Спосіб оцінки біологічних станів, заснований на нечіткій кластеризації даних множини вимірюваних показників
Номер патенту: 91767
Опубліковано: 25.08.2010
Автори: Бодянський Євген Володимирович, Чурюмова Ірина Геннадіївна, Мустецов Микола Петрович






Формула / Реферат
Спосіб автоматизованої оцінки біологічних станів, заснований на нечіткій кластеризації біологічних даних, які надані в чисельній формі та отримані технічними засобами, що включає формування нормалізованого масиву даних, обробку нормалізованого масиву даних та формування множини діагностичних кластерів з обчисленням їхніх векторів-прототипів на стадії навчання, класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів на стадії діагностування, формування множини діагностичних кластерів, що можуть взаємно перекриватися з обчисленням їхніх векторів-прототипів та рівнів належності кожного з векторів-образів навчальної вибірки до сформованих кластерів шляхом обчислення матриці нечіткого (фаззі) розбиття, класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів з обчисленням рівнів належності невідомого вектора-образу до кожного із сформованих кластерів, який відрізняється тим, що кластери формують у вигляді багатовимірних гіпереліпсоїдів, довільно орієнтованих відносно координатних осей, побудованих за допомогою кореляційної матриці вихідних даних, при цьому конкретний біологічний стан визначають за максимальним значенням рівня належності, використовуваного як метрика.
Текст
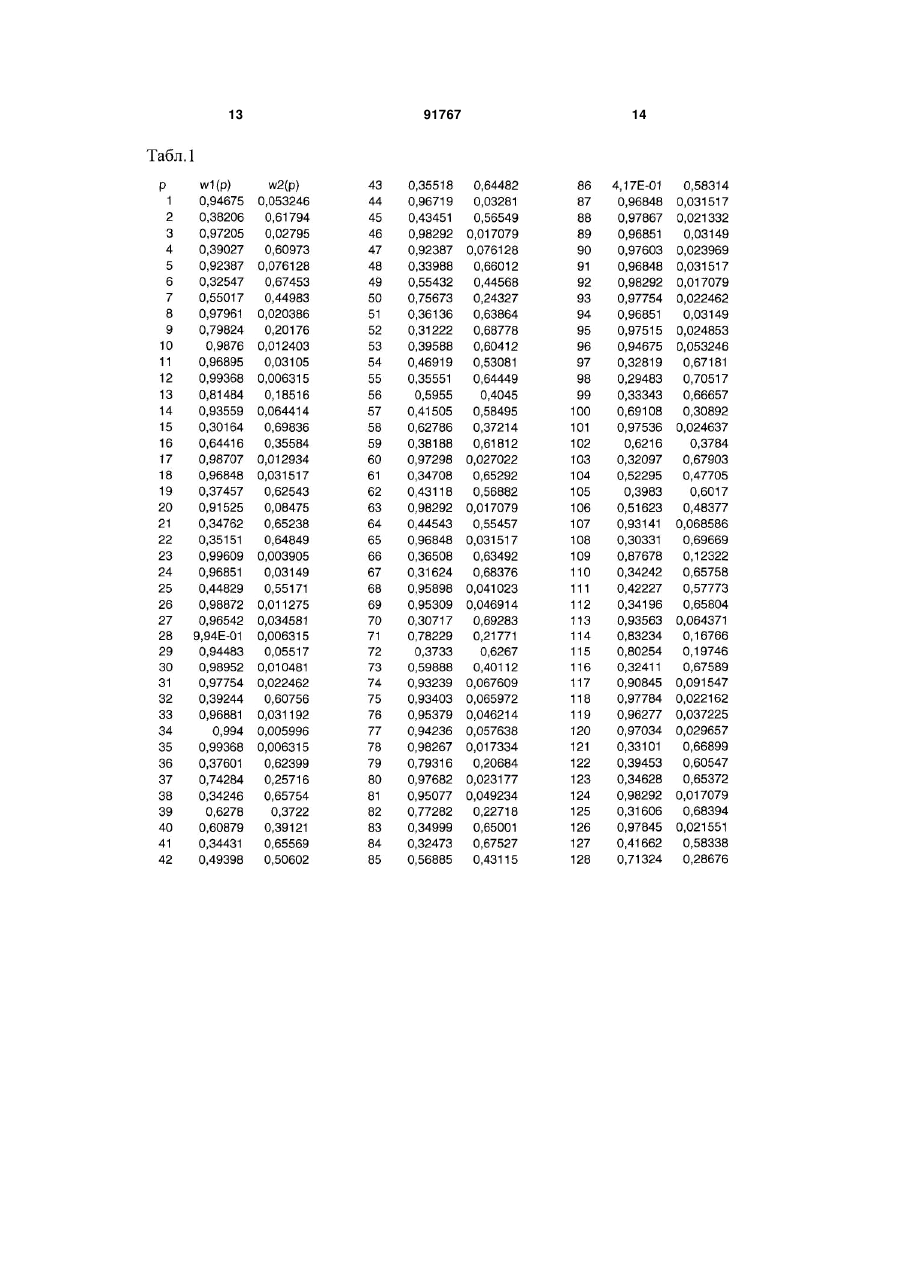
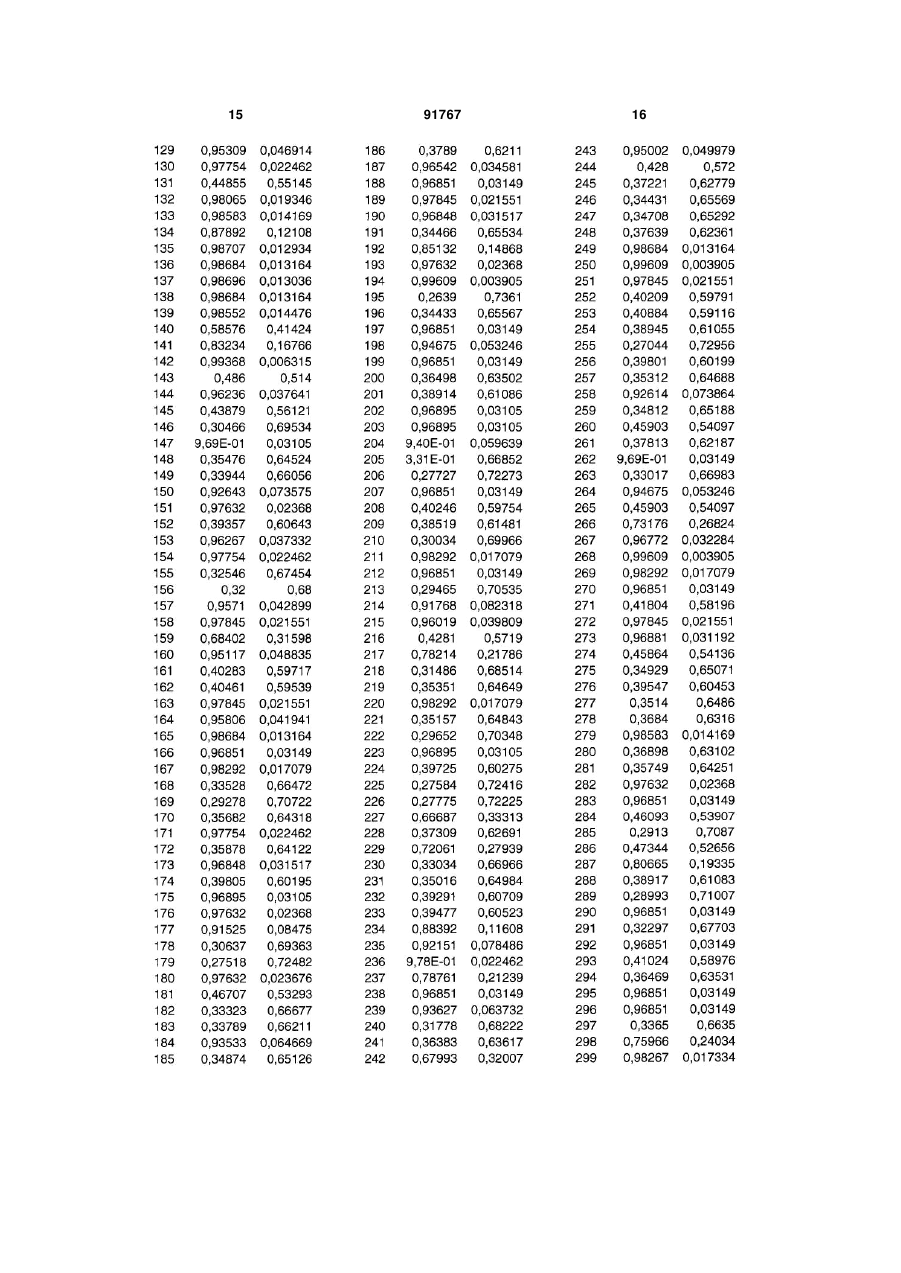
Спосіб автоматизованої оцінки біологічних станів, заснований на нечіткій кластеризації біологічних даних, які надані в чисельній формі та отримані технічними засобами, що включає формування нормалізованого масиву даних, обробку C2 2 (19) 1 3 фахівець із окремих видів хвороб (патологій, класів нозологій) ставить «свій» діагноз. Це обумовлено об'єктивними причинами, пов'язаними з перекриттям і збігом різної кількості показників стану організму для різних діагнозів, і широким розповсюдженням, так званих, полісиндромних станів. Прийняття коректних і ефективних рішень у подібних ситуаціях вимагає істотних витрат часу й засобів на організацію консиліумів висококваліфікованих фахівців. Відомий «Спосіб інтегральної оцінки здоров'я людини» [заявка на видачу патенту Росії №2001114227/14 дата подання 23.05.2001, МПК А61В10/00], заснований на рішенні завдань кластеризації, класифікації тощо, шляхом обстеження людини за кожним елементом системи "здоров'я" (показники здоров'я, хвороба або дефект розвитку, рівень або гармонійність фізичного розвитку, спадковість, фактори середовища й суспільства), оцінювання кожного елемента системи "здоров'я" і прогнозу розвитку цього показника, причому попередньо перед обстеженням множини обстежуваних розбивають на групи за подібними ознаками, у тому числі, за віком, статтю, кліматичною та географічною зоною проживання, подібностями професійної діяльності, соціальним станом в суспільстві, рівнем освіти, факторами здорового способу життя, потім проводять повторні регулярні обстеження стану здоров'я людини протягом всього її життя, для чого складають документ "Паспорт здоров'я й розвитку людини", при цьому використовують інформацію про здоров'я кожної людини, уже наявну в медичних, освітніх і інших установах; критерії оцінки показника здоров'я формують на основі імовірнісної обробки результатів обстежень у даній групі з урахуванням характеру розподілу величин показників здоров'я (нормальне, бінарне й ін.), порівнюють між собою оцінки показників здоров'я для різного часу й групи, прогнозують динаміку розвитку показника здоров'я, виявляють залежність одних показників від інших і співвідношення відповідного показника індивідуального розвитку з аналогічними показниками досить великої популяції людей співпадаючого