Кодування масиву зразків з малою затримкою
Номер патенту: 114670
Опубліковано: 10.07.2017
Автори: Марпе Детлеф, Хенкель Анастасія, Георге Валері, Шірль Томас, Кірххоффер Хайнер







Формула / Реферат
1. Декодер для відновлення масиву зразків з потоку ентропійно кодованих даних, сконфігурований для ентропійного декодування множини ентропійних вирізок в потоці ентропійно кодованих даних для, відповідно, відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, при цьому кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний ряд блоків масиву зразків, які регулярно розташовані в рядках і стовпчиках так, що частини, які відповідають ентропійним вирізкам, складаються з однакової кількості блоків, при цьому ентропійні вирізки підрозбиваються на порції даних, і при цьому ентропійне декодування множини ентропійних вирізок включає:
виконання для кожної ентропійної вирізки ентропійного декодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок ймовірності, при цьому доріжка ентропійного кодування проходить паралельно рядам блоків,
адаптацію відповідних оцінок ймовірності вздовж відповідної доріжки ентропійного кодування з використанням попередньо декодованої частини відповідної ентропійної вирізки,
розпочинання ентропійного декодування множини ентропійних вирізок з послідовним використанням порядку ентропійних вирізок, і
виконання, при ентропійному декодуванні наперед визначеної ентропійної вирізки, ентропійного декодування поточної частини наперед визначеної ентропійної вирізки на основі відповідних оцінок ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо декодованої частини наперед визначеної ентропійної вирізки, із збереженням оцінок ймовірності, які з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає наперед визначеній ентропійній вирізці, для ініціалізації оцінки ймовірності перед декодуванням першого блока частини, яка відповідає наступній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки кодування,
перевірку відповідності поточної порції даних першій субчастині частини, яка відповідає наперед визначеній ентропійній вирізці вздовж доріжки ентропійного кодування,
якщо відповідність існує, то виконання ініціалізації оцінок ймовірності перед декодуванням першого блока частини, яка відповідає наперед визначеній ентропійній вирізці, вздовж відповідної доріжки ентропійного кодування, при цьому оцінки ймовірності з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає попередній ентропійній вирізці згідно з порядком ентропійних вирізок вздовж відповідної доріжки ентропійного кодування, ентропійного декодування поточної порції даних згідно з адаптацією відповідних оцінок ймовірності, і залишення незмінним стану відповідних оцінок ймовірності, у якому вони з'являються самі по собі в кінці ентропійного декодування поточної порції даних, для взяття їх до уваги при ентропійному декодуванні іншої порції даних, яка відповідає другій субчастині частини наперед визначеної ентропійної вирізки, вздовж доріжки ентропійного кодування, і
якщо ні, то продовження ентропійного декодування наперед визначеної ентропійної вирізки в поточній вирізці шляхом залишення незмінним стану відповідних оцінок ймовірності, які з'являються самі по собі в кінці ентропійного декодування порції даних, яка відповідає субчастині частини наперед визначеної ентропійної вирізки, яка передує субчастині, яка відповідає поточній порції даних, вздовж доріжки ентропійного кодування.
2. Декодер за п. 1, який відрізняється тим, що він сконфігурований для керування ентропійним декодуванням безпосередньо послідовних ентропійних вирізок згідно з порядком ентропійних вирізок так, що відстань поточно декодованих блоків частин, які відповідають безпосередньо послідовним ентропійним вирізкам, виміряна в блоках вздовж доріжок кодування, перешкоджає бути меншою за два блоки.
3. Декодер за п. 1 або п. 2, який відрізняється тим, що він сконфігурований для керування ентропійним декодуванням безпосередньо послідовних ентропійних вирізок згідно з порядком ентропійних вирізок так, що відстань поточно декодованих блоків частин, які відповідають безпосередньо послідовним ентропійним вирізкам, виміряна в блоках вздовж доріжок кодування, залишається рівною двом блокам.
4. Декодер за будь-яким із пп. 1-3, який відрізняється тим, що він містить обернений перемежовувач для оберненого перемежовування порцій даних і сконфігурований для початку ентропійного декодування ентропійних вирізок паралельно вздовж доріжок ентропійного декодування навіть перед прийомом в цілому будь-якої з ентропійних вирізок.
5. Декодер за будь-яким із пп. 1-4, який відрізняється тим, що масив зразків є поточним масивом зразків послідовності масивів зразків і декодер сконфігурований при ентропійному декодуванні першої ентропійної вирізки згідно з порядком ентропійних вирізок для ініціалізації відповідних оцінок ймовірності першої ентропійної вирізки згідно з порядком ентропійних вирізок з використанням кінцевого стану оцінок ймовірності, як вони використовуються в ентропійному декодуванні попереднього масиву.
6. Кодер для кодування масиву зразків з одержанням потоку ентропійно кодованих даних, сконфігурований для
ентропійного кодування множини ентропійних вирізок з одержанням потоку даних ентропійного кодера, при цьому кожна ентропійна вирізка зв'язана з іншою частиною масиву зразків, відповідно, таким чином, що кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний ряд блоків масиву зразків, які регулярно розташовані в рядках і стовпчиках так, що частини, які відповідають ентропійним вирізкам, складаються з однакової кількості блоків, при цьому ентропійні вирізки підрозбиваються на порції даних і при цьому ентропійне кодування множини ентропійних вирізок включає:
виконання для кожної ентропійної вирізки ентропійного кодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок ймовірності, при цьому доріжка ентропійного кодування проходить паралельно рядам блоків,
адаптацію відповідних оцінок ймовірності вздовж відповідної доріжки ентропійного кодування з використанням попередньо кодованої частини відповідної ентропійної вирізки,
розпочинання ентропійного кодування множини ентропійних вирізок з послідовним використанням порядку ентропійних вирізок, і
виконання, при ентропійному кодуванні наперед визначеної ентропійної вирізки, ентропійного кодування поточної частини наперед визначеної ентропійної вирізки на основі відповідних оцінок ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо кодованої частини наперед визначеної ентропійної вирізки, із збереженням оцінок ймовірності, які з'являються самі по собі після ентропійного кодування другого блока частини, яка відповідає наперед визначеній ентропійній вирізці, для ініціалізації оцінки ймовірності перед кодуванням першого блока частини, яка відповідає наступній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки ентропійного кодування,
перевірку відповідності поточної порції даних першій субчастині частини, яка відповідає наперед визначеній ентропійній вирізці вздовж доріжки ентропійного кодування,
якщо відповідність існує, то виконання ініціалізації оцінок ймовірності перед кодуванням першого блока частини, яка відповідає наперед визначеній ентропійній вирізці, вздовж відповідної доріжки ентропійного кодування, при цьому оцінки ймовірності з'являються самі по собі після ентропійного кодування другого блока частини, яка відповідає попередній ентропійній вирізці згідно з порядком ентропійних вирізок вздовж відповідної доріжки ентропійного кодування, ентропійного кодування поточної порції даних згідно з адаптацією відповідних оцінок ймовірності і залишення незмінним стану відповідних оцінок ймовірності, у якому вони з'являються самі по собі в кінці ентропійного кодування поточної порції даних, для взяття їх до уваги при ентропійному кодуванні іншої порції даних, яка відповідає другій субчастині частини наперед визначеної ентропійної вирізки, вздовж доріжки ентропійного кодування, і
якщо ні, то продовження ентропійного кодування наперед визначеної ентропійної вирізки в поточній вирізці шляхом залишення незмінним стану відповідних оцінок ймовірності, які з'являються самі по собі в кінці ентропійного кодування порції даних, яка відповідає субчастині частини наперед визначеної ентропійної вирізки, яка передує субчастині, яка відповідає поточній порції даних, вздовж доріжки ентропійного кодування.
