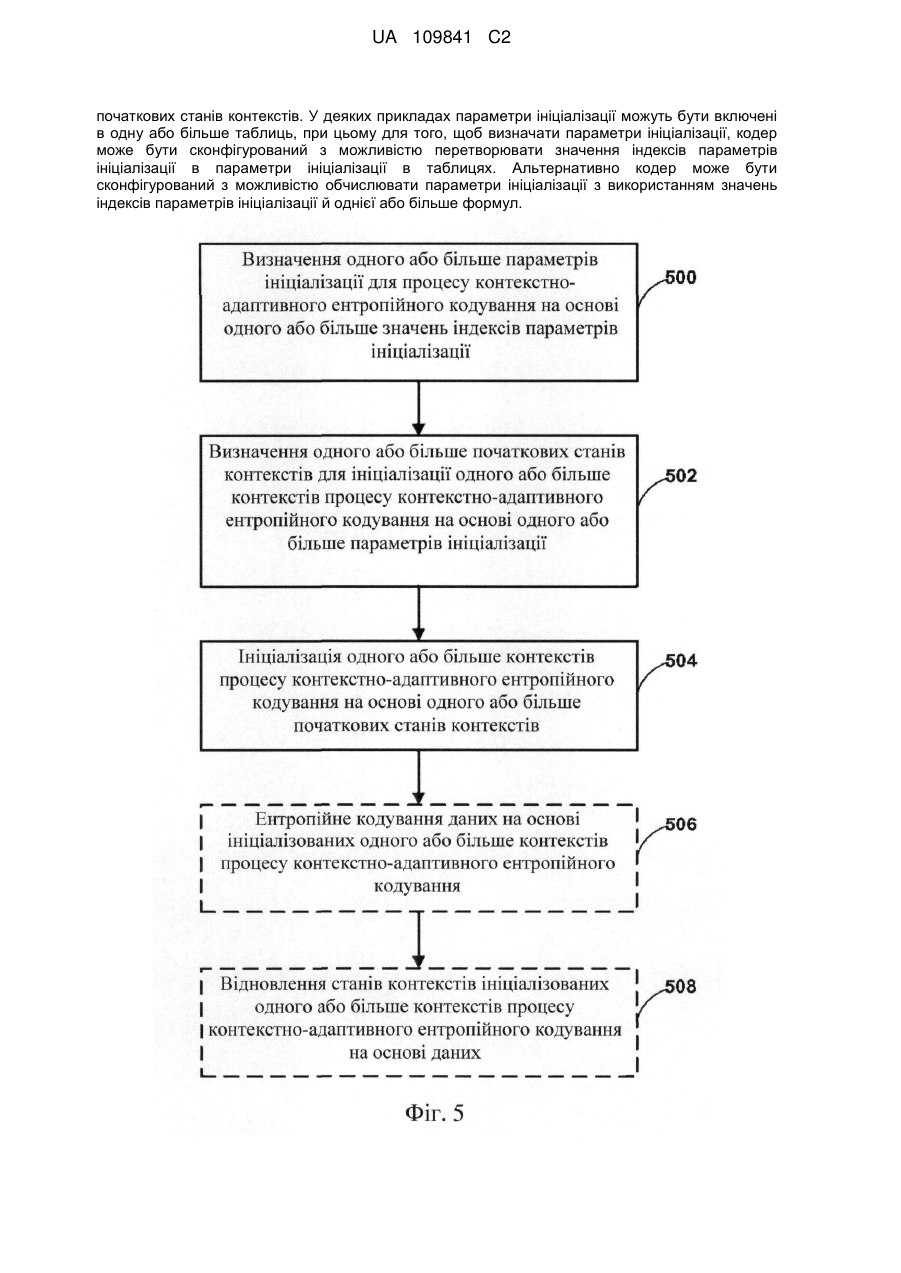
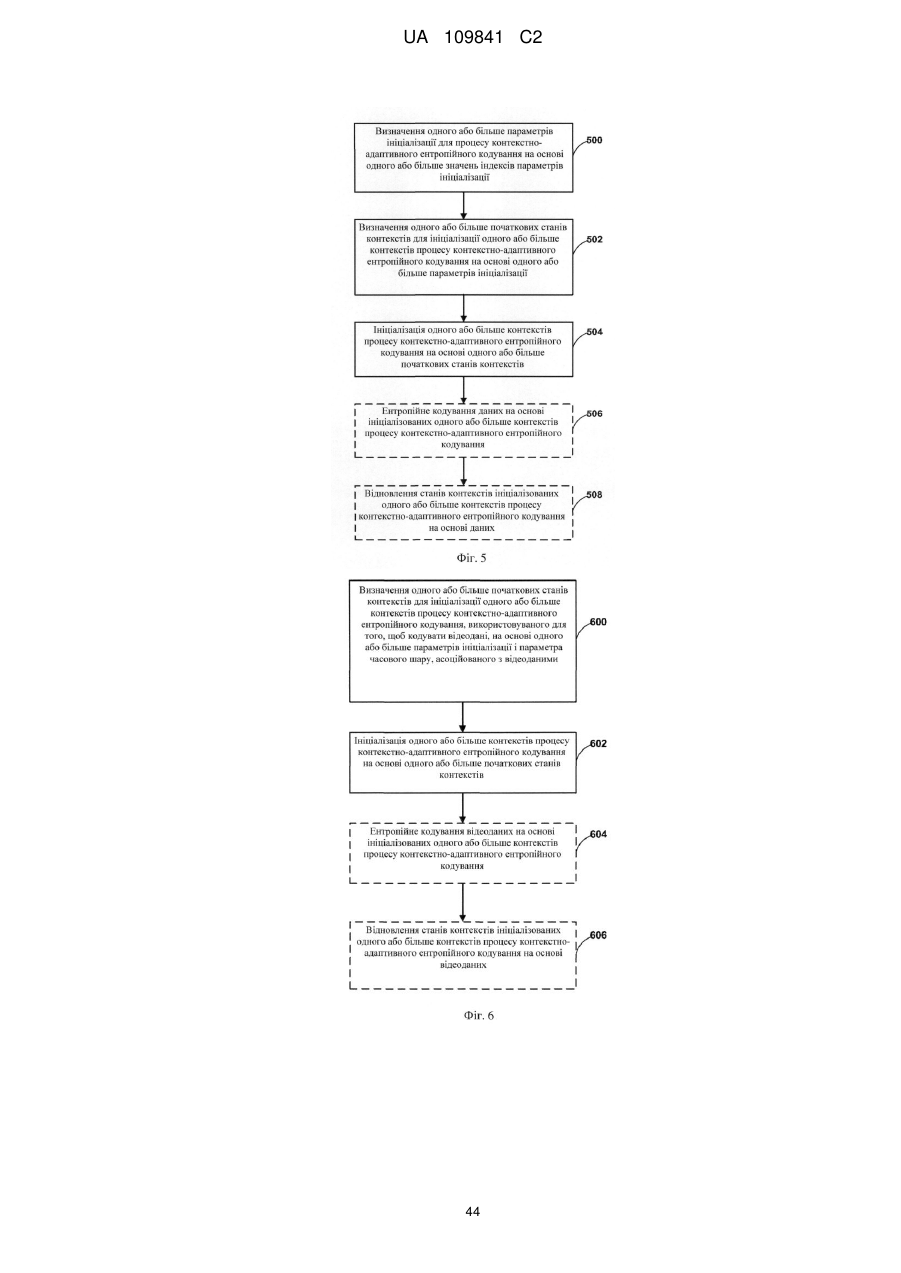
Ініціалізація ймовірностей і станів контекстів для контекстно-адаптивного ентропійного кодування
Номер патенту: 109841
Опубліковано: 12.10.2015
Автори: Ван Сянлінь, Го Лівей, Соле Рохальс Хоель, Карчєвіч Марта











































Формула / Реферат
1. Спосіб ініціалізації контексту, використовуваного для кодування відеоданих в процесі контекстно-адаптивного ентропійного кодування, при цьому спосіб включає:
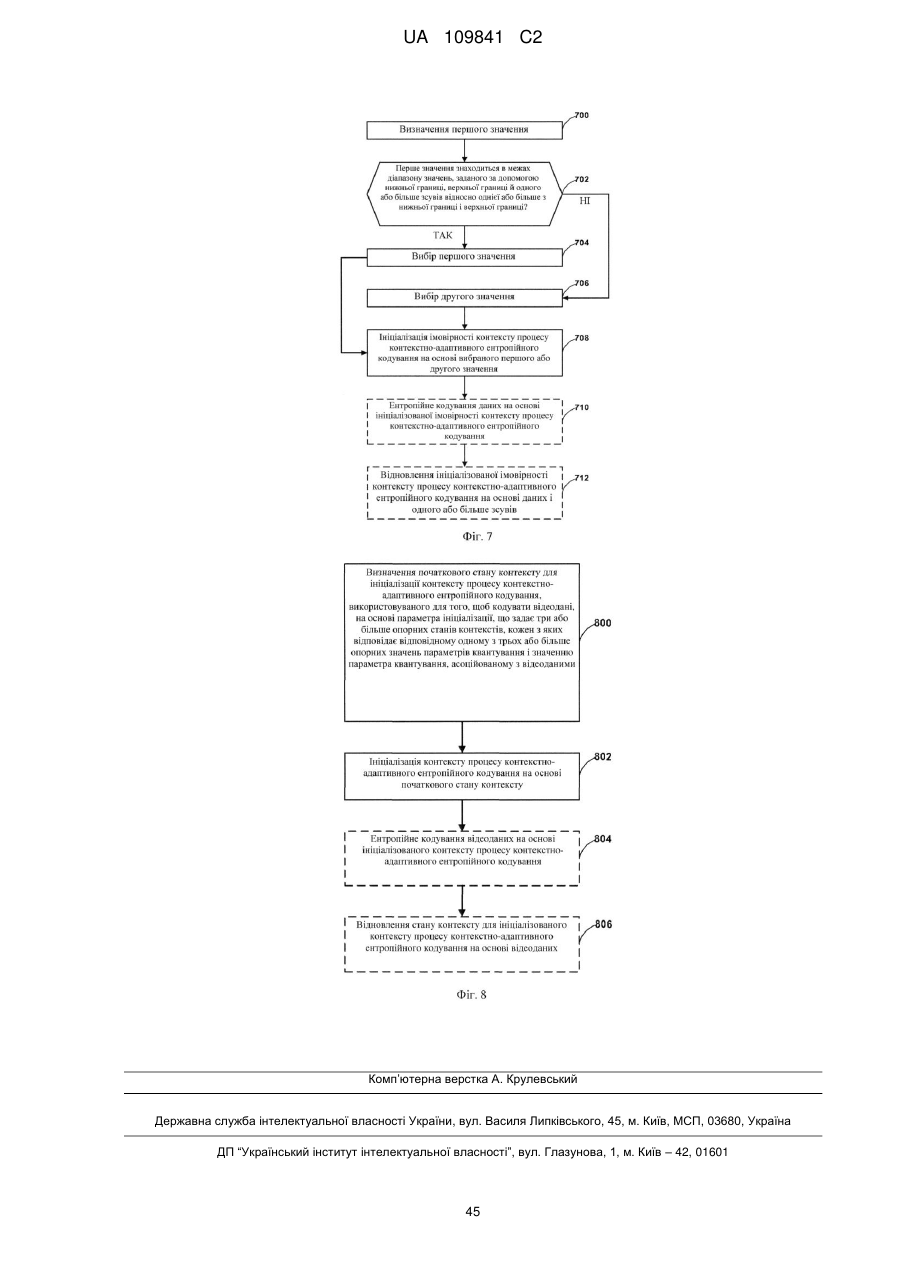
визначення першого значення індексу параметра ініціалізації як х>>4, де х є 8-бітовим параметром;
визначення другого значення індексу параметра ініціалізації як х&15, де х є тим же самим згаданим 8-бітовим параметром;
визначення одного або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі згаданих першого і другого значень індексу параметра ініціалізації; і
ініціалізацію, на основі одного або більше параметрів ініціалізації, стану контексту, використовуваного для кодування відеоданих в процесі контекстно-адаптивного ентропійного кодування.
