Ефективне за пам’яттю моделювання контексту






























Формула / Реферат
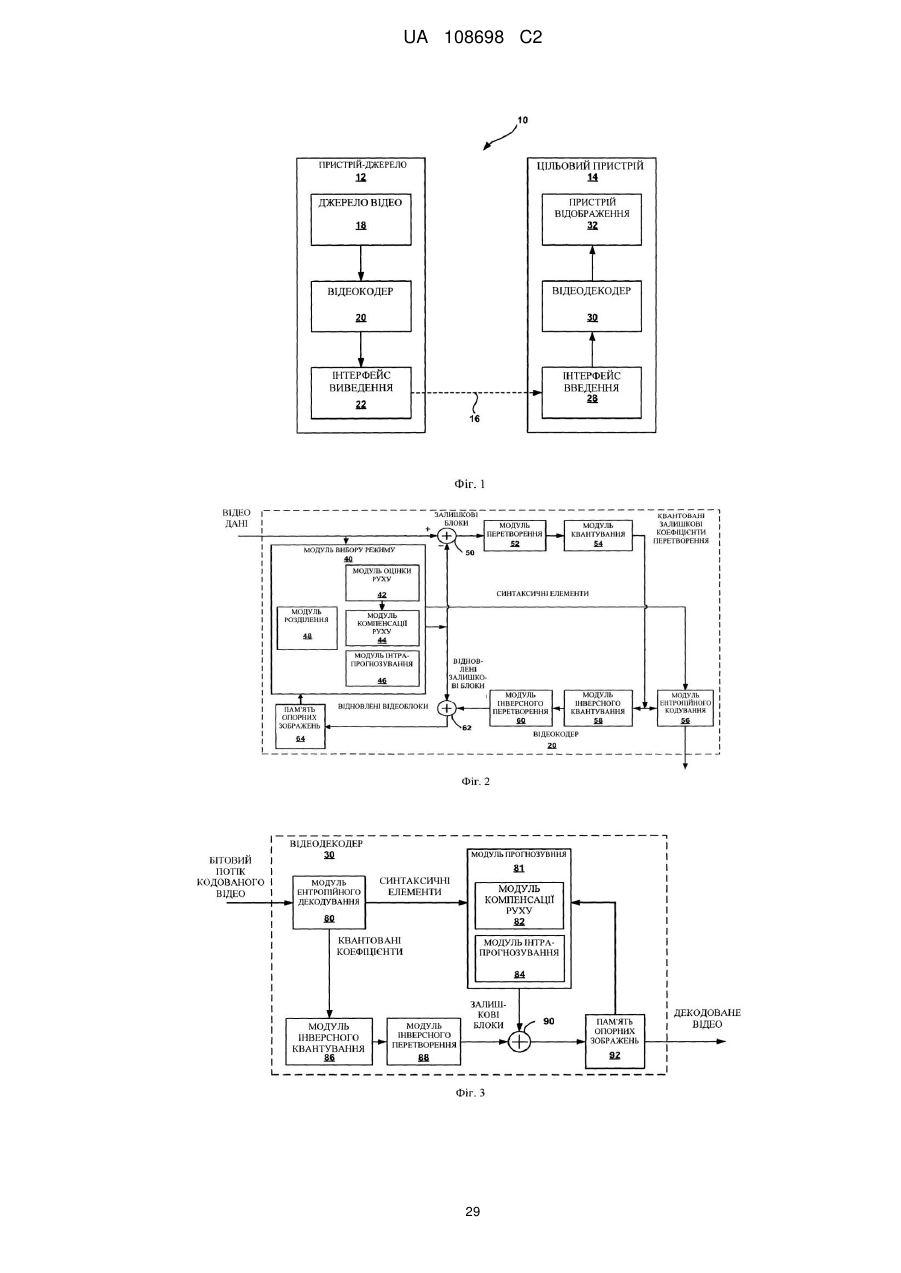
1. Спосіб кодування відеоданих, причому спосіб включає:
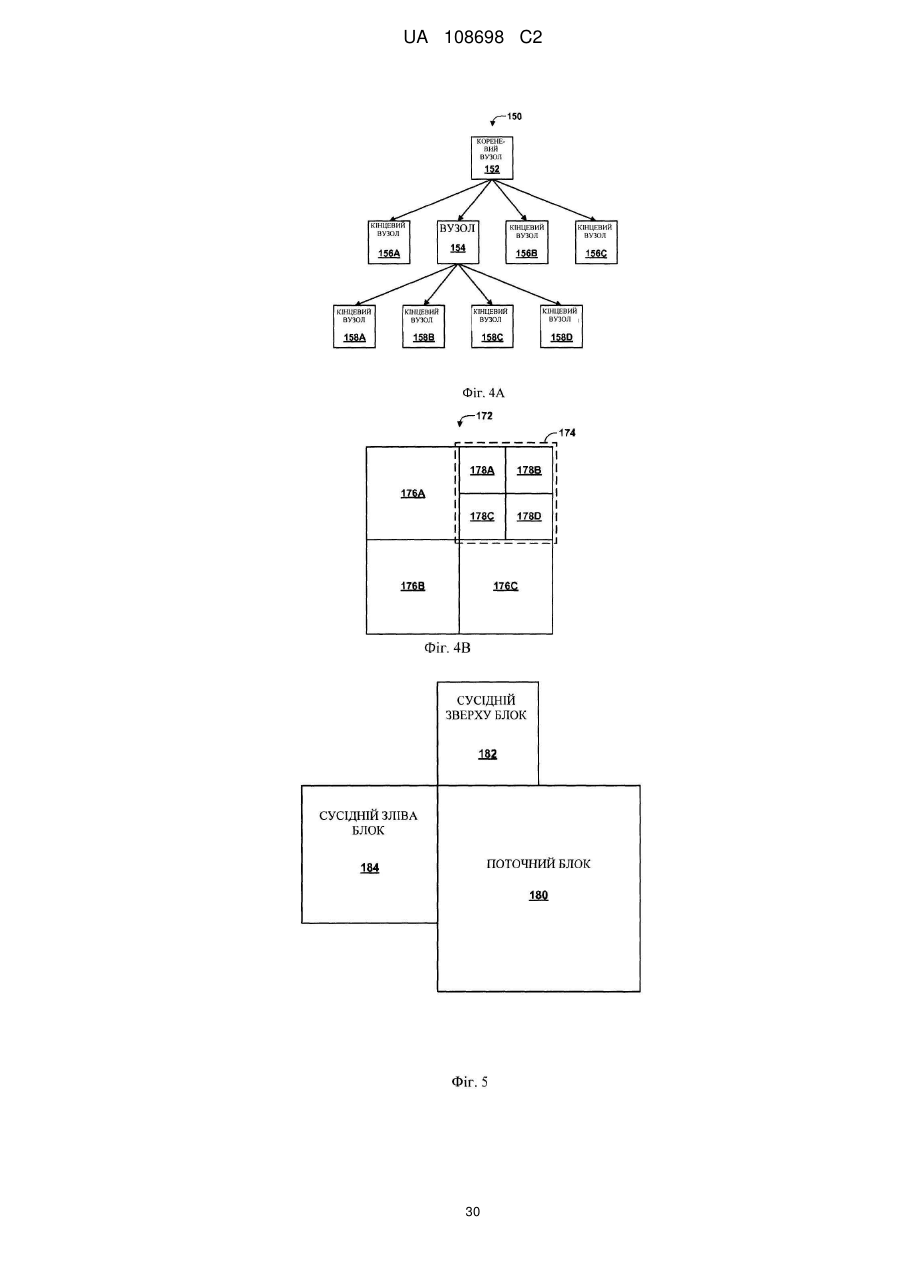
визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформаціі включає визначення контекстної інформації на основі глибини в структурі квадродерева; і
ентропійне кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому ентропійне кодування одного або більше синтаксичних елементів містить контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів, і причому контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів включає вибір імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації.
2. Спосіб за п. 1, в якому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU.
3. Спосіб за п. 2, в якому визначення контекстної інформації для даних інтерпрогнозування CU включає визначення контекстної інформації для прапора інтерпрогнозування (inter_pred_flag) на основі глибини CU.
4. Спосіб за п. 1, в якому CU містить одиницю перетворення (TU), причому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU.
5. Спосіб за п. 4, в якому визначення контекстної інформації включає визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU.
6. Спосіб за п. 2, в якому визначення контекстної інформації для даних інтерпрогнозування CU включає визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU.
7. Спосіб за п. 1, який додатково містить генерацію одного або більше синтаксичних елементів, причому ентропійне кодування одного або більше синтаксичних елементів включає ентропійне кодування одного або більше синтаксичних елементів.
8. Спосіб за п. 4, в якому визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU, включає визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU.
9. Спосіб за п. 7, який додатково включає ентропійне кодування блока відеоданих, що включає застосування перетворення до одного або більше залишкових значень блока для генерації коефіцієнтів перетворення;
квантування коефіцієнтів перетворення для генерації квантованих коефіцієнтів перетворення, і
ентропійне кодування квантованих коефіцієнтів перетворення.
10. Спосіб за п. 1, який додатково включає прийом одного або більше синтаксичних елементів від кодованого бітового потоку, причому ентропійне кодування одного або більше синтаксичних елементів включає ентропійне декодування одного або більше синтаксичних елементів.
11. Спосіб за п. 10, який додатково включає декодування блока відеоданих, що включає ентропійне декодування прийнятого бітового потоку для генерації квантованих коефіцієнтів перетворення, асоційованих з блоком відеоданих;
інверсне квантування квантованих коефіцієнтів перетворення для генерації коефіцієнтів перетворення, і
застосування інверсного перетворення до коефіцієнтів перетворення для генерації залишкових значень, асоційованих з блоком відеоданих.
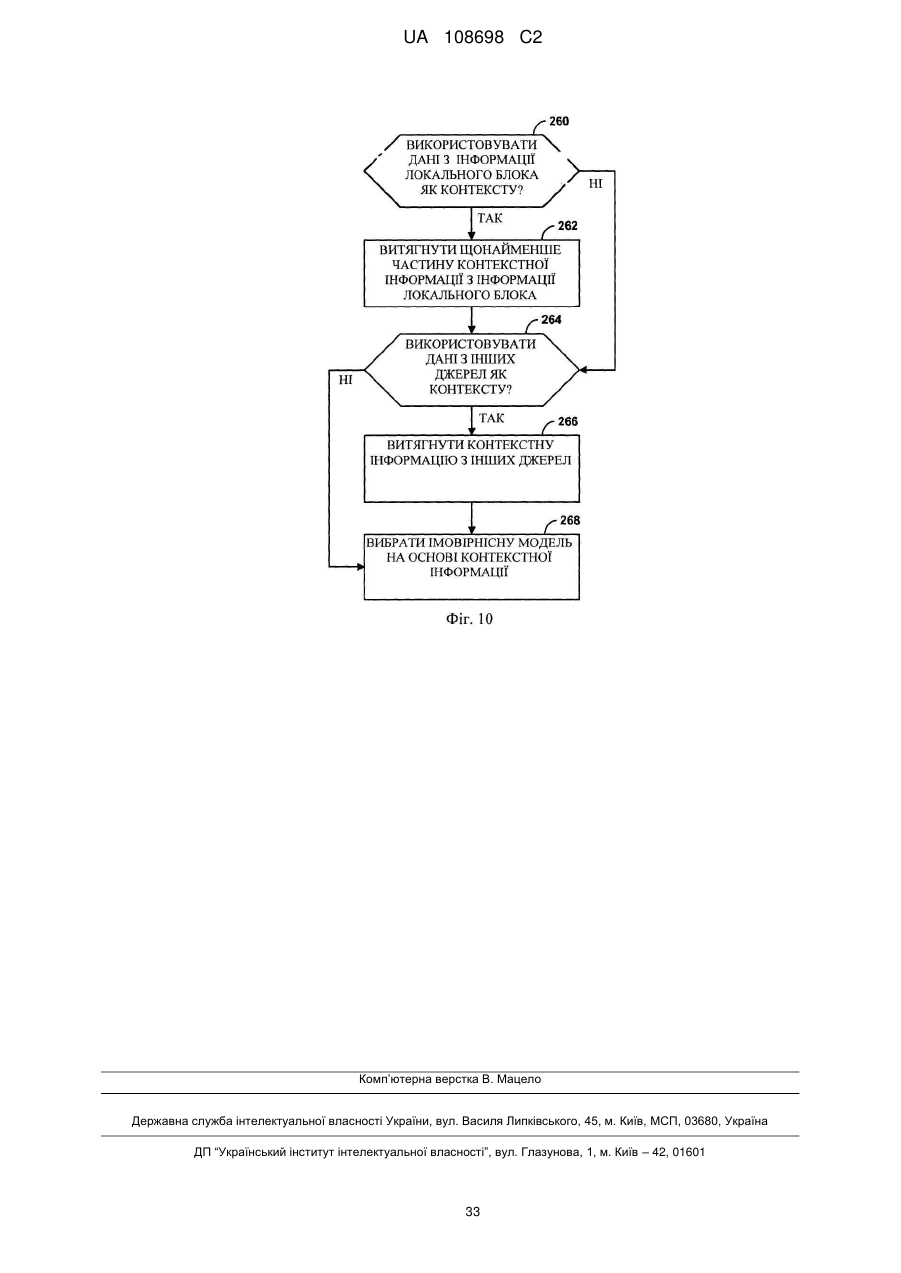
12. Спосіб за п. 1, в якому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення першої контекстної інформації для першого набору синтаксичних елементів, причому спосіб додатково включає визначення другої контекстної інформації для другого набору синтаксичних елементів на основі, щонайменше частини, контекстної інформації від блока, який є сусіднім до згаданого блока.
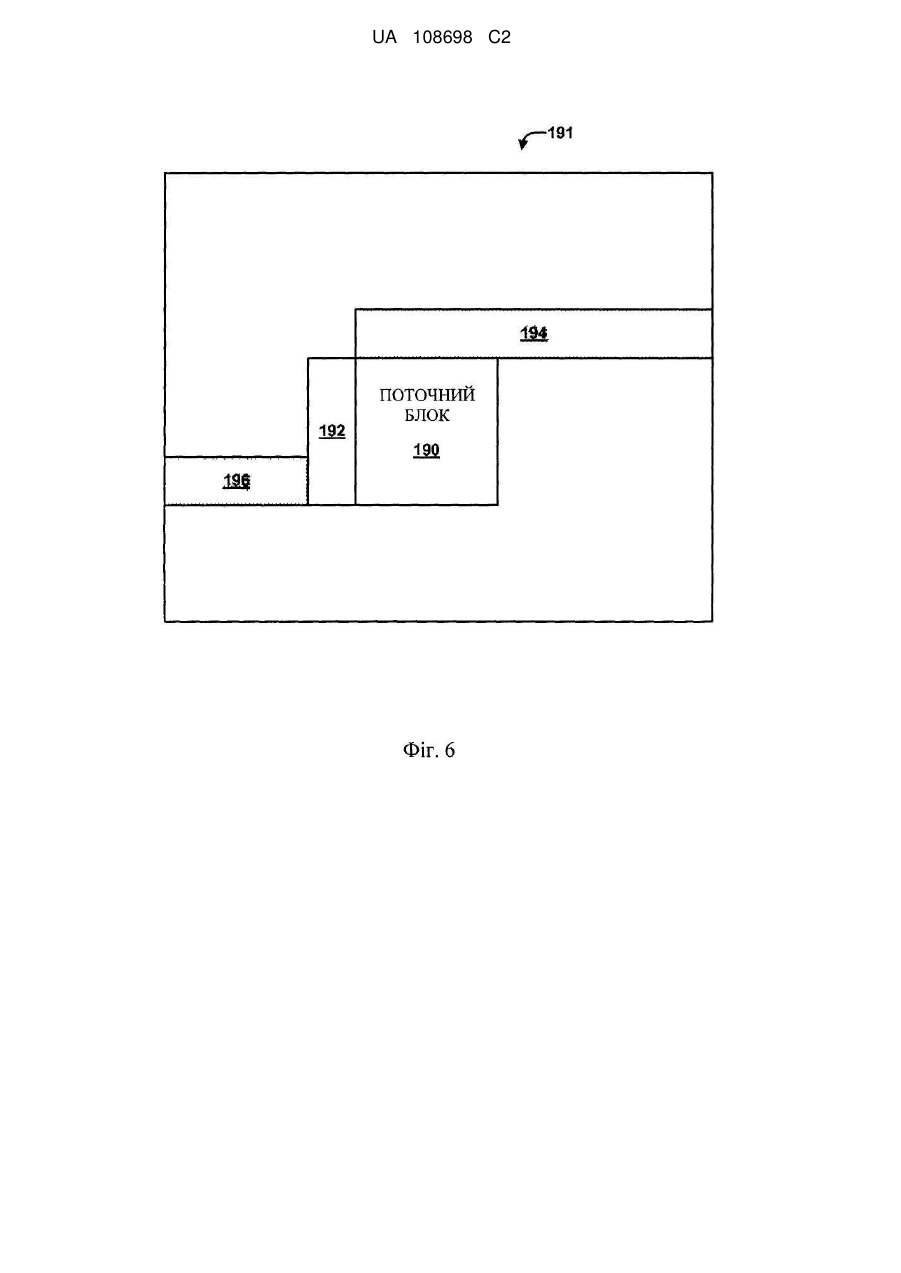
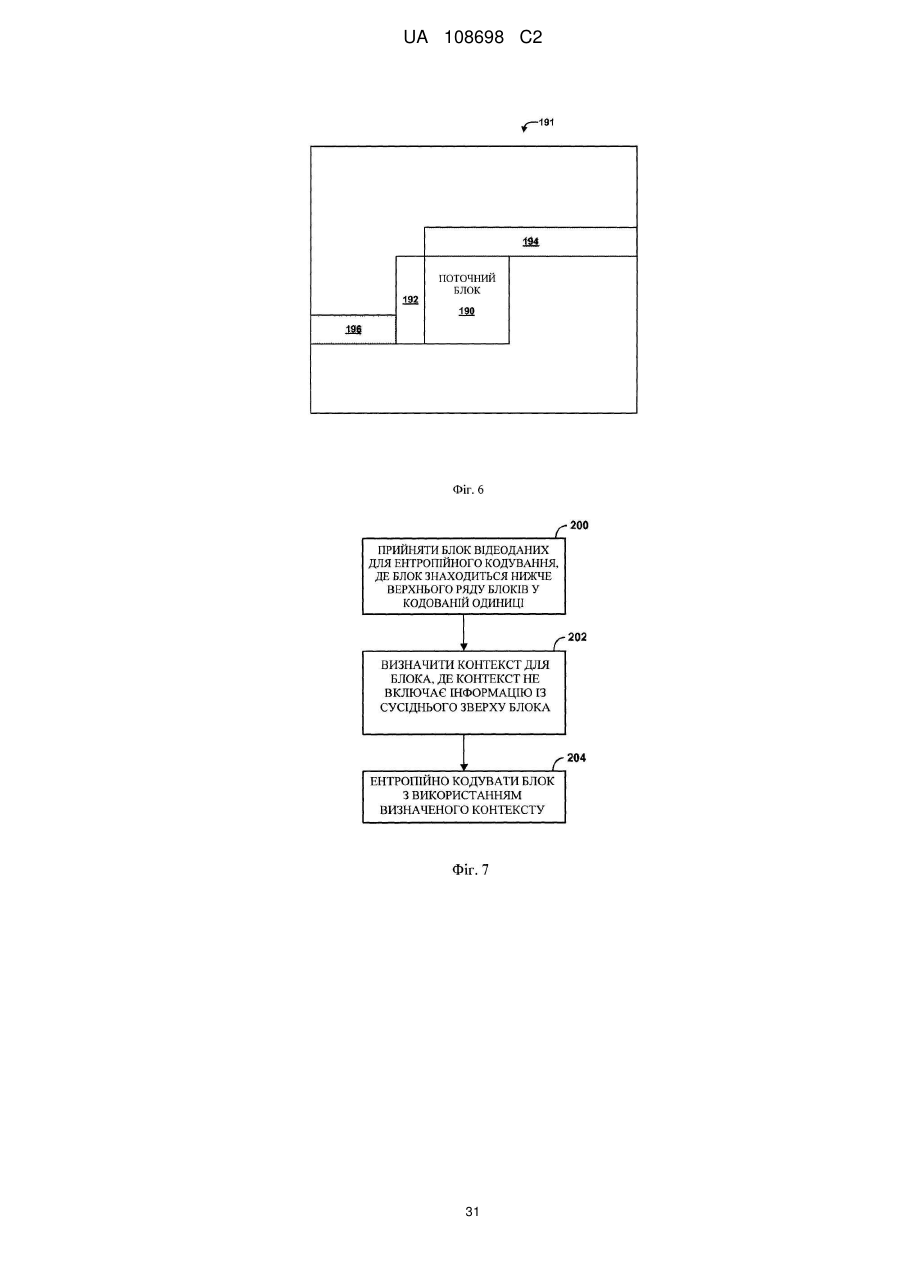
13. Спосіб за п. 12, в якому блок включає один або більше блоків найбільшої одиниці кодування (LCU), яка розташована нижче ряду блоків, що належать одній або більше інших LCU, і причому визначення контекстної інформації для другого набору синтаксичних елементів включає визначення контекстної інформації з використанням інформації, асоційованої з одним або більше блоками LCU, і виключення інформації, що знаходиться поза LCU.