віку, статі й інших ознак, оцінку здоров'я створюють на основі аналізу, зіставлення динамічних змін кожного параметра в часі при повторюваному обстеженні, діагностики змін у часі групи різних показників, пов'язаних між собою кореляційними лінійними й нелінійними зв'язками, визначення величин лінійних і нелінійних кореляційних зв'язків, зіставлення результатів аналізу соціальних показників, показників фізичного розвитку, внутрішньої регуляції, трудової діяльності людини, розумової працездатності, еколого-гігієнічних показників і інших даних. Недоліком цього способу є низька ефективність, пов'язана з тривалістю його реалізації (необхідність регулярних повторних обстежень), необхідністю великих обсягів статистичної інформації для відновлення функцій розподілу, суб'єктивізмом при розбивці обстежуваних на класи-групи. Відомий також «Спосіб розпізнавання біологічних станів, що базуються на прихованих параметрах біологічних даних» [«Process for discriminating 91767 4 between biological states based on hidden patterns from biological data», патент США №6925389 від 02.08.2005, МПК G06F19/00]. Цей спосіб здійснюється шляхом виявлення параметрів, які розрізняють, при тому, що параметри, які розрізняють, описують біологічний стан, з використанням векторних просторів, що містять множину заздалегідь визначених біологічних кластерів, які визначають відомий біологічний стан, та включає наступні стадії: - формування нормалізованого масиву даних з множини біологічних даних, які описують експресію молекул у біологічному зразку, та отримані з клінічних даних, що являють собою будь-які сполучення з клінічними та небіологічними даними; - обробка нормалізованого масиву даних для обчислення векторів-прототипів (центроїдів), які характеризують даний масив; - ідентифікація діагностичного кластера, якщо такий є, у рамках якого залишається векторпрототип; - установлення діагнозу для біологічних даних з ідентифікованого діагностичного кластера; - класифікація невідомих зразків даних з використанням параметрів, що розрізняють. При цьому даний спосіб включає використання сукупності навчальних даних для побудови діагностичного алгоритму розпізнавання біологічного стану, що цікавить, у якому діагностичний алгоритм характеризується наявністю множини діагностичних кластерів заздалегідь заданого однакового розміру у векторному просторі фіксованої розмірності, у якому розміри кластерів даних визначаються евклідовою метрикою, а самі кластери взаємно не перекриваються. Однак цей спосіб має обмежену функціональність та низьку ефективність через те, що множина біологічних даних, описуючих експресію молекул у біологічному зразку, отриманих з клінічних даних, що являють собою будь-які сполучення з клінічними та небіологічними даними, не є вичерпною та не репрезентує достатньо велику чисельність інших комбінацій даних та можливих діагнозів. Також процес формування кластерів обмежений двома досить жорсткими припущеннями про однаковість розмірів кластерів та про їх взаємне не перекриття. Це обмеження пояснюється тим, що в якості засобу інтелектуальної обробки вихідних даних використана штучна нейрона мережа, яка самонавчається, - мапа Т. Кохонена [Kohonen Т. Self-Organizing Maps. - Berlin: Springer-Verlag, 1995. - 362р.], що само організується, яка здатна формувати тільки кластери, що не перекриваються. У той же час у медичних застосуваннях ситуації, пов'язані із кластерами, що не перекриваються, та мають один розмір, практично не зустрічаються [Дюк В., Эмануэль В., Информационные технологии в медико-биологических исследованиях. - СПб: Питер, 2003. - 528с.; Дюк В., Самойленко A. Data mining. - СПб: Питер, 2001. 368с.; Fuzzy Logic in Medicine / Eds: S. Barro, R. Marin. - Berlin-Heidelberg-New York: Springer, 2002.310 p.; Computational Intelligence Processing in Medical Diagnosis / Eds: M. Schmitt; H.