2. Спосіб за п. 1, у якому визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації включає обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданих першого і другого значень індексу параметра ініціалізації й однієї або більше формул.
3. Спосіб за п. 2, у якому обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданих першого і другого індексу параметра ініціалізації й згаданих однієї або більше формул включає обчислення згаданих однієї або більше параметрів ініціалізації відповідно до наступних рівнянь:
нахил=m*5-45; і
перетинання=n*8-16,
при цьому члени нахилу і перетинання є параметрами ініціалізації, а члени m і n є, відповідно, згаданими першим і другим значеннями індексу параметра ініціалізації.
4. Спосіб за п. 2, у якому кожна зі згаданих однієї або більше формул реалізовується з використанням тільки однієї або більше операцій, кожна з яких вибирається з групи, яка складається з:
операції бітового зсуву;
операції підсумовування;
операції віднімання;
операції множення; і
операції ділення.
5. Спосіб за п. 1, у якому згаданий один або більше параметрів ініціалізації містить значення нахилу і значення перетинання, згадане перше значення індексу параметра ініціалізації є значенням індексу нахилу, і згадане друге значення індексу параметра ініціалізації є значенням індексу перетинання, і при цьому визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації включає:
визначення значення нахилу на основі значення індексу нахилу; і
визначення значення перетинання на основі значення індексу перетинання.
6. Спосіб за п. 1, у якому згаданий один або більше параметрів ініціалізації містять значення нахилу і значення перетинання, і при цьому визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації включає визначення значення нахилу і значення перетинання на основі єдиного значення індексу.
7. Спосіб за п. 6, у якому згадане єдине значення індексу містить компонент значення індексу нахилу і компонент значення індексу перетинання, і при цьому визначення значення нахилу і значення перетинання на основі згаданого єдиного значення індексу включає:
визначення значення нахилу на основі компонента значення індексу нахилу; і
визначення значення перетинання на основі компонента значення індексу перетинання.
8. Спосіб за п. 7, у якому єдине значення індексу містить попередньо визначене число бітів, при цьому компонент значення індексу нахилу і компонент значення індексу перетинання містять відповідні підмножини попередньо визначеного числа бітів, і при цьому згадана підмножина, яка відповідає компоненту значення індексу нахилу, включає в себе деяке інше число згаданого попередньо визначеного числа бітів, ніж згадана підмножина, яка відповідає компоненту значення індексу перетинання.
9. Спосіб за п. 1, який додатково включає:
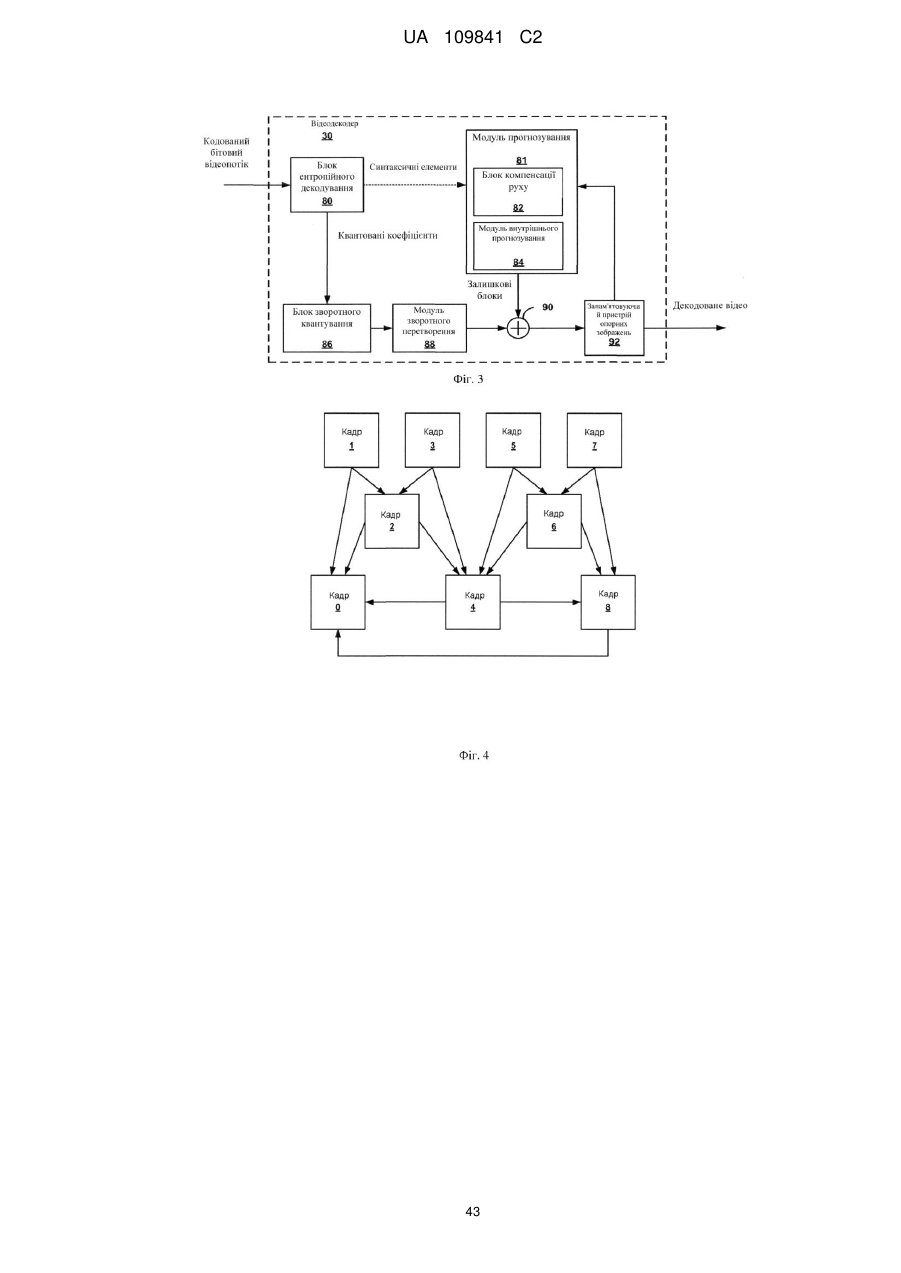
кодування, на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування, одного або більше елементів синтаксису, асоційованих із блоком відеоданих; і
виведення закодованого одного або більше елементів синтаксису в потоці бітів.
10. Спосіб за п. 1, який додатково включає:
прийом одного або більше закодованих елементів синтаксису, асоційованих із блоком відеоданих, у потоці бітів; і
декодування, на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування, згаданого одного або більше закодованих елементів синтаксису.
11. Спосіб за п. 1, в якому згаданий один або більше параметрів ініціалізації включають в себе одне або більше значень нахилу, згадане перше значення індексу параметра ініціалізації включає в себе значення індексу нахилу.
12. Пристрій для контекстно-адаптивного ентропійного кодування, причому пристрій містить:
носій зберігання даних, сконфігурований з можливістю зберігання відеоданих, і
кодер, який містить один або більше процесорів, сконфігурованих з можливістю:
визначати перше значення індексу параметра ініціалізації як х>>4, де х є 8-бітовим параметром;
визначати друге значення індексу параметра ініціалізації як х&15, де х є тим же самим згаданим 8-бітовим параметром;
визначати один або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі згаданих першого і другого значень індексу параметра ініціалізації; і
ініціалізувати на основі згаданого одного або більше параметрів ініціалізації, стану контексту, використовуваного для кодування відеоданих в процесі контекстно-адаптивного ентропійного кодування.
13. Пристрій за п. 12, у якому кодер сконфігурований з можливістю обчислювати згаданий один або більше параметрів ініціалізації з використанням згаданих першого і другого значень індексу параметра ініціалізації й однієї або більше формул.
14. Пристрій за п. 13, у якому для обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданих одного і другого значень індексу параметра ініціалізації й згаданої однієї або більше формул, кодер сконфігурований з можливістю обчислювати згаданий один або більше параметрів ініціалізації відповідно до наступних рівнянь:
нахил=m*5-45; і
перетинання=n*8-16,
при цьому члени нахилу і перетинання є параметрами ініціалізації, а члени m і n є, відповідно, згаданими першим і другим значеннями індексу параметра ініціалізації.
15. Пристрій за п. 13, у якому кожна зі згаданої однієї або більше формул реалізовується з використанням тільки однієї або більше операцій, кожна з яких вибирається з групи, яка складається з:
операції бітового зсуву;
операції підсумовування;
операції віднімання;
операції множення; і
операції ділення.
16. Пристрій за п. 12, у якому згаданий один або більше параметрів ініціалізації включає в себе значення нахилу і значення перетинання, згадане перше значення індексу параметра ініціалізації є значенням індексу нахилу, і згадане друге значення індексу параметра ініціалізації є значенням індексу перетинання, і
при цьому для визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації, кодер сконфігурований з можливістю:
визначати значення нахилу на основі значення індексу нахилу; і
визначати значення перетинання на основі значення індексу перетинання.
17. Пристрій за п. 12, у якому згаданий один або більше параметрів ініціалізації включає в себе значення нахилу і значення перетинання, і при цьому для визначення згаданого одного або більше параметрів ініціалізації на основі згаданого першого і другого значень індексу параметра ініціалізації, кодер сконфігурований з можливістю визначати значення нахилу і значення перетинання на основі єдиного значення індексу.
18. Пристрій за п. 17, у якому згадане єдине значення індексу містить компонент значення індексу нахилу і компонент значення індексу перетинання, і при цьому для визначення значення нахилу і значення перетинання на основі згаданого єдиного значення індексу, кодер сконфігурований з можливістю:
визначати значення нахилу на основі компонента значення індексу нахилу; і
визначати значення перетинання на основі компонента значення індексу перетинання.
19. Пристрій за п. 17, у якому згадане єдине значення індексу містить попередньо визначене число бітів, при цьому компонент значення індексу нахилу і компонент значення індексу перетинання містять відповідні підмножини попередньо визначеного числа бітів, і при цьому згадана підмножина, яка відповідає компоненту значення індексу нахилу, включає в себе деяке інше число згаданого попередньо визначеного числа бітів, ніж згадана підмножина, яка відповідає компоненту значення індексу перетинання.
20. Пристрій за п. 12, у якому кодер містить відеокодер, і при цьому відеокодср додатково сконфігурований з можливістю:
кодувати, на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування, один або більше елементів синтаксису, асоційованих із блоком відеоданих; і
виводити закодовані один або більше елементів синтаксису в потоці бітів.
21. Пристрій за п. 12, у якому кодер містить відеодекодер, і при цьому відеодекодер додатково сконфігурований з можливістю:
приймати один або більше закодованих елементів синтаксису, асоційованих із блоком відеоданих, у потоці бітів; і
декодувати згаданий один або більше закодованих елементів синтаксису на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування.
22. Пристрій за п. 12, при цьому пристрій містить щонайменше одне з:
інтегральної схеми;
мікропроцесора; і
пристрою бездротового зв'язку, що включає у себе кодер.
23. Пристрій за п. 12, в якому згаданий один або більше параметрів ініціалізації включають в себе одне або більше значень нахилу, згадане перше значення індексу параметра ініціалізації включає в себе значення індексу нахилу.
