Кодування картинки з малою затримкою
Номер патенту: 115240
Опубліковано: 10.10.2017
Автори: Скупін Роберт, Марпе Детлеф, Георге Валері, Хенкель Анастасія, Шірль Томас, Грюнеберг Карстен

















































Формула / Реферат
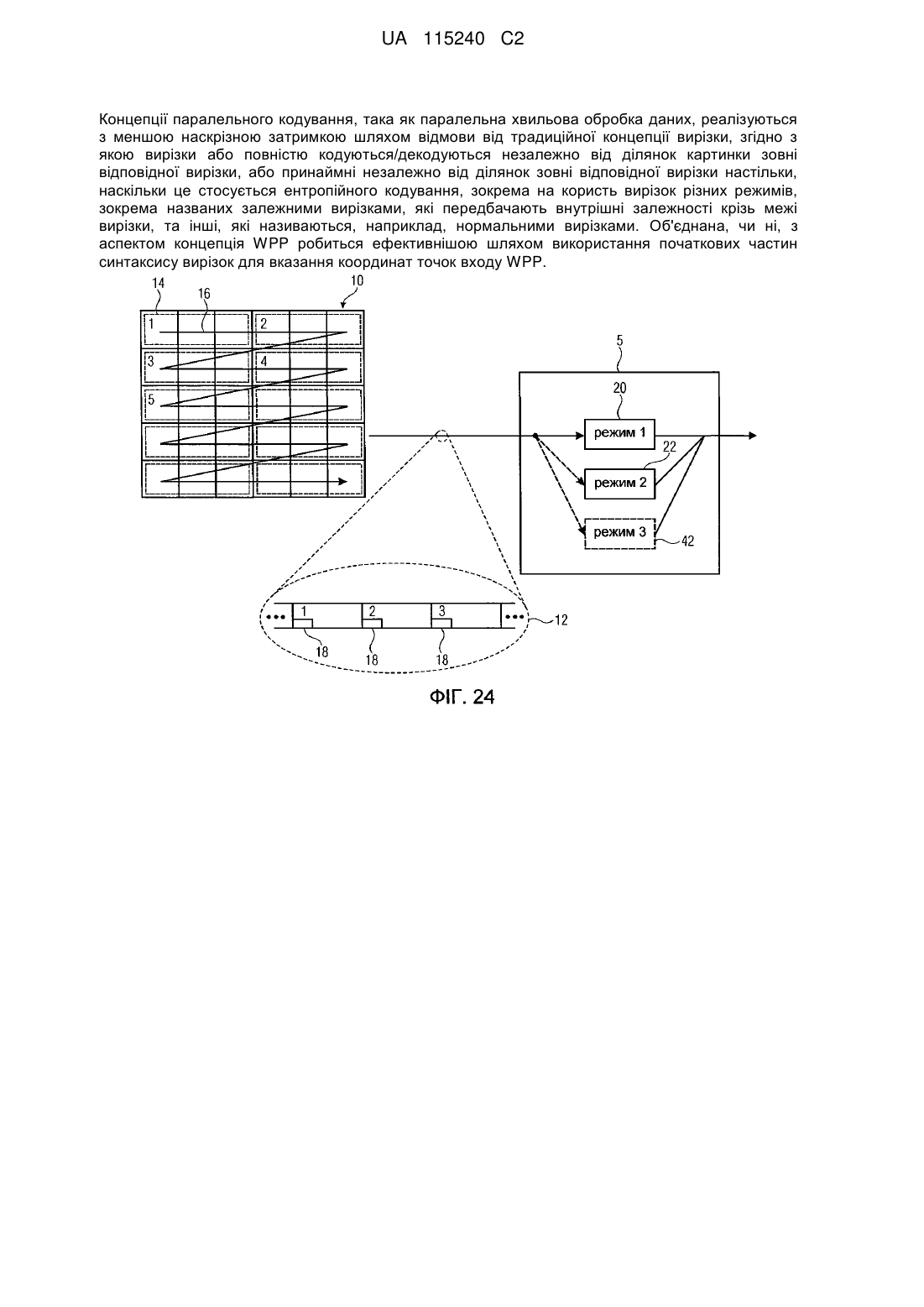
1. Декодер для відтворення картинки (10) з потоку даних (12), в який кодується картинка в одиницях вирізок (14), на які розбивається картинка (10), при цьому декодер сконфігурований для декодування вирізок (14) з потоку даних (12) у відповідності з порядком (16) вирізки і декодер реагує на частину (18) синтаксичного елемента в поточній вирізці з вирізок для декодування поточної вирізки у відповідності з одним з принаймні двох режимів (20, 22), і
у відповідності з першим (20) з принаймні двох режимів для декодування поточної вирізки з потоку даних (12) з використанням адаптивного до контексту ентропійного декодування (24), яке включає одержання контекстів крізь межі вирізки, безперервне оновлення ймовірностей символів контекстів і ініціалізацію (38, 40) ймовірностей символів в залежності від збережених станів ймовірностей символів попередньо декодованої вирізки, і
у відповідності з другим (22) з принаймні двох режимів для декодування поточної вирізки з потоку даних (12) з використанням адаптивного до контексту ентропійного декодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо декодованої вирізки.
2. Декодер за п. 1, який відрізняється тим, що картинку (10) розбивають на кодувальні блоки (32), які розташовані в рядках і стовпчиках, і мають порядок (36) проходження растра, визначений серед них, і декодер сконфігурований для зв'язування кожної вирізки (14) з неперервною підмножиною кодувальних блоків (32) в порядку (36) проходження растра такими чином, що підмножини слідують одна за іншою згідно з порядком (36) проходження растра у відповідності з порядком вирізки.
3. Декодер за п. 2, який відрізняється тим, що сконфігурований для збереження ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному декодуванні попередньо декодованої вирізки до другого кодувального блока (32) в рядку у відповідності з порядком (36) проходження растра, і, при ініціалізації ймовірностей символів для адаптивного до контексту ентропійного декодування поточної вирізки у відповідності з першим режимом, для перевірки, чи є перший кодувальний блок неперервної підмножини кодувальних блоків (32), зв'язаної з поточною вирізкою, першим кодувальним блоком (32) в рядку у відповідності з порядком проходження растра і, якщо так, то для ініціалізації (40) ймовірностей символів для адаптивного до контексту ентропійного декодування поточної вирізки в залежності від збережених ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному декодуванні попередньо декодованої вирізки до другого кодувального блока в рядку у відповідності з порядком (36) проходження растра, і якщо ні, то для ініціалізації (38) ймовірностей символів для адаптивного до контексту ентропійного декодування поточної вирізки в залежності від ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному декодуванні попередньо декодованої вирізки до кінця попередньо декодованої вирізки.
4. Декодер за будь-яким із пп. 1-3, який відрізняється тим, що сконфігурований для реагування на частину (18) синтаксичного елемента в поточній вирізці з вирізок (14) для декодування поточної вирізки у відповідності з одним з принаймні трьох режимів, зокрема в одному з режимів, вибраному серед першого (20) і третього режиму (42) або другого режиму (22), при цьому декодер сконфігурований для декодування у відповідності з першим режимом (20) поточної вирізки з використанням прогнозувального декодування крізь межі вирізки, у відповідності з другим режимом (22) для декодування поточної вирізки з використанням прогнозувального декодування з обмеженням прогнозувального декодування для неперетинання меж вирізки, і у відповідності з третім режимом (42) для декодування поточної вирізки з потоку даних з використанням адаптивного до контексту ентропійного декодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо декодованої вирізки, і прогнозувального декодування крізь межі вирізки, при цьому один режим, вибраний серед першого і третього режиму, вибирається в залежності від синтаксичного елемента.
5. Декодер за будь-яким із пп. 1-3, який відрізняється тим, що сконфігурований для реагування на загальний синтаксичний елемент в потоці даних для роботи в одному з принаймні двох загальних робочих режимів, при цьому, згідно з першим загальним робочим режимом, для реагування на частину синтаксичного елемента для кожної вирізки і, згідно з другим загальним робочим режимом, для неухильного використання іншого з принаймні двох режимів, відмінного від першого режиму.
6. Декодер за п. 2, який відрізняється тим, що сконфігурований для неухильного і неперервного згідно з першим і другим режимом продовження оновлення ймовірностей символів від початку до кінця поточної вирізки.
7. Декодер за п. 2, який відрізняється тим, що сконфігурований для збереження ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному декодуванні попередньо декодованої вирізки до кінця попередньо декодованої вирізки, і, при ініціалізації ймовірностей символів для адаптивного до контексту ентропійного декодування поточної вирізки у відповідності з першим режимом, для ініціалізації ймовірностей символів для адаптивного до контексту ентропійного декодування поточної вирізки в залежності від збережених ймовірностей символів.
8. Декодер за п. 4, який відрізняється тим, що сконфігурований для обмеження в першому і другому режимі прогнозувального декодування в мозаїках, на які підрозбивається картинка.
