Спосіб безартефактного кодування та декодування зображень
Номер патенту: 39378
Опубліковано: 25.02.2009
Автори: Свічкарьов Сергій Іванович, Афанасьєв Денис Миколайович, Палаш Олександр Васильович







Формула / Реферат
Спосіб безартефактного кодування зображень, згідно з яким для зображення, записаного в файл растрового формату, задають розмір підмножини випадково вибраних пікселів; здійснюють генерацію масиву випадково вибраних координат пікселів; формують підмножину випадково вибраних пікселів на основі генерованого масиву координат; формують основну модель зображення шляхом інтерполяції амплітуд кольору на підмножині випадково вибраних пікселів; формують масив даних помилки шляхом обчислення різниці амплітуд кольору пікселів фізичного зображення та пікселів основної моделі; здійснюють формування редукованого масиву даних помилки шляхом задання граничної величини помилки та множника квантування, порівняння значень помилки за абсолютним значенням з попередньо встановленою граничною величиною, присвоєнню значенням помилки, які за абсолютним значенням менші граничної величини, нульового значення, генерації набору значень випадкового шуму за допомогою програмного генератора випадкових чисел, підсумовування значень помилки, які за абсолютним значенням більше граничної величини, з набором значень випадкового шуму; квантування отриманих підсумованих значень з використанням попередньо встановленого множника квантування, здійснюють архівування масиву даних редукованої помилки, записують у файл масив даних редукованої помилки, підмножину випадково вибраних пікселів, координати випадково вибраних пікселів або параметри генерації масиву випадково вибраних координат пікселів.
Текст
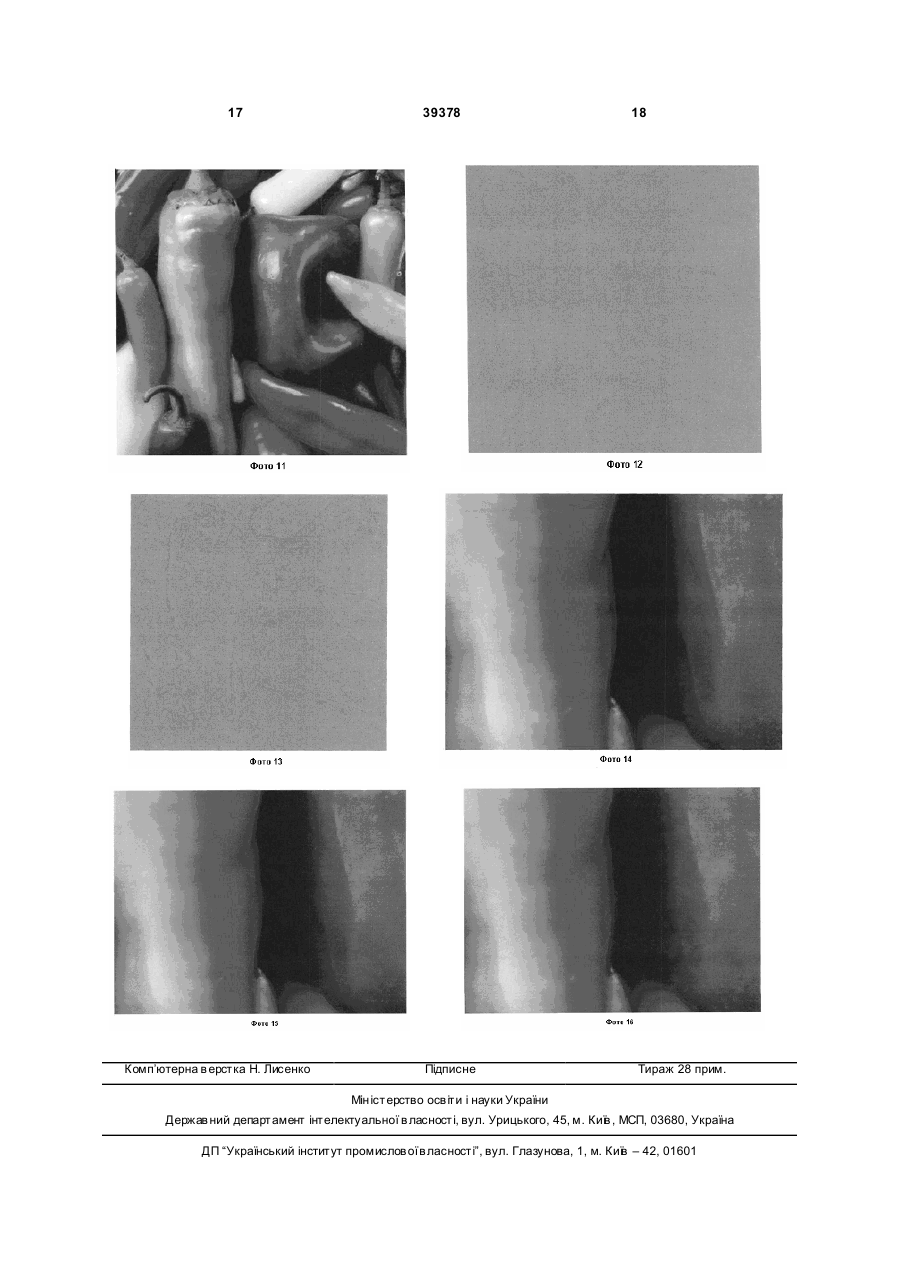
Спосіб безартефактного кодування зображень, згідно з яким для зображення, записаного в файл растрового формату, задають розмір підмножини випадково вибраних пікселів; здійснюють генерацію масиву випадково вибраних координат пікселів; формують підмножину випадково вибраних пікселів на основі генерованого масиву координат; формують основну модель зображення шляхом інтерполяції амплітуд кольору на підмножині випадково вибраних пікселів; формують масив даних помилки шляхом обчислення різниці амплітуд кольору пікселів фізичного зображення U 2 (19) 1 3 39378 отриманому зображенні з'являються артефакти, як результат недотримання вимог теореми відліків [теорема Уіттакера-Найквіста-КотельниковаШеннона, джерело - R. Cook, "Stochastic Sampling in Computer Graphics" ACM Transactions on Graphics, Jan. 1986, стор. 51-72, стор. 52, 53]. Артефактом зображення є будь-яка нова структура або елемент зображення, які не присутні на відображуваному об'єкті, але присутні на його зображенні та які мають невипадковий характер. Артефакти відображаються при виводі цифрового зображення на засіб виводу, наприклад монітор або при печаті зображення на принтері та погіршують якість зображення, а також мають властивість накопичуватися. Прикладом візуального відображення артефактів є східчаста структура ліній або країв об'єктів зображення растрової графіки. Для боротьби з артефактами зображень застосовують, наприклад, пре фільтрацію (попередню фільтрацію) з використанням відомих функцій фільтра або постфільтрацію або сполучення цих засобів [М. Dippé and E. Wold. Antialiasing through Stochastic Sampling. In Computer Graphics (SIGGR APH'85 Conference Proceedings), стор.6978, 1985, стор.69]. Варто відмітити те, що, як правило, при використанні вищезазначених методів ставиться завдання утримання інтенсивності артефактів на визначеному рівні при збільшенні коефіцієнта стиснення зображення. Заявнику відомо багато способів кодування та декодування зображень, серед яких найближчими є наступні. Відомий спосіб кодування та декодування зображень, який здійснює стискання з втратами інформації про зображення, розроблений групою експертів в області фотографії - JPEG (Joint Photographic Experts Group) (http://www.jpeg.org/). Цей метод досить розповсюджений для кодування та декодування зображень та включає наступні етапи: розподіл висхідного зображення, яке представлене множиною амплітуд яскравості та множинами амплітуд кольорів пікселів, на рівні прямокутні області, які являють собою підмножини (матриці) пікселів розміром 8x8, дискретне косинусне перетворення (ДКП), яке формує з множини амплітуд кольору пікселів множину частотних коефіцієнтів амплітуд кольору пікселів. Після здійснення ДКП значення множини частотних коефіцієнтів амплітуд кольору пікселів квантується, для зменшення об'єму інформації, який містить вищезазначена множина. Потім здійснюють стискання квантованої множини частотних коефіцієнтів амплітуд кольору пікселів, наприклад, з допомогою алгоритму Ха ффмана або арифметичного кодування. При декодуванні здійснюють дії, які є такими же, як і при кодуванні, але в зворотному порядку. Після використання