Спосіб описування та розпізнавання мовленнєвих сигналів і пристрій для його реалізації
Номер патенту: 67695
Опубліковано: 15.06.2004
Автори: Гриценко Володимир Ільїч, Вінцюк Тарас Климович, Федорин Ярослав Володимирович



Формула / Реферат
1. Спосіб описування та розпізнавання мовленнєвих сигналів, що представляються послідовностями елементів-векторів із значень поточних параметрів його аналізу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі елементи еталонних образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються, який відрізняється тим, що з метою пришвидшення та підвищення робастності процесів розпізнавання кожен елемент-вектор як еталонних образів, так і мовленнєвого сигналу, що розпізнається, описується бінарним кодом, який в цілому характеризує форму поточного амплітудного спектра мовленнєвого сигналу, а кожен окремий біт цього коду визначається як знак різниці значень амплітудного спектра для двох різних частот, як елементарна міра схожості використовується хемінгова міра, значення якої для пари порівнюваних елементів обчислюється таблично, еталонний мовленнєвий образ формують шляхом потроєння кожного еталонного елемента початкового еталонного образу з мінімально можливою тривалістю вимовляння, утворюючи послідовності трійок, інтегральну міру схожості для першого еталонного елемента кожної із трійок знаходять як суму елементарної міри схожості цього еталонного елемента на поточний спостережуваний елемент з найбільшою із трьох інтегральних мір схожості, накопичених для попередньої трійки еталонних елементів та попереднього спостережуваного елемента мовленнєвого сигналу, що розпізнається, а інтегральні міри схожості для другого та третього еталонних елементів цієї ж трійки знаходять як суми згадуваної елементарної міри схожості та інтегральних мір схожості, накопичених для першого та другого еталонних елементів цієї ж трійки відповідно для попереднього спостережуваного елемента, при цьому інтегральні міри схожості для першого, другого та третього еталонних елементів всіх трійок, окрім першої, всіх еталонних мовленнєвих образів початково, до появи першого спостережуваного елемента, набувають мінімально можливих значень, а для першого, другого та третього еталонних елементів першої трійки всіх еталонних мовленнєвих образів - максимально можливих значень, а як кінцевий результат розпізнавання вибирають той мовленнєвий еталонний образ, одна з трьох інтегральних мір схожості якого, що накопичена для останньої трійки еталонних елементів та останнього розпізнаваного елемента, є абсолютно найбільшою.
2. Пристрій для описування та розпізнавання мовленнєвих сигналів за способом п. 1, що містить спектральний аналізатор, блоки пам'яті еталонних мовленнєвих образів та мовленнєвого сигналу, що розпізнається, обчислювач елементарних мір схожостей та контролер, перший та другий входи якого під'єднані до перших виходів блоків пам'яті розпізнаваного та еталонного мовленнєвих образів, відповідно другі виходи яких під'єднані до першого та другого входів обчислювача елементарних мір схожостей, а адресні входи блоків пам'яті розпізнаваного та еталонного мовленнєвих образів під'єднані до першого та другого виходів контролера відповідно, який відрізняється тим, що з метою пришвидшення та підвищення робастності процесів розпізнавання в нього введені аналізатор форми поточного амплітудного спектра, перший, другий та третій блоки пам'яті інтегральної міри схожості, обчислювач інтегральної міри схожості та регістр, інформаційний вхід якого під'єднаний до виходу обчислювача елементарної міри схожості та до першого інформаційного входу обчислювача інтегральної міри схожості, а керуючий вхід - до третього виходу контролера, першого керуючого входу обчислювача інтегральної міри схожості, входів запису першого, другого та третього блоків пам'яті інтегральної міри схожості, при цьому інформаційний вихід регістра під'єднаний до другого інформаційного входу обчислювача інтегральної міри схожості, вихід котрого є виходом пристрою, а другий та третій керуючі входи під'єднані до першого виходу блока пам'яті еталонного мовленнєвого образу та четвертого виходу контролера відповідно, третій вхід якого є входом пристрою, а другий вихід під'єднаний до адресних входів першого та другого блоків пам'яті інтегральної міри схожості, інформаційні виходи яких під'єднані до третього та четвертого інформаційних входів обчислювача інтегральної міри схожості відповідно, перший та другий інформаційні виходи якого під'єднані до інформаційних входів першого та другого блоків пам'яті інтегральної міри схожості відповідно.
