Терапевтична композиція, що містить моноклональне антитіло проти інгібітора шляху тканинного фактора (tfpi)
Номер патенту: 112050
Опубліковано: 25.07.2016
Автори: Ванг Жуожі, Джянг Хейян, Пан Джунлянг, Мерфі Джон Е., Ліу Бінг







Формула / Реферат
1. Терапевтична композиція, що містить людське моноклональне антитіло IgG антитіло, що зв’язується специфічно з зв’язувальним сайтом, що включає домени Kunitz 1 і Kunitz 2 інгібітору шляху людського тканинного фактора (TFPI), причому
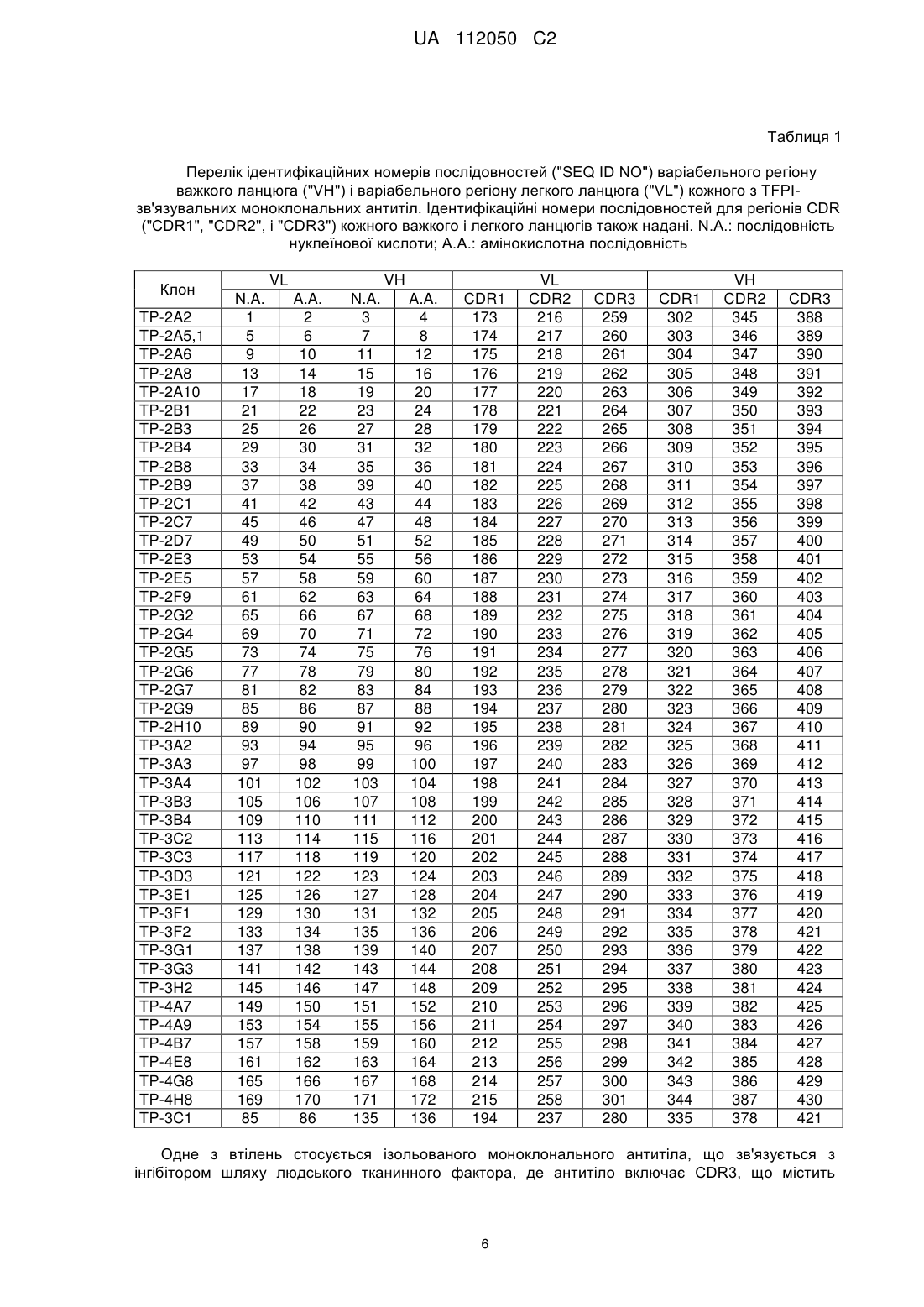
важкий ланцюг антитіла складається з амінокислотної послідовності, яка має принаймні 90 % гомології щодо SEQ ID NO: 16,
легкий ланцюг антитіла складається з амінокислотної послідовності, яка має принаймні 85 % гомології щодо SEQ ID NO: 14,
вказаний важкий ланцюг має CDR1 ділянку, що складається з амінокислотної послідовності, яка має принаймні 80 % гомології щодо SEQ ID NO: 305, CDR2 ділянку, що складається з амінокислотної послідовності, яка має принаймні 80 % гомології щодо SEQ ID NO: 348, та CDR3 ділянку, що складається з амінокислотної послідовності, яка має принаймні 80 % гомології щодо SEQ ID NO: 391, та
антитіло проявляє більше 50 % інгібування активності інгібітору шляху людського тканинного фактора (TFPI).
2. Композиція за п. 1, де важкий ланцюг антитіла має CDR1 ділянку, що містить амінокислотну послідовність SEQ ID NO: 305, CDR2 ділянку, що містить амінокислотну послідовність SEQ ID NO: 348, та CDR3 ділянку, що містить амінокислотну послідовність SEQ ID NO: 391.
3. Композиція за п. 1, що додатково містить фактор VII або фактор IX за суттєвої відсутності фактору VII.
4. Композиція за п. 1, де антитіло має зв’язувальну афінність до інгібітору шляху людського тканинного фактора за тестом Biacora приблизно від 1,25 до 1140 нМ.
5. Композиція за п. 1, де антитіло є включеним до складу в комбінації дози від 10 до 100 мг в фармацевтично прийнятному носії для ін’єкцій.
6. Композиція за п. 1, де CDR2 ділянка має принаймні 85 % гомології до SEQ ID NO: 348.
7. Композиція за п. 1, де CDR3 ділянка має принаймні 85 % гомології до SEQ ID NO: 391.
8. Композиція за п. 1, де антитіло є окремим фрагментом ланцюга.
9. Композиція за п. 1, де важкий ланцюг антитіла складається з амінокислотної послідовності SEQ ID NO: 16.
10. Композиція за п. 1, де легкий ланцюг антитіла має CDR1 ділянку, що складається з амінокислотної послідовності, як показано в SEQ ID NO: 176, CDR2 ділянку, що складається з амінокислотної послідовності, як показано в SEQ ID NO: 219, та CDR3 ділянку, що складається з амінокислотної послідовності, як показано в SEQ ID NO: 262.
Текст
Реферат: Винахід належить до терапевтичної композиції, що містить людське моноклональне антитіло IgG антитіло, що зв’язується специфічно з зв’язувальним сайтом, що включає домени Kunitz 1 s Kunitz 2 інгібітору шляху людського тканинного фактора (TFPI), причому антитіло проявляє більше 50 % інгібування активності інгібітору шляху людського тканинного фактора (TFPI). UA 112050 C2 (12) UA 112050 C2 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 Перелік послідовностей Перелік послідовностей, пов'язаний із цією заявкою, поданий в електронному форматі через EFS-мережу й тим самим включений посиланням у описі повністю. Назва текстового файлу, що містить Перелік Послідовностей, є MSB7329PCT_Sequence_Listing_ST25. Галузь винаходу Винахід стосується ізольованих моноклональних антитіл та їх фрагментів, які зв'язують інгібітор шляху тканинного фактора людини (TFPI), та споріднених винаходів. Попередній рівень техніки Коагуляція крові - процес, яким кров утворює стабільні згустки, щоб припинити кровотечу. Процес залучає багато проферментів і прокофакторів (або "коагуляційних факторів"), які циркулюють у крові. Такі проферменти й прокофактори взаємодіють через декілька шляхів, через які вони перетворюються послідовно або одночасно на активовану форму. В остаточному підсумку процес приводить до активації протромбіну в тромбін активувальним фактором X (FXa) у присутності Фактора Va, іонів кальцію і тромбоцитів. Активований тромбін у свою чергу індукує агрегацію тромбоцитів і перетворює фібриноген у фібрин, який стає потім поперечно зшитим за допомогою активованого Фактора XIII (FXIIIa) з утворенням згустку. Процес, що приводить до активації Фактора X, може бути здійснений двома відмінними шляхами: контактно-активаційним шляхом (раніше відомим як внутрішній шлях) і шляхом тканинного фактора (раніше відомим як зовнішній шлях). Раніше вважалося, що каскад коагуляції складається із двох шляхів однакової важливості, з'єднаних із загальним шляхом. Тепер відомо, що первинний шлях для ініціювання коагуляція крові - шлях тканинного фактора. Фактор X може бути активований тканинним фактором (TF) у комбінації з активованим Фактором VII (FVIIa). Комплекс Фактора VIIa і його есенціального кофактора TF є потужним ініціатором каскаду утворення згустків. Шляхом тканинного фактора коагуляції негативно управляє інгібітор шляху тканинного фактора("TFPI"). TFPI є природним, FXa-залежним інгібітором зворотного зв'язку комплексу FVIIa/TF. Це - член полівалентних інгібіторів серинових протеаз Kunitz-типу. Фізіологічно, TFPI зв'язується з активованим Фактором X (FXa) з утворенням гетеродимерного комплексу, що згодом взаємодіє з комплексом FVIIa/TF, щоб інгібувати його активність, таким чином закриваючи шлях тканинного фактора коагуляції. У принципі, блокування активності TFPI може відновити активність FXa і FVIIa/TF, таким чином, продовжуючи тривалість дії шляху тканинного фактора і підсилюючи генерування FXa, що є загальним дефектом при гемофілії A й B. Дійсно, деякі попередні експериментальні дані показали, що блокування активності TFPI антитілами проти TFPI нормалізує тривалий час коагуляції або скорочує час кровотечі. Наприклад, Nordfang та ін. показали, що тривалий час розрідження протромбіну гемофільної плазми був нормалізований після обробки плазми антитілами до TFPI (Thromb. Haemost., 1991, 66 (4): 464-467). Аналогічно, Erhardtsen та ін. показав, що час кровотечі при моделі гемофілії у кроликів був значно скорочений анти-TFPI антитілами (Blood Coagulation and Fibrinolysis, 1995, 6: 388-394). Ці дослідження припускають, що інгібування TFPI анти-TFPI антитілами може бути корисним для лікування гемофілії A або B. В цих дослідженнях використовувалося тільки поліклональне анти-TFPI антитіло. Використовуючи гібридомні методики, моноклональні антитіла проти рекомбінантного людського TFPI (rhTFPI) були одержані та ідентифіковані. Див. Yang і інші, Chin. Med. J., 1998, 111(8): 718-721. Був досліджений ефект моноклонального антитіла на подовження протромбінового часу (PT) і часу частково активованого тромбопластину (APTT). Експерименти показали, що анти-TFPI моноклональне антитіло скорочувало подовжений час коагуляції тромбопластину Фактора IX дефіцитної плазми. Припускають, що шлях тканинного фактора відіграє важливу роль не тільки у фізіологічній коагуляції, але також й при геморагії при гемофілії (Yang та інші, Hunan Yi Ke Da Xue Xue Bao, 1997, 22(4): 297-300). Патент США 7,015,194 Kjalke та ін. розкриває композиції, що включають FVIIa й інгібітор TFPI, включаючи поліклональні або моноклональні антитіла або їх фрагмент, для лікування або профілактики геморагічних випадків або коагуляційної терапії. Також описується застосування такої композиції для зменшення часу утворення згустків у нормальній плазмі ссавців. В подальшому припускається, що Фактор VIII або його варіант можуть бути включені в описану композицію FVIIa та інгібітора TFPI. Комбінація FVIII або Фактора IX з моноклональним антитілом TFPI не пропонується. Крім лікування гемофілії припускалось також, що інгібітори TFPI, включаючи поліклональні або моноклональні антитіла, могли б використовуватися для лікування раку (див. Патент США 5,902,582 Hung). 1 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 Відповідно, необхідні антитіла, специфічні щодо TFPI, для лікування гематологічних захворювань і раку. Загалом, терапевтичні антитіла для лікування захворювань у людей одержували, використовуючи генну інженерію, щоб одержати мишачі, химерні, гуманізовані або повністю людські антитіла. Мишачі моноклональні антитіла показали обмежене застосування як терапевтичні агенти через короткий період напіврозпаду у сироватці, нездатність викликати ефекторні функції у людей, і продукування антимишачих антитіл. Brekke and Sandlie, “Therapeutic Antibodies for Human Diseases at the Dawn of the Twenty-first Century”, Nature 2, 53, 52-62 (Jan. 2003). Химерні антитіла, як було показано, викликають реакцію на людські антихимерні антитіла. Гуманізовані антитіла, крім того, мінімізують мишачий компонент антитіл. Однак, повністю людське антитіло уникає імуногенності, пов'язаної із мишачими елементами повністю. Таким чином, існує потреба розвити повністю людські антитіла, щоб уникнути імуногенності, пов'язаної з іншими формами генетично розроблених моноклональних антитіл. Зокрема, тривале профілактичне лікування, яке було б потрібне для лікування гемофілії антиTFPI моноклональним антитілом, має високий ризик розвитку імунної реакції на терапію, якщо антитіло із мишачим компонентом або мишачим походженням використовується внаслідок частого необхідного дозування й довготривалої терапії. Наприклад, лікування антитілами гемофілії A може вимагати щотижневого дозування протягом цілого життя пацієнта. Це було б безперервним сенсибілізуванням імунної системи. Таким чином, існує потреба у повністю людських антитілах для терапії гемофілії антитілами та пов'язаних генетичних і набутих дефіцитів або дефектів коагуляції. Терапевтичні антитіла одержували гібридомними способами, описаними Koehler та Milstein в “Continuous Cultures of Fused Cells Secreting Antibody of Predefined Specificity”, Nature 256, 495497 (1975). Повністю людські антитіла можуть також бути одержані рекомбінантно в прокаріотах й еукаріотах. Для терапевтичного антитіла переважним вважається рекомбінантне одержання антитіла в клітині хазяїна, а не гібридомне одержання. У рекомбінантного одержання є переваги більшої стабільності продукту, ймовірно більш високого рівня одержання і контролювання виробництва, що мінімізує або усуває присутність протеїнів тваринного походження. Із цих причин бажано мати рекомбінантно одержане моноклональне анти-TFPI антитіло. Короткий зміст винаходу Винахід стосується моноклональних антитіл до інгібітора шляху людського тканинного фактора (TFPI). Крім того, винахід стосується виділених молекул нуклеїнової кислоти, що кодує їх. Також винахід охоплює фармацевтичні композиції, що включають анти-TFPI моноклональні антитіла, та способи лікування генетичних і набутих дефіцитів або дефектів коагуляції, таких як гемофілія A й B. Також винахід стосується способів скорочення часу кровотечі шляхом введення анти-TFPI моноклонального антитіла пацієнтові, який потребує цього. Також охоплюються способи одержання моноклональних антитіл, що зв'язують людський TFPI, відповідно до даного винаходу. Короткий опис фігур Фіг. 1: Зв'язувальна активність представлених прикладів Fabs, відібраних від пенінгу й скринінгу щодо людського TFPI ("h-TFPI") і мишачого TFPI ("m-TFPI"). Був досліджений контрольний Fab проти Естрадіол-BSA ("EsВ") і 12 Fabs (1-4 й 6-13), відібраних від пенінгу TFPI. Вісь Y означає одиниці флуоресценції за результатами ELISA. Фіг. 2: Дозозалежна функціональна активність in vitro чотирьох представлених анти-TFPI антитіл (4B7: TP-4B7, 2A8: TP-2A8, 2G6: TP-2G6, 2G7: TP-2G7), отриманих від пенінгу й скринінгу людської бібліотеки антитіл, як показано їхнім скороченням dPT. Експеримент залучав 0,5 мкг/мл mTFPI, введеного у збіднену плазму плазму TFPI. Фіг. 3: Функціональна активність in vitro анти-TFPI Fab, Fab-2A8 (від TP-2A8), як протестовано у дослідженні ROTEM. Фіг. 4: Зв'язувальна активність людських TFPI і мишачих TFPI клонів TP-2G6 ("2G6") після перетворення в IgG. Δ: IgG-2G6, що зв'язується з мишачим TFPI; Δ: IgG-2G6, що зв'язується з людським TFPI; ▲: контрольний IgG, що зв'язується з мишачим TFPI; : контрольний IgG, що зв'язується з людським IgG. Фіг. 5: Анти-TFPIантитіла TP-2A8 ("2A8"), TP-3G1 ("3G1"), і TP-3C2 ("3C2"), що скорочували час коагуляції цільної крові при гемофілії А у мишей, як протестовано у дослідженні ROTEM. Кожна крапка представляє одну індивідуальну мишу з гемофілією. Фіг. 6: вирівнювання амінокислотної послідовності між варіабельними легкими ланцюгами анти-TFPI моноклональних антитіл TP-2A10 (SEQ ID NO: 18), TP-2B1 (SEQ ID NO: 22), TP-2A2 (SEQ ID NO: 2), TP-2G2 (SEQ ID NO: 66), TP-2A5,1 (SEQ ID NO: 6), TP-3A3 (SEQ ID NO: 98), TP2A8 (SEQ ID NO: 14), TP-2B8 (SEQ ID NO: 34), TP-2G7 (SEQ ID NO: 82), TP-4H8 (SEQ ID NO: 2 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 170), TP-2G4 (SEQ ID NO: 70), TP-3F2 (SEQ ID NO: 134), TP-2A6 (SEQ ID NO: 10), TP-3A2 (SEQ ID NO: 94), TP-2C1 (SEQ ID NO: 42), TP-3E1 (SEQ ID NO: 126), TP-3F1 (SEQ ID NO: 130), TP-3D3 (SEQ ID NO: 122), TP-4A7 (SEQ ID NO: 150), TP-4G8 (SEQ ID NO: 166), TP-2B3 (SEQ ID NO: 26), TP-2F9 (SEQ ID NO: 62), TP-2G5 (SEQ ID NO: 74), TP-2G6 (SEQ ID NO: 78), TP-2H10 (SEQ ID NO: 90), TP-2B9 (SEQ ID NO: 38 58), TP-3C3 (SEQ ID NO: 118), TP-3G1 (SEQ ID NO: 138), TP2D7 (SEQ ID NO: 50), TP-4B7 (SEQ ID NO: 158), TP-2E3 (SEQ ID NO: 54), TP-2G9 (SEQ ID NO: 86), TP-3C1 (SEQ ID NO: 86), TP-3A4 (SEQ ID NO: 102), TP-2B4 (SEQ ID NO: 30), TP-3H2 (SEQ ID NO: 146), TP-4A9 (SEQ ID NO: 154), TP-4E8 (SEQ ID NO: 162), і TP-3B3 (SEQ ID NO: 106). Фіг. 7: Вирівнювання амінокислотної послідовності між варіабельними важкими ланцюгами анти-TFPI