Ентропійне кодування різниць векторів руху
Номер патенту: 111741
Опубліковано: 10.06.2016
Автори: Штегеманн Ян, Кірххоффер Хайнер, Бросс Бенджамін, Георге Валері, Прайсс Маттіас, Нгуєн Тунг, Марпе Детлеф, Віганд Томас, Зікманн Міша






























































Формула / Реферат
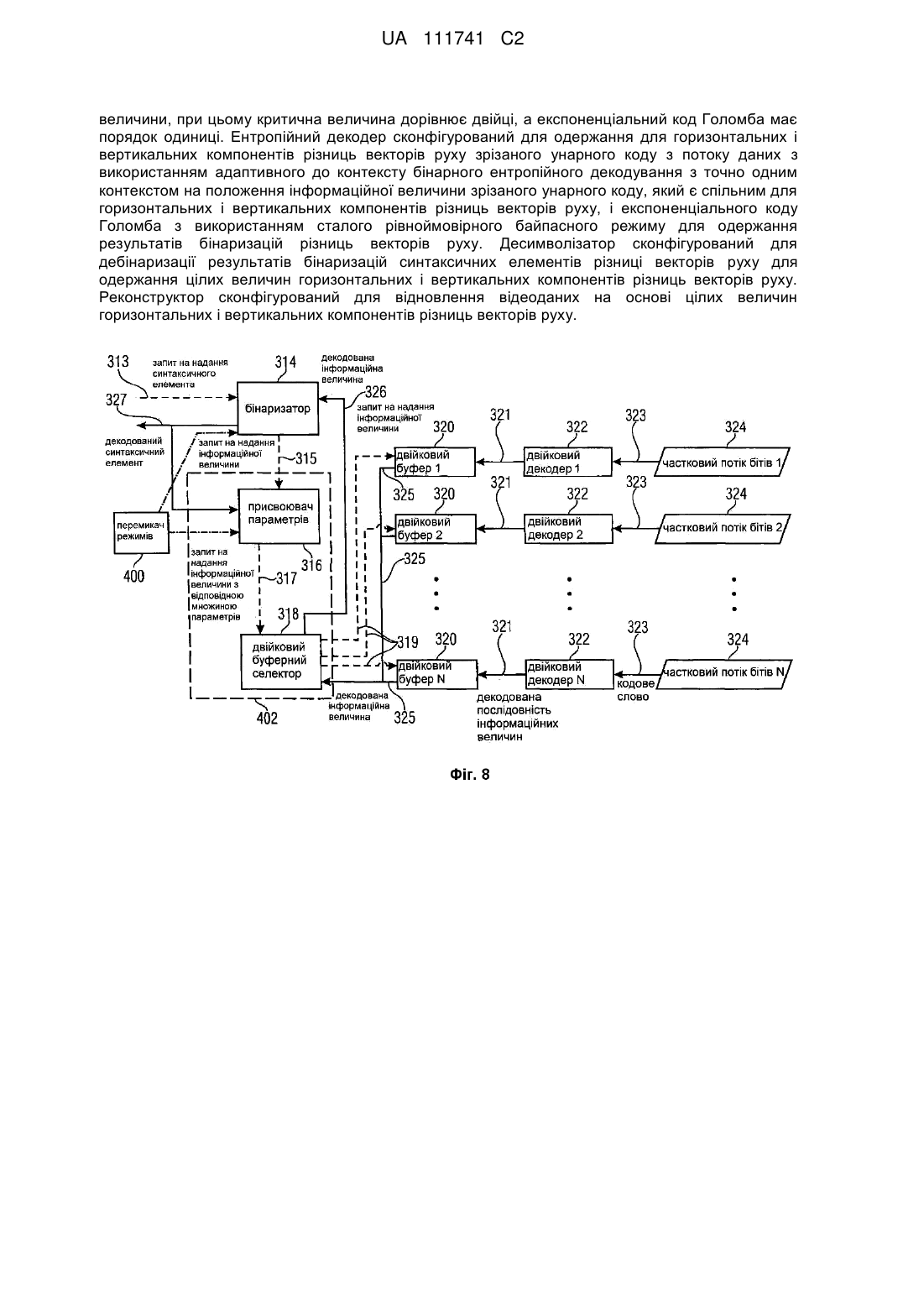
1. Декодер для декодування відеоданих з потоку даних, у якому закодовані горизонтальні і вертикальні компоненти різниць векторів руху з використанням бінаризацій горизонтальних і вертикальних компонентів, при цьому бінаризації зрівнюють усічений унарний код горизонтальних і вертикальних компонентів, відповідно, в першому інтервалі області горизонтальних і вертикальних компонентів нижче критичної величини, і комбінацію префікса у формі усіченого унарного коду для критичної величини і суфікса у формі експоненціального коду Голомба горизонтальних і вертикальних компонентів, відповідно, в другому інтервалі області горизонтальних і вертикальних компонентів включно і з перевищенням критичної величини, при цьому критична величина дорівнює двійці, а експоненціальний код Голомба має порядок одиниці, при цьому декодер містить ентропійний декодер, сконфігурований для одержання усіченого унарного коду з потоку даних для горизонтальних і вертикальних компонентів різниць векторів руху з використанням адаптивного до контексту бінарного ентропійного декодування з точно одним контекстом на положення інформаційної величини усіченого унарного коду, який є спільним для горизонтальних і вертикальних компонентів різниць векторів руху, експоненціального коду Голомба з використанням сталого рівноймовірного байпасного режиму для одержання бінаризацій різниць векторів руху;
десимволізатор, сконфігурований для дебінаризації результатів бінаризацій синтаксичних елементів різниці векторів руху для одержання цілих величини горизонтальних і вертикальних компонентів різниць векторів руху;
реконструктор, сконфігурований для відновлення відеоданих на основі цілих величин горизонтальних і вертикальних компонентів різниць векторів руху.
2. Декодер за п. 1, який відрізняється тим, що ентропійний декодер (409) сконфігурований для одержання усіченого унарного коду (806) з потоку даних (401) з використанням бінарного арифметичного декодування або бінарного PIPE декодування.
3. Декодер за п. 1 або п. 2, який відрізняється тим, що ентропійний декодер (409) сконфігурований для використання різних контекстів для двох положень інформаційної величини усіченого унарного коду 806.
4. Декодер за будь-яким із пп. 1-3, який відрізняється тим, що ентропійний декодер (409) сконфігурований для виконання оновлення стану ймовірності для інформаційної величини, поточно одержаної з усіченого унарного коду (806), шляхом переходу з поточного стану ймовірності, зв'язаного з контекстом, вибраним для поточно одержаної інформаційної величини, до нового стану ймовірності в залежності від поточно одержаної інформаційної величини.
5. Декодер за будь-яким із пп. 1-4, який відрізняється тим, що ентропійний декодер (409) сконфігурований для бінарного арифметичного декодування інформаційної величини, поточно одержаної зі усіченого коду (806), шляхом дискретизації величини ширини поточного інтервалу ймовірності, яка представляє поточний інтервал ймовірності, для одержання індексу інтервалу ймовірності і шляхом виконання підрозбиття інтервалу шляхом індексації вхідної величини таблиці серед вхідних величин таблиці з використанням індексу інтервалу ймовірності і індексу стану ймовірності в залежності від поточного стану ймовірності, зв'язаного з контекстом, вибраним для поточно одержаної інформаційної величини, для одержання підрозбиття поточного інтервалу ймовірності на два часткові інтервали.
6. Декодер за п. 5, який відрізняється тим, що ентропійний декодер (409) сконфігурований для використання 8 бітового представлення для величини ширини поточного інтервалу ймовірності і для одержання 2 або 3 найбільш значущих бітів 8 бітового представлення при дискретизації величини ширини поточного інтервалу ймовірності.
7. Декодр за п. 5 або п. 6, який відрізняється тим, що ентропійний декодер (409) сконфігурований для вибору серед двох часткових інтервалів на основі величини стану зміщення зсередини поточного інтервалу ймовірності, для оновлення величини ширини інтервалу ймовірності і величини стану зміщення, і для виведення величини поточно одержаної інформаційної величини, використовуючи вибраний частковий інтервал, і для виконання повторної нормалізації оновленої величини ширини інтервалу ймовірності і величини стану зміщення, включаючи продовження зчитування бітів з потоку даних (401).
8. Декодер за будь-яким із пп. 5-7, який відрізняється тим, що ентропійний декодер (409) сконфігурований в сталому рівноймовірному байпасному режимі для бінарного арифметичного декодування інформаційної величини з експоненціального коду Голомба шляхом поділу навпіл величини ширини поточного інтервалу ймовірності для одержання підрозбиття поточного інтервалу ймовірності на два часткові інтервали.
9. Декодер за будь-яким із пп. 1-8, який відрізняється тим, що ентропійний декодер (409) сконфігурований для одержання для кожної різниці векторів руху усіченого коду горизонтальних і вертикальних компонентів відповідної різниці векторів руху з потоку даних перед експоненціальним кодом Голомба горизонтальних і вертикальних компонентів відповідної різниці векторів руху.
10. Декодер за будь-яким із пп. 1-9, який відрізняється тим, що реконструктор сконфігурований для просторового і/або тимчасового прогнозування горизонтальних і вертикальних компонентів векторів руху для одержання предикторів для горизонтальних і вертикальних компонентів векторів руху і для відновлення горизонтальних і вертикальних компонентів векторів руху шляхом деталізації предикторів 826 з використанням горизонтальних і вертикальних компонентів різниць векторів руху.
11. Декодер за будь-яким із пп. 1-10, який відрізняється тим, що реконструктор сконфігурований для прогнозування горизонтальних і вертикальних компонентів векторів руху різними способами для одержання упорядкованого списку предикторів для горизонтальних і вертикальних компонентів векторів руху, для одержання індексу списку з
потоку даних і для відновлення горизонтальних і вертикальних компонентів векторів руху шляхом деталізації предиктора, на який вказує індекс списку предикторів, з використанням горизонтальних і вертикальних компонентів різниць векторів руху.
12. Декодер за п. 10 або п. 11, який відрізняється тим, що реконструктор сконфігурований для відновлення відеоданих з використанням прогнозування з компенсацією руху шляхом застосування горизонтальних і вертикальних компонентів векторів руху.
13. Декодер за п. 12, який відрізняється тим, що реконструктор сконфігурований для відновлення відеоданих з використанням прогнозування з компенсацією руху шляхом застосування горизонтальних і вертикальних компонентів векторів руху при просторовій гнулярності, визначеній підрозбиттям відеокартинок в блоках, при цьому реконструктор виконаний з можливістю використання синтаксичних елементів, які зливаються і присутні в потоці даних, для групування блоків в групи для злиття і для застосування цілих величин горизонтальних і вертикальних компонентів різниць векторів руху, одержаних дебінаризатором, в елементах груп для злиття.
14. Декодер за п. 13, який відрізняється тим, що реконструктор сконфігурований для одержання підрозбиття відеокартинок в блоках з частини потоку даних з виключенням синтаксичних елементів, які зливаються.
15. Декодер за п. 13 або п. 14, який відрізняється тим, що реконструктор сконфігурований для прийняття горизонтальних і вертикальних компонентів наперед визначеного вектора руху для усіх блоків відповідної групи для злиття або для деталізації їх горизонтальними і вертикальними компонентами різниць векторів руху, зв'язаних з блоками групи для злиття.
16. Кодер для кодування відеоданих з одержанням потоку даних, який містить реконструтор, сконфігурований для прогнозованого кодування відеоданих за допомогою прогнозування з компенсацією руху з використанням векторів руху і шляхом прогнозованого кодування векторів руху шляхом прогнозування векторів руху і шляхом визначення цілих величин горизонтальних і вертикальних компонентів різниць векторів руху для представлення похибки прогнозування спрогнозованих векторів руху; символізатор, сконфігурований для бінаризації цілих величин для одержання результатів бінаризацій горизонтальних і вертикальних компонентів різниць векторів руху, при цьому бінаризації зрівноважують усічений унарний код горизонтальних і вертикальних компонентів, відповідно, в першому інтервалі області горизонтальних і вертикальних компонентів нижче критичної величини, і комбінацію префікса у формі усіченого унарного коду для критичної величини і суфікса у формі експоненціального коду Голомба горизонтальних і вертикальних компонентів, відповідно, в другому інтервалі області горизонтальних і вертикальних компонентів включно і з перевищенням критичної величини, при цьому критична величина дорівнює двійці, а експоненціальний код Голомба має порядок одиниця; і ентропійний кодер, сконфігурований для кодування для горизонтальних і вертикальних компонентів різниць векторів руху усіченого унарного коду з одержанням потоку даних з використанням адаптивного до контексту бінарного ентропійного кодування з точно одним контекстом на положення інформаційної величини усіченого унарного коду, який є спільним для горизонтальних і вертикальних компонентів різниць векторів руху, і експоненціального коду Голомба з використанням сталого рівноймовірного байпасного режиму.
17. Кодер за п. 16, який відрізняється тим, що ентропійний кодер сконфігурований для кодування усіченого унарного коду з одержанням потоку даних з використанням арифметичного кодування або бінарного PIPE кодування.
18. Кодер за п. 16 або п. 17, який відрізняється тим, що ентропійний кодер сконфігурований для використання різних контекстів для двох положень інформаційної величини усіченого унарного коду.
19. Кодер за будь-яким із пп. 16-18, який відрізняється тим, що ентропійний кодер сконфігурований для виконання оновлення стану ймовірності для інформаційної величини, поточно кодованої зі усіченого унарного коду, шляхом переходу з поточного стану ймовірності, зв'язаного з контекстом, вибраним для поточно кодованої інформаційної величини, в новий стан ймовірності в залежності від поточно одержаної інформаційної величини.
20. Кодер за будь-яким із пп. 16-19, який відрізняється тим, що ентропійний кодер сконфігурований для бінарного арифметичного кодування інформаційної величини, яка поточно кодована зі усіченого унарного коду, шляхом дискретизації величини ширини поточного інтервалу ймовірності, яка представляє поточний інтервал ймовірності, для одержання індексу інтервалу ймовірності і шляхом виконання підрозбиття інтервалу шляхом індексації вхідної величини таблиці серед вхідних величин таблиці з використанням індексу інтервалу ймовірності і індексу стану ймовірності в залежності від поточного стану ймовірності, зв'язаного з контекстом, вибраним для поточно одержаної інформаційної величини, для одержання підрозбиття поточного інтервалу ймовірності на два часткові інтервали.
21. Кодер за п. 20, який відрізняється тим, що ентропійний кодер сконфігурований для використання 8 бітового представлення для величини ширини поточного інтервалу ймовірності і для одержання 2 або 3 найбільш значущих бітів 8 бітового представлення при дискретизації величини ширини поточного інтервалу ймовірності.
22. Кодер за п. 20 або п. 21, який відрізняється тим, що ентропійний кодер сконфігурований для вибору серед двох часткових інтервалів на основі цілої величини поточно кодованої інформаційної величини, для оновлення величини ширини інтервалу ймовірності і зміщення інтервалу ймовірності з використанням вибраного часткового інтервалу і для виконання повторної нормалізації величини ширини інтервалу ймовірності і зміщення інтервалу ймовірності, включаючи продовження запису бітів в потік даних.
23. Кодер за будь яким із пп. 20-21, який відрізняється тим, що ентропійний кодер сконфігурований для бінарного арифметичного кодування інформаційної величини з експоненціального коду Голомба шляхом поділу навпіл величини ширини поточного інтервалу ймовірності для одержання підрозбиття поточного інтервалу ймовірності на два часткові інтервали.
24. Кодер за будь-яким із пп. 16-23, який відрізняється тим, що ентропійний кодер сконфігурований для кодування для кожної різниці векторів руху усіченого унарного коду горизонтальних і вертикальних компонентів відповідної різниці вектора руху з одержанням потоку даних перед експоненціальним кодом Голомба горизонтальних і вертикальних компонентів відповідної різниці векторів руху.
25. Кодер за будь-яким із пп. 16-24, який відрізняється тим, що конструктор сконфігурований для просторового і/або тимчасового прогнозування горизонтальних і вертикальних компонентів векторів руху для одержання предикторів для горизонтальних і вертикальних компонентів векторів руху і для визначення горизонтальних і вертикальних компонентів різниць векторів руху для деталізації предикторів стосовно горизонтальних і вертикальних компонентів векторів руху.
26. Кодер за будь-яким із пп. 16-25, який відрізняється тим, що конструктор сконфігурований для прогнозування горизонтальних і вертикальних компонентів векторів руху різними способами для одержання упорядкованого списку предикторів для горизонтальних і вертикальних компонентів векторів руху, для визначення індексу списку і для введення інформації, яка вказує його, в потік даних, і для визначення горизонтальних і вертикальних компонентів різниць векторів руху для деталізації предиктора, на який вказує індекс списку предикторів, з використанням горизонтальних і вертикальних компонентів векторів руху.
27. Кодер за будь-яким із пп. 16-26, який відрізняється тим, що конструктор сконфігурований для кодування відеоданих з використанням прогнозування з компенсацією руху шляхом застосування горизонтальних і вертикальних компонентів векторів руху при просторовій гранулярності, визначеній підрозбиттям відеокартинок в блоках, при цьому конструктор виконаний з можливістю визначення і введення в потік даних синтаксичних елементів, які зливаються, для групування блоків в групи для злиття і для застосування цілих величин горизонтальних і вертикальних компонентів різниць векторів руху, підданих бінаризації за допомогою бінаризатора, в елементах груп для злиття.
28. Кодер за п. 27, який відрізняється тим, що конструктор сконфігурований для кодування підрозбиття відеокартинок в блоках в частині потоку даних з виключенням синтаксичних елементів, які зливаються.
29. Кодер за п. 27 або п. 28, який відрізняється тим, що конструктор сконфігурований для прийняття горизонтальних і вертикальних компонентів наперед визначеного вектора руху для усіх блоків відповідної групи для злиття або для деталізації їх горизонтальними і вертикальними компонентами різниць векторів руху, зв'язаних з блоками групи для злиття.
