Спосіб і пристрій кодування, а також спосіб і пристрій декодування інформації, що складається з множини слів,та унітарний носій закодованої інформації
Номер патенту: 65588
Опубліковано: 15.04.2004
Автори: Нарахара Тацуя, Ямамото Коухей, Толуйзен Лудовікус М.Г.М., ван Дейк Мартен Е., Хатторі Масаюкі, Сеншу Сусуму, Багген Констант П.М.Дж., Калман Джозеф А.Х.М.






Формула / Реферат
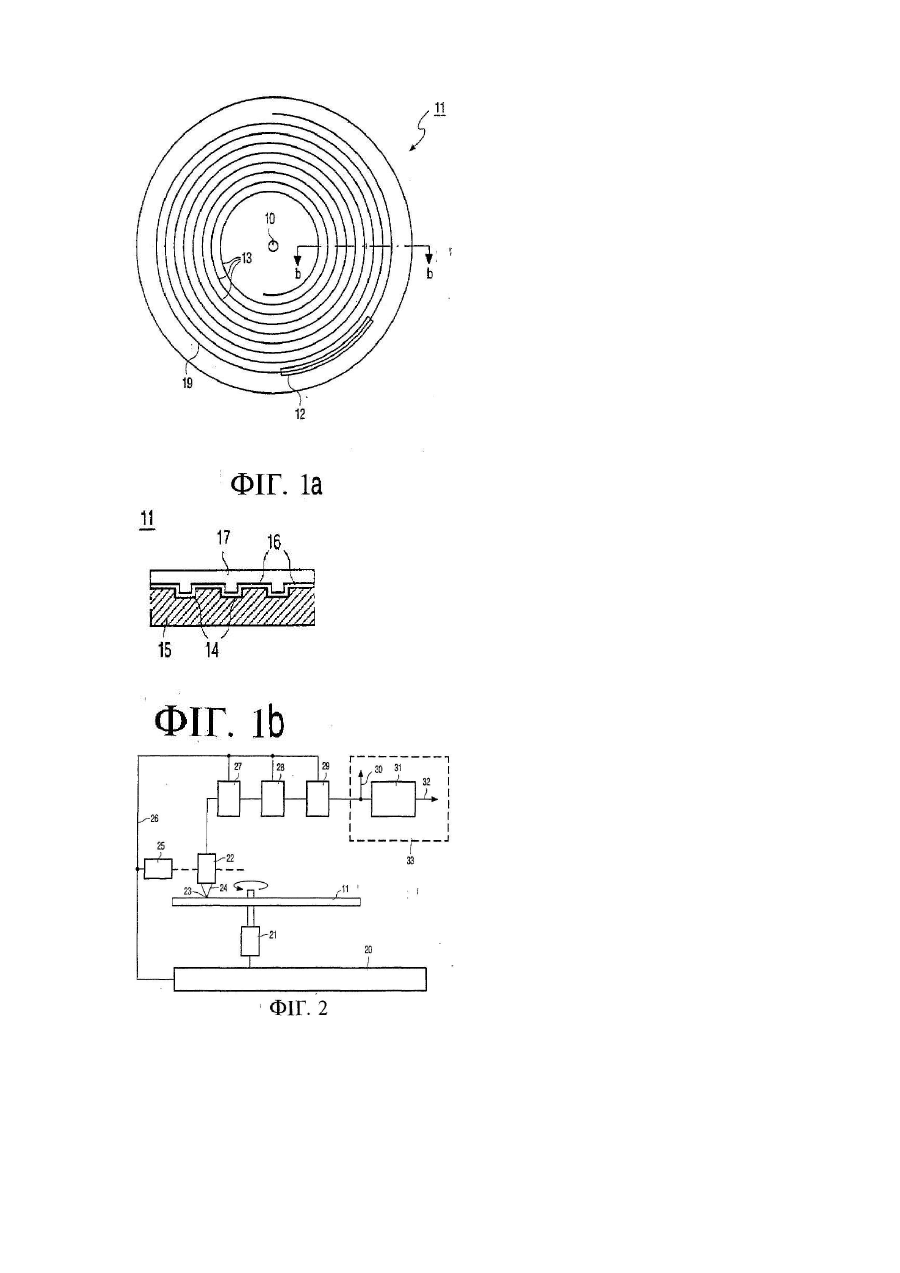
1. Спосіб кодування інформації, що складається з множини слів, в основі якої - багатобітові символи, розташовані на носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, якій притаманні такі властивості, як послівне розпорошення і послівне кодування з захистом від помилок, і в якій для цього серед груп слів, які складаються з множини слів, запроваджені ключі виявлення помилок, який відрізняється тим, що такі ключі утворюють як у ключових словах з високим рівнем захисту (BIS), розпорошених по ключових стовпцях, так і в стовпцях синхронізації, утворених з груп синхробітів, і тим, що вказані стовпці синхронізації розміщують там, де вказані ключові стовпці розташовані відносно рідко, причому вказані ключі призначені для цільових слів з низьким рівнем захисту (LDS), розпорошених у значною мірою рівномірний спосіб по цільових стовпцях, з яких утворюються однакових розмірів групи стовпців, розміщені між періодично розташованими ключовими стовпцями і стовпцями синхронізації.
