Пристрій пофонемного розпізнавання усних команд та усталених словосполучень
Номер патенту: 50039
Опубліковано: 25.05.2010








Формула / Реферат
Пристрій пофонемного розпізнавання усних команд та усталених словосполучень, що містить аналізатор, блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей та блок пам'яті проміжних результатів та контролер, який відрізняється тим, що в нього введені: блок пам'яті навчальної вибірки, процесор кластерного аналізу, блок пам'яті параметрів фонем; блок пам'яті орфографічного тексту та фонемної транскрипції, векторний квантувач, при цьому вихід аналізатора підключений через блок пам'яті мовленнєвих сигналів до входу векторного квантувача, а через блок пам'яті навчальної вибірки до входу процесора кластерного аналізу, виходи якого відповідно підключені до входу векторного квантувача та входу блока пам'яті параметрів фонем, на відповідні входи якого підключені виходи блока пам'яті орфографічного тексту та фонемної транскрипції, та вихід векторного квантувача, що також підключений до входу блока пам'яті табличних значень елементарних мір схожостей, виходи якого підключені до входів обчислювача інтегральних мір схожостей, відповідні виходи блока пам'яті орфографічного тексту та фонемної транскрипції підключені до відповідного входу блока пам'яті табличних значень елементарних мір схожостей та через блок пам'яті проміжних результатів до відповідного входу обчислювача інтегральних мір схожостей, а виходи контролера підключені до відповідних входів блоків пристрою.
Текст
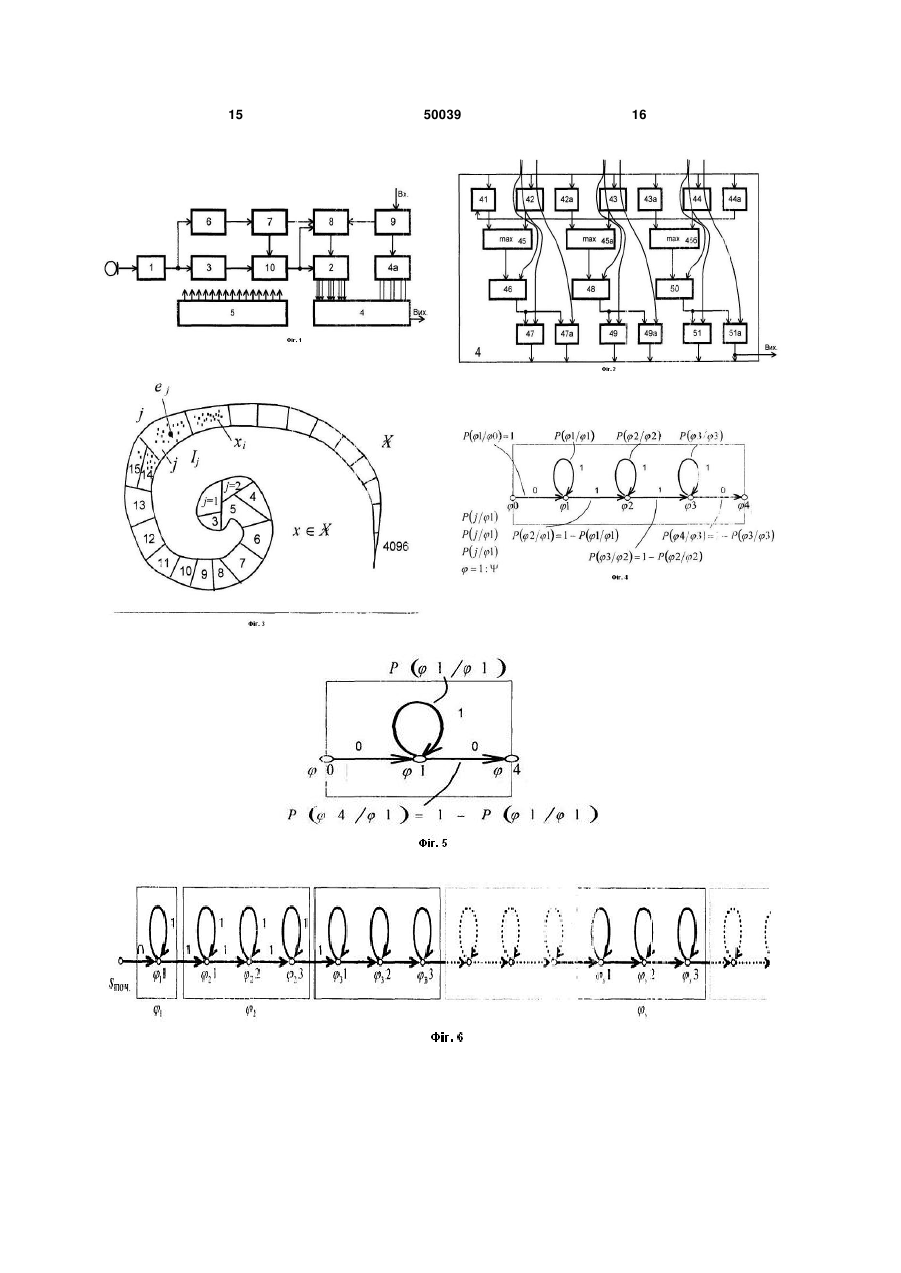
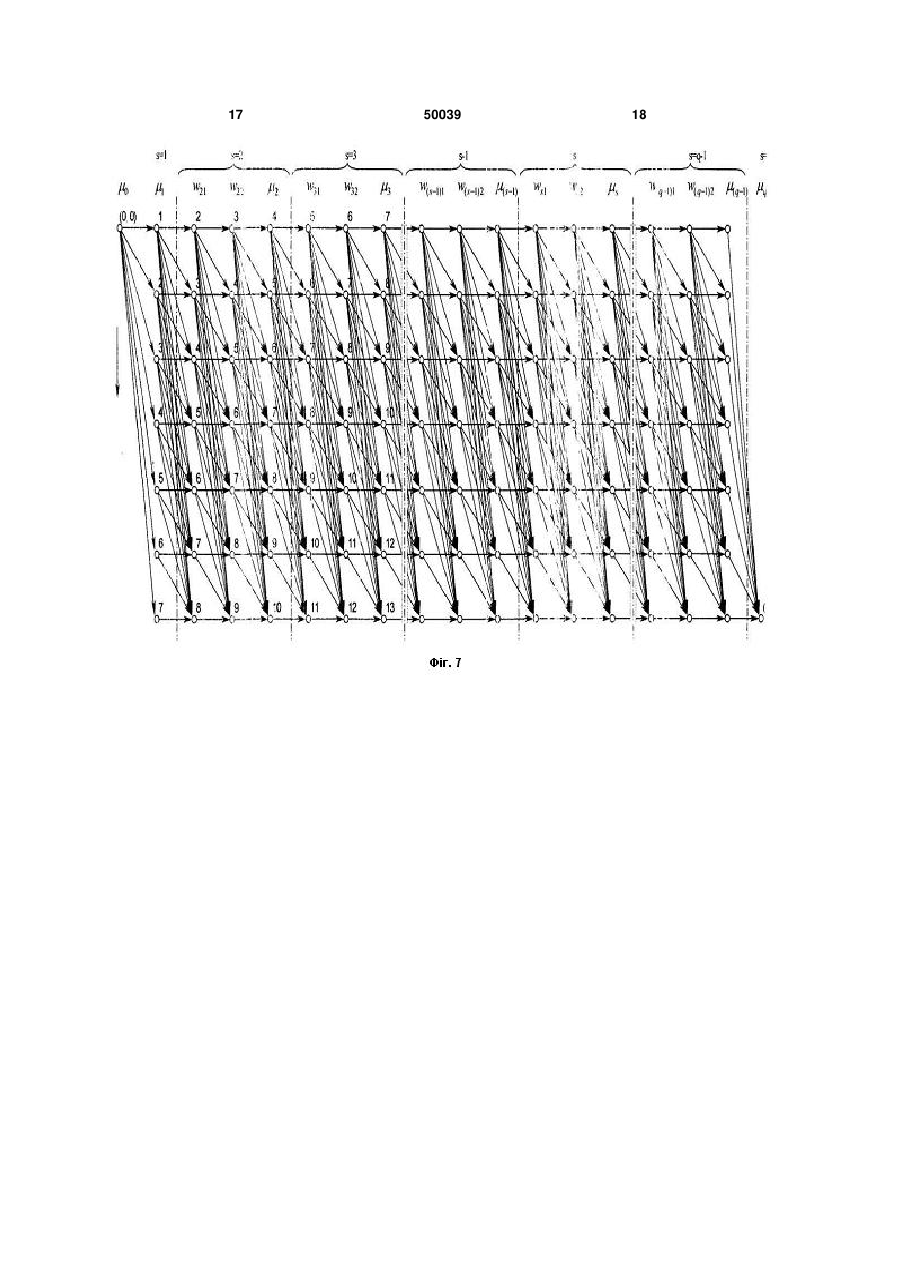
Пристрій пофонемного розпізнавання усних команд та усталених словосполучень, що містить аналізатор, блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей та блок пам'яті проміжних результатів та контролер, який відрізняється тим, що в нього введені: блок пам'яті навчальної вибірки, процесор кластерного аналізу, блок пам'яті параметрів фонем; блок пам'яті орфографічного тексту та фонемної транскрипції, векторний квантувач, при цьому вихід аналізатора підк U 1 3 50039 блоці пам'яті табличних значень визначаються значення елементарних мір належності цього спостереженого елемента до кожного із двох виходів із всіх трьох фаз фонеми; обчислювач 4 інтегральних мір схожості містить сім вхідних регістрів, три компаратори та дев'ять суматорів і для кожного із двох виходів із всіх трьох фаз кожної фонеми фонетичної транскрипції всіх усних команд та усталених словосполучень накопичує інтегральні міри схожості. На Фіг.1 представлена структурна схема пристрою, на Фіг.2 - схема одного з блоків; Фіг.3-8 пояснюють принцип роботи пристрою. Пристрій містить аналізатор 1 мовленнєвого сигналу; блок 3 запам'ятовування мовленнєвого образу у вигляді послідовності елементів-векторів, що утворюються в результаті аналізу вхідного мовленнєвого сигналу; векторний квантувач 10, який кожному поточному спостереженому елементувектору ставить у відповідність номер кластеру, в який він попадає, або, що те саме, номер еталонного елемента, що представляє кластер та є найближчим, в певному розумінні, до спостереженого елемента; блок 9 введення та зберігання орфографічних текстів та фонетичних транскрипцій всіх усних команд та усталених словосполучень, що складають робочий набір та повинні розпізнаватись; блок 8 пам'яті значень параметрів моделей всіх фонем; блок 2 вибору значень елементарних мір приналежності спостережуваного елемента, за номером його кластеру, до фонем та їх фаз; обчислювач 4 інтегральних