14. Пристрій для кодування відеоданих, причому пристрій містить:
пам'ять, виконану з можливістю зберігання блока відеоданих; і
один або більше процесорів, виконаних з можливістю:
визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а CU є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева, і
ентропійно кодувати один або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів, і причому, щоб контекстно-адаптивно двійково арифметично кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю вибору імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації.
15. Пристрій за п. 14, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU.
16. Пристрій за п. 15, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, один або більше процесорів виконані з можливістю визначення контекстної інформації для прапора інтерпрогнозування (inter_prеd_flag) на основі глибини CU.
17. Пристрій за п. 14. в якому CU включає одиницю перетворення (TU), причому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU.
18. Пристрій за п. 17, в якому, щоб визначати контекстну інформацію, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU.
19. Пристрій за п. 15, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU.
20. Пристрій за п. 14, в якому один або більше процесорів додатково виконані з можливістю генерації одного або більше синтаксичних елементів, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю кодування одного або більше синтаксичних елементів.
21. Пристрій за п. 17, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з TU, один або більше процесорів виконані з можливістю визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU.
22. Пристрій за п. 20, в якому один або більше процесорів додатково виконані з можливістю кодування блока відеоданих, причому, щоб кодувати блок відеоданих, один або більше процесорів виконані з можливістю:
застосування перетворення до одного або більше залишкових значень блока для генерації коефіцієнтів перетворення;
квантування коефіцієнтів перетворення для генерації квантованих коефіцієнтів перетворення, і
ентропійного кодування квантованих коефіцієнтів перетворення.
23. Пристрій за п. 14, в якому один або більше процесорів виконані з можливістю прийому одного або більше синтаксичних елементів від кодованого бітового потоку, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю декодування одного або більше синтаксичних елементів.
24. Пристрій за п. 23, в якому один або більше процесорів додатково виконані з можливістю декодування блока відеоданих, причому, щоб декодувати блок відеоданих, один або більше процесорів виконані з можливістю:
ентропійного декодування прийнятого бітового потоку для генерації квантованих коефіцієнтів перетворення, пов'язаних з блоком відеоданих;
інверсного квантування квантованих коефіцієнтів перетворення для генерації коефіцієнтів перетворення, і
застосування інверсного перетворення до коефіцієнтів перетворення для генерації залишкових значень, пов'язаних з блоком відеоданих.
25. Пристрій за п. 14, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення першої контекстної інформації для першого набору синтаксичних елементів, причому один або більше процесорів додатково виконані з можливістю визначення другої контекстної інформації для другого набору синтаксичних елементів на основі щонайменше частини контекстної інформації від блока, який є сусіднім до згаданого блока.
26. Пристрій за п. 25, в якому блок включає один або більше блоків найбільшої одиниці кодування (LCU), яка розташована нижче ряду блоків, що належать одній або більше інших LCU, і причому визначення контекстної інформації для другого набору синтаксичних елементів включає визначення контекстної інформації з використанням інформації, асоційованої з одним або більше блоками LCU, і виключення інформації, що знаходиться поза LCU.
27. Пристрій для кодування відеоданих, причому пристрій містить:
засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева; і
засіб для ентропійного кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому засіб для ентропійного кодування одного або більше синтаксичних елементів включає засіб для контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів, і причому засіб для контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів включає засіб для вибору імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації.
28. Пристрій за п. 27, в якому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів включає засіб для визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU.
29. Пристрій за п. 28, в якому засіб для визначення контекстної інформації для даних інтерпрогнозування CU включає засіб для визначення контекстної інформації для прапора інтерпрогнозування (inter_pred_flag) на основі глибини CU.
30. Пристрій за п. 27, в якому CU включає одиницю перетворення (TU), причому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU.
31. Пристрій за п. 30, в якому засіб для визначення контекстної інформації включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU.
32. Пристрій за п. 27, в якому засіб для визначення контекстної інформації для даних інтерпрогнозування CU включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена СU на основі глибини CU.
33. Пристрій за п. 32, в якому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU, містить засіб для визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU.
34. Постійний машиночитаний носій, який має збережені на ньому інструкції, які при виконанні спонукають один або більше процесорів:
визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева; і
ентропійно кодувати один або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому ентропійне кодування одного або більше синтаксичних елементів включає контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів, і причому контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів включає вибір імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації.
35. Постійний машиночитаний носій за п. 34, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів шляхом визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU.
36. Постійний машиночитаний носій за п. 35, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію для даних інтерпрогнозування CU шляхом визначення контекстної інформації для прапора інтерпрогнозування (inter_рred_flag) на основі глибини CU.
37. Постійний машиночитаний носій за п. 34, в якому CU включає одиницю перетворення (TU), причому інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів шляхом визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU.
38. Машиночитаний носій за п. 37, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію шляхом визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить ТU рівні ненульових коефіцієнтів перетворення на основі глибини ТU.
39. Постійний машиночитаний носій за п. 34, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU.
40. Постійний машиночитаний носій за п. 39, в якому, визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з TU, інструкції спонукають один або більше процесорів визначати контекстну інформацію для залишкових даних інтерпрогнозування TU на основі глибини TU.
Текст
Реферат: В одному прикладі, аспекти даного розкриття стосуються способу кодування відеоданих, який включає в себе визначення контекстної інформації для блока відеоданих, де блок включений в кодовану одиницю відеоданих, де блок знаходиться нижче верхнього ряду блоків у кодованій одиниці, і де контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці. Цей спосіб також включає в себе ентропійне кодування даних блока за допомогою визначеної контекстної інформації. UA 108698 C2 (12) UA 108698 C2 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 Дана заявка заявляє пріоритет попередньої заявки США № 61/493,361, поданої 3 червня 2011 року, попередньої заявки США № 61/504,153, поданої 1 липня 2011 року, і попередньої заявки США 61/546,732, поданої 13 жовтня 2011 року, зміст кожної з яких включений в цей документ за допомогою посилання у всій їх повноті. ГАЛУЗЬ ТЕХНІКИ Даний винахід стосується відеокодування і, більш конкретно, ентропійного кодування відеоданих. ПОПЕРЕДНІЙ РІВЕНЬ ТЕХНІКИ Можливості цифрового відео можуть бути включені в широкий діапазон пристроїв, включаючи цифрові телевізори, цифрові системи прямого мовлення, бездротові системи мовлення, персональні цифрові помічники (PDA), портативні або настільні комп'ютери, планшетні комп'ютери, електронні книги, цифрові камери, цифрові записуючі пристрої, цифрові медіаплеєри, ігрові відеопристрої, ігрові приставки, стільникові або супутникові радіотелефони, так звані смартфони, пристрої відео телеконференції, пристрої потокового відео і тому подібне. Пристрої цифрового відео реалізовують технології стиснення відео, такі як ті, що описані в стандартах, визначених MPEG-2, MPEG-4, ITU-T H.263, ITU-Т H.264/MPEG-4, Part 10, Advanced Video Coding (AVC - Вдосконалене відеокодування), стандарт High Efficiency Video Coding (HEVC - Високоефективне відеокодування), що знаходиться в цей час в стадії розробки, і розширення таких стандартів. Відеопристрої можуть передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію за допомогою реалізації таких методів стиснення відео. Методи стиснення відео виконують просторове (внутрішньо-кадрове) прогнозування і/або часове (між-кадрове) прогнозування для зменшення або усунення надмірності, властивої відеопослідовностям. Для основаного на блоках (блокового) відеокодування, відеосегмент (слайс, тобто відеокадр або частина відеокадру) може бути розділений на відеоблоки, які також можуть згадуватися як блоки дерева, одиниці кодування (CU) і/або вузли кодування. Відеоблоки у внутрішньо- (інтра-) кодованому (I) сегменті зображення кодуються з використанням просторового прогнозування відносно опорних вибірок у сусідніх блоках в тому самому зображенні. Відеоблоки в між- (інтер-) кодованому (Р або В) сегменті зображення можуть використовувати просторове прогнозування відносно опорних вибірок у сусідніх блоках в тому самому зображенні або часове прогнозування відносно опорних вибірок в інших опорних зображеннях. Зображення можуть згадуватися як кадри, і опорні зображення можуть згадуватися як опорні кадри. Просторове або часове прогнозування призводить в результаті до блока прогнозування (предиктивного блока) для блока, що підлягає кодуванню. Залишкові дані представляють піксельні різниці між вихідним блоком, що підлягає кодуванню, і блоком прогнозування. Інтеркодований блок кодується відповідно до вектора руху, який вказує на блок опорних вибірок, утворюючих блок прогнозування, і залишкові дані вказують різницю між кодованим блоком і блоком прогнозування. Інтра-кодований блок кодується відповідно до режиму інтра-кодування і залишкових даних. Для подальшого стиснення, залишкові дані можуть бути перетворені з піксельної ділянки в ділянку перетворення, даючи в результаті залишкові коефіцієнти перетворення, які потім можна квантувати. Квантовані коефіцієнти перетворення, спочатку впорядковані в двомірному масиві, можна сканувати з метою одержання одномірного вектора коефіцієнтів перетворення, і ентропійне кодування може бути застосоване для досягнення ще більшого стиснення. СУТЬ ВИНАХОДУ Загалом, дане розкриття описує методи кодування відеоданих. Наприклад, методи цього розкриття включають в себе зменшення кількості даних, які буферизуються при ентропійному кодуванні відеоданих. При ентропійному кодуванні, пристрій відеокодування може вибрати модель контексту для визначення імовірності значення для даних, що підлягають кодуванню. Модель контексту для конкретного блока відеоданих може бути основана на контекстній інформації, витягнутій із сусідніх блоків відеоданих. Відповідно, пристрій відеокодування може буферизувати інформацію сусідніх блоків відеоданих, так що така інформація доступна для використання як контекстної інформації. Методи даного розкриття стосуються обмеження кількості даних із сусідніх блоків, які буферизуються при ентропійному кодуванні. Згідно з деякими аспектами даного розкриття, пристрій відеокодування може уникати використання даних з блоків відеоданих, які розташовані вище блока відеоданих, який кодується в поточний момент (які наприклад, називаються "сусідніми зверху блоками") як контекстна інформація при кодуванні поточного блока. 1 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 В одному прикладі, аспекти даного розкриття стосуються способу кодування відеоданих, який включає в себе визначення контекстної інформації для блока відеоданих, де блок включений в кодовану одиницю відеоданих, де блок знаходиться нижче верхнього ряду блоків у кодованій одиниці, і де контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці. Цей спосіб також включає в себе ентропійне кодування даних блока за допомогою визначеної контекстної інформації. В іншому прикладі, аспекти даного розкриття стосуються пристрою для кодування відеоданих, який включає в себе один або більше процесорів, сконфігурованих для визначення контекстної інформації для блока відеоданих, причому блок включений в кодовану одиницю відеоданих, причому блок знаходиться нижче верхнього ряду блоків у кодованій одиниці, і причому контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці, і для ентропійного кодування даних блока з використанням визначеної контекстної інформації. В іншому прикладі, аспекти даного розкриття стосуються пристрою для кодування відеоданих, який включає в себе засіб для визначення контекстної інформації для блока відеоданих, причому блок включений в кодовану одиницю відеоданих, причому блок знаходиться нижче верхнього ряду блоків у кодованій одиниці, і причому контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці, і засіб для ентропійного кодування даних блока з використанням визначеної контекстної інформації. В іншому прикладі, аспекти даного розкриття стосуються зчитуваного комп'ютером носія, що має збережені на ньому інструкції, які при виконанні спонукають один або більше процесорів визначати контекстну інформацію для блока відеоданих, причому блок включений в кодовану одиницю відеоданих, причому блок знаходиться нижче верхнього ряду блоків у кодованій одиниці, і причому контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці, і ентропійно кодувати дані блока з використанням визначеної контекстної інформації. Деталі одного або більше аспектів даного розкриття викладені в прикладених кресленнях і в наведеному нижче описі. Інші ознаки, цілі та переваги способів, описаних в даному розкритті, будуть очевидні з опису і креслень, а також з формули винаходу. КОРОТКИЙ ОПИС КРЕСЛЕНЬ На фіг. 1 представлена блок-схема, яка ілюструє зразкову систему відеокодування і декодування, яка може використовувати способи, описані в даному розкритті. На Фіг. 2 представлена блок-схема, яка ілюструє зразковий відеокодер, який може реалізувати способи, описані в даному розкритті. На Фіг. 3 представлена блок-схема, яка ілюструє зразковий відеодекодер, який може реалізувати способи, описані в даному розкритті. На Фіг. 4А та 4B представлені концептуальні схеми, що ілюструють приклад квадродерева і відповідну найбільшу одиницю кодування (LCU). На Фіг. 5 показана блок-схема, яка ілюструє зразкові сусідні блоки, з яких може бути визначений контекст для ентропійного кодування блока. На Фіг. 6 показана блок-схема, яка ілюструє зразкові сусідні блоки, з яких може бути визначений контекст для ентропійного кодування блока. На Фіг. 7 представлена блок-схема послідовності операцій, що ілюструє зразковий спосіб ентропійного кодування блока відеоданих. На Фіг. 8 представлена блок-схема, яка ілюструє інший зразковий спосіб ентропійного кодування блока відеоданих. На Фіг. 9 представлена блок-схема, яка ілюструє інший зразковий спосіб ентропійного кодування блока відеоданих. На Фіг. 10 представлена блок-схема, яка ілюструє інший зразковий спосіб ентропійного кодування блока відеоданих. ДОКЛАДНИЙ ОПИС Пристрій відеокодування може намагатися стискувати відеодані, використовуючи вигоди від просторової та часової надмірності. Наприклад, відеокодер може використовувати вигоди від просторової надмірності шляхом кодування блока по відношенню до сусідніх, раніше кодованих блоків. Крім того, відеокодер може використовувати вигоди від часової надмірності шляхом кодування блока по відношенню до даних раніше кодованих кадрів. Зокрема, відеокодер може прогнозувати поточний блок на основі даних просторового сусіда або на основі даних раніше кодованого кадру. Відеокодер може потім обчислити залишок для блока як різницю між дійсними піксельними значеннями для блока і прогнозованими піксельними значеннями для 2 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 блока. Відповідно, залишок для блока може включати в себе попіксельні різницеві значення в піксельній (або просторовій) ділянці. Відеокодер може потім застосовувати перетворення до значень залишку для стиснення енергії піксельних значень у відносно малу кількість коефіцієнтів перетворення в частотній ділянці. Відеокодер може потім квантувати коефіцієнти перетворення. Відеокодер може сканувати квантовані коефіцієнти перетворення для перетворення двомірної матриці квантованих коефіцієнтів перетворення в одномірний вектор, що включає в себе квантовані коефіцієнти перетворення. У деяких випадках, процеси квантування і сканування можуть відбуватися одночасно. Процес сканування коефіцієнтів іноді називають серіалізацією (перетворенням в послідовну форму) коефіцієнтів. Відеокодер може потім застосувати процес ентропійного кодування для ентропійного кодування сканованих коефіцієнтів. Зразкові процеси ентропійного кодування можуть включати в себе, наприклад, контекстно-адаптивне кодування змінної довжини (CAVLC), контекстноадаптивне двійкове арифметичне кодування (CABAC), основане на синтаксисі контекстноадаптивне двійкове арифметичне кодування (SBAC), ентропійне кодування з розбиттям на інтервали імовірності (PIPE) або інші методології ентропійного кодування. Відеокодер може також ентропійно кодувати синтаксичні елементи, асоційовані з кодованими відеоданими для використання відеодекодером в декодуванні відеоданих. Що стосується (CABAC), відеокодер може вибрати модель контексту, яка працює на контексті для кодування символів, асоційованих з блоком відеоданих. Контекст може стосуватися, наприклад, того, чи є значення нульовими або ненульовими для символів, сусідніх із символом, що кодується в поточний момент. Згідно з деякими прикладами, позиції значущих коефіцієнтів (тобто ненульових коефіцієнтів перетворення) у відеоблоці можуть кодуватися до значень коефіцієнтів перетворення, які можуть згадуватися як "рівні" коефіцієнтів перетворення. Процес кодування місцеположень значущих коефіцієнтів може згадуватися як кодування карти значущості. Карта значущості (SM) включає в себе двомірний масив двійкових значень, які вказують місцеположення значущих коефіцієнтів. Наприклад, SM для блока відеоданих може включати в себе двомірний масив з одиниць і нулів, в якому одиниці вказують позиції значущих коефіцієнтів перетворення в блоці, а нулі вказують позиції незначущих (обнулені) коефіцієнтів перетворення в блоці. Одиниці та нулі згадуються як "прапори значущих коефіцієнтів". Після того, як SM закодована, відеокодер може ентропійно кодувати рівень кожного значущого коефіцієнта перетворення. Наприклад, відеокодер може перетворювати абсолютне значення кожного ненульового коефіцієнта перетворення в двійкову форму. Таким чином, кожний ненульовий коефіцієнт перетворення може бути "бінаризований", наприклад, з використанням унарного коду, що містить один або більше бітів, або "бінів" (елементів кодованих даних). Крім того, ряд інших бінаризованих синтаксичних елементів може бути включений, щоб дозволити відеодекодеру декодувати відеодані. Відеокодер може кодувати кожний "бін" для блока відеоданих, відповідно до коефіцієнтів перетворення і з синтаксичною інформацією для блока, використовуючи імовірнісні оцінки для кожного біна. Імовірнісні оцінки можуть вказувати імовірність того, що бін має дане двійкове (бінарне) значення (наприклад, "0" або "1"). Імовірнісні оцінки можуть бути включені в модель імовірності, також відому як "модель контексту". Відеокодер