Спосіб та комплект для аналізу ahasl генів у рослин







Формула / Реферат
1. Спосіб аналізу AHASL гена рослин, який включає:
(a) забезпечення ДНК, яка включає AHASL ген рослин;
(b) ампліфікацію ДНК з застосуванням прямого праймера AHASL, зворотного праймера AHASL, полімерази та дезоксирибонуклеотидтрифосфатів;
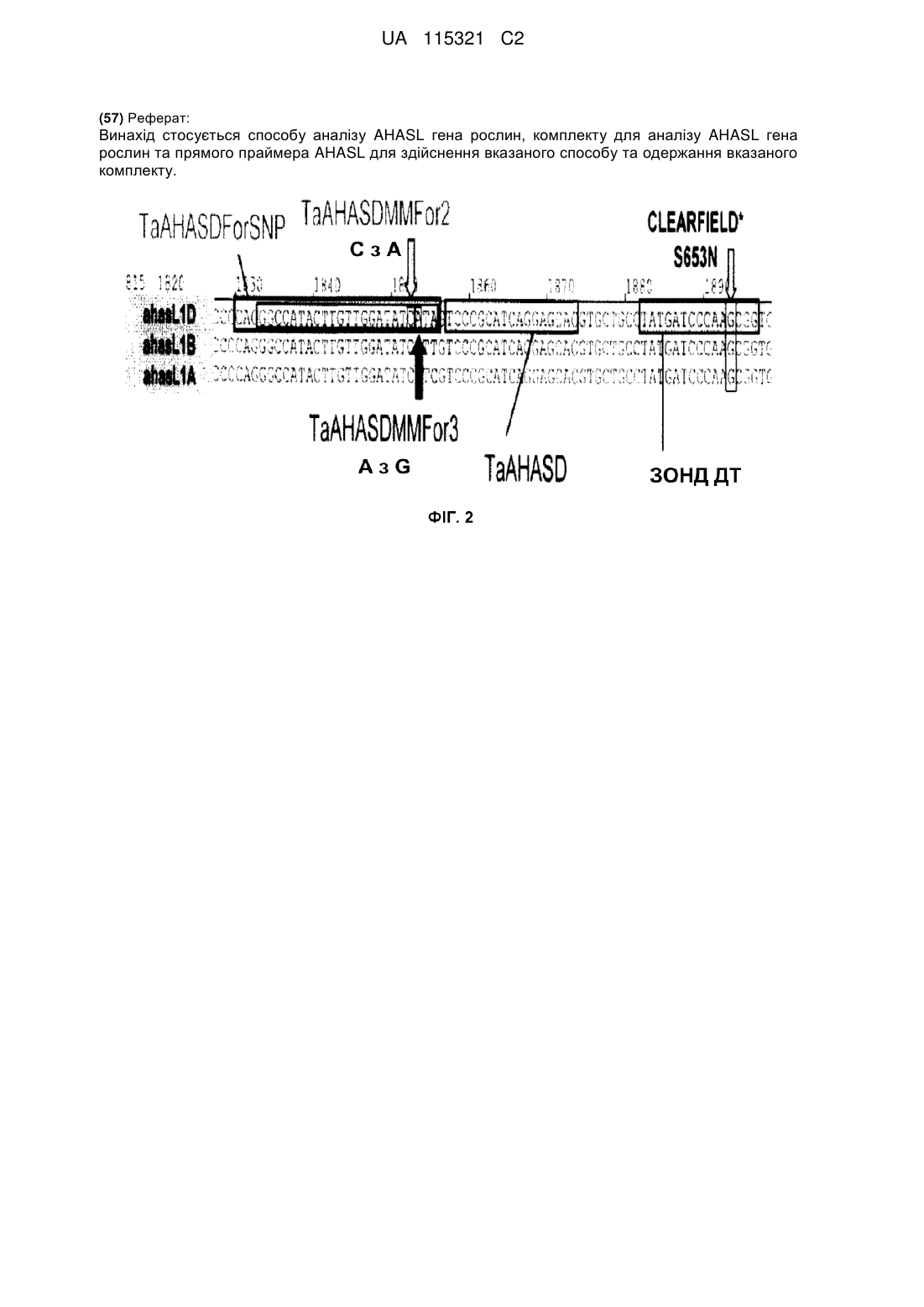
(c) виявлення продуктів ампліфікації за допомогою зонда AHASL дикого типу та толерантного до гербіцидів (НТ) зонда AHASL таким чином розпізнаючи AHASL ген як ген дикого типу або варіант для однонуклеотидного поліморфізму, що в результаті веде до амінокислотного заміщення, яке відповідає заміщенню S653 (At)N;
причому прямий праймер AHASL є олігонуклеотидом, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28;
причому прямий праймер AHASL включає спарювання з AHASL геном рослин, розташованному за 2 або 3 нуклеотиди до 3'-кінцевого нуклеотиду прямого праймера AHASL; та
причому 3'-кінцевий нуклеотид прямого праймера AHASL є AHASL сайтом однонуклеотидного поліморфізму (SNP).
2. Спосіб за п. 1, який відрізняється тим, що вищезгадані етапи ампліфікації та виявлення одночасно здійснюють у ПЛР-аналізі у реальному часі.
3. Спосіб за п. 1, який відрізняється тим, що на вищезгаданому етапі виявлення розпізнають геном походження AHASL гена рослин.
4. Спосіб за п. 3, який відрізняється тим, що геномом походження є: А геном пшениці, В геном пшениці або D геном пшениці.
5. Спосіб за п. 1, який відрізняється тим, що AHASL ген рослин є вибраним з групи, до якої належать AHASL1A ген пшениці, AHASL1В ген пшениці та AHASL1D ген пшениці.
6. Спосіб за п. 1, який відрізняється тим, що також включає повторення вищезгаданих етапів ампліфікації та виявлення іншим прямим праймером AHASL, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28, для визначення зиготності AHASL гена для однонуклеотидного поліморфізму, що в результаті веде до амінокислотного заміщення, яке відповідає заміщенню S653(At)N.
7. Спосіб за п. 1 або 6, який відрізняється тим, що на вищезгаданих етапах виявлення розпізнають джерело AHASL гена рослин.
8. Спосіб за п. 7, який відрізняється тим, що джерелом є поліплоїдна рослина.
9. Спосіб за п. 8, який відрізняється тим, що джерелом є рослина пшениці.
10. Спосіб за п. 9, який відрізняється тим, що джерелом є Triticum aestivum або T. Turgidum видів durum.
11. Спосіб за п. 1, який відрізняється тим, що прямий праймер AHASL є олігонуклеотидом, який складається з послідовності, вибраної з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28.
12. Спосіб за п. 1, який відрізняється тим, що зворотний праймер AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 31.
13. Спосіб за п. 1, який відрізняється тим, що зонд AHASL дикого типу є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 32.
14. Спосіб за п. 1, який відрізняється тим, що НТ-зонд AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 33.
15. Спосіб за п. 14, який відрізняється тим, що зонд AHASL дикого типу є міченим першим типом сигналу, що піддається виявленню, і НТ-зонд AHASL є міченим другим типом сигналу, що піддається виявленню.
16. Спосіб за п. 15, який відрізняється тим, що сигнали, які піддаються виявленню, є флуоресцентними репортерними молекулами.
17. Спосіб за п. 1, який відрізняється тим, що ДНК є геномною ДНК.
18. Спосіб за п. 17, який відрізняється тим, що ДНК одержують з рослини пшениці.
19. Спосіб за п. 18, який відрізняється тим, що рослиною пшениці є Triticum aestivum.
20. Спосіб за п. 18, який відрізняється тим, що рослиною пшениці є T. Turgidum видів durum.
21. Спосіб за п. 1, який відрізняється тим, що AHASL SNP є триалельним SNP.
22. Комплект для аналізу AHASL гена рослин, який включає:
а) прямий праймер AHASL, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28;
b) зворотний праймер AHASL;
c) зонд AHASL дикого типу;
d) толерантний до гербіцидів (НТ) зонд AHASL;
е) полімеразу; та
f) дезоксирибонуклеотидтрифосфати;
причому прямий праймер AHASL включає спарювання з AHASL геном рослин, розташованному за 2 або 3 нуклеотиди до 3'-кінцевого нуклеотиду прямого праймера AHASL; та
причому 3'-кінцевий нуклеотид прямого праймера AHASL є AHASL сайтом однонуклеотидного поліморфізму (SNP).
23. Комплект за п. 22, який відрізняється тим, що прямий праймер AHASL складається з послідовності, вибраної з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28.
24. Комплект за п. 22, який відрізняється тим, що зворотний праймер AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 31.
25. Комплект за п. 22, який відрізняється тим, що зонд AHASL дикого типу є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 32.
26. Комплект за п. 22, який відрізняється тим, що НТ-зонд AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 33.
27. Комплект за п. 22, який відрізняється тим, що зонд AHASL дикого типу є міченим першим типом сигналу, що піддається виявленню, і НТ-зонд AHASL є міченим другим типом сигналу, що піддається виявленню.
28. Прямий праймер AHASL, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28;
причому прямий праймер AHASL включає спарювання з AHASL геном рослин, розташованого за 2 або 3 нуклеотиди до 3'-кінцевого нуклеотиду прямого праймера AHASL; та
причому 3'-кінцевий нуклеотид прямого праймера AHASL є AHASL сайтом однонуклеотидного поліморфізму (SNP).
29. Прямий праймер AHASL за п. 28, складається з послідовності, вибраної з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28.
Текст
Реферат: Винахід стосується способу аналізу AHASL гена рослин, комплекту для аналізу AHASL гена рослин та прямого праймера AHASL для здійснення вказаного способу та одержання вказаного комплекту. UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 ПЕРЕХРЕСНЕ ПОСИЛАННЯ НА СПОРІДНЕНІ ЗАЯВКИ Ця заявка запитує пріоритет згідно з попередньою заявкою на патент США № 61/576,944, поданий 16 грудня 2011 р., та попередньою заявкою на патент США № 61/650,912, поданою 23 травня 2012 р., зміст якої включено до цієї заявки шляхом посилання у повному обсязі ГАЛУЗЬ ВИНАХОДУ Даний винахід стосується галузі аналізу генів, зокрема, способів та композицій для аналізу AHASL генів та визначення їх зиготності. РІВЕНЬ ТЕХНІКИ Синтаза ацетогідроксикислоти (AHAS; EC 4.1.3.18), також відома як ацетолактатсинтаза (ALS), є першим ферментом, який каталізує біохімічний синтез розгалужених амінокислот валін, лейцин та ізолейцин (Singh B. K. (Ed) Plant amino acids. Marcel Dekker Inc. New York, N.Y. Pg 227-247). AHAS є місцем дії чотирьох різних за структурою родин гербіцидів, включаючи сульфонілсечовини (LaRossa R A and Falco S C, 1984 Trends Biotechnol. 2: 158-161), імідазолінони (Shaner et al., 1984 Plant Physiol. 76: 545-546), триазолопіримідини (Subramanian and Gerwick, 1989, Inhibition of acetolactate synthase by triazolopyrimidinesin (ed) Whitaker J R, Sonnet P E Biocatalysis in agricultural biotechnology. ACS Symposium Series, American Chemical Society. Washington, D.C. Pg 277-288), та піримідинілбензоати (Subramanian et al., 1990 Plant Physiol 94: 239-244.). Через інгібування активності AHAS ці родини гербіцидів запобігають подальшому ростові та розвиткові сприйнятливих рослин, включаючи багато видів бур’янів. Такі гербіциди, як імідазолінон (IMI) та сульфонілсечовина (SU) широко застосовуються у сучасному сільському господарстві завдяки їхній ефективності при дуже низьких нормах внесення і з відносною нетоксичністю для тварин. У рослинах фермент AHAS складається з двох субодиниць: великої субодиниці (каталітична роль) та малої субодиниці (регуляторна роль) (Duggleby and Pang (2000) J. Biochem. Mol. Biol. 33: 1-36). Велика субодиниця AHAS (AHASL) може кодуватися одним геном, як у випадках з Arabidopsis та рисом, або представниками кількох родин генів, як у випадках кукурудзою, канолою та бавовною. Специфічні, однонуклеотидні заміщення у великій субодиниці можуть надавати ферментові певного ступеня нечутливості до одного або кількох класів гербіцидів (Chang and Duggleby (1998) Biochem J. 333: 765-777). За визначенням модифікації амінокислотної послідовності AHAS, як правило, розпізнають з врахуванням їх позиції у послідовності AHAS Arabidopsis thaliana (номер доступу EMBL X51514) і позначають (At). Модифікації AHAS генів в результаті можуть забезпечувати толерантні до гербіцидів фенотипи (Hattori, 1995; Warwick, 2008). Заміщення у генах, які кодують велику субодиницю AHAS і які вказуються в цьому описі як AHASL гени, є молекулярною основою толерантності до гербіцидів у культурах CLEARFIELD®, які мають підвищену толерантність до імідазолінонових гербіцидів. Оскільки кожне з цих заміщень в результаті дає напівдомінантний фенотип, одне заміщення у гетерозиготному стані може бути достатнім для забезпечення рівня толерантності до гербіцидів, який є прийнятним для багатьох рослинницьких систем. Однак для певних випадків застосування гербіцидів та культурних рослин, які мають багато AHASL генів, таких, як пшениця, бажаними є комбінації заміщень для досягнення підвищеного рівня толерантності до гербіцидів. Triticum aestivum є гексаплоїдним видом пшениці, який має три геноми, тобто, D геном, B геном та A геном. Кожен геном містить AHAS ген, і гени отримують назву з врахуванням геному походження та еволюційної спорідненості, наприклад, AHAS гени великої субодиниці, розташовані на геномах D, B та A Triticum aestivum, називаються TaAHASL1D, TaAHASL1B та TaAHASL1A, відповідно. Кожен з генів демонструє значну експресію на основі реакції на гербіциди та біохімічних даних варіантів у кожному з трьох генів (Ascenzi et al. (2003) International Society of Plant Molecular Biologists Congress, Barcelona, Spain, Ref. No. S 10-17). Кодуючі послідовності всіх трьох генів мають широку гомологію на нуклеотидному рівні (документ WO 03/014357). Через секвенування AHASL генів з кількох сортів Triticum aestivum було виявлено, що молекулярною основою толерантності до гербіцидів у більшості толерантних до імідазолінону (IMI) ліній є зміна однієї пари основ, що веде до амінокислотного заміщення S653(At)N (S653N), яке означає заміщення серину аспарагіном у позиції, еквівалентній серинові в амінокислоті 653 в Arabidopsis thaliana (документи WO 03/014356; WO 03/014357). Заміщення S653N відбувається через однонуклеотидний поліморфізм (SNP) у послідовності ДНК, яка кодує білок AHASL. Заміщення було виявлено в усіх трьох геномах, і вони повинні легко й швидко розрізнятися для точної селекції та підтвердження партій сортового насіння (Berard, 2009; Dong, 2009). Одне мета селекціонерів рослин полягає у наданні толерантності до імідазолінону існуючим лініям пшениці шляхом викликання заміщення S653N в існуючих лініях або шляхом 1 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 схрещування нетолерантних до IMI ліній з толерантними до IMI лініями з наступним зворотним схрещуванням та відбором на толерантність до імідазолінону. Ще одна мета селекціонерів рослин полягає у створенні пшениці з підвищеним рівнем толерантності до імідазолінону, яка перевищує рівень толерантності, що спостерігається у пшениці, що має одиничне заміщення S653N в одному AHASL гені пшениці. Таким чином, бажаним є виведення сортів пшениці, які мають комбінації заміщень S653N у двох або більшій кількості AHASL генів. Крім того, також бажаним є виведення рослин пшениці, які є гомозиготними щодо заміщеного алеля S653N в одному або кількох AHASL генах. Однак для виведення потрібної пшениці вимагаються швидкі способи розпізнавання потрібних рослин. Існуючі способи виявлення рослин пшениці з толерантністю до імідазолінону не є високоефективними для застосування у виведенні рослин, які мають більше одного алеля S653N в одному гені AHASL. Існуючі способи розпізнавання рослин з підвищеною толерантністю до імідазолінону включають тести з обприскуванням гербіцидами у полі або у теплицях та біохімічні аналізи на активність AHAS. Однак такі способи вимагають багато часу і зазвичай не є придатними для виявлення з-поміж великої кількості окремих рослин ледь помітного збільшення толерантності до імідазолінону, яке може траплятися при введенні другого алеля S653N у рослину пшениці. Альтернативні способи розпізнавання потрібних рослин включають способи на основі ДНК. Наприклад, AHASL гени або їх частини можуть бути ампліфіковані з геномної ДНК шляхом застосування способів полімеразної ланцюгової реакції (ПЛР), і одержаний в результаті ампліфікований AHASL ген або його частину секвенують для розпізнавання заміщеного алеля S653N та конкретного AHASL гена, в якому він присутній. Однак такий спосіб на основі секвенування ДНК не є ефективним для великої кількості зразків. Інший підхід включає застосування радіоактивно мічених або неізотопно мічених, алель-специфічних олігонуклеотидів (ASO) як зондів для дот-блот-аналізу геномної ДНК або ампліфікованої шляхом полімеразної ланцюгової реакції (ПЛР) ДНК (Connor et al. (1983) Proc. Natl. Acad. Sci. USA 80: 278-282; Orkin et al. (1983) J. Clin. Invest. 