконанні її відеокодером 20 і/або відеодекодером 30, може повертати рахунок PicOrderCntVal порядку зображення опорного зображення зі списку LX опорних зображень зображення picX. Приклад здійснення цієї функції визначений наступним чином: RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] зображення picX) (8-141) Залежно від значень slice_type, collocated_from_10_flag і collocated_ref_idx, змінна colPic, що визначає зображення, що містить суміщене розділення, може бути витягнута наступним чином: - Якщо slice_type дорівнює В і collocated_from_10_flag дорівнює 0, то змінна colPic визначає зображення, що містить суміщене розділення, як визначено RefPicList1[collocated_ref_idx]. - Інакше, (slice_type дорівнює В і collocated_from_10_flag дорівнює 1 або slice_type дорівнює Р), змінна colPic визначає зображення, що містить суміщене розділення, як вказано RefPicList0 [collocated_ref_idx]. Відеокодер 20 і відеодекодер 30 можуть витягати змінну colPu і її положення (xPCol, yPCol) з використанням наступного порядку етапів: 1. Відеокодер 20 і відеодекодер 30 можуть витягати змінну colPu наступним чином: yPRb=yP+nPSH (8-139) - Якщо (yP>>Log2CtbSize) дорівнює (yPRb>>Log2CtbSize), то горизонтальний компонент правого нижнього положення яскравості поточного елемента прогнозування визначається так xPRB=xP+nPSW (8-140) і змінна colPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPRb>>4)4)Log2CtbSize) не дорівнює (yPRb>>Log2CtbSize)), то відеокодер 20 і відеодекодер 30 можуть маркувати colPu як "недоступна". 2. Коли colPU кодується в режимі внутрішнього прогнозування, або colPu промаркована як "недоступна", то застосовується наступне, у даному прикладі: - Центральне положення яскравості поточного елемента прогнозування визначається так xPCtr=(xP+(nPSW>>1) (8-141) yPCtr=(yP+(nPSH>>1) (8-142) - Змінна ColPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPCtr>>4)4)1) yPCtr=(yP+(nPSH>>1) 16 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 - Якщо colPu покриває положення, задане ((xPCtr>>4)4)4)4)1))/td (8-144) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145) mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146) де td і tb можуть бути витягнуті так: td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-148). В альтернативному прикладі, довгостроковий вектор руху ніколи не прогнозується з іншого довгострокового вектора руху, якщо значення РОС опорних зображень неоднакові. Відеокодер 20 і відеодекодер 30 можуть бути виконані відповідно до наступного процесу витягування кандидатів предиктора вектора руху, де підкреслений текст являє собою зміни відносно HEVC WD7. Змінна isScaledFlagLX, де Х дорівнює 0 або 1, може вважатися рівною 0. Вектор mvLXA руху і прапор availableFlagLXA доступності витягаються в наступному порядку етапів, де багатокрапки являють собою той же текст, що й у поточній робочій версії HEVC, а підкреслення являє собою зміни відносно поточної робочої версії HEVC: 1. … 17 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 2. … 3. … 4. … 5. Коли availableFlagLXA дорівнює 0, для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), де yA1=yA0MinPuSize, наступне застосовується повторно доти, поки availableFlagLXA не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і RefPicListX[refIdxLX] і RefPicListX[refIdxLX[xAk][yAk]] обидва є довгостроковими опорними зображеннями з різними значеннями РОС або обидва є короткостроковими опорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListА вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xAk][yAk]] обидва є довгостроковими опорними зображеннями з різними значеннями РОС або обидва є короткостроковими опорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, а вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xA k][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, і RеfрісLіstа[rеfіdхLА] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXA витягають, як вказано нижче. Тх=(16384+(Abs(td)>>1))/td (8-126) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127) mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListA[refIdxA])) (8-129) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-130) Відеокодер 20 і відеодекодер 30 можуть витягати вектор mvLXB руху і прапор availableFlagLXB доступності з використанням наступного порядку етапів, де багатокрапки являють собою той же текст, що й у HEVC WD7: 1. … 2. … 3. … 4. … 5. … 6… Коли isScaledFlagLX дорівнює 0, то availableFlagLXB вважається таким, що дорівнює 0 і для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, і xВ2=xPMinPuSize, наступне застосовується повторно, поки availableFlagLXВ не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і RefPicListX[refIdxLX] і RefPicListX[refIdxLX[xВk][yВk]] обидва є довгостроковими опорними зображеннями з різними значеннями РОС або обидва є короткостроковими опорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВ k, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xВk][yВk]] обидва є довгостроковими опорними зображеннями з різними значеннями РОС або обидва є короткостроковими опорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, а вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВ k][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. 