Спосіб кластеризування набору об’єктів з використанням зразка







Формула / Реферат
1. Спосіб кластеризування набору об'єктів з використанням зразка або еталонних значень характеристик об'єктів, наприклад в інформаційно-пошукових системах, який відрізняється тим, що для поділу набору об'єктів на групи об'єктів виконують таку послідовність дій: визначають деякі еталонні значення характеристик об'єкта, ці значення задають безпосередньо або за допомогою чисельних чи математичних співвідношень, або вказують на деякий зразок, що є вибраним об'єктом із даного набору об'єктів, чи деякий, можливо інакший, попередньо вибраний об'єкт не з даного набору об'єктів, наприклад фізичний еталон, і використовують значення характеристик цього вибраного об'єкта; для кожного об'єкта зі згаданого набору об'єктів визначають відмінність значень його характеристик від еталонних значень і виражають цю відмінність у вигляді упорядкованого набору чисел чи вектора, який ставлять у відповідність даному об'єкту; виконують кластеризування отриманого набору векторів або набору упорядкованих наборів чисел; таким чином відповідно до результатів виконаного кластеризування одержують поділ згаданого набору об'єктів на групи об'єктів.
2. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що набором об'єктів є набір документів, що отримані у результаті виконання інформаційного пошуку, який проведений з використанням однієї чи багатьох інформаційно-пошукових систем; при цьому еталонні значення характеристик можуть бути задані за допомогою документа-зразка, який або був зазначений заздалегідь, або вибраний з отриманих документів, чи за допомогою іншого об'єкта, наприклад пошукового запиту.
3. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що для зменшення кількості об'єктів у наборі об'єктів виконують таку послідовність дій: визначають еталонні значення; для кожного з об'єктів визначають відмінність його значень від еталонних; виділяють зі згаданого набору об'єктів деяку його частину, до якої включають тільки такі об'єкти, характеристики яких мало відрізняються від еталонних значень, а всі інші об'єкти з початкового набору виключають з розгляду; виділення такої частини набору об'єктів може бути виконано за допомогою деякої заданої міри для оцінки величини відмінності характеристик об'єкта від еталонних значень; після цього виконують кластеризування отриманого зменшеного набору об'єктів; якщо потрібно, до результатів кластеризування додають окрему групу (кластер), до якої відносять всі об'єкти з початкового набору, що були виключені з розгляду.
4. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що після виконання кластеризування створюють опис (резюме) кожної отриманої групи (кластера) на основі змісту або вибраних характеристик об'єктів з цієї групи (кластера); і, якщо це можливо та потрібно, описи, які отримані, можуть додаватися до набору об'єктів як нові об'єкти.
5. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що після виконання описаного кластеризування принаймні для однієї з отриманих груп (кластерів) об'єктів вибирають чи указують які-небудь інші еталонні значення характеристик, після чого виконують кластеризування об'єктів з цієї групи на кілька груп (підкластерів), і, якщо потрібно, повторюють з отриманими групами об'єктів цю послідовність дій потрібне число разів.
6. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що після виконання кластеризування об'єктів на групи виконують таку послідовність дій: пропонують користувачу групи об'єктів, що отримані; користувач вибирає одну або декілька з цих груп (кластерів) об'єктів; за результатами зробленого вибору змінюють еталонні значення характеристик; виконують нове кластеризування цього набору об'єктів або вибраної частини цього набору, або об'єктів іншого набору об'єктів, що отримані відповідно до згаданих змінених еталонних значень характеристик; якщо необхідно, повторюють дії потрібне число раз.
7. Спосіб кластеризування набору об'єктів з використанням зразка за п. 1, який відрізняється тим, що після виконання описаного кластеризування, якщо кількість отриманих груп (кластерів) об'єктів занадто велика, виконують об'єднання деяких груп; якщо ж кількість отриманих груп (кластерів) занадто мало, деякі групи розділяють на менші групи.
8. Спосіб кластеризування набору об'єктів з використанням зразка або еталонних значень характеристик згаданих об'єктів, який відрізняється тим, що для поділу набору об'єктів на групи об'єктів виконують таку послідовність дій: попередньо визначають набір суттєвих характеристик згаданих об'єктів; попередньо задають деяку першу міру (чи операцію виміру) для визначення у вигляді одного числа абсолютної величини відмінності значень характеристик одного об'єкта від значень характеристик іншого об'єкта; попередньо задають деяку другу міру (чи операцію виміру) для визначення у вигляді одного числа величини близькості між значеннями відмінності одного й іншого об'єктів, причому ця друга міра може бути не тотожною з першою мірою; визначають деякі еталонні значення характеристик об'єкта, ці значення задають безпосередньо або за допомогою чисельних чи математичних співвідношень, або вказують на деякий зразок, що є вибраним об'єктом із даного набору об'єктів, чи деякий, можливо інакший, попередньо вибраний об'єкт не з даного набору об'єктів, і використовують значення характеристик цього вибраного об'єкта; для кожного об'єкта зі згаданого набору об'єктів визначають відмінність значень його характеристик від еталонних значень і виражають цю відмінність у вигляді упорядкованого набору чисел чи вектора, який ставлять у відповідність даному об'єкту; за допомогою заданої першої міри для кожного об'єкта зі згаданого набору об'єктів визначають абсолютну величину відмінності значень його характеристик від еталонних значень; упорядковують згаданий набір об'єктів по незменшуванню згаданих абсолютних величин відмінностей; задають деяке правило (критерій) для визначення приналежності двох вибраних об'єктів зі згаданого набору об'єктів до однієї і тієї ж групи (кластера) об'єктів, причому в згаданому правилі може використовуватися одна чи кілька величин, отриманих за допомогою принаймні однієї з вищезгаданих мір близькості, причому вигляд цього правила може залежати від отриманих вище величин відмінностей значень характеристик об'єктів від еталонних значень; відносять перший в отриманому упорядкованому наборі об'єкт до першої групи (кластера); перевіряють виконання зазначеного правила для наступного об'єкта і для всіх інших об'єктів по черзі відповідно до отриманого упорядкованого набору і, якщо правило дає позитивний результат (критерій виконується), даний об'єкт також відносять до першої групи (кластера); відносять перший в отриманому упорядкованому наборі об'єкт, який ще не був віднесений ні до однієї групи (кластера), до нової, наступної групи (кластера); якщо дозволено створювати кластери, що перекриваються, перевіряють зазначене правило (перевіряють виконання зазначеного критерію) для вищезгаданого об'єкта та по черзі для кожного з усіх інших об'єктів, що мають більші номери в упорядкованому наборі; якщо ж кластери не повинні перекриватися, то перевіряють виконання зазначеного критерію для вищезгаданого об'єкта й один по одному для всіх об'єктів, що мають більші номери в упорядкованому наборі і не були ще віднесені до будь-якого кластера; і коли критерій виконується, відносять об'єкт з більшим номером до новоствореного кластера першого об’єкта; виконують цю послідовність дій доти, поки в отриманому упорядкованому наборі об'єктів не залишиться жодного об'єкта зі згаданого набору об'єктів, що не був віднесений до будь-якої групи (кластера).
