Інтелектуальна розподілена система пам’яті із секціонованими модулями на пліс
Номер патенту: 119772
Опубліковано: 10.10.2017
Автори: Боюн Віталій Петрович, Яковлєв Юрій Сергійович, Палагін Олександр Васильович







Формула / Реферат
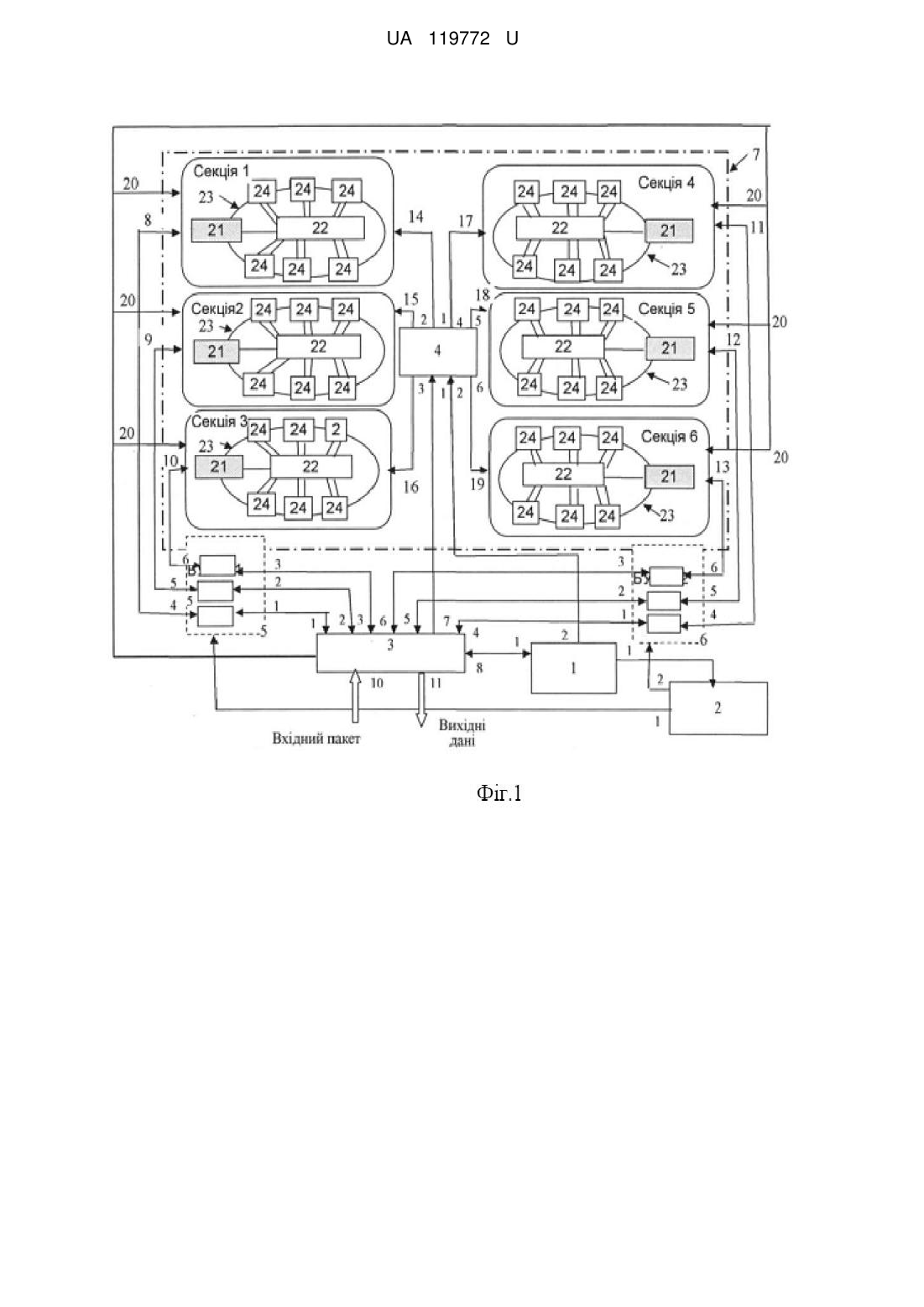
1. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС, що містить комп'ютер, модулі пам'яті, контролери й кільцеві шини, тактовий генератор і безліч буферних схем, які з'єднані із зазначеними вузлами й блоками відповідними зв'язками, при цьому контролер пам'яті забезпечує двоточкові шинні підключення з кожним із двох модулів пам'яті, причому, коли дані посилають від контролера до модуля, половину даних посилають у модуль в одному напрямку уздовж кільця, і половину посилають в іншому напрямку, через інший модуль, яка відрізняється тим, що кожна секція виконана на ПЛІС із можливістю апаратної реалізації фрагментів алгоритму й із застосуванням кільцевої шини, а також інтерфейсу PCI Express і містить системний контролер, блок синхронізації, інтерфейс із сервером, селектор вибору секції, першу буферну схему, другу буферну схему, набір секцій, при цьому перші входи/виходи інтерфейсу із сервером підключені до перших входів/виходів першої буферної схеми, другі входи/виходи якої з'єднані із другими входами/виходами інтерфейсу із сервером, треті входи/виходи якого підключені до третіх входів/виходів першої буферної схеми, четверті входи/виходи інтерфейсу із сервером з'єднані з першими входами/виходами другої буферної схеми, другі входи/виходи якої підключені до п'ятих входів/виходів інтерфейсу із сервером, шості входи/виходи якого з'єднані із третіми входами/виходами другої буферної схеми, при цьому сьомі виходи інтерфейсу з сервером з'єднані з першими входами селектора вибору секції, а його восьмі входи/виходи підключені до перших входів/виходів системного контролера, перший вихід якого з'єднаний із входом блоку синхронізації, перший і другий виходи якого підключені відповідно до входів першої й другої буферних схем, а його другі виходи з'єднані із другими входами селектора вибору секції, четверті входи/виходи першої буферної схеми підключені до перших входів першої секції, п'яті входи/виходи першої буферної схеми з'єднані з першими входами/виходами другої секції, а шості входи/виходи цієї схеми підключені до перших входів/виходів третьої секції, четверті входи/виходи другої буферної схеми підключені до перших входів/виходів четвертої секції, п'яті входи/виходи другої буферної схеми з'єднані з першими входами/виходами п'ятої секції, а шості входи/виходи цієї схеми підключені до перших входів/виходів шостої секції, перші виходи селектора вибору секції з'єднані із другими входами першої секції, другі його виходи підключені до других входів другої секції, а треті його виходи з'єднані із другими входами третьої секції, при цьому четверті виходи селектора вибору секції підключені до других входів четвертої секції, п'яті його виходи з'єднані із другими входами п'ятої секції, а шості виходи селектора підключені до других входів шостої секції, дев'яті виходи інтерфейсу із сервером з'єднані із третіми входами всіх секцій, при цьому входи "Вхідний пакет" підключені до десятих входів інтерфейсу із сервером, а виходи "Вихідні дані" з'єднані з одинадцятими виходами інтерфейсу із сервером.
2. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС за п. 1, яка відрізняється тим, що кожна секція містить блок формування конфігурації системи (БФК), комутатор, кільцеву шину, ПЛІС із апаратною реалізацією фрагментів алгоритму розв'язуваного завдання (наприклад типу Virtex 7 фірми Xilinx), при цьому перші входи/виходи БФК з'єднані з першими входами/виходами комутатора, другі й треті входи/виходи ПЛІС підключені до кільцевої шини, четвертий вхід БФК кожної секції з'єднаний із другим входом, його п'ятий вхід кожної секції - із третім входом секції, а шостий вхід БФК підключений до першого входу секції, кожна мікросхема ПЛІС з'єднана із сусідньою мікросхемою ПЛІС за допомогою PCI Express усередині кожної секції безпосередньо, при цьому четверті входи/виходи кожної мікросхеми ПЛІС підключені до відповідних з першого по шостий входів/виходів комутатора, перші входи кожної мікросхеми ПЛІС з'єднані з відповідними із сьомого по дванадцятий виходами комутатора.
3. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС по п. 1, яка відрізняється тим, що БФК кожної секції містить процесор, схему "І", КЕШ-пам'ять, основну пам'ять, блок службових функцій (БСФ) і інтерфейс, виконаний на ПЛІС, (наприклад Virtex 7 ф.Хіlіnх з можливостями інтерфейсу 8xGen2,0), при цьому другий вхід кожної секції підключений до четвертого входу БФК, який з'єднаний з першим входом схеми "І", на другий вхід якої підключений двадцятий вхід секції через п'ятий вхід БФК, а вихід схеми "І" з'єднаний із входом запуску процесора. Вхід секціонованого першого модуля через вхід блоку формування конфігурації обладнання з'єднаний з першим входом блока службових функцій, другий вхід якого підключений до виходу процесора, входи/виходи якого з'єднані з першими входами/виходами КЕШ-пам'яті, другі входи/виходи якого з'єднані з першими входами/виходами основної пам'яті, другі входи/виходи якого підключені до перших входів/виходів інтерфейсу, треті входи/виходи якого з'єднані з першими входами/виходами БСФ, восьмі входи/виходи секціонованого модуля через шості входи БФК підключені через відповідні входи/виходи БУФСХ1 і БУФСХ2 до з першого по шостий входів/виходів інтерфейсу із сервером, виходи якого з'єднані з "Вихідними даними".
Текст
Реферат: Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС. Кожна секція виконана на ПЛІС із можливістю апаратної реалізації фрагментів алгоритму й із застосуванням кільцевої шини, а також інтерфейсу PCI Express і містить системний контролер, блок синхронізації, інтерфейс із сервером, селектор вибору секції, першу буферну схему, другу буферну схему, набір секцій. Перші входи/виходи інтерфейсу із сервером підключені до перших входів/виходів першої буферної схеми. Другі входи/виходи якої з'єднані із другими входами/виходами інтерфейсу із сервером. Треті входи/виходи якого підключені до третіх входів/виходів першої буферної схеми. Четверті входи/виходи інтерфейсу із сервером з'єднані з першими входами/виходами другої буферної схеми, другі входи/виходи якої підключені до п'ятих входів/виходів інтерфейсу із сервером. Шості входи/виходи якого з'єднані із третіми входами/виходами другої буферної схеми. Сьомі виходи інтерфейсу з сервером з'єднані з першими входами селектора вибору секції, а його восьмі входи/виходи підключені до перших входів/виходів системного контролера. Перший вихід якого з'єднаний із входом блоку синхронізації, перший і другий виходи якого підключені відповідно до входів першої й другої буферних схем. Другі виходи з'єднані із другими входами селектора вибору секції. Четверті входи/виходи першої буферної схеми підключені до перших входів першої секції. П'яті входи/виходи першої буферної схеми з'єднані з першими входами/виходами другої секції. Шості входи/виходи цієї схеми підключені до перших входів/виходів третьої секції. Четверті входи/виходи другої буферної схеми підключені до перших входів/виходів четвертої секції. П'яті входи/виходи другої буферної схеми з'єднані з першими входами/виходами п'ятої секції. Шості входи/виходи схеми підключені до перших входів/виходів шостої секції. Перші виходи селектора вибору секції з'єднані із другими входами першої секції. Другі його виходи підключені до других входів другої секції. Треті його виходи з'єднані із другими входами третьої секції. Четверті виходи селектора вибору секції підключені до других входів четвертої секції. П'яті його виходи з'єднані із другими входами п'ятої секції, а шості виходи селектора підключені до других входів шостої секції, дев'яті виходи інтерфейсу із сервером з'єднані із третіми входами всіх секцій. Входи "Вхідний пакет" підключені до десятих входів інтерфейсу із сервером, а виходи "Вихідні дані" з'єднані з одинадцятими виходами інтерфейсу із сервером. UA 119772 U (54) ІНТЕЛЕКТУАЛЬНА РОЗПОДІЛЕНА СИСТЕМА ПАМ'ЯТІ ІЗ СЕКЦІОНОВАНИМИ МОДУЛЯМИ НА ПЛІС UA 119772 U UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 60 Корисна модель належить до області обчислювальної техніки і може бути використана як інтелектуальна пам'ять в розподілених обчислювальних системах. Під інтелектуальною розподіленою системою пам'яті (ІРСП) комп'ютерних систем (КС) розумітимемо технічний пристрій розподіленої пам'яті, який крім стандартних функцій зберігання, читання і запису даних має також функції логічної і арифметичної обробки інформації за допомогою засобів обробки, розміщених в безпосередній близькості і підключених до виділених масивів пам'яті. Необхідність застосування інтелектуальної системи пам'яті обумовлена зростанням складності завдань, що вимагають для свого вирішення надвисокої продуктивності, яку могли б забезпечити Супер-ЕОМ і навіть масові серійні персональні ЕОМ при мінімальних витратах на їх модифікацію. Як правило, ІРСП використовуються для вирішення складних завдань, що підлягають розпаралелюванню. Вони часто виконані на програмованих логічних інтегральних схемах (ПЛІС) із застосуванням інтерфейсу PCI Express. Сучасні ПЛІС дозволяють реалізувати ряд завдань на апаратному рівні набагато ефективніше по параметрах продуктивності, пропускній здатності, латентності і т.п., ніж їх програмна реалізація навіть на найсучасніших мікропроцесорах (МП). Це досягається за рахунок явних переваг ПЛІС перед сучасною елементною базою іншого типу шляхом адекватного апаратурного відображення на кристалі ПЛІС алгоритму, що реалізовується, або окремих його частин. У відповідність з цим ПЛІС знайшли найширше застосування в різних областях науки і техніки [Н.В. Нестеренко, В.В. Ересько, Ю.С. Яковлев. Застосування ПЛІС для побудови обчислювальних систем і їх компонентів / Математичні машини і системи. - 2016. - № 1. - С. 3 – 13]. Для ряду завдань в області обробки графічної інформації повсюдно використовуються графічні прискорювачі, які застосовують кільцеві шини, що мають ряд переваг перед іншими типами інтерфейсів, [див, наприклад, Ю. С. Яковлев. Про вибір графічних прискорювачів для комп'ютерних систем/ наукові праці ДонНТУ № 2(18), серія: "Інформатика, кібернетика та обчислювальна техніка". - 2013. - С. 61-71]. Відомий пристрій: "Packet data processor in a communications processor architecture". Автори: Munoz; Robert J. [Патент США: № 9,444,737. Клас США: H04L 45/742(20130101); H04L 45/74(20130101). Міжнародний клас: H04L 2/747 (20130101); H04L 12/741 (20130101) (13 вересня 2016)]. Пристрій включає: односпрямовану кільцеву шину, множину ядер процесорів кожен з локальною пам'яттю, множину прискорювачів, модуль введення/виводу і тактовий генератор, розміщені на кільцевій шині, комутатор (switch), пам'ять, що розділяється, які сполучені між собою відповідними зв'язками. При цьому модуль введення/виводу застосований, щоб отримати пакет і зберегти отриманий пакет в пам'яті, що розділяється, а обробляючий модуль, розміщений на кільцевій шині, класифікує цей отриманий пакет і ідентифікує, якому потоку (одному або більшій кількості відомих потоків) отриманий пакет належить, і передає структурні метадані до відповідного ядра процесора. При цьому структурні метадані зберігаються в загальнодоступній системній пам'яті, а заздалегідь вибрані дані зберігаються в локальній пам'яті, при цьому локальна пам'ять включає КЕШ-пам'ять. До недоліків даного пристрою, незалежно від використовуваної елементної бази (великі інтегральні схеми (ВІС) мікропроцесора, пам'яті, ПЛІС і ін.), належать: 1. Великий час очікування ядром будь-якого процесора при зверненні до пам'яті. Наприклад, якщо ядро процесора намагається звернутися на адресу пам'яті, які не знаходяться в його КЕШ, то система пам'яті повинна звернутися в іншу пам'ять (наприклад, в "динамічну оперативну пам'ять"), щоб отримати їх. Це може примусити ядро процесора зупинятися на сотні тактових циклів, щоб чекати дані, які необхідно надати ядру процесора. 