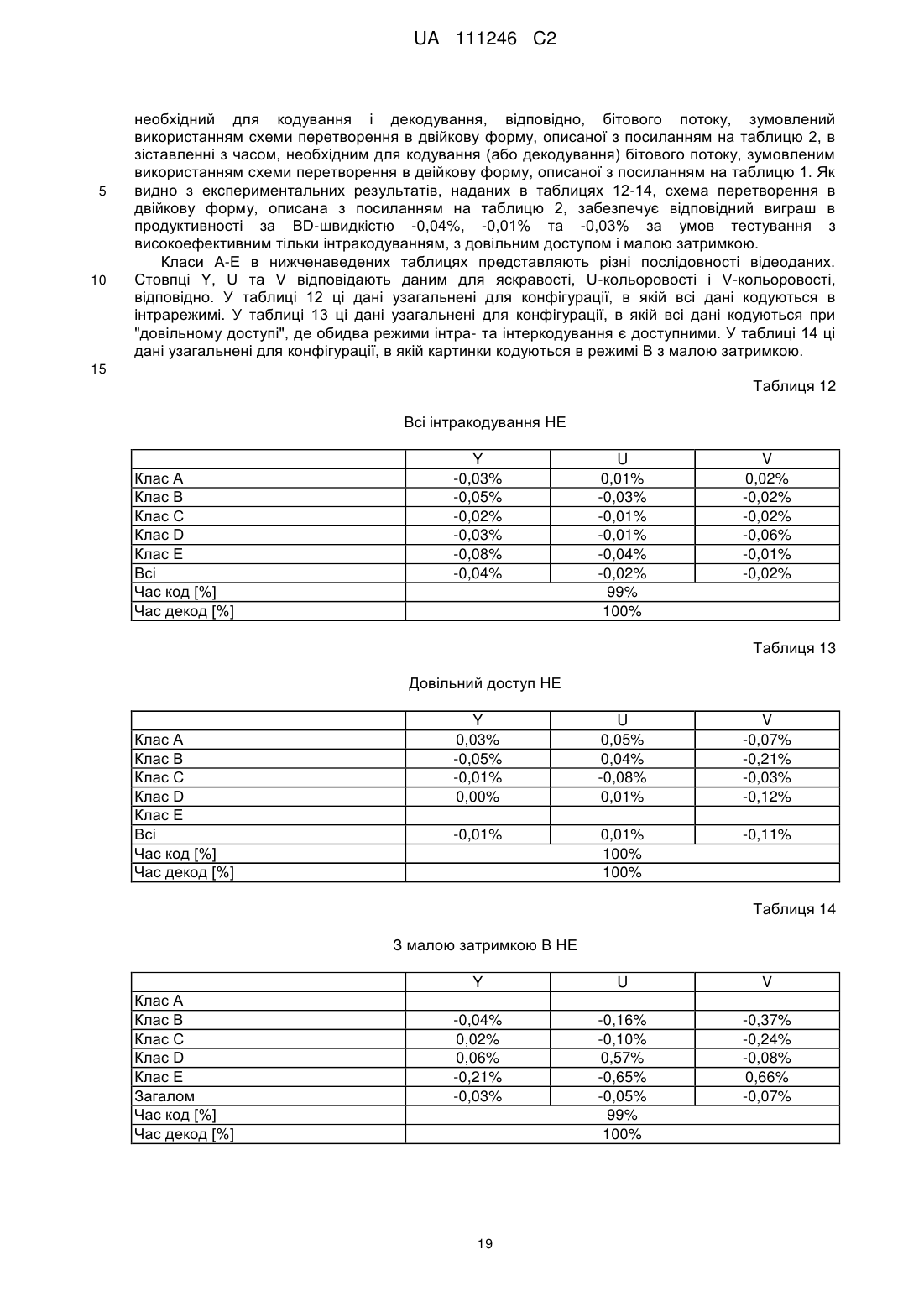
Прогресивне кодування позиції останнього значущого коефіцієнта
Номер патенту: 111246
Опубліковано: 11.04.2016
Автори: Карчєвіч Марта, Чіень Вей-Цзюн, Джоши Раджан Лаксман, Соле Рохальс Хоель














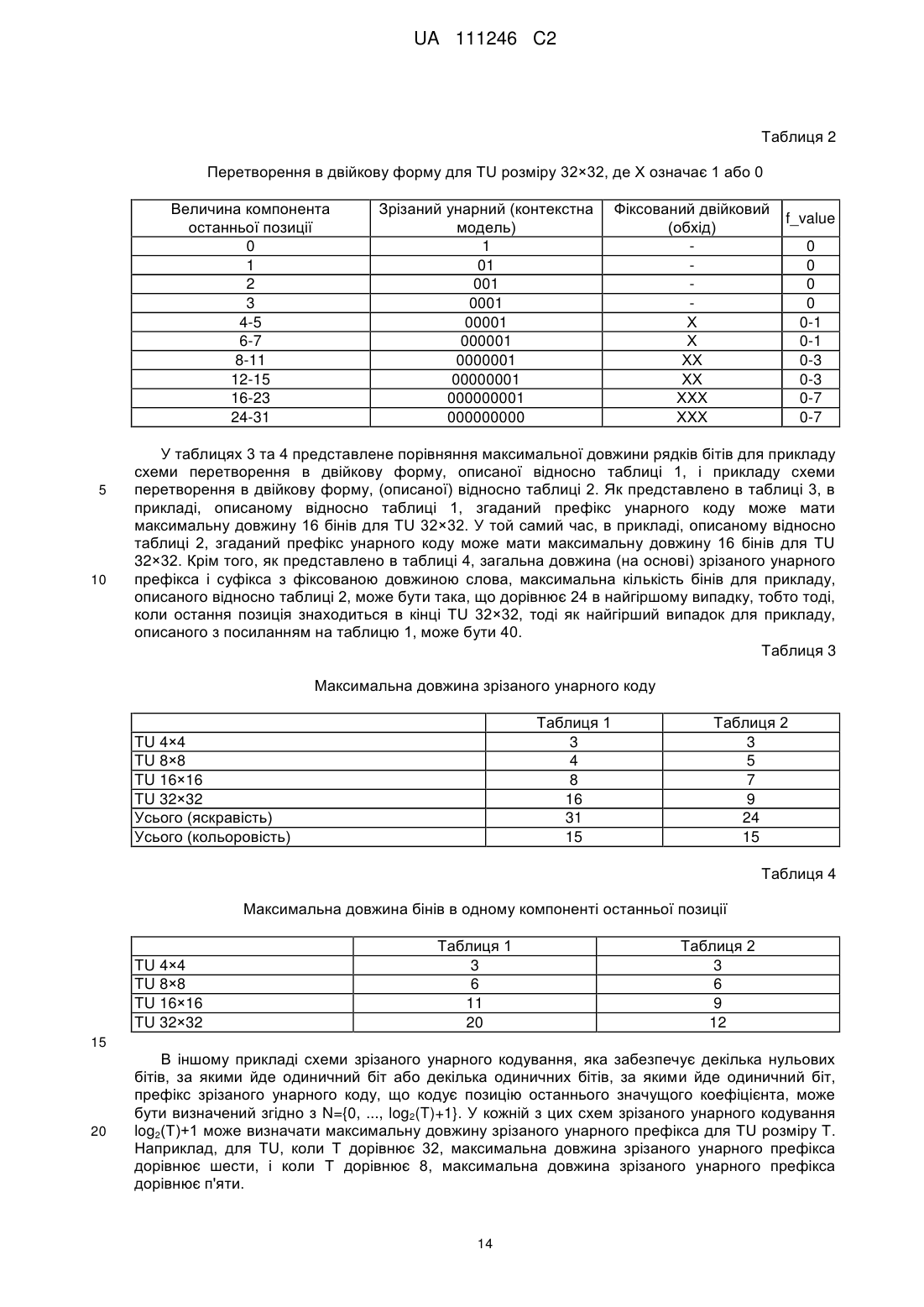

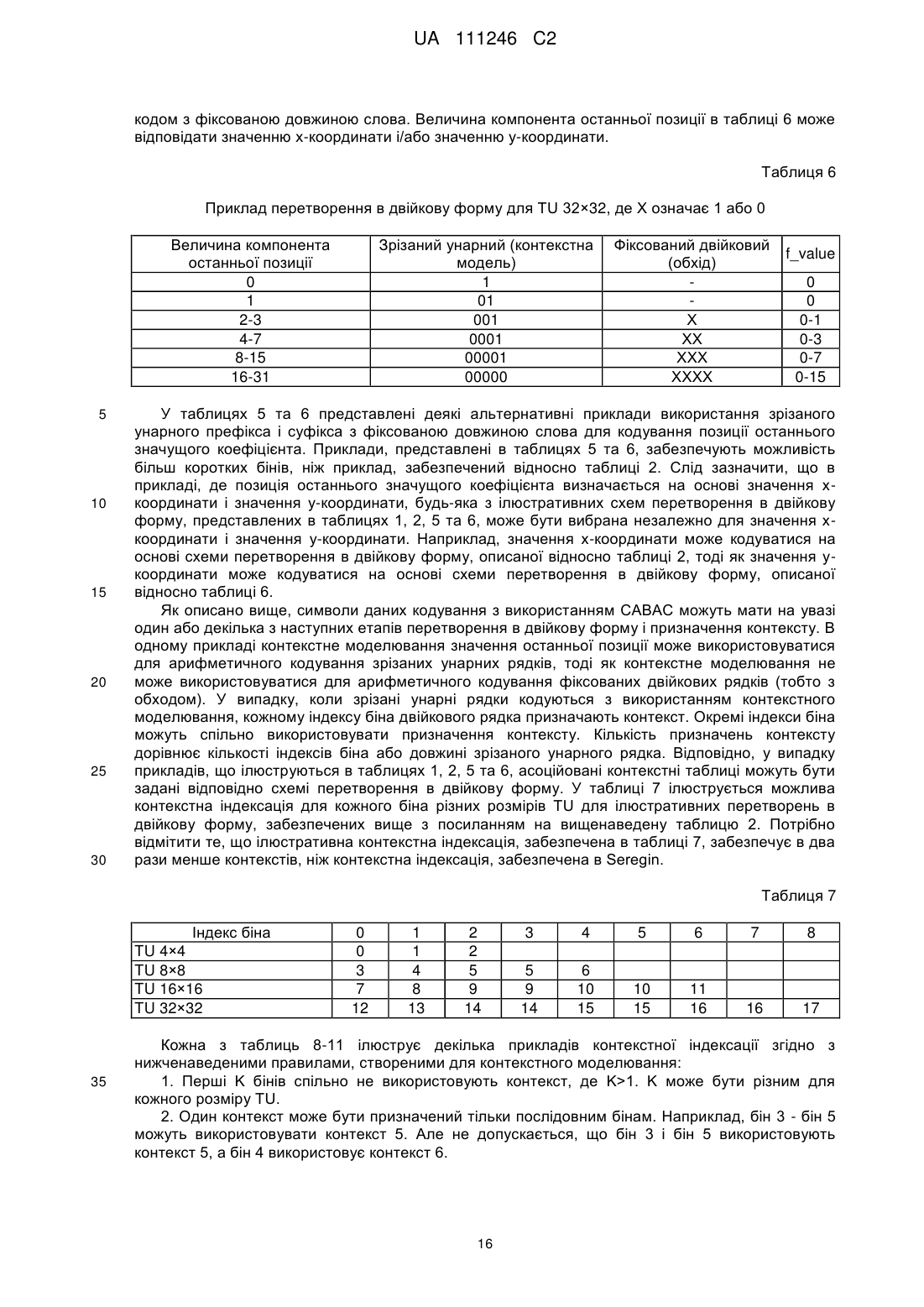
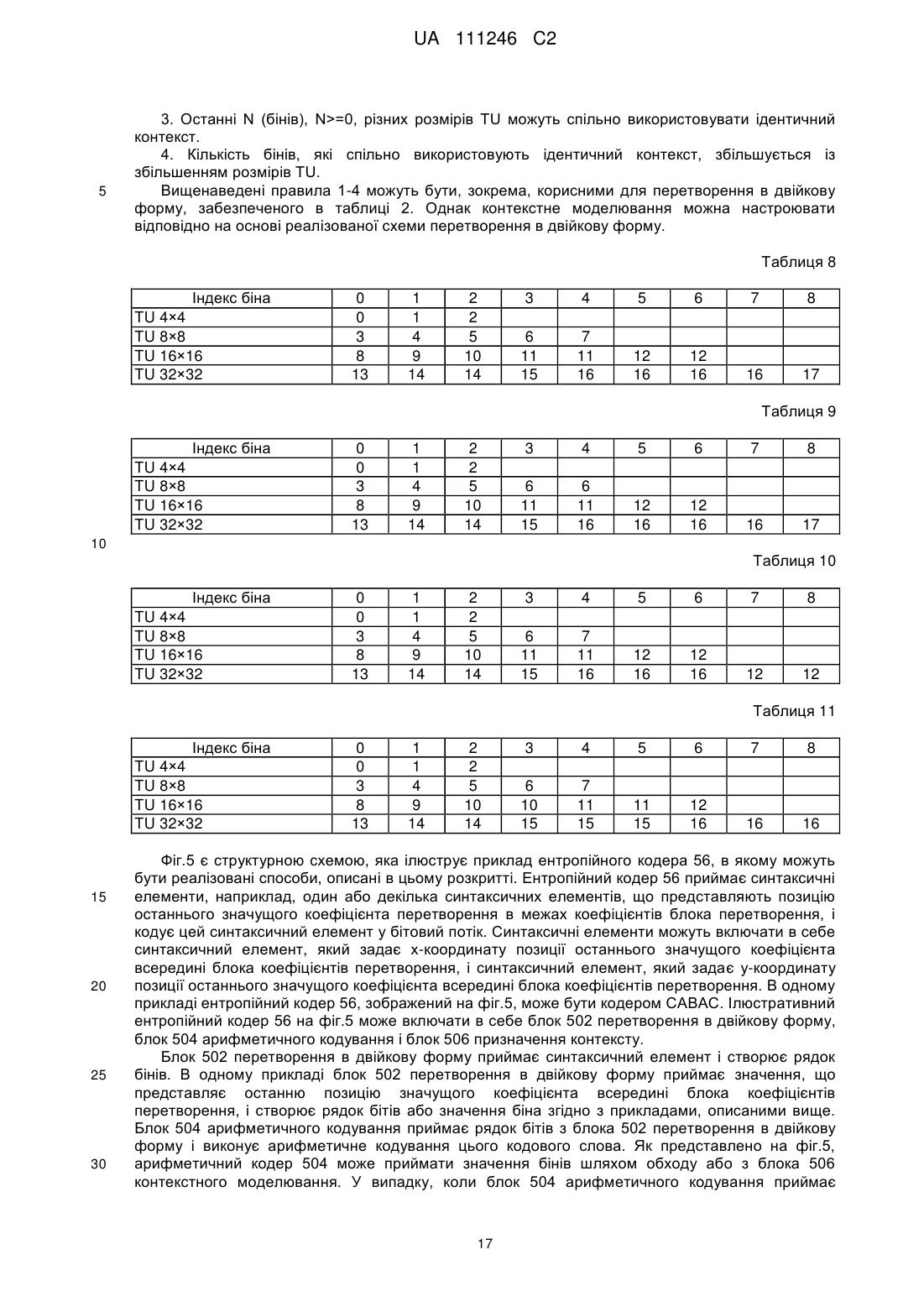










Формула / Реферат
1. Спосіб кодування відеоданих, який містить:
одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т,
визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1,
визначення другого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і
кодування згаданих першого і другого двійкових рядків у бітовий потік.
