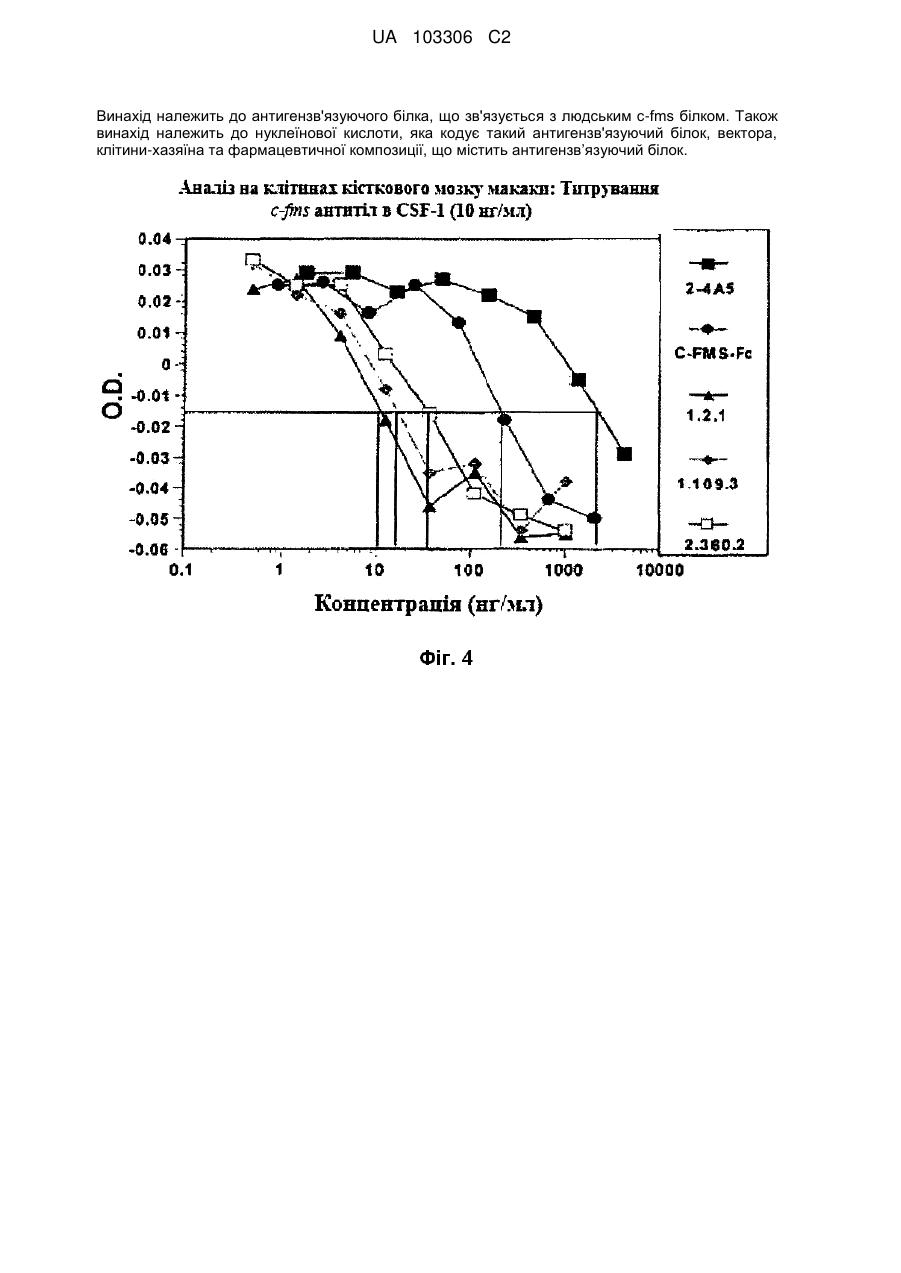
C-fms антигензв’язуючий білок людини
Номер патенту: 103306
Опубліковано: 10.10.2013
Автори: Сан Джілін, Фостер Стефен, Черретті Дуглас Пет, Мехлін Крістофер, Брасел Кеннет Алан, Смозерс Джеймс Ф.







Формула / Реферат
1. Антитіло, що містить ділянки, що визначають комплементарність, (CDRs) CDRH1, CDRH2, CDRH3, CDRL1, CDRL2 і CDRL3, де CDRs містять амінокислотні послідовності, як наведено нижче:
(a) CDRH1 містить SEQ ID NO: 147, CDRH2 містить SEQ ID NO: 163, CDRH3 містить SEQ ID NO: 186, CDRL1 містить SEQ ID NO: 193, CDRL2 містить SEQ ID NO: 214 і CDRL3 містить SEQ ID NO: 228;
(b) CDRH1 містить SEQ ID NO: 137, CDRH2 містить SEQ ID NO: 150, CDRH3 містить SEQ ID NO: 166, CDRL1 містить SEQ ID NO: 198, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 233;
(c) CDRH1 містить SEQ ID NO: 137, CDRH2 містить SEQ ID NO: 150, CDRH3 містить SEQ ID NO: 189, CDRL1 містить SEQ ID NO: 198, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 233;
(d) CDRH1 містить SEQ ID NO: 147, CDRH2 містить SEQ ID NO: 163, CDRH3 містить SEQ ID NO: 186, CDRL1 містить SEQ ID NO: 195, CDRL2 містить SEQ ID NO: 214 і CDRL3 містить SEQ ID NO: 228;
(e) CDRH1 містить SEQ ID NO: 137, CDRH2 містить SEQ ID NO: 152, CDRH3 містить SEQ ID NO: 170, CDRL1 містить SEQ ID NO: 198, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 233;
(f) CDRH1 містить SEQ ID NO: 147, CDRH2 містить SEQ ID NO: 163, CDRH3 містить SEQ ID NO: 186, CDRL1 містить SEQ ID NO: 194, CDRL2 містить SEQ ID NO: 214 і CDRL3 містить SEQ ID NO: 228;
(g) CDRH1 містить SEQ ID NO: 141, CDRH2 містить SEQ ID NO: 156, CDRH3 містить SEQ ID NO: 172, CDRL1 містить SEQ ID NO: 209, CDRL2 містить SEQ ID NO: 223 і CDRL3 містить SEQ ID NO: 245;
(h) CDRH1 містить SEQ ID NO: 143, CDRH2 містить SEQ ID NO: 160, CDRH3 містить SEQ ID NO: 182, CDRL1 містить SEQ ID NO: 203, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 240;
(i) CDRH1 містить SEQ ID NO: 140, CDRH2 містить SEQ ID NO: 155, CDRH3 містить SEQ ID NO: 169, CDRL1 містить SEQ ID NO: 202, CDRL2 містить SEQ ID NO: 218 і CDRL3 містить SEQ ID NO: 236;
(j) CDRH1 містить SEQ ID NO: 140, CDRH2 містить SEQ ID NO: 155, CDRH3 містить SEQ ID NO: 169, CDRL1 містить SEQ ID NO: 201, CDRL2 містить SEQ ID NO: 218 і CDRL3 містить SEQ ID NO: 236;
(k) CDRH1 містить SEQ ID NO: 143, CDRH2 містить SEQ ID NO: 158, CDRH3 містить SEQ ID NO: 190, CDRL1 містить SEQ ID NO: 199, CDRL2 містить SEQ ID NO: 219 і CDRL3 містить SEQ ID NO: 237;
(l) CDRH1 містить SEQ ID NO: 137, CDRH2 містить SEQ ID NO: 151, CDRH3 містить SEQ ID NO: 167, CDRL1 містить SEQ ID NO: 199, CDRL2 містить SEQ ID NO: 217 і CDRL3 містить SEQ ID NO: 233;
(m) CDRH1 містить SEQ ID NO: 137, CDRH2 містить SEQ ID NO: 150, CDRH3 містить SEQ ID NO: 173, CDRL1 містить SEQ ID NO: 198, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 233;
(n) CDRH1 містить SEQ ID NO: 142, CDRH2 містить SEQ ID NO: 157, CDRH3 містить SEQ ID NO: 187, CDRL1 містить SEQ ID NO: 206, CDRL2 містить SEQ ID NO: 221 і CDRL3 містить SEQ ID NO: 242;
(o) CDRH1 містить SEQ ID NO: 143, CDRH2 містить SEQ ID NO: 158, CDRH3 містить SEQ ID NO: 177, CDRL1 містить SEQ ID NO: 200, CDRL2 містить SEQ ID NO: 216 і CDRL3 містить SEQ ID NO: 235;
(p) CDRH1 містить SEQ ID NO: 142, CDRH2 містить SEQ ID NO: 157, CDRH3 містить SEQ ID NO: 176, CDRL1 містить SEQ ID NO: 207, CDRL2 містить SEQ ID NO: 224 і CDRL3 містить SEQ ID NO: 243; і
(q) CDRH1 містить SEQ ID NO: 136, CDRH2 містить SEQ ID NO: 149, CDRH3 містить SEQ ID NO: 171, CDRL1 містить SEQ ID NO: 208, CDRL2 містить SEQ ID NO: 222 і CDRL3 містить SEQ ID NO: 244.
2. Антитіло за п. 1, що містить варіабельну ділянку важкого ланцюга (VH) і варіабельну ділянку легкого ланцюга (VL), де VH і VL містять амінокислотні послідовності, як наведено нижче:
(a) VH містить SEQ ID NO: 77 і VL містить SEQ ID NO: 109;
(b) VH містить SEQ ID NO: 77 і VL містить SEQ ID NO: 110;
(c) VH містить SEQ ID NO: 78 і VL містить SEQ ID NO: 133;
(d) VH містить SEQ ID NO: 79 і VL містить SEQ ID NO: 111;
(e) VH містить SEQ ID NO: 80 і VL містить SEQ ID NO: 112;
(f) VH містить SEQ ID NO: 84 і VL містить SEQ ID NO: 115;
(g) VH містить SEQ ID NO: 85 і VL містить SEQ ID NO: 116;
(h) VH містить SEQ ID NO: 86 і VL містить SEQ ID NO: 117;
(i) VH містить SEQ ID NO: 87 і VL містить SEQ ID NO: 118;
(j) VH містить SEQ ID NO: 70 і VL містить SEQ ID NO: 102;
(k) VH містить SEQ ID NO: 70 і VL містить SEQ ID NO: 103;
(l) VH містить SEQ ID NO: 73 і VL містить SEQ ID NO: 105;
(m) VH містить SEQ ID NO: 74 і VL містить SEQ ID NO: 106;
(n) VH містить SEQ ID NO: 89 і VL містить SEQ ID NO: 121;
(o) VH містить SEQ ID NO: 93 і VL містить SEQ ID NO: 123;
(p) VH містить SEQ ID NO: 94 і VL містить SEQ ID NO: 124;
(q) VH містить SEQ ID NO: 97 і VL містить SEQ ID NO: 127;
(r) VH містить SEQ ID NO: 98 і VL містить SEQ ID NO: 128; або
(s) VH містить SEQ ID NO: 99 і VL містить SEQ ID NO: 129.
3. Антитіло за п. 2, яке містить важкий ланцюг повної довжини і легкий ланцюг повної довжини, де важкий ланцюг повної довжини і легкий ланцюг повної довжини мають амінокислотні послідовності, як наведено нижче:
(a) важкий ланцюг повної довжини містить SEQ ID NO: 11 і легкий ланцюг повної довжини містить SEQ ID NO: 43;
(b) важкий ланцюг повної довжини містить SEQ ID NO: 11 і легкий ланцюг повної довжини містить SEQ ID NO: 44;
(c) важкий ланцюг повної довжини містить SEQ ID NO: 12 і легкий ланцюг повної довжини містить SEQ ID NO: 67;
(d) важкий ланцюг повної довжини містить SEQ ID NO: 13 і легкий ланцюг повної довжини містить SEQ ID NO: 45;
(e) важкий ланцюг повної довжини містить SEQ ID NO: 14 і легкий ланцюг повної довжини містить SEQ ID NO: 46;
(f) важкий ланцюг повної довжини містить SEQ ID NO: 18 і легкий ланцюг повної довжини містить SEQ ID NO: 49;
(g) важкий ланцюг повної довжини містить SEQ ID NO: 19 і легкий ланцюг повної довжини містить SEQ ID NO: 50;
(h) важкий ланцюг повної довжини містить SEQ ID NO: 20 і легкий ланцюг повної довжини містить SEQ ID NO: 51;
(i) важкий ланцюг повної довжини містить SEQ ID NO: 21 і легкий ланцюг повної довжини містить SEQ ID NO: 52;
(j) важкий ланцюг повної довжини містить SEQ ID NO: 4 і легкий ланцюг повної довжини містить SEQ ID NO: 36;
(k) важкий ланцюг повної довжини містить SEQ ID NO: 4 і легкий ланцюг повної довжини містить SEQ ID NO: 37;
(l) важкий ланцюг повної довжини містить SEQ ID NO: 7 і легкий ланцюг повної довжини містить SEQ ID NO: 39;
(m) важкий ланцюг повної довжини містить SEQ ID NO: 8 і легкий ланцюг повної довжини містить SEQ ID NO: 40;
(n) важкий ланцюг повної довжини містить SEQ ID NO: 23 і легкий ланцюг повної довжини містить SEQ ID NO: 55;
(o) важкий ланцюг повної довжини містить SEQ ID NO: 27 і легкий ланцюг повної довжини містить SEQ ID NO: 57;
(p) важкий ланцюг повної довжини містить SEQ ID NO: 28 і легкий ланцюг повної довжини містить SEQ ID NO: 58;
(q) важкий ланцюг повної довжини містить SEQ ID NO: 31 і легкий ланцюг повної довжини містить SEQ ID NO: 61;
(r) важкий ланцюг повної довжини містить SEQ ID NO: 32 і легкий ланцюг повної довжини містить SEQ ID NO: 62; або
(s) важкий ланцюг повної довжини містить SEQ ID NO: 33 і легкий ланцюг повної довжини містить SEQ ID NO: 63.
4. Антитіло, що конкурує за зв'язування з позаклітинною частиною c-fms людини з антитілом за пунктом 2а, 2b, 2j або 2k, і що зв'язується з c-fms людини з афінністю рівноважного зв’язування (KD) меншою ніж 10-8 М.
5. Антитіло, що містить ділянки, що визначають комплементарність, (CDRs) CDRH1, CDRH2, CDRH3, CDRL1, CDRL2 і CDRL3 за п.1 і здатне зв’язуватись з поліпептидом, що містить послідовність амінокислоти SEQ ID NO: 326, де антитіло не зв'язує поліпептид, що містить амінокислоти 20-126 послідовності SEQ ID NO: 1, і не зв’язує поліпептид, що містить амінокислоти 85-223 послідовності SEQ ID NO: 1.
