Спосіб та система перетворення векторних даних
Номер патенту: 102980
Опубліковано: 27.08.2013
Автори: Рачковський Дмитро Андрійович, Гриценко Володимир Ілліч







Формула / Реферат
1. Спосіб перетворення вхідного вектора даних, що представляє об'єкт, в елемент вихідного вектора даних, причому вихідний вектор даних є таким, що спрощує подальшу обробку даних, та/або робить можливою подальшу обробку методами, призначеними для обробки даних у форматі вихідних векторів даних, та/або дозволяє оцінку мір схожості та відмінності вхідного вектора даних по відповідному вихідному вектору даних,
який передбачає дії
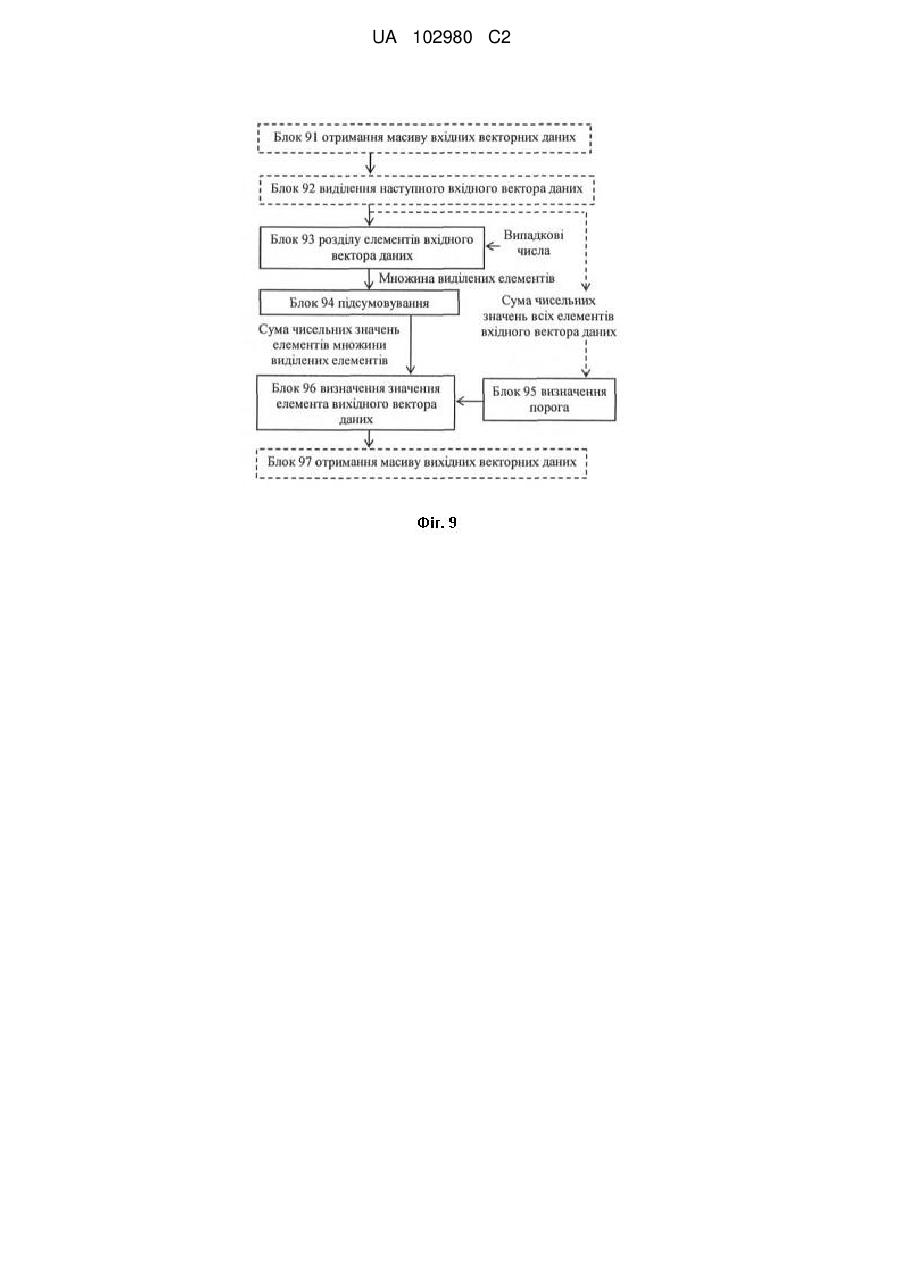
розділення елементів вхідного вектора даних на множини;
підсумовування чисельних значень елементів множин;
визначення значення елемента вихідного вектора даних;
який відрізняється тим, що
розділення елементів вхідного вектора даних на множини виконують шляхом виділення одної множини елементів вхідного вектора даних;
підсумовування чисельних значень елементів множин виконують шляхом підсумовування чисельних значень елементів одної виділеної множини;
визначають значення порога;
визначають значення елемента вихідного вектора даних, використовуючи результат підсумовування та значення порога;
причому вказані дії виконують в автоматичному режимі на відповідних функціональних блоках комп'ютера або іншої обчислювальної системи або обчислювального середовища.
2. Спосіб за п. 1, який відрізняється тим, що розділення елементів вхідного вектора даних на множини шляхом виділення одної множини елементів вхідного вектора даних здійснюють випадково, за допомогою генератора випадкових чисел.
3. Спосіб за будь-яким із пп. 1 або 2, який відрізняється тим, що значення порога визначають як добуток q та sum, де q - відношення числа елементів в одній виділеній множині до числа елементів у вхідному векторі даних, 0<g<1; sum - сума всіх елементів вхідного вектора даних, а значення елемента вихідного вектора даних визначають як різницю між числовим значенням, отриманим в результаті виконання дії підсумовування чисельних значень елементів одної виділеної множини, та значенням порога.
