Система та спосіб для генерування, кодування та представлення даних адаптивного звукового сигналу
Номер патенту: 114793
Опубліковано: 10.08.2017
Автори: Шабанне Крістоф, Робінсон Чарльз К., Тсінгос Ніколас Р.









































Формула / Реферат
1. Система, призначена для обробки звукових сигналів, яка містить:
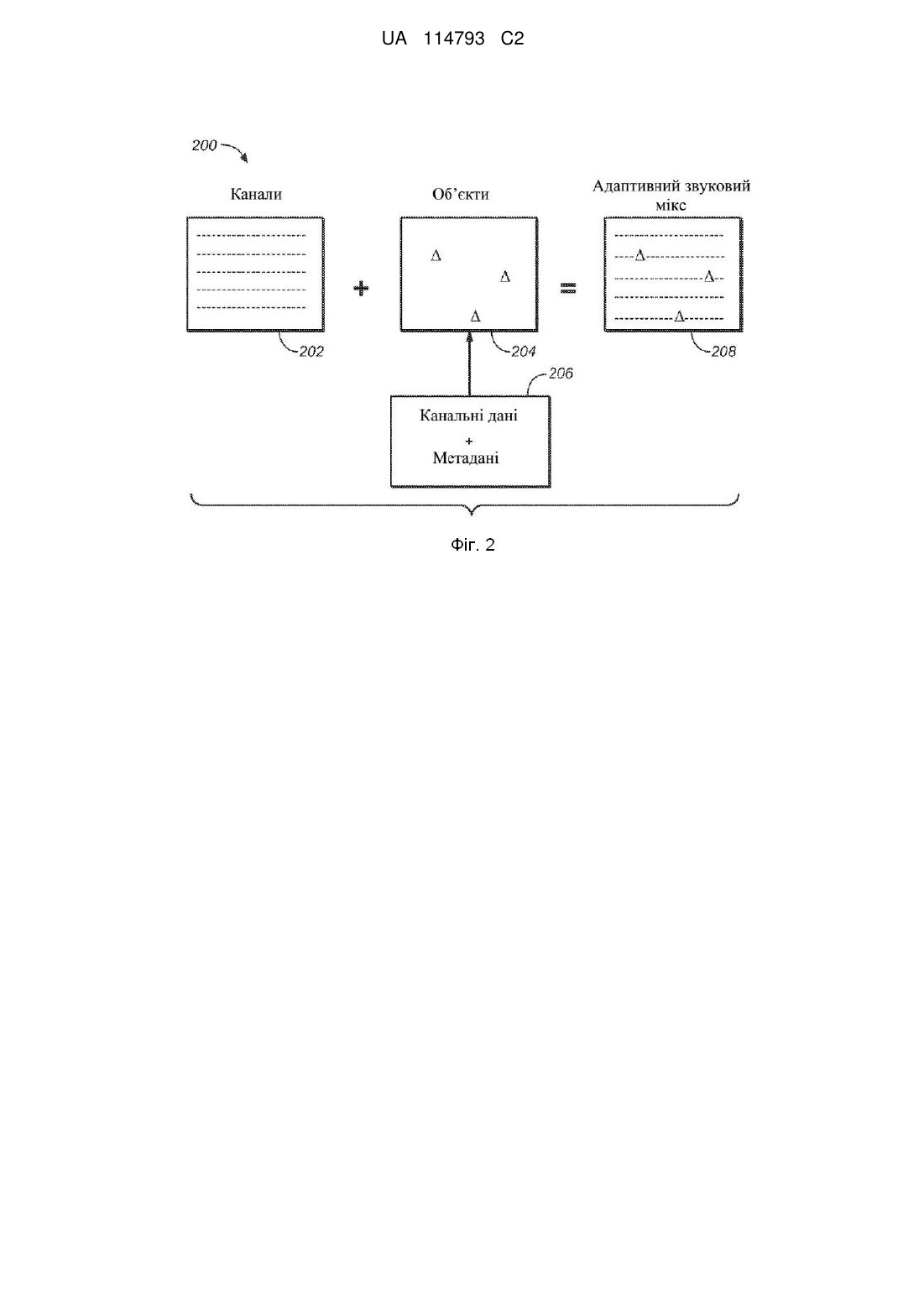
компонент авторської розробки, сконфігурований для прийняття ряду звукових сигналів звукової програми і для генерування адаптивного звукового мікса для звукової програми, що містить ряд монофонічних аудіопотоків, і одного або декількох наборів метаданих, що пов'язані з кожним з ряду монофонічних аудіопотоків і що визначають місце розташування програвання відповідного монофонічного аудіопотоку, і для генерування першого набору метаданих і другого набору метаданих, пов'язаних з одним або декількома з ряду монофонічних аудіопотоків, при цьому щонайменше один з ряду монофонічних аудіопотоків ідентифікується як звук на основі каналів та щонайменше один з інших з ряду монофонічних аудіопотоків ідентифікується як звук на основі об'єктів, і при цьому місце розташування програвання звуку на основі каналів містить позначення гучномовців для гучномовців у масиві гучномовців, і при цьому місце розташування програвання звуку на основі об'єктів містить місце розташування в тривимірному просторі, і при цьому додатково перший набір метаданих за промовчуванням застосовується до одного або декількох монофонічних аудіопотоків з ряду, а другий набір метаданих зв'язано зі специфічними умовами середовища програвання і застосовується до одного або декількох монофонічних аудіопотоків із ряду замість першого набору метаданих у разі відповідності умов середовища програвання специфічним умовам середовища програвання; та
систему представлення даних, пов'язану з компонентом авторської розробки та сконфігуровану для прийняття бітового потоку, усередині якого розміщено ряд монофонічних аудіопотоків та набори метаданих, і для представлення ряду монофонічних аудіопотоків у ряд сигналів, що подаються на гучномовці, що відповідають гучномовцям у середовищі програвання, відповідно до наборів метаданих на основі умов середовища програвання.
2. Система за п. 1, яка відрізняється тим, що кожний набір метаданих містить елементи метаданих, пов'язані з кожним потоком на основі об'єктів, при цьому елементи метаданих для кожного потоку на основі об'єктів описують просторові параметри, що управляють програванням відповідного звуку на основі об'єктів і містять один або декілька наступних параметрів: положення звуку, ширина звуку та швидкість звуку; і також при цьому кожний набір метаданих містить елементи метаданих, пов'язані з кожним потоком на основі каналів, і масив гучномовців містить гучномовці, розташовані в певній конфігурації оточуючого звуку, і при цьому елементи метаданих, пов'язані з кожним потоком на основі каналів, містять позначення каналів оточуючого звуку гучномовців у масиві гучномовців відповідно до певного стандарту оточуючого звуку.
3. Система за п. 1, яка відрізняється тим, що масив гучномовців містить додаткові гучномовці, призначені для програвання потоків на основі об'єктів і розташовані в середовищі програвання відповідно до установчих команд від користувача на основі умов середовища програвання, і при цьому умови програвання залежать від змінних, що містять: розмір і форму приміщення середовища програвання, заповненість, склад матеріалів і оточуючий шум; і також при цьому система приймає від користувача установчий файл, який містить щонайменше список позначень гучномовців і присвоювання каналів окремим гучномовцям масиву гучномовців, інформацію відносно групування гучномовців і присвоювання на основі відносного положення гучномовців у середовищі програвання.
4. Система за п. 1, яка відрізняється тим, що компонент авторської розробки містить мікшерний пульт, що має елементи керування, що приводяться в дію користувачем для визначення рівнів програвання ряду монофонічних аудіопотоків, що містять оригінальний звуковий вміст, і при цьому елементи метаданих, пов'язані з кожним відповідним потоком на основі об'єктів, автоматично генеруються при введенні користувачем керуючих сигналів у мікшерний пульт.
5. Система за п. 1, яка відрізняється тим, що набори метаданих містять метадані, що роблять можливим підвищувальне мікшування або понижувальне мікшування щонайменше одного з монофонічних аудіопотоків на основі каналів і монофонічних аудіопотоків на основі об'єктів відповідно до переходу від першої конфігурації масиву гучномовців до другої конфігурації масиву гучномовців.
6. Система за п. 3, яка відрізняється тим, що набори метаданих містять метадані, які ідентифікують тип вмісту монофонічного аудіопотоку; при цьому тип вмісту вибрано із групи, яка складається з: діалогу, музики та ефектів - і кожний тип вмісту втілений у відповідному наборі потоків на основі каналів або потоків на основі об'єктів, і також при цьому складові звуку для кожного типу вмісту передають у певні групи гучномовців з однієї або декількох груп гучномовців, позначених у межах масиву гучномовців.
7. Система за п. 6, яка відрізняється тим, що гучномовці масиву гучномовців розміщено у певних положеннях у межах середовища програвання, і при цьому елементи метаданих, пов'язані з кожним відповідним потоком на основі об'єктів, визначають, що одну або декілька складових звуку представлено у сигнал, що подають на гучномовець, для програвання через гучномовець, найближчий до присвоєного місця розташування програвання складової звуку, що зазначено метаданими положення.
8. Система за п. 1, яка відрізняється тим, що місце розташування програвання містить положення в просторі в середовищі програвання щодо екрана або поверхні, яка оточує середовище програвання, і при цьому поверхня містить передню площину, задню площину, ліву площину, праву площину, верхню площину та нижню площину.
9. Система за п. 1, яка відрізняється тим, що також містить кодек, пов'язаний з компонентом авторської розробки та компонентом представлення даних і сконфігурований для прийняття ряду монофонічних аудіопотоків і метаданих і для генерування єдиного цифрового бітового потоку, що упорядкованим чином містить ряд монофонічних аудіопотоків.
10. Система за п. 9, яка відрізняється тим, що компонент представлення даних також містить засоби для вибору одного з алгоритмів представлення даних, що використовується компонентом представлення даних, при цьому алгоритм представлення даних вибрано із групи, яка складається з: бінаурального алгоритму, стереодипольного алгоритму, амбіфонії, синтезу хвильового поля (WFS), багатоканального панорамування, неопрацьованих стемів з метаданими положення, подвійного балансу та амплітудного панорамування на векторній основі.
11. Система за п. 1, яка відрізняється тим, що місце розташування програвання для кожного з ряду монофонічних аудіопотоків незалежно визначається відносно егоцентричної системи відліку або алоцентричної системи відліку, при цьому егоцентрична система відліку визначається відносно слухача в середовищі програвання і при цьому алоцентрична система відліку визначається відносно однієї з характеристик середовища програвання.
12. Спосіб авторської розробки звукових сигналів для представлення даних включає:
прийняття ряду звукових сигналів звукової програми;
генерування адаптивного звукового мікса для звукової програми, що містить ряд монофонічних аудіопотоків і одного або декількох наборів метаданих, що пов'язані з кожним з ряду монофонічних аудіопотоків і що визначають місце розташування програвання відповідного монофонічного аудіопотоку, які включають перший набір метаданих та другий набір метаданих, пов'язані з одним або декількома з ряду монофонічних аудіопотоків, при цьому щонайменше один з ряду монофонічних аудіопотоків ідентифікується як звук на основі каналів та при цьому щонайменше один з інших з ряду монофонічних аудіопотоків ідентифікується як звук на основі об'єктів, і при цьому місце розташування програвання звуку на основі каналів містить позначення гучномовців для гучномовців у масиві гучномовців і місце розташування програвання звуку на основі об'єктів містить місце розташування в тривимірному просторі щодо середовища програвання, що містить масив гучномовців; і також при цьому перший набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для перших умов середовища програвання, а другий набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для других умов середовища програвання; та
розміщення ряду монофонічних аудіопотоків і одного або декількох наборів метаданих усередині бітового потоку для передачі в систему представлення даних, сконфігуровану для представлення ряду монофонічних аудіопотоків у ряд сигналів, що подаються на гучномовці, що відповідають гучномовцям у середовищі програвання, відповідно до щонайменше двох наборів метаданих на основі умов середовища програвання.
13. Спосіб за п. 12, який відрізняється тим, що кожний набір метаданих містить елементи метаданих, пов'язані з кожним потоком на основі об'єктів, при цьому елементи метаданих для кожного потоку на основі об'єктів описують просторові параметри, що управляють програванням відповідного звуку на основі об'єктів і містять один або декілька наступних параметрів: положення звуку, ширина звуку та швидкість звуку; і також при цьому кожний набір метаданих містить елементи метаданих, пов'язані з кожним потоком на основі каналів, і масив гучномовців містить гучномовці, розташовані в певній конфігурації оточуючого звуку, і при цьому елементи метаданих, пов'язані з кожним потоком на основі каналів, містять позначення каналів оточуючого звуку гучномовців у масиві гучномовців відповідно до певного стандарту оточуючого звуку.
14. Спосіб за п. 12, який відрізняється тим, що масив гучномовців містить додаткові гучномовці, призначені для програвання потоків на основі об'єктів і розташовані в середовищі програвання, при цьому спосіб також включає прийняття установчих команд від користувача на основі умов середовища програвання, і при цьому умови програвання залежать від змінних, що включають: розмір і форму приміщення середовища програвання, заповненість, склад матеріалів і оточуючий шум; установчі команди також містять щонайменше список позначень гучномовців і присвоювання каналів окремим гучномовцям у масив гучномовців, інформацію відносно групування гучномовців і присвоювання на основі відносного положення гучномовців у середовищі програвання.
15. Спосіб за п. 14, який відрізняється тим, що додатково включає:
прийняття з мікшерного пульта, що має елементи керування, що приводяться в дію користувачем для визначення рівнів програвання ряду монофонічних аудіопотоків, що містять оригінальний звуковий вміст; та
автоматичне генерування при прийнятті користувацького вводу елементів метаданих, пов'язаних з кожним відповідним потоком на основі об'єктів.
16. Спосіб представлення даних звукових сигналів, який включає:
прийняття бітового потоку, усередині якого розміщено ряд монофонічних аудіопотоків і один або декілька наборів метаданих у бітовому потоці з компонента авторської розробки, сконфігурованого для прийняття ряду звукових сигналів звукової програми і генерування для звукової програми ряду монофонічних аудіопотоків і одного або декількох наборів метаданих, що пов'язані з кожним з аудіопотоків і що визначають місце розташування програвання відповідного аудіопотоку, які включають перший набір метаданих та другий набір метаданих, пов'язані з одним або декількома з ряду монофонічних аудіопотоків, при цьому щонайменше один з ряду монофонічних аудіопотоків ідентифікується як звук на основі каналів та щонайменше один із інших з ряду монофонічних аудіопотоків ідентифікується як звук на основі об'єктів, і при цьому місце розташування програвання звуку на основі каналів містить позначення гучномовців для гучномовців у масиві гучномовців, а місце розташування програвання звуку на основі об'єктів містить місце розташування в тривимірному просторі щодо середовища програвання, що містить масив гучномовців; і також при цьому перший набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для перших умов середовища програвання, а другий набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для других умов середовища програвання; та
представлення ряду монофонічних аудіопотоків у ряд сигналів, що подаються на гучномовці, що відповідають гучномовцям у середовищі програвання, відповідно до щонайменше двох наборів метаданих на основі умов середовища програвання.