6. Антитіло за будь-яким з пп. 1-5, яке:
(а) є моноклональним антитілом, рекомбінантним антитілом, людським антитілом, гуманізованим антитілом, химерним антитілом, біспецифічним антитілом або мультиспецифічним антитілом;
(b) є IgG1-, IgG2- IgG3- або IgG4-субтипом;
(с) є людським антитілом IgGl-, IgG2- IgG3- або IgG4-субтипу; або
(d) є фрагментом Fab, фрагментом Fab', фрагментом F(ab')2, фрагментом Fv, діатілом, доменним антитілом або молекулою антитіла з єдиним ланцюгом.
7. Нуклеїнова кислота, що кодує антитіло за будь-яким з пп. 1-6, яка необов`язково є функціонально зв’язаною з контрольною послідовністю.
8. Вектор, що містить нуклеїнову кислоту за пунктом 7.
9. Клітина-хазяїн, що містить нуклеїнову кислоту за пунктом 7.
10. Клітина-хазяїн, що містить вектор за пунктом 8.
11. Фармацевтична композиція, що містить щонайменше одне антитіло за будь-яким з пп. 1-6 і фармацевтично прийнятну допоміжну речовину.
12. Фармацевтична композиція за п. 11, яка додатково містить додатковий активний препарат, вибраний з групи, яка містить протизапальний препарат, протираковий препарат, препарат, який стимулює ріст кістки (анаболік), і препарат, який перешкоджає резорбції кістки.
13. Антитіло за будь-яким з пп. 1-6 для застосування у лікуванні.
14. Антитіло за будь-яким з пп. 1-6 для застосування у лікуванні або профілактиці стану, вибраного з раку, кісткової хвороби або запальної хвороби.
15. Антитіло за п. 13 або п. 14, яке вводиться у комбінації з протизапальним препаратом, протираковим препаратом, з препаратом, який стимулює ріст кістки (анаболік) або препаратом, який перешкоджає резорбції кістки.
16. Спосіб приготування антитіла за будь-яким з пп. 1-6, який включає етап культивування клітини-хазяїна за п. 9 для одержання зазначеного антитіла.
17. Спосіб приготування антитіла за будь-яким з пп. 1-6, який включає етап культивування клітини-хазяїна за п. 10 для одержання зазначеного антитіла.
Текст
Реферат: (56) Перелік документів, взятих до уваги експертизою: WO 2004045532 A, 03.06.2004. DATABASE UniProt [Online] UNIPROT; 1 July 1989 (1989-07-01), "Macrophage colony-stimulating factor 1 (Human)" retrieved from UNIPROT Database accession no. P09603. DATABASE UniProt [Online] UNIPROT; 5 July 2004 (2004-07-05), "Interleukin-34 (Human)" retrieved from UNIPROT Database accession no. Q6ZMJ4. LIN HAISHAN ET AL: "Regulation of myeloid growth and differentiation by a novel cytokine, interleukin-34 (IL-34), via the CSF-1 receptor" CYTOKINE, vol. 39, no. 1, July 2007, page 24. LIN HAISHAN ET AL: "Discovery of a cytokine and its receptor by functional screening of the extracellular proteome." SCIENCE (NEW YORK, N.Y.) 9 MAY 2008, vol. 320, no. 5877, 9 May 2008, pages 807-811. SHERR C J ET AL: "INHIBITION OF COLONYSTIMULATING FACTOR-1 ACTIVITY BY MONOCLONAL ANTIBODIES TO THE HUMAN CSF-1 RECEPTOR" BLOOD, AMERICAN SOCIETY OF HEMATOLOGY, US, vol. 73, no. 7, 15 May 1989, pages 1786-1793. ZHENG G ET AL: "Membrane-bound macrophage colony-stimulating factor and its receptor play adhesion molecule-like roles in leukemic cells." LEUKEMIA RESEARCH MAY 2000, vol. 24, no. 5, May 2000, pages 375-383. RAO QING ET AL: "Membrane-bound macrophage colony-stimulating factor mediated auto-juxtacrine downregulates matrix metalloproteinase-9 release on J6-1 leukemic cell." EXPERIMENTAL BIOLOGY AND MEDICINE (MAYWOOD, N.J.) OCT 2004, vol. 229, no. 9, October 2004, pages 946-953. KITAURA HIDEKI ET AL: "M-CSF mediates TNFinduced inflammatory osteolysis" JOURNAL OF CLINICAL INVESTIGATION, AMERICAN SOCIETY FOR CLINICAL INVESTIGATION, US, vol. 115, no. 12, 1 December 2005, pages 3418-3427. AHARINEJAD SEYEDHOSSEIN ET AL: "Colonystimulating factor-1 blockade by antisense oligonucleotides and small interfering RNAs suppresses growth of human mammary tumor xenografts in mice." CANCER RESEARCH 1 AUG 2004, vol. 64, no. 15, 1 August 2004, pages 53785384. UA 103306 C2 (12) UA 103306 C2 Винахід належить до антигензв'язуючого білка, що зв'язується з людським c-fms білком. Також винахід належить до нуклеїнової кислоти, яка кодує такий антигензв'язуючий білок, вектора, клітини-хазяїна та фармацевтичної композиції, що містить антигензв’язуючий білок. UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 Перехресне посилання на споріднені заявки Дана заявка претендує на пріоритет попередніх заявок США на винахід № 60/957,148, поданої 21 серпня 2007 р. і № 61/084,588, поданої 29 липня 2008 р., які включені у цей опис за посиланням у всій своїй повноті. Рівень знань Багато ліній пухлинних клітин людини і мишей секретують цитокін CSF-1 (колонієстимулюючий фактор-1, відомий також як колонієстимулюючий фактор макрофагів MCSF), який, в свою чергу, притягує, сприяє виживанню і активує клітини моноцити/макрофаги через рецептор c-fms (кошачий вірус саркоми Макдоно). Асоційовані з пухлиною макрофаги (ТАМ) (відомі також як макрофаги, що інфільтрують пухлину (ТІМ)) можуть бути головним компонентом строми пухлини, яка відповідає за цілих 50% маси клітин пухлини (Kelly et al, 1988, Br. J. Cancer 57:174-177; Leek et a l, 1994, J. Leukoc, Biol. 56:423-435). Аналізи первинних пухлин людини виявили багато свідчень на користь експресії мРНК CSF-1. До того ж, в численних дослідженнях було продемонстровано, що підвищений рівень CSF-1 в сироватці, кількості ТПМ чи присутність тканинного CSF-1 та/або c-fms асоціюються з поганим прогнозом для онкологічних хворих. ТАМ підтримують ріст, метастазування і виживання пухлини через широке коло засобів, включаючи пряму мітогенну активність пухлинних клітин у формі секреції PDGF, TGF-β і EGF та метастазування через продукцію ферментів, які розкладають ЕСМ (проаналізовано в статтях Leek & Harris, 2002, J. Mammary Gland Biol and Neoplasia 7:177-189 та Lewis & Pollard, 2006, Cancer Res 66:605-612). Іншим важливим засобом підтримки пухлини асоційованими з пухлиною макрофагами є сприяння неоваскуляризації пухлин через продукцію різних проангіогенних факторів, таких як COX-2, VEGF, FGF, EGF, оксид азоту, ангіопоетини та MMP (Dranoff et al., 2004, Nat. Rev. Cancer 4:11-22; MacMicking et a l, 1997, Annu. Rev. Immunol. 15:323-350; Mantovani et a l, 1992, Immunol. Today 13:265-270). Крім того, похідні від CSF-1 макрофаги можуть бути імуносупресивними через продукцію різних факторів, таких як простагландини, індол аміну 2,3 диоксигенази, оксид азоту, IL-10 та TGFβ (MacMicking et al., 1997, Annu. Rev. Immunol. 15:323-350; Bronte et al, 2001, J. Immunother. 24:431-446). CSF-1 експресується як зв'язаним з мембраною, так і розчинним цитокіном (Cerretti et al , 1988, Mol. Immunol. 25:761-770; Dobbin et al , 2005, Bioinformatics 21:2430-2437; Wong et al, 1987, Biochem. Pharmacol. 36:4325-4329), і регулює виживання, проліферацію, хемотаксис і активацію макрофагів та їх попередників (Bourette et al , 2000, Growth Factors 17:155-166; Cecchini et a l , 1994, Development 120:1357-1372; Hamilton, 1997, J. Leukoc. Biol 62:145-155; Hume, 1985, Sci. Prog. 69:485-494; Sasmono & Hume, in: The innate immune response to infection (eds. Kaufmann, S., Gordon, S. & Medzhitov, R.) 71-94 (ASM Press, New York, 2004); Ross and Auger, в книзі: The macrophage (eds. Burke, B. & Lewis, C.) (Oxford University Press, Oxford, 2002)). Когнатний рецептор, що є c-fms прото-онкогеном (відомим також як M-CSFR, CSF-1R чи CD115), являє собою 165-кД ліпопротеїн з асоційованою активністю тирозинкінази і належить до родини рецепторів тирозинкінази класу ІІІ, який включає PDGFR-α, PDGFR-β, VEGFR1, VEGFR2, VEGFR3, Flt3 та c-kit (Blume-Jensen & Hunter, 2001, Nature 411:355-365; Schlessinger & Ullrich, 1992, Neuron 9:383-391; Sherr et al., 1985 Cell 41:665-676; van der Geer et al , 1994, Annu. Rev. Cell. Biol. 10:251-337). Онкогенна форма c-fms – v-fms, носієм якої є штам Макдоно вірусу кошачої саркоми, мутує, набуваючи активності конститутивно активованої протеїнкінази (Sherr et al., 1985, Cell 41:665-676; Roussel & Sherr, 2003, Cell Cycle 2: 5-6). Експресія c-fms в нормальних клітинах обмежується мієломоноцитарними клітинами (включаючи моноцити, тканинні макрофаги, купферові клітини печінки, клітини Лангерганса, мікрогліальні клітини і остеокласти), гематопоетичними попередниками та трофобластами (Arai et a l, 1999, J. Exp. Med. 190:1741-1754; Dai et a l, 2002, Blood 99:111 -120; Pixley & Stanley, 2004, Trends Cell Biol. 14:628-638. Експресію c-fms було продемонстровано також в клітинах певних пухлин (Kirma et a l, 2007, Cancer Res 67:1918-1926). Цілою низкою досліджень in vitro та аналізів на мутантних мишах продемонстровано, що CSF-1 є лігандом для c-fms (дивись, наприклад, Bourette & Rohrschneider, 2000, Growth Factors 17:155-166; Wiktor-Jedrzejczak et al , 1990, Proc. Natl. Acad. Sci. U.S.A. 87:4828-4832; Yoshida et al., 1990, Nature 345:442-444; van Wesenbeeck & van Hul, 2005, Crit. Rev. Eukaryot. Gene Expr. 15:133-162). Зв'язування CSF-1 з c-fms викликає автофосфориляцію рецептору в конкретних сайтах, що приводить до подальшої активації сигнальних шляхів, включаючи PI3-K/AKT і Ras/Raf/MEK/MAPK, і диференціація макрофагів опосередковується головним чином через стійку активність МЕК (Gosse et al., 2005, Cellular Signaling 17:1352-1362). Свідчення останнього часу вказують на те, що інтерлейкін-34 (IL-34) також є лігандом для c-fms (Lin, et al. 2008, Science 320:807-811). 1 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 Суть винаходу Тут описуються антигензв'язуючі білки, які зв'язують c-fms, c-fms людини включно. Було встановлено, що антигензв'язуючі білки c-fms людини пригнічують, перешкоджають чи модулюють щонайменше одну з біологічних реакцій, пов'язаних з c-fms, і, як такі, є корисними в пом'якшенні ефектів захворювань і розладів, пов'язаних з c-fms. Відтак, зв'язування певних антигензв'язуючих білків з c-fms може мати один чи більше з наступних наслідків: пригнічення, перешкоджання чи модуляція зв'язування c-fms-CSF-1 чи передачі сигналів, пригнічення зв'язування c-fms-IL-34 чи передачі сигналів, зменшення міграції моноцитів в пухлини та/або зменшення накопичення асоційованих з пухлиною макрофагів (ТАМ). Один варіант здійснення включає системи експресії, включаючи клітинні лінії, для продукції антигензв'язуючих білків до рецепторів c-fms, а також способи для діагностики і лікування захворювань, пов'язаних з c-fms людини. Деякі з виділених антигензв'язуючих білків, що тут описуються, включають (А) одну чи більше ділянок важкого ланцюга, що визначають комплементарність (CDRH), вибраних з групи, яка складається з: (i) CDPH1, вибраної з групи, що містить послідовності SEQ ID №№: 136-147; (ii) CDRH2, вибраної з групи, що містить послідовності SEQ ID №№: 148-164; (iii) CDRH3 вибраної з групи, що містить послідовності SEQ ID №№: 165-190; та (iv) CDRH з (i), (ii) і (iii), яка містить одне чи більше амінокислотних заміщень, делецій чи вставок, які разом складають не більше ніж чотири амінокислоти; (В) одну чи більше ділянок легкого ланцюга, що визначають комплементарність (CDRL), вибраних з групи, яка складається з: (i) CDPL1, вибраної з групи, що містить послідовності SEQ ID №№: 191-210; (іі) CDPL2, вибраної з групи, що містить послідовності SEQ ID №№: 211-224; (ііі) CDPL3, вибраної з групи, що містить послідовності SEQ ID №№: 225-246; і (iv) CDRL з (i), (ii) і (iii), яка містить одне чи більше амінокислотних заміщень, делецій чи вставок, які разом складають не більше ніж чотири амінокислоти; або (С) одну чи більше ділянок CDRH важкого ланцюга з (А) і одну чи більше ділянок CDRL легкого ланцюга з (В). В одному варіанті здійснення виділений антигензв'язуючий білок може включати щонайменше одну чи дві ділянки CDRH з вищезгаданих ділянок (А) і щонайменше одну чи дві ділянки CDRL з вищезгаданих ділянок (В). В ще іншому аспекті виділений антигензв'язуючий білок включає CDRH1, CDRH2, CDRH3, CDRL1, CDRL2 і CDRL3. В певних антигензв'язуючих білках ділянка CDRH з вищезгаданих ділянок (А) далі вибирається з групи, яка складається з: (i) CDPH1, вибраної з групи, що містить послідовності SEQ ID №№: 136-147; (ii) CDRH2, вибраної з групи, що містить послідовності SEQ ID №№: 148164; (iii) CDRH3 вибраної з групи, що містить послідовності SEQ ID №№: 165-190; та (iv) CDRH з (i), (ii) і (iii), яка містить одне чи більше амінокислотних заміщень, делецій чи вставок не більше ніж двох амінокислот; ділянка CDRL з вищезгаданих ділянок (В) вибирається з групи, яка складається з: (i) CDPL1, вибраної з групи, що містить послідовності SEQ ID №№: 191-210; (іі) CDPL2, вибраної з групи, що містить послідовності SEQ ID №№: 211-224; (ііі) CDPL3, вибраної з групи, що містить послідовності SEQ ID №№: 225-246; і (iv) CDRL з (i), (ii) і (iii), яка містить одне чи більше амінокислотних заміщень, делецій чи вставок не більше ніж двох амінокислот; або (С) одну чи більше ділянок CDRH важкого ланцюга з (А) і одну чи більше ділянок CDRL легкого ланцюга з (В). В ще іншому варіанті здійснення виділений антигензв'язуючий білок може включати (А) ділянку CDRH, вибрану з групи, що містить (і) CDRH1, вибрану з групи, що включає послідовності SEQ ID №№: 136-147; (ii) CDRH2, вибраної з групи, що містить послідовності SEQ ID №№: 148-164, і (iii) CDRH3 вибраної з групи, що містить послідовності SEQ ID №№: 165-190; (В) ділянку CDRL, вибрану з групи, яка складається з: (i) CDPL1, вибраної з групи, що містить послідовності SEQ ID №№: 191-210; (іі) CDPL2, вибраної з групи, що містить послідовності SEQ ID №№: 211-224, і (ііі) CDPL3, вибраної з групи, що містить послідовності SEQ ID №№: 225-246; або (С) одну чи більше ділянок CDRH важкого ланцюга з (А) і одну чи більше ділянок CDRL легкого ланцюга з (В). В одному варіанті здійснення виділений антигензв'язуючий білок може включати (А) CDRH1 з SEQ ID №№: 136-147, CDRH2 з SEQ ID №№: 148-164 і CDRH3 з SEQ ID №№: 165-190 та (В) CDPL1 з SEQ ID №№: 191-210, CDPL2 з SEQ ID №№: 211-224 і CDPL3 з SEQ ID №№: 225-246. В іншому варіанті здійснення варіабельна ділянка важкого ланцюга (VH) має щонайменше 90% ідентичність послідовності з амінокислотною послідовністю, вибраною з групи, що містить SEQ ID №№: 70-101, та/або варіабельна ділянка легкого ланцюга (VL) має щонайменше 90% ідентичність послідовності з амінокислотною послідовністю, вибраною з групи, що містить SEQ ID №№: 102-135. В подальшому варіанті здійснення VH вибирається з групи, що містить SEQ ID №№: 70-101, та/або VL вибирається з групи, що містить SEQ ID №№: 102-135. 