Текст
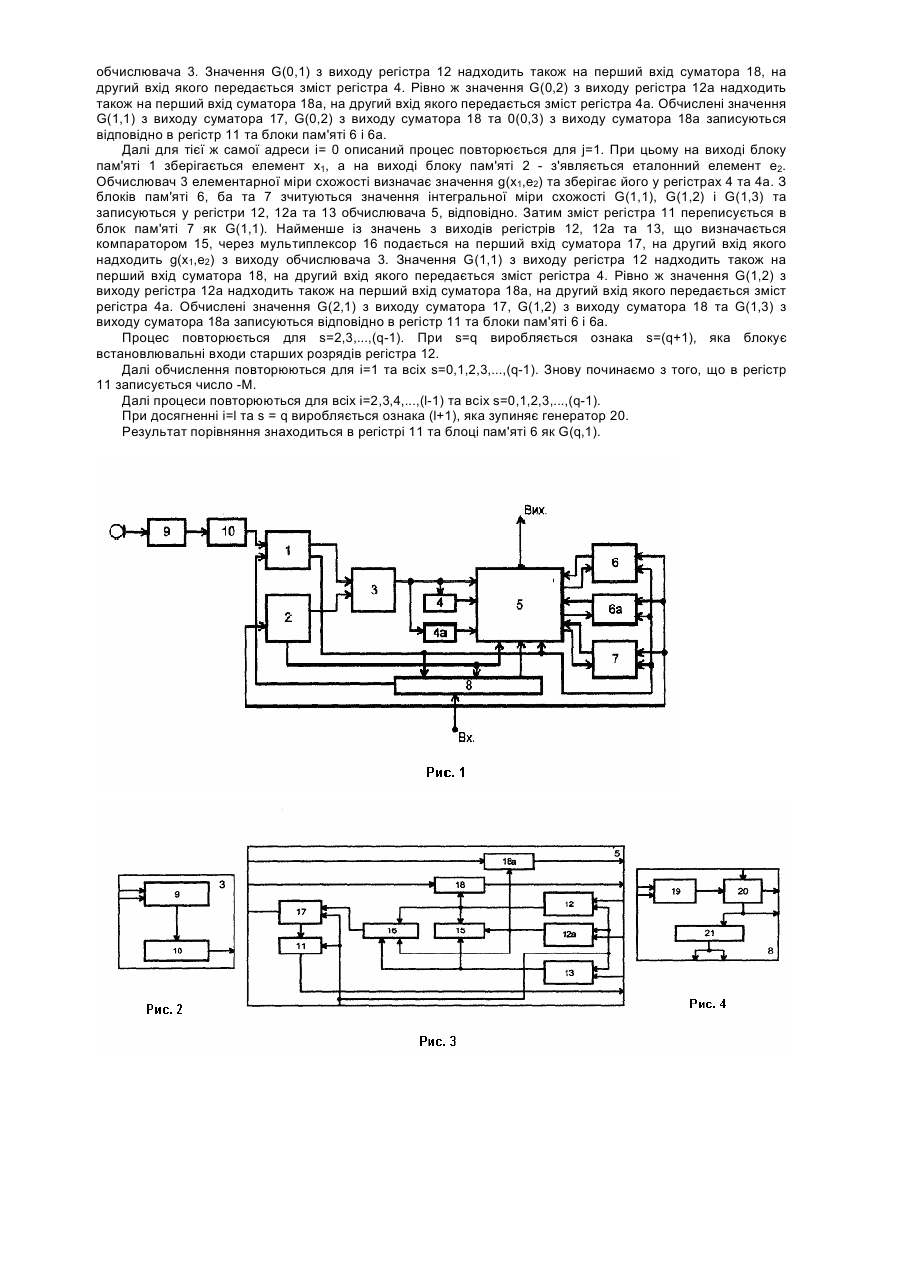
Винахід відноситься до техніки оброблення мовленнєвої інформації з метою її стискування, кодування, автоматичного розпізнавання та відтворення. Може найти використання для голосового керування пристроями. Відомий спосіб описування та розпізнавання мовленнєвих сигналів і пристрій для його реалізації(дивись патент України №48082). Сутність відомого способу полягає в тому, що мовленнєві сигнали представляються послідовностями елементів-векторів із значень поточних параметрів його аналізу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі елементи еталонних образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються. Але він має недоліки, які полягають в тому що він має недостатню швидкодію та низьку робастність процесів автоматичного розпізнавання мовленнєвих сигналів. Відомий пристрій містить спектральний аналізатор, блоки пам'яті еталонних мовленнєвих образів та мовленнєвого сигналу, що розпізнається, обчислювач елементарних мір схожостей та контролер, перший та другий входи якого під'єднані до перших виходів блоків пам'яті розпізнаваного та еталонного мовленнєвих образів, відповідно другі виходи яких під'єднані до першого та другого входів обчислювача елементарних мір схожостей, а адресні входи блоків пам'яті розпізнаваного та еталонного мовленнєвих образів під'єднані до першого та другого виходів контролера відповідно, Але він також має недоліки: недостатня швидкодія та низька робастність автоматичного розпізнавання мовленнєвих сигналів. В основу винаходу покладена задача пришвидшення та підвищення робастності процесів автоматичного розпізнавання мовленнєвих сигналів за рахунок введення нових операцій розпізнавання мовленнєвих сигналів та введення нових конструктивних змін в пристрій для здійснення цього способу. Поставлена задача вирішується способом опису та розпізнавання мовленнєвих сигналів, що представляються послідовностями елементів-векторів із значень поточних параметрів його аналізу, який включає знаходження значень елементарних мір схожості кожного спостережуваного елемента на всі елементи еталонних образів, визначення схожості мовленнєвих образів шляхом рекурентного накопичення методом динамічного програмування інтегральних мір схожості послідовності спостережуваних елементів на послідовності еталонних образів, що розпізнаються, при цьому кожен елемент-вектор як еталонних образів, так і мовленнєвого сигналу, що розпізнається, описується бінарним кодом, який в цілому характеризує форму поточного амплітудного спектру мовленнєвого сигналу, а кожен окремий біт цього коду визначається як знак різниці значень амплітудного спектру для двох різних частот; як елементарна міра схожості використовують хемінгову міру, значення якої для пари порівнюваних елементів обчислюється таблично; еталонний мовленнєвий образ формують шляхом потроєння кожного еталонного елемента початкового еталонного образу з мінімально можливою тривалістю вимовляння, утворюючи послідовності трійок, інтегральну міру схожості для першого еталонного елемента кожної із трійок знаходять як суму елементарної міри схожості цього еталонного