Зміна масштабу часу кадрів в вокодері за допомогою зміни залишку









Формула / Реферат
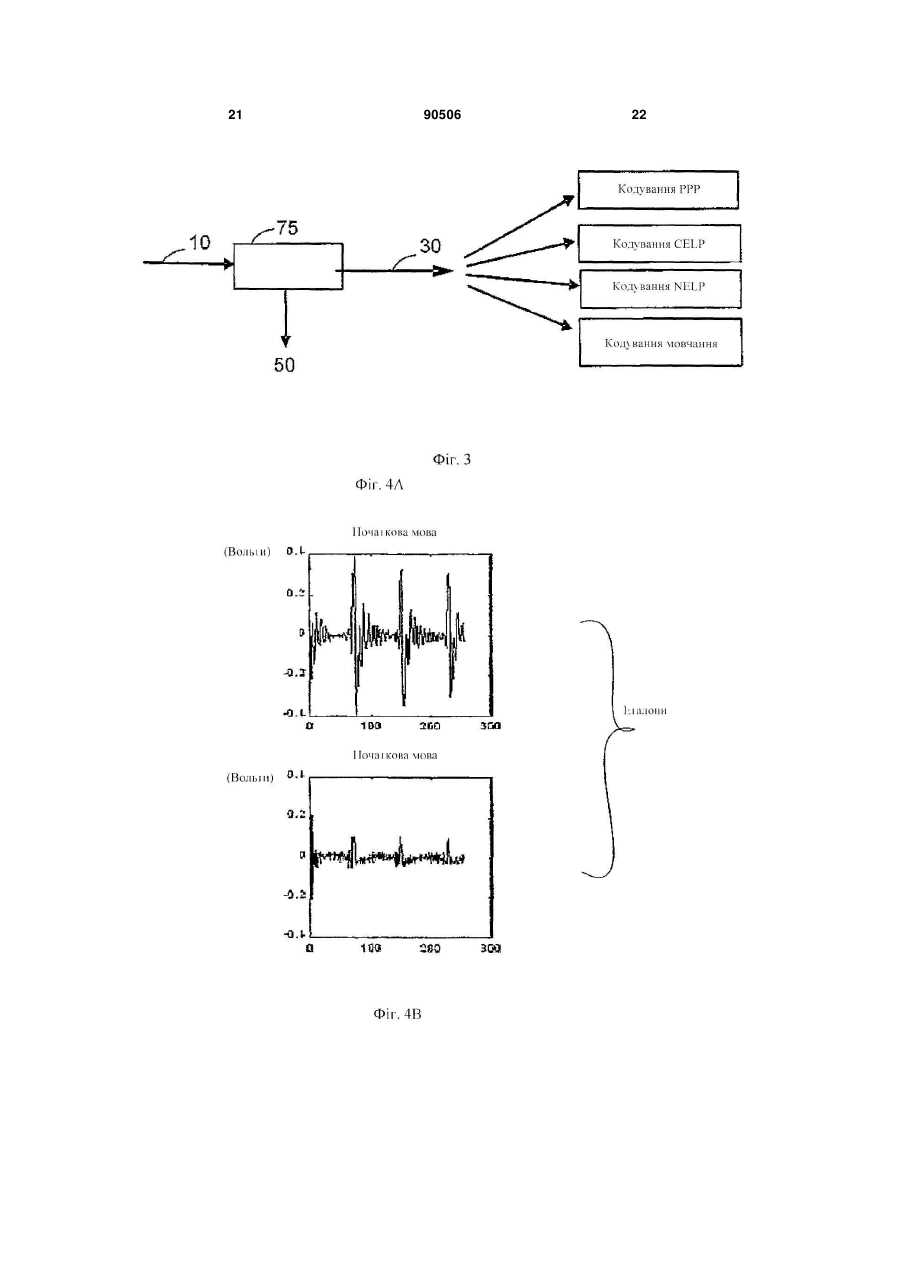
1. Спосіб передачі мовлення, який включає етапи, на яких:
класифікують мовленнєві сегменти;
кодують згадані мовленнєві сегменти;
змінюють масштаб часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації; і
синтезують згаданий залишковий мовленнєвий сигнал, підданий зміні масштабу часу.
2. Спосіб передачі мовлення за п. 1, в якому згаданий етап кодування мовленнєвих сегментів включає використання періодів тону зразка, лінійне передбачення з кодовим збудженням, лінійне передбачення з шумовим збудженням або 1/8 кадрового кодування.
3. Спосіб передачі мовлення за п. 1, який додатково включає етапи, на яких:
відправляють згаданий мовленнєвий сигнал через кодуючий фільтр з лінійним передбаченням, за допомогою цього фільтруючи короткочасні кореляції в згаданому мовленнєвому сигналі; і
видають коефіцієнти кодування з лінійним передбаченням і залишковий сигнал.
4. Спосіб передачі мовлення за п. 1, в якому згаданий стан класифікування мовленнєвих сегментів включає класифікацію мовленнєвих кадрів на періодичні, слабкоперіодичні або шумові залежно від того, чи представляють кадри
вокалізоване, невокалізоване або нестійке мовлення.
5. Спосіб передачі мовлення за п. 1, в якому згадане кодування є кодуванням з лінійним передбаченням з кодовим збудженням.
6. Спосіб передачі мовлення за п. 1, в якому згадане кодування є кодуванням періоду тону зразка.
7. Спосіб передачі мовлення за п. 1, в якому згадане кодування є кодуванням з лінійним передбаченням з шумовим збудженням.
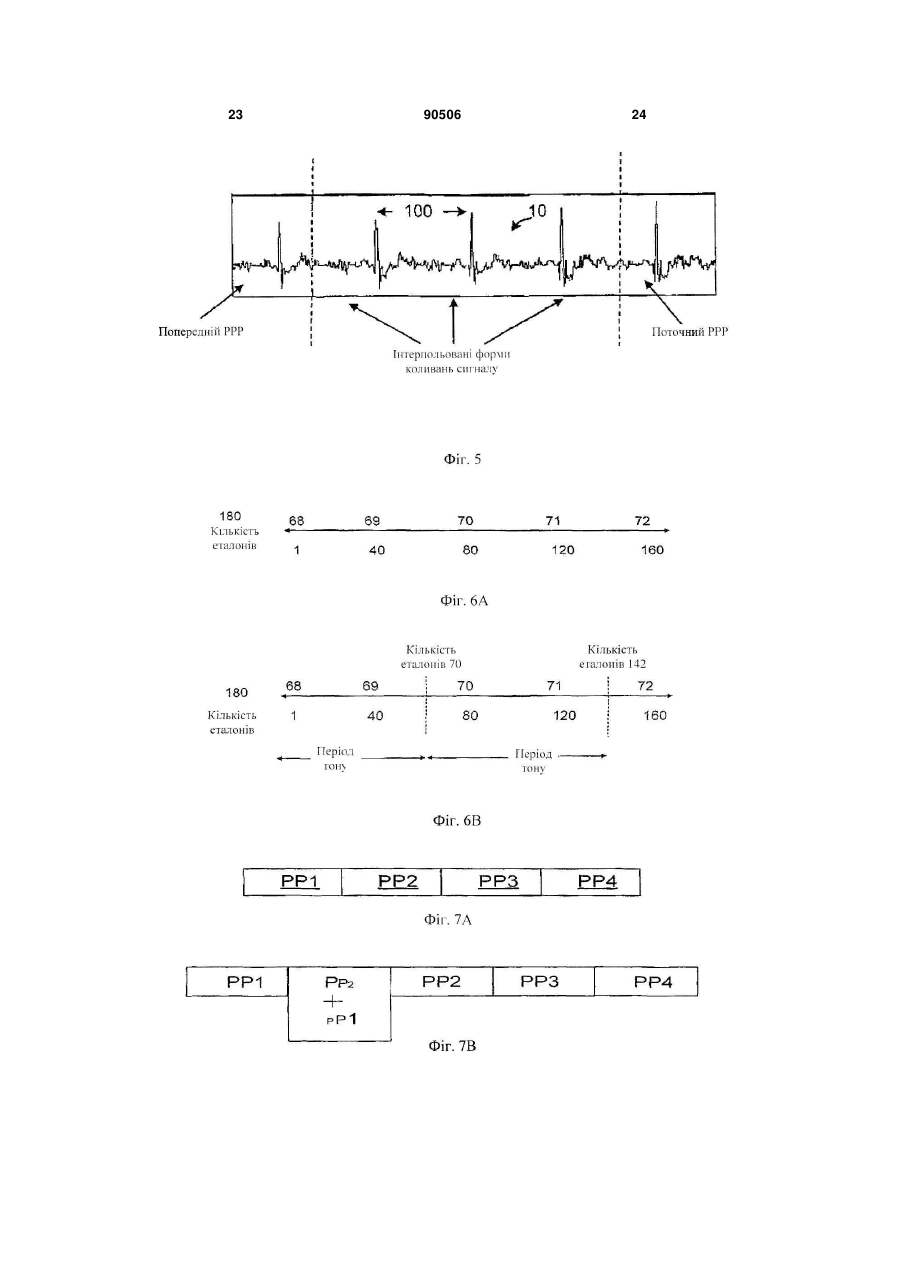
8. Спосіб за п. 5, в якому згаданий етап зміни масштабу часу включає:
оцінювання періоду тону.
9. Спосіб за п. 5, в якому етап зміни масштабу часу включає:
оцінювання затримки тону;
розділення мовленнєвого кадру на періоди тону, при цьому межі згаданих періодів тону визначають, використовуючи згадану затримку тону у різних точках згаданого мовленнєвого кадру;
поєднання згаданих періодів тону, якщо зменшується згаданий залишковий мовленнєвий сигнал; і
додавання згаданих періодів тону, якщо збільшується згаданий залишковий мовленнєвий сигнал.