2. Спосіб за п. 1, в якому кодування першого і другого двійкових рядків у бітовий потік включає в себе арифметичне кодування.
3. Спосіб за п. 2, в якому кодування першого і другого двійкових рядків у бітовий потік включає в себе кодування першого двійкового рядка на основі контекстної моделі.
4. Спосіб за п. 1, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
5. Спосіб за п. 4, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
6. Спосіб за п. 5, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1.
7. Пристрій, що містить відеокодер, виконаний з можливістю:
одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т,
визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1,
визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і
кодування згаданих першого і другого двійкових рядків у бітовий потік.
8. Пристрій за п. 7, в якому відеокодер, виконаний з можливістю кодування згаданих першого і другого двійкових рядків у бітовий потік, виконаний з можливістю виконання арифметичного кодування.
9. Пристрій за п. 8, в якому відеокодер, виконаний з можливістю кодування згаданих першого і другого двійкових рядків у бітовий потік, виконаний з можливістю кодування першого двійкового рядка на основі контекстної моделі.
10. Пристрій за п. 7, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
11. Пристрій за п. 10, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
12. Пристрій за п. 11, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і другий двійковий рядок має довжину в бітах, рівну 1.
13. Пристрій для кодування відеоданих, причому пристрій містить:
засіб для одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т,
засіб для визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1,
засіб для визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і
засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік.
14. Пристрій за п. 13, в якому засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік включає в себе засіб для виконання арифметичного кодування.
15. Пристрій за п. 14, в якому засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік включає в себе засіб для кодування першого двійкового рядка на основі контекстної моделі.
16. Пристрій за п. 13, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
17. Пристрій за п. 16, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
18. Пристрій за п. 17, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1.
19. Зчитуваний комп'ютером носій інформації, який містить інструкції, що зберігаються на ньому, які при виконанні викликають виконання одним або більше процесорами:
одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т,
визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1,
визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і
кодування згаданих першого і другого двійкових рядків у бітовий потік.
20. Зчитуваний комп'ютером носій інформації за п. 19, в якому інструкції, які при виконанні викликають кодування одним або більше процесорами першого і другого двійкових рядків у бітовий потік, включають в себе інструкції, які при виконанні викликають виконання одним або більше процесорами арифметичного кодування.
21. Зчитуваний комп'ютером носій інформації за п. 20, в якому інструкції, які при виконанні викликають кодування одним або більше процесорами першого і другого двійкових рядків у бітовий потік, включають в себе інструкції, які при виконанні викликають кодування одним або більше процесорами першого двійкового рядка на основі контекстної моделі.
22. Зчитуваний комп'ютером носій інформації за п. 19, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
23. Зчитуваний комп'ютером носій інформації за п. 22, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
24. Зчитуваний комп'ютером носій інформації за п. 23, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1.
25. Спосіб декодування відеоданих, який містить:
одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-l, і
визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
26. Спосіб за п. 25, в якому одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку включає в себе виконання арифметичного декодування.
27. Спосіб за п. 25, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
28. Спосіб за п. 27, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
29. Спосіб за п. 28, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення.
30. Спосіб за п. 29, в якому другий двійковий рядок має довжину в бітах, рівну 1.
31. Пристрій, який містить відеодекодер, виконаний з можливістю: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, і
визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
32. Пристрій за п. 31, в якому відеокодер, виконаний з можливістю одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, виконаний з можливістю виконання арифметичного декодування.
33. Пристрій за п. 31, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
34. Пристрій за п. 33, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
35. Пристрій за п. 34, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення.
36. Пристрій за п. 35, в якому другий двійковий рядок має довжину в бітах, рівну 1.
37. Пристрій для декодування відеоданих, причому пристрій містить:
засіб для одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-l, і
засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
38. Пристрій за п. 37, в якому засіб для одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку включає в себе засіб для виконання арифметичного декодування.
39. Пристрій за п. 37, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
40. Пристрій за п. 39, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
41. Пристрій за п. 40, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення.
42. Пристрій за п. 41, в якому другий двійковий рядок має довжину в бітах, рівну 1.
43. Зчитуваний комп'ютером носій інформації, який містить інструкції, що зберігаються на ньому, які при виконанні викликають виконання одним або більше процесорами:
одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-l, і
визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
44. Зчитуваний комп'ютером носій інформації за п. 43, в якому інструкції, які при виконанні викликають одержання одним або більше процесорами першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, включають в себе інструкції, які при виконанні викликають виконання одним або більше процесорами арифметичного декодування.
45. Зчитуваний комп'ютером носій інформації за п. 43, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2.
46. Зчитуваний комп'ютером носій інформації за п. 45, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7.
47. Зчитуваний комп'ютером носій інформації за п. 46, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення.
48. Зчитуваний комп'ютером носій інформації за п. 47, в якому другий двійковий рядок має довжину в бітах, рівну 1.
49. Спосіб декодування відеоданих, який містить:
одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(T)+l, і
визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
50. Спосіб декодування відеоданих, який містить:
одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку,
визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(T), і
визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова.
51. Спосіб за п. 1, в якому кодування першого і другого двійкових рядків містить кодування першого двійкового рядка, за яким йде кодування другого двійкового рядка.
Текст
Реферат: Відеокодер виконаний з можливістю визначення першого і другого двійкових рядків для значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т. Відеодекодер виконаний з можливістю визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, на основі першого і другого двійкових рядків. В одному прикладі перший двійковий рядок оснований на схемі зрізаного унарного UA 111246 C2 (12) UA 111246 C2 кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 21og2(T)-1, і другий двійковий рядок оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 За даною заявкою на патент заявляється пріоритет: попередньої заявки США № 61/557317, поданої 8 листопада 2011 р., і попередньої заявки США № 61/561909, поданої 20 листопада 2011 р., кожна з яких повністю включена в цей документ за посиланням. Галузь техніки, до якої належить винахід Це розкриття належить до кодування відео. Рівень техніки Можливості цифрового відео можуть бути включені в широкий діапазон пристроїв, які включають в себе цифрові телевізори, системи прямого цифрового мовлення, бездротові системи мовлення, персональні цифрові секретарі (PDA), портативні або настільні комп'ютери, планшетні комп'ютери, пристрої для читання електронних книг, цифрові камери, цифрові записуючі пристрої, цифрові медіаплеєри, відеоігрові пристрої, відеоігрові консолі, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої відеоконференцзв'язку, пристрої потокового відео тощо. Цифрові відеопристрої реалізовують способи стиснення відео, наприклад, способи, описані в стандартах, що визначаються MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Частина 10, Advanced Video Coding (AVC, вдосконалене кодування відео), стандарті High Efficiency Video Coding (HEVC, високоефективне кодування відео), що в цей час розробляється, і розширеннях цих стандартів. З реалізацією цих способів стиснення відео відеопристрої можуть більш ефективно передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію. У способах стиснення відео виконується просторове (внутрішньокадрове) прогнозування і/або часове (міжкадрове) прогнозування для зменшення або видалення надмірності, властивої відеопослідовностям. Для блокового кодування відео відеослайс (тобто відеокадр або частина відеокадру) може бути розділений на відеоблоки, які також можуть називатися деревоподібними блоками (treeblock), одиницями кодування (CU) і/або вузлами кодування. Відеоблоки в слайсі з інтракодуванням (I-слайс) картинки кодуються з використанням просторового прогнозування відносно опорних відліків у сусідніх блоках в тій самій картинці. Відеоблоки в слайсах з інтеркодуванням (Р-слайс або В-слайс) картинки можуть використовувати просторове прогнозування відносно опорних відліків у сусідніх блоках в тій самій картинці або часове прогнозування відносно опорних відліків в інших опорних картинках. Картинки можуть називатися кадрами, а опорні картинки можуть називатися опорними кадрами. В результаті просторового або часового прогнозування одержується прогнозуючий блок для блока, який повинен бути закодований. Залишкові дані представляють піксельні різниці між вихідним блоком, який повинен бути закодований, і прогнозуючим блоком. Блок з інтеркодуванням кодується згідно з вектором руху, який вказує на блок опорних відліків, що формують прогнозуючий блок, і залишкові дані, який вказує різницю між закодованим блоком і прогнозуючим блоком. Блок з інтракодуванням кодується згідно з режимом інтракодування і залишковими даними. Для додаткового стиснення залишкові дані можуть бути перетворені з піксельної ділянки в ділянку перетворення, результатом чого є залишкові коефіцієнти перетворення, які після цього можуть бути піддані квантуванню. Для створення одномірного вектора коефіцієнтів перетворення квантовані коефіцієнти перетворення, які спочатку організовані в двомірний масив, можуть бути піддані скануванню, і для досягнення ще більшого стиснення може бути застосоване ентропійне кодування. Короткий опис креслень Фіг.1 є структурною схемою, яка ілюструє приклад системи кодування і декодування відео, яка може використовувати способи, описані в цьому розкритті предмета винаходу. На фіг.2A-2D зображені ілюстративні порядки сканування значень коефіцієнтів. На фіг.3 зображений один приклад карти значущості, що відноситься до блока значень коефіцієнтів. Фіг.4 є структурною схемою, яка ілюструє приклад відеокодера, який може реалізувати способи, описані в цьому розкритті. Фіг.5 є структурною схемою, яка ілюструє приклад ентропійного кодера, який може реалізувати способи, описані в цьому розкритті. Фіг.6 є блок-схемою, що ілюструє приклад способу визначення двійкового рядка для значення, що вказує позицію останнього значущого коефіцієнта, згідно зі способами цього розкриття предмета винаходу. Фіг.7 є структурною схемою, яка ілюструє приклад відеодекодера, який може реалізувати способи, описані в цьому розкритті предмета винаходу. Фіг.8 є блок-схемою, що ілюструє приклад способу визначення значення, що вказує позицію останнього значущого коефіцієнта з двійкового рядка, згідно зі способами цього розкриття. 1 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 Суть винаходу Загалом, в цьому розкритті описуються способи кодування відеоданих. Кодування відео звичайно передбачає прогнозування блока відеоданих з використанням конкретного режиму прогнозування і кодування залишкових значень для блока на основі різниць між прогнозованим і фактичним блоком, який кодується. Залишковий блок включає в себе ці попіксельні різниці. Залишковий блок може зазнавати перетворення і квантування. Відеокодер може включати в себе блок квантування, який відображає коефіцієнти перетворення в дискретні значення рівня. Це розкриття забезпечує способи кодування позиції останнього значущого коефіцієнта всередині відеоблока. В одному прикладі спосіб кодування відеоданих містить одержання значення, що вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для значення, що вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова і кодування першого і другого двійкових рядків у бітовий потік. У ще одному прикладі спосіб декодування відеоданих містить одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. У ще одному прикладі пристрій для кодування відеоданих містить пристрій кодування відео, виконаний з можливістю одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова і кодування першого і другого двійкових рядків у бітовий потік. У ще одному прикладі пристрій для декодування відеоданих містить пристрій декодування відео, виконаний з можливістю одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log 2(Т)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. У ще одному прикладі пристрій для кодування відеоданих містить засіб для одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, засіб для визначення першого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log 2(Т)-1, засіб для визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова і засіб для кодування першого і другого двійкових рядків у бітовий потік. У ще одному прикладі пристрій для декодування відеоданих містить засіб для одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, і засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. У ще одному прикладі зчитуваний комп’ютером носій інформації містить інструкції, що зберігаються на ньому, які при виконанні викликають кодування процесором пристрою 2 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 відеоданих для того, щоб викликати одержання одним або більше процесорами значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова і кодування першого і другого двійкових рядків у бітовий потік. У ще одному прикладі зчитуваний комп’ютером носій інформації містить інструкції, що зберігаються на ньому, які при виконанні викликають одержання процесором пристрою для декодування відеоданих першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log 2(Т)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. В одному прикладі спосіб декодування відеоданих містить одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(Т)+1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. В одному прикладі спосіб декодування відеоданих містить одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(Т), і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. У нижченаведеному описі та прикладених кресленнях детально викладені один або декілька прикладів. Інші