може вибрати модель контексту шляхом визначення контексту для біна. Контекст для біна синтаксичного елемента може включати в себе значення відповідних бінів раніше кодованих сусідніх синтаксичних елементів. У деяких прикладах контекст для кодування поточного синтаксичного елементаможе включати в себе сусідні синтаксичні елементи, розташовані зверху і зліва від поточного синтаксичного елемента. У будь-якому випадку, відмінна модель імовірності визначається для кожного контексту. Після кодування біна, модель контексту додатково оновлюється на основі значення біна, щоб відобразити найбільш актуальні імовірнісні оцінки. У деяких прикладах блоки відеоданих величиною 4 × 4 пікселів можуть бути використані для кодування зображення. Наприклад, кадр з 1920 × 1080 пікселів (наприклад, для відео 1080p) може включати в себе 495 блоків 4 × 4 пікселів. Відповідно, для того щоб біт контекстної інформації був збережений на кожний блок, відеокодер може буферизувати 495 бітів інформації. Крім того, в деяких прикладах більш ніж один біт інформації може бути використаний як контекст для кодування конкретного синтаксичного елемента, що може значно збільшити кількість даних, що буферизуються для ентропійного кодування. Методи даного розкриття загалом стосуються обмеження кількості даних із сусідніх блоків, які буферизуються при ентропійному кодуванні. Наприклад, замість того, щоб використовувати дані сусідніх зверху блоків як контекстну інформацію при кодуванні поточного блока, в деяких 3 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 прикладах пристрій відеокодування може визначати контекст на основі характеристики синтаксичного елемента або блока, що кодується. В інших прикладах, пристрій відеокодування може визначати контекст на основі даних сусідніх зліва блоків при кодуванні поточного блока. В інших прикладах, пристрій відеокодування може визначати контекст на основі даних із сусіднього зверху блока, але тільки тоді, коли поточний блок є підблоком більшого розділу (наприклад, що згадується в стандарті Високоефективного кодування відео (HEVC), який виходить, як найбільша одиниця кодування (LCU), як описано більш детально нижче). Обмеження кількості даних, які буферизуються, відповідно до методів даного розкриття, може зменшити складність, зв'язану з кодуванням відеоданих. Наприклад, ентропійне кодування відповідно до аспектів даного винаходу може дозволити пристрою відеокодування буферизувати менше даних, тим самим знижуючи вимоги до пам'яті, зв'язані з такою буферизацією. Крім того, скорочення місцеположень, з яких виводиться контекст, може поліпшити ефективність ентропійного кодування і/або пропускну здатність. Наприклад, методи даного розкриття можуть бути реалізовані, щоб поліпшити пропускну здатність синтаксичного аналізу. Тобто, коли відеодані приймаються відеокодером, відеодані можуть аналізуватися або зчитуватися і сегментуватися відповідно до конкретного процесу аналізу (наприклад, аналізу хвильового фронту). У деяких прикладах, процес аналізу може включати в себе аналіз кожної LCU сегмента (слайса) після аналізу однієї або декількох первинних LCU (наприклад, найвищої і/або лівої LCU в сегменті). Аналіз LCU може дозволити відеокодеру формувати множину потоків обробки (наприклад, для паралельної обробки), причому кожний потік включає в себе одну або декілька LCU, що аналізуються. Внаслідок залежностей моделі контексту, однак, деякі потоки можуть бути залежними від інших потоків, що може бути не оптимальним для додатків паралельної обробки. Наприклад, перший потік може залежати від даних, що обробляються за допомогою другого, відмінного потоку, що може викликати те, що перший потік буде чекати, доки другий потік не обробить дані. Тобто, дані, як правило, аналізується до точки, де дані корисні, а потім дані кодуються. У випадку звичайних хвильових фронтів, відеокодер може сповільнити кодування даних першого (наприклад, верхнього) хвильового фронту. Це, в свою чергу, може призвести до зупинки наступного потоку, що спричиняє зупинку наступного потоку, і так далі. Усуваючи контекстні залежності, відповідно до аспектів даного розкриття, сповільнення одного потоку не вплине на інші потоки, що обробляються. По відношенню до аналізу, це означає, що аналізатору для потоку не потрібно посилатися на інші потоки, замість цього він може працювати незалежно для кожного потоку. У прикладі для цілей ілюстрації, припустимо, що LCU, яка кодується в поточний момент, розташована нижче верхнього ряду сегмента, причому одна або декілька LCU сегмента розташовані вище поточного сегмента. У цьому прикладі контекст для кодування поточної LCU може бути включений у верхню сусідню LCU (наприклад, LCU, розташовану вище поточну LCU). Тобто контекст для кодування поточної LCU може залежати від одного або декількох значень верхньої сусідньої LCU. Відповідно, поточної LCU, можливо, доведеться чекати, доки верхня сусідня LCU буде закодована, перш ніж зможе кодуватися поточна LCU. Введення такої затримки може сповільнити процес кодування, особливо в додатках паралельної обробки. Аспекти даного розкриття можуть бути реалізовані, щоб обмежити місцеположення, з яких виводиться контекст. Тобто, згідно з деякими аспектами даного розкриття, відеокодер не може використовувати контекстну інформацію з деяких сусідніх блоків, а замість цього виводить контекстну інформацію з інших джерел. Відповідно, методи даного розкриття можуть усунути контекстні залежності, описані вище, і поліпшити пропускну здатність синтаксичного аналізу. Крім того, в деяких випадках, коли блок, що кодується в поточний час, включає в себе контекстну інформацію, яка залежить від іншого, сусіднього блока, поточний блок не може бути закодований, якщо інформація із сусіднього блока втрачена або іншим чином недоступна (наприклад, через помилку передачі або інші помилки). Як приклад для цілей ілюстрації, режим об'єднаного (зі злиттям) кодування може бути використаний для прогнозування поточного блока (наприклад, інформація прогнозування, асоційована з іншим блоком, приймається для поточного блока). Якщо є помилка (наприклад, втрата пакету) для опорного кадру для поточного блока, напрямок інтер-прогнозування для поточного блока не може бути коректно виведений. Крім того, контекст, який залежить від сусіднього блока (з помилкою), також може бути спотворений. Методи даного розкриття можуть виключити контекстні залежності, описані вище, щоб зменшити введення помилок виведення контексту. На Фіг. 1 представлена блок-схема, яка ілюструє зразкову систему 10 кодування і декодування відео, яка може використовувати методи ентропійного кодування відеоданих. Як 4 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 показано на Фіг. 1, система 10 включає в себе пристрій-джерело 12, яке надає кодовані відеодані, що підлягають декодуванню в більш пізній час на цільовому пристрої 14. Зокрема, пристрій-джерело 12 надає відеодані цільовому пристрою 14 за допомогою машинозчитуваного носія 16. Пристрій-джерело 12 і цільовий пристрій 14 можуть включати в себе будь-який з широкого спектра пристроїв, включаючи настільні комп'ютери, ноутбуки (тобто портативні комп'ютери), планшетні комп'ютери, телевізійні приставки, телефонні апарати, такі як так звані смартфони, так звані інтелектуальні планшети, телевізори, камери, дисплейні пристрої, цифрові медіаплеєри, ігрові приставки, пристрій потокового відео і тому подібне. У деяких випадках пристрій-джерело 12 і цільовий пристрій 14 можуть бути оснащені для бездротового зв'язку. Цільовий пристрій 14 може приймати кодовані відеодані, призначені для декодування, за допомогою машинозчитуваного носія 16. Машинозчитуваний носій 16 може включати в себе будь-який тип середовища або пристрою, здатного переміщувати кодовані відеодані від пристрою-джерела 12 до цільового пристрою 14. В одному прикладі машинозчитуваний носій 16 може містити комунікаційне середовище, щоб дозволити пристрою-джерелу 12 передавати кодовані відеодані безпосередньо на цільовий пристрій 14 в реальному часі. Кодовані відеодані можуть модулюватися відповідно до стандарту зв'язку, наприклад протоколу бездротового зв'язку, і передаватися на цільовий пристрій 14. Комунікаційне середовище може містити будьяке бездротове або дротове комунікаційне середовище, наприклад, радіочастотного (RF) спектра або одну або більше фізичних ліній передачі. Комунікаційне середовище може бути частиною пакетної мережі, такої як локальна мережа, мережа широкого охоплення або глобальна мережа, така як Інтернет. Комунікаційне середовище може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, які можуть бути корисні для забезпечення зв'язку від пристрою-джерела 12 до цільового пристрою 14. У деяких прикладах кодовані дані можуть виводитися з інтерфейсу 22 виведення на запам'ятовуючий пристрій. Аналогічним чином, кодовані дані можуть бути доступні із запам'ятовуючого пристрою за допомогою вхідного інтерфейсу. Запам'ятовуючий пристрій може включати в себе будь-який з множини розподілених або локально доступних засобів зберігання даних, таких як жорсткий диск, Blu-ray диски, DVD, CD-ROM, флеш-пам'ять, енергозалежну або енергонезалежну пам'ять або будь-які інші підходящі носії цифрового зберігання даних для зберігання кодованих відеоданих. У ще одному прикладі запам'ятовуючий пристрій може відповідати файловому серверу або іншому проміжному пристрою зберігання, який може зберігати кодоване відео, що генерується пристроєм-джерелом 12. Цільовий пристрій 14 може одержати доступ до збережених відеоданих із запам'ятовуючого пристрою за допомогою потокової передачі або скачування. Файловий сервер може бути сервером будь-якого типу, здатним зберігати кодовані відеодані і передавати ці кодовані відеодані в цільовий пристрій 14. Зразкові файлові сервери включають в себе веб-сервер (наприклад, для веб-сайта), FTPсервер, мережні пристрої зберігання даних (NAS) або локальний жорсткий диск. Цільовий пристрій 14 може одержувати доступ до кодованих відеоданих через будь-яке стандартне з'єднання передачі даних, в тому числі Інтернет-з'єднання. Це може включати в себе бездротовий канал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем тощо) або поєднання того і іншого, яке підходить для доступу до кодованих відеоданих, що зберігаються на файловому сервері. Передача кодованих відеоданих від пристрою зберігання даних може бути потоковою передачею, передачею завантаження або їх поєднання. Дане розкриття може в цілому стосуватися відеокодера 20, що "сигналізує" визначену інформацію до іншого пристрою, такого як відеодекодер 30. Потрібно розуміти, однак, що відеокодер 20 може сигналізувати інформацію шляхом асоціювання визначених синтаксичних елементів з різними ділянками кодованих відеоданих. Тобто, відеокодер 20 може "сигналізувати" дані шляхом збереження визначених синтаксичних елементів у заголовках різних кодованих частин відеоданих. У деяких випадках такі синтаксичні елементи можуть бути закодовані та збережені (наприклад, збережені в носії 34 зберігання даних або файловому сервері 36), перш ніж прийматися і декодуватися відеодекодером 30. Таким чином, термін "сигналізація" може в цілому стосуватися передачі синтаксису або інших даних для декодування стиснутих відеоданих, незалежно від того, чи відбувається така передача в реальному або майже реальному часі або протягом визначеного періоду часу, як це може відбуватися при збереженні синтаксичних елементів на носії під час кодування, які потім можуть бути витягнуті за допомогою декодуючого пристрою в будь-який час після збереження на цьому носії. Методи цього розкриття, які загалом стосуються ентропійного кодування даних, не є обов'язково обмеженими бездротовими додатками або настройками. Ці методи можуть бути застосовані до відеокодування при підтримці будь-якого з множини мультимедійних додатків, таких як ефірне телевізійне мовлення, передачі кабельного телебачення, передачі 5 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 супутникового телебачення, передачі потокового відео через Інтернет, наприклад, динамічна адаптивна потокова передача за протоколом HTTP (DASH), цифрове відео, яке кодується на носії даних, декодування цифрового відео, збереженого на носії даних, або інші додатки. У деяких прикладах, система 10 може бути сконфігурована для підтримки односторонньої або двосторонньої передачі відео для підтримки таких додатків, як потокова передача відео, відтворення відео, відео-мовлення і/або відео-телефонія. У прикладі на Фіг. 1 пристрій-джерело 12 включає в себе джерело 18 відео, відеокодер 20 та інтерфейс 22 виведення. Цільовий пристрій 14 включає інтерфейс 28 введення, відеодекодер 30 і пристрій 32 відображення. Відповідно до даного розкриття, відеокодер 20 з пристроюджерела 12 може бути виконаний з можливістю застосовувати методи для кодування векторів руху і для виконання двонаправленого прогнозування в HEVC і його розширеннях, таких як багатовидові або 3DV розширення. В інших прикладах, пристрій-джерело і цільовий пристрій можуть включати в себе інші компоненти або конфігурації. Наприклад, пристрій-джерело 12 може приймати відеодані від зовнішнього джерела 18 відео, наприклад, зовнішньої камери. Аналогічним чином, цільовий пристрій 14 може взаємодіяти із зовнішнім пристроєм відображення, але не включати в себе інтегрований пристрій відображення. Показана система 10 на Фіг. 1 є лише одним з прикладів. Методи для ентропійного кодування відеоданих можуть бути виконані будь-яким пристроєм цифрового кодування і/або декодування відео. Хоча в цілому методи даного розкриття виконуються за допомогою пристрою відеокодування, ці методи також можуть виконуватися за допомогою відеокодера/декодера, який звичайно називається "кодеком". Крім того, методи даного розкриття можуть також виконуватися за допомогою відео-препроцесор. Пристрій-джерело 12 і цільовий пристрій 14 є лише прикладами таких пристроїв кодування, в яких пристрій-джерело 12 генерує кодовані відеодані для передачі на цільовий пристрій 14. У деяких прикладах пристрою 12, 14 можуть працювати, по суті, симетричним чином, так що кожний з пристроїв 12, 14 включають в себе компоненти кодування і декодування. Таким чином, система 10 може підтримувати односторонню або двосторонню передачу відео між відеопристроями 12, 14, наприклад, для потокової передачі відео, відтворення відео, відео-мовлення або відео-телефонії. Джерело 18 відео пристрою-джерела 12 може включати в себе пристрій захоплення відео, наприклад, відеокамеру, відеоархів, що містять раніше захоплене відео, і/або інтерфейс введення відео для прийому відео від провайдера відеоконтенту. Як додаткова альтернатива, джерело 18 відео може генерувати основані на комп'ютерній графіці дані як вихідне відео або комбінацію відео реального часу, архівного відео і відео, що генерується комп'ютером. У деяких випадках, якщо джерелом 18 відео є відеокамера, пристрій-джерело 12 і цільовий пристрій 14 можуть утворювати так звані камерофони або відеотелефони. Однак, як згадувалося вище, способи, описані в даному розкритті, можуть застосовуватися до відеокодування в цілому і можуть бути застосовані до бездротових і/або дротових додатків. У кожному випадку захоплене, заздалегідь захоплене або відео, що генерується комп'ютером, може кодуватися за допомогою відеокодера 20. Кодована відеоінформація може потім виводитися через інтерфейс 22 виведення на машинозчитуваний носій 16. Машинозчитуваний носій 16 може включати транзитивні (перехідні, часові) носії, такі як передача бездротового або дротового мовлення по мережі, або запам'ятовуючі носії (тобто, не часові (нетранзитивні, постійні) носії інформації), наприклад, жорсткий диск, флеш-пам'ять, компакт-диск, цифровий відео диск, Blu-ray диск або інші машинозчитувані носії. У деяких прикладах мережний сервер (не показаний) може приймати кодовані відеодані від пристроюджерела 12 і надавати кодовані відеодані на цільовий пристрій 14, наприклад, за допомогою передачі по мережі. Аналогічним чином, обчислювальний пристрій обладнання з виробництва носіїв, такого як обладнання штампування дисків, може приймати кодовані відеодані від пристрою-джерела 12 і виробляти диск, що містить кодовані відеодані. Таким чином, машинозчитуваний носій 16 може розумітися як такий, що включає в себе один або декілька машинозчитуваних носіїв різних форм, в різних прикладах. Інтерфейс 28 введення цільового пристрою 14 одержує інформацію з машинозчитуваного носія 16. Інформація машинозчитуваного носія 16 може включати в себе синтаксичну інформацію, визначену відеокодером 20, яка також використовується відеодекодером 30, яка включає в себе синтаксичні елементи, які описують характеристики і/або обробку блоків та інших кодованих одиниць, наприклад GOP. Зокрема, дане розкриття стосується "кодованої одиниці" як одиниці даних, що включає в себе декілька блоків, таких як сегмент, зображення, набір хвильових фронтів, або елемент мозаїчного зображення. Таким чином, термін "кодована одиниця" потрібно розуміти як такий, що включає в себе декілька блоків, наприклад, декілька найбільших одиниць кодування (LCU). Крім того, термін "кодована одиниця" не треба плутати з 6 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 терміном "одиниця кодування" або CU, як використовується в HEVC. Пристрій 32 відображення відображає декодовані відеодані користувачу і може містити будь-який з множини пристроїв відображення, таких як електронно-променева трубка (ЕПТ), рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світловипромінюючих діодах (OLED) або пристрій відображення іншого типу. Відеокодер 20 та відеодекодер 30 можуть працювати відповідно до стандарту відеокодування, такого як стандарт Високоефективного відеокодування (HEVC), що знаходиться в цей час в стадії розвитку, і може відповідати HEVC тестовій моделі (HM). Альтернативно, відеокодер 20 і відеодекодер 30 можуть діяти відповідно до інших пропрієтарних або промислових стандартів, таких як стандарт ITU-T H.264, що альтернативно згадується як MPEG-4, частина 10, Вдосконалене відеокодування (AVC) або розширення таких стандартів. Однак методи даного розкриття не обмежуються яким-небудь конкретним стандартом кодування. Інші приклади стандартів відеокодування включають в себе MPEG-2 і ITU-T H.263. Хоча це не показано на Фіг. 1, в деяких аспектах відеокодер 20 і відеодекодер 30 можуть, кожний, бути інтегровані з аудіокодером і декодером і можуть включати в себе відповідні блоки MUX-DEMUX або інше обладнання і програмне забезпечення для обробки аудіо та відеокодування в загальному потоці даних або окремих потоках даних. Якщо застосовно, блоки MUX-DEMUX можуть відповідати протоколу мультиплексора ITU H.223 або іншим протоколам, таким як протокол користувацьких дейтаграм (UDP). Стандарт ITU-T H.264/MPEG-4 (AVC) був сформульований ITU-T Експертною групою з кодування відео (VCEG) разом з ISO/IEC Експертною групою з рухомих зображень (MPEG) у вигляді продукту колективного партнерства, відомого як Об'єднана відео група (JVT). У деяких аспектах методи, описані в даному розкритті, можуть бути застосовані до пристроїв, які звичайно відповідають стандарту H.264. Стандарт H.264 описаний в ITU-T Рекомендації H.264 Вдосконалене кодування відео для загальних аудіовізуальних послуг ITU-T Дослідницькою групою і датований березнем 2005 року, що може згадуватися тут як стандарт H.264 або специфікація H.264 або стандарт або специфікація H.264/AVC. JVT продовжує роботу над розширеннями H.264/MPEG-4 AVC. JCT-VC працює над розвитком стандарту HEVC. Зусилля зі стандартизації HEVC основані на розвиненій моделі пристрою відеокодування, що згадується як HVEC тестова модель (HM). HM передбачає декілька додаткових можливостей пристроїв відеокодування відносно існуючих пристроїв згідно з, наприклад, ITU-T H.264/AVC. Наприклад, в той час як H.264 забезпечує дев'ять режимів кодування з інтра-прогнозуванням, HM може забезпечити до тридцяти трьох режимів кодування з інтра-прогнозуванням. Загалом, робоча модель HM описує, що відеокадр або зображення може бути розділене на послідовність блоків дерева або найбільших одиниць кодування (LCU), які включають в себе вибірки як яскравості, так і кольоровості. Дані синтаксису в потоці бітів можуть визначати розмір для LCU, яка