-N. Teodorescu; A. Jain e.a. - Berlin-Heidelberg-New 5 York: Springer, 2002. - 496р.]. Справа в тому, що тим самим даним можуть відповідати різні діагнози; близькі діагнози можуть формувати області, що перекриваються, у просторі ознак; розмір кластерів, що відповідають діагнозам, які рідко зустрічаються, не може збігатися з областями станів, що часто зустрічаються. Ці обставини істотно знижують якість оцінювання та, відповідно, ефективність описаного способу. Найбільш близьким за технічною суттю є «Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі даних множини вимірюваних показників» [патент України №79573 С2 МПК G06F19/00, G06F17/00, G06F7/00, C01N33/48, опублікований 25.06.2007, Бюл.№9, 2007р.]. Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі біологічних даних, які надані в чисельній формі та отримані технічними засобами, що включає: формування нормалізованого масиву даних (навчальної множини); оброблення нормалізованого масиву даних та формування множини діагностичних кластерів з обчисленням їхніх векторів-прототипів на стадії навчання; класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів на стадії діагностування, який відрізняється тим, що дані про стан організму, відтворені у вимірюваннях та експериментах, оброблюються та перетворюються засобами обчислювальної техніки шляхом виконання наступної сукупності дій: на стадії навчання формують множину кластерів довільного розміру, що можуть взаємно перекриватися, з розрахунком рівнів належності кожного з векторів-образів навчальної вибірки до сформованих кластерів шляхом обчислення матриці нечіткого (фаззі) розбиття, а на стадії діагностування обчислюють рівні належності пропонованого невідомого вектораобраза до кожного зі сформованих кластерів, при цьому конкретний біологічний стан визначають за максимальним значенням рівня належності, використовуваного як метрика. Недоліком цього способу є те, що кластери, що формуються мають форму гіперкуль, у той час як у багатьох випадках дані формують більш складні форми класів, що веде до зниження точності діагностики. В основу винаходу поставлено задачу синтезу способу оцінки біологічних станів, заснованому на нечіткій кластеризації даних множини вимірюваних показників, шляхом застосування процедур, які дозволяють формувати кластери довільного розміру, що взаємно перекриваються і мають форму багатовимірних гіпереліпсоїдів довільно орієнтованих відносно координатних осей, з одночасним розрахунком рівня належності кожного пропонованого вектора-образа до кожного із кластерів, що дозволяє підвищити ефективність і точність способу оцінки біологічних станів. Ця задача вирішена таким чином. Спосіб оцінки біологічних станів, заснований на нечіткій кластеризації біологічних даних, які надані в чисельній формі та отримані технічними засобами, що включає: формування нормалізованого масиву даних; оброблення нормалізованого масиву даних та формування множини діагностичних кластерів з об 91767 6 численням їхніх векторів-прототипів на стадії навчання; класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів на стадії діагностування; формування множини діагностичних кластерів, що можуть взаємно перекриватися з обчисленням їхніх векторів прототипів та рівнів належності кожного з векторів-образів навчальної вибірки до сформованих кластерів шляхом обчислення матриці нечіткого (фаззі) розбиття, класифікацію невідомих векторів образів даних за допомогою обчислених прототипів з обчисленням рівнів належності невідомого вектора-образа до кожного із сформованих кластерів, згідно винаходу кластери формуються у вигляді багатовимірних гіпереліпсоїдів довільно орієнтованих відносно координатних осей побудованих за допомогою кореляційної матриці вихідних даних, при цьому конкретний біологічний стан визначається за допомогою метрики