Спосіб ущільнення мовних сигналів
Номер патенту: 32410
Опубліковано: 12.05.2008
Автори: Ткаченко Олександр Миколайович, Хрущак Сергій Вікторович, Феферман Олег Дмитрович


Формула / Реферат
Спосіб ущільнення мовних сигналів шляхом кодування вибірок мовного сигналу на основі моделі лінійного прогнозування, який відрізняється тим, що виконують попереднє впорядкування векторів у кодовій книзі за рівнями згідно з відношенням мажорування їх відстаней до заданих точок відліку, кодують вибірки мовного сигналу у вектор лінійних спектральних пар на основі моделі лінійного прогнозування, перетворюють вектор лінійних спектральних пар у вектор відстаней до точок відліку та проводять пошук квантованого значення вектора у кодовій книзі, при пошуку визначають рівень мажоризації, до якого належить перетворений вектор, та виконують пошук квантованого вектора, найближчого до вектора лінійних спектральних пар, на знайденому рівні та декількох сусідніх, індекс знайденого вектора передають у канал зв'язку.
Текст
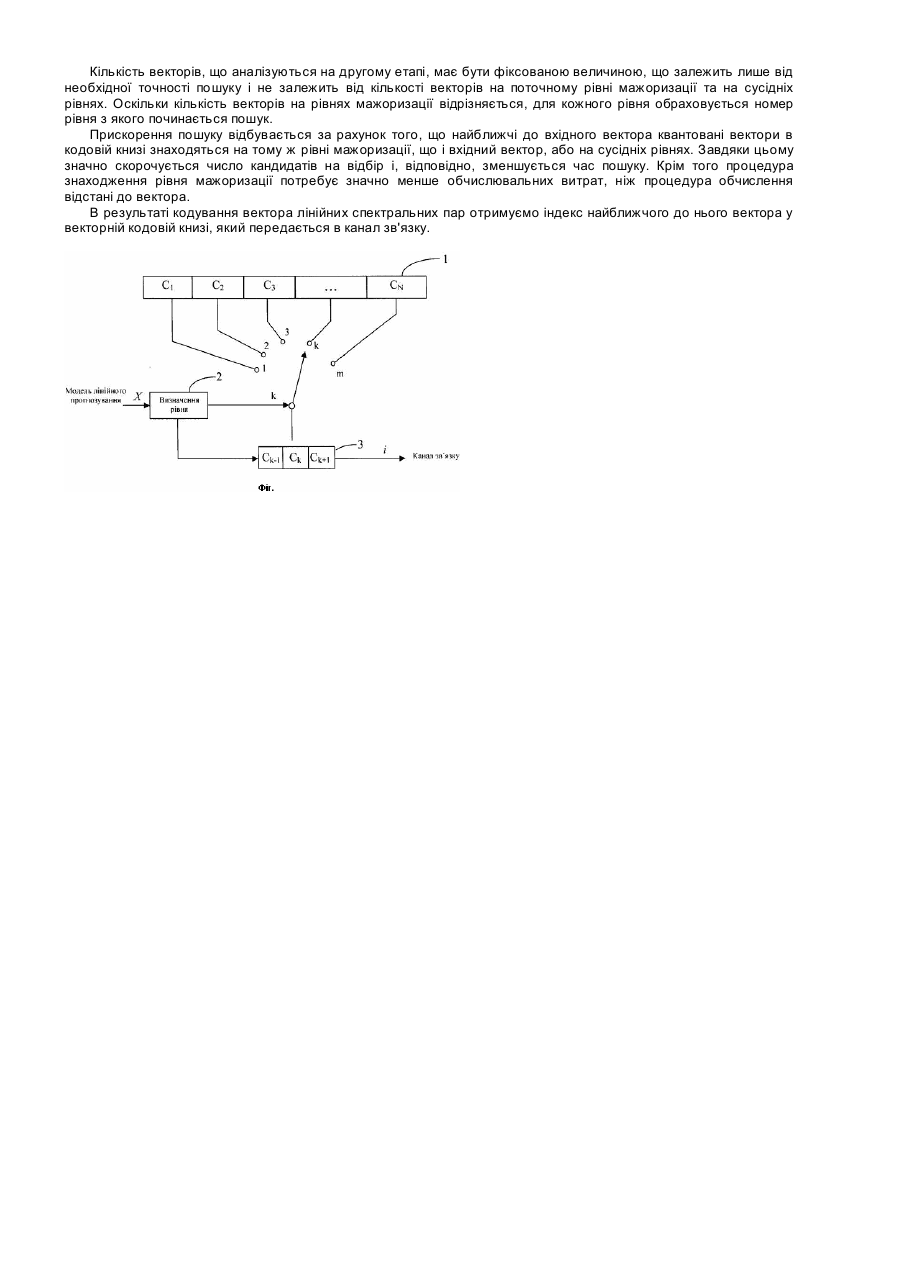
Корисна модель відноситься до галузі обчислювальної техніки, а саме при ущільненні мовних сигналів і може бути використана в засобах запису, відтворення та передачі мовних сигналів, ідентифікації диктора та при розпізнаванні мови. Аналогом даного способу є [«Спосіб та пристрій для кодування аудіо сигналів (варіанти)» (патент України №48191 М. кл. Н03М 3/00, опублікований 15.08.02)], в якому запропоновано спосіб та пристрій кодування звуку, який полягає в тому, що здійснюється кодування аудіосигналу з малою швидкістю передачі бітів та невеликою затримкою, порівняно із затримкою, яка виникає під час кодування сигналу високої якості та передача першого кодованого сигналу на декодер до початку передачі на цей декодер принаймні одного кодованого сигналу, який окремо або разом з першим кодованим сигналом створює під час декодування сигнал вказаної високої якості. Недоліком даного способу є великі матеріальні витрати, пов'язані з потребою використання частотних каналів з широкою смугою пропускання, що зумовлено високою бітовою швидкістю, необхідною для передачі кодованого мовного сигналу. Спосіб, описаний у статті авторів [К. Palival, S. Atal "Efficient Vector Quantization of LPC Parameters at 24 Bits/Frame", IEEE Transactions on Speech and Audio Processing, Vol.1, No.2, 1993 - pp.3-14], розглядається кодування мовного сигналу на основі моделі лінійного прогнозування. Для опису сигналу використовуються лінійні спектральні частоти, які додатково квантуються за допомогою векторних кодових книг. Для порівняння векторів під час пошуку найближчого квантованого значення вектора у кодовій книзі запропоновано використовувати зважену евклідову міру, яка враховує різні ваги коефіцієнтів лінійних спектральних частот. Недоліком даного способу є вузькі функціональні можливості за рахунок того, що пошук вектора в кодовій книзі, враховуючи використання зваженої евклідової міри, потребує значних обчислювальних затрат, що унеможливлює практичне застосування