Рослина brassica, яка містить мутантний алель нерозкривання стручків



































































Формула / Реферат
1. Рослина Brassica, що містить щонайменше два гени IND, або її клітина, частина, насіння або потомство, яка відрізняється тим, що містить в своєму геномі щонайменше два часткові нокаутні мутантні алелі IND, де вказаний частковий нокаутний мутантний алель IND вибирається з групи, що складається з:
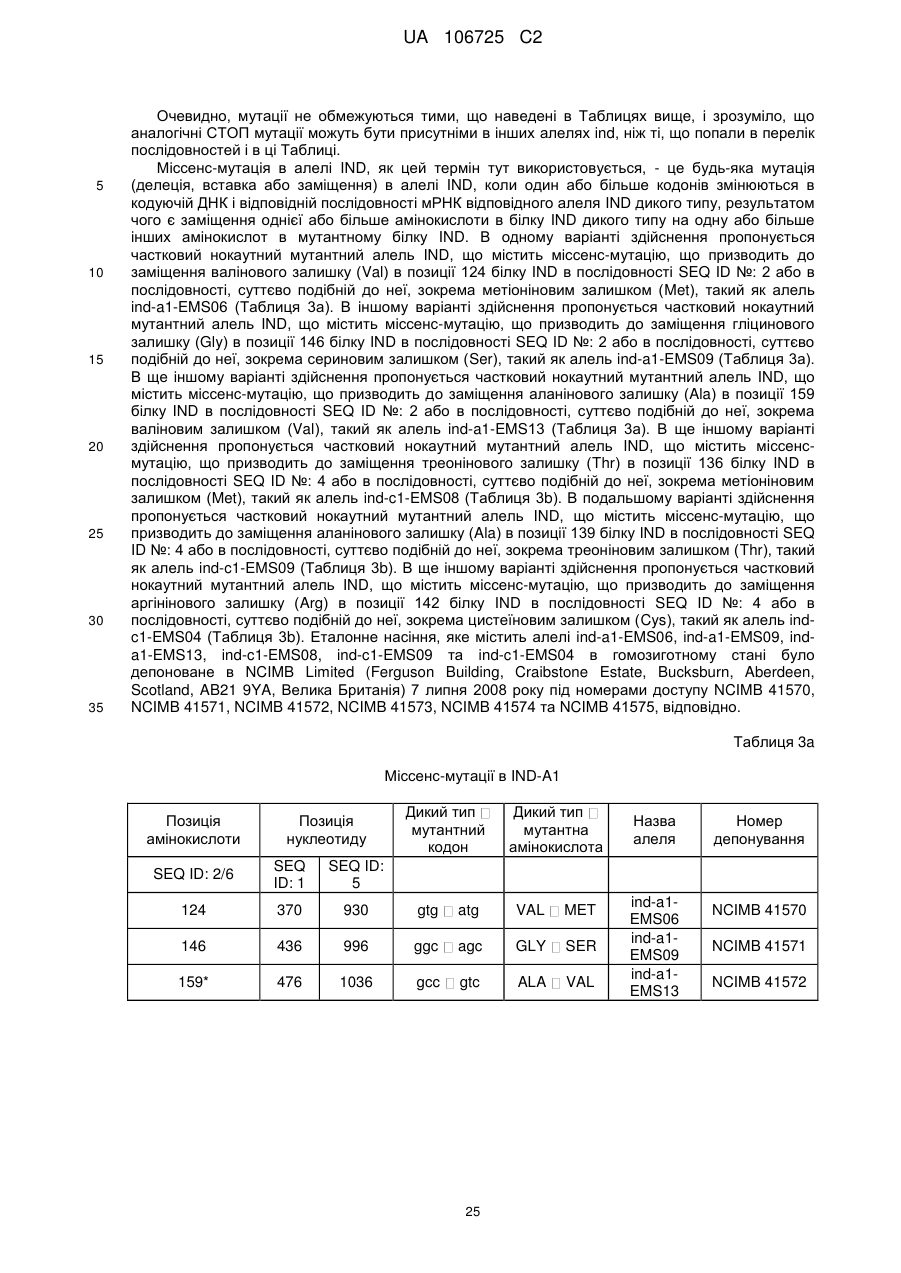
(a) нуклеїнової кислоти, яка кодує білок IND, в якому валін в позиції, що відповідає позиції 124 послідовності SEQ ID NO: 2, заміщений метіоніном;
(b) нуклеїнової кислоти, яка кодує білок IND, в якому гліцин в позиції, що відповідає позиції 146 послідовності SEQ ID NO: 2, заміщений серином;
(c) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 159 послідовності SEQ ID NO: 2, заміщений валіном;
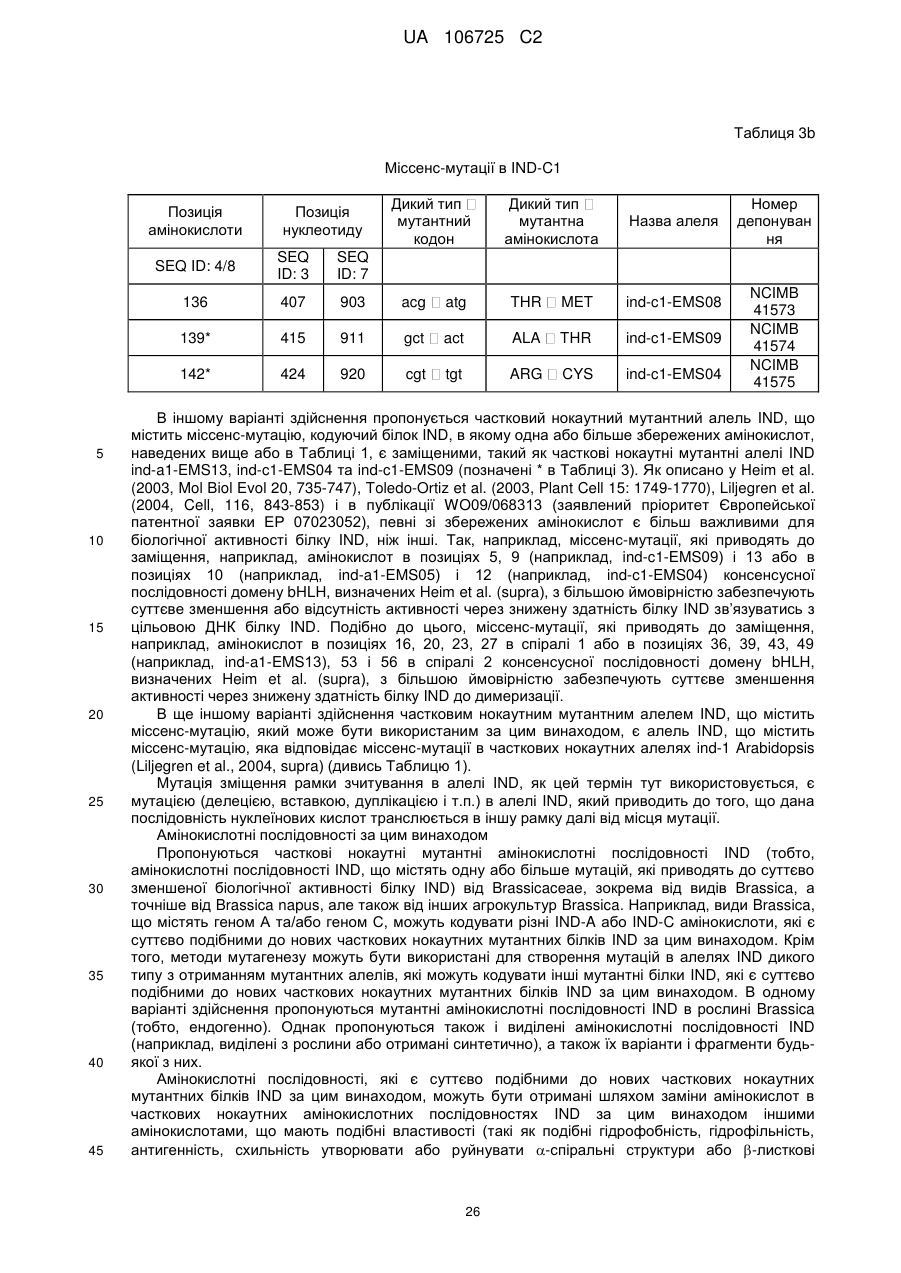
(d) нуклеїнової кислоти, яка кодує білок IND, в якому аргінін в позиції, що відповідає позиції 142 послідовності SEQ ID NO: 4, заміщений цистеїном;
(e) нуклеїнової кислоти, яка кодує білок IND, в якому треонін в позиції, що відповідає позиції 136 послідовності SEQ ID NO: 4, заміщений метіоніном; і
(f) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 139 послідовності SEQ ID NO: 4, заміщений треоніном.
2. Рослина за пунктом 1, яка містить два гени IND в двох локусах, яка відрізняється тим, що вона містить в своєму геномі два мутантні алелі IND в одному локусі.
3. Рослина за пунктом 2, в якій вказані два мутантні алелі IND є гомозиготними.
4. Рослина за будь-яким із пунктів 1-3, в якій гени IND є генами IND-A1 або IND-C1.
5. Рослина за будь-яким із пунктів 1-4, в якій гени IND містять молекулу нуклеїнової кислоти, вибрану з групи, що складається з:
(а) молекули нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 1, SEQ ID NO: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID NO: 3, SEQ ID NO: 5 або SEQ ID NO: 7;
(b) молекули нуклеїнової кислоти, яка кодує амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 2, SEQ ID NO: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 21 або SEQ ID NO: 4.
