Спосіб усномовного перекладу слів і словосполучень
Номер патенту: 48221
Опубліковано: 10.03.2010
Автори: Стасевич Петро Анатолійович, Вінцюк Тарас Климович, Тертичний Григорій Миколайович, Гриценко Володимир Ілліч, Павлов Олег Ігоревич



Формула / Реферат
Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні фонемного складу мовленнєвого сигналу та пошуку за словником схожого за фонемним складом лінгвістично коректного тексту, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, розкладають на сигнали і характеристики вибраної моделі мовотворення, які перетворюють у послідовність її векторів параметрів, яку порівнюють з еталонними варіантами таких послідовностей за словником фонем на основі заданої міри схожості та правил динамічного викривлення часу і отримують послідовність текстових символів транскрипційних позначок розпізнаних фонем, яку порівнюють з наявними еталонними варіантами таких послідовностей за словником слів та словосполучень, з врахуванням встановлених правил заміни, вилучення та додавання окремих позначок фонем з одночасним збільшенням відповідно до штрафних коефіцієнтів інтегральної відстані між послідовностями, за якою вибирають еталонний варіант, який подають у вигляді лінгвістично коректного тексту, на основі якого формують результат перекладу.
Текст
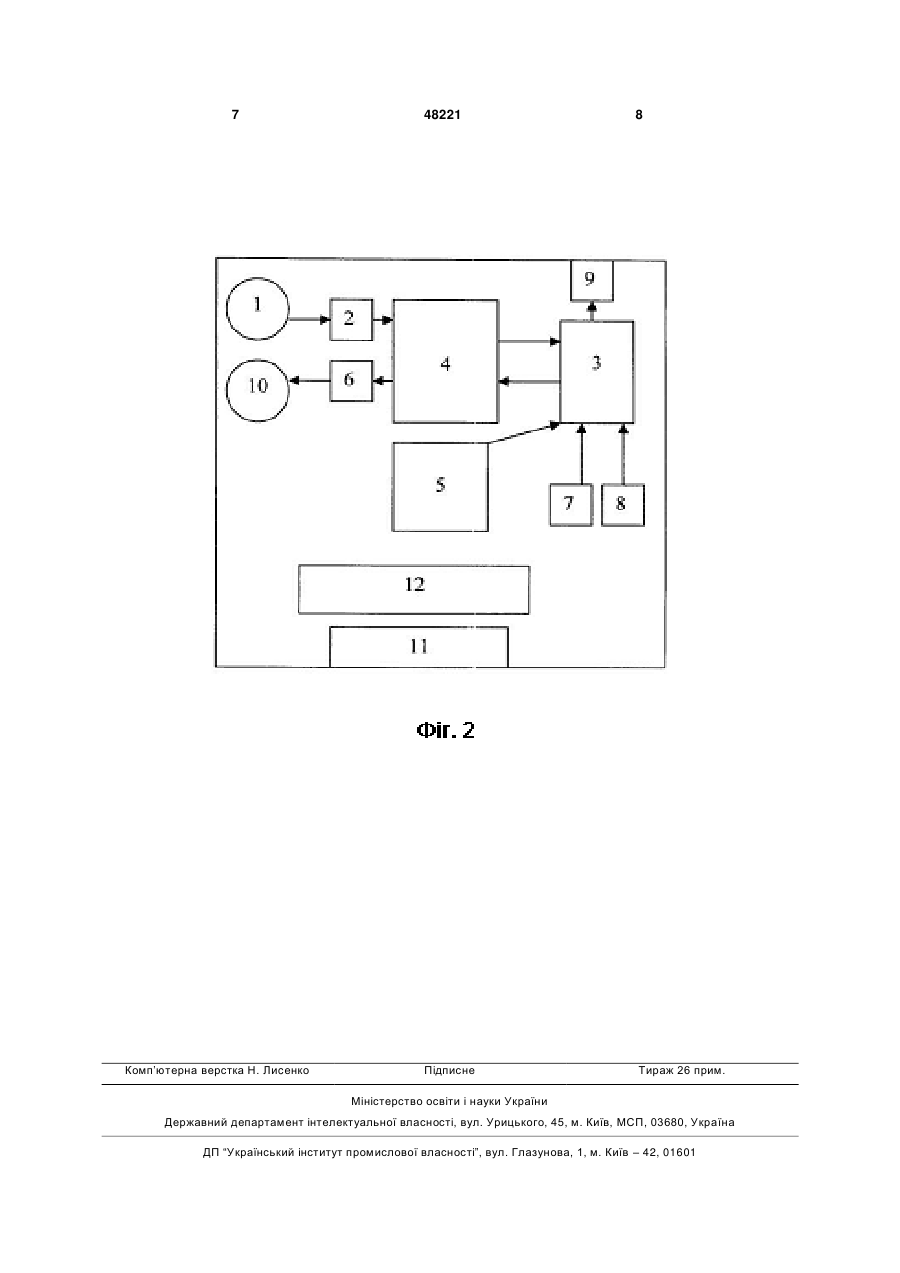
Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні фонемного складу мовленнєвого сигналу та пошуку за словником схожого за фонемним складом лінгвістично коректного тексту, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, розкладають на 3 моделі мовотворення, які перетворюють у послідовність її векторів параметрів, яку порівнюють з еталонними варіантами таких послідовностей за словником фонем на основі заданої міри схожості та правил динамічного викривлення часу і отримують послідовність текстових символів транскрипційних позначок розпізнаних фонем, яку порівнюють з наявними еталонними варіантами таких послідовностей за словником слів та словосполучень, з врахуванням встановлених правил заміни, вилучення та додавання окремих позначок фонем з одночасним збільшенням відповідно до штрафних коефіцієнтів інтегральної відстані між послідовностями, за якою вибирають еталонний варіант, який подають у вигляді лінгвістично коректного тексту, на основі якого формують результат перекладу. Автоматичне пофонемне розпізнавання складається з попереднього параметричного перетворення звукового сигналу на послідовність наборів параметрів (багатомірних векторів параметрів) обраної моделі мовотворення, попереднього розпізнавання фонем за так знаним словником фонем, в якому кожна фонема подана у вигляді послідовності відповідних векторів параметрів, утворення послідовності текстових символів, які є транскрипційними позначками розпізнаних фонем, розпізнавання слів та словосполучень за словником транскрипцій слів та словосполучень і правилами заміни, вилучень або додавань окремих фонем, утворення лінгвістично коректного тексту розпізнаного слова або словосполучення, перекладу слова з одної мови на іншу, відображення результату на екрані та його озвучення. Словник фонем може змінюватися як в залежності від обраної мови, так і в залежності від