даного способу в режимі реального часу. За найближчий аналог обрано [«Спосіб стиснення мовного сигналу шляхом кодування зі змінною швидкістю, схема та пристрій для стиснення акустичного сигналу» (патент України №43311, М. кл. G10L 21/04, G10L 19/00, опублікований 17.12.01)], який включає операції визначення рівня сигналу мовної активності для кадру оцифрованих вибірок мовного сигналу, вибір для вказаного кадру швидкості кодування із групи швидкостей залежно від вказаного визначеного рівня сигналу мовної активності, кодування вказаного кадру відповідно до попередньо визначеного формату кодування для вибраної швидкості, причому кожній швидкості відповідає відмінний від інших формат кодування і різні формати кодування відповідають різним наборам параметрів сигналів, що визначають оцифровані вибірки мовного сигналу відповідно до мовної моделі, та формування для даного кадру відповідного пакету даних з указаними параметрами сигналів. За основу взято вокодер, побудований на основі моделі лінійного прогнозування. При кодуванні параметрів мовного сигналу використовуються скалярні кодові книги. Недоліком наведеного способу є значні спотворення декодованого сигналу, зумовлені кодуванням параметрів за допомогою скалярних кодових книг. За умов передавання однакових обсягів даних, використання скалярних кодових книг призводить до більш значних спотворень сигналу, порівняно з векторними кодовими книгами. Проте значні обчислювальні витрати при використанні векторних кодових книг не дозволяють використовувати їх у режимі реального часу. В основу корисної моделі поставлено задачу створення способу ущільнення мовних сигналів, який не потребує значних обчислювальних витрат на пошук вектора у кодовій книзі. За рахунок цього досягається можливість використовувати векторні кодові книги у режимі реального часу і тим самим зменшити швидкість, необхідну для передавання мовного сигналу по каналам зв'язку. Це приводить до зменшення вимог до необхідної пропускної спроможності каналу для передачі мовного сигналу, зменшення цін на послуги цифрового зв'язку, збільшення кількості абонентів систем цифрового зв'язку. Поставлена задача досягається тим, що в способі ущільнення мовних сигналів виконують попереднє впорядкування векторів у кодовій книзі за рівнями згідно з відношенням мажорування їх відстаней до заданих точок відліку, кодують вибірки мовного сигналу у вектор лінійних спектральних пар на основі моделі лінійного прогнозування, перетворюють вектор лінійних спектральних пар у вектор відстаней до точок відліку та проводять пошук квантованого вектора у кодовій книзі, причому спочатку визначають рівень мажоризації, до якого належить перетворений вектор, а потім виконують пошук квантованого значення вектора, найближчого до вектора лінійних спектральних пар, на знайденому рівні та декількох сусідніх рівнях, та передають індекс знайденого вектора у канал зв'язку. На кресленні представлена схема блоку квантизації, яка пояснює спосіб квантування вектора лінійних частот за допомогою кодової