ДКП здійснюють відкидання високочастотних компонентів амплітуд кольорів зображення шляхом квантування коефіцієнтів ДКП, що дозволяє отримати суттєве стискання зображення, маючі часткову втрату інформації про зображення, проте одночасно дозволяє суттєво збільшити швидкість кодування. Але часткова 4 втрата інформації після проведення ДКП та квантування призводить до появи блочних та інших артефактів. Таким чином, наявність артефактів у відновленому зображенні унеможливлює застосування методу кодування та декодування за алгоритмом JPEG у таких галузях, як, наприклад, медицина або геологія, де потрібні високоякісні зображення, які мають особливу інформацій цінність та які в подальшому можуть бути застосовані не тільки для візуального спостереження, але й будуть піддані подальшій обробці для добування із зображень важливої інформації (наприклад, супутникові або рентгенівські знімки). У таких випадках, як правило, застосовують формально безвтратні методи кодування/декодування зображень. Так, відомий спосіб кодування та декодування зображень JPEG-LS [http://www.jpeg.org/jpeg/jpegls.html], який здійснює кодування зображення без втрат інформації про зображення, або, як опція, з невеликими втратами інформації про зображення. В основі цього способу лежить алгоритм кодування LOCO-I [(LOw Complexity Compression for Images) (M. Weinberger, G. Seroussi, G. Sapiro, "The LOCO-I Lossless Image Compression Algorithm: Principles and Standardization into JPEG-LS", Hewlett-Packard Laboratories Technical Report No. HPL-98-193R1, November 1998, revised October 1999. IEEE Trans. Image Processing, Vol. 9, August 2000, crop. 13091324)]. За цим способом здійснюють формування основної моделі зображення шляхом інтерполяції амплітуди кольору поточного піксела на підмножині амплітуд кольорів попередньо оброблених пікселів, наприклад, двох сусідніх, формують масив помилки між основною моделлю зображення та висхідним зображенням та кодують цю помилку на основі коду Голомба-Райса. Під час формування основної моделі використовують також методи аналізу структури зображення та пошуку та формування контекстної моделі зображення на основі надлишковості інформації зображення, що ускладнює застосування цього способу. При цьому методи формування контекстної моделі зображення не є універсальними для різних типів зображення. Додатково застосування такого способу у галузях, таких як, наприклад, медицина, де повинні використовуватись зображення без жодних артефактів, через що файли для збереження мають дуже великі об'єми, призводить до того, що об'єм графічної інформації медичних закладів збільшується на сотні Тбайт у рік, що неприпустимо. Відомий спосіб кодування та декодування кольорових зображень без втрат, в якому використовують ентропійне кодування. За цим способом формують основну модель зображення з амплітуд кольору поточних пікселів шляхом інтерполяції амплітуд кольору попередньо оброблених пікселів при попередньому заданому правилі обходу усіх пікселів у висхідному зображенні. Далі формують масив даних помилки шляхом обчислення різності між інтерпольованими значеннями пікселів та значеннями пікселів оригінального зображення. Потім здійснюють перетворення величини помилки у бінарний вигляд та здійснюють пошук безперервних серій нульових значень помилки з наступним 5 39378 частковим їх видаленням. Для ненульових значень помилки, які залишилися, генерують код, який показує кількість ненульових значень [заявка № WO 2006/010644, опублікований 04.072007р., МПК: H04N1/417]. Також відомий спосіб кодування та декодування зображень, за яким здійснюють інтерполяцію амплітуди кольорів пікселів, використовуючи підмножину пікселів, які розташовані навколо відносно поточного піксела, для визначення амплітуди кольору поточного, на основі чого формують основну модель зображення. Далі здійснюють квантування підмножини навколишніх пікселів з заданим множником квантування та підраховують загальну помилку для кожної квантованої підмножини навколишніх пікселів. На підставі значень помилки формують кодову таблицю для кожної підмножини, здійснюють кодування величини помилки на основі відновлених значень помилки з кодової таблиці пов'язаних з поточним пікселом. При декодуванні здійснюють відновлення зображення сумуванням величини помилки, взятої з кодової таблиці, з величиною поточного піксела, при цьому використовують підмножини навколишніх пікселів, які використовувалися при кодуванні [патент № US 5 680 129, опублікований 21.10.1997р., МПК: Н03М7/30]. За прототип прийнято спосіб кодування та декодування зображень, за яким здійснюють аналогічні дії з формування основної моделі зображення та обчислення масиву даних помилки. Інтерполяцію здійснюють у визначеним чином розбитих підобластях зображення, здебільше прямокутних, а масив даних помилки обмежують в заданих межах шляхом порівняння з граничним значенням та подальшим розділенням