особливостей артикуляційного апарату диктора шляхом автоматичного налаштування з врахуванням статистики за результатами розпізнавання як фонем, так і слів та словосполучень. Словник транскрипцій слів та словосполучень, а також правила заміни, вилучень або додавань окремих фонем можуть змінюватися як в залежності від обраної мови, так і в залежності від особливостей промови диктором окремих слів та словосполучень. Таким чином, корисна модель пропонує новий, відсутній в прототипі, спосіб розпізнавання усномовних слів та словосполучень, який не обмежується певним набором фраз. На Фіг.1. зображено спосіб усномовного перекладу, що пропонується даною моделлю. Оцифрований звуковий сигнал надходить до блоку, який скорочено названий аналізатором звукового сигналу і в якому послідовність оцифрованих відліків звукового сигналу розділяється на блоки даних, розмір і швидкість утворення яких залежать від обраного режиму роботи. Для кожного з утворених блоків даних за допомогою кореляційного, регресійного, спектрального, кепстрального, дисперсійного, статистичного аналізів (всіх разом, або по окремості в залежності від обраного режиму роботи) розраховується набір параметрів еквівалентної (відповідно обраного режиму роботи) моделі мовотворення, який має значно менший обсяг даних. 48221 4 Кожен з параметрів утвореного набору розглядається не по окремості, а у сукупності з іншими, утворюючи багатомірний вектор параметрів. Послідовність векторів параметрів з виходу аналізатора звукового сигналу, надходить в блок розпізнавання, який складається з процедур векторного квантування та динамічного програмування. Для цього блоку існує два режими роботи: розпізнавання послідовності індексів та розпізнавання послідовності векторів. Вразі вибору режиму розпізнавання послідовності індексів виконується попереднє векторне квантування векторів параметрів, яке зменшує варіантність початкових векторів і дозволяє перейти від послідовності векторів до послідовності їх індексів за кодовою книгою, що застосовується при їх квантуванні. Наступною процедурою завжди є процедура порівняння отриманої послідовності (векторів параметрів або їх індексів за кодовою книгою), що описує зміну звукового сигналу в часі зі всіма еталонними послідовностями (векторів параметрів або їх індексів), що відповідають фонемам обраної мови. При цьому використовується динамічне викривлення часу і підрахунок інтегральної міри відстані для кожної еталонної послідовності. Інтегральна міри відстані обчислюється як сума заданих мір відстаней для кожного з їх векторів або як сума наперед відомих відстаней між векторами кодової книги за їх індексами. Після підрахунку інтегральних мір відстаней для всіх еталонних послідовностей обирається та послідовність, яка має найменше значення інтегральної міри відстані, що відповідає найкращому для заданої міри відстані опису даного фрагменту звукового сигналу певною фонемою та найкращому опису всього звукового сигналу послідовністю фонем. Послідовність фонем, отримана в результаті розпізнавання векторів параметрів або їх індексів за процедурою динамічного програмування подається послідовністю текстових символів, які є транскрипційними позначками розпізнаних фонем. Така