Кодування наборів параметрів і заголовків одиниць nal для кодування відео































































Формула / Реферат
1. Спосіб кодування відеоданих, який включає етапи, на яких:
кодують набір параметрів відео (VPS) для бітового потоку, який містить множину рівнів відеоданих, при цьому кожний із згаданої множини рівнів відеоданих звертається до VPS, і при цьому кодування VPS містить:
кодування даних VPS, що вказують деяке число кадрів, які повинні бути переупорядковані в щонайменше одному зі згаданої множини рівнів відеоданих,
кодування даних VPS, що вказують деяке число зображень, які повинні бути збережені в буфері декодованих зображень (DPB) під час декодування згаданої множини рівнів відеоданих;
кодування даних VPS, що вказують деяке максимальне число тимчасових рівнів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодування даних VPS, що вказують деяке максимальне число видів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодування інформації, яка задає відображення індексу вибірки на покажчик характеристик, при цьому кодування інформації, яка задає згадане відображення, містить кодування одного або більше з: відповідного просторового дозволу для кожного з множини індексів залежності, частоти кадрів для кожного з множини тимчасових індексів або ідентифікатора виду для кожного з множини індексів виду; і
кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS.
2. Спосіб за п. 1, в якому кодування VPS додатково включає кодування даних VPS, що вказують один або більше наборів параметрів гіпотетичного еталонного декодера (HRD).
3. Спосіб за п. 1, в якому кодування VPS додатково включає кодування даних VPS, що вказують, чи включає в себе VPS розширення понад відповідного стандарту, і, коли VPS включає в себе це розширення, даних для цього розширення.
4. Спосіб за п. 1, в якому кодування згаданої множини рівнів відеоданих включає кодування згаданої множини рівнів відеоданих відповідно до Високоефективного кодування відео (HEVC).
5. Спосіб за п. 1, в якому кодування згаданої множини рівнів відеоданих включає кодування згаданої множини рівнів відеоданих відповідно до щонайменше одного з Багатовидового кодування відео (MVC) або Масштабованого кодування відео (SVC).
6. Спосіб за п. 1, в якому кодування VPS включає кодування інформації, що точно визначає для однієї або більше розмірностей згаданої множини рівнів відеоданих одне або більше з:
деякого числа рівнів пріоритету в згаданій множині рівнів відеоданих, деякого числа рівнів залежності в згаданій множині рівнів відеоданих, деякого числа часових рівнів в згаданій множині рівнів відеоданих або максимального числа рівнів якості для будь-якого з рівнів залежності в згаданій множині рівнів відеоданих.
7. Спосіб за п. 6, в якому, коли підмножина із згаданої множини рівнів відеоданих має однакове просторове розрізнення і однакову бітову глибину, кожний з рівнів згаданої підмножини відповідає різним рівням з рівнів залежності.
8. Спосіб за п. 7, в якому кодування інформації, що задає зазначене відображення, включає кодування інформації, яка точно визначає відповідний покажчик характеристик для кожного з множини індексів характеристик, коли покажчик характеристик, який задає характеристики деякої розмірності згаданої множини рівнів відеоданих, не знаходиться в діапазоні індексів від нуля до лічильника розмірності вибірки мінус 1, при цьому лічильник задається індексом.
9. Спосіб за п. 7, в якому кодування інформації, що задає зазначене відображення, включає кодування одного або більше з: пари специфічних значень глибини для яскравості і кольоровості для кожного з множини індексів бітової глибини, або специфічного покажчика формату дискретизації кольоровості для кожного з множини форматів дискретизації кольоровості.
10. Спосіб за п. 1, в якому кодування VPS включає кодування інформації, що задає параметри керування і один або більше прапорів дозволу/заборони інструментів.
11. Спосіб за п. 1, в якому параметри керування і згадані один або більше прапорів дозволу/заборони інструментів містять одне або більше з:
pcm_bit_depth_luma_minus1,
pcm_bit_depth_chroma_minus1,
loop_filter_across_slicе_flag,
pcm_loop_filter_disable_flag,
tеmporal_id_nesting_flag,
одного або більше пов'язаних з елементом мозаїки синтаксичних елементів,
chroma_pred_from_luma_enabled_flag,
sample_adaptive_offset_enabled_flag,
adaptive_loop_filter_enabled_flag, або
inter_4×4_enabled_flag.
12. Спосіб за п. 1, в якому кодування VPS включає кодування інформації, що задає один або більше дескрипторів робочих точок.
13. Спосіб за п. 12, в якому кодування інформації, що задає згадані один або більше дескрипторів робочих точок, включає кодування інформації, що задає одне або більше з:
деякого числа максимальних робочих точок, залежності між різними рівнями або видами, профілю і рівня для кожної з робочих точок або бітрейта для кожної з робочих точок.
14. Спосіб за п. 1, який додатково включає кодування відповідного набору параметрів багаторівневої послідовності (LPS) для кожного із згаданої множини рівнів відеоданих, при цьому кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS, включає кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS і відповідному LPS.
15. Спосіб за п. 14, в якому кодування відповідних LPS для кожного із згаданої множини рівнів відеоданих включає кодування інформації, що задає указання розмірності вибірки, яке для кожної розмірності вказує індекс до кожної розмірності.
16. Спосіб за п. 14, в якому кодування відповідних LPS для кожного із згаданої множини рівнів відеоданих включає кодування інформації, що задає параметри керування і прапори дозволу/заборони інструментів.
17. Спосіб за п. 16, в якому параметри керування і згадані один або більше прапорів дозволу/заборони інструментів містять одне або більше з:
pcm_bit_depth_luma_minus1,
pcm_bit_depth_chroma_minus1,
loop_filtеr_across_slice_flag,
pcm_loop_filter_disable_flag,
одного або більше пов'язаних з елементом мозаїки синтаксичних елементів,
chroma_pred_from_luma_enabled_flag,
sample_adaptive_offset_enabled_flag,
adaptive_loop_filter_enabled_flag, або
ієрархії одиниць кодування (CU).
18. Спосіб за п. 14, в якому кодування відповідних LPS для кожного із згаданої множини рівнів відеоданих включає кодування інформації, що задає інформацію одного або більше інших наборів параметрів, застосовуваних до щонайменше одного зі слайсу, групи слайсів, зображення і декількох зображень, що звертаються до загального набору параметрів зображення (PPS).
19. Спосіб за п. 1, який додатково включає кодування одного або більше наборів параметрів зображення (PPS), так що PPS не звертаються до VPS, не звертаються до наборів параметрів багаторівневої послідовності (LPS) згаданої множини рівнів відеоданих.
20. Спосіб за п. 19, в якому кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS, включає кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS, PPS і LPS, так, що, коли синтаксичний елемент одного з PPS конфліктує з VPS або відповідним одним з LPS, кодують відповідний рівень із згаданої множини рівнів відеоданих на основі синтаксичного елемента згаданого одного з PPS.
21. Спосіб за п. 1, який додатково включає кодування групувального набору параметрів (GPS), який групує разом всі набори параметрів, в тому числі VPS, для згаданої множини рівнів відеоданих.
22. Спосіб за п. 21, в якому кодування GPS включає кодування інформації, що задає ідентифікатор GPS, причому спосіб додатково включає кодування інформації заголовка слайсу, що відповідає ідентифікатору GPS.
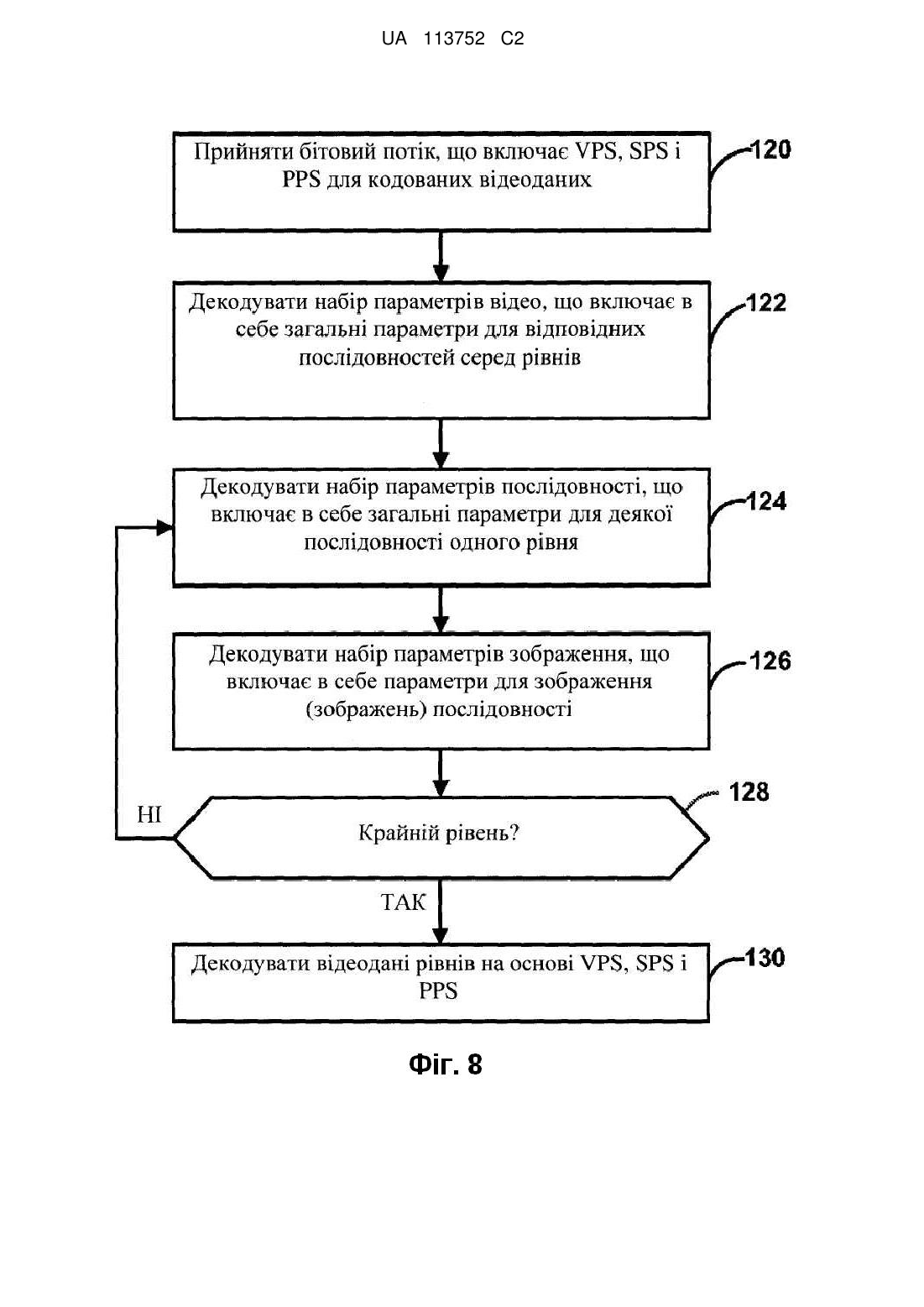
23. Спосіб за п. 1, в якому кодування згаданої множини рівнів відеоданих включає декодування згаданої множини рівнів відеоданих, і в якому кодування VPS містить аналізVPS.
24. Спосіб за п. 1, в якому кодування згаданої множини рівнів відеоданих містить кодування згаданої множини рівнів відеоданих, і в якому кодування VPS містить побудову VPS.
25. Пристрій для кодування відеоданих, що містить відеокодер, сконфігурований для:
кодування набору параметрів відео (VPS) для бітового потоку, який містить множину рівнів відеоданих, при цьому кожен із згаданої множини рівнів відеоданих звертається до VPS, і при цьому відеокодер, сконфігурований для кодування VPS, сконфігурований для: кодування даних VPS, що вказують деяке число кадрів, які повинні бути переупорядковані в щонайменше одному зі згаданої множини рівнів відеоданих, кодування даних VPS, які вказують деяке число зображень, які повинні бути збережені в буфері декодованих зображень (DPB) під час декодування згаданої множини рівнів відеоданих, кодування даних VPS, що вказують деяке максимальне число тимчасових рівнів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодування даних VPS, що вказують деяке максимальне число видів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодування інформації, яка задає відображення індексу вибірки на покажчик характеристик, при цьому для кодування інформації, яка задає згадане відображення, відеокодер сконфігурований для кодування одного або більше з: відповідного просторового дозволу для кожного з множини індексів залежності, частоти кадрів для кожного з множини тимчасових індексів або ідентифікатора виду для кожного з множини індексів виду; і
кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS.
26. Пристрій за п. 25, в якому відеокодер, який сконфігурований для кодування VPS, додатково сконфігурований для кодування даних VPS, що вказують один або більше наборів параметрів гіпотетичного еталонного декодера (HRD).
27. Пристрій за п. 25, в якому відеокодер, який сконфігурований для кодування VPS, додатково сконфігурований для кодування даних VPS, що вказують, чи включає VPS в себе розширення понад відповідного стандарту, і, коли VPS включає в себе це розширення, даних для цього розширення.
28. Пристрій за п. 25, в якому відеокодер сконфігурований для кодування згаданої множини рівнів відеоданих відповідно до одного з Високоефективного кодування відео (HEVC), Багатовидового кодування відео (MVC) і Масштабованого кодування відео (SVC).
29. Пристрій за п. 25, в якому відеокодер містить відеодекодер, і при цьому пристрій додатково містить пристрій відображення, який сконфігурований для відображення відеоданих.
30. Пристрій за п. 25, в якому відеокодер містить кодувальник відео, і при цьому пристрій додатково містить камеру, яка сконфігурована для генерування відеоданих.
31. Пристрій за п. 25, при цьому пристрій містить щонайменше одне з: інтегральної схеми;
мікропроцесора; і пристрою бездротового мобільного зв'язку, який включає в себе відеокодер.
32. Пристрій за п. 25, в якому відеокодер, який сконфігурований для кодування VPS, сконфігурований для кодування інформації, яка задає один або більше дескрипторів робочих точок.
33. Пристрій за п. 32, в якому для кодування інформації, яка задає згадані один або більше дескрипторів робочих точок, відеокодер сконфігурований для кодування інформації, яка задає одне або більше з: деякого числа максимальних робочих точок, залежності між різними рівнями або видами, профілю і рівня для кожної з робочих точок або бітрейта для кожної з робочих точок.
34. Пристрій для кодування відеоданих, що містить: засіб для кодування набору параметрів відео (VPS) для бітового потоку, який містить множину рівнів відеоданих, при цьому кожен із згаданої множини рівнів відеоданих звертається до VPS, і при цьому засіб для кодування VPS містить: засіб для кодування даних VPS, що вказують деяке число кадрів, які повинні бути переупорядковані в щонайменше одному із згаданої множини рівнів відеоданих, засіб для кодування даних VPS, що вказують деяке число зображень, які повинні бути збережені в буфері декодованих зображень (DPB) під час декодування згаданої множини рівнів відеоданих;
засіб для кодування даних VPS, що вказують деяке максимальне число тимчасових рівнів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
засіб для кодування даних VPS, що вказують деяке максимальне число видів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
засіб для кодування інформації, яка задає відображення індексу вибірки на покажчик характеристик, при цьому засіб для кодування інформації, яка задає згадане відображення, містить засіб для кодування одного або більше з: відповідного просторового дозволу для кожного з множини індексів залежності, частоти кадрів для кожного з множини тимчасових індексів або ідентифікатора виду для кожного з множини індексів виду; і
засіб для кодування згаданої множини рівнів відеоданих, основуючись, щонайменше частково, на VPS.
35. Пристрій за п. 34, в якому засіб для кодування VPS додатково містить засіб для кодування даних VPS, що вказують один або більше наборів параметрів гіпотетичного еталонного декодера (HRD).
36. Пристрій за п. 34, в якому засіб для кодування VPS додатково містить засіб для кодування даних VPS, що вказують, чи включає VPS в себе розширення понад відповідного стандарту, і, коли VPS включає в себе це розширення, даних для цього розширення.
37. Пристрій за п. 34, в якому засіб для кодування VPS містить засіб для кодування згаданої множини рівнів відеоданих відповідно до одного з Високоефективного кодування відео (HEVC), Багатовидового кодування відео (MVC) і Масштабованого кодування відео (SVC).
38. Пристрій за п. 34, в якому засіб для кодування VPS містить засіб для кодування інформації, яка задає один або більше дескрипторів робочих точок.