4. Спосіб за будь-яким із пп. 1 або 2, який відрізняється тим, що визначають значення елемента вихідного вектора даних як бінарне 0 або 1 наступним чином: якщо числове значення, отримане в результаті виконання дії підсумовування чисельних значень елементів одної виділеної множини, більше, ніж значення порога, то значення елемента вихідного вектора даних визначають як 1, інакше - як 0, причому значення порога визначають як q sum + d, де значення d регулює ймовірність, що елемент бінарного вихідного вектора даних буде одиничним.
5. Спосіб за будь-яким із пп. 1-4, який відрізняється тим, що спосіб виконують N раз для одного вхідного вектора даних для отримання N елементів одного вихідного вектора даних.
6. Спосіб за п. 5, який відрізняється тим, що спосіб виконують L раз для отримання L вихідних векторів даних з L вхідних векторів даних, які відповідають L об'єктам, так що результатом є вихідний масив з L N-мірних векторів даних.
7. Система перетворення вхідного вектора даних, який представляє об'єкт, причому вхідний вектор даних має щонайменше один елемент, в елемент вихідного вектора даних, яка включає
блок розділення елементів вхідного вектора даних;
блок підсумовування;
блок визначення значення елемента вихідного вектора даних;
яка відрізняється тим, що
містить блок визначення порога для визначення значення порога;
блок розділення елементів вхідного вектора даних виконаний з можливістю виділяти множину елементів вхідного вектора даних;
блок підсумовування виконаний з можливістю підсумовувати чисельні значення виділеної в блоці розділення елементів вхідного вектора даних множини елементів вхідного вектора даних;
блок визначення значення елемента вихідного вектора даних виконаний з можливістю використання для визначення значення елемента вихідного вектора даних числових значень з блока підсумовування і з блока визначення порога.
8. Система за п. 7, яка відрізняється тим, що блок розділення елементів вхідного вектора виконаний з можливістю виділяти множину елементів вхідного вектора даних випадково, за допомогою генератора випадкових чисел.