7. Спосіб відновлення масиву зразків з потоку ентропійно кодованих даних, у якому ентропійно декодують множину ентропійних вирізок в потоці ентропійно кодованих даних для, відповідно, відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, при цьому кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний ряд блоків масиву зразків, які регулярно розташовані в рядках і стовпчиках так, що частини, які відповідають ентропійним вирізкам, складаються з однакової кількості блоків, при цьому ентропійні вирізки підрозбиваються на порції даних і при цьому ентропійне декодування множини ентропійних вирізок включає
виконання для кожної ентропійної вирізки ентропійного декодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок ймовірності, при цьому доріжка ентропійного кодування проходить паралельно рядам блоків,
адаптацію відповідних оцінок ймовірності вздовж відповідної доріжки ентропійного кодування з використанням попередньо декодованої частини відповідної ентропійної вирізки,
розпочинання ентропійного декодування множини ентропійних вирізок послідовно з використанням порядку ентропійних вирізок, і
виконання, при ентропійному декодуванні наперед визначеної ентропійної вирізки, ентропійного декодування поточної частини наперед визначеної ентропійної вирізки на основі відповідних оцінок ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо декодованої частини наперед визначеної ентропійної вирізки із збереженням оцінок ймовірності, які з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає наперед визначеній ентропійній вирізці, для ініціалізації оцінки ймовірності перед декодуванням першого блока частини, яка відповідає наступній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки кодування,
перевірку відповідності поточної порції даних першій субчастині частини, яка відповідає наперед визначеній ентропійній вирізці вздовж доріжки ентропійного кодування,
якщо відповідність існує, то виконання ініціалізації оцінок ймовірності перед декодуванням першого блока частини, яка відповідає наперед визначеній ентропійній вирізці вздовж відповідної доріжки ентропійного кодування, при цьому оцінки ймовірності з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає попередній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки ентропійного кодування, ентропійного декодування поточної порції даних згідно з адаптацією відповідних оцінок ймовірності і залишення незмінним стану відповідних оцінок ймовірності, у якому вони з'являються самі по собі в кінці ентропійного декодування поточної порції даних, для взяття їх до уваги при ентропійному декодуванні іншої порції даних, яка відповідає другій субчастині частини наперед визначеної ентропійної вирізки, вздовж доріжки ентропійного кодування, і
якщо ні, то продовження ентропійного декодування наперед визначеної ентропійної вирізки в поточній вирізці шляхом залишення незмінним стану відповідних оцінок ймовірності, які з'являються самі по собі в кінці ентропійного декодування порції даних, яка відповідає субчастині частини наперед визначеної ентропійної вирізки, яка передує субчастині, яка відповідає поточній порції даних, вздовж доріжки ентропійного кодування.
8. Спосіб кодування масиву зразків з одержанням потоку ентропійно кодованих даних, у якому
ентропійно кодують множину ентропійних вирізок з одержанням потоку даних ентропійного кодера, при цьому кожна ентропійна вирізка зв'язана з іншою частиною масиву зразків, відповідно, таким чином, що кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний ряд блоків масиву зразків, які регулярно розташовані в рядках і стовпчиках так, що частини, які відповідають ентропійним вирізкам, складаються з однакової кількості блоків, при цьому ентропійні вирізки підрозбиваються на порції даних, і при цьому ентропійне кодування множини ентропійних вирізок включає:
виконання для кожної ентропійної вирізки ентропійного кодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок ймовірності, при цьому доріжка ентропійного кодування проходить паралельно рядам блоків,
адаптацію відповідних оцінок ймовірності вздовж відповідної доріжки ентропійного кодування з використанням попередньо кодованої частини відповідної ентропійної вирізки,
розпочинання ентропійного кодування множини ентропійних вирізок з послідовним використанням порядку ентропійних вирізок, і
виконання, при ентропійному кодуванні наперед визначеної ентропійної вирізки, ентропійного кодування поточної частини наперед визначеної ентропійної вирізки на основі відповідних оцінок ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо кодованої частини наперед визначеної ентропійної вирізки із збереженням оцінок ймовірності, які з'являються самі по собі після ентропійного кодування другого блока частини, яка відповідає наперед визначеній ентропійній вирізці, для ініціалізації оцінки ймовірності перед кодуванням першого блока частини, яка відповідає наступній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки ентропійного кодування, перевірку відповідності поточної порції даних першій субчастині частини, яка відповідає наперед визначеній ентропійній вирізці вздовж доріжки ентропійного кодування,
якщо відповідність існує, то виконання ініціалізації оцінок ймовірності перед кодуванням першого блока частини, яка відповідає наперед визначеній ентропійній вирізці, вздовж відповідної доріжки ентропійного кодування, при цьому оцінки ймовірності з'являються самі по собі після ентропійного кодування другого блока частини, яка відповідає попередній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки ентропійного кодування, ентропійного кодування поточної порції даних згідно з адаптацією відповідних оцінок ймовірності і залишення незмінним стану відповідних оцінок ймовірності, у якому вони з'являються самі по собі в кінці ентропійного кодування поточної порції даних, для взяття їх до уваги при ентропійному кодуванні іншої порції даних, яка відповідає другій субчастині частини наперед визначеної ентропійної вирізки, вздовж доріжки ентропійного кодування, і
якщо ні, то продовження ентропійного кодування наперед визначеної ентропійної вирізки в поточній вирізці шляхом залишення незмінним стану відповідних оцінок ймовірності, які з'являються самі по собі в кінці ентропійного кодування порції даних, яка відповідає субчастині частини наперед визначеної ентропійної вирізки, яка передує субчастині, яка відповідає поточній порції даних, вздовж доріжки ентропійного кодування.
9. Середовище для зберігання цифрової інформації, яке містить збережений на ньому струмінь ентропійно кодованих даних, з якого можна відновлювати масив зразків способом, у якому
ентропійно декодують множину ентропійних вирізок в потоці ентропійно кодованих даних для, відповідно, відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, при цьому кожна ентропійна вирізка має ентропійно кодовані в ній дані для відповідної частини масиву зразків, при цьому кожна з різних частин формує відповідний ряд блоків масиву зразків, які регулярно розташовані в рядках і стовпчиках так, що частини, які відповідають ентропійним вирізкам, складаються з однакової кількості блоків, при цьому ентропійні вирізки підрозбиваються на порції даних, і при цьому ентропійне декодування множини ентропійних вирізок включає:
виконання для кожної ентропійної вирізки ентропійного декодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок ймовірності, при цьому доріжка ентропійного кодування проходить паралельно рядам блоків,
адаптацію відповідних оцінок ймовірності вздовж відповідної доріжки ентропійного кодування з використанням попередньо декодованої частини відповідної ентропійної вирізки,
розпочинання ентропійного декодування множини ентропійних вирізок послідовно з використанням порядку ентропійних вирізок, і
виконання, при ентропійному декодуванні наперед визначеної ентропійної вирізки, ентропійного декодування поточної частини наперед визначеної ентропійної вирізки на основі відповідних оцінок ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо декодованої частини наперед визначеної ентропійної вирізки із збереженням оцінок ймовірності, які з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає наперед визначеній ентропійній вирізці, для ініціалізації оцінки ймовірності перед декодуванням першого блока частини, яка відповідає наступній ентропійній вирізці згідно з порядком ентропійних вирізок, вздовж відповідної доріжки кодування,
перевірку відповідності поточної порції даних першій субчастині частини, яка відповідає наперед визначеній ентропійній вирізці вздовж доріжки ентропійного кодування,
якщо відповідність існує, то виконання ініціалізації оцінок ймовірності перед декодуванням першого блока частини, яка відповідає наперед визначеній ентропійній вирізці, вздовж відповідної доріжки ентропійного кодування, при цьому оцінки ймовірності з'являються самі по собі після ентропійного декодування другого блока частини, яка відповідає попередній ентропійній вирізцізгідно з порядком ентропійних вирізок, вздовж відповідної доріжки ентропійного кодування, ентропійного декодування поточної порції даних згідно з адаптацією відповідних оцінок ймовірності, і залишення незмінним стану відповідних оцінок ймовірності, у якому вони з'являються самі по собі в кінці ентропійного декодування поточної порції даних, для взяття їх до уваги при ентропійному декодуванні іншої порції даних, яка відповідає другій субчастині частини наперед визначеної ентропійної вирізки, вздовж доріжки ентропійного кодування, і
якщо ні, то продовження ентропійного декодування наперед визначеної ентропійної вирізки в поточній вирізці шляхом залишення незмінним стану відповідних оцінок ймовірності, які з'являються самі по собі в кінці ентропійного декодування порції даних, яка відповідає субчастині частини наперед визначеної ентропійної вирізки, яка передує субчастині, яка відповідає поточній порції даних, вздовж доріжки ентропійного кодування.