послідовність текстових символів транскрипційних позначок фонем є результатом попереднього розпізнавання усномовних слів та словосполучень і далі подається на блок, який скорочено називається лінгвістичним аналізатором. Лінгвістичний аналізатор виконує функцію порівняння можливих варіантів часткових послідовностей, що утворюються з вхідної послідовності текстових символів транскрипційних позначок фонем зі всіма послідовностями в словнику для кожного його слова або словосполучення, (який може коригуватися та доповнюватися за бажанням користувача). При порівнянні послідовностей текстових символів транскрипційних позначок фонем враховуються дозволені транскрипційні зміни — заміни, вилучення або додавання окремих позначок фонем за правилами обраної мови, якими керується лінгвістичний аналізатор (і які також можуть коригуватися та доповнюватися за бажанням користувача), за рахунок чого робиться спроба забезпечити символьну ідентичність послідовностей. При цьому обчислюються значення інтегральної відстані між вхідною послідовністю і кожним з можливих варіантів змін еталонних послідовностей з врахуванням 5 наявних в правилах штрафних коефіцієнтів щодо застосованих змін. Після розгляду всіх можливих варіантів обирається той, який має найбільшу схожість (найменшу суму штрафних коефіцієнтів), після чого формується результат у вигляді відповідного лінгвістично коректного тексту, виконується його переклад, який виводиться на екран та озвучується. Словник транскрипцій слів та словосполучень формується у вигляді текстових записів, одиницею яких є текстова позначка фонеми. Набір фонем є формальним описом слова або словосполучення. Кожній фонемі відповідає один або декілька векторів параметрів, які використовуються при обчисленні міри відстані. Визначення відповідності фонеми її векторному опису здійснюється на етапі навчання розпізнаванню, на основі знання про особливості мовлення диктора, так званого мовного паспорту. Для створення мовного паспорту диктор має вимовити певний текст, на основі якого система налаштується на його голос. Процедура настроювання на голос диктора, тобто створення його мовного паспорта, є новацією даного винаходу, значно покращує результати розпізнавання у порівнянні з усередненими моделями, які є основою багатодикторних методів розпізнавання. На Фіг.2 зображено структурну схему портативного словника перекладача, в якому реалізований поданий спосіб усномовного перекладу. Словник-перекладач складається з наступних частин: 1 - мікрофона; 2 - аналого-цифрового перетворювача; 3 - мікроконтролера; 4 - процесора цифрової обробки сигналів; 5 - енергонезалежної пам'яті; 6 - цифро-аналогового перетворювача; 7 - кнопки включення живлення; 8 - кнопки керування введенням усномовного сигналу для перекладу; 9 - двох світлових індикаторів; 10 - динаміка; 11 - виходу для з'єднання диктофона з комп'ютером; 48221 6 12 - акумулятору. Мікрофон 1 приєднаний до аналого-цифрового перетворювача 2, який з'єднаний з процесором 4 цифрової обробки сигналу. До процесора 4 підключені мікроконтролер 3, аналого-цифровий 2 та цифро-аналоговий 6 перетворювачі. Мікроконтролер 3 приєднаний до енергонезалежної пам'яті 5, клавіатури 7, 8, та засобів індикації 9. Живлення