30. Спосіб декодування відеоданих з потоку даних, у який кодуються горизонтальні і вертикальні компоненти різниць векторів руху, з використанням бінаризацій горизонтальних і вертикальних компонентів, при цьому бінаризації зрівнюють усічений унарний код горизонтальних і вертикальних компонентів, відповідно, в першому інтервалі області горизонтальних і вертикальних компонентів нижче критичної величини, і комбінацію префікса у формі усіченого унарного коду для критичної величини і суфікса у формі експоненціального коду Голомба горизонтальних і вертикальних компонентів, відповідно, в другому інтервалі області горизонтальних і вертикальних компонентів включно і з перевищенням критичної величини, при цьому критична величина дорівнює двійці, а експоненціальний код Голомба має порядок одиниці, у якому для горизонтальних і вертикальних компонентів різниць векторів руху одержують усічений унарний код з потоку даних з використанням адаптивного до контексту бінарного ентропійного декодування з точно одним контекстом на положення інформаційної величини усіченого унарного коду, який є спільним для горизонтальних і вертикальних компонентів різниць векторів руху, і експоненціального коду Голомба з використанням сталого рівноймовірного байпасного режиму для одержання результатів бінаризацій різниць векторів руху; дебінаризують результати бінаризацій синтаксичних елементів різниці векторів руху для одержання цілих величин горизонтальних і вертикальних компонентів різниць векторів руху;
відновлюють відеодані на основі цілих величин горизонтальних і вертикальних компонентів різниць векторів руху.
31. Спосіб кодування відеоданих з одержанням потоку даних, у якому прогнозовано кодують відеодані за допомогою прогнозування з компенсацією руху з використанням векторів руху і шляхом прогнозованого кодування векторів руху шляхом прогнозування векторів руху, і шляхом визначення цілих величин горизонтальних і вертикальних компонентів різниць векторів руху для представлення похибки прогнозування спрогнозованих векторів руху; бінаризують цілі величини для одержання результатів бінаризацій горизонтальних і вертикальних компонентів різниць векторів руху, при цьому бінаризації зрівнюють усічений унарний код горизонтальних і вертикальних компонентів, відповідно, в першому інтервалі області горизонтальних і вертикальних компонентів нижче критичної величини, і комбінацію префікса у формі усіченого унарного коду для критичної величини і суфікса у формі експоненціального коду Голомба горизонтальних і вертикальних компонентів, відповідно, в другому інтервалі області горизонтальних і вертикальних компонентів включно і з перевищенням критичної величини, при цьому критична величина дорівнює двійці, а експоненціальний код Голомба має порядок одиниці; і для горизонтальних і вертикальних компонентів різниць векторів руху кодують усічений унарний код з одержанням потоку даних з використанням адаптивного до контексту бінарного ентропійного кодування з точно одним контекстом на положення інформаційної величини усіченого унарного коду, який є спільним для горизонтальних і вертикальних компонентів різниць векторів руху, і експоненціального коду Голомба з використанням сталого рівноймовірного байпасного режиму.
32. Машинозчитуваний носій даних, який має збережену в ньому комп'ютерну програму, яка містить програмний код, виконуваний на комп'ютері для здійснення способу за п. 30 або п. 31.
Текст
Реферат: Описується декодер для декодування відеоданих з потоку даних, у який кодуються горизонтальні і вертикальні компоненти різниць векторів руху, з використанням бінаризацій горизонтальних і вертикальних компонентів, при цьому бінаризації зрівнюють зрізаний унарний код горизонтальних і вертикальних компонентів, відповідно, в першому інтервалі області горизонтальних і вертикальних компонентів нижче критичної величини, і комбінацію префікса у формі зрізаного унарного коду для критичної величини і суфікса у формі експоненціального коду Голомба горизонтальних і вертикальних компонентів, відповідно, в другому інтервалі області горизонтальних і вертикальних компонентів включно і з перевищенням критичної UA 111741 C2 (12) UA 111741 C2 величини, при цьому критична величина дорівнює двійці, а експоненціальний код Голомба має порядок одиниці. Ентропійний декодер сконфігурований для одержання для горизонтальних і вертикальних компонентів різниць векторів руху зрізаного унарного коду з потоку даних з використанням адаптивного до контексту бінарного ентропійного декодування з точно одним контекстом на положення інформаційної величини зрізаного унарного коду, який є спільним для горизонтальних і вертикальних компонентів різниць векторів руху, і експоненціального коду Голомба з використанням сталого рівноймовірного байпасного режиму для одержання результатів бінаризацій різниць векторів руху. Десимволізатор сконфігурований для дебінаризації результатів бінаризацій синтаксичних елементів різниці векторів руху для одержання цілих величин горизонтальних і вертикальних компонентів різниць векторів руху. Реконструктор сконфігурований для відновлення відеоданих на основі цілих величин горизонтальних і вертикальних компонентів різниць векторів руху. UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Представлений винахід стосується концепції ентропійного кодування для кодування відеоданих. В рівні техніки відомо багато відеокодеків. Загалом, ці кодеки зменшують кількість даних, необхідних для представлення відеоконтенту, тобто, вони стискають дані. В контексті кодування відеоданих, відомо, що стискання відеоданих переважно досягається послідовним застосуванням різних технологій кодування: для прогнозування змісту картинки використовується прогнозування з компенсацією руху. Вектори руху, визначені в прогнозуванні з компенсацією руху, а також залишок прогнозування піддаються ентропійному кодуванню без втрат. Для подальшого зменшення кількості даних, самі по собі вектори руху піддаються прогнозуванню так, що просто різниці векторів руху, які представляють їх залишок, повинні ентропійно кодуватися. В стандарті H.264, наприклад, тільки що описана процедура застосовується для передачі інформації про різниці векторів руху. Зокрема, різниці векторів руху бінаризуються з одержанням рядків інформаційних величин, які відповідають комбінації усіченого унарного коду і, від певної критичної величини, експоненціального коду Голомба. Хоча інформаційні величини експоненціального коду Голомба легко кодуються з використанням рівноймовірного байпасного режиму з фіксованою ймовірністю 0,5, для перших інформаційних величин передбачаються декілька контекстів. Критична величина вибирається рівною дев'яти. Відповідно, передбачається велика кількість контекстів для кодування різниць векторів руху. Однак, передбачення великої кількості контекстів не тільки підвищує складність кодування, але й може також негативно впливати на ефективність кодування: якщо до контексту звертаються занадто рідко, то адаптація ймовірності, тобто адаптація оцінки ймовірності, зв'язаної з відповідним контекстом, під час ентропійного кодування не є ефективною. Відповідно, непідходящі застосовувані оцінки ймовірності оцінюють реальну статистику символів. Більше того, якщо для певної інформаційної величини бінаризації передбачається декілька контекстів, то вибір серед них може потребувати перевірки значень сусідніх інформаційних величин/синтаксичних елементів, необхідність в яких може перешкоджати виконанню процесу декодування. З іншого боку, якщо надається занадто мала кількість контекстів, то інформаційні величини з сильно варійованою реальною статистикою символів групуються разом в одному контексті і, відповідно, оцінка ймовірності, зв'язана з таким контекстом, ефективно не кодує зв'язані з нею інформаційні величини. Існує постійна потреба у подальшому підвищенні ефективності ентропійного кодування різниць векторів руху. Відповідно, задачею представленого винаходу є надання такої концепції кодування. Ця задача вирішується об'єктом доданих незалежних пунктів формули винаходу. Основним відкриттям представленого винаходу є те, що ефективність ентропійного кодування різниць векторів руху може додатково підвищуватися шляхом зменшення критичної величини, до якої використовується усічений унарний код для бінаризації різниць векторів руху, до двох так, що існують просто два положення інформаційної величини усіченого унарного коду і якщо порядок одного використовується для експоненціального коду Голомба для бінаризації різниць векторів руху від критичної величини, і якщо, окрім того, точно один контекст передбачається для двох положень інформаційної величини усіченого унарного коду, відповідно, так, що вибір контексту на основі інформаційних величин або значень синтаксичного елемента сусідніх блоків зображення не потрібен і уникається занадто точна класифікація інформаційних величин у цих положеннях інформаційних величин відповідно до контекстів так, що адаптація ймовірності здійснюється належним чином, і якщо однакові контексти використовуються для горизонтальних і вертикальних компонентів, таким чином додатково послаблюючи негативні впливи занадто дрібного підрозбиття контексту. Окрім того, було виявлено, що тільки що згадані параметри стосовно ентропійного кодування різниць векторів руху особливо цінні при поєднанні їх з сучасними способами прогнозування векторів руху і зменшення необхідної кількості різниць векторів руху, які передаються. Наприклад, може передбачатися багато предикторів векторів руху для одержання упорядкованого списку предикторів векторів руху і індекс у цьому списку предикторів векторів руху може використовуватися для визначення реального предиктора вектора руху, залишок прогнозування якого представляється розглядуваною різницею векторів руху. Хоча інформація про використовуваний індекс списку, повинна одержуватися з потоку даних на декодувальній стороні, загальна якість прогнозування векторів руху підвищується і, відповідно, величина різниць векторів руху додатково зменшується так, що, в цілому, ефективність кодування додатково збільшується і зменшення критичної величини та спільне використання контексту для горизонтальних і вертикальних компонентів різниць векторів руху узгоджуються з таким покращеним прогнозуванням векторів руху. З іншого боку, може застосовуватися злиття для зменшення кількості різниць векторів руху, які передаються в потоці даних: для цього, 1 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 інформація про злиття може передаватися в потоці даних, який сигналізує декодувальним блокам про підрозбиття блоків, які групуються в групу блоків. Різниці векторів руху можуть потім передаватися в потоці даних в елементах цих об'єднаних груп замість окремих блоків, таким чином зменшуючи кількість різниць векторів руху, які повинні передаватися. Оскільки ця кластеризація блоків послаблює інтеркореляцію між різницями сусідніх векторів руху, то тільки що описана відмова від надання декількох контекстів для одного положення інформаційної величини перешкоджає схемі ентропійного кодування проводити занадто точну класифікацію згідно з контекстами в залежності від різниць сусідніх векторів руху. Скоріше концепція злиття вже використовує інтеркореляцію між різницями векторів руху сусідніх блоків і, відповідно, один контекст для одного положення інформаційної величини: однаковий контекст достатній для горизонтальних і вертикальних компонентів. Переважні варіанти виконання даного винаходу описуються далі з посиланням на Фігури, на яких Фіг. 1 зображає блок-схему кодера згідно з варіантом виконання; Фіг. 2a-2c схематично зображають різні підрозбиття масиву зразків, такого як підрозбиття картинки на блоки; Фіг. 3 зображає блок-схему декодера згідно з варіантом виконання; Фіг. 4 детальніше зображає блок-схему кодера згідно з варіантом виконання; Фіг. 5 детальніше зображає блок-схему декодера згідно з варіантом виконання; Фіг. 6 схематично зображає перетворення блоку з просторової області в спектральну область, одержуваний блок перетворення і його повторне перетворення; Фіг. 7 зображає блок-схему кодера згідно з варіантом виконання; Фіг. 8 зображає блок-схему декодера, придатного для декодування потоку бітів, генерованого кодером з Фіг. 8, згідно з варіантом виконання; Фіг. 9 зображає схематичну діаграму, яка показує пакет даних з мультиплексованими частковими потоками бітів згідно з варіантом виконання; Фіг. 10 зображає схематичну діаграму, яка показує пакет даних з альтернативною сегментацією, яка використовує сегменти фіксованого розміру, згідно з подальшим варіантом виконання; Фіг. 11 зображає декодер, який використовує режим перемикання, згідно з варіантом виконання; Фіг. 12 зображає декодер, який використовує режим перемикання, згідно з подальшим варіантом виконання; Фіг. 13 зображає кодер, який підключається до декодера з Фігури. 11, згідно з варіантом виконання; Фіг. 14 зображає кодер, який підключається до декодера з Фіг. 12, згідно з варіантом виконання; Фіг. 15 зображає графічну залежність pStateCtx і fullCtxState/256; Фіг. 16 зображає декодер згідно з варіантом виконання представленого винаходу; і Фіг. 17 зображає кодер згідно з варіантом виконання представленого винаходу. Фіг. 18 схематично зображає бінаризацію різниці векторів руху у відповідності з варіантом виконання представленого винаходу. Фіг. 19 схематично зображає концепцію злиття у відповідності з варіантом виконання; і Фіг. 20 схематично зображає схему прогнозування векторів руху у відповідності з варіантом виконання. Відзначається, що, під час опису фігур, елементи, які з'являються на декількох з цих Фігур, позначені однаковим позиційним позначенням на кожній з них і повторний опис цих елементів настільки, наскільки це стосується функцій, уникається для уникнення непотрібних повторів. Тим не менше, функції і описи, надані для однієї фігури, повинні також застосовуватися до інших Фігур, якщо чітко не вказано протилежне. Далі, по-перше, описуються варіанти виконання загальної концепції кодування відеоданих стосовно Фіг. 1-10. Фіг. 1-6 відносяться до частини відеокодека, яка працює на синтаксичному рівні. Наступні фігури 8-10 відносяться до варіантів виконання для частини коду, яка відноситься до перетворення потоку синтаксичних елементів на потік даних і навпаки. Потім, спеціальні аспекти і варіанти виконання представленого винаходу описуються у формі можливих втілень загальної концепції, описаної щодо Фіг. 1-10. Фіг. 1 зображає приклад для кодера 10, у якому можуть втілюватися аспекти представленого винаходу. Кодер кодує масив інформаційних зразків 20 з одержанням потоку даних. Масив інформаційних зразків може представляти інформаційні зразки, які відповідають, наприклад, 2 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 значенням світлоти, значенням кольору, значенням яскравості, значенням колірності або подібному. Однак, інформаційні зразки можуть також бути значеннями глибини у випадку масиву зразків 20, який є картою глибини, згенерованою, наприклад, часом датчика світла або подібним. Кодер 10 є блочним кодером. Тобто, кодер 10 кодує масив зразків 20 з одержанням потоку даних 30 у формі елементів з блоків 40. Кодування в елементах з блоків 40 необов'язково означає, що кодер 10 кодує ці блоки 40 цілком незалежно один від іншого. Скоріше, кодер 10 може використовувати відновлення попередньо кодованих блоків для екстраполяції або інтрапрогнозування решти блоків і може використовувати гранулярність блоків для визначення параметрів кодування, тобто, для визначення способу кодування кожної ділянки масиву зразків, яка відповідає відповідному блоку. Окрім того, кодер 10 є перетворювальним кодером. Тобто, кодер 10 кодує блоки 40 шляхом використання перетворення для перенесення зразків інформації в кожному блоці 40 з просторової області на спектральну область. Може використовуватися двовимірне перетворення, таке як DCT (дискретне косинусне перетворення) FFT (швидке перетворення Фур'є) або подібне. Переважно, блоки 40 мають квадратну форму або прямокутну форму. Підрозбиття масиву зразків 20 на блоки 40, зображене на Фіг. 1, просто служить для ілюстраційних цілей. Фіг. 1 зображає масив зразків 20, підрозбитий з одержанням стандартного двовимірного розташування квадратних або прямокутних блоків 40, які примикають один до іншого без налягання. Розмір блоків 40 може попередньо встановлюватися. Тобто, кодер 10 може не переносити інформацію про розмір блоків 40 в потоці даних 30 до декодувальної сторони. Наприклад, декодер може очікувати на наперед встановлений розмір блоку. Однак, можливі декілька альтернатив. Наприклад, блоки можуть налягати один на інший. Налягання може, однак, обмежуватися до такої міри, що кожен блок має частину, на яку не налягає будь-який сусідній блок, або так, що на кожен зразок блоків налягає максимум один блок серед сусідніх блоків, розташованих суміжно з поточним блоком вздовж наперед встановленого напряму. Останнє повинно означати, що ліві і праві сусідні блоки можуть налягати на поточний блок для повного покривання поточного блоку, але вони можуть не налягати один на інший і те ж саме застосовується для сусідніх блоків у вертикальному і діагональному напрямі. Як подальша альтернатива, підрозбиття масиву зразків 20 з одержанням блоків 40 може адаптуватися до контенту масиву зразків 20 кодером 10 за допомогою інформації про використовуване підрозбиття, яка переноситься до декодера потоком бітів 30. Фігури 2a-2c зображають різні приклади для підрозбиття масиву зразків 20 на блоки 40. Фіг. 2a зображає підрозбиття на основі квадродерева масиву зразків 20 на блоки 40 різних розмірів, при цьому відповідні блоки позначені позиціями 40a, 40b, 40c і 40d із зростаючим розміром. У відповідності з підрозбиттям з Фіг. 2a масив зразків 20 спершу ділиться на стандартну двовимірну схему деревних блоків 40d, які, у свою чергу, мають індивідуальну інформацію про підрозбиття, пов'язану з нею, згідно з якою певний деревний блок 40d може додатково підрозбиватися згідно зі структурою квадродерева або ні. Деревний блок зліва від блоку 40d ілюстративно підрозбитий на менші блоки у відповідності з структурою квадродерева. Кодер 10 може виконувати одне двовимірне перетворення для кожного з блоків, зображених суцільною і пунктирною лініями на Фіг. 2a. Іншими словами, кодер 10 може перетворювати масив 20 в елементи підрозбиття блоку. Замість підрозбиття на основі квадродерева може використовуватися більш загальне підрозбиття на основі мультидерева і кількість дочірніх вузлів на ієрархічному рівні може відрізнятися в різних ієрархічних рівнях. Фіг. 2b зображає інший приклад для підрозбиття. У відповідності з Фіг. 2b масив зразків 20 спершу ділиться на макроблоки 40b, розташовані згідно стандартної двовимірної схеми без взаємного налягання з упиранням один в інший, де кожен макроблок 40b зв'язаний з інформацією про підрозбиття, згідно з якою макроблок не підрозбивається або, якщо підрозбивається, то підрозбивається стандартним двовимірним способом на однакові субблоки для досягання різних гранулярностей підрозбиття для різних макроблоків. Результатом є підрозбиття масиву зразків 20 на різного розміру блоки 40 з представниками різних розмірів, які вказані позиціями 40a, 40b and 40a". Як і на Фіг. 2a кодер 10 виконує двовимірне перетворення на кожному з блоків, зображених на Фіг. 2b суцільними і пунктирними лініями. Фіг. 2c буде обговорюватися пізніше. Фіг. 3 зображає декодер 50, який здатен декодувати потік даних 30, генерований кодером 10, для відновлення відновленого варіанту 60 масиву зразків 20. Декодер 50 одержує з потоку даних 30 блок коефіцієнтів перетворення для кожного з блоків 40 і відновлює відновлений 3 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 варіант 60 шляхом виконання оберненого перетворення на кожному з блоків коефіцієнтів перетворення. Кодер 10 і декодер 50 можуть конфігуруватися для виконання ентропійного кодування/декодування для введення інформації про блоки коефіцієнтів перетворення і, відповідно, одержання цієї інформації з потоку даних. Деталі з цього приводу у відповідності