Масштабоване кодування мови та аудіо з використанням комбінаторного кодування mdct-спектра








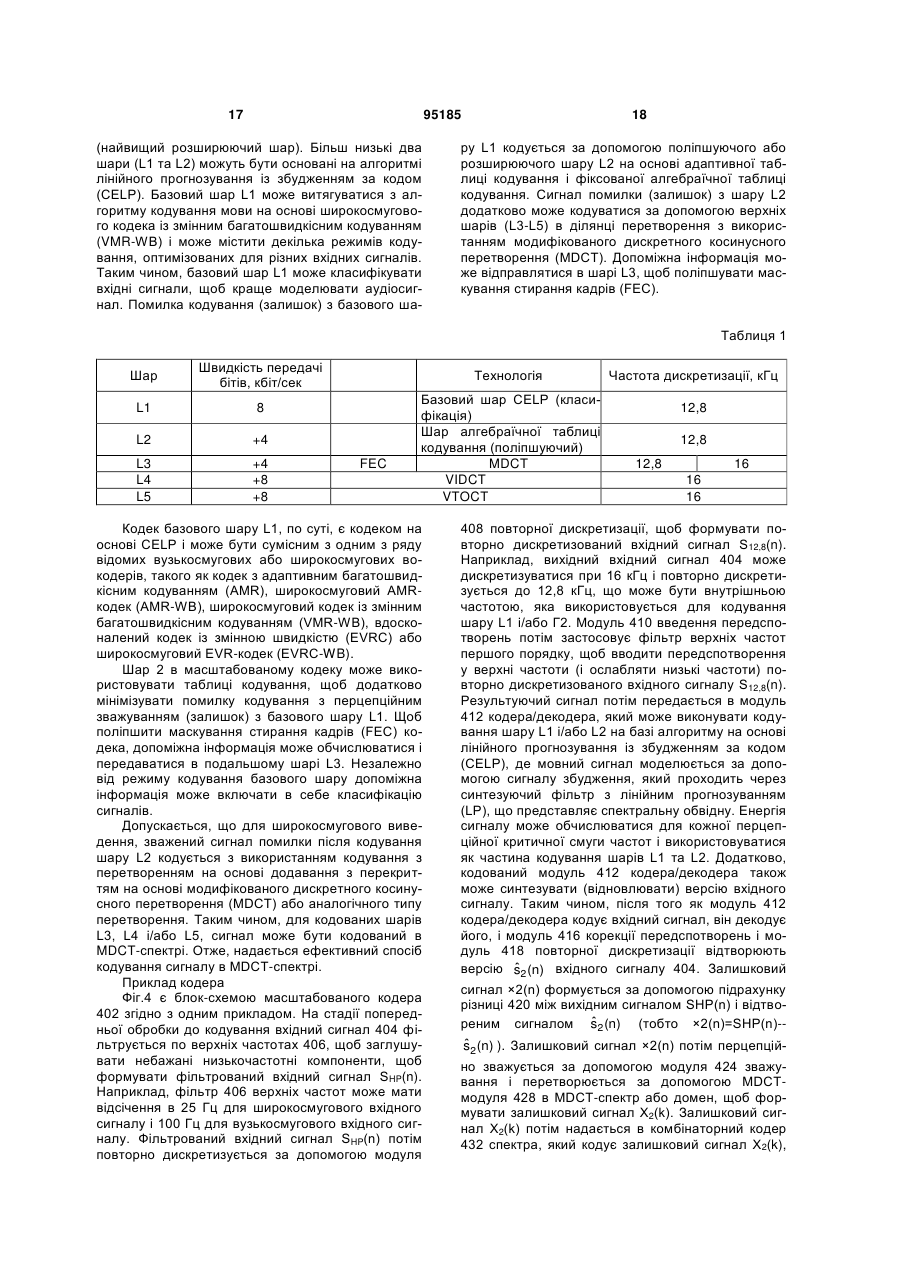











Формула / Реферат
1. Спосіб для кодування в масштабованому мовному та аудіокодеку, що має декілька шарів, який містить етапи, на яких:
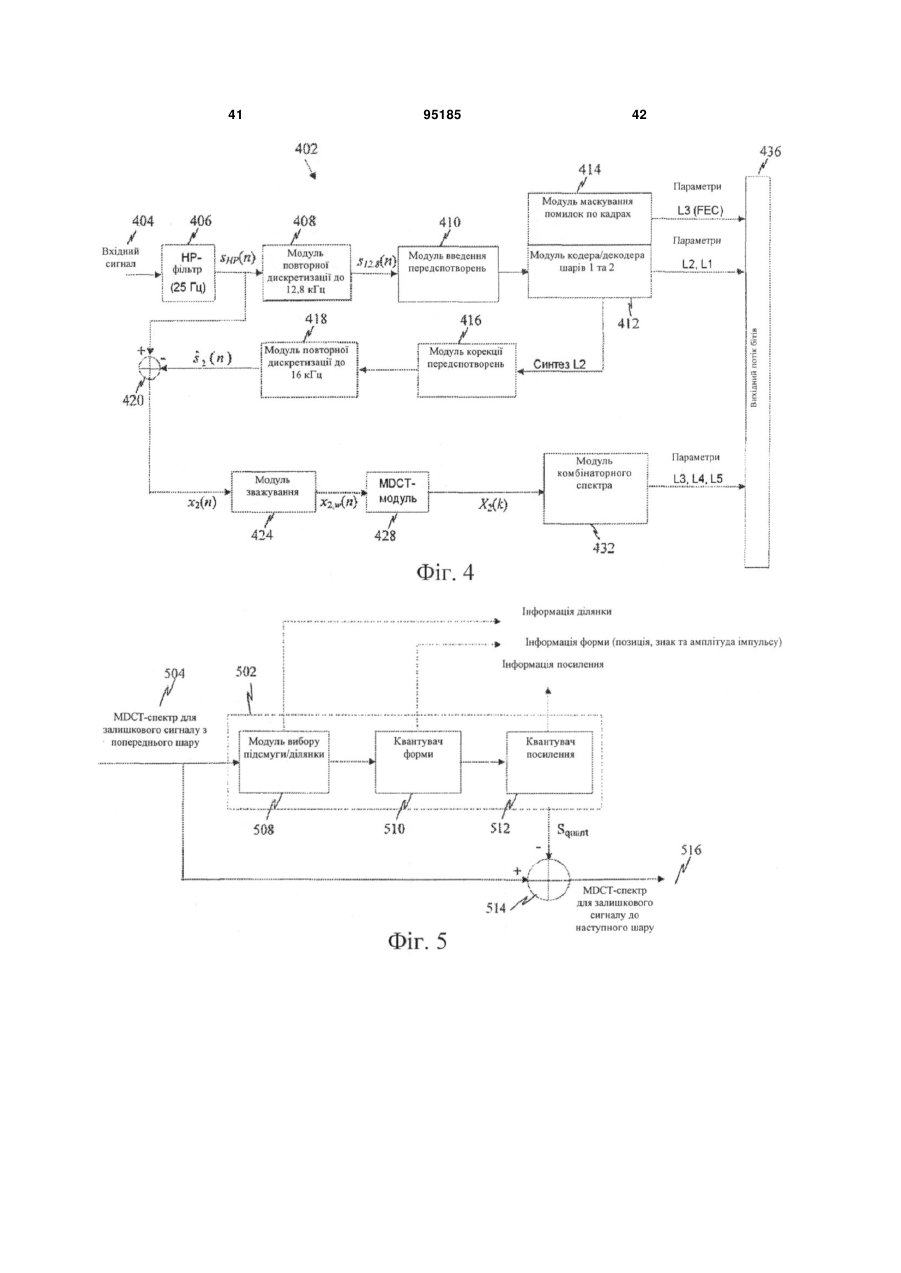
одержують залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому та аудіокодеку, і при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу;
перетворюють залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, що має множину спектральних ліній; і
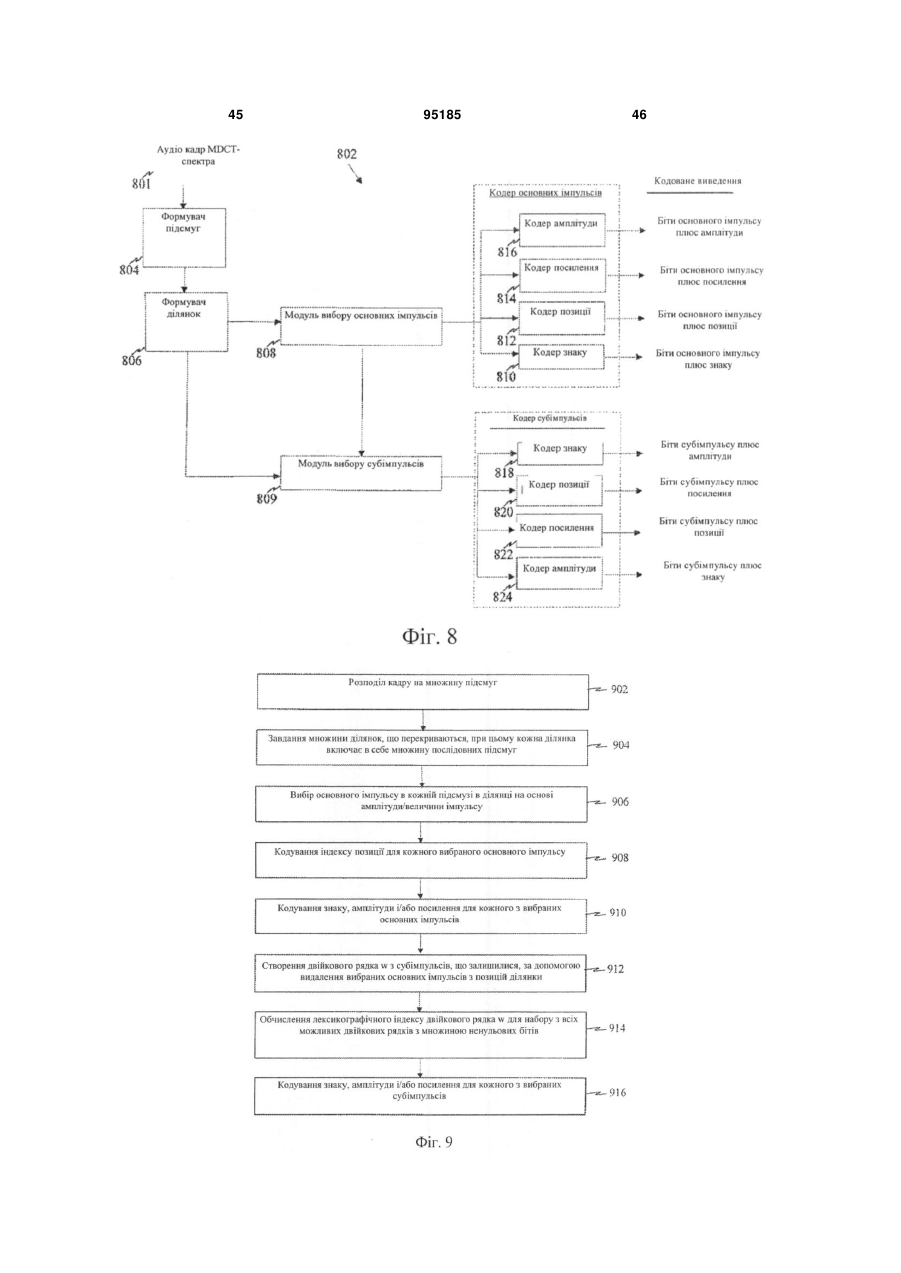
кодують спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній.
2. Спосіб за п. 1, у якому шар перетворення DCT-типу є шаром модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення є MDCT-спектром.
3. Спосіб за п. 1, у якому кодування спектральних ліній спектра перетворення включає в себе етап, на якому:
кодують позиції вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній.
4. Спосіб за п. 1, який додатково містить етапи, на яких:
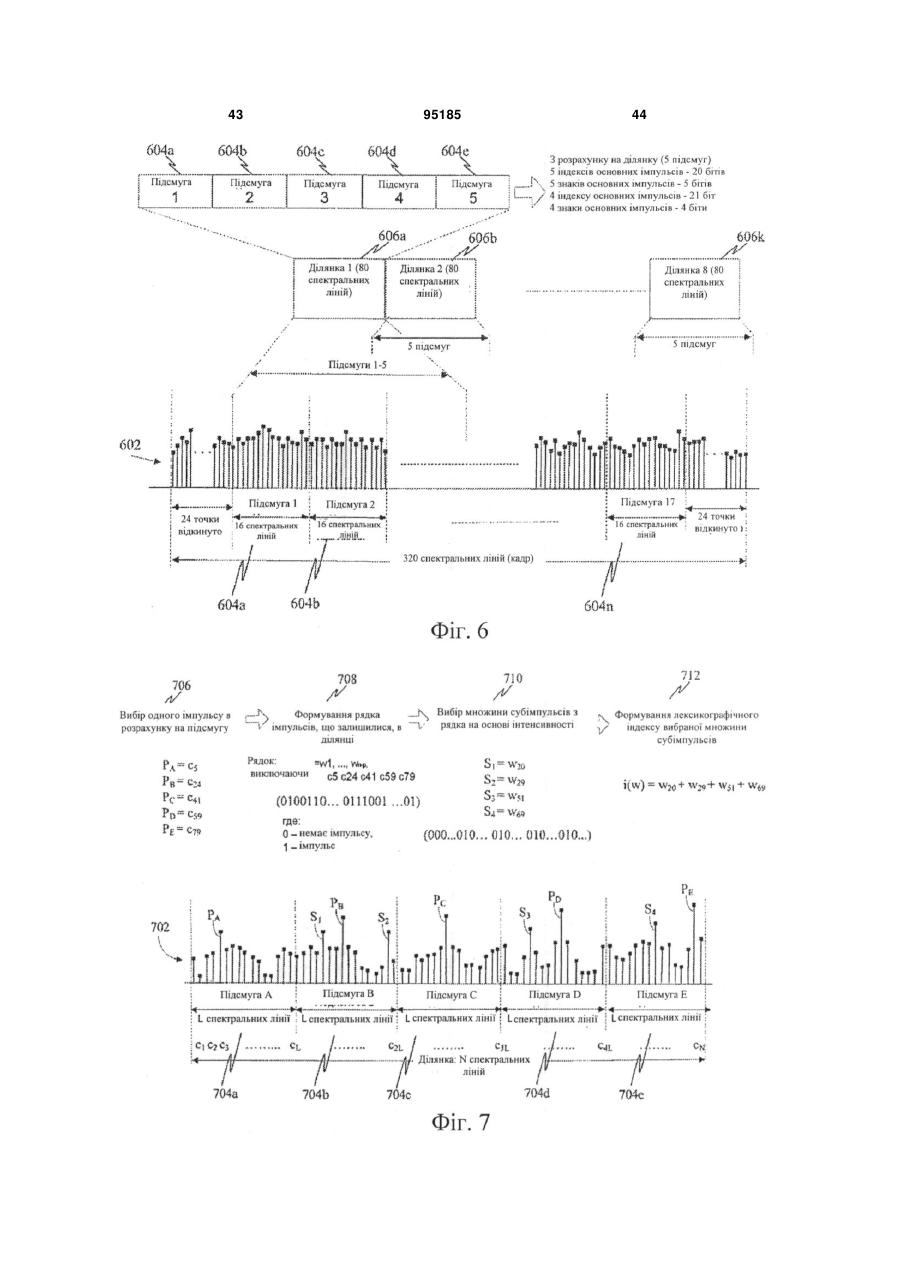
розбивають множину спектральних ліній на множину підсмуг; і
групують послідовні підсмуги в ділянки.
