Пристрій для обробки даних багатопроцесорної системи
Номер патенту: 38850
Опубліковано: 15.05.2001





Формула / Реферат
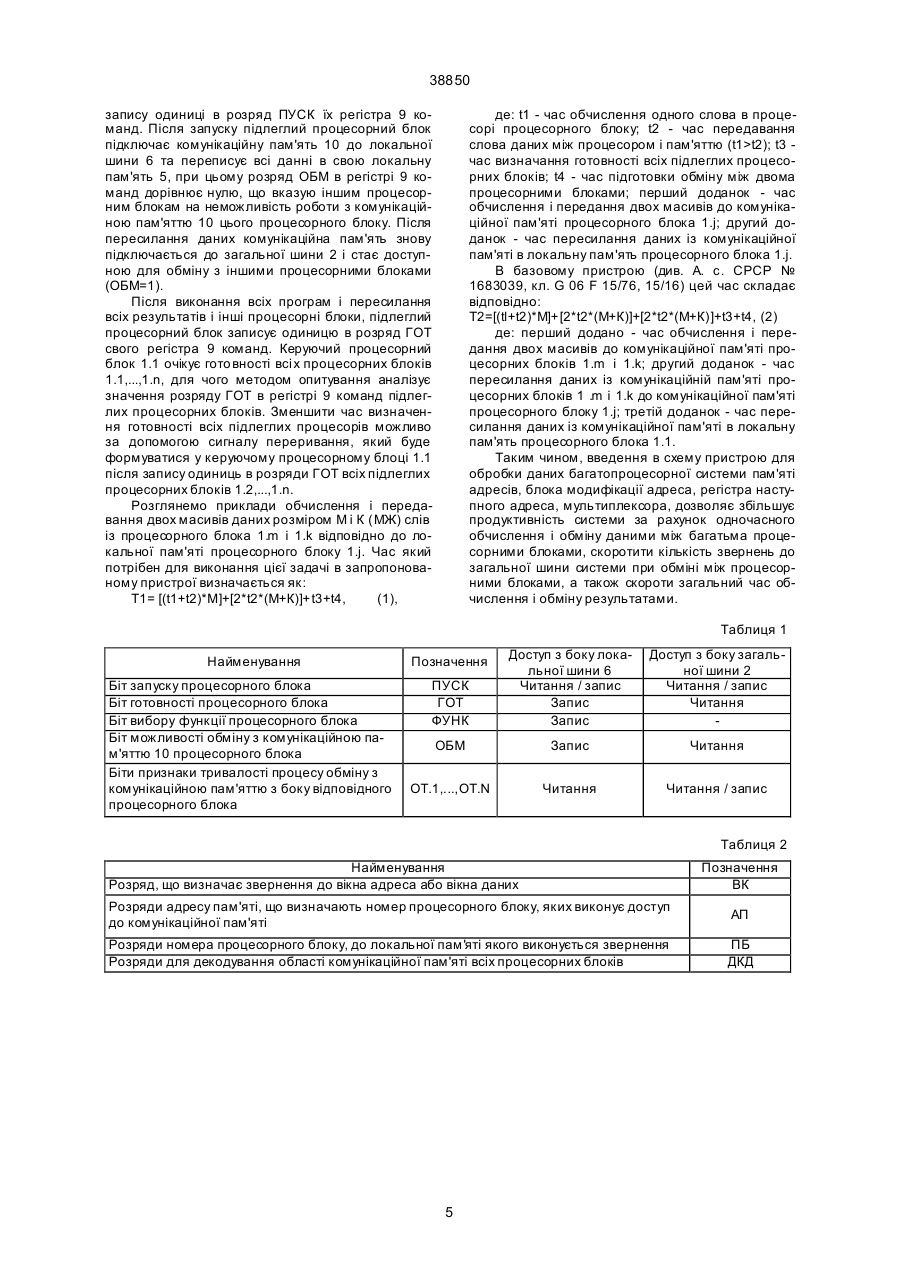
Пристрій для обробки даних багатопроцесорної системи, що містить процесорні блоки і зовнішні пристрої, з'єднані між собою загальною шиною, кожний процесорний блок містить процесор, локальну пам'ять, які з'єднані між собою локальною шиною, до якої підключено перший інформаційний вхід-вихід першого комутатора, перший інформаційний вхід-вихід другого комутатора, і перший інформаційний вхід-вихід регістра команд, другий інформаційний вхід-вихід першого комутатора з'єднано з інформаційним входом-виходом комунікаційної пам'яті, вхід управління якої з'єднано з першим виходом блока управління, другий вихід якого з'єднано з входом управління першого комутатора, третій вихід - з входом управління регістра адреса, четвертий вихід - з входом управління регістра даних, п'ятий вхід-вихід - з входом-виходом управління регістра команд, шостий - з входом-виходом управління другого комутатора, сьомий вхід-вихід - з загальною шиною, до якої підключені другий інформаційний вхід-вихід другого комутатора, другий інформаційний вхід-вихід регістра команд, інформаційний вхід регістра адреса і інформаційний вхід регістра даних, вихід якого підключено до входу даних першого комутатора, який відрізняється тим, що в його склад введені послідовно з'єднані інформаційними виходами та входами мультиплексор, пам'ять адресів, блок модифікації адреса та регістр наступного адреса, вихід якого підключено до першого інформаційного входу мультиплексора, другий інформаційний вхід якого з'єднано з інформаційним виходом регістра даних, вихід регістра адреса з'єднано з входом адреса пам'яті адресів, вихід даних якої також підключено до входу адреса першого комутатора, до восьмого, дев'ятого, десятого і одинадцятого виходів блоку управління підключені відповідно входи управління пам'яті адресів, блоку модифікації адреса, регістра наступного адреса та мультиплексора.
