Спосіб забезпечення конфіденційності текстової інформації







Формула / Реферат
Спосіб забезпечення конфіденційності текстової інформації, згідно з яким здійснюють шифрування/розшифрування зразків тексту із застосуванням симетричного криптографічного алгоритму, що базується на використанні властивостей генератора дискретних (псевдо)випадкових послідовностей, який відрізняється тим, що перед шифруванням зразки вихідного тексту за допомогою засобів лінгвістичного корпусу структуруються за лінгвістичними характеристиками таким чином, щоб шифрування будь-якого зразка вихідного тексту, що складається із елементів тезауруса мови відображення заданої кінцевої множини текстів, приводило до отримання правдоподібного зразка тексту, смисл котрого випадковим чином відрізняється від смислу зразка вихідного тексту.
Текст
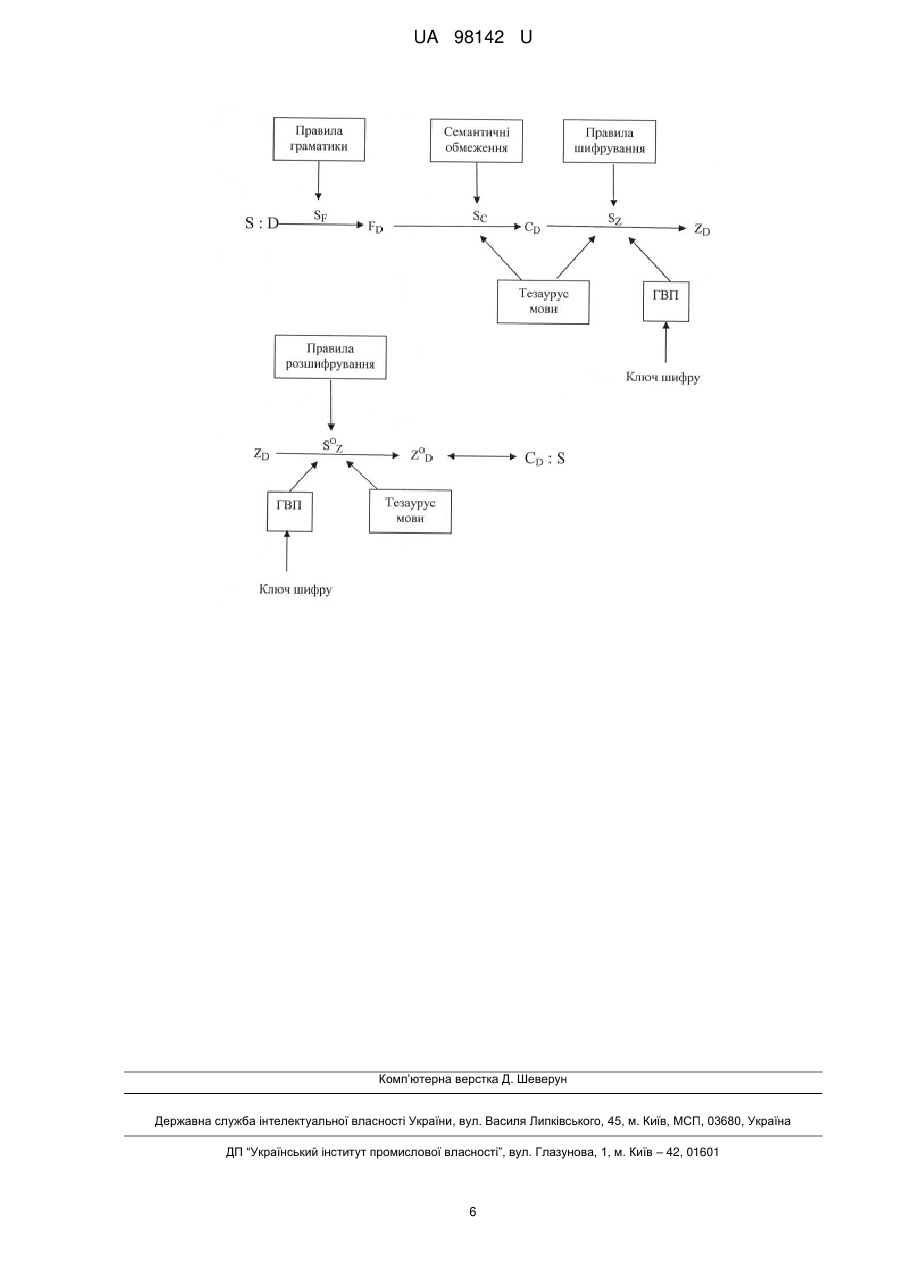
Реферат: UA 98142 U UA 98142 U 5 10 15 20 25 30 35 40 45 50 55 60 Найбільш поширеного застосування корисна модель матиме у системах зберігання та передавання текстової інформації через канали зв'язку, що незахищені від перехоплення інформації, у випадках, коли порушення конфіденційності цієї інформації може призвести до неприйнятних негативних наслідків для її власників. Перш за все, маються на увазі криптографічні системи захисту інформації, події злому котрих (зокрема, порушення конфіденційності текстової інформації) можуть призвести до непоправних втрат. Зокрема, під час перехоплення особливо важливої, у т.ч. таємної, інформації, що транспортується через будь-яке фізичне середовище, до якого існує відкритий доступ з боку потенційних зловмисників. Наприклад, несанкціонований доступ до банківської таємниці, перехоплення терористами перемовин між авіадиспетчером та екіпажем під час приземлення повітряного судна, перехоплення супротивником дипломатичної пошти, перемовин між суб'єктами воєнних дій тощо. У прикладних задачах, де необхідно забезпечити абсолютну гарантованість захисту текстової інформації, використання способу, що заявляється, за певних надалі визначених умов може виявитися безальтернативним технічним рішенням. Як правило, для забезпечення конфіденційності текстової інформації, що циркулює між обмеженим колом уповноважених суб'єктів - власників ключової (парольної) інформації, використовують способи симетричної криптографії, класифікація та основні характеристики котрих надано у працях багатьох авторів (див., зокрема, [1]). Ці способи розділяють на дві групи - блокові та потокові шифри [2]. Типовим прикладом реалізації блокового шифру є спосіб шифрування за алгоритмом DES (Data Encryption Standard), що розроблений фірмою IBM і взятий у 1977 р. за стандарт США, а також численні модифікації та удосконалення цього шифру. Його криптоаналіз надано, зокрема, у [2]. У блокових шифрах, зокрема в алгоритмі DES, використовують принцип збільшення абетки, над знаками якої виконуються операції шифрування. У цьому разі використання статистичних закономірностей відкритих текстів для зламу шифру надто ускладнюється, адже із зростанням потужності абетки зростає й ентропія, що припадає на один знак (блок) нової абетки. Криптостійкість блокового шифру забезпечується багаторазовим застосуванням операцій підстановки (заміни) блоків та перестановки їхніх координат з метою розсіювання та перемішування інформації, що підлягає шифруванню. Цим знищується можливий статистичний зв'язок між знаками відкритого тексту, а також між ключем та криптограмою. Якщо операції шифрування здійснювати з блоками, в