Аутентифікація потоків даних
Номер патенту: 104483
Опубліковано: 10.02.2014
Автори: Бьом Рейнхольд, Вацке Олівер, Шуг Міхель, Шільдбах Вольфганг А., Ціглер Томас, Вольтерс Мартін, Хьоріх Хольгер, Грьошель Александер, Хомм Даніль






















Формула / Реферат
1. Спосіб кодування потоку даних, що включає ряд кадрів даних, де спосіб включає етапи, на яких
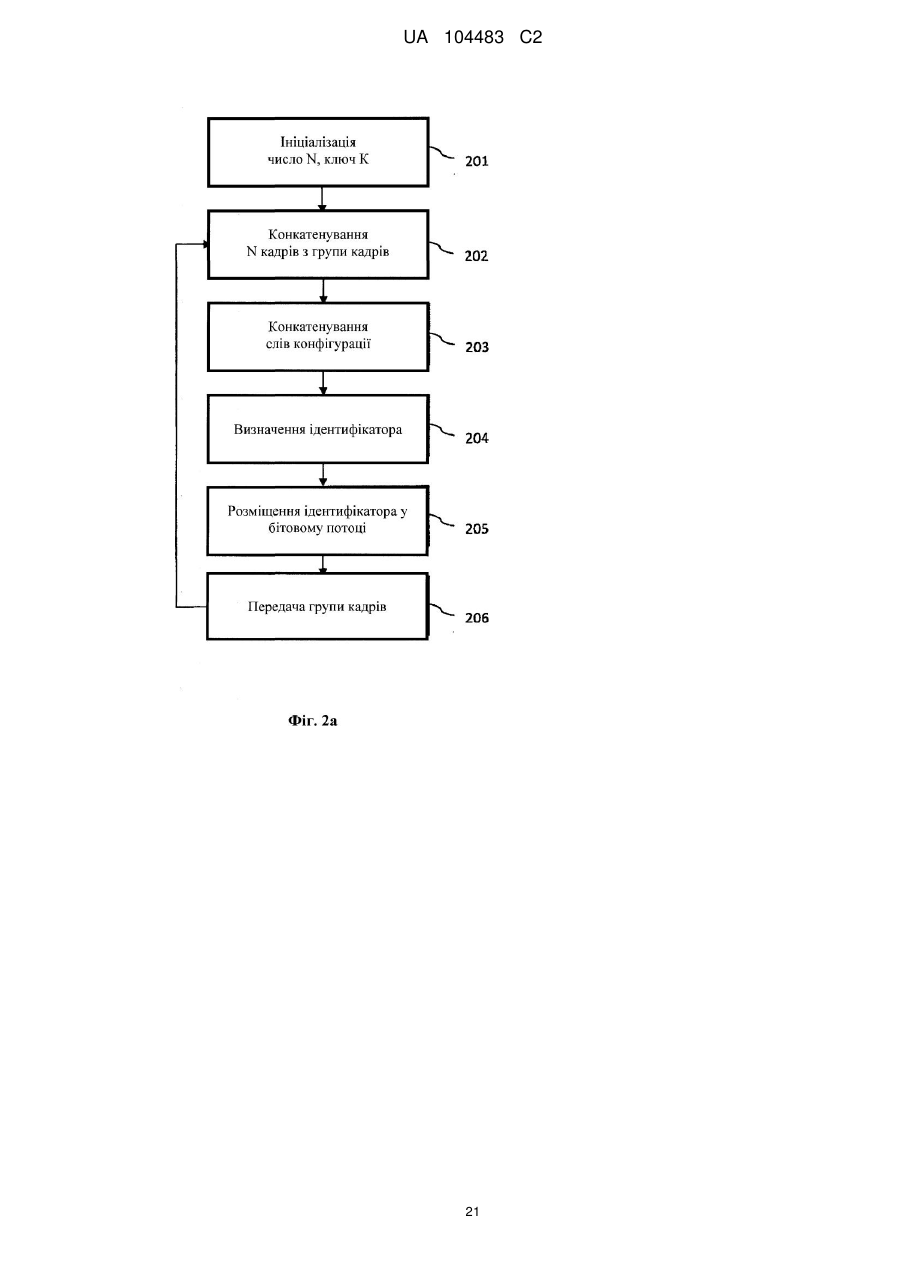
- генерують криптографічну величину для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга потоку даних;
- здійснюють вставку криптографічної величини в кадр потоку даних, що слідує за N послідовними кадрами даних; та
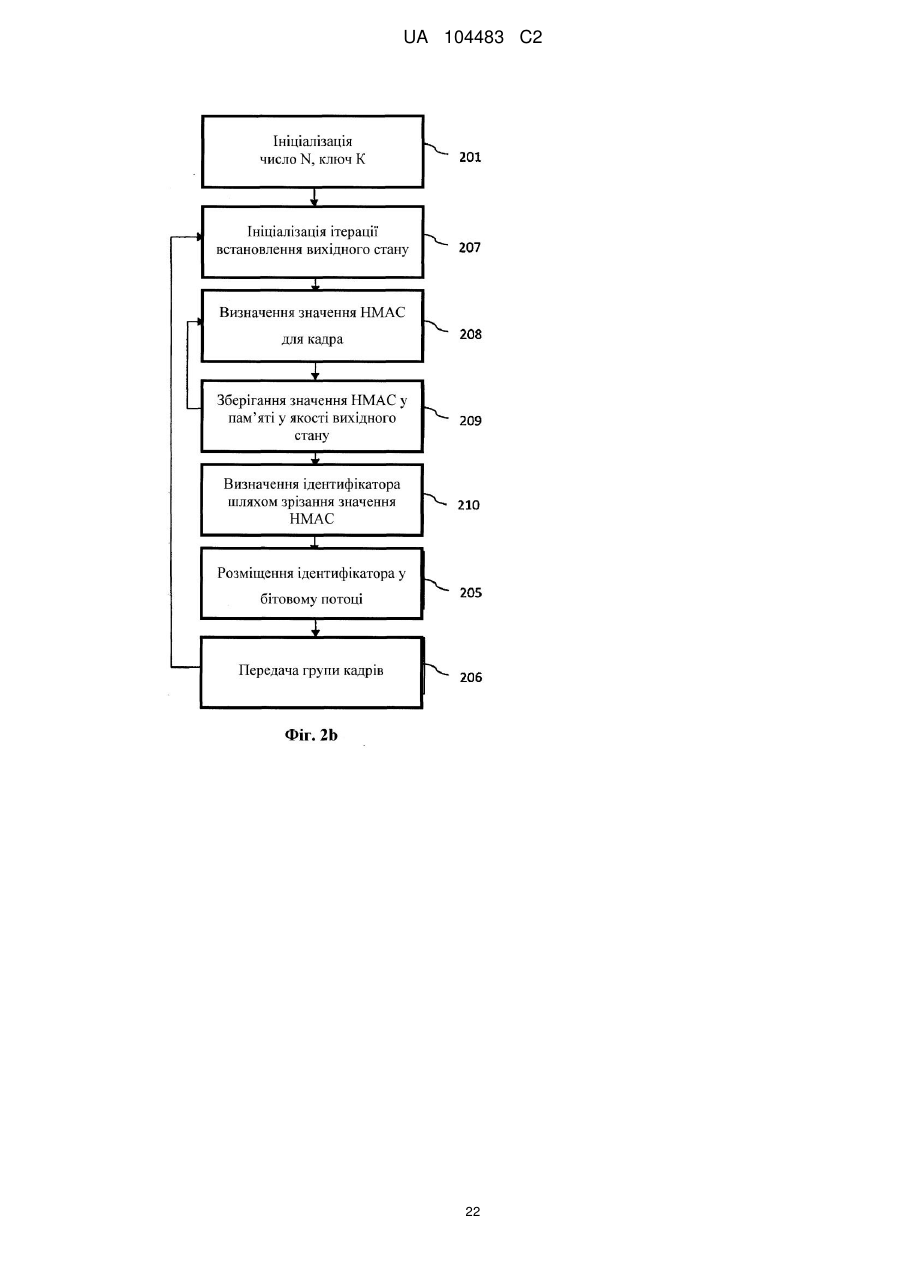
- здійснюють ітеративне генерування проміжної криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну криптографічну величину для інформації про конфігурацію.
2. Спосіб за п. 1, який відрізняється тим, що спосіб додатково включає етапи, на яких
- групують кількість N послідовних кадрів даних для формування першого повідомлення;
- групують перше повідомлення з інформацією про конфігурацію для формування другого повідомлення; і
де криптографічну величину генерують для другого повідомлення.
3. Спосіб за п. 1 або 2 , який відрізняється тим, що криптографічну величину вставляють в елемент <DSE> потоку даних; де елемент <DSE> потоку даних являє собою синтаксичний елемент кадру потоку даних; і де потік даних являє собою потік MPEG4-AAC або MPEG2-AAC.
4. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що кількість кадрів N більше одиниці.
5. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що кадри даних являють собою відео- або аудіокадри.
6. Спосіб за пп. 1-4, який відрізняється тим, що кадри даних являють собою кадри ААС або НЕ-ААС.
7. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що інформація про конфігурацію включає щонайменше один з наступних покажчиків:
- покажчик частоти дискретизації;
- покажчик конфігурації каналів системи кодування звукового сигналу;
- покажчик кількості дискретних значень у кадрі даних.
8. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що криптографічну величину генерують із використанням ключової величини.
9. Спосіб за п. 8, який відрізняється тим, що етап генерування криптографічної величини включає
- обчислення значення HMAC-MD5 для кількості N послідовних кадрів даних і інформації про конфігурацію.
10. Спосіб за п. 9, який відрізняється тим, що етап генерування криптографічної величини включає
- зрізання значення HMAC-MD5 для одержання криптографічної величини.
11. Спосіб за п. 10, який відрізняється тим, що значення HMAC-MD5 зрізають до 16, 24, 32, 48, 64, 80, 96 або 112 біт.
12. Спосіб за будь-яким з попередніх пунктів , який відрізняється тим, що криптографічну величину для N послідовних кадрів даних вставляють у наступний кадр даних.
13. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що додатково включає етап, на якому
- вставляють покажчик синхронізації після N послідовних кадрів даних, де покажчик синхронізації вказує на те, що криптографічна величина була вставлена.
14. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що елемент <DSE> потоку даних вставляють у кінець кадру перед елементом <TERM>.
15. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що вміст елемента <DSE> потоку даних вирівняно за границею байта потоку даних.
16. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що етапи генерування й вставки криптографічної величини повторюють для ряду блоків з N послідовних кадрів даних.
17. Спосіб за п. 16, який відрізняється тим, що криптографічну величину для блока з N послідовних кадрів даних генерують на блоці з N послідовних кадрів даних, що включає криптографічну величину для попереднього блока з N послідовних кадрів даних.
18. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що включає етап, на якому
- вибирають N таким чином, щоб N послідовних кадрів максимально можливо близько покривали заздалегідь визначену тривалість відповідного сигналу при відтворенні у відповідній конфігурації.
19. Спосіб за п. 18, який відрізняється тим, що включає етап, на якому
- вибирають N таким чином, щоб заздалегідь визначена тривалість не була перевищена.
20. Спосіб за п. 18 або 19, який відрізняється тим, що заздалегідь визначена тривалість становить 0,5 секунд.
21. Спосіб за п. 5, який відрізняється тим, що додатково включає етап, на якому
- здійснюють взаємодію з відео- та/або аудіокодером потоку даних.
22. Спосіб за п. 21, який відрізняється тим, що на етапі взаємодії з відео- та/або аудіокодером потоку даних здійснюють
- встановлення для відео- та/або аудіокодера такої максимальної бітової швидкості передачі даних, щоб зазначена бітова швидкість передачі даних для потоку даних, що включає криптографічну величину, не перевищувала заздалегідь визначене значення.
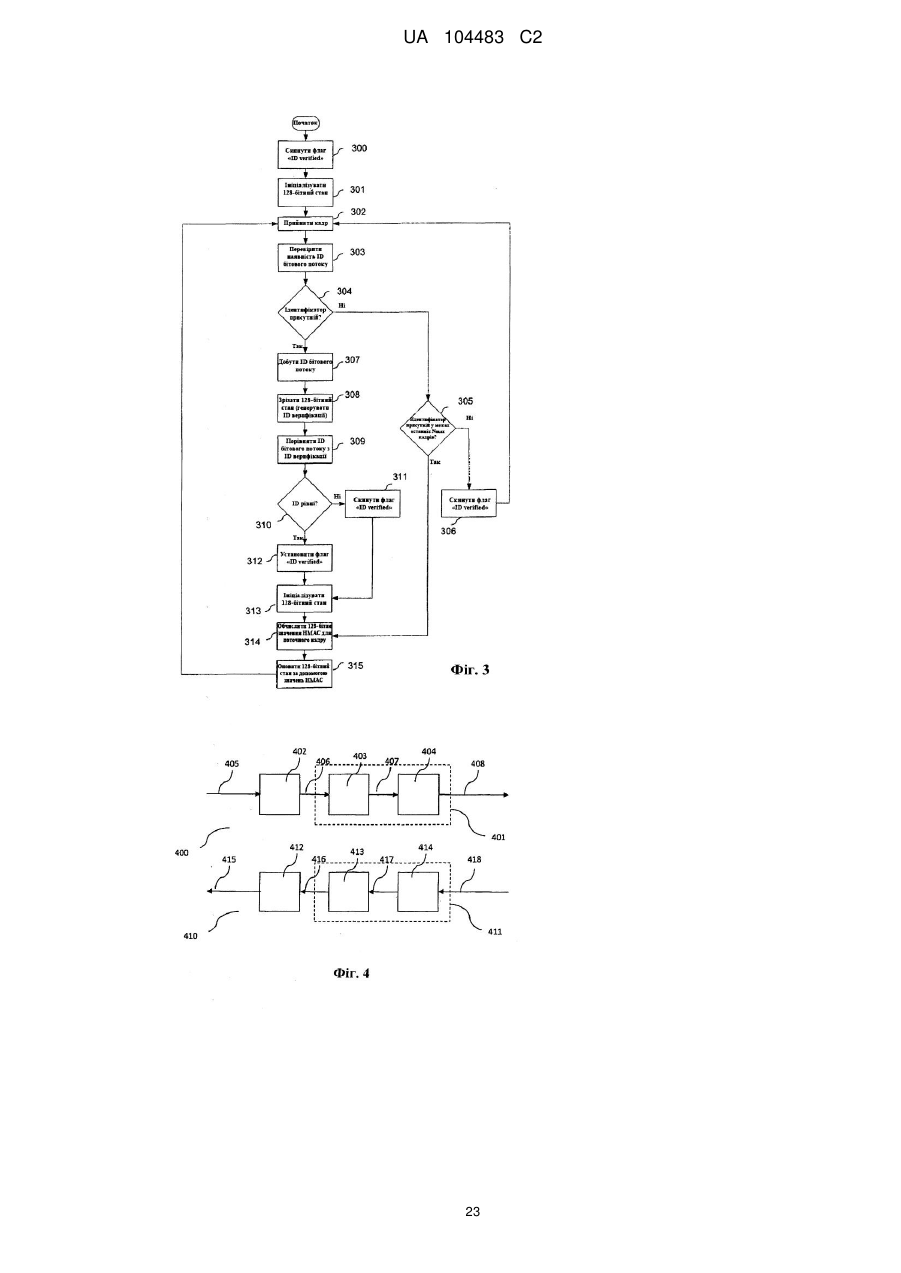
23. Спосіб верифікації потоку даних у декодері, де потік даних включає ряд кадрів даних і криптографічну величину, пов'язану з кількістю N попередніх послідовних кадрів даних, де спосіб включає етапи, на яких
- генерують другу криптографічну величину для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга даних;
- витягають криптографічну величину з потоку даних;
порівнюють криптографічну величину із другою криптографічною величиною; та
- здійснюють ітеративне генерування проміжної другої криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну другу криптографічну величину попередньої ітерації; де вихідний стан першої ітерації являє собою проміжну другу криптографічну величину для інформації про конфігурацію.