2 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 В іншому аспекті пропонується виділений антигензв'язуючий білок, який специфічно зв'язується з епітопом, що містить c-fms субдомени Ig-подібного 1-1 та Ig-подібного 1-2 c-fms людини. В ще іншому аспекті пропонується виділений антигензв'язуючий білок, що зв'язує c-fms, який включає: (А) одну чи більше ділянок CDR важкого ланцюга (CDRH), вибраних з групи, що містить (і) CDRH1 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 136-147; (ii) CDRH2 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 148-164; і CDRH3 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 165-190; (В) одну чи більше ділянок CDR легкого ланцюга (CDRL), вибраних з групи, що містить (і) CDRL1 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 191-210; (ii) CDRL2 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 211-224; і CDRL3 з щонайменше 80% ідентичністю послідовності з SEQ ID №№: 225-246; або (С) одну чи більше ділянок CDRH важкого ланцюга з (А) і одну чи більше ділянок CDRL легкого ланцюга з (В). В одному варіанті здійснення виділений антигензв'язуючий білок включає: (А) одну чи більше ділянок CDRH, вибраних з групи, що містить (і) CDRH1 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 136147; (ii) CDRH2 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 148-164; і CDRH3 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 165-190; (В) одну чи більше ділянок CDRL, вибраних з групи, що містить (і) CDRL1 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 191-210; (ii) CDRL2 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 211-224; і CDRL3 з щонайменше 90% ідентичністю послідовності з SEQ ID №№: 225-246; або (С) одну чи більше ділянок CDRH важкого ланцюга з (А) і одну чи більше ділянок CDRL легкого ланцюга з (В). Інший варіант здійснення стосується виділеного антигензв'язуючого білку, що зв'язує c-fms, причому цей виділений антигензв'язуючий білок включає одну чи комбінацію ділянок CDR, які мають консенсусні послідовності, описані далі. Групи А, В і С стосуються послідовностей, що походять від філогенетично споріднених клонів. В одному аспекті ділянки CDR від різних груп можуть змішуватись і бути сумісними. В іншому аспекті цей антигензв'язуючий білок містить дві чи більше ділянки CDRH з однієї і тієї ж групи А, В чи С. В ще іншому аспекті цей антигензв'язуючий білок містить щонайменше дві чи три ділянки CDRH та/або щонайменше дві чи три ділянки CDRL з однієї і тієї ж групи А, В чи С. Консенсусні послідовності для різних груп є наступними: Група А: (а) CDRH1 загальної формули GYTX1TSYGIS (SEQ ID №:307), де Х1 вибирається з групи, що містить F і L; (b) CDRH2 загальної формули WISAYNGNX1NYAQKX2QG (SEQ ID №:308), де Х1 вибирається з групи, що містить Т і Р, а Х 2 вибирається з групи, що містить L і F; (с) CDRH3 загальної формули X1X2X3X4X4X5FGEX6X7X8X9FDY (SEQ ID №:309), де Х1 вибирається з групи, що містить Е і D, Х 2 вибирається з групи, що містить S і Q, X3 вибирається з групи, що містить G і не містить амінокислоти, Х 4 вибирається з групи, що містить L і не містить амінокислоти, Х5 вибирається з групи, що містить W і G, X6 вибирається з групи, що містить V і L, X7 вибирається з групи, що містить Е і не містить амінокислоти, X8 вибирається з групи, що містить G і не містить амінокислоти, і Х 9 вибирається з групи, що містить F і L; (d) CDRL1 загальної формули KSSX1GVLX2SSX3NKNX4LA (SEQ ID №:310), де Х1 вибирається з групи, що містить Q і S, Х2 вибирається з групи, що містить D і Y, X3 вибирається з групи, що містить N і D та Х4 вибирається з групи, що містить F і Y; (e) CDRL2 загальної формули WASX1RES (SEQ ID №:311), де Х1 вибирається з групи, що містить N і T; та (f) CDRL3 загальної формули QQYYX1X2PX3T (SEQ ID №:312), де Х1вибирається з групи, що містить S і T, X2 вибирається з групи, що містить D і T, та X3 вибирається з групи, що містить F і P. Група В: (а) CDRH1 загальної формули GFTX1X2X3AWMS (SEQ ID №:313), де Х1 вибирається з групи, що містить F і V, X2 вибирається з групи, що містить S і N, та X3 вибирається з групи, що містить N і T; (b) CDRH2 загальної формули RIXX1KTDGX2TX3DX4AAPVKG (SEQ ID №:314), де Х1 вибирається з групи, що містить S і T, X2 вибирається з групи, що містить G і W, X3 вибирається з групи, що містить Y, R, G і не містить амінокислоти T і A, та X4 вибирається з групи, що містить Y і N; (c) CDRH3 загальної формули Х1X2X3X4X5X6X7X8X9X10X11X12X13YYGX14DV (SEQ ID №:315), де Х1 вибирається з групи, що містить E, D і G, X2 вибирається з групи, що містить Y, L і не містить амінокислоти, X3 вибирається з групи, що містить Y, R, G і не містить амінокислоти, X4 вибирається з групи, що містить H, G, S і не містить амінокислоти, X5 вибирається з групи, що містить I, A, L і не містить амінокислоти, X6 вибирається з групи, що містить L, V, T, P і не містить амінокислоти, X 7 вибирається з групи, що містить T, V, Y, G, W і не містить амінокислоти, X 8 вибирається з групи, що містить G, V, S і T, X9 вибирається з групи, що містить S, T, D, N і G, X10 вибирається з групи, що містить G, F, P і Y, X11 вибирається з групи, що містить G, Y і N, X12 вибирається з групи, що 3 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 містить V і Y, X13 вибирається з групи, що містить W, S і Y та X14 вибирається з групи, що містить M, T і V; (d) CDRL1 загальної формули QASQDLX1NYLN (SEQ ID №:316), де Х1 вибирається з групи, що містить S і N; (e) CDRL2 загальної формули DX1SNLEX2 (SEQ ID №:317), де Х1 вибирається з групи, що містить А і Т, а Х2 вибирається з групи, що містить Т і Р; і (f) CDRL3 загальної формули QQYDX1LX2T (SEQ ID №:318), де Х1 вибирається з групи, що містить N і D, та X2 вибирається з групи, що містить L і I. Група C: (а) CDRH1 загальної формули GFTFX1SYGMH (SEQ ID №:319), де Х1 вибирається з групи, що містить S і І; (b) CDRH2 загальної формули VIWYDGSNX 1YYADSVKG (SEQ ID №:320), де Х1 вибирається з групи, що містить Е і К; (c) CDRH3 загальної формули SSX1X2X3YX4MDV (SEQ ID №:321), де Х1 вибирається з групи, що містить G, S і W, X2 вибирається з групи, що містить N, D і S, X3 вибирається з групи, що містить Y і F, а X4 вибирається з групи, що містить D and G; (d) CDRL1 загальної формули QASX 1DIX2NX3LN (SEQ ID NO:322), де Х1 вибирається з групи, що містить Q s H, X2 вибирається з групи, що містить S і N, та X3 вибирається з групи, що містить F і Y; (e) CDRL2 загальної формули DASNLEX 1 (SEQ ID №:323), де Х1 вибирається з групи, що містить Т і І; і (f) CDRL3 загальної формули QX1YDX2X3PX4T (SEQ ID №:324), де Х1 вибирається з групи, що містить Q і R, X2 вибирається з групи, що містить N і D, X3 вибирається з групи, що містить L і F, та X4 вибирається з групи, що містить F, L і I. В ще іншому варіанті здійснення вищеописаний виділений антигензв'язуючий білок містить першу амінокислотну послідовність, що включає щонайменше одну ділянку CDRH, і другу амінокислотну послідовність, що включає щонайменше одну ділянку CDRL. В одному варіанті здійснення ці перша і друга амінокислотні послідовності є ковалентно зв'язаними одна з одною. В іншому варіанті здійснення перша амінокислотна послідовність виділеного антигензв'язуючого білку включає CDRH3 послідовностей SEQ ID №№: 165-190, CDRH2 послідовностей SEQ ID №№: 148-164 і CDRH1 послідовностей SEQ ID №№: 136-147, а друга амінокислотна послідовність виділеного антигензв'язуючого білку включає CDRL3 послідовностей SEQ ID №№: 225-246, CDRL2 послідовностей SEQ ID №№: 211-224 і CDRL1 послідовностей SEQ ID №№: 191-210. В одному аспекті запропонований тут виділений антигензв'язуючий білок може бути моноклональним антитілом, поліклональним антитілом, рекомбінантним антитілом, людським антитілом, гуманізованим антитілом, химерним антитілом, мультиспецифічним антитілом або їх фрагментом. В іншому варіанті здійснення антитільний фрагмент виділених антигензв'язуючих білків може бути фрагментом Fab, фрагментом Fab', фрагментом F(ab')2, фрагментом Fv, діатілом або однонитковою молекулою антитіла. В подальшому варіанті здійснення виділений антигензв'язуючий білок є антитілом людини і може належати до IgGl-, IgG2-, IgG3- чи IgG4типу. В іншому аспекті виділений антигензв'язуючий білок може конкурувати за зв'язування до позаклітинної частини c-fms людини з одним із запропонованих тут антигензв'язуючих білків. В одному варіанті здійснення виділений антигензв'язуючий білок при введенні пацієнту може зменшувати хемотаксис моноцитів, пригнічувати міграцію моноцитів в пухлини, пригнічувати накопичення асоційованих з пухлиною макрофагів в патологічно зміненій тканині. В ще іншому аспекті пропонуються також молекули виділеної нуклеїнової кислоти, які кодують антигензв'язуючі білки, що зв'язуються з c-fms. В певних випадках такі молекули виділеної нуклеїнової кислоти є функціонально зв'язаними з контрольною послідовністю. В іншому аспекті пропонуються також вектори експресії і клітини-хазяї, трансформовані чи трансфіковані векторами експресії, які містять вищезгадані молекули виділеної нуклеїнової кислоти, які кодують антигензв'язуючі білки, що можуть зв'язуватись з c-fms. В іншому аспекті пропонуються також способи отримання антигензв'язуючих білків, які включають етап отримання антигензв'язуючих білків з клітини-хазяїна, яка секретує цей антигензв'язуючий білок. В ще іншому аспекті пропонуються також фармацевтична композиція, яка містить щонайменше один з вищезгаданих антигензв'язуючих білків і фармацевтично прийнятну допоміжну речовину. В одному варіанті здійснення така фармацевтична композиція може містити додатковий активний препарат, який вибирається з групи, що включає радіоізотоп, радіонуклід, токсин або препарат терапевтичної і хіміотерапевтичної групи. Варіанти здійснення даного винаходу пропонують спосіб лікування чи профілактики стану, пов'язаного з c-fms, у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного виділеного антигензв'язуючого білку. В одному варіанті здійснення таким станом є рак, який вибирається з групи, що включає рак молочної залози, рак передміхурової залози, колоректальний рак, ендометріальну аденокарциному, лейкемію, лімфому, меланому, 4 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 лускатоклітинний рак стравоходу, рак шлунку, астроцитому, рак ендометрію, рак шийки матки, рак сечового міхура, рак нирок, рак легень і рак яєчнику. В іншому аспекті даний винахід пропонує спосіб пригнічення зв'язування CSF-1 з позаклітинною частиною c-fms у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного запропонованого тут антигензв'язуючого білку. В ще іншому аспекті пропонується також спосіб пригнічення автофосфориляції людського cfms у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного запропонованого тут антигензв'язуючого білку. Також пропонується, вже як інший аспект, спосіб зниження хемотаксису моноцитів у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного антигензв'язуючого білку. В одному своєму аспекті цей винахід пропонує також спосіб пригнічення міграції моноцитів в пухлини у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного антигензв'язуючого білку. В іншому аспекті пропонується спосіб пригнічення накопичування асоційованих з пухлиною макрофагів в пухлині у пацієнта, який включає введення пацієнту ефективної кількості щонайменше одного антигензв'язуючого білку. Ці та інші аспекти далі будуть описані більш докладно. Кожний з цих запропонованих аспектів може охоплювати різні варіанти здійснення, описані тут. Відповідно, мається на увазі, що кожний з варіантів здійснення, що включає один елемент чи комбінацію елементів, може бути включений в кожний аспект, описаний тут. Інші характерні особливості, цілі і переваги запропонованого винаходу будуть більш зрозумілими з наступного детального опису. Короткий опис малюнків На Фіг. 1А показане порівняння послідовностей запропонованих тут варіабельних ділянок важкого ланцюга. На Фіг. 1В показане порівняння послідовностей запропонованих тут варіабельних ділянок легкого ланцюга. Показані також ділянки CDR і каркасні ділянки. На Фіг. 2 показано аналіз клітинних ліній для 29 анти-c-fms гібридом. Амінокислотні послідовності, які відповідають варіабельному домену важкого ланцюга (VH) чи варіабельному домену легкого ланцюга (VL) всіх клонованих гібридом, були зіставлені і порівняні одна з одною для демонстрації різноманітності антитіл. Показані дендрограми цих порівняльних зіставлень, на яких довжина горизонтальної гілки відповідає відносній кількості заміщень (відмінностей) між будь-якими двома