Система та спосіб розпізнавання контенту програми мовлення
Номер патенту: 113173
Опубліковано: 26.12.2016
Автори: Ю Вільям Еммануель С., Ібаско Алекс Д., Діаз Мануель О., Джосон Едуардо Рамон Дж.







Формула / Реферат
1. Система розпізнавання контенту програми мовлення, яка містить щонайменше один приймач, призначений для вибірки зразка контенту програми мовлення, та механізм розпізнавання контенту для розпізнавання та зберігання відібраного контенту програми мовлення;
при цьому у разі, якщо механізм розпізнавання контенту не має можливості розпізнати відібраний зразок контенту програми мовлення, механізм розпізнавання контенту ділить нерозпізнаний зразок на щонайменше першу та другу послідовні частини та додає першу частину або другу частину до попереднього розпізнаного зразка.
2. Система за п. 1, яка відрізняється тим, що система призначена для відзначання нерозпізнаного зразка як невдалого зразка.
3. Система за п. 1, яка відрізняється тим, що система призначена для ітераційного поділу та додавання нерозпізнаного зразка до тих пір, поки не буде досягнуто умови завершення або, поки не буде розпізнана додана перша або друга частина.
4. Система за будь-яким з попередніх пунктів, яка містить:
базу даних контенту, що має інформаційний зв'язок із механізмом розпізнавання контенту;
базу даних контенту, призначену для видавання інформації щодо контенту програми мовлення при отриманні запиту від пристрою-клієнта.
5. Система за п. 4, яка відрізняється тим, що пристрій-клієнт є мобільним пристроєм, призначеним для прийому контенту програми мовлення.
6. Система за п. 4, яка відрізняється тим, що запит є SMS-запитом або HTTP пост-запитом.
7. Система за п. 4, яка відрізняється тим, що запит містить позначку часу контенту програми мовлення та ідентифікацію, пов'язану з джерелом мовлення.
8. Система за п. 7, яка відрізняється тим, що пристрій-клієнт виконаний з можливістю автоматичного відправлення пасивної інформації на ID станції та позначки часу до бази даних контенту через визначений проміжок часу.
9. Система за п. 8, яка відрізняється тим, що база даних контенту також має інформаційний зв'язок з контент-менеджером додатків, призначеним для обробки отриманої пасивної інформації для налаштування контенту програми мовлення для пристрою-клієнта.
10. Система за п. 8, яка відрізняється тим, що пасивна інформація може бути відправлена за допомогою SMS, MMS, IP, фірмового повідомлення або за допомогою наявного бездротового підключення, такого як Wi-fi, Bluetooth або бездротовий зв'язок (NFC) ближнього радіуса дії.
11. Система за п. 4, яка відрізняється тим, що система додатково містить базу даних профілювання, яка має інформаційний зв'язок з базою даних контенту,
при цьому інформація з бази даних контенту та бази даних профілювання призначена, зібрана та об'єднана для передачі при певному рішенні користувача.
12. Спосіб розпізнавання контенту програми мовлення, який включає наступні етапи, на яких:
a) отримують зразок контенту програми мовлення;
b) визначають те, чи є отриманий зразок розпізнавальним;
с) поділяють отриманий зразок на щонайменше першу та другу послідовні частини, якщо визначається, що зразок не є розпізнавальним; та
d) додають першу частину або другу частину до попереднього розпізнавального зразка.
13. Спосіб за п. 12, який відрізняється тим, що спосіб включає етап повторення етапів b-d до тих пір, поки доданий зразок не стане розпізнавальним.
Текст
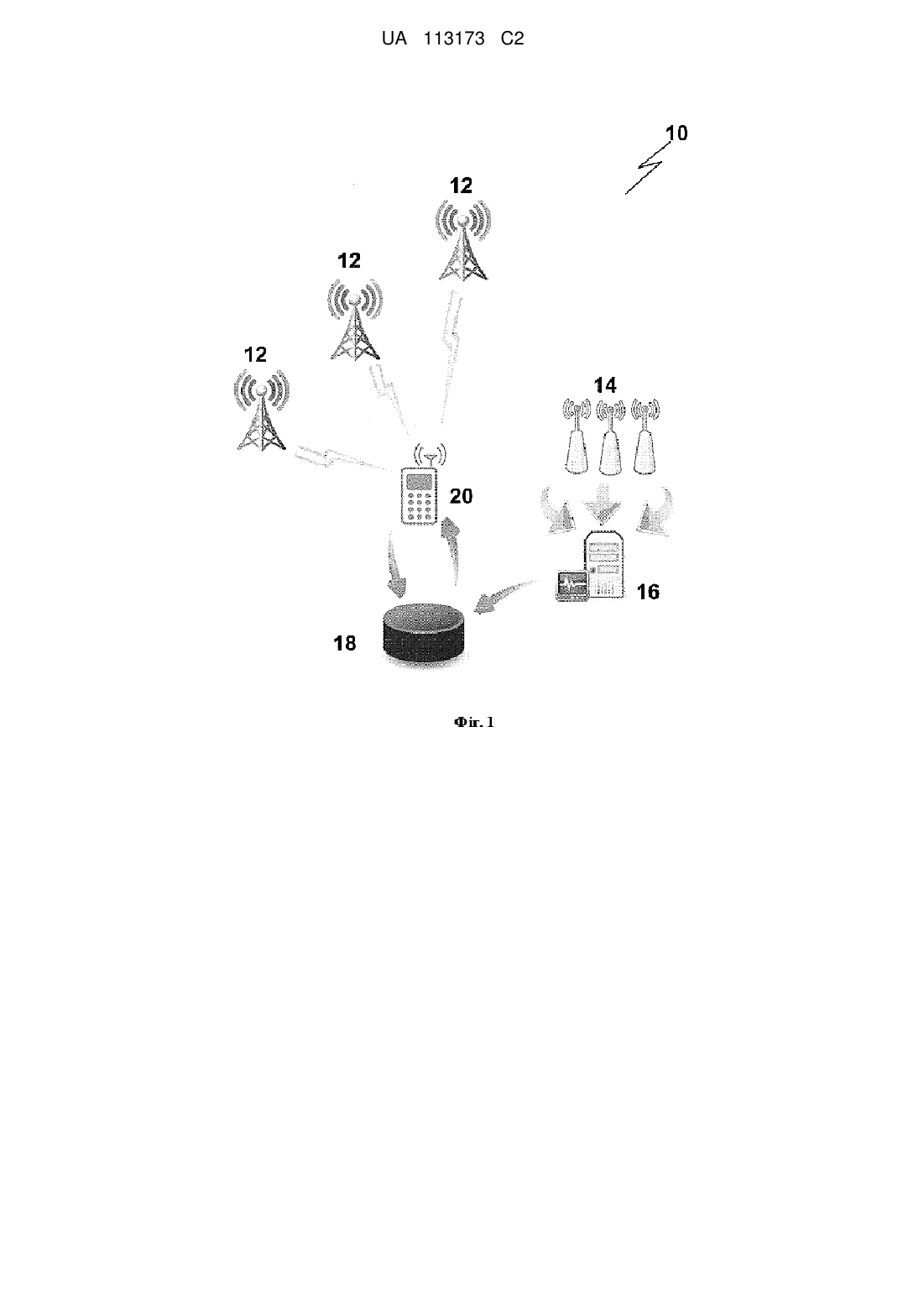
Реферат: Система розпізнавання контенту програми мовлення, яка містить щонайменше один приймач, призначений для вибірки зразків контенту програми мовлення з джерела мовлення; механізм розпізнавання контенту для розпізнавання та зберігання відібраного контенту програми мовлення; та базу даних контенту, що має інформаційний зв'язок із засобами розпізнавання контенту; базу даних контенту, призначену для видавання інформації щодо контенту програми мовлення при отриманні запиту від розкритого пристрою-клієнта. Система налаштовується таким чином, що у разі, якщо механізм розпізнавання контенту не має можливості розпізнати відібраний зразок контенту програми мовлення, тоді засоби розпізнавання контенту ділять нерозпізнаний зразок на щонайменше першу та другу послідовні частини та додають першу частину або другу частину до попереднього розпізнаного зразка. UA 113173 C2 (12) UA 113173 C2 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 60 ОБЛАСТЬ ВИНАХОДУ Даний винахід відноситься до системи та способу розпізнавання контенту програми мовлення. Система та спосіб є найбільш придатними для, але не обмежуються лише розпізнаванням контенту програми мовлення, такого як музика, на який налаштований прилад зв'язку користувача, та будуть описані у даному контексті. ПЕРЕДУМОВИ СТВОРЕННЯ ВИНАХОДУ Наступне обговорення передумов створення винаходу призначене тільки для полегшення розуміння даного винаходу. Слід зазначити, що обговорення не є підтвердженням або припущенням того, що будь-який вказаний матеріал було опубліковано, він був знайомий або був