24. Спосіб за п.23, який відрізняється тим, що потік даних являє собою потік MPEG4-AAC або MPEG2-AAC; де криптографічна величина витягає з елемента <DSE> потоку даних; і де елемент <DSE> потоку даних являє собою синтаксичний елемент кадру потоку даних.
25. Спосіб за пп. 23 або 24, який відрізняється тим, що додатково включає етапи, на яких
- витягають N послідовних кадрів даних для формування першого повідомлення;
- групують перше повідомлення з інформацією про конфігурацію для формування другого повідомлення;
де друга криптографічна величина генерується для другого повідомлення.
26. Спосіб за пп. 23-25, який відрізняється тим, що потік даних включає ряд з N послідовних кадрів даних і пов'язаних з ними криптографічних величин, і де спосіб додатково включає етап, на якому
- визначають число N як кількості кадрів між двома послідовними криптографічними величинами.
27. Спосіб за пп. 23-26, який відрізняється тим, що криптографічну величину генерують у відповідному кодері з N послідовних кадрів даних і інформації про конфігурацію відповідно до способу, що відповідає способу, використовуваному для генерування другої криптографічної величини.
28. Спосіб за п. 27, який відрізняється тим, що
- криптографічну величину й другу криптографічну величину генерують із використанням унікального ключового значення й унікальної криптографічної хеш-функції.
29. Спосіб за пп. 23-28, який відрізняється тим, що додатково включає етапи, на яких
- установлюють прапор у випадку, коли криптографічна величина відповідає другій криптографічній величині; та
- забезпечують візуальну індикацію, якщо прапор установлений.
30. Спосіб за пп. 23-29, який відрізняється тим, що додатково включає етап, на якому
- здійснюють скидання прапора, якщо криптографічна величина не відповідає другій криптографічній величині, або, якщо криптографічна величина не може бути витягнута з потоку даних.
31. Носій інформації для зберігання команд, при виконанні яких отримують потік даних, що включає криптографічну величину, що генерується й вставляється у відповідності зі способом за одним з пп. 1-22.
32. Кодер, що діє для кодування потоку даних, що включає ряд кадрів даних, де кодер містить процесор, що діє для
- генерування криптографічної величини для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга потоку даних;
- вставки криптографічної величини в кадр потоку даних, що слідує за N послідовними кадрами даних; та
- ітеративного генерування проміжної криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну криптографічну величину для інформації про конфігурацію.
33. Декодер, що діє для верифікації потоку даних, що включає ряд кадрів даних і криптографічну величину, пов'язану з кількістю N попередніх послідовних кадрів даних, де декодер містить процесор, що діє для
- генерування другої криптографічної величини для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга даних;
- добування криптографічної величини з кадру потоку даних;
- порівняння криптографічної величини із другою криптографічною величиною; та
- ітеративного генерування проміжної другої криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну другу криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну другу криптографічну величину для інформації про конфігурацію.
34. Носій даних, що включає програму, реалізовану програмно, адаптовану для виконання на процесорі й для виконання етапів способу за одним з пп. 1-30 при здійсненні на обчислювальному пристрої.
35. Зовнішній додатковий пристрій, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал, де зовнішній додатковий пристрій включає декодер за п. 33, призначений для верифікації прийнятого потоку даних.
36. Переносний електронний пристрій, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал, де переносний електронний пристрій включає декодер за п. 33, призначений для верифікації прийнятого потоку даних.
37. Комп'ютер, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал; де комп'ютер включає декодер за п. 33, призначений для верифікації прийнятого потоку даних.
38. Система мовлення, призначена для передачі потоку даних, що включає звуковий сигнал; де система мовлення включає кодер за п. 32.
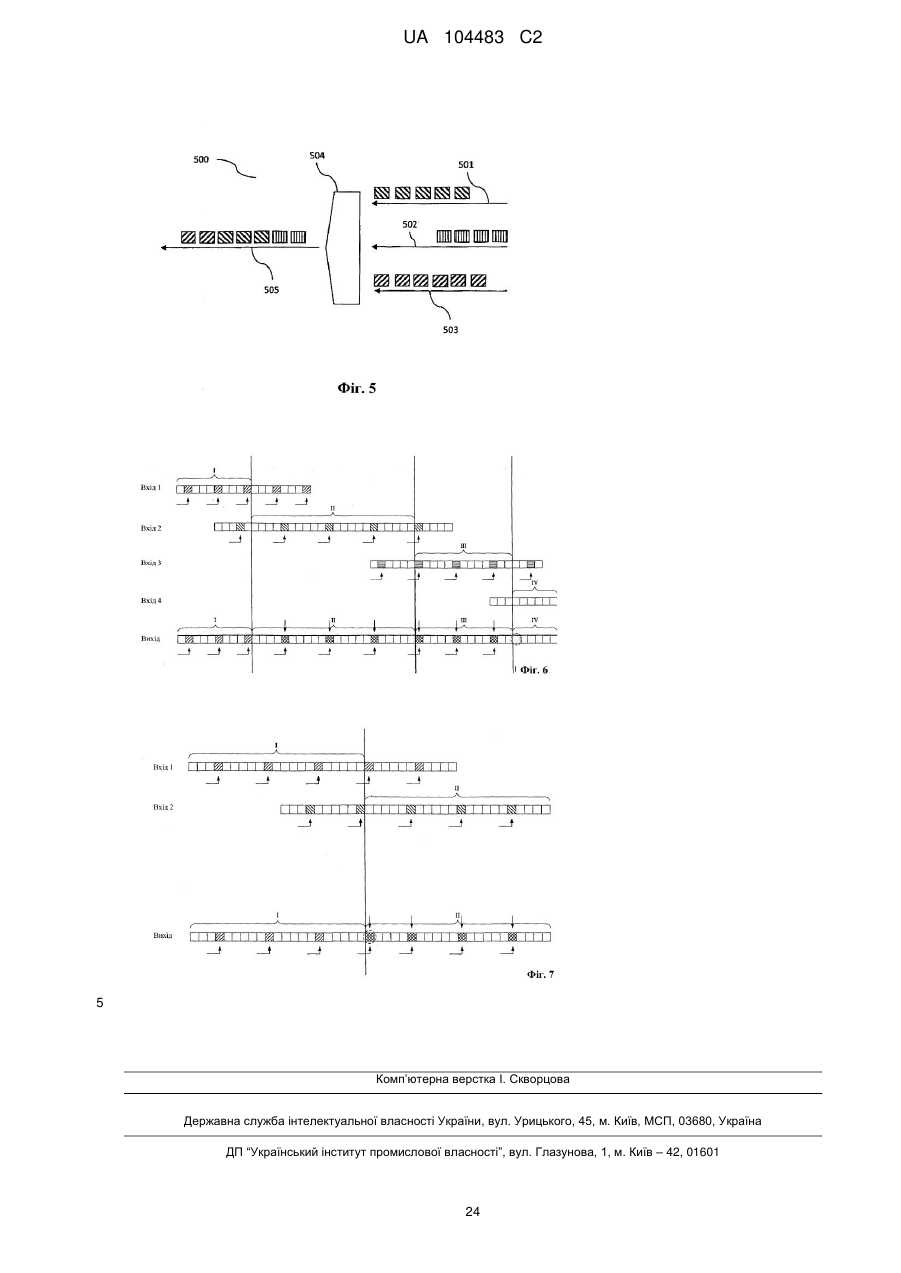
39. Спосіб конкатенації першого та другого бітових потоків, кожний з яких включає ряд кадрів даних та криптографічну величину, пов'язану із заданою кількістю кадрів даних, де спосіб включає етап, на якому
- генерують конкатенований бітовий потік з першого і другого бітових потоків, де конкатенований бітовий потік включає щонайменше частину ряду кадрів даних з першого та другого бітових потоків і включає криптографічну величину, що генерується й вставляється у відповідності зі способом за одним з пп. 1-30.
40. Пристрій для конкатенації, що діє для конкатенації першого та другого бітових потоків, кожний з яких включає ряд кадрів даних і криптографічні величини, пов'язані із заданою кількістю кадрів даних, де пристрій для конкатенації містить
- кодер за п.32, призначений для кодування останніх кадрів першого бітового потоку і перших кадрів другого бітового потоку.
41. Пристрій для конкатенації за п. 40, який відрізняється тим, що додатково містить
- блок перенаправлення, призначений для перенаправлення кадрів і пов'язаних з ними криптографічних величин першого і другого бітових потоків, які не декодуються й не кодуються.
42. Пристрій для конкатенації за п. 40 або 41, який відрізняється тим, що додатково містить
- декодер за п. 33, призначений для кодування останніх кадрів першого бітового потоку, перших кадрів другого бітового потоку й пов'язаних з ними криптографічних величин з метою визначення статусу довіри першого та другого бітових потоків; та
блок керування, що розблокує кодер для вставки криптографічних величин у частину бітового потоку тільки в тому випадку, якщо відповідні перший та другий бітові потоки аутентифіковані.
Текст
Реферат: Даний винахід належить до технологій аутентифікації потоків даних. Зокрема, винахід належить до вставки ідентифікаторів у такий потік даних, як бітовий потік Dolby Pulse, ААС або НЕ ААС, та до аутентифікації й верифікації потоку даних на основі зазначених ідентифікаторів. Описано спосіб та систему для декодування потоку даних, що включає ряд кадрів даних. Спосіб включає етап генерування криптографічної величини для кількості N послідовних кадрів даних та інформації про конфігурацію, який відрізняється тим, що інформація про конфігурацію включає інформацію для рендеринга потоку даних. Потім спосіб вставляє криптографічну величину в потік даних, що слідує за N послідовними кадрами даних. UA 104483 C2 (12) UA 104483 C2 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 Даний винахід відноситься до способів аутентифікації й верифікації потоків даних. Зокрема, винахід відноситься до вставки ідентифікаторів у такий потік даних, як бітовий потік Dolby Pulse, AAC або HE AAC, та до аутентифікації й верифікації потоку даних на основі цього ідентифікатора. ПЕРЕДУМОВИ СТВОРЕННЯ ВИНАХОДУ В умовах зростаючого поширення систем цифрового телебачення й радіо, потоки даних, що включають, наприклад, відеодані та/або аудіодані, транслюються все частіше. На додаток до актуального відео- та/або аудіовмісту ці потоки даних також включають метадані, які дозволяють, наприклад, управляти гучністю й динамічним діапазоном програми на стороні приймача, а також управляти стереофонічним понижувальним мікшуванням та іншими властивостями. У типових мережних сценаріях відеокадри та/або аудіокадри й пов'язані з ними метадані кодуються в системі головного вузла мережі мовлення. Для цього можуть використовуватися різні схеми кодування, такі як Dolby E, Dolby Digital, AAC, HE AAC, DTS або Dolby Pulse. Деякі із цих схем кодування, найбільшою мірою, Dolby Pulse, AAC та HE AAC, особливо добре підходять для передачі через різні засоби передачі інформації, такі як радіо (наприклад, FM-частотний діапазон, DVB/T, ATSC), скручені мідні дроти (DSL), коаксіальні кабелі (наприклад, CATV) або оптичні волокна. Приймач, наприклад, телевізор, радіоприймач, персональний комп'ютер або додатковий зовнішній пристрій, містить відповідний декодер та створює декодований медіапотік. Крім того, приймач звичайно передбачає функції керування, які ініціюються за допомогою метаданих, що супроводжують відео- та/або аудіодані. Приклади схем кодування/декодування визначені в стандарті ISO/IEC 14496-3 (2005) "Information technology-Coding of audio-visual objects-Part 3: Audio" ― для MPEG-4 AAC, та в стандарті ISO/IEC 13818-7 (2003) "Generic Coding of Moving Pictures and Associated Audio information-Part 7: Advanced Audio Coding (AAC)" ― для MPEG-2 AAC, які посиланням включаються в даний опис. Відомі кілька способів аутентифікації та/або ідентифікації. Деякі з них опираються на впровадження даних аутентифікації та/або ідентифікації в кодовані мультимедійні дані. Ці способи відомі також як "водяні знаки" та призначаються, в основному, для захисту авторського права. Ще один спосіб аутентифікації та/або ідентифікації ― це цифровий підпис, де окремі дані аутентифікації передбачаються поряд з файлами даних, такими як файли електронної пошти, та використовуються в декодері для цілей аутентифікації й ідентифікації. Для того, щоб приймач потоків даних був здатний ідентифікувати кодер потоку даних, потрібно поряд з потоком даних забезпечити засоби аутентифікації. Також може бути корисною перевірка цілісності потоку даних. Крім того, може бути корисним забезпечення коректної конфігурації приймача відносно потоку даних, що піддається відтворенню або обробці. Також може бути корисним допущення реалізації додаткових платних послуг або спеціальних функціональних можливостей для потоків даних, які були належним чином аутентифіковані та/або верифіковані. До цього й іншого питань звертається даний патентний документ. КОРОТКИЙ ОПИС Запропоновані спосіб та система використовують ідентифікатор, що може передбачатися у вигляді метаданих у потоці даних. Зазначені потоки даних, переважно, представляють собою потоки даних, які передаються через провідні або бездротові засоби передачі даних, однак потоки даних також можуть бути передбачені на запам'ятовувальному пристрої, такому як CD, DVD або флеш-пам'ять. Ідентифікатор дає можливість декодеру на стороні прийому перевіряти, чи є потік даних, який він приймає, такий, що відбувається з надійного кодера, тобто від легального кодера на стороні передачі та/або кодування. Ця верифікація може бути особливо корисна у випадку, коли декодер сумісний з кодерами різного типу. Наприклад, декодер Dolby Pulse може бути сумісним з кодером HE-AAC version 2. У такому сценарії може знадобитися надання декодеру Dolby Pulse можливості забезпечувати деякі нестандартні, або необов'язкові, можливості тільки в тому випадку, якщо мережний трафік, тобто потоки даних, виходить із відповідних кодерів Dolby Pulse. При використанні зазначеного ідентифікатора декодер Dolby Pulse буде здатним здійснювати розрізнення між потоком даних, або бітовим потоком, що генерується відповідним кодером Dolby Pulse, та потоком даних, або бітовим потоком, що генерується будь-яким довільним кодером, сумісним з HE-AACv2. У цьому зв'язку, можна забезпечити те, що додаткові можливості, наприклад, використання динамічних метаданих, ураховуються декодером тільки в тому випадку, якщо потік даних виходить із надійного кодера. Таким чином, може забезпечуватися коректне функціонування додаткових можливостей. Додатковою перевагою ідентифікатора є те, що він може надавати декодеру можливість перевірки того, що бітовий потік був отриманий коректним чином, а також того, що бітовий потік 1 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 не піддавався модифікації або несанкціонованому втручанню в ході передачі. Іншими словами, ідентифікатор дає декодеру можливість перевірки цілісності прийнятого бітового потоку. Крім того, ідентифікатор може використовуватися для того, щоб гарантувати те, що у декодері задане правильна конфігурація обробки, наприклад, відтворення, з метою належного рендеринга медійного/мультимедійного сигналу. Наприклад, зазначене конфігурування може бути спрямоване на частоту дискретизації, з якою відтворюється медіасигнал. Конфігурування також може бути спрямоване на конфігурування каналів, наприклад, 2-канального стереофонічного сигналу, інші настройки навколишнього звуку і т.д., які будуть використовуватися при відтворенні. Інша особливість конфігурування може бути спрямована на довжину кадру, наприклад, 1024 кадрів дискретних значень, або 960 кадрів дискретних значень у випадку ААС, що використовується у конкретній схемі кодування. Крім цілей ідентифікації кодера й аутентифікації, ідентифікатор може використовуватися для перевірки автентичності корисного навантаження потоку даних. Із цією метою ідентифікатор не повинен легко піддаватися підробці, а маніпуляції із захищеним сегментом повинні бути такими, що ідентифікуються. Крім того, бажано, щоб декодер визначав автентичність бітового потоку за відносно короткі проміжки часу. Переважно, щоб максимальний час, за який декодер, або декодувальний пристрій, здатний ідентифікувати справжній бітовий потік у потоковому режимі не перевищував 1 секунду. Крім того, складність, внесена верифікацією ідентифікатора в декодері, повинна підтримуватися на низькому рівні, тобто збільшення складності декодера має бути незначним. Нарешті, повинні підтримуватися на низькому рівні непродуктивні витрати при передачі, внесені ідентифікатором. Відповідно до одного з варіантів здійснення винаходу, вищезгадані переваги досягаються шляхом використання криптографічної величини, або ідентифікатора, одержуваної відповідно до нижчеописаного способу. Ідентифікатор може визначатися у кодері шляхом застосування однобічної функції до групи з одного або декількох кадрів даних. Кадр, як правило, включає дані, пов'язані з певним сегментом аудіопотоку та/або відеопотоку, наприклад, із сегментом, що включає задану кількість дискретних значень медіапотоку. Наприклад, кадр аудіопотоку може включати 1024 дискретних значень аудіоданих та відповідні метадані. Як було згадано вище, для визначення ідентифікатора певна кількість кадрів групується. Кількість кадрів у кожній групі може обиратися кодером і, як правило, заздалегідь невідома декодеру. Однобічна функція, переважно, представляє собою криптографічну хеш-функцію HMAC-MD5 (хеш-код аутентифікації повідомлень), хоча замість MD5 можуть використовуватися й інші хеш-функції, такі як SHA-1. Можливим критерієм вибору підходящої криптографічної хешфункції може бути її розмір, що повинен залишатися невеликим для того, щоб зменшити необхідні непродуктивні витрати при передачі. Розмір криптографічної хеш-функції, як правило, дається її числом біт. Після того, як ідентифікатор для групи кадрів обчислений, наприклад, з використанням процедури HMAC-MD5, він може бути пов'язаний з кадром з наступної групи кадрів, наприклад, вставлений у кадр із наступної групи кадрів. Як приклад, ідентифікатор може бути записаний у поле даних синтаксичного елемента кадру. Переважно, ідентифікатор вставляється в перший кадр наступної групи кадрів. Це дозволяє обчислити ідентифікатор у ході операції за один прохід без внесення додаткового часу очікування в кодер/декодер, що особливо корисно для передачі медіаданих у реальному часі. Потік даних, що включає ідентифікатор, потім може передаватися у відповідні приймачі/декодери. У приймачі вставлений ідентифікатор може використовуватися з метою ідентифікації кодера, аутентифікації, верифікації та/або конфігурування. Приймач, як правило, включає декодер, що може синхронізуватися із групою кадрів, тобто він може визначати кадри, що включають ідентифікатор. На основі відстані між двома послідовними кадрами, які включають ідентифікатор, можна визначити кількість кадрів, що приходиться на групу кадрів, яка використалася для обчислення ідентифікатора. Іншими словами, це може дозволити декодеру визначити довжину групи кадрів без повідомлення з відповідного кодера. Декодер може обчислювати ідентифікатор для прийнятої групи кадрів. Ідентифікатори, які обчислюються на основі прийнятої групи кадрів, можуть бути названі ідентифікаторами верифікації. Якщо передбачається, що ідентифікатори вставляються в перший кадр із наступної групи кадрів, то кожна група кадрів повинна починатися з першого кадру, що включає ідентифікатор для попередньої групи кадрів, і що вона повинна закінчуватися кадром, що безпосередньо передує наступному кадру, що включає ідентифікатор для поточної групи кадрів. Ідентифікатор верифікації для поточної групи кадрів може бути обчислений відповідно до описаних вище способів. 