Кодування коефіцієнтів перетворення для кодування відео
Номер патенту: 109479
Опубліковано: 25.08.2015
Автори: Соле Рохальс Хоель, Карчевіч Марта, Джоши Раджан Лаксман







Формула / Реферат
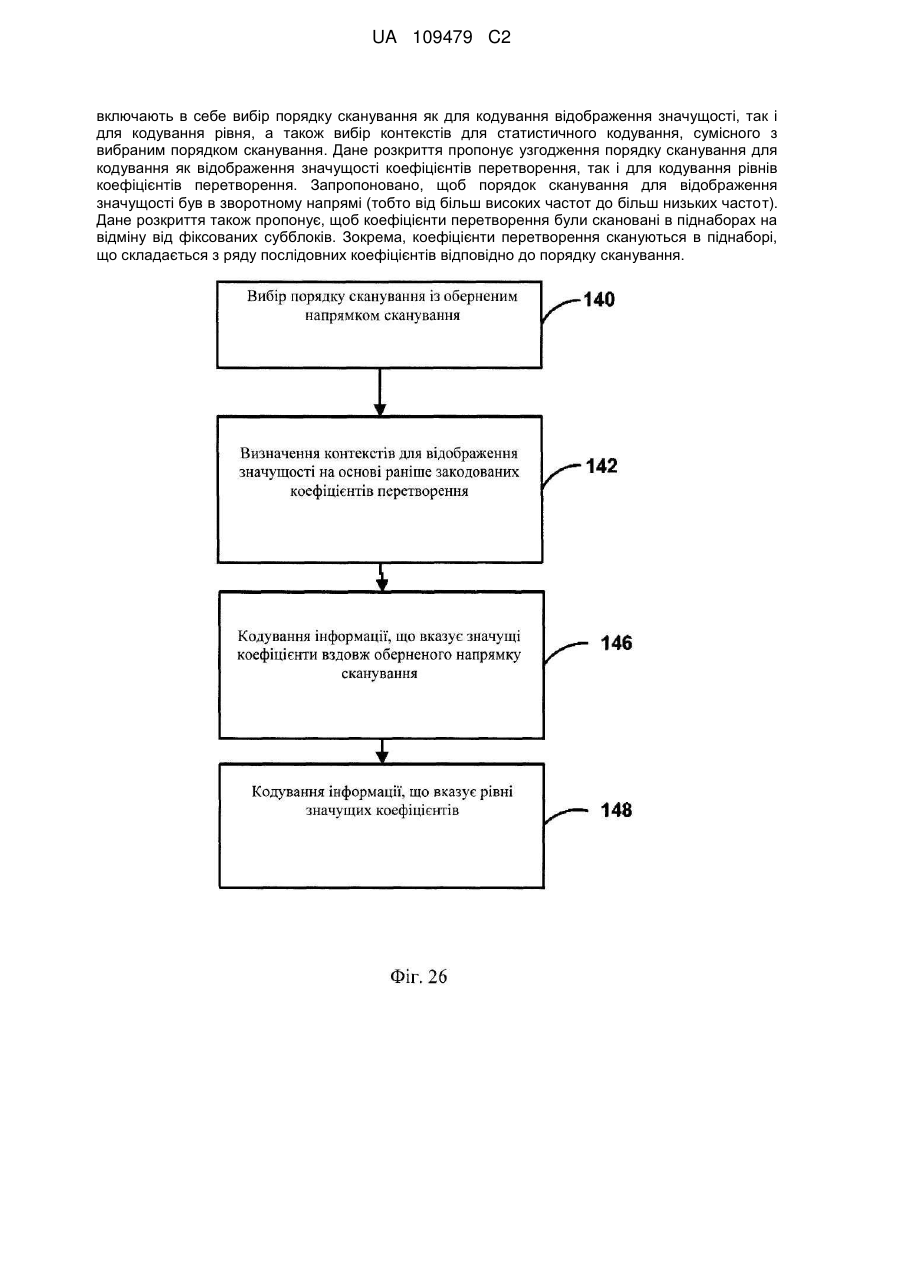
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, причому спосіб включає:
кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення зі скануванням, що здійснюється в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення, і
формування відображення значущості для згаданого блока на основі кодованої інформації, що вказує значущі коефіцієнти перетворення.
2. Спосіб за п. 1, який додатково включає:
кодування інформації, що вказує рівні значущих коефіцієнтів перетворення.
3. Спосіб за п. 2, в якому кодування інформації, що вказує рівні значущих коефіцієнтів перетворення, відбувається в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення.
4. Спосіб за п. 1, який додатково включає:
визначення контекстів для контекстного адаптивного двійкового арифметичного кодування (САВАС) інформації, що вказує поточний один із значущих коефіцієнтів, на основі раніше закодованих значущих коефіцієнтів в зворотному напрямку сканування.
5. Спосіб за п. 4, в якому, якщо раніше закодований значущий коефіцієнт розташований поза блоком перетворення, закодована інформація рівня для раніше закодованого значущого коефіцієнта передбачається рівною нулю.
6. Спосіб за п. 4, в якому сканування має діагональний шаблон, і раніше кодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
7. Спосіб за п. 4, в якому сканування має горизонтальний шаблон, і раніше кодовані значущі коефіцієнти знаходяться в позиціях нижче лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
8. Спосіб за п. 4, в якому сканування має вертикальний шаблон, і раніше кодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
9. Система для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, причому система містить:
пам'ять, виконану з можливістю зберігати блок коефіцієнтів перетворення;
процесор кодування відео, сконфігурований для кодування інформації, що вказує значущі коефіцієнти перетворення в згаданому блоці коефіцієнтів перетворення зі скануванням, що здійснюється в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення,
при цьому процесор кодування відео додатково сконфігурований, щоб формувати відображення значущості для згаданого блока на основі кодованої інформації, що вказує значущі коефіцієнти перетворення.
10. Система за п. 9, в якій процесор кодування відео додатково сконфігурований, щоб кодувати інформацію, що вказує рівні значущих коефіцієнтів перетворення.
11. Система за п. 10, в якій процесор кодування відео додатково сконфігурований так, що кодування інформації, яка вказує рівні значущих коефіцієнтів перетворення, виконується в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення.
12. Система за п. 9, в якій процесор кодування відео додатково сконфігурований, щоб визначити контексти для контекстного адаптивного двійкового арифметичного кодування (САВАС) інформації, що вказує поточний один із значущих коефіцієнтів, на основі раніше закодованих значущих коефіцієнтів в зворотному напрямку сканування.
13. Система за п. 12, в якій, якщо раніше закодований значущий коефіцієнт розташований поза блоком перетворення, закодована інформація рівня для цього раніше кодованого значущого коефіцієнта передбачається рівною нулю.
14. Система за п. 12, в якій сканування має діагональний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
15. Система за п. 12, в якій сканування має горизонтальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях нижче лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
16. Система за п. 12, в якій сканування має вертикальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
17. Система для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, причому система містить:
засіб для кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення зі скануванням, що здійснюється в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення; і
засіб для формування відображення значущості для згаданого блока на основі закодованої інформації, що вказує значущі коефіцієнти перетворення.
18. Система за п. 17, яка додатково містить:
засіб для кодування інформації, що вказує рівні значущих коефіцієнтів перетворення.
19. Система за п. 17, в якій засіб для кодування інформації, що вказує рівні значущих коефіцієнтів перетворення, здійснює роботу в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення.
20. Система за п. 18, яка додатково містить:
засіб для визначення контекстів для контекстного адаптивного двійкового арифметичного кодування (САВАС) інформації, що вказує поточний один із значущих коефіцієнтів, на основі раніше закодованих значущих коефіцієнтів в зворотному напрямку сканування.
21. Система за п. 20, в якій сканування має діагональний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
22. Система за п. 20, в якій сканування має горизонтальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях нижче лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
23. Система за п. 20, в якій сканування має вертикальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
24. Постійний зчитуваний комп'ютером носій даних, що зберігає на ньому інструкції, які, коли виконуються, змушують один або більше процесорів пристрою для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео:
кодувати інформацію, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення зі скануванням, що здійснюється в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення, і
формувати відображення значущості для згаданого блока на основі закодованої інформації, що вказує значущі коефіцієнти перетворення.
25. Постійний зчитуваний комп'ютером носій даних за п. 24, який додатково змушує один або більше процесорів кодувати інформацію, що вказує рівні значущих коефіцієнтів перетворення.
26. Постійний зчитуваний комп'ютером носій даних за п. 25, який додатково змушує один або більше процесорів кодувати інформацію, що вказує рівні значущих коефіцієнтів перетворення, в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому блоці коефіцієнтів перетворення.
27. Постійний зчитуваний комп'ютером носій даних за п. 24, який додатково змушує один або більше процесорів визначати контексти для контекстного адаптивного двійкового арифметичного кодування (САВАС) інформації, що вказує поточний один із значущих коефіцієнтів, на основі раніше закодованих значущих коефіцієнтів в зворотному напрямку сканування.
28. Постійний зчитуваний комп'ютером носій даних за п. 27, в якому сканування має діагональний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
29. Постійний зчитуваний комп'ютером носій даних за п. 27, в якому сканування має горизонтальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях нижче лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
30. Постійний зчитуваний комп'ютером носій даних за п. 27, в якому сканування має вертикальний шаблон, і раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний один із значущих коефіцієнтів.
Текст
Реферат: Дане розкриття описує способи для кодування коефіцієнтів перетворення, асоційованих з блоком залишкових даних відео в процесі кодування відео. Аспекти даного розкриття UA 109479 C2 (12) UA 109479 C2 включають в себе вибір порядку сканування як для кодування відображення значущості, так і для кодування рівня, а також вибір контекстів для статистичного кодування, сумісного з вибраним порядком сканування. Дане розкриття пропонує узгодження порядку сканування для кодування як відображення значущості коефіцієнтів перетворення, так і для кодування рівнів коефіцієнтів перетворення. Запропоновано, щоб порядок сканування для відображення значущості був в зворотному напрямі (тобто від більш високих частот до більш низьких частот). Дане розкриття також пропонує, щоб коефіцієнти перетворення були скановані в піднаборах на відміну від фіксованих субблоків. Зокрема, коефіцієнти перетворення скануються в піднаборі, що складається з ряду послідовних коефіцієнтів відповідно до порядку сканування. UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дана заявка вимагає пріоритет попередньої заявки на патент США № 61/450,555, поданої 8 березня 2011, попередньої заявки на патент США № 61/451,485, поданої 10 березня 2011, попередньої заявки на патент США № 61/451,496, поданої 10 березня 2011, попередньої заявки на патент США № 61/452,384, поданої 14 березня 2011, попередньої заявки на патент США № 61/494,855, поданої 8 червня 2011, і попередньої заявки на патент США № 61/497,345, поданої 15 червня 2011, кожна з яких повністю включена в даний опис за допомогою посилання. ГАЛУЗЬ ТЕХНІКИ, ДО ЯКОЇ НАЛЕЖИТЬ ВИНАХІД Даний опис стосується кодування відео і, більш конкретно, способів для сканування і кодування коефіцієнтів перетворення, згенерованих процесами кодування відео. ПОПЕРЕДНІЙ РІВЕНЬ ТЕХНІКИ Можливості цифрового відео можуть бути вбудовані в широкий діапазон пристроїв, які включають в себе цифрові телевізори, цифрові системи прямого мовлення, системи бездротового мовлення, персональні цифрові асистенти (PDA), ноутбуки або настільні комп'ютери, цифрові камери, цифрові пристрої запису, цифрові медіа-плеєри, ігрові відеопристрої, ігрові відеоприставки, стільникові або супутникові радіотелефони, пристрої відеотелеконференцій і т. п. Цифрові відеопристрої реалізовують способи стиснення відео, такі як способи, описані в стандартах, визначених в MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Частина 10, розширене кодування відео (AVC), на даний час розроблюваний стандарт високоефективного кодування відео (HEVC), і розширеннях таких стандартів для передачі, прийому і зберігання цифровою відео інформації більш ефективно. Способи стиснення відео включають в себе просторове прогнозування і/або часове прогнозування для зменшення або видалення надмірності, властивої відеопослідовностям. Для кодування відео, основаного на блоці, відеокадр або вирізка можуть бути фрагментовані на блоки. Кожний блок може бути додатково фрагментований. Блоки в інтракодованому (внутрішньокодованому) (I) кадрі або вирізці кодуються, використовуючи просторове прогнозування відносно опорних вибірок в сусідніх блоках в тому ж кадрі або вирізці. Блоки в інтеркодованому (зовнішньокодованому) (Р або В) кадрі або вирізці можуть використовувати просторове прогнозування відносно опорних вибірок в сусідніх блоках в тому ж кадрі або вирізці або часове прогнозування відносно опорних вибірок в інших опорних кадрах. Просторове або часове прогнозування приводить до прогнозуючого блока для блока, який повинен бути закодований. Залишкові дані представляють пікселні різниці між оригінальним блоком, який повинен бути закодований, і прогнозуючим блоком. Зовнішньокодований блок кодується відповідно до вектора руху, який вказує на блок опорних вибірок, що формують прогнозуючий блок, і залишкових даних, що вказують різницю між закодованим блоком і прогнозуючим блоком. Внутрішньокодований блок кодується відповідно до режиму внутрішнього кодування і залишкових даних. Для додаткового стиснення залишкові дані можуть бути перетворені з пікселної області в область перетворення, приводячи до залишкових коефіцієнтів перетворення, які потім можуть бути квантовані. Квантовані коефіцієнти перетворення, спочатку скомпоновані в двовимірному масиві, можуть скануватися в конкретному порядку, щоб сформувати одновимірний вектор коефіцієнтів перетворення для статистичного кодування. СУТЬ ВИНАХОДУ Загалом, дане розкриття описує пристрої і способи для кодування коефіцієнтів перетворення, асоційованих з блоком залишкових відеоданих, в процесі кодування відео. Способи, структури і методи, описані в даному розкритті, застосовні для процесів кодування відео, які використовують статистичне кодування (наприклад, контекстне адаптивне двійкове арифметичне кодування (CABAC)) для кодування коефіцієнтів перетворення. Аспекти даного розкриття включають в себе вибір порядку сканування як для кодування відображення значущості, так і для кодування рівня і знака, а також вибір контекстів для статистичного кодування, сумісного з вибраним порядком сканування. Способи, структури і методи даного розкриття застосовні для використання як в кодері відео, так і в декодері відео. Дане розкриття пропонує узгодженість (гармонізацію) порядку сканування для кодування як відображення значущості коефіцієнтів перетворення, так і для кодування рівнів коефіцієнтів перетворення. Тобто, скажімо, в деяких прикладах порядок сканування для кодування відображення значущості і рівня повинен мати один і той же шаблон і напрям. У іншому прикладі передбачається, що порядок сканування для відображення значущості повинен бути в зворотному напрямі (тобто від коефіцієнтів для більш високих частот до коефіцієнтів для більш низьких частот). У ще одному прикладі передбачається, що порядок сканування для кодування відображення значущості і рівня повинен бути узгоджений таким чином, щоб кожний здійснювався в зворотному напрямі. 