Спосіб і пристрій для кодування і оптимальної реконструкції тривимірного акустичного поля







Формула / Реферат
1. Спосіб кодування аудіосигналів і просторової інформації, що стосується їх, в формат, який не залежить від схеми відтворення, причому спосіб включає в себе:
a) призначення першого набору аудіосигналів, які вимагають вузької локалізації, в першу групу, і кодування першої групи як набору моноаудіодоріжок з асоційованими метаданими, що описують напрямок джерела сигналу кожної доріжки відносно позиції запису і час початку його відтворення,
b) призначення другого набору з решти аудіосигналів у другу групу і кодування другої групи як щонайменше одного набору доріжок амбіофонії даного порядку і змішування порядків, і
с) генерування двох груп доріжок, що містять перший і другий набори аудіосигналів.
2. Спосіб за п. 1, що додатково містить кодування параметрів рознесення, асоційованих з доріжками в наборі моноаудіодоріжок.
3. Спосіб за п. 1, що додатково містить кодування додаткових параметрів спрямованості, асоційованих з доріжками в наборі моноаудіодоріжок.
4. Спосіб за п. 1, що додатково містить отримання напрямку джерела сигналів для доріжок в першому наборі з будь-якого тривимірного представлення сцени, що містить звукові джерела, асоційовані з доріжками, і положення запису.
5. Спосіб за п. 1, що додатково містить призначення напрямку джерела сигналів для доріжок в першому наборі відповідно до попередньо визначених правил.
6. Спосіб за п. 1, що додатково містить кодування параметрів спрямованості для кожної доріжки в першому наборі або у вигляді фіксованих сталих значень, або значень, що змінюються з часом.
7. Спосіб за п. 1, що додатково містить кодування метаданих, що описують специфікацію використовуваного формату амбіофонії, наприклад порядок амбіофонії, тип змішування порядків, коефіцієнти посилення доріжок і впорядковування доріжок.
8. Спосіб за п. 1, що додатково містить кодування часу початку відтворення, асоційоване з доріжками амбіофонії.
9. Спосіб за п. 1, що додатково містить кодування вхідних моносигналів з асоційованими даними спрямованості в доріжки амбіофонії даного порядку і змішування порядків.
10. Спосіб за п. 1, що додатково містить кодування будь-яких вхідних багатоканальних сигналів в доріжки амбіофонії даного порядку і змішування порядків.
11. Спосіб за п. 1, що додатково містить кодування будь-яких вхідних амбіофонічних сигналів будь-якого порядку і змішування порядків в доріжки амбіофонії, можливо, іншого даного порядку і змішування порядків.
12. Спосіб за п. 1, що додатково містить перекодування формату, що не залежить від схеми відтворення, причому перекодування включає в себе щонайменше одне з наступного:
a) призначення доріжок з набору монодоріжок в набір амбіофонії,
b) призначення частин аудіо з набору амбіофонії в набір монодоріжок, можливо, включаючи отриману інформацію про спрямованість з амбіофонічних сигналів,
с) зміна порядку або змішування порядків набору доріжок амбіофонії,
d) зміна метаданих спрямованості, асоційованих з набором моно доріжок,
e) зміна доріжок амбіофонії за допомогою виконання операцій, таких як обертання і масштабування.
13. Спосіб за п. 12, що додатково містить перекодування формату, що не залежить від схеми відтворення, в формат, що застосовується для широкомовної передачі, причому перекодування задовольняє наступні обмеження: фіксована кількість безперервних аудіопотоків, використання доступних протоколів для передачі метаданих, що містяться в форматі, який не залежить від схеми відтворення.
14. Спосіб за п. 1, який додатково містить декодування формату, що не залежить від схеми відтворення для даного комплексу з декількох гучномовців, причому декодування використовує специфікацію позицій декількох гучномовців для:
а) декодування набору монодоріжок з використанням алгоритмів, застосовних для відтворення вузьконаправлених звукових джерел;
b) декодування набору доріжок амбіофонії за допомогою алгоритмів, адаптованих для порядку доріжок і змішування порядків, і для специфікованого комплексу.
15. Спосіб за п. 14, що додатково містить використання параметрів рознесення, і, можливо, інших просторових метаданих, асоційованих з набором монодоріжок для використання алгоритмів декодування, застосовних для специфікованого рознесення.
16. Спосіб за п. 14, що додатково містить використання стандартних попередніх настройок схем відтворення, наприклад, стерео і surround 5.1, ITU-R775-1.
17. Спосіб за п. 14, що додатково містить декодування для навушників, за допомогою стандартної технології стереофонії, з використанням баз даних функцій передачі, що враховує особливості сприйняття.
18. Спосіб за п. 14, що додатково містить використання параметрів керування обертанням для виконання обертання повної звукової сцени, причому такі параметри керування можуть бути сформовані, наприклад, пристроями, що відстежують положення голови.
19. Спосіб за п. 14, що додатково містить використання технології для автоматичного отримання позиції гучномовців, для визначення специфікації комплексу для використання декодером.
20. Спосіб за п. 14 або 17, в якому вихідні дані декодування зберігають як набір аудіодоріжок, замість безпосереднього відтворення.
21. Спосіб за пп. 1, 12, 13 або 20, за допомогою якого аудіосигнали, повністю або частково, кодуються в стиснуті аудіоформати.
