Спосіб пошуку текстової інформації за схожістю
Номер патенту: 71159
Опубліковано: 10.07.2012
Автори: Тодоріко Ольга Олексіївна, Добровольський Геннадій Анатолійович







Формула / Реферат
Спосіб пошуку текстової інформації за схожістю, який включає визначення області пошуку як колекції слів; визначення непустого алфавіту; побудову пошукового індексу шляхом обчислення сигнатури кожного слова словника; інтерпретацію кожної сигнатури як двійкового запису числа - значення хеш-функції та збереження слів словника у вигляді хеш-таблиці; завдання пошукового запиту у вигляді рядка, який може містити помилки; створення на основі пошукового запиту сигнатури всього запиту; завдання граничної міри схожості k запису словника та запиту; попередню фільтрацію записів індексу шляхом зчитування знайдених хеш-списків; відбір записів, які відповідають заданим умовам шляхом використання точної рядкової метрики для обчислення схожості рядків; видачу результатів пошуку, який відрізняється тим, що визначають правила трансформації рядків; вибирають одне із правил розділення рядка на підрядки, яке обумовлює формулу розрахунку приблизної рядкової метрики; вибирають правило об'єднання сигнатур; створюють усі форми рядків словника з використанням визначених раніше правил трансформації; групують всі форми одного рядка в один запис; розділяють кожен рядок запису на підрядки з використанням визначеного раніше правила; відображують усі підрядки кожного рядка словника у множину сигнатур; об'єднують сигнатури усіх підрядків за вибраним раніше правилом; створюють на основі пошукового запиту додаткові сигнатури, які описують усі його підрядки, що включає розділення пошукового запиту на підрядки з використанням визначеного раніше правила та обчислення сигнатури кожного підрядка; а попередню фільтрацію записів індексу здійснюють за формулою розрахунку приблизної рядкової метрики з урахуванням граничної міри схожості; вибирають формулу для розрахунку точної рядкової метрики для обчислення схожості рядків; видають результати пошуку, впорядковані за релевантністю.
Текст
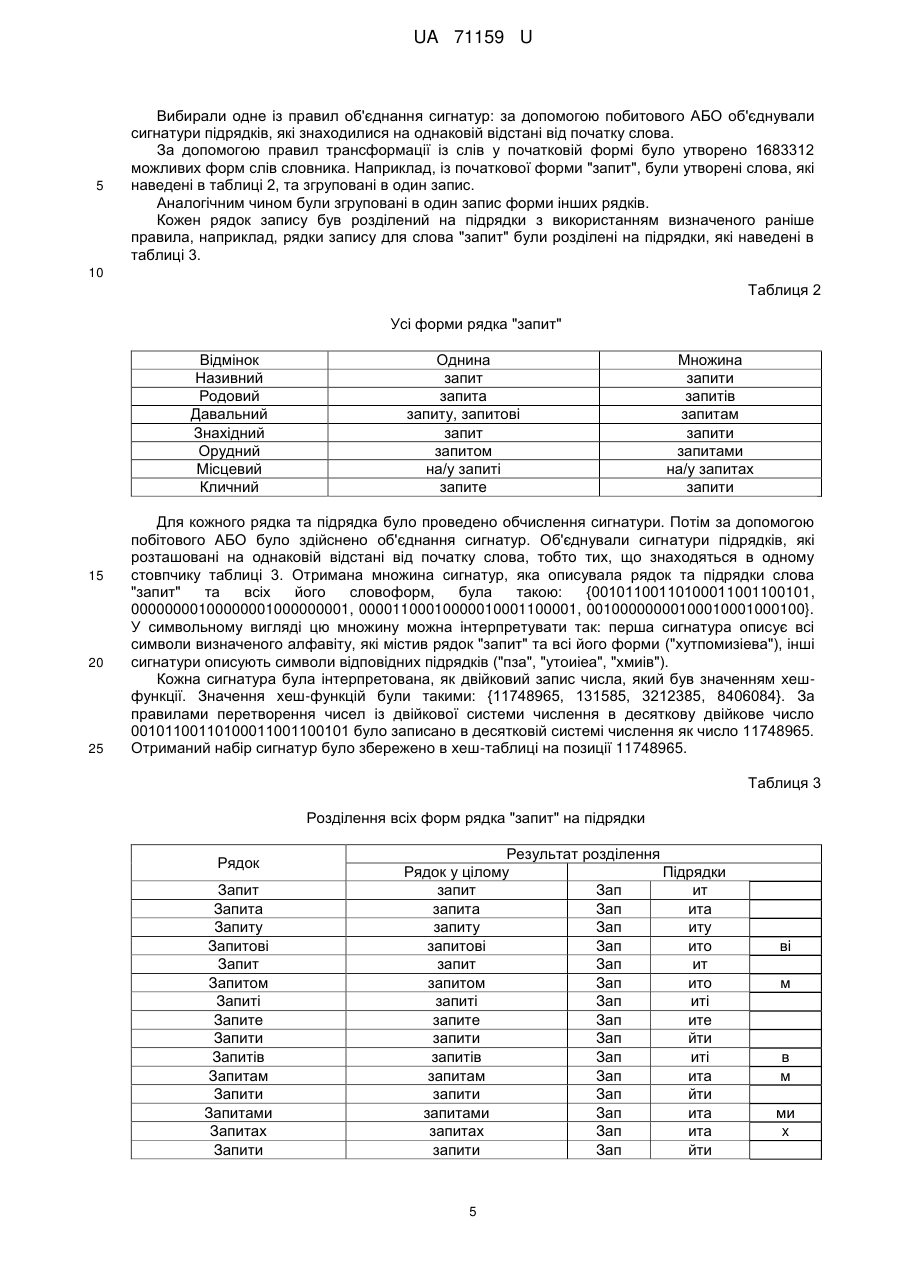
Реферат: Спосіб пошуку текстової інформації за схожістю в масивах текстових даних незалежно від мови включає індексацію текстових даних, для чого здійснюють відображення рядка у множину сигнатур, де одна сигнатура опису є рядок у цілому, а інші є сигнатурами порядків. Приблизну і точну оцінки рядкової метрики застосовують на етапах попередньої і повторної фільтрації пошукового індексу. Спосіб дозволяє суттєво скоротити кількість трудомістких операцій обчислення точної рядкової метрики, підвищити повноту та точність результатів інформаційного пошуку, є стійким до вставки, зміни, видалення символу, перестановки символів, не залежить від мови, дозволяє проводити горизонтальне масштабування. UA 71159 U (54) СПОСІБ ПОШУКУ ТЕКСТОВОЇ ІНФОРМАЦІЇ ЗА СХОЖІСТЮ UA 71159 U UA 71159 U 5 10 15 20 25 30 35 40 45 50 55 60 Спосіб належить до області інформаційного пошуку в масивах текстових даних, незалежно від мови, а саме до пошуку рядків за схожістю. Відомий спосіб пошуку текстової інформації [Patent № US 7,010,522, Method of Performing Approximate Substring Indexing, МПК G06F 17/30, applicant AT&T Corp., New York, NY (US), assignee AT&T Corp., New York, NY (US), Date of Patent Mar. 7, 2006], що включає: визначення області пошуку як колекції рядків або словника, що зберігаються в базі даних; індексацію колекції рядків в базі даних, яка складається з обробки кожного рядка у базі даних з метою генерації множини q-грам, що перекриваються, та доповнення кожної q-грами інформацією про її позицію в рядку; генерацію на основі пошукового запиту, який може містити помилки, множини q-грам та інформації про позицію кожної q-грами в пошуковому запиті; попередню фільтрацію з метою отримання множини наборів q-грам, які потенційно схожі на пошуковий запит; фільтрацію знайденої на попередньому кроці множини записів за допомогою інформації про