Спосіб морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань
Номер патенту: 75250
Опубліковано: 26.11.2012
Автори: Бісікало Олег Володимирович, Кравчук Ірина Анатоліївна




Формула / Реферат
Спосіб морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань, в якому, використовуючи закладені правила, визначають можливі корені кожної основи та використовують корінь слова разом з інформацією, що міститься в повній формі, в якій слово з'являється, тобто, використовують префікси та суфікси, який відрізняється тим, що вхідними даними для морфологічного аналізу є попередньо побудований словник мовних образів з записами у вигляді наборів спільнокореневих слів, що розміщений на зовнішньому електронному носії інформації та надходить в блок морфологічного аналізу по шині вхідних даних, базу знань з морфології формують на основі правил, що отримані шляхом попереднього аналізу структури слова флексійних мов, попередньо відділяючи основу слова, після чого визначають можливі корені кожного слова з вхідного словника мовних образів та префікси і суфікси в блоці морфологічного аналізу на рівні центрального процесору, обмін даними з яким здійснюють через канал зчитування та передачі даних; суфікси та префікси визначають за допомогою коефіцієнтів входження потенційного суфікса/префікса в послідовності символів, отримані за результатами аналізу, які зберігають в оперативному запам'ятовувальному та постійному запам'ятовувальному пристроях.
Текст
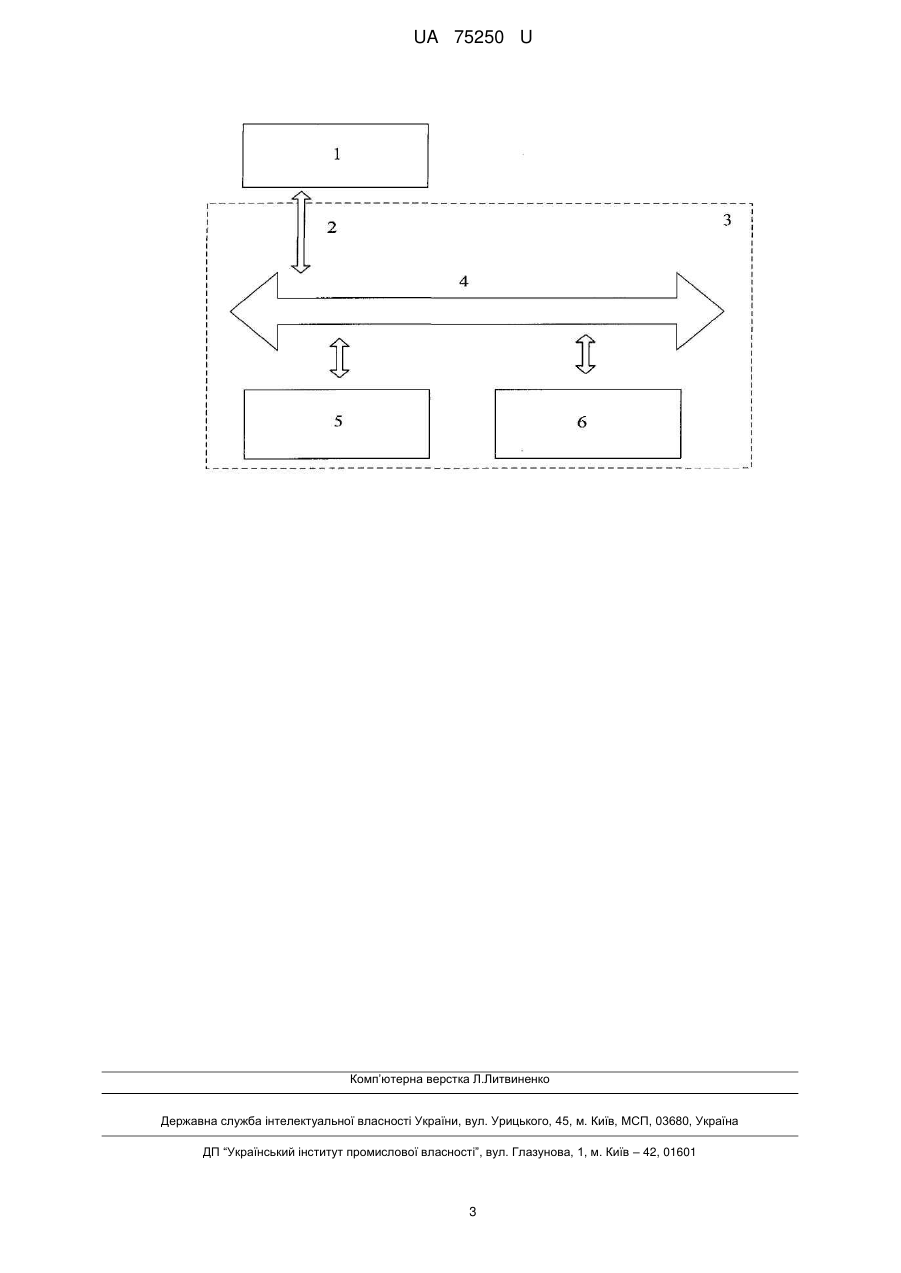
Реферат: UA 75250 U UA 75250 U 5 10 15 20 25 30 35 40 45 50 55 Корисна модель належить до інформаційних технологій і може використовуватись для виконання морфологічного аналізу в системах лінгвістичної обробки природномовних текстів. Відомий морфологічний аналізатор, що виконує морфологічний аналіз вхідного слова (патент США № 5323316, м. кл. G06F 015/38, опубл. 21.06.1994). Спосіб полягає у тому, що формальні лінгвістичні засоби аналізують вхідне слово, починаючи з першого символу і далі по одній літері. Засоби, що знаходять основу, працюють, починаючи від початку вхідного слова і продовжуючи через вхідне слово по одній літері, щоб знайти основу. Засоби, що знаходять основу, починають своє завдання розпізнавання на n-й літері вхідного слова, пропускаючи перші n-1 літери вхідного слова, де n є цілочисельною змінною, яка приймає різні значення в залежності від розміру вхідного слова. Засоби, що знаходять суфікс, продовжують працювати з частиною вхідного слова, залишаючи після основи одну літеру, щоб знайти суфікси. Засоби, що знаходять основу та суфікс, використовують дворівневу морфологічну модель для виконання своїх функцій. Дворівнева морфологічна модель є похідною від набору правил правопису, які перетворюють рядок в лексичний рядок, і це здійснюється одним автоматом. Вказаний спосіб має той недолік, що він не виокремлює префікси вхідних слів, а лише основу та суфікси. Найбільш близьким є спосіб автоматизованого морфологічного аналізу структури слова (патент США № 5251129, м. кл. G06F 17/27, опубл. 10.05.1993). Спосіб полягає у створенні інформації про форму кожного слова тексту шляхом розбиття слова на потенційні пари основа-суфікс і основа-префікс. Тоді, використовуючи правила правопису, визначають можливі корені кожної основи. Для кожного можливого кореня варіант слова отримують зі словника. Для кожного слова отримують словотворчу інформацію для кожного афікса. Потім словотворчу інформацію представляють у словниковій статті. Для кожної пари використовують оптимізаційні операції для визначення ймовірності правильності кожної пари основа-суфікс і основа-префікс. Спосіб забезпечує чітке визначення у текстовому представленні відношень між словами, які є похідними від спільного кореня, шляхом використання кореневого слова разом з інформацією, що міститься в повній формі, в якій слово з'являється, тобто, використання префікса, суфікса і кореня. Вказаний спосіб має той недолік, що морфологічний аналіз