Набір параметрів відео для hevc і розширень







Формула / Реферат
1. Спосіб обробки відеоданих, причому спосіб включає:
обробку одного або більше початкових елементів синтаксису в синтаксичній структурі набору параметрів відео (VPS), асоційованій з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка може бути застосовна до нуля або більше цілих кодованих відеопослідовностей;
прийом, в синтаксичній структурі VPS, елемента синтаксису зсуву для синтаксичної структури VPS, при цьому значення елемента синтаксису зсуву рівне кількості байтів у синтаксичній структурі VPS, для яких обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
на основі елемента синтаксису зсуву пропускання обробки щонайменше одного елемента синтаксису в синтаксичній структурі VPS;
обробку одного або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису в синтаксичній структурі VPS.
2. Спосіб за п. 1, у якому зазначений щонайменше один елемент синтаксису містить один або більше елементів синтаксису, кодованих, використовуючи кодування зі змінною довжиною слова.
3. Спосіб за п. 1, у якому один або більше додаткових елементів синтаксису містять додаткові елементи синтаксису фіксованої довжини, і в якому один або більше додаткових елементів синтаксису ідуть за елементом синтаксису зсуву і ідуть за зазначеним щонайменше одним елементом синтаксису.
4. Спосіб за п. 1, у якому один або більше початкових елементів синтаксису містять елементи синтаксису, що включають в себе інформацію, яка стосується узгодження сеансу.
5. Спосіб за п. 1, у якому один або більше початкових елементів синтаксису містять елементи синтаксису для базового рівня відеоданих, і один або більше додаткових елементів синтаксису містять елементи синтаксису для небазового рівня відеоданих.
6. Спосіб за п. 1, у якому синтаксичну структуру VPS визначають за допомогою вмісту елемента синтаксису ідентифікації VPS, знайденого в наборі параметрів послідовності (SPS), який вказується елементом синтаксису ідентифікації SPS, який знайдений в наборі параметрів зображення (PPS), який зазначається елементом синтаксису ідентифікації PPS, знайденим в кожному заголовку сегмента слайса.
7. Спосіб за п. 1, у якому обробка виконується повідомленим про мультимедіа елементом мережі (ΜΑΝΕ), і в якому спосіб додатково включає направляння відеоданих клієнтському пристрою.
8. Спосіб за п. 1, у якому пропускання обробки згаданого щонайменше одного елемента синтаксису в синтаксичній структурі VPS містить ігнорування значень згаданого щонайменше одного елемента синтаксису.
9. Спосіб обробки відеоданих, причому спосіб включає:
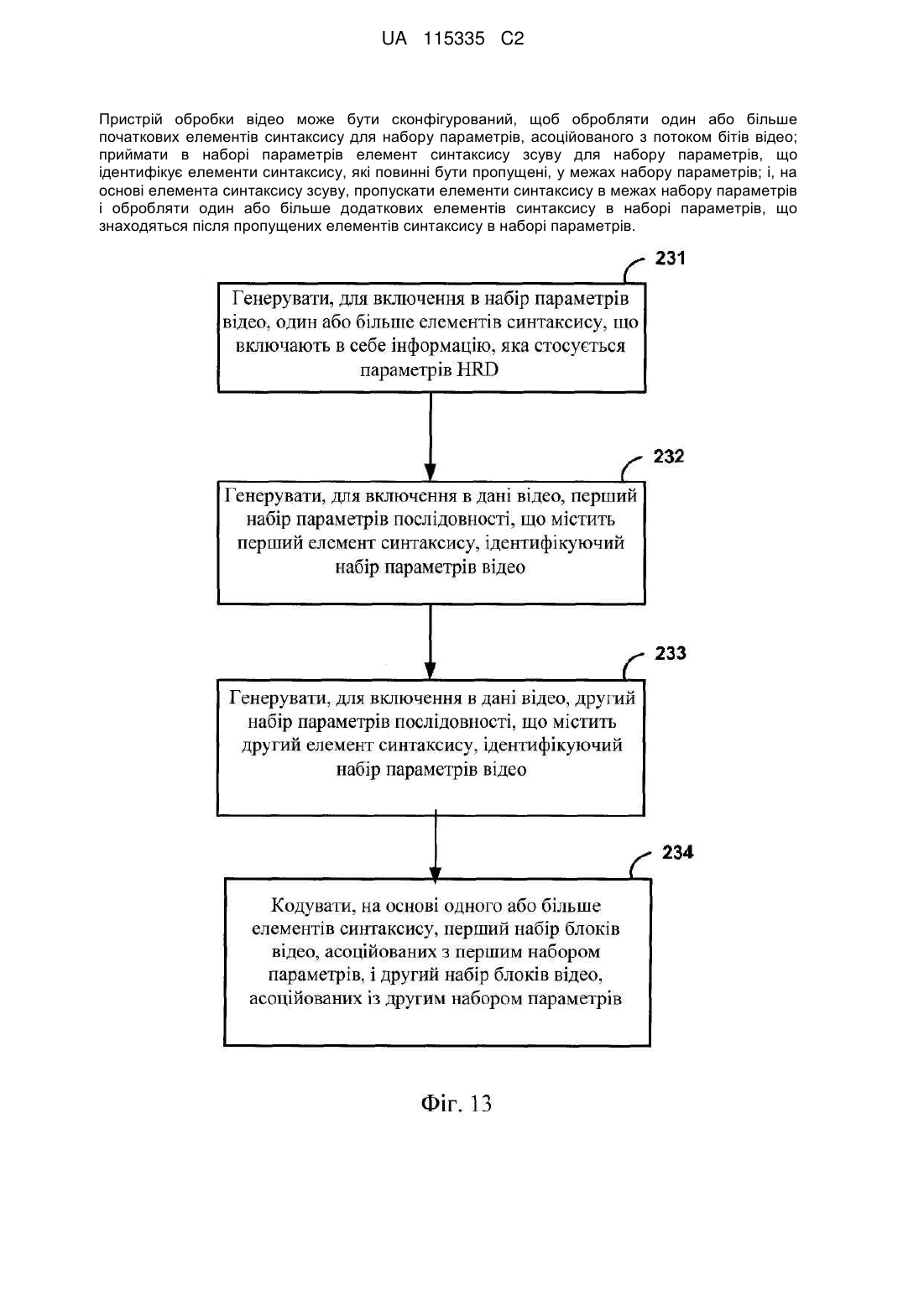
генерування одного або більше початкових елементів синтаксису для синтаксичної структури набора параметрів відео (VPS), асоційованої з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка застосовна до нуля або більше цілих кодованих відеопослідовностей;
генерування елемента синтаксису зсуву для синтаксичної структури VPS, при цьому значення елемента синтаксису зсуву рівне кількості байтів у синтаксичній структурі VPS, для яких обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
генерування щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, котрий відповідає байтам, для яких обробка повинна бути пропущена; і
генерування одного або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, в синтаксичній структурі VPS.
10. Спосіб за п. 9, у якому зазначений щонайменше один елемент синтаксису, для якого обробка повинна бути пропущена, містить один або більше елементів синтаксису, кодованих, використовуючи кодування зі змінною довжиною слова.
11. Спосіб за п. 9, у якому один або більше додаткових елементів синтаксису містять додаткові елементи синтаксису фіксованої довжини, і в якому один або більше додаткових елементів синтаксису ідуть за елементом синтаксису зсуву, і ідуть зазазначеним щонайменше одним елементом синтаксису, для якого обробка повинна бути пропущена.
12. Спосіб за п. 9, у якому один або більше початкових елементів синтаксису містять елементи синтаксису, що включають у себе інформацію, яка стосується узгодження сеансу.
13. Спосіб за п. 9, у якому один або більше початкових елементів синтаксису містять елементи синтаксису для базового рівня відеоданих, і один або більше додаткових елементів синтаксису містять елементи синтаксису для небазового рівня відеоданих.
14. Спосіб за п. 9, у якому синтаксичну структуру VPS визначають за допомогою вмісту елемента синтаксису ідентифікації VPS, знайденого в наборі параметрів послідовності (SPS), який вказується елементом синтаксису ідентифікації SPS, який знайдений в наборі параметрів зображення (PPS), який зазначається елементом синтаксису ідентифікації PPS, знайденим в кожному заголовку сегмента слайса.
15. Спосіб за п. 9, у якому спосіб виконується відеокодером.
16. Спосіб за п. 9, у якому спосіб виконується пристроєм постобробки, сконфігурованим, щоб обробляти закодовані відеодані.
17. Спосіб декодування відеоданих, причому спосіб включає:
декодування одного або більше початкових елементів синтаксису для синтаксичної структури набора параметрів відео (VPS), асоційованої з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка застосовна до нуля або більше цілих кодованих відеопослідовностей;
прийом, у потоці бітів відео, елемента синтаксису зсуву для синтаксичної структури VPS, при цьому значення елемента синтаксису зсуву рівне кількості байтів у синтаксичній структурі VPS, для яких обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
ігнорування значення елемента синтаксису зсуву; і
декодування зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена.
18. Спосіб за п. 17, у якому зазначений щонайменше один елемент синтаксису, для якого обробка повинна бути пропущена, містить один або більше елементів синтаксису змінної довжини, і в якому декодування зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, включає виконання процесу ентропійного декодування.
19. Пристрій обробки відео, який містить:
пам'ять, що зберігає відеодані з потоку бітів відео; і
один або більше процесорів, виконаних з можливістю здійснення операцій, що містять:
обробку одного або більше початкових елементів синтаксису в синтаксичній структурі набору параметрів відео (VPS), асоційованій з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка застосовна до нуля або більше цілих кодованих відеопослідовностей;
прийом, в синтаксичній структурі VPS, елемента синтаксису зсуву зі значенням рівним кількості байтів у синтаксичній структурі VPS, для якої обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
на основі елемента синтаксису зсуву пропускання обробки щонайменше одного елемента синтаксису в синтаксичній структурі VPS; і
обробку одного або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису в синтаксичній структурі VPS.
20. Пристрій обробки відео за п. 19, у якому зазначений щонайменше один елемент синтаксису містить один або більше елементів синтаксису, кодованих, використовуючи кодування зі змінною довжиною слова.
21. Пристрій обробки відео за п. 19, у якому один або більше додаткових елементів синтаксису містять додаткові елементи синтаксису фіксованої довжини, і в якому один або більше додаткових елементів синтаксису ідуть за елементом синтаксису зсуву і ідуть за зазначеним щонайменше одним елементом синтаксису.
22. Пристрій обробки відео за п. 19, у якому один або більше початкових елементів синтаксису містять елементи синтаксису, що включають у себе інформацію, яка стосується узгодження сеансу.
23. Пристрій обробки відео за п. 19, у якому один або більше початкових елементів синтаксису містять елементи синтаксису для базового рівня відеоданих, і один або більше додаткових елементів синтаксису містять елементи синтаксису для небазового рівня відеоданих.