9. Система за будь-яким із пп. 7-8, яка відрізняється тим, що значення порога визначено блоком визначення порога як добуток q та sum, де q - відношення числа елементів в одній виділеній множині до числа елементів у вхідному векторі даних, 0<q<1; sum - сума всіх елементів вхідного вектора даних, а значення елемента вихідного вектора даних визначено блоком визначення значення елемента вихідного вектора даних як різницю між числовим значенням з блока підсумовування та значенням порога.
10. Система за будь-яким із пп. 7-8, яка відрізняється тим, що блок визначення значення елемента вихідного вектора даних виконано з можливістю визначати бінарне 0 або 1 значення елемента вихідного вектора даних наступним чином: якщо числове значення, отримане в блоці підсумовування, більше, ніж значення порога, то значення елемента вихідного є 1, інакше - 0, причому значення порога визначено блоком визначення порога як q sum + d, де значення d регулює ймовірність, що елемент бінарного вихідного вектора даних буде одиничним.
11. Система за будь-яким із пп. 7-10, яка відрізняється тим, що виконана з можливістю працювати N раз для одного вхідного вектора даних для отримання N елементів одного вихідного вектора даних.
12. Система за п. 11, яка відрізняється тим, що виконана з можливістю працювати L раз для отримання L вихідних векторів даних з L вхідних векторів даних, які відповідають L об'єктам, так що в результаті виходить вихідний масив з L N-мірних векторів даних.
Текст
Реферат: Спосіб та система перетворення вхідного вектора даних належать до галузі представлення об'єкта, в елементах вихідного вектора даних. Кількаразове виконання способу або спрацьовування системи дозволяє отримати вихідний вектор даних, відповідний вхідному вектору даних. Результат перетворення еквівалентний виконанню перетворення вхідного вектора даних за допомогою проекційної матриці з елементами, які приймають значення 0 або 1, і наступної порогової трансформації. Перетворення здійснюється ефективно за рахунок використання особливостей застосованого типу проекції. Таким же перетворенням кожного вхідного вектора даних з масиву вхідних векторів даних отримують відповідний масив вихідних векторів даних, який може далі використовуватися системами та/або способами замість вхідного масиву. Цей вихідний масив може займати менше комп'ютерної пам'яті, ніж вхідний, та/або може бути представлений у форматі бінарних векторів даних з регульованою часткою одиничних елементів, що дозволяє обробляти вихідний масив більш ефективно, ніж вхідний, та/або застосовувати для обробки системи та/або способи, які ефективно оперують даними в такому форматі, або призначені для роботи з таким форматом даних. По вихідних векторах даних можна оцінити міри схожості та відмінності відповідних вхідних векторів даних. UA 102980 C2 (12) UA 102980 C2 UA 102980 C2 5 10 15 20 25 30 35 40 45 50 55 60 Винахід належить до області цифрової обробки даних, зокрема, до способів перетворення цифрових даних у вигляді числових векторів і може бути використаний для ефективного перетворення вхідних векторних даних у формат, який спрощує оцінювання мір їхньої схожості та відмінності. Більша частина електронних цифрових даних, які відповідають деяким об'єктам, може бути представлена як матриці або таблиці. Наприклад, масиви текстів при виконанні пошуку або класифікації можна розглядати як матриці слова-тексти, де в стовпцях - тексти, а в рядках слова. Покупки покупців можуть бути представлені матрицею, де в стовпцях - індивідуальні покупці, а в рядках - характеристики покупки, наприклад, місця покупок. Покупки покупців також можуть бути представлені матрицею, де в стовпцях - індивідуальні покупці, а в рядках - характеристики покупки, наприклад, куплені товари. Демографічна інформація про людей може бути представлена матрицею, де в стовпцях індивідуальні люди, а в рядках - їх характеристики, наприклад, вік, зріст, вага, та