з різними варіантами виконання описуються пізніше. Слід відзначити, що потік даних 30 необов'язково містить інформацію про блоки коефіцієнтів перетворення для усіх блоків 40 масиву зразків 20. Скоріше, підмножина блоків 40 може кодуватися іншим способом з одержанням потоку бітів 30. Наприклад, кодер 10 може приймати рішення утриматися від введення блоку коефіцієнтів перетворення для певного блоку з блоків 40 із введенням в потік бітів 30 альтернативних параметрів кодування, замість чого надавати можливість декодеру 50 прогнозувати або, інакше, поміщати відповідний блок у відновлений варіант 60. Наприклад, кодер 10 може виконувати аналіз текстури для поміщення блоків в масиві зразків 20, який може заповнюватися на декодувальній стороні декодером у вигляді синтезу текстури і вказує це, відповідним чином, в потоці бітів. Як це обговорюється стосовно наступних фігур, блоки коефіцієнтів перетворення необов'язково представляють спектральне представлення області зразків первинної інформації відповідного блоку 40 масиву зразків 20. Скоріше такий блок коефіцієнтів перетворення може представляти спектральне представлення області залишкових величин прогнозування відповідного блоку 40. Фіг. 4 зображає варіант виконання для такого кодера. Кодер з Фіг. 4 містить фазу перетворення 100, ентропійний кодер 102, фазу оберненого перетворення 104, предиктор 106 і блок віднімання 108, а також суматор 110. Блок віднімання 108, фаза перетворення 100 і ентропійний кодер 102 послідовно з'єднані в порядку, згаданому між входом 112 і виходом 114 кодера з Фіг. 4. Фаза оберненого перетворення 104, суматор 110 і предиктор 106 з'єднані в порядку, згаданому між виходом фази перетворення 100 і інверсним входом блоку віднімання 108, при цьому вихід предиктора 106 також з'єднаний з подальшим входом суматора 110. Кодер з Фіг. 4 зображає прогнозувальний перетворювальний блочний кодер. Тобто, блоки масиву зразків 20, який надходить на вхід 112, прогнозуються з попередньо кодованих і відновлених частин того ж масиву зразків 20 або попередньо кодованих і відновлених інших масивів зразків, які можуть передувати або слідувати за поточним масивом зразків 20 в даному часі. Прогнозування виконується предиктором 106. Блок віднімання 108 віднімає дані прогнозу від такого первинного блоку, а фаза перетворення 100 виконує двовимірне перетворення на залишкових величинах прогнозування. Двовимірне перетворення саме по собі або наступний захід всередині фази перетворення 100 може приводити до дискретизації коефіцієнтів перетворення в блоках коефіцієнтів перетворення. Дискретизовані блоки коефіцієнтів перетворення кодуються без втрат, наприклад, ентропійним кодуванням в ентропійному кодері 102 з виходом одержуваного потоку даних на виході 114. Фаза оберненого перетворення 104 відновлює дискретизований залишок, а суматор 110, у свою чергу, поєднує відновлений залишок відповідними даними прогнозування для одержання відновлених зразків інформації, на основі яких предиктор 106 може прогнозувати вищезгадані на даний момент кодовані прогнозувальні блоки. Предиктор 106 може використовувати різні режими прогнозування, такі як режими інтрапрогнозування і режими інтерпрогнозування, для прогнозування блоків, а параметри прогнозування направляються до ентропійного кодера 102 для введення в потік даних. Для кожного інтерпрогнозованого прогнозувального блоку відповідні дані руху вводяться в потік бітів за допомогою ентропійного кодера 114 для надання можливості декодувальній стороні повторно робити прогноз. Дані руху для прогнозувального блоку картинки можуть використовувати синтаксичну частину, яка містить синтаксичний елемент, який представляє різницю векторів руху, яка диференціально кодує вектор руху для поточного прогнозувального блоку відносно предиктора вектора руху, одержаного, наприклад, описаним способом з векторів руху сусідніх вже кодованих прогнозувальних блоків. Тобто, у відповідності з варіантом виконання з Фіг. 4, блоки коефіцієнтів перетворення скоріше представляють спектральне представлення залишку масиву зразків, а ніж його інформаційні зразки. Тобто, у відповідності з варіантом виконання з Фіг. 4, послідовність синтаксичних елементів може надходити в ентропійний кодер 102 для ентропійного кодування з одержанням потоку даних 114. Послідовність синтаксичних елементів може містити синтаксичні елементи різниці векторів руху для інтерпрогнозувальних блоків і синтаксичні елементи, які стосуються карти значущості, яка вказує положення рівнів значущості коефіцієнта перетворення, а також синтаксичні елементи, які самі по собі визначають рівні значущості коефіцієнта перетворення для блоків перетворення. 4 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Слід відзначити, що для варіанта виконання з Фіг. 4 існують декілька альтернатив, деякі з яких описані у вступній частині опису, який включений в опис Фіг. 4. Фіг. 5 зображає декодер, здатний декодувати потік даних, генерований кодером з Фіг. 4. Декодер з Фіг. 5 містить ентропійний декодер 150, фазу оберненого перетворення 152, суматор 154 і предиктор 156. Ентропійний декодер 150, фаза оберненого перетворення 152 і суматор 154 послідовно з'єднані між входом 158 і виходом 160 декодера з Фіг. 5 у згаданому порядку. Подальший вихід ентропійного декодера 150 з'єднаний з предиктором 156, який, у свою чергу, з'єднаний між виходом суматора 154 та його подальшим входом. Ентропійний декодер 150 виділяє з потоку даних, який надходить в декодер з Фіг. 5 на вхід 158, блоки коефіцієнтів перетворення, де для блоків коефіцієнтів перетворення на фазі 152 застосовується обернене перетворення для одержання залишкового сигналу. Залишковий сигнал поєднується з прогнозом від предиктора 156 на суматорі 154 для одержання відновленого блоку відновленого варіанту масиву зразків на виході 160. На основі відновлених варіантів предиктор 156 генерує прогнози, таким чином повторно створюючи прогнози, виконані предиктором 106 на кодувальній стороні. Для одержання тих же прогнозів, що використовуються на кодувальній стороні, предиктор 156 використовує параметри прогнозування, які ентропійний декодер 150 також одержує з потоку даних на вході 158. Слід відзначити, що у вищеописаних варіантах виконання просторова гранулярність, з якою виконується прогнозування і перетворення залишку, не повинна бути рівною між собою. Це зображено на Фіг. 2C. Ця фігура зображає підрозбиття для прогнозувальних блоків прогнозувальної гранулярності суцільними лініями і залишкову гранулярність – пунктирними лініями. Як можна побачити, підрозбиття можуть вибиратися кодером незалежно одне від іншого. Для більшої точності, синтаксис потоку даних може передбачати визначення підрозбиття залишку незалежно від підрозбиття прогнозу. Альтернативно, підрозбиття залишку може бути продовженням підрозбиття прогнозу так, що кожен залишковий блок або дорівнює або є належною підмножиною прогнозувального блоку. Це зображено на Фіг. 2a і Фіг. 2b, наприклад, де знову прогнозувальна гранулярність зображена суцільними лініями, а залишкова гранулярність – пунктирними лініями. Тобто, на Фіг. 2a-2c усі блоки, які мають позиційне позначення, повинні бути залишковими блоками, для яких повинно виконуватися двовимірне перетворення, тоді як блоки, вказані товщими суцільними лініями і охоплюють блоки 40a, вказані пунктирними лініями, наприклад, повинні бути прогнозувальними блоками, для яких індивідуально виконується визначення параметрів прогнозування. Вищезгадані варіанти виконання повинні перетворювати загалом такий блок (залишковий або первинний) зразків на кодувальній стороні з одержанням блоку коефіцієнтів перетворення, який, у свою чергу, повинен інверсно перетворюватися на відновлений блок зразків на декодувальній стороні. Це зображено на Фіг. 6. Фіг. 6 зображає блок зразків 200. У випадку Фіг. 6, цей блок 200 є ілюстративно квадратним і за розміром становить 4 × 4 зразки 202. Зразки 202 стандартно розташовані вздовж горизонтального напряму x і вертикального напряму y. Завдяки вищезгаданому двовимірному перетворенню T блок 200 перетворюється на спектральну область, зокрема на блок 204 коефіцієнтів 206 перетворення, який має той же розмір що й блок 200. Тобто, блок перетворення 204 має стільки коефіцієнтів 206 перетворення, скільки блок 200 має зразків як в горизонтальному напрямі так і у вертикальному напрямі. Однак, оскільки перетворення T є спектральним перетворенням, то положення коефіцієнтів 206 перетворення в блоці перетворення 204 не відповідають просторовим положенням, а скоріше спектральним компонентам контенту блоку 200. Зокрема, горизонтальна вісь блоку перетворення 204 відповідає осі, вздовж якої спектральна частота в горизонтальному напрямі монотонно зростає, тоді як вертикальна вісь відповідає осі, вздовж якої просторова частота у вертикальному напрямі монотонно зростає, де коефіцієнт перетворення компонента DC розташований в куті – тут ілюстративно верхній лівий кут - блоку 204 так, що в нижньому правому куті розташований коефіцієнт 206 перетворення, який відповідає найвищій частоті як в горизонтальному так і у вертикальному напрямі. Нехтуючи просторовим напрямом, просторова частота, якій належить певний коефіцієнт 206 перетворення, головним чином зростає від -1 верхнього лівого кута до нижнього правого кута. Завдяки оберненому перетворенню T блок перетворення 204 повторно переноситься з спектральної області на просторову область для повторного одержання копії 208 блоку 200. У випадку відсутності дискретизації/втрати під час перетворення, відновлення повинно бути досконалим. Як вже відзначалося вище, з Фіг. 6 можна побачити, що блок 200 більшого розміру збільшує спектральну роздільну здатність одержуваного спектрального представлення 204. З іншого боку, шум дискретизації має тенденцію до поширення по усьому блоку 208 і, таким чином, круті і дуже локалізовані об'єкти в блоках 200 мають тенденцію до появи відхилень повторно 5 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 перетвореного блоку відносно первинного блоку 200 завдяки шуму дискретизації. Основною перевагою використання більших блоків є, однак, те, що відношення між кількістю значущих, тобто, ненульових (дискретизованих) коефіцієнтів перетворення, тобто рівнів, з одного боку, і кількістю несуттєвих коефіцієнтів перетворення, з іншого боку, може зменшуватися в більших блоках порівняно з меншими блоками, таким чином забезпечуючи кращу ефективність кодування. Іншими словами, часто, рівні значущості коефіцієнта перетворення, тобто, коефіцієнти перетворення, не дискретизовані в нуль, рідко розподіляються по блоку перетворення 204. Завдяки цьому, у відповідності з варіантами виконання, описаними детальніше нижче, положення рівнів значущості коефіцієнта перетворення сигналізуються в потоці даних у вигляді карти значущості. Окремо від них величини значущого коефіцієнта перетворення, тобто, рівні значущості коефіцієнта перетворення у випадку коефіцієнтів перетворення, які дискретизуються, переносяться в потоці даних. Усі описані вище кодери і декодери, таким чином, конфігуруються для певного синтаксису синтаксичних елементів. Тобто, вищезгадані синтаксичні елементи, такі як рівні значущості коефіцієнта перетворення, синтаксичні елементи, які стосуються карти значущості блоків перетворення, синтаксичні елементи даних руху, які стосуються інтерпрогнозувальних блоків і так далі, припускаються тими, що послідовно розташовані в потоці даних попередньо встановленим способом. Такий попередньо встановлений спосіб може представлятися у формі псевдокоду, як це робиться, наприклад, в стандарті H.264 або інших відеокодеках. Ще іншими словами, вищенаведений опис головним чином має справу з перетворенням мультимедійних даних, тут ілюстративних відеоданих, на послідовність синтаксичних елементів у відповідності з попередньо визначеною синтаксичною структурою, яка описує певні типи синтаксичних елементів, їх семантику і порядок серед них. Ентропійний кодер і ентропійний декодер з Фіг. 4 і 5 можуть конфігуруватися для роботи і можуть структуруватися, як вказано далі. Те ж саме відповідає за виконання перетворення між послідовністю синтаксичних елементів і потоком даних, тобто, символьним або бітовим потоком. Ентропійний кодер згідно з варіантом виконання зображений на Фіг. 7. Кодер без втрат перетворює потік синтаксичних елементів 301 на множину з двох або більшої кількості часткових бітових потоків 312. В переважному варіанті виконання винаходу кожен синтаксичний елемент 301 зв'язується з категорією множини з однієї або більшої кількості категорій, тобто, типом синтаксичного елемента. Як приклад, категорії можуть специфікувати тип синтаксичного елемента. В контексті гібридного кодування відеоданих окрема категорія може зв'язуватися з режимами макроблочного кодування, режимами блочного кодування, індексами еталонної картинки, різницями векторів руху, ідентифікаторами підрозбиття, ідентифікаторами кодованих блоків, параметрами дискретизації, рівнями значущості коефіцієнта перетворення і так далі. В інших областях застосування, таких як аудіо-кодування, кодування мови, кодування тексту, кодування документа або кодування загальних даних, можливі різні категоризації синтаксичних елементів. Загалом, кожен синтаксичний елемент може приймати величину із скінченої або зчисленної нескінченої множини величин, де множина можливих величин синтаксичних елементів може відрізнятися для різних категорій синтаксичних елементів. Наприклад, існують бінарні синтаксичні елементи, а також цілі синтаксичні елементи. Для зниження складності алгоритму кодування і декодування, і для надання можливості виконання загальної схеми кодування і декодування для різних синтаксичних елементів і категорій синтаксичних елементів, синтаксичні елементи 301 перетворюються на упорядковані множини бінарних рішень і ці бінарні рішення потім обробляються простими алгоритмами бінарного кодування. Тому, бінаризатор 302 бієктивно перетворює величину кожного синтаксичного елемента 301 на послідовність (або рядок або слово) з двійкових кодів 303. Послідовність двійкових кодів 303 представляє множину упорядкованих бінарних рішень. Кожний двійковий код 303 або бінарне рішення може приймати одну величину з множини з двох величин, наприклад, одну з величин, вибрану з 0 і 1. Схема бінаризації може відрізнятися для різних категорій синтаксичних елементів. Схема бінаризації для окремої категорії синтаксичних елементів може залежати від множини можливих величин синтаксичних елементів і/або інших властивостей синтаксичного елемента для окремої категорії. Таблиця 1 зображає три ілюстративні схеми бінаризації для зчисленних нескінчених множин. Схеми бінаризації для зчисленних нескінчених множин можуть також застосовуватися для скінчених множин величин синтаксичних елементів. Зокрема, для великих скінчених множин величин синтаксичних елементів неефективність (одержувана з невикористаних послідовностей двійкових кодів) може бути нехтуваною, але універсальність таких схем бінаризації надає перевагу з точкизору складності та вимог до пам'яті. Для малих скінчених множин величин 6 UA 111741 C2 5 10 15 синтаксичних елементів часто вигідно (з точки зору ефективності кодування) адаптувати схему бінаризації до кількості можливих символьних величин. Таблиця 2 зображає три ілюстративні схеми бінаризації для скінчених множин з 8 величин. Схеми бінаризації для скінчених множин можна одержати з універсальних схем бінаризації для зчисленних нескінчених множин шляхом модифікації деяких послідовностей двійкових кодів у такий спосіб, що скінчені множини послідовностей двійкових кодів представляють код без резервування (і який потенційно повторно упорядковує послідовності двійкових кодів). Як приклад, схема бінаризації з використанням усічених унарних кодів в Таблиці 2 була створена шляхом модифікації послідовності двійкових кодів для синтаксичного елемента 7 бінаризації з використанням універсальних унарних кодів (дивіться Таблицю 1). Переупорядкована бінаризація з використанням експоненціальних кодів Голомба порядку 0 в Таблиці 2 створена модифікацією послідовності двійкових кодів для синтаксичного елемента 7 бінаризації з використанням універсальних експоненціальних кодів Голомба порядку 0 (дивіться Таблицю 1) і повторним упорядкуванням послідовностей двійкових кодів (послідовність усічених двійкових кодів для символу 7 присвоєна символу 1). Для скінчених множин синтаксичних елементів також можна використовувати несистематичні/неуніверсальні схеми бінаризації, як ілюструється в останньому стовпчику Таблиці 2. Таблиця 1 Приклади бінаризації для зчисленних нескінчених множин (або великих скінчених множин) Бінаризація з Бінаризація з використанням Символьна величина використанням унарних експоненціальних кодів кодів Голомба порядку 0 0 1 1 1 01 010 2 001 011 3 0001 0010 0 4 0000 1 0010 1 5 0000 01 0011 0 6 0000 001 0011 1 7 0000 0001 0001 000 … … … Бінаризація з використанням експоненціальних кодів Голомба порядку 1 10 11 0100 0101 0110 0111 0010 00 0010 01 … Таблиця 2 Приклади бінаризації для скінчених множин переупорядкована бінаризація з Бінаризація з використанням Символьна величина використанням експоненціальних усіченого унарного коду усічених кодів Голомба порядку 0 0 1 1 1 01 000 2 001 010 3 0001 011 4 0000 1 0010 0 5 0000 01 0010 1 6 0000 001 0011 0 7 0000 000 0011 1 Несистематична бінаризація 000 001 01 1000 1001 1010 1011 0 1011 1 20 Кожен двійковий код 303 послідовності двійкових кодів, створеної бінаризатором 302, подається в присвоювач 304 параметрів у послідовному порядку. Присвоювач параметрів присвоює множину з одного або більшої кількості параметрів кожному двійковому коду 303 і видає двійковий код з відповідною множиною параметрів 305. Множина параметрів 7 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 визначається точно одним і тим же способом в кодері і декодері. Множина параметрів може складатися з одного або більшої кількості наступних параметрів: Зокрема, присвоювач 304 параметрів може конфігуруватися для присвоювання поточному двійковому коду 303 моделі контексту. Наприклад, присвоювач 304 параметрів може вибирати один з доступних індексів контексту для поточного двійкового коду 303. Доступна множина контекстів для поточного двійкового коду 303 може залежати від типу двійкового коду, який, у свою чергу, може визначатися типом/категорією синтаксичного елемента 301, в результаті бінаризації якого поточний двійковий код 303 є його частиною, а положення поточного двійкового коду 303 знаходиться в пізнішій бінаризації. Вибір контексту серед множини доступних контекстів може залежати від попередніх двійкових кодів і синтаксичних елементів, пов'язаних з ними. Кожен з цих контекстів має модель ймовірності, зв'язану з ним, тобто, засіб для оцінки ймовірності для поточної інформаційної величини набуття одного з двох можливих значень інформаційної величини. Модель ймовірності може, зокрема, бути засобом для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення, при цьому модель ймовірності додатково визначається ідентифікатором, який специфікує оцінку, яке з двох можливих значень інформаційної величини представляє її менш ймовірне або більш ймовірне значення поточного двійкового коду 303. У випадку просто одного контексту, який доступний для поточної інформаційної величини, вибір контексту може не виконуватися. Як буде описано детальніше нижче, присвоювач 304 параметрів може також виконувати адаптацію моделі ймовірності для адаптації моделей ймовірностей, зв'язаних з різними контекстами, до реальної статистики відповідних інформаційних величин, які належать відповідним контекстам. Як буде також детальніше описуватися нижче, присвоювач 304 параметрів може працювати диференційно в залежності від високоефективного режиму (HE) або режиму низької складності (LC), який активується. В обох режимах модель ймовірності зв'язує поточну інформаційну величину двійкового коду 303 з будь-яким з двійкових кодерів 310, як буде описано нижче, а режим роботи присвоювача 304 параметрів має тенденцію бути менш складним в режимі LC, однак, ефективність кодування зростає у високоефективному режимі внаслідок того, що присвоювач 304 параметрів, який зв'язує окремі інформаційні величини двійкового коду 303 з окремими кодерами 310, акуратніше адаптований до статистики інформаційних величин, таким чином оптимізуючи ентропію відносно режиму LC. Кожна інформаційна величина з відповідною множиною параметрів 305, яка є виходом присвоювача 304 параметрів, подається до двійкового буферного селектора 306. Двійковий буферний селектор 306 потенційно модифікує значення вхідної інформаційної величини 305 на основі її значення і відповідних параметрів 305, і подає вихідну інформаційну величину 307 з потенційно модифікованим значенням до одного з двох або більшої кількості двійкових буферів 308. Двійковий буфер 308, до якого надсилається вихідна інформаційна величина 307, визначається на основі значення вхідної інформаційної величини 305 і/або величини відповідних параметрів 305. В переважному варіанті виконання винаходу двійковий буферний селектор 306 не модифікує значення інформаційної величини, тобто, вихідна інформаційна величина 307 має завжди те ж значення що й вхідна інформаційна величина 305. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 306 визначає значення вихідної інформаційної величини 307 на основі значення вхідної інформаційної величини 305 і відповідне значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень. В переважному варіанті виконання винаходу значення вихідної інформаційної величини 307 встановлюється рівним значенню вхідної інформаційної величини 305, якщо значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох можливих її значень менше за (або менше або рівне) конкретне порогове значення; якщо значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох можливих її значень більше або рівне (або більше) конкретного порогового значення, то значення вихідної інформаційної величини 307 модифікується (тобто, воно встановлюється рівним протилежному значенню вхідної інформаційної величини). В подальшому переважному варіанті виконання винаходу значення вхідної інформаційної величини 307 встановлюється рівним значенню вхідної інформаційної величини 305, якщо значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох можливих її значень більше за (або більше або рівне) конкретне порогове значення; якщо значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох можливих її значень менше або рівне (або менше) конкретного пороговому значенню, то значення вихідної інформаційної величини 307 модифікується (тобто, воно встановлюється 8 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 рівним протилежному значенню вхідної інформаційної величини). В переважному варіанті виконання винаходу значення порогу відповідає величині 0,5 для оціненої ймовірності набуття обох можливих значень інформаційної величини. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 306 визначає значення вихідної інформаційної величини 307 на основі значення вхідної інформаційної величини 305 і відповідного ідентифікатора, який специфікує оцінку, завдяки якій одне з двох можливих значень інформаційної величини представляє менш ймовірне або більш ймовірне значення для поточної інформаційної величини. В переважному варіанті виконання винаходу значення вихідної інформаційної величини 307 встановлюється рівним значенню вхідної інформаційної величини 305, якщо ідентифікатор специфікує, що перше з двох можливих значень інформаційної величини представляє менш ймовірне (або більш ймовірне) значення для поточної інформаційної величини, а значення вихідної інформаційної величини 307 модифікується (тобто, воно встановлюється рівним протилежному значенню вхідної інформаційної величини), якщо ідентифікатор специфікує, що друге з двох можливих значень інформаційної величини представляє менш ймовірне (абобільш ймовірне) значення для поточної інформаційної величини. В переважному варіанті виконання винаходу двійковий буферний селектор 306 визначає двійковий буфер 308, до якого надсилається значення вихідної інформаційної величини 307, на основі відповідного значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень. В переважному варіанті виконання винаходу множина можливих значень для визначення оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень є скінченою і двійковий буферний селектор 306 містить таблицю, яка точно зв'язує один двійковий буфер 308 з кожним можливим значенням для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень, де різні значення для визначення оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень можуть зв'язуватися з одним і тим же двійковим буфером 308. В подальшому переважному варіанті виконання винаходу інтервал можливих значень для визначення оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень ділиться на ряд інтервалів, двійковий буферний селектор 306 визначає індекс інтервалу для поточного значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень і двійковий буферний селектор 306 містить таблицю, яка точно зв'язує один двійковий буфер 308 з кожним можливим значенням для індексу інтервалу, де різні значення для індексу інтервалу можуть зв'язуватися з одним і тим же двійковим буфером 308. В переважному варіанті виконання винаходу вхідні інформаційні величини 305 з протилежними значеннями для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень (протилежні значення є ті, які представляють оцінки ймовірності P і 1 − P) надсилаються в один і той же двійковий буфер 308. В подальшому переважному варіанті виконання винаходу зв'язування значення для оцінки ймовірності набуття поточною інформаційною величиною одного з двох її можливих значень з окремим двійковим буфером адаптується з часом, наприклад, для гарантії того, що створені часткові потоки бітів мають подібні швидкості передачі бітів. Далі нижче, індекс інтервалу буде також називатися pipe індексом, тоді як pipe індекс разом з індексом деталізації і ідентифікатором, який вказує більш ймовірне значення інформаційної величини, індексують фактичну модель ймовірності, тобто, оцінку ймовірності. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 306 визначає двійковий буфер 308, до якого надсилають вихідну інформаційну величину 307, на основі відповідного значення для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення. В переважному варіанті виконання винаходу множина можливих значень для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення є скінченою і двійковий буферний селектор 306 містить таблицю, яка точно зв'язує один двійковий буфер 308 з кожним можливим значенням оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення, де різні значення для визначення оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення можуть зв'язуватися з одним і тим же двійковим буфером 308. В подальшому переважному варіанті виконання винаходу інтервал можливих значень для визначення оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення ділиться на ряд інтервалів, двійковий буферний селектор 306 визначає індекс інтервалу для поточного визначення оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення, а двійковий 9 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 буферний селектор 306 містить таблицю, яка точно зв'язує один двійковий буфер 308 з кожним можливим значенням для індексу інтервалу, де різні значення для індексу інтервалу можуть зв'язуватися з одним і тим же двійковим буфером 308. В подальшому переважному варіанті виконання винаходу зв'язування значення для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення з окремим двійковим буфером адаптується з часом, наприклад, для гарантії того, що створені часткові потоки бітів мають подібні швидкості передачі бітів. Кожен з двох або більшої кількості двійкових буферів 308 з'єднаний точно з одним двійковим кодером 310 і кожен двійковий кодер з'єднаний тільки з одним двійковим буфером 308. Кожен двійковий кодер 310 зчитує інформаційні величини з відповідного двійкового буфера 308 і перетворює послідовність інформаційних величин 309 на кодове слово 311, яке представляє послідовність бітів. Двійкові буфери 308 представляють буфери, які працюють по принципу "першим надійшов-першим вийшов"; інформаційні величини, які подаються пізніше (у послідовному порядку) у двійковий буфер 308, не кодуються перед інформаційним величинами, які подаються раніше (у послідовному порядку) у двійковий буфер. Кодові слова 311, які є виходом з окремого двійкового кодера 310, записуються в окремий частковий потік бітів 312. Загальний алгоритм кодування перетворює синтаксичні елементи 301 на два або більшу кількість часткових потоків бітів 312, де кількість часткових потоків бітів дорівнює кількості двійкових буферів і двійкових кодерів. В переважному варіанті виконання винаходу двійковий кодер 310 перетворює змінну кількість інформаційних величин 309 на кодове слово 311 із змінною кількістю бітів. Однією перевагою вище-і нижчеописаних варіантів виконання винаходу є те, що кодування інформаційних величин може здійснюватися паралельно (наприклад, для різних груп значень ймовірності), що зменшує тривалість обробки для декількох втілень. Іншою перевагою варіантів виконання винаходу є те, що кодування інформаційних величин, яке виконується двійковими кодерами 310, може спеціально розроблятися для різних множин параметрів 305. Зокрема, кодування і декодування інформаційних величин можуть оптимізуватися (з точки зору ефективності кодування і/або складності) для різних груп оцінених ймовірностей. З одного боку, це дозволяє послабити складність кодування/декодування і, з іншого боку, це дозволяє покращити ефективність кодування. В переважному варіанті виконання винаходу двійкові кодери 310 втілюють різні алгоритми кодування (тобто, перетворення послідовностей інформаційних величин на кодові слова) для різних груп значень оцінки ймовірності набуття поточною інформаційною величиною одного з її двох можливих значень. В подальшому переважному варіанті виконання винаходу двійкові кодери 310 втілюють різні алгоритми кодування для різних груп значень для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення. В переважному варіанті виконання винаходу двійкові кодери 310 (або один або більша кількість двійкових кодерів) представляють ентропійні кодери, які безпосередньо перетворюють послідовності вхідних інформаційних величин 309 на кодові слова 310. Такі перетворення можуть ефективно виконуватися і не вимагають складного арифметичного кодувального засобу. Обернене перетворення кодових слів на послідовності інформаційних величин (як це робиться в декодері) повинне бути унікальним для гарантії досконалого декодування вхідної послідовності, але перетворення послідовностей 309 інформаційних величин на кодові слова 310 необов'язково потребує бути унікальною, тобто, можна, щоб окрему послідовність інформаційних величин можна було перетворювати на більше ніж одну послідовність кодових слів. В переважному варіанті виконання винаходу перетворення послідовностей вхідних інформаційних величин 309 на кодові слова 310 є бієктивним. В подальшому переважному варіанті виконання винаходу двійкові кодери 310 (або один або більша кількість двійкових кодерів) представляють ентропійні кодери, які безпосередньо перетворюють послідовності вхідних інформаційних величин 309 змінної довжини на кодові слова 310 змінної довжини. В переважному варіанті виконання винаходу вихідні кодові слова представляють коди без надлишку, такі як загальні коди Хаффмана або канонічні коди Хаффмана. Два приклади для бієктивного перетворення послідовностей інформаційних величин на коди без надлишку зображені в Таблиці 3. В подальшому переважному варіанті виконання винаходу вихідні кодові слова представляють надлишкові коди, придатні для виявлення помилки і виправлення помилки. В подальшому переважному варіанті виконання винаходу вихідні кодові слова представляють шифрувальні коди, придатні для шифрування синтаксичних елементів. 10 UA 111741 C2 Таблиця 3 Приклади для перетворень між послідовностями інформаційних величин і кодовими словами послідовність інформаційних величин (порядок інформаційної величини зліва направо) 0000 0000 0000 0001 0000 001 0000 01 0000 1 0001 001 01 1 послідовність інформаційних величин (порядок інформаційної величини зліва направо) 000 01 001 11 1000 0 1001 1010 1000 1 1011 5 10 15 20 25 кодові слова (порядок бітів зліва направо) 1 0000 0001 0010 0011 0100 0101 0110 0111 кодові слова (порядок бітів зліва направо) 10 11 010 011 0001 0010 0011 0000 0 0000 1 В подальшому переважному варіанті виконання винаходу двійкові кодери 310 (або один або більша кількість двійкових кодерів) представляють ентропійні кодери, які безпосередньо перетворюють послідовності вхідних інформаційних величин 309 змінної довжини на кодові слова 310 фіксованої довжини. В подальшому переважному варіанті виконання винаходу двійкові кодери 310 (або один або більша кількість двійкових кодерів) представляють ентропійні кодери, які безпосередньо перетворюють послідовності вхідних інформаційних величин 309 фіксованої довжини на кодові слова 310 змінної довжини. Декодер згідно з варіантом виконання винаходу зображений на Фігурі 8. Декодер виконує головним чином інверсні операції кодера таким чином, що (попередньо кодована) послідовність синтаксичних елементів 327 декодуються з множини з двох або більшої кількості часткових потоків бітів 324. Декодер містить два різні технологічні потоки: потік для інформаційних запитів, який копіює потік даних кодера, і потік даних, який представляє інверсію потоку даних кодера. На Фіг. 8 стрілки, позначені пунктирними лініями, представляють потік інформаційних запитів, тоді як стрілки, позначені суцільною лінією, представляють потік даних. Стандартні блоки декодера головним чином копіюють стандартні блоки кодера, але виконують обернені операції. Декодування синтаксичного елемента запускається запитом на надання нового декодованого синтаксичного елемента 313, який надсилається до бінаризатора 314. В переважному варіанті виконання винаходу кожен запит на надання нового декодованого синтаксичного елемента 313 зв'язується з категорією множини однієї або більшої кількості категорій. Категорія, яка зв'язується із запитом на надання синтаксичного елемента, є тією ж що й категорія, яка була зв'язана з відповідним синтаксичним елементом під час кодування. Бінаризатор 314 перетворює запит на надання синтаксичного елемента 313 на один або більшу кількість запитів на надання інформаційної величини, які надсилаються до присвоювача 316 параметрів. Як кінцеву відповідь на запит на надання інформаційної величини, який надсилається бінаризатором 314 до присвоювача 316 параметрів, бінаризатор 314 приймає 11 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 декодовану інформаційну величину 326 від двійкового буферного селектора 318. Бінаризатор 314 порівнює прийняту послідовність декодованих двійкових кодів 326 з послідовностями двійкових кодів окремої схеми бінаризації для запрошеного синтаксичного елемента і, якщо прийнята послідовність декодованих двійкових кодів 326 відповідає результатам бінаризації синтаксичного елемента, то бінаризатор спорожнює свій двійковий буфер і видає декодований синтаксичний елемент як остаточну відповідь на запит на надання нового декодованого символу. Якщо вже прийнята послідовність декодованих двійкових кодів не відповідає жодній з послідовностей двійкових кодів для схеми бінаризації для запрошеного синтаксичного елемента, то бінаризатор надсилає інший запит на надання інформаційної величини до присвоювач параметрів до тих пір, доки послідовність декодованих двійкових кодів не відповідатиме одній з послідовностей двійкових кодів схеми бінаризації для запрошеного синтаксичного елемента. Для кожного запиту на надання синтаксичного елемента декодер використовує одну і ту ж схему бінаризації, яку використовували для кодування відповідного синтаксичного елемента. Схема бінаризації може відрізнятися для різних категорій синтаксичних елементів. Схема бінаризації для окремої категорії синтаксичного елемента може залежати від множини можливих значень синтаксичного елемента і/або інших властивостей синтаксичних елементів для окремої категорії. Присвоювач 316 параметрів присвоює множину з одного або більшої кількості параметрів кожному запиту на надання інформаційної величини і надсилає запит на надання інформаційної величини з відповідною множиною параметрів до двійкового буферного селектора. Множина параметрів, які присвоюються запрошеній інформаційній величині присвоювачем параметрів, є тією ж, що була присвоєна відповідній інформаційній величині під час кодування. Множина параметрів може складатися з одного або більшої кількості параметрів, які згадуються в описі кодера з Фіг. 7. В переважному варіанті виконання винаходу присвоювач 316 параметрів зв'язує кожен запит на надання інформаційної величини з одними і тими ж параметрами що й присвоювач 304 параметрів, тобто, контекст і його відповідне значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень, таке як значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення і ідентифікатор, який специфікує оцінку, завдяки якій одне з двох можливих значень інформаційної величини представляє її менш ймовірне або більш ймовірне значення для поточної запрошеної інформаційної величини. Присвоювач 316 параметрів може визначати одну або більшу кількість вищезгаданих значень ймовірності (значення оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень, значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення, ідентифікатор, який специфікує оцінку, завдяки якій одне з двох можливих значень інформаційної величини представляє її менш ймовірне або більш ймовірне значення для поточної запрошеної інформаційної величини) на основі множини з одного або більшої кількості вже декодованих символів. Визначення значень ймовірності для окремого запиту на надання інформаційної величини копіює процес в кодері для відповідної інформаційної величини. Декодовані символи, які використовуються для визначення величин ймовірності, можуть включати один або більшу кількість вже декодованих символів однієї і тієї ж категорії, які відповідають множинам даних (таким як блоки або групи зразків) про сусідні просторові і/або тимчасові розташування (по відношенню до множини даних, зв'язаної з поточним запитом на надання синтаксичного елемента), або один або більшу кількість вже декодованих символів різних категорій, які відповідають множинам даних про однакові і/або сусідні просторові, і/або тимчасові розташування (по відношенню до множини даних, зв'язаної з поточним запитом на надання синтаксичного елемента). Кожен запит на надання інформаційної величини з відповідною множиною параметрів 317, яка є виходом присвоювача 316 параметрів, подається у двійковий буферний селектор 318. На основі відповідної множини параметрів 317 двійковий буферний селектор 318 надсилає запит на надання інформаційної величини 319 до одного з двох або більшої кількості двійкових буферів 320 і приймає декодовану інформаційну величину 325 від вибраного двійкового буфера 320. Декодована вхідна інформаційна величина 325 потенційно модифікується і декодована вихідна інформаційна величина 326 (з потенційно модифікованим значенням) надсилається до бінаризатора 314 як кінцева відповідь на запит на надання інформаційної величини з відповідною множиною параметрів 317. 