Спосіб і пристрій для векторного квантування спектрального представлення обвідної











Формула / Реферат
1. Спосіб обробки сигналів, що містить етапи, на яких:
кодують перший кадр і другий кадр мовного сигналу для формування відповідних першого і другого векторів, причому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру;
формують перший квантований вектор, причому вказане формування містить у собі квантування третього вектора V20a/b, який оснований на частині першого вектора V10;
обчислюють помилку квантування першого квантованого вектора;
обчислюють четвертий вектор, причому вказане обчислення включає в себе підсумовування масштабованої версії помилки квантування з частиною другого вектора V10; і
квантують четвертий вектор.
2. Спосіб за п. 1, у якому згаданий етап обчислення помилки квантування включає в себе обчислення різниці між першим квантованим вектором і третім вектором.
3. Спосіб за п. 1, у якому згаданий етап обчислення помилки квантування містить у собі обчислення різниці між першим квантованим вектором і частиною першого вектора.
4. Спосіб за п. 1, що включає в себе етап, на якому обчислюють масштабовану помилку квантування, причому згаданий етап обчислення містить множення помилки квантування на масштабний коефіцієнт,
при цьому масштабний коефіцієнт оснований на відстані між частиною першого вектора і відповідною частиною другого вектора.
5. Спосіб за п. 4, у якому кожний з першого і другого векторів містить множину частот спектральних ліній.
6. Спосіб за п. 1, у якому кожний з першого і другого векторів включає в себе представлення множини коефіцієнтів фільтра лінійного прогнозу.
7. Спосіб за п. 1, у якому кожний з першого і другого векторів включає в себе множину частот спектральних ліній.
8. Спосіб за п. 1, у якому другий кадр безпосередньо іде за першим кадром у мовному сигналі.
9. Спосіб за п. 1, у якому кожний з першого і другого векторів представляє адаптивно згладжену спектральну обвідну.
10. Спосіб за п. 1, у якому згаданий спосіб містить етапи, на яких: деквантують четвертий вектор; і
обчислюють сигнал збудження на основі десантованого четвертого вектора.
11. Спосіб за п. 1, у якому згаданий спосіб містить етап, на якому фільтрують широкосмуговий мовний сигнал для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру.
12. Спосіб за п. 1, у якому згаданий спосіб містить етап, на якому фільтрують широкосмуговий мовний сигнал для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом другого кадру.
13. Спосіб за п. 1, у якому згаданий спосіб містить етап, на якому: фільтрують широкосмуговий мовний сигнал для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру;
деквантують четвертий вектор;
на основі деквантування четвертого вектора обчислюють сигнал збудження для вузькосмугового мовного сигналу; і
на основі сигналу збудження для вузькосмугового мовного сигналу витягають сигнал збудження мовного сигналу смуги верхніх частот.
14. Спосіб за п. 1, у якому згаданий етап квантування четвертого вектора
містить етап, на якому виконують розщеплене векторне квантування четвертого вектора.
15. Носій для зберігання даних, що містить команди, які виконуються комп'ютером, що описують спосіб за п. 1.
16. Пристрій для обробки сигналів, що містить:
мовний кодер, сконфігурований для кодування першого кадру мовного сигналу в перший вектор, і для кодування другого кадру мовного сигналу в другий вектор, причому перший вектор представляє спектральну обідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру;
квантувач, сконфігурований для квантування третього вектора, який оснований на частині першого вектора, для формування першого квантованого вектора;
перший суматор, сконфігурований для обчислення помилки квантування першого квантованого вектора; і
другий суматор, сконфігурований для підсумовування масштабованої версії помилки квантування із частиною другого вектора, для обчислення четвертого вектора,
причому згаданий квантувач сконфігурований для квантування четвертого вектора.
17. Пристрій за п. 16, у якому згаданий перший суматор конфігу ваний для обчислення помилки квантування на основі різниці між першим квантованим вектором і третім вектором.
18. Пристрій за п. 16, у якому згаданий перший суматор конфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і частиною першого вектора.
19. Пристрій за п. 16, що додатково включає в себе помножувач, конфігурований для обчислення масштабованої помилки квантування на основі добутку помилки квантування і масштабного коефіцієнта,
при цьому пристрій включає в себе логіку, сконфігуровану для обчислення масштабного коефіцієнта на основі відстані між частиною першого вектора і відповідною частиною другого вектора.
20. Пристрій за п. 16, у якому другий кадр безпосередньо іде за першим кадром у мовному сигналі.
21. Пристрій за п. 16, у якому кожний з першого і другого векторів представляє адаптивно згладжену спектральну обвідну.
22. Пристрій за п. 16, який містить:
інверсний квантувач, сконфігурований для деквантування четвертого вектора; і
відбілювальний фільтр, сконфігурований для обчислення сигналу збудження на основі десантованого четвертого вектора.
23. Пристрій за п. 16, у якому згаданий пристрій містить набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру.
24. Пристрій за п. 16, у якому згаданий пристрій містить набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом другого кадру.
25. Пристрій за п. 16, що містить:
набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру;
інверсний квантувач, сконфігурований для деквантування четвертого вектора;
відбілювальний фільтр, сконфігурований для обчислення сигналу збудження для вузькосмугового мовного сигналу на основі десантованого четвертого вектора; і
кодер смуги верхніх частот, сконфігурований для формування сигналу збудження для мовного сигналу смуги верхніх частот на основі сигналу збудження для вузькосмугового мовного сигналу.
26. Пристрій за п. 16, у якому згаданий квантувач сконфігурований для квантування четвертого вектора за допомогою виконання розщепленого векторного квантування четвертого вектора.
27. Пристрій за п. 16, у якому кожний з першого і другого векторів включає в себе множину частот спектральних ліній.
28. Пристрій за п. 16, у якому кожний з першого і другого векторів включає в себе представлення множини коефіцієнтів фільтра лінійного прогнозу.
29. Пристрій за п. 16, у якому кожний з першого і другого векторів включає в себе множину частот спектральних ліній.
30. Пристрій за п. 16, що містить пристрій для бездротового зв'язку.
31. Пристрій за п. 16, що містить пристрій, сконфігурований для передачі множини пакетів, сумісних з версією Інтернет-протоколу, причому множина пакетів описує перший квантований вектор.
32. Пристрій для обробки сигналів, що містить:
засіб для кодування першого кадру і другого кадру мовного сигналу для формування відповідних першого і другого векторів, причому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру;
засіб для формування першого квантованого вектора, причому згадане формування включає в себе квантування третього вектора, який оснований на частині першого вектора;
засіб для обчислення помилки квантування першого квантованого вектора; і засіб для обчислення четвертого вектора, причому згадане обчислення включає в себе підсумовування масштабованої версії помилки квантування із частиною другого вектора;
причому згаданий засіб для формування першого квантованого вектора сконфігурований для квантування четвертого вектора.
33. Пристрій за п. 32, у якому згаданий засіб для обчислення помилки квантування сконфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і третім вектором.
34. Пристрій за п. 32, у якому згаданий засіб для обчислення помилки квантування сконфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і частиною першого вектора.
35. Пристрій за п. 32, що додатково включає в себе засіб для обчислення масштабованої помилки квантування, причому згадане обчислення містить множення помилки квантування на масштабний коефіцієнт,
при цьому пристрій містить логіку, сконфігуровану для обчислення масштабного коефіцієнта на основі відстані між частиною першого вектора і відповідною частиною другого вектора.
36. Пристрій за п. 35, у якому кожний з першого і другого векторів містить множину частот спектральних ліній.
37. Пристрій за п. 32, що містить пристрій для бездротового зв'язку.
38. Пристрій за п. 32, у якому другий кадр безпосередньо іде за першим кадром у мовному сигналі.
39. Пристрій за п. 32, у якому кожний з першого і другого векторів представляє адаптивно згладжену спектральну обвідну.
40. Пристрій за п. 32, що містить:
засіб для деквантування четвертого вектора; і
засіб для обчислення сигналу збудження на основі деквантованого четвертого вектора.
41. Пристрій за п. 32, що містить засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру.
42. Пристрій за п. 32, що містить засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і
при цьому перший вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом першого кадру, і
при цьому другий вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом другого кадру.
43. Пристрій за п. 32, що містить:
засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру;
засіб для деквантування четвертого вектора;
засіб для обчислення сигналу збудження для вузькосмугового мовного сигналу на основі деквантованого четвертого вектора; і
засіб для добування сигналу збудження для мовного сигналу смуги верхніх частот на основі сигналу збудження для вузькосмугового мовного сигналу.
44. Пристрій за п. 32, у якому згаданий засіб для формування першого квантованого вектора сконфігурований для квантування четвертого вектора за допомогою виконання розщепленого векторного квантування четвертого вектора.
45. Машиночитаний носій, що містить команди, які при виконанні в процесорі спонукають процесор:
кодувати перший кадр і другий кадр мовного сигналу для формування першого і другого векторів, при цьому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, і другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру;
формувати перший квантований вектор, причому зазначене формування включає в себе квантування третього вектора, який оснований на частині першого вектора;
обчислювати помилки квантування першого квантованого вектора;
обчислювати четвертий вектор, причому зазначене обчислення містить у собі підсумовування масштабованої версії помилки квантування із частиною другого вектора; і
квантувати четвертий вектор.
46. Машиночитаний носій за п. 45, у якому команди, які спонукають процесор обчислювати помилки квантування, включають в себе команди для обчислення різниці між першим квантованим вектором і третім вектором.
47. Машиночитаний носій по п. 45, у якому команди, які спонукають процесор обчислювати помилки квантування, включають в себе команди для обчислення різниці між першим квантованим вектором і частиною першого вектора.
48. Машиночитаний носій за п. 47, у якому команди, які спонукують процесор обчислювати масштабовану помилку квантування, додатково містять команди для:
множення помилки квантування на масштабний коефіцієнт, при цьому масштабний коефіцієнт оснований на відстані між частиною першого вектора і відповідною частиною другого вектора.
49. Машиночитаний носій за п. 48, у якому кожний з першого і другого векторів включають в себе множину частот спектральних ліній.
50. Машиночитаний носій за п. 45, у якому кожний з першого й другого векторів включає в себе представлення множини коефіцієнтів фільтра лінійного прогнозу.