2. Спосіб за п. 1, який відрізняється тим, що вказану інформацію організують у фізичні кластери однакового розміру, кожен з яких має один стовпець синхронізації і непарну кількість ключових стовпців.
3. Спосіб за п. 1, який відрізняється тим, що дані користувача призначають виключно вказаним цільовим стовпцям, а системні дані призначають, принаймні більшою частиною, вказаним ключовим стовпцям.
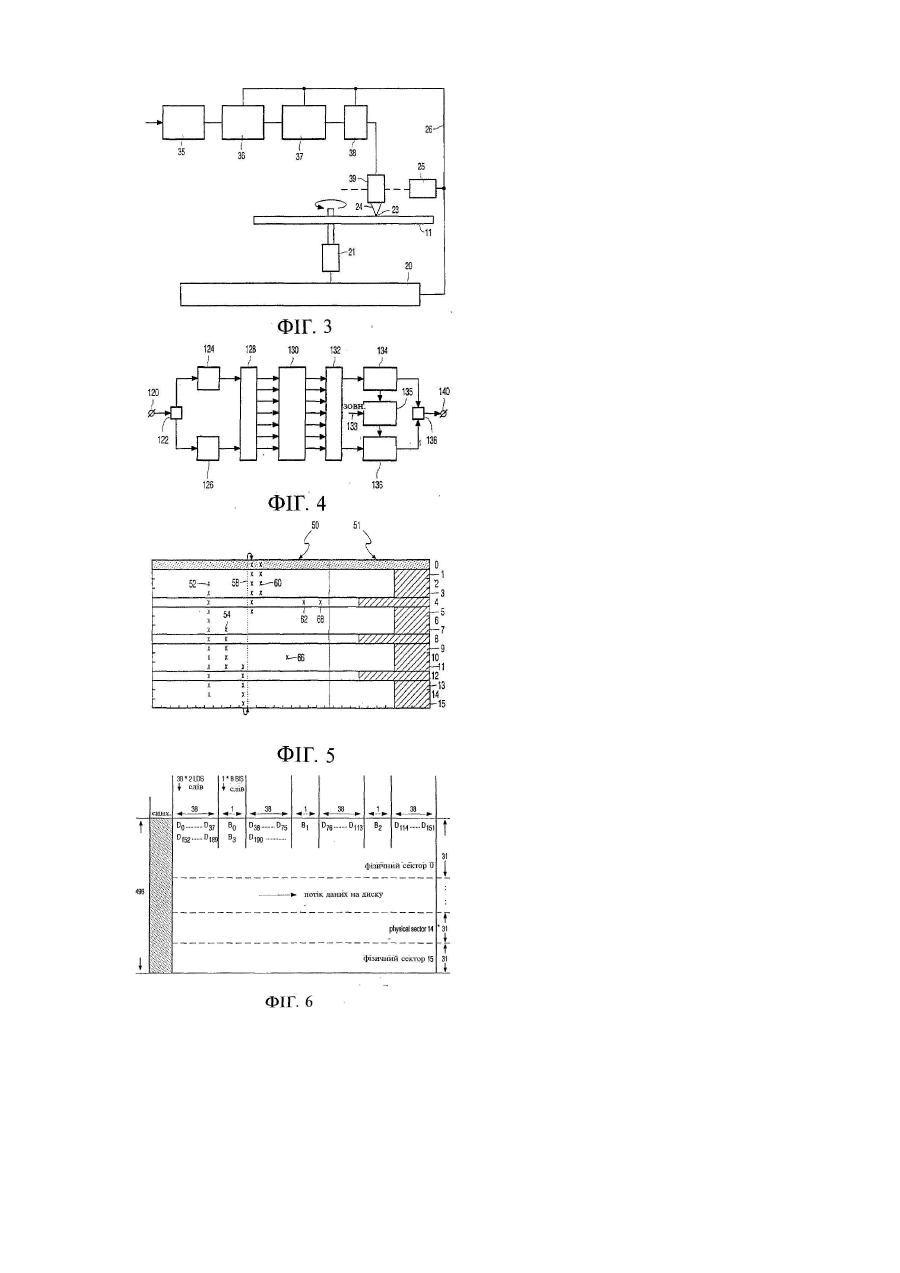
4. Спосіб за п. 1, який відрізняється тим, що на найнижчому рівні фрейм даних, що включає множину цільових символів, містить багатосимвольну, але побітово організовану, групу бітів для виявлення помилок (EDC).
5. Спосіб за п. 4, який відрізняється тим, що на наступному більш високому рівні сектор даних містить декілька фреймів даних для розподілення по ньому множини цільових слів з доданням надлишковості Ріда-Соломона.
6. Спосіб за п. 5, який відрізняється тим, що перед вказаним розпорошенням різні блоки кодових слів послідовно розділяють як прискорюючий захід щодо наступного декодування.
7. Спосіб за п. 1, який відрізняється тим, що окрім вказаного розпорошення здійснюють, рядок за рядком, інкрементний циклічний зсув цільових символів у межах їхнього кластера.
8. Спосіб за п. 1, який відрізняється тим, що його застосовують при зберіганні на оптичному носієві.