10. Машинозчитуваний носій даних, який містить програмний код, виконуваний на комп'ютері для здійснення способу за п. 7 або п. 8.
Текст
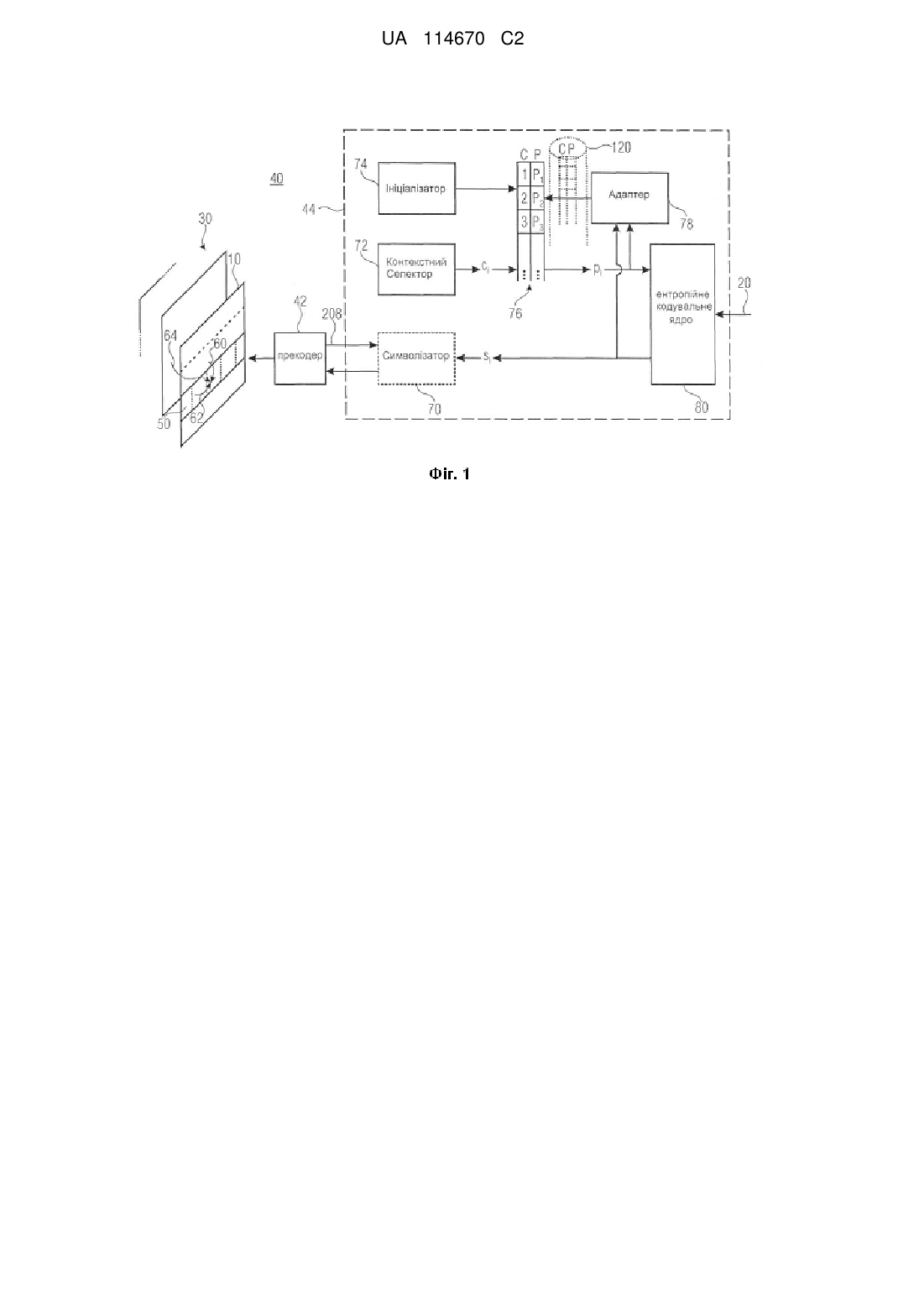
Реферат: Ентропійне кодування поточної частини наперед визначеної ентропійної вирізки базується не тільки на відповідних оцінках ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо кодованої частини наперед визначеної ентропійної вирізки, а й також на оцінках ймовірності, як вони використовуються в ентропійному кодуванні просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки в її сусідній частині. Таким чином, оцінки ймовірності, використовувані в ентропійному кодуванні, ближче адаптуються до реальної символьної статистики, таким чином знижуючи спад ефективності кодування, зазвичай спричинюваний концепціями малої затримки. Додатково або альтернативно використовуються тимчасові взаємозв'язки. UA 114670 C2 (12) UA 114670 C2 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 60 Представлений винахід стосується кодування масиву зразків, такого як кодування картинки або відеоданих. Розпаралелювання роботи кодера і декодера є дуже важливим внаслідок підвищених вимог до обробки стандартом HEVC, а також очікуваним збільшенням роздільної здатності відеозображення. Багатоядерні архітектури стають доступними в широкому діапазоні сучасних електронних пристроїв. Тому, вимагаються ефективні способи для надання можливості використання багатоядерних архітектур. Кодування або декодування LCUs відбувається в растровій розгортці, завдяки якій ймовірність САВАС (контекстно-адаптивне бінарне арифметичне кодування) адаптується до спеціальних ознак кожного зображення. Між сусідніми LCUs існують просторові залежності. Кожна LCU (найбільша кодувальна чарунка) залежить від своїх лівих, верхніх, верхніх лівих і верхніх правих сусідніх LCUs через різні компоненти, наприклад вектор руху, прогноз, інтрапрогноз та інші. Завдяки наданню можливості розпаралелювання при декодуванні, ці залежності типово потребують обриву або обриваються в застосуваннях рівня техніки. Були запропоновані деякі концепції розпаралелювання, зокрема хвильова обробка даних. Мотиватором для подальшого дослідження є розробка технологій, які знижують втрату ефективності кодування і, таким чином, знижують навантаження на потік бітів для розпаралелювання наближень в кодері і декодері. Окрім того, обробка з малою затримкою була неможливою з використанням доступних технологій. Таким чином, задачею представленого винаходу є надання концепції кодування масивів зразків, які дозволяють малу затримку при порівняно менших погіршеннях ефективності кодування. Ця задача вирішується об'єктом доданих незалежних пунктів формули винаходу. Якщо ентропійне кодування поточної частини наперед визначеної ентропійної вирізки базується не тільки на відповідних оцінках ймовірності наперед визначеної ентропійної вирізки, як вони адаптовані з використанням попередньо кодованої частини наперед визначеної ентропійної вирізки, а й також на оцінках ймовірності, як вони використовуються в ентропійному кодуванні просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки в її сусідній частині, то оцінки ймовірності, використовувані в ентропійному кодуванні, ближче адаптуються до реальної символьної статистики, таким чином знижуючи втрату ефективності кодування, зазвичай спричинюваної концепціями з малою затримкою. Можуть додатково або альтернативно використовуватися тимчасові взаємозв'язки. Наприклад, залежність від оцінок ймовірності, як вони використовуються в ентропійному кодуванні просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки може включати ініціалізацію оцінок ймовірності на початку ентропійного кодування наперед визначеної ентропійної вирізки. Зазвичай, оцінки ймовірності ініціалізуються для величин, адаптованих до символьної статистики відповідної комбінації матеріалу масиву зразків. Для уникнення передачі величин ініціалізації оцінок ймовірності, відоме кодування і декодування за правилом. Однак, такі попередньо визначені величини ініціалізації є природно просто компромісом між швидкістю передачі побічної інформації, з одного боку, і ефективністю кодування, з іншого боку, оскільки такі величини ініціалізації природно більш або менш відхиляються від реальної статистики зразків поточно кодованого матеріалу масиву зразків. Адаптація ймовірності в ході кодування ентропійної вирізки адаптує оцінки ймовірності до реальної символьної статистики. Цей процес прискорюється шляхом ініціалізації оцінок ймовірності на початку ентропійного кодування поточної/наперед визначеної ентропійної вирізки з використанням вже адаптованих оцінок ймовірності тільки що згаданої просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки, оскільки останні величини вже певною мірою були адаптовані до реальної символьної статистики поточного масиву зразків. Тим не менше, надавали можливість кодувати з малою затримкою шляхом використання в ініціалізації оцінок ймовірності для наперед визначених/поточних ентропійних вирізок оцінку ймовірності, використовувану в її сусідній частині, скоріше, ніж виявляючи їх в кінці ентропійного кодування попередньої ентропійної вирізки. Завдяки цьому заходу все ще можна здійснювати хвильову обробку даних. Окрім того, вищезгадана залежність від оцінок ймовірності, як вони використовуються в ентропійному кодуванні просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки, може включати адаптацію оцінок ймовірності, використовуваних в ентропійному кодуванні поточної/самої наперед визначеної ентропійної вирізки. Адаптація оцінки ймовірності включає використання тільки що кодованої частини, тобто тільки що кодованого(их) символу(ів), для адаптації поточного стану оцінок ймовірності до реальної символьної статистики. Завдяки цьому заходу ініціалізовані оцінки ймовірності 1 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 60 адаптуються з певною швидкістю до реальної символьної статистики. Ця швидкість адаптації збільшується шляхом виконання тільки що згаданої адаптації оцінки ймовірності не тільки на основі поточно кодованого символу поточної/наперед визначеної ентропійної вирізки, а й також в залежності від оцінок ймовірності, як вони заявляють самі по собі в сусідній частині просторово сусідньої згідно з порядком ентропійних вирізок попередньої ентропійної вирізки. Знову, шляхом належного вибору просторово сусідньої поточної частини поточної ентропійної вирізки і сусідньої частини попередньої ентропійної вирізки все ще можлива хвильова обробка даних. Виграшем від парування власної адаптації оцінки ймовірності вздовж поточної ентропійної вирізки з адаптацією ймовірності попередньої ентропійної вирізки є більша швидкість, з якою