елемента на поточний спостережуваний елемент з найбільшою із трьох інтегральних мір схожості, накопичених для попередньої трійки еталонних елементів та попереднього спостережуваного елемента мовленнєвого сигналу, що розпізнається, а інтегральні міри схожості для другого та третього еталонних елементів цієї ж трійки знаходять як суми згадуваної елементарної міри схожості та інтегральних мір схожості, накопичених для першого та другого еталонних елементів цієї ж трійки відповідно для попереднього спостережуваного елемента, при цьому інтегральні міри схожості для першого, другого та третього еталонних елементів всіх трійок, окрім першої, всіх еталонних мовленнєвих образів початкове, до появи першого спостережуваного елемента, набувають мінімально можливих значень, а для першого, другого та третього еталонних елементів першої трійки всіх еталонних мовленнєвих образів, - максимально можливих значень, а в якості кінцевого результату розпізнавання вибирають той мовленнєвий еталонний образ, одна з трьох інтегральних мір схожості якого, що накопичена для останньої трійки еталонних елементів та останнього розпізнаваного елемента, є абсолютно найбільшою. Поставлена задача вирішується також пристроєм для описування та розпізнавання мовленнєвих сигналів за способом, що вказаний вище, що містить спектральний аналізатор, блоки пам'яті еталонних мовленнєвих образів та мовленнєвого сигналу, що розпізнається, обчислювач елементарних мір схожостей та контролер, перший та другий входи якого під'єднані до перших виходів блоків пам'яті розпізнаваного та еталонного мовленнєвих образів, відповідно другі виходи яких під'єднані до першого та другого входів обчислювача елементарних мір схожостей, а адресні входи блоків пам'яті розпізнаваного та еталонного мовленнєвих образів під'єднані до першого та другого виходів контролера відповідно, при цьому він містить аналізатор форми поточного амплітудного спектру, перший, другий та третій блоки пам'яті інтегральної міри схожості, обчислювач інтегральної міри схожості та регістр, інформаційний вхід якого під'єд-наний до виходу обчислювача елементарної міри схожості та до першого інформаційного входу обчислювача інтегральної міри схожості, а керуючий вхід - до третього виходу контролера, першого керуючого входу обчислювача інтегральної міри схожості, входів запису першого, другого та третього блоків пам'яті інтегральної міри схожості, при цьому інформаційний вихід регістра під'єднаний до другого інформаційного входу обчислювача інтегральної міри схожості, вихід котрого є виходом пристрою, а другий та третій керуючі входи під'єднані до першого виходу блоку пам'яті еталонного мовленнєвого образа та четвертого виходу контролера відповідно, третій вхід якого є входом пристрою, а другий вихід під'єднаний до адресних входів першого та другого блоків пам'яті інтегральної міри схожості, інформаційні виходи яких під'єднані до третього та четвертого інформаційних входів обчислювача інтегральної міри схожості відповідно, перший та другий інформаційні виходи якого під'єднані до інформаційних входів першого та другого блоків пам'яті інтегральної міри