Спосіб представлення і використання знань
Номер патенту: 92484
Опубліковано: 26.08.2014
Автори: Кургаєв Олександр Пилипович, Григор'єв Сергій Миколайович


















Формула / Реферат
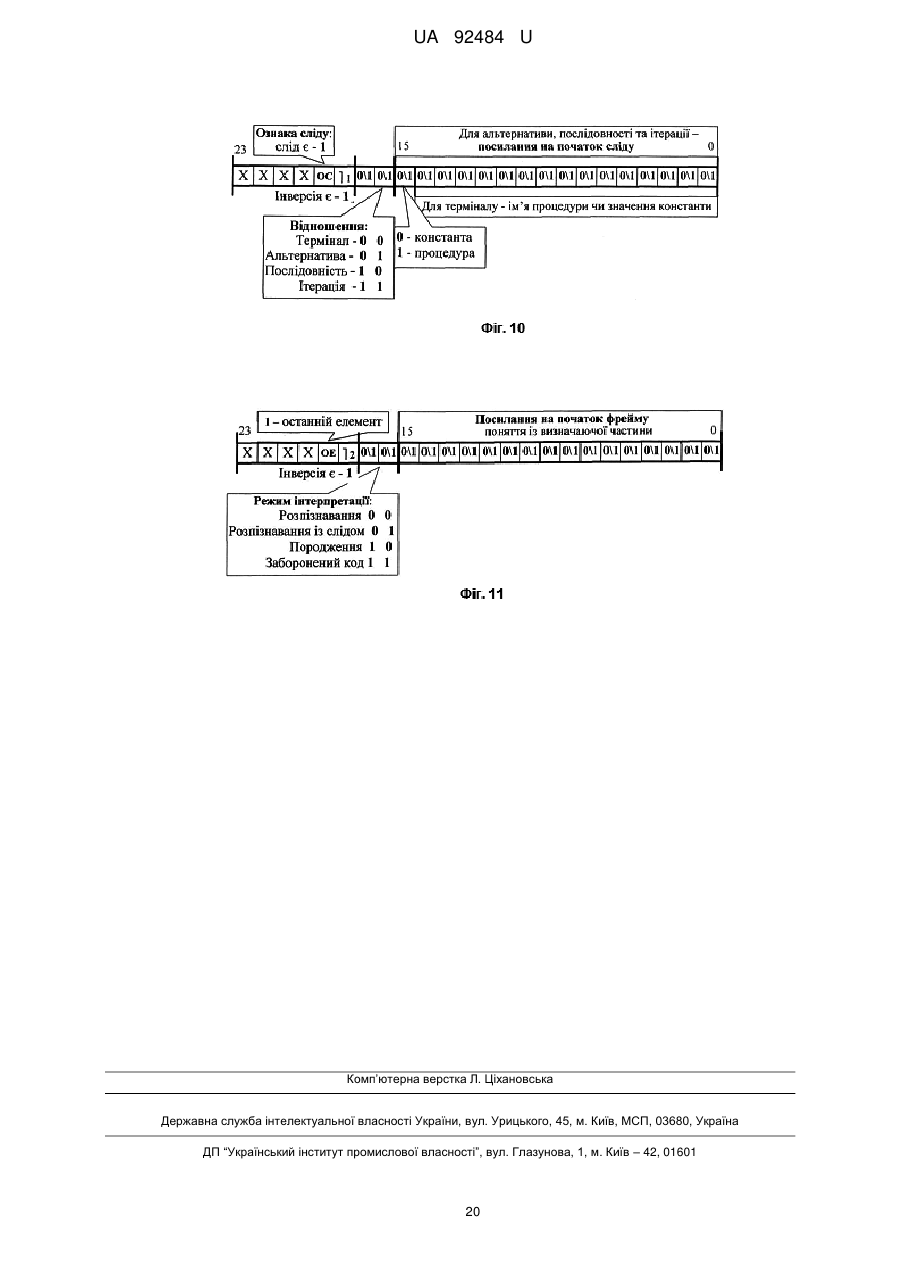
Спосіб представлення і використання знань, який всякий опис бази знань представляє послідовністю визначень понять, кожне з яких містить голову, тіло визначення, відокремлені між собою розподільником, та прикінцевий знак, причому головою визначення є ім'я поняття у формі ідентифікатора, тілом визначення є вираз з елементів, зв'язаних відношенням послідовності або альтернативного вибору, а кожен з елементів є рядком, іменем поняття або ітерацією деякого виразу, який відрізняється тим, що у ньому додатково проводять визначення термінальних понять, тілом кожного з яких є ім'я процедури, що реалізує його смисл, використовують операції інверсії і режимів розпізнавання, розпізнавання із слідом та породження при інтерпретації бази знань, причому застосування операції інверсії до деякого поняття позначається знаком інверсії, що передує відповідному поняттю, а застосування режимів інтерпретації позначається відповідним знаком після імені поняття, на яке цей режим поширюється, а базу знань в машинній формі представляють структурою із фреймів альтернативи, послідовності, ітерації, текстової константи та термінала таким чином, що усякий фрейм є послідовністю слів фіксованої довжини, перше з яких є головою фрейма, друге й наступні слова його елементами, а в кожному зі слів розрізняють перший байт і наступні таким чином, що в першому байті першого слова фреймів кодують тип головного відношення, значення першої інверсії та значення ознаки сліду, в інших розрядах першого слова фреймів для альтернативи, послідовності та ітерації розміщують посилання на початок сліду інтерпретації поняття, що визначається, а для терміналу розміщують код типу термінала та значення константи або імені процедури, в першому байті другого слова фрейму ітерації та другого і кожного з наступних слів фреймів альтернативи і послідовності кодують режим інтерпретації, значення другої інверсії та значення ознаки останнього елемента для поняття, що є елементом тіла визначення, в інших розрядах другого й кожного з наступних слів фреймів кодують посилання на початок фрейму опису поняття, що є елементом тіла визначення.
Текст
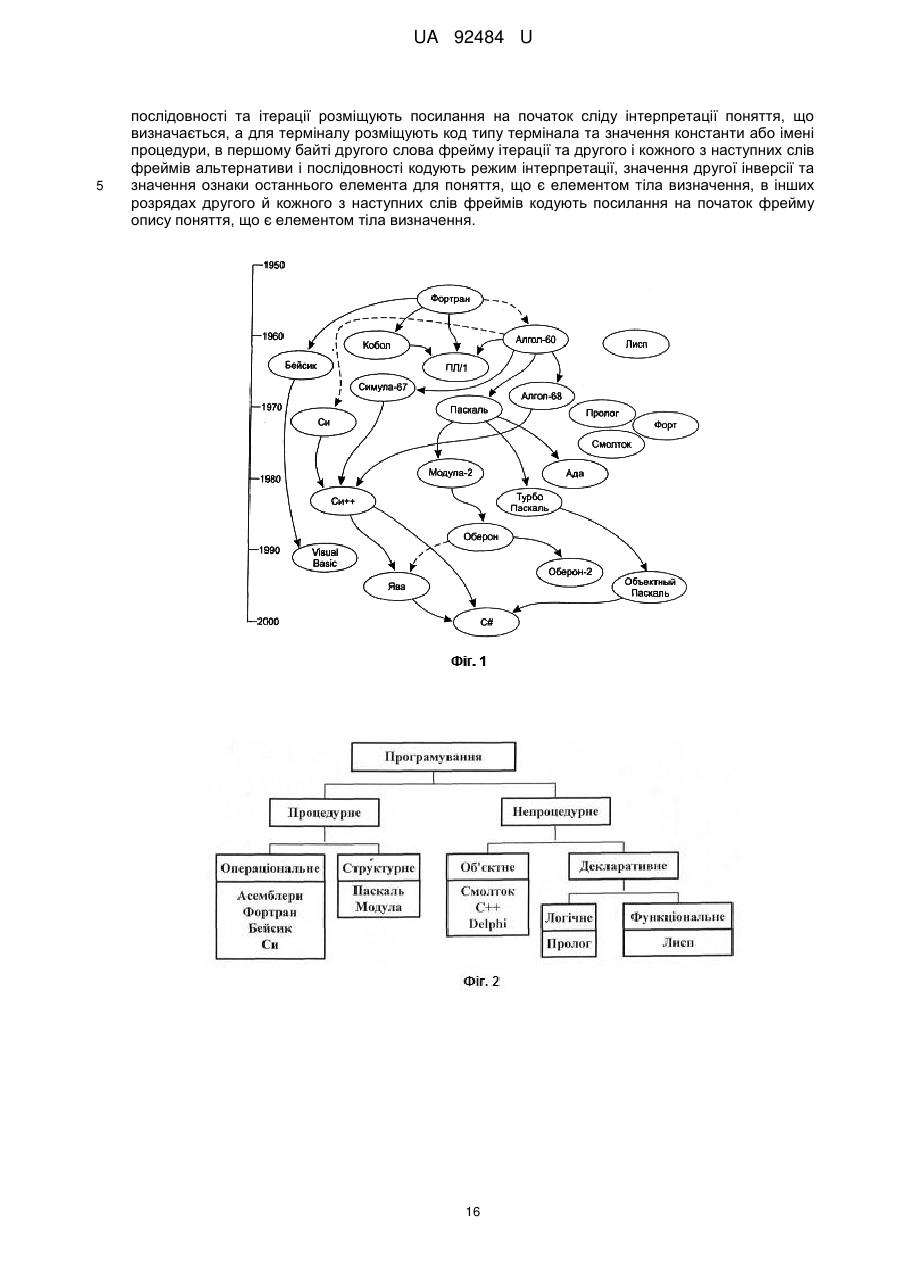
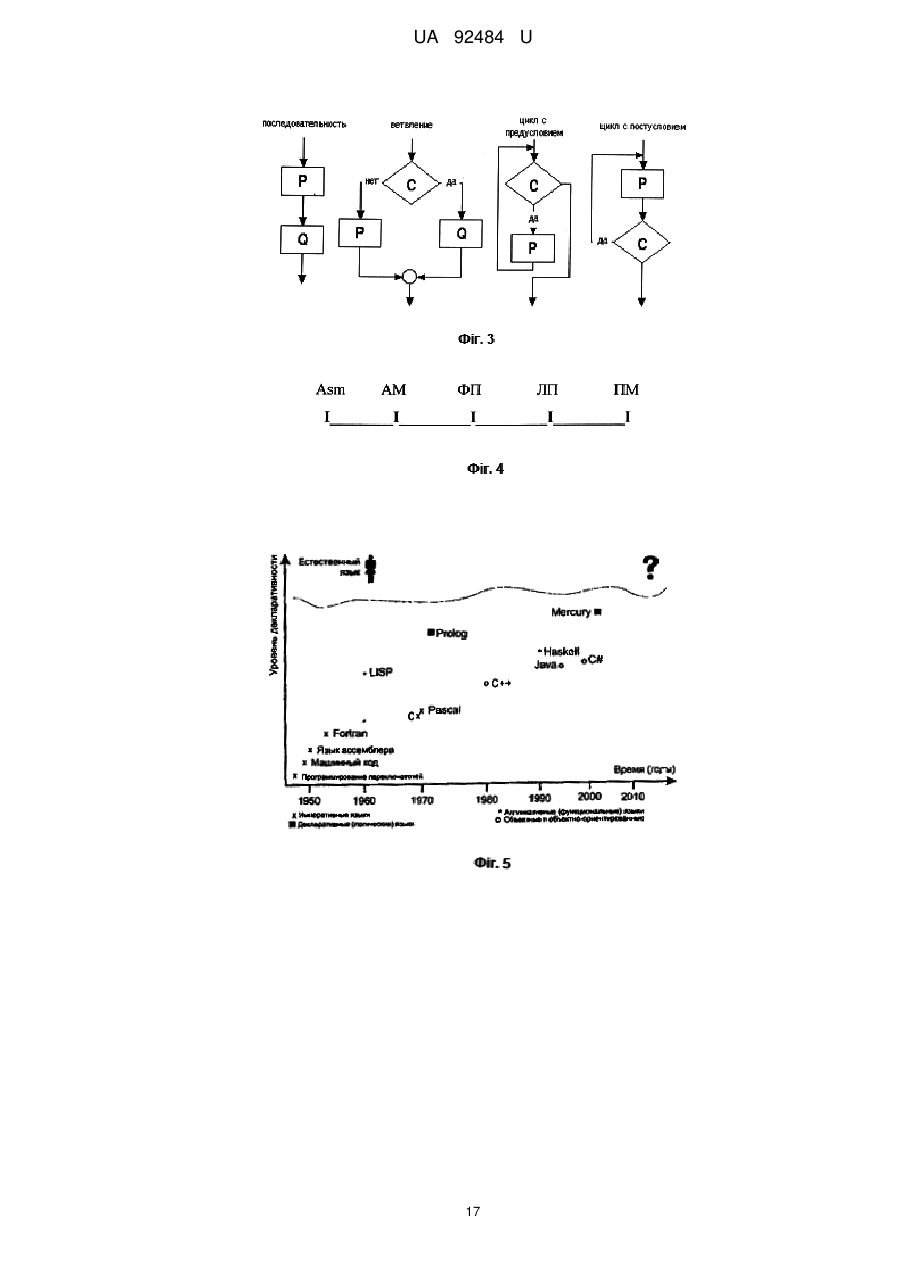
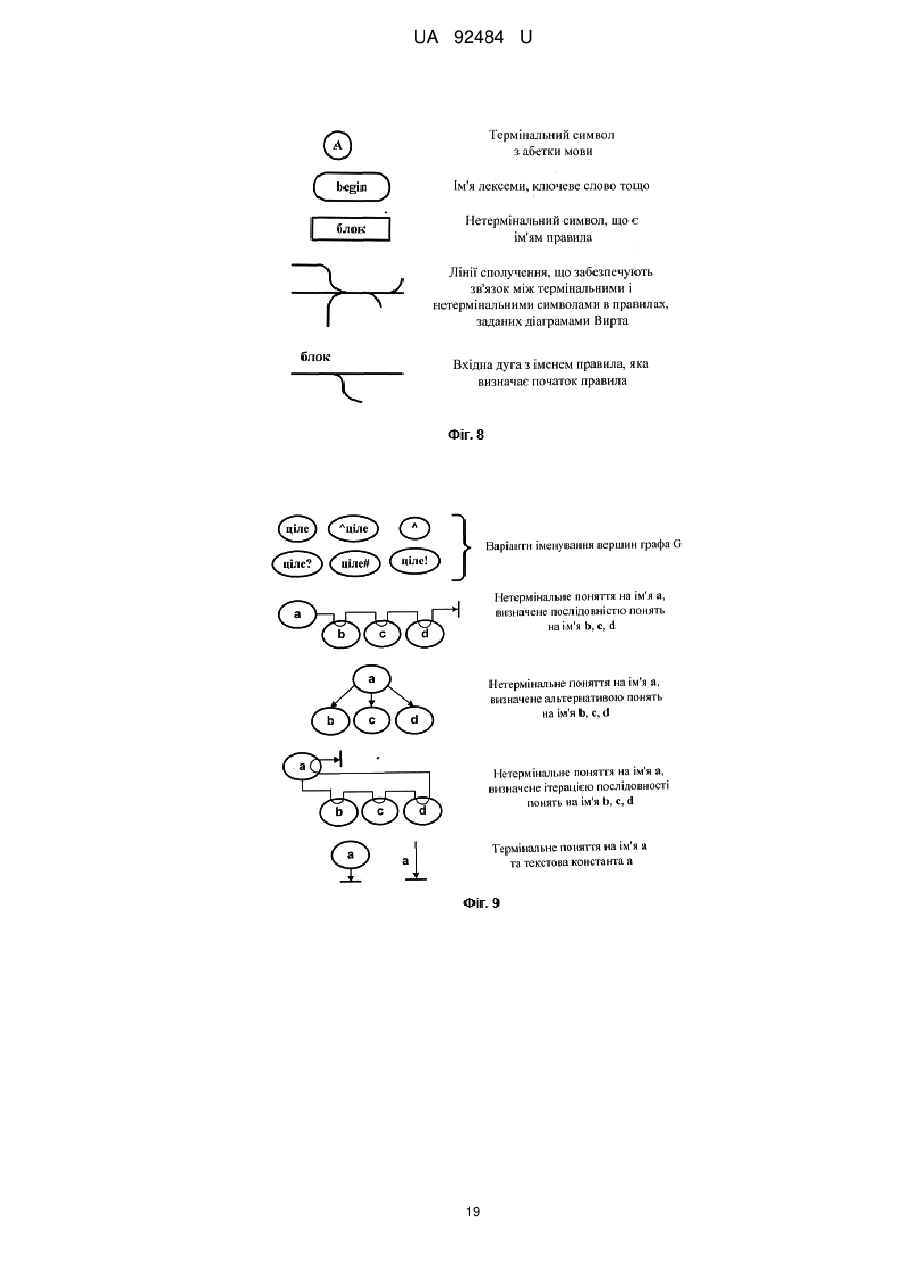
Реферат: UA 92484 U UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 Дана корисна модель належить до області обчислювальної техніки та може бути використана при побудові і використанні високопродуктивних комп'ютерних систем обробки знань довільних прикладних областей. Всяке знання, всяка наукова теорія стають доступними для використання і розвитку (суспільством або комп'ютером) через їхню мову, оскільки думка стає зрозумілою лише після того, як отримує мовне вираження. Абстрагуючись від технічних деталей, всю еволюцію комп'ютерних систем можна в решті решт звести до еволюції мов програмування так само, як еволюцію суспільного інтелекту людської цивілізації можна відслідкувати у розвитку людської мови. Відомо близько 8 500 мов програмування, взаємозв'язок яких у процесі розвитку представляють у формі деякої мережі [1. Сошников Д.В. Логическое программирование. http://blogs.gotdotnet.ru/personal/sos]. У спрощеній формі [2. Свердлов С.З. Языки программирования и методы трансляции: Учебное пособие. - СПб.: Питер, 2007. - 638 с.] деяке наближення до генеалогічного дерева мов високого рівня має вигляд фіг. 1, де явний, безпосередній зв'язок відображений суцільною стрілкою, а побічний вплив - пунктирною. Усі мови програмування впорядковують за різними показниками, найзмістовнішим серед яких є парадигма, покладена в основу мови (Парадигма, згідно з Томасом Куном, - це система ідеалів і норм постановки й вирішення проблем; у програмуванні - це сукупність ідей і понять, що визначають стиль написання програм, тобто сукупність правил, що лежать в основі синтаксису й семантики мови програмування.) Мови й системи програмування за типом їхньої парадигми розподіляють [3. Языки программирования высокого уровня. http://900igr.net/kartinki/informatika/Istorija-razvitija-jazykovprogrammirovanija/Istorija-razvitijа-jazykov-programmirovanija.html] на чотири різновиди (фіг. 2): директивні (directive), процедурні (procedural) або імперативні (imperative), структурні, декларативні (declarative), об'єктно-орієнтовані (object-oriented). Імперативне програмування описує процес обчислення у вигляді інструкцій, що змінюють стан програми; засноване на абстракції машини Тьюринга-Поста, як альтернативного визначення поняття алгоритму. Це - мови Асемблер, Фортран, Алгол, Бейсик, Кобол, Паскаль, Си й багато інших. 1. Вирішуючи задачу, імперативний програміст спочатку створює модель (специфікацію задачі) у деякій формальній системі, а потім переписує рішення на імперативну мову в термінах комп'ютера. Але, по-перше, для людини міркувати в термінах комп'ютера досить неприродно. По-друге, переписування рішення на мову програмування, по-суті, не має відношення до розв'язку вихідної задачі. Часто імперативні програмісти навіть розділяють роботу відповідно до двох вказаних етапів: постановники задач формулюють розв'язок задачі у мові специфікації, а інші - кодують його у мові програмування. 2. Неструктурне програмування допускає використання в явному виді команди безумовного переходу (типу GOTO). Імперативна програма схожа на природно мовні накази, команди, які повинен виконати комп'ютер. В усіх мовах директивного програмування команди зводяться або до присвоювання змінній деякого значення, або до вибору наступної команди. Присвоюванню може передувати ряд арифметичних і інших операцій, а команди вибору реалізуються у вигляді умовних операторів і операторів повторення (циклів). 3. Для класичних директивних мов характерно, що послідовність виконуваних команд однозначно визначається її вхідними даними, тобто поведінка імперативної програми повністю детермінована. 4. Директивне програмування - один з найприродніших для людини стилів написання програм, що призводить зрештою до обчислення шуканих величин. Даний стиль успадкований від програм мовою асемблера, оскільки там команда переходу є обов'язковою. Однак у мовах високого рівня наявність команди переходу спричиняє масу серйозних недоліків: програма перетворюється в "спагеті" з нескінченними переходами на-гору-униз, її дуже важко супроводжувати й модифікувати; фактично неструктурний стиль програмування не дозволяє розробляти великі проекти; первісне навчання програмуванню на базі неструктурної мови призводить до величезних труднощів при переході на більш сучасні стилі. Як зазначав відомий голландський учений Е. Дейкстра: "Студентів, що раніше вивчали Бейсик, практично неможливо навчити гарному програмуванню. Як потенційні програмісти вони піддалися незворотній розумовій деградації.» 1 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 Директивне програмування стали називати процедурним, коли в процесі збільшення складності моделювальних систем і розміру одержуваних програм виникла концепція підпрограм, називаних також процедурами, функціями або методами. Підпрограма дозволяє локалізувати в ній процес виконання певної дії, яка може бути повторена багаторазово за допомогою механізму виклику. Структурне програмування - методологія розробки програмного забезпечення, в основі якої лежить подання програми у вигляді ієрархічної структури блоків. Запропонована в 1968 році Е. Дейкстрой [4. Дал У., Дейкстра Э., Хоор К. Структурное программирование. - М.: Мир, 1975. 247 с.] на противагу необґрунтовно частому використанню програмістами оператора goto безумовного переходу. Розроблена й доповнена Н. Виртом [5. Вирт Н. Систематическое программирование. Введение. - М.: Мир, 1977. - 184 с.]. Відповідно до даної методології Кожен програмний модуль (блок, функція, процедура) повинен мати лише один вхід і тільки один вихід. Задача розбивається на велике число дрібних підзадач, кожна з яких вирішується своєю процедурою або функцією (декомпозиція задачі). Проектування програми йде за принципом зверху вниз: спочатку визначаються необхідні для розв'язку програми модулі, їхні входи й виходи, а потім уже розробляються ці модулі. Такий підхід разом з локальними іменами змінних дозволяє розробляти проект силами великої кількості програмістів. Будь-який алгоритм можна реалізувати, використовуючи лише три керуючі конструкції структурного програмування (фіг. 3): послідовне виконання - однократне виконання операцій у тому порядку, у якому вони записані в тексті програми; розгалуження - однократне виконання однієї із двох або більше операцій, залежно від виконання деякої заданої умови; цикл з передумовою, або із постумовою - багатократне виконання однієї й тієї ж операції доти, поки виконується деяка задана умова (умова продовження циклу); у програмі базові конструкції можуть бути вкладені довільним чином, але інших засобів (зокрема, команди GOTO) керування послідовністю операцій не передбачається. Логічно цілісні обчислювальні блоки (повторювані або не повторювані) можуть оформлюватися у вигляді процедур або функцій. Тоді в тексті основної програми, замість поміщеного в підпрограму фрагмента, вставляється інструкція