5. Спосіб за п. 4, що додатково містить етап, на якому:
кодують основний імпульс, вибраний з множини спектральних ліній для кожної з підсмуг в ділянці.
6. Спосіб за п. 4, що додатково містить етап, на якому:
кодують позиції вибраного піднабору спектральних ліній у рамках ділянки на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній;
при цьому кодування спектральних ліній спектра перетворення включає в себе етап, на якому формують матрицю, на основі позицій вибраного піднабору спектральних ліній, із усіх можливих двійкових рядків довжини, яка дорівнює всім позиціям в ділянці.
7. Спосіб за п. 4, у якому ділянки перекриваються, і кожна ділянка включає в себе множину послідовних підсмуг.
8. Спосіб за п. 4, у якому піднабір спектральних ліній включає в себе:
перший піднабір спектральних ліній, який містить спектральну лінію з найбільшою величиною з кожної підсмуги в групі підсмуг, і
другий піднабір додаткових спектральних ліній, вибраних на основі їх величин із групи підсмуг.
9. Спосіб за п. 1, у якому лексикографічний індекс представляє ненульові спектральні лінії у двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка.
10. Спосіб за п. 1, у якому технологія комбінаторного позиційного кодування включає в себе етап, на якому:
формують індекс, що представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули:
,
де - довжина двійкового рядка, - кількість вибраних спектральних ліній, які повинні бути кодовані, і представляє окремі біти двійкового рядка.
11. Спосіб за п. 1, що додатково містить етап, на якому:
відкидають набір спектральних ліній, щоб скоротити число спектральних ліній, перед кодуванням.
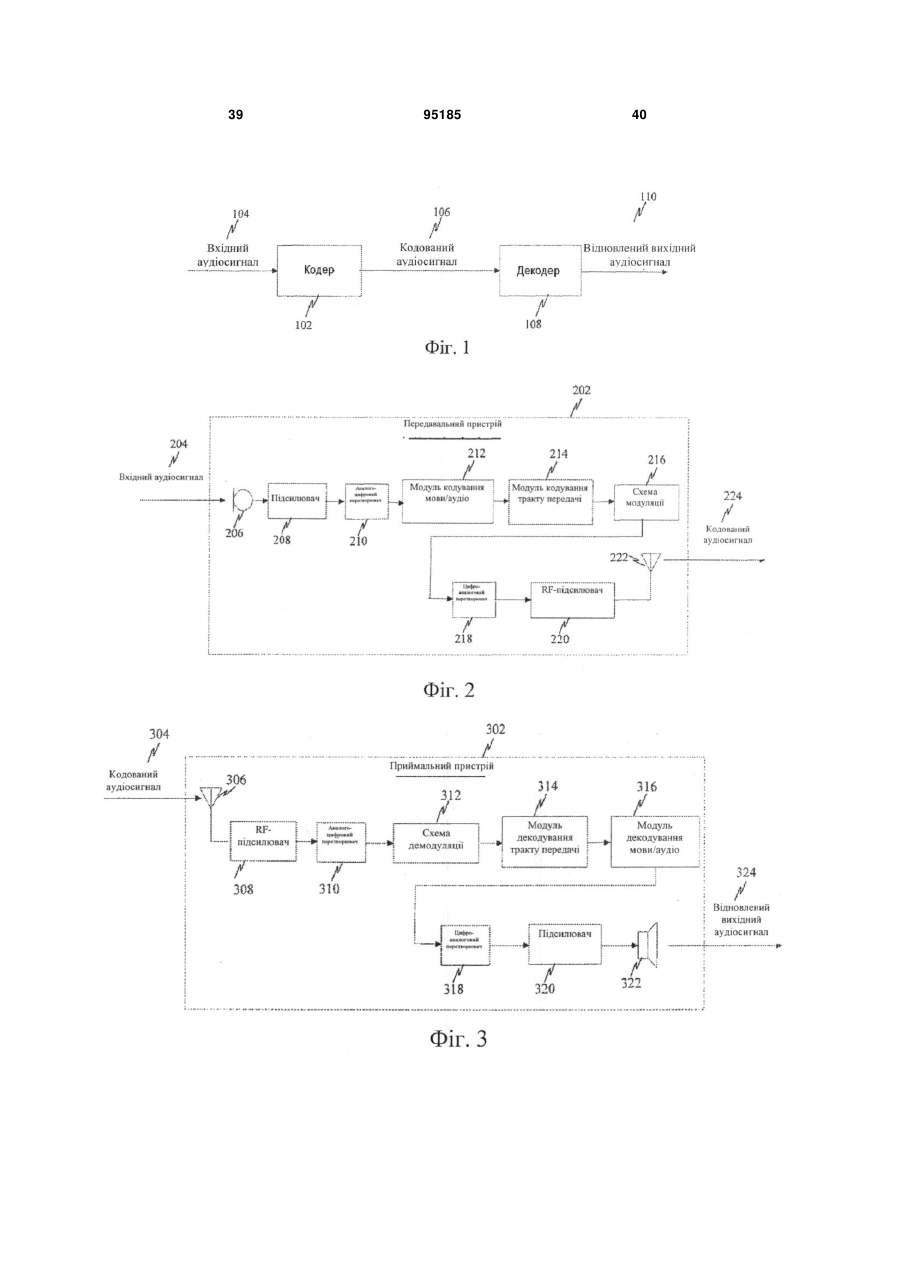
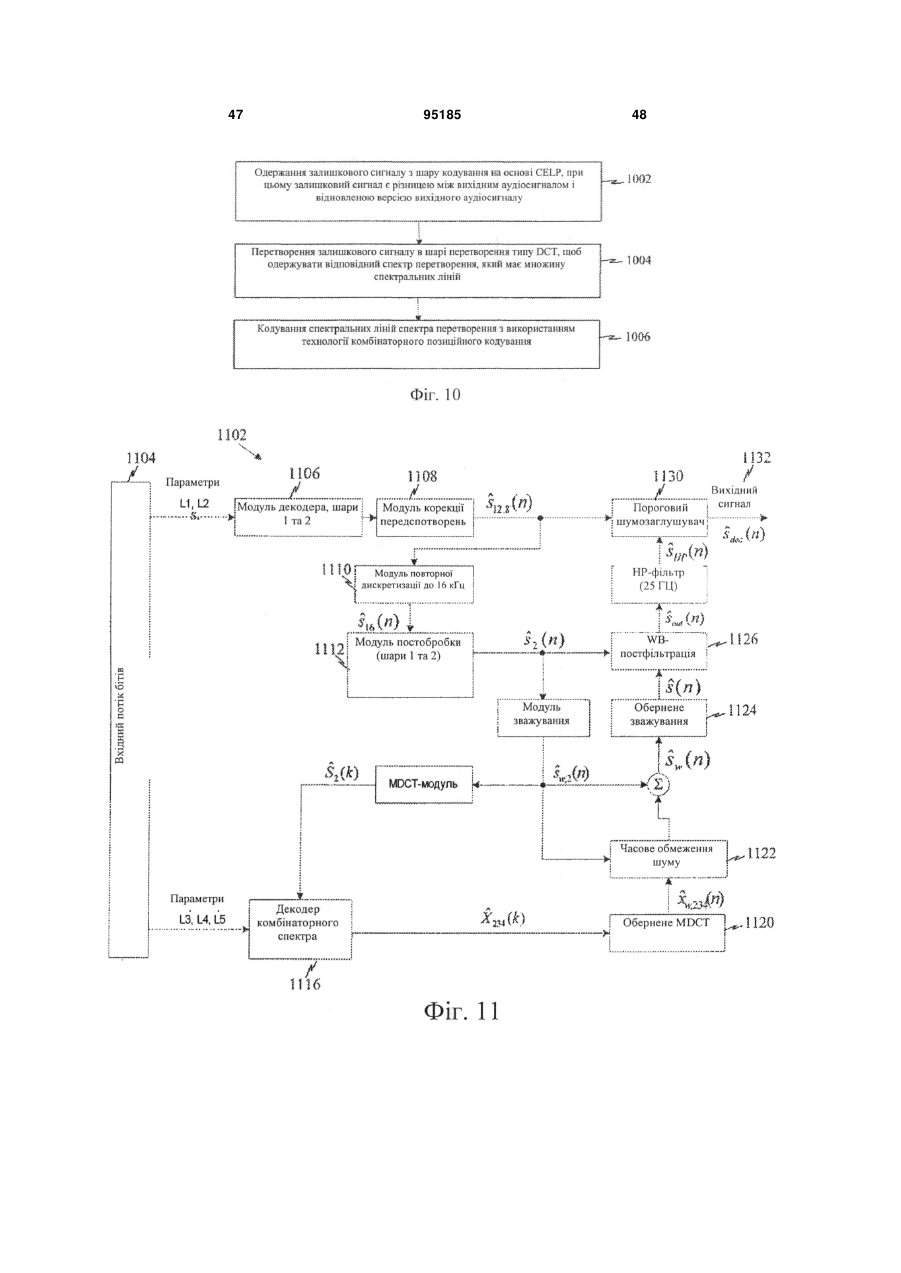
12. Спосіб за п. 1, в якому відновлена версія вихідного аудіосигналу одержується за допомогою етапів, на яких:
синтезують кодовану версію вихідного аудіосигналу із шару кодування на основі CELP, щоб одержувати синтезований сигнал;
повторно вводять передспотворення в синтезований сигнал; і
виконують підвищувальну дискретизацію сигналу після повторного введення передспотворень, щоб одержати відновлену версію вихідного аудіосигналу.
13. Пристрій масштабованого мовного та аудіокодера, який містить:
модуль шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), виконаний з можливістю формувати залишковий сигнал, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу;
модуль шару перетворення типу дискретного косинусного перетворення (DCT), виконаний з можливістю:
одержувати залишковий сигнал з модуля шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому модуль шару кодування на основі CELP містить шар кодування на основі CELP, що має один або два попередніх шари в масштабованому мовному та аудіокодеку; і
перетворювати залишковий сигнал, з попереднього шару, в шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і
комбінаторний кодер спектра, виконаний з можливістю кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній.
14. Пристрій за п. 13, у якому модуль шару перетворення DCT-типу є модулем шару модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення є MDCT-спектром.
15. Пристрій за п. 13, у якому кодування спектральних ліній спектра перетворення включає в себе:
кодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній.
16. Пристрій за п. 13, який додатково містить:
формувач підсмуг, виконаний з можливістю розбивати множину спектральних ліній на множину підсмуг; і
формувач ділянок, виконаний з можливістю групувати послідовні підсмуги в ділянки.
17. Пристрій за п. 16, який додатково містить:
кодер основних імпульсів, виконаний з можливістю кодувати основний імпульс, вибираний з множини спектральних ліній для кожної з підсмуг в ділянці.
18. Пристрій за п. 16, що додатково містить:
кодер субімпульсів, виконаний з можливістю кодувати позиції вибраного піднабору спектральних ліній у рамках ділянки на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній;
при цьому кодування спектральних ліній спектра перетворення включає в себе формування матриці, на основі позицій вибраного піднабору спектральних ліній, з усіх можливих двійкових рядків довжини, яка дорівнює всім позиціям в ділянці.
19. Пристрій за п. 16, у якому ділянки перекриваються, і кожна ділянка включає в себе множину послідовних підсмуг.
20. Пристрій за п. 13, у якому лексикографічний індекс представляє ненульові спектральні лінії у двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка.
21. Пристрій за п.13, у якому комбінаторний кодер спектра виконаний з можливістю формувати індекс, що представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули:
,
де - довжина двійкового рядка, - кількість вибраних спектральних ліній, які повинні бути кодовані, і представляє окремі біти двійкового рядка.
22. Пристрій за п. 13, у якому відновлена версія вихідного аудіосигналу одержується за допомогою наступного:
синтезування кодованої версії вихідного аудіосигналу з шару кодування на основі CELP, щоб одержувати синтезований сигнал;
повторне введення передспотворень у синтезований сигнал; і
підвищувальна дискретизація сигналу після повторного введення передспотворень, щоб одержувати відновлену версію вихідного аудіосигналу.
23. Пристрій масштабованого мовного та аудіокодера, який містить:
засіб для одержання залишкового сигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу;
засіб для перетворення залишкового сигналу, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і
засіб для кодування спектральних ліній спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній.
24. Процесор, який включає в себе схему масштабованого кодування мови та аудіо, виконану з можливістю:
одержувати залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу;
перетворювати залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і
кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній.
25. Машиночитаний носій, який містить інструкції, що застосовуються для масштабованого кодування мови та аудіо, які, коли виконуються за допомогою одного або більше процесорів, спонукають процесори:
одержувати залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу;
перетворювати залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і
кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній.
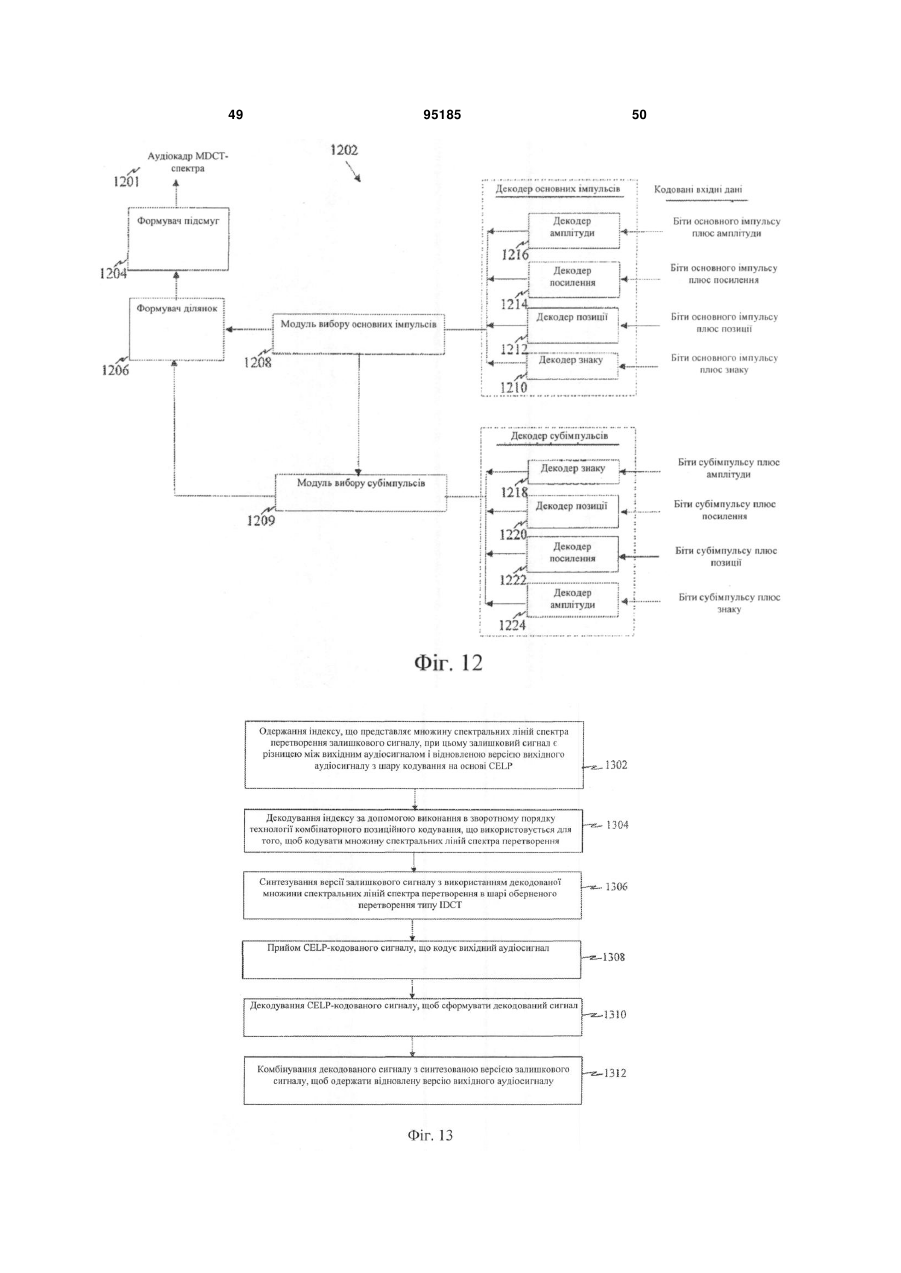
26. Спосіб для декодування в масштабованому мовному та аудіокодеку, що має кілька шарів, який містить етапи, на яких:
одержують індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку;
декодують індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і
синтезують версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT).
