Прогнозування векторів руху при кодуванні відео




































Формула / Реферат
1. Спосіб кодування відеоданих, при цьому спосіб включає:
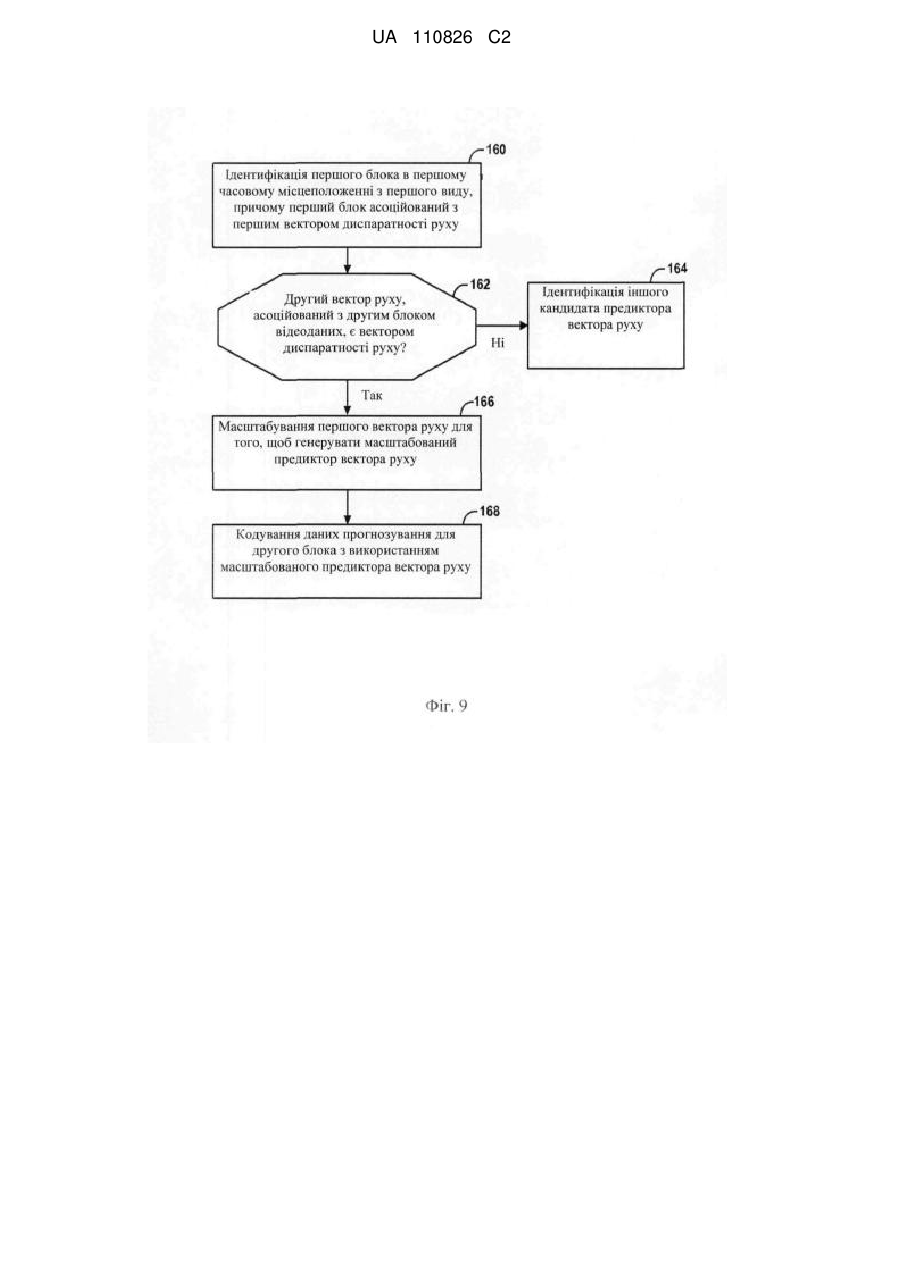
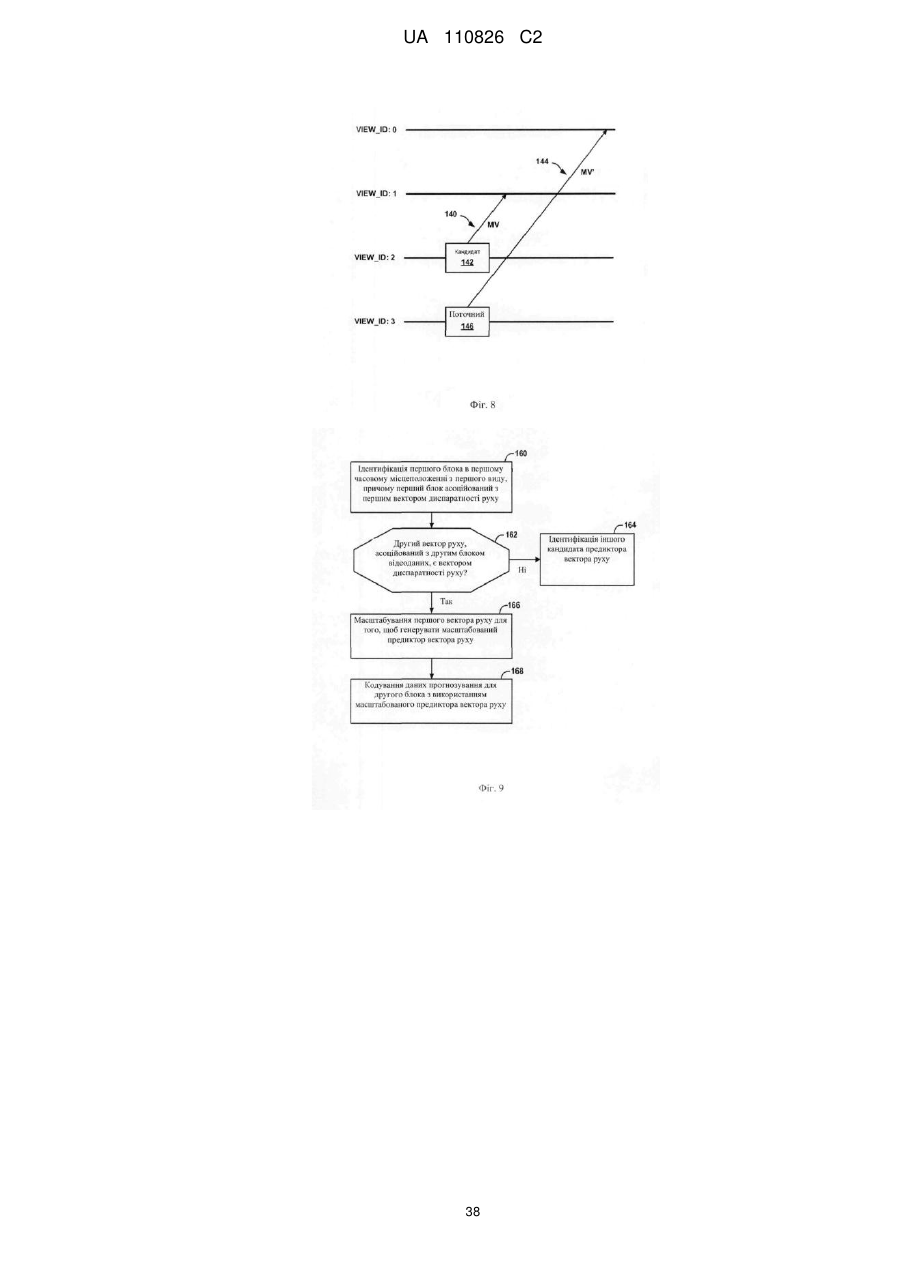
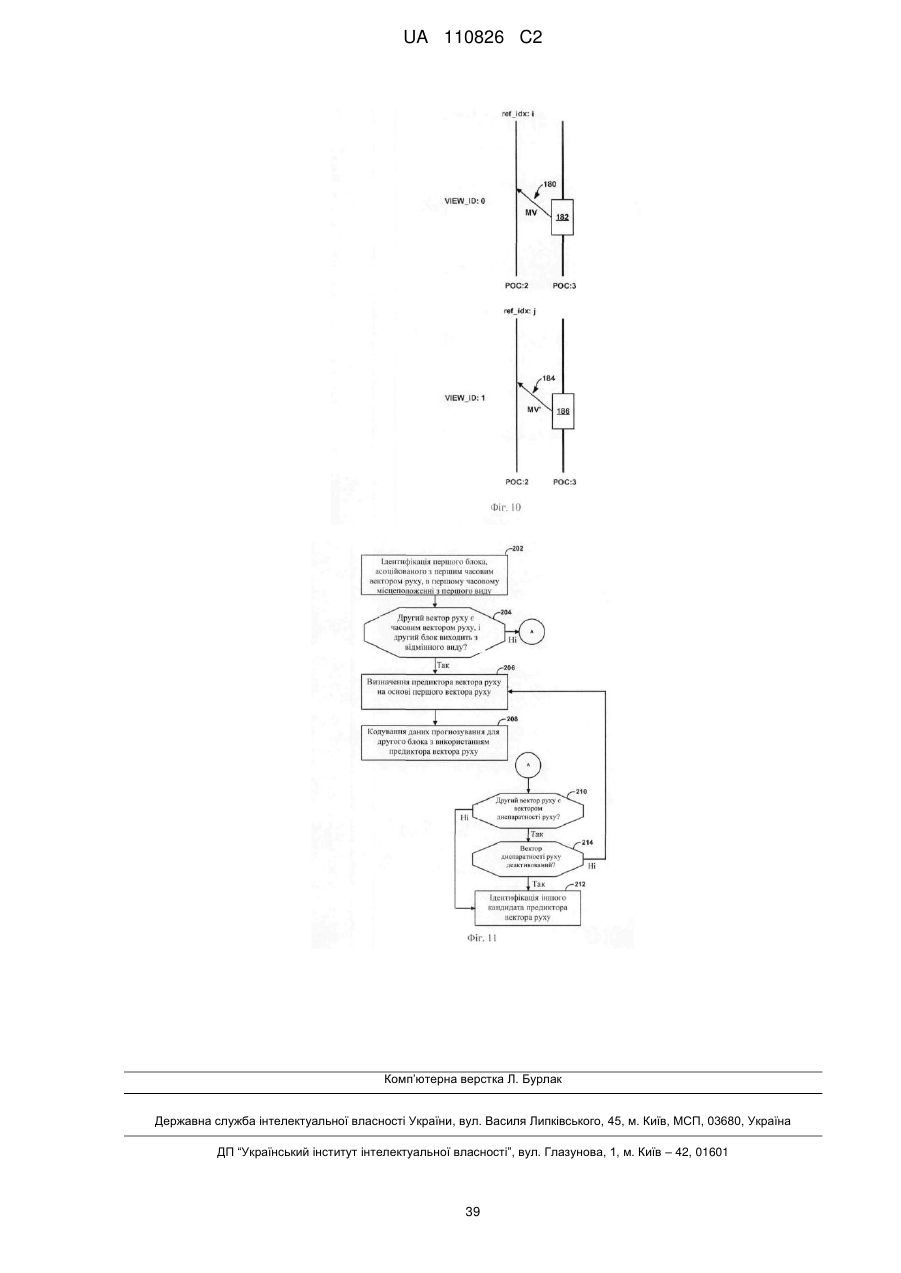
ідентифікацію першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху,
генерування списку кандидатів-предикторів вектора руху для прогнозування першого вектора руху, при цьому генерування списку кандидатів-предикторів вектора руху містить:
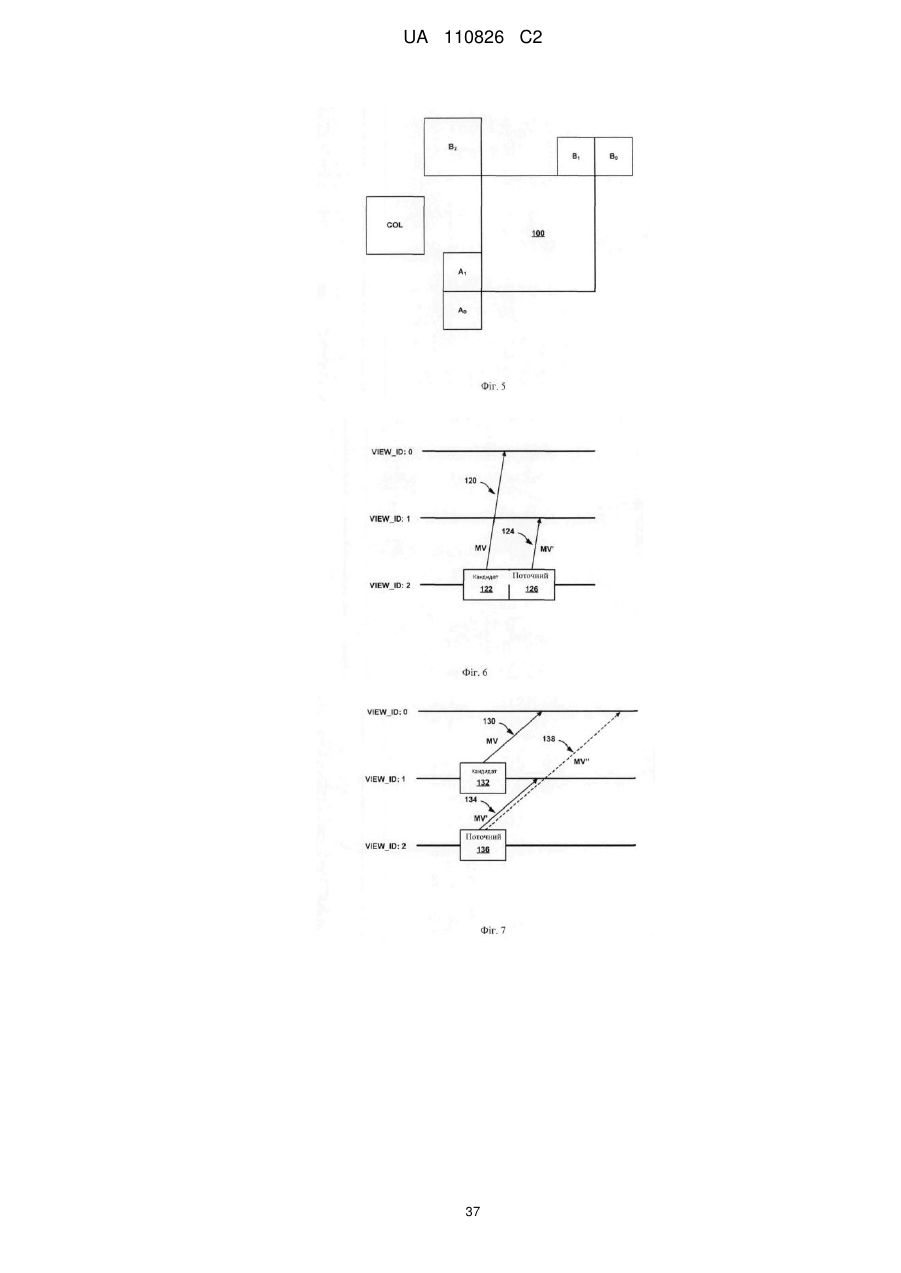
ідентифікацію другого вектора руху для другого блока відеоданих у другому виді, при цьому другий вид відрізняється від першого виду,
коли другий вектор руху є вектором диспаратності руху, додавання предиктора вектора руху на основі другого вектора руху в список кандидатів-предикторів вектора руху,
коли другий вектор руху не є вектором диспаратності руху, визначення, що другий вектор руху недоступний для прогнозування вектора руху так, що другий вектор руху не додається в список кандидатів, і
додавання щонайменше одного іншого вектора диспаратності руху в список кандидатів-предикторів вектора руху, при цьому згаданий щонайменше один інший вектор диспаратності руху включає в себе предиктор вектора руху на основі вектора диспаратності руху з третього блока у другому часовому місцеположенні з першого виду, і
кодування даних прогнозування для першого блока з використанням предиктора вектора руху зі списку кандидатів-предикторів вектора руху.
2. Спосіб за п. 1, в якому другий блок відеоданих знаходиться в першому часовому місцеположенні.
3. Спосіб за п. 2, який додатково включає ідентифікацію другого блока на основі зміщення внаслідок диспаратності між другим блоком другого виду і першим блоком першого виду.
4. Спосіб за п. 1, в якому другий блок відеоданих знаходиться у другому часовому місцеположенні, яке відрізняється від першого часового місцеположення.
5. Спосіб за п. 1, в якому, коли другий вектор руху є вектором диспаратності руху, спосіб додатково включає:
масштабування другого вектора руху для генерування масштабованого предиктора вектора руху, при цьому масштабування другого вектора руху містить застосування масштабного коефіцієнта на основі різниці між компонентами виду, асоційованими з першим вектором диспаратності руху, діленої на різницю між компонентами виду, асоційованими з другим вектором руху, до другого вектора руху,
в якому додавання предиктора вектора руху в список кандидатів-предикторів вектора руху містить додавання масштабованого предиктора вектора руху у список кандидатів-предикторів вектора руху.
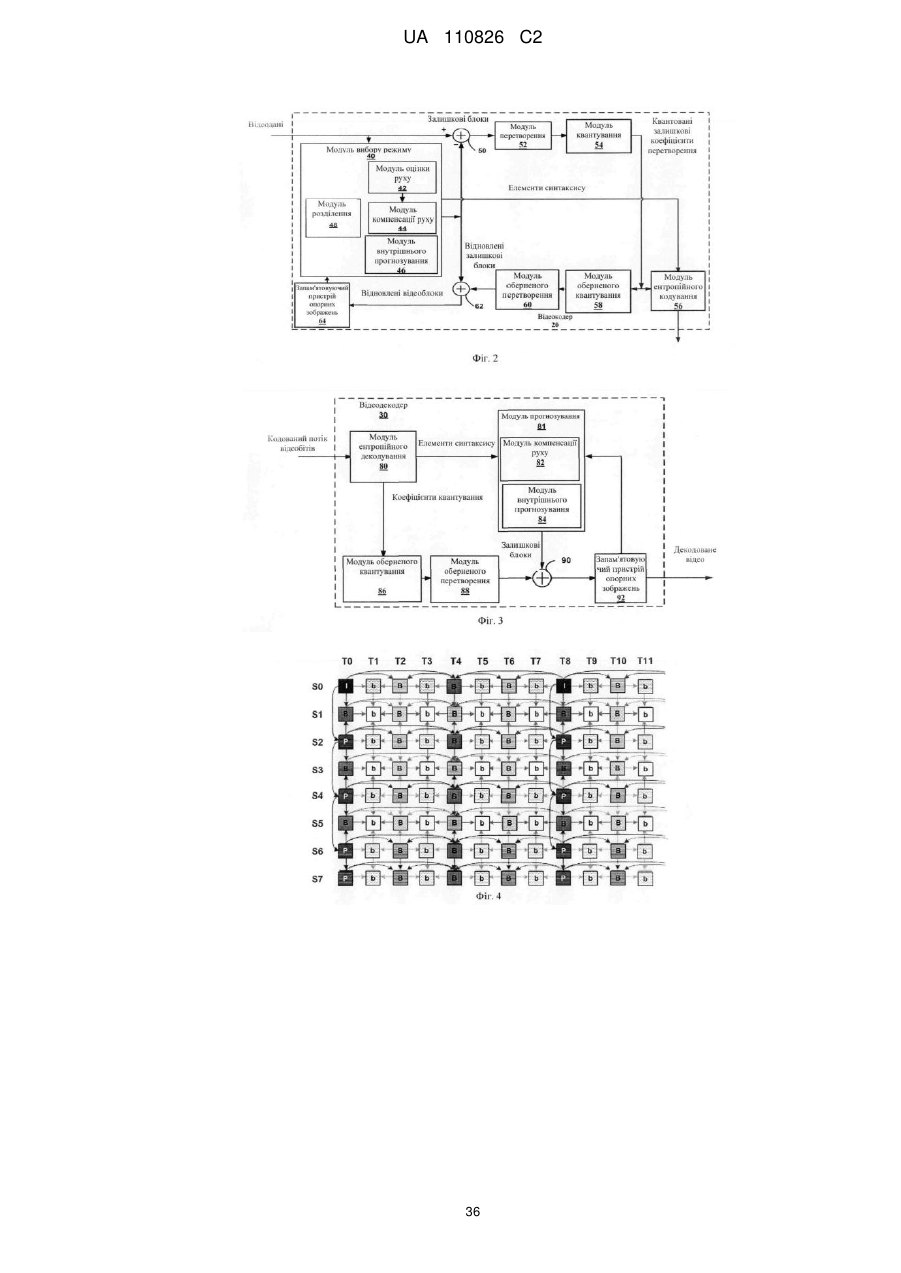
6. Спосіб за п. 1, в якому кодування даних прогнозування для першого блока відеоданих містить кодування даних прогнозування.
7. Спосіб за п. 1, в якому кодування даних прогнозування для першого блока відеоданих містить декодування даних прогнозування.
8. Спосіб за п. 1, який додатково включає кодування першого блока відеоданих з використанням даних прогнозування для першого блока відеоданих.
