Спосіб граматико-статистичного динамічного стискання текстових повідомлень


Формула / Реферат
Спосіб граматико-статистичного динамічного стискання текстових повідомлень, що включає: граматичний розбір повідомлення, що кодується, рекурентну процедуру об'єднання одиночного вхідного сигналу-символу або групи сигналів-символів з наступним сигналом-символом вхідного потоку, зіставлення кода утвореного рядка з кодами з рядків, які проіндексовані і знаходяться в таблицях кодування кодера і декодера, та в яких розміщена початкова інформація, при відсутності його в таблиці кодування вносять код утвореного непорівнянного рядка в таблицю кодування з черговим індексом, відділення кода символу, що призвів до непорівнянного кода рядка, і видачу на вихід кодера індексу зіставленого рядка максимальної довжини, а процедура утворення і зіставлення рядків починається спочатку з останнього вхідного символу текстового повідомлення, що призвів до утворення непорівнянного рядка, який відрізняється тим, що як початкову інформацію в таблиці кодування розміщують з відповідними індексами афіксальні морфеми, які найчастіше зустрічаються в текстових повідомленнях, а також, якщо код додатково утвореного непорівнянного рядка є початком кодової комбінації однієї з розміщених морфем, то додатково виконують об'єднання кода непорівнянного рядка з кодом наступного символу вхідного потоку, порівнюють після кожного приєднання чергового сигналу-символу сформований рядок з усіма можливими варіантами афіксальних морфем, одночасно перевіряють, чи не скінчилася морфема або чи не відбувся незбіг сформованого рядка з морфемою, при збігу кодів рядка і морфеми на вихід кодера виводиться індекс співставленої морфеми, а у випадку незбігу рядка ні з однією з морфем вносять код утвореного непорівнянного рядка в таблицю кодування з черговим індексом.
Текст
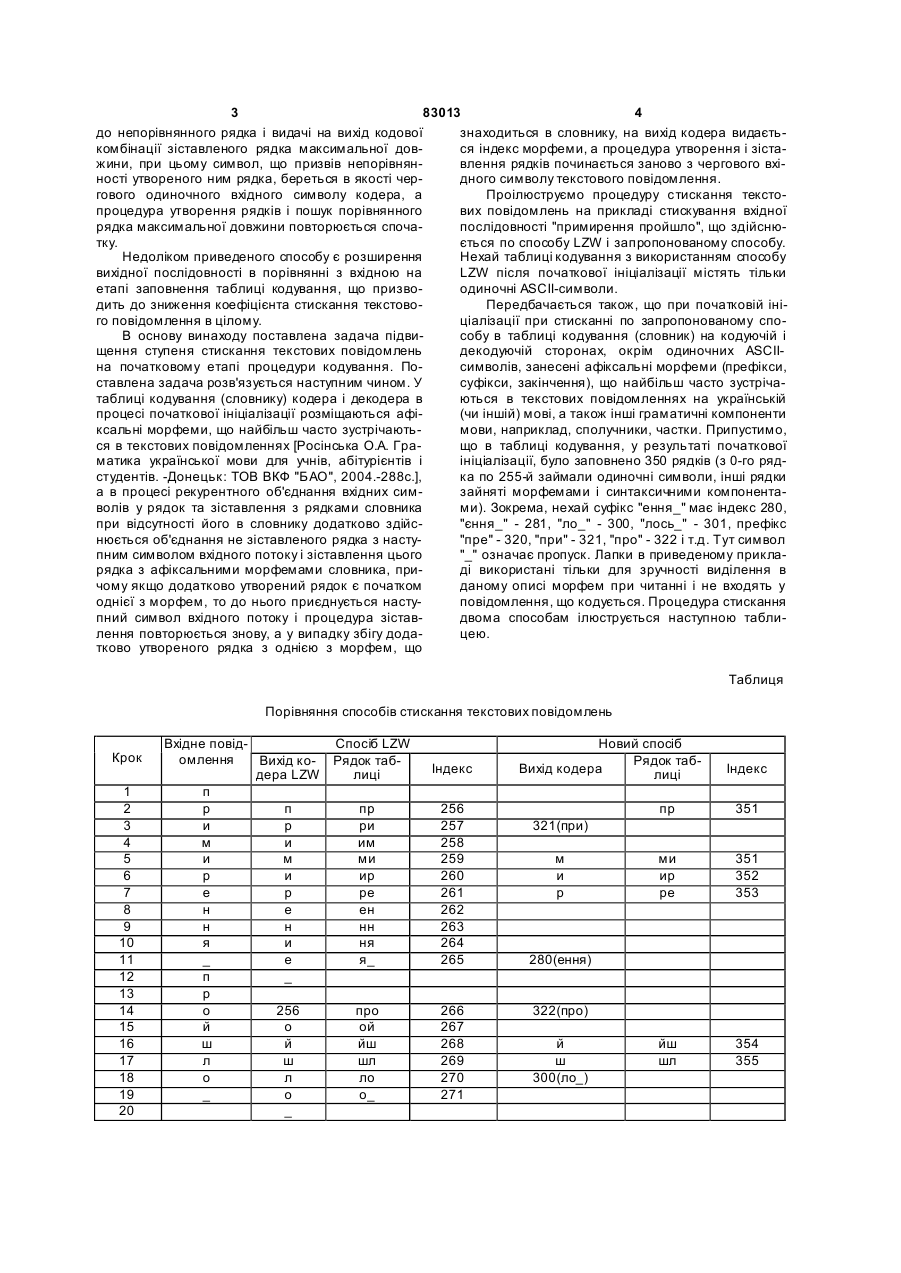
Спосіб граматико-статистичного динамічного стискання текстових повідомлень, що включає: граматичний розбір повідомлення, що кодується, рекурентну процедуру об'єднання одиночного вхідного сигналу-символу або групи сигналівсимволів з наступним сигналом-символом вхідного потоку, зіставлення кода утвореного рядка з кодами з рядків, які проіндексовані і знаходяться в таблицях кодування кодера і декодера, та в яких розміщена початкова інформація, при відсутності його в таблиці кодування вносять код утвореного непорівнянного рядка в таблицю кодування з черговим індексом, відділення кода символу, що призвів до C2 2 (19) 1 3 83013 4 до непорівнянного рядка і видачі на вихід кодової знаходиться в словнику, на вихід кодера видаєтькомбінації зіставленого рядка максимальної довся індекс морфеми, а процедура утворення і зістажини, при цьому символ, що призвів непорівнянвлення рядків починається заново з чергового вхіності утвореного ним рядка, береться в якості чердного символу текстового повідомлення. гового одиночного вхідного символу кодера, а Проілюструємо процедуру стискання текстопроцедура утворення рядків і пошук порівнянного вих повідомлень на прикладі стискування вхідної