послідовностями чи таксонами послідовностей (групами близько споріднених послідовностей). Показано послідовності, згруповані разом для визначення консенсусних послідовностей. На Фіг. 3 показано пригнічення проліферації AML-5 анти-c-fms супернатантами різних гібридом. На Фіг. 3А показана біологічна проба AML-5 анти-c-fms супернатантами гібридом. На Фіг. 3В показана біологічна проба AML-5 з очищеними рекомбінантними анти-c-fms антитілами. Клітини AML-5 інкубувались з 10 нг/мл CSF-1 в присутності концентрацій антитіла, що знижуються. Через 72 години проліферацію клітин оцінювали за допомогою аламару синього (метаболічний барвник, який визначає дихальну активність клітини). На Фіг. 4 показана проба CynoBM з титруванням c-fms антитіл в CSF-1. Показано пригнічення проліферації клітин кісткового мозку макаки, збагачених CSF-1, анти-c-fms супернатантами різних гібридом. Клітини кісткового мозку макаки інкубувались з 10 нг/мл CSF-1 в присутності концентрацій антитіла, що знижуються. Через 72 години проліферацію клітин оцінювали за допомогою аламару синього. На Фіг. 5 показано пригнічення індукованого лігандом pTyr-c-fms антитілами IgG2mAbs (PT, материнські форми). Клітини 293T/c-fms були позбавлені сироватки впродовж 1 години і оброблені антитілами IgG2 mAbs, 1.109, 1.2 або 2.360 (PT) та контрольними анти-c-fms антитілами mAbs 3-4A4 (не блокуючими) і анти-h-CD39 Ml05 (не специфічним) в серіях титрування (1,0 to 0,0001 мкг/мл) або при 1,0 мкг/мл (контроль). Потім клітини стимулювали, 0 використовуючи 50 нг/мл CSF-1, впродовж 5 хвилин при 37 С. Лізати цільних клітин були піддані імунопреципітації під дією анти-c-fms С20, як описано. Вестерн блоти зондували анти-pTyr 4G10 (верхня частина) або анти-c-fms C20 (нижня частина) для виявлення pTyr/c-fms і визначення загального c-fms, відповідно. На Фіг. 6 порівнюється пригнічення індукованого лігандом pTyr-c-fms антитілами IgG2mAbs (PT проти SM (виправлена соматична мутація) форм). Клітини 293T/c-fms були позбавлені сироватки впродовж 1 години і оброблені антитілами IgG 2 mAbs, 1.109, 1.2 чи 2.360 (і PT, і SM) та контрольними анти-c-fms антитілами mAbs 3-4A4 (не блокуючими) при 1,0 і 0,1 мкг/мл. Потім 0 клітини стимулювали, використовуючи 50 нг/мл CSF-1, впродовж 5 хвилин при 37 С. Лізати цільних клітин були піддані імунопреципітації під дією анти-c-fms С20, як описано. Вестерн 5 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 блоти зондували анти-pTyr 4G10 (верхня частина) або анти-c-fms C20 (нижня частина) для виявлення pTyr/c-fms і визначення загального c-fms, відповідно. На Фіг. 7 показано вестерн блотинг імунопреципітації c-fms IgG2 антитілами mAbs (PT versus SM форм). Лізати цільних нестимульованих клітин 293T/c-fms були піддані імунопреципітації впродовж ночі при 4°C з використанням IgG2 антитіл mAbs, 1.109, 1.2 чи 2.360 (і PT, і SM форми) та анти-c-fms C20 при 2,5 мкг/мл. Вестерн блоти зондували анти-c-fms C20 і IgG/HRP проти кроля. На Фіг. 8 показано амінокислотну послідовність (SEQ ID №: 1) ділянки позаклітинного домену c-fms людини. На Фіг. 9 показано вестерн блотинг імунопреципітації c-fms SNP. Конструкції експресії показаних c-fms SNP були створені і тимчасово експресовані в клітинах 293T/c-fms. Лізати цільних нестимульованих клітин були піддані імунопреципітації кожним антитілом mAb і контрольними Ab. Вестерн блоти зондували c-fms Н300 і IgG/HRP проти кроля. На Фіг. 10 показано схему c-fms ECD (позаклітинного домену) людини і усічених конструкцій. Авідинова мітка пришита до каркасу на N-кінці c-fms. Перша і останні чотири амінокислоти показані для кожної конструкції c-fms. На Фіг. 11 показано зв'язування міченого FITC анти-авідину, 1.109, 1.2 і 2.360 c-fms антитіл до c-fms ECD та усічений авідиновий зшитий білок. На Фіг. 12 показано зв'язування міченого FITC анти-авідину, контрольного антитіла і анти-cfms антитіл (мічених FITC) до c-fms повної довжини і гібридного білку Ig-подібної петлі 2 (одної). На Фіг. 13 показано конкурентний аналіз з 20х немічених 1.109, 1.2 і 2.360 c-fms антитіл з наступним додаванням міченого FITC 1.109 в концентрації 1 мкг/мл. На Фіг. 14 показано конкурентний аналіз з 20х немічених 1.109, 1.2 і 2.360 c-fms антитіл з наступним додаванням міченого FITC 1.2 в концентрації 1 мкг/мл. На Фіг. 15 показано конкурентний аналіз з 20х немічених 1.109, 1.2 і 2.360 c-fms антитіл з наступним додаванням міченого FITC 2.360 в концентрації 1 мкг/мл. На Фіг. 16 показано пригнічення росту ксенотрансплантату аденокарциноми молочної залози MDAMB231 c-fms антитілом проти миші з визначенням об'єму пухлини та відсотку некрозу кожної пухлини. Відсоток некрозу кожної пухлини було обчислено за вимірюваннями пухлин і показано на Фіг. 16. На Фіг. 17 показано пригнічення росту встановлених ксенотрансплантатів аденокарциноми легень NCIH1975. Показані виміри пухлин і дні обробки, які показують, що c-fms антитіло проти миші може пригнічувати ріст встановлених ксенотрансплантатів аденокарциноми легень NCIH1975. Докладний опис винаходу Заголовки розділів, використані в цьому описі, призначені виключно для організаційних цілей і жодним чином не обмежують сутність викладеного. Якщо інше визначення не дається, наукові і технічні терміни, використані у зв'язку з даним описом винаходу, будуть мати звичайне значення, зрозуміле спеціалістам в цій галузі. Більш того, коли інше не вимагається контекстом, терміни в однині будуть включати множину, а терміни в множині будуть включати однину. Загалом, номенклатура, використана у зв'язку з культивуванням клітин і тканин, молекулярною біологією, імунологією, мікробіологією, генетикою, а також хімією і гібридизацією білків і нуклеїнових кислот та відповідними методиками, описаними тут, є добре відомою і широко використовуваною в цій галузі. Методи і методики, які зустрічаються в цьому описі, загалом здійснюються у відповідності до звичайних методів і методик, добре відомих в цій галузі і описаних в різних загальних і більш спеціальних джерелах, наведених в даному описі, коли не вказується інше (дивись, наприклад, Sambrook et al., Molecular Cloning: A Laboratory Manual, 3rd ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (2001), Ausubel et a l, Current Protocols in Molecular Biology, Greene Publishing Associates (1992), та Harlow & Lane Antibodies: A Laboratory Manual Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (1990)), які включено в цей опис за посиланням. Ферментативні реакції і методи очистки здійснюються у відповідності до технічних вимог виробника, як це звичайно виконується в цій галузі чи як описано тут. Термінологія, використовувана у зв'язку з аналітичною хімією, хімією органічного синтезу, медичною і фармацевтичною хімією, а також відповідні лабораторні процедури і методики, описані тут, є добре відомими і широко використовуваними в цій галузі. Стандартні методики можуть бути використані для хімічного синтезу, хімічних аналізів, приготування фармацевтичних препаратів, складання рецептури, доставки і лікування пацієнтів. 6 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 Має бути зрозумілим, що цей винахід не обмежується конкретною методологією, протоколами, реактивами і т.п., описаними тут, і, як такі, вони можуть змінюватись. Термінологія, використана тут, призначена тільки для того, щоб описати конкретні варіанти здійснення, і жодним чином не обмежує об'єм викладеного, кий визначається виключно формулою винаходу. Крім робочих прикладів і коли вказується інше, всі використані тут цифри, що стосуються кількості інгредієнтів чи умов реакції, мають розумітись, як модифіковані у всіх випадках терміном "приблизно". Термін "приблизно", коли використовується у зв'язку з відсотками, може означати ±1%. Дефініції Термін "полінуклеотид" або "нуклеїнова кислота" включає як однониткові, так і двониткові нуклеотидні полімери. Нуклеотиди, що являють собою полінуклеотид, можуть бути рибонуклеотидами чи деоксирибонуклеотидами або модифікованою формою будь-якого типу нуклеотиду. Вказані модифікації включають модифікації основи, такі як похідні бромоуридину та інозиту, модифікації рибози, такі як 2',3'-дидеоксирибоза, і модифікації міжнуклеотидних зв'язків, такі як фосфоротіоат, фосфородитіоат, фосфороселеноат, фосфороанілотіоат, фосфоранілідіт і фосфороамідат. Термін "олігонуклеотид" означає полінуклеотид, який містить 200 або менше нуклеотидів. В певних варіантах здійснення олігонуклеотиди мають в довжину від 10 до 60 основ. В певних варіантах здійснення олігонуклеотиди мають 12, 13, 14, 15, 16, 17, 18, 19 чи від 20 до 40 нуклеотидів в довжину. Олігонуклеотиди можуть бути однонитчастими і двонитчастаими, наприклад для використання в конструюванні мутантного гену. Олігонуклеотиди можуть бути смисловими і анти-смисловими олігонуклеотидами. Олігонуклеотид може включати мітку, в тому числі радіоактивну мітку, флуоресцентну мітку, гаптен чи антигенну мітку, для аналізів на виявлення. Олігонуклеотиди можуть використовуватись, наприклад, як праймери ПЛР, праймери для клонування чи зонди для гібридизації. "Молекула виділеної нуклеїнової кислоти" означає ДНК чи РНК геномного, мРНК, кДНК чи синтетичного походження чи певну їх комбінацію, яка не асоціюється зі всім чи частиною полінуклеотиду, де виділений полінуклеотид можна знайти в природі, або є зв'язаною з полінуклеотидом, з яким в природі вона не зв'язується. Для цілей даного опису має бути зрозумілим, що "молекула нуклеїнової кислоти, яка містить" конкретну нуклеотидну послідовність, не охоплює інтактних хромосом. Молекули виділеної нуклеїнової кислоти, які "містять" вказані послідовності нуклеїнових кислот, можуть включати, крім вказаних послідовностей, кодуючі послідовності для десяти чи навіть до двадцяти інших білків чи їх частин або можуть включати функціонально зв'язані регуляторні послідовності, які контролюють експресію кодуючої ділянки вказаних послідовностей нуклеїнових кислот, та/або можуть включати векторні послідовності. Коли не вказується інше, лівий кінець послідовності однониткового полінуклеотиду, про який тут йдеться, є 5' кінцем; лівий напрямок послідовностей двониткового полінуклеотиду називається 5' напрямком. Напрямок додавання від 5' до 3' ланцюга РНК, що росте, називається напрямком транскрипції; ділянки послідовності на нитці ДНК, що мають ту саму послідовність, що й транскрипт РНК, які знаходяться від 5' до 5' кінця транскрипту РНК, називаються "попередніми послідовностями"; ділянки послідовності на нитці ДНК, що мають ту саму послідовність, що й транскрипт РНК, які знаходяться від 3' до 3' кінця транскрипту РНК, називаються "наступними послідовностями". Термін "контрольна послідовність" стосується полінуклеотидної послідовності, яка може впливати на експресію і обробку кодуючих послідовностей, з якою вона зшита. Природа таких контрольних послідовностей може залежати від організму хазяїна. В конкретних варіантах здійснення контрольні послідовності для прокаріотів може включати промотор рибосомного сайту зв'язування і послідовність термінації транскрипції. Наприклад, контрольні послідовності для евкаріотів можуть включати промотори, що містять один чи певну кількість сайтів розпізнання для факторів транскрипції, послідовності енхансеру транскрипції і послідовність термінації транскрипції. "Контрольні послідовності" можуть включати лідерні послідовності та/або послідовності клітин, що зливаються. Термін "вектор" означає будь-яку молекулу чи утворення (наприклад, нуклеїнову кислоту, плазміду, бактеріофаг чи вірус), які використовуються для перенесення кодуючої білок інформації в клітину-хазяїн. Термін "вектор експресії" або "конструкція експресії" стосується вектору, що є придатним для трансформації клітини-хазяїна і містить послідовності нуклеїнових кислот, які спрямовують та/або контролюють (в сполученні з клітиною-хазяїном) експресію однієї чи більше 7 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 гетерологічних кодуючих ділянок, функціонально з ним зв'язаних. Конструкція експресії може включати, не обмежуючись ними, послідовності, які контролюють або впливають на транскрипцію, трансляцію і, коли присутні інтрони, перешкоджають сплайсингу РНК кодуючої ділянки, функціонально зв'язаної з нею. Як він використовується тут, термін "функціонально зв'язані" означає, що компоненти, до яких цей термін застосовується, знаходяться у взаємозв'язку, який дозволяє їм здійснювати властиві їм функції за відповідних умов. Наприклад, контрольна послідовність у векторі, який "функціонально зв'язаний" з кодуючою білок послідовністю, пришита до нього так, що експресія цієї кодуючою білок послідовності досягається за умов, сумісних з транскрипційною активністю контрольних послідовностей. Термін "клітина-хазяїн" означає клітину, яку було трансформовано чи яка є здатною бути трансформованою послідовністю нуклеїнових кислот і яка, як наслідок, експресує ген, що становить інтерес. Цей термін включає потомство материнської клітини незалежно від того, чи є це потомство ідентичним за морфологією чи за генетичною основою з вихідною материнською молекулою, оскільки є присутнім ген, що становить інтерес. Термін "трансдукція" означає перенесення генів від однієї бактерії до іншої, звичайно бактеріофагом. "Трансдукція" стосується також придбання і перенесення евкаріотичних клітинних послідовностей при реплікації дефектних ретро вірусів. Термін "трансфекція" означає захоплення чужорідної чи екзогенної ДНК клітиною, і клітину було "трансфіковано", коли екзогенну