71: 775-779; Brun et al. (1988) Nucl. Acids Res. 16: 352; та Bugawan et al. (1988) Biotechnology 6: 943-947. Хоча такий підхід є корисним для розрізнення між двома алелями в одному локусі, цей підхід є неприйнятним для AHASL генів пшениці, оскільки три AHASL гени є майже ідентичними у ділянці, яка оточує SNP, що викликає утворення S653(At)N-заміщеного білка AHASL. Таким чином, неможливо одержати набір з шести таких олігонуклеотидних зондів, який міг би розрізняти заміщені алелі та алелі дикого типу в кожному з трьох AHASL генів пшениці. Один спосіб, який може бути пристосований для швидкого відбору великої кількості окремих рослин для аналізу SNP, являє собою застосування ампліфікаційної системи для ідентифікації мутацій (ARMS) (Newton et al. (1989) Nucl. Acids Res. 17: 2503-2516). Цей спосіб на основі ПЛР може застосовуватися для розрізнення двох алелей гена, які відрізняються одним нуклеотидом, і також може застосовуватися для відрізнення гетерозигот від гомозигот для будь-якого алеля шляхом огляду продуктів ПЛР після електрофорезу на агарозному гелі та забарвлення бромідом етедію. Спосіб ARMS ґрунтується на припущенні, що олігонуклеотиди з помилково спареним 3'-залишком не функціонують як праймери у ПЛР за належних умов (Newton et al. (1989) Nucl. Acids Res. 17: 2503-2516). Ампліфікаційна система для ідентифікації мутацій (ARMS-ПЛР) з застосуванням способів виявлення на агарозному гелі може включати внутрішнє помилкове спарювання нуклеотидів у межах алель-специфічного (AS) праймера для підвищення специфічності аналізу. Наприклад, позицію внутрішнього помилкового спарювання досліджували у багатоалельній системі у популяції курчат, у якій оптимальний праймер мав помилкове спарювання 2 пар основ з поліморфного нуклеотиду. Застосування умисних помилкових спарень у кількісній ПЛР (кПЛР) було випробувано у медичній галузі. Генотипування однонуклеотидного поліморфізму (SNP) зазвичай здійснюють для оцінки сприйнятливості до хвороби та оцінки химеризму. Розробка однієї системи кПЛР мала на меті контроль над химеризмом. Аналіз з застосуванням SNP-специфічної кПЛР дозволяв виявляти позитивний матричний алель на рівні 0,1%. AS-праймери містили від однієї до двох умисних помилкових спарювань у межах 1-4 пар основ потрібного поліморфізму. Було виявлено, що помилкові спарювання у праймерах, які є спрямованими на поліморфну ділянку гена у неполіплоїдному організмі створюють зсув у C T у напрямку вищих значень під час кПЛР з виявленням за допомогою SYBR-green (наприклад, lim1 гена Picea glauca). Це знижує чутливість аналізу, і, таким чином, ця технологія є недостатньою для зібраних зразків. Зсув є менш різким, коли помилкове спарювання розташовується ближче до 3’ кінця праймера. Однак необхідним є зниження концентрації ДНК для уникнення довільного додавання помилкових спарювань. Хоча спосіб ARMS-ПЛР виявився придатним для аналізу SNP в одному гені, не 2 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 повідомляється про те, чи можна цей спосіб або будь-які інші способи на основі ПЛР застосовувати для аналізу SNP, що забезпечує толерантні до гербіцидів заміщення у природних AHAS генах у різних геномах одного виду, наприклад, заміщення S653N у кожному з трьох AHASL генів пшениці. Існуючі способи мають недостатню чутливість аналізу, що може робити їх небажаними для виявлення SNP, зокрема, для виявлення SNP в аналізі високогомологічних генів в одному виді, наприклад, у виді, який має багато геномів. Таким чином, зберігається потреба у способі, який би ефективніше розрізняв рослини пшениці, які мають AHASL дикого типу та рослини пшениці, які мають варіанти AHASL, та їх зиготність. КОРОТКИЙ ОПИС ВИНАХОДУ Даний винахід забезпечує способи аналізу AHASL генів рослин. Способи можуть включати аналіз, який включає забезпечення ДНК, який включає AHASL ген рослин; ампліфікацію ДНК з застосуванням прямого праймера AHASL, зворотного праймера AHASL, полімерази та дезоксирибонуклеотид трифосфатів; виявлення продуктів ампліфікації за допомогою зонда AHASL дикого типу та толерантного до гербіцидів зонда AHASL для визначення зиготності AHASL гена, наприклад, як гомозиготного дикого типу, гетерозиготного або гомозиготного, з нуклеотидним заміщенням, що створює заміщення S653N. Аналіз може бути ПЛР-аналізом у реальному часі або мультиплексним аналізом, включаючи мультиплексний ПЛР-аналіз у реальному часі. AHASL зонд дикого типу може бути мічений першим типом сигналу, що піддається виявленню, наприклад, першим типом флуоресцентної репортерної молекули, і толерантний до гербіцидів AHASL зонд може бути мічений другим типом сигналу, що піддається виявленню, наприклад, другим типом флуоресцентної репортерної молекули. Зиготність AHASL гена може бути визначена на основі показників dCt, одержаних під час ПЛР-аналізу в реальному часі. Способи аналізу AHASL гена рослин застосовують для аналізу геномної ДНК. Способи можуть застосовуватися для аналізу AHASL генів рослин, які мають багато геномів. Наприклад, способи, описані авторами, можуть застосовуватися для аналізу AHASL генів рослин пшениці, включаючи гексаплоїдні та тетраплоїдні рослини пшениці, такі, як Triticum aestivum та T. turgidum видів durum, відповідно. Існує потреба у способі розрізнення між AHASL генами різних видів пшениці. Також існує потреба в аналізі, який не має зниження чутливості, коли аналізуються високогомологічні гени у межах одного виду, наприклад, таких видів рослин, як пшениця, які мають багато геномів з високою подібністю. Як було описано вище, існуючі способи мають знижену чутливість і є неприйнятними для цих цілей. Описані авторами способи усувають проблему недостатньої чутливості аналізу, характерної для існуючих способів, і дозволяє розрізняти AHASL гени різних видів пшениці ті аналізувати високогомологічні гени у межах одного виду, наприклад, Triticum aestivum та T. turgidum видів durum. Описані авторами способи передбачають застосування побудованих вручну прямих праймерів AHASL. Кожен з прямих праймерів AHASL може включати, як 3’-кінцевий нуклеотид, нуклеотид, який є сумісним з триалельним однонуклеотидним поліморфізмом, розташованим приблизно за 40 нуклеотидів до нуклеотидного заміщення в AHASL гені, що продукує заміщення S653N. Прямий праймер AHASL також може включати один або кілька додаткових умисних помилкових спарювань нуклеотидів з AHASL геном. Умисне помилкове спарювання може розташовуватися за 2 або 3 нуклеотиди до 3’-кінцевого нуклеотиду прямого праймера AHASL. Таким чином, прямі праймери AHASL можуть мати умисне помилкове спарювання нуклеотидів з нуклеотидом в AHASL гені, розташованому за 2 або 3 нуклеотиди до триалельного SNP. Як обговорювалося вище, застосування праймерів з внутрішніми помилковими спарюваннями нуклеотидів може знижувати чутливість аналізу. Описані авторами способи передбачають застосування праймерів, побудованих на основі умисного помилкового спарювання нуклеотидів та унікального поліморфізму та генотипування SNP у реальному часі для потрібної характеристики. Крім того, інші типі маркерів, наприклад, інсерції, делеції, двоабо тринуклеотидні повтори, малі мікросателіти або інші SNP поблизу від заданого поліморфізму можуть забезпечувати унікальну особливість, яка може застосовуватися для підвищення специфічності аналізу. Інші типи маркерів можуть розташовуватися у межах 300 пар основ до або після заданого поліморфізму, в оптимальному варіанті - у межах 200 пар основ, у ще кращому варіанті - у межах 200 пар основ. Описані авторами способи передбачають застосування прямих праймерів AHASL, які включають від десяти до п’ятнадцяти кінцевих нуклеотидів SEQ ID NO:13, SEQ ID NO:14 або SEQ ID NO:17. Прямі праймери AHASL можуть бути вибрані з-поміж олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:13, олігонуклеотидів, які мають послідовність, викладену 3 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 в SEQ ID NO:14, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:15, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:16, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:17, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:18, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:19, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:20; олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:21, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:22, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:23, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:24, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:25, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:26, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:27, олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:28, та олігонуклеотидів, які мають послідовність, викладену в SEQ ID NO:29. Даний винахід також забезпечує комплект для аналізу AHASL гена рослин. Комплект може включати прямий праймер AHASL; зворотний праймер AHASL; зонд AHASL дикого типу; толерантний до гербіцидів зонд AHASL; полімеразу; та дезоксирибонуклеотид трифосфати. Даний винахід також забезпечує прямі праймери AHASL. Прямі праймери можуть бути олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:13, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:14, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:15, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:16, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:17, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:18; олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:19, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:20, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:21, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:22, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:23, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:24, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:25, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:26, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:27, олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:28, та олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:29. Даний винахід також забезпечує зонди AHASL, наприклад, зонди, які можуть бути специфічними до алель AHASL дикого типу або толерантний до гербіцидів алель AHASL. Типову послідовність зонда дикого типу представлено у SEQ ID NO:32. Типову послідовність толерантного до гербіцидів зонда представлено у SEQ ID NO:33. Авторами описуються зонди AHASL, придатні для застосування у мультиплексному форматі описаних авторами способів. Набір таких зондів може включати два або три різні зонди, які включають, як їхні 5’-кінцеві нуклеотиди, різні SNP нуклеотиди, вибрані з-поміж нових триалельних SNP AHASL гена, які описуються авторами, а як їхні 3’-кінцеві нуклеотиди нуклеотид, який викликає заміщення S653N; і може включати принаймні один зонд “дикого типу”, який також має такий нуклеотид SNP як його 5’-кінцевий нуклеотид, але має як його 3’кінцевий нуклеотид нуклеотид