частиною загальних знань спеціалістів в даній області техніки в будь-якій юрисдикції на дату пріоритету винаходу. Сучасні системи та способи розпізнавання музики зазвичай включають використання механізмів розпізнавання музики. Такі механізми розпізнавання музики зазвичай використовують деяку форму алгоритму розпізнавання музики. Алгоритм розпізнавання музики зазвичай отримує аудіо зразок, порівнює аудіо зразок із записами в базі даних та видає певну інформацію відповідно до ідентифікованого аудіо зразка. Сучасні системи розпізнавання музики в значній мірі залишилися в якості автономної функції або онлайн сервісу, доступного для багатьох користувачів. Для підвищення його здатності до обробки одночасних запитів від багатьох користувачів онлайн системи розпізнавання музики зазвичай реалізуються в якості групи серверів з балансуванням навантаження; тобто, система розпізнавання музики буде мати багато проявів самої себе, відтворених у групі серверів, що розділяє навантаження, якщо здійснюється велика кількість одночасних запитів. Однак така реалізація передбачає можливість мережевого підключення з високою пропускною здатністю. Механізми онлайн розпізнавання, незважаючи на велику кількість запитів, все ще забезпечують пристойний час відгуку через використання істотної пропускної здатності Інтернету. Однак, якщо сучасні системи розпізнавання музики реалізуються у контексті послуги мобільного зв'язку, тоді модель групи серверів не буде працювати з таким же успіхом. Це відбувається через обмежену пропускну здатність мобільних мереж, які зазвичай є GSM мережами. У послузі мобільного зв'язку, що обслуговує мільйони користувачів, навантаження на сервер може перевищити можливості обробки механізму розпізнавання, що може призвести до неприйнятної взаємодії з користувачем або фактичної відмови послуги. Такі перешкоди та труднощі також несприятливо вплинуть на мережі, що не використовують передачу даних. Низька якість послуги різко сприяє підвищеному відтоку абонентів, що в дану епоху насиченості ринку та жорстокої конкуренції може призвести до краху оператора мобільної мережі. На додаток до вищесказаного, сучасна система відомого рівня техніки у контексті мобільних послуг вимагає від користувача захоплення фрагменту даної пісні в якості аудіокліпу та його відправлення до механізму розпізнавання пісні. Аудіокліп, незалежно від стислості та незважаючи на метод стиснення, має значний розмір. Даний винахід має забезпечити систему та спосіб розпізнавання контенту, що зменшують вказані вище недоліки. СУТЬ ВИНАХОДУ Даний винахід було розроблено для вирішення завдання зниження обмежень, що виникають через запити розпізнавання музики, щоб уникнути перешкод та труднощів у GSM мережі з відносно низькою пропускною здатністю. Відповідно до першого аспекту даного винаходу запропоновано систему розпізнавання контенту програми мовлення, що містить щонайменше один приймач, призначений для вибірки зразків контенту програми мовлення з джерела мовлення; механізм розпізнавання контенту для розпізнавання та зберігання відібраного контенту програми мовлення; та базу даних контенту, що має інформаційний зв'язок із засобами розпізнавання контенту; базу даних контенту, призначену для видачі інформації щодо контенту програми мовлення при отриманні запиту від пристрою-клієнта. Переважно, пристрій-клієнт є мобільним пристроєм, призначеним для прийому контенту програми мовлення. Переважно, запит є SMS-запитом або HTTP POST запитом. Запит містить позначку часу контенту програми мовлення та ідентифікацію, пов'язану з джерелом мовлення. Переважно, пристрій-клієнт налаштовується на автоматичне відправлення пасивної інформації на ID станції та позначки часу до бази даних контенту через визначений проміжок 1 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 60 часу. В такій конфігурації база даних контенту також має інформаційний зв'язок з контентменеджером додатків, призначеним для обробки отриманої пасивної інформації для налаштування контенту програми мовлення для пристрою-клієнта. Переважно, пасивна інформація може бути відправлена за допомогою SMS, MMS, IP, фірмового повідомлення або за допомогою наявного бездротового підключення, такого як Wi-fi, Bluetooth або бездротовий зв'язок (NFC) ближнього радіусу дії. Переважно, система також містить базу даних профілювання, що має інформаційний зв'язок з базою даних контенту, де інформація з бази даних контенту та бази даних профілювання призначена, зібрана та об'єднана для передачі при певному рішенні користувача. Відповідно до другого аспекту даного винаходу запропоновано систему розпізнавання контенту програми мовлення, яка містить щонайменше один приймач, призначений для вибірки зразку контенту програми мовлення, та механізм розпізнавання контенту для розпізнавання та зберігання відібраного контенту програми мовлення, при цьому у разі, якщо механізм розпізнавання контенту не має можливості розпізнати відібраний зразок контенту програми мовлення, тоді засоби розпізнавання контенту ділять нерозпізнаний зразок на щонайменше