пристрою виконується за допомогою акумулятора 12. Для зв'язку з комп'ютером призначений USBпорт 11. Введення усномовних слів та словосполучень активується натисненням кнопки керування введенням усномовного сигналу. Введення усномовного сигналу полягає в тому, що звуковий сигнал, який з мікрофона 1 поступає в аналого-цифровий перетворювач 2, оцифровується і подається в процесор 4 цифрової обробки сигналу, починає сприйматися ним як послідовність звукових відліків, які починають поділятися на блоки даних, оброблятися, перетворюватися на вектори параметрів та розпізнаватися. Результатом розпізнавання можуть бути переклад або відмова від розпізнавання (наприклад, якщо слово або словосполучення відсутнє в словнику транскрипцій). В залежності від результату розпізнавання, процесор 4 генерує сигнал мікроконтролеру 3, який обирає за заданим алгоритмом слово або словосполучення для озвучення та викликає його із енергонезалежної пам'яті 5. Слово або словосполучення для озвучення подається в процесор 4, декодується в прийнятну для озвучення форму, поступає в цифро-аналоговий перетворювач 6 та озвучується в динаміку 10. Світлові індикатори 9 індексують режими, в яких працює пристрій: очікування, перекладу, озвучення, з'єднання з персональним комп'ютером тощо. Для розширення або зміни набору фраз для розпізнавання користувач має змінити файл словника транскрипцій, який зберігається в пам'яті словника-перекладача. 7 Комп’ютерна верстка Н. Лиcенко 48221 8 Підписне Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП ―Український інститут промислової власності‖, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for oral interpreting words and phrases
Автори англійськоюVintsiuk Taras Klymovych, Hrytsenko Volodymyr Illich, Pavlov Oleh Ihorovych, Stasevych Petro Anatoliiovych, Tertychnyi Hryhorii Mykolaiovych
Назва патенту російськоюСпособ устного перевода слов и словосочетаний
Автори російськоюВинцюк Тарас Климович, Гриценко Владимир Ильич, Павлов Олег Игоревич, Стасевич Петр Анатольевич, Тертичный Григорий Николаевич
МПК / Мітки
МПК: G10L 15/00
Мітки: слів, перекладу, спосіб, усномовного, словосполучень
Код посилання
<a href="https://ua.patents.su/4-48221-sposib-usnomovnogo-perekladu-sliv-i-slovospoluchen.html" target="_blank" rel="follow" title="База патентів України">Спосіб усномовного перекладу слів і словосполучень</a>
Спосіб усномовного перекладу слів і словосполучень та голосовий словник-перекладач для його здійснення

Номер патенту: 67698
Опубліковано: 15.06.2004
Автори: Федорин Ярослав Володимирович, Павлов Олег Ігоревич, Ілюшин Сергій Аркадійович, Куптель Олег Григорович, Гриценко Володимир Ільїч, Вінцюк Тарас Климович, Ситніков Даніїл Анатолійович
МПК: G10L 15/00
Мітки: словник-перекладач, перекладу, слів, здійснення, словосполучень, голосовий, спосіб, усномовного
Формула / Реферат:
1. Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні мовленнєвого сигналу та лінгвістичному аналізі результату розпізнавання, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, аналізують та перетворюють у сукупність векторів, що описують звуковий сигнал із прийнятною для розпізнавання точністю, вибирають найкращий опис даного звукового сигналу послідовністю...