ін. Результати мас-спектрометричного аналізу білків пацієнтів можуть бути представлені матрицею, де в стовпцях - індивідуальні пацієнти, а в рядках - білки з різною масою. Ці лише приклади, далеко не вичерпні різноманітність даних, які відповідають деяким об'єктам та можуть бути представлені як матриці або таблиці. Також, слід розуміти, що об'єкти можуть бути представлені не в стовпцях, а в рядках матриці, і тоді характеристики об'єктів будуть представлені не в рядках, а в стовпцях матриці. Кожен рядок або стовпець матриці є вектором. Цю ж інформацію можна представити як набір векторів або точок в багатовимірному (евклідовому) просторі. Розмірність простору - це число координат (для матриці слова-тексти - це число слів), а кожна точка відповідає об'єкту (тексту). Координатами простору є елементи вектора. Розмірність простору може бути велика і складати, наприклад, сотні тисяч (за кількістю слів у мові), а число точок - мільйони й мільярди (по числу текстів - наприклад, число веб-сторінок Інтернет). У таких ситуаціях бажано перетворити масив даних таким чином, щоб число об'єктів, що представлені точками (векторами), збереглося, але підвищилась ефективність зберігання й обробки за рахунок зменшення витрат пам'яті, підвищення швидкості обробки, застосування спеціалізованих способів зберігання й обробки. Цих переваг можна досягти шляхом переходу в простір із відповідними властивостями: меншої розмірності, ніж вхідне; з більш простими операціями для обробки; або у простір, для якого існують ефективні способі обробки. Багато способів та систем оперують з мірами відмінності та схожості векторів у вхідному просторі, такими як відстань, скалярний добуток, кут та/або відношення відстаней і кутів та ін. Ці міри відмінності та схожості векторів взаємопов'язані. Наприклад, для двох векторів х1 і х2 їх скалярний добуток (х1, х2)=||х1|| ||х2|| cos(x1, x2); евклідова відстань ||х1-х2||=sqrt(||x1|| ||x1|| + ||х2|| ||х2|| - 2 ||х1|| ||х2|| cos(x1, х2)); де ||x1||, ||х2|| - евклідові норми векторів х1 і х2; cos(x1, x2) косинус кута між ними; sqrt - функція квадратного кореня. Мірами відмінності та схожості векторів оперують багато способів та систем інформаційного пошуку, класифікації, кластеризації, апроксимації, навчання і міркувань на основі прикладів, асоціативної пам'яті, і багато інших. В цих способах та системах широко використовувані лінійні моделі, що засновані на скалярному добутку; спосіб найближчого сусіда використовує міри відмінності та схожості, і т.д. Розглянемо приклад. Нехай заданий масив текстів, в якому треба знаходити тексти, близькі до запиту. Для цього, тексти та запити представляють як вектори. Розмірність вектора - число слів у словнику. Елементи вектора - слова словника. Значення елементів вектора - кількість разів уживання слова в тексті або запити. Знаходять схожість бінарних векторів запитів з бінарними векторами текстів бази за мірами схожості. Упорядковують тексти за величиною схожості та видають користувачеві найбільш подібні. Розглянемо інший приклад. Тексти новин треба відносить до ряду рубрик, щоб можна було читати новини з певної тематики. Тексти наявної бази текстів та нові тексти, що підлягають класифікації, представляють як вектори. Розмірність вектора - число слів у словнику. Елементи вектора - слова словника. Значення елементів вектора - кількість разів уживання слова в тексті. Для кожного тексту наявної бази текстів відомі рубрики, до яких вони належать. Знаходять схожість вектора вхідного тексту з векторами текстів бази за мірами схожості бінарних векторів. Надають вхідному тексту мітку класу (рубрику), що відповідає тексту бази з найбільш схожим вектором. Для таких і багатьох інших застосувань було б корисно оперувати з перетвореними векторними даними, які дають результати, що узгоджуються з результатами у вхідному багатовимірному векторному просторі, але