Текст
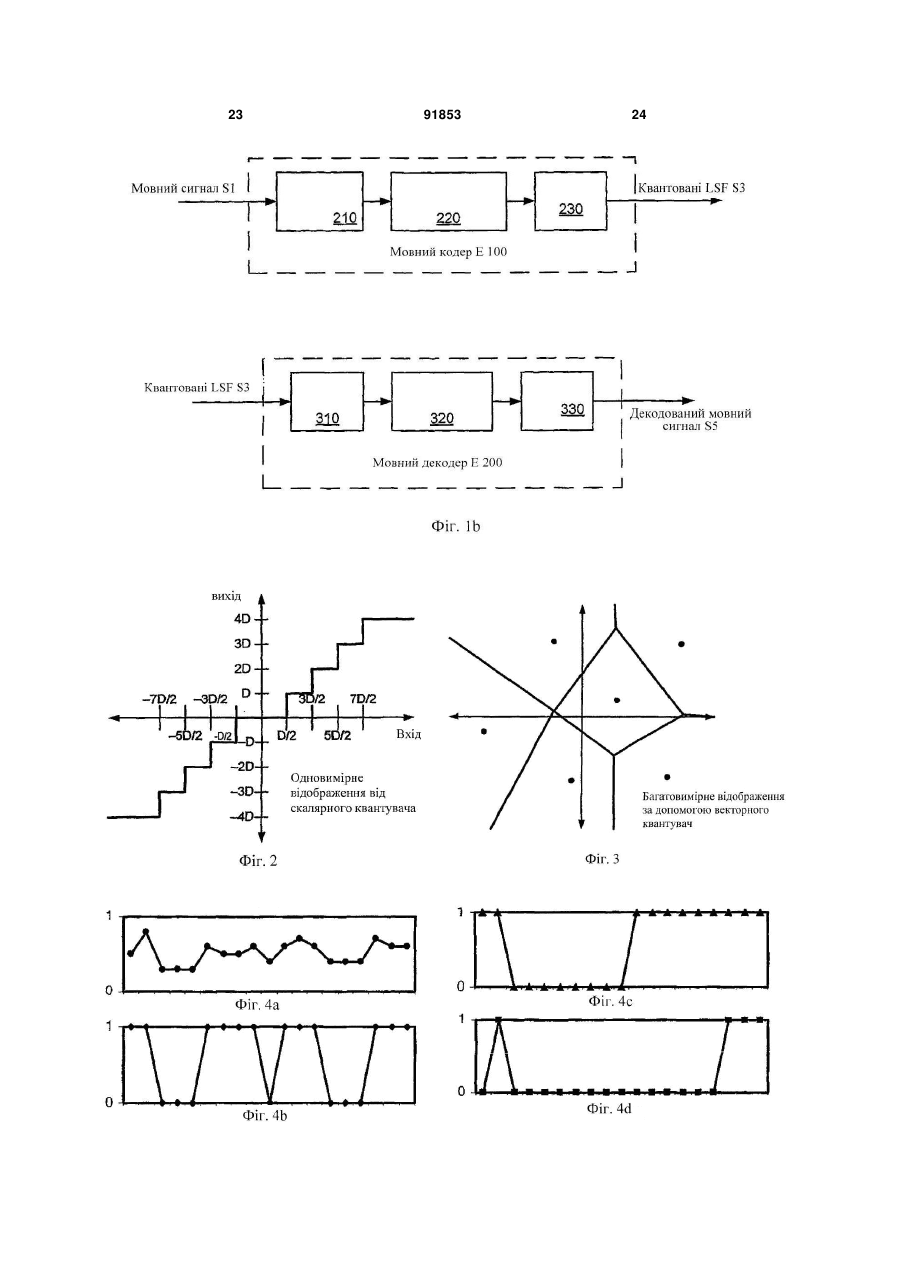
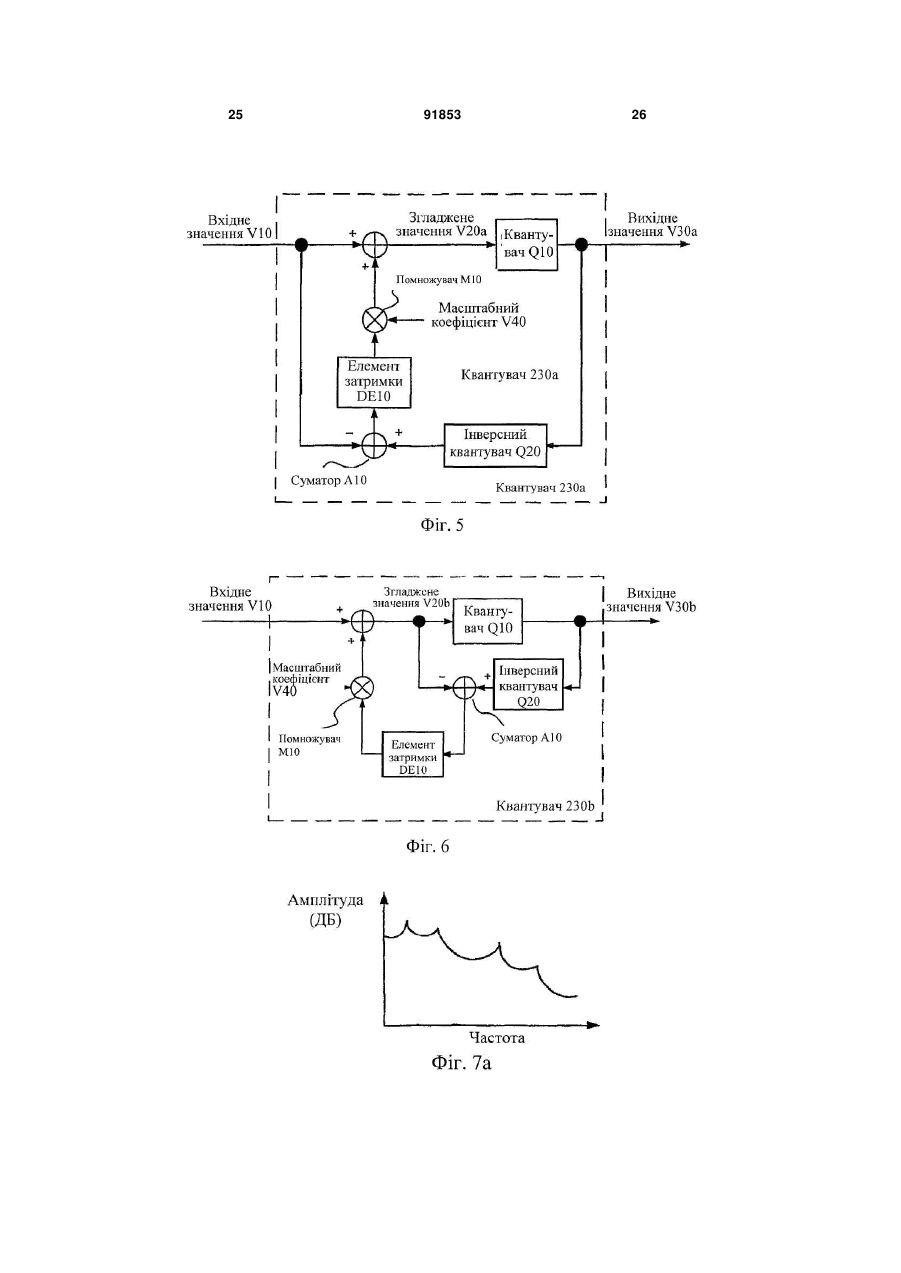
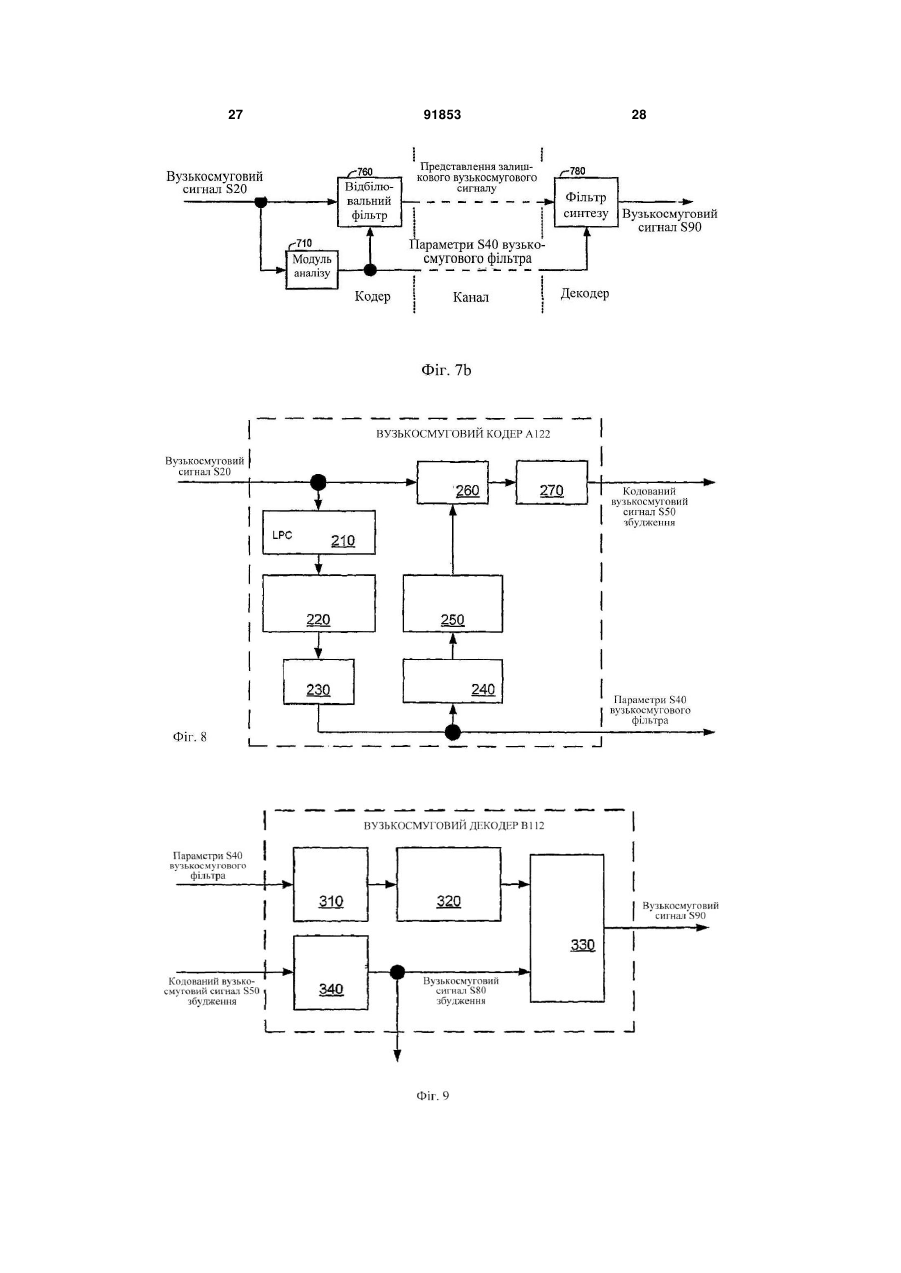
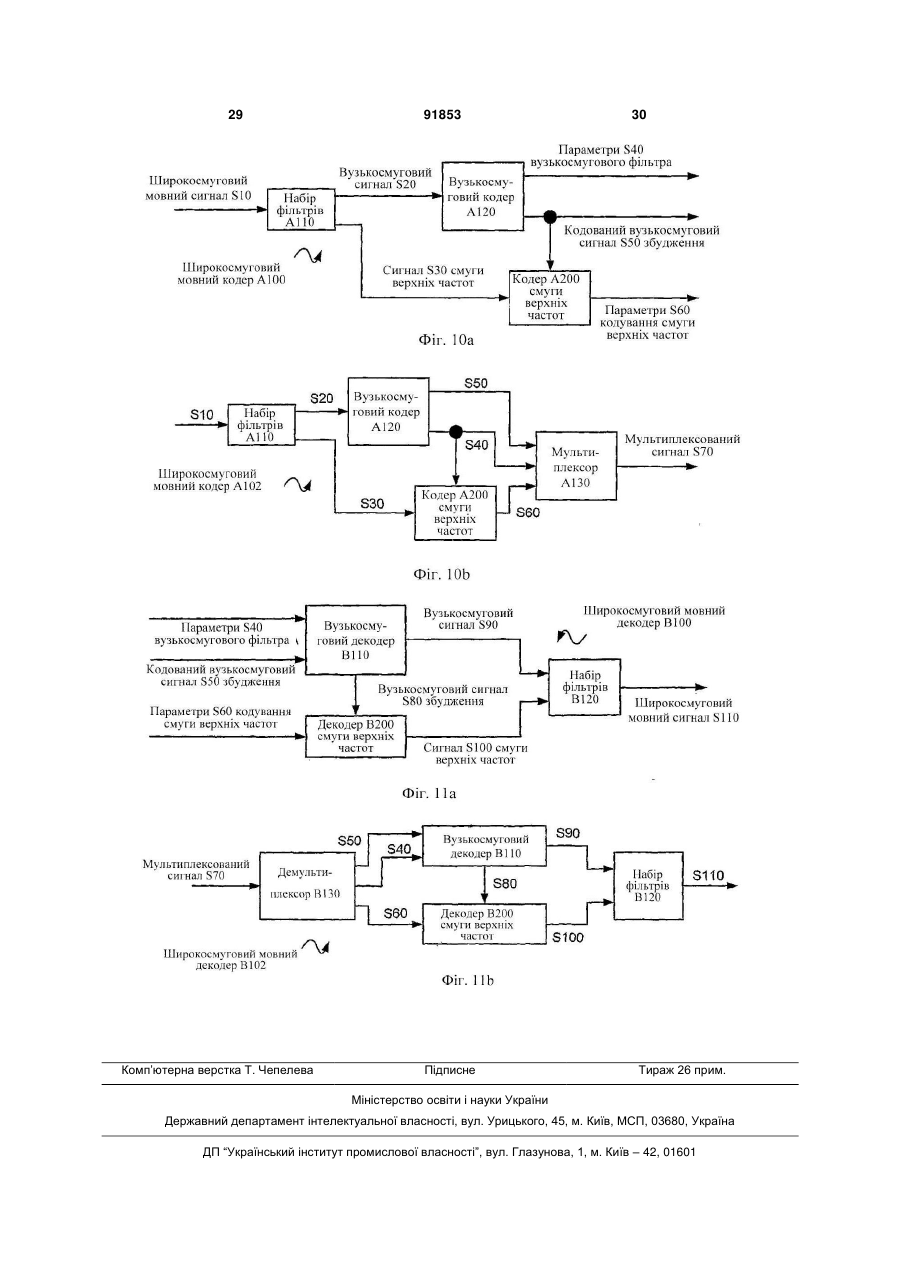
1. Спосіб обробки сигналів, що містить етапи, на яких: кодують перший кадр і другий кадр мовного сигналу для формування відповідних першого і другого векторів, причому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру; формують перший квантований вектор, причому вказане формування містить у собі квантування третього вектора V20a/b, який оснований на частині першого вектора V10; обчислюють помилку квантування першого квантованого вектора; обчислюють четвертий вектор, причому вказане обчислення включає в себе підсумовування масштабованої версії помилки квантування з частиною другого вектора V10; і квантують четвертий вектор. 2. Спосіб за п.1, у якому згаданий етап обчислення помилки квантування включає в себе обчислення різниці між першим квантованим вектором і третім вектором. 3. Спосіб за п.1, у якому згаданий етап обчислення помилки квантування містить у собі обчислення різниці між першим квантованим вектором і частиною першого вектора. 4. Спосіб за п.1, що включає в себе етап, на якому 2 (19) 1 3 тягом другого кадру. 13. Спосіб за п.1, у якому згаданий спосіб містить етап, на якому: фільтрують широкосмуговий мовний сигнал для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру; деквантують четвертий вектор; на основі деквантування четвертого вектора обчислюють сигнал збудження для вузькосмугового мовного сигналу; і на основі сигналу збудження для вузькосмугового мовного сигналу витягають сигнал збудження мовного сигналу смуги верхніх частот. 14. Спосіб за п.1, у якому згаданий етап квантування четвертого вектора містить етап, на якому виконують розщеплене векторне квантування четвертого вектора. 15. Носій для зберігання даних, що містить команди, які виконуються комп'ютером, що описують спосіб за п.1. 16. Пристрій для обробки сигналів, що містить: мовний кодер, сконфігурований для кодування першого кадру мовного сигналу в перший вектор, і для кодування другого кадру мовного сигналу в другий вектор, причому перший вектор представляє спектральну обідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру; квантувач, сконфігурований для квантування третього вектора, який оснований на частині першого вектора, для формування першого квантованого вектора; перший суматор, сконфігурований для обчислення помилки квантування першого квантованого вектора; і другий суматор, сконфігурований для підсумовування масштабованої версії помилки квантування із частиною другого вектора, для обчислення четвертого вектора, причому згаданий квантувач сконфігурований для квантування четвертого вектора. 17. Пристрій за п.16, у якому згаданий перший суматор конфігу ваний для обчислення помилки квантування на основі різниці між першим квантованим вектором і третім вектором. 18. Пристрій за п.16, у якому згаданий перший суматор конфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і частиною першого вектора. 19. Пристрій за п.16, що додатково включає в себе помножувач, конфігурований для обчислення масштабованої помилки квантування на основі добутку помилки квантування і масштабного коефіцієнта, при цьому пристрій включає в себе логіку, сконфігуровану для обчислення масштабного коефіцієнта на основі відстані між частиною першого вектора і відповідною частиною другого вектора. 20. Пристрій за п.16, у якому другий кадр безпосередньо іде за першим кадром у мовному сигналі. 91853 4 21. Пристрій за п.16, у якому кожний з першого і другого векторів представляє адаптивно згладжену спектральну обвідну. 22. Пристрій за п.16, який містить: інверсний квантувач, сконфігурований для деквантування четвертого вектора; і відбілювальний фільтр, сконфігурований для обчислення сигналу збудження на основі десантованого четвертого вектора. 23. Пристрій за п.16, у якому згаданий пристрій містить набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і при цьому перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і при цьому другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру. 24. Пристрій за п.16, у якому згаданий пристрій містить набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і при цьому перший вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом першого кадру, і при цьому другий вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом другого кадру. 25. Пристрій за п.16, що містить: набір фільтрів, сконфігурований для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру, і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру; інверсний квантувач, сконфігурований для деквантування четвертого вектора; відбілювальний фільтр, сконфігурований для обчислення сигналу збудження для вузькосмугового мовного сигналу на основі десантованого четвертого вектора; і кодер смуги верхніх частот, сконфігурований для формування сигналу збудження для мовного сигналу смуги верхніх частот на основі сигналу збудження для вузькосмугового мовного сигналу. 26. Пристрій за п.16, у якому згаданий квантувач сконфігурований для квантування четвертого вектора за допомогою виконання розщепленого векторного квантування четвертого вектора. 27. Пристрій за п.16, у якому кожний з першого і другого векторів включає в себе множину частот спектральних ліній. 28. Пристрій за п.16, у якому кожний з першого і другого векторів включає в себе представлення множини коефіцієнтів фільтра лінійного прогнозу. 29. Пристрій за п.16, у якому кожний з першого і другого векторів включає в себе множину частот спектральних ліній. 30. Пристрій за п.16, що містить пристрій для без 5 дротового зв'язку. 31. Пристрій за п.16, що містить пристрій, сконфігурований для передачі множини пакетів, сумісних з версією Інтернет-протоколу, причому множина пакетів описує перший квантований вектор. 32. Пристрій для обробки сигналів, що містить: засіб для кодування першого кадру і другого кадру мовного сигналу для формування відповідних першого і другого векторів, причому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, а другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру; засіб для формування першого квантованого вектора, причому згадане формування включає в себе квантування третього вектора, який оснований на частині першого вектора; засіб для обчислення помилки квантування першого квантованого вектора; і засіб для обчислення четвертого вектора, причому згадане обчислення включає в себе підсумовування масштабованої версії помилки квантування із частиною другого вектора; причому згаданий засіб для формування першого квантованого вектора сконфігурований для квантування четвертого вектора. 33. Пристрій за п.32, у якому згаданий засіб для обчислення помилки квантування сконфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і третім вектором. 34. Пристрій за п.32, у якому згаданий засіб для обчислення помилки квантування сконфігурований для обчислення помилки квантування на основі різниці між першим квантованим вектором і частиною першого вектора. 35. Пристрій за п.32, що додатково включає в себе засіб для обчислення масштабованої помилки квантування, причому згадане обчислення містить множення помилки квантування на масштабний коефіцієнт, при цьому пристрій містить логіку, сконфігуровану для обчислення масштабного коефіцієнта на основі відстані між частиною першого вектора і відповідною частиною другого вектора. 36. Пристрій за п.35, у якому кожний з першого і другого векторів містить множину частот спектральних ліній. 37. Пристрій за п.32, що містить пристрій для бездротового зв'язку. 38. Пристрій за п.32, у якому другий кадр безпосередньо іде за першим кадром у мовному сигналі. 39. Пристрій за п.32, у якому кожний з першого і другого векторів представляє адаптивно згладжену спектральну обвідну. 40. Пристрій за п.32, що містить: засіб для деквантування четвертого вектора; і засіб для обчислення сигналу збудження на основі деквантованого четвертого вектора. 41. Пристрій за п.32, що містить засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і при цьому перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу про 91853 6 тягом першого кадру, і при цьому другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру. 42. Пристрій за п.32, що містить засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, і при цьому перший вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом першого кадру, і при цьому другий вектор представляє спектральну обвідну мовного сигналу смуги верхніх частот протягом другого кадру. 