9. Спосіб кластеризування набору об'єктів з використанням зразка за п. 8, який відрізняється тим, що після виконання описаного кластеризування, якщо кількість отриманих груп (кластерів) занадто велика або занадто мала, змінюють задане правило визначення (вигляд критерію) приналежності двох об'єктів одній групі (кластера) і потім заново виконують усю подальшу послідовність дій.
10. Спосіб кластеризування набору об'єктів з використанням зразка за п. 8, який відрізняється тим, що набір об'єктів може поповнюватися іншими об'єктами як під час виконання кластеризування, так і після закінчення кластеризування всіх об'єктів з початкового набору об'єктів, і при додаванні нового об'єкта виконують таку послідовність дій: для нового об'єкта визначають відмінність значень його характеристик від еталонних значень і виражають цю відмінність у вигляді вектора або упорядкованого набору чисел; за допомогою заданої першої міри визначають абсолютну величину відмінності значень характеристик нового об'єкта від еталонних значень; додають новий об'єкт до початкового набору об'єктів та знаходять його місце у вже створеному упорядкованому наборі об'єктів по незменшенню абсолютних величин відмінностей; далі менші і більші номери об'єктів щодо нового об'єкта - це місця об'єктів до чи після нового в цьому упорядкованому наборі; перевіряють приналежність нового об'єкта кластерам, до яких входять об'єкти, що мають менші номери в отриманому упорядкованому наборі і, якщо критерій виконується, відносять новий об'єкт до відповідного кластера; якщо новий об'єкт не був віднесений до жодного кластера і в наборі є інші об'єкти з меншими номерами, що не були віднесені до якого-небудь кластера, то переходять до дій або переходять до наступної дії; якщо новий об'єкт не був віднесений до жодного кластера, відносять його до нового, наступного кластера; якщо новий об'єкт був віднесений до нового кластера, перевіряють приналежність цьому кластеру тих об'єктів, що мають більші номери в отриманому упорядкованому наборі і мають найменші номери серед всіх об'єктів у своєму кластері; якщо критерій виконується, відповідний кластер розформовується, і всі об'єкти, що входили в нього, відносять до новоствореного кластера; якщо новий об'єкт був віднесений до нового кластера і дозволено створювати кластери, що перекриваються, перевіряють приналежність цьому кластеру всіх об'єктів, що мають більші номери в отриманому упорядкованому наборі; якщо критерій виконується, відповідний об'єкт відносять також і до даного новоствореного кластера; якщо новий об'єкт був віднесений до нового кластера і в наборі є інші об'єкти з великими номерами, що не були віднесені до жодного кластера, перевіряють приналежність цьому кластеру всіх таких об'єктів; якщо критерій виконується, відповідний об'єкт відносять до даного новоствореного кластера; після цього продовжують дії з цими об'єктами з початкового набору об'єктів; повторюють послідовність дій для кожного об'єкта, що додають до набору об'єктів.
Текст
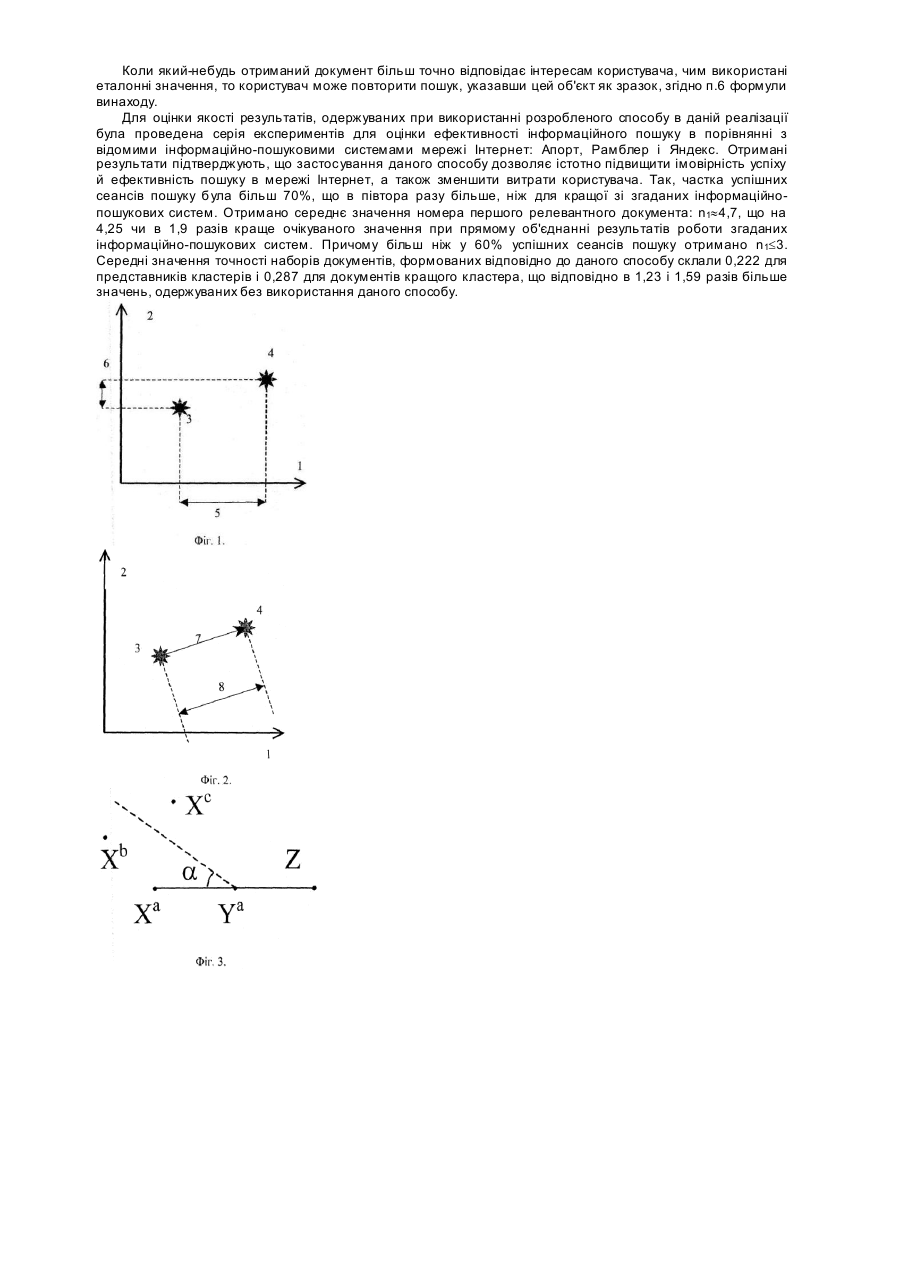
Винахід відноситься до області обробки даних, і може бути використаний для упорядкування набору об'єктів, наприклад, при виконанні інформаційного пошуку, кластерізації наборів даних, класифікації даних, візуалізації даних і т.і. Об'єктами, набір яких може бути кластеризований вказаним способом можуть бути самі різноманітні сутності. Так, наприклад, у задачах геологорозвідки об'єктами можуть бути проби гірничих порід; у задачах екологічного моніторингу - проби ґрунтових вод і атмосферного повітря, у задачах інформаційного пошуку деякі узагальнені «документи», зокрема текстові документи, окремі записи в базі даних, графічні зображення, аудіо- чи відеозаписи, інші об'єкти мультимедіа, і т.п. Кожен об'єкт характеризується деякою сукупністю даних. Говорячи про характеристики об'єкта, ми маємо на увазі важливі характеристики, властивості, параметри об'єкта, які можна яким-небудь чином вимірити і значення яких важливі для рішення поставлених задач. Так, наприклад, важливими характеристиками об'єктів - проб гірничих порід буде зміст (концентрація) тих чи інших корисних хімічних з'єднань. У задачах екологічного моніторингу характеристиками об'єктів будуть навпаки, концентрації шкідливих речовин і хімічних з'єднань. У задачах матеріалознавства важливими характеристиками будуть різні механічні і фізичні властивості матеріалів, наприклад: щільність, модуль пружності, температурний коефіцієнт довжини і т.п. У задачах інформаційного пошуку і класифікації документів важливими характеристиками будуть, наприклад: частоти визначених ключових слів у тексті, спектральна характеристика аудіозапису, дата створення документа, його розмір і ін. Причому характеристика може бути як числовою, наприклад для документів: кількість вживання терміну в тексті, розмір зображення в точках (пікселах) і ін., так і не числовий, наприклад: заголовок тексту, останній кадр відеозапису та ін. У більшості варіантів використовуються чисельні характеристики властивостей інформації, що міститься в об'єкті. Особливо підкреслимо, що характеристика може бути дуже складним параметром, як наприклад, у методі обробки масиву документів, відомому як «латентний семантичний аналіз», кореляції між термінами виявляються за допомогою сингулярного розкладання матриці частот термінів у наборі документів. Характеристики об'єктів ми перелічуємо в якомусь заданому порядку. Значення чисельних характеристик кожного об'єкта дають упорядкований набір чисел. Такий упорядкований набір інакше називають «вектор». Відмінність значень характеристик двох об'єктів або різниця значень упорядкованих наборів чисел є різниця векторів, яка також буде вектором, тобто упорядкованим набором чисел. На Фіг.1. дано приклад визначення такого набору з двох чисел. Вказано: 1. Характеристика №1. 