є найбільшою одиницею кодування в термінах числа пікселів. Сегмент включає в себе ряд послідовних блоків дерева в порядку кодування. Відеокадр або зображення можуть бути розділені на один або більше сегментів. Кожний блок дерева може бути розділений на одиниці кодування (CU) відповідно до квадродерева. Загалом, структура даних квадродерева включає в себе один вузол на СU, причому кореневий вузол відповідає блоку дерева. Якщо CU ділиться на чотири суб-CU, вузол, що відповідає CU, включає в себе чотири вузли листя (кінцевих вузла), кожний з яких відповідає одній з суб-CU. Кожний вузол структури даних квадродерева може надати дані синтаксису для відповідної CU. Наприклад, вузол в квадродереві може включати в себе прапор розділення, що показує, чи розділена CU, яка відповідає вершині, на суб-CU. Елементи синтаксису для CU можуть бути визначені рекурсивно і можуть залежати від того, чи розділена CU на суб-CU. Якщо CU не розділена далі, то вона називається листовою (кінцевою) CU. У даному розкритті чотири суб-CU кінцевої CU також будуть згадуватися як кінцеві CU, навіть якщо немає явного розділення вихідної кінцевої CU. Наприклад, якщо CU розміром 16 × 16 не розділена далі, чотири суб-CU розміром 8 × 8 будуть також згадуватися як кінцеві CU, хоча 16 × 16 CU не була розділена. CU має аналогічне призначення, що і макроблок стандарту H.264, за винятком того, що CU не має відмінності за розмірами. Наприклад, блок дерева може бути розділений на чотири дочірніх вузли (також згадуються як суб-CU), і кожний дочірній вузол в свою чергу може бути батьківським вузлом і може бути розділений на наступні чотири дочірніх вузлів. У результаті, неподілений дочірній вузол, що згадується як кінцевий вузол квадродерева, включає в себе вузол кодування, що також згадується як кінцева CU. Дані синтаксису, зв'язані з кодованим бітовим потоком, можуть визначати максимальну кількість разів розділення блока дерева, що згадується максимальною глибиною CU, а також можуть визначати мінімальний розмір вузлів 7 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодування. Відповідно, бітовий потік може також визначати найменшу одиницю кодування (SCU). Дане розкриття використовує термін "блок", щоб посилатися на будь-якій з CU, PU або TU в контексті HEVC, або аналогічні структури даних у контексті інших стандартів (наприклад, макроблоки та їх підблоки в H.264/AVC). Крім того, дане розкриття може використовувати термін "кодована одиниця", щоб описувати зумовлену кількість відеоданих, яка може включати в себе два або більше блоків відеоданих. Тобто, наприклад, кодована одиниця може стосуватися зображення, сегмента, елемента мозаїчного зображення або набору елементів мозаїчного зображення, набору хвильових фронтів або будь-якій іншій зумовленій одиниці, яка включає в себе відеодані. Відповідно, термін "кодована одиниця" не треба плутати з термінами "одиниця кодування" або CU. CU включає в себе вузол кодування і одиниці прогнозування (PU) і одиниці перетворення (TU), зв'язаний з вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен бути квадратної форми. Розмір CU може знаходитися в діапазоні від 8 × 8 пікселів до розміру блока дерева з максимумом 64 × 64 пікселя або більше. Кожна CU може містити одну або більше PU і одну або більше TU. Дані синтаксису, зв'язані з CU, можуть описувати, наприклад, розбиття CU на одну або більше PU. Режими розділення можуть відрізнятися залежно від того, чи пропущена CU або кодована в прямому режимі, кодована в режимі інтра-прогнозування, кодована в режимі інтер-прогнозування. PU можуть бути розділені так, щоб бути неквадратної форми. Дані синтаксису, зв'язані з CU, також можуть описувати, наприклад, розбиття CU на одну або більше TU відповідно до квадродерева. ТU може бути квадратної або неквадратної (наприклад, прямокутної) форми. Стандарт HEVC забезпечує можливість перетворень відповідно до TU, які можуть бути різними для різних CU. TU звичайно мають розмір залежно від розміру PU в межах даної CU, визначеної для розділеної LCU, хоча це не завжди так. TU, як правило, такого самого розміру, або менше, ніж PU. У деяких прикладах залишкові вибірки, що відповідають CU, можуть бути розділені на більш дрібні одиниці з використанням структури квадродерева, відомої як "залишкове квадродерево" (RQT). Кінцеві вузли RQT можуть згадуватися як одиниці перетворення (TU). Піксельні різницеві значення, зв'язані з TU, можуть бути перетворені для одержання коефіцієнтів перетворення, які можуть бути квантованими. Кінцева CU може включати в себе одну або більше одиниць прогнозування (PU). Загалом, PU являє собою просторову ділянку, що відповідає всій або частині відповідної CU, і може включати дані для витягання еталонної вибірки для PU. Крім того, PU включає в себе дані, зв'язані з прогнозуванням. Наприклад, коли PU кодується в інтра-режимі, дані для PU можуть бути включені в залишкове квадродерево (RQT), яке може включати в себе дані, що описують режим інтра-прогнозування для ТU, що відповідає PU. Як інший приклад, коли PU кодується в інтер-режимі, PU може включати в себе дані, що визначають один або більше векторів руху для PU. Дані, що визначають вектор руху для PU, можуть описувати, наприклад, горизонтальний компонент вектора руху, вертикальний компонент вектора руху, розрізнення для вектора руху (наприклад, точність в одну четверту пікселя або точність в одну восьму пікселя), опорне зображення, на яке вказує вектор руху, і/або список опорних зображень (наприклад, список 0, список 1 або список 3) для вектора руху. Кінцева CU, що має одну або більше PU, може також включати одну або більше одиниць перетворення (ТU). Одиниці перетворення можуть бути визначені за допомогою RQT (також згадується як структура квадродерева ТU), як описано вище. Наприклад, прапор розділення може вказувати, чи є кінцева CU розділеною на чотири одиниці перетворення. Потім кожна одиниця перетворення може бути розділена далі на подальші суб-TU. Якщо ТU не розділяється далі, вона може згадуватися як кінцева ТU. Як правило, для інтра-кодування, всі кінцеві TU, що належать до кінцевої CU, мають той самий режим інтра-прогнозування. Тобто, той самий режим інтра-прогнозування, як правило, застосовується для розрахунку прогнозованих значень для всіх TU з кінцевих CU. Для інтра-кодування, відеокодер 20 може обчислювати залишкове значення для кожної кінцевої TU з використанням режиму інтра-прогнозування, як різницю між частиною CU, що відповідає TU, і вихідним блоком. TU не обов'язково обмежується розміром PU. Таким чином, TU може бути більше або менше, ніж PU. Для інтра-кодування, PU може бути співвіднесена з відповідною кінцевою ТU для тієї самої CU. У деяких прикладах максимальний розмір кінцевої TU може відповідати розміру відповідної кінцевої СU. Крім того, TU кінцевої CU може також бути зв'язана з відповідними структурами даних квадродерева, що згадуються як залишкові квадродерева (RQT). Тобто кінцева CU може включати в себе квадродерево, що вказує, як кінцева CU розділяється на TU. Кореневий вузол з квадродерева ТU в цілому відповідає кінцевій CU, в той час як кореневий вузол квадродерева CU в цілому відповідає блоку дерева (або LCU). TU квадродерева RQT, які не розділені, 8 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 називаються кінцевими TU. Загалом, дане розкриття використовує терміни CU і ТU, щоб посилатися на кінцеву CU і кінцеву ТU, відповідно, якщо не вказане інше. Відеопослідовність звичайно включає в себе ряд відеокадрів або зображень. Група зображень (GOP) звичайно включає в себе серію з одного або більше відеозображень. GOP може включати в себе дані синтаксису в заголовку GOP, заголовку одного або декількох зображень або в іншому місці, які описують ряд зображень, включених в GOP. Кожний сегмент зображення може включати в себе дані синтаксису сегмента, які описують режим кодування для відповідного сегмента. Відеокодер 20 звичайно працює на відеоблоках в окремих відеосегментах, щоб кодувати відеодані. Відеоблок може відповідати вузлу кодування всередині CU. Відеоблоки можуть мати фіксовані або різні розміри і можуть відрізнятися за розмірами відповідно до заданого стандарту кодування. Як приклад, HM підтримує прогнозування в різних розмірах PU. Якщо припустити, що розмір визначеної CU рівний 2N2N, HM підтримує інтра-прогнозування в PU з розмірами 2N2N або NN, і інтер-прогнозування в симетричних розмірах PU, рівних 2N2N, 2NN, N2N або NN. HM також підтримує асиметричне розділення для інтер-прогнозування в PU з розмірами 2NnU, 2NnD, nL2N та nR2N. В асиметричному розділенні один напрямок CU не розділений, а інший напрямок розбивається на 25 % та 75 %. Частина CU, що відповідає 25 %-розділенню, позначається "n", з подальшою вказівкою "Вгору", "Вниз", "Ліворуч" або "Праворуч". Так, наприклад, "2NnU" стосується 2N2N CU, яка розділена горизонтально з 2N0,5N PU зверху і 2N1,5 N PU внизу. В даному розкритті запису "NN" та "N на N" можуть використовуватися як взаємозамінні для посилання на розміри в пікселях відеоблока в термінах вертикального і горизонтального розміру, наприклад, 1616 пікселів або 16 на 16 пікселів. Загалом, 1616 блок буде мати 16 пікселів у вертикальному напрямку (у = 16) і 16 пікселів в горизонтальному напрямку (х = 16). Крім того, блок NN, як правило, має N пікселів у вертикальному напрямку і N пікселів в горизонтальному напрямку, де N являє собою ненегативне ціле число. Пікселі в блоці можуть бути розташовані в рядках і стовпцях. Крім того, блоки не обов'язково повинні мати те саме число пікселів у горизонтальному напрямку, що і у вертикальному напрямку. Наприклад, блоки можуть містити NM пікселів, де М не обов'язково рівне N. Після кодування з інтра-прогнозуванням або інтер-прогнозуванням з використанням PU в CU, відеокодер 20 може обчислити залишкові дані для TU в CU. PU можуть містити синтаксичні дані, що описують метод або режим генерації піксельних даних прогнозування в просторовій ділянці (також згадується як піксельна ділянка), і TU може містити коефіцієнти в ділянці перетворення, що слідують застосуванню перетворення, наприклад, дискретного косинусного перетворення (DCT), цілочисельного перетворення, вейвлет-перетворення, або концептуально подібного перетворення в залишкові відеодані. Залишкові дані можуть відповідати піксельним різницям між пікселями некодованого зображення і значеннями прогнозування, що відповідають PU. Відеокодер 20 може формувати TU, що включають залишкові дані для CU, а потім перетворювати TU для формування коефіцієнтів перетворення для CU. Після будь-яких перетворень, щоб сформувати коефіцієнти перетворення, відеокодер 20 може виконувати квантування коефіцієнтів перетворення. Квантування в цілому стосується процесу, в якому коефіцієнти перетворення квантуються, щоб по можливості зменшити обсяг даних, що використовуються для представлення коефіцієнтів, забезпечуючи подальше стиснення. Процес квантування може зменшити бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, n-бітове значення можна округлити вниз до m-бітового значення при квантуванні, де n більше m. Після квантування, відеокодер може сканувати коефіцієнти перетворення, формуючи одномірний вектор з двомірної матриці, яка включає в себе квантовані коефіцієнти перетворення. Сканування може бути спроектоване так, щоб вміщувати коефіцієнти більш високої енергії (отже, низької частоти) в передню частину матриці і вміщувати коефіцієнти більш низької енергії (отже, високої частоти) в задню частину матриці. У деяких прикладах, відеокодер 20 може використовувати зумовлений порядок сканування для сканування квантованих коефіцієнтів перетворення для одержання серіалізованого (перетвореного в послідовну форму) вектора, який може бути ентропійно кодований. В інших прикладах відеокодер 20 може виконувати адаптивне сканування. Після сканування квантованих коефіцієнтів перетворення, щоб сформувати одномірний вектор, відеокодер 20 може ентропійно кодувати одномірний вектор, наприклад, відповідно до контекстно-адаптивного кодування змінної довжини (CAVLC), контекстно-адаптивного двійкового арифметичного кодування (CABAC), основаного на синтаксисі контекстно-адаптивного двійкового арифметичного кодування (SBAC), ентропійного кодування з розбиттям на інтервали імовірності (PIPE) або іншим методом ентропійного 9 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 кодування. Відеокодер 20 може також ентропійно кодувати синтаксичні елементи, зв'язані з кодованими відеоданими, для використання відеодекодером 30 в декодуванні відеоданих. Для виконання CABAC, відеокодер 20 може призначити контекст в рамках моделі контексту символу, який повинен передаватися. Контекст може відноситися, наприклад, до того, чи є сусідні значення символу ненульовими чи ні. Відеокодер 20 може також ентропійно кодувати синтаксичні елементи, такі як прапор коефіцієнта значущості і прапор останнього коефіцієнта, сформовані при виконанні адаптивного сканування. Загалом, процес декодування відео, що виконується за допомогою відеодекодера 30, може включати в себе взаємно обернені методи по відношенню до методів кодування, що виконуються за допомогою відеокодера 20. Хоча в принципі взаємно обернено, відеодекодер 30 може, в деяких випадках, виконувати методи, аналогічні тим, які виконуються за допомогою відеокодера 20. Відеодекодер 30 також може покладатися на синтаксичні елементи або інші дані, які містяться в бітовому потоці, що приймається, який включає в себе дані, описані в зв'язку з відеокодером 20. Згідно з аспектами даного розкриття, відеокодер 20 і/або відеодекодер 30 може реалізувати способи даного розкриття для обмеження обсягу даних із сусідніх блоків, які буферизуються при ентропійному кодуванні. Наприклад, замість того, щоб використовувати дані сусідніх зверху блоків як контекстну інформацію при кодуванні поточного блока, в деяких прикладах, відеокодер 20 і/або відеодекодер 30 може визначити контекст на основі характеристики синтаксичного елемента або блока, який кодується. В інших прикладах відеокодер 20 і/або відеодекодер 30 може визначити контекст на основі даних сусідніх зліва блоків кодування при кодуванні поточного блока. В інших прикладах, відеокодер 20 і/або відео декодер 30 може визначати контекст на основі даних із сусіднього зверху блока, але тільки тоді, коли поточний блок є суб-блоком більшого розділу (наприклад, LCU). Крім того, в деяких випадках, відеокодер 20 і/або відеодекодер 30 можуть виконувати один або більше способів даного розкриття в комбінації. Відеокодер 20 і відеодекодер 30 можуть бути реалізовані як будь-яка з множини підходящих схем кодера або декодера, якщо це застосовне, наприклад, як один або більше мікропроцесорів, цифрових сигнальних процесорів (DSP), спеціалізованих інтегральних схем (ASIC), масивів програмованих вентильних матриць (FPGA), дискретних логічних схем, як програмне забезпечення, апаратні засоби, програмно-апаратні засоби або будь-які їх комбінації. Кожний з відеокодера 20 і відеодекодера 30 може бути включений в один або більше кодерів або декодерів, кожний з яких може бути інтегрований як частина комбінованого відеокодера/декодера (кодека). Пристрій, що містить відеокодер 20 і/або відеодекодер 30, може містити інтегральну схему, мікропроцесор і/або пристрій бездротового зв'язку, такого як стільниковий телефон. На Фіг. 2 представлена блок-схема, яка ілюструє зразковий відеокодер 20, який може реалізувати способи, описані в даному розкритті для ентропійного кодування відеоданих. Відеокодер 20 може виконувати інтра- та інтер-кодування відеоблоків у відео сегментах. Інтракодування спирається на просторове прогнозування для зменшення або усунення просторової надмірності у відео в межах визначеного відеокадру або зображення. Інтер-кодування основується на часовому прогнозуванні для зменшення або усунення часової надмірності у відео в межах суміжних кадрів або зображень відеопослідовності. Інтра-режим (режим I) може стосуватися будь-якого з різних просторових режимів стиснення. Інтер-режими, такі як однонаправлене прогнозування (режим Р) або двонаправлене прогнозування (режим В), може стосуватися будь-якого з різних часових режимів стиснення. Як показано на Фіг. 2, відеокодер 20 приймає відеодані, які повинні кодуватися. У прикладі на Фіг. 2, відеокодер 20 включає в себе модуль 40 вибору режиму, суматор 50, модуль 52 перетворення, модуль 54 квантування, модуль 56 ентропійного кодування і пам'ять 64 опорних зображень. Модуль 40 вибору режиму, в свою чергу, включає в себе модуль 42 оцінки руху, модуль 44 компенсації руху, модуль 46 інтра-прогнозування і модуль 48 розділення. Для відновлення відеоблока, відеокодер 20 також включає в себе модуль 58 інверсного квантування, модуль 60 інверсного перетворення і суматор 62. Деблокуючий фільтр (не показаний на Фіг. 2) також може бути включений для фільтрації меж блоків, щоб видаляти артефакти блочності з відновленого відео. За бажанням деблокуючий фільтр буде в типовому випадку фільтрувати вихід суматора 62. Додаткові фільтри контуру (внутрішньоконтурні або постконтурні) також можуть бути використані додатково до деблокуючого фільтра. Такі фільтри не показані для стислості, але за бажанням можуть фільтрувати вихід суматора 50 (як внутрішньоконтурний фільтр). 