9. Декодер за будь-яким із пп. 1-8, який відрізняється тим, що сконфігурований для зчитування в першому і другому режимі інформації з поточної вирізки, яка вказує підрозбиття поточної вирізки на паралельні підсекції, для припинення адаптивного до контексту ентропійного декодування в кінці першої паралельної підсекції і для відновлення адаптивного до контексту ентропійного декодування на початку будь-якої наступної паралельної підсекції, яке включає, в першому режимі, ініціалізацію ймовірностей символів в залежності від збережених станів ймовірностей символів попередньої паралельної підсекції і, в другому режимі, ініціалізацію ймовірностей символів незалежно від будь-якої попередньо декодованої вирізки і будь-якої попередньо декодованої паралельної підсекції.
10. Декодер за будь-яким із пп. 1-9, який відрізняється тим, що сконфігурований для копіювання у відповідності з першим (20) з принаймні двох режимів для поточної вирізки частини синтаксису заголовка вирізки з попередньої вирізки, декодованої в другому режимі.
11. Декодер за будь-яким із попередніх пунктів, який відрізняється тим, що сконфігурований для відтворення картинки (10) з потоку даних (12) з використанням WPP, при цьому кожна вирізка (14) містить початкову частину (400) синтаксису, яка вказує положення початку декодування відповідної вирізки в картинці (10), і при цьому декодер сконфігурований для ідентифікації точок входу WPP вкладених потоків, у які групуються вирізки, шляхом ідентифікації з використанням початкових частин синтаксису вирізок, починаючи з лівої сторони картинки, і для паралельного декодування WPP вкладених потоків в шаховому порядку з послідовним початком декодування WPP вкладених потоків у відповідності з порядком вирізки.
12. Декодер за п. 1, який відрізняється тим, що сконфігурований для розбиття блоків перетворення кольоровості по-іншому, ніж блоків перетворення яскравості у відповідь на інформацію в потоці даних.
13. Кодер для кодування картинки (10) з одержанням потоку даних (12) в одиницях вирізок (14), на які розбивається картинка (10), при цьому кодер сконфігурований для кодування вирізок (14) з одержанням потоку даних (12) у відповідності з порядком (16) вирізки і кодер сконфігурований для визначення частини (18) синтаксичного елемента для кодування неї з одержанням поточної вирізки вирізок таким чином, що частина синтаксичного елемента сигналізує поточну вирізку, яка кодується у відповідності з одним з принаймні двох режимів (20, 22), і
якщо поточна вирізка повинна кодуватися у відповідності з першим (20) з принаймні двох режимів, то для кодування поточної вирізки з одержанням потоку даних (12) з використанням адаптивного до контексту ентропійного кодування (24), яке включає одержання контекстів крізь межі вирізки, безперервне оновлення ймовірностей символів контекстів і ініціалізацію (38, 40) ймовірностей символів в залежності від збережених станів ймовірностей символів попередньо кодованої вирізки, і
якщо поточну вирізку потрібно кодувати у відповідності з другим (22) з принаймні двох режимів, то для кодування поточної вирізки з одержанням потоку даних (12) з використанням адаптивного до контексту ентропійного кодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо кодованої вирізки.
14. Кодер за п. 13, який відрізняється тим, що картинку (10) розбивають на кодувальні блоки (32), які розташовані в рядках і стовпчиках, і мають порядок (36) проходження растра, визначений серед них, і кодер сконфігурований для зв'язування кожної вирізки (14) з неперервною підмножиною кодувальних блоків (32) в порядку (36) проходження растра таким чином, що підмножини йдуть одна за іншою згідно з порядком (36) проходження растра у відповідності з порядком вирізки.
15. Кодер за п. 14, який відрізняється тим, що сконфігурований для збереження ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному кодуванні попередньо кодованої вирізки до другого кодувального блока (32) в рядку у відповідності з порядком (36) проходження растра, і, при ініціалізації ймовірностей символів для адаптивного до контексту ентропійного кодування поточної вирізки у відповідності з першим режимом, для перевірки, чи є перший кодувальний блок неперервної підмножини кодувальних блоків (32), зв'язаної з поточною вирізкою, першим кодувальним блоком (32) в рядку у відповідності з порядком проходження растра і, якщо так, то для ініціалізації (40) ймовірності символів для адаптивного до контексту ентропійного кодування поточної вирізки в залежності від збережених ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному кодуванні попередньо кодованої вирізки до другого кодувального блока в рядку у відповідності з порядком (36) проходження растра і, якщо ні, то для ініціалізації (38) ймовірності символів для адаптивного до контексту ентропійного кодування поточної вирізки в залежності від ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному кодуванні попередньо кодованої вирізки до кінця попередньо кодованої вирізки.
16. Кодер за будь-яким із пп. 13-15, який відрізняється тим, що сконфігурований для кодування частини (18) синтаксичного елемента з одержанням поточної вирізки вирізок (14) таким чином, що поточна вирізка сигналізується для кодування з одержанням нею у відповідності з одним з принаймні трьох режимів, зокрема в одному режимі, вибраному серед першого (20) і третього режиму (42) або другого режиму (22), при цьому кодер сконфігурований для кодування у відповідності з першим режимом (20) поточної вирізки з використанням прогнозувального кодування крізь межі вирізки, у відповідності з другим режимом (22) для кодування поточної вирізки з використанням прогнозувального кодування з обмеженням прогнозувального кодування для неперетинання меж вирізки і у відповідності з третім режимом (42) для кодування поточної вирізки з одержанням потоку даних з використанням адаптивного до контексту ентропійного кодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо кодованої вирізки, і прогнозувального кодування крізь межі вирізки, при цьому кодер розрізняє один режим, вибраний серед першого і третього режиму, з використанням синтаксичного елемента.
17. Кодер за будь-яким із пп. 13-16, який відрізняється тим, що сконфігурований для визначення загального синтаксичного елемента і запису його в потік даних з роботою в одному з принаймні двох загальних робочих режимів в залежності від загального синтаксичного елемента, зокрема, згідно з першим загальним робочим режимом, з виконанням кодування частини синтаксичного елемента для кожної вирізки і, згідно з другим загальним робочим режимом, з неухильним використанням іншого режиму, вибраного серед принаймні двох режимів, відмінного від першого режиму.
18. Кодер за п. 14, який відрізняється тим, що сконфігурований для неухильного і безперервного згідно з першим і другим режимом безперервного продовження оновлення ймовірностей символів від початку до кінця поточної вирізки.
19. Кодер за п. 14, який відрізняється тим, що сконфігурований для збереження ймовірностей символів, як вони одержані в адаптивному до контексту ентропійному кодуванні попередньо кодованої вирізки до кінця попередньо кодованої вирізки і, при ініціалізації ймовірностей символів для адаптивного до контексту ентропіиного кодування поточної вирізки у відповідності з першим режимом, для ініціалізації ймовірності символів для адаптивного до контексту ентропіиного кодування поточної вирізки в залежності від збережених ймовірностей символів.
20. Кодер за п. 16, який відрізняється тим, що сконфігурований для обмеження у першому і другому режимі прогнозувального кодування в мозаїках, на які підрозбивається картинка.
21. Кодер за п. 13, який відрізняється тим, що сконфігурований таким чином, що потік даних містить інформацію, у відповідь на яку блоки перетворення кольоровості розбиваються по-іншому, ніж блоки перетворення яскравості.
22. Спосіб відтворення картинки (10) з потоку даних (12), у який кодується картинка в одиницях вирізок (14), на які розбивають картинку (10), при цьому декодують вирізки (14) з потоку даних (12) у відповідності з порядком (16) вирізки і реагують на частину (18) синтаксичного елемента в поточній вирізці з вирізок для декодування поточної вирізки у відповідності з одним з принаймні двох режимів (20, 22),
при цьому у відповідності з першим (20) з принаймні двох режимів поточну вирізку декодують з потоку даних (12) з використанням адаптивного до контексту ентропійного декодування (24), яке включає одержання контекстів крізь межі вирізки, безперервне оновлення ймовірностей символів контекстів і ініціалізацію (38, 40) ймовірностей символів в залежності від збережених станів ймовірностей символів попередньо декодованої вирізки, і
у відповідності з другим (22) з принаймні двох режимів, поточну вирізку декодують з потоку даних (12) з використанням адаптивного до контексту ентропійного декодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо декодованої вирізки.
23. Спосіб кодування картинки (10) з одержанням потоку даних (12) в одиницях вирізок (14), на які розбивають картинку (10), при цьому у способі кодують вирізки (14) з одержанням потоку даних (12) у відповідності з порядком (16) вирізки і у ньому визначають частину (18) синтаксичного елемента для кодування нею з одержанням поточної вирізки з вирізок таким чином, що частина синтаксичного елемента сигналізує поточну вирізку для кодування у відповідності з одним з принаймні двох режимів (20, 22), і
якщо поточну вирізку потрібно кодувати у відповідності з першим (20) з принаймні двох режимів, то кодують поточну вирізку з одержанням потоку даних (12) з використанням адаптивного до контексту ентропійного кодування (24), яке включає одержання контекстів крізь межі вирізки, безперервне оновлення ймовірностей символів контекстів і ініціалізацію (38, 40) ймовірностей символів в залежності від збережених станів ймовірностей символів попередньо кодованої вирізки, і
якщо поточну вирізку необхідно кодувати у відповідності з другим (22) з принаймні двох режимів, то кодують поточну вирізку з одержанням потоку даних (12) з використанням адаптивного до контексту ентропійного кодування з обмеженням одержання контекстів для неперетинання меж вирізки, безперервного оновлення ймовірностей символів контекстів і ініціалізації ймовірностей символів незалежно від будь-якої попередньо кодованої вирізки.