мір схожості, який накопичує, сумує, значення елементарних мір схожості для послідовності спостережуваних елементіввекторів для кожної із усних команд або кожного усталеного словосполучення відповідно до їх фонетичних транскрипції; блок пам'яті 4а, який тимчасово зберігає накопичені інтегральні міри схожості; контролер 5, який синхронізує роботу всіх блоків, зокрема блоків 2, 4, 4а, 8, 9, 10; накопичувач 6 стандартизованої навчальної вибірки; блок 7 кластерного аналізу та обчислення параметрів фонем за навчальною вибіркою. Вихід пристрою з блоку 4 визначає номер усної команди або усталеного словосполучення, для фонетичної транскрипції якого накопичена найбільша інтегральна міра схожості. Якщо пристрій не налаштований на голос користувача, тобто пам'ять 8 про значення параметрів моделей фонем є порожньою, він пропонує користувачеві наговорити навчальну вибірку - треба промовляти окремі слова або фрази, які голосом називає пристрій. В аналізаторі 1 мовленнєвий сигнал, що подається і мікрофона під час накопичення стандартизованої навчальної вибірки, піддається поточному автокореляційному та предиктивному аналізові в дискретному рівномірному часі і T з кроком T, наприклад T=10мс. Для поточного інтервалу аналізу і із M відліків fn, n 0 : (M 1) мовленнєвого сигнал), які зважуються вікном Хемінга, обчислюM відліків автокореляційються перші m 1, m ної функції BS ють поточний M 1 s n 0 fn fn s, вектор s 0 , які і утворюавтокореляції 4 Bi Розв'язуючи (Bi0, Bi1,..., Bis,..., Bim ) . m u 1 рівнянь u Bu v систему 1 : m, та обчислюю Bv , 1 M1 0 1 , описуємо u 0 uBu , де M кожний поточний спостережуваний елемент Bi , 2 чи потім еквівалентним вектором-елементом ( i , ( bi , параметрів i ) ( 1, 2..., m u 0 b0 s ,..., m) 2 u, . ) - або i передбачення: b (b0, b1, b2,..., bs,..., bm ); m s u 0 bs 2 u u s, . s 1 : m. Обчислені в аналізаторі 1 елементи-вектори накопичуються в блоці 6 у вигляді послідовності як векторів автокореляцій Bi так векторів параметрів передбачення, утворюючи навчальну вибірку X0 l ( x1, x 2,..., xi,..., xl із l спостережених елементів xi . В блоці 7 кластерного аналізу та обчислення параметрів фонем спершу за навчальною вибіркою X0l з-посеред усіх l спостережених елементів x i , за допомогою деякої ітераційної процедури вибираємо задану тів (b* , * ), j j j кількість J, J елемен l, 1 : J , таких, які б найкращим чином апроксимували всі елементи навчальної вибірки: (b* , j * j ), j 1: J J j 1 arq min min (b j , j ), j 1:J Ij i Ij M ( In 2 1 2 j 2 2 j (Bi, b j )) , де через (B, b ) позначено скалярний добуток векторів-елементів В і b розмірності m+1, а через j - розбиття навчальної вибірки на J кластерів. В j останньому i : ji arq min ( j M ln 2 виразі 2 j 1 2 j 2 через (Bi, b j )) позна j чено j-ий кластер. Всі елементи j-го кластера найкраще апроксимуються представником цього кластера M 1 2 (b* , * ) arq min (Bi, bW )). . j j i I j ( ln W 2 2 2 (b w , w ),w I j W Ітераційний процес кластеризації починаємо з того, що на першому кроці нульової ітерації в якості представників кластерів вибирається кожний третій елемент (b(j0), (0 ) j ) (b3 j, 3 j ), j 1 : J навча льної вибірки. На другому кроці нульової ітерації за знайденими представниками кластерів (b(j0), I(j0 ) (0) j ), j i : j(0 ) i 1 : J знаходимо arq min ( j M ln( 2 (0) 2 j ) самі 1 2( (0) 2 j ) кластери (Bi, b(j0 ) )) j , j 1 : J. . Далі на першому кроці r - тої ітерації, r=1,2,..., за кластерізацією I(jr 1) 1 : J, ) (r-1)-ої ітерації виби ,j раємо (b(jr ), (jr ) ) нових arq min (b W , W ),w