9. Пристрій для кодування відеоданих, який містить один або більше процесорів, причому один або більше процесорів виконані з можливістю:
ідентифікувати перший блок відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху,
генерувати список кандидатів-предикторів вектора руху для прогнозування першого вектора руху, при цьому для генерування списку кандидатів-предикторів вектора руху згаданий один або більше процесорів виконані з можливістю:
ідентифікації другого вектора руху для другого блока відеоданих у другому виді, при цьому другий вид відрізняється від першого виду,
коли другий вектор руху є вектором диспаратності руху, додавання предиктора вектора руху на основі другого вектора руху у список кандидатів-предикторів вектора руху,
коли другий вектор руху не є вектором диспаратності руху, визначення, що другий вектор руху недоступний для прогнозування вектора руху так, що другий вектор руху не додається в список кандидатів, і
додавання щонайменше одного іншого вектора диспаратності руху у список кандидатів-предикторів вектора руху, при цьому згаданий щонайменше один інший вектор диспаратності руху включає в себе предиктор вектора руху на основі вектора диспаратності руху з третього блока у другому часовому місцеположенні з першого виду, і кодувати дані прогнозування для першого блока з використанням предиктора вектора руху зі списку кандидатів-предикторів вектора руху.
10. Пристрій за п. 9, в якому другий блок відеоданих знаходиться в першому часовому місцеположенні.
11. Пристрій за п. 10, в якому згадані один або більше процесорів додатково виконані з можливістю ідентифікації другого блока на основі зміщення внаслідок диспаратності між другим блоком другого виду і першим блоком першого виду.
12. Пристрій за п. 9, в якому другий блок відеоданих знаходиться у другому часовому місцеположенні, яке відрізняється від першого часового місцеположення.
13. Пристрій за п. 9, в якому, коли другий вектор руху є вектором диспаратності руху, згадані один або більше процесорів додатково виконані з можливістю:
масштабування другого вектора руху для генерування масштабованого предиктора вектора руху, при цьому масштабування другого вектора руху містить застосування масштабного коефіцієнта на основі різниці між компонентами виду, асоційованими з першим вектором диспаратності руху, діленої на різницю між компонентами виду, асоційованими з другим вектором руху, до другого вектора руху,
в якому для додавання предиктора вектора руху у список кандидатів-предикторів вектора руху згадані один або більше процесорів виконані з можливістю додавання масштабованого предиктора вектора руху у список кандидатів-предикторів вектора руху.
14. Пристрій за п. 9, в якому для кодування даних прогнозування для першого блока відеоданих, згадані один або більше процесорів виконані з можливістю кодування даних прогнозування.
15. Пристрій за п. 9, в якому для кодування даних прогнозування для першого блока відеоданих, згадані один або більше процесорів виконані з можливістю декодування даних прогнозування.
16. Пристрій за п. 9, в якому згадані один або більше процесорів додатково виконані з можливістю кодування першого блока відеоданих з використанням даних прогнозування для першого блока відеоданих.
17. Пристрій для кодування відеоданих, який містить:
засіб для ідентифікації першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху,
засіб для генерування списку кандидатів-предикторів вектора руху для прогнозування першого вектора руху, при цьому засіб для генерування списку кандидатів-предикторів вектора руху містить:
засіб для ідентифікації другого вектора руху для другого блока відеоданих у другому виді, при цьому другий вид відрізняється від першого виду,
засіб для додавання, коли другий вектор руху є вектором диспаратності руху, предиктора вектора руху на основі другого вектора руху у список кандидатів-предикторів вектора руху,
засіб для визначення, коли другий вектор руху не є вектором диспаратності руху, що другий вектор руху недоступний для прогнозування вектора руху так, що другий вектор руху не додається у список кандидатів, і
засіб для додавання щонайменше одного іншого вектора диспаратності руху у список кандидатів-предикторів вектора руху, при цьому згаданий щонайменше один інший вектор диспаратності руху включає в себе предиктор вектора руху на основі вектора диспаратності руху з третього блока у другому часовому місцеположенні з першого виду, і
засіб для кодування даних прогнозування для першого блока на основі предиктора вектора руху зі списку кандидатів-предикторів вектора руху.
18. Пристрій за п. 17, в якому другий блок відеоданих знаходиться у першому часовому місцеположенні.
19. Пристрій за п. 18, який додатково містить засіб для ідентифікації другого блока на основі зміщення внаслідок диспаратності між другим блоком другого виду і першим блоком першого виду.
20. Пристрій за п. 17, в якому другий блок відеоданих знаходиться у другому часовому місцеположенні, яке відрізняється від першого часового місцеположення.
21. Пристрій за п. 17, який додатково містить:
засіб для масштабування, коли другий вектор руху є вектором диспаратності руху, другого вектора руху для генерування масштабованого предиктора вектора руху, при цьому масштабування другого вектора руху містить застосування масштабного коефіцієнта на основі різниці між компонентами виду, асоційованими з першим вектором диспаратності руху, діленої на різницю між компонентами виду, асоційованими з другим вектором руху, до другого вектора руху,
в якому засіб для додавання предиктора вектора руху у список кандидатів-предикторів вектора руху містить засіб для додавання масштабованого предиктора вектора руху у список кандидатів-предикторів вектора руху.
22. Пристрій за п. 17, в якому засіб для кодування даних прогнозування для першого блока відеоданих містить засіб для кодування даних прогнозування.
23. Пристрій за п. 17, в якому засіб для кодування даних прогнозування для першого блока відеоданих містить засіб для декодування даних прогнозування.
24. Пристрій за п. 17, який додатково містить засіб для кодування першого блока відеоданих з використанням даних прогнозування для першого блока відеоданих.
25. Зчитуваний комп'ютером носій даних, що має збережені на ньому інструкції, які при виконанні спонукають один або більше процесорів:
ідентифікувати перший блок відеоданих у першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху,
генерувати список кандидатів-предикторів вектора руху для прогнозування першого вектора руху, при цьому для генерування списку кандидатів-предикторів вектора руху інструкції спонукають згадані один або більше процесорів:
ідентифікувати другий вектор руху для другого блока відеоданих у другому виді, при цьому другий вид відрізняється від першого виду,
коли другий вектор руху є вектором диспаратності руху, додавати предиктор вектора руху на основі другого вектора руху у список кандидатів-предикторів вектора руху,
коли другий вектор руху не є вектором диспаратності руху, визначати, що другий вектор руху недоступний для прогнозування вектора руху так, що другий вектор руху не додається у список кандидатів, і
додавати щонайменше один інший вектор диспаратності руху у список кандидатів-предикторів вектора руху, при цьому згаданий щонайменше один інший вектор диспаратності руху включає в себе предиктор вектора руху на основі вектора диспаратності руху з третього блока у другому часовому місцеположенні з першого виду, і
кодувати дані прогнозування для першого блока на основі предиктора вектора руху зі списку кандидатів-предикторів вектора руху.
26. Зчитуваний комп'ютером носій даних за п. 25, в якому другий блок відеоданих знаходиться у першому часовому місцеположенні.
27. Зчитуваний комп'ютером носій даних за п. 26, який додатково містить інструкції, які спонукають згадані один або більше процесорів ідентифікувати другий блок на основі зміщення внаслідок диспаратності між другим блоком другого виду і першим блоком першого виду.
28. Зчитуваний комп'ютером носій даних за п. 25, в якому другий блок відеоданих знаходиться у другому часовому місцеположенні, яке відрізняється від першого часового місцеположення.
29. Зчитуваний комп'ютером носій даних за п. 25, який додатково містить інструкції, які спонукають згадані один або більше процесорів, коли другий вектор руху є вектором диспаратності руху:
масштабувати другий вектор руху для генерування масштабованого предиктора вектора руху, при цьому масштабування другого вектора руху містить застосування масштабного коефіцієнта на основі різниці між компонентами виду, асоційованими з першим вектором диспаратності руху, діленої на різницю між компонентами виду, асоційованими з другим вектором руху, до другого вектора руху,
в якому для додавання предиктора вектора руху у список кандидатів-предикторів вектора руху інструкції спонукають згадані один або більше процесорів додавати масштабований предиктор вектора руху у список кандидатів-предикторів вектора руху.
30. Зчитуваний комп'ютером носій даних за п. 25, в якому інструкції, які спонукають згадані один або більше процесорів кодувати дані прогнозування для першого блока відеоданих, містять інструкції, які спонукають згадані один або більше процесорів кодувати дані прогнозування.
31. Зчитуваний комп'ютером носій даних за п. 25, в якому інструкції, які спонукають згадані один або більше процесорів кодувати дані прогнозування для першого блока відеоданих, містять інструкції, які спонукають згадані один або більше процесорів декодувати дані прогнозування.
32. Зчитуваний комп'ютером носій даних за п. 25, який додатково містить інструкції, які спонукають згадані один або більше процесорів кодувати перший блок відеоданих з використанням даних прогнозування для першого блока відеоданих.
Текст
Реферат: Аспекти цього розкриття суті належать, в прикладі, до способу, який включає в себе ідентифікацію першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху. Спосіб також включає в себе визначення предиктора вектора руху для другого вектора руху, асоційованого з другим блоком відеоданих, при цьому предиктор вектора руху оснований на першому векторі диспаратності руху. Коли другий вектор руху містить вектор диспаратності руху, спосіб включає в себе визначення предиктора вектора руху містить масштабування першого вектора диспаратності руху, щоб генерувати масштабований предиктор вектора руху, при цьому масштабування першого вектора диспаратності руху містить застосування коефіцієнта масштабування, що містить відстань для виду другого вектора диспаратності руху, ділену на відстань для виду першого вектора руху, до першого вектора диспаратності руху. UA 110826 C2 (12) UA 110826 C2 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 Це розкриття суті заявляє пріоритет попередньої заявки на патент (США) № 61/477,561, поданої 20 квітня 2011 року, і попередньої заявки на патент (США) № 61/512,765, поданої 28 липня 2011 року, вміст обох з яких повністю міститься в даному документі за посиланням. ГАЛУЗЬ ТЕХНІКИ, ДО ЯКОЇ НАЛЕЖИТЬ ВИНАХІД Дане розкриття суті належить до кодування відео. РІВЕНЬ ТЕХНІКИ Підтримка цифрового відео може бути включена в широкий діапазон пристроїв, які включають в себе цифрові телевізійні приймачі, системи цифрової прямої широкомовної передачі, бездротові широкомовні системи, персональні цифрові пристрої (PDA), переносні або настільні комп'ютери, планшетні комп'ютери, пристрої для читання електронних книг, цифрові камери, цифрові записуючі пристрої, цифрові мультимедійні програвачі, пристрої відеоігор, консолі для відеоігор, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої відеоконференц-зв'язку, пристрої потокової передачі відео тощо. Цифрові відеопристрої реалізовують такі технології стиснення відео, як технології стиснення відео, описані в стандартах, заданих за допомогою стандартів MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, частина 10, вдосконалене кодування відео (AVC), стандарту високоефективного кодування відео (HEVC), що розробляються в цей час, і розширень таких стандартів. Відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію більш ефективно за допомогою реалізації таких технологій стиснення відео. Способи стиснення відео виконують просторове (внутрішньокадрове, intra-picture) прогнозування і/або часове (міжкадрове, inter-picture) прогнозування для того, щоб зменшувати або видаляти надмірність, внутрішньо властиву відеопослідовностям. Для блокового кодування відео зріз (секція) відео (тобто зображення або частина зображення) може бути розділений на відеоблоки, які також можуть називатися "деревоподібними блоками", "одиницями кодування (CU)» і/або "вузлами кодування". Відеоблоки у внутрішньо-кодованому (I) зрізі зображення кодуються з використанням просторового прогнозування відносно опорних вибірок у сусідніх блоках в ідентичному зображенні. Відеоблоки у зовні кодованому (Р- або В-) зрізі зображення можуть використовувати просторове прогнозування відносно опорних вибірок у сусідніх блоках в ідентичному зображенні або часове прогнозування відносно опорних вибірок в інших опорних зображеннях. Просторове або часове прогнозування призводить в результаті до прогнозуючого блока для блока, який повинен бути кодований. Залишкові дані представляють піксельні різниці між вихідним блоком, який повинен бути кодований, і прогнозуючим блоком. Зовні кодований блок кодується згідно з вектором руху, який вказує на блок опорних вибірок, що формують прогнозуючий блок, і залишковими даними, що вказують різницю між кодованим блоком і прогнозуючим блоком. Внутрішньо кодований блок кодується згідно з режимом внутрішнього кодування і залишковими даними. Для додаткового стиснення залишкові дані можуть бути перетворені з піксельної ділянки в ділянку перетворення, приводячи до залишкових коефіцієнтів перетворення, які потім можуть бути квантовані. Квантовані коефіцієнти перетворення, які спочатку розміщуються в двомірному масиві, можуть скануватися для того, щоб генерувати одномірний вектор коефіцієнтів перетворення, і може застосовуватися ентропійне кодування з тим, щоб досягати ще більшого стиснення. СУТЬ ВИНАХОДУ Загалом, це розкриття суті описує технології для кодування відеоданих. Це розкриття суті описує технології для виконання прогнозування векторів руху, оцінки руху і компенсації руху при кодуванні у зовнішньому режимі (тобто кодуванні поточного блока відносно блоків інших зображень (кадрів)) при кодуванні багатовидового відео (MVC). Загалом, MVC є стандартом кодування відео для інкапсуляції декількох видів відеоданих. Кожний вид може відповідати різній перспективі або куту, під яким захоплені відповідні відеодані загальної сцени. Технології цього розкриття суті, загалом, включають в себе прогнозування даних прогнозування руху в контексті кодування багатовидового відео. Іншими словами, наприклад, згідно з технологіями цього розкриття суті вектор диспаратності (неспівпадання) руху з блока в ідентичному або відмінному виді відносно блока, в даний момент кодованого, може бути використаний для того, щоб прогнозувати вектор руху поточного блока. В іншому прикладі, згідно з технологіями цього розкриття суті часовий вектор руху з блока в ідентичному або відмінному виді відносно блока, в даний момент кодованого, може бути використаний для того, щоб прогнозувати вектор руху поточного блока. У прикладі, аспекти цього розкриття суті відносяться до способу кодування відеоданих, при цьому спосіб містить ідентифікацію першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором 1 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 диспаратності руху; визначення предиктора вектора руху для другого вектора руху, асоційованого з другим блоком відеоданих, при цьому предиктор вектора руху оснований на першому векторі диспаратності руху; при цьому, коли другий вектор руху містить вектор диспаратності руху, визначення предиктора вектора руху містить масштабування першого вектора диспаратності руху, щоб генерувати масштабований предиктор вектора руху, при цьому масштабування першого вектора диспаратності руху містить застосування коефіцієнта масштабування, що містить відстань для виду другого вектора диспаратності руху, ділену на відстань для виду першого вектора руху, до першого вектора диспаратності руху; і кодування даних прогнозування для другого блока з використанням масштабованого предиктора вектора руху. В іншому прикладі, аспекти цього розкриття суті відносяться до пристрою для кодування відеоданих, що містить один або більше процесорів, причому один або більше процесорів виконані з можливістю ідентифікувати перший блок відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху; визначати предиктор вектора руху для другого вектора руху, асоційованого з другим блоком відеоданих, при цьому предиктор вектора руху оснований на першому векторі диспаратності руху; при цьому, коли другий вектор руху містить вектор диспаратності руху, один або більше процесорів виконані з можливістю визначати предиктор вектора руху за допомогою масштабування першого вектора диспаратності руху, щоб генерувати масштабований предиктор вектора руху, при цьому масштабування першого вектора диспаратності руху містить застосування коефіцієнта масштабування, що містить відстань для виду другого вектора диспаратності руху, ділену на відстань для виду першого вектора руху, до першого вектора диспаратності руху; і кодувати дані прогнозування для другого блока на основі масштабованого предиктора вектора руху. В іншому прикладі аспекти цього розкриття суті відносяться до пристрою для кодування відеоданих, що містить засіб для ідентифікації першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху; засіб для визначення предиктора вектора руху для другого вектора руху, асоційованого з другим блоком відеоданих, при цьому предиктор вектора руху оснований на першому векторі диспаратності руху; при цьому, коли другий вектор руху містить вектор диспаратності руху, засіб для визначення предиктора вектора руху виконаний з можливістю визначати предиктор вектора руху за допомогою масштабування першого вектора диспаратності руху, щоб генерувати масштабований предиктор вектора руху, при цьому масштабування першого вектора диспаратності руху містить застосування коефіцієнта масштабування, що містить відстань для виду другого вектора диспаратності руху, ділену на відстань для виду першого вектора руху, до першого вектора диспаратності руху; і засіб для кодування даних прогнозування для другого блока на основі масштабованого предиктора вектора руху. В іншому прикладі аспекти цього розкриття суті відносяться до зчитуваного комп'ютером носія даних, що має збережені інструкції, які, при виконанні, спонукають один або більше процесорів ідентифікувати перший блок відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху; визначати предиктор вектора руху для другого вектора руху, асоційованого з другим блоком відеоданих, при цьому предиктор вектора руху оснований на першому векторі диспаратності руху; при цьому, коли другий вектор руху містить вектор диспаратності руху, інструкції спонукають один або більше процесорів визначати предиктор вектора руху за допомогою масштабування першого вектора диспаратності руху, щоб генерувати масштабований предиктор вектора руху, при цьому масштабування першого вектора диспаратності руху містить застосування коефіцієнта масштабування, що містить відстань для виду другого вектора диспаратності руху, ділену на відстань для виду першого вектора руху, до першого вектора диспаратності руху; і кодувати дані прогнозування для другого блока на основі масштабованого предиктора вектора руху. В іншому прикладі аспекти цього розкриття суті відносяться до способу кодування відеоданих, при цьому спосіб містить ідентифікацію першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок відеоданих асоційований з першим часовим вектором руху; визначення, коли другий вектор руху, асоційований з другим блоком відеоданих, містить часовий вектор руху, і другий блок виходить з другого виду, предиктора вектора руху для другого вектора руху на основі першого часового вектора руху; і кодування даних прогнозування для другого блока з використанням предиктора вектора руху. 2 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 В іншому прикладі аспекти цього розкриття суті відносяться до пристрою для кодування відеоданих, що містить один або більше процесорів, виконаних з можливістю ідентифікувати перший блок відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок відеоданих асоційований з першим часовим вектором руху; визначати, коли другий вектор руху, асоційований з другим блоком відеоданих, містить часовий вектор руху, і другий блок виходить з другого виду, предиктор вектора руху для другого вектора руху на основі першого часового вектора руху; і кодувати дані прогнозування для другого блока з використанням предиктора вектора руху. В іншому прикладі аспекти цього розкриття суті відносяться до пристрою для кодування відеоданих, що містить засіб для ідентифікації першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок відеоданих асоційований з першим часовим вектором руху; засіб для визначення, коли другий вектор руху, асоційований з другим блоком відеоданих, містить часовий вектор руху, і другий блок виходить з другого виду, предиктора вектора руху для другого вектора руху на основі першого часового вектора руху; і засіб для кодування даних прогнозування для другого блока з використанням предиктора вектора руху. У прикладі, аспекти цього розкриття суті відносяться до зчитуваного комп'ютером носія даних, що має збережені інструкції, які при виконанні спонукають один або більше процесорів ідентифікувати перший блок відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок відеоданих асоційований з першим часовим вектором руху; визначати, коли другий вектор руху, асоційований з другим блоком відеоданих, містить часовий вектор руху, і другий блок виходить з другого виду, предиктор вектора руху для другого вектора руху на основі першого часового вектора руху; і кодувати дані прогнозування для другого блока з використанням предиктора вектора руху. Подробиці одного або більше варіантів здійснення даного розкриття суті викладені на прикладених кресленнях і в нижченаведеному описі. Інші ознаки, цілі та переваги технологій, описаних в даному розкритті суті, повинні ставати очевидними з опису і креслень, а також з формули винаходу. КОРОТКИЙ ОПИС КРЕСЛЕНЬ Фіг. 1 є блок-схемою, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати технології, описані в цьому розкритті суті. Фіг. 2 є блок-схемою, що ілюструє зразковий відеокодер, який може реалізовувати способи, описані в цьому розкритті суті.