виклику підпрограми. При виконанні такої інструкції виконується викликана підпрограма, після чого виконується інструкція, наступна за командою виклику підпрограми. В 1966 році італійські математики К. Бом і Дж. Якопини [6. Структурное программирование. Википедия] сформулювали теорему, як можна уникнути використання оператора переходу GOTO. Теорема про структурне програмування: Будь-яку схему алгоритму можна представити у вигляді композиції вкладених блоків begin і end, умовних операторів if, then, else, циклів із предумовою (while, ) і можливо додаткових логічних змінних (прапорів). Правила зв'язку програмних модулів по керуванню: Передача керування викликуваному модулю завжди здійснюється через його початок, тобто через перший оператор або команду. По закінченні виконання викликуваного модуля керування передається у модуль, що викликав, на оператор, безпосередньо наступний за оператором виклику. Модулі нижчих рівнів чи одного рівня ієрархії можуть викликатись для виконання лише модулями вищих рівнів, тобто модулі нижчих рівнів не можуть викликати модулі вищих рівнів, а модулі одного рівня - викликати один одного. Для виконання модуля з деякої внутрішньої точки виклик здійснюється стандартним чином (через перший оператор), а точка початку задається параметром. При цьому на початку викликуваного модуля повинен стояти перемикач, що забезпечує передачу керування до внутрішніх точок входів по параметру, зазначеному у зверненні. У будь-якому модулі повинна бути передбачена можливість підключення контрольних засобів і засобів налагодження; оператори, що реалізують ці засоби, звичайно зосереджують наприкінці модуля. Правила зв'язку програмних модулів по інформації: Інформація зон глобальних змінних доступна для використання будь-яким модулям із складу комплекса програм або групи програм, згідно з областю дії зони глобальних змінних. Тобто глобальні змінні можуть бути доступні не для всього комплекса програм, а лише для зазначеної в описі групи модулів. 2 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 Локальні змінні доступні лише в межах того модуля, у якому вони визначені або оголошені. Для міжмодульної взаємодії створюються зони обмінних змінних, інформація з яких доступна лише модулям, безпосередньо зв'язаним по керуванню. Для обміну інформацією між модулями забороняється користуватись регістрами й комірками пам'яті, використовуваними як регістри. Тобто по закінченню роботи викликуваного модуля вважається, що регістри не містять інформації щодо результату його роботи. Інформація, наявна в регістрах модуля виклику, має бути збережена на період виконання викликуваного модуля і відновлена при поверненні у модуль виклику. Регістри можуть зберігати як модуль виклику, так і викликуваний модуль, однак прийнята угода повинна бути єдиною для всіх викликів модулів. Принципи структурного програмування були реалізовані в мові Алгол, але найбільшу популярність завоювала мова Паскаль, створена в 1970 році швейцарським ученим Н. Виртом. Вона може вважатись зразковою мовою програмування, найбільш популярною і зараз (наприклад у версії Delphi фірми Imprise). Деякі позитивні якості структурного програмування: 1. Структурне програмування значно скорочує число варіантів побудови програми згідно специфікації, що значно знижує складність програми й, що ще важливіше, полегшує розуміння її іншими розроблювачами. 2. У структурованих програмах логічно зв'язані оператори перебувають візуально ближче, а слабко зв'язані - далі, що дозволяє обходитись без блок-схем і інших графічних форм зображення алгоритмів (по суті, сама програма є власною блок-схемою). 3. Сильно спрощується процес тестування і налагодження структурованих програм. Попри всі позитивні якості, структурне програмування залишається імперативним, основним недоліком якого є необхідність детерміновано визначити увесь процес отримання рішення довільної задачі. Структурне програмування лише додатково фіксує деякі корисні прийоми технології програмування. Задачі штучного інтелекту вимагають роботи з даними й знаннями у вигляді символьних структур. В обробці символьної інформації важлива не лише форма розглянутих знань, але і їхній зміст і значення. Причиною виникнення наприкінці 1950-х років програмних засобів символьної обробки є нездатність процедурних мов у вигляді чисел і масивів відображати природно об'єкти і ситуації дійсності. Цей недолік зокрема утруднював реалізацію евристичних методів, застосовуваних у розв'язку задач штучного інтелекту. В основі декларативних мов лежить формалізована людська логіка: людина лише формулює розв'язувану задачу, а пошуком рішення займається імперативна система [7. Дехтяренко И.А. Декларативное программирование. http://softcraft.ru/paradigm/dp/dpref.shtml]. У підсумку одержуємо: значно більшу швидкість розробки додатків, значно менший розмір вихідного коду, легкість запису знань на декларативних мовах, програми, більш зрозумілі за імперативні. Відомим [8. Введение в функциональное программирование. Лекция 1. http://www.machinelearning.ru/wiki/images/4/41/Lect_1_fp_mdv.pdf] є впорядкування мов програмування за їхньою близькістю або до машинної, або до природної мови (фіг. 4), де: Asm асемблер, AM - алгоритмічні (процедурні) мови, ФП - мови функціонального програмування, ЛП - мови логічного програмування, ПМ - Природні мови (англійська, українська й ін.). Ті, що ближчі до комп'ютера, належать до мов низького рівня, а ті, що ближчі людям, - до мов високого рівня. У цьому сенсі декларативні мови можна назвати мовами надвисокого або найвищого рівня, оскільки вони дуже близькі до людської мови й людського мислення. За рівнем декларативності та часом появи найвідоміші мови програмування розташовуються відповідно до фіг. 5 [9. Сошников Д.В. Парадигма логического программирования. - М.: "Вузовская книга", 2006. - 220 с]. Декларативними є функціональні (functional), або аплікативні, і логічні (logic) мови. Головне полягає в наступному: декларативна програма заявляє (декларує), що повинно бути досягнуте як мета, а директивна - пропонує, як її досягти. Декларативні програми не пропонують послідовність дій, у них лише дається дозвіл на них. Виконавець сам має знайти спосіб досягнення мети, поставленої програмістом, причому найчастіше це можна зробити по-різному - детермінованість у цьому випадку відсутня. 3 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 Функціональне програмування припускає достатнім обчислення функцій від вихідних даних і результатів інших функцій, і не припускає явного зберігання стану програми. Найвідоміші мови: LISP, F#, Haskell, Erlang, APL, ML, Scala, Miranda, Nemerle, XQuery, Python. Концепція функціонального програмування: 1. Функціональне - це програмування за допомогою функцій у їхньому математичному розумінні. Воно засноване на ідеї: результатом кожної дії є значення, яке може бути аргументом наступної дії. 2. Програми будуються з визначень функцій, кожне з них складається з керуючих структур і із вкладених, у тому числі рекурсивних, викликів функцій. Кожна функція повертає деяке значення у ту функцію, що її викликала, обчислення якої після цього продовжується; цей процес повторюється доти, поки функція, що почала процес обчислень, не поверне кінцевий результат. 3. "Чисте" функціональне програмування не має оператора присвоювання, у ньому обчислення функції не призводить до побічних ефектів. Розгалуження обчислень засноване на обробці аргументів умовного твердження, а циклічні обчислення реалізуються за допомогою рекурсії. 4. Відсутність оператора присвоювання робить змінні функціональних мов програмування подібними до змінних в математиці - одержавши одного разу свої значення, вони більш ніколи їх не міняють. 5. Відсутність побічних ефектів у процесі обчислення функцій має за наслідок несуттєвість порядку виконання окремих фрагментів програми - підсумкове значення в кожному разі буде однаковим. 6. Функціональне програмування досить привабливе й іноді як перша мова програмування, досліджувана студентами, вибирається Haskell або Lisp. Для успішного оволодіння даним стилем програмування, втім, необхідне досить глибоке розуміння багатьох розділів математики. Логічне програмування засноване на автоматичному доказі теорем, на теорії й апараті математичної логіки з використанням математичних принципів резолюцій. Найвідомішою мовою логічного програмування є Prolog [10. Интернет-Университет Информационных Технологий. http://www.INTUIT.ru Основы программирования на языке Пролог. - 1. Лекция: Введение в язык логического программирования Пролог]. Пролог (програмування в логіці) - одна з найбільш широко використовуваних мов логічного програмування. Як і в інших декларативних мовах, для рішення задачі описують ситуацію (правила й факти) і формулюють мету (запит), доручаючи інтерпретаторові Прологу знайти розв'язок задачі. Програма на Прологу складається з предикатів. Програма на Прологу і база знань синоніми. Мета формулюється також у вигляді предикатів. Виконання програми на Прологу - це резолюція (виведення) мети. Під інтерпретатором Прологу розуміють механізм рішення задачі, сформульованої у мові Пролог. Інакше кажучи, інтерпретатор мови Пролог - це виконавець Пролог-програм, тобто та "активна сила", яка виконує програми, написані на Прологу. У кожної з мов програмування є своє коло задач, при розв'язку яких вони використовуються