позиції q-грам; визначення максимальної дистанції редагування к між рядком у базі даних та запитом; відбір записів, які відповідають заданим умовам шляхом обчислення відстані редагування від пошукового запиту до кожного рядка з множини, отриманої на попередніх кроках; видалення з множини всіх рядків, які мають відстань редагування більшу ніж k; видача результатів пошуку. Недоліками даного способу є те, що: записи індексу не об'єднуються і для кожного варіанта рядка потрібно будувати окремий запис індексу, що збільшує його розмір та потребує більше оперативної пам'яті або дискових операцій зчитування; спосіб не гарантує успішного пошуку для рядків довжиною, яка менше 2q, що знижує повноту пошуку. Спільними з способом, що заявляється, ознаками є: визначення області пошуку як колекції рядків; обробка кожного рядка для побудови індексу; генерація пошукового індексу; завдання пошукового запиту, як рядка, який може містити помилки; завдання граничної міри схожості k запису словника та запиту; попередня фільтрація записів індексу з метою отримання множини рядків, які потенційно схожі на пошуковий запит; відбір записів, які відповідають заданим умовам шляхом додаткової фільтрації з використанням точної рядкової метрики для обчислення схожості рядків; видача результатів пошуку. Відомий спосіб пошуку текстової інформації за схожістю [Бойцов Л. Поиск по сходству в документальных базах данных / Леонид Моисеевич Бойцов // Программист, 2001. - № 1. - С. 3235], що включає: визначення області пошуку, як колекції слів або словника; відображення словника у множину двійкових чисел за допомогою методу хешування за сигнатурою, де задають: непустий алфавіт А, відображення f() символів алфавіту в цілі числа від 1 до m, сигнатуру sign(w) слова w (бітовий вектор розмірності m, і-й елемент якого дорівнює одиниці, якщо в слові w є символ такий, що функція f()=i, та нулю в іншому випадку), бітовий вектор сигнатури інтерпретують як двійковий запис значення хеш-функції; зберігання словника у вигляді хеш-таблиці; відображення пошукового запиту, який може містити помилки, у множину двійкових чисел за допомогою хеш-функції на основі сигнатур; пошук елементів хеш-таблиці, в яких відстань Хеммінга до сигнатури пошукового запиту не перевищує заданої граничної міри схожості k (етап попередньої фільтрації) шляхом зчитування знайдених хеш-списків словника і відбір записів, які відповідають заданим умовам, безпосередньою перевіркою на предмет відповідності запиту; видачу результатів пошуку. Недоліками даного способу є те, що: записи індексу не об'єднуються і для кожної форми слова потрібно будувати окремий запис індексу, що збільшує його розмір та потребує більше оперативної пам'яті або дискових операцій зчитування; даний спосіб не зберігає позиції символів, що знижує точність пошуку. Спільними з способом, що заявляється, ознаками є: визначення області пошуку як колекції слів; визначення непустого алфавіту; побудова пошукового індексу шляхом обчислення сигнатури кожного слова словника; інтерпретація кожної сигнатури як двійкового запису числа (значення хеш-функції) та збереження слів словника у вигляді хеш-таблиці; завдання пошукового запиту у вигляді рядка, який може містити помилки; створення на основі пошукового запиту сигнатури всього запиту; завдання граничної міри схожості k запису словника та запиту; попередня фільтрація записів індексу шляхом зчитування знайдених хеш-списків з метою отримання множини рядків, які потенційно схожі на пошуковий запит; відбір записів, які відповідають заданим умовам шляхом використання точної рядкової метрики для обчислення схожості рядків; видача результатів пошуку. В основу корисної моделі поставлено задачу розробити спосіб пошуку текстової інформації, що шляхом побудови пошукового індексу з метою відображення словника у множину двійкових чисел за допомогою методу хешування за декількома сигнатурами, проведення попередньої фільтрації рядків словника за допомогою приблизної рядкової