ДНК було введено всередину мембрани клітини. Ціла низка методів трансфекції є добре відомою в цій галузі і описуються тут (дивись, наприклад, Graham et al., 1973, Virology 52:456; Sambrook et a l. , 2001, Molecular Cloning: A Laboratory Manual, supra; Davis et al ., 1986, Basic Methods in Molecular Biology, Elsevier; Chu et a l. , 1981, Gene 13:197). Такі методи можуть бути використані для введення однієї чи більше форм екзогенної ДНК в придатні клітини-хазяї. Термін "трансформація" стосується зміни в генетичних характеристиках клітини, і клітину було трансформовано, коли її було модифіковано так, що вона містить нову ДНК чи РНК. Наприклад, клітину трансформовано, коли її генетично модифіковано відносно її нативного стану шляхом введення нового генетичного матеріалу через трансфекцію, трансдукцію та іншими методами. Після трансфекції чи трансдукції ДНК, що викликала трансформацію, може рекомбінуватись з ДНК клітини шляхом фізичної інтеграції в хромосому клітини, або може тимчасово підтримуватись як елемент епітопи без реплікації, або може реплікувати незалежно як плазміда. Вважається, що клітину "стабільно трансформовано", коли ДНК, що викликала трансформацію, реплікує з поділом клітини. Терміни "поліпептид" чи "білок" використовуються тут взаємозамінно і стосуються полімеру з амінокислотних залишків. Ці терміни застосовуються також до амінокислотних полімерів, в яких один чи більше амінокислотних залишків є аналогом чи міметиком відповідної природної амінокислоти, а також природних амінокислотних полімерів. Ці терміни можуть охоплювати амінокислотні полімери, які було модифіковано, наприклад шляхом додавання вуглеводневих залишків з утворенням глікопротеїнів, чи фосфорильовано. Поліпептиди і білки можуть продукуватись природною і нерекомбінантною клітиною; або вони продукуються підданою генній інженерії чи рекомбінантною клітиною і містять молекули з амінокислотною послідовністю нативного білку або молекули з делеціями, добавками чи заміщеннями однієї чи більше амінокислот нативної послідовності. Терміни "поліпептид" і "білок" специфічно охоплюють c-fms антигензв'язуючі білки, антитіла чи послідовності з делеціями, добавками чи заміщеннями однієї чи більше амінокислот антигензв'язуючого білку. Термін "фрагмент поліпептиду" стосується поліпептиду, який має аміно-термінальну делецію, карбоксил-термінальну делецію та/або внутрішню делецію у порівнянні з білком повної довжини. В певних варіантах здійснення фрагменти мають в довжину від 5 до 500 амінокислот. Наприклад, фрагменти можуть мати щонайменше 5, 6, 8, 10, 14, 20, 50, 70, 100, 110, 150, 200, 250, 300, 350, 400 чи 450 амінокислот в довжину. Корисні поліпептидні фрагменти включають імунологічно функціональні фрагменти антитіл, включаючи домени зв'язування. У випадку c-fms-зв'язуючого антитіла корисні фрагменти включають, не обмежуючись ділянкою CDR, варіабельний домен важкого чи легкого ланцюга, частину ланцюга антитіла чи тільки його варіабельну ділянку, що включає дві ділянки CDR і т.п. Термін "виділений білок" означає, що білок, про який йдеться, (1) є вільним від щонайменше певних інших білків, з якими він звичайно трапляється, (2) є суттєво вільним від інших білків з того самого джерела, наприклад від того самого виду, (3) експресується клітиною від іншого виду, (4) був відділений від щонайменше приблизно 50% полінуклеотидів, ліпідів, вуглеводів чи інших матеріалів, з якими він асоціюється в природі, (5) функціонально зв'язаний (ковалентною 8 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 чи не ковалентною взаємодією) з поліпептидом, з яким він не асоціюється в природі, або (6) не трапляється в природі. Типово, "виділений білок" становить щонайменше біля 5%, щонайменше біля 10%, щонайменше біля 25% чи щонайменше біля 50% даного зразку. Геномна ДНК, кДНК, мРНК чи інша РНК синтетичного походження або будь-яка їх комбінація може кодувати такий виділений білок. Переважно, виділений білок є суттєво вільним від білків, чи поліпептидів, чи інших контамінантів, які знаходяться в його природному оточенні і могли б перешкоджати його терапевтичному, діагностичному, профілактичному чи науково-дослідницькому чи іншому застосуванню. "Варіант" поліпептиду (наприклад, антигензв'язуючий білок чи антитіло) містить амінокислотну послідовність, в якій один чи більше амінокислотних залишків введені, видалені чи заміщені по відношенню до іншої поліпептидної послідовності. Варіанти включають гібридні (злиті) білки. "Похідним" поліпептиду є поліпептид (наприклад, антигензв'язуючий білок чи антитіло), який було хімічно модифіковано в певний спосіб, що відрізняється від варіантів делеції, вставки чи заміщення, наприклад через кон'югацію з іншим хімічним утворенням. Термін "трапляється в природі", як він використовується в цьому описі у зв'язку з біологічними матеріалами, такими як поліпептиди, нуклеїнові кислоти, клітини-хазяї і т.п., стосується матеріалів, які знаходять в природі. "Антигензв'язуючий білок", як цей термін тут використовується, означає білок, який специфічно зв'язує конкретний антиген-мішень, такий як c-fms або c-fms людини. Кажуть, що антигензв'язуючий білок "специфічно зв'язує" свій антиген-мішень, коли -8 константа дисоціації KD < 10 M. Антитіло специфічно зв'язує антиген з "високою афінністю", -9 -10 коли KD < 5×10 M, і з "дуже високою афінністю", коли KD < 5×10 M. В одному варіанті -9 -4 здійснення антитіло має KD of ≤ 10 M і швидкість дисоціації 1×10 /сек. В одному варіанті -5 здійснення швидкість дисоціації становить 1×10 /сек. В інших варіантах здійснення антитіла -8 -10 будуть зв'язуватись з c-fms чи c-fms людини з KD між приблизно 10 M and 10 M, а в ще -10 іншому варіанті здійснення воно буде зв'язуватись з KD < 2×10 М. "Ділянка, що зв'язує антиген" означає білок чи частину білка, які специфічно зв'язують даний антиген. Наприклад, та частина антигензв'язуючого білку, яка містить амінокислотні залишки, що взаємодіють з антигеном і забезпечують антигензв'язуючому білку його специфічність і афінність до цього антигену, називається "ділянкою, що зв'язує антиген". Ділянка, що зв'язує антиген, типово включає одну чи більше "ділянок, що визначають комплементарність" ("CDR"). Певні ділянки, що зв'язують антиген, включають також одну чи більше "каркасних" ділянок. "CDR" – це амінокислотна послідовність, що робить всій внесок в специфічність і афінність до зв'язування антигену. "Каркасні" ділянки можуть допомагати в підтриманні правильної конформації ділянок CDR, сприяючи зв'язуванню між ділянкою, що зв'язує антиген, і антигеном. В певних аспектах пропонуються рекомбінантні антигензв'язуючі білки, які зв'язують c-fms білок чи с-fms людини. В цьому контексті "рекомбінантний білок" – це білок, отриманий рекомбінантними методами, тобто шляхом експресії рекомбінантної нуклеїнової кислоти, як тут описано. Методи і технічне оснащення для отримання рекомбінантних білків є добре відомими в цій галузі. Термін "антитіло" стосується інтактного імуноглобуліну будь-якого ізотипу, чи його фрагменту, який може конкурувати з інтактним антитілом за специфічне зв'язування з антигеном-мішенню, і включає, наприклад, химерне, гуманізоване, повністю людське і біспецифічне антитіла. "Антитіло", як таке, є видом антигензв'язуючого білку. Загалом, інтактне антитіло буде включати щонайменше два важкі ланцюги повної довжини і два легкі ланцюги повної довжини, але в певних випадках може включати і менше ланцюгів, як це природно трапляється у камелідів (верблюдових), у яких антитіло може містити тільки важкі ланцюги. Антитіла можуть походити з єдиного джерела чи можуть бути "химерними", тобто різні частини антитіла можуть походити від двох різних антитіл, як докладніше буде описано далі. Антигензв'язуючі білки, антитіла чи зв'язувальні фрагменти можуть бути отриманими в гібридомах, методами рекомбінантної ДНК або шляхом ферментативного чи хімічного розщеплення інтактних антитіл. Коли не вказується інше, термін "антитіло" включає, крім антитіл, що містять два важкі ланцюги повної довжини і два легкі ланцюги повної довжини, їх похідні, варіанти, фрагменти і мутації, приклади яких будуть описані далі. Термін "легкий ланцюг" включає легкий ланцюг повної довжини і його фрагменти, що мають достатню послідовність варіабельної ділянки, щоб забезпечити специфічність зв'язування. Легкий ланцюг повної довжини включає домен варіабельної ділянки VL і домен постійної ділянки CL. Домен варіабельної ділянки легкого ланцюга знаходиться на аміно-кінці поліпептиду. Легкі ланцюги включають каппа ланцюги і лямбда ланцюги. 9 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 Термін "важкий ланцюг" включає важкий ланцюг повної довжини і його фрагменти, що мають достатню послідовність варіабельної ділянки, щоб забезпечити специфічність зв'язування. Важкий ланцюг повної довжини включає домен варіабельної ділянки VL і три домени постійної ділянки CH1, CH2 and CH3. Домен VH знаходиться на аміно-кінці поліпептиду, а домени CH – на карбокси-кінці, причому CH3 знаходиться ближче всього до С-кінця поліпептиду. Важкі ланцюги можуть бути будь-якого ізотипу, включаючи IgG (в тому числі підтипи IgGl, IgG2, IgG3 і IgG4), IgA (в тому числі підтипи IgAl і IgA2), IgM and IgE. Термін "імунологічно функціональний фрагмент" (або просто "фрагмент") антитіла чи імуноглобулінового ланцюга (важкого чи легкого ланцюга), як він тут використовується, означає антигензв'язуючий білок, що містить частину (незалежно від того, як цю частину було отримано чи синтезовано) антитіла, якій бракує щонайменше певних амінокислот, присутніх в ланцюзі повної довжини, але яка здатна специфічно зв'язуватись з антигеном. Такі фрагменти є біологічно активними в тому відношенні, що вони специфічно зв'язуються з антигеном-мішенню і можуть конкурувати з іншими антигензв'язуючими білками, включаючи інтактні антитіла, за специфічне зв'язування з даним епітопом. В одному аспекті такий фрагмент буде зберігати щонайменше одну ділянку CDR присутньою в важкому чи легкому ланцюзі повної довжини і, в певних варіантах здійснення, буде містити єдиний важкий ланцюг та/або легкий ланцюг чи його частину. Такі біологічно активні фрагменти можуть бути отримані методами рекомбінантної ДНК або шляхом ферментативного чи хімічного розщеплення антигензв'язуючих білків, включаючи інтактні антитіла. Імунологічно функціональні фрагменти імуноглобуліну включають, не обмежуючись ними, Fab, Fab', F(ab')2, Fv, домен-специфічні антитіла і антитіла з єдиним ланцюгом, і можуть походити від будь-яких ссавців, включаючи, але не обмежуючись ними, людину, мишей, щурів, верблюдових чи кролів. Мається на увазі також, що функціональна частина антигензв'язуючих білків, описаних тут, наприклад одна чи більше ділянок CDR, може бути ковалентно зв'язаною з другим білком чи з малою молекулою з утворенням терапевтичного препарату, спрямованого на конкретну мішень в організмі, який володіє біфункціональними терапевтичними властивостями або має пролонгований період напіввиведення з сироватки. "Fab фрагмент" складається з одного легкого ланцюга і C H1, а також варіабельних ділянок одного важкого ланцюга. Важкий ланцюг молекули Fab не може утворювати дисульфідний зв'язок з іншою молекулою важкого ланцюга. "Fc" ділянка містить фрагменти двох важких ланцюгів, що включають домени CH1 і CH2 антитіла. Фрагменти двох важких ланцюгів утримуються разом двома чи більше дисульфідними зв'язками та за рахунок гідрофобних взаємодій доменів CH3. "Fab' фрагмент" містить один легкий ланцюг і частину одного важкого ланцюга, яка включає домен VH і домен CH1, а також ділянку між доменами CH1 і CH2, так що дисульфідний зв'язок між ланцюгами може бути утворений між двома важкими ланцюгами двох Fab' фрагментів з отриманням молекули F(ab')2. "F(ab')2 фрагмент" містить два легкі ланцюги і два важких ланцюги, що включають частину постійної ділянки між доменами CH1 і CH2, так що дисульфідний зв'язок між ланцюгами може бути утворений між двома важкими ланцюгами. Отже, F(ab') 2 фрагмент складається з двох Fab' фрагментів, які утримуються разом дисульфідним зв'язком між двома важкими ланцюгами. "Fv ділянка" включає варіабельні ділянки від важкого і легкого ланцюгів, але не містить постійних ділянок. "Антитіла з єдиним ланцюгом" – це молекули Fv, в яких варіабельні ділянки від важкого і легкого ланцюгів з'єднані гнучким лінкером з утворенням єдиного поліпептидного ланцюга, завдяки чому формується ділянка, що зв'язує антиген. Антитіла з єдиним ланцюгом докладно розглядаються в публікації Міжнародної патентної заявки № WO 88/01649 та в патентах США №№ 4,946,778 і No. 5,260,203, описи яких вважаються включеними за посиланням. "Домен-специфічне антитіло" – це імунологічно функціональний фрагмент імуноглобуліну, який містить тільки варіабельну ділянку важкого ланцюга чи варіабельну ділянку легкого ланцюга. В певних випадках дві чи більше ділянки VH є ковалентно з'єднаними пептидним лінкером з утворенням двохвалентного домен-специфічного антитіла. Дві ділянки VH двохвалентного домен-специфічного антитіла можуть націлюватись на той самий чи різні антигени. "Двохвалентний антигензв'язуючий білок" чи "двохвалентне антитіло" містить два сайти зв'язування антигену. В певних випадках ці два сайти зв'язування мають специфічність до того самого антигену. Двохвалентні антигензв'язуючі білки і двохвалентні антитіла можуть бути біспецифічними (дивись далі). 