22. Аудіокодер для кодування аудіосигналів і просторової інформації, що стосується їх, в формат, який не залежить від схеми відтворення, причому кодер включає в себе:
a) кодер для призначення першого набору аудіосигналів, які вимагають вузької локалізації, в першу групу і кодування першої групи в набір монодоріжок з інформацією про спрямованість і час початку відтворення,
b) кодер для призначення другого набору з решти аудіосигналів у другу групу і кодування другої групи в набір доріжок амбіофонії будь-якого порядку і змішування порядків, і
c) кодер для генерації двох групп доріжок, що містять перший і другий набори аудіосигналів.
23. Пристрій для перекодування і перетворення аудіо для маніпулювання і перекодування аудіо у вхідному форматі, який не залежить від схеми відтворення, причому вихідні дані перетворюються згідно зі способом за п. 12, причому пристрій для перекодування виконаний з можливістю виконання щонайменше одного з нижченаведеного:
a) призначати доріжки з набору монодоріжок в набір амбіофонії,
b) призначати частини аудіо з набору амбіофонії в набір монодоріжок, по можливості включаючи отриману з сигналів амбіофонії інформацію про спрямованість,
с) змінювати порядок або змішування порядків набору доріжок амбіофонії,
d) змінювати метадані спрямованості, асоційовані з набором моно доріжок,
e) змінювати доріжки амбіофонії за допомогою таких операцій, як обертання і масштабування.
24. Аудіодекодер для декодування формату, що не залежить від схеми відтворення, для даної системи відтворення з N каналами, причому формат, який не залежить від схеми відтворення, генерують згідно зі способом за п. 1, причому аудіодекодер містить:
a) декодер для декодування набору монодоріжок з інформацією про спрямованість і час початку відтворення в N аудіоканалів на основі специфікації комплексу відтворення,
b) декодер для декодування набору доріжок амбіофонії в N аудіоканалів на основі специфікації комплексу відтворення,
с) мікшер для змішування вихідних даних двох попередніх декодерів для генерації N вихідних аудіоканалів, готових для відтворення або збереження.
25. Система для кодування і перекодування просторового аудіо в форматі, що не залежить від схеми відтворення, і для декодування і відтворення в будь-якому комплексі декількох гучномовців або для навушників, причому система містить:
а) аудіокодер для кодування набору аудіосигналів і просторової інформації, що стосується їх, в формат, який не залежить від схеми відтворення, як в п. 22,
b) пристрій для перекодування і перетворення аудіо для маніпулювання і перекодування аудіо у вхідному форматі, що не залежить від схеми відтворення, як в п. 23,
с) аудіодекодер для декодування формату, що не залежить від схеми відтворення, для даної системи відтворення або комплексу декількох гучномовців, або навушників, як в п. 24.
26. Комп'ютерочитаний носій інформації, який містить команди для реалізації способу за пп. 1-21 при виконанні їх на комп'ютері.
Текст
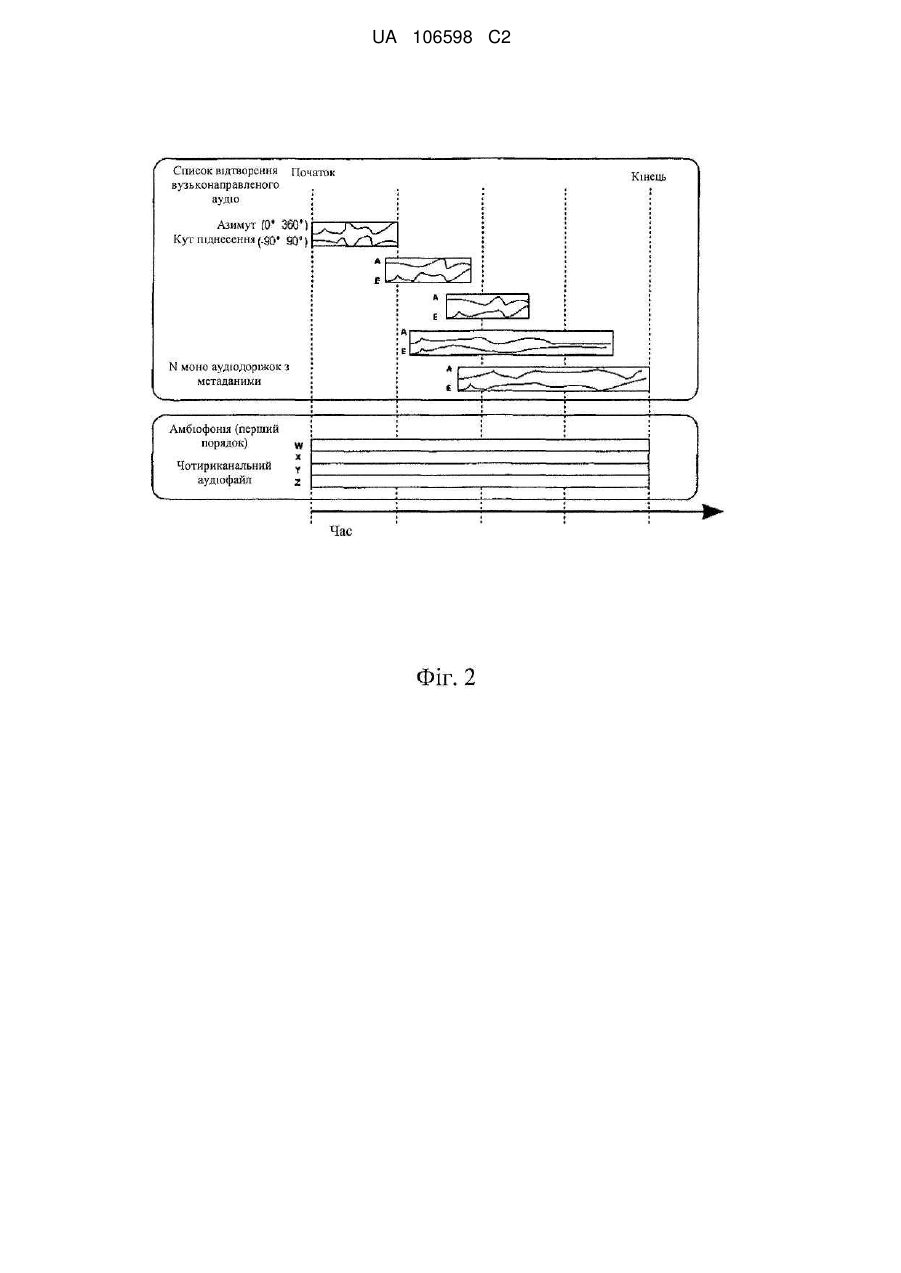
Реферат: Спосіб і пристрій для кодування аудіо з просторовою інформацією таким чином, який не залежить від демонстраційного комплексу, і для декодування і оптимального відтворення в будь-якому даному демонстраційному комплексі, максимально збільшуючи область найкращого сприйняття і включаючи комплекси з гучномовцями на різних висотах, а також навушники. Частину аудіо, що вимагає дуже точної локалізації, кодують в набір монодоріжок, з асоційованими параметрами спрямованості, в той час як аудіо, що залишилося, кодують в набір доріжок амбіофонії вибраного порядку і змішування. Після специфікації даної демонстраційної системи, формат, який не залежить від демонстрації, декодують, адаптуючи для специфікованої системи, використовуючи різні способи декодування для кожної призначеної групи. UA 106598 C2 (12) UA 106598 C2 UA 106598 C2 5 10 15 20 25 30 35 40 45 50 55 60 Галузь винаходу Даний винахід стосується технологій, що дозволяють поліпшити кодування, розподіл, і декодування тривимірного акустичного поля. Зокрема, даний винахід стосується технологій кодування аудіосигналів разом з просторовою інформацією незалежним від демонстраційного комплексу методом; і для оптимального декодування для даної демонстраційної системи, або комплексу гучномовців, або навушників. Попередній рівень техніки При багатоканальному відтворенні і прослуховуванні, слухач, звичайно, оточений множиною гучномовців. Як правило, однією задачею відтворення є створення акустичного поля, в якому слухач може сприймати намічені місцеположення джерел звуку, наприклад, розташування музиканта в групі. Різні комплекси гучномовців можуть створювати різні просторові враження. Наприклад, стандартні стерео комплекси можуть переконливо відтворювати акустичну сцену в просторі між двома гучномовцями, але не справляються з такою задачею при кутах поза простором між двома гучномовцями. Комплекси