Спосіб спеціалізованого пошуку інформації в масиві текстів
Номер патенту: 85420
Опубліковано: 25.11.2013
Автори: Бондаренко Марина Володимирівна, Бондаренко Сергій Анатолійович, Петрушкевич Ірина Віталіївна, Глазунов Дмитро Олегович, Зелінська Марина Олегівна, Лук'яненко Сергій Миколайович, Матвєєва Олександра Семенівна, Барков Антон Євгенович






Формула / Реферат
1. Спосіб спеціалізованого пошуку інформації в масиві текстів, згідно з яким за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, а в кінці обробки проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів зв'язку на віддалений прилад користувача, при цьому документи сховища даних складається з двох частин - тексту документу та картки з його реквізитами, а корегування запиту здійснюють з використанням даних сховища статистичної інформації про картки та тексти документів, далі запит додатково проходить розширення і тільки після цього проводять пошук даних в сховищі даних шляхом обробки змісту запиту по словам, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку даних в сховищі даних проводять оцінку відповідності реквізитів і ключових слів та оцінку відповідності тексту запиту, далі проводять сортування за відповідністю тексту запиту, наступним етапом є пошук та оцінка місць документів, що містять шукану інформацію, після чого реалізують механізм оцінки, сортування та вибору кращих ідентифікаторів документів визначаючи релевантність результатів пошуку, який відрізняється тим, що механізм оцінки додатково включає в себе послідовність дій з оцінки за матеріальністю/процесуальністю рішень, оцінку за судовою інстанцією, оцінку за давниною, оцінку за авторитетністю посилань та оцінку за популярністю.
2. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що корегування пошукового запиту реалізують через сервер баз даних зі сховищем статистичної інформації про картки та тексти документів.
3. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що віддаленим приладом користувача є: персональний комп'ютер, портативний комп'ютер, планшетний прилад, смартфон та/або будь-який прилад за допомогою якого можливо реалізувати запит інформаційного пошуку.
4. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що каналами зв'язку є Інтернет мережа, локальна мережа або безпосередньо канали зв'язку пристрою користувача.
5. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що розширення запиту реалізують за допомогою бази даних сховища пов'язаних понять та бази даних зв'язків між картками документів.
6. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що картки та реквізити документа містять інформацію щодо дати, видавника, типу документу, ключових слів тощо, а частини документа пов'язані між собою.
7. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що при пошуку даних в сховищі даних зберігають лише ідентифікатор документу, по якому проводять вибір документів зі сховища даних.
8. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що сховище даних являє собою сукупність пов'язаних між собою логічними й правовими зв'язками документів.
9. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що механізм оцінки здійснюється за допомогою сховища відносних оцінок.
10. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що пошук та оцінка місць документів здійснюється за допомогою сховища відносного знаходження в текстах місцезнаходження шуканого.
11. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що сховище даних, в якому здійснюється пошук, являє собою сукупність пов'язаних між собою логічними та правовими зв'язками документів.