ознаки, цілі та переваги будуть очевидні із згаданих опису і креслень і з формули винаходу. Докладний опис У цьому розкритті забезпечені способи скорочення довжини рядка бітів, що використовується для вказівки позиції останнього значущого коефіцієнта всередині блока коефіцієнтів перетворення. Згаданий рядок бітів може бути, зокрема, корисним для контекстноадаптивного двійкового арифметичного кодування (context adaptive binary arithmetic coding, CABAC). В одному прикладі для вказівки позиції останнього значущого коефіцієнта може бути використана прогресивна структура кодового слова зі скороченою кількістю бінів (bin) і більш короткими зрізаними унарними кодами. Крім того, в одному прикладі із скороченням максимальної довжини зрізаного унарного коду кількість контекстних моделей CABAC для позиції останнього значущого коефіцієнта може також бути скорочена. Відеокодер може бути виконаний з можливістю визначення першого і другого двійкових рядків для значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру T. Відеодекодер може бути виконаний з можливістю визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, на основі першого і другого двійкових рядків. В одному прикладі перший двійковий рядок може бути оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, і другий двійковий рядок може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)-2. У ще одному прикладі перший двійковий рядок може бути оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)+1, і другий двійковий рядок може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)-1. У ще одному прикладі перший двійковий рядок може бути оснований на схемі зрізаного унарного кодування, яка визначається 3 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 максимальною довжиною в бітах, яка визначається за допомогою log 2(Т), і другий двійковий рядок може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log 2(Т)-1. Фіг.1 є структурною схемою, яка ілюструє приклад системи 10 кодування і декодування відео, яка може використовувати способи, описані в цьому розкритті. Як представлено на фіг.1, система 10 включає в себе пристрій-джерело 12, який генерує закодовані відеодані, які згодом повинні бути декодовані пристроєм-адресатом 14. Пристрій-джерело 12 і пристрій-адресат 14 можуть містити будь-який з широкого діапазону пристроїв, що включають в себе настільні комп'ютери, комп'ютери-ноутбуки (тобто переносні комп'ютери), планшетні комп'ютери, телевізійні приставки, мікротелефоні трубки, наприклад, так звані "смартфони", так звані "смартпади", телевізори, камери, пристрої відображення, цифрові медіаплеєри, відеоігрові консолі, пристрій потокового відео тощо. В деяких випадках пристрій-джерело 12 і пристрійадресат 14 можуть бути оснащені бездротовим зв'язком. Пристрій-адресат 14 може приймати закодовані відеодані, які повинні бути декодовані, через лінію 16 зв'язку. Лінія 16 зв'язку може містити будь-який тип носія або пристрою, за допомогою яких можна переміщувати закодовані відеодані з пристрою-джерела 12 в пристрійадресат 14. В одному прикладі лінія 16 зв'язку може містити середовище зв'язку для забезпечення можливості передачі пристроєм-джерелом 12 закодованих відеоданих безпосередньо в пристрій-адресат 14 в реальному часі. Закодовані відеодані можуть модулюватися згідно зі стандартом зв'язку, наприклад, протоколом бездротового зв’язку, і передаватися в пристрій-адресат 14. Середовище зв'язку може містити будь-яке середовище бездротового або дротового зв'язку, наприклад, спектр радіочастот (RF) або одну або декілька фізичних ліній передачі. Середовище зв'язку може бути частиною пакетної мережі, наприклад, локальної мережі, широкомасштабної мережі або глобальної мережі, наприклад, Internet. Середовище зв'язку може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути корисним для сприяння передачі інформації з пристрою-джерела 12 в пристрій-адресат 14. Як альтернатива, закодовані дані можуть виводитися з вихідного інтерфейсу 22 в запам'ятовуючий пристрій 32. Аналогічно, може бути здійснений доступ до закодованих даних із запам'ятовуючого пристрою 32 за допомогою вхідного інтерфейсу 28. Запам'ятовуючий пристрій 32 може включати в себе будь-який з множини розподілених або локальних накопичувачів даних, наприклад, жорсткий диск, диски блю-рей (Blu-ray), DVD, CD-ROM, флеш-пам'ять, енергозалежну або енергонезалежну пам'ять або будь-які інші підходящі цифрові носії інформації для зберігання закодованих відеоданих. У ще одному прикладі запам'ятовуючий пристрій 32 може відповідати файловому серверу або іншому проміжному запам'ятовуючому пристрою, який може зберігати закодоване відео, що генерується пристроєм-джерелом 12. Пристрій-адресат 14 може здійснювати доступ до відеоданих, що зберігаються, із запам'ятовуючого пристрою 32 через потік або завантаження. Файловий сервер може бути будь-яким типом сервера, на якому можуть зберігатися закодовані відеодані і який може передавати ці закодовані відеодані в пристрій-адресат 14. Приклади файлових серверів включають в себе web-сервер (наприклад, для веб-сайта), FTP-сервер, мережний пристрій зберігання даних (NAS) або локальний накопичувач на дисках. Пристрій-адресат 14 може здійснювати доступ до закодованих відеоданих через будь-яке стандартне інформаційне з'єднання, що включає в себе Internet-з'єднання. Воно може включати в себе канал бездротового зв’язку (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем тощо) або комбінацію обох, яка є підходящою для здійснення доступу до закодованих відеоданих, що зберігаються на файловому сервері. Передача закодованих відеоданих із запам'ятовуючого пристрою 32 може бути потоковою передачею, передачею за допомогою завантаження або комбінацією обох. Способи цього розкриття не обов'язково обмежуються бездротовими застосуваннями або установками. Згадані способи можуть бути застосовані до кодування відео в підтримку будьякого з множини мультимедійних додатків, наприклад, передач мовлення ефірного телебачення, передач кабельного телебачення, передач супутникового телебачення, передач потокового відео, наприклад, через Internet, кодування цифрового відео для зберігання на накопичувачі даних, декодування цифрового відео, що зберігається на накопичувачі даних, або інших додатків. У деяких прикладах система 10 може бути виконана з можливістю підтримки односторонньої або двосторонньої відеопередачі для підтримки таких додатків, як потокове відео, відтворення відео, відеомовлення і/або відеотелефонія. У прикладі за фіг.1 пристрій-джерело 12 включає в себе відеоджерело 18, відеокодер 20 і вихідний інтерфейс 22. У деяких випадках вихідний інтерфейс 22 може включати в себе 4 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 модулятор/демодулятор (модем) і/або передавач. У пристрої-джерелі 12 відеоджерело 18 може включати в себе таке джерело, як пристрій відеозахоплення, наприклад, відеокамеру, відеоархіви, що містять раніше захоплене відео, інтерфейс для зовнішнього відео для прийому відео від провайдера відеоконтенту і/або систему комп'ютерної графіки для генерації даних комп'ютерної графіки як вихідного відео, або комбінацію таких джерел. Як один приклад, якщо відеоджерело 18 є відеокамерою, то пристрій-джерело 12 і пристрій-адресат 14 можуть бути так званими камерофонами або відеотелефонами. Однак способи, описані в цьому розкритті, можуть бути застосовані до кодування відео взагалі і можуть бути застосовані до бездротових і/або дротових додатків. Захоплене, заздалегідь захоплене відео або відео, що генерується комп'ютером, може бути закодоване за допомогою відеокодера 12. Закодовані відеодані з пристрою-джерела 20 можуть передаватися безпосередньо в пристрій-адресат 14 через вихідний інтерфейс 22. Закодовані відеодані можуть також (або як альтернатива) бути збережені на запам'ятовуючому пристрої 32 для подальшої вибірки пристроєм-адресатом 14 або іншими пристроями для декодування і/або відтворення. Пристрій-адресат 14 включає в себе вхідний інтерфейс 28, відеодекодер 30 і пристрій 32 відображення. У деяких випадках вхідний інтерфейс 28 може включати в себе приймач і/або модем. Вхідний інтерфейс 28 пристрою-адресата 14 приймає закодовані відеодані по лінії 16 зв'язку. Закодовані відеодані, що передаються по лінії 16 зв'язку або забезпечуються на запам'ятовуючому пристрої 32, можуть включати в себе множину синтаксичних елементів, що генеруються відеокодером 20, для використання відеодекодером, наприклад, відеодекодером 30, при декодуванні відеоданих. Такі синтаксичні елементи можуть бути включені в закодовані відеодані, що передаються по середовищу зв'язку, які зберігаються на накопичувачі інформації або зберігаються на файловому сервері. Пристрій 32 відображення може бути інтегрований з пристроєм-адресатом 14 або бути зовнішнім по відношенню до нього. У деяких прикладах пристрій-адресат 14 може включати в себе інтегрований пристрій відображення, а також бути виконаний з можливістю забезпечення інтерфейсу із зовнішнім пристроєм відображення. В інших прикладах пристрій-адресат 14 може бути пристроєм відображення. Загалом, пристрій 32 відображення виводить на екран декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, наприклад, рідкокристалічний пристрій відображення (LCD), плазмовий пристрій відображення, пристрій відображення на основі органічного світлодіода (OLED) або інший тип пристрою відображення. Відеокодер 20 і відеодекодер 30 можуть функціонувати згідно із стандартом стиснення відео, наприклад, стандартом високоефективного кодування відео (HEVC), що розробляється в цей час, і можуть відповідати Тестовій моделі HEVC (HEVC Test Model) (HM). Як альтернатива, відеокодер 20 і відеодекодер 30 можуть функціонувати згідно з іншими приватними або галузевими стандартами, наприклад, стандартом ITU-T H.264, який як альтернатива називається MPEG-4, Частина 10, Вдосконаленим кодуванням відео (Advanced Video Coding, AVC) або розширенням таких стандартів. Способи цього розкриття, однак, не обмежуються яким-небудь конкретним стандартом кодування. Інші приклади стандартів стиснення відео включають в себе MPEG-2 та ITU-T H.263. Незважаючи на те, що на фіг.1 не зображено, згідно з деякими аспектами кожний з відеокодера 20 і відеодекодера 30 може бути інтегрований з аудіокодером та аудіодекодером і може включати в себе належні блоки MUX-DEMUX або інші апаратні і програмні засоби, оперувати кодуванням як аудіо, так і відео в загальному потоці даних або окремих потоках даних. У підходящих випадках, в деяких прикладах, блоки MUX-DEMUX можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, наприклад, протоколу передачі дейтаграм користувача (UDP). Кожний з відеокодера 20 і відеодекодера 30 може бути реалізований як будь-яка з множини підходящих схем кодера, наприклад, один або декілька мікропроцесорів, цифрові сигнальні процесори (DSP), спеціалізовані інтегральні схеми (ASIC), програмовані користувачем вентильні матриці (FPGA), дискретна логіка, програмні засоби, апаратні засоби, програмноапаратні засоби або будь-які їх комбінації. Для виконання способів цього розкриття, при частковій реалізації цих способів у програмних засобах, пристрій може зберігати інструкції для цих програмних засобів на підходящому не проміжному зчитуваному комп'ютером носії і виконувати ці інструкції в апаратних засобах з використанням одного або декількох процесорів. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або декілька кодерів або декодерів, будь-який з яких може бути інтегрований як частина об'єднаного кодера/декодера (КОДЕК) у відповідний пристрій. 5 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 Над розробкою стандарту HEVC працює JCT-VC. Зусилля із стандартизації HEVC направлені на розробку моделі пристрою кодування відео, яка називається Тестова модель HEVC (HEVC Test Model, HM). HM передбачає декілька додаткових можливостей пристроїв кодування відео в порівнянні з існуючими пристроями відповідно до, наприклад, ITU-T H.264/AVC. Наприклад, тоді як H.264 забезпечує дев'ять режимів кодування з інтрапрогнозуванням, HM може забезпечити цілих тридцять три режими кодування з інтрапрогнозуванням. Загалом, робоча модель HM описує те, що відеокадр або картинка можуть бути розділені на послідовність деревоподібних блоків або найбільших одиниць кодування (largest coding unit, LCU), які включають в себе відліки як кольоровості, так і яскравості. Призначення деревоподібного блока є аналогічним призначенню макроблока в стандарті H.264. Слайс включає в себе декілька послідовних деревоподібних блоків у порядку кодування. Відеокадр або картинка може бути розділена на один або декілька слайсів. Кожний деревоподібний блок може бути розділений на одиниці кодування (CU) згідно з квадрадеревом. Наприклад, деревоподібний блок, як кореневий вузол квадрадерева, може бути розділений на чотири дочірніх вузли, і кожний дочірній вузол в свою чергу може бути батьківським вузлом і бути розділений ще на чотири дочірніх вузли. Кінцевий, неподілений дочірній вузол, як листовий вузол квадрадерева, містить вузол кодування, тобто закодований відеоблок. Синтаксичні дані, асоційовані із закодованим бітовим потоком, можуть визначати максимально можливе число розділень деревоподібного блока і можуть також визначати мінімальний розмір вузлів кодування. CU включає в себе вузол кодування і одиниці прогнозування (PU) і одиниці перетворення (TU), асоційовані із згаданим вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен мати квадратну форму. Розмір CU може змінитися в межах від 8×8 пікселів до розміру деревоподібного блока з максимумом 64×64 пікселів або більше. Кожний CU може містити один або декілька PU і один або декілька TU. Синтаксичні дані, асоційовані з CU, можуть описувати, наприклад, розділення CU на одну або декілька PU. Режими розділення можуть відрізнятися залежно від того, чи кодується CU в прямому режимі або з пропусканням, в режимі з інтрапрогнозуванням або в режимі з інтерпрогнозуванням. PU можуть бути розділені на блоки неквадратної форми. Синтаксичні дані, асоційовані з CU, також можуть описувати, наприклад, розділення CU на одну або декілька TU відповідно до квадрадерева. TU може мати квадратну або неквадратну форму. Стандарт HEVC забезпечує можливість перетворень відповідно до TU, які можуть бути різними для різних CU. Розмір одиниць TU звичайно задається на основі розміру одиниць PU в межах даної CU, визначеної для розділеної LCU, хоча це може не завжди мати місце. TU звичайно мають розмір, ідентичний розміру PU, або менше, ніж у неї. У деяких прикладах залишкові відліки, що відповідають CU, можуть поділятися на менші одиниці з використанням структури квадрадерева, відомої як "залишкове квадрадерево" (RQT). Листові вузли RQT можуть називатися одиницями перетворення (TU). Значення різниці пікселів, асоційовані з TU, можуть бути перетворені для створення коефіцієнтів перетворення, які можуть квантуватися. Загалом, PU включає в себе дані, що відносяться до процесу прогнозування. Наприклад, коли PU кодується в режимі з інтрапрогнозуванням, PU може включати в себе дані, що описують режим з інтрапрогнозуванням для PU. Як інший приклад, коли PU кодується в інтеррежимі, PU може включати в себе дані, що визначають вектор руху для PU. Дані, що визначають вектор руху для PU, можуть описувати, наприклад, горизонтальну складову вектора руху, вертикальну складову вектора руху, розрізнення для вектора руху (наприклад, точність до однієї чверті пікселя або точність до однієї восьмої пікселя), опорну картинку, на яку вказує вектор руху, і/або список опорних картинок (наприклад, список 0, список 1 або список С) для вектора руху. Загалом, TU використовується для процесів квантування і перетворення. Дана CU, що має одну або декілька PU, також може включати в себе одну або декілька TU. Після прогнозування відеокодер 20 може обчислювати залишкові значення, що