I(j r 1) i M I(j r 1) ( ln 2 2 W 1 2 2 W (Bi, bW )), j 1 : J представників кластерів. Потім на другому кроці r 5 50039 тої ітерації, r=1,2,..., знаходимо r-ту кластеризацію I(jr ) i : j(r ) i arq min ( j M ln( 2 1 (r ) 2 j ) 2( (r ) 2 j ) (Bi, b(jr ) )) j , j 1 : J. І так далі. За скінчене число ітерацій досягнемо рівноваги, коли набори представників кластерів для двох сусідніх ітерацій збігатимуться. Отримані представники кластерів оголошуються еталонними елементами-векторами (b j, j ), j 1 : J . Вони далі використовуватимуться у векторному квантувачеві 10 при визначенні номера еталонного елемента ji , що є найбільш схожим на спостережуваний елемент Bi : ji a rq min q,(Bi, (b j, де j )), j q(Bi, (b j, j )) ( M ln( 2 1 2 j) 2( j )2 (Bi, b j )) виступає як елементарна міра схожості елементів Bi (b j, j) . В процесорі 7 також обчислюються значення параметрів моделей фонем за навчальною вибіркою. Кожна фонема у різному фонемному контексті подається породжувальною моделлю, що є ланцюгом З п'яти прихованих станів 0, 1, 2, 3, 4 , що моделюють три стадії, три фази, розвитку процесу породження сигналів фонеми. Параметрами моделей є: ймовірність p( 1/ 0) переходу з нульового стану в перший стан, і що дорівнює одиниці, ймовірність p( 1 / 1) переходу з першого стану в перший же стан та ймовірність p( 2 / 1) переходу з першого стану в другий стан, що доповнює до одиниці попередню ймовірність, ймовірність p( 2 / 2) переходу з другого стану в другий же стан та ймовірність p( 3 / 2) переходу з другого стану в третій стан, що доповнює до одиниці попередню ймовірність, ймовірність p( 3 / 3 ) переходу з третього стану в третій же стан та ймовірність p( 4 / 3 ) переходу з третього стану в четвертий стан, що доповнює до одиниці попередню ймовірність, та ймовірності p( j / t ), j 1 : J, t 1,2,3 попадань спо G(J v [( w 2 [( v / ) max {[( w1 v (j 1, j 2,..., jv ) стережуваних елементів B в кожен із всіх кластерів j arq min q(B, (bu, u )) за умови перебування в u 1:J першому, другому та третьому станах t кожної фонеми . Окремо виділена фонема-пауза, що має один стан t 1 Представники кластерів або еталонні елементи-вектори (b j, j ), j 1 : J та логарифми всіх ймовірностей p( t / t ), p( j / t ), j 1 : J, t 1 : 3, - де алфавіт фонем, складають індивідуальний усномовний паспорт людини. Згадані ймовірності також оцінюються за навчальною вибіркою X0l за допомогою деякої іншої ітераційної процедури. Навчальна вибірка складається з реалізацій окремо вимовлених слів, словосполучень та фраз. В свою чергу, кожне слово чи фраза описується фонетичною транскрипцією 0q ( 1, 2,...., s ,..., q ) , де s - фонема з порядковим номером s у транскрипції, q –довжина транскрипції. Еталонні мовленнєві образи усних команд та усталених словосполучень формують шляхом об'єднання у послідовності ланцюгів породжувальних граматик фонем з п'яти прихованих станів відповідно до фонетичних транскрипцій усних команд або словосполучень, причому так, щоб вихідний, четвертий, стан попередньої фонеми збігався з нульовим та першим станами наступної. Сегмент мовленнєвого сигналу у вигляді послідовності спостережених елементів X v ( x 1, x 2,..., x v ) або у вигляді послідовності спостережених символів J w1 1) ln p( 2 / 2) ln p( 3 / 2) w 2 1) ln p( 3 / 3) ln p( 4 / 3) їсь усної команди чи словосполучення з фонетичною транскрипцією 0q ( 1, 2,..., s,..., q ) , то (j 1, j 2,..., jv ) мо мо виразом w1 ln p( ji i 1 1) ln p( 1/ 1) ln p( 2 / 1) розглядати як реалізацію яко v жна розглядати як такий, що утворений в результаті