24. Пристрій обробки відео за п. 19, у якому синтаксична структура VPS визначається за допомогою вмісту елемента синтаксису ідентифікації VPS, знайденого в наборі параметрів послідовності (SPS), який вказується елементом синтаксису ідентифікації SPS, який знайдений в наборі параметрів зображення (PPS), який зазначається елементом синтаксису ідентифікації PPS, знайденим в кожному заголовку сегмента слайса.
25. Пристрій обробки відео за п. 19, у якому пристрій містить повідомлений про мультимедіа елемент мережі (ΜΑΝΕ), виконаний з можливістю направлення підпотоку потоку бітів відео клієнтському пристрою.
26. Пристрій обробки відео за п. 19, у якому для пропускання обробки згаданого щонайменше одного елемента синтаксису в синтаксичній структурі VPS згадані один або більше процесорів виконані з можливістю ігнорування значень згаданого щонайменше одного елемента синтаксису.
27. Пристрій обробки відео, який містить:
пам'ять, що зберігає відеодані з потоку бітів відео; і
один або більше процесорів, виконаних з можливістю здійснення операцій, що включають:
генерування одного або більше початкових елементів синтаксису для синтаксичної структури набора параметрів відео (VPS), асоційованої з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка застосовна до нуля або більше цілих кодованих відеопослідовностей;
генерування елемента синтаксису зсуву для синтаксичної структури VPS, при цьому значення елемента синтаксису зсуву рівне кількості байтів у синтаксичній структурі VPS, для якої обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
генерування щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, котрий відповідає байтам, для яких обробка повинна бути пропущена; і
генерування одного або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, в синтаксичній структурі VPS.
28. Пристрій обробки відео за п. 27, у якому зазначений щонайменше один елемент синтаксису, для якого обробка повинна бути пропущена, містить один або більше елементів синтаксису, кодованих, використовуючи кодування зі змінною довжиною слова.
29. Пристрій обробки відео за п. 27, у якому один або більше додаткових елементів синтаксису містять додаткові елементи синтаксису фіксованої довжини, і в якому один або більше додаткових елементів синтаксису ідуть за елементом синтаксису зсуву і ідуть за зазначеним щонайменше одним елементом синтаксису, для якого обробка повинна бути пропущена.
30. Пристрій обробки відео за п. 27, у якому один або більше початкових елементів синтаксису містять елементи синтаксису, що включають у себе інформацію, яка стосується узгодження сеансу.
31. Пристрій обробки відео за п. 27, у якому один або більше початкових елементів синтаксису містять елементи синтаксису для базового рівня відеоданих, і один або більше додаткових елементів синтаксису містять елементи синтаксису для небазового рівня відеоданих.
32. Пристрій обробки відео за п. 27, у якому синтаксична структура VPS визначається за допомогою вмісту елемента синтаксису ідентифікації VPS, знайденого в наборі параметрів послідовності (SPS), який вказується елементом синтаксису ідентифікації SPS, який знайдений в наборі параметрів зображення (PPS), який зазначається елементом синтаксису ідентифікації PPS, знайденим в кожному заголовку сегмента слайса.
33. Пристрій обробки відео за п. 27, у якому один або більше процесорів містять відеокодер.
34. Пристрій обробки відео за п. 27, у якому пристрій обробки відео містить пристрій постобробки, виконаний з можливістю обробки закодованих відеоданих.
35. Пристрій обробки відео за п. 27, який містить щонайменше одне з:
інтегральної схеми;
мікропроцесора; і
пристрою бездротового зв'язку, що містить відеодекодер.
36. Пристрій обробки відео, який містить:
пам'ять, що зберігає відеодані з потоку бітів відео; і
один або більше процесорів, виконаних з можливістю здійснення операцій, що містить:
декодування одного або більше початкових елементів синтаксису для синтаксичної структури набора параметрів відео (VPS), асоційованої з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS, при цьому синтаксична структура VPS включає в себе інформацію, яка застосовна до нуля або більше цілих кодованих відеопослідовностей;
прийом, у потоці бітів відео, елемента синтаксису зсуву для синтаксичної структури VPS, при цьому значення елемента синтаксису зсуву рівне кількості байтів у синтаксичній структурі VPS, для якої обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
ігнорування значення елемента синтаксису зсуву; і
декодування зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, в синтаксичній структурі VPS.
37. Пристрій обробки відео за п. 36, у якому зазначений щонайменше один елемент синтаксису, для якого обробка повинна бути пропущена, містить один або більше елементів синтаксису змінної довжини, і в якому декодування зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, включає виконання процесу ентропійного декодування.
38. Пристрій обробки відео за п. 36, який містить щонайменше одне з:
інтегральної схеми;
мікропроцесора; і
пристрою бездротового зв'язку, що містить відеодекодер.
39. Пристрій обробки відео, який містить:
засіб для обробки одного або більше початкових елементів синтаксису для синтаксичної структури VPS, асоційованої з потоком бітів відео, у якому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS;
засіб для прийому, в синтаксичній структурі VPS, елемента синтаксичного зсуву для синтаксичної структури VPS, при цьому елемент синтаксису зсуву ідентифікує кількість байтів у синтаксичній структурі VPS, для якої обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
засіб для пропускання щонайменше одного елемента синтаксису в межах синтаксичної структури VPS на основі елемента синтаксису зсуву; і
засіб для обробки одного або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена, в синтаксичній структурі VPS.
40. Зчитуваний комп'ютером запам'ятовуючий носій, що зберігає інструкції, які, коли виконуються, змушують один або більше процесорів:
обробляти один або більше початкових елементів синтаксису для синтаксичної структури VPS, асоційованої з потоком бітів відео, при цьому один або більше початкових елементів синтаксису містять елементи синтаксису фіксованої довжини, що розташовані до будь-яких елементів синтаксису змінної довжини в синтаксичній структурі VPS;
приймати, в синтаксичній структурі VPS, елемент синтаксису зсуву для синтаксичної структури VPS, при цьому елемент синтаксису зсуву ідентифікує кількість байтів у синтаксичній структурі VPS, для якої обробка повинна бути пропущена, при цьому один або більше початкових елементів синтаксису передують елементу синтаксису зсуву в синтаксичній структурі VPS;
пропускати елементи синтаксису в межах синтаксичної структури VPS на основі елемента синтаксису зсуву; і
обробляти один або більше додаткових елементів синтаксису в синтаксичній структурі VPS, при цьому один або більше додаткових елементів синтаксису розташовані після зазначеного щонайменше одного елемента синтаксису, для якого обробка повинна бути пропущена в синтаксичній структурі VPS.
41. Зчитуваний комп'ютером запам'ятовуючий носій за п. 40, в якому зазначений щонайменше один елемент синтаксису містить один або більше елементів синтаксису, кодованих, використовуючи кодування зі змінною довжиною слова.
42. Зчитуваний комп'ютером запам'ятовуючий носій за п. 40, в якому один або більше додаткових елементів синтаксису містять додаткові елементи синтаксису фіксованої довжини, і в якому один або більше додаткових елементів синтаксису ідуть за елементом синтаксису зсуву і ідуть за зазначеним щонайменше одним елементом синтаксису.
43. Зчитуваний комп'ютером запам'ятовуючий носій за п. 40, в якому один або більше початкових елементів синтаксису містять елементи синтаксису, що включають у себе інформацію, яка стосується узгодження сеансу.
44. Зчитуваний комп'ютером запам'ятовуючий носій за п. 40, в якому один або більше початкових елементів синтаксису містять елементи синтаксису для базового рівня відеоданих, і один або більше додаткових елементів синтаксису містять елементи синтаксису для небазового рівня відеоданих.
45. Зчитуваний комп'ютером запам'ятовуючий носій за п. 40, що зберігає додаткові інструкції, які, коли виконуються, змушують один або більше процесорів відправляти відеодані клієнтському пристрою.