дикого типу у позиції, яка відповідає позиції 653(At) AHASL гена. Наприклад, у мультиплексному аналізі можуть застосовуватися зонди, специфічні до кожного алеля AHASL, наприклад, набір з шести зондів, по одному для кожного з алелів дикого типу та толерантних до гербіцидів алелів AHASL1D, AHASL1B та AHASL1A, причому зонд для кожного алеля є міченим унікальним сигналом, що піддається виявленню, який забезпечує можливість виявлення всіх алелів AHASL, присутніх у зразку. КОРОТКИЙ ОПИС ФІГУР Фіг. 1A показує часткову нуклеотидну (SEQ ID NO:1) та часткову амінокислотну (SEQ ID NO:2) послідовності дикого типу (WT) AHASL1D і часткову нуклеотидну (SEQ ID NO:3) та часткову амінокислотну (SEQ ID NO: 4) послідовності толерантного до гербіцидів (HT) AHASL1D. Фіг. 1B показує часткову нуклеотидну (SEQ ID NO:5) та часткову амінокислотну (SEQ ID NO:6) послідовності дикого типу (WT) AHASL1B і часткову нуклеотидну (SEQ ID NO:7) та часткову амінокислотну (SEQ ID NO:8) послідовності толерантного до гербіцидів (HT) AHASL1B. Фіг. 1C показує часткову нуклеотидну (SEQ ID NO:9) та часткову амінокислотну (SEQ ID NO:10) послідовності дикого типу (WT) AHASL1A і часткову нуклеотидну (SEQ ID NO:11) та часткову амінокислотну (SEQ ID NO:12) послідовності толерантного до гербіцидів (HT) AHASL1A. Фіг. 2 показує часткове вирівнювання трьох послідовностей ДНК AHASL пшениці (AHASL1D, AHASL1B; та AHASL1A) з прямими праймерами AHASL TaAHASDMMFor2 (SEQ ID NO:16), 4 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 TaAHASDMMFor3 (SEQ ID NO:18), TaAHASDForSNP (SEQ ID NO:19) та TaAHASD (SEQ ID NO:30) і зондом AHASL дикого типу (SEQ ID NO:32). Фіг. 3 є таблицею, в якій вказується відсоток ідентичності нуклеотидних послідовностей з попарних порівнянь кодуючих послідовностей AHASL гена пшениці. Гексаплоїдний L1D, гексаплоїдний L1B та гексаплоїдний L1A означають AHASL1D, AHASL1B та AHASL1A гени, відповідно, з Triticum aestivum. Тетраплоїдний L1B та тетраплоїдний L1A означають гени AHASL1B та AHASL1A, відповідно, з T. turgidum виду durum. Фіг. 4 є діаграмою розкиду значень dCt перевірного аналізу з застосуванням праймера TaAHASDMMFor2 (SEQ ID NO:16). Фіг. 5 є діаграмою розкиду значень dCt перевірного аналізу з застосуванням праймера TaAHASDMMFor3 (SEQ ID NO:18). Фіг. 6 є діаграмою розкиду значень dCt експериментального аналізу з застосуванням праймера TaAHASDMMFor2 (SEQ ID NO:16). Фіг. 7 є частковим вирівнюванням трьох послідовностей кДНК AHASL пшениці (AHASL1D, SEQ ID NO:34; AHASL1B, SEQ ID NO:35; та AHASL1A, SEQ ID NO:36) з посиланням на порівняльну позицію нуклеотидної послідовності AHAS Arabidopsis thaliana. ПЕРЕЛІК ПОСЛІДОВНОСТЕЙ Нуклеїновокислотні та амінокислотні послідовності, перелічені у супровідному переліку послідовностей, показано з застосуванням стандартних літерних скорочень для нуклеотидних основ. Нуклеїновокислотні послідовності позначаються згідно з прийнятими стандартами, починаючи з 5'-кінця послідовності з просуванням далі (тобто, зліва направо у кожному ряді) до 3'-кінця. Показано лише один ланцюг кожної нуклеїновокислотної послідовності, але передбачається, що комплементарний ланцюг включається шляхом будь-якого посилання на показаний ланцюг. Амінокислотні послідовності вказуються згідно з прийнятим стандартом, починаючи з аміно-кінця з просуванням далі (тобто, зліва направо у кожному ряді) до карбоксикінця. SEQ ID NO:1 представляє нуклеотидну послідовність частини алеля AHASL1D дикого типу. SEQ ID NO:2 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:1. SEQ ID NO:3 представляє нуклеотидну послідовність частини толерантного до гербіцидів (HT) алеля AHASL1D. SEQ ID NO:4 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:3. SEQ ID NO:5 представляє нуклеотидну послідовність частини алеля AHASL1B дикого типу. SEQ ID NO:6 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:5. SEQ ID NO:7 представляє нуклеотидну послідовність толерантного до гербіцидів (HT) алеля AHASL1B. SEQ ID NO:8 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:7. SEQ ID NO:9 представляє нуклеотидну послідовність частини алеля AHASL1A дикого типу. SEQ ID NO:10 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:9. SEQ ID NO:11 представляє нуклеотидну послідовність частини толерантного до гербіцидів (HT) алеля AHASL1A. SEQ ID NO:12 представляє амінокислотну послідовність, яка кодується нуклеотидною послідовністю SEQ ID NO:11. SEQ ID NO:13 представляє нуклеотидну послідовність прямого праймера AHASL1, що також вказується авторами як TaAHASMMFor2. SEQ ID NO:14 представляє нуклеотидну послідовність прямого праймера AHASL1, що також вказується авторами як TaAHASMMFor3. SEQ ID NO:15 представляє нуклеотидну послідовність прямого праймера AHASL1D, що також вказується авторами як TaAHASDMMFor2Gen. SEQ ID NO:16 представляє нуклеотидну послідовність прямого праймера AHASL1D, що також вказується авторами як TaAHASDMMFor2. SEQ ID NO:17 представляє нуклеотидну послідовність прямого праймера AHASL1D, що також вказується авторами як TaAHASDMMFor3Gen. SEQ ID NO:18 представляє нуклеотидну послідовність прямого праймера AHASL1D, що також вказується авторами як TaAHASDMMFor3. SEQ ID NO:19 представляє нуклеотидну послідовність для прямого праймера AHASL1D, що 5 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 також вказується авторами як TaAHASDForSNP. SEQ ID NO:20 представляє нуклеотидну послідовність прямого праймера AHASL1B, що також вказується авторами як TaAHASBMMFor2Gen. SEQ ID NO:21 представляє нуклеотидну послідовність прямого праймера AHASL1B, що також вказується авторами як TaAHASBMMFor2. SEQ ID NO:22 представляє нуклеотидну послідовність прямого праймера AHASL1B, що також вказується авторами як TaAHASBMMFor3Gen. SEQ ID NO:23 представляє нуклеотидну послідовність прямого праймера AHASL1B, що також вказується авторами як TaAHASBMMFor3. SEQ ID NO:24 представляє нуклеотидну послідовність для прямого праймера AHASL1B, що також вказується авторами як TaAHASBForSNP. SEQ ID NO:25 представляє нуклеотидну послідовність прямого праймера AHASL1А, що також вказується авторами як TaAHASAMMFor2Gen. SEQ ID NO:26 представляє нуклеотидну послідовність прямого праймера AHASL1А, що також вказується авторами як TaAHASAMMFor2. SEQ ID NO:27 представляє нуклеотидну послідовність прямого праймера AHASL1А, що також вказується авторами як TaAHASAMMFor3Gen. SEQ ID NO:28 представляє нуклеотидну послідовність прямого праймера AHASL1А, що також вказується авторами як TaAHASAMMFor3. SEQ ID NO:29 представляє нуклеотидну послідовність для прямого праймера AHASL1А, що також вказується авторами як TaAHASAForSNP. SEQ ID NO:30 представляє нуклеотидну послідовність для прямого праймера AHASL, що також вказується авторами як TaAHASD. SEQ ID NO:31 представляє нуклеотидну послідовність для зворотного праймера AHASL. SEQ ID NO:32 представляє нуклеотидну послідовність для зонда AHASL дикого типу. SEQ ID NO:33 представляє нуклеотидну послідовність для толерантного до гербіцидів (HT) зонда AHASL. SEQ ID NO:34 представляє часткову послідовність кДНК AHASL1D пшениці. SEQ ID NO:35 представляє часткову послідовність кДНК AHASL1В пшениці. SEQ ID NO:36 представляє часткову послідовність кДНК AHASL1А пшениці. ДЕТАЛЬНИЙ ОПИС ВИНАХОДУ Даний винахід забезпечує способи, комплекти та праймери для аналізу геномів рослин, зокрема, для аналізу AHASL генів у них. Описані авторами способи включають аналіз однонуклеотидного поліморфізму (SNP) через виявлення заданої ампліфікації у реальному часі шляхом вимірювання сигналів, що піддаються виявленню, наприклад, флуоресцентних сигналів, які випускаються репортерними зондами після гібридизації з SNP-мішенями. Описані авторами способи включають ПЛР-аналіз у реальному часі для визначення присутності толерантного до гербіцидів (HT) алеля або алеля дикого типу в одному або кількох AHASL генах у геномі рослини. HT алель може включати нуклеотидні послідовності, які кодують толерантні до гербіцидів білки AHASL, які мають заміщення S653N. Способи забезпечують можливість визначення зиготності кожного AHASL гена у рослині. Ці способи є особливо придатними для аналізу AHASL генів рослин, які мають багато AHASL генів, таких, як, наприклад, м’яка пшениця, Triticum aestivum, та тверда пшениця, T. turgidum видів durum. Амінокислотне заміщення S653N є результатом переходу від G до A у позиції, що відповідає нуклеотидові 1958 нуклеотидної послідовності AHASL Arabidopsis thaliana, викладеної під номером доступу EMBL X51514, яку включено до цього опису шляхом посилання. Фігури з 1A по 1C показують нуклеотидні послідовності дикого типу та HT та кодовані амінокислотні послідовності для AHASL1D, AHASL1B та AHASL1A, відповідно. Способи, комплекти та праймери, описані авторами, застосовують для визначення зиготності рослини, наприклад, чи є рослина пшениці гомозиготною щодо толерантного до гербіцидів (HT) алеля AHASL, гетерозиготною, гомозиготною щодо алеля дикого типу, гемізиготною щодо HT алеля або алеля дикого типу, нульовою щодо AHASL ген, у кожному з трьох AHASL генів у рослині пшениці T. aestivum або з двох AHASL генів у твердих сортах пшениці T. turgidum. Способи можуть застосовуватись у селекційних програмах для одержання толерантних до імідазолінону рослин пшениці, які мають один, два, три, чотири, п’ять або шість алелів AHASL у їх геномах. T. aestivum має гексаплоїдний геном, який включає три дуже подібні, але різні AHASL гени, позначені як AHASL1D, AHASL1B та AHASL1A. Натомість, T. turgidum видів durum має тетраплоїдний геном, який включає два дуже подібні, але різні AHASL гени, позначені як AHASL1B та AHASL1A. Хоча вони й не є ідентичними, AHASL1B та AHASL1A T. aestivum 6 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 виявилися близько спорідненими з AHASL1B та AHASL1A T. turgidum видів durum на основі вирівнювання послідовностей та розрахунків відсотка ідентичності послідовностей. Фіг. 3 показує ідентичність нуклеотидних послідовностей з попарних порівнянь кодуючих AHASL ген послідовностей T. aestivum та T. turgidum видів durum. Нижче визначаються вживані авторами терміни. "Праймер" є одноланцюговим олігонуклеотидом, який має 3'-кінець та 5'-кінець, здатним до ренатурації з сайтом ренатурації на ланцюгу ДНК-мішені та служити сайтом ініціації для синтезу ДНК ДНК-полімеразою, зокрема, при ПЛР-ампліфікації. Такий праймер може бути або не бути повністю комплементарним його сайтові ренатурації на ДНК-мішені. "Сайт ренатурації” на ланцюгу ДНК-мішені є сайтом, з яким може ренатуруватися праймер. Як правило, для ампліфікації фрагмента гена шляхом ПЛР застосовують пару праймерів, які ренатуруються з протилежними ланцюгами дволанцюгової молекули ДНК. Згідно з прийнятим стандартом, "прямий праймер" ренатурується з некодуючим ланцюгом гена, а "зворотний праймер" ренатурується з кодуючим ланцюгом. Описані авторами "прямий праймер AHASL" та "зворотний праймер AHASL" застосовують як пару праймерів при ампліфікації фрагмента конкретного AHASL гена, наприклад, AHASL1D, AHASL1B та AHASL1A T. aestivum і/або AHASL1B та AHASL1A T. turgidum видів durum. Описаний авторами прямий праймер AHASL може бути специфічним до конкретного AHASL гена, наприклад, специфічним до одного з-поміж AHASL1D, AHASL1B та AHASL1A. Зворотний праймер AHASL може застосовуватися для кожного AHASL гена. Терміни “толерантний до гербіцидів (HT) алель”, “толерантний до гербіцидів алель AHASL”, “толерантний до гербіцидів AHASL ген”, “варіантний алель”, “варіантний алель AHASL”, “варіантний AHASL ген”, “заміщений алель”, “заміщений алель AHASL” та “заміщений AHASL ген”, якщо в тексті не вказано іншого, стосуються полінуклеотиду, який кодує толерантний до імідазолінону білок AHASL, який включає заміщення S653N. Терміни "алель дикого типу", "алель AHASL дикого типу", "AHASL ген дикого типу", “сприйнятливий алель”, “сприйнятливий алель AHASL” та “сприйнятливий AHASL ген”, якщо в тексті не вказано іншого, стосуються полінуклеотиду, який кодує білок AHASL, у якому