2 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 На наступному етапі декодер може витягти ідентифікатор, переданий кодером, з відповідного кадру наступної групи кадрів. І знову, якщо в кодері ідентифікатори вставляються в перший кадр наступної групи кадрів, то приймач також витягає ідентифікатор із цього, першого кадру. Цей ідентифікатор, витягнутий з потоку даних, може рівнятися з ідентифікатором верифікації, тобто з ідентифікатором, що обчислюється декодером на основі прийнятого потоку даних. Якщо обидва ідентифікатори збігаються, декодер, як правило, може прийняти, що в ході передачі помилки не виникли, група кадрів прийнята незачепленою, група кадрів не була модифікована в ході передачі, і група кадрів отримана з надійного та/або легітимного кодера. Крім того, якщо обидва ідентифікатори збігаються, декодер може обрати розблокування однієї або декількох можливостей, що залежать від кодека, або поліпшень, які не були б дозволені при декодуванні довільного бітового потоку. Наприклад, додаткові функції можуть бути дозволені, якщо декодер ідентифікує бітовий потік, специфічний для Dolby Pulse, у той час як зазначені додаткові функції не були б доступні для стандартного кодованого бітового потоку HE-AAC 2-ї версії. Проте, декодеру може бути надана можливість декодування стандартного кодованого бітового потоку HE-AAC 2-ї версії, однак без використання додаткових функцій. Треба на додаток відзначити, що ідентифікатору може бути надана можливість забезпечення установки в декодері конфігурації, що відповідає коректному декодуванню та/або відтворенню медіапотоку. У цих випадках збіг ідентифікатора верифікації й переданого ідентифікатора повинне вказувати на те, що декодер використовує коректні настройки конфігурації. Якщо, з іншого боку, ідентифікатори, тобто ідентифікатор верифікації й переданий ідентифікатор, не збігаються, то декодер буде знати, що в ході передачі виникла помилка, група кадрів не була прийнята незачепленою, група кадрів була модифікована в ході передачі, або група кадрів передана не з надійного кодера. У цих випадках декодер може бути повністю заблокований, або, в альтернативному варіанті, можуть блокуватися специфічні можливості або поліпшення. Слід зазначити, що ідентифікатор також може використовуватися для того, щоб інформувати декодер про те, що встановлені невірні настройки конфігурації. У цих випадках розбіжність між ідентифікатором верифікації й переданим ідентифікатором можуть бути пов'язані з тим, що декодер використовує невірні настройки конфігурації, навіть якщо група кадрів була прийнята незачепленою й з надійного кодера. Може бути передбачено, що у цих випадках декодер може діяти для модифікації настройок його конфігурації та для визначення відповідних ідентифікаторів верифікації до тих пір, доки ідентифікатор верифікації не буде співпадати із переданим ідентифікатором. Ця модифікація може надавати декодеру можливість актуально встановлювати його конфігурацію у відповідності із потребами бітового потоку, що приймають. Нижче описані різні особливості пропонованого способу. Відповідно до першої особливості, описується спосіб кодування потоку даних, що включає ряд кадрів даних. Потоки даних можуть представляти собою потоки аудіо-, відео- та/або інших медійних та мультимедійних даних. Зокрема, потоки даних можуть представляти собою потоки даних Dolby Pulse, AAC або HE-AAC. Потоки даних, як правило, упорядковані в кадри даних, які включають певну кількість дискретних значень даних та покривають певний сегмент потоку даних. Наприклад, кадр може включати 1024 дискретних значень звукового сигналу, дискретизованого на частоті дискретизації 44,1 КГц, тобто він покриває сегмент, біля 23 мс. Слід зазначити, що дискретні значення можуть кодуватися з постійними або змінними бітовими швидкостями передачі даних, і фактична кількість біт у кадрі може варіюватися. Спосіб може включати етап групування ряду з N послідовних кадрів даних для формування першого повідомлення. Кількість N послідовних кадрів даних, як правило, обирається відповідно до міркувань непродуктивних витрат швидкості передачі даних. Звичайно непродуктивні витрати зменшуються при збільшенні кількості N. N переважно більше одиниці. Типові значення N становлять, біля 20. У переважному варіанті здійснення винаходу N може обиратися так, щоб N послідовних кадрів покривали 0,5 секунд відповідного сигналу при відтворенні відповідним декодером з відповідною конфігурацією декодера. Слід зазначити, що етап групування може включати конкатенацію N послідовних кадрів у їх природному, тобто потоковому, порядку. На наступному етапі перше повідомлення може групуватися з інформацією про конфігурацію для формування другого повідомлення. Зазначена інформація про конфігурацію включає інформацію поза потоком даних, що, як правило, відноситься до потоку даних, зокрема, представляє собою інформацію для рендеринга потоку даних на стороні приймача. Інформація про конфігурацію може включати інформацію, що відноситься до настройок відповідного приймача та/або декодера, що повинен застосовуватися для обробки потоку 3 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 даних. Оскільки зазначена інформація про конфігурацію, як правило, не передається, або не включається, у потік даних, вона також може називатися позасмуговими даними на противагу потоку даних, що також може називатися внутрішньосмуговими даними. Інформація про конфігурацію може різними способами групуватися з першим повідомленням. Вона може конкатенуватися з першим повідомленням, тобто розміщатися на початку та/або наприкінці першого повідомлення. Інформація про конфігурацію також може розміщатися в певних положеннях усередині першого повідомлення, наприклад, між деякими, або всіма, послідовними кадрами. Типові приклади інформації про конфігурацію включають покажчик частоти дискретизації, що використовувалася при дискретизації базового аналогового потоку медіаданих. Інформація про конфігурацію також може включати покажчик конфігурації каналів системи кодування звукового сигналу, таку як монофонічна конфігурація каналів, 2-канальна стереофонічна конфігурація або 5.1-конфігурація навколишнього звуку. Інформація про конфігурацію також може включати покажчик кількості дискретних значень у кадрі даних, наприклад, 960, 1024 або 2048 дискретних значень, що які приходяться на кадр даних. Також спосіб включає етап генерування криптографічної величини для першого та/або другого повідомлення. Криптографічна величина також може називатися ідентифікатором. Зазначена криптографічна величина може генеруватися з використанням ключового значення й криптографічної хеш-функції. Зокрема, криптографічна величина може генеруватися шляхом обчислення значення HMAC-MD5 для першого та/або другого повідомлення. Крім того, генерування криптографічної величини може включати зрізання значення HMAC-MD5, наприклад, зрізання до 16, 24, 32, 48 або 64 біт. Це може виявитися корисним через зменшення необхідних непродуктивних витрат для криптографічної величини в потоці даних. Крім того, спосіб включає вставлення криптографічної величини в потік даних після N послідовних кадрів даних. Переважно, криптографічна величина вставляється в перший кадр, що слідує за N послідовними кадрами даних для того, щоб дозволити її швидке декодування й аутентифікацію й верифікацію кодера у відповідному декодері. Також може виявитися корисною вставка покажчика синхронізації після N послідовних кадрів даних, де покажчик синхронізації вказує на вставку криптографічної величини. Зазначений покажчик синхронізації може розміщатися поруч із криптографічною величиною, дозволяючи зручно витягати криптографічну величину у відповідному декодері. В ілюстративному варіанті здійснення винаходу потік даних представляє собою потік MPEG4-AAC або MPEG2-AAC, і криптографічна величина вставляється у вигляді елемента потоку даних. Зазначений елемент потоку даних може вставлятися в кінець кадру перед елементом . Крім того, вміст зазначеного елемента потоку даних, переважно, може вирівнюватися за межею байта потоку даних для того, щоб спростити витягання елемента потоку даних і, зокрема, криптографічної величини та/або покажчика синхронізації у відповідному декодері. Слід зазначити, що етап генерування криптографічної величини, переважно, може виконуватися ітеративно на окремих кадрах групи з N послідовних кадрів. Із цією метою для кожного з N послідовних кадрів з використанням вихідного стану може генеруватися проміжна криптографічна величина. Вихідний стан може представляти собою проміжну криптографічну величину попередньої ітерації. Наприклад, проміжна криптографічна величина може генеруватися для першого кадру. Ця проміжна криптографічна величина може потім використовуватися як вихідний стан для генерування проміжної криптографічної величини другого кадру. Цей процес повторюється доти, доки не буде генерована проміжна криптографічна величина N-го кадру. Ця остання проміжна криптографічна величина, як правило, представляє собою криптографічну величину для групи з N послідовних кадрів. Для того, щоб врахувати інформацію про конфігурації, вихідний стан першої ітерації може представляти собою проміжну криптографічну величину для інформації про конфігурацію. У переважному варіанті здійснення винаходу криптографічна величина для блоку з N послідовних кадрів даних генерується на блоці з N послідовних кадрів даних, що включає криптографічну величину для попереднього блоку з N послідовних кадрів даних. Таким чином, може бути генерований потік взаємозалежних криптографічних величин. Відповідно до іншої особливості, спосіб може включати етап взаємодії з відео- та/або аудіокодером потоку даних. Цей етап може бути реалізований шляхом виконання кодування відео- та/або аудіосигнала, а також як генерування криптографічної величини інтегрованим способом. Зокрема, взаємодію між відео- та/або аудіокодером потоку даних та генеруванням криптографічної величини може бути спрямовано на установку максимальної бітової швидкості передачі даних для відео- та/або аудіокодера так, щоб бітова швидкість передачі даних потоку 4 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 даних, що включає криптографічну величину, не перевищувала заздалегідь визначене значення. Це може виявитися особливо корисним, якщо базовий кодек потоку даних установлює більш високу межу бітової швидкості передачі даних для повного потоку даних. Відповідно до наступної особливості, описаний спосіб верифікації потоку даних у декодері та/або приймачі. Слід зазначити, що описані способи й системи можуть застосовуватися в контексті переданих потоків даних, а також потоків даних, що передбачаються на носії даних. Як описано вище, потік даних, як правило, включає ряд кадрів даних та криптографічну величину, зв'язану рядом з N попередніх послідовних кадрів даних. Тут варто звернутися до обговорення, здійсненого в даному документі, особливо, відносно можливих значень N та структури потоку даних та його кадрів. Спосіб включає етап витягання N послідовних кадрів даних для формування першого повідомлення. Спосіб також може включати етап визначення значення N. Цей етап може виконуватися в потоці даних, що включає ряд з N послідовних кадрів даних та пов'язані з ним криптографічні величини. Якщо N послідовних кадрів даних назвати групою кадрів, то зазначений потік даних, як правило, включає ряд груп кадрів та криптографічні величини, пов'язані з кожною із груп кадрів. У цих випадках, число N може бути визначене як кількість кадрів між двома послідовними криптографічними величинами. Слід зазначити, що поточна група кадрів, що використовується для обчислення другої криптографічної величини, може включати криптографічну величину для попередньої групи кадрів. В альтернативному варіанті, криптографічна величина для попередньої групи кадрів та будь-який пов'язаний з нею покажчик синхронізації та/або синтаксичний елемент повинен бути вилучений з поточної групи кадрів перед обчисленням другої криптографічної величини. Останнє рішення може виявитися кращим з метою попередження змін та відхилень від поширення при переході від однієї групи кадрів до наступної. Спосіб також може включати етап групування першого повідомлення з інформацією про конфігурацію з метою формування другого повідомлення, де інформація про конфігурацію, як правило, включає інформацію поза потоком даних, таку як інформація для рендеринга потоку даних. Етап групування й різні особливості, що відносяться до інформації про конфігурацію, описані вище. Ці особливості рівною мірою застосовні до декодера. Спосіб триває шляхом генеруванням другої криптографічної величини для першого та/або другого повідомлення, шляхом витягання криптографічної величини з потоку даних та порівняння криптографічної величини із другою криптографічною величиною. Друга криптографічна величина також може називатися криптографічною величиною для верифікації, або ідентифікатором верифікації. Слід зазначити, що друга криптографічна величина може генеруватися ітеративним способом, як це описано в контексті генерування криптографічної величини. У переважному варіанті здійснення винаходу криптографічна величина генерується у відповідному кодері та/або передавачі з N послідовних кадрів даних та інформації про конфігурацію відповідно до способу, що відповідає способу, використовуваному для генерування