27. Спосіб за п. 26, який додатково містить етапи, на яких:
приймають CELP-кодований сигнал, що кодує вихідний аудіосигнал;
декодують CELP-кодований сигнал, щоб формувати декодований сигнал; і
комбінують декодований сигнал з синтезованою версією залишкового сигналу, щоб одержувати відновлену версію вихідного аудіосигналу.
28. Спосіб за п. 26, в якому синтезування версії залишкового сигналу включає в себе етап, на якому:
застосовують зворотне перетворення DCT-типу до спектральних ліній спектра перетворення, щоб сформувати версію залишкового сигналу в часовій ділянці.
29. Спосіб за п. 26, в якому декодування спектральних ліній спектра перетворення включає в себе етап, на якому:
декодують позиції вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній.
30. Спосіб за п. 26, в якому індекс представляє ненульові спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка.
31. Спосіб за п. 26, в якому шар зворотного перетворення DCT-типу є шаром зворотного модифікованого дискретного косинусного перетворення (IMDCT), і спектр перетворення є MDCT-спектром.
32. Спосіб за п. 26, в якому одержаний індекс представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули:
,
де - довжина двійкового рядка, - кількість вибраних спектральних ліній, які повинні бути кодовані, і представляє окремі біти двійкового рядка.
33. Спосіб за п. 26, в якому піднабір спектральних ліній включає в себе: перший піднабір спектральних ліній, який містить спектральну лінію з
найбільшою величиною з кожної підсмуги в групі підсмуг, і
другий піднабір додаткових спектральних ліній, вибраних на основі їх величин із групи підсмуг.
34. Пристрій масштабованого мовного та аудіодекодера, який містить:
комбінаторний декодер спектра, виконаний з можливістю:
одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з модуля шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому модуль шару кодування на основі CELP містить шар кодування на основі CELP, що має один або два попередніх шари в масштабованому мовному та аудіокодеку;
декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і
модуль шару зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT), виконаний з можливістю синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення.
35. Пристрій за п. 34, що додатково містить:
CELP- декодер, виконаний з можливістю:
приймати CELP-кодований сигнал, що кодує вихідний аудіосигнал;
декодувати CELP-кодований сигнал, щоб формувати декодований сигнал; і
комбінувати декодований сигнал із синтезованою версією залишкового сигналу, щоб одержувати відновлену версію вихідного аудіосигналу.
36. Пристрій за п. 34, в якому при синтезуванні версії залишкового сигналу, модуль шару зворотного перетворення IDCT-типу виконаний з можливістю застосовувати зворотне перетворення типу DCT до спектральних ліній спектра перетворення, щоб сформувати версію залишкового сигналу в часовій ділянці.
37. Пристрій за п. 34, в якому індекс представляє ненульові спектральні лінії у двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка.
38. Пристрій масштабованого мовного та аудіодекодера, що містить:
засіб для одержання індексу, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку;
засіб для декодування індексу, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, використовуваної для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і
засіб для синтезування версії залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT).
39. Процесор, який включає в себе схему масштабованого декодування мови та аудіо, виконану з можливістю:
одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку;
декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і
синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT).
40. Машиночитаний носій, який містить інструкції, що застосовуються для масштабованого декодування мови та аудіо, які, коли виконуються за допомогою одного або більше процесорів, спонукують процесори:
одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку;
декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і
синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT).
Текст
1. Спосіб для кодування в масштабованому мовному та аудіокодеку, що має декілька шарів, який містить етапи, на яких: одержують залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому та аудіокодеку, і при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу; перетворюють залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, що має множину спектральних ліній; і кодують спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. 2. Спосіб за п. 1, у якому шар перетворення DCTтипу є шаром модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення є MDCT-спектром. 2 (19) 1 3 формують індекс, що представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: , де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і w j представляє окремі біти двійкового рядка. 11. Спосіб за п. 1, що додатково містить етап, на якому: відкидають набір спектральних ліній, щоб скоротити число спектральних ліній, перед кодуванням. 12. Спосіб за п. 1, в якому відновлена версія вихідного аудіосигналу одержується за допомогою етапів, на яких: синтезують кодовану версію вихідного аудіосигналу із шару кодування на основі CELP, щоб одержувати синтезований сигнал; повторно вводять передспотворення в синтезований сигнал; і виконують підвищувальну дискретизацію сигналу після повторного введення передспотворень, щоб одержати відновлену версію вихідного аудіосигналу. 13. Пристрій масштабованого мовного та аудіокодера, який містить: модуль шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), виконаний з можливістю формувати залишковий сигнал, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу; модуль шару перетворення типу дискретного косинусного перетворення (DCT), виконаний з можливістю: одержувати залишковий сигнал з модуля шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому модуль шару кодування на основі CELP містить шар кодування на основі CELP, що має один або два попередніх шари в масштабованому мовному та аудіокодеку; і перетворювати залишковий сигнал, з попереднього шару, в шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і комбінаторний кодер спектра, виконаний з можливістю кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. 95185 4 14. Пристрій за п. 13, у якому модуль шару перетворення DCT-типу є модулем шару модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення є MDCT-спектром. 15. Пристрій за п. 13, у якому кодування спектральних ліній спектра перетворення включає в себе: кодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. 16. Пристрій за п. 13, який додатково містить: формувач підсмуг, виконаний з можливістю розбивати множину спектральних ліній на множину підсмуг; і формувач ділянок, виконаний з можливістю групувати послідовні підсмуги в ділянки. 17. Пристрій за п. 16, який додатково містить: кодер основних імпульсів, виконаний з можливістю кодувати основний імпульс, вибираний з множини спектральних ліній для кожної з підсмуг в ділянці. 18. Пристрій за п. 16, що додатково містить: кодер субімпульсів, виконаний з можливістю кодувати позиції вибраного піднабору спектральних ліній у рамках ділянки на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній; при цьому кодування спектральних ліній спектра перетворення включає в себе формування матриці, на основі позицій вибраного піднабору спектральних ліній, з усіх можливих двійкових рядків довжини, яка дорівнює всім позиціям в ділянці. 19. Пристрій за п. 16, у якому ділянки перекриваються, і кожна ділянка включає в себе множину послідовних підсмуг. 20. Пристрій за п. 13, у якому лексикографічний індекс представляє ненульові спектральні лінії у двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. 21. Пристрій за п.13, у якому комбінаторний кодер спектра виконаний з можливістю формувати індекс, що представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: , де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і w j представляє окремі біти двійкового рядка. 22. Пристрій за п. 13, у якому відновлена версія вихідного аудіосигналу одержується за допомогою наступного: синтезування кодованої версії вихідного аудіосигналу з шару кодування на основі CELP, щоб одержувати синтезований сигнал; повторне введення передспотворень у синтезований сигнал; і 5 підвищувальна дискретизація сигналу після повторного введення передспотворень, щоб одержувати відновлену версію вихідного аудіосигналу. 23. Пристрій масштабованого мовного та аудіокодера, який містить: засіб для одержання залишкового сигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу; засіб для перетворення залишкового сигналу, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і засіб для кодування спектральних ліній спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. 24. Процесор, який включає в себе схему масштабованого кодування мови та аудіо, виконану з можливістю: одержувати залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу; перетворювати залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. 25. Машиночитаний носій, який містить інструкції, що застосовуються для масштабованого кодування мови та аудіо, які, коли виконуються за допомогою одного або більше процесорів, спонукають процесори: одержувати залишковий сигнал з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку, при цьому залишковий сигнал є різницею між вихідним 95185 6 аудіосигналом і відновленою версією вихідного аудіосигналу; перетворювати залишковий сигнал, з попереднього шару, у шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній; і кодувати спектральні лінії спектра перетворення з використанням технології комбінаторного позиційного кодування, причому технологія комбінаторного позиційного кодування включає в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. 26. Спосіб для декодування в масштабованому мовному та аудіокодеку, що має кілька шарів, який містить етапи, на яких: одержують індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку; декодують індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і синтезують версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT). 27. Спосіб за п. 26, який додатково містить етапи, на яких: приймають CELP-кодований сигнал, що кодує вихідний аудіосигнал; декодують CELP-кодований сигнал, щоб формувати декодований сигнал; і комбінують декодований сигнал з синтезованою версією залишкового сигналу, щоб одержувати відновлену версію вихідного аудіосигналу. 28. Спосіб за п. 26, в якому синтезування версії залишкового сигналу включає в себе етап, на якому: застосовують зворотне перетворення DCT-типу до спектральних ліній спектра перетворення, щоб сформувати версію залишкового сигналу в часовій ділянці. 29. Спосіб за п. 26, в якому декодування спектральних ліній спектра перетворення включає в себе етап, на якому: 7 декодують позиції вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. 30. Спосіб за п. 26, в якому індекс представляє ненульові спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. 31. Спосіб за п. 26, в якому шар зворотного перетворення DCT-типу є шаром зворотного модифікованого дискретного косинусного перетворення (IMDCT), і спектр перетворення є MDCT-спектром. 32. Спосіб за п. 26, в якому одержаний індекс представляє позиції спектральних ліній у рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: , де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і w j представляє окремі біти двійкового рядка. 33. Спосіб за п. 26, в якому піднабір спектральних ліній включає в себе: перший піднабір спектральних ліній, який містить спектральну лінію з найбільшою величиною з кожної підсмуги в групі підсмуг, і другий піднабір додаткових спектральних ліній, вибраних на основі їх величин із групи підсмуг. 34. Пристрій масштабованого мовного та аудіодекодера, який містить: комбінаторний декодер спектра, виконаний з можливістю: одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з модуля шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому модуль шару кодування на основі CELP містить шар кодування на основі CELP, що має один або два попередніх шари в масштабованому мовному та аудіокодеку; декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і модуль шару зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT), виконаний з можливістю синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення. 95185 8 35. Пристрій за п. 34, що додатково містить: CELP- декодер, виконаний з можливістю: приймати CELP-кодований сигнал, що кодує вихідний аудіосигнал; декодувати CELP-кодований сигнал, щоб формувати декодований сигнал; і комбінувати декодований сигнал із синтезованою версією залишкового сигналу, щоб одержувати відновлену версію вихідного аудіосигналу. 36. Пристрій за п. 34, в якому при синтезуванні версії залишкового сигналу, модуль шару зворотного перетворення IDCT-типу виконаний з можливістю застосовувати зворотне перетворення типу DCT до спектральних ліній спектра перетворення, щоб сформувати версію залишкового сигналу в часовій ділянці. 37. Пристрій за п. 34, в якому індекс представляє ненульові спектральні лінії у двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. 38. Пристрій масштабованого мовного та аудіодекодера, що містить: засіб для одержання індексу, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку; засіб для декодування індексу, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, використовуваної для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і засіб для синтезування версії залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT). 39. Процесор, який включає в себе схему масштабованого декодування мови та аудіо, виконану з можливістю: одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку; декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому 9 95185 10 цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT). 