поточної під області на менші підобласті до досягнення мінімального розміру підобласті [патент № US 4 791 486, опублікований 13.12.1988р., МПК: H04N7/12]. За цим способом здійснюють обмеження значень помилки у визначених межах, що дозволяє покращити стиснення масиву даних помилки та зменшення об'єму вихідного файлу при кодуванні. Але у відновленому зображенні, отриманому цим способом, зберігаються когерентні складові спектру помилки, які погіршують зображення. Також при повторних стисненнях такого зображення за цим способом отримують накопичення вказаних артефактів, що зменшує область його використання (наприклад, унеможливлюють застосування отриманих зображень у медицині або геології, де потрібні зображення без сторонніх елементів). Зазначені способи кодування не привносять нових артефактів у силу безвтратності кодування, але й не дозволяють здійснити видалення артефактів у вхідному (оригінальному) зображенні, а також мають неефективні показники «стиснення/якість» зображення при переході до кодування з втратами. В основу корисної моделі поставлено задачу покращення способу кодування та декодування зображень, який би забезпечував часткову або повну відсутність когерентних артефактів у відновленому зображенні (отриманому при декодуванні) при одночасному збільшенні ефективності сти 6 снення цифрового зображення без втрат та покращення співвідношення стиснення-якість зображення шляхом забезпечення характеру помилки у вигляді випадкового шуму при декодуванні зображення. Поставлена задача вирішується таким чином, що у способі безартефактного кодування зображень, згідно з яким для зображення, записанного в файл растрового формату, за корисною моделлю: - задають розмір підмножини випадково обраних пікселів; - здійснюють генерацію масиву випадково обраних координат пікселів; - формують підмножину випадково обраних пікселів на основі генерованого масиву координат; - формують основну модель зображення шляхом інтерполяції амплітуд кольору на підмножині випадково обраних пікселів; - формують масив даних помилки шляхом обчислення різниці амплітуд кольору пікселів фізичного зображення та пікселів основної моделі; - здійснюють архівування масиву даних помилки; - записують у файл масив даних помилки, підмножину випадково обраних пікселів, координати випадково обраних пікселів або параметри генерації масиву випадково обраних координат пікселів. Для отримання відновленого зображення здійснюють декодування даних, кодованих ви щеописаним чином. При цьому виконують наступні дії: - розкривають файл зображення та відновлюють архівований масив даних помилки; - формують основну модель зображення шляхом інтерполяції амплітуд кольору на підмножині випадково обраних пікселів, з використанням алгоритму інтерполяції, який тотожній застосованому при кодуванні; - формують відновлене зображення шляхом підсумовування інтерпольованих амплітуд кольору з відновленими значеннями помилки. В якості додаткових дій, направлених на покращення параметрів вихідного зображення, покращення параметрів «стиснення/якість» при здійсненні способу кодування та декодування, тощо можуть здійснювати наступні дії. Ці дії є окремими випадками реалізації етапів способу кодування та декодування та ніяким чином не обмежують переліку дій, який викладено у формулі корисної моделі. Формування підмножини випадково обраних пікселів можуть здійснювати шляхом розбиття вхідного зображення на ідентичні елементарні області з суміжними межами, завдання єдиного правила обходу пікселів у вищеназваних елементарних областях та вибору єдиного піксела в кожній елементарній області з координатою, яку обирають з попередньо генерованого масиву випадкових чисел. В якості ідентичних елементарних областей можуть використовува ти прямокутники. Додатково можуть задавати правило обходу пікселів у елементарних областях, яке полягає в послідовному переборі пікселів, що належать до 7 39378 елементарної області, в напрямку зліва направо та зверху донизу. В якості методу інтерполяції при формуванні основної моделі зображення можуть використовувати тріангуляцію Делоне. Додатково можуть здійснювати архівування підмножини випадково обраних пікселів та координат випадково обраних пікселів. Також можуть здійснювати корекцію координат випадково обраних пікселів, багаторівневе подання масиву даних значень помилки або здійснюють нелінійне квантування при редукції помилки. В якості параметрів генерації масиву випадково обраних пікселів можуть використовувати параметр синхронізації генератора випадкових чисел, наприклад, кодове слово. В якості параметрів генерації масиву випадково обраних пікселів можуть використовувати посилання на попередньо задану таблицю координат випадково обраних пікселів, розташовану в окремому файлі на матеріальному носії даних. При декодуванні зображень можуть розкривати файл зображення та відновлювати архівований масив даних помилки, підмножину