Спосіб усномовного перекладу фраз та голосовий фразник-перекладач на його основі

Номер патенту: 67700
Опубліковано: 25.04.2007
Автори: Вінцюк Тарас Климович, Гриценко Володимир Ільїч, Федорин Ярослав Володимирович, Ситніков Даніїл Анатолійович
МПК: G10L 15/00
Мітки: спосіб, основі, усномовного, перекладу, фразник-перекладач, голосовий, фраз
Формула / Реферат:
1. Спосіб усномовного перекладу фраз, який заснований на перетворенні звукового сигналу, що несе інформацію про відповідну фразу, в електричний аналоговий сигнал, підсилюванні його та перетворенні у цифровий сигнал, розпізнаванні останнього та лінгвістичному аналізі результату розпізнавання, генеруванні цифрового сигналу, що несе інформацію про переклад відповідної фрази, перетворенні його в електричний аналоговий сигнал, підсилюванні...
Голосовий портативний словник-перекладач

Номер патенту: 48218
Опубліковано: 10.03.2010
Автори: Павлов Олег Ігоревич, Тертичний Григорій Миколайович, Стасевич Петро Анатолійович, Гриценко Володимир Ілліч, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: словник-перекладач, голосовий, портативний
Формула / Реферат:
Голосовий портативний словник-перекладач, що містить мікрофон, з'єднаний з аналого-цифровим перетворювачем, динамік, з'єднаний з цифро-аналоговим перетворювачем, процесор цифрової обробки сигналів, виходами підключений до динаміка через цифро-аналоговий перетворювач та до входу мікроконтролера, на входи якого підключені кнопка включення живлення такнопка керування процесами введення усномовного сигналу, його подальшого розпізнавання і...
Спосіб побудови словника для перекладу з іноземної мови

Номер патенту: 60217
Опубліковано: 15.09.2003
Автор: Карпусь Ігор Васильович
МПК: G09B 19/06
Мітки: побудови, спосіб, словника, перекладу, іноземної, мови
Формула / Реферат:
Спосіб побудови словника для перекладу з іноземної мови, який полягає в тому, що слова іноземної мови, які відібрані зі словникового запасу, розташовують на носії інформації послідовно, починаючи з початку слова, який відрізняється тим, що перед кожним написом слова розташовують його семантичний код та після кожного напису групують семантичні коди слів, близьких за змістом, при цьому при слові, яке є перекладом, також розташовують його...
Спосіб побудови словника для перекладу з іноземної мови

Номер патенту: 23847
Опубліковано: 30.08.1999
Автори: Бродський Анатолій Леонідович, Бродська Олена Анатоліївна
МПК: G09B 19/06
Мітки: спосіб, мови, словника, іноземної, побудови, перекладу
Формула / Реферат:
1. Спосіб побудови словника для перекладу з іноземної мови, який полягає у тому, що слова іноземної мови, які відібрані з словникового запасу, розташовують на носії інформації послідовно, починаючи з початку слова, який відрізняється тим, що слова іноземної мови записують у їх фонетичній транскрипції та розташовують згідно з транскрипційним рядом.2. Спосіб побудови словника для перекладу з іноземної мови за п. 1, який відрізняється...
Попередній патент: Голосовий електронний довідник
Наступний патент: Спосіб отримання структурованого продукту пастоподібного
Випадковий патент: Утримувач одноразового стаканчика