ефективно виконується лише для тих слів, інформацію про які попередньо розміщено у словнику, що вимагає залучення кваліфікованих експертів-лінгвістів. В основу корисної моделі поставлено задачу підвищення ефективності виконання морфологічного аналізу слів тексту. Поставлена задача вирішується тим, що в способі морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань, в якому вхідними даними є попередньо побудований словник мовних образів з записами у вигляді наборів спільнокореневих слів, що розміщений на зовнішньому електронному носії інформації, яку обробляє блок морфологічного аналізу, формують базу знань з морфології на основі правил, що отримані шляхом попереднього аналізу структури слова флексійних мов, попередньо відділяють основу слова, після чого визначають можливі корені кожного слова з вхідного словника мовних образів та префікси і суфікси в блоці морфологічного аналізу, обмін даними здійснюють через канал зчитування та передачі даних, суфікси та префікси визначають за допомогою коефіцієнтів входження потенційного суфікса/префікса в послідовності символів, отриманих за результатами аналізу, що зберігаються в оперативному запам'ятовувальному пристрої та постійному запам'ятовувальному пристрої. Спосіб морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань має програмно-апаратну реалізацію у вигляді блока морфологічного аналізу, схема якого представлена на кресленні. Схема для реалізації способу морфологічного аналізу на основі асоціативно-статистичного підходу складається з зовнішнього носія інформації 1, шини вхідних даних 2, персонального комп'ютера 3 та його складових - каналу зчитування та передачі даних 4, центрального процесору 5, запам'ятовувальних пристроїв 6 - оперативний запам'ятовувальний пристрій (ОЗП) та постійний запам'ятовувальний пристрій (ПЗП). Спосіб здійснюється наступним чином. На вхід каналу зчитування та передачі даних 4 надходить словник мовних образів, що містить записи у вигляді наборів спільнокореневих слів, та список можливих закінчень, що розміщені на зовнішньому електронному носії інформації 1. Частина словника мовних образів має вигляд: 60 1 UA 75250 U 1 2 3 5 10 15 20 25 30 мова вода друк мовний підводний роздрукований безмовний безводний друкарня мовленнєвий надводна друкарський мовлення підводна друкарка водний друкар Список закінчень має вигляд: "ий, а, я, …" У блоці морфологічного аналізу на рівні центрального процесору 5 кожний елемент словника порівнюють з переліком можливих закінчень, що надходять по шині вхідних даних 2. У випадку співпадіння останніх символів слова зі словника з можливим закінченням, закінчення відсікають, після чого отримане слово без закінчення є основою і зберігається в блоці пам'яті 6 для подальшого аналізу. В блоці морфологічного аналізу на рівні центрального процесору 5 порівнюють слова без закінчень (основи), що вже зберігаються в блоці пам'яті 6 з метою визначення найбільш довгої спільної послідовності символів для всіх слів списку, що відповідають окремому мовному образу. Визначена послідовність символів є коренем. На даному етапі слово як послідовність символів розбивають на 3 частини - символи, що розташовані до кореня, символи, що розташовані після кореня, які передають в блок пам'яті 6 для зберігання до подальшої обробки, та, власне, корінь. Потім в блоці морфологічного аналізу на рівні центрального процесору 5 визначають суфікси слів. Для цього символи, що розташовані після кореня, передають з блока пам'яті 6. Кожному післякореневому набору символів привласнюють початкове значення коефіцієнта входження, що, по замовчуванню, дорівнює одиниці. Коефіцієнт входження показує кількість входжень певного набору післякореневих символів. Після чого визначають початкову послідовність символів як найкоротшу послідовність. Після цього у блоці аналізу на рівні центрального процесору 5 порівнюють решту післякореневих наборів символів з початковою послідовністю. У випадку співпадіння символів початкової