2. Характеристика №2. 3. Зразок (еталон). 4. Об'єкт. 5. Відмінність значення характеристики №1 об'єкту від еталонного значення характеристики №1. 6. Відмінність значення характеристики №2 об'єкту від еталонного значення характеристики №2. Абсолютна величина відмінності значень характеристик одного об'єкта від значень характеристик іншого об'єкта, є абсолютна величина вектора різниці двох зазначених векторів. Абсолютна величина - це одне число, що відповідає «довжині» цього вектора. Див., на приклад, визначення абсолютної величини на Фіг.2. Вказано: 7. Вектор відмінності. 8. Абсолютна величина відмінності значень характеристик об'єкту від еталонних. Коли ми говоримо про кластеризування (або кластеризацію) набору об'єктів, то маємо на увазі поділ усього набору на деяку кількість (більше однієї) груп об'єктів так, що кожен об'єкт із набору входить в одну груп у (а в деяких спеціальних варіантах кластеризування об'єкт може входити до кількох груп), всі об'єкти з кожної групи входять у набір і у кожній групі є принаймні один об'єкт. При необхідності кожна група (у який більш одного об'єкта) може бути розділена на кілька менших гр уп. Груп у об'єктів інакше називають кластером. Для виконання кластеризування набору фізичних об'єктів ми оперуємо не самими об'єктами безпосередньо, а обробляємо дані (інформацію) про значення характеристик об'єктів з набору. Перед цим дані звичайно записуються на один чи кілька носіїв інформації і містяться там. Якщо потрібно виконати кластеризацію набору фізичних об'єктів, то кожному фізичному об'єкту ставлять у відповідність інформаційний об'єкт - сукупність даних (інформації) про характеристики цього фізичного об'єкта. Далі будемо говорити тільки про інформаційні об'єкти. У послідовності дій, що запропоновано у способі, основні дії мають бути виконані не людиною вручну, а автоматично, за допомогою відповідного електронного чи механічного пристрою, або електроннообчислювальної системи. Так, наприклад, зі вказаної у способі по п.1 послідовності дій лише перша дія визначення деякого зразка або еталонних значень може виконуватися людиною - користувачем. В опису винаходу йдеться про процес (як об'єкт технології). Терміни кластеризування та кластеризация є синонімами. У минулому, коли не існувало ні дешевих високопродуктивних ЕОМ, ні зручних пристроїв збереження даних, і носії інформації, наприклад, перфокарти були незручні, кількість систем для автоматизованої обробки інформації була дуже невеликою. В останні десятиліття бурхливий розвиток комп'ютерної техніки надав можливості створювати величезну кількість різних сховищ даних, що можуть містити від тисяч до сотень мільйонів інформаційних об'єктів. Найбільше поширення мають бази даних, схови ща текстових і комбінованих (текст + графічні зображення) документів, а також банки зображень. Інші види схови щ, що містять, наприклад, аудіозаписи, відеозображення і т.п., менш поширені. При використанні сховищ даних виникає цілий ряд задач, для ефективного рішення яких потрібна побудова деяких упорядкувань наборів об'єктів, що містяться в цих схови щах. Серед цих задач найбільш важливими, на наш погляд, є перегляд і візуалізація даних, що містяться в цих сховища х, пошук інформації за запитами користувачів, побудова класифікацій і розпізнавання образів, видобуток даних чи ви тяг знань, оптимізація розподілу даних по різних пристроях збереження й ін. Одним з найбільш ефективних підходів для рішення цих задач є кластеризування. Цей підхід полягає у виявленні подібних у деякому сенсі (схожих, однорідних, гомогенних) об'єктів і об'єднанні їх у групи. У процесі кластеризування кожен об'єкт представлений як точка, яка розташована в деякому багатомірному просторі. На цьому просторі задають деяку міру близькості, що дозволяє чисельно вимірити відстань між точками. Чим менше ця відстань, тим більше схожі відповідні об'єкти. Відома безліч різних способів кластеризування. Близько 150 різних варіантів кластеризування, а також проблема вибору найбільш придатного з них розглянуті в [Мендель И.Д. Кластерный анализ. М: Финанси и статистика. 1988. 176с]. Основні способи виконання кластеризування можна розділити на такі групи: 1) кластеризація всього набору об'єктів без будь-якої додаткової інформації, крім, можливо, значень деяких параметрів обраної процедури кластеризування. 2) інтерактивна кластеризація всього набору об'єктів, коли після виконання чергового етапу кластеризування, користувач (чи інформаційний агент) надає додаткову інформація, яка впливає на наступні дії. 3) кластеризація підмножини об'єктів, що знаходиться поблизу деякої виділеної області. Перша група способів найбільш зручна в тих випадках, коли набір об'єктів є незмінним або змінюється дуже повільно. Наприклад, відомий спосіб [Пат. 5706503 США, G06F007/00; G06F017/18. Method of clustering multidimensional related data in a computer database by combining the two verticles of a graph connected by an edge having the highest score. / Poppen, et al. - №245690; заявлено: 18 травня 1994; опубліковано: 06 січня 1998p.], що складається в обробці деякого графа, на основі якого будується ієрархічна кластеризація, причому спочатку кожному запису з бази даних ставлять у відповідність вершину графа; потім вибирають пари вершин і обчислюють чисельні оцінки якості з'єднання обраних пар; з'єднують такі пари вершин, що одержали найкращі оцінки; визначають вершини з нових з'єднань для подальших дій; повторюють обчислення оцінок і з'єднання