40. Машиночитаний носій, який містить інструкції, що застосовуються для масштабованого декодування мови та аудіо, які, коли виконуються за допомогою одного або більше процесорів, спонукують процесори: одержувати індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, при цьому залишковий сигнал є різницею між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому шар кодування на основі CELP містить один або два попередніх шари в масштабованому мовному та аудіокодеку; декодувати індекс, у верхньому шарі, за допомогою виконання у зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення, причому цей індекс є лексикографічним індексом для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній; і синтезувати версію залишкового сигналу з використанням декодованої множини спектральних ліній спектра перетворення в шарі зворотного перетворення типу зворотного дискретного косинусного перетворення (IDCT). Дана заявка на патент заявляє пріоритет згідно з попередньою заявкою США № 60/981814, озаглавленою «Low-Complexity Technique for Encoding/Decoding of Quantized MDCT Spectrum in Scalable Speech+Audio Codecs», поданою 22 жовтня 2007 року, переуступленою правонаступнику даної заявки та явно включеною до складу даного документа за допомогою посилання. Подальший опис, загалом, належить до кодерів і декодерів і, зокрема, до ефективного способу кодування спектра модифікованого дискретного косинусного перетворення (MDCT) як частини масштабованого мовного та аудіокодека. Одна мета кодування аудіо полягає в тому, щоб стискати аудіосигнал в необхідний обмежений обсяг інформації при збереженні максимально можливої вихідної якості звуку. У процесі кодування аудіосигнал у часовій ділянці перетворюється в частотну ділянку. Технології перцепційного кодування аудіо, такі як MPEG Layer-З (МРЗ), MPEG-2 та MPEG-4, використовують властивості маскування сигналів людського вуха, щоб зменшувати обсяг даних. За рахунок цього шум квантування розподіляється по смугах частот таким чином, що він маскується за допомогою домінуючого повного сигналу, тобто він залишається нечутним. Значне зменшення ємності для зберігання можливе при невеликих або за відсутності втрат якості звучання, що сприймаються. Технології перцепційного кодування аудіо часто є масштабованими і формують багатошаровий потік бітів, який має основний або базовий шар і щонайменше один поліпшуючий шар. Це забезпечує масштабованість швидкості передачі бітів, тобто декодування при різних рівнях якості звучання на стороні декодера або зменшення швидкості передачі бітів у мережі за допомогою формування або узгодження трафіку. Лінійне прогнозування із збудженням за кодом (CELP) є класом алгоритмів, які включають в себе алгебраїчне CELP (ACELP), ослаблене CELP (RCELP), з низькою затримкою (LD-CELP) і лінійне прогнозування із збудженням по векторній сумі (VSELP), які широко використовуються для кодування мови. Один принцип в основі CELP називається аналізом через синтез (AbS) і означає, що кодування (аналіз) виконується за допомогою перцепційної оптимізації декодованого (синтез) сигналу в замкненому контурі. У теорії кращий потік CELP повинен формуватися за допомогою випробовування всіх можливих наборів двійкових знаків і вибору того з них, який формує декодований сигнал, що оптимально звучить. Очевидно, що це неможливе на практиці з двох причин: його дуже складно реалізувати, і критерій вибору «оптимального звучання» має на увазі слухача-людину. Щоб досягати кодування в реальному часі з використанням обмежених обчислювальних ресурсів, пошук CELP поділяється на менші, більш керовані, послідовні пошуки з використанням перцепційної вагової функції. Як правило, кодування включає в себе (а) обчислення і/або квантування (звичайно як пара спектральних ліній) коефіцієнтів кодування з лінійним прогнозуванням для вхідного аудіосигналу, (b) використання таблиць кодування, щоб виконувати пошук найкращого збігу, щоб формувати кодований сигнал, (с) формування сигналу помилки, який є різницею між кодованим сигналом і дійсним вхідним сигналом, і (d) додаткове кодування такого сигналу помилки (звичайно в MDCTспектрі) в одному або більше шарів, щоб підвищувати якість відновленого або синтезованого сигналу. Безліч різних технологій доступна для того, щоб реалізовувати мовні і аудіокодеки на основі алгоритмів CELP. У деяких з цих технологій формується сигнал помилки, який потім перетворюється (звичайно за допомогою DCT, MDCT або аналогічного перетворення) і кодується, щоб додатково підвищувати якість кодованого сигналу. Проте, внаслідок обмежень по обробці і смузі пропускання багатьох мобільних пристроїв і мереж 11 бажана ефективна реалізація такого кодування MDCT-спектра, щоб зменшувати розмір інформації, яка зберігається або передається. Далі представлене спрощене розкриття суті одного або більше варіантів здійснення винаходу, для того щоб надати базове розуміння деяких варіантів здійснення. Ця суть не є всебічним оглядом всіх варіантів здійснення, що розглядаються, і вона не має наміром ні те, щоб визначати ключові або найважливіші елементи всіх варіантів здійснення, ні те, щоб змальовувати сферу застосування яких-небудь або всіх варіантів здійснення. її єдина мета - представляти деякі поняття одного або більше варіантів здійснення в спрощеній формі як вступ в більш докладний опис, який представлений далі. Надається ефективна технологія для кодування/декодування спектра MDCT (або аналогічного основаного на перетворенні) в алгоритмах масштабованого стиснення аудіо і мови. Ця технологія використовує властивість розрідженості перцепційно квантованого MDCT-спектра при завданні структури коду, який включає в себе елемент, що описує позиції ненульових спектральних ліній в кодованій смузі частот, і використовує технології комбінаторного переліку, щоб обчислювати цей елемент. В одному прикладі надається спосіб для кодування MDCT-спектра в масштабованому мовному та аудіокодеку. Таке кодування спектра перетворення може виконуватися за допомогою апаратних засобів кодера, програмного забезпечення для кодування і/або комбінації зазначеного і може бути здійснене в процесорі, схемі обробки і/або машинозчитуваному носії. Залишковий сигнал одержується із шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому залишковий сигнал - це різниця між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу. Відновлена версія вихідного аудіосигналу може одержуватися за допомогою наступного: (а) синтезування кодованої версії вихідного аудіосигналу із шару кодування на основі CELP, щоб одержувати синтезований сигнал, (Ь) повторне введення передспотворень у синтезований сигнал і/або (с) підвищуюча дискретизація сигналу після повторного введення передспотворень, щоб одержувати відновлену версію вихідного аудіосигналу. Залишковий сигнал перетворюється в шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній. Шар перетворення DCT-типу може бути шаром модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення - це MDCT-спектр. Спектральні лінії спектра перетворення кодуються з використанням технології комбінаторного позиційного кодування. Кодування спектральних ліній спектра перетворення може включати в себе кодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій 95185 12 ненульових спектральних ліній. У деяких реалізаціях набір спектральних ліній може відкидатися, щоб скоротити кількість спектральних ліній, перед кодуванням. В іншому прикладі технологія комбінаторного позиційного кодування може включати в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що представляють позиції вибраного піднабору спектральних ліній. Лексикографічний індекс може представляти спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. В іншому прикладі технологія комбінаторного позиційного кодування може включати в себе формування індексу, що представляє позиції спектральних ліній в рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: n j n n index(n, k, w ) i( w ) w j w j j1 i j де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і wj представляє окремі біти двійкового рядка. У деяких реалізаціях множина спектральних ліній може бути розбита на множину підсмуг, і послідовні підсмуги можуть групуватися в ділянки. Основний імпульс, вибираний з множини спектральних ліній для кожної з підсмуг в ділянці, може бути кодований, при цьому вибраний піднабір спектральних ліній в ділянці виключає основний імпульс для кожної з підсмуг. Додатково, позиції вибраного піднабору спектральних ліній в рамках ділянки можуть бути кодовані на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. Вибраний піднабір спектральних ліній в ділянці може виключати основний імпульс для кожної з підсмуг. Кодування спектральних ліній спектра перетворення може включати в себе формування матриці, на основі позицій вибраного піднабору спектральних ліній, з усіх можливих двійкових рядків довжини, яка дорівнює всім позиціям в ділянці. Ділянки можуть перекриватися, і кожна ділянка може включати в себе множину послідовних підсмуг. В іншому прикладі надається спосіб для декодування спектра перетворення в масштабованому мовному та аудіокодеку. Таке декодування спектра перетворення може виконуватися за допомогою апаратних засобів декодера, програмного забезпечення для декодування і/або комбінації зазначеного і може бути здійснене в процесорі, схемі обробки і/або машинозчитуваному носії. Індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, одержується, при цьому залишковий сигнал - це різниця між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP). Індекс може представляти ненульові спек 13 тральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. В одному прикладі одержаний індекс може представляти позиції спектральних ліній в рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: n j n index(n, k, w ) i( w ) w j w j i j j 1 n де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і wj представляє окремі біти двійкового рядка. Індекс декодується за допомогою виконання в зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення. Версія залишкового сигналу синтезується з використанням декодованої множини спектральних ліній спектра перетворення в шарі оберненого перетворення типу оберненого дискретного косинусного перетворення (IDCT). Синтезування версії залишкового сигналу може включати в себе застосування оберненого перетворення DCT-типу до спектральних ліній спектра перетворення, щоб формувати версію залишкового сигналу у часовій ділянці. Декодування спектральних ліній спектра перетворення може включати в себе декодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. Шар оберненого перетворення DCT-типу може бути шаром оберненого модифікованого дискретного косинусного перетворення (IMDCT), і спектр перетворення - це MDCT-спектр. Додатково, може прийматися CELP-кодований сигнал, що кодує вихідний аудіосигнал. CELPкодований сигнал може бути декодований, щоб сформувати декодований сигнал. Декодований сигнал може бути комбінований зі синтезованою версією залишкового сигналу, щоб одержувати відновлену версію (з більш високою точністю відтворення) вихідного аудіосигналу. Різні ознаки, характер і переваги можуть стати очевидними з нижчевикладеного докладного опису при розгляді разом з кресленнями, на яких аналогічні посилання з номером ідентифікуються відповідним чином по всьому документу. Фіг.1 є блок-схемою, яка ілюструє систему зв'язку, в якій можуть реалізовуватися одна або більше ознак кодування. Фіг.2 є блок-схемою, яка ілюструє передавальний пристрій, який може бути виконаний з можливістю здійснювати ефективне кодування аудіо згідно з одним прикладом. Фіг.3 є блок-схемою, яка ілюструє приймальний пристрій, який може бути виконаний з можливістю здійснювати ефективне декодування аудіо згідно з одним прикладом. Фіг.4 є блок-схемою масштабованого кодера згідно з одним прикладом. 95185 14 Фіг.5 є блок-схемою, яка ілюструє процес кодування MDCT-спектра, який може реалізовуватися за допомогою кодера. Фіг.6 є схемою, яка ілюструє один приклад того, як кадр може вибиратися і розділятися на ділянки і підсмуги, щоб спрощувати кодування MDCTспектра. Фіг.7 ілюструє загальний підхід для кодування аудіокадру ефективним способом. Фіг.8 є блок-схемою, яка ілюструє кодер, який може ефективно кодувати імпульси в MDCTаудіокадрі. Фіг.9 є блок-схемою послідовності операцій, яка ілюструє спосіб для одержання вектора форми для кадру. Фіг.10 є блок-схемою, яка ілюструє спосіб для кодування спектра перетворення в масштабованому мовному та аудіокодеку. Фіг.11 є блок-схемою, яка ілюструє приклад відеодекодера. Фіг.12 є блок-схемою, яка ілюструє спосіб для кодування спектра перетворення в масштабованому мовному та аудіокодеку. Фіг.13 є блок-схемою, яка ілюструє спосіб для декодування спектра перетворення в масштабованому мовному та аудіокодеку. Далі описуються різні варіанти здійснення з посиланнями на креслення, на яких однакові номери посилань використовуються для того, щоб посилатися на однакові елементи. У подальшому описі, для цілей пояснення, багато конкретних деталей викладені для того, щоб надавати повне розуміння одного або більше варіантів здійснення. Проте, може бути очевидним, що ці варіанти здійснення можуть застосовуватися на практиці без даних конкретних деталей. В інших випадках, поширені структури і пристрої показані в формі блоксхем для того, щоб спрощувати опис одного або більше варіантів здійснення. Огляд У масштабованому кодеку для кодування/декодування аудіосигналів, в якому декілька шарів кодування використовуються для того, щоб ітеративно кодувати аудіосигнал, модифіковане дискретне косинусне перетворення може використовуватися в одному або більше шарів кодування, де залишки аудіосигналу перетворюються (наприклад, в MDCT-домен) для кодування. У MDCTдомені кадр спектральних ліній може бути розділений на підсмуги, і задаються ділянки підсмуг, що перекриваються. Для кожної підсмуги в ділянці може вибиратися основний імпульс (тобто найсильніша спектральна лінія або група спектральних ліній в підсмузі). Позиція основних імпульсів може бути кодована за допомогою використання цілого числа, щоб представляти її позицію в рамках кожної з підсмуг. Амплітуда/величина кожного з основних імпульсів може бути окремо кодована. Додатково, вибирається множина (наприклад, чотири) субімпульсів (наприклад, спектральні лінії, що залишилися) в ділянці, виключаючи вже вибрані основні імпульси. Вибрані субімпульси кодуються на основі їх повної позиції в рамках ділянки. Позиції цих субімпульсів можуть кодуватися з використанням технології комбінаторного позиційного коду 15 вання, щоб формувати лексикографічні індекси, які можуть представлятися в меншій кількості бітів, ніж по всій довжині ділянки. За допомогою представлення основних імпульсів і субімпульсів таким чином, вони можуть бути кодовані з використанням відносно невеликої кількості бітів для зберігання і/або передачі. Система зв'язку Фіг.1 є блок-схемою, яка ілюструє систему зв'язку, в якій можуть реалізовуватися одна або більше ознак кодування. Кодер 102 приймає вхідний аудіосигнал 104, що надходить, і формує і кодований аудіосигнал 106. Кодований аудіосигнал 106 може бути переданий по каналу передачі (наприклад, бездротовому або дротовому) в декодер 108. Декодер 108 намагається відновлювати вхідний аудіосигнал 104 на основі кодованого аудіосигналу 106, щоб формувати відновлений вихідний аудіосигнал 110. З метою ілюстрації, кодер 102 може працювати в передавальному пристрої, тоді як пристрій декодера може працювати в приймальному пристрої. Проте, повинне бути очевидним, що всі такі пристрої можуть включати в себе як кодер, так і декодер. Фіг.2 є блок-схемою, яка ілюструє передавальний пристрій 202, який може бути виконаний з можливістю здійснювати ефективне кодування аудіо згідно з одним прикладом. Вхідний аудіосигнал 204 захоплюється за допомогою мікрофона 206, посилюється за допомогою підсилювача 208 і перетворюється за допомогою аналого-цифрового перетворювача 210 в цифровий сигнал, який відправляється в модуль 212 кодування мови. Модуль 212 кодування мови виконаний з можливістю здійснювати багатошарове (масштабоване) кодування вхідного сигналу, де щонайменше один такий шар містить в собі кодування залишку (сигналу помилки) в MDCT-спектрі. Модуль 212 кодування мови може виконувати кодування, як пояснюється в зв'язку з фіг.4, 5, 6, 7, 8, 9 та 10. Вихідні сигнали з модуля 212 кодування мови можуть відправлятися в модуль 214 кодування тракту передачі, де канальне декодування виконується, і результуючі вихідні сигнали відправляються в схему 216 модуляції і модулюються, щоб відправлятися через цифроаналоговий перетворювач 218 і RP-підсилювач 220 в антену 222 для передачі кодованого аудіосигналу 224. Фіг.3 є блок-схемою, яка ілюструє приймальний пристрій 302, який може бути виконаний з можливістю здійснювати ефективне декодування аудіо згідно з одним прикладом. Кодований аудіосигнал 304 приймається за допомогою антени 306 і посилюється за допомогою RF-підсилювача 308 і відправляється через аналого-цифровий перетворювач 310 в схему 312 демодуляції так, що демодульовані сигнали надаються в модуль 314 декодування тракту передачі. Вихідний сигнал з модуля 314 декодування тракту передачі