першу та другу послідовні частини та додають першу частину або другу частину до попереднього розпізнаного зразку. Переважно, система призначена для ітераційного поділу та додавання нерозпізнаного зразку до тих пір, поки не буде досягнуто умови завершення або, поки не буде розпізнана додана перша або друга частина. Переважно, система призначена для відзначання нерозпізнаного зразка в якості невдалого зразка. Відповідно до третього аспекту даного винаходу запропоновано спосіб розпізнавання контенту програми мовлення, який включає наступні етапи, на яких: a. отримують зразок контенту програми мовлення; b. визначають те, чи є отриманий зразок розпізнавальним; c. поділяють отриманий зразок на першу та другу послідовні частини, якщо визначається, що зразок не є розпізнавальним; та d. додають першу частину до попереднього розпізнавального зразку. Переважно, що спосіб включає етап, на якому повторюють етапи b-d до тих пір, поки доданий зразок не стане розпізнавальним. Стислий ОПИС графічних матеріалів Даний винахід зараз буде описано тільки в якості прикладу з посиланням на прикладені графічні матеріали, на яких: На Фіг. 1 представлено схематичне зображення системи розпізнавання контенту відповідно до першого варіанту даного винаходу. На Фіг. 2 представлено схематичне зображення системи розпізнавання контенту відповідно до другого варіанту даного винаходу. На Фіг. 3 представлена блок-схема, що зображує алгоритм вибірки відповідно до варіантів даного винаходу. На Фіг. 4 зображено зразок, що виходить за межі тривалості контенту, що призведе до неможливості його розпізнавання системою розпізнавання контенту. На Фіг. 5 зображено поділ нерозпізнавального зразку за різних умов. ОПИС варіантів винаходу Відповідно до першого варіанту даного винаходу передбачається система 10 розпізнавання контенту програми мовлення. Система 10 розпізнавання контенту містить декілька приймачів 14 мовлення, кожен з яких призначений для прийому контенту програми мовлення від одного або декількох джерел 12 мовлення; механізм 16 розпізнавання контенту; та базу даних 18 контенту. Джерелами 12 мовлення зазвичай є станції мовлення. З ціллю ілюстрації, джерела 12 мовлення є станціями мовлення з частотною модуляцією (FM). Кожна станція 12 мовлення транслює контент програми у різних діапазонах FM частот. В цілях ілюстрації, у даному варіанті контентом мовлення, що транслюється з різних джерел мовлення, є музика, хоча слід розуміти, що контент мовлення може бути іншим аудіо контентом, включаючи аудіо рекламу і т.д. Кожен приймач 14 має зв'язок з відповідним йому джерелом 12 мовлення. Слід розуміти, що кожен приймач 14 може бути розміщено у тій самій зоні джерела мовлення або розділено географічно. Кожен приймач 14 призначений для безперервної вибірки зразку музики, що транслюється з відповідного йому джерела 12 мовлення. Кожен приймач 14 налаштовується на вибірку зразку контенту програми мовлення у час t вибірки. Механізм 16 розпізнавання музики включає програму, яка може бути стороннім програмним TM додатком, як буде зрозуміло спеціалістам в даній області техніки (наприклад, SoundHound ). 2 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 Механізм 16 розпізнавання музики призначений для прийому та обробки зразків музики з кожного приймача 14. Обробка виконується за допомогою механізму 16 розпізнавання музики, що включає аналізування та ідентифікацію зразку за встановлений час розпізнавання. База даних 18 контенту постійно поповнюється за допомогою механізму 16 розпізнавання контенту. Дані, передані до бази даних 18 контенту з механізму 16 розпізнавання, можуть бути у будь-якому бажаному форматі. Наприклад, база даних 18 контенту може мати свою власну систему декодеру, що декодує код з механізму 16 розпізнавання та перекладає зразок у істотну інформацію, таку як назва, жанр, виконавець і т.д., за допомогою звичайного запиту перегляду бази даних, наприклад, за допомогою SQL запиту, але не обмежуючись лише цим запитом. База даних 18 призначений для прийому запитів від щонайменше одного пристрою-клієнта 20, де кожен запит включає позначку часу та ID станції, що відноситься до станції 12 мовлення, на яку налаштовуються пристрої-клієнти 20. База даних 18 контенту організує інформацію, отриману від механізму 16 розпізнавання, відповідно до часу отримання та таким чином здатна надавати архівні записи контенту, отриманого від механізму 16 розпізнавання контенту. Архівні записи, які може отримати користувач, залежать від розміру та ємності бази 18 даних. Пристрій-клієнт 20 зазвичай є мобільним пристроєм. В даному варіанті мобільний пристрій 20 оснащений FM тюнером, так що користувач мобільного пристрою 20 може налаштуватися на обрану станцію 12 мовлення. Мобільний пристрій 20 призначений для інформаційного зв'язку з базою даних 18 контенту та може відправляти запит до бази даних 18 контенту, використовуючи механізми запиту даних, такі як HTTP POST запит, звернення до методів, SMS запит на основі ключового слова і т.