кращих пар в отриманому наборі вершин, доти, поки не буде виконана умова останову; зберігають отриманий граф як ієрархію кластерів. Побудова ієрархії кластерів приводить до того, що в залежності від умови останову, або не досягається необхідна деталізація кластерів, або виконується значна кількість непотрібних обчислень. Відомі два шляхи усунення цього недоліку: можна відмовитися від ієрархії і виконувати розбивки тільки на одному рівні, або використовува ти додаткову інформацію про мету кластеризування. Іншими важливими недоліками даного способу є труднощі наочної візуалізації отриманої ієрархії і необхідність виконання користувачем додаткових дій для того, щоб потрапити до потрібної області даних. Ще один істотний недолік ієрархічних способів кластеризування полягає в тому, що у користувача часто виникають труднощі при виборіодного з кластерів на кожнім рівні. Навіть один невірний вибір на верхніх рівнях ієрархії може завести дуже далеко від потрібного кластера. Відомі два шляхи усунення цього недоліку: можна використовувати кластери, що перекриваються, або дозволити вибирати кілька кластерів, як це зроблено в наступному способі. У більшості практичних задач, є додаткова інформація (тобто така, що не може бути однозначно визначена з характеристик розглянутого набору об'єктів). Розглянемо спочатку другу гр упу способів кластеризування, коли ця інформація надходить у ході виконання кластеризування. Найбільш зручний спосіб з цієї групи [Пат. 5442778 США, МКИ G06F017/30. Scatter-gather: a clusterbased method and apparatus for browsing large document collections. / Pedersen, et al. - №790316; заявлено: 12 листопада 1991; опубліковано: 15 серпня 1995p.] призначений для перегляду сукупності документів за допомогою комп'ютера, і передбачає наступні дії: виконують розподіл усіх документів із сукупності по першому набору кластерів, без використання додаткової інформації; для кожного кластера створюється резюме - опис документів з цього кластеру; отриманий набір кластерів і їх описів (резюме) пред'являють користувачу, який вибирає один або кілька кластерів з отриманого набору; документи, що входять в обрані кластери створюють нову сук упність документів (яка є підмножина початкової сукупності); документи з отриманої сукупності розподіляють по іншому набору кластерів; повторюють чотири попередні дії, поки не буде досягнутий потрібний рівень деталізації. Основним недоліком, на наш погляд, є те, що спосіб не дозволяє врахувати початкову інформацію про цілі кластеризування, про те, яка саме область даних є цікавою для користувача. Це приводить до необхідності виконати деяку кількість циклів кластеризування і вибору, щоб потрапити в потрібну користувача область. А це потребує затрат часу, виконання зайвих обчислень, додаткових дії користувача. Особливо значимо цей недолік при роботі з великими сховищами документів. Один з істотних ознак способу (який вимагає обчислень) - складання опису (чи резюме - короткого змісту) кластера, на наш погляд, може бути виключений, і тоді замість опису, кластер може бути представлений, наприклад, одним із документів, що входить до нього. Розглянемо тепер третю групу способів кластеризування. Відомий спосіб [Пат. 5546529 США, МКИ G06F015/72. Method and apparatus for visualization of database search results. / Bowers, et al. - №283004; заявлено: 28 липня 1994; опубліковано: 13 серпня 1996p.], що полягає у виконанні такої послідовності дій: задають значення першого набору характеристик піднабору документів, треба знайти; з наявного набору документів вибирають документи, що входять у цій піднабір; вказують другий упорядкований набір з N характеристик документів для поділу отриманого піднабору на групи, причому цей другий набір може не збігатися з першим; використовують другий набір характеристик для поділу піднабору документів і одержують N+1 - рівневу ієрархію, тобто стр уктуру графа "дерево"; потім розміщають отриману стр уктуру на деякій поверхні, а потім відображають її. Тут знову, одним з недоліків даного способу є багаторівневе групування, що утр удняє відображення і сприйняття результатів (а також вимагає додаткових обчислювальних витрат). Ін шим важливим недоліком є те, що вибір набору характеристик для одержання розбивки залишений на розсуд користувача. Таким чином, по-перше, стає дуже скрутним використання будь-яких складних характеристик, а це обмежує можливості застосування способу тільки областю баз даних; по-друге, вибір і упорядкування цих характеристик вимагає досить високої кваліфікації користувача. Відомий спосіб [пункт 11. Пат. 5911140 США, МКИ G06F017/30. Method of ordering document clusters given some knowledge of user interests. / Tukey, et al. - №572399; заявлено 14 грудня 1995; опубліковано; 08 червня 1999p.] перегляду сукупності документів, з використанням процесора і пам'яті, якій складається з наступної послідовності дій: a) одержують від користувача опис необхідної підмножини документів у виді деякого обмеження (умови) і перевіряють кожен документ із сукупності, чи задовольняє він даному обмеженню; b) упорядковують сукупність документів, розподіляючи їх по набору кластерів, кожний з який включає принаймні один документ; c) для кожного кластера визначають величину, що характеризує кластер, на основі кількості документів у кластері, які задовольняють обмеженню; і d) представляють отримані кластери користувачу на основі отриманих величин. Основними недоліками даного способу є: по-перше, використання бінарної оцінки приналежності документа необхідної підмножині, замість того, щоб використовува ти оцінку у виді числа; по-друге, у способі не враховується взаємне