метрики, обчислення релевантності кожного рядка як точної рядкової метрики, видачі впорядкованих за 1 UA 71159 U 5 10 15 20 25 30 35 40 45 50 55 60 релевантністю результатів пошуку дозволяє суттєво скоротити кількість трудомістких операцій обчислення точної рядкової метрики, підвищити повноту та точність результатів інформаційного пошуку, проводити горизонтальне масштабування пошуку, а також включити в результати пошуку рядки, що відрізняються від пошукового запиту формою, яка також може містити помилки, виконувати пошук у тексті незалежно від мови. Суттєвими ознаками способу є: - визначення області пошуку як колекції рядків; - визначення непустого алфавіту; - побудова пошукового індексу шляхом: - визначення правил трансформації рядків; - вибір одного із правил розділення рядка на підрядки, яке обумовлює формулу розрахунку приблизної рядкової метрики; - вибір правила об'єднання сигнатур; - відображення кожного рядка словника у множину двійкових чисел за допомогою методу хешування за декількома сигнатурами, що включає: - створення всіх форм рядків словника з використанням визначених раніше правил трансформації; - групування всіх форм одного рядка в один запис; - розділення кожного рядка запису на підрядки з використанням визначеного раніше правила; - обчислення сигнатури кожного рядка та підрядка; - об'єднання сигнатур усіх підрядків за вибраним раніше правилом; - інтерпретацію кожної сигнатури як двійкового запису значення хеш-функції; - збереження отриманого набору сигнатур запису у вигляді хеш-таблиці, яка є пошуковим індексом; - завдання пошукового запиту, як рядка, який може містити помилки; - створення на основі пошукового запиту сигнатури, яка описує запит у цілому та додаткових сигнатур, які описують усі його підрядки, що включає: - розділення пошукового запиту на підрядки з використанням визначеного раніше правила; - обчислення сигнатури кожного рядка та підрядка; - інтерпретацію кожної сигнатури як двійкового запису значення хеш-функції; - вибір формули для розрахунку точної рядкової метрики для обчислення схожості рядків; - завдання граничної міри схожості k запису словника та запиту; - попередня фільтрація записів індексу за формулою розрахунку приблизної рядкової метрики, з урахуванням граничної міри схожості, шляхом зчитування знайдених хеш-списків з метою отримання множини рядків, які потенційно схожі на пошуковий запит; - відбір записів, які відповідають заданим умовам шляхом виконання повторної фільтрації записів індексу, з урахуванням граничної міри схожості, за формулою обчислення релевантності як точної рядкової метрики, обмеженої заданою граничною мірою схожості k; - видача результатів пошуку, впорядкованих за релевантністю. Відмінними від прототипу ознаками є: - визначення правил трансформації рядків; - вибір одного із правил розділення рядка на підрядки, яке обумовлює формулу розрахунку приблизної рядкової метрики; - вибір правила об'єднання сигнатур; - створення всіх форм рядків словника з використанням визначених раніше правил трансформації; - групування всіх форм одного рядка в один запис; - розділення кожного рядка запису на підрядки з використанням визначеного раніше правила; - відображення всіх підрядкiв кожного рядка словника у множину сигнатур; - об'єднання сигнатур усіх підрядків за вибраним раніше правилом; - створення на основі пошукового запиту додаткових сигнатур, які описують усі його підрядки, що включає: - розділення пошукового запиту на підрядки з використанням визначеного раніше правила; - обчислення сигнатури кожного підрядка; - попередня фільтрація записів індексу за формулою розрахунку приблизної рядкової метрики, з урахуванням граничної міри схожості, з метою отримання множини рядків, які потенційно схожі на пошуковий запит; - вибір формули для розрахунку точної рядкової метрики для обчислення схожості рядків; 2 UA 71159 U 5 10 15 20 25 30 35 - видача результатів пошуку, впорядкованих за релевантністю. Запропонований спосіб, за рахунок