при цьому більш ефективні - з точки зору економії 1 UA 102980 C2 5 10 15 20 25 30 35 40 45 50 55 60 пам'яті, швидкості обробки, можливості застосування для обробки даних інших класів систем, пристроїв та способів. Один з підходів до перетворення, яке дозволяє відновити відстані та кути між вхідними векторами по результуючим, полягає в застосуванні спеціально сконструйованої випадкової проекційної матриці R розмірністю NxA [W.B. Johnson & J. Lindenstrauss. Extensions of Lipschitz mappings into a Hilbert space // Contemporary Mathematics, 26:189-206, 1984; C.H. Papadimitriou, P. Raghavan, H. Tamaki, & S. Vempala. Latent semantic indexing: A probabilistic analysis, J. Comput. System Sci., 61:217-235, 2000; D.Achlioptas. System and method adapted to facilitate dimensional transform. U.S.Pat. 7318078; M.S. Charikar. Methods and apparatus for estimating similarity. U.S.Pat. 7158961; Мисуно И.С., Рачковский Д.А., Слипченко С.В. Векторные и распределенные представления, отражающие меру семантической связи слов // Математические машины и системы - 2005 - № 3 - С. 50-66], де А - число елементів вектора у вхідному просторі, N - число елементів вектора в результуючому просторі. Вхідний масив даних представлений вхідною матрицею X розмірністю AxL, L - число векторів. Проміжний результат перетворення - матриця Y - має розмірність NxL і отримується множенням Y=RX. Вихідна матриця Z(NxL), яка використовується для роботи подальшими способами обробки масиву даних, є результатом трансформації Y: Z=f(Y) і має розмірність NxL, як і Y. При певному виборі проекційної матриці R та трансформації f по векторам матриці Z можна оцінювати міри схожості відповідних векторів матриці X, які представляють деякі об'єкти (наприклад, тексти) - тобто, оцінювати схожість цих об'єктів. Так, в роботі [W.B. Johnson & J. Lindenstrauss. Extensions of Lipschitz mappings into a Hilbert space // Contemporary Mathematics, 26:189-206, 1984] за проекційну матрицю R було запропоновано використовувати випадкову ґаусову матрицю і використовувати в якості вихідної матриці Z безпосередньо матрицю Y=RX (що може розглядатися як тотожна трансформація, яка реалізується шляхом привласнення або переписування в елементи матриці Z значень елементів матриці Y): Z=Y. Показано, що за отриманими N-мірними векторами-стовпцями Z можна з високою точністю оцінити відстані між вхідними A-мірними векторами в X навіть при N
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod and system for conversion of data input vector
Автори англійськоюRachkovskyi Dmytro Andriiovych, Hrytsenko Volodymyr Illich
Назва патенту російськоюСпособ и система преобразования векторных данных
Автори російськоюРачковский Дмитрий Андреевич, Гриценко Владимир Ильич
МПК / Мітки
МПК: G06F 17/14
Мітки: векторних, система, спосіб, даних, перетворення
Код посилання
<a href="https://ua.patents.su/27-102980-sposib-ta-sistema-peretvorennya-vektornikh-danikh.html" target="_blank" rel="follow" title="База патентів України">Спосіб та система перетворення векторних даних</a>
Спосіб керування доступом станції даних до мобільних носіїв даних, мобільний носій даних, станція даних і система для здійснення способу

Номер патенту: 46781
Опубліковано: 17.06.2002
Автор: Райнер Роберт
МПК: G06K 19/07, G06K 7/00, G06K 17/00, H04L 12/407
Мітки: здійснення, даних, мобільній, доступом, станція, керування, спосіб, носіїв, мобільних, носій, станції, система, способу
Формула / Реферат:
1. Спосіб керування доступом станції даних (61) до щонайменше двох мобільних носіїв даних (51), при якому ці носії даних на вимогу станції даних синхронно передають свої ідентифікаційні номери, і станція даних визначає, чи приймаються щонайменше в одному двійковому розряді прийнятих ідентифікаційних номерів два різних значення біта, і потім, якщо принаймні в одному двійковому розряді прийнятих ідентифікаційних номерів будуть визначені як...