10 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 Під час процесу кодування відеокодер 20 приймає відеокадр або сегмент, що підлягає кодуванню. Кадр або сегмент може бути розділений на декілька відеоблоків. Модуль 42 оцінки руху і модуль 44 компенсації руху виконують кодування з інтер-прогнозуванням відеоблока, що приймається, по відношенню до одного або більше блоків в одному або більше опорних кадрів, щоб забезпечити часове стиснення. Модуль 46 інтра-прогнозування може альтернативно виконувати кодування з інтра-прогнозуванням прийнятого відеоблока по відношенню до одного або більше сусідніх блоків у тому самому кадрі або сегменті як блока, який повинен бути закодований, щоб забезпечити просторове стиснення. Відеокодер 20 може виконувати декілька проходів кодування, наприклад, щоб вибрати відповідний режим кодування для кожного блока відеоданих. Крім того, модуль 48 розділення може розділяти блоки відеоданих на суб-блоки, на основі оцінки попередніх схем розділення в попередніх проходах кодування. Наприклад, модуль 48 розділення може спочатку розділити кадр або сегмент на LCU, і розділити кожну з LCU на субCU на основі аналізу швидкості-спотворення (наприклад, оптимізації співвідношення швидкістьспотворення). Модуль 40 вибору режиму може додатково формувати структуру даних квадродерева, що вказує розділення LCU на суб-CU. CU кінцевого вузла квадродерева можуть включати в себе одну або більше PU і одну або більше TU. Модуль 40 вибору режиму може вибрати один з режимів кодування, інтра- або інтер-, наприклад, на основі результатів помилок, і надає результуючий інтра- або інтер-кодований блок на суматор 50 для генерації даних залишкового блока і на суматор 62, щоб відновити кодований блок для використання як опорного кадру. Модуль 40 вибору режиму також надає синтаксичні елементи, такі як вектора руху, покажчики інтра-режиму, інформація розділення та інша така синтаксична інформація, на модуль 56 ентропійного кодування. Модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути високою мірою інтегровані, але проілюстровані окремо для концептуальних цілей. Оцінка руху, що виконується модулем 42 оцінки руху, є процесом створення векторів руху, які оцінюють рух для відео блоків. Вектор руху, наприклад, може вказувати на зміщення PU відеоблока всередині поточного відеокадру або зображення по відношенню до блока прогнозування в опорному кадрі (або іншій кодованій одиниці) відносно поточного блока, що кодується в межах поточного кадру (або іншої кодованої одиниці). Блок прогнозування являє собою блок, який передбачається точно відповідним блоку, що кодується, в термінах піксельної різниці, що може бути визначено сумою абсолютних різниць (SAD), сумою квадратів різниць (SSD) або інших метрик різниць. У деяких прикладах, відеокодер 20 може обчислити значення для суб-цілочисельних піксельних позицій опорних зображень, що зберігаються в пам'яті 64 опорних зображень. Наприклад, відеокодер 20 може інтерполювати значення піксельних позицій в одну чверть, піксельних позицій в одну восьму або інших дробових піксельних позицій опорного зображення. Таким чином, модуль 42 оцінки руху може виконати пошук руху відносно повних піксельних позицій і дробових піксельних позицій і виводити вектори руху з точністю, що визначається часткою пікселя. Модуль 42 оцінки руху обчислює вектор руху для PU у відеоблока в інтра-кодованому сегменті шляхом порівняння позиції PU з позицією блока прогнозування опорного зображення. Опорне зображення може бути вибране з першого списку опорних зображень (список 0) або другого списку опорних зображень (список 1), кожний з яких ідентифікує одне або більше опорних зображень, збережених в пам'яті 64 опорних кадрів. Модуль 42 оцінки руху посилає обчислений вектор руху в модуль 56 ентропійного кодування і модуль 44 компенсації руху. Компенсація руху, що виконується модулем 44 компенсації руху, може включати в себе витягання або генерацію блока прогнозування на основі вектора руху, визначеного модулем 42 оцінки руху. Знову, модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути функціонально інтегровані, в деяких прикладах. Після прийому вектора руху для PU поточного блока відео, модуль 44 компенсації руху може вмістити блок прогнозування, на який вказує вектор руху, в один з списків опорних зображень. Суматор 50 формує залишковий відеоблок шляхом віднімання піксельних значень блока прогнозування з піксельних значень поточного відеоблока, який кодується, формуючи піксельні різницеві значення, як обговорюється нижче. В цілому, модуль 42 оцінки руху виконує оцінку руху по відношенню до компонентів яскравості, і модуль 44 компенсації руху використовує вектори руху, обчислені на основі компонентів яскравості, для компонентів кольоровості та компонентів яскравості. Модуль 40 вибору режиму також може генерувати синтаксичні елементи, зв'язані з відеоблоками і відеосегментами для використання відеодекодером 30 в декодуванні відеоблоків відеосегмента. Модуль 46 інтра-прогнозування може виконувати інтра-прогнозування поточного блока, як альтернативу інтер-прогнозуванню, що виконується модулем 42 оцінки руху і модулем 44 11 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 компенсації руху, як описано вище. Зокрема, модуль 46 інтра-прогнозування може визначити режим інтра-прогнозування, що використовується для кодування поточного блока. У деяких прикладах модуль 46 інтра-прогнозування може кодувати поточний блок, використовуючи різні режими інтра-прогнозування, наприклад, під час окремого проходу кодування, і модуль 46 інтрапрогнозування (або модуль 40 вибору режиму, в деяких прикладах) може вибрати відповідний режим інтра-прогнозування для використання з режимів, що тестуються. Наприклад, модуль 46 інтра-прогнозування може обчислювати значення швидкостіспотворення з використанням аналізу швидкості-спотворення для різних режимів інтрапрогнозування, що тестуються, і вибирати режим інтра-прогнозування, який має кращі характеристики швидкості-спотворення серед режимів, що тестуються. Аналіз швидкостіспотворення звичайно визначає ступінь спотворення (або помилку) між кодованим блоком і вихідним, некодованим блоком, який кодувався, щоб сформувати кодований блок, а також бітову швидкість (тобто число бітів), що використовується для формування кодованого блока. Модуль 46 інтра-прогнозування може обчислити відношення зі спотворень і швидкостей для різних кодованих блоків, щоб визначити, який режим інтра-прогнозування демонструє краще значення швидкості-спотворення для блока. Відеокодер 20 формує залишковий відеоблок шляхом віднімання даних прогнозування з модуля 40 вибору режиму з вихідного відеоблока, який кодується. Суматор 50 являє собою компонент або компоненти, які виконують цю операцію віднімання. Модуль 52 обробки перетворення застосовує перетворення, таке як дискретне косинусне перетворення (DCT) або концептуально схоже перетворення до залишкового блока, формуючи відеоблок, що містить залишкові значення коефіцієнтів перетворення. Модуль 52 обробки перетворення може виконувати інші перетворення, які концептуально подібні на DCT. Вейвлет-перетворення, цілочисельні перетворення, піддіапазонні перетворення або інші типи перетворень також можуть використовуватися. У будь-якому випадку, модуль 52 обробки перетворення застосовує перетворення до залишкового блока, формуючи блок залишкових коефіцієнтів перетворення. Перетворення може перетворити залишкову інформацію з ділянки піксельних значень в ділянку перетворення, таку як частотна ділянка. Модуль 52 обробки перетворення може посилати результуючі коефіцієнти перетворення в модуль 54 квантування. Модуль 54 квантування квантує коефіцієнти перетворення для подальшого зниження бітової швидкості. Процес квантування може зменшити бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Ступінь квантування може бути змінений шляхом регулювання параметра квантування. У деяких прикладах, модуль 54 квантування може потім виконати сканування матриці, яка включає в себе квантовані коефіцієнти перетворення. Як альтернатива, модуль 56 ентропійного кодування може виконувати сканування. Після квантування, модуль 56 ентропійного кодування ентропійно кодує квантовані коефіцієнти перетворення. Наприклад, модуль 56 ентропійного кодування може виконувати контекстно-адаптивне кодування змінної довжини (CAVLC), контекстно-адаптивне двійкове арифметичне кодування (CABAC), основане на синтаксисі контекстно-адаптивне двійкове арифметичне кодування (SBAC), ентропійне кодування з розбиттям на інтервали імовірності (PIPE) або інший метод ентропійного кодування. У випадку контекстно-залежного ентропійного кодування, контекст може бути оснований на сусідніх блоках. Що стосується САВАС, модуль 56 ентропійного кодування може вибрати модель контексту, яка працює на контексті для кодування символів, зв'язаних з блоком відеоданих. Наприклад, блок 56 ентропійного кодування може ентропійно кодувати кожний синтаксичний елемент для блока відеоданих з використанням оцінки імовірності для кожного синтаксичного елемента. Оцінки імовірності можуть вказувати імовірність того, що елемент має задане значення. Оцінки імовірності можуть бути включені в модель імовірності, що також згадується як модель контексту. Модуль 56 ентропійного кодування може вибрати модель контексту шляхом визначення контекстної інформації (або, простіше кажучи, "контексту") для синтаксичного елемента. Відмінна модель імовірності визначається для кожного контексту. Після кодування синтаксичного елемента, модуль 56 ентропійного кодування може оновити вибрану модель контексту на основі фактичного значення синтаксичного елемента, щоб відображати найбільш актуальні оцінки імовірності. Тобто, наприклад, модуль 56 ентропійного кодування може оновлювати спосіб, яким вибирається модель контексту для переходу до нової моделі контексту. У деяких прикладах контекст для конкретного синтаксичного елемента може включати значення зв'язаних синтаксичних елементів з раніше кодованих сусідніх синтаксичних елементів. Наприклад, модуль 56 ентропійного кодування може визначити контекст для 12 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодування поточного синтаксичного елемента на основі сусідніх синтаксичних елементів, розташованих зверху і зліва від поточного синтаксичного елемента. Як відмічалося вище, новий стандарт HEVC дозволяє рекурсивно розділяти LCU на суб-CU величиною 4 × 4 пікселя. Відповідно, піксельне зображення 1920 × 1080 (наприклад, для 1080p відео) може включати в себе більше, ніж 495 4 × 4 піксельних блоків у буфері рядка, що продовжується горизонтально по зображенню. Якщо відеокодер 20 буферизує біт контекстної інформації на кожний блок, відеокодер 20 може буферизувати 495 бітів інформації. Відповідно до методів даного розкриття, модуль 56 ентропійного кодування може визначити контекст для ентропійного кодування відеоданих таким чином, що зменшує або усуває кількість інформації, яка буферизується за допомогою відеокодера 20. Наприклад, відповідно до аспектів даного розкриття, замість використання даних сусідніх зверху блоків як контекст при кодуванні синтаксичних елементів, зв'язаних з поточним блоком (наприклад, блока, який не знаходиться у верхньому рядку кодованої одиниці, наприклад, кадру або сегмента), модуль 56 ентропійного кодування може використовувати тільки інформацію із сусідніх зліва блоків. Як інший приклад, модуль 56 ентропійного кодування може використовувати дані із сусіднього зверху блока як контекст для кодування синтаксичних елементів, зв'язаних з поточним блоком, але тільки тоді, коли поточний блок є суб-CU секціонованої найбільшої одиниці кодування (LCU), і сусідній зверху блок знаходиться в тій самій LCU. Іншими словами, модуль 56 ентропійного кодування може бути сконфігурований, щоб уникнути використання контекстної інформації, яка перетинає верхню межу LCU. Як ще один приклад, модуль 56 ентропійного кодування може виводити контекст для кодування синтаксичних елементів, зв'язаних з поточним блоком, на основі локальної інформації LCU. Наприклад, модуль 56 ентропійного кодування може одержати контекстну інформацію для даних інтер-прогнозування на основі глибини CU, яка звичайно відповідає кількості разів розділення LCU, щоб досягнути CU. Як приклад для цілей пояснення, припустимо, що ця LCU має розмір 6464 пікселів (глибина дорівнює нулю). Суб-CU з LCU може бути розміром 3232 пікселів на глибині CU, що дорівнює одиниці, в той час як додаткова субCU цієї суб-CU може бути розміром 1616 пікселів на глибині CU, що дорівнює двом. Відповідно до методів даного розкриття, модуль 56 ентропійного кодування може визначити контекст для даних інтер-прогнозування поточного блока на основі глибини CU поточного блока. Тобто, наприклад, глибина CU, рівна одиниці, може відповідати відмінній імовірнісній моделі, в порівнянні з глибиною CU, рівною двом. Іншими словами, при кодуванні синтаксичних елементів для CU на визначеній глибині CU, модуль 56 ентропійного кодування може використовувати глибину CU як контекстну інформацію для вибору імовірнісної моделі для кодування синтаксичних елементів. Як інший приклад, модуль 56 ентропійного кодування може одержувати контекстну інформацію для даних інтра-прогнозування на основі інформації глибини перетворення. Інформація глибини перетворення може бути подібна до глибини CU, але описує кількість разів розбиття TU (наприклад, розбиття відповідно до структури RQT). Відповідно, наприклад, глибина ТU, рівна одиниці, може відповідати відмінній імовірнісній моделі, в порівнянні з глибиною ТU, рівною двом. Іншими словами, при кодуванні синтаксичних елементів для ТU на визначеній глибині TU, модуль 56 ентропійного кодування може використовувати глибину TU як контекстну інформацію для вибору імовірнісної моделі для кодування синтаксичних елементів. Після ентропійного кодування модулем 56 ентропійного кодування, кодований бітовий потік може бути переданий на інший пристрій (наприклад, відеодекодер 30) або збережений для подальшої передачі або витягання. Модуль 58 інверсного квантування і модуль 60 інверсного перетворення застосовують інверсне квантування та інверсне перетворення, відповідно, для відновлення залишкового блока в піксельній ділянці, наприклад, для подальшого використання як опорного блока. Модуль 44 компенсації руху може обчислити опорний блок шляхом додавання залишкового блока до блока прогнозування одного з кадрів пам'яті 64 опорних кадрів. Модуль 44 компенсації руху може також застосовувати один або декілька фільтрів інтерполяції до відновленого залишкового блока для обчислення значення суб-цілочисельних піксельних значень для використання в оцінці руху. Суматор 62 додає відновлений залишковий блок до скомпенсованого за рухом блока прогнозування, сформованого модулем 44 компенсації руху, для одержання відновленого відеоблока для збереження в системі 64 опорних кадрів. Відновлений відеоблок може бути використаний модулем 42 оцінки руху і модулем 44 компенсації руху як опорний блок, щоб інтер-кодувати блок в подальшому відеокадрі. Таким чином, відеокодер 20 є прикладом відеокодера, який може виконувати спосіб, що включає в себе визначення контекстної інформації для блока відеоданих, де блок включений в кодовану одиницю відеоданих, де блок знаходиться нижче верхнього ряду блоків у кодованій 13 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 одиниці і де контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці. Спосіб може також включати в себе ентропійне кодування даних блока з використанням визначеної контекстної інформації. На Фіг. 3 представлена блок-схема, яка ілюструє зразковий відеодекодер 30, який може реалізувати способи, описані в даному розкритті, для ентропійного кодування відеоданих. У прикладі на Фіг. 3 відеодекодер 30 включає в себе модуль 80 ентропійного декодування, модуль 81 прогнозування, модуль 86 інверсного квантування, модуль 88 інверсного перетворення, суматор 90 і пам'ять 92 опорних кадрів. Модуль 81 прогнозування включає в себе модуль 82 компенсації руху 82 і модуль 84 інтра-прогнозування. Під час процесу декодування, відеодекодер 30 приймає кодований бітовий потік відеоданих, який представляє відеоблоки кодованих відеосегментів і зв'язані з ними синтаксичні елементи з відеокодера 20. Модуль 80 ентропійного декодування відеодекодера 30 ентропійно декодує бітовий потік для генерації квантованих коефіцієнтів, векторів руху та інших синтаксичних елементів. Відеодекодер 30 може одержати синтаксичні елементи на рівні відео сегмента і/або на рівні відеоблока. Наприклад, як приклад, відеодекодер 30 може одержувати стиснуті відеодані, які були стиснуті для передачі через мережу в так звані "одиниці рівня мережної абстракції" або NAL одиниці. Кожна NAL одиниця може містити заголовок, який ідентифікує тип даних, збережених в NAL одиниці. Існують два типи даних, які звичайно зберігаються в NAL одиниці. Дані першого типу, що зберігаються в NAL одиниці, є даними рівня відеокодування (VCL), які включають в себе стиснуті відеодані. Дані другого типу, що зберігаються в NAL одиниці, називаються не-VCL даними, які включають в себе додаткову інформацію, таку як набори параметрів, які визначають дані заголовка, загальні для великої кількості NAL одиниць, і додаткову інформацію розширення (SEI). Наприклад, набори параметрів можуть містити інформацію послідовності на рівні заголовка (наприклад, в наборах параметрів послідовності (SPS)) і інформацію заголовка, що нечасто змінюється, на рівні зображення (наприклад, в наборах параметрів зображення (PPS)). Інформацію, що нечасто змінюється, яка міститься в наборах параметрів, не потрібно повторювати для кожної послідовності або зображення, тим самим поліпшуючи ефективність кодування. Крім того, використання наборів параметрів дозволяє здійснювати позадіапазонну передачу інформації заголовка, тим самим уникаючи необхідності надмірних передач для забезпечення стійкості до помилок. Модуль 80 ентропійного декодування може бути виконаний аналогічно модулю 56 ентропійного кодування, як описано вище з посиланням на відеокодер 20 за Фіг. 2. Наприклад, модуль 80 ентропійного декодування може вибрати модель контексту, яка працює на контексті для декодування символів, зв'язаних з блоком відеоданих. Тобто, модуль 80 ентропійного декодування може ентропійно декодувати кожний синтаксичний елемент для блока відеоданих за допомогою імовірнісної оцінки для кожного синтаксичного елемента. Відповідно до методів даного розкриття модуль 80 ентропійного декодування може визначити контекст для ентропійного декодування відеоданих таким чином, що зменшує або усуває кількість інформації, яка буферизується відеодекодером 30. Наприклад, відповідно до аспектів даного опису, замість використання даних сусідніх зверху блоків як контексту при декодуванні синтаксичних елементів, зв'язаних з поточним блоком (наприклад, блока, який знаходиться не у верхньому рядку кодованої одиниці, наприклад, кадру або сегмента), модуль 80 ентропійного декодування може використовувати тільки дані із сусідніх зліва блоків. Як інший приклад, модуль 80 ентропійного декодування може використовувати дані із сусіднього зверху блока як контекст для декодування синтаксичних елементів, зв'язаних з поточним блоком, але тільки тоді, коли поточний блок є суб-CU із секціонованої найбільшої одиниці кодування (LCU), і сусідній зверху блок знаходиться в тій самій LCU. Іншими словами, модуль 80 ентропійного декодування може бути сконфігурований, щоб уникати використання контексту, який перетинає верхню межу LCU. Як ще один приклад, модуль 80 ентропійного декодування може виводити контекст для декодування синтаксичних елементів, зв'язаних з поточним блоком, на основі локальної інформації LCU (наприклад, глибина CU, глибина ТU тощо). В іншому прикладі модуль 80 ентропійного декодування може використовувати один контекст для декодування деяких синтаксичних елементів синтаксису на основі самих елементів. Модуль 80 ентропійного декодування може в деяких випадках використовувати поєднання цих методів, щоб визначити контекст. Після визначення контексту для декодування конкретного синтаксичного елемента, модуль 80 ентропійного декодування може вибрати імовірнісну модель, що відповідає контексту, і декодувати синтаксичний елемент з використанням вибраної імовірнісної моделі. 