відправляється в модуль 316 декодування мови, виконаний з можливістю здійснювати багатошарове (масштабоване) декодування вхідного сигналу, де щонайменше один такий шар містить в собі декодування залишку (сигналу помилки) в IMDCTспектрі. Модуль 316 декодування мови може вико 95185 16 нувати декодування сигналів, як пояснюється в зв'язку з фіг.11, 12 та 13. Вихідні сигнали з модуля 316 декодування мови відправляються в цифроаналоговий перетворювач 318. Аналоговий мовний сигнал з цифро-аналогового перетворювача 318 відправляється через підсилювач 320 на динамік 322, щоб надавати відновлений вихідний аудіосигнал 324. Архітектура масштабованого аудіокодека Кодер 102 (фіг.1), декодер 108 (фіг.1), модуль 212 кодування мови/аудіо (фіг.2) і/або модуль 316 декодування мови/аудіо (фіг.3) можуть реалізовуватися як масштабований аудіокодек. Такий масштабований аудіокодек може реалізовуватися, щоб надавати високопродуктивне широкосмугове кодування мови для схильних до помилки каналів передачі даних, з високою якістю кодованих вузькосмугових мовних сигналів або широкосмугових аудіо/музичних сигналів, що доставляються. Один підхід до масштабованого аудіокодеку полягає в тому, щоб надавати ітераційні шари кодування, де сигнал помилки (залишок) з одного шару кодується в подальшому шарі, щоб додатково поліпшувати аудіосигнал, кодований в попередніх шарах. Наприклад, лінійне прогнозування із збудженням по таблиці кодування (CELP) основане на принципі кодування з лінійним прогнозуванням, в якому таблиця кодування різних сигналів збудження підтримується в кодері і декодері. Кодер знаходить найбільш підходящий сигнал збудження і відправляє його відповідний індекс (з фіксованої, алгебраїчної і/або адаптивної таблиці кодування) в декодер, який потім використовує його, щоб відтворювати сигнал (на основі таблиці кодування). Кодер виконує аналіз через синтез за допомогою кодування і подальшого декодування аудіосигналу, щоб формувати відновлений або синтезований аудіосигнал. Кодер потім знаходить параметри, які мінімізують енергію сигналу помилки, тобто різницю між вихідним аудіосигналом і відновленим або синтезованим аудіосигналом. Вихідна швидкість передачі бітів може регулюватися за допомогою використання більшої або меншої кількості шарів кодування, щоб задовольняти вимогам каналу і необхідній якості звучання. Такий масштабований аудіокодек може включати в себе декілька шарів, де потоки бітів верхнього шару можуть бути відкинуті без впливу на декодування нижніх шарів. Приклади існуючих масштабованих кодеків, які використовують таку багатошарову архітектуру, включають в себе ITU-T Recommendation ITU-T і вхідний стандарт ITU-T під кодовою назвою G.EVVBR. Наприклад, кодек з вбудованою змінною швидкістю передачі бітів (EV-VBR) може реалізовуватися як декілька шарів від L1 (базовий шар) до LX (де X - номер найвищого розширюючого шару). Такий кодек може приймати як широкосмугові (WB) сигнали, дискретизовані при 16 кГц, так і вузькосмугові (NB) сигнали, дискретизовані при 8 кГц. Аналогічно, виведення кодека може бути широкосмуговим або вузькосмуговим. Приклад структури шарів для кодека (наприклад, EV-VBR-кодека) показаний в таблиці 1, яка містить п'ять шарів: від L1 (базовий шар) до L5 17 95185 (найвищий розширюючий шар). Більш низькі два шари (L1 та L2) можуть бути основані на алгоритмі лінійного прогнозування із збудженням за кодом (CELP). Базовий шар L1 може витягуватися з алгоритму кодування мови на основі широкосмугового кодека із змінним багатошвидкісним кодуванням (VMR-WB) і може містити декілька режимів кодування, оптимізованих для різних вхідних сигналів. Таким чином, базовий шар L1 може класифікувати вхідні сигнали, щоб краще моделювати аудіосигнал. Помилка кодування (залишок) з базового ша 18 ру L1 кодується за допомогою поліпшуючого або розширюючого шару L2 на основі адаптивної таблиці кодування і фіксованої алгебраїчної таблиці кодування. Сигнал помилки (залишок) з шару L2 додатково може кодуватися за допомогою верхніх шарів (L3-L5) в ділянці перетворення з використанням модифікованого дискретного косинусного перетворення (MDCT). Допоміжна інформація може відправлятися в шарі L3, щоб поліпшувати маскування стирання кадрів (FEC). Таблиця 1 Шар Швидкість передачі бітів, кбіт/сек L1 8 L2 +4 L3 L4 L5 +4 +8 +8 Технологія FEC Базовий шар CELP (класифікація) Шар алгебраїчної таблиці кодування (поліпшуючий) MDCT VIDCT VTOCT Кодек базового шару L1, по суті, є кодеком на основі CELP і може бути сумісним з одним з ряду відомих вузькосмугових або широкосмугових вокодерів, такого як кодек з адаптивним багатошвидкісним кодуванням (AMR), широкосмуговий AMRкодек (AMR-WB), широкосмуговий кодек із змінним багатошвидкісним кодуванням (VMR-WB), вдосконалений кодек із змінною швидкістю (EVRC) або широкосмуговий EVR-кодек (EVRC-WB). Шар 2 в масштабованому кодеку може використовувати таблиці кодування, щоб додатково мінімізувати помилку кодування з перцепційним зважуванням (залишок) з базового шару L1. Щоб поліпшити маскування стирання кадрів (FEC) кодека, допоміжна інформація може обчислюватися і передаватися в подальшому шарі L3. Незалежно від режиму кодування базового шару допоміжна інформація може включати в себе класифікацію сигналів. Допускається, що для широкосмугового виведення, зважений сигнал помилки після кодування шару L2 кодується з використанням кодування з перетворенням на основі додавання з перекриттям на основі модифікованого дискретного косинусного перетворення (MDCT) або аналогічного типу перетворення. Таким чином, для кодованих шарів L3, L4 і/або L5, сигнал може бути кодований в MDCT-спектрі. Отже, надається ефективний спосіб кодування сигналу в MDCT-спектрі. Приклад кодера Фіг.4 є блок-схемою масштабованого кодера 402 згідно з одним прикладом. На стадії попередньої обробки до кодування вхідний сигнал 404 фільтрується по верхніх частотах 406, щоб заглушувати небажані низькочастотні компоненти, щоб формувати фільтрований вхідний сигнал SHP(n). Наприклад, фільтр 406 верхніх частот може мати відсічення в 25 Гц для широкосмугового вхідного сигналу і 100 Гц для вузькосмугового вхідного сигналу. Фільтрований вхідний сигнал SHP(n) потім повторно дискретизується за допомогою модуля Частота дискретизації, кГц 12,8 12,8 12,8 16 16 16 408 повторної дискретизації, щоб формувати повторно дискретизований вхідний сигнал S12,8(n). Наприклад, вихідний вхідний сигнал 404 може дискретизуватися при 16 кГц і повторно дискретизується до 12,8 кГц, що може бути внутрішньою частотою, яка використовується для кодування шару L1 і/або Г2. Модуль 410 введення передспотворень потім застосовує фільтр верхніх частот першого порядку, щоб вводити передспотворення у верхні частоти (і ослабляти низькі частоти) повторно дискретизованого вхідного сигналу S12,8(n). Результуючий сигнал потім передається в модуль 412 кодера/декодера, який може виконувати кодування шару L1 і/або L2 на базі алгоритму на основі лінійного прогнозування із збудженням за кодом (CELP), де мовний сигнал моделюється за допомогою сигналу збудження, який проходить через синтезуючий фільтр з лінійним прогнозуванням (LР), що представляє спектральну обвідну. Енергія сигналу може обчислюватися для кожної перцепційної критичної смуги частот і використовуватися як частина кодування шарів L1 та L2. Додатково, кодований модуль 412 кодера/декодера також може синтезувати (відновлювати) версію вхідного сигналу. Таким чином, після того як модуль 412 кодера/декодера кодує вхідний сигнал, він декодує його, і модуль 416 корекції передспотворень і модуль 418 повторної дискретизації відтворюють ˆ версію s2 (n) вхідного сигналу 404. Залишковий сигнал ×2(n) формується за допомогою підрахунку різниці 420 між вихідним сигналом SHP(n) і відтвоˆ реним сигналом s2 (n) (тобто ×2(n)=SHP(n)- ˆ s2 (n) ). Залишковий сигнал ×2(n) потім перцепційно зважується за допомогою модуля 424 зважування і перетворюється за допомогою MDCTмодуля 428 в MDCT-спектр або домен, щоб формувати залишковий сигнал Х2(k). Залишковий сигнал Х2(k) потім надається в комбінаторний кодер 432 спектра, який кодує залишковий сигнал Х2(k), 19 щоб формувати кодовані параметри для шарів L3, L4 і/або L5. В одному прикладі комбінаторний кодер 432 спектра формує індекс, що представляє ненульові спектральні лінії (імпульси) в залишковому сигналі Х2(k). Наприклад, індекс може представляти один з множини можливих двійкових рядків, що представляють позиції ненульових спектральних ліній. Внаслідок комбінаторної технології, індекс може представляти ненульові спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. Параметри з шарів L1-L5 потім можуть виступати як вихідний потік бітів 436 і далі можуть використовуватися для того, щоб відновлювати або синтезувати версію вихідного вхідного сигналу 404 в декодері. Шар 1 - кодування класифікації: Базовий шар L1 може реалізовуватися в модулі 412 кодера/декодера і може використовувати класифікацію сигналів і чотири різних режими кодування, щоб підвищувати продуктивність кодування. В одному прикладі ці чотири різних класи сигналів, які можуть розглядатися для різного кодування кожного кадру, можуть включати в себе: (1) невокалізоване кодування (UC) для невокалізованих мовних кадрів, (2) вокалізоване кодування (VC), оптимізоване для квазіперіодичних сегментів з гладкою зміною основного тону, (3) перехідний режим(ТС) для кадрів після вокалізованих вступів, виконаний з можливістю мінімізувати поширення помилки у випадку стирань кадрів, і (4) загальне кодування (GC) для інших кадрів. При невокалізованому кодуванні (UC) адаптивна таблиця кодування не використовується, і збудження вибирається з гаусової таблиці кодування. Квазіперіодичні сегменти кодуються за допомогою режиму вокалізованого кодування (VC). Вибір вокалізованого кодування зумовлюється за допомогою гладкої зміни основного тону. Режим вокалізованого кодування може використовувати технологію ACELP. У кадрі після перехідного кодування (ТС) адаптивна таблиця кодування в субкадрі, який містить горловий імпульс першого періоду основного тону, замінюється фіксованою таблицею кодування. У базовому шарі L1 сигнал може моделюватися з використанням парадигми на основі CELP за допомогою сигналу збудження, який проходить через синтезуючий фільтр з лінійним прогнозуванням (LP), що представляє спектральну обвідну. LP-фільтр може квантуватися в домені спектральних частот імітансу (ISF) з використанням підходу «страхувальної сітки» і багатостадійного векторного квантування (MSVQ) для режимів загального і вокалізованого кодування. Аналіз основного тону з розімкненим контуром (OL) виконується за допомогою алгоритму відстеження основного тону, щоб забезпечувати гладкий контур основного тону. Проте, щоб підвищувати стійкість оцінки основного тону, два паралельних контури зміни основного тону можуть порівнюватися, і вибирається доріжка, яка дає в результаті більш плавний контур. Два набори параметрів LPC оцінюються і кодуються з розрахунку на кожний кадр в більшості режимів з використанням вікна аналізу в 20 мс, один для кінця кадру та один для середини кадру. 95185 20 ISF середини кадру кодуються за допомогою інтерполяційного роздільного VQ з виявленням коефіцієнта лінійної інтерполяції для кожної ISFпідгрупи, так що різниця між оціненими та інтерпольованими квантованими ISF мінімізується. В одному прикладі, щоб квантувати ISF-представлення LP-коефіцієнтів, пошук може здійснюватися в двох наборах таблиць кодування (що відповідають слабкому і сильному прогнозуванню) можуть шукатися паралельно, щоб знаходити прогнозуючий параметр і запис таблиці кодування, які мінімізують спотворення оціненої спектральної обвідної. Основна причина для цього підходу «страхувальної сітки» полягає в тому, щоб зменшувати поширення помилки, коли стирання кадрів співпадають із сегментами, де спектральна обвідна швидко змінюється. Щоб надавати додаткову стійкість до помилок, слабкий прогнозуючий параметр іноді задається рівним нулю, що призводить до квантування без прогнозування. Тракт без прогнозування може завжди вибиратися, коли його спотворення квантування досить близьке до спотворення з прогнозуванням або коли його спотворення квантування є досить невеликим, щоб надавати прозоре кодування. Крім цього в сильно прогнозуючому пошуку таблиці кодування субоптимальний кодовий вектор вибирається, якщо це не впливає на продуктивність чистого каналу, але очікувано знижує поширення помилки при наявності стирань кадрів. ISF UC- та ТС-кадрів додатково систематично квантуються без прогнозування. Для UCкадрів досить бітів доступно для того, щоб надавати можливість дуже хорошого спектрального квантування навіть без прогнозування. ТС-кадри вважаються дуже чутливими до стирань кадрів для прогнозування, яке повинне використовуватися, незважаючи на потенційне зменшення продуктивності чистого каналу. Для вузькосмугових (NB) сигналів оцінка основного тону виконується з використанням збудження L2, сформованого з неквантованими оптимальними посиленнями. Цей підхід видаляє ефекти квантування посилення і поліпшує оцінку запізнення основного тону в шарах. Для широкосмугових (WB) сигналів використовується стандартна оцінка основного тону (збудження L1 з квантованими посиленнями). Шар 2 - поліпшуюче кодування: У шарі L2 модуль 412 кодера/декодера може кодувати помилку квантування з базового шару L1 знов з використанням алгебраїчних таблиць кодування. У шарі L2 кодер додатково модифікує адаптивну таблицю кодування так, щоб включати в себе не тільки попередню частку L1, але також і попередню частку L2. Адаптивне запізнення основного тону є однаковим в L1 та L2, щоб підтримувати часову синхронізацію між шарами. Посилення адаптивних та алгебраїчних таблиць кодування, відповідні L1 та L2, потім повторно оптимізуються, щоб мінімізувати помилку кодування з перцепційним зважуванням. Оновлені посилення L1 і посилення L2 прогнозним чином векторно квантуються відносно посилень, вже квантованих в L1. Шари CELP (L1 та L2) можуть працювати на внутрішній (наприклад, 12,8 кГц) частоті дискретизації. Виведення із 21 шару L2 тим самим включає в себе синтезований сигнал, кодований в смузі частот на 0-6,4 кГц. Для широкосмугового виведення розширення смуги пропускання AMR-WB може використовуватися для того, щоб формувати пропущену смугу пропускання на 6,4-7 кГц. Шар 3 - маскування стирання кадрів: Щоб підвищувати продуктивність в умовах стирання кадрів (FEC), модуль 414 маскування помилок по кадрах може одержувати допоміжну інформацію з модуля 412 кодера/декодера і використовувати її для того, щоб формувати параметри шару L3. Допоміжна інформація може включати в себе інформацію класу для всіх режимів кодування. Інформація спектральної обвідної попереднього кадру також може бути передана для перехідного кодування базового шару. Для інших режимів кодування базового шару також можуть відправлятися інформація фази і синхронна по основному тону енергія синтезованого сигналу. Шари - 3, 4, 5 кодування з перетворенням: Залишковий сигнал Х2(k), що витікає з CELPкодування другої стадії в шарі L2, може квантуватися в шарах L3, L4 та L5 з використанням MDCT або аналогічного перетворення із структурою додавання з перекриттям. Таким чином, сигнал залишку або «помилки» з попереднього шару використовується за допомогою подальшого шару, щоб формувати його параметри (які направлені на те, щоб ефективно представляти таку помилку для передачі в декодер). MDCT-коефіцієнти можуть квантуватися за допомогою використання декількох технологій. У деяких випадках, MDCT-коефіцієнти квантуються з використанням