Спосіб розпізнавання мовних образів
Номер патенту: 66184
Опубліковано: 15.04.2004


Формула / Реферат
Спосіб розпізнавання мовних образів, що включає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих результатів приймається рішення про розпізнавання мовного образу, який відрізняється тим, що двійковий опис послідовності, що розпізнається, проводиться на основі двійкових кодів, які зберігають ранги відстаней між елементами.
Текст
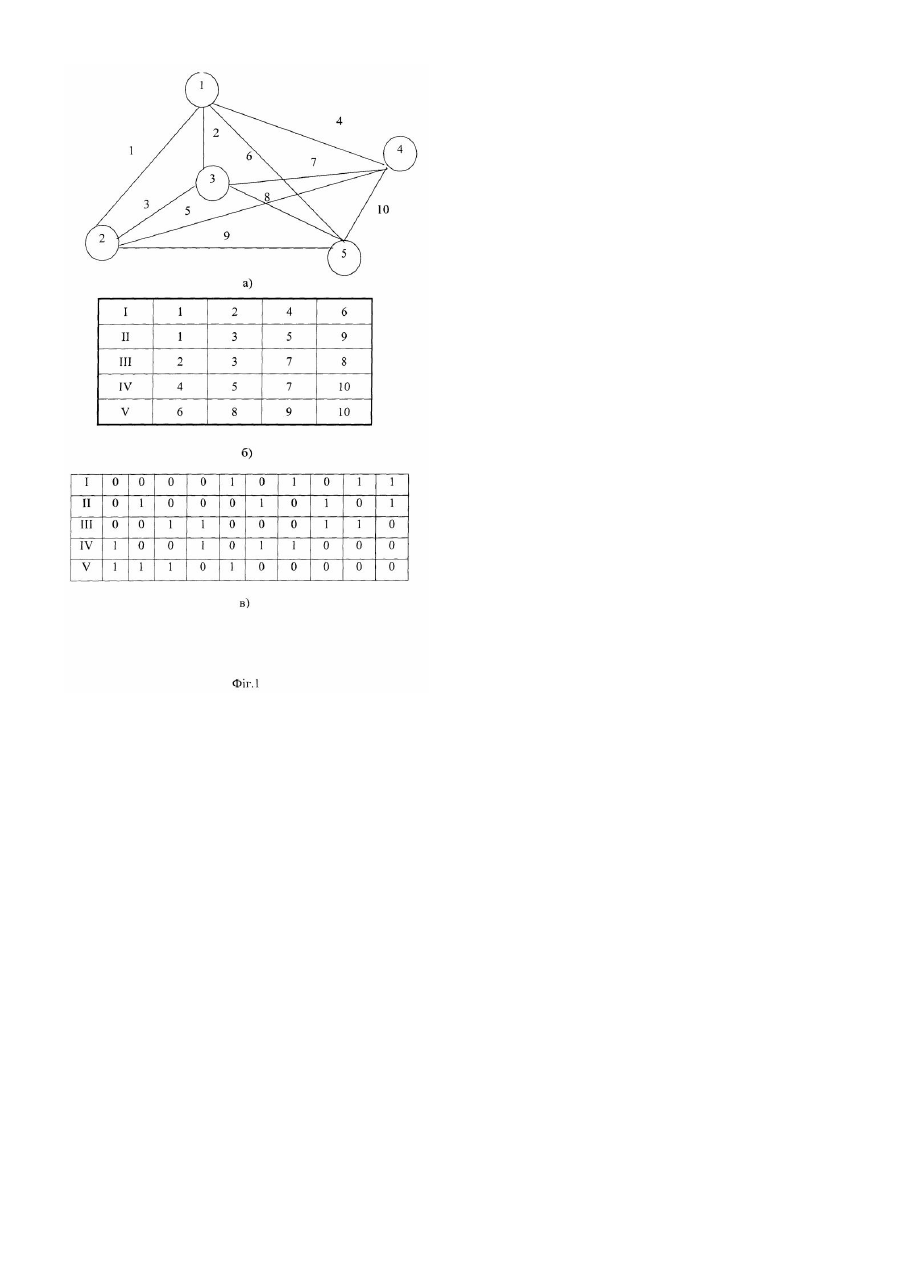
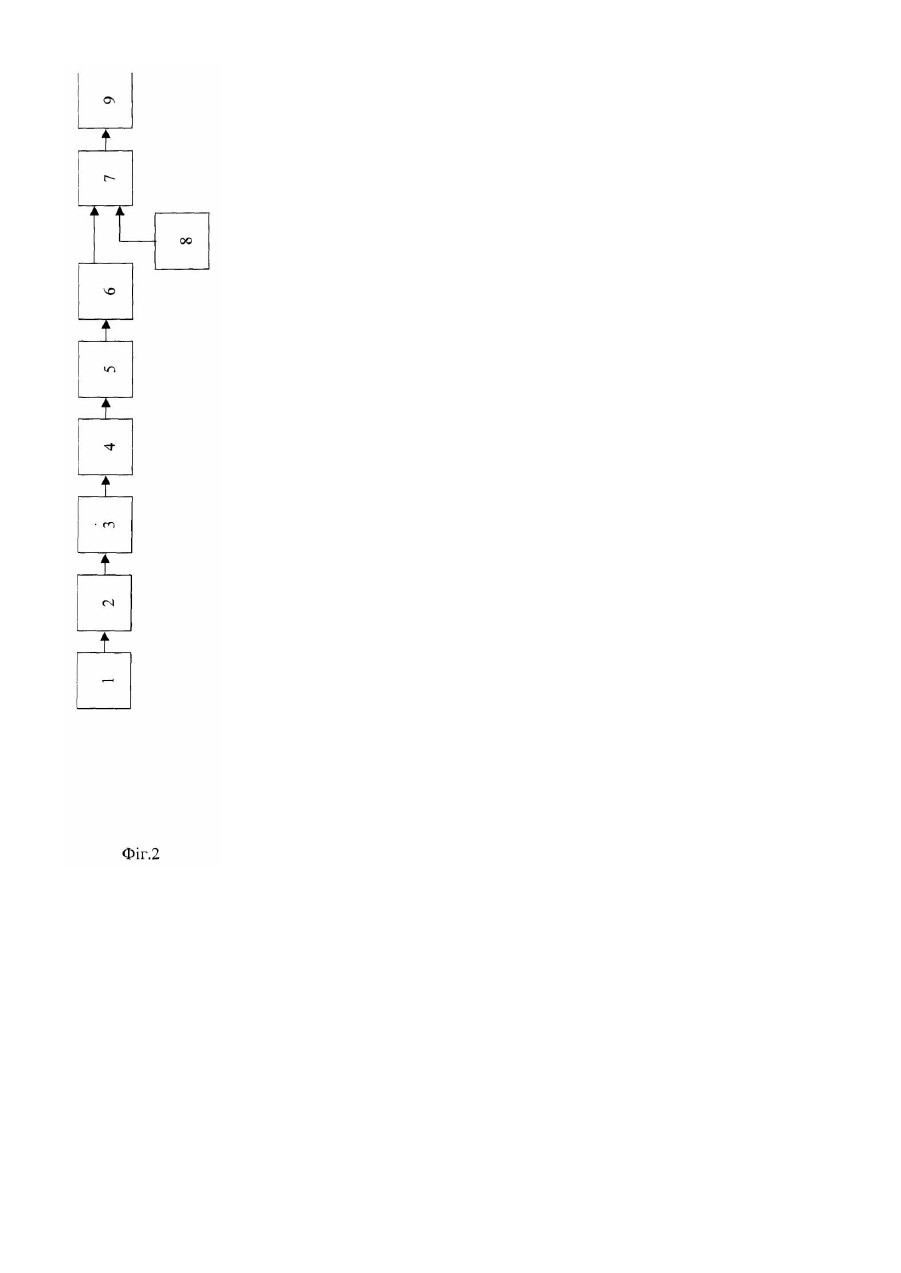
Винахід відноситься до галузі автоматики та обчислювальної техніки і може бути використаний для автоматичного розпізнавання мовних образів. Відомий спосіб розпізнавання образів, відповідно якому сприймають неперервний образ, що розпізнається, проводять його перетворення, виділяють характерні ознаки, виконують дискретизацію образу в послідовність елементів, проводять сегментне маркування елементів, формують двійковий опис стрічки символів, що розпізнається, різними для різних символів двійковими кодами і виконують розпізнавання за мінімумом відстані до одного з еталонних образів, для чого послідовно зчитують з пам'яті коди відстаней між кожною з порівнюваних пар символів з стрічки, що розпізнається, та еталонної стрічки, а потім додають ці відстані [Glave R.D., Vander Giet. The David speech recognition system. - Proc. IEEE Int. Conf. ASSP. - Tulsa. 1978, p. 429-432]. До недоліків даного способу розпізнавання потрібно віднести те, що він потребує додаткових витрат пам'яті на зберігання кодів відстаней, а також значного обмеження швидкості розпізнавання через втрати часу на зчитування кодів цих відстаней з пам'яті. Найбільш близьким до способу, що заявляється, є спосіб розпізнавання образів, відповідно якому неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають різниці відстаней, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів шляхом визначення відстані Хемінга між ними, на основі отриманих результатів приймають рішення про розпізнавання мовного образу [Preparata F.P., Nivergelt J. Difference-Preserving Codes. - TEE Trans. Information Theory, IT-20, 1974, p.643-649.]