з найбільшою ефективністю. Для Прологу - це задачі, пов'язані з розробкою систем штучного інтелекту (різні експертні системи, програми-перекладачі, інтелектуальні ігри тощо). Використовується для обробки природної мови й має потужні, принципово відмінні від традиційних, засоби для вилучення інформації з баз даних. Пролог знайшов застосування і в інших областях, наприклад, при рішенні задач складання розкладів. При цьому він не є універсальною мовою програмування й не призначений, зокрема, для розв'язку задач, пов'язаних із графікою або чисельними методами. Логічне програмування - це концепція, що дозволяє описувати предметну область проблеми без складання алгоритму пошуку розв'язку. Складність програмування нікуди не зникає, вона просто "перетікає" з області побудови алгоритму машинною мовою в область формулювання задачі для її розв'язку машиною. Пролог є не стільки мовою для програмування, скільки мовою для опису даних і логіки їхньої обробки. І рішення задачі записується не в термінах комп'ютера, а в термінах предметної області задачі, у дусі модного зараз об'єктно-орієнтованого програмування. Пролог дуже добре підходить для опису відношень між об'єктами. Тому Пролог називають реляційною мовою. Причому "реляційність" Прологу значно могутніша й розвинена, чим "реляційність" мов для обробки баз даних. Часто Пролог використається для створення систем керування базами даних, де є дуже складні запити, які досить легко записати на Прологу. 4 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 У Прологу дуже компактно, порівняно з імперативними мовами, описуються багато алгоритмів. По статистиці, рядок тексту програми мовою Пролог відповідає чотирнадцяти рядкам тексту програми тої ж задачі імперативною мовою. Пролог-програму, як правило, дуже легко писати, розуміти й налагоджувати. Це призводить до того, що час розробки додатка мовою Пролог у багатьох випадках на порядок швидший, ніж на імперативних мовах. У Прологу легко описувати й обробляти складні структури даних. Прологу властивий ряд механізмів, відсутніх у традиційних мовах програмування: зіставлення зі зразком, вивід з пошуком і вертанням. Ще одна істотна відмінність полягає в тім, що для зберігання даних у Прологу використаються списки, а не масиви. У мові відсутні оператори присвоювання й безумовного переходу, покажчики. Природним і найчастіше єдиним методом програмування є рекурсія. Пролог вимагає відмови від стереотипів, стилю мислення імперативного програмування. Основні області застосування Прологу: швидка розробка прототипів прикладних програм; автоматичний переклад з однієї мови на іншу; створення природно-мовних інтерфейсів для існуючих систем; символьні обчислення для рішення рівнянь, диференціювання й інтегрування; проектування динамічних реляційних баз даних; експертні системи й оболонки експертних систем; автоматизоване керування виробничими процесами; автоматичний доказ теорем; напівавтоматичне складання розкладів; системи автоматизованого проектування; базоване на знаннях програмне забезпечення; організація сервера даних або, точніше, сервера знань, до якого може звертатись клієнтський додаток, написаний на якій-небудь мові програмування. Області, для яких Пролог не призначений: великий обсяг арифметичних обчислень (обробка аудіо, відео й т.д.); написання драйверів. Сучасний етап розвитку декларативних мов полягає в наступному. Зріст продуктивності комп'ютерів при зниженні їхньої вартості в другій половині 1990-х pp. з одночасним зростом складності розв'язуваних задач і вдосконаленням техніки реалізації компіляторів і інтерпретаторів призвели до значного підвищення ефективності рішення задач саме за допомогою декларативних мов. Так, застосовуючи методи глобального аналізу програм, творці систем Aquarius Prolog [11. Van Roy P. Can Logic Programming Execute as Fast as Imperative Programming? // http://www.info.ucl.ac.be/people/PVR/Peter.thesis/ Pe-ter.thesis.html] і Parma [12. Taylor A. LIPS on a MIPS: Results from a Prolog Compiler for a RISC. In ICLP, 1990] змогли впритул наблизитись до кращих компіляторів імперативних мов. Маленькою сенсацією став компілятор для функціональної мови Sisal [13. Feo J. T et al. A Report on the SISAL Language Project. 1990., Cann D. Retire FORTRAN? A debate rekindled. СACM 35(8), 1992], орієнтованої на чисельні розрахунки, що створена в американському ядерному дослідному центрі (Lawrence Livermore National Laboratory). Він перевершив не тільки Си, але й Фортран, що був у цій області поза конкуренцією. Інші напрямки досліджень в області декларативних мов в останнє десятиліття: підвищення "чистоти" мов, тобто усунення з них не декларативних засобів; створення спеціалізованих засобів для ефективного розв'язку певних класів задач. Це, насамперед, мови "програмування в обмеженнях". Ці мови містять вбудовані "вирішувачі рівнянь" специфічних видів, наприклад, лінійні рівняння / нерівності й рівняння приналежності в скінчених областях. Такі засоби дозволяють практично вирішувати багато задач, які не реально розв'язати загальними методами; синтез різних стилів програмування. Зокрема об'єднання функціонального й логічного програмування та, навіть, об'єднання їх з об'єктно-орієнтованим програмуванням. Важливий принцип цих досліджень - знайти просту теоретичну основу для такого синтезу. Об'єктно-орієнтоване програмування (надалі ООП) розглядає програму як набір взаємодіючих об'єктів [2]. ООП, в основному, є по суті імперативне програмування, доповнене принципом інкапсуляції даних і методів в об'єкт (принцип модульності) і спадкуванням (принципом повторного використання розробленого функціонала). Це - мови Смолток, Си++, Java, Ada і ін. Об'єктно-орієнтований підхід є зараз домінуючим і дозволяє скоротити час розробки й збільшити надійність великих проектів. Однак програми в даному стилі відрізняються 5 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 громіздким синтаксисом; у цілому об'єктно-орієнтована ідеологія досить неочевидна, часто сприймається із труднощами (особливо це характерно для мови Си, яка і у своєму первісному виді відрізняється вкрай складним синтаксисом), і перехід до її використання важкий для багатьох програмістів. На думку Алана Кея, творця мови Smalltalk, якого вважають одним з "батьків-засновників" ООП, об'єктно-орієнтований підхід полягає в наступному наборі основних принципів. Усе є об'єктом. Обчислення здійснюються шляхом взаємодії (обміну даними) між об'єктами, при якому один об'єкт вимагає, щоб інший об'єкт виконав якусь дію. Об'єкти взаємодіють, посилаючи й одержуючи повідомлення. Повідомлення - це запит на виконання дії, доповнений набором аргументів, які можуть знадобитись при виконанні дії. Кожний об'єкт має незалежну пам'ять, яка складається з інших об'єктів. Кожний об'єкт є представником (екземпляром) класу, який виражає загальні властивості об'єктів. У класі задається поведінка (функціональність) об'єкта. Тим самим усі об'єкти, які є екземплярами одного класу, можуть виконувати однакові дії. Класи організовані в єдину деревоподібну структуру із загальним коренем, називану ієрархією спадкування. Пам'ять і поведінка, пов'язані з екземплярами певного класу, автоматично доступні будь-якому класу, розташованому нижче в ієрархічному дереві. Таким чином, програма є набором об'єктів, що мають стан і поведінку та взаємодіють за допомогою повідомлень. Природним чином вибудовується ієрархія об'єктів: програма в цілому - це об'єкт, для виконання своїх функцій вона звертається до вхідних у неї об'єктів, які, у свою чергу, виконують запитане шляхом звернення до інших об'єктів програми. Природно, щоб уникнути нескінченної рекурсії у звертаннях, на якомусь етапі об'єкт трансформує звернене до нього повідомлення в повідомлення до стандартних системних об'єктів, надаваних мовою й середовищем програмування. Стійкість і керованість системи забезпечується: чітким поділом відповідальності об'єктів (за кожну дію відповідає певний об'єкт), однозначним визначенням інтерфейсів міжоб'єктної взаємодії, повною ізольованістю внутрішньої структури об'єкта від зовнішнього середовища (інкапсуляцією). Нарівні із позитивними якостями ООП, практика програмування засвідчує про його певні недоліки [14. Почему объектно-ориентированное программирование провалилось? http://blogerator.ru/page/oop_why-obiects-have-failed]: Пол Грем, стверджував, що половина всіх концепцій ООП є скоріш поганими, чим гарними, у зв'язку із чим він щиро співчуває ООП-програмістам. Тоді як друга половина від концепцій, що залишилися, і зовсім не має ніякого відношення до ООП, з якими їх чомусь постійно асоціюють. Никлаус Вирт, творець мов Паскаль і Модула, стверджував, що ООП - не більш ніж тривіальна надбудова над структурним програмуванням, і перебільшення її значимості, що виражається, у тому числі, у включенні в мови програмування все нових модних "об'єктноорієнтованих" засобів, безумовно, шкодить якості розроблювального програмного забезпечення. Никлаус дуже здивований тою увагою, яка приділяється нині ООП. Олександр Степанов повністю розчарувався в парадигмі ООП, зокрема стверджує, що ООП методологічно невірна, оскільки починає з побудови класів. Це якби математики починали б з аксіом. Але реально ніхто не починає з аксіом, усі починають із доказів. Річард Столлман, також відомий своїм критичним відношенням до ООП, особливо любить жартувати