відбувається адаптація до реальної символьної статистики, оскільки кількість символів, які переглядаються в поточній і попередній ентропійній вирізці, робить кращий внесок в адаптацію, ніж просто символи поточної ентропійної вирізки. Переважні варіанти виконання представленого винаходу є об'єктом залежних пунктів формули винаходу. Окрім того, переважні варіанти виконання описуються відносно до фігур, на яких: На Фіг. 1 зображена блок-схема ілюстративного кодера; На Фіг. 2 зображена схематична діаграма поділу картинки на вирізки і частини вирізок (тобто, блоки або кодувальні чарунки) разом з визначеними серед них порядками кодування; На Фіг. 3 зображена блок-схема функцій ілюстративного кодера, такого як з Фіг. 1; На Фіг. 4 зображена схематична діаграма для пояснення функцій ілюстративного кодера, такого як з Фіг. 1; На Фіг. 5 зображена схематична діаграма для паралельного робочого втілення кодера і декодера; На Фіг. 6 зображена блок-схема ілюстративного декодера; На Фіг. 7 зображує блок-схему функцій ілюстративного декодера, такого як з Фіг. 6; На Фіг. 8 зображена схематична діаграма для ілюстративного потоку бітів, який одержується із схеми кодування з Фіг. 1-6; На Фіг. 9 схематично зображено приклад того, як обраховувати ймовірність за допомогою інших LCUs; На Фіг. 10 зображено графік, який показує результати RD (оптимізації випадкового спотворення) для Інтрапрогнозу (4 потоки) в порівнянні з НМ3.0; На Фіг. 11 зображено графік, який показує результати RD для малої затримки (1 потік) в порівнянні з НМ3.0; На Фіг. 12 зображено графік, який показує результати RD для довільного доступу (1 потік) в порівнянні з НМ3.0; На Фіг. 13 зображено графік, який показує результати RD для малої затримки (4 потоки) в порівнянні з НМ3.0; На Фіг. 14 схематично і ілюстративно зображено можливі поєднання ентропійних вирізок, На Фіг. 15 схематично і ілюстративно зображено можливу сигналізацію ентропійної вирізки, На Фіг. 16 схематично і ілюстративно зображено кодування, сегментацію, перемежовування і декодування даних ентропійної вирізки за допомогою порцій даних; На Фіг. 17 схематично і ілюстративно зображено можливе поєднання між кадрами; На Фіг. 18 схематично і ілюстративно зображено можливе використання зв'язаної інформації; На Фіг. 19 схематично зображено можливість похилого проходження фронту хвильової обробки в просторовому/часовому проміжку, який охоплений послідовними масивами зразків; і На Фіг. 20 схематично зображено інший приклад для підрозбиття ентропійних вирізок на порції даних. Для полегшення розуміння нижчевказаних заходів для покращення досягання малої затримки при менших втратах з точки зору ефективності кодування, кодер з Фіг. 1 спершу описують в більш загальних термінах без попереднього обговорення вигідних концепцій варіантів виконання представленого винаходу і того, як вони можуть вноситися у варіант виконання з Фіг. 1. Однак, слід зазначити, що структура, зображена на Фіг. 1, просто служить як ілюстративне середовище, у якому можуть використовуватися варіанти виконання представленого винаходу. Також коротко обговорюються узагальнення і альтернативи для кодерів і декодерів у відповідності з варіантами виконання представленого винаходу. На Фіг. 1 зображено кодер для кодування масиву 10 зразків з одержанням потоку 20 ентропійно кодованих даних. Як зображено на Фіг. 1, масив 10 зразків може бути однією послідовністю 30 масивів зразків, а кодер може конфігуруватися для кодування послідовності 30 з одержанням потоку даних 20. 2 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 Кодер з Фіг. 1 головним чином вказаний позиційним позначенням 40 і містить прекодер 42, який розташований перед фазою 44 ентропійного кодування, вихід якої видає потік даних 20. Прекодер 42 сконфігурований для прийому і роботи на масиві 10 зразків для опису його контенту у вигляді синтаксичних елементів наперед визначеного синтаксису, кожен з яких є відповідним одним з наперед визначеної множини типів синтаксичних елементів, які, у свою чергу, зв'язані з відповідною семантикою. При описі масиву 10 зразків з використанням синтаксичних елементів, прекодер 42 може підрозбивати масив 10 зразків на кодувальні чарунки 50. Термін "кодувальна чарунка" може з причин, викладених детальніше нижче, альтернативно називатися "кодувальні деревоподібні чарунки" (CTU)s. Одна можливість того, як прекодер 42 може підрозбивати масив 10 зразків на кодувальні чарунки 50, ілюстративно показана на Фіг. 2. У відповідності з цим прикладом підрозбиття регулярно підрозбиває масив 10 зразків на кодувальні чарунки 50 таким чином, що останні розташовуються в рядках і стовпчиках для того щоб без проміжків покривати увесь масив 10 зразків без налягання. Іншими словами, прекодер 42 може конфігуруватися для опису кожної кодувальної чарунки 50 за допомогою синтаксичних елементів. Деякі з цих синтаксичних елементів можуть формувати інформацію про підрозбиття для подальшого підрозбиття відповідної кодувальної чарунки 50. Наприклад, шляхом підрозбиття у формі мультидерева інформація про підрозбиття може описувати підрозбиття відповідної кодувальної чарунки 50 на прогнозувальні блоки 52 прекодером 42, який зв'язує режим прогнозування з відповідними параметрами прогнозування для кожного з цих прогнозувальних блоків 52. Це прогнозувальне підрозбиття може передбачати прогнозувальні блоки 52, які мають різний розмір, як показано на Фіг. 2. Прекодер 42 може також зв'язувати інформацію про підрозбиття залишку з прогнозувальними блоками 52 для подальшого підрозбиття прогнозувальних блоків 52 на залишкові блоки 54 для опису залишку прогнозування для кожного прогнозувального блока 52. Таким чином, прекодер може конфігуруватися для генерування синтаксичного опису масиву 10 зразків у відповідності з схемою гібридного кодування. Однак, як вже відзначалося вище, тільки що згаданий спосіб, у який прекодер 42 описує масив 10 зразків за допомогою синтаксичних елементів, був просто представлений для ілюстрації цілей і також може по різному втілюватися. Прекодер 42 може використовувати просторові взаємозв'язки між контентом сусідніх кодувальних чарунок 50 масиву 10 зразків. Наприклад, прекодер 42 може прогнозувати синтаксичні елементи для певної кодувальної чарунки 50 з синтаксичних елементів, визначених для попередньо кодованих кодувальних чарунок 50, які просторово примикають до поточно кодованої кодувальної чарунки 50. На Фіг. 1 і 2, наприклад, верхні ліві сусідні чарунки служать для прогнозування, як це вказано стрілками 60 і 62. Більше того, прекодер 42 може в режимі інтрапрогнозування екстраполювати вже кодований контент сусідніх кодувальних чарунок 50 з одержанням поточної кодувальної чарунки 50 для одержання прогнозу зразків поточної