Текст
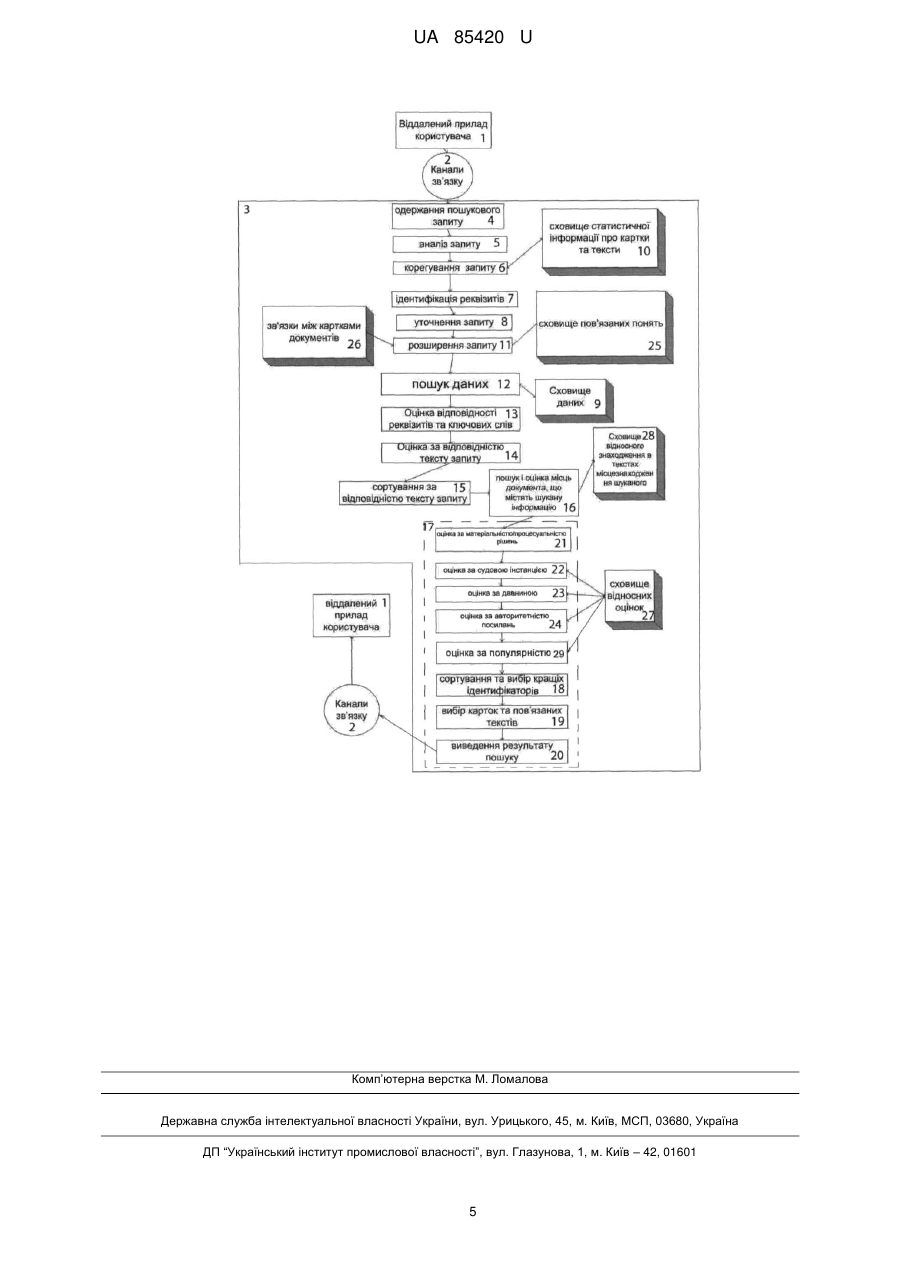
Реферат: Спосіб спеціалізованого пошуку інформації в масиві текстів, згідно з яким за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту. При цьому документи сховища даних складається з двох частин - тексту документу та картки з його реквізитами, а корегування запиту здійснюють з використанням даних сховища статистичної інформації про картки та тексти документів, далі запит додатково проходить розширення і тільки після цього проводять пошук даних в сховищі даних шляхом обробки змісту запиту по словам, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку даних в сховищі даних проводять оцінку відповідності реквізитів і ключових слів та оцінку відповідності тексту запиту, далі проводять сортування за відповідністю тексту запиту, наступним етапом є пошук та оцінка місць документів, що містять шукану інформацію, після чого реалізують механізм оцінки. Механізм оцінки додатково включає послідовність дій з оцінки за матеріальністю/процесуальністю рішень, оцінку за судовою інстанцією, оцінку за давниною, оцінку за авторитетністю посилань та оцінку за популярністю. UA 85420 U (12) UA 85420 U UA 85420 U 5 10 15 20 25 30 35 40 45 50 55 60 Корисна модель належить до обробляння цифрових даних за допомогою електронних пристроїв, а саме до способів пошуку інформації в масивах текстів, та може бути застосована, для автоматизації пошуку та аналізу судових рішень в базі даних сховища даних сформованої певним чином. В галузі пошуку цифрової інформації в масивах текстів, існує суттєва проблема актуальності, точності та швидкості проведення пошукових робіт. Зазвичай це обумовлено недосконалими пошуковими алгоритмами, що працюють за загальними схемами та алгоритмами, що не дозволяє досягти необхідних результатів при роботі зі специфічними масивами текстів. Також важливим є надання відібраної інформації, без так званого "шуму" та в логічному порядку, тобто відсіювати неактуальну та застарілу інформацію та сортувати її в зручному для розуміння користувача порядку та обсязі. Існує відомий спосіб введення та пошуку інформації про об'єкт у віддаленій базі даних (патент України на винахід № 92117 "спосіб введення та пошуку інформації про об'єкт у віддаленій базі даних", дата подання 04.06.2007, опубліковано 27.09.2010, Бюл. № 18, 2010 p.), що включає передачу за допомогою мережі глобальної системи мобільного зв'язку через устаткування оператора стільникового зв'язку та за допомогою мережі Інтернет на сервер від мобільного термінала зв'язку повідомлення з ідентифікатором об'єкта, прийом сервером повідомлення з ідентифікатором об'єкта, пошук ідентифікатора об'єкта у базі даних сервера, а при його знаходженні передачу від сервера повідомлення мобільному терміналу зв'язку про знаходження ідентифікатора об'єкта, згідно з винаходом, на мобільному терміналі зв'язку та сервері встановлюють програмне забезпечення, що дозволяє як ідентифікатор об'єкта використовувати слово, а як повідомлення з ідентифікатором об'єкта, що передане від мобільного термінала зв'язку, використовують щонайменше одне слово, що характеризує найменування/діяльність юридичної/фізичної особи, при пошуку ідентифікатора об'єкта у базі даних сервера сервер зіставляє слово з доменними іменами, що зберігаються у його базі даних, і при виявленні доменних імен, принаймні частина яких збігається зі словом, передає на мобільний термінал зв'язку список з доменними іменами, при виборі користувачем на мобільному терміналі зв'язку одного доменного імені зі списку користувач за допомогою мобільного термінала зв'язку формує повідомлення з вибраним доменним іменем і передає його на сервер, який проводить додатковий пошук цього доменного імені та відповідного йому телефонного номера