з великою кількістю гучномовців, оточуючих слухача, можуть досягати кращого просторового враження при більшому наборі кутів. Наприклад, одним з найбільш широко відомих стандартів комплексів декількох гучномовців є Surround 5.1 (ITU-R775-1), що складається з 5 гучномовців, розташованих по азимутах -30, 0, 30, -110, 110 градусів навколо слухача, де 0 означає фронтальний напрямок. Однак, такий комплекс не може справитися зі звуком, розташованим вище горизонтальної площини слухача. Для збільшення враження занурення у слухача, дані тенденції полягають в тому, щоб використовувати комплекси гучномовців з великою кількістю гучномовців, включаючи гучномовці, розташовані на різній висоті. Одним з прикладів є система 22.2, розроблена Hamasaki з NHK, Японія, яка складається з 24 гучномовців, розташованих на трьох різних висотах. У теперішньому часі, парадигма виробництва просторового аудіо в професійних застосуваннях таких комплексів полягає в тому, щоб надати одну аудіодоріжку для кожного каналу, що використовується при відтворенні. Наприклад, для стерео комплексу потрібно дві аудіодоріжки; для комплексу 5.1 потрібно шість аудіодоріжок, і т. п. Ці доріжки, звичайно, з'являються на етапі поствиробництва, хоча їх і можна створити безпосередньо на етапі запису для мовлення. Варто зазначити, що в багатьох випадках декілька гучномовців використовують для того, щоб відтворювати один і той же аудіоканал. Так йде справа у випадку більшості кінотеатрів 5.1, де кожен surround канал програють через три або більше гучномовці. Таким чином, в цих випадках, незважаючи на те, що кількість гучномовців може перевищувати 6, кількість різних аудіоканалів як і раніше 6, і, сумарно, програється тільки 6 різних сигналів. Одним з наслідків цієї парадигми "однієї доріжки на канал" є те, що робота, що виконується на етапах запису і поствиробництва, зв'язується з демонстраційним комплексом, на якому буде демонструватися створюваний інформаційний вміст (контент). На етапі запису, наприклад, при трансляції, тип і розташування використовуваних мікрофонів і метод мікшування визначається як функція від комплексу, на якому буде відтворюватися подія. Аналогічно, при виробництві носія, інженери поствиробництва повинні знати деталі комплексу, на якому буде демонструватися контент, і потурбуватися про кожен з каналів. Невдача при спробі правильно встановити демонстраційну схему з декількома гучномовцями, для якої був допрацьований контент, приведе до зниження якості відтворення. Якщо контент буде демонструватися на різних комплексах, то на етапі поствиробництва необхідно створити декілька версій. Це приводить до збільшення фінансових витрат і витрат часу. Іншим наслідком цієї парадигми "однієї доріжки на канал" є розмір необхідних даних. З одного боку, без додаткового кодування, парадигма вимагає стільки доріжок, скільки використовують каналів. З іншого боку, якщо необхідно надати декілька версій, то їх надають або окремо, що, знову-таки, збільшують розмір даних, або виконують деяке перетворення по зниженню кількості каналів, що погіршує якість результату. І нарешті, останнім недоліком парадигми "однієї доріжки на канал" є те, що зроблений таким чином контент не витримує перевірки часом. Наприклад, 6 доріжок, присутні в даному фільмі, виробленому для комплексу 5.1, не включають в себе джерела звуку, розташованих над слухачем, і не повністю введуть в дію комплекси, в яких гучномовці розташовані на різних висотах. У цей час існує декілька технологій, здатних надати просторове аудіо, що не залежить від демонстраційної системи. Можливо, найпростішою технологією є векторне амплітудне перенесення (VBAP). Воно основане на подачі одного і того ж моносигналу на гучномовці, найближчі до наміченого розташування джерела звуку, з регулюванням гучності для кожного гучномовця. Така система може працювати для двовимірних або тривимірних (з висотами) 1 UA 106598 C2 5 10 15 20 25 30 35 40 45 50 55 60 комплексів, звичайно, вибираючи два або три, відповідно, найближчих гучномовця. Одне з достоїнств цього способу полягає в тому, що він забезпечує велику зону найкращого сприйняття, що означає, що в комплексі гучномовців є велика область, в якій звук сприймають як такий, що виходить з наміченого напрямку. Однак, цей спосіб непридатний ні для відтворення полів реверберуючого звуку, таких, як присутні в ревербераційних камерах, ні для відтворення джерел звуку з великим рознесенням. Щонайбільше із застосуванням цих способів можна відтворити перші відображення звуку, що видається джерелами, але, проте, цей спосіб надає дороге і низькоякісне рішення. Іншою технологією, здатною надати просторове аудіо, незалежне від демонстраційної системи, є амбіофонія. Цю технологію розробив в 70-х Michael Gerzon, вона надає повну методологію ланцюга кодування-декодування. При кодуванні зберігається набір сферичних гармонік акустичного поля в одній