Текст
Реферат: WENGER S ET AL, "Adaptation Parameter Set (APS)", 97. MPEG MEETING; 18-7-2011 - 22-72011; TORINO; (MOTION PICTURE EXPERT GROUP OR ISO/IEC JTC1/SC29/WG11),, (20120607), no. m21385, XP030049948 [X] 1,35,10,12-14,18-20,22,24-26,30,31,33-35,39-42,4446,48-50 * sections 4.1.3, 4.2.1 and 4.2.2 * [Y] 2,69,11,15-17,21,23,27-29,32,36-38,43,47,51-54 C-Y TSAI ET AL, "Non-CE8: Pure VLC for SAO and ALF", 7. JCT-VC MEETING; 98. MPEG MEETING; 21-11-2011 - 30-11-2011; GENEVA; (JOINT COLLABORATIVE TEAM ON VIDEO CODING OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ); URL: HTTP://WFTP3.ITU.INT/AV-ARCH/JCTVCSITE/,, (20111108), no. JCTVC-G220, XP030110204 [Y] 2,11,21,23,32,43,47 * section 1 * [A] 1,3-10,12-20,22,24-31,33-42,44-46,48-54 BOYCE J ET AL, "SEI message for sub-bitstream profile & level indicators", 9. JCT-VC MEETING; 100. MPEG MEETING; 27-4-2012 - 7-5-2012; GENEVA; (JOINT COLLABORATIVE TEAM ON VIDEO CODING OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ); URL: HTTP://WFTP3.ITU.INT/AV-ARCH/JCTVC-SITE/,, (20120416), no. JCTVC-I0231, XP030111994 [Y] 6,7,9,15,16,27,28,36,37,51,52,54 * section 2.2 * [A] 1-5,8,10-14,17-26,29-35,38-50,53 CHEN Y ET AL, "AHG12: Video parameter set and its use in 3D-HEVC", 9. JCT-VC MEETING; 100. MPEG MEETING; 27-4-2012 - 7-5-2012; GENEVA; (JOINT COLLABORATIVE TEAM ON VIDEO CODING OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ); URL: HTTP://WFTP3.ITU.INT/AVARCH/JCTVC-SITE/,, (20120428), no. JCTVCI0571, XP030112334 [Y] 8,17,29,38,53 * sections 1.2.1 and 1.2.2 * [A] 1-7,9-16,18-28,30-37,39-52,54 UA 115335 C2 (12) UA 115335 C2 Пристрій обробки відео може бути сконфігурований, щоб обробляти один або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; приймати в наборі параметрів елемент синтаксису зсуву для набору параметрів, що ідентифікує елементи синтаксису, які повинні бути пропущені, у межах набору параметрів; і, на основі елемента синтаксису зсуву, пропускати елементи синтаксису в межах набору параметрів і обробляти один або більше додаткових елементів синтаксису в наборі параметрів, що знаходяться після пропущених елементів синтаксису в наборі параметрів. UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 Дана заявка належить до: попередньої заявки на патент США № 61/667,387, поданої 2 липня 2012, попередньої заявки на патент США № 61/669,587, поданої 9 липня 2012, і попередньої заявки на патент США № 61/798,135, поданої 15 березня 2013, весь зміст кожної з яких включений в даний опис по посиланню. ГАЛУЗЬ ТЕХНІКИ Дане розкриття стосується обробки даних відео, і, більш конкретно, дане розкриття описує методи, що стосуються генерування й обробки наборів параметрів для відеоданих. РІВЕНЬ ТЕХНІКИ Цифрові можливості відео можуть бути включені в широкий діапазон пристроїв, що включає в себе цифрові телевізори, цифрові системи прямого мовлення, бездротові системи мовлення, персональні цифрові помічники (PDA), ноутбуки або настільні комп'ютери, планшетні комп'ютери, електронні книги, цифрові камери, цифрові пристрої реєстрації, цифрові медіаплеєри, відеоігрові пристрої, пульти відеоігор, стільникові або супутникові радіотелефони, так називані "смартфони", відеопристрої організації телеконференцій, пристрої потокової передачі відео і т. п. Ці цифрові відеопристрої реалізують способи стиснення відео, такі, як описані в стандартах, визначених MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Частина 10, Удосконалене кодування відео (AVC), стандарт високоефективне кодування відео (HEVC), що знаходиться на даний час у розробці, і розширеннях таких стандартів. Цифрові відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову інформацію відео більш ефективно, реалізовуючи такі способи стиснення відео. Способи стиснення відео виконують просторове (усередині картинки) прогнозування і/або часове (між картинками) прогнозування, щоб зменшити або видалити надмірність, властиву відеопослідовностям. Для основаного на блоці кодування відео відеовирізка (тобто відеокадр або частина відеокадру) може бути розділена на блоки відео, що можуть також згадуватися як блоки дерева, одиниці кодування (CU) і/або вузли кодування. Блоки відео у кодованій внутрішньо (I) вирізці картинки кодують, використовуючи просторове прогнозування відносно опорних вибірок у сусідніх блоках у тій же самій картинці. Блоки відео в кодованій зовнішньо (P або B) вирізці картинки можуть використовувати просторове прогнозування відносно опорних вибірок у сусідніх блоках у тій же самій картинці або часове прогнозування відносно опорних вибірок в інших опорних картинках. Картинки можуть згадуватися як кадри, і опорні картинки можуть згадуватися як опорні кадри. Просторове або часове прогнозування приводить до прогнозуючого блока для блока, який повинен бути закодований. Залишкові дані представляють пікселні різниці між початковим блоком, який повинен бути закодований, і прогнозуючим блоком. Кодований зовнішньо блок кодують відповідно до вектора руху, який вказує на блок опорних вибірок, що формують прогнозуючий блок, і залишкових даних, що вказують різницю між закодованим блоком і прогнозуючим блоком. Кодований внутрішньо блок кодують відповідно до режиму внутрішнього кодування і залишкових даних. Для подальшого стиснення залишкові дані можуть бути перетворені з пікселної області в область перетворення, приводячи до залишкових коефіцієнтів перетворення, які потім можуть бути квантовані. Квантовані коефіцієнти перетворення, початково розміщені в двовимірному масиві, можуть бути скановані, щоб сформувати одновимірний вектор коефіцієнтів перетворення, і ентропійне кодування може бути застосоване, щоб досягти ще більшого стиснення. СУТЬ ВИНАХОДУ Дане розкриття описує методи побудови для наборів параметрів при кодуванні відео, і, більш конкретно, дане розкриття описує методи, що стосуються наборів параметрів відео (VPS). VPSs є синтаксичною структурою, яка може застосовуватися до множинних цілих послідовностей відео. Відповідно до методів даного розкриття, VPS може включати в себе елемент синтаксису зсуву, щоб дозволити повідомленому про медіа елементу мережі (MANE) здійснювати пропускання від одного набору елементів синтаксису фіксованої довжини до іншого набору елементів синтаксису фіксованої довжини, причому пропущений елемент синтаксису потенційно включає в себе елементи синтаксису змінної довжини. В одному прикладі спосіб обробки відеоданих включає в себе обробку одного або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; прийом у наборі параметрів елемента синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; на основі елемента синтаксису зсуву, пропускання елементів синтаксису в межах набору параметрів; і обробку одного або більше додаткових елементів 1 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 синтаксису в наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після пропущених елементів синтаксису в наборі параметрів. В іншому прикладі спосіб обробки відеоданих включає в себе генерування одного або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; генерування елемента синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує кількість елементів синтаксису, що повинні бути пропущені, у межах набору параметрів; генерування елементів синтаксису, що повинні бути пропущені; і генерування одного або більше додаткових елементів синтаксису в наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після елементів синтаксису, що повинні бути пропущені в наборі параметрів. В іншому прикладі спосіб декодування відеоданих включає в себе декодування одного або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; прийом у потоці бітів відео елемента синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; і декодування елементів синтаксису, що повинні бути пропущені. В іншому прикладі пристрій обробки відео включає в себе елемент обробки відео, сконфігурований, щоб обробляти один або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; приймати у наборі параметрів елемент синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; на основі елемента синтаксису зсуву, пропускати елементи синтаксису в межах набору параметрів; і обробляти один або більше додаткових елементів синтаксису в наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після пропущених елементів синтаксису в наборі параметрів. В іншому прикладі пристрій обробки відео включає в себе елемент обробки відео, сконфігурований, щоб генерувати один або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; генерувати елемент синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує кількість елементів синтаксису, що повинні бути пропущені, у межах набору параметрів; генерувати елементи синтаксису, що повинні бути пропущені; генерувати один або більше додаткових елементів синтаксису у наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після елементів синтаксису, що повинні бути пропущені в наборі параметрів. В іншому прикладі пристрій обробки відео включає в себе елемент обробки відео, сконфігурований, щоб декодувати один або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; приймати у потоці бітів відео елемент синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; і декодувати елементи синтаксису, що повинні бути пропущені. В іншому прикладі пристрій обробки відео включає в себе засіб для обробки одного або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; засіб для прийому у наборі параметрів елемента синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; засіб для пропускання елементів синтаксису в межах набору параметрів на основі елемента синтаксису зсуву; засіб для обробки одного або більше додаткових елементів синтаксису в наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після пропущених елементів синтаксису в наборі параметрів. В іншому прикладі, зчитуваний комп'ютером запам'ятовуючий носій зберігає інструкції, які, коли виконуються, змушують один або більше процесорів обробляти один або більше початкових елементів синтаксису для набору параметрів, асоційованого з потоком бітів відео; приймати в наборі параметрів елемент синтаксису зсуву для набору параметрів, при цьому елемент синтаксису зсуву ідентифікує елементи синтаксису, що повинні бути пропущені, у межах набору параметрів; пропускати елементи синтаксису в межах набору параметрів на основі елемента синтаксису зсуву; і обробляти один або більше додаткових елементів синтаксису в наборі параметрів, при цьому один або більше додаткових елементів синтаксису знаходяться після пропущених елементів синтаксису в наборі параметрів. Подробиці одного або більше прикладів сформульовані в супровідних кресленнях і описі нижче. Інші ознаки, об'єкти і переваги будуть очевидні з опису і креслень і з формули винаходу. КОРОТКИЙ ОПИС КРЕСЛЕНЬ 2 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 ФІГ. 1 є блок-схемою, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати методи, описані в даному розкритті. ФІГ. 2 є концептуальною діаграмою, що ілюструє зразковий порядок декодування MVC. ФІГ. 3 є концептуальною діаграмою, що показує зразкову часову і міжвидову структуру прогнозування MVC. ФІГ. 4 є блок-схемою, що ілюструє зразковий кодер відео, який може реалізувати методи, описані в даному розкритті. ФІГ. 5 є блок-схемою, що ілюструє зразковий декодер відео, який може реалізувати методи, описані в даному розкритті. ФІГ. 6 є блок-схемою, що ілюструє зразковий набір пристроїв, які є частиною мережі. ФІГ. 7 є послідовністю операцій, що показує зразковий спосіб для