1 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дане розкриття також пропонує, щоб в деяких прикладах коефіцієнти перетворення були скановані в піднаборах. Зокрема, коефіцієнти перетворення скануються в піднаборі, що складається з ряду послідовних коефіцієнтів, відповідно до порядку сканування. Такі піднабори можуть бути застосовні як для сканування відображення значущості, так і для сканування рівня коефіцієнтів. Додатково, дане розкриття пропонує, щоб в деяких прикладах сканування відображення значущості і сканування рівня коефіцієнтів були виконані в послідовних скануваннях і відповідно до одного і того ж порядку сканування. У одному аспекті порядком сканування є зворотний порядок сканування. Послідовні сканування можуть складатися з декількох проходів сканування. Кожний прохід сканування може складатися з проходу сканування елементів синтаксису. Наприклад, першим скануванням є сканування відображення значущості (також зване контейнером (накопичувачем) 0 рівня коефіцієнтів перетворення), друге сканування має контейнер один рівнів коефіцієнтів перетворення в кожному піднаборі, третє сканування може мати контейнер два рівнів коефіцієнтів перетворення в кожному піднаборі, четверте сканування має контейнери, що залишилися, рівнів коефіцієнтів перетворення, і п'яте сканування виконується для знака рівнів коефіцієнтів перетворення. Прохід для знака може мати місце в будь-який момент після проходу відображення значущості. Додатково, кількість проходів сканування може бути зменшена за допомогою кодування більше ніж одного елемента синтаксису для кожного проходу. Наприклад, один прохід сканування для елементів синтаксису використовує закодовані контейнери, і другий прохід сканування для елементів синтаксису використовує контейнери обходу (наприклад, рівні і знак, що залишилися). У цьому контексті контейнером є частина рядка контейнера, яка статистично кодується. Заданий елемент синтаксису з недвійковим значенням відображається в двійкову послідовність (так званий рядок контейнерів). Дане розкриття також пропонує, щоб в деяких прикладах коефіцієнти перетворення були закодовані, використовуючи CABAC, в двох різних областях контексту. Виведення контексту для першої області контексту залежить від позиції коефіцієнтів перетворення, в той час як виведення контексту для другої області залежить від казуальних (випадкових) сусідніх коефіцієнтів перетворення. У іншому прикладі друга область контексту може використовувати дві різні моделі контексту залежно від місцеположення коефіцієнтів перетворення. У одному прикладі даного розкриття запропонований спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео. Спосіб включає кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення зі скануванням, яке здійснюється в зворотному напрямі сканування від коефіцієнтів більш високої частоти в блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в блоці коефіцієнтів перетворення. У іншому прикладі даного розкриттязапропонована система для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео. Система містить модуль кодування відео, сконфігурований для кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення, зі скануванням, яке здійснюється в зворотному напрямі сканування від коефіцієнтів більш високої частоти в блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в блоці коефіцієнтів перетворення. У іншому прикладі даного розкриття запропонована система для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео. Система містить засіб для кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення, зі скануванням, яке здійснюється в зворотному напрямі сканування від коефіцієнтів більш високої частоти в блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в блоці коефіцієнтів перетворення, і засіб для формування відображення значущості для блока, на основі кодованої інформації, що вказує значущі коефіцієнти перетворення. У іншому прикладі даного розкриття комп'ютерний програмний продукт містить зчитуваний комп'ютером запам'ятовуючий носій, що зберігає збережені на ньому команди, які при виконанні змушують процесор пристрою для кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, кодувати інформацію, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення, зі скануванням, яке здійснюється в зворотному напрямі сканування від коефіцієнтів більш високої частоти в блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в блоці коефіцієнтів перетворення. Подробиці одного або більше прикладів наводяться в супровідних кресленнях і описі, представлених нижче. Інші ознаки, задачі і переваги будуть очевидні з опису, креслень і з формули винаходу. 2 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 КОРОТКИЙ ОПИС КРЕСЛЕНЬ Фіг. 1 є концептуальною діаграмою, яка ілюструє процес кодування відображення значущості. Фіг. 2 є концептуальною діаграмою, яка ілюструє шаблони і напрями сканування для кодування відображення значущості. Фіг. 3 є концептуальною діаграмою, яка ілюструє спосіб сканування для кодування рівня блока перетворення. Фіг. 4 є блок-схемою, яка ілюструє зразкову систему кодування відео. Фіг. 5 є блок-схемою, яка ілюструє зразковий кодер відео. Фіг. 6 є концептуальною діаграмою, яка ілюструє зворотні порядки сканування для кодування відображення значущості і рівня коефіцієнтів. Фіг. 7 є концептуальною діаграмою, яка ілюструє перший піднабір коефіцієнтів перетворення відповідно до зворотного діагонального порядку сканування. Фіг. 8 є концептуальною діаграмою, яка ілюструє перший піднабір коефіцієнтів перетворення відповідно до зворотного порядку горизонтального сканування. Фіг. 9 є концептуальною діаграмою, яка ілюструє перший піднабір коефіцієнтів перетворення відповідно до зворотного порядку вертикального сканування. Фіг. 10 є концептуальною діаграмою, яка ілюструє області контексту для кодування відображення значущості. Фіг. 11 є концептуальною діаграмою, яка ілюструє зразкові області контексту для кодування відображення значущості, що використовує зворотний порядок сканування. Фіг. 12 є концептуальною діаграмою, яка ілюструє зразкових казуальних сусідів для статистичного кодування, що використовує прямий порядок сканування. Фіг. 13 є концептуальною діаграмою, яка ілюструє зразкових казуальних сусідів для статистичного кодування, що використовує зворотний порядок сканування. Фіг. 14 є концептуальною діаграмою, яка ілюструє зразкові області контексту для статистичного кодування, що використовує зворотний порядок сканування. Фіг. 15 є концептуальною діаграмою, яка ілюструє зразкових казуальних сусідів для статистичного кодування, що використовує зворотний порядок сканування. Фіг. 16 є концептуальною діаграмою, яка ілюструє інший приклад областей контексту для CABAC, що використовує зворотний порядок сканування. Фіг. 17 є концептуальною діаграмою, яка ілюструє інший приклад областей контексту для CABAC, що використовує зворотний порядок сканування. Фіг. 18 є концептуальною діаграмою, яка ілюструє інший приклад областей контексту для CABAC, що використовує зворотний порядок сканування. Фіг. 19 є блок-схемою, яка ілюструє зразковий блок статистичного кодування. Фіг. 20 є блок-схемою, яка ілюструє зразковий декодер відео. Фіг. 21 є блок-схемою, яка ілюструє зразковий блок статистичного декодування. Фіг. 22 є блок-схемою, яка ілюструє зразковий процес для сканування відображення значущості і рівня коефіцієнтів з узгодженим порядком сканування. Фіг. 23 є блок-схемою, яка ілюструє зразковий процес для сканування відображення значущості і рівня коефіцієнтів і виведення контексту статистичного кодування. Фіг. 24 є блок-схемою, яка ілюструє інший зразковий процес для сканування відображення значущості і рівня коефіцієнтів і виведення контексту статистичного кодування. Фіг. 25 є блок-схемою, яка ілюструє інший зразковий процес для сканування відображення значущості і рівня коефіцієнтів і виведення контексту статистичного кодування. Фіг. 26 є блок-схемою, яка ілюструє зразковий процес для кодування відображення значущості, що використовує зворотний напрям сканування. Фіг. 27 є блок-схемою, яка ілюструє зразковий процес для сканування відображення значущості і рівня коефіцієнтів згідно з піднабором коефіцієнтів перетворення. Фіг. 28 є блок-схемою, яка ілюструє інший зразковий процес для сканування відображення значущості і рівня коефіцієнтів, згідно з піднабором коефіцієнтів перетворення. Фіг. 29 є блок-схемою, яка ілюструє інший зразковий процес для сканування відображення значущості і рівня коефіцієнтів згідно з піднабором коефіцієнтів перетворення. Фіг. 30 є блок-схемою, яка ілюструє зразковий процес для статистичного кодування, що використовує множинні області. ДОКЛАДНИЙ ОПИС Цифрові відеопристрої реалізовують способи стиснення відео, щоб більш ефективно передавати і приймати цифрову відеоінформацію. Стиснення відео може застосовувати 3 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 способи просторового (внутрішньокадрового) прогнозування і/або часового (міжкадрового) прогнозування, щоб зменшити або видалити надмірність, властиву послідовностям відео. Для кодування відео згідно зі стандартом високоефективного кодування відео (HEVC), на даний час розроблюваним спільною об'єднаною командою для кодування відео (JCT-VC), як один приклад, відеокадр може бути фрагментований на блоки кодування. Блок кодування загалом належить до області зображення, яка служить базовим блоком, до якого застосовуються різні інструменти кодування для стиснення відео. Блок кодування звичайно є квадратним (хоч необов'язково) і може бути розглянутий як аналогічний так званому макроблоку, наприклад, відповідно до інших стандартів кодування відео, таких як ITU-T H.264. Кодування, відповідно до деяких з на даний час запропонованих аспектів розвитку стандарту HEVC, описане нижче в даній заявці з метою ілюстрації. Однак способи, описані в даному розкритті, можуть бути корисні для інших процесів кодування відео, таких як процеси, визначені згідно з H.264 або іншим стандартом, або процеси кодування відео, що складають власність. Щоб досягнути бажаної ефективності кодування, блок кодування (CU) може мати змінні розміри залежно від відеоконтенту. На доповнення, блок кодування може бути розбитий на менші блоки для прогнозування або перетворення. Зокрема, кожний блок кодування може бути додатково фрагментований на блоки прогнозування (блоки PU) і блоки перетворення (блоки TU). Блоки прогнозування можуть бути розглянуті як аналогічні так званим фрагментам (розділенням) відповідно до інших стандартів кодування відео, таких як стандарт H.264. Блок перетворення (TU) загалом належить до блока залишкових даних, до яких застосовується перетворення, щоб сформувати коефіцієнти перетворення. Блок кодування звичайно має компоненту яскравості, позначену як Y, і дві компоненти кольоровості, позначені як U і V. Залежно від формату дискретизації відео, розмір компонент U і V, в термінах кількості вибірок, може бути однаковим або відрізнятися від розміру компоненти Y. Щоб закодувати блок (наприклад, блок прогнозування даних відео), спочатку виводиться прогнозувач для блока. Прогнозувач, також званий прогнозуючим блоком, може бути виведений або за допомогою інтрапрогнозування (I) (тобто просторового прогнозування) або інтерпрогнозування (Р або В) (тобто часового прогнозування). Отже, деякі блоки прогнозування можуть бути інтракодовані (I), використовуючи просторове прогнозування відносно опорних вибірок в сусідніх опорних блоках в одному і тому ж кадрі (або вирізці), і інші блоки прогнозування можуть бути однонаправлено зовнішньокодовані (Р) або двонаправлено зовнішньокодовані (В) відносно блоків опорних вибірок в інших раніше закодованих кадрах (або вирізках). У кожному випадкуопорні вибірки можуть бути використані для формування прогнозуючого блока для блока, який повинен бути закодований. Після ідентифікації прогнозуючого блока, визначається різниця між оригінальним блоком даних відео і його прогнозуючим блоком. Ця різниця може називатися залишковими даними прогнозування і вказує пікселні різниці між пікселними значеннями в блоці, який повинен бути закодований, і пікселними значеннями в прогнозуючому блоці, вибраному для представлення закодованого блока. Щоб досягнути кращого стиснення, залишкові дані прогнозування можуть бути перетворені, наприклад, використовуючи дискретне косинусне перетворення (DCT), цілочислове перетворення, перетворення Карунена-Лева (Karhunen-Loeve) (K-L) або інше перетворення. Залишкові дані в блоці перетворення, такому як TU, можуть бути скомпоновані в двовимірному (2D) масиві значень пікселної різниці, що знаходяться в просторовій, пікселній області. Перетворення перетворює залишкові пікселні значення в двовимірний масив коефіцієнтів перетворення в області перетворення, такій як частотна область. Для додаткового стиснення коефіцієнти перетворення можуть бути квантовані перед статистичним кодуванням. Статистичний кодер потім застосовує статистичне кодування, таке як контекстне адаптивне кодування із змінною довжиною коду (CAVLC), контекстне адаптивне двійкове арифметичне кодування (CABAC), статистичне кодування з фрагментуванням інтервалу імовірності (PIPE) і т. п., до квантованих коефіцієнтів перетворення. Для виконання статистичного кодування блока квантованих коефіцієнтів перетворення звичайно виконується процес сканування таким чином, щоб двовимірний (2D) масив квантованих коефіцієнтів перетворення в блоці був оброблений відповідно до конкретного порядку сканування у впорядкований одновимірний (1D) масив, тобто вектор, коефіцієнтів перетворення. Статистичне кодування застосовується в одновимірному (1D) порядку коефіцієнтів перетворення. Сканування квантованих коефіцієнтів перетворення в блоці перетворення перетворює в послідовну форму 2D-масив коефіцієнтів перетворення для статистичного кодера. Відображення значущості може бути згенероване для указання позицій значущих (тобто ненульових) коефіцієнтів. Сканування може бути застосоване для сканування 4 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 рівнів значущих (тобто ненульових) коефіцієнтів і/або для кодування знаків значущих коефіцієнтів. Для DCT, як приклад, часто є більш висока імовірність ненульових коефіцієнтів у напрямі до лівого верхнього кута (тобто низькочастотної області) 2D-блока перетворення. Може бути бажано сканувати коефіцієнти способом, який збільшує імовірність групування ненульових коефіцієнтів разом в одному кінці перетвореної в послідовну форму серії коефіцієнтів, дозволяючи нульовим коефіцієнтам групуватися разом у напрямі до іншого кінця перетвореного в послідовну форму вектора і більш ефективно кодуватися як серії нулів. Тому порядок сканування може бути важливий для ефективного статистичного кодування. Як один приклад, так званий діагональний (або хвильового фронту) порядок сканування був прийнятий для використання при скануванні квантованих коефіцієнтів перетворення в стандарті HEVC. Альтернативно, можуть бути використані зигзагоподібний, горизонтальний, вертикальний або інші порядки сканування. За допомогою перетворення і квантування, як згадано вище, ненульові коефіцієнти перетворення загалом розташовуються в низькочастотній області у напрямі до верхньої лівої області блока, наприклад, де перетворенням є DCT. У результаті після процесу діагонального сканування, який може спочатку перетнути верхню ліву область, ненульові коефіцієнти перетворення звичайно більш ймовірно повинні бути розташовані у фронтальній частині сканування. Для процесу діагонального сканування, який спочатку перетинає більш нижню праву область, ненульові коефіцієнти перетворення звичайно більш ймовірно повинні бути розташовані в задній частині сканування. Ряд нульових коефіцієнтів звичайно буде згрупований в одному кінці сканування, залежно від напряму сканування, через зменшену енергію на більш високих частотах і через ефекти квантування, які можуть змушувати деякі ненульові коефіцієнти ставати нульовими коефіцієнтами після зменшення глибини в бітах. Ці характеристики розподілу коефіцієнтів в перетвореному в послідовну форму 1D-масиві можуть бути використані в структурі статистичного кодера для підвищення ефективності кодування. Іншими словами, якщо ненульові коефіцієнти можуть бути ефективно скомпоновані в одній частині 1D-масиву за допомогою деякого відповідного порядку сканування, може очікуватися поліпшена ефективність кодування через структуру багатьох статистичних кодерів. Щоб досягнути цієї задачі розміщення більшої кількості ненульових коефіцієнтів в одному кінці 