незалежних спостережень ланцюгів із трьох прихованих станів. Логарифм правдоподібності сегменту X v чи J v , за уМОВИ фонеми пода w 1, w 2 де кожна складова в квадратних дужках виражає вклад кожної з трьох фаз фонеми. Сегмент X v чи J v відноситься до тієї фонеми, для котрої досягається найбільше значення виразу правдоподібності. Якщо ж сегмент X v ( x 1, x 2,..., x v ) або J 6 w2 ln p( ji i w1 1 v ln p( ji i w2 1 / 1)] / 2)] / 3)]} логарифм правдоподібності цього сегмента за умови усної команди чи словосполучення 0 q виразимо як суму логарифмів правдоподібностей за всіма s підсегментами, що відповідають окремим фонемам s у послідовності 0 q , причому кожен з цих логарифмів, в свою чергу, є сумою з трьох доданків відповідно до трьох фаз розвитку фонем: 7 G( J 50039 /( 1, v 2 ,..., s ,..., q {[( w s1 s 1 [( w s2 {( де через J s 1 s 1) ln p( s 1 w s1 1) ln p( w s2 1) ln p( s /( s, ws1, ws2 ) (J q ); ( s , w s1, w s2, )s s1 / s2 / s3 / s1) s 2) s 3) ln p( w s1 , Jw s1w s 2 , Jw s 2 s 1 s s2 / s3 / s1) w s2 ln p( ji i w s1 1 s 2) s4 / ) (j q G(J s 1 s /( s , w s1, w s2)) s 1 w s1 ln p( ji / s1)] i s1 1 1: q) ln p( ln p( 8 s 3) s 1 s i w s2 1 / s 2)} ln p( ji / s 3 )]} 1,..., jw s1 ; jw s1 1,..., jw s 2 ; jws2 1,..., j s ) позначено можливий s-тий підсегмент для фонеми s з трьома його відповідними підпідсегмента максимізує критерій правдоподібності, визначає інтегральну міру схожості сегмента X v чи J v на ми, причому усну команду з фонетичною транскрипцією , 0 v . Оптимальне s, q s 1 розбиття чи сегментація (( * , w*1, w* 2 ), s 1: q) , яка s s s 0q : G(J (( s v / 0q ) m ax Сегмент X v чи J v G( j G(J v ,w s1,w s 2 ),s 1:q v * * * 2,..., s ,..., q ); ( s , w s1, w s2 ), s /( 1, /( 1, 2,..., s ,..., q ); ( s,w s1, w s2 ), s команди чи усталеного словосполучення, для котрої чи котрого досягатиметься абсолютно найбільше значення виразу правдоподібності. Вся ж навчальна вибірка X0l ( x1, x2,..., xi,..., xl ) чи J0l ( j1, j2,..., ji,..., jl ), що відповідає стандартизованому тексту, складається з реалізацій окремо вимовлених слів, словосполучень та фраз, границі котрих -- початок та кінець початкової та кінцевої фонем-пауз - у навчальній 0Q ; P; {( s , w s1, w s2 ), s Q {[( w s1 s 1 1) ln p( s1 / s 1 [( w s2 [( s w s1 1) ln p( w s2 1) ln p( s2 / s3 / s 2) s 3) 1 : q) вибірці визначаються автоматично в процесі накопичення введення реалізацій. oQ ( 1, 2,..., s,..., Q ) - фонетична транскрипція всієї навчальної вибірки з Q реалізацій фонем. Максимально правдоподібні оцінка ймовірнос} , де тей P {p( t / t ), p( j / t ), j 1 : J, t 1 : 3, - алфавіт фонем, обчислюються процесором 7 шляхом максимізації критерію правдоподібності для навчальної вибірки відноситиметься до тієї усної G(J0Q / 1 q) ; 1 : q}) s1) ln p( ln p( ln p( s3 / s4 / s2 / w s1 i s s1) 1 1 w s2 ln p( ji i w s1 1 s2 s 3) s i w s2 1 ln p ( ji / / s1)] s 2)] ln p( j / s 3)]}. і Критерій правдоподібності можна переписати в де .до іншій еквівалентній формі, згрупувавши окремо всі реалізації однієї й тієї ж фонеми: G(J0Q / 0Q ; P; {( s , w s1, w s2 ), s s: [( w s2 [( s s {[( w s1 w s1 1) ln p( w s2 1) ln p( s2 / s3 / s 1 s 2) s 3) 1 : q}) 1) ln p( 1/ 1) ln p( 2 / 1) ln p( ln p( s3 / s4 / s2 s 3) З останнього запису випливає, що якщо відомі границі {( w s1 i s w s2 ln p( ji i w s1 1 s i w s2 1 1 1 ln p( ji / 1)] / s 2)] ln p(ji / 3 )]}. s , w s1,w s2 ), s 1 : Q} сегментів всіх реалізацій всіх фонем із навчальної вибірки, то максимально правдоподібні оцінки ймовірностей обчислюються як: 9 50039 p( 1/ 1) ( s: ( w