Махаланобіса з визначенням максимального значення рівня належності у цій метриці. На Фіг.1 відображена двовимірна проекція набору даних з мінімальною втратою інформації за допомогою методу головних компонент для приклада 1; На Фіг.2 відображена двовимірна проекція результатів кластеризації вибірки для приклада 1; На Фіг.3 відображена двовимірна проекція набору даних з мінімальною втратою інформації за допомогою методу головних компонент для приклада 2; На Фіг.4 відображена двовимірна проекція результатів кластеризації вибірки для приклада 2; У табл. 1 представлені рівні належності кожного об'єкта до кожного з кластерів для приклада 1; У табл. 2 представлені рівні належності кожного об'єкта до кожного з кластерів для приклада 2; Найбільш строгими з математичної точки зору з процедур нечіткої кластеризації (fuzzy clustering), є так звані алгоритми нечіткої кластеризації, засновані на цільових функціях [Bezdek J.C. Pattern Recognition with Fuzzy Objective Function Algorithms. - N.Y.: Plenum Press, 1981. - 272р.; Hoppner F., Klawonn F., Kruze R. Fuzzy Clusteranalyse. - Braunschweig: Vieweg, 1999. - 280 S.; Bodyanskiy Ye. Computational intelligence techniques for data analysis // In "Lecture Notes in Informatics". - V. P-72. - Bonn: Gl, 2005. - P.15-36.] і призначені для рішення завдання автоматичної класифікації (без вчителя) шляхом оптимізації наперед заданого критерію якості. Такий алгоритм покладено в основу прототипу, в якому використовується процедура ймовірнісної нечіткої кластеризації на основі евклідової метрики, що веде до того, що кластери, що формуються, мають форму гіперкуль, що істотно обмежує можливість використання такого алгоритму для обробки даних більш складних форм. Поставлена задача вирішується за рахунок того, що у відомому способі розпізнавання біологічних станів, що базується на прихованих параметрах біологічних даних та включає формування нормалізованого масиву даних; оброблення нормалізованого масиву даних та формування множини діагностичних кластерів з обчисленням їхніх 7 91767 векторів-прототипів на стадії навчання; класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів на стадії діагностування; формування множини діагностичних кластерів, що можуть взаємно перекриватися з обчисленням їхніх векторів прототипів та рівнів належності кожного з векторів-образів навчальної вибірки до сформованих кластерів шляхом обчислення матриці нечіткого (фаззі) розбиття; класифікацію невідомих векторів образів даних за допомогою обчислених прототипів з обчисленням рівнів належності невідомого вектора-образа до кожного із сформованих кластерів з метою підвищення точності класифікації кластери формуються у вигляді багатовимірних гіпереліпсоїдів довільно орієнтованих відносно координатних осей побудованих за допомогою кореляційної матриці вихідних даних, при цьому конкретний біологічний стан визначається за допомогою метрики Махаланобіса, на основі якої І формуються довільно орієнтовані гіпереліпсоїди, з визначенням максимального значення рівня належності у цій метриці. Технічний результат, якого можна досягти при використанні пропонованого винаходу, виражений у тому, що забезпечується підвищення ефективності і точності способу оцінки біологічних станів за рахунок того, що розширюється клас вимірюваних показників стану біологічного об'єкту, з'являється можливість проведення діагностики станів в умовах кластерів довільного розміру, що можуть взаємно перекриватися, з оцінкою рівня належності до кожного зі сформованих кластерів, що представляють собою підмножини усередині масиву даних навчальної вибірки, що мають форму багатовимірних гіпереліпсоїдів, довільно орієнтованих N m E w j k ,c j w k xk j k 1j 1 c j TA 1 x k j cj 8 відносно координатних осей, які описують приховані закономірності, що містяться в ньому, при цьому задовольняється