кодувальної чарунки 50. Як зображено на Фіг. 1, прекодер 42 може, окрім використання просторових взаємозв'язків, тимчасово прогнозувати зразки і/або синтаксичні елементи для поточної кодувальної чарунки 50 з попередньо кодованих масивів зразків, як це зображено на Фіг. 1 стрілкою 64. Тобто, прекодером 42 може використовуватися прогнозування з компенсацією руху, а самі вектори руху можуть тимчасово прогнозуватися з векторів руху попередньо кодованих масивів зразків. Тобто, прекодер 42 може описувати контент масиву 10 зразків кодувальної чарунки і може, для цього, використовувати просторове прогнозування. Просторове прогнозування обмежується для кожної кодувальної чарунки 50 просторово сусідніми кодувальними чарунками одного і того ж масиву 10 зразків так, що, при дотриманні порядку 66 кодування серед кодувальних чарунок 50 масиву 10 зразків, сусідні кодувальні чарунки, які служать еталоном прогнозування для просторового прогнозування, головним чином проходяться згідно з порядками 66 кодування перед поточною кодувальною чарункою 50. Як зображено на Фіг. 2, порядок 66 кодування, визначений серед кодувальних чарунок 50, може, наприклад, формувати порядок растрової розгортки, згідно з яким кодувальні чарунки 50 проходяться ряд за рядом зверху донизу. Необов'язково, підрозбиття масиву 10 на масив мозаїчних елементів може формувати порядок 66 растрової розгортки для проходження в ньому кодувальних чарунок 50, які містять спершу один мозаїчний елемент перед переходом до наступного по порядку мозаїчного елемента, який, у свою чергу, може також мати вид растрової розгортки. Наприклад, просторове прогнозування може включати просто сусідні кодувальні чарунки 50 в ряді кодувальних чарунок над рядом кодувальних чарунок, в якому розташована поточна кодувальна чарунка 50, і кодувальну чарунку в одному і тому ж ряді кодувальних чарунок, але зліва відносно поточної кодувальної чарунки. Як буде пояснюватися детальніше нижче, це 3 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 60 обмеження, яке накладається на просторовий взаємозв'язок/просторовий прогноз, дозволяє паралельну хвильову обробку даних. Прекодер 42 надсилає синтаксичні елементи на фазу 44 ентропійного кодування. Як тільки що зазначено, деякі з цих синтаксичних елементів були прогнозовано кодовані, тобто, представляють залишки прогнозування. Прекодер 42 може, таким чином, розглядатися як прогнозувальний кодер. Окрім цього, прекодер 42 може бути перетворювальним кодером, сконфігурованим для перетворення залишків кодів прогнозування контенту кодувальних чарунок 50. Ілюстративна внутрішня структура фази 44 ентропійного кодування також зображена на Фіг. 1. Як зображено, фаза 44 ентропійного кодування може містити, необов'язково, символізатор для перетворення кожного з синтаксичних елементів, прийнятих від прекодера 42, ряд можливих станів яких перевищують потужність символьного алфавіту, на послідовність символів si символьного алфавіту, на основі якого працює фаза 44 ентропійного кодування. Окрім цього, довільний символізатор 70, фаза 44 ентропійного кодування можуть містити контекстний селектор 72 і ініціалізатор 74, засіб 76 керування оцінкою ймовірності, адаптер 78 оцінки ймовірності і ентропійне кодувальне ядро 80. Вихід ентропійного кодувального ядра формує вихід фази 44 ентропійного кодування. Окрім цього, ентропійне кодувальне ядро 80 містить два входи, а саме: один для прийому символів s i послідовності символів, а інший для прийому оцінки ймовірності ρ, для кожного з символів. Дякуючи властивостям ентропійного кодування, ефективність кодування з точки зору ступеня стискання збільшується покращенням оцінки ймовірності: чим краще оцінка ймовірності узгоджується з реальною символьною статистикою, тим кращий ступінь стискання. В прикладі з Фіг. 1 контекстний селектор 72 сконфігурований для вибору для кожного символу si відповідного контексту сі серед множини доступних контекстів, контрольованими керувальним засобом 76. Однак, слід відзначити, що вибір контексту формує просто довільну ознаку і може не братися до уваги, наприклад, використанням однакового контексту для кожного символу. Однак, якщо використовувати вибір контексту, то контекстний селектор 72 може конфігуруватися для виконання вибору контексту принаймні частково на основі інформації, яка стосується кодувальних чарунок зовні поточної кодувальної чарунки, зокрема, яка стосується сусідніх кодувальних чарунок в обговореному вище обмеженому сусідстві. Керувальний засіб 76 містить зберігальний засіб, який зберігає для кожного наявного контексту відповідну оцінку ймовірності.Наприклад, символьний алфавіт може бути бінарним алфавітом, так що для кожного символьного контексту може бути потрібним просто зберігати одну величину ймовірності. Ініціалізатор 74 може періодично ініціалізувати або повторно ініціалізувати оцінки ймовірності, збережені в керувальному засобі 76, для доступних контекстів. Можливі моменти часу, в які така ініціалізація може виконуватися, обговорюються далі нижче. Адаптер 78 має доступ до пар символів si і відповідних оцінок ймовірності рi, і відповідно адаптує оцінки ймовірності в керувальному засобі 76. Тобто, кожен раз, коли оцінка ймовірності застосовується ентропійним кодувальним ядром 80 для ентропійного кодування відповідного символу ε, з одержанням потоку даних 20, адаптер 78 може варіювати цю оцінку ймовірності у відповідності 3 величиною цього поточного символу s i так, що ця оцінка ймовірності рi краще адаптується до реальної символьної статистики при кодуванні наступного символу, який зв'язаний з такою оцінкою ймовірності (за допомогою його контексту). Тобто, адаптер 78 приймає оцінку ймовірності для вибраного контексту від керувального засобу 76 разом з відповідним символом si і відповідно адаптує оцінку ймовірності рi так, що для наступного символу si одного і того ж контексту сі використовують адаптивну оцінку ймовірності. Ентропійне кодувальне ядро 80, наприклад, конфігурується для роботи у відповідності з схемою арифметичного кодування або в схемі ентропійного кодування з розбиттям інтервалу ймовірності. В арифметичному кодуванні ентропійне кодувальне ядро 80 повинне, наприклад, безперервно оновлювати свій стан при кодуванні послідовності символів, при цьому стан визначається інтервалом ймовірності, визначеним величиною його ширини і, наприклад, величиною його зміщення. При роботі в концепції pipe, ентропійне кодувальне ядро 80 повинно, наприклад, підрозбивати область можливих величин оцінок ймовірності на різні інтервали з виконанням ентропійного кодування з фіксованою ймовірністю відносно до кожного з цих інтервалів, таким чином одержуючи вкладений потік для кожного з підінтервалів, ефективність кодування якого відповідно налаштовується на відповідний інтервал ймовірності. У випадку ентропійного кодування, вихід потоку даних 20 повинен бути арифметично кодованим потоком даних, який сигналізує декодувальній стороні інформацію, яка дозволяє емуляцію або повторення процесу підрозбиття інтервалу. 