відповідають PU. Залишкові значення містять значення різниці пікселів, які можуть перетворюватися в коефіцієнти перетворення, квантуватися і скануватися з використанням TU для створення перетворених у послідовну форму коефіцієнтів перетворення для ентропійного кодування. Термін "відеоблок" в цьому розкритті може відноситися до вузла кодування CU або блока коефіцієнтів перетворення. Один або декілька блоків коефіцієнтів перетворення можуть визначати TU. У деяких конкретних випадках в цьому розкритті термін "відеоблок" також може використовуватися для посилання на деревоподібний блок, тобто LCU або CU, яка включає в себе вузол кодування і блоки PU та TU. 6 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 Відеопослідовність звичайно включає в себе ряд відеокадрів або картинок. Група картинок (group of pictures, GOP) звичайно містить ряд з одного або декількох відеокадрів. GOP може включати в себе синтаксичні дані в своєму заголовку, заголовку однієї або декількох згаданих картинок або в якому-небудь іншому місці, які описують декілька картинок, включених в цю GOP. Кожний слайс картинки може включати в себе синтаксичні дані слайса, які описують режим кодування для відповідного слайса. Відеокодер 20 звичайно виконує ряд операцій над відеоблоками всередині окремих відеослайсів для кодування відеоданих. Відеоблок може включати в себе одну або декілька TU або PU, які відповідають вузлу кодування всередині CU. Відеоблоки можуть мати фіксовані або змінні розміри і можуть відрізнятися за розміром згідно із заданим стандартом кодування. Як приклад, HM підтримує прогнозування при різних розмірах PU. З припущенням того, що розмір конкретної CU дорівнює 2N×2N, HM підтримує інтрапрогнозування при розмірах PU 2N×2N або N×N і інтерпрогнозування при симетричних розмірах PU 2N×2N, 2N×N, N×2N або N×N. HM також підтримує асиметричне розділення для інтерпрогнозування при розмірах PU 2N×nU, 2N×nD, nL×2N та nR×2N. При асиметричному розділенні CU в одному напрямку не ділиться,тоді як в іншому напрямку ділиться на 25% та 75%. Частина CU, що відповідає сегменту в 25%, позначена "n", за яким йде позначення "Up" ( "Вгорі"), "Down" ("Внизу"), "Left" ("Зліва") або "Right" ("Праворуч"). Відповідно, наприклад, "2N×nU" відноситься до CU 2N×2N, яка розділена по горизонталі з PU 2N×0,5N вгорі і PU 2N×1,5N внизу. У цьому розкритті "N×N" та "N на N" є взаємозамінними і відносяться до розмірів відеоблоків у пікселях відносно розмірів по вертикалі і по горизонталі, наприклад, 16×16 пікселів або 16 на 16 пікселів. Загалом, блок 16×16 містить 16 пікселів у вертикальному напрямку (у=16) і 16 пікселів у горизонтальному напрямку (х=16). Аналогічно, блок N×N звичайно містить N пікселів у вертикальному напрямку і N пікселів у горизонтальному напрямку, де N представляє ненегативне цілочисельне значення. Пікселі в блоці можуть бути організовані в рядки і стовпці. Крім того, блоки не обов'язково повинні мати однакову кількість пікселів у горизонтальному напрямку і у вертикальному напрямку. Наприклад, блоки можуть містити N×M пікселів, де M не обов'язково дорівнює N. Після кодування з інтрапрогнозуванням або з інтерпрогнозуванням з використанням одиниць PU одиниці CU, відеокодер 20 може обчислювати залишкові дані для одиниць TU одиниці CU. PU можуть містити дані пікселів у просторовій ділянці (яка також називається піксельною ділянкою), і TU можуть містити коефіцієнти в ділянці перетворення після застосування перетворення, наприклад, дискретного косинусного перетворення (DCT), цілочисельного перетворення, вейвлет-перетворення або концептуально аналогічного перетворення залишкових відеоданих. Залишкові дані можуть відповідати різницям пікселів між пікселями незакодованої картинки і значеннями прогнозування, що відповідають блокам PU. З одного або декількох блоків коефіцієнтів перетворення відеокодер 20 може формувати TU. TU можуть включати в себе залишкові дані для CU. Відеокодер 20 може після цього перетворити TU для створення коефіцієнтів перетворення для CU. Після будь-яких перетворень для створення коефіцієнтів перетворення відеокодер 20 може виконувати квантування цих коефіцієнтів перетворення. Квантування звичайно відноситься до процесу, в якому коефіцієнти перетворення квантуються з метою максимально можливого скорочення обсягу даних, що використовуються для представлення коефіцієнтів, із забезпеченням додаткового стиснення. Процес квантування може скорочувати бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, під час квантування n-бітове значення може округлятися в менший бік до m-бітового значення, де n більше, ніж m. У деяких прикладах відеокодер 20 може використовувати зумовлений порядок сканування для сканування квантованих коефіцієнтів перетворення для створення перетвореного в послідовну форму вектора, який може бути закодований з використанням ентропійного кодування. В інших прикладах відеокодер 20 може виконувати адаптивне сканування. На фіг.2A-2D зображені деякі різні ілюстративні порядки сканування. Також можуть використовуватися інші визначені порядки сканування або адаптивні (що змінюються) порядки сканування. На фіг.2A зображений зигзагоподібний порядок сканування, на фіг.2B зображений горизонтальний порядок сканування, на фіг.2C зображений вертикальний порядок сканування і на фіг.2D зображений діагональний порядок сканування. Також можуть бути визначені і використовуватися комбінації цих порядків сканування. У деяких прикладах способи цього розкриття можуть конкретно застосовуватися в процесі кодування відео під час кодування так званої карти значущості. Для вказівки позиції останнього значущого коефіцієнта (тобто ненульового коефіцієнта), який може залежати від порядку сканування, асоційованого з блоком коефіцієнтів, можуть бути 7 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 визначені один або декілька синтаксичних елементів. Наприклад, один синтаксичний елемент може визначати позицію стовпця останнього значущого коефіцієнта всередині блока значень коефіцієнтів, а інший синтаксичний елемент може визначати позицію рядка останнього значущого коефіцієнта всередині блока значень коефіцієнтів. На фіг.3 зображений один приклад карти значущості, що відноситься до блока значень коефіцієнтів. Праворуч зображена карта значущості, в якій однобітові прапорці ідентифікують коефіцієнти у відеоблоці зліва, які є значущими, тобто ненульовими. В одному прикладі заданий набір значущих коефіцієнтів (наприклад, який визначається картою значущості) і порядок сканування, (за допомогою якого) може бути визначена позиція останнього значущого коефіцієнта. У стандарті HEVC, що виходить, коефіцієнти перетворення можуть бути згруповані в порцію. Порція може містити всю TU, або в деяких випадках TU можуть бути поділені на менші порції. Для кожного коефіцієнта в порції кодуються карта значущості та інформація про рівень (абсолютне значення і знак). В одному прикладі порція складається з 16 послідовних коефіцієнтів у порядку оберненого сканування (наприклад, діагональному, горизонтальному або вертикальному) для TU 4×4 та TU 8×8. Для TU 16×16 та 32×32 коефіцієнти всередині субблока 4×4 обробляються як порція. Для представлення інформації про рівень коефіцієнтів всередині порції кодують і сигналізують синтаксичні елементи. В одному прикладі всі символи кодуються в порядку оберненого сканування. Способи цього розкриття можуть поліпшити кодування синтаксичного елемента, що використовується для визначення цієї позиції останнього значущого коефіцієнта блока коефіцієнтів. Як один приклад, способи цього розкриття можуть бути використані для кодування позиції останнього значущого коефіцієнта блока коефіцієнтів (наприклад, TU або порції TU). Далі, після кодування позиції останнього значущого коефіцієнта може бути закодована інформація про рівень і знак. При кодуванні інформації про рівень і знак може виконуватися обробка згідно з підходом з п'ятьма проходами за допомогою кодування наступних символів у порядку оберненого сканування (наприклад, для TU або порції TU): significant_coeff_flag (скор. sigMapFlag): цей прапорець може вказувати значущість кожного коефіцієнта в порції. Вважають, що коефіцієнт, значення якого більше або дорівнює одиниці, є значущим. coeff_abs_level_greater1_flag (скор. gr1Flag): цей прапорець може вказувати на те, чи є абсолютне значення коефіцієнта для ненульових коефіцієнтів (тобто коефіцієнтів з sigMapFlag, рівним 1) більшим, ніж одиниця. coeff_abs_level_greater2_flag (скор. gr2Flag): цей прапорець може вказувати на те, чи є абсолютне значення коефіцієнта для коефіцієнтів з абсолютним значенням, більшим, ніж одиниця (тобто коефіцієнтів з gr1Flag, рівним 1), більшим, ніж два. coeff_sign_flag (скор. signFlag): цей прапорець може вказувати на інформацію про знак для ненульових коефіцієнтів. Наприклад, нуль для цього прапорця вказує на позитивний знак, тоді як 1 вказує на знак мінус. coeff_abs_level_remain (скор. levelRem): є залишком абсолютного значення від рівня коефіцієнта перетворення. Для цього прапорця абсолютне значення коефіцієнта - х кодується (abs(level)-x) для кожного коефіцієнта з амплітудою, більшою ніж х, при цьому значення х залежить від даних gr1Flag та gr2Flag. Відповідно, коефіцієнти перетворення для TU або порції TU можуть бути закодовані. У будьякому випадку, для остаточного кодування інформації про рівень і знак коефіцієнтів перетворення, способи цього розкриття, які стосуються кодування синтаксичного елемента, що використовується для визначення позиції останнього значущого коефіцієнта блока коефіцієнтів, також можуть використовуватися з іншими типами способів. Підхід з п'ятьма проходами для кодування інформації про знак, рівень і значущість є тільки одним ілюстративним способом, який може використовуватися після кодування позиції останнього значущого коефіцієнта блока, як викладено в цьому розкритті. Після сканування квантованих коефіцієнтів перетворення для формування одномірного вектора відеокодер 20 може кодувати одномірний вектор з використанням ентропійного кодування, наприклад, згідно з контекстно-адаптивним кодуванням із змінною довжиною (context adaptive variable length coding, CAVLC), контекстно-адаптивним двійковим арифметичним кодуванням (context adaptive binary arithmetic coding, CABAC), контекстноадаптивним двійковим арифметичним кодуванням на основі синтаксису (syntax-based contextadaptive binary arithmetic coding, SBAC), ентропійним кодуванням з розділенням на інтервали імовірності (Probability Interval Partitioning Entropy, PIPE) або іншій методології ентропійного кодування. Відеокодер 20 також може кодувати синтаксичні елементи, асоційовані з відеоданими, що кодуються, з використанням ентропійного кодування для використання 8 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 відеодекодером 30 при декодуванні цих відеоданих. Способи ентропійного кодування цього розкриття конкретно описані для застосування до CABAC, хоча ці способи також можуть бути застосовані до інших способів ентропійного кодування, наприклад, CAVLC, SBAC, PIPE або інших способів. Для виконання CABAC відеокодер 20 може в межах контекстної моделі призначати контекст символу, який повинен бути переданий. Контекст може відноситися, наприклад, до того, чи є сусідні значення символу ненульовими чи ні. Для виконання CAVLC відеокодер 20може вибирати для символу, який повинен бути переданий, код змінної довжини. Кодові слова в кодуванні із змінною довжиною (VLC) можуть конструюватися так, що відносно більш короткі коди відповідають більш імовірним символам, тоді як більш довгі коди відповідають менш імовірним символам. Отже, з використанням VLC можна досягнути деякої економії, наприклад, в порівнянні з використанням для кожного символу, який повинен бути переданий, кодових слів рівної довжини. Визначення імовірності може бути основане на контексті, призначеному символу. Загалом, символи даних кодування з використанням CABAC можуть мати на увазі один або декілька з наступних етапів: (1) Перетворення в двійкову форму: якщо символ, який повинен бути закодований, не є двійковим значенням, то він відображається в послідовність так званих "бінів". Кожний бін має значення "0" або "1". (2) Призначення контексту: кожний бін (в звичайному режимі) призначається контексту. Контекстна модель визначає те, як обчислюється контекст для даного біна, на основі інформації, доступній для цього біна, наприклад, значення раніше закодованих символів або номера біна. (3) Кодування біна: біни кодуються за допомогою арифметичного кодера. Для кодування біна, арифметичному кодеру як вхідні дані потрібна імовірність значення біна, тобто імовірність того, що значення біна дорівнює "0", і імовірність того, що значення біна дорівнює "1". (Оцінена) імовірність кожного контексту представляється цілочисельним значенням, яке називається "станом контексту". Кожний контекст має стан, і, відповідно, цей стан (тобто оцінена імовірність) є ідентичним для бінів, призначених одному контексту, і відрізняється між контекстами. (4) Оновлення стану: імовірність (стан) для вибраного контексту оновлюється на основі фактичного закодованого значення біна (наприклад, якщо значення біна було "1", то імовірність "1" збільшується). Потрібно зазначити, що ентропійне кодування з розділенням на інтервали імовірності (PIPE) використовує принципи, аналогічні принципам арифметичного кодування, і може використовувати способи, аналогічні способам цього розкриття, які спочатку описані у відношенні CABAC. Способи цього розкриття, однак, можуть використовуватися з CABAC, PIPE або іншими методологіями ентропійного кодування, які використовують технології перетворення в двійкову форму. Один спосіб, недавно прийнятий для HM4.0, описаний в V. Seregin, I.-K Kim, "Binarisation modification for last position coding", JCTVC-F375, 6th JCT-VC Meeting, Torino, IT, July, 2011 (в цьому описі "Seregin"). Спосіб, прийнятий в HM4.0, скорочує контексти, що використовуються при кодуванні останньої позиції, для CABAC за допомогою введення кодів з фіксованою довжиною слова з режимом обходу. Режим обходу означає, що процедура контекстного моделювання відсутня, і кожний символ кодується за станом рівної імовірності. Збільшення числа бінів, що кодуються в режимі обходу, нарівні із скороченням бінів у звичайному режимі може сприяти прискоренню і розпаралелюванню кодека. У способі, прийнятому в HM4.0, максимально можлива величина компонента останньої позиції, max_length, ділиться порівну на дві половини. Перша половина кодується за допомогою зрізаного унарного коду, а друга половина кодується за допомогою кодів з фіксованою довжиною слова (причому кількість бінів дорівнює log2(max_length/2)). При найгіршому сценарії кількість бінів, які використовують контекстне моделювання, дорівнює max_length/2. В таблиці 1 представлене перетворення в двійкову форму для TU 32×32 в HM4.0. 