д. Система 10 буде зараз описана у контексті своєї роботи. У якості ілюстрації користувач мобільного пристрою 20 налаштовується на конкретну станцію 12 мовлення із багатьох станцій 12 мовлення за допомогою регулювання FM тюнеру, вбудованого у мобільний пристрій 20. Користувач бажає знати назву пісні, що транслюється, на яку він/вона налаштувалися, тому він звертається до інтерфейсу мобільного пристрою аби відправити запит до бази 18 даних плейлистів, оснований на протоколі, що було згадано раніше (за допомогою HTTP POST, SMS запиту і т.д.). База 18 даних контенту виконує звичайний пошук, оснований на двох параметрах: а. позначці часу запиту; та б. ID станції. База даних 18 контенту перевіряє позначку часу запиту для визначення того, чи підпадає позначка часу під встановлений відомий інтервал tk вибірки, що є інтервалом часу, під час якого відбувається програвання контенту програми мовлення. Якщо позначка часу не підпадає під відомий інтервал tk вибірки, тоді база даних 18 контенту відправляє помилку про збій виявлення до пристрою-клієнта 20 та опціонально нагадує користувачеві пристрою-клієнта 20 повторити спробу. Зазвичай значення інтервалу t вибірки визначається за допомогою алгоритму розпізнавання музики, враховуючи мінімальний час вибірки, необхідний для успішної ідентифікації зразку музики. Будь-який коротший інтервал часу фактично перешкодить ідентифікації аудіо зразку механізмом 14 розпізнавання. Однак для запобігання охоплення вибіркою двох різних зразків музики, що перешкодить ідентифікацію зразку механізмом розпізнавання, слід дотримуватися якомога коротшого інтервалу t вибірки. Звідси випливає, що для того, щоб запобігти перекривання зразків під час вибірки, інтервал t вибірки в ідеалі має бути менше або щонайбільше дорівнюватися довжині програвання контенту, що транслюється. Однак на практиці кожен контент, що транслюється, має різну довжину програвання, тому інтервал t вибірки має бути невеликим та щонайбільше дорівнюватися довжині програвання найкоротшого контенту, що транслюється. Навіть у цьому випадку залишається ймовірність перекривання, оскільки довжини програвань кожного контенту програми мовлення будуть змінюватися. В варіанті метод передбачає відповідність інтервалу t вибірки та мінімального інтервалу вибірки, що потребується механізму 16 розпізнавання контенту, що використовується, та усунення будь-яких зразків, що перекриваються. У випадку, якщо виникає перекривання зразку (відоме як умова/сценарій перекривання), тоді алгоритм вибірки механізму 16 розпізнавання контенту виконає необхідні операції для вирішення умови перекривання (що буде описана далі). Незалежно від того, здійснюються запити користувачем (користувачами), чи ні, кожен приймач 14 постійно здійснює вибірку музики, що транслюється, на налаштованій на ньому станції 12 мовлення. Вибірка здійснюється на основі алгоритму вибірки, зображеному на Фіг. 3, та описаному далі: 3 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 60 Обробка починається з взяття зразку контенту, що транслюється, з джерела 12 мовлення (етап 32). Хоча вибірка є безперервною, але взяття одного зразку у визначений інтервал вважається за етап взяття зразку. Алгоритм перевіряє, чи готовий зразок (етап 34). Етап перевірки включає підтвердження того, чи наявний зразок. Зазвичай зразок є вихідним зразком. У якості альтернативи етап перевірки може бути виконаний з використанням перекодованого зразку (тобто може включати опціональний етап перекодування, що перетворює вихідний зразок у шістнадцятковий незашифрований текст або будь-який унікальний код). У такому випадку етап перевірки підтверджує наявність перекодованого зразку. Як тільки зразок готовий, він завантажується до механізму 16 розпізнавання (етап 36). Механізм 16 розпізнавання виконує розпізнавання контенту на основі відомих методів та перевіряє, чи є розпізнавання успішним (етап 38). Якщо визначається, що розпізнавання контенту є успішним, тоді інформація зберігається у базі 18 даних контенту (етап 40). Зразок також зберігається у круговому буфері черг. Круговий буфер черг може бути системою масового обслуговування "Перший на вході, перший на виході" та є засобом скидання буферного контенту у випадку, якщо контент більше не є необхідним. Якщо розпізнавання контенту не є успішним, тоді здійснюється відмітка про невдачу (етап 42). Невдале розпізнавання означає, що зразок підпадає під категорію умови перекривання та тим самим потребує поділу (етап 44), етапи якого зображені на Фіг. 5. Потім поділений зразок та перша частина додаються до попереднього зразку, який знаходиться у буферній черзі пам'яті (етап 46). Потім об'єднаний зразок завантажується до механізму розпізнавання контенту (етап 36). Процес повторюється до тих пір, поки зразок не буде розпізнано та збережено (етап 40). Якщо розпізнавання є невдалим, тоді половина першої частини раніше поділеного зразку буде поділена та потім додана до попереднього зразку у черзі буфера. Етап 44 також описано нижче та зображено на Фіг. 5. На Фіг. 5 зображено контент А та Б програми, що програється на конкретній станції 12 