довгостроково існуюча потреба в автоматизації діагностики полісиндромних станів. Спосіб, що пропонується, реалізується таким чином. Дані навчальної вибірки у вигляді багатовимірних векторів, що поступають на оброблення, І які містять вимірювані показники, попередньо нормалізуються за всіма ознаками так, щоб усі компоненти векторів належали n-вимірному гіперкубу [1,1]n. Таким чином, вихідною інформацією для наступної обробки (стадія навчання) є вибірка спостережень, що сформована з N n-вимірних векторів-ознак Х={x(1),x(2)….,x(N)}, x(k) X, k=1,2,...,N. Результат роботи стадії навчання є розбивкою вихідного масиву даних на m кластерів, що перетинаються, з деяким рівнем wj(k) належності k-гo вектора ознак j-му кластеру. У прототипі як метрика використовується стандартна евклідова метрика, в результаті чого кластери, що формуються мають форму гіперкуль. У випадку, коли кластери об'єктивно можуть мати більш складну форму точність класифікації, що досягається, може бути недостатньою. Для підвищення точності пропонується використовувати кластери у формі не гіперкуль, а багатовимірних гіпереліпсоїдів довільно орієнтованих відносно координатних осей. Для цього в якості цільової функції, що підлягає оптимізації (мінімізації), використовується функція виду: min , (1) при обмеженнях m m wj k j 1 1 , k 1 N ,..., (2) m 0 w j k N, j 1 m ,..., (3) j 1 де wj(k) [0,1] - рівень належності вектора ознак x(k) до j-го кластера, сj - прототип (центроїд) 7-го кластера, - невід'ємний параметр, що називається «фаззіфікатором», Аj - кореляційна матриця вихідних даних. Aj w k xk j j 1 m cj x k cj T wj k j 1 Результатом кластеризації є N w матриця W={wj(k)}, яку називають матрицею нечіткого розбиття. Відзначимо також, що крім можливості роботи в умовах кластерів, що перетинаються, алгоритми нечіткої кластеризації не використовують поняття «розмір кластера», що дозволяє виключити цей суб'єктивно обраний параметр, використаний у прототипі, з алгоритму, що, у свою чергу, підвищує точність і ефективність вирішення задачі. Використовуючи техніку нелінійного програмування, уводячи функцію Лагранжа 9 91767 N m E w j k , c j, k N cj m k k 1 N c j TA 1 x k j w k xk j k 1j 1 10 wj k j 1 1 N k 1 k 1 w k xk j , m cj TA 1 x k j cj k wj k j 1 (тут (k) - невизначений множник Лагранжа) і вирішуючи систему рівнянь Куна-Таккера L w j k , c j, k 0, wj k c j L w j k ,c j, k (5) 0, L w j k , c j, k 0, k можна здобути шукане вирішення у вигляді 1 TA 1 x k c 1 x k cj j j wj k (6) 1 m x k cj TA 1 x k cj 1 j l 1 m w kxk j (7) cj l 1 m w k j l 1 1 1 m (8) k x k cj TA 1 x k cj 1 j l 1 Рівняння (6)-(8) породжують залежно від значення фаззіфікатора широкий клас процедур нечіткої кластеризації у обраній метриці. Оскільки як метрика використовується метрика Махаланобіса, обираємо =2. Таким чином результатом стадії навчання є m векторів прототипів C j c j1, c j2,..., c ji ,..., c jn T (центроїдів) кластерів розміру (n 1) й (N m) матриця нечіткої розбивки елементів навчальної вибірки W={wj(k)}, j=1,2,...,m; k=1,2,...,N. Стадія діагностики зводиться до класифікації невідомих векторів-образів х(р) р=N+1, N+2,... за допомогою сформованих кластерів. При цьому для образа х(р) обчислюється його рівень належності до кожного із кластерів відповідно до виразів 1 xk wj k cj 1 1 m xk l 1 cj TA 1 x k j cj TA 1 x k j (4) cj 1 , j 1,2,..., m (9) 1 Обчислені рівні належності wj(р) стають оцінками імовірності того, що образ х(р) належить 7-му кластеру. Найбільше значення wmax (p) визначає j найбільш імовірний біологічний стан (діагноз). Можливість здійснення запропонованого способу оцінки біологічних станів підтверджується прикладами на даних із загальнодоступних репозитаріїв університету Каліфорнії [Murphy P.M., Aha D.W. UCI Repostory of machine learning databases. URL : http://www.uci.edu/-mleam/ MLRepository.html. - С