високоякісної попередньої фільтрації пошукового індексу, дозволяє суттєво скоротити кількість трудомістких операцій обчислення точної рядкової метрики, підвищити повноту та точність результатів інформаційного пошуку, проводити горизонтальне масштабування пошуку, а також включити в результати пошуку рядки, що відрізняються від пошукового запиту формою, яка також може містити помилки, виконувати пошук у тексті незалежно від мови. Спосіб здійснюють таким чином. Визначають область пошуку, як колекцію рядків, задають непустий алфавіт. Рядком вважають послідовність символів заданого алфавіту, наприклад, алфавіт природної чи штучної мови, або об'єднання декількох алфавітів природної мови в один. Будують пошуковий індекс, для чого: - визначають правило трансформації рядків, наприклад, правило словотвору та словозміни слів мови; - вибирають одне із правил розділення рядка на підрядки, яке обумовлює формулу розрахунку приблизної рядкової метрики, за якою обчислюють ступінь близькості або відмінності між записами словника та пошуковим запитом (таблиця 1). У перших трьох випадках найбільш релевантними вважають записи з найбільшою величиною міри схожості SimDist(u, h), a в четвертому випадку - з найменшою мірою відмінності Dist(u, h); - вибирають правило об'єднання сигнатур, наприклад, за допомогою побітового АБО об'єднують сигнатури підрядків, які розташовані на однаковій відстані від початку слова; - відображують кожне слово словника у множину двійкових чисел за допомогою методу хешування за декількома сигнатурами, для чого: - створюють усі форми рядків словника з використанням визначених раніше правил трансформації; - групують усі форми одного рядка в один запис; - розділюють кожен рядок запису на підрядки з використанням визначеного раніше правила; - обчислюють сигнатури кожного рядка та підрядка, для чого відображують символи алфавіту в цілі числа від 1 до m, і сигнатурою sign(w) слова w вважають бітовий вектор розмірності m, i-й елемент якого дорівнює одиниці, якщо в слові w є символ а такий, що функція f()=і, та нулю в іншому випадку; - об'єднують сигнатури всіх підрядків за правилом, вибраним вище. Наприклад, з кожного рядка запису був вибраний підрядок, що містить перші три символи, і сигнатури таких підрядків потрібно об'єднувати за допомогою побітового АБО, тобто не можна об'єднувати сигнатури перших трьох символів з сигнатурами, які знаходяться на інших позиціях; Таблиця 1 Правила розділення рядків на підрядки та відповідні їм формули приблизної рядкової метрики № з/п 1 2 3 Правила Формула приблизної рядкової метрики n 1-й підрядок є рядком у SimDistu, h dw wi цілому, а інші i 1 підрядками довжини , (1) n=3, що не де перетинаються - u - запис, рядок та всі його форми; - h - пошуковий запит, рядок; 1-й підрядок є рядком у - n - кількість сигнатур; цілому, а iнші - всіма - SimDist(u, h) - міра схожості запису u та пошукового запиту h, можливими підрядками безрозмірна величина; довжини n=3 - dw - кількість спільних символів записів; - wi - кількість співпадаючих біт і-ї сигнатури запиту h та запису u. 1-й підрядок є рядком у Міру схожості обчислюють за формулою (1), але у цьому цілому, а інші - всіма випадку: можливими підрядками wi - кількість співпадаючих біт і-ї сигнатури запиту h та довжини n=1 об'єднання і=1, і, і+1 сигнатур запису u. 3 UA 71159 U Продовження таблиці 1 № з/п Правила Формула приблизної рядкової метрики Dist u, h diff dw n3 w i i3 4 5 10 15 20 25 30 35 (2) - u - запис, рядок та всі його форми; - h - пошуковий запит, рядок; - n - кількість сигнатур; 1-й підрядок є рядком у - Dist(u, h) - міра відмінності запису u та пошукового запиту h, цілому, а інші безрозмірна величина; оточенням кожного з - diff - кількість символів, які є в записі u, але немає в запиті h; найчастіше вживаних - dw - кількість символів, які є в запиту h, але немає в записі u; символів алфавіту - wi - міра відмінності z-ї сигнатури запису u та і-ї сигнатури пошукового запиту h, безрозмірна величина, яка