абонента, при знаходженні відповідного телефонного номера абонента сервер передає цей номер на мобільний термінал зв'язку, при підтвердженні вибору користувачем на мобільному терміналі зв'язку цього доменного імені/телефонного номера абонента програмне забезпечення за допомогою мобільного термінала зв'язку ініціює зв'язок через глобальну систему мобільного зв'язку та устаткування оператора стільникового зв'язку з телефонним номером абонента, здійснюючи через них голосове з'єднання з телефонним номером абонента. Недоліками відомого способу є обов'язкове застосування пристроїв мобільного зв'язку та мобільних терміналів, що обмежує обсяг інформації та швидкість проведення пошукових робіт. Існує відомий спосіб пошуку інформаційних об'єктів (описаний в патенті України на винахід № 90764, дата подання 13.05.2008, опубліковано 25.05.2010, бюл. № 10, 2010 р. "Спосіб пошуку інформаційних об'єктів та система для його здійснення"), згідно з яким приймають запит, здійснюють збір інформації, пошук по інформаційному сховищу на наявність об'єктів, що відповідають запиту користувача на пошук, згідно з винаходом включає визначення елементів уточнення на основі щонайменше одного з рейтингу елементів уточнення та інформації про елементи уточнення, після чого вибирають елементи уточнення, включають вибрані елементи у запит, остаточно редагують та підтверджують запит, визначають еквіваленти дескрипторів та елементів уточнення, отримують від користувача команду на підключення інтеграції запиту, обробляють пошуковою системою запит шляхом вибору документів або текстів із сховища даних та здійснюють виведення результатів. Недоліками відомого способу є недостатня точність проведення пошукових робіт та відносно довгий час обробки інформації. Найбільш близьким до запропонованого, є відомий спосіб пошуку інформації в масиві текстів (патент України на корисну модель № 60952 "Спосіб пошуку інформацій в масиві текстів", патент опублікований 25.06.2011, бюл. № 12), згідно з яким, за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, згідно з корисною моделлю, документи сховища даних складається з двох частин - тексту документу та картки з його реквізитами, а корегування запиту здійснюють з використанням даних сховища статистичної 1 UA 85420 U 5 10 15 20 25 30 35 40 45 50 55 інформації про картки та тексти документів, далі запит додатково проходить розширення і тільки після цього проводять пошук даних у сховищі даних шляхом обробки змісту запиту за словами, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку даних в сховищі даних проводять оцінку відповідності реквізитів і ключових слів та оцінку відповідності тексту запиту, далі проводять сортування за відповідністю тексту запиту, наступним етапом є пошук та оцінка місць документів, що містять інформацію, що шукається, після чого реалізують механізм оцінки, сортування та вибору кращих ідентифікаторів документів, далі проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів зв'язку на віддалений прилад користувача визначаючи та враховуючи релевантність. Недоліком найбільш близького способу пошуку інформації є вузько профільний механізм оцінки інформації, що шукається. Це не дозволяє повноцінно застосовувати спосіб в сфері пошуку інформації в масивах текстів судових рішень, та як наслідок має недостатню чистоту пошуку в даній сфері. Задачею корисної моделі є вдосконалення способу пошуку інформації в масивах текстів в базі даних сховища даних, який би за допомогою вдосконаленого механізму оцінки інформації розширював функціональні можливості та підвищував техніко-експлуатаційні характеристики пошукових робіт, підвищував швидкість, актуальність та чистоту пошуку в масивах текстів судових рішень. Також важливим питанням, що