Фіг. 3 є блок-схемою, що ілюструє зразковий відеодекодер, який може реалізовувати способи, описані в цьому розкритті суті. Фіг. 4 є концептуальною схемою, що ілюструє зразковий шаблон прогнозування за стандартом кодування багатовидового відео (MVC). Фіг. 5 є блок-схемою, що ілюструє зразкові місцеположення для кандидатів предикторів вектора руху. Фіг. 6 є концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху, згідно з аспектами цього розкриття суті. Фіг. 7 є іншою концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху, згідно з аспектами цього розкриття суті. Фіг. 8 є іншою концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху, згідно з аспектами цього розкриття суті. Фіг. 9 є блок-схемою послідовності операцій способу, що ілюструє зразковий спосіб кодування інформації прогнозування для блока відеоданих. Фіг. 10 є концептуальною схемою, що ілюструє генерування предиктора вектора руху з блока у відмінному виді відносно поточного блока. Фіг. 11 є блок-схемою послідовності операцій способу, що ілюструє зразковий спосіб генерування предиктора вектора руху з блока у відмінному виді відносно поточного блока. ДОКЛАДНИЙ ОПИС ВИНАХОДУ Згідно з визначеними системами кодування відео, оцінка руху і компенсація руху можуть бути використані для того, щоб зменшувати часову надмірність у відеопослідовності, з тим щоб досягати стиснення даних. У цьому випадку, може бути згенерований вектор руху, який ідентифікує прогнозуючий блок відеоданих, наприклад, блок з іншого відеозображення або зрізу, який може бути використаний для того, щоб прогнозувати значення поточного відеоблока, що кодується. Значення прогнозуючого відеоблока віднімаються із значень поточного відеоблока, щоб генерувати блок залишкових даних. Інформація руху (наприклад, вектор руху, індекси векторів руху, напрямки прогнозування або інша інформація) передається з відеокодера 3 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 у відеодекодер, разом із залишковими даними. Декодер може знаходити ідентичний прогнозуючий блок (на основі вектора руху) і відновлювати кодований відеоблок за допомогою комбінування залишкових даних з даними прогнозуючого блока. У деяких випадках, також застосовується кодування з прогнозуванням векторів руху, щоб додатково зменшувати обсяг даних, необхідних для того, щоб передавати вектор руху. Коли вектор руху встановлюється, він виходить з цільового зображення до опорного зображення. Вектор руху може просторово або часово прогнозуватися. Просторово прогнозований вектор руху асоційований з доступними просторовими блоками (блоком для ідентичного моменту часу). Часово прогнозований вектор руху асоційований з доступними часовими блоками (блоком для іншого моменту часу). У випадку прогнозування векторів руху, замість кодування і передачі самого вектора руху, кодер кодує і передає різницю векторів руху (MVD) відносно відомого (або впізнаваного) вектора руху. У H.264/AVC відомий вектор руху, який може бути використаний з MVD, щоб задавати поточний вектор руху, може бути заданий за допомогою так званого предиктора вектора руху (MVP). Для того, щоб бути допустимим MVP, вектор руху повинен вказувати на зображення, ідентичне зображенню вектора руху, в даний момент кодованого за допомогою MVP та MVD. Відеокодер може компонувати список кандидатів предикторів вектора руху, який включає в себе декілька сусідніх блоків в просторовому і часовому напрямках як кандидатів для MVP. У цьому випадку, відеокодер може вибирати найбільш точний предиктор з набору кандидатів на основі аналізу швидкості кодування і спотворення (наприклад, з використанням аналізу функції витрат на спотворення залежно від швидкості передачі або іншого аналізу ефективності кодування). Індекс предиктора вектора руху (mvp_idx) може бути переданий у відеодекодер, щоб повідомляти в декодер те, де знаходити MVP. MVD також передається. Декодер може комбінувати MVD з MVP (заданим за допомогою індексу предиктора вектора руху) з тим, щоб відновлювати вектор руху. Також може бути доступним так званий "режим злиття", в якому інформація руху (така як вектори руху, індекси опорних зображень, напрямки прогнозування або інша інформація) сусіднього відеоблока успадковується для поточного відеоблока, що кодується. Значення індексу може бути використане для того, щоб ідентифікувати сусіда, з якого поточний відеоблок успадковує свою інформацію руху. Кодування багатовидового відео (MVC) є стандартом кодування відео для інкапсуляції декількох видів відеоданих. Загалом, кожний вид відповідає різній перспективі або куту, під яким захоплені відповідні відеодані загальної сцени. MVC надає набір метаданих, тобто описових даних для видів спільно і окремо. Кодовані види можуть використовуватися для трьохмірного відображення відеоданих. Наприклад, два види (наприклад, види для лівого і правого ока людини-глядача) можуть відображатися одночасно або практично одночасно з використанням різних поляризацій світла, і глядач може носити пасивні поляризовані окуляри, так що кожне з очей глядача приймає відповідний з видів. Альтернативно, глядач може носити активні окуляри, які закривають кожне око незалежно, і відображення може швидко чергуватися між зображеннями для кожного ока синхронно з окулярами. У MVC конкретне зображення конкретного виду називається "компонентою виду". Іншими словами, компонента виду для виду відповідає конкретному часовому моменту виду. Типово, ідентичні або відповідні об'єкти двох видів не є спільно розміщеними. Термін "вектор диспаратності" може бути використаний для позначення вектора як такого, що вказує зміщення об'єкта в зображенні виду відносно відповідного об'єкта в іншому виді. Такий вектор також може називатися "вектором зміщення". Вектор диспаратності також може бути застосовним до пікселя або блока відеоданих зображення. Наприклад, піксель в зображенні першого виду може бути зміщений відносно відповідного пікселя в зображенні другого виду за допомогою конкретної диспаратності, зв'язаної з відмінними місцеположеннями камери, з яких захоплюються перший вид і другий вид. У деяких прикладах, диспаратніть може бути використана для того, щоб прогнозувати вектор руху від одного виду до іншого виду. У контексті MVC зображення одного виду можуть бути передбачені із зображень іншого виду. Наприклад, блок відеоданих може бути прогнозований відносно блока відеоданих в опорному зображенні ідентичного часового моменту, але іншого виду. У прикладі, блок, який в даний момент кодується, може називатися "поточним блоком". Вектор руху, що прогнозує поточний блок з блока в іншому виді, але в ідентичний момент часу, називається "вектором диспаратності руху". Вектор диспаратності руху типово є застосовним в контексті кодування багатовидового відео, в якому декілька видів можуть бути доступними. Згідно з цим розкриттям суті, "відстань для виду" для вектора диспаратності руху може означати різницю переміщення 4 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 між видом опорного зображення і видом цільового зображення. Іншими словами, відстань для виду може представлятися як різниця ідентифікаторів видів між ідентифікатором виду опорного зображення і ідентифікатором виду цільового зображення. Інший тип вектора руху є "часовим вектором руху". У контексті кодування багатовидового відео, часовий вектор руху означає вектор руху, що прогнозує поточний блок з блока в інший момент часу, але в ідентичному виді. Згідно з цим розкриттям суті, "часова відстань" часового вектора руху може означати відстань на основі номера в послідовності зображень (POC) від опорного зображення до цільового зображення. Деякі способи цього розкриття суті направлені на використання інформації руху (наприклад, вектора руху, індексів векторів руху, напрямків прогнозування або іншої інформації), асоційованої з блоком відеоданих в багатовидовій настройці, щоб прогнозувати інформацію руху блока, в даний момент кодованого. Наприклад, згідно з аспектами цього розкриття суті, вектор руху, прогнозований з іншого виду, може додаватися як кандидат для одного або більше списків векторів руху, що використовуються для прогнозування векторів руху поточного блока. У деяких прикладах відеокодер може використовувати вектор диспаратності руху, асоційований з блоком у відмінному виді відносно блока, в даний момент кодованого, щоб прогнозувати вектор руху для поточного блока, і може додавати прогнозований вектор диспаратності руху в список кандидатів векторів руху. В інших прикладах, відеокодер може використовувати часовий вектор руху, асоційований з блоком у відмінному виді відносно блока, в даний момент кодованого, щоб прогнозувати вектор руху для поточного блока, і може додавати прогнозований часовий вектор руху в список кандидатів векторів руху. Згідно з аспектами цього розкриття суті, вектор диспаратності руху може масштабуватися до використання як предиктора вектора руху для блока, в даний момент кодованого. Наприклад, якщо вектор диспаратності руху ідентифікує опорне зображення, яке має ідентифікатор виду, ідентичний ідентифікатору виду поточного вектора руху, що прогнозується, і вектор диспаратності руху має цільове зображення з ідентифікатором виду, ідентичним ідентифікатору виду прогнозованого поточного вектора руху, вектор диспаратності руху не може масштабуватися до використання для того, щоб прогнозувати вектор руху для поточного блока. В інших випадках, вектор диспаратності руху може масштабуватися до використання для того, щоб прогнозувати вектор руху для поточного блока. В іншому прикладі вектор диспаратності руху може бути прогнозований з вектора диспаратності руху, асоційованого з просторово сусіднім блоком. У цьому прикладі, якщо ідентифікатор виду опорного зображення вектора диспаратності руху є ідентичним ідентифікатору виду опорного зображення вектора руху, який повинен бути прогнозований (наприклад, вектора руху, асоційованого з блоком, що прогнозується в даний момент), масштабування може не вимагатися. В іншому випадку, вектор диспаратності руху може масштабуватися на основі місцеположення камери для камери, що використовується для того, щоб захоплювати відеодані. Іншими словами, наприклад, вектор диспаратності руху, що використовується для прогнозування, може масштабуватися згідно з різницею між ідентифікатором виду опорного зображення вектора диспаратності руху і ідентифікатором виду цільового зображення вектора руху. У деяких прикладах, масштабування векторів диспаратності руху може здійснюватися на основі трансляцій видів. В іншому прикладі вектор диспаратності руху може бути прогнозований з вектора диспаратності руху, асоційованого з часово сусіднім (у часі) блоком. У цьому прикладі, якщо ідентифікатор виду опорного зображення вектора диспаратності руху є ідентичним ідентифікатору виду опорного зображення вектора руху, який повинен бути прогнозований, і ідентифікатор виду цільового зображення вектора диспаратності руху є ідентичним ідентифікатору виду опорного зображення вектора руху, який повинен бути прогнозований, масштабування може не вимагатися. В іншому випадку, вектор диспаратності руху може масштабуватися на основі різниці в ідентифікаторі виду, як описано відносно попереднього прикладу. Що стосується часового прогнозування векторів руху, згідно з аспектами цього розкриття суті, часовий вектор руху, який має цільове зображення в першому виді, може бути використаний для того, щоб прогнозувати часовий вектор руху, який має цільове зображення у другому іншому виді. У деяких прикладах, блок в цільовому зображенні часового вектора руху, що використовується для прогнозування, може спільно розміщуватися з блоком, що в даний момент прогнозується в іншому виді. В інших прикладах, блок в цільовому зображенні часового вектора руху, що використовується для прогнозування, може зміщатися від поточного блока внаслідок диспаратності між двома видами. 5 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 У деяких прикладах, коли вектор руху, що прогнозується з іншого виду, є часовим вектором руху, вектор руху може масштабуватися на основі різниці у відстанях на основі номера в послідовності зображень (POC). Наприклад, згідно з аспектами цього розкриття суті, якщо опорне зображення часового вектора руху, що використовується для прогнозування, має РОСзначення, ідентичне РОС-значенню опорного зображення прогнозованого поточного вектора руху, і цільове зображення часового вектора руху, що використовується для прогнозування, має РОС-значення, ідентичне РОС-значенню опорного зображення прогнозованого поточного вектора руху, вектор руху, що використовується для прогнозування, не може масштабуватися. Проте, в іншому випадку, вектор руху, що використовується для прогнозування, може масштабуватися на основі різниці в РОС-значенні між опорним зображенням вектора руху, що використовується для прогнозування, і опорним зображенням вектора руху, що в даний момент прогнозується. Згідно з деякими аспектами цього розкриття суті, часові вектори руху і/або вектори диспаратності руху з різних видів можуть бути використані як кандидати MVP. Наприклад, часові вектори руху і/або вектори диспаратності руху можуть бути використані для того, щоб обчислювати MVD для поточного блока. Згідно з іншими аспектами цього розкриття суті, часові вектори руху і/або вектори диспаратності руху з різних видів можуть бути використані як кандидати злиття. Наприклад, часові вектори руху і/або вектори диспаратності руху можуть бути успадковані для поточного блока. У таких прикладах, значення індексу може бути використане для того, щоб ідентифікувати сусіда, з якого поточний відеоблок успадковує свою інформацію руху. У будь-якому випадку, вектор диспаратності руху і/або часовий вектор руху з іншого виду, що використовується як кандидат MVP або злиття, може масштабуватися до використання як кандидат MVP або злиття. Фіг. 1 є блок-схемою, що ілюструє зразкову систему 10 кодування і декодування відео, яка може використовувати способи для прогнозування векторів руху при багатовидовому кодуванні. Як показано на фіг. 1, система 10 включає в себе пристрій-джерело 12, яке надає кодовані відеодані, які повинні бути декодовані пізніше за допомогою пристрою-адресата 14. Зокрема, пристрій-джерело 12 надає відеодані в пристрій-адресат 14 через зчитуваний комп'ютером носій 16. Пристрій-джерело 12 і пристрій-адресат 14 можуть містити будь-який з широкого діапазону пристроїв, що включають в себе настільні комп'ютери, ноутбуки (тобто переносні комп'ютери), планшетні комп'ютери, абонентські приставки, телефонні апарати, наприклад, так звані смартфони, так звані інтелектуальні планшети, телевізійні приймачі, камери, пристрої відображення, цифрові мультимедійні програвачі, консолі для відеоігор, пристрій потокової передачі відео тощо. В деяких випадках, пристрій-джерело 12 і пристрій-адресат 14 можуть бути оснащені можливостями бездротового зв'язку. Пристрій-адресат 14 може приймати кодовані відеодані, які повинні бути декодовані, через зчитуваний комп'ютером носій 16. Зчитуваний комп'ютером носій 16 може містити будь-який тип носія або пристрою, що допускає переміщення кодованих відеоданих з пристрою-джерела 12 в пристрій-адресат 14. В одному прикладі зчитуваний комп'ютером носій 16 може містити середовище зв'язку, щоб давати можливість пристрою-джерелу 12 передавати кодовані відеодані безпосередньо в пристрій-адресат 14 в реальному часі. Кодовані відеодані можуть бути модульовані згідно зі стандартом зв'язку, таким як протокол бездротового зв'язку, і передані в пристрій-адресат 14. Середовище зв'язку може містити будьяке бездротове або дротове середовище зв'язку, таке як радіочастотний (RF) спектр або одна або більше фізичних ліній передачі. Середовище зв'язку може формувати частину мережі з комутацією пакетів, такою як локальна обчислювальна мережа, глобальна обчислювальна мережа або глобальна мережа, така як Інтернет. Середовище зв'язку може включати в себе маршрутизатори, перемикачі, базові станції або будь-яке інше обладнання, яке може бути корисним, щоб спрощувати передачу з пристрою-джерела 12 в пристрій-адресат 14. У деяких прикладах кодовані дані можуть виводитися з інтерфейсу 22 виводу в пристрій зберігання даних. Аналогічно, до кодованих даних може здійснюватися доступ з пристрою зберігання даних за допомогою інтерфейсу вводу. Пристрій зберігання даних може включати в себе будь-який з множини носіїв зберігання даних з розподіленим або локальним доступом, такі як жорсткий диск, Blu-Ray-диски, DVD, CD-ROM, флеш-пам'ять, енергозалежний або енергонезалежний запам'ятовуючий пристрій або будь-які інші підходящі цифрові носії зберігання даних для збереження кодованих відеоданих. У додатковому прикладі пристрій зберігання даних може відповідати файловому серверу або іншому проміжному пристрою зберігання даних, який може зберігати кодоване відео, згенероване за допомогою пристроюджерела 12. 6 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 Пристрій-адресат 14 може здійснювати доступ до збережених відеоданих з пристрою зберігання даних через потокову передачу або завантаження. Файловий сервер може бути будь-яким типом сервера, що допускає збереження кодованих відеоданих і передачу цих кодованих відеоданих в пристрій-адресат 14. Зразкові файлові сервери включають в себе вебсервер (наприклад, для веб-вузла), FTP-сервер, пристрої системи зберігання даних з підключенням по мережі (NAS) або локальний накопичувач на дисках. Пристрій-адресат 14 може здійснювати доступ до кодованих відеоданих через будь-яке стандартне підключення для передачі даних, що включає в себе Інтернет-підключення. Воно може включати в себе бездротовий канал (наприклад, Wi-Fi-підключення), дротове підключення (наприклад, DSL, кабельний модем тощо) або комбінацію зазначеного, яка є підходящою для того, щоб здійснювати доступ до кодованих відеоданих, збережених на файловому сервері. Передача кодованих відеоданих з пристрою зберігання даних може являти собою потокову передачу, передачу на основі завантаження або комбінацію вищезазначеного. Способи цього розкриття суті не обов'язково обмежені додатками або настройками бездротового зв'язку. Способи можуть застосовуватися до кодування відео в підтримку будьяких з множини мультимедійних додатків, таких як широкомовні телепередачі по радіоінтерфейсу, кабельні телепередачі, супутникові телепередачі, потокові передачі відео по Інтернету, такі як динамічна адаптивна потокова передача по HTTP (DASH), цифрове відео, яке кодується на носій зберігання даних, декодування цифрового відео, збереженого на носії зберігання даних, або інші додатки. У деяких прикладах система 10 може бути виконана з можливістю підтримувати односторонню або двосторонню передачу відео, щоб підтримувати такі додатки, як потокова передача відео, відтворення відео, широкомовна передача відео і/або відеотелефонія. У прикладі за фіг. 1 пристрій-джерело 12 включає в себе відеоджерело 18, відеокодер 20 та інтерфейс 22 виводу. Пристрій-адресат 14 включає в себе інтерфейс 28 вводу, відеодекодер 30 і пристрій 32 відображення. Відповідно до цього розкриття суті, відеокодер 20 пристроюджерела 12 може бути виконаний з можливістю застосовувати способи для прогнозування векторів руху при багатовидовому кодуванні. В інших прикладах пристрій джерело і пристрій адресат можуть включати в себе інші компоненти або компонування. Наприклад, пристрійджерело 12 може приймати відеодані із зовнішнього відеоджерела 18, такого як зовнішня камера. Аналогічно, пристрій-адресат 14 може взаємодіяти із зовнішнім пристроєм відображення замість включення в себе інтегрованого пристрою відображення. Проілюстрована система 10 за фіг. 1 є просто одним прикладом. Способи для прогнозування векторів руху при багатовидовому кодуванні можуть виконуватися за допомогою будь-якого пристрою кодування і/або декодування цифрового відео. Хоча, загалом, способи цього розкриття суті виконуються за допомогою пристрою кодування відео, способи також можуть виконуватися за допомогою відеокодера/декодера, який типово називається "кодеком". Крім того, способи цього розкриття суті також можуть виконуватися за допомогою відеопрепроцесора. Пристрій-джерело 12 і пристрій-адресат 14 є просто прикладами таких пристроїв кодування, в яких пристрій-джерело 12 формує кодовані відеодані для передачі в пристрій-адресат 14. У деяких прикладах пристрої 12, 14 можуть працювати практично симетрично так, що кожний з пристроїв 12, 14 включає в себе компоненти кодування і декодування відео. Отже, система 10 може підтримувати односторонню та двосторонню передачу відео між відеопристроями 12, 14, наприклад, для потокової передачі відео, відтворення відео, широкомовної передачі відео або відеотелефонії. Відеоджерело 18 пристрою-джерела 12 може включати в себе пристрій відеозахоплення, такий як відеокамера, відеоархів, що містить раніше захоплене відео, і/або інтерфейс прямої відеотрансляції, щоб приймати відео від постачальника відеоконтенту. Як додаткова альтернатива, відеоджерело 18 може генерувати основані на комп'ютерній графіці дані як вихідне відео або комбінацію відео, що передається наживо, архівного відео і відео, що генерується комп'ютером. У деяких випадках, якщо відеоджерелом 18 є відеокамера, пристрійджерело 12 і пристрій-адресат 14 можуть