послідовності з символами поточної послідовності, коефіцієнт входження для початкової послідовності збільшують на 1. При цьому символи початкової послідовності видаляють з проаналізованої. Після цього вибирають нову наступну початкову післякореневу послідовність символів з блока пам'яті 6 і повторюють процедуру аналізу. Після виконання аналізу всіх післякореневих послідовностей, що містяться у блоці пам'яті 6, за коефіцієнтами входження визначають суфікси. Суфіксом визначають послідовності символів, коефіцієнт входження для якого більший, ніж у самої післякореневої послідовності, до складу якої вони входять. Префікси визначають в блоці аналізу на рівні центрального процесору 5, використовуючи передкореневі послідовності символів, що зберігаються в блоці пам'яті 6, аналогічно до визначення суфіксів. ФОРМУЛА КОРИСНОЇ МОДЕЛІ 35 40 45 Спосіб морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань, в якому, використовуючи закладені правила, визначають можливі корені кожної основи та використовують корінь слова разом з інформацією, що міститься в повній формі, в якій слово з'являється, тобто, використовують префікси та суфікси, який відрізняється тим, що вхідними даними для морфологічного аналізу є попередньо побудований словник мовних образів з записами у вигляді наборів спільнокореневих слів, що розміщений на зовнішньому електронному носії інформації та надходить в блок морфологічного аналізу по шині вхідних даних, базу знань з морфології формують на основі правил, що отримані шляхом попереднього аналізу структури слова флексійних мов, попередньо відділяючи основу слова, після чого визначають можливі корені кожного слова з вхідного словника мовних образів та префікси і суфікси в блоці морфологічного аналізу на рівні центрального процесору, обмін даними з яким здійснюють через канал зчитування та передачі даних; суфікси та префікси визначають за допомогою коефіцієнтів входження потенційного суфікса/префікса в послідовності символів, отримані за результатами аналізу, які зберігають в оперативному запам'ятовувальному та постійному запам'ятовувальному пристроях. 2 UA 75250 U Комп’ютерна верстка Л.Литвиненко Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 3
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod of morphological analysis based on content addressable statistical approach to education
Автори англійськоюBisikalo Oleh Volodymyrovych, Kravchuk Iryna Anatoliivna
Назва патенту російськоюСпособ морфологического анализа на основе ассоциативно-статистического подхода к получению знаний
Автори російськоюБисикало Олег Владимирович, Кравчук Ирина Анатольевна
МПК / Мітки
МПК: G06F 17/27
Мітки: морфологічного, аналізу, основі, спосіб, асоціативно-статистичного, підходу, знань, отримання
Код посилання
<a href="https://ua.patents.su/5-75250-sposib-morfologichnogo-analizu-na-osnovi-asociativno-statistichnogo-pidkhodu-do-otrimannya-znan.html" target="_blank" rel="follow" title="База патентів України">Спосіб морфологічного аналізу на основі асоціативно-статистичного підходу до отримання знань</a>
Пристрій для морфологічного аналізу природномовних текстів

Номер патенту: 72914
Опубліковано: 27.08.2012
Автори: Величко Віталій Юрійович, Кривий Сергій Лук'янович, Петренко Микола Григорович, Опанасенко Володимир Миколайович, Софіюк Олександр Танасович, Мушка Віра Михайлівна, Палагін Олександр Васильович, Митрофанова Ганна Євгенівна
МПК: G06F 15/16, G06F 15/00
Мітки: природномовних, аналізу, текстів, морфологічного, пристрій
Формула / Реферат:
Пристрій морфологічного аналізу природномовних текстів, який містить блок регістрів символів, блок дешифраторів символів, блок пам'яті основ, блок пам'яті закінчень, блок комутаторів, блок ключів і блок мікропрограмного керування, при цьому перший інформаційний вихід блока дешифраторів символів підключений до першого інформаційного входу блока пам'яті основ, а групи з першої по q-ту інформаційних виходів підключені відповідно до групи перших...