мовлення, та зразки 1, 2, 3 та 4, узяті під час послідовного програвання контенту А та Б програми. Легко помітити, що зразки 1, 2 та 4 є остаточними, тобто контент А може бути встановлено з використанням зразків 1 та 2, в той час як контент Б може бути встановлено з використанням зразку 4. Однак зразок 3 представляє проблему перекривання, оскільки частина зразку 3 береться під час транслювання контенту А, а інша частина зразку 3 береться під час транслювання контенту Б. В результаті розпізнавання зразку 3 буде невдалим на основі етапу 38, оскільки алгоритм розпізнавання музики не зможе визначити, з яким контентом А чи Б зразок 3 пов'язаний. При виявленні невдалого зразку 3 алгоритм вибірки переходить до позначання невдалого зразку (етап 42) та поділу зразку 3 на зразок S3L (перша частина) та зразок S3R. При додаванні зразку S3L до зразку 2 механізм розпізнавання контенту зможе позначити дійсне розпізнавання зразку 2+S3L. Однак зразок S3R все ще буде невдалим на основі етапу 38 та таким чином залишиться у якості проблеми перекривання. Потім невдалий зразок S3R викликає інший поділ зразку RL та зразку RR. Слід зауважити, що додавання RR до зразку 4 призведе до дійсної ідентифікації контенту Б. Однак додавання RL до зразку 2 або зразку 4 призведе до збою у процесі ідентифікації. Слід розуміти, що, хоча було проілюстровано та описано випадок "лівого додавання", "праве додавання" (тобто додавання зразку S3R до зразку 3, наприклад) також у рівній мірі підтримується системою. Як зображено на Фіг. 5, інтервал стабільності збільшується, оскільки зразок перекривання, зразок 3, ділиться. Без етапу 44 поділу інтервал стабільності, тобто період, коли механізм 16 розпізнавання контенту в змозі ідентифікувати контент А програми, що транслюється, відомий як Перший інтервал стабільності, коротший, оскільки зразок 3 підпадає під умову перекривання. Запит користувача, що здійснюється після Першого інтервалу стабільності та підпадає під зразок 3, буде видавати помилку. Однак при застосуванні процесу/етапу 44 поділу інтервал стабільності підвищується. Перша частина Зразку S3L додається до Першого інтервалу стабільності, що призводить до Другого інтервалу стабільності, який є довшим. Отже теж самий запит користувача, що підпадає під Другий інтервал стабільності, призведе до позитивної ідентифікації контенту А програми. Результати будуть кращими при Другому інтервалі стабільності, як проілюстровано для одного і того ж самого запиту. При успішному розпізнаванні зразки та їх інформація зберігаються, та механізм 16 розпізнавання оновлює відомий інтервал tk в цілях включення часу t вибірки плюс часу, витраченого на додавання частини. Для кожного збереженого зразку система перевіряє, чи була зроблена відмітка про невдачу (етап 48) під час етапу 42. Якщо відмітка про невдачу виявляється, то це означає, що нещодавно оброблений зразок є поділеним та 4 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 60 об'єднаним/доданим зразком (що відрізняється від зразку звичайної довжини), отже з'являється час на перехід до наступного зразку звичайної довжини (етап 32). Якщо відмітки про невдачу немає, тоді система перевіряє, чи існує наступний поділ на обробку (етап 50). Якщо немає більше зразків на обробку, тоді алгоритм вибірки переходить до іншого зразку (етап 32). Процес поділу (етап 44) та додавання є багаторазовим, як було описано, але він має умову завершення. Така умова може бути обумовлена бізнес-правилами, такими як встановлення певної кількості n повторювань або, поки значення ½t дорівнює тривалості мінімального часу tmin вибірки. Значення tmin є інтервалом мінімального часу вибірки, необхідним для отримання придатного зразку; будь-який зразок, обраний за менший час, аніж tmin не буде розпізнавальним. Початково n може дорівнювати 2. Відповідно до другого варіанту винаходу, де подібні цифри вказують на подібні частини, передбачається система 10 розпізнавання контенту. Система 10 розпізнавання контенту містить декілька приймачів 14 мовлення, кожен с яких налаштовано на прийом контенту програми мовлення з джерела 12 мовлення, механізм 16 розпізнавання контенту та базу 18 даних контенту. Джерела 12 мовлення зазвичай є станціями мовлення. З ціллю ілюстрації джерела 12 мовлення є FM станціями мовлення. Кожна станція мовлення транслює контент програми мовлення в різних діапазонах FM частот. В цілях ілюстрації, у даному варіанті контентом, що транслюється з різних джерел мовлення, є музика, хоча слід розуміти, що контент мовлення може бути іншим аудіо контентом, включаючи аудіо рекламу і т.д. На додаток до першого варіанту передбачається оператор мобільної мережі або контентменеджер 900 додатків та база 950 даних профілювання. Замість звичайного запиту, описаного у першому варіанті, пристрій-клієнт 20 відправляє пасивну інформацію на ID станції та позначку часу до бази 18 даних контенту на регулярній основі без необхідності активного запиту інформації користувачем. Це може бути виконано, наприклад, за допомогою налаштувань пристрою-клієнта та не буде далі описуватися більш детально. Пасивна інформація, відправлена таким чином, зможе відобразити, що користувач пристрою-клієнта 20 перемкнувся на іншу станцію 12 (на основі перемикання ID станції). Пасивна інформація може бути відправлена через мережу GSM за допомогою SMS, MMS, IP, механізму фірмового повідомлення і т.