17. Система, призначена для обробки звукових сигналів, що містить компонент авторської розробки, сконфігурований для:
прийняття ряду звукових сигналів звукової програми;
генерування адаптивного звукового мікса для звукової програми, що містить ряд монофонічних аудіопотоків, і одного або декількох наборів метаданих, що пов'язані з кожним з ряду монофонічних аудіопотоків і що визначають місце розташування програвання відповідного монофонічного аудіопотоку, які включають перший набір метаданих та другий набір метаданих, пов'язані з одним або декількома з ряду монофонічних аудіопотоків, при цьому щонайменше один з ряду монофонічних аудіопотоків ідентифікується як звук на основі каналів та при цьому щонайменше один з інших з ряду монофонічних аудіопотоків ідентифікується як звук на основі об'єктів, і при цьому місце розташування програвання звуку на основі каналів містить позначення гучномовців для гучномовців у масиві гучномовців і місце розташування програвання звуку на основі об'єктів містить місце розташування в тривимірному просторі щодо середовища програвання, що містить масив гучномовців; і також при цьому перший набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для перших умов середовища програвання, а другий набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для других умов середовища програвання; та
розміщення ряду монофонічних аудіопотоків і щонайменше двох наборів метаданих усередині бітового потоку для передачі в систему представлення даних, сконфігуровану для представлення ряду монофонічних аудіопотоків у ряд сигналів, що подаються на гучномовці, що відповідають гучномовцям у середовищі програвання, відповідно до щонайменше двох наборів метаданих на основі умов середовища програвання.
18. Система, призначена для обробки звукових сигналів, що містить систему представлення даних, сконфігуровану для:
прийняття бітового потоку, усередині якого розміщено ряд монофонічних аудіопотоків і щонайменше два набори метаданих у бітовому потоці з компонента авторської розробки, сконфігурованого для прийняття ряду звукових сигналів звукової програми і генерування для звукової програми ряду монофонічних аудіопотоків і одного або декількох наборів метаданих, що пов'язані з кожним з аудіопотоків і що визначають місце розташування програвання відповідного аудіопотоку, які включають перший набір метаданих та другий набір метаданих, пов'язані з одним або декількома з ряду монофонічних аудіопотоків, при цьому щонайменше один з ряду монофонічних аудіопотоків ідентифікується як звук на основі каналів і при цьому щонайменше один з інших з ряду монофонічних аудіопотоків ідентифікується як звук на основі об'єктів, і при цьому місце розташування програвання звуку на основі каналів містить позначення гучномовців для гучномовців у масиві гучномовців, а місце розташування програвання звуку на основі об'єктів містить місце розташування в тривимірному просторі щодо середовища програвання, що містить масив гучномовців; і також при цьому перший набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для перших умов середовища програвання, а другий набір метаданих застосовують до одного або декількох з ряду монофонічних аудіопотоків для других умов середовища програвання; та
представлення ряду монофонічних аудіопотоків у ряд сигналів, що подаються на гучномовці, що відповідають гучномовцям у середовищі програвання, відповідно до щонайменше двох наборів метаданих на основі умов середовища програвання.
Текст
Реферат: Описано варіанти здійснення системи адаптивного звуку, яка обробляє аудіодані, що містять деяку кількість незалежних монофонічних аудіопотоків. З одним або декількома з потоків були зв'язані метадані, які описують, чи є зазначений потік потоком на основі каналів або потоком на основі об'єктів. Потоки на основі каналів містять інформацію представлення даних, кодовану за допомогою назви каналу; а потоки на основі об'єктів містять інформацію місця розташування, кодовану через вираження місця розташування, закодовані у зв'язаних метаданих. Кодек упаковує незалежні аудіопотоки в єдину двійкову послідовність, яка містить усі аудіодані. Така конфігурація дозволяє представляти дані звуку відповідно до алоцентричної системи відліку, у якій, для відповідності задуму оператора мікшування, місце розташування представлення даних звуку ґрунтується на характеристиках середовища програвання (наприклад, на розмірі приміщення, його формі тощо). Метадані положення об'єктів містять відповідну інформацію алоцентричної системи відліку, необхідну для вірного програвання звуку з використанням положень доступних гучномовців у приміщенні, яке пристосовано для програвання адаптивного звукового вмісту. UA 114793 C2 (12) UA 114793 C2 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 ПЕРЕХРЕСНЕ ПОСИЛАННЯ НА СПОРІДНЕНІ ЗАЯВКИ [0001] Дана заявка заявляє пріоритет попередньої заявки на патент США № 61/504005, поданої 1 липня 2011 р., та попередньої заявки на патент США № 61/636429, поданої 20 квітня 2012 р.; обидві ці заявки посиланням включаються в дане розкриття повністю у всіх відносинах. ОБЛАСТЬ ТЕХНІЧНОГО ЗАСТОСУВАННЯ [0002] Одна або кілька реалізацій, в цілому, відносяться до обробки звукових сигналів та, конкретніше, до гібридної обробки звуку на основі об'єктів та каналів для використання в кінематографічних, домашніх та інших середовищах. ПЕРЕДУМОВИ [0003] Не слід вважати, що предмет винаходу, обговорюваний у розділі передумов, являє собою відомий рівень техніки єдино в результаті його згадування в розділі передумов. Аналогічно, не слід вважати, що проблема, що згадується в розділі передумов або пов'язана із предметом винаходу в розділі передумов, є визнаною на відомому рівні техніки. Предмет винаходу в розділі передумов лише представляє різні підходи, які самі по собі також можуть являти собою винаходи. [0004] З моменту введення звуку у фільми відбувався сталий розвиток технології, призначеної для фіксації художнього задуму творця звукової доріжки кінокартини та для його точного відтворення в середовищі кінотеатру. Основна роль звуку в кінематографії полягає в сприянні сюжету на екрані. Типові звукові доріжки для кінематографії містять безліч різних звукових елементів, що відповідають елементам і зображенням на екрані, діалогам, шумам та звуковим ефектам, які виходять від різних елементів на екрані та сполучаються з музичним фоном і ефектами навколишнього середовища, створюючи загальне враження від перегляду. Художній задум творців і продюсерів відображає їхнє бажання відтворювати зазначені звуки таким чином, який як можна точніше відповідає тому, що демонструється на екрані, в тому, що стосується положення, інтенсивності, переміщення та інших аналогічних параметрів джерел звуку. [0005] Сучасна авторська розробка, поширення та програвання кінофільмів страждає від обмежень, які стримують створення по-справжньому життєвого звуку, що створює ефект присутності. Традиційні аудіосистеми на основі каналів передають звуковий вміст у формі сигналів, що подаються на гучномовці, для окремих гучномовців у такому середовищі програвання, як стереофонічна система або система 5.1. Впровадження цифрової кінематографії створило такі нові стандарти звуку у фільмах, як об'єднання до 16 звукових каналів, що дозволяє збільшувати творчі можливості творців вмісту, а також більше охоплення та реалістичність вражень від прослуховування для глядачів. Введення оточуючих систем 7.1 забезпечило новий формат, який збільшує кількість оточуючих каналів шляхом розбивки існуючого лівого та правого оточуючих каналів на чотири зони, що, таким чином, розширює межі можливостей операторів обробки та синтезу звуку та операторів мікшування при керуванні місцями розташування звукових елементів у кінотеатрі. [0006] Для подальшого поліпшення користувацького сприйняття, програвання звуку у віртуальних тривимірних середовищах стало областю посилених проектно-конструкторських розробок. Представлення звуку в просторі використовує звукові об'єкти, які являютьсобою звукові сигнали зі зв'язаними параметричними описами джерел для положень гаданого джерела (наприклад, тривимірних координат), ширини гаданого джерела та інших параметрів. Звук на основі об'єктів в усе зростаючій мірі використовується для багатьох сучасних мультимедійних застосувань, таких як цифрові кінофільми, відеоігри, симулятори та тривимірне відео. [0007] Вирішальним є вихід за межі традиційних сигналів, що подаються на гучномовці, і звуку на основі каналів як засобів поширення звуку в просторі, і існує значний інтерес до опису звуку на основі моделей, яке є багатообіцяючим для того, щоб давати слухачеві/кінопрокатникові свободу вибору конфігурації програвання, яка відповідає їхнім індивідуальним потребам або бюджету, зі звуком, дані якого представляються спеціально для обраної ними конфігурації. На високому рівні в цей час існує чотири основні формати просторового опису звуку: сигнали, що подаються на гучномовці, де звук описується як сигнали, призначені для гучномовців у номінальних положеннях гучномовців; сигнал, що подається на мікрофон, де звук описується як сигнали, захоплювані віртуальними або фактичними мікрофонами в попередньо обумовленому масиві; опис на основі моделей, у якому звук описується в термінах послідовності звукових подій в описуваних положеннях; і бінауральний, у якому звук описується сигналами, які досягають вух користувача. Ці чотири формати опису часто пов'язані з однієї або декількома технологіями представлення даних, які перетворюють звукові сигнали в сигнали, що подаються на гучномовці. Сучасні технології представлення 1 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 даних включають панорамування, при якому аудіопотік перетворюється в сигнали, що подаються на гучномовці, з використанням набору законів панорамування та відомих, або передбачуваних, положень гучномовців (як правило, представлення даних відбувається перед поширенням); амбіфонію, при якій сигнали мікрофонів перетворюються в подавані сигнали для масштабованого масиву гучномовців (як правило, представлення даних відбувається після поширення); WFS (синтез хвильового поля), при якому звукові події перетворюються в відповідні сигнали гучномовців для синтезу звукового поля (як правило, представлення даних відбувається після поширення); і бінауральну технологію, у якій бінауральні сигнали L/R (лівий/правий) доставляються у вуха L/R, як правило, з використанням навушників, але також з використанням гучномовців та придушення перехресних перешкод (представлення даних відбувається до або після поширення). Серед цих форматів найбільш загальним є формат подачі сигналів на гучномовці, оскільки він є простим і ефективним. Найкращі акустичні результати (найбільш точні, найбільш достовірні) досягаються шляхом мікшування/поточного контролю та поширення безпосередньо в сигнали, що подаються на гучномовці, оскільки між творцем вмісту та слухачем обробка відсутня. Якщо система, що програє, відома заздалегідь, опис сигналів, що подаються на гучномовці, звичайно забезпечує найвищу точність відтворення. Однак в багатьох застосуваннях на практиці система, що програє, невідома. Найбільш адаптованим вважається опис на основі моделей, оскільки він не робить припущень про технологію представлення даних, і тому він легше всього застосовується для будь-якої технології представлення даних. Незважаючи на те, що опис на основі моделей ефективно збирає просторову інформацію, він стає надзвичайно неефективним у міру збільшення кількості джерел звуку. [0008] Протягом багатьох років системи для кінематографії характеризувалися дискретними екранними каналами у формі лівого, центрального, правого та, іноді, "внутрішнього лівого" і "внутрішнього правого" каналів. Ці дискретні джерела звичайно мають достатню амплітудночастотну характеристику та потужність, що комутується, для того, щоб дозволяти точно розміщати звуки в різних областях екрана та допускати тембральне узгодження в міру того, як звуки переміщаються, або панорамуються, між місцями розташування. Сучасні розробки з посилення сприйняття слухача прагнуть до точного відтворення місця розташування звуків щодо слухача. В установці 5.1 оточуючі "зони" включають масив гучномовців, всі з яких несуть однакову звукову інформацію в межах кожної, лівої оточуючої або правої оточуючої зони. Зазначені масиви можуть бути ефективні для ефектів "навколишнього середовища" і розсіяного оточуючого звуку, однак у повсякденному житті багато звукових ефектів виникають із випадково розміщених точкових джерел. Наприклад, у ресторані здається, що оточуюча музика відіграє з усіх боків, у той час як з певних точок виникають дискретні звуки: розмова людини – з однієї точки, стукіт ножа по тарілці – з іншої. Наявність можливості дискретного розміщення цих звуків навколо залу для глядачів може створювати посилене відчуття реальності, не будучи при цьому занадто помітним. Також важливої складової чіткості оточуючого звуку є звуки зверху. У реальному світі звуки приходять із усіх напрямків, і не завжди – з єдиної горизонтальної площини. Додаткове почуття реальності може досягатися, якщо звуки можуть чутися зверху, іншими словами з "верхньої півсфери". Сучасні системи, однак, не пропонують по-справжньому точного відтворення звуку для різних типів звуку для ряду різних середовищ програвання. Буде потрібно ще чимало зробити в області обробки, знання та конфігурації фактичних середовищ програвання, щоб, використовуючи існуючі системи, спробувати точно відтворювати місце розташування певних звуків і, таким чином, зробити сучасні системи непридатними до вживання для більшості застосувань. [0009] Те, що є необхідним, являє собою систему, яка підтримує кілька екранних каналів, що в результаті приводить до підвищеної чіткості та поліпшеної аудіовізуальної когерентності для звуків або діалогу на екрані та до можливості точно розташовувати джерела де завгодно в оточуючих зонах, поліпшуючи аудіовізуальний перехід від екрана в приміщення. Наприклад, якщо герой на екрані дивиться усередину приміщення в напрямку джерела звуку, звукоінженер ("оператор мікшування") повинен мати можливість точно розміщати звук так, щоб він збігався з лінією погляду героя, і щоб цей ефект був однаковим для всіх глядачів. Однак при традиційному мікшуванні оточуючого звуку 5.1 або 7.1 ефект сильно залежить від положення посадкового місця слухача, що є несприятливим для більшості великих середовищ прослуховування. Підвищена роздільність оточуючого звуку створює нові можливості для використання звуку центрованим у приміщенні чином, на відміну від традиційного підходу, де вміст створюється в припущенні єдиного слухача в "зоні найкращого сприйняття". [0010] Крім просторових проблем, багатоканальні системи на сучасному рівні техніки страждають відносно тембру. Наприклад, при відтворенні масивом гучномовців може страждати 2 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 тембральна якість деяких звуків, таких як шипіння пари, що виходить із ушкодженої труби. Здатність направляти певні звуки в єдиний гучномовець дає операторові мікшування можливість усувати викривлення при відтворенні масивом і домагатися більш реалістичного сприйняття глядачами. Традиційно, оточуючі гучномовці не підтримують настільки ж повний діапазон звукових частот і рівень, які підтримують більші екранні канали. У минулому це створювало труднощі для операторів мікшування, зменшуючи їх можливості вільно переміщати широкосмугові звуки від екрана в приміщення. У результаті, власники кінотеатрів не відчували необхідності в модернізації конфігурації оточуючих каналів, що перешкоджало широкому впровадженню більш високоякісних установок. КОРОТКИЙ ОПИС ВАРІАНТІВ ЗДІЙСНЕННЯ ВИНАХОДУ [0011] Системи та способи описуються для формату звуку для кінематографії та системи