Текст
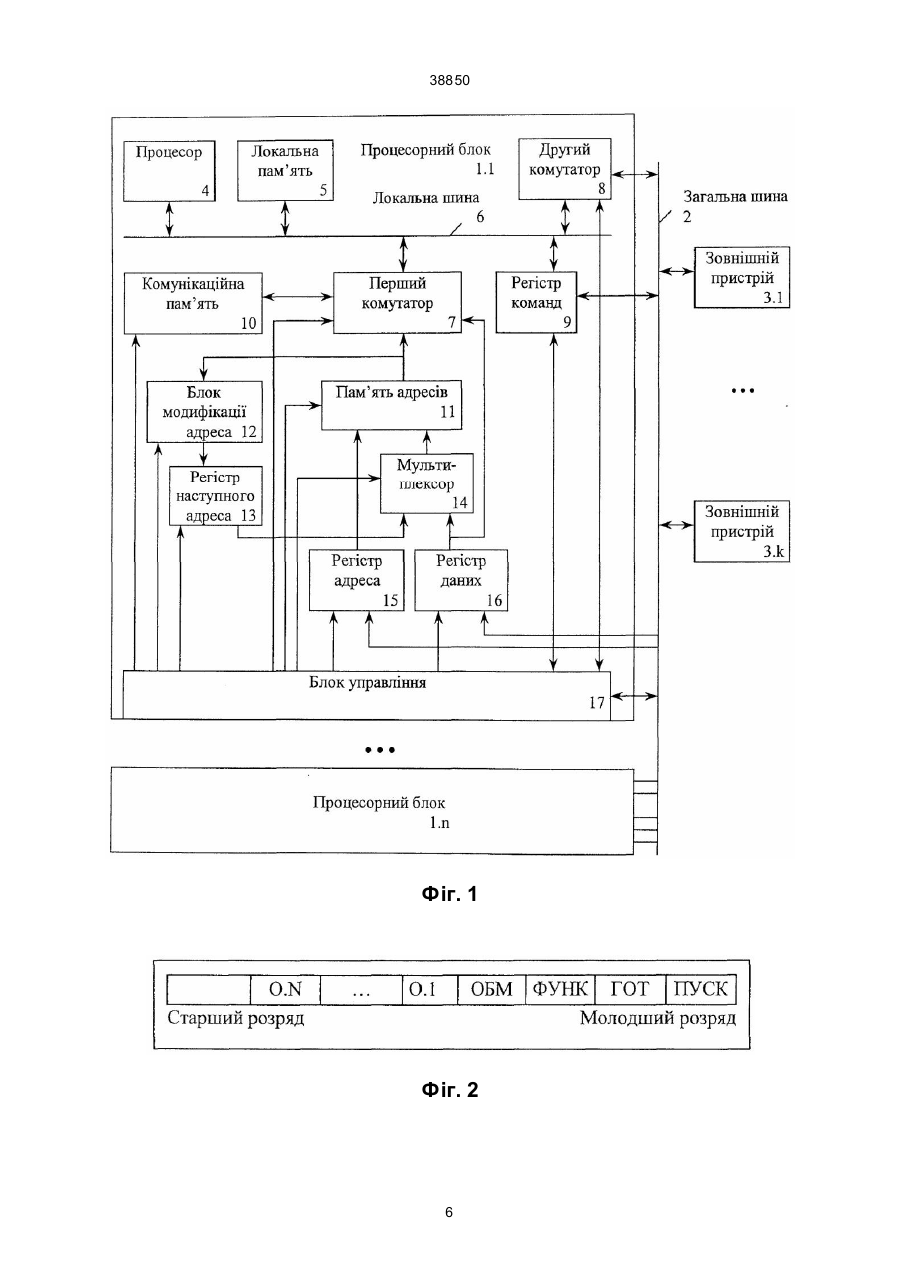
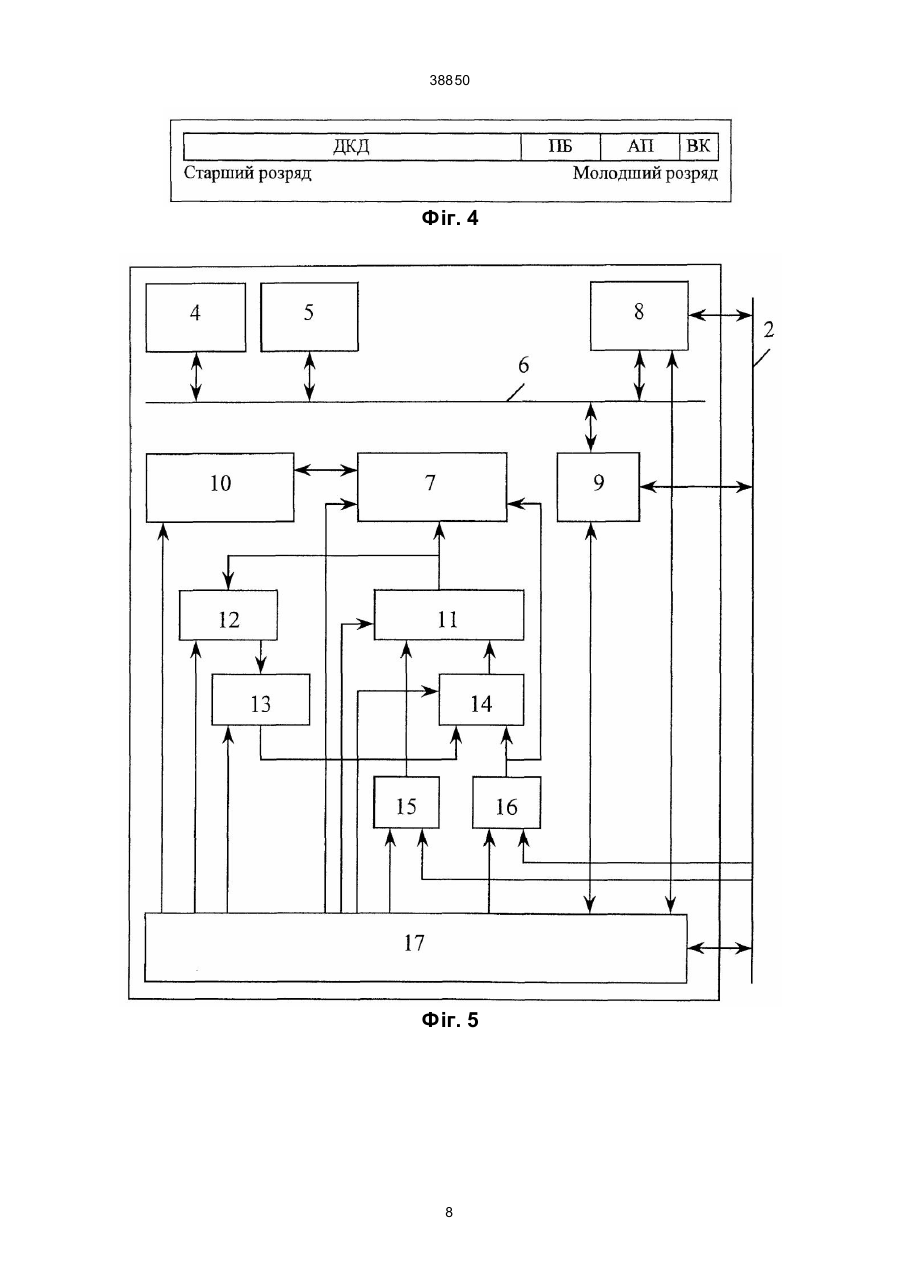
Пристрій для обробки даних багатопроцесорної системи, що містить процесорні блоки і зовнішні пристрої, з'єднані між собою загальною шиною, кожний процесорний блок містить процесор, локальну пам'ять, які з'єднані між собою локальною шиною, до якої підключено перший інформаційний вхід-ви хід першого комутатора, перший інформаційний вхід-вихід другого комутатора, і перший інформаційний вхід-вихід регістра команд, другий інформаційний вхід-вихід першого комутатора з'єднано з інформаційним входом-виходом комунікаційної пам'яті, вхід управління якої з'єднано з першим виходом блока управління, другий вихід якого з'єднано з входом управління першого комутатора, третій вихід - з входом управління регістра адреса, четвертий вихід - з входом управ A (54) ПРИСТРІЙ ДЛЯ ОБРОБКИ Д АНИХ БАГАТОПРОЦ ЕСОРНОЇ СИСТЕМИ 38850 регістра даних з'єднано відповідно з третім і четвертим входами першого комутатора. Другий вихід другого комутатора, другій вхід-ви хід регістра команд, другий вхід регістра адреса і другий вхід регістра даних зв'язано з загальною шиною. Третій вхід регістра команд, тертій вхід регістра адреса, третій вхід регістра даних та третій вхід другого комутатора зв'язані з блоком управління (див. А. с. СРСР № 1683039, кл. G 06 F 15/76, 15/16). Недоліком даного пристрою є те, що він потребує значних ви трат часу на обмін даними між процесорними блоками. Це обумовлено по-перше тим, що обмін даними водночас можливо виконувати тільки між двома процесорними блоками, подруге пересилання одного слова з одного процесорного блоку в інший потребує двох звернень до загальної шини, по-третіх, обмін даними можливо виконувати тільки між комунікаційними пам'я тями процесорних блоків і тільки після їх відключення від локальної шини. В основу винаходу поставлено задачу удосконалення пристрою для обробки даних багатопроцесорної системи шляхом введення пам'яті адресів, блока модифікації адреса, регістра наступного адреса, мультиплексора, що дозволяє збільшити продуктивність системи за рахунок одночасного обміну даними між багатьма процесорними блоками і скоротити кількість звернень до загальної шини при обміні між процесорними блоками. Встановлена задача виконується тим, що в пристрої для обробки даних багатопроцесорної системи, що містить процесорні блоки і зовнішні пристрої, з'єднані між собою загальною шиною, кожний процесорний блок містить процесор, локальну пам'ять, які з'єднані між собою локальною шиною, до якої підключено перший інформаційний вхід-ви хід першого комутатора, перший інформаційний вхід-ви хід другого комутатора, і перший інформаційний вхід-вихід регістра команд, другий інформаційний вхід-вихід першого комутатора з'єднано з інформаційним входом-виходом комунікаційної пам'яті, вхід управління якої з'єднано з першим виходом блока управління, другий ви хід якого з'єднано з входом управління першого комутатора, третій вихід - з входом управління регістра адреса, четвертий вихід - з входом управління регістра даних, п'ятий вхід-ви хід - з входом-виходом управління регістра команд, шостий - з входом-виходом управління другого комутатора, сьомий вхід-вихід - з загальною шиною, до якої підключені другий інформаційний вхід-вихід другого комутатора, другий інформаційний вхід-вихід регістра команд, інформаційний вхід регістра адреса і інформаційний вхід регістра даних, ви хід якого підключено до входу даних першого комутатора, новим є те, що в його склад введені послідовно з'єднані інформаційними виходами та входами мультиплексор, пам'ять адресів, блок модифікації адреса та регістр наступного адреса, вихід якого підключено до першого інформаційного входу мультиплексора, другий інформаційний вхід якого з'єднано з інформаційним виходом регістра даних, вихід регістра адреса з'єднано з входом адреса пам'яті адресів, вихід даних якої також підключено до входу адреса першого комутатора, до восьмого, дев'ятого, десятого і одинадцятого виходів блоку управління підключені відповідно входи управ ління пам'яті адресів, блоку модифікації адреса, регістра наступного адреса та мультиплексора. Підвищення продуктивності пристрою досягається шляхом одночасної роботи декількох процесорних блоків з комунікаційними пам'я тями інших процесорних блоків, а також за рахунок скорочення кількості звернень процесорного блоку до загальної шини до одного звернення при передаванні одного слова даних. Для цього в процесорний блок введено пам'ять адресів, в якій зберігаються значення всіх адресів для роботи з комунікаційною пам'яттю цього процесорного блоку з боку всіх інших процесорних блоків багатопроцесорній системі, а також введено блок модифікації адреса, якій обчислює адрес наступного слова в комунікаційній пам'яті після звернення до неї. Це дозволяє виконувати наступну операцію з комунікаційною пам'яттю з боку відповідного процесорного блоку з словом у наступному адресі, що скорочує кількість звернень до загальної шини. На фіг. 1 показана структурна схема пристрою обробки даних для багатопроцесорної системи; на фіг. 2 - приклад формату регістра команд; на фіг. 3 - приклад розподілення адресного простору загальної шини; на фіг. 4 - приклад розподілення розрядів адреса загальної шини, що дозволяє спростити роботу з комунікаційною пам'я ттю; фі г. 5 конфігурація зв'язків процесорного блоку на етапі виконання програм і обміну результатами; на фіг. 6 - конфігурація зв'язків процесорного блоку на етапі обробки результатів виконання програми; в табл. 1 наведені найменування, позначення і типи операцій з розрядами регістра команд; в табл. 2 найменування і позначення груп розрядів шини адреса, які використовуються блоком керування пристрою під час декодування адреса. Пристрій для обробки даних (фіг. 1) багатопроцесорної системи містіть процесорні блоки 1.1,..., 1.n, загальну шину 2, до якої підключені зовнішні пристрої 3.1,..., 3.k. До складу кожного процесорного блоку 1.і входить процесор 4, локальна пам'ять 5, локальна шина 6, перший 7 і другий 8 комутатори, регістр команд 9, комунікаційна пам'ять 10, пам'ять 11 адресів, блок 12 модифікації адреса, регістр 13 наступного адреса, мультиплексор 14, регістр 15 адреса, регістр 16 даних, блок 17 управління. В кожному процесорному блоці 1.і процесор 4 і локальна пам'ять 5 з'єднані за допомогою локальної шини 6, до якої також підключені перший інформаційний вхід-вихід першого комутатора 7, першій інформаційний вхід-ви хід др угого комутатора 8 і першій інформаційний вхід-вихід регістра 9 команд. Локальна шина 6 через другий інформаційний вхід-ви хід першого комутатора 7 підключена до інформаційного входу-виходу комунікаційної пам'яті 10, і через вхід адреса першого комутатора 7 підключена до виходу даних пам'яті 11 адресів. Вихід даних пам'яті 11 адресів також підключено до інформаційного входу блока 12 модифікації адреса, вихід якого підключений до інформаційного входу регістра 13 наступного адреса, вихід якого підключений до першого інформаційного входу мультиплексора 14, вихід якого підключений до входу даних пам'яті 11 адресів, до входу адреса якої підключений вихід регістра 15 адреса. Вихід 2 38850 регістра 16 даних зв'язаний з другим інформаційним входом мультиплексора 14 і з входом даних першого комутатора 7. До загальної шини 2 підключені другий інформаційний вхід-вихід другого комутатора 8, другий інформаційний вхід-ви хід регістра команд 9, інформаційний вхід регістра 15 адреса, інформаційний вхід регістра 16 даних та перший вхід-ви хід блока 17 управління, входи-виходи якого підключені до входу управління першого комутатора 7, входувиходу управління другого комутатора 8, входувиходу управління регістра 9 команд, входу управління комунікаційної пам'яті 10, входу управління пам'яті 11 адресів, входу управління блока 12 модифікації адреса, входу управління регістра 13 наступного адреса, входу управління мультиплексора 14, входу управління регістра 15 адреса, входу управління регістра 16 даних. Призначення блока 17 управління полягає у формуванні сигналів, які необхідні для реалізації циклів звернення до загальної шини 2 через другий комутатор 8, сигналів управління для внутрішніх вузлів процесорного блоку 1.