масштабованого алгебраїчного векторного квантування. MDCT може обчислюватися кожні 20 мілісекунд (мс), і його спектральні коефіцієнти квантуються в 8-мірних блоках. Застосовується модуль очищення звуку (фільтр обмеження шуму MDCT-домену), що витягується із спектра вихідного сигналу. Глобальні посилення передаються в шарі L3. Додатково, декілька бітів використовуються для високочастотної компенсації. Біти шару L3, що залишилися, використовуються для квантування MDCT-коефіцієнтів. Біти шарів L4 та L5 використовуються так, що продуктивність максимізується незалежно в шарах L5 та шарах L4. У деяких реалізаціях MDCT-коефіцієнти можуть квантуватися по-іншому для мовного і музичного домінуючого аудіовмісту. Розрізнення між мовним і музичним вмістом основане на оцінці ефективності CELP-моделі за допомогою порівняння MDCT-компонентів зваженого синтезу L2 з відповідними компонентами вхідного сигналу. Для мовного домінуючого вмісту масштабоване алгебраїчне векторне квантування (AVQ) використовується в L3 та L4 зі спектральними коефіцієнтами, квантованими в 8-мірних блоках. Глобальне посилення передається в L3, і декілька бітів використовуються для високочастотної компенсації. Біти L3 та L4, що залишилися, використовуються для квантування MDCT-коефіцієнтів. Спосіб квантування багатошвидкісне решітчасте VQ (MRLVQ). Новий алгоритм на основі багаторівневих перестановок 95185 22 використаний для того, щоб зменшувати складність і витрати по запам'ятовуючому пристрою процедури індексації. Обчислення рангу виконується в декілька етапів. По-перше, вхідний вектор розкладається на вектор знаку і вектор абсолютних значень. По-друге, вектор абсолютних значень додатково розкладається на декілька рівнів. Вектор найвищого рівня - це вихідний вектор абсолютних значень. Кожний вектор нижнього рівня одержується за допомогою видалення найбільш частого елемента з вектора верхнього рівня. Параметр позиції кожного вектора нижнього рівня, зв'язаного з вектором верхнього рівня, індексується на основі функції перестановок і комбінування. Нарешті, індекс всіх нижніх рівнів і знак компонуються у вихідний індекс. Для музичного домінуючого вмісту, вибіркове по смузі частот векторне квантування посилення форми (VQ посилення форми) може використовуватися в шарі L3, і додатковий векторний квантувач позиції імпульсу може застосовуватися до шару L4. У шарі L3 вибір смуги частот може виконуватися за допомогою обчислення спочатку енергії MDCT-коефіцієнтів. Потім MDCTкоефіцієнти у вибраній смузі частот квантуються з використанням багатоімпульсної таблиці кодування. Векторний квантувач використовується для того, щоб квантувати підсмугові посилення для MDCT-коефіцієнтів. Для шару L4 вся смуга пропускання може кодуватися з використанням технології позиціонування імпульсів. Коли мовна модель формує небажаний шум, внаслідок неспівпадання в моделі аудіоджерела, визначені частоти виведення шару L2 можуть бути ослаблені, щоб давати можливість більш активного кодування MDCTкоефіцієнтів. Це здійснюється способом із замкненим контуром за допомогою мінімізації квадратичної помилки між MDCT вхідного сигналу і MDCT кодованого аудіосигналу через шар L4. Величина ослаблення, що застосовується, може складати аж до 6 дБ, що може передаватися за допомогою використання 2 або меншої кількості бітів. Шар L5 може використовувати додаткову технологію позиційного кодування імпульсів. Кодування МРСТ-спектра Оскільки шари L3, L4 та L5 виконують кодування в MDCT-спектрі (наприклад, MDCTкоефіцієнти, що представляють залишок для попереднього шару), бажано для такого кодування MDCT-спектра бути ефективним. Отже, надається ефективний спосіб кодування MDCT-спектра. Вхідними даними в цей процес є або готовий MDCT-спектр сигналу помилки (залишку) після бази CELP (шари L1 і/або L2), або залишковий MDCT-спектр після попереднього шару. Таким чином, в шарі L3 готовий MDCT-спектр приймається і частково кодується. Потім в шарі L4, залишковий MDCT-спектр кодованого сигналу в шарі L3 кодується. Цей процес може повторюватися для шару L5 та інших подальших шарів. Фіг.5 є блок-схемою, яка ілюструє зразковий процес кодування MDCT-спектра, який може реалізовуватися у верхніх шарах кодера. Кодер 502 одержує MDCT-спектр залишкового сигналу 504 з попередніх шарів. Такий залишковий сигнал 504 23 може бути різницею між вихідним сигналом і відновленою версією вихідного сигналу (наприклад, відновленою з кодованої версії вихідного сигналу). MDCT-коефіцієнти залишкового сигналу можуть квантуватися, щоб формувати спектральні лінії для даного аудіокадру. В одному прикладі модуль 508 вибору підсмуги/ділянки може розділяти залишковий сигнал 504 на множину (наприклад, 17) однорідних підсмуг. Наприклад, за умови аудіокадру з трьохсот двадцятьма (320) спектральними лініями, перші і останні двадцять чотири (24) точки (спектральні лінії) можуть відкидатися, і двісті сімдесят дві (272) спектральних лінії, що залишилися, можуть бути розділені на сімнадцять (17) підсмуг по шістнадцять (16) спектральних ліній кожна. Потрібно розуміти, що в різних реалізаціях різна кількість підсмуг може використовуватися, кількість перших і останніх точок, які можуть відкидатися, може варіюватися, і/або кількість спектральних ліній, які можуть бути розбиватися в розрахунку на підсмугу або кадр, також може варіюватися. Фіг.6 є схемою, яка ілюструє один приклад того, як аудіокадр 602 може вибиратися і розділятися на ділянки і підсмуги, щоб спрощувати кодування MDCT-спектра. Згідно з цим прикладом, множині ділянок (наприклад, 8) може бути задано, що складаються з множини (наприклад, 5) послідовних або суміжних підсмуг 604 (наприклад, ділянка може покривати 5 підсмуг×16 спектральних ліній/підсмуга=80 спектральних ліній). Множина ділянок 606 може бути виконана з можливістю перекриватися з кожною сусідньою ділянкою і покривати повну смугу пропускання (наприклад, 7 кГц). Інформація про ділянку може бути сформована для кодування. Як тільки ділянка вибрана, MDCT-спектр в ділянці квантується за допомогою квантувача форми 510 і квантувача посилення 512 з використанням квантування посилення форми, в якому послідовно квантується форма (синонімічно з визначенням місцеположення і знаком) і посилення цільового вектора. Формування може містити формування визначення місцеположення, знаку спектральних ліній, що відповідають основному імпульсу і множини субімпульсів в розрахунку на підсмугу, нарівні з величиною для основних імпульсів і субімпульсів. У прикладі, проілюстрованому на фіг.6, вісімдесят (80) спектральних ліній в рамках ділянки 606 можуть представлятися за допомогою вектора форми, що складається з 5 основних імпульсів (один основний імпульс для кожної з 5 послідовних підсмуг 604а, 604b, 604c, 604d та 604е) і 4 додаткових субімпульсів з розрахунку на кожну ділянку. Таким чином, для кожної підсмуги 604 вибирається основний імпульс (тобто найсильніший імпульс в рамках цих 16 спектральних ліній в цій підсмузі). Додатково, для кожної ділянки 606, вибираються додаткові 4 субімпульси (тобто наступні найсильніші імпульси спектральної лінії в рамках цих 80 спектральних ліній). Як проілюстровано на фіг.6, в одному прикладі комбінація позицій і знаків основних імпульсів і субімпульсів може бути кодована за допомогою 50 бітів, де: 95185 24 - 20 бітів для індексів для 5 основних імпульсів (один основний імпульс в розрахунку на підсмугу); - 5 бітів для знаків 5 основних імпульсів; - 21 біт для індексів 4 субімпульсів в будьякому місці в рамках ділянки в 80 спектральних ліній; - 4 біти для знаків 4 субімпульсів. Кожний основний імпульс може представлятися за допомогою його позиції в рамках підсмуги в 16 спектральних ліній з використанням 4 бітів (наприклад, число 0-16, представлене за допомогою 4 бітів). Отже, для п'яти (5) основних імпульсів у ділянці це віднімає всього 20 бітів. Знак кожного основного імпульсу і/або субімпульсу може представлятися за допомогою одного біта (наприклад, 0 або 1 для позитивного або негативного). Позиція кожного з чотирьох (4) вибраних субімпульсів в рамках ділянки може кодуватися з використанням технології комбінаторного позиційного кодування (з використанням біноміальних коефіцієнтів для того, щоб представляти позицію кожного вибраного субімпульсу), щоб формувати лексикографічні індекси, так що загальне число бітів, яка використовуються для того, щоб представляти позицію цих чотирьох субімпульсів в рамках ділянки, менше довжини ділянки. Потрібно зазначити, що додаткові біти можуть бути використані для кодування амплітуди і/або величини основних імпульсів і/або субімпульсів. У деяких реалізаціях амплітуда/величина імпульсу може бути кодована з використанням двох бітів (тобто 00 - немає імпульсу, 01 - субімпульс, і/або 10 - основний імпульс). Після квантування форми квантування посилення виконується для обчислених підсмугових посилень. Оскільки ділянка містить 5 підсмуг, 5 посилень одержуються для ділянки, яка може бути вектором, квантованим за допомогою 10 бітів. Векторне квантування використовує схему прогнозування, що перемикається. Потрібно зазначити, що вихідний залишковий сигнал 516 може одержуватися (за допомогою віднімання 514 квантованого залишкового сигналу 3 Squant вихідного вхідного залишкового сигналу 504), який може використовуватися як вхідні дані для наступного шару кодування. Фіг.7 ілюструє загальний підхід для кодування аудіокадру ефективним способом. Ділянка 702 з N спектральних ліній можуть бути задана з множини послідовних або суміжних підсмуг, де кожна підсмуга 704 має L спектральних ліній. Ділянка 702 і/або підсмуги 704 можуть бути призначені для залишкового сигналу аудіокадру. Для кожної підсмуги основний імпульс вибирається 706. Наприклад, найсильніший імпульс в рамках L спектральних ліній підсмуги вибирається як основний імпульс для цієї підсмуги. Найсильніший імпульс може вибиратися як імпульс, який має найбільшу амплітуду або величину в підсмузі. Наприклад, перший основний імпульс РА вибирається для підсмуги А 704а, другий основний імпульс РВ вибирається для підсмуги В 704b тощо для кожної з підсмуг 704. Потрібно зазначити, що, оскільки ділянка 702 має N спектральних ліній, позиція кожної спектральної лінії в рамках ділянки 702 може позначатися за допомогою c i (для 25 1≤i≤N). В одному прикладі перший основний імпульс РА може знаходитися в позиції с3, другий основний імпульс РB може знаходитися в позиції c24, третій основний імпульс РC може знаходитися в позиції с4ь четвертий основний імпульс PD може знаходитися в позиції c59, п'ятий основний імпульс РE може знаходитися в позиції с79. Ці основні імпульси можуть бути кодовані за допомогою використання цілого числа, щоб представляти їх позицію в рамках відповідної підсмуги. Отже, для спектральних ліній L=16, позиція кожного основного імпульсу може бути представлена за допомогою використання чотирьох (4) бітів. Рядок w формується з спектральних ліній або імпульсів у ділянці 708, що залишилися. Щоб формувати рядок, вибрані основні імпульси видаляються з рядка w, і імпульси w1, ..., wN-p, що залишилися, залишаються в рядку (де p - кількість основних імпульсів у ділянці). Потрібно зазначити, що рядок може представлятися за допомогою нулів «0» та «1», де «0» представляє, що імпульс відсутній в конкретній позиції, а «1» представляє, що імпульс присутній в конкретній позиції. Множина субімпульсів вибирається з рядка w на основі потужності імпульсу 710. Наприклад, чотири (4) субімпульси S1, S2, S3 та S4 можуть вибиратися на основі їх інтенсивності (амплітуда/величина) (тобто найсильніші 4 імпульси, що залишаються в рядку w, вибираються). В одному прикладі перший субімпульс S1 може знаходитися у позиції субімпульс, другий субімпульс S2 може знаходитися у позиції w29, третій субімпульс S3 може знаходитися у позиції w51, і четвертий імпульс S4 може знаходитися у позиції w69. Позиція кожного з вибраних субімпульсів потім кодується з використанням лексикографічного індексу 712 на основі біноміальних коефіцієнтів так, що лексикографічний індекс i(w) оснований на комбінації вибраних позицій субімпульсу, i(w)=w20+w29+w51+w69. Фіг.8 є блок-схемою, яка ілюструє кодер, який може ефективно кодувати імпульси в MDCTаудіокадрі. Кодер 802 може включати в себе формувач 802 підсмуг, який ділить аудіокадр MDCTспектра 801, що приймається, на декілька смуг частот, які мають множину спектральних ліній. Формувач 806 ділянок потім формує множину ділянок, що перекриваються, де кожна ділянка складається з множини суміжних підсмуг. Модуль 808 вибору основного імпульсу потім вибирає основний імпульс з кожної з підсмуг в ділянці. Основний імпульс може бути імпульсом (однієї або більше спектральних ліній або точок), який має найбільшу амплітуду/величину в рамках підсмуги. Вибраний основний імпульс для кожної підсмуги в ділянці потім кодується за допомогою кодера 810 знаку, кодера 812 позиції, кодера 814 посилення і кодера 816 амплітуди, щоб формувати відповідні кодовані біти для кожного основного імпульсу. Аналогічно, модуль 809 вибору субімпульсів потім вибирає множину (наприклад, чотири) субімпульсів з усієї ділянки (тобто безвідносно того, якій підсмузі субімпульси належать). Субімпульси можуть вибиратися з імпульсів, що залишилися, в ділянці (тобто виключаючи вже вибрані основні імпульси), які мають найбільшу ампліту 95185 26 ду/величину в рамках підсмуги. Вибрані субімпульси для ділянки потім кодуються за допомогою кодера 818 знаку, кодера 820 позиції, кодера 822 посилення і кодера 822 амплітуди, щоб формувати відповідні кодовані біти для субімпульсу. Кодер 820 позиції може бути виконаний з можливістю здійснювати технологію комбінаторного позиційного кодування, щоб формувати лексикографічний індекс, який зменшує повний розмір бітів, які використовуються для того, щоб кодувати позицію субімпульсів. Зокрема, якщо тільки декілька з імпульсів у всій ділянці повинні бути кодовані, більш ефективно представляти декілька субімпульсів як лексикографічний індекс, ніж представляти повну довжину ділянки. Фіг.9 є блок-схемою послідовності операцій, яка ілюструє спосіб для одержання вектора форми для кадру. Як вказано раніше, вектор форми складається з 5 основних та 4 субімпульсів (спектральних ліній), причому ці визначення місцеположення (в рамках ділянки в 80 ліній) і знаки повинні передаватися за допомогою використання найменшої можливої кількості бітів. Для цього прикладу робляться декілька припущень за характеристиками основних і субімпульсів. По-перше, допускається, що величина основних імпульсів вище величини субімпульсів, і це відношення може бути заздалегідь встановленою константою (наприклад, 0,8). Це означає, що запропонована технологія квантування може призначати один з трьох можливих рівнів (величин) відновлення MDCT-спектру в кожній підсмузі: нуль (0), рівень субімпульсу (наприклад, 0,8) і рівень основного імпульсу (наприклад, 1). По-друге, допускається, що кожна 16-точкова (з 16 спектральними лініями) під смуга має рівно один основний імпульс (з виділеним посиленням, яке також передається один раз в розрахунку на підсмугу). Отже, основний імпульс присутній для кожної підсмуги в ділянці. По-третє, чотири (4) (або менше) субімпульси, що залишилися, можуть бути введені в будьякій підсмузі в ділянці в 80 ліній, але вони не повинні зміщати жоден з вибраних основних імпульсів. Субімпульс може представляти максимальну кількість бітів, що використовується для того, щоб представляти спектральні лінії в підсмузі. Наприклад, чотири (4) субімпульси в підсмузі можуть представляти 16 спектральних ліній в будь-якій підсмузі, таким