24. Зчитуваний комп’ютером носій, який зберігає код потоку даних, одержаного способом за п. 23.
25. Зчитуваний комп’ютером носій за п. 24, який відрізняється тим, що містить код інформації, у відповідь на який блоки перетворення кольоровості розбивають по-іншому, ніж блоки перетворення яскравості.
Текст
УКРАЇНА (19) UA (11) 115240 (13) C2 (51) МПК H04N 19/91 (2014.01) H04N 19/174 (2014.01) H04N 19/13 (2014.01) H04N 19/436 (2014.01) МІНІСТЕРСТВО ЕКОНОМІЧНОГО РОЗВИТКУ І ТОРГІВЛІ УКРАЇНИ ОПИС ДО ПАТЕНТУ НА ВИНАХІД (21) Номер заявки: a 2014 12222 Дата подання заявки: 15.04.2013 (22) (24) Дата, з якої є чинними 10.10.2017 (72) Винахідник(и): Ширль Томас (DE), Георге Валері (DE), Хенкель Анастасія (DE), Марпе Детлеф (DE), Грюнеберг Карстен (DE), Скупін Роберт (DE) (73) Власник(и): Дж.І. Відіеу Кемпрешн, ЛЛСі, 8 Southwoods Boulevard Albany, New York, USA (US) (74) Представник: Пахаренко Антонiна Павлiвна, реєстр. №4 (56) Перелік документів, взятих до уваги експертизою: MAURICIO ALVAREZ-MESA ET AL, "Parallel video decoding in the emerging HEVC standard", 2012 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL PROCESSING (ICASSP 2012) : KYOTO, JAPAN, 25 - 30 MARCH 2012 ; [PROCEEDINGS], IEEE, PISCATAWAY, NJ, (20120325), doi:10.1109/ICASSP.2012.6288186, ISBN 978-14673-0045-2, pages 1545 - 1548, XP032227426 [I] 1-8,10-19,22-23,26 * the whole document * MISRA K ET AL, "Entropy Slices for Parallel Entropy Coding", 94. MPEG MEETING; 07-10-2010 - 15-102010; GUANGZHOU; (MOTION PICTURE EXPERT GROUP OR ISO/IEC JTC1/SC29/WG11),, (20101007), no. M18297, XP030046887 [I] 1-8,1019,22-23,26 * the whole document * LEE T ET AL, "Simplification on tiles and slices", 99. MPEG MEETING; 6-2-2012 - 10-2-2012; SAN JOSÃ CR ; (MOTION PICTURE EXPERT GROUP OR ISO/IEC JTC1/SC29/WG11),, (20120206), no. m23223, XP030051748 [I] 1-8,10-19,22-23,26 * the whole document * GORDON C ET AL, "Wavefront Parallel Processing for HEVC Encoding and Decoding", 6. JCT-VC MEETING; 97. MPEG MEETING; 14-7-2011 - 22-72011; TORINO; (JOINT COLLABORATIVE TEAM ON VIDEO CODING OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ); URL: HTTP://WFTP3.ITU.INT/AV-ARCH/JCTVC-SITE/,, (20110716), no. JCTVC-F274, XP030009297 [A] 18,10-19,22-23,26 * the whole document * права на винахід: (31) Номер попередньої 61/624,098, 61/666,185 (32) Дата подання 13.04.2012, 29.06.2012 заявки відповідно до Паризької конвенції: попередньої заявки відповідно до Паризької конвенції: (33) Код держави-учасниці US, Паризької конвенції, US до якої подано попередню заявку: (41) Публікація відомостей 25.02.2015, Бюл.№ 4 про заявку: (46) Публікація відомостей 10.10.2017, Бюл.№ 19 про видачу патенту: (86) Номер та дата подання міжнародної заявки, поданої відповідно до Договору PCT PCT/EP2013/057798, 15.04.2013 (54) КОДУВАННЯ КАРТИНКИ З МАЛОЮ ЗАТРИМКОЮ (57) Реферат: UA 115240 C2 (12) UA 115240 C2 Концепції паралельного кодування, така як паралельна хвильова обробка даних, реалізуються з меншою наскрізною затримкою шляхом відмови від традиційної концепції вирізки, згідно з якою вирізки або повністю кодуються/декодуються незалежно від ділянок картинки зовні відповідної вирізки, або принаймні незалежно від ділянок зовні відповідної вирізки настільки, наскільки це стосується ентропійного кодування, зокрема на користь вирізок різних режимів, зокрема названих залежними вирізками, які передбачають внутрішні залежності крізь межі вирізки, та інші, які називаються, наприклад, нормальними вирізками. Об'єднана, чи ні, з аспектом концепція WPP робиться ефективнішою шляхом використання початкових частин синтаксису вирізок для вказання координат точок входу WPP. UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 Представлений винахід стосується кодування картинок з малою затримкою В поточній структурі стандарту HEVC вирізки, ентропійні вирізки (колишні вирізки малої ваги), мозаїки і WPP (паралельна хвильова обробка даних) розглядаються як засоби для розпаралелювання процесу. Для розпаралелювання роботи відеокодерів і відеодекодерів, розбиття картинки має декілька переваг порівняно з іншими наближеннями. В попередніх відеокодеках, таких як H.264/AVC [1], розбиття картинки були можливими тільки зі стандартними вирізками та високою вартістю з точки зору ефективності кодування. Для здатного до масштабування паралельного декодування за допомогою H.264/AVC, необхідно поєднувати розпаралелювання роботи на рівні макроблоків для відтворення картинки і розпаралелювання роботи на рівні кадру для ентропійного декодування. Однак, це наближення забезпечує обмежене зменшення затримок в кодуванні картинки і використання великих об‘ємів пам‘яті. Для подолання цих обмежень, в кодек HEVC були включені нові стратегії розбиття картинки. Поточна еталонна версія програмного забезпечення (HM-6) містить 4 різні наближення: стандартні або нормальні вирізки, ентропійні вирізки, вкладені потоки даних паралельної хвильової обробки даних (WPP) і мозаїки. Типово, ці розбиття картинки містять множину найбільших кодувальних чарунок (LCUs) або в синонімічному формулюванні кодувальних деревоподібних чарунок (CTU), як визначено в стандарті HEVC, або навіть їх підмножини. Фігура 1 зображає як картинка 898 ілюстративно розбита на стандартні вирізки 900, кожна з яких утворює ряд 902 LCUs або макроблоків в картинці. Стандартні або нормальні вирізки (як визначено в стандарті H.264 [1]) мають найбільше погіршення якості кодування, оскільки вони порушують залежності ентропійного декодування і прогнозування. Ентропійні вирізки, такі як вирізки, порушують залежності ентропійного декодування, але дозволяють прогнозування (і фільтрування) крізь межі вирізки. В паралельній хвильовій обробці даних (WPP) розбиття картинки перемежовуються в рядках і дозволяються як ентропійне декодування так і прогнозування для використання даних з блоків в інших розбиттях. У цей спосіб втрати кодування мінімізуються з одночасною можливістю використання розпаралелювання хвильової обробки даних. Однак, перемежовування порушує причинність бітового потоку, оскільки попереднє розбиття потребує наступного розбиття для декодування. Фігура 2 ілюстративно зображає картинку 898, поділену на два рядки 904, 904b горизонтально подільних мозаїк 906. Мозаїки визначають горизонтальну 908 і вертикальну межу 910, які розбивають картинку 898 на стовпчики 912a,b,c мозаїк і рядки 904a,b мозаїк. Подібно до стандартних вирізок 900, мозаїки 906 порушують залежності ентропійного декодування і прогнозування, але не вимагають заголовка для кожної мозаїки. Для кожної з цих технологій кодером може вільно вибиратися ряд розбиттів. Головним чином, більше розбиттів приводить до більших втрат стискання. Однак в WPP поширення втрат не є таким великим і, тому, ряд розбиттів картинки навіть може фіксуватися по одному на рядок. Це також приводить до кількох переваг. По-перше, гарантується причинність WPP бітового потоку. По-друге, втілення декодера можуть припускати, що доступне певне розпаралелювання роботи, що також підвищується роздільною здатністю. І, нарешті, жодна із залежностей вибору контексту і прогнозування не повинна порушуватися при декодування у хвильовому порядку, призводячи до відносно малих втрат кодування. Однак, до цих пір усе паралельне кодування в концепціях перетворення не забезпечує досягання високої ефективності стискання в поєднанні із збереженням малої затримки. Це також вірно для концепції WPP. Вирізки є найменшими одиницями транспортування в кодуванні каналу інформації і декілька WPP вкладених потоків все ще повинні передаватися послідовно. Відповідно, задачею представленого винаходу є надання концепції кодування картинки, яка передбачає паралельне декодування згідно з, наприклад, паралельною хвильовою обробкою даних з підвищеною ефективністю, як, наприклад, навіть з подальшим зменшенням наскрізної затримки або підвищенням ефективності кодування шляхом зменшення використовуваного заголовку кодування. Ця задача вирішується об‘єктом незалежних пунктів формули винаходу. Основне відкриття представленого винаходу полягає в тому, що концепції паралельної обробки даних, такі як паралельна хвильова обробка даних, можуть реалізовуватися з меншою наскрізною затримкою, якщо відмовитися від звичайної концепції вирізки, згідно з якою вирізки або кодуються/декодуються повністю незалежно від ділянок картинки зовні відповідної вирізки, або принаймні незалежно від ділянок зовні відповідної вирізки настільки, наскільки це стосується ентропійного кодування, на користь вирізок різних режимів, а саме: так званих 1 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 залежних вирізок, які передбачають внутрішні залежності крізь границі вирізки, та інших, які, наприклад, називаються нормальними вирізками. Подальше основне відкриття представленого винаходу, яке може поєднуватися з першим відкриттям