2. Кожен прискорювач, розміщений на односпрямованій кільцевій шині разом з процесорами, не виконує свої функції прискорення обчислювального процесу повною мірою за рахунок витрат часу при послідовній передачі обробленої ним інформації через комутатор "своєму" процесору або на вихід пристрою (наприклад через 128 процесорів і прискорювачів). 3. Виключається можливість паралельної обробки інформації декількома процесорами і/або декількома прискорювачами, оскільки при передачі пакета інформації активізуються по шляху його проходження і процесори і прискорювачі. 4. Велика кількість устаткування, що входить до складу системного КЕШ мережевого процесора (безліч локальних пристроїв типу КЕШ і, так званих, пристроїв типу підКЕШ для кожного ядра процесора і прискорювача, розміщених на кільцевій шині), а також безліч вузлів мережевого процесора. 5. Прискорювачі і ядра процесорів разом з відповідним інтерфейсом введення/виводу об'єднані за допомогою односпрямованої кільцевої шини, що при великій кількості прискорювачів і ядер процесорів істотно ускладнюють комутатор (наприклад при реалізації 1 UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 60 зв'язку "кожен з кожним"), або забезпечує велику затримку при застосуванні простого комутатора (наприклад загальної шини) при пересилках пакета між будь-якими пристроями, розміщеними на кільцевій шині. 6. Не використовуються повністю можливості кільцевої шини, оскільки застосована односпрямована кільцева шина, що виключає можливості скоротити загальну кількість ліній у складі кільцевої шини за рахунок передачі від процесора частини інформації зліва - направо, а іншій частині справа - наліво і з'єднання їх разом, наприклад в інтерфейсі введення/виводу при відповідній синхронізації. Крім цього, не використовується одночасна передача декількох пакетів по кільцевій шині в певні кванти часу. При цьому односпрямованість кільцевої шини забезпечує велику затримку при передачі пакета (або його частини) через відповідну схему комутатора між двома крайніми пристроями, розміщеними на кільцевій шині. Відомий пристрій "Distributed shared memory multiprocessor system based on a unidirectional ring bus using a snooping scheme". Автори: Jhang; Seong Tae, Jlion; Chu Shik, Kim; Hyung Ho [патент США № 6,253,292, клас США: 711/146; 709/218; 711/148; 711/Е12.025. Міжнародний клас: G06F 12/08 (20060101); G06F 012/00]. Пристрій включає: групу вузлів процесора, де кожен вузол включає пам'ять і генерує сигнал запиту для блока даних і кільцевої шини для того, щоб підключити вузли процесора у вигляді кільця, причому кожен з вузлів процесора далі включає: множину модулів процесора, контролер вузла, причому множина модулів процесора і контролер вузла пов'язані один з одним місцевою системною шиною. При цьому пам'ять містить: місцеву пам'ять, що розділяється, для того, щоб зберегти блоки даних, віддалений КЕШ для того, щоб зберегти відповідність блока даних сигналу запиту, КЕШ каталогу пам'яті. При цьому місцева пам'ять, що розділяється, містить: пам'ять даних для того, щоб зберегти інформаційні наповнення блока даних, контролер пам'яті, пов'язаний з місцевою системною шиною і КЕШ каталогу пам'яті, підключений до контролера вузла для того, щоб зберігати дані, і кільцевий інтерфейс для того, щоб підключити контролер вузла до кільцевої шини. Сигнал запиту містить наступні різновиди пакетів: пакет запиту, пакет віщання, пакет індивідуальної розсилки. У свою чергу, пакет запиту віщання ділиться ще на декілька категорій. При цьому використовуються як односпрямована, так і двоспрямована кільцеві шини. Недоліки цього пристрою: 1. Процедура виконання операції читання або запису в такій системі з підтримкою когерентності КЕШ є громіздкою і тривалою за часом, оскільки включає процедури звернення до КЕШ даних і КЕШ тегів, процедури аналізу стану блоків пам'яті кожного процесора і процедури формування процесорами необхідних пакетів запиту, пакетів підтвердження запитів і відповіді на запити. 2. Застосування великої кількості устаткування і відповідних програмних засобів, включаючи множину вузлів процесора, множину КЕШ даних і КЕШ тегів, контролерів вузла з відповідними функціями, а також множину блоків пам'яті для зберігання ознак (тегів) для локальної пам'яті кожного процесорного вузла, що розділяється. 2. Безліч різновидів сигналів запиту вимагають безліч різновидів апаратного і програмного забезпечення для їх аналізу і вироблення відповідних процедур. 3. Застосування великої кількості устаткування і відповідних програмних засобів, включаючи множину вузлів процесора, множину КЕШ даних і КЕШ тегів, контролерів вузла з відповідними функціями, а також множину блоків пам'яті для зберігання ознак (тегів) для локальної пам'яті кожного процесорного вузла, що розділяється. Відомий також пристрій "Multiple processor accelerator for logic imulation". Автори: Catlin; Gary M. [патент, США № 4,872,125. Клас США: 703/16; 700/3; 710/100. Міжнародний клас: G06F 17/50(20060101); G06F 15/16]. Пристрій містить: односпрямовану кільцеву шину, прискорювач (акселератор) процесора, який включає: процесор задавач і множину процесорів, впорядкованих в модулях, де процесори в межах модуля, здатні до дії незалежно один від одного. Різні модулі також здатні до дії незалежно один від одного і спілкуються один з одним та провідним модулем за допомогою односпрямованої кільцевої шини. При цьому кожен модуль процесора містить:множину процесорів моделювання, причому кожен процесор моделювання містить пам'ять моделювання, щоб зберігати дані моделювання. Інтерфейс для односпрямованої кільцевої шини і міжпроцесорної шини використовується, щоб передати дані між процесорами. Кожен інтерфейс кожного модуля процесора включає засіб обходу для того, щоб обійти дані від кільцевої шини і повернутися знову до кільцевої шини для подальшої передачі інформації по кільцевій шині, якщо дані не призначені для цього відповідного модуля процесора. При цьому передача усередині модуля даних по міжпроцесорній кільцевій шині відбувається незалежно від 2 UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 60 передачі даних по односпрямованій шині. Пристрій також включає: пам'ять, яка зберігає хронологію змін дій елементів каналу, що моделюються процесорами моделювання; першу пам'ять, щоб зберігати дані для кільцевої шини, другу пам'ять, щоб зберігати дані від процесора моделювання, коли вони призначені для передачі в кільцеву шину; таблицю посилань для того, щоб зберегти логічну адресу для кожного з процесорів моделювання. При цьому пам'ять задавача зберігає інформацію синхронізації для всіх користувачів, а кожна пам'ять моделювання зберігає інформацію синхронізації для відповідного користувача, алгоритм якого виконується. Комп'ютерна система, крім множини процесорів моделювання включає також програмний процесор і апаратний процесор, а пам'ять випадку - оперативна пам'ять, яка зберігає зумовлене число історичних циклів подій, при цьому, коли зумовлене число історичних циклів перевищене, найстаріша зміна випадку замінюється найновішою зміною випадку. До недоліків такого пристрою (незалежно від