схожості відповідно. На фіг. 1 представлена структурна схема пристрою, що реалізує спосіб; на фіг. 2-4 - схеми окремих блоків; фіг. 5 пояснює принцип роботи пристрою. Пристрій містить блок 1 пам'яті мовленнєвого образу, що поданий для аналізу та розпізнавання, блок 2 пам'яті еталонного образа, обчислювач 3 елементарної міри схожості, регістр 4, обчислювач 5 інтегральної міри схожості, блоки 6,7 та 7а пам'яті, контролер 8, аналізатор 9-10 мовленнєвого сигналу. В аналізаторі 9 мовленнєвий сигнал, що подається з мікрофона, піддається поточному спектральному аналізові в n спектральних каналах. Отже, кожний поточний спектральний елемент yi, що спостерігається в дискретному рівномірному часі iDT з кроком DT , наприклад DT = 10мс, є елементом-вектором: уi = (уi1,yi2,…,yim,…,yin). В аналізаторі 10 форми спектру кожен спостережуваний елемент уi описується вектором-матрицею хi з двійковими компонентами ì1, якщо ((y iu - y in ) ³ 0) & (y iu ³ Qu ) ï x iun = í0 в іншихвипадках, n < u; u, n = 1 : n. ï î 1 Двійковий опис-елемент х містить m = n(n - 1) компонент та несе інформацію про форму спектру, 2 визначає відносні амплітуди спектральних компонентів та не залежить від гучності промовляння. Як правило, пороги Q u , u = 1 : n вибираються так, щоб в стаціонарних умовах, коли на вхід мікрофона надходять лише акустичні завади приміщення, формувались тільки нульові елементи-коди. У випадку, коли n = u - 1, двійковий код х має n-1 компонент, він стає дискретним аналогом знаку похідної спектру за частотою. В блоці пам'яті 1 розпізнаваного мовленнєвого образу зберігається послідовність поточних бінарних елементів-векторів: Х0l =(х1,x2,...,хi,...,хl), де l - довжина мовленнєвого образу. В блоці 2 пам'яті еталонного образу зберігається еталонний образ слова, представлений аналогічною послідовністю бінарних еталонних елементів-кодів: Еоq=(е1,е2,...,еs„...,eq), причому вона відповідає самому швидкому та все ще чіткому промовлянню слова; q - довжина початкового еталона слова. При автоматичному порівнянні та розпізнаванні початковий еталон Еоq слова піддається нелінійним перетворенням в часі шляхом повторення кожного еталонного елемента початкового еталона нуль (нема повторення), один або два рази, причому так, щоб зберігався порядок слідування еталонних елементів, визначений початковим еталоном, й так, щоб в результаті у перетвореному еталоні слова було всього / еталонних елементів. Перетворені еталонні послідовності довжини l порівнюються з мовленнєвим сигналом Х0l, що розпізнається, та обчислюються інтегральні міри G схожості сигналу Х0l, на перетворені еталонні образи слова як суми відповідних значень елементарних мір схожості g(x,e): G(X 0l,E 0l ) = l å g(x e ( ) ), i, s i i=1 де функція s(i): s(1) = 1, s(l) = q, - встановлює відповідність номерів еталонних та спостережуваних елементів. Найбільше значення інтегральної міри схожості, що досягається на множині {s(i):s(1)=1,s(l)=q} допустимих відповідностей визначає схожість мовленнєвого образу Х0l, що розпізнається, на еталонний мовленнєвий образ Е0q. Елементи хi зберігаються в блоці пам'яті 1 за адресами 0...