розташування різних кластерів. Прототипом даного винаходу є спосіб з третьої групи [пункт 1. Пат. 5911140 США, МКИ G06F017/30. Method of ordering document clusters given some knowledge of user interests. / Tukey, et al. - №572399; заявлено 14 грудня 1995; опубліковано: 08 червня 1999p.], що призначений для перегляду сукупності документів, отриманих у відповідь на запит користувача, причому кожен документ із сукупності має ранг; спосіб передбачає використання команд, що виконує процесор, і полягає в такій послідовності дій: упорядковують сук упність у набір кластерів, причому кожен кластер, включає, принаймні, один документ; визначають ранг кожного кластера на основі рангу одного з документів у кластері; і представляють кластери користувачу комп'ютера в порядку, заснованому на ранзі кластерів. Перелічимо суттєві ознаки прототипу. - Використовується отримана від користувача інформація для одержання початкової сукупності документів; - У способі зазначено джерело інформації від користувача; і це джерело - запит користувача; - Кожен документ має ранг; - Виконують упорядкування в кластери (один рівень); - Для кожного кластера визначають ранг; - Виведення результатів виконують тільки відповідно до рангу кластерів; - Виведення результатів (користувачу представляють отримані кластери) виконують послідовно. 1. У прототипі зазначено, що інформацію від користувача одержують у виді пошукового запиту. Таким чином, невиправдано обмежується область застосування методу тільки лише інформаційним пошуком. Можливі інші форми одержання цієї інформації, наприклад так, як визначено в пункті 11 того ж винаходу, де запропоновано використовувати не пошуковий запит, а деяку умову, яку задає користувач, щоб обмежити підмножину документів. 2. У прототипі зазначено, що кожен документ, а потім і кожен кластер, має ранг. По визначенню, ранг є місце об'єкта в деякім упорядкуванні, в окремому випадку ранг це номер об'єкта. В інформаційному пошуку під ранжируванням звичайно розуміють обчислення відстані між кожним документом і запитом, у результаті якого одержують набір чисел; ранг об'єкта визначає номер відповідного числа в упорядкуванні цих чисел. Таким чином, виконується проекція точок багатомірного простору на напівпряму, при цьому зберігається інформація про відстань від об'єкта до пошукового запиту, але відбувається втрата практично всієї інформації про взаємне розташування об'єктів. 3. У прототипі зазначено, що користувачу представляють отримані кластери послідовно. Це значно знижує наочність і збільшує інформаційне навантаження на користувача, тому що не дозволяє застосувати ефективні методи візуалізації, наприклад методи, відомі під назвами «конічні дерева», «риб'яче око», «зоряне небо» і ін. Задачею винаходу є побудова ефективної розбивки набору об'єктів на групи, тобто кластеризація набору об'єктів так, щоб отримані кластери відображали найбільш важливі особливості співвідношень характеристик розглянутих об'єктів. Причому отримане кластеризування має відображати зазначені співвідношення з погляду інтересів користувача, тобто так, щоб поблизу області інтересів користувача ці відносини були розкриті в істотно більшій повноті, ніж в удалині від області інтересів користувача. Іншою задачею винаходу є досягнення необхідної деталізації без великих обчислювальних витрат, які у загальному випадку мають зростати повільніше квадрата кількості об'єктів у розглянутому наборі, а у випадку однієї розбивки по кластерах мають лінійно залежати від кількості об'єктів у розглянутому наборі. У застосуванні до задач навігації у великих наборах об'єктів, метою винаходу є забезпечити уточнення місцезнаходження цікавої для користувача області об'єктів за можливо меншу кількість дій користувача, з можливо меншим інформаційним навантаженням на користувача, з можливо меншими витратами часу й обчислювальних ресурсів. У застосуванні до задач інформаційного пошуку у великих наборах об'єктів, метою винаходу є: забезпечити знаходження потрібних документів з можливо меншими витратами (за меншу кількість операцій), якщо ці документи є в розглянутому наборі, і забезпечити удосконалення пошукового запиту за допомогою зворотного зв'язку по релевантності, з можливо меншими витратами (за меншу кількість операцій), якщо потрібних документів у розглянутому наборі немає. У застосуванні до задач метапошуку, тобто виконання інформаційного пошуку за допомогою багатьох пошукових механізмів метою винаходу є: об'єднання наборів об'єктів, отриманих від багатьох різних інформаційних джерел. Іншою метою є усунення дублікатів, тобто однакових об'єктів в о триманих наборах. Винахід передбачає побудову такого кластеризування набору об'єктів, щоб отримані кластери відображали найбільш важливі особливості співвідношень характеристик розглянутих об'єктів. Для цього необхідно визначити, по-перше, які саме об'єкти є важливими, і по-друге, які саме співвідношення між об'єктами є важливими. Щоб відповісти на перше питання, потрібно спочатку вказати область, яка цікавить користувача. У прототипі це роблять за допомогою пошукового запиту, який одержують від користувача. В аналогу [п.11. Пат. 5911140 США] для цього користувач надає опис необхідного піднабору документів у виді деякого обмеження (умови). Ми пропонуємо більш загальний підхід, відповідно до якого визначають деякі еталонні значення характеристик об'єкта. Передбачено кілька варіантів їхнього визначення. Відповідно до першого варіанта, можна вказати на деякий зразок, що може бути обраним об'єктом з даного набору об'єктів чи попередньо обраним об'єктом не з даного набору об'єктів, визначити значення його характеристик і використовувати