або використовуватися індивідуально, полягає в тому, що концепція WPP може робитися ефективнішою, якщо для визначення координат WPP точок входу використовуються початкові частини синтаксису вирізок. Переважні варіанти виконання представленого винаходу описуються нижче стосовно фігур, при цьому переважні варіанти виконання є об‘єктами залежних пунктів формули винаходу. На фігурах: Фіг. 1 зображає картинку, ілюстративно розбиту на стандартні вирізки, які формують рядки LCUs або макроблоків в картинці; Фіг. 2 зображає картинку, ілюстративно поділену на два рядки горизонтально розбитих мозаїк; Фіг. 3 ілюстративно зображає присвоєння паралельно кодованих розбиттів вирізці або транспортувальному сегменту мережі; Фіг. 4 зображає схематичну діаграму, яка показує загальну фрагментацію кадру з наближенням мозаїкового кодування для мінімальної наскрізної затримки; Фіг. 5 зображає схематичну діаграму, яка показує ілюстративну фрагментацію кадру з наближенням WPP кодування для мінімальної наскрізної затримки; Фіг. 6 зображає схему, яка показує сценарій розмови з використанням відеопослуг; Фіг. 7 схематично зображає можливу годинну диспетчеризацію кодування, передачі даних і декодування для мозаїк з спільними підмножинами з мінімальною наскрізною затримкою; Фіг. 8 схематично зображає годинну диспетчеризацію, яка зазвичай досягає наскрізної затримки; Фіг. 9 зображає картинку, яка ілюстративно має 11x9 кодувальних деревовидних блоків, яка ділиться на дві вирізки; Фіг. 10 зображає картинку, яка ілюстративно має 13x8 кодувальних деревовидних блоків, яка розбивається на три мозаїки; Фіг. 11 зображає приклад для синтаксису множини значень параметра послідовності; Фіг. 12 зображає приклад для синтаксису множини значень параметра послідовності; Фіг. 13 зображає приклад для синтаксису заголовка вирізки; Фіг. 14 ілюструє розбиття картинки для WPP на стандартну вирізку і для обробки з малою затримкою – на залежні вирізки; Фіг. 15 зображає приклад для частини в синтаксисі множини значень параметра картинки; Фіг. 16 зображає можливий синтаксис заголовка вирізки; Фіг. 17 схематично зображає внутрішні залежності кодування для нормальних вирізок (і залежних вирізок); Фіг. 18 зображає схематичну діаграму, яка порівнює кодування для передачі мозаїк з малою затримкою (паралельна хвильова обробка даних з використанням залежних вирізок); Фіг. 19 зображає годинну диспетчеризацію, яка показує ілюстративне WPP кодування з передачею даних з малою затримкою по каналу зв‘язку при використанні паралельної хвильової обробки даних з використанням залежних вирізок, як зображено справа на Фіг. 18; Фіг. 20 зображає схематичну діаграму, яка показує покращення надійності шляхом використання стандартних вирізок як якорів; Фіг. 21 зображає інший варіант виконання для синтаксису заголовка вирізки; Фіг. 22 зображає інший варіант виконання для синтаксису множини значень параметра картинки; Фіг. 23 зображає схематичну діаграму, яка показує спосіб ініціалізації ймовірності символу для залежної вирізки у випадку початку на лівій межі картинки; Фіг. 24 зображає схему декодера; Фіг. 25 схематично зображає схему декодера разом з схематичним зображенням розбиття картинки на кодувальні блоки і вирізки; Фіг. 26 схематично зображає схему кодера; Фіг. 27 схематично зображає картинку, розбиту на нормальні і залежні вирізки (тут названі сегментами вирізки); Фіг. 28a і 28b схематично зображають картинку, розбиту на нормальні і залежні вирізки (тут названі сегментами вирізки), з одного боку, і мозаїки, з іншого боку; Фіг. 29 зображає блок-схему, яка показує процес ініціалізації контексту з використанням залежних вирізок; 2 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 60 Фіг. 30 зображає блок-схему, яка показує процес зберігання контексту для використання залежних вирізок; і Фіг. 31 схематично зображає різні можливості сигналізації WPP точок входу. Далі, опис починається з опису сьогоднішніх концепцій для надання можливості паралельної обробки картинки і, відповідно, кодування з малою затримкою. Окреслюються проблеми, які з‘являються при бажанні мати обидві можливості. Зокрема, як виявиться з наступного обговорення, концепція WPP вкладеного потоку, як зазначалося до цих пір, деяким чином конфліктує з бажанням мати малу затримку внаслідок необхідності передавати WPP вкладені потоки шляхом групування їх в одну вирізку. Наступні варіанти виконання реалізують концепції паралельної обробки даних, такі як концепція WPP, застосовувані для випадків, які потребують навіть меншу затримку шляхом розширення концепції вирізки, зокрема шляхом введення іншого типу вирізки, далі названими залежними вирізками. Мінімізація наскрізної відеозатримки від уловлювання зображення до відображення його є однією з головних цілей у застосуваннях, таких як відеоконференція і подібне. Контур обробки сигналу для передачі цифрових відеоданих складається з відеокамери, уловлювального пристрою, кодера, інкапсулятора, передавача, демультиплексора, декодера, рендерера і відображального пристрою. Кожен з цих етапів робить внесок в наскрізну затримку шляхом буферизації даних зображення перед їх послідовною передачею на наступний етап. Деякі застосування вимагають мінімізації такої затримки, наприклад дистанційного оперування об‘єктами на небезпечних ділянках, без прямого огляду об‘єкта, яким оперують, або мінімального докучливого втручання. Кожна мала затримка може приводити до серйозних труднощів, пов‘язаних з належним оперуванням, або навіть приводити до катастрофічних помилок. В багатьох випадках, на етапі обробки буферизується увесь відеокадр, наприклад, для забезпечення внутрішньокадрової обробки даних. Деякі етапи збирають дані для формування пакетів, які подаються на наступний етап. Загалом, існує нижня межа для затримки, яка випливає з вимог локальної обробки даних. Нижче детальніше аналізується цей факт для кожного окремого етапу. Обробка даних всередині відеокамери обов‘язково не вимагає внутрішньокадрової обробки сигналу таким чином, що мінімальна затримка забезпечується періодом інтегрування датчика, який обмежується частотою кадрів, і деякими виборами виробником структури апаратного засобу. Вихідні дані відеокамери типово зв‘язуються з порядком проходження, згідно з яким обробка даних зазвичай починається у верхньому лівому куті, далі здійснюється до верхнього правого кута і продовжується рядок за рядком до нижнього правого кута. Тому, це займає приблизно період проходження одного кадру до тих пір, доки усі дані не будуть передані від датчика до виходу відеокамери. Уловлювальний пристрій може передавати дані відеокамери зразу ж після їх прийому; однак, він буде типово буферизувати деяку кількість даних і генерувати пакети для оптимізації доступу даних до запам‘ятовуючого пристрою або зберігального пристрою. Окрім того, з‘єднання між відеокамерою/уловлювальним пристроєм і запам‘ятовуючим пристроєм комп‘ютера типово обмежує швидкість передачі бітів для передачі уловлених даних зображення до запам‘ятовуючого пристрою для подальшої обробки (кодування). Типово, відеокамери з‘єднані між собою за допомогою USB 2.0 або скоріше за допомогою USB 3.0, що будуть завжди частково передавати дані зображення до кодера. Це обмежує здатність до розпаралелювання процесу на кодувальній стороні з надзвичайно малою затримкою, тобто, кодер буде намагатися розпочинати кодування якомога скоріше, коли дані з відеокамери стають доступними, наприклад в порядку проходження растру: зверху донизу зображення. В кодері існує декілька ступенів свободи, які дозволяють узгоджувати ефективність кодування з точки зору швидкості передачі даних, необхідної для точності передачі певних відеоданих для зменшення затримки в обробці даних. Кодер використовує дані, які вже були надіслані, для прогнозування зображення, яке потім кодується. Загалом, різниця між реальним зображенням і прогнозом може кодуватися меншою кількістю бітів ніж, як це повинно потребуватися у випадку без прогнозування. Величини цього прогнозування повинні бути доступними для декодера, таким чином прогноз базується на попередньо декодованих частинах одного і того ж зображення (внутрішньокадрове прогнозування) або на інших зображеннях (міжкадрове прогнозування), які були оброблені раніше. В попередньому кодуванні відеоданих стандарти HEVC використовують тільки частину зображення зверху або в тому ж рядку, але ліву, яка була попередньо кодована, для внутіршньокадрового прогнозування, прогнозування вектора руху і ентропійного кодування (CABAC). 