Спосіб узагальненого розміщення даних з урахуванням модифікаційності структури сховища







Формула / Реферат
1. Спосіб узагальненого розміщення даних із забезпеченням модифікаційності структури сховища, який полягає в тому, що розміщувані дані розподіляють на групи, що кожна сутність, яка об'єднує кожну таку групу, має спільний набір параметрів, що відповідають спільному предикату, а групи сутностей перебувають між собою у рівноправних або в ієрархічних відносинах, у сховищі формують систему реляційних таблиць і заповнюють їх відповідними даними, який відрізняється тим, що при розміщенні даних, які належать певній предметній області, спочатку враховують всі можливі часткові копії сутностей, утворюючи маски сутностей, а вже після цього моделюють всі зв'язки між групами цих масок сутностей у довільній предметній області, для чого кожній групі масок відводять у сховищі декілька ділянок пам'яті для розміщення елементів зберігання, тобто резервують в кожній ділянці пам'яті домен-маску з відповідним сурогатним ідентифікаційним ключем, створюючи таким чином універсальну множину ділянок пам'яті, так, що кількість доменів-масок, що там розміщують, дорівнює кількості масок кожної сутності, причому домени-маски призначають маскам всіх сутностей, навіть і маскам тих сутностей, які мають ієрархічну залежність від своїх інформаційних предків, тобто слабких сутностей, чим позбуваються цієї слабкості, причому, оскільки у загальному випадку слабкі сутності залежать від ланцюга сутностей, де кожна сутність-ланка в свою чергу є також слабкою, виключаючи лише найвищу сутність в цьому ланцюжку, домени-маски призначають так, ніби цієї залежності не існує, тобто ігнорують ієрархічну залежність, при цьому такі зв'язки не будуть втрачені, оскільки алгоритм способу враховує всі типи зв'язків між доменами-масками, а значить і початкових ієрархічних зв'язків між сутностями.
2. Спосіб за пунктом 1, який відрізняється тим, що структуру сховища будують в цифровій пам'яті у відповідності до декартового перемноження всіх доменів-масок між собою за принципом "всі на всі", при цьому загальна кількість S(t) таких таблиць, з урахуванням множини доменів-масок кожної сутності та залежності цього параметра від номера проміжку часу, визначається виразом:
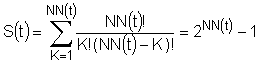 ,
,
де K - поточна арність зв'язків груп доменів-масок, a NN(t) - загальне число доменів-масок, що залежить від t - номера проміжку часу актуальності структури сховища, протягом якого ця структура не зазнає модифікації, а загальна кількість доменів-масок визначається формулою:
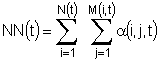 ,
,
де, в свою чергу, α(i,j,t) - ознака актуальності домену-маски, формальний масив цілих чисел, кожне з яких визначається сукупністю індексів (i,j,t) та в межах способу, що заявляється, приймається рівним 0, що символізує анулювання домену-маски, або 1, що символізує актуальність домену-маски, t - номер проміжку часу актуальності, і - індекс, що символізує номер сутності, N(t) - загальна кількість сутностей на відрізку часу під номером t, M(i,t) - кількість доменів-масок кожної і-ї сутності на відрізку часу під номером t, причому кількість доменів-масок не може бути будь-якою чи відокремленою від кількості доменів-масок інших сутностей, тому що при утворенні бінарних, тернарних чи зв'язків більш високої арності з боку кожної задіяної в цьому зв'язку сутності має вистачати доменів-масок для участі у зв'язку, а це означає, що у сховищі домени-маски актуалізуються або анулюються синхронізовано з актуалізацією чи анулюванням відповідних зв'язків, тобто ролей, в яких беруть участь ті чи інші групи сутностей, j - індекс, що символізує номер домену-маски, сумарну кількість яких для і-ї сутності надає внутрішня сума, а зовнішня сума надає загальну кількість доменів-масок, після чого синхронізовано заповнюють відповідними даними отримані семантично сумісні реляційні таблиці.
3. Спосіб за пунктом 2, який відрізняється тим, що в структурі комірки пам'яті, де розміщено домен-маску, передбачають специфічну цифрову адресу - узагальнений сурогатний ключ, який має єдине базове ім'я для всіх доменів-масок, а також наскрізну тривимірну індексацію (i,j,t), що унікально відповідає кожному домену-масці кожної сутності, тобто, кожний з індексів відповідає за свій базовий фактор способу, де: t - номер відрізка часу актуальності поточного стану t-ї модифікації сукупності всіх (i,j)-х реляційних таблиць даних, i=1,N(t) - номер кожної сутності, N(t) - загальна кількість сутностей на відрізку часу під номером t, j=l,M(i,t) - номери кожного домену-маски і-ї сутності на відрізку часу під номером t, отже, за проміжок часу, що має номер t, структура всієї сукупності реляційних таблиць залишається без змін, тобто, не модифікується, а на моменті часу, що має номер t+1, ця ж сукупність реляційних таблиць вже отримує модифікацію свого стану, що надає можливість призначити та використати будь-яку формальну умову переходу до нового коду відрізка часу актуальності стану сховища, а значить до нової сукупності таблиць і кортежів, а також побудувати темпорально-шаровий архів даних.