24. Пристрій за п. 12, який додатково містить пристрій відображення, сконфігурований з можливістю відображати відеодані.
25. Пристрій за п. 12, який додатково містить камеру,
сконфігурований з можливістю захоплювати відеодані.
26. Пристрій для контекстно-адаптивного ентропійного кодування, причому пристрій містить:
засіб для визначення першого значення індексу параметра ініціалізації як х>>4, де х є 8-бітовим параметром;
засіб для визначення другого значення індексу параметра ініціалізації як x&15, де х є тим же самим згаданим 8-бітовим параметром;
засіб для визначення одного або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі згаданих першого і другого значень індексу параметра ініціалізації;
засіб для ініціалізації, на основі одного або більше параметрів ініціалізації, стану контексту, використовуваного для кодування відеоданих в процесі контекстно-адаптивного ентропійного кодування.
27. Пристрій за п. 26, в якому засіб для визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації містить засіб для обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданого першого і другого значень індексу параметра ініціалізації та однієї або більше формул.
28. Пристрій за п. 27, у якому обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданих одного або другого значень індексу параметра ініціалізації й згаданої однієї або більше формул містить обчислення згаданого одного або більше параметрів ініціалізації відповідно до наступних рівнянь:
нахил=m*5-45; і
перетинання=n*8-16,
при цьому члени нахилу і перетинання є параметрами ініціалізації, а члени m і n є, відповідно, згаданими першим і другим значеннями індексу параметра ініціалізації.
29. Пристрій за п. 27, у якому кожна зі згаданої однієї або більше формул реалізовується з використанням тільки однієї або більше операцій, кожна з яких вибирається з групи, яка складається з:
операції бітового зсуву;
операції підсумовування;
операції віднімання;
операції множення; і
операції ділення.
30. Пристрій за п. 26, у якому згаданий один або більше параметрів ініціалізації містить значення нахилу і значення перетинання, згадане перше значення індексу параметра ініціалізації є значенням індексу нахилу, і згадане друге значення індексу параметра ініціалізації є значенням індексу перетинання, і при цьому засіб для визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексів параметрів ініціалізації містить:
засіб для визначення значення нахилу на основі значення індексу нахилу; і
засіб для визначення значення перетинання на основі значення індексу перетинання.
31. Пристрій за п. 26, в якому згаданий один або більше параметрів ініціалізації включають в себе значення нахилу і значення перетинання, і при цьому засіб для визначення згаданого одного або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації містить засіб для визначення значення нахилу і значення перетинання на основі єдиного значення індексу.
32. Пристрій за п. 31, в якому згадане єдине значення індексу містить компонент значення індексу нахилу і компонент значення індексу перетинання, і при цьому засіб для визначення значення нахилу і значення перетинання на основі згаданого єдиного значення індексу містить:
засіб для визначення значення нахилу на основі компонента значення індексу нахилу; і
засіб для визначення значення перетинання на основі компонента значення індексу перетинання.
33. Пристрій за п. 32, в якому згадане єдине значення індексу містить попередньо визначене число бітів, при цьому компонент значення індексу нахилу і компонент значення індексу перетинання містять відповідні підмножини згаданого попередньо визначеного числа бітів, і при цьому підмножина, яка відповідає компоненту значення індексу нахилу, включає в себе деяке інше число згаданого попередньо визначеного числа бітів, ніж згадана підмножина, яка відповідає компоненту значення індексу перетинання.
34. Пристрій за п. 26, який додатково містить:
засіб для кодування, на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування, одного або більше елементів синтаксису, асоційованих з блоком відеоданих; і
засіб для виведення закодованих одного або більше елементів синтаксису в потоці бітів.
35. Пристрій за п. 26, який додатково містить:
засіб для прийому одного або більше закодованих елементів синтаксису, асоційованих з блоком відеоданих, в потоці бітів; і
засіб для декодування згаданого одного або більше закодованих елементів синтаксису на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування.
36. Пристрій за п. 26, в якому згаданий один або більше параметрів ініціалізації включають в себе одне або більше значень нахилу, згадане перше значення індексу параметра ініціалізації включає в себе значення індексу нахилу.
37. Зчитуваний комп'ютером носій даних, що має збережені інструкції, які при виконанні спонукають один або більше процесорів виконувати контекстно-адаптивне ентропійне кодування, при цьому інструкції спонукають один або більше процесорів:
визначати перше значення індексу параметра ініціалізації як х>>4, де х є 8-бітовим параметром;
визначати друге значення індексу параметра ініціалізації як х&15, де х є тим же самим згаданим 8-бітовим параметром;
визначати один або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі згаданих першого і другого значень індексу параметра ініціалізації;
ініціалізувати, на основі згаданих одного або більше параметрів ініціалізації, стан контексту, використовуваного для кодування відеоданих в процесі контекстно-адаптивного ентропійного кодування.
38. Зчитуваний комп'ютером носій даних за п. 37, у якому інструкції, що спонукають згаданий один або більше процесорів визначати згаданий один або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації, містять інструкції, які спонукають згаданий один або більше процесорів обчислювати один або більше параметрів ініціалізації з використанням згаданих першого і другого значень індексу параметра ініціалізації й однієї або більше формул.
39. Зчитуваний комп'ютером носій даних за п. 38, при цьому для обчислення згаданого одного або більше параметрів ініціалізації з використанням згаданих першого і другого значень індексу параметра ініціалізації та згаданої однієї або більше формул, інструкції спонукають згаданий один або більше процесорів обчислювати згаданий один або більше параметрів ініціалізації відповідно до наступних рівнянь:
нахил=m*5-45; i
перетинання=n*8-16,
при цьому члени нахилу і перетинання є параметрами ініціалізації, а члени m i n є, відповідно, першим і другим значенням індексу параметра ініціалізації.
40. Зчитуваний комп'ютером носій даних за п. 38, при цьому кожна зі згаданих однієї або більше формул реалізується з використанням тільки однієї або більше операцій, кожна з яких вибирається з групи, яка складається з:
операції бітового зсуву;
операції підсумовування;
операції віднімання;
операції множення; і
операції ділення.
41. Зчитуваний комп'ютером носій даних за п. 37, при цьому згаданий один або більше параметрів ініціалізації включають в себе значення нахилу і значення перетинання, згадане перше значення індексу параметра ініціалізації є значенням індексу нахилу, і згадане друге значення індексу параметра ініціалізації є значенням індексу перетинання, і при цьому інструкції, які спонукають згаданий один або більше процесорів визначати згаданий один або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації, містять інструкції, які спонукають згаданий один або більше процесорів:
визначати значення нахилу на основі значення індексу нахилу; і
визначати значення перетинання на основі значення індексу перетинання.
42. Зчитуваний комп'ютером носій даних за п. 37, при цьому згаданий один або більше параметрів ініціалізації включають в себе значення нахилу і значення перетинання, і при цьому інструкції, які спонукають згаданий один або більше процесорів визначати згаданий один або більше параметрів ініціалізації на основі згаданих першого і другого значень індексу параметра ініціалізації, містять інструкції, які спонукають згаданий один або більше процесорів визначати значення нахилу і значення перетинання на основі єдиного значення індексу.
43. Зчитуваний комп'ютером носій даних за п. 42, при цьому згадане єдине значення індексу містить компонент значення індексу нахилу і компонент значення індексу перетинання, і при цьому інструкції, які спонукають згаданий один або більше процесорів визначати значення нахилу і значення перетинання на основі згаданого єдиного значення індексу, містять інструкції, які спонукають згаданий один або більше процесорів:
визначати значення нахилу на основі компонента значення індексу нахилу; і
визначати значення перетинання на основі компонента значення індексу перетинання.
44. Зчитуваний комп'ютером носій даних за п. 43, при цьому згадане єдине значення індексу містить попередньо визначене число бітів, при цьому компонент значення індексу нахилу і компонент значення індексу перетинання містять відповідні підмножини згаданого попередньо визначеного числа бітів, і при цьому згадана підмножина, яка відповідає компоненту значення індексу нахилу, включає в себе деяке інше число згаданого попередньо визначеного числа бітів, ніж згадана підмножина, яка відповідає компоненту значення індексу перетинання.
45. Зчитуваний комп'ютером носій даних за п. 37, який додатково містить інструкції, які спонукають згаданий один або більше процесорів:
кодувати, на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування, один або більше елементів синтаксису, асоційованих з блоком відеоданих; і
виводити закодовані один або більше елементів синтаксису в потоці бітів.
46. Зчитуваний комп'ютером носій даних за п. 37, який додатково містить інструкції, які спонукають згаданий один або більше процесорів:
приймати один або більше закодованих елементів синтаксису, асоційованих з блоком відеоданих, в потоці бітів; і
декодувати згаданий один або більше закодованих елементів синтаксису на основі ініціалізованого контексту процесу контекстно-адаптивного ентропійного кодування.
47. Зчитуваний комп'ютером носій даних за п. 37, при цьому згаданий один або більше параметрів ініціалізації включають в себе одне або більше значень нахилу, згаданий перший індекс параметра ініціалізації включає в себе значення індексу нахилу.