18 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 - Коли аvаіlаblеFlаgLХВ дорівнює 1, PicOrderCnt(RefPicListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListХ[refIdxLX]), і RefPicListВ[refIdxLВ] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXВ витягають, як вказано нижче. tx=(16384+(Abs(td)>>1))/td (8-134) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135) mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136) де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicList[refIdxB])) (8-137) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-138) Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати часові предиктори вектора руху яскравості, відповідно до наступного процесу, де підкреслений текст являє собою зміни відносно HEVC WD7. Змінні mvLXCol і availableFlagLXCol можуть бути витягнуті наступним чином: - Якщо одна або кілька наступних умов істинні, ті обидві компоненти mvLXCol вважаються такими, що дорівнюють 0, і availableFlagLXCol вважається таким, що дорівнює 0. - colPU кодується в режимі внутрішнього прогнозування. - colPu промаркована як "недоступна". - pic_temporal_mvp_enable_flag дорівнює 0. - Інакше, вектор mvCol руху, опорний індекс refIdxCol і ідентифікатор listCol опорного списку витягаються наступним чином. - Якщо PredFlagL0[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] і L1, відповідно. - Інакше, (PredFlagL0[xPCol][yPCol] дорівнює 1), застосовується наступне. - Якщо PredFlagL1[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] і L0, відповідно. - Інакше, (PredFlagL1[xPCol][yPCol] дорівнює 1), виконуються наступні призначення. - Якщо PicOrderCnt(pic) кожного зображення pic у кожному списку опорних зображень менше або дорівнює PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] і LХ, відповідно, де Х є значенням X, для якого викликаний цей процес. - Інакше, (PicOrderCnt(pic) щонайменше одного зображення pic у щонайменше одному списку опорних зображень, більше, ніж PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] і LN, відповідно, де N є значенням collocated_from_10_flag. - Якщо одна з наступних умов істинна, то змінна availableFlagLXCol вважається такою, що дорівнює 0: - RefPicListX[refIdxLX] є довгостроковим опорним зображенням, і LongTermRefPic(colPic, refIdxCol, listCol) дорівнює 0; - RefPicListX[refIdxLX] є короткостроковим опорним зображенням, і LongTermRefPic(colPic, refIdxCol, listCol) дорівнює 1; - RefPicListX[refIdxLX] є довгостроковим опорним зображенням, і LongTermRefPic(colPic, refIdxCol, listCol) дорівнює 1, і RefPicOrderCnt(colPic, refIdxCol, listCol) не дорівнює PicOrderCnt(RefPicListX[refIdxL]_. - Інакше, змінна availableFlagLXCol вважається такою, що дорівнює 1, і застосовується наступне. Якщо RefPicListX[refIdxLX] є довгостроковим опорним зображенням, або LongTermRefPic(colPic, refIdxCol, listCol) дорівнює 1, або PicOrderCnt(colPic) RefPicOrderCnt(colPic, refIdxCol, listCol) дорівнює PicOrderCntValPicOrderCnt(RefPicListX[refIdxLX]), то mvLXCol=mvCol (8-143) - Інакше, mvLXCol витягається як масштабована версія вектора mvCol руху, як визначено нижче tx=(16384+(Abs(td)>>1))/td (8-144) - DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145) mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-148). 19 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 В іншому прикладі, міжвидове опорне зображення може бути марковане як "невикористовуване для посилання". Для простоти, таке зображення можна називати неопорне зображення в базовій специфікації HEVC, і зображення, марковане як "використовуване для довгострокового посилання" або "використовуване для короткострокового посилання" можна називати опорним зображенням у базовій специфікації HEVC. Терміни "опорне зображення" і "неопорне зображення" можна замінити на "зображення, марковане як "використовуване для посилання" і "зображення, марковане як "невикористовуване для посилання". Функцію UnusedRefPic(picX, refIdx, LX) можна визначити наступним чином. Якщо опорне зображення з індексом refIdx зі списку LX опорних зображень зображення picX було марковане як "невикористовуване для посилання" у момент, коли picX було поточним зображенням, то UnusedRefPic(picX, refIdx, LX) повертає 1; інакше, UnusedRefPic(picX, refIdx, LX) повертає 0. Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати процес витягування кандидатів предиктора вектора руху наступним чином, де підкреслений текст являє собою зміни відносно HEVC WD7, а багатокрапки являють собою той же текст, що й у HEVC WD7: Змінна isScaledFlagLX, де Х дорівнює 0 або 1, може вважатися такою, що дорівнює 1 або 0. Вектор mvLXA руху і прапор availableFlagLXA доступності можуть бути витягнуті в наступному порядку етапів: 1. … 2. … 3. … 4. … 5. Коли availableFlagLXA дорівнює 0, то для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), де yA1=yA0MinPuSize, наступне застосовується повторно, поки availableFlagLXA не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і RefPicListX[refIdxLX] і RefPicListX[refIdxLX[xAk][yAk]] обидва є опорними зображеннями або обидва є неопорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xA k][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListА вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xAk][yAk]] обидва є опорними зображеннями або обидва є неопорними зображеннями, то availableFlagLXA вважається таким, що дорівнює 1, а вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, і RefPicListА[refIdxLА] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXA витягають, як вказано нижче. Tx=(16384+(Abs(td)>>1))/td (8-126) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127) mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListA[refIdxA])) (8-129) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-130). Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати вектор mvLXB руху і прапор availableFlagLXB доступності з використанням наступного порядку етапів, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. … 2. … 3. … 4. … 5. … 6… Коли isScaledFlagLX дорівнює 0, то availableFlagLXB вважається таким, що дорівнює 0 і для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, і xВ2=xPMinPuSize, наступне застосовується повторно, поки availableFlagLXВ не дорівнює 1: 20 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і RefPicListX[refIdxLX] і RefPicListX[refIdxLX[xВk][yВk]] обидва є опорними зображеннями або обидва є неопорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВ k][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і RefPicListX[refIdxLX] і RefPicListY[refIdxLY[xВk][yВk]] обидва є опорними зображеннями або обидва є неопорними зображеннями, то availableFlagLXВ вважається таким, що дорівнює 1, а вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. - Коли availableFlagLXВ дорівнює 1, PicOrderCnt(RefPicListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]), і RefPicListВ[refIdxLВ] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXВ витягають, як вказано нижче. tx=(16384+(Abs(td)>>1))/td (8-134) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135) mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicList[refIdxB])) (8-137) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-138) Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати часові предиктори вектора руху яскравості наступним чином, де підкреслений текст являє собою зміни відносно HEVC WD7: Змінні mvLXCol і availableFlagLXCol можуть бути витягнуті наступним чином. - Якщо одна або кілька наступних умов істинні, ті обидві компоненти mvLXCol вважаються такими, що дорівнюють 0, і availableFlagLXCol вважається таким, що дорівнює 0. - colPU кодується в режимі внутрішнього прогнозування. - colPu промаркована як "недоступна". - pic_temporal_mvp_enable_flag дорівнює 0. - Інакше, вектор mvCol руху, опорний індекс refIdxCol і ідентифікатор listCol опорного списку витягаються наступним чином. - Якщо PredFlagL0[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] і L1, відповідно. - Інакше, (PredFlagL0[xPCol][yPCol] дорівнює 1), застосовується наступне. - Якщо PredFlagL1[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] і L0, відповідно. - Інакше, (PredFlagL1[xPCol][yPCol] дорівнює 1), виконуються наступні призначення. - Якщо PicOrderCnt(pic) кожного зображення pic у кожному списку опорних зображень менше або дорівнює PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] і LХ, відповідно, де Х є значенням X, для якого викликаний цей процес. - Інакше, (PicOrderCnt(pic) щонайменше одного зображення pic у щонайменше одному списку опорних зображень, більше, ніж PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] і LN, відповідно, де N є значенням collocated_from_10_flag. - Якщо одна з наступних умов істинна, то змінна availableFlagLXCol вважається такою, що дорівнює 0: - RefPicListX[refIdxLX] є неопорним зображенням, і UnusedRefPic(colPic, refIdxCol, listCol) дорівнює 0; - RefPicListX[refIdxLX] є опорним зображенням, і UnusedRefPic(colPic, refIdxCol, listCol) дорівнює 1; - Інакше, змінна availableFlagLXCol вважається такою, що дорівнює 1, і застосовується наступне. Якщо RefPicListX[refIdxLX] є довгостроковим опорним зображенням, або LongTermRefPic(colPic, refIdxCol, listCol) дорівнює 1, або PicOrderCnt(colPic) 21 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 RefPicOrderCnt(colPic, refIdxCol, listCol) дорівнює PicOrderCntValPicOrderCnt(RefPicListX[refIdxLX]), то mvLXCol=mvCol (8-143) - Інакше, mvLXCol витягається як масштабована версія вектора mvCol руху, як визначено нижче tx=(16384+(Abs(td)>>1))/td (8-144) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145) mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCnt(colPic) - RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-148). Відносно приклада, який називається вище "п'ятим прикладом", відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати будь-який або усі з наступних способів. У даному прикладі, прогнозування між векторами руху, що посилаються на різні довгострокові опорні зображення, може бути заборонене, прогнозування між векторами руху, що посилаються на різні міжвидові опорні зображення, може бути заборонене, і прогнозування між векторами руху, що посилаються на міжвидове опорне зображення і довгострокове опорне зображення, може бути заборонене. У даному прикладі, функція AddPicId(pic) повертає індекс порядку виду або ID рівня виду, або рівень, якому належить зображення pic. Таким чином, для будь-якого зображення "pic", що належить базовому виду або рівню, AddPicId(pic) повертає 0. У базовій специфікації HEVC, може застосовуватися наступне: функція AddPicId(pic) може бути визначена наступним чином: AddPicId(pic) повертає 0 (або reserved_one_5bits мінус 1). У даному прикладі, коли AddPicId(pic) не дорівнює 0, то зображення pic не є часовим опорним зображенням (тобто, ні короткостроковим опорним зображенням, ні довгостроковим опорним зображенням). AddPicId(picX, refIdx, LX) може повертати AddPicId(pic), причому pic є опорним зображенням з індексом refIdx зі списку LX опорних зображень зображення picX. Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати процес витягування кандидатів предиктора вектора руху. Введення в процес можуть містити в собі місцерозташування (хР, уР) яскравості, що указує верхній лівий відлік яскравості поточного елемента прогнозування відносно верхнього лівого відліку поточного зображення, змінні, що вказують ширину і висоту елемента прогнозування для яскравості, nPSW і nPSH, і опорний індекс refIdxLX (де Х дорівнює 0 або 1) розділення поточного елемента прогнозування. Виведення цього процесу можуть містити в собі (де N заміщений або на А, або на В): вектори mvLXN руху сусідніх елементів прогнозування і прапори availableFlagLXN доступності сусідніх елементів прогнозування. Змінна isScaledFlagLX, де Х дорівнює 0 або 1, може вважатися такою, що дорівнює 1 або 0. Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати вектор mvLXA руху і прапор availableFlagLXA доступності з використанням наступного порядку етапів, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. Нехай набір із двох місцерозташувань відліку буде (xAk, yAk), де k=0, 1, що вказує місцерозташування відліку, де xAk=xP-1, yAo=yP+nPSH і yA1=yA0-MinPuSize. Набір місцерозташувань відліку (xAk, yAk) являє собою місцерозташування відліку безпосередньо з лівої сторони лівої межі розділення і її продовженої лінії. 2. Нехай прапор availableFlagLXA доступності буде спочатку вважатися таким, що дорівнює 0, і обидві компоненти mvLXA вважатися такими, що дорівнюють 0. 3. Коли одна або декілька з наступних умов істинні, змінна isScaledFlagLX вважається такою, що дорівнює 1: - елемент прогнозування, що покриває місцерозташування (xA0, yA0) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, - елемент прогнозування, що покриває місцерозташування (xA1, yA1) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA. 4. Для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), де yA1=yA0-MinPuSize, якщо availableFlagLXA дорівнює 0, то застосовується наступне: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і 22 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 опорний індекс refIdxLX[xAk][yAk] дорівнює опорному індексу refIdxLX поточного елемента прогнозування, то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListА вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, AddPicId(RefPicListX[refIdxLX]) дорівнює AddPicId(RefPicListY[refIdxLY[xAk][yAk]]), і PicOrderCnt(RefPicListY[refIdxLY[xAk][yAk]]) дорівнює PicOrderCnt(RefPicListХ[refIdxLХ]), то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY, і mvLXA вважається таким, що дорівнює mvLXA. - Коли availableFlagLXA дорівнює 1, то availableFlagLXA вважається таким, що дорівнює 0, якщо одна або декілька з наступних умов істинна: - Одне і тільки одне з RefPicListX[refIdxLX] і ListA[refIdxA] є довгостроковим опорним зображенням; - Обидва RefPicListX[refIdxLX] і ListA[refIdxA] є довгостроковими опорними зображеннями, і PicOrderCnt(ListA[refIdxA]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]). 5. Коли availableFlagLXA дорівнює 0, то для (xAk, yAk) від (xA0, yA0) до (xA1, yA1), где yA1=yA0MinPuSize, якщо availableFlagLXA дорівнює 0, застосовується наступне: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і AddPicId(RefPicListLX[refIdxLX]) дорівнює AddPicId(RefPicListLX[refIdxLX[xAk][yAk]]), то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListА вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, і AddPicId(RefPicListLX[refIdxLX]) дорівнює AddPicId(RefPicListLY[refIdxLY[xAk][yAk]]), то availableFlagLXA вважається таким, що дорівнює 1, а вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xA k][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, то availableFlagLXA вважається таким, що дорівнює 0, якщо одна або декілька з наступних умов істинна: - Одне і тільки одне з RefPicListX[refIdxLX] і ListA[refIdxA] є довгостроковим опорним зображенням; - Обидва RefPicListX[refIdxLX] і ListA[refIdxA] є довгостроковими опорними зображеннями, і PicOrderCnt(ListA[refIdxA]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]). - Коли availableFlagLXA дорівнює 1, і обидва RefPicListА[refIdxLА] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXA витягають, як вказано нижче. tx=(16384+(Abs(td)>>1))/td (8-126) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127) mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListA[refIdxA])) (8-129) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-130). Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати вектор mvLXB руху і прапор availableFlagLXB доступності з використанням наступного порядку етапів, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. Нехай набір із трьох місцерозташувань відліку буде (xВk, yВk), де k=0, 1, 2, що вказує місцерозташування відліку, де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, хВ2=хP-MinPuSize і yВk=yР-1. Набір місцерозташувань відліку (xВk, yВk) являє собою місцерозташування відліку безпосередньо з верхньої сторони межі розділення зверху і її продовженої лінії. [Ed. (BB): Визначити MinPuSize у SPS, але витягування повинне залежати від використання прапора AMP] 2. Коли уР-1 менше, ніж ((yC>>Log2CtbSize)3)3)1)*7 (8-131) 23 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 xB1=(xB1>>3)3)1)*7 (8-132) xB2=(xB2>>3)3)1)*7 (8-133) 3. Нехай прапор availableFlagLXВ доступності буде спочатку вважатися таким, що дорівнює 0, і обидві компоненти mvLXВ вважатися такими, що дорівнюють 0. 