4. Спосіб за пунктом 3, який відрізняється тим, що для побудови розподілених сховищ даних, розміщених на фізично різних серверах, кожний атрибут з логічної моделі, що в фізичній моделі є цифровим даним, розміщують у цифровій пам'яті з використанням сурогатного ключа як фізичного коду адресації до даних, тобто, того ж самого сурогатного ключа логічної моделі, який є реляційним ідентифікатором і носієм переваг реляційної моделі даних, що надає можливість рознесення груп даних на фізично різні сервери без втрат реляційних зв'язків, що значно збільшує гнучкість структури сховища.
Текст
1. Спосіб узагальненого розміщення даних із забезпеченням модифікаційності структури сховища, який полягає в тому, що розміщувані дані розподіляють на групи, що кожна сутність, яка об'єднує кожну таку групу, має спільний набір параметрів, що відповідають спільному предикату, а групи сутностей перебувають між собою у рівноправних або в ієрархічних відносинах, у сховищі формують систему реляційних таблиць і заповнюють їх відповідними даними, який відрізняється тим, що при розміщенні даних, які належать певній предметній області, спочатку враховують всі можливі часткові копії сутностей, утворюючи маски сутностей, а вже після цього моделюють всі зв'язки між групами цих масок сутностей у довільній предметній області, для чого кожній групі масок відводять у сховищі декілька ділянок пам'яті для розміщення елементів зберігання, тобто резервують в кожній ділянці пам'яті домен-маску з відповідним сурогатним ідентифікаційним ключем, створюючи таким чином універсальну множину ділянок пам'яті, так, що кількість доменів-масок, що там розміщують, дорівнює кількості масок кожної сутності, причому домени-маски призначають маскам всіх сутностей, навіть і маскам тих сутностей, які 2 (19) 1 3 92248 4 льна кількість сутностей на відрізку часу під номером t, M(i,t) - кількість доменів-масок кожної і-ї сутності на відрізку часу під номером t, причому кількість доменів-масок не може бути будь-якою чи відокремленою від кількості доменів-масок інших сутностей, тому що при утворенні бінарних, тернарних чи зв'язків більш високої арності з боку кожної задіяної в цьому зв'язку сутності має вистачати доменів-масок для участі у зв'язку, а це означає, що у сховищі домени-маски актуалізуються або анулюються синхронізовано з актуалізацією чи анулюванням відповідних зв'язків, тобто ролей, в яких беруть участь ті чи інші групи сутностей, j індекс, що символізує номер домену-маски, сумарну кількість яких для і-ї сутності надає внутрішня сума, а зовнішня сума надає загальну кількість доменів-масок, після чого синхронізовано заповнюють відповідними даними отримані семантично сумісні реляційні таблиці. 3. Спосіб за пунктом 2, який відрізняється тим, що в структурі комірки пам'яті, де розміщено домен-маску, передбачають специфічну цифрову адресу - узагальнений сурогатний ключ, який має єдине базове ім'я для всіх доменів-масок, а також наскрізну тривимірну індексацію (i,j,t), що унікально відповідає кожному домену-масці кожної сутності, тобто, кожний з індексів відповідає за свій базовий фактор способу, де: t - номер відрізка часу актуальності поточного стану t-ї модифікації суку пності всіх (i,j)-х реляційних таблиць даних, i=1,N(t) - номер кожної сутності, N(t) - загальна кількість сутностей на відрізку часу під номером t, j=l,M(i,t) номери кожного домену-маски і-ї сутності на відрізку часу під номером t, отже, за проміжок часу, що має номер t, структура всієї сукупності реляційних таблиць залишається без змін, тобто, не модифікується, а на моменті часу, що має номер t+1, ця ж сукупність реляційних таблиць вже отримує модифікацію свого стану, що надає можливість призначити та використати будь-яку формальну умову переходу до нового коду відрізка часу актуальності стану сховища, а значить до нової сукупності таблиць і кортежів, а також побудувати темпоральношаровий архів даних. 4. Спосіб за пунктом 3, який відрізняється тим, що для побудови розподілених сховищ даних, розміщених на фізично різних серверах, кожний атрибут з логічної моделі, що в фізичній моделі є цифровим даним, розміщують у цифровій пам'яті з використанням сурогатного ключа як фізичного коду адресації до даних, тобто, того ж самого сурогатного ключа логічної моделі, який є реляційним ідентифікатором і носієм переваг реляційної моделі даних, що надає можливість рознесення груп даних на фізично різні сервери без втрат реляційних зв'язків, що значно збільшує гнучкість структури сховища. Винахід належить до галузі інформаційних технологій і може бути використаний для побудови гнучких автоматизованих систем зберігання та обробки даних із можливістю гнучкої модифікації структури сховища для довільної предметної області. Широко відомі традиційні способи розміщення даних, які базуються на класичних декомпозиційних технологіях Кодда у межах реляційної моделі даних (Codd E.F. A Relational Model of Data for Large Shared Data Banks. - Comm. ACM, 13, 6 (jun), 1970, p.377-387; Codd E.F. Normalised Data Base Struchture: a Brief Tutorial. - Proc. ACM, SIGFIDET, 1971, Workshop, San Diego, Calif, Nov. 1971, p.118). Відомий також об'єктно-орієнтований підхід (Маіеr D. Why isn't there an object-oriented data model? - Proceedings IFIP 11th World Computer Conference, San Francisco, СA, August-September, 1989). Ці методи мають основний недолік - вони не вирішують питання отримання універсальної та гнучкої структури сховища. ER-модель Чена (Chen P.P. The Entity-Relationship Model: toward a unified view of data. - ACM Trans, on Data base systems, 1:1, 1976, h. 9-36) також створює сховище залежним від початкової семантики предметної області і не вирішує питання гнучкої модифікаційної здатності у подальшій експлуатації. Найбільш близьким до запропонованого є спосіб розміщення даних у цифровому сховищі, яке побудовано у відповідності до декартового перемноженням сурогатних ключів сутностей (Панченко Б.