Текст
Реферат: Пристрій для контекстно-адаптивного ентропійного кодування може містити в собі кодер, сконфігурований з можливістю визначати один або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації. Кодер може бути додатково сконфігурований з можливістю визначати один або більше початкових станів контекстів для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі параметрів ініціалізації. Кодер може бути додатково сконфігурований з можливістю ініціалізувати контексти на основі UA 109841 C2 (12) UA 109841 C2 початкових станів контекстів. У деяких прикладах параметри ініціалізації можуть бути включені в одну або більше таблиць, при цьому для того, щоб визначати параметри ініціалізації, кодер може бути сконфігурований з можливістю перетворювати значення індексів параметрів ініціалізації в параметри ініціалізації в таблицях. Альтернативно кодер може бути сконфігурований з можливістю обчислювати параметри ініціалізації з використанням значень індексів параметрів ініціалізації й однієї або більше формул. UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дана заявка заявляє пріоритет попередньої заявки на патент (США) № 61/555469, поданої 3 листопада 2011 року, попередньої заявки на патент (США) № 61/556808, поданої 7 листопада 2011 року, попередньої заявки на патент (США) № 61/557785, поданої 9 листопада 2011 року, і попередньої заявки на патент (США) № 61/560107, поданої 15 листопада 2011 року, вміст кожної з яких повністю міститься в даному документі по посиланню. Галузь техніки, до якої належить винахід Дане розкриття суті стосується ентропійного кодування відеоданих і т. п., а більш конкретно - контекстно-адаптивного ентропійного кодування. Рівень техніки Підтримка цифрового відео може бути включена в широкий діапазон пристроїв, що включають у себе цифрові телевізійні приймачі, системи цифрової прямої широкомовної передачі, бездротові широкомовні системи, персональні цифрові пристрої (PDA), переносні або настільні комп'ютери, планшетні комп'ютери, пристрої для читання електронних книг, цифрові камери, цифрові записуючі пристрої, цифрові мультимедийні програвачі, пристрої відеоігор, консолі для відеоігор, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої відеоконференцзв’язку, пристрої потокової передачі відео і т. п. Цифрові відеопристрої реалізовують такі технології стиснення відео, як технології стиснення відео, описані в стандартах, заданих за допомогою розроблювальних у даний час стандартів MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, частина 10, удосконалене кодування відео (AVC), стандарту високоефективного кодування відео (HEVC) і розширень таких стандартів. Відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію більш ефективно за допомогою реалізації таких технологій стиснення відео. Технології стиснення відео виконують просторове (внутрішньокадрове) прогнозування і/або часове (міжкадрове) прогнозування для того, щоб зменшувати або видаляти надмірність, внутрішньо властиву у відеопослідовностях. Для блокового кодування відео відеослайс (тобто відеокадр або частина відеокадру) може бути сегментований на відеоблоки, що також можуть згадуватися як деревоподібні блоки, одиниці кодування (CU) і/або вузли кодування. Відеоблоки у внутрішньо (інтра-) кодованому (I-) слайсі зображення кодуються з використанням просторового прогнозування відносно опорних вибірок у сусідніх блоках в ідентичному зображенні. Відеоблоки в зовнішньо (інтер-) кодованому (P- або B-) слайсі зображення можуть використовувати просторове прогнозування відносно опорних вибірок у сусідніх блоках в ідентичному зображенні або часове прогнозування відносно опорних вибірок в інших опорних зображеннях. Зображення можуть згадуватися як кадри, і опорні зображення можуть згадуватися як опорні кадри. Просторове або часове прогнозування приводить у результаті до прогнозного блока для блока, який повинен бути кодований. Залишкові дані представляють піксельні різниці між вихідним блоком, який повинен бути кодований, і прогнозним блоком. Зовнішньо кодований блок кодується відповідно до вектора руху, що вказує на блок опорних вибірок, що формують прогнозний блок, і залишкових даних, що вказують різницю між кодованим блоком і прогнозним блоком. Внутрішньо кодований блок кодується відповідно до режиму внутрішнього кодування і залишкових даних. Для додаткового стиснення залишкові дані можуть бути перетворені з піксельної області в область перетворення, приводячи до залишкових коефіцієнтів перетворення, що потім можуть бути квантовані. Квантовані коефіцієнти перетворення, які спочатку розташовуються в двовимірному масиві, можуть скануватися для того, щоб формувати одновимірний вектор коефіцієнтів перетворення, і може застосовуватися ентропійне кодування для того, щоб досягати ще більшого стиснення. Суть винаходу Це розкриття суті описує технології для кодування даних, таких як відеодані. Наприклад, технології можуть бути використані для того, щоб кодувати відеодані, такі як залишкові коефіцієнти перетворення і/або інші елементи синтаксису, сформовані за допомогою процесів кодування відео. Зокрема, розкриття суті описує технології, що можуть сприяти ефективному кодуванню відеоданих з використанням процесів контекстно-адаптивного ентропійного кодування. Розкриття суті описує кодування відео тільки з метою ілюстрації. У зв'язку з цим технології, описані в цьому розкритті суті, можуть бути застосовними до кодування інших типів даних. Як один приклад технології цього розкриття суті можуть забезпечувати можливість системі або пристрою кодування кодувати різні типи даних, такі як, наприклад, відеодані, більш ефективно в порівнянні з використанням інших технологій. Зокрема, технології, описані в даному документі, можуть забезпечувати можливість системі або пристрою кодування мати меншу складність відносно інших систем або пристроїв при кодуванні даних з використанням 1 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 процесу контекстно-адаптивного ентропійного кодування, такого як, наприклад, процес контекстно-адаптивного двійкового арифметичного кодування (CABAC). Наприклад, технології можуть зменшувати обсяг інформації, збереженої в системі або пристрої кодування і/або переданої в/з системи або пристрою кодування, з метою ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування. Як один приклад обсяг інформації може бути скорочений за допомогою збереження і/або передачі значень індексів параметрів ініціалізації, що вказують параметри ініціалізації, використовувані для того, щоб ініціалізувати контексти, замість збереження і/або передачі безпосередньо параметрів ініціалізації. Додатково як інший приклад технології можуть поліпшувати стиснення даних, коли система або пристрій кодування сконфігурована з можливістю кодувати дані з використанням процесу контекстно-адаптивного ентропійного кодування. Наприклад, технології можуть поліпшувати стиснення даних за допомогою забезпечення можливості системі або пристрою кодування ініціалізувати один або більше контекстів процесу контекстно-адаптивного ентропійного кодування таким чином, що контексти містять у собі відносно більш точні початкові імовірності в порівнянні з початковими ймовірностями, визначеними з використанням інших технологій ініціалізації контекстів. Зокрема, контексти можуть бути ініціалізовані на основі інформації часових шарів, асоційованої з даними, з використанням інформації опорних станів контекстів і параметрів квантування і різних співвідношень або з використанням одного або більше зміщень ймовірностей. Додатково технології додатково можуть поліпшувати стиснення даних за допомогою забезпечення можливості системі кодування або пристрою кодування згодом оновлювати імовірності контекстів таким чином, що оновлені імовірності є відносно більш точними в порівнянні з ймовірностями, оновленими з використанням інших технологій відновлення ймовірностей контекстів, з використанням технологій, ідентичних або аналогічних технологіям, описаним вище. В одному прикладі спосіб контекстно-адаптивного ентропійного кодування може містити в собі визначення одного або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації. Спосіб також може містити в собі визначення одного або більше станів початкових контекстів для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше параметрів ініціалізації. Крім цього, спосіб може містити в собі ініціалізацію одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше початкових станів контекстів. В іншому прикладі апарат для контекстно-адаптивного ентропійного кодування може містити в собі кодер. У цьому прикладі кодер може бути сконфігурований з можливістю визначати один або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації. Кодер може бути додатково сконфігурований з можливістю визначати один або більше початкових станів контекстів для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше параметрів ініціалізації. Кодер може бути додатково сконфігурований з можливістю ініціалізувати один або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше початкових станів контекстів. У ще одному іншому прикладі пристрій для контекстно-адаптивного ентропійного кодування може містити в собі засіб для визначення одного або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації. Пристрій додатково може містити в собі засіб для визначення одного або більше станів початкових контекстів для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше параметрів ініціалізації. Пристрій додатково може містити в собі засіб для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше початкових станів контекстів. Технології, описані в даному розкритті суті, можуть бути реалізовані в апаратних засобах, програмному забезпеченні, мікропрограмному забезпеченні або в будь-якій комбінації вищезазначеного. При реалізації в апаратних засобах апарат може бути реалізований як одна або більше інтегральних схем, один або більше процесорів, дискретна логіка або будь-яка комбінація вищезазначеного. При реалізації в програмному забезпеченні програмне забезпечення може виконуватися в одному або більше процесорів, таких як один або більше мікропроцесорів, спеціалізованих інтегральних схем (ASIC), програмувальних користувачем вентильних матриць (FPGA) або процесорів цифрових сигналів (DSP). Програмне 2 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 забезпечення, що виконує технології, може спочатку зберігатися в матеріальному або енергонезалежному зчитуваному комп'ютером носії даних і завантажуватися і виконуватися в одному або більше процесорах. Відповідно це розкриття суті також розглядає постійний зчитуваний комп’ютером носій даних, що має збережені інструкції, які при виконанні можуть інструктувати один або більше процесорів виконувати контекстно-адаптивне ентропійне кодування. У цьому прикладі інструкції можуть інструктувати один або більше процесорів визначати один або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації. Інструкції додатково можуть інструктувати один або більше процесорів визначати один або більше початкових станів контекстів для ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше параметрів ініціалізації. Інструкції можуть додатково інструктувати один або більше процесорів ініціалізувати один або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше початкових станів контекстів. Подробиці одного або більше прикладів викладені на прикладених кресленнях і в нижчеподаному описі. Інші ознаки, цілі і переваги повинні ставати очевидними з опису і креслень і з формули винаходу. Короткий опис креслень Фіг. 1 є блок-схемою, яка ілюструє приклад системи кодування і декодування відео, яка може реалізовувати технології для ініціалізації станів і ймовірностей контекстів для контекстноадаптивного ентропійного кодування відповідно до технологій цього розкриття суті. Фіг. 2 є блок-схемою, яка ілюструє приклад відеокодера, що може реалізовувати технології для ініціалізації станів і ймовірностей контекстів для контекстно-адаптивного ентропійного кодування відповідно до технологій цього розкриття суті. Фіг. 3 є блок-схемою, яка ілюструє приклад відеодекодера, що може реалізовувати технології для ініціалізації станів і ймовірностей контекстів для контекстно-адаптивного ентропійного кодування відповідно до технологій цього розкриття суті. Фіг. 4 є концептуальною схемою, яка ілюструє приклад часової ієрархії кодованої відеопослідовності, кодованої з використанням масштабованого кодування відео відповідно до технологій цього розкриття суті. Фіг. 5-8 є блок-схемами послідовності операцій способу, які ілюструють зразкові способи ініціалізації одного або більше контекстів і ймовірностей процесу контекстно-адаптивного ентропійного кодування відповідно до технологій цього розкриття суті. Детальний опис винаходу Це розкриття суті описує