1D-масиву, різні порядки сканування можуть бути використані у відеокодері-декодері (кодеку), щоб закодувати коефіцієнти перетворення. У деяких випадках діагональне сканування може бути ефективним. У інших випадках різні типи сканування, такі як зигзагоподібне, вертикальне або горизонтальне сканування, можуть бути більш ефективними. Різні порядки сканування можуть бути здійснені різними способами. Один приклад полягає в тому, що для кожного блока коефіцієнтів перетворення "найкращий" порядок сканування може бути вибраний з ряду доступних порядків сканування. Пристрій кодування відео потім може забезпечити декодеру індикацію, для кожного блока, індексу найкращого порядку сканування серед набору порядків сканування, позначених відповідними індексами. Вибір найкращого порядку сканування може бути визначений за допомогою застосування декількох порядків сканування і вибору одного, який є найбільш ефективним при розміщенні ненульових коефіцієнтів біля початку або кінця 1D-вектора, таким чином сприяючи ефективному статистичному кодуванню. У іншому прикладі порядок сканування для поточного блока може бути визначений на основі різних факторів, що стосуються кодування придатного блока прогнозування, таких як режим прогнозування (I, В, Р), розмір блока, перетворення або інші фактори. У деяких випадках, оскільки одна і та ж інформація, наприклад режим прогнозування, може бути виведена як на стороні кодера, так і на стороні декодера, може не бути необхідності забезпечувати індикацію індексу порядку сканування декодеру. Замість цього декодер відео може зберегти дані конфігурації, які вказують задане знання придатного порядку сканування режиму прогнозування для блока і один або більше критеріїв, які відображають режим прогнозування в конкретний порядок сканування. Щоб додатково підвищити ефективність кодування, доступні порядки сканування можуть не бути постійними весь час. Замість цього деяка адаптація може бути дозволена таким чином, щоб порядок сканування адаптивно регулювався, наприклад, на основі коефіцієнтів, які вже закодовані. Звичайно адаптація порядку сканування може бути виконана таким чином, щоб відповідно до вибраного порядку сканування більш ймовірно були згруповані нульові і ненульові коефіцієнти. У деяких кодеках відео первинні доступні порядки сканування можуть бути в дуже регулярній формі, такій як тільки горизонтальне, вертикальне, діагональне або зигзагоподібне 5 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 сканування. Альтернативно, порядки сканування можуть бути виведені за допомогою процесу навчання і тому можуть здатися декілька випадковими. Процес навчання може включати застосування різних порядків сканування до блока або послідовностей блоків для ідентифікації порядку сканування, який приводить до бажаних результатів, наприклад, з точки зору ефективного розміщення ненульових коефіцієнтів і нульових коефіцієнтів, як згадано вище. Якщо порядок сканування виведений (одержаний) з процесу навчання, або якщо множина різних порядків сканування може бути вибрана, може бути вигідно зберегти конкретні порядки сканування як на стороні кодера, так і на стороні декодера. Об'єм даних, що задають такі порядки сканування, може бути суттєвим. Наприклад, для блока перетворення 32×32 один порядок сканування може містити 1024 позицій коефіцієнтів перетворення. Оскільки можуть існувати блоки різних розмірів, і для кожного розміру блока перетворення може існувати ряд різних порядків сканування, загальний об'єм даних, які повинні бути збережені, не є нехтуваним. Звичайні порядки сканування, такі як діагональний, горизонтальний, вертикальний або зигзагоподібний порядок, можуть не вимагати області зберігання або можуть вимагати мінімальної області зберігання. Однак діагональний, горизонтальний, вертикальний або зигзагоподібний порядки можуть не забезпечити достатньої різноманітності, щоб забезпечити продуктивність кодування, яка знаходиться нарівні з навченими порядками сканування. У одному звичайному прикладі для стандарту H.264 і HEVC, на даний час розроблюваного, коли використовується статистичний кодер CABAC, позиції значущих коефіцієнтів (тобто ненульових коефіцієнтів перетворення) в блоці перетворення (тобто блоці перетворення в HEVC) є кодованими перед рівнями коефіцієнтів. Процес кодування місцеположень значущих коефіцієнтів називається кодуванням відображення значущості. Значущість коефіцієнта є такою ж, що і контейнер нуль рівня коефіцієнтів. Як показано на ФІГ. 1, кодування відображення значущості квантованих коефіцієнтів 11 перетворення здійснює відображення 13 значущості. Відображення 13 значущості є відображенням (картою) одиниць і нулів, де одиниці вказують місцеположення значущих коефіцієнтів. Відображення значущості звичайно вимагає високого процентного змісту швидкості передачі відео. Способи даного розкриття можуть також застосовуватися для використання з іншими статистичними кодерами (наприклад, PIPE). Зразковий процес для кодування відображення значущості описаний в Marpe D., Schwarz H. and Wiegand T. "Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard", IEEE Trans. Circuits and Systems for Video Technology, Vol. 13, № 7, July 2003. У цьому процесі кодується відображення значущості, якщо є щонайменше один значущий коефіцієнт в блоці, як указано прапором закодованого блока (CBF), який визначений як: Прапор закодованого блока: coded_block_flag є однобітовим символом, який вказує, чи є значущі, тобто ненульові, коефіцієнти в єдиному блоці коефіцієнтів перетворення, для якого шаблон закодованого блока вказує ненульові записи. Якщо coded_block_flag є нулем, ніяка додаткова інформація не передається для пов'язаного блока. Якщо є значущі коефіцієнти в блоці, відображення значущості кодується наступним порядком сканування коефіцієнтів перетворення в блоці таким чином: Сканування коефіцієнтів перетворення: двовимірні масиви рівнів коефіцієнтів перетворення субблоків, для яких coded_block_flag вказує ненульові записи, спочатку відображаються в одновимірний список, використовуючи заданий шаблон сканування. Іншими словами, субблоки зі значущими коефіцієнтами скануються відповідно до шаблона сканування. При заданому шаблоні сканування відображення значущості сканується наступним чином: Відображення значущості: якщо coded_block_flag вказує, що блок має значущі коефіцієнти, кодується відображення значущості з двійковими значеннями. Для кожного коефіцієнта перетворення в порядку сканування передається однобітовий символ significant_coeff_flag. Якщо символ significant_coeff_flag дорівнює одиниці, тобто, якщо ненульовий коефіцієнт існує в цій позиції сканування, відправляється додатковий однобітовий last_significant_coeff_flag. Цей символ вказує, чи є поточний значущий коефіцієнт останнім в блоці або чи ідуть додаткові значущі коефіцієнти. Якщо досягнута остання позиція сканування і кодування відображення значущості не було ще закінчене за допомогою last_significant_coeff_flag зі значенням одиниця, очевидно, що останній коефіцієнт повинен бути значущим. Останні пропозиції для HEVC видалили last_significant_coeff_flag. У цих пропозиціях перед відправленням відображення значущості відправляється індикація позиції X і Y останнього значущого коефіцієнта. На даний час в HEVC запропоновано, щоб три шаблони сканування використовувалися для відображення значущості: діагональний, вертикальний і горизонтальний. ФІГ. 2 показує приклад зигзагоподібного сканування 17, вертикального сканування 19, горизонтального сканування 21 і діагонального сканування 15. Як показано на ФІГ. 2, кожне з цих сканувань здійснюється в 6 UA 109479 C2 5 10 15 20 25 30 35 прямому напрямі, тобто від коефіцієнтів перетворення більш низької частоти у верхньому лівому кутку блока перетворення до коефіцієнтів перетворення більш високої частоти в правому нижньому кутку блока перетворення. Після кодування відображення значущості кодується інформація про рівень, що залишилася (контейнери 1-N, де N є загальною кількістю контейнерів), для кожного значущого коефіцієнта перетворення (тобто значення коефіцієнта). У процесі CABAC, раніше визначеному в стандарті H.264, після обробки субблоків 4×4 кожний з рівнів коефіцієнтів перетворення перетворюється в двійкову форму, наприклад, відповідно до унарного коду, щоб сформувати послідовність контейнерів. У H.264 модель контексту CABAC, встановлена для кожного субблока, складається з моделей контексту два на п'ять з п'ятьма моделями як для першого контейнера, так і для всіх контейнерів, що залишилися (аж до і включаючи 14-ий контейнер), елемента синтаксису coeff_abs_level_minus_one, який кодує абсолютне значення коефіцієнта перетворення. Зокрема, в одній запропонованій версії HEVC контейнери, що залишилися, включають в себе тільки контейнер 1 і контейнер 2. Залишок від рівнів коефіцієнтів кодується кодуванням Голомба-Райса і експоненціальними кодами Голомба. У HEVC вибір моделей контексту може бути виконаний так, як в оригінальному процесі CABAC, запропонованому для стандарту H.264. Однак різні набори моделей контексту можуть бути вибрані для різних субблоків. Зокрема, вибір моделі контексту, встановленої для даного субблока, залежить від деякої статистичної інформації про раніше закодовані субблоки. ФІГ. 3 показує порядок сканування, що відповідає одній запропонованій версії процесу HEVC, щоб закодувати рівні коефіцієнтів перетворення (абсолютне значення рівня і знак рівня) в блоці 25 перетворення. Повинно бути зазначено, що є прямий зигзагоподібний шаблон 27 для сканування субблоків 4×4 більшого блока і зворотний зигзагоподібний шаблон 23 для сканування рівнів коефіцієнтів перетворення в кожному субблоці. Іншими словами, послідовність з субблоків 4×4 сканується в прямому зигзагоподібному шаблоні таким чином, щоб субблоки сканувалися в послідовності. Потім в кожному субблоці зворотне зигзагоподібне сканування виконується для сканування рівнів коефіцієнтів перетворення в субблоці. Отже, коефіцієнти перетворення в двовимірному масиві, сформованому блоком перетворення, перетворюються в послідовну форму в одновимірний масив таким чином, щоб за коефіцієнтами, які зворотно скануються в даному субблоці, потім ішли коефіцієнти, які зворотно скануються в подальшому субблоці. У одному прикладі САВАС-кодування коефіцієнтів, сканованих відповідно до підходу сканування субблока, показаному на ФІГ. 3, може використовувати 60 контекстів, тобто 6 наборів з 10 контекстів, розподілених, як описано нижче. Для блока 4×4 може бути використано 10 моделей контексту (5 моделей для контейнера 1 і 5 моделей для контейнерів 2-14), як показано в Таблиці 1. Таблиця 1 Контексти для контейнера 1 і контейнерів 2-14 рівнів коефіцієнтів субблока 0 1 2 3 4 40 Контейнер 1 моделі Закодований коефіцієнт більше ніж 1 Первинний - немає хвостових одиниць в субблоці 1 хвостова одиниця в субблоці 2 хвостові одиниці в субблоці 3 або більше хвостових одиниць в субблоці Контейнер 2-14 моделі (контейнери, що залишилися) 0 1 2 3 4 Первинні або 0 коефіцієнтів більше ніж одиниця 1 коефіцієнт більше ніж одиниця 2 коефіцієнти більше ніж одиниця 3 коефіцієнти більше ніж одиниця 4 або більше коефіцієнтів більше ніж одиниця Для Таблиці 1 одна з моделей 0-4 контексту в наборі контекстів використовується для контейнера 1, якщо, відповідно, в даний час закодований коефіцієнт, який сканується в субблоці, закодований після того, як коефіцієнт більше ніж 1 був закодований в субблоці, цей в даний час закодований коефіцієнт є первинним коефіцієнтом, сканованим в субблоці, або 7 UA 109479 C2 5 10 немає ніяких хвостових одиниць (ніяких раніше закодованих коефіцієнтів) в субблоці, є одна хвостова одиниця в субблоці (тобто одиниця була закодована, але ніякі коефіцієнти більше ніж одиниця не були закодовані), є дві хвостові одиниці в субблоці або в субблоці є три або більше хвостових одиниць. Для кожного з контейнерів 2-14 (хоч на даний час запропонована версія HEVC кодує тільки контейнер 2, використовуючи CABAC, з подальшими контейнерами рівня коефіцієнтів, кодованих експоненціальним кодом Голомба), одна з моделей 0-4 контексту може бути використана, відповідно, якщо коефіцієнт є первинним коефіцієнтом, сканованим в субблоці, або є нульові раніше закодовані коефіцієнти більше ніж одиниця, є один раніше закодований коефіцієнт більше ніж одиниця, є два раніше закодованих коефіцієнти більше ніж одиниця, є три раніше закодованих коефіцієнти більше ніж одиниця або є чотири раніше закодованих коефіцієнти більше ніж одиниця. Існують 6 різних наборів цих 10 моделей, залежно від кількості коефіцієнтів, більше ніж 1 в раніше закодованому субблоці 4×4 в прямому скануванні субблоків. Таблиця 2 Контексти для контейнера 1 і контейнерів 2-14 0 1 2 3 4 5 Набір контекстів Тільки для розміру блока 4×4 0-3 коефіцієнти більше ніж 1 в попередньому субблоці 4-7 коефіцієнтів більше ніж 1 в попередньому субблоці 8-11 коефіцієнтів більше ніж 1 в попередньому субблоці 12-15 коефіцієнтів більше ніж 1 в попередньому субблоці Перший субблок 4×4 16 коефіцієнтів більше ніж 1 в попередньому субблоці 15 20 25 30 35 40 45 Для Таблиці 2 набори 0-5 моделей контексту використовуються для заданого субблока, якщо, відповідно, розмір субблока становить 4×4, є 0-3 коефіцієнти більше ніж 1 в раніше закодованому субблоці, є 4-7 коефіцієнтів більше ніж 1 в раніше закодованому субблоці, є 8-11 коефіцієнтів більше ніж 1 в раніше закодованому субблоці, є 12-15 коефіцієнтів більше ніж 1 враніше закодованому субблоці, або даний субблок є першим субблоком 4×4 (верхній лівий субблок), або є 16 коефіцієнтів більше ніж 1 в раніше закодованому субблоці. Вищеописаний процес кодування для H.264 і процес, на даний час запропонований для HEVC, мають декілька недоліків. Як показано на ФІГ. 3, один недолік полягає в тому, що сканування рівнів коефіцієнтів здійснюється уперед для сканування субблоків (тобто починаючи з верхнього лівого субблока), а потім зворотно для сканування рівнів коефіцієнтів в кожному субблоці (тобто починаючи з нижнього правого коефіцієнта в кожному субблоці). Цей підхід має на увазі рух назад і уперед в межах блока, що може зробити вибірку даних більш складною. Інший недолік зумовлений тим фактом, що порядок сканування рівня коефіцієнтів відрізняється від порядку сканування відображення значущості. У HEVC є три різні запропоновані порядки сканування для відображення значущості: прямий діагональний, прямий горизонтальний і прямий вертикальний, як показано на ФІГ. 2. Всі сканування значущих коефіцієнтів відрізняються від сканувань рівнів коефіцієнтів, на даний час запропонованих для HEVC, оскільки сканування рівня здійснюються в зворотному напрямі. Оскільки напрям і шаблон сканування рівня коефіцієнтів не співпадають з напрямом і шаблоном сканування значущості, повинно бути перевірено більше рівнів