43. Пристрій за п.32, що містить: засіб для фільтрування широкосмугового мовного сигналу для одержання вузькосмугового мовного сигналу і мовного сигналу смуги верхніх частот, при цьому (А) перший вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом першого кадру і (В) другий вектор представляє спектральну обвідну вузькосмугового мовного сигналу протягом другого кадру; засіб для деквантування четвертого вектора; засіб для обчислення сигналу збудження для вузькосмугового мовного сигналу на основі деквантованого четвертого вектора; і засіб для добування сигналу збудження для мовного сигналу смуги верхніх частот на основі сигналу збудження для вузькосмугового мовного сигналу. 44. Пристрій за п.32, у якому згаданий засіб для формування першого квантованого вектора сконфігурований для квантування четвертого вектора за допомогою виконання розщепленого векторного квантування четвертого вектора. 45. Машиночитаний носій, що містить команди, які при виконанні в процесорі спонукають процесор: кодувати перший кадр і другий кадр мовного сигналу для формування першого і другого векторів, при цьому перший вектор представляє спектральну обвідну мовного сигналу протягом першого кадру, і другий вектор представляє спектральну обвідну мовного сигналу протягом другого кадру; формувати перший квантований вектор, причому зазначене формування включає в себе квантування третього вектора, який оснований на частині першого вектора; обчислювати помилки квантування першого квантованого вектора; обчислювати четвертий вектор, причому зазначене обчислення містить у собі підсумовування масштабованої версії помилки квантування із частиною другого вектора; і квантувати четвертий вектор. 46. Машиночитаний носій за п.45, у якому команди, які спонукають процесор обчислювати помилки квантування, включають в себе команди для обчислення різниці між першим квантованим вектором і третім вектором. 47. Машиночитаний носій за п.45, у якому команди, які спонукають процесор обчислювати помилки квантування, включають в себе команди для обчислення різниці між першим квантованим вектором і частиною першого вектора. 7 91853 8 48. Машиночитаний носій за п.47, у якому команди, які спонукують процесор обчислювати масштабовану помилку квантування, додатково містять команди для: множення помилки квантування на масштабний коефіцієнт, при цьому масштабний коефіцієнт оснований на відстані між частиною першого вектора і відповідною частиною другого вектора. 49. Машиночитаний носій за п.48, у якому кожний з першого і другого векторів включають в себе множину частот спектральних ліній. 50. Машиночитаний носій за п.45, у якому кожний з першого й другого векторів включає в себе представлення множини коефіцієнтів фільтра лінійного прогнозу. Дана заявка запитує пріоритет попередньої патентної заявки США №60/667,901 на «Кодування смуги верхніх частот широкосмугової мови», поданої 1 квітня 2005. Дана заявка також запитує пріоритет попередньої патентної заявки США №60/673,965 на «Параметричне кодування в мовному кодері смугі верхніх частот», поданої 22 квітня 2005. Даний винахід належить до обробки сигналу. Мовний кодер посилає характеристику спектральної обвідної мовного сигналу на декодер в формі вектора частот спектральних ліній (LSP) або подібного представлення. Для ефективної передачі ці LSF квантуються. Квантувач згідно з одним варіантом здійснення конфігурований для квантування згладженого значення вхідного значення (такого, як вектор частот спектральних ліній, або його частина) для формування відповідного вихідного значення, де згладжене значення основане на масштабному коефіцієнті і помилці квантування попереднього вихідного значення. Фіг.1а - блок-схема мовного кодера Е100 згідно з варіантом здійснення. Фіг.1b - блок-схема мовного декодера Н200. Фіг.2 - приклад одновимірного відображення, що звичайно виконується скалярним квантувачем. Фіг.3 - простий приклад багатовимірного відображення, що виконується векторним квантувачем. Фіг.4а - приклад одновимірного сигналу, і Фіг.4b - приклад версії цього сигналу після квантування. Фіг.4с - приклад сигналу за Фіг.4а. квантованого квантувачем 230b, як показано на Фіг.6. Фіг.4d - приклад сигналу за Фіг.4а, квантованого квангувачем 230а, як показано на Фіг.5. Фіг.5 - блок-схема реалізації 230а квантувача 230 згідно з варіантом здійснення. Фіг.6 - блок-схема реалізації 230b квантувача 230 згідно з варіантом здійснення. Фіг.7а - приклад графіка залежності логарифмічної амплітуди від частоти для мовного сигналу. Фіг.7b - блок схема базової системи кодування з лінійним прогнозом. Фіг.8 - блок-схема реалізації А122 вузькосмугового кодера А120 (як показано на Фіг.10а). Фіг.9 - блок-схема реалізації В112 вузькосмугового декодера В110 (як показано на Фіг.11а). Фіг.10а - блок-схема широкосмугового мовного кодера А100. Фіг.10b - блок-схема реалізації А102 широкосмугового мовного кодера А100. Фіг.11а - блок-схема широкосмугового мовного декодера В100, відповідного широкосмуговому мовному кодеру Α100. Фіг.11b - блок-схема широкосмугового мовного декодера В102, відповідного широкосмуговому мовному кодеру А102. У зв'язку з помилками квантування, спектральна обвідна, відновлювана в декодері, може зазнавати надмірних флуктуацій. Ці флуктуації можуть формувати небажану якість флуктуюючого звучання в декодованому сигналі. Варіанти здійснення включають в себе системи, способи і пристрій, конфігуровані для виконання високоякісного широкосмугового мовного кодування з використанням часового квантування з обмеженням шуму параметрів спектральної обвідної. Ознаки включають фіксоване або адаптивне згладжування представлень коефіцієнтів, таких як LSF смуги верхніх частот. Конкретні описані застосування включають широкосмуговий мовний кодер, який комбінує сигнал смуги нижніх частот і сигнал смуги верхніх частот. Якщо явно не обмежено контекстом, термін «обчислення», використаний тут, вказує на одне з його звичайних значень, таких як обчислення, формування і вибір зі списку значень. Там, де термін «що містить» використовується в даному описі і формулі винаходу, не виключається наявність інших елементів або операцій. Термін «А основане на В» використовується для вказівки на будь-яке з його звичайних значень, включаючи випадки (і) «А дорівнює В» і (іі) «А основане на щонайменше В». Термін «Інтернет-протокол» включає в себе версію 4, як описано в IETF (Цільова група інженерної підтримки Інтернет) RFC (Запит на коментарі) 791, і подальші версії, такі як версія 6. Мовний кодер може бути реалізований відповідно до моделі фільтра-джерела, яка кодує вхідний мовний сигнал як набір параметрів, які описують фільтр. Наприклад, спектральна обвідна мовного сигналу характеризується рядом піків, які представляють резонанси голосового тракту і називаються формантами. На Фіг.7а представлений приклад такої спектральної обвідної. Більшість мовних кодерів кодують щонайменше цю грубу спектральну структуру як набір параметрів, таких як коефіцієнти фільтра. На Фіг.1а показана блок-схема мовного кодера Е100 згідно з варіантом здійснення. Як показано в даному прикладі, модуль аналізу може бути реалі 9 зований як модуль 210 аналізу кодування з лінійним прогнозом (LPC), який кодує спектральну обвідну мовного сигналу S1 як набір коефіцієнтів лінійного прогнозу (LP) (наприклад, коефіцієнтів фільтра з одними полюсами (полюсного фільтра) 1/Α(z)). Модуль аналізу в типовому випадку обробляє вхідний сигнал як послідовність неперекривних кадрів, причому новий набір коефіцієнтів обчислюється для кожного кадру. Період кадру в загальному випадку є періодом, в якому сигнал може бути локально стаціонарним; звичайний приклад відповідає 20мс (еквівалентно 160 вибіркам з частотою дискретизації 8кГц). Один приклад модуля аналізу LPC смуги нижніх частот (як показано, наприклад, на Фіг.8 як модуль 210 аналізу LPC) конфігурований для обчислення десяти коефіцієнтів фільтра LP, щоб характеризувати формантну структуру кожного кадру тривалістю 20мс вузькосмугового сигналу S20, і один приклад модуля аналізу LPC смуги верхніх частот (як показано, наприклад, на Фіг.10а як кодер А200 смуги верхніх частот) конфігурований для обчислення набору з шести (або восьми) коефіцієнтів фільтра LP, щоб характеризувати формантну структуру кожного кадру тривалістю 20мс сигналу S30 смуги верхніх частот. Також можливо реалізувати модуль аналізу для обробки вхідного сигналу як послідовності перекривних кадрів. Модуль аналізу може бути конфігурований для аналізу вибірок кожного кадру безпосередньо, або вибірки можуть спочатку зважуватися відповідно до функції вікна (наприклад, вікна Хеммінга). Аналіз також може виконуватися в межах вікна, тривалість якого більше тривалості кадру, наприклад вікна тривалістю 30мс. Це вікно може бути симетричним (наприклад, 