точці. Нульовий порядок (W) відповідає тому, що запише всенаправлений мікрофон, розташований в цій точці. Перший порядок, що складається з трьох сигналів (X, Y, Z), відповідає тому, що запишуть в цій точці три мікрофони з діаграмою спрямованості у вигляді вісімки, вирівняні по осях декартової системи координат. Сигнали вищих порядків відповідають тому, що запишуть мікрофони в більш складних схемах розташування. Існує також кодування амбіофонії змішаного порядку, коли використовують тільки частину набору сигналів кожного порядку; наприклад, при використанні тільки сигналів W, X, Y з амбіофонії першого порядку, таким чином, ігноруючи сигнал Z. Не дивлячись на те, що генерація сигналів за межами першого порядку нескладна на етапі поствиробництва, або за допомогою моделювання акустичного поля, при записі даного акустичного поля мікрофонами це ускладняється; і дійсно, донедавна, для застосування в професійних галузях, були доступні тільки мікрофони, здатні вимірювати сигнали нульового і першого порядків. Приклад мікрофонів амбіофонії першого порядку являють собою мікрофони Soundfield, і сучасніші TetraMic. При декодування, після специфікування комплексу декількох гучномовців (кількість і положення кожного гучномовця), сигнал, що направляється на кожен гучномовець, звичайно визначають, вимагаючи максимального збігу акустичного поля, створеного комплексом загалом, з наміченим полем (або створеним на етапі поствиробництва, або тому, з якого були записані сигнали). Крім незалежності від демонстраційної системи, додатковими перевагами даної технології є високий рівень маніпуляції (в основному, обертанням і масштабуванням звукової сцени), що забезпечується нею, і її здатність точно відтворювати ревербераційне поле. Однак, технологія амбіофонії обмежена двома основними недоліками: нездатністю відтворювати близькі джерела звуку, і малий розмір зони найкращого сприйняття. Концепцію близьких або рознесених джерел звуку використовують в даному контексті як вказуючу кутову ширину звукової картини, що сприймається. Перша проблема виникає з факту того, що, навіть при спробі відтворити дуже вузьке джерело звуку, амбіофонічне декодування введе більше гучномовців, ніж в дію розташовану поблизу наміченої позиції джерела. Друга проблема виникає з того факту, що, незважаючи на розташування в зоні найкращого сприйняття, хвилі, що виходять з кожного гучномовця, фазово підсумовуються для створення бажаного акустичного поля, поза зоною найкращого сприйняття, хвилі утворюють некоректну фазову інтерференцію. Це змінює забарвлення звуку, і, що більш важливо, звук представляється таким, що виходить з гучномовця, розташованого ближче до слухача, через загальновідомий ефект психоакустичної переваги. Для фіксованого розміру кімнати прослуховування, єдиним способом зменшити обидві проблеми є збільшення використовуваного порядку амбіофонії, але це має на увазі швидке зростання в кількості задіяних каналів і гучномовців. Варто зазначити, що існує ще одна технологія, здатна точно відтворювати довільне звукове поле, так званий синтез хвильового поля (WFS). Однак, ця технологія вимагає розташування гучномовців на видаленні один від одного менше ніж в 15-20 сантиметрах, що вимагає додаткових апроксимацій (і, відповідно, втрати якості) і сильно збільшує кількість необхідних гучномовців; існуючі комплекси використовують між 100 і 500 гучномовців, що звужує галузь її застосування до подій дуже високого рівня підготовки. Потрібно забезпечити технологію, здатну надавати просторовий аудіоконтент, який можна розподіляти незалежно від демонстраційного комплексу, як двовимірний, так і тривимірний; який, після специфікування комплексу, можна декодувати для використання її повних можливостей; яка здатна відтворювати всі типи акустичних полів (вузькі джерела, ревербераційні або дифундуючі поля) для всіх слухачів в просторі, тобто, з великою областю найкращого сприйняття; і яка не вимагає використання великої кількості гучномовців. Це забезпечить можливість створювати контент, придатний для використання в майбутньому, в тому значенні, що вона буде легко пристосуватися до всіх існуючих і майбутніх комплексів з декількох гучномовців, і дасть можливість кінотеатрам або домашнім користувачам вибирати 2 UA 106598 C2 5 10 15 20 25 30 35 40 45 50 55 60 комплекс з декількох гучномовців, який максимально відповідає їх цілям і задачам, забезпечуючи при цьому упевненість в тому, що знайдеться велика кількість контенту, який зможе повністю використовувати можливості вибраного ними комплексу. Суть винаходу Спосіб і пристрій для кодування аудіо з просторовою інформацією незалежним від демонстраційного комплексу чином, і декодування і оптимальне відтворення для будь-якого даного демонстраційного комплексу, включаючи і комплекси з гучномовцями, розташованими на різних висотах, і навушники. Винахід оснований на способі для кодування деякого