. Недоліками даного способу є обмеження об'єму словника образів, що розпізнаються, яке обумовлене можливістю виникнення помилок через властивості кодів, що зберігають різниці, а також обмеження швидкодії через необхідність обчислення відстаней Хемінга. Наприклад, якщо елементи образа позначити символами типу «ціле», то для двійкового коду, що зберігає різниці, виконуються наступні умови: 1) з i - j £ t настає H(Di , DJ ) = i - j , 2) з i - j > t настає H(Di , D J ) ¹ i - j , де: i, j Î { , 2,... N} - цілі числа (символи елементів); t - поріг, заданий цілим числом; 1 Di , DJ - двійкові коди елементів і, j, які зберігають різниці; H(Di , DJ ) - відстань Хемінга між двома кодовими словами. При цьому для всякої трійки образів {Ok1, O k2 , Ok3 } , описаної у вигляді стрічок символів: O k1 = j1 + 1, j2 + 1 jm + 1 ; ,... O k2 = j1, j2 ,... jm ; O k3 = j1 - 1 j 2 - 1 jm - 1 , , ,... Хемінгові відстані H(O k1, O k2 ) і H(O k 2 , O k3 ) рівні між собою. Вказана невизначеність викликає помилки в розпізнаванні при наявності в словникові образів з вказаними описами. При виконанні класифікації за відомим способом при логічному порівнянні послідовності елементів, що розпізнається, з еталонною послідовністю необхідно визначати відстань Хемінга між ними, що знижує швидкодію вказаного способу розпізнавання образів. Внаслідок вище зазначеного даний спосіб має невисоку надійність розпізнавання мовних образів, малий об'єм словника та низьку швидкодію. В основу винаходу поставлена задача створення способу розпізнавання мовних образів, в якому за рахунок використання кодування образів DRP-кодами (distance rank preserving codes - кодами, що зберігають ранги відстаней) досягається збільшення надійності розпізнавання мовних образів, збільшення словника мовних образів та підвищення швидкодії розпізнавання. Поставлена задача вирішується тим, що неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають ранги відстаней між елементами, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів, і на основі отриманих результатів приймають рішення про розпізнавання мовного образу. Двійковим кодом b який зберігає ранги відстаней (DRP - кодом) є відображення i ® b i множини m = { ,2,... m} 1 в множину {0,1 n двійкових послідовностей довжиною n таке, що: } " (R dij = k Þ R h ij = k ) , i, jÎm ( ) ( ) ( ) де: R dij - ранг відстані d ij між елементами i тa j в просторі елементів; ( ) R h ij - ранг відстані h ij в просторі двійкових кодів; k - ціле число, величина рангу. Виконання класифікації образа по запропонованому способу не потребує обчислення відстані Хемінга після логічного порівняння послідовності елементів, що розпізнається, і еталонної послідовності елементів, які описують образи. Сума одиниць в двійкові послідовності, яка визначає відстань Хемінга, може бути підрахована в відомому способі апаратним або програмним