39. Пристрій за п. 38, в якому засіб для кодування інформації, яка задає згадані один або більше дескрипторів робочих точок, містить засіб для кодування інформації, яка задає одне або більше з: деякого числа максимальних робочих точок, залежності між різними рівнями або видами, профілю і рівня для кожної з робочих точок або бітрейта для кожної з робочих точок.
40. Довготривалий зчитуваний комп'ютером носій інформації, який зберігає інструкції, які, при виконанні, спонукають процесор: кодувати набір параметрів відео (VPS) для бітового потоку, який містить множину рівнів відеоданих, при цьому кожен із згаданої множини рівнів відеоданих звертається до VPS, і при цьому інструкції, які спонукають процесор кодувати VPS, містять інструкції, які спонукають процесор: кодувати дані VPS, що вказують деяке число кадрів, які повинні бути переупорядковані в щонайменше одному із згаданої множини рівнів відеоданих, кодувати дані VPS, що вказують деяке число зображень, які повинні бути збережені в буфері декодованих зображень (DPB) під час декодування згаданої множини рівнів відеоданих;
кодувати дані VPS, що вказують деяке максимальне число тимчасових рівнів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодувати дані VPS, що вказують деяке максимальне число видів в бітовому потоці, що включає в себе згадану множину рівнів відеоданих;
кодувати інформацію, яка задає відображення індексу вибірки на покажчик характеристик, при цьому інструкції, які спонукають процесор кодувати інформацію, яка задає згадане відображення, додатково містять інструкції, які, при виконанні, спонукають процесор кодувати одне або більше з: відповідного просторового дозволу для кожного з множини індексів залежності, частоти кадрів для кожного з множини тимчасових індексів або ідентифікатора виду для кожного з множини індексів виду; і кодувати згадану множину рівнів відеоданих, основуючись, щонайменше частково, на VPS.
41. Довготривалий зчитуваний комп'ютером носій інформації за п. 40, в якому інструкції, які спонукають процесор кодувати VPS, додатково містять інструкції, які, при виконанні, спонукають процесор кодувати дані VPS, що вказують один або більше наборів параметрів гіпотетичного еталонного декодера (НRD).
42. Довготривалий зчитуваний комп'ютером носій інформації за п. 40, в якому інструкції, які при виконанні, спонукають процесор кодувати VPS, додатково містять інструкції, які спонукають процесор кодувати дані VPS, що вказують, чи включає VPS в себе розширення понад відповідного стандарту, і, коли VPS включає в себе це розширення, дані для цього розширення.
43. Довготривалий зчитуваний комп'ютером носій інформації за п. 40, в якому інструкції, які спонукають процесор кодувати згадану множину рівнів відеоданих, містять інструкції, які, при виконанні, спонукають процесор кодувати згадану множину рівнів відеоданих відповідно до одного з Високоефективного кодування відео (HEVC), Багатовидового кодування відео (MVC) і Масштабованого кодування відео (SVC).
44. Довготривалий зчитування комп'ютером носій інформації за п. 40, в якому інструкції, які спонукають процесор кодувати VPS, додатково містять інструкції, які, при виконанні, спонукають процесор кодувати інформацію, яка задає один або більше дескрипторів робочих точок.
45. Довготривалий зчитування комп'ютером носій інформації по п. 44, в якому інструкції, які спонукають процесор кодувати інформацію, яка задає один або більше дескрипторів робочих точок, додатково містять інструкції, які, при виконанні, спонукають процесор кодувати інформацію, яка задає одне або більше з: деякого числа максимальних робочих точок, залежності між різними рівнями або видами, профілю і рівня для кожної з робочих точок або бітрейта для кожної з робочих точок.
Текст
Реферат: У одному прикладі кодер відео, наприклад відеокодер або відеодекодер, конфігурується для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодування одного або більше рівнів відеоданих, основуючись, щонайменше частково, на VPS. Кодер відео може кодувати VPS для відеоданих, відповідних Високоефективному кодуванню відео, Багатовидовому кодуванню відео, Масштабованому кодуванню відео або іншим стандартам кодування відео, або розширенням стандартів кодування відео. VPS може включати в себе дані, що задають параметри для відповідних послідовностей відеоданих на різних рівнях (наприклад, видах, рівнях якості або т. п.). Параметри VPS можуть надавати указання про те, як кодуються відповідні відеодані. UA 113752 C2 (12) UA 113752 C2 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 Дана заявка вимагає пріоритет: попередньої заявки США з порядковим № 61/586,777, поданої 14 січня 2012 р.; попередньої заявки США з порядковим № 61/587,070, поданої 16 січня 2012 р.; попередньої заявки США з порядковим № 61/588,629, поданої 19 січня 2012 р.; попередньої заявки США з порядковим № 61/637,195, поданої 23 квітня 2012 р.; і попередньої заявки США з порядковим № 61/637,774, поданої 24 квітня 2012 р., кожна з яких повністю включена в цей документ шляхом посилання. ГАЛУЗЬ ТЕХНІКИ Дане розкриття винаходу стосується кодування відео. РІВЕНЬ ТЕХНІКИ Можливості цифрового відео можуть вбудовуватися в широкий діапазон пристроїв, включаючи цифрові телевізори, системи цифрового прямого мовлення, системи бездротового мовлення, персональні цифрові помічники (PDA), переносні або настільні комп'ютери, планшетні комп'ютери, електронні книги, цифрові камери, цифрові пристрої запису, цифрові мультимедійні програвачі, відеоігрові пристрої, ігрові приставки, стільникові або супутникові радіотелефони, так звані "смартфони", пристрої для відеоконференцзв'язку, пристрої для потокового відео і т. п. Цифрові відеопристрої реалізовують методики кодування відео, наприклад, описані в стандартах, заданих MPEG-2, MPEG-4, H.263 ITU-T, H.264/MPEG-4 ITU-T, частина 10, Поліпшене кодування відео (AVC), стандартом Високоефективного кодування відео (HEVC), що на даний час знаходиться в розробці, і розширеннях таких стандартів. Останній варіант майбутнього стандарту HEVC доступний за адресою http://phenix.intevry.fr/jct/doc_end_user/documents/7_Geneva/wg11/JCTVC-G1103-v3.zip. Відеопристрої можуть ефективніше передавати, приймати, кодувати, декодувати і/або зберігати цифрову відеоінформацію за допомогою реалізації таких методик кодування відео. Методики кодування відео включають в себе просторове (всередині (intra) зображення) прогнозування і/або часове (між (inter) зображеннями) прогнозування для зменшення або усунення надмірності, властивої відеопослідовностям. Для блокового кодування відео слайс (вирізка) відео (наприклад, відеокадр або частина відеокадру) може розбиватися на відеоблоки, які також можуть називатися блоками дерева, одиницями кодування (CU) і/або вузлами кодування. Відеоблоки в слайсі з внутрішнім кодуванням (I) зображення кодуються з використанням просторового прогнозування відносно опорних вибірок (відліків) в сусідніх блоках в тому ж зображенні. Відеоблоки в слайсі із зовнішнім кодуванням (Р або В) зображення можуть використовувати просторове прогнозування відносно опорних вибірок в сусідніх блоках в тому ж зображенні або часове прогнозування відносно опорних вибірок в інших опорних зображеннях. Зображення можуть називатися кадрами, а опорні зображення можуть називатися опорними кадрами. Просторове або часове прогнозування приводить до блока з прогнозуванням для блока, який повинен бути кодований. Залишкові дані являють собою різниці пікселів між вихідним блоком, який повинен бути кодований, і блоком з прогнозуванням. Блок із зовнішнім кодуванням кодується відповідно до вектора руху, який вказує на блок опорних вибірок, що утворюють блок з прогнозуванням, і залишкових даних, що вказують різницю між кодованим блоком і блоком з прогнозуванням. Блок з внутрішнім кодуванням кодується відповідно до режиму внутрішнього кодування і залишкових даних. Для додаткового стиснення залишкові дані можуть бути перетворені з області пікселів в область перетворення, що приводить до залишкових коефіцієнтів перетворення, які потім можна квантувати. Квантовані коефіцієнти перетворення, організовані спочатку в двовимірний масив, можна сканувати для створення одновимірного вектора коефіцієнтів перетворення, і може застосовуватися ентропійне кодування для досягнення ще більшого стиснення. СУТЬ ВИНАХОДУ Загалом дане розкриття винаходу описує методики для кодування наборів параметрів і одиниць рівня абстракції мережі (NAL) для кодування відео. Ці методики можуть застосовуватися до однорівневих кодованих даних, наприклад двовимірних відеоданих, а також до відеоданих масштабованого кодування відео (SVC) і відеоданих багатовидового кодування відео (MVC). Таким чином, набори параметрів і одиниці NAL можуть бути взаємно сумісні між різними типами відеоданих. Наприклад, кодер відео, такий як відеокодер або відеодекодер, може кодувати набір параметрів відео (VPS), який задає параметри для одного або більше рівнів відеоданих. Рівні можуть відповідати, наприклад, рівням SVC (що мають різні частоти кадрів, просторові розрізнення і/або рівні якості) і/або видам в даних MVC (наприклад, послідовностям зображень сцени, захоплених з різних ракурсів камер відносно горизонтальної осі). 1 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 У одному прикладі спосіб кодування відеоданих включає в себе кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. У іншому прикладі пристрій для кодування відеоданих включає в себе кодер відео, наприклад відеокодер або відеодекодер, який конфігурується для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. У іншому прикладі пристрій для кодування відеоданих включає в себе засіб для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і засіб для кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. У іншому прикладі зчитуваний комп'ютером носій інформації містить збережені на ньому інструкції, які при виконанні спонукають процесор кодувати набір параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодувати один або більше рівнів відеоданих, основуючись щонайменше частково на VPS. Подробиці одного або більше прикладів викладаються на прикладених кресленнях і в описі нижче. Інші ознаки, цілі і переваги стануть очевидні з опису, креслень і з формули винаходу. КОРОТКИЙ ОПИС КРЕСЛЕНЬ Фіг. 1 - блок-схема, що ілюструє зразкову систему кодування і декодування відео, яка може використовувати методики для кодування наборів параметрів і одиниць рівня абстракції мережі (NAL) для одного або більше рівнів відеоданих. Фіг. 2 - блок-схема, що ілюструє приклад відеокодера 20, який може реалізувати методики для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих. Фіг. 3 - блок-схема, що ілюструє приклад відеодекодера 30, який може реалізувати методики для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих. Фіг. 4 - концептуальна схема, що ілюструє зразковий шаблон прогнозування MVC. Фіг. 5 - концептуальна схема, що ілюструє набір параметрів відео (VPS) і різні набори параметрів рівнів (LPS). Фіг. 6 - концептуальна схема, що ілюструє зразковий групувальний набір параметрів (GPS) і взаємозв'язку GPS з іншими наборами параметрів і заголовками слайсів. Фіг. 7 - блок-схема послідовності операцій, що ілюструє зразковий спосіб для кодування відеоданих відповідно до методик з даного розкриття винаходу. Фіг. 8 - блок-схема послідовності операцій, що ілюструє зразковий спосіб для декодування відеоданих відповідно до методик з даного розкриття винаходу. Фіг. 9 - блок-схема послідовності операцій, що ілюструє зразковий спосіб кодування відеоданих, основуючись щонайменше частково на числі часових рівнів, які сигналізовані в VPS. Фіг. 10 - блок-схема послідовності операцій, що ілюструє зразковий спосіб кодування відеоданих, основуючись щонайменше частково на числі зображень, які повинні бути переупорядковані на одному або більше рівнях, і зображень, які повинні бути збережені в буфер декодованих зображень. Фіг. 11 - блок-схема послідовності операцій, що ілюструє зразковий спосіб кодування відеоданих, основуючись щонайменше частково на параметрах гіпотетичного еталонного декодера (HRD), сигналізованих в VPS. Фіг. 12 - блок-схема послідовності операцій, що ілюструє зразковий спосіб кодування відеоданих, основуючись щонайменше частково на даних розширення, сигналізованих в VPS. ДОКЛАДНИЙ ОПИС Взагалі дане розкриття винаходу описує кодування відеоданих з використанням набору параметрів відео (VPS). Відеодані можна категоризувати ієрархічно як такі, що включають в себе множину рівнів, послідовність зображень на заданому рівні, зображення в послідовності, слайси в зображенні і блоки (наприклад, макроблоки або одиниці дерева кодування) в слайсі. Набори параметрів послідовності (SPS) можуть використовуватися для сигналізації параметрів, що нечасто змінюються, для послідовності зображень, а набори параметрів зображення (PPS) можуть використовуватися для сигналізації параметрів, що нечасто змінюються, для окремих зображень. Відповідно до методик з даного розкриття винаходу VPS може сигналізувати параметри, що нечасто змінюються, для множини послідовностей між відповідними рівнями. Тобто VPS може 2 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 включати в себе параметри для набору суміщених у часі послідовностей різних рівнів. Різні рівні можуть включати в себе, наприклад, різні види для багатовидових відеоданих, різні рівні якості, різні рівні просторового розрізнення, масштабовані у часі рівні (тобто рівні, що допускають різні частоти кадрів) і т. п. Таким чином, один VPS може надаватися для множини різних рівнів, так що VPS сигналізує параметри, які є загальними для кожного з відповідних рівнів (наприклад, відповідні послідовності на відповідних рівнях). Бітовий потік може вважатися таким, що включає в себе кожний з множини рівнів, і відповідні рівні можуть утворювати відповідні бітові субпотоки. Крім того, бітовий субпотік може відповідати поєднанню двох або більше рівнів. Дане розкриття винаходу описує різні приклади даних, які можуть включатися в VPS. Такі дані в деяких прикладах можуть включати в себе указування числа підрівнів (наприклад, максимальне число підрівнів) на відповідних рівнях. Наприклад, VPS може включати в себе дані, які сигналізують число часових рівнів і/або максимальне число часових рівнів (наприклад, ідентифікатор найвищого часового рівня). Як інший приклад VPS додатково або альтернативно може включати в себе дані, практично аналогічні будь-яким даним, раніше сигналізованим в SPS (тобто сигналізованим в традиційних SPS). Таким чином, коли послідовності двох або більше рівнів бітового потоку включають в себе практично аналогічні або ідентичні параметри, кодер відео може кодувати VPS для сигналізації параметрів для послідовностей цих рівнів замість надмірного кодування таких даних у відповідних SPS для різних послідовностей між різними рівнями. VPS додатково або альтернативно може включати в себе дані, що задають інформацію про застосовність відео (VUI), наприклад інформацію про представлення відео, параметри гіпотетичного еталонного декодера (HRD) і/або інформацію про обмеження бітового потоку. Інформація про обмеження бітового потоку може включати в себе обмеження по діапазону векторів руху, розміру буфера декодованих зображень (DPB) (наприклад, в показниках числа зображень, які повинні бути збережені за допомогою DPB), числу переупорядковуваних кадрів (тобто указування числа кадрів, які повинні бути переупорядковані з порядку декодування в порядок відображення), кодованих розмірах блоків (наприклад, макроблоків (MB) або одиниць дерева кодування) і кодованих розмірах зображень. VPS може додатково надавати дані для одного або більше розширень VPS, так що VPS може розширятися майбутніми стандартами або розширеннями до майбутнього стандарту HEVC. Фіг. 1 - блок-схема, що ілюструє зразкову систему 10 кодування і декодування відео, яка може використовувати методики для кодування наборів параметрів і одиниць рівня абстракції мережі (NAL) для одного або більше рівнів відеоданих. Як показано на фіг. 1, система 10 включає в себе пристрій-джерело 12, що надає кодовані відеодані, які пізніше повинні бути декодовані пристроєм-адресатом 14. Зокрема, пристрій-джерело 12 надає відеодані пристроюадресату 14 за допомогою зчитуваного комп'ютером носія 16. Пристрій-джерело 12 і пристрійадресат 14 можуть бути виконані у вигляді будь-якого з широкого діапазону пристроїв, що включають в себе настільні комп'ютери, блокнотні (тобто переносні) комп'ютери, планшетні комп'ютери, телевізійні приставки, телефонні трубки, наприклад так звані "інтелектуальні" телефони, так звані "інтелектуальні" планшети, телевізори, камери, пристрої відображення, цифрові