Спосіб розпізнавання мовних образів
Номер патенту: 93719
Опубліковано: 10.10.2014
Автори: Філатова Мар'яна Михайлівна, Биков Микола Максимович, Грищук Тетяна Вікторівна





Формула / Реферат
Спосіб розпізнавання мовних образів, що передбачає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих результатів приймається рішення про розпізнавання мовного образу, який відрізняється тим, що логічне порівняння здійснюється на основі порозрядної логічної операції "І" з "самоблокуванням".
Текст
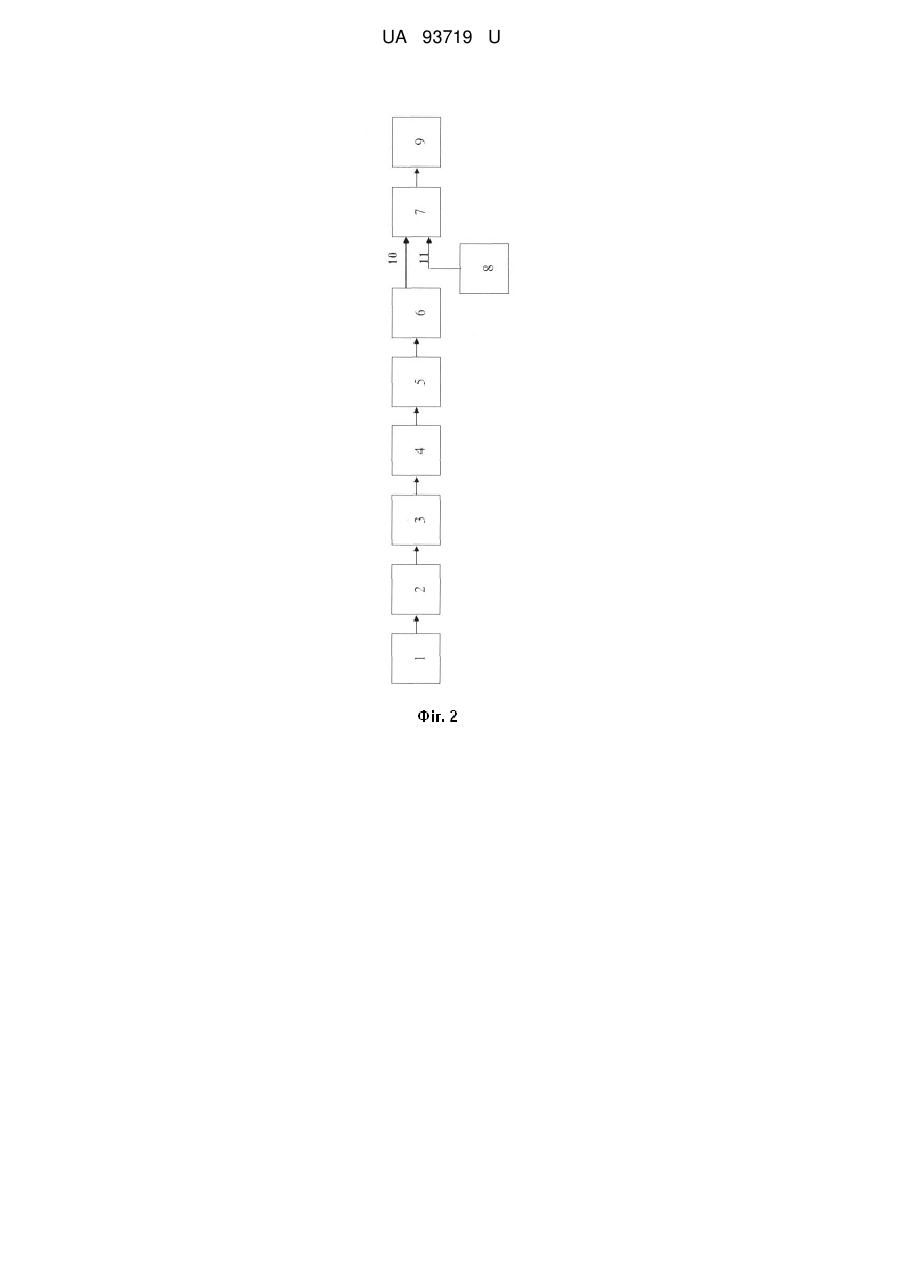
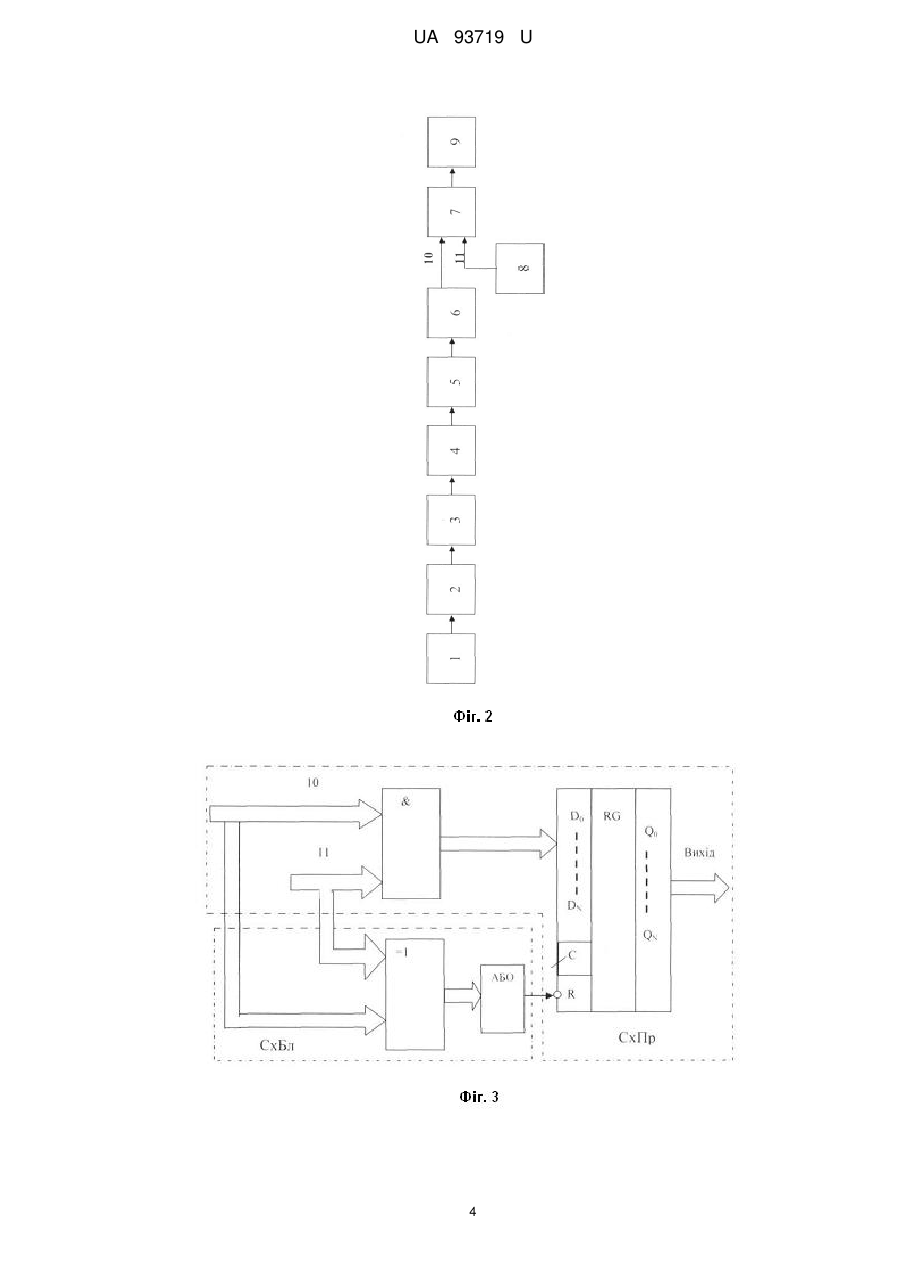
Реферат: UA 93719 U UA 93719 U 5 10 15 20 25 30 35 40 Корисна модель належить до галузі автоматики та обчислювальної техніки і може бути використана для автоматичного розпізнавання мовних образів. Відомий спосіб розпізнавання образів, відповідно якому сприймають неперервний образ, що розпізнається, проводять його перетворення, виділяють характерні ознаки, виконують дискретизацію образу в послідовність елементів, проводять сегментне маркування елементів, формують двійковий опис стрічки символів, що розпізнається, різними для різних символів двійковими кодами і виконують розпізнавання за мінімумом відстані до одного з еталонних образів, для чого послідовно зчитують з пам'яті коди відстаней між кожною з порівнюваних пар символів з стрічки, що розпізнається, та еталонної стрічки, а потім додають ці відстані [Glave R.D., Vander Giet. The David speech recognition system. - Proc. IEEE Int. Conf. ASSP. - Tulsa, 1978, p. 429-432]. До недоліків даного способу розпізнавання потрібно віднести те, що він потребує додаткових витрат пам'яті на зберігання кодів відстаней, а також значного обмеження швидкості розпізнавання через втрати часу на зчитування кодів цих відстаней з пам'яті. Відомий також спосіб розпізнавання образів, відповідно якому неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають різниці відстаней, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів шляхом визначення відстані Хемінга між ними, на основі отриманих результатів приймають рішення про розпізнавання мовного образу [Preparata F.P., Nivergelt J. DifferencePreserving Codes. - IEE Trans. Information Theory, IT-20, 1974, p. 643-649.]. Недоліками даного способу є обмеження об'єму словника образів, що розпізнаються, яке обумовлене можливістю виникнення помилок через властивості кодів, що зберігають різниці, а також обмеження швидкодії через необхідність обчислення відстаней Хемінга. Найбільш близьким до способу, що заявляється, є спосіб розпізнавання мовних образів, що передбачає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають ранги відстаней між елементами, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих результатів приймається рішення про розпізнавання мовного образу [Патент України на винахід № 66184 А, м.кл.: 7 G06E 1/04, G10L 1/00, опубл. 15.04.2004, Б. № 4.]