6. Рослина за пунктом 4 або 5, в якій часткові нокаутні мутантні алелі IND є мутантними алелями IND гена IND-C1.
7. Рослина за будь-яким із попередніх пунктів, в якій часткові нокаутні мутантні алелі IND вибираються з групи, що складається з ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 і ind-c1-EMS09.
8. Рослина за будь-яким з попередніх пунктів, яка додатково містить в своєму геномі щонайменше один повний нокаутний мутантний алель IND.
9. Рослина за пунктом 8, в якій повний нокаутний мутантний алель IND є мутантним алелем IND гена IND-C1.
10. Рослина за пунктом 8 або 9, в якій повний нокаутний мутантний алель IND вибирається з групи, що складається з ind-a1-EMS01, ind-a1-EMS05, ind-c1-EMS01 і ind-c1-EMS03.
11. Рослина за будь-яким із попередніх пунктів, яка є гомозиготною щодо часткового та/або повного нокаутного мутантного алеля IND.
12. Рослина за будь-яким із попередніх пунктів, яка продукує суттєво зменшену кількість функціонального білка IND, у порівнянні з кількістю функціонального білка IND, яку продукує відповідна рослина, що не містить мутантних алелів IND.
13. Рослина за будь-яким із попередніх пунктів, де осипання насіння рослини є суттєво зменшеним або відстроченим, у порівнянні з осипанням насіння відповідної рослини, що не містить мутантних алелів IND.
14. Рослина за пунктом 13, яка зберігає агрономічно релевантну змолочуваність стручків.
15. Рослина за будь-яким із попередніх пунктів, яка є рослиною з агрокультури Brassica, переважно Brassica napus, Brassica juncea, Brassica carinata, Brassica rapa або Brassica oleracea.
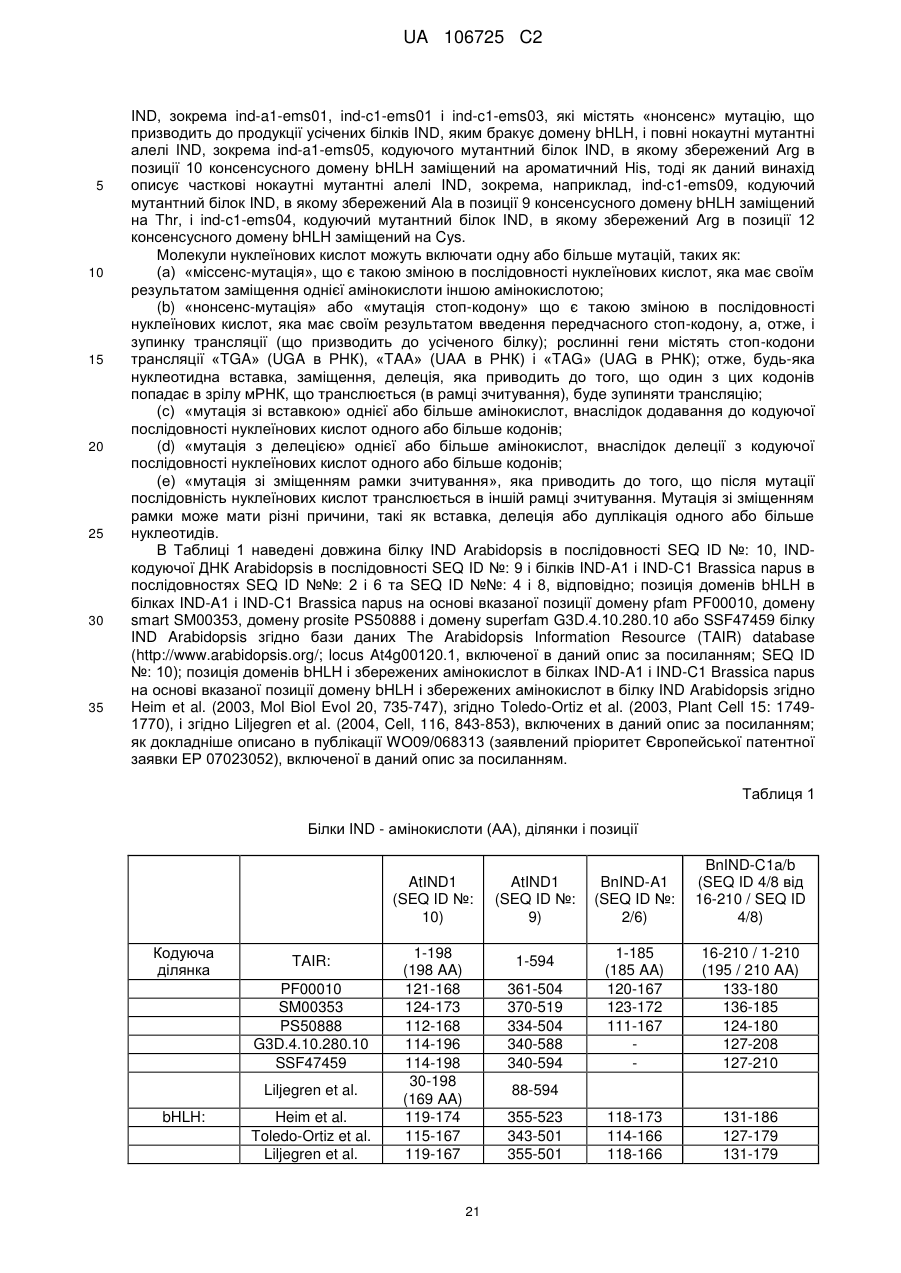
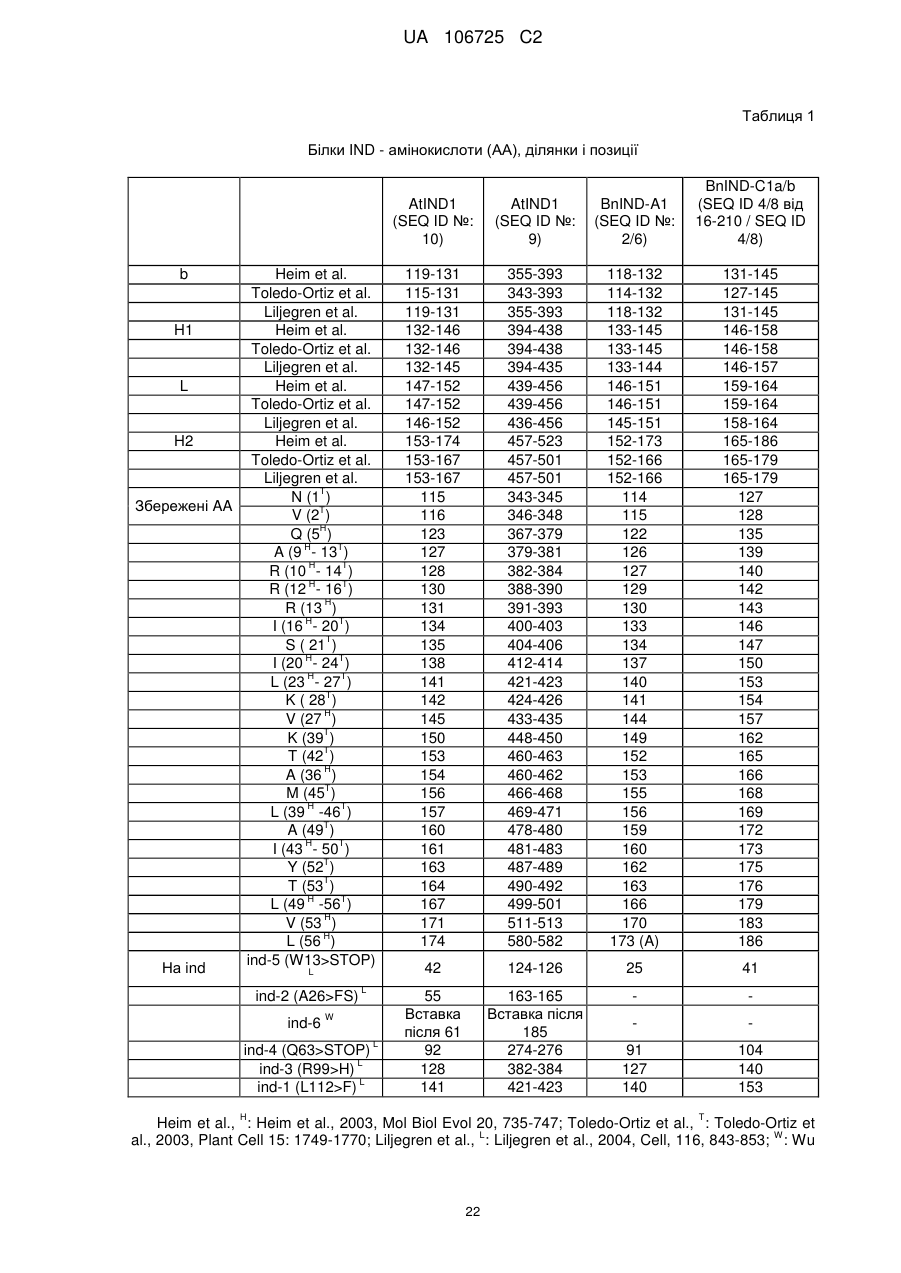
16. Рослина за будь-яким із попередніх пунктів, яка є рослиною з олійного виду Brassica, переважно Brassica napus, Brassica juncea або Brassica rapa.