дорівнює: - кількості не співпадаючих біт і-ї сигнатури запиту h й і-ї сигнатури запису u, якщо в записах і-а сигнатура не дорівнює нулю, - 0, якщо обидві сигнатури нульові, - 1, якщо одна із сигнатур дорівнює нулю. - інтерпретують бітовий вектор кожної сигнатури як двійковий запис значення хеш-функції; - зберігають отриманий набір сигнатур запису у вигляді хеш-таблиці, яка є пошуковим індексом. Задають пошуковий запит як рядок, який може містити помилки, тобто мати іншу форму або містити видалені, вставлені, пропущені, переставлені символи. Створюють на основі пошукового запиту сигнатуру, яка описує запит у цілому, та додаткові сигнатури, які описують усі його підрядки, що включає: - розділення пошукового запиту на підрядки з використанням визначеного раніше правила; - обчислення сигнатури кожного рядка та пiдрядка; - інтерпретацію кожної сигнатури як двійкового запису значення хеш-функції. Вибирають формулу для розрахунку точної рядкової метрики для обчислення схожості рядків, які знайдено в результаті попередньої фільтрації, наприклад, метрику ДамерауЛевенштейна. Задають граничну міру схожості k запису словника та запиту. Попередньо фільтрують записи індексу з метою отримання записів, потенційно схожих на пошуковий запит, що полягає у швидкому обчисленні приблизної рядкової метрики для кожного запису та пошукового запиту за допомогою їх сигнатур та зчитуванні знайдених хеш-списків. Обчислену величину вважають приблизним значенням релевантності та за її значенням, враховуючи граничну міру схожості, виключають нерелевантні записи з результатів пошуку. Відбирають записи, які відповідають заданим умовам, шляхом повторної фільтрації записів пошукового індексу, які залишилися після попередньої фільтрації. За вибраною раніше формулою розраховують релевантність як точну рядкову метрику та відфільтровують записи з урахуванням заданого раніше граничного значення k. Видають результати пошуку, впорядковані за релевантністю. Приклад конкретного виконання: Спосіб був застосований для пошуку за схожістю в українському електронному орфографічному словнику ispell, який містив 258888 слів у початковій формі, що були використані як колекція рядків для завдання області пошуку. В цьому випадку слово розглядалось як рядок. Алфавітом були символи української та російської мов "абвгдеіїжзийклмнопрстуфхцчшщъьєюя'ґзы". Будували пошуковий індекс, для чого використовували правила трансформації рядків - у цьому випадку правила словотвору та словозміни української мови. Правила трансформації рядків також є частиною словника ispell. Вибирали в таблиці 1 одне із правил розділення рядка на підрядки, а саме правило 1: рядок у цілому та всі підрядки довжини n=3, що не перетинались. Такий вибір обумовив розрахунок приблизної рядкової метрики за формулою (1). 4 UA 71159 U 5 Вибирали одне із правил об'єднання сигнатур: за допомогою побитового АБО об'єднували сигнатури підрядків, які знаходилися на однаковій відстані від початку слова. За допомогою правил трансформації із слів у початковій формі було утворено 1683312 можливих форм слів словника. Наприклад, із початкової форми "запит", були утворені слова, які наведені в таблиці 2, та згруповані в один запис. Аналогічним чином були згруповані в один запис форми інших рядків. Кожен рядок запису був розділений на підрядки з використанням визначеного раніше правила, наприклад, рядки запису для слова "запит" були розділені на підрядки, які наведені в таблиці 3. 