Спосіб та пристрій пофонемного розпізнавання усних команд та усталених словосполучень
Номер патенту: 67696
Опубліковано: 15.06.2004
Автори: Федорин Ярослав Володимирович, Вінцюк Тарас Климович, Гриценко Володимир Ільїч







Формула / Реферат
1. Спосіб пофонемного розпізнавання усних команд та усталених словосполучень, що грунтується на поданні мовленнєвого сигналу послідовностями елементів-векторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного, програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються, який відрізняється тим, що кожна особа характеризується своїм індивідуальним усномовним паспортом, що укладається при разовому зачитуванні вголос цією особою стандартизованого тексту - навчальної вибірки; індивідуальний усномовний паспорт людини складають: задана кількість еталонних елементів, які найкращим чином апроксимують всі спостережувані елементи навчальної вибірки та визначають розбиття мультимножини спостережуваних елементів навчальної вибірки на задану кількість кластерів й параметри моделей всіх фонем у різному фонемному контексті - попередньої та наступної фонем; цими моделями фонем є ланцюги породжувальних граматик з п'яти прихованих станів, що моделюють три стадії розвитку процесу породження реалізації фонеми, а параметрами моделей є: ймовірність переходу з нульового стану в перший стан, що дорівнює одиниці, ймовірність переходу з першого стану в перший же стан та ймовірність переходу з першого стану в другий стан, що доповнює до одиниці попередню ймовірність, ймовірність переходу з другого стану в другий же стан та ймовірність переходу з другого стану в третій стан, що доповнює до одиниці попередню ймовірність, ймовірність переходу з третього стану в третій же стан та ймовірність переходу з третього стану в четвертий стан, що доповнює до одиниці попередню ймовірність, та ймовірності попадань спостережуваних елементів в кожен із всіх кластерів за умови перебування в першому, другому та третьому станах кожної фонеми; при розпізнаванні для кожного поточного спостережуваного елемента визначається номер кластера, в який цей елемент попадає, а як елементарна міра належності спостережуваного елемента-вектора до першої, другої чи третьої фази фонеми використовується сума логарифмів ймовірності спостережуваного кластера за умови першого, другого чи третього станів фонеми та ймовірності наступного переходу з першого в перший або другий, з другого в другий або третій, з третього в третій або четвертий стани фонеми відповідно до фази фонеми; еталонні мовленнєві образи усних команд та усталених словосполучень формують шляхом об'єднання у послідовності ланцюгів породжувальних граматик фонем з п'яти прихованих станів відповідно до фонетичних транскрипцій усних команд або словосполучень, причому так, щоб вихідний, четвертий, стан попередньої фонеми збігався з нульовим та першим станами наступної; інтегральні міри схожості початкових еталонних образів усних команд та усталених словосполучень, що визначаються для кожного із двох виходів із першого, другого чи третього станів поточної фонеми їх транскрипцій, знаходять як суми значень відповідної елементарної міри схожості, обчисленої для поточного спостережуваного елемента для кожного із двох виходів із першого, другого чи третього станів поточної фонеми, з більшою із двох інтегральних мір схожості, накопичених для попереднього спостережуваного вектора-елемента на другому виході з третього стану попередньої фонеми та на першому виході з першого стану поточної фонеми, на другому виході з першого стану поточної фонеми та на першому виході з другого стану поточної фонеми й на другому виході з другого стану поточної фонеми та на першому виході з третього стану поточної фонеми, відповідно; значення інтегральної міри схожості, накопичене після оброблення останнього спостереженого елемента на другому виході із третього стану останньої фонеми, яка визначається фонетичною транскрипцією усної команди або словосполучення, визначає схожість пред'явленого мовленнєвого сигналу на цю усну команду або словосполучення; пред'явлений мовленнєвий сигнал відноситься до тієї усної команди або усталеного словосполучення, для котрого накопичена схожість є абсолютно найбільшою.