12 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Двійковий буфер 320, до якого надсилається запит на надання інформаційної величини, вибирається тим же способом що й двійковий буфер, до якого була надіслана вихідна інформаційна величина двійкового буферного селектора на кодувальній стороні. В переважному варіанті виконання винаходу двійковий буферний селектор 318 визначає двійковий буфер 320, до якого надсилається запит на надання інформаційної величини 319, на основі відповідного значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень. В переважному варіанті виконання винаходу множина можливих значень для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень є скінченою, а двійковий буферний селектор 318 містить таблицю, яка точно зв'язує один двійковий буфер 320 з кожним можливим значенням оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень, де різні значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень можуть зв'язуватися з одним і тим же двійковим буфером 320. В подальшому переважному варіанті виконання винаходу інтервал можливих значень для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень ділиться на ряд інтервалів, двійковий буферний селектор 318 визначає індекс інтервалу для поточної оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень і двійковий буферний селектор 318 містить таблицю, яка точно зв'язує один двійковий буфер 320 з кожним можливим значенням для індексу інтервалу, де різні значення для індексу інтервалу можуть зв'язуватися з одним і тим же двійковим буфером 320. В переважному варіанті виконання винаходу запити на надання інформаційних величин 317 з протилежними значеннями для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень (протилежні значення є тими, які представляють оцінки ймовірностей P і 1 − P) надсилаються до одного і того ж двійкового буфера 320. В подальшому переважному варіанті виконання винаходу зв'язування значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень з конкретним двійковим буфером адаптується з часом. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 318 визначає двійковий буфер 320, до якого надсилається запит на надання інформаційної величини 319, на основі відповідного значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення. В переважному варіанті виконання винаходу множина можливих значень для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення є скінченою і двійковий буферний селектор 318 містить таблицю, яка точно зв'язує один двійковий буфер 320 з кожним можливим значенням оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення, де різні значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення можуть зв'язуватися з одним і тим же двійковим буфером 320. В подальшому переважному варіанті виконання винаходу інтервал можливих величин для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення ділиться на ряд інтервалів, двійковий буферний селектор 318 визначає індекс інтервалу для поточної оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення і двійковий буферний селектор 318 містить таблицю, яка точно зв'язує один двійковий буфер 320 з кожним можливим значення для індексу інтервалу, де різні значення для індексу інтервалу можуть зв'язуватися з одним і тим же двійковим буфером 320. В подальшому переважному варіанті виконання винаходу зв'язування оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення з окремим двійковим буфером адаптується з часом. Після одержання декодованої інформаційної величини 325 від вибраного двійкового буфера 320 двійковий буферний селектор 318 потенційно модифікує вхідну інформаційну величину 325 і надсилає вихідну інформаційну величину 326 (з потенційно модифікованим значенням) до бінаризатора 314. Перетворення вхідної/вихідної інформаційної величини двійкового буферного селектора 318 є оберненим перетворенням вхідної/вихідної інформаційної величини двійкового буферного селектора на кодувальній стороні. В переважному варіанті виконання винаходу двійковий буферний селектор 318 не змінює значення інформаційної величини, тобто, вихідна інформаційна величина 326 завжди має одне і те ж значення що й вхідна інформаційна величина 325. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 318 визначає значення вихідної 13 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 інформаційної величини 326 на основі значення вхідної інформаційної величини 325 і значення для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень, яке зв'язане із запитом на надання інформаційної величини 317. В переважному варіанті виконання винаходу значення вихідної інформаційної величини 326 встановлюється рівним значенню вхідної інформаційної величини 325, якщо значення ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень менше ніж (або менше ніж або дорівнює) окреме порогове значення; якщо значення ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень більше або дорівнює (або більше за) окремому пороговому значенню, то значення вихідної інформаційної величини 326 модифікується (тобто, воно встановлюється рівним протилежному значенню вхідної інформаційної величини). В подальшому переважному варіанті виконання винаходу значення вихідної інформаційної величини 326 встановлюється рівним значенню вхідної інформаційної величини 325, якщо значення ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень більше за (або більше за або дорівнює) окреме порогове значення; якщо значення ймовірності на набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень менше ніж або дорівнює (або менше ніж) окремому пороговому значенню, то значення вихідної інформаційної величини 326 модифікується (тобто, воно встановлюється рівним протилежному значенню вхідної інформаційної величини). В переважному варіанті виконання винаходу значення порогу відповідає величині 0,5 для оціненої ймовірності набуття поточною запрошеною інформаційною величиною обох її можливих величин. В подальшому переважному варіанті виконання винаходу двійковий буферний селектор 318 визначає значення вихідної інформаційної величини 326 на основі значення вхідної інформаційної величини 325, а ідентифікатор, який специфікує оцінку, завдяки якій одне з двох можливих значень інформаційної величини представляє її менш ймовірне або більш ймовірне значення для поточної запрошеної інформаційної величини, яке зв'язане із запитом на надання інформаційної величини 317. В переважному варіанті виконання винаходу значення вихідної інформаційної величини 326 встановлюється рівним значенню вхідної інформаційної величини 325, якщо ідентифікатор специфікує, що перше з двох можливих значень інформаційної величини представляє її менш ймовірне (або більш ймовірне) значення для поточної запрошеної інформаційної величини і значення вихідної інформаційної величини 326 модифікується (тобто, воно встановлюється рівним протилежному значенню вхідної інформаційної величини), якщо ідентифікатор специфікує, що друге з двох можливих значень інформаційної величини представляє її менш ймовірне (або більш ймовірне) значення для поточної запрошеної інформаційної величини. Як описано вище, двійковий буферний селектор надсилає запит на надання інформаційної величини 319 одному з двох або більшої кількості двійкових буферів 320. Двійкові буфери 20 представляють собою буфери, які працюють по принципу „першим прийшов першим вийшов", до яких подаються послідовності декодованих інформаційних величин 321 від під'єднаних двійкових декодерів 322. Як відповідь на запит на надання інформаційної величини 319, яка надсилається до двійкового буфера 320 від двійкового буферного селектора 318, двійковий буфер 320 видаляє інформаційну величину з свого контенту, який спершу був поданий в двійковий буфер 320, і надсилає його до двійкового буферного селектора 318. Інформаційні величини, які раніше надсилаються до двійкового буфера 320, раніше видаляються і надсилаються до двійкового буферного селектора 318. Кожен з двох або більшої кількості двійкових буферів 320 точно з'єднаний з одним двійковим декодером 322 і кожен двійковий декодер з'єднаний тільки з одним двійковим буфером 320. Кожен двійковий декодер 322 зчитує кодові слова 323, які представляють послідовності бітів, з окремого часткового потоку бітів 324. Двійковий декодер перетворює кодове слово 323 на послідовність інформаційних величин 321, яка надсилається до під'єднаного двійкового буфера 320. Загальний алгоритм декодування перетворює два або більшу кількість часткових потоків бітів 324 на ряд декодованих синтаксичних елементів, де кількість часткових потоків бітів дорівнює кількості двійкових буферів і двійкових декодерів, а декодування синтаксичних елементів запускається запитами на надання нових синтаксичних елементів. В переважному варіанті виконання винаходу двійковий декодер 322 перетворює кодові слова 323 із змінною кількістю бітів на послідовність змінної кількості інформаційних величин 321. Одна перевага варіантів виконання винаходу полягає в тому, що декодування інформаційних величин з двох або більшої кількості часткових потоків бітів може виконуватися паралельно (наприклад, для різних груп значень ймовірності), що зменшує час обробки для декількох втілень. 14 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Інша перевага варіантів виконання винаходу полягає в тому, що декодування інформаційних величин, яке виконується двійковими декодерами 322, може спеціально розроблятися для різних множин параметрів 317. Зокрема, кодування і декодування інформаційних величин можуть оптимізуватися (з точки зору ефективності кодування і/або складності) для різних груп оцінених ймовірностей. З одного боку, це дозволяє послаблення складності кодування/декодування відносно алгоритмів ентропійного кодування рівня техніки з подібною ефективністю кодування. З іншого боку, це дозволяє покращити ефективність кодування відносно алгоритмів ентропійного кодування рівня техніки з подібною складністю кодування/декодування. В переважному варіанті виконання винаходу двійкові декодери 322 втілюють різні алгоритми декодування (тобто, перетворення послідовностей інформаційних величин на кодові слова) для різних груп значень для оцінки ймовірності набуття поточною запрошеною інформаційною величиною одного з двох її можливих значень 317. В подальшому переважному варіанті виконання винаходу двійкові декодери 322 втілюють різні алгоритми декодування для різних груп значень для оцінки ймовірності набуття поточною запрошеною інформаційною величиною її менш ймовірного або більш ймовірного значення. Двійкові декодери 322 виконують обернене перетворення по відношенню до перетворення, здійснюваного відповідними двійковими кодерами на кодувальній стороні. В переважному варіанті виконання винаходу двійкові декодери 322 (або один або більша кількість двійкових декодерів) представляють ентропійні декодери, які безпосередньо перетворюють кодові слова 323 на послідовності інформаційних величин 321. Такі перетворення можуть ефективно виконуватися і не вимагають складного арифметичного кодувального засобу. Перетворення кодових слів на послідовності інформаційних величин повинно бути унікальним. В переважному варіанті виконання винаходу перетворення кодових слів 323 на послідовності інформаційних величин 321 є бієктивним. В подальшому переважному варіанті виконання винаходу двійкові декодери 310 (або один або більша кількість двійкових декодерів) представляють ентропійні декодери, які безпосередньо перетворюють кодові слова 323 змінної довжини на послідовності інформаційних величин 321 змінної довжини. В переважному варіанті виконання винаходу вхідні кодові слова представляють коди без надлишку, такі як загальні коди Хаффмана або канонічні коди Хаффмана. Два приклади для бієктивного перетворення кодів без надлишку на послідовності інформаційних величин вказані в Таблиці 3. В подальшому переважному варіанті виконання винаходу двійкові декодери 322 (або один або більша кількість двійкових декодерів) представляють ентропійні декодери, які безпосередньо перетворюють кодові слова 323 фіксованої довжини на послідовності інформаційних величин 321 змінної довжини. В подальшому переважному варіанті виконання винаходу двійкові декодери 322 (або один або більша кількість двійкових декодерів) представляють ентропійні декодери, які безпосередньо перетворюють кодові слова 323 змінної довжини на послідовності інформаційних величин 321 фіксованої довжини. Таким чином, Фіг. 7 і 8 зображають варіант виконання кодера для кодування послідовності символів 3 і декодер для їх відновлення. Кодер містить присвоювач 304, сконфігурований для присвоєння ряду параметрів 305 кожному символу послідовності символів. Присвоєння базується на інформації, яка міститься в попередніх символах послідовності символів, такій як категорія синтаксичного елемента 1 для представлення, такого як бінаризація, якому належить поточний символ і яке, згідно з синтаксичною структурою синтаксичних елементів 1, на даний момент очікується, очікування якого, у свою чергу, можна одержати з історії попередніх синтаксичних елементів 1 і символів 3. Окрім того, кодер містить множину ентропійних кодерів 10, кожен з яких сконфігурований для перетворення символів 3, надісланих до відповідного ентропійного кодера, на відповідний потік бітів 312, і селектор 306, сконфігурований для надсилання кожного символа 3 до вибраного одного з множини ентропійних кодерів 10, при цьому вибір залежить від кількості параметрів 305, присвоєних відповідному символу 3. Присвоювач 304 міг би передбачатися інтегрованим в селектор 206 для одержання відповідного селектора 502. Декодер для відновлення послідовності символів містить множину ентропійних декодерів 322, кожен з яких сконфігурований для перетворення відповідного потоку бітів 323 на символи 321; присвоювач 316, сконфігурований для присвоєння ряду параметрів 317 кожному символу 315 послідовності символів, які відновлюються на основі інформації, яка міститься в попередньо відновлених символах послідовності символів (дивіться позиції 326 і 327 на Фіг. 8); і селектор 318, сконфігурований для одержання кожного символа послідовності символів, які відновлюються, з вибраного одного з множини ентропійних кодерів 322, при цьому вибір залежить від кількості параметрів, визначених для відповідного символа. Присвоювач 316 може 15 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 конфігуруватися так, що кількість параметрів, присвоєних кожному символу, містить або є засобом для оцінки ймовірності розподілу можливих значень символу, які він може припускати. Знову, присвоювач 316 і селектор 318 можуть передбачатися як інтегровані в один блок селектор 402. Послідовність символів, які відновлюються, може бути бінарним алфавітом і присвоювач 316 може конфігуруватися так, що оцінка розподілу ймовірності складається із значення для оцінки ймовірності набуття поточною інформаційною величиною її менш ймовірного або більш ймовірного значення з двох її можливих значень бінарного алфавіту, а ідентифікатор, який специфікує оцінку, завдяки якій одне з двох можливих значень інформаційної величини представляє її менш ймовірне або більш ймовірне значення. Присвоювач 316 може додатково конфігуруватися для внутрішнього присвоювання контексту кожному символу послідовності символів 315, які відновлюються на основі інформації, яка міститься в попередньо відновлених символах послідовності символів, які відновлюються, при цьому кожен контекст має відповідну зв'язану з ним оцінку розподілу ймовірності, і для адаптації оцінки розподілу ймовірності для кожного контексту до реальної символьної статистики на основі значень попередньо відновлених символів, якій присвоєний відповідний контекст. Контекст може брати до уваги просторовий зв'язок або сусідство положень, яким належать синтаксичні елементи, такі як у кодуванні відеоданих або кодуванні картинки, або навіть в таблицях у випадку застосувань у фінансовій сфері. Потім, значення для оцінки розподілу ймовірності для кожного символа може визначатися на основі оцінки розподілу ймовірності, зв'язаної з контекстом, присвоєного відповідному символу, як наприклад за допомогою дискретизації, або використовуючи індекс у відповідній таблиці, на основі оцінки розподілу ймовірності, зв'язаної з контекстом, присвоєного відповідним символом (у нижченаведених варіантах виконання, індексованих pipe індексом разом з індексом деталізації) одному з множини представників оцінки розподілу ймовірності (відрізняється від індексу деталізації) для одержання значення оцінки розподілу ймовірності (pipe індекс, який позначає частковий потік бітів 312). Селектор може конфігуруватися так, що між множиною ентропійних кодерів і множиною представників оцінки розподілу ймовірності визначається бієктивний зв'язок. Селектор 18 може конфігуруватися для зміни дискретного перетворення з інтервалу оцінок розподілу ймовірності на множину представників оцінки розподілу ймовірності наперед встановленим детерміністичним способом в залежності від попередньо відновлених символів послідовності символів протягом часу. Тобто, селектор 318 може змінювати розміри кроку дискретизації, тобто, інтервали розподілу ймовірності, перетворені на окремі індекси ймовірності, бієктивно зв'язані з окремими ентропійними декодерами. Множина ентропійних декодерів 322, у свою чергу, може конфігуруватися для адаптації свого способу перетворення символів на потоки бітів, яка відповідає за зміну в дискретному перетворенні. Наприклад, кожен ентропійний декодер 322 може оптимізуватися, тобто, може мати оптимальний коефіцієнт стискання для певної оцінки розподілу ймовірності у відповідному інтервалі дискретизації оцінки розподілу ймовірності і може змінювати перетворення своєї послідовності кодових слів/ символів для адаптації положення цієї певної оцінки розподілу ймовірності у відповідному інтервалі дискретизації оцінки розподілу ймовірності при зміні останнього для його оптимізації. Селектор може конфігуруватися для зміни дискретного перетворення так, що швидкості, з якими символи виділяються з множини ентропійних декодерів, робляться менш розкиданими. Щодо бінаризатора 314, відмічається, що він може усуватися, якщо синтаксичні елементи є вже двійковими. Окрім того, в залежності від типу декодера 322, існування буферів 320 не потрібне. Окрім того, буфери можуть інтегруватися в декодери. Закінчення скінчених послідовностей синтаксичних елементів В переважному варіанті виконання винаходу кодуванняі декодування виконується для скінченої множини синтаксичних елементів. Часто кодується певна кількість даних, таких як нерухоме зображення, кадр або поле послідовності відеоданих, частина зображення, частина кадру або поля послідовності відеоданих, або множина послідовних аудіозразків і так далі. Для скінчених множин синтаксичних елементів, головним чином, часткові потоки бітів, які створюються на кодувальній стороні, повинні закінчуватися, тобто, слід гарантувати можливість декодування усіх синтаксичних елементів з переданих або збережених часткових потоків бітів. Після введення останньої інформаційної величини у відповідний двійковий буфер 308, двійковий кодер 310 повинен гарантувати запис повного кодового слова в частковий потік бітів 312. Якщо двійковий кодер 310 представляє ентропійний кодер, який втілює пряме перетворення послідовностей інформаційних величин на кодові слова, то послідовність інформаційних величин, яка зберігається в двійковому буфері після запису останньої інформаційної величини у двійковий буфер, може не представляти послідовність інформаційних величин, яка зв'язується з кодовим словом (тобто, вона могла б представляти префікс двох або 16 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 більшої кількості послідовностей інформаційних величин, які зв'язуються з кодовими словами). У такому випадку, будь-яке з кодових слів, зв'язане з послідовністю інформаційних величин, яке містить послідовність інформаційних величин у двійковому буфері як префікс, повинно записуватися в частковий потік бітів (двійковий буфер повинен очищатися). Це могло б виконуватися вставлянням інформаційних величин з окремим або довільним значенням у двійковий буфер, доки не буде записане кодове слово. В переважному варіанті виконання винаходу двійковий кодер вибирає одне з кодових слів з мінімальною довжиною (на додаток до властивості, яка полягає в тому, що відповідна послідовність інформаційних величин повинна містити послідовність інформаційних величин у двійковому буфері як префікс). На декодувальній стороні двійковий декодер 322 може декодувати більше інформаційних величин ніж вимагається для останнього кодового слова в частковому потоці бітів; ці інформаційні величини не запрошуються двійковим буферним селектором 318 і викидаються та ігноруються. Декодування скінченої множини символів