10 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 "Мультиспецифічний антигензв'язуючий білок" чи "мультиспецифічне антитіло" є таким, що націлене більше ніж на один антиген чи епітоп. "Біспецифічний", "з подвійною специфічністю" чи "біфункціональний" антигензв'язуючий білок чи антитіло є гібридним антигензв'язуючим білком чи антитілом, відповідно, що має два різних сайти зв'язування антигену. Біспецифічні антигензв'язуючі білки і антитіла є видом мультиспецифічного антигензв'язуючого білку чи мультиспецифічного антитіла. Вони можуть отримуватись різними методами, включаючи, але не обмежуючись ними, злиття гібридом чи зшивання фрагментів Fab' (дивись, наприклад, Songsivilai & Lachmann, 1990, Clin. Exp. Immunol. 79:315-321; Kostelny et a l. , 1992, J. Immunol. 148:1547-1553). Два сайти зв'язування біспецифічного антигензв'язуючого білку чи антитіла будуть зв'язуватись з двома різними епітопами, які можуть знаходитись на тому самому чи різних білкових мішеней. Термін "нейтралізуючий антигензв'язуючий білок" чи "нейтралізуюче антитіло" стосується антигензв'язуючого білку чи антитіла, відповідно, які зв'язуються з лігандом, запобігають зв'язуванню ліганду з його партнером по зв'язуванню і переривають біологічну реакцію, яка інакше була б наслідком зв'язування ліганду з його партнером по зв'язуванню. При оцінці зв'язування і специфічності антигензв'язуючого білку, наприклад антитіла чи його імунологічно функціонального фрагменту, антитіло чи фрагмент будуть суттєво пригнічувати зв'язування ліганду з його партнером по зв'язуванню, коли надлишок антитіла зменшує кількість партнеру по зв'язуванню, зв'язаного з цим лігандом, щонайменше приблизно на 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 97%, 99% чи більше (що визначається за допомогою аналізу in vitro на конкурентне зв'язування). У випадку антигензв'язуючих білків до c-fms така нейтралізуюча молекула буде зменшувати здатність c-fms зв'язувати CSF-1. В певних варіантах здійснення нейтралізуючий антигензв'язуючий білок пригнічує здатність c-fms зв'язувати IL-34. В інших варіантах здійснення нейтралізуючий антигензв'язуючий білок пригнічує здатність c-fms зв'язувати CSF-1 і IL-34. Термін "конкурувати", коли використовується в контексті антигензв'язуючих білків (наприклад, нейтралізуючих антигензв'язуючих білків чи нейтралізуючих антитіл), що конкурують за той самий епітоп, означає конкуренцію між антигензв'язуючими білками, яку оцінюють за допомогою аналізу, в якому антигензв'язуючий білок (наприклад, антитіло чи його імунологічно функціональний фрагмент), що тестується, пригнічує чи запобігає специфічному зв'язуванню контрольного антигензв'язуючого білку (наприклад, ліганду чи контрольного антитіла) до спільного антигену (наприклад c-fms чи його фрагменту). Можуть бути використані різні види аналізу на конкурентне зв'язування, наприклад: твердофазна пряма чи непряма радіоімунопроба (RIA), твердофазна пряма чи непряма ферментативна імунопроба (ЕІА), конкурентний сандвіч-аналіз (дивись, наприклад, Stahli et a l ., 1983, Methods in Enzymology 9:242-253); твердофазна пряма ЕІА з біотином-авідином (дивись, наприклад, Kirkland et a l, 1986, J. Immunol. 137:3614-3619), твердофазна пряма проба з міткою, твердофазна пряма сандвіч-проба з міткою (дивись, наприклад, Harlow & Lane, 1988, Antibodies, A Laboratory 125 Manual, Cold Spring Harbor Press); твердофазна пряма (RIA)з міткою І (дивись, наприклад, Morel et a l, 1988, Molec. Immunol. 25:7-15); твердофазна пряма EIA з біотином-авідином (дивись, наприклад, Cheung, et al , 1990, Virology 176:546-552); і пряма RIA з міткою (Moldenhauer et a l , 1990, Scand. J . Immunol. 32:77-82). Типово, така проба передбачає використання очищеного антигену, зв'язаного з твердою поверхнею чи клітинами, що несуть або немічений антигензв'язуючий білок, що тестується, або мічений контрольний антигензв'язуючий білок. Конкурентне пригнічення оцінюють шляхом визначення кількості мітки, зв'язаної з твердою поверхнею чи клітинами, в присутності контрольного антигензв'язуючого білку, що тестується. Звичайно, антигензв'язуючий білок, що тестується, має бути присутнім у надлишку. Антигензв'язуючі білки, ідентифіковані за допомогою проби на конкурентне зв'язування (конкуруючих антигензв'язуючих білків), включають антигензв'язуючі білки, що зв'язуються з тим самим епітопом, що й контрольні антигензв'язуючі білки, і антигензв'язуючі білки, що зв'язуються з суміжним епітопом, достатньо проксимальним до епітопу, зв'язаного контрольним антигензв'язуючим білком, щоб здійснилась стерична невідповідність. Додаткові деталі стосовно методів визначення ступеня конкурентного зв'язування наведені в подальших прикладах. Звичайно, коли конкуруючий антигензв'язуючий білок є присутнім у надлишку, він буде пригнічувати специфічне зв'язування контрольного антигензв'язуючого білку до спільного антигену щонайменше на 40%, 45%, 50%, 55%, 60%, 65%, 70% чи 75%. В певних випадках зв'язування пригнічується щонайменше на 80%, 85%, 90%, 95% чи 97% або більше. Термін "антиген" стосується молекули чи частини молекули, здатних бути зв'язаними селективним зв'язувальним агентом, таким як антигензв'язуючий білок (включаючи, наприклад, антитіло чи його імунологічно функціональний фрагмент), і додатково здатних бути 11 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 використаними у тварини для продукування антитіл, здатних зв'язуватись з цим антигеном. Антиген може володіти одним чи більше епітопами, здатними взаємодіяти з різними антигензв'язуючими білками, наприклад антитілами. Термін "епітоп" стосується частини молекули, яка зв'язується антигензв'язуючим білком (наприклад, антитілом). Цей термін включає будь-яку детермінанту, здатну специфічно зв'язуватись з антигензв'язуючим білком, таким як антитіло, чи з Т-клітинним рецептором. Епітоп може бути прилеглим або неприлеглим (наприклад, в поліпептиді, амінокислотні залишки, які не є стичними один з одним в поліпептидній послідовності, але які в контексті молекули зв'язуються антигензв'язуючим білком). В певних варіантах здійснення епітопи можуть бути міметичними в тому, що являють собою тривимірну структуру, яка є подібною до епітопу, який використовується для отримання антигензв'язуючих білків, але не містить або містить тільки певні амінокислотні залишки з тих, що містяться в епітопі, який використовується для отримання антигензв'язуючого білку. Найчастіше епітопи знаходяться на білках, але в певних випадках вони можуть перебувати на інших видах молекул, таких як нуклеїнові кислоти. Детермінанти епітопу можуть включати хімічно активні поверхневі угрупування молекул, таких як амінокислоти, бічні ланцюги цукру, фосфорильна чи сульфонільна групи, і можуть мати конкретні тривимірні структурні характеристики та/або нести специфічний заряд. Загалом, антитіла, специфічні до конкретного антигену-мішені, будуть переважно розпізнавати епітоп на цьому антигені-мішені в складній суміші білків та/або макромолекул. Термін "ідентичність" стосується взаємозв'язку між послідовностями двох чи більше поліпептидних молекул або двох чи більше молекул нуклеїнових кислот, який визначається шляхом зіставлення і порівняння цих послідовностей. "Відсоток ідентичності" означає відсоток ідентичних залишків між двома амінокислотами чи нуклеотидами в порівнюваних молекулах і обчислюється на основі найменшої з молекул, що порівнюються. При здійсненні таких обчислень прогалини, які виявляються при зіставленні, обробляються з використанням особливої математичної моделі або комп'ютерної програми (тобто, "алгоритму"). Методи, які можуть бути використані для оцінки ідентичності зіставлених нуклеїнових кислот чи поліпептидів, включають ті, що описані в Computational Molecular Biology, (Lesk, A. M., ed.), 1988, New York: Oxford University Press; Biocomputing Informatics and Genome Projects, (Smith, D. W., ed.), 1993, New York: Academic Press; Computer Analysis of Sequence Data, Part I, (Griffin, A. M., and Griffin, H. G., eds.), 1994, New Jersey: Humana Press; von Heinje, G., 1987, Sequence Analysis in Molecular Biology, New York: Academic Press; Sequence Analysis Primer, (Gribskov, M. and Devereux, J., eds.), 1991, New York: M. Stockton Press; та Carillo et a l , 1988, SI AM J. Applied Math. 48:1073. При обчисленні відсотку ідентичності порівнювані послідовності зіставляються у спосіб, який дає найбільший збіг між цими послідовностями. Комп'ютерною програмою, яка використовується для обчислення відсотку ідентичності, є пакет програмного забезпечення GCG, який включає GAP (Devereux et a l. , 1984, Nucl. Acid Res. 12:387; Genetics Computer Group, University of Wisconsin, Madison, WI). Комп'ютерний алгоритм GAP використовується для зіставлення двох поліпептидів чи полінуклеотидів, для яких визначається відсоток ідентичності послідовностей. Послідовності зіставляють для оптимального збігу їх відповідної амінокислоти чи нуклеотиду ("суміщений інтервал", який визначається алгоритмом). Штраф за прогалину в послідовності (який обчислюється як 3х середню діагональ, де "середня діагональ" є середнім значенням діагоналі використовуваної порівняльної матриці; "діагональ" – це бал чи число, яке приписується кожному довершеному збігу амінокислот в конкретній порівняльній матриці) і штраф за протяжність прогалини (який звичайно становить 1/10 від штрафу за прогалину в послідовності), а також порівняльна матриця, така як PAM 250 чи BLOSUM 62, використовуються в сукупності з цим алгоритмом. В певних варіантах здійснення цей алгоритм використовує також стандартну порівняльну матрицю (дивись Dayhoff et a l. , 1978, Atlas of Protein Sequence and Structure 5:345-352 для порівняльної матриці PAM 250; Henikoff et al ., 1992, Proc. Natl. Acad. Sci. U.S.A. 89:10915-10919 для порівняльної матриці BLOSUM 62). Рекомендовані параметри для визначення відсотку ідентичності для поліпептидів чи нуклеотидних послідовностей за допомогою програми GAP є наступними: Алгоритм: Needleman et a l. , 1970, J. Mol. Biol. 48:443-453; Порівняльна матриця: BLOSUM 62 від Henikoff et al., 1992, supra; Штраф за прогалину в послідовності: 12 (але без штрафу за кінцеві прогалини) Штраф за протяжність прогалини: 4 Поріг подібності: 0 Певні схеми зіставлення двох амінокислотних послідовностей можуть виявити збіг тільки якоїсь короткої ділянки цих двох послідовностей, і ця невелика зіставлена ділянка може мати 12 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 дуже високу ідентичність послідовностей, не дивлячись на відсутність суттєвого взаємозв'язку між послідовностями повної довжини. Відповідно, обраний спосіб зіставлення (програма GAP) може за бажанням регулюватись так, щоб забезпечувалось зіставлення відрізків, які охоплюють не менше 50 стичних амінокислот цільового поліпептиду. Як він тут використовується, термін "суттєво чистий" означає, що описуваний вид молекули є домінуючим присутнім видом, тобто на молярній основі він є більш широко представлений, ніж будь-який інший індивідуальний вид в тій самій суміші. В певних варіантах здійснення суттєво чистою молекулою є композиція, в якій цільовий вид становить щонайменше 50% (на молярній основі) від усіх присутні макромолекулярних видів. В інших варіантах здійснення суттєво чиста композиція буде містити щонайменше 80%, 85%, 90%, 95% чи 99% від усіх макромолекулярних видів, присутніх в цій композиції. В інших варіантах здійснення цільовий вид піддають очистці до суттєвої гомогенності, коли контамінуючі види вже не можуть бути виявлені в композиції звичайними методами аналізу, і отже така композиція складається з єдиного макромолекулярного виду, який піддається виявленню. Термін "лікування" стосується будь-яких ознак успіху в лікуванні чи пом'якшенні ушкодження, патології чи стану, включаючи будь-який об'єктивний чи суб'єктивний параметр, такий як ослаблення болю; ремісія; зменшення симптомів або переведення ушкодження, патології чи стану в більш стерпний для пацієнта вимір; уповільнення швидкості дегенерації чи погіршення; переведення кінцевої точки дегенерації на менш інвалідизуючий рівень; поліпшення фізичного чи ментального самопочуття пацієнта. Лікування чи пом'якшення симптомів може базуватись на об'єктивних чи суб'єктивних параметрах, включаючи результати фізичного обстеження, психоневрологічного обстеження та/або психіатричної оцінки. Наприклад, певні способи, представлені тут, успішно лікують рак, знижуючи частоту розвитку раку, викликаючи ремісію раку та/або пом'якшуючи симптоми, що асоціюються з раком чи запаленням. "Ефективна кількість" – це загалом кількість, достатня для зменшення тяжкості та/або частоти симптомів, усунення симптомів та/або причини, що їх викликає, попередження розвитку симптомів та/або причини, що їх викликає, та/або поліпшення чи зцілення ушкодження, що є результатом раку чи пов'язане з ним. В певних варіантах здійснення ефективна кількість є терапевтично ефективною кількістю чи профілактично ефективною кількістю. "Терапевтично ефективна кількість" – це кількість, достатня для виліковування патологічного стану (наприклад, раку) чи симптомів, зокрема стану чи симптомів, пов'язаних з патологічним станом, або для того, щоб попередити, перешкодити, пригальмувати чи реверсувати прогресування патологічного стану чи будь-якого іншого небажаного симптому, пов'язаного з хворобою у який завгодно спосіб. "Профілактично ефективна кількість" – це кількість фармацевтичної композиції, яка, при введенні суб'єкту, буде мати задуманий профілактичний ефект, наприклад попередить чи відстрочить