відсутнє заміщення S653N. Однак такий "алель дикого типу", "алель AHASL дикого типу", "AHASL ген дикого типу", “сприйнятливий алель”, “сприйнятливий алель AHASL” або “сприйнятливий AHASL ген” можуть необов’язково включати заміщення, відмінні від заміщення, що викликає заміщення S653N. У контексті цього опису “дикого типу” або “відповідна рослина дикого типу” означає типову форму організму або його генетичного матеріалу, яка зазвичай трапляється, наприклад, у відмінній від варіантних, заміщених та/або рекомбінантних форм. Якщо в тексті не вказано іншого, "полімераза" означає ДНК-полімеразу, зокрема, ДНКполімеразу, яка є прийнятною для застосування при ПЛР ампліфікації, як описано авторами, наприклад, Taq полімеразу. Описані авторами способи включають аналізи для розпізнавання SNP та визначення зиготності в AHASL генах пшениці стосовно нуклеотидного перетворення, що дає заміщення S653N. Описаний авторами процес розпізнавання SNP може являти собою виявлення заданої ампліфікації у реальному часі шляхом вимірювання флуоресцентних сигналів, які випускаються репортерними молекулами на зондах після гібридизації з мішенями SNP. Зазвичай після цього відбувається ферментативне розщеплення молекули-гасника Taq полімеразою через ПЛР. Точне визначення зміни однієї пари основ може бути надзвичайно важким. Це зазвичай зумовлюється перехресною гібридизацією специфічних до HT алеля та специфічних до алеля дикого типу зондів з будь-яким алелем незалежно від фактичного генотипу. Брак специфічності може бути результатом ідентичної гомології ділянки гена, що містить потрібний SNP. План аналізу може включати білок, що зв’язується з малою борозенкою, або закриту нуклеїнову кислоту на 3’-кінці флуоресцентного зонда для підвищення специфічності. Через жорсткі параметри, пов’язані з розробкою аналізу в реальному часі аналізи зазвичай повністю плануються з застосуванням програмного забезпечення. Однак описані авторами аналізи можуть включати особливості, передбачені без застосування програмного забезпечення або інших технологій планування аналізів, наприклад, праймерні послідовності та послідовності зондів будують без застосування програмного забезпечення або технологій планування аналізів. Зокрема, описані авторами прямі праймери AHASL можуть бути побудовані без застосування програмного забезпечення або інших технологій планування аналізів. Іншими словами, прямі праймери AHASL можуть бути побудовані вручну. Прямі праймери AHASL можуть використовувати триалельний SNP, який існує між трьома AHASL генами, або відповідний двоалельний SNP, який існує між двома AHASL генами. Деякі описані 7 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 авторами прямі праймери AHASL також можуть включати умисне помилкове спарювання нуклеотидів між праймером та AHASL геном для посилення розпізнавання заміщення S653N. Застосування умисного помилкового спарювання нуклеотидів між праймерами та заданими послідовностями не є типовим для спланованих за допомогою програмного забезпечення ПЛРаналізів у реальному часі для AHASL гена рослин, включаючи пшеницю. У контексті цього опису “триалельний SNP” та “біалельний SNP” означають однонуклеотидні поліморфізми між різними AHASL генами у багатогенній рослині, наприклад, між кожним з AHASL1D, AHASL1B та AHASL1A генів гексаплоїдної пшениці або між кожним з AHASL1B та AHASL1A генів тетраплоїдної пшениці. Триалельний SNP та біалельний SNP у контексті цього опису можуть розпізнавати конкретний AHASL ген рослини, що має кілька AHASL генів. Триалельний SNP та біалельний SNP у контексті цього опису не розрізняють алелі AHASL дикого типу та HT. Прямі праймери AHASL, які застосовують згідно з описаними авторами способами, називаються TaAHASMMFor2 (SEQ ID NO:13) та TaAHASMMFor3 (SEQ ID NO:14). Описані авторами способи передбачають застосування прямих праймерів AHASL, які можуть бути специфічними до конкретного AHASL гена. Прямі праймери AHASL1D для застосування згідно з описаними авторами способами вказуються як TaAHASDMMFor2Gen праймер (SEQ ID NO:15), TaAHASDMMFor2 праймер (SEQ ID NO:16), TaAHASDMMFor3Gen праймер (SEQ ID NO:17), TaAHASDMMFor3 праймер (SEQ ID NO:18) та Праймер TaAHASDForSNP (SEQ ID NO:19). Прямі праймери AHASL1B для застосування згідно з описаними авторами способами вказуються як TaAHASBMMFor2Gen праймер (SEQ ID NO:20), TaAHASBMMFor2 праймер (SEQ ID NO:21), TaAHASBMMFor3Gen праймер (SEQ ID NO:22), TaAHASBMMFor3 праймер (SEQ ID NO:23) та TaAHASBForSNP праймер (SEQ ID NO:24). Прямі праймери AHASL1A для застосування згідно з описаними авторами способами вказуються як TaAHASAMMFor2Gen праймер (SEQ ID NO:25), TaAHASAMMFor2 праймер (SEQ ID NO:26), TaAHASAMMFor3Gen праймер (SEQ ID NO:27), TaAHASAMMFor3 праймер (SEQ ID NO:28) та TaAHASAForSNP праймер (SEQ ID NO:29). Прямі праймери AHASLB та AHASLA є придатними для застосування у T. aestivum та T. turgidum видів durum. Ці прямі праймери AHASL будують без застосування програмного забезпечення або інших технологій планування аналізів, і вони включають триалельний SNP між геномами AHASL1D, AHASL1A та AHASL1B T. aestivum або, у разі T. turgidum видів durum, біалельний SNP між AHASL1A та AHASL1B. SNP розташовується приблизно за 40 нуклеотидів до заміщення, що кодує заміщення S653N. SNP для кожного геному T. aestivum є таким: AHASL1D має аденін, AHASL1B має тимін, і AHASL1A має цитозин. SNP для AHASL1B та AHASL1A у T. turgidum видів durum є однаковими. Крім включення триалельного SNP у побудову прямого праймера AHASL, прямі праймери TaAHASMMFor2 (SEQ ID NO:13), TaAHASMMFor3 (SEQ ID NO:14), TaAHASDMMFor2Gen (SEQ ID NO:15), TaAHASDMMFor2 (SEQ ID NO:16), TaAHASBMMFor2Gen (SEQ ID NO:20), TaAHASBMMFor2 (SEQ ID NO:21), TaAHASBMMFor3Gen (SEQ ID NO:22), TaAHASBMMFor3 (SEQ ID NO:23), TaAHASAMMFor2Gen (SEQ ID NO: 25), TaAHASAMMFor2 (SEQ ID NO:26), TaAHASAMMFor3Gen (SEQ ID NO:27) та TaAHASMMFor3 (SEQ ID NO:28) мають умисне помилкове спарювання нуклеотидів з AHASL геном, розташованим за три нуклеотиди до кінцевого нуклеотиду праймера. Умисне помилкове спарювання нуклеотидів прямого праймера TaAHASDMMFor2 (SEQ ID NO:16) показано на Фіг. 2. Фіг. 2 показує помилково спарений нуклеотид як помилкове спарювання C з A, розташоване за 3 нуклеотиди до 3’-кінцевого нуклеотиду. Праймери TaAHASBMMFor2 (SEQ ID NO:21), TaAHASAMMFor2 (SEQ ID NO:26) та TaAHASAMMFor3 (SEQ ID NO:28) також можуть мати умисне помилкове спарювання C з A. Праймер TaAHASBMMFor3 (SEQ ID NO:23) може мати C з G умисне помилкове спарювання. Помилкове спарювання може бути помилковим спарюванням C з A, помилковим спарюванням C з G або помилковим спарюванням C з T, як у праймерах TaAHASMMFor2 (SEQ ID NO:13), TaAHASMMFor3 (SEQ ID NO:14), TaAHASDMMFor2Gen (SEQ ID NO:15), TaAHASBMMFor2Gen (SEQ ID NO:20), TaAHASBMMFor3Gen (SEQ ID NO:22), TaAHASAMMFor2Gen (SEQ ID NO: 23) та TaAHASAMMFor3Gen (SEQ ID NO:27). Крім включення триалельного SNP у конструкцію прямого праймера AHASL, прямі праймери TaAHASDMMFor3Gen (SEQ ID NO:17) та TaAHASDMMFor3 (SEQ ID NO:18) мають умисне помилкове спарювання нуклеотидів з AHASL геном, розташованим за два нуклеотиди до кінцевого нуклеотиду праймера. Умисне помилкове спарювання нуклеотидів праймера TaAHASDMMFor3 (SEQ ID NO:18) праймер показано на Фіг. 2. Фіг. 2 показує помилково спарені нуклеотиди як помилкове спарювання A з G. Однак помилкове спарювання може бути помилковим спарюванням A з G, помилковим спарюванням A з C або помилковим спарюванням 8 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 A з Т, як у праймері TaAHASDMMFor3Gen (SEQ ID NO:17). Застосування умисного помилкового спарювання нуклеотидів між прямим праймером AHASL та AHASL геном може поліпшувати точність визначення зиготності аналізів у реальному часі порівняно з прямими праймерами AHASL, які включають триалельний SNP, але не мають додаткового помилково спареного нуклеотиду. Наприклад, праймер TaAHASDForSNP не включає умисно помилково спареного нуклеотиду, як у праймерах TaAHASDMMFor2 та TaAHASDMMFor3. Праймер TaAHASDForSNP не забезпечує настільки точного визначення зиготності у ПЛР-аналізі у реальному часі, як праймери TaAHASDMMFor2 та TaAHASDMMFor3. Прямі праймери AHASL, які включають триалельний SNP AHASL гена, можуть мати температуру плавлення Tm за межами рекомендованого діапазону температур плавлення для технологій на основі ПЛР у реальному часі. Рекомендований діапазон температур плавлення для праймерів, які застосовують для технологій на основі ПЛР у реальному часі може становити 58-60C. Температура плавлення описаних авторами прямих праймерів AHASL може становити приблизно 54C. Вищеописані прямі праймери AHASL не обмежуються олігонуклеотидами точної довжини послідовностей, представлених у послідовностях з SEQ ID NO:13 по SEQ ID NO:29. Прямі праймери AHASL, які застосовують згідно з описаними авторами способами, можуть бути коротшими, за умови, що вони включають триалельний або біалельний SNP як кінцевий нуклеотид та, необов’язково, вищеописане умисне помилкове спарювання. Наприклад, прийнятні прямі праймери AHASL можуть включати від десяти до п’ятнадцяти кінцевих нуклеотидів, представлених у послідовностях з SEQ ID NO:13 по SEQ ID NO:29. Прямий праймер TaAHASD (SEQ ID NO:30) є комп’ютерно-побудованим праймером. Цей комп’ютерно-побудований праймер не включає триалельного SNP між AHASL генами або умисного помилкового спарювання нуклеотидів між праймером та мішенню, яке включають у побудовані вручну прямі праймери AHASL. Хоча він і є побудованим як прямий праймер для AHASL1D гена, прямий праймер TaAHASD може застосовуватися для AHASL1B та AHASL1A генів. Однак прямий праймер TaAHASD є неприйнятним для застосування у ПЛР-аналіз у реальному часі для аналізу AHASL генів, оскільки він не може розрізняти гомозиготні зразки дикого типу та гетерозиготні зразки. Як було зазначено, праймери TaAHASMMFor2, TaAHASMMFor3, TaAHASDMMFor2Gen, TaAHASDMMFor2, TaAHASDMMFor3Gen, TaAHASDMMFor3, TaAHASDForSNP, TaAHASBMMFor2Gen, TaAHASBMMFor2, TaAHASBMMFor3Gen, TaAHASBMMFor3, TaAHASBForSNP, TaAHASAMMFor2Gen, TaAHASAMMFor2, TaAHASAMMFor3Gen, TaAHASAMMFor2 та TaAHASAForSNP є побудованими без застосування програмного забезпечення або інших технологій планування аналізів. Програма для побудови праймерів відхиляє ці конструкції праймерів як неприйнятні для ПЛР-аналізу в реальному часі для аналізу рослинних AHASL генів. Зворотний праймер AHASL для застосування згідно з описаними авторами способами представлено як SEQ ID NO:31. Зворотний праймер AHASL може бути застосований для AHASL1D, AHASL1B та AHASL1A генів. Зворотний праймер AHASL вирівнюється з AHASL геном після нуклеотидного заміщення, що в результаті дає заміщення S653N. Зворотні праймери AHASL, прийнятні для описаних авторами способів, не обмежуються олігонуклеотидами, які мають послідовність, викладену в SEQ ID NO:31. Прийнятні зворотні праймери AHASL можуть бути вибрані таким чином, щоб створювати амплікон, який має максимальну довжину 200 пар основ, з яких прямий праймер та зонд займають від 40 до 80 пар основ амплікона, в оптимальному варіанті - від 50 до 75 пар основ, у ще кращому варіанті - від 60 до 75 пар основ, і у найкращому варіанті - приблизно 67 пар основ. Амплікон може мати довжину приблизно 100-200 пар основ, в оптимальному варіанті - приблизно 120-180 пар основ, у ще кращому варіанті - приблизно 140-160 пар основ, і у найкращому варіанті - від приблизно 150 до приблизно 160 пар основ. Амплікон може мати довжину приблизно 155 пар основ або приблизно 156 пар основ. Амплікон, який є довшим за 200 пар основ, може вести до неспецифічної ампліфікації геномної ДНК. Прийнятні зворотні праймери AHASL можуть мати температуру плавлення у діапазоні від приблизно 55C до приблизно 60C. Для аналізу SNP будують два олігонуклеотидні зонди для диференціації між двома різними алелями: дикого типу/сприйнятливим та варіантним/толерантним до гербіцидів. Прийнятний зонд дикого типу представлено послідовністю SEQ ID NO:32. Прийнятний толерантний