рядка максимальної довжини повторюється спочапослідовності "примирення пройшло", що здійснютку. ється по способу LZW і запропонованому способу. Недоліком приведеного способу є розширення Нехай таблиці кодування з використанням способу вихідної послідовності в порівнянні з вхідною на LZW після початкової ініціалізації містять тільки етапі заповнення таблиці кодування, що призвоодиночні ASCІІ-символи. дить до зниження коефіцієнта стискання текстовоПередбачається також, що при початковій ініго повідомлення в цілому. ціалізації при стисканні по запропонованому споВ основу винаходу поставлена задача підвисобу в таблиці кодування (словник) на кодуючій і щення ступеня стискання текстових повідомлень декодуючій сторонах, окрім одиночних ASCІІна початковому етапі процедури кодування. Посимволів, занесені афіксальні морфеми (префікси, ставлена задача розв'язується наступним чином. У суфікси, закінчення), що найбільш часто зустрічатаблиці кодування (словнику) кодера і декодера в ються в текстових повідомленнях на українській процесі початкової ініціалізації розміщаються афі(чи іншій) мові, а також інші граматичні компоненти ксальні морфеми, що найбільш часто зустрічаютьмови, наприклад, сполучники, частки. Припустимо, ся в текстових повідомленнях [Росінська O.A. Гращо в таблиці кодування, у результаті початкової матика української мови для учнів, абітурієнтів і ініціалізації, було заповнено 350 рядків (з 0-го рядстудентів. -Донецьк: TOB ВКФ "БАО", 2004.-288с.], ка по 255-й займали одиночні символи, інші рядки а в процесі рекурентного об'єднання вхідних симзайняті морфемами і синтаксичними компонентаволів у рядок та зіставлення з рядками словника ми). Зокрема, нехай суфікс "ення_" має індекс 280, при відсутності його в словнику додатково здійс"єння_" - 281, "ло_" - 300, "лось_" - 301, префікс нюється об'єднання не зіставленого рядка з насту"пре" - 320, "при" - 321, "про" - 322 і т.д. Тут символ пним символом вхідного потоку і зіставлення цього "_" означає пропуск. Лапки в приведеному прикларядка з афіксальними морфемами словника, приді використані тільки для зручності виділення в чому якщо додатково утворений рядок є початком даному описі морфем при читанні і не входять у однієї з морфем, то до нього приєднується наступовідомлення, що кодується. Процедура стискання пний символ вхідного потоку і процедура зіставдвома способам ілюструється наступною таблилення повторюється знову, а у випадку збігу додацею. тково утвореного рядка з однією з морфем, що Таблиця Порівняння способів стискання текстових повідомлень Крок 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Вхідне повідСпосіб LZW омлення Вихід ко- Рядок табдера LZW лиці п р п пр и р ри м и им и м ми р и ир е р ре н е ен н н нн я и ня _ е я_ п _ р о 256 про й о ой ш й йш л ш шл о л ло _ о о_ _ Індекс 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 Новий спосіб Рядок табВихід кодера лиці Індекс пр 351 ми ир ре 351 352 353 йш шл 354 355 321(при) м и р 280(ення) 322(про) й ш 300(ло_) 5 83013 6 При надходженні на вхід кодера першого симзакодованих символів