другої криптографічної величини. Іншими словами, спосіб генерування криптографічної величини у відповідному кодері відповідає способу генерування другої криптографічної величини в декодері. Зокрема, криптографічна величина й друга криптографічна величина генеруються з використанням унікального ключового значення та/або унікальної криптографічної хеш-функції. Крім того, набір N послідовних кадрів, використовуваних для генерування криптографічної величини в кодері відповідає набору N послідовних кадрів, використовуваних для генерування другої криптографічної величини в декодері. Як згадувалося вище, криптографічна величина й друга криптографічна величина можуть бути визначені на наборі N послідовних кадрів, які включають, або які не включають, криптографічну величину для попереднього набору з N послідовних кадрів. Аналогічне правило варто застосовувати до кодера й декодера. Навіть якщо набір кадрів, використовуваний у кодері й декодері, повинен бути ідентичним, слід зазначити, що вміст кадрів у кодері й декодері може розрізнятися, наприклад, через модифікації, яким кадри піддаються в ході їхньої передачі, або через помилки на носії потоку даних. У відповідності з наступною особливістю, спосіб може включати етап установки прапора у випадку, коли криптографічна величина відповідає другій криптографічній величині та/або етап забезпечення візуальної індикації в приймачі та/або декодері, якщо прапор установлений. Аналогічним чином прапор та/або візуальна індикація може бути вилучений, якщо криптографічна величина не відповідає другій криптографічній величині, або якщо криптографічна величина не може бути витягнута з потоку даних. Це може бути корисним для 5 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 забезпечення користувача декодера й глядача/слухача потоку даних інформацією про автентичність потоку даних. Відповідно до іншої особливості, описаний потік даних, що включає криптографічну величину таку, що генерують та вставляють у відповідності зі способами, описаними в даному патентному документі. Відповідно до іншої особливості, описаний кодер, що діє для кодування потоку даних, що включає ряд кадрів даних. Кодер діє для виконання етапів способу, описаних у даному патентному документі. Зокрема, кодер може включати процесор, що діє на групу з кількості N послідовних кадрів даних з метою формування першого повідомлення; де N більше одиниці; для групування першого повідомлення з інформацією про конфігурацію з метою формування другого повідомлення; де інформація про конфігурацію включає інформацію поза потоком даних, таку як інформація для рендеринга потоку даних; для генерування криптографічної величини для другого повідомлення; і для вставки криптографічної величини в потік даних, що слідує за N послідовними кадрами даних. Відповідно до наступної особливості, описаний декодер, що діє для верифікації потоку даних, що включає ряд кадрів даних та криптографічну величину, пов'язану з кількістю N попередніх послідовних кадрів даних, де N більше одиниці. Декодер діє для виконання етапів способу, описаних у даному патентному документі. Зокрема, декодер може включати процесор, що діє для витягання N послідовних кадрів даних з метою формування першого повідомлення; для групування першого повідомлення з інформацією про конфігурацію з метою формування другого повідомлення; де інформація про конфігурацію включає інформацію для рендеринга потоку даних; для генерування другої криптографічної величини для другого повідомлення; для витягання криптографічної величини з потоку даних; та для порівняння криптографічної величини із другою криптографічною величиною. Відповідно до наступної особливості, описана програма, реалізована програмно. Програма, реалізована програмно, адаптована для виконання на процесорі й для виконання етапів способу, описаних у даному патентному документі, при здійсненні на обчислювальному пристрої. Відповідно до наступної особливості, описаний носій даних. Носій даних включає програму, реалізовану програмно, що адаптована для виконання на процесорі й для виконання етапів способу, описаних у даному патентному документі, при здійсненні на обчислювальному пристрої. Відповідно до наступної особливості, описаний комп'ютерний програмний продукт. Комп'ютерний програмний продукт включає команди, що виконуються, для виконання етапів способу, описаних у даному патентному документі, при здійсненні на комп'ютері. Відповідно до наступної особливості, описаний додатковий зовнішній пристрій, переносний електронний пристрій (наприклад, мобільний телефон, PDA, смартфон і т.д.) або комп'ютер (наприклад, настільний комп'ютер, ноутбук і т.д.), призначений для декодування потоку даних. Потік даних може включати звуковий сигнал. Додатковий зовнішній пристрій, переважно, включає декодер, що відповідає особливостям, описаним у даному патентному документі. Відповідно до наступної особливості, описана система мовлення, призначена для передання потоку даних. Потік даних може включати звуковий сигнал. Система мовлення, переважно, включає кодер, що відповідає особливостям, описаним у даному патентному документі. Відповідно до іншої особливості, описаний спосіб конкатенації першого та другого бітових потоків у точці конкатенації. Кожен із двох бітових потоків може включати ряд кадрів даних та криптографічну величину, пов'язану із заданою кількістю кадрів даних. Перший бітовий потік може включати криптографічну величину для кожних N1 послідовних кадрів, у той час як другий бітовий потік може включати криптографічну величину для кожних N2 послідовних кадрів. Числа N1 та N2 можуть бути ідентичні, тобто обидва бітових потоки мають однаковий період криптографічного повторення, або числа N1 та N2 можуть бути різні, тобто в бітових потоках можуть бути різні кількості кадрів, після яких включені криптографічні величини. Спосіб конкатенації включає етап генерування конкатенованого бітового потоку з першого та другого бітових потоків, де конкатенований бітовий потік включає, щонайменше, частину з ряду кадрів даних з першого та другого бітових потоків. Іншими словами, другий бітовий потік, або частина другого бітового потоку, прикріплюється у точці конкатенації до першого бітового потоку, або частини першого бітового потоку. Конкатенований бітовий потік включає криптографічні величини, такі, що генеруються та вставляються у відповідності зі способами, описаними в даному патентному документі. Переважно, криптографічні величини в конкатенованому бітовому потоці гладко покривають 6 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 точку конкатенації так, щоб у приймачі/декодері не було помітно переривання автентичності бітового потоку. Це може досягатися шляхом генерування в явному вигляді нових криптографічних величин для конкатенованого бітового потоку після точки конкатенації. Нові криптографічні величини можуть генеруватися, щонайменше, для деякої кількості послідовних кадрів у секції конкатенованого бітового потоку, що починається в точці конкатенації. У деяких випадках криптографічні величини другого бітового потоку можуть бути використані повторно й скопійовані в конкатенований бітовий потік після секції, у яку включені нові криптографічні величини. Таке повторне використання застосовується, зокрема, тоді, коли криптографічна величина для попередньої групи кадрів, включена в перший кадр наступної групи, не враховується при обчисленні криптографічної величини наступної групи, та групи обробляються незалежно, тобто зміни в криптографічних величинах не поширюються від однієї групи до наступної. Генерування криптографічних величин у явному вигляді у відповідності зі способами, описаними в даному патентному документі, може бути практично корисним на межах між першим бітовим потоком та другим бітовим потоком, тобто для кінцевих кадрів першого бітового потоку й для перших кадрів другого бітового потоку, включених у конкатенований бітовий потік. У цілому, при конкатенації двох бітових потоків кількість фінальних кадрів першого бітового потоку, як правило, менше або дорівнює N1, та/або кількість кадрів, узятих із другого бітового потоку перед включенням першої криптографічної величини, як правило, менше або дорівнює N2. Іншими словами, точка конкатенації, як правило, не розташовується на границях груп першого та другого бітового потоків. Відповідно до однієї з особливостей способу конкатенації або з'єднання, нова криптографічна величина генерується для кінцевих кадрів першого бітового потоку й вставляється в наступний кадр конкатенованого бітового потоку, що представляє собою перший кадр, узятий із другого бітового потоку. Ця нова криптографічна величина вважається "завершальною" перший бітовий потік. Нові криптографічні величини можуть потім генеруватися для другого бітового потоку й включатися у відповідні положення конкатенованого бітового потоку. Це особливо є придатним у тих випадках, коли без додаткової криптографічної величини, вставленої в перший кадр, узятий із другого бітового потоку, кількість кадрів між останньою криптографічною величиною, що генерується для кадрів з першого бітового потоку, та першою криптографічною величиною, що генерується для кадрів із другого бітового потоку, буде перевищувати максимальну кількість, що допускається системою. У випадку, якщо точка конкатенації не вирівняна із групами кадрів першого та другого бітових потоків, спосіб конкатенації може генерувати криптографічну величину для змішаної групи, що включає кадри, взяті з першого та другого бітових потоків. Як уже було згадано, криптографічні величини, як правило, включаються в кадр, що слідує за групою кадрів, використовуваної для обчислення відповідної криптографічної величини. Відповідно до наступної особливості, описаний пристрій для конкатенації та/або головний вузол мережі мовлення. Зазначений пристрій для конкатенації та/або головний вузол мережі мовлення діє для конкатенації першого та другого бітових потоків, кожен з яких включає ряд кадрів даних та криптографічні величини, пов'язані із заданою кількістю кадрів даних. Пристрій може включати декодер, що містить будь-яку комбінацію характерних ознак, описаних у даному патентному документі. Зазначений декодер може використовуватися для декодування фінальних кадрів першого бітового потоку, перших кадрів другого бітового потоку й пов'язаних з ними криптографічних величин. Пристрій для конкатенації та/або головний вузол мережі мовлення також може включати кодер, що містить будь-яку комбінацію характерних ознак, описаних у даному патентному документі. Кодер може використовуватися для кодування кінцевих кадрів першого бітового потоку й перших кадрів другого бітового потоку. Крім того, пристрій для конкатенації та/або головний вузол мережі мовлення може включати блок перенаправлення, призначений для перенаправлення тих кадрів та пов'язаних з ними криптографічних величин першого та другого бітового потоків, які не декодуються й не кодуються. Іншими словами, блок просування може просто копіювати, або перенаправляти, або переносити, кадри й зв'язані криптографічні величини в конкатенований бітовий потік. Слід зазначити, що пристрій для конкатенації також може діяти для декодування й кодування повних потоків даних, тобто для декодування криптографічних величин вхідного потоку даних та для генерування криптографічних величин для вихідного потоку даних. Це може бути корисно для того, щоб генерувати безперервний взаємозв'язок бітового потоку за допомогою криптографічних величин. Фактично, ряд бітових потоків може декодуватися й конкатенований бітовий потік, що включає частини бітових потоків з ряду, може кодуватися за допомогою безупинно взаємозалежних криптографічних величин. Таким чином, приймач 7 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 конкатенованого бітового потоку буде сприймати конкатенований бітовий потік як бітовий потік, що відбувається з одиничного кодера, що заслуговує довіри. Також слід зазначити, що для цілі декодування та/або кодування бітових потоків, що включають криптографічні величини, пристрій для конкатенації може не випробовувати необхідності у тому, щоб бути обізнаним про базовий кодек потоку даних. Наприклад, пристрій для конкатенації не має потреби в можливості виконання декодування/кодування HE-AAC для того, щоб витягати та/або генерувати криптографічні величини для потоків даних. У деяких ситуаціях, наприклад, тоді, коли нова криптографічна величина вставляється в кадр, який раніше не містив криптографічну величину, декодування й наступне повторне кодування потоку даних може бути необхідне для створення в бітовому потоці вільного місця для нової криптографічної величини, зокрема, для задоволення вимог бітового потоку. Слід зазначити, що способи й системи, що включають переважні варіанти здійснення винаходу у тому вигляді, як вони описані в даному патентному документі, можуть використовуватися автономно або в комбінації з іншими способами та системами, описаними в даному документі. Крім того, всі особливості способів та систем, описаних у даній патентній заявці, можуть довільно комбінуватися. Зокрема, характерні ознаки пунктів формули винаходу можуть довільним чином комбінуватися одна з одною. Також слід зазначити, що може змінюватися порядок етапів способу. ОПИС ГРАФІЧНИХ МАТЕРІАЛІВ Нижче винахід пояснюється на прикладах з відсиланням до супровідних графічних матеріалів, де Фіг. 1 ― ілюстративний спосіб визначення ідентифікатора відповідно до винаходу; Фіг. 2a та 2b ― схеми послідовності операцій ілюстративного способу генерування ідентифікатора та його вставки у кодері; Фіг. 3 ― схема послідовності операцій на ілюстративних етапах аутентифікації й верифікації, що вживаються в декодері; Фіг. 4 ― ілюстративний варіант здійснення кодера й декодера; Фіг. 5 ― приклад використання ідентифікатора в системі мовлення; і Фіг. 6 та 7 ― приклади конкатенації бітових потоків з метою формування конкатенованого бітового потоку. Нижченаведені варіанти здійснення винаходу описані на прикладах та не обмежують обсяг правової охорони даного патентного документа. Винахід буде описуватися в контексті AAC (Advanced Audio Coding) і, зокрема, MPEG-2 AAC та MPEG-4 AAC. Слід зазначити, однак, що винахід також застосовний до інших схем кодування медіасигналів, зокрема, до схем кодування аудіосигналів, відеосигналів та/або інших мультмедійних сигналів. Крім того, винахід застосовний до пристрою для конкатенації, що створює комбінований бітовий потік з ряду кодерів. Фіг. 1 ілюструє бітовий потік 100 та спосіб визначення ідентифікатора для цього бітового потоку 100. Прикладами такого бітового потоку є кодовані бітові відео- та/або аудіопотоки з базовим кодеком AAC, HE-AAC (High Efficiency-Advanced Audio Coding), Dolby Pulse, MPEG-4 AVC/H.264, MPEG-2 Video або MPEG-4 Video. Зазначені кодеки та їх формат визначений, наприклад, в описі стандарту ISO/TEC 14496-3 ― для MPEG-4 AAC, в описі стандарту ISO/IEC 13818-7 ― для MPEG-2 AAC, в описі стандарту ISO/IEC 14496-10 ― для MPEG-4 AVC/H.264, в описі