щодо міфу об'єктників, що ООП "прискорює розробку програм": "Як тільки ти сказав слово "об'єкт", можеш відразу забути про модульність". Спадкування - це сама більша провокація в індустрії. Ні в якому моделюванні спадкування не існує (і в реальному житті його немає теж) - ні в електроніці, ні в бухгалтерії, ні в політиці, ні будь-де ще. Томас Потік з МІТ навіть провів масштабне прикладне дослідження, яке продемонструвало, що немає ніякої помітної різниці в продуктивності між програмістами, працюючими в ООП і у звичайному процедурному стилі програмування. Таким чином, викладений аналіз еволюції мов програмування засвідчив, що жодна з відомих парадигм програмування не має беззаперечних переваг щодо ефективності процесів опису і рішення задач. Не можна казати, що одна мова краща за іншу лише тому, що в ній є можливості, які відсутні в іншій. Тут більш важливе не те, які можливості має мова, а те, чи наявні в неї можливості підтримки стилю програмування, обраного для розв'язку певного кола задач. В кожному випадку, коли йдеться про оцінку і вибір мови, мають розглядатись в першу чергу ті її ознаки, які важливі для конкретного проекту і конкретних обставин. [2]. У 6 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 програмуванні найкращий результат досягається при індивідуальному підході, що виходить із класу задачі, рівня й інтересів програміста [3]. Важливо зазначити, що парадигма програмування не визначається однозначно мовою програмування - багато сучасних мов програмування є мультипарадигменними, тобто допускають використання різних парадигм з метою часткової компенсації недоліків окремих із них. Наприклад: С# - імперативна (OO) + елементи функціональності; F# - функціональна з елементами імперативності; Mercury - функціонально-логічна. Подальший розвиток мов і систем програмування пов'язаний із представленням знань в інтелектуальних інформаційних системах і комп'ютерах. Відома множина моделей подання знань [15. Классификация моделей представления знаний, http://www.aiportal.ru/articles/lmowledge-models/classification.html]. Ґрунтуючись на цих моделях й їхніх певних сполученнях створено й використають багато мов подання знань. Більшість моделей реальних систем є гібридними. У методичних цілях найвідоміші моделі класифікують в рамках схеми, наведеної на фіг. 6. Перший підхід, названий емпіричним, заснований на розумінні організації людської пам'яті й моделюванні механізмів рішення задач людиною. Згідно з цим підходом, розроблені й одержали найбільшу популярність: продукційні моделі, засновані на правилах у вигляді пропозицій типу: "ЯКЩО умова, ТО дія; мережні моделі (або семантичні мережі) - в інженерії знань їх розуміють як граф, що відображає зміст цілісного образа. Вузли графа відповідають поняттям і об'єктам, а дуги відношенням між об'єктами; фреймова модель ґрунтується на понятті фрейма (англ. frame - рамка, каркас). Фрейм структура даних для подання деякого концептуального об'єкта. Інформація, що належить до фрейму, утримується у слотах з його складу. Слоти можуть бути термінальними або бути самі фреймами, утворюючи таким чином цілу ієрархічну мережу. Продукційна система включає: базу правил IF-THEN, що вказують, які виведення в різних ситуаціях мають бути зроблені або ні, глобальну базу даних і інтерпретатор правил. База правил - область пам'яті, яка містить базу знань у формі послідовності правил виду: i; Q; P; A ==> В; N. Тут елемент і - ім'я продукції, за допомогою якого ця продукція виділяється із множини продукцій. Елемент Q характеризує сферу проблемної області застосування продукції. Основним елементом продукції є її ядро: А ==> В. Інтерпретація ядра продукції може бути різною й залежить від умови А, що є ліворуч від знака секвенції ==>. Звичайно, ядро продукції має сенс: ЯКЩО А, ТО В. Більш складні конструкції ядра допускають у правій частині альтернативний вибір, наприклад, ЯКЩО А, ТО В1, ІНАКШЕ В2. Секвенція може тлумачитися у звичайному логічному змісті як знак логічного наслідку В з істинного А (якщо А не є істинним, то про В нічого сказати не можна). Можливі й інші інтерпретації ядра продукції, наприклад А описує деяку умову, необхідну, щоб зробити дію В. Елемент Р є зовнішня умова застосовності ядра продукції. Звичайно Р є логічним виразом (як правило, предикат). Коли Р має значення "істина", ядро продукції активізується. Якщо Р помилкове, то ядро продукції не може бути використане. Елемент N описує постумови продукції, які вказують зміни в базі знань після виконання продукції. Вони актуалізуються лише, якщо реалізувалося ядро продукції. Якщо в пам'яті системи зберігається деякий набір продукцій, то вони утворюють систему продукцій. У системі продукцій повинні бути задані спеціальні процедури керування продукціями, за допомогою яких відбувається актуалізація й вибір для виконання тої або іншої продукції із числа актуалізованих. Глобальна база даних - область пам'яті, яка містить факти (опис початкових, поточних даних і станів системи). Бази даних мають різну форму, але можуть бути описані як масив, який містить ім'я даних, атрибути й значення атрибутів. Інтерпретатор реалізує виведення заключень, користуючись базою правил і даних. Механізм виведення включає пошук у базі знань, виконання операцій над знаннями й формування висновків; звичайно реалізується певне з'єднання прямих (висхідних, керованих даними) і зворотних (спадних або орієнтованих на мету) виведень. Подання знань правилами й виведення на них легко розуміються, оскільки близькі силогізмам, а одноманітність форми забезпечує легку модифікацію системи продукцій уведенням і/або видаленням правил незалежно від змісту інших. Ці властивості - достоїнство при постановці простих, однорідних за змістом задач (у формі переходів між станами) і спричинюють падіння ефективності вирішення проблем у складі декількох різнорідних задач. Навіть для простої проблеми важко побудувати систему керування знаннями як єдиним цілим, тому весь процес керування повинен контролюватися людиною. 7 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 Широке застосування систем, заснованих на правилах, обумовлене наступним. Модульна організація. Завдяки цьому спрощується представлення знань і розширення системи методом інкрементної розробки. Наявність засобів пояснення. Оскільки антецеденти точно вказують умови активізації правила, за допомогою правил легко створювати засоби пояснення. Засіб пояснення дозволяє стежити за порядком запуску правил, тому дає можливість відновити хід міркувань, які привели до певного висновку. Наявність аналогії із процесом пізнання людини. Згідно з результатами Нью-елла й Саймона правила є природний спосіб моделювання процесу розв'язку задач. При розробці бази знань спрощується процес формалізації знань експертів, застосовуючи просте подання правил IF-THEN. Правила належать до типу продукцій, ідея яких започаткована в роботах 1940-х років. У символьній логіці продукційні системи вперше були використані Е. Постом. Він довів, що будьяка система математики або логіки може бути оформлена у вигляді системи продукційних правил певного типу. На відміну від звичайної мови програмування, такої як С або C++, порядок, у якому записані правила, не має значення. Основним обмеженням продукційних правил Поста з погляду програмування є відсутність стратегії керування щодо впорядкування виклику правил. Система Поста дозволяє застосовувати правила до рядків будь-якої форми. Основні недоліки систем продукцій: труднощі складання продукційного правила, адекватного елемента знання, тому що важко виразити складні правила; неможливий виклик одного правила з іншого (зв'язок між правилами тільки через дані); відсутність внутрішньої структури веде до нерозв'язності проблеми несуперечності бази знань; нема залежності кроків виводу від стратегії вибору, що ускладнює їхню інтерпретацію. Висновок. Продукційним системам не вистачає строгої теорії. Поки в них панує евристика. При заданій моделі проблемної області у вигляді сукупності продукцій не можна бути впевненим у її повноті й несуперечності. Причина невдач створення теорії криється в розпливчастості поняття продукції, у тій інтерпретації, що приписується ядру, а також у різних способах керування системою продукцій [16. Искусственный интеллект. Справочник: В 3 кн. / Под ред. Э.