повідомлення; Nбсм - кільволу "п" кодери по обом способам об'являють його кість біт, затрачуваних на кодування одиночних поточним рядком і шукають у словниках співпадасимволів у первинному ASCII-коді. ючий рядок. В зв'язку з тим, що всі одиночні симДля нашого приклада число закодованих символи присутні в словнику, кодери поєднують цей волів вхідного повідомлення з врахуванням двох символ з наступним символом із вхідного потоку і пропусків Nсм = 19, а кількість біт на символ перпроцедура пошуку порівнянного рядка в словнику винного коду Nбсм =8. Як видно з таблиці, кількість повторюється. У результаті утвориться рядок "пр". рядків, закодованих по способу LZW, дорівнює 18, По LZW-способу: у зв'язку з відсутністю в слоа кількість рядків, закодованих по запропоновановнику рядка, що співпадає з "пр", він заноситься у му способі - 9. Якщо таблиця кодування містить вхідний словник з черговим індексом 256. Потім 4096 рядків (найбільше часто використовуваний виконується відділення останнього символу ("р"), випадок), то число біт, затрачуваних на кодування що призвів до непорівнянного рядка, на вихід вирядка Nбp = 12. дається код символу "п", а відділений символ "р" Таким чином, коефіцієнт стискання по способу використовується для утворення наступного рядка LZW текстового повідомлення довжиною 19 сим"ри", який заноситься в словник з індексом 257. волів дорівнює Аналогічним способом відбувається кодування Kст_LZW =18´12/(19´8) =1,42. всього повідомлення. З таблиці видно, що на 14-м Тобто, на початковій стадії кодування має міскроці кодування кодер виявляє в словнику порівце розширення повідомлення. нянний рядок, що складається з двох символів Коефіцієнт стискання Kст_зс того ж повідомлен"пр" і видає на вихід двійкову кодову комбінацію ня по запропонованому способі дорівнює індексу цього рядка 256. При цьому він формує Ксж_зс_ = 9´12/(19´8) = 0,71. трьохсимвольний рядок "про" і заносить його в Таким чином, підвищення ефективності стиссловник з черговим індексом 266. кання повідомлення xст, запропонованим способом При стисканні по запропонованому способу: складає після формування рядка "пр" і занесення його в xст = Kст_LZW /Kст_зс = 1,42/0,72 = 2. словник з черговим індексом 351 відділення осОчевидно, що підвищення ступеня стискувантаннього символу (у нашому прикладі "р"), що приня в запропонованому способі досягається за развів до утворення непорівнянного рядка, не викохунок трохи більших витрат пам'яті на збереження нується, а здійснюється аналіз на предмет збігу морфемних рядків у словнику. Однак при сучасних сформованого рядка ("пр") з початком однієї з афідосягненнях мікроелектроніки, у тому числі, в обксальних морфем, що занесена в таблицю на еталасті створення елементів пам'яті, декілька кілопі початкової ініціалізації. У випадку відсутності в байт пам'яті не грають істотної ролі. словнику морфеми з таким початком, подальша Варто помітити, що при досить довгому вхідпроцедура виконується по способу LZW. Якщо ж ному повідомленні в таблиці кодування по способу сформований рядок збігається з початком однієї з LZW можуть