д., що використовує пристрій-клієнт 20, або за допомогою іншого наявного бездротового підключення, такого як Wi-fi, Bluetooth, бездротовий зв'язок (NFC) ближнього радіусу дії, тощо, якщо пристрій-клієнт 20 оснащений такими функціями. База даних 18 контенту знаходиться у інформаційному зв'язку з базою даних 950 профілювання. Інформація з бази даних 18 контенту та бази даних 950 профілювання може в подальшому бути призначена, збережена та об'єднана (зібрані дані) для передачі при певному рішенні користувача, наприклад, показуючи, який конкретно контент змушує користувача пристрою-клієнта 20 перемикати канали, а який спонукає залишитися на налаштованому каналі, прослуховуючи уподобання користувача, хоча інша інформація також може відслідковуватися, така як пісні, що прослуховуються, кількість часу, протягом якого користувач залишається на конкретному каналі, контент, що транслюється у той час, коли користувач змінює канали і т.д. База даних 950 профілювання передає цю інформацію оператору мобільної мережі або контент-менеджеру 900 додатків. Далі контент-менеджер 900 має можливість налаштовувати контент для мобільного пристрою 20 за допомогою сугестивного маркетингу або цільової реклами, такої як, наприклад, наявність для продажу оптичного медіа контенту того ж жанру, що є переважним для абонента, або майбутній концерт виконавця, що відноситься до такого жанру, тощо. Інформація з бази даних 18 контенту та бази даних 950 профілювання також може бути використана різними способами. Інформація щодо поведінки користувача може бути збережена та об'єднана, щоб відобразити, який конкретний контент програми мовлення змушує користувачів пристрою-клієнта 20 перемкнутися на інший канал, а який спонукає залишитися на налаштованому каналі. Інформація щодо кількості слухачів, налаштованих на станції 12 мовлення в будь-який визначений момент часу може бути доступна, надаючи контентменеджеру 900 додатків інформацію щодо найкращого часу/періоду часу для транслювання конкретного контенту програми мовлення. Далі інформація може бути використана провайдерами контенту та станціями 12 мовлення для визначення відповідного змісту програми, що у більшій мірі приверне увагу слухачів. Крім того, даний варіант може бути також доречним для підвищення рейтингу станцій 12 мовлення. Слід розуміти, що інформація, що збирається та оцінюється, зазвичай збирається за допомогою засобів, починаючи з неавтоматичних вибіркових оглядів та завершуючи автоматичним збором даних, використовуючи пристрої, встановлені випадковим чином у житлових будинках та у окремих 5 UA 113173 C2 5 10 15 20 25 30 35 40 45 50 55 60 громадян. Для використання даного варіанту всі мобільні пристрої 20 з вбудованим тюнером можуть супроводжуватися інтегрованою системою збору інформації, яка у реальному часі дозволяє визначення того, скільки пристроїв-клієнтів 20 (та отже кінцевих користувачів) налаштовано на прослуховування конкретного каналу 12 мовлення у будь-який час. Даний варіант дозволяє рекламодавцям бути більш обізнаними щодо того, на якому каналі 12 мовлення, яку рекламу краще використовувати в залежності від цільової аудиторії. Інтегрована система збору інформації, згадана вище, реалізується попутно та її робота є схожою на відправку пасивної інформації пристроєм-клієнтом 20. Пасивна інформація може бути звичайним повідомленням, якщо користувач пристрою-клієнта 20 налаштовується на конкретний канал, та такі повідомлення збираються у базі даних, сповіщення з якої здійснюються у якості іншого сервісу, доступного безкоштовно, на абонентській основі, на основі разового платежу за перегляд або інших бізнес моделей, що будуть визначені далі. Варіант також може бути використаний для оцінки музики, що найчастіше програється на певній території. Без необхідності участі кінцевого користувача об'єднані елементи 14, 16 та 18 можуть бути використані для моніторингу та оцінки музики, пісні або альбому, що є найбільш популярним у даний момент часу. Щільність слухачів також може бути визначена на основі місцеположення та кількості мобільних пристроїв 20. Інформація про місцеположення також може бути представлена оператором 900 мобільної мережі за допомогою бази даних 950 профілювання. З використанням інформації географічне профілювання може бути здійснено для передачі найбільш відповідного контенту та змісту програми. У наступних варіантах даного винаходу приймачі 14 та механізм 16 розпізнавання музики можуть бути замінені гібридними станціями мовлення. Супутньою перевагою системи 10 розпізнавання контенту є можливість відслідковувати архівні дані. У зв'язку з цим, якщо користувач відправляє запит на кшталт "що це за пісня тільки що програвалася?", тоді база даних 18 контенту зчитує інформацію