до гербіцидів (HT) зонд представлено послідовністю SEQ ID NO:33. Кожен зонд має свій сигнал, що піддається виявленню, наприклад, різні флуоресцентні молекули, які можуть бути незалежно виявлені у межах дуплексної ПЛР, наприклад, через випускання флуоресцентних сигналів різної довжини хвиль. Прийнятні зонди для застосування згідно з описаними авторами 9 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 способами не обмежуються зондами, представленими послідовностями SEQ ID NO:32 та SEQ ID NO:33. Наприклад, прийнятні зонди можуть відрізнятися за довжиною від зондів SEQ ID NO:32 та SEQ ID NO:33. Як ще один приклад, прийнятні зонди можуть бути побудовані для ренатурації з будь-яким ланцюгом, наприклад, зворотним зондом. Зонд HT будують для специфічної гібридизації з резистентним алелем, і зонд дикого типу є специфічним до сприйнятливого алеля. Згідно з описаними авторами способами, зонди HT та зонди дикого типу можуть змішуватися в одній лунці зі стандартним набором праймерів ПЛР, наприклад, одним з прямих праймерів AHASL та зворотнимпраймером AHASL. Кожен із зондів HT та зондів дикого типу специфічно гібридизується з ділянкою AHASL, яка має SNP, розташований між прямим та зворотним праймерами. Обидва зонди вирівнюються й гібридизуються з ділянкою AHASL генів, які включають однонуклеотидний поліморфізм, який в результаті забезпечує заміщення S653N. Активність 5’ екзонуклеази під час полімеразного подовження зонда з ідеальною відповідністю в результаті веде до розщеплення репортерної молекули, яка випускає флуоресцентний сигнал. Показники довжини хвилі флуоресцентного сигналу вимірюють за допомогою термоциклера у реальному часі. Різницю у накопиченні флуоресцентних сигналів між алелем HT та алелем дикого типу розраховують у конкретній точці під час ампліфікації, яку називають “значення циклу в пороговій області” або “Ct-значення”. Поріг визначають вручну або автоматично за допомогою програми, пов’язані з приладами для вимірювань у реальному часі. Порогове значення зазвичай встановлюють таким чином, щоб забезпечувалося вимірювання сигналу під час експоненціальної фази ПЛР. Ці порогові значення термічного циклу, з обома показниками довжини хвилі, потім порівнюють і визначають генотипи. У ПЛР-аналізі у реальному часі зиготність та позначення генотипу можуть розраховуватися шляхом віднімання Ct-значення зонда дикого типу від Ct-значення зонда HT. Цей розрахунок забезпечує “дельта-Ct-значення”, що також вказується як “dCt-значення” для кожного зразка. Дельта-Ct-значення зразків дикого типу, гетерозиготних та гомозиготних толерантних до гербіцидів стандартних контрольних зразків можуть використовуватися для забезпечення еталона для визначення зиготності невідомих зразків. dCt-значення для гомозиготних HT та гетерозиготних зразків можуть бути від’ємними числами. Значення стандартних контрольних зразків можуть використовуватися для відокремлення генотипічних кластерів невідомих зразків. Таким чином, критично важливим є включення стандартних контрольних зразків з відомих генотипів на кожному планшеті для ПЛР. Графічне представлення dCt-значень на діаграмі розкиду може сприяти тлумаченню результатів. Межові значення для визначення зиготності одержують для контрольних зразків шляхом автоматичного розрахунку середнього значення між подвійними dCt для відповідного діапазону. Межові значення встановлюють для розрізнення між гомозиготними зразками дикого типу та гетерозиготними зразками і між гетерозиготними та гомозиготними толерантними до гербіцидів зразками. Аналізи для різних AHASL генів, наприклад, AHASL1D, AHASL1B або AHASL1A, може мати інший діапазон дельта-Ct-значень для контрольного набору. Діапазон залежить від показників ефективності праймера, які можуть бути знижені через обмежену досліджувану ділянку для виявлення SNP; специфічності зонда SNP та характерної мінливості, яка трапляється між планшетами. Описані авторами способи не обмежуються конкретним флуорофором та молекулоюгасником. Вибір конкретного флуорофора може залежати від типу застосовуваної аналітичної платформи, і прийнятні флуорофори для пристрою зазвичай передбачаються в інструкціях виробника. Для описаних авторами способів репортерні молекули можуть мати діапазон випускання флуоресценції 500 - 660 нм. До флуорофорів з цим діапазоном випускання належать FAM, TET, JOE, Yakima Yellow, VIC, Hex, Cy3, TAMRA, Texas Red та Redmond Red. Cy5 має випускання флуоресценції за межами діапазону 500-660 нм, але може застосовуватися. BHQ-1 та BHQplus-1 можуть використовуватись як молекули-гасники. Вибір конкретної молекули-гасника може ґрунтуватися на виборі флуорофора та довжині зонда, як стане зрозуміло спеціалістам у даній галузі. Хоча описані авторами способи було описано для аналізу AHASL генів гексаплоїдних та тетраплоїдних рослин пшениці, способи можуть застосовуватися для аналізу AHASL генів диплоїдних рослин пшениці, наприклад, пшениці-однозернянки (Triticum monococcum). Наприклад, прямі праймери AHASL1A, TaAHASAMMFor2Gen (SEQ ID NO:25), TaAHASAMMFor2 (SEQ ID NO:26), TaAHASAMMFor3Gen (SEQ ID NO:27), TaAHASMMFor3 (SEQ ID NO:28) та TaAHASAForSNP (SEQ ID NO:29) є придатними для застосування для ПЛР-аналізу в реальному часі для визначення зиготності AHASL гена пшениці-однозернянки. Такі способи також передбачають застосування зворотного праймера AHASL, Зондів AHASL дикого типу та 10 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 описаних авторами зондів HT AHASL. Описані авторами способи можуть бути пристосовані до мультиплексних форматів для аналізу та визначення зиготності рослинних AHASL генів, включаючи мультиплексні ПЛРаналізи в реальному часі. Наприклад, зонди можуть бути побудовані таким чином, щоб включати, як 5’-кінцевий нуклеотид, нуклеотид триалельного SNP і, як 3’-кінцевий нуклеотид, нуклеотид у позиції заміщення G на A, що викликає заміщення S653N. Придатні зонди для застосування у мультиплексних форматах можуть мати довжину від приблизно 15 нуклеотидів до приблизно 250 нуклеотидів, в оптимальному варіанті - від приблизно 25 нуклеотидів до приблизно 50 нуклеотидів. Довжина зонда може бути оптимізована згідно з типом аналітичної платформи, як стане зрозуміло спеціалістам у даній галузі. Наприклад, описані авторами способи та праймери, можуть бути пристосовані для застосування в аналітичних платформах на основі Invader®, аналітичних платформах з молекулярними маяками, аналітичних платформах на основі Luminex®, аналітичних платформах на основі Scorpion®, аналітичних платформах на основі TaqMan® та аналітичних платформах на основі Amplifluor®. Ці аналітичні платформи передбачають застосування зондів, які мають довжину 50-150 нуклеотидів, 80-140 нуклеотидів, 100-130 нуклеотидів або 120 нуклеотидів. Зонди також можуть бути побудовані у конформації петлі “шпилька”, такій, як молекулярний маяк. У мультиплексному ПЛР-аналізі у реальному часі зонди можуть бути мічені, як стане зрозуміло спеціалістові у даній галузі. Наприклад, можуть бути побудовані набори зондів з застосуванням двох або трьох різних флуорофорів, по одному для кожного алель-специфічного SNP для розрізнення між геномними алелями поліплоїдної пшениці. Можуть застосовуватися флуорофор для розпізнавання алелів дикого типу та флуорофор для розпізнавання толерантних до гербіцидів алелів. Це може забезпечувати алель-специфічне виявлення та, при застосуванні з вищеописаними прямими праймерами AHASL, алель-специфічну ампліфікацію. Такі зонди можуть застосовуватися, наприклад, у мультиплексному аналізі з застосуванням вищеописаних прямих праймерів AHASL або універсального набору прямих праймерів AHASL. Даний винахід також забезпечує комплекти для здійснення описаних авторами способів. Такі комплекти можуть включати принаймні один описаний авторами прямий праймер AHASL, принаймні один зворотний праймер AHASL, принаймні одну полімеразу, здатну каталізувати ПЛР-ампліфікацію, принаймні один HT-алельний зонд та принаймні один алельний зонд дикого типу, причому зонди включають репортерну молекулу. Даний винахід також забезпечує прямі праймери AHASL, як описано авторами. Описані авторами прямі праймери можуть застосовуватись у форматах аналізів, у яких не застосовуються зонди, наприклад, аналізах на агарозному гелі та аналізах з піросеквенуванням. Такі способи можуть включати етапи забезпечення ДНК, яка включає рослинні AHASL гени; ампліфікацію ДНК з застосуванням прямого праймера AHASL, зворотного праймера AHASL, полімерази та дезоксирибонуклеотид трифосфатів; та виявлення продуктів ампліфікації з розпізнаванням у такий спосіб зиготності AHASL гена; причому прямий праймер AHASL є олігонуклеотидом, який має послідовність, яка включає десять кінцевих нуклеотидів SEQ ID NO:13, SEQ ID NO:14 або SEQ ID NO:17. Для цих способів виявлення продуктів ампліфікації може включати способи, прийнятні для аналітичних платформ, які є зрозумілими спеціалістам у даній галузі. Хоча описані авторами способи та комплекти не залежать від праймерів ПЛР з будь-якою конкретною кількістю нуклеотидів, вважається, що частина праймера ПЛР, яка ренатурується з комплементарною мішенню на матричній ДНК, зазвичай складає приблизно від 10 до 50 суміжних нуклеотидів, в оптимальному варіанті - 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 або більше суміжних нуклеотидів. Однак праймер ПЛР згідно з винаходом також може включати на його 5’-кінці додаткові нуклеотиди, як не передбачені для ренатурації з мішенню, наприклад, послідовністю ДНК, яка включає один або кілька сайтів розпізнавання рестрикційного фермента, коротких тандемних повторів, мінливу кількість тандемних повторів, повтори з простою послідовністю та поліморфізми довжини з простою послідовністю. Описані авторами способи включають застосування ДНК-полімераз для ПЛР-ампліфікації ДНК. Способи не залежать від конкретної ДНК-полімерази для ПЛР ампліфікації ДНК, за умови, що такі полімерази є здатними ампліфікувати один або кілька рослинних AHASL генів або їх фрагментів і включають активність 5’-3’ екзонуклеази, включаючи, крім інших: Taq полімерази; Pfu полімерази; Tth полімерази; Tfl полімерази; Tfu полімерази; термостійкі ДНК-полімерази з Thermococcus gorgonarious, також відомі як Tgo ДНК-полімерази; термостійкі ДНК-полімерази з Thermococcus litoralis, такі, як, наприклад, ті, що є відомими як Vent® ДНК-полімерази, термостійкі ДНК-полімерази з Pyrococcus виду GB-D, наприклад, ті, що є відомими як Deep 11 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 Vent® ДНК-полімерази; та модифіковані варіанти та їх суміші. В оптимальному варіанті ДНКполімерази, які застосовують згідно з описаними способами, є термостійкими ДНК-полімеразам, ДНК-полімеразами, які мають активність 5’-3’ екзонуклеази, та/або ДНК-полімерази, які мають корекційну активність. Описані авторами способи включають ампліфікацію послідовності ДНК-мішені шляхом ПЛР. У деяких варіантах втілення послідовність ДНК-мішені можуть бути ампліфіковані безпосередньо зі зразка, який включає геномну ДНК, виділену з принаймні однієї рослини або її частини, органа, тканини або клітини. Спеціалістам у даній галузі стане зрозуміло, що кількість або концентрація геномної ДНК залежить від будь-якої кількості чинників, включаючи, крім інших, умови ПЛР (наприклад, температуру ренатурації, температуру денатурації, кількість циклів, концентрація праймерів, концентрація дНТФ і т. ін.), термостійку ДНК-полімеразу, послідовність праймерів та послідовність мішені. Як правило, в описаних авторами варіантах втілення концентрація геномної ДНК становить принаймні або від приблизно 5 нг/мкл до приблизно 100 нг/мкл. Описані авторами способи також є прийнятними для застосування з ДНК, відмінними від геномної ДНК. Наприклад, кДНК або продукти ген-специфічної ПЛР можуть застосовуватись як первісні матриці ДНК в описаними авторами способах. Крім ПЛР-ампліфікації, описані авторами способи можуть включати різні технології молекулярної біології, включаючи, наприклад, виділення