4 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 Зазвичай, для фази 44 ентропійного кодування повинно бути можливим ентропійно кодувати усю інформацію, тобто усі синтаксичні елементи/символи s i, які належать до масиву 10 зразків, просто один раз на початку кодування ініціалізуючи оцінки ймовірності, а потім безперервно оновлюючи оцінки ймовірності адаптером 78. Однак, це повинно надавати потік даних 20, який повинен послідовно декодуватися на декодувальній стороні. Іншими словами, для будь-якого декодера не повинно бути можливості підрозбивати одержуваний потік даних на декілька підпорцій і паралельно декодувати підпорції. Це повинно, у свою чергу, перешкоджати будь-якому зусиллю для виконання малої затримки. Відповідно, як буде обговорено детальніше нижче, вигідно підрозбивати об'єм даних, які описують масив 10 зразків, на так звані ентропійні вирізки. Кожна з цих ентропійних вирізок повинна, відповідно, охоплювати іншу множину синтаксичних елементів, які належать до масиву 10 зразків. Якщо фаза 44 ентропійного кодування повинна, однак, ентропійно кодувати кожну ентропійну вирізку цілком незалежно від кожної іншої ентропійної вирізки спершу один раз ініціалізуючи оцінку ймовірності з наступним безперервним оновленням оцінки ймовірності індивідуально для кожної ентропійної вирізки, то потім ефективність кодування повинна знижуватися внаслідок підвищеного відсотку даних, які належать і описують масив 10 зразків, для якого використовувані оцінки ймовірності (все ще) менш точно адаптуються до реальної символьної статистики. Для подолання тільки що згаданих проблем з виконанням бажання мати малу затримку кодування, з одного боку, і високу ефективність кодування, з іншого боку, може використовуватися наступна схема кодування, яка тепер описується відносно Фіг. 3. По-перше, дані, які описують масив 10 зразків, підрозбиваються на частини, названі далі "ентропійними вирізками". Підрозбиття 80 не повинно бути без налягань. З одного боку, це підрозбиття може принаймні частково відповідати просторовому підрозбиттю масиву 10 зразків на різні частини. Тобто,згідно з підрозбиттям 80 синтаксичні елементи, які описують масив 10 зразків, можуть розподілятися по різних ентропійних вирізках в залежності від розташування кодувальної чарунки 50, якій відповідає відповідний синтаксичний елемент. Дивіться, наприклад, Фіг. 2. Фіг. 2 зображає ілюстративне підрозбиття масиву 10 зразків на різні частини 12. Кожна частина відповідає відповідній ентропійній вирізці. Як ілюстративно зображено, кожна частина 12 відповідає ряду кодувальних чарунок 50. Однак, також реальні інші підрозбиття. Однак, вигідно, коли підрозбиття масиву 10 зразків на частини 12 відповідає вищезгаданому порядку 66 кодування так, що частини 12 охоплюють послідовні ряди кодувальних чарунок 50 згідно з порядком 66 кодування. Навіть, однак, якщо це так, то початкове і кінцеве положення частини 12 згідно з порядком 66 кодування не повинні співпадати з лівим і, відповідно, правим краєм рядів кодувальних чарунок 50. Навіть співпадіння з границями кодувальних чарунок 50, які безпосередньо ідуть одна за іншою, і порядок 66 кодування не повинні бути обов'язковими. Підрозбиваючи у такий спосіб масив 10 зразків, порядок 16 ентропійної вирізки визначається серед частин 12, які ідуть одна за іншою згідно з порядком 66 кодування. Більше того, для кожної ентропійної вирізки визначається відповідна доріжка 14 ентропійного кодування, а саме фрагмент доріжки 14 кодування, який проходить до відповідної частини 12. В прикладі з Фіг. 2, де частини 12 співпадають з рядами кодувальних чарунок 50, доріжки 14 ентропійного кодування кожної ентропійної вирізки орієнтовані вздовж ряду паралельно одна до іншої, тобто тут зліва на право. Слід відзначити, що повинно бути можливим обмежувати просторові прогнози, виконувані прекодером 42, і деривації контексту, виконувані контекстним селектором 72, для того, щоб не перетинати границі вирізки, тобто так, щоб просторові прогнози і вибори контексту не залежали від даних, які відповідають іншій ентропійній вирізці. Цим способом "ентропійні вирізки" повинні відповідати звичайному визначенню "вирізок" в стандарті Н.264, наприклад, які здатні повністю кодуватися незалежно одна від іншої, за виключенням нижчеописаної ініціалізації ймовірності/залежності адаптації. Однак, також повинно бути реальним дозволяти просторовим прогнозам і виборам контексту, тобто, головним чином мовним залежностям, перетинати границі вирізки для використання локальних/просторових взаємних залежностей, оскільки обробка WPP все ще реальна навіть до тієї міри, до якої це стосується оберненого попереднього кодування, тобто, відновлення на основі синтаксичних елементів, і вибору ентропійного контексту. Наскільки це доцільно, ентропійні вирізки повинні деякою мірою відповідати "залежним вирізкам". Підрозбиття 80 може, наприклад, виконуватися фазою 44 ентропійного кодування. Підрозбиття може бути фіксованим або може змінюватися вздовж масиву послідовності 30. Підрозбиття може бути фіксованим за правилом або може сигналізуватися в потоці даних 20. 5 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 60 На основі ентропійних вирізок може здійснюватися реальне ентропійне кодування, тобто 82. Для кожної ентропійної вирізки ентропійне кодування може структуруватися на початкову фазу 84 і фазу 86 продовження. Початкова фаза 84 включає, наприклад, ініціалізацію оцінок ймовірності, а також запуск процесу реального ентропійного кодування для відповідної ентропійної вирізки. Реальне ентропійне кодування потім виконується під час фази 86 продовження. Ентропійне кодування під час фази 86 продовження виконується вздовж відповідної доріжки 14 ентропійного кодування. Початкова фаза 84 для кожної ентропійної вирізки контролюється так, що ентропійне кодування множини ентропійних вирізок починається послідовно з використанням порядку 16 ентропійної вирізки. Тепер, для уникнення вищезгаданого недоліку, який повинен випливати з ентропійного кодування кожної ентропійної вирізки цілком незалежно одна від іншої, процес 82 ентропійного кодування контролюється так, що поточна частина, наприклад поточна кодувальна чарунка поточної ентропійної вирізки ентропійно кодується на основі відповідних оцінок ймовірності поточної ентропійної вирізки, як вони адаптовані з використанням попередньо кодованої частини поточної ентропійної вирізки, тобто, частини поточної