Є., Спосіб розміщення даних у комп'ютерному сховищі із забезпеченням модифікаційності його структури, Патент України №63036 від 15.01.2004). За цією моделлю завдяки декартовому перемноженню множин сурогатних ключів сутностей формують сховище із системи реляційних таблиць, які заповнюють даними - атрибутами сутностей та атрибутами зв'язків. Цей спосіб враховує всі можливі зв'язки між групами сутностей, які утворюють довільну предметну область. Проте він не враховує вплив розмаїття ролей кожної сутності (масок сутностей) на розмаїття зв'язків, що обмежує застосування попереднього способу і не дає можливості гнучко врахувати ролі сутностей у довільній предметній області. Задачею винаходу є створення узагальненого універсально-гнучкого способу розташування даних у сховищі, який моделював би довільну предметну область і дозволяв використовувати єдину процедуру автоматизації процесу створення структури такого сховища. Така процедура мусить надавати сховищу максимальну модифікаційну здатність, тобто мінімізувати кількість операцій для модифікації. А також оптимізувати об'єднання різних сховищ, побудованих за цим способом, в єдину інформаційну систему. Ця задача вирішується тим, що при розміщенні даних, які належать певній предметній області, спочатку враховують всі можливі часткові копії сутностей, утворюючи маски сутностей, а вже після цього моделюють всі зв'язки між групами сутностей у довільній предметній області. Тут під мас 5 кою розуміється така часткова копія сутності, що є носієм обмеженої групи характеристик-атрибутів цієї сутності, які відповідають лише за одну конкретну роль сутності. Кожна сутність може мати в будь-якій предметній області певну кількість різних масок. Тобто, або безліч, або декілька, або лише одну. Проте, як буде зазначено нижче, кількість масок обумовлюється кількістю ролей предметної області, тобто зв'язків, у яких бере участь сутність. Наприклад, якщо розглядається сутність "людина", то таких масок може бути дуже багато. Це і "фах", і "посада", і "військове звання", і "науковий ступінь" і т.д. Проте, якщо це сутність "тварина", то масок може бути набагато менше: "домашня тварина", "дика тварина", "худоба" і т.д. Спочатку традиційно розміщувані дані розподіляють на групи так, що сутності кожної групи мають спільний набір параметрів, які відповідають спільному предикату, а групи сутностей перебувають між собою у різноманітних зв'язках. Потім, відповідно до способу, що заявляється, формування сховища здійснюють наступним чином. 1. Для кожної сутності відводять в пам'яті декілька ділянок для розміщення елементів зберігання, тобто розміщують в кожній ділянці домен-маску з відповідним сурогатним ідентифікаційним ключем, створюючи таким чином множину доменівмасок. Будемо вживати термін "маска" у значенні логічної часткової копії сутності, та "домен-маска" у значенні фізичного розміщення даних з маски в ділянці пам'яті. При цьому домени-маски призначають всім маскам сутностей, навіть і маскам тих сутностей, які перебувають між собою не у рівноправних, а в ієрархічних зв'язках. Ієрархічно залежні сутності - це так звані "слабкі" сутності, які без зв'язку зі своїми інформаційними "предками" не мають можливості брати самостійну участь у рівноправних зв'язках. Оскільки у загальному випадку слабкі сутності залежать від ланцюга сутностей, де кожна сутність-ланка в свою чергу є також слабкою сутністю, виключаючи лише найвищу сутність в цьому ланцюжку, маски призначають так, ніби цієї залежності не існує, тобто ігноруючи ієрархічну залежність. Проте таке ігнорування ієрархічних залежностей між сутностями є тимчасовим. Алгоритм способу передбачає подальше врахування всіх типів зв'язків між масками, а значить і ієрархічних зв'язків між сутностями. Тому ця дія не призведе до втрати ієрархічних зв'язків. При цьому припускається, що одна маска унікально відповідає одній ролі, і навпаки - виконання однієї ролі, тобто участі в одному типі зв'язку, потребує від сутності використання однієї маски. Користувач способу (проектувальник сховища) мусить лише відстежувати семантичну відповідність кожної маски кожній ролі, тобто відповідність масок та зв'язків. 2. Здійснюють декартове перемноження всіх згаданих доменів-масок між собою за принципом "всі на всі". Загальна кількість S(t) одержаних таким чином таблиць суттєво збільшується у порівнянні з іншими способами і, з урахуванням множини масок кожної сутності та залежності кількості сутностей від номеру проміжку часу актуальності 92248 6 структури сховища, загальна кількість таблиць визначається виразом: NN t St K 1 NN t ! K! (NN t K )! 