використовуваної елементної бази) належать: 1. Великий час аналізу інформації, розміщеної в пакеті, що передається, з метою визначення потрібного для обробки модуля і передачі йому пакета. Плата інтерфейсу визначає, чи призначений отриманий інформаційний пакет на кільцевій шині для її конкретного модуля. Якщо інформація не призначена для її модуля, тоді інформація передається назад на кільцеву шину. Якщо інформація призначена для її модуля, плата інтерфейсу передає інформацію відповідному процесору. Такий процес є особливо затяжним і займає багато часу, якщо потрібний для обробки модуль є найвіддаленішим від входу запиту. Так само, якщо інформаційний пакет потрібно послати від одного з процесорів в межах його модуля, інтерфейс також управляє ухваленням інформації від процесора і передає інформаційний пакет на кільцеву шину, згідно з протоколом кільцевої шини. 2. Великий час передачі отриманої після обробки інформації модулем, розміщеному на середині кільцевої шини, що містить N модулів, оскільки інформація, перш ніж потрапити в хостпристрій (головний процесор), повинна пройти мінімум через N/2 модулів, або обробити таку ж кількість логічних процедур їх обходу. 3. Велика кількість використовуваного устаткування, оскільки пам'ять складається з безлічі модулів і комунікацій між різними модулями, а провідний модуль включений в односпрямовану кільцеву шину. При цьому кожен модуль включає плату інтерфейсу, підключену до кільцевої шини, і складається з безлічі процесорів, реалізація схемотехніки кожного з яких є достатньо складною. 4. Згідно з описом даного винаходу, тільки один пакет може знаходитися на кільцевій шині у будь-який момент часу, що виключає ущільнення інформації на кільцевій шині в певні кванти часу а це, у свою чергу, вказує на відсутність ресурсів для підвищення продуктивності системи в цілому. Найближчим по технічним рішенням є пристрій Multi-tier point-to-point ring memory interface. Автори: Randy M. Bonella John B. Halbert [Патент США: 6 658509 Bl. Клас США: 710/100; 370/223; 710/300. Міжнародний клас: G06F 13/42 (20060101); G06F 013/00; G01R 031/08]. Пристрій містить: головний комп'ютер (наприклад центральний процесор), пристрої (модулі і банки) пам'яті, контролери і кільцеві шини, тактовий генератор і множину буферних схем, які сполучені з вказаними вузлами і блоками відповідними зв'язками. При цьому первинний контролер пам'яті забезпечує двоточкові шинні підключення з кожним з двох модулів пам'яті; ці два модулі забезпечують третє двоточкове шинне підключення між собою, таким чином, що ці три підключення разом формують кільцеву шину. Коли дані посилають від контролера до модуля, половина даних посилається в модуль в одному напрямі уздовж кільця, а половину посилають в іншому напрямі, через інший модуль. Кожен модуль містить два банки пам'яті, які розміщуються в другій кільцевій шині, ближчій до модуля. Це може потребувати подвоїти щільність пристроїв, встановлених на модулі, при скороченні числа виводів мікросхеми і при спрощенні маршрутизації сигналу на модулі. Пристрій має наступні недоліки. 1. Використовується двоточкова кільцева шина з безліччю М підключених до неї модулів пам'яті, представлена у вигляді послідовного з'єднання вхідних і вихідних портів всіх модулів. Тому при зверненні до N-гo модуля пам'яті з М затримка сигналу звернення до пам'яті визначається його послідовним проходженням по кільцевій шині через 2N портів модулів пам'яті в одному напрямі (наприклад за годинниковою стрілкою) і орієнтовно через 2(М - N) портів в іншому напрямі (проти годинникової стрілки). 2. При використанні кільцевих шин аналогічного типу усередині кожного модуля пам'яті (другий рівень кільцевої шини) затримка при зверненні до пам'яті другого рівня істотно збільшується. Так для системи пам'яті, що складається всього лише з одного модуля пам'яті першого рівня і одного модуля пам'яті другого рівня і що використовує кільцеві шини відповідно 3 UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 60 першого і другого рівнів, операція читання або запису даних за запитом від хост-машини через первинний контролер пам'яті може бути виконана не менше, ніж за 10 тактів процесора. При цьому повинні бути виконані різні команди (читання, запис, пересилки адреси і даних і ін.) не менше 20 разів. Крім цього збільшення часу затримки сигналу при зверненні до кожного доданого до кільцевої шини модуля пам'яті пропорційно логарифму від загальної кількості модулів, що обмежує масштабованість системи пам'яті. 3. Оскільки кільцеві шини різних рівнів пристрою представлені у вигляді шлейфового (послідовного) з'єднання вхідних і вихідних портів кожного модуля відповідного рівня і при зверненні до одного модуля пам'яті фактично ініціалізуються всі порти модулів цього рівня (при передачі інформації по за годинниковою і одночасно проти годинникової стрілки), що залишилися, то одночасне звернення до декількох модулів пам'яті цього рівня за даними і, отже, їх паралельна обробка практично неможлива. Реалізація одночасного читання або запису даних при зверненні до модулів пам'яті різних рівнів приводить до невиправданого ускладнення апаратури, а також алгоритмів синхронізації і передачі даних. Таким чином, пристрій має низьку швидкодію із-за великих часових затримок при проходженні сигналів до відповідних входів модулів пам'яті при виконанні операцій читання або запису даних, виключає можливість одночасного звернення до пам'яті за декількома даними або для паралельного запису масиву даних, має обмежені властивості масштабованості при нарощуванні ємкості пам'яті і створює технологічні труднощі при розміщенні великої кількості шин (сигнальних ліній) усередині кожного модуля пам'яті і системи пам'яті. В основу корисної моделі поставлена задача створення інтелектуальної розподіленої системи пам'яті з секціонованими модулями на ПЛІС, яке дозволяє суттєво скоротити час реалізації програм користувача за рахунок апаратної підтримки з використанням ПЛІС, що дозволило розпаралелити виконання фрагментів алгоритму або підпрограм як в самій секції, так і між секціями. Поставлена задача вирішується тим, що розподілена інтелектуальна система пам'яті розділена на паралельні секції, кожна з яких виконана на ПЛІС з апаратною адаптацією під клас вирішуваних задач, і містить кільцеву шину, а також інтерфейс PCI Express, що забезпечує паралельне виконання частин алгоритму або підпрограм кожною секцією незалежно від інших. Так за наявності N секцій загальний час реалізації алгоритму може бути зменшений приблизно в N разів. При цьому кільцеві шини і інтерфейс PCI Express мають істотні переваги в порівнянні з іншими типами шин і інтерфейсів [Яковлев Ю.С., Тихонов Б.М., Елисеева Е.В. Комп'ютерна система типу "Процесор-в-пам'яті" з модифікованою кільцевою шиною / Управляющие машины и системы. - 2011. - № 3.С. 54-61.], а також [Яковлев Ю.С. "О применении PCI-Express для построения компьютерных систем с применением ПЛИС"/ Управляющие машины и системы. 