3 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 60 На додаток до оптимізації структури прогнозування, може розглядатися вплив паралельної обробки даних. Паралельна обробка даних вимагає ідентифікації ділянок картинки, які можуть оброблятися незалежно. З практичних причин, вибирають суміжні ділянки, такі як горизонтальні або вертикальні прямокутники, які часто називають “мозаїками”. У випадку обмеження малої затримки, такі ділянки повинні дозволяти розпаралелене кодування даних, які якомога скоріше надходять від уловлювального пристрою до запам‘ятовуючого пристрою. Припускаючи передачу даних пам‘яті в порядку проходження растру, мають сенс вертикальні розбиття необроблених даних для негайного початку кодування. Всередині таких мозаїк, які ділять картинку на вертикальні рядки (порівняти фігуру нижче), інтрапрогнозування, прогнозування вектора руху і ентропійне кодування (CABAC) можуть приводити до раціональної ефективності кодування. Для мінімізації затримки, тільки частина картинки, починаючи зверху, повинна передаватися до пристрою для запам‘ятовування кадру кодера і у вертикальних мозаїках повинна розпочинатися паралельна обробка даних. Іншим способом забезпечення паралельної обробки даних є використання WPP в стандартній вирізці, що повинна порівнюватися з мозаїками, “рядком” мозаїк, включених в єдину вирізку. Дані у такій вирізці можна також паралельно обробляти з використанням WPP вкладених потоків у вирізці. Розбиття картинки на вирізки 900 і мозаїки/WPP вкладені потоки 914, зображені на Фіг. 3/1, є прикладами. Фіг. 3, таким чином, зображає присвоєння паралельно кодованих частин, таких як 906 або 914, вирізці або мережевому транспортному сегменту (єдиний мережевий пакет або множина мережевих пакетів 900). Інкапсуляція кодованих даних в блоки мережевого рівня абстракції (NAL), як визначено в стандарті H.264 або HEVC, перед передачею даних або під час процесу кодування додає деякий заголовок до блоків даних, який дозволяє ідентифікацію кожного блока і повторне упорядковування блоків, якщо це застосовується. В стандартному випадку, не вимагається додаткової сигналізації, оскільки порядок кодувальних елементів завжди відповідає порядку декодування, тобто, надається неявне присвоєння положення мозаїки або загального кодувального фрагмента. Якщо паралельна обробка розглядається з додатковим транспортувальним шаром для паралельного транспортування з малою затримкою, тобто, транспортувальний шар може переупорядковувати ділянки картинки для мозаїк для забезпечення передачі даних з малою затримкою, означаючи передачу фрагментів, як зображено на Фіг. 4, коли вони кодуються. Такі фрагменти можуть також бути не повністю кодованими вирізками, вони можуть бути підмножиною вирізки або можуть міститися у залежній вирізці. У випадку створення додаткових фрагментів, існує узгодження між ефективністю, яка повинна бути найвищою з великими блоками даних, оскільки інформація заголовку додає сталу кількість байтів, і затримкою, оскільки великі блоки даних паралельних кодерів повинні потребувати буферизації перед передачею. Загальна затримка може зменшуватися, якщо кодоване представлення вертикальних мозаїк 906 розбивається на ряд фрагментів 916, які передаються, як тільки фрагмент стає повністю кодованим. Розмір кожного фрагмента може визначатися в термінах фіксованої ділянки зображення, такої як макроблоки, LCUs, або в термінах максимальної кількості даних, як зображено на Фіг. 4. Фіг. 4, таким чином, зображає загальну фрагментацію кадру з наближенням мозаїкового кодування для мінімальної наскрізної затримки. Подібним чином, Фіг. 5 зображає фрагментацію кадру з WPP кодувальним наближенням для мінімальної наскрізної затримки. Передача даних може додавати додаткову затримку, наприклад, якщо застосовується додаткова орієнтована на блоки обробка даних, така як коди прямого виправлення помилок, яка підвищує надійність передачі даних. Окрім того, інфраструктура мережі (маршрутизатори і так далі) або фізичний канал передачі даних можуть вносити затримку, для з‘єднання це типово відоме як латентність. На додаток до латентності, швидкість передачі бітів визначає тривалість (затримку) передачі даних від сторони a до сторони b у спілкуванні, як зображено на Фіг. 6, яке використовує відеопослуги. Якщо кодовані блоки даних передаються без порядку, то потрібно розглядати затримку у переупорядкуванні. Декодування може розпочинатися зразу з при надходженні блока даних, припускаючи, що доступні інші блоки даних, які потрібно декодувати перед цим. У випадку мозаїк, між мозаїками відсутні залежності, таким чином, мозаїка може зразу ж декодуватися. Якщо фрагменти сформовані з мозаїки, такі як окремі вирізки на кожен фрагмент, як зображено на Фіг 4, то фрагменти можуть безпосередньо транспортуватися, як тільки вони відповідно стануть кодованими або їх LCUs або CUs стануть кодованими. 4 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 Рендерер збирає вихідні дані паралельних декодерів і направляє комбіновану картинку рядок за рядком до відображального пристрою. Відображальний пристрій обов‘язково не додає якусь затримку, але, на практиці, може виконувати деяку внутрішньокадрову обробку даних перед реальним відображенням даних зображення. Це залежить від виборів виробником структури апаратного засобу. Підсумовуючи, для досягання мінімальної наскрізної затримки, можна впливати на етапи кодування, інкапсуляції, передачу даних та декодування. Якщо використовується паралельна обробка даних, мозаїки і фрагментація в мозаїках, то загальна затримка може значно зменшуватися, як зображено на Фіг. 7, порівняно із зазвичай використовуваним контуром обробки даних, який додає приблизно одну кадрову затримку на кожному з цих етапів, як зображено на Фіг. 8. Зокрема, хоча Фіг. 7 зображає кодування, передачу даних і декодування для мозаїк із загальними підмножинами з мінімальною наскрізною затримкою, Фіг. 8 зображає загалом одержану наскрізну затримку. Стандарт HEVC дозволяє використання розбиття вирізки, розбиття мозаїки наступним чином. мозаїка: ціла кількість деревоподібних блоків, які сумісно розташовані в одному стовпчику і одному рядку, послідовно упорядковані в порядку проходження растру деревоподібного блоку мозаїки. Поділ кожної картинки на мозаїки є розбиттям. Мозаїки в картинці послідовно упорядковані в порядку проходження растру картинки. Хоча вирізка містить деревоподібні блоки, які розташовані послідовно в порядку проходження растру деревоподібного блоку мозаїки, ці деревоподібні блоки обов‘язково не послідовно розташовані в порядку проходження растру деревоподібного блока картинки. вирізка: ціла кількість деревоподібних блоків послідовно упорядковані в порядку проходження растру. Поділ кожної картинки на вирізки є розбиттям. Адреси деревоподібних блоків одержуються з адреси першого деревоподібного блока у вирізці (як представлено у заголовку вирізки). проходження растру: перетворення прямокутної двовимірної структури на одновимірну структуру так, що перші вхідні дані в одновимірній структурі одержуються з першого верхнього рядка двовимірної структури, який проходиться зліва направо, подібним чином зліва направо проходиться другий, третій і так далі, рядки структури (донизу). деревоподібний блок: блок NxN зразків яскравості і два відповідних блоки зразків кольоровості картинки, яка має три масиви зразків або блок NxN зразків монохромної картинки або картинки, яка кодується з використанням трьох окремих кольорових площин. Поділ вирізки на деревоподібні блоки є розбиттям. розбиття: поділ множини на підмножини так, що кожен елемент множини знаходиться точно в одній з підмножин. квадрадерево: дерево, у якому батьківський вузол може розбиватися на чотири вузлинащадки. Вузол-нащадок може стати батьківським вузлом для іншого розбиття на чотири вузланащадки. Далі, пояснюється просторове підрозбиття картинок, вирізок і мозаїк. Зокрема, подальший опис уточнює як картинка розбивається на вирізки, мозаїки і кодувальні деревоподібні блоки. Картинки діляться на вирізки і мозаїки. Вирізка є послідовністю кодувальних деревоподібних блоків. Подібним чином, мозаїка є послідовністю кодувальних деревоподібних блоків. Зразки обробляються в одиницях кодувальних деревоподібних блоків. Розмір масиву яскравості для кожного деревоподібного блока в зразках як по ширині так і по висоті становить CtbSize. Ширина і висота масивів кольоровості для кожного кодувального деревоподібного блока становлять CtbWidthC і, відповідно, CtbHeightC. Наприклад, картинка може ділитися на дві вирізки, як зображено на наступній фігурі. Як інший приклад, картинка може ділитися на три мозаїки, як зображено на другій наступній фігурі. На відміну від вирізок, мозаїки є завжди прямокутними і завжди містять цілу кількість кодувальних деревоподібних блоків в порядку проходження растру кодувального деревоподібного блока. Мозаїка може складатися з кодувальних деревоподібних блоків, які містяться у більше ніж одній вирізці. Подібним чином, вирізка може містити кодувальні деревоподібні блоки, які містяться у більше ніж одній мозаїці. Фіг. 9 зображає картинку 898 з 11 х 9 кодувальними деревоподібними блоками 918, яка розбиваються на дві вирізки 900a,b. Фіг. 10 зображає картинку з 13 х 8 кодувальними деревоподібними блоками 918, яка розбивається на три вирізки. 