випадково обраних пікселів та координати випадково обраних пікселів. Також можуть здійснювати обчислення координат випадково обраних пікселів за допомогою синхронізованого генератора випадкових чисел. Додатково можуть здійснювати постфільтрацію відновленого зображення. Між сукупністю суттєви х ознак способу безартефактного кодування та декодування зображень, що заявляється, і технічним результатом, що досягається, існує наступний причинно-наслідковий зв'язок. При проведенні пошуку винахідниками встановлено, що існують теоретичні роботи з використання стохастичної (випадкової) вибірки для зменшення кількості артефактів у відновленому зображенні при кодуванні та декодуванні. Так, у роботі [М. Dippé and E. Wold. Antialiasing through Stochastic Sampling. In Computer Graphics (SIGGR APH'85 Conference Proceedings), стор. 6978, 1985, стор.69] досліджена задача перетворення масиву даних помилки, значення якої носять постійний характер (як було зазначено раніше, це і є артефакти), у випадковий шум, амплітуда якого плавно зростає по мірі росту коефіцієнта стискання. Таким чином, помилка перетворення на зображенні буде мати вигляд зернистості та розмитості, що близько до звичайного фізичного зображення, наприклад, фотознімку, який отримано за допомогою звичайного плівкового фотоапарату. При проведенні досліджень з отримання стисненого відновленого зображення та використовуючи данні роботи, винахідниками з'ясовано, що формування основної моделі зображення на основі стохастичної вибірки пікселів вхідного зображення в поєднанні з архівуванням масиву даних помилки та формуванням файлу для зберігання інформації про зображення, який містить масив даних помилки, підмножину випадково обраних пікселів, координат випадково обраних пікселів, 8 дозволяє здійснити часткове або повне перетворення вищеназваних артефактів, отриманих при первинному перетворенні фізичного зображення, у шумоподібний вид. Використання при кодуванні випадкової вибірки пікселів шляхом завдання розміру підмножини випадково обраних пікселів, генерації масиву випадково обраних координат пікселів, формування підмножини випадково обраних пікселів на основі генерованого масиву координат, дозволяє уникнути генерації артефактів при одночасному наближені величин масиву помилки до випадкового шуму. При застосуванні випадкової вибірки пікселів масив величин помилки буде мати вигляд випадкового шуму (візуально - розмитості), а не регулярної структури, яку мають сходові та блочні артефакти та яка помітна візуально. Метою застосування стохастичної вибірки пікселів для побудови основної моделі зображення є формування такої підмножини пікселів вихідного зображення, яка містить мінімум надлишковості інформації про зображення, згідно з теоремою Уиттакера-Найквиста-Котельникова-Шеннона. На відмінність від відомих способів кодування та декодування зображень, наприклад вищеописаного JPEG, частина інформації зображення артефактна складова (когерентний спектр помилки), яка виникає після первинного оцифровування, при декодуванні заміщується випадковим шумом, амплітуда якого плавно зростає пропорційно росту коефіцієнта стискання до визначеної межі, яка обумовлена візуально прийнятною якістю зображення та може змінюватися в залежності від потреб застосування відновленого зображення. Виконання випадкової вибірки за допомогою поділу вихідного зображення на ідентичні елементарні області з суміжними межами, завдання єдиного правила обходу пікселів у названих елементарних областях та вибору одного піксела у кожній елементарній області з координатою, яку обирають з попередньо генерованого масиву випадкових чисел, дозволяє гарантувати, що в кожній елементарній області буде обрано один піксел та середня щільність пікселів з декілька елементарних областей буде близька до середній щільності пікселів по всій площині малюнка, а також спростити вибір та запам'ятовування координат випадково відібраних пікселів у файл при кодуванні та витяг при декодуванні. У роботі [М. Dippé and E. Wold. Antialiasing through Stochastic Sampling. In Computer Graphics (SIGGRAPH'85 Conference Proceedings), стор. 69-78, 1985] описано, що шляхом застосування різних засобів стохастичної (випадкової) дискретизації [розподіл Пуссона (стор. 71, Фіг.2, 3 або розпиленої дискретизації (стор.72, Фіг.4, 5)] можна регулювати відношення «сигнал/шум» та розподільчу здатність відновленого зображення. Інтерполяція амплітуд кольору на підмножині випадково обраних пікселів призначена для обчислення величин амплітуд кольору решти пікселів, які складають основну модель зображення. Використання в якості алгоритму інтерполяції білінійної інтерполяції на трикутниках (тріангуляції Делоне) дозволяє отримати розмитості дрібних деталей в 9 39378 основній моделі зображення, що виконує функцію фільтру, що згладжує. Редукція масиву величин помилки вищевказаним чином призводить до відтворення вихідних величин помилки