10. Спосіб за п. 6, в якому згаданий етап зміни масштабу часу включає етапи,
на яких:
оцінюють щонайменше один період тону;
інтерполюють згаданий щонайменше один період тону;
додають згаданий щонайменше один період тону, коли додають щонайменше один еталон; і
виділяють згаданий щонайменше один період тону, коли виділяють щонайменше один еталон.
11. Спосіб за п. 7, в якому згаданий етап кодування включає кодування інформації кодування з лінійним передбаченням як коефіцієнти підсилення різних частин мовленнєвого сегмента.
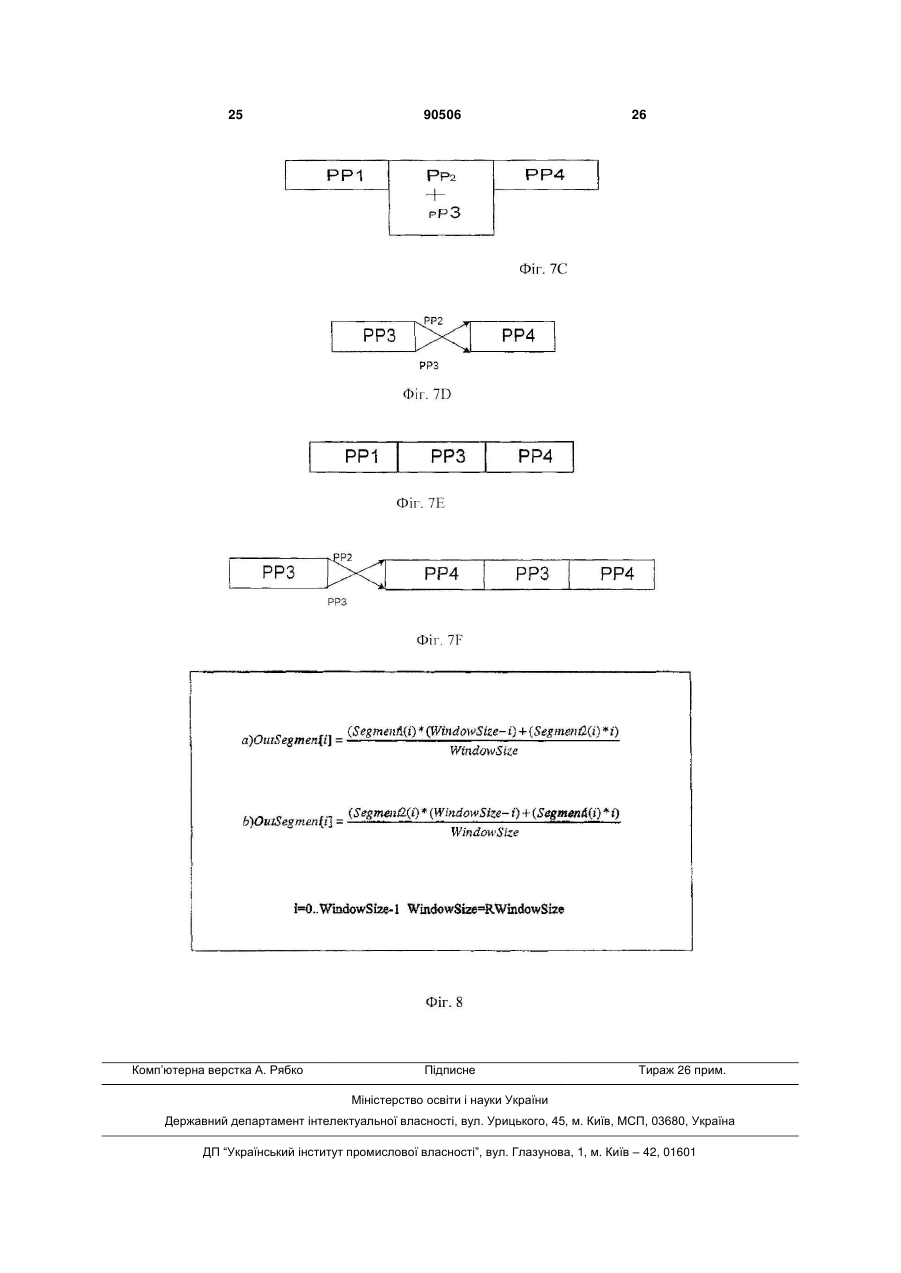
12. Спосіб за п. 9, в якому згаданий етап поєднання згаданих періодів тону, якщо зменшується згаданий мовленнєвий залишковий сигнал, включає:
сегментування вхідної еталонної послідовності у блоки еталонів;
видалення сегментів згаданого залишкового сигналу за постійні інтервали часу;
об'єднання згаданих видалених сегментів; і
заміну згаданих видалених сегментів на об'єднаний сегмент.
13. Спосіб за п. 9, в якому згаданий етап оцінювання затримки тону включає інтерполяцію між затримкою тону кінця останнього кадру і кінця поточного кадру.
14. Спосіб за п. 9, в якому згаданий етап додавання згаданих періодів тону включає об'єднання мовленнєвих сегментів.
15. Спосіб за п. 9, в якому згаданий етап додавання згаданих періодів тону, якщо збільшується згаданий залишковий мовленнєвий сигнал, включає додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону.
16. Спосіб за п. 11, в якому згадані коефіцієнти підсилення кодуються для наборів мовленнєвих еталонів.
17. Спосіб за п. 12, в якому згаданий етап об'єднання згаданих видалених сегментів включає збільшення частки першого сегмента періоду тону і зменшення частки другого сегмента періоду тону.
18. Спосіб за п. 14, який додатково включає етап вибору подібних мовленнєвих сегментів, при цьому об'єднують згадані подібні мовленнєві сегменти.
19. Спосіб за п. 14, який додатково включає етап кореляції мовленнєвих сегментів, за допомогою чого вибирають подібні мовленнєві сегменти.
20. Спосіб за п. 15, в якому згаданий етап додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону, включає складання згаданого першого і згаданого другого сегментів тону таким чином, що збільшується частка згаданого першого сегмента періоду тону і зменшується частка згаданого другого сегмента періоду тону.
21. Спосіб за п. 16, який додатково включає етап генерування залишкового сигналу за допомогою генерування випадкових значень і подальшого застосування згаданих коефіцієнтів підсилення до згаданих випадкових значень.
22. Спосіб за п. 16, який додатково включає етап представлення згаданої інформації кодування з лінійним передбаченням як 10 кодованих значень коефіцієнтів підсилення, при цьому кожне кодоване значення коефіцієнта підсилення представляє 16 еталонів мовлення.
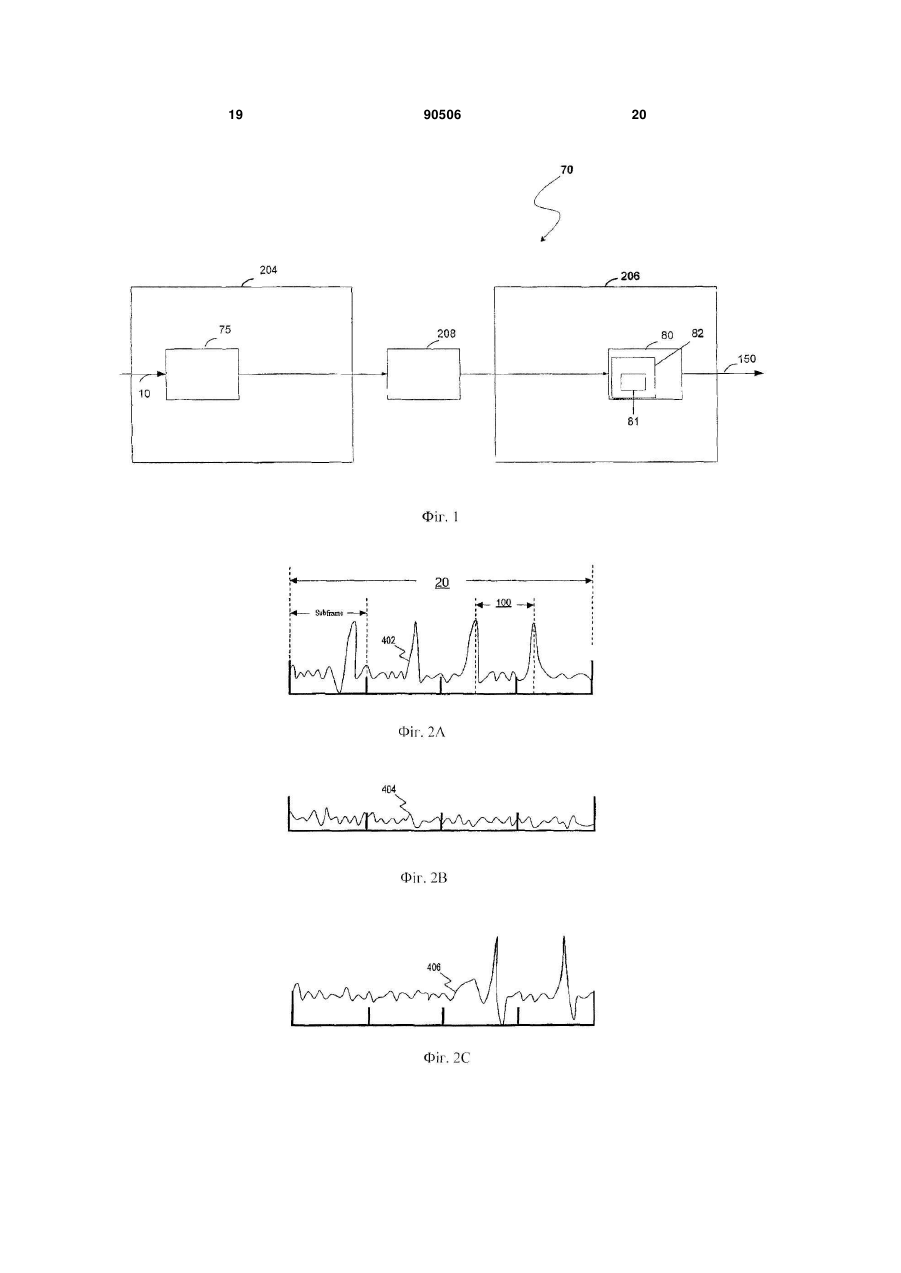
23. Вокодер, який має щонайменше один вхід і щонайменше один вихід, який включає:
кодер, що включає фільтр, який має щонайменше один вхід, функціонально зв'язаний з входом вокодера, і щонайменше один вихід; і
декодер, що включає синтезатор, який має щонайменше один вхід, функціонально зв'язаний зі згаданим щонайменше одним виходом згаданого кодера, і щонайменше один вихід, функціонально зв'язаний зі згаданим щонайменше одним виходом вокодера, і пам'ять, причому декодер виконаний з можливістю виконання програмних команд у пам'яті, які виконують для зміни масштабу часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів.
24. Вокодер за п. 23, в якому згаданий кодер включає:
пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять класифікацію мовленнєвих сегментів, по 1/8 кадру, періоди тону зразка, лінійне передбачення з кодовим збудженням або лінійне передбачення з шумовим збудженням.
25. Вокодер за п. 24, в якому згаданий фільтр є кодуючим фільтром з лінійним передбаченням, який виконаний з можливістю:
фільтрації короткострокових кореляцій у мовленнєвому сигналі; і
видачі коефіцієнтів кодування з лінійним передбаченням і залишкового сигналу.
26. Вокодер за п. 24, в якому згаданий кодер включає:
пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування з лінійним передбаченням з кодовим збудженням.
27. Вокодер за п. 24, в якому згаданий кодер включає:
пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування періоду тону зразка.
28. Вокодер за п. 24, в якому згаданий кодер включає:
пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування з лінійним передбаченням з шумовим збудженням.
29. Вокодер за п. 26, в якому згадана програмна команда зміни масштабу часу включає:
оцінювання щонайменше одного періоду тону.
30. Вокодер за п. 26, в якому згадана програмна команда зміни масштабу часу включає
оцінювання затримки тону;
розділення мовленнєвого кадру на періоди тону, при цьому межі згаданих періодів тону визначають, використовуючи згадану затримку тону в різних точках згаданого мовленнєвого кадру;
поєднання згаданих періодів тону, якщо зменшується згаданий залишковий мовленнєвий сигнал; і
додавання згаданих періодів тону, якщо збільшується залишковий мовленнєвий сигнал.
31. Вокодер за п. 27, в якому згадана програмна команда зміни масштабу часу включає
оцінювання щонайменше одного періоду тону;
інтерполяцію згаданого щонайменше одного періоду тону;
додавання згаданого щонайменше одного періоду тону, коли додають щонайменше один еталон; і
виділення згаданого щонайменше одного періоду тону, коли виділяють
щонайменше один еталон.
32. Вокодер за п. 28, в якому згадане кодування згаданих мовленнєвих сегментів, використовуючи програмну команду кодування з лінійним передбаченням з шумовим збудженням, включає кодування інформації кодування з лінійним передбаченням як коефіцієнтів підсилення різних частин мовленнєвих сегментів.
33. Вокодер за п. 30, в якому згадане поєднання згаданих періодів тону, якщо зменшується згаданий мовленнєвий залишковий сигнал, включає сегментацію вхідної еталонної послідовності на блоки еталонів;
видалення сегментів згаданого залишкового сигналу в постійні інтервали часу;
об'єднання згаданих об'єднаних сегментів; і
заміну згаданих видалених сегментів на об'єднаний сегмент.
34. Вокодер за п. 30, в якому згадана команда оцінювання затримки тону включає інтерполяцію між затримкою тону кінця останнього кадру і кінця поточного кадру.
35. Вокодер за п. 30, в якому згадана команда підсумовування згаданих періодів тону включає об'єднання мовленнєвих сегментів.
36. Вокодер за п. 30, в якому згадана команда додавання згаданих періодів тону, якщо збільшується згаданий мовленнєвий залишковий сигнал, включає додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону.
37. Вокодер за п. 32, в якому згадані коефіцієнти підсилення кодуються для наборів мовленнєвих еталонів.
38. Вокодер за п. 33, в якому згадана команда об'єднання згаданих видалених сегментів включає збільшення частки першого сегмента періоду тону і зменшення частки другого сегмента періоду тону.
39. Вокодер за п. 35, який додатково включає етап вибору подібних мовленнєвих сегментів, при цьому об'єднуються згадані подібні мовленнєві сегменти.
40. Вокодер за п. 35, в якому згадана команда зміни масштабу часу додатково включає кореляцію мовленнєвих сегментів, за допомогою чого вибираються подібні мовленнєві сегменти.
41. Вокодер за п. 36, в якому згадана команда доповнення додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону, включає додавання згаданого першого і другого сегментів тону таким чином, що збільшується згадана частка першого сегмента періоду тону і зменшується частка другого сегмента періоду тону.
42. Вокодер за п. 37, в якому згадана команда зміни масштабу часу додатково включає генерування залишкового сигналу за допомогою генерування випадкових значень, з подальшим застосуванням згаданих коефіцієнтів підсилення до згаданих випадкових значень.
43. Вокодер за п. 37, в якому згадана команда зміни масштабу часу додатково включає представлення згаданої інформації кодування з лінійним передбаченням як 10 кодованих значень коефіцієнта підсилення, при цьому кожне кодоване значення коефіцієнта підсилення представляє 16 еталонів мовлення.
44. Вокодер, який включає:
засоби для класифікування мовленнєвих сегментів;
засоби для кодування згаданих мовленнєвих сегментів;
засоби для зміни масштабу часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів; і
засоби для синтезування згаданого залишкового мовленнєвого сигналу, підданого зміні масштабу часу.
45. Зчитуваний процесором носій для передачі мовлення, що включає команди для:
класифікування мовленнєвих сегментів;
кодування згаданих мовленнєвих сегментів;
зміни масштабу часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів; і
синтезування згаданого залишкового мовленнєвого сигналу, підданого зміні масштабу часу.
Текст
1. Спосіб передачі мовлення, який включає етапи, на яких: класифікують мовленнєві сегменти; кодують згадані мовленнєві сегменти; змінюють масштаб часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації; і синтезують згаданий залишковий мовленнєвий сигнал, підданий зміні масштабу часу. 2. Спосіб передачі мовлення за п. 1, в якому згаданий етап кодування мовленнєвих сегментів включає використання періодів тону зразка, лінійне передбачення з кодовим збудженням, лінійне передбачення з шумовим збудженням або 1/8 кадрового кодування. 3. Спосіб передачі мовлення за п. 1, який додатково включає етапи, на яких: відправляють згаданий мовленнєвий сигнал через кодуючий фільтр з лінійним передбаченням, за допомогою цього фільтруючи короткочасні кореляції в згаданому мовленнєвому сигналі; і видають коефіцієнти кодування з лінійним передбаченням і залишковий сигнал. 2 (19) 1 3 видалення сегментів згаданого залишкового сигналу за постійні інтервали часу; об'єднання згаданих видалених сегментів; і заміну згаданих видалених сегментів на об'єднаний сегмент. 13. Спосіб за п. 9, в якому згаданий етап оцінювання затримки тону включає інтерполяцію між затримкою тону кінця останнього кадру і кінця поточного кадру. 14. Спосіб за п. 9, в якому згаданий етап додавання згаданих періодів тону включає об'єднання мовленнєвих сегментів. 15. Спосіб за п. 9, в якому згаданий етап додавання згаданих періодів тону, якщо збільшується згаданий залишковий мовленнєвий сигнал, включає додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону. 16. Спосіб за п. 11, в якому згадані коефіцієнти підсилення кодуються для наборів мовленнєвих еталонів. 17. Спосіб за п. 12, в якому згаданий етап об'єднання згаданих видалених сегментів включає збільшення частки першого сегмента періоду тону і зменшення частки другого сегмента періоду тону. 18. Спосіб за п. 14, який додатково включає етап вибору подібних мовленнєвих сегментів, при цьому об'єднують згадані подібні мовленнєві сегменти. 19. Спосіб за п. 14, який додатково включає етап кореляції мовленнєвих сегментів, за допомогою чого вибирають подібні мовленнєві сегменти. 20. Спосіб за п. 15, в якому згаданий етап додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону, включає складання згаданого першого і згаданого другого сегментів тону таким чином, що збільшується частка згаданого першого сегмента періоду тону і зменшується частка згаданого другого сегмента періоду тону. 21. Спосіб за п. 16, який додатково включає етап генерування залишкового сигналу за допомогою генерування випадкових значень і подальшого застосування згаданих коефіцієнтів підсилення до згаданих випадкових значень. 22. Спосіб за п. 16, який додатково включає етап представлення згаданої інформації кодування з лінійним передбаченням як 10 кодованих значень коефіцієнтів підсилення, при цьому кожне кодоване значення коефіцієнта підсилення представляє 16 еталонів мовлення. 23. Вокодер, який має щонайменше один вхід і щонайменше один вихід, який включає: кодер, що включає фільтр, який має щонайменше один вхід, функціонально зв'язаний з входом вокодера, і щонайменше один вихід; і декодер, що включає синтезатор, який має щонайменше один вхід, функціонально зв'язаний зі згаданим щонайменше одним виходом згаданого кодера, і щонайменше один вихід, функціонально зв'язаний зі згаданим щонайменше одним виходом вокодера, і пам'ять, причому декодер виконаний з можливістю виконання програмних команд у пам'яті, які виконують для зміни масштабу часу залишкового мовленнєвого сигналу шляхом дода 90506 4 вання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів. 24. Вокодер за п. 23, в якому згаданий кодер включає: пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять класифікацію мовленнєвих сегментів, по 1/8 кадру, періоди тону зразка, лінійне передбачення з кодовим збудженням або лінійне передбачення з шумовим збудженням. 