способом. При апаратній реалізації підрахунку кількості одиниць, часові затрати на визначення Хемінгової відстані будуть визначатися виразом: Tx = t × n × m × p , де: t - тривалість тактового періоду; n - розрядність двійкового DRP-коду; m - число елементів в послідовності; p - кількість образів в словнику образів, що розпізнається. Виграш d в швидкодії розпізнавання згідно запропонованого способу може бути охарактеризований скороченням часових витрат на розрахунок Хемінгових відстаней: T Tu d = u × 100% = × 100% = Tn Tu - Tx , Tu = × 100% Tu - t × n × m × p де: Tn - час розпізнавання згідно запропонованого способу; Tu - час розпізнавання за відомим способом. Наприклад, для випадку розпізнавання мовних образів акустичний сигнал, який відповідає одному слову, може бути перетворений в послідовність, яка складається в середньому з 10 фонемоподібних елементів, а число образів, що розпізнаються, у словнику в середньому складає 200 слів, при цьому середня тривалість слова складає приблизно 0,8сек. Розрядність DRP-коду для кодування алфавіту А, який містить 40-60 фонемоподібних елементів, визначається співвідношенням n ³ 7 . Якщо час розпізнавання по відомому способу Tu прийняти рівним приблизно реальному часу пред'явлення мовного образа, Tu » (1 ¸ 1 2 ) Tp , що характерно для найбільш , досконалих пристроїв розпізнавання мови, а тривалість t тактового періоду прийняти рівною 2мксек, (що справедливе, наприклад, для мікропроцесорів середньої продуктивності), то виграш в швидкодії буде чисельно дорівнювати: æ 2 × 10 -6 × 7 × 10 × 200 ö ÷ × 100% » 104% . d = ç1 ç ÷ 0,8 è ø Фіг.1 зображує приклад конфігурації простору елементів, що підлягають двійковому кодуванню RP-кодом. а) - просторова конфігурація кодованої множини елементів, де цифри в колі позначають елемент, а числа над лініями визначають ранги відстаней між елементами; б) - матриця інцидентності рангів відстаней кодованих елементів, останні позначені для зручності розрізнення римськими цифрами; в) - DRP- код рангової конфігурації елементів Фіг.2 - стр уктурна схема пристрою для здійснення способу розпізнавання мовних образів. Пристрій містить датчик сприйняття пред'явленого образа 1, який послідовно з'єднано з блоком перетворення сприйнятого образа 2, який підключено до входу блока виділення ознак 3, вихід якого з'єднують з блоком перетворення неперервного образа в послідовність елементів 4, який послідовно з'єднано з блоком формування двійкового опису 5, вихід якого підключено до входу регістра 