книги. В схему входять наступні вузли: 1 - векторна кодова книга; 2 - блок визначення рівня вектора; 3 - блок пошуку найближчого квантованого значення вектора на рівні. Спосіб здійснюється наступним чином: на основі моделі лінійного прогнозування здійснюють обчислення параметрів голосового тракту - коефіцієнтів лінійного прогнозування та функції збудження - періоду основного тону та підсилення. Оцінка параметрів виконується кадрами та відбувається кожні 20мс. Параметри моделі лінійного прогнозування оцінюються автокореляційним методом з використанням рекурсії Левінсона-Дарбіна. Отримані коефіцієнти лінійного прогнозування (LPC) ak є параметрами передатної функції A p (z ) , що описує голосовий тракт людини: Ap (z ) = 1 + p åa k × z -k . (1) k =1 Надалі отримані LPC параметри перетворюються в лінійні спектральні пари (LSP), які в свою чергу є коренями поліномів: (p 1) 1 P(z ) = Pp+1(z) = A p (z ) + z - + A p (z - ) ; (2) ( ). Q (z) = Q p+1(z ) = A p (z) - z -(p+1)Ap z-1 (3) Корені поліномів P(z) і Q(z) x j та y j лежать на одиничному колі, тому: x j = cos w2 j-1 ± i sin w2 j -1 ; (4) y j = cos q2 j ± i sin q2 j ; (5) 1£ j £ p / 2 . Набори w2 j -1 та q2 j { } { } за визначенням є LSP. Перехід до лінійних спектральних пар дозволяє здійснити подальше кодування параметрів за допомогою кодових книг. Векторна кодова книга містить набір векторів значень LSP. Для структуризації кодової книги за властивістю мажорування, створюється додаткова кодова книга, яка містить відстані від векторів значень LSP до заданих n точок відліку V0 = (0,0, K,0 ), V1 = (N1,0, K ,0 ) , K , Vn-1 = (0,0, K , Nn -1,0 ) , де n - розмірність підвектора LSP-параметрів. Оскільки LSP-параметри лежать в межах (0,4000), обрано значення N1 = N2 = K = Nn-1 = 4000 . Перехід від вектора LSP-параметрів X = (x1, x 2, K , x n ) до вектора відстаней X¢ = æ x1¢, x 2¢, K , xn¢ ö задається ç ÷ è ø формулами: x1¢ = D(X, V0 ), K , xn¢ = D( X, Vn-1) , (6) де D - евклідова відстань між векторами, що обчислюється за формулою: n å (x - y ) D(X, Y ) = i i 2 i =1 (7) Структуризація векторної кодової книги починається з обчислення відстаней від векторів LSP- параметрів до точок відліку за формулами (6). Вектори відстаней X¢ утворюють кодову книгу відстаней, розмірність якої збігається з розмірністю кодової книги LSP-параметрів. У подальшому для мажоризації використовуються вектори з кодової книги відстаней, але результатом буде синхронне впорядкування векторів в обох кодових книгах. Рівні мажоризації формуються на основі кодової книги відстаней від векторів до точок відліку згідно з таким правилом. Рівень мажоризації Li мажорується рівнем мажоризації L j , якщо для кожного вектора X , що належить Li , на рівні L j знайдеться вектор Y , що слабо мажорує X , або формально Li p L j , якщо "X, X Î L i, $Y, Y Î L j , такий що X p w Y . (8) Вектор Y слабо мажорує X (позначається X p w Y ), якщо виконується нерівність: k å i =1 k xi £ å y , k = 1,2,K , n , i (9) i =1 Мажоризація здійснюється за таким алгоритмом: ¢ 1. Вектори у кодовій книзі відстаней сортуються у спадному порядку за компонентою x1 . Якщо у деяких векторів перші компоненти збігаються, їх сортування відбувається за наступними компонентами. 