s1 s p( 2 / 1) ( s: s 10 1)) /( s 1 1) /( s: s: ( w s1 s ( w s1 s s 1)), 1)), s p( 2 / 2) ( s: s ( w s2 w s1 1)) /( s: s ( w s2 w s1)), p( 3 / 2) ( s: s 1) /( s: s ( w s2 w s1)), p( 3 / 3) ( s: s ( s w s2 1)) /( p( 4 / 3) ( s: s 1) /( s: s s: s j [) /( s: s s ]j i w s2 1 i j [) /( s: s s: s ( s: p( j / 3) ( s: s Ітераційний процес обчислення параметрів Р починаємо з того, що на першому кроці нульової ітерації знаходимо початкову сегментацію всієї ( 0) ( 0) (0) s , w s1 , w s2 ), s q 1 {[min s 2 j [min w s1 i s s i w s2 1 j ( 1 1 M ln 2 ( M ln 2 1 2 1 2 j {( ( 0) ( 0) (0) s , w s1 , w s2 ), s 1: Q} j {( (r ) (r ) (r ) s , w s1 , w s2 ), s [( w s2 [( s 1 1 ln p(r s: 1) ( 1, 0q 2,..., (0) 2 2 j s 1 ( M ln 2 2 j 1 2 2 j 1 2 j 2 w s2 1) ln p(r 1) 1) викона (Bi, b j ))] (Bi, b j ))}. вибірки знаходимо {p ( t / t ),p ( j / t ), j 1 : J, t 1 : 3, } Далі на першому кроці r-тої ітерації, r=1,2,... за параметрами моделей фонем P(r 1) {p(r 1) ( t / t ),p(r 1) ( j / t ), j 1 : J, t 1 : 3, } , знайденими на (r 1) -шій ітерації, вибираємо нову сегментацією {[( w s1 ( 2 / 2) ln p(r ( 3 / 3) ln p(r ймовірності (0) s 1 1) ln p(r 1) ( 1/ 1) ln p(r 1) ( 2 / 1) ( ji / 2)] w s1 1) ln p(r q ), (Bi, b j )) 2 j 2 (0) P 1 2 j M w s2 ( ln w s1 1 wq q 1 M ln 2 1 : Q} : s ,w s1,w s 2 ),s 1 Q } w s1 i s . 1: Q} на arq max {( w s2 )), j 1 : J, s вчальної всієї навчальної ( 0) ( 0) (0) s , w s1 , w s2 ), s ( j вибірки. Потім на другому кроці нульової ітерації за відомою сегментацією {( 1 (Bi, b j ))] [min Оптимальне розбиття знаходимо як найкоротший шлях на графі із вершини (0, 0) у вершину (l, q) . Це ілюструється Фіг.7. Повторивши процедуру розбиття для всіх реалізацій слів та фраз, отримаємо початкову сегментацію ( i 1 j (Bi, b j ))]} min 2 j 2 2 j w s1)), ( x1, x2,..., xi,..., xl ), , відповідно до його (фо {min : s ,w s1,w s 2 ),s 1 q} 2 j ( w s2 ємо його оптимальне розбиття на q сегментів, виходячи із моделі однорідності сегментів та апелюючи до вже знайдених еталонних елементів - представників кластерів (b j, j ), j 1 : J : arq min {( s 1)), нетичної транскрипції 1: Q} . Для 1 : q} ( w s1 s та Xol цього виокремимо із навчальної вибірки сегменти, що відповідають окремо вимовленим словам, словосполученням чи фразам. Далі для кожного таким чином виділеного сегмен(0) (0) (0) s , w s1 , w s2 s s j[) /( ( p( j / 2) {( ( s w s2 )), w s2 )), s w s1 ]j i s1 1 i w s2 ]j i w s1 1 i p( j / 1) навчальної вибірки {( s: ( 1) 1) ( 3 / 2) ( 4 / 3) w s2 ln p(r 1) ( ji i w s1 1 s i w s2 1 ln p(r 1) / 2)] ( ji / 3)]} навчальної вибірки та на її основі - нові значення параметрів моделей фонем 11 50039 P(r ) p(r ) t / t , p(r ) j / t , j 1 : J, t p(r ) ( 1/ 1) ( p(r ) ( 2 / 2) ( s: p(r ) ( 3 / 3) ( s: p(r ) ( j / 1) s: ( w (r1) s s s: s s: s s (r ) s w (sr1) ]j i (sr )1 1 i (r ) w s2 ]j i w (sr1) 1 i ( (r ) s ]j i w (sr2) 1 i s k M,F2 ( s1) M,Fk ( 1 k M,F2 ( s 2) де (-M) - велике від'ємне число, qk - довжина транскрипції k-го слова, K- обсяг словника. Контролер 5, як тільки отримує інформацію від аналізатора 1 про появу першого спостереженого елемента B1 забезпечує: пересилку його на векторний квантувач 10, де визначається номер етаM лонного елемента ji arqmin ln 2 (B1, b j )), , що ( j 2 j 1:J є найбільш схожим на стоcтережуваний. Під управлінням контролера 5 з блока 9 зчитується ім’я першої фонеми 1 першого слова. За цим іменем фонеми та номером еталонного елемента j1 з блока пам'яті 4а накопичуваних інтегральних мір схожості на обчислювач 4 інтегральних мір k F1,1( 11) k max (F0,2 ( k F1,2 ( 