25. Вокодер за п. 24, в якому згаданий фільтр є кодуючим фільтром з лінійним передбаченням, який виконаний з можливістю: фільтрації короткострокових кореляцій у мовленнєвому сигналі; і видачі коефіцієнтів кодування з лінійним передбаченням і залишкового сигналу. 26. Вокодер за п. 24, в якому згаданий кодер включає: пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування з лінійним передбаченням з кодовим збудженням. 27. Вокодер за п. 24, в якому згаданий кодер включає: пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування періоду тону зразка. 28. Вокодер за п. 24, в якому згаданий кодер включає: пам'ять і згаданий кодер виконаний з можливістю виконання програмних команд, збережених у згаданій пам'яті, що містять кодування згаданих мовленнєвих сегментів, використовуючи кодування з лінійним передбаченням з шумовим збудженням. 29. Вокодер за п. 26, в якому згадана програмна команда зміни масштабу часу включає: оцінювання щонайменше одного періоду тону. 30. Вокодер за п. 26, в якому згадана програмна команда зміни масштабу часу включає оцінювання затримки тону; розділення мовленнєвого кадру на періоди тону, при цьому межі згаданих періодів тону визначають, використовуючи згадану затримку тону в різних точках згаданого мовленнєвого кадру; поєднання згаданих періодів тону, якщо зменшується згаданий залишковий мовленнєвий сигнал; і додавання згаданих періодів тону, якщо збільшується залишковий мовленнєвий сигнал. 31. Вокодер за п. 27, в якому згадана програмна команда зміни масштабу часу включає оцінювання щонайменше одного періоду тону; інтерполяцію згаданого щонайменше одного періоду тону; додавання згаданого щонайменше одного періоду тону, коли додають щонайменше один еталон; і виділення згаданого щонайменше одного періоду тону, коли виділяють щонайменше один еталон. 5 90506 6 32. Вокодер за п. 28, в якому згадане кодування згаданих мовленнєвих сегментів, використовуючи програмну команду кодування з лінійним передбаченням з шумовим збудженням, включає кодування інформації кодування з лінійним передбаченням як коефіцієнтів підсилення різних частин мовленнєвих сегментів. 33. Вокодер за п. 30, в якому згадане поєднання згаданих періодів тону, якщо зменшується згаданий мовленнєвий залишковий сигнал, включає сегментацію вхідної еталонної послідовності на блоки еталонів; видалення сегментів згаданого залишкового сигналу в постійні інтервали часу; об'єднання згаданих об'єднаних сегментів; і заміну згаданих видалених сегментів на об'єднаний сегмент. 34. Вокодер за п. 30, в якому згадана команда оцінювання затримки тону включає інтерполяцію між затримкою тону кінця останнього кадру і кінця поточного кадру. 35. Вокодер за п. 30, в якому згадана команда підсумовування згаданих періодів тону включає об'єднання мовленнєвих сегментів. 36. Вокодер за п. 30, в якому згадана команда додавання згаданих періодів тону, якщо збільшується згаданий мовленнєвий залишковий сигнал, включає додавання додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону. 37. Вокодер за п. 32, в якому згадані коефіцієнти підсилення кодуються для наборів мовленнєвих еталонів. 38. Вокодер за п. 33, в якому згадана команда об'єднання згаданих видалених сегментів включає збільшення частки першого сегмента періоду тону і зменшення частки другого сегмента періоду тону. 39. Вокодер за п. 35, який додатково включає етап вибору подібних мовленнєвих сегментів, при цьому об'єднуються згадані подібні мовленнєві сегменти. 40. Вокодер за п. 35, в якому згадана команда зміни масштабу часу додатково включає кореляцію мовленнєвих сегментів, за допомогою чого вибираються подібні мовленнєві сегменти. 41. Вокодер за п. 36, в якому згадана команда доповнення додаткового періоду тону, утвореного з першого сегмента тону і другого сегмента періоду тону, включає додавання згаданого першого і другого сегментів тону таким чином, що збільшується згадана частка першого сегмента періоду тону і зменшується частка другого сегмента періоду тону. 42. Вокодер за п. 37, в якому згадана команда зміни масштабу часу додатково включає генерування залишкового сигналу за допомогою генерування випадкових значень, з подальшим застосуванням згаданих коефіцієнтів підсилення до згаданих випадкових значень. 43. Вокодер за п. 37, в якому згадана команда зміни масштабу часу додатково включає представлення згаданої інформації кодування з лінійним передбаченням як 10 кодованих значень коефіцієнта підсилення, при цьому кожне кодоване значення коефіцієнта підсилення представляє 16 еталонів мовлення. 44. Вокодер, який включає: засоби для класифікування мовленнєвих сегментів; засоби для кодування згаданих мовленнєвих сегментів; засоби для зміни масштабу часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів; і засоби для синтезування згаданого залишкового мовленнєвого сигналу, підданого зміні масштабу часу. 45. Зчитуваний процесором носій для передачі мовлення, що включає команди для: класифікування мовленнєвих сегментів; кодування згаданих мовленнєвих сегментів; зміни масштабу часу залишкового мовленнєвого сигналу шляхом додавання або виділення щонайменше одного еталона до залишкового мовленнєвого сигналу, використовуючи спосіб зміни масштабу часу, оснований на класифікації мовленнєвих сегментів; і синтезування згаданого залишкового мовленнєвого сигналу, підданого зміні масштабу часу. Ця заявка заявляє пріоритет по попередній заявці №60/660.824. названій «Зміна масштабу часу кадрів у вокодері за допомогою зміни залишку», поданій 11 березня 2005. повний опис, якої вважається частиною опису цієї заявки і включений сюди як посилання. Даний винахід належить загалом до способу зміни масштабу часу (розширення або стиснення) вокодерних кадрів у вокодері. Зміна масштабу часу мас ряд застосувань в мережах з перемиканням пакетів, де пакет вокодера можуть поступати асинхронно. Поки може виконуватися зміна масштабу часу у вокодері або поза вокодером, викону ючи його у вокодері, надається ряд переваг, такі як краща якість кадрів, які зазнали зміни масштабу часу, і зменшення обчислювального навантаження. Способи, представлені в документах, можуть застосовування в будь-якому вокодері, який використовує схожі методи, про які йде мова в цій заявці на патент для вокодерних голосових даних. Даний винахід містить пристрій і спосіб для зміни масштабу часу мовних кадрів за допомогою маніпуляції мовним сигналом. У одному варіації здійснення даний спосіб і пристрій використовуються в, але не обмежуючи. Четвертому Генеруючому Вокодері (4ГВ) (4GV). Описані варіацій здійс 7 нення містять способи і пристрої для розширення/стиснення різних типів мовних сегментів. У зв'язку з вищевикладеним описані ознаки даною винаходу загалом належать до однієї або більше поліпшених систем, способів і/або пристроїв для передачі мови. У одному варіації здійснення даний винахід місіть спосіб передачі мови. який включає етапи на яких класифікують мовні сегменти, кодують мовні сегменти, використовуючи лінійний прогноз з кодовим збудженням, і змінюють масштабу часу залишкового мовного сигналу до розширеною або стисненого вигляду залишкового мовного сигналу. У іншому варіанті здійснення спосіб передачі мови додатково включає відправлення мовного сигналу через кодуючий фільтр з лінійним прогнозом, за допомогою чого фільтруючи короткочасні кореляції в мовному сигналі і видаючи коефіцієнти кодування з лінійним прогнозом і залишковий сигнал. У іншому варіанті здійснення кодування с кодуванням з лінійним прогнозом з кодовим збудженням і етап зміни масштабу часу містить оцінку затримки тону, розділення мовного кадру на періоди тону, при цьому границі періодів тону визначаються з використанням затримки тону в різних точках мовного кадру. поєднання періодів тону, якщо стискується залишковий мовний сигнал, і додавання періодів тону, якщо розширюється залишковий мовний сигнал. У іншому варіанті здійснення кодування є кодуванням періоду топу зразка і етап зміни масштабу часу містить оцінку щонайменше одного періоду тону, інтерполяцію щонайменше одного періоду тону, додавання щонайменше одного періоду тону, коли розширюють залишковий мовний сигнал, і виділення щонайменше одного періоду тону, коли стискають залишковий мовний сигнал. У іншому варіанті здійснення кодуванням є кодування з лінійним прогнозом з шумовим збудженням і етап зміни масштабу часу містить застосування можливих різних коефіцієнтів посилень до різних частин мовного сегмента до його синтезу. У іншому варіанті здійснення даний винахід містить вокодер, що має щонайменше один вхід і щонайменше один вихід, кодер, що включає в себе фільтр, який має щонайменше один вхід, функціонально зв'язаний з входом вокодера, і щонайменше один вихід, декодер, який включає в себе синтезатор, що має щонайменше один вхід, функціонально зв'язаний з щонайменше одним виходом згаданого кодера, і щонайменше один вихід, функціонально зв'язаний з щонайменше одним виходом згаданого вокодера. У іншому варіанті здійснення кодер