17. Рослина Brassica або її клітина, частина, насіння або потомство, що містить в своєму геномі щонайменше один частковий нокаутний мутантний алель гена IND, де вказаний частковий нокаутний мутантний алель IND вибирається з групи, яка складається з:
(a) нуклеїнової кислоти, яка кодує білок IND, в якому валін в позиції, що відповідає позиції 124 послідовності SEQ ID NO: 2, заміщений метіоніном;
(b) нуклеїнової кислоти, яка кодує білок IND, в якому гліцин в позиції, що відповідає позиції 146 послідовності SEQ ID NO: 2, заміщений серином;
(c) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 159 послідовності SEQ ID NO: 2, заміщений валіном;
(d) нуклеїнової кислоти, яка кодує білок IND, в якому аргінін в позиції, що відповідає позиції 142 послідовності SEQ ID NO: 4, заміщений цистеїном;
(e) нуклеїнової кислоти, яка кодує білок IND, в якому треонін в позиції, що відповідає позиції 136 послідовності SEQ ID NO: 4, заміщений метіоніном; і
(f) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 139 послідовності SEQ ID NO: 4, заміщений треоніном; і
в якій ген IND містить молекулу нуклеїнової кислоти, вибрану з групи, яка складається з:
(а) молекули нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 1, SEQ ID NO: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID NO: 3, SEQ ID NO: 5 або SEQ ID NO: 7;
(b) молекули нуклеїнової кислоти, яка кодує амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 2, SEQ ID NO: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 210 або SEQ ID NO: 4.
18. Рослина за пунктом 17, в якій частковий нокаутний мутантний алель IND вибирається з групи, що складається з ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 і ind-c1-EMS09.
19. Частковий нокаутний мутантний алель гена IND, де вказаний частковий нокаутний мутантний алель IND вибирається з групи, яка складається з:
(a) нуклеїнової кислоти, яка кодує білок IND, в якому валін в позиції, що відповідає позиції 124 послідовності SEQ ID NO: 2, заміщений метіоніном;
(b) нуклеїнової кислоти, яка кодує білок IND, в якому гліцин в позиції, що відповідає позиції 146 послідовності SEQ ID NO: 2, заміщений серином;
(c) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 159 послідовності SEQ ID NO: 2, заміщений валіном;
(d) нуклеїнової кислоти, яка кодує білок IND, в якому аргінін в позиції, що відповідає позиції 142 послідовності SEQ ID NO: 4, заміщений цистеїном;
(e) нуклеїнової кислоти, яка кодує білок IND, в якому треонін в позиції, що відповідає позиції 136 послідовності SEQ ID NO: 4, заміщений метіоніном; і
(f) нуклеїнової кислоти, яка кодує білок IND, в якому аланін в позиції, що відповідає позиції 139 послідовності SEQ ID NO: 4, заміщений треоніном; і
і де ген IND містить молекулу нуклеїнової кислоти, вибрану з групи, яка складається з:
(а) молекули нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 1, SEQ ID NO: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID NO: 3, SEQ ID NO: 5 або SEQ ID NO: 7;
(b) молекули нуклеїнової кислоти, яка кодує амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID NO: 2, SEQ ID NO: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 21 або SEQ ID NO: 4.
20. Мутантний алель за пунктом 19, який вибирається з групи, що складається з ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 і ind-c1-EMS09.
21. Мутантний алель за будь-яким із пунктів 19, 20, який походить від рослини виду Brassica, переважно від агрокультури Brassica або олійного виду Brassica.
22. Мутантний білок IND, кодований мутантним алелем за будь-яким із пунктів 19-21.
23. Спосіб ідентифікації мутантного алеля IND за будь-яким із пунктів 19-21 в біологічному зразку, який включає визначення присутності специфічної мутантної ділянки IND в нуклеїновій кислоті, присутній в біологічному зразку.
24. Спосіб за пунктом 23, який додатково включає піддавання біологічного зразка полімеразній ланцюговій реакції з використанням комплекту з щонайменше двох праймерів, де вказаний комплект вибирається з групи, що складається з:
- комплекту праймерів, в якому один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ мутантного алеля IND, а інший з вказаних праймерів специфічно розпізнає фланкуючу ділянку 3’ мутантного алеля IND, відповідно;
- комплекту праймерів, в якому один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних праймерів специфічно розпізнає ділянку мутації мутантного алеля IND;
- комплекту праймерів, в якому один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних праймерів специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алеля IND, відповідно.
25. Спосіб за пунктом 23, який додатково включає піддавання біологічного зразка гібридизації з використанням комплекту специфічних зондів, що містить щонайменше один специфічний зонд, де вказаний комплект вибраний з групи, яка складається з:
- комплекту специфічних зондів, в якому один з вказаних зондів специфічно розпізнає фланкуючу ділянку 5’ мутантного алеля IND, а інший з вказаних зондів специфічно розпізнає фланкуючу ділянку 3’ мутантного алеля IND;
- комплекту специфічних зондів, в якому один з вказаних зондів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних зондів специфічно розпізнає ділянку мутації мутантного алеля IND;
- комплекту специфічних зондів, в якому один з вказаних зондів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних зондів специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алеля IND, відповідно;
- специфічного зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алеля IND.
26. Спосіб за пунктом 24 або 25, в якому
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID NO: 5 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 930 або від нуклеотиду 930 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуючаділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 або від нуклеотиду 997 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 996 послідовності SEQ ID NO: 5 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплемент, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID NO: 5 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1036 або від нуклеотиду 1036 до нуклеотиду 1622 або її комплемент, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID NO: 7 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID NO: 7 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID NO: 7 або її комплемент; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплементу, відповідно.
27. Спосіб за пунктом 25 або 26, в якому вказаний комплект зондів вибирають з групи, що складається з:
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 11, та/або один зонд, що містить послідовність SEQ ID NO: 12;
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 14, та/або один зонд, що містить послідовність SEQ ID NO: 15;
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 17, та/або один зонд, що містить послідовність SEQ ID NO: 18;
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 20, та/або один зонд, що містить послідовність SEQ ID NO: 21;
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 23, та/або один зонд, що містить послідовність SEQ ID NO: 24;
- комплекту зондів, який містить один зонд, що містить послідовність SEQ ID NO: 26, та/або один зонд, що містить послідовність SEQ ID NO: 27.
28. Спосіб за будь-яким із пунктів 23-27, який додатково включає стадію визначення присутності відповідної специфічної ділянки IND дикого типу в геномній ДНК вказаної рослини або її клітині, частині, насінні або потомстві.
29. Спосіб за пунктом 28, який додатково включає піддавання геномної ДНК вказаної рослини або її клітини, частини, насіння або потомства полімеразній ланцюговій реакції з використанням комплекту з щонайменше двох або щонайменше трьох праймерів, де щонайменше два з вказаних праймерів специфічно розпізнають алель IND дикого типу, при цьому вказані щонайменше два праймери вибираються з групи, яка складається з:
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого праймера, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного і дикого типу алеля IND, відповідно,
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого праймера, який специфічно розпізнає ділянку мутації алеля IND дикого типу,
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого праймера, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації алеля IND дикого типу, відповідно, і
де щонайменше два з вказаних праймерів специфічно розпізнають мутантний алель IND, при цьому вказані щонайменше два праймери вибираються з групи, яка складається з:
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого праймера, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного і дикого типу алеля IND, відповідно,
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і третього праймера, який специфічно розпізнає ділянку мутації мутантного алеля IND,
- першого праймера, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і третього праймера, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алеля IND, відповідно.
30. Спосіб за пунктом 28, який додатково включає піддавання геномної ДНК вказаної рослини або її клітини, частини, насіння або потомства гібридизації з використанням комплекту щонайменше двох специфічних зондів, де щонайменше один з вказаних специфічних зондів специфічно розпізнає алель IND дикого типу, де вказаний щонайменше один зонд вибирається з групи, яка складається з:
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого зонда, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного і дикого типу алеля IND, відповідно,
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого зонда, який специфічно розпізнає ділянку мутації алеля IND дикого типу,
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації алеля IND дикого типу, відповідно,
- зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації алеля IND дикого типу, і
де щонайменше один з вказаних специфічних зондів специфічно розпізнає мутантний алель IND, при цьому щонайменше один зонд вибирається з групи, яка складається з:
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і другого зонда, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного і дикого типу алеля IND, відповідно,
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і третього зонда, який специфічно розпізнає ділянку мутації мутантного алеля IND,
- першого зонда, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, і третього зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алеля IND,
- зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алеля IND.
31. Спосіб за пунктом 29 або 30, в якому
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 930 або від нуклеотиду 930 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 931 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 або від нуклеотиду 997 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 996 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 997 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1036 або від нуклеотиду 1036 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 1037 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 904 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 912 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно.
32. Спосіб за пунктом 30 або 31, де вказаний комплект з щонайменше трьох специфічних зондів вибирається з групи, яка складається з:
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 11, один зонд, що має послідовність SEQ ID NO: 12, та/або один зонд, що має послідовність SEQ ID NO: 13,
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 14, один зонд, що має послідовність SEQ ID NO: 15, та/або один зонд, що має послідовність SEQ ID NO: 16,
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 17, один зонд, що має послідовність SEQ ID NO: 18, та/або один зонд, що має послідовність SEQ ID NO: 19,
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 20, один зонд, що має послідовність SEQ ID NO: 21, та/або один зонд, що має послідовність SEQ ID NO: 22,
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 23, один зонд, що має послідовність SEQ ID NO: 24, та/або один зонд, що має послідовність SEQ ID NO: 25, і
- комплекту зондів, що містить один зонд, що має послідовність SEQ ID NO: 26, один зонд, що має послідовність SEQ ID NO: 27, та/або один зонд, що має послідовність SEQ ID NO: 28.