Спосіб криптографічного перетворення даних для систем обробки інформації в еом

Номер патенту: 42345
Опубліковано: 15.10.2001
Автори: Горбенко Іван Дмитрович, Олійников Роман Васильович, Горбенко Юрій Іванович, Головашич Сергій Олександрович, Потій Олександр Володимирович
МПК: H04L 9/14
Мітки: спосіб, криптографічного, систем, інформації, еом, перетворення, даних, обробки
Формула / Реферат:
Спосіб криптографічного перетворення даних для систем обробки інформації в ЕОМ, що полягає в тому, що на першому етапі зашифрування відкриті дані розбивають на 64-розрядні блоки Т0, зашифрування якої включає 32 цикли, у ключовий запам'ятовуючий пристрій вводять 256 бітів ключа К у вигляді восьми 32-розрядних підключів Кі, послідовність бітів блока розбивають на дві послідовності по 32 біти і вводять у накопичувачі N1, N2 на початку першого...
Спосіб недетермінованого криптографічного перетворення блоків даних

Номер патенту: 53949
Опубліковано: 17.02.2003
Автори: Долгов Віктор Іванович, Супронюк Сергій Володимирович, Лисицька Ірина Вікторівна
МПК: H04L 29/14
Мітки: блоків, спосіб, недетермінованого, криптографічного, перетворення, даних
Формула / Реферат:
Спосіб недетермінованого криптографічного перетворення блоків даних, що полягає у формуванні ключа шифрування у вигляді сукупності підключів, розбивці блока даних на підблоки і почерговому перетворенні підблоків на основі керованих підстановок, який відрізняється тим, що таблицю підстановок подають у вигляді латинського прямокутника, розмірність якого визначається підблоком, що шифрують, а саме перетворення на основі керованої підстановки...
Спосіб криптографічного перетворення блоків двійкових даних

Номер патенту: 49102
Опубліковано: 16.09.2002
Автори: Молдовян Алєксандр Андрєєвіч, Молдовян Ніколай Андрєєвіч
МПК: H04K 1/06, H04L 29/06, H04L 12/56, H04L 12/22, H04L 9/08
Мітки: двійкових, блоків, криптографічного, перетворення, спосіб, даних
Формула / Реферат:
1. Спосіб криптографічного перетворення блоків двійкових даних, який полягає в розбитті блока даних на підблоків, почерговому перетворенні підблоків шляхом виконання над і-тим, де підблоком принаймні однієї операції перетворення, що залежить від значення j-того підблока, який відрізняється тим, що як...
Спосіб криптографічного перетворення l-бітових вхідних блоків цифрових даних в l-бітові вихідні блоки

Номер патенту: 55496
Опубліковано: 15.04.2003
Автори: Молдовян Ніколай Андрєєвіч, Молдовян Алєксандр Андрєєвіч
Мітки: перетворення, вихідні, блоки, вхідних, даних, l-бітові, блоків, l-бітових, цифрових, криптографічного, спосіб
Формула / Реферат:
1. Спосіб криптографічного перетворення L-бітових вхідних блоків цифрових даних в L-бітові вихідні блоки, який полягає в розбитті блоку даних на підблоки, почерговому перетворенні підблоків шляхом формування принаймні одного бінарного вектора за значенням підблоку і зміни підблоку з використанням бінарного вектора, який відрізняється тим, що формування бінарного вектора на...
Попередній патент: Модульна планетарна бетономішалка для виробництва бетону
Наступний патент: Спосіб корекції похибки головної термопари
Випадковий патент: Сенсорний електропровідний органо-неорганічний матеріал