моноклональних антитіл TP-2A10 (SEQ ID NO: 20), TP-3B3 (SEQ ID NO: 108), TP-2G4 (SEQ ID NO: 72), TP-2A5,1 (SEQ ID NO: 8), TP-4A9 (SEQ ID NO: 156), TP-2A8 (SEQ ID NO: 16), TP-2B3 (SEQ ID NO: 28), TP-2B9 (SEQ ID NO: 40), TP-2H10 (SEQ ID NO: 92), TP-3B4 (SEQ ID NO: 112), TP-2C7 (SEQ ID NO: 48), TP-2E3 (SEQ ID NO: 56), TP-3C3 (SEQ ID NO: 120), TP-2G5 (SEQ ID NO: 76), TP-4B7 (SEQ ID NO: 160), TP-2G6 (SEQ ID NO: 80), TP-3C2 (SEQ ID NO: 116), TP-2D7 (SEQ ID NO: 52), TP-3G1 (SEQ ID NO: 140), TP-2E5 (SEQ ID NO: 60), TP-2B8 (SEQ ID NO: 36), TP-3F1 (SEQ ID NO: 132), TP-3A3 (SEQ ID NO: 100), TP-4E8 (SEQ ID NO: 164), TP-4A7 (SEQ ID NO: 152), TP-4H8 (SEQ ID NO: 172 84), TP-3H2 (SEQ ID NO: 148), TP-2A2 (SEQ ID NO: 4), TP-3E1 (SEQ ID NO: 128), TP-2G2 (SEQ ID NO: 68), TP-3D3 (SEQ ID NO: 124), TP-2G9 (SEQ ID NO: 88), TP-2B4 (SEQ ID NO: 32), TP-3A2 (SEQ ID NO: 96), TP-2F9 (SEQ ID NO: 64), TP-3A4 (SEQ ID NO: 104), TP-3C1 (SEQ ID NO: 136), TP-3F2 (SEQ ID NO: 136), і TP-4G8 (SEQ ID NO: 168). Фіг. 8: Діаграма, що показує виживаність через 24 години після поперечного розрізу вени хвоста мишей, оброблених (1) анти-TFPI антитілом TP-2A8 ("2A8"), (2) 2A8 і рекомбінантним фактором VIII, (3) мишачим IgG, і (4) рекомбінантним фактором VIII. Фіг. 9: Діаграма, що показує дослідження часу коагуляції і часу утворення згустка у мишей, оброблених анти-TFPI антитілом TP-2A8 ("2A8"), фактором VIIa, і комбінацією 2A8 і фактора VIIa. Фіг. 10: Діаграма, що показує час коагуляції нормальної людської крові, обробленої інгібітором FVIII з анти-TFPI антитілом TP-2A8 ("2A8") і анти-TFPI антитілом TP-4B7 ("4B7") у порівнянні з одним тільки інгібітором FVIII. Детальний опис Визначення Термін "інгібітор шляху тканинного фактора" або "TFPI", як використовується тут, відноситься до будь-якого варіанта, ізоформи і гомологічних видів людського TFPI, що природно експресується клітинами. У переважному втіленні винаходу зв'язування антитіла винаходу з TFPI зменшує час коагуляції крові. Як використовується тут, "антитіло" відноситься до цілого антитіла та будь-якого антигензв'язувального фрагменту (тобто, "антиген-зв'язувальної частини") або його окремого ланцюга. Термін включає молекулу імуноглобуліну повної довжини (наприклад, антитіло IgG), що природно зустрічається, або який утворений рекомбінаторними процесами генних фрагментів нормального імуноглобуліну або імунологічно активною частиною молекули імуноглобуліну, такою як фрагмент антитіла, що зберігає специфічну зв'язувальну активність. Незалежно від структури фрагмент антитіла зв'язується з тим же самим антигеном, що розпізнаний повнорозмірним антитілом. Наприклад, анти-TFPI фрагмент моноклонального антитіла зв'язується з антигенною детермінантою TFPI. Антиген-зв'язуюча функція антитіла може бути здійснена фрагментами повнорозмірного антитіла. Приклади зв'язувальних фрагментів, охоплених терміном "антиген-зв'язувальна частина" антитіла, включають (i) Fab фрагмент, моновалентий фрагмент, що складається з VL, VH, CL та CH1 доменів; (ii) F(ab")2 фрагмент, бівалентний фрагмент, що включає два Fab фрагменти, зв'язані дисульфидним містком в шарнірній області; (iii) фрагмент Fd, що складається з V H та CH1 доменів; (iv) фрагмент Fv, що складається з VL й VH доменів одноплечового антитіла, (v) фрагмент dAb (Ward та ін., (1989) Nature 341:544-546), що складається з домену VH; і (vi) ізольований гіперваріабельний регіон (CDR). Крім того, хоча два домена Fv фрагмента, VL і VH, кодуються окремими генами, вони можуть бути з'єднані, використовуючи рекомбінантні способи, синтетичним лінкером, що дозволяє їм бути зробленими як єдиний ланцюг білка в якому V L і VH пари доменів утворюють моноваленті молекули (відомий як одиночний ланцюг Fv (scFv); див. наприклад, Bird та ін. (1988) Science 242:423-426; і Huston та інші (1988) Proc. Natl. Acad. Sci. США 85:5879-5883). Такі одноланцюгові антитіла також охоплюються терміном "антиген-зв'язувальна частина" антитіла. Ці фрагменти антитіла отримують, використовуючи звичайні способи, відомі фахівцям у даній 3 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 галузі, і фрагменти піддають скринінгу на корисність тим же самим способом, як інтактні антитіла. Як використовується тут, терміни "інгібування зв'язування" й "блокування зв'язування" (наприклад, відноситься до інгібування/блокування зв'язування TFPI-ліганда з TFPI) використовуються поперемінно й охоплюють як часткове, так і повне інгібування або блокування. Слід мати на увазі, що інгібування й блокування також включають будь-яке вимірюване зменшення афінності зв'язування TFPI з фізіологічним субстратом у разі контакту з анти-TFPI антитілом, у порівнянні з TFPI за відсутності контакту з анти-TFPI антитілом, наприклад, блокування взаємодії TFPI з фактором Xa або блокування взаємодії комплекса TFPI-фактор Xa з тканинним фактором, фактором VIIa або комплексом фактор/тканинний фактор VIIa принаймні на приблизно 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 95 %, 96 %, 97 %, 98 %, 99 % або 100 %. Терміни "моноклональне антитіло" або "композиція моноклонального антитіла", як використовується тут, відносяться до препарату молекул антитіл єдиного молекулярного складу. Композиція моноклонального антитіла виявляє єдину специфічність зв'язування й афінність щодо специфічної антигенної детермінанти. Відповідно, термін "людське моноклональне антитіло" відноситься до антитіл, що показують єдину специфічність зв'язування, які мають варіабельні й константні регіони, що походять від послідовностей зародкової лінії людських імуноглобулінів. Людські антитіла винаходу можуть включати амінокислотні залишки, не кодовані послідовностями зародкової лінії людських імуноглобулінів (наприклад, мутації, уведені випадковим або сайт-специфічним мутагенезом in vitro або соматичною мутацією in vivo). Під терміном "ізольоване антитіло", використовуваним тут, мається на увазі антитіло, що істотно вільне від інших антитіл, які мають різні антигенні специфічності (наприклад, ізольоване антитіло, що зв'язується з TFPI, істотно вільне від антитіл, які зв'язують антигени, відмінні від TFPI). Однак, у ізольованого антитіла, що зв'язується з антигенною детермінантою, ізоформом або варіантом людського TFPI, може, бути перехресна реактивність до інших споріднених антигенів, наприклад, від інших видів (наприклад, гомологічні види TFPI). Крім того, ізольоване антитіло може бути істотно вільним від іншого клітинного матеріалу та/або хімікатів. Як використовується тут, термін "специфічне зв'язування" відноситься до зв'язування антитіла з предетермінованим антигеном. Як правило, антитіло зв'язується з афінністю 5 -1 принаймні приблизно 10 M і зв'язується з предетермінованим антигеном із афінністю, що є вищою, наприклад, принаймні у 2 рази більшою, ніж афінність зв'язування із стороннім антигеном (наприклад, BSA, казеїн), відмінним від предетермінованого антигену або тісно пов'язаного антигену. Фрази "розпізнавання антигену антитілом" й "специфічне щодо антигену антитіло", використовуються поперемінно тут з терміном "антитіло, що специфічно зв'язується з антигеном". Як використовується тут, термін "висока афінність" щодо IgG антитіла відноситься до 7 -1 афінності зв'язування принаймні приблизно 10 M , у деяких втіленнях принаймні приблизно 8 -1 9 -1 10 -1 11 -1 10 M , у деяких втіленнях принаймні приблизно 10 M , 10 M , 10 M або більше, наприклад, 13 -1 до 10 M або більше. Однак, "висока афінність" зв'язування може змінюватися для інших ізотипів антитіл. Наприклад, "висока афінність" зв'язування для ізотипа IgМ, відноситься до 7 -1, афінності зв'язування принаймні приблизно 1,0 × 10 M Як використовується тут, "ізотип" відноситься до класу антитіл (наприклад, IgМ або IgG1), що кодується генами константного регіону важкого ланцюга. "Комплементарно-детермінований регіон" або "CDR" відноситься до одного з трьох гіперваріабельних регіонів у межах варіабельного регіону важкого ланцюга або варіабельного регіону легкого ланцюга молекули антитіла, які утворюють N-терміновану антиген-зв'язуючу поверхню, що є комплементарною до тривимірної структури зв'язуваного антигену. Походячи від N-сайту термінації важкого або легкого ланцюга, ці комплементарно-детерміновані регіони позначаються як "CDR1", "CDR2", і "CDR3", відповідно. CDR залучаються у зв'язування антитілом антигену, і CDR3 включає унікальний регіон, специфічний щодо зв'язування антитілом антигену. Антиген-зв'язувальний сайт, таким чином, може включати шість CDR, включаючи регіони CDR від кожного V регіону важкого й легкого ланцюга. Як використовуються тут, "консервативне заміщення" відноситься до модифікацій поліпептиду, які включають заміну однієї або кількох амінокислот на амінокислоти, що мають подібні біохімічні властивості, які не приводять до втрати біологічної або біохімічної функції поліпептиду. "Консервативне амінокислотне заміщення" є заміщенням, в якому амінокислотний залишок замінюється амінокислотним залишком, що має подібний бічний ланцюг. Родини амінокислотних залишків, що мають подібні бічні ланцюги, були визначені в даній галузі. Ці 4 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 родини включають амінокислоти з основними бічними ланцюгами (наприклад, лізин, аргінін, гістидин), кислотними бічними ланцюгами (наприклад, аспарагінова кислота, глутамінова кислота), незаряджені полярні бічні ланцюги (наприклад, гліцин, аспарагін, глутамін, серин, треонін, тірозин, цистеїн), неполярні бічні ланцюги (наприклад, аланін, валін, лейцин, ізолейцин, пролін, фенілаланін, метіонін, триптофан), бета-розгалужені бічні ланцюги (наприклад, треонін, валін, ізолейцин), та ароматичні бічні ланцюги (наприклад, тірозин, фенілаланін, триптофан, гістидин). Передбачається, що антитіла даного винаходу можуть консервативні амінокислотні заміщення й усе ще зберігати активність. Для нуклеїнових кислот і поліпептидів, термін "істотна гомологія" вказує, що дві нуклеїнові кислоти або два поліпептиди, або їх визначені послідовності, що оптимально вирівняні та порівняні, є ідентичними, з відповідними нуклеотидними або амінокислотними інсерціями або делеціями, принаймні приблизно у 80 % нуклеотидів або амінокислот, звичайно у принаймні приблизно 85 %, переважно приблизно у 90 %, 91 %, 92 %, 93 %, 94 %, або 95 %, більш переважно принаймні приблизно у 96 %, 97 %, 98 %, 99 %, 99,1 %, 99,2 %, 99,3 %, 99,4 %, або 99,5 % нуклеотидів або амінокислот. Альтернативно, істотна гомологія для нуклеїнових кислот існує, коли сегменти гібридизуються при селективних умовах гібридизації з комплементом ланцюга. Винахід включає послідовності нуклеїнової кислоти та поліпептидні послідовності, що мають істотну гомологію щодо певних послідовностей нуклеїнової кислоти та амінокислотних послідовностей, наведених тут. Відсоток ідентичності між двома послідовностями є функцією числа ідентичних положень, розділених послідовностями (тобто, % гомології = # ідентичних позицій / загальна кількість # позицій x 100), беручи до уваги число розривів, і довжину кожного розриву, що повинен бути уведений для оптимального вирівнювання цих двох послідовностей. Порівняння послідовностей і визначення відсотка ідентичності між двома послідовностями може бути досягнуте, використовуючи математичний алгоритм, такий як без обмеження AlignХ™ модуль VectorNTI™ (Корпорація Invitrogen, Карлсбад, Каліфорнія). Для AlignХ™, параметри за замовчуванням багаторазового вирівнювання: штраф за відкритий проміжок: 10; штраф за поширення проміжку: 0,05; діапазон штрафу поділу проміжку: 8; % ідентичністі для затримки вирівнювання: 40, (подальші деталі, можуть бути знайдені на http://www.invitrogen.com/site/us/en/home/LINNEAOnline-Guides/LINNEA-Communities/Vector-NTI-Community/Sequence-analysis-and-data-man agement-software-for-PCs/AlignX-Module-for-Vector-NTI-Advance.reg.us.html). Інший спосіб визначення найкращої загальної сумісності між заявленою послідовністю (послідовністю даного винаходу) і суб'єктною послідовністю, також згадуваний як глобальне вирівнювання послідовності, може бути визначений, використовуючи комп'ютерну програму CLUSTALW (Thompson та ін., Nucleic Acids Research, 1994, 2(22): 4673-4680), яка базується на алгоритмі Higgins та ін., (Computer Applications in the Biosciences (CABIOS), 1992, 8(2): 189-191). У вирівнюванні послідовностей заявлена послідовність і суб'єктна послідовність обидві є ДНКпослідовностями. Результат згадуваного глобального вирівнювання послідовності становить відсоток ідентичності. Переважними параметрами, використовуваними у вирівнюванні CLUSTALW послідовностей ДНК, для розрахунку відсотка ідентичності через попарні вирівнювання є: Матриця = IUB, k-кортеж = 1, Число Головних Діагоналей = 5, Штраф за проміжок в послідовності = 3, Штраф за відкритий проміжок в послідовності= 10, Штраф за поширення проміжку = 0,1, Для багаторазових вирівнювань переважні наступні параметри CLUSTALW: Штраф за відкритий проміжок в послідовності = 10, Параметр Поширення Проміжку = 0,05; Діапазон Штрафу Поділу Проміжку = 8; % Ідентичності для Затримки Вирівнювання = 40. Нуклеїнові кислоти можуть бути присутні у цілих клітинах, у клітинному лізаті або в частково очищеній або істотно чистій формі. Нуклеїнова кислота є "ізольованою" або "істотно чистою", коли вона очищена від інших клітинних компонентів, з якими вона зазвичай зв'язана в природному навколишньому середовищі. Щоб ізолювати нуклеїнову кислоту, можуть використовуватися стандартні способи, такі як наступні: лужна обробка/обробка SDS, CsCl об'єднання, колонкова хроматографія, електрофорез агарозного гелю й інші, відомі в даній галузі. Моноклональні антитіла Сорок чотири TFPI-зв'язувальних антитіла були ідентифіковані від пенінгу й скринінгу людських бібліотек антитіл проти людського TFPI. Варіабельний регіон важкого ланцюга і варіабельний регіон легкого ланцюга кожного моноклонального антитіла були впорядковані, та їх CDR регіони були ідентифіковані. Ідентифікаційні номери послідовностей ("SEQ ID NO"), що відповідають цим регіонам кожного моноклонального антитіла, наведені в Таблиці 1. 