містить пам'ять, при цьому кодер виконаний з можливістю виконання команд, збережених в пам'яті, які містять класифікацію мовних сегментів по 1/8 кадру, період топу зразка, лінійний прогноз з кодовим збудженням або лінійний прогноз з шумовим збудженням. У іншому варіанті здійснення декодер містить пам'ять і декодер викопаний з можливістю виконання команд, збережених в пам'яті, які містять 90506 8 зміну масштабу часу залишкового сигналу до розширеного або стисненого вигляду залишкового сигналу. Крім того, об'єм застосування даного винаходу сіане очевидним з подальшого докладного опису, формули і креслень. Однак, буде зрозуміло, що докладний опис і конкретні приклади, незважаючи на те, що показують переважні варіанти здійснення винаходу, даються тільки для ілюстрації, оскільки різні зміни і модифікації в суті і об'ємі винаходу стануть очевидними для фахівця в рівні техніки. Даний винахід стане більш зрозумілим з докладного опису, наданого тут нижче, прикладеної формули і супроводжуючих креслень, на яких: Фіг.1 - блок-схема Кодуючого вокодера з Лінійним 1 Ірогпозом (КЛП) (LPC); Фіг.2а - мовний сигнал, що містить вокалізовапу мову; Фіг.2в - мовний сигнал, що містить невокалізовану мову; Фіг.2с - мовний сигнал, що містить змінну мову; Фіг.3 - блок-схема, що показує Фільтрацію з LPC мови, що іде за Кодуванням Залишку; Фіг.4а - крива Первинної Мови; Фіг.4в - крива Залишковою Мовного Сигналу після Фільтрації з LPC; Фіг.5 показує генерацію форм коливань сигналу, використовуючи Інтерполяцію між Попереднім і Поточним Періодами Гону Зразка; Фіг.6а показує визначення Затримок Гону за допомогою Інтерполяції; Фіг.6в показує ідентифікацію періодів гону: Фіг.7а представляє первинний мовний сигнал в формі періодів гону: Фіг.7в представляє розширений мовний сигнал, використовуючи поєднання-додавання; Фіг.7с представляє мовний сигнал, стиснений з використанням поєднання-додавання; Фіг.7d представляє, як використовується зважування для стиснення залишкового сигналу; Фіг.7е представляє мовний сигнал, стиснений без використання поєднання-додавання; Фіг.7f представляє, як використовується зважування для розширення залишкового сигналу; і Фіг.8 містить два вирази, що використовуються в способі додавання-поєднання. Слово «ілюстративний» використовується тут для позначення «слугує як приклад, зразок або ілюстрація». Будь-який варіант здійснення, описаний туї як «ілюстративний», необов'язково інтерпретується як переважний або переважний над іншими варіантами здійснення. Людські голоси складаються з двох компонентів. Один компонент містить основні гармоніки, які є чутливими до тону, і інший є фіксованими гармоніками, які не є чутливими до чопу. Топ звуку, що сприймається, є частотою, що сприймається вухом, тобто для більшості конкретних цілей тон є частотою. Компоненти гармоніки додають відмітні характеристики до персонального голосу. Вони змінюють також голосові зв'язки і фізичну форму вокального тракту і називаються формантами. Людський голос може представлятися цифровим сигналом s(n) 10. Представлення s(n) 10 є 9 цифровим мовним сигналом, одержаним під час звичайної розмови, що включає в себе різні голосові звуки і періоди мовчання. Мовний сигнал s(n) 10 переважно розділяється на кадри 20. У одному варіанті здійснення, s(n) 10 квантується по 8кГц. Поточні схеми кодування стискають цифровий мовний сигнал 10 в сигнал з низькою бітовою швидкістю за допомогою видалення всіх природних надмірностей (тобто корельовані елементи) властивих мові. Мова звичайно являє собою тимчасові надмірності, що виходять з механічної дії губ і язика, і довготривалі надмірності, що виходять з вібрації голосових зв'язок. Кодування з лінійним прогнозом (КЛП) (LPC) фільтрує мовний сигнал 10 за допомогою видалення надмірностей, створюючи залишковий мовний сигнал 30. Він потім моделює підсумковий залишковий сигнал 30 як білий шум Гаусса. Еталонне значення форми коливання мовного сигналу може прогнозуватися за допомогою зважування суми числа попередніх еталонів 40, кожний з яких множиться на коефіцієнт 50 лінійного прогнозу. Тому кодери з лінійним прогнозом забезпечують зменшену бітову швидкість за допомогою передачі коефіцієнтів 50 фільтра і квантованого шуму замість мовного сигналу 10 повного діапазону. Залишковий сигнал 30 кодується за допомогою виділення періоду 100 зразка з поточного кадру 20 залишкового сигналу 30. Блок-схему в одному варіанті здійснення вокодера 70 LPC, що використовується даним способом, і пристрій, можна побачити па Фіг.1. Функція LPC призначена для мінімізації суми квадрата різниці між первинним мовним сигналом і оціненим мовним сигналом за визначений проміжок часу. Це може створювати унікальний набір коефіцієнтів 50 засобу прогнозу, які звичайно оцінюють кожний кадр 20. Кадр 20 звичайно дорівнює 20мс. Функція передачі цифрового фільтра 75 з часовою зміною виражається: G H( z ) , k 1 kz де коефіцієнти 50 засобу прогнозу представляються як k і коефіцієнт посилення як G. Сума обчислюється від k=1 до k=р. Якщо використовується спосіб LPC-10, тоді р=10. Це означає, і до тільки перші 10 коефіцієнтів передаються на синтезатор 80 LPC. Два найбільш звичайно використовуваних способи для обчислення коефіцієнтів є, але не обмежуючи, коваріаційним способом і автокореляційним способом. Говорити з різною швидкістю є загальним для різних говорячих. Час стиснення є одним способом зменшення ефекту зміни швидкості для індивідуальних говорячих. Часові різниці між двома зразками мови можуть бути зменшені за допомогою зміни масштабу часової осі одного з тим. щоб досягнути максимального збігу з іншим. Цей метод часового стиснення відомий як зміна масштабу часу. Крім того, зміна масштабу часу стискує або розширює голосові сигнали без зміни їх тону. Звичайно вокодери створюють кадри 20 з тривалістю 20мсек., включаючи в себе 160 еталонів 90 з переважною швидкістю 8КГц. Стиснений вигляд зміни масштабу часу цього кадру 20 має три 90506 10 валість менше ніж 20меск., в той час як розширений вигляд зміни масштабу часу має тривалість більше ніж 20мсек. Зміна масштабу часу голосових даних має значні переваги, коли відправляють голосові дані через мережі з перемиканням пакетів, які представляють флуктуації часу затримки в передачі голосових пакетів. У таких мережах зміна масштабу часу може використовуватися для зменшення ефектів такої флуктуації часової затримки і створення голосового потоку, ідо «синхронно» переглядається. Варіанти здійснення винаходу належать до пристрою і способу зміни масштабу часу кадрів 20 у вокодері 70 за допомогою маніпулювання мовним залишком 30. У одному варіанті здійснення даний спосіб і пристрій використовуються в 4GV. Описані варіанти здійснення містять способи і пристрої або системи для розширення/стиснення різних типів 4GV мовних сегментів 110, кодованих за допомогою Періоду Тону Зразка (ПТЗ) (РРР), кодування з Лінійним Прогнозом 3 Кодовим Збудженням (ЛПЗК) (CЕLP) або (Лінійним Прогнозом З Шумовим Збудженням (ЛПЗШ) (NELP). Терміном «вокодер» 70 звичайно називається пристрій, який стискає вокалізовану мову за допомогою витягання параметрів па основі моделі генерації людської мови. Вокодери 70 включають в себе кодер 204 і декодер 206. Кодер 204 аналізує вхідну мову і витягує релевантні параметри. У одному варіанті здійснення кодер містить фільтр 75. Декодер 206 синтезує мову, використовуючи параметри, які він приймає від кодера 204 по каналу 208 передачі. У одному варіанті здійснення декодер містить синтезатор 80. Мовний сигнал 10 часто розділяють на кадри 20 даних і блок обробляється вокодером 70. Фахівцеві в рівні техніки буде зрозуміло, що людська мова може класифікуватися різними шляхами. Трьома звичайними класифікаціями мови є вокалізоваиі, невокалізовані звуки і нестійка мова. Фіг.2а показує вокалізований мовний сигнал s(n) 402. Фіг.2а показує вимірювану загальну властивість вокалізованої мови, відому як період 100 топу. Фіг.2в - певокалізований мовний сигнал s(n) 404. Новокалізований мовний сигнал 404 нагадує кольоровий шум. Фіг.2с показує нестійкий мовний сигнал s(n) 406 (тобто мова, яка є ні локалізованою, ні невокалізованою). Приклад нестійкої мови 406, показаний на Фіг.2с, може представляти перехід s(n) між невокалізованою мовою і вокалізованою мовою. Ці три класифікації включають в себе не все. Є багато різних класифікацій мови, які можуть використовуватися відповідно до способів, описаних тут, для досягнення порівнянних результатів. Четвертий генеруючий вокодер (4ГВ) (4GV) 70, що використовується в одному з варіантів здійснення винаходу, забезпечує ефективні ознаки для використання в безпровідних мережах. Деякі з цих ознак включають в себе здатність у співвідношенні якості в порівнянні з біговою швидкістю, більш гнучке кодування мовних сигналів незважаючи на збільшену швидкість пакетних помилок (ШПП) (PER), краще маскування стирань і т.д. 4GV воко 11 дер 70 може використовувати будь-які чотири різних кодера 204 і декодера 206. Різні кодери 204 і декодери 206 працюють відповідно до різних схем кодування. Деякі кодери 204 більш ефективні в частинах кодування мовного сигналу s(n) 10, представляючи визначені властивості. Тому, в одному варіанті здійснення режими кодерів 204 і декодерів 206 можуть вибиратися на основі класифікації поточного кадру 20. 