коефіцієнтів. Наприклад, передбачимо, що горизонтальне сканування використовується для відображення значущості, і останній коефіцієнт значущості знайдений в кінці першого рядка коефіцієнтів. Сканування рівня коефіцієнтів в HEVC буде вимагати діагонального сканування через множинні рядки для сканування рівня, коли тільки перший рядок фактично містить рівні коефіцієнтів, відмінні від 0. Такий процес сканування може ввести небажану неефективність. У поточній пропозиції по HEVC сканування відображення значущості здійснюється уперед в блоці від коефіцієнта DC, знайденого в лівому верхньому кутку блока, до коефіцієнта найбільш високої частоти, звичайно знайденого в правому нижньому кутку блока, в той час як сканування рівнів коефіцієнтів є в зворотному напрямі в кожному субблоці 4×4. Це також може привести до більш складної і більш неефективної вибірки даних. Інший недолік для поточних пропозицій HEVC зумовлений наборами контекстів. Набір контекстів (див. Таблицю 2 вище) для CABAC відрізняється для розміру блока 4×4, ніж для інших розмірів блока. Відповідно до цього розкриття, було б бажано узгодити (гармонізувати) 8 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 контексти для всіх розмірів блока таким чином, щоб менше пам'яті було виділено на зберігання різних наборів контекстів. Крім того, як описано більш детально нижче, на даний час запропоновані контексти CABAC для відображення значущості для HEVC дійсні тільки тоді, коли порядок сканування є прямим (уперед). Також, це може не враховувати зворотні сканування відображення значущості. Крім того, контексти, описані вище для кодування рівня квантованого коефіцієнта, намагаються використовувати локальну кореляцію рівнів коефіцієнтів. Ці контексти залежать від кореляції серед субблоків 4×4 (див. набір контекстів в Таблиці 2) і кореляції в кожному субблоці (див. моделі контексту в Таблиці 1). Недолік цих контекстів полягає в тому, що залежність може бути дуже віддаленою (тобто є низька залежність між коефіцієнтами, які відділені один від одного декількома іншими коефіцієнтами, від одного субблока до іншого). Крім того, в кожному субблоці залежність може бути слабкою. Дане розкриття пропонує декілька різних особливостей, які можуть зменшити або усунути деякі з недоліків, описаних вище. У деяких прикладах ці особливості можуть забезпечити більш ефективний і узгоджений порядок сканування коефіцієнтів перетворення при кодуванні відео. У інших прикладах даного розкриття ці особливості забезпечують більш ефективний набір контекстів, які повинні бути використані в основаному на CABAC статистичному кодуванні коефіцієнтів перетворення, сумісному із запропонованим порядком сканування. Повинно бути зазначено, що всі способи, описані в даному розкритті, можуть бути використані незалежно або можуть бути використані разом в будь-якій комбінації. ФІГ. 4 є блок-схемою, що ілюструє зразкову систему 10 кодування і декодування відео, яка може бути сконфігурована для використання способів для кодування коефіцієнтів перетворення відповідно до прикладів даного розкриття. Як показано на ФІГ. 4, система 10 включає в себе пристрій-джерело 12, який передає закодоване відео на пристрій 14 призначення за допомогою каналу 16 зв'язку. Закодоване відео може бути також збережене на запам'ятовуючому носії 34 або файловому сервері 36 і може бути доступне за допомогою пристрою 14 призначення, якщо необхідно. Пристрій-джерело 12 і пристрій 14 призначення можуть містити будь-яку велику різноманітність пристроїв, що включають в себе настільні комп'ютери, портативні комп'ютери (тобто ноутбук), планшетні комп'ютери, телевізійні приставки, телефонні трубки, такі як так звані смартфони, телевізори, камери, пристрої відображення, цифрові медіа-плеєри, консолі для відеоігор і т. п. В багатьох випадках такі пристрої можуть бути обладнані для бездротового зв'язку. Отже, канал 16 зв'язку може містити бездротовий канал, дротовий канал або комбінацію бездротових і дротових каналів, придатних для передачі закодованих відеоданих. Аналогічно, файловий сервер 36 може бути доступний за допомогою пристрою 14 призначення через будьяке стандартне з'єднання передачі даних, що включає в себе Інтернет-з'єднання. Воно може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем і т. д.) або їх комбінацію, яка придатна для того, щоб одержати доступ до закодованих відеоданих, збережених на файловому сервері. Способи для кодування коефіцієнтів перетворення відповідно до прикладів даного розкриття можуть застосовуватися до кодування відео на підтримання будь-якого з множини мультимедійних додатків, таких як телевізійні мовлення по повітрю, передачі кабельного телебачення, передачі супутникового телебачення, поточні відеопередачі, наприклад за допомогою Інтернету, кодування цифрового відео для зберігання на запам'ятовуючому носії даних, декодування цифрового відео, збереженого на запам'ятовуючому носії даних або інші додатки. У деяких прикладах система 10 може бути сконфігурована для підтримання односторонньої або двосторонньої передачі відео, щоб підтримати додатки, такі як потокова передача відео, відтворення відео, мовлення відео і/або відеотелефонія. У прикладі згідно з ФІГ. 4 пристрій-джерело 12 включає в себе джерело 18 відео, кодер 20 відео, модулятор/демодулятор 22 і передавач 24. У пристрої-джерелі 12 джерело 18 відео може включати в себе джерело, таке як пристрій захоплення відео, наприклад відеокамеру, відеоархів, що містить раніше захоплене відео, інтерфейс подачі відео для прийому відео від постачальника відеоконтенту, і/або систему комп'ютерної графіки для генерування даних комп'ютерної графіки як вихідного відео або комбінація таких джерел. Як один приклад, якщо джерелом 18 відео є відеокамера, пристрій-джерело 12 і пристрій 14 призначення можуть формувати так звані камерофони або відеотелефони. Однак способи, описані в даному розкритті, можуть застосовуватися до кодування відео загалом і можуть застосовуватися до бездротових і/або дротових додатків. Захоплене, попередньо захоплене або згенероване комп'ютером відео може бути закодоване кодером 20 відео. Закодована інформація відео може бути модульована модемом 22 згідно зі стандартом зв'язку, таким як протокол бездротового зв'язку, і передаватися на 9 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 пристрій 14 призначення за допомогою передавача 24. Модем 22 може включати в себе різні змішувачі, фільтри, підсилювачі або інші компоненти, сконструйовані для модуляції сигналу. Передавач 24 може включати в себе схеми, сконструйовані для передачі даних, що включають в себе підсилювачі, фільтри і одну або більше антен. Захоплене, попередньо захоплене або згенероване комп'ютером відео, яке кодується кодером 20 відео, може також бути збережене на запам'ятовуючому носії 34 або файловому сервері 36 для більш пізнього використання. Запам'ятовуючий носій 34 може включати в себе диски Blu-ray, диски DVD, диски CD-ROM, флеш-пам'ять або будь-які інші придатні цифрові запам'ятовуючі носії для зберігання закодованого відео. Закодоване відео, збережене на запам'ятовуючому носії 34, потім може бути доступне за допомогою пристрою 14 призначення для декодування і відтворення. Файловий сервер 36 може бути будь-яким типом сервера, здатного зберігати закодоване відео і передавати це закодоване відео на пристрій 14 призначення. Зразкові файлові сервери включають в себе web-сервер (наприклад, для web-сайта), сервер FTP, мережеві пристрої зберігання даних (NAS), локальний дисковий накопичувач або будь-який інший тип пристрою, здатного зберігати закодовані відеодані і передавати їх на приймальний пристрій. Передача закодованих відеоданих від файлового сервера 36 може бутипотоковою передачею, передачею завантаження або їх комбінацією. Файловий сервер 36 може бути доступний за допомогою пристрою 14 призначення через будь-яке стандартне з'єднання передачі даних, що включає в себе Інтернет-з'єднання. Воно може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем, Ethernet, USB і т. д.) або їх комбінацію, яка придатна для того, щоб одержати доступ до закодованих відеоданих, збережених на файловому сервері. Пристрій 14 призначення в прикладі на ФІГ. 4 включає в себе приймач 26, модем 28, декодер 30 відео і пристрій 32 відображення. Приймач 26 пристрою 14 призначення приймає інформацію по каналу 16, і модем 28 демодулює інформацію, щоб сформувати демодульований бітовий потік для декодера 30 відео. Інформація, передана по каналу 16, може включати в себе різну інформацію синтаксису, згенеровану кодером 20 відео, для використання за допомогою декодера 30 відео при декодуванні відеоданих. Такий синтаксис може бути також включений з закодованими відеоданими, збереженими на запам'ятовуючому носії 34 або файловому сервері 36. Кожний з кодера 20 відео і декодера 30 відео може бути частиною відповідного кодека (CODEC), який здатний кодувати або декодувати відеодані. Пристрій 32 відображення може бути об'єднаний з, або бути зовнішнім відносно, пристроєм 14 призначення. У деяких прикладах пристрій 14 призначення може включати в себе інтегрований пристрій відображення і також бути сконфігурований для того, щоб взаємодіяти із зовнішнім пристроєм відображення. У інших прикладах пристрій 14 призначення може бути пристроєм відображення. Загалом, пристрій 32 відображення відображає декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, таких як рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світлодіодах (OLED) або інший тип пристрою відображення. У прикладі на ФІГ. 4 канал 16 зв'язку може містити будь-який бездротовий або дротовий комунікаційний носій, такий як радіочастотний (RF) спектр або одна або більше фізичних ліній передачі, або будь-яку комбінацію бездротових і дротових носіїв. Канал 16 зв'язку може бути частиною основаної на пакетній передачі мережі, такої як локальна мережа, широкомасштабна мережа або глобальна мережа, така як Інтернет. Канал 16 зв'язку загалом представляє будьякий придатний комунікаційний носій або колекцію різних комунікаційних носіїв для передачі даних відео від пристрою-джерела 12 на пристрій 14 призначення, включаючи будь-яку придатну комбінацію дротових або бездротових носіїв. Канал 16 зв'язку може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути корисним, щоб полегшити передачу даних від пристрою-джерела 12 на пристрій 14 призначення. Кодер 20 відео і декодер 30 відео можуть працювати згідно зі стандартом стиснення відео, таким як на даний час розроблюваний стандарт високоефективного кодування відео (HEVC), і можуть відповідати тестовій моделі HEVC (HM). Альтернативно, кодер 20 відео і декодер 30 відео можуть працювати відповідно до інших стандартів, що складають власність або є промисловими, таких як стандарт ITU-T H.264, альтернативно званий MPEG-4, Частина 10, вдосконалене кодування відео (AVC), або розширень таких стандартів. Способи даного розкриття, однак, не обмежуються ніяким особливим стандартом кодування. Інші приклади включають в себе MPEG-2 і ITU-T H.263. 10 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 Хоч не показано на ФІГ. 4, в деяких аспектах кодер 20 відео і декодер 30 відео можуть бути об'єднані з кодером і декодером аудіо і можуть включати в себе відповідні блоки MUX-DEMUX або інше апаратне і програмне забезпечення, щоб виконувати кодування як аудіо, так і відео в загальному потоці даних або окремих потоках даних. Якщо застосовно, в деяких прикладах блоки MUX-DEMUX можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Кодер 20 відео і декодер 30 відео можуть бути реалізовані як будь-яка з множини придатних схем кодера, наприклад один або більше мікропроцесорів, цифрові сигнальні процесори (процесори DSP), спеціалізовані інтегральні схеми (схеми ASIC), програмовані користувачем вентильні матриці (матриці FPGA), дискретна логіка, програмне забезпечення, апаратне забезпечення, програмно-апаратне забезпечення або будь-які їх комбінації. Коли способи реалізовані частково в програмному забезпеченні, пристрій може зберегти команди для програмного забезпечення у придатному постійному зчитуваному комп'ютером носії і виконувати команди в апаратному забезпеченні, використовуючи один або більше процесорів для виконання способів даного розкриття. Кожний з кодера 20 відео і декодера 30 відео може бути включений в один або більше кодерів або декодерів, будь-який з яких може бути інтегрований як частина об'єднаного кодера/декодера (CODEC) у відповідному пристрої. Кодер 20 відео може реалізувати будь-які або всі зі способів даного розкриття, щоб поліпшити кодування коефіцієнтів перетворення в процесі кодування відео. Аналогічно, декодер 30 відео може реалізувати будь-які або всі з цих способів, щоб поліпшити декодування коефіцієнтів перетворення в процесі кодування відео. Відеокодер, як описано в даному розкритті, може належати до кодера відео або декодера відео. Аналогічно, блок кодування відео може належати до кодера відео або декодера відео. Аналогічно, кодування відео може належати до кодування відео або декодування відео. У одному прикладі розкриття кодер відео (такий, як кодер 20 відео або декодер 30 відео) може бути сконфігурований для кодування множини коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео. Кодер відео може бути сконфігурований для кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення відповідно до порядку сканування, і кодування інформації, що вказує рівні множини коефіцієнтів перетворення відповідно до порядку сканування. У іншому прикладі розкриття кодер відео (такий, як кодер 20 відео або декодер 30 відео) може бути сконфігурований для кодування множини коефіцієнтів перетворення, асоційованих із залишковими відеоданими в процесі кодування відео. Кодер відео може бути сконфігурований для кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення, зі скануванням, що здійснюється в зворотному напрямі сканування від коефіцієнтів більш високої частоти в блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в блоці коефіцієнтів перетворення. У іншому прикладі розкриття кодер відео (такий, як кодер 20 відео або декодер 30 відео) може бути сконфігурований для кодування множини коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео. Кодер відео може бути сконфігурований для компонування блока коефіцієнтів перетворення в один або більше піднаборів коефіцієнтів перетворення на основі порядку сканування, кодування першої частини рівнів коефіцієнтів перетворення в кожному піднаборі, причому перша частина рівнів включає в себе щонайменше значущість коефіцієнтів перетворення в кожному піднаборі, і кодування другої частини рівнів коефіцієнтів перетворення в кожному піднаборі. У іншому прикладі розкриття кодер відео (такий, як кодер 20 відео або декодер 30 відео) може бути сконфігурований для кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення відповідно до порядку сканування, розділення закодованої інформації на щонайменше першу область і другу область, статистичного кодування закодованої інформації в першій області відповідно до першого набору контекстів, використовуючи критерії виведення контексту, і статистичного кодування закодованої інформації у другій області згідно з другим набором контекстів, використовуючи ті ж критерії виведення контексту, що і в першій області. ФІГ. 5 є блок-схемою, що ілюструє приклад кодера 20 відео, який може використовувати способи для кодування коефіцієнтів перетворення, як описано в даному розкритті. Кодер 20 відео буде описаний в контексті кодування HEVC з метою ілюстрації, а не обмеження, даного розкриття відносно інших стандартів або способів кодування, які можуть вимагати сканування коефіцієнтів перетворення. Кодер 20 відео може виконувати внутрішнє (інтра) і зовнішнє (інтер) кодування блоків CU у відеокадрах. Внутрішнє кодування основане на просторовому прогнозуванні, щоб зменшити або видалити просторову надмірність у відео в заданому кадрі 11 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 відео. Зовнішнє кодування основане на часовому прогнозуванні, щоб зменшити або видалити часову надмірність між поточним кадром і раніше закодованими кадрами відеопослідовності. Внутрішній режим (I-режим) може належати до будь-якого з декількох режимів, основаних на просторовому стисненні відео. Зовнішні режими, такі як однонаправлене прогнозування (Ррежим) або двонаправлене прогнозування (В-режим), можуть належати до будь-якого з декількох режимів, основаних на часовому стисненні відео. Як показано на ФІГ. 5, кодер 20 відео приймає поточний блок відео в кадрі відео, який повинен бути закодований. У прикладі згідно з ФІГ. 5 кодер 20 відео включає в себе модуль 44 компенсації руху, модуль 42 оцінки руху, модуль 46 внутрішнього прогнозування, буфер 64 опорних кадрів, суматор 50, модуль 52 перетворення, модуль 54 квантування і модуль 56 статистичного кодування. Модуль 52 перетворення, ілюстрований на ФІГ. 5, є модулем, який застосовує фактичне перетворення до блока залишкових даних, і не повинен бути переплутаний з блоком коефіцієнтів перетворення, який також може називатися блоком перетворення (TU) CU. Для відновлення блока відео кодер 20 відео також включає в себе модуль 58 зворотного квантування, модуль 60 зворотного перетворення і суматор 62. Фільтр видалення блочності (не показаний на ФІГ. 5) також може бути включений, щоб фільтрувати границі блока для видалення артефактів блочності з відновленого відео. При бажанні фільтр видалення блочності звичайно буде фільтрувати вихідний сигнал суматора 62. Під час процесу кодування кодер 20 відео приймає кадр або вирізку відео, які повинні бути закодовані. Кадр або вирізка можуть бути розділені на множинні блоки відео, наприклад найбільші блоки кодування (блоки LCU). Модуль 42 оцінки руху і модуль 44 компенсації руху виконують кодування із зовнішнім прогнозуванням прийнятого блока відео відносно одного або більше блоків в одному або більше опорних кадрах, щоб забезпечити часове стиснення. Модуль 46 внутрішнього прогнозування може виконати кодування з внутрішньому прогнозуванням прийнятого блока відео відносно одного або більше сусідніх блоків в одних і тих же кадрі або вирізці як блока, який повинен бути закодований, щоб забезпечити просторове стиснення. Модуль 40 вибору режиму може вибрати один з режимів кодування, внутрішній або зовнішній, наприклад, на основі результатів помилки (тобто спотворення) для кожного режиму, і видати одержаний в результаті внутрішньо- або зовнішньокодований блок до суматора 50 для генерування залишкових даних блока і суматора 62 для відновлення закодованого блока, щоб використовувати в опорному кадрі. Деякі кадри відео можуть бути позначені як I-кадри, де всі блоки в I-кадрі закодовані в режимі внутрішнього прогнозування. У деяких випадках модуль 46 внутрішнього прогнозування може виконувати кодування з внутрішнім прогнозуванням блока в Р- або В-кадрі, наприклад, коли пошук руху, виконаний модулем 42 оцінки руху, не приводить до достатнього прогнозування блока. Модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути високоінтегровані, але ілюструються окремо в концептуальних цілях. Оцінка руху є процесом генерування векторів руху, які оцінюють рух для блоків відео. Вектор руху, наприклад, може указати зміщення блока прогнозування в поточному кадрі відносно опорної вибірки опорного кадру. Опорна вибірка може бути блоком, який, як вважається, точно відповідає частині CU, який включає в себе PU, що кодується в термінах пікселної різниці, яка може бути визначена сумою абсолютної різниці (SAD), сумою квадратичної різниці (SSD) або іншими метриками різниці. Компенсація руху, виконана модулем 44 компенсації руху, може включати вибірку або генерування значень для блока прогнозування на основі вектора руху, визначеного за допомогою оцінки руху. Знов, модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути функціонально об'єднані в деяких прикладах. Модуль 42 оцінки руху обчислює вектор руху для блока прогнозування зовнішньокодованого кадру за допомогою порівняння блока прогнозування з опорними вибірками опорного кадру, збереженого в буфері 64 опорних кадрів. У деяких прикладах кодер 20 відео може обчислювати значення для субцілочислових пікселних позицій опорних кадрів, збережених в буфері 64 опорних кадрів. Наприклад, кодер 20 відео може обчислювати значення одночетвертних пікселних позицій, однієї восьмої від пікселних позицій або інших фракційних пікселних позицій опорного кадру. Тому, модуль 42 оцінки руху може виконувати пошук руху відносно повних пікселних позицій і фракційних пікселних позицій і сформувати вектор руху з фракційною пікселнию точністю. Модуль 42 оцінки руху відправляє обчислений вектор руху на модуль 56 статистичного кодування і модуль 44 компенсації руху. Частина опорного кадру, ідентифікована вектором руху, може називатися опорною вибіркою. Модуль 44 компенсації руху може обчислювати значення прогнозування для блока прогнозування поточного CU, наприклад, за допомогою витягання опорної вибірки, ідентифікованої вектором руху для PU. 12 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 Модуль 46 внутрішнього прогнозування може кодувати з внутрішнім прогнозуванням прийнятий блок, як альтернатива зовнішньому прогнозуванню, виконуваному модулем 42 оцінки руху і модулем 44 компенсації руху. Модуль 46 внутрішнього прогнозування може кодувати прийнятий блок відносно сусідніх раніше закодованих блоків, наприклад блоків вище, вище і праворуч, вище і ліворуч або ліворуч від поточного блока, приймаючи порядок кодування зліва направо, знизу вгору для блоків. Модуль 46 внутрішнього прогнозування може бути сконфігурований з множиною різних режимів внутрішнього прогнозування. Наприклад, модуль 46 внутрішнього прогнозування може бути сконфігурований з деякою кількістю направлених режимів прогнозування, наприклад 33 направленими режимами прогнозування, на основі розміру кодованого CU. Модуль 46 внутрішнього прогнозування може вибрати режим внутрішнього прогнозування, наприклад, за допомогою обчислення значення помилки для різних режимів внутрішнього прогнозування і вибору режиму, який забезпечує найбільш низьке значення помилки. Направлені режими прогнозування можуть включати в себе функції для комбінування значень просторово сусідніх пікселів і застосування комбінованих значень до однієї або більше пікселних позицій в PU. Як тільки значення для всіх пікселних позицій в PU будуть обчислені, модуль 46 внутрішнього прогнозування може обчислювати значення помилки для режиму прогнозування на основі пікселних різниць між PU і прийнятим блоком, який повинен бути закодований. Модуль 46 внутрішнього прогнозування може продовжити перевіряти режими внутрішнього прогнозування доти, поки не буде виявлений режим внутрішнього прогнозування, який забезпечує прийнятне значення помилки. Модуль 46 внутрішнього прогнозування може потім відправити PU в суматор 50. Кодер 20 відео формує залишковий блок за допомогою віднімання даних прогнозування, обчислених модулем 44 компенсації руху або модулем 46 внутрішнього прогнозування, із закодованого оригінального блока відео. Суматор 50 представляє компонент або компоненти, які виконують цю операцію віднімання. Залишковий блок може відповідати двовимірній матриці значень пікселної різниці, де кількість значень в залишковому блоці є тією ж, що і кількість пікселів в PU, відповідному залишковому блоку. Значення в залишковому блоці можуть відповідати різницям, тобто помилці, між значеннями спільно розташованих пікселів в PU і в оригінальному блоці, який повинен бути закодований. Різниці можуть бути різницями в кольоровості або яскравості залежно від типу блока, який кодується. Модуль 52 перетворення може формувати один або більше блоків перетворення (блоків TU) із залишкового блока. Модуль 52 перетворення застосовує перетворення, таке як дискретне косинусне перетворення (DCT), направлене перетворення або концептуально аналогічне перетворення, до TU, формуючи блок відео, що містить коефіцієнти перетворення. Модуль 52 перетворення може відправити одержані в результаті коефіцієнти перетворення на модуль 54 квантування. Модуль 54 квантування може потім квантувати коефіцієнти перетворення. Модуль 56 статистичного кодування може потім виконати сканування квантованих коефіцієнтів перетворення в матриці відповідно до заданого порядку сканування. Дане розкриття описує модуль 56 статистичного кодування як такий, що виконує сканування. Однак, повинно бути зрозуміло, що в інших прикладах інші блоки обробки, такі як модуль 54 квантування, можуть виконувати сканування. Як згадано вище, сканування коефіцієнтів перетворення може включати в себе два сканування. Одне сканування ідентифікує, які з коефіцієнтів є значущими (тобто ненульовими), щоб сформувати відображення значущості, і інше сканування кодує рівні коефіцієнтів перетворення. У одному прикладі дане розкриття пропонує, щоб порядок сканування, використовуваний для кодування рівнів коефіцієнтів в блоці, був таким же, що і порядок сканування для кодування значущих коефіцієнтів у відображенні значущості для цього блока. У HEVC блок може бути блоком перетворення. Використовуваний в даному описі термін "порядок сканування" може стосуватися будь-якого напряму сканування і/або шаблона сканування. Як такі, сканування для відображення значущості і рівнів коефіцієнтів можуть бути одними і тими ж в шаблоні сканування і/або напрямі сканування. Таким чином, як один приклад, якщо порядок сканування, використовуваний для формування відображення значущості, є шаблоном горизонтального сканування в прямому напрямі, то порядок сканування для рівнів коефіцієнтів також повинен бути шаблоном горизонтального сканування в прямому напрямі. Аналогічно, як інший приклад, якщо порядок сканування для відображення значущості є шаблоном вертикального сканування в зворотному напрямі, то порядок сканування для рівнів коефіцієнтів також повинен бути шаблоном вертикального сканування в зворотному напрямі. Те ж саме можна застосовувати для діагонального, зигзагоподібного або інших шаблонів сканування. 13 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 ФІГ. 6 показує приклади зворотних порядків сканування для блока коефіцієнтів перетворення, тобто блока перетворення. Блок перетворення може бути сформований, використовуючи перетворення, таке як, наприклад, дискретне косинусне перетворення (DCT). Повинно бути зазначено, що кожний із зворотного діагонального шаблона 9, зворотного зигзагоподібного шаблона 29, зворотного вертикального шаблона 31 і зворотного горизонтального шаблона 33 здійснюється від коефіцієнтів більш високої частоти в правому нижньому кутку блока перетворення до коефіцієнтів більш низької частоти в лівому верхньому кутку блока перетворення. Отже, один аспект розкриття представляє уніфікований порядок сканування для кодування відображення значущості і кодування рівнів коефіцієнтів. Запропонований спосіб застосовує порядок сканування, використовуваний для відображення значущості, до порядку сканування, використовуваного для кодування рівня коефіцієнтів. Загалом, горизонтальний, вертикальний і діагональний шаблони сканування були показані, щоб ефективно працювати, таким чином, зменшуючи потребу в додаткових шаблонах сканування. Однак, загальні способи даного розкриття застосовуються для використання з будь-яким шаблоном сканування. Відповідно до іншого аспекту, дане розкриття пропонує, щоб сканування значущості було виконане як зворотне сканування, від останнього значущого коефіцієнта в блоці перетворення до першого коефіцієнта (тобто коефіцієнта DC) в блоці перетворення. Приклади зворотних порядків сканування показані на ФІГ. 6. Зокрема, сканування значущості здійснюється від останнього значущого коефіцієнта в позиції більш високої частоти до значущих коефіцієнтів в позиціях більш низької частоти, і, зрештою, до позиції коефіцієнта DC. Щоб полегшити зворотне сканування, можуть бути використані способи для ідентифікації останнього значущого коефіцієнта. Процес для ідентифікації останнього значущого коефіцієнта описаний в Sole J., Joshi R., Chong I. S., Coban M., Karczewicz M. "Parallel Context Processing for the significance map in high coding efficiency" JCTVC-D262, 4th Meeting JCT-VC, Daegu, KR, January 2011, і в американській попередній заявці на патент № 61/419,740, поданій 3 грудня 2010, в Joel Sole Rojals і ін., названій "Encoding of the position of the last significant transform coefficient in video coding". Як тільки ідентифікований останній значущий коефіцієнт в блоці, потім може бути застосований зворотний порядок сканування як для відображення значущості, так і для рівня коефіцієнтів. Дане розкриття також пропонує, щоб сканування значущості і сканування рівня коефіцієнтів не були зворотними і прямими, відповідно, але, замість цього, мали один і той же напрям сканування і, більш детально, тільки один напрям в блоці. Зокрема, запропоновано, щоб сканування значущості і сканування рівня коефіцієнтів використовували зворотний порядок сканування від останнього значущого коефіцієнта в блоці перетворення до першого коефіцієнта. Отже, сканування значущості здійснюється в зворотному напрямі (зворотне сканування відносно на даний час пропонованого сканування для HEVC) від останнього значущого коефіцієнта до першого коефіцієнта (коефіцієнта DC). Цей аспект розкриття представляє уніфікований однонаправлений порядок сканування для кодування відображення значущості і кодування рівнів коефіцієнтів. Зокрема, цей уніфікований однонаправлений порядок сканування може бути уніфікованим зворотним порядком сканування. Порядки сканування для сканувань