обробки даних, яка включає новий шар гучномовців (конфігурацію каналів) і зв'язаний формат просторового опису. Визначена система адаптивного звуку та формат, який підтримує кілька технологій представлення даних. Аудіопотоки передаються поряд з метаданими, які описують "задум оператора мікшування", що включає необхідне положення аудіопотоку. Зазначене положення може бути виражене як названий канал (з каналів у межах попередньо визначеної конфігурації каналів) або як інформація про тривимірне положення. Такий формат – канали плюс об'єкти - поєднує оптимальні способи опису звукової картини на основі каналів і на основі моделей. Аудіодані для системи адаптивного звуку містять деяку кількість незалежних монофонічних аудіопотоків. Кожний потік має пов'язані з ним метадані, які описують, буде потік являти собою потік на основі каналів або потік на основі об'єктів. Потоки на основі каналів містять інформацію представлення даних, кодовану за допомогою назви каналу; а потоки на основі об'єктів містять інформацію місця розташування, кодовану через математичні вираження, кодовані в додаткових зв'язаних метаданих. Оригінальні незалежні аудіопотоки упаковуються як єдина двійкова послідовність, яка містить усі аудіодані. Дана конфігурація дозволяє представляти звук відповідно до алоцентричної системи відліку, у якій представлення даних місця розташування звуку ґрунтується на характеристиках середовища програвання (наприклад, на розмірі приміщення, його формі, тощо) для відповідності задуму оператора мікшування. Метадані положення об'єкта містять відповідну інформацію алоцентричної системи координат, необхідну для правильного програвання звуку з використанням положень доступних гучномовців у приміщенні, яке підготовлено для програвання адаптивного звукового вмісту. Це дозволяє оптимально мікшувати звук для певного середовища програвання, яке може відрізнятися від середовища мікшування, яке випробовує звукоінженер. [0012] Система адаптивного звуку підвищує якість звуку в різних приміщеннях за допомогою таких переваг, як удосконалене керування корекцією амплітудно-частотної характеристики в приміщенні та оточуючими басами для того, щоб оператор мікшування міг вільно звертатися до гучномовців (як таких, що перебувають на екрані, так і тих, що перебувають поза екраном) без необхідності думати про тембральне узгодженні. Система адаптивного звуку додає в традиційні послідовності операцій на основі каналів гнучкість і можливості динамічних звукових об'єктів. Зазначені звукові об'єкти дозволяють творцям контролювати дискретні звукові елементи незалежно від конкретних конфігурацій гучномовців, що програють, у тому числі верхніх гучномовців. Система також вносить нову ефективність у процес компонування, дозволяючи звукоінженерам ефективно фіксувати всі їх задуми, а потім, у ході поточного контролю в реальному часі або автоматично, генерувати версії оточуючого звуку 7.1 або 5.1. [0013] Система адаптивного звуку спрощує поширення, виділяючи звукову сутність художнього задуму в єдиний файл доріжки в пристрої обробки даних для цифрової кінематографії, який може точно програватися в широкому діапазоні конфігурацій кінотеатрів. Система забезпечує оптимальне відтворення художнього задуму, коли засоби мікшування та представлення даних використовують однакову конфігурацію каналів і єдиний інвентар зі спадною адаптацією до конфігурації представлення даних, тобто з понижувальним мікшуванням. [0014] Ці та інші переваги представлені через варіанти здійснення винаходу, які спрямовані на звукову платформу для кінематографії, звертаючись до обмежень сучасних систем, і доставляють враження від звуку, який перебуває за межами досяжності систем, доступних сьогодні. КОРОТКИЙ ОПИС ГРАФІЧНИХ МАТЕРІАЛІВ [0015] У нижченаведених графічних матеріалах подібні посилальні позиції використовуються для посилання на подібні елементи. Незважаючи на те, що наступні фігури зображують різні приклади, одна або кілька реалізацій не обмежуються прикладами, зображеними на зазначених фігурах. 3 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 [0016] ФІГ. 1 являє собою загальний вид зверху середовища створення та програвання звуку, що використовує систему адаптивного звуку відповідно до одного з варіантів здійснення винаходу. [0017] ФІГ. 2 ілюструє об'єднання даних на основі каналів і на основі об'єктів з метою генерування адаптивного звукового мікса відповідно до одного з варіантів здійснення винаходу. [0018] ФІГ. 3 являє собою блок-схему, що ілюструє послідовність операцій створення, упакування та представлення даних адаптивного звукового вмісту відповідно до одного з варіантів здійснення винаходу. [0019] ФІГ. 4 являє собою блок-схему етапу представлення даних системи адаптивного звуку відповідно до одного з варіантів здійснення винаходу. [0020] ФІГ. 5 являє собою таблицю, у якій перелічуються типи метаданих і зв'язані елементи метаданих для системи адаптивного звуку відповідно до одного з варіантів здійснення винаходу. [0021] ФІГ. 6 являє собою схему, яка ілюструє компонування та остаточну обробку для системи адаптивного звуку відповідно до одного з варіантів здійснення винаходу. [0022] ФІГ. 7 являє собою схему одного із прикладів послідовності операцій процесу упакування цифрового кінофільму з використанням файлів адаптивного звуку відповідно до одного з варіантів здійснення винаходу. [0023] ФІГ. 8 являє собою вид зверху одного із прикладів схеми розташування передбачуваних місць розташування гучномовців для їхнього використання із системою адаптивного звуку в типовому залі для глядачів. [0024] ФІГ. 9 являє собою вид спереду одного із прикладів розміщення передбачуваних місць розташування гучномовців на екрані для використання в типовому залі дляглядачів. [0025] ФІГ. 10 являє собою вид збоку одного із прикладів схеми розташування передбачуваних місць розташування гучномовців для їхнього використання із системою адаптивного звуку в типовому залі для глядачів. [0026] ФІГ. 11 являє собою один із прикладів розташування верхніх оточуючих гучномовців і бічних оточуючих гучномовців відносно початку відліку відповідно до одного з варіантів здійснення винаходу. ДОКЛАДНИЙ ОПИС [0027] Описуються системи та способи для системи адаптивного звуку та зв'язаного звукового сигналу та формату даних, які підтримують кілька технологій представлення даних. Особливості для одного або декількох варіантів здійснення винаходу, описувані в даному розкритті, можуть реалізовуватися в аудіосистемі або аудіовізуальній системі, яка обробляє вихідну звукову інформацію в системі мікшування, представлення даних і програвання, яка містить один або кілька комп'ютерів або пристроїв обробки даних, що виконують команди програмного забезпечення. Кожний з описуваних варіантів здійснення винаходу може використовуватися сам по собі або разом з якими-небудь іншими варіантами в будь-якій комбінації. Незважаючи на те, що різні варіанти здійснення винаходу могли бути мотивовані різними недоліками на відомому рівні техніки, які можуть обговорюватися або згадуватися в одному або декількох місцях у даному описі, варіанти здійснення винаходу необов'язково звертаються до якого-небудь із цих недоліків. Іншими словами, різні варіанти здійснення винаходу можуть звертатися до різних недоліків, які можуть обговорюватися в даному описі. Деякі варіанти здійснення винаходу можуть лише частково звертатися до деяких недоліків або тільки до одному недоліку, описуваному в даному описі, а деякі варіанти здійснення винаходу можуть не звертатися до жодного із цих недоліків. [0028] Для цілей даного опису, нижченаведені терміни мають наступні зв'язані значення: [0029] Канал, або звуковий канал: монофонічний звуковий сигнал, або аудіопотік, плюс метадані, у яких положення закодоване як ідентифікатор каналу, наприклад "лівий передній" або "правий верхній оточуючий". Канальний об'єкт може управляти декількома гучномовцями, наприклад, ліві оточуючі канали (Ls) будуть подаватися на гучномовці масиву Ls. [0030] Конфігурація каналів: попередньо визначений набір зон гучномовців зі зв'язаними номінальними місцями розташування, наприклад, 5.1, 7.1 тощо; 5.1 відноситься до шестиканальної аудіосистемі оточуючого звуку, що містить передні лівий і правий канали, центральний канал, два оточуючі канали та наднизькочастотний канал; 7.1 відноситься до восьмиканальної системи оточуючого звуку, у якій до системи 5.1 додано два додаткові оточуючі канали. Приклади конфігурацій 5.1 і 7.1 включають системи Dolby® surround. [0031] Гучномовець: перетворювач звуку або набір перетворювачів, які представляють дані звукового сигналу. 4 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 [0032] Зона гучномовців: масив з одного або декількох гучномовців, які можуть бути однозначно віднесені і які приймають єдиний, наприклад лівий оточуючий, звуковий сигнал, звичайно перебувають у кінотеатрі й, зокрема, призначені для виключення або включення у представлення даних об'єкта. [0033] Канал гучномовця, або канал сигналу, що подається на гучномовець: звуковий канал, який пов'язаний з названим гучномовцем, або зоною гучномовців, у межах певної конфігурації гучномовців. Канал гучномовця звичайно представляється з використанням зв'язаної зони гучномовців. [0034] Група каналів гучномовців: набір з одного або декількох каналів гучномовців, що відповідають конфігурації каналів (наприклад, зі стереодоріжками, монодоріжками, тощо). [0035] Об'єкт, або канал об'єкта: один або кілька звукових каналів з таким параметричним описом джерела, як положення гаданого джерела (наприклад, тривимірні координати), ширина гаданого джерела, тощо Аудіопотік плюс метадані, у яких положення закодоване як тривимірне положення в просторі. [0036] Звукова програма: повний набір каналів гучномовців та/або об'єктних каналів і зв'язаних метаданих, які описують необхідне представлення звуку в просторі. [0037] Алоцентрична система відліку: просторова система відліку, у якій звукові об'єкти визначаються в межах середовища представлення даних щодо таких ознак, як стіни та кути приміщення, стандартні місця розташування гучномовців і місце розташування екрана (наприклад, передній лівий кут приміщення). [0038] Егоцентрична система відліку: просторова система відліку, у якій об'єкти визначаються щодо перспективи (глядачів) слухача, і яка часто визначається щодо кутів стосовно слухача (наприклад, 30 градусів праворуч від слухача). [0039] Кадр: кадри являють собою короткі сегменти, що декодуються незалежно, на які розділяється повна звукова програма. Розмір та границі аудіокадрів звичайно вирівняні з відеокадрами. [0040] Адаптивний звук: звукові сигнали на основі каналів та/або на основі об'єктів плюс метадані, які представляють дані звукових сигналів на основі середовища програвання. [0041] Описуваний у даному розкритті формат звуку для кінематографії та система обробки даних, також іменована "системою адаптивного звуку", використовують нову технологію опису та представлення просторових даних звуку, що дозволяє підсилювати ефект присутності в глядачів, підвищувати художній контроль, гнучкість і масштабованість системи та простоту установки та обслуговування. Варіанти здійснення звукової платформи для кінематографії включають кілька дискретних компонентів, у тому числі інструментальні засоби мікшування, пристрій упакування/кодер, пристрій розпакування/декодер, компоненти остаточного мікшування та представлення даних у кінотеатрі, нові схеми гучномовців та об'єднані в мережу підсилювачі. Система включає рекомендації для нової конфігурації каналів, що підлягає використанню творцями та кінопрокатниками. Система використовує опис на основі моделей, яке підтримує кілька таких характерних ознак, як: єдиний інвентар зі спадною та висхідною адаптацією до конфігурації представлення даних, тобто відстрочене представлення даних і забезпечення можливості оптимального використання доступних гучномовців; поліпшений охват звуку, включення оптимізованого понижувального мікшування, щоб уникнути кореляції між каналами; підвищена просторова роздільність через наскрізне керування масивами (наприклад, звуковий об'єкт динамічно приписується до одного або декількох гучномовців у межах масиву оточуючого звуку); і підтримка альтернативних способів представлення даних. [0042] ФІГ. 1 являє собою загальний вид зверху середовища створення та програвання звуку, що використовує систему адаптивного звуку, відповідно до одного з варіантів здійснення винаходу. Як показано на ФІГ. 1, повне, безперервне середовище 100 містить компоненти створення вмісту, упакування, поширення та/або програвання/представлення даних у велику кількість кінцевих пристроїв і варіантів використання. Система 100 у цілому веде свій початок від вмісту, захопленого з і для деякої кількості різних варіантів використання, які включають сприйняття 112 глядачами. Елемент 102 захвата даних вмісту включає, наприклад, кінематографію, телебачення, пряму трансляцію, вміст, що генерується користувачем, записаний вміст, ігри, музику, тощо і може включати звуковий/візуальний або чисто звуковий вміст. Вміст у міру просування через систему 100 від етапу 102 захвата даних до сприйняття 112 кінцевими користувачами проходить кілька ключових етапів обробки через дискретні компоненти системи. Зазначені етапи процесу включають попередню обробку звуку 104, інструментальні засоби та процеси 106 авторської розробки, кодування аудіокодеком 108, який веде збір, наприклад, аудіоданих, додаткових метаданих і інформації відтворення, і об'єктні канали. Для успішного та захищеного поширення за допомогою різних носіїв до об'єктних 5 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 каналів можуть застосовуватися такі різноманітні впливи обробки, як стиск (із втратами або без втрат), шифрування, тощо Для відтворення та передачі певного сприйняття 112 користувачем адаптивного звуку потім застосовуються відповідні специфічні для кінцевих точок процеси 110 декодування та представлення даних. Сприйняття 112 звуку представляє програвання звукового або аудіовізуального вмісту через відповідні гучномовці та пристрої, що програють, і може представляти будь-яке середовище, у якому слухач зазнає відтворення захопленого вмісту, таке як кінотеатр, концертний зал, відкритий кінотеатр, будинок або приміщення, кабінка для прослуховування, автомобіль, ігрова приставка, навушники або гарнітура, система оповіщення або інше середовище, що програє. [0043] Даний варіант здійснення системи 100 включає аудіокодек 108, який здатний ефективно поширювати та зберігати в пам'яті багатоканальні звукові програми, і тому може йменуватися як "гібридний" кодек. Кодек 108 поєднує традиційні аудіодані на основі каналів зі зв'язаними метаданими, утворюючи звукові об'єкти, які полегшують створення та доставку звуку, який є адаптованим і оптимізованим для представлення даних і програвання в середовищах, які, можливо, відрізняються від середовища мікшування. Це дозволяє звукоінженеру кодувати його або її задум у тому, як кінцевий звук повинен чутися слухачем, на основі фактичного середовища прослуховування слухачем. [0044] Традиційні аудіокодеки на основі каналів діють у припущенні, що звукова програма буде відтворюватися масивом гучномовців, що перебувають у попередньо визначених положеннях щодо слухача. Для створення повної багатоканальної звукової програми, звукоінженери звичайно мікшують велику кількість окремих аудіопотоків (наприклад, діалог, музику, ефекти) з метою створення необхідного загального сприйняття. При мікшуванні звуку рішення звичайно приймаються шляхом прослуховування звукової програми, відтвореної масивом гучномовців, що перебувають у попередньо визначених положеннях, наприклад, зокрема, у системі 5.1 або 7.1 у певному кінотеатрі. Кінцевий, мікшований сигнал служить уведенням в