4GV кодер 204 кодує кожний фрейм 20 голосових даних в одному з чотирьох різних типів кадрів 20: Інтерполяція Форми Коливання Сигналу Періоду Гону Зразка (ІФКСПТЗ) (PPPWI), Лінійний прогноз з кодовим збудженням (ЛПЗК) (CELP), Лінійний прогноз з шумовим збудженням (ЛПЗШ) (NELP) або кадр 1/8 швидкості мовчання. CELP використовується для кодування мови з малою періодичністю або мови, яка включає в себе зміну від одного періодичного сегмента 110 до іншого. Гак режим CELP звичайно вибирається для кодування кадрів, покласифікованих як нестійка мова. Оскільки такі сегменти 110 не можуть бути точно відновлені тільки з одного періоду тону зразка, CELP кодує характеристики завершеного мовного сегмента 110. Режим CELP викликає модель лінійного прогнозу голосового тракту з квантованим виглядом залишкового сигналу 30 лінійного прогнозу. Зі всіх кодерів 204 і декодерів 206, описаних тут, CELP звичайно створює більш точне мовне відновлення, але вимагає високої бітової швидкості. Режим періоду тону зразка (ПТЗ) (РРР) може вибиратися для кодових фреймів 20, покласифікованих як вокалізована мова. Вокалізована мова містить повільно змінювані у часі періодичні компоненти, які використовуються режимом РРР. Режим РРР кодує піднабір періодів 100 топу в кожному кадрі 20. Інші періоди 100 мовного сигналу 10 відновлюються за допомогою інтерполяції між цими періодами 100 зразка. При використанні періодичності вокалізованої мови, РРР здатний досягати бітової швидкості нижче, ніж CELP, і ще відтворювати мовний сигнал 10 в перцепційно точній манері. PPPWI використовується для кодування мовних даних, які є періодичними за природою. Така мова характеризується різними періодами 100 тону, схожими з періодом тону «зразка» (ПТЗ) (РРР). Цей РРР є тільки голосовою інформацією, яка необхідна кодеру 204 для кодування. Декодер може використовувати цей РРР для відновлення інших періодів 100 тону в мовному сегменті 110. Кодер 204 з «Лінійним Прогнозом 3 Шумовим Збудженням» (ЛИЗНІ) (NELP) вибирається для кодових фреймів 20. покласифіковапих як псвокалізована мова. Кодування NELP працює ефективно в термінах відновлення сигналу, де мовний сигнал 10 має малу або не малу структуру тону. Більш конкретно, NELP використовується для кодування мови, яка має характер, подібний шуму, такий як невокалізована мова або фон. NELP використовує фільтровані сигнали псевдовипадкового шуму в моделі невокалізованої мови. Шумовий характер таких мовних сегментів 110 може відновлюватися за допомогою генерування випадкових 90506 12 сигналів в декодері 206 і застосування до них призначених коефіцієнтів посилень. NELP використовує найпростішу модель для кодування мови і тому досягає низької бітової швидкості. Кадри 1/8 швидкості використовуються для кодування мовчання, наприклад, періодів, коли користувач не розмовляє. Всі з чотирьох схем кодування мовних сигналів, описаних вище, спільно використовують початкову процедуру фільтрації LPC. як показано на Фіг.3. Після класифікації мови по чотирьох категоріях, мовний сигнал 10 відправляється через кодуючий фільтр 80 з лінійним прогнозом (КЛП) (LPC), який фільтрує короткочасні кореляції в мові, використовуючи лінійний прогноз. Вихідні сигнали цього блока є коефіцієнтами 50 LPC і «залишковим» сигналом 30, який в основному є початковим мовним сигналом 10 з короткочасними кореляціями. видаленими з нього. Потім залишковий сигнал 30 кодується, застосовуючи конкретні способи, які використовуються способами кодування мовного сигналу. вибраними для кадру 20. Фіг.4а-4в показують приклад початкового мовного сигналу 10 і залишкового сигнал) 30 після блока 80 LPC. Можна бачиш, що залишковий сигнал 30 показує періоди 100 тону більш виразно, ніж початкова мова 10. Зрозуміло, таким чином, що залишковий сигнал 30 може використовуватися для визначення періоду 100 тону мовного сигналу більш точно, ніж початковий сигнал 10 (який також містить короткочасні кореляції). Як встановлено вище, зміна масштабу часу може використовуватися для розширення або стиснення мовного сигналу 10. Хоч ряд способів може використовуватися для досягнення цього, багато які з них засновуються на додаванні або видаленні періодів 100 тону з сигналу 10. Додавання або видалення періодів 100 тону можуть виконуватися в декодері 206 після прийому залишкового сигналу 30, але до синтезу сигналу 30. Для мовних даних, які кодуються за допомогою CELP або РРР (не NELP), сигнал включає в себе ряд періодів 100 тонів. Таким чином, найменший блок, який може додаватися або видалятися з мовного сигналу 10, є періодом 100 тону, оскільки будь-який блок менший, ніж цей, буде приводити до фазового розриву в представленні помічного мовного артефакту. Так. одним кроком в способах зміни масштабу часу, що застосовуються для мови CELP або РРР, с оцінка періоду 100 тону. Такий період 100 тону вже відомий для декодера 206 для мовних кадрів 20 CELP/PPP. У випадку РРР і CELP. інформація тону обчислюється кодером 204 за допомогою автокореляційних способів і передається на декодер 206. Таким чином, декодер 206 має точні знання про період 100 тону. Це створює простоту застосування способу зміни масштаб) часу даного винаходу в декодері 206. Крім того, як встановлено вище, простіше змінити масштаб часу сигналу 10 до синтезу сигналу 10. Якщо такі способи зміни масштабу часу були застосовані після декодування сигналу 10. необхідно буде оцінити період 100 тону сигналу 10. Це вимагає не тільки додаткового обчислення, але також оцінки періоду 100 топу можуть не бути точ 13 ними, оскільки залишковий сигнал 30 також містить інформацію 170 LPC. З іншого боку, якщо додаткові оцінки періоду 100 тону також не с комплексними, тоді виконання зміни масштабу часу після декодування не вимагає змін в декодері 206, і тому може виконуватися тільки один раз для всіх вокодерів 80. Інша причина виконання зміни масштабу часу в декодері 206 до синтезу сигналу, використовуючи кодуючий синтез LPC, полягає в тому, що стиснення/розширення може застосовуватися до залишкового сигналу 30. Це дозволяє синтезу кодування з лінійним прогнозом (LPC) застосовуватися для залишкового сигналу 30, що піддався зміні масштабу часу. Коефіцієнти 50 LPC грають роль в тому, як мовні звуки і застосування синтезу після зміни масштабу гарантують, що підтримується коректна інформація 170 LPC в сигналі 10. Якщо, з одного боку зміна масштабу часу виконується після декодування залишкового сигналу 30, синтез LPC вже викопаний до зміни масштабу часу. Таким чином, процедура зміни масштабу може змінювати інформацію 170 LPC сигналу 10. особливо, якщо прогноз періоду 100 тону після декодування не був дуже точним. У одному варіанті здійснення, стани, що виконуються способами зміни масштабу часу, описані в даній заявці, зберігаються як команди, розташовані в програмному забезпеченні або вбудованій програмі 81, розташованій в пам'яті 82. На Фіг.1 пам'ять показується розташованою в декодері 206. Пам'ять 82 може також розташовуватися поза декодером 206. Кодер 204 (такий, як один з 4GV) може класифікувати мовні кадри 20 як РРР (періодичні), CELP (слабо періодичні) або NELP (шумові) в залежності від того, чи представляють кадри 20 вокалізовану, новокалізовану або нестійку мову. Використовуючи інформацію про тип мовного кадру, декодер 206 може змінювати масштаб часу різних типів кадрів 20, використовуючи різні способи. Наприклад, мовний кадр 20 NEEP не знає про періоди тону і його залишковий сигнал 30 генерується в декодері 206, використовуючи «випадкову» інформацію. Таким чином, оцінка періоду 100 тону CELP/PPP не застосовується до NELP і загалом кадри 20 NЕLP можуть змінювати масштаб часу (розширюватися/стискуватися) на менше ніж період 100 тону. Така інформація не є придатною, якщо зміна масштабу часу виконується після декодування залишкового сигналу 30 в декодері 206. Загалом зміна масштабу часу кадрів 20, подібних NELP, після декодування приводить до артефактів. Зміна масштабу часу кадрів 20 NELP в декодері 206, з іншого боку, створює більш кращу якість. Таким чином, с дві переваги виконання зміни масштабу часу в декодері 206 (тобто до синтезу залишкового сигналу 30) проти пост-декодера (тобто після синтезу залишкового сигналу 30): (і) зменшення додаткових розрахунків (наприклад, уникнення пошуку періоду 100 тону); і (іі) поліпшена якість, зміни масштабу часу внаслідок а) знання типу кадру 20, b) виконання синтезу LPC сигналу, який піддався зміні масштабу часу, і с) більш точна оцінка/знання періоду тону. 90506 14 Подальший опис варіантів здійснення, в яких дані спосіб і пристрій змінюють масштаб часу мовного залишку 30 в декодерах РРР, CELP і NELP. Наступні два стани виконуються в кожному декодері 206: (і) зміна масштабу часу залишкового сигналу 30 до розширеного або стисненого вигляду; і (іі) відправлення залишку 30. який піддався зміні масштабу часу, через фільтр 80 LPC. Крім того, етап (і) по-різному виконується для мовних сегментів 110 РРР, CHLP і NELP. Варіанти здійснення будуть описані нижче. Як встановлено вище, коли мовний сегмент 110 є РРР, найменшим блоком, який може додаватися або видалятися з сигналу, є період 100 тону. До того, як сигнал 10 може декодуватися (і відновлений залишок 30) з періоду 100 тону зразка, декодер 206 інтерполює сигнал 10 з попереднього періоду 100 тону зразка (який зберігається) в період 100 тону зразка в поточному кадрі 20, додаючи бракуючі періоди 100 тону в процес. Цей процес показаний на Фіг.5. Гака інтерполяція додає простоти в зміні масштабу часу за допомогою створення менш або більш інтерпольованих періодів 100 тону. Це буде приводити до стиснення або розширення залишкових сигналів 30, які потім відправляються через синтез LPC. Як встановлено раніше, коли мовний сегмент 110 є РРР, найменшим блоком. який може додаватися або видалятися з сигналу, є період 100 тону. З іншою боку, у випадку CELP, зміна масштабу часу також не є безпосередньою для РРР. Для зміни масштабу часу залишку 30, декодер 206 використовує інформацію про затримку 180 тону, яка міститься в кодованому кадрі 20. Ця затримка 180 тону дійсно є затримкою 180 тону в кінці кадру 20. Потрібно зазначити, що навіть в періодичному кадрі 20, затримка 180 тону може трохи змінюватися. Затримки 180 тону в будь-якій точці в кадрі можуть оцінюватися інтерполяцією між затримкою 180 тону в кінці останнього кадру 20 і в кінці поточного кадру 20. Це показано на Фіг.6. Як тільки відомі затримки 180 тону у всіх точках кадру 20, кадр може розділятися на періоди 100 тону. Границі періодів 100 тону визначаються, використовуючи затримки 100 тону в різних ι очках в кадрі 20. Фіг.6а показує приклад того, як розділяють кадр 20 на його періоди 100 тону. Наприклад, кількість еталонів 70 має затримку 70 тону, яка дорівнює приблизно 70, і кількість еталонів 142 має затримку 190 приблизно 72. Таким чином, періоди 100 тону виходять з числа еталонів [1-70] і з числа еталонів [71-142]. Дивись Фіг.6в. Один кадр 20 розділений на періоди 100 тону, ці періоди 100 тону можуть потім поєднуватисядодаватися для збільшення/зменшення розміру залишку 30. Дивись Фіг.7в-7f. У синтезі поєднання і додавання, змінений сигнал виходить за допомогою видалення сегментів 110 з вхідного сигналу 10. переміщення їх вздовж часової осі і виконання зваженого суміщеного підсумовування для с і ворсини синтезованого сигналу 150. У одному варіанті здійснення сегмент 110 може дорівнювати періоду 100 тону. Спосіб поєднання-додавання замінює два різних мовних сегменти 110 на один мовний 15 сегмент 110 за допомогою «об'єднання» сегментів 110 мови. Об'єднання мови виконується способом збереження, на скільки можливо, більшої якості мови. Якість захисту мови і мінімізації представлення артефактів в мові викопується за допомогою ретельного вибору сегментів 110 для об'єднання. (Артефакти є небажаними об'єктами подібно клацанню, хлопанню і т.д.). Вибір мовних сегментів 110 базується на «схожості» сегментів. Близькість «схожості» мовних сегментів 110, краща результуюча мовна якість і низька імовірність представлення мовного артефакту, коли два сегмент 110 мови поєднуються для зменшення/збільшення розміру мовною залишку 30. Правилом корисності для визначення, чи повинні періоди тону поєднуватися-додаватися, є, якщо схожі затримки тону двох (як наприклад, якщо затримки тону розрізнюються менше ніж 15 еталонам, які відповідають близько 1,8мсек.). Фіг.7с показує, як використовується поєднання-додавання для стиснення залишку 30. Першим етапом способу поєднання/додавання є сегментування вхідних еталонних послідовностей s(n) 10 на їх періоди топу, як пояснено вище. На Фіг.7а показаний початковий мовний сигнал 10, що включає 4 періоди 100 (ПТ) (РР) гону. Наступний етап включає в себе видалення періодів 100 тону сигналу 10, показаних на Фіг.7а, і заміну цих періодів 100 тону на об'єднані періоди 100 тону. Наприклад на Фіг.7с, періоди РР2 і РР3 топу видаляються і потім замінюються одним періодом 100 тону, в якому РР2 і РР3 поєднуються-підсумовуються. Більш конкретно, на Фіг.7с, періоди 100 РР2 і РР3 чопи поєднуються-додаються таким чином, що частка другого періоду 100 (РР2) тону зменшується і РР3 збільшується. Спосіб додавання-поєднання створює один мовний сегмент 110 з двох різних мовних сегментів 110. У одному варіанті здійснення, додавання-поєднання виконується, використовуючи зважені еталони. Це показується виразами а) і b), показаними на Фіг.8. Зважування використовується для забезпечення згладжування переходу між першим еталоном PMC (IKM) (ІмпульсноКодової Модуляції) Сегмента 1 (110) і останнім еталоном РМС Сегмента 2 (110). Фіг.7d є іншою графічною ілюстрацією суміщених-доданих РР2 і РР3. Плавне мікшування поліпшує якість часу сигналу 10, стисненого цим способом, в порівнянні з простим видаленням одного сегмента 110 і з'єднання сусідніх сегментів 110, що залишилися (як показано на Фіг. 7с). У випадку, коли період 100 тону змінюється, спосіб поєднання-додавання може об'єднувати два періоди 110 тону нерівної довжини. У цьому випадку краще об'єднання може досягатися за допомогою вирівнювання піків двох періодів 100 тону до їх поєднання-додавання. Розширений/стиснутий залишок потім відправляється через синтез LPC. Простим підходом в розширенні мови є виконання множини повторень однакових еталонів РМС. Однак повторения однакових еталонів РМС більше ніж один раз може створити області з рівними тонами, які є артефактами, які легко визначаються людьми (наприклад, мова може звучати 90506 16 трохи роботизовано). Для збереження я косі і мови може використовуватися спосіб додаванняпоєднання. Фіг.7в показує, як цей мовний сигнал 10 може розширятися, використовуючи спосіб поєднаннядодавання даного винаходу. На Фіг.7в додається додатковий період 100 тону, створений з періодів 100 РР1 і РР2 тону. У додатковому періоді 100 гону, періоди 100 РР2 і РР1 гону поєднуютьсядодаються таким чином, що частка другого періоду 100 (РР2) тону зменшується і РР1 збільшується. Фіг.7f є іншою графічною ілюстрацією суміщених-доданих РР2 і РР3. Для мовних сегментів NELP. кодер кодує інформацію LPC, а також коефіцієнти посилення для різних частин мовного сегмента 110. Необхідно кодувати будь-яку іншу інформацію, оскільки мова за природою дуже подібна до шуму. У одному варіанті здійснення коефіцієнти посилення кодуються в наборі з 16 еталонів РМС. Гак. наприклад, кадр з 160 еталонів може представлятися 10 кодованими значеннями коефіцієнта посилення, один для кожних 16 еталонів мови. Декодер 206 генерує залишковий сигнал 30 за допомогою генерування випадкових значень і потім застосовуючи до них відповідні коефіцієнти посилення. У цьому випадку тут не може бути поняття період 100 тону і по суті розширення/стиснення не може виконуватися, не маючи нерівномірності періоду 100 тону. Для розширення або стиснення NEL сегмента, декодер 206 генерує кількість сегментів (110) більше або менше ніж 160 в залежності від того, розширюється або звужується сегмент 110. 10 декодованих коефіцієнтів посилення потім застосовуються до еталонів для генерування розширеного або стисненого залишку 30. Оскільки ці 10 декодованих коефіцієнтів посилення відповідають початковим 160 еталонам, вони прямо не застосовуються для розширення/стиснення еталонів. Різні способи можуть використовуватися для застосування цих коефіцієнтів посилення. Деякі з цих способів описуються нижче. Якщо кількість еталонів, що генеруються, менше ніж 160, тоді немає необхідності в застосуванні всіх 10 коефіцієнтів посилення. Наприклад, якщо кількість еталонів дорівнює 144, можуть застосовуватися перші 9 коефіцієнтів посилень. У цьому прикладі перший коефіцієнт посилення застосовується до перших 16 еталонів, еталони 116, другий коефіцієнт посилення застосовується до наступних 16 еталонів, еталони 17-32, і т.д. Аналогічно, якщо еталонів більше ніж 160, тоді 10тий коефіцієнт посилення може застосовуватися більше ніж один раз. Наприклад, якщо кількість еталонів дорівнює 192, 10-тий коефіцієнт посилення може застосовуватися до еталонів 145-160, 161-176 і 177-192. Альтернативно, еталони можуть розділятися на 10 наборів з однакової кількості, кожний набір має однакову кількість еталонів, і 10 коефіцієнтів посилення можуть застосовуватися до 10 наборів. Наприклад, якщо кількість еталонів дорівнює 140, 10 коефіцієнтів посилень можуть застосовуватися до наборів з 14 еталонів в кожному. У цьому прикладі перший коефіцієнт посилення застосовується 17 до перших 14 еталонів, еталони 1-14, другий коефіцієнт посилення застосовується до наступних 14 еталонів, еталони 14-28, і т.