10 Таблиця 2 Усі форми рядка "запит" Відмінок Називний Родовий Давальний Знахідний Орудний Місцевий Кличний 15 20 25 Однина запит запита запиту, запитові запит запитом на/у запиті запите Множина запити запитів запитам запити запитами на/у запитах запити Для кожного рядка та підрядка було проведено обчислення сигнатури. Потім за допомогою побітового АБО було здійснено об'єднання сигнатур. Об'єднували сигнатури підрядків, які розташовані на однаковій відстані від початку слова, тобто тих, що знаходяться в одному стовпчику таблиці 3. Отримана множина сигнатур, яка описувала рядок та підрядки слова "запит" та всіх його словоформ, була такою: {00101100110100011001100101, 00000000100000001000000001, 00001100010000010001100001, 00100000000100010001000100}. У символьному вигляді цю множину можна інтерпретувати так: перша сигнатура описує всі символи визначеного алфавіту, які містив рядок "запит" та всі його форми ("хутпомизіева"), інші сигнатури описують символи відповідних підрядків ("пза", "утоиіеа", "хмиів"). Кожна сигнатура була інтерпретована, як двійковий запис числа, який був значенням хешфункції. Значення хеш-функцій були такими: {11748965, 131585, 3212385, 8406084}. За правилами перетворення чисел із двійкової системи числення в десяткову двійкове число 00101100110100011001100101 було записано в десятковій системі числення як число 11748965. Отриманий набір сигнатур було збережено в хеш-таблиці на позиції 11748965. Таблиця 3 Розділення всіх форм рядка "запит" на підрядки Рядок Запит Запита Запиту Запитові Запит Запитом Запиті Запите Запити Запитів Запитам Запити Запитами Запитах Запити Результат розділення Рядок у цілому Підрядки запит Зап ит запита Зап ита запиту Зап иту запитові Зап ито запит Зап ит запитом Зап ито запиті Зап иті запите Зап ите запити Зап йти запитів Зап иті запитам Зап ита запити Зап йти запитами Зап ита запитах Зап ита запити Зап йти 5 ві м в м ми x UA 71159 U 5 10 15 20 Описаним вище способом було оброблено кожне слово словника ispell. Заповнена таким чином хеш-таблиця була готова для використання як пошуковий індекс. Пошуковий запит був заданий як рядок із помилкою "запіт", який був помилковим варіантом слова "запит". За наведеною вище схемою для цього пошукового запиту було створено набір сигнатур {00100100000001001000001, 00100000001000000001, 00100000000000001000000}. Значення хеш-функцій для запиту було таким {1180225, 131585,1048640}. Була вибрана формула Вагнера-Фішера [Смит, Билл. Методы и алгоритмы вычислений на строках: Пер. с англ. / Билл Смит. - М.: Вильямc, 2006. - 496 с: ил. - Парал. тит. англ. ISBN 58459-1081-1 (рус), С. 283] для обчислення точної рядкової метрики Дамерау-Левенштейна (відстань редагування). Граничною мірою схожості до запису словника та запиту була максимальна відстань редагування, яка дорівнювала 2. Попередня фільтрація записів пошукового індексу була здійснена за формулою (1) для розрахунку приблизної рядкової метрики. Зчитувалися хеш-списки словника, для яких обчислена приблизна рядкова метрика не перевищувала заданої вище межі k. У результаті фільтрації було залишено 117248 записів. Додатково виконали повторну фільтрацію записів пошукового індексу за відомою формулою Вагнера-Фішера розрахунку точної рядкової метрики Дамерау-Левенштейна. Після повторної фільтрації перелік знайдених записів словника скоротився до 148 рядків. Обчислені значення точної рядкової метрики були використані як релевантність. Результати пошуку були впорядковані за значенням релевантності. У таблиці 4 наведена частина найбільш релевантних до запиту "запіт" записів словника. 25 Таблиця 4 Результати роботи алгоритму, початок вибірки № з/п 1. 2. 3. 4. 5. 6. 7. 8. 9. 30 35 Точна рядкова метрика 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 2.0 Приблизна рядкова Початкова форма Найближча до запиту форма рядка, метрика за знайдених рядків операції редагування формулою (1) 18 запекти запік, заміна к→т 18 запит запит, заміна и→і 17 запій запій, заміна й→т 17 запіл запіл, заміна л→т 17 запір запір, заміна р→т 16 завіт завіт, заміна в→п 16 заліт заліт, заміна л→п 16 капіт капіт, заміна к→з 18 запасти запав, заміна а→і, в→т Якість роботи способу визначають за такими відомими показниками, як: повнота та макроусереднена середня точність [Маннинг, Кристофер. Введение в информационный поиск: пер. с англ. / Кристофер Д. Маннинг, Прабхакар Рагхаван, Хайнрих Шютце. - М.: Вильямс, 2011. - 528 с: ил. - парал. тит. англ. - ISBN 978-5-8459-1623-5, стр. 168-173]. Щоб обчислити повноту результатів пошуку, підрахували відношення загальної кількості релевантних записів (148) та кількості знайдених релевантних записів (148). Таким чином, повнота результатів пошуку дорівнювала 148/148=1.0, макроусереднена середня точність МАР=1.8778024/19=0.098831706. Таким чином, спосіб, що заявляється, дозволяє суттєво скоротити кількість трудомістких операцій обчислення точної рядкової метрики, є стійким до вставки, заміни, видалення символу, перестановки символів, не залежить від мови, дозволяє проводити горизонтальне масштабування. 