яких не менше 64 розрядів, то спосіб шифрування за алгоритмом DES здатний забезпечити високий рівень практичної стійкості шифру. Потокові шифри оперують бітовими або байтовими потоками відкритого тексту і на кожному кроці шифрування перетворюють один й той самий біт відкритого тексту у різні біти криптограми залежно від використаного ключа шифру та від розташування біта (байта) у тексті [2]. У сучасних потокових шифрах ключовий потік бітів (гама) генерується із короткого основного ключа за допомогою певних детермінованих алгоритмів. Для забезпечення стійкості шифрування гама має якомога достовірніше виглядати випадковою. Основний режим роботи будь-якого потокового шифру - гамування, коли генератор гами видає потік її бітів γ 1, γ2,…,γn, який далі накладають на потік бітів відкритого тексту x1,x2,…,xn, тобто здійснюють операцію XOR (додавання за модулем 2). Як результат, утворюється потік шифрованого тексту z1,z2,…,zn, де zi=xi+γі (у даному випадку, + - це символ операції додавання за модулем 2). Під час розшифрування для відновлення бітів відкритого тексту над бітами шифротексту і тієї самої гами виконують операцію XOR: xi=zi+γi повторно. За певних чітко визначених умов [2] потокові шифри також здатні забезпечити високі рівні практичної стійкості. Однак, названі вище способи симетричного шифрування не забезпечують абсолютну гарантованість захисту текстової інформації (іншими словами, не забезпечують теоретично стійке шифрування), тому що завжди існує можливість здійснити прямий перебір можливих варіантів паролю (хоч для цього необхідно, у більшості випадків, виконати невиправдано великий обсяг обчислювальних робіт) і, врешті решт, "зламати" захист, тобто зробити обґрунтований висновок щодо змісту вихідної інформації. Вибраний як прототип, спосіб захисту текстової інформації базується на використанні так званої схеми Моборна/Вернама ("метод одноразових блокнотів") [2]. Схема Моборна/Вернама, як на формальному рівні довів К. Шеннон [3], забезпечує абсолютний, тобто теоретично необмежений, рівень стійкості зашифрованих текстів, але за умови, коли сумарна довжина цих текстів не перевищує довжину ключа шифру. Це означає, що на відміну від вищеназваних, цей спосіб не може бути скомпрометований шляхом прямого перебору можливих варіантів паролю, але лише у разі, якщо обсяг даних, що підлягає шифруванню, не перевищує довжину паролю. Назване вище обмеження потребує частої зміни ключів шифру, що унеможливлює доцільність застосування цього способу для більшості прикладних задач на практиці, особливо у випадках, 1 UA 98142 U 5 10 15 20 25 30 35 40 45 50 55 60 коли розповсюдження парольної інформації з економічної точки зору не є виправданим або внаслідок технологічних обмежень не може бути здійснено. Відображеному у прототипі криптографічному способу, як і всім іншим вищеописаним криптографічним способам захисту текстової інформації, властивий недолік, який суттєво звужує можливі області їхнього використання на практиці. Цей недолік полягає у тому, що у процесі злому будь-якої із відомих криптографічних систем захисту текстової інформації крипто аналітик має можливість визначити момент успішного завершення своєї роботи. Дійсно, під час криптографічного шифрування тексту смисловий зміст інформації, що захищається, як правило, перетворюється у семантично невизначений набір символів алфавіту, що використовується. Тому факт успішного злому системи захисту крипто аналітик визначає у момент перетворення беззмістовного зашифрованого тексту в