аудіокодек. Просторово точні звукові поля досягаються при відтворенні тільки тоді, коли гучномовці розміщаються в попередньо визначених положеннях. [0045] Одна з нових форм кодування звуку, що зветься кодуванням звукових об'єктів, передбачає в якості введення в кодер окремі джерела звуку (звукові об'єкти) у формі окремих аудіопотоків. Приклади звукових об'єктів включають діалогові доріжки, окремі інструменти, окремі звукові ефекти та інші точкові джерела. Кожний звуковий об'єкт пов'язаний із просторовими параметрами, які можуть включати в якості необмежуючих прикладів положення звуку, ширину звуку та інформацію швидкості. Для поширення та зберігання звукові об'єкти та зв'язані параметри потім кодуються. Остаточне мікшування та представлення даних звукового об'єкта виконується на стороні прийняття в ланцюзі поширення звуку як частина програвання звукової програми. Цей етап може ґрунтуватися на відомостях про фактичні положення гучномовців, тому результатом є система поширення звуку, яка є такою, що настроюється відповідно до умов прослуховування конкретним користувачем. Дві зазначені форми кодування, на основі каналів і на основі об'єктів, оптимально діють для різних умов вхідного сигналу. Аудіокодери на основі каналів звичайно більш ефективні для кодування вхідних сигналів, що містять щільні суміші різних джерел звуку, а також для розсіяних звуків. Кодери звукових об'єктів, навпаки, більш ефективні для кодування невеликої кількості високоспрямованих джерел звуку. [0046] У одному з варіантів здійснення винаходу, способи та компоненти системи 100 включають систему кодування, поширення та декодування звуку, сконфігуровану для генерування одного або декількох бітових потоків, що містять як традиційні звукові елементи на основі каналів, так і елементи кодування звукових об'єктів. Такий комбінований підхід забезпечує більшу ефективність кодування та гнучкість представлення даних у порівнянні з узятими окремо підходами на основі каналів і на основі об'єктів. [0047] Інші особливості описуваних варіантів здійснення винаходу включають розширення назад сумісно попередньо визначеного аудіокодека на основі каналів для включення елементів кодування звукових об'єктів. Новий "шар розширення", що містить елементи кодування звукових об'єктів, визначається та додається до "основного", або "зворотно сумісного", шару бітового потоку аудіокодека на основі каналів. Такий підхід дозволяє успадкованим декодерам обробляти один або кілька бітових потоків, які містять шар розширення, і, у той же час, забезпечує поліпшене враження від прослуховування для користувачів з новими декодерами. Один із прикладів посилення користувацького сприйняття включає керування представленням даних звукового об'єкта. Додатковою перевагою цього підходу є те, що звукові об'єкти можуть додаватися або модифікуватися всюди по ланцюжку поширення без 6 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 декодування/мікшування/повторного кодування багатоканального звуку, кодованого аудіокодеком на основі каналів. [0048] Відносно системи координат, просторові ефекти звукових сигналів є вирішальними при забезпеченні для слухача враження ефекту присутності. Звуки, які маються на увазі як вихідні з певної області глядацького екрана або приміщення повинні відтворюватися через гучномовець (гучномовці), розташований у тому ж самому відносному місці розташування. Тому первинним елементом метаданих звуку для звукової події в описі на основі моделей є положення, хоча можуть також описуватися і такі інші параметри, як розмір, орієнтація, швидкість і дисперсія звуку. Для передачі положення тривимірний просторовий опис звуку на основі моделей вимагає тривимірної системи координат. Система координат, що використовується для передачі (евклідова, сферична, тощо), звичайно вибирається для зручності або компактності, однак для обробки представлення даних можуть використовуватися й інші системи координат. Окрім системи координат для представлення місць розташування об'єктів у просторі потрібна система відліку. Вибір належної системи відліку може бути вирішальним фактором точного відтворення звуку системами на основі положення в безлічі різних середовищ. У алоцентричній системі відліку положення джерела звуку визначається щодо таких ознак у межах середовища представлення даних, як стіни та кути приміщення, стандартні місця розташування гучномовців і місце розташування екрана. У егоцентричній системі відліку місця розташування представляються щодо перспективи слухача, як, наприклад, "переді мною, трохи вліво", тощо. Наукові дослідження просторового сприйняття (звуку та ін.) показали, що найбільш універсальним є використання егоцентричної перспективи. Однак для кінематографа з ряду причин більш підходящою є алоцентрична система. Наприклад, точне місце розташування звукового об'єкта є більш важливим, коли зв'язаний об'єкт перебуває на екрані. При використанні алоцентричної системи відліку для кожного положення прослуховування та для екрана будь-якого розміру звук буде локалізовуватися в тому самому положенні на екрані, наприклад на третину більш вліво середини екрана. Іншою причиною є те, що оператори мікшування схильні міркувати та мікшувати в алоцентричному вирахуванні, і засоби панорамування компонуються в алоцентричній системі відліку (стіни приміщення), і оператори мікшування очікують, що представлятися ці засоби будуть саме таким чином, наприклад "цей звук повинен перебувати на екрані", "цей звук повинен перебувати за екраном" або "від лівої стіни", тощо [0049] Незважаючи на використання алоцентричної системи відліку в середовищі для кінематографії, існують деякі випадки, для яких може бути корисна егоцентрична система відліку. Ці випадки включають закадрові звуки, тобто звуки, які не присутні в "просторі фільму", наприклад музичний супровід, для якого може вимагатися однорідне егоцентричне представлення. Інший випадок – ефекти в близькій зоні (наприклад, дзижчання комара в лівому вусі слухача), які вимагають егоцентричного представлення. На сьогоднішній день не існує засобів для представлення даних такого близького звукового поля з використанням навушників або гучномовців близької зони. Крім того, нескінченно віддалені джерела звуку (і результуючі плоскі хвилі) здаються такими, що надходять з постійного егоцентричного положення (наприклад, 30 градусів ліворуч), і такі звуки легше описати в егоцентричному вирахуванні, а не в алоцентричному. [0050] У деяких випадках можна використовувати алоцентричну систему відліку доти, доки є визначеним номінальне положення прослуховування, незважаючи на те, що деякі приклади вимагають егоцентричного представлення, дані якого дотепер неможливо представити. І хоча алоцентрична система відліку може бути більш корисною та підходящою, представлення звуку повинно бути розширюваним, оскільки багато нових особливостей, у тому числі й егоцентричне представлення, можуть виявитися більш бажаними в деяких застосуваннях і середовищах прослуховування. Варіанти здійснення системи адаптованого звуку включають гібридний підхід до просторового опису, який включає рекомендовану конфігурацію каналів для оптимальної точності відтворення та для представлення даних розсіяних або складних, багатоточкових джерел (наприклад, юрба на стадіоні, навколишнє середовище) з використанням егоцентричної системи відліку плюс алоцентричний опис звуку на основі моделей – для того, щоб допускалися висока просторова роздільність та масштабованість. Компоненти системи [0051] З посиланням на ФІГ. 1, оригінальні дані 102 звукового вмісту, у першу чергу, обробляються в блоці 104 попередньої обробки. Блок 104 попередньої обробки системи 100 містить компонент фільтрації об'єктних каналів. У багатьох випадках, звукові об'єкти містять окремі джерела звуку, що дозволяють панорамувати звуки незалежно. У деяких випадках, як, наприклад, при створенні звукових програм з використанням природного або "виробничого" 7 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 звуку, може виявитися необхідним отримання окремих звукових об'єктів із запису, який містить кілька джерел звуку. Варіанти здійснення винаходу включають спосіб виділення незалежних звукових сигналів з більш складного сигналу. Небажані елементи, що підлягають відділенню від незалежних сигналів джерел, можуть включати в якості необмежуючих прикладів інші незалежні джерела звуку та фоновий шум. Крім того, для відтворення "сухих" джерел звуку може усуватися реверберація. [0052] Пристрій 104 попередньої обробки даних також включає функціональну можливість поділу джерел і виявлення типу вмісту. Система передбачає автоматичне генерування метаданих шляхом аналізу вхідного звуку. Позиційні метадані виходять із багатоканального запису шляхом аналізу відносних рівнів корельованого вхідного сигналу між парами каналів. Виявлення типу вмісту, такого як "мова" або "музика", може виконуватися, наприклад, шляхом отримання та класифікації характерних ознак. Інструментальні засоби авторської розробки [0053] Блок 106 інструментальних засобів авторської розробки включає характерні ознаки, призначені для вдосконалення авторської розробки звукових програм шляхом оптимізації введення та кодифікації творчого задуму звукоінженера, дозволяючи йому створювати кінцевий звуковий мікс, як тільки вона буде оптимізована для програвання практично в будь-якому середовищі програвання. Це виконується шляхом використання звукових об'єктів і позиційних даних, які зв'язуються та кодуються разом з оригінальним звуковим вмістом. Для того, щоб точно розмістити звуки по периметру залу для глядачів, звукоінженеру необхідно мати контроль над тим, як звук буде в остаточному підсумку представлятися на основі фактичних обмежень і характерних ознак середовища програвання. Система адаптивного звуку передбачає такий контроль, дозволяючи звукоінженеру змінювати те, яким чином звуковий вміст розробляється та мікшується шляхом використання звукових об'єктів і позиційних даних. [0054] Звукові об'єкти можна вважати групами звукових елементів, які можуть сприйматися як вихідні з певного фізичного місця розташування, або місць розташування, у залі для глядачів. Такі об'єкти можуть бути нерухомими, або вони можуть переміщатися. У системі 100 адаптивного звуку звукові об'єкти управляються метаданими, які, серед іншого, докладно описують місце розташування звуку в цей момент часу. Коли об'єкти піддаються поточному контролю, або програються в кінотеатрі, їх дані представляються згідно з позиційними метаданими з використанням гучномовців, які є в наявності, замість обов'язкового виводу у фізичний канал. Доріжка в сесії може являти собою звуковий об'єкт, а стандартні дані панорамування можуть бути аналогічні позиційним метаданим. Таким чином, вміст, що розташовується на екрані, може ефективно панорамуватися точно так само, як у випадку вмісту на основі каналів, однак дані вмісту, розташовуваного в навколишніх каналах, можуть при бажанні представлятися в окремий канал. Незважаючи на те, що використання звукових об'єктів забезпечує необхідний контроль над дискретними ефектами, інші особливості звукової доріжки кінофільму ефективніше працюють у середовищі на основі каналів. Наприклад, багато ефектів навколишнього середовища або реверберація фактично виграють від подачі в масиви гучномовців. І хоча вони можуть оброблятися як об'єкти із шириною, достатньою для заповнення масиву, більш корисним є збереження деяких функціональних можливостей на основі каналів. [0055] У одному з варіантів здійснення винаходу система адаптивного звуку на додаток до звукових об'єктів підтримує "тракти", де тракти являють собою ефективно субмікшовані сигнали на основі каналів, або стемів. Залежно від задуму творця вмісту вони можуть виходити для кінцевого програвання (представлення даних) або окремо, або об'єднаними в єдиний тракт. Зазначені тракти можуть створюватися в таких різних конфігураціях на основі каналів, як 5.1, 7.1, і являються розповсюджуваними на такі більш великі формати, як 9.1 і масиви, що включають верхні гучномовці. [0056] ФІГ. 2 ілюструє комбінацію даних на основі каналів і об'єктів при генеруванні адаптивного звукового мікса відповідно до одного з варіантів здійснення винаходу. Як показано в процесі 200, дані 202 на основі каналів, які, наприклад, можуть являти собою дані оточуючого звуку 5.1 або 7.1, представлені у формі даних з імпульсно-кодовою модуляцією (PCM), поєднуються з даними 204 звукових об'єктів, утворюючи адаптивний звуковий мікс 208. Дані 204 звукових об'єктів генеруються шляхом об'єднання елементів оригінальних даних на основі каналів зі зв'язаними метаданими, які вказують деякі параметри, що мають відношення до місця розташування звукових об'єктів. [0057] Як концептуально показано на ФІГ. 2, інструментальні засоби авторської розробки забезпечують можливість створення звукових програм, які одночасно містять комбінацію груп каналів гучномовців і об'єктних каналів. Наприклад, звукова програма може містити один або 8 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 кілька каналів гучномовців, необов'язково, організованих у групи (або доріжки, наприклад, стереофонічну доріжку або доріжку 5.1), і описові метадані для одного або декількох каналів гучномовців, один або кілька об'єктних каналів і описові метадані для одного або декількох об'єктних каналів. У межах звукової програми кожна група каналів гучномовців і кожний об'єктний канал можуть бути представленими з використанням однієї або декількох частот дискретизації. Наприклад, програма Digital Cinema (D-Cinema) підтримує частоти дискретизації 48 кГц і 96 кГц, однак також можуть підтримуватися й інші частоти дискретизації. Крім того, також може підтримуватися прийняття, збереження в пам'яті та редагування каналів з різними частотами дискретизації. [0058] Створення звукової програми вимагає етапу звукової сценографії, який включає об'єднання звукових елементів як суми складених звукових елементів з відрегульованими рівнями для створення необхідного нового звукового ефекту. Інструментальні засоби авторської розробки системи адаптивного звуку дозволяють створювати звукові ефекти як сукупність звукових об'єктів з відносними положеннями, використовуючи просторово-візуальний графічний користувацький інтерфейс звукової сценографії. Наприклад, візуальне відображення об'єкта, що генерує звук (наприклад, автомобіля), може використовуватися в якості шаблону для складання звукових елементів (шум вихлопу, шурхіт шин, шум двигуна) у якості об'єктних каналів, що містять звук і відповідне положення в просторі (біля вихлопної труби, шин і капота). Канали окремих об'єктів можуть потім зв'язуватися та оброблятися як група. Інструментальний засіб 106 авторської розробки містить кілька елементів користувацького інтерфейсу, що дозволяють звукоінженеру вводити керуючу інформацію та переглядати параметри мікшування, а також удосконалювати функціональні можливості системи. Процес звукової сценографії й авторської розробки також удосконалюється шляхом уможливлення зв'язування та обробки об'єктних каналів і каналів гучномовців як групи. Одним із прикладів є об'єднання об'єктного каналу з дискретним, сухим джерелом звуку з набором каналів гучномовців, які містять зв'язаний реверберований сигнал. [0059] Інструментальний засіб 106 авторської розробки підтримує можливість об'єднання декількох звукових каналів, загальновідому під найменуванням "мікшування". Підтримується безліч способів мікшування, які можуть включати традиційне мікшування на основі рівнів і мікшування на основі гучності. При мікшуванні на основі рівнів до звукових каналів застосовується широкосмугове масштабування, і масштабовані звукові канали потім підсумуються. Коефіцієнти широкосмугового масштабування для кожного каналу вибираються так, щоб вони управляли