і, а також сигналів для зміни з'єднань між функціональними вузлами за допомогою першого комутатора 7. Режим роботи блоку 17 управління визначається значеннями відповідних розрядів регістра 9 команд. Можливий формат регістра 9 команд наведено на фіг. 2, а призначення кожного з його розрядів відповідно в табл. 1. Перший комутатор 7 призначений для виконання з'єднань у відповідності зі значенням у розряді ОБМ регістра 9 команд між локальною шиною 6 і комунікаційною пам'яттю 10, або між комунікаційною пам'яттю 10, ви ходом пам'яті 11 адресів і виходом регістра 16 даних. Перший комутатор може бути реалізовано на базі стандартних мікросхем мультиплексорів і двоспрямованих шинних формувачів. Пам'ять 11 адресів призначена для зберігання адресів доступу до комунікаційної пам'яті 10 процесорного блоку 1.і з боку інших процесорних блоків 1.j. При цьому за допомогою першого комутатора 7 її вихід даних може бути підключений до розрядів адресу інформаційного входу-виходу комунікаційної пам'яті 10. Ємність пам'яті 11 адресів повинна бути ні менш чим п k-розрядних слів, де n - кількість процесорних блоків у системі, a k - кількість розрядів адресу комунікаційної пам'яті 10. Пам'ять адресів 11, наприклад, може бути побудована за допомогою мікросхем статичної пам'яті достатньої ємності, в якої входи і виходи даних виконані окремо. Призначення блока 12 модифікації адреса полягає в обчислені адресу слова, яке буде записуватись в комунікаційну пам'ять 10 при наступному звернення до неї з боку відповідного процесорного блоку 1.j. Блок 12 модифікації адреса, наприклад, може бути побудовано за допомогою суматора, який є стандартним елементом більшості існуючих серій мікросхем. Можливий варіант розподілення адресного простору загальної шини наведено на фіг. 3, де заштриховані області адресів загальної шини відображають незадіяні у цьому пристрою або блоку адреси. Старші адреси адресного простору загальної шини виділено для локальної пам'яті 5 про цесорних блоків 1.1,..., 1.n, яка доступна тільки з боку процесора 4 того процесорного блоку, в якому ця пам'ять знаходиться. Наступну область виділено для доступу комунікаційної пам'яті 10 кожного процесорного блоку з боку інших процесорних блоків, молодші адреси розподілено між регістрами 9 команд, зовнішніми пристроями 3.1,...,3.k і незадіяними адресами. В області комунікаційної пам'яті для звернення до комунікаційної пам'яті 10 процесорного блоку 1.і з боку процесорного блоку 1.j виділено 2n адресів, n адресів для вікон адресу і n адресів для вікон даних, позначених на фіг. 3 відповідно як BAij і ВДij, при цьому загальна кількість задіяних адресів в усіх процесорних блоках 1.1,...,1.n становить 2n2. Сигнали управління на виходах блок управління 17 формуються на основі декодування інформації, що надходить з загальної шини 2. Для спрощення декодування адресу на загальній шині 2 можливо цей m-розрядний адрес умовно поділити на чотири групи, як наведено на фіг. 4 і в табл. 2. 1) група ПБ, містить р=]log2(n)[ розрядів, де функція ]х[ обчислює найближче більше аргументу х. Ця гр упа визначає номер процесорного блока 1.і, до комунікаційної пам'яті 10 якого виконується звернення з боку загальної шини; 2) група АП, містить а=]log2(n)[ розрядів і використовуються для визначення адреса в пам'яті 11 адресів, із якої зчитується адрес для роботи з комунікаційною пам'яттю 10. Розряди цієї групи записуються у регістр 15 адреса при звернені до цього процесорного блоку по адресах вікон адреса BAij і даних ВДij; 3) група ВК, що містить один розряд, використовується блоком 17 управління для визначення типа вікна (вікно адресу або вікно даних) до якого виконується звернення. Наприклад, для адреса ВДij V=0, а для адреса BAij V=1; 4) група ДКД, що містить останні (m-p-a-l) розрядів, використовується блоком 17 управління для визначення циклів звернення з боку загальної шини 2 до адресів області комунікаційної пам'яті що вказана на фіг. 3. Якщо цей адрес належить вказаній області, то блок 17 управління виробляє всі необхідні сигнали управління для внутрішніх вузлів процесорного блока 1.