5-20-5, так що воно включає в себе 5мс безпосередньо перед і після кадру тривалістю 20мс) або асиметричним (наприклад, 1020, так що воно включає в себе останні 10мс попереднього кадру). Модуль аналізу LPC в типовому випадку конфігурується для обчислення коефіцієнтів LP-фільтра з використанням рекурсії Левінсона-Дарбіна або алгоритму Leroux-Gueguen. У іншій реалізації модуль аналізу може бути конфігурований для обчислення набору кепстральних коефіцієнтів для кожного кадру замість набору коефіцієнтів LP-фільтра. Вихідна швидкість передачі інформації у бітах мовного кодера може бути суттєво знижена, при відносно малому впливі на якість відтворення, шляхом квантування параметрів фільтра. Коефіцієнти LP-фільтра важко квантувати ефективним чином, і вони звичайно відображаються мовним кодером на інше представлення, таке як пари спектральних ліній (LSP) або частоти спектральних ліній (LSF), для квантування і/або ентропійного (статистичного) кодування. Мовний кодер Ε100, як показано на Фіг.1а, містить перетворювач 220 коефіцієнтів LP-фільтра в LSF для перетворення коефіцієнтів LP-фільтра у відповідний вектор LSF S3. Інші однозначні представлення коефіцієнтів LP-фільтра включають в себе коефіцієнти парціальних кореляцій, значень коефіцієнтів логарифмів площ, пари спектральних імітансів (ISP) і частот спектральних імітансів (ISF), які використовуються 91853 10 в адаптивному багатошвидкісному широкосмуговому кодеку (AMR-WB кодеку) системи GSM. У типовому випадку перетворення між набором коефіцієнтів LP-фільтра і відповідним набором LSF є реверсивним, але варіанти здійснення також включають в себе реалізації мовного кодера, в якому перетворення є не реверсивним без помилок. Мовний кодер в типовому випадку включає в себе квантувач, конфігурований для квантування набору вузькосмугових LSF (або іншого представлення коефіцієнтів) і для виведення цього квантування як параметрів фільтра. Квантування в типовому випадку виконується з використанням векторного квантувача, який кодує вхідний вектор як індекс для відповідного векторного запису в таблиці або кодовій книзі. Такий квантувач також може конфігуруватися для вибору одного з набору кодових книг на основі інформації, яка вже була кодована в тому ж кадрі (наприклад, в каналі смуги нижніх частот і/або каналі смуги верхніх частот). Такий метод в типовому випадку забезпечує збільшену ефективність кодування за рахунок додаткової пам'яті кодової книги. Фіг.1b показує блок-схему відповідною мовного декодера Е200, який включає в себе інверсний квантувач 310, конфігурований для зворотного квантування (деквантування) квантованих LSF S3, і перетворювач 320 LSF в коефіцієнти LP-фільтра, конфігурований для перетворення деквантованого вектора LSF в набір коефіцієнтів LP-фільтра. Фільтр 330 синтезу, конфігурований відповідно до коефіцієнтів LP-фільтра, в типовому випадку збуджується сигналом збудження для формування синтезованого відтворення, тобто декодованого мовного сигналу S5, вхідного мовного сигналу. Сигнал збудження може бути заснований на випадковому шумовому сигналі і/або на квантованому представленні залишку, як послано кодером. У деяких багатодіапазонних кодерах, таких як широкосмуговий мовний кодер А100 і декодер В100 (як описано тут з посиланнями, наприклад, на Фіг.10а,b і 11а,b), сигнал збудження для одного діапазону збуджується сигналом збудження для іншого діапазону. Квантування LSF вносить випадкову помилку, яка звичайно не корельована від одного кадру до наступного кадру, Ця помилка може обумовити те, що квантовані LSF будуть менш згладженими, ніж неквантовані LSF, і може знизити перцептуальну (що сприймається) якість декодований сигналу. Незалежне квантування векторів LSF в загальному випадку збільшує величину спектральних флуктуацій від кадру до кадру в порівнянні з вектором неквантованих LSF, причому ці спектральні флуктуації можуть зумовити ненатуральне звучання декодованого сигналу. Одне складне рішення було запропоноване Knagenhjelm і Kleijn, "Spectral Dynamics is More Important that Spectral Distortion", 1995 Міжнародна конференція з акустики, мовлення і обробки сигналів (ICASSP-95), том 1, стор.732-735, 9-12 травня 1995, згідно з яким згладжування десантованих параметрів LSF виконується в декодері. Це знижує спектральні флуктуації, але реалізовується за ра 11 хунок додаткової затримки. Дана заявка описує способи, які використовують тимчасове обмеження шумів на стороні кодера, так що спектральні флуктуації можуть бути знижені без додаткової затримки. Квантувач звичайно конфігурується для відображення вхідного значення на одне з набору дискретних вихідних значень. Є обмежене число вихідних значень, так що діапазон вхідних значень відображається на одне вихідне значення. Квантування збільшує ефективність кодування, оскільки індекс, який вказує на відповідне вхідне значення, може бути переданий в меншій кількості бітів, ніж початкове вхідне значення. Фіг.2 показує приклад одновимірного відображення, звичайно виконуваного скалярним квантувачем. Квантувач може також являти собою векторний квантувач, і LSF звичайно квантуються з використанням векторного квантувача. Фіг.3 показує один простий приклад багатовимірного відображення, виконуваного у векторному квантувачі. У цьому прикладі вхідний простір розділяється на деяке число Voronoi-областей (наприклад, відповідно до критерію найближчого сусіда). Квантування відображає кожне вхідне значення на значення, яке представляє відповідну Voronoi-область (в типовому випадку центроїд), показане тут точкою. У цьому прикладі вхідний простір поділений на шість областей, так що будь-яке вхідне значення може бути представлене індексом, який має тільки один з шести різних станів. Якщо вхідний сигнал дуже згладжений, може статися так, що квантований вихідний сигнал буде набагато менш згладженим, відповідно до мінімального кроку між значеннями у вихідному просторі квантування. Фіг.4а показує один приклад згладженого одновимірного сигналу, який змінюється тільки в межах одного рівня квантування (тільки один такий рівень показаний на кресленні), а Фіг.4b показує приклад цього сигналу після квантування. Навіть хоч вхідний сигнал на Фіг.4а змінюється усього лише в невеликому діапазоні, результуючий вихідний сигнал на Фіг.4b містить більш різкі переходи і набагато менш згладжений. Такий ефект може привести до артефактів, що прослуховуються, і може виявитися бажаним знизити цей ефект для LSF (або інших представлень спектральної обвідної, яка піддається квантуванню). Наприклад, характеристики квантування LSF можуть бути поліпшені за рахунок включення тимчасового обмеження шуму. У способі, відповідному одному варіанту здійснення, вектор спектральних параметрів обвідної оцінюється однократно для кожного кадру (або іншого блока) мови в кодері. Вектор параметрів квантується для ефективної передачі в декодер. Після квантування помилка квантування (визначена як різниця між квантованим і неквантованим вектором параметрів) зберігається. Помилка квантування кадру N-1 зменшується на масштабний коефіцієнт і додається до вектора параметрів кадру N перед квантуванням вектора параметрів кадру N. Може бути бажаним, щоб значення масштабного коефіцієнта було меншим, якщо різниця між поточною і поперед 91853 12 ньою оціненими спектральними обвідними відносно велика. У способі згідно з одним варіантом здійснення вектор помилок квантування LSF обчислюється для кожного кадру і множиться на масштабний коефіцієнт b, що має значення менше ніж 1,0. Перед квантуванням масштабована помилка квантування для попереднього кадру підсумовується з вектором LSF (вхідним значенням V10). Операція квантування в такому способі може бути описана наступним виразом: у(n)=Q(s(n)+b[y(n-1)-s(n-1)]), де s(n) - згладжений вектор LSF, що належить до кадру n, у(n) - квантований вектор LSF, що належить до кадру n, Q(·) - операція квантування найближчого сусіда і b - масштабний коефіцієнт. Квантувач 230 згідно з варіантом здійснення конфігурований для формування квантованого вихідного значення V30 згладженого значення V20 вхідного значення V10 (тобто вектора LSF), де згладжене значення V20 засноване на масштабному коефіцієнті V40 і помилці квантування попереднього вихідного значення V30a. Такий квантувач може бути застосований для зменшення спектральних флуктуацій без додаткової затримки. На Фіг.5 показана блок-схема реалізації 230а квантувача 230, в якому значення, які належать конкретно до цієї реалізації, вказані індексом а. В цьому прикладі помилка квантування обчислюється за допомогою використання суматора А10 для віднімання поточного вхідного значення V10 з поточного вихідного значення V30a, як воно деквантоване