В. Попова. - М.: Радио и связь, 1990. - Кн. 2: Модели и методы. - 304 с. - С. 55]. Семантичні мережі, або просто мережі, - це класичний спосіб подання пропозиційної інформації у штучним інтелекті. Пропозиційним твердженням (або висловленням) є речення, що може бути істинним або помилковим. Висловлення мають форму декларативних знань, оскільки в них стверджуються факти. З погляду математики семантична мережа є позначений орієнтований граф. Семантичні мережі вперше були розроблені в 1968 році Квілліаном для досліджень в області штучного інтелекту, як спосіб опису людської пам'яті й мови. Відтоді семантичні мережі успішно застосовувались для рішення багатьох задач подання знань. Розуміння сенсу за допомогою семантичних мереж дозволяє вийти за межі можливостей програмного забезпечення простих експертних систем або штучного інтелекту. Зв'язки в семантичній мережі застосовуються для подання відношень, а вузли, як правило, служать для подання фізичних об'єктів, концептів або ситуацій. Для семантичних мереж відношення мають винятково важливе значення, оскільки надають знанням базову структуру. Без них знання стають лише колекцію незв'язаних даних, а при їхній наявності базові структури дозволяють виводити інші знання. Семантичні мережі ще називають асоціативними мережами, оскільки одні вузли в таких мережах асоційовані або зв'язані з іншими. В оригінальній роботі Квілліана людська пам'ять моделювалась асоціативною мережею, де поняття були вузлами, а зв'язки показували їхнє з'єднання між собою. Згідно з цим, якщо при читанні слів речення стимулюється один вузол, то активізуються його зв'язки з іншими, і така активність поширюється по мережі. Якщо ж достатню активізацію одержує інший вузол, то у свідомості спливає концепція, представлена ним. Наприклад, хоча людина знає тисячі слів, але в його свідомості відбиваються лише слова тої пропозиції, що він читає. До двох найпоширеніших зв'язок належать is-a (є екземпляром) та a-kind-of (останню записують як АКО - є підмножиною, підкласом). При цьому більш загальний клас, на який указує стрілка АКО, називається суперкласом. Якщо суперклас має зв'язок АКО, що вказує на інший вузол, то він одночасно є класом суперкласу, на який вказує стрілка АКО. 8 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 60 Всі об'єкти класу повинні мати деякі спільні атрибути, кожен з них набуває значення. Комбінація атрибуту й значення називається властивістю. У семантичних мережах можна також знайти зв'язки інших типів. Повторення характеристик вузла в його нащадках називається спадкуванням. Якщо не стверджується зворотне, то вважається, що всі елементи деякого класу успадковують всі властивості своїх суперкласів. Спадкування є корисний засіб у поданні знань, оскільки дозволяє загальні характеристики не вказувати повторно. Зв'язки й спадкування є основою ефективних способів подання знань, даючи можливість показувати складні відношення за допомогою декількох вузлів і зв'язок. Визнаними є наступні недоліки семантичних мереж. Одна з проблем, пов'язаних із застосуванням семантичних мереж, полягає в тому, що не передбачені стандартні визначення для імен зв'язок. Наприклад у деяких книгах зв'язку is-а використають для подання і індивідуальних, і загальних відношень, тобто окрім свого значення їй надають також значення зв'язки АКО. Відсутнє однозначне визначення семантичної мережі. Фреймова система - модель подання знань, заснована на теорії М. Мінського, як один з підходів до опису знань, придатний для розуміння сцен і мови. У фреймовій системі одиниця подання інформації - об'єкт, називаний фреймом. Він є формою подання деякої ситуації, описуваної сукупністю понять і даних. Кожен фрейм має ім'я, єдине у фреймовій системі, та певну внутрішню структуру на множині іменованих слотів, які також мають певну структуру даних. Раз встановлену структуру фрейму можна міняти лише в деталях. Ця модель заснована на властивості концептів мати аналогії та будувати ієрархічні структури відношень типу "абстрактне-конкретне". її застосування обмежене випадками чіткої ієрархії між фрагментами даних або знань. Прикладами можуть бути класифікації рослин, тварин, несправностей апаратури, захворювань людей в медичній діагностиці тощо. Характеристики фрейму: ім'я - символ, унікальний у даній системі; положення в ієрархічній структурі задається покажчиками на батьківський фрейм і список дочірніх фреймів; інформація щодо фрейму міститься в слотах. Кожен слот є атом чи список, чий перший елемент завжди є ключ (ім'я слота); приєднані процедури - службові програми, як значення слотів. їх запуск за повідомленнями з інших фреймів (аналоги методів в ООП). Мова фреймового типу відрізняється від OO- мови об'єднанням процедурних і декларативних знань та відсутністю спеціального механізму керування виводом. Ознака: універсальність. Виводи у фреймовій системі виконуються обмінами повідомлень між фреймами. Специфічною функцією у фреймах є демон, що задає процедуру, яка запускається автоматично, коли у слот підставляється якесь значення або коли значення співставляються. Із створенням теорії фреймів з'явились і мови (FRL, KRL, RLL, FMS, КЕЕ, KRJNE, LOOPS й ін.), що описують формальні процеси у вигляді програм дій, які виконуються для кожного об'єктного миру (фрейму). Програми викликаються з відповідного фрейму, а при спілкуванні між фреймами здійснюється міжфреймовий обмін інформацією чи передача керування. До недоліків фреймових систем належать наступні. Оскільки знання у фреймовій системі описуються в процедурній формі, це подання, по-суті, є розширенням звичайних систем процедурного типу. Тому тут складнішими (чим в інших моделях) є придбання й зміна знань. Використання фреймів припустиме для порівняно невеликих проблем, а з ростом складності проблеми зростають труднощі розуміння опису, опис і керування стають складнішими, чим у традиційних процедурних системах. У фреймовій системі не вирішена проблема виявлення семантичних протиріч. Умовно в групу емпіричного підходу включають нейронні мережі й генетичні алгоритми, які належать до біонічного напрямку штучного інтелекту. Особливістю моделей цього типу є широке використання евристик, що в кожному випадку вимагає доказу правильності одержуваних рішень. Другий підхід (що об'єднує теоретичні моделі на фіг. 6) вважають теоретично обґрунтованим, гарантуючим правильність рішень. Він в основному представлений моделями, заснованими на формальній логіці (числення висловлень, числення предикатів), формальних граматиках, комбінаторними моделями, зокрема моделями скінчених проективних геометрій, 9 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 теорії графів, тензорними і алгебраїчними моделями. Визнано [15], що у рамках цього підходу дотепер вдавалося вирішувати лише порівняно прості задачі з вузької предметної області. Таким чином, жодна з відомих моделей мов програмування і представлення знань не має вирішальних переваг перед іншими щодо представлення і використання знань, - кожна з них має свої, більш або менш суттєві недоліки. На цьому фоні залишається єдиний варіант перейти на більш високий рівень абстракції, на рівень метамов. Серед відомих теоретичних моделей представлення знань лише генеративна граматика цілеспрямована на формалізацію знань, теорії довільної мовної компетенції, як сутнісної основи мовної діяльності. Для строгого й точного опису мов програмування використовують спеціальні метамови (мови для опису інших мов) [17. SoftCraft разноликое программирование: Основы разработки трансляторов. http://sl-ur.narod2.ru /studentu/vtoroi_semestr_2010_g/pyavu/Osnovy_razrabotki_translyatorov_.rar]. Найпоширенішими метамовами є металінгвістичні формули Бекуса - Наура та розширені Бекусо-Наурові форми. Метамовою Бекусо-Наурових форм представляють специфікацію довільної мови у вигляді системи взаємозв'язаних формул, схожих на математичні. Для кожного поняття мови існує єдина метаформула (нормальна форма). Вона складається з лівої й правої частин. У лівій частині вказується поняття, що визначається, а в правій - множина припустимих конструкцій мови, які поєднуються в це поняття. У формулі використовують спеціальні метасимволи у вигляді: символ «:=» - поділяє ліву й праву частини формули, його сенс еквівалентний словам "є за визначенням"; символи - кутові дужки виділяють нетермінали (представлені довільним символьним рядком) - поняття мови, що визначається; символ - "або" розмежовує альтернативні варіанти визначень у правій частині формул; термінальні символи записуються як є, не використовуючи якихось метасимволів. Метамова Бекусо-Наурових форм вперше була застосована для опису Алгола-60, а також використана Н. Виртом при опису мови Паскаль. Бекусо-Наурових форм та інших метамов (Хомського, Хомського-Щутценберже) достатньо для опису синтаксиса довільних мов. Та відсутність в нотації метамов засобів явного завдання повторень створює ряд труднощів. Поперше, визначення виявляються складними для розуміння, недостатньо наочними через насиченість рекурсіями. По-друге, виникають проблеми з тим, що граматики, що дають підходящі семантичні дерева, виявляються ліворекурсивними. Для підвищення зручності й компактності опису, в метамову вводять додаткові конструкції. Зокрема, спеціальні метасимволи були розроблені для опису необов'язкових ланцюжків, повторюваних ланцюжків, обов'язкових альтернативних ланцюжків. Існують різні розширення форми метамов, що незначно відрізняються між собою. їхня різноманітність найчастіше пояснюється бажанням розроблювачів мов програмування по-своєму описати створювану мову. До прикладів таких широко відомих метамов можна віднести: метамову PL/I, метамову Вирта, використану при описі Модули-2, метамову Кернигана-Ритчи, що описує Си. Найчастіше такі мови називаються розширеними формами Бекуса-Наура. Найближчим до запропонованого є спосіб представлення і використання знань розширеними формами Бекуса-Наура, який використав Н. Вирт при описі Модули-2 і Оберона [18. Никлаус Вирт. Построение компиляторов / Пер. с англ. Борисов Е. В., Чернышов Л. Н. - М: ДМК Пресс, 2010.