вхідного аудіоматеріалу, в формат, який не залежить від демонстрації, шляхом розподілу його в дві групи: перша група містить в собі аудіо, яке вимагає точно направленої локалізації; друга група містить аудіо, для якого достатньо локалізації, що забезпечується технологією амбіофонії низького порядку. Все аудіо в першій групі кодується у вигляді набору роздільних моно аудіодоріжок з відповідними метаданими. Кількість окремих моно аудіодоріжок не обмежена, однак, в деяких варіантах здійснення можна накладати певні обмеження, як описано нижче. Метадані повинні містити в собі інформацію про точний час, коли необхідно відтворити кожну таку аудіодоріжку, а також просторову інформацію, що описує щонайменше напрямок джерела сигналу в кожен момент часу. Всю аудіо у другій групі кодують в набір аудіодоріжок, що являють собою даний порядок амбіофонічних сигналів. В ідеальному випадку присутній один набір амбіофонічних каналів, хоча в певних варіантах здійснення можна використовувати більше одного. При відтворенні, коли стає відома демонстраційна система, першу групу аудіодоріжок декодують для відтворення з використанням стандартних алгоритмів перенесення, які використовують невелику кількість гучномовців поблизу від наміченого положення аудіоджерела. Другий набір аудіоканалів декодують для відтворення з використанням амбіофонічних декодерів, оптимізованих для даної демонстраційної системи. Ці спосіб і пристрій вирішують вищеописані проблеми, як це описано далі. По-перше, це дозволяє етапам запису аудіо, поствиробництва і поширення звичайних матеріалів пройти незалежно від комплексів, на яких буде демонструватися контент. Одним з наслідків цього факту є те, що створений цим способом контент придатний для використання в майбутньому, в тому значенні, що його можна легко адаптувати до будь-якого довільного комплексу декількох гучномовців, як існуючому, так і створеному в майбутньому. Цю якість також задовольняє і технологія амбіофонії. По-друге, з'являється можливість коректно відтворювати дуже вузькі джерела. Їх кодують в індивідуальні аудіодоріжки, разом з асоційованими метаданими напрямку, дозволяючи використовувати декодуючі алгоритми, що використовують меншу кількість гучномовців навколо наміченого місця розташування аудіоджерела, такі, як двовимірне або тривимірне векторне амплітудне перенесення. У протилежність цьому, амбіофонія вимагає використання дуже високих порядків для досягнення таких результатів, з відповідним збільшенням кількості пов'язаних доріжок, даних, і складності декодування. По-третє, цей спосіб і пристрій здатні в більшості ситуацій забезпечити велику область найкращого сприйняття, таким чином, збільшуючи область оптимальної реконструкції звукового поля. Це досягається шляхом відділення в першу групу аудіодоріжок всіх частин аудіо, які будуть приводити до зменшення області найкращого сприйняття. Наприклад, у варіанті здійснення, проілюстрованому на Фіг. 8, і описаному нижче, прямий звук діалогу кодують у вигляді окремої аудіодоріжки з інформацією про напрямок, з якого він виходить, в той час як реверберантна частина кодується у вигляді набору доріжок амбіофонії першого порядку. Таким чином, велика частина публіки сприймає прямий звук цього джерела як такий, що виходить з правильного місцеположення, головним чином з декількох гучномовців в наміченому напрямку; таким чином, з прямого звуку усувають ефекти дефазованого забарвлення і передування, що закріплює звукове зображення в його правильному місцеположенні. По-четверте, кількість даних, в більшій частині випадків кодування аудіо для комплексів декількох гучномовців, зменшується, в порівнянні з парадигмою однієї доріжки на канал, і в порівнянні з кодуванням амбіофонії вищого порядку. Цей факт забезпечує перевагу для цілей зберігання і поширення. Для цього є дві причини. З одного боку, призначення звуку високого ступеня спрямованості до списку відтворення вузького аудіо дозволяє використовувати для реконструкції іншої частини звукової сцени амбіофонію усього лише першого порядку, що складається з рознесеного, дифундованого або з невисоким ступенем спрямованості звуку. Таким чином, 4 доріжки групи амбіофонії першого порядку достатньо. Навпаки, для коректної реконструкції вузьких джерел потрібно, наприклад, 16 аудіоканалів для третього, або 25 для четвертого порядку. З іншого боку, кількість вузьких джерел, що вимагають одночасного 3 UA 106598 C2 5 10 15 20 25 30 35 40 45 50 55 60 програвання, в багатьох випадках невелика; це так, наприклад, фільму, де в список відтворення вузького аудіо входять тільки діалоги і деякі спецефекти. Більш того все аудіо в групі списку відтворення вузького аудіо являє собою набір доріжок з тривалістю, відповідною тільки тривалості даного джерела аудіо. Наприклад, аудіо, яке відповідає автомобілю, що знаходиться в одній сцені протягом трьох секунд, має тривалість тільки в три