бути поступово сформовані афіксаморфем (як у нашому прикладі), то з вхідного польні морфеми, що зустрічаються кілька разів у току береться наступний символ і процедура зівхідному повідомленні, що кодується, після чого ставлення утвореного рядка з початком морфем коефіцієнт стискання на цій стадії кодування буде словника повторюється. У випадку збігу вхідного наближатися до коефіцієнта, що досягається в рядка з однієї з морфем (у нашому прикладі "при") запропонованому способі. Однак у середньому на вихід кодера видається її код (у нашому прикоефіцієнт стискання запропонованого способу кладі 321), а описана вище рекурентна процедура буде завжди вище за рахунок виключення явища утворення і зіставлення рядків продовжується з розширення вихідної послідовності на початковій наступного вхідного символу (у нашому прикладі стадії стискання. "м") доти, поки не буде виявлений символ кінця Таким чином, запропонований спосіб є найповідомлення. більш ефективним при передачі коротких текстоКоефіцієнт стискання вхідного повідомлення вих запитів, збереженні і видачі довідок, а також визначається по формулі різних текстових підказок, що широко використоKст = NpNбp/(Nсм Nбсм ), вуються в сучасних комп'ютерних і Інтернетде Np - кількість закодованих рядків; Nбp - кільдодатках. кість біт, що затрачуються на кодування рядка символів (довжина індексу в бітах); Nсм - число Комп’ютерна в ерстка Л.Литв иненко Підписне Тираж 26 прим. Міністерство осв іт и і науки України Держав ний департамент інтелектуальної в ласності, вул. Урицького, 45, м. Київ , МСП, 03680, Україна ДП “Український інститут промислов ої в ласності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for grammatical-statistical dynamical compression of text messages
Автори англійськоюCherneha Viktor Stepanovych
Назва патенту російськоюСпособ грамматико-статистического динамического сжатия текстовых сообщений
Автори російськоюЧернега Виктор Степанович
МПК / Мітки
МПК: G06F 17/21, G06F 5/00
Мітки: стискання, динамічного, спосіб, текстових, граматико-статистичного, повідомлень
Код посилання
<a href="https://ua.patents.su/3-83013-sposib-gramatiko-statistichnogo-dinamichnogo-stiskannya-tekstovikh-povidomlen.html" target="_blank" rel="follow" title="База патентів України">Спосіб граматико-статистичного динамічного стискання текстових повідомлень</a>
Адаптивний пристрій для стискання текстових повідомлень

Номер патенту: 64907
Опубліковано: 15.03.2004
Автори: Шишкевич Володимир Євгенович, Чернега Віктор Степанович
МПК: G11C 15/00, G11C 19/00, G06F 11/00
Мітки: текстових, повідомлень, стискання, адаптивний, пристрій
Формула / Реферат:
Адаптивний пристрій для стискання текстових повідомлень, що містить регістр вхідних символів, до якого підключений префіксний регістр формування коду підрядка, вихід цього регістра і другий вихід регістра вхідних символів з'єднані з відповідними входами блока порівняння, який, в свою чергу, з'єднаний з блоком оперативних запам'ятовуючих пристроїв, а також генератор тактових імпульсів, який відрізняється тим, що між входом в пристрій і блоком...