з визначеною величиною погрішності, яка залежить від параметрів редукції, тобто граничної величини помилки та множника квантування. Спектр такої залишкової погрішності має вигляд, близький до випадкового шуму, та практично не відрізняється від шуму, який має місце при застосуванні засобів аналогового представлення зображувальної інформації. Враховуючі те, що у вихідному (природному) зображенні є шум, як було зазначено раніше, то додатковий шум, який вносять за допомогою редукції масиву величин помилки, візуально невидимий до визначеної межі. При цьому на відновленому зображенні залишаються дрібні деталі, тонкі лінії та межі або вони передаються з невеликим контрольованим розмиттям. Шумова складова величини помилки необхідна тільки для «розмазування» помилок квантування, особливо у нижній частині діапазону амплітуд кольору. Цьому видалення шумоподібної складової при архівуванні масиву даних помилки дозволяє значно підвищити ступінь архівування масиву величин помилки за рахунок появи в масиві значної кількості нульових величин. При відновленні зображення в процесі декодування когерентні складові спектру помилки будуть замінені складовою шумоподібного виду. Варто відмітити, що погрішність вихідних величин помилки прямо пропорційна попередньо встановленим множнику квантування та граничній величині помилки. Здійснення попереднього завдання величини множника квантування та граничної величини помилки дозволяє обмежити середньоквадратичну величину помилки в визначених межах, що спрощує процес кодування та декодування. Це також призводить до відсутності необхідності застосування додаткових алгоритмів для утримання середньої величини помилки у заданих межах, які застосовуються, зокрема, у наведених аналогах при описі рівня техніки. Багаторівневе кодування дозволяє додатково підвищити коефіцієнт стиснення зображення та оптимізувати швидкість стискання. Уточнення координат масиву випадково відібраних пікселів дозволяє зменшити величини помилки. Спосіб безартефактного кодування та декодування зображень здійснюють наступним чином. У вхідному цифровому зображенні, яке представляє собою в загальному розумінні матрицю [b(i, j)], де і - кількість пікселів у горизонтальному рядку, j - кількість рядків у вхідному зображенні, задають розмір підмножини випадково вибраних пікселів. Розмір підмножини обмежується визначеною кількістю пікселів і залежить від розмірів вихідного зображення та необхідною точністю відтворення відновленого зображення при декодуванні. Далі розбивають вихідне зображення на ідентичні елементарні області з суміжними межами. В якості елементарних областей вибирають, напри 10 клад, прямокутники. Також такими областями можуть бути будь-які прямокутники з суміжними межами. Задають єдине правило обходу для кожної елементарної області, яке полягає в послідовному переборі пікселів, які розташовані усередині елементарної області, в напрямку зліва направо та зверху донизу. Потім здійснюють генерацію координат пікселів в кожній з елементарних областей. На основі з цих координат формують масив випадково обраних координат пікселів. В кожній з отриманих елементарних областей обирають піксел за координатами, які отримані попередньою генерацію, використовуючи для кожної елементарної області єдине визначене правило обходу, після чого формують підмножину випадково обраних пікселів. Далі здійснюють інтерполяцію амплітуд кольору на підмножині випадково обраних пікселів. В якості методу інтерполяції, наприклад, використовують двомірну інтерполяцію на основі тріангуляції Делоне. Для цього підмножина випадково обраних пікселів, яка утворює характеристичну поверхню амплітуди кольору, розбивається на елементарні трикутники з суміжними сторонами. Усередині кожного з цих елементарних трикутників здійснюють апроксимацію вищевказаної характеристичної поверхні за допомогою частини площини. Коефіцієнти а, в, с рівняння, яке описує площину f(x,y)=ax+b y+c обчислюють локально для кожного трикутника шляхом вирішення лінійної системи. Така інтерполяція одночасно має властивості фільтру, який згладжує дрібні деталі зображення. Також можливе використання таких відомих методів просторової інтерполяції, як метод найближчого сусідства, білінійну, біквадратичну, бікубічну інтерполяцію, В-сплайн інтерполяцію, інтерполяцію Лагранжа тощо. На основі інтерпольованих пікселів та випадково обраних пікселів формують основну модель зображення. Далі обчислюють помилку між амплітудами кольору пікселів вихідного зображення та пікселів основної моделі зображення. Для мінімізації помилки здійснюють формування підмножини відкорельованих випадково обраних пікселів на основі підмножини випадково обраних пікселів. З отриманих різниць формують масив даних помилки, який на наступному етапі кодування архівують за допомогою відомих алгоритмів архівації даних, наприклад, алгоритму Хаффмана, кодування серій послідовностей (Run Length