контролюється запитами на надання декодованих синтаксичних елементів; якщо не запрошується додатковий синтаксичний елемент для певної кількості даних, то декодування припиняється. Передача і мультиплексування часткових потоків бітів Часткові потоки бітів 312, які створюються кодером, можуть передаватися окремо або вони можуть мультиплексуватися в єдиний потік бітів, або кодові слова часткових потоків бітів можуть чергуватися в єдиному потоці бітів. У варіанті виконання винаходу кожен частковий потік бітів для певної кількості даних записується в один пакет даних. Кількість даних може бути довільною множиною синтаксичних елементів, таких як нерухоме зображення, поле або кадр послідовності відеоданих, частина нерухомого зображення, частина поля або кадру послідовності відеоданих, або основа аудіовибірок і так далі. В іншому переважному варіанті виконання винаходу два або більша кількість часткових потоків бітів для певної кількості даних або усі часткові потоки бітів для певної кількості даних мультиплексуються в один пакет даних. Структура пакету даних, який містить мультиплексовані часткові потоки бітів, зображений на Фігурі 9. Пакет даних 400 складається із заголовка і одного розділу для даних кожного часткового потоку бітів (для розглядуваної кількості даних). Заголовок 400 пакету даних містить індикатори для поділу (решти) пакета даних на сегменти даних 402 потоку бітів. Окрім індикаторів для поділу заголовок може містити додаткову інформацію. У переважному варіанті виконання винаходу індикатори для поділу пакета даних є місцями початку сегментів даних, виражених у бітах або байтах, або множин бітів, або множин байтів. В переважному варіанті виконання винаходу розташування початку сегментів даних кодуються як абсолютні величини в заголовку пакету даних або відносно початку пакету даних або відносно кінця заголовка, або відносно початку попереднього пакету даних. В подальшому переважному варіанті виконання винаходу розташування початку сегментів даних кодуються диференціально, тобто, кодується тільки різниця між реальним початком сегмента даних і прогнозом для початку сегменту даних. Прогноз може одержуватися на основі вже відомої або переданої інформації, такої як загальний розмір пакету даних, розмір заголовку, кількість сегментів даних в пакеті даних, розташування початку попередніх сегментів даних. В переважному варіанті виконання винаходу розташування початку першого пакету даних не кодується, а кодується передбачуване розташування на основі розміру заголовка пакету даних. На декодувальній стороні передані індикатори поділу використовуються для одержання інформації про початок сегментів даних. Сегменти даних потім використовуються як часткові потоки бітів і дані, які містяться в сегментах даних, надсилаються у відповідні двійкові декодери у послідовному порядку. Існує декілька альтернатив для мультиплексування часткових потоків бітів з одержанням пакету даних. Одна альтернатива, яка може послабити потребу у побічній інформації, зокрема для випадків, у яких розміри часткових потоків бітів дуже подібні, зображена на Фіг. 10. Корисне навантаження пакета даних, тобто, пакет даних 410 без свого заголовка 411, ділиться на сегменти 412 наперед визначеним способом. Як приклад, корисне навантаження пакету даних може ділитися на сегменти однакового розміру. Потім кожен сегмент зв'язується з частковим потоком бітів або з першою частиною часткового потоку бітів 413. Якщо частковий потік бітів більший за відповідний сегмент даних, то його залишок 414 поміщається у невикористаний простір в кінці інших сегментів даних. Це може виконуватися у такий спосіб, що решта потоку бітів вставляється в зворотному порядку (починаючи з кінця сегмента даних), що зменшує побічну інформацію. Зв'язування решт часткових потоків бітів з сегментами даних і, коли до сегмента даних додається більше ніж один залишок, то початкова точка для одного або більшої 17 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 кількості залишків повинна сигналізуватися всередині потоку бітів, наприклад в заголовку пакету даних. Чергування кодових слів змінної довжини Для деяких застосувань вищеописане мультиплексування часткових потоків бітів (для певної кількості синтаксичних елементів) в одному пакеті даних може мати наступні недоліки: з одного боку, для малих пакетів даних кількість бітів для побічної інформації, яка вимагається для сигналізації поділу, може стати значущою по відношенню до реальних даних в часткових потоках бітів, що, врешті решт, знижує ефективність кодування. З іншого боку, мультиплексування може не підходити для застосувань, які вимагають малої затримки (наприклад, проведення відеоконференцій). За допомогою описаного мультииплексування кодер не може починати передачу пакета даних перед повним формуванням часткових потоків бітів, оскільки розташування початку поділів перед цим не відомі. Окрім того, головним чином, декодер повинен чекати до тих пір, доки він не прийме початок останнього сегмента даних перед тим, як він зможе розпочати декодування пакета даних. Для застосувань у формі систем для проведення відеоконференцій, ці затримки можуть робити внесок у додаткову загальну затримку системи з декількох відеокартинок (зокрема, для швидкостей передачі бітів, які близькі до швидкості передачі даних, і для кодерів/декодерів, які вимагають часового інтервалу між двома картинками для кодування/декодування картинки), що є важливим для таких застосувань. Для усунення недоліків певних застосувань, кодер переважного варіанта виконання винаходу може конфігуруватися у такий спосіб, що кодові слова, які генеруються двома або більшою кількістю двійкових кодерів, чергуються в єдиному потоці бітів. Потік бітів з чергованими кодовими словами може безпосередньо надсилатися до декодера (при нехтуванні малою затримкою буфера, дивіться нижче). На декодувальній стороні два або більша кількість двійкових декодерів зчитують кодові слова безпосередньо з потоку бітів в порядку декодування; декодування може починатися з першим прийнятим бітом. Окрім того, не вимагається побічної інформації для сигналізації мультиплексування (або чергування) часткових потоків бітів. Подальше послаблення складності декодера може досягатися, коли двійкові декодери 322 не зчитують кодові слова змінної довжини з глобального бітового буфера, а замість цього вони завжди зчитують послідовності бітів фіксованої довжини з глобального бітового буфера і додають ці послідовності бітів фіксованої довжини до локального бітового буфера, де кожен двійковий декодер 322 з'єднаний з окремим локальним бітовим буфером. Кодові слова змінної довжини потім зчитуються з локального бітового буфера. Тому, синтаксичний аналіз кодових слів змінної довжини може виконуватися паралельно, тільки доступ до послідовностей бітів фіксованої довжини повинен виконуватися синхронно, але такий доступ до послідовностей бітів фіксованої довжини зазвичай є дуже швидким таким чином, що загальна складність декодування може послаблюватися для деяких архітектур. Фіксована кількість інформаційних величин, які надсилаються до окремого локального бітового буфера, може бути іншою для іншого локального бітового буфера і вона може також змінюватися з часом в залежності від певних параметрів як подій в двійковому декодері, двійковому буфері або бітовому буфері. Однак, кількість бітів, які зчитуються окремим доступом, не залежать від реальних бітів, які зчитуються під час окремого доступу, що є важливою відмінністю для зчитування кодових слів змінної довжини. Зчитування послідовностей бітів фіксованої довжини запускається певними подіями в двійкових буферах, двійкових декодерах або локальних бітових буферах. Як приклад, можна запрошувати зчитування нової послідовності бітів фіксованої довжини, коли кількість бітів, які присутні у підключеному бітовому буфері, падає нижче наперед встановленої порогової величини, де різні порогові величини можуть використовуватися для різних бітових буферів. В кодері потрібно гарантувати, щоб послідовності інформаційних величин фіксованої довжини вставлялися в одному і тому ж порядку в потік бітів, у якому вони зчитуються з потоку бітів на декодувальній стороні. Також можна поєднувати це чергування послідовностей фіксованої довжини з контролем малої затримки, подібного до пояснених вище. Далі, описується переважний варіант виконання для чергування послідовностей бітів фіксованої довжини. За подальшими деталями, які стосуються останніх схем чергування, звертайтесь до документа WO2011/128268A1. Після опису варіантів виконання, згідно з якими навіть попереднє кодування використовується для стискання відеоданих, описується навіть подальший варіант виконання представленого винаходу, який робить втілення особливо ефективним з точки зору гарного компромісу між коефіцієнтом стискання, з одного боку, і таблицею пошуку та додатковими обрахунками, з іншого боку. Зокрема, наступні варіанти виконання дозволяють використання з обрахункової точки зору менш складних кодів змінної довжини для індивідуального ентропійного кодування потоків бітів і ефективного охоплення частин оцінки ймовірності. В 18 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 описаних нижче варіантах виконання символи є бінарними і коди змінної довжини (VLC), представлені нижче, ефективно охоплюють оцінку ймовірності, представлену, наприклад R LPS, яке розташоване в інтервалі [0;0,5]. Зокрема, вказані нижче варіанти виконання описують можливі втілення для індивідуальних ентропійних кодерів 310 і декодерів 322, відповідно, на Фіг. 7-17. Вони придатні для кодування інформаційних величин, тобто бінарних символів, оскільки вони трапляються в стисканні зображення або відеоданих. Відповідно, ці варіанти виконання також застосовуються для кодування зображення або відеоданих, де такі бінарні символи діляться на один або більшу кількість потоків інформаційних величин 307, які кодуються, і, відповідно, потоки бітів 324, які декодуються, де кожен такий потік інформаційних величин може розглядатися як реалізація процесу Бернуллі. Описані нижче варіанти виконання використовують один або більшу кількість пояснених нижче різних способів так званого кодування з перетворенням послідовності символів змінної довжини на послідовність бітів змінної довжини (v2v-коди) для кодування потоків інформаційних величин. v2v-код може розглядатися як два коди без префіксу з однією і тією ж кількістю кодових слів: головний і допоміжний код без префіксу. Кожне кодове слово головного коду без префіксу зв'язується з одним кодовим словом допоміжного коду без префіксу. У відповідності з нижчеописаними варіантами виконання принаймні деякі з кодерів 310 і декодерів 322 працюють наступним чином: Для кодування окремої послідовності інформаційних величин 307 кожен раз, коли кодове слово головного коду без префіксу зчитується з буфера 308, відповідне кодове слово допоміжного коду без префікса записується в потік бітів 312. Та ж сама процедура використовується для декодування такого потоку бітів 24, але з чергуванням головного і допоміжного коду без префікса. Тобто, для декодування потоку бітів 324, кожен раз, коли кодове слово допоміжногокоду без префіксу зчитується з відповідного потоку бітів 324, відповідне кодове число допоміжного коду без префіксу записується в буфер 320. Переважно, описані нижче коди не потребують таблиць пошуку. Коди здатні втілюватися у формі машин з кінцевим числом станів. Представлені тут v2v-коди можуть генеруватися простими правилами конструювання так, що для кодових слів не потрібно зберігати великі таблиці. Замість цього, може використовуватися простий алгоритм для виконання кодування або декодування. Нижче описуються три правила формування, де два з них можуть параметризуватися. Вони охоплюють різні або навіть окремі частини вищезгаданого інтервалу ймовірності і є, відповідно, особливо вигідними, коли використовуються разом, так як усі три коди або два з них використовуються паралельно (кожен для різних кодерів/декодерів 11 і 22). За допомогою описаних нижче правил формування можна формувати множину v2v-кодів так, що для процесів Бернуллі з довільною ймовірністю p один з кодів гарно працює з точки зору надмірної довжини коду. Як визначено вище, кодування і декодування потоків 312 і, відповідно, 324 може виконуватися або незалежно для кожного потоку або поперемінно. Однак, це не є спеціальним для представлених класів v2v-кодів і, тому, далі описується тільки кодування і декодування окремого кодового слова для кожного з трьох правил формування. Однак, підкреслюється, що усі вищезгадані варіанти виконання, які стосуються рішень з поперемінним виконанням, також здатні поєднуватися з на даний момент описаними кодами або кодерами і декодерами 310 і, відповідно, 322. Правило формування 1: "унарні двійкові pipe" коди або кодери/декодери 310 і 322 Унарні двійкові pipe коди (PIPE = ентропія поділу інтервалу ймовірності) є спеціальним варіантом так званих "двійкових pipe" кодів, тобто, кодів, придатних для кодування будь-якого з окремих потоків бітів 12 і 24, кожен з яких переносить дані статистики бінарних символів, яка належить певному підінтервалу ймовірності вищезгаданого інтервалу ймовірності [0;0,5]. Спершу описується формування двійкових pipe кодів. Двійковий pipe код може формуватися з будь-якого коду без префіксу з принаймні трьома кодовими словами. Для формування v2v-коду, використовують код без префіксу як головний і допоміжний код, але з чергуванням двох кодових слів допоміжного коду без префіксу. Це означає, що, за виключенням двох кодових слів, інформаційні величини записуються в незмінний потік бітів. За допомогою цієї технології необхідно зберігати тільки один код без префіксу разом з інформацією, які два кодові слова чергуються між собою, і, таким чином, використання пам'яті зменшується. Відзначається, що доцільно обмінюватися тільки кодовими словами різної довжини, оскільки, інакше, потік бітів повинен мати ту ж довжину що й потік інформаційних величин (нехтуючи ефектами, які трапляються в кінці потоку інформаційних величин). Завдяки цьому правилу формування чудовою властивістю двійкових pipe кодів є те, що, коли головний і допоміжний код без префіксу міняються між собою (тоді як перетворення 19 UA 111741 C2 5 10 кодових слів зберігається), то одержуваний v2v-код ідентичний оригінальному v2v-коду. Тому, алгоритм кодування і алгоритм декодування ідентичні для двійкових pipe кодів. Унарний двійковий pipe код формується з спеціального коду без префіксу. Цей спеціальний код без префіксу формується наступним чином. Спершу, генерують код без префіксу, який складається з n унарних кодових слів, починаючи з '01', '001', '0001', … до тих пір, доки не одержиться n кодових слів. n є параметром для унарного двійкового pipe коду. З найдовшого кодового слова видаляється слід 1. Це відповідає усіченому унарному коду (але без кодового слова '0'). Потім, генеруються n-1 унарних кодових слів, починаючи з '10', '110', '1110', … до тих пір, доки не буде створено n-1 кодових слів. З найдовшого з цих кодових слів видаляють слід 0. Об'єднана множина цих двох кодів без префікса використовується як вхідні дані для генерування унарного двійкового pipe коду. Два кодові слова, які міняються між собою, є тими, де одне з них складається тільки з 0, а інше складається тільки з 1. Приклад для n=4: № 1 2 3 4 5 6 7 Головний 0000 0001 001 01 10 110 111 Допоміжний 111 0001 001 01 10 110 0000 15 20 25 Правило формування 2: коди, які відображають перетворення "унарних кодів на коди Райса" і кодери/декодери 10 і 22, які використовують перетворення унарних кодів на коди Райса: Коди, які відображають перетворення унарних кодів на коди Райса, використовують усічений унарний код як головний код. Тобто, унарні кодові слова генеруються починаючи з '1', '01', '001', n … до тих пір, доки не буде згенеровано 2 +1 кодових слів і з найдовшого кодового слова видаляють слід 1. n є параметром коду, який відображає перетворення унарного коду на код Райса. Допоміжний код без префіксу формується з кодових слів головного коду без префіксу наступним чином. Головному кодовому слову, яке складається тільки з 0, присвоюється кодове слово '1'. Усі інші кодові слова складаються з конкатенації кодового слова '0' з n-бітовим двійковим представленням ряду 0 відповідного кодового слова головного коду без префіксу. Приклад для n=3: № 1 2 3 4 5 6 7 8 9 30 Головний 1 01 001 0001 00001 000001 0000001 00000001 00000000 Допоміжний 0000 0001 0010 0011 0100 0101 0110 0111 1 Відзначаємо, що це ідентичне перетворенню нескінченного унарного коду на код Райса з параметром Райса 2n. Правило формування 3: 'Потрійний двійковий' код Потрійний двійковий код надається наступним чином: № 1 2 3 4 5 6 7 8 Головний 000 001 010 100 110 101 011 111 Допоміжний 0 100 101 110 11100 11101 11110 11111 20 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Він має ту властивість, що головний код (послідовності символів) має фіксовану довжину (завжди три інформаційні величини), а кодові слова відбираються по висхідним кількостям 1. Далі описується ефективне втілення потрійного двійкового коду. Кодер і декодер для потрійного двійкового коду можуть втілюватися без зберігання таблиць наступним чином. В кодері (будь-який з кодерів 10) три інформаційні величини зчитуються з потоку інформаційних величин (тобто, з потоку 7). Якщо ці три інформаційні величини містять точно одну 1, то кодове слово '1' записується в потік бітів після двох інформаційних величин, які складаються з двійкового представлення положення 1 (починаючи з права з 00). Якщо три інформаційні величини містять точно один 0, то кодове слово '111' записується в потік бітів після двох інформаційних величин, які складаються з двійкового представлення положення 0 (починаючи з права з 00). Решта кодових слів '000' і '111' перетворюються на '0' і, відповідно, '11111'. В декодері (будь-який з декодерів 22) одна інформаційна величина або біт зчитується з відповідного потоку бітів 24. Якщо вона дорівнює '0', то кодове слово '000' декодується з одержанням потоку інформаційних величин 21. Якщо вона дорівнює '1', то дві або більша кількість інформаційних величин зчитуються з потоку бітів 24. Якщо ці два біти не дорівнюють '11', то вони інтерпретуються як двійкове представлення числа і два 0 та одна 1 декодується з одержанням потоку бітів так, що положення 1 визначається числом. Якщо два біти дорівнюють '11', то два додаткових біти зчитуються і інтерпретуються як двійкове представлення числа. Якщо це число менше ніж 3, то дві 1 і один 0 декодуються і число визначає положення 0. Якщо воно дорівнює 3, то '111' декодується з одержанням потоку інформаційних величин. Далі описується ефективне втілення унарних двійкових pipe кодів. Кодер і декодер для унарних двійкових pipe кодів можуть ефективно втілюватися шляхом використання лічильника. Завдяки структурі двійкових pipe кодів кодування і декодування двійкових pipe кодів легко втілювати: В кодері (будь-який з кодерів 10), якщо перша інформаційна величина кодового слова дорівнює '0', то інформаційні величини обробляються до появи '1' або до зчитування n 0 (включаючи перший '0' кодового слова). Якщо трапилася '1', то зчитані інформаційні величини записуються в незмінний потік бітів. Інакше (тобто, зчитано n 0), то n-1 1 записується в потік бітів. Якщо перша інформаційна величина кодового слова дорівнює '1', то інформаційні величини обробляються доки не трапиться '0' або доки не зчитається n-1 1 (включаючи першу '1' кодового слова). Якщо трапився '0', то зчитані інформаційні величини записуються в незмінний потік бітів. Інакше (тобто, зчитано n-1 1), n 0 записуються в потік бітів. В декодері (будь-який з декодерів 322) використовується той же алгоритм для кодера, оскільки це застосовується для двійкових pipe кодів, як описано вище. Далі описується ефективне втілення кодів, які відображають перетворення унарних кодів на коди Райса. Кодер і декодер для кодів, які відображають перетворення унарних кодів на коди Райса, можуть ефективно втілюватися шляхом використання лічильника, як тепер буде описуватися. В