2016. - № 5. - С. 37-46]. Структурна схема пропонованого пристрою приведена на фіг. 1 та містить: системний контролер 1, блок синхронізації 2, інтерфейс з сервером 3, селектор вибору секції 4, першу буферну схему 5, другу буферну схему 6, набір секцій 7. При цьому перші входи/виходи інтерфейсу 3 підключені до перших входів/виходів першої буферної схеми 5, другі входи/виходи якої сполучені з другими входами/виходами інтерфейсу 3, треті входи/виходи якого підключені до третіх входів/виходів буферної схеми 5. Четверті входи/виходи інтерфейсу 3 сполучені з першими входами/виходами другої буферної схеми 6, другі входи/виходи якої підключені до п'ятих входів/виходів інтерфейсу 3, шості входи/виходи якого сполучені з третіми входами/виходами другої буферної схеми 6. При цьому сьомі виходи інтерфейсу 3 сполучені з першими входами селектора вибору секції 4, а його восьмі входи/виходи підключені до перших входів/виходів системного контролера 1, перший вихід якого сполучений з входом блока синхронізації 2, перший і другий виходи якого підключені відповідно до входів першої 5 і другої 6 буферних схем, а другі виходи системного контролера 1 сполучені з другими входами селектора вибору секції 4. Четверті входи/виходи першої буферної схеми 5 підключені до входів/виходів 8 першої секції, п'яті входи/виходи першої буферної схеми сполучені з входами/виходами 9 другої секції, а шості входи/виходи цієї схеми підключені до входів/виходів 10 третьої секції. Четверті входи/виходи другої буферної схеми 6 підключені до входів/виходів 11 четвертої секції, п'яті входи/виходи другої буферної схеми сполучені з входами/виходами 12 п'ятої секції, а шості входи/виходи цієї схеми підключені до входів/виходів 13 шостої секції. Перші виходи селектора 4 вибору секції сполучено з входами 14 першої секції, другі його виходи підключені до входів 15 другої секції, а треті його виходи сполучені з входами 16 третьої секції. При цьому четверті виходи селектора вибору секції підключені до входів 17 четвертої секції, п'яті виходи сполучені з входами 18 п'ятої секції, а шості виходи селектора підключені до входів 19 шостої секції. Дев'яті виходи інтерфейсу з сервером 3 сполучено з входами 20 всіх 4 UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 секцій, при цьому входи "Вхідний пакет" підключені до десятих входів інтерфейсу з сервером 3, а виходи "Вихідні дані" сполучені з одинадцятими виходами інтерфейсу з сервером 3. Секціонований модуль призначений для виконання за допомогою процесора, розміщеного в кожній ПЛІС, паралельно і незалежно один від одного фрагментів алгоритму (або підпрограм), що реалізуються, а також ланцюжка фрагментів неперервно один за іншим каскадним способом, причому завдяки застосуванню комутатора, побудованого за принципом "кожен з кожним", ПЛІС, що реалізує попередній фрагмент алгоритму, може передати свої результати будь-який з п'яти ПЛІС, що залишилися, цієї секції. Результати виконання ланцюжка операцій надходять по кільцевій шині в основну пам'ять процесора блока формування конфігурації (БФК) і далі через власний інтерфейс БФК і буферні схеми 5 і 6 на відповідні входи/виходи інтерфейсу з сервером 3. Структурна схема секціонованого модуля відображена на фіг. 2. Оскільки всі секціоновані модулі - однакові, то ми покажемо структуру тільки одного модуля, наприклад, першого, який містить: БФК системи 21, комутатор 22, а також містить кільцеву шину 23, ПЛІС 24 (наприклад, типу Virtex 7 фірми Xilinx). При цьому перший вихід БФК сполучений з першим входом комутатора, другі і треті входи/виходи кожної ПЛІС підключені до кільцевої шини 23 (входи 2, виходи 3 при передачі даних по кільцевій шині проти годинникової стрілки, або входи 3, виходи 2 при передачі даних за годинниковою стрілкою). Четвертий вхід БФК сполучений через другий вхід секції з входом 14 секції 1 (фіг. 1), його п'ятий вхід сполучений через третій вхід секції з входом 20 секції, а шостий вхід підключений через перший вхід секції до входу 8 секції 1 (фіг. 1). Кожна мікросхема (наприклад, ПЛІС Virtex 7) сполучена з сусідньою мікросхемою ПЛІС за допомогою PCI Express безпосередньо (всього 6 мікросхем), про що компанія Xilinx продемонструвала таку можливість (Sunita Jain, Guru Prasanna, "Point-to-Point Connectivity Using Integrated Endpoint Block for PCI Express Designs", Xilinx Corporation, XAPP869, 2007), або таку ж процедуру можна реалізувати, використовуючи технологію GPUDirect (nVidiaCorporation. GPUDirect. https://developer.nvidia.com/gpudirect). Якщо кільцева шина має для одночасної передачі 8 - розрядів даних, то ПЛІС Virtex 7 повинна мати 32 двопровідних входів/виходів, оскільки 8 з них сполучають відповідні входи/виходи комутатора 22, що, згідно зі стандартами, позначається як 8xGen1,0 (16/32). При 16-розрядній кільцевій шині - відповідно 16xGen1,0 (32/64). При цьому другі і треті входи/виходи кожної мікросхеми ПЛІС сполучені з кільцевою шиною, а четверті входи/виходи кожної мікросхеми ПЛІС підключені до відповідних входів/виходів (від одного до шостого включно) комутатора 22 (фіг. 2). Перші входи кожної мікросхеми ПЛІС сполучені з відповідними виходами (від сьомого до дванадцятого включно) комутатора 22. У відповідності з цим комутатор 22 містить два типи схем: одну схему для передачі n-розрядних даних між будь-якими ПЛІС, що знаходяться в даній секції, при реалізації прямого і зворотного зв'язку, а також між довільною кількістю ПЛІС. Ця частина комутатора може бути виконана у вигляді спеціалізованої схеми. Друга схема призначена для ініціалізації і запуску на обробку за допомогою однієї або довільної кількості ПЛІС ланцюжка фрагментів алгоритму, що реалізуються. Блок формування конфігурації (БФК) призначений для зберігання службових підпрограм і реалізації з їх допомогою службових функцій (розподіл пам'яті, розділення алгоритму на фрагменти, що паралельно реалізовуються, і розподіл їх по процесорах і ін.), зберігання для відповідної секції кодових полів вхідного пакета і результатів обробки даних, а також сигналів запуску ПЛІС цієї секції для обробки. Структурна схема БФК приведена на фіг. 3 та містить: процесор 25, схему "І" 26, КЕШпам'ять 27, основну пам'ять 28, блок службових функцій (БСФ) 29 і інтерфейс 30, виконаний на ПЛІС (наприклад, Virtex 7 ф.Хіlіnх з можливостями інтерфейсу 8xGen2,0 (32/64)). При цьому вхід 14 секції 1 через четвертий вхід БФК сполучений з першим входом схеми "І" 26, на другий вхід якої підключений двадцятий вхід секції через п'ятий вхід БФК, а вихід схеми "І" сполучений з входом запуску процесора 25. Вхід 20 секціонованого першого модуля через вхід 5 блока формування конфігурації пристрою сполучений з першим входом блока службових функцій, другий вхід якого підключений до виходу процесора 25, входи/виходи якого сполучені з першими входами/виходами КЕШ-пам'яті 27, другі входи/виходи якого сполучені з першими входами/виходами основної пам'яті 28, другі входи/виходи якого підключені до перших входів/виходів інтерфейсу 30, треті входи/виходи основної пам'яті 28 сполучені з першими входами/виходами БСФ. Восьмі входи/виходи першого секціонованого модуля через шості входи БФК, забезпечують надходження в БФК конкретних полів вхідного пакета для N-ої секції, при цьому ці ж входи/виходи в подальші моменти часу забезпечують видачу результатів обробки від N-ої секції. 