обробки набору параметрів відповідно до методів даного розкриття. ФІГ. 8 є послідовністю операцій, що показує зразковий спосіб для генерування набору параметрів відповідно до методів даного розкриття. ФІГ. 9 є послідовністю операцій, що показує зразковий спосіб для декодування набору параметрів відповідно до методів даного розкриття. ФІГ. 10 є послідовністю операцій, що показує зразковий спосіб для обробки набору параметрів відповідно до методів даного розкриття. ФІГ. 11 є послідовністю операцій, що показує зразковий спосіб для генерування набору параметрів відповідно до методів даного розкриття. ФІГ. 12 є послідовністю операцій, що показує зразковий спосіб для обробки набору параметрів відповідно до методів даного розкриття. ФІГ. 13 є послідовністю операцій, що показує зразковий спосіб для генерування набору параметрів відповідно до методів даного розкриття. ДОКЛАДНИЙ ОПИС Дане розкриття описує методи побудови для наборів параметрів при кодуванні відео, і, більш конкретно, дане розкриття описує методи, що стосуються наборів параметрів відео (VPS). На доповнення до VPS інші приклади наборів параметрів включають в себе набори параметрів послідовності (SPSs), набори параметрів картинки (PPSs) і набори параметрів адаптації (APSs), причому названі тільки деякі. Відеокодер кодує дані відео. Дані відео можуть включати в себе одну або більше картинок, де кожна з картинок є нерухомим зображенням, що є частиною відео. Коли відеокодер кодує дані відео, відеокодер генерує потік бітів, що включає в себе послідовність бітів, які формують закодоване представлення даних відео. Потік бітів може включати в себе закодовані картинки й асоційовані дані, при цьому закодована картинка посилається на закодоване представлення картинки. Асоційовані дані можуть включати в себе різні типи наборів параметрів, включаючи VPSs, SPSs, PPSs і APSs, і потенційно інші синтаксичні структури. SPSs використовуються для перенесення даних, що є дійсними для цілої послідовності відео, тоді як PPSs несуть інформацію, дійсну на основі картинка-за-картинкою. APSs несуть адаптивну для картинки інформацію, що також є дійсною на основі картинка-за-картинкою, але, як очікується, буде змінюватися більш часто, ніж інформація в PPS. HEVC також ввів VPS, які робочий проект HEVC описує наступним чином: набір параметрів відео (VPS): синтаксична структура, що містить елементи синтаксису, які застосовуються до нуля або більше цілих закодованих послідовностей відео, як визначається вмістом елемента синтаксису video_parameter_set_id, знайденого в наборі параметрів послідовності, на який посилається елемент синтаксису seq_parameter_set_id, що знайдений у наборі параметрів картинки, на який посилається елемент синтаксису pic_parameter_set_id, знайдений у кожному заголовку сегмента вирізки. Таким чином, оскільки набори VPS застосовуються до всіх закодованих відеопослідовностей, VPS включає в себе елементи синтаксису, що змінюються нечасто. Механізм VPS, SPS, PPS і APS у деяких версіях HEVC розділяє передачу інформації, що нечасто змінюється, від передачі закодованих даних блока відео. Набори VPS, SPS, PPS і APSs у деяких застосуваннях можуть бути передані "поза смугою частот", тобто транспортовані не разом з блоками, що містять закодовані дані відео. Передача поза смугою частот звичайно надійна, і може бути бажана поліпшена надійність відносно передачі в смузі частот. У HEVC WD7, ідентифікатор (ID) для VPS, SPS, PPS або APS може бути закодований для кожного набору параметрів. Кожен SPS включає в себе ID SPS і ID VPS, кожен PPS включає в себе ID PPS і ID SPS, і кожен заголовок вирізки включає в себе ID PPS і можливо ID APS. Таким чином, ID може бути використаний для ідентифікації належного набору параметрів, що повинен використовуватися в різних випадках. 3 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 Як описано вище, відеокодери звичайно кодують дані відео, і декодери типово декодують дані відео. Кодери і декодери, однак, не є єдиними пристроями, використовуваними для обробки даних відео. Коли відео транспортується, наприклад як частина основаної на пакетній передачі мережі, такої як локальна мережа, регіональна мережа або глобальна мережа, така як Інтернет, пристрої маршрутизації й інші такі пристрої можуть обробляти дані відео, щоб доставити їх із пристрою джерела до пристрою призначення. Спеціальні пристрої маршрутизації, іноді називані "повідомлені про медіа елементи мережі" (MANE), можуть виконувати різні функції маршрутизації на основі вмісту даних відео. Щоб визначити вміст даних відео і виконати ці функції маршрутизації, MANE може звернутися до інформації в закодованому потоці бітів, такої як інформація в VPS або SPS. У наборі параметрів деякі елементи синтаксису закодовані, використовуючи фіксовану кількість бітів, у той час як деякі елементи синтаксису закодовані, використовуючи змінну кількість бітів. Щоб обробляти елементи синтаксису змінної довжини, пристрій може вимагати функціональних можливостей ентропійного декодування. Виконання ентропійного декодування, однак, може ввести рівень складності, що небажаний для MANE або інших елементів мережі. Відповідно до одного методу, введеного в даному розкритті, елемент синтаксису зсуву може бути включений у набір параметрів, такий як VPS, щоб допомогти елементам мережі в ідентифікації елементів синтаксису, що можуть бути декодовані без якого-небудь ентропійного декодування. Елементу синтаксису зсуву можуть передувати елементи синтаксису фіксованої довжини. Елемент синтаксису зсуву може потім ідентифікувати елементи синтаксису в наборі параметрів, що повинні бути закодовані, використовуючи елементи синтаксису змінної довжини. Використовуючи елемент синтаксису зсуву, пристрій, такий як MANE, може перескочити через закодовані елементи синтаксису змінної довжини і відновити обробку елементів синтаксису фіксованої довжини. Елемент синтаксису зсуву може ідентифікувати елементи синтаксису, що повинні бути пропущені, за допомогою ідентифікації кількості байтів у межах набору параметрів, що повинні бути пропущені. Ці пропущені байти можуть відповідати пропущеним елементам синтаксису. Як згадано вище, пропущені елементи синтаксису можуть включати в себе закодовані елементи синтаксису змінної довжини і можуть також включати в себе закодовані елементи синтаксису фіксованої довжини. У цьому контексті, пропускання елементів синтаксису означає, що MANE може уникнути синтаксичних розборів або іншої обробки елементів синтаксису, що закодовані зі змінними довжинами. Таким чином, MANE може обробляти деякі елементи синтаксису в VPS (наприклад, елементи фіксованої довжини), не маючи необхідності виконувати ентропійне декодування, у той же час пропускаючи деякі елементи синтаксису, що можуть інакше вимагати ентропійного декодування. Елементи синтаксису, пропущені MANE, не обмежені елементами синтаксису змінної довжини, оскільки деякі елементи синтаксису фіксованої довжини можуть також бути пропущені в різних прикладах. Відеодекодер може бути сконфігурований для, після прийому елемента синтаксису зсуву, по суті ігнорування одного або більше елементів синтаксису, що означає, що відеодекодер може уникнути синтаксичного розбору й обробки елементів синтаксису, що були пропущені за допомогою MANE. Використання елемента синтаксису зсуву може зменшити складність, необхідну для MANE, щоб обробляти частини набору параметрів, наприклад, звільняючи від необхідності MANE виконувати ентропійне декодування. Додатково, використання елемента синтаксису зсуву, як запропоновано в даному розкритті, може забезпечити використання ієрархічного формату для наборів параметрів. Як приклад ієрархічного формату, у VPS, замість того, щоб мати елементи синтаксису для базового рівня і рівня розширення, змішаних у межах VPS, всі або по суті всі елементи синтаксису базового рівня можуть передувати всім або по суті всім елементам синтаксису першого рівня розширення, які, у свою чергу, можуть передувати всім або по суті всім елементам синтаксису для другого рівня розширення, і так далі. Використовуючи елемент синтаксису зсуву, введений у даному розкритті, MANE може обробляти кількість елементів синтаксису фіксованої довжини для базового рівня, пропускати кількість елементів синтаксису змінної довжини для базового рівня, обробляти кількість елементів синтаксису фіксованої довжини для першого рівня розширення, пропускати кількість елементів синтаксису змінної довжини для першого рівня розширення, обробляти кількість елементів синтаксису фіксованої довжини для другого рівня розширення і так далі. Відеодекодер може бути сконфігурований, щоб синтаксично розбирати й обробляти елементи синтаксису, пропущені MANE. Використання елемента синтаксису зсуву може додатково забезпечити майбутні розширення для стандарту кодування відео. Наприклад, навіть якщо інші типи закодованої інформації змінної довжини були додані до потоку бітів (наприклад, згідно з майбутнім розширенням до HEVC), один або більше елементів синтаксису зсуву можуть бути визначені, 4 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 щоб полегшити пропускання таких елементів змінної довжини. Іншими словами, один або більше елементів синтаксису зсуву можуть бути використані для ідентифікації місцеположення елементів синтаксису фіксованої довжини в межах потоку бітів, і елементи синтаксису зсуву можуть бути модифіковані, щоб врахувати доповнення будь-яких інших елементів у потоці бітів, для яких декодування можна уникнути, наприклад, за допомогою MANE. Дане розкриття додатково пропонує включення елементів синтаксису, що стосуються узгодження сеансу в наборі параметрів відео на противагу іншому набору параметрів, такому як SPS. За допомогою включення елементів синтаксису, що стосуються узгодження сеансу в VPS, службові витрати сигналізації можуть бути зменшені, особливо коли VPS описує інформацію для множинних рівнів відео на противагу інформації тільки для єдиного рівня. Крім того, дане розкриття пропонує використовувати елементи синтаксису фіксованої довжини для елементів синтаксису погоджень сеансу, і елементи синтаксису погоджень сеансу фіксованої довжини можуть бути розташовані перед будь-якими елементами синтаксису змінної довжини. Щоб обробляти елементи синтаксису змінної довжини, пристрій повинен мати змогу виконувати ентропійне декодування. Виконання ентропійного декодування, однак, може ввести рівень складності, що небажаний для MANE. Таким чином, за допомогою використання елементів синтаксису фіксованої довжини, що присутні в VPS до яких-небудь елементів синтаксису змінної довжини, MANE може мати змогу синтаксично розбирати елементи синтаксису для погоджень сеансу, не маючи необхідності виконувати ентропійне декодування. Таблиця 2 нижче показує приклади елементів синтаксису, що стосуються узгодження сеансу, які можуть бути включені в VPS. Приклади інформації для узгодження сеансу включають в себе інформацію, що ідентифікує профілі, яруси і рівні. Робочий проект HEVC описує профілі, яруси і рівні наступним чином. "Профіль" є піднабором синтаксису всього потоку бітів, що визначений відповідно до цієї Рекомендації Міжнародним Стандартом (Recommendation|International Standard). У межах границь, накладених синтаксисом заданого профілю, усе ще можливо вимагати дуже великої варіації в продуктивності кодерів і декодерів залежно від значень, прийнятих елементами синтаксису в потоці бітів, такими як заданий розмір декодованих картинок. У багатьох застосуваннях не є на даний час ні практичним, ні економічно вигідним, щоб