Encoding RLE) тощо. При різновидах реалізації заявленого способу також додатково здійснюють архівацію підмножини випадково обраних пікселів та координат випадково обраних пікселів. На останньому етапі записують масив даних помилки, підмножину випадково обраних пікселів, координати випадково обраних пікселів у файл, який розташовують у запам'ятовувальному пристрої комп'ютера (наприклад, оперативній пам'яті комп'ютера, жорсткому диски) або іншому запам'я товувальному пристрої, призначеному для зберігання файлів. Для декодування і отримання відновленого зображення виконують аналогічні дії в зворотній 11 39378 послідовності та використовують такі ж параметри, як і при кодуванні. Так, розкривають файл зображення та розархівовують масив даних помилки, підмножину випадково обраних пікселів, координати випадково обраних пікселів. Після чого формують основну модель зображення шляхом інтерполяції амплітуд кольору на підмножині випадково обраних пікселів. Далі виконують підсумовування множини інтерпольованих амплітуд кольору з масивом даних помилки та таким чином отримують відновлене зображення. За таким способом кодування масив амплітуд кольору пікселів співпадає з вихідним зображенням, тобто виконується кодування без втрат. При кодуванні з втратами, як запропоновано у варіанті реалізації способу, виконують такі ж самі дії в тій же послідовності, але після формування масиву даних помилки здійснюють формування редукованого масиву даних помилки. Для цього на начальному етапі кодування з втратами сумісно з завданням таких параметрів кодування, як розмір підмножини випадково обраних пікселів, завдають граничну величину помилки та множник квантування. Далі виконують порівняння значень помилки з граничною величиною помилки по абсолютному значенню. Значенням, які менші за граничну величину помилки, присвоюють нульове значення. До значень, які більше граничної величини помилки, додають значення випадкового шуму, які отримані за допомогою генератора випадкових чисел. При декодуванні файлу з редукованим масивом даних помилки додатково здійснюють відновлення редукованої помилки шляхом множення на множник квантування та вирахування набора значень випадкового шум у, як і отримано з використанням синхронізованим генератором випадкових чисел. Така синхронізація здійснюються, наприклад, ініціюванням такого ж саме генератора випадкових чисел за допомогою того ж саме начального значення, що й при генерації набору значень випадкового шум у при кодуванні. Інтервал значень такого шуму задають при кодуванні в начальних параметрах, він визначає амплітуду випадкового шуму. Для редукування масиву даних помилки можливо здійснення нелінійного квантування отриманих ненульових значень помилки з випадковим шумом з будь-яким з відомих методів, використовуючи необхідний для цього набір параметрів. При цьому у подальшому у файл записують масив даних редукованої помилки. При кодуванні з втратами може виконуватися багаторівневе кодування масиву даних помилки. Для цього в масиві даних помилки виконують випадкову вибірку, причому її розмір задають більшим ніж розмір підмножини випадково обраних пікселів. На основі цієї вибірки формують наступний рівень представлення значень помилки, тобто підмножину випадкових даних помилки. З цією множиною також виконують обробку за допомогою граничного порогу або нелінійне квантування та отримують масив даних помилки, в якому багато нульових значень та який краще піддається кодуванню. В подальшому можливо, що здійснюють ще випадкову вибірку підмножину випадкових да 12 них помилки та граничну обробку та квантування. Кількість таких рівнів масиву даних помилки обирають пропорційно розмірам вихідного зображення та розміру відновленого зображення. Таким чином досягають формування такої підмножини випадково обраних пікселів, яка містить мінімум надлишковості інформації пікселів. Для подальшого підвищення ефективності кодування здійснюють корекцію координат випадково обраних пікселів після формування масиву даних помилки, наприклад, таким чином. Спочатку в кожній ідентичній елементарній області обирають один піксел, відмінний від піксела, який було обрано під час формування підмножини випадково обраних пікселів. Попередньо задають розмір підмножини випадково обраних пікселів, яка включає в себе декілька ідентичних елементарних областей, та задають граничне значення помилки для такої підмножини випадково обраних пікселів. Далі формують підмножину випадково обраних пікселів з декількох ідентичних елементарних областей. На основі цієї підмножини здійснюють аналіз статистики значень помилки по вказаній підмножині шляхом побудови гістограми на основі обчислення середньоквадратичного та пікового значень помилки та порівняння значення помилки по абсолютній величині з заданим граничним значенням. Далі визначають ті елементарні області, в яких значення помилки, які перевищують задану граничну