кодері (будь-який з кодерів 310) інформаційні величини зчитуються з потоку інформаційних величин (тобто, потоку 7) доки не трапиться 1 або доки не буде зчитано 2n 0. Кількість 0 підраховується. Якщо підрахована кількість дорівнює 2n, то кодове слово '1' записується в потік бітів. Інакше, '0' записується перед двійковим представленням підрахованої кількості записаної з n бітами. В декодері (будь-який з декодерів 322) зчитуєтьсяодин біт. Якщо він дорівнює '1', то 2n 0 декодуються з одержанням рядка інформаційних величин. Якщо він дорівнює '0', то зчитується n додаткових бітів, які інтерпретуються як двійкове представлення числа. Ця кількість 0 декодується з одержанням потоку інформаційних величин, за яким слідує '1'. Іншими словами тільки що описані варіанти виконання розкривають кодер для кодування послідовності символів 303, який містить присвоювач 316, сконфігурований для присвоювання ряду параметрів 305 кожному символу послідовності символів на основі інформації, яка міститься в попередніх символах послідовності символів; певну кількість ентропійних кодерів 310, кожен з яких сконфігурований для перетворення символів 307, надісланих до відповідного ентропійного кодера 310, на відповідний потік бітів 312; і селектор 6, сконфігурований для надсилання кожного символа 303 до вибраного одного з множини ентропійних кодерів 10, при цьому вибір залежить від кількості параметрів 305, присвоєних відповідному символу 303. Згідно з тільки що зазначеними варіантами виконання принаймні перша підмножина ентропійних кодерів може бути кодером змінної довжини, сконфігурованим для перетворення послідовностей символів змінної довжини в потоці символів 307 на кодові слова змінних 21 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 довжин, які вставляються в потік бітів 312, при цьому, відповідно, кожен з ентропійних кодерів 310 першої підмножини використовує правило бієктивного перетворення, згідно з яким кодові слова головного коду без префіксу з (2n-1) ≥ 3 кодовими словами перетворюються на кодові слова допоміжного коду без префіксу, який ідентичний головному коду з префіксом так, що усі, але два кодові слова головного коду без префіксу перетворюються на ідентичні кодові слова допоміжного коду без префіксу, тоді як два кодові слова головного і допоміжного кодів без префіксу мають різні довжини і перетворюються один на інший взаємозамінно, при цьому ентропійні кодери можуть використовувати різне n для охоплення різних частин вищезгаданого інтервалу ймовірності. Перший код без префіксу може формуватися так, що його кодовими словами є (a, b)2, (a, a,b)3,…, (a, …,a, b)n, (a, …,a)n, (b, a)2, (b, b,a)3,…, (b, …,b, a)n-1, (b, …,b)n-1, і двома кодовими словами, які взаємозамінно перетворюються одне на інше, є (a, …,a) n і (b, …,b)n-1 з b ≠ a і a, b {0,1}. Однак, альтернативи є реальними. Іншими словами кожен з першої підмножини ентропійних кодерів може конфігуруватися при перетворенні символів, надісланих до відповідного ентропійного кодера, на відповідний потік бітів для перевірки першого символа, надісланого до відповідного ентропійного кодера, для визначення чи (1) перший символ дорівнює a {0,1}, у випадку чого відповідний ентропійний кодер конфігурується для перевірки наступних символів, надісланих до відповідного ентропійного кодера, для визначення чи (1.1) b ≠ a і b {0,1} серед наступних n-1 символів, які слідують після першого символу, у випадку чого відповідний ентропійний кодер конфігурується для запису кодового слова у відповідний потік бітів, який дорівнює першому символу, за яким слідують наступні символи, надіслані до відповідного ентропійного кодера, аж до символа b; (1.2) чи символ b не трапляється серед наступних n-1 символів, які слідують після першого символу, у випадку чого відповідний ентропійний кодер конфігурується для запису кодового слова у відповідний потік бітів, яке дорівнює (b, …,b) n-1; або (2) чи перший символ дорівнює b, у випадку чого відповідний ентропійний кодер конфігурується для перевірки наступних символів, надісланих до відповідного ентропійного кодера, для визначення (2.1) чи трапляється a серед наступних n-2 символів, які слідують після першого символу, у випадку чого відповідний ентропійний кодер конфігурується для запису кодового слова у відповідний потік бітів, який дорівнює першому символу, за яким слідують наступні символи, надіслані до відповідного ентропійного кодера, аж до символа a; або (2.2) чи не трапляється a серед наступних n-2 символів, які слідують після першого символа, у випадку чого відповідний ентропійний кодер конфігурується для запису кодового слова у відповідний потік бітів, яке дорівнює (a, …,a) n. Окрім того або альтернативно, друга підмножина ентропійних кодерів 10 може бути кодером змінної довжини, сконфігурованим для перетворення послідовностей символів змінних довжин на, відповідно, кодові слова фіксованих довжин, при цьому кожен з ентропійних кодерів другої підмножини використовує правило бієктивного перетворення, згідно з яким кодові слова n головного усіченого унарного коду з 2 +1 кодовими словами типу {(a), (ba), (bba), …,(b…ba), (bb…b)} з b ≠ a і a, b {0,1} перетворюються на кодові слова допоміжного коду без префіксу так, що кодове слово (bb…b) головного усіченого унарного коду перетворюється на кодове слово (c) допоміжного коду без префіксу і усі інші кодові слова {(a), (ba), (bba), …,(b…ba)} головного усіченого унарного коду перетворюються на кодові слова, які мають (d) з c ≠ d і c, d {0,1} як префікс і n-бітове слово як суфікс, при цьому ентропійні кодери використовують різне n. Кожен з другої підмножини ентропійних кодерів може конфігуруватися так, що n-бітове слово є n-бітовим представленням кількості чисел b у відповідному кодовому слові головного усіченого унарного коду. Однак, альтернативи є реальними. Знову, з проекції режиму роботи відповідного кодера 10 кожен з другої підмножини ентропійних кодерів може конфігуруватися під час перетворення символів, надісланих до відповідного ентропійного кодера, на відповідний потік бітів для підрахунку кількості символів b в послідовності символів, надісланих до відповідного ентропійного кодера, доки не трапиться символ a або доки кількість послідовності символів, надісланих до відповідного ентропійного n n кодера, не досягне величини 2 з усіма 2 символами послідовності, яка є числом b, і (1), якщо n кількість символів b дорівнює 2 , записують c з c {0,1} як кодове слово допоміжного коду без n префіксу у відповідний потік бітів, і (2) якщо кількість символів b менша ніж 2 , то записують кодове слово допоміжного коду без префіксу у відповідний потік бітів, який має (d) з c ≠ d і d {0,1} як префікс, а n-бітове слово, яке визначається в залежності від кількості символів b, як суфікс. Також додатково або альтернативно, наперед визначений один з ентропійних кодерів 10 може бути кодером змінної довжини, сконфігурованим для перетворення послідовностей символів фіксованих довжин на, відповідно, кодові слова змінних довжин, при цьому наперед 3 визначений ентропійний кодер використовує правило бієктивного перетворення, згідно з яким 2 22 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодових слів довжиною 3 головного коду перетворюються на кодові слова допоміжного коду без префікса так, що кодове слово (aaa)3 головного коду з a {0,1} перетворюється на кодове слово (c) з c {0,1}, при цьому усі три кодові слова головного коду, які мають точно одне b з b≠a і b {0,1}, перетворюються на кодові слова, які мають (d) з c ≠ d і d {0,1} як префікс і відповідне перше 2-бітове слово з першої множини 2-бітових слів як суфікс, при цьому усі три кодові слова головного коду, які мають точно одне a, перетворюються на кодові слова, які мають (d) як префікс, і конкатенацію першого 2-бітового слова, яке не являється елементом першої множини, і другого 2-бітового слова з другої множини 2-бітових слів як суфікс, і при цьому кодове слово (bbb)3 перетворюється на кодове слово, яке має (d) як префікс, і конкатенацію першого 2-бітового слова, яке не є елементом першої множини, і другого 2бітового слова, яке не є елементом другої множини, як суфікс. Перше 2-бітове слово кодових слів головного коду, яке має точно один символ b, може бути 2-бітовим представленням положення символа b у відповідному кодовому слові головного коду, а друге 2-бітове слово кодових слів головного коду, який має точно один символ a, може бути 2-бітовим представленням положення символа a у відповідному кодовому слові головного коду. Однак, альтернативи є реальними. Знову, наперед визначений один з ентропійних кодерів може конфігуруватися під час перетворення символів, надісланих до наперед встановленого ентропійного кодера, на відповідний потік бітів, для перевірки символів, які надсилаються до наперед встановленого ентропійного кодера в триплетах, щодо того (1) чи триплет складається з символів a, у випадку чого наперед визначений ентропійний кодер конфігурується для запису кодового слова (c) у відповідний потік бітів, (2) чи триплет точно містить один символ b, у випадку чого наперед визначений ентропійний кодер конфігурується для запису кодового слова, яке має (d) як префікс, а 2-бітове представлення положення символа b в триплеті як суфікс, у відповідний потік бітів; (3) чи триплет точно містить один символ a, у випадку чого наперед визначений ентропійний кодер конфігурується для запису кодового слова, яке має (d) як префікс і конкатенацію першого 2-бітового слова, яке не є елементом першої множини, і 2-бітового представлення положення символа a в триплеті як суфікс, у відповідний потік бітів; або (4) чи триплет складається з символів b, у випадку чого наперед визначений ентропійний кодер конфігурується для запису кодового слова, яке має (d) як префікс і конкатенацію першого 2бітового слова, яке не є елементом першої множини, і першого 2-бітового слова, яке не є елементом другої множини, як суфікс, у відповідний потік бітів. Розглядаючи декодувальну сторону, бачимо, що тільки що описані варіанти виконання розкривають декодер для відновлення послідовності символів 326, який містить множину ентропійних декодерів 322, кожен з яких сконфігурований для перетворення відповідного потоку бітів 324 на символи 321; присвоювач 316, сконфігурований для присвоєння ряду параметрів на кожен символ 326 послідовності символів, які відновлюються, на основі інформації, яка міститься в попередньо відновлених символах послідовності символів; і селектор 318, сконфігурований для одержання кожного символа 325 з послідовності символів, які відновлюються, з вибраного одного з множини ентропійних декодерів, при цьому вибір залежить від ряду параметрів, визначених для відповідного символу. Згідно з тільки що описаними варіантами виконання принаймні перша підмножина ентропійних декодерів 322 є декодерами змінної довжини, сконфігурованими для перетворення кодових слів змінних довжин на послідовності символів змінних довжин, при цьому, відповідно, кожен з ентропійних декодерів 22 першої підмножини використовує правило бієктивного перетворення, згідно з яким кодові слова головного коду без префіксу з (2n-1) ≥ 3 кодовими словами перетворюються на кодові слова допоміжного коду без префіксу, який ідентичний головному коду з префіксом, так, що усі, але два кодові слова головного коду без префіксу перетворюються на ідентичні кодові слова допоміжного коду без префіксу, тоді як два кодові слова головного і допоміжного коду без префіксу мають різні довжини і перетворюються один на інший взаємозамінно, при цьому ентропійні кодери використовують різні n. Перший код без префіксу може формуватися так, що кодовими словами першого коду без префіксу є (a, b) 2, (a, a,b)3,…, (a, …,a, b)n, (a, …,a)n, (b, a)2, (b, b,a)3,…, (b, …,b, a)n-1, (b, …,b)n-1, і двома кодовими словами, які перетворюються одне на інше взаємозамінним чином, можуть бути (a, …,a)n і (b, …,b)n-1 з b ≠ a і a, b {0,1}. Однак, альтернативи є реальними. Кожен з першої підмножини ентропійних кодерів може конфігуруватися під час перетворення відповідного потоку бітів на символи для перевірки першого біту відповідного потоку бітів для визначення (1) чи перший біт дорівнює {0,1}, у випадку чого відповідний ентропійний кодер конфігурується для перевірки наступних бітів відповідного бітового потоку для визначення чи (1.1) b з b ≠ a і b {0,1} трапляється в наступних n-1 бітах, які слідують після 23 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 першого біта, у випадку чого відповідний ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює першому біту, за яким слідують наступні біти відповідного потоку бітів аж до біту b; або (1.2) чи не трапляється біт b серед наступних n-1 бітів, які слідують після першого біта, у випадку чого відповідний ентропійний декодер конфігурують для відновлення послідовності символів, яка дорівнює (b, …,b) n-1; або (2) чи перший біт дорівнює b, у випадку чого відповідний ентропійний декодер конфігурують для перевірки наступних бітів відповідного потоку бітів для визначення того (2.1) чи трапляється символ a серед наступних n2 бітів, які слідують після першого біта, у випадку чого відповідний ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює першому біту, за яким слідують наступні біти відповідного бітового потоку аж до символа a; або (2.2) чи не трапляється символ a серед наступних n-2 бітів, які слідують після першого біта, у випадку чого відповідний ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює (a, …,a)n. Додатково або альтернативно, принаймні друга підмножина ентропійних декодерів 322 може бути декодером змінної довжини, сконфігурованим для перетворення кодових слів фіксованих довжин на, відповідно, послідовності символів змінних довжин, при цьому кожен з ентропійних декодерів другої підмножини використовує правило бієктивного перетворення, згідно з яким кодові слова допоміжного коду без префіксу перетворюються на кодові слова n головного усіченого унарного коду з 2 +1 кодовими словами типу {(a), (ba), (bba), …,(b…ba), (bb…b)} з b ≠ a і a, b {0,1} так, що кодове слово (c) допоміжного коду без префіксу перетворюється на кодове слово (bb…b) головного усіченого унарного коду і кодові слова, які мають (d) з c ≠ d і c, d {0,1} як префікс і n-бітове слово як суфікс, перетворюються на відповідне одне з інших кодових слів {(a), (ba), (bba), …,(b…ba)} головного усіченого унарного коду, при цьому ентропійні декодери використовують різні n. Кожен з другої підмножини ентропійних декодерів може конфігуруватися так, що n-бітове слово є n-бітовим представленням кількості символів b у відповідному кодовому слові головного усіченого унарного коду. Однак, альтернативи є реальними. Кожен з другої підмножини ентропійних декодерів може бути декодером змінної довжини, сконфігурованим для перетворення кодових слів фіксованих довжин на, відповідно, послідовності символів змінних довжин і сконфігурованим під час перетворення потоку бітів відповідного ентропійного декодера на символи для перевірки першого біта відповідного потоку бітів для визначення того чи (1) він дорівнює c з c {0,1}, у випадку чого відповідний ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює n (bb…b)2 з b {0,1}; або (2) чи він дорівнює d з c ≠ d і c, d {0,1}, у випадку чого відповідний ентропійний декодер конфігурується для визначення n-бітового слова з n подальших бітів відповідного потоку бітів, які слідують після першого біту, і для відновлення з нього послідовності символів, яка має тип {(a), (ba), (bba), …,(b…ba), (bb…b)} з b ≠ a і b {0,1} з кількістю символів b, яка залежить від n-бітового слова. Додатково або альтернативно, наперед визначений один з ентропійних декодерів 322 може бути декодером змінної довжини, сконфігурованим для перетворення кодових слів змінних довжин на, відповідно, послідовності символів фіксованих довжин, при цьому наперед визначений ентропійний декодер використовує правило бієктивного перетворення, згідно з яким 3 кодові слова допоміжного коду без префіксу перетворюються на 2 кодові слова довжиною 3 головного коду так, що кодове слово (c) з c {0,1} перетворюється на кодове слово (aaa)3 головного коду з a {0,1}, при цьому кодові слова, які мають (d) з c ≠ d і d {0,1} як префікс і відповідне перше 2-бітове слово з першої множини трьох 2-бітових слів як суфікс, перетворюються на усі три кодові слова головного коду, який має точно один символ b з b≠a і b {0,1}, при цьому кодові слова, які мають (d) як префікс і конкатенацію першого 2-бітового слова, яке не є елементом першої множини, і другого 2-бітового слова з другої множини трьох 2-бітових слів як суфікс, перетворюються на усі три кодові слова головного коду, який має точно один символ a, і кодове слово, яке має (d) як префікс і конкатенацію першого 2-бітового слова, яке не є елементом першої множини, і другого 2-бітового слова, яке не є елементом другої множини, як суфікс перетворюється на кодове слово (bbb) 3. Перше 2-бітове слово кодових слів головного коду, який має точно один символ b, може бути 2-бітовим представленням положення символа b у відповідному кодовому слові головного коду, а друге 2-бітове слово кодових слів головного коду, який має точно один символ a, може бути 2-бітовим представленням положення символа a у відповідному кодовому слові головного коду. Однак, альтернативи є реальними. Наперед визначений один з ентропійних декодерів може бути декодером змінної довжини, сконфігурованим для перетворення кодових слів змінних довжин на послідовності символів, кожна з яких містить три символи, відповідно, і під час перетворення потоку бітів відповідного 24 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 ентропійного декодера на символи сконфігурований для дослідження першого біту відповідного потоку бітів для визначення того факту (1) чи перший біт відповідного потоку бітів дорівнює c з c {0,1}, у випадку чого наперед визначений ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює (aaa) 3 з а 0 {0,1}, або (2) чи перший біт відповідного потоку бітів дорівнює d з c ≠ d і d {0,1}, у випадку чого наперед визначений ентропійний декодер конфігурується для визначення першого 2-бітового слова з 2 подальшими бітами відповідного потоку бітів, які слідують після першого біта, і перевірки першого 2-бітового слова для визначення того факту (2.1) чи перше 2-бітове слово не є елементом першої множини з трьох 2-бітових слів, у випадку чого наперед визначений ентропійний декодер конфігурується для відновлення послідовності символів, яка має точно один символ b з b≠a і b 0 {0,1}, при цьому положення символа b у відповідній послідовності символів залежить від першого 2-бітового слова, або (2.2) чи перше 2-бітове слово є елементом першої множини, у випадку чого наперед визначений ентропійний декодер конфігурується для визначення другого 2-бітового слова з 2 подальших бітів відповідного потоку бітів, які слідують після двох бітів, з яких було визначене перше 2-бітове слово, і для перевірки другого 2-бітового слова для визначення того факту (3.1) чи друге 2-бітове слово не є елементом другої множини з трьох 2бітових слів, у випадку чого наперед визначений ентропійний декодер конфігурується для відновлення послідовності символів, яка має точно один символ a, при цьому положення символа a у відповідній послідовності символів залежить від другого 2-бітового слова, або (3.2) чи друге 2-бітове слово є елементом другої множини з трьох 2-бітових слів, у випадку чого наперед визначений ентропійний декодер конфігурується для відновлення послідовності символів, яка дорівнює (bbb)3. Тепер, після опису загальної концепції схеми кодування відеоданих, варіанти виконання представленого винаходу описуються відносно вищезгаданих варіантів виконання. Іншими словами, охарактеризовані нижче варіанти виконання можуть втілюватися шляхом використання вищенаведених схем і, навпаки, вищезгадані схеми кодування можуть втілюватися з використанням охарактеризованих нижче варіантів виконання. У вищенаведених варіантах виконання, описаних відносно Фіг. 7-9, ентропійний кодер і декодери з Фіг. 1-6 втілювалися у відповідності з концепцією PIPE (ентропія поділу інтервалу ймовірності). Один спеціальний варіант виконання використовує арифметичні кодери/декодери 310 і 322 з єдиним станом ймовірності. Як буде описуватися нижче, у відповідності з альтернативним варіантом виконання, об'єкти 306-310 і відповідні об'єкти 318-322 можуть замінятися спільним ентропійним кодувальним засобом. Як приклад, уявіть арифметичний кодувальний засіб, який просто керує одним спільним станом R і L, і кодує усі символи з одержанням одного спільного потоку бітів, таким чином відмовляючись від вигідних аспектів представленої концепції PIPE, що стосується паралельної обробки, але уникаючи необхідності чергування часткових потоків бітів, як обговорюється нижче. Роблячи це, кількість станів ймовірності, завдяки яким ймовірності контексту оцінюються шляхом оновлення даних (таких як таблиця пошуку), може бути більшою за кількість станів ймовірності, завдяки яким виконується підрозбиття інтервалу ймовірності. Тобто, аналогічно до дискретизації величина ширини інтервалу ймовірності перед індексацією в таблиці Rtab, а також індекс стану ймовірності можуть дискретизуватися. Вищенаведений опис можливого втілення для окремих кодерів/декодерів 310 і 322 може, таким чином, поширюватися, наприклад, на втілення ентропійних кодерів/декодерів 318-322/306-310 як адаптивних до контексту двійкових арифметичних кодувальних/декодувальних засобів: Будучи більш точними, у відповідності з варіантом виконання, ентропійний кодер, підключений до виходу присвоювача параметрів (який функціонує тут як контекстний присвоювач), може працювати наступним чином: 0. Присвоювач 304 надсилає значення інформаційної величини разом з параметром ймовірності. Ймовірністю є pState_current[bin]. 