реалізувати декодер, здатний працювати з усіма гіпотетичними використаннями синтаксису в межах конкретного профілю. Щоб вирішувати цю проблему, "яруси" і "рівні" визначені в межах кожного профілю. Рівень ярусу є заданим набором обмежень, накладених на значення елементів синтаксису в потоці бітів. Ці обмеження можуть бути простими межами відносно значень. Альтернативно вони можуть приймати форму обмежень відносно арифметичних комбінацій значень (наприклад, ширина картинки, помножена на висоту картинки, помножена на кількість картинок, декодованих у секунду). Рівень, визначений для нижнього ярусу, є більш обмеженим, ніж рівень, визначений для більш високого ярусу. Під час погоджень сеансу між клієнтом і MANE, клієнт може зробити запит про придатність у MANE даних відео, закодованих відповідно до деякого профілю, рівня і/або ярусу. MANE може мати змогу синтаксично розбирати першу частину (тобто закодовану частину фіксованої довжини) для VPS, що включає в себе інформацію профілю, рівня і ярусу. Серед точок операції, доступних у MANE, належна може бути вибрана клієнтом, і MANE може відправити відповідні пакети клієнту після того, як сеанс погоджений. Дане розкриття додатково пропонує включення елементів синтаксису для ідентифікації гіпотетичного опорного декодера (HRD) у наборі параметрів відео на противагу іншому набору параметрів, такому як SPS. Параметри HRD ідентифікують гіпотетичну модель декодера, що задає обмеження на мінливість (варіабельність) узгоджуваних потоків одиниць NAL або узгоджуваних потоків байтів, які може виробляти процес кодування. Два типи наборів параметрів HRD (параметри HRD NAL і параметри HRD VCL) можуть бути включені в VPS. Параметри HRD NAL належать до погодженості потоку бітів Типу II, у той час як параметри HRD VCL належать до погодженості всього бітового потоку. HEVC на даний час розрізняє два типи потоку бітів, що підлягають погодженості HRD. Перший називають потоком бітів Типу I і він належить до потоку одиниць NAL, що містить тільки одиниці NAL VCL і одиниці NAL даних заповнення для всіх одиниць доступу в потоці бітів. Другий тип потоку бітів називають потоком бітів Типу II і він містить одиниці NAL VCL і одиниці NAL даних заповнення для всіх одиниць доступу в потоці бітів плюс інші типи додаткових одиниць NAL. Методи даного розкриття можуть бути застосовані при кодуванні єдиного рівня так само, як до масштабованого кодування і кодування відео множинних видів. Рівень може, наприклад, бути просторовим масштабованим рівнем, рівнем масштабованої якості, видом текстури або 5 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 видом глибини. У HEVC рівень взагалі належить до набору одиниць NAL рівня кодування відео (VCL) і асоційованих одиниць NAL не-VCL, що усі мають значення ID конкретного рівня. Рівні можуть бути ієрархічними в розумінні, що перший рівень може містити більш низький рівень. Набір рівнів іноді використовується для звертання до набору рівнів, представлених у межах потоку бітів, створеного з іншого потоку бітів за допомогою операції процесу витягання підпотоку бітів. Точка операції загалом належить до потоку бітів, створеного з іншого потоку бітів за допомогою операції процесу витягання підпотоку бітів з іншим потоком бітів. Точка операції або може включати в себе всі рівні в набір рівнів, або може бути потоком бітів, сформованим як піднабір набору рівнів. ФІГ. 1 є блок-схемою, що ілюструє зразкову систему 10 кодування і декодування відео, яка може використовувати методи, описані в даному розкритті. Як показано на ФІГ. 1, система 10 включає в себе вихідний пристрій 12, що генерує закодовані дані відео, які повинні бути декодовані в більш пізній час пристроєм 14 призначення. Закодовані дані відео можуть бути маршрутизовані від вихідного пристрою 12 до пристрою 14 призначення повідомленим про медіа елементом мережі (MANE) 29. Вихідний пристрій 12 і пристрій 14 призначення можуть містити будь-який із широкого діапазону пристроїв, включаючи настільні комп'ютери, портативні (тобто ноутбуки) комп'ютери, планшетні комп'ютери, телевізійні приставки, телефонні трубки, такі як так називані "інтелектуальні" ("смарт") телефони, так називані "інтелектуальні" клавіатури, телевізори, камери, пристрої відображення, цифрові медіаплеєри, пульти відеоігор, пристрій потокової передачі відео або подібне. У деяких випадках вихідний пристрій 12 і пристрій 14 призначення можуть бути обладнані для бездротового зв'язку. Система 10 може працювати відповідно до різних стандартів кодування відео, стандарту, що складає власність, або будь-якого іншого способу кодування множинних видів. Наприклад, відеокодер 20 і відеодекодер 30 можуть працювати відповідно до стандарту стиснення відео, такого як ITU-T H.261, ISO/IEC MPEG-1 Visual, ITU-T H.262 або ISO/IEC MPEG-2 Visual, ITU-T H.263, ISO/IEC MPEG-4 Visual і ITU-T H.264 (також відомий як ISO/IEC MPEG-4 AVC), включаючи його розширення масштабованого кодування відео (SVC) і кодування відео множинних видів (MVC). Нещодавній, публічно доступний спільний проект розширення MVC описаний у "Advanced video coding for generic audiovisual services", Recommendation H.264 ITU-T, березень 2010. Більш новий, публічно доступний спільний проект розширення MVC описаний у "Advanced video coding for generic audiovisual services", ITU-T Recommendation H.264 ITU-T, червень 2011. Поточний об'єднаний проект розширення MVC був схвалений у січні 2012. Крім того, є новий стандарт кодування відео, а саме стандарт високоефективного кодування відео (HEVC), що розвивається Об'єднаною Командою Співробітництва по кодуванню відео (JCT-VC) Групи Експертів по Кодуванню відео ITU-T (VCEG) і ISO/IEC Групи Експертів по рухомих зображеннях (MPEG). Нещодавній робочий проект (WD) HEVC, названий HEVC WD7 надалі, доступний, на 1 липня 2013, за адресою http://phenix.intevry.fr/jct/doc_end_user/documents/9_Geneva/wg11/JCTVC-I1003-v6.zip. Розвиток стандарту HEVC продовжується, і більш новий робочий проект (WD) HEVC, названий HEVC WD9, доступний, на 1 липня 2013, за адресою http://phenix.intevry.fr/jct/doc_end_user/documents/11_Shanghai/wg11/JCTVC-K1003-10.zip. З метою опису відеокодер 20 і відеодекодер 30 описані в контексті HEVC або H.264 стандарту і розширень таких стандартів. Методи даного розкриття, однак, не обмежені конкретним стандартом кодування. Інші приклади стандартів стиснення відео включають в себе MPEG-2 і ITU-T H.263. Методи кодування, що складають власність, такі як названі On2 VP6/VP7/VP8, можуть також реалізувати один або більше методів, описаних тут. Більш новий проект майбутнього стандарту HEVC, названого "HEVC Робочий Проект 10" або "HEVC WD10", описаний у Bross et al., "Editors" proposed corrections to HEVC version 1", Joint Collaborative Team on Video Coding (JCT-VC) of th ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 13 Meeting, Incheon, KR, квітень 2013, що на 1 липня 2013 доступний за адресою http://phenix.intevry.fr/jct/doc_end_user/documents/13_Incheon/wg11/JCTVC-M0432-v3.zip, весь зміст якого тим самим включено по посиланню. Методи даного розкриття потенційно застосовні до декількох MVC і/або стандартів кодування 3D-відео, включаючи 3D-кодування відео на основі HEVC (3D-HEVC). Методи даного розкриття можуть також бути застосовними до H.264/3D-AVC і H.264/MVC+D стандартів кодування відео або їх розширень, так само як і інших стандартів кодування. Методи даного розкриття можуть час від часу бути описані з посиланнями на або використовуючи термінологію конкретного стандарту кодування відео; однак, такий опис не повинен інтерпретуватися, щоб означати, що описані методи обмежені тільки таким конкретним стандартом. 6 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 Пристрій 14 призначення може прийняти закодовані дані відео, що повинні бути декодовані, через лінію 16 зв'язку. Лінія 16 зв'язку може містити будь-який тип носія або пристрою, здатного до переміщення закодованих даних відео від вихідного пристрою 12 до пристрою 14 призначення. В одному прикладі, лінія 16 зв'язку може містити комунікаційний носій, щоб дозволити вихідному пристрою 12 передавати закодовані дані відео безпосередньо до пристрою 14 призначення в реальному часі. Закодовані дані відео можуть бути модульовані відповідно до стандарту зв'язку, такого як протокол бездротового зв'язку, і передані до пристрою 14 призначення. Комунікаційний носій може містити будь-який бездротовий або дротовий комунікаційний носій, такий як радіочастотний (RF) спектр, або одну або більше фізичних ліній передачі. Комунікаційний носій може бути частиною основаної на пакетній передачі мережі, такої як локальна мережа, регіональна мережа або глобальна мережа, така як Інтернет. Комунікаційний носій може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути корисним, щоб полегшити зв'язок від вихідного пристрою 12 до пристрою 14 призначення. Лінія 16 зв'язку може включати в себе один або більше MANE, такий як MANE 29, які маршрутизують дані відео від вихідного пристрою 12 до пристрою 14 призначення. Альтернативно, закодовані дані можуть бути виведені з інтерфейсу 22 виведення на пристрій 27 зберігання. Аналогічно, закодовані дані можуть бути доступні від пристрою 27 зберігання за допомогою інтерфейсу введення. Пристрій 27 зберігання може включати в себе будь-який з множини розподілених або локально доступних запам'ятовуючих носіїв даних, таких як накопичувач на твердих дисках, диски Blu-ray, DVD, CD-ROM, флеш-пам'ять, енергозалежна або енергонезалежна пам'ять, або будь-які інші придатні цифрові запам'ятовуючі носії для того, щоб зберігати закодовані дані відео. В іншому прикладі пристрій 27 зберігання може відповідати файловому серверу або іншому проміжному пристрою зберігання, який може зчитувати закодоване відео, генероване вихідним пристроєм 12. Пристрій 14 призначення може одержати доступ до збережених даних відео від пристрою 27 зберігання через потокову передачу або завантаження. Файловий сервер може бути будь-яким типом сервера, здатного до того, щоб зберігати закодовані дані відео і передавати ці закодовані дані відео до пристрою 14 призначення. Зразкові файлові сервери включають в себе web-сервер (наприклад, для вебсайта), сервер FTP, пристрої мережного зберігання (NAS) або локальний дисковий накопичувач. Пристрій 14 призначення може звертатися до закодованих відеоданих через будь-яке стандартне з'єднання даних, включаючи Інтернет-з'єднання. Воно може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем і т. д.) або комбінацію обох, яка є придатною для того, щоб звернутися до закодованих відеоданих, що зберігаються на файловому сервері. Передача закодованих даних відео від пристрою 27 зберігання може бути потоковою передачею, передачею завантаження або комбінацією обох. Дані відео, витягнуті з пристрою 27 зберігання, можуть бути маршрутизовані до пристрою 14 призначення, використовуючи один або більше MANE, таких як MANE 29. Методи даного розкриття не обов'язково обмежені бездротовими додатками або параметрами настроювання. Ці методи можуть бути застосовані до кодування відео в підтримку будь-якої множини мультимедійних додатків, таких як ефірне телебачення, передачі кабельного телебачення, передачі супутникового телебачення, потокові передачі відео, наприклад через Інтернет, кодування цифрового відео для зберігання на запам'ятовуючому носії даних, декодування цифрового відео, збереженого на запам'ятовуючому носії даних, або інших додатків. У деяких прикладах система 10 може бути сконфігурована, щоб підтримувати односторонню або двосторонню відеопередачу, щоб підтримувати додатки, такі як потокова передача відео, відтворення відео, мовлення відео і/або відеотелефонія. У прикладі згідно з ФІГ. 1 вихідний пристрій 12 включає в себе відеоджерело 18, відеокодер 20 і інтерфейс 22 виведення. Відеокодер 20 може, наприклад, генерувати синтаксис зсуву, описаний у даному розкритті. У деяких випадках інтерфейс 22 виведення може включати в себе модулятор/демодулятор (модем) і/або передавач. У вихідному пристрої 12 відеоджерело 18 може включати в себе джерело, таке як пристрій захоплення відео, наприклад відеокамера, відеоархів, що містить раніше захоплене відео, інтерфейс подачі відео, щоб прийняти відео від постачальника контенту відео, і/або систему комп'ютерної графіки для того, щоб генерувати дані комп'ютерної графіки як вихідне відео, або комбінацію таких джерел. Як один приклад, якщо відеоджерело 18 є відеокамерою, вихідний пристрій 12 і пристрій 14 призначення можуть сформувати так називані камерофони або відеотелефони. Однак, методи, описані в даному розкритті, можуть бути застосовними до кодування відео взагалі і можуть бути застосовані до бездротових і/або дротових додатків. 