2. Всі вектори у кодовій книзі помічаються як немажоровані. 3. Створюється цикл від 1 до М, де М - кількість векторів у кодовій книзі. ¢ ¢ 3.1. У циклі за формулою (9) послідовно перевіряються всі вектори X1 , K , XM . ¢ 3.2. Якщо знаходиться немажорований вектор Xi , він помічається як мажорований і додається на рівень мажоризації L j . Кількість рівнів мажоризації збільшується на 1. 3.3. Створюється цикл від i + 1 до М. ¢ ¢ 3.3.1. У циклі за формулою (9) послідовно перевіряються всі вектори Xi+1 , K , XM . 3.3.2. Якщо знаходиться вектор, який не мажорується жодним вектором рівня L j , він помічається як мажорований і додається на рівень мажоризації L j . Кількість створених рівнів мажоризації К (число класів у кодових книгах) дорівнює кількості повторів п. 3.3. Таким чином робота алгоритму завершується за МхК ітерацій. Результатом роботи алгоритму є векторна кодова книга, структурована за рівнями мажоризації. Пошук найближчого вектора відбувається в два етапи. На першому етапі вхідний вектор LSP- параметрів X перетворюється за формулами (6) у вектор відстаней до точок відліку X¢ . Далі у кодовій книзі відстаней відбувається пошук рівня мажоризації, якому належить вхідний вектор. При цьому послідовно, починаючи з верхнього, перевіряються всі рівні мажоризації. Якщо на рівні мажоризації L j знаходиться вектор Y¢ , такий що X¢ p w Y ¢ відбувається перехід до наступного рівня. Пошук завершується, коли буде знайдено рівень Lk , на якому жоден вектор Y¢ не мажорує вхідний вектор X¢ , або коли досягається останній рівень мажоризації. На другому етапі відбувається пошук найближчого до вхідного квантованого вектора на знайденому рівні мажоризації та кількох сусідніх рівнях Фіг. Пошук виконується у кодовій книзі LSP- параметрів за методом повного перебору, при цьому вибирається той вектор Y кодової книги, для якого D(X, Y ) = min . Кількість векторів, що аналізуються на другому етапі, має бути фіксованою величиною, що залежить лише від необхідної точності пошуку і не залежить від кількості векторів на поточному рівні мажоризації та на сусідніх рівнях. Оскільки кількість векторів на рівнях мажоризації відрізняється, для кожного рівня обраховується номер рівня з якого починається пошук. Прискорення пошуку відбувається за рахунок того, що найближчі до вхідного вектора квантовані вектори в кодовій книзі знаходяться на тому ж рівні мажоризації, що і вхідний вектор, або на сусідніх рівнях. Завдяки цьому значно скорочується число кандидатів на відбір і, відповідно, зменшується час пошуку. Крім того процедура знаходження рівня мажоризації потребує значно менше обчислювальних витрат, ніж процедура обчислення відстані до вектора. В результаті кодування вектора лінійних спектральних пар отримуємо індекс найближчого до нього вектора у векторній кодовій книзі, який передається в канал зв'язку.