секунди. Таким чином, в прикладі застосування до фільму, де необхідно створити звукову доріжку фільму для комплексу 22.2, в парадигмі однієї доріжки на канал буде потрібно 24 аудіодоріжки, і кодування амбіофонії третього порядку потребує 16 аудіодоріжок. Навпаки, в запропонованому форматі, що не залежить від демонстрації, буде потрібно тільки 4 аудіодоріжки повної тривалості, плюс набір окремих аудіодоріжок різної тривалості, які зменшують таким чином, щоб вони покривали тільки намічену тривалість вузьких джерел аудіо. Короткий опис креслень На Фіг. 1 показаний варіант здійснення способу для, маючи даний набір вихідних звукових доріжок, вибору і кодування їх, і нарешті, декодування і оптимального відтворення в довільному демонстраційному комплексі. На Фіг. 2 показана схема запропонованого формату, що не залежить від демонстрації, з двома групами аудіо: списку відтворення вузького аудіо з просторовою інформацією і доріжками амбіофонії. На Фіг. 3 показаний декодер, що використовує різні алгоритми для обробки будь-якої з груп аудіо. На Фіг. 4 показаний варіант здійснення способу, яким можна перекодувати дві групи аудіо. На Фіг. 5 показаний варіант здійснення, в якому незалежний від демонстрації формат можна заснувати на аудіопотоках, замість повних аудіофайлів, збережених на дисках або в пам'яті інших типів. На Фіг. 6 показаний додатковий варіант здійснення способу, в якому незалежний від демонстрації формат вводять в декодер, який може відтворювати контентв будь-якому демонстраційному комплексі. На Фіг. 7 показані деякі технічні деталі процесу ротації, який відповідає простим операціям, що проводяться з обома групами аудіо. На Фіг. 8 показаний варіант здійснення способу в робочому оточенні аудіовізуального поствиробництва. На Фіг. 9 показаний додатковий варіант здійснення, у вигляді частини виробництва аудіо і поствиробництва у віртуальній сцені (наприклад, в анімаційному кіно або тривимірній грі). На Фіг. 10 показаний додатковий варіант здійснення способу, у вигляді частини цифрового сервера фільмів. На Фіг. 11 показаний альтернативний варіант здійснення способу для кіно, в якому контент можна декодувати до розподілу. Докладний опис переважних варіантів здійснення На Фіг. 1 показаний варіант здійснення способу для, маючи даний набір вихідних аудіодоріжок, вибору і кодування їх, і, нарешті, декодування і оптимального відтворення в довільному демонстраційному комплексі. Таким чином, для даного розташування гучномовців, просторове звукове поле буде реконструйоване максимально якісно, адаптовано для гучномовців, що є, і збільшуючи область оптимального відтворення до максимально можливої межі. Первинний звук може вийти з будь-якого джерела, наприклад: використовуючи будь-який тип мікрофона з будь-якою діаграмою спрямованості або будь-якою амплітудно-частотною чутливістю; використовуючи амбіофонічні мікрофони, здатні видавати амбіофонічні сигнали будь-якого порядку або змішаного порядку; або використовуючи синтезовану аудіо, або спецефекти, такі, як кімнатна реверберація. Процес вибору і кодування складається з створення двох груп доріжок з первинного аудіо. Перша група складається з тих частин аудіо, які вимагають вузької локалізації, в той час як друга група складається з аудіо, що залишилося, для якого достатньо спрямованості даного порядку амбіофонії. Аудіосигнали, розподілені в першу групу, містять в моно аудіодоріжках, разом з просторовими методаними про напрямок джерела у часі, і часом первинного відтворення. Вибір являє собою процес, що проводиться користувачем, хоча над деякими типами первинного аудіо можна виконувати дії за умовчанням. У загальному випадку, (тобто, для не амбіофонічних аудіодоріжок), користувач визначає, для кожного елемента вихідного аудіо, напрямок джерела і тип джерела: вузьке або амбіофонічне джерело, відповідно до описаних раніше груп кодування. Кути напрямку можна визначити, наприклад, азимутом і кутом піднесення джерела відносно слухача, і його можна вказувати як фіксовані значення для 4 UA 106598 C2 5 10 15 20 25 30 35 40 45 50 55 доріжки, або як дані, що змінюються з часом. Якщо для деяких доріжок напрямок не вказують, можна визначити призначення за умовчанням, наприклад, призначаючи таким доріжкам даний фіксований сталий напрямок. Додатково, кути напрямку може супроводжувати параметр рознесення. Терміни рознесений і вузький, в даному контексті необхідно розуміти як кутову ширину звукової картини джерела, що сприймається. Наприклад, можна квантифікувати рознесення, використовуючи значення на інтервалі [0, 1], де значення 0 означає точно спрямований звук (тобто, звук, вихідний від тільки одного чітко визначеного напрямку), і значення 1 означає звук, що виходить з усіх напрямків з однаковою енергетикою. Для деяких типів первинних доріжок, можна визначити дії за умовчанням. Наприклад, доріжки, ідентифіковані як стереопари, можна вміщувати в