5 UA 119772 U 5 10 15 20 25 30 35 40 Інтерфейс з сервером 3 містить мікросхеми ПЛІС і відповідні мікросхеми, що реалізовують для ПЛІС необхідні набори логічних операцій, пов'язаних з аналізом вхідного пакета, виділення його відповідних полів і формування окремих управляючих сигналів, а також операцій збереження інформації, наприклад вхідного пакета, результатів виконання секціями операцій і ін. При цьому як ПЛІС можуть бути використані мікросхеми (наприклад Virtex7) з інтерфейсом PCI Express з різною кількістю для різних ПЛІС двопровідних ліній (від 2xGen2 до 16xGen2). Для збільшення потужності вихідних сигналів до складу інтерфейсу 3 включені відповідні мікросхеми. Системний контролер 1 є проблемно-орієнтованим пристроєм, який призначений для управління режимами роботи пристрою в цілому, і містить процесор, оперативну пам'ять і набір логічних схем, що визначають послідовність процедур при управлінні процесом обробки інформації для пристрою в цілому. При цьому системний контролер разом з управляючим сигналом від інтерфейсу 3 визначає або паралельну, або послідовну участь кожної секції в обробці інформації за наявності відповідних сигналів, які надходять на селектор вибору секції 4. Селектор вибору секції 4 містить вхідний регістр для зберігання коду вибору і спеціалізовану схему вибору секції, яка визначає участь кожної секції (послідовно або паралельно) в реалізації крупних фрагментів або підпрограм алгоритму, що реалізуються. Буферні схеми 5 і 6 - однакові, і кожна з них містить п - розрядні регістри для передачі інформації в прямому (до секцій) і в зворотному (до інтерфейсу з сервером) напрямах, які синхронізуються тактовим сигналом, схеми затримки для встановлення збалансованих затримок інформації, що надходить від різних секцій в результаті паралельного виконання множини фрагментів (або підпрограм) алгоритму, що реалізуються пристроєм, і регістр видачі результату для передачі його серверу через інтерфейс з сервером, сполучені між собою відповідними зв'язками. Блок синхронізації 2 містить тактовий генератор, що виробляє послідовність тактових сигналів, а також схеми, що змінюють щілинність цієї послідовності, наприклад, шляхом ділення початкової частоти тактового генератора, що необхідне, наприклад для налагодження пристрою в цілому. При цьому для підвищення потужності тактових сигналів застосовані відповідні мікросхеми. Робота пристрою відбувається в пакетному режимі. Приклад структури пакета, що містить необхідні коди полів, відображений на фіг. 4. При цьому прийняті наступні позначення, які зведені в таблицю. Слід зазначити, що склад полів управляючого пакета і розрядність кожного поля визначається типом і функціональними можливостями інтелектуальної розподіленої системи пам'яті (ІРСП), а також особливостями вирішуваних за допомогою ІРСП завдань. При цьому довжина (кількість розрядів) управляючого пакета може бути рівна довжині даних (наприклад 64 біти), що зберігаються, і тому пакети можуть бути збережені в рядку широких регістрів і оброблені безпосередньо процесором БФК. Стосовно запропонованої системи інтелектуальної пам'яті (фіг. 1) управляючий пакет містить поля і ознаки, що відображають послідовність дій, а також ресурсів системи (П НАЛ), що забезпечують налагодження і апаратне відображення фрагментів алгоритму (підпрограм) перед запуском її на розв'язання конкретної задачі, а також при необхідності переналагодження в процесі роботи. Таблиця Призначення і функції полів пакета інтелектуальної розподіленої системи пам'яті з секціонованими модулями на ПЛІС 1 1 2 Поля пакета 2 ССБ ІДП 3 ЗБСФСП 4 ВЗС № Функціональне призначення поля пакета: 3 поле системного та інших типів сигналу скидання обладнання у вихідний стан ідентифікатор пакета код поля запуску блока службових функцій для реалізації сервісних програм: розподілу пам'яті й розміщення даних, розбивки завдання на паралельні фрагменти, запуску бібліотеки стандартних підпрограм, завантаження даних і ін. код поля вибору й запуску секціонованих модулів 45 6 UA 119772 U 5 6 7 8 Поля пакета ВЗПЛІС ВРРПЛІС КППСК ПДм.ПЛІС 9 СДПОП № 10 ПД1 11 ПРРЕЖ 12 ПРРЕС 13 КРКШ 14 ККСЕК 15 ПНАЛ 16 ПДОП 17 ПДЗАК 5 10 15 20 25 30 Функціональне призначення поля пакета: код поля вибору й запуску ПЛІС у складі секцій вибір режимів роботи ПЛІС в обраних секціях код поля, що визначає передачі інформації між секціями поле адреси для передачі блоків даних між ПЛІС різних секцій специфікатор дії пакета, що визначає типи логічних і арифметичних операцій, які повинні бути виконані об'єктом - адресатом після одержання пакета поле значення параметрів (даних), які можуть використовуватися при виконанні поточного дії поле ознаки, що відбиває характер і послідовність дій у різних режимах роботи системи пам'яті, у тому числі - як звичайна пам'ять, а також як інтелектуальна й КЕШ - пам'яті поле ознаки використання ресурсів обробки інформації власної системи або додаткових ресурсів за рахунок інших систем, підключених через відповідні інтерфейси код для керування режимами роботи кільцевих шин (виділення секцій і відповідно ПЛІС, широкомовної передачі по кільцевих шинах даних або команд, передачі інформації з кільцевих шин за годинниковою стрілкою та проти годинникової стрілки і ін.) код для керування комутацією усередині секції код поля для попереднього й у процесі роботи налагодження системи додаткові (допоміжні) поля, необхідні для надійного транспортування, виявлення помилок, маршрутизації й керування контекстом заключний елемент пакета - поле, що визначає наступні дії після закінчення виконання даного пакета, наприклад, може бути створено один або більш дочірніх пакетів Пакет може змінюватися по довжині, забезпечуючи, таким чином, ефективну обробку простих операцій з маленькими пакетами і ефективним використанням смуги пропускання для переміщення великих блоків даних. Пакети також можуть використовуватися для виконання операцій типу віддаленого завантаження або зберігання, а також для виклику методів обробки на іншій аналогічній системі пам'яті, переміщаючи тим самим за допомогою пакетів обробку ближче до даних за менший час, чим дані (як завжди) передаються до них. Пакети дозволяють здійснювати розбиття або розщеплення операцій, забезпечуючи тим самим допустимий час очікування для всієї системи. Інтелектуальна розподілена система пам'яті з секціонованими модулями на ПЛІС може працювати в наступних режимах: як розподілена пам'ять з множинним доступом при реалізації запису і читання даних в/з основної пам'яті БФК, а також пам'яті ПЛІС кожної секції; режим налагодження конфігурації системи із застосуванням методів апаратурної реалізації на ПЛІС окремих фрагментів алгоритму (або підпрограм), а також відповідних підпрограм розподілу пам'яті, розділення алгоритму на паралельні ділянки (фрагменти) і розподілу їх по процесорах; організація паралельного обчислювального процесу з використанням декількох з наявних секцій; організація паралельного обчислювального процесу з використанням усіх секцій; організація послідовного обчислювального процесу каскадним способом процесорами, розміщеними на ПЛІС у середині кожної (одній) секції, і паралельної обробки результатів всіх секцій. Оскільки метою даного пристрою є створення структури пристрою для підвищення продуктивності системи в цілому (в даному випадку сервера), то розглянемо роботу пристрою при організації паралельного обчислювального процесу з використанням всіх секцій інтелектуальної системи пам'яті, оскільки решта режимів є поодинокими випадками даного. Суть корисної моделі пояснюють креслення. На першому етапі відбувається формування конфігурації інтелектуальної розподіленої системи пам'яті. Для цього на десятий вхід інтерфейсу з сервером 3 надходить вхідний пакет, який запам'ятовують на широких регістрах цього інтерфейсу. Основні функціональні призначення полів вхідного пакета вказані в таблиці. Логічні схеми, що є у складі інтерфейсу 3 спочатку аналізують ідентифікатор пакета ІДП (свій, чужий) і виділяють код поля ССБ для 7 UA 119772 U 5 10 15 20 25 30 35 40 45 50 55 