33. Набір для ідентифікації мутантного алеля IND за будь-яким із пунктів 19-21 в біологічному зразку, який містить комплект праймерів або зондів, при цьому вказаний комплект вибирається з групи, що складається з:
- комплекту праймерів або зондів, де один з вказаних праймерів або зондів специфічно розпізнає фланкуючу ділянку 5’ мутантного алеля IND, а інший з вказаних праймерів або зондів специфічно розпізнає фланкуючу ділянку 3’ мутантного алеля IND,
- комплекту праймерів або зондів, де один з вказаних праймерів або зондів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних праймерів або зондів специфічно розпізнає ділянку мутації мутантного алеля IND,
- комплекту праймерів або зондів, де один з вказаних праймерів або зондів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алеля IND, а інший з вказаних праймерів або зондів специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алеля IND, відповідно,
- зонда, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алеля IND.
34. Набір за пунктом 33, в якому
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID NO: 5 або її комплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 930 або від нуклеотиду 930 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 або від нуклеотиду 997 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 996 послідовності SEQ ID NO: 5 або її комплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID NO: 5 або їїкомплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1036 або від нуклеотиду 1036 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID NO: 7 або її комплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID NO: 7 або її комплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID NO: 7 або її комплементу; і вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплементу, відповідно.
35. Набір за пунктом 33 або 34, в якому вказаний комплект зондів вибирається з групи, яка складається з:
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 11, та/або один зонд, що має послідовність SEQ ID NO: 12,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 14, та/або один зонд, що має послідовність SEQ ID NO: 15,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 17, та/або один зонд, що має послідовність SEQ ID NO: 18,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 20, та/або один зонд, що має послідовність SEQ ID NO: 21,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 23, та/або один зонд, що має послідовність SEQ ID NO: 24,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 26, та/або один зонд, що має послідовність SEQ ID NO: 27.
36. Набір за будь-яким із пунктів 33-35, який додатково містить комплект праймерів або зондів, де щонайменше два з вказаних праймерів або щонайменше один з вказаних зондів специфічно розпізнають алель IND дикого типу, вибраний з групи, що складається з:
- комплекту з щонайменше двох праймерів або зондів, де перший праймер або зонд специфічно розпізнає фланкуючу ділянку 5’ мутантного і дикого типу алеля IND, а другий праймер або зонд специфічно розпізнає фланкуючу ділянку 3’ мутантного і дикого типу алеля IND,
- комплекту з щонайменше трьох праймерів або зондів, де перший праймер або зонд специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, другий праймер або зонд специфічно розпізнає ділянку мутації мутантного алеля IND, а третій праймер або зонд специфічно розпізнає ділянку мутації алеля IND дикого типу,
- комплекту з щонайменше трьох праймерів або зондів, де перший праймер або зонд специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного і дикого типу алеля IND, другий праймер або зонд специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алеля IND, відповідно, а третій праймер або зонд специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації алеля IND дикого типу, відповідно,
- комплекту з щонайменше двох зондів, де перший зонд специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алеля IND, а другий зонд специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації алеля IND дикого типу.
37. Набір за пунктом 36, в якому
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 930 або від нуклеотиду 930 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 929 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 931 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 або від нуклеотиду 997 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 996 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 995 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 997 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID NO: 5 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1036 або від нуклеотиду 1036 до нуклеотиду 1622 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 5 від нуклеотиду 1 до нуклеотиду 1035 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 5 від нуклеотиду 1037 до нуклеотиду 1622 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 902 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 904 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність а або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 910 з наступною послідовністю а або послідовність а з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 912 до нуклеотиду 1593 або її комплементу, відповідно, або
- вказана фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно; вказана ділянка мутації алеля IND дикого типу має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID NO: 7 або її комплементу; вказана ділянка мутації мутантного алеля IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алеля IND дикого типу містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплементу, відповідно; і вказана з’єднувальна ділянка мутантного алеля IND містить нуклеотидну послідовність SEQ ID NO: 7 від нуклеотиду 1 до нуклеотиду 919 з наступною послідовністю t або послідовність t з наступною нуклеотидною послідовністю SEQ ID NO: 7 від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно.
38. Набір за пунктом 36 або 37, в якому вказаний комплект з щонайменше трьох специфічних зондів вибирається з групи, яка складається з:
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 11, один зонд, що має послідовність SEQ ID NO: 12, та/або один зонд, що має послідовність SEQ ID NO: 13,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 14, один зонд, що має послідовність SEQ ID NO: 15, та/або один зонд, що має послідовність SEQ ID NO: 16,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 17, один зонд, що має послідовність SEQ ID NO: 18, та/або один зонд, що має послідовність SEQ ID NO: 19,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 20, один зонд, що має послідовність SEQ ID NO: 21, та/або один зонд, що має послідовність SEQ ID NO: 22,
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 23, один зонд, що має послідовність SEQ ID NO: 24, та/або один зонд, що має послідовність SEQ ID NO: 25, і
- комплекту зондів, який містить один зонд, що має послідовність SEQ ID NO: 26, один зонд, що має послідовність SEQ ID NO: 27, та/або один зонд, що має послідовність SEQ ID NO: 28.
39. Спосіб об’єднання щонайменше двох часткових нокаутних мутантних алелів IND за будь-яким із пунктів 19-21 в одній рослині, який включає наступні етапи:
(а) ідентифікація щонайменше двох рослин, кожна з яких містить щонайменше один частковий нокаутний мутантний алель IND за будь-яким з пунктів 25-29;
(b) схрещування щонайменше двох рослин і збирання гібридного насіння F1 з щонайменше одного кросу.
40. Спосіб за пунктом 39, який додатково включає етап ідентифікації рослини F1, яка містить щонайменше два часткові нокаутні мутантні алелі IND за будь-яким з пунктів 23-27.
41. Спосіб за пунктом 39, який додатково включає етап ідентифікації рослини F1, що є гомозиготною або гетерозиготною щодо часткового нокаутного мутантного алеля IND, шляхом визначення статусу зиготності відібраного мутантного алеля IND за будь-яким з пунктів 28-32.
42. Спосіб перенесення щонайменше одного часткового нокаутного мутантного алеля IND від однієї рослини до іншої, який включає наступні етапи:
(a) ідентифікація першої рослини, яка містить щонайменше один частковий нокаутний мутантний алель IND за будь-яким із пунктів 23-27, або створення першої рослини, яка містить щонайменше два часткові нокаутні мутантні алелі IND за пунктом 39,
(b) схрещування першої рослини з другою рослиною, яка не містить щонайменше одного часткового нокаутного мутантного алеля IND, і збирання насіння F1 з цього кросу,
(c) зворотне схрещування рослин F1, що містять щонайменше один частковий нокаутний мутантний алель IND, з другою рослиною, яка не містить щонайменше одного часткового нокаутного мутантного алеля IND, впродовж принаймні одного покоління (х) і збирання насінні ВСх з цих кросів,
(d) ідентифікація в кожному поколінні рослин ВСх, які містять щонайменше один частковий нокаутний мутантний алель IND за будь-яким із пунктів 23-27.
43. Спосіб за пунктом 42, який додатково включає етап ідентифікації рослин F1, які містять щонайменше один частковий нокаутний мутантний алель IND за будь-яким із пунктів 23-27.
44. Спосіб за пунктом 42, який додатково включає етап ідентифікації рослини ВСх, яка є гомозиготною або гетерозиготною щодо часткового нокаутного мутантного алеля IND, шляхом визначення статусу зиготності цього часткового нокаутного мутантного алеля IND за будь-яким із пунктів 28-32.
45. Спосіб за пунктом 39, в якому зазначена рослини F1 є рослиною за пунктом 1.
46. Спосіб за пунктом 45, який додатково включає об’єднання та/або перенесення часткових нокаутних мутантних алелів IND за будь-яким із пунктів 19-21 в одній рослині з повними нокаутними мутантними алелями IND та/або до однієї рослини, що містить повні нокаутні мутантні алелі IND.
47. Спосіб за пунктом 46, в якому повні нокаутні мутантні алелі IND вибираються з групи, яка складається з ind-a1-EMS01, ind-a1-EMS05, ind-c1-EMS01 та ind-c1-EMS03.
48. Спосіб за пунктом 42, який відрізняється тим, що вказані щонайменше дві рослини містять першу рослину, яка містить перший частковий нокаутний мутантний алель IND в гомозиготному стані, і другу рослину, яка містить другий частковий нокаутний мутантний алель IND в гомозиготному стані, і де вказане насіння F1 є гібридним насінням за пунктом 1.
49. Спосіб за пунктом 48, в якому перший і другий часткові нокаутні мутантні алелі IND є однаковими.
50. Спосіб за пунктом 48 або 49, в якому перша рослина додатково містить перший повний нокаутний мутантний алель IND в гомозиготному стані, і друга рослина містить другий повний нокаутний мутантний алель IND в гомозиготному стані.
51. Спосіб за пунктом 50, в якому перший і другий повні нокаутні мутантні алелі IND є однаковими.