4. Для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де хВ0=xP+nPSW, xB1=xB0-MinPuSize и xB2=xPMinPuSize, якщо availableFlagLXВ дорівнює 0, то застосовується наступне: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і опорний індекс refIdxLX[xВk][yВk] дорівнює опорному індексу refIdxLX поточного елемента прогнозування, то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВ k, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, AddPicId(RefPicListX[refIdxLX]) дорівнює AddPicId(RefPicListLY[refIdx[xВk][yВk]]), і PicOrderCnt(RefPicListY[refIdxLY[xВk][yВk]]) дорівнює PicOrderCnt(RefPicListX[refIdxLX]), то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, то availableFlagLXA вважається таким, що дорівнює 0, якщо одна або декілька з наступних умов істинна: - Одне і тільки одне з RefPicListX[refIdxLX] і ListB[refIdxB] є довгостроковим опорним зображенням. - AddPicId(RefPicListX[refIdxLX]) не дорівнює AddPicId(ListB[refIdxB]). - Обидва RefPicListX[redIdxLX] і ListB[refIdxB] є довгостроковими опорними зображеннями, і PicOrderCnt(ListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]). 5. Коли isScaledFlagLX дорівнює 0 і availableFalgLXB дорівнює 1, то mvLXA вважається таким, що дорівнює mvLXB, refIdxA вважається таким, що дорівнює refIdxB, і availableFlagLXA вважається таким, що дорівнює 1. 6. Коли isScaledFlagLX дорівнює 0, то availableFlagLXB вважається таким, що дорівнює 0 і для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, і xВ2=xPMinPuSize, якщо availableFlagLXВ дорівнює 0, то застосовується наступне: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і AddPicId(RefPicListX[refIdxLX]) дорівнює AddPicId(RefPicListX[refIdxLX[xВk][yВk]]), то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і AddPicId(RefPicListX[refIdxLX]) дорівнює AddPicId(RefPicListY[refIdxLY[xВk][yВk]]), то availableFlagLXВ вважається таким, що дорівнює 1, а вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВ k][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, то availableFlagLXA вважається таким, що дорівнює 0, якщо одна або декілька з наступних умов істинна: - Одне і тільки одне з RefPicListX[refIdxLX] і ListB[refIdxB] є довгостроковим опорним зображенням. - Обидва RefPicListX[refIdxLX] і ListB[refIdxB] є довгостроковими опорними зображеннями, і PicOrderCnt(ListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]). - Коли availableFlagLXВ дорівнює 1, PicOrderCnt(RefPicListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]), і RefPicListВ[refIdxLВ] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXВ витягають, як вказано нижче. tx=(16384+(Abs(td)>>1))/td (8-134) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135) 24 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicList[refIdxB])) (8-137) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-138). Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю витягати часові предиктори вектора руху. Введення в цей процес можуть містити в собі місцерозташування (хР, уР) яскравості, що указує верхній лівий відлік яскравості поточного елемента прогнозування відносно верхнього лівого відліку поточного зображення, змінні, що вказують ширину і висоту елемента прогнозування для яскравості, nPSW і nPSH, і опорний індекс розділення refIdxLX (де Х дорівнює 0 або 1) поточного елемента прогнозування. Виведення цього процесу можуть містити в собі прогнозування mvLXCol вектора руху і прапор availableFlagLXCol доступності. Функція RefPicOrderCnt(picX, refIdx, LX), що може повертати рахунок PicOrderCntVal порядку зображення опорного зображення з індексом refIdx зі списку LX опорних зображень зображення рісХ, може бути визначена наступним чином: RefPicOrderCnt(picX, refIdx, LX)= PicOrderCnt(RefPicListX[refIdx] зображення PicX) (8-141) Залежно від значень slice_type, collocated_from_10_flag і collocated_ref_idx, відеокодер 20 і відеодекодер 30 можуть витягати змінну colPic, що визначає зображення, яке містить суміщене розділення, наступним чином: - Якщо slice_type дорівнює В і collocated_from_10_flag дорівнює 0, то змінна colPic визначає зображення, що містить суміщене розділення, як визначено RefPicList1[collocated_ref_idx]. - Інакше, (slice_type дорівнює В і collocated_from_10_flag дорівнює 1 або slice_type дорівнює Р), змінна colPic визначає зображення, що містить суміщене розділення, як вказано RefPicList0 [collocated_ref_idx]. Відеокодер 20 і відеодекодер 30 можуть витягати змінну colPu і її положення (xPCol, yPCol) з використанням наступного порядку етапів, де підкреслений текст являє собою зміни відносно HEVC WD7: 1. Змінна colPu може бути витягнута наступним чином yPRb=yP+nPSH (8-139) - Якщо (yP>>Log2CtbSize) дорівнює (yPRb>>Log2CtbSize), то горизонтальний компонент правого нижнього положення яскравості поточного елемента прогнозування визначається так xPRB=xP+nPSW (8-140) і змінна colPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPRb>>4)4)Log2CtbSize) не дорівнює (yPRB>>Log2CtbSize)), colPu маркується як "недоступна". 