9 UA 111246 C2 Таблиця 1 Перетворення в двійкову форму для TU 32×32 в HM4.0, де X означає 1 або 0 Величина компонента останньої позиції 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16-31 5 10 15 20 25 30 35 Зрізаний унарний (контекстна модель) 1 01 001 0001 00001 000001 0000001 00000001 000000001 0000000001 00000000001 000000000001 0000000000001 00000000000001 000000000000001 0000000000000001 0000000000000000 Фіксований двійковий (обхід) ХХХХ Це розкриття забезпечує способи для контекстно-адаптивного двійкового арифметичного кодування (CABAC) позиції останнього значущого коефіцієнта. В одному прикладі може використовуватися прогресивна структура кодового слова із скороченою кількістю бінів і більш короткими зрізаними унарними кодами. Крім того, в одному прикладі із скороченням максимальної довжини зрізаного унарного коду кількість контекстних моделей для позиції останнього значущого коефіцієнта може бути скорочена на два. Фіг.4 є структурною схемою, яка ілюструє приклад відеокодера 20, в якому можуть бути реалізовані способи, описані в цьому розкритті. Відеокодер 20 може виконувати інтра- та інтеркодування відеоблоків всередині відеослайсів. Інтракодування основане на просторовому прогнозуванні для скорочення або видалення просторової надмірності у відео всередині даного відеокадру або картинки. Інтеркодування основане на часовому прогнозуванні для скорочення або видалення часової надмірності у відео всередині суміжних кадрів або картинок відеопослідовності. Інтрарежим (I-режим) може відноситися до будь-якого з декількох просторових режимів стиснення. Інтеррежими, наприклад, однонаправлене прогнозування (Ррежим) або двонаправлене прогнозування (В-режим), можуть відноситися до будь-якого з декількох часових режимів стиснення. У прикладі на фіг.4 відеокодер 20 включає в себе блок 35 розділення, модуль 41 прогнозування, пам'ять 64 для опорних картинок, суматор 50, модуль 52 перетворення, блок 54 квантування і блок 56 ентропійного кодування. Модуль 41 прогнозування включає в себе блок 42 оцінки руху, блок 44 компенсації руху і модуль 46 інтрапрогнозування. Для відновлення відеоблока відеокодер 20 також включає в себе блок 58 оберненого квантування, модуль 60 оберненого перетворення і суматор 62. Для фільтрації меж блока для усунення артефактів блочності з відновленого відео в склад також може бути включений фільтр для видалення блочності (не зображений на фіг.2). Якщо потрібно, то фільтр для видалення блочності може в основному фільтрувати вихідні дані суматора 62. Додатково до фільтра для видалення блочності також можуть використовуватися додаткові контурні фільтри (в циклі або після циклу). Як подано на фіг.4, відеокодер 20 приймає відеодані, і блок 35 розділення розділяє дані на відеоблоки. Це розділення також може включати в себе розділення на слайси, мозаїчні фрагменти або інші великі одиниці, а також розділення на відеоблоки, наприклад, згідно зі структурою квадрадерева одиниць LCU та CU. У відеокодері 20 звичайно ілюструються компоненти, за допомогою яких кодують відеоблоки всередині відеослайса, який повинен бути закодований. Слайс може бути розділений на множину відеоблоків (і, можливо, на набори відеоблоків, які називаються мозаїчними фрагментами). Модуль 41 прогнозування для поточного відеоблока може вибирати один з множини можливих способів кодування, наприклад, 10 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 один з множини режимів інтракодування або один з множини режимів інтеркодування, на основі результатів розузгодження (наприклад, швидкість кодування і рівень спотворення). Модуль 41 прогнозування може забезпечувати результуючий блок, закодований за допомогою інтра- або інтеркодування, в суматор 50 для генерації даних залишкового блока і в суматор 62 для відновлення закодованого блока для використання як опорної картинки. Модуль 46 інтрапрогнозування всередині модуля 41 прогнозування може виконувати кодування з інтрапрогнозуванням поточного відеоблока відносно одного або декількох сусідніх блоків у ідентичному кадрі або слайсі як поточного блока, який повинен бути закодований, для забезпечення просторового стиснення. Блок 42 оцінки руху і блок 44 компенсації руху всередині модуля 41 прогнозування виконують кодування з інтерпрогнозуванням поточного відеоблока відносно одного або декількох прогнозуючих блоків в одній або декількох опорних картинках для забезпечення часового стиснення. Блок 42 оцінки руху може бути виконаний з можливістю визначення режиму інтерпрогнозування для відеослайса згідно із зумовленим конкретним набором для відеопослідовності. У зумовленому конкретному наборі відеослайси в послідовності можуть маркуватися як прогнозуючі слайси (Р-слайси), слайси з двонаправленим прогнозуванням (Вслайси) або узагальнені Р- та В-слайси (GPB-слайси). Р-слайс може посилатися на попередню картинку послідовності. В-слайс може посилатися на попередню картинку послідовності або подальшу картинку послідовності. GPB-слайси відносяться до випадку, коли два списки опорних картинок є ідентичними. Блок 42 оцінки руху і блок 44 компенсації руху можуть бути високоінтегрованими, але зображені окремо для представлення у вигляді схеми. Оцінка руху, що виконується блоком 42 оцінки руху, є процесом генерації векторів руху, які оцінюють рух для відеоблоків. Вектор руху, наприклад, може вказувати зміщення PU відеоблока всередині поточного відеокадру або картинки відносно прогнозуючого блока всередині опорної картинки. Прогнозуючий блок є блоком, який згідно з обчисленнями краще усього узгодиться з PU відеоблока, який повинен бути закодований, в значенні різниці пікселів, яка може визначатися сумою абсолютних значень різниці (sum of absolute difference, SAD), сумою квадратів різниць (sum of square difference, SSD) або іншими різницевими метриками. У деяких прикладах відеокодер 20 може обчислювати значення для позицій менше, ніж цілого пікселя, опорних картинок, що зберігається в пам'яті 64 для опорних картинок. Наприклад, відеокодер 20 може інтерполювати значення позицій однієї чверті пікселя, позицій однієї восьмої пікселя або інших позицій дробового пікселя опорного картинки. Отже, блок 42 оцінки руху може виконувати пошук руху відносно позицій повного пікселя і позицій дробового пікселя і виводити вектор руху з точністю дробового пікселя. Блок 42 оцінки руху обчислює вектор руху для PU відеоблока в слайсі з інтеркодуванням за допомогою порівняння позиції PU з позицією прогнозуючого блока опорної картинки. Опорна картинка може бути вибрана з першого списку опорних картинок (список 0) або другого списку опорних картинок (список 1), кожний з яких ідентифікує одну або декілька опорних картинок, що зберігаються в пам'яті 64 для опорних картинок. Блок 42 оцінки руху відправляє обчислений вектор руху в блок 56 ентропійного кодування і блок 44 компенсації руху. Компенсація руху, що виконується блоком 44 компенсації руху, може містити вибірку або генерацію прогнозуючого блока на основі вектора руху, що визначається за допомогою оцінки руху, можливо, з виконанням інтерполяції з точністю менше, ніж цілий піксель. Після прийому вектора руху для PU поточного відеоблока блок 44 компенсації руху може визначати місцеположення прогнозуючого блока, на який вказує вектор руху в одному зі списків опорних картинок. Відеокодер 20 формує залишковий відеоблок за допомогою віднімання значень пікселів прогнозуючого блока із значень пікселів поточного кодованого відеоблока з формуванням значень різниць пікселів. Значення різниць пікселів формують залишкові дані для блока і можуть включати в себе компоненти різниці як кольоровості, так і яскравості. Суматор 50 представляє компонент або компоненти, які виконують цю операцію віднімання. Блок 44 компенсації руху також може генерувати синтаксичні елементи, асоційовані з відеоблоками і відеослайсом, для використання відеодекодером 30 при декодуванні відеоблоків відеослайса. Модуль 46 інтрапрогнозування може виконувати інтрапрогнозування поточного блока як альтернативу інтерпрогнозуванню, що виконується блоком 42 оцінки руху і блоком 44 компенсації руху, як описано вище. Зокрема, модуль 46 інтрапрогнозування може визначати режим інтрапрогнозування для використання його для кодування поточного блока. У деяких прикладах модуль 46 інтрапрогнозування може кодувати поточний блок з використанням різних режимів інтрапрогнозування, наприклад, під час окремих проходів кодування, і модуль 46 інтрапрогнозування (або блок 40 вибору режиму в деяких прикладах) може вибирати для використання адекватний режим інтрапрогнозування з режимів, що тестуються. Наприклад, 11 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 модуль 46 інтрапрогнозування може обчислювати значення швидкість-спотворення з використанням аналізу швидкість-спотворення для різних режимів інтрапрогнозування, що тестуються, і вибирати з числа згаданих режимів, що тестуються, режим інтрапрогнозування з кращими характеристиками швидкість-спотворення. Аналіз швидкість-спотворення звичайно визначає ступінь спотворення (або помилку) між закодованим блоком і вихідним, незакодованим блоком, який був закодований для створення закодованого блока, а також швидкість передачі бітів (тобто кількість бітів), що використовується для створення закодованого блока. Модуль 46 інтрапрогнозування може обчислювати відношення, виходячи зі спотворень і швидкостей для різних закодованих блоків для визначення того, який режим інтрапрогнозування демонструє краще значення швидкість-спотворення для цього блока. У будь-якому випадку, після вибору режиму інтрапрогнозування для блока модуль 46 інтрапрогнозування може забезпечувати інформацію, яка вказує вибраний режим інтрапрогнозування для згаданого блока, в блок 56 ентропійного кодування. Блок 56 ентропійного кодування може кодувати інформацію, яка вказує вибраний режим інтрапрогнозування, відповідно до способів цього розкриття. Відеокодер 20 може включати в дані конфігурації бітового потоку, що передаються, які можуть включати в себе множину таблиць індексів режиму інтрапрогнозування і множину модифікованих таблиць індексів режиму інтрапрогнозування (які також називаються таблицями відображення кодових слів), визначення контекстів кодування для різних блоків і вказівки найбільш імовірного режиму інтрапрогнозування, таблицю індексів режиму інтрапрогнозування і модифіковану таблицю індексів режиму інтрапрогнозування для використання для кожного з контекстів. Після того як модуль прогнозування 41 генерує прогнозуючий блок для поточного блока відеоданих, або за допомогою інтерпрогнозування або за допомогою інтрапрогнозування, відеокодер 20 формує залишковий блок відеоданих за допомогою віднімання прогнозуючого блока з поточного блока відеоданих. Залишкові відеодані в залишковому блоці можуть бути включені в одну або декілька TU і застосовуватися в модулі 52 перетворення. З використанням перетворення, наприклад, дискретного косинусного перетворення (DCT) або концептуально аналогічного перетворення, модуль 52 перетворення перетворює залишкові відеодані в залишкові коефіцієнти перетворення. Модуль 52 перетворення може перетворювати залишкові відеодані з піксельної ділянки в ділянку перетворення, наприклад, в частотну ділянку. Модуль 52 перетворення може відправляти результуючі коефіцієнти перетворення в блок 54 квантування. Блок 54 квантування квантує коефіцієнти перетворення для подальшого скорочення швидкості передачі бітів. Процес квантування може скорочувати бітову глибину, асоційовану з деякими або усіма коефіцієнтами. Ступінь квантування може бути модифікована за допомогою настройки параметрів квантування. У деяких прикладах блок 54 квантування може після цього виконувати сканування матриці, що включає в себе квантовані коефіцієнти перетворення. Як альтернатива, згадане сканування може виконувати блок 56 ентропійного кодування. Блок 58 оберненого квантування і модуль 60 оберненого перетворення застосовують обернене квантування та обернене перетворення, відповідно, для відновлення залишкового блока в піксельній ділянці для подальшого використання як опорного блока опорної картинки. Блок 44 компенсації руху може обчислювати опорний блок за допомогою додавання залишкового блока до прогнозуючого блока однієї з опорних картинок в межах одного зі списків опорних картинок. Блок 44 компенсації руху також може застосовувати один або декілька фільтрів-інтерполяторів до відновленого залишкового блока для обчислення значень менше, ніж цілого пікселя, для використання при оцінці руху. Суматор 62 додає відновлений залишковий блок до блока прогнозування з компенсованим рухом, створеного блоком 44 компенсації руху, для створення опорного блока для зберігання в пам'яті 64 для опорних картинок. Згаданий опорний блок може використовуватися блоком 42 оцінки руху і блоком 44 компенсації руху як опорний блок для інтерпрогнозування блока в подальшому відеокадрі або картинці. Після квантування блок 56 ентропійного кодування кодує квантовані коефіцієнти перетворення з використанням ентропійного кодування. Наприклад, блок 56 ентропійного кодування може виконувати контекстно-адаптивне кодування із змінною довжиною (CAVLC), контекстно-адаптивне двійкове арифметичне кодування (CABAC), контекстно-адаптивне двійкове арифметичне кодування на основі синтаксису (SBAC), ентропійне кодування з розділенням на інтервали імовірності (PIPE) або інший спосіб або методологію ентропійного кодування. Після ентропійного кодування блоком 56 ентропійного кодування закодований бітовий потік може передаватися у відеодекодер 30 або архівуватися для подальших передачі або витягання відеодекодером 30. Блок 56 ентропійного кодування також може кодувати з 12 UA 111246 C2 5 10 15 20 25 30 35 40 45 використанням ентропійного кодування вектори руху та інші синтаксичні елементи для поточного кодованого відеослайса. В одному прикладі блок 56 ентропійного кодування може кодувати позицію останнього значущого коефіцієнта з використанням способу, прийнятого в HM4.0, описаному вище. В інших прикладах блок 56 ентропійного кодування може кодувати позицію останнього значущого коефіцієнта з використанням способів, які можуть забезпечувати поліпшене кодування. Зокрема, блок 56 ентропійного кодування може використовувати прогресивну схему кодування останньої позиції для декількох можливих розмірів TU. В одному прикладі кодове слово для позиції останнього значущого коефіцієнта може включати в себе префікс зрізаного унарного коду, за яким йде суфікс коду з фіксованою довжиною слова. В одному прикладі кожна величина останньої позиції може використовувати ідентичне перетворення в двійкову форму для всіляких розмірів TU, крім тих випадків, коли остання позиція дорівнює розміру TU мінус 1. Ця виняткова ситуація має місце через властивості зрізаного унарного кодування. В одному прикладі позиція останнього значущого коефіцієнта в межах коефіцієнта ортогонального перетворення може бути задана за допомогою завдання значення х-координати і значення у-координати. В іншому прикладі блок коефіцієнтів перетворення може бути у вигляді вектора 1×N, і позиція останнього значущого коефіцієнта всередині цього вектора може задаватися значенням позиції сигналу. В одному прикладі розмір TU може визначатися T. Як детально описано вище, TU може мати квадратну або неквадратну форму. Відповідно, Т може відноситься або до кількості рядків або стовпців двомірної TU або до довжини вектора. У прикладі, де схема зрізаного унарного кодування забезпечує декілька нульових бітів, за якими йде одиничний біт, кількість нулів префікса зрізаного унарного коду, що кодує позицію останнього значущого коефіцієнта, може бути визначена згідно з N={0, ..., 2log2(T)-1}. Потрібно зазначити, що в прикладі, де схема зрізаного унарного кодування забезпечує декілька одиничних бітів, за якими йде нульовий біт, N={0, ..., 2log2(T)-1} також може визначати кількість одиниць. У кожному з цих альтернативних варіантів зрізаного унарного кодування 2log2(T)-1 може визначати максимальну довжину зрізаного унарного префікса для TU розміру T. Наприклад, для TU, коли Т дорівнює 32, максимальна довжина зрізаного унарного префікса дорівнює дев'яти, і коли Т дорівнює 16, максимальна довжина зрізаного унарного префікса дорівнює семи. Для зрізаного унарного коду, значення n, суфікс коду з фіксованою довжиною слова може включати в себе наступні b бітів двійкового коду з фіксованою довжиною слова зі значенням з b тих, що визначаються таким чином: f_value={0, ..., 2 -1}, де b=max(0, n/2-1). Відповідно, величина останньої позиції, last_pos, може бути одержана з n та f_value як: де mod(.) представляє модулярну операцію, і f_value представляє значення коду з фіксованою довжиною слова. У таблиці 2 представлений приклад перетворення в двійкову форму позиції останнього значущого коефіцієнта згідно з визначеннями, що забезпечуються згідно з рівнянням 1 для TU 32×32. Другий стовпець таблиці 2 передбачає відповідні значення зрізаного унарного префікса для можливих значень позиції останнього значущого коефіцієнта всередині TU розміру Т з 2log2(Т)-1, що визначаються максимальною довжиною зрізаного унарного префікса. Третій стовпець таблиці 2 забезпечує відповідний суфікс з фіксованою довжиною слова для кожного зрізаного унарного префікса. Скорочено таблиця 2 включає в себе значення X, які вказують на значення біта або одиницю або нуль. Потрібно відмітити те, що значення X однозначно відображають кожне значення зі спільним використанням зрізаного унарного префікса згідно з кодом з фіксованою довжиною слова. Величина компонента останньої позиції в таблиці 2 може відповідати значенню х-координати і/або значенню у-координати. 