2NN t 1 , де K - поточна арність зв'язків груп доменівмасок, a NN(t) - загальне число доменів-масок, що залежить від t - номеру проміжку часу актуальності структури сховища, протягом якого ця структура не зазнає модифікації. Загальна ж кількість доменів-масок визначаються формулою: Nt M i,t i 1 j 1 NN t i, j, t , де, в свою чергу, α(i,j,t) - ознака актуальності домену-маски, формальний масив цілих чисел, кожне з яких визначається сукупністю індексів (i,j,t) та в межах способу, що заявляється, приймається рівним 0, що символізує анулювання доменумаски, або 1, що символізує актуальність доменумаски, і - індекс, що символізує номер сутності, N(t) - загальна кількість сутностей на проміжок часу t, M(i,t) - кількість доменів-масок кожної і-ї сутності на проміжку часу t, a j - індекс, що символізує номер домену-маски і-ї сутності, сумарну кількість яких для однієї сутності надає внутрішня сума. Тож, зовнішня сума надає загальну кількість доменів-масок. Окремо зазначимо, що кількість доменів-маски будь-якої сутність не може бути будь-яким або відокремленим від кількості інших доменів-масок власної сутності або інших сутностей. Адже при утворенні бінарних, тернарних чи зв'язків більш високої арності з боку кожної задіяної в цьому зв'язку сутності має буди "надано" відповідну маску. А це, в свою чергу, означає, що маски актуалізуються або анулюються синхронізовано з актуалізацією чи анулюванням відповідних зв'язків, тобто ролей, в яких ті чи інші групи сутностей беруть участь. Ця відповідність масок суттєво спрощує побудову концептуальної моделі будь-якої предметної області. Під час з'ясування переліку сутностей та переліку ролей цих сутностей завдяки вищезгаданій відповідності виявляються «приховані" маски, наявність яких не є очевидною на початку .аналізу предметної області. 3. Після цього синхронізовано заповнюють відповідними даними отримані семантично сумісні реляційні таблиці. Основною відмінністю способу, що замовляється, є використання у множині елементів декартового перемноження не сутностей як таких, а груп їх масок. Тож, семантичною ознакою віднесення характеристик-атрибутів до тієї чи іншої маски є змістова залежність конкретної характеристикиатрибута від конкретної маски сутності. Процедура такого віднесення відповідає припущенню, що кожна характеристика-атрибут належить лише одній унікальній сутності. А також припущенню, що лише певна група характеристик-атрибутів утворює повну взаємно-незалежну сукупність властивостей. І що об'єднання цих різних груп характеристик в одну множину, або в одну реляційну таблицю, може призвести до появи небажаних міжатрибутних 7 функціональних залежностей. В подальшому "характеристику-атрибут" будемо називати просто "атрибутом", маючи при цьому на увазі саме певну характеристику сутності або її маски. Формальною ж ознакою відбору атрибутів сутності в окрему маску є відсутність в множині таких атрибутів транзитивних функціональних залежностей, а також відсутність складених потенційних ключів у кортежах реляційних таблиць, що утворюються на множині атрибутів маски сутності. Виключенням є лише один складений потенційний ключ - сумарно всі атрибути кортежу. Адже унікальність кортежу - це вимога реляційної моделі. При такому відборі атрибутів сутності до множини атрибутів маски сутності, не виникає умов існування функціональної залежності частин складених ключів від неключових атрибутів. З наведеного витікає ще одне припущення, що семантичною відмінністю атрибуту від сутності є наявність або відсутність "підлеглої" характеристики, яка, якщо є атрибутом, вже ніяких "підлеглих" характеристик не має. При цьому будь який атрибут завжди функціонально залежить від певної унікальної "старшої" сутності, а також може бути транзитивно залежним від інших атрибутів цієї ж сутності, якщо вони належать до інших її масок (не входять до множини атрибутів маски, до якої належить цей атрибут). Проте в межах групи атрибутів, що виключно всі належать до певної маскивласника, вже ніяких міжатрибутних функціональних залежностей не існує. Отже, сама маска є не лише пойменованою частковою копією сутності, а й ексклюзивним носієм групи взаємонезалежних атрибутів саме цієї сутності. Таким чином, кожна таблиця, що створюється на базі домену-маски, вміщує лише сурогатний ключовий атрибут та групу функціонально незалежних один від одного атрибутів маски, які залежать лише від ключового атрибуту. Таким чином, спосіб передбачає, що кожна домен-маска перебуває лише у реляційній нормальній формі Бойса-Кодда. А оскільки реляційні таблиці, що відображають домени-маски, ніяким чином не можуть мати в своєму складі ще й багатозначні залежності, спосіб гарантує, що вони відносяться по крайній мірі до 4-ї нормальної форми. Зазначимо також, що композиційний метод утворення структур реляційних таблиць даних завдяки алгоритму керування функціональними залежностями запропонував П.А. Бернштейн в 1975 році (Bernstein P., Swenson J., Thichritzis D. A Unified Approach to Functional Dependencies and Relations. - Proc. 1975 ACM SIGMOD - International Conference on the Management of Data, 237-245; Bernstein PA. Synthesizing third normal form relation from functional dependencies, ACM Transactions on Database Systems 1:4, 1976, pp.277-298). Там же зазначалося, що під функціональною залежністю розуміється зв'язок між сутностями та між сутностями та атрибутами. Проте, оскільки вхідними факторами вищезгаданого методу є набір функціональних залежностей певної предметної області, це є його суттєвим недоліком. Адже реляційні схеми, що утворюються за цим алгоритмом, залежать від семантики предметних областей. На відміну 92248 8 від згаданого, спосіб, що замовляється, надає алгоритм абстрагування від функціональних залежностей, тобто від впливу