семантично коректну послідовність символів, як правило, таку, що відбиває істинний смисл повідомлень. Таким чином, щодо відомих способів захисту текстової інформації є справедливим наступне твердження: якщо у розпорядженні крипто аналітика знаходиться достатньо великий обсяг зразків зашифрованої інформації (завідома більший, ніж обсяг парольної інформації) та застосовується метод прямого перебору ключів шифру, то існує теоретична, а в багатьох випадках і практична, можливість здійснити компрометацію будь-якого із відомих способів симетричного шифрування текстової інформації. Тому рівень довіри до формальних визначень криптографічної стійкості відомих способів захисту текстової інформації не є абсолютним. Так що, відомі криптографічні системи не забезпечують абсолютну гарантованість захисту текстової інформації від порушень її конфіденційності. В основу корисної моделі поставлено задачу: за рахунок попередньої лінгвістичної обробки зразків текстової інформації, що підлягають шифруванню, забезпечити можливість функціонування криптографічної системи захисту текстової інформації з будь-яким наперед визначеним формально обґрунтованим рівнем стійкості до крипто аналітичних атак, а за певних формально визначених умов забезпечити абсолютну гарантію захисту текстової інформації від порушень конфіденційності як під час її зберігання у комп'ютерах, так і під час її передавання через незахищені середовища транспортування інформації. При цьому абсолютна гарантованість захисту має забезпечуватися як з теоретичної, так і з практичної точок зору. Поставлена задача вирішується тим, що у рамках формально визначених обмежень щодо множини смислових образів, що відображають тезаурус вибраної сфери прикладних застосувань розроблюють лексикографічну систему, яку реалізують у вигляді прикладного лінгвістичного корпусу, і далі безпосередньо перед шифруванням текстової інформації згідно з будь-яким вибраним способом симетричної криптографії здійснюють семантичну структуризацію цієї інформації з використанням засобів побудованого лінгвістичного корпусу таким чином, щоб зразки зашифрованих текстових повідомлень представляли семантично правдоподібні уривки тексту, а будь-який результат застосування будь-якого із можливих способів криптоаналізу приводив до отримання нехай інших щодо смислу, але теж семантично правдоподібних текстових повідомлень. Лінгвістичний корпус визначається як програмний засіб автоматичного розбиття електронного тексту, що підлягає захисту, на "мікроконтексти" - фрагменти тексту, які "групуються" навколо лінгвістичних одиниць (зокрема, слів, фраз, сценаріїв тощо), що є об'єктами тлумачення [4]. Під тезаурусом мови розуміється лексика мови із визначеними семантичними відношеннями між лінгвістичними одиницями. У даному випадку тезаурус - ієрархічна структура семантичних словників, що визначає семантичні відношення між лінгвістичними одиницями мови, що прийнята для відображення текстових повідомлень заданої сфери застосувань. Тут і далі словоутворення "сутність", "смисл" та "суть змісту" вважаються синонімами. Спосіб захисту текстової інформації, що заявляється, базується на забезпеченні неоднозначності зворотного переходу від зашифрованого відображення сутності (тобто, смислу або, іншим словом, суті змісту) вихідного текстового повідомлення, представленого у вигляді однієї із можливих форм цього відображення, до вихідного текстового повідомлення (і, отже, і до суті його змісту). В основу даного способу покладена фундаментальна особливість