6, який з'єднано з першим входом блоку порівняння 7, до другого входу якого підключено блок пам'яті 8, при цьому вихід блоку 8 з'єднано з блоком прийняття рішення 9. Спосіб розпізнавання мовних образів реалізується наступним чином. Неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають ранги відстаней між елементами, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів, на основі отриманих результатів приймають рішення про розпізнавання мовного образа. Пред'явлений образ сприймається датчиком сприйняття пред'явленого образа 1, перетворюється в потрібну форму за допомогою блок перетворення сприйнятого образа 2, який з'єднується зі входом блока виділення ознак 3. На основі цих ознак в блоці перетворення неперервного образу в послідовність елементів 4 неперервний образ перетворюється в послідовність елементів, в блоці формування двійкового опису 5 формується її двійковий опис кодами, що зберігають ранги відстаней, в регістрі 6 послідовність, що розпізнається, запам'ятовується і послідовно порівнюється додаванням "по модулю 2" в блоці порівняння 7 зі всіма еталонними послідовностями, які зберігаються в блоці пам'яті 8. На основі результатів порівняння в блоці прийняття рішення 9 виконується класифікація пред'явленого образа.
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod of identifying voice elements
Автори англійськоюBykov Mykola Maksymovych
Назва патенту російськоюСпособ распознавания элементов речевых сообщений
Автори російськоюБыков Николай Максимович
МПК / Мітки
МПК: G10L 15/00
Мітки: образів, спосіб, розпізнавання, мовних
Код посилання
<a href="https://ua.patents.su/4-66184-sposib-rozpiznavannya-movnikh-obraziv.html" target="_blank" rel="follow" title="База патентів України">Спосіб розпізнавання мовних образів</a>
Спосіб порівняння мовних образів та пристрій для його здійснення

Номер патенту: 48082
Опубліковано: 15.08.2002
Автори: Лисенко Олександр Борисович, Вінцюк Тарас Климович
МПК: G10L 13/00
Мітки: порівняння, здійснення, мовних, спосіб, образів, пристрій
Формула / Реферат:
1. Способ сравнения речевых образов, представленных последовательностями отсчетов текущих параметров, включающий нахождение элементарного сходства для каждого отсчета эталонного речевого образа с каждым отсчетом распознаваемого речевого образа, определение сходства речевых образов путем рекуррентного накапливания интегральных мер сходства между последовательностями отсчетов текущих параметров эталонного и распознаваемого речевых образов...