семантики зв'язків на структуру сховища даних. З одного боку, резервування певної кількості доменів-масок кожної сутності здійснюється у відповідності до умов конкретної предметної області. Тобто, враховують, що кількість груп незалежних атрибутів певної сутності, що виявлено в предметній області, дорівнює кількості доменів-масок цієї сутності. Проте, при цьому враховується також, що кількість доменів-масок є параметром умовним. Адже в способі, що замовляється, не існує обмежень кількості сутностей, а також сумарної кількості доменів-масок. Тому, з іншого боку, резервування ділянок пам'яті для доменів-масок мусить враховувати можливість значного збільшення як кількості доменів-масок, так і кількості багатоарних таблиць. Ще одна відмінність способу, що заявляється, полягає в структурі узагальненого сурогатного ключа, який має єдине ім'я для всіх таблиць та наскрізну тривимірну індексацію (i,j,t). Індекси мають той самий зміст, що й у виразі загальної кількості доменів-масок. Кожний з індексів ключа унікально відповідає кожній масці кожної сутності. Тобто, кожний з індексів відповідає за свій базовий фактор способу, а саме: i=1,N(t) - символізує номер кожної сутності, де N(t) - загальна кількість сутностей за t-й проміжок часу, j=1,M(i,t) - символізує номер маски і-ї сутності за t-й проміжок часу, a t - номер відрізку часу актуальності поточного стану t-й модифікації сукупності всіх (i,j) - x реляційних таблиць даних. Отже, за проміжок часу, що має номер t, структура всієї сукупності таблиць залишається без змін, тобто, не модифікується. А на моменті часу, що має номер t+1, ця ж сукупність таблиць вже отримує модифікацію свого стану. Така модифікація може виявитися як у мізерній зміни лише розміру одного зі стовпців вже існуючої таблиці, так і у появі нової групи таблиць. Користувач способу отримує можливість самостійно призначати та використовувати будь-яку формальну умову переходу до нового коду відрізку часу актуальності стану структури сховища, а значить до нової сукупності таблиць і кортежів. Тож, спосіб гарантує, що будь яка модифікація структури сховища не торкнеться зв'язків між попередніми даними і таким чином не призведе до докорінних перетворень таблиць. А також, завдяки кодуванню проміжків часу, протягом яких стан структури сукупності таблиць зберігає актуальність, спосіб надає можливість аналізувати всі шари станів структури таблиць або відокремлено один від одного, або у повній сукупності. Така технологія побудови сховища надає можливість зберігання кожного окремого t-шару сукупності таблиць у цілісному вигляді з усіма напрацьованими даними за цей проміжок часу. І побудувати темпорально-шаровий архів даних. В наведеному способі також не існує обмежень щодо моменту додавання додаткових доменів-масок від початкових, або навіть від нових сутностей, які не були враховані проектувальником на 9 початковому етапі. Адже таке додавання і є згадуваною модифікацією чергового стану структури сховища. Суттєвою відмінністю способу, що заявляється, є можливість надати кожному зв'язку між сутностями окрему багато-арну реляційну таблицю. А це, у свою чергу, надає можливість користувачеві не обмежувати концептуальну модель проектування і не зводити багато-арні зв'язки між сутностями до бінарних, як рекомендує будь яка загальновідома теорія побудови реляційних сховищ. Адже саме багато-арність зв'язків є однією з ознак довільної предметної області. До того ж, спосіб дає можливість використання в структурі сховища лише багато-арних таблиць, які містять окрім багато-арних ключів ще й атрибути зв'язків. Як відомо із загальновживаної теореми Фейджина (Fagin, R, Multi-valued dependencies and a new normal form for relational databases, ACM Transactions on Database Systems, vol. 2, no. 3, 1977, p.262-278), багато-арні таблиці, кожний кортеж яких побудований лише на декартовому перемноженні ключових атрибутів декількох сутностей (де кількість сутностей більше двох), мають аномалії типа "багатозначні залежності" і не належать до 4-ї нормальної форми. Проте, якщо в кожній такій реляційній таблиці до кожного такого багато-арного ключа додаються ще й незалежні атрибути - характеристики цього зв'язку, багатозначні залежності зникають. Реляційна таблиця звільняється від аномалій. Такі таблиці належить до 4-ї нормальної форми. Оскільки саме зв'язки між сутностями і моделює спосіб, що замовляється, саме заради характеристик-атрибутів зв'язків будуються багато-арні реляційні таблиці. А розмаїття типів зв'язків, в яких у довільній предметній області перебувають різноманітні сутності, моделюються множиною доменів-масок, тому що кожна маска, як зазначалося вище, це унікальна група характеристик сутності для виконання певної конкретної ролі. Тобто, для перебування у цьому зв'язку. Отже, в межах способу, що замовляється, існує можливість не використовувати багато-арні реляційні таблиці з аномаліями, тобто, з багатозначними залежностями в їх структурі, які побудовані лише на декартовому перемноженні ключів, оскільки вони моделюють лише факт зв'язку, а не несуть ніякої інформації - в них відсутні характеристики цього зв'язку. В алгоритмі способу, що замовляється, використовуються лише багато-арні реляційні таблиці, що завдяки незалежним атрибутам перебувають у 4-й нормальній формі. Зазначимо, що «додатковий" фізичний зміст констант α(i,j,t) - це ще й факт розмноження певної маски, коли певна константа дорівнює 2, 3, 4 і т.