. Недоліками даного способу є обмеження об'єму словника образів, що розпізнаються, яке обумовлене можливістю виникнення помилок через визначення рангу відстані між окремими елементами послідовностей еталонної та тієї, що розпізнається, за допомогою логічної операції "І", яка не має властивості аксіоми ідентичності для отриманих рангів. Наприклад, якщо ми маємо рангову конфігурацію мовних елементів (в нашому випадку - фонотипів), зображену на фіг. 1, то їх рангові коди (DRP-коди, коди що зберігають ранги відстаней) будуть такими, як це показано в табл. Таблиця Елементи b1 Рангові (DRP) коди 0 0 0 1 b2 1 0 1 b3 1 1 0 b4 0 0 1 1 1 0 0 1 1 0 0 1 1 0 Нехай тепер еталонна послідовність (рядок) S e буде конкатенацією елементів b 2 b 3 b 4 , а рядок S r , що розпізнається - b 1 b 2 b 3 . 45 Тоді ранги відстаней між відповідними елементами послідовностей S e і S r визначаються логічною операцією "І" таким чином: R hb b log 2 b 3 b1 log 2 110100 010011 log 2 0100000 log 2 25 5 ; (1) 3 1 Rhb2b2 log 2 b 2 b 2 log 2 101001 101001 log 2 101001 log 2 91 5 . (2) 1 UA 93719 U З отриманого результату у виразі (2) видно, що відстань hb b між однаковими елементами 2 2 5 10 15 20 25 30 35 40 45 50 55 b 2 і b 2 та ранг цієї відстані не дорівнюють нулю, тобто аксіома ідентичності для рангів відстаней між елементами, визначених порозрядною логічною операцією "І", не виконується. Внаслідок вищезазначеного даний спосіб має обмежену надійність розпізнавання мовних образів і обмежений склад словника слів, що розпізнаються. В основу винаходу поставлена задача створення способу розпізнавання мовних образів, в якому за рахунок використання порозрядної логічної операції "І" з "самоблокуванням" для визначення рангів відстаней між елементами стрічок досягається збільшення надійності розпізнавання мовних образів та розширення складу словника мовних образів. Поставлена задача вирішується тим, що неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають ранги відстаней між елементами, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів за допомогою порозрядної логічної операції "I" з "самоблокуванням", і на основі отриманих результатів приймають рішення про розпізнавання мовного образу. Виконання класифікації образу по запропонованому способу дозволяє уникнути помилок визначення відстаней під час логічного порівняння послідовності елементів, що розпізнається, і еталонної послідовності елементів, які описують образи. Порозрядна логічна операція "І" з "самоблокуванням" блокує до логічного "0" виходи схеми порівняння при наявності однакових кодів елементів на її входах. На фіг. 1 зображено приклад рангової конфігурації мовних елементів, на фіг. 2 - структурна схема пристрою для реалізації запропонованого способу розпізнавання мовних образів, на фіг. 3 зображена функціональна схема блока порівняння для реалізації логічної операції "І" з "самоблокуванням". Пристрій