появу (чи рецидив) раку або зменшить ймовірність появи (чи рецидиву) раку чи симптомів раку. Повний терапевтичний чи профілактичний ефект не обов'язково трапляється після введення однієї дози і може спостерігатись тільки після введення серії доз. Отже, терапевтично чи профілактично ефективна кількість може вводитись за одне чи більше введень. Термін "амінокислоти" застосовується в своєму звичайному значенні в цій галузі. Двадцять природних амінокислот і їх скорочені назви є загальноприйнятними. Дивись Immunology-A Synthesis, 2nd Edition, (E. S. Golub and D. R. Green, eds.), Sinauer Associates: Sunderland, Mass. (1991), включену в цей опис за посиланням для будь-якої цілі. Стереоізомери (наприклад, Dамінокислоти) цих двадцяти звичайних амінокислот, неприродні амінокислоти, такі як [альфа]-, [альфа]-дизаміщені амінокислоти N-алкіл амінокислоти та інші незвичайні амінокислоти також можуть бути придатними компонентами для поліпептидів і включаються в термін "амінокислоти". Приклади незвичайних амінокислот включають: 4-гідроксипролін, [гамма]карбоксиглутамат, [епсилон]-N,N,N-триметиллізин, [епсилон]-N-ацетиллізин, O-фосфосерин, Nацетилсерин, N-формілметіонін, 3-метилгістидин, 5-гідроксилізин, [сигма]-N-метиларгінін та інші подібні амінокислоти та імінокислоти (наприклад, 4-гідроксипролін). При описі поліпептидів лівий напрямок – це напрямок до аміно-кінця, а правий напрямок – це напрямок до карбоксикінця, що відповідає стандартному застосуванню цих термінів. Загальний огляд Туту пропонуються антигензв'язуючі білки, що зв'язують білок c-fms, включаючи c-fms людини (hc-fms). Запропоновані антигензв'язуючі білки є поліпептидами, в які вставлена чи до яких приєднана одна чи більше ділянка, що визначає комплементарність (CDR), як тут описано. В певних антигензв'язуючих білках ділянки CDR вставлені в "каркасну" ділянку, яка орієнтує ділянки CDR для забезпечення відповідних антигензв'язуючих властивостей CDR. Загалом, 13 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 антигензв'язуючі білки, запропоновані в цьому винаході, можуть перешкоджати, блокувати, зменшувати чи модулювати взаємодію між CSF-1 і c-fms. Певні антигензв'язуючі білки, описані тут, є антитілами або походять від антитіл. В певних варіантах здійснення поліпептидна структура антигензв'язуючих білків базується на антитілах, включаючи, але не обмежуючись ними, моноклональні антитіла, біспецифічні антитіла, мінітіла, домен-специфічні антитіла, синтетичні антитіла (які деколи називають імітаторами антитіл), химерні антитіла, гуманізовані антитіла, людські антитіла, злиття антитіл (які деколи називають кон'югатами антитіл) та їх фрагменти. Ці різні структури детальніше будуть описані далі. Запропоновані тут антигензв'язуючі білки продемонстрували здатність зв'язуватись з позаклітинним доменом c-fms, зокрема c-fms людини. Як буде описано далі в прикладах, певні антигензв'язуючі білки були тестовані і виявилось, що вони зв'язуються з іншими епітопами, ніж епітопи, з якими зв'язується низка інших анти-c-fms антитіл. Запропоновані тут антигензв'язуючі білки конкурують з CSF-1, чим перешкоджають зв'язуванню CSF-1 з його рецептором. В певних варіантах здійснення антигензв'язуючі білки пригнічують зв'язування між IL-34 і c-fms. В інших варіантах здійснення антигензв'язуючі білки пригнічують здатність c-fms зв'язуватись і з CSF-1, і з IL-34. Як наслідок, запропоновані тут антигензв'язуючі білки здатні пригнічувати активність cfms. Зокрема, антигензв'язуючі білки, що зв'язуються з цими епітопами, можуть мати одну чи більше активність з наступних: пригнічення, між іншим, автофосфорилювання c-fms, індукція шляхів проведення сигналів c-fms, індукованого c-fms росту клітин, хемотаксису моноцитів, накопичення макрофагів, асоційованих з пухлиною, в пухлині чи в стромі пухлини, продукція стимулюючих пухлину факторів та інші фізіологічні ефекти, які викликаються c-fms після зв'язування з CSF-1. Описані тут антигензв'язуючі білки мають широке коло застосувань. Деякі з таких антигензв'язуючих білків, наприклад, використовуються в аналізах на специфічне зв'язування, афінній очистці c-fms, зокрема hc-fms чи його лігандів, а також в скринінг-аналізах для ідентифікації інших антагоністів активності c-fms. Деякі з таких антигензв'язуючих білків використовуються для пригнічення зв'язування CSF-1 з c-fms або для пригнічення автофосфорилювання c-fms. Запропоновані тут антигензв'язуючі білки можуть знайти широке використання в медицині, як тут пояснюється. Наприклад, певні антигензв'язуючі білки до c-fms є корисними для лікування станів, пов'язаних з c-fms, таких як зменшення хемотаксису моноцитів у пацієнта, пригнічення міграції моноцитів в пухлини, пригнічення накопичення асоційованих з пухлиною макрофагів в пухлині чи пригнічення ангіогенезу, як далі буде описано. В певних варіантах здійснення антигензв'язуючі білки пригнічують здатність ТАМ стимулювати ріст, прогресування та/або метастазування пухлини. Крім того, у випадках, коли самі пухлинні клітини експресують і використовують c-fms, зв'язування антитіла з c-fms могло б пригнітити їх ріст/виживання. Інші застосування для антигензв'язуючих білків включають, наприклад, діагностику асоційованих з cfms захворювань і станів, а також скринінг-аналізи для виявлення присутності чи відсутності cfms. Деякі з описаних тут антигензв'язуючих білків є корисними в лікуванні наслідків, симптомів та/або патології, асоційованих з активністю c-fms. Вони включають, не обмежуючись ними, різні види раку і запалення, а також ракову кахексію. В певних варіантах здійснення антигензв'язуючі білки можуть використовуватись для лікування різних кісткових розладів. C-fms Колонієстимулюючий фактор (CSF-1) сприяє виживанню, проліферації і диференціації ліній мононуклеарних фагоцитів. CSF-1 здійснює свою активність шляхом зв'язування з рецептором c-fms клітинної поверхні, що приводить до його автофосфорилювання кіназою рецептору c-fms і наступного каскаду внутрішньоклітинних сигналів. Терміни "c-fms", "рецептор c-fms", "c-fms людини" і "людський рецептор c-fms" стосуються рецептору поверхні клітини, який зв'язується з лігандом, включаючи, але не обмежуючись ним, CSF-1, і як результат ініціює шлях проведення сигналів в клітині. В певних варіантах здійснення цей рецептор може зв'язувати IL-34 або і CSF-1, і IL-34. Описані тут антигензв'язуючі білки зв'язуються з c-fms, зокрема з c-fms людини. Показовий позаклітинний домен амінокислотної послідовності c-fms людини показаний в SEQ ID №: 1. Як описується далі, білки c-fms можуть включати також фрагменти. Як вони тут використовуються, ці терміни можуть використовуватись взаємозамінно, означаючи рецептор, зокрема рецептор людини, який специфічно зв'язується з CSF-1. Термін рецептор c-fms людини, як він тут використовується, включає також природні алелі, включаючи мутації A245S, V279M і H362R. Термін c-fms включає також пост-трансляційні модифікації амінокислотної послідовності c-fms. Наприклад, позаклітинний домен (ECD) c-fms людини (залишки 20-512 цього рецептору) має одинадцять можливих N-зв'язаних сайтів глікозилювання в цій послідовності. Отже, ці антигензв'язуючі білки можуть зв'язуватись з 14 UA 103306 C2 5 10 15 20 25 30 35 40 45 50 55 60 білками, глікозильованими в одній чи більше з цих позицій, або бути генерованими від білків, глікозильованих в одній чи більше з цих позицій. Шлях проведення сигналів c-fms регулюється на підвищення при численних патологіях людини, що має своїм наслідком хронічну активацію тканинних популяцій макрофагів. Підвищення продукції CSF-1 асоціюється також з накопиченням тканинних макрофагів, як це спостерігається при різних запальних захворюваннях, таких як запальне захворювання кишечнику. Крім того, ріст кількох типів пухлин асоціюється з надекспресією CSF-1 і рецептору c-fms в ракових клітинах та/або стромі пухлини. Антигензв'язуючі білки до рецептору c-fms Пропонується широкий вибір селективних зв'язувальних агентів для регулювання активності c-fms. Ці агенти включають, наприклад, антигензв'язуючі білки, які містять антигензв'язуючий домен (наприклад, антитіла з єдиним ланцюгом, домен-специфічні антитіла, імуноадгезії і поліпептиди з ділянкою, що зв'язує антиген) і специфічно зв'язуються з поліпептидом c-fms, зокрема з c-fms людини. Певні з таких агентів, наприклад, є здатними пригнічувати зв'язування CSF-1 з c-fms, а отже можуть використовуватись для того, щоб пригнітити, перешкодити чи модулювати одну чи більше активність, асоційовану з сигнальним шляхом c-fms. В певних варіантах здійснення антигензв'язуючі білки можуть бути використані для пригнічення зв'язування між IL-34 і c-fms. В певних варіантах здійснення антигензв'язуючі білки перешкоджають реалізації здатності c-fms зв'язуватись і з CSF-1, і з IL-34. Загалом, запропоновані антигензв'язуючі білки типово включають одну чи більше ділянок CDR, як тут описується (наприклад, 1, 2, 3, 4, 5 чи 6). В певних випадках антигензв'язуючий білок містить (а) поліпептидну структуру і (б) одну чи більше ділянок CDR, вставлених в цю поліпептидну структуру та/або з'єднаних з нею. Поліпептидна структура може приймати багато різних форм. Наприклад, вона може бути, або включає, каркасом природного антитіла або його фрагментом чи варіантом, або може бути повністю синтетичною за своєю природою. Приклади різних поліпептидних структур далі будуть описані докладно. В певних варіантах здійснення поліпептидною структурою антигензв'язуючих білків є антитіло чи вона походить від антитіла, включаючи, але не обмежуючись ними, моноклональні антитіла, біспецифічні антитіла, мінітіла, домен-специфічні антитіла, синтетичні антитіла (які деколи називають імітаторами антитіл), химерні антитіла, гуманізовані антитіла, людські антитіла, злиття антитіл (які деколи називають кон'югатами антитіл) та частини чи фрагменти кожного, відповідно. В певних випадках, антигензв'язуючий білок є імунологічним фрагментом антитіла (наприклад, Fab, Fab', F(ab')2 чи scFv). Ці різні структури далі будуть описуватись і визначатись докладно. Деякі з запропонованих тут антигензв'язуючих білків специфічно зв'язуються з c-fms людини. В одному конкретному варіанті здійснення антигензв'язуючий білок специфічно зв'язується з білком c-fms людини, який має амінокислотну послідовність SEQ ID №: 1. У варіантах здійснення, де антигензв'язуючий білок використовується для терапевтичних застосувань, антигензв'язуючий білок може пригнічувати, перешкоджати реалізації чи модулювати одну чи більше біологічну активність c-fms. В цьому випадку антигензв'язуючий білок специфічно зв'язується та/або суттєво пригнічує зв'язування c-fms людини з CSF-1, коли надлишок антитіла зменшує кількість c-fms людини, зв'язаного з CSF-1, або vice versa, щонайменше приблизно на 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 97%, 99% чи більше (що оцінюється, наприклад, за допомогою аналізу конкурентного зв'язування in vitro). Cfms має багато різних біологічних ефектів, які можуть оцінюватись різними методами на різних типах клітин; приклади таких методів будуть наведені далі. Природна структура антитіла Деякі з запропонованих тут антигензв'язуючих білків мають таку структуру, яка типово асоціюється з антитілами, що трапляються у природі. Структурні одиниці цих антитіл типово включають один чи більше тетраметрів, кожний з яких складається з двох ідентичних пар поліпептидних ланцюгів, хоча певні види ссавців виробляють антитіла, що мають єдиний важкий ланцюг. В типовому антитілі кожна така пара включає один "легкий" ланцюг повної довжини (в певних варіантах здійснення біля 25 кДа) і один "важкий" ланцюг повної довжини (в певних варіантах здійснення біля 50-70 кДа). Кожний індивідуальний імуноглобуліновий ланцюг складається з кількох "імуноглобулінових доменів", кожний з яких містить грубо від 90 до 110 амінокислот і виявляє характерну картину укладки. Ці домени є основними одиницями, з яких складаються поліпептиди антитіла. Аміно-термінальна частина кожного ланцюга типово включає варіабельний домен, який є відповідальним за розпізнання антигену. Карбокситермінальна частина є більш збереженою в ході еволюції, ніж інший кінець ланцюга, і його називають "постійною ділянкою" чи "С-ділянкою". Легкі ланцюги людини загалом 15 UA 103306 C2 5 10 15 20 25 30 35 40 45 класифікуються як каппа і лямбда легкі ланцюги, і кожний з них містить один варіабельний домен і один постійний домен. Важкі ланцюги типово класифікуються як мю, дельта, гамма, альфа чи іпсилон ланцюги, і вони визначають ізотип антитіла як IgM, IgD, IgG, IgA і IgE, відповідно. IgG має кілька підтипів, включаючи, але не обмежуючись ними, IgGl, IgG2, IgG3 і IgG4. Підтипи IgM включають IgM і IgM2. Підтипи IgA включають IgAl і IgA2. У людини ізотипи IgA і IgD містять чотири важкі ланцюги і чотири легкі ланцюги; ізотипи IgG і IgE містять два важкі ланцюги і два легкі ланцюги; і ізотип IgM містить п'ять важких ланцюгів і п'ять легких ланцюгів. С ділянка важкого ланцюга типово включає один чи більше доменів, які можуть бути відповідальними за ефекторну функцію. Кількість доменів постійної ділянки важкого ланцюга буде залежати від ізотипу. Кожний з IgG важких ланцюгів, наприклад, містить три домени С ділянки, відомі як C H 1, C H 2 and C H 3. Запропоновані тут антитіла можуть мати будь-який з цих ізотипів і підтипів. В певних варіантах здійснення c-fms антитіло належить до IgGl, IgG2 чи IgG4 підтипу. В легких і важких ланцюгах повної довжини варіабельні