амбіофонічну групу з азимутами -30 і 30 градусів для лівого і правого каналів, відповідно. Доріжки, ідентифіковані як surround 5.1 (ITUR775-1) можна, аналогічно, призначати на азимути -30, 0, 30, -110, 110 градусів. І, нарешті, доріжки, ідентифіковані як амбіофонічні першого порядку (або В-формат), можна призначати в групу амбіофонії без запиту додаткової інформації про спрямованість. Процес кодування з Фіг. 1, отримує вищезазначену певну користувачем інформацію і видає незалежний від демонстрації аудіоформат з просторовою інформацією, як описано на Фіг. 2. Вихідні дані процесу кодування являють собою, для першої групи, набір моно аудіодоріжок з аудіосигналами, відповідними різним джерелам звуку, з асоційованими просторовими методаними, що включають в себе напрямки джерела відповідно до даної системи відліку, або параметрів рознесення аудіо. Вихідні дані процесу перетворення для другої групи аудіо являють собою один єдиний набір амбіофонічних доріжок вибраного порядку (наприклад, 4 доріжки, якщо вибрана амбіофонія першого порядку), який відповідає змішенню всіх джерел в амбіофонічній групі. Потім, вихідних даних процесу кодування використовує декодер, який використовує інформацію про вибраний демонстраційний комплекс для створення однієї аудіодоріжки або потік аудіо для кожного каналу комплексу. На Фіг. 3 показаний декодер, що використовує різні алгоритми для обробки кожної з груп аудіо. Групу амбіофонічних доріжок декодують з використанням придатних для конкретного комплексу амбіофонічних декодерів. Доріжки в списку відтворення вузьконаправленого аудіо декодують, використовуючи алгоритми, придатні для цієї мети; вони використовують просторову інформацію з метаданих кожної доріжки для декодування, звичайно, з використанням дуже малої кількості гучномовців навколо наміченого місцеположення кожної доріжки. Одним з прикладів такого алгоритму є векторне амплітудне перенесення. Метадані часу використовують для початку відтворення кожного такого аудіо в правильний момент. Нарешті, декодований канали відправляються для відтворення на гучномовці або навушники. На Фіг. 4 показаний додатковий варіант здійснення способу, яким дві групи аудіо можна перекодувати. У загальному випадку, процес перекодування приймає на вхід список відтворення вузьконаправленого аудіо, що містить в собі N різних аудіодоріжок з асоційованими метаданими спрямованості, і набір амбіофонічних доріжок даного порядку Р, і даний тип суміші А (наприклад, вона може містити в собі всі доріжки нульового і першого порядку, але тільки дві доріжки, що відповідають сигналам другого порядку). Вихідні дані процесу перекодування являють собою список відтворення вузьконаправленого аудіо, який містить в собі М різних аудіодоріжок з асоційованими метаданими спрямованості, і набір амбіофонічних доріжок даного порядку Q, з даним типом суміші B. В процесі перекодування, M, Q, В можуть відрізнятися від N, Р, А, відповідно. Перекодування можна використовувати, наприклад, для зменшення кількості даних, що містяться. Цього можна досягнути, наприклад, шляхом вибору однієї або декількох доріжок, що міститься в списку відтворення вузьконаправленого аудіо, і перепризначувати їх в групу амбіофонії, конвертуючи, з використанням асоційованою з монодоріжкою інформації спрямованості моно, в амбіофонію. У цьому випадку, стає можливим досягнути M
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod and apparatus for three-dimensional acoustic field encoding and optimal reconstruction
Автори російськоюMateos Sole, Antonio, Arumi Albo, Pau
МПК / Мітки
МПК: G10L 19/00, H04S 3/00
Мітки: тривимірного, акустичного, кодування, реконструкції, оптимальної, спосіб, пристрій, поля
Код посилання
<a href="https://ua.patents.su/20-106598-sposib-i-pristrijj-dlya-koduvannya-i-optimalno-rekonstrukci-trivimirnogo-akustichnogo-polya.html" target="_blank" rel="follow" title="База патентів України">Спосіб і пристрій для кодування і оптимальної реконструкції тривимірного акустичного поля</a>
Спосіб стиснення мовного сигналу шляхом кодування зі змінною швидкістю, схема та пристрій для стиснення акустичного сигналу

Номер патенту: 43311
Опубліковано: 17.12.2001
Автори: Мінг-Чанг Цай, Пол Є. Джейкобс, Клайн С. Гілхаузен, Уільям Р. Гарднер, Чонг Ю. Лі, Кетрін С. Лем
МПК: G10L 19/00, G10L 21/00
Мітки: мовного, кодування, схема, акустичного, стиснення, пристрій, швидкістю, спосіб, сигналу, змінною, шляхом
Формула / Реферат:
1. Способ сжатия речевого сигнала путем кодирования с переменной скоростью кадров оцифрованных выборок речевого сигнала, отличающийся тем, что включает операции определения уровня сигнала речевой активности для кадра оцифрованных выборок речевого сигнала, выбора для указанного кадра скорости кодирования из группы скоростей в зависимости от указанного определенного уровня сигнала речевой активности, кодирования указанного кадра в соответствии...