5 UA 112050 C2 Таблиця 1 Перелік ідентифікаційних номерів послідовностей ("SEQ ID NO") варіабельного регіону важкого ланцюга ("VH") і варіабельного регіону легкого ланцюга ("VL") кожного з TFPIзв'язувальних моноклональних антитіл. Ідентифікаційні номери послідовностей для регіонів CDR ("CDR1", "CDR2", і "CDR3") кожного важкого і легкого ланцюгів також надані. N.A.: послідовність нуклеїнової кислоти; A.A.: амінокислотна послідовність Клон TP-2A2 TP-2A5,1 TP-2A6 TP-2A8 TP-2A10 TP-2B1 TP-2B3 TP-2B4 TP-2B8 TP-2B9 TP-2C1 TP-2C7 TP-2D7 TP-2E3 TP-2E5 TP-2F9 TP-2G2 TP-2G4 TP-2G5 TP-2G6 TP-2G7 TP-2G9 TP-2H10 TP-3A2 TP-3A3 TP-3A4 TP-3B3 TP-3B4 TP-3C2 TP-3C3 TP-3D3 TP-3E1 TP-3F1 TP-3F2 TP-3G1 TP-3G3 TP-3H2 TP-4A7 TP-4A9 TP-4B7 TP-4E8 TP-4G8 TP-4H8 TP-3C1 VL N.A. 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97 101 105 109 113 117 121 125 129 133 137 141 145 149 153 157 161 165 169 85 VH A.A. 2 6 10 14 18 22 26 30 34 38 42 46 50 54 58 62 66 70 74 78 82 86 90 94 98 102 106 110 114 118 122 126 130 134 138 142 146 150 154 158 162 166 170 86 N.A. 3 7 11 15 19 23 27 31 35 39 43 47 51 55 59 63 67 71 75 79 83 87 91 95 99 103 107 111 115 119 123 127 131 135 139 143 147 151 155 159 163 167 171 135 A.A. 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96 100 104 108 112 116 120 124 128 132 136 140 144 148 152 156 160 164 168 172 136 CDR1 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 194 VL CDR2 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 237 CDR3 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 280 CDR1 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 335 VH CDR2 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 378 CDR3 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 421 Одне з втілень стосується ізольованого моноклонального антитіла, що зв'язується з інгібітором шляху людського тканинного фактора, де антитіло включає CDR3, що містить 6 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 388-430. Ці CDR3 ідентифіковані з важких ланцюгів антитіл, що ідентифіковані під час пенінгу й скринінгу. У подальшому втіленні це антитіло додатково включає: (a) CDR1, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 302-344, (b) CDR2, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 345-387, або (c) CDR1, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 302-344, та CDR2, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 345-387. Інше втілення стосується антитіл, які розділяють CDR3 від одного з легких ланцюгів антитіл, ідентифікованих під час пенінгу й скринінгу. Таким чином, даний винахід відноситься до ізольованого моноклонального антитіла, яке зв'язується з інгібітором шляху людського тканинного фактора, де антитіло включає CDR3, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 259-301. У подальших втіленнях антитіло додатково включає: (a) CDR1, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 173-215, (b) CDR2, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 216-258, або (c) CDR1, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 173-215, та CDR2, що містить амінокислотну послідовність, вибрану із групи, що складається з SEQ ID NO: 216-258. В іншому втіленні антитіло включає CDR3 від важкого ланцюга та CDR3 від легкого ланцюга антитіл, ідентифікованих від скринінгу й пенінгу. Таким чином, забезпечується антитіло, яке зв'язується з інгібітором шляху людського тканинного фактора, де антитіло включає CDR3, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 388-430 та CDR3, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 259-301. У подальшому втіленні антитіло додатково включає: (a) CDR1, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 302-344, (b) CDR2, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 345387, (c) CDR1, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 173-215, та/або (d) CDR2, що містить амінокислотну послідовність, вибрану із групи, яка складається з SEQ ID NO: 216-258. В інших конкретних втіленнях антитіло містить варіабельні регіони важкого й легкого ланцюга, які включають: (a) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 173, 216 і 259, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 302, 345 й 388; (b) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 174, 217 і 260, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 303, 346 й 389; (c) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 175, 218 і 261, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 304, 347 й 390; (d) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 176, 219 і 262, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 305, 348 й 391; (e) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 177, 220 і 263, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 306, 349 й 392; (f) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 178, 221 і 264, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 307, 350 й 393; (g) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 179, 222 і 265, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 308, 351 й 394; (h) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 180, 223 і 266, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 309, 352 й 395; (i) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 181, 224 і 267, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 310, 353 й 396; 7 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 (j) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 182, 225 і 268, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 311, 354 й 397; (k) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 183, 226 і 269, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 312, 355 й 398; мкл) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 184, 227 і 270, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 313, 356 й 399; (m) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 185, 228 і 271, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 314, 357 й 400; (n) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 186, 229 і 272, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 315, 358 й 401; (o) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 187, 230 і 273, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 316, 359 й 402; (p) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 188, 231 і 274, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 317, 360 й 403; (q) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 189, 232 і 275, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 318, 361 й 404; (r) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 190, 233 і 276, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 319, 362 й 405; (s) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 191, 234 і 277, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 320, 363 й 406; (t) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 192, 235 і 278, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQID NO: 321, 364 й 407; (u) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 193, 236 і 279, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 322, 365 й 408; (v) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 194, 237 і 280, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 323, 366 й 409; (w) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 195, 238 і 281, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 324, 367 й 410; (x) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 196, 239 і 282, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 325, 368 й 411; (y) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 197, 240 і 283, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 326, 369 й 412; (z) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 198, 241 і 284, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 327, 370 й 413; (aa) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 199, 242 і 285, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 328, 371 й 414; (bb) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 200, 243 і 286, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 329, 372 й 415; (cc) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 201, 244 і 287, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 330, 373 й; 8 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 (dd) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 202, 245 і 288, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 331, 374 й 417; (ее) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 203, 246 і 289, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 332, 375 й 418; (ff) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 204, 247 і 290, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 333, 376 й 419; (gg) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 205, 248 і 291, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 334, 377 й 420; (hh) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 206, 249 і 292, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 335, 378 й 421; (ii) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 207, 250 і 293, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 336, 379 й 422; (jj) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 208, 251 і 294, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 337, 380 й 423; (kk) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 209, 252 і 295, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 338, 381 й 424; мклl) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 210, 253 і 296, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 339, 382 й 425; (mm) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 211, 254 і 297, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 340, 383 й 426; (nn) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 212, 255 і 298, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 341, 384 й 427; (oo) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність,яка включає SEQ ID NO: 213, 256 і 299, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 342, 385 й 428; (pp) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 214, 257 і 300, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 343, 386 й 429; (qq) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 215, 258 і 301, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 344, 387 й 430; або (rr) варіабельний регіон легкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 194, 237 і 280, та варіабельний регіон важкого ланцюга, що містить амінокислотну послідовність, яка включає SEQ ID NO: 335, 378 й 421. В іншому втіленні винахід відноситься до антитіл, що включають: (a) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 2, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 4; (b) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 6, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 8; (c) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 10, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 12; (d) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 14, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 16; 9 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 (e) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 18, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 20; (f) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 22, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 24; (g) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 26, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 28; (h) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 30, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 32; (i) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 34, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 36; (j) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 38, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 40; (k) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 42, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 44; мкл) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 46, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 48; (m) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 50, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 52; (n) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 54, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 56; (o) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 58, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 60; (p) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 62, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 64; (q) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 66, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 68; (r) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 70, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 72; (s) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 74, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 76; (t) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 78, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 80; (u) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 82, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 84; (v) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 86, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 88; (w) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 90, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 92; (x) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 94, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 96; 10 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 (y) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 98, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 100; (z) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 102, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 104; (aa) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 106, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 108; (bb) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 110, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 112; (cc) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 114, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 116; (dd) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 118, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 120; (ее) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 122, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 124; (ff) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 126, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 128; (gg) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 130, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 132; (hh) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 134, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 136; (ii) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 138, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 140; (jj) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 142, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 144; (kk) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 146, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 148; мклl) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 150, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 152; (mm) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 154, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 156; (nn) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 158, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 160; (oo) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 162, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 164; (pp) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 166, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 168; (qq) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 170, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 172; або (rr) варіабельний регіон легкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 86, та варіабельний регіон важкого ланцюга, що містить поліпептидну послідовність SEQ ID NO: 136. 11 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 Також винаходом забезпечується ізольоване моноклональне антитіло, що зв'язується з інгібітором шляху людського тканинного фактора, де антитіло включає варіабельний регіон людського важкого ланцюга, що містить амінокислотну послідовність, яка має принаймні 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 %, або 99,5 % ідентичності щодо амінокислотної послідовності, вибраної із групи, яка складається з амінокислотних послідовностей, описаних як: SEQ ID NO:4, SEQ ID NO:8, SEQ ID NO:12, SEQ ID NO:16, SEQ ID NO:20, SEQ ID NO:24, SEQ ID NO:28, SEQ ID NO:32, SEQ ID NO:36, SEQ ID NO:40, SEQ ID NO:44, SEQ ID NO:48, SEQ ID NO:52, SEQ ID NO:56, SEQ ID NO:60, SEQ ID NO:64, SEQ ID NO:68, SEQ ID NO:72, SEQ ID NO:76, SEQ ID NO:80, SEQ ID NO:84, SEQ ID NO:88, SEQ ID NO:92, SEQ ID NO:96, SEQ ID NO:100, SEQ ID NO:104, SEQ ID NO:108, SEQ ID NO:112, SEQ ID NO:116, SEQ ID NO:120, SEQ ID NO:124, SEQ ID NO:128, SEQ ID NO:132, SEQ ID NO:136, SEQ ID NO:140, SEQ ID NO:144, SEQ ID NO:148, SEQ ID NO:152, SEQ ID NO:156, SEQ ID NO:160, SEQ ID NO:164, SEQ ID NO:168 SEQ, і SEQ ID NO:172. Також винаходом забезпечується ізольоване моноклональне антитіло, що зв'язується з інгібітором шляху людського тканинного фактора, де антитіло включає варіабельний регіон людського легкого ланцюга, що містить амінокислотну послідовність, яка має принаймні 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 %, або 99,5 % ідентичності до амінокислотної послідовності, вибраної із групи, що складається з амінокислотних послідовностей, описаних як:SEQ ID NO:2, SEQ ID NO:6, SEQ ID NO:10, SEQ ID NO:14, SEQ ID NO:18, SEQ ID NO:22, SEQ ID NO:26, SEQ ID NO:30, SEQ ID NO:34, SEQ ID NO:38, SEQ ID NO:42, SEQ ID NO:46, SEQ ID NO:50, SEQ ID NO:54, SEQ ID NO:58, SEQ ID NO:62, SEQ ID NO:66, SEQ ID NO:70, SEQ ID NO:74, SEQ ID NO:78, SEQ ID NO:82, SEQ ID NO:86, SEQ ID NO:90, SEQ ID NO:94, SEQ ID NO:98, SEQ ID NO:102, SEQ ID NO:106, SEQ ID NO:110, SEQ ID NO:114, SEQ ID NO:118, SEQ ID NO:122, SEQ ID NO:126, SEQ ID NO:130, SEQ ID NO:134, SEQ ID NO:138, SEQ ID NO:142, SEQ ID NO:146, SEQ ID NO:150, SEQ ID NO:154, SEQ ID NO:158, SEQ ID NO:162, SEQ ID NO:166 SEQ, і SEQ ID NO:170. На додаток до опису антитіл з використанням ідентифікаторів послідовності, обговорених вище, деякі втілення можуть також бути описані з посиланням на Fab клони, ізольовані в експериментах, описаних тут. У деяких втіленнях рекомбінантні антитіла включають CDR3 важких та/або легких ланцюгів наступних клонів: TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8 або TP-4H8. У деяких втіленнях антитіла додатково можуть включати CDR2 цих антитіл і ще додатково включати CDR1 цих антитіл. В інших втіленнях антитіла можуть додатково включати будь-які комбінації CDR. Відповідно, в іншому втіленні забезпечуються анти-TFPI антитіла, що включають: (1) каркасний регіон людського важкого ланцюга, CDR1 регіон людського важкого ланцюга, CDR2 регіон людського важкого ланцюга, і CDR3 регіон людського важкого ланцюга, де регіон людського важкого ланцюга CDR3 є важким ланцюгом CDR3 TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP-2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP-3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP-4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8; і (2) каркасний регіон людського легкого ланцюга, CDR1 регіон людського легкого ланцюга, CDR2 регіон людського легкого ланцюга, і CDR3 регіон людського легкого ланцюга, де регіон людського легкого ланцюга CDR3 є легким ланцюгом CDR3 TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP-2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP-3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP-4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8, де антитіло зв'язує TFPI. Антитіло може додатково включати важкий ланцюг CDR2 та/або легкий ланцюг CDR2 TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8. Антитіло може додатково включати важкий ланцюг CDR1 та/або легкий ланцюг CDR1 TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP-2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP-3B4, 12 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP-4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8. CDR1, 2, та/або 3 регіони сконструйованих антитіл, описаних вище, можуть включати точну(і) амінокислотну(і) послідовність(і), як такі: TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8, описані тут. Однак, фахівець зрозуміє, що деяке відхилення від точних CDR послідовностей TP-2A2, TP2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP-2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP2D7, TP-2E3, TP-2E5, TP-2F9, TP-2G2, TP-2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP3A2, TP-3A3, TP-3A4, TP-3B3, TP-3B4, TP-3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP3F2, TP-3G1, TP-3G3, TP-3H2, TP-4A7, TP-4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8 може бути можливим при все ще збереженій здатності антитіла ефективно зв'язувати TFPI. Відповідно, в іншому втіленні сконструйоване антитіло може складатися з одного або кількох CDR, які є, наприклад, принаймні на 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % або 99,5 % ідентичними одному або більше CDR TP-2A2, TP-2A5,1, TP-2A6, TP-2A8, TP-2A10, TP-2B1, TP2B3, TP-2B4, TP-2B8, TP-2B9, TP-2C1, TP-2C7, TP-2D7, TP-2E3, TP-2E5, TP-2F9, TP-2G2, TP2G4, TP-2G5, TP-2G6, TP-2G7, TP-2G9, TP-2H10, TP-3A2, TP-3A3, TP-3A4, TP-3B3, TP-3B4, TP3C1, TP-3C2, TP-3C3, TP-3D3, TP-3E1, TP-3F1, TP-3F2, TP-3G1, TP-3G3, TP-3H2, TP-4A7, TP4A9, TP-4B7, TP-4E8, TP-4G8, або TP-4H8. Антитіло може бути будь яким з різних класів антитіл, таким як, але без обмеження, антитіло:IgG1, IgG2, IgG3, IgG4, IgM, IgA1, IgA2, секреторні IgА, IgD, і IgE антитіла. В одному з втілень забезпечується ізольоване повністю людське моноклональне антитіло щодо інгібітора шляху людського тканинного фактору. В іншому втіленні забезпечується ізольоване повністю людське моноклональне антитіло щодо домену 2 Kunitz інгібітора шляху людського тканинного фактору. Нуклеїнові кислоти Також забезпечуються виділені молекули нуклеїнової кислоти, що кодують кожне з моноклональних антитіл, описаних вище. Способи Одержання Антитіл до TFPI Моноклональне антитіло може бути одержано рекомбінантно, експресуючи нуклеотидну послідовність, що кодує варіабельні регіони моноклонального антитіла відповідно до втілень винаходу в клітині хазяїна. За допомогою вектора експресії нуклеїнова кислота, що включає нуклеотидну послідовність, може бути трансфекована і експресована у клітині хазяїна, придатній для продукування. Відповідно, також забезпечується спосіб продукування моноклонального антитіла, що зв'язується з людським TFPI, що включає: (a) трансфекцію молекули нуклеїнової кислоти, що кодує моноклональне антитіло винаходу в клітині хазяїна, (b) культивування клітини хазяїна для експресії моноклонального антитіла в клітині хазяїна, і довільно (c) виділення й очищення одержаного моноклонального антитіла, де молекула нуклеїнової кислоти включає нуклеотидну послідовність, що кодує моноклональне антитіло даного винаходу. В одному з прикладів, щоб експресувати антитіла або фрагменти антитіл, ДНК, що кодують часткову або повну довжину легких або важких ланцюгів, отримані стандартними способами молекулярної біології, вставляють у вектори експресії таким чином, що гени оперативно зв'язуються з транскрипційними і трансляційними контрольними послідовностями. У цьому контексті під терміном "оперативно зв'язаний" розуміють, що ген антитіла замикається у вектор таким чином, що транскрипційна і трансляційна контрольні послідовності в межах вектора служать їхній призначеній функції регулювання транскрипції й трансляції гена антитіла. Вектор експресії і контроль експресії послідовностей вибирають, щоб бути сумісними з використовуваною експресованою клітиною хазяїна. Ген легкого ланцюга антитіла й ген важкого ланцюга антитіла можуть бути вставлені в окремі вектори або, більш типово, обидва гени вставлені в той же самий вектор експресії. Гени антитіла вставляють у вектор експресії стандартними способами (наприклад, лігування комплементарних сайтів рестрикції на генному фрагменті антитіла та вектора, або лігування тупих кінців, якщо рестрикційні сайти відсутні). Варіабельні регіони легкого й важкого ланцюга антитіл, описаних тут, можуть використовуватися, щоб створити гени повнорозмірного антитіла будь-якого ізотипу антитіла, вставляючи їх у вектори експресії, що вже кодують костантні регіони важкого ланцюга й легкого 13 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 ланцюга бажаного ізотипу таким чином, що сегмент VH є оперативно зв'язаним із сегментом (ами) CH у межах вектора, і сегмент VL є оперативно зв'язаний із сегментом CL у межах вектора. Додатково або альтернативно, рекомбінантний вектор експресії може кодувати сигнальний пептид, що полегшує секрецію ланцюга антитіла з клітини хазяїна. Ген ланцюга антитіла може бути клонований у вектор таким чином, що сигнальний пептид зв'язаний у каркасі з амінотермінацією ланцюга гена антитіла. Сигнальний пептид може бути імуноглобуліновим сигнальним пептидом або гетерологічним сигнальним пептидом (тобто, сигнальним пептидом від не-імуноглобулінового білка). На додаток до генів кодування ланцюга антитіла, рекомбінантні вектори експресії винаходу несуть регуляторні послідовності, які контролюють експресію генів ланцюга антитіла в клітині хазяїні. Під терміном "регуляторна послідовність" розуміється, що він включає промотри, підсилювачі та інші елементи контролю експресії (наприклад, поліаденілаційні сигнали), які управляють транскрипцією або трансляцією генів ланцюга антитіла. Такі регулюючі послідовності описані, наприклад, в Goeddel; Gene Expression Technology. Methods in Enzymology 185, Academic Press, San Diego, Calif. (1990). Фахівцям буде зрозумілим, що проект вектора експресії, включаючи селекцію регуляторних послідовностей, може залежати від таких факторів, як вибір клітини хазяїна, що буде трансфекована, рівень експресії бажаного білка, і т.