52. Насіння Brassica, яке містить частковий нокаутний алель ind, вибране з групи, що складається з: насіння, що містить алель ind-a1-EMS06, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41570, насіння, що містить алель ind-a1-EMS09, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41571; насіння, що містить алель ind-a1-EMS13, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41572; насіння, що містить алель ind-c1-EMS04, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41575; насіння, що містить алель ind-c1-EMS08, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41573; насіння, що містить алель ind-c1-EMS09, який є присутнім в еталонному насінні, депонованому в NCIMB під номером доступу NCIMB 41574, та похідні від нього.
53. Рослина Brassica або її клітина, частина, насіння або потомство, що містить алель ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 або ind-c1-EMS09, одержана з насіння за пунктом 52.
Текст
Реферат: Винахід належить до рослини Brassica, що містить щонайменше два гени IND, причому містить в своєму геномі щонайменше два часткових нокаутних мутантних алелі IND. Також винахід належить до вдосконалених способів і засобів для зменшення осипання насіння або відстрочення осипання насіння на період після збирання врожаю, при збереженні в той самий час агрономічно релевантної змолочуваності стручків, а також для підвищення врожаю. UA 106725 C2 (12) UA 106725 C2 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 Галузь знань Даний винахід стосується галузі сільського господарства, точніше застосування методів молекулярної біології для зміни рослин, насіння яких розкривається, зокрема рослин родини Brassicaceae, а саме видів Brassica, та/або прискорення виведення таких рослин, насіння яких розкривається. Більш конкретно, даний винахід стосується вдосконалених способів і засобів для зменшення осипання насіння або відстрочення осипання насіння до періоду після збирання врожаю таких рослин, як рослини Brassicaceae, зокрема рослини Brassicaceae, вирощувані для отримання насіння, при збереженні в той самий час агрономічно релевантної змолочуваності стручків. Також пропонуються способи для ідентифікації молекулярних маркерів, пов’язаних зі зменшеним або відстроченим осипанням насіння в популяції рослин, насіння яких розкривається. Також пропонуються способи і засоби для збільшення врожаю, зокрема врожаю зерна і насіння. Фенотип зі збільшеною врожайністю може бути відділеним від фенотипу зі зменшеним або відстроченим осипанням насіння. Рівень знань Стручки рослини Brassica вивільнюють своє насіння у спосіб, який називають розкриванням плоду. Стручок складається з двох плодолистиків (стулок), з’єднаних своїми краями. Шов між краями утворює товсте ребро, яке називають перегородкою. Коли стручок досягає зрілості, дві його стулки поступово відділяються від перегородки по призначеним для цього лініям слабкості в стручку, що в кінці кінців призводить до осипання насіння, яке було прикріпленим до перегородки. Зона розкривання визначає точне місце роз’єднання стулок стручка. Осипання насіння (яке називають також «розкриванням стручка») із зрілих стручків до або під час збирання врожаю є загальним явищем для сільськогосподарських культур, які дають сухі плоди, що розкриваються. Передчасне осипання насіння призводить до втрати врожаю, що становить проблему в разі вирощування сільськогосподарських культур головним чином заради насіння, таких як олійні сорти Brassica, зокрема олійний рапс. Ще однією проблемою, пов’язаною з передчасним осипанням насіння, є збільшення мимовільного росту на наступний рік. Для олійного рапсу втрати врожаю через розкривання стручків становлять в середньому 20% (Child et al., 1998, J Exp Bot 49: 829-838), але можуть досягати 50% в залежності від погодних умов (MacLeod, 1981, Harvesting in Oilseed Rape, pp. 107-120, Cambridge Agricultural Publishing, Cambridge). Сучасні промислові сорти олійного рапсу є дуже чутливими до осипання. Серед існуючих програм селекції B. napus спостерігається незначна різниця щодо резистентності до осипання, але резистентні лінії були виявлені серед диплоїдних батьківських видів B. napus (B. oleracea і B. rapa), а також серед інших представників роду Brassica, зокрема B. juncea, B. carinata і B. nigra. Kadkol et al. (1986, Aust. J. Botany 34 (5): 595-601) повідомляють про підвищену резистентність щодо осипання у певних зразків B. campestris, яку було пов’язано з відсутністю шару поділу на ділянці приєднання стулок стручка до перегородки. Prakash і Chopra (1988, Plant breeding 101: 167-168) описують інтрогресію резистентності до осипання в Brassica napus від Brassica juncea шляхом негомологічної рекомбінації. Spence et al. (1996, J of Microscopy 181: 195-203) повідомляють, що певні лінії Brassica juncea демонструють знижену тенденцію до осипання у порівнянні з лініями Brassica napus. Morgan et al., 1998 (Fields Crop Research 58, 153165) описали генетичну мінливість щодо резистентності до розкривання стручків серед ліній олійного рапсу, отриманих з синтетичного B. napus, і дійшли висновку, що лінії, які вимагають значної енергії для розкривання своїх стручків, очевидно мають підвищену васкуляризацію в зоні розкривання і зменшене розкладання стінок клітин в цій зоні. Ними також була встановлена достовірна негативна кореляція між довжиною носика стручка і зусиллям, необхідним для розкривання стручка. Child і Huttly (1999, Proc 10th Int. Rapeseed Congress) описують зміну в дозріванні стручків у змутованого під дією опромінення B. napus і популяцію його батьківського культурного сорту, Jet Neuf, в якій найбільш резистентні рослини дикого типу і мутантні рослини демонстрували значну лігніфікацію груп клітин по всій зоні розкривання і в якій судинні сліди, розміщені близько до внутрішнього краю зони розкривання, у мутанта були описані як такі, що скріплюють стулки стручка. Child et al. (2003, J Exp Botany 54 (389): 1919-1930) описують також зв’язок між підвищеною резистентністю до розкривання стручка і змінами в судинній структурі стручків повторно синтезованої лінії Brassica napus. Однак традиційні методи селекції не досягли успіху у введенні резистентності до розкривання в культурні сорти рапсу без пошкодження інших бажаних ознак, таких як раннє цвітіння, дозрівання і резистентність до чорної ніжки (Prakash and Chopra, 1990, Genetical Research 56: 1-2). Шляхом аналізу мутантів Arabidopsis thaliana було ідентифіковано кілька генів, які сприяють розкриванню або пригнічують розкривання стручка. Комбіновані мутанти в обох генах СТІЙКИЙ ДО ОСИПАННЯ 1 (SHP1; спочатку називався AGL1) і СТІЙКИЙ ДО ОСИПАННЯ 2 (SHP2; 1 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 спочатку називався AGL5) мають стручки, що не розкриваються (тобто, стручки, що залишаються закритими після дозрівання у Arabidopsis thaliana) (Liljegren et al., 2000, Nature 404, 766-770). Подібним чином, мутанти в гені НЕРОЗКРИВАННЯ (який називають IND1) у Arabidopsis thaliana (Liljegren et al., 2004, Cell 116: 843-853; PCT публікація WO 01/79517), а також в АЛЬКАТРАС (який називають ALC; Rajani et al. 2001, Current Biology 11, 1914-1922) впливали на розкривання стручків, призводячи до резистентності щодо осипання насіння. Конститутивна експресія FRUITFUL (FUL), репресору SHP і IND, у Arabidopsis thaliana також мала своїм результатом стручки, що не розкривались (Ferrandiz et al., 2000, Science, 289, 436438). Вважається, що ці фактори транскрипції утворюють нелінійну транскрипційну систему, яка контролює особливості країв стулок і розкривання стручка. Liljegren et al. (2004, Cell 116: 843853) описують також, що IND, атиповий базовий ген спіраль-петля-спіраль (bHLH), спрямовує диференціацію краю стулок в напрямку розділення і лігніфікованих шарів у Arabidopsis thaliana. Шар лігніфікованих клітин, суміжних з шаром розділення, разом з шаром b ендокарпію (шар одиночних лігніфікованих клітин в кожній стулці), розвивають напруження по типу пружини у плоді, який висихає, що сприяє його розкриванню. Лігніфікація шару b ендокарпію вимагає активності IND, SHP, ALC і FUL, фактору транскрипції MADS-домену, який експресується в стулках (Liljegren et al., 2004, supra; Mandel & Yanofsky, 1995, Plant Cell 7, 1763-1771). Було встановлено, що FUL і REPLUMLESS (RPL), фактор транскрипції гомеодомену, який експресується в перегородці (Roeder et al., 2003, Curr Biol 13, 1630-1635), встановлюють межі генів, які забезпечують особливості країв стулок (Gu et al., 1998, Development 125, 1509-1517; Ferrandiz et al., 2000, Science, 289, 436-438; Roeder et al., 2003, supra). Насамкінець, були ідентифіковані FILAMENTOUS FLOWER (філаментозна квітка) (FIL) і YABBY3 (YAB3), два фактори транскрипції YABBY-родини (Sawa et al., 1999, Genes Dev 13, 1079-1088; Siegfried et al., 1999, Development 126, 4117-4128), і JAGGED (JAG), фактор транскрипції цинковий палець C2H2 (Dinneny et al., 2004, Development 131, 1101-1110; Ohno et al., 2004, Development 131, 11111122), які вносять значний вклад у правильний розвиток стулок і країв стулок, сприяючи експресії FUL і SHP у спосіб, специфічний до регіону (Dinneny et al., 2005, Development 132, 4687-4696). Ідентифіковані також гени для низки гідролітичних ферментів, таких як ендополігалактуронази, які під час розкривання стручка відіграють певну роль в запрограмованому руйнуванні відповідної зони в стручках рослин Brassica (дивись, наприклад, WO 97/13865; Petersen et al., Plant. Mol. Biol., 1996, 31:517-527). Liljegren et al. (2004, Cell 116: 843-853) описують п’ять мутантних алелів IND у Arabidopsis. Лігніфіковані клітини зони розкривання є відсутніми або присутніми в рослинах, що містять ці мутантні алелі, в залежності від тяжкості мутацій (тяжкі мутації ind не містять лігніфікованих клітин на ділянці, яка відповідає внутрішній частині краю стулки в рослинах дикого типу), але у всіх випадках стручки є такими, що не розкриваються. Wu et al. (2006), Planta 224, 971-979) описують шостий мутантний алель IND у Arabidopsis. Рослини, що містять цей мутантний алель, не мають лігніфікованих клітин в місцях сполучення краю стулки і перегородки, містять менше клітин на ділянці семи шарів клітин, яка очевидно охоплює загальновідому зону розкривання і межу перегородки в рослинах дикого типу, і демонструють неповний цитокінез в цьому шарі. Публікації US 2005/0120417 і US 2007/0006336 описують ідентифікацію і виділення двох ортологів IND1 з Brassica napus. Публікації