генерувати так звані камерофони або відеофони. Проте, як згадано вище, способи, описані в цьому розкритті суті, можуть бути застосовними до кодування відео в цілому і можуть застосовуватися до бездротових і/або дротових варіантів застосування. У кожному випадку захоплене, заздалегідь захоплене відео або відео, що генерується комп'ютером, може бути кодоване за допомогою відеокодера 20. Кодована відеоінформація потім може виводитися за допомогою інтерфейсу 22 виводу на зчитуваний комп'ютером носій 16. Зчитуваний комп'ютером носій 16 може включати в себе енергозалежні носії, такі як бездротова широкомовна передача або дротова мережна передача, або носії зберігання даних 7 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 (тобто енергонезалежні носії зберігання даних), такі як жорсткий диск, флеш-накопичувач, компакт-диск, цифровий відеодиск, Blu-Ray-диск або інші зчитувані комп'ютером носії. У деяких прикладах мережний сервер (не показаний) може приймати кодовані відеодані з пристроюджерела 12 і надавати кодовані відеодані в пристрій-адресат 14, наприклад, через мережну передачу. Аналогічно, обчислювальний пристрій обладнання для виготовлення носіїв, таке як обладнання для штампування дисків, може приймати кодовані відеодані з пристрою-джерела 12 і виготовляти диск, що містить кодовані відеодані. Отже, можна розуміти, що зчитуваний комп'ютером носій 16 включає в себе один або більше зчитуваних комп'ютером носіїв різних форм в різних прикладах. Інтерфейс 28 вводу пристрою-адресата 14 приймає інформацію зі зчитуваного комп'ютером носія 16. Інформація зчитуваного комп'ютером носія 16 може включати в себе синтаксичну інформацію, задану за допомогою відеокодера 20, яка також використовується за допомогою відеодекодера 30, яка включає в себе елементи синтаксису, які описують характеристики і/або обробку блоків та інших кодованих одиниць, наприклад, GOP. Пристрій 32 відображення відображає декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, таких як пристрій відображення на електронно-променевій трубці (CRT), рідкокристалічний пристрій відображення (LCD), плазмовий пристрій відображення, пристрій відображення на органічних світлодіодах (OLED) або інший тип пристрою відображення. Відеокодер 20 і відеодекодер 30 можуть працювати згідно з таким стандартом кодування відео, як стандарт високоефективного кодування відео (HEVC), що розробляється в цей час, і можуть відповідати тестовій моделі HEVC (HM). Альтернативно, відеокодер 20 і відеодекодер 30 можуть працювати згідно з іншими власними або галузевими стандартами, такими як стандарт ITU-T H.264, який альтернативно називається "MPEG-4, частина 10, вдосконалене кодування відео (AVC)», або розширеннями таких стандартів. Проте, способи цього розкриття суті не обмежені яким-небудь конкретним стандартом кодування. Інші приклади стандартів кодування відео включають в себе MPEG-2 та ITU-T H.263. Хоча не показано на фіг. 1, в деяких аспектах, відеокодер 20 і відеодекодер 30 можуть бути інтегровані з аудіо-кодером і декодером, відповідно, і можуть включати в себе відповідні модулі мультиплексора-демультиплексора або інші апаратні засоби і програмне забезпечення, щоб обробляти кодування як аудіо, так і відео в загальному потоці даних або в окремих потоках даних. Якщо застосовно, блоки мультиплексора-демультиплексора можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Стандарт ITU H.264/MPEG-4 (AVC) сформульований за допомогою експертної групи в ділянці кодування відео (VCEG) ITU-T спільно з експертною групою з кінозображення (MPEG) ISO/IEC як продукт спільного партнерського проекту, відомого як об'єднана група з відеостандартів (JVT). У деяких аспектах, способи, описані в цьому розкритті суті, можуть бути застосовані до пристроїв, які, загалом, відповідають стандарту H.264. Стандарт H.264 описаний в "ITU-T Recommendation H.264 Advanced Video Coding for Generic Audiovisual Services" від Дослідницької групи ITU-T і датований березнем 2005 року, який може згадуватися в даному документі як стандарт H.264 або специфікація H.264 або стандарт або специфікація H.264/AVC. Об'єднана група з відеостандартів (JVT) продовжує працювати над доповненнями до H.264/MPEG-4 AVC. JCT-VC проводить роботи з розробки HEVC-стандарту. Робота зі стандартизації HEVC основана на вдосконаленій моделі пристрою кодування відео, яка називається "тестової моделлю HEVC (HM)». HM передбачає декілька додаткових можливостей пристроїв кодування відео відносно існуючих пристроїв згідно, наприклад, ITU-T H.264/AVC. Наприклад, тоді як H.264 надає дев'ять режимів кодування з внутрішнім прогнозуванням, HM може надавати цілих тридцять три режими кодування з внутрішнім прогнозуванням. Загалом, робоча модель HM описує, що відеозображення (або "кадр") може бути розділене на послідовність блоків дерева або найбільших одиниць кодування (LCU), які включають в себе вибірки як сигналу яскравості, так і сигналу кольоровості. Синтаксичні дані в потоці бітів можуть задавати розмір для LCU, яка є найбільшою одиницею кодування з точки зору числа пікселів. Зріз включає в себе деяку кількість послідовних блоків дерева в порядку кодування. Зображення може бути розділене на один або більше зрізів. Кожний блок дерева може розбиватися на одиниці кодування (CU) згідно з деревом квадрантів. Загалом, структура даних у вигляді дерева квадрантів включає в себе один вузол для кожного CU, при цьому кореневий вузол відповідає блоку дерева. Якщо CU розбивається на чотири суб-CU, вузол, що відповідає CU, включає в себе чотири кінцевих вузли, кожний з яких відповідає одній з суб-CU. Кожний вузол структури даних у вигляді дерева квадрантів може надавати синтаксичні дані для відповідної CU. Наприклад, вузол в дереві квадрантів може включати в себе прапор 8 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 розбиття, що вказує те, розбивається чи ні CU, що відповідає вузлу, на суб-CU. Елементи синтаксису для CU можуть бути задані рекурсивно і можуть залежати від того, розбивається чи ні CU на суб-CU. Якщо CU не розбивається додатково, вона називається "кінцевою CU". У цьому розкритті суті, чотири суб-CU кінцевої CU також називаються "кінцевими CU", навіть якщо відсутнє явне розбиття вихідної кінцевої CU. Наприклад, якщо CU розміру 16 × 16 не розбивається додатково, чотири суб-CU 8 × 8 також називаються "кінцевими CU", хоча CU 16 × 16 взагалі не розбивається. CU має призначення, аналогічне призначенню макроблока стандарту H.264, за винятком того, що CU не має розрізнення розміру. Наприклад, блок дерева може розбиватися на чотири дочірніх вузли (які також називаються "суб-CU"), і кожний дочірній вузол, в свою чергу, може бути батьківським вузлом і розбиватися ще на чотири дочірніх вузли. Кінцевий дочірній вузол, що не розбивається, який називається "кінцевим вузлом дерева квадрантів", містить вузол кодування, який також називається "кінцевою CU". Синтаксичні дані, асоційовані з кодованим потоком бітів, можуть задавати максимальне число разів, яке може розбиватися блок дерева, яке називається "максимальною CU-глибиною", і також може задавати мінімальний розмір вузлів кодування. Відповідно, потік бітів також може задавати найменшу одиницю кодування (SCU). Це розкриття суті використовує термін "блок", щоб посилатися на будь-яку з CU, PU або TU в контексті HEVC, або аналогічні структури даних в контексті інших стандартів (наприклад, макроблоки та їх субблоки в H.264/AVC). CU включає в себе вузол кодування і одиниці прогнозування (PU) і одиниці перетворення (TU), асоційовані з вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен мати квадратну форму. Розмір CU може коливатися від 8 × 8 пікселів аж до розміру блока дерева максимум в 64 × 64 пікселів або більше. Кожна CU може містити одну або більше PU і одну або більше TU. Синтаксичні дані, асоційовані з CU, можуть описувати, наприклад, розділення CU на одну або більше PU. Режими розділення можуть відрізнятися між тим, є CU кодованої в режимі пропуску або прямому режимі, кодованою в режимі внутрішнього прогнозування або кодованою в режимі зовнішнього прогнозування. PU можуть бути розділені таким чином, що вони мають неквадратну форму. Синтаксичні дані, асоційовані з CU, також можуть описувати, наприклад, розділення CU на одну або більше TU згідно з деревом квадрантів. TU може мати квадратну або неквадратну (наприклад, прямокутну) форму. HEVC-стандарт забезпечує можливість перетворень згідно з TU, які можуть відрізнятися для різних CU. Розміри NU типово задаються на основі розміру PU в даній CU, заданого для розділеної LCU, хоча це може не завжди мати місце. TU типово має ідентичний розмір або менше, ніж PU. У деяких прикладах залишкові вибірки, що відповідають CU, можуть поділятися на менші одиниці з використанням структури у вигляді дерева квадрантів, відомої як "залишкове дерево квадрантів" (RQT). Кінцеві вузли RQT можуть називатися "одиницями перетворення (TU)». Значення піксельних різниць, асоційовані з TU, можуть бути перетворені, щоб генерувати коефіцієнти перетворення, які можуть бути квантовані. Кінцева CU може включати в себе одну або більше одиниць прогнозування (PU). Загалом, PU представляє просторову ділянку, що відповідає всім або частині відповідної CU, і може включати в себе дані для витягання опорної вибірки для PU. Крім того, PU включає в себе дані, зв'язані з прогнозуванням. Наприклад, коли PU кодується у внутрішньому режимі, дані для PU можуть бути включені в залишкове дерево квадрантів (RQT), яке може включати в себе дані, що описують режим внутрішнього прогнозування для TU, що відповідає PU. Як інший приклад, коли PU кодується у зовнішньому режимі, PU може включати в себе дані, які задають один або більше векторів руху для PU. Дані, що задають вектор руху для PU, можуть описувати, наприклад, горизонтальну компоненту вектора руху, вертикальну компоненту вектора руху, розрізнення для вектора руху (наприклад, точність в одну чверть пікселя або точність в одну восьму пікселя), опорний кадр, на який вказує вектор руху, і/або опорний список (наприклад, список 0, список 1 або список с) для вектора руху. Кінцева CU, що має одну або більше PU, також може включати в себе одну або більше одиниць перетворення (TU). Одиниці перетворення можуть вказуватися з використанням RQT (яка також називається "структурою у вигляді дерева квадрантів TU"), як пояснено вище. Наприклад, прапор розбиття може вказувати те, розбивається чи ні кінцева CU на чотири одиниці перетворення. Потім, кожна одиниця перетворення додатково може розбиватися на додаткові під-TU. Коли TU не розбивається додатково, вона може називатися "кінцевою TU". Загалом, для внутрішнього кодування, всі кінцеві TU, що належать кінцевій CU, спільно використовують ідентичний режим внутрішнього прогнозування. Іншими словами, ідентичний режим внутрішнього прогнозування, загалом, застосовується для того, щоб обчислювати передбачені значення для всіх TU кінцевої CU. Для внутрішнього кодування відеокодер 20 може 9 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 обчислювати залишкове значення для кожної кінцевої TU з використанням режиму внутрішнього прогнозування, як різницю між частиною CU, що відповідає TU, і вихідним блоком. TU не обов'язково обмежується розміром PU. Таким чином, TU можуть бути більше або менше PU. Для внутрішнього кодування PU може спільно розміщуватися з відповідною кінцевою TU для ідентичної CU. У деяких прикладах максимальний розмір кінцевої TU може відповідати розміру відповідної кінцевої CU. Крім того, TU кінцевих CU також можуть бути асоційовані з відповідними структурами даних у вигляді дерева квадрантів, які називаються "залишковими деревами квадрантів (RQT)». Іншими словами, кінцева CU може включати в себе дерево квадрантів, що вказує те, як кінцева CU розділяється на TU. Кореневий вузол дерева квадрантів TU, загалом, відповідає кінцевій CU, в той час як кореневий вузол дерева квадрантів CU, загалом, відповідає блоку дерева (або LCU). TU RQT, які не розбиваються, називаються "кінцевими TU". Загалом, це розкриття суті використовує терміни CU та TU, щоб посилатися на кінцеву CU і кінцеву TU, відповідно, якщо не вказане інше. Відеопослідовність типово включає в себе послідовність зображень. Як описано в даному документі, "зображення" і "кадр" можуть бути використані взаємозамінно. Іншими словами, зображення, що містить відеодані, може називатися "відеокадром" або просто "кадром". Група зображень (GOP), загалом, містить послідовність з одного або більше відеозображень. GOP може включати в себе в заголовку GOP, в заголовку одного або більше зображень або в іншому місці синтаксичні дані, які описують число зображень, включених в GOP. Кожний зріз зображення може включати в себе синтаксичні дані зрізу, які описують режим кодування для відповідного зрізу. Відеокодер 20 типово оперує з відеоблоками в межах окремих зрізів, щоб кодувати відеодані. Відеоблок може відповідати вузлу кодування в CU. Відеоблоки можуть мати фіксовані розміри або розміри, що варіюються, і можуть відрізнятися за розміром згідно з вказаним стандартом кодування. Як приклад, HM підтримує прогнозування для різних PU-розмірів. За умови, що розмір конкретної CU становить 2Nx2N, HM підтримує внутрішнє прогнозування для PU-розмірів 2Nx2N або NxN і зовнішнє прогнозування для симетричних PU-розмірів 2Nx2N, 2NxN, Nx2N або NxN. HM також підтримує асиметричне розділення для зовнішнього прогнозування для PU-розмірів 2NxnU, 2NxnD, nLx2N та nRx2N. При асиметричному розділенні один напрямок CU не розділяється, в той час як інший напрямок розділяється на 25 % та 75 %. Частина CU, що відповідає 25 %-ому розділу, вказується за допомогою "n", після чого йде індикатор відносно "вгору (Up)», "вниз (Down)», "ліворуч (Left)» або "праворуч (Right)». Таким чином, наприклад, "2NxnU" означає CU 2Nx2N, яка розділяється горизонтально з PU 2Nx0,5N вгорі та PU 2Nx1,5N внизу. У цьому розкритті суті, "NxN" та "N на N" можуть бути використані взаємозамінно для того, щоб посилатися на розміри пікселя відеоблока з точки зору розмірів по вертикалі і горизонталі, наприклад, 16 × 16 пікселів або 16 на 16 пікселів. Загалом, блок 16 × 16 повинен мати 16 пікселів у вертикальному напрямку (у=16) і 16 пікселів в горизонтальному напрямку (х=16). Аналогічно, блок NxN, загалом, має N пікселів у вертикальному напрямку і N пікселів в горизонтальному напрямку, при цьому N представляє ненегативне цілочисельне значення. Пікселі в блоці можуть розміщуватися в рядках і стовпцях. Крім того, блок не обов'язково повинен мати співпадаюче число пікселів у горизонтальному напрямку і у вертикальному напрямку. Наприклад, блоки можуть містити NxM пікселів, причому M не обов'язково дорівнює N. Після кодування з внутрішнім прогнозуванням або кодування із зовнішнім прогнозуванням з використанням PU CU, відеокодер 20 може обчислювати залишкові дані для TU CU. PU можуть містити синтаксичні дані, що описують спосіб або режим генерування прогнозуючих піксельних даних в просторовій ділянці (яка також називається "піксельною ділянкою"), і TU можуть містити коефіцієнти в ділянці перетворення після застосування перетворення, наприклад, дискретного косинусного перетворення (DCT), цілочисельного перетворення, вейвлет-перетворення або концептуально аналогічного перетворення до залишкових відеоданих. Залишкові дані можуть відповідати піксельним різницям між пікселями некодованого зображення і значеннями прогнозування, що відповідають PU. Відеокодер 20 може генерувати TU, що включає в себе залишкові дані для CU, і потім перетворювати TU таким чином, щоб генерувати коефіцієнти перетворення для CU. Після яких-небудь перетворень, щоб генерувати коефіцієнти перетворення, відеокодер 20 може виконувати квантування коефіцієнтів перетворення. Квантування, загалом, означає процес, в якому коефіцієнти перетворення квантуються, щоб, можливо, зменшувати обсяг даних, що використовуються для того, щоб представляти коефіцієнти, забезпечуючи додаткове 10 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 стиснення. Процес квантування може зменшувати бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, n-бітове значення може бути округлене в менший бік до mбітового значення під час квантування, при цьому n більше m. Після квантування відеокодер може сканувати коефіцієнти перетворення, які формують одномірний вектор, з двомірної матриці, що включає в себе квантовані коефіцієнти перетворення. Сканування може бути спроектоване з можливістю розміщувати коефіцієнти з більш високою енергією (і, отже, більш низькою частотою) на початку масиву і розміщувати коефіцієнти з більш низькою енергією (і, отже, більш високою частотою) в кінці масиву. У деяких прикладах відеокодер 20 може використовувати заздалегідь заданий порядок сканування для того, щоб сканувати квантовані коефіцієнти перетворення, так щоб генерувати перетворений в послідовну форму вектор, який може ентропійно кодуватися. В інших прикладах відеокодер 20 може виконувати адаптивне сканування. Після сканування квантованих коефіцієнтів перетворення, щоб генерувати одномірний вектор, відеокодер 20 може ентропійно кодувати одномірний вектор, наприклад, згідно з контекстно-адаптивним кодуванням змінної довжини (CAVLC), контекстно-адаптивним двійковим арифметичним кодуванням (CABAC), синтаксичним контекстно-адаптивним двійковим арифметичним кодуванням (SBAC), ентропійним кодуванням на основі розділення на інтервали імовірності (PIPE) або інший спосіб ентропійного кодування. Відеокодер 20 також може ентропійно кодувати елементи синтаксису, асоційовані з кодованими відеоданими, для використання за допомогою відеодекодера 30 при декодуванні відеоданих. Щоб виконувати CABAC, відеокодер 20 може призначати контекст в контекстній моделі символу, який повинен бути переданий. Контекст може бути зв'язаний, наприклад, з тим, є сусідні значення символу ненульовими чи ні. Щоб виконувати CAVLC, відеокодер 20 може вибирати код змінної довжини для символу, який повинен бути переданий. Кодові слова в VLC можуть мати таку структуру, що відносно більш короткі коди відповідають більш імовірним символам, в той час як більш довгі коди відповідають менш імовірним символам. Таким чином, використання VLC дозволяє домагатися економії бітів, наприклад, в порівнянні з використанням кодових слів рівної довжини для кожного символу, який повинен бути переданий. Визначення імовірності може бути основане на контексті, що призначається символу. Відеокодер 20 додатково може відправляти синтаксичні дані, наприклад, синтаксичні дані на основі блоків, синтаксичні дані на основі зображень і синтаксичні GOP-дані, у відеодекодер 30, наприклад, в заголовку зображення, в заголовку блока, в заголовку зрізу або в GOP-заголовку. Синтаксичні GOP-дані можуть описувати число зображень у відповідній GOP, і синтаксичні дані зображень можуть вказувати режим кодування/прогнозування, що використовується для того, щоб кодувати відповідне зображення. Відеокодер 20 і відеодекодер 30 можуть бути реалізовані як будь-яка з множини належних схем кодера або декодера за відповідних умов, наприклад, як один або більше мікропроцесорів, процесори цифрових сигналів (DSP), спеціалізовані інтегральні схеми (ASIC), програмовані користувачем вентильні матриці (FPGA), дискретна логічна схема, програмне забезпечення, апаратні засоби, мікропрограмне забезпечення або будь-які комбінації вищезазначеного. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або більше кодерів або декодерів, будь-який з яких може бути інтегрований як частина комбінованого відеокодера/декодера (кодека). Пристрій, що включає в себе відеокодер 20 і/або відеодекодер 30, може містити інтегральну схему, мікропроцесор і/або пристрій бездротового зв'язку, такий як стільниковий телефон. Фіг. 2 є блок-схемою, що ілюструє зразковий відеокодер 20, який може реалізовувати способи, описані в цьому розкритті суті для прогнозування векторів руху при багатовидовому кодуванні. Відеокодер 20 може виконувати внутрішнє і зовнішнє кодування відеоблоків у зрізах. Внутрішнє кодування основане на просторовому прогнозуванні, з тим щоб зменшувати або видаляти просторову надмірність відео в даному зображенні. Зовнішнє кодування основане на часовому прогнозуванні, щоб зменшувати або видаляти часову надмірність відео в суміжних зображеннях або зображеннях відеопослідовності. Внутрішній режим (I-режим) може означати будь-який з декількох режимів просторового стиснення. Зовнішні режими, наприклад, однонаправлене прогнозування (Р-режим) або біпрогнозування (В-режим), можуть означати будь-який з декількох режимів часового стиснення. Як показано на фіг. 2, відеокодер 20 приймає відеодані, які повинні бути кодовані. У прикладі за фіг. 2, відеокодер 20 включає в себе модуль 40 вибору режиму, суматор 50, модуль 52 перетворення, модуль 54 квантування, модуль 56 ентропійного кодування і запам'ятовуючий пристрій 64 опорних зображень. Модуль 40 вибору режиму, в свою чергу, включає в себе модуль 42 оцінки руху, модуль 44 компенсації руху, модуль 46 внутрішнього прогнозування і модуль 48 розділення. Для відновлення відеоблоків відеокодер 20 також включає в себе модуль 11 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 58 оберненого квантування, модуль 60 оберненого перетворення і суматор 62. Фільтр видалення блочності (не показаний на фіг. 2) також може бути включений для того, щоб фільтрувати межі блоків, щоб видаляти артефакти блочності з відновленого відео. Якщо потрібно, фільтр видалення блочності типово повинен фільтрувати вивід суматора 62. Додаткові контурні фільтри (в контурі або пост-контурі) також можуть бути використані додатково до фільтра видалення блочності. Такі фільтри не показані для стислості, але якщо потрібно, можуть фільтрувати вивід суматора 50 (як внутрішньоконтурний фільтр). Під час процесу кодування відеокодер 20 приймає зображення або зріз, які повинні бути кодовані. Зображення або зріз можуть бути розділені на декілька відеоблоків. Модуль 42 оцінки руху і модуль 44 компенсації руху виконують кодування із зовнішнім прогнозуванням відеоблока, що приймається, відносно одного або більше блоків в одному або більше опорних зображень, щоб надавати часове стиснення. Модуль 46 внутрішнього прогнозування альтернативно може виконувати внутрішнє кодування з прогнозуванням відеоблока, що приймається, відносно одного або більше сусідніх блоків в ідентичному зображенні або зрізі, що і блок, який повинен бути кодований, щоб надавати просторове стиснення. Відеокодер 20 може виконувати декілька проходів кодування, наприклад, для того щоб вибирати належний режим кодування для кожного блока відеоданих. Крім того, модуль 48 розділення може розділяти блоки відеоданих на субблоки на основі оцінки попередніх схем розділення в попередніх проходах кодування. Наприклад, модуль 48 розділення може спочатку розділяти зображення або зріз на LCU і розділяти кожну з LCU на суб-CU на основі аналізу спотворення залежно від швидкості передачі (наприклад, оптимізації спотворення залежно від швидкості передачі). Модуль 40 вибору режиму додатково може генерувати структуру даних у вигляді дерева квадрантів, що вказує розділення LCU на суб-CU. CU вершини дерева квадрантів можуть включати в себе одну або більше PU і одну або більше TU. Модуль 40 вибору режиму може вибирати один з режимів кодування, внутрішніх або зовнішніх, наприклад, на основі результатів за помилками і надає результуючий внутрішньо або зовні кодований блок в суматор 50, щоб генерувати залишкові блокові дані, і в суматор 62, щоб відновлювати кодований блок для використання як опорне зображення. Модуль 40 вибору режиму також надає елементи синтаксису, такі як вектори руху, індикатори внутрішнього режиму, інформація розділів та інша така синтаксична інформація, в модуль 56 ентропійного кодування. Модуль 42 оцінки руху, модуль 43 прогнозування векторів руху і модуль 44 компенсації руху можуть мати високий ступінь інтеграції, але проілюстровані окремо в концептуальних цілях. Оцінка руху, що виконується за допомогою модуля 42 оцінки руху, є процесом генерування векторів руху, які оцінюють рух для відеоблоків. Вектор руху, наприклад, може вказувати зміщення PU відеоблока в поточному зображенні відносно прогнозуючого блока в опорному зображенні (або іншої кодованої одиниці) відносно поточного блока, що кодується в поточному зображенні (або іншої кодованої одиниці). Прогнозуючий блок є блоком, для якого виявляється, що він практично співпадає з блоком, який повинен бути кодований, з точки зору піксельної різниці, яка може бути визначена за допомогою суми абсолютних різниць (SAD), суми квадратів різниць (SSD) або інших різницевих показників. У деяких прикладах відеокодер 20 може обчислювати значення для субцілочисельнопіксельних позицій опорних зображень, збережених в запам'ятовуючому пристрої 64 опорних зображень, який також може називатися "буфером опорних зображень". Наприклад, відеокодер 20 може інтерполювати значення позицій в одну чверть пікселя, позицій в одну восьму пікселя або інших дробовопіксельних позицій опорного зображення. Отже, модуль 42 оцінки руху може виконувати пошук руху відносно повнопіксельних позицій і дробовопіксельних позицій і виводити вектор руху з дробово-піксельною точністю. Модуль 42 оцінки руху обчислює вектор руху для PU відеоблока у зовні-кодованому зрізі за допомогою порівняння позиції PU з позицією прогнозуючого блока опорного зображення. Відповідно, загалом, дані для вектора руху можуть включати в себе список опорних зображень, індекс в списку опорних зображень (ref_idx), горизонтальну компоненту і вертикальну компоненту. Опорне зображення може бути вибране з першого списку опорних зображень (списку 0), другого списку опорних зображень (списку 1) або комбінованого списку опорних зображень (списку с), кожний з яких ідентифікує одне або більше опорних зображень, збережених в запам'ятовуючому пристрої 64 опорних зображень. Модуль 42 оцінки руху може генерувати і відправляти вектор руху, який ідентифікує прогнозуючий блок опорного зображення, в модуль 56 ентропійного кодування і модуль 44 компенсації руху. Іншими словами, модуль 42 оцінки руху може генерувати і відправляти дані 12 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 вектора руху, які ідентифікують список опорних зображень, що містить прогнозуючий блок, індекс в списку опорних зображень, що ідентифікує зображення прогнозуючого блока, і горизонтальну і вертикальну компоненту, щоб знаходити прогнозуючий блок в ідентифікованому зображенні. У деяких прикладах замість відправки фактичного вектора руху для поточної PU, модуль 43 прогнозування векторів руху може прогнозувати вектор руху, щоб додатково зменшувати обсяг даних, необхідних для того, щоб передавати вектор руху. У цьому випадку, замість кодування і передачі самого вектора руху, модуль 43 прогнозування векторів руху може генерувати різницю векторів руху (MVD) відносно відомого (або впізнаваного) вектора руху. Відомий вектор руху, який може бути використаний з MVD для того, щоб задавати поточний вектор руху, може бути заданий за допомогою так званого предиктора вектора руху (MVP). Загалом, для того щоб бути допустимим MVP, вектор руху, що використовується для прогнозування, повинен вказувати на опорне зображення, ідентичне опорному зображенню вектора руху, в даний момент кодованого. У деяких прикладах, як детальніше описано відносно фіг. 5 нижче, модуль 43 прогнозування векторів руху може компонувати список кандидатів предикторів вектора руху, який включає в себе декілька сусідніх блоків у просторовому і/або часовому напрямках як кандидатів для MVP. Згідно з аспектами цього розкриття суті, як детальніше описано нижче, кандидати предикторів вектора руху також можуть бути ідентифіковані в зображеннях різних видів (наприклад, при багатовидовому кодуванні). Коли декілька кандидатів предикторів вектора руху доступні (з декількох кандидатів блоків), модуль 43 прогнозування векторів руху може визначати предиктор вектора руху для поточного блока згідно із заздалегідь визначеними критеріями вибору. Наприклад, модуль 43 прогнозування векторів руху може вибирати найбільш точний предиктор з набору кандидатів на основі аналізу швидкості кодування і спотворення (наприклад, з використанням аналізу функції витрат на спотворення залежно від швидкості передачі або іншого аналізу ефективності кодування). В інших прикладах модуль 43 прогнозування векторів руху може генерувати середнє кандидатів предикторів вектора руху. Інші способи вибору предиктора вектора руху також є можливими. Після вибору предиктора вектора руху модуль 43 прогнозування векторів руху може визначати індекс предиктора вектора руху (mvp_flag), який може бути використаний для того, щоб повідомляти у відеодекодер (наприклад, такий як відеодекодер 30), де знаходити MVP в списку опорних зображень, що містить кандидати MVP-блоків. Модуль 43 прогнозування векторів руху також може визначати MVD між поточним блоком і вибраним MVP. MVP-індекс і MVD можуть бути використані для того, щоб відновлювати вектор руху. У деяких прикладах модуль 43 прогнозування векторів руху замість цього може реалізовувати так званий "режим злиття", в якому модуль 43 прогнозування векторів руху може "здійснювати злиття" інформації руху (такої як вектори руху, індекси опорних зображень, напрямки прогнозування або інша інформація) прогнозуючого відеоблока з поточним відеоблоком. Відповідно, відносно режиму злиття, поточний відеоблок успадковує інформацію руху з іншого відомого (або впізнаваного) відеоблока. Модуль 43 прогнозування векторів руху може компонувати список кандидатів режиму злиття, який включає в себе декілька сусідніх блоків у просторовому і/або часовому напрямках як кандидатів для режиму злиття. Модуль 43 прогнозування векторів руху може визначати значення індексу (наприклад, merge_idx), яке може бути використане для того, щоб повідомляти у відеодекодер (наприклад, такий як відеодекодер 30), де знаходити відеоблок для злиття в списку опорних зображень, що містить кандидати блоків злиття. Згідно з аспектами цього розкриття суті, модуль 43 прогнозування векторів руху може ідентифікувати предиктор вектора руху, наприклад, для генерування MVD або злиття, при багатовидовому кодуванні. Наприклад, модуль 43 прогнозування векторів руху може ідентифікувати вектор диспаратності руху з блока у відмінному компоненті виду відносно поточного блока, щоб прогнозувати вектор руху для поточного блока. В інших прикладах модуль 43 прогнозування векторів руху може ідентифікувати часовий вектор руху з блока у відмінному компоненті виду відносно поточного блока, щоб прогнозувати вектор руху для поточного блока. Що стосується прогнозування векторів диспаратності руху, модуль 43 прогнозування векторів руху може ідентифікувати кандидата вектора диспаратності руху з кандидата блока, щоб прогнозувати вектор руху для відеоблока, в даний момент кодованого (який називається "поточним блоком"). Поточний блок може знаходитися в зображенні, ідентичному зображенню кандидата блока (наприклад, просторово гранично з кандидатом блока), або може знаходитися в іншому зображенні у виді, ідентичному з видом кандидата блока. У деяких прикладах модуль 43 прогнозування векторів руху може ідентифікувати предиктор вектора руху, який посилається 13 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 на опорне зображення у відмінному виді відносно вектора руху для поточного блока. У таких випадках, згідно з технологіями цього розкриття суті, модуль 43 прогнозування векторів руху може масштабувати предиктор вектора руху на основі різниці в місцеположеннях камери між двома видами (наприклад, видом, на який посилається предиктор вектора руху, і видом, на який посилається поточний вектор руху). Наприклад, модуль 43 прогнозування векторів руху може масштабувати предиктор вектора диспаратності руху згідно з різницею між двома видами. У деяких прикладах різниця між двома видами може бути представлена за допомогою різниці між ідентифікаторами видів (view_id), асоційованими з видами. Що стосується часового прогнозування векторів руху, модуль 43 прогнозування векторів руху може ідентифікувати часового кандидата вектора руху з кандидата блока у відмінному виді відносно поточного блока, щоб прогнозувати вектор руху для поточного блока. Наприклад, модуль 43 прогнозування векторів руху може ідентифікувати кандидата часового предиктора вектора руху в першому виді, який посилається на блок в зображенні в іншому часовому місцеположенні першого виду. Згідно з аспектами цього розкриття суті, модуль 43 прогнозування векторів руху може використовувати ідентифікованого кандидата часового предиктора вектора руху для того, щоб прогнозувати вектор руху, асоційований з поточним блоком у другому іншому виді. Кандидат блока (який включає в себе кандидата предиктора вектора руху) і поточний блок можуть спільно розміщуватися. Проте, відносне місцеположення кандидата блока може зміщатися від поточного блока внаслідок диспаратності між двома видами. Згідно з аспектами цього розкриття суті, модуль 43 прогнозування векторів руху може генерувати MVP-індекс (mvp_flag) і MVD або може генерувати індекс злиття (merge_idx). Наприклад, модуль 43 прогнозування векторів руху може генерувати список кандидатів MVP або злиття. Згідно з аспектами цього розкриття суті, кандидати MVP і/або злиття включають в себе один або більше відеоблоків, розташованих у відмінному виді відносно відеоблока, в даний момент декодованого. Компенсація руху, що виконується за допомогою модуля 44 компенсації руху, може містити в собі вибірку або генерування прогнозуючого блока на основі вектора руху, визначеного за допомогою модуля 42 оцінки руху, і/або інформації з модуля 43 прогнозування векторів руху. З іншого боку, модуль 42 оцінки руху, модуль 43 прогнозування векторів руху і модуль 44 компенсації руху можуть бути функціонально інтегровані в деяких прикладах. При прийомі вектора руху для PU поточного відеоблока модуль 44 компенсації руху може знаходити прогнозуючий блок, на який вказує вектор руху в одному зі списків опорних зображень. Суматор 50 формує залишковий відеоблок за допомогою віднімання піксельних значень прогнозуючого блока з піксельних значень поточного кодованого відеоблока, формуючи значення піксельних різниць, як пояснено нижче. Загалом, модуль 42 оцінки руху виконує оцінку руху відносно компонент сигналу яскравості, і модуль 44 компенсації руху використовує вектори руху, обчислені на основі компонент сигналу яскравості, як для компонент сигналу кольоровості, так і для компонент сигналу яскравості. Модуль 40 вибору режиму також може генерувати елементи синтаксису, асоційовані з відеоблоками і зрізом, для використання за допомогою відеодекодера 30 при декодуванні відеоблоків зрізу. Модуль 46 внутрішнього прогнозування може внутрішньо прогнозувати поточний блок, як альтернативу зовнішньому прогнозування, що виконується за допомогою модуля 42 оцінки руху і модуля 44 компенсації руху, як описано вище. Зокрема, модуль 46 внутрішнього прогнозування може визначати режим внутрішнього прогнозування для використання для того, щоб кодувати поточний блок. У деяких прикладах модуль 46 внутрішнього прогнозування може кодувати поточний блок з використанням різних режимів внутрішнього прогнозування, наприклад, під час окремих проходів кодування, і модуль 46 внутрішнього прогнозування (або модуль 40 вибору режиму в деяких прикладах) може вибирати належний режим внутрішнього прогнозування для використання з тестованих режимів. Наприклад, модуль 46 внутрішнього прогнозування може обчислювати значення спотворення залежно від швидкості передачі з використанням аналізу спотворення залежно від швидкості передачі для різних тестованих режимів внутрішнього прогнозування і вибирати режим внутрішнього прогнозування, що має найкращі характеристики спотворення залежно від швидкості передачі, з тестованих режимів. Аналіз спотворення залежно від швидкості передачі, загалом, визначає величину спотворення (або помилки) між кодованим блоком і вихідним некодованим блоком, який кодований для того, щоб генерувати кодований блок, а також швидкість передачі бітів (тобто число бітів), що використовується для того, щоб генерувати кодований блок. Модуль 46 внутрішнього прогнозування може обчислювати відношення зі спотворень і швидкостей для різних кодованих блоків, щоб визначати те, який режим 14 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 внутрішнього прогнозування демонструє найкраще значення спотворення залежно від швидкості передачі для блока. Після вибору режиму внутрішнього прогнозування для блока модуль 46 внутрішнього прогнозування може надавати інформацію, що вказує вибраний режим внутрішнього прогнозування для блока, в модуль 56 ентропійного кодування. Модуль 56 ентропійного кодування може кодувати інформацію, що вказує вибраний режим внутрішнього прогнозування. Відеокодер 20 може включати в потік бітів, що передається, конфігураційні дані, які можуть включати в себе множину індексних таблиць режиму внутрішнього прогнозування і множину модифікованих індексних таблиць режиму внутрішнього прогнозування (які також називаються "таблицями перетворення кодових слів"), визначення контекстів кодування для різних блоків і індикатори відносно найбільш імовірного режиму внутрішнього прогнозування, індексної таблиці режиму внутрішнього прогнозування і модифікованої індексної таблиці режиму внутрішнього прогнозування, які потрібно використовувати для кожного з контекстів. Відеокодер 20 формує залишковий відеоблок за допомогою віднімання даних прогнозування з модуля 40 вибору режиму з вихідного відеоблока, що кодується. Суматор 50 представляє компонент або компоненти, які виконують цю операцію віднімання. Процесор 52 перетворення застосовує перетворення, таке як дискретне косинусне перетворення (DCT) або концептуально аналогічне перетворення, до залишкового блока, формуючи відеоблок, що містить значення залишкових коефіцієнтів перетворення. Процесор 52 перетворення може виконувати інші перетворення, які концептуально є аналогічними DCT. Вейвлет-перетворення, цілочисельні перетворення, субсмугові перетворення або інші типи перетворень також можуть використовуватися. У будь-якому випадку, процесор 52 перетворення застосовує перетворення до залишкового блока, формуючи блок залишкових коефіцієнтів перетворення. Перетворення може перетворювати залишкову інформацію з піксельної ділянки в ділянку перетворення, таку як частотна ділянка. Процесор 52 перетворення може відправляти результуючі коефіцієнти перетворення в модуль 54 квантування. Модуль 54 квантування квантує коефіцієнти перетворення, щоб додатково зменшувати швидкість передачі бітів. Процес квантування може зменшувати бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Ступінь квантування може бути модифікований за допомогою регулювання параметра квантування. У деяких прикладах модуль 54 квантування потім може виконувати сканування матриці, що включає в себе квантовані коефіцієнти перетворення. Альтернативно, модуль 56 ентропійного кодування може виконувати сканування. Після квантування модуль 56 ентропійного кодування ентропійно кодує квантовані коефіцієнти перетворення. Наприклад, модуль 56 ентропійного кодування може виконувати контекстно-адаптивне кодування змінної довжини (CAVLC), контекстно-адаптивне двійкове арифметичне кодування (CABAC), синтаксичне контекстно-адаптивне двійкове арифметичне кодування (SBAC), ентропійне кодування на основі розділення на інтервали імовірності (PIPE) або іншу технологію ентропійного кодування. У випадку контекстного ентропійного кодування контекст може бути оснований на сусідніх блоках. Після ентропійного кодування за допомогою модуля 56 ентропійного кодування, кодований потік бітів може бути переданий в інший пристрій (наприклад, відеодекодер 30) або заархівований для подальшої передачі або витягання. Модуль 58 оберненого квантування і модуль 60 оберненого перетворення застосовують обернене квантування та обернене перетворення, відповідно, щоб відновлювати залишковий блок в піксельній ділянці, наприклад, для подальшого використання як опорного блока. Модуль 44 компенсації руху може обчислювати опорний блок за допомогою підсумовування залишкового блока з прогнозуючим блоком одного із зображень запам'ятовуючого пристрою 64 опорних зображень. Модуль 44 компенсації руху також може застосовувати один або більше інтерполяційних фільтрів до відновленого залишкового блока, щоб обчислювати субцілочислені піксельні значення для використання при оцінці руху. Суматор 62 підсумовує відновлений залишковий блок з прогнозуючим блоком з компенсацією руху, сформованим за допомогою модуля 44 компенсації руху, щоб сформувати відновлений відеоблок для зберігання в запам'ятовуючому пристрої 64 опорних зображень. Відновлений відеоблок може використовуватися за допомогою модуля 42 оцінки руху і модуля 44 компенсації руху як опорний блок для того, щоб зовні кодувати блок в подальшому зображенні. Фіг. 3 є блок-схемою, що ілюструє зразковий відеодекодер 30, який може реалізовувати способи, описані в цьому розкритті суті для прогнозування векторів руху при багатовидовому кодуванні. У прикладі за фіг. 3, відеодекодер 30 включає в себе модуль 80 ентропійного декодування, модуль 81 прогнозування, модуль 86 оберненого квантування, модуль 88 оберненого перетворення, суматор 90 і запам'ятовуючий пристрій 92 опорних зображень. 