для реалізації запропонованого способу містить датчик сприйняття пред'явленого образу 1, який послідовно з'єднано з блоком перетворення сприйнятого образу 2, який підключено до входу блока виділення ознак 3, вихід якого з'єднаний з блоком перетворення неперервного образу в послідовність елементів 4, який послідовно з'єднано з блоком формування двійкового опису 5, вихід якого підключено до входу регістра 6, який з'єднано з першим входом 10 блока порівняння 7, до другого входу 11 якого підключено блок пам'яті еталонних послідовностей 8, при цьому вихід блока 8 з'єднано з блоком прийняття рішення 9. Блок порівняння для реалізації логічної операції "І" з "самоблокуванням" (фіг. 3) складається з блока порівняння пристрою-аналога у вигляді схеми порівняння СхПр, доповненого схемою самоблокування СхБл. Входи 10 і 11 пристрою підключені паралельно до схеми "&" порозрядної логічної операції "І" і схеми "=1" порозрядної логічної операції "сума за модулем 2" ("виключне АБО"), вихід схеми "&" підключений до входу даних регістра RG, вихід схеми "=1" підключений до входу логічної схеми "АБО", вихід якої підключений до входу скиду " R " регістра RG в нульовий стан, а вихід регістра RG під'єднаний до входу схеми прийняття рішення. Спосіб розпізнавання мовних образів реалізується наступним чином. Неперервний образ сприймають, перетворюють в послідовність елементів, формують двійковий опис елементів послідовності, що розпізнається, у вигляді двійкових кодів, що зберігають ранги відстаней між елементами, виконують класифікацію за мінімумом відстані до однієї з еталонних послідовностей, для чого проводять логічне порівняння послідовності, що розпізнається, і еталонної послідовності елементів за допомогою порозрядної логічної операції "I" з "самоблокуванням", на основі отриманих результатів приймають рішення про розпізнавання мовного образу. Пред'явлений образ сприймається датчиком сприйняття пред'явленого образу 1 (фіг. 2), перетворюється в потрібну форму за допомогою блок перетворення сприйнятого образу 2, який з'єднується зі входом блока виділення ознак 3. На основі цих ознак в блоці перетворення неперервного образу в послідовність елементів 4 неперервний образ перетворюється в послідовність елементів, в блоці формування двійкового опису 5 формується її двійковий опис кодами, що зберігають ранги відстаней, в регістрі 6 послідовність, що розпізнається, запам'ятовується і послідовно порівнюється за допомогою порозрядної логічної операції "I" з "самоблокуванням" в блоці порівняння 7 зі всіма еталонними послідовностями, які зберігаються в блоці пам'яті еталонів 8. На основі результатів порівняння в блоці прийняття рішення 9 виконується класифікація пред'явленого образу. Блок порівняння працює наступним чином. На входи 10 і 11 надходять рангові коди елементів послідовності, що розпізнається, і еталонної послідовності, відповідно. Якщо 2 UA 