установки всієї системи в початковий стан (ці ланцюги на схемі рисі не показані). Далі виділяють код поля ЗБСФСП і формують управляючий сигнал, який з дев'ятого виходу інтерфейсу 3 надходить на входи 20 і запускає блоки службових функцій (БСФ) всіх секцій для реалізації сервісних програм в кожній секції. На наступному етапі інтерфейс 3 виділяє коди полів ВЗС (див. таблицю) і формує на входах 14-19 всіх секцій спільно з сигналом 20 відповідні сигнали (фіг. 3) для вибору і запуску одного або декількох секціонованих модулів за умови наявності сигналу з сьомого виходу інтерфейсу З на перші входи селектора вибору 4, які визначають кількість вибраних модулів. При цьому сигнали дозволу на вході 2 селектора 4 формують системним контролером 1, використовуючи код поля ВЗС, який надходить з восьмих входів/виходів інтерфейсу 3 на відповідні входи/виходи системного контролера 1. Сигнал запуску ПЛІС у складі кожного модуля (вихідні сигнали 7-12 комутатора секції) формують, використовуючи код поля ВЗПЛІС. При цьому на перших входах/виходах комутатора 22 повинен бути присутнім набір сигналів з перших виходів БФК, що визначає кількість вибраних ПЛІС, і сигнали вибору режимів роботи ВРРПЛІС. У вибраних секціях (сигнали 7-12, фіг. 1 - фіг. 3). Ці сигнали формують на основі аналізу вказаних кодів полів, які надходять через відповідні входи/виходи БУФСх1 і БУФСх2 з першого по шостий входи/виходи інтерфейсу 3. Таким чином, за наявності сигналів на першому і другому входах мікросхеми "І" 26 (сигнали 20 і 14, фіг 1, фіг. 3) відбувається запуск процесора 25 блока БФК, який розподіляє свідомо розділені фрагменти алгоритму за допомогою БСФ 29 по пам'яті ПЛІС на незалежні або каскадно залежні ділянки для паралельного, або каскадно залежного виконання фрагментів алгоритму завдання користувача, використовуючи при цьому входи/виходи 2 і 3 кільцевої шини 23 і комутатора 22, а також специфікатор дії пакета СДПОП, що визначає типи логічних і арифметичних операцій, які повинні бути виконані об'єктом-адресатом після отримання пакета. Безпосередня обробка алгоритму вирішуваної задачі користувача здійснюється за наявності сигналів запуску на перших входах кожної мікросхеми ПЛІС, підключених до кільцевої шини, які надходять з сьомих по дванадцяті виходи комутатора 22 всіх секцій, сформовані інтерфейсом БФК на основі інформації з основної пам'яті 28. Результати обробки всього алгоритму надходять через шості входи/виходи інтерфейсу 30 БФК і далі через входи-виходи буферних схем 5 і 6 (під управлінням сигналів синхронізації) на з першого по шостий входи/виходи інтерфейсу з сервером 3. У разі застосування двох комутаторів у складі комутатора 22 типу "кожний з кожним" виконання операцій кожною попередньою ПЛІС вибраної секції може бути передано будь-якій ПЛІС цієї секції. При цьому використовується код поля ККСЕК. Аналогічна процедура може бути виконана і для вибору безпосередньо секцій, якщо селектор вибору секції 4 побудований на аналогічних принципах, що і комутатор 22. При цьому використовуються коди секцій КПП СК і ПДм.ПШС (таблиця). Сигнал синхронізації формують під час надходження від системного контролера 1 коду поля ВРРПЛІС, який надходить з першого виходу системного контролера на відповідний вхід блока синхронізації, з першого і другого виходів якого сигнали синхронізації надходять на відповідні входи буферних схем БУФСх1 і БУФСх2, виконуючи при цьому функції глобальної синхронізації всіх результатів (а при необхідності їх підстиковку), отриманих від кожної секції. При реалізації інших режимів роботи інтелектуальної розподіленої системи пам'яті з секціонованими модулями на ПЛІС використовуються коди полів ПР РЕЖ, ПРРЕС, ККСЕК, ПДОП, ПДЗAК (див. таблицю), а також різні модифікації кодів вище зазначених полів. Наприклад, при використанні пристрою як розподілена пам'ять з множинним доступом для виконання запису і читання даних в/з основної пам'яті БФК, а також пам'яті ПЛІС кожної секції використовуються коди полів ПРРЕЖ і ККСЕК, на підставі яких формуються сигнали запиту 8-13 на входах відповідних секцій. Ці сигнали сформовані, використовуючи внутрішні схемні ресурси БФК, забезпечуючи можливості паралельного доступу до пам'яті. При цьому інформація на запис надходить з восьмого по тринадцятий входи через буферні схеми БУФСх1 і БУФСх2 з першого по шостий вхід/вихід інтерфейсу з сервером 3 під управлінням блока синхронізації 1. Зчитана інформація з пам'яті кожної ПЛІС 24 з четвертих входів/виходів всіх ПЛІС кожної секції надходить на входи/виходи 1-6 комутатора 22. Далі ця інформація через перші входи/виходи БФК після конкатенації під управлінням сигналів синхронізації, проходять через буферні схеми БУФСх1 і БУФСх2 на входи/виходи з першого по шостий інтерфейсу з сервером 3. При цьому сигнали 20 на входи всіх секцій не надходять, і запуск процесора БФК заблокований. 8 UA 119772 U ФОРМУЛА КОРИСНОЇ МОДЕЛІ 5 10 15 20 25 30 35 40 45 50 55 60 1. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС, що містить комп'ютер, модулі пам'яті, контролери й кільцеві шини, тактовий генератор і безліч буферних схем, які з'єднані із зазначеними вузлами й блоками відповідними зв'язками, при цьому контролер пам'яті забезпечує двоточкові шинні підключення з кожним із двох модулів пам'яті, причому, коли дані посилають від контролера до модуля, половину данихпосилають у модуль в одному напрямку уздовж кільця, і половину посилають в іншому напрямку, через інший модуль, яка відрізняється тим, що кожна секція виконана на ПЛІС із можливістю апаратної реалізації фрагментів алгоритму й із застосуванням кільцевої шини, а також інтерфейсу PCI Express і містить системний контролер, блок синхронізації, інтерфейс із сервером, селектор вибору секції, першу буферну схему, другу буферну схему, набір секцій, при цьому перші входи/виходи інтерфейсу із сервером підключені до перших входів/виходів першої буферної схеми, другі входи/виходи якої з'єднані із другими входами/виходами інтерфейсу із сервером, треті входи/виходи якого підключені до третіх входів/виходів першої буферної схеми, четверті входи/виходи інтерфейсу із сервером з'єднані з першими входами/виходами другої буферної схеми, другі входи/виходи якої підключені до п'ятих входів/виходів інтерфейсу із сервером, шості входи/виходи якого з'єднані із третіми входами/виходами другої буферної схеми, при цьому сьомі виходи інтерфейсу з сервером з'єднані з першими входами селектора вибору секції, а його восьмі входи/виходи підключені до перших входів/виходів системного контролера, перший вихід якого з'єднаний із входом блоку синхронізації, перший і другий виходи якого підключені відповідно до входів першої й другої буферних схем, а його другі виходи з'єднані із другими входами селектора вибору секції, четверті входи/виходи першої буферної схеми підключені до перших входів першої секції, п'яті входи/виходи першої буферної схеми з'єднані з першими входами/виходами другої секції, а шості входи/виходи цієї схеми підключені до перших входів/виходів третьої секції, четверті входи/виходи другої буферної схеми підключені до перших входів/виходів четвертої секції, п'яті входи/виходи другої буферної схеми з'єднані з першими входами/виходами п'ятої секції, а шості входи/виходи цієї схеми підключені до перших входів/виходів шостої секції, перші виходи селектора вибору секції з'єднані із другими входами першої секції, другі його виходи підключені до других входів другої секції, а треті його виходи з'єднані із другими входами третьої секції, при цьому четверті виходи селектора вибору секції підключені до других входів четвертої секції, п'яті його виходи з'єднані із другими входами п'ятої секції, а шості виходи селектора підключені до других входів шостої секції, дев'яті виходи інтерфейсу із сервером з'єднані із третіми входами всіх секцій, при цьому входи "Вхідний пакет" підключені до десятих входів інтерфейсу із сервером, а виходи "Вихідні дані" з'єднані з одинадцятими виходами інтерфейсу із сервером. 2. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС за п. 1, яка відрізняється тим, що кожна секція містить блок формування конфігурації системи (БФК), комутатор, кільцеву шину, ПЛІС із апаратною реалізацією фрагментів алгоритму розв'язуваного завдання (наприклад типу Virtex 7 фірми Xilinx), при цьому перші входи/виходи БФК з'єднані з першими входами/виходами комутатора, другі й треті входи/виходи ПЛІС підключені до кільцевої шини, четвертий вхід БФК кожної секції з'єднаний із другим входом, його п'ятий вхід кожної секції - із третім входом секції, а шостий вхід БФК підключений до першого входу секції, кожна мікросхема ПЛІС з'єднана із сусідньою мікросхемою ПЛІС за допомогою PCI Express усередині кожної секції безпосередньо, при цьому четверті входи/виходи кожної мікросхеми ПЛІС підключені до відповідних з першого по шостий входів/виходів комутатора, перші входи кожної мікросхеми ПЛІС з'єднані з відповідними із сьомого по дванадцятий виходами комутатора. 3. Інтелектуальна розподілена система пам'яті із секціонованими модулями на ПЛІС за п. 1, яка відрізняється тим, що БФК кожної секції містить процесор, схему "І", КЕШ-пам'ять, основну пам'ять, блок службових функцій (БСФ) і інтерфейс, виконаний на ПЛІС, (наприклад Virtex 7 ф.Хіlіnх з можливостями інтерфейсу 8×Gen2,0), при цьому другий вхід кожної секції підключений до четвертого входу БФК, який з'єднаний з першим входом схеми "І", на другий вхід якої підключений двадцятий вхід секції через п'ятий вхід БФК, а вихід схеми "І" з'єднаний із входом запуску процесора. Вхід секціонованого першого модуля через вхід блоку формування конфігурації обладнання з'єднаний з першим входом блока службових функцій, другий вхід якого підключений до виходу процесора, входи/виходи якого з'єднані з першими входами/виходами КЕШ-пам'яті, другі входи/виходи якого з'єднані з першими входами/виходами основної пам'яті, другі входи/виходи якого підключені до перших входів/виходів інтерфейсу, 9 UA 119772 U треті входи/виходи якого з'єднані з першими входами/виходами БСФ, восьмі входи/виходи секціонованого модуля через шості входи БФК підключені через відповідні входи/виходи БУФСХ1 і БУФСХ2 до з першого по шостий входів/виходів інтерфейсу із сервером, виходи якого з'єднані з "Вихідними даними". 10 UA 119772 U Комп’ютерна верстка В. Мацело Міністерство економічного розвитку і торгівлі України, вул. М. Грушевського, 12/2, м. Київ, 01008, Україна ДП “Український інститут інтелектуальної власності”, вул. Глазунова, 1, м. Київ – 42, 01601 11
ДивитисяДодаткова інформація
МПК / Мітки
МПК: G06F 13/42
Мітки: розподілена, секціонованими, пам'яті, інтелектуальна, пліс, модулями, система
Код посилання
<a href="https://ua.patents.su/13-119772-intelektualna-rozpodilena-sistema-pamyati-iz-sekcionovanimi-modulyami-na-plis.html" target="_blank" rel="follow" title="База патентів України">Інтелектуальна розподілена система пам’яті із секціонованими модулями на пліс</a>
Інтелектуальна розподілена система пам’яті з ієрархічними кільцевими шинами

Номер патенту: 112237
Опубліковано: 12.12.2016
Автори: Яковлєв Юрій Сергійович, Боюн Віталій Петрович
МПК: G06F 13/42, G06F 15/16
Мітки: інтелектуальна, розподілена, кільцевими, ієрархічними, система, пам'яті, шинами
Формула / Реферат:
1. Інтелектуальна розподілена система пам'яті з ієрархічними кільцевими шинами, що містить підсистему інтелектуальної пам'яті першого рівня (ПІП-1), до складу якої входять системний контролер пам'яті, множина N блоків інтелектуальної пам'яті, кільцева шина, що складається з кільцевої шини даних і кільцевої шини управління, блок управління кільцевої шиною, локальна шина даних, система вводу/виводу даних, система вводу/виводу управляючих...
Інтелектуальна розподілена система пам’яті з кільцевою шиною

Номер патенту: 57629
Опубліковано: 10.03.2011
Автори: Тихонов Борис Михайлович, Єлісєєва Олена Володимирівна, Яковлєв Юрій Сергійович, Палагін Олександр Васильович
МПК: G06F 15/16, G06F 13/42
Мітки: розподілена, система, шиною, кільцевою, пам'яті, інтелектуальна
Формула / Реферат:
1. Інтелектуальна розподілена система пам'яті з кільцевою шиною, яка містить системний контролер пам'яті, множину N блоків інтелектуальної пам'яті, кільцеву шину, що складається з кільцевої шини даних i кільцевої шини керування, блок керування кільцевою шиною, локальну шину даних, системний ввід/вивід даних, системний ввід/вивід керуючих сигналів, при цьому перший ввід/вивід системного контролера з'єднаний із системним вводом/виводом...
Інтелектуальна розподілена система пам’яті з кільцевою шиною

Номер патенту: 99164
Опубліковано: 25.07.2012
Автори: Яковлєв Юрій Сергійович, Тихонов Борис Михайлович, Палагін Олександр Васильович, Єлісєєва Олена Володимирівна
МПК: G06F 13/42, G06F 15/16
Мітки: система, шиною, розподілена, інтелектуальна, пам'яті, кільцевою
Формула / Реферат:
1. Інтелектуальна розподілена система пам'яті з кільцевою шиною, що містить системний контролер пам'яті, множину N блоків інтелектуальної пам'яті, кільцеву шину, що складається з кільцевої шини даних і кільцевої шини керування, блок керування кільцевою шиною, локальну шину даних, системний ввід/вивід даних, системний ввід/вивід керуючих сигналів, при цьому перший ввід/вивід системного контролера з'єднаний із системним вводом/виводом керуючих...
Пліс-орієнтований функціональний перетворювач двійкових кодів

Номер патенту: 81811
Опубліковано: 10.07.2013
Автори: Клятченко Ярослав Михайлович, Тарасенко Володимир Петрович, Тесленко Олександр Кирилович
МПК: G06F 7/38
Мітки: двійкових, функціональний, перетворювач, пліс-орієнтований, кодів
Формула / Реферат:
ПЛІС-орієнтований функціональний перетворювач двійкових кодів, що містить вхідні та вихідні лінії, логічні елементи І та АБО, лінії зв'язку, який відрізняється тим, що виконаний у вигляді комбінаційної схеми з подвійною матричною структурою, яка складається з n рядків та t стовпчиків 6-входових логічних елементів І, що утворюють вузли матриці 1 та з n рядків та t стовпчиків 6-входових логічних елементів АБО, що утворюють вузли матриці 2, і...
Діагностична система

Номер патенту: 20837
Опубліковано: 15.02.2007
Автори: Чумаченко Тетяна Олександрівна, Сіріца Ганна Володимирівна
МПК: G06F 15/00
Мітки: система, діагностична
Формула / Реферат:
Діагностична система, яка має дві схеми порівняння, блок пам'яті, причому перша група виходів якого з'єднана з першою групою входів першої схеми порівняння, друга група виходів блока памяті з'єднана з першою групою входів другої схеми порівняння, вихідну шину, яка відрізняється тим, що має блок оцінки стану, блок оцінки оптичної густини сироватки, блок обчислення індексу позитивності, аналізатор результатів, причому виходи блока оцінки стану...
Попередній патент: Спосіб отримання n-заміщених 1,4-бензо(нафто)хінонмоноімінів
Наступний патент: Мережевий пристрій управління
Випадковий патент: Пристрій для контролю ресурсу повітряних високовольтних вимикачів