технології для кодування даних, таких як відеодані. Наприклад, технології можуть бути використані для того, щоб кодувати відеодані, такі як залишкові коефіцієнти перетворення і/або інші елементи синтаксису, сформовані за допомогою процесів кодування відео. Зокрема, розкриття суті описує технології, що можуть сприяти ефективному кодуванню відеоданих з використанням процесів контекстно-адаптивного ентропійного кодування. Розкриття суті описує кодування відео тільки з метою ілюстрації. У зв'язку з цим технології, описані в цьому розкритті суті, можуть бути застосовними до кодування інших типів даних. У цьому розкритті суті термін "кодування" (coding) означає кодування (encoding), що здійснюється в кодері, або декодування, що здійснюється в декодері. Аналогічно термін "кодер" (coder) означає кодер (encoder), декодер або комбінований кодер/декодер (наприклад, "кодек"). Терміни «кодер» (coder), «кодер» (encoder), «декодер» і «кодек» означають конкретні машини, спроектовані з можливістю кодування (coding) (тобто кодування (encoding) і/або декодування) даних, таких як відеодані, відповідно до цього розкриття суті. Як один приклад технології цього розкриття суті можуть забезпечувати можливість системі або пристрою кодування кодувати різні типи даних, такі як, наприклад, відеодані, більш ефективно в порівнянні з використанням інших технологій. Зокрема, технології, описані в даному документі, можуть забезпечувати можливість системі або пристрою кодування мати меншу складність відносно інших систем або пристроїв при кодуванні даних з використанням процесу контекстно-адаптивного ентропійного кодування, такого як, наприклад, процес контекстно-адаптивного двійкового арифметичного кодування (CABAC). Наприклад, технології можуть зменшувати обсяг інформації, збереженої в системі або пристрої кодування і/або переданої в/з системи або пристрою кодування, з метою ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування. Як один приклад обсяг інформації може бути скорочений за допомогою збереження і/або передачі значень індексів параметрів ініціалізації, що вказують параметри ініціалізації, використовувані для того, щоб 3 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 ініціалізувати контексти, замість збереження і/або передачі безпосередньо параметрів ініціалізації. Додатково як інший приклад технології можуть поліпшувати стиснення даних, коли система або пристрій кодування сконфігурована з можливістю кодувати дані з використанням процесу контекстно-адаптивного ентропійного кодування. Наприклад, технології можуть поліпшувати стиснення даних за допомогою забезпечення можливості системі або пристрою кодування ініціалізувати один або більше контекстів процесу контекстно-адаптивного ентропійного кодування таким чином, що контексти містять у собі відносно більш точні початкові імовірності в порівнянні з початковими ймовірностями, визначеними з використанням інших технологій ініціалізації контекстів. Зокрема, контексти можуть бути ініціалізовані на основі інформації часових шарів, асоційованої з даними, з використанням інформації опорних станів контекстів і параметрів квантування і різних співвідношень або з використанням одного або більше зміщень ймовірностей. Додатково технології додатково можуть поліпшувати стиснення даних за допомогою забезпечення можливості системі або пристрою кодування згодом оновлювати імовірності контекстів таким чином, що оновлені імовірності є відносно більш точними в порівнянні з ймовірностями, оновленими з використанням інших технологій відновлення ймовірностей контекстів, з використанням технологій, ідентичних або аналогічних технологіям, описаним вище. Відповідно може забезпечуватися відносна економія бітів для кодованого потоку бітів, що містить у собі кодовані дані, а також іншу синтаксичну інформацію (наприклад, значення індексів параметрів ініціалізації), передану в/з системи або пристрою кодування, і відносне зменшення складності системи або пристрою кодування, використовуваного для того, щоб кодувати дані, при використанні технологій цього розкриття суті. Технології цього розкриття суті в деяких прикладах можуть бути використані з будь-якою технологією контекстно-адаптивного ентропійного кодування, що включає в себе контекстноадаптивне кодування змінної довжини (CAVLC), CABAC, синтаксичне контекстно-адаптивне двійкове арифметичне кодування (SBAC), ентропійне кодування на основі сегментування на інтервали імовірності (PIPE) або іншу технологію контекстно-адаптивного ентропійного кодування. CABAC описано в даному документі тільки з метою ілюстрації і без обмеження відносно технологій, описаних у широкому змісті в цьому розкритті суті. Крім того, технології, описані в даному документі, можуть, загалом, застосовуватися до кодування інших типів даних, наприклад, на додаток до відеоданих. Фіг. 1 є блок-схемою, яка ілюструє приклад системи кодування і декодування відео, що може реалізовувати технології для ініціалізації станів і ймовірностей контекстів для контекстноадаптивного ентропійного кодування відповідно до технологій цього розкриття суті. Як показано на фіг. 1, система 10 містить у собі пристрій-джерело 12, що формує кодовані відеодані, які повинні бути декодовані згодом за допомогою пристрою-адресата 14. Пристрій-джерело 12 і пристрій-адресат 14 можуть містити будь-які із широкого діапазону пристроїв, що включають у себе настільні комп'ютери, ноутбуки (тобто переносні комп'ютери), планшетні комп'ютери, абонентські приставки, слухавки, наприклад, так звані смартфони, так звані інтелектуальні сенсорні панелі, телевізійні приймачі, камери, пристрої відображення, цифрові мультимедійні програвачі, консолі для відеоігор, пристрої потокової передачі відео і т. п. У деяких випадках пристрій-джерело 12 і пристрій-адресат 14 можуть бути оснащені можливостями бездротового зв'язку. Пристрій-адресат 14 може приймати кодовані відеодані, які повинні бути декодовані, через лінію 16 зв'язку. Лінія 16 зв'язку може містити будь-який тип носія або пристрою, що допускає переміщення кодованих відеоданих з пристрою-джерела 12 в пристрій-адресат 14. В одному прикладі лінія 16 зв'язку може містити середовище зв'язку, щоб забезпечувати можливість пристрою-джерелу 12 передавати кодовані відеодані безпосередньо в пристрій-адресат 14 у реальному часі. Кодовані відеодані можуть бути модульовані відповідно до стандарту зв'язку, такого як протокол бездротового зв'язку, і передані в пристрій-адресат 14. Середовище зв'язку може містити будь-яке бездротове або дротове середовище зв'язку, таке як радіочастотний (RF) спектр або одна або більше фізичних ліній передачі. Середовище зв'язку може формувати частину мережі з комутацією пакетів, таку як локальна обчислювальна мережа, глобальна обчислювальна мережа або глобальна мережа, така як Інтернет. Середовище зв'язку може містити в собі маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, що може бути корисним для того, щоб спрощувати передачу з пристрою-джерела 12 в пристрійадресат 14. Альтернативно кодовані відеодані можуть виводитися з інтерфейсу 22 виведення в пристрій 24 збереження. Аналогічно доступ до кодованих відеоданих може здійснюватися з пристрою 24 4 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 збереження за допомогою інтерфейсу 26 введення. Пристрій 24 збереження може містити в собі будь-який з множини розподілених або локально доступних носіїв збереження даних, таких як жорсткий диск, Blu-Ray-диски, DVD, CD-ROM, флеш-пам’ять, енергозалежний або енергонезалежний запам’ятовуючий пристрій або будь-які інші придатні цифрові носії збереження даних для збереження кодованих відеоданих. У додатковому прикладі пристрій 24 збереження може відповідати файловому серверу або іншому проміжному пристрою збереження даних, який може зберігати кодоване відео, сформоване за допомогою пристроюджерела 12. Пристрій-адресат 14 може здійснювати доступ до збережених відеоданих із пристрою 24 збереження через потокову передачу або завантаження. Файловий сервер може бути будь-яким типом сервера, що допускає збереження кодованих відеоданих і передачу цих кодованих відеоданих в пристрій-адресат 14. Зразкові файлові сервери містять у собі вебсервер (наприклад, для веб-вузла), FTP-сервер, пристрої системи збереження даних з підключенням по мережі (NAS) або локальний накопичувач на дисках. Пристрій-адресат 14 може здійснювати доступ до кодованих відеоданих через будь-яке стандартне підключення для передачі даних, що включає в себе Інтернет-підключення. Він може містити в собі бездротовий канал (наприклад, Wi-Fi-підключення), дротове підключення (наприклад, DSL, кабельний модем і т. д.) або комбінацію зазначеного, яка є придатною для того, щоб здійснювати доступ до кодованих відеоданих, збережених на файловому сервері. Передача кодованих відеоданих із пристрою 24 збереження може являти собою потокову передачу, передачу на основі завантаження або комбінацію вищезазначеного. Технології цього розкриття суті не обов'язково обмежені додатками або налаштуваннями бездротового зв'язку. Технології можуть застосовуватися до кодування відео в підтримку будьяких з множини мультимедійних додатків, таких як телевізійні широкомовні передачі по радіоінтерфейсу, кабельні телевізійні передачі, супутникові телевізійні передачі, потокові передачі відео, наприклад, через Інтернет, кодування цифрового відео для збереження на носії збереження даних, декодування цифрового відео, збереженого на носії збереження даних, або інші додатки. У деяких прикладах система 10 може бути сконфігурована з можливістю підтримувати односторонню або двосторонню передачу відео, щоб підтримувати такі додатки, як потокова передача відео, відтворення відео, широкомовна передача відео і/або відеотелефонія. У прикладі по фіг. 1 пристрій-джерело 12 містить у собі відеоджерело 18, відеокодер 20 і інтерфейс 22 виведення. У деяких випадках інтерфейс 22 виведення може містити в собі модулятор/демодулятор (модем) і/або передавальний пристрій. В пристрої-джерелі 12 відеоджерело 18 може містити в собі джерело, таке як пристрій відеозахоплення, наприклад, відеокамера, відеоархів, що містить раніше захоплене відео, інтерфейс прямих відеотрансляцій, щоб приймати відео від постачальника відеоконтенту, і/або комп'ютерну графічну систему для формування комп'ютерних графічних даних як вихідного відео, або комбінацію таких джерел. Як один приклад, якщо відеоджерелом 18 є відеокамера, пристрійджерело 12 і пристрій-адресат 14 можуть формувати так звані камерофони або відеофони. Проте, технології, описані в цьому розкритті суті, можуть бути застосовними до кодування відео в цілому і можуть застосовуватися до бездротових і/або дротових варіантів застосування. Захоплене, попередньо захоплене або генероване комп'ютером відео може бути кодоване за допомогою відеокодера 20. Кодовані відеодані можуть бути передані безпосередньо в пристрій-адресат 14 через інтерфейс 22 виведення пристрою-джерела 12. Кодовані відеодані також (або альтернативно) можуть зберігатися на пристрій 24 збереження для наступного доступу за допомогою пристрою-адресата 14 або інших пристроїв для декодування і/або відтворення. Пристрій-адресат 14 містить у собі інтерфейс 26 введення, відеодекодер 30 і пристрій 28 відображення. У деяких випадках інтерфейс 26 введення може містити в собі приймальний пристрій і/або модем. Інтерфейс 26 введення пристрою-адресата 14 приймає кодовані відеодані по лінії 16 зв'язку або з пристрою 24 збереження. Кодовані відеодані, передані по лінії 16 зв'язку або надані на пристрої 24 збереження, можуть містити в собі множину елементів синтаксису, сформованих за допомогою відеокодера 20 для використання за допомогою відеодекодера, такого як відеодекодер 30, при декодуванні відеоданих. Такі елементи синтаксису можуть бути включені з кодованими відеоданими, які передаються на середовищі зв'язку, збереженими на носії збереження даних або збереженими на файловому сервері. Пристрій 28 відображення може бути інтегрованим або зовнішнім для пристрою-адресата 14. У деяких прикладах пристрій-адресат 14 може містити в собі інтегрований пристрій відображення, такий як, наприклад, пристрій 28 відображення, і/або сконфігурований з можливістю взаємодіяти з зовнішнім пристроєм відображення. В інших прикладах саме 5 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 пристрій-адресат 14 може бути пристроєм відображення. Загалом, пристрій 28 відображення відображає декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, таких як рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світлодіодах (OLED) або інший тип пристрою відображення. Відеокодер 20 і відеодекодер 30 можуть працювати відповідно до стандарту стиснення відео, такого як стандарт високоефективного кодування відео (HEVC), розроблювальний у даний момент за допомогою об'єднаної