вирішує запропонований спосіб є визначення релевантності для результатів пошуку. Поставлена задача вирішується тим, що завдяки запропонованому способу, згідно з яким: за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування; пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, а в кінці обробки проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів зв'язку на віддалений прилад користувача, при цьому документи сховища даних складається з двох частин - тексту документу та картки з його реквізитами, а корегування запиту здійснюють з використанням даних сховища статистичної інформації про картки та тексти документів; запит додатково проходить розширення і тільки після цього проводять пошук даних в сховищі даних шляхом обробки змісту запиту за словами, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку даних в сховищі даних проводять оцінку відповідності реквізитів і ключових слів та оцінку відповідності тексту запиту; проводять сортування за відповідністю тексту запиту; наступним етапом є пошук та оцінка місць документів, що містять інформацію, що шукається, після чого реалізують механізм оцінки, сортування та вибору кращих ідентифікаторів документів визначаючи релевантність результатів пошуку, згідно з корисною моделлю механізм оцінки додатково включає послідовність дій з оцінки за матеріальністю/процесуальністю рішень, оцінку за судовою інстанцією, оцінку за ретроспективою, оцінку за авторитетністю посилань та оцінку за популярністю. Корегування пошукового запиту реалізують через сервер баз даних зі сховищем статистичної інформації про картки та тексти документів. Віддаленим приладом користувача є: персональний комп'ютер, портативний комп'ютер, планшетний прилад, смартфон та/або будьякий прилад, за допомогою якого можливо реалізувати запит інформаційного пошуку. Каналами зв'язку є Інтернет мережа, локальна мережа або безпосередньо канали зв'язку пристрою користувача. Розширення запиту реалізують за допомогою бази даних сховища пов'язаних понять та бази даних зв'язків між картками документів. Картки та реквізити документа містять інформацію щодо дати, видавника, типу документу, ключових слів тощо, а частини документа пов'язані між собою. При пошуку даних в сховищі даних зберігають лише ідентифікатор документу, по якому проводять вибір документів зі сховища даних. Сховище даних являє собою сукупність пов'язаних між собою логічними й правовими зв'язками документів. Механізм оцінки здійснюється за допомогою сховища відносних оцінок. Пошук та оцінка місць документів здійснюється за допомогою сховища відносних оцінок, шляхом знаходження в текстах місцезнаходження шуканого. Корисна модель пояснюється кресленням на якій зображено - загальний блок схеми способу спеціалізованого пошуку інформації в масиві текстів. 2 UA 85420 U 5 10 15 20 25 30 35 40 45 Спосіб здійснюють наступним чином: за допомогою віддаленого приладу користувача 1 через канали зв'язку 2 пошуковий сервер 3 одержує пошуковий запит 4 із реквізитами та ключовими словами, який проходить аналіз 5 та коригування 6, далі пошуковий сервер 3 проводить ідентифікацію 7 реквізитів та уточнення запиту 8, згідно з корисною моделлю, документи сховища даних 9 складається з двох частин тексту документу та картки з його реквізитами, а корегування 6 запиту здійснюють з використанням даних сховища статистичної інформації 10 про картки та тексти документів, далі запит додатково проходить розширення 11 і тільки після цього проводять пошук даних 12 в сховищі даних 9 шляхом обробки змісту запиту за словами, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку даних 12 в сховищі даних 9 проводять оцінку відповідності реквізитів і ключових слів 13 та оцінку відповідності тексту запиту 14, далі проводять