2. Коли colPU кодується в режимі внутрішнього прогнозування, або colPu промаркована як "недоступна", то застосовується наступне. - Центральне положення яскравості поточного елемента прогнозування визначається так xPCtr=(xP+(nPSW>>1) (8-141) yPCtr=(yP+(nPSH>>1) (8-142) - Змінна ColPu вважається такою, що дорівнює елементу прогнозування, що покриває модифіковане положення, задане ((xPCtr>>4)4)>1))/td (8-144) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-145) mvLXCol=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvCol)* ((Abs(DistScaleFactor* mvCol)+127)>>8)) (8-146), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCnt(colPic)- RefPicOrderCnt(colPic, refIdxCol, listCol)) (8-147) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-148) Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати наступний процес витягування комбінованих бі-прогнозуючих кандидатів злиття. Введення в цей процес можуть містити в собі список mergeCandList кандидатів злиття, опорні індекси refIdxL0N і refIdxL1N кожного кандидата N, що знаходиться в mergeCandList, прапори predFlagL0N і predFlagL1N використання списку прогнозування кожного кандидата N, що знаходиться в mergeCandList, вектори mvL0N і mvL1N руху кожного кандидата N, що знаходиться в mergeCandList, число елементів numMergeCand усередині mergeCandList, і число елементів numOrigMergeCand усередині mergeCandList після процесу витягування просторових і часових кандидатів злиття. Виведення цього процесу можуть містити в собі список mergeCandList кандидатів злиття, число елементів numMergeCand усередині mergeCandList, індекси refIdxL0combCandk і refIdxL1combCandk кожного нового кандидата combCandk, доданого в mergeCandList під час виклику цього процесу, прапори predFlagL0combCandk і predFalgL1combCandk використання списку прогнозування кожного нового кандидата combCandk, що додається в mergeCandList під час виклику цього процесу, і вектори mvL0combCandk і mvL1combCandk руху кожного нового кандидата combCandk, що додається в mergeCandList під час виклику цього процесу. Коли numOrigMergeCand більше, ніж 1, і менше, ніж MaxNumMergeCand, то змінна numInputMergeCand може вважатися такою, що дорівнює numMergeCand, змінні combIdx і combCnt можуть вважатися такими, що дорівнюють 0, змінна combStop може вважатися такою, що дорівнює FALSE (НЕПРАВДА), і наступні етапи можуть повторюватися доти, поки combStop 26 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 не дорівнює TRUE (ПРАВДА) (де багатокрапки являють собою ті ж етапи, що й у HEVC WD7, а підкреслений текст являє собою зміни відносно HEVC WD7): 1. Змінні 10CandIdx і 11CandIdx витягають з використанням combIdx, як вказано в Таблиці 88. 2. Наступні призначення виконуються, коли 10Cand є кандидатом у положенні 10CandIdx, а 11Cand є кандидатом у положенні 11CandIdx у списку mergeCandList кандидатів злиття (10Cand=mergeCandList[10CandIdx], 11Cand=mergeCandList[11CandIdx]). 3. Коли усі з наступних умов істинні, - predFlagL010Cand = = 1 - predFlagL111Cand = = 1 AddPicId(RefPicListL0[refIdxL010Cand])!= AddPicId(RefPicListL1[refIdxL111Cand]) || PicOrderCnt(RefPicList0[refIdxL010Cand])!= PicOrderCnt(RefPicList) [refIdxL111Cand]) || mvL010Cand!= mvL111Cand, то застосовується наступне. -… 4. … 5. … Як альтернатива, прогнозування між двома довгостроковими опорними зображеннями може бути дозволене без масштабування, і прогнозування між двома міжвидовими опорними зображеннями може бути дозволене без масштабування. Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати процес витягування кандидатів предиктора вектора руху наступним чином, де підкреслений текст являє собою зміни відносно HEVC WD7, а багатокрапки являють собою той же текст, що й у HEVC WD7: Змінна isScaledFlagLX, де Х дорівнює 0 або 1, може вважатися такою, що дорівнює 0. Вектор mvLXA руху і прапор availableFlagLXA доступності можуть бути витягнуті в наступному порядку етапів: 1. … 2. … 3. … 4. … 5. Коли availableFlagLXA дорівнює 0, то для (xAk, yAk) від xA0, yA0) до (xA1, yA1), де yA1=yA0MinPuSize, наступне застосовується повторно, поки availableFlagLXA не дорівнює 1, у даному прикладі: - Якщо елемент прогнозування, що покриває місцерозташування (xAk, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xA k][yAk] дорівнює 1, і RefPicType(RefPicListX[refIdxLX]) дорівнює RefPicType(RefPicListX[refIdxLX[xAk][yAk]]), то availableFlagLXA вважається таким, що дорівнює 1, вектор mvLXA руху вважається таким, що дорівнює вектору mvLX[xAk][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLX[xAk][yAk], а ListА вважається таким, що дорівнює ListХ. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xA k, yAk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xAk][yAk] (де Y=!X) дорівнює 1, і RefPicType(RefPicListX[refIdxLX]) дорівнює RefPicType(RefPicListY[refIdxLY[xAk][yAk]]), то availableFlagLXA вважається таким, що дорівнює 1, а вектор mvLXA руху вважається таким, що дорівнює вектору mvLY[xA k][yAk] руху, refIdxA вважається таким, що дорівнює refIdxLY[xAk][yAk], а ListА вважається таким, що дорівнює ListY. - Коли availableFlagLXA дорівнює 1, і RefPicListА[refIdxLА] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXA витягають, як вказано нижче. Тх=(16384+(Abs(td)>>1))/td (8-126) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-127) mvLXA=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-128), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListA[refIdxA])) (8-129) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-130). Відеокодер 20 і відеодекодер 30 можуть витягати вектор mvLXB руху і прапор availableFlagLXB доступності з використанням наступного порядку етапів, де підкреслений текст являє собою зміни відносно HEVC WD7, а багатокрапки являють собою той же текст, що в HEVC WD7: 27 UA 114103 C2 5 10 15 20 25 30 35 40 45 50 55 