значущості і рівня коефіцієнтів відповідно до уніфікованого шаблона зворотного сканування можуть бути зворотним діагональним, зворотним зигзагоподібним, зворотним горизонтальним або зворотним вертикальним, як показано на ФІГ. 6. Однак, може бути використаний будь-який шаблон сканування. Замість того, щоб визначити набори коефіцієнтів в двовимірних субблоках, як показано на ФІГ. 3, для мети виведення контексту CABAC, дане розкриття пропонує визначити набори коефіцієнтів як декілька коефіцієнтів, які послідовно скануються відповідно до порядку сканування. Зокрема, кожний набір коефіцієнтів може містити послідовні коефіцієнти в порядку сканування по всьому блоку. Будь-який розмір набору може бути розглянутий, хоч було виявлено, що розмір з 16 коефіцієнтів в наборі сканування працював ефективно. Розмір набору може бути фіксованим або адаптивним. Це визначення забезпечує набори, які повинні бути 2Dблоками (якщо використовується спосіб сканування субблока), прямокутниками (якщо використовуються горизонтальне або вертикальне сканування) або діагональними формами (якщо використовуються зигзагоподібне або діагональне сканування). Набори діагонально сформованих коефіцієнтів можуть бути частиною діагональної форми, послідовних діагональних форм або частин послідовних діагональних форм. ФІГ. 7-9 показують приклади коефіцієнтів, скомпонованих в піднаборах з 16 коефіцієнтів, відповідно до конкретних порядків сканування поза компонуванням в фіксованих блоках 4×4. ФІГ. 7 зображує піднабір 51 з 16 коефіцієнтів, які складаються з перших 16 коефіцієнтів в 14 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 зворотному діагональному порядку сканування. Наступний піднабір в цьому прикладі буде просто складатися з наступних 16 послідовних коефіцієнтів вздовж зворотного діагонального порядку сканування. Аналогічно, ФІГ. 8 зображує піднабір 53 з 16 коефіцієнтів для перших 16 коефіцієнтів в зворотному горизонтальному порядку сканування. ФІГ. 9 зображує піднабір 55 з 16 коефіцієнтів для перших 16 коефіцієнтів в зворотному вертикальному порядку сканування. Цей спосіб сумісний з порядком сканування рівнів коефіцієнтів, який є тим же, що і порядок сканування для відображення значущості. У цьому випадку немає необхідності у відмінному (і іноді трудомісткому) порядку сканування рівнів коефіцієнтів, таких, як показані на ФІГ. 3. Сканування рівнів коефіцієнтів може бути сформоване, подібно скануванню відображення значущості, на даний час запропонованому для HEVC, як пряме сканування, яке здійснюється від положення останнього значущого коефіцієнта в блоці перетворення до позиції коефіцієнта DC. Як на даний час запропоновано в HEVC, для статистичного кодування, що використовує CABAC, коефіцієнти перетворення кодуються наступним чином. По-перше, є один прохід (в порядку сканування відображення значущості) в повному блоці перетворення для кодування відображення значущості. Потім, є три проходи (в порядку сканування рівнів коефіцієнтів) для кодування контейнера 1 рівня (1-й прохід), іншої частини рівня коефіцієнтів (2-й прохід) і знака рівня коефіцієнтів (3-й прохід). Ці три проходи для кодування рівнів коефіцієнтів не робляться для повного блока перетворення. Замість цього кожний прохід виконується в субблоках 4×4, як показано на ФІГ. 3. Коли три проходи були закінчені в одному субблоці, наступний субблок обробляється за допомогою послідовного виконання тих же трьох проходів кодування. Цей підхід полегшує паралелізацію кодування. Як описано вище, дане розкриття пропонує сканування коефіцієнтів перетворення більш узгодженим чином так, щоб порядок сканування для рівнів коефіцієнтів був тим же, що і порядок сканування значущих коефіцієнтів, щоб сформувати відображення значущості. На доповнення запропоновано, щоб сканування рівня коефіцієнтів і значущих коефіцієнтів були виконані в зворотному напрямі, який здійснюється від останнього значущого коефіцієнта в блоці до першого коефіцієнта (компонента DC) в блоці. Це зворотне сканування є протилежним скануванню, використовуваному для значущих коефіцієнтів згідно з HEVC, як запропоновано на даний час. Як описано раніше з посиланнями на ФІГ. 7-9, дане розкриття додатково пропонує, щоб контексти для рівнів коефіцієнтів (включаючи відображення значущості) були розділені на піднабори. Таким чином, контекст визначений для кожного піднабору коефіцієнтів. Отже, в цьому прикладі один і той же контекст не обов'язково використовується для всього сканування коефіцієнтів. Замість цього різні піднабори коефіцієнтів в блоці перетворення можуть мати різні контексти, які індивідуально визначені для кожного піднабору. Кожний піднабір може містити одновимірний масив послідовно сканованих коефіцієнтів в порядку сканування. Тому, сканування рівня коефіцієнтів йде від останнього значущого коефіцієнта до першого коефіцієнта (компонента DC), де сканування концептуально фрагментується на різні піднабори послідовно сканованих коефіцієнтів відповідно до порядку сканування. Наприклад, кожний піднабір може включати в себе n послідовно сканованих коефіцієнтів для конкретного порядку сканування. Групування коефіцієнтів в піднаборах відповідно до їх порядку сканування може забезпечити кращу кореляцію між коефіцієнтами і, таким чином, більш ефективне статистичне кодування. Дане розкриття додатково пропонує збільшити розпаралелювання основаного на CABAC статистичного кодування коефіцієнтів перетворення за допомогою розширення концепції декількох проходів рівня коефіцієнтів для включення додаткового проходу для відображення значущості. Таким чином, приклад з чотирма проходами може включати в себе: (1) кодування значень прапора значущих коефіцієнтів для коефіцієнтів перетворення, наприклад, щоб сформувати відображення значущості, (2) кодування контейнера 1 значень рівня для коефіцієнтів перетворення, (3) кодування контейнерів, що залишилися, значень рівня коефіцієнтів, і (4) кодування знаків рівнів коефіцієнтів, всіх в одному і тому ж порядку сканування. Використовуючи способи, описані в даному розкритті, може бути полегшене кодування з чотирма проходами, викладене вище. Таким чином, сканування значущих коефіцієнтів і рівнів для коефіцієнтів перетворення в одному і тому ж порядку сканування, де порядок сканування здійснюється в зворотному напрямі від високочастотного коефіцієнта до низькочастотного коефіцієнта, підтримує роботу способу кодування з декількома проходами, описаного вище. У іншому прикладі п'ять способів сканування проходу можуть включати в себе: (1) кодування значень прапора значущого коефіцієнта для коефіцієнтів перетворення, наприклад, щоб 15 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 сформувати відображення значущості, (2) кодування контейнера 1 значень рівня для коефіцієнтів перетворення, (3) кодування контейнера 2 значень рівня для коефіцієнтів перетворення, (4) кодування знаків рівнів коефіцієнтів (наприклад, в режимі обходу), і (5) кодування контейнерів, що залишилися, значень рівня коефіцієнтів (наприклад, в режимі обходу), причому всі проходи використовують один і той же порядок сканування. Приклад з меншою кількістю проходів може бути також використаний. Наприклад, двопрохідне сканування, де рівень і інформація про знак обробляються паралельно, може включати в себе: (1) кодування регулярних контейнерів проходу в проході (наприклад, значущість, рівень контейнера 1 і рівень контейнера 2), і (2) кодування контейнерів обходу в іншому (наприклад, рівні, що залишилися і знак, що залишилися), причому кожний прохід використовує один і той же порядок сканування. Регулярні контейнери є контейнерами, закодованими за допомогою CABAC, використовуючи оновлений контекст, визначений критеріями виведення контексту. Наприклад, як буде пояснено більш детально нижче, критерії виведення контексту можуть включати в себе закодовану інформацію про рівень казуального (випадкового) сусіднього коефіцієнта відносно поточного коефіцієнта перетворення. Контейнери обходу є контейнерами, закодованими з допомогою CABAC, що має фіксований контекст. Приклади декількох проходів сканування, описаних вище, можуть бути узагальнені як такі, що включають в себе перший прохід сканування першої частини рівнів коефіцієнтів, причому перша частина включає в себе прохід значущості, і другий прохід сканування другої частини рівнів коефіцієнтів. У кожному з прикладів, представлених вище, проходи можуть бути виконані послідовно в кожному піднаборі. Хоч використання одновимірних піднаборів, що містять послідовно скановані коефіцієнти, може бути бажаним, декілька способів проходу також можуть застосовуватися до субблоків, таких як субблоки 4×4. Приклад процесів з двома проходами і з чотирма проходами для послідовно сканованих піднаборів викладений більш детально нижче. У спрощеному процесі з двома проходами для кожного піднабору блока перетворення перший прохід кодує значущість коефіцієнтів в піднаборі, відповідно до порядку сканування, і другий прохід кодує рівень коефіцієнтів з коефіцієнтів в піднаборі, відповідно до того ж порядку сканування. Порядок сканування може бути охарактеризований напрямом сканування (прямим або зворотним) і шаблоном сканування (наприклад, горизонтальним, вертикальним або діагональним). Алгоритм може бути більш придатним для паралельної обробки, якщо обидва проходи в кожному піднаборі відповідають одному і тому ж порядку сканування, як описано вище. У більш вдосконаленому процесі з чотирма проходами для кожного піднабору блока перетворення перший прохід кодує значущість коефіцієнтів в піднаборі, другий прохід кодує контейнер 1 рівня коефіцієнтів з коефіцієнтів в піднаборі, третій прохід кодує контейнери, що залишилися, рівня коефіцієнтів з коефіцієнтів в піднаборі, і четвертий прохід кодує знак рівня коефіцієнтів з коефіцієнтів в піднаборі. Знов, щоб бути більш придатними для паралельної обробки, всі проходи в кожному піднаборі повинні мати один і той же порядок сканування. Як описано вище, порядок сканування із зворотним напрямом був показаний як ефективно працюючий. Повинно бути зазначено, що четвертий прохід (тобто кодування знака рівнів коефіцієнтів) може бути зроблений безпосередньо після першого проходу (тобто кодування відображення значущості) або безпосередньо перед значеннями, що залишилися, проходу рівня коефіцієнтів. Для деяких розмірів перетворення піднабір може бути цілим блоком перетворення. У цьому випадку є єдиний піднабір, відповідний всім значущим коефіцієнтам для всього блока перетворення, і сканування значущості і сканування рівня здійснюються в одному і тому ж порядку сканування. У цьому випадку замість обмеженого числа n (наприклад, n=16) коефіцієнтів в піднаборі, піднабір може бути єдиним піднабором для блока перетворення, причому єдиний піднабір включає в себе всі значущі коефіцієнти. Посилаючись на ФІГ. 5, як тільки коефіцієнти перетворення скановані, модуль 56 статистичного кодування може застосувати статистичне кодування, таке як CAVLC або CABAC, до цих коефіцієнтів. На доповнення, модуль 56 статистичного кодування може кодувати інформацію про вектор руху (MV) і будь-який з множини елементів синтаксису, корисних при декодуванні відеоданих в декодері 30 відео. Елементи синтаксису можуть включати в себе відображення значущості з прапорами значущих коефіцієнтів, які вказують, чи є значущими конкретні коефіцієнти (наприклад, ненульові), і прапор останнього значущого коефіцієнта, який вказує, чи є конкретний коефіцієнт останнім значущим коефіцієнтом. Декодер 30 відео може використовувати ці елементи синтаксису, щоб відновити закодовані відеодані. Після статистичного кодування за допомогою модуля 56 статистичного кодування одержане в 16 UA 109479 C2 5 10 15 20 25 30 35 результаті закодоване відео може бути передане на інший пристрій, такий як декодер 30 відео, або заархівоване для більш пізньої передачі або пошуку. Для статистичного кодування елементів синтаксису модуль 56 статистичного кодування може виконувати CABAC і вибрати моделі контексту на основі, наприклад, кількості значущих коефіцієнтів в раніше сканованих N-коефіцієнтах, де N є цілочисловим значенням, яке може бути пов'язане з розміром сканованого блока. Модуль 56 статистичного кодування може також вибрати модель контексту на основі режиму прогнозування, використовуваного для обчислення залишкових даних, які були перетворені в блок коефіцієнтів перетворення, і типу перетворення, використовуваного для перетворення залишкових даних в блок коефіцієнтів перетворення. Коли відповідні дані прогнозування були прогнозовані, використовуючи режим внутрішнього прогнозування, модуль 56 статистичного кодування може додатково основувати вибір моделі контексту на напрямі режиму внутрішнього прогнозування. Додатково, відповідно до іншого аспекту даного розкриття, запропоновано, щоб контексти для CABAC були розділені на піднабори коефіцієнтів (наприклад, піднабори, показані на ФІГ. 79). Запропоновано, щоб кожний піднабір складався з послідовних коефіцієнтів в порядку сканування по всьому блоку. Будь-який розмір піднаборів може бути розглянутий, хоч розмір 16 коефіцієнтів в піднаборі сканування вважався працюючим ефективно. У цьому прикладі піднабір може бути 16 послідовними коефіцієнтами в порядку сканування, який може бути в будь-якому шаблоні сканування, включаючи субблоковий, діагональний, зигзагоподібний, горизонтальний і вертикальний шаблони сканування. Відповідно до цієї пропозиції сканування рівня коефіцієнтів здійснюється від останнього значущого коефіцієнта в блоці. Тому сканування рівня коефіцієнтів йде від останнього значущого коефіцієнта до першого коефіцієнта (компонента DC) в блоці, де сканування концептуально фрагментоване в різних піднаборах коефіцієнтів, щоб одержати контексти для застосування. Наприклад, сканування організоване в піднаборах з n послідовних коефіцієнтів в порядку сканування. Останнім значущим коефіцієнтом є перший значущий коефіцієнт, що зустрічається в зворотному скануванні від коефіцієнта найбільш високої частоти блока (що звичайно вважається близьким до правого нижнього кута блока) до коефіцієнта DC блока (лівий верхній кут блока). У іншому аспекті розкриття запропоновано, щоб критерії виведення контексту CABAC були узгоджені (гармонізовані) для всіх розмірів блока. Іншими словами, замість того, щоб мати різні виведення контексту на основі розміру блока, як розглянуто вище, кожний розмір блока буде покладатися на одне і те ж виведення контекстів CABAC. Таким чином, немає необхідності брати до уваги конкретний розмір блока, щоб одержати контекст CABAC для блока. Виведення контексту є одним і тим же як для кодування значущості, так і для кодування рівня коефіцієнтів. Також запропоновано, щоб набори контексту CABAC залежали від того, чи є піднабір піднабором 0 (визначеним як піднабір з коефіцієнтами для найнижчих