інверсним квантувачем Q20. Помилка зберігається в елементі затримки DE10. Згладжене значення V20a є сумою поточного вхідного значення V10 і помилки квантування попереднього кадру, масштабованою (наприклад, шляхом множення в помножувачі Μ10) масштабним коефіцієнтом V40. Квантувач 230а може також бути реалізований таким чином, що масштабний коефіцієнт V40 застосовується перед збереженням помилки квантування в елементі затримки DE10. На Фіг.4d показаний приклад (десантованої) послідовності вихідних значень V30a, сформованої квантувачем 230а у відповідь на вхідний сигнал за Фіг.4а. В цьому прикладі значення масштабного коефіцієнта V40 фіксоване на 0,5. Можна бачити, що сигнал на Фіг.4d більш згладжений, ніж флуктуюючий сигнал на Фіг.4а. Може бути бажаним використовувати рекурсивну функцію для обчислення величини зворотного зв'язку. Наприклад, помилка квантування може бути обчислена відносно поточного вхідного значення, а не відносно поточного згладженого значення. Такий спосіб може бути описаний наступним виразом: y(n)=Q[s(n)], s(n)=x(n)+b[y(n-1)-s(n-1)], де х(n) - вхідний вектор LSF, що належить до кадру n. На Фіг.6 показана блок-схема реалізації 230b квантувача 230, на якій значення, які відповідають даній реалізації, позначені індексом Ь. В цьому прикладі помилка квантування обчислюється за допомогою використання суматора А10 для віднімання поточного значення згладженого значення V20b з поточного вихідного значення V30b, сфор 13 мованого інверсним квантувачем Q20. Помилка зберігається в елементі затримки DE10. Згладжене значення V20b є сумою поточного вхідного значення V10 і помилки квантування попереднього кадру, масштабованою (наприклад, шляхом множення у помножувачі Μ10) за допомогою масштабного коефіцієнта V40. Квантувач 230b може бути також реалізований таким чином, що масштабний коефіцієнт V40 застосовується перед збереженням помилки квантування в елементі затримки DE10. Також можливо використовувати різні масштабні коефіцієнти V40 в реалізації 230а в порівнянні з реалізацією 230b. На Фіг.4с показаний приклад (десантованої) послідовності вихідних значень V30b, сформованої квантувачем 230b у відповідь на вхідний сигнал за Фіг.4а. В цьому прикладі значення масштабного коефіцієнта V40 фіксоване на 0,5. Можна бачити, що сигнал згідно з Фіг.4с більш згладжений, ніж флуктуюючий сигнал за Фіг.4а. Потрібно зазначити, що варіанти здійснення, представлені вище, можуть бути реалізовані шляхом заміни або удосконалення існуючого квантувача Q10 згідно з конфігурацією, показаною на Фіг.5 або 6. Наприклад, квантувач Q10 може бути реалізований як прогнозуючий векторний квантувач, розщеплений векторний квантувач або відповідно до якої-небудь іншої схеми для квантування LSF. У одному прикладі значення масштабного коефіцієнта фіксоване на бажаному значенні в межах від 0 до 1. Альтернативно, може бути бажаним настроювати значення масштабного коефіцієнта динамічно. Наприклад, може бути бажаним настроювати значення масштабного коефіцієнта в залежності від міри флуктуації, вже присутньої в неквантованих векторах LSF. Якщо різниця між поточним і попереднім векторами LSF велика, то масштабний коефіцієнт близький до нуля і, по суті, не приводить до обмеження шумів. Якщо поточний вектор LSF відрізняється трохи від попереднього вектора LSF, то масштабний коефіцієнт близький до 1,0. Таким способом можуть зберігатися переходи в обвідній спектра у часі, мінімізуючи спектральні спотворення, коли мовний сигнал змінюється, в той час як спектральні флуктуації можуть знижуватися, якщо мовний сигнал відносно постійний від кадру до кадру. Значення масштабного коефіцієнта може бути зроблене пропорційним відстані (мірі відмінності) між послідовними LSF, і деякі з різних відстаней між векторами можуть використовуватися для визначення зміни між LSF. Звичайно використовується евклідова норма, але інші можуть включати в себе манхеттенську відстань (1-норма), відстань Чебишева (нескінченна норма), відстань Махаланобіса, відстань Хеммінга. Може бути бажаним використовувати зважену міру відстані (міри відмінності) для визначення зміни між послідовними векторами LSF. Наприклад, відстань d може бути обчислена відповідно до наступного виразу: P d ci (li i 1 ˆ )2 li 91853 14 де l вказує поточний вектор LSF, ˆ вказує поl передній вектор LSF, P вказує число елементів в кожному векторі LSF, індекс i вказує елемент вектора LSF, і с вказує масштабні коефіцієнти. Значення с можуть бути вибрані для акцентування компонентом нижніх частот, які є більш значними для сприйняття. У одному прикладі ci має значення 1,0 для i від 1 до 8; 0,8 для і=9 і 0,4 для i=10. У іншому прикладі відстань d між послідовними векторами LSF може бути обчислена відповідно до наступного виразу: P d ciw i (li ˆ )2 li i 1 де w вказує вектор змінних вагових коефіцієнтів. У одному такому прикладі wi має значення P(fi)r, де Ρ означає спектр потужності LPC, оцінений на відповідній частоті f і r - стала, що має типове значення, наприклад, 0,15 або 0,3. У іншому прикладі значення w вибираються відповідно до вагової функції, використаної в стандарті ITU-T G.729: 10 , якщо (2 (li 1 li 1) 1) 0 wi 2 10(2 (li 1 li 1) 1) 1 інакше причому граничні значення, близькі до 0 і 0,5, вибираються замість li-1 і li+1 для найнижчого і найвищого елементів в w, відповідно. У таких випадках сі може мати значення, як указано вище. У іншому прикладі сi має значення 1,0, за винятком c4 і с5, які мають значення 1,2. З Фіг.4a-d можна бачити, що на покадровій основі метод тимчасового обмеження шумів, як описано тут, може збільшувати помилку квантування. Хоч абсолютна квадратична помилка операції квантування може збільшуватися, однак, потенційна перевага полягає в тому, що помилка квантування може бути зміщена до нижніх частот, тим самим стаючи більш згладженою. Оскільки вхідний сигнал також згладжений, то може бути одержаний більш згладжений вихідний сигнал як сума вхідного сигналу і згладженої помилки квантування. На Фіг.7b показаний приклад базової конфігурації фільтра-джерела в застосуванні до кодування спектральної обвідної вузькосмугового сигналу S20. Модуль 710 аналізу обчислює набір параметрів, які характеризують фільтр, відповідний мовним звукам за період часу (звичайно 20мс). Відбілювальний фільтр 760 (також званий фільтром аналізу або помилки прогнозу), конфігурований відповідно до цих параметрів, видаляє спектральну обвідну для спектрального вирівнювання сигналу. Результуючий відбілений сигнал (також званий залишком) має меншу енергію і, таким чином, меншу дисперсію і легше кодується, в порівнянні з початковим мовним сигналом. Помилки, виникаючі внаслідок кодування залишкового сигналу, також можуть бути розподілені більш рівномірно по спектру. Параметри фільтра і залишок в типовому випадку квантуються для ефективної передачі по каналу. У декодері фільтр 780 синтезу, конфігурований відповідно до параметрів фільтра, збуджується сигналом, основаним на залишку, для формування синтезованої версії початкового мовного сигналу. Фільтр синтезу в типовому випадку конфі 15 гурується так, щоб мати передавальну функцію, яка є зворотною передавальній функції відбілювального фільтра. На Фіг.8 показана блок-схема базової реалізації А122 вузькосмугового кодера А120 як показано на Фіг.10а. Як показано на Фіг.8, вузькосмуговий кодер А122 також генерує залишковий сигнал шляхом пропускання вузькосмугового сигналу S20 через відбілювальний фільтр 260 (який також називається фільтром аналізу або помилки прогнозу), конфігурований відповідно до набору коефіцієнтів фільтра. У даному конкретному прикладі відбілювальний фільтр 260 реалізований як фільтр з кінцевою імпульсною характеристикою (КІХ), хоч може бути також використана реалізація з нескінченною імпульсною характеристикою (НІХ). Цей залишковий сигнал в типовому випадку буде містити важливу для сприйняття інформацію мовного кадру, таку як довготривала структура, що належить до основного тону, яка не представлена параметрами S40 вузькосмугового фільтра. Квантувач 270 конфігурований для обчислення квантованого представлення цього залишкового сигналу для вихідного сигналу у вигляді кодованого вузькосмугового сигналу S50 збудження. Такий квантувач в типовому випадку включає в себе векторний квантувач, який кодує вхідний вектор як індекс для відповідного векторного запису в таблиці або кодовій книзі. Альтернативно, такий квантувач може бути конфігурований для посилання одного або більше параметрів, з яких вектор може бути генерований динамічно в декодері, а не витягнутий з пам'яті, як в методі з прорідженою кодовою книгою. Такий метод використовується в схемах кодування, таких як алгебраїчний метод