9. Спосіб за п. 1, який відрізняється тим, що усі ключові слова та цільові слова мають однаковий обсяг надлишковості, але цільові слова мають більше символів даних, ніж ключові слова.
10. Спосіб за п. 1, який відрізняється тим, що кількість ключових слів у повному фізичному кластері кратна кількості ключових стовпців у фізичному кластері, при цьому відповідну кількість символів ключових слів розподіляють групами, що містять стільки ж символів, скільки є ключових стовпців у фізичному кластері, по відповідних фреймах запису різних фізичних секторів фізичного кластера згідно з зигзагуватою, але в інших відношеннях однорідною схемою розпорошення по різних фреймах запису.
11. Спосіб за п. 10, який відрізняється тим, що рядки символів з парними номерами призначають першій групі суміжних секторів, що включає половину фізичних секторів, а рядки символів з непарними номерами призначають другій групі суміжних секторів, що включає половину фізичних секторів.
12. Спосіб за п. 10, який відрізняється тим, що рядки символів ключових стовпців піддають зигзагуватому і систематичному циклічному зсуву по різних ключових стовпцях.
13. Спосіб за п. 10, який відрізняється тим, що ключовим словам призначають адресні дані як логічних, так і фізичних адрес, що стосуються фактичного фізичного кластера.