11) k F1,1( 12) k F1,2 ( 12) k F1,1( 13) k F1,2 ( 13) k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( k k F1,1( 11) , F1,2 ( 11) , Fk1( 12) 1 , k , F1,2 ( 12) , Fk1( 13) 1 , , k F1,2 ( 13) пересилаємо на зберігання в блок пам'яті 4а за адресами значень k F0,1( 11) , k F0,2 ( 11) , k k k k F0,1( 12) , F0,2 ( 12) , F0,1( 13) , F0,2 ( 13) відповідно. s: 1)) /( s: s 1)) /( s: s j[) /( s: j [) /( s: s s s: ( s s (r ) s ( w (r1) s (r ) s 1)), w (r1) )), s ) w (r2 )), s (r ) s 1)), ) ( w (r2 s (r ) s (r ) ( w s1 ( ) ( w (r2 s w (r1) )), s ) w(r2 )), j s 1 : J, . усних команд та усталених словосполучень разом з їхніми фонетичними транскрипціями, пристрій стає готовим до автоматичного розпізнавання: на кожну усну команду з номером k в блоці нам'яті 4а проміжних результатів робляться початкові устаk новки F0,2 ( s 2) M,Fk ( 1 0 3) 0; k M,F2 ( s 3) M), s 1: qk ,k 1: K, s 3) k схожості зчитуються значення F0,2 ( 0 3), k F0,1( 11), k k k k k F0,2 ( 11),F0,1( 12),F0,2 ( 12),F0,1( 13),F0,2 ( 13) на регі стри 41, 42, 42а, 43, 43а, 44, 44а відповідно. Одночасно за номером еталонного елемента ji , та ім'ям фонеми 1 на другі входи суматорів 46, 47, 47а, 48, 49, 49а, 50, 51, 51а надходять логарифми ймоln p( j1 / 11),ln p( 11/ 11),ln p( 12 / 11), вірностей ln p( j1 / 12), ln p( 1 2 / 1 2), ln p( 13 / 12), ln p( j1 / 13),ln p( 13 / 13),ln p( 14 / 13) відповідно. Оскільки порівнювані 45, 45а, 45б вибирають більше з двох чисел, то на виходах суматорів 47, 47а, 49, 49а, 51, 51а матимемо відповідно k 0 3),F0,1( 11)) k 0 3),F0,1( 11)) k 11),F0,1( 12)) k 11),F0,1( 12)) k 12),F0,1( 13)) k 12),F0,1( 13)) Далі значення регістра 44a пересилаємо в регістр 41, щоб підготуватись до оброблення наступної фонеми слова k, затим обчислена вище значення інтегральних мір схожості : 1)) /( j [) /( За скінчене число ітерацій досягнемо рівноваги, коли значення параметрів моделей фонем для двох сусідніх ітерацій збігатимуться. Отримані значення параметрів моделей фонем пересилаються у блок 8, де і зберігаються. В разі заповнення блоків 7 та 8 еталонними елементами та значеннями параметрів моделей фонем, відповідно, а блока 9 - робочим словником (Fk ( s1) 1 1 : 3, (r ) s 1 w (r1) s ) w (r2 s ) ( w (r2 s s ( p ( j / 2) ( s: ( (r ) p(r ) ( j / 3) 12 ln p( j1 / 11) ln p( j1 / 11) ln p( 12 / ln p( 11/ 11), 11) ln p( j1 / 12) ln p( 12 / 12) ln p( j1 / 12) ln p( 13 / 12) ln p( j1 / 13) ln p( 13 / 13) ln p( j1 / 13) ln p( 14 / 13) Далі за тим же номером еталонного елемента j1, послідовно для всіх решти фонем s 2 : qk слова k діємо аналогічно. За іменем фонеми s з блока пам'яті 4а накопичуваних інтегральних мір схожості на обчислювач 4 інтегральних мір схожоk k сті зчитуються значення F0,1( s 11), F0,2 ( s 11), k F0,1( k k k s 12),F0,2 ( s 12),F0,1( s 13),F0,2 ( s 13) на ті ж регіст ри 41, 42, 42а, 43, 43а, 44, 44а відповідно. Одночасно за номером еталонного елемента ji , та ім'ям 13 50039 фонеми s на другі входи суматорів 46, 47, 47а, 48, 49, 49а, 50, 51, 51а надходять логарифми ймовірностей ln p( j1 / s1),ln p( s1/ s1),ln p( s 2 / s1), k F1,1( s1) k max (F0,2 ( k F1,2 ( s1) k F1,1( s 2) k F1,2 ( s 2) k F1,1( s 3) k F1,2 ( s 3) k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( k max (F0,2 ( 14 ln p( j1 / s 2),ln p( s 2 / s 2),ln p( s 3 / s12),ln p( j1 / s 3),ln p( s 3 / s 3),ln p( s 4 / s 3), відповідно. На виходах суматорів 47, 47а, 49, 49a, 51, 51а матимемо відповідно k s 2 3),F0,1( s 11)) k s 2 3),F0,1( s 11)) k s 11),F0,1( s 12)) k s 11),F0,1( s 12)) k s 12),F0,1( s 13)) k s 12),F0,1( s 