ентропійної вирізки зліва від поточної кодувальної чарунки 50 у випадку з Фіг. 2, і оцінок ймовірності, як вони використовуються в ентропійному кодуванні просторово сусідньої згідно з порядком 16 ентропійних вирізок попередньої ентропійної вирізки в сусідній частині, тобто її сусідній кодувальній чарунці. Для чіткішого опису вищезгаданої залежності, робиться посилання на Фіг. 4. Фіг. 4 показує n1, n і n+1 ентропійну вирізку згідно з порядком 16 ентропійних вирізок з позицією 90. Кожна ентропійна вирізка 90 охоплює послідовність синтаксичних елементів, яка описує частину 12 масиву 10 зразків, з якою зв'язана відповідна ентропійна вирізка 90. Вздовж доріжки 14 ентропійного кодування ентропійна вирізка 19 сегментується на послідовність сегментів 92, кожен з яких відповідає відповідній одній з кодувальних чарунок 50 частини 12, до якої належить ентропійна вирізка 90. Як описано вище, оцінки ймовірності, використовувані в ентропійному кодуванні ентропійних вирізок 90, безперервно оновлюються під час фази 86 продовження вздовж доріжки 14 ентропійного кодування так, що оцінки ймовірності значно краще адаптують реальну символьну статистику відповідної ентропійної вирізки 90, тобто, оцінки ймовірності зв'язуються з відповідною ентропійною вирізкою. Хоча оцінки ймовірності 94, використовувані для ентропійного кодування ентропійної вирізки 90 під час фази 86 продовження, безперервно оновлюються, на Фіг. 4 просто зображені стани оцінок ймовірності 94, які з'являються в початкових і кінцевих положеннях сегментів 92, і згадуються далі нижче. Зокрема, стан перед ентропійним кодуванням першого сегмента 92, як він ініціалізований під час початкової фази 84, зображений в позиції 96, стан, який з'являється сам по собі після кодування першого сегмента, зображений в позиції 98, а стан, який з'являється сам по собі після кодування перших двох сегментів, вказаний в позиції 100. Ті ж елементи зображені на Фіг. 4 також для n-1 ентропійної вирізки згідно з її порядком 16 і наступної ентропійної вирізки, тобто ентропійної вирізки n+1. Тепер, для досягання вищеописаної залежності, початковий стан 96 для ентропійного кодування n-ї ентропійної вирізки 90 робиться залежним від будь-якого проміжного стану оцінок ймовірності 94, який з'являється сам по собі під час кодування попередньої ентропійної вирізки n-1. "Проміжний стан" повинен позначати будь-який стан оцінок ймовірності 94, виключаючи початковий стан 96 і кінцевий стан, який з'являється сам по собі після ентропійного кодування усієї ентропійної вирізки n-1. Роблячи це, ентропійне кодування послідовності ентропійних вирізок 90 згідно з їх порядком 16 може розпаралелюватися зі ступенем розпаралелювання, який визначається відношенням кількості сегментів 92, які передують стану, використовуваному для ініціалізації оцінок ймовірності 94 для ентропійного кодування наступної ентропійної вирізки, тобто а, і кількості сегментів 92, яка іде за цим станом, тобто b. Зокрема, на Фіг. 4а ілюстративно встановлено ініціалізацію, рівну адаптації стану 100 для встановлення стану 96 поточної ентропійної вирізки рівним стану 100 попередньої ентропійної вирізки, як вказано стрілкою 104. Завдяки цьому заходу ентропійне кодування будь-якого сегмента 92, який відповідає стану 100 в порядку доріжки 14 ентропійного кодування, повинне залежати від оцінки ймовірності 94, як вона адаптована під час фази 86 продовження на основі попередніх сегментів однієї і тієї ж ентропійної вирізки, а також оцінки ймовірності, як вона використовується в ентропійному кодуванні третього сегмента 92 попередньої ентропійної вирізки 90. Відповідно, ентропійне кодування ентропійних вирізок 90 могло б виконуватися паралельно в конвеєрному плануванні. Єдині обмеження, які накладаються на часове планування, повинні полягати в тому, що ентропійне кодування деякої ентропійної вирізки може починатися просто 6 UA 114670 C2 5 10 15 20 25 30 35 40 45 50 55 після закінчення ентропійного кодування а-го сегменту 92 попередньої ентропійної вирізки. Ентропійні вирізки 90, які безпосередньо ідуть одна за іншою згідно з їх порядком 16, не піддаються дії якихось інших обмежень, що стосуються узгодження часу процедури ентропійного кодування під час фази 86 продовження. Однак, у відповідності з іншим варіантом виконання додатково і/або альтернативно використовується сильніший зв'язок. Зокрема, як зображено на Фіг. 4 відповідними стрілками 106, адаптація оцінки ймовірності під час фази 86 продовження змушує дані кодувальної чарунки, яка відповідає певному сегменту 92, змінювати оцінки ймовірності 94 від стану на початку відповідного сегменту 92 до кінця цього сегмента 92, таким чином покращуючи апроксимацію реальної символьної статистики, як вказано вище. Тобто, адаптація 106 виконується для ентропійної вирізки n-1 просто в залежності від даних ентропійної вирізки n-1 і те ж саме застосовується до адаптації 106 оцінки ймовірності ентропійної вирізки n і так далі. Наприклад, повинно бути можливим виконувати ініціалізацію, як пояснювалося вище відносно до стрілок 104, з виконанням адаптації 106 оцінки ймовірності без будь-якого подальшого взаємного впливу між ентропійними вирізками 90. Однак, для прискорення апроксимації оцінки ймовірності реальної символьної статистики, адаптація 106 оцінки ймовірності послідовних ентропійних вирізок можуть паруватися так, що адаптація 106 оцінки ймовірності попередньої ентропійної вирізки n-1 також впливає або береться до уваги при адаптації оцінки ймовірності поточної ентропійної вирізки n. Це вказано на Фіг. 4 стрілкою 108, яка проходить від стану 110 просторово сусідніх оцінок ймовірності 94 для ентропійного кодування n-1-ї ентропійної вирізки 90 до стану 100 оцінок ймовірності 94 для ентропійного кодування n-ї ентропійної вирізки 90. При використанні вищевказаної ініціалізації стану 96, парування 108 адаптації ймовірності може, наприклад, використовуватися в будь-якому з b станів оцінки ймовірності, які з'являються самі по собі після ентропійного кодування b сегментів 92 попередньої ентропійної вирізки. Точніше, оцінки ймовірності, які з'являються самі по собі після ентропійного кодування першого сегмента 92 поточної ентропійної вирізки, можуть бути результатом звичайної адаптації 106 ймовірності і беручи до уваги парування 108 станів оцінки ймовірності, які випливають з адаптації 106 оцінки ймовірності під час ентропійного кодування (а+1)-го сегмента 92 попередньої ентропійної вирізки n-1. Фраза "береться до уваги" може, наприклад, включати деяку операцію осереднення. Приклад буде додатково описуватися нижче. Іншими словами, стан 98 оцінок ймовірності 94 для ентропійного кодування n-ї ентропійної вирізки 90 на початку її ентропійного кодувального