абсолютним рівнем результуючого мікшованого сигналу, а також відносними рівнями мікшованих каналів у мікшованому сигналі. При мікшуванні на основі гучності один або кілька вхідних сигналів модифікуються з використанням масштабування залежних від частоти амплітуд, де залежна від частоти амплітуда вибирається так, щоб вона забезпечувала необхідну сприйману абсолютну та відносну гучність і, у той же час, зберігала сприйманий тембр вхідного звуку. [0060] Інструментальні засоби авторської розробки допускають можливість створення каналів гучномовців і груп каналів гучномовців. Це дозволяє зв'язувати метадані з кожною із груп каналів гучномовців. Кожна із груп каналів гучномовців може позначатися відповідно до типу вмісту. Тип вмісту поширюється за допомогою текстового опису. Типи вмісту можуть включати в якості необмежуючих прикладів діалог, музику та ефекти. Кожній з груп каналів гучномовців можуть привласнюватися унікальні команди про те, як слід виконувати підвищувальне мікшування з однієї конфігурації каналів в іншу, де підвищувальне мікшування визначається як створення М звукових каналів з N звукових каналів, де M>N. Команди підвищувального мікшування можуть включати в якості необмежуючих прикладів наступні команди: прапор розблокування/блокування, що вказує допустимість підвищувального мікшування; матрицю підвищувального мікшування, призначену для керування присвоюванням між кожним вхідним та вихідним каналами; а розблокування за промовчуванням та установки матриці можуть привласнюватися на основі типу вмісту, наприклад розблокувати підвищувальне мікшування тільки для музики. Кожній із груп каналів гучномовців також можуть привласнюватися унікальні команди про те, яким чином виконувати понижувальне мікшування від однієї конфігурації каналів до іншої, де понижувальне мікшування визначається як створення Y звукових каналів з X звукових каналів, де Y>X. Команди понижувального мікшування можуть включати в якості необмежуючих прикладів наступні команди: матрицю, призначену для керування присвоюванням між кожним вхідним і вихідним каналами; і настроювання матриці за промовчуванням, які можуть привласнюватися на основі типу вмісту, наприклад діалог повинен зазнавати понижувальне мікшування на екран; ефекти повинні зазнавати понижувальне мікшування за межі екрана. Кожний канал гучномовців також може 9 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 бути пов'язаний із прапором метаданих, що блокують керування басами в ході представлення даних. [0061] Варіанти здійснення винаходу включають характерну ознаку, яка допускає створення об'єктних каналів і груп об'єктних каналів. Винахід дозволяє зв'язувати метадані з кожної із груп об'єктних каналів. Кожна із груп об'єктних каналів може позначатися відповідно до типу вмісту. Тип вмісту поширюється за допомогою текстового опису, де типи вмісту можуть включати в якості необмежуючих прикладів діалог, музику та ефекти. Кожній з груп об'єктних каналів можуть привласнюватися метадані для опису того, як слід представляти дані об'єкта (об'єктів). [0062] Інформація положення передбачається для зазначення необхідного положення гаданого джерела. Положення може вказуватися з використанням егоцентричної або алоцентричної системи відліку. Егоцентрична система відліку є підходящою тоді, коли положення джерела повинне опиратися на слухача. Для опису положення в егоцентричній системі придатні сферичні координати. Алоцентрична система відліку є типовою системою відліку для кінематографічних або інших аудіовізуальних вистав, де положення джерела вказується щодо таких об'єктів у середовищі представлення, як положення екрана відеомонітора або границі приміщення. Інформація тривимірної (3D) траєкторії надається для того, щоб дозволяти інтерполювати положення, або для використання інших рішень представлення даних, таких як розблокування "прив'язки до режиму". Інформація розміру представляється для указання необхідного сприйманого розміру гаданого джерела звуку. [0063] Просторове квантування передбачається за допомогою елемента керування "прив'язка до найближчого гучномовця", який вказує задум звукоінженера, або оператора мікшування, представити дані об'єкта в точності одним гучномовцем (потенційно жертвуючи просторовою точністю). Межа припустимого просторового викривлення може вказуватися за допомогою граничних значень допусків піднесення та азимута для того, щоб, якщо граничне значення перевищується, функція "прив'язка" не виконувалася. На додаток до граничних значень відстаней може вказуватися параметр швидкості плавного переходу, призначений для контролю над тим, наскільки швидко об'єкт, що рухається, перейде, або зробить стрибок, з одного гучномовця в іншій, коли необхідне положення перебуває між гучномовцями. [0064] У одному з варіантів здійснення винаходу для деяких метаданих положення використовуються залежні просторові метадані. Наприклад, метадані можуть автоматично генеруватися для "відомого" об'єкта шляхом зв'язування його з "повідним" об'єктом, за яким повинен слідувати ведений об'єкт. Для веденого об'єкта може задаватися затримка в часі або відносна швидкість. Також можуть передбачатися механізми, що дозволяють визначати акустичний центр ваги для наборів, або груп, об'єктів для того, щоб дані об'єкта могли представлятися таким чином, щоб він сприймався, як такий, що рухається біля іншого об'єкта. У цьому випадку один або кілька об'єктів можуть обертатися навколо деякого об'єкта, або певної області, як панівної точки або приямка приміщення. Тоді акустичний центр ваги можна було б використовувати на етапі представлення даних для того, щоб сприяти визначенню інформації місця розташування для кожного з звуків на основі об'єктів, навіть якщо остаточна інформація місця розташування буде виражатися як місце розташування щодо приміщення, на відміну від місця розташування щодо іншого об'єкта. [0065] Коли представляються дані об'єкта, він, відповідно до метаданих положення та місцю розташування гучномовців, що програють, привласнюється одному або декільком гучномовцям. З метою обмеження гучномовців, які могли б використовуватися, з об'єктом можуть зв'язуватися додаткові метадані. Використання обмежень може забороняти використання зазначених гучномовців або тільки заглушати зазначені гучномовці (допускати в гучномовець, або гучномовці, менше енергії, ніж могло б застосовуватися). Набори гучномовців, що підлягають обмеженню, можуть включати в якості необмежуючих прикладів які-небудь названі гучномовці, або зони гучномовців (наприклад, L, C, R, тощо), або такі зони гучномовців, як передня стіна, задня стіна, ліва стіна, права стіна, стеля, підлога, гучномовці в приміщенні, тощо Аналогічно, у ході зазначення необхідного мікшування декількох звукових елементів можна викликати перетворення одного або декількох звукових елементів у нечутні, або "замасковані", через присутність інших, "маскувальних" звукових елементів. Наприклад, якщо виявляються "замасковані" звукові елементи, їх можна ідентифікувати за допомогою графічного дисплея. [0066] Як описано в іншому місці, опис звукової програми може адаптуватися для представлення даних на широкому виборі установок гучномовців і конфігурацій каналів. Коли автором розробляється звукова програма, важливо виконувати поточний контроль програми в очікуваних конфігураціях програвання для того, щоб переконатися, що досягаються необхідні результати. Даний винахід включає можливість вибору цільових конфігурацій програвання та здійснення поточного контролю результату. Крім того, система може автоматично 10 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 відслідковувати гірший випадок рівнів сигналу (тобто найвищі рівні), які могли б генеруватися в кожній з очікуваних конфігурацій відтворення та передбачати покажчик, якщо буде виникати обрізка або обмеження. [0067] ФІГ. 3 являє собою блок-схему, що ілюструє послідовність операцій створення, упакування та представлення даних адаптивного звукового вмісту відповідно до одного з варіантів здійснення винаходу. Послідовність 300 операцій за ФІГ. 3 розділена на три окремі групи завдань, позначених як створення/авторська розробка, упакування та демонстрація. Загалом, гібридна модель трактів і об'єктів, показана на ФІГ. 2, дозволяє виконувати більшість завдань – звукову сценографію, редагування, попереднє мікшування та остаточне мікшування – у такий же спосіб, яким вони виконуються в цей час, без додавання до сучасних процесів надлишкових службових даних. У одному з варіантів здійснення винаходу функціональна можливість адаптації звуку передбачається у формі програмного забезпечення, апаратнопрограмного забезпечення або схеми, яка використовується в комбінації з устаткуванням для генерування та обробки звуку, де зазначене устаткування може являти собою нові апаратні системи або модифікації існуючих систем. Наприклад, для робочих станцій цифрового звуку можуть передбачатися модульні застосування, що дозволяють залишати без зміни існуючі методики панорамування в ході звукової сценографії та редагування. Таким чином, можна сформувати як тракти, так і об'єкти для робочої станції в робочій станції 5.1 або аналогічних монтажних, оснащених оточуючими каналами. Метадані об'єктів і звуку записуються в ході сесії з підготовки етапів попереднього та остаточного мікшування в дублюючому кінотеатрі. [0068] Як показано на ФІГ. 3, створення або авторська розробка завдань включає введення користувачем, наприклад у нижченаведеному прикладі звукоінженером, сигналів 302, що управляють, мікшування в мікшерний пульт або звукову робочу станцію 304. У одному з варіантів здійснення винаходу, метадані вбудовуються в поверхню мікшерного пульта, дозволяючи регуляторам настроювання каналів, панорамування та обробки звуку працювати як із трактами, або стемами, так і з звуковими об'єктами. Метадані можуть редагуватися з використанням поверхні пульта або користувацького інтерфейсу робочої станції, а поточний контроль звуку здійснюється з використанням модуля 306 представлення даних і остаточної обробки (RMU). Аудіодані трактів і об'єктів і зв'язані метадані записуються в ході сесії остаточної обробки з метою створення "контрольної копії", яка включає адаптивний звуковий мікс 310 і будь-які інші кінцеві видавані дані 308 (такі як оточуючий мікс 7.1 або 5.1 для кінотеатрів). Для того, щоб дозволити звукоінженерам позначати окремі звукові доріжки в ході сесії мікшування, можуть використовуватися існуючі інструментальні засоби авторської розробки (наприклад, такі цифрові звукові робочі станції, як Pro Tools). Варіанти здійснення винаходу поширюють цю концепцію, дозволяючи користувачам позначати окремі субсегменти в межах доріжки для сприяння пошуку або швидкій ідентифікації звукових елементів. Користувацький інтерфейс для мікшерного пульта, який дозволяє визначати та створювати метадані, може реалізовуватися через елементи графічного користувацького інтерфейсу, фізичні елементи керування (наприклад, повзунки та кнопки) або будь-які їхні комбінації. [0069] На етапі упакування файл контрольної копії поміщається в оболонку з використанням процедур поміщення в оболонку згідно із промисловим стандартом MXF, хеширується й, необов'язково, зашифровується для забезпечення цілісності звукового вмісту при доставці до устаткування упакування даних цифрової кінематографії. Даний етап може виконуватися пристроєм 312 обробки даних цифрової кінематографії (DCP), або будь-яким підходящим пристроєм для обробки звуку, залежно від кінцевого середовища програвання, такого як кінотеатр 318, оснащений стандартним оточуючим звуком, кінотеатр 320, що допускає адаптивний звук, або яке-небудь інше середовище програвання. Як показано на ФІГ. 3, пристрій 312 обробки даних виводить відповідні звукові сигнали 314 і 316 залежно від середовища, що демонструє. [0070] У одному з варіантів здійснення винаходу контрольна копія адаптивного звуку містить адаптивний аудіомікс поряд зі стандартним DCI-сумісним міксом з імпульсно-кодовою модуляцією (РСМ). Мікс РСМ може представлятися модулем представлення даних і остаточної обробки в дублюючому кінотеатрі або, за бажанням, створюватися окремим прогоном мікшування. Звук РСМ утворює в пристрої 312 обробки даних для цифрової кінематографії файл стандартної основної звукової доріжки, а адаптивний звук утворює файл додаткової доріжки. Зазначений файл доріжки може бути сумісним з існуючими промисловими стандартами та може ігноруватися DCI-сумісними серверами, які не можуть його використовувати. [0071] У одному із прикладів середовища, що програє, для кінематографії DCP, що містить файл доріжки адаптивного звуку, розпізнається сервером як достовірний пакет і приймається сервером, а потім передається у вигляді потоку в пристрій обробки адаптивних аудіоданих для 11 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 кінематографії. Система, для якої доступні як лінійний РСМ-, так і адаптивний звукові файли, може по необхідності перемикатися між ними. Для поширення на етап демонстрації схема упакування адаптивного звуку допускає доставку в кінотеатр пакетів одного типу. Пакет DCP містить як файл РСМ, так й адаптивні звукові файли. Для забезпечення захищеної доставки вмісту кінофільму, або іншого подібного вмісту, може включатися використання ключів захисту, таких як доставка повідомлення, зашифрованого на певному ключі (KDM). [0072] Як показано на ФІГ. 3, методологія адаптивного звуку реалізується шляхом створення для звукоінженера можливості вираження його задуму відносно представлення даних і програвання звукового вмісту через звукову робочу станцію 304. Керуючи деякими елементами управління введення, інженер здатний указувати, де і як програвати звукові об'єкти та звукові елементи залежно від середовища прослуховування. Метадані генеруються у звуковій робочій станції 304 у відповідь на вхідні дані 302 мікшування інженера, забезпечуючи черги на представлення даних, які управляють просторовими параметрами (наприклад, положенням, швидкістю, інтенсивністю, тембром, тощо) і вказують, який гучномовець (гучномовці), або групи гучномовців, у середовищі прослуховування програють відповідні звуки в ході демонстрації. Метадані зв'язуються з відповідними аудіоданими в робочій станції 304 або RMU 306 з метою упакування та передачі за допомогою DCP 312. [0073] Графічний користувацький інтерфейс і засоби програмного забезпечення, які забезпечують керування робочою станцією 304 інженером, містять, щонайменше, частину інструментальних засобів 106 авторської розробки за ФІГ. 1. Гібридний аудіокодек [0074] Як показано на ФІГ. 1, система 100 включає гібридний аудіокодек 108. Цей компонент містить систему кодування, поширення та декодування звуку, яка сконфігурована для генерування єдиного бітового потоку, що містить як традиційні звукові елементи на основі каналів, так і елементи кодування звукових об'єктів. Гібридна система кодування звуку вибудовується навколо системи кодування на основі каналів, яка сконфігурована для генерування єдиного (уніфікованого) бітового потоку, який одночасно є сумісним з першим декодером (наприклад, може їм декодуватися), сконфігурованим для декодування аудіоданих, кодованих відповідно до першого протоколу кодування (на основі каналів), і один або кілька вторинних декодерів, сконфігурованих для декодування аудіоданих, кодованих відповідно до одного або декількох вторинних протоколів декодування (на основі об'єктів). Бітовий потік може включати як кодовані дані (у формі пакетів даних), що декодуються першим декодером (і ігноровані кожним із вторинних декодерів), так і кодовані дані (наприклад, інші пакети даних), що декодуються одним або декількома вторинними декодерами (і ігноровані першим декодером). Декодований звук і зв'язана інформація (метадані) з першого та одного або декількох вторинних