і постійні ділянки з'єднуються ділянкою "J" приблизно з дванадцяти чи більше амінокислот, при цьому важкий ланцюг включає також ділянку "D", що має на десять амінокислот більше. Дивись, наприклад, Fundamental Immunology, 2nd ed., Ch. 7 (Paul, W., ed.) 1989, New York: Raven Press (яку включено за посиланням у всій повноті і для будь-якої цілі). Варіабельні ділянки кожної пари легкий/важкий ланцюги типово утворюють сайт зв'язування антигену. Один приклад постійного домену IgG2 важкого ланцюга показового c-fms моноклонального антитіла має таку амінокислотну послідовність: (SEQ ID №: 2; зірочка відповідає стоп-кодону). Один приклад постійного домену каппа легкого ланцюга показового c-fms моноклонального антитіла має таку амінокислотну послідовність: (SEQ ID №: 3; зірочка відповідає стоп-кодону). Варіабельні ділянки імуноглобулінових ланцюгів загалом демонструють однакову загальну структуру, яка включає відносно збережені каркасні ділянки (FR), з'єднані трьома гіперваріабельними ділянками, які частіше називають "ділянками, що визначають комплементарність" або CDR. Ділянки CDR від двох ланцюгів кожної пари важкий ланцюг/легкий ланцюг, згаданої вище, типово з'єднуються каркасними ділянками, утворюючи структуру, що специфічно зв'язується з специфічним епітопом на цільовому білку (наприклад, c-fms). Від Nкінця до С-кінця варіабельні ділянки природних легких і важких ланцюгів типово розміщуються в такому порядку: FR1, CDR1, FR2, CDR2, FR3, CDR3 і FR4. Було розроблено систему нумерації для призначення номерів амінокислотам, які займають позиції в кожному з цих доменів. Ця система нумерації визначена в Kabat Sequences of Proteins of Immunological Interest (1987 та 1991, NIH, Bethesda, MD), або Chothia & Lesk, 1987, J. Mol. Biol. 196:901-917; Chothia et a l , 1989, Nature 342:878-883. Запропоновані тут різні варіабельні ділянки важкого і легкого ланцюгів наведені в Таблиці 2. Кожна з цих варіабельних ділянок може бути приєднаною до вже згадуваних постійних ділянок важкого і легкого ланцюгів з утворенням важкого і легкого ланцюга повного антитіла, відповідно. Далі, кожна з таким чином генерованих послідовностей важкого і легкого ланцюгів може комбінуватись з утворенням структури повного антитіла. Слід розуміти, що запропоновані тут варіабельні ділянки важкого і легкого ланцюгів можуть приєднуватись до інших постійних доменів, що мають інші послідовності, ніж наведені вище показові послідовності. Конкретні приклади деяких з легких і важких ланцюгів повної довжини запропонованих тут антитіл і відповідні амінокислотні послідовності підсумовані в Таблиці 1. 16 UA 103306 C2 Таблиця 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № Н1 109 1N1G1 H1 4 H1 13 1N1G1 H2 5 H1 131 1N1G1 H3 6 H1 134 1N1G1 H4 7 H1 143 1N1G1 H5 8 Амінокислотна послідовність 17 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 144 1N1G1 H6 9 H1 16 1N1G1 H7 10 H121N1G1 H8 11 H1 26 1N1G1 H9 12 H1 27 1N1G1 H10 13 Амінокислотна послідовність 18 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 30 1N1G1 H11 14 H1 33-1 1N1G1 H12 15 H1 33 1N1G1 H13 16 H1 34 1N1G1 H14 17 H1 39 1N1G1 H15 18 Амінокислотна послідовність 19 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 42 1N1G1 H16 19 H1 64 1N1G1 H17 20 H1 66 1N1G1 H18 21 H1 72 1N1G1 H19 22 H1 103 1N1G1 H20 23 Амінокислотна послідовність 20 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 90 1N1G1 H21 24 H2 131 1N1G2 H22 25 H2 291 1N1G2 H23 26 H2 360 1N1G2 H24 27 H2 360 1N1G2 SM H25 28 Амінокислотна послідовність 21 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H2 369 1N1G2 H26 29 H2 380 1N1G2 H27 30 H2 475 1N1G2 H28 31 H2 508 1N1G2 H29 32 H2 534 1N1G2 H30 33 Амінокислотна послідовність 22 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H2 550 1N1G2 H31 34 H2 65 1N1G2 H32 35 H1 109 1N1K L1 36 H1 109 1N1K SM L2 37 H1 131 1N1K L3 38 H1 134 1N1K L4 39 H1 143 1N1K L5 40 H1 144 1N1K L6 41 Амінокислотна послідовність 23 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 16 1N1K L7 42 H1 2 1N1K L8 43 H1 2 1N1K SM L9 44 H1 27 1N1K L10 45 H1 30 1N1K L11 46 H1 33-1 1N1K L12 47 H1 34 1N1K L13 48 H1 39 1N1K L14 49 H1 42 1N1K L15 50 H1 64 1N1K L16 51 Амінокислотна послідовність 24 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання Позначення SEQ ID № H1 66 1N1K L17 52 H1 72 1N1K L18 53 H1 90 1N1K L19 54 H2 103 1N1K L20 55 H2 131 1N1K L21 56 H2 360 1N1K L22 57 H2 360 1N1K SM L23 58 H2 369 1N1K L24 59 H2 380 1N1K L25 60 H2 475 1N1K L26 61 Амінокислотна послідовність 25 UA 103306 C2 Продовження таблиці 1 Показові важкі і легкі ланцюги Посилання L27 62 H2 534 1N1K L28 63 H2 550 1N1K L29 64 H2 65 1N1K L30 65 H1 13 1N1K L31 66 H1 26 1N1K L32 67 Н1 13Н1 13 1NVK2KK L33 68 H1 26H1 26 1NVK2KK 10 SEQ ID № H2 508 1N1K 5 Позначення L34 69 Амінокислотна послідовність І на цей раз, кожний з показових важких ланцюгів (HI, H2, H3 etc.), наведених в Таблиці 1, може комбінуватись з будь-яким показовим легким ланцюгом, наведеним в Таблиці 1, з утворенням антитіла. Приклади таких комбінацій включають Н1, комбінований з будь-яким з L1L34; H2, комбінований з будь-яким з L1-L34; Н3, комбінований з будь-яким з L1-L34 і т.д. В певних випадках такі антитіла включають щонайменше один важкий ланцюг і один легкий ланцюг з тих, що наведені в Таблиці 1. В певних випадках антитіла включають два різні важкі ланцюги і два різні легкі ланцюги, наведені в Таблиці 1. В інших випадках антитіла містять два ідентичні легкі ланцюги і два ідентичні важкі ланцюги. В якості прикладу, антитіло чи його імунологічно функціональний фрагмент можуть включати два важкі ланцюги Н1 і два легкі ланцюги L1, або два важкі ланцюги Н2 і два легкі ланцюги L2, або два важкі ланцюги Н3 і два легкі ланцюги L3 та інші подібні комбінації пар легких ланцюгів і пар важких ланцюгів, як наведено в Таблиці 1. 26 UA 103306 C2 5 10 15 20 Інші запропоновані антигензв'язуючі білки є варіантами антитіл, утворених комбінацією важких і легких ланцюгів, показаних в Таблиці 1, і включають легкі та/або важкі ланцюги, кожний з яких має щонайменше 70%, 75%, 80%, 85%, 90%, 95%, 97% чи 99% ідентичність з амінокислотними послідовностями цих ланцюгів. В певних випадках такі антитіла включають щонайменше один важкий ланцюг і один легкий ланцюг, тоді як в інших випадках варіантні форми містять два ідентичні легкі ланцюги і два ідентичні важкі ланцюги. Варіабельні домени антитіл Також пропонуються антигензв'язуючі білки, які містять варіабельну ділянку важкого ланцюга антитіла, вибрану з групи, що включає VH1, VH2, VH3, VH4, VH5, VH6, VH7, VH8, VH9, VH10, VH11, VH12, VH13, VH14, VH15, VH16, VH17, VH18, VH19, VH20, VH21, VH22, VH23, VH24, VH25, VH26, VH27, VH28, VH29, VH30, VH31 і VH32, та/або варіабельну ділянку легкого ланцюга антитіла, вибрану з групи, що включає VL1, VL2, VL3, VL4, VL5, VL6, VL7, VL8, VL9, VL10, VL11, VL12, VL13, VL14, VL15, VL16, VL17, VL18, VL19, VL20, VL21, VL22, VL23, VL24, VL25, VL26, VL27, VL28, VL29, VL30, VL31, VL32, VL33 і VL34, як показано в Таблиці 2 далі, а також імунологічно функціональні фрагменти, похідні, мутеїни (мутантні білки) і варіанти цих варіабельних ділянок легкого ланцюга і важкого ланцюга. Зіставлення послідовностей різних варіабельних ділянок легкого ланцюга і важкого ланцюга, відповідно, показані на Фіг. 1А і 1В. Антигензв'язуючі білки цього типу загалом можуть позначатись формулою "VHx / VLy", де "х" відповідає числу варіабельних ділянок важкого ланцюга, а "у" відповідає числу варіабельних ділянок легкого ланцюга (загалом, кожний з х і у дорівнюють 1 чи 2), як наведено в Таблиці 2: Таблиця 2 Показові VH і VL ланцюги Посилання Позначення SEQ ID № H1 109 1N1G1 VH1 70 H1 13 1N1G1 VH2 71 H1 131 1N1G1 VH3 72 H1 134 1N1G1 VH4 73 H1 143 1N1G1 VH5 74 H1 144 1N1G1 VH6 75 H1 16 1N1G1 VH7 76 H1 2 1N1G1 VH8 77 H1 26 1N1G1 VH9 Амінокислотна послідовність 78 27 UA 103306 C2 Продовження таблиці 2 Показові VH і VL ланцюги Посилання Позначення SEQ ID № H1 27 1N1G1 VH10 79 H1 30 1N1G1 VH11 80 H1 33-1 1N1G1 VH12 81 H1 33 1N1G1 VH13 82 H1 34 1N1G1 VH14 83 H1 39 1N1G1 VH15 84 H1 42 1N1G1 VH16 85 H1 64 1N1G1 VH17 86 H1 66 1N1G1 VH18 87 H1 72 1N1G1 VH19 88 H2 103 1N1G1 VH20 89 H1 90 1N1G1 VH21 90 H2 131 1N1G2 VH22 91 H2 291 1N1G2 VH23 92 H2 360 1N1G2 VH24 93 H2 360 1N1G2 SM VH25 Амінокислотна послідовність 94 28
ДивитисяДодаткова інформація
Автори російськоюBrasel, Kenneth, Allan, Foster, Stephen, Cerretti, Douglas, Pat, Sun, Jilin, Smothers, James, F., Mehlin, Christopher
МПК / Мітки
МПК: C07K 14/715, A61P 35/00, C07K 16/28, A61K 39/395
Мітки: людини, білок, c-fms, антигензв'язуючий
Код посилання
<a href="https://ua.patents.su/245-103306-c-fms-antigenzvyazuyuchijj-bilok-lyudini.html" target="_blank" rel="follow" title="База патентів України">C-fms антигензв’язуючий білок людини</a>
Рекомбінантний, очищений, модифікований генноінженерно білок, продукований бактеріями е.coli, імітуючий коровий білок вірусу імунодефіциту людини першого типу ( gag віл-1)

Номер патенту: 14847
Опубліковано: 18.02.1997
Автори: Мартиненко Дмитро Леонідович, Чумак Ростислав Максимович, Чєрєпанов Пьотр Алєксєєвіч, Міхайлова Татьяна Гавріловна
МПК: C07K 14/155, C12N 15/49
Мітки: рекомбінантний, бактеріями, очищений, першого, e.coli, віл-1, імунодефіциту, типу, модифікований, генноінженерно, коровий, людини, вірусу, імітуючий, продукований, білок
Формула / Реферат:
Рекомбінантний, очищений, модифікований генно-інженерно білок, продукований бактеріями Е.соlі, імітуючий коровий білок вірусу імунодефіциту людини першого типу (GAG ВІЛ-1), який має основні імунодомінантігі епітопи, притаманні нативним білкам gpl7, gp24 і gpl5 BІЛ-1, злитний, має молекулярну масу 70376 Д, містить в собі 623 амінокислотних залишка, ізоелектричну точку 8,54 і відповідає загальній формулі N-бета-Gal-pl7-p24-pl5-COOH.
Рекомбінантний, очищений, модифікований генно-інженерно білок, продукований бактеріями е.coli, імітуючий білок оболонки вірусу імунодефіциту людини першого типу (env biл-1)

Номер патенту: 14845
Опубліковано: 18.02.1997
Автори: Чєрєпанов Пьотр Алєксєєвіч, Мартиненко Дмитро Леонідович, Міхайлова Татьяна Гавріловна, Чумак Ростислав Максимович
МПК: C12N 15/49, C07K 14/155
Мітки: бактеріями, типу, білок, імітуючий, продукований, людини, імунодефіциту, першого, оболонки, вірусу, e.coli, генно-інженерно, biл-1, рекомбінантний, очищений, модифікований
Формула / Реферат:
Рекомбінаитний, очищений, модифікований генно-інженерно білок, продукований бактеріями Е.соlі, імітуючий білок оболонки вірусу імунодефіциту людини першого типу (Env ВІЛ-1), містить в собі 531 амінокислотний залишок і відповідає загальній формулі N-бета-Gal-pl20-р41-СООН.
Рекомбінантний, очищений, модифікований генно-інжерно білок, продукований бактеріями е.coli, імітуючий білок оболонки вірусу імунодефіциту людини другого типу ( env віл-2)

Номер патенту: 14842
Опубліковано: 18.02.1997
Автори: Чєрєпанов Пьотр Алєксєєвіч, Мартиненко Дмитро Леонідович, Чумак Ростислав Максимович, Міхайлова Татьяна Гавріловна
МПК: G01N 33/531, C12N 15/49, C07K 14/155
Мітки: вірусу, бактеріями, імунодефіциту, генно-інжерно, білок, модифікований, віл-2, рекомбінантний, очищений, оболонки, типу, людини, e.coli, імітуючий, другого, продукований
Формула / Реферат:
Рекомбінантний, очищений, модифікований генно-інженерно білок, продукований бактеріями Е.соlі, імітуючий білок оболонки вірусу імунодефіциту людини другого типу (Env ВІЛ-2), який має основні імунодомінантні епітопи, притаманні нативним білкам gp 110, gp38 ВІЛ-2, злитний, має молекулярну масу 67750 Д, містить в собі 1382 амінокислотних залишка і відповідає загальній формулі N-бета-GаІ-рІ 10-р38-СООН.
Дезоксирибонуклеїнова кислота, яка кодує білок глутатіон-s-трансферазу, білок

Номер патенту: 51642
Опубліковано: 16.12.2002
Автори: Хайн Рюдігер, Райнемер Петер, Бізелер Барбара, Манн Карльхайнц, Райф Ханс-Йорг, Томцік Юрген
МПК: C12N 1/21, C12N 15/54, C12N 9/10, C12N 15/82, A01H 5/00
Мітки: кислота, яка, кодує, дезоксирибонуклеїнова, білок, глутатіон-s-трансферазу
Формула / Реферат:
1. ДНК (дезоксирибонуклеїнова кислота), яка кодує білок глутатіон-S-трансферазу IIIс (GSTIIIc) з послідовністю:.2. ДНК згідно з п. 1, яка відрізняється тим, що має послідовність3. ДНК згідно з п. 1, яка відрізняється тим, що має послідовність ДНК GSTIIIc, яка міститься у векторній плазміді рЕТЗа- GSTIIIc.4. ДНК згідно з будь яким з пп. 1-3, яка відрізняється тим, що існує у формі дволанцюгової...
Рекомбінантний, очищений, модифікований генно-інженерно білок, продуктований бактеріями e.coli, імітуючий білок оболонки trepanema pallidum

Номер патенту: 14746
Опубліковано: 04.02.1997
Автори: Мартиненко Дмитро Леонідович, Чєрєпанов Пьотр Алєксєєвіч, Міхайлова Татьяна Гавріловна, Чумак Ростислав Максимович
МПК: C12N 15/31, C07K 14/20
Мітки: білок, бактеріями, модифікований, очищений, генно-інженерно, trepanema, продуктований, pallidum, імітуючий, e.coli, рекомбінантний, оболонки
Формула / Реферат:
Рекомбінантний, очищений, модифікований генно-інженерно білок, продукований бактеріями Е.соlі, імітуючий білок оболонки Trepanema pallidum, який має основні імунодомінантні епітопи, притаманні нативному білку, має молекулярну масу 106 кД, містить в собі 883 амінокислотних залишків і відповідає загальній формулі N-бетa-Gal-pTr-COOH.
Попередній патент: Гальмівна система залізничного транспортного засобу
Наступний патент: Розсувний снігоочисний відвал
Випадковий патент: Похідні піролотриазинону як інгібітори рі3к