мультимедійні програвачі, ігрові приставки, пристрій для потокового відео або т. п. В деяких випадках пристрій-джерело 12 і пристрій-адресат 14 можуть бути обладнані для бездротового зв'язку. Пристрій-адресат 14 може приймати кодовані відеодані, які повинні бути декодовані, за допомогою зчитуваного комп'ютером носія 16. Зчитуваний комп'ютером носій 16 може бути виконаний у вигляді будь-якого типу носія або пристрою, що допускає переміщення кодованих відеоданих від пристрою-джерела 12 до пристрою-адресата 14. У одному прикладі зчитуваний комп'ютером носій 16 може бути виконаний у вигляді засобу зв'язку, щоб дати пристроюджерелу 12 можливість передавати кодовані відеодані безпосередньо до пристрою-адресата 14 в реальному масштабі часу. Кодовані відеодані можуть модулюватися згідно зі стандартом зв'язку, наприклад протоколом бездротового зв'язку, і передаватися пристрою-адресату 14. Засіб зв'язку може бути виконаний у вигляді будь-якого засобу бездротового або дротового зв'язку, наприклад радіочастотного (RF) спектра або однієї або більше фізичних ліній передачі. Засіб зв'язку може утворювати частину пакетної мережі, наприклад локальної мережі, регіональної мережі або глобальної мережі, такої як Інтернет. Засіб зв'язку може включати в себе маршрутизатори, комутатори, базові станції або будь-яке інше обладнання, яке може бути корисне для спрощення зв'язку від пристрою-джерела 12 до пристрою-адресата 14. У деяких прикладах кодовані дані можуть виводитися з інтерфейсу 22 виведення в запам'ятовуючий пристрій. Аналогічним чином до кодованих даних можна звертатися із запам'ятовуючого пристрою за допомогою інтерфейсу введення. Запам'ятовуючий пристрій 3 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 може включати в себе будь-який з ряду розподілених або локально доступних носіїв інформації, наприклад жорсткий диск, диски Blu-ray, DVD, CD-ROM, флеш-пам'ять, енергозалежний або енергонезалежний запам'ятовуючий пристрій або будь-які інші придатні цифрові носії інформації для зберігання кодованих відеоданих. У додатковому прикладі запам'ятовуючий пристрій може відповідати файловому серверу або іншому проміжному запам'ятовуючому пристрою, який може зберігати кодоване відео, сформоване пристроєм-джерелом 12. Пристрійадресат 14 може звертатися до збережених відеоданих із запам'ятовуючого пристрою за допомогою потокової передачі або завантаження. Файловий сервер може бути будь-яким типом сервера, що допускає зберігання кодованих відеоданих і передачу цих кодованих відеоданих пристрою-адресату 14. Зразкові файлові сервери включають в себе веб-сервер (наприклад, для веб-сайта), FTP-сервер, мережеві пристрої зберігання (NAS) або локальний накопичувач на дисках. Пристрій-адресат 14 може звертатися до кодованих відеоданих за допомогою будьякого стандартного інформаційного з'єднання, включаючи Інтернет-з'єднання. Це з'єднання може включати в себе радіоканал (наприклад, з'єднання Wi-Fi), дротове з'єднання (наприклад, DSL, кабельний модем і т. п.) або поєднання їх обох, яке придатне для звертання до кодованих відеоданих, збережених на файловому сервері. Передача кодованих відеоданих із запам'ятовуючого пристрою може бути потоковою передачею, завантаженням або їх поєднанням. Методики з даного розкриття винаходу не обов'язково обмежуються бездротовими додатками або настройками. Методики можуть застосовуватися до кодування відео в підтримання будь-якого з ряду мультимедійних додатків, таких як ефірні телепередачі, кабельні телепередачі, супутникові телепередачі, передачі потокового відео по Інтернету, наприклад динамічна адаптивна потокова передача по HTTP (DASH), цифрове відео, яке кодується на носії інформації, декодування цифрового відео, збереженого на носії інформації, або інших додатків. У деяких прикладах система 10 може конфігуруватися для підтримання однонаправленої або двонаправленої передачі відео для підтримання таких додатків, як потокова передача відео, відтворення відео, телевізійне мовлення і/або відеотелефонія. У прикладі з фіг. 1 пристрій-джерело 12 включає в себе джерело 18 відео, відеокодер 20 і інтерфейс 22 виведення. Пристрій-адресат 14 включає в себе інтерфейс 28 введення, відеодекодер 30 і пристрій 32 відображення. Відповідно до даного розкриття винаходу відеокодер 20 в пристрої-джерелі 12 може конфігуруватися для застосування методик для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих. У інших прикладах пристрій-джерело і пристрій-адресат можуть включати в себе інші компоненти або компонування. Наприклад, пристрій-джерело 12 може приймати відеодані із зовнішнього джерела 18 відео, наприклад зовнішньої камери. Також пристрій-адресат 14 може взаємодіяти із зовнішнім пристроєм відображення замість включення в себе вбудованого пристрою відображення. Проілюстрована система 10 з фіг. 1 є усього лише одним прикладом. Методики для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих можуть виконуватися будь-яким пристроєм кодування і/або декодування цифрового відео. Хоч методики з даного розкриття винаходу виконуються, як правило, пристроєм кодування відео, методики також можуть виконуватися відеокодером/декодером, звичайно називаним "кодеком". Крім того, методики з даного розкриття винаходу також можуть виконуватися препроцесором відео. Пристрій-джерело 12 і пристрій-адресат 14 є усього лише прикладами таких пристроїв кодування, в яких пристрій-джерело 12 формує кодовані відеодані для передачі пристроюадресату 14. У деяких прикладах пристрої 12, 14 можуть працювати практично симетричним чином, так що кожен з пристроїв 12, 14 включає в себе компоненти кодування і декодування відео. Тому система 10 може підтримувати однонаправлену або двонаправлену передачу відео між відеопристроями 12, 14, наприклад, для потокової передачі відео, відтворення відео, телевізійного мовлення або відеотелефонії. Джерело 18 відео в пристрої-джерелі 12 може включати в себе пристрій відеозахоплення, наприклад відеокамеру, відеоархів, що містить раніше захоплене відео, і/або інтерфейс джерела відеосигналу для прийому відео від постачальника відеоконтенту. Як додаткова альтернатива джерело 18 відео може формувати дані на основі комп'ютерної графіки як вихідне відео або поєднання "реального" відео, архівного відео і сформованого комп'ютером відео. У деяких випадках, якщо джерелом 18 відео є відеокамера, то пристрій-джерело 12 і пристрійадресат 14 можуть утворювати так звані камерофони або відеотелефони. Однак, як згадувалося вище, описані в даному розкритті винаходу методики можуть бути застосовні до кодування відео загалом і можуть застосовуватися до бездротових і/або дротових додатків. У кожному випадку захоплене, попередньо захоплене або сформоване комп'ютером відео може 4 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 кодуватися відеокодером 20. Кодована відеоінформація потім може виводитися за допомогою інтерфейсу 22 виведення на зчитуваний комп'ютером носій 16. Зчитуваний комп'ютером носій 16 може включати в себе тимчасові носії, наприклад бездротову широкомовну або дротову мережеву передачу, або носії інформації (тобто постійні носії інформації), наприклад жорсткий диск, флеш-накопичувач, компакт-диск, цифровий відеодиск, диск Blu-ray або інші зчитувані комп'ютером носії. У деяких прикладах мережевий сервер (не показаний) може приймати кодовані відеодані від пристрою-джерела 12 і надавати кодовані відеодані пристрою-адресату 14, наприклад, за допомогою мережевої передачі. Аналогічним чином обчислювальний пристрій з обладнання по виробництву носіїв, наприклад обладнання по штампуванню оптичних дисків, може прийняти кодовані відеодані від пристроюджерела 12 і виробити диск, що містить кодовані відеодані. Тому в різних прикладах зчитуваний комп'ютером носій 16 може вважатися таким, що включає в себе один або більше зчитуваних комп'ютером носіїв різних видів. Інтерфейс 28 введення в пристрої-адресаті 14 приймає інформацію зі зчитуваного комп'ютером носія 16. Інформація зі зчитуваного комп'ютером носія 16 може включати в себе синтаксичну інформацію, задану відеокодером 20, яка також використовується відеодекодером 30, що включає в себе синтаксичні елементи, які описують характеристики і/або обробку блоків і інших кодованих одиниць, наприклад GOP. Пристрій 32 відображення відображає користувачу декодовані відеодані і може бути виконаний у вигляді будь-якого з ряду пристроїв відображення, таких як електронно-променева трубка (CRT), рідкокристалічний дисплей (LCD), плазмовий дисплей, дисплей на органічних світловипромінюючих діодах (OLED) або інший тип пристрою відображення. Відеокодер 20 і відеодекодер 30 можуть працювати відповідно до деякого стандарту кодування відео, наприклад стандарту Високоефективного кодування відео (HEVC), що на даний час знаходиться в розробці, і можуть відповідати Експериментальній моделі HEVC (HM). Як альтернатива відеокодер 20 і відеодекодер 30 можуть працювати відповідно до інших власних або промислових стандартів, наприклад стандарту H.264 ITU-T, як альтернатива називаного MPEG-4, частина 10, Поліпшене кодування відео (AVC), або розширень таких стандартів. Однак методики в даному розкритті винаходу не обмежуються ніяким конкретним стандартом кодування. Інші приклади стандартів кодування відео включають в себе MPEG-2 і H.263 ITU-T. Хоч і не показано на фіг. 1, в деяких особливостях відеокодер 20 і відеодекодер 30 можуть бути об'єднані зі звуковим кодером і декодером і можуть включати в себе придатні модулі мультиплексування-демультиплексування або інші апаратні засоби і програмне забезпечення, щоб кодувати звук і відео в загальному потоці даних або в окремих потоках даних. Якщо застосовно, то модулі мультиплексування-демультиплексування можуть відповідати протоколу мультиплексора H.223 ITU або іншим протоколам, наприклад протоколу дейтаграм користувача (UDP). Стандарт H.264/MPEG-4 (AVC) ITU-T був сформульований Експертною групою в галузі кодування відео (VCEG) ITU-T разом з Експертною групою по рухомих зображеннях (MPEG) ISO/IEC як результат колективної співпраці, відомої як Об'єднана команда по відео (JVT). У деяких особливостях описані в даному розкритті винаходу методики можуть застосовуватися до пристроїв, які загалом відповідають стандарту H.264. Стандарт H.264 описується Дослідницькою групою ITU-T в Рекомендації H.264 ITU-T, Поліпшене кодування відео для універсальних аудіовізуальних служб, датований березнем 2005 року і в цьому документі може називатися стандартом H.264 або специфікацією H.264 або стандартом або специфікацією H.264/AVC. Об'єднана команда по відео (JVT) продовжує працювати над розширеннями до H.264/MPEG-4 (AVC). Відеокодер 20 і відеодекодер 30 можуть бути реалізовані у вигляді будь-якої з ряду придатних схем кодера, наприклад одного або більше мікропроцесорів, цифрових процесорів сигналів (DSP), спеціалізованих інтегральних схем (ASIC), програмованих користувачем вентильних матриць (FPGA), дискретної логіки, програмного забезпечення, апаратних засобів, мікропрограмного забезпечення або будь-яких їх поєднань. Коли методики реалізовуються частково в програмному забезпеченні, пристрій може зберігати інструкції для програмного забезпечення на придатному, незмінному з часом зчитуваному комп'ютером носії і виконувати інструкції на апаратних засобах, що використовують один або більше процесорів, для виконання методик з даного розкриття винаходу. Кожний з відеокодера 20 і відеодекодера 30 може включатися в один або більше кодерів або декодерів, будь-який з яких може вбудовуватися як частина об'єднаного кодера/декодера (кодека) у відповідному пристрої. JCT-VC працює над розвитком стандарту HEVC. Роботи по стандартизації HEVC основуються на моделі пристрою кодування відео, що розвивається, називаній 5 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 Експериментальною моделлю HEVC (HM). HM передбачає декілька додаткових можливостей у пристроїв кодування відео в порівнянні з існуючими пристроями, відповідними, наприклад, H.264/AVC ITU-T. Наприклад, тоді як H.264 надає дев'ять режимів кодування з внутрішнім прогнозуванням, HM може надати цілих тридцять три режими кодування з внутрішнім прогнозуванням. Взагалі, робоча модель HM описує, що відеокадр або зображення можна розділити на послідовність блоків дерева або найбільших одиниць кодування (LCU), які включають в себе вибірки яскравості і кольоровості. Синтаксичні дані в бітовому потоці можуть задавати розмір для LCU, яка є найбільшою одиницею кодування в показниках числа пікселів. Слайс включає в себе деяке число послідовних блоків дерева в порядку кодування. Відеокадр або зображення може розбиватися на один або більше слайсів. Кожний блок дерева можна розділити на одиниці кодування (CU) згідно з квадродеревом. Звичайно структура даних квадродерева включає в себе один вузол на CU, причому кореневий вузол відповідає блоку дерева. Якщо CU розділяється на чотири суб-CU, то вузол, відповідний CU, включає в себе чотири листи, кожний з яких відповідає одній з суб-CU. Кожний вузол в структурі даних квадродерева може надавати синтаксичні дані для відповідної CU. Наприклад, вузол в квадродереві може включати в себе прапор розділення, що вказує, чи розділяється відповідна вузлу CU на суб-CU. Синтаксичні елементи для CU можна задати рекурсивно, і вони можуть залежати від того, чи розділяється CU на суб-CU. Якщо CU більше не розділяється, то вона називається листовою CU. У даному розкритті винаходу чотири суб-CU в листовій CU також будуть називатися листовими CU, навіть якщо відсутнє явне розділення вихідної листової CU. Наприклад, якщо CU з розміром 16×16 більше не розділяється, то чотири суб-CU 8×8 також будуть називатися листовими CU, хоч CU 16×16 ніколи не розділялася. CU має схожу з макроблоком зі стандарту H.264 ціль за винятком того, що CU не має відмінності в розмірі. Наприклад, блок дерева можна розділити на чотири дочірніх вузли (також звані суб-CU), і кожний дочірній вузол, в свою чергу, може бути батьківським вузлом і розділятися на чотири інших дочірніх вузли. Кінцевий, нерозділений дочірній вузол, називаний листом квадродерева, містить вузол кодування, також називаний листовою CU. Синтаксичні дані, асоційовані з кодованим бітовим потоком, можуть задавати максимальне число разів, яке можна ділити блок дерева, називане максимальною глибиною CU, а також можуть задавати мінімальний розмір вузлів кодування. Відповідно, бітовий потік також може задавати найменшу одиницю кодування (SCU). Дане розкриття винаходу використовує термін "блок", щоб посилатися на будь-яку з CU, PU або TU, застосовно до HEVC, або аналогічні структури даних, застосовно до інших стандартів (наприклад, макроблоки і їх субблоки в H.264/AVC). CU включає в себе вузол кодування і одиниці прогнозування (PU) і одиниці перетворення (TU), асоційовані з вузлом кодування. Розмір CU відповідає розміру вузла кодування і повинен мати квадратну форму. Розмір CU може варіюватися від 8×8 пікселів до розміру блока дерева з максимальним числом 64×64 пікселів або більше. Кожна CU може містити одну або більше PU і одну або більше TU. Синтаксичні дані, асоційовані з CU, можуть описувати, наприклад, розбиття CU на одну або більше PU. Режими розбиття можуть відрізнятися між тим, чи кодується CU в режимі пропуску або в прямому режимі, режимі внутрішнього прогнозування або режимі зовнішнього прогнозування. PU можуть розбиватися, щоб мати неквадратну форму. Синтаксичні дані, асоційовані з CU, також можуть описувати, наприклад, розбиття CU на одну або більше TU згідно з квадродеревом. TU може мати квадратну або неквадратну (наприклад, прямокутну) форму. Стандарт HEVC допускає перетворення згідно з TU, які можуть відрізнятися для різних CU. TU звичайно мають розмір на основі розміру PU в даній CU, заданій для розділеної LCU, хоч це не завжди може бути так. TU звичайно мають такий же розмір або менше, ніж PU. У деяких прикладах залишкові вибірки, відповідні CU, можна розділити на менші одиниці, використовуючи структуру квадродерева, відому як "залишкове квадродерево" (RQT). Листи RQT можуть називатися одиницями перетворення (TU). Значення різниці пікселів, асоційовані з TU, можна перетворити для створення коефіцієнтів перетворення, які можна квантувати. Листова CU може включати в себе одну або більше одиниць прогнозування (PU). Звичайно PU представляє просторову область, відповідну всій або частині відповідної CU, і може включати в себе дані для витягання опорної вибірки для PU. Крім того, PU включає в себе дані, пов'язані з прогнозуванням. Наприклад, коли PU кодується у внутрішньому режимі, дані для PU можуть включатися в залишкове квадродерево (RQT), яке може включати в себе дані, що описують режим внутрішнього прогнозування для TU, відповідної