15 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 Модуль 81 прогнозування включає в себе модуль 82 компенсації руху і модуль 84 внутрішнього прогнозування. Під час процесу декодування відеодекодер 30 приймає кодований потік відеобітів, який представляє відеоблоки кодованого зрізу, і асоційовані елементи синтаксису з відеокодера 20. Модуль 80 ентропійного декодування відеодекодера 30 ентропійно декодує потік бітів, щоб генерувати квантовані коефіцієнти, вектори руху та інші елементи синтаксису. Модуль 80 ентропійного декодування перенаправляє вектори руху та інші елементи синтаксису в модуль 81 прогнозування. Відеодекодер 30 може приймати елементи синтаксису на рівні зрізу і/або на рівні відеоблока. Наприклад, як вихідну інформацію, відеодекодер 30 може приймати стиснуті відеодані, які стиснуті для передачі через мережу в так звані "одиниці рівня абстрагування від мережі" або NAL-одиниці. Кожна NAL-одиниця може включати в себе заголовок, який ідентифікує тип даних, збережених до NAL-одиниці. Існує два типи даних, які звичайно зберігаються в NAL-одиницях. Перший тип даних, збережених до NAL-одиниці, являє собою дані рівня кодування відео (VCL), які включають в себе стиснуті відеодані. Другий тип даних, збережених в NAL-одиниці, називається "не-VCL-даними", які включають в себе додаткову інформацію, таку як набори параметрів, які задають дані заголовка, загальні для великого числа NAL-одиниць, і додаткову поліпшуючу інформацію (SEI). Наприклад, набори параметрів можуть містити інформацію заголовка рівня послідовності (наприклад, в наборах параметрів послідовності (SPS)) і нечасто інформацію заголовка рівня зображення, що змінюється, (наприклад, в наборах параметрів зображення (PPS)). Нечасто інформація, що змінюється, яка міститься в наборах параметрів, не повинна повторюватися для кожної послідовності або зображення, внаслідок цього підвищуючи ефективність кодування. Крім цього, використання наборів параметрів забезпечує позасмугову передачу інформації заголовка, за рахунок цього виключаючи необхідність надмірних передач для стійкості до помилок. Коли зріз відео кодується як внутрішньо-кодований (I-) зріз, модуль 84 внутрішнього прогнозування модуля 81 прогнозування може генерувати дані прогнозування для відеоблока поточного зрізу на основі режиму внутрішнього прогнозування, що передається в службових сигналах, і даних з раніше декодованих блоків поточного зображення. Коли зображення кодується як зовні-кодований зріз (тобто B-, Р- або GPB-) макроблоків, модуль 82 компенсації руху модуля 81 прогнозування формує прогнозуючі блоки для відеоблока поточного зрізу на основі векторів руху та інших елементів синтаксису, що приймаються з модуля 80 ентропійного декодування. Прогнозуючі блоки можуть генеруватися з одного з опорних зображень в одному зі списків опорних зображень. Відеодекодер 30 може складати списки опорних зображень, список 0 і список 1, з використанням технологій складання за умовчанням на основі опорних зображень, збережених в запам'ятовуючому пристрої 92 опорних зображень. Модуль 82 компенсації руху визначає інформацію прогнозування для відеоблока поточного зрізу за допомогою синтаксичного аналізу векторів руху та інших елементів синтаксису і використовує інформацію прогнозування, щоб генерувати прогнозуючі блоки для поточного декодованого відеоблока. Наприклад, модуль 82 компенсації руху використовує деякі з елементів синтаксису, що приймаються, для того, щоб визначати режим прогнозування (наприклад, внутрішнє або зовнішнє прогнозування), що використовується для того, щоб кодувати відеоблоки зрізу, тип зрізу зовнішнього прогнозування (наприклад, В-зріз, Р-зріз або GPB-зріз), інформацію складання для одного або більше списків опорних зображень для зрізу, вектори руху для кожного зовні-кодованого відеоблока зрізу, стан зовнішнього прогнозування для кожного зовні-кодованого відеоблока зрізу та іншу інформацію для того, щоб декодувати відеоблоки в поточному зрізі. У деяких прикладах модуль 82 компенсації руху може приймати визначену інформацію руху з модуля 83 прогнозування векторів руху. Згідно з аспектами цього розкриття суті, модуль 83 прогнозування векторів руху може приймати дані прогнозування, що вказують те, де витягувати інформацію руху для поточного блока. Наприклад, модуль 83 прогнозування векторів руху може приймати інформацію прогнозування векторів руху, таку як MVP-індекс (mvp_flag), MVD, прапор злиття (merge_flag) і/або індекс злиття (merge_idx), і використовувати цю інформацію для того, щоб ідентифікувати інформацію руху, що використовується для того, щоб прогнозувати поточний блок. Іншими словами, як зазначено вище відносно відеокодера 20, згідно з аспектами цього розкриття суті, модуль 83 прогнозування векторів руху може приймати MVP-індекс (mvp_flag) і MVD і використовувати цю інформацію для того, щоб визначати вектор руху, що використовується для того, щоб прогнозувати поточний блок. Модуль 83 прогнозування векторів руху може генерувати список кандидатів MVP або злиття. Згідно з аспектами цього розкриття суті, кандидати MVP 16 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 і/або злиття можуть включати в себе один або більше відеоблоків, розташованих у відмінному виді відносно відеоблока, в даний момент декодованого. Модуль 83 прогнозування векторів руху може використовувати MVP або індекс злиття, щоб ідентифікувати інформацію руху, що використовується для того, щоб прогнозувати вектор руху поточного блока. Іншими словами, наприклад, модуль 83 прогнозування векторів руху може ідентифікувати MVP зі списку опорного зображення з використанням MVP-індексу (mvp_flag). Модуль 83 прогнозування векторів руху може комбінувати ідентифікований MVP з MVD, що приймається, щоб визначати вектор руху для поточного блока. В інших прикладах модуль 83 прогнозування векторів руху може ідентифікувати кандидата злиття зі списку опорних зображень з використанням індексу злиття (merge_idx), щоб визначати інформацію руху для поточного блока. У будь-якому випадку, після визначення інформації руху для поточного блока, модуль 83 прогнозування векторів руху може генерувати прогнозуючий блок для поточного блока. Згідно з аспектами цього розкриття суті, модуль 83 прогнозування векторів руху може визначати предиктор вектора руху при багатовидовому кодуванні. Наприклад, модуль 83 прогнозування векторів руху може приймати інформацію, що вказує вектор диспаратності руху, з блока у відмінному компоненті виду відносно поточного блока, який використовується для того, щоб прогнозувати вектор руху для поточного блока. В інших прикладах модуль 83 прогнозування векторів руху може приймати інформацію, що ідентифікує часовий вектор руху, з блока у відмінному компоненті виду відносно поточного блока, який використовується для того, щоб прогнозувати вектор руху для поточного блока. Що стосується прогнозування векторів диспаратності руху, модуль 83 прогнозування векторів руху може прогнозувати вектор диспаратності руху для поточного блока з кандидата блока. Кандидат блока може знаходитися в зображенні, ідентичному зображенню поточного блока (наприклад, просторово гранично з кандидатом блока), або може знаходитися в іншому зображенні у виді, ідентичному з видом поточного блока. Кандидат блока також може знаходитися в зображенні іншого виду, але в момент часу, ідентичний з моментом часу для поточного блока. Наприклад, відносно MVP або відносно режиму злиття, відомі (раніше визначені) цільове зображення і опорне зображення для вектора А диспаратності руху поточного блока, який повинен бути прогнозований. З метою пояснення припустимо, що вектор руху з кандидата блока являє собою "B". Згідно з аспектами цього розкриття суті, якщо вектор В руху не є вектором диспаратності руху, модуль 83 прогнозування векторів руху може вважати кандидата блока недоступним (наприклад, недоступним для прогнозування вектора А руху). Іншими словами, модуль 83 прогнозування векторів руху може деактивувати можливість використовувати кандидата блока з метою прогнозування векторів руху. Якщо вектор В руху є вектором диспаратності руху, і опорне зображення вектора В руху належить виду, ідентичному виду опорного зображення вектора А диспаратності руху, і цільове зображення вектора В руху належить виду, ідентичному виду цільового зображення вектора А диспаратності руху, модуль 83 прогнозування векторів руху може використовувати вектор В руху безпосередньо як предиктор кандидата вектора А руху. В іншому випадку, модуль 83 прогнозування векторів руху може масштабувати вектор В диспаратності руху до того, як він може бути використаний як предиктор кандидата вектора А руху. У таких випадках, згідно з технологіями цього розкриття суті, модуль 83 прогнозування векторів руху може масштабувати вектор диспаратності руху на основі відстані для виду вектора А руху і відстаней для виду вектора В руху. Наприклад, модуль 83 прогнозування векторів руху може масштабувати вектор В диспаратності руху за допомогою коефіцієнта масштабування, який дорівнює відстані для виду вектора А руху, діленому на відстань для виду вектора В руху. У деяких прикладах модуль 83 прогнозування векторів руху може виконувати таке масштабування з використанням ідентифікаторів видів опорних зображень і цільових зображень. Що стосується часового прогнозування векторів руху, модуль 83 прогнозування векторів руху може прогнозувати часовий вектор руху для поточного блока з кандидата блока у відмінному виді відносно виду поточного блока. Наприклад, модуль 83 прогнозування векторів руху може ідентифікувати кандидата часового предиктора вектора руху, що має цільове зображення в першому виді, який посилається на блок в опорному зображенні в іншому часовому місцеположенні першого виду. Згідно з аспектами цього розкриття суті, модуль 83 прогнозування векторів руху може використовувати ідентифікованого кандидата часового предиктора вектора руху для того, щоб прогнозувати вектор руху, асоційований з поточним блоком у другому іншому виді. 17 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 Наприклад, відносно MVP або відносно режиму злиття, відомі (раніше визначені) цільове зображення та опорне зображення для часового вектора А руху поточного блока, який повинен бути прогнозований. З метою пояснення припустимо, що вектор руху з кандидата блока являє собою "B". Згідно з аспектами цього розкриття суті, якщо вектор В руху з кандидата блока не є часовим вектором руху, модуль 83 прогнозування векторів руху може вважати кандидата блока недоступним (наприклад, недоступним для прогнозування вектора А руху). Іншими словами, В деяких прикладах модуль 83 прогнозування векторів руху може деактивувати можливість використовувати кандидата блока з метою прогнозування векторів руху. Якщо вектор В руху є часовим вектором руху, і POC опорного зображення вектора В руху є ідентичним опорному зображенню вектора А руху, і POC цільового зображення вектора В руху є ідентичним цільовому зображенню вектора В руху, модуль 83 прогнозування векторів руху може використовувати вектор В руху безпосередньо як предиктор кандидата вектора А руху. В іншому випадку, модуль 83 прогнозування векторів руху може масштабувати часовий вектор В руху на основі часової відстані. Кандидат блока (який включає в себе кандидата предиктора вектора руху) і поточний блок можуть спільно розміщуватися в іншому виді. Проте, відносне місцеположення кандидата блока може зміщатися від поточного блока внаслідок диспаратності між двома видами. Модуль 86 оберненого квантування обернено квантує, тобто деквантує, квантовані коефіцієнти перетворення, надані в потоці бітів і декодовані за допомогою модуля 80 ентропійного декодування. Процес оберненого квантування може включати в себе використання параметра квантування, обчисленого за допомогою відеокодера 20 для кожного відеоблока в зрізі, щоб визначати ступінь квантування і, аналогічно, ступінь оберненого квантування, яке повинне застосовуватися. Модуль 88 оберненого перетворення застосовує обернене перетворення, наприклад, обернене DCT, обернене цілочисельне перетворення або концептуально аналогічний процес оберненого перетворення, до коефіцієнтів перетворення, щоб генерувати залишкові блоки в піксельній діялнці. Згідно з аспектами цього розкриття суті, модуль 88 оберненого перетворення може визначати спосіб, яким перетворення застосовані до залишкових даних. Іншими словами, наприклад, модуль 88 оберненого перетворення може визначати RQT, яке представляє спосіб, яким перетворення (наприклад, DCT, цілочисельне перетворення, вейвлет-перетворення або одне або більше інших перетворень) застосовані до залишкових вибірок сигналу яскравості та залишкових вибірок сигналу кольоровості, асоційованих з блоком відеоданих, що приймаються. Після того, як модуль 82 компенсації руху формує прогнозуючий блок для поточного відеоблока на основі векторів руху та інших елементів синтаксису, відеодекодер 30 формує декодований відеоблок за допомогою підсумовування залишкових блоків з модуля 88 оберненого перетворення з відповідними прогнозуючими блоками, сформованими за допомогою модуля 82 компенсації руху. Суматор 90 представляє компонент або компоненти, які виконують цю операцію підсумовування. Якщо потрібно, фільтр видалення блочності також може бути застосований для того, щоб фільтрувати декодовані блоки, щоб видаляти артефакти блочності. Інші контурні фільтри (в контурі кодування або після контуру кодування) також можуть бути використані для того, щоб згладжувати піксельні переходи або іншим чином підвищувати якість відео. Декодовані відеоблоки в даному зображенні потім зберігаються в запам'ятовуючому пристрої 92 опорних зображень, який зберігає опорні зображення, що використовуються для подальшої компенсації руху. Запам'ятовуючий пристрій 92 опорних зображень також зберігає декодоване відео для подальшого представлення відносно пристрою відображення, такого як пристрій 32 відображення за фіг. 1. Фіг. 4 є концептуальною схемою, що ілюструє зразковий шаблон MVC-прогнозування. У прикладі за фіг. 4, проілюстровані вісім видів, і дванадцять часових місцеположень проілюстровані для кожного виду. Загалом, кожний рядок на фіг. 4 відповідає виду, в той час як кожний стовпець вказує часове місцеположення. Кожний з видів може бути ідентифікований з використанням ідентифікатора виду ("view_id"), який може бути використаний для того, щоб вказувати відносне місцеположення камери відносно інших видів. У прикладі, показаному на фіг. 4, ідентифікатори видів вказуються як "S0-S7", хоча числові ідентифікатори видів також можуть бути використані. Крім цього, кожне з часових місцеположень може бути ідентифіковане з використанням значення номера в послідовності зображень (POC), яке вказує порядок відображення зображень. У прикладі, показаному на фіг. 4, РОС-значення вказуються як "T0T11". Хоча MVC має так званий базовий вид, який може декодуватися за допомогою H.264/AVCдекодерів, і пара стереовидів може підтримуватися за допомогою MVC, MVC може 18 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 підтримувати більше двох видів як трьохмірного відеовводу. Відповідно, модуль рендерингу клієнта, що має MVC-декодер, може чекати трьохмірний відеоконтент з декількома видами. Зображення на фіг. 4 вказуються з використанням затіненого блока, що включає в себе літеру, що позначає те, відповідне зображення внутрішньо кодується (тобто як I-кадр) або зовні кодується в одному напрямку (тобто як Р-кадр) або в декількох напрямках (тобто як В-кадр). Загалом, прогнозування вказуються за допомогою стрілок, при цьому зображення, що вказується, використовує вказуючий об'єкт для опорного елемента прогнозування. Наприклад, Р-кадр виду S2 у часовому місцеположенні T0 прогнозується з I-кадру виду S0 у часовому місцеположенні T0. Аналогічно кодуванню одновидового відео, зображення послідовності багатовидового відео можуть бути прогнозовано кодовані відносно зображень в різних часових місцеположеннях. Наприклад, b-кадр виду S0 у часовому місцеположенні T1 має стрілку, що вказує на нього з Iкадру виду S0 у часовому місцеположенні T0, що показує те, що b-кадр прогнозується з I-кадру. Проте, додатково, в контексті кодування багатовидового відео, зображення можуть міжвидово прогнозуватися. Іншими словами, компонента виду може використовувати компоненти видів у інших видах для опорних елементів. У MVC, наприклад, реалізовується міжвидове прогнозування, неначе компонента виду в іншому виді є опорним елементом зовнішнього прогнозування. Потенційні міжвидові опорні елементи можуть бути передані в службових сигналах в MVC-розширенні набору параметрів послідовності (SPS) і можуть бути модифіковані за допомогою процесу складання списку опорних зображень, який забезпечує гнучке упорядкування опорних елементів зовнішнього прогнозування або міжвидового прогнозування. Фіг. 4 надає різні приклади міжвидового прогнозування. Зображення виду S1, в прикладі за фіг. 4, проілюстровані як такі, що прогнозуються із зображень в різних часових місцеположеннях виду S1, а також міжвидово передбачені із зображень для зображень видів S0 та S2 в ідентичних часових місцеположеннях. Наприклад, b-кадр виду S1 у часовому місцеположенні T1 прогнозується з кожного з В-кадрів виду S1 у часових місцеположеннях T0 та T2, а також bкадрів видів S0 та S2 у часовому місцеположенні T1. У прикладі за фіг. 4, заголовна літера "B" і мала літера "b" мають намір вказувати різні ієрархічні взаємозв'язки між зображеннями, а не різні способи кодування. Загалом, кадри із заголовної літери "B" розташовуються відносно вище в ієрархії прогнозування, ніж кадри з малої літери "b". Фіг. 4 також ілюструє зміни в ієрархії прогнозування з використанням різних рівнів затінення, при цьому зображення з більшою величиною затінення (тобто відносно темніші) розташовуються вище в ієрархії прогнозування, ніж зображення, що мають менше затінення (тобто відносно світліші). Наприклад, всі I-кадри на фіг. 4 проілюстровані з повним затіненням, в той час як Р-кадри мають певною мірою світліше затінення, і В-кадри (і кадри з малої літери b) мають різні рівні затінення відносно один одного, але завжди світліше затінення Р-кадрів та Iкадри. Загалом, ієрархія прогнозування зв'язана з індексами порядку видів таким чином, що зображення відносно вище в ієрархії прогнозування повинні бути декодовані до декодувань зображень, які розташовуються відносно нижче в ієрархії, так що зображення відносно вище в ієрархії можуть бути використані як опорні зображення під час декодування зображень, відносно нижче в ієрархії. Індекс порядку видів є індексом, який вказує порядок декодування компонент видів у одиниці доступу. Індекси порядку видів можуть матися на увазі в наборі параметрів, наприклад, SPS. Таким чином, зображення, що використовуються як опорні зображення, можуть бути декодовані до декодування зображень, які кодуються відносно опорних зображень. Індекс порядку видів є індексом, який вказує порядок декодування компонент видів в одиниці доступу. Для кожного індексу i порядку видів відповідний view_id передається в службових сигналах. Декодування компонент видів дотримується порядку за зростанням індексів порядку видів. Якщо всі види представляються, то набір індексів порядку видів містить послідовно впорядкований набір від нуля до на одиницю менше повного числа видів. У MVC піднабір всього потоку бітів може бути витягнутий для того, щоб генерувати субпотік бітів, який як і раніше відповідає MVC. Існує множина можливих субпотоків бітів, яких можуть вимагати конкретні додатки, на основі, наприклад, послуг, що надаються за допомогою сервера, пропускної здатності, підтримки і характеристик декодерів одного або більше клієнтів і/або переваг одного або більше клієнтів. Наприклад, клієнт може вимагати тільки трьох видів, і може бути передбачено два сценарії. В одному прикладі один клієнт може вимагати плавного враження від перегляду і може віддавати перевагу видам зі значеннями view_id в S0, S1 та S2, в той час як інший клієнт може вимагати масштабованість виду і віддавати перевагу видам зі 19 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 значеннями view_id в S0, S2 та S4. Зазначимо, що обидва з цих субпотоків бітів можуть бути декодовані як незалежні MVC-потоки бітів і можуть підтримуватися одночасно. Фіг. 5 є блок-схемою, що ілюструє потенційні кандидати предикторів вектора руху при виконанні прогнозування векторів руху (що включає в себе режим злиття). Іншими словами, для блока 100, в даний момент кодованого, інформація руху (наприклад, вектор руху, що містить горизонтальну компоненту і вертикальну компоненту, індекси векторів руху, напрямки прогнозування або іншу інформацію) із сусідніх блоків A0, A1, B0, B1 та B2 може бути використана для того, щоб прогнозувати інформацію руху для блока 100. Крім цього, інформація руху, асоційована зі спільно розміщеним блоком COL, також може бути використана для того, щоб прогнозувати інформацію руху для блока 100. Сусідні блоки A0, A1, B0, B1 та B2 і спільно розміщений блок COL, в контексті прогнозування векторів руху, можуть, загалом, називатися нижче "можливими варіантами предикторів вектора руху". У деяких прикладах кандидати предикторів вектора руху, показані на фіг. 5, можуть бути ідентифіковані при виконанні прогнозування векторів руху (наприклад, при формуванні MVD або при виконанні режиму злиття). В інших прикладах різні кандидати можуть бути ідентифіковані при виконанні режиму злиття і прогнозування векторів руху. Іншими словами, відеокодер може ідентифікувати відмінний набір кандидатів предикторів вектора руху для виконання режиму злиття відносно виконання прогнозування векторів руху. Щоб виконувати режим злиття, в прикладі, відеокодер (наприклад, відеокодер 20) може спочатку визначати те, які вектори руху з кандидатів предикторів вектора руху доступні для того, щоб зливатися з блоком 100. Іншими словами, в деяких випадках, інформація руху з одного або більше кандидатів предикторів вектора руху може бути недоступна внаслідок, наприклад, внутрішньо кодованого, ще не кодованого або не існуючого кандидата предиктора вектора руху (наприклад, один або більше кандидатів предикторів вектора руху знаходяться в іншому зображенні або зрізу). Відеокодер 20 може складати список кандидатів предикторів вектора руху, який включає в себе кожний з доступних кандидатів блоків предикторів вектора руху. Після складання списку кандидатів відеокодер 20 може вибирати вектор руху зі списку кандидатів, який повинен бути використаний як вектор руху для поточного блока 100. У деяких прикладах відеокодер 20 може вибирати вектор руху зі списку кандидатів, який краще усього співпадає з вектором руху для блока 100. Іншими словами, відеокодер 20 може вибирати вектор руху зі списку кандидатів згідно з аналізом спотворення залежно від швидкості передачі. Відеокодер 20 може надавати індикатор того, що блок 100 кодується з використанням режиму злиття. Наприклад, відеокодер 20 може задавати прапор або інший елемент синтаксису, який вказує, що вектор руху для блока 100 прогнозується з використанням режиму злиття. У прикладі, відеокодер 20 може вказувати, що параметри зовнішнього прогнозування для блока 100 логічно виводяться з кандидата предиктора вектора руху за допомогою завдання merge_flag [x0][y0]. У цьому прикладі, індекси x0, y0 масиву можуть вказувати місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості прогнозуючого блока відносно верхньої лівої вибірки сигналу яскравості зображення (або зрізу). Крім цього, у деяких прикладах відеокодер 20 може надавати індекс, що ідентифікує кандидата злиття, з якого блок 100 успадковує свій вектор руху. Наприклад, merge_idx [x0][y0] може вказувати індекс кандидата злиття, який ідентифікує зображення в списку кандидатів злиття, де x0, y0 вказує місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості прогнозуючого блока відносно верхньої лівої вибірки сигналу яскравості зображення (або зрізу). Відеодекодер (наприклад, відеодекодер 30) може виконувати аналогічні етапи, щоб ідентифікувати належного кандидата злиття при декодуванні блока 100. Наприклад, відеодекодер 30 може приймати індикатор того, що блок 100 прогнозується з використанням режиму злиття. У прикладі, відеодекодер 30 може приймати merge_flag [x0][y0], де (x0, y0) вказує місцеположення верхньої лівої вибірки сигналу яскравості прогнозуючого блока відносно верхньої лівої вибірки сигналу яскравості зображення (або зрізу). Крім цього, відеодекодер 30 може складати список кандидатів злиття. Наприклад, відеодекодер 30 може