д. Це, в свою чергу, означає моделювання можливості багаторазового одночасного виконання однією сутністю однієї ролі, тобто участь сутності своєю однією маскою в одному типі зв'язку декілька раз. Така ситуація не має аналогів в предметних областях. Адже, як вже зазначалося, використовується принцип унікальності - кожна маска використовується лише для однієї ролі, а в кожній ролі, тобто у кожному типі зв'язку, сутність бере участь цією маскою лише один раз. Тому, навіть рекурсивний 92248 10 зв'язок довільної арності одного і того ж екземпляру сутності, що в теорії проектування сховищ даних вважається одним з суттєвих протиріч предметних областей, органічно моделюється способом, що замовляється, за рахунок різних доменів-масок, які належать одній сутності. Проте в межах способу, що замовляється, розмноження ще й доменів-масок - така, суто теоретична ситуація - не створить суттєвих структурних проблем та протиріч. Єдине, що при цьому виникає - це потреба розрізняти однойменні ключові атрибути. Проте, поява додаткових семантично не визначених доменів-масок, а також і реляційних таблиць, що ними породжуються, може суттєво вплинути лише на швидкодію процедур відстеження цілісності всього сховища, що значно знижує оптимізацію його використання. Анулювання ж чи актуалізація доменів-масок на певний проміжок часу актуальності - це один із різновидів модифікації структури сховища. Значною перевагою способу, що замовляється, є можливість використовувати фізичну модель зберігання даних у повній відповідності до логічної моделі. А це означає, що спосіб вирішує класичну проблему Кодда щодо пошуку оптимального рішення між одним універсальним відношенням (крайність уніфікації) і значної сукупності бінарних відношень (крайність декомпозиції). Історично вважається, що ні той, ні інший варіант не має перспектив. А ці протиріччя в більшій мірі, на думку автора, торкаються саме моделювання фізичного розміщення даних у цифровому сховищі. Спосіб, що замовляється, є формалізованим рішенням проблеми Кодда. Адже, коли стверджується, що для довільної предметної області існує універсальна рівнозначна і логічна, і фізична морель розміщення даних, вільна від аномалій, тим самим стверджується, що вирішено проблему Кодда. Отже, унікальна побудова сурогатного ключа надає можливість користувачеві проектувати фізично-розподілені системи зберігання даних, проте з урахуванням реляційної моделі. Адже кожне дане має унікальний ідентифікатор і може розміщуватися прямою адресацією у цифрову пам'ять. А цей ідентифікатор, з одного боку, є реляційним ключем і носієм основних властивостей логічної моделі даних. А з іншого боку, є вирішальним чинником адресації до даних у сховищі. При побудові розподіленого сховища основним фактором віднесення тієї чи іншої групи даних до тих чи інших серверів в мережах є статистика запитів. Вищеописана структура сховища надає можливість рознесення груп даних без втрат реляційних зв'язків. Така концепція створення сховища значно збільшує гнучкість структури сховища. Тож, стисло повторимо послідовність дій щодо способу узагальненого розміщення даних у сховищі, що заявляється. 1. Обмежується предметна область - відбираються групи сутностей, що цікавлять проектувальника. Під сутністю розуміють множину, що має спільний набір властивостей, які відповідають спільному предикату. 2. Виконується процедура резервування доменів-масок кожної сутності у кількості, обумовле 11 ної вимогами предметної області. При цьому враховується, що кількість доменів-масок кожної сутності є параметром умовним. Як рівноправні, так і ієрархічно-залежні сутності моделюються рівноправними масками. Тобто, при обох типах зв'язків між множинами сутностей А та В у загальному випадку виникають зв'язки типу "багато до багатьох", причому кожна сутність із множини А може незалежно вступати у відношення з будь-якою підмножиною сутностей із множини В, а також у відношення з будь-якими підмножинами сутностей з інших множин, тобто С, D, ..., N,..., Z і т.д. 3. До кожного домену-маски кожної сутності ставиться у відповідність ключовий атрибут - сурогатний ідентифікаційний ключ єдиної структури, який має загальні найменування та структуру, побудовану за принципом індексованого тривимірного масиву. Наприклад, ключ першої маски першої сутності для першого відрізку часу актуальності може позначатися, наприклад, як К (1,1,1) або К111. Він же може позначати адресу комірки цифрової пам'яті: К010101 або К001001001 і т.д. в залежності від проектного діапазону кількості кортежів у таблицях, для яких проектується цей ключ. При цьому враховується, що для будь-якої предметної області її семантика визначається двома типами відношень між об'єктами - рівноправними та залежними. Тож проектувальник формує окремий довідник, де фіксується, які сутності належать до яких груп. Адже після побудови сховища користувач мусить відрізняти одні сутності від інших. 4. У межах множини одержаних доменів-масок методом декартова перемноження доменів-масок між собою створюють каркас майбутніх реляційних таблиць зв'язків (Фіг. 1), який і визначає структуру сховища. Причому перемноження здійснюють за принципом "всі на всі". Отже, на початковому рівні маємо NN(t0) доменів-масок: N0 M i,t 0 i 1 j 1 NN t 0 i, j, t 0 де α(i,j,t0)=1 для всіх (і,j,t0), t0 - номер початкового проміжку часу (який також може дорівнювати 1), і - індекс, що символізує номер сутності, N0 кількість сутностей початкового to проміжку часу, M(i,t0) - кількість доменів-масок кожної і-ї сутності початкового to проміжку часу, а j - індекс, що символізує номер конкретної маски, сумарну кількість яких надає внутрішня сума. А зовнішня сума надає загальну кількість доменів-масок. На цей початковий проміжок часу рівнях арності, вище за перший, опиниться NN!