та надає інформацію щодо пісні. Крім того, описані варіанти здійснення є сумісними з низхідною сумісністю з відносно більш старшим поколінням пристроїв користувача до тих пір, поки пристрою доступні СМС. У такій ситуації, користувач може все ще послати простий текст запиту (у тому числі станції ID), і система 10 відповість за допомогою текстового повідомлення з назвою пісні, яка грала з радіостанції, наприклад. Варіанти - База 950 даних профілювання та геолокаційний сервіс, що є результатом об'єднаних елементів 14, 16 та 18, можуть бути замінені будь-яким еквівалентом відповідної функціональності, таким як запис попередніх операцій або подій, здійснених одним і тим самим користувачем, або будь-який зразок, що може бути добуто з наявних записів. - Безперервна вибірка, що здійснюється за допомогою приймачів 14, може виконуватися 24/7. Слід розуміти, що вищезгадані варіанти були надані лише у якості ілюстрації даного винаходу, описаного нижче більш детально, та наступні його модифікації та поліпшення, що будуть зрозумілі спеціалістам в даній області техніки, мають підпадати під загальну сферу та межі описаного даного винаходу. Крім того, хоча окремі варіанти винаходу були описані, передбачається, що винахід також охоплює комбінації обговорених варіантів. ФОРМУЛА ВИНАХОДУ 1. Система розпізнавання контенту програми мовлення, яка містить щонайменше один приймач, призначений для вибірки зразка контенту програми мовлення, та механізм розпізнавання контенту для розпізнавання та зберігання відібраного контенту програми мовлення; при цьому у разі, якщо механізм розпізнавання контенту не має можливості розпізнати відібраний зразок контенту програми мовлення, механізм розпізнавання контенту ділить нерозпізнаний зразок на щонайменше першу та другу послідовні частини та додає першу частину або другу частину до попереднього розпізнаного зразка. 2. Система за п. 1, яка відрізняється тим, що система призначена для відзначання нерозпізнаного зразка як невдалого зразка. 3. Система за п. 1, яка відрізняється тим, що система призначена для ітераційного поділу та додавання нерозпізнаного зразка до тих пір, поки не буде досягнуто умови завершення або, поки не буде розпізнана додана перша або друга частина. 4. Система за будь-яким з попередніх пунктів, яка містить: 6 UA 113173 C2 5 10 15 20 25 базу даних контенту, що має інформаційний зв'язок із механізмом розпізнавання контенту; базу даних контенту, призначену для видавання інформації щодо контенту програми мовлення при отриманні запиту від пристрою-клієнта. 5. Система за п. 4, яка відрізняється тим, що пристрій-клієнт є мобільним пристроєм, призначеним для прийому контенту програми мовлення. 6. Система за п. 4, яка відрізняється тим, що запит є SMS-запитом або HTTP пост-запитом. 7. Система за п. 4, яка відрізняється тим, що запит містить позначку часу контенту програми мовлення та ідентифікацію, пов'язану з джерелом мовлення. 8. Система за п. 7, яка відрізняється тим, що пристрій-клієнт виконаний з можливістю автоматичного відправлення пасивної інформації на ID станції та позначки часу до бази даних контенту через визначений проміжок часу. 9. Система за п. 8, яка відрізняється тим, що база даних контенту також має інформаційний зв'язок з контент-менеджером додатків, призначеним для обробки отриманої пасивної інформації для налаштування контенту програми мовлення для пристрою-клієнта. 10. Система за п. 8, яка відрізняється тим, що пасивна інформація може бути відправлена за допомогою SMS, MMS, IP, фірмового повідомлення або за допомогою наявного бездротового підключення, такого як Wi-Fi, Bluetooth або бездротовий зв'язок (NFC) ближнього радіуса дії. 11. Система за п. 4, яка відрізняється тим, що система додатково містить базу даних профілювання, яка має інформаційний зв'язок з базою даних контенту, при цьому інформація з бази даних контенту та бази даних профілювання призначена, зібрана та об'єднана для передачі при певному рішенні користувача. 12. Спосіб розпізнавання контенту програми мовлення, який включає наступні етапи, на яких: a) отримують зразок контенту програми мовлення; b) визначають те, чи є отриманий зразок розпізнавальним; с) поділяють отриманий зразок на щонайменше першу та другу послідовні частини, якщо визначається, що зразок не є розпізнавальним; та d) додають першу частину або другу частину до попереднього розпізнавального зразка. 13. Спосіб за п. 12, який відрізняється тим, що спосіб включає етап повторення етапів b-d до тих пір, поки доданий зразок не стане розпізнавальним. 7 UA 113173 C2 8 UA 113173 C2 9 UA 113173 C2 10 UA 113173 C2 Комп’ютерна верстка О. Гергіль Державна служба інтелектуальної власності України, вул. Василя Липківського, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут інтелектуальної власності”, вул. Глазунова, 1, м. Київ – 42, 01601 11
ДивитисяДодаткова інформація
Назва патенту англійськоюSystem and method for recognizing broadcast program content
Автори англійськоюIbasco, Alex D., Joson, Eduardo Ramon G., Yu, William Emmanuel S., Diaz, Manuel O.