чином, максимальна кількість бітів, що використовується для того, щоб представляти 16 спектральних ліній в підсмузі, становить 4. На основі вищенаведеного опису, спосіб кодування для імпульсів може витягуватися таким чином. Кадр (який має множину спектральних ліній) ділиться на множину підсмуг 902. Множина ділянок, що перекриваються, може бути задана, де колена ділянка включає в себе множину послідовних/суміжних підсмуг 904. Основний імпульс вибирається в кожній підсмузі в ділянці на основі амплітуди/величини імпульсу 906. Індекс позиції кодується для кожного вибраного основного імпульсу 908. В одному прикладі, оскільки основний імпульс може потрапити в будь-яке місце в рамках підсмуги, яка має 16 спектральних ліній, його позиція може представлятися за допомогою 4 бітів 27 (наприклад, цілочисельне значення в 0...15). Аналогічно, знак, амплітуда і/або посилення можуть бути кодовані для кожного з основних імпульсів 910. Знак може представлятися за допомогою 1 біта (1 або 0). Оскільки колений індекс для основного імпульсу займає 4 біти, 20 бітів можуть використовуватися для того, щоб представляти п'ять індексів основного імпульсу (наприклад, 5 підсмуг), і 5 бітів для знаків основних імпульсів, в доповнення до бітів, що використовуються для кодування посилення та амплітуди для коленого основного імпульсу. Для кодування субімпульсів двійковий рядок створюється з вибраної множини субімпульсів з імпульсів, що залишилися, в ділянці, де вибрані основні імпульси видалені 912. «Вибрана множина субімпульсів» може бути числом k імпульсів, що мають найбільшу величину/амплітуду з імпульсів, що залишилися. Крім того, для ділянки, що має 80 спектральних ліній, якщо всі 5 основних імпульсів видалені, це залишає 80-5=75 позицій для субімпульсів, що розглядаються. Отже, може бути створений 75-бітовий двійковий рядок w, що складається з наступного: - 0: вказує відсутність субімпульсу - 1: вказує наявність вибраного субімпульсу в позиції. Лексикографічний індекс потім обчислюється цього двійкового рядка w для набору всіх можливих двійкових рядків з множиною k ненульових бітів 914. Знак, амплітуда і/або посилення також можуть бути кодовані для кожного з вибраних субімпульсів 916. Формування лексикографічного індексу Лексикографічний індекс, що представляє вибрані субімпульси, може бути сформований з використанням технології комбінаторного позиційного кодування на основі біноміальних коефіцієнтів. Наприклад, двійковий рядок w може обчислювати 95185 28 n ся для набору всіх можливих двійкових рядків k довжини n з k ненульовими бітами (кожний ненульовий біт в рядку w вказує позицію імпульсу, який повинен кодуватися). В одному прикладі наступна комбінаторна формула може використовуватися для того, щоб формувати індекс, який кодує позицію всіх k імпульсів в рамках двійкового рядка w: n j n n index(n, k, w ) i( w ) w j w j j1 i j де n - довжина двійкового рядка (наприклад, n=75), k - кількість вибраних субімпульсів (наприклад, k=4), wj - представляє окремі біти двійкового n рядка w, і допускається, що =0 для всіх k>n. k Для прикладу, де k=4 та n=75, повний діапазон значень, що займаються за допомогою індексів всіх можливих векторів субімпульсу, отже, наступний: 75 75 75 75 75 1285826 4 3 2 1 0 Отже, це може представлятися як Iog21285826≈20,294... бітів. Використання найближчого цілого числа повинне приводити до використання 21 біта. Потрібно зазначити, що це менше 75 бітів для двійкового рядка або бітів, що залишаються в 80-бітовій ділянці. Приклад формування лексикографічного індексу з рядка Згідно з одним прикладом, лексикографічний індекс для двійкового рядка, що представляє позиції вибраних субімпульсів, може обчислюватися на основі біноміальних коефіцієнтів, які в одній можливій реалізації можуть заздалегідь обчислюватися і зберігатися в трикутній матриці (трикутник Паскаля) таким чином: 29 Отже, біноміальний коефіцієнт може обчислюватися для двійкового рядка w, що представляє множину субімпульсів (наприклад, двійкове значення «1») в різних позиціях двійкового рядка w. З використанням цієї матриці біноміальних коефіцієнтів обчислення лексикографічного індексу (і) може реалізовуватися таким чином: Зразковий спосіб кодування Фіг. 10 є блок-схемою, яка ілюструє спосіб для кодування спектра перетворення в масштабованому мовному та аудіокодеку. Залишковий сигнал одержується з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP), при цьому залишковий сигнал - це різниця між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу 1002. Відновлена версія вихідного аудіосигналу може одержуватися за допомогою наступного: (а) синтезування кодованої версії вихідного аудіосигналу з шару кодування на основі CELP, щоб одержувати синтезований сигнал, (Ь) повторне введення передспотворень в синтезований сигнал і/або (с) підвищуюча дискретизація сигналу після повторного введення передспотворень, щоб одержувати відновлену версію вихідного аудіосигналу. Залишковий сигнал перетворюється в шарі перетворення типу дискретного косинусного перетворення (DCT), щоб одержувати відповідний спектр перетворення, який має множину спектральних ліній 1004. Шар перетворення DCT-типу може бути шаром модифікованого дискретного косинусного перетворення (MDCT), і спектр перетворення - це MDCT-спектр. Спектральні лінії спектра перетворення кодуються з використанням технології комбінаторного позиційного кодування 1006. Кодування спектральних ліній спектра перетворення може включати в себе кодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. У деяких реалізаціях набір спектральних ліній може відкидатися, щоб скоротити кількість спектральних ліній, перед кодуванням. В іншому прикладі технологія комбінаторного позиційного кодування може включати в себе формування лексикографічного індексу для вибраного піднабору спектральних ліній, при цьому кожний лексикографічний індекс представляє один з множини можливих двійкових рядків, що 95185 30 представляють позиції вибраного піднабору спектральних ліній. Лексикографічний індекс може представляти спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. В іншому прикладі технологія комбінаторного позиційного кодування може включати в себе формування індексу, що представляє позиції спектральних ліній в рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: n j n n index(n, k, w ) i( w ) w j w i j1 i j де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і wj представляє окремі біти двійкового рядка. В одному прикладі множина спектральних ліній може бути розбита на множину підсмуг, і послідовні підсмуги можуть групуватися в ділянки. Основний імпульс, вибираний з множини спектральних ліній для кожної з підсмуг в ділянці, може бути кодований, при цьому вибраний піднабір спектральних ліній в ділянці виключає основний імпульс для кожної з підсмуг. Додатково, позиції вибраного піднабору спектральних ліній в рамках ділянки можуть бути кодовані на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. Вибраний піднабір спектральних ліній в ділянці може виключати основний імпульс для кожної з підсмуг. Кодування спектральних ліній спектра перетворення може включати в себе формування матриці, на основі позицій вибраного піднабору спектральних ліній, з усіх можливих двійкових рядків довжини, яка дорівнює всім позиціям в ділянці. Ділянки можуть перекриватися, і кожна ділянка може включати в себе множину послідовних підсмуг. Процес декодування лексикографічного індексу, щоб синтезувати кодовані імпульси, є просто інверсією операцій, описаних для кодування. Декодування МРСТ-спектра Фіг. 11 є блок-схемою, яка ілюструє приклад відеодекодера. У кожному аудіокадрі (наприклад, 20-мілісекундном кадрі), декодер 1102 може приймати вхідний потік бітів 1104, що містить інформацію одного або більше шарів. Шари, що приймаються, можуть коливатися від шару 1 до шару 5, що може відповідати швидкостям передачі бітів від 8 Кбіт/с до 32 Кбіт/с. Це означає, що робота декодера зумовлюється за допомогою кількості бітів (шарів), що приймаються в кожному кадрі. У цьому прикладі допускається, що вихідний сигнал 1132 є WB, і що всі шари коректно прийняті в декодері 1102. Базовий шар (шар 1) і поліпшуючий шар ACELP (шар 2) спочатку декодуються за допомогою модуля 1106 декодера, і виконується синтез сигналів. У синтезованому сигналі потім коректуються передспотворення за допомогою модуля 1108 корекції передспотворень, і він повторно дис 31 95185 кретизується до 16 кГц за допомогою модуля 1110 повторної дискретизації, щоб формувати сигнал. Модуль пост обробки додатково обробляє сигнал ˆ ˆ s16 (n) щoб формувати синтезований сигнал s2 (n) шару 1 або шару 2. Верхні шари (шари 3, 4, 5) потім декодуються за допомогою модуля 1116 комбінаторного декодера спектра, щоб одержувати сигнал MDCTˆ ˆ спектра X (k ) . Сигнал MDCT-спектра X (k ) 234 234 обернено перетворюється за допомогою модуля 1120 оберненого MDCT, і результуючий сигнал ˆ x w,234 (n) додається до перцепційно зваженого синтезованого сигналу Єw,2(n) шарів 1 та 2. Часове обмеження шуму потім застосовується за допомогою формуючого модуля 1122. Зважений синтезований сигнал попереднього кадру, що перекривається з поточним кадром, потім додається до синтезу. Обернене перцепційне зважування 1124 потім застосовується, щоб відновлювати синтезований WB-сигнал. Нарешті, постфільтр 1126 основного тону застосовується для відновленого сигналу, після чого йде фільтр 1128 верхніх частот. Постфільтр 1126 використовує додаткову затримку декодера, що вводиться за допомогою синтезу на основі додавання з перекриттям MDCT (шари 3, 4, 5). Він комбінує, оптимальним способом, два сигнали постфільтра основного тону. Сигнал є високоякісним сигналом пост фільтра основного ˆ тону s2 (n) виведення декодера шару 1 або шару 2, який формується за допомогою використання додаткової затримки декодера. Інший сигнал - це сигнал постфільтра основного тону з низькою заˆ тримкою s(n) для синтезуючого сигналу верхніх шарів (шарів 3, 4, 5). Фільтрований синтезований ˆ сигнал sНР(n) потім виводиться за допомогою порогового шумозаглушувача 1130. Фіг. 12 є блок-схемою, яка ілюструє декодер, який може ефективно декодувати імпульси аудіокадру MDCT-спектра. Приймається множина кодованих вхідних бітів, які включають в себе знак, позицію, амплітуду і/або посилення для основних і/або субімпульсів в MDCT-спектрі для аудіокадру. Біти для одного або більше основних імпульсів декодуються за допомогою декодера основних імпульсів, який може включати в себе декодер 1210 знаку, декодер 1212 позиції, декодер 1214 посилення і/або декодер 1216 амплітуди. Синтезатор 1208 основних імпульсів потім відновлює один або більше основних імпульсів з використанням декодованої інформації. Аналогічно, біти для одного або більше субімпульсів можуть бути декодовані в декодері субімпульсів, який включає в себе декодер 1218 знаку, декодер 1220 позиції, декодер 1222 посилення і/або декодер 1224 амплітуди. Потрібно зазначити, що позиція субімпульсів може бути кодована з використанням лексикографічного індексу на основі технології комбінаторного позиційного кодування. Отже, декодер 1220 позиції може бути комбінаторним декодером спектра. Синтезатор 1209 субімпульсів потім відновлює один або більше субімпульсів з використанням декодованої інформації. Повторний формувач 1206 діля 32 нок потім відновлює множину ділянок, що перекриваються, на основі субімпульсів, причому кожна ділянка складається з множини суміжних підсмуг. Повторний формувач субімпульсів 1204 потім відновлює підсмуги з використанням основних імпульсів і/або субімпульсів, що приводить до відновленого MDCT-спектра для аудіокадру 1201. Приклад формування рядка з лексикографічного індексу Щоб декодувати лексикографічний індекс, що приймається, який представляє позицію субімпульсів, зворотний процес може виконуватися для того, щоб одержувати послідовність або двійковий рядок на основі даного лексикографічного індексу. Один приклад такого зворотного процесу може реалізовуватися таким чином: У випадку довгої послідовності (наприклад, де п=75) тільки з декількома наборами бітів (наприклад, де к=4), ця процедура додатково може модифікуватися, щоб робити їх більш практичними. Наприклад, замість виконання пошуку в послідовності бітів, індекси ненульових бітів можуть передаватися для кодування, так що функція index() стає рівною: Потрібно зазначити, що використовуються тільки перші 4 стовпці біноміальної матриці. Отже, тільки 75*4=300 слів запам'ятовуючого пристрою використовуються для того, щоб зберігати її. В одному прикладі процес декодування може бути виконаний за допомогою наступного алгоритму: 33 Це розгорнений цикл з n ітераціями тільки з пошуками і порівняннями, що використовуються на кожному етапі. Зразковий спосіб кодування Фіг.13 є блок-схемою, яка ілюструє спосіб для декодування спектра перетворення в масштабованому мовному та аудіокодеку. Індекс, що представляє множину спектральних ліній спектра перетворення залишкового сигналу, одержується, при цьому залишковий сигнал - це різниця між вихідним аудіосигналом і відновленою версією вихідного аудіосигналу з шару кодування на основі лінійного прогнозування із збудженням за кодом (CELP) 1302. Індекс може представляти ненульові спектральні лінії в двійковому рядку в меншій кількості бітів, ніж довжина двійкового рядка. В одному прикладі одержаний індекс може представляти позиції спектральних ліній в рамках двійкового рядка, причому позиції спектральних ліній кодуються на основі комбінаторної формули: n j n n index(n, k, w ) i( w ) w j w i j1 i j де n - довжина двійкового рядка, k - кількість вибраних спектральних ліній, які повинні бути кодовані, і wj - представляє окремі біти двійкового рядка. Індекс декодується за допомогою виконання в зворотному порядку технології комбінаторного позиційного кодування, що використовується для того, щоб кодувати множину спектральних ліній спектра перетворення 1304. Версія залишкового сигналу синтезується з використанням декодованої множини спектральних ліній спектра перетворення в шарі оберненого перетворення типу оберненого дискретного косинусного перетворення 95185 34 (IDCT) 1306. Синтезування версії залишкового сигналу може включати в себе застосування оберненого перетворення DCT-типу до спектральних ліній спектра перетворення, щоб формувати версію залишкового сигналу у часовій ділянці. Декодування спектральних ліній спектра перетворення може включати в себе декодування позицій вибраного піднабору спектральних ліній на основі представлення позицій спектральних ліній з використанням технології комбінаторного позиційного кодування для позицій ненульових спектральних ліній. Шар оберненого перетворення DCT-типу може бути шаром оберненого модифікованого дискретного косинусного перетворення (IMDCT), і спектр перетворення - це MDCT-спектр. Додатково, CELP-кодований сигнал, що кодує вихідний аудіосигнал, може прийматися 1308. CELP-кодований сигнал може бути декодований, щоб формувати декодований сигнал 1310. Декодований сигнал може бути комбінований з синтезованою версією залишкового сигналу, щоб одержувати відновлену версію (з більш високою точністю відтворення) вихідного аудіосигналу 1312. Різні ілюстративні логічні блоки, модулі і схеми та етапи алгоритму, описані в даному документі, можуть реалізовуватися або виконуватися як електронні апаратні засоби, програмне забезпечення або комбінації зазначеного. Щоб зрозуміло ілюструвати цю взаємозамінність апаратних засобів і програмного забезпечення, різні ілюстративні компоненти, блоки, модулі, схеми та етапи описані вище, загалом, на основі