40 ФОРМУЛА КОРИСНОЇ МОДЕЛІ Спосіб пошуку текстової інформації за схожістю, який включає визначення області пошуку як колекції слів; визначення непустого алфавіту; побудову пошукового індексу шляхом обчислення 6 UA 71159 U 5 10 15 20 сигнатури кожного слова словника; інтерпретацію кожної сигнатури як двійкового запису числа значення хеш-функції та збереження слів словника у вигляді хеш-таблиці; завдання пошукового запиту у вигляді рядка, який може містити помилки; створення на основі пошукового запиту сигнатури всього запиту; завдання граничної міри схожості k запису словника та запиту; попередню фільтрацію записів індексу шляхом зчитування знайдених хеш-списків; відбір записів, які відповідають заданим умовам шляхом використання точної рядкової метрики для обчислення схожості рядків; видачу результатів пошуку, який відрізняється тим, що визначають правила трансформації рядків; вибирають одне із правил розділення рядка на підрядки, яке обумовлює формулу розрахунку приблизної рядкової метрики; вибирають правило об'єднання сигнатур; створюють усі форми рядків словника з використанням визначених раніше правил трансформації; групують всі форми одного рядка в один запис; розділяють кожен рядок запису на підрядки з використанням визначеного раніше правила; відображують усі підрядки кожного рядка словника у множину сигнатур; об'єднують сигнатури усіх підрядків за вибраним раніше правилом; створюють на основі пошукового запиту додаткові сигнатури, які описують усі його підрядки, що включає розділення пошукового запиту на підрядки з використанням визначеного раніше правила та обчислення сигнатури кожного підрядка; а попередню фільтрацію записів індексу здійснюють за формулою розрахунку приблизної рядкової метрики з урахуванням граничної міри схожості; вибирають формулу для розрахунку точної рядкової метрики для обчислення схожості рядків; видають результати пошуку, впорядковані за релевантністю. Комп’ютерна верстка А. Крулевський Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 7
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for search of text information by analogy
Автори англійськоюTodoriko Olha Oleksiivna, Dobrovolskyi Hennadii Anatoliiovych
Назва патенту російськоюСпособ поиска текстовой информации по сходству
Автори російськоюТодорико Ольга Алексеевна, Добровольский Геннадий Анатольевич
МПК / Мітки
МПК: G06F 7/10
Мітки: схожістю, текстової, спосіб, пошуку, інформації
Код посилання
<a href="https://ua.patents.su/9-71159-sposib-poshuku-tekstovo-informaci-za-skhozhistyu.html" target="_blank" rel="follow" title="База патентів України">Спосіб пошуку текстової інформації за схожістю</a>
Спосіб пошуку інформації в масиві текстів

Номер патенту: 60952
Опубліковано: 25.06.2011
Автори: Правдива Ольга Василівна, Барков Антон Євгенович, Зелінська Марина Олегівна, Глазунов Дмитро Олегович, Петрушкевич Ірина Віталіївна
МПК: G06F 17/30
Мітки: спосіб, пошуку, текстів, масиві, інформації
Формула / Реферат:
1. Спосіб пошуку інформації в масиві текстів, згідно з яким за допомогою віддаленого приладу користувача через канали зв'язку пошуковим сервером одержують пошуковий запит із реквізитами та ключовими словами, який проходить аналіз та коригування, далі пошуковий сервер проводить ідентифікацію реквізитів та уточнення запиту, а в кінці обробки проводиться вибір документів зі сховища даних та виведення результатів пошуку за допомогою каналів...