величину, мають максимальну величину, та обирають в цих областях інші піксели таким чином, що значення помилки зменшувались. Після цього записують у файл відкориговані координати пікселів та масив даних помилки, який сформовано на основі відкорегованих пікселів. Варто відмітити, що при здійснені корекції координат випадково обраних пікселів розмір вихідного файлу залишається таким же, як і без здійснення корекції. Таким чином, корекція координат випадково обраних пікселів служить для звуження статистичного розподілення значень помилки, що призводить до покращення стискання масиву даних помилки при архівуванні. Прикладом здійснення безартефактного способу кодування та декодування зображень є отримання стиснених зображень, представлених на наступних фото. На фото 1 та 9 представлені вхідні кольорові зображення без стискання. На фото 2 та 10 представлені зображення, для яких застосовано стискання з втратами (здійснення редукції масиву даних помилки) з попередньо заданими граничною величиною помилки, яка дорівнює 4, та множником квантування, який дорівнює 4. На фото 3 та 11 представлене зображення, для якого застосовано стискання з втратами (здійснення редукції масиву даних помилки) з попередньо заданими граничною величиною помилки, яка дорівнює 8, та множником квантування, який дорівнює 8. На фото 4 та 12 представлені зображення на основі масиву даних помилки, який сформовано при здійсненні стискання зображення на фото 1 та 9. 13 На фото 5 та 13 представлено зображення на основі масиву даних помилки, який сформовано при здійсненні стискання зображення на фото 1 та 9. На фото 6 та 14 представлено збільшений фрагмент зображення на фото 1 та 9. На фото 7 та 15 представлено збільшений фрагмент зображення на фото 2 та 10. На фото 8 та 16 представлено збільшений фрагмент зображення на фото 3 та 11. Арте факти у вигляді невеличких сходинок по контурах предметів на фото 6, 7, 8, 14, 15, 16 виникають та етапі перетворення фізичного (оригінального) зображення у цифрову форму. Представлені зображення наочно демонструють відсутність когерентних складових помилки артефактів на стиснених зображеннях та заміщення їх випадковим шумом, який має вигляд розмитості. Також очевидна залежність кількості дрібних деталей зображення від значень попередньо заданих граничної величини помилки та множника квантування при стисненні зображення. Варто відмітити, що наданні зображення являють собою зображення невиткої розподільної здатності 39378 14 (512x512 пікселів), що свідчить про ефективність запропонованого методу навіть для зображень такого розміру, тим більше про підвищення ефективності для зображень з більшою розподільною здатністю, які, як правило, використовують у раніше названих галузях, не тільки для візуального спостереження. Заявлений спосіб безартефактного кодування та декодування зображень за допомогою перетворення когерентного спектру помилки (артефактних складових зображення) у шумоподібний спектр дозволяє забезпечити відсутність когерентних артефактів при стисненні цифрового зображення та може бути використаний, наприклад, для медичних зображень або зображень, які отримують під час наукових експериментів, у галузях, де потрібні зображення високої якості з повною неприпустимістю наявності артефактів, а також підвищення якості декодованого зображення та спрощення процедури кодування та декодування шляхом відсутності спеціальних методів аналізу структури зображення. 15 39378 16 17 Комп’ютерна в ерстка Н. Лисенко 39378 Підписне 18 Тираж 28 прим. Міністерство осв іт и і науки України Держав ний департамент інтелектуальної в ласності, вул. Урицького, 45, м. Київ , МСП, 03680, Україна ДП “Український інститут промислов ої в ласності”, вул. Глазунова, 1, м. Київ – 42, 01601
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod for artifact-less coding and decoding of images
Автори англійськоюAfanasiev Denys Mykolaiovych, Palash Oleksandr Vasyliovych, Svichkariov Serhii Ivanovych
Назва патенту російськоюСпособ безартефактного кодирования и декодирования изображений
Автори російськоюАфанасьев Денис Николаевич, Палаш Александр Васильевич, Свичкарев Сергей Иванович
МПК / Мітки
МПК: G06K 9/60, G06K 9/00, G06T 9/00, G06T 9/20, G06K 9/36, H03M 13/00
Мітки: спосіб, декодування, безартефактного, зображень, кодування
Код посилання
<a href="https://ua.patents.su/9-39378-sposib-bezartefaktnogo-koduvannya-ta-dekoduvannya-zobrazhen.html" target="_blank" rel="follow" title="База патентів України">Спосіб безартефактного кодування та декодування зображень</a>
Спосіб і пристрій кодування, а також спосіб і пристрій декодування інформації, що складається з множини слів,та унітарний носій закодованої інформації

Номер патенту: 65588
Опубліковано: 15.04.2004
Автори: ван Дейк Мартен Е., Сеншу Сусуму, Толуйзен Лудовікус М.Г.М., Нарахара Тацуя, Калман Джозеф А.Х.М., Ямамото Коухей, Хатторі Масаюкі, Багген Констант П.М.Дж.