14. Спосіб декодування інформації, що складається з множини слів, в основі якої - багатобітові символи, розташовані на носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, якій притаманні такі властивості, як послівне розпорошення і послівне кодування з захистом від помилок, і в якій для цього серед груп слів, які складаються з множини слів, запроваджені ключі виявлення помилок, який відрізняється тим, що такі ключі одержують як з ключових слів з високим рівнем захисту, розпорошених по ключових стовпцях, так і зі стовпців синхронізації, утворених з груп синхробітів, шляхом звернення до вказаних стовпців синхронізації у випадку, коли вказані ключові стовпці розташовані відносно рідко, причому вказані ключі призначені для цільових слів з низьким рівнем захисту, розпорошених у значною мірою рівномірний спосіб по цільових стовпцях, з яких утворюються однакових розмірів групи стовпців, розміщені між періодично розташованими ключовими стовпцями і стовпцями синхронізації.
15. Спосіб за п. 14, який відрізняється тим, що здійснюють звернення до вказаної інформації згідно з фізичними кластерами однакових розмірів, кожен з яких має один стовпець синхронізації і непарну кількість ключових стовпців.
16. Спосіб за п. 14, який відрізняється тим, що дані користувача відновлюють виключно із вказаних цільових стовпців, а системні дані, принаймні більшою частиною, відновлюють із вказаних ключових стовпців.
17. Спосіб за п. 14, який відрізняється тим, що здійснюють, як попередній етап декодування, звернення на найнижчому рівні, у фреймі даних, що включає множину цільових символів, до багатосимвольної, але побітово організованої групи бітів для виявлення помилок.
18. Спосіб за п. 17, який відрізняється тим, що на наступному більш високому рівні здійснюється звернення, в секторі даних, до множини відповідних фреймів даних, по яких розподілена множина цільових слів, з оцінюванням доданої надлишковості Ріда-Соломона.
19. Спосіб за п. 14, який відрізняється тим, що додатково до виправлення вказаного розпорошення здійснюють, рядок за рядком, інкрементний циклічний зсув цільових символів у межах їхнього кластера.
20. Спосіб за п. 14, який відрізняється тим, що його застосовують при зберіганні на оптичному носієві.
21. Спосіб за п. 14, який відрізняється тим, що ключові слова та цільові слова декодують як такі, що мають однаковий обсяг надлишковості, але передбачаючи у цільових словах більшу кількість символів даних, ніж у ключових словах.
22. Спосіб за п. 14, який відрізняється тим, що кількість ключових слів у повному фізичному кластері кратна кількості ключових стовпців у фізичному кластері, при цьому відповідна кількість символів вказаних ключових слів відновлюється з груп, що містять стільки ж символів, скільки є ключових стовпців у фізичному кластері, з відповідних фреймів запису різних фізичних секторів фізичного кластера згідно з зигзагуватою, але в інших відношеннях однорідною схемою зворотного розпорошення по різних фреймах запису.
23. Спосіб за п. 22, який відрізняється тим, що рядки символів з парними номерами відновлюють з першої групи суміжних секторів, що включає половину фізичних секторів, а рядки символів з непарними номерами відновлюють з другої групи суміжних секторів, що включає половину фізичних секторів.
24. Спосіб за п. 22, який відрізняється тим, що рядки символів ключових стовпців відновлюють з символів, що зазнали зигзагуватого і систематичного циклічного зсуву по різних ключових стовпцях.
25. Спосіб за п. 22, який відрізняється тим, що з ключових слів відновлюють адресні дані як логічних, так і фізичних адрес, що стосуються фактичного фізичного кластера.
26. Пристрій для кодування інформації, що складається з множини слів, в основі якої - багатобітові символи, що розташовуються на носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, який має засіб для кодування, виконаний з можливістю здійснення послівного розпорошення і послівного кодування з захистом від помилок, і з можливістю запровадження серед груп слів, які складаються з множини слів, ключів виявлення помилок, який відрізняється тим, що вказаний засіб для кодування виконаний з можливістю створювання таких ключів як у ключових словах з високим рівнем захисту, розпорошених по ключових стовпцях, так і у стовпцях синхронізації, утворених з груп синхробітів, за допомогою розміщувального засобу для розміщення вказаних стовпців синхронізації там, де вказані ключові стовпці розташовані відносно рідко, причому всі ключі призначені для цільових слів з низьким рівнем захисту, розпорошених у значною мірою рівномірний спосіб по цільових стовпцях, з яких утворюються однакових розмірів групи стовпців, розміщені між періодично розташованими ключовими стовпцями і стовпцями синхронізації.