PU. Як інший приклад, коли PU кодується у зовнішньому режимі, PU може включати в себе дані, що задають один або 6 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 більше векторів руху для PU. Дані, що задають вектор руху для PU, можуть описувати, наприклад, горизонтальну складову вектора руху, вертикальну складову вектора руху, розрізнення для вектора руху (наприклад, точність в одну чверть піксела або точність в одну восьму піксела), опорне зображення, на яке вказує вектор руху, і/або список опорних зображень (наприклад, Список 0, Список 1 або Список С) для вектора руху. Листова CU, що має одну або більше PU, також може включати в себе одну або більше одиниць перетворення (TU). Одиниці перетворення можуть бути точно визначені з використанням RQT (також званого структурою квадродерева TU), як обговорювалося вище. Наприклад, прапор розділення може вказувати, чи розділяється листова CU на чотири одиниці перетворення. Потім кожну одиницю перетворення можна далі розділити на додаткові суб-TU. Коли TU більше не розділяється, вона може називатися листовою TU. Як правило, для внутрішнього кодування всі листові TU, що належать листовій CU, спільно використовують один і той же режим внутрішнього прогнозування. Тобто один і той же режим внутрішнього прогнозування застосовується, як правило, для обчислення прогнозованих значень для всіх TU в листовій CU. Для внутрішнього кодування відеокодер може обчислювати залишкове значення для кожної листової TU, використовуючи режим внутрішнього прогнозування, як різницю між частиною CU, відповідною TU, і вихідним блоком. TU не обов'язково обмежується розміром PU. Таким чином, TU можуть бути більше або менше PU. Для внутрішнього кодування PU може співвідноситися з відповідною листовою TU для однієї і тієї ж CU. У деяких прикладах максимальний розмір листової TU може відповідати розміру відповідної листової CU. Крім того, TU в листових CU також можуть асоціюватися з відповідними структурами даних квадродерева, званими залишковими квадродеревами (RQT). Тобто листова CU може включати в себе квадродерево, що вказує, як листова CU розбивається на TU. Кореневий вузол квадродерева TU, як правило, відповідає листовій CU, тоді як кореневий вузол квадродерева CU, як правило, відповідає блоку дерева (або LCU). TU в RQT, які не розділяються, називаються листовими TU. Взагалі, дане розкриття винаходу використовує терміни "CU" і "TU", щоб посилатися на листову CU і листову TU, відповідно, коли не вказане інше. Відеопослідовність, як правило, включає в себе послідовність відеокадрів або зображень. Група зображень (GOP), як правило, містить послідовність з одного або більше відеозображень. GOP може включати в себе синтаксичні дані в заголовку GOP, заголовку одного або більше зображень або де-небудь в іншому місці, які описують число зображень, включених в GOP. Кожний слайс зображення може включати в себе синтаксичні дані слайсу, які описують режим кодування для відповідного слайсу. Відеокодер 20 звичайно діє на відеоблоки в окремих слайсах відео, щоб кодувати відеодані. Відеоблок може відповідати вузлу кодування в CU. Відеоблоки можуть мати фіксовані або змінні розміри і можуть відрізнятися за розміром відповідно до точно визначеного стандарту кодування. Як приклад HM підтримує прогнозування в різних розмірах PU. Передбачаючи, що розмір конкретної CU дорівнює 2N×2N, HM підтримує внутрішнє прогнозування в розмірах PU 2N×2N або N×N і зовнішнє прогнозування в симетричних розмірах PU 2N×2N, 2N×N, N×2N або N×N. HM також підтримує асиметричне розбиття для зовнішнього прогнозування в розмірах PU 2N×nU, 2N×nD, nL×2N і nR×2N. При асиметричному розбитті один напрямок CU не розбивається, тоді як інший напрямок розбивається на 25 % і 75 %. Частина CU, відповідна розбиттю 25 %, вказується за допомогою "n" з подальшим указанням "Зверху", "Знизу", "Зліва" або "Справа". Таким чином, наприклад, "2N×nU" посилається на CU 2N×2N, яка розбивається горизонтально з PU 2N×0,5N зверху і PU 2N×1,5N знизу. У даному розкритті винаходу "N×N" і "N на N" можуть використовуватися взаємозамінно, щоб посилатися на розміри піксела відеоблока в показниках вертикального і горизонтального розмірів, наприклад 16×16 пікселів або 16 на 16 пікселів. Звичайно блок 16×16 буде мати 16 пікселів у вертикальному напрямку (у=16) і 16 пікселів в горизонтальному напрямку (х=16). Також блок N×N, як правило, має N пікселів у вертикальному напрямку і N пікселів в горизонтальному напрямку, де N представляє ненегативне ціле значення. Пікселі в блоці можуть розташовуватися в рядках і стовпцях. Крім того, блокам не обов'язково мати таке ж число пікселів в горизонтальному напрямку, як і у вертикальному напрямку. Наприклад, блоки можуть містити N×M пікселів, де M не обов'язково дорівнює N. Після кодування з внутрішнім прогнозуванням або зовнішнім прогнозуванням, що використовує PU в CU, відеокодер 20 може обчислити залишкові дані для TU в CU. PU можуть містити синтаксичні дані, що описують спосіб або режим формування даних піксела з прогнозуванням в просторовій області (також називаній областю пікселів), а TU можуть містити коефіцієнти в області перетворення після застосування перетворення, наприклад дискретного косинусного перетворення (DCT), цілочислового перетворення, вейвлет-перетворення або 7 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 концептуально схожого перетворення, до залишкових відеоданих. Залишкові дані можуть відповідати різницям пікселів між пікселами некодованого зображення і значеннями прогнозування, відповідними PU. Відеокодер 20 може утворити TU, що включають в себе залишкові дані для CU, а потім перетворити TU для створення коефіцієнтів перетворення для CU. Після будь-яких перетворень для створення коефіцієнтів перетворення відеокодер 20 може виконати квантування коефіцієнтів перетворення. Квантування загалом належить до процесу, в якому коефіцієнти перетворення квантуються, щоб зменшити по можливості об'єм даних, використовуваний для представлення коефіцієнтів, забезпечуючи додаткове стиснення. Процес квантування може зменшити бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Наприклад, n-бітове значення під час квантування можна округлити в меншу сторону до mбітового значення, де n більше m. Після квантування відеокодер може сканувати коефіцієнти перетворення, утворюючи одновимірний вектор з двовимірної матриці, що включає в себе квантовані коефіцієнти перетворення. Сканування може бути призначене для поміщення коефіцієнтів з більшою енергією (і тому з меншою частотою) попереду масиву і поміщення коефіцієнтів з меншою енергією (і тому більшою частотою) позаду масиву. У деяких прикладах відеокодер 20 може використовувати попередньо визначений порядок сканування, щоб сканувати квантовані коефіцієнти перетворення для створення серіалізованого вектора, який можна ентропійно кодувати. У інших прикладах відеокодер 20 може виконувати адаптивне сканування. Після сканування квантованих коефіцієнтів перетворення для утворення одновимірного вектора відеокодер 20 може ентропійно кодувати одновимірний вектор, наприклад, відповідно до контекстно-адаптивного кодування із змінною довжиною (CAVLC), контекстно-адаптивного двійкового арифметичного кодування (CABAC), синтаксичного контекстно-адаптивного двійкового арифметичного кодування (SBAC), ентропійного кодування з розбиттям на інтервали імовірності (PIPE) або іншої методології ентропійного кодування. Відеокодер 20 також може ентропійно кодувати синтаксичні елементи, асоційовані з кодованими відеоданими, для використання відеодекодером 30 при декодуванні відеоданих. Для виконання CABAC відеокодер 20 може призначити контекст в рамках контекстної моделі символу, який повинен бути переданий. Контекст може стосуватися, наприклад, того, чи є сусідні значення символу ненульовими. Для виконання CAVLC відеокодер 20 може вибрати код змінної довжини для символу, який повинен бути переданий. Кодові слова при VLC можуть бути побудовані так, що відносно більш короткі коди відповідають більш імовірним символам, тоді як більш довгі коди відповідають менш імовірним символам. Таким чином, за допомогою використання VLC може добитися економії бітів в порівнянні, наприклад, з використанням кодових слів рівної довжини для кожного символу, який повинен бути переданий. Визначення імовірності може основуватися на контексті, призначеному символу. Відповідно до методик з даного розкриття винаходу кодер відео, наприклад відеокодер 20 або відеодекодер 30, може конфігуруватися для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих і кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. Таблиці 2 і 5, детальніше описані нижче, включають в себе зразкові набори синтаксичних елементів в VPS. Кожний з одного або більше рівнів відеоданих може посилатися на VPS, тобто на один і той же VPS. Іншими словами, VPS може застосовуватися до всіх рівнів загального набору відеоданих, наприклад всіх рівнів SVC і/або всіх видів у відеоданих MVC. VPS може включати в себе різні категорії інформації. Наприклад, VPS може включати в себе опис лічильника вимірювань вибірок (SDCD). Тобто для кожного вимірювання кодер відео може сигналізувати набір індексів. Можливі вимірювання включають в себе cnt_p: число рівнів пріоритету, що містяться в кодованій відеопослідовності; cnt_d: скільки різних рівнів залежності в бітовому потоці, декілька рівнів з однаковими просторовим розрізненням і бітовою глибиною можуть належати різним рівням залежності; cnt_t: скільки часових рівнів в бітовому потоці; cnt_q: максимальне число рівнів якості для будь-якого рівня залежності в бітовому потоці; і cnt_v: максимальне число видів. Настройки бітової глибини можуть включати в себе 8-бітову або 12-бітову і можуть відрізнятися для різних складових кольору. Формати дискретизації кольоровості можуть включати в себе 4:0:0, 4:2:0 і 4:4:4. VPS також може включати в себе відображення індексу вибірки на характеристики. Якщо для кожного вимірювання покажчик характеристик не дорівнює індексу, що міняється від 0 до лічильника вимірювань вибірок мінус 1, то можна ввести цикл для точного визначення покажчика характеристик для кожного індексу характеристик. Відображення для кожного індексу залежності може включати в себе специфічне просторове розрізнення зі специфічним 8 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 значенням бітової глибини і специфічним форматом вибірки кольоровості. Зазначимо, що це можна було б пропустити, якби на декодері завжди була фіксована довідкова таблиця, наприклад 0 може відповідати 4:2:0, 1 може відповідати 4:4:4 і 2 може відповідати 4:0:0. Відображення додатково або альтернативно може включати в себе: для кожного часового індексу/id - специфічну частоту кадрів або середню частоту кадрів; для кожного індексу виду специфічний id виду; для кожного індексу бітової глибини - пару специфічних значень бітової глибини для яскравості і кольоровості; і для кожного формату дискретизації кольоровості специфічний покажчик формату дискретизації кольоровості. VPS також може включати в себе параметри керування і прапори дозволу/заборони інструментів, наприклад наступні: pcm_bit_depth_luma_minus1, pcm_bit_depth_chroma_minus1, loop_filter_across_slice_flag, pcm_loop_filter_disable_flag, temporal_id_nesting_flag, один або більше пов'язаних з фрагментом синтаксичних елементів, chroma_pred_from_luma_enabled_flag, sample_adaptive_offset_enabled_flag, adaptive_loop_filter_enabled_flag і inter_44_enabled_flag. VPS також може включати в себе один або більше описів робочих точок. Робочі точки, як правило, описують підмножину загального числа видів у відеоданих, включених в бітовий потік. Робоча точка може включати в себе конкретне число видів, намічених для виведення, а також інші види, які можуть використовуватися для посилання при декодуванні, виведенні або тому і іншому. Бітовий потік може включати в себе одну або більше робочих точок, описаних за допомогою описів робочих точок. Описи робочих точок можуть включати в себе інформацію, що задає число максимальних робочих точок, залежність між різними рівнями або видами, профіль і рівень для кожної робочої точки, бітрейт (частота проходження бітів) для кожної робочої точки, залежність між робочими точками для кожної робочої точки, інші обмеження для кожної робочої точки, інформації про застосовність відео (VUI) або частини VUI, і/або VUI або частини VUI для кожного рівня або виду. Додатково або альтернативно описи робочих точок можуть включати в себе для кожної робочої точки представлення одиниці рівня абстракції мережі (NAL) рівня кодування відео (VCL) робочої точки. У деяких прикладах представлення одиниці NAL VCL робочої точки може включати в себе три можливих вибори для кожного вимірювання: (1) специфічне значення індексу: наприклад, для просторового розрізнення - бітова глибина для формату дискретизації кольоровості; (2) діапазон значення індексу: наприклад, для часових рівнів - від 0 до id найвищого часового рівня, для рівнів якості - від 0 до id найвищого рівня якості; або (3) список значень індексу, наприклад, для видів - список значень індексів виду. У деяких прикладах VPS може включати в себе дані, що вказують максимальне число часових рівнів серед рівнів бітового потоку. Тобто відеокодер 20 і/або відеодекодер 30 можуть конфігуруватися для кодування VPS, що включає в себе дані, які вказують максимальне число часових рівнів для відповідного бітового потоку. Наприклад, відеокодер 20 може визначити максимальне число часових рівнів і кодувати VPS для включення в нього даних, що представляють визначене максимальне число часових рівнів, тоді як відеодекодер 30 може декодувати VPS для визначення максимального числа часових рівнів. Відеокодер 20 і відеодекодер 30 також можуть кодувати відеодані бітового потоку на основі визначеного максимального числа часових рівнів. Наприклад, максимальне число часових рівнів може впливати на число часових ідентифікаторів, які потрібні для представлення різних часових рівнів. Як інший приклад максимальне число часових рівнів може впливати на спосіб, яким відеокодер 20 і відеодекодер 30 кодують ідентифікатори опорних зображень, наприклад, з використанням значень лічильника послідовності зображення (POC). Як ще один приклад відеокодер 20 і відеодекодер 30 можуть конфігуруватися для кодування даних конкретного часового рівня з використанням тільки опорних даних аж до і включаючи той же часовий рівень. Іншими словами, відеокодер 20 і відеодекодер 30 можуть конфігуруватися, щоб уникати кодування даних конкретного часового рівня з використанням опорних даних більш високого часового рівня. Таким чином, відеодекодер 30 може бути впевнений в точному декодуванні відеоданих даного набору часових рівнів навіть після витягання бітового субпотоку. Тобто, якщо виконується витягання бітового субпотоку, то деякі часові рівні вище найвищого рівня витягнутого бітового субпотоку не будуть доступні для посилання. За допомогою кодування даних кожного часового рівня тільки з посиланням на дані рівнів на поточному рівні або нижче можна уникнути помилок, які в іншому випадку могли б відбутися внаслідок залежності даних на конкретному рівні від даних з більш високого рівня, який був би втрачений внаслідок витягання бітового субпотоку. У деяких прикладах VPS додатково або альтернативно включає в себе дані, що вказують будь-яке або обидва з числа зображень, які повинні бути переупорядковані на одному або більше рівнях бітового потоку, і/або числа зображень, які повинні бути збережені в буфер декодованих зображень (DPB). Як відмічалося вище, такі дані можуть називатися інформацією 9 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 про обмеження бітового потоку. Відповідно, пристрій-адресат 14 може визначити можливості відеодекодера 30 і використовувати інформацію про обмеження бітового потоку для визначення, чи придатний відповідний бітовий потік для декодування відеодекодером 30 або чи потрібно пристрою-адресату 14 вибрати альтернативний контент (наприклад, від постачальника мережевого контенту, передбачаючи, що доступно декілька версій контенту). Крім того, відеокодер 20 і відеодекодер 30 можуть використовувати інформацію про обмеження бітового потоку під час кодування відеоданих. Наприклад, відеокодер 20 може гарантувати, що інформація про обмеження бітового потоку не порушується. Тобто, передбачаючи, що інформація про обмеження бітового потоку вказує, що потрібно зберегти не більше N зображень в DPB, відеокодер 20 може гарантувати, що не більше N зображень включається в будь-яке поєднання одного або більше списків опорних зображень в будь-який момент часу. Як інший приклад, передбачаючи, що інформація про переупорядкування зображень