WO99/00503, WO01/79517 і WO0159122 описують негативну регуляцію експресії генів ALC, IND, AGL1 і AGL5 Arabidopsis та їх ортологів за допомогою методів пригнічення транскрипції гену (таких як анти-смислова супресія або ко-супресія) і мутагенезу. Vancanneyt et al., 2002 (XIII International Conference on Arabidopsis Research, Sevilla, Spain June 28-July 2; 2002) повідомляли, що експресія FUL від A. thaliana під контролем промотору CaMV 35S в олійному рапсі мала своїм результатом низку трансформантів, резистентних щодо розкривання стручка. Стручки таких резистентних до розкривання ліній не мають зони розкривання, і відкривання стручків досягається тільки шляхом безсистемного ламання стулок під дією прикладеного значного тиску. Vancanneyt et al., 2002 (XIII International Conference on Arabidopsis Research, Sevilla, Spain June 28-July 2; 2002) повідомляли також, що сайленсинг гену IND у Arabidopsis thaliana з використанням так званих методів дсРНК сайленсингу мав своїм результатом майже повну резистентність до розкривання стручка. У 98% трансгенних ліній Arabidopsis розвинулись стручки, які не розкривались по шву стулок і які можна було розкрити тільки приклавши до стулок значний тиск. Важливо усвідомлювати, що, хоча осипання насіння становить важливу проблему у вирощування олійного рапсу, яку можна подолати, створивши резистентні до розкривання 2 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 стручка лінії, в кінцевому рахунку ще необхідно відділити насіння від стручків. В нормальній сільськогосподарській практиці це досягається обмолотом стручків з використанням збирального комбайну. Обмолочування стручків у збиральному комбайні має бути повним і має причиняти мінімальне ушкодження насінню, яке вивільнюється у такий спосіб. Однак, оскільки міцність стручків зростає, прикладене до них при обмолоті зусилля спричинює до неприйнятного рівня пошкодження насіння. Отже, стручки резистентних до осипання рослин Brassicaceae не повинні бути надто міцними, щоб їх можна було обмолотити в збиральному комбайні (Bruce et al. 2001, J. Agric. Engng Res. 80, 343-350). В публікації WO 2004/113542 описується, що помірний сайленсинг гену дсРНК з числа генів, задіяних в розвитку зони розкривання і країв стулок стручків в рослинах Brassicaceae, дозволяє виділити трансгенні лінії з підвищеною резистентністю до розкривання стручків і зменшеним осипанням насіння, стручки яких, однак, все ще можуть розкриватись в зоні розкривання при прикладанні обмеженого фізичного зусилля. В публікації WO09/068313 (з заявленим пріоритетом Європейської патентної заявки EP 07023052) описуються рослини Brassica, що містять щонайменше два гени IND, зокрема рослини Brassica napus, які характеризуються тим, що містять три повні нокаутні мутантні алелі IND в своєму геномі, і в яких резистентність до розкривання стручків є значно посиленою у порівнянні з резистентністю до розкривання стручків рослини, яка не містить мутантних алелів IND, але які переважно зберігають агрономічно релевантну змолочуваність стручків. Винахід, описаний тут в різних варіантах здійснення, прикладах і формулі винаходу, пропонує вдосконалені способи і засоби для модулювання пов’язаних з розкриттям стручків властивостей рослин, насіння яких розкривається. Більш конкретно, даний винахід описує вдосконалені способи і засоби для зменшення осипання насіння або відстрочення осипання насіння до періоду після збирання врожаю таких рослин, як рослини Brassicaceae, зокрема рослини Brassicaceae, вирощувані для отримання насіння, при збереженні, в той самий час, агрономічно релевантної змолочуваності стручків. Конкретно, дана заявка описує рослини Brassica, що містять принаймні два гени IND, зокрема рослини Brassica napus, які характеризуються тим, що містять два часткові нокаутні мутантні алелі IND в своєму геномі або два часткові і два повні нокаутні мутантні алелі IND, і в яких резистентність до розкривання стручків є значно посиленою у порівнянні з резистентністю до розкривання стручків рослини, яка не містить мутантних алелів IND, але які переважно зберігають агрономічно релевантну змолочуваність стручків. Також пропонуються способи і засоби для збільшення врожаю, зокрема врожаю зерна і насіння. Фенотип зі збільшеною врожайністю може бути відділеним від фенотипу зі зменшеним або відстроченим осипанням насіння. Суть винаходу Винахідниками було встановлено, що рослини Brassica napus з фенотипом розкривання стручків, подібним до рослин Brassica, описаних в публікації WO09/068313 (з заявленим пріоритетом Європейської патентної заявки EP 07023052), тобто такі, що поєднують підвищену резистентність до розкривання стручків з агрономічно релевантною змолочуваністю стручків, можуть бути отримані також шляхом комбінування двох часткових нокаутних мутантних алелів IND з двома повними нокаутними мутантними алелями IND або без них, замість комбінування трьох повних нокаутних мутантних алелів IND. Відповідно, в своєму першому аспекті даний винахід пропонує рослину Brassica, яка містить щонайменше два гени IND, зокрема рослину Brassica napus або її клітину, частину, насіння або потомство, яка характеризується тим, що в своєму геномі вона містить щонайменше два часткові нокаутні мутантні алелі IND. В одному варіанті здійснення ці гени IND є генами IND-A1 або IND-C1. В іншому варіанті здійснення гени IND містять молекулу нуклеїнової кислоти, вибрану з групи, що включає: молекулу нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 1, SEQ ID №: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID №: 3, SEQ ID №: 5 або SEQ ID №: 7, і молекулу нуклеїнової кислоти, кодуючу амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 2, SEQ ID №: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 21 або SEQ ID №: 4. В подальшому варіанті здійснення часткові нокаутні мутантні алелі IND є мутантними алелями IND гену IND-C1. В ще іншому варіанті здійснення часткові нокаутні мутантні алелі IND вибираються з групи, яка включає ind-a1-EMS06, ind-a1-EMS09, ind-a1EMS13, ind-c1-EMS04, ind-c1-EMS08 та ind-c1-EMS09. В ще іншому варіанті здійснення така рослина додатково містить в своєму геномі щонайменше один повний нокаутний мутантний алель IND. В ще іншому варіанті здійснення цим повним нокаутним мутантним алелем IND є мутантний алель IND гену IND-C1. В іншому варіанті здійснення повний нокаутний мутантний алель IND вибирається з групи, яка включає ind-a1-EMS01, ind-a1-EMS05, ind-c1-EMS01 та ind 3 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 c1-EMS03. В ще іншому варіанті здійснення така рослина є гомозиготною щодо часткового та/або повного нокаутного мутантного алелю IND. В ще іншому варіанті здійснення така рослина продукує суттєво зменшену кількість функціонального білку IND, у порівнянні з кількістю функціонального білку IND, яку продукує відповідна рослина, що не містить мутантних алелів IND. В подальшому варіанті здійснення осипання насіння рослиною є суттєво зменшеним або відстроченим, у порівнянні з осипанням насіння відповідною рослиною, що не містить мутантних алелів IND. В ще іншому варіанті здійснення така рослина зберігає агрономічно релевантну змолочуваність стручків. В ще іншому варіанті здійснення така рослина є рослиною з агрокультур Brassica, переважно Brassica napus, Brassica juncea, Brassica carinata, Brassica rapa або Brassica oleracea. В ще іншому варіанті здійснення така рослина є рослиною з олійних агрокультур Brassica, переважно Brassica napus, Brassica juncea або Brassica rapa. У відповідності до іншого свого аспекту, даний винахід пропонує рослину або її клітину, частину, насіння або потомство, яка містить в своєму геномі щонайменше один частковий нокаутний мутантний алель гену IND, де ген IND містить молекулу нуклеїнової кислоти, вибрану з групи, яка включає: молекулу нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 1, SEQ ID №: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID №: 3, SEQ ID №: 5 або SEQ ID №: 7; і молекулу нуклеїнової кислоти, кодуючу амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 2, SEQ ID №: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 21 або SEQ ID №: 4. В одному варіанті здійснення частковий нокаутний мутантний алель IND вибирається з групи, яка включає ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 та ind-c1EMS09. В іншому варіанті здійснення мутантний алель IND походить від рослини виду Brassica. В ще іншому варіанті здійснення цією рослиною є рослина з виду Brassica. У відповідності до подальшого свого аспекту, даний винахід пропонує сім’яний стручок (сім’янку), отримувану від рослин за цим винаходом. У відповідності до іншого свого аспекту, даний винахід пропонує частковий нокаутний мутантний алель гену IND, де ген IND містить молекулу нуклеїнової кислоти, вибрану з групи, яка включає: молекулу нуклеїнової кислоти, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 1, SEQ ID №: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID №: 3, SEQ ID №: 5 або SEQ ID №: 7; і молекулу нуклеїнової кислоти, кодуючу амінокислотну послідовність, яка має щонайменше 90% ідентичність послідовності з SEQ ID №: 2, SEQ ID №: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 21 або SEQ ID №: 4. В одному варіанті здійснення частковий нокаутний мутантний алель IND вибирається з групи, яка включає ind-a1-EMS06, ind-a1-EMS09, ind-a1-EMS13, ind-c1-EMS04, ind-c1-EMS08 та ind-c1EMS09. В іншому варіанті здійснення мутантний алель IND походить від рослини з видів Brassica, переважно від агрокультури Brassica або олійного сорту Brassica. У відповідності до ще іншого свого аспекту, даний винахід пропонує мутантний білок IND, кодований мутантними алелями IND за цим винаходом. У відповідності до ще іншого свого аспекту, даний винахід пропонує спосіб для ідентифікації мутантного алелю IND за цим винаходом у біологічному зразку, який включає визначення присутності мутантної IND специфічної ділянки в нуклеїновій кислоті, наявній в цьомубіологічному зразку. В одному варіанті здійснення цей спосіб додатково включає піддавання біологічного зразку полімеразній ланцюговій реакції з використанням комплекту з щонайменше двох праймерів, де вказаний комплект вибирається з групи, яка містить: комплект праймерів, де один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ мутантного алелю IND, а другий з вказаних праймерів специфічно розпізнає фланкуючу ділянку 3’ мутантного алелю IND, відповідно; комплект праймерів, де