декодерів можуть потім поєднуватися таким чином, щоб представлення даних як інформації на основі каналів, так і інформації на основі об'єктів відбувалося одночасно для відтворення точної копії середовища, каналів, просторової інформації та об'єктів, представлених у гібридну систему кодування (наприклад, у межах тривимірного простору або середовища прослуховування). [0075] Кодек 108 генерує бітовий потік, що містить інформацію кодованого звуку та інформацію, що відноситься до декількох наборів положень каналів (гучномовців). У одному з варіантів здійснення винаходу один набір положень каналів фіксується та використовується для протоколу кодування на основі каналів, у той час як інший набір положень каналів є адаптивним і використовується для протоколу кодування на основі звукових об'єктів, і, таким чином, конфігурація каналів для звукового об'єкта може змінюватися залежно від часу (залежно від того, де у звуковому полі розміщається об'єкт). Таким чином, гібридна система кодування звуку може нести інформацію про два набори місць розташування гучномовців для програвання, де один набір може бути фіксованим і являти собою підмножину іншого набору. Пристрої, які підтримують успадковану інформацію кодованого звуку, можуть декодуватися та представляти дані для звукової інформації з фіксованої підмножини, у той час як пристрій, здатний підтримувати більший набір, може декодувати та представляти дані для додаткової інформації кодованого звуку, яка може зі зміною у часі приписуватися різним гучномовцям з більшого набору. Крім того, система не залежить від першого та одного або декількох вторинних декодерів, одночасно присутніх у системі та/або пристрої. Тому успадкований та/або існуючий пристрій/система, що містить тільки декодер, що підтримує перший протокол, може виводити повністю сумісне звукове поле, дані якого підлягають представленню через традиційні системи відтворення на основі каналів. У цьому випадку невідома, або непідтримувана, частка (частки) протоколу гібридного бітового потоку (тобто звукова інформація, представлена вторинним 12 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 протоколом кодування) може ігноруватися системою або пристроєм декодера, що підтримує перший протокол гібридного кодування. [0076] У іншому варіанті здійснення винаходу кодек 108 сконфігурований для роботи в режимі, де перша підсистема кодування (підтримуюча перший протокол) містить комбіноване представлення всієї інформації звукового поля (каналів і об'єктів), що представляється як у першій, так і в одній або декількох вторинних підсистемах кодера, присутніх у гібридному кодері. Це забезпечує те, що гібридний бітовий потік включає зворотну сумісність із декодерами, що підтримують тільки протокол першої підсистеми кодера, дозволяючи звуковим об'єктам (як правило, таким, що переносяться в одному або декількох вторинних протоколах кодера) бути відображуваними, що й представляються в декодерах, що підтримують тільки перший протокол. [0077] У ще одному варіанті здійснення винаходу кодек 108 включає дві або більшу кількість підсистем кодування, де кожна з цих підсистем сконфігурована для кодування аудіоданих відповідно до протоколу, що відрізняється, та сконфігурована для об'єднання виводів підсистем з метою генерування гібридного формату (уніфікованого) бітового потоку. [0078] Однією з вигід варіантів здійснення винаходу є можливість переносу гібридного бітового потоку кодованого звуку через широкий вибір систем поширення вмісту, де кожна із систем поширення традиційно підтримує тільки дані, кодовані відповідно до першого протоколу кодування. Це виключає необхідність у модифікації/зміні протоколу будь-якої системи та/або транспортного рівня з метою спеціальної підтримки гібридної системи кодування. [0079] Системи кодування звуку, як правило, використовують стандартизовані елементи бітового потоку, що дозволяють передавати додаткові (довільні) дані усередині самого бітового потоку. Ці додаткові (довільні) дані, як правило, пропускаються (тобто ігноруються) у ході декодування кодованого звуку, поміщеного в бітовому потоці, але можуть використовуватися з іншими цілями ніж декодування. Різні стандарти кодування звуку виражають ці додаткові поля даних з використанням унікальної номенклатури. Елементи бітового потоку зазначеного загального типу можуть включати в якості необмежуючих прикладів допоміжні дані, пропущені поля, елементи потоку даних, що заповнюють елементи, службові дані та елементи вкладених потоків даних. Якщо не обумовлене інше, використання виразу "довільні дані" у даному документі не має на увазі певний тип або формат додаткових даних, але, навпаки, його слід інтерпретувати як загальний вираз, який охоплює будь-який або всі приклади, пов'язані зі даним винаходом. [0080] Канал даних, забезпечуваний за допомогою "довільних" елементів бітового потоку першого протоколу кодування в комбінованому бітовому потоці гібридної системи кодування, може нести один або декілька вторинних (залежних або незалежних) бітових потоків аудіоданих (кодованих відповідно до одного або декількох вторинних протоколів кодування). Один або кілька вторинних бітових звукових потоків можуть розбиватися на блоки з N дискретних значень і ущільнюватися в поля "допоміжних даних" першого бітового потоку. Перший бітовий потік декодується відповідним (додатковим) декодером. Крім того, допоміжні дані першого бітового потоку можуть отримуватися та знову поєднуватися в один або кілька вторинних бітових потоків аудіоданих, що декодуються пристроєм обробки даних, що підтримують синтаксис одного або декількох вторинних бітових потоків, а потім спільно або незалежно комбінуватися та представлятися. Крім того, також можна поміняти ролі першого та другого бітових потоків так, щоб блоки даних першого бітового потоку ущільнювалися в допоміжні дані другого бітового потоку. [0081] Елементи бітового потоку, зв'язані із другим протоколом кодування, також переносять і передають характеристики інформації (метадані) покладеного в їхню основу звуку, які можуть у якості необмежуючих прикладів включати необхідне положення, швидкість і розмір джерела звуку. Ці метадані використовуються в ході процесів декодування та представлення даних для відтворення належного (тобто оригінального) положення зв'язаного звукового об'єкта, що переносяться в застосовному бітовому потоці. Також можна переносити вищеописані метадані, які застосовні до звукових об'єктів, що містяться в одному або декількох вторинних бітових потоках, присутніх у гібридному потоці, в елементах бітового потоку, пов'язаних з першим протоколом кодування. [0082] Елементи бітового потоку, пов'язані з одним, першим або другим, протоколом кодування або з обома протоколами кодування гібридної системи кодування, переносять/передають контекстні метадані, які ідентифікують просторові параметри (наприклад, сутність властивостей самого сигналу), і додаткову інформацію, що описує тип сутності покладеного в її основу звуку у формі спеціальних класів звуку, які переносяться в гібридному бітовому потоці кодованого звуку. Такі метадані можуть указувати, наприклад, на присутність мовного діалогу, музики, діалогу на тлі музики, оплесків, співу, тощо і можуть 13 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 використовуватися для адаптивної модифікації поведінки взаємозалежних модулів попередньої та наступної обробки у висхідному напрямку або в спадному напрямку щодо гібридної системи кодування. [0083] У одному з варіантів здійснення винаходу кодек 108 сконфігурований для роботи зі спільно використовуваним, або загальним, бітовим пулом, у якому біти, доступні для кодування, "діляться" між усіма або частиною підсистем кодування, що підтримують один або кілька протоколів. Такий кодек може розподіляти доступні біти (із загального, "спільно використовуваного" бітового пулу) між підсистемами кодування з метою оптимізації загальної якості звуку в уніфікованому бітовому потоці. Наприклад, протягом першого проміжку часу кодек може привласнювати більше доступних бітів першій підсистемі кодування і менше доступних бітів – іншим підсистемам, у той час як протягом другого проміжку часу кодек може привласнювати менше доступних бітів першій підсистемі кодування і більше доступних бітів – іншим підсистемам кодування. Рішення про те, яким чином розподіляти біти між підсистемами кодування, може залежати, наприклад, від результатів статистичного аналізу спільно використовуваного бітового пулу та/або від аналізу звукового вмісту, кодованого кожною з підсистем. Кодек може привласнювати біти зі спільно використовуваного пулу таким чином, щоб уніфікований бітовий потік, сконструйований шляхом ущільнення виводів підсистем кодування, зберігав постійну довжину кадру/бітову швидкість передачі даних протягом заданого проміжку часу. Також, у деяких випадках, можлива зміна довжини кадра/бітової швидкості передачі даних протягом заданого проміжку часу. [0084] У альтернативному варіанті здійснення винаходу кодек 108 генерує уніфікований бітовий потік, що включає дані, кодовані відповідно до першого протоколу кодування, конфігуровані та передані як незалежний підпотік потоку кодованих даних (який буде декодуватися декодером, що підтримує перший протокол кодування), а дані, що кодуються у відповідності із другим протоколом, передаються як незалежний або залежний підпотік потоку кодованих даних (потік, який буде ігноруватися декодером, що підтримують перший протокол). У більш загальному розумінні в одному із класів варіантів здійснення винаходу кодек генерує уніфікований бітовий потік, що включає два або більшу кількість незалежних або залежних підпотоків (де кожний підпотік включає дані, кодовані відповідно до ідентичного протоколу кодування або такого, що відрізняється). [0085] У ще одному альтернативному варіанті здійснення винаходу кодек 108 генерує уніфікований бітовий потік, що включає дані, кодовані відповідно до першого протоколу кодування, сконфігуровані та передані з унікальним ідентифікатором бітового потоку (який буде декодуватися декодером, що підтримує перший протокол кодування, пов'язаний з унікальним ідентифікатором бітового потоку), і дані, кодовані у відповідності із другим протоколом, сконфігуровані та передані з унікальним ідентифікатором бітового потоку, який декодер, що підтримує перший протокол, буде ігнорувати. У більш загальному розумінні в одному із класів варіантів здійснення винаходу кодек генерує уніфікований бітовий потік, що містить два або більшу кількість підпотоків (де кожний підпотік містить дані, що кодуються відповідно до ідентичного протоколу кодування або такого, що відрізняється, і де кожний підпотік несе унікальний ідентифікатор бітового потоку). Вищеописані способи та системи, призначені для створення уніфікованого бітового потоку, передбачають можливість передачі (у декодер) недвозначного сигналу про те, яке чергування та/або протокол були використані у гібридному бітовому потоці (наприклад, передавати сигнал про те, чи використовуються дані AUX, SKIP, DSE або описаний підхід на основі підпотоків). [0086] Гібридна система кодування сконфігурована для підтримки усунення чергування/разущільнення та повторного чергування/повторного ущільнення бітових потоків, що підтримують один або кілька вторинних протоколів, у перший бітовий потік (підтримуючий перший протокол) у будь-якій точці обробки всюди в системі доставки мультимедійних даних. Гібридний кодек також сконфігурований для володіння здатністю кодування вхідних аудіопотоків з різними частотами дискретизації в один бітовий потік. Це створює засоби для ефективного кодування та поширення джерел звукових сигналів, що містять сигнали з різними по своїй суті смугами пропущення. Наприклад, діалогові доріжки звичайно мають суттєво меншу ширину смуги пропускання, ніж у доріжки музики та ефектів. Представлення даних [0087] У одному з варіантів здійснення винаходу система адаптивного звуку допускає упакування декількох (наприклад, до 128) доріжок зазвичай у якості комбінації трактів і об'єктів. Основний формат аудіоданих для системи адаптивного звуку включає декілька незалежних монофонічних аудіопотоків. Кожний потік містить пов'язані з ним метадані, які вказують, чи є даний потік потоком на основі каналів або потоком на основі об'єктів. Потоки на основі каналів 14 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 містять інформацію представлення даних, кодовану за допомогою назви, або мітки, каналу; а потоки на основі об'єктів містять інформацію місця розташування, кодовану через математичні вираження, закодовані в додаткових зв'язаних метаданих. Оригінальні незалежні аудіопотоки потім упаковуються в єдину двійкову послідовність, яка містить усі аудіодані в упорядкованому виді. Така конфігурація адаптивних даних дозволяє представляти дані звуку відповідно до алоцентричної системою відліку, у якій остаточне місце розташування представлення даних звуку ґрунтується на середовищі програвання так, щоб воно відповідало задуму оператора мікшування. Таким чином, походження звуку може вказуватися в системі відліку приміщення для програвання (наприклад, середина лівої стіни), а не з певного позначеного гучномовця або групи гучномовців (наприклад, лівої оточуючої). Метадані положення об'єкта містять інформацію відповідної алоцентричної системи відліку, необхідну для правильного програвання звуку з використанням положень доступних гучномовців у приміщенні, яке підготовлено для програвання адаптивного звукового вмісту. [0088] Оператор представлення даних ухвалює бітовий потік, що кодує звукові доріжки, і обробляє вміст відповідно до типу сигналу. Тракти подаються на масиви, що потенційно буде вимагати інших затримок і обробки зрівнювання, ніж окремі об'єкти. Процес підтримує представлення даних зазначених трактів і об'єктів у кілька (до 64) вихідних сигналів гучномовців. ФІГ. 4 являє собою блок-схему етапу представлення даних системи адаптивного звуку відповідно до одного з варіантів здійснення винаходу. Як показано в системі 400 за ФІГ. 4, кілька вхідних сигналів, таких як звукові доріжки в кількості до 128, які включають адаптивні звукові сигнали 402, створюються певними компонентами етапів створення, авторської розробки та упакування системи 300, такими як RMU 306 і пристрій 312 обробки даних. Ці сигнали містять тракти на основі каналів і об'єкти, які використовуються оператором 404 представлення даних. Звук на основі каналів (тракти) і об'єкти вводяться в пристрій 406 керування рівнем, який забезпечує керування вихідними рівнями, або амплітудами, різних звукових складових. Деякі звукові складові можуть оброблятися компонентом 408 корекції масивів. Адаптивні звукові сигнали потім пропускаються через компонент 410 обробки в ланцюгу В, який генерує певну кількість (наприклад, до 64) вихідних сигналів, що подаються на гучномовці. Загалом, сигнали ланцюга В відносяться до сигналів, оброблюваних підсилювачами потужності, роздільниками спектра сигналу та гучномовцями, на відміну від вмісту ланцюга А, який становить звукову доріжку на кіноплівці. [0089] У одному з варіантів здійснення винаходу оператор 404 представлення даних запускає алгоритм представлення даних, який якнайкраще, розумно використовує можливості оточуючих гучномовців у кінотеатрі. Шляхом поліпшення комутації потужності та амплітудночастотних характеристик оточуючих гучномовців, а також шляхом підтримки однакового опорного рівня поточного контролю для кожного вихідного каналу, або гучномовця, у кінотеатрі об'єкти, що панорамуються між екранними та оточуючими гучномовцями, можуть зберігати рівень їх звукового тиску та мати більш близьке тембральне узгодження, що важливо, без збільшення загального рівня звукового тиску в кінотеатрі. Масив відповідним чином зазначених оточуючих гучномовців, як