2. Пристрій для розпізнавання усних команд та усталених словосполучень за способом п. 1, що містить аналізатор, блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей, блок пам'яті проміжних результатів та контролер, який відрізняється тим, що в нього введені: блок пам'яті навчальної вибірки, процесор кластерного аналізу, блок пам'яті параметрів фонем; блок пам'яті орфографічного тексту та фонемної транскрипції, векторний квантувач, при цьому вихід аналізатора підключений через блок пам'яті мовленнєвих сигналів до входу векторного квантувача, а блок пам'яті навчальної вибірки підключений до входу процесора кластерного аналізу, виходи якого відповідно підключені до входу векторного квантувача та входу блоку пам'яті параметрів фонем, на відповідні входи якого підключені виходи блока пам'яті орфографічного тексту та фонемної транскрипції та вихід векторного квантувача, що також підключений до входу блока пам'яті табличних значень елементарних мір схожостей, виходи якого підключені до входів обчислювача інтегральних мір схожостей, відповідні виходи блока пам'яті орфографічного тексту та фонемної транскрипції підключені до відповідного входу блока пам'яті табличних значень елементарних мір схожостей та через блок пам'яті проміжних результатів - до відповідного входу обчислювача інтегральних мір схожостей, а виходи контролера підключені до відповідних входів блоків пристрою.
Текст
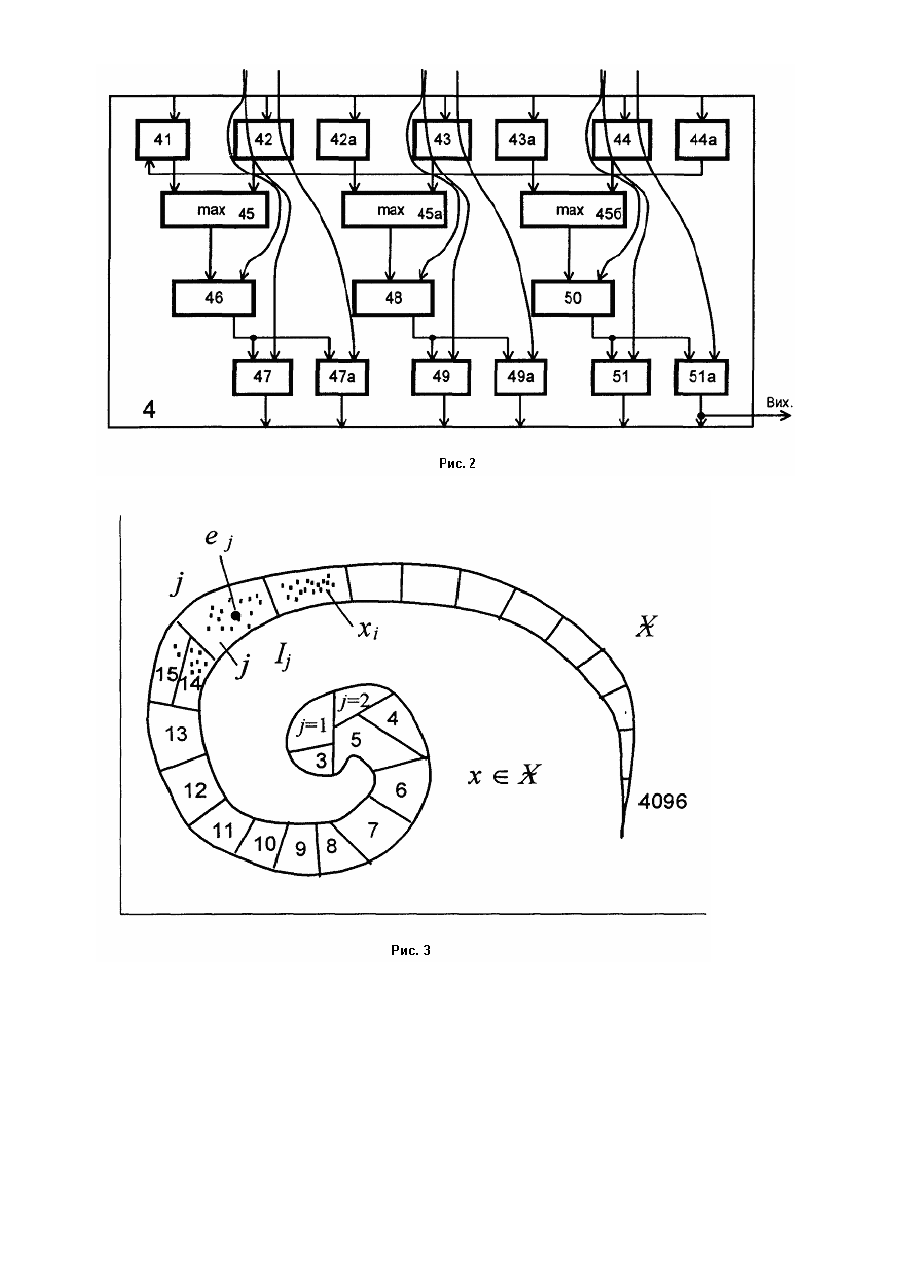
Винахід відноситься до техніки оброблення мовленнєвої інформації з метою її стискання, кодування та автоматичного розпізнавання. Може найти використання для голосового управління пристроями. Відомий спосіб та пристрій пофонемного розпізнавання усних команд та усталених словосполучень (дивись патент України №48082) Сутність відомого способу полягає в тому, що розпізнавання окремо вимовлюваних усних команд та усталених словосполучень грунтується на поданні мовленнєвого сигналу послідовностями елементіввекторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються. Але він має недоліки, які полягають в тому, що в нього мала швидкодія та низька надійність розпізнавання. Відомий пристрій для розпізнавання усних команд та усталених словосполучень містить аналізатор, блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей та блок пам'яті проміжних результатів та контролер. Але він має ті ж недоліки, а саме малу швидкодію та низьку надійність розпізнавання. В основу винаходу покладена задача за рахунок введення нових операцій обробки сигналів та введення конструктивних елементів у пристрій створити спосіб та пристрій для пофонемного розпізнавання усних команд та усталених словосполучень, що мають високу швидкодію та надійність розпізнавання без необхідності перенастроювання системи. Поставлена задача вирішується способом розпізнавання окремо вимовлюваних усних команд та усталених словосполучень, що грунтується на поданні мовленнєвого сигналу послідовностями елементіввекторів із значень поточних параметрів аналізу мовленнєвого сигналу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі еталонні елементи еталонних мовленнєвих образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються, при цьому кожна особа характеризується своїм індивідуальним усномовним паспортом, що укладається при разовому зачитуванні вголос цією особою стандартизованого тексту - навчальної вибірки; індивідуальний усномовний паспорт людини складають: задана кількість еталонних елементів, які найкращим чином апроксимують всі спостережувані елементи навчальної вибірки та визначають розбиття мультимножини спостережуваних елемента навчальної вибірки на задану кількість кластерів й параметри моделей всіх фонем у різному фонемному контексті попередньої та наступної фонем; цими моделями фонем є ланцюги породжувальних граматик з п'яти