93719 U 5 10 15 20 25 елементи на входах 10 і 11 одинакові, то одинакові і їх рангові коди, при цьому на виходах схеми "=1" встановляться стани логічного "0", які надійдуть на входи схеми "АБО", її вихід встановиться в стан логічного "0", який скине вихід регістра RG в нульовий стан. Якщо ж елементи на входах 10 і 11 неодинакові, то хоча б на одному з виходів схеми "=1" з'явиться логічна "1", тоді на виході схеми "АБО" встановиться логічна "1", яка на вхід скиду " R " регістра не впливає, і на його виході з'явиться правильний код рангу відстані, який надходить на його вхід з виходу схеми "І", що виконує порозрядне логічне порівняння рангових кодів елементів. Таким чином, для однакових рангових кодів елементів результат порозрядного логічного порівняння схемою "І" блокується до нуля, і ранг відстані між ними встановлюється рівним 0, що і повинно бути насправді, а для неоднакових встановлюється код дійсного рангу відстані. Логічне рівняння, яке описує порозрядну операцію "І" з "самоблокуванням", можна записати у вигляді: & =&(), (3) де & - позначення операції "І" з самоблокуванням"; & - операція порозрядне "І"; - операція логічного множення, кон'юнкція; - операція порозрядне "XOR" ("сума за модулем 2"); операція логічного додавання, диз'юнкція. Запис (3) означає, що самоблокування здійснюється логічним множенням результату виконання операції порозрядне "І" над вхідними кодами на результат логічного додавання вихідних значень операції порозрядне "XOR" над цими ж кодами. Оскільки запропонований метод і блок логічного порівняння усувають помилки визначення рангів відстаней між однаковим елементами образів, що розпізнаються, то це дозволяє зняти обмеження з складу словника образів, що розпізнаються, і розширити його до потрібних розмірів. При цьому усуваються помилки розпізнавання образів з однаковими елементами, що підвищує надійність розпізнавання. Якщо вважати, що весь словник образів містить N слів, і серед них є М слів з однаковими символами, то надійність розпізнавання збільшується на (N/M)*100 %. ФОРМУЛА КОРИСНОЇ МОДЕЛІ 30 35 Спосіб розпізнавання мовних образів, що передбачає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих результатів приймається рішення про розпізнавання мовного образу, який відрізняється тим, що логічне порівняння здійснюється на основі порозрядної логічної операції "І" з "самоблокуванням". 3 UA 93719 U 4 UA 93719 U Комп’ютерна верстка А. Крулевський Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 5
ДивитисяДодаткова інформація
Автори англійськоюBykov Mykola Maksymovych
Автори російськоюБыков Николай Максимович
МПК / Мітки
МПК: G10L 15/00
Мітки: мовних, розпізнавання, образів, спосіб
Код посилання
<a href="https://ua.patents.su/7-93719-sposib-rozpiznavannya-movnikh-obraziv.html" target="_blank" rel="follow" title="База патентів України">Спосіб розпізнавання мовних образів</a>