вказує, що зображення потрібно зсунути не більше ніж на M зображень, відеокодер 20 може гарантувати, що ніяке зображення не зсувається більше ніж на M зображень. Зсув зображень цим способом звичайно відповідає різниці між порядком декодування і порядком відображення зображення. Відеодекодер 30 також може використовувати таку інформацію під час кодування, наприклад, для виконання керування DPB, наприклад очищення DPB. Відеокодер 20 і відеодекодер 30 також можуть використовувати інформацію про обмеження бітового потоку, наприклад максимальне число зображень, які повинні бути збережені в DPB, і/або число зображень, які повинні бути переупорядковані, при кодуванні значень ідентифікаторів опорних зображень. У деяких прикладах VPS додатково або альтернативно включає в себе дані, що вказують параметри гіпотетичного еталонного декодера (HRD). Параметри HRD включають в себе, наприклад, дані, що описують моменти, в які дані потрібно видалити з буфера кодованих зображень (CPB). У декодерах, наприклад відеодекодері 30, CPB являє собою буфер, в якому кодовані відеодані зберігаються доти, поки дані не будуть готові для декодування. Декодери, наприклад відеодекодер 30, також можуть включати в себе буфер декодованих зображень (DPB), в якому зберігаються декодовані відеодані, наприклад, для використання як опорних даних для прогнозованих зовнішньо даних і для переупорядкування зображень з порядку декодування в порядок відображення. Параметри HRD можуть включати в себе дані, що вказують, коли конкретні зображення потрібно видалити з CPB і декодувати. Таким чином, відеокодер 20 може кодувати параметри HRD у VPS для указання, коли зображення можна видалити з CPB і декодувати, тоді як відеодекодер 30 може декодувати параметри HRD у VPS для визначення, коли видаляти зображення з CPB. Також відеокодер 20 і відеодекодер 30 можуть кодувати зображення відповідно до параметрів HRD, наприклад, в порядку кодування, вказаному параметрами HRD. Таким чином, відеокодер 20 і/або відеодекодер 30 можуть конфігуруватися для кодування VPS, що включає в себе параметри HRD, і кодування відеоданих, відповідних VPS, основуючись щонайменше частково на параметрах HRD. VPS також може включати в себе дані розширення, що вказують, чи розширений VPS, наприклад, щоб надати дані для одного або більше додаткових інструментів кодування. Такі інструменти кодування можуть бути інструментами, які відрізняються від інструментів у відповідному стандарті кодування відео, наприклад H.264/AVC ITU-T або майбутньому стандарті HEVC. Крім того, такі інструменти кодування можуть вимагати конфігураційні дані. Ці конфігураційні дані можуть надаватися в даних розширення VPS. Таким чином, при кодуванні відеоданих з використанням таких інструментів кодування відеокодер 20 і/або відеодекодер 30 можуть кодувати VPS, що вказує, чи присутні дані розширення, і, якщо це так, дані розширення VPS. Крім того, коли присутні такі дані розширення, відеокодер 20 і/або відеодекодер 30 можуть використовувати відповідні інструменти кодування для кодування відеоданих з використанням даних розширення. Різні стандарти кодування відео задають відповідний синтаксис, семантику і процес декодування для безпомилкових бітових потоків, будь-який з яких відповідає деякому профілю або рівню. Стандарти кодування відео, як правило, точно не визначають кодер, але в задачу кодера входить гарантування того, що сформовані бітові потоки відповідають стандарту для декодера. Застосовно до стандартів кодування відео "профіль" відповідає підмножині алгоритмів, властивостей або інструментів і обмежень, які до них застосовуються. Як задано, наприклад, стандартом H.264, "профіль" є підмножиною всього синтаксису бітового потоку, який точно визначається стандартом H.264. "Рівень" відповідає обмеженням споживання ресурсів декодера, наприклад, запам'ятовуючого пристрою і обчислення декодера, які належать до розрізнення зображень, бітрейту і швидкості обробки блоків. Профіль можна сигналізувати за 10 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 допомогою значення profile_idc (покажчик профілю), тоді як рівень можна сигналізувати за допомогою значення level_idc (покажчик рівня). Відповідно до методик з даного розкриття винаходу інформація про профіль і рівень може точно визначатися в описах робочих точок, які обговорювалися вище. У деяких прикладах кожний рівень або вид в бітовому потоці посилається на набір параметрів відео (VPS), і набір параметрів багаторівневої послідовності (LPS) може бути активним для кожного рівня. LPS можна підтримувати якомога більш легковагим шляхом посилання на VPS при проектуванні. LPS може включати в себе будь-яку або всю обговорювану нижче інформацію. LPS може включати в себе указання вимірювання вибірки, яке для кожного вимірювання вказує індекс до кожного вимірювання. Наприклад, якщо в VPS індекс до просторового розрізнення 0 призначається просторовій характеристиці 320×240, а індекс до просторового розрізнення 1 призначається 640×480, і поточному рівню потрібно призначити розрізнення 640×480, то відеокодер 20 і/або відеодекодер 30 можуть кодувати синтаксичний елемент значенням 1 для поточного рівня. Тобто відеокодер 20 може сигналізувати значення 1 для синтаксичного елемента, щоб точно визначати розрізнення 640×480, тоді як відеодекодер 30 на основі значення 1 для синтаксичного елемента може визначити, що поточний рівень з синтаксичним елементом, що має значення 1, має розрізнення 640×480. LPS також може включати в себе параметри керування і прапори дозволу/заборони інструментів. Наприклад, параметри керування і прапори дозволу/заборони інструментів можуть включати в себе pcm_bit_depth_luma_minus1, pcm_bit_depth_chroma_minus1, loop_filter_across_slice_flag, pcm_loop_filter_disable_flag, один або більше пов'язаних з фрагментом синтаксичних елементів, chroma_pred_from_luma_enabled_flag, sample_adaptive_offset_enabled_flag, adaptive_loop_filter_enabled_flag і ієрархію одиниць кодування (CU). LPS може додатково включати в себе інформацію про інші типи наборів параметрів, застосовуваних до слайсу, групи слайсів, зображення або декількох зображень. Кожний з цих наборів параметрів може посилатися на специфічний набір параметрів зображення (PPS). Кодер відео, наприклад відеокодер 20 і відеодекодер 30, може конфігуруватися для підтвердження і/або визначення, що PPS не посилається на LPS або VPS. Таким чином, кодер відео може гарантувати, що кожний PPS бітового потоку не посилається на LPS або VPS. Синтаксичний аналіз PPS може бути незалежним. Коли PPS включає в себе один або більше таких же синтаксичних елементів, як і в VPS або LPS, синтаксичні елементи PPS можуть перезаписати елементи в VPS або LPS. Кодер відео може додатково конфігуруватися для кодування групувального набору параметрів (GPS), який групує всі набори параметрів. Кодер відео може кодувати множину різних груп в GPS, причому кожна має окремі ідентифікатори GPS (id). Кожна з груп в GPS може включати в себе різне поєднання наборів параметрів. Таким чином, заголовку слайсу потрібно включати в себе тільки посилання на відповідний id GPS і не потрібно включати в себе указання типу набору параметрів. Попередня заявка США з порядковим № 61/590702, подана 25 січня 2012 р., також описує методики, в яких групуються різні типи наборів параметрів, і тільки ID у RBSP групування набору параметрів детальніше сигналізується в заголовку слайсу. Як обговорювалося вище, кодер відео, наприклад відеокодер 20 або відеодекодер 30, може конфігуруватися для кодування набору параметрів відео і/або групувального набору параметрів. Приклади набору параметрів відео детальніше обговорюються відносно фіг. 5, тоді як приклади групувального набору параметрів детальніше обговорюються відносно фіг. 6. Відеокодер 20 додатково може відправляти відеодекодеру 30 синтаксичні дані, наприклад блокові синтаксичні дані, кадрові синтаксичні дані і основані на GOP синтаксичні дані, наприклад, в заголовку кадру, заголовку блока, заголовку слайсу або заголовку GOP. Синтаксичні дані GOP можуть описувати число кадрів у відповідній GOP, а синтаксичні дані кадру можуть вказувати режим кодування/прогнозування, використовуваний для кодування відповідного кадру. Відеокодер 20 і відеодекодер 30 можуть бути реалізовані у вигляді будь-якої з ряду придатних схем кодера або декодера у відповідних випадках, наприклад одного або більше мікропроцесорів, цифрових процесорів сигналів (DSP), спеціалізованих інтегральних схем (ASIC), програмованих користувачем вентильних матриць (FPGA), дискретних логічних схемам, програмного забезпечення, апаратних засобів, мікропрограмного забезпечення або будь-яких їх поєднань. Кожний з відеокодера 20 і відеодекодера 30 може включатися в один або більше кодерів або декодерів, будь-який з яких може вбудовуватися як частина об'єднаного відеокодера/декодера (кодека). Пристрій, що включає в себе відеокодер 20 і/або відеодекодер 11 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 30, може містити інтегральну схему, мікропроцесор і/або пристрій бездротового зв'язку, наприклад стільниковий телефон. Фіг. 2 - блок-схема, що ілюструє приклад відеокодера 20, який може реалізувати методики для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих. Відеокодер 20 може виконувати внутрішнє і зовнішнє кодування відеоблоків в слайсах відео. Внутрішнє кодування спирається на просторове прогнозування, щоб зменшити або усунути просторову надмірність у відео в даному відеокадрі або зображенні. Зовнішнє кодування спирається на часове прогнозування, щоб зменшити або усунути часову надмірність у відео в сусідніх кадрах або зображеннях відеопослідовності. Внутрішній режим (I-режим) може належати до будь-якого з декількох режимів просторового кодування. Зовнішні режими, наприклад однонаправлене прогнозування (Р-режим) або двонаправлене прогнозування (Врежим), можуть належати до будь-якого з декількох режимів часового кодування. Як показано на фіг. 2, відеокодер 20 приймає поточний відеоблок у відеокадрі, який повинен бути кодований. У прикладі з фіг. 2 відеокодер 20 включає в себе модуль 40 вибору режиму, запам'ятовуючий пристрій 64 опорних зображень, суматор 50, модуль 52 обробки перетворення, модуль 54 квантування і модуль 56 ентропійного кодування. Модуль 40 вибору режиму в свою чергу включає в себе модуль 44 компенсації руху, модуль 42 оцінки руху, модуль 46 внутрішнього прогнозування і модуль 48 розбиття. Для відновлення відеоблока відеокодер 20 також включає в себе модуль 58 зворотного квантування, модуль 60 зворотного перетворення і суматор 62. Також може включатися фільтр зменшення блоковості (не показаний на фіг. 2) для фільтрації границь блока, щоб видалити артефакти блоковості з відновленого відео. При бажанні фільтр зменшення блоковості звичайно фільтрував би виведення суматора 62. Також можуть використовуватися додаткові фільтри (в циклі або після циклу) на доповнення до фільтра зменшення блоковості. Такі фільтри скорочено не показані, але при бажанні можуть фільтрувати виведення суматора 50 (як фільтр в циклі). Під час процесу кодування відеокодер 20 приймає відеокадр або слайс, який повинен бути кодований. Кадр або слайс можна розділити на декілька відеоблоків. Модуль 42 оцінки руху і модуль 44 компенсації руху виконують кодування із зовнішнім прогнозуванням прийнятого відеоблока відносно одного або більше блоків в одному або більше опорних кадрах, щоб забезпечити часове прогнозування. Модуль 46 внутрішнього прогнозування альтернативно може виконувати кодування з внутрішнім прогнозуванням прийнятого відеоблока відносно одного або більше сусідніх блоків в тому ж кадрі або слайсі як блока, який повинен бути кодований, щоб забезпечити просторове прогнозування. Відеокодер 20 може виконувати декілька проходів кодування, наприклад, для вибору придатного режиму кодування для кожного блока відеоданих. Крім того, модуль 48 розбиття може розбити блоки відеоданих на субблоки на основі оцінки попередніх схем розбиття в попередніх проходах кодування. Наприклад, модуль 48 розбиття може спочатку розбити кадр або слайс на LCU і розбити кожну з LCU на суб-CU на основі аналізу спотворення залежно від швидкості передачі (наприклад, оптимізації спотворення залежно від швидкості передачі). Модуль 40 вибору режиму додатково може створити структуру даних квадродерева, що вказує розбиття LCU на суб-CU. CU листа в квадродереві можуть включати в себе одну або більше PU і одну або більше TU. Модуль 40 вибору режиму може вибрати один з режимів кодування, внутрішній або зовнішній, наприклад, на основі помилкових результатів і надає результуючий блок з внутрішнім або зовнішнім кодуванням суматору 50, щоб сформувати дані залишкового блока, і суматору 62, щоб відновити кодований блок для використання як опорного кадру. Модуль 40 вибору режиму також надає синтаксичні елементи, наприклад вектори руху, покажчики внутрішнього режиму, інформацію про розбиття і іншу таку синтаксичну інформацію, модулю 56 ентропійного кодування. Модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути спільно інтегровані, але ілюструються окремо з концептуальною метою. Оцінка руху, виконувана модулем 42 оцінки руху, є процесом формування векторів руху, які оцінюють руху для відеоблоків. Вектор руху може вказувати, наприклад, зміщення PU відеоблока в поточному відеокадрі або зображенні відносно блока з прогнозуванням в опорному кадрі (або іншій кодованій одиниці) відносно поточного блока, кодованого в поточному кадрі (або іншій кодованій одиниці). Блок з прогнозуванням є блоком, який визнаний точно співпадаючим з блоком, який повинен бути кодований, в показниках різниці пікселів, що може визначатися за допомогою суми абсолютних різниць (SAD), суми квадратів різниць (SSD) або інших показників різниці. У деяких прикладах відеокодер 20 може обчислювати значення для положень субцілого піксела в опорних зображеннях, збережених в запам'ятовуючому пристрої 64 опорних зображень. Наприклад, 12 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 відеокодер 20 може інтерполювати значення положень однієї чверті піксела, положень однієї восьмої піксела або інших положень дробового піксела в опорному зображенні. Тому модуль 42 оцінки руху може виконати пошук руху відносно положень повного піксела і положень дробового піксела і вивести вектор руху з точністю до дробового піксела. Модуль 42 оцінки руху обчислює вектор руху для PU відеоблока в слайсі із зовнішнім кодуванням шляхом порівняння положення PU з положенням блока з прогнозуванням в опорному зображенні. Опорне зображення може вибиратися з першого списку опорних зображень (Список 0) або другого списку опорних зображень (Список 1), кожний з яких ідентифікує одне або більше опорних зображень, збережених в запам'ятовуючому пристрої 64 опорних зображень. Модуль 42 оцінки руху відправляє обчислений вектор руху модулю 56 ентропійного кодування і модулю 44 компенсації руху. Компенсація руху, виконувана модулем 44 компенсації руху, може включати в себе вибірку або формування блока з прогнозуванням на основі вектора руху, визначеного модулем 42 оцінки руху. Знов в деяких прикладах модуль 42 оцінки руху і модуль 44 компенсації руху можуть бути об'єднані функціонально. Після прийому вектора руху для PU поточного відеоблока модуль 44 компенсації руху може знайти блок з прогнозуванням, на який вказує вектор руху, в одному зі списків опорних зображень. Суматор 50 утворює залишковий відеоблок шляхом віднімання значень пікселів блока з прогнозуванням із значень пікселів поточного кодованого відеоблока, утворюючи значення різниці пікселів, які обговорюються нижче. Звичайно модуль 42 оцінки руху виконує оцінку руху відносно компонентів яскравості, а модуль 44 компенсації руху використовує вектори руху, обчислені на основі компонентів яскравості, для компонентів кольоровості і компонентів яскравості. Модуль 40 вибору режиму також може формувати синтаксичні елементи, асоційовані з відеоблоками і слайсом відео, для використання відеодекодером 30 при декодуванні відеоблоків в слайсі відео. Модуль 46 внутрішнього прогнозування може внутрішньо прогнозувати поточний блок альтернативно зовнішньому прогнозуванню, виконуваному модулем 42 оцінки руху і модулем 44 компенсації руху, як описано вище. Зокрема, модуль 46 внутрішнього прогнозування може визначити режим внутрішнього прогнозування, щоб використовувати його для кодування поточного блока. У деяких прикладах модуль 46 внутрішнього прогнозування може кодувати поточний блок з використанням різних режимів внутрішнього прогнозування, наприклад, під час окремих проходів кодування, а модуль 46 внутрішнього прогнозування (або модуль 40 вибору режиму в деяких прикладах) може вибирати придатний режим внутрішнього