60 1. … 2. … 3. … 4. … 5. … 6… Коли isScaledFlagLX дорівнює 0, то availableFlagLXB вважається таким, що дорівнює 0 і для (xВk, yВk) від (xВ0, yВ0) до (xВ2, yВ2), де xВ0=xP+nPSW, xВ1=xВ0-MinPuSize, і xВ2=xPMinPuSize, то наступне застосовується повторно, поки availableFlagLXВ не дорівнює 1: - Якщо елемент прогнозування, що покриває місцерозташування (xВk, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLX[xВ k][yВk] дорівнює 1, і RefPicType(RefPicListX[refIdxLX]) дорівнює RefPicType(RefPicListX[refIdxLX[xВk][yВk]]), то availableFlagLXВ вважається таким, що дорівнює 1, вектор mvLXВ руху вважається таким, що дорівнює вектору mvLX[xВk][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLX[xВk][yВk], а ListВ вважається таким, що дорівнює ListX. - Інакше, якщо елемент прогнозування, що покриває місцерозташування (xВ k, yВk) яскравості доступний [Ed. (BB): Переписати з використанням MinCbAddrZS[][] і процесу доступності для мінімальних блоків кодування], і PredMode не MODE_INTRA, predFlagLY[xВk][yВk] (де Y=!X) дорівнює 1, і RefPicType(RefPicListX[refIdxLX]) дорівнює RefPicType(RefPicListY[refIdxLY[xВk][yВk]]), то availableFlagLXВ вважається таким, що дорівнює 1, а вектор mvLXВ руху вважається таким, що дорівнює вектору mvLY[xВ k][yВk] руху, refIdxВ вважається таким, що дорівнює refIdxLY[xВk][yВk], а ListВ вважається таким, що дорівнює ListY. - Коли availableFlagLXВ дорівнює 1, PicOrderCnt(RefPicListB[refIdxB]) не дорівнює PicOrderCnt(RefPicListX[refIdxLX]), і обидва RefPicListВ[refIdxLВ] і RefPicListX[refIdxLX] обидва є короткостроковими опорними зображеннями, то mvLXВ витягають, як вказано нижче. tx=(16384+(Abs(td)>>1))/td (8-134) DistScaleFactor=Clip3(-4096, 4095, (tb* tx+32)>>6) (8-135) mvLXB=Clip3(-8192, 8191.75, Sign(DistScaleFactor* mvLXA)* ((Abs(DistScaleFactor* mvLXA)+127)>>8)) (8-136), де td і tb можуть бути витягнуті так td=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicList[refIdxB])) (8-137) tb=Clip3(-128, 127, PicOrderCntVal-PicOrderCnt(RefPicListX[refIdxLX])) (8-138). Відеокодер 20 і відеодекодер 30 можуть бути виконані з можливістю виконувати процес витягування часового прогнозування вектора руху яскравості наступним чином. Змінні mvLXCol і availableFlagLXCol можуть бути витягнуті наступним чином. - Якщо одна або кілька наступних умов істинні, то обидві компоненти mvLXCol вважаються такими, що дорівнюють 0, і availableFlagLXCol вважається таким, що дорівнює 0. - colPU кодується в режимі внутрішнього прогнозування. - colPu промаркована як "недоступна". - pic_temporal_mvp_enable_flag дорівнює 0. - Інакше, вектор mvCol руху, опорний індекс refIdxCol і ідентифікатор listCol опорного списку витягаються наступним чином. - Якщо PredFlagL0[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL1[xPCol][yPCol], RefIdxL1[xPCol][yPCol] і L1, відповідно. - Інакше, (PredFlagL0[xPCol][yPCol] дорівнює 1), застосовується наступне. - Якщо PredFlagL1[xPCol][yPCol] дорівнює 0, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvL0[xPCol][yPCol], RefIdxL0[xPCol][yPCol] і L0, відповідно. - Інакше, (PredFlagL1[xPCol][yPCol] дорівнює 1), виконуються наступні призначення. - Якщо PicOrderCnt(pic) кожного зображення pic у кожному списку опорних зображень менше або дорівнює PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLХ[xPCol][yPCol], RefIdxLХ[xPCol][yPCol] і LХ, відповідно, де Х є значенням X, для якого викликаний цей процес. - Інакше, (PicOrderCnt(pic) щонайменше одного зображення pic у щонайменше одному списку опорних зображень, більше, ніж PicOrderCntVal, то mvCol, refIdxCol і listCol вважаються такими, що дорівнюють MvLN[xPCol][yPCol], RefIdxLN[xPCol][yPCol] і LN, відповідно, де N є значенням collocated_from_10_flag. - Якщо RefPicType(RefPicListX[refIdxLX]) не дорівнює RefPicType(colPic, refIdxCol, listCol), то змінна availableFlagLXCol вважається такою, що дорівнює 0. - Інакше, змінна availableFlagLXCol вважається такою, що дорівнює 1, і застосовується наступне. 28
ДивитисяДодаткова інформація
Назва патенту англійськоюHigh-level syntax extensions for high efficiency video coding
Автори англійськоюChen, Ying, Wang, Ye-Kui, Zhang, Li
Автори російськоюЧэнь Ин, Ван Е-Куй, Чжан Ли
МПК / Мітки
МПК: H04N 7/00
Мітки: високого, рівня, високоефективного, синтаксичні, відеокодування, розширення
Код посилання
<a href="https://ua.patents.su/62-114103-sintaksichni-rozshirennya-visokogo-rivnya-dlya-visokoefektivnogo-videokoduvannya.html" target="_blank" rel="follow" title="База патентів України">Синтаксичні розширення високого рівня для високоефективного відеокодування</a>
Спосіб підвищення рівня рекомбінаційної і розширення спектру генотипової мінливостей

Номер патенту: 46947
Опубліковано: 17.06.2002
Автори: Жучєнко Алєксандр Алєксандровіч (мол.), Монтвід Павло Юрійович, Юрченко Олексій Петрович, Жівко П. Данаїлов, Самовол Олексій Петрович
МПК: A01H 1/04
Мітки: спектру, спосіб, рівня, розширення, підвищення, генотипової, мінливостей, рекомбінаційної
Формула / Реферат:
1. Спосіб підвищення рівня рекомбінаційної і розширення спектра генотипічної мінливостей у пасльонових рослин, що включає схрещування материнської лінії з батьківськими формами, вирощування F1 в умовах недостатнього мінерального живлення, високого загущення, який відрізняється тим, що гібриди F1 вирощують у вісім коротких (70-100 годин) і три тривалих (1 місяць) часових періоди в режимах водозабезпечення 80 % НВ до появи перших справжніх...