13)) ln p( j1 / s1) ln p( s1 / s1), ln p( j1 / s1) ln p( s2 / s1) ln p( j1 / s 2) ln p( s2 / s 2) ln p( j1 / s 2) ln p( s3 / s 2) ln p( j1 / s 3) ln p( s3 / s 3) ln p( j1 / s 3) ln p( s4 / s 3) k F1,2 ( s 3) пересилаємо на зберігання в блок пам'яті точної фонеми їх транскрипцій, знаходять як суми значень відповідних елементарних мір схожості, обчислених для поточного спостереженого елемента ji , для кожного із двох виходів із першого, другого чи третього станів поточної фонеми ln p( ji / s1),ln p( s1/ s1),ln p( s 2 / s1), 4а за адресами ln p( ji / k F0,1( k k k s 12),F0,2 ( s 12),F0,1( s 13),F0,2 ( s 13) відповідно. Далі значення регістра 44а пересилаємо в регістр 41, затим обчислені вище значення інтегральних мір схожості k k k k 1 1 1 s1) , F ,2 ( s1) , F ,1( s 2) , F ,2 ( s 2) , F ,1( s 3) , 1 k F1,1( значень k F0,1( k s 11),F0,2 ( s 11), Після закінчення оброблення слова k: за адk ресом F0,2 ( 0 3) пересилаємо (-М). Далі процес повторюємо в циклі по k 2 K . Далі процес повторюється в циклі по i 2 : l При порівнянні спостережуваного сигналу X0i ( x1, x2,..., xi ) , відповідно J0i ( j1, j2,..., ji ), з фонетичними транскрипціями усних команд чи усталених словосполучень інтегральні міри схожості Fik ( ,1 Fik2 ( , s 3) k s1) , F,2 ( i k s1) , F,1( i k s 2) , Fi,2 ( k s 2) , F,1( i s 3) , ЩО визначаються для кожного із двох s 2), ln p( s 2 / s 2), ln p( s 3 / s12), ln p( ji / s 3),ln p( s 3 / s 3),ln p( s 4 / s 3), з більшою із двох інтегральних мір схожості, накопичених для попереднього спостереженого елемента ji 1 на другому виході з третього стану попередньої фонеми s 13 та на першому виході з першого стану поточної фонеми s1 , на другому виході з першого стану поточної фонеми s1 та на першому виході з другого стану поточної фонеми s2 й на другому виході з другого стану поточної фонеми s 2 та на першому виході з третього стану поточної фонеми s 3 , відповідно: виходів із першого, другого чи третього станів по Fik ( ,1 s1) Fik2 ( s1) , Fik ( s 2) ,1 Fik2 ( s 2) , Fik ( s 3) ,1 Fik2 ( s 3) , max (Fik 1,2 ( k s 2 3),Fi 1,1( s 11)) max (Fik 1,2 ( s 2 3),Fik 1,1( s 11)) max (Fik 1,2 ( s 11),Fik 1,1( s 12)) max (Fik 1,2 ( s 11),Fik 1,1( s 12)) max (Fik 1,2 ( s 12),Fi 1k,1( s 13)) 0 max (Fik 1,2 ( s 12),Fik 1,1( s 13)) Значення інтегральної міри схожості Flk2 ( , qk 3) , накопичене після оброблення останнього спостереженого елемента на другому виході із третього стану останньої фонеми qk , яка визначається фонетичною транскрипцією усної команди або словосполучення, визначає схожість пред'явленого мо ln p( ji / s1) ln p( s1 / s1), ln p( ji / s1) ln p( s 2 / s1) ln p( ji / s 2) ln p( s 2 / s 2) ln p( ji / s 2) ln p( s 3 / s 2) ln p( ji / ln p( ji / s 3) s 3) ln p( ln p( s 3 / s 3) s 4 / s 3) вленнєвого сигналу на цю усну команду або словосполучення. Пред’явлений мовленнєвий сигнал контролером 5 відноситься до тієї усної команди або усталеного словосполучення, для котрого накопичена схожість є абсолютно найбільшою. 15 50039 16 17 50039 18 19 Комп’ютерна верстка А. Крижанівський 50039 Підписне 20 Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюPhonemic oral command and collocation recognition device
Автори англійськоюVintsiuk Taras Klymovych, Hrytsenko Volodymyr Illich
Назва патенту російськоюУстройство пофонемного распознавания устных команд и устойчивых словосочетаний
Автори російськоюВинцюк Тарас Климович, Гриценко Владимир Ильич
МПК / Мітки
МПК: G10L 15/00
Мітки: розпізнавання, команд, пристрій, усних, пофонемного, словосполучень, усталених
Код посилання