філософської категорії "співвідношення форма-зміст". А саме: будь-яка сутність може бути відображена різноманітними формами. Тобто, у загальному випадку однозначного зв'язку між сутністю текстових повідомлень та формою їхнього відображення не існує. Отже, якщо перехоплені криптоаналітиком зразки зашифрованих текстових повідомлень (у рамках формально визначених обмежень вибраної сфери прикладних застосувань) являють собою семантично правдоподібні уривки тексту, а будь-який результат застосування будь-якого із можливих способів криптоаналізу приводить до отримання нехай іншого щодо смислу, але теж 2 UA 98142 U 5 10 15 20 25 30 35 40 45 50 55 семантично правдоподібного уривку тексту, то істинність вихідного повідомлення за певних формально визначених умов не є можливим виявити, оскільки криптоаналітик не має можливостей визначити факт успішного завершення своєї роботи. Конфіденційність текстової інформації згідно зі способом, що заявляється, забезпечують наступним чином. Зразок незашифрованого вихідного текстового повідомлення D за допомогою засобів спеціально розробленого лінгвістичного корпусу оброблюють за правилами SF граматики мови (природної або штучної), що прийнята для відображення текстових повідомлень заданої сфери прикладних застосувань. Як результат, отримують коректно сформований за правилами граматики зразок FD вихідного текстового повідомлення та додаткову інформацію щодо структури цього повідомлення (прийняту систему мовних одиниць, локалізацію мовних одиниць у дискретній послідовності цих одиниць, результати маркування (розмітки) вихідного повідомлення за лінгвістичними характеристиками тощо). Далі виконують аналіз SC зразка FD на відповідність тезауруса мови, спеціально розробленого для відображення смислових одиниць заданої сфери застосувань. Як результат, отримують зразок вихідного відкритого тексту CD, що без спотворень відображає смисл вихідного текстового повідомлення і відповідає прийнятим граматичним правилам та семантичним обмеженням. Далі безпосередньо виконують шифрування з використанням будь-якого відомого потокового шифру SZ, що заснований на застосуванні генератора псевдовипадкових послідовностей. А саме, згідно з паролем встановлюють ГПВП у початковий стан і далі шляхом гамування (тобто, виконання операції XOR - додавання за модулем 2) елементи повідомлення CD заміняють на елементи тезауруса. Як результат, отримують зразок зашифрованого текстового повідомлення ZD, що має правдоподібний, але, найбільш ймовірно, інший смисл (чим забезпечується неоднозначність у сприйнятті смислу зашифрованого повідомлення). Для розшифрування повідомлення ZD 0 застосовують оператор зворотного перетворення S Z. А саме, за допомогою відомого пароля встановлюють ГПВП у той самий початковий стан, що і під час шифрування, і далі використовують операцію XOR повторно, тобто елементи неоднозначного щодо смислу зашифрованого повідомлення ZD шляхом відповідного вибору із тезауруса заміняють на 0 елементи тексту Z D, що однозначно відображає смисл вихідного текстового повідомлення CD. Область використання заявленого способу обмежується наступною умовою: елементи усіх можливих зразків текстової інформації мають знайти своє відображення у тезаурусі, спеціально розробленому для відображення смислу текстових повідомлень заданої сфери застосувань. Послідовність операцій з обробки текстової інформації на кожному із технологічних етапів реалізації заявленого способу показана на кресленні у вигляді діаграми форм представлення оброблюваного