ДНК, виділення геномної ДНК, розклад ДНК рестрикційними ферментами та нуклеазами, зшивання ДНК, секвенування ДНК і т. ін. Описані авторами способи включають застосування геномної ДНК, виділеної з рослини. Способи згідно з винаходом не залежать від геномної ДНК, виділеної будь-яким конкретним способом. Будь-який відомий спеціалістам спосіб виділення або очищення з рослини геномної ДНК, яка може бути застосована як джерело матричної ДНК для описаних вище ПЛРампліфікацій, може бути застосований згідно зі способами винаходу. В оптимальному варіанті такі способи виділення рослинної геномної ДНК підбираються або пристосовуються спеціалістами у даній галузі для виділення геномної ДНК з відносно великої кількості зразків рослинних тканин. Для описаних авторами способів геномна ДНК може бути виділена з цілих рослин або будьяких їх частин, органів, тканин або клітин. Наприклад, геномна ДНК може бути виділена з сіянців, листя, стебел, коріння, суцвіть, насіння, зародків, паростків, колеоптилів, пиляків, дихалець, культивованих клітин і т. ін. Крім того, способи не залежать від виділення геномної ДНК з рослин або їх частин, органів, тканин або клітин, які перебувають на будь-якій конкретній стадії розвитку. Способи передбачають застосування геномної ДНК, яку виділяють, наприклад, із сіянців або зрілих рослин або будь-яких їх частин, органів, тканин або клітин. Крім того, способи не залежать від будь-яких конкретних умов росту рослин. Рослини можуть рости, наприклад, у полі, у теплиці або кліматичній камері, у культурі або гідропонічним способом у теплиці або у кліматичній камері. Як правило, рослини вирощують в умовах світла, температури, живлення та вологи, які сприяють ростові та розвиткові рослин. Крім того, для описаних авторами способів геномна ДНК може бути виділена з агрономічних продуктів, наприклад, насінної олії, макухи і т. ін. Спеціалістові у відповідній галузі легко стане зрозуміло, що інші прийнятні модифікації та пристосування описаних авторами способів та технологій є очевидними і можуть здійснюватися без відхилення від обсягу винаходу або будь-якого варіанта його втілення. По ознайомленню з детальним описом даного винаходу він стане краще зрозумілим через посилання на представлені нижче приклади, які включено лише з метою пояснення і не є обмежувальними для обсягу винаходу. ПРИКЛАДИ Конкретні приклади описаних авторами способів представлено нижче. ПРИКЛАД 1 AHASL гени пшениці Для Triticum aestivum три варіанти послідовності великої субодиниці синтази ацетогідроксикислоти (AHASL) розпізнають за секвенуванням кДНК пшениці. Гени, що відповідають цим варіантам, картуються в їх відповідному геномі та плечі хромосоми (6L) і отримують назву на основі геному, в якому вони перебувають (наприклад, AHASL на геномі A=AHASL1A). Одержують нуклеотидні послідовності для багатьох різновидів транскриптів Triticum aestivum AHASL1A, AHASL1B та AHASL1D. Ці послідовності включають повні кодуючі послідовності для зрілих поліпептидів. Для T. turgidum видів durum два варіанти послідовності великої субодиниці синтази ацетогідроксикислоти (AHASL) розпізнають за секвенуванням кДНК пшениці. Гени, що 12 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 60 відповідають цим варіантам, картуються в їх відповідному геномі і отримують назву на основі геному, в якому вони перебувають (наприклад, AHASL на геномі A=AHASL1A). Одержують нуклеотидні послідовності для багатьох різновидів транскриптів AHASL1A та AHASL1B T. turgidum видів durum. Ці послідовності включають повні кодуючі послідовності для зрілих поліпептидів. Для Triticum aestivum та T. turgidum видів durum порівняння імідазолінон (IMI)-толерантних різновидів з попередниками дикого типу показує, що найпоширенішим типом заміщення є перехід від G до A, який створює заміщення серину (S) на аспарагін (N) у позиції, що відповідає S653 у змодельованому таксоні, Arabidopsis thaliana. Порівняння послідовностей AHASL A, B та D геномів Triticum aestivum (тобто, AHASL1A, AHASL1B та AHASL1D) демонструє, що існує триалельний SNP, розташований приблизно за 40 нуклеотидів до переходу, що створює заміщення S653N. Поліморфізмом у цій позиції є аденін на D геномі, тимін на B геномі та цитозин на A геномі. Порівняння послідовностей AHASL A та B геномів T. turgidum видів durum (тобто, AHASL1A та AHASL1B) демонструє, що існує біалельний SNP, розташований приблизно за 40 нуклеотидів до переходу, що створює заміщення S653N. Поліморфізмом у цій позиції є тимін на B геномі та цитозин на A геномі. ПРИКЛАД 2 Побудова прямого праймера Прямі праймери будують для застосування в аналізі, наприклад, ПЛР-аналізі у реальному часі, для виявлення заміщення S653N у пшениці. Праймер TaAHASD (SEQ ID NO:30) є комп’ютерно-побудованим праймером (тобто, прямим праймером, побудованим за допомогою програми планування аналізу RealTimeDesign від BioSearch Technologies.) Додаткові прямі праймери будують без застосування програмного забезпечення або технології планування аналізу на основі SNP між геномами AHASL, описаними у Приклад 1. Ці праймери включають SNP як кінцевий нуклеотид праймера. Деякі прямі праймери будують таким чином, щоб вони включали умисне помилкове спарювання нуклеотидів із заданою нуклеотидною послідовністю, розташованою за 2 або 3 нуклеотиди до кінцевого нуклеотиду праймера. Кожен праймер може бути специфічним до AHASL гена на конкретному геномі. Кожен прямий праймер для B геному та A геному AHASL може застосовуватись у Triticum aestivum та T. turgidum видів durum. Побудовані вручну прямі праймери для геному AHASL1D будують як TaAHASDMMFor2 праймер (SEQ ID NO:16), TaAHASDMMFor3 праймер (SEQ ID NO:18) та TaAHASDForSNP праймер (SEQ ID NO:19). Побудовані вручну прямі праймери для геному AHASL1B позначають як TaAHASBMMFor2 праймер (SEQ ID NO:21), TaAHASBMMFor3 праймер (SEQ ID NO:23) та TaAHASBForSNP праймер (SEQ ID NO:24). Побудовані вручну праймер для геному AHASL1A позначають як TaAHASAMMFor2 праймер (SEQ ID NO:26), TaAHASAMMFor3 праймер (2SEQ ID NO:28) та TaAHASAForSNP праймер (SEQ ID NO:29). Температура плавлення T m праймерів, які включають триалельний SNP, становить приблизно 54C. TaAHASDMMFor2 праймер (SEQ ID NO:16), TaAHASBMMFor2 праймер (SEQ ID NO:21), TaAHASAMMFor2 праймер (SEQ ID NO:26) та TaAHASAMMFor3 праймер (SEQ ID NO: 28) мають умисне помилкове спарювання нуклеотидів за три нуклеотиди до кінцевого нуклеотиду праймера. Помилковим спарюванням є заміщення C на A з нуклеотидної послідовності AHASL. TaAHASBMMFor3 праймер (SEQ ID NO:23) має умисне помилкове спарювання нуклеотидів за три нуклеотиди до кінцевого нуклеотиду праймера. Помилковим спарюванням є заміщення C на G з нуклеотидної послідовності AHASL. TaAHASDMMFor3 праймер (SEQ ID NO:18) має умисне помилкове спарювання нуклеотидів за два нуклеотиди до кінцевого нуклеотиду праймера. Помилковим спарюванням є заміщення A на G з нуклеотидної послідовності AHASL. Програма побудови праймерів RealTimeDesign відхиляє вищеописані побудовані вручну прямі праймери для застосування у ПЛР-аналізах у реальному часі. Параметри за замовчуванням є “найбільш обмежувальними” параметрами. Програма продовжує відхиляти побудовані вручну прямі праймери за “найменш обмежувальними” параметрами побудови праймера. Програма побудови праймерів RealTimeDesign забезпечує послідовність для прямого праймера AHASL TaAHASD (SEQ ID NO:30). ПРИКЛАД 3 Перевірка прямих праймерів AHASL Аналізи у реальному часі з застосуванням зразків AHASL пшениці відомої зиготності здійснюють з TaAHASDMMFor2 праймером (SEQ ID NO:16), TaAHASDMMFor3 праймером (SEQ 13 UA 115321 C2 5 10 15 ID NO:18), TaAHASDForSNP праймером (SEQ ID NO:19), TaAHASBMMFor2 праймером (SEQ ID NO:21), TaAHASBMMFor3 праймером (SEQ ID NO:23), TaAHASBForSNP праймером (SEQ ID NO:24), TaAHASAMMFor2 праймером (SEQ ID NO:26), TaAHASAMMFor3 праймером (SEQ ID NO:28), TaAHASAForSNP праймером (SEQ ID NO:29) та TaAHASD праймером (SEQ ID NO:30) з метою перевірки. Зразки можуть бути одержані шляхом видобування геномної ДНК з борошна сортів пшениці, які представляють, наприклад, гомозиготні варіанти S653N AHASL1D, AHASL1B та AHASL1A генів T. aestivum і AHASL1B та AHASL1A генів T. turgidum видів durum. Гетерозиготний зразок може бути одержаний, наприклад, з метою контролю шляхом комбінування геномної ДНК рослини пшениці, що має AHASL ген дикого типу (визначається авторами як “Група W”) та гомозиготний варіант для AHASL1D гена (визначається авторами як “Група D” та “CV9804”) у співвідношенні 1:1. Геномну ДНК підрозділяють на аліквоти по три копії для кожного різновиду. Розчин для кожного прямого праймера приготовляють для забезпечення 25X концентрованих сумішей (вказаних авторами як “WheatDSNP”), як показано у Таблиці 1. Зворотний праймер AHASL (SEQ ID NO:31), зонд AHASL дикого типу (SEQ ID NO:32) та HT-зонд AHASL (SEQ ID NO:33) включають у кожен з вихідних розчинів. Кожну з сумішей WheatDSNP зберігають при -20C. Таблиця 1 Суміш WheatDSNP Реагент 22,5 мкл 100 мкM прямого праймера 22,5 мкл 100 мкM зворотного праймера 100 мкл 25x вихідного 5 мкл 100 мкM зонда (дикого типу) розчину: 5 мкл 100 мкM зонда (HT) 45 мкл ddH2O 20 Кінц. конц. (мкM) 22,5 22,5 5 5 - Полімеразну суміш (“Доповнену 2x полімеразну суміш”) приготовляють, як показано у Таблиці 2. Доповнену 2x полімеразну суміш зберігають при 4C. Таблиця 2 Доповнення всього 10 мл вихідного розчину по отриманню або після першого розморожування. 10 мл 2x полімеразної суміші 110 мкл 1M MgCl2 40 мкл 300 мкM Сульфородаміну 101 (Sigma Catalog #S7635) 25 Кінц. конц. (2x) Містить 3 мM MgCl2 11 мM 1200 нM Мастер-мікс для аналізу в реальному часі для AHASL1D S653N приготовляють із кожної з сумішей WheatDSNP та доповненої 2x полімеразної суміші, як показано у Таблиці 3. Таблиця 3 Компоненти 1x мастер-міксу Доповнена 2x полімеразна суміш Об’єм у мкл на 96x мкл на лунковий планшет (130 5 мкл реакції реакцій) 2,5 325 25X суміш WheatDSNP 26 вода Загалом 30 0,2 0,3 3,0 39 390 Кінц. конц. 1x 900 нM праймера / 200 нM зонда -- Аналіз у реальному часі здійснюють з застосуванням Biomek FxP згідно з представленим нижче протоколом. 45 мкл 1x мастер-міксу розподіляють по лунках ряду з 8 пробірок. Ряд поміщають на спеціальний штатив з 96-лунковим планшетом з колонкою 1 для квадранта 1, колонкою 2 для квадранта 2, колонкою 3 для квадранта 3 та колонкою 4 для квадранта 4 384лункового планшета для ПЛР. 3 мкл робочого мастер-міксу (1x) ‘WheatDSNP’ в реальному часі на лунку з 2 мкл ДНК елююють у 1X TE на лунку (початкова концентрація гДНК становить 14 UA 115321 C2 приблизно 5-10 нг/мкл). Планшети відразу заклеюють оптичною ущільнювальною стрічкою і проганяють протягом 2 хвилин при 1000 об/хв. Планшети зберігають при 4C до 48 годин. Планшет проганяють на світловому циклері в умовах циклування, показаних у Таблиці 4. Таблиця 4 o Умови реакції Темп. C 95 95 60 Цикл Утримання Цикл Загальний час прогону ~ 1:40 Час 5:00 0:20 1:00 Повтор 0 40 5 10 15 20 За результатами ПЛР-аналізу в реальному часі визначають зиготність та позначення генотипу шляхом віднімання значення Ct (циклу у пороговій області) специфічного зонда дикого типу від значення Ct специфічного зонда HT для одержання значення дельта Ct (dCt) для кожного контрольного зразка. Значення dCt гомозиготних дикого типу, гетерозиготних та гомозиготних HT стандартних контрольних зразків забезпечують критерій для визначення зиготності невідомих зразків. Значення стандартних контрольних зразків можуть використовуватися для розділення генотипічних кластерів невідомих зразків. Графічне представлення значень dCt на діаграмі розкиду сприяє тлумаченню результатів. Межові значення одержують від контрольних зразків шляхом автоматичного розрахунку середнього значення між подвійними dCt для відповідного діапазону. Існує межове значення, утворене між нульовим (гомозиготним дикого типу) та гетерозиготним варіантами і межове значення, утворене між гетерозиготним та гомозиготним варіантами. Визначення генотипу зразків