7 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 Захоплене, попередньо захоплене або генероване машиною відео може бути закодоване відеокодером 12. Закодовані дані відео можуть бути передані безпосередньо до пристрою 14 призначення через інтерфейс 22 виведення з вихідного пристрою 20. Закодовані дані відео можуть також (або альтернативно) зберігатися на пристрої 27 зберігання для більш пізнього доступу пристроєм 14 призначення або іншим пристроєм для декодування і/або відтворення. Пристрій 14 призначення включає в себе інтерфейс 28 введення, відеодекодер 30 і пристрій 32 відображення. Відеодекодер 30 може синтаксично розбирати елемент синтаксису зсуву, описаний у даному розкритті. Як описано вище, відеодекодер 30 може в деяких випадках проігнорувати елемент синтаксису зсуву, що дозволяє відеодекодеру 30 синтаксично розбирати елементи синтаксису, пропущені за допомогою MANE. У деяких випадках інтерфейс 28 введення може включати в себе приймач і/або модем. Інтерфейс 28 введення з пристрою 14 призначення приймає закодовані дані відео по лінії 16 зв'язку. Закодовані дані відео, передані по лінії 16 зв'язку, або надані на пристрої 27 зберігання, можуть включати в себе множину елементів синтаксису, генерованих відеокодером 20 для використання відеодекодером, таким як відеодекодер 30, при декодуванні даних відео. Такі елементи синтаксису можуть бути включені з закодованими відеоданими, переданими на комунікаційному носії, збереженими на запам'ятовуючому носії або збереженими файловим сервером. Пристрій 32 відображення може бути інтегрований з, або бути зовнішнім до, пристроєм 14 призначення. У деяких прикладах пристрій 14 призначення може включати в себе інтегрований пристрій відображення і також бути сконфігурованим, щоб з'єднуватися з зовнішнім пристроєм відображення. В інших прикладах пристрій 14 призначення може бути пристроєм відображення. Взагалі, пристрій 32 відображення відображає декодовані дані відео користувачу і може містити будь-який з множини пристроїв відображення, таких як рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світловипромінюючих діодах (OLED) або інший тип пристрою відображення. Хоча не показано на ФІГ. 1, у деяких аспектах відеокодер 20 і відеодекодер 30 можуть, кожний, бути інтегровані з аудіокодером/декодером і можуть включати в себе відповідні блоки MUX-DEMUX або інше апаратне забезпечення і програмне забезпечення, щоб обробляти кодування і аудіо, і відео в загальному потоці даних або окремих потоках даних. Якщо застосовно, у деяких прикладах блоки MUX-DEMUX можуть відповідати ITU H.223 протоколу мультиплексора або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Відеокодер 20 і відеодекодер 30, кожний, можуть бути реалізовані як будь-яка з множини придатних схем кодера, таких як один або більше мікропроцесорів, цифрових сигнальних процесорів (DSP), спеціалізованих інтегральних схем (ASIC), програмованих користувачем вентильних матриць (FPGA), дискретної логіки, програмного забезпечення, апаратного забезпечення, програмно-апаратних засобів або будь-яких їх комбінацій. Коли методи реалізовані частково в програмному забезпеченні, пристрій може зберегти інструкції для програмного забезпечення в придатному постійному зчитуваному комп'ютером носії і виконувати інструкції в апаратному забезпеченні, використовуючи один або більше процесорів, щоб виконати методи даного розкриття. Кожен відеокодер 20 і відеодекодер 30 може бути включений в один або більше кодерів або декодерів, будь-який з яких може інтегруватися як частина об'єднаного кодера/декодера (кодек) у відповідному пристрої. JCT-VC працює над розвитком стандарту HEVC. Зусилля по стандартизації HEVC основані на моделі пристрою кодування відео, що розвивається, називаній тестовою моделлю HEVC (HM). HM передбачає декілька додаткових функціональних можливостей пристроїв кодування відео відносно існуючих пристроїв згідно, наприклад, з ITU-T H.264/AVC. Наприклад, тоді як H.264 забезпечує дев'ять режимів кодування з внутрішнім прогнозуванням, HM може забезпечити цілих тридцять три режими кодування з внутрішнім прогнозуванням. У цілому, робоча модель HM описує, що відеокадр або картинка можуть бути розділені на послідовність блоків дерева або найбільших одиниць кодування (LCU), що включають в себе вибірки і яскравості, і кольоровості. Блок дерева має мету, аналогічну макроблоку зі стандарту H.264. Вирізка включає в себе ряд послідовних блоків дерева в порядку кодування. Відеокадр або картинка можуть бути розділені на одну або більше вирізок. Кожен блок дерева може бути розділений на одиниці кодування (CU) згідно з квадродеревом. Наприклад, блок дерева, як кореневий вузол квадродерева, може бути розділений на чотири дочірніх вузли, і кожен дочірній вузол може у свою чергу бути батьківським вузлом і бути розділений ще на чотири дочірніх вузли. Заключний, нерозділений дочірній вузол, як листовий вузол квадродерева, містить вузол кодування, тобто закодований блок відео. Дані синтаксису, асоційовані з закодованим потоком бітів, можуть визначити максимальну кількість разів, скільки блок дерева може бути розділений, і може також визначити мінімальний розмір вузлів кодування. 8 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 CU включає в себе вузол кодування й одиниці прогнозування (PU) і одиниці перетворення (TU), асоційовані з вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен бути квадратним за формою. Розмір CU може ранжуватися від 8×8 пікселів до розміру блока дерева з максимумом 64×64 пікселів або більше. Кожна CU може містити одну або більш PU і одну або більш TU. Дані синтаксису, асоційовані з CU, можуть описувати, наприклад, розділення CU в одну або більше PU. Режим розділення може відрізнятися між тим, чи є CU закодованою в режимі пропускання або прямому, закодованою в режимі внутрішнього прогнозування або закодованою в режимі зовнішнього прогнозування. Одиниці PU можуть бути розділені, щоб бути неквадратними за формою. Дані синтаксису, асоційовані з CU, можуть також описувати, наприклад, розділення CU в одну або більше TU згідно з квадродеревом. TU може бути квадратною або неквадратною за формою. Стандарт HEVC забезпечує перетворення згідно з TU, що можуть бути різними для різних CU. TU типово вимірюється на основі розміру одиниць PU у межах заданої CU, визначеної для розділеної LCU, хоча це може не завжди мати місце. Одиниці TU типово мають той же розмір або менший, ніж одиниці PU. У деяких прикладах залишкові вибірки, що відповідають CU, можуть бути підрозділені на менші одиниці, використовуючи структуру квадродерева, відому як "залишкове квадродерево" (RQT). Листові вузли RQT можуть згадуватися як одиниці перетворення (TU). Значення пікселної різниці, асоційовані з одиницями TU, можуть бути перетворені, щоб сформувати коефіцієнти перетворення, які можуть бути квантовані. Звичайно PU включає в себе дані, що стосуються процесу прогнозування. Наприклад, коли PU є закодованою у внутрішньому режимі, PU може включати в себе дані, що описують режим внутрішнього прогнозування для PU. Як інший приклад, коли PU є закодованою в зовнішньому режимі, PU може включати в себе дані, що визначають вектор руху для PU. Дані, що визначають вектор руху для PU, можуть описувати, наприклад, горизонтальний компонент вектора руху, вертикальний компонент вектора руху, розрізнення для вектора руху (наприклад, пікселну точність в одну чверть або пікселну точність в одну восьму), опорну картинку, на яку вектор руху вказує, і/або список опорних картинок (наприклад, Список 0, Список 1 або Список C) для вектора руху. Взагалі, TU використовується для процесів квантування і перетворення. Задана CU, що має одну або більше одиниць PU, може також включати в себе одну або більше одиниць перетворення (TU). Додержуючись прогнозування, відеокодер 20 може обчислити залишкові значення, що відповідають PU. Залишкові значення містять значення пікселної різниці, що можуть бути перетворені в коефіцієнти перетворення, квантовані і скановані, використовуючи одиниці TU, щоб сформувати перетворені в послідовну форму коефіцієнти перетворення для ентропійного кодування. Дане розкриття звичайно використовує термін "блок відео", щоб посилатися на вузол кодування CU. У деяких конкретних випадках дане розкриття може також використовувати термін "блок відео", щоб посилатися на блок дерева, тобто LCU, або CU, що включає в себе вузол кодування й одиниці PU і одиниці TU. Відеопослідовність типово включає в себе послідовність відеокадрів або картинок. Група картинок (GOP) загалом містить послідовність з однієї або більше відеокартинок. GOP може включати дані синтаксису в заголовку GOP, заголовку однієї або більше картинок або ще будьде, які описують кількість картинок, включених у GOP. Кожна вирізка картинки може включати в себе дані синтаксису вирізки, що описують режим кодування для відповідної вирізки. Відеокодер 20 типово оперує над блоком відео в межах індивідуальних відеовирізок, щоб закодувати дані відео. Блок відео може відповідати вузлу кодування в межах CU. Блоки відео можуть мати фіксований або змінний розмір і можуть відрізнятися за розміром відповідно до зазначеного стандарту кодування. Як приклад HM підтримує прогнозування в різних розмірах PU. Передбачаючи, що розмір конкретної CU дорівнює 2N×2N, HM підтримує внутрішнє прогнозування в розмірах PU 2N×2N або N×N і зовнішнє прогнозування в симетричних розмірах PU 2N×2N, 2N×N, N×2N або N×N. HM також підтримує асиметричне розділення для зовнішнього прогнозування в розмірах PU 2NnU, 2NnD, nL2N і nR2N. При асиметричному розділенні один напрямок CU не розділяється, у той час як інший напрямок розділяється на 25 % і 75 %. Частина CU, що відповідає 25 %-ому розділенню, позначена "n", що супроводжується індикацією "верхній", "нижній", "лівий" або "правий". Таким чином, наприклад, "2NnU" посилається на CU розміром 2N2N, що розділена горизонтально з PU розміром 2N0,5N вверху і PU розміром 2N1,5N внизу. У даному розкритті "NN" і "N на N" можуть використовуватися взаємозамінно, щоб посилатися на вимірювання у пікселах блока відео в термінах вертикальних і горизонтальних вимірювань, наприклад 16×16 пікселів або 16 на 16 пікселів. Взагалі блок 1616 має 16 пікселів 9 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 у вертикальному напрямку (y=16) і 16 пікселів