Спосіб морфологічного аналізу якості м’яса при різному виді консервування

Номер патенту: 34176
Опубліковано: 25.07.2008
Автори: Криштофорова Беса Владиславівна, Янович Галина Вікторівна, Прокушенкова Олена Геннадіївна
МПК: G01N 33/02
Мітки: м'яса, якості, різному, аналізу, види, морфологічного, спосіб, консервування
Формула / Реферат:
Спосіб морфологічного аналізу якості м'яса при різному виді консервування, що включає мікроструктурний аналіз м'яса, який відрізняється тим, що включає визначення морфології, за допомогою світлової мікроскопії, поперечно-посмугованих м'язових волокон, розташування ядер, наявності посмугованості та цілісності міофібрил та сарколеми міоцитів.
Спосіб статистичного аналізу бази даних підготовки кадрового потенціалу

Номер патенту: 59188
Опубліковано: 15.08.2003
Автори: Сергієнко Іван Васильович, Згуровський Михайло Захарович, Бобовкін Віктор Тихонович, Воробйов Юрій Євгенович, Артеменко Віктор Іванович, Прокоф'єв Валентин Якович
Мітки: підготовки, даних, статистичного, аналізу, спосіб, потенціалу, базі, кадрового
Формула / Реферат:
Спосіб статистичного аналізу бази даних підготовки кадрового потенціалу в інформаційно-виробничій системі, яку використовують для управління освітою, яким передбачено запис в банк даних системи наданої низовими структурами галузей первинної інформації про наявний кадровий потенціал, який відрізняється тим, що вказану первинну інформацію структуризують по всіх галузях, при цьому кожній структурній одиниці, що відповідає тій чи іншій галузі,...
Спосіб визначення часу формування гематом за допомогою статистичного аналізу поляризаційних зображень біологічних тканин трупа людини

Номер патенту: 32310
Опубліковано: 12.05.2008
Автор: Бачинський Віктор Теодосович
МПК: G01N 33/00
Мітки: аналізу, людини, гематом, тканин, поляризаційних, формування, визначення, спосіб, трупа, часу, статистичного, біологічних, допомогою, зображень
Формула / Реферат:
Спосіб визначення часу формування гематом за допомогою статистичного аналізу поляризаційних зображень біологічних тканин трупа людини шляхом оцінки часових значень характеру змін тканин, який відрізняється тим, що використовують висококогерентне лінійно поляризоване випромінювання з довжиною хвилі 0,6328 мкм, формують поляризаційне зображення гематоми в площині світлочутливої цифрової камери, обчислюють статистичні моменти 1-го - 4-го...
Спосіб побудови системи для аналізу мовних брендів

Номер патенту: 9180
Опубліковано: 15.09.2005
Автори: Пєвнєв Володимир Яковлевич, Логвиненко Микола Федорович, Чурюмов Геннадій Іванович, Серков Олександр Анатолійович
МПК: G06G 7/12, G06F 17/20, G10L 15/00
Мітки: побудови, аналізу, мовних, брендів, системі, спосіб
Формула / Реферат:
Спосіб побудови системи для аналізу мовних брендів, що включає аналіз дослівного перекладу коренів іноземних слів, перевірку сполучення складів на мелодійність звучання, який відрізняється тим, що додатково здійснюється переведення букв в звук з підраховуванням шкали звуків за існуючою таблицею з подальшим аналізом слова по семантичному, фонетичному фільтру та фільтру звукового символізму з подальшим синтезом нових мелодійних слів -...
Попередній патент: Спосіб вимірювання мотивації студентів до навчання при роботі в інтерактивному комп’ютерному середовищі
Наступний патент: Регульований широкочастотний динамічний гасник коливань роторної машини
Випадковий патент: Спосіб вимірювання пікової напруги електричних імпульсів та пристрій для його реалізації