Спосіб пошуку та сортування інформації

Номер патенту: 5323
Опубліковано: 15.03.2005
Автори: Серков Олександр Анатолійович, Судаков Борис Миколайович, Пантелеєва Ірина Анатоліївна
МПК: G06F 7/06
Мітки: пошуку, сортування, інформації, спосіб
Формула / Реферат:
Спосіб пошуку та сортування інформації, до складу якого включено подачу неупорядкованого списку фрагментів інформації, їх сортування, запис та збереження у базі даних, видачу упорядкованого списку фрагментів інформації, який відрізняється тим, що кожному фрагменту інформації надається рейтинговий коефіцієнт, який обчислюється шляхом порівняння кожної позиції запиту із відповідною позицією записаного фрагмента інформації у базі даних, та у...
Спосіб пошуку чи перевірки достовірності інформації за допомогою мобільного (стільникового) телефону

Номер патенту: 56082
Опубліковано: 15.04.2003
Автори: Босих Юрій Станіславович, Череменко Анатолій Миколайович, Олійник Інна Леонідівна, Останіна Наталя Вадимівна, Брязкало Вадим Вадимович, Сердюк Андрій Михайлович
МПК: G06Q 99/00
Мітки: телефону, допомогою, спосіб, інформації, пошуку, мобільного, стільникового, достовірності, перевірки
Формула / Реферат:
1. Спосіб пошуку чи перевірки достовірності інформації за допомогою мобільного (стільникового) телефону, який передбачає використання мобільного (стільникового) телефону та мережі Інтернет, який відрізняється тим, що закодований запит у вигляді SMS повідомлення відправляють на визначену адресу електронної пошти мережі Інтернет, де, використовуючи шлюз до мережі Інтернет, оператором мобільного (стільникового) зв'язку це повідомлення з запитом...
Спосіб пошуку та ідентифікації інформації з електронних баз даних

Номер патенту: 80549
Опубліковано: 10.10.2007
Автор: Судак Володимир Сергійович
МПК: G06F 17/20, G06F 5/00, G06F 12/00
Мітки: електронних, баз, ідентифікації, інформації, даних, пошуку, спосіб
Формула / Реферат:
1. Спосіб пошуку інформації в електронних систематизованих базах даних, яка розміщена в доступних каталогах та файлах та містить в банку даних ототожнюючу та інформаційну частину даних, які відтворюють, зчитують і зіставляють з ототожнюючими частинами даних та наносять на носії інформації, які містять інформаційні та додаткові частини даних, який відрізняється тим, що інформаційну частину даних розміщують на екрані дисплея шляхом створення...
Спосіб захисту текстової, табличної та графічної інформації

Номер патенту: 38479
Опубліковано: 12.01.2009
Автори: Назаркевич Марія Андріївна, Дронюк Іванна Мирославівна
МПК: G06K 15/22
Мітки: текстової, табличної, захисту, спосіб, інформації, графічної
Формула / Реферат:
1. Спосіб захисту текстової, табличної та графічної інформації, згідно з яким утворюють графічний елемент, його копіюють, розмножують, поєднуючи різні комбінації, та будують захисну сітку, накладають її на текстову, табличну та графічну інформацію, відтворюють інформацію у векторному форматі, який відрізняється тим, що графічний елемент захисної сітки вибирають як графік протабульованої Ateb-функції, яка побудована згідно з...
Попередній патент: Спосіб виготовлення гранульованого фосфогіпсу
Наступний патент: Спосіб прогнозування туберкульозу легень у дорослих
Випадковий патент: Спосіб виробництва фітоолійного напівфабрикату