приймати один або більше елементів синтаксису (наприклад, прапорів), що вказують відеоблоки, які доступні для прогнозування векторів руху. Відеодекодер 30 може складати список кандидатів злиття на основі прапорів, що приймаються. Згідно з деякими прикладами, відеодекодер 30 може складати список кандидатів злиття (наприклад, mergeCandList) згідно з наступною послідовністю: 1 A1, якщо availableFlagA1 рівний 1 2. B1, якщо availableFlagB1 рівний 1 3. B0, якщо availableFlagB0 рівний 1 20 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 4. A0, якщо availableFlagA0 рівний 1 5. B2, якщо availableFlagB2 рівний 1 6. Col, якщо availableFlagCol рівний 1 Якщо декілька кандидатів злиття мають ідентичні вектори руху та ідентичні опорні індекси, кандидати злиття можуть видалятися зі списку. Відеодекодер 30 може ідентифікувати належного кандидата злиття згідно з індексом, що приймається. Наприклад, відеодекодер 30 може приймати індекс, що ідентифікує кандидата злиття, з якого блок 100 успадковує свій вектор руху. У прикладі, merge_idx [x0][y0] може вказувати індекс кандидата злиття, який ідентифікує зображення в списку кандидатів злиття, де x0, y0 вказує місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості прогнозуючого блока відносно верхньої лівої вибірки сигналу яскравості зображення (або зрізу). У деяких прикладах відеодекодер 30 може масштабувати предиктор вектора руху до злиття інформації руху кандидата блока з блоком 100. Наприклад, відносно часового предиктора вектора руху, якщо предиктор вектора руху посилається на прогнозуючий блок в опорному зображенні, який знаходиться у відмінному часовому місцеположенні відносно прогнозуючого блока, на який посилається блок 100 (наприклад, фактичний вектор руху для блока 100), відеодекодер 30 може масштабувати предиктор вектора руху. Наприклад, відеодекодер 30 може масштабувати предиктор вектора руху таким чином, що він посилається на опорне зображення, ідентичне опорному зображенню для блока 100. У деяких прикладах відеодекодер 30 може масштабувати предиктор вектора руху згідно з різницею в значеннях номера в послідовності зображень (POC). Іншими словами, відеодекодер 30 може масштабувати предиктор вектора руху на основі різниці між РОС-відстанню між кандидатом блока і прогнозуючим блоком, на який посилається предиктор вектора руху, і РОС-відстанню між блоком 100 і поточним опорним зображенням (наприклад, на яке посилається фактичний вектор руху для блока 100). Після вибору належного предиктора вектора руху відеодекодер 30 може здійснювати злиття інформації руху, асоційованої з предиктором вектора руху, з інформацією руху для блока 100. Аналогічний процес може бути реалізований за допомогою відеокодера 20 і відеодекодера 30, щоб виконувати прогнозування векторів руху для поточного блока відеоданих. Наприклад, відеокодер 20 може спочатку визначати те, які вектори руху з кандидатів предикторів вектора руху доступні для використання як MVP. Інформація руху з одного або більше кандидатів предикторів вектора руху може бути недоступна внаслідок, наприклад, внутрішньо кодованого, ще не кодованого або не існуючого кандидата предиктора вектора руху. Щоб визначати те, які з кандидатів предикторів вектора руху доступні, відеокодер 20 може аналізувати кожний з кандидатів предикторів вектора руху почергово згідно із заздалегідь визначеною схемою на основі пріоритету. Наприклад, для кожного кандидата предиктора вектора руху, відеокодер 20 може визначати те, посилається чи ні предиктор вектора руху на опорне зображення, ідентичне опорному зображенню фактичного вектора руху для блока 100. Якщо предиктор вектора руху посилається на ідентичне опорне зображення, відеокодер 20 може додавати кандидата предиктора вектора руху в список кандидатів MVP. Якщо предиктор вектора руху не посилається на ідентичне опорне зображення, предиктор вектора руху може масштабуватися (наприклад, масштабуватися на основі РОС-відстаней, як пояснено вище) перед додаванням в список кандидатів MVP. Відносно спільно розміщеного блока COL, якщо спільно розміщений блок включає в себе декілька предикторів вектора руху (наприклад, COL прогнозується як В-кадр), відеокодер 20 може вибирати один з часових предикторів вектора руху згідно з поточним списком і поточним опорним зображенням (для блока 100). Відеокодер 20 потім може додавати вибраний часовий предиктор вектора руху в список кандидатів предикторів вектора руху. Відеокодер 20 може передавати в службових сигналах те, що один або більше предикторів вектора руху доступні, за допомогою завдання enable_temporal_mvp_flag. Після компонування списку кандидатів відеокодер 20 може вибирати вектор руху з кандидатів, який повинен використовуватися як предиктор вектора руху для блока 100. У деяких прикладах відеокодер 20 може вибирати кандидата вектора руху згідно з аналізом спотворення залежно від швидкості передачі. Відеокодер 20 може передавати в службових сигналах вибраний предиктор вектора руху з використанням MVP-індексу (mvp_flag), який ідентифікує MVP в списку кандидатів. Наприклад, відеокодер 20 може задавати mvp_l0_flag [x0][y0], щоб вказувати індекс предиктора вектора руху списку 0, де x0, y0 вказує місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості кандидата блока відносно верхньої лівої вибірки сигналу яскравості зображення. В іншому прикладі відеокодер 20 може задавати mvp_l1_flag [x0][y0], щоб вказувати індекс предиктора 21 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 вектора руху списку 1, де x0, y0 вказує місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості кандидата блока відносно верхньої лівої вибірки сигналу яскравості зображення. У ще одному іншому прикладі, відеокодер 20 може задавати mvp_lc_flag [x0][y0], щоб вказувати індекс предиктора вектора руху списку с, де x0, y0 вказує місцеположення (x0, y0) верхньої лівої вибірки сигналу яскравості кандидата блока відносно верхньої лівої вибірки сигналу яскравості зображення. Відеокодер 20 також може генерувати значення різниці векторів руху (MVD). MVD може складати різницю між вибраним предиктором вектора руху і фактичним вектором руху для блока 100. Відеокодер 20 може передавати в службових сигналах MVD з MVP-індексом. Відеодекодер 30 може виконувати аналогічні операції, щоб визначати вектор руху для поточного блока з використанням предиктора вектора руху. Наприклад, відеодекодер 30 може приймати індикатор в наборі параметрів (наприклад, в наборі параметрів зображення (PPS)), що вказує те, що прогнозування векторів руху активується для одного або більше зображень. Іншими словами, в прикладі, відеодекодер 30 може приймати enable_temporal_mvp_flag в PPS. Коли конкретне зображення звертається до PPS, що має enable_temporal_mvp_flag, рівне нулю, опорні зображення в запам'ятовуючому пристрої опорних зображень можуть позначатися як такі, "що не використовуються для часового прогнозування векторів руху". Якщо реалізовується прогнозування векторів руху, після прийому блока 100 відеодекодер 30 може складати список кандидатів MVP. Відеодекодер 30 може використовувати ідентичну схему, пояснену вище відносно відеокодера 20, для того щоб складати список кандидатів MVP. У деяких випадках, відеодекодер 30 може виконувати масштабування векторів руху, аналогічне масштабуванню векторів руху, описаному вище відносно відеокодера 20. Наприклад, якщо предиктор вектора руху не посилається на опорне зображення, ідентичне опорному зображенню для блока 100, предиктор вектора руху може масштабуватися (наприклад, масштабуватися на основі РОС-відстаней, як пояснено вище) перед додаванням у список кандидатів MVP. Відеодекодер 30 може ідентифікувати належний предиктор вектора руху для блока 100 з використанням MVP-індексу (mvp_flag), що приймається, який ідентифікує MVP в списку кандидатів. Відеодекодер 30 потім може генерувати вектор руху для блока 100 з використанням MVP та MVD, що приймається. Фіг. 5, загалом, ілюструє режим злиття і прогнозування векторів руху в одному виді. Потрібно розуміти, що кандидати блоків предикторів вектора руху, показані на фіг. 5, надаються тільки з метою прикладу, більше число, менше число або інші блоки можуть використовуватися для цілей прогнозування інформації руху. Згідно з аспектами цього розкриття суті, як описано нижче, режим злиття і прогнозування векторів руху також можуть застосовуватися, коли кодуються декілька видів (наприклад, в MVC). У таких випадках, предиктори вектора руху і прогнозуючі блоки можуть знаходитися у відмінних видах відносно блока 100. Фіг. 6 є концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху при багатовидовому кодуванні. Наприклад, згідно з аспектами цього розкриття суті, відеокодер (наприклад, відеокодер 20 або відеодекодер 30) може масштабувати вектор 120 диспаратності руху (mv) з кандидата 122 блока предиктора вектора диспаратності руху ("кандидата блока"), щоб генерувати предиктор 124 вектора руху (mv') для поточного блока 126. Хоча фіг. 6 описується відносно відеодекодера 30, потрібно розуміти, що способи цього розкриття суті можуть виконуватися за допомогою множини інших відеокодерів, що включають в себе інші процесори, модулі обробки, апаратні модулі кодування, такі як кодери/декодери (кодеки) тощо. У прикладі за фіг. 6, кандидат 122 блока просторово сусідує з поточним блоком 126 в компоненті виду два (view_id 2). Кандидат 122 блока зовні прогнозується і включає в себе вектор 120 руху, який посилається (або "вказує") на прогнозуючий блок в компоненті виду нуль (view_id 0). Наприклад, вектор 120 руху має цільове зображення у виді два (view_id 2) і опорне зображення у виді нуль (view_id 0). Поточний блок 126 також зовні прогнозується і включає в себе фактичний вектор руху (не показаний), який посилається на прогнозуючий блок в компоненті виду один (view_id 1). Іншими словами, наприклад, фактичний вектор руху для поточного блока 126 має цільове зображення у виді два (view_id 2) і опорний блок у виді один (view_id 1). Згідно з аспектами цього розкриття суті, відеодекодер 30 може генерувати предиктор 124 вектора руху для поточного блока 126 з використанням масштабованої версії вектора 120 руху. Наприклад, відеодекодер 30 може масштабувати вектор 120 руху на основі різниці у відстанях для виду між вектором 120 руху і фактичним вектором руху для поточного блока 126. Іншими словами, відеодекодер 30 може масштабувати вектор 120 руху на основі різниці між місцеположенням камери для камери, що використовується для того, щоб захоплювати 22 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 прогнозуючий блок (в опорному зображенні) для кандидата 122 блока і прогнозуючий блок (в опорному зображенні) для поточного блока 126. Відповідно, відеодекодер 30 може масштабувати вектор 120 диспаратності руху (наприклад, вектор руху, що використовується для прогнозування) згідно з різницею між компонентою виду, на який посилається вектор 120 руху для кандидата 122 блока, і компонентою виду, на який посилається фактичний вектор руху для поточного блока 126. У прикладі, відеодекодер 30 може генерувати масштабований предиктор вектора руху для поточного блока згідно з рівнянням (1), показаним нижче: View Distan ce(mv ' ) mv ' mv View Distan ce(mv ) , (1) де ViewDistance(mv) дорівнює різниці між ідентифікатором виду опорного зображення вектора 120 руху (наприклад, ViewId(RefPic(mv)) та ідентифікатором виду цільового зображення вектора 120 руху (наприклад, ViewId(TargetPic(mv)), і ViewDistance(mv') дорівнює різниці між ідентифікатором виду опорного зображення предиктора 124 вектора руху (наприклад, ViewId(RefPic(mv')) і ідентифікатором виду цільового зображення предиктора 124 вектора руху (наприклад, ViewId(TargetPic(mv')). Відповідно, в цьому прикладі, опорне зображення предиктора 124 вектора руху, RefPic(mv'), належить новому цільовому виду, і цільове зображення предиктора 124 вектора руху, TargetPic(mv'), належить поточному виду. Аналогічно, опорне зображення вектора 120 руху, RefPic(mv), належить виду, на який вказує кандидат вектора руху, і цільове зображення вектора 120 руху, TargetPic(mv), належить поточному виду. Відповідно, відеодекодер 30 може генерувати масштабований предиктор вектора руху згідно з нижченаведеним рівнянням (2): View ID( NewTarget ) View ID(Current ) mv ' mv View ID(Candidate ) View Id(Current ) , (2) де mv' представляє масштабований предиктор вектора руху для поточного блока, mv представляє вектор руху для кандидата блока, ViewID(NewTarget) є компонентою виду, на який посилається фактичний вектор руху для поточного блока, ViewID(Current) є компонентою виду поточного блока, і ViewID(Candidate) є компонентою виду кандидата блока. При застосуванні рівняння (2) наприклад на фіг. 6, mv' представляє масштабований предиктор вектора руху для поточного блока 126, mv представляє вектор 120 руху, ViewID(NewTarget) є компонентою виду, на який посилається вектор 124 руху, ViewID(Current) є компонентою виду поточного блока 126, і ViewID(Candidate) є компонентою виду кандидата 122 блока. Відповідно, в прикладі, показаному на фіг. 4, предиктор 124 вектора руху є вектором 120 1 2 mv ' mv 0 2 ). Іншими словами, руху, масштабованим на коефіцієнт одна друга (наприклад, відеодекодер 30 може масштабувати як горизонтальну компоненту зміщення, так і вертикальну компоненту зміщення вектора 120 руху на коефіцієнт одна друга, щоб генерувати предиктор 124 вектора руху для поточного блока 126. Масштабування векторів руху, описане відносно фіг. 6, може виконуватися як для злиття, так і для прогнозування векторів руху. Іншими словами, наприклад, відеодекодер 30 може масштабувати вектор 120 руху перед злиттям вектора 120 руху з інформацією руху для поточного блока 126. В іншому прикладі відеодекодер 30 може масштабувати вектор 120 руху перед обчисленням значення різниці вектора руху (MVD) згідно з різницею між предиктором 124 вектора руху і фактичним вектором руху для поточного блока 126. Як показано в прикладі за фіг. 6, кандидат 122 блока і поточний блок 126 можуть знаходитися в ідентичному компоненті виду. Проте, в інших прикладах як детальніше описано відносно фіг. 7 та 8, кандидат блока може знаходитися у відмінному компоненті виду відносно поточного блока. Фіг. 7 є іншою концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху. Наприклад, згідно з аспектами цього розкриття суті, відеокодер (наприклад, відеокодер 20 або відеодекодер 30) може масштабувати вектор 130 диспаратності руху (mv) з кандидата 132 блока предиктора вектора диспаратності руху (x', y'), щоб генерувати предиктор 134 вектора руху (mv') для поточного блока 136 (х, у), причому кандидат 132 блока належить відмінному компоненту виду відносно поточного блока 136. Відповідно, процес, показаний та описаний відносно фіг. 7 може, загалом, називатися "міжвидовим прогнозуванням векторів диспаратності руху". Хоча фіг. 7 описується відносно відеодекодера 30, потрібно розуміти, що способи цього розкриття суті можуть виконуватися за допомогою множини інших 23 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 відеокодерів, що включають в себе інші процесори, модулі обробки, апаратні модулі кодування, такі як кодери/декодери (кодеки) тощо. У прикладі, показаному на фіг. 7, кандидат 132 блока знаходиться в компоненті виду один (view_id 1). Кандидат 132 блока зовні прогнозується і включає в себе вектор 130 руху (mv), який посилається на прогнозуючий блок в компоненті виду нуль (view_id 0). Наприклад, вектор 130 руху має цільове зображення у виді один (view_id 1) і опорне зображення у виді нуль (view_id 0). Поточний блок 136 спільно розміщується з кандидатом 132 блока і знаходиться в компоненті виду два (view_id 2). Як детальніше описано нижче, у деяких прикладах поточний блок 136 може включати в себе фактичний вектор руху (не показаний), який ідентифікує блок в першому опорному виді (view_id 1). Іншими словами, наприклад, фактичний вектор руху для поточного блока 136 має цільове зображення у виді два (view_id 2) і може мати опорний блок у виді один (view_id 1). В інших прикладах поточний блок може включати в себе фактичний вектор руху, який ідентифікує блок у другому опорному виді (view_id 0). Іншими словами, наприклад, фактичний вектор руху для поточного блока 136 має цільове зображення у виді два (view_id 2), і може мати опорний блок у виді нуль (view_id 0). Відповідно, предиктор 134 вектора руху (mv') може посилатися на блок в першому опорному виді (view_id 1). В іншому прикладі другий предиктор 138 вектора руху (mv'') може посилатися на блок у другому опорному виді (view_id 0). У деяких прикладах другий предиктор 138 вектора руху може бути недоступним для прогнозування векторів руху. Наприклад, другий предиктор 138 вектора руху може бути згенерований тільки в тому випадку, якщо прогнозуючий блок у другому опорному виді доступний для прямого міжвидового прогнозування. Доступність прогнозуючого блока у другому опорному виді може вказуватися, наприклад, в наборі параметрів (наприклад, в наборі параметрів послідовності (SPS) або в наборі параметрів зображення (PPS)) або в заголовку зрізу, асоційованому з поточним блоком 136. Згідно з аспектами цього розкриття суті, відеодекодер може виконувати міжвидове прогнозування векторів диспаратності руху з використанням режиму злиття або з використанням прогнозування векторів руху. Відносно режиму злиття відеодекодер 30 може спочатку вибирати "цільовий вид" для поточного блока 136. Загалом, цільовий вид включає в себе прогнозуючий блок для поточного блока 136. У деяких прикладах цільовий вид може бути першим опорним видом (показаний на фіг. 7 як view_id 1). В інших прикладах цільовий вид може бути другим опорним видом (показаний на фіг. 7 як view_id 0). Проте, як зазначено вище, в деяких прикладах другий опорний вид може бути використаний як цільовий вид тільки в тому випадку, якщо прогнозуючий блок у другому опорному виді доступний для використання для цілей міжвидового прогнозування. У деяких прикладах відеодекодер 30 може вибирати перший опорний вид як цільовий вид. В інших прикладах відеодекодер 30 може вибирати, коли доступний, другий опорний вид як цільовий вид. Вибір цільового виду може бути визначений, наприклад, на основі доступності прогнозуючого блока і/або заздалегідь визначеного алгоритму вибору. Опорний індекс (ref_idx) поточного блока 136 відповідає індексу зображення, що містить прогнозуючий блок цільового виду, який додається в список опорних зображень поточного блока 136. Після вибору цільового виду відеодекодер 30 може знаходити кандидат 132 блока. У прикладі з метою ілюстрації припустимо, що верхня ліва вибірка сигналу яскравості поточного блока 136 знаходиться в зображенні (або зрізу) з координатами (х, у). Відеодекодер 30 може визначати спільно розміщені координати в компоненті виду один для кандидата 132 блока. Крім цього, у деяких прикладах відеодекодер 30 може регулювати координати на основі диспаратності між компонентою виду поточного блока 136 (компонентою виду два) і компонентою виду кандидата 132 блока (компонентою виду один). Відповідно, відеодекодер 30 може визначати координати для кандидата 132 блока як (x', y'), де (x', y',)=(х, у)+диспаратність. У деяких прикладах диспаратність може бути включена і/або обчислена в SPS, PPS, заголовку зрізу, синтаксисі CU і/або синтаксисі PU. Після знаходження кандидата 132 блока відеодекодер 30 може масштабувати вектор 130 руху для кандидата 132 блока на основі різниці у відстанях для виду між вектором 130 руху і фактичним вектором руху для поточного блока 136. Іншими словами, відеодекодер 30 може масштабувати вектор 130 руху на основі різниці в місцеположенні камери для камери, що використовується для того, щоб захоплювати прогнозуючий блок для кандидата 132 блока і прогнозуючий блок для поточного блока 136 (наприклад, прогнозуючий блок в цільовому виді). Іншими словами, відеодекодер 30 може масштабувати вектор 130 диспаратності руху (наприклад, вектор руху, що використовується для прогнозування) згідно з різницею між компонентою виду, на який посилається вектор 130 руху для кандидата 132 блока, і компонентою виду для цільового виду. 24 UA 110826 C2 У прикладі, відеодекодер 30 може генерувати масштабований предиктор вектора руху для поточного блока згідно з рівнянням (3), показаним нижче: View ID(Target ) View ID(Current ) mv ' mv View ID(Second Reference ) View Id(Reference ) , (3) 5 10 15 20 25 30 35 40 45 50 55 де mv' представляє масштабований предиктор вектора руху для поточного блока, mv представляє вектор руху для кандидата блока, ViewID(Target) є компонентою виду вибраного цільового виду, ViewID(Current) є компонентою виду поточного блока, і ViewID(SecondReference) є компонентою виду другого опорного виду (за наявності), і ViewID(Reference) є компонентою виду першого опорного виду. У деяких прикладах ViewID(Target) мінус ViewID(Current) може називатися "відстанню для виду" предиктора 134 вектора руху, в той час як ViewID(SecondReference) мінус ViewID(Reference) може називатися "відстанню для виду" вектора 130 руху. Іншими словами, відстань для виду предиктора 134 вектора руху є різницею між цільовим зображенням (view_id 1) і опорним зображенням (view_id 2) предиктора 134 вектора руху, в той час як відстань для виду вектора 130 руху є різницею між цільовим зображенням (view_id 0) та опорним зображенням (view_id 1) вектора 130 руху. При застосуванні рівняння (3) наприклад на фіг. 7, mv' представляє масштабований предиктор 134 вектора руху або масштабований предиктор 138 вектора руху, залежно від того, якій компонента виду вибирається для цільового виду. Наприклад, якщо перший опорний вид (view_id 1) вибирається як цільовий вид, mv' представляє масштабований предиктор 134 вектора руху, mv представляє вектор 130 руху, ViewID(Target) є компонентою виду, на який посилається предиктор 134 вектора руху, ViewID(Current) є компонентою виду поточного блока 136, ViewID(SecondReference) є компонентою виду другого опорного виду (view_id 0), і ViewID(Reference) є компонентою