14 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 Модуль 80 ентропійного декодування посилає вектора руху та інші декодовані синтаксичні елементи в модуль 81 прогнозування 81. Коли відео сегмент кодується як інтра-кодований (I) сегмент, модуль 84 інтра-прогнозування модуля 81 прогнозування може генерувати дані прогнозування для відеоблока поточного відео сегмента на основі сигналізованого режиму інтра-прогнозування і даних з раніше декодованих блоків поточного кадру або зображення. Коли відео кадр кодується як інтер-кодований (тобто В, Р або GPB) сегмент, модуль 82 компенсації руху модуля 81 прогнозування 81 формує блоки прогнозування для відеоблока поточного відео сегмента на основі векторів руху та інших синтаксичних елементів, прийнятих з модуля 80 ентропійного декодування. Блоки прогнозування можуть бути сформовані з одного з опорних зображень в одному зі списків опорних зображень. Відео декодер 30 може сформувати списки опорних кадрів, список 0 і список 1, використовуючи методи формування за умовчанням на основі опорних зображень, що зберігаються в пам'яті 92 опорних зображень. Модуль 82 компенсації руху визначає інформацію прогнозування для відеоблока поточного відео сегмента шляхом аналізу векторів руху та інших синтаксичних елементів і використовує інформацію прогнозування для одержання блоків прогнозування для поточного декодованого відеоблока. Наприклад, модуль 82 компенсації руху використовує деякі з одержаних синтаксичних елементів для визначення режиму прогнозування (наприклад, інтра- або інтерпрогнозування), використаних для кодування відеоблоків відеосегментів, тип сегмента інтерпрогнозування (наприклад, В-сегмент, Р-сегмент або GPB-сегмент), інформацію формування для одного або більше списків опорних зображень для сегмента, вектори руху для кожного інтер-кодованого відеоблока сегмента, статус інтер-прогнозування для кожного інтеркодованого відеоблока сегмента і іншу інформацію для декодування відеоблоків у поточному відеосегменті. Модуль 82 компенсації руху також може виконувати інтерполяцію на основі фільтрів інтерполяції. Модуль 82 компенсації руху може використовувати фільтри інтерполяції, які використовуються відеокодером 20 під час кодування відеоблоків для розрахунку інтерпольованих значень для суб-цілочисельних пікселів опорних блоків. У цьому випадку модуль 82 компенсації руху може визначити фільтри інтерполяції, що використовуються відеокодером 20, з прийнятих синтаксичних елементів і використовувати фільтри інтерполяції для формування блоків прогнозування. Модуль 86 інверсного квантування інверсно квантує, тобто де-квантує, квантовані коефіцієнти перетворення, передбачені в бітовому потоці та декодовані модулем 80 ентропійного декодування. Процес інверсного квантування може включати в себе використання параметра квантування, обчисленого за допомогою відеокодера 20 для кожного відеоблока у відеосегменті, щоб визначити ступінь квантування і, аналогічно, ступінь інверсного квантування, яка повинна бути застосована. Модуль 88 інверсного перетворення застосовує інверсне перетворення, наприклад, інверсне ДКП, інверсне цілочисельне перетворення або концептуально подібний процес інверсного перетворення, до коефіцієнтів перетворення для одержання залишкових блоків у піксельній ділянці. Згідно з аспектами даного розкриття, модуль 88 інверсного перетворення може визначити, яким чином перетворення були застосовані до залишкових даних. Тобто, наприклад, модуль 88 інверсного перетворення може визначити RQT, що представляє те, яким чином перетворення (наприклад, DCT, цілочисельне перетворення, вейвлет-перетворення або одне або більше інших перетворень) були застосовані до залишкових вибірок яскравості та залишкових вибірок кольоровості, зв'язаних з блоком прийнятих відеоданих. Після того, як модуль 82 компенсації руху генерує блок прогнозування для поточного відеоблока на основі векторів руху та інших синтаксичних елементів, відеодекодер 30 формує декодований відеоблок шляхом підсумовування залишкових блоків з модуля 88 інверсного перетворення з відповідними блоками прогнозування, сформованими модулем 82 компенсації руху. Суматор 90 являє собою компонент або компоненти, які виконують цю операцію підсумовування. За бажанням фільтр усунення блочності може також застосовуватися для фільтрації декодованих блоків, щоб видалити артефакти блочності. Інші фільтри контуру (в контурі кодування або після контуру кодування) також можуть бути використані для згладжування піксельних переходів або іншим чином поліпшення якості відео. Декодовані відеоблоки в даному кадрі або зображенні потім зберігаються в пам'яті 92 опорних зображень, в якій зберігаються опорні кадри, що використовуються для подальшої компенсації руху. Пам'ять 92 опорних зображень також зберігає декодоване відео для подальшого представлення на пристрої відображення, такому як пристрій відображення 32 на Фіг. 1. Таким чином, відеодекодер 30 є прикладом відеодекодера, який може виконувати спосіб, що включає в себе визначення контекстної інформації для блока відеоданих, де цей блок включений в кодовану 15 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 одиницю відеоданих, де блок знаходиться нижче верхнього ряд блоків у кодованій одиниці, і де контекстна інформація не включає в себе інформацію із сусіднього зверху блока в кодованій одиниці. Спосіб може також включати ентропійне декодування даних блока з використанням визначеної контекстної інформації. Фіг. 4А та 4В являють собою концептуальні схеми, що ілюструють приклад квадродерева 150 і відповідної найбільшої одиниці 172 кодування. Фіг. 4А показує зразкове квадродерево 150, яке включає в себе вузли, розташовані в ієрархічному порядку. Квадродерево 150 може бути зв'язано, наприклад, з блоком дерева відповідно до стандарту HEVC, що пропонується. Кожний вузол в квадродереві, наприклад, квадродереві 150, може бути кінцевим вузлом без потомків або з чотирма дочірніми вузлами. У прикладі на Фіг. 4А, квадродерево 150 включає в себе кореневий вузол 152. Кореневий вузол 152 має чотири дочірніх вузли, в тому числі кінцеві вузли 156A-156C (кінцеві вузли 156) і вузол 154. Оскільки вузол 154 не є кінцевим вузлом, вузол 154 включає в себе чотири дочірніх вузли, які в цьому прикладі є кінцевими вузлами 158A-158D (кінцеві вузли 158). Квадродерево 150 може включати в себе дані, що описують характеристики відповідної найбільшої одиниці кодування (LCU), такої як LCU 172 в цьому прикладі. Наприклад, квадродерево 150, за своєю структурою, може описувати розщеплення LCU на суб-CU. Припустимо, що LCU 172 має розмір 2Nx2N. LCU 172, в цьому прикладі, має чотири суб-CU 176A-176C (суб-CU 176) і 174, кожна розміром NxN. Суб-CU 174 додатково розбита на чотири підгрупи CU 178А-178D (суб-CU 178), кожна розміром N/2xN/2. Структура квадродерева 150 відповідає розбиттю LCU 172, в даному прикладі. Тобто, кореневий вузол 152 відповідає LCU 172, кінцеві вузли 156 відповідають суб-CU 176, вузол 154 відповідає суб-CU 174 і кінцеві вузли 158 відповідають суб-CU 178. Дані для вузлів квадродерева 150 можуть описувати, чи розділена CU, що відповідає вузлу. Якщо CU розділена, чотири додаткових вузли можуть бути присутніми в квадродереві 150. У деяких прикладах, вузол квадродерева може бути реалізований аналогічно наступному псевдокоду: квадродерево_вузол{ булеве розділення_прапор(1); //дані сигналізації якщо (розділення_прапор){ квадродерево_дочірній вузол1; квадродерево_дочірній вузол2; квадродерево_дочірній вузол3; квадродерево_дочірній вузол4; } } Значення розділення_прапор (split_flag) може бути однобітовим значенням, що представляє, чи розділена CU, що відповідає поточному вузлу. Якщо CU не розділена, то значення split_flag може бути таке, що дорівнює "0", а якщо CU розділена, то значення split_flag може бути таке, що дорівнює "1". Що стосується прикладу квадродерева 150, масив значень split_flag може бути 101000000. Як вже відмічалося вище, глибина CU може стосуватися міри, в якій LCU, така як LCU 172, була розділена. Наприклад, кореневий вузол 152 може відповідати глибині CU, яка дорівнює нулю, в той час як вузол 154 і кінцеві вузли 156 можуть відповідати глибині CU, яка дорівнює одиниці. Крім того, кінцеві вузли 158 можуть відповідати глибині CU, яка дорівнює двом. Згідно з аспектами даного розкриття, глибина CU і/або глибина TU може бути використана як контекст для ентропійного кодування визначених синтаксичних елементів. Як приклад для цілей пояснення, один або більше синтаксичних елементів, зв'язаних з кінцевим вузлом 156A, можуть бути ентропійно кодовані з використанням відмінних моделей контексту, в порівнянні з кінцевим вузлом 158A, оскільки кінцевий вузол 156A знаходиться на глибині, яка дорівнює одиниці, а кінцевий вузол 158А знаходиться на глибині, яка дорівнює двом. У той час як Фіг. 4А ілюструє приклад CU квадродерева, потрібно розуміти, що аналогічні квадродерева можуть бути застосовані до TU кінцевого вузла CU. Тобто, кінцевий вузол CU може включати в себе TU квадродерево (що згадується як залишкове квадродерево (RQT)), якийе описує розбиття TU для CU. ТU квадродерево може в цілому нагадувати CU квадродерево, за винятком того, що TU квадродерево може сигналізувати режими інтрапрогнозування для одиниць TU одиниці CU в індивідуальному порядку. Відповідно до способів даного розкриття, відеокодер (наприклад, відеокодер 20 і/або відеодекодер 30) може визначити контекст для даних інтер-прогнозування поточного блока на 16 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 основі CU глибини поточного блока. Тобто, наприклад, при кодуванні синтаксичних елементів для CU на визначеній глибині CU, відеокодер може використовувати CU глибину як контекстну інформацію для вибору імовірнісної моделі для кодування синтаксичних елементів. Як інший приклад, відеокодер може виводити контекстну інформацію для даних інтра-прогнозування на основі інформації глибини перетворення. Тобто, наприклад, при кодуванні синтаксичних елементів для ТU на визначеній глибині TU, модуль 56 ентропійного кодування може використовувати глибину TU як контекстну інформацію для вибору імовірнісної моделі для кодування синтаксичних елементів. На Фіг. 5 показана блок-схема, яка ілюструє приклад сусідніх блоків, з яких може бути визначений контекст для ентропійного кодування блока. У той час як Фіг. 5 описана у відношенні відеодекодера 30, потрібно розуміти, що методи даного винаходу можуть бути виконані за допомогою різних інших відеокодерів, в тому числі відеокодера 20 (Фіг. 1 та 2), інших процесорів, блоків обробки, апаратних модулів кодування, таких як кодери/декодери (кодеки), і тому подібне. Відеодекодер 30 може приймати ентропійно кодовані дані, зв'язані з поточним блоком 180. Наприклад, відеодекодер 30 може приймати ентропійно кодовану карту значущості, коефіцієнти перетворення, а також ряд інших синтаксичних елементів, щоб дозволити відеодекодеру 30 належним чином декодувати поточний блок 180. Відеодекодер 30 може визначити контекст для одного або більше з прийнятих синтаксичних елементів на основі значень синтаксичних елементів, зв'язаних із сусіднім зверху блоком 182 і сусіднім зліва блоком 184. Припустимо, для цілей пояснення, що відеодекодер 30 в поточний момент декодує синтаксичний елемент, що вказує конкретний режим прогнозування (наприклад, режим інтрапрогнозування) пікселів в межах поточного блока 180. У цьому прикладі відеодекодер 30 може ідентифікувати режими інтра- прогнозування із сусіднього зверху блока 182 і сусіднього зліва блока 184, щоб визначити контекст для поточного синтаксичного елемента. Відповідно, модель контексту, що використовується для ентропійного декодування поточного синтаксичного елемента, може залежати від режимів інтра-прогнозування сусіднього зверху блока 182 і сусіднього зліва блока 184. Таким чином, відеодекодер 30 може зберігати або буферизувати дані, що вказують режими інтра-прогнозування із сусіднього зверху блока 182 і сусіднього зліва блока 184, так що такі дані доступні при виконанні ентропійного декодування. У той час як ентропійне кодування синтаксичного елемента, зв'язаного з режимом інтрапрогнозування, описане для прикладу, інші синтаксичні елементи можуть також кодуватися на основі даних сусідніх блоків. Наприклад, по відношенню до нового стандарту HEVC, наступні синтаксичні елементи можуть бути ентропійно кодовані з використанням контексту, який включає в себе дані із сусідніх блоків, в тому числі сусіднього зверху блока 182 і сусіднього зліва блока 184: 1. skip_flag [х0] [у0]. а) spkip_flag, рівний 1, вказує, що для поточної CU, при декодуванні Р або В-сегмента, ніякі додаткові синтаксичні елементи не обробляються після skip_flag[х0][y0], крім індексів прогнозувальника вектора руху. skip_flag[х0][y0], рівний 0, вказує, що одиниця кодування не пропускається. Індекси х0, у0 масиву вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока кодування відносно верхньої лівої вибірки яскравості зображення. 2. split_coding_unit_flag а) split_coding_unit_flag [х0] [y0] вказує, чи розділена одиниця кодування на одиниці кодування з половинним горизонтальним і вертикальним розміром. Індекси х0, у0 масиву вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока кодування відносно верхньої лівої вибірки яскравості зображення. 3. cpb блока яскравості а) Структура блока (CBP), що кодується, визначає, які блоки яскравості містить рівні ненульових коефіцієнтів перетворення. Тобто, CBP блока яскравості може відповідати одному або більше прапорам кодованих блоків, кожний з прапорів кодованих блоків має значення, що вказує, чи кодований відповідний блок яскравості (включає одне або більше ненульових значень рівнів коефіцієнтів перетворення), або він не кодований (включає в себе всі нульові значення коефіцієнтів перетворення). 4. cbp блока кольоровості а) Структура блока кольоровості (CBP) визначає, які блоки кольоровості містять рівні ненульових коефіцієнтів перетворення. Тобто, CBP блока кольоровості може відповідати одному або більше прапорам кодованих блоків, кожний з прапорів кодованих блоків має значення, що вказує, чи є відповідний блок кольоровості кодованим (включає одне або більше 17 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 ненульових значень рівнів коефіцієнтів перетворення), або він не кодований (включає в себе всі нульові значення коефіцієнтів перетворення). 5. bin0 інтра-режими кольоровості а) intra_chroma_pred_mode[х0][y0] визначає режим інтра- прогнозування для вибірок кольоровості. Індекси х0, у0 масиву вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування (PU) по відношенню до верхньої лівої вибірки яскравості зображення. 6. no_residual_data_flag (прапор відсутності залишкових даних) а) no_residual_data_flag, рівний 1, вказує, що залишкові дані відсутні в поточній одиниці кодування. no_residual_data_flag, рівний 0, вказує, що залишкові дані присутні в поточній одиниці кодування. 7. merge_flag (прапор злиття) а) merge_flag[х0][y0] вказує, чи виведені параметри інтер-прогнозування для поточної PU із сусіднього розділу інтер-прогнозування. Індекси х0, у0 масиву вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування відносно верхньої лівої вибірки яскравості зображення, що розглядається. 8. bin0 °F ref_idx а) ref_idx_10[х0][y0] визначає індекс опорного зображення списку 0 для поточного PU. Індекси х0, у0 вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування відносно верхньої лівої вибірки яскравості зображення. b) ref_idx_11[х0][y0] має ту саму семантику, що і ref_idx_10, причому 10 і список 0 замінені на 11 і список 1, відповідно. с) ref_idx_1c[х0][y0] має ту саму семантику, що і ref_idx_10, причому 10 і список 0 замінені на 1c і комбінацію списків, відповідно. 9. bin0 °F mvd а) mvd_10[х0][y0][compIdx] визначає різницю між векторним компонентом списку 0, який буде використовуватися, і вектором прогнозування. Індекси х0, у0 масиву вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування відносно верхньої лівої вибірки яскравості зображення. Різниці горизонтальних компонентів вектора руху призначається compIdx=0, а вертикальній компоненті вектора руху призначається compIdx=1. b) mvd_11[х0][y0][compIdx] має ту саму семантику, що і mvd_10, причому 10 і список 0 замінені на 11 і список 1, відповідно. c) mvd_1c[х0][y0][compIdx] має ту саму семантику, що і mvd_10, причому 10 і список 0 замінені на 1с і комбінацію списків, відповідно. 10. inter_pred_flag а) inter_pred_flag[х0][y0] вказує, чи використовується однонаправлене прогнозування або двонаправлене прогнозування для поточного блока прогнозуванню. Індекси масиву х0, у0 вказують місцеположення (х0, у0) верхньої лівої вибірки яскравості блока прогнозування відносно верхньої лівої вибірки яскравості зображення. 11. cbp внутрішнього блока кольоровості а) Структура блока (CBP), що кодується, визначає, які блоки можуть містити ненульові рівні коефіцієнтів перетворення. Синтаксичні елементи, перераховані вище, представлені тільки як приклад. Тобто, відеодекодер 30 може використовувати дані із сусідніх блоків, таких як сусідній зверху блок 182 і сусідній зліва блок 184, при виконанні ентропійного кодування інших синтаксичних елементів, зв'язаних з поточним блоком 180. На Фіг. 6 показана блок-схема, яка ілюструє приклад сусідніх блоків, з яких може бути визначений контекст для ентропійного кодування блока, відповідно до аспектів даного винаходу. У той час як Фіг. 6 описана по відношенню до відеодекодера 30, потрібно розуміти, що способи даного винаходу можуть бути виконані за допомогою різних інших відеокодерів, в тому числі відеокодера 20 (Фіг. 1 та 2), інших процесорів, модулів обробки, апаратних модулів кодування, таких як кодери/декодери (кодеки), і тому подібне. Відеодекодер 30 може прийняти ентропійно кодовані дані, зв'язані з поточним блоком 190 кодованої одиниці 191. Наприклад, відеодекодер 30 може прийняти ентропійно кодовану карту значущості, коефіцієнти перетворення (інтра- або інтер- прогнозування), а також ряд інших синтаксичних елементів, щоб дозволити відеодекодеру 30 належним чином декодувати поточний блок 190 кодованої одиниці 191. Кодована одиниця 191 може в загальному випадку включати в себе зумовлену кількість відеоданих, включаючи множину блоків відеоданих, таких як, наприклад, сегмент, елемент мозаїчного зображення або набір елементів мозаїчного зображення, набір хвильових фронтів, або будь-який інший зумовлений блок, який включає в 18 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 себе множину блоків відеоданих. У той час як сусідні зверху блоки 194, сусідні зліва блоки 192 і блоки 196 загалом показані у вигляді неподілених блоків у прикладі на Фіг. 6, потрібно розуміти, що такі блоки можуть бути розділені на один або більше менших блоків. Відповідно до аспектів даного розкриття, замість використання даних із сусідніх зверху блоків 194 (як показано, наприклад, на Фіг. 5), як контекстної інформації для визначення імовірнісної моделі при кодуванні синтаксичного елемента, відеодекодер 30 може використовувати тільки дані із сусіднього зліва блока 192 як контекстну інформацію для ентропійного кодування поточного блока 190. Наприклад, відеодекодер 30 може не використовувати дані із сусідніх зверху блоків 194 або раніше кодованих блоків 196, які не розташовані поруч з поточним блоком 190, як контекстну інформацію для визначення імовірнісної моделі для ентропійного кодування поточного блока 190. У цьому прикладі відеодекодер 30 може буферизувати менше даних, ніж в прикладі, показаному на Фіг. 5. Наприклад, в припущенні, що максимальний розмір LCU рівний 6464 пікселі і найменший розмір CU рівний 44 пікселів, відеодекодер 30 може потенційно буферизувати дані, зв'язані тільки з 16 блоками відеоданих (наприклад, 64/4=16 потенційних сусідніх зліва блоків). Відповідно до інших аспектів даного розкриття, відеодекодер 30 може використовувати тільки дані із сусідніх блоків при визначенні контексту для ентропійного кодування поточного блока 190, коли сусідні блоки є частиною однієї і тієї самої LCU як поточного блока 190. Наприклад, відеодекодер 30 може використовувати тільки дані із сусідніх блоків для визначення контексту для поточного блока 190, коли поточний блок 190 і сусідні блоки є суб-CU тієї самої LCU. Тобто, в деяких прикладах відеодекодер 30 не використовує дані з перетином межі LCU при визначенні контексту для ентропійного кодування поточного блока 190. Обмеження на межу LCU може бути накладене на сусідні зверху блоки 194, сусідні зліва блоки 192 або як на сусідні зверху блоки 194, так і сусідні зліва блоки 192. Відповідно до інших аспектів даного розкриття відеодекодер 30 може визначити контекст для ентропійного кодування поточного блока 190 залежно від інформації локальної CU і/або LCU, зв'язаної з поточним блоком 190. Наприклад, відеодекодер 30 може визначити контекст для даних інтер-прогнозування (наприклад, inter_pred_flag) на основі глибини CU, яка в загальному випадку відповідає кількості разів, в яку була розділена LCU, до якої належить поточний блок 190. Як інший приклад, відеодекодер 30 може визначити контекст для даних інтра-прогнозування (наприклад, cbp внутрішнього блока кольоровості) на основі глибини TU, яка в загальному випадку відповідає кількості разів, на яку була розділена TU поточного блока 190. У деяких прикладах відео декодер 30 може використовувати дані з комбінації джерел як контекстну інформацію при визначенні імовірнісної моделі для ентропійного кодування поточного блока 190. Наприклад, відеодекодер 30 може реалізувати будь-яку комбінацію способів даного розкриття при визначенні контексту для ентропійного кодування поточного блока 190. Тобто, як приклад, відеодекодер 30 може використовувати дані із сусідніх зліва блоків 192 (наприклад, виключаючи сусідні зверху блоки або інші блоки), а також дані з інформації локальної CU і/або LCU, зв'язаної з поточним блоком 190, як контекстну інформацію при визначенні імовірнісної моделі. В іншому прикладі, відео декодер 30 може використовувати дані із сусідніх блоків, які є частиною тієї самої LCU, що і поточний блок 190 (наприклад, виключаючи інші сусідні блоки), а також з інформації локальної CU і/або LCU, зв'язаної з поточним блоком 190, як контекстну інформацію при визначенні імовірнісної моделі. Додатково або альтернативно, відеодекодер 30 може використовувати один контекст для ентропійного кодування поточного блока 190. Наприклад, відеодекодер 30 може визначити контекст для конкретного синтаксичного елемента, зв'язаного з поточним блоком 190 на основі самого синтаксичного елемента. У деяких прикладах відеодекодер 30 може використовувати один контекст для синтаксичних елементів, включаючи no_residual_data_flag, merge_flag, bin0 °F ref_idx і bin0 °F mvd, як описано вище з посиланням на Фіг. 5. При обмеженні місцеположень, з яких виводиться контекстна інформація, як показано та описано на прикладі Фіг. 6, відеодекодер 30 може зменшити кількість даних, що буферизуються з метою виведення контексту. Крім того, відеодекодер 30 може збільшити пропускну здатність і/або надійність синтаксичного аналізу. Наприклад, як зазначено вище, відеодекодер 30 може аналізувати відеодані, що приймаються, відповідно до конкретного процесу аналізу (наприклад, синтаксичного аналізу хвильового фронту). У прикладах, в яких відеодекодер 30 не визначає контекст з використанням даних з визначених сусідніх блоків, відеодекодер 30 може усунути контекстні залежності, щоб поліпшити пропускну здатність аналізу і можливість обробки відеоданих паралельно. Крім того, усунення контекстних залежностей може знизити імовірність помилок виведення контексту, тим самим поліпшуючи надійність аналізу. 