прогнозування для використання з перевірених режимів. Наприклад, модуль 46 внутрішнього прогнозування може обчислити значення спотворення залежно від швидкості передачі, використовуючи аналіз спотворення залежно від швидкості передачі для різних перевірених режимів внутрішнього прогнозування, і вибрати режим внутрішнього прогнозування, що має найкращі характеристики спотворення залежно від швидкості передачі серед перевірених режимів. Аналіз спотворення залежно від швидкості передачі, як правило, визначає величину спотворення (або помилки) між кодованим блоком і вихідним, некодованим блоком, який кодувався для створення кодованого блока, а також бітрейт (тобто число бітів), використовуваний для створення кодованого блока. Модуль 46 внутрішнього прогнозування може обчислити відношення зі спотворень і швидкостей для різних кодованих блоків, щоб визначити, який режим внутрішнього прогнозування демонструє найкраще значення спотворення залежно від швидкості передачі для блока. Після вибору режиму внутрішнього прогнозування для блока модуль 46 внутрішнього прогнозування може надати модулю 56 ентропійного кодування інформацію, що вказує вибраний режим внутрішнього прогнозування для блока. Модуль 56 ентропійного кодування може кодувати інформацію, що вказує вибраний режим внутрішнього прогнозування. Відеокодер 20 може включити в переданий бітовий потік конфігураційний дані, які можуть включати в себе множину таблиць індексів режимів внутрішнього прогнозування і множину таблиць індексів змінених режимів внутрішнього прогнозування (також званих таблицями відображення кодових слів), визначення контекстів кодування для різних блоків і указання найбільш імовірного режиму внутрішнього прогнозування, таблиці індексів режимів внутрішнього прогнозування і таблиці індексів зміненого режиму внутрішнього прогнозування для використання для кожного з контекстів. Відеокодер 20 утворює залишковий відеоблок шляхом віднімання даних прогнозування від модуля 40 вибору режиму з вихідного кодованого відеоблока. Суматор 50 являє собою компонент або компоненти, які виконують цю операцію віднімання. Модуль 52 обробки перетворення застосовує до залишкового блока перетворення, наприклад дискретне косинусне перетворення (DCT) або концептуально схоже перетворення, створюючи відеоблок, що містить 13 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 значення залишкових коефіцієнтів перетворення. Модуль 52 обробки перетворення може виконувати і інші перетворення, які концептуально схожі з DCT. Також могли б використовуватися вейвлет-перетворення, цілочислові перетворення, перетворення піддіапазонів або інші типи перетворень. У будь-якому випадку модуль 52 обробки перетворення застосовує перетворення до залишкового блока, створюючи блок залишкових коефіцієнтів перетворення. Перетворення може перетворювати залишкову інформацію з області значень пікселів в область перетворення, наприклад частотну область. Модуль 52 обробки перетворення може відправити результуючі коефіцієнти перетворення модулю 54 квантування. Модуль 54 квантування квантує коефіцієнти перетворення для додаткового зменшення бітрейту. Процес квантування може зменшити бітову глибину, асоційовану з деякими або всіма коефіцієнтами. Міру квантування можна змінювати шляхом регулювання параметра квантування. У деяких прикладах модуль 54 квантування потім може виконати сканування матриці, що включає в себе квантовані коефіцієнти перетворення. Альтернативно сканування може виконати модуль 56 ентропійного кодування. Після квантування модуль 56 ентропійного кодування ентропійно кодує квантовані коефіцієнти перетворення. Наприклад, модуль 56 ентропійного кодування може виконувати контекстно-адаптивне кодування із змінною довжиною (CAVLC), контекстно-адаптивне двійкове арифметичне кодування (CABAC), синтаксичне контекстно-адаптивне двійкове арифметичне кодування (SBAC), ентропійне кодування з розбиттям на інтервали імовірності (PIPE) або іншу методику ентропійного кодування. У випадку контекстного ентропійного кодування контекст може основуватися на сусідніх блоках. Після ентропійного кодування за допомогою модуля 56 ентропійного кодування кодований бітовий потік може передаватися іншому пристрою (наприклад, відеодекодеру 30) або архівуватися для подальшої передачі або витягання. Модуль 58 зворотного квантування і модуль 60 зворотного перетворення застосовують зворотне квантування і зворотне перетворення відповідно, щоб відновити залишковий блок в області пікселів, наприклад, для подальшого використання як опорного блока. Модуль 44 компенсації руху може обчислити опорний блок шляхом додавання залишкового блока до блока з прогнозуванням в одному з кадрів в запам'ятовуючому пристрої 64 опорних зображень. Модуль 44 компенсації руху також може застосувати один або більше інтерполюючих фільтрів до відновленого залишкового блока, щоб обчислити значення субцілих пікселів для використання при оцінці руху. Суматор 62 додає відновлений залишковий блок до блока прогнозування з компенсованим рухом, створеного модулем 44 компенсації руху, щоб створити відновлений відеоблок для збереження в запам'ятовуючому пристрої 64 опорних зображень. Відновлений відеоблок може використовуватися модулем 42 оцінки руху і модулем 44 компенсації руху як опорний блок, щоб зовнішньо кодувати блок в подальшому відеокадрі. Відеокодер 20 може додатково конфігуруватися для кодування набору параметрів відео (VPS), набору параметрів рівня (LPS) і/або групувального набору параметрів відповідно до методик з даного розкриття винаходу, а також набору параметрів послідовності (SPS), набору параметрів зображення (PPS), набору параметрів адаптації (APS) або інших таких структур сигнальних даних. Конкретніше, модуль 56 ентропійного кодування може конфігуруватися для кодування будь-якої або всіх цих структур даних. У випадку, якщо параметри цих різних структур даних можуть впливати на продуктивність кодування, модуль 40 вибору режиму може вибрати придатні параметри і передати ці параметри модулю 56 ентропійного кодування для включення, наприклад, в VPS. Інші параметри, наприклад число часових рівнів, число зображень, які повинні бути переупорядковані, і число зображень, які повинні бути збережені в буфер декодованих зображень, можуть вибиратися користувачем, наприклад адміністратором. У інших прикладах деякі параметри, наприклад параметри HRD, можуть виникати протягом процесу кодування. Модуль 56 ентропійного кодування може кодувати VPS для включення будь-якого або всіх різних типів даних, описаних даним розкриттям винаходу. Відеокодер 20 також може кодувати дані відповідно до параметрів VPS. Конкретніше, відеокодер 20 може кодувати послідовності зображень з числа одного або більше рівнів відеоданих, яким відповідає VPS, відповідно до параметрів VPS. Таким чином, відеокодер 20 з фіг. 2 представляє приклад відеокодера, сконфігурованого для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. Кодування VPS, хоч загалом і описане відносно відеокодера, може виконуватися іншими пристроями, наприклад інформованим про середовище мережевим елементом (MANE). MANE може відповідати мережевому елементу між пристроєм-джерелом (наприклад, пристроєм 14 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 джерелом 12 з фіг. 1) і пристроєм-адресатом (наприклад, пристроєм-адресатом 14). MANE може конфігуруватися для кодування VPS відповідно до методик з даного розкриття винаходу. MANE може формувати VPS, використовуючи дані з іншими структурами даних, прийнятими MANE, наприклад набори параметрів послідовності. Фіг. 3 - блок-схема, що ілюструє приклад відеодекодера 30, який може реалізувати методики для кодування наборів параметрів і одиниць NAL для одного або більше рівнів відеоданих. У прикладі з фіг. 3 відеодекодер 30 включає в себе модуль 70 ентропійного декодування, модуль 72 компенсації руху, модуль 74 внутрішнього прогнозування, модуль 76 зворотного квантування, модуль 78 зворотного перетворення, запам'ятовуючий пристрій 82 опорних зображень і суматор 80. Запам'ятовуючий пристрій 82 опорних зображень також може називатися "буфером декодованих зображень" або DPB. Відеодекодер 30 в деяких прикладах може виконувати прохід декодування, загалом зворотний відносно проходу кодування, описаного відносно відеокодера 20 (фіг. 2). Модуль 72 компенсації руху може формувати дані прогнозування на основі векторів руху, прийнятих від модуля 70 ентропійного декодування, тоді як модуль 74 внутрішнього прогнозування може формувати дані прогнозування на основі покажчиків режиму внутрішнього прогнозування, прийнятих від модуля 70 ентропійного декодування. Під час процесу декодування відеодекодер 30 приймає від відеокодера 20 бітовий потік кодованого відео, який являє собою відеоблоки кодованого слайсу відео і асоційовані синтаксичні елементи. Модуль 70 ентропійного декодування у відеодекодері 30 ентропійно декодує бітовий потік, щоб сформувати квантовані коефіцієнти, вектори руху або покажчики режиму внутрішнього прогнозування і інші синтаксичні елементи. Модуль 70 ентропійного декодування перенаправляє вектори руху і інші синтаксичні елементи в модуль 72 компенсації руху. Відеодекодер 30 може прийняти синтаксичні елементи на рівні слайсу відео і/або рівні відеоблока. Коли слайс відео кодується у вигляді слайсу з внутрішнім кодуванням (I), модуль 74 внутрішнього прогнозування може сформувати дані прогнозування длявідеоблока поточного слайсу відео на основі сигналізованого режиму внутрішнього прогнозування і даних з раніше декодованих блоків поточного кадру або зображення. Коли відеокадр кодується у вигляді слайсу із зовнішнім кодуванням (тобто В, Р або GPB), модуль 72 компенсації руху створює блоки з прогнозуванням для відеоблока поточного слайсу відео на основі векторів руху і інших синтаксичних елементів, прийнятих від модуля 70 ентропійного декодування. Блоки з прогнозуванням можуть створюватися з одного з опорних зображень в одному зі списків опорних зображень. Відеодекодер 30 може побудувати списки опорних кадрів, Список 0 і Список 1, використовуючи методики побудови за замовченням на основі опорних зображень, збережених в запам'ятовуючому пристрої 82 опорних зображень. Модуль 72 компенсації руху визначає інформацію прогнозування для відеоблока поточного слайсу відео шляхом синтаксичного аналізу векторів руху і інших синтаксичних елементів і використовує інформацію прогнозування для створення блоків з прогнозуванням для поточного декодованого відеоблока. Наприклад, модуль 72 компенсації руху використовує деякі з прийнятих синтаксичних елементів для визначення режиму прогнозування (наприклад, внутрішнє або зовнішнє прогнозування), використовуваного для кодування відеоблоків в слайсі відео, типу слайсу зовнішнього прогнозування (наприклад, В-слайс, Р-слайс або GPB-слайс), інформації побудови для одного або більше списків опорних зображень для слайсу, векторів руху для кожного відеоблока із зовнішнім кодуванням в слайсі, стану зовнішнього прогнозування для кожного відеоблока із зовнішнім кодуванням в слайсі і іншої інформації для декодування відеоблоків в поточному слайсі відео. Модуль 72 компенсації руху також може виконати інтерполяцію на основі інтерполюючих фільтрів. Модуль 72 компенсації руху може використовувати інтерполюючі фільтри, які використовувалися відеокодером 20 під час кодування відеоблоків, щоб обчислити інтерпольовані значення для субцілих пікселів опорних блоків. У цьому випадку модуль 72 компенсації руху може визначити інтерполюючі фільтри, використовувані відеокодером 20, з прийнятих синтаксичних елементів і використовувати інтерполюючі фільтри для створення блоків з прогнозуванням. Модуль 76 зворотного квантування зворотно квантує, тобто деквантує, квантовані коефіцієнти перетворення, надані в бітовому потоці і декодовані модулем 80 ентропійного декодування. Процес зворотного квантування може включати в себе використання параметра QPY квантування, обчисленого відеодекодером 30 для кожного відеоблока в слайсі відео, щоб визначити міру квантування, а також міру зворотного квантування, що потрібно застосувати. Модуль 78 зворотного перетворення застосовує до коефіцієнтів перетворення зворотне 15 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 перетворення, наприклад зворотне DCT, зворотне цілочислове перетворення або концептуально схожий процес зворотного перетворення, щоб створити залишкові блоки в області пікселів. Після того, як модуль 72 компенсації руху сформує блок з прогнозуванням для поточного відеоблока на основі векторів руху і інших синтаксичних елементів, відеодекодер 30 утворює декодований відеоблок шляхом підсумовування залишкових блоків від модуля 78 зворотного перетворення з відповідними блоками з прогнозуванням, сформованими модулем 72 компенсації руху. Суматор 90 являє собою компонент або компоненти, які виконують цю операцію підсумовування. При бажанні також можна застосувати фільтр зменшення блоковості для фільтрації декодованих блоків, щоб видалити артефакти блоковості. Інші фільтри циклу (або в циклі кодування, або після циклу кодування) також можуть використовуватися для згладжування переходів пікселів або іншого підвищення якості відео. Декодовані відеоблоки в заданому кадрі або зображенні потім зберігаються в запам'ятовуючому пристрої 82 опорних зображень, який зберігає опорні зображення, використовувані для подальшої компенсації руху. Запам'ятовуючий пристрій 82 опорних зображень також зберігає декодоване відео для подальшого представлення на пристрої відображення, наприклад пристрої 32 відображення з фіг. 1. Відповідно до методик з даного розкриття винаходу відеодекодер 30 може декодувати набір параметрів відео (VPS), набір параметрів рівня (LPS) і/або групувальний набір параметрів відповідно до методик з даного розкриття винаходу, а також набір параметрів послідовності (SPS), набір параметрів зображення (PPS), набір параметрів адаптації (APS) або інші такі структури сигнальних даних. Конкретніше, модуль 70 ентропійного декодування може конфігуруватися для декодування будь-якої або всіх цих структур даних. Внаслідок декодування цих різних структур даних модуль 70 ентропійного декодування може визначити параметри, які повинні бути використані для декодування відповідних відеоданих. Наприклад, відеодекодер 30 може декодувати відповідні послідовності відеоданих одного або більше рівнів, використовуючи параметри декодованого VPS. Хоч і не показано на фіг. 3, відеодекодер 30 додатково може включати в себе буфер кодованих зображень (CPB). CPB звичайно надавався б перед модулем 70 ентропійного декодування. Як альтернатива CPB може сполучатися з модулем 70 ентропійного декодування для тимчасового зберігання або з виведенням модуля 70 ентропійного декодування для зберігання ентропійно декодованих даних, поки такі дані потрібно декодувати. Звичайно CPB зберігає кодовані відеодані, поки кодовані відеодані потрібно декодувати, наприклад, як указано параметрами HRD, які відеодекодер 30 може витягнути з декодованого VPS. Також інші елементи відеодекодера 30 можуть конфігуруватися для декодування відеоданих з використанням, наприклад, VPS. Наприклад, відеодекодер 30 може декодувати часові ідентифікатори для зображень різних часових рівнів, дані, що вказують число зображень, які повинні бути переупорядковані і/або збережені в запам'ятовуючому пристрої 82 опорних зображень (що представляє DPB). Крім того, відеодекодер 30 може включати в себе додаткові модулі обробки для обробки відеоданих відповідно до різних інструментів кодування, наданих розширеннями стандарту кодування відео. Альтернативно існуючі елементи відеодекодера 30, показані на фіг. 3, можуть конфігуруватися для використання інструментів кодування з таких розширень. Модуль 70 ентропійного декодування може конфігуруватися для декодування даних розширення VPS і надання таких даних розширення модулям, сконфігурованим для виконання інструментів кодування, наданих розширеннями. Таким чином, відеодекодер 30 з фіг. 3 представляє приклад відеодекодера, сконфігурованого для кодування набору параметрів відео (VPS) для одного або більше рівнів відеоданих, при цьому кожний з одного або більше рівнів відеоданих посилається на VPS, і кодування одного або більше рівнів відеоданих, основуючись щонайменше частково на VPS. Декодування VPS, хоч загалом і описане відносно відеодекодера, може виконуватися іншими пристроями, наприклад інформованим про середовище мережевим елементом (MANE). MANE може конфігуруватися для декодування VPS відповідно до методик з даного розкриття винаходу. MANE додатково може формувати дані інших наборів параметрів, наприклад один або більше наборів параметрів послідовності, використовуючи дані в VPS. Таким