правило, буде мати достатній запас за рівнем для відтворення максимального доступного динамічного діапазону в межах оточуючої звукової доріжки 7.1 або 5.1 (тобто на 20 дБ вище опорного рівня), однак малоймовірно, щоб одиничний оточуючий гучномовець мав такий же запас за рівнем, що й великий багатопозиційний екранний гучномовець. Як результат, імовірні випадки, коли об'єкт, поміщений у навколишнє поле зажадає більшого звукового тиску, ніж звуковий тиск, досяжний з використанням єдиного оточуючого гучномовця. У цих випадках, оператор представлення даних буде поширювати звук по відповідній кількості гучномовців з метою досягнення необхідного рівня звукового тиску. Система адаптивного звуку поліпшує якість і комутацію потужності оточуючих гучномовців, забезпечуючи поліпшення вірогідності представлення даних. Вона передбачає підтримку керування басами оточуючих гучномовців через використання необов'язкових задніх наднизькочастотних гучномовців, які дозволяють кожному оточуючому гучномовцю досягати поліпшеної комутації потужності, одночасно потенційно використовуючи корпуса гучномовців меншого розміру. Вона також дозволяє додавати бічні оточуючі гучномовці ближче до екрана, ніж в сучасній практиці, для того, щоб забезпечити плавний перехід об'єктів від екрана до оточення. [0090] Шляхом використання метаданих для зазначення інформації місця розташування звукових об'єктів поряд з певними процесами представлення даних система 400 надає творцям вмісту всебічний, гнучкий спосіб виходу за межі обмежень існуючих систем. Як визначено вище, сучасні системи створюють і поширюють звук, який є фіксованим у місцях розташування певних гучномовців з обмеженими відомостями про тип вмісту, переданого у звуковій сутності (у тій 15 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 частині звуку, яка програється). Система 100 адаптивного звуку передбачає новий, гібридний підхід, який включає можливості як для звуку, специфічного для місць розташування гучномовців (лівий канал, правий канал тощо), так і для об'єктно-орієнтованих звукових елементів, які містять узагальнену просторову інформацію, яка може в якості необмежуючих прикладів включати місце розташування, розмір і швидкість. Такий гібридний підхід забезпечує збалансований підхід до точності (забезпечуваної фіксованими місцями розташування гучномовців) і гнучкості представлення даних (узагальнені звукові об'єкти). Система також передбачає додаткову корисну інформацію про звуковий вміст, яку творець вмісту спаровує зі звуковою сутністю в момент створення вмісту. Ця інформація забезпечує значну, докладну інформацію про характерні властивості звуку, яка може використовуватися надзвичайно діючими способами в ході представлення даних. Зазначені характерні властивості можуть включати в якості необмежуючих прикладів тип вмісту (діалог, музика, ефект, шумовий ефект, фон/навколишнє середовище тощо), характерні властивості в просторі (тривимірне положення, тривимірний розмір, швидкість) і інформацію представлення даних (прив'язку до місця розташування гучномовця, вагові коефіцієнти каналів, коефіцієнт посилення, інформація керування басами, тощо). [0091] Система адаптивного звуку, описувана в даному розкритті, передбачає значну інформацію, яка може використовуватися для представлення даних широко варіювальною кількістю кінцевих точок. У багатьох випадках, застосовувана оптимальна методика представлення даних у значній мірі залежить від пристрою в кінцевій точці. Наприклад, системи домашніх кінотеатрів і звукові панелі можуть містити 2, 3, 5, 7 або навіть 9 окремих гучномовців. Системи багатьох інших типів, такі як телевізори, комп'ютери та музичні апаратні модулі містять лише два гучномовці, і майже всі традиційно використовувані пристрої мають бінауральний вихід для навушників (ПК, ноутбук, планшетний комп'ютер, стільниковий телефон, музичний програвач, тощо). Однак для традиційного звуку, розповсюджуваного сьогодні (монофонічні, стереофонічні канали, канали 5.1, 7.1), пристрої в кінцевих точках часто потребують прийняття спрощених рішень і компромісів для представлення даних і відтворення звуку, який сьогодні поширюється у формі, специфічної для каналів/гучномовців. Крім того, є небагато або зовсім немає інформації, переданої відносно фактичного вмісту, який поширюється (діалог, музика, оточення), а також є небагато або зовсім немає інформації про задум творця вмісту для відтворення звуку. Однак система 100 адаптивного звуку надає цю інформацію й, потенційно, доступ до звукових об'єктів, які можуть використовуватися для створення захоплюючого користувацького враження нового покоління. [0092] Система 100 дозволяє творцеві вмісту впроваджувати просторовий задум мікса в бітовому потоці, використовуючи такі метадані, як метадані положення, розміру, швидкості, тощо, через унікальні та вагомі метадані та формат передачі адаптивного звуку. Це дозволяє набагато збільшити гнучкість при відтворенні звуку в просторі. З погляду просторового представлення даних адаптивний звук дозволяє адаптувати мікс до точного положення гучномовців у конкретному приміщенні, уникаючи просторового викривлення, яке виникає тоді, коли геометрія системи програвання не ідентична системі авторської розробки. У сучасних системах відтворення звуку, де передається тільки звук для каналу гучномовця, задум творця вмісту невідомий. Система 100 використовує метадані, передані по всьому конвеєру створення та поширення. Система відтворення, орієнтована на адаптивний звук, може використовувати цю інформацію метаданих для відтворення вмісту тим способом, який узгоджується з оригінальним задумом творця вмісту. Більше того, мікс може адаптуватися до точної конфігурації апаратного забезпечення системи відтворення. Сьогодні у такому устаткуванні для представлення даних, як телевізори, домашні кінотеатри,звукові панелі, переносні апаратні модулі музичних програвачів, тощо, існує безліч різних можливих конфігурацій і типів гучномовців. Коли ці системи сьогодні передають специфічну для каналів звукову інформацію (тобто звук лівого та правого каналів або багатоканальний звук), система повинна обробляти звук так, щоб він відповідним чином узгоджувався з можливостями устаткування для представлення даних. Одним із прикладів є стандартний стереофонічний звук, переданий на звукову панель, що містить більше двох гучномовців. У сучасному звуковідтворенні, де передається тільки звук для каналів гучномовців, задум творця вмісту невідомий. Шляхом використання метаданих, переданих по всьому процесі створення та поширення, система відтворення, орієнтована на адаптивний звук, може використовувати цю інформацію для відтворення вмісту тим способом, який узгоджується з оригінальним задумом творця вмісту. Наприклад, деякі звукові панелі містять бічні додаткові гучномовці, призначені для створення відчуття охвату. Для адаптивного звуку просторова інформація та тип вмісту (такий як ефекти 16 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 навколишнього середовища) можуть використовуватися звуковою панеллю для передачі на зазначені бічні додаткові гучномовці тільки відповідного звуку. [0093] Система адаптивного звуку допускає необмежену інтерполяцію гучномовців у системі у всіх передніх/задніх, лівих/правих, верхніх/нижніх, близьких/дальніх розмірах. У сучасних системах звуковідтворення не існує інформації про те, яким чином обробляти звук тоді, коли може бути бажано розташувати звук так, щоб він сприймався слухачем як такий, що перебуває між двома гучномовцями. Сьогодні для звуку, який привласнюється тільки певному гучномовцю, уводиться коефіцієнт просторового квантування. У випадку адаптивного звуку, просторове розташування звуку може бути відомо точно, і воно може відповідним чином відтворюватися системою звуковідтворення. [0094] Відносно представлення даних навушниками, задум творця реалізується шляхом приведення передатних функцій, що відносяться до голови (HRTF), у відповідність із положенням у просторі. Коли звук відтворюється через навушники, просторова віртуалізація може досягатися шляхом застосування передатної функції, що відноситься до голови, яка обробляє звук, додаючи сприймані властивості, які створюють сприйняття звуку, що програється в тривимірному просторі, а не через навушники. Точність просторового відтворення залежить від вибору підходящої HRTF, яка може мінятися на основі декількох факторів, що включають положення в просторі. Використання просторової інформації, що передбачається системою адаптивного звуку, може в результаті приводити до вибору однієї HRTF, або кількості HRTF, що постійно змінюється, для того, щоб значно підсилити сприйняття відтворення. [0095] Просторова інформація, передана системою адаптивного звуку, може використовуватися не тільки творцем вмісту для створення захоплюючого розважального враження (від фільму, телевізійної програми, музики, тощо), але також просторова інформація також може вказувати, де розташовується слухач щодо таких фізичних об'єктів, як будинки або географічні точки, що представляють інтерес. Це могло б дозволити користувачеві взаємодіяти з віртуалізованим звуковим враженням, яке пов'язане з реальним миром, тобто з додатковою реальністю. [0096] Варіанти здійснення винаходу допускають просторове підвищувальне мікшування шляхом виконання вдосконаленого підвищувального мікшування за допомогою зчитування метаданих тільки в тому випадку, якщо аудіодані об'єктів недоступні. Відомості про положення всіх об'єктів і їх типів дозволяють операторові підвищувального мікшування краще розрізняти елементи в доріжках на основі каналів. Для створення високоякісного підвищувального мікшування з мінімальними чутними викривленнями або з їхньою відсутністю алгоритмам підвищувального мікшування, що існують, доводиться виводити таку інформацію, як тип звукового вмісту (мова, музика, ефекти навколишнього середовища), а також місце розташування різних елементів в аудіопотоці. У багатьох випадках зазначена виведена інформація може виявитися невірною або невідповідною. Для адаптивного звуку додаткова інформація, доступна з метаданих, що відносяться, наприклад, до типу звукового вмісту, положенню в просторі, швидкості, розміру звукового об'єкта, тощо, може використовуватися алгоритмом підвищувального мікшування для створення високоякісного результату відтворення. Система також просторово співвідносить звук і відеозображення, точно розташовуючи звуковий об'єкт на екрані стосовно видимих елементів. У цьому випадку можливе захоплююче враження від відтворення звуку/відеозображення, особливо, на екранах великого розміру, якщо відтворене місце розташування деяких звукових елементів у просторі відповідає елементам зображення на екрані. Одним із прикладів є діалог у фільмі або телевізійній програмі, що просторово збігається з людиною або героєм, який говорить на екрані. Для звичайного звуку на основі каналів гучномовців не існує простого способу визначення того, де в просторі повинен розташовуватися діалог для того, щоб він збігався з місцем розташування людини або героя на екрані. Для звукової інформації, доступної через адаптивний звук, таке аудіовізуальне вирівнювання може досягатися. Візуальне позиційне та просторове звукове вирівнювання також може використовуватися для таких нерольових/недіалогових об'єктів, як автомобілі, вантажівки, анімація, тощо [0097] Система 100 сприяє обробці просторового маскування, оскільки відомості про просторовий задум мікшування, доступні через метадані адаптивного звуку, означають, що мікс може бути адаптованим до будь-якої конфігурації гучномовців. Однак, виникає ризик понижувального мікшування об'єктів у такому ж або майже такому ж місці розташування через обмеження системи, що програє. Наприклад, об'єкт, який, як мається на увазі, підлягає панорамуванню в лівий задній канал, може зазнати понижувального мікшування в лівий передній канал, якщо оточуючі канали відсутні, однак якщо, у той же час, у лівому передньому каналі виникає більш голосний елемент, підданий понижувальному мікшуванню об'єкт буде 17 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 60 маскуватися та зникати з мікса. З використанням метаданих адаптивного звуку просторове маскування може передбачатися оператором представлення даних, і параметри понижувального мікшування в просторі та/або по гучності для кожного об'єкта можуть коректуватися так, щоб усі звукові елементи мікса залишалися сприйманими точно так само, як і в оригінальному міксі. Оскільки оператор представлення даних розуміє просторовий взаємозв'язок між міксом і системою програвання, він має можливість "прив'язувати" об'єкти до найближчих гучномовців замість створення паразитного зображення між двома або більшою кількістю гучномовців. Незважаючи на те, що може трохи спотворюватися просторове представлення мікса, це також дозволяє операторові представлення даних уникати ненавмисного паразитного зображення. Наприклад, якщо кутове положення лівого гучномовця на етапі мікшування не відповідає кутовому положенню лівого гучномовця у відтворюючій системі, використання функції прив'язки до найближчого гучномовця може дозволити уникнути відтворення системою, що програє, постійного паразитного зображення лівого каналу етапу мікшування. [0098] Відносно обробки вмісту, система 100 адаптивного звуку дозволяє творцеві вмісту створювати окремі звукові об'єкти та додавати інформацію про вміст, яка може передаватися у відтворюючу систему. Це допускає більшу гнучкість при обробці звуку перед відтворенням. З погляду обробки вмісту та представлення даних система адаптивного звуку дозволяє адаптувати обробку до типу об'єкта. Наприклад, діалогове посилення може застосовуватися тільки до діалогових об'єктів. Діалогове посилення відноситься до способу обробки звуку, який містить діалог, таким чином, щоб чутність та/або розбірливість діалогу підвищувалася та/або поліпшувалася. У багатьох випадках обробка звуку, яка застосовується до діалогу, є невідповідною для недіалогового звукового вмісту (тобто музики, ефектів навколишнього середовища, тощо) і в результаті може приводити до небажаних чутних викривлень. Для адаптивного звуку звуковий об'єкт може містити тільки діалог в одному із фрагментів вмісту, і він може відповідним чином позначатися так, щоб рішення представлення даних могло вибірково застосовувати діалогове посилення тільки до діалогового вмісту. Крім того, якщо звуковий об'єкт являє собою тільки діалог (а не, як часто буває, суміш діалогу та іншого вмісту), то обробка діалогового посилення може обробляти винятково діалог (таким чином, обмежуючи будь-яку обробку, виконувану на будь-якому іншому вмісті). Аналогічно, керування басами (фільтрація, ослаблення, посилення) може бути націлене на певні об'єкти на основі їх типу. Керування басами відноситься до вибіркового виділення та обробки тільки басових(або ще більш низьких) частот у певному фрагменті вмісту. У сучасних звукових системах і механізмах доставки цей процес є "сліпим", тобто застосовується до всього звуку. Для адаптивного звуку певні звукові об'єкти, для яких керування басами є підходящим, можуть ідентифікуватися по метаданим, і обробка представлення даних може застосовуватися відповідно. [0099] Система 100 адаптивного звуку також передбачає стиск динамічного діапазону та вибіркове підвищувальне мікшування на основі об'єктів. Традиційні звукові доріжки мають таку ж тривалість, як і сам вміст, у той час як звуковий об'єкт може з'являтися у вмісті лише протягом обмеженої кількості часу. Метадані, пов'язані з об'єктом, можуть містити інформацію про його середню та пікову амплітуду сигналу, а також про час його появи, або час наростання (особливо, для короткочасного матеріалу). Ця інформація могла б дозволяти пристрою стиску краще адаптувати його постійні стиску та часу (наростання, вивільнення, тощо) для кращої відповідності вмісту. Для вибіркового підвищувального мікшування творці вмісту можуть вибрати вказівку в бітовому потоці адаптивного звуку на те, чи слід піддавати об'єкт підвищувальному мікшуванню чи ні. Ця інформація дозволяє операторові представлення даних адаптивного звуку та операторові підвищувального мікшування розрізняти, які звукові елементи можуть безпечно піддаватися підвищувальному мікшуванню, у той же час не порушуючи задум творця. [00100] Варіанти здійснення винаходу також дозволяють системі адаптивного звуку вибирати кращий алгоритм представлення даних з деякої кількості доступних алгоритмів представлення даних та/або форматів оточуючого звуку. Приклади доступних алгоритмів представлення даних включають: бінауральний, стереодіпольний, амбіофонічний, синтез хвильового поля (WFS), багатоканальне панорамування, неопрацьовані стеми з метаданими положення. Інші алгоритми включають подвійний баланс і амплітудне панорамування на векторній основі. [00101] Бінауральний формат поширення використовує двоканальне представлення звукового поля на основі сигналу, присутнього в лівому та правому вухах. Бінауральна інформація може створюватися за допомогою внутрішньоканального запису або синтезуватися з використанням моделей HRTF. Програвання бінаурального представлення, як правило, 18 UA 114793 C2 5 10 15 20 25 30 35 40 45 50 55 здійснюється через навушники або шляхом використання заглушення перехресних перешкод. Програвання через довільну схему гучномовців потребувало б аналізу сигналу для визначення зв'язаного звукового поля та/або джерела (джерел) сигналу. [00102] Стереодіпольний спосіб представлення даних являє собою трансауральний процес заглушення перехресних перешкод для того, щоб зробити бінауральні сигнали придатними для програвання через стереофонічні гучномовці (наприклад, на + і – 10 градусів від центру). [00103] Амбіофонія являє собою формат поширення та спосіб відтворення, який кодується в чотириканальній формі, що зветься форматом В. Перший канал W – це сигнал ненаправленого тиску; другий канал Х – це градієнт спрямованого тиску, що містить передню та задню інформацію; третій канал, Y, містить ліво та право, і Z – верх і низ. Ці канали визначають дискретне значення першого порядку для повного звукового поля в даній точці. Амбіофонія використовує всі доступні гучномовці для відтворення дискретизованого (або синтезованого) звукового поля в межах масиву гучномовців так, щоб коли деякі з гучномовців штовхають, інші – тягли. [00104] Синтез хвильового поля являє собою спосіб представлення даних для звуковідтворення на основі точної побудови хвильового поля вторинними джерелами. WFS ґрунтується на принципі Гюйгенса та реалізується як масиви гучномовців (десятки або сотні), які оточують кільцем простір прослуховування та скоординованим, сфазованим чином діють для відтворення кожної окремої звукової хвилі. [00105] Багатоканальне панорамування являє собою формат поширення та/або спосіб представлення даних і може йменуватися звуком на основі каналів. У цьому випадку звук відображається як деяка кількість дискретних джерел для програвання через рівну кількість гучномовців, розташованих під певними кутами щодо слухача. Творець вмісту/оператор мікшування може створювати віртуальні зображення шляхом панорамування сигналів між суміжними каналами з метою створення сприйняття напрямку; для створення сприйняття напрямку та властивостей навколишнього середовища у кілька каналів можуть мікшуватися первинні відбиття, реверберація, тощо [00106] Неопрацьовані стеми з метаданими положення являють собою формат поширення, який також може йменуватися звуком на основі об'єктів. У цьому форматі виразні джерела звуку "із близького мікрофона" представляються поряд з метаданими положення та середовища. Дані віртуальних джерел представляються на основі метаданих устаткування, що програє, і середовища прослуховування. [00107] Формат адаптивного звуку являє собою гібрид формату багатоканального панорамування та формату неопрацьованих стемів. Способом представлення даних у даному варіанті здійснення винаходу є багатоканальне панорамування. Для звукових каналів, представлення даних (панорамування) відбувається в момент авторської розробки, у той час як для об'єктів представлення даних (панорамування) відбувається при програванні. Метадані та формат передачі адаптивного звуку [00108] Як викладено вище, метадані генеруються на етапі створення з метою кодування певної інформації положення для звукових об'єктів і для супроводу звукової програми з метою сприяння при представленні даних звукової програми й, зокрема, для опису звукової програми способом, який дозволяє представляти дані звукової програми для широкого вибору устаткування, що програє, і середовищ програвання. Метадані генеруються для даної програми та редакторів і операторів мікшування, які створюють, збирають, редагують і обробляють звук у ході компонування. Важливою характерною ознакою формату адаптивного звуку є можливість контролю над тим, яким чином звук буде транслюватися в системи та середовища відтворення, які відрізняються від середовища мікшування. Зокрема, даний кінотеатр може мати менші можливості, ніж середовище мікшування. [00109] Оператор представлення даних адаптивного звуку націлений на найкраще використання доступного устаткування для відтворення задуму оператора мікшування. Крім того, інструментальні засоби авторської розробки адаптивного звуку дозволяють операторові мікшування попередньо переглядати та коректувати те, яким чином дані мікса будуть представлятися в різних конфігураціях програвання. Усі значення метаданих можуть обумовлюватися середовищем програвання та конфігурацією гучномовців. Наприклад, на основі конфігурації або режиму програвання для даного звукового елемента може вказуватися інший рівень мікшування. У одному з варіантів здійснення винаходу список обумовлених режимів програвання є розширюваним і включає наступні режими: (1) програвання тільки на основі каналів: 5.1, 7.1, 7.1 (з верхніми), 9.1; і (2) програвання дискретними гучномовцями: тривимірне, двовимірне (без верхніх). 19 UA 114793 C2 5 10 15 [00110] У одному з варіантів здійснення винаходу метадані контролюють, або диктують, різні особливості адаптивного звукового вмісту і є організованими на основі різних типів, у тому числі: програмні метадані, метадані звуку та метадані представлення даних (для каналів і об'єктів). Кожний тип метаданих включає один або кілька елементів метаданих, які передбачають значення для характеристик, на які посилається ідентифікатор (ID). ФІГ. 5 являє собою таблицю, яка перераховує типи метаданих і зв'язані елементи метаданих для системи адаптивного звуку, відповідно до одного з варіантів здійснення винаходу. [00111] Як показано в таблиці 500 за ФІГ. 5, метадані першого типу являють собою програмні метадані, які включають елементи метаданих, що визначають частоту кадрів, підрахунок доріжок, розширюваний опис каналів і опис етапу мікшування. Елемент метаданих "частота кадрів" описує частоту кадрів звукового вмісту в одиницях кадрів у секунду (fps). Формат неопрацьованого звуку не вимагає включення кадрування звуку або метаданих, оскільки звук доставляється у вигляді повних доріжок (тривалість котушки або всього кінофільму), а не сегментів звуку (тривалість об'єкта). Неопрацьований формат не вимагає переносу всієї інформації, необхідної для розблокування адаптивного аудіокодера з метою кадрування аудіоданих і метаданих, включаючи фактичну частоту кадрів. Таблиця 1 показує ID, приклади значень і опис елемента метаданих "частота кадрів". ТАБЛИЦЯ 1 Значення ID 24,25,30,48,50,60, 96, 100, 120, розширюваний (кадри/сек.) FrameRate 20 Опис 2 Покажчик передбачуваної частоти кадрів для всієї програми. Поле може забезпечувати ефективне кодування загальноприйнятих частот, а також можливість розширення до розширюваного поля з рухомою комою та з дозволом 0,01 [00112] Елемент метаданих "рахунок доріжок" указує кількість звукових доріжок у кадрі. Один із прикладів декодера/пристрою обробки даних адаптивного звуку може одночасно підтримувати до 128 звукових доріжок, у той час як формат адаптивного звуку буде підтримувати будь-яку кількість звукових доріжок. Таблиця 2 показує ID, приклади значень і опис елемента метаданих "рахунок доріжок". ТАБЛИЦЯ 2 ID nTracks Значення Опис 2 Позитивне ціле число, розширюваний Покажчик кількості звукових доріжок у інтервал кадрі 25 [00113] Звук на основі каналів може приписуватися нестандартним каналам, і елемент метаданих "опис розширюваних каналів" дозволяє міксам використовувати нові положення каналів. Для кожного каналу розширення повинні створюватися наступні метадані, показані в Таблиці 3. 30 ТАБЛИЦЯ 3 ID ExtChanPosition ExtChanWidth 35 Значення Координати x, y,z Координати x, y,z Опис 2 Положення Ширина [00114] Елемент метаданих "опис етапу мікшування" визначає частоту, на якій певний гучномовець генерує половину потужності смуги пропущення. Таблиця 4 показує ID, приклади значень і опис елемента метаданих "опис етапу мікшування", де LF — нижня частота, HF — верхня частота, точка 3 дБ – край смуги пропущення гучномовця. 20 UA 114793 C2 ТАБЛИЦЯ 4 ID nMixspeakers MixSpeakerPos MixSpeakerTyp MixSpeaker3dB MixChannel MixSpeakerSub MixPos MixRoomDim MixRoomRT60 MixScreenDim MixScreenPos 5 Значення Позитивне ціле число Координати x, y, z для кожного гучномовця Опис Повний діапазон, обмежена амплітудно-частотна характеристика для LF, наднизькочастотний гучномовець Низькочастотна точка 3 дБ для гучномовців FR і LLF, високочастотна точка 3 дБ для гучномовців Позитивне ціле число (Гц) для наднизькочастотних типів. Може кожного гучномовця використовуватися для приведення у відповідність із можливостями відтворення спектра устаткуванням етапу мікшування. Відображення гучномовець→канал. {L, C, R, Ls, Rs, Lss, Rss, Lrs, Rrs, Використовувати "жодного" для Lts, Rts, жодного, інший}, для гучномовців, які не являються кожного гучномовця зв'язаними Відображення гучномовець→наднизькочастотний канал. Використовується для зазначення цільового наднизькочастотного гучномовця для керування басами кожного гучномовця. Список пар (коефіцієнт посилення, Баси кожного гучномовця можуть номер гучномовця). Коефіцієнт управлятися більш ніж одним посилення має дійсне значення: наднизькочастотним гучномовцем. 0≤коефіцієнт посилення≤1,0. Коефіцієнт посилення вказує частку Номер гучномовця – ціле число. сигналу басів, яка повинна проходити 0
ДивитисяДодаткова інформація
Назва патенту англійськоюSystem and method for adaptive audio signal generation, coding and rendering
Автори англійськоюRobinson, Charles Q., Tsingos, Nicolas R., Chabanne, Christophe
Автори російськоюРобинсон Чарльз К., Тсингос Николас Р., Шабанне Кристоф
МПК / Мітки
Мітки: адаптивного, система, сигналу, представлення, даних, спосіб, звукового, кодування, генерування
Код посилання
<a href="https://ua.patents.su/42-114793-sistema-ta-sposib-dlya-generuvannya-koduvannya-ta-predstavlennya-danikh-adaptivnogo-zvukovogo-signalu.html" target="_blank" rel="follow" title="База патентів України">Система та спосіб для генерування, кодування та представлення даних адаптивного звукового сигналу</a>
Система цифрового кодування-декодування, кодер, декодер, носій запису та спосіб передавання широкосмугового цифрового звукового сигналу

Номер патенту: 73532
Опубліковано: 15.08.2005
Автори: Тайле Гюнтер, Локофф Герардус Корнеліс Петрус, Деері Ів Франсуа, Штолль Герхард
МПК: H04B 1/66, H04J 3/00, G11B 20/10
Мітки: кодер, запису, декодер, кодування-декодування, передавання, сигналу, звукового, широкосмугового, носій, система, спосіб, цифрового
Формула / Реферат:
1. Система цифрового кодування-декодування, яка включає в себе кодер і декодер, для кодування-декодування широкосмугового цифрового звукового сигналу, що включає в себе щонайменше перший і другий компоненти сигналу, причому згаданий кодер має засіб із фільтрами аналізу для фільтрування згаданих компонентів сигналу таким чином, щоб одержувати певну кількість (n) субсигналів для згаданих щонайменше двох компонентів сигналу, і засіб виведення...
Спосіб передачі звукового сигналу всередині автомобіля

Номер патенту: 62190
Опубліковано: 10.08.2011
Автори: Бабарикін Олексій Валентинович, Голубєв Олександр Анатолійович, Тарадін Віталій Євгенович, Ткаленко Андрій Олександрович, Алексєєв Олег Вадимович, Камбуров Артем Дмитрович
МПК: B60R 25/00, B60R 99/00
Мітки: передачі, сигналу, звукового, спосіб, автомобіля
Формула / Реферат:
Спосіб передачі звукового сигналу всередині автомобіля, що включає передачу звукового сигналу від мультимедійного головного пристрою до звукового підсилювача, який відрізняється тим, що за допомогою звукового каналу мультимедійного головного пристрою після обробки звуку по команді мікропроцесора видають звуковий сигнал в RF-модуль зв'язку, де обробляють і кодують звуковий сигнал, перетворюють у цифровий сигнал і передають його по...
Представлення даних звукових об’єктів з позірним розміром у довільні схеми розташування гучномовців

Номер патенту: 113344
Опубліковано: 10.01.2017
Автори: Тсінгос Ніколас Р., Матеос Соле Антоніо
МПК: H04S 3/00
Мітки: даних, позірним, об'єктів, розташування, звукових, представлення, довільні, розміром, схемі, гучномовців
Формула / Реферат:
1. Спосіб, що включає:приймання даних звуковідтворення, що включають один або декілька звукових об'єктів, при цьому звукові об'єкти включають звукові сигнали та зв'язані метадані, при цьому метадані включають щонайменше дані положення звукового об'єкта та дані розміру звукового об'єкта;обчислення для звукового об'єкта з одного або декількох звукових об'єктів значень коефіцієнта підсилення віртуального джерела від віртуальних...
Система бездротової передачі даних, спосіб бездротової передачі даних між передавальним і отримуючим пристроями, спосіб бездротового отримання сигналу, передавальний пристрій для бездротової передачі даних і от

Номер патенту: 102893
Опубліковано: 27.08.2013
Автор: Босенко Ростислав Володимирович
МПК: H04B 7/00, H04L 12/00, H04M 1/00
Мітки: даних, бездротової, отримуючим, пристрій, отримання, пристроями, передавальний, передавальним, сигналу, спосіб, бездротового, система, передачі
Формула / Реферат:
1. Система бездротової передачі, що включає:передавальний апарат, який виконано з можливістю передачі потоку даних, який включає:підготовлювач сигналу, з'єднаний із потоком даних і виконаний з можливістю вироблення повторювального сигналу та інвертованого сигналу;перший передавальний термінал, з'єднаний із підготовлювачем сигналу таким чином, щоб перший передавальний термінал створював електричне поле, що представляє...
Поліпшення звукового сигналу з використанням оцінювальних просторових параметрів

Номер патенту: 113682
Опубліковано: 27.02.2017
Автори: Девіс Марк Ф., Єн Куан-Чіех, Дейвідсон Грант А., Філлерс Метью, Мелкоте Вінай
МПК: G10L 19/008, G10L 19/02
Мітки: звукового, параметрів, використанням, поліпшення, оцінювальних, просторових, сигналу
Формула / Реферат:
1. Спосіб, який включає:приймання аудіоданих, що включають перший набір частотних коефіцієнтів і другий набір частотних коефіцієнтів;оцінювання на основі щонайменше частини першого набору частотних коефіцієнтів, просторових параметрів щонайменше для частини другого набору частотних коефіцієнтів; ізастосування оцінювальних просторових параметрів до другого набору частотних коефіцієнтів для генерування модифікованого...
Попередній патент: Коагоніст глюкагонового рецептора/glp-1-рецептора
Наступний патент: Використання неорганічної солі, що містить бромід, і активованого вугілля для скорочення викиду ртуті з потоку горючого газу
Випадковий патент: Спосіб отримання плоских багатошарових зливків в електронно-променевій установці