і відповідно до інформації в група х ВК, АП і ПБ та інших сигналів на загальній шині 2, в іншому випадку - ні. Пристрій працює наступним чином. Після початку роботи багатопроцесорної системи (по зовнішньому сигналу "Старт") процесори 4 починають виконувати програми, які записані в локальні пам'яті 5 відповідних процесорних блоків 1.1,...,1.n. Результатом роботи цих програм є ініціалізація кожного процесорного блока. Один з процесорних блоків, наприклад 1.1, виконує функції керуючого процесорного блока, а інші - підлеглих процесорних блоків 1.2.....1.n. Це досягається, наприклад, встановленням значення розряду ФУНК в регістрі 9 команд по зовнішньому сигналу "Старт" в одиницю для керуючого процесорного блока і в нуль відповідно для підлеглих (всі інших). Функціями керуючого процесорного блоку 1.1 є на сам перед розподілення завдань між підлеглими процесорними блоками 1.2,...,1.n, запуск цих процесорних блоків для виконання завдань, підготовка підлеглих блоків для обміну результатами. 3 38850 Функціями підлеглих процесорних блоків 1.2,...,1.n є виконання завдань і обмін результатами з іншими підлеглими процесорними блоками і з керуючим процесорним блоком 1.1. Робота системи при розв'язанні заданої задачі складається з черги етапів паралельного виконання програм з обміном результатами між комунікаційними пам'ятями процесорних блоків 1.1,...,1.n, та етапів обробки результатів в процесорних блоках. На етапі виконання програми кожний процесорний блок 1.і маєконфігурацію наведену на фіг. 5, в який процесор 4 має доступ до своєї локальної пам'яті 5 і через другий комутатор 8 до загальної шини, і далі через регістр 5 адреса, пам'ять 11 адресів, регістр 6 даних і перший комутатор 7 інших процесорних блоків до їх комутаційної пам'яті 10. Таким чином, в процесі виконання програми в процесорі 4 одного процесорного блока 1.і формуються результати, які записуються в комунікаційні пам'яті 10 інших процесорних блоків 1.j. Зазначена на фіг. 5 конфігурація зв'язків, при який комунікаційна пам'ять 10 відключена від локальної шини 6 і підключена до виходу даних пам'яті 11 адресів і виходу регістра 16 даних, досягається за допомогою першого комутатора 7, який переключається під управлінням блока 17 управління після запису в розряд ОБМ регістра 9 команд одиниці. На етапі обробки результатів процесорний блок 1.і має конфігурацію фіг. 6, в який процесор 4 має доступ до своєї локальної пам'яті 5 і через перший комутатор 7 до комунікаційної пам'яті 10. Таким чином на етапі обробки результатів, данні яки поступили в комунікаційну пам'ять 10 процесорного блоку 1.і з інших процесорних блоків, стають доступними для процесора 4 цього процесорного блоку і пересилаються в його локальну пам'ять 5 для подальшої обробки. Зазначена на фіг. 6 конфігурація зв'язків, при який комунікаційна пам'ять 10 підключена до локальної шини 6 і відключена від виходу даних пам'яті 11 адресів і виходу регістра 16 даних, досягається за допомогою першого комутатора 7, який переключається під управлінням блока управління 17 після запису в розряд ОБМ регістра 9 команд нуля. Після завершення етапу обробки результатів у процесорному блоці 1.і процесор 4 встановлює в своєму регістрі 9 команд розряд ОБМ в одиницю, в результаті чого комунікаційна пам'ять 10 відключається від локальної шини 6 процесорного блоку і стає доступною для обміну з блоку загальної шини 2, тобто інши х процесорних блоків 1.1,...,1.n. Розглянемо роботу процесорного блоку 1.і на етапі обміну між його комунікаційною пам'яттю 10 і процесорним блоком 1.j. На початку обміну процесорний блок 1.j записує в процесорний блок 1.і адрес комунікаційної пам'яті з якого почнеться масив результатів. Для цього процесорний блок 1 .j виконує цикл записі по адресу вікна адреса BAij (див. фіг. 3) в якому передає адрес початку масиву. Після початку цієї операції адрес масиву записується в регістр 16 даних процесорного блоку 1.