27. Пристрій за п. 26, який відрізняється тим, що він має засіб форматування для організації вказаної інформації у фізичні кластери однакових розмірів, кожен з яких має один стовпець синхронізації і непарну кількість ключових стовпців.
28. Пристрій за п. 26, який відрізняється тим, що він виконаний з можливістю призначення даних користувача виключно вказаним цільовим стовпцям, і призначення системних даних, принаймні більшою частиною, вказаним ключовим стовпцям.
29. Пристрій за п. 26, який відрізняється тим, що він має засіб генерування, виконаний з можливістю генерування на найнижчому рівні у фреймі даних, що включає множину цільових символів багатосимвольної, але побітово організованої групи бітів для виявлення помилок.
30. Пристрій за п. 29, який відрізняється тим, що він виконаний з можливістю утворення на наступному більш високому рівні сектора даних, що містить декілька фреймів даних, для розподілення по ньому множини цільових слів з доданням надлишковості Ріда-Соломона.
31. Пристрій за п. 26, який відрізняється тим, що він має засіб для здійснення, окрім розпорошення, інкрементного циклічного зсуву цільових символів у межах їхнього кластера, рядок за рядком.
32. Пристрій за п. 26, який відрізняється тим, що він має засоби для взаємодії з оптичним носієм.
33. Пристрій за п. 26, який відрізняється тим, що вказаний засіб для кодування виконаний з можливістю призначення всім ключовим словам і цільовим словам надлишковості однакового обсягу і з можливістю призначення цільовим словам більшої кількості символів даних, ніж ключовим словам.
34. Пристрій за п. 26, який відрізняється тим, що кількість ключових слів повного фізичного кластера кратна кількості ключових стовпців у фізичному кластері, і тим, що пристрій має розподілювальний засіб для розподілення відповідної кількості символів вказаних ключових слів групами, що містять стільки ж символів, скільки є ключових стовпців у фізичному кластері, по відповідних фреймах запису різних фізичних секторів фізичного кластера згідно з зигзагуватою, але в інших відношеннях однорідною схемою розпорошення по різних фреймах запису.
35. Пристрій за п. 26, який відрізняється тим, що він має засіб для призначення рядків символів з парними номерами першій групі суміжних секторів, що включає половину фізичних секторів, а рядків символів з непарними номерами - другій групі суміжних секторів, що включає половину фізичних секторів.
36. Пристрій за п. 26, який відрізняється тим, що він має засіб зсуву для піддавання рядків символів ключових стовпців зигзагуватому і систематичному циклічному зсуву по різних ключових стовпцях.
37. Пристрій за п. 26, який відрізняється тим, що він має засіб призначення адрес для призначення ключовим словам адресних даних як логічних, так і фізичних адрес, що стосуються фактичного фізичного кластера.
38. Пристрій для декодування інформації, що складається з множини слів, в основі якої - багатобітові символи, розташовані на носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, якій притаманні такі властивості, як послівне розпорошення і послівне кодування з захистом від помилок, і в якій для цього серед груп слів, які складаються з множини слів, запроваджені ключі виявлення помилок, який відрізняється тим, що він виконаний з можливістю одержання таких ключів як з ключових слів з високим рівнем захисту, розпорошених по ключових стовпцях, так і зі стовпців синхронізації, утворених з груп синхробітів, із зверненням до вказаних стовпців синхронізації у випадку, коли вказані ключові стовпці розташовані відносно рідко, причому всі вказані ключі призначені для цільових слів з низьким рівнем захисту, розпорошених у значною мірою рівномірний спосіб по цільових стовпцях, з яких утворюються однакових розмірів групи стовпців, розміщені між періодично розташованими ключовими стовпцями і стовпцями синхронізації.