д. Приклади регуляторних послідовностей для експресії клітин хазяїна ссавця включають вірусні елементи, які дають високі рівні експресії білка в клітинах ссавця, такі як промотори та/або підсилювачі, одержані від: цитомегаловірусу (CMV), Simian Virus 40 (SV40), аденовірусу (наприклад, аденовірусний головний пізній промотер (AdMLP)) і поліома. Альтернативно, можуть використовуватися невірусні регуляторні послідовності, такі як убіквітиновий промотер або бета-глобіновий промотер. На додаток до генів ланцюга антитіл та регуляторних послідовностей, рекомбінантні вектори експресії можуть нести додаткові послідовності, такі як послідовності, які регулюють реплікацію вектора в клітинах хазяїна (наприклад, початок реплікації) і здатних до селекції маркерних генів. Здатні до селекції маркерні гени полегшують селекцію клітин хазяна, у які був уведений вектор (див., наприклад, Патенти США 4,399,216; 4,634,665 та 5,179,017, Axel та ін.). Наприклад, зазвичай здатний до селекції маркерний ген надає резистентності до медикаментів, таких як G418, гігроміцин або метотрексат у клітині хазяїна, у яку був уведений вектор. Приклади здатних до селекції маркерних генів включають ген дигідрофолатредуктази (DHFR) (для використання в dhfr-клітинах хазяїна з селекцією/збільшенням метотрексата) і нео ген (для селекції G418). Для експресії легких і важких ланцюгів, вектор(и) експресії, що кодує(ють) важкі й легкі ланцюги, трансфекують у клітину хазяїна стандартними способами. Різні форми терміна "трансфекція" призначені, щоб охопити широку розмаїтість способів, звичайно використовуваних для введення екзогенної ДНК у прокаріотичну або еукаріотичну клітину хазяїна, наприклад, електропорація, кальцій-фосфатна преципітація, DEAE-декстранова трансфекція й т.п. Хоча теоретично можливо експресувати антитіла винаходу в прокаріотичних або в еукаріотичних клітинах хазяїна, експресія антитіл в еукаріотичних клітинах, і найбільш переважно в клітинах хазяїна ссавця, є переважною, тому що такі еукаріотичні клітини, і зокрема, клітини ссавця, є більш прийнятними, ніж прокаріотичні клітини у відношенні збирання й властивостей секреції та імунологічної активності антитіла. Приклади клітин ссавця для експресування рекомбінантних антитіло включають клітини яєчника хом'яка (клітини CHO) (включаючи dhfr-клітини CHO, описані в Urlaub і Chasin, (1980) Proc. Natl. Acad. Sci. США 77:4216-4220, використовувані із маркером селекції DHFR, наприклад, як описано в R. J. Kaufman й P. A. Sharp (1982) Mol. Biol. 159:601-621), клітини мієломи NSO, COS клітини, клітини HKB11 і клітини SP2. Коли рекомбінантні вектори експресії, що кодують гени антитіл вводять у клітини хазяїна ссавця, антитіла, одержані культивуванням клітин хазяїна протягом достатнього періоду часу, дозволяють експресувати антитіла в клітинах хазяїна або секретувати антитіла в культуральному середовищі, у якому вирощені клітини хазяїна. Антитіла можуть бути виділені з культурального середовища, використовуючи стандартні способи очищення білка, такі як ультрафільтрація, ексклюзійна хроматографія, іонно-обмінна хроматографія й центрифугування. Використання часткових послідовностей антитіл для експресії інтактних антитіл Антитіла взаємодіють із антигенами-мішенями переважно через амінокислотні залишки, які розташовані в шести CDR важкого й легкого ланцюга. Тому, амінокислотні послідовності в межах CDR більш різноманітні між індивідуальними антитілами, ніж послідовності за межами CDR. Див., наприклад, Фіг. 6 й 7, у яких CDR регіони ідентифіковані в легких і важких варіабельних ланцюгах моноклонального антитіла відповідно до даного винаходу. Оскільки 14 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 послідовності CDR відповідальні за більшість взаємодій антиген-антитіло, можливо експресувати рекомбінантні антитіла, які наслідують властивості специфічних природних антитіл, конструюючи вектори експресії, які включають послідовності CDR від специфічного природного антитіла, пересадженого на каркас послідовності від різних антитіл з різними властивостями (див., наприклад, Riechmann, L. та ін., 1998, Nature 332:323-327; Jones, P. та ін., 1986, Nature 321:522-525; and Queen, C. та ін., 1989, Proc. Natl. Acad. Sci. U.S.A. 86:1002910033). Такі каркасні послідовності можуть бути отримані із суспільних баз даних ДНК, які включають зародкові послідовності гену антитіла. Ці зародкові послідовності будуть відрізнятися від зрілих послідовностей гену антитіла, тому що вони не будуть включати повністю зібрані варіабельні гени, які утворені V (D) J, що приєднуються під час дозрівання Bклітини. Немає необхідності отримувати всю ДНК-послідовність специфічного антитіла, щоб відновити інтактне рекомбінантне антитіло, що має зв'язувальні властивості, подібні до властивостей оригінального антитіла (див. WO 99/45962). Для цієї мети зазвичай достатньою є часткова послідовність важкого й легкого ланцюга, що охоплює регіони CDR. Часткова послідовність використовується, щоб визначити які зародкові варіабельні й з'єднувальні сегменти гена внесені до варіабельних генів рекомбінантних антитіл. Зародкова послідовність потім використовується, щоб заповнити відсутні частини варіабельних регіонів. Лідерні послідовності важкого й легкого ланцюга розколюються під час дозрівання білка й не сприяють властивостям заключного антитіла. З цією метою необхідно використовувати відповідну зародкову лідерну послідовність для експресії конструкту. Щоб додати відсутні послідовності, клоновані кДНК послідовності можуть бути об'єднані із синтетичними олігонуклеотидами лігуванням або ампліфікацією PCR. Альтернативно, повний варіабельний регіон може бути синтезований як ряд коротких перекриваючих олігонуклеотидів та об'єднаний ампліфікацією PCR, щоб створити повністю синтетичний варіабельний клон регіону. У цього процесу є певні переваги, такі як виключення або включення, або специфічна рестрикція сайтів, або оптимізація специфічних кодонів. Нуклеотидні послідовності транскриптів важкого й легкого ланцюга використовуються для того, щоб проектувати набір перекривання синтетичних олігонуклеотидів, щоб створити синтетичні V послідовності з ідентичною здатністю кодування амінокислотою як і в природних послідовностях. Синтетичні послідовності важкого й каппа ланцюга можуть відрізнятися від природних послідовностей трьома способами: ланцюг повторюваних нуклеотидних основ переривається, щоб полегшити синтез олігонуклеотида й ампліфікацію PCR; оптимальні сайти ініціювання трансляції включають відповідно до правил Kozak's (Kozak, 1991, J. Biol. Chem. 266:19867-19870); і сайти HindIII конструюють вище сайтів ініціювання трансляції. Для варіабельних регіонів як важкого, так і для легкого ланцюга, оптимізованого кодування і відповідного некодування, послідовності ланцюга розламували на 30-50 нуклеотидних частин приблизно в середині відповідного некодованого олігонуклеотиду. Таким чином, для кожного ланцюга, олігонуклеотиди можуть бути зібрані в перекриваючі подвійні ланцюгові набори, які охоплюють сегменти з 150-400 нуклеотидів. Об'єднання потім використовують як матриці, щоб одержати продукти ампліфікації PCR 150-400 нуклеотидів. Як правило, єдиний варіабельний регіон олігонуклеотидного набору буде розламаний на два пули, які окремо ампліфікують з утворенням двох перекриваючих продуктів PCR. Ці продукти перекривання потім об'єднують ампліфікацією PCR, щоб утворити повний варіабельний регіон. Може також бути бажаним включати перекриваючий фрагмент константного регіону важкого або легкого ланцюга в ампліфікацію PCR, щоб генерувати фрагменти, які можуть легко бути клоновані в конструкти вектора експресії. Варіабельні регіони відновленого важкого й легкого ланцюга потім об'єднували із клонованим промотором, ініціатором трансляції, константним регіоном, 3' нетрансльованою, поліаденілованою і завершеною транскрипційною послідовністями, щоб утворити конструкти вектора експресії. Конструкти експресії важкого й легкого ланцюга можуть бути об'єднані в єдиний вектор, ко-трансфековані, послідовно трансфековані або окремо трансфековані у клітинах хазяїна, які потім сплавляли, щоб утворити клітину хазяїна, що експресує обидва ланцюги. Таким чином, в іншому аспекті, використовуються структурні особливості людського антиTFPI антитіла, наприклад, TP2A8, TP2G6, TP2G7, TP4B7, і т.д., щоб створити структурно пов'язані людські анти-TFPI антитіла, які зберігають функцію зв'язування з TFPI. Більш конкретно, один або кілька CDR специфічно ідентифікованих регіонів важкого й легкого ланцюга моноклональних антитіл винаходу можуть бути об'єднані рекомбінантно з відомими людськими каркасними регіонами та CDR, щоб створити додаткові, рекомбінантно-сконструйовані людські анти-TFPI антитіла винаходу. 15 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 Відповідно, в іншому втіленні забезпечується спосіб одержання анти-TFPI антитіла, що включає: одержання антитіла, яке містить (1) каркасний регіон людського важкого ланцюга та CDR людського важкого ланцюга, де CDR3 людського важкого ланцюга включають амінокислотну послідовність, вибрану з амінокислотних послідовностей SEQ ID NO: 388-430 та/або (2) каркасний регіон людського легкого ланцюга й CDR людського легкоголанцюга, де CDR3 легкого ланцюга містить амінокислотну послідовність, вибрану з амінокислотних послідовностей SEQ ID NO: 259-301; де антитіло зберігає здатність зв'язуватися з TFPI. В інших втіленнях спосіб здійснюють, використовуючи інші CDR винаходу. Фармацевтичні Композиції Винахід також охоплює фармацевтичні композиції, що включають терапевтично ефективну кількість анти-TFPI моноклонального антитіла й фармацевтично прийнятний носій. "Фармацевтично прийнятний носій" є речовиною, що може додаватися до активного компонента, щоб допомогти утворити або стабілізувати препарат, й не спричиняє істотних несприятливих токсикологічних ефектів пацієнтові. Приклади таких носіїв відомі фахівцям у даній галузі і включають воду, цукор, такий як мальтоза або сахароза, альбумін, солі, такі як хлорид натрію, і т.д. Інші носії описані наприклад у Remington's Pharmaceutical Sciences by E. W. Martin. Такі композиції будуть містити терапевтично ефективну кількість принаймні одного антиTFPI моноклонального антитіла. Фармацевтично прийнятні носії включають стерильні водні розчини або дисперсії та стерильні порошки для екстемпорального виготовлення стерильних ін'єкційних розчинів або дисперсій. Використання такого середовища й агентів для фармацевтично активних речовин відомо в даній галузі. Композиція переважно утворена для парентерального введення. Композиція може бути утворена як розчин, мікроемульсія, ліпосома або як інша форма, що прийнятна для високої концентрації лікарської речовини. Носій може бути розчинником або дисперсійним середовищем, що містить, наприклад, воду, етанол, поліол (наприклад, гліцерин, пропіленгліколь і рідкий поліетиленгліколь, і т.п.), та їх прийнятні суміші. У деяких випадках у композицію будуть включені ізотонічні агенти, наприклад, цукри, поліалкоголі, такі як маніт, сорбіт або хлорид натрію. Стерильні водні розчини можуть бути одержані шляхом введення активної сполуки у необхідній кількості у відповідний розчинник з одним або комбінацією компонентів, перерахованих вище, при необхідності з наступною стерилізацією мікрофільтрацією. Взагалі, дисперсію одержують, включаючи активну сполуку у стерильний носій, що містить основне дисперсійне середовище та необхідні інші компоненти, перераховані вище. У випадку стерильних порошків для одержання стерильних ін'єкційних розчинів деякими способами одержання є вакуумна сушка й сублімаційна сушка (ліофілізація), якими отримують порошок активного компонента плюс будь-який додатковий бажаний компонент із раніше стерильно фільтрованого розчину. Фармацевтичне застосування Моноклональне антитіло може використовуватися в терапевтичних цілях для лікування генетичних і набутих дефіцитів або дефектів коагуляції. Наприклад, моноклональні антитіла у втіленнях, описаних вище, можуть використовуватися, щоб блокувати взаємодію TFPI з FXa, або запобігти TFPI-залежному інгібуванню активності TF/FVIIa. Додатково моноклональне антитіло також може використовуватися для відновлення TF/FVIIa-стимульованої генерації FXa, щоб обійти недолік FVIII- або FIX-залежної ампліфікації FXa. Моноклональні антитіла використовуються для лікування розладів гемостазу, таких як тромбоцитопенія, тромбоцитарні розлади і геморагії (наприклад, гемофілія A і гемофілія B). Такі розлади лікують, призначаючи терапевтично ефективну кількість анти-TFPI моноклонального антитіла пацієнтові, який потребує цього. Моноклональні антитіла також застосовують у лікуванні неконтрольованої геморагії, такої як травма та геморагічний інсульт. Таким чином, також забезпечується спосіб скорочення часу кровотечі, що включає призначення терапевтично ефективної кількості анти-TFPI моноклонального антитіла винаходу пацієнтові, який потребує цього. Антитіла можуть використовуватися як монотерапія або в комбінації з іншими способами лікування гемостатичних розладів. Наприклад, сумісне призначення одного або більше антитіл винаходу з фактором коагуляція крові, таким як фактор VIIa, фактор VIII або фактор IX, є корисним для лікування гемофілії. В одному з втілень забезпечується спосіб лікування генетичних і набутих дефіцитів або дефектів коагуляції, що включає введення (a) першої кількості моноклонального антитіла, що зв'язується з інгібітором шляху людського тканинного фактора та (b) другої кількості фактора VIII або фактора IX, де згадувана перша і друга кількості разом є ефективними для лікування згадуваних дефіцитів або дефектів. В іншому втіленні 16 UA 112050 C2 5 10 15 20 25 30 35 40 45 50 55 60 забезпечується спосіб лікування генетичних і набутихдефіцитів або дефектів коагуляції, що включає введення (a) першої кількості моноклонального антитіла, що зв'язується з інгібітором шляху людського тканинного фактора та (b) другої кількості фактора VIII або фактора IX, де згадувана перша і друга кількості разом є ефективними для лікування