зразка текстового повідомлення та операторів перетворення цих форм засобами системи захисту. На кресл. прийнято наступні позначення: S - людина або комп'ютерна програма, що синтезує зразок вихідного текстового повідомлення D у процесі вирішення прикладних завдань заданої сфери застосувань; D - зразок вихідного (незашифрованого, відкритого) текстового повідомлення, що потребує захисту (S:D, де «:» - знак візуального сприйняття); SF - оператор обробки вихідного зразка за правилами граматики мови (природної або штучної), що прийнята для відображення текстових повідомлень заданої сфери застосувань, з використанням засобів спеціально розробленого лінгвістичного корпусу; FD - зразок коректно сформованого за правилами граматики вихідного текстового повідомлення та додаткова інформація щодо структури цього повідомлення (прийнята система мовних одиниць, локалізація мовних одиниць у дискретній послідовності цих одиниць, результати маркування (розмітки) вихідного повідомлення за лінгвістичними характеристиками тощо); SC - оператор аналізу зразка текстового повідомлення на відповідність тезаурусу мови, спеціально розробленого для відображення смислу текстових повідомлень заданої сфери застосувань; CD - зразок тексту, що безпосередньо відображає смисл вихідного текстового повідомлення і відповідає прийнятим граматичним правилам та семантичним обмеженням; SZ - оператор шифрування, що перетворює вихідний зразок відкритого текстового повідомлення на зразок зашифрованого текстового повідомлення, що має правдоподібний, але, найбільш ймовірно, інший смисл (чим забезпечується неоднозначність у сприйнятті смислу зашифрованого повідомлення); ZD - зразок зашифрованого текстового повідомлення (синтезований із семантичних одиниць використаного тезаурусу), смисловий зміст котрого, найбільш ймовірно, відрізняється від смислу вихідного текстового повідомлення; 3 UA 98142 U 0 5 10 15 20 25 30 35 40 45 50 55 60 S Z - оператор розшифрування, що забезпечує перетворення неоднозначного щодо смислу зашифрованого повідомлення на зразок тексту, що однозначно відображає смисл вихідного текстового повідомлення; 0 Z D - зразок розшифрованого текстового повідомлення, що повністю співпадає із CD, тобто 0 0 Z D↔CD, де символ ↔ означає співпадіння форми та смислу повідомлень Z D та CD. Щодо кресл. слід надати наступні пояснення. Як вихідні дані, що є необхідними для реалізації оператора SF, окрім вихідних текстових повідомлень, використовують дані щодо структури текстів, їхніх лінгвістичних характеристик, зокрема правила граматики мови, що прийнята для відображення текстових повідомлень заданої сфери застосувань. Засоби відтворення цих даних складають так званий лінгвістичний корпус, з використанням котрого здійснюється маркування (розмітка) текстового повідомлення за його лінгвістичними характеристиками. Оператор SF забезпечує коректність граматичної структури вихідних повідомлень, що створюються людиною або комп'ютерною програмою, відповідно до правил та обмежень, що задаються засобами лінгвістичного корпусу. У випадках невідповідності цим правилам текстові повідомлення повертаються їхнім створювачам на доопрацювання. Стисло суть способу, який заявляється, можна визначити як включення до системи криптографічного захисту інформації засобів лексикографічної системи таким чином, щоб у процесі шифрування забезпечувалась семантична неоднозначність зашифрованих зразків тексту. При цьому засоби лексикографічної системи, що використовуються, мають бути спроможними здійснювати