сегмента 92 може бути результатом осереднення попереднього стану 96 оцінок ймовірності 94 для ентропійного кодування поточної ентропійної вирізки n, як вони адаптовані з використанням адаптації 106, і стану перед ентропійним кодуванням (а+1)-го сегмента 92 попередньої ентропійної вирізки n-1, модифікованої згідно з адаптацією 106 ймовірності. Аналогічно, стан 100 може бути результатом осереднення результату адаптації 106, виконуваної під час ентропійного кодування поточної ентропійної вирізки n, і результату адаптації ймовірності під час ентропійного кодування (а+2)-го сегмента 92 попередньої ентропійної вирізки n-1 і так далі. Точніше, нехай p(n)→{i,j}, де i,j вказують положення будь-якої кодувальної чарунки (з (0,0), яка знаходиться в лівому верхньому положенні, a (I, J) - в правому нижньому положенні), і{1…І} і j{1…J}, І є кількістю стовпчиків, J є кількістю рядків, а р() визначає порядок 66 доріжки, P{i,j} є оцінкою ймовірності, використовуваної в ентропійній кодувальній чарунці {i,j}; і T(P{i,j}) є результатом адаптації 106 ймовірності P{i,j} на основі кодувальної чарунки {i,j}; Потім, оцінки 106 ймовірності послідовних ентропійних вирізок 90 можуть комбінуватися для заміни звичайної внутрішньої адаптації ентропійної вирізки згідно з рівністю P p(n+1)=T(Pp(n)), де Ppn1 average (T(Ppn ) , T(Pi, j1 ),..., T(Pi, jN )) , де N може бути 1 або більшим ніж 1 і i, j1...N вибирається/вибираються з (лежить в) будьякої попередньої (згідно з порядком (16) ентропійної вирізки) ентропійної вирізки 90 і, відповідно, її відповідної частини 12. Функція "average" може бути однією, вибраною серед зваженої суми, медіанної функції і так далі. p(n)={i,j} є поточною кодувальною чарункою, а р(n+1) іде у відповідності з порядком кодування 14 і, відповідно, 66. В переважних варіантах виконання p(n+1)={i+1,j}. Переважно, {i,j}1…N задовольняють для кожного k{1…N} рівність {i,j}1…N={ik,jk} і ik
ДивитисяДодаткова інформація
Автори російськоюGeorge, Valeri, Henkel, Anastasia, Kirchhoffer, Heiner, Marpe, Detlev, Schierl, Thomas
МПК / Мітки
МПК: H04N 7/00, H03M 7/40, H03M 7/30, H04N 7/12, H04N 19/42
Мітки: кодування, зразків, затримкою, малою, масиву
Код посилання
<a href="https://ua.patents.su/42-114670-koduvannya-masivu-zrazkiv-z-maloyu-zatrimkoyu.html" target="_blank" rel="follow" title="База патентів України">Кодування масиву зразків з малою затримкою</a>
Кодування масиву зразків з малою затримкою

Номер патенту: 111362
Опубліковано: 25.04.2016
Автори: Марпе Детлеф, Георге Валері, Шірль Томас, Кірххоффер Хайнер, Хенкель Анастасія
Мітки: малою, кодування, затримкою, масиву, зразків
Формула / Реферат:
1. Декодер для відновлення масиву зразків з потоку ентропійно кодованих даних, сконфігурований для ентропійного декодування множини ентропійних вирізок в потоці даних ентропійного кодера для відновлення різних частин масиву зразків, зв'язаних з ентропійними вирізками, відповідно, звиконанням для кожної ентропійної вирізки ентропійного декодування вздовж відповідної доріжки ентропійного кодування з використанням відповідних оцінок...
Перетворення дійсних спектральних компонентів в комплексні з малою затримкою в блоках фільтрів, що перекриваються, для частково комплексної обробки

Номер патенту: 109749
Опубліковано: 25.09.2015
Автори: Віллемоес Ларс, Мундт Харальд
МПК: H03H 17/02
Мітки: компонентів, перекриваються, обробки, спектральних, затримкою, блоках, комплексні, малою, комплексної, перетворення, частково, дійсних, фільтрів
Формула / Реферат:
1. Система (600; 700) обробки звукових сигналів, що містить багатосмуговий фільтр (660; 770) для забезпечення частково комплексного частотного представлення сигналу, причому багатосмуговий фільтр містить:відсік (691; 710; 810, 870) синтезу, що отримує перший діапазон підсмуги частот першого частотного представлення сигналу, при цьому перше частотне представлення розділене на часові блоки та містить перші спектральні компоненти, що...
Перетворена структура для попереднього кодування, що базується на рознесенні з циклічною затримкою

Номер патенту: 96189
Опубліковано: 10.10.2011
Автори: Кім Біоунг-Хоон, Йоо Таєсанг, Чжан Сяося
Мітки: перетворена, затримкою, кодування, попереднього, рознесенні, структура, базується, циклічною
Формула / Реферат:
1. Спосіб, що полегшує застосування рознесення з циклічною затримкою (CDD) і попереднього кодування до бездротових передач, який включає етапи:перетворення множини векторів даних, пов'язаних з антенами приймача, в область віртуальної антени;вибір матриці CDD на основі, щонайменше частково, типу приймача, кількості антен приймача або множини векторів даних;застосування цієї матриці CDD до множини векторів даних, щоб...
Спосіб діагностики плодів із затримкою внутрішньоутробного розвитку серед плодів із малою для гестаційного віку вагою при багатоплідній вагітності

Номер патенту: 62148
Опубліковано: 10.08.2011
Автори: Ткаченко Андрій Володимирович, Чернов Артем Володимирович, Гопчук Олена Миколаївна
МПК: A61B 8/00
Мітки: вагітності, гестаційного, плодів, вагою, затримкою, малою, багатоплідній, спосіб, розвитку, діагностики, віку, внутрішньоутробного
Формула / Реферат:
Спосіб діагностики плодів із затримкою внутрішньоутробного розвитку серед плодів із малою для гестаційного віку вагою при багатоплідній вагітності, який відрізняється тим, що жінці із багатаплідною вагітністю та встановленим діагнозом малого для гестаційного віку плоду для діагностики затримки внутрішньоутробного розвитку здійснюють динамічне спостереження за темпами росту плода і виконують серію вимірювань таких показників як кровоплин у...
Концепція кодування, яка дозволяє паралельну обробку даних, транспортний демультиплексор і відеобітовий потік

Номер патенту: 114618
Опубліковано: 10.07.2017
Автори: Шірль Томас, Марпе Детлеф, Георге Валері, Хенкель Анастасія, Грюнеберг Карстен, Кірххоффер Хайнер
МПК: H04N 7/00
Мітки: дозволяє, обробку, кодування, яка, даних, потік, відеобітовий, транспортний, концепція, паралельну, демультиплексор
Формула / Реферат:
1. Декодер, сконфігурований для прийому корисної інформації необробленої послідовності байтів, яка описує картинку у вкладених потоках WPP з одним вкладеним потоком WPP на рядок LCU картинки, і кодованої з використанням САВАС, від кодера в траншах, на які розбиті вкладені потоки WPP, таким чином вводячи в них межі траншів;для ентропійного декодування траншів з продовженням адаптації ймовірності САВАС крізь межі траншів, введених у...
Попередній патент: Титановий виливок для гарячої прокатки і спосіб його виготовлення
Наступний патент: Спосіб підвищення зносостійкості робочих поверхонь сталевих кілець імпульсних торцевих ущільнень
Випадковий патент: Спосіб термічної обробки дротової заготовки