19 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 На Фіг. 7 представлена блок-схема, яка ілюструє зразковий метод ентропійного кодування блока відеоданих. Приклад, показаний на Фіг. 7, загалом, описаний як такий, що виконується відеокодером. Потрібно розуміти, що в деяких прикладах метод за Фіг. 7 може бути виконаний за допомогою відеокодера 20 (фіг. 1 та 2) або відеодекодера 30 (Фіг. 1 та 3), описаних вище. В інших прикладах, метод за Фіг. 7 може бути виконаний різними іншими процесорами, модулями обробки, апаратними модулями кодування, такими як кодери/декодери (кодеки), і тому подібне. Відео кодер може прийняти блок відеоданих кодованої одиниці (наприклад, зображення, сегмент, елемент мозаїчного зображення, набір хвильових фронтів і тому подібне) для ентропійного кодування (200). Згідно з аспектами даного розкриття, блок відеоданих може бути розташований нижче верхнього рядка кодованої одиниці (CU). Наприклад, відеокодер може визначити, чи розташований блок, що ентропійно кодується в поточний момент, нижче іншого ряду блоків кодованої одиниці. У деяких прикладах, в цей час блок, що ентропійно кодується, може бути суб-CU, яка включена в ту саму LCU, що і сусідні зверху суб-CU. В інших прикладах, блок може бути розташований на краю LCU, так що сусідні зверху блоки стосуються LCU іншій, ніж у поточного блока. Відеокодер може потім визначити контекст для блока, який не включає інформацію із сусіднього зверху блока (202). Наприклад, згідно з аспектами даного розкриття, замість використання інформації із сусідніх зверху блоків, відеокодер може використовувати інформацію із сусідніх зліва блоків при визначенні контексту для вибору імовірнісної моделі. У деяких прикладах сусідні зліва блоки можуть бути включені в ту саму LCU, що і у блока, який кодується в цей час. В інших прикладах сусідні зліва блоки можуть бути включені в LCU іншу, ніж для блока, що кодується в цей час. В іншому прикладі, блок відеоданих може включати в себе один або більше блоків LCU, і сусідні зверху блоки можуть включати в себе одну або більше інших LCU. У такому прикладі, згідно з аспектами даного розкриття, відеокодер може визначити контекст для блока з використанням інформації, зв'язаної з іншими блоками LCU, але виключати сусідні зверху блоки (включені в інші LCU). Як приклад для цілей ілюстрації, блок, що кодується, може містити першу суб-CU з LCU, і сусідні зверху блоки можуть включати в себе одну або більше інших LCU. Припустимо також, що друга суб-CU розташована над першої суб-CU (в тій самій LCU). У цьому прикладі, відеокодер може визначити контекстну інформацію для першої суб-CU з використанням інформації з другої суб-CU, яка розташована вище першої суб-CU. В іншому прикладі згідно з аспектами даного розкриття, відео кодер може визначити контекст для ентропійного кодування блока на основі інформації локальної CU і/або LCU, зв'язаної з блоком. Наприклад, відеокодер може визначити контекст на основі глибини CU або глибини ТU (наприклад, відповідно до структури квадродерева, як показано на Фіг. 4), розміру LCU або інших характеристик. Тобто, відеокодер може визначити контекст для даних інтрапрогнозування на основі глибини CU, яка звичайно відповідає кількості разів, в яку була розділена LCU, щоб досягнути поточного блока. Як інший приклад, відеокодер може визначити контекст для даних інтра-прогнозування на основі глибини перетворення, яка описує кількість разів, в яку була розділена ТU для поточного блока. Інші приклади також можливі, наприклад, для визначення контексту для поточного блока залежно від розміру CU, до якої належить блок, розміру ТU, зв'язаного з блоком, і тому подібне. В інших прикладах відеокодер може визначити контекст для блока іншими способами. Наприклад, згідно з деякими аспектами, відеокодер може використовувати один контекст при ентропійному кодуванні блока. Тобто, відеокодер може визначити контекст для кодування поточного блока на основі синтаксичного елемента, що кодується в цей час (наприклад, синтаксичний елемент відображається безпосередньо на визначений контекст). У деяких прикладах відеокодер може використовувати інформацію з комбінації джерел при визначенні контексту для ентропійного кодування блока. Наприклад, відеокодер може використовувати інформацію як із сусідніх зліва блоків, так і інформацію з характеристик локальної CU і/або LCU характеристик. В іншому прикладі, відеокодер може використовувати інформацію із сусідніх блоків, які є частиною тієї самої LCU, що і блок, і інформацію з характеристик локальної CU і/або LCU. Після визначення контексту, відео кодер може ентропійно кодувати блок з використанням визначеного контексту, як відмічалося вище (204). У той час як процес, показаний на Фіг. 7, описаний загалом по відношенню до кодування блока відеоданих, потрібно розуміти, що блок відеоданих може включати в себе більше одного зв'язаних синтаксичних елементів (як описано, наприклад, у відношенні Фіг. 5 та 6 вище). Відповідно, процес, показаний та описаний в прикладі на Фіг. 7, може виконуватися багато разів при ентропійному кодуванні блока відеоданих. Тобто, наприклад, відеокодер може ентропійно кодувати деякі синтаксичні елементи, зв'язані з блоком відеоданих, інакше, ніж інші. Таким 20 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 чином, один синтаксичний елемент може ентропійно кодуватися з використанням контексту на основі характеристики блока, а інший синтаксичний елемент може ентропійно кодуватися іншим способом. Потрібно також розуміти, що етапи, показані та описані з посиланням на Фіг. 7, наведені лише як один з прикладів. Тобто, етапи способу за Фіг. 7 не обов'язково повинні виконуватися в порядку, показаному на Фіг. 7, і може виконуватися менше етапів, або можуть виконуватися додаткові або альтернативні етапи. На Фіг. 8 показана блок-схема, яка ілюструє зразковий метод ентропійного кодування блока відеоданих. Приклад, показаний на Фіг. 8, загалом, описаний як такий, що виконується відеокодером. Потрібно розуміти, що в деяких прикладах метод згідно з Фіг. 8 може бути виконаний за допомогою відеокодера 20 (фіг. 1 та 2) або відеодекодера 30 (Фіг. 1 та 3), описаних вище. В інших прикладах, метод за Фіг. 8 може виконуватися різними іншими процесорами, модулями обробки, апаратними модулями кодування, такими як кодери/декодери (кодеки), і тому подібне. Згідно з деякими прикладами, методи прикладу, показаного на Фіг. 8, можуть виконуватися з методами, показаними на Фіг. 7. Наприклад, методи прикладу, показаного на Фіг. 8 можуть виконуватися на етапі 202 за Фіг. 7. У прикладі на Фіг. 8, відеокодер визначає, чи потрібно використовувати дані із сусідніх зліва блоків як контекстну інформацію для вибору імовірнісної моделі ентропійного кодування конкретного синтаксичного елемента (210). Наприклад, як відмічено вище з посиланням на Фіг. 7, відеокодер може не використовувати інформацію із сусіднього зверху блока при визначенні контексту для ентропійного кодування одного або більше синтаксичних елементів. Згідно з аспектами даного розкриття, замість використання інформації із сусідніх зверху блоків, відеокодер може використовувати інформацію із сусідніх зліва блоків при визначенні контексту для вибору імовірнісної моделі. У таких прикладах (наприклад, гілка ТАК на етапі 210), відеокодер може витягнути щонайменше частину контекстної інформації із сусідніх зліва блоків (212). У деяких прикладах сусідні зліва блоки можуть бути включені в ту саму LCU, що і блок, який кодується в цей час. В інших прикладах сусідні зліва блоки можуть бути включені в LCU іншу, ніж для блока, що кодується в цей час. Відеокодер може потім визначити, чи потрібно використовувати дані з інших джерел як контекст для ентропійного кодування (214). Якщо відеокодер не використовує дані із сусідніх зліва блоків як контекст (наприклад, гілка НІ на етапі 210), відеокодер може перейти безпосередньо до етапу 214. У будь-якому випадку, відеокодер може визначити контекст, оснований на інформації локальної CU і/або LCU, зв'язаної з блоком. Тобто, відеокодер може визначити контекст на основі глибини CU або глибини ТU (наприклад, відповідно до структури квадродерева, як показано на Фіг. 4), розміру LCU або інших характеристик. В інших прикладах відеокодер може визначити один контекст. Тобто, відеокодер може визначити контекст на основі синтаксичного елемента, що кодується в цей час (наприклад, синтаксичний елемент відображається безпосередньо на визначений контекст). Якщо відеокодер дійсно використовує дані з інших джерел як контекст (наприклад, гілка ТАК на етапі 214), відеокодер може витягувати відповідну контекстну інформацію з іншого джерела або джерел (216). Відеокодер може потім вибрати імовірнісну модель, основану на визначеній контекстній інформації (218). Якщо відеокодер не використовує дані з інших джерел як контекст, відеокодер може перейти безпосередньо до етапу 218. Потрібно також розуміти, що етапи, показані та описані з посиланням на Фіг. 8, наведені лише як один з прикладів. Тобто, етапи способу за Фіг. 8 не обов'язково повинні виконуватися в порядку, показаному на Фіг. 8, і може виконуватися менше етапів, або можуть виконуватися додаткові або альтернативні етапи. На Фіг. 9 показана блок-схема, яка ілюструє зразковий метод ентропійного кодування блока відеоданих. Приклад, показаний на Фіг. 9, загалом, описаний як такий, що виконується відеокодером. Потрібно розуміти, що в деяких прикладах метод за Фіг. 9 може бути виконаний за допомогою відеокодера 20 (фіг. 1 та 2) або відеодекодера 30 (Фіг. 1 та 3), описаних вище. В інших прикладах, метод за Фіг. 9 може виконуватися різними іншими процесорами, модулями обробки, апаратними модулями кодування, такими як кодери/декодери (кодеки), і тому подібне. Згідно з деякими прикладами, методи прикладу, показаного на Фіг. 9, можуть виконуватися з методами, показаними на Фіг. 7. Наприклад, методи прикладу, показаного на Фіг. 9 можуть виконуватися на етапі 202 за Фіг. 7. У прикладі на Фіг. 9, відеокодер визначає, чи потрібно використовувати дані з поточної LCU як контекстну інформацію для вибору імовірнісної моделі, щоб ентропійно кодувати конкретний синтаксичний елемент з поточної LCU (230). Наприклад, як відмічено вище з посиланням на Фіг. 21 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 7, в деяких випадках відеокодер може не використовувати інформацію із сусіднього зверху блока при визначенні контексту для ентропійного кодування одного або декількох синтаксичних елементів. Проте, згідно з аспектами даного розкриття, відеокодер може використовувати дані, зв'язані із сусіднім зверху блоком, при визначенні контексту, але тільки тоді, коли сусідній зверху блок знаходиться в тій самій LCU, що і блок, який кодується в цей час. Тобто, відеокодер може втриматися від перетину межі LCU при визначенні контексту для кодування синтаксичних елементів, зв'язаних з LCU. У таких прикладах (наприклад, гілка ТАК на етапі 230), відеокодер може витягувати щонайменше частину контекстної інформації з блоків для LCU (232). Відеокодер може потім визначити, чи потрібно використовувати дані з інших джерел як контекст для ентропійного кодування (234). Якщо відеокодер не використовує дані з поточної CU як контекст (наприклад, гілка НІ на етапі 230), відеокодер може перейти безпосередньо до етапу 234. У будь-якому випадку, відеокодер може визначити контекст на основі інформації локальної CU і/або LCU, зв'язаної з даним блоком. Тобто, відеокодер може визначити контекст на основі глибини CU або глибини ТU (наприклад, відповідно до структури квадродерева, як показано на Фіг. 4), розміру LCU або інших характеристик. В інших прикладах відеокодер може визначити один контекст. Тобто, відеокодер може визначити контекст на основі синтаксичного елемента, що кодується в цей час (наприклад, синтаксичний елемент відображається безпосередньо на визначений контекст). Якщо відеокодер дійсно використовує дані з інших джерел як контекст (наприклад, гілка ТАК на етапі 234), відеокодер може одержати відповідну контекстну інформацію з іншого джерела або джерел (236). Відеокодер може потім вибрати імовірнісну модель на основі визначеної контекстної інформації (238). Якщо відеокодер не використовує дані з інших джерел як контекст, відеокодер може перейти безпосередньо до етапу 238. Потрібно також розуміти, що етапи, показані та описані з посиланням на Фіг. 9, наведені лише як один з прикладів. Тобто, етапи способу за Фіг. 9 не обов'язково повинні виконуватися в порядку, показаному на Фіг. 9, і може виконуватися менше етапів, або можуть виконуватися додаткові або альтернативні етапи. На Фіг. 10 показана блок-схема, яка ілюструє зразковий спосіб ентропійного кодування блока відеоданих. Приклад, показаний на Фіг. 10, загалом, описаний як такий, що виконується відеокодером. Потрібно розуміти, що в деяких прикладах спосіб за Фіг. 10 може бути виконаний за допомогою відеокодера 20 (фіг. 1 та 2) або відеодекодера 30 (Фіг. 1 та 3), описаних вище. В інших прикладах, спосіб за Фіг. 8 може бути виконаний різними іншими процесорами, модулями обробки, апаратними модулями кодування, такими як кодери/декодери (кодеки) і тому подібне. Згідно з деякими прикладами, способи в прикладі, показаному на Фіг. 10, можуть виконуватися зі способами, показаними на Фіг. 7. Наприклад, способи прикладу, показаного на Фіг. 10, можуть виконуватися на етапі 202 за Фіг. 7. У прикладі на Фіг. 10, відеокодер визначає, чи потрібно використовувати дані з інформації локального блока як контекстну інформацію для вибору імовірнісної моделі, щоб ентропійно кодувати конкретний синтаксичний елемент (260). Наприклад, як відмічено вище з посиланням на Фіг. 7, відеокодер може не використовувати інформацію із сусіднього зверху блока при визначенні контексту для ентропійного кодування одного або більше синтаксичних елементів. Згідно з аспектами даного розкриття, замість використання інформації із сусідніх зверху блоків, відеокодер може використовувати дані з інформації локального блока. У таких прикладах (наприклад, гілка ТАК на етапі 210), відеокодер може витягнути щонайменше частину контекстної інформації з інформації локального блока (212). Наприклад, відеокодер може використовувати дані з однієї або більше характеристик CU при визначенні контекстної інформації. Тобто, як приклад, відеокодер може ентропійно кодувати залишкові дані інтер-прогнозування для CU. У цьому прикладі, відеокодер може визначити глибину CU при визначенні контекстної інформації для ентропійного кодування залишкових даних інтер-прогнозування. Іншими словами, при кодуванні синтаксичних елементів для CU на визначеній глибині CU, відеокодер може використовувати глибину CU як контекстну інформацію для вибору імовірнісної моделі. Як приклад для цілей ілюстрації, відеокодер може ентропійно кодувати прапор інтер-прогнозування (inter_pred_flag), зв'язаний з даними інтер-прогнозування на конкретній глибині CU, з використанням конкретної глибини CU як контекстної інформації. В іншому прикладі, відеокодер може використовувати дані з однієї або більше характеристик ТU при визначенні контекстної інформації. Тобто, як приклад, відеокодер може ентропійно кодувати залишкові дані інтра-прогнозування для ТU. У цьому прикладі, відеокодер може визначити глибину ТU при визначенні контекстної інформації для ентропійного кодування залишкових даних інтра-прогнозування. Іншими словами, при кодуванні синтаксичних елементів 22 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 для ТU на визначеній глибині ТU, відеокодер може використовувати глибину TU як контекстну інформацію для вибору імовірнісної моделі. Як приклад для цілей ілюстрації, відеокодер може ентропійно кодувати один або більше синтаксичних елементів структури блока, що кодується, на конкретній глибині ТU з використанням конкретної глибини TU як контекстної інформації. Відеокодер може потім визначити, чи потрібно використовувати дані з інших джерел як контекст для ентропійного кодування (264). Наприклад, відеокодер може визначити контекст для ентропійного кодування, використовуючи дані із сусідніх зліва блоків (наприклад, на Фіг. 8) або дані з інших блоків у LCU, що кодується (наприклад, Фіг. 9). В інших прикладах відеокодер може визначити контекст на основі синтаксичного елемента, що кодується в цей час (наприклад, синтаксичний елемент відображається безпосередньо на визначений контекст). Якщо відеокодер дійсно використовує дані з інших джерел як контекст (наприклад, гілка ТАК на етапі 264), відеокодер може одержати відповідну контексту інформацію з іншого джерела або джерел (266). Відеокодер може потім вибрати імовірнісну модель на основі визначеної контекстної інформації (268). Якщо відеокодер не використовує дані з інших джерел як контекст, то відеокодер може перейти безпосередньо до етапу 268. Потрібно також розуміти, що етапи, показані та описані з посиланням на Фіг. 10, наведені лише як один з прикладів. Тобто, етапи способу за Фіг. 10 не обов'язково повинні виконуватися в порядку, показаному на Фіг. 10, і може виконуватися менше етапів, або можуть виконуватися додаткові або альтернативні етапи. Крім того, потрібно розуміти, що, залежно від прикладу, деякі дії або події будь-якого зі способів, описаних тут, можуть бути виконані в іншому порядку, можуть бути доповнені, об'єднані або виключені зовсім (наприклад, не всі описані дії або події є необхідними для практичної реалізації способу). Крім того, в деяких прикладах дії або події можуть виконуватися одночасно, наприклад, за рахунок багатопотокової обробки, обробки переривань або декількох процесорів, а не послідовно. Крім того, в той час як деякі аспекти цього розкриття описані як такі, що виконуються в одному модулі або пристрої для розуміння, потрібно розуміти, що способи даного винаходу можуть бути виконані за допомогою комбінації блоків або модулів, зв'язаних з відеокодером. В одному або декількох прикладах здійснення описані функції можуть бути реалізовані в апаратних засобах, програмному забезпеченні, мікропрограмному забезпеченні або будь-якій їх комбінації. При реалізації в програмному забезпеченні, функції можуть бути збережені або передані як одна або більше інструкцій або код на машинозчитуваному носії і можуть виконуватися апаратним модулем обробки. Машинозчитувані носії можуть включати в себе машинозчитуваний носій інформації, який відповідає матеріальному носію, такому як носії інформації, або комунікаційні середовища, включаючи будь-яке середовище, яке сприяє передачі комп'ютерної програми з одного місця в інше, наприклад, відповідно до комунікаційного протоколу. Таким чином, машинозчитувані носії звичайно можуть відповідати (1) матеріальному машинозчитуваному носію, який є не тимчасовим (нетранзитивним) або (2) комунікаційному середовищу, такому як сигнал або несуча хвиля. Носії даних можуть бути будь-якими доступними носіями, до яких можна одержати доступ одним або більше комп'ютерами або одним або більше процесорами для витягання інструкцій, коду і/або структур даних для реалізації методів, описаних у даному розкритті. Комп'ютерний програмний продукт може включати в себе машинозчитуваний носій. Як приклад, а не обмеження, такі машинозчитувані носії зберігання можуть містити RAM, ROM, EEPROM, CD-ROM або інший оптичний диск, накопичувач на магнітних дисках або інші магнітні запам'ятовуючі пристрої, флеш-пам'ять або будь-який інший носій, який може використовуватися для зберігання бажаного програмного коду в формі інструкцій або структур даних і до якого можна звертатися за допомогою комп'ютера. Крім того, будь-яке підключення коректно називати машинозчитуваним носієм. Наприклад, якщо інструкції передаються від вебсайта, сервера або іншого віддаленого джерела за допомогою коаксіального