у горизонтальному напрямку (x=16). Аналогічно, блок NN взагалі має N пікселів у вертикальному напрямку і N пікселів у горизонтальному напрямку, де N представляє ненегативне цілочислове значення. Піксели в блоці можуть бути розміщені в рядках і стовпцях. Крім того, блоки не обов'язково повинні мати ту ж кількість пікселів у горизонтальному напрямку, що і у вертикальному напрямку. Наприклад, блоки можуть містити піксели NM, де М не обов'язково дорівнює N. Після кодування з внутрішнім прогнозуванням або зовнішнім прогнозуванням, використовуючи одиниці PU у CU, відеокодер 20 може обчислити залишкові дані для одиниць TU у CU. Одиниці PU можуть містити пікселні дані в просторовій області (також називаній пікселною областю), і одиниці TU можуть містити коефіцієнти в області перетворення після застосування перетворення, наприклад дискретного косинусного перетворення (DCT), цілочислового перетворення, вейвлет-перетворення або концептуально подібного перетворення, до залишкових відеоданих. Залишкові дані можуть відповідати пікселним різницям між пікселами незакодованої картинки і значеннями прогнозування, що відповідають одиницям PU. Відеокодер 20 може сформувати одиниці TU, включаючи залишкові дані для CU, і потім перетворити одиниці TU, щоб сформувати коефіцієнти перетворення для CU. Після будь-якого перетворення, щоб сформувати коефіцієнти перетворення, відеокодер 20 може виконати квантування коефіцієнтів перетворення. Квантування взагалі належить до процесу, у якому коефіцієнти перетворення квантуються, щоб можливо зменшити об'єм даних, використаних для представлення коефіцієнтів, забезпечуючи подальше стиснення. Процес квантування може зменшити бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, значення n-бітів може бути округлене в меншу сторону до m-бітового значення під час квантування, де n більше m. У деяких прикладах відеокодер 20 може використовувати попередньо заданий порядок сканування, щоб сканувати квантовані коефіцієнти перетворення, щоб сформувати перетворений у послідовну форму вектор, що може бути ентропійно кодований. В інших прикладах відеокодер 20 може виконати адаптивне сканування. Після перегляду квантованих коефіцієнтів перетворення, щоб сформувати одновимірний вектор, відеокодер 20 може ентропійно кодувати одновимірний вектор, наприклад, відповідно до контекстно-адаптивного кодування зі змінною довжиною коду (CAVLC), контекстно-адаптивного двійкового арифметичного кодування (CABAC), основаного на синтаксисі контекстно-адаптивного двійкового арифметичного кодування (SBAC), ентропійного кодування з розділенням інтервалу імовірності (PIPE) або іншої методології ентропійного кодування. Відеокодер 20 може також ентропійно кодувати елементи синтаксису, асоційовані з закодованими відеоданими, для використання відеодекодером 30 при декодуванні даних відео. Щоб виконати CABAC, відеокодер 20 може призначити контекст у межах контекстної моделі символу, що повинен бути переданий. Контекст може стосуватися того, наприклад, чи є сусідні значення символу ненульовими або ні. Щоб виконати CAVLC, відеокодер 20 може вибрати код зі змінною довжиною слова для символу, що повинен бути переданий. Кодові слова в VLC можуть бути побудовані таким чином, що відносно більш короткі коди відповідають більш ймовірним символам, у той час як більш довгі коди відповідають менш ймовірним символам. Таким чином, використання VLC може досягти економії бітів, наприклад, використовуючи ключові слова рівної довжини для кожного символу, що повинен бути переданий. Визначення імовірності може бути основане на контексті, призначеному на символ. Дане розкриття описує способи побудови для наборів параметрів, включаючи як набори параметрів відео, так і набори параметрів послідовності, які можуть бути застосовані при кодуванні єдиного рівня, так само як масштабоване кодування і кодування множинних видів взаємно сумісним способом. Кодування відео з множинними видами (MVC) є розширенням H.264/AVC. Специфікація MVC коротко описана нижче. ФІГ. 2 є графічною діаграмою, що ілюструє приклад кодування або порядок декодування MVC відповідно до одного або більше прикладів, описаних в даному розкритті. Наприклад, компонування порядку декодування, ілюстроване на ФІГ. 2, згадується як початкове кодування. На ФІГ. 2, S0-S7, кожний, посилаються на різні види відео з множинними видами. T0-T8, кожне, представляють один момент часу виведення. Одиниця доступу може включати в себе закодовані картинки усіх видів для одного моменту часу виведення. Наприклад, перша одиниця доступу включає в себе усі види S0-S7 для моменту часу T0 (тобто картинки 0-7), друга одиниця доступу включає в себе усі види S0-S7 для моменту часу T1 (тобто картинки 8-15), і т. д. У цьому приклади картинки 0-7 знаходяться в одному і тому ж моменті часу (тобто момент часу T0), картинки 8-15 знаходяться в одному і тому ж моменті часу (тобто момент часу T1). Картинки з одним і тим же моментом часу взагалі показані в один і той же час, і є різниця по 10 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 горизонталі, і можливо невелика різниця по вертикалі, між об'єктами в межах картинок одного і того ж моменту часу, які змушують глядача сприймати зображення, що охоплює 3D-об'єм. На ФІГ. 2 кожний з видів включає в себе набори картинок. Наприклад, вид S0 включає в себе набір картинок 0, 8, 16, 24, 32, 40, 48, 56 і 64, вид S1 включає в себе набір картинок 1, 9, 17, 25, 33, 41, 49, 57 і 65, і т. д. Кожен набір включає в себе дві картинки: одна картинка згадується як компонент виду текстури, а інша картинка згадується як компонент виду глибини. Компонент виду текстури і компонент виду глибини в межах набору картинок виду можна розглядати як відповідні один одному. Наприклад, компонент виду текстури в межах набору картинок виду можна розглядати як відповідний компоненту виду глибини в межах набору картинок виду, і навпаки (тобто компонент виду глибини відповідає своєму компоненту виду текстури в наборі, і навпаки). Як використовується в даному розкритті, компонент виду текстури і компонент виду глибини, що відповідні, можуть бути розглянуті як частина одного і того ж виду єдиної одиниці доступу. Компонент виду текстури включає в себе фактичний контент зображення, який відображається. Наприклад, компонент виду текстури може включати в себе компоненти яскравості (Y) і кольоровості (Cb і Cr). Компонент виду глибини може вказувати, що відносні глибини пікселів у його відповідному компоненті виду текстури. Як один приклад, компонент виду глибини може бути аналогічним зображенню шкали сірого, котра включає в себе тільки значення яскравості. Іншими словами, компонент виду глибини може не передавати контент зображення, а замість цього забезпечує міру відносних глибин пікселів у компоненті виду текстури. Наприклад, пікселне значення, що відповідає чисто білому пікселу в компоненті виду глибини, може вказувати, що його відповідний піксел або піксели у відповідному компоненті виду текстури знаходяться ближче з точки зору глядача, і пікселне значення, що відповідає чисто чорному пікселу в компоненті виду глибини, може вказувати, що його відповідний піксел або піксели у відповідному компоненті виду текстури знаходяться далі від перспективи глядача. Пікселні значення, що відповідають різним відтінкам сірого між чорним і білим, указують різні рівні глибини. Наприклад, дуже сірий піксел у компоненті виду глибини вказує, що його відповідний піксел у компоненті виду текстури знаходиться далі, ніж слабко-сірий піксел у компоненті виду глибини. Оскільки тільки одне пікселне значення, аналогічне шкалі сірого, необхідне, щоб ідентифікувати глибину пікселів, компонент виду глибини може включати в себе тільки одне пікселне значення. Таким чином, значення, аналогічні компонентам кольоровості, не є необхідними при кодуванні глибини. Компонент виду глибини, що використовує тільки значення яскравості (наприклад, значення інтенсивності), щоб ідентифікувати глибину, наданий з метою ілюстрації і не повинен розглядатися як обмеження. В інших прикладах будь-який метод може бути використаний, щоб указати відносні глибини пікселів у компоненті виду текстури. Відповідно до MVC, компоненти виду текстури є прогнозованими зовнішньо з компонентів виду текстури в одному і тому ж виді або з компонентів виду текстури в одному або більше інших видах. Компоненти виду текстури можуть бути закодовані в блоках даних відео, що згадуються "як блоки відео" і звичайно називаються "макроблоками" у контексті H.264. У MVC прогнозування між видами підтримується компенсацією руху різниці, що використовує синтаксис компенсації руху згідно з H.264/AVC, але дозволяє картинці в іншому виді використовуватися як опорна картинка для прогнозування закодованої картинки. Кодування двох видів може також підтримуватися за допомогою MVC. Одна потенційна перевага MVC полягає в тому, що кодер MVC може взяти більше ніж два види як вхідне 3D-відео, і декодер MVC може декодувати таке представлення з множинними видами захопленого відео. Будь-який модуль відтворення з декодером MVC може обробляти контенти 3D-відео з більше ніж двома видами. У MVC прогнозування між видами дозволяється між картинками в одній і тій же одиниці доступу (тобто з тим же самим моментом часу). При кодуванні картинки в небазовому виді картинка може бути додана в список опорних картинок, якщо картинка знаходиться в іншому виді, але з тим же самим моментом часу. Опорна картинка прогнозування між видами може бути поміщена в будь-яку позицію списку опорних картинок, точно так само, як будь-яка опорна картинка при зовнішньому прогнозуванні. ФІГ. 3 є концептуальною діаграмою, що ілюструє зразковий шаблон прогнозування MVC. У прикладі на ФІГ. 3 ілюстровані вісім видів (що мають ідентифікатори виду "S0"-"S7"), і дванадцять часових місцеположень ("T0"-"T11") ілюструються для кожного виду. Таким чином, кожен рядок на ФІГ. 3 відповідає виду, у той час як кожен стовпчик указує часове місцеположення. У прикладі на ФІГ. 3, заголовні "B" і рядкові "b" букви використовуються для 11 UA 115335 C2 5 10 15 20 25 30 35 40 45 50 55 60 указання різних ієрархічних відношень між картинками, а не різних методологій кодування. У цілому, картинки з заголовними "B" знаходяться відносно вище в ієрархії прогнозування, ніж кадри з рядковими "b". На ФІГ. 3 вид S0 може бути розглянутий як базовий вид, і види S1-S7 можуть бути розглянуті як залежні види. Базовий вид включає в себе картинки, що не є прогнозованими між видами. Картинка в базовому виді може бути прогнозована зовнішньо відносно інших картинок у тому ж самому виді. Наприклад, жодна з картинок у полі зору S0 не може бути прогнозована зовнішньо відносно картинки в будь-якому з видів S1-S7, але деякі з картинок у виді S0 можуть бути прогнозовані зовнішньо відносно інших картинок у виді S0. Залежний вид включає в себе картинки, що є прогнозованими між видами. Наприклад, кожний один з видів S1-S7 включає в себе щонайменше одну картинку, що є прогнозованою зовнішньо відносно картинки в іншому виді. Картинки в залежному виді можуть бути прогнозовані зовнішньо відносно картинок у базовому виді або можуть бути прогнозовані зовнішньо відносно картинок в інших залежних видах. Потік відео, що включає в себе і базовий вид, і один або більше залежних видів, може бути декодованим за допомогою різних типів відеодекодерів. Наприклад, один основний тип відеодекодера може бути сконфігурований, щоб декодувати тільки базовий вид. Крім того, інший тип відеодекодера може бути сконфігурований, щоб