(l-1), що задаються сигналом з першого виходу контролера 8. Адресі 0 відповідає елемент х1, адресі (l-1) - елемент хl. За адресою l зберігається ознака (l+1) - "Кінець образу, що розпізнається", формально відповідний елементові хl+1. Ця ознака зчитується з першого виходу блоку 1 та подається на перший вхід контролера 8. Елементи еs зберігаються в блоці пам'яті 2 за адресами 0...(q-1), що задаються сигналом з другого виходу контролера 8. Адресі 0 відповідає елемент е1, адресі (q-1) - елемент eq. За адресою q зберігається ознака (q+1)- "Кінець еталонного образу". Ця ознака організована аналогічно ознаці (l+1), вона зчитується з першого виходу блоку 2 й подається на другий та третій входи контролера 8 та через другий та третій входи обчислювача 5 інтегральної міри схожості - на входи установок регістрів 12, 12а і 14. За адресами 0...q зберігаються також проміжні значення інтегральної міри схожості в блоках пам'яті 6, ба та 7. За адресою 0 в блоках пам'яті 6, 6а та 7 записуються відповідно початкові значення (G(0,1)= 0, G(0,2)=0 та G(0,3)=0, а за адресами 1,2,..., s,...(q-1) цих же блоків запишемо відповідно початкові значення G(s,1)=G(s,2)=G(s,3)=M, де М - велике ціле додатне число. Перед початком порівняння та розпізнавання всі регістри, а також лічильник 21 обнуляються. В регістр 11 записується число - М. Імпульсом "Старт" запускається генератор 20 контролера 8. Лічильник 21 контролера 8 формує адреси блоку пам'яті 1 та блоку пам'яті 2. Ці адреси надалі будуть позначатись як і та s відповідно. Окрім того, адреса s використовується в трьох блоках пам'яті 6, 6а та 7. В регістр 11 записується число - М. За адресою i=0 на виході блоку пам'яті 1 з'являється елемент х1 у вигляді m- розрядного двійкового коду, який подається на перший вхід обчислювача елементарної міри схожості 3. Одночасно за адресою s=0 на виході блоку пам'яті 2 з'являється еталонний елемент е1, також у вигляді m-розрядного двійкового коду, який подається на другий вхід обчислювача елементарної міри схожості 3. Останній обчислює значення елементарної міри схожості g(x1,e1) - хемінгову відстань між кодами x1 та е1. За адресою s=0 одночасно з блоків пам'яті 6, 6а та 7 зчитуються значення інтегральної міри схожості G(0,1), G(0,2) і G(0,3) та записуються у регістри 12, 12а та 13, відповідно. Затим зміст регістра 11 переписується в блок пам'яті 7 як G(01). Змісти регістрів 12, 12а та 13 порівнюються в компараторі 15, і менше з-посеред них через мультиплексор 16 подається на перший вхід суматора 17, на другий вхід якого надходить g(x1,e1) з обчислювача 3. Значення G(0,1) з виходу регістра 12 надходить також на перший вхід суматора 18, на другий вхід якого передається зміст регістра 4. Рівно ж значення G(0,2) з виходу регістра 12а надходить також на перший вхід суматора 18а, на другий вхід якого передається зміст регістра 4а. Обчислені значення G(1,1) з виходу суматора 17, G(0,2) з виходу суматора 18 та 0(0,3) з виходу суматора 18а записуються відповідно в регістр 11 та блоки пам'яті 6 і 6а. Далі для тієї ж самої адреси i= 0 описаний процес повторюється для j=1. При цьому на виході блоку пам'яті 1 зберігається елемент