A: University of California, Department of information and Computer science, 1994.] і Массачусетського університету в Амхерсті [http://wwwunix.oit.umass.edu/-statdata/statdata/], призначених для тестування методів і алгоритмів інтелектуального аналізу даних. Як приклади для обробки взято масиви біологічних та медичних даних (WBC, Thirods), такі самі як і у прототипі. Опис приклада 1. Набір даних описує результати цитологічних досліджень пухлин, узятих у пацієнток з підозрою на рак грудей у госпіталі Висконсинського університету [Wolberg W.H., Mangasarian O.L. Multisurface method of pattern separation for medical diagnosis applied to breast cytology // Proc. Nat. Acad. Sci. - U.S.A. - Vol.87. - December 1990. P.9193-9196.]. Усього у вибірці 699 спостережень, описуваних 11 параметрами, з них один є ідентифікатором спостереження й ще один - атрибут класу, тобто діагноз, поставлений на підставі аналізу спостережень експертом, що вважається вірним. Існує 2 варіанти діагнозу: доброякісна пухлина (клас 1) або злоякісна пухлина (клас 2). 16 спостережень мають пропуски в значеннях параметрів і тому виключаються з подальшого розгляду. Із тих що залишилися 683 спостережень 444 (65%) ставляться до класу 1, 239 (35%) - до класу 2. Таким чином, для задачі кластеризації використовуються тільки 9 значущих параметрів, кожний з яких оцінюється по шкалі від 1 до 10: товщина агрегації клітин (Clump Thickness), однорідність розміру клітин, однорідність форми клітин, поверхнева адгезія (Marginal Adhesion), розмір одиничної епітеліальної клітини (Single Epithelian Cell Size), оголені ядра (Bare Nuclei), хроматин (Bland Chromatin), нормальні ядерця (Normal Nucleoli), мітози (Mitoses). Для виконання попереднього аналізу даних побудуємо двовимірну проекцію набору даних з мінімальною втратою інформації за допомогою 11 методу головних компонент (Фіг.1), «•» - відповідають доброякісній пухлині, «х» - злоякісній пухлині: На проекції збережено 76% інформації з вихідного 9-вимірного простору, що дозволяє затверджувати про її вірогідність. На представленій проекції добре видно, що кластери, що відповідають пацієнтам з різними діагнозами, мають різні розміри й значно перекриваються і мають форму еліпсоїдів, що робить застосування для даної задачі способу, наведеного в прототипі менш точним. Застосуємо для кластеризації вибірки запропонований спосіб і результати також представимо у вигляді двовимірної проекції (Фіг.2). Кодування тут таке, «о» (координати: 0.42978, 0.013553) і (координати: -0.98126, -0.02523) показують центри відповідних кластерів. Помилка кластеризації склала 3,7657%. Рівні належності кожного з об'єктів до кожного з кластерів представлені у табл.1. Таким чином, запропонований спосіб дозволив одержати результат з більш високою точністю, ніж у прототипі, в умовах кластерів нерівних розмірів, що перекриваються. Опис приклада 2. Дані описують виживаність пацієнтів при хворобах серця [Hosmer D.W., Lemeshow, S. Applied Survival Analysis: Regression Modeling of Time to Event Data. -New York: John Wiley and Sons Inc., 1998]. У вибірці представлено інформацію про 481 пацієнта. Кожне спостереження описується 10 параметрами, один із яких є атрибутом класу: пацієнт вмер (клас 1, 48%) або вижив (клас 2, 52%). У підсумку, для задачі кластеризації використовується 9 значущих параметрів: вік (роки), стать (чоловіча/жіноча), пікове значення серцевого ензиму Peak Cardiac Enzyme (міжнародні одиниці), кардіогенні шокові ускладнення (так/немає), ускладнення лівих відділів серця (так/немає), MI Order (перший/рекурентні), МІ Туре (Q-Хвиля / не Q-Хвиля / невизначений), тривалість лікування в лікарні (дні), тривалість спостереження після виписки з лікарні (дні). 