згадуваних дефіцитів або дефектів, і додатково фактор VII не призначають. Винахід також включає фармацевтичну композицію, яка містить терапевтично ефективну кількість комбінації моноклонального антитіла винаходу та фактора VIII або фактора IX, де композиція не містить фактор VII. "Фактор VII" включає фактор VII і фактор VIIa. Ці комбіновані терапії, ймовірно, зменшать необхідну частоту інфузії фактора коагуляція крові. Сумісне введення або комбінована терапія означає введення двох терапевтичних препаратів, кожен з яких утворений окремо або утворений разом в одній композиції і, коли утворений окремо, вводиться або в приблизно той же самий час, або в різний час, але за той же самий терапевтичний період. Фармацевтичні композиції можуть вводитися парентерально суб'єктам, які страждають від гемофілії A або B у дозуванні та частоті, що може мінятися залежно від серйозності геморагічнного епізоду або, у випадку профілактичної терапії, може мінятися залежно від серйозності дефіциту коагуляції у пацієнта. Композиції можуть вводитися пацієнтам при необхідності як болюсна або безперервна інфузія. Наприклад, введення болюсу антитіла винаходу, представленого як Fab фрагмент, може бути в кількості від 0,0025 до 100 мг/кг ваги тіла, 0,025-0,25 мг/кг, 0,010-0,10 мг/кг або 0,100,50 мг/кг. Для безперервної інфузії антитіла винаходу, представленого як Fab фрагмент, можна вводити 0,001-100 мг/кг/хв, 0,0125 – 1,25 мг/кг/хв, 0,010-0,75 мг/кг/хв, 0,010 – 1,0 мг/кг/хв. або 0,10-0,50 мг/кг/хв протягом 1-24 годин, 1-12 годин, 2-12 годин, 6-12 годин, 2-8 годин, або 1-2 години. Для введення антитіла винаходу, представленого як повнорозмірне антитіло (з повними константними регыонами), кількість дозування може становити приблизно 1-10 мг/кг, 2-8 мг/кг або 5-6 мг/кг. Такі повнорозмірні антитіла повинні зазвичай вводитися інфузією, тривалістю від тридцяти хвилин до трьох годин. Частота призначення може залежати від серйозності стану. Частота може коливатися від трьох разів у тиждень до одного разу кожні два або три тижні. Додатково, композицію можна вводити пацієнтам підшкірною ін'єкцією. Наприклад, 10-100 мг анти-TFPI антитіла можна вводити пацієнтам підшкірною ін'єкцією щотижня, кожні два тижні або щомісяця. Як використовується тут, "терапевтично-ефективна кількість" означає кількість анти-TFPI моноклонального антитіла або комбінації такого антитіла та фактора VIII або фактора IX, які є необхідними, щоб ефективно збільшити час коагуляції in vivo або інакше викликати in vivo переваги пацієнтові, який потребує цього. Точна кількість буде залежати від численних факторів, включаючи, але не обмежуючись ними, компоненти та фізичні особливості терапевтичної композиції, намічену популяції пацієнтів, індивідуальні особливості пацієнтів, і т.п., і може бути визначена фахівцем у даній галузі. Приклади Загальні матеріали та способи Приклад 1. Пенінг і скринінг бібліотеки людських антитіл проти людського TFPI Пенінг бібліотеки людських антитіл проти TFPI Анти-TFPI антитіла були вибрані пенінгом фагів, що демонстрували комбінаторні бібліотеки людських антитіл HuCal Gold(Rothe та ін., J. Mol. Biol., 2008, 376: 1182-1200) проти людського TFPI (American Diagnostica). Коротко, 200 мкл TFPI (5 мкл/мл) поміщали в 96-лункові планшети Maxisorp на ніч при 4 °C, і планшети блокували з буфером PBS, що містив 5 % молока. Після промивання планшетів з PBS, що містив 0,01 % Tween-20 (PBST), певну кількість комбінаторної бібліотеки людських антитіл додавали до TFPI-вкритих лунок і культивували протягом 2 годин. Незв'язаний фаг промивали з PBST, і антиген-зв'язаний фаг елюювали з дитіотреітолом, ініфікували і ампліфікували в E. coli, штам TG1. Фаг був урятований фагом-хелпером для наступного циклу пенінгу. У цілому проводилося три цикли пенінгу, і клони від останніх двох циклів піддавали скринінгу проти людського TFPI у дослідженні ELISA. Скринінг клонів антитіла зв'язуванням антигену в ELISA Щоб відібрати клони антитіла, які зв'язуються із людським TFPI, Fab гени клонів фага від другого й третього циклів пенінгу субклонували в бактеріальний вектор експресії та експресували в E. coli, штам TG1. До лунок людських TFPI-покритих Maxisorp планшетів додавали бактеріальний лізат. Після промивання HRP-кон'юговані козячі анти-людські FAb використовували як антитіла виявлення, і планшети розвивали, додаючи AmplexRed (Invitrogen) з перекисом водню. Сигнал принаймні вп'ятеро вищий, ніж попередній, розглядали як позитивний. Перехресна реактивність антилюдських антитіл TFPI щодо мишачих TFPI була визначена подібно мишачим TFPI-зв'язуючим ELISA. Планшети покривали мишачими TFPI 17 UA 112050 C2 5 (R&D System), BSA і лізозимом. Пізніше два антигени використовували як негативний контроль. Представлений набір даних показаний на Фіг. 1. Послідовності анти-TFPI людських антитіл Після пенінгу та скринінгу HuCal Gold бібліотеки людських антитіл проти TFPI, виконували секвенування ДНК на позитивних клонах антитіла, що приводять до 44 унікальних послідовностей антитіла (Таблиця 2). Серед цих послідовностей антитіла, 29 були лямбдалегкими ланцюгами, і 15 були каппа-легкими ланцюгами Наш аналіз варіабельного регіону важких ланцюгів показує 28-VH3, 14-VH6, 1-VH1 й 1-VH5. Таблиця 2 Пептидна послідовність варіабельного регіону 44 анти-TFPI антитіл Клон TP-2A2 TP-2A5,1 TP-2A6 TP-2A8 TP-2A10 TP-2B1 TP-2B3 VL DIELTQPPSVSVAPGQTARISCSGDNI RTYYVHWYQQKPGQAPVV VIYGDSKRPSGIPER FSGSNSGNTATLTISGTQAEDEA DYYCQSYDSEADSEVFGG GTKLTVLGQ (SEQ ID NO: 2) DIELTQPPSVSVAPGQTARISCSG DNIPEKYVHWYQQKPGQA PVLVIHGDNNRPSGIPERFS GSNSGNTATLTISGTQAEDEADY YCQSFDAGSYFVFGGGTKLTVLGQ (SEQ ID NO: 6) DIELTQPPSVSVAPGQTARISCS GDKIGSKYVYWYQQKPGQAP VLVIYDSNRPSGIPERF SGSNSGNTATLTISGTQAEDEAD YYCASYDSIYSYWVFG GGTKLTVLGQ (SEQ ID NO: 10) DIELTQPPSVSVAPGQTARISCSG DNLRNYYAHWYQQKPGQA PVVVIYYDNNRPSGIPER FSGSNSGNTATLTISGTQAEDEADYY CQSWDDGVPVFGGGTKLTVLGQ (SEQ ID NO: 14) DIELTQPPSVSVAPGQTARISCSGDK LGKKYVHWYQQKPGQAPV LVIYGDDKRPSGIPER FSGSNSGNTATLTISGTQAEDEADYY CQAWGSISRFVFGGGTKLTVLGQ (SEQ ID NO: 18) DIELTQPPSVSVAPGQTARISCSGD NLGNKYAHWYQQKPGQAPVL VIYYDNKRPSGIPERF SGSNSGNTATLTISGTQAEDEADY YCQSWTPGSNTMVFGGGTRLTVLGQ (SEQ ID NO: 22) DIVLTQSPATLSLSPGERATL SCRASQNIGSNYLAWYQQKPG QAPRLLIYGASTRATGVPAR FNGSGSGTDFTLTISSLEPED FAVYYCQQLNSIPVTFGQGTKVEIKRT (SEQ ID NO: 26) 10 18 VH QVQLVESGGGLVQPGGSLRLSC AASGFTFSNNAMNWVRQAPGKGL EWVSTISYDGSNTYYADSVKGRFTI SRDNSKNTLYLQMNSLRAEDTAVY YCARQAGGWTYSYTDVWGQGTL VTVSS (SEQ ID NO: 4) QVQLVESGGGLVQPGGSLRLSC AASGFTFSSYGSWVRQAPGKGLE WVSVISGSGSSTYYADSVKGRFTIS RDNSKNTLYLQMNSLRAEDTAVYY CARVNISTHFDVWGQGTLVTVSS (SEQ ID NO: 8) QVQLVESGGGLVQPGGSLRLSCA ASGFTFSRYAMSWVRQAPGKGLE WVSSIISSSSETYYADSVKGRFTIS RDNSKNTLYLQMNSLRAEDTAVYY CARLMGYGHYYPFDYWGQ GTLVTVSS (SEQ ID NO: 12) QVQLVESGGGLVQPGGSLRLSCA ASGFTFRSYGMSWVRQAPG KGLEWVSSIRGSSSSTYYADS VKGRFTISRDNSKNTLYLQM NSLRAEDTAVYYCARKYRYW FDYWGQGTLVTVSS (SEQ ID NO: 16) QVQLVESGGGLVQPGGSLRLSCA ASGFTFTSYSMNWVRQAPGKGLE WVSAISYTGSNTHYADSVKGRFTI SRDNSKNTLYLQMNSLRAEDTAVY YCARAFLGYKESYFDIWGQGTLVTVSS (SEQ ID NO: 20) QVQLVESGGGLVQPGGSLRLSCA ASGFTFSSYSMSWVRQASGKGLE WVSSIKGSGSNTYYADSVKGRFTIS RDNSKNTLYLQMNSLRAEDTAVYYC ARNGGLIDVWGQGTLVTVSS (SEQ ID NO: 24) QVQLQQSGPGLVKPSQTLSLTCAIS GDSVSSNSAAWGWIRQSPGRGLE WLGMIYYRSKWYNSYAVSVKSRITI NPDTSKNQFSLQLNSVTPEDTAVYY CARTMSKYGGPGMDVWGQGTLVTVSS (SEQ ID NO: 28) UA 112050 C2 TP-2B4 TP-2B8 TP-2B9 TP-2C1 TP-2C7 TP-2D7 TP-2E3 TP-2E5 TP-2F9 DIELTQPPSVSVAPGQTARISCS GDALGTYYAYWYQQKPGQAPV LVIYGDMNRPSGIPER FSGSNSGNTATLTISGTQAEDE ADYYCQSYDAGVKPAVFGGGTKL TVLGQ (SEQ ID NO: 30) DIELTQPPSVSVAPGQTARISCSG DNLRGYYASWYQQKPGQAPV LVIYEDNNRPSGIPERFS GSNSGNTATLTISGTQAEDEAD YYCQSWDSPYVHVFGG GTKLTVLGQ (SEQ ID NO: 34) DIQMTQSPSSLSASVGDRVT ITCRASQSIRSYLAWYQQKP GKAPKLLIYKASNLQSGVPSRF SGSGSGTDFTLTISSLQPED FAVYYCHQYSDSPVTFGQG TKVEIKRT (SEQ ID NO: 38) DIELTQPPSVSVAPGQTARIS CSGDSIGSYYAHWYQQKPG QAPVLVIYYDSKRPSGIPERFS GSNSGNTATLTISGTQAEDE ADYYCQAYTGQSISRVFG GGTKLTVLGQ (SEQ ID NO: 42) DIQMTQSPSSLSASVGDRV TITCRASQDIRNNLAWYQQ KPGKAPKLLIYAASSLQSGVPSR FSGSGSGTDFTLTISSLQPE DFAVYYCQQRNGFPLTF GQGTKVEIKRT (SEQ ID NO: 46) DIVMTQSPLSLPVTPGEPAS ISCRSSQSLLHSNGYTYLS WYLQKPGQSPQLLIYLGSNRA SGVPDRFSGSGSGTDFTL KISRVEAEDVGVYYCQQYD NAPITFGQGTKVEIKRT (SEQ ID NO: 50) DIALTQPASVSGSPGQSITIS CTGTSSDIGGYNYVSWYQQHPGKAP KLMIYGVNYRPSGVSNRFSGSKSG NTASLTISGLQAEDEADYYCSS ADKFTMSIVFGGGTKLTVLGQ (SEQ ID NO: 54) DIQMTQSPSSLSASVGDR VTITCRASQPIYNSLSWYQ QKPGKAPKLLIYGVSNLQSGVPS RFSGSGSGTDFTLTISSLQ PEDFAVYYCLQVDNLPITF GQGTKVEIKRT (SEQ ID NO: 58) DIVLTQSPATLSLSPGERA TLSCRASQSVSSQYLAWY QQKPGQAPRLLIYAASSRATGV PARFSGSGSGTDFTLTISSL EPEDFAVYYCQQDSNLPAT FGQGTKVEIKRT (SEQ ID NO: 62) 19 QVQLVESGGGLVQPGGSLRLSCA ASGFTFSNYSMTWVRQAPGKGLEWV SGISYNGSNTYYADSVKGRFTISRDNSKN TLYLQMNSLRAEDTAVYYCARIYYMNLLA GWGQGTLVTVSS (SEQ ID NO: 32) QVQLVQSGAEVKKPGASVKVSCKASG YTFTGNSMHWVRQAPGQGLEWMGTIF PYDGTTKYAQKFQGRVTMTRDTSISTA YMELSSLRSEDTAVYYCARGVHSYFDY WGQGTLVTVSS (SEQ ID NO: 36) QVQLQQSGPGLVKPSQTLSLTCAISG DSVSSNSAAWGWIRQSPGRGLEWLG MIYHRSKWYNDYAVSVKSRITINPDTSK NQFSLQLNSVTPEDTAVYYCARYSSIGH MDYWGQGTLVTVSS (SEQ ID NO: 40) QVQLVESGGGLVQPGGSLRLSCAASG FTFSPYVMSWVRQAPGKGLEWVSSISS SSSNTYYADSVKGRFTISRDNSKNTLYLQ MNSLRAEDTAVYYCARGDSYMYD VWGQGTLVTVSS (SEQ ID NO: 44) QVQLQQSGPGLVKPSQTLSLTCAISGD SVSSNSAAWGWIRQSPGRGLEWLGII YYRSKWYNHYAVSVKSRITINPDTSKN QFSLQLNSVTPEDTAVYYCARSNWSG YFDYWGQGTLVTVSS (SEQ ID NO: 48) QVQLQQSGPGLVKPSQTLSLTCAISGD SVSSNSAAWGWIRQSPGRGLEWLGLI YYRSKWYNDYAVSVKSRITINPDTSKNQ FSLQLNSVTPEDTAVYYCARFGDTNRN GTDVWGQGTLVTVSS (SEQ ID NO: 52) QVQLQQSGPGLVKPSQTLSLTCAISGD SVSSNSAAWGWIRQSPGRGLEWLGMI YYRSKWYNDYAVSVKSRITINPDTSKNQ FSLQLNSVTPEDTAVYYCARVNQYTSSD YWGQGTLVTVSS (SEQ ID NO: 56) QVQLQQSGPGLVKPSQTLSLTCAISG DSVSSNSAAWSWIRQSPGRGLEWLG MIFYRSKWNNDYAVSVKSRITINPDTSKNQ FSLQLNSVTPEDTAVYYCARVNANGYY AYVDLWGQGTLVTVSS (SEQ ID NO: 60) QVQLVESGGGLVQPGGSLRLSCAASG FTFYKYAMHWVRQAPGKGLEWVSGIQ YDGSYTYYADSVKGRFTISRDNSKNTL YLQMNSLRAEDTAVYYCARYYCKCVD LWGQGTLVTVSS (SEQ ID NO: 64) UA 112050 C2 TP-2G2 TP-2G4 TP-2G5 TP-2G6 TP-2G7 TP-2G9 TP-2H10 TP-3A2 TP-3A3 DIELTQPPSVSVAPGQTARIS CSGDNIRKFYVHWYQQKPG QAPVLVIYGTNKRPSGIPERF SGSNSGNTATLTISGTQAED EADYYCQSYDSKFNTVFGGG TKLTVLGQ (SEQ ID NO: 66) DIELTQPPSVSVAPGQTARIS CSGDALRKHYVYWYQQKPGQ APVLVIYGDNNRPSGIPE RFSGSNSGNTATLTISGTQAED EADYYCQSYDKPYPILVFGG GTKLTVLGQ (SEQ ID NO: 70) DIVLTQSPATLSLSPGERATL SCRASQNVSSNYLAWYQQK PGQAPRLLIYDASNRATGVPA RFSGSGSGTDFTLTISSLEPE DFAVYYCQQFYDSPQTFG QGTKVEIKRT (SEQ ID NO: 74) DIVLTQSPATLSLSPGERATL SCRASQYVTSSYLAWYQQK PGQAPRLLIYGSSRATGVPAR FSGSGSGTDFTLTISSLEPED FATYYCQQYSSSPITFGQG TKVEIKRT (SEQ ID NO: 78) DIELTQPPSVSVAPGQTARIS CSGDNLGTYYVHWYQQKPG QAPVLVIYGDNNRPSGIPER FSGSNSGNTATLTISGTQAED EADYYCQTYDSNNESIVFGG GTKLTVLGQ (SEQ ID NO: 82) DIALTQPASVSGSPGQSITI SCTGTSSDLGGFNTVSWY QQHPGKAPKLMIYSVSSRPSGV SNRFSGSKSGNTASLTISGLQ AEDEADYYCQSYDLNNLVFG GGTKLTVLGQ (SEQ ID NO: 86) DIVLTQSPATLSLSPGERATL SCRASQSVSSFYLAWYQQK PGQAPRLLIYGSSSRATGVPA RFSGSGSGTDFTLTISSLEPE DFATYYCQQYDSTPSTFGQ GTKVEIKRT (SEQ ID NO: 90) DIELTQPPSVSVAPGQTARISCSGDN IGSRYAYWYQQKPGQAPV VVIYDDSDRPSGIPERF SGSNSGNTATLTISGTQAE DEADYYCAAYTFYARTV FGGGTKLTVLGQ (SEQ ID NO: 94) DIELTQPPSVSVAPGQTAR ISCSGDNIGSKYVHWYQ QKPGQAPVVVIYEDSDRP SGIPERFSGSNSGNTATLTISGTQAE DEADYYCQSWDKSEG YVFGGGTKLTVLGQ (SEQ ID NO: 98) 20 QVQLVESGGGLVQPGGSLRLSCAAS GFTFSSYAMNWVRQAPGKGLEWVS AILSDGSSTSYADSVKGRFTISRDNS KNTLYLQMNSLRAEDTAVYYCARYP DWGWYTDVWGQGTLVTVSS (SEQ ID NO: 68) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSSYAMTWVRQAPGKGLEWV SNISYSGSNTYYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARV GYYYGFDYWGQGTLVTVSS (SEQ ID NO: 72) QVQLQQSGPGLVKPSQTLSLTCAI SGDSVSSNSAAWSWIRQSPGRGL EWLGFIYYRSKWYNDYAVSVKSRITI NPDTSKNQFSLQLNSVTPEDTAVYY CARHNPDLGFDYWGQGTLVTVSS (SEQ ID NO: 76) QVQLQQSGPGLVKPSQTLSLTCAI SGDSVSSSSAAWSWIRQSPGRGLE WLGIIYYRSKWYNDYAVSVKSRITIN PDTSKNQFSLQLNSVTPEDTAVYYC ARHSMVGFDVWGQGTLVTVSS (SEQ ID NO: 80) QVQLVESGGGLVQPGGSLRLSCAA SGFTFNSYAMSWVRQAPGKGLEWV SNISSNSSNTYYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARK GGGEHGFFPSDIWGQGTLVTVSS (SEQ ID NO: 84) QVQLVESGGGLVQPGGSLRLSCAA SGFTFNSYAMTWVRQAPGKGLEWV SAIKSDGSNTYYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARN DSGWFDVWGQGTLVTVSS (SEQ ID NO: 88) QVQLQQSGPGLVKPSQTLSLTCAIS GDSVSSNGAAWGWIRQSPGRGLE WLGFIYRRSKWYNSYAVSVKSRITI NPDTSKNQFSLQLNSVTPEDTAVYY CARQDGMGGMDSWGQGTLVTVSS (SEQ ID NO: 92) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSNYYLSWVRQAPGKGLEWV SGISYNGSSTNYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARM WRYSLGADSWGQGTLVTVSS (SEQ ID NO: 96) QVQLVESGGGLVQPGGSLRLSCA ASGFTFNNNAISWVRQAPGKGLEWV SAINSSSSSTSYADSVKGRFTISRDNSK NTLYLQMNSLRAEDTAVYYCARGHHRG HSWASFIDYWGQGTLVTVSS (SEQ ID NO: 100) UA 112050 C2 TP-3A4 TP-3B3 TP-3B4 TP-3C1 TP-3C2 TP-3C3 TP-3D3 TP-3E1 TP-3F1 DIELTQPPSVSVAPGQTARISC SGDNLRDKYASW YQQKPGQAPVLVIYSKSER PSGIPERFSGSNSGNTATLT ISGTQAEDEADYYCSSYTLNP NLNYVFGGGTKLTVLGQ (SEQ ID NO: 102) DIELTQPASVSVAPGQTARI SCSGDNLRSKYAHW YQQKPGQAPVLVIYGDNN RPSGIPERFSGSNSGNTATL TISGTQAEDEADYYCSAYAMGS SPVFGGGTKLTVLGQ (SEQ ID NO: 106) DIQMTQSPSSLSASVGDR VTITCRASQNISNYLNWYQQKP GKAPKLLIYGTSSLQSGVPSR FSGSGSGTDFTLTISSLQ PEDFAVYYCQQYGNN PTTFGQGTKVEIKRT (SEQ ID NO: 110) DIALTQPASVSGSPGQ SITISCTGTSSDLGGFNT VSWYQQHPGKAPKLMI YSVSSRPSGVSNRFSGS KSGNTASLTISGLQAEDEADYYCQS YDLNNLVFGGGTKL TVLGQ (SEQ ID NO: 86) DIQMTQSPSSLSASVGD RVTITCRASQSITNYLN WYQQKPGKAPKLLIYD VSNLQSGVPSRFSGSGS GTDFTLTISSLQPEDFAVYYCQQYSG YPLTFGQGTKVEIKRT (SEQ ID NO: 114) DIQMTQSPSSLSASV GDRVTITCRASQSINPYLNW YQQKPGKAPKLLIYAASNLQSGVP SRFSGSGSGTDFTLTI SSLQPEDFAVYYCQQLDN RSITFGQGTKVEIKRT (SEQ ID NO: 118) DIELTQPPSVSVAPGQT ARISCSGDSLGSKFAHWY QQKPGQAPVLVIYDDS NRPSGIPERFSGSNSGNTATLTI SGTQAEDEADYYCSTYTSR SHSYVFGGGTKLTVLGQ (SEQ ID NO: 122) DIELTQPPSVSVAPGQTARI SCSGDNIGSYYAYWY QQKPGQAPVLVIYDDSNRPSGIP ERFSGSNSGNTATLTISG