їх як еталонні. Так, наприклад, коли ці об'єкти є текстовими документами, як характеристики часто вибирають частоти вживання термінів (ключових слів) у цих текстах. Тоді, щоб одержати значення згаданих характеристик, потрібно підрахувати частоти термінів в обраному документі, а частоти всіх інших термінів (яких не було вжито) прийняти рівними нулю. Відповідно до другого варіанту, зразок може бути об'єктом іншого класу, ніж об'єкти з даного набору об'єктів. При цьому потрібно тільки, щоб частина їхніх характеристик були сумісними (наприклад, тотожними). Наприклад, для інформаційного пошуку текстови х документів, таким зразком - об'єктом іншого класу буде пошуковий запит, як у прототипі. І в першому, і в другому варіанті може бути використаний набір з більш ніж одного об'єкта-зразка. Відповідно одержимо і набір еталонних значень. У третьому варіанті, можна безпосередньо задати склад характеристик і еталонні значення. При цьому еталонні значення можуть бути як деякими точними значеннями, так і набором значень, зокрема інтервалом. Приклади інтервалів еталонних значень для текстових документів можна задати у виді пар характеристика-значення; наприклад: «довжина тексту - не більш п'яти абзаців»; «частота вживання терміна "користувач" - від 0,002 до 0,01». Область еталонних значень може бути задана й у більш складному виді, за допомогою математичних співвідношень, тобто умов, що включають кілька характеристик. Приведемо приклад такої умови: «кількість двоскладових слів у півтора разів більше суми кількостей одне- і трискладових слів». Зрозуміло, що використовувані співвідношення можуть бути записані у виді істотно більш складних математичних формул. У ряді інших предметних областей як зразок може бути використаний і деякий фізичний еталон. Таким чином, перша істотна ознака винаходу це виконанні такої дії: деяким образом визначають (указують) деякі еталонні значення характеристик об'єкта. При цьому вказують і склад набору цих характеристик. На відміну від прототипу, ми допускаємо різні варіанти визначення цих еталонних значень. Тепер, щоб виявити найбільш важливі об'єкти зі згаданого набору об'єктів, потрібно визначити відмінність значень характеристик цих об'єктів від еталонних значень (див. Фіг.1.). Коли характеристика є числом, то відмінність значень є різниця. Якщо маємо набір еталонних значень, то одержуємо і набір різниць. З цього набору варто вибрати найменшу різницю, для чого потрібно різниці порівнювати. Тобто, у випадку набору еталонних значень на цьому наборі має бути задана операція визначення абсолютної величини. Наприклад, для векторів такою величиною буде довжина чи модуль вектора (див. Фіг.2.). Якщо ж характеристика є нечисловою, то необхідно визначити міру для цієї характеристики, щоб виразити відмінність значень у чисельному виді. Таким чином, ми зможемо виразити сукупність відмінностей значень характеристик кожного об'єкта зі згаданого набору об'єктів від еталонних значень у виді упорядкованого набору чисел. Звичайно приймають, що ці числа є компоненти деякого вектора, однак це припущення не завжди виконується, зокрема, ці величини (сукупність відмінностей значень характеристик) можуть мати інші властивості і бути компонентами матриці, тензора й ін. Отже, друга істотна ознака винаходу є визначення відмінності між значеннями характеристик кожного об'єкта зі згаданого набору об'єктів і еталонних значень, яку виражають у виді вектора чи упорядкованого набору чисел. Ми використовуємо ці значення далі, замість того, щоб як у прототипі, використовувати тільки одне значення, яке виражає ранг об'єкта. Таке значення (ранг об'єкта) можна одержати, наприклад, виконавши проекцію точок багатомірного простору, що відповідають об'єктам, на напівпряму, початок якої знаходиться в точці з еталонними значеннями (точніше в найближчій з цих точок), або упорядкувавши набір об'єктів по абсолютній величині. Тепер потрібно виділити важливі співвідношення між об'єктами. Такими відносинами в нашому підході є подібність отриманих відмінностей (між значеннями характеристик об'єктів з набору об'єктів і еталонних значень). Ці відмінності виражені у виді упорядкованого набору чисел. Потім варто використовувати будьякий відомий метод (спосіб) кластеризації (групування об'єктів), щоб згрупувати отримані набори чисел, а отже, і відповідні їм об'єкти з початкового набору об'єктів, так, щоб в отримані групи включалися об'єкти з подібними наборами чисел, тобто з подібними відмінностями від еталонних значень. Звичайно методи кластеризування припускають використання деякої міри - функції багатьох перемінних, котра дає чисельну оцінку близькості двох упорядкованих наборів чисел, що характеризують розглянуті об'єкти. Розподіл об'єктів по групах (кластерам), що буде отриманий, залежить від вибору методу кластеризування і обраної міри. Таким чином, третя суттєва ознака винаходу полягає у виконанні кластеризування отриманих упорядкованих наборів даних, і результати цього кластеризування дають груповання відповідних цім наборам об'єктів з початкового набору об'єктів. Отримане групування об'єктів по кластерах є результатом застосування даного способу. Ці обов'язкові суттєві ознаки винаходу зазначені в п.1 формули винаходу. Розглянемо тепер інші, необов'язкові істотні ознаки винаходу, що згадані в інших пунктах формули. В інформаційному пошуку часто загальна кількість об'єктів є дуже великою. Для одного з найбільш актуальних напрямків - пошук у мережі Інтернет, кількість доступних текстових документів уже зараз перевершує 8 мільярдів одиниць і продовжує швидко зростати. У таких умовах, незважаючи на лінійну залежність числа обчислень від