Комплект лабораторного обладнання для здійснення тривимірного комп’ютерного та матеріального моделювання або реконструкції об’єктів, процесів під час проведення судових експертиз

Номер патенту: 77435
Опубліковано: 11.02.2013
Автор: Шехавцов Руслан Миколайович
МПК: G06C 19/00, G01C 3/08, B29C 31/00
Мітки: моделювання, лабораторного, експертиз, комплект, тривимірного, об'єктів, комп'ютерного, проведення, обладнання, процесів, судових, матеріального, реконструкції, здійснення
Формула / Реферат:
Комплект лабораторного обладнання для здійснення тривимірного комп'ютерного та матеріального моделювання або реконструкції об'єктів, процесів під час проведення судових експертиз, що містить тривимірний принтер, змінні картриджі, які містять полімерні матеріали та фарби для кольорового друку, диск для лазерних систем зчитування з програмним забезпеченням для здійснення друку тривимірних монохромних або кольорових полімерних моделей об'єктів,...
Спосіб та пристрій для кодування аудіосигналів ( варіанти )

Номер патенту: 48191
Опубліковано: 15.08.2002
Автори: Зайтцер Дітер, Бранденбург Карлхайнц, Грілль Бернхард
МПК: H04B 1/66
Мітки: аудіосигналів, пристрій, спосіб, варіанти, кодування
Формула / Реферат:
1. Спосіб кодування принаймні одного аудіосигналу, який полягає у здійсненні таких операцій:-створення першого кодованого сигналу шляхом кодування аудіосигналу з малою швидкістю передачі бітів та невеликою затримкою у порівнянні з затримкою, яка виникає під час кодування аудіосигналу високої якості, та-передача першого кодованого сигналу на декодер до початку передачі на цей декодер принаймні одного додаткового кодованого...
Пристрій для декодування одиночних недвійкових помилок із застосуванням послідовного алгоритму кодування

Номер патенту: 62874
Опубліковано: 26.09.2011
Автори: Жуков Ігор Анатолійович, Кубіцкій Валерій Івановіч, Синельников Олексій Олексійович
МПК: H03M 13/00
Мітки: алгоритму, одиночних, послідовного, кодування, помилок, недвійкових, пристрій, декодування, застосуванням
Формула / Реферат:
Пристрій для декодування одиночних недвійкових помилок, який містить блок інформаційних вузлів, який відрізняється тим, що перший вихід блока інформаційних вузлів з'єднаний з входом блока обчислення викривленого полінома, а другий вихід з'єднаний з другим входом блока контрольних вузлів, а вихід блока обчислення викривленого полінома з'єднаний з першим входом блока контрольних вузлів, вихід якого з'єднаний з входом блока виявлення помилок,...
Спосіб визначення оптимальної потужності сигналів стирання та спосіб визначення оптимальної потужності сигналів записування, записувальний пристрій з пристроями для реалізації зазначених способів

Номер патенту: 73921
Опубліковано: 17.10.2005
Автори: Ван Вуденберг Роел, Шоу Гуо-Фу, Спруйт Йоханнес Х.М.
МПК: G11B 7/00
Мітки: пристрій, сигналів, способів, стирання, оптимальної, пристроями, визначення, потужності, спосіб, записування, зазначених, записувальний, реалізації
Формула / Реферат:
1. Спосіб визначення оптимальної потужності сигналів стирання для стирання міток, запроваджених на оптичному носії запису такого типу, на якому подібні мітки створюються шляхом місцевого нагрівання носія запису імпульсами випромінення певної потужності, високої настільки, щоб викликати зміни оптичних властивостей даного носія запису, причому такі зміни виявляються в зменшенні відбивання зазначених імпульсів випромінення, який відрізняється...
Попередній патент: Ячмінь зі зниженою активністю ліпоксигенази та напій, одержаний з нього
Наступний патент: Система для приготування напоїв
Випадковий патент: Шестиступеневий стенд автотестування