МПК: H03M 13/00, H03M 13/27
Мітки: носій, також, декодування, слів,та, складається, спосіб, пристрій, кодування, множині, унітарний, інформації, закодованої
Формула / Реферат:
1. Спосіб кодування інформації, що складається з множини слів, в основі якої - багатобітові символи, розташовані на носії так, що їх місцезнаходження задають певне відношення між вказаними багатобітовими символами, якій притаманні такі властивості, як послівне розпорошення і послівне кодування з захистом від помилок, і в якій для цього серед груп слів, які складаються з множини слів, запроваджені ключі виявлення помилок, який відрізняється...
Спосіб кодування і декодування дискретних сигналів

Номер патенту: 18780
Опубліковано: 25.12.1997
Автори: Туваржиєв Валентин Карпович, Тонкаль Володимир Юхимович, Михайлов Олександр Михайлович, Ленчевський Євген Анатолійович
МПК: H04B 3/54, H03M 13/00
Мітки: сигналів, декодування, спосіб, кодування, дискретних
Формула / Реферат:
Способ кодирования и декодирования дискретных сигналов, включающий формирование первой - N-й импульсных последовательностей (N ≥ 2) периодически повторяющихся пачек импульсов, каждая пачка импульсов в i-й импульсной последовательности состоит из Κi импульсов (Κi > 1) одной и двух возможных длительностей t1 или t2, передачу сформированного импульсного сигнала по линии связи, выделение в принятом из линии связи сигнале пачки...
Спосіб кодування та декодування, блок кодерів, блок декодерів, і система кодера та декодера

Номер патенту: 44779
Опубліковано: 15.03.2002
Автори: Андерсон Джон Бейлі, Хладік Стефен Майкл
МПК: H03M 13/23, H03M 13/27
Мітки: кодера, кодерів, спосіб, система, декодування, блок, кодування, декодера, декодерів
Формула / Реферат:
1. Спосіб паралельно-каскадного згорнутого кодування, що складається з кроку: надходження блока, даних на блок кодерів, що складається з множини N кодерів та N-1 переміжників з'єднаних паралельно, який відрізняється тим, що додатково містить кроки:кодування блока, даних у першому кодері за допомогою нерекурсивного систематичного згорнутого коду з відтинанням закінчень та одержанням відповідної першої складової кодованого слова, що...
Система кодування та декодування відеоінформації

Номер патенту: 1094
Опубліковано: 30.12.1993
Автори: Перевертун Валентина Вікторівна, Коваль Анатолій Васильович, Лазаренко Людмила Савелівна, Довбиш Сергій Анатолійович
МПК: H04N 7/16
Мітки: декодування, відеоінформації, система, кодування
Формула / Реферат:
Система кодирования и декодирования видеоинформации, включающая на передающей стороне датчик телевизионного сигнала, последовательно соединенные первый инвертор, первый электронный коммутатор, передатчик, выход датчика телевизионного сигнала подключен ко входу первого инвертора и ко второму входу первого электронного коммутатора, первый генератор псевдослучайной последовательности, выход которого подключен к третьему входу первого...
Пристрій статистичного кодування та декодування факсимільних сигналів
Номер патенту: 8392
Опубліковано: 29.03.1996
Автори: Сапунков Михайло Наумович, Балькін Геннадій Федорович, Голосний Валентин Іванович, Зайченко Олександр Григорович
МПК: H04N 1/40
Мітки: сигналів, факсимільних, кодування, декодування, статистичного, пристрій
Формула / Реферат:
Устройство статистического кодирования и декодирования факсимильных сигналов, содержащее на передающей стороне входной делитель, выход которого соединен с входом кодера видеосигнала и через формирователь разделительных бит и формирователь бит описания с двумя первыми входами сумматора, выход которого подключен ко входу первого буферного блока, а на приемной стороне последовательно соединенные второй буферный блок, дешифратор...
Попередній патент: Самохідний автомобіль о. кугушова
Наступний патент: Спосіб безвтратного кодування та декодування зображень на основі безартефактної моделі
Випадковий патент: Багатофункціональний пожежний причіп