граматичний та семантичний аналіз текстів у рамках заданої прикладної області. Як вихідні дані, що є необхідними для реалізації оператора Sc, окрім граматично коректних вихідних текстових повідомлень, використовують семантичні конструкції задіяного тезаурусу мови. Оператор SC забезпечує відповідність текстових повідомлень елементам тезаурусу, що гарантує потенціальну можливість шифрування смислу цих повідомлень. Оператор шифрування SZ здійснює заміну вихідного (скоригованого операторами SF та SC) зразка відкритого текстового повідомлення на лінгвістичну конструкцію, елементи котрої обрані випадковим чином із тезаурусу. Характер випадковості визначається властивостями генератора псевдовипадкових послідовностей (ГПВП), що має функціонувати у складі задіяної схеми шифрування. Заявлений набір операцій з обробки текстової інформації та заявлена послідовність їхнього виконання забезпечують можливість отримання абсолютної гарантії захисту текстової інформації від порушень конфіденційності в умовах, коли обсяги текстової інформації, що підлягають шифруванню, суттєво перевищують обсяги парольної (ключової) інформації, що містяться у ключах задіяних шифрів. Зазначений вище технічний результат, який досягається в процесі реалізації запропонованого способу, обумовлений ознаками, які відрізняють його від ознак інших способів захисту текстової інформації, описаних згідно відомого рівня техніки, зокрема, у джерелі інформації, прийнятому за прототип. Сукупність методів, що покладені в основу даного способу захисту текстової інформації, доцільно виділити в окрему групу криптографічних методів, яку назвати як семантична криптографія, оскільки об'єктами захисту у рамках цієї групи є смисловий зміст текстової інформації, що захищається. Приклад 1 Криптографічна система (КС), що реалізує викладений вище спосіб, може бути використана в системах авіаційного радіозв'язку для забезпечення конфіденційності радіообміну текстовими повідомленнями між екіпажами повітряних суден та авіадиспетчерами. У цьому випадку КС має містити у своєму складі усі основні елементи симетричної криптографічної системи потокового шифрування та забезпечувати захист радіообміну за умови синхронізації генераторів псевдовипадкових послідовностей (ГПВП), що розташовані на передавальній та приймальній сторонах каналу секретного обміну інформацією. Розшифрування здійснюється з використанням відомого ключа шифру (пароля). Окрім засобів шифрування/розшифрування, у блок-схему КС включаються засоби лінгвістичного корпусу у складі лінгвістичного аналізатора текстів, тезауруса мови відображення текстів предметної області та програмного комплексу маркування (розмітки) вихідних текстів. Лінгвістичний аналізатор контролює відповідність вихідних зразків текстової інформації граматичним та семантичним правилам та обмеженням, що прийняті у стандартних сценаріях авіаційного радіообміну. Тезаурус створюється за результатами статистичного та семантичного аналізів предметної області і повинен містити усі 4 UA 98142 U 5 10 15 20 25 30 35 лінгвістичні одиниці, котрі потенційно можуть бути включені до складу будь-якого зразка (фрагмента, повідомлення) відкритого тексту, що має бути захищений від втрати конфіденційності. Як вихідні дані для створення тезауруса використовуються чинні Правила ведення радіотелефонного зв'язку та фразеологія радіообміну в повітряному просторі України, що затверджені постановою Кабінету Міністрів України від 7 вересня 2002 року, № 1328. Приклад 2 Викладений вище спосіб