CELP (лінійний прогноз із збудженням кодової книги), і кодеках, таких як 3GPP2 EVRC (вдосконалений кодек змінної швидкості стандарту 3GPP2). Для вузькосмугового кодера А120 бажано генерувати кодований вузькосмуговий сигнал збудження відповідно до тих же самих параметрів фільтра, які будуть доступні у відповідному вузькосмуговому декодері. Таким способом результуючий кодований вузькосмуговий сигнал збудження може вже враховувати до деякої міри неідеальності в цих значеннях параметрів, такі як помилки квантування. Відповідно, бажаним є конфігурувати відбілювальний фільтр з використанням тих же самих значень коефіцієнтів, які будуть доступні в декодері. У базовому прикладі декодера А122, як показано на Фіг.8, інверсний квантувач 240 деквантує параметри S40 вузькосмугового фільтра, перетворювач 250 LSF в коефіцієнти LP-фільтра відображає результуючі значення на відповідний набір коефіцієнтів LP-фільтра, і цей набір коефіцієнтів використовується для конфігурування відбілювального фільтра 260 для генерації залишкового сигналу, який квантований квантувачем 270. Деякі конфігурації вузькосмугового кодера А120 конфігуруються для обчислення кодованого вузькосмугового сигналу S50 збудження шляхом ідентифікації одного з набору векторів кодової книги, який найкращим чином узгоджується із залишковим сигналом. Потрібно відмітити, однак, що вузькосмуговий кодер А120 може також бути реа 91853 16 лізований для обчислення квантованого представлення залишкового сигналу без дійсної генерації залишкового сигналу. Наприклад, вузькосмуговий кодер А120 може бути конфігурований для використання ряду векторів кодової книги для генерації відповідних синтезованих сигналів (наприклад, відповідно до поточного набору параметрів фільтра) і для вибору вектора кодової книги, асоційованого з генерованим сигналом, який найкращим чином узгоджується з початковим вузькосмуговим сигналом S20 в перцептуально зваженій області. На Фіг.9 представлена блок-схема реалізації В112 вузькосмугового декодера В110. Інверсний квантувач 310 деквантує параметри S40 вузькосмугового фільтра (в цьому випадку набір LSF), перетворювач 320 LSF в коефіцієнти LP-фільтра відображає LSF на набір коефіцієнтів LP-фільтра (наприклад, як описано вище з посиланням на інверсний квантувач 240 і перетворювач 250 вузькосмугового кодера А122). Інверсний квантувач 340 деквантує кодований вузькосмуговий сигнал збудження S50 для формування вузькосмугового сигналу S80 збудження. На основі коефіцієнтів фільтра і вузькосмугового сигналу S80 збудження вузькосмуговий фільтр 330 синтезу синтезує вузькосмуговий сигнал S90. Іншими словами, вузькосмуговий фільтр 330 синтезу конфігурований для спектрального формування вузькосмугового сигналу S80 збудження відповідно до деквантованих коефіцієнтів фільтра для формування вузькосмугового сигналу S90. Як показано на Фіг.11a, вузькосмуговий декодер В112 (у вигляді вузькосмугового декодера В110) також подає вузькосмуговий сигнал S80 збудження на декодер В200 смуги верхніх частот, який використовує його для виведення сигналу збудження смуги верхніх частот. У деяких реалізаціях вузькосмуговий декодер В110 може бути конфігурований для надання додаткової інформації на декодер В200 смуги верхніх частот, яка належить до вузькосмугового сигналу, такої як спектральний нахил, посилення і запізнення основного тону, режим мови. Система вузькосмугового кодера А122 і вузькосмугового декодера В112 є базовим прикладом мовного кодека, основаного на принципі аналізу через синтез. Мовні передачі по комутованій телефонній мережі загального користування (PSTN) традиційно обмежені по ширині смуги частотним діапазоном 300-3400кГц. Нові мережі мовного зв'язку, такі як мережі стільникової і телефонії і протоколу VoIP (мова через IP), можуть не мати тих же обмежень по ширині смуги, і може бути бажаним передавати і приймати мовні передачі, які включають в себе широкосмуговий частотний діапазон, по таких мережах. Наприклад, може бути бажаним підтримувати діапазон аудіочастот від 50Гц до 7 або 8кГц. Також може бути бажаним підтримувати інші додатки, такі як високоякісні аудіо- і/або аудіо/відеоконференції, які можуть мати мовний контент в діапазонах, що перевищують межі мережі PSTN. Один підхід до широкосмугового мовного кодування пов'язаний з масштабуванням методу вузькосмугового мовного кодування (наприклад, 17 конфігурованого для кодування діапазону 0-4кГц) для покриття широкосмугового спектра. Наприклад, мовний сигнал може дискретизуватися з більш високою частотою, щоб включати компоненти на високих частотах, а метод вузькосмугового кодування може бути модифікований для використання більшого числа коефіцієнтів фільтра для представлення цього широкосмугового сигналу. Методи вузькосмугового кодування, такі як CELP, пов'язані з високими обчислювальними витратами, і широкосмуговий CELP-кодер може використовувати дуже багато циклів обробки, щоб бути практичним для багатьох мобільних і інших вбудованих додатків. Кодування всього спектра широкосмугового сигналу з бажаною якістю з використанням такого методу може призвести до неприйнятно великого збільшення ширини смуги. Крім того, транскодування такого кодованого сигналу було потрібне б, перш ніж навіть його вузькосмугова частина могла бути передана і декодована системою, яка підтримує тільки вузькосмугове кодування. На Фіг.10а показана блок-схема широкосмугового мовного кодера А100, який включає в себе окремі вузькосмуговий і широкосмуговий мовні код ери А120 і А200, відповідно. Будь-який або обидва з вузькосмугового і широкосмугового мовних кодерів А120 і А200 можуть бути конфігуровані для виконання квантування LSF (або іншого представлення коефіцієнтів) з використанням реалізації квантувача 230, як описано тут. На Фіг.11а показана блок-схема відповідного широкосмугового мовного декодера В100. На Фіг.10а набір А110 фільтрів може бути реалізований для формування вузькосмугового сигналу S20 і широкосмугового сигналу S30 з широкосмугового мовного сигналу S10 відповідно до принципів і реалізацій, розкритих в патентній заявці США «Системи, способи і пристрій для фільтрації мовного сигналу», поданій разом з даною заявкою, публікація США 2007/0088558, і відповідне розкриття в ній таких наборів фільтрів включено в цей документ за допомогою посилання. Як показано на Фіг.11а набір В120 фільтрів також може бути реалізований для формування декодованого широкосмугового мовного сигналу S110 з декодованого вузькосмугового сигналу S90 і декодованого сигналу S100 смуги верхніх частот. На Фіг.11а також показаний вузькосмуговий декодер В110, конфігурований для декодування параметрів S40 вузькосмугового фільтра і кодованого вузькосмугового сигналу S50 збудження щоб формувати вузькосмуговий сигнал S90 і вузькосмуговий сигнал S80 збудження, і декодер В200 смуги верхніх частот, конфіїурований для формування сигналу S100 смуги верхніх частот на основі параметрів S60 кодування смуги верхніх частот і вузькосмугового сигналу S80 збудження. Може бути бажаним реалізувати широкосмугове мовне кодування так, щоб щонайменше вузькосмугова частина кодованого сигналу могла бути передана через вузькосмуговий канал (такий як канал мережі PSTN) без транскодування або іншої значної зміни. Ефективність розширення широкосмугового кодування може також бути бажаною, 91853 18 наприклад, для уникнення значного зменшення числа користувачів, які можуть обслуговуватися в рамках додатків, таких як безпровідна стільникова телефонія і широкомовна передача через провідні і безпровідні канали. Один підхід до широкосмугового мовного кодування пов'язаний з екстраполяцією спектральної обвідної смуги верхніх частот з кодованої вузькосмугової спектральної обвідної. Хоч такий метод може бути реалізований без якого-небудь збільшення в ширині смуги і не вимагаючи транскодування, однак груба спектральна обвідна або форматна структура частини смуги верхніх частот мовного сигналу в загальному випадку не може точно прогнозуватися з спектральної обвідної частини смуги верхніх частот. Один конкретний приклад широкосмугового мовного кодера А100 конфігурований для кодування широкосмугового мовного сигналу S10 зі швидкістю близько 8,55кбіт/с, причому близько 7,55кбіт/с використовується для параметрів S40 вузькосмугового фільтра і кодованого вузькосмугового сигналу S50 збудження, і близько 1кбіт/с використовується для параметрів S60 кодування смуги верхніх частот (наприклад, параметрів фільтра і/або параметрів посилення). Може бути бажаним об'єднати кодовані сигнали смуги нижніх частот і смуги верхніх частот в єдиний бітовий потік. Наприклад, може бути бажаним мультиплексувати кодовані сигнали разом для передачі (наприклад, по провідному, оптичному або безпровідному каналу передачі) або для зберігання у вигляді кодованого широкосмугового мовного сигналу. На Фіг.10b показана блок-схема широкосмугового мовного кодера А102, який включає в себе мультиплексор А130, конфігурований для об'єднання параметрів S40 вузькосмугового фільтра і кодованого вузькосмугового сигналу S50 збудження і параметрів S60 кодування смуги верхніх частот в мультиплексований сигнал S70. На Фіг.11b показана блок-схема відповідної реалізації В102 широкосмугового мовного декодера В100. Декодер В102 включає в себе демультиплексор В130, конфігурований для демультиплексування мультиплексованого сигналу S70 для одержання параметрів S40 вузькосмугового фільтра, кодованого вузькосмугового сигналу S50 збудження, і параметрів S60 кодування смуги верхніх частот. Може бути бажаним таким чином конфігурувати мультиплексор А130, щоб включати кодований сигнал смуги нижніх частот (включаючи параметри S40 вузькосмугового фільтра і кодований вузькосмуговий сигнал S50 збудження) у вигляді підпотоку мультиплексованого сигналу, що виділяється S70, так що кодований сигнал смуги нижніх частот може бути відновлений і декодований незалежно від іншої частини мультиплексованого сигналу S70, такої як сигнал смуги верхніх частот або сигнал смуги дуже низьких частот. Наприклад, мультиплексований сигнал S70 може бути конфігурований таким чином, що кодований сигнал смуги нижніх частот може бути відновлений шляхом відділення параметрів S60 кодування смуги верхніх частот. Потенційна перевага такої характеристики полягає 19 у виключенні необхідності транскодування кодованого широкосмугового сигналу перед пропусканням його в систему, яка підтримує декодування сигналу смуги нижніх частот, але не підтримує декодування частини смуги верхніх частот. Пристрій, що містить квантувач з обмеженням шумів і/або мовний кодер смуги нижніх частот, смуги верхніх частот і/або широкої смуги, як описано тут, також може містити схеми, конфігуровані для передачі кодованого сигналу в канал передачі, такий як провідний, оптичний або безпровідний канал. Такий пристрій також може бути конфігурований для виконання однієї або більше операцій канального кодування над сигналом, таких як кодування з виправленням помилок (наприклад, сумісне по швидкості згорткове кодування) і/або кодування з виявленням помилок (наприклад, кодування з циклічною надмірністю) і/або один або більше рівнів кодування мережного протоколу (наприклад, Ethernet, TCP/IP, cdma2000). Може бути бажаним реалізувати мовний кодер А120 смуги нижніх частот як мовний кодер аналізу через синтез. Кодування лінійного прогнозу із збудженням кодової книги (CELP) є популярним сімейством методів кодування аналізом через синтез, і реалізації таких кодерів можуть виконувати кодування коливань відносно залишку, включаючи такі операції, як вибір записів з фіксованої і адаптивної кодових книг, операції мінімізації помилок і/або операції перцептуального зважування. Інші реалізації методів кодування аналізом через синтез включають кодування лінійного прогнозу зі змішаним збудженням (MELP), алгебраїчне CELP (ACELP), релаксаційне CELP (RCELP), регулярне імпульсне збудження (RPE), багатоімпульсний CELP (МРЕ), лінійний прогноз із збудженням векторною сумою (VSELP). Родинні методи кодування включають кодування з багатодіапазонним збудженням (МВЕ) і кодування з інтерполяцією первісних коливань (PWI). Приклади стандартизованих мовних кодеків аналізу через синтез включають кодек повної швидкості GSM 06.10 ETSI (Європейський інститут стандартів в галузі телекомунікації)С8М, який використовує лінійний прогноз із збудженням залишковим сигналом (RELP); вдосконалений кодек повної швидкості GSM (ETSI-GSM 06.60); кодер стандарту ITU (Міжнародний союз з телекомунікацій) на швидкість 11,8кбіт/с G.729 Annex Ε; кодеки IS (Проміжний стандарт)-641 для IS-36 (схема множинного доступу з часовим розділенням); адаптивні багатошвидкісні кодеки GSM (GSM-AMR); і кодек 4GVTM (Fourth-Generation VocoderTM вокодер четвертого покоління) від компанії Qualcomm Incorporated (San Diego, CA). Існуючі реалізації кодерів RCELP включають в себе вдосконалений кодек змінній швидкості (EVRC), як описано в ТІА (Асоціація галузей телекомунікаційний індустрії) IS-127, і вокодер селективних режимів (SMV) стандарту 3GPP2 (Проект 2 партнерства з розробки систем третього покоління). Різні код ери смуги нижніх частот, смуги верхніх частот і широкосмугові код ери, описані тут, можуть бути реалізовані згідно з будь-якою з цих технологій або будь-якою іншою технологією мовного кодування (як відомою, так і такою, що підлягає розро 91853 20 бці), яка представляє мовний сигнал як (А) набір параметрів, які описують фільтр, і (В) квантоване представлення залишкового сигналу, який надає щонайменше частину збудження, використовуваного для керування описаним фільтром для відтворення мовного сигналу. Як відмічено вище, описані варіанти здійснення включають реалізації, які можуть бути використані для виконання вбудованого кодування, підтримки сумісності з вузькосмуговими системами і усунення необхідності в транскодуванні. Підтримка кодування смуги верхніх частот може також служити для проведення відмінностей, на основі вартості, між мікросхемами, наборами мікросхем, пристроями і/або мережами, що мають широкосмугову підтримку із зворотною сумісністю, і тими, які мають тільки вузькосмугову підтримку. Підтримка кодування смуги верхніх частот, як описано тут, може також використовуватися у взаємозв'язку з методом підтримки кодування смуги нижніх частот, і система, спосіб або пристрій згідно з таким варіантом здійснення можуть підтримувати кодування частотних компонентів, від порядку 50 або 100Гц до порядку 7 або 8кГц. Як відмічено вище, додаткова підтримка смуги верхніх частот для мовного кодера може поліпшити розбірливість, зокрема, відносно розрізнення фрикативних звуків. Хоч таке розрізнення може звичайно виводитися слухачем з конкретного контексту, підтримка смуги верхніх частот може служити як функція, яка сприяє розпізнаванню мови і використовується в інших додатках машинної інтерпретації, таких як системи для автоматизованого переміщення по голосовому меню і/або автоматичної обробки виклику. Пристрій, відповідний варіанту здійснення, може бути вбудований в портативний пристрій безпровідного зв'язку, такий як стільниковий телефон або персональний цифровий помічник (PDA). Альтернативно, такий пристрій може бути включений в інший комунікаційний пристрій, такий як мікротелефонна трубка стандарту VoIP, персональний комп'ютер, конфігурований для підтримки зв'язку за протоколом VoIP, або мережний пристрій, конфігурований для маршрутизації телефонних викликів або передач за протоколом VoIP. Наприклад, пристрій згідно з варіантом здійснення може бути реалізований на мікросхемі або наборі мікросхем для пристрою зв'язку. У залежності від конкретного додатку, такий пристрій може включати в себе такі функції, як аналогово-цифрове і/або цифро-аналогове перетворення мовного сигналу, схеми для виконання посилення і/або іншої обробки мовного сигналу і/або радіочастотні схеми для передачі і/або прийому кодованого мовного сигналу. У явному вигляді передбачається і розкрито те, що варіанти здійснення можуть включати в себе і/або використовуватися у взаємозв'язку з будь-якою одною або більше іншими ознаками, розкритими в попередній патентній заявці США №60/667,901, публікація США №2007/0088542. Такі ознаки включають в себе зсув сигналу S30 смуги верхніх частот і/або сигналу S120 збудження смуги верхніх частот відповідно до деякого впоря 21 дкування або інший зсув вузькосмугового сигналу S80 збудження або вузькосмугового залишкового сигналу S50. Такі ознаки включають в себе адаптивне згладжування LSF, яке може виконуватися перед квантуванням, як описано тут. Такі ознаки також включають в себе фіксоване або адаптивне згладжування обвідної посилення і адаптивне ослаблення обвідної посилення. Наведене вище представлення описаних варіантів здійснення надане для того, щоб фахівці в даній галузі техніки могли реалізувати і використати даний винахід. Можливі різні модифікації цих варіантів здійснення, і загальні принципи, представлені тут, також можуть бути застосовані до інших варіантів здійснення. Наприклад, один варіант здійснення може бути реалізований частково як жорстко реалізована схема, як схемна конфігурація, виконана у вигляді спеціалізованої інтегральної схеми, як мікропрограма, завантажена в енергонезалежну пам'ять, або програма, завантажена з носія для зберігання даних або на нього у вигляді машиночитаного коду, причому такий код являє собою інструкції, що виконуються