x1, а на виході блоку пам'яті 2 - з'являється еталонний елемент е2. Обчислювач 3 елементарної міри схожості визначає значення g(x1,e2) та зберігає його у регістрах 4 та 4а. З блоків пам'яті 6, ба та 7 зчитуються значення інтегральної міри схожості G(1,1), G(1,2) і G(1,3) та записуються у регістри 12, 12а та 13 обчислювача 5, відповідно. Затим зміст регістра 11 переписується в блок пам'яті 7 як G(1,1). Найменше із значень з виходів регістрів 12, 12а та 13, що визначається компаратором 15, через мультиплексор 16 подається на перший вхід суматора 17, на другий вхід якого надходить g(x1,e2) з виходу обчислювача 3. Значення G(1,1) з виходу регістра 12 надходить також на перший вхід суматора 18, на другий вхід якого передається зміст регістра 4. Рівно ж значення G(1,2) з виходу регістра 12а надходить також на перший вхід суматора 18а, на другий вхід якого передається зміст регістра 4а. Обчислені значення G(2,1) з виходу суматора 17, G(1,2) з виходу суматора 18 та G(1,3) з виходу суматора 18а записуються відповідно в регістр 11 та блоки пам'яті 6 і 6а. Процес повторюється для s=2,3,...,(q-1). При s=q виробляється ознака s=(q+1), яка блокує встановлювальні входи старших розрядів регістра 12. Далі обчислення повторюються для i=1 та всіх s=0,1,2,3,...,(q-1). Знову починаємо з того, що в регістр 11 записується число -М. Далі процеси повторюються для всіх i=2,3,4,...,(l-1) та всіх s=0,1,2,3,...,(q-1). При досягненні i=l та s = q виробляється ознака (l+1), яка зупиняє генератор 20. Результат порівняння знаходиться в регістрі 11 та блоці пам'яті 6 як G(q,1).
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for describing and identifying voice signals and the device for the realization of the method
Автори англійськоюVintsiuk Taras Klymovych, Fedoryn Yaroslav Volodymyrovych
Назва патенту російськоюСпособ описания и распознавания речевых сигналов и устройство для осуществления способа
Автори російськоюВинцюк Тарас Климович, Федорин Ярослав Владимирович
МПК / Мітки
МПК: G10L 15/00
Мітки: спосіб, реалізації, пристрій, сигналів, розпізнавання, описування, мовленнєвих
Код посилання
<a href="https://ua.patents.su/4-67695-sposib-opisuvannya-ta-rozpiznavannya-movlennehvikh-signaliv-i-pristrijj-dlya-jjogo-realizaci.html" target="_blank" rel="follow" title="База патентів України">Спосіб описування та розпізнавання мовленнєвих сигналів і пристрій для його реалізації</a>
Спосіб розпізнавання мовленнєвих одиниць

Номер патенту: 61248
Опубліковано: 17.11.2003
Автори: Старушко Дмитро Георгійович, Шелєпов Владислав Юрійович, Шевченко Анатолій Іванович
МПК: G10L 15/00, G10L 13/00
Мітки: мовленнєвих, одиниць, розпізнавання, спосіб
Формула / Реферат:
1. Спосіб розпізнавання мовленнєвих одиниць, що полягає в перетворенні мовленнєвого сигналу на електричний сигнал, дискретизації й оцифровці, виділенні фрагмента цифрового сигналу, визначенні енергії цифрового сигналу виділеного фрагмента, формуванні еталонів, обчисленні відстані й ухваленні рішення про розпізнавання, який відрізняється тим, що виконують високочастотну фільтрацію цифрового сигналу виділеного фрагмента, визначають енергію...