забезпечення конфіденційності текстової інформації може бути використаний для захисту даних, що містяться у заданих табличних формах довільної розмірності. У цьому випадку КС, що реалізує захист табличних даних, має містити у своєму складі ті ж самі елементи, що і КС, яка описана у попередньому прикладі. Відмінність лише у структурах тезаурусів. Елементи усіх можливих зразків табличних даних мають знайти своє відображення у тезаурусі, спеціально розробленому для відображення смислу цих даних у заданій сфері прикладних застосувань. Джерела інформації: nd 1. Schneier В., Applied Cryptography: Protocols, Algorithms, and Source Code in C, 2 ed. New York // John Wiley and Sons, 1996. Шнайер Брюс. Прикладная криптография. Протоколы, алгоритмы, исходные тексты на языке Си - М.: Издательство ТРИУМФ, 2003. - 816 с. 2. Математичні основи криптоаналізу [Текст]: навч. посібник / С.О. Сушко, Г.В. Кузнецов, Л.Я. Фомичова, А.В. Корабльов. - Д.: Національний гірничий університет, 2010. - 465 с. 3. Шеннон К.Э. "Теория связи в секретных системах". В кн.: Шеннон К.Э. Работы по теории информации и кибернетике. М.: Иностранная литература. 1963, с. 332-402, 829 с. 4. Корпусна лінгвістика / В.А. Широков, О.В. Бугаков, Т.О. Грязнухіна та ін. - К.: Довіра, 2005. - 471 с. ФОРМУЛА КОРИСНОЇ МОДЕЛІ Спосіб забезпечення конфіденційності текстової інформації, згідно з яким здійснюють шифрування/розшифрування зразків тексту із застосуванням симетричного криптографічного алгоритму, що базується на використанні властивостей генератора дискретних (псевдо)випадкових послідовностей, який відрізняється тим, що перед шифруванням зразки вихідного тексту за допомогою засобів лінгвістичного корпусу структуруються за лінгвістичними характеристиками таким чином, щоб шифрування будь-якого зразка вихідного тексту, що складається із елементів тезауруса мови відображення заданої кінцевої множини текстів, приводило до отримання правдоподібного зразка тексту, смисл котрого випадковим чином відрізняється від смислу зразка вихідного тексту. 5 UA 98142 U Комп’ютерна верстка Д. Шеверун Державна служба інтелектуальної власності України, вул. Василя Липківського, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 6
ДивитисяДодаткова інформація
Автори англійськоюKocherhin Yurii Anatoliiovych
Автори російськоюКочергин Юрий Анатольевич
МПК / Мітки
МПК: H04K 1/00, G09C 1/00, G06K 1/00
Мітки: забезпечення, текстової, конфіденційності, спосіб, інформації
Код посилання
<a href="https://ua.patents.su/8-98142-sposib-zabezpechennya-konfidencijjnosti-tekstovo-informaci.html" target="_blank" rel="follow" title="База патентів України">Спосіб забезпечення конфіденційності текстової інформації</a>
Спосіб забезпечення конфіденційності інформації на базі коду умовних лишків

Номер патенту: 78182
Опубліковано: 11.03.2013
Автори: Василенко Вячеслав Сергійович, Василенко Микола Юрійович, Чунарьова Анна Вадимівна, Чунарьов Андрій Вадимович
МПК: H03M 13/03
Мітки: забезпечення, конфіденційності, лишків, базі, умовних, коду, спосіб, інформації
Формула / Реферат:
Спосіб забезпечення конфіденційності інформації на базі коду умовних лишків, що полягає у використанні механізму формування блоків зашифрованого повідомлення, який відрізняється тим, що при шифруванні елементи блока початкового інформаційного об'єкту розглядають як узагальнені символи - лишки в умовній системі числення в лишкових класах, що надає змогу при прямому криптографічному перетворенні застосувати до них алгоритми перетворення з цієї...