прихованих станів, що моделюють три стадії розвитку процесу породження реалізації фонеми, а параметрами моделей є: ймовірність переходу з нульового стану в перший стан, що дорівнює одиниці, ймовірність переходу з першого стану в перший же стан та ймовірність переходу з першого стану в другий стан, що доповнює до одиниці попередню ймовірність, ймовірність переходу з другого стану в другий же стан та ймовірність переходу з другого стану в третій стан, що доповнює до одиниці попередню ймовірність, ймовірність переходу з третього стану в третій же стан та ймовірність переходу з третього стану в четвертий стан, що доповнює до одиниці попередню ймовірність, та ймовірності попадань спостережуваних елементів в кожен із всіх кластерів за умови перебування в першому, другому та третьому станах кожної фонеми; при розпізнаванні для кожного поточного спостережуваного елемента визначається номер кластера, в який цей елемент попадає, а в якості елементарної міри належності спостережуваного елемента-вектора до першої, другої чи третьої фази фонеми використовується сума логарифмів ймовірності спостереженого кластера за умови першого, другого чи третього станів фонеми та ймовірності наступного переходу з першого в перший або другий, з другого в другий або третій, з третього в третій або четвертий стани фонеми відповідно до фази фонеми; еталонні мовленнєві образи усних команд та усталених словосполучень формують шляхом об'єднання у послідовності ланцюгів породжувальних граматик фонем з п'яти прихованих станів відповідно до фонетичних транскрипцій усних команд або словосполучень, причому так, щоб вихідний, четвертий, стан попередньої фонеми збігався з нульовим та першим станами наступної; інтегральні міри схожості початкових еталонних образів усних команд та усталених словосполучень, що визначаються для кожного із двох виходів із першого, другого чи третього станів поточної фонеми їх транскрипцій, знаходять як суми значень відповідної елементарної міри схожості, обчисленої для поточного спостереженого елемента для кожного із двох виходів із першого, другого чи третього станів поточної фонеми, з більшою із двох інтегральних мір схожості, накопичених для попереднього спостереженого вектора-елемента на другому виході з третього стану попередньої фонеми та на першому виході з першого стану поточної фонеми, на другому виході з першого стану поточної фонеми та на першому виході з другого стану поточної фонеми й на другому виході з другого стану поточної фонеми та на першому виході з третього стану поточної фонеми, відповідно; значення інтегральної міри схожості, накопичене після оброблення останнього спостереженого елемента на другому виході із третього стану останньої фонеми, яка визначається фонетичною транскрипцією усної команди або словосполучення, визначає схожість пред'явленого мовленнєвого сигналу на цю усну команду або словосполучення; пред'явлений мовленнєвий сигнал відноситься до тієї усної команди або усталеного словосполучення, для котрого накопичена схожість є абсолютно найбільшою. Задача вирішується також пристроєм для розпізнавання усних команд та усталених словосполучень, що містить аналізатор , блок пам'яті табличних значень елементарних мір схожостей та блок пам'яті мовленнєвого сигналу, що розпізнається, обчислювач інтегральних мір схожостей та блок пам'яті проміжних результатів та контролер, при цьому в нього введені: блок пам'яті для накопичення навчальної вибірки через аналізатор, процесор кластерного аналізу, вибору представників кластерів та оцінювання параметрів фонем; блок пам'яті для зберігання параметрів фонем; блок пам'яті для зберігання орфографічного тексту та фонемної транскрипції, якими супроводжується навчальна вибірка, та орфографічних текстів і фонемних транскрипцій всіх усних команд та усталених