5 UA 115240 C2 5 10 15 20 25 Кожен кодувальний деревоподібний блок 918 картинки 898 присвоюється сигналу розбиття для ідентифікації розмірів блока для інтра- або інтерпрогнозування і для кодування з перетворенням. Розбиття є рекурсивним підрозбиттям квадрадерева. Корінь квадрадерева зв‘язаний з кодувальним деревоподібним блоком. Квадрадерево розбивається до досягання листка, який називається кодувальним блоком. Кодувальний блок є кореневим вузлом двох дерев, дерева прогнозу і дерева перетворення. Дерево прогнозу вказує положення і розмір прогнозувальних блоків. Прогнозувальні блоки і відповідні дані прогнозування названі прогнозувальною одиницею. Фіг. 11 зображає ілюстративний RBSP(Дані Необробленої Послідовності Байтів) синтаксис множини значень параметра послідовності. Дерево перетворення вказує положення і розмір блоків перетворення. Блоки перетворення і відповідні дані перетворення називаються одиницею перетворення. Інформація про розбиття для яскравості і кольоровості ідентична для дерева прогнозування і може або може не бути ідентичною для дерева перетворення. Кодувальний блок, відповідні дані кодування і відповідні одиниці прогнозування і перетворення формують разом кодувальну одиницю. Спосіб перетворення адреси кодувального деревоподібного блока в порядку проходження растру кодувального деревоподібного блока на порядок проходження мозаїки може бути наступним: Вихідними даними для цього способу є – масив CtbAddrTS[ctbAddrRS], з ctbAddrRS в інтервалі 0 - PicHeightInCtbs * PicWidthInCtbs − 1, включно. – масив TileId[ctbAddrTS], з ctbAddrTS в інтервалі 0 - PicHeightInCtbs * PicWidthInCtbs − 1, включно. Масив CtbAddrTS[ ] одержується наступним чином: Масив TileId[ ] одержується наступним чином: 30 35 40 Відповідний ілюстративний синтаксис зображений на Фіг. 11, 12 і 13, при цьому Фіг. 12 має ілюстративний RBSP синтаксис множини значень параметра картинки. Фіг. 13 зображає ілюстративний синтаксис заголовка вирізки. В прикладі синтаксису може застосовуватися наступна семантика: entropy_slice_flag equal to 1 вказує, що відсутнє значення синтаксичних елементів заголовку вирізки дорівнює значенню синтаксичних елементів заголовку вирізки в попередній вирізці, де попередня вирізка визначається як вирізка, яка містить кодувальний деревоподібний блок з координатами (SliceCtbAddrRS − 1). entropy_slice_flag повинен дорівнювати 0, коли SliceCtbAddrRS дорівнює 0. tiles_or_entropy_coding_sync_idc equal to 0 вказує, що існує тільки одна мозаїка в кожній картинці в послідовності кодованих відеоданих і не викликається спеціальний процес синхронізації для змінних контексту перед декодуванням першого кодувального деревоподібного блока рядка кодувальних деревоподібних блоків. 6 UA 115240 C2 5 10 15 20 25 30 tiles_or_entropy_coding_sync_idc equal to 1 вказує, що тут в кожній картинці може бути більше ніж одна мозаїка в послідовності кодованих відеоданих, і не викликається спеціальний процес синхронізації змінних контексту перед декодуванням першого кодувального деревоподібного блока рядка кодувальних деревоподібних блоків. tiles_or_entropy_coding_sync_idc equal to 2 вказує, що в кожній картинці існує тільки одна мозаїка в послідовності кодованих відеоданих, викликається спеціальний процес синхронізації для змінних контексту перед декодуванням першого кодувального деревоподібного блока рядка кодувальних деревоподібних блоків і викликається спеціальний процес збереження змінних контексту в запам‘ятовуючому пристрої після декодування двох кодувальних деревоподібних блоків рядка кодувальних деревоподібних блоків. Значення tiles_or_entropy_coding_sync_idc повинно становити 0 - 2, включно. num_tile_columns_minus1 plus 1 вказує кількість стовпчиків мозаїк, які розбивають картинку. num_tile_rows_minus1 plus 1 вказує кількість рядків мозаїк, які розбивають картинку. Коли num_tile_columns_minus1 дорівнює 0, то num_tile_rows_minus1 не повинен бути рівним 0. Одна або обидві з наступних умов повинні задовольнятися для кожної вирізки і мозаїки: – Усі кодовані блоки у вирізці належать одній і тій же мозаїці. – Усі кодовані блоки в мозаїці належать одній і тій же вирізці. ПНРИМІТКА – В одній і тій же картинці можуть бути присутніми обидві вирізки, які містять множину мозаїк, і мозаїки, які містять множину вирізок. uniform_spacing_flag equal to 1 вказує, що межі стовпчика і, подібним чином, межі рядка однорідно розподілені по картинці. uniform_spacing_flag equal to 0 вказує, що межі стовпчика і, подібним чином, межі рядка однорідно не розподілені по картинці, але явно сигналізовані з використанням синтаксичних елементів column_width[ i ] і row_height[ i ]. column_width[ i ] вказує ширину i-го стовпчика мозаїки в одиницях кодувальних деревоподібних блоків. row_height[ i ] вказує висоту i-го рядка мозаїки в одиницях кодувальних деревоподібних блоків. Значення ColumnWidth[ i ], який вказує ширину i-го стовпчика мозаїки в одиницях кодувальних деревоподібних блоків, і значення ColumnWidthInLumaSamples[ i ], які вказують ширину i-го стовпчика мозаїки в одиницях зразків яскравості, одержуються наступним чином: Значення RowHeight[ i ], які вказують висоту i-го рядка мозаїки в одиницях кодувальних деревоподібних блоків, одержуються наступним чином: 35 Значення ColBd[ i ], які вказують координати лівої межі i-го стовпчика мозаїки в одиницях кодувальних деревоподібних блоків, одержуються наступним чином: Значення RowBd[ i ], які вказують координати верхньої межі i-го рядка мозаїки в одиницях кодувальних деревоподібних блоків, одержуються наступним чином: 40 7 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 num_substreams_minus1 plus 1 вказує максимальну кількість підмножин, включених у вирізку, коли tiles_or_entropy_coding_sync_idc дорівнює 2. Коли він відсутній, то величина num_substreams_minus1 дорівнює 0. num_entry_point_offsets вказує кількість синтаксичних елементів entry_point_offset[ i ] у заголовку вирізки. Коли tiles_or_entropy_coding_sync_idc дорівнює 1, то величина num_entry_point_offsets повинна становити 0 - ( num_tile_columns_minus1 + 1 ) * ( num_tile_rows_minus1 + 1 ) − 1, включно. Коли tiles_or_entropy_coding_sync_idc дорівнює 2, то величина num_entry_point_offsets повинна становити 0 - num_substreams_minus1, включно. Коли він відсутній, то величина num_entry_point_offsets дорівнює 0. offset_len_minus1 plus 1 вказує довжину синтаксичних елементів entry_point_offset[ i ] в бітах. entry_point_offset[ i ] вказує зміщення i-ї точки входу в байтах і повинна представлятися бітами offset_len_minus1 plus 1. Кодований блок NAL вирізки складається з підмножин num_entry_point_offsets + 1, при цьому значення індексу яких становлять від 0 до num_entry_point_offsets, включно. Підмножина 0 складається з байтів 0 - entry_point_offset[ 0 ] − 1 кодованого блока NAL вирізки, включно, при цьому підмножина k з k, яке становить 1 num_entry_point_offsets – 1, включно, складається з байтів entry_point_offset[ k − 1 ] entry_point_offset[ k ] + entry_point_offset[ k − 1 ] − 1 кодованого блока NAL вирізки, включно, і остання підмножина (з індексом підмножини, рівним num_entry_point_offsets) складається з решти байтів кодованого блока NAL вирізки. ПРИМІТКА – Заголовок блока NAL і заголовок вирізки кодованого блока NAL вирізки завжди включаються в підмножину 0. Коли tiles_or_entropy_coding_sync_idc дорівнює 1 і num_entry_point_offsets більший за 0, то кожна підмножина повинна містити усі кодовані біти однієї або множини повних мозаїк, а кількість підмножин повинна дорівнювати або бути меншою за кількість мозаїк у вирізці. Коли tiles_or_entropy_coding_sync_idc дорівнює 2, а num_entry_point_offsets більша за 0, то підмножина k для кожної з усіх можливих величин k повинна містити усі біти, які використовуються під час процесу ініціалізації для поточного вказівника k бітового потоку. Розглядаючи семантику даних вирізки, можна застосувати наступне. end_of_slice_flag equal to 0 вказує, що інший макроблок є наступним у вирізці. end_of_slice_flag equal to 1 вказує кінець вирізки і що далі відсутній додатковий макроблок. entry_point_marker_two_3bytes є фіксованою послідовністю з 3 байтів, яка дорівнює 0x000002. Цей синтаксичний елемент називається вхідним префіксом маркера. tile_idx_minus_1 вказує TileID в порядку проходження растру. Перша мозаїка в картинці повинна мати TileID, рівний 0. Величина tile_idx_minus_1 повинна становити 0 - ( num_tile_columns_minus1 + 1 ) * ( num_tile_rows_minus1 + 1 ) − 1. Процес CABAC синтаксичного аналізу для даних вирізки може бути наступним: Цей процес може вимагатися при виконанні синтаксичного аналізу синтаксичних елементів дескриптором ae(v). Вхідними даними