групи для спільної роботи над відеостандартами (JCTVC) експертної групи в галузі кодування відео (VCEG) ITU-T і експертної групи по кінозображенню (MPEG) ISO/IEC, і можутьвідповідати тестовій моделі HEVC (HM). Альтернативно відеокодер 20 і відеодекодер 30 можуть працювати відповідно до інших власних або галузевих стандартів, таких як стандарт ITU-T H.264, який альтернативно називається "MPEG-4, частина 10, удосконалене кодування відео (AVC) (далі H.264/AVC)", або розширенням таких стандартів. Проте, технології цього розкриття суті не обмежені яким-небудь конкретним стандартом кодування. Інші приклади стандартів стиснення відео містять у собі MPEG-2 і ITU-T H.263. Останній проект HEVC-стандарту, який називається "робочим проектом HEVC 8" або "WD8", описується в документі JCTVC-J1003_d7, Bross і ін., "High efficiency video coding (HEVC) text specification draft 8", Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 10th Meeting: Стокгольм, SE, 11-20 липня 2012 року. Хоча не показано на фіг. 1, у деяких аспектах, відеокодер 20 і відеодекодер 30 можуть бути інтегровані з аудіо-кодером і декодером, відповідно, і можуть містити в собі відповідні модулі мультиплексора-демультиплексора або інші апаратні засоби і програмне забезпечення, щоб обробляти кодування як аудіо, так і відео в загальному потоці даних або в окремих потоках даних. Якщо застосовно, у деяких прикладах блоки мультиплексора-демультиплексора можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Відеокодер 20 і відеодекодер 30 можуть бути реалізовані як будь-яка з множини належних схем кодера або декодера, наприклад, один або більше мікропроцесорів, процесорів цифрових сигналів (DSP), спеціалізованих інтегральних схем (ASIC), програмувальних користувачем вентильних матриць (FPGA), дискретних логік, програмного забезпечення, апаратних засобів, мікропрограмного забезпечення або будь-яких комбінацій вищезазначеного. Коли технології реалізуються частково в програмному забезпеченні, пристрій може зберігати інструкції для програмного забезпечення на придатному енергонезалежному зчитуваному комп’ютером носії даних і виконувати інструкції в апаратних засобах з використанням одного або більше процесорів, щоб здійснювати технології цього розкриття суті. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або більш кодерів або декодерів, будь-який з яких може бути інтегрований як частина комбінованого кодера/декодера (наприклад, кодека) у відповідному пристрої. Робота по стандартизації HEVC основана на удосконаленій моделі пристрою кодування відео, яка називається "тестовою моделлю HEVC (HM)". HM припускає кілька додаткових можливостей пристроїв кодування відео відносно існуючих пристроїв згідно, наприклад, з ITU-T H.264/AVC. Наприклад, тоді як H.264 надає дев'ять режимів внутрішнього прогнозуючого кодування, HM може надавати всього тридцять п'ять режимів внутрішнього прогнозуючого кодування. Загалом, робоча модель HM описує, що відеокадр або зображення може бути розділене на послідовність деревоподібних блоків або найбільших одиниць кодування (LCU), що містять у собі вибірки як сигналу яскравості, так і сигналу кольоровості. Деревоподібний блок має призначення, аналогічне призначенню макроблоку по стандарту H.264. Слайс містить у собі певну кількість послідовних деревоподібних блоків у порядку кодування. Відеокадр або зображення може бути сегментоване на один або більше слайсів. Кожен деревоподібний блок може розбиватися на одиниці кодування (CU) відповідно до дерева квадрантів. Наприклад, деревоподібний блок, як кореневий вузол дерева квадрантів, може розбиватися на чотири дочірні вузли, і кожен дочірній вузол, у свою чергу, може бути батьківським вузлом і розбиватися ще на чотири дочірні вузли. Кінцевий, нерозбитий дочірній вузол, як кінцевий вузол дерева квадрантів, містить вузол кодування, тобто кодований відеоблок. Синтаксичні дані, асоційовані з кодованим потоком бітів, можуть задавати максимальну кількість разів, що може розбиватися деревоподібний блок і також може задавати мінімальний розмір вузлів кодування. CU містить у собі вузол кодування й одиниці прогнозування (PU) і одиниці перетворення (TU), асоційовані з вузлом кодування. Розмір CU відповідає розміру вузла кодування і може мати квадратну форму. Розмір CU може коливатися від 8×8 пікселів аж до розміру деревоподібного блока максимум у 64×64 пікселів або більше. Кожна CU може містити одну або 6 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 більше PU і одну або більше TU. Синтаксичні дані, асоційовані з CU, можуть описувати, наприклад, сегментування CU на одну або більше PU. Режими сегментування можуть відрізнятися між тим, чи є CU кодованою в режимі пропуску або прямому режимі, кодованою в режимі внутрішнього прогнозування або кодованою в режимі зовнішнього прогнозування. PU можуть бути сегментовані таким чином, що вони мають неквадратну форму. Синтаксичні дані, асоційовані з CU, також можуть описувати, наприклад, сегментування CU на одну або більше TU відповідно до дерева квадрантів. TU може мати квадратну або неквадратну форму. HEVC-стандарт виконує перетворення згідно з TU, які можуть відрізнятися для різних CU. Розміри NU типово задаються на основі розміру PU в даній CU, заданого для сегментованої LCU, хоча це може не завжди мати місце. TU типово має ідентичний розмір або менший, ніж PU. У деяких прикладах залишкові вибірки, що відповідають CU, можуть підрозділятися на менші одиниці з використанням структури у вигляді дерева квадрантів, відомої як "залишкове дерево квадрантів" (RQT). Кінцеві вузли RQT можуть називатися "одиницями перетворення (TU)". Значення піксельних різниць, асоційовані з TU, можуть бути перетворені, щоб формувати коефіцієнти перетворення, що можуть бути квантовані. Загалом, PU містить у собі дані, пов'язані з процесом прогнозування. Наприклад, коли PU кодується у внутрішньому режимі, PU може містити в собі дані, що описують режим внутрішнього прогнозування для PU. Як інший приклад, коли PU кодується в зовнішньому режимі, PU може містити в собі дані, що задають вектор руху для PU. Дані, що задають вектор руху для PU, можуть описувати, наприклад, горизонтальний компонент вектора руху, вертикальний компонент вектора руху, дозвіл для вектора руху (наприклад, точність в одну чверть пікселя або точність в одну восьму пікселя), опорний кадр, на який указує вектор руху, і/або список опорних зображень (наприклад, список 0, список 1 або список C) для вектора руху. Загалом, TU використовується для процесів перетворення і квантування. Дана CU, що має одну або більше PU, також може містити в собі одну або більше TU. Після прогнозування відеокодер 20 може обчислювати залишкові значення, що відповідають PU. Залишкові значення містять значення піксельних різниць, що можуть бути перетворені в коефіцієнти перетворення, квантовані і скановані з використанням TU, щоб формувати перетворені в послідовну форму коефіцієнти перетворення для ентропійного кодування. Це розкриття суті типово використовує термін "відеоблок" для того, щоб позначати вузол кодування CU. У деяких конкретних випадках це розкриття суті також може використовувати термін "відеоблок" для того, щоб позначати деревоподібний блок, тобто LCU або CU, що містить у собі вузол кодування і PU і TU. Відеопослідовність типово містить у собі серії відеокадрів або зображень. Група зображень (GOP), загалом, містить послідовність з одного або більше відеозображень. GOP може містити в собі в заголовку GOP, у заголовку одного або більше зображень або в іншому місці синтаксичні дані, які описують кількість зображень, включених у GOP. Кожен слайс зображення може містити в собі синтаксичні дані слайса, що описують режим кодування для відповідного слайса. Відеокодер 20 типово оперує з відеоблоками в межах окремих відеослайсів, щоб кодувати відеодані. Відеоблок може відповідати вузлу кодування в CU. Відеоблоки можуть мати фіксовані або варійовані розміри і можуть відрізнятися по розміру відповідно до вказаного стандарту кодування. Як приклад HM підтримує прогнозування для різних PU-розмірів. За умови, що розмір конкретної CU складає 2N×2N, HM підтримує внутрішнє прогнозування для PU-розмірів 2N×2N або N×N і зовнішнє прогнозування для симетричних PU-розмірів 2N×2N, 2N×N, N×2N або N×N. HM також підтримує асиметричне сегментування для зовнішнього прогнозування для PUрозмірів 2N×nU, 2N×nD, nL×2N і nR×2N. При асиметричному сегментуванні один напрямок CU не сегментується, у той час як інший напрямок сегментується на 25% і 75%. Частина CU, що відповідає 25%-ому сегменту, указується за допомогою "n", після чого йде індикатор відносно "нагору (Up)", "униз (Down)", "уліво (Left)" або "вправо (Right)". Таким чином, наприклад, "2NxnU " посилається на CU 2N×2N, яка сегментується горизонтально з PU 2N×0,5N вгорі і PU 2N×1,5N унизу. У цьому розкритті суті "N×N" і "N на N" можуть бути використані взаємозамінно для того, щоб посилатися на розміри пікселя відеоблока з погляду розмірів по вертикалі і горизонталі, наприклад, 16×16 пікселів або 16 на 16 пікселів. Загалом, блок 16×16 повинен мати 16 пікселів у вертикальному напрямку (y=16) і 16 пікселів у горизонтальному напрямку (х=16). Аналогічно блок N×N, загалом, має N пікселів у вертикальному напрямку і N пікселів у горизонтальному напрямку, при цьому N представляє ненегативне цілочисельне значення. Пікселі в блоці можуть розміщуватися в рядках і стовпцях. Крім того, блок не обов'язково повинен мати співпадаюче число пікселів у горизонтальному напрямку й у вертикальному напрямку. Наприклад, блоки можуть містити N×M пікселів, причому M не обов'язково дорівнює N. 7 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 Після внутрішнього прогнозуючого кодування або зовнішнього прогнозуючого кодування з використанням PU CU відеокодер 20 може обчислювати залишкові дані для TU CU. PU можуть містити піксельні дані в просторовій області (яка також називається "піксельною областю"), і TU можуть містити коефіцієнти в області перетворення після застосування перетворення, наприклад, дискретного косинусного перетворення (DCT), цілочисельного перетворення, вейвлет-перетворення або концептуально аналогічного перетворення до залишкових відеоданих. Залишкові дані можуть відповідати піксельним різницям між пікселями некодованого зображення і прогнозних значень, що відповідають PU. Відеокодер 20 може формувати TU, що включає в себе залишкові дані для CU, і потім перетворювати TU таким чином, щоб формувати коефіцієнти перетворення для CU. Після перетворень, щоб формувати коефіцієнти перетворення, відеокодер 20 може виконувати квантування коефіцієнтів перетворення. Квантування, загалом, означає процес, у якому коефіцієнти перетворення квантуються, щоб, можливо, зменшувати обсяг даних, використовуваних для того, щоб представляти коефіцієнти, забезпечуючи додатковий стиснення. Процес квантування може зменшувати бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, n-бітове значення може бути округлене в меншу сторону до mбітового значення в ході квантування, при цьому n більше m. У деяких прикладах відеокодер 20 може використовувати один або більше попередньо заданих порядків сканування для того, щоб сканувати квантовані коефіцієнти перетворення, так щоб формувати перетворений у послідовну форму вектор, що може ентропійно кодуватися. Попередньо задані порядки сканування можуть варіюватися на основі таких факторів, як режим кодування або розмір або форма перетворення, використовуваного в процесі кодування. Крім того, в інших прикладах відеокодер 20 може виконувати адаптивне сканування, наприклад, з використанням порядку сканування, що періодично адаптується. Порядок сканування може адаптуватися по-різному для різних блоків, наприклад, на основі режиму кодування або інших факторів. У будь-якому випадку, після сканування квантованих коефіцієнтів перетворення для того, щоб формувати перетворений у послідовну форму "одновимірний" вектор, відеокодер 20 додатково може ентропійно кодувати одновимірний вектор, наприклад, згідно з CAVLC, CABAC, SBAC, PIPE або іншою технологією контекстно-адаптивного ентропійного кодування. Відеокодер 20 також може ентропійно кодувати інші елементи синтаксису, асоційовані з кодованими відеоданими, для використання за допомогою відеодекодера 30 при декодуванні відеоданих. Крім того, відеодекодер 30 може виконувати технології контекстно-адаптивного ентропійного кодування, ідентичні або аналогічні технологіям відеокодера 20, для того щоб декодувати кодовані відеодані і всі додаткові елементи синтаксису, асоційовані з відеоданими. Як один приклад, щоб виконувати CABAC, відеокодер 20 може призначати контекст у контекстній моделі символу, який повинен бути переданий. Контекст може бути пов'язаний, наприклад, з тим, є сусідні значення символу ненульовими чи ні. Як інший приклад, щоб виконувати CAVLC, відеокодер 20 може вибирати код змінної довжини для символу, який повинен бути переданий. Кодові слова при CAVLC і кодуванні змінної довжини, загалом, можуть мати таку структуру, що відносно менші коди відповідають більш ймовірним символам, у той час як відносно більш довгі коди відповідають менш ймовірним символам. Таким чином, використання CAVLC дозволяє досягати економії бітів, наприклад, у порівнянні з використанням кодових слів однакової довжини для кожного символу, який повинен бути переданий. Визначення імовірності може бути основане на контексті, який призначається символу. Додатково технології, описані вище, є в однаковій мірі застосовними до відеодекодера 30, використовуваного для того, щоб декодувати один або більше символів, кодованих за допомогою відеокодера 20 способом, описаним вище. Загалом, відповідно до технологій H.264/AVC і визначених попередніх версій HEVC, описаних вище, кодування символу даних (наприклад, елемента синтаксису або частини елемента синтаксису для кодованого блока відеоданих) з використанням CABAC може містити в собі наступні етапи: (1) Перетворення в двійкову форму: якщо символ, який повинен бути кодований, має недвійкове значення, він перетворюється в послідовність так званих "елементів вибірки". Кожен елемент вибірки може мати значення 0 або 1. (2) Призначення контексту: кожен елемент вибірки (наприклад, у так званому "регулярному" режимі кодування) призначається контексту. Контекстна модель визначає те, як контекст обчислюється (наприклад, призначається) для даного елемента вибірки, на основі інформації, доступної для елемента вибірки, такої як значення раніше кодованих символів або номер елемента вибірки (наприклад, позиція елемента вибірки в послідовності елементів вибірки, що містить у собі елемент вибірки). 