/(2!*(NN-2)!) два-стовпчикових, NN!/(3!*(NN-З)!) тристовпчикових, NN!/(4!*(NN-4)!) чотиристовпчикових і т.д., ... NN!/(NN-1)! (NN-1)стовпчикових, а також однієї NN-стовпчикової реляційної таблиці, де NN - сума всіх масок всіх сутностей. Для спрощення запису константа NN позначена тут без посилання на номер проміжку часу t0 . 5. Для кожної з отриманих таблиць генерується ідентифікаційний ключ шляхом розмноження ідентифікаційних ключів, що містилися у наборі доменів-масок. їх розташовують у відповідних 92248 12 таблицях за аналогією з доменами-масками. Тобто, кожну групу генерованих ідентифікаційних ключів розміщують у ту таблицю, яка є безпосереднім породженням групи відповідних цим ключам доменів-масок. 6. Виконується дія, передбачена способом, наведеним у патенті України No 63036: будується система групових навігаційних функцій, за допомогою яких у режимі квазі-реального часу синхронізовано заповнюються сформовані у сховищі семантично сумісні таблиці відповідними даними і обробляють групи цих даних, тобто здійснюють групове відстеження їх цілісності, групове введення, групове коригування, групову ліквідацію, груповий перегляд, виведення даних на друкуючий пристрій і т.і. При цьому, заповнюють даними лише ті з семантично сумісні таблиці, які знаходяться у семантичній відповідності до очікуваних запитів від користувачів. Решту залишають "у резерві" і використовують лише згідно із виникненням непередбачених запитів. Отже, семантично несумісні таблиці можуть залишатися неактуальними і незаповненими за принципом "про всяк випадок". Запропонованим узагальненим способом створюється універсальна технологія розміщення даних у цифровому сховищі, яка не залежить від особливостей певної предметної області та дозволяє без переробки експлуатуючого програмного забезпечення здійснювати мінімально необхідними операціями будь-які семантично доцільні модифікації структури сховища, а також сформувати набір єдиних процедур обробки даних - групових функцій, і таким чином стандартизувати технологію генерації та експлуатації сховищ даних. З наведеного витікає ще один різновид впровадження винаходу - підготовка та експлуатація у всесвітній мережі спеціалізованого електронного "тлумачного" словника сутностей, їх масок та атрибутів. Такий словник, перекладений на декілька мов, може використовуватись як базове загальновживане сховище, до якого посилаються прикладні системи маніпулювання даними. Суть винаходу пояснюється кресленням, де на Фіг. 1 наведено універсальну структуру сховища, яка моделює довільну предметну область, де К111, К121, К131, К141, ..., КNNM1 - сукупність сурогатних ключових атрибутів нескінченних стовпців доменів-масок, а також структура багато-арних таблиць кожного рівня зв'язків, що одержана шляхом декартова перемноження доменів-масок між собою. При цьому літерою М позначено, як і вище за текстом, залежний від номеру сутності масив, що означає кількість масок кожної сутності. Для економії місця на схемі-кресленні символ "і" не наведено. З цієї ж причини наведено лише деякі випадкові таблиці бінарних зв'язків, а також на третьому та четвертому рівні арності таблиць місце тривимірного ключа Kijt узагальнено позначено масивами А, В, С, D, ... N, тобто, використані символи імен сутностей, які узагальнюють імена своїх масок. Остання ж NN-арна таблиця показана з розкритою структурою ключа. 13 Комп’ютерна верстка Д. Шеверун 92248 Підписне 14 Тираж 26 прим. Міністерство освіти і науки України Державний департамент інтелектуальної власності, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюGeneralized data allocation method with due account for modification of storage structure
Автори англійськоюPanchenko Borys Yevheniovych
Назва патенту російськоюСпособ обобщенного размещения данных с учетом модификации структуры хранилища
Автори російськоюПанченко Борис Евгеньевич
МПК / Мітки
МПК: G06F 17/30, G06F 17/00, G06F 12/00
Мітки: даних, узагальненого, спосіб, урахуванням, сховища, розміщення, модифікаційності, структури
Код посилання
<a href="https://ua.patents.su/7-92248-sposib-uzagalnenogo-rozmishhennya-danikh-z-urakhuvannyam-modifikacijjnosti-strukturi-skhovishha.html" target="_blank" rel="follow" title="База патентів України">Спосіб узагальненого розміщення даних з урахуванням модифікаційності структури сховища</a>
Спосіб розміщення даних у комп’ютерному сховищі із забезпеченням модифікаційності його структури

Номер патенту: 63036
Опубліковано: 15.01.2004
Автор: Панченко Борис Євгенійович
МПК: G06F 17/30, G06F 17/00
Мітки: сховищі, забезпеченням, комп'ютерному, спосіб, модифікаційності, даних, структури, розміщення
Формула / Реферат:
1. Спосіб розміщення даних у комп'ютерному сховищі, який полягає у тому, що розміщувані дані розподіляють на групи так, що об'єкти кожної групи мають спільний набір параметрів, які відповідають спільному предикату, а групи об'єктів перебувають між собою у рівноправних та/або у ієрархічних відносинах, у сховищі формують систему кортежних таблиць і заповнюють їх відповідними даними, який відрізняється тим, що формування системи таблиць...