кількості об'єктів, доцільно обмежити кількість об'єктів у початковому наборі. Для цього бажано використовувати методи з малими обчислювальними витратами, але з високою повнотою одержуваних результатів. Таким чином, у пункті 2 формули додається операція, яку виконують перед операціями з п.1 формули. Початковий набір об'єктів одержують у результаті виконання інформаційного пошуку за допомогою однієї чи більшої кількості інформаційно-пошукових систем. Для виконання цього пошуку доцільно використовувати той же опис області, що цікавить користувача, якій заданий за допомогою еталонних значень з першого пункту основної формули. При цьому не є важливим що первинно - пошуковий запит будується на основі еталонних значень, чи еталонні значення визначаються з пошукового запиту. Можна й іншим шляхом обмежити початковий набір об'єктів, щоб не розглядати ті з них, що певно не відповідають зазначеній області інтересів користувача. Для цього потрібно задати деяку умову, наприклад, оцінити абсолютну величину відмінності від еталонних значень і порівняти її з деяким числом . Відповідну ознаку запишемо в п.3 формули винаходу: для зменшення кількості об'єктів у наборі об'єктів, задають деяку умову, яка обмежує область поблизу еталонних значень і виключають з розглянутого набору всі об'єкти, що розташовані поза цією областю. Якщо виключені об'єкти згодом можуть бути потрібні, то доцільно створити додатковий кластер і віднести їх до нього. Для того щоб користувач оцінив, наскільки відповідає даний кластер його інтересам, користувач звичайно має ознайомитися з об'єктами з цього кластера. Інший більш зручний шлях полягає в підготовці короткого опису змісту кластера - резюме. Відповідну ознаку запишемо в п.4. формули: для кожного виділеного кластера створюється його опис (резюме) на основі характеристик або/та змісту включених у нього об'єктів. Якщо об'єктами з набору є деякі документи, то оскільки отримане резюме кластера також є документ, то якщо це потрібно, ми можемо додати його в набір, як ще один об'єкт. Розглянемо тепер можливі дії після виконання кластеризування. Якщо кількість об'єктів у початковому наборі була занадто велика, то ймовірно й в обраному кластері виявиться досить багато об'єктів. Тоді і його потрібно буде розділити на підкластери. Для цього будемо повторно застосовувати запропонований спосіб. Виберемо нові еталонні значення характеристик об'єкта для зазначеного кластера і виконаємо поділ набору об'єктів, що входять до зазначеного кластера, на групи. Якщо й в отриманих групах буде більше об'єктів чим потрібно, станемо повторювати цю операцію доти, поки не одержимо достатньо деталізовану розбивку цікавих для користувача піднаборів об'єктів. У крайньому випадку, у кожному підкластері останнього піднабору буде тільки один об'єкт. Таким чином, у п.5 формули зазначено, що даний спосіб кластеризування може застосовуватися ітеративно, коли принаймні, для одного з отриманих кластерів указують нові еталонні значення і виконують кластеризацію об'єктів цього кластера на підкластери. При цьому нові еталонні значення можуть бути зазначені або на той же спосіб, як і при першому кластеризуванні, або будь-яким іншим способом, як вказано у п.1. Ітеративність цієї дії означає, що при необхідності можна зробити кластеризування підкластерів потрібну кількість разів. У ряді використань (у першу чергу в інформаційному пошуку) доцільно при виборі нових еталонних значень одержати і новий набір об'єктів. Це дозволить одержати більш адекватну інформацію, зокрема, досягти більшої повноти пошуку. Причому ми не накладаємо ніяких обмежень на кількість ітерацій, що виконуються у такий спосіб. Відповідну ознаку запишемо в п.6 формули винаходу: отримана розбивка пропонується користувачу, якій вибирає один чи кілька запропонованих кластерів, після чого відповідно зі зробленим вибором змінюють або вказують нові еталонні характеристики, які використовують потім для нового кластеризування цього набору об'єктів або частини цього набору або об'єктів іншого набору об'єктів, отриманого наприклад, при виконанні пошуку за допомогою запиту - нового еталону. Виходячи з відомих психологічних і ергономічних розумінь, ми вважаємо, що для роботи користувача оптимальна кількість кластерів має бути 7±2. Для будь-яких автоматичних систем також, можливо є деякий зручний інтервал значень числа отриманих гр уп. У ряді випадків отримана кількість кластерів є занадто великою, або занадто малою. Тоді варто змінити отримане число кластерів у потрібну сторону шляхом об'єднання деяких кластерів (якщо їх занадто багато) чи поділу великих кластерів, якщо кластерів отримано занадто мало. Відповідну ознаку запишемо в п.7 формули винаходу. Перейдемо тепер до окремого випадку розглянутого способу кластеризування який описано у п.8. формули винаходу й розглянемо його суть більш детально, з використанням математичних позначень. Покладемо, що визначено скінчений, упорядкований набір, що складається з N характеристик розглянути х об'єктів, і цей набір задає деякий N-мірний простір, такий, що для будь-якої можливої комбінації припустимих значень характеристик з цього набору, існує відповідна точка даного N-мірного {} Хi º xij простору. Тоді кожному об'єкту буде відповідати деяка точка з координатами , j=1…N, де і є номер об'єкта. Задамо в цьому просторі деяку першу міру відстані (близькості) m1, що дозволить одержати у виді одного числа величину відстані між будь-якими двома точками цього простору. Ця міра близькості буде скалярною функцією 2Ν перемінних, тобто m1ºm1(Χa ;Χb). Будь-які еталонні значення характеристик об'єкта будуть визначати деякі точки заданого простору, і тому перша міра близькості дозволить для будь-якого об'єкта одержати абсолютну величину відмінності значень його характеристик від еталонних значень. Тепер задамо деяку другу міру відстані (близькості) m2, що дозволить одержати у виді одного числа величину подібності між відмінністю одного й іншого об'єктів, які виражені у виді упорядкованих наборів N чисел. Ця міра близькості також буде скалярною функцією 2Ν перемінних, тобто m2ºm2(Da;Db), де Di є набір чисел, що описують відмінність значень характеристик і-об'єкта від еталонних значень. У деяких випадках ця друга міра може збігатися з першою мірою. {} Zk º zk j Нехай задані, як потрібно, еталонні значення. Позначимо їхній набір як , j=1...