Пристрій для відображення текстової і графічної інформації

Номер патенту: 25406
Опубліковано: 10.08.2007
Автори: Гаращенко Сергій Олександрович, Попенко Віктор Олександрович
МПК: G09G 3/00
Мітки: пристрій, інформації, текстової, графічної, відображення
Формула / Реферат:
1. Пристрій для відображення текстової і графічної інформації, що містить світловий екран, який включає щонайменше один екранний модуль, блок комутації, блок пам'яті, блок керування інформацією у вигляді процесора з інформаційним входом і інформаційним виходом, з'єднаним через блок комутації зі світловим екраном, і джерело живлення, який відрізняється тим, що інформаційний вхід процесора з'єднаний з приймачем сигналів цифрового...
Спосіб захисту текстової, табличної та графічної інформації

Номер патенту: 38479
Опубліковано: 12.01.2009
Автори: Назаркевич Марія Андріївна, Дронюк Іванна Мирославівна
МПК: G06K 15/22
Мітки: інформації, спосіб, текстової, табличної, графічної, захисту
Формула / Реферат:
1. Спосіб захисту текстової, табличної та графічної інформації, згідно з яким утворюють графічний елемент, його копіюють, розмножують, поєднуючи різні комбінації, та будують захисну сітку, накладають її на текстову, табличну та графічну інформацію, відтворюють інформацію у векторному форматі, який відрізняється тим, що графічний елемент захисної сітки вибирають як графік протабульованої Ateb-функції, яка побудована згідно з...
Автоматизована інформаційно-сервісна система “топзв’язок” для з’єднання користувачів та пересилання інформації із перекладом гоглосової або текстової інформації, сортування, аналізування, консультування, з еле

Номер патенту: 92266
Опубліковано: 11.08.2014
Автори: Костенко Максим Вікторович, Костенко Віктор Андрійович
МПК: H04M 13/00, G06F 17/30, G06F 13/00, G06Q 90/00, G06F 17/28
Мітки: пересилання, гоглосової, інформації, автоматизована, текстової, консультування, користувачів, інформаційно-сервісна, сортування, з'єднання, аналізування, еле, система, перекладом, топзв'язок
Формула / Реферат:
1. Автоматизована інформаційно-сервісна система для з'єднання користувачів та пересилання інформації із перекладом голосової або текстової інформації, сортування, аналізування, консультування, з електронною книгою відгуків, що включає щонайменше один сервер системи з щонайменше одним Інтернет-сайтом, модуль управління, встановлений на сервері системи, виконана із можливістю електронного та мобільного зв'язку, із можливістю пересилання SMS...
Спосіб пошуку текстової інформації за схожістю

Номер патенту: 71159
Опубліковано: 10.07.2012
Автори: Добровольський Геннадій Анатолійович, Тодоріко Ольга Олексіївна
МПК: G06F 7/10
Мітки: інформації, текстової, спосіб, пошуку, схожістю
Формула / Реферат:
Спосіб пошуку текстової інформації за схожістю, який включає визначення області пошуку як колекції слів; визначення непустого алфавіту; побудову пошукового індексу шляхом обчислення сигнатури кожного слова словника; інтерпретацію кожної сигнатури як двійкового запису числа - значення хеш-функції та збереження слів словника у вигляді хеш-таблиці; завдання пошукового запиту у вигляді рядка, який може містити помилки; створення на основі...
Попередній патент: Пристрій для введення в мікропроцесор багатоканальної аналогової інформації, яка швидко змінюється
Наступний патент: Пристрій контролю переміщення електромобілів по нахилених дорогах
Випадковий патент: Пристрій для розрізання рулонного матеріалу на заготовки