і, а група АП розрядів адреса, з загальної шині записується в регістр 15 адресу цього ж процесорного блоку. По завершенні циклу записі адрес масиву з виходу регістра 16 даних через другий інформаційний вхід мультиплексора 14, дали через його вихід подається на вхід даних пам'яті 11 адресів і записується в ній по адресу з ви ходу регістра 15 адресу, тобто по адресу j. Безпосередньо пересилання результатів в процесорний блок 1.і виконується в циклі запису даних із процесорного блоку l.j по адресу вікна даних ВДij (див. фіг. 3). На початку циклу запису адрес із групи АП розрядів адресу загальної шини 2 фіксується в регістрі 15 адресу, а данні, що записуються, фіксуються в регістрі 16 даних. Далі із пам'яті 11 адресів зчитується заданий раніш адрес початку масиву результатів, який через вхід адресу першого комутатора 7 подається на інформаційний вхід-ви хід комунікаційної пам'яті 10, а данні для запису через вхід даних цього ж комутатора з виходу регістра 16 даних. При цьому на управляючий вхід комунікаційної пам'яті 10 подається сигнал запису. Адрес з виходу даних пам'яті 11 адресів також подається на інформаційний вхід блоку 12 модифікації адресу, який обчислює адрес наступного слова масиву в комунікаційній пам'яті і видає його на інформаційний вхід регістра 13 наступного адреса. Після завершення циклу запису загальної шини 2 новий адрес з виходу регістра 13 наступного адресу через перший інформаційний вхід м ультиплексора 14 записується в пам'ять 11 адресів по адресу на виході регістра 15 адреса. Таким чином, після запису слова даних в комунікаційну пам'ять 10 процесорного блока 1.і із процесорного блока 1.j, відповідний йому адрес комунікаційній пам'яті змінюється і адресує наступні слова. Синхронізація процесорних блоків 1.1,...,1.n під час розв'язання заданої задачі виконується за допомогою інформації в регістрі 9 команд. Після ініціалізації всіх процесорних блоків по сигналу "Старт", їх комунікаційні пам'яті 10 підключено до загальної шини 2 (див. фіг. 5), при цьому в розряд ОБМ регістра 9 команд записано одиницю, що сигналізує керуючому процесорному блоку 1.1 о можливості обміну даними з підлеглими процесорними блоками 1.2,...,1.n. В результаті цього керуючий процесорний блок 1.1 загружає в комунікаційні пам'яті 11 підлеглих процесорних блоків 1.2,...,1.n дані, яки необхідні їм для початку роботи. Такими даними, наприклад, можуть бути номера програм, що будуть розв'язувати підлеглі процесорні блоки, а також адреси і розмірності масивів результатів, яки будуть пересилатися між процесорними блоками. Для вилучення можливості відключення комунікаційної пам'яті процесорного блоку 1.і від загальної шини 2 до завершення пересилання всього масиву результатів із процесорного блоку 1.j, може використовуватися біт признака тривалості процесу обміну OT.j, який розташовано в регістрі 9 команд процесорного блоку 1.і. На початку обміну процесорний блок 1.j записує в цей розряд одиницю, а після завершення обміну - н уль. Таким чином перед переключенням комунікаційної пам'яті 10 від загальної шини 2 до локальної шини 6 процесорного блока 1.i, його процесор 4 повинен перевірити тотожність нулеві всіх розрядів OT.k свого регістра 9 команд. Після передачі всіх початкових даних в підлеглі процесорні блоки 1.2,...,1.n, керуючий процесорний блок 1.1 послідовно запускає їх за допомогою 4 38850 запису одиниці в розряд ПУСК їх регістра 9 команд. Після запуску підлеглий процесорний блок підключає комунікаційну пам'ять 10 до локальної шини 6 та переписує всі данні в свою локальну пам'ять 5, при цьому розряд ОБМ в регістрі 9 команд дорівнює нулю, що вказую іншим процесорним блокам на неможливість роботи з комунікаційною пам'яттю 10 цього процесорного блоку. Після пересилання даних комунікаційна пам'ять знову підключається до загальної шини 2 і стає доступною для обміну з іншими процесорними блоками (ОБМ=1). Після виконання всіх програм і пересилання всіх результатів і інші процесорні блоки, підлеглий процесорний блок записує одиницю в розряд ГОТ свого регістра 9 команд. Керуючий процесорний блок 1.1 