один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, а інший з вказаних праймерів специфічно розпізнає ділянку мутації мутантного алелю IND; і комплект праймерів, де один з вказаних праймерів специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, а інший з вказаних праймерів специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, відповідно. В іншому варіанті здійснення праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, містить нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або з її комплементу, відповідно, або праймер, який специфічно розпізнає ділянку мутації, містить нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або з її комплементу, відповідно, або праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, містить нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну 4 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, або з її комплементу, де вказані від 17 до 200 послідовних нуклеотидів не походять виключно ні з послідовності мутації, ні з фланкуючої послідовності. В ще іншому варіанті здійснення праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, містить на своєму кінці 3’ нуклеотидну послідовність з щонайменше 17 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ або з її комплементу, відповідно, або який специфічно розпізнає ділянку мутації мутантного алелю IND, містить на своєму кінці 3’ нуклеотидну послідовність з щонайменше 17 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або з її комплементу, або праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, містить на своєму кінці 3’ нуклеотидну послідовність з щонайменше 17 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, або з її комплементу, де вказані локалізовані на 3’ кінці 17 послідовних нуклеотидів не походять виключно ні з послідовності мутації, ні з фланкуючої послідовності. В ще іншому варіанті здійснення запропонований спосіб додатково включає піддавання біологічного зразку гібридизації з використанням комплекту специфічних зондів, що містить щонайменше один специфічний зонд, де вказаний комплект вибирається з групи, яка містить: комплект специфічних зондів, один з яких специфічно розпізнає фланкуючу ділянку 5’ мутантного алелю IND, а інший специфічно розпізнає фланкуючу ділянку 3’ мутантного алелю IND; комплект специфічних зондів, один з яких специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, а інший специфічно розпізнає ділянку мутації мутантного алелю IND; комплект специфічних зондів, один з яких специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, а інший специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND, відповідно; і специфічний зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND. В ще іншому варіанті здійснення зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або з її комплементу, відповідно, або послідовність, яка має щонайменше 80% ідентичність послідовності з нею, або зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або з її комплементу, або послідовності, яка має щонайменше 80% ідентичність послідовності з нею, або зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND, або з її комплементу, відповідно, де вказані від 13 до 1000 послідовних нуклеотидів не походять виключно ні з послідовності мутації, ні з фланкуючої послідовності, або послідовності, яка має щонайменше 80% ідентичність послідовності з нею. В одному конкретному варіанті здійснення зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND, містить нуклеотидну послідовність з щонайменше 13 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або з її комплементу, відповідно, або зонд, який специфічно розпізнає ділянку мутації мутантного алелю IND, містить нуклеотидну послідовність з щонайменше 13 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або з її комплементу, або зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, містить нуклеотидну послідовність з щонайменше 13 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, або з її комплементу, відповідно, де вказані щонайменше 13 послідовних нуклеотидів не походять виключно ні з послідовності мутації, ні з фланкуючої послідовності. В іншому конкретному варіанті здійснення фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID №: 5 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 930 або від нуклеотиду 930 до нуклеотиду 1622 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 995 або від нуклеотиду 997 до нуклеотиду 1622 або її комплемент, відповідно; 5 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 996 послідовності SEQ ID №: 5 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID №: 5 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 1036 або від нуклеотиду 1036 до нуклеотиду 1622 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID №: 7 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1593 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID №: 7 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID №: 7 або її комплементу; а вказана з’єднувальна ділянка містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплемент, відповідно. В ще іншому конкретному варіанті здійснення комплект зондів вибирається з групи, яка включає: комплект зондів, який містить один зонд з послідовністю SEQ ID №: 11 та/або один зонд з послідовністю SEQ ID №: 12; комплект зондів, який містить один зонд з послідовністю SEQ ID №: 14 та/або один зонд з послідовністю SEQ ID №: 15; комплект зондів, який містить один зонд з послідовністю SEQ ID №: 17 та/або один зонд з послідовністю SEQ ID №: 18; комплект зондів, який містить один зонд з послідовністю SEQ ID №: 20 та/або один зонд з послідовністю SEQ ID №: 21; комплект зондів, який містить один зонд з послідовністю SEQ ID №: 23 та/або один зонд з послідовністю SEQ ID №: 24; комплект зондів, який містить один зонд з послідовністю SEQ ID №: 26 та/або один зонд з послідовністю SEQ ID №: 27. У відповідності до іншого свого аспекту, даний винахід пропонує спосіб для визначення статусу зиготності мутантного алелю IND за цим винаходом в рослині або її клітині, частині, насінні або потомстві, який включає встановлення присутності мутантної та/або відповідної специфічної ділянки IND дикого типу в геномній ДНК вказаної рослини або її клітини, частини, насіння або потомства. В одному варіанті здійснення цей спосіб додатково включає піддавання геномної ДНК вказаної рослини або її клітини, частини, насіння або потомства полімеразній ланцюговій реакції з використанням комплекту з щонайменше двох або щонайменше трьох праймерів, де щонайменше два з вказаних праймерів специфічно розпізнають алель IND дикого типу і вибираються з групи, що містить: перший праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий праймер, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного алелю IND і алелю IND дикого типу, відповідно; перший праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий праймер, який специфічно розпізнає ділянку мутації алелю IND дикого типу; і перший праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації алелю IND дикого типу, відповідно; і де щонайменше два з вказаних праймерів специфічно розпізнають мутантний алель IND, ці вказані щонайменше два праймери вибираються з групи, що містить: перший праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий праймер, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного алелю IND і алелю IND дикого типу, відповідно; перший праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і третій праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND, відповідно. В подальшому варіанті здійснення праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, містить 6 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або алелю IND дикого типу або з її комплементу, відповідно; або праймер, який специфічно розпізнає ділянку мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або алелю IND дикого типу або з її комплементу, відповідно; або праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з від 17 до 200 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, або з її комплементу, відповідно; де вказані від 17 до 200 послідовних нуклеотидів не походять виключно ні від послідовності мутації, ні від фланкуючої послідовності. В ще іншому варіанті здійснення праймер, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, містить на своєму 3’ кінці нуклеотидну послідовність з 17 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND і алелю IND дикого типу або з її комплементу, відповідно; або праймер, який специфічно розпізнає ділянку мутації мутантного алелю IND або алелю IND дикого типу, містить на своєму 3’ кінці нуклеотидну послідовність з 17 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або алелю IND дикого типу або з її комплементу, відповідно; або праймер, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, містить на своєму 3’ кінці нуклеотидну послідовність з 17 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, або з її комплементу, відповідно, де вказані 17 послідовних нуклеотидів, локалізованих на 3’ кінці, не походять виключно ні від послідовності сайту або ділянки мутації, ні від фланкуючої послідовності. В ще іншому варіанті здійснення запропонований спосіб додатково включає піддавання геномної ДНК вказаної рослини або її клітини, частини, насіння або потомства гібридизації з використанням комплекту з щонайменше двох специфічних зондів, щонайменше один з яких специфічно розпізнає алель IND дикого типу і вибирається з групи, що містить: перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий зонд, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного алелю IND і алелю IND дикого типу, відповідно; перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий зонд, який специфічно розпізнає ділянку мутації алелю IND дикого типу; перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 3’ або 5’ і ділянкою мутації алелю IND дикого типу, відповідно; і зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації алелю IND дикого типу; і де щонайменше один з вказаних специфічних зондів специфічно розпізнає мутантний алель IND і вибирається з групи, що містить: перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і другий зонд, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного алелю IND і алелю IND дикого типу, відповідно; перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і третій зонд, який специфічно розпізнає ділянку мутації