Автори російськоюИбаско Алекс Д., Джосон Эдуардо Рамон Дж., Ю Вильям Эммануель С., Диаз Мануель О.
МПК / Мітки
МПК: G06F 17/30, H04H 60/37, H04H 60/58
Мітки: система, контенту, мовлення, спосіб, програми, розпізнавання
Код посилання
<a href="https://ua.patents.su/13-113173-sistema-ta-sposib-rozpiznavannya-kontentu-programi-movlennya.html" target="_blank" rel="follow" title="База патентів України">Система та спосіб розпізнавання контенту програми мовлення</a>
Спосіб пофонемного розпізнавання злитого мовлення

Номер патенту: 50040
Опубліковано: 25.05.2010
Автори: Гриценко Володимир Ілліч, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: пофонемного, спосіб, розпізнавання, злитого, мовлення
Формула / Реферат:
Спосіб пофонемного розпізнавання злитого мовлення, що ґрунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, що визначаються фонетичними транскрипціями допустимих в мові діалогу послідовностей слів, визначення...
Спосіб та пристрій пофонемного розпізнавання злитого мовлення

Номер патенту: 67697
Опубліковано: 15.06.2004
Автори: Родіонов Олександр Олександрович, Гриценко Володимир Ільїч, Федорин Ярослав Володимирович, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: розпізнавання, спосіб, злитого, пофонемного, мовлення, пристрій
Формула / Реферат:
1. Спосіб пофонемного розпізнавання злитого мовлення, що грунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, що визначаються фонетичними транcкрипціями допустимих в мові діалогу послідовностей слів, визначення...
Пристрій пофонемного розпізнавання злитого мовлення

Номер патенту: 50041
Опубліковано: 25.05.2010
Автори: Гриценко Володимир Ілліч, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: пристрій, пофонемного, мовлення, злитого, розпізнавання
Формула / Реферат:
Пристрій пофонемного розпізнавання злитого мовлення, що містить аналізатор, блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей та контролер, який відрізняється тим, що в нього введені блок пам'яті навчальної вибірки, процесор кластерного аналізу, блок пам'яті параметрів фонем, блок пам'яті орфографічного тексту та фонемної транскрипції,...
Система передачі контенту

Номер патенту: 65101
Опубліковано: 25.11.2011
Автори: Цимідан Георгій Анатолійович, Вустяк Микола Пилипович
МПК: G06F 1/00, G06F 21/00
Мітки: передачі, система, контенту
Формула / Реферат:
1. Система передачі контенту, яка містить цифрову камеру або веб-камеру, або сервер з даними (відео, аудіо та ін. контент) тощо, через який надходить інформація, яка відрізняється тим, що система містить конвертор, який стискає надіслану інформацію, для передачі по каналах зв'язку, він підключений через мережеву карту, яка може бути провідною по витій парі або бездротовою Wi-Fi, до роутера, який передає інформацію на сервер...
Сумісна система стереофонічного мовлення

Номер патенту: 33668
Опубліковано: 15.02.2001
Автори: Балан Микола Макарович, Захарін Віталій Михайлович, Виходець Анатолій Васильович
МПК: H04H 5/00
Мітки: сумісна, мовлення, стереофонічного, система
Формула / Реферат:
Сумісна система стереофонічного мовлення для діапазону метрових хвиль, яка містить на передавальній стороні матрицю, балансний модулятор, генератор пілот-тону, подвоювач частоти, блок затримки, суматор, передавач, а на приймальній .стороні приймач, вузькосмуговий фільтр пілот-тону, подвоювач частоти, балансний детектор, матрицю, фільтри нижніх частот, яка відрізняється тим, що в передавальну сторону додатково уведено другий балансний...
Попередній патент: Стійкий рідкий препарат етанерцепту
Наступний патент: Стабільна ліофілізована композиція на основі fgf-18
Випадковий патент: Автогенераторний слідкувальний фільтр з додатковим корегуванням похибки