кабелю, волоконно-оптичного кабелю, витої пари, цифрової абонентської лінії (DSL) або бездротових технологій, таких як інфрачервона, радіо і мікрохвильова, то коаксіальний кабель, волоконнооптичний кабель, вита пара, DSL або бездротові технології, такі як інфрачервона, радіо і мікрохвильова, включаються у визначення носія. Потрібно розуміти, однак, що зчитувані комп'ютером носії даних і носії зберігання даних не включають в себе з'єднання, несучі хвилі, сигнали або інші перехідні середовища, а направлені, навпаки, на неперехідні, матеріальні носії. Магнітний диск і немагнітний диск, як використовується тут, включають в себе компакт-диск (CD), лазерний диск, оптичний диск, цифровий універсальний диск (DVD), гнучкий диск і Blu-ray диск, де магнітні диски (disks) 23 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 60 звичайно відтворюють дані магнітним способом, в той час як немагнітні диски (discs) відтворюють дані оптично за допомогою лазерів. Комбінації вищепереліченого також повинні бути включені в обсяг машинозчитуваних носіїв. Інструкції можуть виконуватися одним або більше процесорами, такими як один або більше цифрових сигнальних процесорів (DSP), мікропроцесорів загального призначення, спеціалізованих інтегральних схемах (ASIC), програмованих логічних матриць (FPGA), або інші еквівалентні інтегровані або дискретні логічні схеми. Відповідно, термін "процесор", як він використаний тут, може стосуватися будь-якої з вказаних вище структур або будь-якої іншої структури, придатної для реалізації описаних тут методів. Крім того, в деяких аспектах, функціональність, описана тут, може бути представлена в спеціалізованих апаратних засобах і/або програмних модулях, сконфігурованих для кодування і декодування, або включена в комбінований кодек. Крім того, ці способи можуть бути повністю реалізовані в одній або більше схемах або логічних елементах. Способи даного розкриття можуть бути реалізовані в широкому спектрі приладів або пристроїв, в тому числі бездротовому телефоні, інтегральній схемі (IC) або наборі мікросхем (наприклад, чіпсеті). Різні компоненти, модулі або блоки описані в даному розкритті, щоб підкреслити функціональні аспекти пристроїв, сконфігурованих для виконання описаних способів, але не обов'язково вимагають реалізації різними електронними пристроями. Швидше, як описано вище, різні модулі можуть бути об'єднані в апаратному модулі кодека або забезпечуються комбінацією взаємодіючих електронних пристроїв, в тому числі одного або більше процесорів, як описано вище, в поєднанні з відповідним програмним забезпеченням і/або програмно-апаратними засобами. Вище були описані різні аспекти розкриття. Ці та інші аспекти знаходяться в межах обсягу наступної формули винаходу. Посилальні позиції 10 система кодування і декодування відео 12 пристрій-джерело 14 цільовий пристрій 16 машинозчитуваний носій 18 джерело відео 20 відеокодер 22 інтерфейс виведення 28 інтерфейс введення 30 відеодекодер 32 пристрій відображення 34 носій зберігання даних 36 сервер 40 модуль вибору режиму 42 модуль оцінки руху 44 модуль компенсації руху 46 модуль інтра-прогнозування 48 модуль розділення 50 суматор 52 модуль перетворення 54 модуль квантування 56 модуль ентропійного кодування 58 модуль інверсного квантування 60 модуль інверсного перетворення 62 суматор 64 пам'ять опорних зображень 80 модуль ентропійного декодування 81 модуль прогнозування 82 модуль компенсації руху 84 модуль інтра-прогнозування 86 модуль інверсного квантування 88 модуль інверсного перетворення 90 суматор 92 пам'ять опорних кадрів 150 квадродерево 152 кореневий вузол 24 UA 108698 C2 5 10 154 вузол 156, 158 кінцевий вузол 172 одиниця кодування 174, 176, 178 суб-CU 180 поточний блок 182, 194 сусідній зверху блок 184, 192 сусідній зліва блок 190 поточний блок 191 кодована одиниця 196 блоки ФОРМУЛА ВИНАХОДУ 15 20 25 30 35 40 45 50 55 1. Спосіб кодування відеоданих, причому спосіб включає: визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформаціі включає визначення контекстної інформації на основі глибини в структурі квадродерева; і ентропійне кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому ентропійне кодування одного або більше синтаксичних елементів містить контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів, і причому контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів включає вибір імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації. 2. Спосіб за п. 1, в якому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU. 3. Спосіб за п. 2, в якому визначення контекстної інформації для даних інтерпрогнозування CU включає визначення контекстної інформації для прапора інтерпрогнозування (inter_pred_flag) на основі глибини CU. 4. Спосіб за п. 1, в якому CU містить одиницю перетворення (TU), причому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU. 5. Спосіб за п. 4, в якому визначення контекстної інформації включає визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU. 6. Спосіб за п. 2, в якому визначення контекстної інформації для даних інтерпрогнозування CU включає визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU. 7. Спосіб за п. 1, який додатково містить генерацію одного або більше синтаксичних елементів, причому ентропійне кодування одного або більше синтаксичних елементів включає ентропійне кодування одного або більше синтаксичних елементів. 8. Спосіб за п. 4, в якому визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU, включає визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU. 9. Спосіб за п. 7, який додатково включає ентропійне кодування блока відеоданих, що включає застосування перетворення до одного або більше залишкових значень блока для генерації коефіцієнтів перетворення; квантування коефіцієнтів перетворення для генерації квантованих коефіцієнтів перетворення, і ентропійне кодування квантованих коефіцієнтів перетворення. 10. Спосіб за п. 1, який додатково включає прийом одного або більше синтаксичних елементів від кодованого бітового потоку, причому ентропійне кодування одного або більше синтаксичних елементів включає ентропійне декодування одного або більше синтаксичних елементів. 11. Спосіб за п. 10, який додатково включає декодування блока відеоданих, що включає ентропійне декодування прийнятого бітового потоку для генерації квантованих коефіцієнтів перетворення, асоційованих з блоком відеоданих; 25 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 інверсне квантування квантованих коефіцієнтів перетворення для генерації коефіцієнтів перетворення, і застосування інверсного перетворення до коефіцієнтів перетворення для генерації залишкових значень, асоційованих з блоком відеоданих. 12. Спосіб за п. 1, в якому визначення контекстної інформації для одного або більше синтаксичних елементів включає визначення першої контекстної інформації для першого набору синтаксичних елементів, причому спосіб додатково включає визначення другої контекстної інформації для другого набору синтаксичних елементів на основі, щонайменше частини, контекстної інформації від блока, який є сусіднім до згаданого блока. 13. Спосіб за п. 12, в якому блок включає один або більше блоків найбільшої одиниці кодування (LCU), яка розташована нижче ряду блоків, що належать одній або більше інших LCU, і причому визначення контекстної інформації для другого набору синтаксичних елементів включає визначення контекстної інформації з використанням інформації, асоційованої з одним або більше блоками LCU, і виключення інформації, що знаходиться поза LCU. 14. Пристрій для кодування відеоданих, причому пристрій містить: пам'ять, виконану з можливістю зберігання блока відеоданих; і один або більше процесорів, виконаних з можливістю: визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а CU є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева, і ентропійно кодувати один або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів, і причому, щоб контекстно-адаптивно двійково арифметично кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю вибору імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації. 15. Пристрій за п. 14, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU. 16. Пристрій за п. 15, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, один або більше процесорів виконані з можливістю визначення контекстної інформації для прапора інтерпрогнозування (inter_prеd_flag) на основі глибини CU. 17. Пристрій за п. 14. в якому CU включає одиницю перетворення (TU), причому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU. 18. Пристрій за п. 17, в якому, щоб визначати контекстну інформацію, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU. 19. Пристрій за п. 15, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, один або більше процесорів виконані з можливістю визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU. 20. Пристрій за п. 14, в якому один або більше процесорів додатково виконані з можливістю генерації одного або більше синтаксичних елементів, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю кодування одного або більше синтаксичних елементів. 21. Пристрій за п. 17, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з TU, один або більше процесорів виконані з можливістю визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU. 22. Пристрій за п. 20, в якому один або більше процесорів додатково виконані з можливістю кодування блока відеоданих, причому, щоб кодувати блок відеоданих, один або більше процесорів виконані з можливістю: 26 UA 108698 C2 5 10 15 20 25 30 35 40 45 50 55 застосування перетворення до одного або більше залишкових значень блока для генерації коефіцієнтів перетворення; квантування коефіцієнтів перетворення для генерації квантованих коефіцієнтів перетворення, і ентропійного кодування квантованих коефіцієнтів перетворення. 23. Пристрій за п. 14, в якому один або більше процесорів виконані з можливістю прийому одного або більше синтаксичних елементів від кодованого бітового потоку, причому, щоб ентропійно кодувати один або більше синтаксичних елементів, один або більше процесорів виконані з можливістю декодування одного або більше синтаксичних елементів. 24. Пристрій за п. 23, в якому один або більше процесорів додатково виконані з можливістю декодування блока відеоданих, причому, щоб декодувати блок відеоданих, один або більше процесорів виконані з можливістю: ентропійного декодування прийнятого бітового потоку для генерації квантованих коефіцієнтів перетворення, пов'язаних з блоком відеоданих; інверсного квантування квантованих коефіцієнтів перетворення для генерації коефіцієнтів перетворення, і застосування інверсного перетворення до коефіцієнтів перетворення для генерації залишкових значень, пов'язаних з блоком відеоданих. 25. Пристрій за п. 14, в якому, щоб визначати контекстну інформацію для одного або більше синтаксичних елементів, один або більше процесорів виконані з можливістю визначення першої контекстної інформації для першого набору синтаксичних елементів, причому один або більше процесорів додатково виконані з можливістю визначення другої контекстної інформації для другого набору синтаксичних елементів на основі щонайменше частини контекстної інформації від блока, який є сусіднім до згаданого блока. 26. Пристрій за п. 25, в якому блок включає один або більше блоків найбільшої одиниці кодування (LCU), яка розташована нижче ряду блоків, що належать одній або більше інших LCU, і причому визначення контекстної інформації для другого набору синтаксичних елементів включає визначення контекстної інформації з використанням інформації, асоційованої з одним або більше блоками LCU, і виключення інформації, що знаходиться поза LCU. 27. Пристрій для кодування відеоданих, причому пристрій містить: засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева; і засіб для ентропійного кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому засіб для ентропійного кодування одного або більше синтаксичних елементів включає засіб для контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів, і причому засіб для контекстно-адаптивного двійкового арифметичного кодування одного або більше синтаксичних елементів включає засіб для вибору імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації. 28. Пристрій за п. 27, в якому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів включає засіб для визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU. 29. Пристрій за п. 28, в якому засіб для визначення контекстної інформації для даних інтерпрогнозування CU включає засіб для визначення контекстної інформації для прапора інтерпрогнозування (inter_pred_flag) на основі глибини CU. 30. Пристрій за п. 27, в якому CU включає одиницю перетворення (TU), причому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU. 31. Пристрій за п. 30, в якому засіб для визначення контекстної інформації включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить TU рівні ненульових коефіцієнтів перетворення на основі глибини TU. 32. Пристрій за п. 27, в якому засіб для визначення контекстної інформації для даних інтерпрогнозування CU включає засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи розділена СU на основі глибини CU. 27 UA 108698 C2 5 10 15 20 25 30 35 40 33. Пристрій за п. 32, в якому засіб для визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU, містить засіб для визначення контекстної інформації для залишкових даних інтерпрогнозування TU на основі глибини TU. 34. Постійний машиночитаний носій, який має збережені на ньому інструкції, які при виконанні спонукають один або більше процесорів: визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з блоком відеоданих, причому блок включений в одиницю кодування (CU) відеоданих, причому відеодані визначають структуру квадродерева, а одиниця кодування є вузлом структури квадродерева, і причому визначення контекстної інформації включає визначення контекстної інформації на основі глибини в структурі квадродерева; і ентропійно кодувати один або більше синтаксичних елементів з використанням визначеної контекстної інформації, причому ентропійне кодування одного або більше синтаксичних елементів включає контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів, і причому контекстно-адаптивне двійкове арифметичне кодування одного або більше синтаксичних елементів включає вибір імовірнісної моделі з множини імовірнісних моделей для кодування одного або більше синтаксичних елементів з використанням визначеної контекстної інформації. 35. Постійний машиночитаний носій за п. 34, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів шляхом визначення контекстної інформації для залишкових даних інтерпрогнозування CU на основі глибини CU. 36. Постійний машиночитаний носій за п. 35, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію для даних інтерпрогнозування CU шляхом визначення контекстної інформації для прапора інтерпрогнозування (inter_рred_flag) на основі глибини CU. 37. Постійний машиночитаний носій за п. 34, в якому CU включає одиницю перетворення (TU), причому інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів шляхом визначення контекстної інформації для одного або більше синтаксичних елементів, асоційованих з TU на основі глибини TU. 38. Машиночитаний носій за п. 37, в якому інструкції спонукають один або більше процесорів визначати контекстну інформацію шляхом визначення контекстної інформації для одного або більше синтаксичних елементів, які вказують, чи містить ТU рівні ненульових коефіцієнтів перетворення на основі глибини ТU. 39. Постійний машиночитаний носій за п. 34, в якому, щоб визначати контекстну інформацію для даних інтерпрогнозування CU, інструкції спонукають один або більше процесорів визначати контекстну інформацію для одного або більше синтаксичних елементів, які вказують, чи розділена CU на основі глибини CU. 40. Постійний машиночитаний носій за п. 39, в якому, визначати контекстну інформацію для одного або більше синтаксичних елементів, асоційованих з TU, інструкції спонукають один або більше процесорів визначати контекстну інформацію для залишкових даних інтерпрогнозування TU на основі глибини TU. 28
ДивитисяДодаткова інформація
Автори російськоюChien, Wei-Jung, Karczewicz, Marta, Wang, Xianglin
МПК / Мітки
МПК: H04N 19/70, H04N 19/96, H04N 19/13, H04N 7/00
Мітки: моделювання, пам'яттю, ефективне, контексту
Код посилання
<a href="https://ua.patents.su/35-108698-efektivne-za-pamyattyu-modelyuvannya-kontekstu.html" target="_blank" rel="follow" title="База патентів України">Ефективне за пам’яттю моделювання контексту</a>
Ефективне фільтрування за допомогою комплексного модульованого блока фільтрів

Номер патенту: 91890
Опубліковано: 10.09.2010
Автор: Віллемоес Ларс
МПК: H03H 17/02
Мітки: комплексного, модульованого, фільтрування, блока, допомогою, ефективне, фільтрів
Формула / Реферат:
1. Фільтрувальний пристрій для фільтрування залежного від часу вхідного сигналу для одержання залежного від часу вихідного сигналу, який є представленням залежного від часу вхідного сигналу, відфільтрованого з використанням характеристики фільтра, який має неоднорідну амплітудну/частотну характеристику, який має:- блок фільтрів (101) комплексного аналізу для генерування L комплексних сигналів піддіапазону із залежного від часу вхідного...
Ефективне здійснення персонального виклику у безпровідній системі зв’язку

Номер патенту: 101188
Опубліковано: 11.03.2013
Автори: Лі Цзюньі, Ранган Сандіп, Лароя Раджив, Ханде Прашантх
МПК: H04W 68/00
Мітки: зв'язку, ефективне, безпровідній, системі, здійснення, виклику, персонального
Формула / Реферат:
1. Спосіб здійснення персонального виклику безпровідного термінала, що містить етапи, на якихмодулюють першу кількість бітів інформації для формування першого сигналу персонального виклику, що вказує, чи є повідомлення персонального виклику для щонайменше одного безпровідного термінала в першій групі безпровідних терміналів, причому згадана перша група є однією групою з множини груп безпровідних терміналів;модулюють другу...
Ефективне застосування диспергаторів у стіновій плиті, яка містить піну

Номер патенту: 92749
Опубліковано: 10.12.2010
Автори: Лю Цинся, Хіншо Стюарт, Шейк Майкл П., Блекберн Девід Р.
МПК: C04B 28/14, C04B 16/00, C04B 11/00, C04B 20/00, C04B 24/08, C04B 24/36
Мітки: піну, диспергаторів, плити, містить, стіновий, яка, ефективне, застосування
Формула / Реферат:
1. Спосіб застосування піни і диспергатора в суспензії гіпсу, який включаєзмішування штукатурки, першого диспергатора і першої кількості води, з одержанням суспензії гіпсу,змішування мила, другого диспергатора і другої кількості води, з одержанням піни, іоб'єднання піни з суспензією.2. Спосіб за п. 1, де перший диспергатор і другий диспергатор являють собою один і той же диспергатор.3. Спосіб за п. 1, де...
Пристрій для моделювання нейрона

Номер патенту: 40452
Опубліковано: 10.04.2009
Автори: Колісник Петро Федорович, Фофанова Наталя Володимирівна, Мартинюк Тетяна Борисівна, Оначенко Марат Сергійович
МПК: G06G 7/60
Мітки: пристрій, нейрона, моделювання
Формула / Реферат:
Пристрій для моделювання нейрона, який містить блоки моделювання синапсів, що складаються з послідовно з'єднаних узгоджуючих елементів, елементів затримки і масштабуючих елементів, виходи яких є виходами блоків моделювання синапсів, входами яких є входи узгоджуючих елементів, адитивний суматор, блок моделювання викликаних постсинаптичних потенціалів, формувач імпульсів, послідовно з'єднані перший перетворювач частоти в напругу, компаратор,...
Пристрій для моделювання фізичних об’єктів

Номер патенту: 59086
Опубліковано: 10.05.2011
Автори: Суровцев Ігор Вікторович, Татарінов Олексій Едуардович, Бабак Олег Володимирович
МПК: G01D 1/00
Мітки: об'єктів, фізичних, пристрій, моделювання
Формула / Реферат:
Пристрій для моделювання фізичних об'єктів, який містить інтерполятор, з'єднаний з коректором, який відрізняється тим, що він містить блок введення даних, блок індикації напрямку складових градієнта лінійної функції відгуку, блок комбінаторного перебору моделей-претендентів, другий інтерполятор, датчик якості моделі, при цьому інтерполятор виходом підключений до першого входу блока індикації напрямку складових градієнта лінійної функції...