39. Пристрій за п. 38, який відрізняється тим, що він має засіб для звернення до вказаної інформації згідно з фізичними кластерами однакового розміру, кожен з яких має один стовпець синхронізації і непарну кількість ключових стовпців.
40. Пристрій за п. 38, який відрізняється тим, що він виконаний з можливістю відновлення даних користувача виключно з цільових стовпців і з можливістю відновлення системних даних, принаймні більшою частиною, з ключових стовпців.
41. Пристрій за п. 38, який відрізняється тим, що він має засіб доступу для звернення на найнижчому рівні у фреймі даних, що включає множину цільових символів, до багатосимвольної, але побітово організованої групи бітів для виявлення помилок, для одержання сигналу виявлення помилки.
42. Пристрій за п. 41, який відрізняється тим, що зазначений засіб доступу виконаний з можливістю звернення на наступному більш високому рівні, у секторі даних, до множини відповідних фреймів даних, по яких розподілені множина цільових слів, з оцінюванням доданої надлишковості Ріда-Соломона.
43. Пристрій за п. 38, який відрізняється тим, що він має коректувальний засіб для здійснення, додатково до виправлення вказаного розпорошення, інкрементного циклічного зсуву цільових символів у межах їхнього кластера, рядок за рядком.
44. Пристрій за п. 38, який відрізняється тим, що він має засоби для взаємодії з оптичним носієм.
45. Пристрій за п. 38, який відрізняється тим, що він має засіб декодування, виконаний з можливістю декодування всіх ключових і всіх цільових слів, з огляду на однаковий обсяг надлишкової інформації у всіх цих словах, але з одержуванням з цільових слів більшої кількості символів даних, ніж з ключових слів.
46. Пристрій за п. 38, який відрізняється тим, що кількість ключових слів повного фізичного кластера кратна кількості ключових стовпців у фізичному кластері, і тим, що він виконаний з можливістю відновлення відповідної кількості символів ключових слів, розподілених групами, що містять стільки ж символів, скільки є ключових стовпців у фізичному кластері, з відповідних фреймів запису різних фізичних секторів фізичного кластера згідно з зигзагуватою, але в інших відношеннях однорідною схемою розпорошення по різних фреймах запису.
47. Пристрій за п. 46, який відрізняється тим, що він виконаний з можливістю відновлення рядків символів з парними номерами з першої групи суміжних секторів, що включає половину фізичних секторів, і з можливістю відновлення рядків символів з непарними номерами з другої групи суміжних секторів, що включає половину фізичних секторів.
48. Пристрій за п. 46, який відрізняється тим, що він виконаний з можливістю відновлення рядків символів ключових стовпців з застосуванням зигзагуватого і систематичного зворотного циклічного зсуву по різних ключових стовпцях.
49. Пристрій за п. 38, який відрізняється тим, що він виконаний з можливістю відновлення з ключових стовпців адресних даних як логічних, так і фізичних адрес, що стосуються фактичного фізичного кластера.
50.Унітарний носій закодованої інформації, одержаний з застосуванням способу за п. 1, на якому зберігається інформація, що складається з множини слів, в основі якої - багатобітові символи, розташовані по цьому носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, якій притаманні такі властивості, як послівне розпорошення і послівне кодування з захистом від помилок, і в якій для цього серед груп слів, які складаються з множини слів, запроваджені ключі виявлення помилок, який відрізняється тим, що такі ключі наявні як у ключових словах з високим рівнем захисту, розпорошених по ключових стовпцях, так і в стовпцях синхронізації, утворених з груп синхробітів, і тим, що вказані стовпці синхронізації розміщені там, де вказані ключові стовпці розташовані відносно рідко, причому всі вказані ключі призначені для цільових слів з низьким рівнем захисту, розпорошених у значною мірою рівномірний спосіб по цільових стовпцях, з яких утворюються однакових розмірів групи стовпців, розміщені між періодично розташованими ключовими стовпцями і стовпцями синхронізації.