чином, MANE може передбачати зворотну сумісність з попередніми стандартами, наприклад H.264/AVC ITUT. Фіг. 4 - концептуальна схема, що ілюструє зразковий шаблон прогнозування MVC. Багатовидове кодування відео (MVC) є розширенням H.264/AVC ITU-T. Аналогічна методика може застосовуватися до HEVC. У прикладі з фіг. 4 ілюструється вісім видів (що мають ID видів 16 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 з "S0" по "S7"), і для кожного виду ілюструється дванадцять положень у часі (з "T0" по "T11"). Тобто кожний рядок на фіг. 4 відповідає виду, тоді як кожний стовпець вказує положення у часі. На фіг. 4 показана типова структура прогнозування MVC (що включає зовнішнє прогнозування зображення в кожному виді і міжвидове прогнозування) для багатовидового кодування відео, де прогнозування вказуються стрілками, причому вказуваний об'єкт використовує вказуючий об'єкт для посилання для прогнозування. У MVC міжвидове прогнозування спирається на компенсацію диспаратності/руху, яка може використовувати синтаксис компенсації руху H.264/AVC, але дозволяє використовувати зображення в іншому виді як опорне зображення. Кодування двох видів також могло б підтримуватися MVC, і одна з переваг MVC полягає в тому, що кодер MVC міг би приймати більше двох видів як вхід тривимірного відео, а декодер MVC міг би декодувати таке багатовидове представлення. Тому будь-який засіб візуалізації з декодером MVC може конфігуруватися для прийому тривимірного відеоконтенту більше ніж з двома видами. Хоч MVC має так званий основний вид, який є декодованим декодерами H.264/AVC, і стереопара також могла б підтримуватися MVC, одна перевага MVC полягає в тому, що воно могло б підтримувати приклад, який використовує більше двох видів як вхід тривимірного відео і декодує це тривимірне відео, представлене декількома видами. Засіб візуалізації клієнта, що має декодер MVC, може очікувати тривимірний відеоконтент з декількома видами. Типовий порядок декодування MVC називається кодуванням переважно за часом. Одиниця доступу може включати в себе кодовані зображення всіх видів для одного вихідного моменту часу. Наприклад, кожне із зображень моменту T0 може включатися в загальну одиницю доступу, кожне із зображень моменту T1 може включатися у другу, загальну одиницю доступу і так далі. Порядок декодування не обов'язково ідентичний порядку виведення або відображення. Кадри на фіг. 4 вказуються на перетині кожного рядка і кожного стовпця на фіг. 4, використовуючи заштрихований блок, що включає в себе букву, яка вказує, чи має відповідний кадр внутрішнє кодування (тобто I-кадр) або зовнішнє кодування в одному напрямку (тобто Ркадр) або в декількох напрямках (тобто В-кадр). Взагалі, прогнозування вказуються стрілками, де вказуваний кадр використовує вказуючий об'єкт для посилання для прогнозування. Наприклад, Р-кадр у виді S2 в положенні T0 у часі прогнозується з I-кадру у виді S0 в положенні T0 у часі. Як і у випадку кодування відео з одиночним видом кадри у відеопослідовності багатовидового кодування відео можуть кодуватися з прогнозуванням відносно кадрів в інших положеннях у часі. Наприклад, b-кадр у виді S0 в положенні T1 у часі має стрілку, що вказує на нього від I-кадру у виді S0 в положенні T0 у часі, вказуючи, що b-кадр прогнозується з I-кадру. Однак застосовно до багатовидового кодування відео кадри можуть прогнозуватися між видами. Тобто деякий компонент виду може використовувати компоненти виду в інших видах для посилання. У MVC, наприклад, міжвидове прогнозування реалізовується, як якби компонент виду в іншому виді був посиланням для зовнішнього прогнозування. Можливі міжвидові посилання сигналізуються в розширенні набору параметрів послідовності (SPS) MVC і можуть змінюватися процесом побудови списку опорних зображень, який дає можливість гнучкого упорядкування посилань для зовнішнього прогнозування або міжвидового прогнозування. У розширенні MVC в H.264/AVC як приклад міжвидове прогнозування спирається на компенсацію диспаратності/руху, яка використовує синтаксис компенсації руху H.264/AVC, але дозволяє використовувати зображення в іншому виді як опорне зображення. Кодування двох видів може підтримуватися MVC, що звичайно називається стереоскопічними видами. Одна з переваг MVC полягає в тому, що кодер MVC міг би приймати більше двох видів як вхід тривимірного відео, а декодер MVC міг би декодувати таке багатовидове представлення. Тому пристрій візуалізації з декодером MVC може очікувати тривимірний відеоконтент більше ніж з двома видами. У MVC міжвидове прогнозування (IVP) дозволене серед зображень в одній і тій же одиниці доступу (тобто з однаковим моментом часу). Одиниця доступу, як правило, є одиницею даних, що включає в себе всі компоненти виду (наприклад, всі одиниці NAL) для загального моменту часу. Таким чином, в MVC міжвидове прогнозування дозволене серед зображень в одній і тій же одиниці доступу. При кодуванні зображення в одному з неосновних видів зображення може додаватися в список опорних зображень, якщо воно знаходиться в іншому виді, але з таким же моментом часу (наприклад, таким же значенням POC і, відповідно, в тій же одиниці доступу). Опорне зображення міжвидового прогнозування можна помістити в будь-яке положення списку опорних зображень, як і будь-яке опорне зображення зовнішнього прогнозування. 17 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 60 Застосовно до багатовидового кодування відео існує два види векторів руху. Один є звичайними векторами руху, що вказують на часові опорні зображення, і відповідний режим зовнішнього прогнозування називається прогнозуванням з компенсованим рухом (MCP). Інший є векторами диспаратності/руху, що вказують на зображення в іншому виді, і відповідний режим міжвидового прогнозування називається прогнозуванням з компенсованою диспаратністю (DCP). У традиційному HEVC є два режими для прогнозування параметрів руху: один є режимом злиття, а інший є поліпшеним прогнозуванням вектора руху (AMVP). У режимі злиття будується список кандидатів в параметри руху (опорні зображення і вектори руху), де кандидат може бути з просторових або часових сусідніх блоків. Сусідні в просторі і у часі блоки можуть утворювати список кандидатів, тобто набір кандидатів, з якого може вибиратися інформація прогнозування руху. Відповідно, відеокодер 20 може кодувати параметри руху, вибрані як інформація прогнозування руху, шляхом кодуванняіндексу в списку кандидатів. Після того, як відеодекодер 30 декодував індекс, в режимі злиття можуть успадковуватися всі параметри руху відповідного блока, куди вказує індекс. У AMVP, відповідно і в традиційному HEVC, список кандидатів в предиктори векторів руху для кожної гіпотези руху виводиться на основі кодованого опорного індексу. Цей список включає в себе вектори руху сусідніх блоків, які асоціюються з однаковим опорним індексом, а також предиктор часового вектора руху, який виводиться на основі параметрів руху сусіднього блока в суміщеному блоці у часовому опорному зображенні. Вибрані вектори руху сигналізуються шляхом передачі індексу в списку кандидатів. До того ж значення опорного індексу і різниці векторів руху також сигналізуються. Фіг. 4 надає різні приклади міжвидового прогнозування. У прикладі з фіг. 4 кадри у виді S1 ілюструються як прогнозовані з кадрів в інших положеннях у часі у виді S1, а також прогнозовані між видами з кадрів у видах S0 і S2 в тих же положеннях у часі. Наприклад, b-кадр у виді S1 в положенні T1 у часі прогнозується з кожного з В-кадрів у виді S1 в положеннях T0 і T2 у часі, а також b-кадрів у видах S0 і S2 в положенні T1 у часі. У прикладі з фіг. 4 заголовна буква "B" і мала буква "b" призначені для указання різних ієрархічних взаємозв'язків між кадрами, а не різних методологій кодування. Взагалі, кадри з заголовною "B" знаходяться відносно вище по ієрархії прогнозування, ніж кадри з рядковою "b". Фіг. 4 також ілюструє зміни в ієрархії прогнозування, використовуючи різні рівні штриховки, де кадри з більшою величиною штриховки (тобто відносно більш темні) знаходяться вище по ієрархії прогнозування, ніж кадри, що мають менше штриховки (тобто відносно більш світлі). Наприклад, всі I-кадри на фіг. 4 ілюструються з повною штриховкою, тоді як Р-кадри мають частково більш світлу штриховку, а В-кадри (і b-кадри з малою буквою) мають різні рівні штриховки один відносно одного, але завжди світліше штриховки Р-кадрів і I-кадрів. Звичайно ієрархія прогнозування стосується індексів порядку видів в тому, що кадри відносно вище по ієрархії прогнозування потрібно декодувати перед декодуванням кадрів, які знаходяться відносно нижче по ієрархії, так що кадри відносно вище по ієрархії можуть використовуватися як опорні кадри під час декодування кадрів відносно нижче по ієрархії. Індекс порядку видів є індексом, який вказує порядок декодування компонентів виду в одиниці доступу. Індекси порядку видів маються на увазі в розширенні SPS MVC, яке точно визначене Додатком Н до H.264/AVC (поправка MVC). У SPS для кожного індексу i сигналізується відповідний view_id. У деяких прикладах декодування компонентів виду повинно додержуватися зростаючого порядку індексу порядку видів. Якщо представляються всі види, то індекси порядку видів знаходяться в послідовному порядку від 0 до num_views_minus_1. Таким чином, кадри, використовувані як опорні кадри, можуть декодуватися перед декодуванням кадрів, які кодуються з посиланням на опорні кадри. Індекс порядку видів є індексом, який вказує порядок декодування компонентів виду в одиниці доступу. Для кожного індексу i порядку видів сигналізується відповідний view_id. Декодування компонентів виду додержується зростаючого порядку індексів порядку видів. Якщо представляються всі види, то набір індексів порядку видів може містити послідовно впорядкований набір від нуля до повного числа видів, меншого на одиницю. Для деяких кадрів на рівних рівнях ієрархії порядок декодування один відносно одного може не мати значення. Наприклад, I-кадр у виді S0 в положенні T0 у часі використовується як опорний кадр для Р-кадру у виді S2 в положенні T0 у часі, який, в свою чергу, використовується як опорний кадр для Р-кадру у виді S4 в положенні T0 у часі. Відповідно, I-кадр у виді S0 в положенні T0 у часі потрібно декодувати перед Р-кадром у виді S2 в положенні T0 у часі, який потрібно декодувати перед Р-кадром у виді S4 в положенні T0 у часі. Однак між видами S1 і S3 порядок декодування не має значення, оскільки види S1 і S3 не спираються один на одного для 18 UA 113752 C2 5 10 15 20 25 прогнозування, а замість цього прогнозуються тільки з видів, які вище по ієрархії прогнозування. Крім того, вид S1 можна декодувати перед видом S4 при умові, що вид S1 декодується після видів S0 і S2. Таким чином, ієрархічне упорядкування може використовуватися для опису видів S0-S7. Нехай нотація SASB означає, що вид SA потрібно декодувати перед видом SB. Використовуючи цю нотацію, в прикладі з фіг. 4 S0S2S4S6S7. Також відносно прикладу фіг. 4 S0S1, S2S1, S2S3, S4S3, S4S5 і S6S5. Можливий будь-який порядок декодування для видів, який не порушує ці вимоги. Відповідно, можливі багато які різні порядки декодування, тільки з деякими обмеженнями. Відповідно до методик з даного розкриття винаходу кожний з видів S0-S7 може вважатися відповідним рівнем відповідного бітового потоку. Таким чином, VPS може описувати параметри бітового потоку, застосовні до будь-якого або всіх видів S0-S7, хоч окремі набори параметрів рівнів можуть надаватися для будь-якого або всіх видів S0-S7. До того ж групувальний набір параметрів може надаватися для групи наборів параметрів, так що слайси в окремих зображеннях у видах S0-S7 можуть просто посилатися на ідентифікатор групувального набору параметрів. Як показано на фіг. 4, компонент виду може використовувати компоненти виду в інших видах для посилання. Це називається міжвидовим прогнозуванням. У MVC міжвидове прогнозування реалізовується, як якби компонент виду в іншому виді був посиланням для зовнішнього прогнозування. Відеокодер 20 і відеодекодер 30 можуть кодувати можливі міжвидові посилання в розширенні набору параметрів послідовності (SPS) MVC (як показано в прикладі Таблиці 1). Відеокодер 20 і відеодекодер 30 додатково можуть змінювати можливі міжвидові посилання шляхом виконання процесу побудови списку опорних зображень, який може зробити можливим гнучке упорядкування посилань для зовнішнього прогнозування або міжвидового прогнозування. 19 UA 113752 C2 Таблиця 1 5 10 У розширенні SPS MVC, показаному в Таблиці 1, для кожного виду сигналізується число видів, яке може використовуватися для утворення Списку 0 опорних зображень і Списку 1 опорних зображень. Взаємозв'язок прогнозування для опорного зображення, яке сигналізується в розширенні SPS MVC, може відрізнятися від взаємозв'язку прогнозування для неопорного зображення (сигналізованого в розширенні SPS MVC) в тому ж виді. Стандарти кодування відео включають в себе H.261 ITU-T, MPEG-1 Visual ISO/IEC, H.262 ITU-T або MPEG-2 Visual ISO/IEC, H.263 ITU-T, MPEG-4 Visual ISO/IEC і H.264 ITU-T (також відомий як MPEG-4 AVC ISO/IEC), включаючи його розширення Масштабованого кодування відео (SVC) і Багатовидового кодування відео (MVC). 20 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 До того ж є новий стандарт кодування відео, а саме Високоефективне кодування відео (HEVC), розроблюваний Об'єднаною командою по кодуванню відео (JCT-VC) з Експертної групи в галузі кодування відео (VCEG) ITU-T і Експертної групи по рухомих зображеннях (MPEG) ISO/IEC. Останній робочий варіант (WD) HEVC, в подальшому званий WD4 HEVC, доступний за адресою http://phenix.int-evry.fr/jct/doc_end_user/documents/6_Torino/wg11/JCTVC-F803-v3.zip, позначений як WD4d1 HEVC. Механізм набору параметрів послідовності і зображення відділяє передачу інформації, що нечасто змінюється, від передачі даних кодованого блока. Набори параметрів послідовності і зображення в деяких застосуваннях можуть передаватися "поза смугою", використовуючи надійний транспортний механізм. Корисне навантаження необробленої послідовності байтів (RBSP) набору параметрів зображення може включати в себе параметри, на які можуть посилатися одиниці рівня абстракції мережі (NAL) кодованого слайсу в одному або більше кодованих зображеннях. RBSP набору параметрів послідовності може включати в себе параметри, на які можуть посилатися одне або більше RBSP набору параметрів зображення або одна або більше одиниць NAL додаткової інформації розширення (SEI), що містять повідомлення SEI про період буферизації. RBSP набору параметрів послідовності може включати в себе параметри, на які можуть посилатися одне або більше RBSP набору параметрів зображення або одна або більше одиниць NAL SEI, що містять повідомлення SEI про період буферизації. Набір параметрів послідовності може включати в себе необов'язковий набір параметрів, називаний інформацією про застосовність відео (VUI). VUI може включати в себе наступні три категорії необов'язкової інформації: інформація про представлення відео, інформація про гіпотетичний еталонний декодер (HRD) і інформація про обмеження бітового потоку. Інформація про представлення відео включає в себе співвідношення сторін, пов'язану з перетворенням колірного простору інформацію, фазові зсуви кольоровості відносно яскравості і частоту кадрів. HRD включає в себе параметри буферизації відео для кодованих відеопослідовностей. Інформація про обмеження бітового потоку включає в себе обмеження по діапазону векторів руху, розміру буфера декодованих зображень (DPB), числу переупорядковуваних кадрів і кодованих розмірах блоків (наприклад, макроблоків або одиниць кодування (CU)) і зображень. WD5 HEVC включає в себе підтримання набору параметрів адаптації (APS). Поняття набору параметрів адаптації (APS) також можна знайти в JCTVC-F747, доступному за адресою http://phenix.int-evry.fr/jct/doc_end_user/documents/6_Torino/wg11/JCTVC-F747-v4.zip. Уніфікований заголовок одиниці NAL може використовуватися для немасштабованих бітових потоків HEVC, а також для масштабованих бітових потоків, відповідних можливим масштабованим або багатовидовим розширенням HEVC. Уніфікований заголовок одиниці NAL може відрізнятися від діючого заголовка одиниці NAL HEVC в наступних особливостях: може мати місце фіксована довжина заголовка одиниці NAL для однієї повністю кодованої відеопослідовності, тоді як довжина може мінятися між різними кодованими відеопослідовностями, і ефективне кодування синтаксичних елементів масштабованості в заголовку одиниці NAL, і коли конкретний синтаксичний елемент не потрібен, йому не потрібно бути присутнім. При такому виконанні різний тип одиниці NAL або набір параметрів може використовуватися для