-192 с]. Головні модифікації Бекусо-Наурових форм стосуються введення дужок для повторень входження ланцюжків терміналів і нетерміналів у праві частини формул. Угоди щодо позначень терміналів і нетерміналів також змінені. Опис структури розширеними формами Бекуса-Наура є набір правил, що визначають відношення між терміналами і нетерміналами. Термінали - елементи структури, що не мають власної структури, це визначені поза описом розширеними формами Бекуса-Наура ідентифікатори (імена, що вважаються заданими для даного опису структури) або ланцюжки послідовності символів у лапках або апострофах. Нетермінали - елементи структури, що мають власні імена й структуру. Кожний з них визначається правилами, що фіксують його залежність від одного або більше терміналів і/або нетерміналів. Семантика правила розширених форм Бекуса-Наура: нетермінал, заданий ідентифікатором ліворуч від знака "=", визначається деяким відношенням терміналів і нетерміналів. Повний опис структури є набір правил, що визначають всі нетермінали так, що кожен нетермінал може бути зведений до комбінації терміналів шляхом послідовного (рекурсивного) застосування правил. 10 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 Набір основних конструкцій розширених форм Бекуса-Наура: конкатенація, альтернативний вибір та ітерація, а додаткових, стилістичних - відношення необов'язковості (необов'язковий елемент виразу виділяють квадратними дужками) і структурні круглі дужки (використаються для групування елементів при формуванні складних виразів). Конкатенація визначається послідовним записом символів виразу, що розділяються одним або більше пробільними символами. Правило виду А = В С. позначає, що нетермінал А складається із двох символів - В і С. Альтернативний вибір позначається вертикальною рискою. Правило А = B|C|D. позначає, що нетермінал А може складатись або з В, або з С, або з D. Ітерацію - конкатенацію будь-якого числа (включаючи нуль) елементів позначають фігурними дужками, що виокремлюють ітеровані елементи. Правило виду А = {В}, позначає, що А - або порожній, або є конкатенація деякого числа символів В. У варіанті Бекусо-Наурових форм відношення ітерації описувалось за допомогою рекурсії. Метамова розширених Бекусо-Наурових форм придатна для опису мов, що мають практичний інтерес. У тому числі засобами розширених Бекусо-Наурових форм визначають і саму метамову розширених Бекусо-Наурових форм [18]: 1. опис = визначення { визначення }. 2. визначення = імя_поняття тіло_визначення тчк. 3. імя_поняття = ідентифікатор. 4. ідентифікатор = буква { буква | цифра }. 5. тіло_визначення = є_структура вираз. 6. вираз = елемент (відношення_АБО елемент |відношення_І елемент). 7. елемент = імя_поняття | рядок | "(" вираз ")" | "[" вираз "]" | "{" вираз "}". 8. рядок = лапки {знак} лапки. Метамова (та або інша) використовується для конструювання специфікації об'єктної мови програмування, згідно з якої мовою реалізації розробляється програма розпізнавання - аналізу і побудови дерева виводу (розбору) тверджень об'єктної мови програмування. Побудова дерева розбору підтверджує приналежність вхідного ланцюга символів даній мові [17; 18; 19. Грогоно П. Программирование на языке Паскаль: Пер. С англ. - М.: Мир, 1982. - 384 с]. Однак як мову представлення знань метамова розширених Бекусо-Наурових форм (і всі інші відомі метамови) має певні недоліки. 1. Створена первинно для вузькоспеціальних цілей і така, що добре їх забезпечує, метамова розширених Бекусо-Наурових форм не є функціонально повною мовою і тому не придатна для представлення знань довільних прикладних областей. 2. Семантичний розрив [17; 20. Майерс Г. Архитектура современных ЭВМ: В 2-х книгах. Кн. 1. - М.: Мир, 1985. - 364 с] між формальним описом мов програмування і методами реалізації трансляторів цих мов призводить до необхідності долати ряд проблем при розробці трансляторів. 2.1. Перша з них - необхідність перетворення моделі формальної граматики в автоматну модель розпізнавана. Між цими моделями існує кілька протиріч: 2.1.1. Протиріччя між ієрархічною структурою вихідного опису мови з використанням формальної граматики й однорівневою табличною моделлю автомата, що реалізує синтаксичний розбір. 2.1.2. Протиріччя між високорівневими засобами опису мов і обмеженнями на граматики, використовувані для переходу до автоматної моделі розпізнавача. 2.1.3. Формальний опис мови, в остаточному підсумку, повинен бути перетворений в модель автомата, що здійснює розбір. Це перетворення ґрунтується на евристичних алгоритмах, кожний з яких орієнтований на конкретний клас граматик і автоматів. У результаті необхідності застосування даного кроку губиться зв'язок між вихідним описом мови і його реалізацією. 2.2. Друга проблема - це необхідність перетворення граматики. Для перетворення вихідного опису мови у відповідну автоматну модель необхідно, щоб граматика належала якому-небудь конкретному класу. Якщо ця умова не виконується, то автомат не може бути реалізований, і, отже, потрібне перетворення граматики. Існують причини, по яких бажано уникати таких перетворень. По-перше, важко вибрати вид перетворення, по-друге, неможливо гарантувати, що вони не змінять створювану мову. В основу корисної моделі поставлена задача розбудови нового способу представлення і використання знань, технологічно адекватного процесу рішення структурно складних задач, за рахунок розвитку функціональних можливостей мови опису знань та подолання семантичного розриву між формальним описом знань і реалізацією використання знань. Завдяки цьому має 11 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 бути спрощений процес опису знань, забезпечена ефективна реалізація мови опису знань та використання знань. Визначення "Алгоритми + структури даних = програми" [21. Вирт Н. Алгоритмы + структуры данных = программы: Пер. с англ. - М.: Мир, 1985. - 406 с.] перетворимо у форму: Структури (Алгоритми + Дані) = Програми, тобто представимо, що програми є структурами над елементарними алгоритмами (операціями, аксіомами) обробки елементарних даних. Відповідно до цього, кінцевий програмний продукт, розроблений для виконання на інформаційній машині, буде складатись з двох частин. Перша є структурою з множини ієрархічних визначень понять (нетерміналів), зв'язаних між собою базовими відношеннями метамови (мови представлення знань). Конкретну структуру визначень понять деякої конкретної предметної області будемо називати базою знань цієї предметної області та описувати функціонально повною метамовою, що є розвитком основних виразних можливостей метамови розширених Бекусо-Наурових форм Н. Вирта. Друга частина складається з двох підмножин - множини елементарних алгоритмів обробки даних і множини елементарних структур даних. Надалі, переважно, не будемо розрізняти ці дві підмножини, називаючи їх множиною терміналів, тобто кінцевих, елементарних з точки зору структури, з точки зору бази знань. Складові множини терміналів реалізують на одній з традиційних мов програмування програмами, що мають єдиний інтерфейс, і об'єднують в єдину бібліотечну систему. Кожен з них має власне ім'я і у метамовному описі бази знань може використатись нарівні з іншими (нетермінальними) поняттями. Структурно складні (нетермінали) і елементарні (термінали) поняття не розрізняються за синтаксисом імен. Цей поділ понять на прості й складні не є абсолютним: кожне з понять є простим лише тоді, коли їхня внутрішня структура є несуттєвою при опису предметної області. Якщо ж це не так, то нема ніяких обмежень на їхній опис у вигляді деякої структури, елементарними складовими якої є інші поняття. Для досягнення функціональної повноти основні виразні можливості метамови розширених Бекусо-Наурових форм розвинемо наступним чином. А 1. Введемо в неї відношення інверсії, позначене символом " ". Дозволимо використання А символа інверсії перед іменем будь-якого поняття в описі. При цьому символ " " у правій частині визначення довільного поняття трактується загальноприйнятим у логіці способом - як інверсія поняття, перед іменем якого стоїть знак інверсії, а його використання перед іменем описуваного поняття (тобто в лівій частині визначення цього поняття) трактується як застосування інверсії до всього тіла визначення поняття. 2. Над інформаційними структурами, які є моделями, базами знань відповідних прикладних областей, введемо три елементарні операції, що виконуються в процесі інтерпретації баз знань: розпізнавання (позначається після імені поняття, що розпізнається, необов'язковим знаком режиму інтерпретації "?"), розпізнавання із слідом (позначається після імені поняття, що розпізнається, знаком режиму інтерпретації "#") і породження (позначається після імені поняття, що породжується, знаком режиму інтерпретації "!"). 2.1. Перша операція обчислює значення істинності твердження про адекватність об'єкта, заданого в просторі даних, зазначеному поняттю із простору знань; 2.2. Операція розпізнавання із слідом додатково до обчислення значення істинності твердження про адекватність об'єкта, заданого в просторі даних, зазначеному поняттю із простору знань, запам'ятовує результат розпізнавання поняття; 2.3. Операція породження будує в просторі даних об'єкт, адекватний зазначеному поняттю із простору знань. Поставлена задача вирішується тим, що у способі, який всякий опис бази знань представляє послідовністю визначень понять, кожне з яких містить голову, тіло визначення, відокремлені між собою розподільником, та прикінцевий знак, причому головою визначення є ім'я поняття у формі ідентифікатора, тілом визначення є вираз з елементів, зв'язаних відношенням конкатенації або альтернативного вибору, а кожен з елементів є рядком, іменем поняття або ітерацією деякого виразу, додатково проводять іменування понять, що визначаються, у формі цілого та ланцюга знаків, визначення термінальних понять, тілом кожного з яких є номер процедури, що реалізує його сенс, та операції інверсії і режимів розпізнавання, розпізнавання із слідом та породження при інтерпретації бази знань, причому застосування операції інверсії до деякого поняття позначається знаком інверсії, що передує відповідному поняттю, а застосування режимів інтерпретації позначається відповідним знаком після імені поняття, на яке цей режим поширюється. 