13 UA 111246 C2 Таблиця 2 Перетворення в двійкову форму для TU розміру 32×32, де X означає 1 або 0 Величина компонента останньої позиції 0 1 2 3 4-5 6-7 8-11 12-15 16-23 24-31 5 10 Зрізаний унарний (контекстна модель) 1 01 001 0001 00001 000001 0000001 00000001 000000001 000000000 Фіксований двійковий (обхід) Х Х ХХ ХХ ХХХ ХХХ f_value 0 0 0 0 0-1 0-1 0-3 0-3 0-7 0-7 У таблицях 3 та 4 представлене порівняння максимальної довжини рядків бітів для прикладу схеми перетворення в двійкову форму, описаної відносно таблиці 1, і прикладу схеми перетворення в двійкову форму, (описаної) відносно таблиці 2. Як представлено в таблиці 3, в прикладі, описаному відносно таблиці 1, згаданий префікс унарного коду може мати максимальну довжину 16 бінів для TU 32×32. У той самий час, в прикладі, описаному відносно таблиці 2, згаданий префікс унарного коду може мати максимальну довжину 16 бінів для TU 32×32. Крім того, як представлено в таблиці 4, загальна довжина (на основі) зрізаного унарного префікса і суфікса з фіксованою довжиною слова, максимальна кількість бінів для прикладу, описаного відносно таблиці 2, може бути така, що дорівнює 24 в найгіршому випадку, тобто тоді, коли остання позиція знаходиться в кінці TU 32×32, тоді як найгірший випадок для прикладу, описаного з посиланням на таблицю 1, може бути 40. Таблиця 3 Максимальна довжина зрізаного унарного коду Таблиця 1 3 4 8 16 31 15 TU 4×4 TU 8×8 TU 16×16 TU 32×32 Усього (яскравість) Усього (кольоровість) Таблиця 2 3 5 7 9 24 15 Таблиця 4 Максимальна довжина бінів в одному компоненті останньої позиції TU 4×4 TU 8×8 TU 16×16 TU 32×32 Таблиця 1 3 6 11 20 Таблиця 2 3 6 9 12 15 20 В іншому прикладі схеми зрізаного унарного кодування, яка забезпечує декілька нульових бітів, за якими йде одиничний біт або декілька одиничних бітів, за якими йде одиничний біт, префікс зрізаного унарного коду, що кодує позицію останнього значущого коефіцієнта, може бути визначений згідно з N={0, ..., log2(T)+1}. У кожній з цих схем зрізаного унарного кодування log2(Т)+1 може визначати максимальну довжину зрізаного унарного префікса для TU розміру T. Наприклад, для TU, коли Т дорівнює 32, максимальна довжина зрізаного унарного префікса дорівнює шести, і коли Т дорівнює 8, максимальна довжина зрізаного унарного префікса дорівнює п'яти. 14 UA 111246 C2 Для зрізаного унарного коду, значення n, суфікс коду з фіксованою довжиною слова може включати в себе наступні b бітів двійкового коду з фіксованою довжиною слова зі значенням з b тих, що визначаються таким чином: f_value={0,. .., 2 -1}, де b=n-2. Відповідно, величина останньої позиції, last_pos, може бути одержана з n та f_value як: 5 10 15 де f_value представляє значення коду з фіксованою довжиною слова. У таблиці 5 представлений приклад перетворення в двійкову форму позиції останнього значущого коефіцієнта згідно з визначеннями, що забезпечуються згідно з рівнянням 2 для TU 32×32. Другий стовпець таблиці 5 передбачає відповідні значення зрізаного унарного префікса для можливих значень позиції останнього значущого коефіцієнта всередині TU розміру Т з log2(Т)+1, що визначаються максимальною довжиною зрізаного унарного префікса. Третій стовпець таблиці 5 забезпечує відповідний суфікс з фіксованою довжиною слова для кожного зрізаного унарного префікса. Скорочено таблиця 2 включає в себе значення X, які вказують на значення біта або одиницю або нуль. Потрібно відмітити те, що значення X однозначно відображають кожне значення зі спільним використанням зрізаного унарного префікса згідно з кодом з фіксованою довжиною слова. Величина компонента останньої позиції в таблиці 5 може відповідати значенню х-координати і/або значенню у-координати. Таблиця 5 Приклад перетворення в двійкову форму для TU 32×32, де X означає 1 або 0 Величина компонента останньої позиції 0 1 2 3 4-7 8-15 16-31 20 25 30 35 40 Зрізаний унарний (контекстна модель) 1 01 001 0001 00001 000001 000000 Фіксований двійковий (обхід) ХХ ХХХ ХХХХ f_value 0 0 0 0 0-3 0-7 0-15 В іншому прикладі схеми зрізаного унарного кодування, яка забезпечує декілька нульових бітів, за якими йде одиничний біт або декілька одиничних бітів, за якими йде одиничний біт, префікс зрізаного унарного коду, що кодує позицію останнього значущого коефіцієнта, може бути визначений згідно з N={0,. .., log2(Т)}. У кожній з цих схем зрізаного унарного кодування log2(Т) може визначати максимальну довжину зрізаного унарного префікса для TU розміру T. Наприклад, для TU, коли Т дорівнює 32, максимальна довжина зрізаного унарного префікса дорівнює п'яти, і коли Т дорівнює 8, максимальна довжина зрізаного унарного префікса дорівнює п'яти. Для зрізаного унарного коду, значення n, суфікс коду з фіксованою довжиною слова може включати в себе наступні b бітів двійкового коду з фіксованою довжиною слова зі значенням з b тих, що визначаються таким чином: f_value={0,. .., 2 -1}, де b=n-1. Відповідно, величина останньої позиції, last_pos, може бути одержана з n та f_value як: де f_value представляє значення коду з фіксованою довжиною слова. У таблиці 6 представлений приклад перетворення в двійкову форму позиції останнього значущого коефіцієнта згідно з визначеннями, що забезпечуються згідно з рівнянням 3 для TU 32×32. Другий стовпець таблиці 6 передбачає відповідні значення зрізаного унарного префікса для можливих значень позиції останнього значущого коефіцієнта всередині TU розміру Т з log2(Т), що визначаються максимальною довжиною зрізаного унарного префікса. Третій стовпець таблиці 6 забезпечує відповідний суфікс з фіксованою довжиною слова для кожного зрізаного унарного префікса. Скорочено таблиця 6 включає в себе значення X, які вказують на значення біта або одиницю або нуль. Потрібно відмітити те, що значення X однозначно відображають кожне значення зі спільним використанням зрізаного унарного префікса згідно з 15 UA 111246 C2 кодом з фіксованою довжиною слова. Величина компонента останньої позиції в таблиці 6 може відповідати значенню х-координати і/або значенню у-координати. Таблиця 6 Приклад перетворення в двійкову форму для TU 32×32, де X означає 1 або 0 Величина компонента останньої позиції 0 1 2-3 4-7 8-15 16-31 5 10 15 20 25 30 Зрізаний унарний (контекстна модель) 1 01 001 0001 00001 00000 Фіксований двійковий (обхід) Х ХХ ХХХ ХХХХ f_value 0 0 0-1 0-3 0-7 0-15 У таблицях 5 та 6 представлені деякі альтернативні приклади використання зрізаного унарного префікса і суфікса з фіксованою довжиною слова для кодування позиції останнього значущого коефіцієнта. Приклади, представлені в таблицях 5 та 6, забезпечують можливістьбільш коротких бінів, ніж приклад, забезпечений відносно таблиці 2. Слід зазначити, що в прикладі, де позиція останнього значущого коефіцієнта визначається на основі значення хкоординати і значення у-координати, будь-яка з ілюстративних схем перетворення в двійкову форму, представлених в таблицях 1, 2, 5 та 6, може бути вибрана незалежно для значення хкоординати і значення у-координати. Наприклад, значення х-координати може кодуватися на основі схеми перетворення в двійкову форму, описаної відносно таблиці 2, тоді як значення укоординати може кодуватися на основі схеми перетворення в двійкову форму, описаної відносно таблиці 6. Як описано вище, символи даних кодування з використанням CABAC можуть мати на увазі один або декілька з наступних етапів перетворення в двійкову форму і призначення контексту. В одному прикладі контекстне моделювання значення останньої позиції може використовуватися для арифметичного кодування зрізаних унарних рядків, тоді як контекстне моделювання не може використовуватися для арифметичного кодування фіксованих двійкових рядків (тобто з обходом). У випадку, коли зрізані унарні рядки кодуються з використанням контекстного моделювання, кожному індексу біна двійкового рядка призначають контекст. Окремі індекси біна можуть спільно використовувати призначення контексту. Кількість призначень контексту дорівнює кількості індексів біна або довжині зрізаного унарного рядка. Відповідно, у випадку прикладів, що ілюструються в таблицях 1, 2, 5 та 6, асоційовані контекстні таблиці можуть бути задані відповідно схемі перетворення в двійкову форму. У таблиці 7 ілюструється можлива контекстна індексація для кожного біна різних розмірів TU для ілюстративних перетворень в двійкову форму, забезпечених вище з посиланням на вищенаведену таблицю 2. Потрібно відмітити те, що ілюстративна контекстна індексація, забезпечена в таблиці 7, забезпечує в два рази менше контекстів, ніж контекстна індексація, забезпечена в Seregin. Таблиця 7 Індекс біна TU 4×4 TU 8×8 TU 16×16 TU 32×32 35 0 0 3 7 12 1 1 4 8 13 2 2 5 9 14 3 4 5 6 7 8 5 9 14 6 10 15 10 15 11 16 16 17 Кожна з таблиць 8-11 ілюструє декілька прикладів контекстної індексації згідно з нижченаведеними правилами, створеними для контекстного моделювання: 1. Перші K бінів спільно не використовують контекст, де K>1. K може бути різним для кожного розміру TU. 2. Один контекст може бути призначений тільки послідовним бінам. Наприклад, бін 3 - бін 5 можуть використовувати контекст 5. Але не допускається, що бін 3 і бін 5 використовують контекст 5, а бін 4 використовує контекст 6. 16 UA 111246 C2 5 3. Останні N (бінів), N>=0, різних розмірів TU можуть спільно використовувати ідентичний контекст. 4. Кількість бінів, які спільно використовують ідентичний контекст, збільшується із збільшенням розмірів TU. Вищенаведені правила 1-4 можуть бути, зокрема, корисними для перетворення в двійкову форму, забезпеченого в таблиці 2. Однак контекстне моделювання можна настроювати відповідно на основі реалізованої схеми перетворення в двійкову форму. Таблиця 8 Індекс біна TU 4×4 TU 8×8 TU 16×16 TU 32×32 0 0 3 8 13 1 1 4 9 14 2 2 5 10 14 3 4 5 6 7 8 6 11 15 7 11 16 12 16 12 16 16 17 Таблиця 9 Індекс біна TU 4×4 TU 8×8 TU 16×16 TU 32×32 0 0 3 8 13 1 1 4 9 14 2 2 5 10 14 3 4 5 6 7 8 6 11 15 6 11 16 12 16 12 16 16 17 10 Таблиця 10 Індекс біна TU 4×4 TU 8×8 TU 16×16 TU 32×32 0 0 3 8 13 1 1 4 9 14 2 2 5 10 14 3 4 5 6 7 8 6 11 15 7 11 16 12 16 12 16 12 12 Таблиця 11 Індекс біна TU 4×4 TU 8×8 TU 16×16 TU 32×32 15 20 25 30 0 0 3 8 13 1 1 4 9 14 2 2 5 10 14 3 4 5 6 7 8 6 10 15 7 11 15 11 15 12 16 16 16 Фіг.5 є структурною схемою, яка ілюструє приклад ентропійного кодера 56, в якому можуть бути реалізовані способи, описані в цьому розкритті. Ентропійний кодер 56 приймає синтаксичні елементи, наприклад, один або декілька синтаксичних елементів, що представляють позицію останнього значущого коефіцієнта перетворення в межах коефіцієнтів блока перетворення, і кодує цей синтаксичний елемент у бітовий потік. Синтаксичні елементи можуть включати в себе синтаксичний елемент, який задає х-координату позиції останнього значущого коефіцієнта всередині блока коефіцієнтів перетворення, і синтаксичний елемент, який задає у-координату позиції останнього значущого коефіцієнта всередині блока коефіцієнтів перетворення. В одному прикладі ентропійний кодер 56, зображений на фіг.5, може бути кодером CABAC. Ілюстративний ентропійний кодер 56 на фіг.5 може включати в себе блок 502 перетворення в двійкову форму, блок 504 арифметичного кодування і блок 506 призначення контексту. Блок 502 перетворення в двійкову форму приймає синтаксичний елемент і створює рядок бінів. В одному прикладі блок 502 перетворення в двійкову форму приймає значення, що представляє останню позицію значущого коефіцієнта всередині блока коефіцієнтів перетворення, і створює рядок бітів або значення біна згідно з прикладами, описаними вище. Блок 504 арифметичного кодування приймає рядок бітів з блока 502 перетворення в двійкову форму і виконує арифметичне кодування цього кодового слова. Як представлено на фіг.5, арифметичний кодер 504 може приймати значення бінів шляхом обходу або з блока 506 контекстного моделювання. У випадку, коли блок 504 арифметичного кодування приймає 17 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 значення бінів з блока 506 контекстного моделювання, блок 504 арифметичного кодування може виконувати арифметичне кодування на основі призначення контекстів, що забезпечуються блоком 506 призначення контексту. В одному прикладі блок 504 арифметичного кодування може використовувати призначення контекстів для кодування частини префікса рядка бітів і може кодувати частину суфікса рядка бітів без використання призначення контекстів. В одному прикладі блок 506 призначення контексту може призначати контексти на основі ілюстративної контекстної індексації, забезпеченої у вищенаведених таблицях 7-11. Відповідно, відеокодер 20 представляє відеокодер, виконаний з можливістю одержання значення, який вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, log2(Т)+1 або log2(Т), визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова і кодування першого і другого двійкових рядків у бітовий потік. Фіг.6 є блок-схемою, що ілюструє приклад способу визначення двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, згідно зі способами цього розкриття. Спосіб, описаний на фіг.6, може бути виконаний будь-яким з ілюстративних відеокодерів або ентропійних кодерів, описаних в цьому документі. На етапі 602 одержують значення, яке вказує позицію останнього значущого коефіцієнта перетворення всередині відеоблока. На етапі 604 визначають двійковий рядок префікса для значення, яке вказує позицію останнього значущого коефіцієнта. Двійковий рядок префікса може бути визначений з використанням будь-якого зі способів, описаних в цьому документі. В одному прикладі двійковий код префікса може бути оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log 2(Т)-1, де Т визначає розмір відеоблока. У ще одному прикладі двійковий код префікса може бути оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)+1, де Т визначає розмір відеоблока. У ще одному прикладі двійковий код префікса може бути оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т), де Т визначає розмір відеоблока. Двійковий рядок префікса може визначатися кодером, що виконує ряд обчислень, кодером, що використовує таблиці відповідності, або їх комбінацією. Наприклад, для визначення двійкового рядка префікса кодер може використовувати будь-яку з таблиць 2, 5 та 6. На етапі 606 визначають двійковий рядок суфікса для значення, яке вказує позицію останнього значущого коефіцієнта. Двійковий рядок суфікса може бути визначений з використанням будь-якого зі способів, описаних в цьому документі. В одному прикладі двійковий рядок суфікса може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log 2(Т)-2, де Т визначає розмір відеоблока. У ще одному прикладі двійковий рядок суфікса може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)-1, де Т визначає розмір відеоблока. Двійковий рядок суфікса може визначатися кодером, що виконує ряд обчислень, кодером, що використовує таблиці відповідності, або їх комбінацією. Наприклад, для визначення двійкового рядка суфікса кодер може використовувати будь-яку з таблиць 2, 5 та 6. На етапі 608 двійкові рядки суфікса і префікса кодуються в бітовий потік. В одному прикладі двійкові рядки суфікса і префікса можутькодуватися з використанням арифметичного кодування. Потрібно відмітити те, що частину суфікса і префікса бітового потоку можна поміняти місцями. Арифметичне кодування може бути частиною процесу кодування CABAC або частиною іншого процесу ентропійного кодування. Таблиці 12-14 забезпечують зведення результатів моделювання виконання кодування ілюстративної схеми перетворення в двійкову форму, описаної з посиланням на таблицю 1, і ілюстративної схеми перетворення в двійкову форму, описаної з посиланням на таблицю 2. Результати моделювання в таблицях 12-14 були одержані з використанням загальних умов тестування з високоефективним кодуванням, як визначено в: F. Bossen, "Common test conditions and software reference configurations", JCTVC-F900. Негативні значення в таблицях 12-14 вказують на більш низьку швидкість передачі бітів схеми перетворення в двійкову форму, описаної з посиланням на таблицю 2, в порівнянні зі схемою перетворення в двійкову форму, описаною з посиланням на таблицю 1. Час код і Час декод в таблицях 12-14 описують час, 18 UA 111246 C2 5 10 необхідний для кодування і декодування, відповідно, бітового потоку, зумовлений використанням схеми перетворення в двійкову форму, описаної з посиланням на таблицю 2, в зіставленні з часом, необхідним для кодування (або декодування) бітового потоку, зумовленим використанням схеми перетворення в двійкову форму, описаної з посиланням на таблицю 1. Як видно з експериментальних результатів, наданих в таблицях 12-14, схема перетворення в двійкову форму, описана з посиланням на таблицю 2, забезпечує відповідний виграш в продуктивності за BD-швидкістю -0,04%, -0,01% та -0,03% за умов тестування з високоефективним тільки інтракодуванням, з довільним доступом і малою затримкою. Класи A-E в нижченаведених таблицях представляють різні послідовності відеоданих. Стовпці Y, U та V відповідають даним для яскравості, U-кольоровості і V-кольоровості, відповідно. У таблиці 12 ці дані узагальнені для конфігурації, в якій всі дані кодуються в інтрарежимі. У таблиці 13 ці дані узагальнені для конфігурації, в якій всі дані кодуються при "довільному доступі", де обидва режими інтра- та інтеркодування є доступними. У таблиці 14 ці дані узагальнені для конфігурації, в якій картинки кодуються в режимі В з малою затримкою. 