91767 12 Побудуємо двовимірну проекцію набору даних з мінімальною втратою інформації за допомогою методу головних компонент (Фіг.3),- «•» -відповідає класу 1, «х» - класу 2. На проекції збережено 97 % інформації з вихідного 9-вимірного простору, що дозволяє затверджувати про її вірогідність. На представленій проекції видно, що кластери, що відповідають різним наслідкам лікування, істотно перекриваються, мають різні розміри й несферичну форму, що робить застосування для даної задачі способу, наведеного в прототипі менш точним. Застосуємо для кластеризації вибірки запропонований спосіб і результати також представимо у вигляді двовимірної проекції (Фіг.4). Кодування аналогічне Фіг.3, великі «о» (координати: 2.4435, 1.3576) і (координати: 1.3197, 0.60292) указують центри відповідних кластерів. Помилка кластеризації склала 13,362%. Слід відмітити, що в прототипі помилка кластеризації складала 25,98%. Підвищення точності кластеризації обумовлено можливістю формувати кластери у формі гіпереліпсоїдів, довільно орієнтованих відносно координатних осей з можливістю їх перекриття. Рівні належності кожного з об'єктів до кожного з кластерів представлені у табл.2. Результати тестових перевірок показують можливість застосування пропонованого способу в ситуаціях, де не виконуються умови застосування прототипу. Застосування пропонованого способу, наприклад, в медичній практиці й профілактичному моніторингу індивідуального стану здоров'я, дозволяє оперативно одержувати оцінку стану організму, що у свою чергу може привести до поліпшення діагностики хвороб і оздоровленню способу життя. Застосування пропонованого способу вже сьогодні може знайти широке поширення в медичних установах з достатнім технічним забезпеченням. 13 91767 14 15 91767 16 17 91767 18 19 91767 20 21 91767 22 23 91767 24 25 91767 26 27 91767 28 29 91767 30 31 Комп’ютерна верстка Т. Чепелева 91767 Підписне 32 Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюAutomated estimation method for biological states based on fuzzy clasterization of measuring index data sets
Автори англійськоюBodianskyi Yevhenii Volodymyrovych, Mustetsov Mykola Petrovych, Churiumova Iryna Hennadiivna
Назва патенту російськоюСпособ оценки биологических состояний, основанный на нечеткой кластеризации данных множеств измерительных показателей
Автори російськоюБодянский Евгений Владимирович, Мустецов Николай Петрович, Чурюмова Ирина Геннадьевна
МПК / Мітки
МПК: G06F 7/00, G01N 33/48, G06F 19/00, G06F 17/00
Мітки: біологічних, станів, заснований, спосіб, кластеризації, множині, нечіткий, вимірюваних, даних, показників, оцінки
Код посилання
<a href="https://ua.patents.su/16-91767-sposib-ocinki-biologichnikh-staniv-zasnovanijj-na-nechitkijj-klasterizaci-danikh-mnozhini-vimiryuvanikh-pokaznikiv.html" target="_blank" rel="follow" title="База патентів України">Спосіб оцінки біологічних станів, заснований на нечіткій кластеризації даних множини вимірюваних показників</a>
Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі даних множини вимірюваних показників

Номер патенту: 79573
Опубліковано: 25.06.2007
Автори: Клімова Олена Михайлівна, Божков Анатолій Іванович, Леонтьєва Фріда Соломонівна, Дьомін Олег Олексійович, Бондаренко Михайло Федорович, Бодянський Євгеній Володимирович, Попов Сергій Віталійович, Кушнарьов Володимир Михайлович
МПК: G01N 33/48, G06F 17/00, G06F 7/00, G06F 19/00
Мітки: інтелектуальному, даних, біологічних, спосіб, вимірюваних, заснований, станів, оцінки, показників, аналізі, множині
Формула / Реферат:
Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі біологічних даних, які надані в чисельній формі та отримані технічними засобами, що включає: формування нормалізованого масиву даних (навчальної множини); оброблення нормалізованого масиву даних та формування множини діагностичних кластерів з обчисленням їхніх векторів-прототипів на стадії навчання; класифікацію невідомих векторів-образів даних за допомогою...
Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі даних множини вимірюваних показників

Номер патенту: 22868
Опубліковано: 25.04.2007
Автори: Кушнарьов Володимир Михайлович, Леонтьєва Фріда Соломонівна, Дьомін Олег Олексійович, Бондаренко Михайло Федорович, Божков Анатолій Іванович, Клімова Олена Михайлівна, Бодянський Євгеній Володимирович, Попов Сергій Віталійович
МПК: G06F 19/00
Мітки: заснований, аналізі, спосіб, станів, множині, даних, вимірюваних, біологічних, інтелектуальному, показників, оцінки
Формула / Реферат:
Спосіб оцінки біологічних станів, заснований на інтелектуальному аналізі біологічних даних, що включає формування нормалізованого масиву даних; оброблення нормалізованого масиву даних та формування множини діагностичних кластерів з обчисленням їх векторів-прототипів (центроїдів) на стадії навчання; класифікацію невідомих векторів-образів даних за допомогою обчислених прототипів на стадії діагностування, який відрізняється тим, що дані про...
Система і спосіб мультиплексування даних керування для множини каналів передачі даних у одному каналі керування (варіанти)

Номер патенту: 83256
Опубліковано: 25.06.2008
Автори: Чжан Сяося, Вілленеггер Серж Д., Малладі Дурга Прасад
Мітки: каналів, каналі, передачі, даних, спосіб, мультиплексування, множині, варіанти, одному, керування, система
Формула / Реферат:
1. Спосіб мультиплексування даних керування, який реалізовується в мобільній станції системи безпровідного зв'язку, який включаєкомбінування інформації про швидкість передачі даних для першого каналу передачі даних і інформації про швидкість передачі даних для другого каналу передачі даних;кодування комбінованої інформації про швидкість передачі даних, і передачу кодованої комбінованої інформації про швидкість передачі...
Спосіб керування передачами (варіанти), спосіб експлуатації множини передавальних вузлів (варіанти) та спосіб забезпечення передачі даних до множини приймальних вузлів (варіанти) у безпровідній системі зв’язку

Номер патенту: 73979
Опубліковано: 17.10.2005
Автори: Голцман Джек, Антоніо Франклін П., Волтон Джей Р., Воллес Марк
Мітки: передачами, вузлів, забезпечення, передавальних, передачі, приймальних, спосіб, безпровідній, системі, керування, варіанти, експлуатації, даних, множині, зв'язку
Формула / Реферат:
1. Спосіб керування передачами у системі зв'язку, який полягає у:визначенні однієї або декількох характеристик системи зв'язку, включаючи імовірності навантажень для системи зв'язку,розділенні наявних ресурсів системи на множину каналів,визначенні множини коефіцієнтів втрати потужності для множини каналів, на основі щонайменше частково визначених одній або декількох характеристиках системи зв'язку, причому кожний канал...
Спосіб оцінки ступеня розвитку астенічних станів

Номер патенту: 36842
Опубліковано: 10.11.2008
Автори: Денищук Павло Андрійович, Вретік Галина Михайлівна, Брюзгіна Тетяна Семенівна
МПК: G01N 33/68
Мітки: астенічних, станів, ступеня, спосіб, розвитку, оцінки
Формула / Реферат:
Спосіб оцінки ступеня розвитку астенічних станів шляхом дослідження поту, який відрізняється тим, що за допомогою методу газорідинної хроматографії визначають наявність вищих жирних кислот (ЖК): стеаринової; олеїнової; арахідонової, розраховують їх співвідношення відносно контролю за формулами:, ,...
Попередній патент: Грунтообробна машина з ножами, що входять в грунт періодично
Наступний патент: Джерело живлення для дугового навантаження
Випадковий патент: Спосіб лікування макулодистрофії, що виникла внаслідок регматогенного відшарування сітківки