усього бітового потоку. Фіг. 5 - концептуальна схема, що ілюструє набір параметрів відео (VPS) і різні набори параметрів рівнів (LPS). Три крапки після другого LPS на фіг. 5 призначені для указання, що може мати місце будь-яке число N VPS, де N - ціле число. Наприклад, кожний рівень (наприклад, кожний рівень SVC або кожний вид MVC) може мати відповідний LPS. Кодер відео, наприклад відеокодер 20 або відеодекодер 30, може конфігуруватися для кодування VPS і одного або більше LPS, наприклад, проілюстрованих на фіг. 5. Нижче Таблиця 2 надає зразковий синтаксис корисного навантаження необробленої послідовності байтів (RBPS) для VPS. 21 UA 113752 C2 Таблиця 2 5 Кодери відео можуть конфігуруватися так, що кодована відеопослідовність (наприклад, бітовий потік, що включає в себе один або більше рівнів) може мати тільки один активний набір параметрів відео (VPS). VPS можна помістити в одиницю NAL конкретного типу. Наприклад, 22 UA 113752 C2 5 10 15 20 25 30 35 40 45 50 55 nal_unit_type для RBSP VPS може дорівнювати 10. Зразкова семантика для VPS з Таблиці 2 описується нижче. У цьому прикладі video_para_set_id ідентифікує відповідний набір параметрів відео (VPS). У цьому прикладі cnt_p точно визначає максимальне число значень priority_id, присутніх у відповідній кодованій відеопослідовності. У цьому прикладі cnt_d точно визначає максимальне число рівнів залежності, присутніх у відповідній кодованій відеопослідовності. Декілька видів з однаковим розрізненням можуть вважатися такими, що належать до одного рівня залежності. Два рівні залежності можуть мати однакове просторове розрізнення. У цьому прикладі cnt_t точно визначає максимальне число часових рівнів, присутніх в кодованій відеопослідовності. У цьому прикладі cnt_q точно визначає максимальне число рівнів якості, присутніх на деякому рівні залежності в кодованій відеопослідовності. У цьому прикладі cnt_v точно визначає максимальне число видів, присутніх в кодованій відеопослідовності. У цьому прикладі cnt_f точно визначає число бітів, використовуване для представлення синтаксичного елемента reserved_flags в заголовку одиниці NAL. У цьому прикладі pic_width_in_luma_samples[i] і pic_height_in_luma_samples[i] точно визначають відповідно ширину і висоту розрізнення i-го рівня залежності в одиницях вибірок яскравості. У цьому прикладі bit_depth_luma_minus8[i] плюс 8 і bit_depth_chroma_minus8[i] плюс 8 точно визначають бітову глибину компонентів яскравості і кольоровості у i-го представлення бітової глибини. У цьому прикладі chroma_format_idc[i] точно визначає формат вибірки кольоровості у i-го представлення формату вибірки кольоровості. Наприклад, значення, що дорівнює 0, може вказувати 4:2:0; значення, що дорівнює 1, може вказувати 4:4:4, значення, що дорівнює 2, може вказувати 4:2:2, і значення, що дорівнює 3, може вказувати 4:0:0. У цьому прикладі average_frame_rate[i] точно визначає середню частоту кадрів у i-го представлення часового рівня в одиницях кадрів в 256 секунд. У цьому прикладі view_id[i] точно визначає ідентифікатор виду у i-го виду, який має індекс порядку видів, що дорівнює i. Коли відсутній, значення view_id[0] можна передбачити рівним 0. vps_extension_flag, що дорівнює 0, точно визначає, що ніякі синтаксичні елементи vps_extension_data_flag не присутні в структурі синтаксису RBSP набору параметрів відео. vps_extension_flag може дорівнювати 0 в бітових потоках, відповідних майбутньому стандарту HEVC. Значення 1 для vps_extension_flag може бути зарезервоване, наприклад, для майбутнього використання ITU-T|ISO/IEC. Декодери, наприклад відеодекодер 30, можуть ігнорувати всі дані, які ідуть за значенням 1 для vps_extension_flag в одиниці NAL набору параметрів відео. У цьому прикладі vps_extension_data_flag може мати будь-яке значення. Це не впливає на відповідність профілям, точно визначеним в майбутньому стандарті HEVC, а передбачає подальший розвиток майбутнього стандарту. Інші синтаксичні елементи в VPS можуть мати таку ж семантику, як і синтаксичні елементи з такими ж назвами в SPS поточного робочого варіанта HEVC. Ці синтаксичні елементи можуть застосовуватися до кодованої відеопослідовності, яка посилається на цей VPS, поки не перезаписані наборами параметрів більш низького рівня. У деяких прикладах в VPS може додатково сигналізуватися 3DV_flag для указання, чи присутня глибина в кодованій відеопослідовності. У деяких прикладах параметри VUI сигналізуються в LPS. У деяких прикладах синтаксичні елементи cnt_p, cnt_t, cnt_d, cnt_q і cnt_v точно визначають числа бітів, використовувані для кодування priority_id, temporal_id, dependency_id, quality_id і view_idx, відповідно, і максимальні числа значень priority_id, часових рівнів, рівнів залежності, рівнів якості і видів, присутніх в кодованих відеопослідовностях, також можуть сигналізуватися в VPS. У деяких прикладах можна ввести інший тип одиниці NAL, щоб він містив синтаксичні елементи cnt_p, cnt_t, cnt_d, cnt_q, cnt_v і cnt_f. Цей новий тип одиниці NAL також може включати в себе ідентифікатор (ID), і на цей ID можуть посилатися в VPS. У деяких прикладах синтаксичні елементи від log2_max_pic_order_cnt_lsb_minus4 до inter_4×4_enabled_flag в Таблиці 2 не сигналізуються в VPS, а замість цього відеокодер 20 і відеодекодер 30 можуть кодувати ці синтаксичні елементи в LPS. 23 UA 113752 C2 5 10 15 20 25 30 35 40 У деяких прикладах структура синтаксису operation_point_desription() з Таблиці 2 не включається в VPS; замість цього відеокодер 20 і відеодекодер 30 або інші елементи (наприклад, інтерфейс 22 виведення і/або інтерфейс 28 введення) можуть кодувати контент в структурі синтаксису operation_point_desription() в повідомленні з додатковою інформацією розширення (SEI). У деяких прикладах відеокодер 20 і/або відеодекодер 30 можуть кодувати параметри інформації про застосовність відео (VUI) в VPS. Наприклад, VPS може включати в себе дані, що точно визначають інформацію про обмеження бітового потоку, наприклад обмеження по діапазону векторів руху, розміру DPB, числу переупорядковуваних кадрів і кодованих розмірах блоків (наприклад, макроблоків або CU) і зображень. Таким чином, VPS може точно визначати інформацію, що вказує необхідний розмір DPB, щоб відеодекодер (наприклад, відеодекодер 30) належно декодував відповідний бітовий потік, тобто бітовий потік, що включає в себе VPS. Також VPS може точно визначати інформацію про переупорядковування зображень, тобто число зображень, яке може передувати даному зображенню в порядку декодування і яке іде за даним зображенням в порядку виведення (тобто порядку відображення). Додатково або альтернативно VPS може включати в себе дані, що точно визначають інформацію про гіпотетичний еталонний декодер (HRD). Як відмічалося вище, відеокодер 20 і/або відеодекодер 30 можуть кодувати (тобто сигналізувати) в VPS параметри VUI, які можуть включати в себе інформацію про HRD. Таким чином, VPS може включати в себе дані, які описують, наприклад, робочі точки відповідного бітового потоку. Наприклад, VPS може включати в себе дані, які описують одне або більше з числа максимальних робочих точок, залежності між різними рівнями або видами, інформації про профіль і рівень для кожної робочої точки, представлення одиниці NAL VCL робочої точки для кожної робочої точки, бітрейту для кожної робочої точки, залежності між робочими точками, обмежень для кожної робочої точки, VUI або часткової VUI для кожної робочої точки і/або VUI або часткової VUI для кожного рівня або виду. VPS також може включати в себе для кожного вимірювання: специфічне значення індексу, діапазон значень індексу або список значень індексу. Наприклад, коли VPS включає в себе дані, які описують специфічне значення індексу, значення індексу може, для просторового розрізнення, відповідати бітовій глибині для формату дискретизації кольоровості. Як інший приклад, коли VPS включає в себе діапазон значень індексу, для часових рівнів цей діапазон може містити від нуля (0) до ID найвищого часового рівня, а для рівнів якості діапазон може містити від нуля (0) до ID найвищого рівня якості. Як ще один приклад, коли VPS включає в себе дані, які описують список значень індексу, цей список може містити список значень індексів виду для декількох видів. У деяких прикладах відеокодер 20 може кодувати (тобто сигналізувати), а відеодекодер може декодувати один або більше параметрів формату представлення (ширина, висота, бітова глибина і т. п.), і можуть мати місце різні набори параметрів формату представлення. Рівень або робоча точка тоді можуть посилатися на індекс такого набору параметрів формату представлення. Приклад проекту синтаксису для такого набору показаний в Таблиці 3 нижче. Таблиця 3 24 UA 113752 C2 У деяких прикладах замість цього може сигналізуватися ref_format_idx в наборі параметрів рівня. Нижче Таблиця 4 надає зразковий синтаксис для описів робочих точок. 5 Таблиця 4 10 15 Приклади семантики для синтаксичних елементів з Таблиці 4 обговорюються нижче. У цьому прикладі num_operation_point_minus1 плюс 1 точно визначає максимальне число робочих точок, які присутні в кодованій відеопослідовності і для яких інформація про робочі Дескриптор точки сигналізується наступними синтаксичними елементами. У цьому прикладі op_profile_level_idc[i], operation_point_id[i], priority_id[i], num_target_output_views_minus1[i], frm_rate_info_present_flag[i], avg_bitrate[i], max_bitrate[i], max_bitrate_calc_window[i], constant_frm_rate_idc[i] і num_directly_dependent_views[i] можуть мати таку ж семантику, як і синтаксичні елементи з такими ж назвами в повідомленні SEI з інформацією про масштабованість виду з H.264. 25 UA 113752 C2 5 10 15 20 У цьому прикладі quality_id[i] і dependency_id[i] можуть мати таку ж семантику, як і синтаксичні елементи з такими ж назвами в повідомленні SEI з інформацією про масштабованість з H.264. У цьому прикладі directly_dependent_view_idx[i][j] точно визначає індекс виду у j-го виду, від якого безпосередньо залежить цільовий вихідний вид поточної робочої точки в рамках представлення поточної робочої точки. У цьому прикладі num_ref_views[i] точно визначає число компонентів виду для міжвидового прогнозування в початковому списку RefPicList0 і RefPicList1 опорних зображень при декодуванні компонентів виду з індексом порядку видів, що дорівнює i. В цьому прикладі значення num_ref_views[i] не повинно бути більше Min(15, num_views_minus1). У деяких прикладах значення num_ref_views[0] дорівнює 0. У цьому прикладі ref_view_idx[i][j] точно визначає індекс порядку видів у j-го компонента виду для міжвидового прогнозування в початковому списку RefPicList0 і RefPicList1 опорних зображень при декодуванні компонента виду з індексом порядку видів, що дорівнює i. В цьому прикладі значення ref_view_idx[i][j] повинно бути в діапазоні від 0 до 31, включно. У деяких прикладах як альтернатива деякі з синтаксичних елементів в повідомленні SEI з інформацією про масштабованість (наприклад, яке описане в H.264), наприклад синтаксичні елементи, пов'язані з інформацією про залежність рівнів, можуть включатися в структуру синтаксису operation_points_description() з Таблиці 4. У деяких прикладах відеокодер 20 і/або відеодекодер 30 можуть кодувати (тобто сигналізувати) деякі параметри VUI в структурі синтаксису operation_points_description() з Таблиці 4. Нижче Таблиця 5 надає альтернативний синтаксис для набору параметрів відео. 26 UA 113752 C2 Таблиця 5 27 UA 113752 C2 5 10 15 Приклади семантики для синтаксису набору параметрів відео з Таблиці 5 обговорюються нижче. Взагалі, аналогічно названі синтаксичні елементи, які не обговорюються нижче, можуть мати таку ж семантику, як обговорювалася вище відносно Таблиці 2. Семантика для інших синтаксичних елементів може бути наступною. У цьому прикладі bit_equal_to_one дорівнює 1 (тобто значенню двійкової "1"). У цьому прикладі extention_type, що дорівнює 0, вказує, що декілька рівнів виду може бути присутньо в бітовому потоці. У цьому прикладі extension_type, що дорівнює 1, точно визначає, що декілька рівнів залежності і/або якості може бути присутньо в бітовому потоці. У цьому прикладі num_rep_formats_minus1 плюс 1 точно визначає максимальне число різних наборів форматів представлення, підтримуваних цим набором параметрів відео, причому формат представлення включає в себе бітову глибину і формат кольоровості (тобто набори із значень bit_depth_luma_minus8, bit_depth_chroma_minus8 і chroma_format_idc), розрізнення зображення і інформацію про вікно обрізання в кодованій відеопослідовності. Значення num_rep_formats_minus1 може бути в діапазоні від 0 до X, включно. Відеокодер 20 і 28
ДивитисяДодаткова інформація
Автори англійськоюChen, Ying, Wang, Ye-Kui
Автори російськоюЧень Ин, Ван Е-Куй
МПК / Мітки
МПК: H04N 19/31, H04N 19/46, H04N 19/70
Мітки: кодування, одиниць, заголовків, наборів, параметрів, відео
Код посилання
<a href="https://ua.patents.su/64-113752-koduvannya-naboriv-parametriv-i-zagolovkiv-odinic-nal-dlya-koduvannya-video.html" target="_blank" rel="follow" title="База патентів України">Кодування наборів параметрів і заголовків одиниць nal для кодування відео</a>
Кодування одиниць nal sei для кодування відео

Номер патенту: 113446
Опубліковано: 25.01.2017
Автор: Ван Є-Куй
МПК: H04N 7/00
Мітки: кодування, одиниць, відео
Формула / Реферат:
1. Спосіб декодування даних відео, причому спосіб містить:визначення, для одиниці рівня абстракції мережі (NAL) додаткової інформації розширення (SEI) потоку бітів, чи вказує значення типу одиниці NAL для одиниці NAL SEI, що одиниця NAL містить одиницю NAL SEI префікса, яка включає в себе повідомлення SEI префікса, або одиницю NAL SEI суфікса, яка включає в себе повідомлення SEI суфікса; ідекодування даних відео потоку бітів...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 106704
Опубліковано: 25.09.2014
Автори: Джоши Раджан Лаксман, Соле Рохальс Хоель, Карчевіч Марта
МПК: H04N 19/00
Мітки: коефіцієнтів, перетворення, кодування, відео
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео, в процесі кодування відео, причому спосіб включає:компонування блока коефіцієнтів перетворення в один або більше піднаборів коефіцієнтів перетворення на основі порядку сканування;кодування першої частини рівнів коефіцієнтів перетворення в кожному піднаборі, причому перша частина рівнів включає в себе щонайменше значущість коефіцієнтів...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 109479
Опубліковано: 25.08.2015
Автори: Джоши Раджан Лаксман, Соле Рохальс Хоель, Карчевіч Марта
МПК: H04N 19/91, H04N 19/463, H04N 19/18, H04N 19/134, H04N 19/167, H04N 7/00, H04N 19/70
Мітки: коефіцієнтів, кодування, перетворення, відео
Формула / Реферат:
1. Спосіб кодування коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, причому спосіб включає:кодування інформації, що вказує значущі коефіцієнти перетворення в блоці коефіцієнтів перетворення зі скануванням, що здійснюється в зворотному напрямку сканування від коефіцієнтів більш високої частоти в згаданому блоці коефіцієнтів перетворення до коефіцієнтів більш низької частоти в згаданому...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 107157
Опубліковано: 25.11.2014
Автори: Карчевіч Марта, Соле Рохальс Хоель, Джоши Раджан Лаксман
МПК: H04N 19/00
Мітки: відео, кодування, коефіцієнтів, перетворення
Формула / Реферат:
1. Спосіб кодування множини коефіцієнтів перетворення, асоційованих із залишковими відеоданими в процесі кодування відео, причому спосіб включає:кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення згідно з порядком сканування; ікодування інформації, що вказує рівні значущих коефіцієнтів множини коефіцієнтів перетворення згідно із згаданим порядком сканування,причому згаданий порядок...
Кодування коефіцієнтів перетворення для кодування відео

Номер патенту: 109573
Опубліковано: 10.09.2015
Автори: Джоши Раджан Лаксман, Соле Рохальс Хоель, Карчевіч Марта
МПК: H04N 7/00, H04N 19/129, H04N 19/167, H04N 19/136, H04N 7/52, H04N 7/20
Мітки: перетворення, кодування, коефіцієнтів, відео
Формула / Реферат:
1. Спосіб кодування множини коефіцієнтів перетворення, асоційованих із залишковими даними відео в процесі кодування відео, причому спосіб містить:кодування інформації, що вказує значущі коефіцієнти для множини коефіцієнтів перетворення згідно з порядком сканування;розподіл закодованої інформації на щонайменше першу ділянку і другу ділянку, причому перша ділянка містить щонайменше DC- коефіцієнт з множини коефіцієнтів...
Попередній патент: Спосіб і пристрій для відновлення залізооксидовмісних сировинних матеріалів
Наступний патент: Фенілзаміщені кетоеноли для боротьби з паразитами риб
Випадковий патент: Пристрій для контролю цілісності відривних закупорювальних пристроїв