декодувати кожний з видів S0-S7. Декодер, який конфігурується, щоб декодувати і базовий вид, і залежні види, може згадуватися як декодер, що підтримує кодування з множинними видами. Картинки на ФІГ. 3 позначені в перетинанні кожного рядка і кожного стовпчика на ФІГ. 3. Стандарт H.264/AVC з розширеннями MVC може використовувати термін "кадр", щоб представити частину відео, у той час як стандарт HEVC може використовувати термін "картинка", щоб представити частину відео. Дане розкриття використовує терміни картинка і кадр взаємозамінно. Картинки на ФІГ. 3 ілюструються, використовуючи затемнений блок, що включає в себе букву, яка позначає, чи кодована внутрішньо відповідна картинка (тобто I-картинка), кодована зовнішньо в одному напрямку (тобто як P-картинка) або кодована зовнішньо в множинних напрямках (тобто як B- картинка). Звичайно прогнозування вказуються стрільцями, де картинки, на які вказують, використовують картинки, з яких указують для посилання прогнозування. Наприклад, P-картинка виду S2 у часовому місцеположенні T0 прогнозована з I-картинки виду S0 у часовому місцеположенні T0. Як з кодуванням відео з єдиним видом, картинки послідовності відео кодування відео з множинними видами можуть бути закодовані з прогнозуванням відносно картинок в інших часових місцеположеннях. Наприклад, B-картинка виду S0 у часовому місцеположенні T1 має стрілку, що вказує на неї з I-картинки виду S0 у часовому місцеположенні T0, указуючи, що bкартинка прогнозована з I-картинки. Додатково, однак, у контексті кодування відео з множинними видами, картинки можуть бути прогнозованими між видами. Таким чином, компонент виду (наприклад, компонент виду текстури) може використовувати компоненти виду в інших видах для посилання. У MVC, наприклад, реалізується прогнозування між видами, як якщо компонент виду в іншому виді є посиланням зовнішнього прогнозування. Потенційні посилання між видами сигналізуються в розширенні MVC набору параметрів послідовності (SPS) і можуть бути модифіковані процесом побудови списку опорних картинок, що дозволяє гнучке упорядкування посилань зовнішнього прогнозування або прогнозування між видами. ФІГ. 3 забезпечує різні приклади прогнозування між видами. Картинки виду S1, у прикладі на ФІГ. 3, ілюструються як прогнозовані з картинок в інших часових місцеположеннях виду S1, а також як прогнозовані між видами з картинок видів S0 і S2 у одних і тих же часових місцеположеннях. Наприклад, B-картинка виду S1 у часовому місцеположенні T1 прогнозується з кожної з B-картинок виду S1 у часових місцеположеннях T0 і T2, так само як B-картинок видів S0 і S2 у часовому місцеположенні T1. ФІГ. 3 також ілюструє зміни в ієрархії прогнозування, використовуючи різні рівні затінення, де кадри з більшою величиною затінення (тобто відносно більш темні) знаходяться вище в ієрархії прогнозування, ніж кадри, що мають менше затінення (тобто відносно більш світлі). Наприклад, усі I-картинки на ФІГ. 3 ілюструються з повним затіненням, у той час як P-картинки мають трохи більш світле затінення, і B-картинки (і рядкові b-картинки) мають різні рівні затінення одна відносно одної, але завжди світліше, ніж затінення P-картинок і I-картинок. Звичайно ієрархія прогнозування може стосуватися індексів порядку видів, у якому картинки відносно вище в ієрархії прогнозування повинні бути декодовані раніше декодування картинок, що знаходяться відносно нижче в ієрархії. Картинки відносно вище в ієрархії можуть бути використані як опорні картинки під час декодування картинок, відносно більш низьких в ієрархії. 12 UA 115335 C2 5 10 15 20 25 30 35 40 Індекс порядку виду є індексом, що вказує порядок декодування компонентів виду в одиниці доступу. Індекси порядку виду маються на увазі в розширенні MVC набору параметрів послідовності (SPS), як визначено в Додатку H для H.264/AVC (поправка MVC). У SPS для кожного індексу і сигналізується відповідний view_id. Декодування компонентів виду може додержуватися зростаючого порядку індексу порядку виду. Якщо усі види представлені, то індекси порядку виду знаходяться в послідовному порядку від 0 до num_views_minus_1. У цьому способі картинки, використовувані як опорні картинки, декодуються перед картинками, що залежать від опорних картинок. Індекс порядку виду є індексом, що вказує порядок декодування компонентів виду в одиниці доступу. Для кожного індексу і порядку виду сигналізується відповідний view_id. Декодування компонентів виду додержується зростаючого порядку індексів порядку виду. Якщо усі види представлені, то набір індексів порядку виду може містити послідовно упорядкований набір від нуля до менше ніж повна кількість видів. Для деяких картинок на рівних рівнях ієрархії порядок декодування може не мати значення. Наприклад, I-картинка виду S0 у часовому місцеположенні T0 може використовуватися як опорна картинка для P-картинки виду S2 у часовому місцеположенні T0, яка, у свою чергу, може використовуватися як опорна картинка для P-картинки виду S4 у часовому місцеположенні T0. Відповідно, I-картинка виду S0 у часовому місцеположенні T0 повинна бути декодована перед P-картинкою виду S2 у часовому місцеположенні T0, яка, у свою чергу, повинна бути декодована перед P-картинкою виду S4 у часовому місцеположенні T0. Однак, між видами S1 і S3 порядок декодування не має значення, оскільки види S1 і S3 не покладаються один на одний для прогнозування. Замість цього види S1 і S3 прогнозуються тільки з інших видів, що знаходяться вище в ієрархії прогнозування. Крім того, вид S1 може бути декодований перед видом S4, поки вид S1 декодується після видів S0 і S2. У цьому способі ієрархічне упорядкування може бути використане для опису видів S0-S7. У даному розкритті нотація "SA>SB" означає, що вид SA повинен бути декодований перед видом SB. Використовуючи цю нотацію S0>S2>S4>S6>S7, у прикладі на ФІГ. 2. Крім того, з посиланнями на приклад на ФІГ. 2, S0>S1, S2>S1, S2>S3, S4>S3, S4>S5 і S6>S5. Будь-який порядок декодування для видів, що не порушує це ієрархічне упорядкування, можливий. Відповідно, можливі багато різних порядків декодування, з обмеженнями на основі ієрархічного упорядкування. Розширення MVC SPS описане нижче. Компонент виду може використовувати компоненти виду в інших видах для посилання, що називають прогнозуванням між видами. У MVC реалізується прогнозування між видами, як якщо компонент виду віншому виді був посиланням зовнішнього прогнозування. Потенційні посилання між видами, однак, сигналізуються в розширенні MVC набору параметрів послідовності (SPS) (як показано в наступній таблиці синтаксису, Таблиці 1) і можуть бути модифіковані процесом побудови списку опорних картинок, що дозволяє гнучке упорядкування посилань зовнішнього прогнозування або прогнозування між видами. Відеокодер 20 представляє приклад відеокодера, сконфігурованого, щоб генерувати синтаксис, як показано в Таблиці 1, і відеодекодер 30 представляє приклад відеодекодера, сконфігурованого, щоб синтаксично розбирати й обробляти такий синтаксис. Таблиця 1 seq_parameter_set_mvc_extension() { num_views_minus1 for(i=0; i
ДивитисяДодаткова інформація
Назва патенту англійськоюVideo parameter set for hevc and extensions
Автори англійськоюChen, Ying, Wang, Ye-Kui
Автори російськоюЧень Ин, Ван Е-Куй
МПК / Мітки
МПК: H04N 19/30, H04N 19/70, H04N 19/597
Мітки: набір, розширень, відео, параметрів
Код посилання
<a href="https://ua.patents.su/62-115335-nabir-parametriv-video-dlya-hevc-i-rozshiren.html" target="_blank" rel="follow" title="База патентів України">Набір параметрів відео для hevc і розширень</a>
Індикація та активація наборів параметрів для кодування відео

Номер патенту: 114339
Опубліковано: 25.05.2017
Автор: Ван Є-Куй
МПК: H04N 19/70, H04N 19/46, H04N 19/30
Мітки: індикація, наборів, параметрів, активація, кодування, відео
Формула / Реферат:
1. Спосіб декодування відеоданих, причому спосіб включає:декодування потоку бітів, який включає в себе відеодані та інформацію синтаксису для декодування відеоданих, при цьому інформація синтаксису містить повідомлення додаткової інформації розширення (SEI) активних наборів параметрів, при цьому повідомлення SEI активних наборів параметрів вказує один або більше наборів параметрів послідовності (SPS) і набір параметрів відео (VPS),...
Індикація та активація наборів параметрів для кодування відео

Номер патенту: 114929
Опубліковано: 28.08.2017
Автор: Ван Є-Куй
МПК: H04N 19/30, H04N 19/50, H04N 19/70, H04N 19/46
Мітки: наборів, кодування, індикація, параметрів, відео, активація
Формула / Реферат:
1. Спосіб декодування відеоданих, причому спосіб містить: декодування потоку бітів, який включає в себе відеодані та інформацію синтаксису для декодування відеоданих, в якому інформація синтаксису містить повідомлення додаткової інформації розширення (SEI) активних наборів параметрів одиниці доступу, в якому повідомлення SEI активних наборів параметрів вказує множину наборів параметрів послідовності (SPSs) і набір параметрів відео...
Сигналізація параметрів фільтра видалення блочності при кодуванні відео

Номер патенту: 113072
Опубліковано: 12.12.2016
Автори: Карчєвіч Марта, Ван Є-Куй, Ван Дер Аувера Герт
МПК: H04N 7/00
Мітки: блочності, кодуванні, видалення, параметрів, відео, сигналізація, фільтра
Формула / Реферат:
1. Спосіб декодування відеоданих, причому спосіб включає етапи, на яких:декодують перший синтаксичний елемент, заданий для вказівки, чи присутні параметри фільтра видалення блочності як в наборі параметрів рівня зображення, так і в заголовку слайсу;коли перший синтаксичний елемент вказує, що параметри фільтра видалення блочності присутні як в наборі параметрів рівня зображення, так і в заголовку слайсу, декодують другий...
Кодування наборів параметрів і заголовків одиниць nal для кодування відео

Номер патенту: 113752
Опубліковано: 10.03.2017
МПК: H04N 19/70, H04N 19/46, H04N 19/31
Мітки: одиниць, кодування, параметрів, наборів, відео, заголовків
Формула / Реферат:
1. Спосіб кодування відеоданих, який включає етапи, на яких:кодують набір параметрів відео (VPS) для бітового потоку, який містить множину рівнів відеоданих, при цьому кожний із згаданої множини рівнів відеоданих звертається до VPS, і при цьому кодування VPS містить:кодування даних VPS, що вказують деяке число кадрів, які повинні бути переупорядковані в щонайменше одному зі згаданої множини рівнів відеоданих,кодування...
Сигналізування взаємозв’язків номерів в порядку зображень і інформації синхронізації для синхронізації відео при кодуванні відео

Номер патенту: 115163
Опубліковано: 25.09.2017
Автор: Ван Є-Куй
МПК: H04N 19/149, H04N 19/46, H04N 19/70, H04N 19/44
Мітки: кодуванні, взаємозв'язків, відео, синхронізації, порядку, інформації, номерів, сигналізування, зображень
Формула / Реферат:
1. Спосіб обробки відеоданих, при цьому спосіб включає етапи, на яких:приймають (700) кодовану відеопослідовність, що містить кодовані зображення відеопослідовності; іприймають (702) параметри синхронізації для кодованої відеопослідовності, які включають в себе указання відносно того, є чи ні значення номера в порядку зображень (РОС) для кожного зображення в кодованій відеопослідовності, яке не є першим зображенням в кодованій...
Попередній патент: Пристрій для зачищування електричних кабелів з використанням фіолетових або синіх лазерних діодів
Наступний патент: Гербіцидні композиції, які містять 4-аміно-3-хлор-5-фтор-6-(4-хлор-2-фтор-3-метоксифеніл)піридин-2-карбонову кислоту
Випадковий патент: Спосіб отримання гранул та пристрій для його здійснення