здійснюють на основі цих межових значень. Таблиця 5 та її умовні позначення забезпечують контрольні дані для прямого праймера TaAHASDMMFor2 (SEQ ID NO:16). Фіг. 4 показує діаграму розкиду значень dCt на основі цих даних. Таблиця 5 40 40 40 40 40 40 Ct дикого типу 40 40 40 40 40 40 не визн. не визн. не визн. не визн. не визн. не визн. Зиготність (спосіб dCt) Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Група W 40 29,803118 10,196882 Дикого типу 76 Група W 40 29,724152 10,275848 Дикого типу C2 124 Група W 40 29,708704 10,291296 Дикого типу D2 E2 F2 G2 H2 A3 B3 C3 D3 E3 F3 G3 H3 A4 B4 C4 D4 E4 172 220 268 316 364 30 78 126 174 222 270 318 366 32 80 128 176 224 Група D Група D Група D Група D HET Група D HET Група D HET CV9804 CV9804 CV9804 CV9804 HET CV9804 HET CV9804 HET BW255-2 BW255-2 BW255-2 Група B Група B Група B 28,533606 28,649118 28,12679 29,184525 29,702597 30,94369 28,315844 28,134075 28,69106 30,412355 29,99291 30,114641 40 40 40 40 40 40 40 40 40 31,502728 31,20019 29,723372 40 40 40 30,413248 31,235846 30,941849 29,943615 29,805761 29,25382 29,5461 28,947887 29,434076 -11,466394 -11,350882 -11,87321 -2,318203 -1,497593 1,220318 -11,684156 -11,865925 -11,30894 -0,000893 -1,242936 -0,827208 10,056385 10,194239 10,74618 10,4539 11,052113 10,565924 Гомозиготний Гомозиготний Гомозиготний Гетерозиготний Гетерозиготний Гетерозиготний Гомозиготний Гомозиготний Гомозиготний Гетерозиготний Гетерозиготний Гетерозиготний Дикого типу Дикого типу Дикого типу Дикого типу Дикого типу Дикого типу Зразок Аналіз Зразок ID Ct HT A1 B1 C1 D1 E1 F1 G1 H1 26 74 122 170 218 266 314 362 Дикого типу Дикого типу Гетерозиготний Гетерозиготний Гомозиготний Гомозиготний A2 28 B2 15 dCt Коментарі М’яка пшениця дикого типу М’яка пшениця дикого типу М’яка пшениця дикого типу М’яка пшениця D HT М’яка пшениця D HT М’яка пшениця D HT М’яка пшениця D гет. М’яка пшениця D гет. М’яка пшениця D гет. М’яка пшениця D HT М’яка пшениця D HT М’яка пшениця D HT М’яка пшениця D гет. М’яка пшениця D гет. М’яка пшениця D гет. М’яка пшениця A HT М’яка пшениця A HT М’яка пшениця A HT М’яка пшениця B HT М’яка пшениця B HT М’яка пшениця B HT UA 115321 C2 Таблиця 5 Зразок Аналіз Зразок ID Ct HT F4 G4 H4 A5 B5 C5 272 320 368 34 82 130 UT-12-2 UT-12-2 UT-12-2 DIMI-39 DIMI-39 DIMI-39 36,31313 35,846695 37,536434 35,83397 36,14197 35,096363 Умовні позначення меж зн. dCt між нул. та гет. меж зн. dCt між гет. та гомо Меж. зн. WT-TET Меж. зн. HT-FAM 5 Ct дикого типу 36,140057 35,667755 36,63924 37,589897 36,788425 36,812702 dCt 0,173073 0,17894 0,897194 -1,755927 -0,646455 -1,716339 Зиготність (спосіб dCt) Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Коментарі Тверда пшениця Тверда пшениця Тверда пшениця Тверда пшениця Тверда пшениця Тверда пшениця 5 -5 39 39 Таблиця 6 та її умовні позначення забезпечують контрольні дані для прямого праймера TaAHASDMMFor3 (SEQ ID NO:18). Фіг. 5 показує діаграму розкиду значень dCt на основі цих даних. Таблиця 6 40 40 40 40 40 40 Ct дикого типу 40 40 40 40 40 40 не визн. не визн. не визн. не визн. не визн. не визн. Зиготність (спосіб dCt) Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК 40 40 40 29,380377 29,383379 28,898722 29,856798 30,772238 31,818707 33,97833 29,250994 29,335287 31,243635 31,18066 30,902334 40 40 40 40 40 40 37,0332 39,64275 40 39,767876 37,09119 36,86376 29,34243 29,224567 29,310955 36,519726 40 40 31,415937 30,318415 29,703732 40 38,0116 40 29,766205 30,622314 30,596828 29,219034 29,1813 29,013493 28,962784 28,329138 28,766186 37,246914 36,364605 37,55851 36,78326 36,66263 37,060997 10,65757 10,775433 10,689045 -7,139349 -10,616621 -11,101278 -1,559139 0,453823 2,114975 -6,02167 -8,760606 -10,664713 1,47743 0,558346 0,305506 10,780966 10,8187 10,986507 11,037216 11,670862 11,233814 -0,213714 3,278145 2,44149 2,984616 0,42856 -0,197237 Дикого типу Дикого типу Дикого типу Гомозиготний Гомозиготний Гомозиготний Гетерозиготний Гетерозиготний Гетерозиготний Гомозиготний Гомозиготний Гомозиготний Гетерозиготний Гетерозиготний Гетерозиготний Дикого типу Дикого типу Дикого типу Дикого типу Дикого типу Дикого типу Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Без ДНК Зразок Аналіз Зразок ID Ct HT A1 B1 C1 D1 E1 F1 G1 H1 A2 B2 C2 D2 E2 F2 G2 H2 A3 B3 C3 D3 E3 F3 G3 H3 A4 B4 C4 D4 E4 F4 G4 H4 A5 B5 C5 25 73 121 169 217 265 313 361 27 75 123 171 219 267 315 363 29 77 125 173 221 269 317 365 31 79 127 175 223 271 319 367 33 81 129 Дикого типу Дикого типу Гетерозиготний Гетерозиготний Гомозиготний Гомозиготний Група W Група W Група W Група D Група D Група D Група D HET Група D HET Група D HET CV9804 CV9804 CV9804 CV9804 HET CV9804 HET CV9804 HET BW255-2 BW255-2 BW255-2 Група B Група B Група B UT-12-2 UT-12-2 UT-12-2 DIMI-39 DIMI-39 DIMI-39 16 dCt UA 115321 C2 Умовні позначення меж зн. dCt між нул. та гет. меж зн. dCt між гет. та гомо Меж. зн. WT-TET Меж. зн. HTt-FAM 5 10 15 20 25 30 35 40 45 50 55 5 -5 39 39 Аналізи у реальному часі з використанням розчинів з прямими праймерами TaAHASDMMFor2 (SEQ ID NO:16) та TaAHASDMMFor3 (SEQ ID NO:18) забезпечують значення dCt, які є достатньо розділеними для забезпечення точного визначення зиготності та позначення генотипу між зразками дикого типу, гетерозиготним та гомозиготним толерантним до гербіцидів. Прямий праймер TaAHASDMMFor2 (SEQ ID NO:16) демонструє щільніше кластерування у копіях і збільшує розділення у значеннях dCt між гомозиготними зразками дикого типу, гетерозиготними та гомозиготними толерантними до гербіцидів відносно прямого праймера TaAHASDMMFor3 (SEQ ID NO:18). TaAHASDMMFor2 (SEQ ID NO:16) та TaAHASDMMFor3 (SEQ ID NO:18) обидва можуть застосовуватися в аналізах для забезпечення точного визначення зиготності та позначення генотипу. Аналізи у реальному часі з використанням розчину з прямим праймером TaAHASDForSNP (SEQ ID NO:19) забезпечують значення dCt, які забезпечують можливість розпізнавання трьох класів генотипу. Однак значення dCt є близькими, що може призводити до помилкового визначення зиготності та позначення генотипу. Аналізи у реальному часі з використанням розчинів з прямими праймерами TaAHASBMMFor2 (SEQ ID NO:21) та TaAHASBMMFor3 (SEQ ID NO:23) забезпечують значення dCt, які є порівнянними зі значеннями dCt в аналізах з використанням TaAHASDMMFor2 (SEQ ID NO:16) та TaAHASDMMFor3 (SEQ ID NO:18). Праймери TaAHASBMMFor2 (SEQ ID NO:21) та TaAHASBMMFor3 (SEQ ID NO:23) забезпечують значення dCt, які є достатньо розділеними для забезпечення точного визначення зиготності та позначення генотипу між зразками дикого типу, гетерозиготним та гомозиготним толерантним до гербіцидів. Прямий праймер TaAHASBMMFor2 (SEQ ID NO:21) дає вдвічі вищий середній показник dCt між гетерозиготним та гомозиготним толерантним до гербіцидів зразками. Аналізи у реальному часі з використанням розчину з прямим праймером TaAHASBForSNP (SEQ ID NO:24) забезпечують значення dCt, які дозволяють розпізнавати три класи генотипу. Однак значення dCt є близькими, що може призводити до помилкового визначення зиготності та позначення генотипу. Аналізи у реальному часі з використанням розчинів з прямими праймерами TaAHASAMMFor2 (SEQ ID NO:26) та TaAHASAMMFor3 (SEQ ID NO:28) забезпечують значення dCt, які є порівнянними зі значеннями dCt в аналізах з використанням TaAHASDMMFor2 (SEQ ID NO:16) та TaAHASDMMFor3 (SEQ ID NO:18). TaAHASAMMFor2 (SEQ ID NO:26) та TaAHASAMMFor3 (SEQ ID NO:28) праймери забезпечують значення dCt, які є достатньо розділеними для забезпечення точного визначення зиготності та позначення генотипу між зразками дикого типу, гетерозиготним та гомозиготним толерантним до гербіцидів. Ці праймери працюють однаково добре і можуть застосовуватися в аналізах для забезпечення точного визначення зиготності та позначення генотипу. Аналізи у реальному часі з використанням розчину з прямим праймером TaAHASAForSNP (SEQ ID NO:29) забезпечують значення dCt, які дозволяють розпізнавати три класи генотипу. Однак значення dCt є близькими, що може призводити до помилкового визначення зиготності та позначення генотипу. Аналізи у реальному часі з використанням розчину побудованого за допомогою програми прямого праймера TaAHASD (SEQ ID NO:30) не дозволяють проводити розрізнення між зразками дикого типу та гетерозиготними зразками для будь-якого з AHASL генів. ПРИКЛАД 4 Аналіз у реальному часі для AHASL D геному пшениці Зразок, який містить геномну ДНК, одержують будь-яким способом, відомим спеціалістам у даній галузі, для очищення геномної ДНК з рослинних тканин, наприклад, Triticum aestivum. Геномну ДНК пшениці одержують, наприклад, з тканини молодого листя або насінного борошна. Зразки одержують шляхом видобування геномної ДНК з борошна сортів пшениці, які представляють, наприклад, S653N гомозиготні варіанти AHASL1D, AHASL1B та AHASL1A генів T. aestivum і AHASL1B та AHASL1A генів T. turgidum видів durum. При порівнянні двох або більше рослин пшениці використовують рівноцінну кількість тканини з кожної рослини для очищення геномної ДНК з метою забезпечення наявності у 17 UA 115321 C2 5 10 15 20 25 30 зразках кожної з рослин подібних концентрацій геномної ДНК. Концентрація ДНК у зразку становить приблизно 5-10 нг ДНК на мкл. Хоча спосіб не залежить від конкретної концентрації ДНК, концентрація ДНК зразка в оптимальному варіанті складає від приблизно 5 до приблизно 100 нг ДНК на мкл. Вихідний розчин праймера TaAHASDMMFor2 (SEQ ID NO:16) приготовляють для забезпечення 25X концентрованої суміші згідно з протоколом Прикладу 3 і як показано у Таблиці 1. Зворотний праймер AHASL (SEQ ID NO:31), зонд AHASL дикого типу (SEQ ID NO:32) та HT-зонд AHASL (SEQ ID NO:33) включають у кожен з вихідних розчинів. Кожну з сумішей WheatDSNP зберігають при -20C. Полімеразну суміш (“Доповнену 2x полімеразну суміш”) приготовляють згідно з протоколом за Прикладом 3 і як показано у Таблиці 2. Доповнену 2x полімеразну суміш зберігають при 4C. Мастер-мікс для аналізу в реальному часі для AHASL1D S653N приготовляють із сумішей WheatDSNP та доповненої 2x полімеразної суміші згідно з протоколом за Прикладом 3 і як показано у Таблиці 3. Аналіз у реальному часі здійснюють, застосовуючи Biomek FxP згідно з представленим нижче протоколом. 45 мкл 1x мастер-міксу розподіляють по лунках ряду з 8 пробірок. Ряд поміщають на спеціальний штатив з 96-лунковим планшетом з колонкою 1 для квадранта 1, колонкою 2 для квадранта 2, колонкою 3 для квадранта 3 та колонкою 4 для квадранта 4 384 лункового реакційного планшета для ПЛР. 3 мкл робочого мастер-міксу (1x) ‘WheatDSNP’ в реальному часі на лунку з 2 мкл ДНК елююють у 1X TE на лунку (початкова концентрація гДНК становить приблизно 5-10 нг/мкл). Планшети відразу заклеюють оптичною ущільнювальною стрічкою і проганяють протягом 2 хвилин при 1000 об/хв. Планшети зберігають при 4C до 48 годин. Планшет проганяють на світловому циклері в умовах циклування згідно з протоколом з Прикладу 3 і як показано у Таблиці 4. Зиготність, позначення генотипу та межові значення розраховують згідно з протоколом за Прикладом 3. Таблиця 7 та її умовні позначення забезпечують результати для аналізу з застосуванням прямого праймера TaAHASDMMFor2 (SEQ ID NO:16). Фіг. 6 показує діаграму розкиду значення dCt за результатами аналізу. Таблиця 7 Аналіз Зразок ID Ct HT WT Ct dCt 26 74 Контроль дикого типу Контроль дикого типу Гетерозиготний контроль Гетерозиготний контроль Гомозиготний контроль Гомозиготний контроль 40 40 26,84739 26,97574 13,15261 13,02426 Зиготність (спосіб dCt) Дикого типу Дикого типу 31,491217 31,42351 0,067707 Гетерозиготний 31,34674 31,652384 -0,305644 Гетерозиготний 29,99533 29,802464 40 40 -10,00467 -10,197536 Гомозиготний Гомозиготний 28,347878 28,538382 27,452032 27,142103 27,91621 28,403366 28,981049 28,346386 30,446072 28,556992 27,556402 27,093315 27,8551 28,137955 40 40 40 40 40 40 40 40 40 40 40 40 40 40 -11,652122 -11,461618 -12,547968 -12,857897 -12,08379 -11,596634 -11,018951 -11,653614 -9,553928 -11,443008 -12,443598 -12,906685 -12,1449 -11,862045 Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний 122 170 218 266 314 362 28 76 124 172 220 268 316 364 30 78 126 174 222 270 20212_1 20212_2 20212_3 20212_4 20212_5 20212_6 20212_7 20212_8 20212_1 20212_2 20212_3 20212_4 20212_5 20212_6 18 UA 115321 C2 Таблиця 7 Аналіз Зразок ID Ct HT WT Ct dCt 318 366 32 80 128 176 224 272 320 368 34 82 130 178 226 274 322 370 36 84 132 180 228 276 324 372 38 86 134 182 20212_7 20212_8 20212_9 20212_10 20216_1 20216_2 20216_3 20216_4 20216_5 20216_6 20212_9 20212_10 20216_1 20216_2 20216_3 20216_4 20216_5 20216_6 20216_7 20216_8 20216_9 20216_10 порожн. порожн. порожн. порожн. 