Спосіб виконання розширення основи ґрунтоцементної палі нижче рівня підземних вод

Номер патенту: 99997
Опубліковано: 25.06.2015
Автори: Менейлюк Олександр Іванович, Підойма Анастасія Сергіївна, Галушко Олександр Маркович, Болюк Сергій Васильович, Колодяжна Інна Валентинівна, Галушко Валентина Олександрівна, Донченко Мар'яна Миколаївна
МПК: E02D 5/00
Мітки: виконання, спосіб, ґрунтоцементної, вод, основі, рівня, розширення, підземних, палі
Формула / Реферат:
1. Спосіб виконання розширення основи ґрунтоцементної палі нижче рівня підземних вод, що забезпечує створення свердловини в масиві ґрунтів шляхом свердління (продавлювання), введення пластично-текучої суміші з одночасним перемішуванням та ущільненням, який відрізняється тим, що як обсадна труба використовується оболонка із ґрунтоцементу пробита порожниноутворюючим робочим органом в стовбурі палі.2. Спосіб виконання розширення основи...
Спосіб підвищення рівня рекомбінаційної і розширення спектра генотипічної мінливостей у пасльонових рослин

Номер патенту: 46947
Опубліковано: 15.08.2005
Автори: Юрченко Олексій Петрович, Жівко П. Данаїлов, Самовол Олексій Петрович, Жучєнко Алєксандр Алєксандровіч (мол.), Монтвід Павло Юрійович
МПК: A01H 1/04
Мітки: генотипічної, мінливостей, рівня, рослин, спектра, пасльонових, рекомбінаційної, спосіб, підвищення, розширення
Формула / Реферат:
1. Спосіб підвищення рівня рекомбінаційної і розширення спектра генотипічної мінливостей у пасльонових рослин, що включає схрещування материнської лінії з батьківськими формами, вирощування F1 в умовах недостатнього мінерального живлення, високого загущення, який відрізняється тим, що гібриди F1 вирощують у вісім коротких (70-100 годин) і три тривалих (1 місяць) часових періоди в режимах водозабезпечення 80 % НВ до появи перших справжніх...
Спосіб визначення високого рівня підготовленості бігунів стайєрів

Номер патенту: 41526
Опубліковано: 17.09.2001
Автор: Юшковська Ольга Геннадіївна
МПК: G01N 33/49, A61B 5/145
Мітки: стайєрів, рівня, спосіб, визначення, підготовленості, високого, бігунів
Формула / Реферат:
Спосіб визначення високого рівня підготовленості бігунів-стаєрів шляхом гематологічних досліджень, який відрізняється тим, що їх проводять з початку змагального періоду на піку спортивної форми спортсменів з урахуванням їх кваліфікації і при зміні процентного співвідношення показників лейкоцитарної форми судять про високий рівень підготовленості, а саме: у спортсменів високої кваліфікації при значеннях моноцитів 3,6±0,14% (250±29), лімфоцитів...
Побудова списку опорних зображень для відеокодування

Номер патенту: 108452
Опубліковано: 27.04.2015
МПК: H04N 7/00
Мітки: зображень, побудова, відеокодування, опорних, списку
Формула / Реферат:
1. Спосіб кодування відеоданих, який містить:кодування інформації, що вказує опорні зображення, які належать набору опорних зображень, при цьому набір опорних зображень ідентифікує опорні зображення, що потенційно можуть бути використані для зовнішнього прогнозування поточного зображення і потенційно можуть бути використані для зовнішнього прогнозування одного або більше зображень, які йдуть після поточного зображення в черговості...
Попередній патент: Спосіб отримання мезофазного пеку шляхом гідрогенізації високотемпературної кам’яноговугільної смоли
Наступний патент: Отримання контексту для кодування останньої позиції при виконанні відеокодування
Випадковий патент: Процес вилучення механічних і рідинних домішок з газового середовища