8 UA 109841 C2 5 10 15 20 25 30 35 (3) Кодування елементів вибірки: елементи вибірки кодуються за допомогою арифметичного кодера. Щоб кодувати даний елемент вибірки, арифметичний кодер вимагає як введення імовірність (наприклад, оцінену імовірність) значення елемента вибірки, тобто імовірність того, що значення елемента вибірки дорівнює 0, і імовірність того, що значення елемента вибірки дорівнює 1. Наприклад, контекст, який призначається елементу вибірки, як описано вище на етапі (2), може вказувати цю імовірність значення елемента вибірки. Як один приклад імовірність кожного контексту (наприклад, оцінена імовірність, що вказується за допомогою кожного контексту) може бути представлена за допомогою цілочисельного значення, асоційованого з контекстом, який називається "станом" контексту. Кожен контекст має стан контексту (наприклад, конкретний стан контексту в будь-який момент часу). У зв'язку з цим стан контексту (тобто оцінена імовірність) є ідентичним для елементів вибірки, які призначаються одному контексту, і відрізняється між контекстами (наприклад, варіюється між різними контекстами й у деяких випадках для даного контексту в часі). Додатково, для того щоб кодувати елемент вибірки, арифметичний кодер додатково вимагає як введення значення елемента вибірки, як описано вище. (4) Відновлення стану: імовірність (наприклад, стан контексту) для вибраного контексту оновлюється на основі фактичного кодованого значення елемента вибірки. Наприклад, якщо значення елемента вибірки дорівнює 1, імовірність "одиниць" збільшується, а якщо значення елемента вибірки дорівнює 0, імовірність "нулів" збільшується для вибраного контексту. Велика кількість аспектів цього розкриття суті докладно описані в контексті CABAC. Додатково PIPE, CAVLC, SBAC або інші технології контекстно-адаптивного ентропійного кодування можуть використовувати принципи, аналогічні принципам, описаним у даному документі відносно CABAC. Зокрема, ці або інші технології контекстно-адаптивного ентропійного кодування можуть використовувати ініціалізацію станів контекстів і, отже, також можуть мати вигоду з технологій цього розкриття суті. Крім того, як описано вище, CABAC-технології H.264/AVC містять у собі стани контекстів використання, при цьому кожен стан контексту неявно пов'язаний з імовірністю. Передбачено різновиди CABAC, у яких імовірність (наприклад, 0 або 1) даного кодованого символу використовується безпосередньо, тобто імовірність (або цілочисельна версія імовірності) являє собою сам стан контексту, як детальніше описано нижче. До ініціювання процесу CABAC-кодування або декодування початковий стан контексту, можливо, повинен призначатися кожному контексту CABAC-процесу. У H.264/AVC і певних попередніх версіях HEVC, лінійне співвідношення або "модель" використовується для того, щоб призначати початкові стани контекстів для кожного контексту. Зокрема, для кожного контексту попередньо задані параметри ініціалізації, нахил (m) і перетинання (n), використовуються для того, щоб визначати початковий стан контексту для контексту. Наприклад, згідно з H.264/AVC і певними попередніми версіями HEVC, початковий стан контексту для даного контексту може отримуватися з використанням наступних співвідношень: Int iInitState=((m*iQp)/16)+n; 40 45 50 55 рівняння (1) iInitState=min(max(1, iInitState), 126), рівняння (2) У рівнянні EQ (1) m і n відповідають параметрам ініціалізації для ініціалізованого контексту (тобто для визначення початкового стану iInitState контексту для контексту). Крім того, iQP, що може згадуватися як параметр квантування (QP) при ініціалізації, може відповідати QP для кодованих даних (наприклад, блока відеоданих). Значення QP для даних і в силу цього значення iQP може задаватися, наприклад, на покадровой основі, на основі слайсів або на поблоковій основі. Додатково значення параметрів m і n ініціалізації можуть варіюватися для різних контекстів. Крім того, рівняння EQ (2) може згадуватися як функція "відсікання", що може бути використана для того, щоб гарантувати, що значення iInitState розташовується між 1 і 126, через це даючи можливість представлення значення з використанням 7 бітів даних. У деяких прикладах iInitState може бути додатково перетворений у фактичний стан контексту для контексту в CABAC, плюс символ "найбільш ймовірний символ (MPS)/найменш ймовірний символ (LPS)", з використанням наступних виразів: if (iInitState>=64) { m_ucState=min(62, iInitState-64); m_ucState+=m_ucState+1; } Else { 9 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 m_ucState=min(62, 63-iInitState); m_ucState+=m_ucState; }, де m_ucState відповідає фактичному стану контексту для контексту в CABAC плюс MPS/LPS-символ. У деяких прикладах CABAC, у випадках якщо стан контексту для контексту безпосередньо відповідає імовірності контексту, як описано вище, наступні співвідношення можуть бути використані для того, щоб ініціалізувати конкретний контекст: Int c=asCtxInit[0]+asCtxInit[1]*(iQp-iQPreper); рівняння (3) iP0=min(max(1, c), 32767). рівняння (4) Значення iP0 може вказувати імовірність кодованого символу, що вказується безпосередньо за допомогою стану контексту для даного контексту. Відповідно в цьому прикладі немає необхідності перетворювати імовірність символу iP0 у MPS- і LPS-символи і фактичний стан контексту, як описано вище. Крім того, як показано, співвідношення, або "модель", рівняння EQ (3) також є лінійним і ґрунтується на двох параметрах ініціалізації, а саме, asCtxInit[0] і asCtxInit[1]. Наприклад, iQP знову може відповідати QP для кодованих даних. Додатково в деяких прикладах iQPreper може відповідати константі, наприклад, offset, використовуваній для того, щоб модифікувати iQp. У вищеописаному прикладі імовірність символу iP0 виражається як ціле число з використанням 15 бітів даних, при цьому мінімальна ненульова імовірність дорівнює 1, а максимальна імовірність дорівнює 32767. У цьому прикладі "фактична" імовірність отримується з використанням виразу iP0/32768. Додатково рівняння EQ (4) також може згадуватися як функція "відсікання" і може бути використане для того, щоб гарантувати, що значення iP0 розташовується між 1 і 32767, через це даючи можливість представлення значення з використанням 15 бітів даних. Підхід, описаний вище, має кілька недоліків. Як один приклад, оскільки CABAC-процес, описаний вище відносно H.264/AVC і визначених попередніх версій HEVC, містить у собі значну кількість контекстів (наприклад, всього 369 контекстів), кожен контекст може бути ініціалізований з використанням конкретного набору або "пари" параметрів m і n ініціалізації. Як результат, значна кількість параметрів m і n ініціалізації (наприклад, всього 369 різних пар параметрів m і n ініціалізації) може бути використана для того, щоб визначати початкові стани контекстів для контекстів. Крім того, оскільки кожний з параметрів m і n ініціалізації може бути представлений з використанням всього 8 бітів даних, значний обсяг інформації (наприклад, кількість бітів даних) може вимагатися для того, щоб зберігати і/або передавати параметри m і n ініціалізації з метою визначення початкових станів контекстів для контекстів. Наприклад, всього 5904 біти даних можуть вимагатися для того, щоб зберігати і/або передавати 369 різних пар параметрів m і n ініціалізації, кожна з яких містить 16 бітів даних (тобто кожний з параметрів m і n ініціалізації конкретної пари містить 8 бітів даних). Додатково як інший приклад лінійне співвідношення, використовуване для того, щоб визначати початкові стани контекстів для контекстів, як також описано вище відносно H.264/AVC і визначених попередніх версій HEVC, може приводити до визначення початкових ймовірностей контекстів, як зазначено за допомогою початкових станів контекстів, що є відносно менш точними в порівнянні з початковими ймовірностями, визначеними з використанням інших технологій. Як один приклад використання лінійного співвідношення, описаного вище, може приводити до меншої відносної точності початкових ймовірностей у порівнянні з початковими ймовірностями, визначеними з використанням лінійного співвідношення, що додатково враховує часовий шар, асоційований з кодованими даними (наприклад, відеоданими). Як інший приклад використання лінійного співвідношення, описаного вище, може приводити до меншої відносної точності початкових ймовірностей у порівнянні з початковими ймовірностями, визначеними з використанням нелінійного, частково нелінійного або білінійного співвідношення. Як ще один інший приклад у випадках, якщо початкові імовірності контекстів визначаються безпосередньо (тобто замість визначення початкових станів контекстів, що вказують початкові імовірності контекстів), початкові імовірності можуть бути відносно менш точними (наприклад, перекошеними) у порівнянні з початковими ймовірностями, що додатково регулюються на основі їхньої близькості до однієї або більше з верхньої границі і нижньої границі діапазону ймовірностей, що містить у собі початкові імовірності. Це розкриття суті описує кілька технологій, що можуть у деяких випадках зменшувати або виключати деякі недоліки, описані вище відносно ініціалізації станів контекстів (тобто визначення початкових станів контекстів для контекстів, при цьому початкові стани контекстів указують початкові імовірності контекстів), і ініціалізації ймовірностей (тобто безпосереднього 10 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 визначення початкових ймовірностей контекстів) процесу контекстно-адаптивного ентропійного кодування. Зокрема, технології, описані в даному документі, можуть забезпечувати можливість системам або пристроям контекстно-адаптивного ентропійного кодування (наприклад, CABAC, CAVLC, SBAC, PIPE і т. д.), використовуваним для того, щоб кодувати дані, такі як, наприклад, відеодані, мати меншу складність відносно інших систем або пристроїв. Як один приклад технології цього розкриття суті можуть забезпечувати можливість системі або пристрою зберігати і/або передавати значення індексів параметрів ініціалізації, що вказують параметри ініціалізації m і m, описані вище, що використовуються для того, щоб визначати початкові стани контекстів для контекстів процесу контекстно-адаптивного ентропійного кодування, замість збереження і/або передачі безпосередньо параметрів ініціалізації. У цьому прикладі значення індексів параметрів ініціалізації можуть бути представлені з використанням меншого обсягу інформації (наприклад, меншої кількості бітів даних) у порівнянні з параметрами ініціалізації, можливо приводячи до зменшеного обсягу інформації, збереженої в системах або пристроях і в деяких випадках переданої із систем в інші системи або пристрої. Додатково технології, описані в даному документі, можуть забезпечувати більш ефективне контекстно-адаптивне ентропійне кодування даних, таких як, наприклад, відеодані, за допомогою ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування таким чином, що початкові імовірності контекстів є більш точними відносно початкових ймовірностей, що