частот, тобто, який містить коефіцієнт DC і суміжні низькочастотні коефіцієнти), чи ні (тобто критерії виведення контексту). Див. Таблиці 3a і 3b, представлені нижче. Таблиця 3а Набір контекстів 0 1 2 3 4 5 Найнижча частота Найнижча частота Найнижча частота Найвища частота Найвища частота Найвища частота 0 більше ніж 1 в попередньому піднаборі 1 більше ніж 1 в попередньому піднаборі >1 більше ніж 1 в попередньому піднаборі 0 більше ніж 1 в попередньому піднаборі 1 більше ніж 1 в попередньому піднаборі >1 більше ніж 1 в попередньому піднаборі 40 45 Для порівняння з Таблицею 2. Є залежність від піднабору, чи є він піднабором 0 (найнижчі частоти), чи ні. Для Таблиці 3a, представленої вище, набори 0-2 моделей контексту використовуються для піднаборів сканування найнижчої частоти (тобто набір n послідовних коефіцієнтів), якщо, відповідно, є нуль коефіцієнтів більше ніж одиниця в раніше закодованому піднаборі, є один коефіцієнт більше ніж одиниця в раніше закодованому піднаборі або є більше ніж один коефіцієнт більше ніж одиниця в раніше закодованому піднаборі. Набори 3-5 моделей контексту використовуються для всіх піднаборів, більш високих, ніж піднабір найнижчої частоти, якщо, відповідно, є нуль коефіцієнтів більше ніж одиниця в раніше закодованому піднаборі, є один 17 UA 109479 C2 коефіцієнт більше ніж одиниця в раніше закодованому піднаборі або є більше ніж один коефіцієнт більше ніж одиниця в раніше закодованому піднаборі. Таблиця 3b Набір контекстів 0 1 2 3 4 5 5 10 Найнижча частота Найнижча частота Найнижча частота Найвища частота Найвища частота Найвища частота 0 більше ніж 1 в попередньому піднаборі 1-3 більше ніж 1 в попередньому піднаборі >3 більше ніж 1 в попередньому піднаборі 0 більше ніж 1 в попередньому піднаборі 1-3 більше ніж 1 в попередньому піднаборі >3 більше ніж 1 в попередньому піднаборі Таблиця 3b показує таблицю набору контекстів, яка показала хорошу продуктивність, оскільки вона враховує більш точну кількість числа більше ніж одиниця коефіцієнтів в попередньому піднаборі. Таблиця 3b може бути використана як альтернатива Таблиці 3a, представленій вище. Таблиця 3c показує спрощену таблицю набору контекстів з критеріями виведення контексту, яка також може бути альтернативно використана. Таблиця 3c Набір контекстів 0 1 2 3 15 20 25 30 35 40 Найнижча частота Найнижча частота Найвища частота Найвища частота 0 більше ніж 1 в попередньому піднаборі 1 більше ніж 1 в попередньому піднаборі 0 більше ніж 1 в попередньому піднаборі 1 більше ніж 1 в попередньому піднаборі На доповнення піднабір, що містить останній значущий коефіцієнт в блоці перетворення, може використати унікальний набір контекстів. Дане розкриття також пропонує, щоб контекст для піднаборів все ще залежав від кількості коефіцієнтів більше ніж 1 в попередніх піднаборах. Наприклад, якщо кількість коефіцієнтів в попередніх піднаборах є ковзним вікном, нехай ця кількість буде uiNumOne. Як тільки це значення буде перевірене, щоб розв'язати контекст для поточного набору субсканування, тоді це значення не встановлюється в нуль. Замість цього це значення нормалізується (наприклад, використовується uiNumOne=uiNumOne/4, що еквівалентно uiNumOne >>=2 або uiNumOne=uiNumOne/2, що еквівалентно uiNumOne >>=1). Виконуючи це, значення піднаборів раніше безпосередньо попередніх піднаборів можуть бути все ще розглянуті, але беручи до уваги меншу вагу в розв'язанні контексту CABAC для на даний час закодованого піднабору. Зокрема, розв'язання контексту CABAC для заданого піднабору бере до уваги не тільки кількість коефіцієнтів більше ніж одиниця в безпосередньо попередньому піднаборі, але також і зважену кількість коефіцієнтів більше ніж одиниця в раніше закодованих піднаборах. Додатково, набір контекстів може залежати від наступного: (1) кількості значущих коефіцієнтів у на даний час сканованому піднаборі, (2) чи є поточний піднабір останнім піднабором зі значущим коефіцієнтом (тобто використовуючи зворотний порядок сканування, це стосується того, чи є піднабір першим сканованим для рівнів коефіцієнтів, чи ні). Додатково, модель контексту для рівня коефіцієнтів може залежати від того, чи є поточний коефіцієнт останнім коефіцієнтом. Підхід високоадаптивного вибору контексту був раніше запропонований для кодування відображення значущості блоків 16×16 і 32×32 коефіцієнтів перетворення в HEVC. Повинно бути зазначено, що цей підхід вибору контексту може бути розширений до всіх розмірів блока. Як показано на ФІГ. 10, цей підхід ділить блок 16×16 на чотири області, де кожний коефіцієнт в області 41 більш низької частоти (ці чотири коефіцієнти у верхньому лівому кутку в координатних позиціях х, у [0,0], [0,1], [1,0], [1,1] в прикладі блока 16×16, де [0,0] вказує лівий верхній кут, коефіцієнт DC) має свій власний контекст, коефіцієнти у верхній області 37 (коефіцієнти у верхньому рядку з координатних позицій х, у [2,0]-[15,0] в прикладі блока 16×16) спільно використовують 3 контексти, коефіцієнти в лівій області 35 (коефіцієнти в лівому стовпці 18 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 з координатних позицій х, у [0,2]-[0,15] в прикладі блока 16×16) спільно використовують ще 3 контексти, і коефіцієнти в області 39, що залишилася (коефіцієнти, що залишилися, в блоці 16×16), спільно використовують 5 контекстів. Вибір контексту для коефіцієнта X перетворення в області 39, як приклад, оснований на сумі значущості максимум цих 5 коефіцієнтів перетворення В, Е, F, Н і I. Оскільки X не залежить від інших позицій в одній і тій же діагональній лінії X вздовж напряму сканування (в цьому прикладі зигзагоподібний або діагональний шаблон сканування), контекст значущості коефіцієнтів перетворення вздовж діагональної лінії в порядку сканування може бути обчислений паралельно від попередніх діагональних ліній в порядку сканування. Запропоновані контексти для відображення значущості, як показано на ФІГ. 10, дійсні тільки тоді, коли порядок сканування є прямим, оскільки контекст стає неказуальним в декодері, якщо використовується зворотне сканування. Тобто декодер ще не декодував коефіцієнти В, Е, F, Н і I, як показано на ФІГ. 10, якщо використовується зворотне сканування. У результаті бітовий потік не є декодованим. Однак, дане розкриття пропонує використання сканування в зворотному напрямі. Таким чином, відображення значущості має відповідну кореляцію серед коефіцієнтів, коли порядок сканування знаходиться в зворотному напрямі, як показано на ФІГ. 6. Тому, використання зворотного сканування для відображення значущості, як описано вище, пропонує бажану ефективність кодування. Крім того, використання зворотного сканування для відображення значущості служить для узгодження сканування, використовуваного для кодування рівня коефіцієнтів і відображення значущості. Щоб підтримати зворотне сканування значущих коефіцієнтів, контексти повинні бути змінені таким чином, щоб вони були сумісні із зворотним скануванням. Запропоновано, щоб кодування значущих коефіцієнтів використовувало контексти, які є казуальними відносно зворотного сканування. Дане розкриття додатково пропонує, в одному прикладі, спосіб для кодування відображення значущості, який використовує контексти, зображені на ФІГ. 11. Кожний коефіцієнт в області 43 більш низької частоти (ці три коефіцієнти у верхньому лівому кутку в координатних позиціях х, у [0,0], [0,1], [1,0] в прикладі блока 16×16, де [0,0] вказує лівий верхній кут, коефіцієнт DC) має своє власне виведення контексту. Коефіцієнти у верхній області 45 (коефіцієнти у верхньому рядку з координатних позицій х, у [2,0]-[15,0] в прикладі блока 16×16) мають контекст, що залежить від значущості двох попередніх коефіцієнтів у верхній області 45 (наприклад, два коефіцієнти безпосередньо праворуч від коефіцієнта, який повинен бути закодований, де такі коефіцієнти є казуальними (випадковими) сусідами з метою декодування, беручи до уваги зворотне сканування). Коефіцієнти в лівій області 47 (коефіцієнти в лівому стовпці з координатних позицій х, у [0,2]-[0,15] в прикладі блока 16×16) мають контекст, що залежить від значущості двох попередніх коефіцієнтів (наприклад, два коефіцієнти безпосередньо нижче коефіцієнта, який повинен бути закодований, де такі коефіцієнти є казуальними сусідами з метою декодування, беручи до уваги зворотну орієнтацію сканування). Повинно бути зазначено, що ці контексти у верхній області 45 і лівій області 47 на ФІГ. 11 є інверсією контекстів, показаних на ФІГ. 10 (наприклад, де коефіцієнти у верхній області 37 мають контекст, що залежить від коефіцієнтів зліва, і коефіцієнти в лівій області 35 мають контекст, що залежить від коефіцієнтів, представлених вище). Посилаючись на ФІГ. 11, контексти для коефіцієнтів в області 40, що залишилася (тобто коефіцієнти, що залишилися, поза областю 43 більш низької частоти, верхньої області 45 і лівої області 47), залежать від суми (або будь-якої іншої функції) значущості коефіцієнтів в позиціях, відмічених за допомогою I, Н, F, Е і В. У іншому прикладі коефіцієнти у верхній області 45 і лівій області 47 можуть використовувати точно одне і те ж виведення контексту як коефіцієнти в області 49. У зворотному скануванні таке можливо, оскільки сусідні позиції, відмічені за допомогою I, Н, F, Е і В, доступні для коефіцієнтів у верхній області 45 і лівій області 47. У кінці рядків/стовпців позиції для казуальних коефіцієнтів I, Н, F, Е і В можуть знаходитися поза блоком. У цьому випадку передбачається, що значення таких коефіцієнтів дорівнює нулю (тобто є незначущим). Є багато варіантів при виборі контекстів. Основна ідея полягає в тому, щоб використовувати значущість коефіцієнтів, які були вже закодовані, відповідно до порядку сканування. У прикладі, показаному на ФІГ. 10, контекст коефіцієнта в позиції X виводиться на основі суми значущості коефіцієнтів в позиціях В, Е, F, Н і I. Ці коефіцієнти контексту з'являються до поточного коефіцієнта в порядку зворотного сканування, запропонованого в даному розкритті для відображення значущості. Контексти, які були казуальними в прямому скануванні, стають неказуальними (недоступними) в порядку зворотного сканування. Спосіб для розв'язання цієї проблеми полягає в тому, щоб дзеркально відобразити контексти звичайного випадку на ФІГ. 10 до показаних на ФІГ. 11 для зворотного сканування. Для сканування значущості, яке 19 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 здійснюється в зворотному напрямі від останнього значущого коефіцієнта до позиції коефіцієнта DC, сусідство контексту для коефіцієнта X складається з коефіцієнтів В, Е, F, Н, I, які асоційовані з позиціями більш високої частоти відносно позиції коефіцієнта X і які були вже оброблені кодером або декодером в зворотному скануванні до кодування коефіцієнта X. Як розглянуто вище, контексти і моделі контексту, ілюстровані в Таблицях 1 і 2, намагаються використовувати локальну кореляцію рівнів коефіцієнтів серед субблоків 4×4. Однак залежність може бути дуже віддаленою. Тобто може бути низька залежність між коефіцієнтами, які відділені один від одного декількома коефіцієнтами, наприклад від одного субблока до іншого. Крім того, в кожному субблоці залежність між коефіцієнтами може бути слабкою. Дане розкриття описує способи для розв'язання цих проблем шляхом створення набору контекстів для рівнів коефіцієнтів, які використовують більш локальне сусідство контексту. Дане розкриття пропонує використовувати локальне сусідство для виведення контексту рівнів коефіцієнтів перетворення, наприклад, при кодуванні відео згідно з HEVC або іншими стандартами. Це сусідство складається з коефіцієнтів, вже закодованих (або декодованих), які мають високу кореляцію з рівнем поточного коефіцієнта. Коефіцієнти можуть просторово граничити з коефіцієнтом, який повинен бути закодований, і можуть включати в себе як коефіцієнти, які служать границею коефіцієнту, який повинен кодуватися, так і інші сусідні коефіцієнти, такі, як показані на ФІГ. 11 або ФІГ. 13. Зокрема, коефіцієнти, використовувані для виведення контексту, не обмежуються субблоком або попереднім субблоком. Замість цього локальне сусідство може містити коефіцієнти, які просторово розташовані близько до коефіцієнта, який повинен бути закодований, але можуть не обов'язково знаходитися в тому ж субблоці, що і коефіцієнт, який повинен бути закодований, або в тому ж субблоці, що один інший, якщо коефіцієнти були скомпоновані в субблоках. Замість того, щоб покладатися на коефіцієнти, розташовані в фіксованому субблоці, дане розкриття пропонує використовувати сусідні коефіцієнти, які доступні (тобто були вже закодовані), беручи до уваги заданий використовуваний порядок сканування. Різні набори контексту CABAC можуть бути задані для різних піднаборів коефіцієнтів, наприклад, на основі раніше закодованих піднаборів коефіцієнтів. У заданих піднаборах коефіцієнтів контексти виводяться на основі локального сусідства коефіцієнтів, іноді званого сусідством контексту. Відповідно до даного розкриття, приклад сусідства контексту показаний на ФІГ. 12. Коефіцієнти в сусідстві контексту можуть бути просторово розташовані біля коефіцієнта, який повинен бути закодований. Як показано на ФІГ. 12, для прямого сканування контекст рівня для коефіцієнта X перетворення залежить від значень коефіцієнтів В, Е, F, Н і I. В прямому скануванні коефіцієнти В, Е, F, Н і I асоційовані з позиціями більш низької частоти відносно позиції і коефіцієнта X і вже були оброблені кодером або декодером до кодування коефіцієнта X. Для кодування контейнера 1 для CABAC контекст залежить від суми кількості значущих коефіцієнтів в цьому сусідстві контексту (тобто, в цьому прикладі, коефіцієнтів В, Е, F, Н і I). Якщо коефіцієнт в сусідстві контексту випадає з блока, тобто через втрату даних, можна вважати, що це значення дорівнює 0 з метою визначення контексту коефіцієнта X. Для кодування інших контейнерів для CABAC, контекст залежить від суми кількості коефіцієнтів в сусідстві, які дорівнюють 1, а також від суми кількості коефіцієнтів в сусідстві, які більше ніж 1. В іншому прикладі контекст для контейнера 1 може залежати від суми значень контейнера 1 коефіцієнтів в локальному сусідстві контексту. У іншому прикладі контекст для контейнера 1 може залежати від комбінації суми коефіцієнтів значущості і значень контейнера 1 в цьому сусідстві контексту. Є багато можливостей для вибору сусідства контексту. Однак сусідство контексту повинно складатися з коефіцієнтів таким чином, щоб кодер і декодер мали доступ до однієї і тієї ж інформації. Зокрема, коефіцієнти В, F, Е, I і Н в сусідстві повинні бути казуальними сусідами в тому значенні, що вони були раніше закодовані або декодовані, і доступні для посилання при визначенні контексту для коефіцієнта X. Контексти, описані вище з посиланнями на ФІГ. 12, є однією з багатьох можливостей. Такі контексти можуть застосовуватися до будь-якого з трьох сканувань, на даний час запропонованих для використання в HEVC: діагонального, горизонтального і вертикального. Дане розкриття пропонує, щоб сусідство контексту, використовуване для виведення контексту для рівня коефіцієнтів, могло бути тим же самим, що і сусідство контексту, використовуване для виведення контекстів для відображення значущості. Наприклад, сусідство контексту, використовуване для виведення контексту для рівня коефіцієнтів, може бути локальним сусідством, як у випадку кодування відображення значущості. 