12 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 Сформовану таким чином метамову назвемо мовою нормальних форм представлення знань. Визначення мови нормальних форм представлення знань у тій же мові представлення знань має вигляд згідно фіг. 7. Де: = - позначає "є за визначенням"; / - позначає альтернативний вибір (логічне АБО); () - позначає ітераційні дужки, що виокремлюють ітеровану структуру; - позначає заперечення; пробіл між іменами в правих частинах визначень - позначає конкатенацію (логічне І). Для даного опису (фіг. 7) наступні поняття є термінальними. буква=А/Б/В/Г/…./а/б/в/г/…./я/А/В/С//…./a/b/c/…./z; цифра=0/1/2/3/4/5/6/7/8/9; знак=-/)/(/*/&//%/$/#/@/!/~/"/'/;/://,/./\/|/=/_/?///; метазнак - це знаки "(",")","","/",";"; є_структура - розподілювач, зображується символом "="; відношення_І - відношення конкатенації, послідовності, зображується символом пробіл " "; відношення_АБО відношення диз'юнкції, альтернативного вибору, зображується символом "/"; дужка_відкр - ітераційна скобка, зображується символом "("; дужка_закр - ітераційна скобка, зображується символом ")"; тзпт - кінець визначення, зображується символом ";"; лапка - текстова лапка, зображується символом " ' "; заперечення - відношення заперечення, зображується символом " "; істина - відношення "тотожня істина", порожнє значення; пробіл - розподілювач, зображується символом " "; є_термінал - розподілювач, зображується символом " ~ ". Представлена (на фіг. 7) база знань задає синтаксис опису мовою нормальних форм довільної бази знань, згідно з яким, опис бази знань - це довільна по числу й порядку послідовність визначень понять. Опис термінальних понять задається тільки іменем процедури, описаної зовнішніми стосовно бази знань засобами. Нетермінальне поняття може бути описане як альтернатива або послідовність деяких понять (серед яких може бути й описуване поняття), кожне з яких у свою чергу може бути ітерацією деякої структури, текстом або задане визначенням. Описана у такий спосіб мова (метамова) нормальних форм є функціонально повною та складає основу перспективної інформаційної технології, що забезпечує економію праці користувачів, пам'яті комп'ютерів і часу обчислень. Поряд з текстовими способами опису синтаксису мов широко використаються й графічні метамови, серед яких найбільшу популярність одержала мова діаграм Н. Вирта [5, 17], уперше застосована для опису мови Паскаль. Метасимволи замінені наступними графічними позначеннями [5, 17], наведеними на фіг. 8: термінальні символи і їхні постійні групи розташовують у колах або прямокутниках із округленими вертикальними сторонами; нетермінальні символи заносять усередину прямокутників; кожен графічний елемент, що відповідає терміналу або нетерміналу, має по одному входу й виходу, які звичайно малюють на протилежних сторонах; кожному правилу відповідає своя графічна діаграма, на якій термінали й нетермінали з'єднують за допомогою дуг; альтернативи в правилах задають розгалуженням дуг, а ітерації - їхнім злиттям; має бути одна вхідна дуга (розташовується звичайно ліворуч і зверху), яка задає початок правила й позначена ім'ям нетермінала, що визначається, і одна вихідна, що задає його кінець (звичайно розташовується праворуч і знизу). Звичайно стрілки на дугах діаграм не ставлять, а напрямки зв'язків відслідковують рухом від початкової дуги відповідно до плавних вигинів проміжних дуг і розгалужень. У такий же спосіб визначають входи й виходи терміналів і нетерміналів. Спеціальних стандартів на діаграми Вирта нема, тому графічні позначення можуть мінятися залежно від засобів малювання. Можна наприклад використати псевдографіку або просто текстові символи, зв'язки зі стрілками. Однак такий вид правил менш зручний для сприйняття й тому застосовується вкрай рідко. Діаграми Вирта дозволяють задавати альтернативи, рекурсії, ітерації й за виразністю еквівалентні розширеним Бекусо-Науровим формам, але графічне відображення правил є більш наочним за текстове подання в розширених Бекусо-Наурових формах. Діаграми Вирта є 13 UA 92484 U 5 10 15 20 25 30 35 40 45 50 55 зручним первинним документом (специфікацією) для побудови лексичного й синтаксичного аналізаторів. Графічні засоби побудови синтаксичних діаграм метамови нормальних форм розвивають графічні засоби побудови діаграм Вирта так само, як метамова нормальних форм розвиває розширені Бекусо-Наурови форми, та мають вигляд, згідно з фіг. 9. Граф G синтаксичних діаграм, еквівалентних за виразними можливостями метамові нормальних форм, представляють: Множиною іменованих вершин V, кожна з яких зображує одне з понять (термінальне або нетермінальне), графічне подання всіх вершин однакове: кожна вершина v V - коло або овал, усередині нього - ім'я поняття, знак інверсії або ім'я поняття разом з попереднім знаком інверсії, останнє має сенс інверсії визначення поняття, чиє ім'я зазначене; імена терміналів і нетерміналів синтаксично не розрізняються; після (без пробілу) імені поняття з визначальної частини деякого визначення можливий запис одного з метазнаків "?", "#" або "!". Множиною дуг Е. Структура й різновид дуг множини Е представляють відношення послідовності, альтернативи, ітерації, інверсії між поняттями та бути терміналом відповідно до обмежень: кожна вершина має довільне число входів, але не менш одного; кожна термінальна вершина має єдиний вихід, що закінчується тупиковою стрілкою; кожна вершина інверсії має єдиний вхід, з'єднаний із виходом одної вершини, що містить ім'я поняття, і єдиний вихід, з'єднаний із входом однієї й тільки однієї вершини, що містить ім'я поняття; кожна нетермінальна вершина, що визначається, може мати один або кілька виходів, кожен з яких зображує одне з множини альтернативних визначень нетермінала; кожен вихід нетермінальної вершини, що визначається, має бути з'єднаний із входом ланцюжка з однієї або більше вершин, серед яких може бути й нетермінальна вершина, що визначається, причому кожен ланцюжок зображує визначення нетермінала відношенням послідовності. Серед вершин ланцюжка може бути одна або кілька послідовно з'єднаних пар із інверсії та іменованої вершини; визначення нетермінала у формі ітерації послідовності зображується ланцюжком з однієї або кількох послідовно з'єднаних вершин, що виходить і закінчується у вершині, яка зображує нетермінал, що визначається. Всяка база знань, описана мовою нормальних форм, перетворюється транслятором у машинну форму представлення знань таким чином, що ім'я кожного поняття, що визначається, та імена понять, що є елементами тіла його визначення, відокремлюють від опису і включають в словник понять, а в структурній частині, що залишилась, виявляють головне відношення та множину поєднаних ним елементів, кожному з яких призначають режим і інші ознаки інтерпретації та у міру накопичення знань присвоюють значення посилання на множину елементів, зв'язаних головним відношенням із визначення відповідного елемента, також з головним відношенням визначення кожного поняття зв'язують змінну, якій в процесі інтерпретації в режимі розпізнавання із слідом присвоюють інформацію про успішний варіант інтерпретації цього поняття, а в процесі інтерпретації в режимі породження варіант інтерпретації поняття обирають згідно із значенням цієї змінної, також якщо термінал при інтерпретації в режимі розпізнавання обчислює значення істинності істина, то модифікують координату відповідних даних, якщо ж при інтерпретації бази знань поточний варіант підструктури бази знань не відповідає даним, свідченням чого є обчислене значення істинності лож, то відновлюють початкове значення координати даних. Отже база знань в машинній формі складається із структури взаємозв'язаних визначень понять, кожне з яких подане у формі одного з п'яти фреймів: альтернативи, послідовності, ітерації, текстової константи або термінала. Усякий фрейм - послідовність слів фіксованої довжини (наприклад, трибайтових), серед яких розрізняють голову - перше слово (фіг. 10, де тут і далі: 0\1 - значущі, X - не значущі розряди) фрейма та його елементи - друге й наступні слова (фіг. 11), а в кожному зі слів - перший байт і наступні. Фрейми текстової константи й термінала однослівні, ітерації - двохслівні, альтернативи й послідовності - багатослівні. В першому байті (розряди 16-23) першого слова фреймів (фіг. 10) значущими є півбайта, чиї розряди кодують наступну інформацію визначення поняття: 17, 16 розряди - містять код головного відношення (00 - термінал, 01 - альтернативний вибір, 10 - конкатенація, 11 - ітерація); 14 UA 92484 U 5 10 15 20 25 30 35 40 18 розряд - містить значення першої інверсії 1 (1=1 стверджує наявність заперечення визначення відповідного поняття, що визначається); 19 розряд - містить значення ознаки сліду ОС (ОС=1 стверджує наявність сліду інтерпретації відповідного поняття, що