Спосіб розпізнавання мовних образів

Номер патенту: 66184
Опубліковано: 15.04.2004
Автори: Биков Микола Максимович, Грищук Тетяна Вікторівна
МПК: G10L 15/00
Мітки: образів, спосіб, мовних, розпізнавання
Формула / Реферат:
Спосіб розпізнавання мовних образів, що включає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих...
Спосіб розпізнавання мовних образів

Номер патенту: 43743
Опубліковано: 25.08.2009
Автори: Кучерук Наталя Олександрівна, Биков Микола Максимович, Балховський Дмитро Євгенійович
МПК: G06E 1/00
Мітки: спосіб, образів, розпізнавання, мовних
Формула / Реферат:
Спосіб для розпізнавання мовних образів, що передбачає сприйняття неперервного образу, перетворення його в послідовність елементів, формування двійкового опису елементів послідовності, що розпізнається, у вигляді двійкових кодів, виконання класифікації за мінімумом відстані до однієї з еталонних послідовностей, для чого проводиться логічне порівняння послідовності, що розпізнається, та еталонної послідовності елементів, і на основі отриманих...
Спосіб розпізнавання образів

Номер патенту: 92493
Опубліковано: 26.08.2014
Автори: Захожай Олег Ігорович, Меняйленко Олександр Сергійович
МПК: G06K 9/00
Мітки: спосіб, образів, розпізнавання
Формула / Реферат:
Спосіб розпізнавання образів, що передбачає сприйняття образу об'єкта розпізнавання за допомогою пристроїв реєстрації його характеристик, попередню обробку і нормалізацію отриманих характеристик, формування сукупності інформаційних ознак образу та подальше проведення аналізу цих ознак для відношення образу до одного з передвизначених класів на основі подібності інформаційних ознак, який відрізняється тим, що на основі отриманої сукупності...
Пристрій розпізнавання образів

Номер патенту: 90109
Опубліковано: 12.05.2014
Автори: Меняйленко Олександр Сергійович, Захожай Олег Ігорович
МПК: G06K 9/00
Мітки: пристрій, розпізнавання, образів
Формула / Реферат:
Пристрій розпізнавання образів, що містить вхідний блок, блок класифікації, який відрізняється тим, що в нього вводиться блок селекції інформаційних образів та інформативних ознак, який включається між вхідним блоком та блоком класифікації, а також блок аналізу результатів класифікації, підключений на вихід блока класифікації, виходи блока аналізу підключені до блока селекції інформаційних образів та інформативних ознак, а також до блока...
Спосіб розпізнавання образів в оптико-цифрових кореляторах

Номер патенту: 60820
Опубліковано: 15.12.2005
Автори: Комаров В'ячеслав Олександрович, Єжов Павло Валентинович, Кузьменко Олександр Васильович
МПК: G02B 27/46, G06E 3/00
Мітки: оптико-цифрових, образів, спосіб, кореляторах, розпізнавання
Формула / Реферат:
Спосіб розпізнавання образів в оптико-цифрових кореляторах, який складається з операцій:а) в цифрову частину корелятора вводять зображення об'єкта розпізнавання та еталонного об'єкта б) перетворюють зображення в...