TQAEDEADYYCQSYDST GLLVFGGGTKLTVLGQ (SEQ ID NO: 126) DIELTQPPSVSVAPGQTARI SCSGDNIGSYFASWYQ QKPGQAPVLVIYDDSNRPSGIP ERFSGSNSGNTATLTISGT QAEDEADYYCEGSNVF GGGTKLTVLGQ (SEQ ID NO: 130) 21 QVQLVESGGGLVQPGGSLRLSCAASG FTFSSYWMHWVRQAPGKGLEWVSSIS YDSSNTYYADSVKGRFTISRDNSKNTL YLQMNSLRAEDTAVYYCARYGGMD YWGQGTLVTVSS (SEQ ID NO: 104) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSSYGMHWVRQAPGKGLEWV SNISYMGSNTNYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARGL FPGYFDYWGQGTLVTVSS (SEQ ID NO: 108) QVQLQQSGPGLVKPSQTLSLTCAIS GDSVSSNGAAWGWIRQSPGRGLEW LGHIYYRSKWYNSYAVSVKSRITINPD TSKNQFSLQLNSVTPEDTAVYYCARW GGIHDGDIYFDYWGQGTLVTVSS (SEQ ID NO: 112) QVQLVESGGGLVQPGGSLRLSCA ASGFTFSSYSMHWVRQAPGKGLEWV SGISYSSSFTYYADSVKGRFTISRDNSKNT L YLQMNSLRAEDTAVYYCARALGGGV DYWGQGTLVTVSS (SEQ ID NO: 136) QVQLQQSGPGLVKPSQTLSLTCAI SGDSVSSSSAAWSWIRQSPGRGLE WLGMIYYRSKWYNHYAVSVKSRITI NPDTSKNQFSLQLNSVTPEDTAVYY CARGGSGVMDVWGQGTLVTVSS (SEQ ID NO: 116) QVQLQQSGPGLVKPSQTLSLTCAI SGDSVSSNSAAWGWIRQSPGRGL EWLGVIYYRSKWYNDYAVSVKSRI TINPDTSKNQFSLQLNSVTPEDTAV YYCARARAKKSGGFDYWGQGTLVTVSS (SEQ ID NO: 120) QVQLVESGGGLVQPGGSLRLSCA ASGFTFSSYASWVRQAPGKGLEWV SGISGDGSNTHYADSVKGRFTISRDN SKNTLYLQMNSLRAEDTAVYYCARYD NFYFDVWGQGTLVTVSS (SEQ ID NO: 124) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSNYAMTWVRQAPGKGLEWV SVISSVGSNTYYADSVKGRFTISRDNS KNTLYLQMNSLRAEDTAVYYCARPTKA GRTWWWGPYMDVWGQGTLVTVSS (SEQ ID NO: 128) QVQLVQSGAEVKKPGESLKISCKGS GYSFTDYWIGWVRQMPGKGLEWM GIIQPSDSDTNYSPSFQGQVTISADKS ISTAYLQWSSLKASDTAMYYCARFM WWGKYDSGFDVWGQGTLVTVSS (SEQ ID NO: 132) UA 112050 C2 TP-3F2 TP-3G1 TP-3G3 TP-3H2 TP-4A7 TP-4A9 TP-4B7 TP-4E8 TP-4G8 DIELTQPPSVSVAPGQTARI SCSGDNLPSKSVYWY QQKPGQAPVLVIYGDNNRPSGI PERFSGSNSGNTATLTISGT QAEDEADYYCQSWT SRPMVVFGGGTKLTVLGQ (SEQ ID NO: 134) DIQMTQSPSSLSASVGD RVTITCRASQGISSYLHW YQQKPGKAPKLLIYGASTLQSG VPSRFSGSGSGTDFTLTI SSLQPEDFATYYCQQQN GYPFTFGQGTKVEIKRT (SEQ ID NO: 138) DIQMTQSPSSLSASVGDR VTITCRASQNIHSHLNW YQQKPGKAPKLLIYDASSLQSG VPSRFSGSGSGTDFTLTISSL QPEDFAVYYCQQYYDYPLTFGQ GTKVEIKRT (SEQ ID NO: 142) DIELTQPPSVSVAPGQTA RISCSGDKLGKYYAYW YQQKPGQAPVLVIYGDSKRPSG IPERFSGSNSGNTATLTIS GTQAEDEADYYCSSAA FGSTVFGGGTKLTVLGQ (SEQ ID NO: 146) DIELTQPPSVSVAPGQTARI SCSGDALGSKFAHW YQQKPGQAPVLVIYDDSERPSG IPERFSGSNSGNTATLTISGT QAEDEADYYCQAYDSGLLYVFG GGTKLTVLGQ (SEQ ID NO: 150) DIELTQPPSVSVAPGQTAR ISCSGDALGKYYASW YQQKPGQAPVLVIYGDNKRPSG IPERFSGSNSGNTATLTISG TQAEDEADYYCQSY TTRSLVFGGGTKLTVLGQ (SEQ ID NO: 154) DIVMTQSPLSLPVTPGEPASI SCRSSQSLVFSDGNTYLNWYLQ KPGQSPQLLIYKGSNRASG VPDRFSGSGSGTDFTLKISRVE AEDVGVYYCQQYDSYPL TFGQGTKVEIKRT (SEQ ID NO: 158) DIELTQPPSVSVAPGQTAR ISCSGDALGSKYVSWYQ QKPGQAPVLVIYGDNKRPS GIPERFSGSNSGNTATLTI SGTQAEDEADYYCQSYT YSLNQVFGGGTKLTVLGQ (SEQ ID NO: 162) DIELTQPPSVSVAPGQTARI SCSGDKLGSKSVHWY QQKPGQAPVLVIYRDTDRPSG IPERFSGSNSGNTATLTISG TQAEDEADYYCQTYD YILNVFGGGTKLTVLGQ (SEQ ID NO: 166) 22 QVQLVESGGGLVQPGGSLRLSC AASGFTFSSYSMHWVRQAPGKGL EWVSGISYSSSFTYYADSVKGRFTI SRDNSKNTLYLQMNSLRAEDTAVYY CARALGGGVDYWGQGTLVTVSS (SEQ ID NO: 136) QVQLQQSGPGLVKPSQTLSLTCAIS GDSVSSNSGGWGWIRQSPGRGLEW LGLIYYRSKWYNAYAVSVKSRITINPD TSKNQFSLQLNSVTPEDTAVYYCARYL GSNFYVYSDVWGQGTLVTVSS (SEQ ID NO: 140) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSSYSMSWVRQAPGKGLEWV SSISSSSSNTYYGDSVKGRFTISRDNS KNTLYLQMNSLRAEDTAVYYCARMHYK GMDIWGQGTLVTVSS (SEQ ID NO: 144) QVQLVESGGGLVQPGGSLRLSCAAS GFTFNSYYMSWVRQAPGKGLEWVSNI SSSGSNTNYADSVKGRFTISRDNSKNTL YLQMNSLRAEDTAVYYCARVHYGFDFW GQGTLVTVSS (SEQ ID NO: 148) QVQLVESGGGLVQPGGSLRLSCAA SGFTFRNYAMNWVRQAPGKGLEWV SVISGSSSYTYYADSVKGRFTISRDNS KNTLYLQMNSLRAEDTAVYYCARADL PYMVFDYWGQGTLVTVSS (SEQ ID NO: 152) QVQLVESGGGLVQPGGSLRLSCAA SGFTFSSYGMSWVRQAPGKGLEWVS LISGVSSSTYYADSVKGRFTISRDNSK NTLYLQMNSLRAEDTAVYYCARSYLG YFDVWGQGTLVTVSS (SEQ ID NO: 156) QVQLQQSGPGLVKPSQTLSLTCAIS GDSVSSNSAAWSWIRQSPGRGLE WLGIIYKRSKWYNDYAVSVKSRITI NPDTSKNQFSLQLNSVTPEDTAVY YCARWHSDKHWGFDYWGQGTLV TVSS (SEQ ID NO: 160) QVQLVESGGGLVQPGGSLRLS CAASGFTFNDYAMSWVRQAPG KGLEWVSLIESVSSSTYYADSVK GRFTISRDNSKNTLYLQMNSLRA EDTAVYYCARTIGVLWDDVWGQ GTLVTVSS (SEQ ID NO: 164) QVQLVESGGGLVQPGGSLRLS CAASGFTFSTYAMHWVRQAPG KGLEWVSTISGYGSFTYYADSV KGRFTISRDNSKNTLYLQMNSL RAEDTAVYYCARNGRKYGQM DNWGQGTLVTVSS (SEQ ID NO: 168) UA 112050 C2 TP-4H8 5 10 15 20 25 30 DIELTQPPSVSVAPGQTA RISCSGDSIGKKYVHWY QQKPGQAPVLVIYGDNNRPSG IPERFSGSNSGNTATLTIS GTQAEDEADYYCSTAD SVITYKNVFGGGTKLTVL GQ (SEQ ID NO: 170) QVQLVESGGGLVQPGGSL RLSCAASGFTFSDHAMHWV RQAPGKGLEWVSVIEYSGSK TNYADSVKGRFTISRDNSKNTL YLQMNSLRAEDTAVYYCARGD YYPYLVFAIWGQGTLVTVSS (SEQ ID NO: 172) Перехресна реактивність щодо мишачих TFPI Вищезгадані 44 людські TFPI-зв'язувальні клони тестували на зв'язування з мишачими TFPI в ELISA. Було виявлено, що дев'ятнадцять антитіл є перехресно реактивними щодо мишачих TFPI. Щоб полегшити дослідження, використовуючи модель гемофілії у мишей, ми далі характеризували ці 19 антитіл так само як п'ять антитіл, які були специфічними щодо людських TFPI. Представлений набір даних показаний на Фіг. 1. Жодне з цих антитіл не зв'язувалось з BSA або лізозимом в ELISA. Приклад 2. Експресія й очищення анти-TFPI антитіл Анти-TFPI антитіла (як Fab фрагменти) експресували й очищали від бактеріального штаму TG1. Коротко, єдина колонія бактеріального штаму TG1, що містить плазміду експресії антитіла, була обрана й вирощена протягом ночі в 8 мл 2xYT середовища в присутності 34 мк/мл хлорамфенікола і 1 % глюкози. Об'єм культури 7 мл переносили до 250 мл 2xYT свіжого середовища, що містив 34 мк/мл хлорамфенікола і 0,1 % глюкози. Після 3 годин інкубації додавали 0,5 мМ IPTG, щоб індукувати Fab експресію. Культуру витримували протягом ночі при 25 °C. Культуру центрифугували до грудкування бактеріальних клітин. Грудки потім ресуспендували в Bug Buster лізисному буфері (Novagen). Після центрифугування супернатант бактеріального лізису фільтрували. Fab фрагменти афінно-очищали через колонку Ni-NTA (Qiagen) відповідно до інструкції виробника. Приклад 3. Визначення EC50 й зв'язувальної афінності анти-TFPI антитіл. Очищені Fab антитіла використовувалися для визначення EC 50 анти-TFPI антитіл до людьких або мишачих TFPI. EC50 оцінювали в ELISA, так само, як описано вище. Результати аналізували, використовуючи SoftMax. Зв'язувальну афінність анти-TFPI антитіл визначали у дослідженні Biacore. Коротко, антиген або людські або мишачі TFPI, імобілізували на CM5чипах, використовуючи аміно-з'єднувальний комплект (GE HealthCare) відповідно до інструкцій виробника. Кількість імобілізованого TFPI коригували до маси антигену, щоб одержати приблизно 300 RU. Антитіла Fabs аналізували в мобільній фазі при принаймні п'яти різних концентраціях (0,1, 0,4, 1,6, 6,4 й 25 нМ) очищених антитіл, використовуваних у дослідженні Biacore. Кінетика й зв'язувальна афінність обчислювали, використовуючи Biacore T100 оцінювальне програмне забезпечення. Як показано в Таблиці 3, 24 анти-TFPI Fabs показали різні EC50 щодо людських TFPI (0,09 до 792 нМ) і мишачих TFPI (0,06-1035 нМ) і афінність, визначена Biacore, була відповідно різною щодо людських TFPI (1,25-1140 нМ). У дослідженні Biacore Fabs щодо мишачих TFPI, варіація афінності була меншою (3,08 до 51,8 нМ). 35 Таблиця 3 Зв'язувальна активність 24 антитіл проти людських або мишачих TFPI, як визначено ELISA та Biacore (hTFPI: людські TFPI; mTFPI: мишачі TFPI; Neg.(негативний): сигнал був меншим в два рази, ніж фоновий; ND - не наданий) Клони антитіла TP-2A2 TP-2A5 TP-2A8 TP-2B11 TP-2B3 TP-2C1 TP-2C7 TP-2E5 TP-2G5 TP-2G6 Зв'язування EC50 (нМ) hTFPI mTFPI 0,62 1035,88 28,64 14,54 0,09 0,06 11,52 0,52 0,84 20,18 0,40 Негативний 0,60 0,60 791,60 202,28 342,52 871,34 0,48 5,18 23 Афінність (нМ) hTFPI mTFPI 6,57 29,8 35,4 19,6 1,25 3,08 21,5 16,3 7,40 27,0 2,64 Негативний 2,01 9,33 115 25,2 42,1 16,1 5,06 46,1 UA 112050 C2 TP-2G7 TP-2G9 TP-2H10 TP-3A4 TP-3B4 TP-3C1 TP-3C2 TP-3G1 TP-3G3 TP-4A9 TP-4B7 TP-4E8 TP-4G8 TP-4H8 5 10 15 20 25 30 35 40 45 23,48 10,80 2,18 42,84 35,76 32,80 59,00 74,40 33,60 0,17 0,74 36,94 846,92 72,50 Негативний 194,42 32,40 326,58 34,62 108,40 956,68 8,68 47,06 117,68 2,64 Негативний Негативний Негативний 26,9 48,5 10,2 21,6 14,1 21,6 17,1 1140 16,0 7,60 15,8 35,9 25,2 32,2 Негативний 35,7 11,5 23,7 20,4 33,6 28,5 49,1 25,7 Негативний 51,8 ND ND ND Приклад 4. Перетворення анти-TFPI Fab до IgG Всі ідентифіковані анти-TFPI антитіла є повністю людcькими Fabs, що можуть бути здійсненно перетворені у людські IgG як терапевтичний агент. У цьому прикладі, однак, вибрані Fabs перетворювали у химерні антитіла, що містили мишачий константний регіон IgG, таким чином вони є більше прийнятними для тестування в мишачій моделі. Варіабельний регіон вибраних антитіл пересаджували у ссавцевий вектор експресії, що містив мишачі константні регіони. Повністю зібрану молекулу IgG потім трансфектували і експресували в клітинах HKB11 (Mei та ін., Mol. Biotechnol., 2006, 34: 165-178). Супернатантну культуру збирали та концентрували. Молекули анти-TFPI IgG афінно очищували через колонку Hitrap Protein G (GE HealthCare), супроводжувану інструкцією виробника. Приклад 5 Селекція анти-TFPI нейтралізуючих антитіл Анти-TFPI нейтралізуючі антитіла вибирали на основі їх інгібувальної активності TFPI за трьома експериментальними умовами. Активність TFPI вимірювали, використовуючи ACTICHROME® TFPI дослідження активності (American Diagnostica Inc, Stamford, CT), три стадії хромогенного дослідження для вимірювання здатності TFPI інгібувати каталітичну активність комплексу TF/FVIIa, щоб активувати фактор X до фактора Xa. Активність нейтралізації антиTFPI антитіла є пропорційною кількості відновленої генерації FXa. На першому етапі очищені анти-TFPI антитіла культивували з людським або мишачим рекомбінантним TFPI (R&D System) при визначених концентраціях. Після інкубації зразки змішували з TF/FVIIa й FX, і потім вимірювали залишкову активність комплексу TF/FVIIa, використовуючи SPECTROZYME® FXa, високоспецифічний fXa хромогенний субстрат. Цей субстрат розщеплювали тільки за допомогою FXa, генерованого у дослідженні, вивільняючи п-нітроаніліновий (pNA) хромофор, який вимірювали при 405 нм. Активність TFPI, представлену у зразку, інтерполювали від каліброваної кривої, побудованої з використанням відомих рівней активності TFPI. Дослідження виконували способом граничних точок. У двох інших параметрах настроювання, анти-TFPI антитіла вводили в нормальну людську плазму або гемофільну плазму, і відновлену генерацію FXa вимірювали. Приклад 6. Дослідження скорочення часу коагуляції при подовженому протромбіновому часі (dPT) анти-TFPI антитілами Дослідження подовження протромбінового часу виконанували, власне кажучи, як описане Welsch та ін., Thrombosis Res., 1991, 64(2): 213-222. Коротко, людську нормальну плазму (FACT, George King Biomedical), людську TFPI збіднену плазму American Diagnostica) або гемофільну А плазму (George King Biomedical) одержували, змішуючи плазму з 0,1 об'ємами контрольного буфера або анти-TFPI антитілами. Після інкубації протягом 30 хвилин при 25 °C зразки плазми (100 мкл) об'єднували з 200 мкл відповідно розбавленого (1:500 розбавлення) Simplastin (Biometieux) як джерела тромбопластину, і час коагуляції визначали, використовуючи фіброметр STA4 (Stago). Тромбопластин розбавляли з PBS або 0,05 М Трис буфером (pН 7,5), що містив: 0,1 М хлориду натрію, 0,1 % бичачого сироваткового альбуміну та 20 мкМ хлориду кальцію. Приклад 7. Скорочення часу коагуляції крові у дослідженні ROTEM анти-TFPI антитілами, самостійно або в комбінації з рекомбінантним фактором VIII або фактором IX. Система ROTEM (Pentapharm Gmb) включала інструмент із чотирма каналами, комп'ютер, стандарнтні плазми, активатори і доступні чашки та голки. Тромбеластографічні параметри гемостатичної системи ROTEM включали: Час коагуляції (СТ), що відбиває час реакції (час, необхідний, щоб одержати 2-мм амплітуду після ініціювання збору даних), необхідний для початку коагуляція крові; час утворення згустка (CFT) і альфа-кут, щоб відбити поширення 24 UA 112050 C2 5 10 15 20 25 30 коагуляції, та максимальну амплітуду й максимальний пружний модуль, щоб відбити твердість згустка. У дослідженні ROTEM оцінювали 300 мкл свіжої цитратної цільної крові або плазми. Усі компоненти відтворювали й змішували відповідно до інструкцій виробника, зі збором даних для періоду часу, необхідного для кожної системи. Коротко, зразки змішували видаленням/розподілом 300 мкл крові або плазми автоматизованою піпеткою в чаші ROTEM з 20 мкл CaCl2 (200 ммоль), з наступним негайним змішуванням зразка та ініціюванням збору даних. Дані збирали протягом 2 годин, використовуючи керовану комп'ютером (версія 2,96 програмного забезпечення) систему ROTEM. Зразковий результат дослідження ROTEM у виявленні впливу анти-TFPI антитіл на час скорочення коагуляції крові показаний на Фіг. 3 та 5. Фіг. 3 показує, що TP-2A8-Fab скорочував час коагуляції у людській гемофільній А плазмі або мишачій гемофільній А цільній крові, самостійно або в комбінації з рекомбінантним FVIII, коли система ROTEM була ініційована NATEM. Фіг. 5 показує, що анти-TFPI антитіла у форматі IgG (TP-2A8, TP-3G1, і TP-3C2) скорочують час коагуляції крові у порівнянні з негативним контролем мишачого антитіла IgG. Базуючись на цих результатах і розумінні в цій галузі, фахівець очікував би, що ці анти-TFPI антитіла також скорочують час коагуляції у комбінації з рекомбінантним FIX у порівнянні з одними тільки цими антитілами. Приклад 8. In vitro функціональна активність анти-TFPI антитіл Щоб досліджувати антитіла TFPI у блокуванні функції TFPI використовували як хромогенне дослідження ACTICHROME, так і подовжений протромбіновий час (dPT), щоб перевірити функціональну активність антитіл, отриманих від пенінгу й скринінгу В обох дослідженнях моноклональні щурячі анти-TFPI антитіла (R&D System) використовували як позитивний контроль, і людські поліклональні Fab використовували як негативний контроль У хромогенному дослідженні вісім з антитіл інгібували більше, ніж 50 % активності TFPI у порівнянні з моноклональним антитілом пацюка (Таблиця 4). У дослідженні dPT всі ці вісім анти-TFPI Fabs показли високий інгібувальний ефект, скорочуючи час коагуляції менше 80 секунд, і чотири з восьми Fabs скорочували dPT менше 70 секунд Залежність дози чотирьох із представлених клонів у скороченні dPT показано на Фіг. 2 Однак, інші людські анти-TFPI Fabs з низькою або відсутньою інгібувальною активністю TFPI також скорочували час коагуляції у dPT Наприклад, TP-3B4 і TP-2C7, показуючи менше, ніж 25 % інгібувальну активність, могли скоротити dPT до менше, ніж 70 секунд Простий аналіз лінійної регресії інгібувальної активності та dPT пропонує істотну кореляцію (p=0,0095), але велике розходження (R квадрат = 0,258). Таблиця 4 Функціональна активність анти-TFPI антитіл in vitro, визначена за їх інгібувальною активністю в дослідженні людських TFPI і дослідженні dPT Клон анти-TFPI TP-2B3 TP-4B7 TP-3G1 TP-3C2 TP-2G6 TP-2A8 TP-2H10 TP-2G7 TP-4G8 TP-2G5 TP-2A5 TP-4E8 TP-4H8 TP-3B4 TP-2A2 TP-2C1 TP-3G3 TP-2E5 TP-3A4 % інгібувальної активності hTFPI 100 % 100 % 100 % 93 % 92 % 86 % 100 % 63 % 55 % 39 % 36 % 30 % 29 % 28 % 25 % 23 % 21 % 15 % 0% 0% 25 dPT в гемо А плазмі (сек.) 63,5 74,0 53,9 75,1 68,9 62,8 57,9 79,5 72,2 73,9 73,2 70,8 71,9 76,5 69,1 70,9 70,9 70,7 79,0 72,3 UA 112050 C2 TP-3C1 TP-2B11 TP-2C7 TP-2G9 Необроб. 