визначається). Інші два байти (розряди 0-15) першого слова фреймів (фіг. 10) для альтернативи, послідовності та ітерації (тобто при ненульовому коді 16,17 розрядів цього слова) містять посилання на початок сліду інтерпретації відповідного поняття, що визначається, а для терміналу (тобто при нульовому коді 16, 17 розрядів цього слова) 15 розряд містить код типу терміналу (0 - константа, 1 - процедура) та 0-14 розряди містять код значення константи або імені процедури. В першому байті (розряди 16-23) другого слова фрейму ітерації та другого і наступних слів фреймів альтернативи і послідовності (фіг. 11), значущими є лише півбайта, розряди якого кодують наступну інформацію щодо інтерпретації понять із складу тіла визначення: 17, 16 розряди - містять код режиму (00 - розпізнавання, 01 - розпізнавання із слідом, 10 породження) інтерпретації поняття; 18 розряд - містить значення другої інверсії 2 (2=1 стверджує наявність заперечення використання відповідного поняття); 19 розряд - містить значення ознаки останнього елемента ОЕ (ОЕ=1 стверджує, що відповідне поняття є останнім у визначені альтернативи або послідовності). Інші два байти (розряди 0-15) другого й наступних слів фреймів (фіг. 10) містять посилання на початок фрейму опису поняття, вказаного у тілі визначення. Таке кодування машинної форми представлення знань забезпечує зв'язність різних фреймів у єдину багаторазово вкладену структуру, що містить рекурсивні конструкції, та є адекватним текстовій і графічній формам представлення. Складність опису (потужність множини понять, структура їхнього взаємозв'язку) може бути довільною та обмежується ресурсами конкретної реалізації. В запропонованому способі знання гранично відокремлені від даних. В описі представлені знання і дані відокремлені фізично: знання сконцентровані в інформаційній структурі, представлення ж даних, локалізовані в термінальних алгоритмах. Оці дві компоненти представлені двома різними підпросторами єдиного простору рішення задач. Відокремлення просторів і механізмів обробки знань і даних дозволяє застосувати для кожного з них оптимальні апаратні засоби інтерпретації при збереженні єдності всього двоєдиного процесу рішення задач. Знання - опис об'єктивно існуючої інформаційної структури прикладної області. На одних і тих же знаннях можна вирішувати всі задачі, що існують для цієї області (якщо достатньою є точність опису прикладної області), тобто знання - це компонента інформації, інваріантна відносно задач, що вирішуються в цій області. Отже, знання, колись усвідомлені, формалізовані і введені в комп'ютер, можуть використовуватись багатократно для рішення багатьох задач. Запропонований спосіб порівняно з відомими характеризується більшою технологічною адекватністю подання і використання знань можливостям людини. ФОРМУЛА КОРИСНОЇ МОДЕЛІ 45 50 55 60 Спосіб представлення і використання знань, який всякий опис бази знань представляє послідовністю визначень понять, кожне з яких містить голову, тіло визначення, відокремлені між собою розподільником, та прикінцевий знак, причому головою визначення є ім'я поняття у формі ідентифікатора, тілом визначення є вираз з елементів, зв'язаних відношенням послідовності або альтернативного вибору, а кожен з елементів є рядком, іменем поняття або ітерацією деякого виразу, який відрізняється тим, що у ньому додатково проводять визначення термінальних понять, тілом кожного з яких є ім'я процедури, що реалізує його смисл, використовують операції інверсії і режимів розпізнавання, розпізнавання із слідом та породження при інтерпретації бази знань, причому застосування операції інверсії до деякого поняття позначається знаком інверсії, що передує відповідному поняттю, а застосування режимів інтерпретації позначається відповідним знаком після імені поняття, на яке цей режим поширюється, а базу знань в машинній формі представляють структурою із фреймів альтернативи, послідовності, ітерації, текстової константи та термінала таким чином, що усякий фрейм є послідовністю слів фіксованої довжини, перше з яких є головою фрейма, друге й наступні слова його елементами, а в кожному зі слів розрізняють перший байт і наступні таким чином, що в першому байті першого слова фреймів кодують тип головного відношення, значення першої інверсії та значення ознаки сліду, в інших розрядах першого слова фреймів для альтернативи, 15 UA 92484 U 5 послідовності та ітерації розміщують посилання на початок сліду інтерпретації поняття, що визначається, а для терміналу розміщують код типу термінала та значення константи або імені процедури, в першому байті другого слова фрейму ітерації та другого і кожного з наступних слів фреймів альтернативи і послідовності кодують режим інтерпретації, значення другої інверсії та значення ознаки останнього елемента для поняття, що є елементом тіла визначення, в інших розрядах другого й кожного з наступних слів фреймів кодують посилання на початок фрейму опису поняття, що є елементом тіла визначення. 16 UA 92484 U 17 UA 92484 U 18 UA 92484 U 19 UA 92484 U Комп’ютерна верстка Л. Ціхановська Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 20
ДивитисяДодаткова інформація
Автори англійськоюHryhoriev Serhii Mykolaiovych
Автори російськоюГригоръев Сергей Николаевич
МПК / Мітки
МПК: G06F 15/00
Мітки: представлення, використання, знань, спосіб
Код посилання
<a href="https://ua.patents.su/22-92484-sposib-predstavlennya-i-vikoristannya-znan.html" target="_blank" rel="follow" title="База патентів України">Спосіб представлення і використання знань</a>
Спосіб систематизації інформації і контролю знань

Номер патенту: 65224
Опубліковано: 15.03.2004
Автори: Гарькавий Анатолій Дмитрович, Пльонсак Володимир Адамович, Середа Леонід Павлович
МПК: G09B 1/00, G06K 21/00, G09B 19/00
Мітки: спосіб, знань, контролю, інформації, систематизації
Формула / Реферат:
1. Спосіб систематизації інформації і контролю знань, що включає використання діаграм, який відрізняється тим, що діаграми виконані у вигляді карток опорних знань, які включають мету вивчення етапу навчання, наприклад розділу, курсу або предмета, при необхідності, визначення значення термінів, які використовують для вивчення дисципліни, теоретичну і прикладну частини, питання для самоперевірки і тести для контролю знань.2. Спосіб за п....
Спосіб виміру рівня знань учнів при комп’ютерному тестуванні

Номер патенту: 51559
Опубліковано: 26.07.2010
Автори: Тараненко Юрій Карлович, Різун Ніна Олегівна
МПК: G06F 7/00
Мітки: спосіб, рівня, учнів, комп'ютерному, знань, виміру, тестуванні
Формула / Реферат:
Спосіб виміру рівня знань учнів при комп'ютерному тестуванні, що включає подання матеріалу для тестування, визначення величини сигналу оцінки як суми всіх сигналів, кожний з яких пропорційний нормі балів за вірну відповідь на дане питання та значенню сигналу, пропорційному заданій нормі часу для даного питання та часу, фактично витраченому на підготовку, який відрізняється тим, що попередньо задають величину коефіцієнта кореляції як...
Спосіб виміру рівня знань учнів при комп’ютерному тестуванні

Номер патенту: 97149
Опубліковано: 10.01.2012
Автори: Тараненко Юрій Карлович, Різун Ніна Олегівна, Холод Борис Іванович
МПК: G06F 7/04
Мітки: тестуванні, рівня, виміру, комп'ютерному, учнів, знань, спосіб
Формула / Реферат:
Спосіб виміру рівня знань учнів при комп'ютерному тестуванні, що включає введення матеріалу для тестування за допомогою блока подачі матеріалу, визначення величини оцінки блоком формування оцінки як суми всіх балів за вірну відповідь на дане питання та значення, пропорційного заданій нормі часу для даного питання та часу, фактично витраченому на підготовку, який відрізняється тим, що перед проведенням тестування за допомогою блока пам'яті та...
Спосіб вибірки даних у процесі комп’ютерної перевірки знань

Номер патенту: 67215
Опубліковано: 15.06.2004
Автори: Велігура Антон Володимирович, Ткаченко Віктор Петрович, Лехціер Леонід Романович
МПК: G06F 7/06
Мітки: знань, комп'ютерної, процесі, спосіб, даних, перевірки, вибірки
Формула / Реферат:
1. Спосіб вибірки даних у процесі комп'ютерної перевірки знань, при якому рівень складності чергового питання визначають в залежності від вірності відповідей на попередні питання, який відрізняється тим, що рівень складності чергового питання не змінюють, якщо число вірних і невірних відповідей, отриманих на парне число попередніх питань, однакове, а у випадку, якщо число вірних відповідей більше або менше за число невірних відповідей, рівень...
Спосіб проведення комп’ютерного тестування знань студентів

Номер патенту: 58657
Опубліковано: 26.04.2011
Автори: Тараненко Юрій Карлович, Різун Ніна Олегівна
МПК: G06F 7/00
Мітки: студентів, знань, комп'ютерного, проведення, спосіб, тестування
Формула / Реферат:
Спосіб проведення комп'ютерного тестування знань студентів, який включає формування матеріалу для тестування з тестових завдань різних типів та визначення величини сигналу оцінки як суми всіх сигналів, кожний з яких пропорційний нормі балів за вірну відповідь на дане питання у відповідності з рівнем його складності, який відрізняється тим, що перед проведенням тестування визначають рівень складності завдань тестового сеансу у залежності від...
Попередній патент: Вільнопоршневий двигун-гідронасос
Наступний патент: Абразивне клиновидне свердло
Випадковий патент: Спосіб прогнозування зрощення перелому