стандарту ISO/IEC 13818-2 ― для MPEG-2 Video, та в описі стандарту ISO/IEC 14496-2 ― для MPEG-4 Video. Ці описи включені посиланням. У зазначених кодеках потоки даних організовані в так звані кадри, де кадри включають певну кількість дискретних значень медіасигналу. Різні кодеки можуть використовувати різні кількості дискретних значень, що припадають на кадр. Типовими прикладами є кількості 960, 1024 або 2048 дискретних значень на кадр. Крім фактичних медіаданих кадри також можуть включати так звані метадані, які можуть нести додаткову керуючу інформацію, наприклад, таку, що відноситься до гучності або динамічного діапазону програми. На фіг. 1 показана послідовність кадрів 101, 102, 103,…, 106. Вісь часу проходить зліва направо, тому кадр 101 обробляється перед кадром 106. Як описано вище, кожний кадр може включати медіадані й додаткові метадані. Структура кожного кадру й можливі поля, або елементи, даних, які може включати кадр, визначаються базовою схемою кодування. Наприклад, кадр MPEG-4 AAC, або кадр MPEG-2 AAC, може включати аудіодані для періоду часу, що містить 1024, або 960, дискретних значень, зв'язану інформацію й інші дані. Синтаксис та структура кадру визначені в розділах 4.4 та 4.5 вищезгаданого опису стандарту ISO/IEC 8 UA 104483 C2 5 10 15 20 25 30 35 14496-3 ― для MPEG-4 AAC, та в розділах 6 та 8 вищезгаданого опису стандарту ISO/IEC 13818-7 ― для MPEG-2 AAC. Ці розділи посиланням включаються в даний опис. Кадр MPEG-4 AAC, або MPEG-2 AAC, може включати різні синтаксичні елементи, такі як: • Елемент single_channel_element(), позначуваний абревіатурою SCE, що представляє собою синтаксичний елемент бітового потоку, що містить кодовані дані для одиничного аудіоканала. • Елемент channel_pair_element(), позначуваний абревіатурою CPE, що представляє собою синтаксичний елемент корисного навантаження бітового потоку, що містить кодовані дані для пари каналів. • Елемент coupling_channel_element(), позначуваний абревіатурою CС, що представляє собою синтаксичний елемент, що містить кодовані аудіодані для зв'язаного каналу. • Елемент lfe_channel_element(), позначуваний абревіатурою LFE, що представляє собою синтаксичний елемент, що містить канал збільшення низької частоти дискретизації. • Елемент program_config_element(), позначуваний абревіатурою РСЕ, що представляє собою синтаксичний елемент, що містить дані про конфігурацію програми. • Елемент fill_element(), позначуваний абревіатурою FIL, що представляє собою синтаксичний елемент, що містить дані про заповнення. • Елемент data_stream_element(), позначуваний абревіатурою DSE, що представляє собою синтаксичний елемент, що містить допоміжні дані. • Синтаксичний елемент TERM, що вказує кінець блоку неопрацьованих даних, або кадру. Зазначені синтаксичні елементи використовуються в межах кадру, або блоку неопрацьованих даних, з метою визначення медіаданих та пов'язаних з ними керуючих даних. Наприклад, два кадри монофонічного звукового сигналу можуть бути визначені за допомогою синтаксичних елементів . Два кадри стереофонічного звукового сигналу можуть бути визначені синтаксичними елементами . Два кадри 5.1-канального звукового сигналу можуть бути визначені синтаксичними елементами . Пропонований спосіб групує певна кількість N таких кадрів і, таким чином, формує групи кадрів 111, 112 та 113. На фіг. 1 показана повна група кадрів 112, що включає N=5 кадрів від 103 до 105. П'ять кадрів групи кадрів 112 конкатенуються з метою формування першого повідомлення. Хеш-код аутентифікації повідомлення (HMAC) для першого повідомлення можна визначити, використовуючи криптографічну хеш-функцію H(.) та "секретний" ключ ДО, що, як правило, заповнюється праворуч додатковими нулями до розміру блоку хеш-функції H(.). Нехай знак || позначає конкатенацію, знак позначає АБО, що виключає, а зовнішнє заповнення й внутрішнє заповнення є константами, що мають довжину розміру блоку хеш-функції H(.), тоді значення HMAC для першого повідомлення можна записати як 40 45 50 55 , де m — повідомлення, також називане в даному описі першим повідомленням. Розмір блоку, використовуваний хеш-функціями MD5 або SHA-1, як правило, становить 512 біт. Розмір вихідного сигналу операції HMAC є таким самим, як у базової хеш-функції, тобто 128 біт – у випадку MD5, та 160 біт – у випадку SHA-1. Значення HMAC для першого повідомлення, тобто значення HMAC конкатенованих кадрів 103-105 групи кадрів 112, можна використовувати як ідентифікатор групи кадрів 112. Для того, щоб зменшити довжину ідентифікатора, значення НМАС можна зрізати, наприклад, зрізати до 16, 24, 32, 48 або 64 біт. Треба, однак, відзначити, що зазначена операція зрізання, як правило, впливає на безпеку хеш-коду аутентифікації повідомлення. Оскільки ідентифікатор вставляється в потік даних, пропонований спосіб переважно використовує як ідентифікатор зрізану версію значення HMAC. Як показано на фіг. 1, ідентифікатор 122 групи кадрів 112 вставляється в кадр наступної групи кадрів 113. Переважно, ідентифікатор 122 вставляється в перший кадр 106 наступної групи кадрів 113. Подібним чином, ідентифікатор 121 був визначений для попередньої групи кадрів 111 та вставлений у перший кадр 103 групи кадрів 112. Слід зазначити, що ідентифікатор 122 групи кадрів 112 можна обчислити на основі першого повідомлення m, що включає ідентифікатор 121 попередньої групи кадрів 111, або його можна обчислити на основі першого повідомлення m, що не включає ідентифікатор 121 попередньої групи кадрів 111. В останньому випадку, інформацію, що відноситься до ідентифікатора 121, необхідно буде видалити з першого повідомлення m перед визначенням ідентифікатора 122. 9 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 Може знадобитися забезпечення того, щоб кодер та декодер застосовували той самий спосіб для визначення першого повідомлення m. У переважному варіанті здійснення винаходу ідентифікатор 122 визначається на основі першого повідомлення m, що включає ідентифікатор 121 попередньої групи кадрів 111. Таким чином, ідентифікатори можуть бути безупинно взаємозалежні й, відповідно, можна створити взаємозалежний бітовий потік, який не можна модифікувати, наприклад, шляхом модифікації або заміни деяких груп кадрів бітового потоку. Як наслідок, можна забезпечити автентичність повного потоку даних, або бітового потоку. З іншого боку, як і раніше забезпечується можливість повторної синхронізації приймача на частково ушкодженому бітовому потоці, навіть у тому випадку, коли ідентифікатори взаємозалежні. В переважному варіанті здійснення винаходу ідентифікатор розміщується в одиничному елементі data_stream_element(), позначуваному абревіатурою та обумовленому у стандарті ISO/IEC 14496-3, таблиця 4.10 — для MPEG-4 AAC, або обумовленому у стандарті ISO/IEC 13818-7, таблиця 24 — для MPEG-2 AAC, які посиланням включаються в даний опис. Для полегшення синхронізації декодера, кадр ААС повинен включати тільки один елемент data_stream_element() , що несе ідентифікатор, тому декодер може визначати довжину групи кадрів як відстань між двома прийнятими ідентифікаторами. Іншими словами, кадр ААС може включати кілька елементів data_stream_element() , але повинен включати тільки один елемент data_stream_element() , що включає ідентифікатор. У переважному варіанті здійснення винаходу положення перебуває наприкінці кадру ААС безпосередньо перед елементом . Для того, щоб дозволити швидке витягання ідентифікатора, може використовуватися функція DSE по вирівнюванню за межею байта. З цією метою DSE, як правило, включає поле, або біт, що вказує на те, що дані, які включаються в DSE, є вирівняними за межею байта. Це вказує декодеру на те, що фактичні дані DSE починаються на позиції біта на початку байта. Бітовий потік, або потік даних, може включати кілька елементів . Для того, щоб мати можливість відрізняти один елемент від іншого, кожний елемент , як правило, включає мітку element_instance_tag, обумовлену для MPEG-4 AAC у стандарті ISO/EEC 14496-3, розділ 4.5.2.1.1, і для MPEG-2 AAC — у стандарті ISO/IEC 13818-7, розділ 8.2.2, при цьому обидва ці розділи посиланням включаються у даний опис. Слід зазначити, що значення мітки element_instance_tag елемента data_stream_element(), що включає ідентифікатор, не обмежується якою-небудь конкретною величиною, тобто застосовуються загальні правила стандартів ISO/IEC. Іншими словами, переважно не існує спеціальних правил для мітки element_instance_tag в елементі , що містить ідентифікатор, крім тих, які встановлені для MPEG-4 AAC у документі стандарту ISO/IEC 14496-3, та для MPEG-2 AAC — у документі стандарту ISO/IEC 13818-7. За аналогією з наведеними вище прикладами можливих потоків даних, потік даних для 2канальної аудіопрограми може включати синтаксичні елементи …. 2-канальна аудіопрограма з SBR (реплікацією спектральних смуг) може включати синтаксичні елементи …, де - синтаксичний елемент, специфічний для SBR. 5.1-канальна аудіопрограма може бути складена із синтаксичних елементів …. У переважному варіанті здійснення винаходу поле ідентифікатора, розташоване в елементі , може включати поле identifier_sync та поле identifier_value. Поле identifier_sync може використовуватися для того, щоб дозволити швидку ідентифікацію на підставі того, що даний конкретний елемент включає ідентифікатор. Наприклад, кодер може встановлювати заздалегідь задане значення цього поля, наприклад, двійковий вихідний сигнал, для вказівки того, що елемент включає поле ідентифікатора. Декодер може використовувати це поле для перевірки доступності значення ідентифікатора. Іншими словами, декодер інформується про те, що прийнятий потік даних включає ідентифікатор, що може бути використаний з метою вищеописаної аутентифікації, верифікації й, можливо, конфігурування. У переважному варіанті здійснення винаходу поле identifier_value включає значення ідентифікатора, що визначено так, як це описано в даному документі. Це поле включає кількість біт, необхідну для ідентифікатора, тобто для зрізаної версії значення НМАС. Як описано вище, ідентифікатор, як правило, покриває N кадрів ААС, де N>1, та кожний N-й кадр ААС включає ідентифікатор, тобто він включає елемент , що включає елемент ідентифікатора так, як це описано вище. Як правило, рішення про кількість N кадрів, що покриваються, ААС приймає 10 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодер. Декодер здатний визначити цю величину по вираженій в кадрах відстані між двома кадрами ААС, що включають відповідні ідентифікатори. Як описано вище, ідентифікатор також може використовуватися для забезпечення того, щоб декодер використав коректні настройки конфігурації. Із цією метою ідентифікатор може генеруватися на основі розширеного повідомлення, що включає не тільки конкатенацію N послідовних кадрів, але також включає й дані про конфігурацію. Іншими словами, перше повідомлення, що включає N послідовних кадрів, як описано вище, також може включати дані про конфігурацію. Зазначені дані про конфігурацію можуть включати індекс samplingFrequencyIndex, тобто покажчик базової частоти дискретизації звукового сигналу, індекс channelConfiguration, тобто покажчик використовуваної конфігурації каналів, та прапор frameLengthFIag, тобто покажчик використовуваної довжини кадру. Також можливі й інші параметри конфігурації. Ці параметри, тобто (базова) частота дискретизації ААС, або "samplingFrequencyIndex", конфігурація каналів та покажчик довжини ААС-перетворення, або "frameLengthFIag", можуть використовуватися для формування слова configuration_word. Слово configuration_word також може включати біти, що заповнюють, для того, щоб привести його до заздалегідь заданого розміру. У переважному варіанті здійснення винаходу параметри "samplingFrequencyIndex" та "channelConfiguration" мають той же зміст та значення, що й однойменні елементи в "AudioSpecificConfig", описані у відповідному описі стандарту ISO/IEC (наприклад, у розділі 1.6.2.1 стандарту ISO/IEC 14496-3). Параметр "frameLengthFIag" має той же зміст та значення, що й однойменний елемент в "GASpecificConfig", описаний у відповідному описі стандарту ISO/IEC (наприклад, у розділі 4.4.1 та таблиці 4.1 стандарту ISO/IEC 14496-3). Слово configuration_word та N кадрів ААС конкатенуються, даючи повідомлення m, що також може називатися другим повідомленням та яке включає слово configuration_word на додаток до першого повідомлення, що включає конкатенацію N кадрів ААС: ; де || позначає конкатенацію. У наведеному вище прикладі слово configuration_word розміщається перед першим повідомленням. Слід зазначити, що слово configuration_word також може розміщатися й в інших положеннях, наприклад, наприкінці першого повідомлення. Аналогічно описаному вище, значення НМАС, наприклад код HMAC-MD5, HMAC(m) за повідомленням m обчислюється з використанням "секретного" ключа К. Ключ К може, наприклад, представляти собою заданий код ASCII або будь-яку іншу секретну величину, а значення HMAC для повідомлення m обчислюється з використанням вищезгаданої формули для НМАС. Слід зазначити, що значення HMAC для повідомлення m може бути визначене послідовно. Це означає, що на першому етапі може визначатися значення НМАС для слова configuration_word. Це приводить до першого значення НМАС як вихідному стану для визначення значення НМАС для кадру 1 ААС. Вихідним сигналом цієї операції є друге значення НМАС для кадру 2 ААС, і т.