виду першого опорного виду (view_id 1). Відповідно, в прикладі, показаному на фіг. 7, предиктор 134 вектора руху є вектором 130 руху, 1 2 mv ' mv 0 1 ). Іншими словами, масштабованим на коефіцієнт один (наприклад, горизонтальну компоненту зміщення і вертикальну компоненту зміщення вектора 130 руху можуть бути ідентичними горизонтальному компоненту зміщення і вертикальному компоненту зміщення предиктора 134 вектора руху. Альтернативно, якщо другий опорний вид (view_id 0) вибирається для цільового виду, mv' представляє масштабований предиктор 138 вектора руху, mv представляє вектор 130 руху, ViewID(Target) є компонентою виду, на який посилається предиктор 138 вектора руху, ViewID(Current) є компонентою виду поточного блока 136, ViewID(SecondReference) є компонентою виду другого опорного виду (view_id 0)), і ViewID(Reference) є компонентою виду першого опорного виду (view_id 1). Відповідно, в прикладі, показаному на фіг. 7, предиктор 138 вектора руху є вектором 130 руху, масштабованим на коефіцієнт два (наприклад, 0 2 mv ' mv 0 1 ). Іншими словами, відеодекодер 30 може масштабувати як горизонтальну компоненту зміщення, так і вертикальну компоненту зміщення вектора 130 руху на коефіцієнт два, щоб генерувати предиктор 138 вектора руху для поточного блока 136. Згідно з аспектами цього розкриття суті, відеодекодер 30 може виконувати аналогічні етапи при виконанні прогнозування векторів руху (наприклад, формуванні MVP). Наприклад, відеодекодер 30 може вибирати цільовий вид, який може бути першим опорним видом (view_id 1) або другим опорним видом (view_id 0). Проте, якщо опорне зображення компонента виду, що містить прогнозуючий блок для поточного блока, недоступне з метою міжвидового прогнозування, відповідний предиктор не може бути використаний. Відповідно, вибір цільового виду може бути визначений, наприклад, на основі доступності прогнозуючого блока і/або заздалегідь визначеного алгоритму вибору. Якщо прогнозуючий блок для поточного блока 136 недоступний для використання для прямого міжвидового прогнозування в першому опорному виді (view_id 1) або другому опорному виді (view_id 0), відеодекодер 30 не може виконувати прогнозування векторів руху. Якщо щонайменше один прогнозуючий блок доступний, відеодекодер 30 може вибирати опорний вид, який включає в себе прогнозуючий блок, асоційований з фактичним вектором руху для поточного блока 136. Після вибору цільового виду відеодекодер 30 потім може повторювати етапи, описані вище відносно режиму злиття. Наприклад, відеодекодер 30 може знаходити кандидат 132 блока. Іншими словами, відеодекодер 30 може визначати спільно розміщені координати в компоненті виду один для кандидата 132 блока. Крім цього, у деяких прикладах відеодекодер 30 може 25 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 регулювати координати на основі диспаратності між компонентою виду поточного блока 136 (компонентою виду два) і компонентою виду кандидата блока (компонентою виду один) 132. Крім цього, після знаходження кандидата 132 блока, відеодекодер 30 може масштабувати вектор 130 руху для кандидата 132 блока на основі різниці в місцеположенні камери для камери, що використовується для того, щоб захоплювати прогнозуючий блок для кандидата 132 блока і прогнозуючий блок для поточного блока 136 (наприклад, прогнозуючий блок в цільовому виді). Іншими словами, відеодекодер 30 може масштабувати вектор 130 диспаратності руху (наприклад, вектор руху, що використовується для прогнозування) згідно з різницею між компонентою виду, на який посилається вектор 130 руху для кандидата 132 блока, і компонентою виду для цільового виду. У деяких прикладах відеодекодер 30 може виконувати масштабування предикторів вектора руху з використанням вищенаведеного рівняння (2). В інших прикладах як описано відносно фіг. 8 нижче, масштабування предикторів вектора руху може бути розширене до інших видів. Відеодекодер 30 може додавати кандидат 132 блока в список кандидатів при виконанні режиму злиття і/або прогнозування векторів руху (описаного, наприклад, відносно фіг. 5 вище). Згідно з аспектами цього розкриття суті, кандидат блока може додаватися в список кандидатів предикторів вектора руху (наприклад, для режиму злиття або для прогнозування векторів руху з MVP) множиною способів. Наприклад, відеодекодер 30 може складати список кандидатів за допомогою знаходження кандидатів режиму злиття згідно з наступною схемою: 1. A1, якщо availableFlagA1 рівний 1 2. V, якщо availableFlagV рівний 1 3. B1, если availableFlagB1 рівний 1 4. B0, якщо availableFlagB0 рівний 1 5. A0, якщо availableFlagA0 рівний 1 6. B2, якщо availableFlagB2 рівний 1 7. Col, якщо availableFlagCol рівний 1 - де V представляє кандидат 132 блока. В інших прикладах кандидат 132 блока може знаходитися і додаватися в список кандидатів в будь-якій іншій позиції списку кандидатів. Фіг. 8 є іншою концептуальною схемою, що ілюструє генерування і масштабування предиктора вектора руху, згідно з аспектами цього розкриття суті. Наприклад, згідно з аспектами цього розкриття суті, відеокодер (наприклад, відеокодер 20 або відеодекодер 30) може масштабувати вектор 140 диспаратності руху (mv) з кандидата 142 блока предиктора вектора диспаратності руху, щоб генерувати предиктор 144 вектора руху (mv') для поточного блока 146, причому кандидат 142 блока належить відмінному компоненту виду відносно поточного блока 146. Хоча фіг. 8 описується відносно відеодекодера 30, потрібно розуміти, що способи цього розкриття суті можуть виконуватися за допомогою множини інших відеокодерів, що включають в себе інші процесори, модулі обробки, апаратні модулі кодування, такі як кодери/декодери (кодеки) тощо. Приклад, показаний на фіг. 8, розширює прогнозування векторів руху, показане та описане відносно фіг. 7, на оточення, яке включає в себе більше трьох видів. Наприклад, як показано на фіг. 8, кандидат 142 блока знаходиться в компоненті виду два (view_id 2). Кандидат 142 блока зовні прогнозується і включає в себе вектор 140 руху (mv), який посилається на прогнозуючий блок в компоненті виду один (view_id 1). Наприклад, вектор 140 руху має цільове зображення у виді два (view_id 2) і опорне зображення у виді один (view_id 1). Поточний блок 146 спільно розміщується з кандидатом 142 блока і знаходиться в компоненті виду три (view_id 3). Згідно з аспектами цього розкриття суті, відеодекодер 30 може вибирати цільовий вид для поточного блока 146 як компонент виду нуль (view_id 0). Наприклад, цільовий вид, загалом, включає в себе прогнозуючий блок для поточного блока. Якщо зображення, що містить прогнозуючий блок, є міжвидовим опорним зображенням, і прогнозуючий блок для поточного блока 146 знаходиться в третьому опорному виді (view_id 0), відеодекодер 30 може вибирати третій опорний вид як цільовий вид. Після вибору цільового виду відеодекодер 30 може знаходити кандидат 142 блока. Наприклад, за умови, що верхня ліва вибірка сигналу яскравості поточного блока 146 знаходиться в зображенні (або зрізу) з координатами (х, у) в компоненті виду три, відеодекодер 30 може визначати спільно розміщені координати в компоненті виду два для кандидата 142 блока. Крім цього, як зазначено вище, відеодекодер 30 може регулювати координати на основі диспаратності між компонентою виду поточного блока 146 (компонентою виду три) і компонентою виду кандидата 142 блока (компонентою виду два). Після знаходження кандидата 142 блока відеодекодер 30 може масштабувати вектор 140 руху для кандидата 142 блока на основі різниці у відстанях для виду між вектором 140 руху і 26 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 фактичним вектором руху для поточного блока 146. Іншими словами, відеодекодер 30 може масштабувати вектор 130 руху на основі різниці в місцеположенні камери для камери, що використовується для того, щоб захоплювати прогнозуючий блок для кандидата 142 блока і прогнозуючий блок для поточного блока 146 (наприклад, прогнозуючий блок в цільовому виді). Іншими словами, відеодекодер 30 може масштабувати вектор 140 диспаратності руху (наприклад, вектор руху, що використовується для прогнозування) згідно з різницею між компонентою виду, на який посилається вектор 140 руху для кандидата 142 блока, і компонентою виду для цільового виду (view_id 0). У прикладі, відеодекодер 30 може генерувати масштабований предиктор вектора руху для поточного блока згідно з рівнянням (4), показаним нижче: View ID(Third ) View ID(Current ) mv ' mv View ID(Second Reference ) View Id(Reference ) , (4) де mv' представляє масштабований предиктор вектора руху для поточного блока, mv представляє вектор руху для кандидата блока, ViewID(Third) є компонентою виду третього опорного виду, ViewID(Current) є компонентою виду поточного блока, і ViewID(SecondReference) є компонентою виду другого опорного виду (за наявності), і ViewID(Reference) є компонентою виду першого опорного виду. У деяких прикладах ViewID(Third) мінус ViewID(Current) може називатися "відстанню для виду" предиктора 144 вектора руху, в той час як ViewID(SecondReference) мінус ViewID(Reference) може називатися "відстанню для виду" вектора 140 руху. Іншими словами, відстань для виду предиктора 144 вектора руху є різницею між цільовим зображенням (view_id 0) і опорним зображенням (view_id 3) предиктора 144 вектора руху, в той час як відстань для виду вектора 140 руху є різницею між цільовим зображенням (view_id 1) і опорним зображенням (view_id 2) вектора 140 руху. При застосуванні рівняння (3) наприклад на фіг. 8, mv' представляє масштабований предиктор 144 вектора руху. Наприклад, ViewID(Third) є третім опорним видом (view_id 0), mv' представляє масштабований предиктор 144 вектора руху, mv представляє вектор 140 руху, ViewID(Current) є компонентою виду поточного блока 146, ViewID(SecondReference) є компонентою виду другого опорного виду (view_id 1), і ViewID(Reference) є компонентою виду першого опорного виду (view_id 2). Відповідно, в прикладі, показаному на фіг. 8, предиктор 144 вектора руху є вектором 140 руху, масштабованим на коефіцієнт три (наприклад, 03 mv ' mv 1 2 ). Іншими словами, відеодекодер 30 може масштабувати горизонтальну компоненту зміщення і вертикальну компоненту зміщення вектора 140 руху на три, щоб генерувати предиктор 144 вектора руху. Хоча фіг. 7-8 надають приклади для міжвидового прогнозування векторів диспаратності руху, потрібно розуміти, що такі приклади надаються просто з метою ілюстрації. Іншими словами, способи для прогнозування векторів диспаратності руху можуть застосовуватися до більшого або меншого числа видів, ніж показано. Додатково або альтернативно, способи для прогнозування векторів диспаратності руху можуть застосовуватися у випадках, в яких види мають різні ідентифікатори видів. Фіг. 9 є блок-схемою послідовності операцій способу, що ілюструє зразковий спосіб кодування інформації прогнозування для блока відеоданих. Приклад, показаний на фіг. 9, загалом, описується як такий, що виконується за допомогою відеокодера. Потрібно розуміти, що, у деяких прикладах спосіб за фіг. 9 може виконуватися за допомогою відеокодера 20 (фіг. 1 та 2) або відеодекодера 30 (фіг. 1 та 3), описаних вище. В інших прикладах спосіб за фіг. 9 може виконуватися за допомогою множини інших процесорів, модулів обробки, апаратних модулів кодування, таких як кодери/декодери (кодеки) тощо. Згідно із зразковим способом, показаним на фіг. 9, відеокодер може ідентифікувати перший блок відеоданих в першому виді, причому перший блок відеоданих асоційований з першим вектором диспаратності руху (160). Наприклад, вектор руху для першого блока відеоданих може бути вектором диспаратності руху, який ідентифікує опорний блок в іншому компоненті виду. Відеокодер потім може визначати те, є чи ні другий вектор руху, асоційований з другим блоком відеоданих, вектором диспаратності руху (162). Якщо другий вектор руху не є вектором диспаратності руху (гілка "Ні" етапу 162), відеокодер може ідентифікувати інший кандидат предиктора вектора руху (164). Іншими словами, згідно з деякими аспектами цього розкриття суті, можливість використовувати вектор диспаратності руху (наприклад, перший вектор руху) для того, щоб прогнозувати часовий вектор руху (наприклад, другий вектор руху, коли другий вектор руху є часовим вектором руху), може 27 UA 110826 C2 5 10 15 20 25 30 35 40 45 50 55 60 деактивуватися. У таких випадках, відеокодер може ідентифікувати перший вектор руху як недоступний для використання для цілей прогнозування векторів руху. Якщо другий вектор руху є вектором диспаратності руху (гілка "Так" етапу 162), відеокодер може масштабувати перший вектор руху, щоб генерувати предиктор вектора руху для другого вектора руху (166). Наприклад, згідно з аспектами цього розкриття суті, відеокодер може масштабувати перший вектор руху, щоб генерувати предиктор вектора диспаратності руху на основі різниць у відстанях для виду, асоційованих з першим вектором диспаратності руху і другим вектором руху. Іншими словами, у деяких прикладах відеокодер може масштабувати предиктор вектора руху для другого блока на основі місцеположень камери. Наприклад, відеокодер може масштабувати другий вектор руху згідно з різницею в ідентифікаторах видів, як показано та описано відносно фіг. 6-8. Відеокодер потім може кодувати дані прогнозування для другого блока з використанням масштабованого предиктора вектора руху (168). Наприклад, відеокодер може кодувати дані прогнозування для другого блока з використанням режиму злиття або з використанням прогнозування векторів руху. Для режиму злиття відеокодер може безпосередньо кодувати дані прогнозування для другого блока з використанням масштабованого другого предиктора вектора руху. Для прогнозування векторів руху відеокодер може кодувати дані прогнозування для другого блока за допомогою генерування MVD. MVD може включати в себе різницю між першим вектором руху і масштабованим другим вектором руху. Також потрібно розуміти, що етапи, показані та описані відносно фіг. 9, надаються як тільки один приклад. Іншими словами, етапи способу за фіг. 9 не обов'язково повинні виконуватися в порядку, показаному на фіг. 9, і можуть виконуватися менша кількість, додаткові або альтернативні етапи. Фіг. 10 є концептуальною схемою, що ілюструє генерування предиктора вектора руху з блока у відмінному виді відносно поточного блока. Наприклад, згідно з аспектами цього розкриття суті, відеокодер (наприклад, відеокодер 20 або відеодекодер 30) може використовувати часовий вектор 180 руху (mv) з кандидата 182 блока часового предиктора вектора руху для того, щоб генерувати предиктор 184 вектора руху (mv') для поточного блока 186, причому кандидат 182 блока належить відмінному компоненту виду відносно поточного блока 186. Хоча фіг. 10 описується відносно відеодекодера 30, потрібно розуміти, що способи цього розкриття суті можуть виконуватися за допомогою множини інших відеокодерів, що включають в себе інші процесори, модулі обробки, апаратні модулі кодування, такі як кодери/декодери (кодеки) тощо. Як показано на фіг. 10, поточний блок 186 знаходиться в компоненті виду один (view_id 1). Кандидат 182 блока знаходиться в компоненті виду нуль (view_id 0). Кандидат 182 блока часово прогнозується і включає в себе вектор 180 руху (mv), який посилається на прогнозуючий блок в іншому часовому місцеположенні в ідентичному компоненті виду. Іншими словами, в прикладі, показаному на фіг. 10, вектор 180 руху ідентифікує прогнозуючий блок в зображенні, що має опорний індекс, рівний змінній i (ref_idx=i). Припустимо, що верхня ліва вибірка сигналу яскравості поточного блока 186 знаходиться в зображенні (або зрізу) з координатами (х, у). Відеодекодер 30 може знаходити кандидат 182 блока за допомогою визначення спільно розміщених координат в компоненті виду нуль для кандидата 182 блока. У деяких прикладах відеодекодер 30 може регулювати координати кандидата 182 блока на основі диспаратності між компонентою виду поточного блока 186 (view_id 1) і компонентою виду кандидата 182 блока (view_id 0). Відповідно, відеодекодер 30 може визначати координати для кандидата 182 блока як (x', y'), де (x', y')=(х, у)+диспаратність. У деяких прикладах диспаратність може бути включена і/або обчислена в SPS, PPS, заголовку зрізу, синтаксисі CU і/або синтаксисі PU. Згідно з аспектами цього розкриття суті, відеодекодер 30 потім може повторно перетворювати опорний індекс вектора 180 руху, що використовується для цілей прогнозування. Загалом, як зазначено вище, дані для вектора руху включають в себе список опорних зображень, індекс в списку опорних зображень (який називається "ref_idx"), горизонтальну компоненту і вертикальну компоненту. У HEVC може бути два звичайних списки опорних зображень (наприклад, список 0 і список 1) і комбінований список опорних зображень (наприклад, список с). Без втрати спільності припустимо, що поточний список опорних зображень є списком t (який може відповідати будь-якому зі списку 0, списку 1 або списку с). Згідно з прикладом, показаним на фіг. 10, вектор 180 руху для кандидата 182 блока може ідентифікувати прогнозуючий блок в зображенні, розташованому в компоненті виду нуль (view_id 0), що має РОС-значення в два і ref_idx, рівний i. Згідно з аспектами цього розкриття суті, відеодекодер 30 може ідентифікувати спільно розміщений прогнозуючий блок для 28
ДивитисяДодаткова інформація
Назва патенту англійськоюMotion vector prediction in video coding
Автори англійськоюChen, Ying, Chen, Peisong, Karczewicz, Marta
Автори російськоюЧень Ин, Чень Пейсун, Карчевич Марта
МПК / Мітки
МПК: H04N 7/00
Мітки: прогнозування, векторів, руху, кодуванні, відео
Код посилання
<a href="https://ua.patents.su/41-110826-prognozuvannya-vektoriv-rukhu-pri-koduvanni-video.html" target="_blank" rel="follow" title="База патентів України">Прогнозування векторів руху при кодуванні відео</a>
Сканування коефіцієнтів при кодуванні відео

Номер патенту: 110655
Опубліковано: 25.01.2016
Автори: Соле Рохальс Хоель, Карчєвіч Марта, Ван Сянлінь, Джоши Раджан Лаксман, Чжен Юньфей
МПК: H04N 7/00
Мітки: коефіцієнтів, сканування, відео, кодуванні
Формула / Реферат:
1. Спосіб декодування коефіцієнтів перетворення в процесі декодування відео, який включає етапи, на яких:- декодують одновимірну матрицю коефіцієнтів перетворення; і- виконують сканування для одновимірної матриці коефіцієнтів перетворення згідно з порядком сканування субблоків, в якому скануються і декодуються субблоки з множини субблоків, і порядком сканування коефіцієнтів, в якому скануються і декодуються коефіцієнти...
Подвійний прогнозуючий режим злиття, оснований на одинарних прогнозуючих сусідах, в кодуванні відео

Номер патенту: 109480
Опубліковано: 25.08.2015
Автори: Чіень Вей-Цзюн, Карчевіч Марта, Чжен Юньфей
МПК: H04N 21/4385, H04N 21/43, H04N 21/236
Мітки: режим, злиття, оснований, сусідах, прогнозуючих, прогнозуючий, відео, подвійний, одинарних, кодуванні
Формула / Реферат:
1. Спосіб декодування даних відео, причому спосіб містить етапи, на яких: приймають один або більше елементів синтаксису для поточного блока відео, при цьому згаданий один або більше елементів синтаксису задають один або більше кандидатів режиму злиття з набору кандидатів, які повинні бути використані, щоб кодувати поточний блок відео згідно з режимом злиття, при цьому перший кандидат в наборі кандидатів є кандидатом зліва, другий...
Окреме кодування позиції останнього значущого коефіцієнта відеоблока при кодуванні відео

Номер патенту: 109684
Опубліковано: 25.09.2015
Автори: Соле Рохальс Хоель, Джоши Раджан Лаксман, Карчевіч Марта
МПК: H03M 7/40, H04N 11/02, H04N 19/129, H04N 11/04
Мітки: відеоблока, кодуванні, кодування, окреме, останнього, позиції, значущого, відео, коефіцієнта
Формула / Реферат:
1. Спосіб кодування коефіцієнтів, асоційованих з блоком відеоданих, під час процесу кодування відео, при цьому спосіб включає етапи, на яких:кодують інформацію, яка ідентифікує позицію останнього ненульового коефіцієнта в блоці згідно з порядком сканування, асоційованим з блоком, до кодування інформації, яка ідентифікує позиції інших ненульових коефіцієнтів в блоці,при цьому кодування інформації, яка ідентифікує позицію...
Кодування позиції останнього значущого коефіцієнта у відеоблоці на основі порядку сканування для блока при кодуванні відео

Номер патенту: 106162
Опубліковано: 25.07.2014
Автори: Кобан Мухаммед Зейд, Чжен Юньфей, Соле Рохальс Хоель, Джоши Раджан Лаксман, Карчевіч Марта
Мітки: блока, сканування, відео, основі, позиції, кодуванні, кодування, коефіцієнта, значущого, відеоблоці, останнього, порядку
Формула / Реферат:
1. Спосіб кодування коефіцієнтів, асоційованих з блоком відеоданих, під час процесу кодування відео, при цьому спосіб включає етапи, на яких:визначають статистику, яка вказує імовірність того, що кожна з координат X і Y містить дане значення, коли порядок сканування, асоційований з блоком, містить перший порядок сканування, при цьому координати X і Y вказують горизонтальну позицію і вертикальну позицію, відповідно, останнього...
Довільний доступ з вдосконаленим керуванням буфером декодованих зображень кадрів (dpb) при кодуванні відео

Номер патенту: 109981
Опубліковано: 26.10.2015
Автори: Чень Цзяньле, Ван Є-Куй, Чен Ін
МПК: H04N 7/00
Мітки: кодуванні, доступ, довільний, відео, кадрів, зображень, буфером, керуванням, dpb, вдосконаленим, декодованих
Формула / Реферат:
1. Спосіб декодування відеоданих, причому спосіб включає:прийом потоку бітів, що містить одне або більше зображень кодованої відеопослідовності (GVS);декодування першого зображення зі згаданого одного або більше зображень згідно з порядком декодування, асоційованим з CVS, при цьому згадане перше зображення є зображенням на основі точки довільного доступу (RAP), яке не є зображенням на основі миттєвого оновлення при декодуванні...
Попередній патент: Пестицидні сполуки піразолу
Наступний патент: Спосіб задання поживного складу яблука
Випадковий патент: Засіб для боротьби з паразитами тварин та застосування компонентів у засобі