Спосіб настроювання вагових коефіцієнтів двошарового персептрона для рішення задач розпізнавання образів і діагностики

Номер патенту: 49380
Опубліковано: 16.09.2002
Автори: Внуков Юрій Миколайович, Субботін Сергій Олександрович, Дубровін Валерій Іванович, Жеманюк Павло Дмитрович
МПК: G06G 7/60
Мітки: спосіб, діагностики, двошарового, розпізнавання, коефіцієнтів, настроювання, образів, вагових, персептрона, задач, рішення
Формула / Реферат:
Спосіб настроювання вагових коефіцієнтів двошарового персептрона для рішення задач розпізнавання образів і діагностики, який полягає в тому, що класифікацію об’єктів за ознаками здійснюють на основі двошарового персептрона, який перетворює вхідну інформацію у бінарний номер класу екземпляра, який відрізняється тим, що ваги двошарового персептрона настроюють автоматично у безітераційному режимі, для чого здійснюють одномірну класифікацію...
Спосіб настроювання вагових коефіцієнтів тришарового персептрона для вирішення задач розпізнавання образів і діагностики

Номер патенту: 47881
Опубліковано: 15.07.2002
Автори: Субботін Сергій Олександрович, Лук'янов Валентин Семенович, Дубровін Валерій Іванович
МПК: G06G 7/60
Мітки: персептрона, спосіб, розпізнавання, вирішення, образів, тришарового, діагностики, задач, коефіцієнтів, настроювання, вагових
Формула / Реферат:
Спосіб настроювання вагових коефіцієнтів тришарового персептрона для вирішення задач розпізнавання образів і діагностики, який полягає у тому, що класифікацію об'єктів за ознаками роблять на основі тришарового персептрона, що перетворює вхідну інформацію у бінарний номер класу екземпляра, який відрізняється тим, що ваги тришарового персептрона настроюють автоматично у безітераційному режимі на основі інформації, що характеризує поділ об'єктів...
Спосіб розпізнавання плоских геометричних фігур

Номер патенту: 51190
Опубліковано: 15.11.2002
Автори: Білан Степан Миколайович, Ал Зобі Салім
Мітки: спосіб, розпізнавання, геометричних, фігур, плоских
Формула / Реферат:
Спосіб розпізнавання плоских геометричних фігур, що полягає у перетворенні зображення фігури в набір сигналів, який відрізняється тим, що проектують зображення фігури на фоточутливий елемент, виділяють вершини фігури і визначають відстані між сусідніми вершинами, визначають площу та периметр фігури шляхом підрахунку точок, що належать контуру та площині зображення фігури, формують вектор ознак, до якого входять величини площини, периметра,...
Спосіб розпізнавання плоских геометричних фігур

Номер патенту: 48903
Опубліковано: 15.08.2002
Автори: Домбровська Наталія Валентинівна, Бендерук Ірина Миколаївна, Южаков Сергій Васильович, Білан Степан Миколайович
Мітки: геометричних, фігур, спосіб, розпізнавання, плоских
Формула / Реферат:
Спосіб розпізнавання плоских геометричних фігур, який полягає в тому, що сканують і перетворюють зображення в послідовність сигналів, який відрізняється тим, що визначають функцію площі перетину вхідної фігури та її копії, паралельно зсувають копію фігури і на кожному кроці зсуву визначають площу перетину вхідної фігури та її копії, проводять зсув до отримання площі перетину, яка дорівнює нулю, що відповідає максимальному зсуву у відповідному...
Попередній патент: Мембрана твердоконтактного іонселективного електроду для визначення концентрації іонів декаметоксину
Наступний патент: Пристрій для поліпшення зчеплення колеса з рейкою
Випадковий патент: Змішувач