<a href="https://ua.patents.su/10-50039-pristrijj-pofonemnogo-rozpiznavannya-usnikh-komand-ta-ustalenikh-slovospoluchen.html" target="_blank" rel="follow" title="База патентів України">Пристрій пофонемного розпізнавання усних команд та усталених словосполучень</a>
Спосіб та пристрій пофонемного розпізнавання усних команд та усталених словосполучень

Номер патенту: 67696
Опубліковано: 15.06.2004
Автори: Федорин Ярослав Володимирович, Вінцюк Тарас Климович, Гриценко Володимир Ільїч
МПК: G10L 15/00
Мітки: пристрій, усталених, словосполучень, усних, пофонемного, розпізнавання, команд, спосіб
Формула / Реферат:
1. Спосіб пофонемного розпізнавання усних команд та усталених словосполучень, що грунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення...
Спосіб пофонемного розпізнавання усних команд та усталених словосполучень

Номер патенту: 50038
Опубліковано: 25.05.2010
Автори: Вінцюк Тарас Климович, Гриценко Володимир Ілліч
МПК: G10L 15/00
Мітки: пофонемного, команд, усталених, спосіб, словосполучень, усних, розпізнавання
Формула / Реферат:
Спосіб пофонемного розпізнавання усних команд та усталених словосполучень, що ґрунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення...
Спосіб та пристрій пофонемного розпізнавання злитого мовлення

Номер патенту: 67697
Опубліковано: 15.06.2004
Автори: Вінцюк Тарас Климович, Родіонов Олександр Олександрович, Гриценко Володимир Ільїч, Федорин Ярослав Володимирович
МПК: G10L 15/00
Мітки: злитого, мовлення, пофонемного, пристрій, розпізнавання, спосіб
Формула / Реферат:
1. Спосіб пофонемного розпізнавання злитого мовлення, що грунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, що визначаються фонетичними транcкрипціями допустимих в мові діалогу послідовностей слів, визначення...
Спосіб усномовного перекладу слів і словосполучень

Номер патенту: 48221
Опубліковано: 10.03.2010
Автори: Стасевич Петро Анатолійович, Тертичний Григорій Миколайович, Павлов Олег Ігоревич, Вінцюк Тарас Климович, Гриценко Володимир Ілліч
МПК: G10L 15/00
Мітки: перекладу, словосполучень, усномовного, слів, спосіб
Формула / Реферат:
Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні фонемного складу мовленнєвого сигналу та пошуку за словником схожого за фонемним складом лінгвістично коректного тексту, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, розкладають на сигнали і характеристики вибраної моделі мовотворення, які перетворюють у послідовність її векторів параметрів, яку порівнюють...
Спосіб усномовного перекладу слів і словосполучень та голосовий словник-перекладач для його здійснення

Номер патенту: 67698
Опубліковано: 15.06.2004
Автори: Ілюшин Сергій Аркадійович, Павлов Олег Ігоревич, Ситніков Даніїл Анатолійович, Гриценко Володимир Ільїч, Федорин Ярослав Володимирович, Вінцюк Тарас Климович, Куптель Олег Григорович
МПК: G10L 15/00
Мітки: спосіб, словосполучень, голосовий, перекладу, здійснення, усномовного, словник-перекладач, слів
Формула / Реферат:
1. Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні мовленнєвого сигналу та лінгвістичному аналізі результату розпізнавання, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, аналізують та перетворюють у сукупність векторів, що описують звуковий сигнал із прийнятною для розпізнавання точністю, вибирають найкращий опис даного звукового сигналу послідовністю...
Попередній патент: Спосіб пофонемного розпізнавання усних команд та усталених словосполучень
Наступний патент: Спосіб пофонемного розпізнавання злитого мовлення
Випадковий патент: Адсорбент діоксиду сірки