для цього процесу є запит на надання величини синтаксичного елемента і величин попередньо синтаксично проаналізованих синтаксичних елементів. Виходом цього процесу є величина синтаксичного елемента. При розпочинанні синтаксичного аналізу даних вирізки, вимагається процес ініціалізації CABAC процесу синтаксичного аналізу. Коли tiles_or_entropy_coding_sync_idc дорівнює 2 і num_substreams_minus1 більший за 0, то таблиця перетворення BitStreamTable з вхідними даними num_substreams_minus1 + 1, які визначають таблицю вказівників бітового потоку для використання для пізнішого одержання вказівника поточного бітового потоку, одержується наступним чином. – BitStreamTable[ 0 ] ініціалізується для включення вказівника бітового потоку. – Для усіх індексів і, більших за 0 і менших за num_substreams_minus1+1, BitStreamTable[ i ] містить вказівник бітового потоку для entry_point_offset[ i ] bytes після BitStreamTable[ i − 1 ]. Поточний вказівник бітового потоку встановлюють рівним BitStreamTable[ 0 ]. Адреса мінімального кодувального деревоподібного блока, який містить просторово сусідній блок T, ctbMinCbAddrT, одержується з використанням координат ( x0, y0 ) верхнього лівого зразка яскравості поточного кодувального деревоподібного блока, наприклад, наступним чином. x = x0 + 2 > Log2MinCbSize ][ y >> Log2MinCbSize ] Змінна availableFlagT одержується запитуванням відповідного процесу одержання доступу до кодувального блока з ctbMinCbAddrT, як вхідною величиною. 8 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 При розпочинанні процесу синтаксичного аналізу кодувального дерева і tiles_or_entropy_coding_sync_idc is equal to 2 та num_substreams_minus1 is greater than 0, використовується наступне. – Якщо CtbAddrRS % PicWidthInCtbs дорівнює 0, то застосовується наступне. – Коли availableFlagT дорівнює 1, то вимагається процес синхронізації процесу CABAC синтаксичного аналізу, як це вказано в підпункті “Synchronization process for context variables”. – Процес декодування для бінарних рішень перед вимогою завершення слідує за процесом ініціалізації для арифметичного декодера. – Вказівник поточного бітового потоку вказує BitStreamTable[ i ] з індексом і, одержаним наступним чином. i = ( CtbAddrRS / PicWidthInCtbs ) % ( num_substreams_minus1 + 1 ) – Інакше, якщо CtbAddrRS % PicWidthInCtbs дорівнює 2, то вимагається процес введення даних в запам‘ятовуючий пристрій в процесі CABAC синтаксичного аналізу, як це вказано в підпункті “Memorization process for context variables”. Процес ініціалізації може бути наступним: Вихідні дані цього процесу є ініціалізованими CABAC внутрішніми змінними. Спеціальні обробки його даних вимагаються при розпочинанні синтаксичного аналізу даних вирізки або при розпочинанні синтаксичного аналізу даних кодувального дерева і кодувальне дерево є першим кодувальним деревом в мозаїці. Процес введення змінних контексту в запам‘ятовуючий пристрій може бути наступним: Вхідними даними цього процесу є CABAC змінні контексту, позначені індексом ctxIdx. Вихідні дані цього процесу є змінні TableStateSync і TableMPSSync, які містять значення змінних m і n, використовуваних в процесі ініціалізації змінних контексту, які присвоюються синтаксичним елементам, за виключенням прапорця кінця вирізки. Для кожної змінної контексту відповідні вхідні дані n і m таблиць TableStateSync і TableMPSSync ініціалізуються для відповідних pStateIdx і valMPS. Процес синхронізації змінних контексту може бути наступним: Вхідні дані цього процесу є змінними TableStateSync і TableMPSSync, які містять значення змінних n і m, використовуваних в процесі введення змінних контексту в запам‘ятовуючий пристрій, які присвоюються синтаксичним елементам, за виключенням прапорця кінця вирізки. Вихідні дані цього процесу є CABAC змінні контексту, позначені індексом ctxIdx. Для кожної змінної контексту відповідні змінні контексту pStateIdx і valMPS ініціалізуються для відповідних вхідних величин n і m таблиць TableStateSync і TableMPSSync. Далі пояснюється кодування з малою затримкою і транспортування з використанням WPP. Зокрема, нижченаведене обговорення вказує як транспортування з малою затримкою, як описано на Фіг. 7, може також застосовуватися до WPP. Перш за все, важливо, що може надсилатися підмножина картинки перед завершенням усієї картинки. Зазвичай, це може досягатися з використанням вирізок, як вже показано на Фіг. 5. Для зменшення затримки порівняно з мозаїками, як зображено на наступних фігурах, існує потреба у застосуванні єдиного WPP вкладеного потоку на рядок LCUs і, окрім того, дозволяє окрему передачу кожного з таких рядків. Для збереження високої ефективності кодування, не можна використовувати вирізки на кожен рядок/вкладеноий потік. Тому, нижче вводиться так звана залежна вирізка, як визначено в наступному розділі. Ця вирізка, наприклад, не має усіх полів повного заголовка вирізки стандарту HEVC, але має поля, використовувані для ентропійних вирізок. Окрім того, може бути присутнім перемикач для усунення розриву CABAC між рядками. У випадку WPP, використання CABAC контексту (стрілки на Фіг. 14) і прогнозування рядків повинно дозволятися для збереження виграшу ефективності кодування WPP по усіх мозаїках. Зокрема, Фіг. 14 ілюструє картинку 10 для WPP у стандартній вирізці 900 (ділянка SL) і для обробки даних з малою затримкою у залежних вирізках (OS) 920. На даний момент, стандарт HEVC, що розробляється, пропонує два типи розбиття з точки зору вирізок. Існує стандартна (нормальна) вирізка і ентропійна вирізка. Стандартна вирізка є повністю незалежним розбиттям картинки, за виключенням деяких залежностей, які можуть бути доступними внаслідок деблокування процесу фільтрування на межах вирізки. Ентропійна вирізка також незалежна, але тільки з точки зору ентропійного кодування. Ідеєю з Фіг. 14 є узагальнення концепції розбиття на вирізки. Таким чином, стандарт HEVC, що розробляється, повинен пропонувати два загальні типи вирізок: незалежна (стандартна) або залежна. Тому, вводиться новий тип вирізки: залежна вирізка. 9 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 60 Залежна вирізка є вирізкою, яка має залежності для попередньої вирізки. Залежності є спеціальними даними, які можуть використовуватися між вирізками в процесі ентропійного декодування і/або процесі відтворення елемента зображення. На Фігурі 14 ілюстративно представлена концепція залежних вирізок. Картинка починається, наприклад, завжди зі стандартної вирізки. Відзначається, що у цій концепції поведінка стандартної вирізки трохи змінюється. Типово, в стандартах, таких як H264/AVC або HEVC, стандартна вирізка є повністю незалежним розбиттям і не повинна зберігати жодних даних після декодування, за виключенням деяких даних для деблокування процесу фільтрування. Проте обробка майбутньої залежної вирізки 920 можлива тільки завдяки посиланню на дані верхньої вирізки (тут в першому рядку): стандартна вирізка 900. Для встановлення цього, стандартні вирізки 900 повинні зберігати дані останнього рядка CU (кодувальна чарунка). Ці дані включають: - CABAC дані кодера (стани моделі контексту однієї CU, з яких може ініціалізуватися процес ентропійного декодування залежної вирізки), - усі декодовані синтаксичні елементи CUs для стандартного CABAC процесу декодування залежних CUs, - Дані інтрапрогнозування і прогнозування вектора руху. Тому, кожна залежна вирізка 920 повинна виконувати ту ж процедуру – зберігати дані для майбутньої залежної вирізки в тій же картинці. На практиці, ці додаткові етапи не повинні бути проблемою, оскільки процес декодування загалом зберігає деякі дані, такі як синтаксичні елементи. В нижченаведених розділах представлені можливі зміни для синтаксису стандарту HEVC, які вимагаються для реалізації концепції залежних вирізок. Фіг. 5, наприклад, зображає можливі зміни в синтаксисі RBSP множини значень параметра картинки. Семантика множини значень параметра картинки для залежних вирізок може бути наступною: dependent_slices_present_flag equal to 1 вказує, що картинка містить залежні вирізки і процес декодування кожної (стандартної або залежної) вирізки повинен зберігати стани ентропійного декодування і дані інтрапрогнозування і прогнозування вектора руху для наступної вирізки, яка може бути залежною вирізкою, яка може також відповідати стандартній вирізці. Наступна залежна вирізка може посилатися на такі збережені дані. Фіг. 16 зображає можливий slice_header syntax із змінами відносно поточного статусу HEVC. dependent_slice_flag equal to 1 вказує, що значення відсутніх синтаксичних елементів заголовка вирізки дорівнює значенню синтаксичних елементів заголовка вирізки в попередній (стандартній) вирізці, де попередня вирізка визначається як вирізка, яка містить кодувальний деревоподібний блок з координатами (SliceCtbAddrRS − 1). dependent_slice_flag