очікує гото вності всі х процесорних блоків 1.1,...,1.n, для чого методом опитування аналізує значення розряду ГОТ в регістрі 9 команд підлеглих процесорних блоків. Зменшити час визначення готовності всіх підлеглих процесорів можливо за допомогою сигналу переривання, який буде формуватися у керуючому процесорному блоці 1.1 після запису одиниць в розряди ГОТ всіх підлеглих процесорних блоків 1.2,...,1.n. Розглянемо приклади обчислення і передавання двох масивів даних розміром М і К (МЖ) слів із процесорного блока 1.m і 1.k відповідно до локальної пам'яті процесорного блоку 1.j. Час який потрібен для виконання цієї задачі в запропонованому пристрої визначається як: Т1= [(t1+t2)*М]+[2*t2*(М+К)]+t3+t4, (1), де: t1 - час обчислення одного слова в процесорі процесорного блоку; t2 - час передавання слова даних між процесором і пам'яттю (t1>t2); t3 час визначання готовності всіх підлеглих процесорних блоків; t4 - час підготовки обміну між двома процесорними блоками; перший доданок - час обчислення і передання двох масивів до комунікаційної пам'яті процесорного блока 1.j; другий доданок - час пересилання даних із комунікаційної пам'яті в локальну пам'ять процесорного блока 1.j. В базовому пристрою (див. А. с. СРСР № 1683039, кл. G 06 F 15/76, 15/16) цей час складає відповідно: Т2=[(tl+t2)*M]+[2*t2*(М+К)]+[2*t2*(М+К)]+t3+t4, (2) де: перший додано - час обчислення і передання двох масивів до комунікаційної пам'яті процесорних блоків 1.m і 1.k; другий доданок - час пересилання даних із комунікаційній пам'яті процесорних блоків 1 .m і 1.k до комунікаційної пам'яті процесорного блоку 1.j; третій доданок - час пересилання даних із комунікаційної пам'яті в локальну пам'ять процесорного блока 1.1. Таким чином, введення в схему пристрою для обробки даних багатопроцесорної системи пам'яті адресів, блока модифікації адреса, регістра наступного адреса, мультиплексора, дозволяє збільшує продуктивність системи за рахунок одночасного обчислення і обміну даними між багатьма процесорними блоками, скоротити кількість звернень до загальної шини системи при обміні між процесорними блоками, а також скороти загальний час обчислення і обміну результатами. Таблиця 1 ПУСК ГОТ ФУНК Доступ з боку локальної шини 6 Читання / запис Запис Запис Доступ з боку загальної шини 2 Читання / запис Читання ОБМ Запис Читання ОТ.1,...,OT.N Читання Читання / запис Найменування Позначення Біт запуску процесорного блока Біт готовності процесорного блока Біт вибору функції процесорного блока Біт можливості обміну з комунікаційною пам'яттю 10 процесорного блока Біти признаки тривалості процесу обміну з комунікаційною пам'яттю з боку відповідного процесорного блока Таблиця 2 Найменування Розряд, що визначає звернення до вікна адреса або вікна даних Позначення ВК Розряди адресу пам'яті, що визначають номер процесорного блоку, яких виконує доступ до комунікаційної пам'яті АП Розряди номера процесорного блоку, до локальної пам'яті якого виконується звернення Розряди для декодування області комунікаційної пам'яті всіх процесорних блоків ПБ ДКД 5 38850 Фіг. 1 Фіг. 2 6 38850 Фіг. 3 7 38850 Фіг. 4 Фіг. 5 8 38850 Фіг. 6 __________________________________________________________ ДП "Український інститут промислової власності" (Укрпатент) Україна, 01133, Київ-133, бульв. Лесі Українки, 26 (044) 295-81-42, 295-61-97 __________________________________________________________ Підписано до друку ________ 2001 р. Формат 60х84 1/8. Обсяг ______ обл.-вид. арк. Тираж 50 прим. Зам._______ ____________________________________________________________ УкрІНТЕІ, 03680, Київ-39 МСП, вул. Горького, 180. (044) 268-25-22 ___________________________________________________________ 9
ДивитисяДодаткова інформація
Назва патенту англійськоюData processing device of multi-processor system
Автори англійськоюZhabin Valerii Ivanovych, Antonov Ruslan Leonidovych
Назва патенту російськоюУстройство для обработки данных многопроцессорной системы
Автори російськоюЖабин Валерий Иванович, Антонов Руслан Леонидович
МПК / Мітки
МПК: G06F 15/16, G06F 15/76