функціональності. Реалізована ця функціональність як апаратні засоби або програмне забезпечення, залежить від конкретного варіанта застосування і проектних обмежень, що накладаються на систему в цілому. Потрібно зазначити, що конфігурації можуть 35 описуватися як процес, який ілюструється як блоксхема послідовності операцій способу, блоксхема, структурна схема або блок-схема. Хоча блок-схема послідовності операцій способу може описувати операції як послідовний процес, багато які операції можуть виконуватися паралельно або одночасно. Крім цього порядок операцій може бути перевизначений. Процес завершується, коли його операції закінчені. Процес може відповідати способу, функції, процедурі, підпрограмі, підпрограмі тощо. Коли процес відповідає функції, її завершення відповідає поверненню функції у викликаючу функцію або основну функцію. При реалізації в апаратних засобах, різні приклади можуть використовувати процесор загального призначення, процесор цифрових сигналів (DSP), спеціалізовану інтегральну схему (ASIC), сигнал програмованої користувачем вентильної матриці (FPGA) або програмований інший логічний пристрій, дискретний логічний вентиль або транзисторну логіку, дискретні апаратні компоненти або будь-яку комбінацію вищезазначеного, призначену для того, щоб виконувати функції, описані в даному документі. Процесором загального призначення може бути мікропроцесор, але в альтернативному варіанті, процесором може бути будьякий традиційний процесор, контролер, мікроконтролер або кінцевий автомат. Процесор також може бути реалізований як комбінація обчислювальних пристроїв, наприклад, комбінація DSP і мікропроцесора, множина мікропроцесорів, один або більше мікропроцесорів разом з ядром DSP або будь-яка інша аналогічна конфігурація. При реалізації в програмному забезпеченні, різні приклади можуть використовувати мікропрограмне забезпечення, проміжне програмне забезпечення або мікрокод. Програмний код або сегменти коду для того, щоб виконувати необхідні задачі, можуть зберігатися в машинозчитуваному носії, такому як носій зберігання даних або інший пристрій(ої) зберігання. Процесор може виконувати необхідні задачі. Сегмент коду може представляти процедуру, функцію, підпрограму, програму, стандартну процедуру, вкладену процедуру, модуль, комплект програмного забезпечення, клас або будь-яке поєднання інструкцій, структур даних або операторів програми. Сегмент коду може бути зв'язаний з іншим сегментом коду або апаратною схемою за допомогою передачі і/або прийому інформації, даних, аргументів, параметрів або вмісту пам'яті. Інформація, аргументи, параметри, дані тощо можуть бути передані, переадресовані або переслані за допомогою будь-якого належного засобу, в тому числі спільного використання пам'яті, передачі повідомлень, естафетної передачі даних, передачі по мережі тощо. При використанні в даній заявці терміни «компонент», «модуль», «система» тощо мають намір посилатися на зв'язаний з комп'ютером об'єкт, будь то апаратні засоби, мікропрограмне забезпечення, комбінація апаратних засобів і програмного забезпечення, програмне забезпечення або програмне забезпечення під час виконання. Наприклад, компонент може бути, але не тільки, процесом, запущеним на процесорі, процесором, 95185 36 об'єктом, що виконується файлом, потоком виконання, програмою і/або комп'ютером. Як ілюстрація, і додаток, запущений на обчислювальному пристрої, і обчислювальний пристрій може бути компонентом. Один або більше компонентів можуть постійно розміщуватися всередині процесу і/або потоку виконання, і компонент може бути локалізований на комп'ютері і/або розподілений між двома і більше комп'ютерами. Крім того, ці компоненти можуть виконуватися з різних машинозчитуваних носіїв, що зберігають різні структури даних. Компоненти можуть обмінюватися даними за допомогою локальних і/або віддалених процесів, наприклад, відповідно до сигналу, який має один або більше пакетів даних (наприклад, даних з одного компонента, взаємодіючого з іншим компонентом в локальній системі, розподіленій системі і/або по мережі, наприклад, по Інтернету з іншими системами за допомогою сигналу). В одному або більше прикладах в даному документі, описані функції можуть бути реалізовані в апаратних засобах, програмному забезпеченні, мікропрограмному забезпеченні або будь-якій комбінації вищезазначеного. Якщо реалізовані в програмному забезпеченні, функції можуть бути збережені або передані як одна або більше інструкцій або код на машинозчитуваному носії. Машинозчитувані носії включають в себе як комп'ютерні носії зберігання даних, так і середовище зв'язку, що включає в себе будь-яке передавальне середовище, яке спрощує переміщення комп'ютерної програми з одного місця в інше. Носіями зберігання можуть бути будь-які доступні носії, до яких можна здійснювати доступ за допомогою комп'ютера. Як приклад, але не обмеження, ці машинозчитувані носії можуть містити RAM, ROM, EEPROM, CD-ROM або інший пристрій зберігання на оптичних дисках, пристрій зберігання на магнітних дисках або інші магнітні пристрої зберігання, або будь-який інший носій, який може бути використаний для того, щоб переносити або зберігати необхідний програмний код в формі інструкцій або структур даних, і до якого можна здійснювати доступ за допомогою комп'ютера. Також будь-яке підключення коректно називати машинозчитуваним носієм. Наприклад, якщо програмне забезпечення передається з веб-вузла, сервера або іншого віддаленого джерела за допомогою коаксіального кабелю, оптоволоконного кабелю, «витої пари», цифрової абонентської лінії (DSL) або бездротових технологій, таких як інфрачервоні, радіопередавальні і мікрохвильові середовища, то коаксіальний кабель, оптоволоконний кабель, «вита пара», DSL або бездротові технології, такі як інфрачервоні, радіопередавальні і мікрохвильові середовища, включені у визначення носія. Диск (disk) і диск (disc) при використанні в даному документі включають в себе компакт-диск (CD), лазерний диск, оптичний диск, універсальний цифровий диск (DVD), гнучкий диск і диск Blu-Ray, при цьому диски (disk) звичайно відтворюють дані магнітно, тоді як диски (disc) звичайно відтворюють дані оптично за допомогою лазерів. Комбінації вищепереліченого також потрібно включати в число машинозчитуваних носіїв. Програмне забезпечен 37 ня може містити одну інструкцію або множину інструкцій і може бути розподілене по декількох різних сегментах коду, по різних програмах і по декількох носіях зберігання даних. Зразковий носій зберігання даних може бути з'єднаний з процесором так, що процесор може зчитувати інформацію і записувати інформацію на носій зберігання даних. В альтернативному варіанті, носій зберігання даних може бути вбудований в процесор. Способи, розкриті в даному документі, містять один або більше етапів або дій для здійснення описаного способу. Етапи і/або дії способу можуть мінятися один з одним без відступу від обсягу формули винаходу. Іншими словами, якщо конкретний порядок етапів або дій не потрібний для належної роботи варіанта здійснення, який описується, порядок і/або застосування конкретних етапів і/або дій може модифікуватися без відступу від обсягу формули винаходу. Один або більше з компонентів, етапів і/або функцій, проілюстрованих на фіг. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 і/або 13, можуть бути перегруповані і/або комбіновані в один компонент, етап або функцію або здійснений в декількох компонентах, етапах або функціях. Додаткові елементи, компоненти, етапи і/або функції також можуть додаватися. Пристрій, пристрої і/або компоненти, проілюстровані на фіг. 1, 2, 3, 4, 5, 8, 11 та 12, можуть бути виконані з можливістю або пристосовані здійснювати один або більше із способів, ознак або етапів, описаних на фіг.6-7 та 10-13. Алгоритми, описані в даному документі, можуть ефективно реалізовуватися в програмному забезпеченні і/або вбудованих апаратних засобах. Потрібно зазначити, що попередні конфігурації є просто прикладами і не повинні розглядатися як обмежуючі формулу винаходи. Опис конфігурацій має намір бути ілюстративним і не обмежувати обсяг формули винаходу. По суті, дані технології можуть бути легко застосовані до інших типів пристроїв, і множина альтернатив, модифікацій і варіацій повинна бути очевидна фахівцям в даній галузі техніки. Посилальні позиції 102 кодер 104 вхідний аудіосигнал 106 кодований аудіосигнал 108 декодер 110 вихідний аудіосигнал 202 передавальний пристрій 204 вхідний аудіосигнал 206 мікрофон 208 підсилювач 210, 310 аналого-цифровий перетворювач 212 модуль кодування мови (мови/аудіо) 214 модуль кодування тракту передачі 216 модуль модуляції 218, 318 цифроаналоговий перетворювач 220, 308 RF-підсилювач 222, 306 антена 224, 304 кодований аудіосигнал 302 приймальний пристрій 312 схема демодуляції 314 модуль декодування тракту передачі 316 модуль декодування мови (мови/аудіо) 95185 38 320 підсилювач 322 динамік 324 вихідний аудіосигнал 402 масштабований кодер 404 вхідний сигнал 406 фільтр верхніх частот 408 модуль повторної дискретизації 410 модуль введення передспотворень 412 модуль кодера/декодера 414 модуль маскування помилок по кадрах 416 модуль корекції передспотворень 418 модуль повторної дискретизації 420 різниця між вихідним сигналом і відтвореним сигналом 424 модуль зважування 428 MDCT-модуль 432 комбінаторний кодер спектра 436 вихідний потік бітів 502 кодер 504 MDCT-спектр залишкового сигналу 508 модуль вибору підсмуги/ділянки 510 квантувач форми 512 квантувач посилення 514 віднімання квантованого залишкового сигналу з вихідного вхідного залишкового сигналу 516 вихідний залишковий сигнал 602 аудіокадр 604 підсмуги 606 множина ділянок 702 ділянка з N спектральних ліній 704 підсмуга 706 основний імпульс 708 ділянка 710 потужність імпульсу 712 лексикографічний індекс 801 аудіокадр MDCT-спектр 802 кодер 806 формувач ділянок 808 модуль вибір основного імпульсу 809 модуль вибору субімпульсів 810,818 кодер знаку 812, 820 кодер позиції 814, 822 кодер посилення 816, 824 кодер амплітуди 1102 декодер 1104 вхідний потік бітів 1106 модуль декодера 1108 модуль корекції передспотворень 1110 модуль повторної дискретизації 1116 модуль комбінаторного декодера спектра 1122 формуючий модуль 1124 обернене перцепційне зважування 1126 постфільтр основного тону 1128 фільтр верхніх частот 1130 пороговий шумозаглушувач 1132 вихідний сигнал 1201 аудіокадр 1204 повторний формувач субімпульсів 1206 повторний формувач ділянок 1208 синтезатор основних імпульсів 1209 синтезатор субімпульсів 1210, 1218 декодер знаку 1212, 1220 декодер позиції 1214, 1222 декодер посилення 1216, 1224 декодер амплітуди 39 95185 40 41 95185 42 43 95185 44 45 95185 46 47 95185 48 49 95185 50 51 Комп’ютерна верстка Т. Чепелева 95185 Підписне 52 Тираж 24 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюScalable speech and audio codec using combinatorial mdct-spectrum encoding
Автори англійськоюReznik, Yurii, Huang, Pengjun
Назва патенту російськоюМасштабированное кодирование и аудио с использованием комбинаторного кодирования mdct-спектра
Автори російськоюРезник Юрий, Хуан Пенцзюнь
МПК / Мітки
МПК: G10L 19/00
Мітки: аудіо, масштабоване, використанням, комбінаторного, кодування, мови, mdct-спектра
Код посилання
<a href="https://ua.patents.su/26-95185-masshtabovane-koduvannya-movi-ta-audio-z-vikoristannyam-kombinatornogo-koduvannya-mdct-spektra.html" target="_blank" rel="follow" title="База патентів України">Масштабоване кодування мови та аудіо з використанням комбінаторного кодування mdct-спектра</a>
Обробка динамічних властивостей аудіо з використанням перенастройки

Номер патенту: 94968
Опубліковано: 25.06.2011
Автори: Сіфельдт Алан Джеффрі, Гандрі Кеннет Джеймс
Мітки: властивостей, аудіо, перенастройки, обробка, динамічних, використанням
Формула / Реферат:
1. Спосіб обробки звукового сигналу з використанням перенастройки, який полягає в тому, що:міняють динамічні властивості звукового сигналу відповідно до послідовності операцій регулювання динамічних властивостей,виявляють подію у часовому розвитку звукового сигналу, при якому рівень звукового сигналу знижується на величину, більшу ніж поріг помітності, Ldrop, в межах часового інтервалу, не більшого ніж друге порогове значення...
Спосіб вимірювання енергетичного спектра нвч сигналу

Номер патенту: 33038
Опубліковано: 10.06.2008
Автори: Ларкін Сергій Юрійович, Мірошніков Анатолій Миколайович, Горб Василь Миколайович
МПК: G01J 3/28
Мітки: сигналу, спектра, спосіб, нвч, енергетичного, вимірювання
Формула / Реферат:
Спосіб вимірювання енергетичного спектра НВЧ сигналу, що включає реєстрацію відгуку низькотемпературного приймача на основі надпровідного переходу Джозефсона як функції змінного параметра, який відрізняється тим, що формують відгуки, які піддають обробці, N низькотемпературних приймачів на основі переходів Джозефсона, в яких здійснюють попереднє задання струмів зміщення надпровідних переходів, вибір значень струмів попереднього зміщення і...
Спосіб захисту від несанкціонованого прослуховування та маскувальник мови для його здійснення

Номер патенту: 44665
Опубліковано: 15.02.2002
Автори: Тимощук Андрій Олександрович, Старіков Вячеслав Дмитрович, Стасюк Володимир Іванович, Зайченко Микола Миколайович
МПК: G10L 19/00
Мітки: маскувальник, захисту, прослуховування, мови, здійснення, несанкціонованого, спосіб
Формула / Реферат:
1. Спосіб захисту мови від несанкціонованого прослуховування, що включає інверсію спектральних складових мовного сигналу, який відрізняється тим, що спочатку аналоговий мовний сигнал перетворюють у цифрові відліки за допомогою аналого-цифрового перетворювача, потім обробляють цифрові відліки блоками заданої тривалості, після чого здійснюють розкладення цифрового еквівалента мови на комплексні спектральні складові на основі блока смугових...
Спосіб кодування аудіосигналу, оцифрованого з низькою частотою дискретизації

Номер патенту: 48195
Опубліковано: 15.08.2002
Автори: Дітц Мартін, Кунц Олівер, Целлер Юрген, Бухта Райнер, Герхойзер Хайнц, Зилер Мартін, Бранденбург Карлхайнц
Мітки: низькою, спосіб, кодування, аудіосигналу, дискретизації, частотою, оцифрованого
Формула / Реферат:
1. Спосіб кодування аудіосигналу, оцифрованого з низькою частотою дискретизації, в якому в кожному випадку деяку кількість розташованих у порядку зростання ліній спектра частот оцифрованого аудіосигналу, які відповідають певному діапазону масштабних множників, кодують одним і тим самим масштабним множником і в якому всі послідовно розташовані діапазони масштабних множників утворюють область, всередині якої всі масштабні множники кодують...
Покращене кодування і відображення параметрів багатоканального кодування мікшованих об’єктів

Номер патенту: 94117
Опубліковано: 11.04.2011
Автори: Пурнхаген Хейко, Реш Барбара, Енгдегард Джонас, Віллємоус Ларс
МПК: G10L 19/00
Мітки: багатоканального, покращене, мікшованих, параметрів, відображення, кодування, об'єктів
Формула / Реферат:
1. Кодер аудіооб'єктів для генерування кодованого сигналу аудіооб'єктів, що використовує множинність аудіооб'єктів, де множинність аудіооб'єктів включає стереооб'єкт, представлений двома аудіооб'єктами, які мають певну ненульову кореляцію, складається з:генератора інформації мікшування (96), призначеного для генерування інформації мікшування, що вказує на розподіл множинності аудіооб'єктів на щонайменше два канали...
Наступний патент: Карбофункціональні борвмісні олігоестероспирти як пластифікатори епоксидних композицій
Випадковий патент: Спосіб видалення вуглеводородного конденсату з газової свердловини