д. В остаточному підсумку, з використанням як вихідний стан значення НМАС для кадру N–1 ААС визначається значення НМАС для кадру N ААС. Використовуючи таке послідовне визначення значення НМАС по всьому повідомленню m, тобто по всій послідовності кадрів та/або слову configuration_word, можна генерувати ідентифікатор без збільшення затримки, внесеної в бітовий потік. Крім того, вимоги до пам'яті для генерування значення НМАС та/або ідентифікатора підтримуються на низькому рівні, оскільки необхідне зберігання в пам'яті тільки поточного кадру бітового потоку й вихідного стану, тобто 128-бітної величини. Генерування й зберігання повного повідомлення m не потрібне. Для того, щоб зменшити непродуктивні витрати в бітовому потоці, викликані додатковим ідентифікатором, значення НМАС зрізується від 128 біт до зменшеної кількості біт шляхом відкидання найменш значимого біта. Наприклад, значення НМАС "9el07d9d372bb6826bd81d3542a419d6" може бути зрізане до "9el07d9d". Ступінь зрізання, переважно, обирається як компроміс між безпекою ідентифікатора й необхідних непродуктивних витрат бітової швидкості передачі даних. Можливі довжини ідентифікатора можуть, наприклад, становити 16, 24, 32, 48, 64, 80 або 96. Зрізане значення НМАС представляє собою ідентифікатор, що вставляється в поле identifier_value елемента DSE. Нижче наводяться додаткові подробиці, що відносяться до процесу кодування. Як уже згадувалося, саме кодер, як правило, ухвалює рішення щодо кількості N кадрів ААС, які покриваються одним ідентифікатором. Наприклад, може виявитися бажаним забезпечити здатність декодера синхронізуватися з довжиною групи кадрів протягом не більш ніж 1-ї секунди. Оскільки необхідно два ідентифікатори для того, щоб декодер міг синхронізуватися з 11 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 довжиною групи кадрів, що задається кількістю кадрів між двома кадрами, що включають ідентифікатор, необхідно забезпечити те, що декодер прийме, щонайменше, два ідентифікатори в межах необхідного інтервалу часу. Тому кодер повинен обрати значення N так, щоб тимчасове подання N кадрів ААС не перевищувало, або мінімально перевищувало, 0,5 секунд. Оскільки тимчасове подання N кадрів ААС залежить від обраної (базової) частоти дискретизації ААС, значення N, обране кодером, може змінюватися залежно від обраної (базової) частоти дискретизації ААС. Для того, щоб мінімізувати непродуктивні витрати бітової швидкості передачі даних, внесені ідентифікатором, кодер може обрати найбільше значення N, що задовольняє обмеженню, що полягає у тому, що тимчасове подання N кадрів ААС не повинне перевищувати 0,5 секунд. У деяких додатках для тимчасового подання N кадрів ААС припустиме невелике перевищення 0,5 секунд. У цих додатках кодер може обирати значення N так, щоб тимчасове подання N кадрів ААС було максимально можливо близьким до 0,5 секунд, навіть якщо це, у деяких випадках, може приводити до тимчасового подання N кадрів ААС, що трохи перевищує 0,5 секунд. Непродуктивні витрати, які вносяться передачею ідентифікатора, можна визначити шляхом оцінки співвідношення між довжиною елемента DSE, що включає ідентифікатор, та загальною довжиною групи кадрів (у кількості біт). Крім того, рекомендується вирівняти вставку ідентифікатора із вставкою інших конфігураційних елементів, таких як заголовок SBR. Це дозволяє декодеру легко синхронізуватися з бітовим потоком, а також дозволяє прийняти всі конфігураційні слова в ході декодування одиничного кадру. Слід зазначити, що перший генерований кадр ААС може містити помилковий ідентифікатор. Призначенням першого ідентифікатора може бути передача декодеру сигналу про початок послідовності кадрів ААС, що включають ідентифікатори. Однак декодер може не виявитися в положенні для виконання аутентифікації й верифікації, оскільки ідентифікатор може не ґрунтуватися на фактичних медіаданих. Як описувалося відносно фіг. 1, перший обчислений ідентифікатор покриває кадри ААС від 1 до N та зберігається в кадрі N+1 ААС. Наступний ідентифікатор покриває кадри ААС від N+1 до 2N та зберігається в кадрі 2N+1 ААС, і т.д. Фиг. 2а ілюструє схему послідовності операцій процесу кодування. На етапі 201 кодер ініціалізується шляхом постачання деякої кількості N кадрів, що містяться у групі кадрів. Крім того, передбачається ключ К. На наступному етапі 202 N кадрів у групі кадрів конкатенуються з метою створення першого повідомлення. Потім на етапі 203 перше повідомлення конкатенується зі словом конфігурації, даючи друге повідомлення. На етапі 204 визначається ідентифікатор у вигляді зрізаної версії значення НМАС, обчисленого по другому повідомленню. Цей ідентифікатор розміщується в першому кадрі наступної групи кадрів (етап 205). Нарешті, на етапі 206 виконується передача групи кадрів. Слід зазначити, що передана група кадрів містить ідентифікатор групи кадрів, переданої перед нею. Етапи 202―206 повторюються доти, доки не буде переданий повний потік даних. Як уже згадувалося, описаний вище процес може виконуватися послідовним ітеративним способом. Це означає, що ідентифікатор може визначатися покадрово без необхідності в попередній конкатенації N кадрів та слова configuration_word та виконанні обчислення НМАС на цьому повністю конкатенованому повідомленні. Цей процес проілюстрований на фіг. 2b. Ітеративна процедура ініціалізується на етапі 207 шляхом задання вихідного стану. Вихідний стан може представляти собою значення НМАС для слова configuration_word, що зберігається в 128 бітах пам'яті. Потім значення НМАС може визначатися для першого з N кадрів (етап 208). Результуюче значення НМАС зберігається в 128 бітах пам'яті (етап 209) та використовується як вихідний стан для обчислення значення НМАС другого кадру (етап 208). Цей процес повторюється доти, доки не буде визначене значення НМАС для N-го кадру, де значення НМАС для N-1-го кадру береться з 128 біт пам'яті й використовується як вихідний стан (етап 208). Ідентифікатор визначається як зрізана версія значення НМАС для N-го кадру (етап 210). Як альтернатива етапу 206, кожний кадр може відправлятися безпосередньо після обробки з метою обчислення значення НМАС без буферизації всієї групи кадрів. Ідентифікатор потім додається до N+1-го кадру й відправляється із цим кадром. Таким чином, цей кадр представляє собою перший кадр, що використовується для ітеративного обчислення значення НМАС для наступних N кадрів. При використанні цього процесу процес кодування може виконуватися покадрово з низькою затримкою, низькою обчислювальною складністю й низькими вимогами до пам'яті. Нижче наведені додаткові подробиці, що відносяться до процесу декодування. Як правило, декодер починає з припущення того, що потік, який необхідно декодувати, не включає 12 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 ідентифікатор, що має силу. Тобто покажчик наявності ідентифікатора, що має силу, у бітовому медіапотоці первісно встановлюється в значення "неправда" і, як правило, буде встановлений у значення "істина" тільки при першому успішному прийомі ідентифікатора, що має силу. Це може показуватися на приймачі, наприклад, на додатковому зовнішньому пристрої, за допомогою візуального індикатора, такого як LED, що вказує користувачеві на те, що прийнятий бітовий потік є аутентифікованим і таким, що має силу. Як наслідок, ідентифікатор може використовуватися для вказівки користувачеві якості прийнятого потоку даних. З іншого боку, якщо покажчик на декодері встановлений у значення "істина", але для більш ніж Nmax кадрів відсутнє відновлення відносно ідентифікатора в бітовому потоці, покажчик може бути встановлений у значення "неправда". Іншими словами, декодер може бути проінформований про максимальне значення N, наприклад, Nmax, що не повинне перевищуватися. Якщо декодер не виявляє ідентифікатор, що має силу, для більш ніж Nmax кадрів, то це вказує декодеру на те, що прийнятий бітовий потік більше не виходить із легального кодера, або, що прийнятий бітовий потік, можливо, був змінений. Як наслідок, декодер установлює відповідний покажчик у значення "неправда". Це може приводити до того, що візуальний індикатор, наприклад, LED, як правило, вертається у вихідний стан. Процедура декодування ідентифікатора проілюстрована на фіг. 3 та може бути описана в такий спосіб: • На етапі 300 декодер запускається й скидає прапор "ID Verified". • Потім на етапі 301 ініціалізується (128-бітний) стан внутрішньої пам'яті. • На етапі 303 декодер очікує прийому кадру (етап 302) та перевіряє прийнятий кадр на наявність ідентифікатора бітового потоку. Наявність ідентифікатора в кадрі може бути виявлена за допомогою описаного вище поля identifier_sync. На етапі 307, якщо ідентифікатор був виявлений на етапі 304, декодер витягує identifier_value з відповідного поля в . • Потім на етапі 308 шляхом зрізання значення НМАС, що втримується в 128-бітному стані, генерується ідентифікатор верифікації. • Декодер продовжує роботу, порівнюючи на етапі 309 ідентифікатор бітового потоку з ідентифікатором верифікації. Якщо визначається, що два ID не рівні (етап 310), на етапі 311 прапор "ID Verified" скидається, вказуючи на те, що бітовий потік не виходить із кодера, що заслуговує довіри. У випадку ідентичних ID на етапі 312 установлюється прапор "ID Verified", що вказує на те, що ідентифікатор верифікован та що бітовий потік вважається таким, що має силу, оскільки він приходить із кодера, що заслуговує довіри. У цьому випадку можуть бути розблоковані додаткові функції декодера, та/або користувач може бути проінформований про стан верифікації бітового потоку. В альтернативному варіанті, деякі функції можуть блокуватися, якщо визначено, що бітовий потік не виходить із кодера, що заслуговує довіри, та/або користувач може бути відповідним чином проінформований. • Процес декодування триває на етапі 313 шляхом ініціалізації 128-бітного стану внутрішньої пам'яті. • Потім на етапі 314 обчислюється 128-бітне значення НМАС для поточного кадру, та на етапі 315 128-бітний стан внутрішньої пам'яті обновляється відповідно до обчисленого значення НМАС. Потім декодер вертається на етап 302 для очікування прийому наступного кадру. • Якщо в зазначеному кадрі відсутній ідентифікатор (що визначається на етапі 304) декодер переходить на етап 305, де декодер визначає, чи був присутній ідентифікатор в одному з останніх Nmax кадрів. • У випадку, якщо ідентифікатор був відсутній в одному з останніх Nmax кадрів, декодер на етапі 306 скидає прапор "ID verified", оскільки прийнято максимальну кількість кадрів Nmax, що пройшло без ідентифікатора. Декодер потім вертається до етапу 302 для очікування наступного кадру. • Якщо ідентифікатор присутній в одному з останніх Nmax кадрів, що визначається на етапі 305, декодер переходить на етап 314 для обчислення 128-бітного значення НМАС для поточного кадру. Як описано вище, декодер може визначати ідентифікатор верифікації в ході послідовного ітеративного процесу. Це означає, що обробляється тільки поточний кадр, та немає необхідності спочатку конкатенувати набір кадрів для визначення ідентифікатора верифікації. Відповідно, декодування ідентифікатора може виконуватися з низькою затримкою, низькою обчислювальною складністю й низькими вимогами до пам'яті. На фіг. 4 зображений ілюстративний варіант здійснення кодера 400 та декодера 410 потоку даних. Аналоговий потік даних 405, наприклад, аудіопотік, перетворюється в цифровий потік даних 406 з використанням аналого-цифрового перетворювача 402. Цифровий потік даних 406 кодується з використанням аудіокодера 403, наприклад, Dolby E, Dolby Digital, AAC, HE AAC, 13 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 DTS або Dolby Pulse. Аудіокодер 403, як правило, сегментує цифровий потік даних 406 у кадри звукового сигналу й здійснює стискання даних. Крім того, аудіокодер 403 може виконувати додавання метаданих. Вихідний сигнал аудіокодера 403 представляє собою потік даних 407, що включає ряд кадрів звукового сигналу. Потім потік даних 407 входить у додатковий кодер 404 кадрів, що додає до потоку даних 407 ідентифікатори, або криптографічні величини. Кодер 404 кадрів функціонує відповідно до особливостей, описаних в даному патентному документі. Слід зазначити, що ідентифікатори, як правило, визначаються й додаються послідовно, і, таким чином, кожний кадр, що приходить із аудіокодера 403, безпосередньо обробляється кодером 404 кадрів. Переважно, аудіокодер 403 та кодер 404 кадрів утворюють об'єднаний кодер 401, що може бути реалізований на процесорі цифрової обробки сигналів. Таким чином, особливості кодування звукового сигналу й особливості генерування ідентифікатора можуть впливати один на одного. Зокрема, у ході кодування аудіопотоку може знадобитися облік додаткових непродуктивних витрат, викликаних ідентифікатором. Це означає, що доступна бітова швидкість передачі даних для бітового аудіопотоку може бути зменшена. Подібна взаємодія між аудіокодером та генеруванням ідентифікатора може бути використана для відповідності загальній ширині смуги пропускання та/або обмеженню бітової швидкості передачі даних у деяких схемах кодування, наприклад, в HE-AAC. Об'єднаний кодер 401 виводить потік даних 408, що включає ряд груп кадрів та пов'язані з ними ідентифікатори. Потік даних 408, як правило, подається у зв'язаний декодер та/або приймач 410 з використанням різних засобів передачі даних та/або носіїв даних. Він досягає декодера 410 у вигляді потоку даних 418, що міг бути змінений щодо потоку даних 408. Потік даних 418 входить у декодер 414 кадрів, що виконує верифікацію й аутентифікацію потоку даних 418 у відповідності зі способами й системами, описаними в даному патентному документі. Декодер 414 кадрів виводить потік даних 417, що, як правило, відповідає потоку даних 418 без ідентифікаторів та відповідного поля даних, або синтаксичних елементів. Потік даних 417 декодується в аудіодекодері 413, де він розпаковується і де видаляються додані метадані. Як описано, вище, декодування кадрів, як правило, виконується послідовним ітеративним способом, і, таким чином, обробка виконується покадрово. Також слід зазначити, що різні компоненти декодування/прийому можуть групуватися з метою формування об'єднаного декодера. Наприклад, декодер 414 кадрів та аудіодекодер 413 можуть утворювати об'єднаний декодер/приймач 411, що може реалізовуватися на процесорі цифрової обробки сигналів. Як описано вище, це може бути корисним для того, щоб дозволити здійснювати взаємодії між аудіодекодером та верифікацією ідентифікатора. В остаточному підсумку, об'єднаний декодер/приймач 411 виводить потік даних 416, що перетворюється в аналоговий звуковий сигнал 415 з використанням цифро-аналогового перетворювача 412. Слід зазначити, що в даному документі термін "кодер" може відноситись до повного кодера 400, об'єднаного кодера 401 або до кодера 404 кадрів. Термін "декодер" може відноситись до повного декодера 410, об'єднаного декодера 411 або до декодера 414 кадрів. З іншого боку, так звані "ненадійні кодери" представляють собою кодери, які взагалі не генерують ідентифікатор, або не генерують ідентифікатор у відповідності зі способами, описаними в даному документі. Фіг. 5 ілюструє ілюстративну систему 500 мовлення, що включає головний вузол 504 мовлення. Головний вузол 504 також включає пристрій для конкатенації, або засобу конкатенації, що діє для комбінування бітових потоків 501, 502, 503, що виходять з різних кодерів. У системі радіомовлення бітові потоки, що відрізняються, 501, 502, 503 можуть представляти собою бітові аудіопотоки, які, як правило, кодуються різними аудіокодерами. Бітові потоки 501, 502, 503 складаються з ряду кадрів, які представлені по-різному заштрихованими блоками. В ілюстрованому прикладі бітовий потік 501 включає п'ять кадрів, бітовий потік 502 включає чотири кадри, та бітовий потік 503 включає шість кадрів. Пристрій для конкатенації та/або головний вузол 504 діє для комбінування бітових потоків з метою створення об'єднаного бітового потоку 505. Як показано в прикладі, це комбінування може здійснюватися шляхом прикріплення бітового потоку 501 до бітового потоку 503 та шляхом прикріплення бітового потоку 502 до бітового потоку 501. Однак, що також показано на фіг. 5, може знадобитися обрати тільки деякі частини оригінальних бітових потоків 501, 502 та 503, наприклад, тільки частини бітових аудіопотоків. Як такий, комбінований бітовий потік 505 включає тільки два кадри бітового потоку 503, три кадри бітового потоку 501, що слідують за ними, та наступні за ними два кадри бітового потоку 502. Оригінальні бітові потоки 501, 502, 503 можуть включати ідентифікатори, тобто бітові потоки 501, 502, 503 можуть виходити з надійних кодерів. Кожний