5 10 15 20 25 30 35 40 45 50 0% 0% 0% 0% 0% 72,3 82,6 62,5 82,7 92,9 Один з анти-TFPI Fab, Fab-2A8, також тестували у дослідженні ROTEM, у якому використовували людську гемофільну А плазму з низьким рівнем фактора VIII або гемофільну А мишачу цільну кров. Як показано на Фіг. 3, порівнюючи поліклональне кроляче анти-TFPI антитіло, Fab-2A8, показав подібну активність у людській гемофільній А плазмі, зменшуючи час коагуляції (СТ) з 2200 секунд до приблизно 1700 сек. Коли використовувалася гемофільна А мишача цільна кров, кроляче контрольне анти-TFPI антитіло скорочувало СТ від 2700 секунд до 1000 секунд, тоді як Fab-2A8 скорочують СТ від 2650 секунд до секунд 1700. Ці результати вказують, що Fab-2A8 може значно скоротити час коагуляції в людській плазмі й у крові миші (p=0,03). Приклад 9. Функції анти-TFPI антитіл після перетворення у химерний IgG In vitro дослідження фактора генерації Xa і подовжений час протромбіну вказує, що принаймні шість із 24 анти-TFPI Fabs, TP-2A8, TP-2B3, TP-2G6, TP-3C2, TP-3G1 й TP-4B7, можуть блокувати функцію TFPI. Щоб полегшити in vivo дослідження, використовуючи гемофілію А миші, ми перетворили ці шість анти-TFPI людських Fabs у химерний IgG, використовуючи щурячий ізотип IgG1. Вектор експресії IgG був трансформований у клітини HKB11 і експресоване антитіло було зібрано у супернатантній культурі й очищене на колонці Protein G. Коли представлений 2G6-Fab клон перетворювали до IgG, 2G6-IgG показав двократне збільшення зв'язування EC50 з людським TFPI (від 0,48 нМ до 0,22 нМ) і 10-кратне збільшення мишачих TFPI (від 5,18 нМ до 0,51 нМ). Результати зв'язування IgG-2G6 з людськими й мишачими TFPI, показані на Фіг. 4. Приклад 10. Ефекти на ступінь виживання при моделі гемофілії А (HemA) у мишей з поперечним розрізом вени хвоста Модель поперечного розрізу вени хвоста миші була встановлена для фармакологічної оцінки. Ця модель моделює широкий діапазон фенотипів геморагій, спостережуваних між нормальними індивідуумами й індивідуумами з серйозною гемофілією. Для цих досліджень використовували самців мишей з гемофілією А (8 тижнів й 20-26 грамів). Миші були дозовані через інфузію вени хвоста анти-TFPI моноклональним антитілом (40 мкг/миша), самостійно або разом з фактором коагуляції крові, таким як FVIII (0,1 МО/миша) перед пошкодженням. На 24 годину після дозування ліва вена хвоста в 2,7 мм від верхівки (у діаметрі) була розсічена. Виживання спостерігалося більше, ніж 24 години після поперечного розрізу. Виживаність була продемонстрована, як залежна від дози, коли вводять з рекомбінантним FVIII (дані не показані). Дані, показані на Фіг. 8, були від двох окремих досліджень (n=15 й n=10, відповідно). Результати показали, що TP-2A8-IgG значно продовжив виживання мишей з гемофілією А, порівняно з контрольним мишачим IgG; і, у комбінації з рекомбінантним FVIII, показав кращу виживаність, чим тільки будь-який агент самостійнно. Приклад 11. Додаткове скорочення часу коагуляції і час утворення згустка комбінацією антиTFPI антитіла з рекомбінантним фактором VIIa Комбіновані ефекти анти-TFPI антитіла й рекомбінантного FVIIa (Novo Nordisk) оцінювали у системі ROTEM, використовуючи EXTEM (1:1000 розбавлення) і мишачу цільну гемофільну А кров. Вказанe кількість анти-TFPI антитіла, TP-2A8-IgG ("2A8"), і рекомбінантний FVIIa ("FVIIa") додавали у 300 мкл цитратної мишачої цільної гемофільної А крові, і коагуляцію крові ініціювали, використовуючи систему EXTEM. Фіг. 9 показує що додавання TP-2A8-IgG або рекомбінантної FVIIa мишачої гемофільної А цільної крові скорочує час коагуляції і час утворення згустка, відповідно. Комбінація TP-2A8-IgG і рекомбінантного FVIIa ("2A8+FVIIa") додатково скорочує час коагуляції і час утворення згустка, вказуючи, що комбінація анти-TFPI антитіла з рекомбінантним FVIIa корисна в лікуванні пацієнтів з гемофілією з або без інгібіторів. Приклад 12. Скороченння часу коагуляції анти-TFPI антитілами в FVIII індукованій інгібітором людській гемофільній крові. Вибрані анти-TFPI антитіла, 2A8 й 4B7 були також протестовані у дослідженні ROTEM, використовуючи нейтралізуючі антитіла FVIII, щоб індукувати гемофілію в цільній крові від негемофільних пацієнтів. Фіг. 10 показує, що нормальна людська крові має час коагуляції приблизно 1000 секунд. У присутності FVIII нейтралізуючих антитіл (РАН, 100 мкг/мл) час коагуляції був продовжений приблизно до 5200 секунд. Тривалий час коагуляції був значно 26 UA 112050 C2 5 10 15 скорочений додаванням анти-TFPI антитіла, 2A8 або 4B7, що вказуює, що анти-TFPI антитіло корисно в лікуванні пацієнтів з гемофілією інгібіторами. Приклад 13. Зв'язування інгібіторними анти-TFPI антитілами Kunitz домена 2 людських TFPI Вестерн-блотинг й ELISA використовувалися, щоб визначити, який домен (и) зв'язують TFPI інгібувальні антитіла. Рекомбінантний повної довжини людський TFPI або TFPI домен використовували для цих досліджень. ELISA дослідження було подібне до Прикладу 3. У Вестерн-блотингу людські TFPI або домени додатково включали 4-12 % Bis-Tris SDS PAGE рухливий буфер MES (Invitrogen, Carlsbad, CA) і потім переносили на мембрану целюлози. Після інкубації із інгібувальними антитілами протягом 10 хвилин мембрану промивали три рази, використовуючи систему SNAPid (Millipore, Billerica, MA). HRP кон'юговані віслюкові анти-мишачі антитіла (Pierce, Rockford, IL) в 1-10 000 розбавленні культивували з мембраною 10 хв. Після подібного кроку промивання мембрана була розвинена, використовуючи субстрат SuperSignal (Pierce, Rockford, IL). Беручи до уваги, що контрольний анти-Kunitz домен 1 антитіла зв'язується з повною довжиною TFPI, усічений TFPI й домени, інгібувальні анти-TFPI антитіла тільки зв'язуються з TFPI, що містить домен Kunitz 2. Це вказує, що зв'язування з Kunitz доменом 2 необхідно для інгібувальноїфункції антитіла. Таблиця 5 Домени, зв'язані антитілами, як визначено Вестерн-блоттингом й ELISA Повна довжина K1+K2+K3 K1+K2 K1 20 Анти-K1 + + + + mIgG TP-2A8 TP-2B3 TP-2G6 TP-3C2 TP-3G1 TP-4B7 + + + + + + + + + + + + + + + + + + У той час як даний винахід був описаний відносно певних втілень і прикладів, потрібно мати на увазі, що різні модифікації й зміни можуть бути зроблені і замінені еквівалентними, не відступаючи від суті й змісту винаходу. Опис й приклади повинні, відповідно, бути розцінені як ілюстративні, ніж такі, що обмежують обсяг винаходу. Крім того, всі статті, книги, заявки на патент й патенти, згадані тут, включені посиланням у всій повноті. 27 UA 112050 C2 28
ДивитисяДодаткова інформація
Назва патенту англійськоюMonoclonal antibodies against tissue factor pathway inhibitor (tfpi)
Автори російськоюWang, Zhuozhi, Murphy, John, E., Pan, Junliang, Jiang, Haiyan, Liu, Bing
МПК / Мітки
МПК: C12P 21/08, C07K 16/36
Мітки: містить, тканинного, композиція, антитіло, терапевтична, інгібітора, моноклональне, фактора, шляху, tfpi
Код посилання
<a href="https://ua.patents.su/127-112050-terapevtichna-kompoziciya-shho-mistit-monoklonalne-antitilo-proti-ingibitora-shlyakhu-tkaninnogo-faktora-tfpi.html" target="_blank" rel="follow" title="База патентів України">Терапевтична композиція, що містить моноклональне антитіло проти інгібітора шляху тканинного фактора (tfpi)</a>
Химерне антитіло проти cd40 людини, молекула нуклеїнової кислоти, вектор експресії, фармацевтична композиція для лікування захворювань, опосередкованих т-клітинами, яка містить химерне антитіло

Номер патенту: 71909
Опубліковано: 17.01.2005
Автори: Ву Херрен, Торн Барбара А., Хьюз Уільям Д., Аруффо Аледжандро А., Уоткінс Джеффрі Д., Холленбау Даєн, Сайдек Ентоні В., Беррі Карен К., Бейорет Юрген, Херріс Лінда Дж.
МПК: A61P 19/02, C12N 15/09, A61P 29/00, C12N 15/13, C07K 16/28, A61P 43/00, A61K 39/395, C07K 14/46, A61P 37/02, A61P 37/06, C12N 1/21, C07K 14/725
Мітки: молекула, захворювань, вектор, химерне, яка, містить, лікування, антитіло, опосередкованих, нуклеїнової, людини, фармацевтична, експресії, т-клітинами, композиція, кислоти
Формула / Реферат:
1. Варіабельна ділянка легкого ланцюга химерного антитіла, що зв’язується з CD40 людини, яка містить амінокислотну послідовність SEQ ID NО:1 (Фіг. 4а).2. Варіабельна ділянка важкого ланцюга химерного антитіла, що зв’язується з CD40 людини, яка містить амінокислотну послідовність SEQ ID NО:2 (Фіг. 4b).3. Химерне антитіло, що зв'язується з CD40 людини, яке містить легкий і важкий ланцюг, причому зазначений легкий ланцюг містить ...
Антитіло людини проти тканинного фактора

Номер патенту: 109633
Опубліковано: 25.09.2015
Автори: де Йонґ Роб Н., Бадсґард Оле, Сатейн Давід П. Е., Хут Рене М. А., Паррен Пауль, Хауткамп Міса, Вінк Том, Блекер Віллем Карел, Аудсхорн Маруска, ван де Вінкел Ян, Ехрнрот Ева, Верплуґен Сандра, Брайнхольт Вібеке Міллер
МПК: C07K 16/36, A61P 35/00
Мітки: фактора, антитіло, тканинного, людини
Формула / Реферат:
1. Антитіло людини, яке зв'язує тканинний фактор людини, і яке містить VH область, що включає CDR1, 2 і 3 послідовності SEQ ID NO: 10, 11 і 12, і VL область, що включає CDR1, 2 і 3 послідовності SEQ ID NO: 66, 67 і 68.2. Антитіло за п. 1, яке відрізняється тим, що це антитіло має одну або декілька характеристик:а)...
Ізольоване антитіло, що специфічно зв’язується з рецептором фактора росту фібробластів-3 та фармацевтична композиція, що містить зазначене антитіло

Номер патенту: 101681
Опубліковано: 25.04.2013
Автори: Лю Лін, Сун Хайчжун
МПК: C07K 16/28
Мітки: специфічно, росту, містить, фармацевтична, зазначене, ізольоване, фактора, антитіло, зв'язується, композиція, фібробластів-3, рецептором
Формула / Реферат:
1. Антитіло, що специфічно зв'язується з людським FGFR-3, що містить CDRH1, яка має послідовність GYMFTSYGIS (SEQ ID NO:1), CDRH2, яка має послідовність WVSTYNGDTNYAQKFQG (SEQ ID NO:2), CDRH3, яка має послідовність VLGYYDSIDGYYYGMDV (SEQ ID NO: 3), CDRL1, яка має послідовність GGNNIGDKSVH (SEQ ID NO:4), CDRL2, яка має послідовність LDTERPS (SEQ ID NO:5), і CDRL3, яка має послідовність QVWDSGSDHVV (SEQ ID NO:6).2. Антитіло за п. 1, яке...
Виділене моноклональне антитіло, яке зв’язується з hgm-csf, і композиція медичного призначення, що його містить

Номер патенту: 102085
Опубліковано: 10.06.2013
Автори: Такада Кензо, Кістлер Барбара, Накадзіма Канто, Парк Джон
МПК: A61P 35/02, A61P 11/00, C07K 16/24, A61P 19/02, A61P 17/06
Мітки: зв'язується, яке, призначення, композиція, антитіло, моноклональне, містить, hgm-csf, виділене, медичного
Формула / Реферат:
1. Виділене моноклональне антитіло до hGM-CSF або його антигензв'язуючий фрагмент, де антитіло або антигензв'язуючий фрагмент містить:(а) важкий ланцюг, що включає VН-CDR1-утримуючу послідовність, VН-CDR2-утримуючу послідовність і VН-CDR3-утримуючу послідовність, в яких:(I) VH-CDR1-утримуюча послідовність являє собою SYGMH (SEQ ID NO: 4),(II) VH-CDR2-утримуючa послідовність являє собою LTYHHGNRKFYADSVRG (SEQ ID NO: 5),...
Протипухлинна вакцина, що містить моноклональне антиідіотипове антитіло проти са-125 та алюміній

Номер патенту: 95806
Опубліковано: 12.09.2011
Автори: Флеммінг Єнс, Грогер Карстен, Шмітц Райнхард, Мандзіні Стефано
МПК: A61P 35/00, A61K 33/06, A61K 39/39
Мітки: алюміній, са-125, містить, антитіло, моноклональне, вакцина, антиідіотипове, протипухлинна
Формула / Реферат:
1. Фармацевтична композиція для парентерального введення як протипухлинна вакцина, яка містить моноклональне антитіло і похідну алюмінію як ад'ювант, в якій концентрація іонів алюмінію у межах від 2,4 мг/мл до 5,2 мг/мл, причому:- згадане моноклональне антитіло являє собою моноклональне антиідіотипове антитіло MEN2234 проти СА-125, адсорбоване сполукою алюмінію, яке містить Послідовність № 1 та Послідовність № 2, і концентрація якого...
Попередній патент: Пристрій для промивання стінок порожнини носа
Наступний патент: Композиція інкапсульованого пестициду і спосіб обробки ним сільськогосподарської культури
Випадковий патент: Спосіб визначення активності протеїназ та альфа-і-інгібітора протеїназ в біологічних рідинах