Спосіб розміщення даних в обчислювальній мережі з топологією “кільце”

Номер патенту: 20451
Опубліковано: 15.01.2007
Автори: Назаров Олександр Володимирович, Пєвнєв Володимир Яковлевич, Серков Олександр Анатолійович, Чурюмов Геннадій Іванович, Логвиненко Микола Федорович
МПК: G06F 17/30
Мітки: спосіб, обчислювальній, кільце, топологією, даних, мережі, розміщення
Формула / Реферат:
Спосіб оптимального розміщення даних в обчислювальній мережі з топологією «Кільце», який включає розподілення даних в інформаційній мережі та збереження таблиць розподілення на носії, який відрізняється тим, що розподілення виконують за умови мінімізації обсягу фрагментів даних, які пересилаються, причому остаточне розподілення даних виконують за умови порушення первинного розподілення.
Спосіб пошуку геологічної структури для підземного сховища газу

Номер патенту: 21237
Опубліковано: 15.03.2007
Автори: Черняков Олександр Маркович, Локтєва Тетяна Миколаївна, Локтєв Валентин Сергійович, Черняков Євгеній Олександрович, Садовський Микола Іванович
Мітки: сховища, структури, спосіб, геологічної, пошуку, підземного, газу
Формула / Реферат:
Спосіб пошуку геологічної структури для підземного сховища газу, який включає виділення водоносних пластів у межах локальної надштокової антиклінальної структури, визначення параметрів залягання водоносних пластів шляхом буріння свердловин у склепінні та на крилах структури, при цьому як параметри залягання водоносних пластів визначають глибину залягання покрівлі водоносного пласта в точках спостереження - свердловинах, побудову структурних...
Спосіб розміщення даних в обчислювальній мережі з топологією “зірка”

Номер патенту: 20450
Опубліковано: 15.01.2007
Автори: Логвиненко Микола Федорович, Серков Олександр Анатолійович, Кутіщев Станіслав Юрійович, Чурюмов Геннадій Іванович, Пєвнєв Володимир Яковлевич
МПК: G06F 17/30
Мітки: спосіб, топологією, зірка, мережі, даних, обчислювальній, розміщення
Формула / Реферат:
Спосіб розміщення даних в обчислювальній мережі з топологією «Зірка», який включає актуалізацію даних, розміщення даних по вузлах мережі, видачу інформації у реальному масштабі часу, який відрізняється тим, що оптимальне розміщення даних здійснюється шляхом розрахунку загального поточного часу відповіді на запит по обчислювальній мережі для кожної з можливих комбінацій розміщення даних по вузлах мережі та вибір оптимальної комбінації з...
Спосіб розміщення даних в електронній бібліотеці

Номер патенту: 34694
Опубліковано: 26.08.2008
Автори: Слєсаренко Владислава Дмитрівна, Заволодько Ганна Едвардівна
МПК: G06F 17/30
Мітки: розміщення, спосіб, даних, електронний, бібліотеці
Формула / Реферат:
Спосіб розміщення даних в електронній бібліотеці, який включає введення електронних учбових матеріалів до пам'яті комп'ютера, створення банку електронних учбових матеріалів та збереження їх на сервері, доповнення електронними матеріалами власної розробки, використання комп'ютерів-клієнтів для розміщення матеріалів, перегляд матеріалів в комунікаційній мережі за допомогою комп'ютерів-клієнтів шляхом переміщення за раніше розміщеними...
Попередній патент: Спосіб виготовлення, відновлення і зміцнення циліндричних деталей
Наступний патент: Спосіб настроювання зусилля преса з шарнірно-важільним механізмом затиску
Випадковий патент: Спосіб діагностики фіброзу печінки у хворих на хронічні гепатити вірусної та вірусно-алкогольної етіології