Мітки: обробки, багатопроцесорної, системі, даних, пристрій
Код посилання
<a href="https://ua.patents.su/9-38850-pristrijj-dlya-obrobki-danikh-bagatoprocesorno-sistemi.html" target="_blank" rel="follow" title="База патентів України">Пристрій для обробки даних багатопроцесорної системи</a>
Пристрій для обробки інформації мультипроцесорної системи

Номер патенту: 5007
Опубліковано: 28.12.1994
Автор: Коссовський Владіслав Георгійович
МПК: G06F 15/00, G06F 15/76
Мітки: обробки, системі, інформації, пристрій, мультипроцесорної
Формула / Реферат:
Устройство для обработки информации мультипроцессорной системы, содержащее процессор, блок оперативной памяти, блок памяти команд, первый блок управления и входной регистр, отличающееся тем, что, с целью повышения быстродействия, оно содержит второй блок управления, блок памяти признаков, блок памяти готовых сегментов, блок памяти готовых результатов, блок памяти адресов, селектор адреса, селектор команд, блок модификации признаков, блок...
Буферний запам’ятовуючий пристрій

Номер патенту: 23357
Опубліковано: 31.08.1998
Автори: Рашкевич Юрій Михайлович, Демида Богдан Адамович, Цмоць Іван Григорович
МПК: G06F 7/08, G11C 11/407
Мітки: буферний, пристрій, запам'ятовуючий
Формула / Реферат:
Буферний запам'ятовуючий пристрій, який містить блок пам'яті з n комірок, вхід управління, вхід синхронізації, адресний вхід, iнформаційний вхід, інформаційний вихід, блок сортування адреси з n вузлів порівняння, кожний з яких містить регістр, елемент порівняння, елемент АБО, тригер, перший елемент І, при цьому інформаційний вхід першої комірки пам'яті є інформаційним входом пристрою, вхід синхронізації блока сортування адреси є одноіменним...
Пристрій формування значень тригонометричних функцій для цифрового аналізатора спектра

Номер патенту: 25782
Опубліковано: 30.10.1998
Автори: Рашкевич Юрій Михайлович, Процько Ігор Омельянович
МПК: G01R 23/16, G06F 15/00
Мітки: аналізатора, спектра, цифрового, пристрій, значень, тригонометричних, формування, функцій
Формула / Реферат:
Пристрій формування значень тригонометричних функцій для цифрового аналізатора спектра, що містить блок завдання постійних кодів, вихід якого з'єднаний з входами установки регістрів і входом блоку перемноження, другий вхід якого з'єднаний з виходом першого регістра, а вихід блоку перемноження з'єднаний з першим входом суматора, вихід якого підключений до входу першого регістра, вихід останнього з'єднаний з входом другого регістра, який...
Пристрій канонічного розкладу числа на множники

Номер патенту: 19531
Опубліковано: 25.12.1997
Автори: Рашкевич Юрій Михайлович, Процько Ігор Омельянович
МПК: G06F 7/496, G06F 7/04
Мітки: числа, розкладу, пристрій, канонічного, множники
Формула / Реферат:
Пристрій канонічного розкладу числа на множники, що містить вхід числа розкладу, вихід множника розкладу в блоці керування, блок порівняння, блок пам'яті простих множників, вхід якого з'єднаний з першим виходом блоку керування, а перший вхід блоку керування з'єднаний з виходом блоку порівняння, який відрізняється тим, що додатково містить блок пам'яті залишків, суматор-накопичувач, мультиплексор, регістр зсуву, елементи "І",...
Пристрій для формування і відбору переставлень

Номер патенту: 25783
Опубліковано: 30.10.1998
Автори: Процько Ігор Омельянович, Рашкевич Юрій Михайлович
МПК: G06F 7/16, G06F 7/04, G06F 7/575
Мітки: переставлень, пристрій, формування, відбору
Формула / Реферат:
Пристрій для формування і відбору переставлень, що містить блок пам'яті мультиплексор, вихід вибору, вхід завдання відбору, вхід числа, які є входами даних і адресу відповідно в блоці пам'яті, виходи якого з'єднані з входами мультиплексора, який містить вихід вибору, який відрізняється тим, що додатково містить лічильник стовпця, лічильник вибору, лічильник лінійки, блок віднімання адресів, блок віднімання позицій, блок порівняння зміщення,...
Попередній патент: Пристрій для дугового зварювання
Наступний патент: Спосіб отримання ароматичних вуглеводнів
Випадковий патент: Система автоматичного управління