51. Носій за п. 50, який відрізняється тим, що вказана інформація організована у фізичні кластери однакових розмірів, кожен з яких має один стовпець синхронізації і непарну кількість ключових стовпців.
52. Носій за п. 50, який відрізняється тим, що дані користувача містяться виключно у вказаних цільових стовпцях, і системні дані містяться, принаймні більшою частиною, у вказаних ключових стовпцях.
53. Носій за п. 50, який відрізняється тим, що на найнижчому рівні фрейм даних, що включає множину цільових символів, містить також багатосимвольну, але побітово організовану групу бітів для виявлення помилок.
54. Носій за п. 50, який відрізняється тим, що на наступному більш високому рівні сектор даних містить декілька фреймів даних і по ньому розподілені множина цільових слів з доданням надлишковості Ріда-Соломона.
55. Носій за п. 54, який відрізняється тим, що окрім вказаного розпорошення застосовано інкрементний циклічний зсув цільових символів у межах їхнього кластера, здійснений рядок за рядком.
56. Носій за п. 50, який відрізняється тим, що є оптичним.
57. Носій за п. 50, який відрізняється тим, що як ключові, так і цільові слова мають однаковий обсяг надлишковості, але цільові слова мають більше символів даних, ніж ключові слова.
58. Носій згідно з п. 50, який відрізняється тим, що кількість ключових слів у повному фізичномукластері кратна кількості ключових стовпців у фізичному кластері, при цьому відповідна кількість символів вказаних ключових слів розподілена групами, що містять стільки ж символів, скільки є ключових стовпців у фізичному кластері, по відповідних фреймах запису різних фізичних секторів фізичного кластера згідно з зигзагуватою, але в інших відношеннях однорідною схемою розпорошення по різних фреймах запису.
59. Носій за п. 58, який відрізняється тим, що рядки символів з парними номерами призначені першій групі суміжних секторів, що включає половину фізичних секторів, а рядки символів з непарними номерами - другій групі суміжних секторів, що включає половину фізичних секторів.
60. Носій згідно з п. 58, який відрізняється тим, що рядки символів ключових стовпців зазнали зигзагуватого і систематичного циклічного зсуву по різних ключових стовпцях.
61. Носій за п. 58, який відрізняється тим, що ключові стовпці містять адресні дані як логічних, так і фізичних адрес, що стосуються фактичного фізичного кластера.
Додаткова інформація
Назва патенту англійськоюCoding of multiword information by means of alternation
Назва патенту російськоюКодирование информации, состоящей из множества слов, при помощи чередования
МПК / Мітки
МПК: H03M 13/27, H03M 13/00
Мітки: інформації, множині, спосіб, кодування, також, пристрій, декодування, носій, закодованої, унітарний, слів,та, складається
Код посилання
<a href="https://ua.patents.su/13-65588-sposib-i-pristrijj-koduvannya-a-takozh-sposib-i-pristrijj-dekoduvannya-informaci-shho-skladaehtsya-z-mnozhini-slivta-unitarnijj-nosijj-zakodovano-informaci.html" target="_blank" rel="follow" title="База патентів України">Спосіб і пристрій кодування, а також спосіб і пристрій декодування інформації, що складається з множини слів,та унітарний носій закодованої інформації</a>
Спосіб зберігання здебільшого звукової інформації на унітарному носії інформації, унітарний носій та пристрій читання для взаємодії з носієм

Номер патенту: 52725
Опубліковано: 15.01.2003
Автор: Монс Йоханнес Ян
МПК: G11B 27/00
Мітки: здебільшого, пристрій, читання, носій, унітарному, зберігання, унітарний, спосіб, інформації, носієм, звукової, носії, взаємодії
Формула / Реферат:
1. Спосіб зберігання здебільшого звукової інформації на унітарному носії інформації із використанням реєстру даних (ТОС), що характеризує фактичну конфігурацію різних звукових фрагментів на зазначеному носії, який відрізняється тим, що для кожного з множини різних стандартизованих звукових форматів призначають один або декілька суб-ТОС, і також надають один головний ТОС, який окремо вказує на кожний з зазначених суб-ТОС.2. Спосіб за п....