матрицею логічних елементів, зокрема, мікропроцесором або іншим цифровим блоком обробки сигналу. Носій для зберігання даних може являти собою масив елементів пам'яті, наприклад, напівпровідникову пам'ять (яка без обмеження може включати в себе динамічну або статичну пам'ять з довільним доступом (RAM, ОЗП), постійну пам'ять (ROM, ПЗП) і/або флеш-RAM) або сегнетоелектричну, магніторезистивну пам'ять, пам'ять на аморфних напівпровідниках, на полімерах або пам'ять із зміною фази; або носій на диску, такому як магнітний або оптичний диск. Термін «програмне забезпечення» повинен розумітися як такий, що включає в себе початковий код, код на мові асемблера, машинний код, двійковий код, мікропрограмне забезпечення, макрокод, мікрокод, будь-яку одну або більше послідовностей команд, що виконуються матрицею логічних елементів, і будь-яку комбінацію наведених прикладів. Різні елементи реалізації квантувача з обмеженням шумів, мовний кодер А200 смуги верхніх частот, широкосмуговий мовний кодер А100 і Α102 і пристрої, конфігурації, що включають в себе один або більше таких пристроїв, знаходяться, наприклад, на одній і тій же мікросхемі з двох або більше мікросхем в наборі мікросхем, в той час як можливі і інші конфігурації, що не включають такі обмеження. Один або більше елементів такого пристрою можуть бути реалізовані повністю або частково як один або більше наборів команд, призначених для виконання однієї або більше фіксованих або програмованих матриць логічних еле 91853 22 ментів (наприклад, транзисторів, вентилів, таких як, мікропроцесори, вбудовані процесори, IP-ядра, цифрові процесори сигналів, програмовані користувачем матриці логічних елементів (FPGA), орієнтовані на додаток стандартні продукти (ASSP), спеціалізовані інтегральні схеми (ASIC). Також можливо, що один або більше таких елементів мають загальну структуру (наприклад, процесор, що використовується для виконання частин коду, відповідних різним елементам, в різний час; набір команд, що виконуються для виконання задач, відповідних різним елементам, в різний час; або конфігурація електронних і/або оптичних пристроїв, що виконують операції різних елементів в різний час). Крім того, можливо, що один або більше таких елементів використовуються для виконання задач або виконання інших наборів команд, які безпосередньо не пов'язані з роботою даного пристрою, таких як задача, що належить до іншої операції пристрою або системи, в яку вбудований даний пристрій. Варіанти здійснення також включають в себе додаткові способи обробки мови і кодування мови до тих, які розкриті тут в явному вигляді, наприклад, шляхом описів конструктивних варіантів здійснення, конфігурованих для виконання таких способів, як і способів пригнічення імпульсних викидів смуги верхніх частот. Кожний з цих способів може бути матеріально реалізований (наприклад, в одному або більше носіях для зберігання даних, як перераховано вище) у вигляді одного або більше наборів команд, зчитуваних і/або виконуваних машиною, що включає в себе матрицю логічних елементів (наприклад, процесором, мікропроцесором, мікроконтролером або кінцевим автоматом). Таким чином, даний винахід не призначений для обмеження варіантами здійснення, розкритими вище, а повинен відповідати самому широкому об'єму, сумісному з принципами і новими ознаками, розкритими яким-небудь чином в цьому документі. Перелік посилальних позицій 210 Модуль аналізу LPC 220 Перетворювач коефіцієнтів LP-фільтра в LSF 230, 270 Квантувач 240 Інверсний квантувач 250 Перетворювач LSF в коефіцієнти LPфільтра 260 Відбілювальний фільтр 310 Інверсний квантувач 320 Перетворювач LSF у коефіцієнти LPфільтра 330 Фільтр синтезу 330 Вузькосмуговий фільтр синтезу 340 Інверсний кантувач 23 91853 24 25 91853 26 27 91853 28 29 Комп’ютерна верстка Т. Чепелева 91853 Підписне 30 Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod and device for vector quantization of spectral representation of envelope
Автори англійськоюVos Kon Bernard
Назва патенту російськоюСпособ и устройство для векторного квантования спектрального представления огибающей
Автори російськоюВос Кон Бернард
МПК / Мітки
МПК: G01L 19/06
Мітки: пристрій, представлення, квантування, спектрального, векторного, обвідної, спосіб
Код посилання
<a href="https://ua.patents.su/15-91853-sposib-i-pristrijj-dlya-vektornogo-kvantuvannya-spektralnogo-predstavlennya-obvidno.html" target="_blank" rel="follow" title="База патентів України">Спосіб і пристрій для векторного квантування спектрального представлення обвідної</a>
Спосіб і пристрій стійкого векторного прогнозувального квантування параметрів лінійного прогнозування у кодуванні мови з змінною бітовою швидкістю

Номер патенту: 83207
Опубліковано: 25.06.2008
Автор: Єлінек Мілан
МПК: G10L 19/00
Мітки: векторного, лінійного, квантування, змінною, прогнозування, прогнозувального, кодуванні, мови, спосіб, пристрій, швидкістю, параметрів, бітовою, стійкого
Формула / Реферат:
1. Спосіб квантування параметрів лінійного прогнозування у кодуванні звукового сигналу з змінною бітовою швидкістю, який включає:- прийом вхідного вектора параметрів лінійного прогнозування;- класифікацію кадру звукового сигналу, що відповідає вхідному вектору параметрів лінійного прогнозування;- обчислення вектора прогнозу;- видалення обчисленого вектора прогнозу з вхідного вектора параметрів лінійного...
Спосіб квантування періодичних сигналів (варіанти) та пристрій для його здійснення (варіанти)

Номер патенту: 44862
Опубліковано: 15.03.2002
Автори: Гриб Олег Герасимович, Левін Владислав Ілліч, Левін Ілля Рувімович
МПК: H04N 3/00, G01R 13/00
Мітки: варіанти, квантування, спосіб, періодичних, сигналів, пристрій, здійснення
Формула / Реферат:
1. Спосіб квантування періодичних сигналів, який включає задання кількості точок квантування, вимірювання тривалості періоду у вигляді кількості імпульсів вимірювального генератора протягом тривалості періоду, безперервне ділення тривалості періоду на кількість точок квантування, починаючи з початку періоду, наступного після виміряного, шляхом послідовного віднімання з одержанням результату ділення у вигляді цілої частини та остачі та...
Пристрій та спосіб корекції обвідної спектра сигналу

Номер патенту: 79301
Опубліковано: 11.06.2007
Автори: Чьорлінг Крістофер, Віллємоес Ларс
МПК: H03H 17/02, G10L 19/00
Мітки: корекції, сигналу, обвідної, спосіб, спектра, пристрій
Формула / Реферат:
1. Пристрій для корекції обвідної спектра сигналу, що містить:засоби (80) для формування множини сигналів піддіапазонів, де сигнал піддіапазону зв'язаний з каналом номер k, який вказує на діапазон частот, що охоплюється сигналом піддіапазону, а сигнал піддіапазону походить з фільтра каналу, котрий має номер k в аналізуючому блоці фільтрів, який складається з множини фільтрів для каналів, де фільтр каналу з номером k має відклик...
Спосіб визначення якості форми обвідної сигналу і пристрій для його реалізації (варіанти)

Номер патенту: 74399
Опубліковано: 15.12.2005
Автори: Монтохо Хуан, Блек Пітер, Сіндгушаяна Наґабгушана
МПК: H04L 1/24, H04B 1/00, H04B 3/00, H04B 17/00
Мітки: спосіб, варіанти, реалізації, пристрій, сигналу, якості, форми, обвідної, визначення
Формула / Реферат:
1. Спосіб визначення, за результатами вимірювання, якості форми обвідної, який включає:- визначення сукупності зсувів параметрів поточного сигналу відносно ідеального сигналу,- компенсацію поточного сигналу сукупністю зсувів для генерування компенсованого поточного сигналу,- фільтрування компенсованого поточного сигналу для генерування фільтрованого сигналу,- модифікування ідеального сигналу, відповідного...
Спосіб регулювання спектрального складу квазисинусоїдальної напруги з широтно-імпульсною модуляцією та пристрій для його здійснення

Номер патенту: 33417
Опубліковано: 15.02.2001
Автор: Левчук Анатолій Павлович
МПК: H02M 1/08
Мітки: широтно-імпульсною, модуляцією, квазісинусоїдальної, спосіб, спектрального, складу, пристрій, регулювання, напруги, здійснення
Текст:
...яких, на кожному кроці регулювання величини першої гармоніки, є задане значення величини першої гармоніки, при цьому пристрій для регулювання спектрального складу квазисинусоїдальної напруги є широтно-імпульсною модуляцією, що включає перший програмований запам'ятовуючий пристрій, додається тим, що в нього введені другий і третій програмовані запам'ятовуючі пристрої, перший і другий лічильники, реверсивний лічильник, керований...
Попередній патент: Фармацевтична дозована форма, яка містить метформін та піоглітазон як активні медикаменти
Наступний патент: Фунгіцидна комбінація активних речовин
Випадковий патент: Композиції dhea для лікування менопаузи