сортування 15 за відповідністю тексту запиту, наступним етапом є пошук та оцінка місць документів 16, що містять шукану інформацію, після чого реалізують механізм оцінки 17, який включає механізм оцінки включає в себе оцінку за матеріальністю/процесуальністю рішень 21, оцінку за судовою інстанцією 22, оцінку за давниною 23, оцінку за авторитетністю посилань 24 та оцінку за популярністю 29. Далі проводять сортування 18 та вибір 19 кращих ідентифікаторів документів, після чого проводиться вибір документів зі сховища даних 9 та виведення результатів 20 пошуку за допомогою каналів зв'язку 2 на віддалений прилад користувача 1. Віддаленим приладом користувача 1 є: персональний комп'ютер, портативний комп'ютер, планшетний прилад, смартфон та/або будь-який прилад, за допомогою якого можливо реалізувати запит інформаційного пошуку. Каналами зв'язку 2 є Інтернет мережа, локальна мережа або безпосередньо канали зв'язку пристрою користувача. Розширення запиту 4 реалізують за допомогою сховища пов'язаних понять 25 та бази даних зв'язків між картками документів 26. Картки та реквізити документа містять інформацію щодо дати, видавника, типу документу, ключових слів тощо, а частини документа пов'язані між собою. При пошуку даних в сховищі даних зберігають лише ідентифікатор документу, по якому проводять вибір документів зі сховища даних. Сховище даних 9 являє собою сукупність пов'язаних між собою логічними й правовими зв'язками документів. Механізм оцінки 17 здійснюється за допомогою сховища відносних оцінок 27, а пошук та оцінка місць документів 16 здійснюється за допомогою сховища відносного знаходження в текстах місцезнаходження шуканого 28. Визначення релевантності результатів пошуку при запитах користувача відіграє важливу роль при аналізі користувачем отриманої, в результаті пошуку, інформації. Важливо, щоб користувач в першу чергу побачив найактуальнішу та вагомішу на цей час інформацію з усього результату пошуку. При визначенні релевантності в даному способі беруться до уваги специфічні оцінки документів, що визначають значимість для певного запиту, а це тип документу, видавник документу, дата документу, актуальність, популярність та цитованість документу, оцінка авторитетності органу що видав документ та категорії нормативно-правових документів. Всі ці дії та наявність необхідної інформації в сховищах даних, дозволяють отримувати результати пошуку в актуальному порядку, що значно полегшує роботу користувача з отриманими результатами пошуку. Таким чином завдяки розробленому та запропонованому способу пошуку інформації в масивах текстів в сховищах даних, завдяки використанню спеціалізованого механізму оцінки результатів запиту, досягається розширення функціональних можливостей пошуку, підвищується техніко-експлуатаційні характеристики, зменшується час на обробку інформації, покращується актуальність та чистота пошуку в масивах текстів судових рішень. ФОРМУЛА КОРИСНОЇ МОДЕЛІ 50 55 60 1. Спосіб спеціалізованого пошуку інформації в масиві текстів, згідно з яким за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, а в кінці обробки проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів зв'язку на віддалений прилад користувача, при цьому документи сховища даних складається з двох частин - тексту документу та картки з його реквізитами, а корегування запиту здійснюють з використанням даних сховища статистичної інформації про картки та тексти документів, далі запит додатково проходить розширення і тільки після цього проводять пошук даних в сховищі даних шляхом обробки змісту запиту по словам, використовуючи попарне співставлення абзаців масиву тестів та пошукового запиту, причому, після пошуку 3 UA 85420 U 5 10 15 20 25 30 35 даних в сховищі даних проводять оцінку