20 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 Як описано більш детально вище, дане розкриття пропонує використання зворотного порядку сканування для сканування значущих коефіцієнтів, щоб сформувати відображення значущості. Зворотний порядок сканування може бути зворотним зигзагоподібним шаблоном, вертикальним шаблоном або горизонтальним шаблоном, як показано на ФІГ. 6. Якщо порядок сканування для сканування рівня коефіцієнтів також знаходиться в зворотному шаблоні, то сусідство контексту, показане на ФІГ. 12, буде неказуальним. Дане розкриття пропонує інвертувати позицію сусідства контексту таким чином, щоб воно було казуальним відносно зворотного порядку сканування. ФІГ. 13 показує приклад сусідства контексту для зворотного порядку сканування. Як показано на ФІГ. 13, для сканування рівня, яке виконується в зворотному напрямі від останнього значущого коефіцієнта до позиції коефіцієнта DC, сусідство контексту для коефіцієнта X складається з коефіцієнтів В, Е, F, Н і I, які асоційовані з позиціями більш високої частоти відносно позиції коефіцієнта X. Враховуючи зворотне сканування, коефіцієнти В, Е, F, Н і I були вже оброблені кодером або декодером до кодування коефіцієнта X і тому є казуальними в тому розумінні, що вони є доступними. Аналогічно, це сусідство контексту може бути застосоване до рівнів коефіцієнтів. Дане розкриття додатково пропонує в одному прикладі інший спосіб для кодування відображення значущості, який використовує контексти, вибрані для підтримання зворотного сканування. Як розглянуто вище, високоадаптивний підхід вибору контексту був запропонований для HEVC для кодування відображення значущості блоків 16×16 і 32×32 коефіцієнтів перетворення. Наприклад, як було описано відносно ФІГ. 10 вище, цей підхід ділить блок 16×16 на чотири області, де кожна позиція в області 41 має свій власний набір контекстів, область 37 має контексти, область 35 має інші 3 контексти, і область 39 має 5 контекстів. Вибір контексту для коефіцієнта перетворення X, як приклад, оснований на сумі значущості максимум цих 5 позицій В, Е, F, Н, I. Оскільки X є незалежним від інших позицій на одній і тій же діагональній лінії X вздовж напряму сканування, контекст значущості коефіцієнтів перетворення вздовж діагональної лінії в порядку сканування може бути обчислений паралельно від попередніх діагональних ліній в порядку сканування. Поточний підхід HEVC для виведень контексту має декілька недоліків. Однією проблемою є кількість контекстів для кожного блока. Наявність більшої кількості контекстів має на увазі більше пам'яті і більше обробки кожного разу, коли контексти оновлюються. Тому, може бути вигідно мати алгоритм, який має небагато контекстів і також небагато способів для генерування контекстів (наприклад, менше, ніж ці чотири способи, тобто чотири шаблони, в попередньому прикладі). Одним способом подолання таких недоліків є кодування відображення значущості в зворотному порядку, тобто від останнього значущого коефіцієнта (більш високої частоти) до компонента DC (найнижчої частоти). Наслідок цього процесу в зворотному порядку полягає в тому, що контексти для прямого сканування більше не є достовірними. Способи, описані вище, включають в себе спосіб для визначення контекстів для адаптивного двійкового арифметичного кодування, основаного на контексті (CABAC) для інформації, що вказує поточний один із значущих коефіцієнтів на основі раніше закодованих значущих коефіцієнтів в зворотному напрямі сканування. У прикладі зворотного зигзагоподібного сканування раніше закодовані значущі коефіцієнти знаходяться в позиціях праворуч від лінії сканування, на якій знаходиться поточний із значущих коефіцієнтів. Генерування контексту може відрізнятися для різних позицій блоків перетворення на основі щонайменше відстані від границь і відстані від компонента DC. У зразковому способі, описаному вище, було запропоновано, щоб кодування відображення значущості використовувало набори контекстів, зображених на ФІГ. 11. Дане розкриття пропонує набір контекстів для зворотного сканування відображення значущості, яке може привести до більш високої продуктивності через зменшення кількості контекстів для кожного блока. Знов посилаючись на ФІГ. 11, зменшення кількості контексту для кожного блока може бути досягнуте, дозволяючи лівій області 47 і верхній області 45 використовувати те ж виведення контексту, що і для області 49, що залишилася. У зворотному скануванні це можливе, оскільки сусідні позиції, відмічені I, Н, F, Е і В, є доступними для коефіцієнтів в областях 47 і 45. ФІГ. 14 показує приклад виведення контексту відповідно до цього прикладу. У цьому прикладі є тільки дві області контексту: низькочастотна область 57 для коефіцієнта DC і область 59, що залишилася, для всіх інших коефіцієнтів. Також, цей приклад пропонує усього два способи для виведення контексту. У низькочастотній області 57 (коефіцієнт DC в позиції х, у [0,0]) контекст виводять на основі позиції, тобто коефіцієнт DC має контекст його самого. У 21 UA 109479 C2 5 10 15 20 25 30 35 40 45 50 55 60 області 57, що залишилася, контекст виводять на основі значущості сусідніх коефіцієнтів в локальному сусідстві для кожного коефіцієнта, який повинен бути закодований. У цьому прикладі він виводиться залежно від суми значущості 5 сусідів, позначених I, Н, F, Е і В на ФІГ. 14. Тому, кількість способів для виведення контексту в блоці зменшена з 4 до 2. Крім того, кількість контекстів зменшена на 8 відносно попереднього прикладу на ФІГ. 11 (2 для області 43 більш низьких частот і 3 для кожної з верхньої області 45 і лівої області 47). У іншому прикладі коефіцієнт DC може використовувати той же спосіб, що і для іншої частини блока, таким чином кількість способів для виведення контексту в блоці зменшується до 1. ФІГ. 15 показує приклад, в якому поточна позиція коефіцієнта X змушує деякі з сусідніх коефіцієнтів (в цьому випадку Н і В) знаходитися поза поточним блоком. Якщо будь-які з сусідів поточного коефіцієнта знаходиться поза цим блоком, можна передбачити, що такі сусідні коефіцієнти мають значущість 0 (тобто вони є нульовими значеннями і, тому, незначущими). Альтернативно, один або декілька спеціальних контекстів можуть бути задані для одного або більше коефіцієнти нижче праворуч. Таким чином, коефіцієнти більш високої частоти можуть мати контексти залежно від позиції, аналогічно коефіцієнту DC. Однак припущення, що сусіди повинні бути нульовими, може забезпечити достатні результати, зокрема, тому, що нижні праві коефіцієнти звичайно будуть мати низьку імовірність наявності значущих коефіцієнтів або щонайменше значущих коефіцієнтів з великими значеннями. Зменшення кількості контекстів в прикладі на ФІГ. 14 добре для реалізації. Однак це може привести до невеликого зниження продуктивності. Дане розкриття пропонує додатковий спосіб, щоб підвищити продуктивність, в той же час все ще зменшуючи кількість контекстів. Зокрема, пропонується мати другий набір контекстів, який також оснований на сусідніх коефіцієнтах. Алгоритм виведення контексту є точно таким же, але використовуються два набори контекстів з різними моделями імовірності. Набір контекстів, які використовуються, залежить від позиції коефіцієнта, який повинен бути закодований в блоці перетворення. Більш точно, збільшена продуктивність була показана при використанні моделі контексту для коефіцієнтів більш високої частоти (наприклад, нижні праві координатні позиції х, у коефіцієнтів), яка відрізняється від моделі контексту для коефіцієнтів в більш низьких частотах (наприклад, верхні ліві координати х, у коефіцієнтів). Один спосіб для відділення коефіцієнтів більш низької частоти від коефіцієнтів більш високої частоти, і, таким чином, моделі контексту, використовуваної для кожних коефіцієнтів, полягає в тому, щоб обчислити значення х+у для коефіцієнта, де х є горизонтальною позицією і у є вертикальною позицією коефіцієнта. Якщо це значення менше, ніж деякий поріг (наприклад, 4 був показаний як працюючий ефективно), то використовується набір контекстів 1. Якщо значення дорівнює або більше, ніж цей поріг, то використовується набір контекстів 2. Знову, набори контекстів 1 і 2 мають різні моделі імовірності. ФІГ. 16 показує приклад областей контексту для цього прикладу. Знов, коефіцієнт DC в позиції (0,0) має свою власну область 61 контексту. Область 63 контексту більш низької частоти складається з коефіцієнтів перетворення в позиції х+у, що дорівнює або менше, ніж поріг 4 (не включаючи коефіцієнт DC). Область 65 контексту більш високої частоти складається з коефіцієнтів перетворення в позиції х+у, що більше, ніж поріг 4. Поріг 4 використовується як приклад і може бути пристосований до будь-якої кількості, яка передбачає кращу продуктивність. У іншому прикладі поріг може залежати від розміру TU. Виведення контексту для області 63 контексту більш низької частоти і області 65 контексту більш високої частоти є точно таким же в термінах способу, яким використовуються сусіди для вибору контексту, але використовувані імовірності (тобто контексти) відрізняються. Зокрема, можуть бути використані одні і ті ж критерії для вибору контексту на основі сусідів, але застосування таких критеріїв приводить до вибору відмінного контексту для різних позицій коефіцієнта, оскільки різні позиції коефіцієнта можуть бути асоційовані з різними наборами контекстів. Таким чином, знання, що коефіцієнти більш низької і високої частоти мають різну статистику, включене в алгоритм таким чином, щоб могли бути використані різні набори контекстів для відмінного коефіцієнта. У інших прикладах функція х+у може бути змінена на інші функції залежно від позиції коефіцієнта. Наприклад, опція повинна надати один і той же набір контекстів для всіх коефіцієнтів з х
ДивитисяДодаткова інформація
Автори англійськоюSole Rojals, Joel, Joshi, Rajan Laxman, Karczewicz, Marta
Автори російськоюСоле Рохальс Хоель, Джоши Раджан Лаксман, Карчевич Марта
МПК / Мітки
МПК: H04N 19/70, H04N 19/167, H04N 19/134, H04N 7/00, H04N 19/91, H04N 19/463, H04N 19/18
Мітки: перетворення, відео, кодування, коефіцієнтів
Код посилання
<a href="https://ua.patents.su/54-109479-koduvannya-koeficiehntiv-peretvorennya-dlya-koduvannya-video.html" target="_blank" rel="follow" title="База патентів України">Кодування коефіцієнтів перетворення для кодування відео</a>
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 106704
Опубліковано: 25.09.2014
Автори: Карчевіч Марта, Соле Рохальс Хоель, Джоши Раджан Лаксман
МПК: H04N 19/00
Мітки: перетворення, відео, коефіцієнтів, кодування
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео, в процесі кодування відео, причому спосіб включає:компонування блока коефіцієнтів перетворення в один або більше піднаборів коефіцієнтів перетворення на основі порядку сканування;кодування першої частини рівнів коефіцієнтів перетворення в кожному піднаборі, причому перша частина рівнів включає в себе щонайменше значущість коефіцієнтів...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 107157
Опубліковано: 25.11.2014
Автори: Карчевіч Марта, Соле Рохальс Хоель, Джоши Раджан Лаксман
МПК: H04N 19/00
Мітки: перетворення, коефіцієнтів, кодування, відео
Формула / Реферат:
1. Спосіб кодування множини коефіцієнтів перетворення, асоційованих із залишковими відеоданими в процесі кодування відео, причому спосіб включає:кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення згідно з порядком сканування; ікодування інформації, що вказує рівні значущих коефіцієнтів множини коефіцієнтів перетворення згідно із згаданим порядком сканування,причому згаданий порядок...
Статистичне кодування коефіцієнтів, використовуючи об’єднану контекстну модель

Номер патенту: 106937
Опубліковано: 27.10.2014
Автори: Карчевіч Марта, Соле Рохальс Хоель, Джоши Раджан Л.
МПК: H04N 7/00
Мітки: використовуючи, статистичне, модель, контекстну, об'єднану, кодування, коефіцієнтів
Формула / Реферат:
1. Спосіб кодування даних відео, який включає:підтримування об'єднаної контекстної моделі, що використовується спільно першим блоком перетворення, який має перший розмір, і другим блоком перетворення, який має другий розмір, при цьому перший розмір і другий розмір різні, і при цьому кожен із згаданих блоків перетворення містить блок залишкових даних відео, що включає в себе множину блоків коефіцієнтів перетворення;вибір...
Кодування позиції останнього значущого коефіцієнта у відеоблоці на основі порядку сканування для блока при кодуванні відео

Номер патенту: 106162
Опубліковано: 25.07.2014
Автори: Соле Рохальс Хоель, Карчевіч Марта, Чжен Юньфей, Кобан Мухаммед Зейд, Джоши Раджан Лаксман
Мітки: відеоблоці, основі, кодування, сканування, кодуванні, блока, коефіцієнта, відео, останнього, позиції, значущого, порядку
Формула / Реферат:
1. Спосіб кодування коефіцієнтів, асоційованих з блоком відеоданих, під час процесу кодування відео, при цьому спосіб включає етапи, на яких:визначають статистику, яка вказує імовірність того, що кожна з координат X і Y містить дане значення, коли порядок сканування, асоційований з блоком, містить перший порядок сканування, при цьому координати X і Y вказують горизонтальну позицію і вертикальну позицію, відповідно, останнього...
Фільтр з внутрішнім згладжуванням для кодування відео

Номер патенту: 106936
Опубліковано: 27.10.2014
Автори: Карчевіч Марта, Ван Сянлінь, Чжен Юньфей, Кобан Мухаммед Зейд, Ван Дер Аувера Герт
МПК: H04N 7/00
Мітки: згладжуванням, кодування, внутрішнім, відео, фільтр
Формула / Реферат:
1. Спосіб кодування відеоданих, причому спосіб включає:визначення розміру блока, асоційованого з поточним блоком відеоданих, причому розмір блока визначений з множини розмірів блока, які включають в себе розмір блока 4×4, розмір блока 8×8, розмір блока 16×16 і розмір блока 32×32;визначення режиму кодування з внутрішнім прогнозуванням, асоційованого з поточним блоком відеоданих, причому режим кодування з...
Попередній патент: Штам streptomyces albus – продуцент комплексу літичних ферментів
Наступний патент: Подвійний прогнозуючий режим злиття, оснований на одинарних прогнозуючих сусідах, в кодуванні відео
Випадковий патент: Вимірювальний двотактний симетричний підсилювач постійного струму