словосполучень, що входять до робочого словника; векторний квантувач 10, за вихідним сигналом якого, що вказує номер кластера, в який попадає поточний спостережуваний елемент, в блоці пам'яті табличних значень визначаються значення елементарних мір належності цього спостереженого елемента до кожного із двох виходів із всіх трьох фаз фонеми; обчислювач 4 інтегральних мір схожості містить сім вхідних регістрів, три компаратори та дев'ять суматорів і для кожного із двох виходів із всіх трьох фаз кожної фонеми фонетичної транскрипції всіх усних команд та усталених словосполучень накопичує інтегральні міри схожості. На рис. 1 представлена структурна схема пристрою, що реалізує спосіб; на рис. 2 - схема одного з блоків; рис. 3-8 пояснюють принцип роботи пристрою. Пристрій містить аналізатор 1 мовленнєвого сигналу; блок 3 запам'ятовування мовленнєвого образу у вигляді послідовності елементів-векторів, що утворюються в результаті аналізу вхідного мовленнєвого сигналу; векторний квантувач 10, який кожному поточному спостереженому елементу-вектору ставить у відповідність номер кластеру, в який він попадає, або, що те саме, номер еталонного елемента, що представляє кластер та є найближчим, в певному розумінні, до спостереженого елемента; блок 9 введення та зберігання орфографічних текстів та фонетичних транскрипцій всіх усних команд та усталених словосполучень, що складають робочий набір та повинні розпізнаватись; блок 8 пам'яті значень параметрів моделей всіх фонем; блок 2 вибору значень елементарних мір приналежності спостережуваного елемента, за номером його кластеру, до фонем та їх фаз; обчислювач 4 інтегральних мір схожості, який накопичує, сумує, значення елементарних мір схожості для послідовності спостережуваних елементів-векторів для кожної із усних команд або кожного усталеного словосполучення відповідно до їх фонетичних транскрипцій; блок пам'яті 4а, який тимчасово зберігає накопичені інтегральні міри схожості; контролер 5, який синхронізує роботу всіх блоків, зокрема блоків 2, 4, 4а, 8, 9, 10; накопичувач 6 стандартизованої навчальної вибірки; блок 7 кластерного аналізу та обчислення параметрів фонем за навчальною вибіркою. Вихід пристрою з блоку 4 визначає номер усної команди або усталеного словосполучення, для фонетичної транскрипції якого накопичена найбільша інтегральна міра схожості. Якщо пристрій не налаштований на голос користувача, тобто пам'ять 8 про значення параметрів моделей фонем є порожньою, він пропонує користувачеві наговорити навчальну вибірку - треба промовляти окремі слова або фрази, які голосом називає пристрій. В аналізаторі 1 мовленнєвий сигнал, що подається з мікрофона під час накопичення стандартизованої навчальної вибірки, піддається поточному автокореляційному та предиктивному аналізові в дискретному рівномірному часі iDT з кроком DT , наприклад DT =10мс. Для поточного інтервалу аналізу i із М відліків fn, n=0:(М-1) мовленнєвого сигналу, які зважуються вікном Хемінга, обчислюються перші m+1, m
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod and device for identifying voice commands and specified word combinations by phonemes
Автори англійськоюVintsiuk Taras Klymovych, Fedoryn Yaroslav Volodymyrovych
Назва патенту російськоюСпособ и устройство для распознавания речевых управляющих сигналов и заданных словосочетаний по фонемам
Автори російськоюВинцюк Тарас Климович, Федорин Ярослав Владимирович
МПК / Мітки
МПК: G10L 15/00
Мітки: розпізнавання, пристрій, пофонемного, спосіб, команд, словосполучень, усних, усталених
Код посилання
<a href="https://ua.patents.su/10-67696-sposib-ta-pristrijj-pofonemnogo-rozpiznavannya-usnikh-komand-ta-ustalenikh-slovospoluchen.html" target="_blank" rel="follow" title="База патентів України">Спосіб та пристрій пофонемного розпізнавання усних команд та усталених словосполучень</a>