повинен дорівнювати 0, коли SliceCtbAddrRS дорівнює 0. no_cabac_reset_flag equal to 1 вказує CABAC ініціалізацію із збереженого стану попередньо декодованої вирізки (і не початковими значеннями). Інакше, тобто, якщо 0, то CABAC ініціалізація не залежить від жодного стану попередньо декодованої вирізки, тобто з початковими значеннями. last_ctb_cabac_init_flag equal to 1 вказує CABAC ініціалізацію із збереженого стану останнього кодованого деревоподібного блока попередньо декодованої вирізки (наприклад, для мозаїк завжди дорівнює 1). Інакше (дорівнює 0), дані ініціалізації вказуються із збереженого стану другого кодованого деревоподібного блока останнього (сусіднього) ctb-рядка попередньо декодованої вирізки, якщо перший кодований деревоподібний блок поточної вирізки є першим кодованим деревоподібним блоком в рядку (тобто, WPP режим), інакше, CABAC ініціалізація виконується із збереженого стану останнього кодованого деревоподібного блока попередньо декодованої вирізки. Нижче надається порівняння залежних вирізок та інших схем розбиття(інформативних). На Фіг. 17 зображується відмінність між нормальною і залежною вирізкою. Можливе кодування і передачу WPP вкладених потоків в залежних вирізках (DS), як описано стосовно Фіг. 18, порівнюють з кодуванням для транспортування мозаїк(ліві) з малою затримкою і WPP/DS (праві). Товсті хрестики, зображені товстими суцільними лініями, на Фіг. 18 зображають однаковий момент часу для двох способів, припускаючи, що кодування WPP рядка займає той же час що й кодування єдиної мозаїки. Завдяки кодувальним залежностям, готовим є тільки перший рядок WPP після кодування усіх мозаїк. Проте використання наближення залежної вирізки дозволяє WPP наближенню передавати перший рядок зразу ж після його кодування. Це відрізняється від раніших присвоєнь WPP вкладеного потоку, “вкладений потік” 10 UA 115240 C2 5 10 15 20 25 30 35 40 45 50 55 60 визначається для WPP як конкатенація рядків CU вирізки, які WPP декодуються тим же потоком декодера, тобто, тим же ядром/процесором. Хоча перед цим повинен також бути можливим вкладений потік на рядок і на ентропійну вирізку, ентропійна вирізка порушує залежності ентропійного кодування і, тому, має низьку ефективність кодування, тобто втрачається виграш WPP ефективності. Окрім того, відмінність у затримці між обома наближеннями може бути реально малою, припускаючи передачу даних, як це зображено на Фіг. 19. Зокрема, Фіг. 19 зображає WPP кодування з передачею даних по каналу інформації з малою затримкою. Припускаючи, що кодування останніх двох CUs DS #1.1 в WPP наближенні на Фіг. 18 не займає більше часу ніж передача першого рядка SL #1, між мозаїками і WPP відсутня відмінність у випадку малої затримки. Проте ефективність WP/DS перевищує ефективність концепції мозаїки. Для підвищення надійності для WPP режиму з малою затримкою, Фіг. 20 вказує, що покращення надійності досягається використанням стандартних вирізок (RS) як якорів. На картинці, зображеній на Фіг. 20, за (стандартною) вирізкою (RS) слідують залежні вирізки (DS). Тут, (стандартна) вирізка функціонує як якір для порушення залежностей для попередніх вирізок, тому, забезпечується більша надійність в таких точках вставляння (стандартної) вирізки. В принципі, це жодним чином не відрізняється від вставляння (стандартних) вирізок. Концепція залежних вирізок може також втілюватися наступним чином. Тут, Фіг. 21 зображає можливий синтаксис заголовка вирізки. Семантика заголовка вирізки є наступною: dependent_slice_flag equal to 1 вказує, що значення кожного відсутнього синтаксичного елемента заголовка вирізки дорівнює значенню відповідного синтаксичного елемента заголовка вирізки в попередній вирізці, яка містить кодувальний деревоподібний блок, адресою якого є SliceCtbAddrRS − 1. Коли він відсутній, то значення dependent_slice_flag дорівнює 0. Значення dependent_slice_flag повинно дорівнювати 0, коли SliceCtbAddrRS дорівнює 0. slice_address вказує адресу в роздільній здатності вирізки, у якій починається вирізка. Довжина синтаксичного елемента slice_address становить ( Ceil( Log2( PicWidthInCtbs * PicHeightInCtbs ) ) + SliceGranularity ) біт. Змінна SliceCtbAddrRS, яка вказує кодувальний деревоподібний блок, у якому починається вирізка в порядку проходження растру кодувального деревоподібного блока, одержується наступним чином. SliceCtbAddrRS = ( slice_address >> SliceGranularity ) Змінна SliceCbAddrZS, яка вказує адресу першого кодувального блока у вирізці в гранулярності мінімального кодувального блока в порядку z-проходження, одержується наступним чином. SliceCbAddrZS = slice_address
ДивитисяДодаткова інформація
Автори англійськоюShierl, Thomas, George, Valeri, Henkel, Anastasia, Marpe, Detlev, Gruneberg, Karsten, Skupin, Robert
Автори російськоюШирль Томас, Георге Валери, Хэнкэль Анастасия, Марпе Детлеф, Грюнэбэрг Карстэн, Скупин Роберт
МПК / Мітки
МПК: H04N 19/13, H04N 19/174, H04N 19/436, H04N 19/91
Мітки: картинки, кодування, затримкою, малою
Код посилання
<a href="https://ua.patents.su/50-115240-koduvannya-kartinki-z-maloyu-zatrimkoyu.html" target="_blank" rel="follow" title="База патентів України">Кодування картинки з малою затримкою</a>
Кодування масиву зразків з малою затримкою

Номер патенту: 111362
Опубліковано: 25.04.2016
Автори: Кірххоффер Хайнер, Шірль Томас, Хенкель Анастасія, Георге Валері, Марпе Детлеф
Мітки: зразків, кодування, малою, затримкою, масиву
Формула / Реферат:
1. Декодер для відновлення масиву зразків з потоку ентропійно кодованих даних, сконфігурований для ентропійного декодування множини ентропійних вирізок в потоці даних ентропійного кодера для відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, відповідно, звиконанням для кожної ентропійної вирізки ентропійного декодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок...
Кодування масиву зразків з малою затримкою

Номер патенту: 114670
Опубліковано: 10.07.2017
Автори: Георге Валері, Шірль Томас, Марпе Детлеф, Кірххоффер Хайнер, Хенкель Анастасія
МПК: H04N 19/42, H04N 7/12, H03M 7/40, H04N 7/00, H03M 7/30
Мітки: масиву, кодування, зразків, малою, затримкою
Формула / Реферат:
1. Декодер для відновлення масиву зразків з потоку ентропійно кодованих даних, сконфігурований для ентропійного декодування множини ентропійних вирізок в потоці ентропійно кодованих даних для, відповідно, відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, при цьому кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний...
Об’єднана структура для схем розподілу картинки

Номер патенту: 113527
Опубліковано: 10.02.2017
Автори: Ван Є-Куй, Кобан Мухаммед Зейд, Карчєвіч Марта
МПК: H04N 19/105, H04N 19/46, H04N 19/11, H04N 19/70
Мітки: структура, картинки, схем, об'єднана, розподілу
Формула / Реферат:
1. Спосіб кодування даних відео, причому спосіб містить: кодування, в наборі параметрів картинки, першого елемента синтаксису для першої картинки даних відео, при цьому перше значення для згаданого першого елемента синтаксису вказує, що прогнозування в картинці дозволяється крізь вирізки для вирізок першої картинки шляхом зазначення, що елементи синтаксису в заголовках для однієї або більше вирізок першої картинки дозволено...
Кодування коефіцієнтів перетворення

Номер патенту: 114311
Опубліковано: 25.05.2017
Автори: Марпе Детлеф, Нгуєн Тунг, Кірххоффер Хайнер
МПК: H03M 7/40
Мітки: коефіцієнтів, перетворення, кодування
Формула / Реферат:
1. Пристрій для декодування множини коефіцієнтів перетворення (12), які мають рівні, з потоку даних (32), який містить адаптивний до контексту ентропійний декодер (80), сконфігурований для ентропійного декодування першого набору (44) з одного або більшої кількості символів з потоку даних (32) для поточного коефіцієнта перетворення (х);десимволізатор (82), сконфігурований для перетворення першого набору (44) з одного або більшої...
Перетворена структура для попереднього кодування, що базується на рознесенні з циклічною затримкою

Номер патенту: 96189
Опубліковано: 10.10.2011
Автори: Йоо Таєсанг, Чжан Сяося, Кім Біоунг-Хоон
Мітки: структура, рознесенні, перетворена, затримкою, кодування, попереднього, базується, циклічною
Формула / Реферат:
1. Спосіб, що полегшує застосування рознесення з циклічною затримкою (CDD) і попереднього кодування до бездротових передач, який включає етапи:перетворення множини векторів даних, пов'язаних з антенами приймача, в область віртуальної антени;вибір матриці CDD на основі, щонайменше частково, типу приймача, кількості антен приймача або множини векторів даних;застосування цієї матриці CDD до множини векторів даних, щоб...
Попередній патент: Модуль контактного струмознімання
Наступний патент: Протез серцевого клапана
Випадковий патент: Спосіб вирівнювання осьових навантажень по несучій поверхні упорних підшипників і упорний підшипник для його здійснення (варіанти)