з ідентифікаторів може ґрунтуватися на різній кількості N кадрів. Без відхилення від спільності (узагальнення?) можна припустити, що ідентифікатори бітових потоків 501 та 503 були визначені для групи кадрів, що включає два 14 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 кадри. З іншого боку, бітовий потік 502 не виходить із надійного кодера й тому не включає ідентифікатор. Бажано, щоб пристрій для конкатенації та/або головний вузол 504 транслював бітовий потік 505, що також включав би ідентифікатор, якщо вхідні бітові потоки 501 та 503 виходять із надійного кодера. Зазначений ідентифікатор повинен відправлятися в бітовому потоці 505 для всіх частин бітового потоку 505, які виходять із надійного кодера. З іншого боку, частини бітового потоку 505, які не виходять із надійного кодера, тобто частини, взяті з бітового потоку 502, не повинні включати ідентифікатор. Для того, щоб досягти цієї мети, пристрій для конкатенації може діяти, виконуючи декодування та/або кодування ідентифікатора. Як показано на фіг. 5, перші два кадри вихідного бітового потоку 505 виходять із бітового потоку 503. Якщо ці два кадри відповідають групі кадрів, то ідентифікатор цієї групи кадрів може розміщатися в третьому кадрі бітового потоку 505. Це розміщення описане відносно фіг. 1. Якщо, з іншого боку, два кадри належать різним групам кадрів, то головний вузол 504 може діяти для • перевірки того, чи є бітовий потік 503 таким, що виходить з надійного кодера; і • генерування нового ідентифікатора для вихідних кадрів бітового потоку 503, тобто для перших двох кадрів бітового потоку 505. Число N, використовуване для генерування ідентифікатора на вихідному бітовому потоці 505, необов'язково повинне бути рівним числу N, використовуваному для генерування ідентифікатора на вихідних бітових потоках 501 та 503. Це можна розглянути в контексті бітового потоку 501, для якого тільки три кадри включаються у вихідний бітовий потік 505. Перший ідентифікатор може генеруватися для перших двох кадрів, у той час як другий ідентифікатор може генеруватися для третього кадру. Іншими словами, N може дорівнювати двом для перших двох кадрів, та N може дорівнювати одиниці для третього кадру. Тому, загалом, можна стверджувати, що N може змінюватися в межах бітового потоку 505. Це пов'язане з тим, що N може визначатися в декодері незалежно. Переважно, число N, використовуване для вихідного бітового потоку 505 менше або дорівнює числу N, використовуваному для вхідних бітових потоків 501 та 503. Крім того, слід зазначити, що вхідний бітовий потік 502 не включає ідентифікатор, тобто бітовий потік 502 не виходить із надійного кодера. Відповідно, пристрій для конкатенації та/або головний вузол не передбачає в бітовому потоці 505 ідентифікатор для кадрів, що відбуваються з бітового потоку 502. Як уже було описано вище, декодер, як правило, діє для виявлення відсутності ідентифікатора в бітовому потоці 505. Якщо кількість кадрів, що не включають ідентифікатор, перевищує заздалегідь задану максимальну кількість Nmax, то декодер, як правило, буде виявляти, що бітовий потік 505 більше не є таким, що виходить з надійного кодера. Як показано в прикладі за фіг. 5, бітовий потік 505 складається із частин, які виходять із надійного кодера, та інших частин, які не виходять із надійного кодера. Відповідно, бітовий потік 505 може включати частини, які включають ідентифікатор, що має силу, та інші частини, які не включають ідентифікатор, що має силу. Пристрій для конкатенації та/або головний вузол 504 може діяти для • виявлення вхідних бітових потоків, що включають ідентифікатор; • перенаправлення бітового потоку, що включає ідентифікатор, як вихідного бітового потоку; • аутентифікації вхідного бітового потоку на основі ідентифікатора; і • кодування бітового потоку за допомогою нового ідентифікатора. Іншими словами, пристрій для конкатенації та/або головний вузол 504 може включати функції кодера та/або декодера, описані в даному патентному документі. Тобто пристрій для конкатенації та/або головний вузол 504 може функціонувати як декодер при прийманні вхідного бітового потоку, та він може функціонувати в якості кодера при генеруванні вихідного бітового потоку. Крім того, він може діяти для перенаправлення бітового потоку, що включає ідентифікатор, без виконання аутентифікації й повторного кодування. Операція перенаправлення може виконуватися для безперервної передачі того самого бітового потоку, у той час як декодування й повторне кодування, переважно, можуть використовуватися на межах між бітовими потоками з різних кодерів. Використовуючи операцію перенаправлення, можна знизити обчислювальне навантаження на пристрій для конкатенації та/або головний вузол 504. Слід зазначити, що операція перенаправлення може використовуватися в тих випадках, коли ідентифікатор попередньої групи кадрів не впливає на значення ідентифікатора поточної групи кадрів. У цих випадках групу кадрів та пов'язаний з нею ідентифікатор можна розглядати як незалежний логічний об'єкт, що може бути безпосередньо перенаправлений у вихідний бітовий потік. З іншого боку, якщо використовуються безперервні взаємозалежні 15 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 60 ідентифікатори, де ідентифікатор поточної групи кадрів залежить від ідентифікатора попередньої групи кадрів, то пристрій для конкатенації, переважно, буде повторно кодувати весь бітовий потік для того, щоб генерувати для вихідного бітового потоку потік безупинно взаємозалежних ідентифікаторів. Це може гарантувати те, що не уповноважена сторона не буде мати можливість заміни сегментів вихідного бітового потоку. Слід зазначити, що в більшості випадків повторне кодування пристроєм для конкатенації обмежується тільки генеруванням нових ідентифікаторів. Сам по собі бітовий потік, тобто, особливо, бітовий потік кодування звукового сигналу, як правило, не зачіпається. Відповідно, повторне кодування бітового потоку може виконуватися з низькою обчислювальною складністю. Однак якщо криптографічна величина вставляється в кадр, що попередньо не містив криптографічну величину, може виникнути необхідність у виконанні повторного кодування звукового сигналу. Фіг. 6 також ілюструє конкатенацію вхідних бітових потоків 1―4 у вихідний конкатенований бітовий потік для кращого варіанта здійснення винаходу. В ілюстрованому прикладі вхідний бітовий потік 1 утворить групи з 4 кадрів для генерування криптографічних величин. Кутові стрілки під бітовим потоком ілюструють те, що криптографічна величина групи кадрів вставляється в перший кадр наступної групи. Кадри, у які вставлені криптографічні величини, на фігурі заштриховані. Групи кадрів вхідного бітового потоку 2 включають 6 кадрів, і групи кадрів вхідного бітового потоку 3 включають 5 кадрів. Вхідний бітовий потік 4 не містить криптографічних величин і не є верифікованим та таким, що заслуговує на довіру. Вертикальні лінії на фігурі вказують точки конкатенації. Як видно з фігури, бітовий потік, що виходить, включає першу секцію I, що відповідає вхідному бітовому потоку 1, другу секцію II, що відповідає вхідному бітовому потоку 2, третю секцію III, що відповідає вхідному бітовому потоку 3, та четверту секцію IV, що відповідає вхідному бітовому потоку 4, де секції конкатеновані в точках конкатенації. Перед першою точкою конкатенації вхідний бітовий потік 1, що включає криптографічні величини, може бути скопійований у конкатенований бітовий потік. Однак перша криптографічна величина в секції II має потребу в повторному обчисленні, оскільки через конкатенацію вона відноситься до інших кадрів даних, ніж відповідна криптографічна величина бітового потоку 2. Докладніше, ця криптографічна величина ґрунтується на 5 кадрах: одному, що належить вхідному бітовому потоку 1 (перед точкою конкатенації), та чотирьох ― що належать вхідному потоку 2 (після точки конкатенації). Повторне обчислення криптографічних величин позначено стрілками над бітовим потоком та зміною штрихування. Через поширення зміни в першій повторно обчисленій криптографічній величині на конкатенований бітовий потік, що слідують криптографічні величини бітового потоку 2 також повинні обчислюватися повторно. У другій точці конкатенації обраний бітовий потік змінюється від 2 до 3. Криптографічна величина першого кадру бітового потоку III повторно обчислюється на основі попередніх 6 кадрів бітового потоку 2. У наступній точці конкатенації обирається ненадійний бітовий потік 4, та в секцію IV конкатенованого потоку криптографічні величини не вставляються. В альтернативному варіанті, криптографічна величина може генеруватися для кінцевих кадрів бітового потоку 3, скопійованого в конкатенований бітовий потік, для того щоб правильно вказувати закінчення секції, що заслуговує довіри, конкатенованого бітового потоку. Ця додаткова криптографічна величина, переважно, вставляється в перший кадр секції IV, що показано на фігурі пунктирним колом. Залежно від вимог бітової швидкості передачі даних може виникати необхідність повторного кодування цього кадру з метою створення вільного місця для вставки додаткової криптографічної величини. Фіг. 7 ілюструє інший приклад конкатенації вхідних бітових потоків 1 та 2 у вихідний бітовий потік. Тут точка конкатенації перебуває в першому бітовому потоці прямо перед кадром, що несе криптографічну величину, і в другому бітовому потоці ― відразу після кадру, що несе криптографічну величину. Якщо взяти положення криптографічних величин з першого та другого бітових потоків, то в результаті в конкатенованому бітовому потоці може виникнути великий розрив між криптографічними величинами. Відстань між криптографічними величинами в даній секції конкатенованого бітового потоку може перевищити максимальне значення Nmax, прийнятне для декодера, без зазначення втрати довіри в бітовому потоці. Тому кращою є вставка додаткової криптографічної величини в точці конкатенації, наприклад, у перший кадр другого бітового потоку, і, таким чином, кількість кадрів у групах не буде перевищувати Nmax. І знову, залежно від вимог бітової швидкості передачі даних, може виникнути необхідність у повторному кодуванні цього кадру з метою створення вільного місця для вставлення в бітовий потік додаткової криптографічної величини. Слід зазначити, що криптографічна величина в цьому випадку може бути скопійована з першого кадру бітового потоку 1 після точки конкатенації, оскільки додаткова криптографічна величина в конкатенованому бітовому потоці 16 UA 104483 C2 5 10 15 20 25 30 35 відноситься до тих же 6 кадрів бітового потоку 1. Зміст даних кадру, у який включається додаткова криптографічна величина, однак, належить бітовому потоку 2 (точніше, воно відповідає першому кадру бітового потоку 2 після точки конкатенації). Даний документ описує спосіб та систему, які дозволяють уводити ідентифікатор, або криптографічну величину, у потік даних. Ідентифікатор може використовуватися для аутентифікації й верифікації потоку даних. Крім того, ідентифікатор може використовуватися для забезпечення правильного настроювання конфігурації декодера для потоку даних, що відтворюється або обробляється. Зокрема, спосіб та система додають до бітового потоку HE AAC додаткові дані, тобто ідентифікатор, що аутентифікує цей бітовий потік як такий, що виходить з легального кодера або передавача. Ця аутентифікація може вказувати приймачу на те, що бітовий потік HE AAC дотримується певної специфікації та/або певного стандарту якості. Переважно, ідентифікатор здобувається шляхом обчислення HMAC-MD5. Спосіб та система можуть використовуватися для аутентифікації мультимедійних файлів та мультимедійних потоків, а також вони можуть виявляти конкатенацію декількох захищених потоків без розриву аутентифікації в цілому. Це означає, що на відповідність перевіряється не тільки повний потік, але й набір послідовних кадрів. Ця перевірка підтримує типові сценарії мовлення, тобто так звані "конкатенацію", де часто для створення фактичного вихідного потоку пристрій переключається між різними кодерами бітового потоку. Крім того, спосіб та система можуть також використовуватися для захисту внутрішньосмугової та зовнішньосмугової інформації, де внутрішньосмугова інформація, як правило, включає медіадані й пов'язані з ними метадані, а зовнішньосмугова інформація, як правило, включає дані про конфігурацію. Таким чином, спосіб та система дозволяють управляти та/або виявляти коректне відтворення та/або декодування мультимедійного потоку. Спосіб та система, описані в даному документі, можуть бути реалізовані як програмне забезпечення, вбудоване програмне забезпечення та/або апаратне забезпечення. Деякі компоненти можуть бути реалізовані, наприклад, як програмне забезпечення, що запускається на процесорі цифрової обробки сигналів або мікропроцесорі. Інші компоненти можуть бути реалізовані, наприклад, як апаратне забезпечення або як спеціалізовані інтегральні схеми. Сигнали, що містяться в описаних способах та системах, можуть зберігатися на носіях, таких як оперативна пам'ять або оптичні носії даних. Вони можуть передаватися по мережах, таким як радіомережі, супутникові мережі, бездротові мережі, або провідні мережі, наприклад, Інтернет. Типовими пристроями, що використовують спосіб та систему, описані в даному документі, є додаткові зовнішні пристрої або інше устаткування на території користувача, що декодує звукові сигнали. На стороні кодування спосіб та система можуть використовуватися на станціях мовлення, наприклад в аудіо- та відеосистемах головних вузлів мовлення. ФОРМУЛА ВИНАХОДУ 40 45 50 55 1. Спосіб кодування потоку даних, що включає ряд кадрів даних, де спосіб включає етапи, на яких - генерують криптографічну величину для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга потоку даних; - здійснюють вставку криптографічної величини в кадр потоку даних, що слідує за N послідовними кадрами даних; та - здійснюють ітеративне генерування проміжної криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну криптографічну величину для інформації про конфігурацію. 2. Спосіб за п. 1, який відрізняється тим, що спосіб додатково включає етапи, на яких - групують кількість N послідовних кадрів даних для формування першого повідомлення; - групують перше повідомлення з інформацією про конфігурацію для формування другого повідомлення; і де криптографічну величину генерують для другого повідомлення. 3. Спосіб за п. 1 або 2 , який відрізняється тим, що криптографічну величину вставляють в елемент потоку даних; де елемент потоку даних являє собою синтаксичний елемент кадру потоку даних; і де потік даних являє собою потік MPEG4-AAC або MPEG2-AAC. 4. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що кількість кадрів N більше одиниці. 17 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 5. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що кадри даних являють собою відео- або аудіокадри. 6. Спосіб за пп. 1-4, який відрізняється тим, що кадри даних являють собою кадри ААС або НЕ-ААС. 7. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що інформація про конфігурацію включає щонайменше один з наступних покажчиків: - покажчик частоти дискретизації; - покажчик конфігурації каналів системи кодування звукового сигналу; - покажчик кількості дискретних значень у кадрі даних. 8. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що криптографічну величину генерують із використанням ключової величини. 9. Спосіб за п. 8, який відрізняється тим, що етап генерування криптографічної величини включає - обчислення значення HMAC-MD5 для кількості N послідовних кадрів даних і інформації про конфігурацію. 10. Спосіб за п. 9, який відрізняється тим, що етап генерування криптографічної величини включає - зрізання значення HMAC-MD5 для одержання криптографічної величини. 11. Спосіб за п. 10, який відрізняється тим, що значення HMAC-MD5 зрізають до 16, 24, 32, 48, 64, 80, 96 або 112 біт. 12. Спосіб за будь-яким з попередніх пунктів , який відрізняється тим, що криптографічну величину для N послідовних кадрів даних вставляють у наступний кадр даних. 13. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що додатково включає етап, на якому - вставляють покажчик синхронізації після N послідовних кадрів даних, де покажчик синхронізації вказує на те, що криптографічна величина була вставлена. 14. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що елемент потоку даних вставляють у кінець кадру перед елементом . 15. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що вміст елемента потоку даних вирівняно за границею байта потоку даних. 16. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що етапи генерування й вставки криптографічної величини повторюють для ряду блоків з N послідовних кадрів даних. 17. Спосіб за п. 16, який відрізняється тим, що криптографічну величину для блока з N послідовних кадрів даних генерують на блоці з N послідовних кадрів даних, що включає криптографічну величину для попереднього блока з N послідовних кадрів даних. 18. Спосіб за будь-яким з попередніх пунктів, який відрізняється тим, що включає етап, на якому - вибирають N таким чином, щоб N послідовних кадрів максимально можливо близько покривали заздалегідь визначену тривалість відповідного сигналу при відтворенні у відповідній конфігурації. 19. Спосіб за п. 18, який відрізняється тим, що включає етап, на якому - вибирають N таким чином, щоб заздалегідь визначена тривалість не була перевищена. 20. Спосіб за п. 18 або 19, який відрізняється тим, що заздалегідь визначена тривалість становить 0,5 секунд. 21. Спосіб за п. 5, який відрізняється тим, що додатково включає етап, на якому - здійснюють взаємодію з відео- та/або аудіокодером потоку даних. 22. Спосіб за п. 21, який відрізняється тим, що на етапі взаємодії з відео- та/або аудіокодером потоку даних здійснюють - встановлення для відео- та/або аудіокодера такої максимальної бітової швидкості передачі даних, щоб зазначена бітова швидкість передачі даних для потоку даних, що включає криптографічну величину, не перевищувала заздалегідь визначене значення. 23. Спосіб верифікації потоку даних у декодері, де потік даних включає ряд кадрів даних і криптографічну величину, пов'язану з кількістю N попередніх послідовних кадрів даних, де спосіб включає етапи, на яких - генерують другу криптографічну величину для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга даних; - витягають криптографічну величину з потоку даних; порівнюють криптографічну величину із другою криптографічною величиною; та 18 UA 104483 C2 5 10 15 20 25 30 35 40 45 50 55 - здійснюють ітеративне генерування проміжної другої криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну другу криптографічну величину попередньої ітерації; де вихідний стан першої ітерації являє собою проміжну другу криптографічну величину для інформації про конфігурацію. 24. Спосіб за п. 23, який відрізняється тим, що потік даних являє собою потік MPEG4-AAC або MPEG2-AAC; де криптографічна величина витягає з елемента потоку даних; і де елемент потоку даних являє собою синтаксичний елемент кадру потоку даних. 25. Спосіб за п. 23 або 24, який відрізняється тим, що додатково включає етапи, на яких - витягають N послідовних кадрів даних для формування першого повідомлення; - групують перше повідомлення з інформацією про конфігурацію для формування другого повідомлення; де друга криптографічна величина генерується для другого повідомлення. 26. Спосіб за пп. 23-25, який відрізняється тим, що потік даних включає ряд з N послідовних кадрів даних і пов'язаних з ними криптографічних величин, і де спосіб додатково включає етап, на якому - визначають число N як кількості кадрів між двома послідовними криптографічними величинами. 27. Спосіб за пп. 23-26, який відрізняється тим, що криптографічну величину генерують у відповідному кодері з N послідовних кадрів даних і інформації про конфігурацію відповідно до способу, що відповідає способу, використовуваному для генерування другої криптографічної величини. 28. Спосіб за п. 27, який відрізняється тим, що - криптографічну величину й другу криптографічну величину генерують із використанням унікального ключового значення й унікальної криптографічної хеш-функції. 29. Спосіб за пп. 23-28, який відрізняється тим, що додатково включає етапи, на яких - установлюють прапор у випадку, коли криптографічна величина відповідає другій криптографічній величині; та - забезпечують візуальну індикацію, якщо прапор установлений. 30. Спосіб за пп. 23-29, який відрізняється тим, що додатково включає етап, на якому - здійснюють скидання прапора, якщо криптографічна величина не відповідає другій криптографічній величині, або, якщо криптографічна величина не може бути витягнута з потоку даних. 31. Носій інформації для зберігання команд, при виконанні яких отримують потік даних, що включає криптографічну величину, що генерується й вставляється у відповідності зі способом за одним з пп. 1-22. 32. Кодер, що діє для кодування потоку даних, що включає ряд кадрів даних, де кодер містить процесор, що діє для - генерування криптографічної величини для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга потоку даних; - вставки криптографічної величини в кадр потоку даних, що слідує за N послідовними кадрами даних; та - ітеративного генерування проміжної криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну криптографічну величину для інформації про конфігурацію. 33. Декодер, що діє для верифікації потоку даних, що включає ряд кадрів даних і криптографічну величину, пов'язану з кількістю N попередніх послідовних кадрів даних, де декодер містить процесор, що діє для - генерування другої криптографічної величини для кількості N послідовних кадрів даних і інформації про конфігурацію з використанням криптографічної хеш-функції; де інформація про конфігурацію включає інформацію для рендеринга даних; - добування криптографічної величини з кадру потоку даних; - порівняння криптографічної величини із другою криптографічною величиною; та - ітеративного генерування проміжної другої криптографічної величини для кожного з N послідовних кадрів з використанням вихідного стану; де вихідний стан являє собою проміжну другу криптографічну величину попередньої ітерації; і де вихідний стан першої ітерації являє собою проміжну другу криптографічну величину для інформації про конфігурацію. 19 UA 104483 C2 5 10 15 20 25 30 35 34. Носій даних, що включає програму, реалізовану програмно, адаптовану для виконання на процесорі й для виконання етапів способу за одним з пп. 1-30 при здійсненні на обчислювальному пристрої. 35. Зовнішній додатковий пристрій, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал, де зовнішній додатковий пристрій включає декодер за п. 33, призначений для верифікації прийнятого потоку даних. 36. Переносний електронний пристрій, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал, де переносний електронний пристрій включає декодер за п. 33, призначений для верифікації прийнятого потоку даних. 37. Комп'ютер, призначений для декодування прийнятого потоку даних, що включає звуковий сигнал; де комп'ютер включає декодер за п. 33, призначений для верифікації прийнятого потоку даних. 38. Система мовлення, призначена для передачі потоку даних, що включає звуковий сигнал; де система мовлення включає кодер за п. 32. 39. Спосіб конкатенації першого та другого бітових потоків, кожний з яких включає ряд кадрів даних та криптографічну величину, пов'язану із заданою кількістю кадрів даних, де спосіб включає етап, на якому - генерують конкатенований бітовий потік з першого і другого бітових потоків, де конкатенований бітовий потік включає щонайменше частину ряду кадрів даних з першого та другого бітових потоків і включає криптографічну величину, що генерується й вставляється у відповідності зі способом за одним з пп. 1-30. 40. Пристрій для конкатенації, що діє для конкатенації першого та другого бітових потоків, кожний з яких включає ряд кадрів даних і криптографічні величини, пов'язані із заданою кількістю кадрів даних, де пристрій для конкатенації містить - кодер за п. 32, призначений для кодування останніх кадрів першого бітового потоку і перших кадрів другого бітового потоку. 41. Пристрій для конкатенації за п. 40, який відрізняється тим, що додатково містить - блок перенаправлення, призначений для перенаправлення кадрів і пов'язаних з ними криптографічних величин першого і другого бітових потоків, які не декодуються й не кодуються. 42. Пристрій для конкатенації за п. 40 або 41, який відрізняється тим, що додатково містить - декодер за п. 33, призначений для кодування останніх кадрів першого бітового потоку, перших кадрів другого бітового потоку й пов'язаних з ними криптографічних величин з метою визначення статусу довіри першого та другого бітових потоків; та блок керування, що розблокує кодер для вставки криптографічних величин у частину бітового потоку тільки в тому випадку, якщо відповідні перший та другий бітові потоки аутентифіковані. 20 UA 104483 C2 21 UA 104483 C2 22 UA 104483 C2 23 UA 104483 C2 5 Комп’ютерна верстка І. Скворцова Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 24
ДивитисяДодаткова інформація
Назва патенту англійськоюAuthintication of data streams
Автори англійськоюBoehm, Reinhold, Groeschel, Alexander, Hoerich, Holger, Homm, Daniel, Schildbach, Wolfgang A., Schug, Michael, Watzke, Oliver, Wolters, Martin, Ziegler, Thomas
Автори російськоюБём Рейнхольд, Грёшель Александер, Хёрих Хольгер, Хомм Даниль, Шильдбах Вольфганг А., Шуг Михель, Вацке Оливер, Вольтерс Мартин, Циглер Томас
МПК / Мітки
МПК: H04L 29/06, H04N 7/24, G06F 21/30, H04N 7/167, G11B 20/00, H04N 7/52
Мітки: потоків, даних, аутентифікація
Код посилання
<a href="https://ua.patents.su/26-104483-autentifikaciya-potokiv-danikh.html" target="_blank" rel="follow" title="База патентів України">Аутентифікація потоків даних</a>
Спосіб керування потужністю передачі даних на основі оцінки біта зворотної активності, заданих лінійно-зростаючими/спадними функціями потоків даних, і відповідний термінал безпровідного доступу

Номер патенту: 100889
Опубліковано: 11.02.2013
Автори: Аттар Рашід А., Аю Жан Пут Лінг, Гхош Донна, Лотт Крістофер Ж., Бхушан Нага
МПК: H04W 72/00, H04L 12/56, H04W 52/00
Мітки: заданих, доступу, передачі, зворотної, спосіб, керування, активності, відповідний, безпровідного, термінал, потужністю, основі, оцінки, біта, потоків, даних, функціями
Формула / Реферат:
1. Спосіб одержання поточної призначеної потужності для потоків в терміналі доступу, який відрізняється тим, що:приймають з планувальника повідомлення дозволу, що включає в себе щонайменше один дозвіл призначеної поточної потужності,встановлюють призначену поточну потужність для відповідного потоку такою, що дорівнює згаданому щонайменше одному дозволу призначеної поточної потужності в згаданому повідомленні дозволу.2....
Аналізатор для множини потоків даних в системі зв’язку

Номер патенту: 89217
Опубліковано: 11.01.2010
Автори: Уоллейс Марк С., Кетчум Джон У.
МПК: H04L 1/00
Мітки: зв'язку, системі, множині, потоків, аналізатор, даних
Формула / Реферат:
1. Спосіб розбирання даних в системі зв'язку, який містить етапи, на яких: формують послідовність циклів виключення для множини потоків за умови, щоб для кожного потоку з множиною циклів виключення множина циклів виключення для потоку розподілялася по послідовності циклів виключення рівномірно або майже рівномірно; ірозбирають кодові біти на множину потоків, виходячи з послідовності циклів виключення.2. Спосіб за п. 1, який...
Керування політикою для потоків інкапсульованих даних

Номер патенту: 99335
Опубліковано: 10.08.2012
Автори: Ахмаваара Каллє І., Касаччія Лоренцо, Цирцис Джорджиос, Джаретта Джерардо
МПК: H04L 29/06
Мітки: інкапсульованих, керування, політикою, потоків, даних
Формула / Реферат:
1. Спосіб оперування правилами політики в бездротових мережах, що містить етапи, на яких:приймають інформацію інкапсуляції, що належить до обміну потоками даних, з шлюзу базової мережі;генерують одне або більше правил політики, що належать до обміну потоками даних; іпередають правила політики в шлюз мережі доступу;причому інформація інкапсуляції включає в себе заголовок інкапсуляції, що належить до типу протоколу...
Спосіб завантаження даних, приймач-декодер, система передавання та система передавання і приймання для його здійснення

Номер патенту: 63976
Опубліковано: 16.02.2004
Автор: Сарфаті Жан-Клод
Мітки: завантаження, приймання, приймач-декодер, даних, спосіб, здійснення, передавання, система
Формула / Реферат:
1. Спосіб завантаження даних в приймач-декодер, який включає виконання в приймачі-декодері таких операцій:приймання бітового потоку, що містить згадані дані;завантаження завантажувача для завантаження згаданих даних з бітового потоку в приймач-декодер; ізавантаження згаданих даних з бітового потоку з використанням згаданого завантаженого завантажувача даних.2. Спосіб за п. 1, який відрізняється тим, що завантажений...
Спосіб і пристрій (варіанти) для призначення потоків даних із заданими обмеженнями часових інтервалів передачі

Номер патенту: 77952
Опубліковано: 15.02.2007
Автори: Лі Пенґ, ріллі Франческо, Ваянос Алкіноос
МПК: H04B 7/26, H04J 15/00
Мітки: обмеженнями, часових, потоків, даних, інтервалів, призначення, пристрій, заданими, передачі, варіанти, спосіб
Формула / Реферат:
1. Спосіб розподілу потоків даних для передачі, який полягає у тому, що приймають множину комбінацій транспортних форматів (КТФ) і виключають з прийнятої множини КТФ такі КТФ, що мають транспортні формати (ТФ), які не мають часових інтервалів передачі (ЧІП), що знаходяться на межі поточного часового інтервалу передачі, причому кожна КТФ включає в себе комбінацію ТФ, і кожний ТФ відповідає транспортному каналу, що переносить...
Попередній патент: Сильний гербіцидний концентрат диметиламінної солі клопіраліду низької в’язкості
Наступний патент: Противірусна сполука множинної дії, її склад та спосіб лікування вірусних захворювань
Випадковий патент: Пристрій для дугового зварювання