Спосіб усномовного перекладу слів і словосполучень та голосовий словник-перекладач для його здійснення

Номер патенту: 67698
Опубліковано: 15.06.2004
Автори: Гриценко Володимир Ільїч, Ілюшин Сергій Аркадійович, Вінцюк Тарас Климович, Павлов Олег Ігоревич, Федорин Ярослав Володимирович, Ситніков Даніїл Анатолійович, Куптель Олег Григорович
МПК: G10L 15/00
Мітки: словник-перекладач, спосіб, здійснення, усномовного, слів, словосполучень, перекладу, голосовий
Формула / Реферат:
1. Спосіб усномовного перекладу слів та словосполучень, який базується на розпізнаванні мовленнєвого сигналу та лінгвістичному аналізі результату розпізнавання, який відрізняється тим, що слова та словосполучення, представлені звуковим сигналом, оцифровують, аналізують та перетворюють у сукупність векторів, що описують звуковий сигнал із прийнятною для розпізнавання точністю, вибирають найкращий опис даного звукового сигналу послідовністю...
Спосіб описування та розпізнавання мовленнєвих сигналів і пристрій для його реалізації

Номер патенту: 67695
Опубліковано: 15.06.2004
Автори: Вінцюк Тарас Климович, Гриценко Володимир Ільїч, Федорин Ярослав Володимирович
МПК: G10L 15/00
Мітки: описування, спосіб, пристрій, мовленнєвих, сигналів, розпізнавання, реалізації
Формула / Реферат:
1. Спосіб описування та розпізнавання мовленнєвих сигналів, що представляються послідовностями елементів-векторів із значень поточних параметрів його аналізу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі елементи еталонних образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності...
Пристрій прийому команд захисту бпк-дпи

Номер патенту: 2023
Опубліковано: 15.09.2003
Автор: Бахмач Євген Степанович
МПК: G05B 19/02
Мітки: команд, пристрій, захисту, прийому, бпк-дпи
Формула / Реферат:
Пристрій прийому команд захисту БПК-ДПИ, що містить вузол команд від захисту, вузол опробування каналу команд від захисту, вузол логічної обробки вхідних сигналів, вузол сигналізації команд від захисту, перетворювач вихідних сигналів, який відрізняється тим, що в нього введено вузол діагностики функціонування та передачі діагностичної інформації, виконаний на мікроконтролері, перетворювач вихідних сигналів, крім того, в вузол команд від...
Пристрій для формування команд керування по шляху переміщення рухомого об’єкта

Номер патенту: 1715
Опубліковано: 25.10.1994
Автор: Клименко Віталій Васильович
МПК: B66B 1/34
Мітки: рухомого, шляху, об'єкта, формування, переміщення, керування, пристрій, команд
Формула / Реферат:
1. Устройство формирования путевых команд управления подвижным объектом, содержащее датчик путевых импульсов, соединенный с реверсивным счетчиком, усилитель, узел программирования, отличающееся тем, что в него введены датчик конечного положения подвижного объекта и, соответственно количеству формируемых команд, блоки формирования путевых команд, каждый из которых содержит реверсивный счетчик, узел программирования и усилитель причем выходы...
Пристрій контролю та формування команд бфк1-дпи

Номер патенту: 2022
Опубліковано: 15.09.2003
Автор: Бахмач Євген Степанович
МПК: G05B 19/00
Мітки: контролю, бфк1-дпи, пристрій, команд, формування
Формула / Реферат:
Пристрій контролю та формування команд, що містить канал основного входу, канал опробування, вузол логічної обробки вхідних сигналів, вузол сигналізації вихідних сигналів, який відрізняється тим, що в нього введено вузол діагностики функціонування та передачі діагностичної інформації, реалізований на мікроконтролері, перетворювач вихідних сигналів із семи каналів, перетворювач вихідних сигналів із восьми каналів, групу із шести ключів...
Попередній патент: Спосіб екстрагування з твердого тіла
Наступний патент: Спосіб та пристрій пофонемного розпізнавання злитого мовлення
Випадковий патент: Зірочка