відповідності реквізитів і ключових слів та оцінку відповідності тексту запиту, далі проводять сортування за відповідністю тексту запиту, наступним етапом є пошук та оцінка місць документів, що містять шукану інформацію, після чого реалізують механізм оцінки, сортування та вибору кращих ідентифікаторів документів визначаючи релевантність результатів пошуку, який відрізняється тим, що механізм оцінки додатково включає в себе послідовність дій з оцінки за матеріальністю/процесуальністю рішень, оцінку за судовою інстанцією, оцінку за давниною, оцінку за авторитетністю посилань та оцінку за популярністю. 2. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що корегування пошукового запиту реалізують через сервер баз даних зі сховищем статистичної інформації про картки та тексти документів. 3. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що віддаленим приладом користувача є: персональний комп'ютер, портативний комп'ютер, планшетний прилад, смартфон та/або будь-який прилад за допомогою якого можливо реалізувати запит інформаційного пошуку. 4. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що каналами зв'язку є Інтернет мережа, локальна мережа або безпосередньо канали зв'язку пристрою користувача. 5. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що розширення запиту реалізують за допомогою бази даних сховища пов'язаних понять та бази даних зв'язків між картками документів. 6. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що картки та реквізити документа містять інформацію щодо дати, видавника, типу документа, ключових слів тощо, а частини документа пов'язані між собою. 7. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що при пошуку даних в сховищі даних зберігають лише ідентифікатор документа, по якому проводять вибір документів зі сховища даних. 8. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що сховище даних являє собою сукупність пов'язаних між собою логічними й правовими зв'язками документів. 9. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що механізм оцінки здійснюється за допомогою сховища відносних оцінок. 10. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що пошук та оцінка місць документів здійснюється за допомогою сховища відносного знаходження в текстах місцезнаходження шуканого. 11. Спосіб пошуку інформації в масиві текстів за п. 1, який відрізняється тим, що сховище даних, в якому здійснюється пошук, являє собою сукупність пов'язаних між собою логічними та правовими зв'язками документів. 4 UA 85420 U Комп’ютерна верстка М. Ломалова Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 5
ДивитисяДодаткова інформація
Автори англійськоюHlazunov Dmytro Olehovych, Petrushevych Iryna Vitaliivna, Zelinska Maryna Olehivna, Barkov Anton Yevhenovych
Автори російськоюГлазунов Дмитрий Олегович, Петрушкевич Ирина Витальевна, Зелинская Марина Олеговна, Барков Антон Евгеньевич
МПК / Мітки
МПК: G06F 17/30
Мітки: спосіб, пошуку, масиві, спеціалізованого, інформації, текстів
Код посилання
<a href="https://ua.patents.su/7-85420-sposib-specializovanogo-poshuku-informaci-v-masivi-tekstiv.html" target="_blank" rel="follow" title="База патентів України">Спосіб спеціалізованого пошуку інформації в масиві текстів</a>
Спосіб пошуку інформації в масиві текстів

Номер патенту: 60952
Опубліковано: 25.06.2011
Автори: Барков Антон Євгенович, Глазунов Дмитро Олегович, Петрушкевич Ірина Віталіївна, Правдива Ольга Василівна, Зелінська Марина Олегівна
МПК: G06F 17/30
Мітки: пошуку, масиві, інформації, текстів, спосіб
Формула / Реферат:
1. Спосіб пошуку інформації в масиві текстів, згідно з яким за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, а в кінці обробки проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів...