Пристрій статистичного кодування та декодування факсимільних сигналів
Номер патенту: 8392
Опубліковано: 29.03.1996
Автори: Балькін Геннадій Федорович, Голосний Валентин Іванович, Зайченко Олександр Григорович, Сапунков Михайло Наумович
МПК: H04N 1/40
Мітки: статистичного, кодування, факсимільних, декодування, сигналів, пристрій
Формула / Реферат:
Устройство статистического кодирования и декодирования факсимильных сигналов, содержащее на передающей стороне входной делитель, выход которого соединен с входом кодера видеосигнала и через формирователь разделительных бит и формирователь бит описания с двумя первыми входами сумматора, выход которого подключен ко входу первого буферного блока, а на приемной стороне последовательно соединенные второй буферный блок, дешифратор...
Спосіб передачі інформації з використанням носія даних, носій інформації і пристрій для відтворення інформації з такого носія

Номер патенту: 26980
Опубліковано: 28.02.2000
Автор: Блютген Бйорн
МПК: G11B 20/10, H04N 5/76, G11B 7/24
Мітки: спосіб, носій, даних, носія, передачі, пристрій, такого, інформації, використанням, відтворення
Формула / Реферат:
1. Способ передачи информации с использованием носителя данных, заключающийся в форматировании данных с добавлением к основной информации цифровых субкодовых данных, записи полученной информации на носителе данных с образцами участков, имеющими различные физические свойства и представляющими основную и субкодовую информацию, считывании носителя записи с преобразованием образцов участков носителя в сигнал, изменения физической величины...
Оптично зчитуваний носій запису, спосіб та пристрій для виготовлення такого носія запису, пристрій для запису інформації на такий носій запису та пристрій для зчитування інформації з такого носія запису

Номер патенту: 39846
Опубліковано: 16.07.2001
Автори: Раймакерс Вільхельмус Петрус Марія, Веніс Арте Віллеміна, Кейперс Франціскус Ламбертус Йоханнус Марія, Пасман Йоханнес Херманус Теодорус, Мюлдер Хендрікус Антоніус Марія
МПК: G11B 7/007
Мітки: зчитування, запису, виготовлення, носія, спосіб, оптично, пристрій, такого, зчитуваний, носій, інформації
Формула / Реферат:
1. Оптически считываемый носитель записи, содержащий чувствительный к излучению слой записи информации на подложке, имеющей форму диска, снабженной непрерывной дорожкой постоянной ширины, организованной в соответствии со спиральной или концентрической структурой дорожки, для записи вдоль нее информации с в существенной степени постоянной линейной скоростью, причем упомянутая дорожка выполнена в виде периодического радиального...
Спосіб кодування та передавання інформації із захистом та пристрій для його здійснення

Номер патенту: 48866
Опубліковано: 15.08.2002
Автори: Роптанова Юлія Володимирівна, Гармаш Володимир Володимирович, Кулик Анатолій Ярославович, Кривогубченко Денис Сергійович, Квєтний Роман Наумович
МПК: H03M 13/00
Мітки: передавання, спосіб, пристрій, захистом, інформації, кодування, здійснення
Формула / Реферат:
1. Спосіб кодування та передавання інформації із захистом, що містить зчитування з носія стандартного блока даних і передавання по каналу зв'язку, який відрізняється тим, що на передавальному боці числовими методами розраховують функції Уолша, програмним шляхом розраховують номери відповідних функцій Уолша, які апроксимують зчитаний стандартний блок, вибирають таку послідовність номерів функцій Уолша, яка є мінімальною, отримані номери...
Попередній патент: Спосіб підготовки газу для синтезу метанолу
Наступний патент: Оптичний диск і пристрій для сканування оптичного диска
Випадковий патент: Кожухотрубний теплообмінник