15 Таблиця 12 Всі інтракодування HE Клас А Клас В Клас С Клас D Клас Е Всі Час код [%] Час декод [%] Y -0,03% -0,05% -0,02% -0,03% -0,08% -0,04% U 0,01% -0,03% -0,01% -0,01% -0,04% -0,02% 99% 100% V 0,02% -0,02% -0,02% -0,06% -0,01% -0,02% Таблиця 13 Довільний доступ HE Клас А Клас В Клас С Клас D Клас Е Всі Час код [%] Час декод [%] Y 0,03% -0,05% -0,01% 0,00% U 0,05% 0,04% -0,08% 0,01% V -0,07% -0,21% -0,03% -0,12% -0,01% 0,01% 100% 100% -0,11% Таблиця 14 З малою затримкою В HE Y Клас А Клас В Клас С Клас D Клас Е Загалом Час код [%] Час декод [%] U V -0,04% 0,02% 0,06% -0,21% -0,03% -0,16% -0,10% 0,57% -0,65% -0,05% 99% 100% -0,37% -0,24% -0,08% 0,66% -0,07% 19 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 Фіг.7 є структурною схемою, яка ілюструє приклад відеодекодера 30, в якому можуть бути реалізовані способи, описані в цьому розкритті. У прикладі за фіг.7 відеодекодер 30 включає в себе блок 80 ентропійного декодування, модуль 81 прогнозування, блок 86 оберненого квантування, модуль 88 оберненого перетворення, суматор 90 і пам'ять 92 для опорних картинок. Модуль 81 прогнозування включає в себе блок 82 компенсації руху і модуль 84 інтрапрогнозування. Відеодекодер 30, в деяких прикладах, виконує прохід декодування, звичайно обернений до проходу кодування, описаного з посиланням на відеокодер 20 з фіг.4. Під час процесу декодування відеодекодер 30 приймає бітовий потік закодованого відео, який представляє відеоблоки закодованого відеослайса, і асоційовані синтаксичні елементи з відеокодера 20. Блок 80 ентропійного декодування відеодекодера 30 декодує бітовий потік з використанням ентропійного декодування для генерації квантованих коефіцієнтів, векторів руху та інших синтаксичних елементів. Блок 80 ентропійного декодування може визначати значення, яке вказує позицію останнього значущого коефіцієнта в межах коефіцієнта перетворення, на основі способів, описаних в цьому документі. Блок 80 ентропійного декодування пересилає вектори руху та інші синтаксичні елементи в модуль 81 прогнозування. Відеодекодер 30 може приймати синтаксичні елементи на рівні відеослайса і/або на рівні відеоблока. Коли відеослайс закодований як слайс з інтракодуванням (I), модуль 84 інтрапрогнозування модуля 81 прогнозування може генерувати дані прогнозування для відеоблока поточного відеослайса на основі сигналізованого режиму інтрапрогнозування і дані з раніше декодованих блоків поточного кадру або картинки. Коли відеокадр закодований як слайс з інтеркодуванням (тобто В, Р або GPB), блок 82 компенсації руху модуля 81 прогнозування створює прогнозуючі блоки для відеоблока поточного відеослайса на основі векторів руху та інших синтаксичних елементів, прийнятих з блока 80 ентропійного декодування. Прогнозуючі блоки можуть створюватися з однієї з опорних картинок в межах одного зі списків опорних картинок. Відеодекодер 30 може конструювати списки опорних кадрів, список 0 і список 1, з використанням способів конструювання за умовчанням на основі опорних картинок, що зберігаються в пам'яті 92 для опорних кадрів. Блок 82 компенсації руху визначає інформацію прогнозування для відеоблока поточного відеослайса за допомогою здійснення синтаксичного аналізу векторів руху та інших синтаксичних елементів і використовує цю інформацію прогнозування для створення прогнозуючих блоків для поточного декодованого відеоблока. Наприклад, блок 82 компенсації руху використовує деякі з прийнятих синтаксичних елементів для визначення режиму прогнозування (наприклад, інтра- або інтерпрогнозування), використаного для кодування відеоблоків відеослайса, типу слайса інтерпрогнозування (наприклад, В-слайс, Р-слайс або GPB-слайс), інформації конструювання для одного або декількох зі списків опорних картинок для слайса, векторів руху для кожного відеоблока з інтеркодуванням слайса, статусу інтерпрогнозування для кожного відеоблока з інтеркодуванням слайса та іншої інформації для декодування відеоблоків у поточному відеослайсі. Блок 82 компенсації руху також може виконувати інтерполяцію на основі фільтрівінтерполяторів. Блок 82 компенсації руху може використовувати фільтри-інтерполятори, що використовуються відеокодером 20 під час кодування відеоблоків, для обчислення інтерпольованих значень для менше, ніж цілих пікселів опорних блоків. У цьому випадку блок 82 компенсації руху може визначати фільтри-інтерполятори, що використовуються відеокодером 20, виходячи з прийнятих синтаксичних елементів, і використовувати ці фільтри-інтерполятори для створення прогнозуючих блоків. Блок 86 оберненого квантування виконує обернене квантування, тобто деквантує квантовані коефіцієнти перетворення, забезпечені в бітовому потоці і декодовані блоком 80 ентропійного декодування. Процес оберненого квантування може включати в себе використання параметра квантування, що обчислюється відеокодером 20 для кожного відеоблока у відеослайсі, для визначення ступеня квантування, а також ступеня оберненого квантування, які повинні бути застосовані. Модуль 88 оберненого перетворення застосовує обернене перетворення, наприклад, обернене DCT, обернене цілочисельне перетворення або концептуально аналогічний процес оберненого перетворення, до коефіцієнтів перетворення для створення залишкових блоків у піксельній ділянці. Після генерації модулем 81 прогнозування прогнозуючого блока для поточного відеоблока на основі або інтер- або інтрапрогнозування відеодекодер 30 формує декодований відеоблок за допомогою підсумовування залишкових блоків з модуля 88 оберненого перетворення з відповідними прогнозуючими блоками, згенерованими модулем 81 прогнозування. Суматор 90 представляє компонент або компоненти, які виконують цю операцію підсумовування. Якщо потрібно, для усунення артефактів блочності також може бути застосований фільтр для 20 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 видалення блочності для фільтрації декодованих блоків. Для згладжування переходів між пікселями або поліпшення якості відео іншим чином також можуть використовуватися інші контурні фільтри (або в циклі кодування або після циклу кодування). Декодовані відеоблоки в даному кадрі або картинці після цього зберігаються в пам'яті 92 для опорних картинок, в якій зберігаються опорні картинки, що використовуються для подальшої компенсації руху. У пам'яті 92 для опорних кадрів також зберігається декодоване відео для подальшого відтворення на пристрої відображення, наприклад, на пристрої 32 відображення за фіг.1. Відповідно, відеодекодер 30 представляє відеодекодер, виконаний з можливістю одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. Фіг.8 є блок-схемою, що ілюструє приклад способу визначення значення, яке вказує позицію останнього значущого коефіцієнта в межах коефіцієнта перетворення, з двійкового рядка згідно зі способами цього розкриття. Спосіб, описаний на фіг.8, може бути виконаний будь-яким з ілюстративних відеодекодерів або блоків ентропійного декодування, описаних в цьому документі. На етапі 802 одержують закодований бітовий потік. Закодований бітовий потік може бути витягнутий з пам'яті або через передачу. Закодований бітовий потік може бути закодований згідно з процесом кодування CABAC або іншим процесом ентропійного кодування. На етапі 804 одержують двійковий рядок префікса. На етапі 806 одержують двійковий рядок суфікса. Двійковий рядок префікса і двійковий рядок суфікса можуть бути одержані за допомогою декодування закодованого бітового потоку. Декодування може включати в себе арифметичне декодування. Арифметичне декодування може бути частиною процесора для декодування CABAC або іншого процесу ентропійного декодування. На етапі 808 в межах відеоблока розміру Т визначають значення, яке вказує позицію останнього значущого коефіцієнта. В одному прикладі позиція останнього значущого коефіцієнта визначається, основуючись частково на двійковому рядку префікса, причому двійковий рядок префікса визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, де Т визначає розмір відеоблока. В одному прикладі позиція останнього значущого коефіцієнта визначається, основуючись частково на двійковому рядку префікса, причому двійковий рядок префікса визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log 2(Т)+1, де Т визначає розмір відеоблока. В одному прикладі позиція останнього значущого коефіцієнта визначається, основуючись частково на двійковому рядку префікса, причому двійковий рядок префікса визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(Т), де Т визначає розмір відеоблока. В одному прикладі позиція останнього значущого коефіцієнта (основана) частково на двійковому рядку суфікса, причому двійковий рядок суфікса визначається схемою кодування з фіксованою довжиною слова з максимальною довжиною в бітах, яка визначається за допомогою log 2(Т)-2, де Т визначає розмір відеоблока. У ще одному прикладі другий двійковий рядок може бути оснований на схемі кодування з фіксованою довжиною слова, яка визначається максимальною довжиною в бітах, яка визначається за допомогою log2(Т)-1, де Т визначає розмір відеоблока. Потрібно відмітити те, що частину суфікса і префікса бітового потоку можна поміняти місцями. В одному або декількох прикладах описані функції можуть бути реалізовані в апаратних засобах, програмному забезпеченні, програмно-апаратних засобах або будь-якій їх комбінації. Якщо функції реалізовані в програмному забезпеченні, то вони можуть зберігатися на зчитуваному комп'ютером носії або передаватися через нього у вигляді однієї або декількох інструкцій або коду, і виконуватися апаратним блоком обробки даних. Зчитувані комп'ютером носії можуть включати в себе зчитувані комп'ютером носії інформації, які відповідають матеріальному носію, наприклад, накопичувачам даних або середовищу зв'язку, що включає в себе будь-який носій, який сприяє передачі комп'ютерної програми з одного місця в інше, наприклад, згідно з протоколом зв'язку. Отже, зчитувані комп’ютером носії звичайно можуть відповідати (1) матеріальним зчитуваними комп'ютером носіям інформації, які не є проміжними, або (2) середовищам зв'язку, наприклад, сигналу або несучій хвилі. Накопичувачі даних можуть бути будь-якими доступними носіями, до яких можна одержати доступ за допомогою одного або декількох комп'ютерів або одного або декількох процесорів для витягання інструкцій, коду і/або 21 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 структур даних для реалізації способів, описаних в цьому розкритті. Комп'ютерний програмний продукт може включати в себе зчитуваний комп’ютером носій. В інших прикладах це розкриття передбачає зчитуваний комп’ютером носій, що містить структуру даних, яка зберігається на ньому, причому ця структура даних включає в себе закодований бітовий потік, що відповідає цьому розкриттю. Зокрема, закодований бітовий потік може включати в себе бітовий потік з ентропійним кодуванням, що включає в себе перший двійковий рядок і другий двійковий рядок, причому перший двійковий рядок вказує на значення, яке вказує позицію останнього значущого коефіцієнта, і оснований на схемі зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(Т)-1, і другий двійковий рядок вказує на значення, яке вказує позицію останнього значущого коефіцієнта, і оснований на схемі кодування з фіксованою довжиною слова. Наприклад, такі зчитувані комп'ютером носії інформації можуть містити RAM, ROM, EEPROM, CD-ROM або інший накопичувач на оптичних дисках, накопичувач на магнітних дисках, або інші магнітні запам'ятовуючі пристрої, флеш-пам'ять або будь-який інший носій, який може бути використаний для зберігання необхідного коду програми у вигляді інструкцій або структур даних і до якого комп'ютер може одержати доступ. Крім того, будь-яке з'єднання відповідно називають зчитуваним комп'ютером носієм. Наприклад, якщо інструкції передають з web-сайта, сервера або іншого віддаленого джерела з використанням коаксіального кабелю, оптоволоконного кабелю, витої пари, цифрової абонентської лінії (DSL) або бездротових технологій, наприклад інфрачервоного випромінювання, радіомовлення і надвисокочастотних хвиль, то коаксіальний кабель, оптоволоконний кабель, вита пара, DSL або бездротові технології, наприклад, інфрачервоне випромінювання, радіомовлення і надвисокочастотні хвилі, включають у визначення носія. Однак потрібно розуміти, що зчитувані комп'ютером носії інформації і накопичувачі даних не включають в себе з'єднання, несучі хвилі, сигнали або інші короткочасні середовища, а є замість цього направленими на постійні, матеріальні носії інформації. Магнітний і немагнітний диски, що використовуються в цьому описі, включають в себе компакт-диск (CD), лазерний диск, оптичний диск, універсальний цифровий диск (DVD), гнучкий диск і диск блю-рей (Blu-ray), причому магнітні диски звичайно відтворюють дані магнітним способом, в той час як немагнітні диски відтворюють дані оптично за допомогою лазерів. Комбінації наведених вище носіїв також повинні бути включені в зчитувані комп’ютером носії. Інструкції можуть виконуватися одним або більше процесорами, наприклад, одним або більше цифровими сигнальними процесорами (DSP), універсальними мікропроцесорами, спеціалізованими інтегральними схемами (ASIC), програмованими користувачем логічними матрицями (FPGA) або іншою еквівалентною інтегрованою або окремою логічною схемою. Відповідно, термін "процесор", що використовується в цьому документі, може відноситися до будь-якої вищевикладеної структури або будь-якої іншої структури, підходящої для реалізації способів, описаних в цьому документі. Крім того, в деяких аспектах функціональні можливості, описані в цьому документі, можуть бути забезпечені в спеціалізованих апаратних і/або програмних модулях, виконаних з можливістю кодування і декодування, або включені в склад об'єднаного кодека. Також згадані способи можуть бути повністю реалізовані в одній або декількох схемах або в одному або декількох логічних елементах. Способи цього розкриття можуть бути реалізовані в найрізноманітніших пристроях або приладах, які включають в себе бездротову мікротелефону трубку, інтегральну схему (IC) або набір IC (наприклад, набір мікросхем). У цьому розкритті для виділення функціональних аспектів пристроїв, виконаних з можливістю виконання розкритих способів, але без обов'язкової вимоги реалізації різними апаратними блоками, описані різні компоненти, модулі або блоки. Навпаки, як описано вище, різні блоки можуть бути об'єднані в апаратному блоці кодека або забезпечені сукупністю взаємодіючих апаратних блоків, які включають в себе один або декілька процесорів, як описано вище, разом з підходящими програмними засобами і/або програмноапаратними засобами. Описані різні приклади. Ці та інші приклади включені в обсяг нижченаведеної формули винаходу. Посилальні позиції 10 система кодування і декодування відео 12 пристрій-джерело 14 пристрій-адресат 16 лінія зв'язку 20 відеокодер 22 вихідний інтерфейс 22 UA 111246 C2 5 10 15 20 25 28 вхідний інтерфейс 30 відеодекодер 32 запам'ятовуючий пристрій 35 блок розділення 41 модуль прогнозування 42 блок оцінки руху 44 блок компенсації руху 46 модуль інтрапрогнозування 50 суматор 52 модуль перетворення 54 блок квантування 56 блок ентропійного кодування 58 блок оберненого квантування 60 модуль оберненого перетворення 62 суматор 64 пам'ять для опорних картинок 502 блок перетворення в двійкову форму 504 блок арифметичного кодування 506 блок призначення контексту 80 блок ентропійного декодування 81 модуль прогнозування 82 блок компенсації руху модуля 86 блок оберненого квантування 88 модуль оберненого перетворення 90 суматор 92 пам'ять для опорних картинок ФОРМУЛА ВИНАХОДУ 30 35 40 45 50 55 1. Спосіб кодування відеоданих, який містить: одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, визначення другого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і кодування згаданих першого і другого двійкових рядків у бітовий потік. 