Спосіб пошуку та сортування інформації

Номер патенту: 5323
Опубліковано: 15.03.2005
Автори: Серков Олександр Анатолійович, Пантелеєва Ірина Анатоліївна, Судаков Борис Миколайович
МПК: G06F 7/06
Мітки: інформації, сортування, пошуку, спосіб
Формула / Реферат:
Спосіб пошуку та сортування інформації, до складу якого включено подачу неупорядкованого списку фрагментів інформації, їх сортування, запис та збереження у базі даних, видачу упорядкованого списку фрагментів інформації, який відрізняється тим, що кожному фрагменту інформації надається рейтинговий коефіцієнт, який обчислюється шляхом порівняння кожної позиції запиту із відповідною позицією записаного фрагмента інформації у базі даних, та у...
Спосіб пошуку і вибірки інформації з різних баз даних

Номер патенту: 63222
Опубліковано: 26.09.2011
Автори: Стоєцький Дмитро Васильович, Петрук Олександр Віталійович
МПК: G06F 17/30
Мітки: інформації, спосіб, пошуку, вибірки, даних, баз, різних
Формула / Реферат:
1. Спосіб пошуку і вибірки інформації з різних баз даних, згідно з яким пошукові запити, що сформовані користувачами, передають у пошукову систему сервера, що здійснює обробку цих запитів шляхом вибору документів з різних баз даних, який відрізняється тим, що спочатку користувачі створюють на сервері системи облікові записи, здійснюючи авторизацію шляхом введення їх персональних даних і одержуючи паролі для отримання доступу до інформації з...
Спосіб автоматичного пошуку мовленнєвого фрагмента в суцільному масиві звукозапису та голосовий електронний довідник на його основі

Номер патенту: 67699
Опубліковано: 15.06.2004
Автори: Ілюшин Сергій Аркадійович, Павлов Олег Ігоревич, Вінцюк Тарас Климович, Федорин Ярослав Володимирович, Ситніков Даніїл Анатолійович, Гриценко Володимир Ільїч, Куптель Олег Григорович
МПК: G10L 15/00
Мітки: автоматичного, спосіб, мовленнєвого, суцільному, голосовий, фрагмента, електронний, масиві, довідник, основі, пошуку, звукозапису
Формула / Реферат:
1. Спосіб автоматичного пошуку мовленнєвого фрагмента в суцільному масиві звукозапису, який базується на виборі фрагмента, найбільш подібного до фрагмента, що шукається, який відрізняється тим, що введений для пошуку звуковий сигнал, перетворюють до цифрової форми, виділяють параметри розпізнавання, далі за алгоритмом автоматичного пошуку ключового слова порівнюють зі всіма фрагментами в масиві аудіозапису і в результаті порівняння отримують...
Спосіб автоматичного пошуку мовленнєвого фрагмента в суцільному масиві звукозапису

Номер патенту: 48219
Опубліковано: 10.03.2010
Автори: Тертичний Григорій Миколайович, Стасевич Петро Анатолійович, Павлов Олег Ігоревич, Вінцюк Тарас Климович, Гриценко Володимир Ілліч
МПК: G10L 15/00
Мітки: автоматичного, фрагмента, мовленнєвого, масиві, звукозапису, спосіб, пошуку, суцільному
Формула / Реферат:
Спосіб автоматичного пошуку мовленнєвого фрагмента в суцільному масиві звукозапису, який базується на виборі зі всіх можливих фрагментів таких фрагментів, для яких інтегральна міра відмінності отриманих з них послідовностей наборів параметрів вибраної моделі мовотворення від аналогічної послідовності, отриманої з мовленнєвого фрагмента, який шукається, не перевищує встановлений поріг при використанні динамічного програмування в процесі їх...
Попередній патент: Спосіб прискореного відновлення формних циліндрів рулонних та аркушевих офсетних друкарських машин
Наступний патент: Спосіб передавання та відтворення мультимедійних файлів через мережі зв’язку
Випадковий патент: Полівінілхлоридна композиція