1. Таким чином, ентропійний кодувальний засіб приймає: 1) valLPS, 2) інформаційну величину і 3) оцінку розподілу ймовірності pState_current[bin]. pState_current[bin] може мати більше станів ніж кількість розрізнюваних індексів стану ймовірності Rtab. Якщо так, то pState_current[bin] може дискретизуватися як, наприклад, шляхом ігнорування m LSBs з m, більшим за або рівним 1 і переважно рівним 2 або 3, для одержання p_state, тобто індексу, який потім використовується для доступу до таблиці Rtab. Однак, дискретизація може не виконуватися, тобто. p_state може дорівнювати pState_current[bin]. 2. Потім виконується дискретизація R (Як згадується вище: будь-який один R (і відповідний L з одним спільним потоком бітів) використовується/контролюється для усіх розрізнюваних величин p_state або один R (і відповідний L з відповідним частковим потоком бітів на пару R/L) 25 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 на розрізнювану величину p_state, яка в останньому випадку повинна відповідати наявності одного двійкового кодера 310 на таку величину) q_index=Qtab[R>>q] (або деяка інша форма дискретизації) 3. Потім, виконується визначення RLPS і R: RLPS=Rtab[p_state][q_index]; Rtab зберегла попередньо обраховані величини для p[p_state]·Q[q_index] R=R – RLPS [тобто, R попередньо оновлюється якщо б "елемент вибірки" був MPS] 4. Обрахунок нового часткового інтервалу: if (bin=1 - valMPS) then L ¬ L+R R ¬ RLPS 5. Повторна нормалізація L і R, запис бітів, Аналогічно, ентропійний декодер, підключений до виходу присвоювача параметрів (який функціонує тут як контекстний присвоювач), може працювати наступним чином: 0. Присвоювач 304 надсилає значення інформаційної величини разом з параметром ймовірності. Ймовірність дорівнює pState_current[bin]. 1. Таким чином, ентропійний кодувальний засіб приймає запит на надання інформаційної величини разом з: 1) valLPS, і 2) оцінкою розподілу ймовірності pState_current[bin]. pState_current[bin] може мати більше станів ніж кількість розрізнюваних індексів станів ймовірності таблиці Rtab. Якщо так, то pState_current[bin] може дискретизуватися, наприклад, шляхом ігнорування m LSBs з m, яке більше за або рівне 1 і переважно дорівнює 2 або 3, для одержання p_state, тобто індексу, який потім використовується для доступу до таблиці Rtab. Дискретизація може, однак, не виконуватися, тобто, p_state може дорівнювати pState_current[bin]. 2. Потім виконується дискретизація R (як згадано вище: будь-який один R (і відповідний V з одним спільним потоком бітів) використовується/контролюється для усіх розрізнюваних величин p_state, або один R (і відповідний V з відповідним частковим потоком бітів на пару R/L) на розрізнювану величину p_state, яка в останньому випадку повинна відповідати наявності одного двійкового кодера 310 на таку величину) q_index=Qtab[R>>q] (або деяка інша форма дискретизації) 3. Потім виконують визначення RLPS і R: RLPS=Rtab[p_state][q_index]; Rtab зберегла попередньо обраховані величини для p[p_state]·Q[q_index] R=R – RLPS [тобто, R попередньо оновлюється, якщо "інформаційною величиною" було MPS] 4. Визначення інформаційної величини, яке залежить від положення часткового інтервалу: if (V³ R) then bin ¬ 1-valMPS (інформаційна величина декодується як LPS; двійковий буферний селектор 18 буде одержувати реальне значення інформаційної величини шляхом використання цієї інформації про інформаційну величину і valMPS) V ¬ V-R R ¬ RLPS або bin ¬ valMPS (інформаційна величина декодується як MPS; реальне значення інформаційної величини одержується шляхом використання цієї інформації про інформаційну величину та valMPS) 5. Повторна нормалізація R, зчитування одного біта і оновлення V, Як описано вище, присвоювач 4 присвоює pState_current[bin] кожній інформаційній величині. Зв'язування може виконуватися на основі вибору контексту. Тобто, присвоювач 4 може вибирати контекст, використовуючи індекс контексту ctxIdx, який, у свою чергу, має відповідну зв'язану з ним ймовірність pState_current. Оновлення ймовірності може виконуватися кожен раз, коли ймовірність pState_current[bin] використана для поточної інформаційної величини. Оновлення стану ймовірності pState_current[bin] виконується в залежності від значення кодованого біту: if (bit=1 - valMPS) then pState_current ← Next_State_LPS [pState_current] if (pState_current=0) then valMPS ← 1 – valMPS else pState_current ← Next_State_MPS [pState_current] 26 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 60 Якщо надається більше ніж один контекст, то адаптація виконується контекстно, тобто, pState_current[ctxIdx] використовується для кодування і потім для оновлення з використанням поточного значення інформаційної величини (кодованої або, відповідно, декодованої). Як буде описано детальніше нижче, у відповідності з описаними тепер варіантами виконання кодер і декодер можуть необов'язково втілюватися для роботи в різних режимах, а саме: в режимі низької складності (LC) і високоефективному режимі (HE). Це головним чином ілюструється далі по відношенню до PIPE кодування (потім згадуючи режими LC і HE PIPE), але опис деталей складності масштабування легко переноситься на інші втілення засобів ентропійного кодування/декодування, таких як варіант виконання з використанням одного спільного адаптивного до контексту арифметичного кодера/декодера. У відповідності з описаними нижче варіантами виконання обидва режими ентропійного кодування можуть використовувати - однаковий синтаксис і семантику (для послідовності синтаксичних елементів 301 і, відповідно, 327) - однакові схеми бінаризації для усіх синтаксичних елементів (як на даний момент специфікується для CABAC) (тобто, бінаризатори можуть працювати незалежно від активованого режиму) - використання одних і тих же PIPE кодів (тобто, двійкові кодери/декодери можуть працювати незалежно від активованого режиму) - використання 8 бітових ініціалізуючих величин моделі ймовірності (замість 16 бітових ініціалізуючих величин, як на даний момент специфіковано для CABAC) Загалом кажучи, LC-PIPE відрізняється від HE-PIPE складністю обробки, як, наприклад, складність вибору PIPE доріжки 312 для кожної інформаційної величини. Наприклад, режим низької складності (LC) може функціонувати за наступних обмежень: для кожної інформаційної величини (binIdx) може існувати точно одна модель ймовірності, тобто, одне значення ctxIdx. Тобто, може не передбачатися вибір/адаптація контексту в LC PIPE. Спеціальні синтаксичні елементи, такі як ті, що використовуються для залишкового кодування, можуть, однак, кодуватися з використанням контекстів, як далі описано нижче. Більше того, усі моделі ймовірності можуть бути неадаптивними, тобто, усі моделі можуть ініціалізуватися на початку кожної частини інформації відповідними модельованими ймовірностями (в залежності від вибору типу частини інформації і QP частини інформації) і можуть зберігатися фіксованими протягом усього процесу обробки частини інформації. Наприклад, можуть підтримуватися тільки 8 різних модельованих ймовірностей, які відповідають 8 різним PIPE кодам 310/322, для моделювання контексту і кодування. Спеціальні синтаксичні елементи для залишкового кодування, тобто, significance_coeff_flag і coeff_abs_level_greaterX (з X=1,2), семантика яких описана детальніше нижче, можуть присвоюватися моделям ймовірності так, що (принаймні) групи, наприклад, з 4 синтаксичних елементів кодуються/декодуються однією і тією ж модельованою ймовірністю. Порівняно з CAVLC режим LC-PIPE досягає приблизно тих же характеристик R-D і тієї ж продуктивності. HE-PIPE може конфігуруватися концептуально подібно до CABAC стандарту H.264 з наступними відмінностями: Двійкове арифметичне кодування (BAC) замінюється PIPE кодуванням (теж саме що й у випадку LC-PIPE). Кожна модель ймовірності, тобто, кожен ctxIdx, може представлятися pipeIdx і refineIdx, де pipeIdx із значеннями в інтервалі 0…7 представляє модельовану ймовірність 8 різних PIPE кодів. Ця зміна впливає тільки на внутрішнє представлення станів, а не на поведінку самої машину стану (тобто, оцінку ймовірності). Як буде детальніше описано нижче, ініціалізація моделей ймовірності може використовувати 8 бітові ініціалізуючі величини, як вказано вище. Зворотне сканування синтаксичних елементів coeff_abs_level_greaterX (з X=1, 2), coeff_abs_level_minus3 і coeff_sign_flag (семантика яких стане яснішою з нижченаведеного обговорення) може виконуватися вздовж тієї ж доріжки сканування що й пряме сканування (використовуване, наприклад, в кодування карти значущості). Може також спрощуватися одержання контексту для кодування coeff_abs_level_greaterX (with X=1, 2). Порівняно з CABAC запропонований HE-PIPE приблизно досягає тих же характеристик R-D з кращою продуктивністю. Легко побачити, що тільки що згадані режими легко генеруються шляхом виконання, наприклад, вищезгаданого адаптивного до контексту двійкового арифметичного кодувального/декодувального засобу так, що він працює в різних режимах. Таким чином, у відповідності з варіантом виконання у відповідності з першим аспектом представленого винаходу декодер для декодування потоку даних може формуватися, як зображено на Фіг. 11. Декодер передбачений для декодування потоку даних 401, такого як поперемінний потік бітів 340, в який кодуються мультимедійні дані, такі як відеодані. Декодер 27 UA 111741 C2 5 10 15 20 25 30 35 40 45 50 55 містить перемикач режимів 400, сконфігурований для активування режиму низької складності або високоефективного режиму в залежності від потоку даних 401. Для цього, потік даних 401 може містити синтаксичний елемент, такий як двійковий синтаксичний елемент, який має двійкову величину 1 у випадку режиму низької складності, який активується, і має двійкову величину 0 у випадку високоефективного режиму, який активується. Очевидно, зв'язок між інформаційною величиною і режимом кодування може перемикатися, а недвійковий синтаксичний елемент, який має більше ніж два можливі значення, міг би також використовуватися. Оскільки реальний вибір між обома режимами все ще нечіткий до прийому відповідного синтаксичного елемента, то цей синтаксичний елемент може міститися в деякому ведучому заголовку кодованого потоку даних 401, наприклад, з фіксованою оцінкою ймовірності або моделлю ймовірності, або записуватися в потік даних 401, тобто, коли використовується байпасний режим. Окрім того, декодер з Фіг. 11 містить множину ентропійних декодерів 322, кожен з яких сконфігурований для перетворення кодових слів в потоці даних 401 на часткові послідовності 321 символів. Як описано вище, обернений перемежовувач 404 може підключатися між входами ентропійних декодерів 322, з одного боку, і входом декодера з Фіг. 11, де використовується потік даних 401, з іншого боку. Окрім того, як вже описувалося вище, кожен з ентропійних декодерів 322 може зв'язуватися з відповідним інтервалом ймовірності, при цьому інтервали ймовірності різних ентропійних декодерів разом охоплюють увесь інтервал ймовірності від 0 до 1 або від 0 до 0,5 у випадку ентропійних декодерів 322, які мають справу з MPS і LPS скоріше ніж з абсолютними символьними величинами. Деталі, які стосуються цього питання, були описані вище. Пізніше припускається, що кількість декодерів 322 становить 8 з PIPE індексом, який присвоюється кожному декодеру, але будь-яка інша кількість також можлива. Окрім того, один з цих кодерів (далі це ілюстративно той кодер, який має pipe_id 0) оптимізується для інформаційних величин, які мають рівноцінну статистику, тобто, їх двійкова величина рівноцінно припускає 1 і 0. Цей декодер може просто проходитися по інформаційним величинам. Відповідний кодер 310 працює так само. Навіть будь-яка маніпуляція з інформаційною величиною, яка залежить від значення найбільш ймовірної інформаційної величини, valMPS, за допомогою селекторів 402 і, відповідно, 502 може усуватися. Іншими словами, ентропія відповідного часткового потоку є вже оптимальною. Окрім того, декодер з Фіг. 11 містить селектор 402, сконфігурований для одержання кожного символу послідовності 326 символів з вибраного одного з множини ентропійних декодерів 322. Як згадано вище, селектор 402 може ділитися на присвоювач параметрів 316 і селектор 318. Десимволізатор 314 конфігурується для десимволізації послідовності 326 символів для одержання послідовності 327 синтаксичних елементів. Реконструктор 404 конфігурується для відновлення мультимедійних даних 405 на основі послідовності синтаксичних елементів 327. Селектор 402 конфігурується для виконання вибору, який залежить від одного активованого режиму, вибраного серед режиму низької складності і високоефективного режиму, як вказано стрілкою 406. Як вже відзначено вище, реконструктор 404 може бути частиною блочного прогнозувального відеодекодера, який працює на фіксованому синтаксисі і семантиці синтаксичних елементів, тобто, фіксований відносно вибору режиму за допомогою перемикача режимів 400. Тобто, структура реконструктора 404 не страждає від здатності перемикати режими. Точніше, реконструктор 404 не збільшує надмірне втілення завдяки здатності перемикання режимів, яке забезпечується перемикачем режимів 400 і принаймні функціональністю стосовно залишкових даних, і дані прогнозування залишаються однаковими незалежно від режиму, вибраного перемикачем 400. Те ж саме застосовується, однак, стосовно ентропійних декодерів 322. Усі ці декодери 322 повторно використовуються в обох режимах і, відповідно, відсутні додаткові втілення, хоча декодер з Фіг. 11 сумісний з обома режимами: режимом низької складності і високоефективним режимом. Як побічний аспект слід відзначити, що декодер з Фіг. 11 не тільки здатен працювати на незалежних потоках даних або в одному режимі або в іншому режимі. Скоріше, декодер з Фіг. 11, а також потік даних 401 можуть конфігуруватися так, що перемикання між обома режимами повинно бути навіть можливим під час обробки однієї частини мультимедійних даних, як, наприклад під час обробки відеоданих або деякої частини аудіоінформації, для, наприклад, керування складністю кодування на кодувальній стороні в залежності від зовнішніх або навколишніх умов, таких як стан акумулятора або подібне, з використанням каналу зворотного зв'язку від декодера до кодера, відповідно, для керування в замкненому контурі вибором режиму. 28
ДивитисяДодаткова інформація
Назва патенту англійськоюEntropy coding of motion vector differences
Автори англійськоюGeorge, Valeri, Bross, Benjamin, Kirchhoffer, Heiner, Marpe, Detlev, Nguyen, Tung, Preiss, Matthias, Siekmann, Mischa, Stegemann, Jan, Wiegand, Thomas
Автори російськоюГеорге Валери, Бросс Бенджамин, Кирххоффер Хайнер, Марпе Детлеф, Нгуен Тунг, Прайсс Маттиас, Зикманн Миша, Штегеманн Ян, Виганд Томас
МПК / Мітки
МПК: H03M 7/42, H04N 7/24, H04N 7/52
Мітки: різниць, ентропійне, руху, векторів, кодування
Код посилання
<a href="https://ua.patents.su/64-111741-entropijjne-koduvannya-riznic-vektoriv-rukhu.html" target="_blank" rel="follow" title="База патентів України">Ентропійне кодування різниць векторів руху</a>
Прогнозування векторів руху при кодуванні відео

Номер патенту: 110826
Опубліковано: 25.02.2016
Автори: Чень Пейсун, Карчевіч Марта, Чен Ін
МПК: H04N 7/00
Мітки: прогнозування, відео, руху, векторів, кодуванні
Формула / Реферат:
1. Спосіб кодування відеоданих, при цьому спосіб включає: ідентифікацію першого блока відеоданих в першому часовому місцеположенні з першого виду, при цьому перший блок асоційований з першим вектором диспаратності руху,генерування списку кандидатів-предикторів вектора руху для прогнозування першого вектора руху, при цьому генерування списку кандидатів-предикторів вектора руху містить:ідентифікацію другого вектора руху...
Спосіб і пристрій для призначення векторів руху

Номер патенту: 88017
Опубліковано: 10.09.2009
Автори: Равіндран Віджаялакшмі Р., Ши Фан
МПК: H04N 7/26, H04N 7/46, H04N 7/01
Мітки: пристрій, спосіб, векторів, руху, призначення
Формула / Реферат:
1. Спосіб обробки множини векторів руху для відеокадру, що інтерполюється з використанням першого опорного кадру й другого опорного кадру, причому кожний опорний кадр містить карту змісту, який включає етапи, на яких: ділять відеокадр, що інтерполюється у множину зон; визначають кількість векторів руху, що проходять через одну із множини зон, на основі карт змісту першого опорного кадру й другого опорного кадру; і...
Кодування відео, використовуючи адаптивне розрізнення вектора руху

Номер патенту: 110981
Опубліковано: 10.03.2016
Автори: Чіень Вей-Цзюн, Карчєвіч Марта, Чень Пейсун
МПК: H04N 19/61, H04N 19/13, H04N 19/52, H04N 19/70, H04N 19/513
Мітки: вектора, кодування, використовуючи, адаптивне, розрізнення, руху, відео
Формула / Реферат:
1. Спосіб ентропійного кодування відеоданих, причому спосіб включає: коли абсолютне значення -компоненти значення різниці векторів руху для поточного блока більше ніж нуль, і коли абсолютне значення -компоненти значення різниці векторів руху для поточного блока більше ніж нуль, ентропійне кодування...
Спосіб кодування/декодування інформації

Номер патенту: 76529
Опубліковано: 10.01.2013
Автори: Шабанов Михайло Валерійович, Полєтаєв Дмитро Олександрович
МПК: H03M 13/00
Мітки: інформації, спосіб
Формула / Реферат:
Спосіб кодування/декодування інформації, що включає операцію зчитування інформації, який відрізняється тим, що додатково включає формування стартової послідовності сигналів, поділ послідовності бітів для кодування на комбінації бітів фіксованої довжини, обчислення числа дискретних рівнів, обчислення значення сигналу для поточної комбінації бітів як різниці попереднього значення сигналу і добутку величини рівня на значення поточної комбінації...
Спосіб двоетапного пошуку векторів під час ущільнення мовних векторів

Номер патенту: 70762
Опубліковано: 25.06.2012
Автор: ВІННИЦЬКИЙ НАЦІОНАЛЬНИЙ ТЕХНІЧНИЙ УНІВЕРСИТЕТ
МПК: G10L 19/00, G10L 21/00
Мітки: спосіб, ущільнення, пошуку, векторів, двоетапного, мовних
Формула / Реферат:
Спосіб двоетапного пошуку векторів під час ущільнення мовних сигналів, в якому простір векторів кодової книги розбивають на підобласті на основі бінарного дерева, здійснюють пошук вектора кодової книги, найближчого до вхідного за евклідовою метрикою згідно з формулою:,де - вхідний...
Попередній патент: Оптоелектронний сенсор
Наступний патент: Фармацевтичні композиції
Випадковий патент: Імітансний логічний елемент або-ні