Спосіб розпізнавання симетричності зображень об’єктів і пристрій для його реалізації

Номер патенту: 3741
Опубліковано: 27.12.1994
Автори: Кожем'яко Володимир Прокопович, КРАСИЛЕНКО ВОЛОДИМИР ГРИГОРОВИЧ, Мартинюк Тетяна Борисівна, Буда Антоніна Георгіївна
МПК: G06K 9/52, G06K 9/58, G06K 11/00
Мітки: спосіб, розпізнавання, пристрій, симетричності, об'єктів, реалізації, зображень
Формула / Реферат:
1. Способ распознавания симметричности изображений объектов, включающий формирование светового потока исходного изображения в неподвижной системе координат с первой и второй ортогональными осями, разделение сформированного светового потока на два одинаковых равноинтенсивных световых потока, пространственную модуляцию первого и второго разделенных световых потоков вдоль одноименной координатной оси с симметрией относительно другой...
Спосіб обробки сигналів при звірянні шкал часу та пристрій для його реалізації

Номер патенту: 20380
Опубліковано: 15.07.1997
Автори: Нестеренко Георгій Вікторович, Леман Юрій Олександрович, Кундюков Сергій Григорович, Семенов Станіслав Федорович, Макаренко Борис Іванович, Коваль Юрій Олександрович, Кащеєв Борис Леонідович, Дуднік Борис Савич
МПК: G04C 11/00
Мітки: шкал, обробки, часу, пристрій, спосіб, сигналів, реалізації, звірянні
Формула / Реферат:
1. Способ обработки сигналов при сверке шкал времени, основанный на равенстве времени распространения радиосигнала в прямом и обратном направлении, при котором пропускают принимаемый сигнал через тракт приемника, а передаваемый сигнал через тракт передатчика и дополнительно через тракт приемника, отличающийся тем, что излучаемый радиосигнал дополнительно зеркально инвертируют во времени относительно реперной метки времени собственной...
Спосіб ультразвукового контролю хімічного складу навколишнього середовища та пристрій для його реалізації

Номер патенту: 33870
Опубліковано: 15.02.2001
Автори: Соченко Петро Степанович, Зеленков Олександр Аврамович, Зубченко Олександр Миколайович
МПК: G01N 29/024, G01N 29/07
Мітки: пристрій, хімічного, контролю, навколишнього, реалізації, ультразвукового, середовища, спосіб, складу
Текст:
...означене прямокутником, приймається приймачем 7, підсилюється підсилювачем 8 та детектирується детектором 9 і надходить до першого входу блока 4 вимірювача затримки. На фіг. 3 показана можлива реалізація блока 4 вимірювання затримки. Імпульс з генератора 1, який формується в момент запуску процесу вимірювань, надходить на другі входи першого 10 та другого 11 тригерів, які переключаються в стан, що відкриває першу 12 та другу 13 схему збігу...
Спосіб передачі телевізійних сигналів і система для його реалізації

Номер патенту: 39476
Опубліковано: 15.06.2001
Автори: Крихтін Олексій Євгенович, Погоржельський Вадим Леонідович
Мітки: реалізації, спосіб, система, телевізійних, сигналів, передачі
Формула / Реферат:
1. Спосіб передачі телевізійних сигналів, при якому здійснюють приймання НВЧ і ВЧ антенами сигналів декількох телеканалів від супутників і/або із ефіру, перетворюють ці сигнали в аудіо/відеосигнали, який відрізняється тим, що одержані аудіо-відео сигнали зазначених телеканалів перетворюють в амплітудно-модульовані сигнали телевізійного діапазону за допомогою передавачів, підсумовують їх в об'єднаний сигнал і випромінюють споживачам за...
Попередній патент: Спосіб одержання мінерального в’яжучого кремнеземистого складу
Наступний патент: Спосіб одержання литтям-прокаткою листів (штаб) шириною, більшою від довжини бочки обтискуючих валків
Випадковий патент: Пристрій для транспортування і очистки коренебульбоплодів