2. Спосіб за п. 1, в якому кодування першого і другого двійкових рядків у бітовий потік включає в себе арифметичне кодування. 3. Спосіб за п. 2, в якому кодування першого і другого двійкових рядків у бітовий потік включає в себе кодування першого двійкового рядка на основі контекстної моделі. 4. Спосіб за п. 1, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log 2(T)-2. 5. Спосіб за п. 4, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 6. Спосіб за п. 5, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1. 7. Пристрій, що містить відеокодер, виконаний з можливістю: одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і кодування згаданих першого і другого двійкових рядків у бітовий потік. 23 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 8. Пристрій за п. 7, в якому відеокодер, виконаний з можливістю кодування згаданих першого і другого двійкових рядків у бітовий потік, виконаний з можливістю виконання арифметичного кодування. 9. Пристрій за п. 8, в якому відеокодер, виконаний з можливістю кодування згаданих першого і другого двійкових рядків у бітовий потік, виконаний з можливістю кодування першого двійкового рядка на основі контекстної моделі. 10. Пристрій за п. 7, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 11. Пристрій за п. 10, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 12. Пристрій за п. 11, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і другий двійковий рядок має довжину в бітах, рівну 1. 13. Пристрій для кодування відеоданих, причому пристрій містить: засіб для одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, засіб для визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, засіб для визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік. 14. Пристрій за п. 13, в якому засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік включає в себе засіб для виконання арифметичного кодування. 15. Пристрій за п. 14, в якому засіб для кодування згаданих першого і другого двійкових рядків у бітовий потік включає в себе засіб для кодування першого двійкового рядка на основі контекстної моделі. 16. Пристрій за п. 13, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 17. Пристрій за п. 16, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 18. Пристрій за п. 17, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1. 19. Зчитуваний комп'ютером носій інформації, який містить інструкції, що зберігаються на ньому, які при виконанні викликають виконання одним або більше процесорами: одержання значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, визначення першого двійкового рядка для згаданого значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми зрізаного унарного кодування, яка визначається максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, визначення другого двійкового рядка для значення, яке вказує позицію останнього значущого коефіцієнта, на основі схеми кодування з фіксованою довжиною слова, і кодування згаданих першого і другого двійкових рядків у бітовий потік. 20. Зчитуваний комп'ютером носій інформації за п. 19, в якому інструкції, які при виконанні викликають кодування одним або більше процесорами першого і другого двійкових рядків у бітовий потік, включають в себе інструкції, які при виконанні викликають виконання одним або більше процесорами арифметичного кодування. 21. Зчитуваний комп'ютером носій інформації за п. 20, в якому інструкції, які при виконанні викликають кодування одним або більше процесорами першого і другого двійкових рядків у бітовий потік, включають в себе інструкції, які при виконанні викликають кодування одним або більше процесорами першого двійкового рядка на основі контекстної моделі. 22. Зчитуваний комп'ютером носій інформації за п. 19, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 23. Зчитуваний комп'ютером носій інформації за п. 22, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 24 UA 111246 C2 5 10 15 20 25 30 35 40 45 50 55 60 24. Зчитуваний комп'ютером носій інформації за п. 23, в якому перший двійковий рядок включає в себе шість послідовних бітів, що мають одне і те саме значення, і один біт, що має протилежне значення, і в якому другий двійковий рядок має довжину в бітах, рівну 1. 25. Спосіб декодування відеоданих, який містить: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 26. Спосіб за п. 25, в якому одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку включає в себе виконання арифметичного декодування. 27. Спосіб за п. 25, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log 2(T)-2. 28. Спосіб за п. 27, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 29. Спосіб за п. 28, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення. 30. Спосіб за п. 29, в якому другий двійковий рядок має довжину в бітах, рівну 1. 31. Пристрій, який містить відеодекодер, виконаний з можливістю: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 32. Пристрій за п. 31, в якому відеокодер, виконаний з можливістю одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, виконаний з можливістю виконання арифметичного декодування. 33. Пристрій за п. 31, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 34. Пристрій за п. 33, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 35. Пристрій за п. 34, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення. 36. Пристрій за п. 35, в якому другий двійковий рядок має довжину в бітах, рівну 1. 37. Пристрій для декодування відеоданих, причому пристрій містить: засіб для одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, і засіб для визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 38. Пристрій за п. 37, в якому засіб для одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку включає в себе засіб для виконання арифметичного декодування. 39. Пристрій за п. 37, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 40. Пристрій за п. 39, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 25 UA 111246 C2 5 10 15 20 25 30 35 40 45 41. Пристрій за п. 40, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення. 42. Пристрій за п. 41, в якому другий двійковий рядок має довжину в бітах, рівну 1. 43. Зчитуваний комп'ютером носій інформації, який містить інструкції, що зберігаються на ньому, які при виконанні викликають виконання одним або більше процесорами: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою 2log2(T)-1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 44. Зчитуваний комп'ютером носій інформації за п. 43, в якому інструкції, які при виконанні викликають одержання одним або більше процесорами першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, включають в себе інструкції, які при виконанні викликають виконання одним або більше процесорами арифметичного декодування. 45. Зчитуваний комп'ютером носій інформації за п. 43, в якому схема кодування з фіксованою довжиною слова визначається максимальною довжиною в бітах, яка визначається за допомогою log2(T)-2. 46. Зчитуваний комп'ютером носій інформації за п. 45, в якому Т дорівнює 32, при цьому значення, яке вказує позицію останнього значущого коефіцієнта, дорівнює 8, і в якому перший двійковий рядок має довжину в бітах, рівну 7. 47. Зчитуваний комп'ютером носій інформації за п. 46, в якому перший двійковий рядок включає в себе 6 послідовних бітів, що мають одне і те саме значення, і 1 біт, що має протилежне значення. 48. Зчитуваний комп'ютером носій інформації за п. 47, в якому другий двійковий рядок має довжину в бітах, рівну 1. 49. Спосіб декодування відеоданих, який містить: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(T)+1, і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 50. Спосіб декодування відеоданих, який містить: одержання першого двійкового рядка і другого двійкового рядка із закодованого бітового потоку, визначення значення, яке вказує позицію останнього значущого коефіцієнта всередині відеоблока розміру Т, основуючись частково на першому двійковому рядку, при цьому цей перший двійковий рядок визначається схемою зрізаного унарного кодування з максимальною довжиною в бітах, яка визначається за допомогою log2(T), і визначення значення, яке вказує позицію останнього значущого коефіцієнта, основуючись частково на другому двійковому рядку, при цьому цей другий двійковий рядок визначається схемою кодування з фіксованою довжиною слова. 51. Спосіб за п. 1, в якому кодування першого і другого двійкових рядків містить кодування першого двійкового рядка, за яким йде кодування другого двійкового рядка. 26 UA 111246 C2 27 UA 111246 C2 28
ДивитисяДодаткова інформація
Назва патенту англійськоюProgressive coding of position of last significant coefficient
Автори англійськоюChien, Wei-Jung, Sole Rojals, Joel, Karczewicz, Marta, Joshi, Rajan Laxman
Назва патенту російськоюПрогрессивное кодирование позиции последнего значащего коэффициента
Автори російськоюЧиэнь Вэй-Цзюн, Соле Рохальс Хоэль, Карчевич Марта, Джоши Раджан Лаксман
МПК / Мітки
Мітки: позиції, кодування, коефіцієнта, значущого, прогресивне, останнього
Код посилання
<a href="https://ua.patents.su/32-111246-progresivne-koduvannya-pozici-ostannogo-znachushhogo-koeficiehnta.html" target="_blank" rel="follow" title="База патентів України">Прогресивне кодування позиції останнього значущого коефіцієнта</a>
Окреме кодування позиції останнього значущого коефіцієнта відеоблока при кодуванні відео

Номер патенту: 109684
Опубліковано: 25.09.2015
Автори: Соле Рохальс Хоель, Джоши Раджан Лаксман, Карчевіч Марта
МПК: H04N 11/02, H03M 7/40, H04N 11/04, H04N 19/129
Мітки: значущого, останнього, відео, відеоблока, коефіцієнта, позиції, кодування, кодуванні, окреме
Формула / Реферат:
1. Спосіб кодування коефіцієнтів, асоційованих з блоком відеоданих, під час процесу кодування відео, при цьому спосіб включає етапи, на яких:кодують інформацію, яка ідентифікує позицію останнього ненульового коефіцієнта в блоці згідно з порядком сканування, асоційованим з блоком, до кодування інформації, яка ідентифікує позиції інших ненульових коефіцієнтів в блоці,при цьому кодування інформації, яка ідентифікує позицію...
Кодування позиції останнього значущого коефіцієнта у відеоблоці на основі порядку сканування для блока при кодуванні відео

Номер патенту: 106162
Опубліковано: 25.07.2014
Автори: Соле Рохальс Хоель, Джоши Раджан Лаксман, Кобан Мухаммед Зейд, Карчевіч Марта, Чжен Юньфей
Мітки: сканування, коефіцієнта, останнього, значущого, позиції, блока, кодуванні, відео, відеоблоці, порядку, кодування, основі
Формула / Реферат:
1. Спосіб кодування коефіцієнтів, асоційованих з блоком відеоданих, під час процесу кодування відео, при цьому спосіб включає етапи, на яких:визначають статистику, яка вказує імовірність того, що кожна з координат X і Y містить дане значення, коли порядок сканування, асоційований з блоком, містить перший порядок сканування, при цьому координати X і Y вказують горизонтальну позицію і вертикальну позицію, відповідно, останнього...
Контекстна оптимізація для кодування положення останнього значущого коефіцієнта

Номер патенту: 109505
Опубліковано: 25.08.2015
Автори: Го Лівей, Чіень Вей-Цзюн, Карчєвіч Марта
Мітки: останнього, положення, коефіцієнта, оптимізація, значущого, контекстна, кодування
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення для блока перетворення, який включає:одержання двійкового ланцюжка, який вказує положення останнього значущого коефіцієнта всередині блока перетворення коефіцієнтів перетворення;визначення контексту для двійкового індексу двійкового ланцюжка на основі розміру блока перетворення, причому контекст призначається щонайменше двом двійковим індексам, причому кожний з щонайменше двох...
Пристрій для переміщення рулону листового прокату з позиції завантаження до позиції розмотки, а також для відгинання переднього кінця стрічки

Номер патенту: 16146
Опубліковано: 29.08.1997
Автори: Рассошенко Анатолій Іванович, Кравченко Сергій Олексійович, Котелевець Юрій Сергійович, Магала Олександр Андрійович, Проткін Олексій Єгорович, Кабанов Едуард Констянтинович, Білобров Володимир Іванович
МПК: B21C 47/24
Мітки: переднього, листового, прокату, розмотки, стрічки, рулону, відгинання, також, завантаження, переміщення, пристрій, кінця, позиції
Формула / Реферат:
Устройство для перемещения рулона листового проката с позиции загрузки на позицию размотки, а также для отгибки переднего конца полосы, содержащее смонтированную на направляющих приводную тележку с подъемным столом и опорными приводными роликами, раму со скребковым отгибателем, привод перемещения рамы в виде цилиндра, скалки с размещенными на них верхним и нижним задающими роликами, а также прижим и цилиндр привода перемещения...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 106704
Опубліковано: 25.09.2014
Автори: Карчевіч Марта, Джоши Раджан Лаксман, Соле Рохальс Хоель
МПК: H04N 19/00
Мітки: відео, коефіцієнтів, перетворення, кодування
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео, в процесі кодування відео, причому спосіб включає:компонування блока коефіцієнтів перетворення в один або більше піднаборів коефіцієнтів перетворення на основі порядку сканування;кодування першої частини рівнів коефіцієнтів перетворення в кожному піднаборі, причому перша частина рівнів включає в себе щонайменше значущість коефіцієнтів...
Попередній патент: 6-моно- та 6,6-дизаміщені 3-r-8-r3-9-r4-10-r5-11-r6-6,7-дигідро-2н-[1,2,4]триазино[2,3-с]хіназолін-2-они
Наступний патент: Спосіб вимірювання профілів поверхонь в працюючих алюмінієвих електролізерах
Випадковий патент: Спосіб улаштування залізобетонного перекриття полегшеного типу