д. Якщо кількість еталонів повністю не ділиться на 10, тоді 10-тий коефіцієнт посилення може застосовуватися до еталонів, що залишилися, одержаних після розділення на 10. Наприклад, якщо кількість еталонів дорівнює 145, 10 коефіцієнтів посилення може застосовуватися до наборів з 14 еталонів в кожному. Додатково, 10-тий коефіцієнт посилення застосовується до еталонів 141-145. Після зміни масштабу часу, розширений/стиснений залишок 30 відправляється через синтез LPC, де використовуються будь-які перераховані вище способи кодування. Фахівцеві в рівні техніки буде зрозуміло, що інформація і сигнали можуть представлятися, використовуючи будь-що з множини різних технологій і методів. Наприклад, дані, інструкції, команди, інформація, сигнали, біти, символи і чини, які можуть посилатися по згаданому вище опису, можуть представлялися напругами, струмами, електромагнітними хвилями, магнітними полями або частинками, оптичними полями або частинками або будьякою їх комбінацією. Фахівцеві в рівні техніки буде очевидно, що різні ілюстративні логічні блоки, модулі, схеми і етапи алгоритму, описані в зв'язці з варіантами здійснення, описаними тут. можуть викопуватися як електронна апаратура, комп'ютерне програмне забезпечення або їх комбінація. Для ясності ілюстрації цієї рівноцінності апаратури і програмного забезпечення, різні ілюстративні компоненти, блоки, модулі, схеми і етапи описані вище в термінах їх функціональності. Будь-яка така функціональність виконується апаратно або програмно в залежності від конкретного застосування і обмежень конструкції, заданих на всю систему. Фахівець може виконати описану функціональність різними способами для кожної о конкретного застосування, але такі рішення виконання не треба інтерпретувати як відхід від об'єму даного винаходу. Різні ілюстративні логічні блоки, модулі і схеми, описані в зв'язці з варіантами здійснення, описаними тут, можуть втілюватися або виконуватися в процесорі загального призначення. Процесорі Цифрових Сигналів (ПЦС) (DSP), Спеціалізованій Інтегральній схемі (СІС) (ASIC), Програмованій 90506 18 Користувачем Вентильній Матриці (ПКВМ) (FPGA) або інших програмно-логічних пристроях, логічному елементі на дискретних компонентах або транзисторній логіці. дискретних апаратних компонентах або будь-якій їх комбінації, призначеній для виконання функцій, описаних тут. Процесором загального призначення може бути мікропроцесор, але в альтернативі, процесором може були будьякий звичайний процесор, контролер, мікроконтролер або кінцевий автомат. Процесор може також виконуватися як комбінація обчислювальних пристроїв, наприклад, комбінація DSP і мікропроцесора. множина мікропроцесорів, один або більше мікропроцесорів в сполученні з ядром DSP або будь-яка інша така конфігурація. Етапи способу або алгоритму, описані в зв'язці з варіантами здійснення, описаними тут, можуть виконуватися прямо в апаратурі, в програмному модулі, виконуваному процесором або в комбінації цих двох. Програмний модуль може розташовуватися в Оперативній пам'яті (RAM), флеш-пам'яті, Постійній Пам'яті (ROM), Електрично Програмованій ROM (EPROM), Електрично Стираній Програмованій ROM (EEPROM), регістрах, жорсткому диску, змінному диску. CD-ROM або будь-якій іншій формі запам'ятовуючого носія, відомого з рівня техніки. Ілюстративний носій підключається до процесора так, щоб процесор міг зчитувати інформацію з і записувати інформацію на запам'ятовуючий посій. У альтернативі, запам'ятовуючий носій може вбудовуватися в процесор. Процесор і запам'ятовуючий носій можуть розташовуватися в ASIC. ASIC може розташовуватися в користувацькому терміналі. У альтернативі, процесор і запам'ятовуючий носій можуть розташовуватися як дискретні компоненти в користувацькому терміналі. Попередній опис розкритих варіантів здійснення пристосований для створення або використання даного винаходу будь-яким фахівцем в рівні техніці. Різні модифікації цих варіантів здійснення будуть без великих зусиль очевидні фахівцеві в рівні техніки і загальні принципи, визначені тут, можуть застосовуватися для інших варіантів здійснення без відхилення від суті або об'єму винаходу. Таким чином, даний винахід не підлягає обмеженню варіантами здійснення, показаними тут, але підлягає узгодженню з широким об'ємом, що узгоджується з принципами і новими ознаками, описаними тут. 19 90506 20 21 90506 22 23 90506 24 25 Комп’ютерна верстка А. Рябко 90506 Підписне 26 Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюChange of time scale of cadres in vocoder by means of residual change
Автори англійськоюKapoor Rohit, Dias Spindola Serafin
Назва патенту російськоюИзменение масштаба времени кадров в вокодере с помощью изменения остатка
Автори російськоюКапур Рохит, Диас Спиндола Серафин
МПК / Мітки
МПК: G10L 19/00
Мітки: масштабу, часу, кадрів, залишку, зміни, вокодері, зміна, допомогою
Код посилання
<a href="https://ua.patents.su/13-90506-zmina-masshtabu-chasu-kadriv-v-vokoderi-za-dopomogoyu-zmini-zalishku.html" target="_blank" rel="follow" title="База патентів України">Зміна масштабу часу кадрів в вокодері за допомогою зміни залишку</a>
Спосіб перетворення часового масштабу пакета імпульсних електричних сигналів

Номер патенту: 49705
Опубліковано: 16.09.2002
Автори: Бобер Андрій Григорович, Олійник Максим Олексійович, Нечитайло Юрій Іванович, Кавун Марія Олександрівна, Федорович Наталя Володимирівна, Серков Олександр Анатолійович
МПК: H03K 5/13
Мітки: сигналів, імпульсних, електричних, масштабу, перетворення, пакета, часового, спосіб
Формула / Реферат:
Спосіб перетворення часового масштабу пакета імпульсних електричних сигналів, при якому пакет сигналів подають на вхід штучної лінії затримки, пропускають сигнал уздовж штучної лінії затримки, передають його на кінцеві пристрої, який відрізняється тим, що параметри штучної лінії затримки змінюють водночас із проходженням пакета імпульсних електричних сигналів.
Пристрій перетворення часового масштабу пакета імпульсних електричних сигналів

Номер патенту: 62224
Опубліковано: 15.12.2003
Автори: Корольова Наталія Анатолійовна, Пєвнєв Володимир Яковлевич, Загарій Генадій Іванович, Серков Олександр Анатолійович, Логвиненко Микола Федорович, Яценко Ірина Леонідівна
МПК: H03K 5/13
Мітки: масштабу, пристрій, сигналів, електричних, імпульсних, часового, пакета, перетворення
Формула / Реферат:
Пристрій перетворення часового масштабу пакета імпульсних електричних сигналів, що включає генератор, штучну лінію затримки, який відрізняється тим, що додатково введено n штучних ліній затримки, входи яких під'єднано через розгалужувач до інформаційного пакета імпульсних електричних сигналів, а виходи - через розгалужувач до генератора строб-імпульсів, n змішувачів, вхід кожного з котрих під'єднано до відповідної штучної лінії затримки на...
Спосіб контролю зміни розмірів об`єкта за допомогою шаблона

Номер патенту: 84380
Опубліковано: 10.10.2008
Автори: Новосельцев Ігор Валерійович, Кушнарьов Максим Володимирович, Аксак Наталія Георгіївна, Тихун Алла Юріївна
МПК: G01C 11/00
Мітки: розмірів, зміни, контролю, спосіб, шаблона, об'єкта, допомогою
Формула / Реферат:
Спосіб контролю зміни розмірів об'єкта за допомогою шаблона, що включає одержання фотографій з часовим інтервалом за допомогою цифрового фотоапарата, позиціонованого для одночасного захоплювання шаблона й області інтересу об'єкта спостереження, занесених у базу даних персонального комп'ютера, причому отримана при першому спостереженні фотографія вважається базовою, а при повторному спостереженні шаблон розміщують біля області інтересу,...
Пристрій перетворення часового масштабу пакета імпульсних електричних сигналів

Номер патенту: 37087
Опубліковано: 16.04.2001
Автори: Ковальов В'ячеслав Едуардович, Бреславець Владислав Сергійович, Серков Олександр Анатолійович, Постін Михайло Євгенович, Касілов Олег Вікторович
МПК: H03K 5/13
Мітки: перетворення, сигналів, пристрій, імпульсних, масштабу, пакета, електричних, часового
Текст:
...затримки 3 та з'я вляється на затисках 8, 9. Одночасно подається від генератора 1 лінійно змінююча напруга на затиски 5, 7, яка розповсюджується вдовж додаткової штучної лінії затримки 2, змінюючи параметри штучної лінії затримки 3 та розсіюється на навантажені 4. Таким чином, швидкість розповсюдження інформаційного пакета імпульсних електричних сигналів змінюєть ся в залежності від часу та місця знаходження інформаційного імпульсного...
Спосіб визначення часу формування гематом за допомогою статистичного аналізу поляризаційних зображень біологічних тканин трупа людини

Номер патенту: 32310
Опубліковано: 12.05.2008
Автор: Бачинський Віктор Теодосович
МПК: G01N 33/00
Мітки: людини, зображень, біологічних, спосіб, аналізу, визначення, допомогою, часу, трупа, гематом, формування, тканин, поляризаційних, статистичного
Формула / Реферат:
Спосіб визначення часу формування гематом за допомогою статистичного аналізу поляризаційних зображень біологічних тканин трупа людини шляхом оцінки часових значень характеру змін тканин, який відрізняється тим, що використовують висококогерентне лінійно поляризоване випромінювання з довжиною хвилі 0,6328 мкм, формують поляризаційне зображення гематоми в площині світлочутливої цифрової камери, обчислюють статистичні моменти 1-го - 4-го...
Попередній патент: Підписки мобільних пристроїв через ефір
Наступний патент: Мукоадгезивна композиція для приготування медичних засобів та фармацевтичних композицій
Випадковий патент: Рідинозаповнена електрична машина