20216_7 20216_8 20216_9 20216_10 28,819048 28,168386 28,063032 29,152721 30,606934 27,00255 28,186663 27,655886 29,225403 28,849354 27,97749 28,978636 30,920435 26,890776 28,095255 27,534174 29,027134 28,849108 28,879118 29,3099 40 29,814688 40 40 40 40 28,879456 29,277208 40 29,88885 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 27,394365 40 40 40 40 40 40 40 27,689241 40 -11,180952 -11,831614 -11,936968 -10,847279 -9,393066 -12,99745 -11,813337 -12,344114 -10,774597 -11,150646 -12,02251 -11,021364 -9,079565 -13,109224 -11,904745 -12,465826 -10,972866 -11,150892 -11,120882 -10,6901 12,605635 -10,185312 не визн. не визн. не визн. не визн. -11,120544 -10,722792 12,310759 -10,11115 Умовні позначення меж зн. dCt між нул. та гет. меж зн. dCt між гет. та гомо Меж. зн. WT-TET Меж. зн. HT-FAM 5 Зиготність (спосіб dCt) Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Гомозиготний Дикого типу Гомозиготний Без ДНК Без ДНК Без ДНК Без ДНК Гомозиготний Гомозиготний Дикого типу Гомозиготний 5 -5 39 39 Хоча представлений вище опис подано у певних деталях для кращого розуміння та пояснення, спеціалістам у даній галузі по ознайомленню з цим описом стане зрозумілою можливість різних змін у формі та деталях без відхилення від обсягу опису та супровідної формули винаходу. 19 UA 115321 C2 20 UA 115321 C2 21 UA 115321 C2 22 UA 115321 C2 23 UA 115321 C2 24 UA 115321 C2 25 UA 115321 C2 26 UA 115321 C2 ФОРМУЛА ВИНАХОДУ 5 10 15 1. Спосіб аналізу AHASL гена рослин, який включає: (a) забезпечення ДНК, яка включає AHASL ген рослин; (b) ампліфікацію ДНК з застосуванням прямого праймера AHASL, зворотного праймера AHASL, полімерази та дезоксирибонуклеотидтрифосфатів; (c) виявлення продуктів ампліфікації за допомогою зонда AHASL дикого типу та толерантного до гербіцидів (НТ) зонда AHASL таким чином розпізнаючи AHASL ген як ген дикого типу або варіант для однонуклеотидного поліморфізму, що в результаті веде до амінокислотного заміщення, яке відповідає заміщенню S653 (At)N; причому прямий праймер AHASL є олігонуклеотидом, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28; причому прямий праймер AHASL включає спарювання з AHASL геном рослин, розташованному за 2 або 3 нуклеотиди до 3'-кінцевого нуклеотиду прямого праймера AHASL; та причому 3'-кінцевий нуклеотид прямого праймера AHASL є AHASL сайтом однонуклеотидного поліморфізму (SNP). 27 UA 115321 C2 5 10 15 20 25 30 35 40 45 50 55 2. Спосіб за п. 1, який відрізняється тим, що вищезгадані етапи ампліфікації та виявлення одночасно здійснюють у ПЛР-аналізі у реальному часі. 3. Спосіб за п. 1, який відрізняється тим, що на вищезгаданому етапі виявлення розпізнають геном походження AHASL гена рослин. 4. Спосіб за п. 3, який відрізняється тим, що геномом походження є: А геном пшениці, В геном пшениці або D геном пшениці. 5. Спосіб за п. 1, який відрізняється тим, що AHASL ген рослин є вибраним з групи, до якої належать AHASL1A ген пшениці, AHASL1В ген пшениці та AHASL1D ген пшениці. 6. Спосіб за п. 1, який відрізняється тим, що також включає повторення вищезгаданих етапів ампліфікації та виявлення іншим прямим праймером AHASL, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28, для визначення зиготності AHASL гена для однонуклеотидного поліморфізму, що в результаті веде до амінокислотного заміщення, яке відповідає заміщенню S653(At)N. 7. Спосіб за п. 1 або 6, який відрізняється тим, що на вищезгаданих етапах виявлення розпізнають джерело AHASL гена рослин. 8. Спосіб за п. 7, який відрізняється тим, що джерелом є поліплоїдна рослина. 9. Спосіб за п. 8, який відрізняється тим, що джерелом є рослина пшениці. 10. Спосіб за п. 9, який відрізняється тим, що джерелом є Triticum aestivum або T. Turgidum видів durum. 11. Спосіб за п. 1, який відрізняється тим, що прямий праймер AHASL є олігонуклеотидом, який складається з послідовності, вибраної з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28. 12. Спосіб за п. 1, який відрізняється тим, що зворотний праймер AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 31. 13. Спосіб за п. 1, який відрізняється тим, що зонд AHASL дикого типу є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 32. 14. Спосіб за п. 1, який відрізняється тим, що НТ-зонд AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 33. 15. Спосіб за п. 14, який відрізняється тим, що зонд AHASL дикого типу є міченим першим типом сигналу, що піддається виявленню, і НТ-зонд AHASL є міченим другим типом сигналу, що піддається виявленню. 16. Спосіб за п. 15, який відрізняється тим, що сигнали, які піддаються виявленню, є флуоресцентними репортерними молекулами. 17. Спосіб за п. 1, який відрізняється тим, що ДНК є геномною ДНК. 18. Спосіб за п. 17, який відрізняється тим, що ДНК одержують з рослини пшениці. 19. Спосіб за п. 18, який відрізняється тим, що рослиною пшениці є Triticum aestivum. 20. Спосіб за п. 18, який відрізняється тим, що рослиною пшениці є T. Turgidum видів durum. 21. Спосіб за п. 1, який відрізняється тим, що AHASL SNP є триалельним SNP. 22. Комплект для аналізу AHASL гена рослин, який включає: а) прямий праймер AHASL, який включає послідовність, вибрану з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28; b) зворотний праймер AHASL; c) зонд AHASL дикого типу; d) толерантний до гербіцидів (НТ) зонд AHASL; е) полімеразу; та f) дезоксирибонуклеотидтрифосфати; причому прямий праймер AHASL включає спарювання з AHASL геном рослин, розташованим за 2 або 3 нуклеотиди до 3'-кінцевого нуклеотиду прямого праймера AHASL; та причому 3'-кінцевий нуклеотид прямого праймера AHASL є AHASL сайтом однонуклеотидного поліморфізму (SNP). 23. Комплект за п. 22, який відрізняється тим, що прямий праймер AHASL складається з послідовності, вибраної з SEQ ID NO: 16, SEQ ID NO: 18, SEQ ID NO: 21, SEQ ID NO: 23, SEQ ID NO: 26 та SEQ ID NO: 28. 24. Комплект за п. 22, який відрізняється тим, що зворотний праймер AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 31. 25. Комплект за п. 22, який відрізняється тим, що зонд AHASL дикого типу є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 32. 26. Комплект за п. 22, який відрізняється тим, що НТ-зонд AHASL є олігонуклеотидом, який має послідовність, викладену в SEQ ID NO: 33. 28
ДивитисяДодаткова інформація
Назва патенту англійськоюMethods and compositions for analyzing ahasl genes in wheat
Автори англійськоюWhitt, Sherry, Rodgers, Cory
Автори російськоюВитт Шэри, Роджерс Кори
МПК / Мітки
МПК: C12Q 1/68
Мітки: аналізу, спосіб, комплект, рослин, ahasl, генів
Код посилання
<a href="https://ua.patents.su/34-115321-sposib-ta-komplekt-dlya-analizu-ahasl-geniv-u-roslin.html" target="_blank" rel="follow" title="База патентів України">Спосіб та комплект для аналізу ahasl генів у рослин</a>
Ізольований фрагмент днк промотору гена синтази ацетооксикислот (ahas) для експресії генів в рослинах, вектор для трансформації рослин, спосіб високорівневого експресування гетерологічного гена в рослині та в

Номер патенту: 48951
Опубліковано: 16.09.2002
Автори: Сміт Джейн, Пенг Джіань Їнг., Дітріх Габріель
МПК: C12N 15/29, C12N 9/88, C12N 15/60, C12N 15/09, C12N 15/82, A01H 5/00, C12N 5/10
Мітки: фрагмент, спосіб, експресування, ізольований, рослин, вектор, гетерологічного, синтази, промотору, ацетооксикислот, експресії, генів, трансформації, гена, високорівневого, рослинах, рослини, днк, ahas
Формула / Реферат:
1. Изолированный фрагмент ДНК промотора гена синтазы ацетооксикислот (AHAS) для экспрессии генов в растениях, выбранный из группы, состоящей из SEQ ID №1,SEQ ID № 2,SEQ ID № 3.2. Изолированный фрагмент ДНК по п. 1, отличающийся тем, что растение является однодольным.3. Изолированный фрагмент ДНК по п. 2, отличающийся тем, что растение представляет собой кукурузу.4. Вектор для...
Спосіб аналізу рослин у стресових умовах

Номер патенту: 61148
Опубліковано: 17.11.2003
Автори: Кожем'яко Ярина Василівна, Посудін Юрій Іванович
МПК: A01G 7/00, G01N 21/64
Мітки: умовах, спосіб, аналізу, рослин, стресових
Формула / Реферат:
Спосіб аналізу рослин у стресових умовах, заснований на збудженні флуоресценції хлорофілу зеленого листка та реєстрації флуоресцентного параметра (індекса) який відрізняється тим, що одночасно реєструють декілька флуоресцентних індексів та оцінюють величину і напрямок вектора або в
Спосіб корегування результатів спектрального аналізу матеріалів дистанційного моніторингу рослин

Номер патенту: 111101
Опубліковано: 25.10.2016
Автори: Пасічник Наталія Анатоліївна, Лисенко Віталій Пилипович, Опришко Олексій Олександрович, Комарчук Дмитро Сергійович, Іванов Павло Вікторович
Мітки: корегування, результатів, матеріалів, рослин, аналізу, спектрального, моніторингу, спосіб, дистанційного
Формула / Реферат:
Спосіб корегування результатів спектрального аналізу матеріалів дистанційного моніторингу рослин, що базується на синхронному вимірюванні спектральної яскравості з можливістю корекції отриманих результатів щодо коефіцієнтів яскравості, який відрізняється тим, що калібрування здійснюється на базі відбитого від дослідних зразків світла, а не прямого світла, яке фіксується спрямованою вертикально вверх фотокамерою чи спектрофотометром.
Спосіб аналізу, апарат для його здійснення (варіанти), касета для проведення аналізу (варіанти) і пристрій для проведення аналізу

Номер патенту: 74071
Опубліковано: 17.10.2005
Автори: Янсон Туре, Лаувстад Інгер Лісе, Борк Стіг Мортен, Карлсон Ян Рогер, Сейм Торстейн, Тьон Хеге, Холтлунн Йостейн
МПК: G01N 1/00, G01N 21/27, G01N 21/64, G01N 21/76, G01N 35/10, B01L 3/02, G01N 1/10, G01N 33/86, G01N 33/68, B01L 3/00, G01N 35/02, G01N 21/63
Мітки: аналізу, здійснення, касета, проведення, спосіб, пристрій, варіанти, апарат
Формула / Реферат:
1. Апарат для проведення аналізів, що містить піпетку, яка має ближній кінець та дальній кінець, джерело тиску газу, касету для проведення аналізів, яка містить принаймні одну комірку, та пристрій для проведення аналізів, який містить тримач згаданої касети, влаштований для її прийому, і детектор випромінювання, який відрізняється тим, що касета для проведення аналізів містить принаймні другу комірку та згадану піпетку, пристосовану до...
Спосіб аналізу газів і парів летких речовин та їх сумішей за допомогою пристрою для здійснення цього аналізу

Номер патенту: 47450
Опубліковано: 10.02.2010
Автори: Філіппов Олексій Павлинович, Снопок Борис Анатолійович, Стрижак Петро Євгенович, Серебрій Таміла Григорівна
МПК: G01R 23/00, G01N 30/00, G01N 29/00
Мітки: сумішей, аналізу, цього, пристрою, летких, допомогою, здійснення, газів, спосіб, речовин, парів
Формула / Реферат:
1. Спосіб аналізу газів і парів летких речовин та їх сумішей за допомогою пристрою для здійснення цього аналізу, що здійснюють шляхом хроматографічного розділення проби на окремі компоненти та здійснюють одночасний аналіз кожної компоненти за допомогою мультисенсорної збірки типу Електронний ніс.2. Спосіб за п. 1, який відрізняється тим, що використовують газовий хроматограф з проточною коміркою, який містить збірку з кількох сенсорів...
Попередній патент: Інгібітори кінази
Наступний патент: Багатоступінчаста аераційна установка
Випадковий патент: Рекомбінантний аденовірусний вектор, фармацевтична композиція, що його містить, та набір для зменшення проліферації пухлинних клітин