Ν. В окремому випадку заданий тільки один еталон - одна точка даного Ν-мірного простору. Тепер потрібно одержати значення відмінностей: Di=mink(Хi-Ζ k), де у випадку набору еталонних значень, беремо найближче з них, тобто вибираємо таке k, щоб m1(Χi;Ζ k) було найменшим; у випадку з одним еталоном: Di=Xi-Ζ. При цьому за допомогою першої міри близькості для кожного об'єкта визначимо величину відмінності значень його характеристик від еталонних значень r1=minkm1(Хi;Ζ k). Після цього упорядкуємо набір об'єктів по неубуванню отриманих величин відмінності ri, тобто так, щоб a b r £r ;"a
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for the clusterization of a set of objects by using a reference
Назва патенту російськоюСпособ кластеризации набора объектов с использованием образца
МПК / Мітки
МПК: G06F 7/16, G06F 7/00, G06F 17/30
Мітки: спосіб, кластеризування, використанням, об'єктів, набору, зразка
Код посилання
<a href="https://ua.patents.su/9-72720-sposib-klasterizuvannya-naboru-obehktiv-z-vikoristannyam-zrazka.html" target="_blank" rel="follow" title="База патентів України">Спосіб кластеризування набору об’єктів з використанням зразка</a>
Спосіб визначення якості зразка насіння

Номер патенту: 43650
Опубліковано: 17.12.2001
Автори: Путятін Валерій Петрович, Коваленко Олександр Іванович, Мунтян Володимир Олексійович
МПК: A01C 1/00
Мітки: визначення, зразка, якості, спосіб, насіння
Формула / Реферат:
Спосіб визначення якості зразка насіння, що включає освітлення розчину з біоматеріалом у прохідному світлі, одержання оптичної інформації та її обробку, яка виконується шляхом кодування зображення у проекціях0, який відрізняється тим, що використовують декілька фотооб'єктивів, які конструктивно з'єднані з відповідними телекамерами, котрі за допомогою пристрою з зарядовим зв'язком (ПЗЗ - матриці), що знаходиться у кожній з них, кодують...
Спосіб перевірки цілісності та автентичності набору даних (варіанти)

Номер патенту: 66940
Опубліковано: 15.06.2004
Автори: Хілл Майкл Джон, Ніколас Крістоф, Сасселлі Марко
МПК: H04L 9/32, H04N 7/167
Мітки: автентичності, перевірки, цілісності, набору, спосіб, варіанти, даних
Формула / Реферат:
1. Спосіб перевірки цілісності та автентичності набору даних (від М1 до Мn), прийнятих блоком декодування приймача платного телебачення, до складу якого входять декодер (IRD) і блок захисту (SC), а також засоби зв'язку (NET, REC) з центром управління, згідно з яким здійснюють розрахунок контрольної інформації (Нх), що є відображенням результату застосування однонаправленої і вільної від конфліктів функції до всіх або лише до частини даних...
Перетворювач набору двійкових кодів

Номер патенту: 32052
Опубліковано: 15.12.2000
Автор: Лукашенко Валентина Максимівна
Мітки: набору, перетворювач, кодів, двійкових
Текст:
...операції 7, блок вентилів 8, блок керування 9. Розглянемо, наприклад, метод для переводу чисел з двійковою системою зчислення в двійково-десяткову. 5 5 Двійковий код поданий у вигляді: А = Ап.іАп.2...АіАо,А-іА_2...А.т. (1) Зобразимо (1) як: а^ ак.2і. аі аоа_] а.2 . а.!? (2) де кожна а; - змінна МІСТИТЬ ПО чотири розряди. Нехай відповідний коду (1) двійково-десятковий код має вигляд: В = Bk_i Bk_2.. Ві Во ;В.і В_2.. В_і. Кінцевий...
Перетворювач набору двійкових кодів

Номер патенту: 59246
Опубліковано: 15.08.2003
Автори: Лукашенко Дмитро Андрійович, Шарапов Валерій Михайлович, Корпань Ярослав Васильович, Шеховцов Борис Анатолійович, Лукашенко Валентина Максимівна
МПК: G06F 5/00
Мітки: двійкових, кодів, набору, перетворювач
Формула / Реферат:
Перетворювач набору двійкових кодів, що містить регістр входу, який виконано на тригерах з лічильними входами та інформаційними входами, які з'єднані з входами пристрою, комбінаційну схему адреси, інформаційні входи якої з'єднані з виходами регістра входу, комутатор, входи якого з'єднані з виходами комбінаційної схеми адреси, а виходи з'єднані з входами блока елементів АБО, виходи якого з'єднані з входами числового блока пам'яті, виходи якого...
Ротор з інтегральною конструкцією набору лопаток

Номер патенту: 57816
Опубліковано: 15.07.2003
Автори: Россманн Аксель, Сікорскі Зігфрид, Крюгер Вольфганг
МПК: F01D 5/00, F01D 5/14, F01D 5/28
Мітки: лопаток, інтегральною, набору, ротор, конструкцією
Формула / Реферат:
1. Ротор з інтегральною конструкцією набору лопаток (1), які розташовуються по його периметру й проходять, головним чином, у радіальному напрямку, який використовується, насамперед, у двигунах або силових установках , який відрізняється тим, що лопатки (1) ротора устатковано металевим хвостовиком (2), металевою ділянкою (3) пера й пером (4) з армованого волокном пластику, при цьому металева ділянка (3) пера лопатки утворює частину вхідної...
Попередній патент: Пристрій для обмолоту сільськогосподарських культур на корені
Наступний патент: Кабель волоконно-оптичний комбінований
Випадковий патент: Барокомплекс для корекції психосоматичних розладів