Спосіб та пристрій для передачі коротких текстових повідомлень (sms) між стільниковими телефонами стандарту gsm без участі сервісного центру коротких повідомлень (smsc)

Номер патенту: 66068
Опубліковано: 15.04.2004
Автор: Іренков Артем Вячеславович
МПК: H04L 29/06
Мітки: smsc, повідомлень, участі, центру, сервісного, sms, спосіб, стільниковими, текстових, коротких, пристрій, стандарту, передачі, телефонами
Формула / Реферат:
1. Спосіб передачі коротких текстових повідомлень між двома стільниковими телефонами у мережах стільникового зв'язку стандарту GSM, який відрізняється тим, що передача повідомлень відбувається без участі сервісного центру коротких повідомлень оператора мережі GSM, тобто прямо з телефону на телефон, за допомогою допоміжних спеціально розроблених пристроїв "DataSMS ключ", які реалізовуються на основі мікроконтролера, керованого...
Спосіб безвтратного стискання зображень

Номер патенту: 35499
Опубліковано: 15.03.2001
Автори: Русин Богдан Павлович, Мосоров Володимир Якович
Мітки: стискання, спосіб, зображень, безвтратного
Формула / Реферат:
Спосіб безвтратного стискання зображень, згідно з яким формують з вхідного оцифрованого зображення, представленого матрицею [b(i,j)], i=1, 2, ..., N; j=1, 2, ..., M, де N, M - відповідно, кількість елементів у рядку та кількість рядків, довідкове субзображення [r(і,j)], елементи якого формують з елементів, які знаходяться за парними адресами кожного парного рядка, горизонтальне субзображення [h(i,j)], елементи якого формують з елементів, які...
Спосіб вимірювання деформації розтягнення і стискання текстильних матеріалів одягу

Номер патенту: 15696
Опубліковано: 17.07.2006
Автори: Михайловський Юрій Броніславович, Стрижова Оксана Петрівна, Баннова Ірина Мусіївна
МПК: G01L 1/00
Мітки: спосіб, одягу, текстильних, стискання, матеріалів, деформації, вимірювання, розтягнення
Формула / Реферат:
Спосіб для вимірювання деформацій розтягнення і стискання текстильних матеріалів одягу під час його експлуатації, що включає вимірювання деформації тензорезисторним перетворювачем, який відрізняється тим, що вимірювання проводять безпосередньо з поверхні дослідного матеріалу, в яку попередньо вмонтовують дротяні контакти та наносять по всій її площі електрострумопровідну графітову суміш.
Спосіб передачі коротких повідомлень між абонентами телекомунікаційної мережі

Номер патенту: 20525
Опубліковано: 15.01.2007
Автор: Танйу Ахмет
МПК: H04M 11/00, G06F 17/30, G06Q 90/00, G06F 17/20, G06F 17/40
Мітки: передачі, повідомлень, телекомунікаційної, коротких, абонентами, спосіб, мережі
Формула / Реферат:
Спосіб передачі коротких повідомлень між абонентами телекомунікаційної мережі, який відрізняється тим, що абонент-замовник послуги формує короткі тестові повідомлення „голосової пошти”, передає їх оператору чи провайдеру телекомунікацій, який кодує ці повідомлення та заносить їх у базу даних на сервер телекомунікаційної мережі, а при виклику абонента-замовника послуги іншим абонентом, оператор чи провайдер спочатку надсилає іншому абоненту...
Попередній патент: Кристалічна форма натрієвої солі 3-піридил-1-гідроксіетиліден-1,1-бісфосфонової кислоти
Наступний патент: Басейн для витримки відпрацьованого ядерного палива
Випадковий патент: Спосіб одержання електричної енергії за допомогою обертового руху коліс автодорожніх транспортних засобів