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for compacting language signals
Автори англійськоюTkachenko Oleksandr Mykolaiovych, Feferman Oleh Dmytrovych, Khruschak Serhii Viktorovych
Назва патенту російськоюСпособ уплотнения языковых сигналов
Автори російськоюТкаченко Александр Николаевич, Феферман Олег Дмитриевич, Хрущак Сергей Викторович
МПК / Мітки
МПК: G10L 19/00, G10L 21/00
Мітки: ущільнення, сигналів, мовних, спосіб
Код посилання
<a href="https://ua.patents.su/3-32410-sposib-ushhilnennya-movnikh-signaliv.html" target="_blank" rel="follow" title="База патентів України">Спосіб ущільнення мовних сигналів</a>
Пристрій для стиснення мовних сигналів

Номер патенту: 71189
Опубліковано: 15.11.2004
Автори: Биков Микола Максимович, Раїмі Абдурахман, Ковтун В'ячеслав Васильович
МПК: G10L 19/00
Мітки: мовних, стиснення, сигналів, пристрій
Формула / Реферат:
Пристрій для стиснення мовних сигналів, який складається з аналого-цифрового перетворювача (АЦП), що має один вхід та два виходи - готовності та інформаційний, компаратора, першого та другого регістрів та першого, другого та третього елементів АБО, який відрізняється тим, що додатково введені четвертий елемент АБО, перший, другий, третій, четвертий та п'ятий елементи І, третій регістр, лічильний тригер по модулю два, лічильний тригер по...
Пристрій для виділення ознак мовних сигналів

Номер патенту: 55863
Опубліковано: 15.04.2003
Автори: Грищук Тетяна Вікторівна, Биков Микола Максимович, Ковтун В'ячеслав Васильович
МПК: G10L 15/00
Мітки: пристрій, мовних, виділення, ознак, сигналів
Формула / Реферат:
Пристрій для виділення ознак мовних сигналів містить послідовно з'єднані перший акустичний датчик, і перший формувач, вихід якого підключено до входу першого амплітудного детектора, другий акустичний датчик і послідовно з ним з'єднане електричне коло, яке складається з другого формувача і другого амплітудного детектора, першу і другу порогові схеми, а також схему порівняння, який відрізняється тим, що до виходів обох акустичних датчиків...
Спосіб розпізнавання мовних образів

Номер патенту: 66184
Опубліковано: 15.04.2004
Автори: Биков Микола Максимович, Грищук Тетяна Вікторівна
МПК: G10L 15/00
Мітки: мовних, розпізнавання, образів, спосіб
Формула / Реферат:
Спосіб розпізнавання мовних образів, що включає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих...
Адаптивний дельта-модулятор у системі стиснення мовних сигналів

Номер патенту: 15202
Опубліковано: 30.06.1997
Автори: Давлетьянц Олександр Іванович, Коломієць Олександр Вікторович
МПК: H03M 3/02
Мітки: дельта-модулятор, адаптивний, стиснення, мовних, сигналів, системі
Формула / Реферат:
Адаптивный дельта-модулятор в системе сжатия речевых сигналов, содержащий собственно модулятор, первый вход которого является первым (сигнальным) входом устройства, а второй выход - первым выходом устройства, отличающийся тем, что в него дополнительно введены блок оценки среднеквадратического отклонения разностного сигнала, аналого-цифровой преобразователь (АЦП), фиксированный делитель частоты и управляемый делитель частоты, причем вход блока...
Спосіб ущільнення даних при передачі та/або накопиченні цифрових сигналів

Номер патенту: 27130
Опубліковано: 28.02.2000
Автори: Зайтцер Дітер, Херре Юрген
МПК: H04S 1/00
Мітки: спосіб, цифрових, ущільнення, сигналів, накопиченні, передачі, даних
Формула / Реферат:
1. Способ уплотнения данных при передаче и/или накоплении цифровых сигналов из N зависимых друг от друга каналов, при котором считываемые величины входных сигналов переводят блоками из временного диапазона в спектральные величины частотного диапазона, спектральные величины кодируют, передают и/ или накапливают, декодируют и обратно передают по N каналам во временном диапазоне, отличающийся тем, что из соответствующих спектральным величинам...
Попередній патент: Котел водогрійний
Наступний патент: Повітряний сепаратор
Випадковий патент: Спосіб запису інформації на носій запису та пристрій для його здійснення