витягаються з використанням інших технологій. В одному прикладі технології цього розкриття суті можуть забезпечувати ініціалізацію контекстів для того, щоб мати відносно більш точні початкові імовірності за допомогою визначення початкових станів контекстів, що служать ознакою початкових ймовірностей, для контекстів на основі часового шару, асоційованого з даними. В іншому прикладі технології можуть забезпечувати ініціалізацію одного або більше контекстів за допомогою визначення початкових станів контекстів для контекстів з використанням опорних станів контекстів і відповідних опорних значень параметрів квантування. У ще одному іншому прикладі у випадках, якщо початкові імовірності контекстів визначаються безпосередньо, технології можуть забезпечувати можливість визначення початкових ймовірностей на основі одного або більше зміщень ймовірностей. Як один приклад це розкриття суті описує технології для визначення одного або більше параметрів ініціалізації для процесу контекстно-адаптивного ентропійного кодування на основі одного або більше значень індексів параметрів ініціалізації, визначення одного або більше станів початкових контекстів для ініціалізації одного або більше контекстів процесу контекстноадаптивного ентропійного кодування на основі одного або більше параметрів ініціалізації й ініціалізації одного або більше контекстів процесу контекстно-адаптивного ентропійного кодування на основі одного або більше початкових станів контекстів. Наприклад, розробка технологій цього розкриття суті демонструє, що в деяких випадках використання лінійного співвідношення між початковими станами контекстів і QP кодованих даних (наприклад, відеоданих), як описано вище відносно H.264/AVC і HEVC, може приводити до відносно менш точних початкових ймовірностей контекстів у порівнянні з використанням інших технологій. Як результат, початкові імовірності, що вказуються за допомогою початкових станів контекстів, можуть істотно відрізнятися від фактичних ймовірностей кодованих даних. Відповідно, як детальніше описане нижче, це розкриття суті пропонує кілька способів формування або визначення значень ініціалізації (тобто початкових станів контекстів або початкових ймовірностей безпосередньо) для контекстів, щоб підвищувати точність так званих початкових "оцінок станів/ймовірностей" (тобто ймовірностей) контекстів. Додатково це розкриття суті також пропонує технології для зменшення бітової ширини параметрів ініціалізації на основі лінійної моделі (тобто m і n), описаної вище, так що може зменшуватися простір збереження для таблиці ініціалізації (наприклад, розмір таблиці), що містить у собі інформацію ініціалізації для контекстів (наприклад, параметри m і n ініціалізації). Наприклад, у HM параметри m і n ініціалізації, описані вище, зберігаються з використанням 16-бітових цілих чисел зі знаком. У зв'язку з цим 16 бітів даних використовуються для збереження кожного параметра ініціалізації m і n. Оскільки технології H.264/AVC і визначені попередні версії HEVC можуть містити в собі всього 369 контекстів, всього 369 наборів або "пар" параметрів m і n ініціалізації (наприклад, 369" (m, n)" пари) можуть бути збережені в конкретному кодері, через це споживаючи досить великий обсяг запам'ятовуючого пристрою або пристрою збереження. У деяких прикладах це розкриття суті описує використання 4 бітів даних для кожного з параметрів m і n ініціалізації. Щоб охоплювати досить великий спектр значень нахилу (m) і перетинання (n), замість безпосереднього використання m для того, щоб представляти нахил, і 11 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 n для того, щоб представляти перетинання, розкриті технології пропонують використання m для того, щоб представляти індекс нахилу, і n для того, щоб представляти індекс перетинання. У цьому прикладі фактичне значення нахилу може витягатися з використанням значення m індексу параметра ініціалізації з використанням наступного співвідношення (тобто з використанням таблиці нахилів): Нахил=SlopeTable[m] Аналогічно фактичне значення перетинання може витягатися з використанням значення n індексу параметра ініціалізації з використанням наступного співвідношення (тобто з використанням таблиці перетинань): Перетинання=IntersectionTable[n] Іншими словами, відповідно до розкритих технологій, параметри m і n ініціалізації, описані вище відносно H.264/AVC і HEVC, можуть перевизначатися як значення m і n індексів параметрів ініціалізації, які, у свою чергу, указують параметри ініціалізації (які можуть згадуватися як просто параметри slope і intersection ініціалізації). Проте, в інших прикладах параметри m і n ініціалізації H.264/AVC і HEVC можуть зберігати свій вихідний зміст, у той час як значення індексів параметрів ініціалізації технологій, розкритих у даному документі, можуть згадуватися як значення idx_m і idx_n індексів параметрів ініціалізації. У наступних прикладах значення індексів параметрів ініціалізації згадуються як значення m і n індексів параметрів ініціалізації. Приклад таблиці нахилів і таблиці перетинань, що містить у собі значення нахилу і перетинання, відповідно, визначені з використанням значень m і n індексів параметрів ініціалізації, показується нижче: SlopeTable[16]={-46, -39, -33, -28, -21, -14, -11, -6, 0, 7, 12, 17, 21, 26, 34, 40} IntersectionTable[16]={-42, -25, -11, 0, 9, 20, 32, 43, 54, 63, 71, 79, 92, 104, 114, 132} У деяких прикладах 4-бітове значення m і 4-бітове значення n індексів параметрів ініціалізації можуть бути комбіновані з використанням 8-бітового параметра x, при цьому "m=x>>4 і n=x&15", або навпаки, "n=x>>4 і m=x&15" може бути використане для того, щоб витягати m і n з використанням x. У цьому прикладі ">>" вказує операцію зрушення вправо, і "and" указує логічну операцію "І". В інших прикладах також можна використовувати нерівні числа бітів, щоб представляти значення m і n індексів параметрів ініціалізації. Наприклад, 5 бітів даних можуть бути використані для того, щоб представляти m, і 3 біти даних можуть бути використані для того, щоб представляти n або навпаки. У ще одних інших прикладах замість збереження таблиці значень нахилу і перетинання, як описано вище, значення нахилу і перетинання можуть бути обчислені з відповідного значення індексу нахилу або перетинання з використанням однієї або більше формул або функцій, наприклад, наступних функцій нахилу і/або перетинання: Нахил=function(m), і/або Перетинання=function(n) З використанням нахилу (slope) як прикладу функція нахилу може бути лінійною функцією, такою як, наприклад, наступний вираз: нахил=c0*m+c1, де c0 і c1 є параметрами лінійної функції. В іншому прикладі функція нахилу може містити в собі тільки операції зсуву і додавання, як, наприклад, у наступному виразі: нахил=m4, n=x&15 (або навпаки, n=x>>4 і m=x&15). Також у цьому прикладі ">>" вказує операцію зсуву вправо, і "and" указує логічну операцію "І". У деяких прикладах замість збереження SlopeTable і IntersectionTable, як описано вище, значення нахилу і перетинання можуть бути обчислені з використанням наступних виразів: Нахил=m*5-45 Перетинання=n*8-16 12 UA 109841 C2 5 10 15 20 25 30 35 40 45 50 55 60 (або еквівалентне Перетинання=(n>5) and31)", і x1 може бути отримане з використанням операції "x1=(InitParam>>10)". Таким чином, параметр InitParam містить параметри, необхідні для витягування початкового стану контексту. Також у цьому прикладі ">>" вказує операцію зрушення вправо, і "and" указує логічну операцію «І». Три значення (тобто x1, x2 і x3), з використанням всього 16 бітів даних квантованих станів контекстів надають три точки (наприклад, "пари" значень, причому кожна пара містить у собі одне з x1, x2 і x3 і відповідне QP-значення), що можуть використовуватися для інтерполяції стану контексту для контексту в інші QP-значення. Іншими словами, опорні значення x 1, x2 і x3 станів контексту і відповідні опорні QP-значення можуть бути використані для того, щоб визначати початковий стан контексту для контексту за допомогою інтерполяції між опорними значеннями і використання фактичного QP, асоційованого з кодованими даними, для того щоб визначати початковий стан контексту для контексту. Як один приклад вищеописане визначення може бути виконане з використанням подвійної лінійної апроксимації (наприклад, сплайнів). Наприклад, можуть використовуватися наступні співвідношення: if QP
ДивитисяДодаткова інформація
Автори англійськоюGuo, Liwei, Wang, Xianglin, Karczewicz, Marta, Sole Rojals, Joel
Автори російськоюГо Ливэй, Ван Сянлинь, Карчевич Марта, Соле Рохальс Хоэль
МПК / Мітки
Мітки: ентропійного, контекстів, ініціалізація, кодування, контекстно-адаптивного, ймовірностей, станів
Код посилання
<a href="https://ua.patents.su/47-109841-inicializaciya-jjmovirnostejj-i-staniv-kontekstiv-dlya-kontekstno-adaptivnogo-entropijjnogo-koduvannya.html" target="_blank" rel="follow" title="База патентів України">Ініціалізація ймовірностей і станів контекстів для контекстно-адаптивного ентропійного кодування</a>
Скорочення кількості контекстів для контекстно-адаптивного бінарного арифметичного кодування

Номер патенту: 109506
Опубліковано: 25.08.2015
Автори: Соле Рохальс Хоель, Чіень Вей-Цзюн, Карчєвіч Марта
Мітки: скорочення, кількості, арифметичного, контекстно-адаптивного, кодування, контекстів, бінарного
Формула / Реферат:
1. Спосіб кодування відеоданих, що включає:вибір контексту з одного або більше контекстів на основі глибини перетворення одиниці перетворення, асоційованої з блоком відеоданих;кодування прапора кодованого блока кольоровості Сb для блока відеоданих з використанням контекстно-адаптивного бінарного арифметичного кодування (САВАС) і вибраного контексту, причому кодування прапора кодованого блока кольоровості Сb включає використання...
Скорочення контексту для контекстно-адаптивного бінарного арифметичного кодування

Номер патенту: 109507
Опубліковано: 25.08.2015
Автори: Соле Рохальс Хоель, Карчєвіч Марта, Чіень Вей-Цзюн
Мітки: контекстно-адаптивного, кодування, бінарного, скорочення, контексту, арифметичного
Формула / Реферат:
1. Спосіб кодування відеоданих, який містить:визначення першого типу прогнозування для блока відеоданих у Р сегменті;представлення першого типу прогнозування як синтаксичного елемента типу прогнозування Р сегмента;визначення другого типу прогнозування для блока відеоданих у В сегменті;представлення другого типу прогнозування як синтаксичного елемента типу прогнозування В сегмента;визначення бінаризації Р...
Спосіб адаптивного контекстно-граматичного стискання текстових повідомлень

Номер патенту: 90653
Опубліковано: 25.05.2010
Автори: Чернега Віктор Степанович, Ісаєва Олеся Володимирівна
МПК: H03M 7/30, G10L 19/00, G06F 11/00
Мітки: адаптивного, повідомлень, стискання, спосіб, текстових, контекстно-граматичного
Формула / Реферат:
Спосіб адаптивного контекстно-граматичного стискання текстових повідомлень, заснований на підрахунку на кожному кроці стискання кількості появи символів у вхідному тексту, зв'язаних з поточними контекстами різних порядків, обчисленні сумарних оцінок імовірностей появи символів у відповідних контекстах, наступного множення цих оцінок на вагові коефіцієнти відповідних контекстів та присвоєнні символам тексту кодових комбінацій у відповідності...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 107157
Опубліковано: 25.11.2014
Автори: Джоши Раджан Лаксман, Карчевіч Марта, Соле Рохальс Хоель
МПК: H04N 19/00
Мітки: коефіцієнтів, кодування, перетворення, відео
Формула / Реферат:
1. Спосіб кодування множини коефіцієнтів перетворення, асоційованих із залишковими відеоданими в процесі кодування відео, причому спосіб включає:кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення згідно з порядком сканування; ікодування інформації, що вказує рівні значущих коефіцієнтів множини коефіцієнтів перетворення згідно із згаданим порядком сканування,причому згаданий порядок...
Залежна від rnti ініціалізація послідовності скремблювання

Номер патенту: 96901
Опубліковано: 12.12.2011
Автори: Монтохо Хуан, Ло Тао, Чень Ваньши
МПК: H04W 48/00
Мітки: послідовності, скремблювання, ініціалізація, залежна
Формула / Реферат:
1. Спосіб забезпечення скремблювання даних для передачі в середовищі бездротового зв'язку, що містить етапи, на яких:вибирають тип часового ідентифікатора радіомережі (RNTI) залежно від типу передачі, що відповідає даним;ініціалізують формування послідовності скремблювання на основі, щонайменше частково, значення RNTI вибраного типу RNTI;скремблюють згадані дані за допомогою послідовності скремблювання для отримання...
Попередній патент: Спосіб визначення “робочої” площі правого шлуночка серця при синдромі гіпоплазії лівих відділів серця
Наступний патент: Вакуум-апарат для кристалізації цукру
Випадковий патент: Спосіб виробництва великогабаритного швелерного профілю