мутантного алелю IND, відповідно; перший зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND і алелю IND дикого типу, і третій зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND, відповідно; і зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND. В одному конкретному варіанті здійснення зонд, який специфічно розпізнає фланкуючу ділянку 5’ або 3’ мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або алелю IND дикого типу або з її комплементу, відповідно, або послідовність, яка має щонайменше 80% ідентичність послідовності з нею, або зонд, який специфічно розпізнає ділянку мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з послідовності ділянки мутації мутантного алелю IND або алелю IND дикого типу, відповідно, або послідовність, яка має щонайменше 80% ідентичність послідовності з нею, або зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну 7 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, відповідно, або послідовності, яка має щонайменше 80% ідентичність послідовності з нею, де вказані від 13 до 1000 послідовних нуклеотидів не походять виключно ні від послідовності сайту або ділянки мутації, ні від фланкуючої послідовності. В ще іншому конкретному варіанті здійснення зонд, який специфічно розпізнає фланкуючу ділянку 3’ або 5’ мутантного алелю IND і алелю IND дикого типу, містить нуклеотидну послідовність з щонайменше 13 послідовних нуклеотидів, вибраних з фланкуючої послідовності 5’ або 3’ мутантного алелю IND або алелю IND дикого типу або з її комплементу, відповідно, або зонд, який специфічно розпізнає ділянку мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з щонайменше 13 послідовних нуклеотидів, вибраних з послідовності мутації мутантного алелю IND або алелю IND дикого типу або з її комплементу, або зонд, який специфічно розпізнає з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, містить нуклеотидну послідовність з від 13 до 1000 послідовних нуклеотидів, вибраних з послідовності, що охоплює з’єднувальну ділянку між фланкуючою ділянкою 5’ або 3’ і ділянкою мутації мутантного алелю IND або алелю IND дикого типу, або з її комплементу, відповідно, де вказані 13 послідовних нуклеотидів не походять виключно ні від послідовності мутації, ні від фланкуючої послідовності. В подальшому конкретному варіанті здійснення фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 929 або від нуклеотиду 931 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації алелю IND дикого типу має нуклеотидну послідовність нуклеотиду 930 послідовності SEQ ID №: 5 або її комплементу; вказана ділянка мутації мутантного алелю IND має нуклеотидну послідовність а або її комплемент; вказана з’єднувальна ділянка алелю IND дикого типу містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 996 або від нуклеотиду 996 до нуклеотиду 1622 або її комплемент, відповідно; а вказана з’єднувальна ділянка мутантного алелю IND містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 995 з наступною нуклеотидною послідовністю а або послідовність а з наступною послідовністю SEQ ID №: 5 від нуклеотиду 997 до нуклеотиду 1622 або її комплементом, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 1035 або від нуклеотиду 1037 до нуклеотиду 1622 або її комплемент, відповідно; вказана ділянка мутації алелю IND дикого типу має нуклеотидну послідовність нуклеотиду 1036 послідовності SEQ ID №: 5 або її комплементу; вказана ділянка мутації мутантного алелю IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алелю IND дикого типу містить нуклеотидну послідовність SEQ ID №: 5 від нуклеотиду 1 до нуклеотиду 1035 з наступною послідовністю t або t з наступною нуклеотидною послідовністю SEQ ID №: 5 від нуклеотиду 1037 до нуклеотиду 1622 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 902 або від нуклеотиду 904 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації алелю IND дикого типу має нуклеотидну послідовність нуклеотиду 903 послідовності SEQ ID №: 7 або її комплементу; вказана ділянка мутації мутантного алелю IND має послідовність t або її комплемент; вказана з’єднувальна ділянка алелю IND дикого типу містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 903 або від нуклеотиду 903 до нуклеотиду 1953 або її комплемент; і вказана з’єднувальна ділянка мутантного алелю IND містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 902 з наступною послідовністю t або t з наступною нуклеотидною послідовністю SEQ ID №: 7 від нуклеотиду 904 до нуклеотиду 1593 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 910 або від нуклеотиду 912 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації алелю IND дикого типу має нуклеотидну послідовність нуклеотиду 911 послідовності SEQ ID №: 7 або її комплементу; вказана ділянка мутації мутантного алелю IND має послідовність а або її комплемент; і вказана з’єднувальна ділянка алелю IND дикого типу містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 911 або від нуклеотиду 911 до нуклеотиду 1593 або її комплемент, відповідно; і вказана з’єднувальна ділянка мутантного алелю IND містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 910 з наступною послідовністю а або а з наступною нуклеотидною послідовністю SEQ ID №: 7 від нуклеотиду 912 до нуклеотиду 1593 або її комплемент, відповідно; або фланкуюча ділянка 5’ або 3’ містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 919 або від нуклеотиду 921 до нуклеотиду 1593 або її комплемент, відповідно; вказана ділянка мутації алелю IND дикого типу має нуклеотидну послідовність нуклеотиду 920 послідовності SEQ ID №: 8 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 7 або її комплементу; вказана ділянка мутації мутантного алелю IND має послідовність t або її комплемент; і вказана з’єднувальна ділянка алелю IND дикого типу містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 920 або від нуклеотиду 920 до нуклеотиду 1593 або її комплемент, відповідно; а вказана з’єднувальна ділянка мутантного алелю IND містить нуклеотидну послідовність SEQ ID №: 7 від нуклеотиду 1 до нуклеотиду 919 з наступною послідовністю t або t з наступною нуклеотидною послідовністю SEQ ID №: 7 від нуклеотиду 921 до нуклеотиду 1593 або її комплементу, відповідно. В одному конкретному варіанті здійснення комплект з щонайменше трьох специфічних зондів вибирається з групи, яка включає: комплект зондів, один з яких має послідовність SEQ ID №: 11, один зонд має послідовність SEQ ID №: 12 та/або один зонд, що має послідовність SEQ ID №: 13; комплект зондів, один з яких має послідовність SEQ ID №: 14, один зонд має послідовність SEQ ID №: 15 та/або один зонд, що має послідовність SEQ ID №: 16; комплект зондів, один з яких має послідовність SEQ ID №: 17, один зонд має послідовність SEQ ID №: 18 та/або один зонд, що має послідовність SEQ ID №: 19; комплект зондів, один з яких має послідовність SEQ ID №: 20, один зонд має послідовність SEQ ID №: 21 та/або один зонд, що має послідовність SEQ ID №: 22; комплект зондів, один з яких має послідовність SEQ ID №: 23, один зонд має послідовність SEQ ID №: 24 та/або один зонд, що має послідовність SEQ ID №: 25; і комплект зондів, один з яких має послідовність SEQ ID №: 26, один зонд має послідовність SEQ ID №: 27 та/або один зонд, що має послідовність SEQ ID №: 28. Пропонуються також набори для ідентифікації мутантного алелю IND за цим винаходом в біологічному зразку і комплекти для встановлення статусу зиготності мутантного алелю IND за цим винаходом в рослині або її клітині, частині, насінні або потомстві, які включають праймери і зонди, описані вище. Пропонуються також способи для поєднання мутантних алелів IND за цим винаходом в одній рослині, способи для перенесення мутантних алелів IND за цим винаходом від однієї рослини до іншої рослини і способи для отримання (гібридної) рослини або насіння за цим винаходом. В іншому варіанті здійснення цього винаходу мутантні алелі IND за цим винаходом використовуються для збільшення виходу зібраного насіння або зерна з рослин Brassica. Такий збільшений вихід може бути результатом зменшеного або відстроченого осипання насіння, але може також бути незалежним від зменшеного або відстроченого осипання насіння. Зокрема, пропонуються рослини Brassica, які містять щонайменше два гени IND, або їх клітина, частина, насіння або потомство, які характеризуються тим, що містять в своєму геномі два мутантні гомозиготні алелі IND, як вони тут описані. Загальні дефініції Вирази «зростання резистентності до розкривання стручків» і «зменшення осипання насіння» стосуються зменшеної тенденції до осипання насіння та/або відстрочення моменту осипання насіння, зокрема на період після збирання врожаю, рослин Brassica, плоди яких звичайно дозрівають не одночасно, а послідовно, так що певні стручки тріскаються раніше, і насіння осипається до або під час збирання врожаю. Рівень резистентності до розкривання стручків позитивно корелює з зусиллям, яке необхідно прикласти для руйнування стручків в тесті на розрив (Davies and Bruce, 1997, J Mat Sci 32: 5895-5899; Morgan et al., 1998, Fields Crop Research 58, 153-165), і може оцінюватись шляхом визначення цього зусилля. Мірою можуть слугувати кількість інтактних стручків, що залишились через 20 секунд («IP20»; Morgan et al., 1998, supra), 9,7 або 17 секунд (Bruce et al., 2002, Biosystems Eng 81(2): 179-184), в «рандомізованому ударному тесті», період напівжиття зразка стручків («LD50») в «рандомізованому ударному тесті», тобто тривалість обробки, необхідна для забезпечення розкривання 50% стручків в тестованому зразку стручків, і «польова оцінка розкривання» (Morgan et al., 1998, supra). Рандомізовані ударні тести (RIT) і алгоритми для визначення напівжиття зразку стручків в таких RIT описані у Bruce et al., 2002 (supra), Morgan et al., 1998 (supra) і Прикладах, які будуть наведені далі. Обидві вказані публікації включені в даний опис за посиланням. В короткому викладі: зразок інтактних зрілих стручків поміщають в закритий барабан разом зі стальними сферами, і активно перемішують вміст барабану впродовж визначеного часу (наприклад, 10 с, 20 с, 40 с, 80 с). Після кожного періоду барабан відкривають і підраховують кількість зруйнованих і пошкоджених стручків. Найточніша оцінка рівня резистентності до розкривання обчислюється шляхом підгонки лінійного х лінійного графіку до всіх наявних даних і визначення часу, який пішов на руйнування половини стручків у взятому зразку («період півжиття зразку стручків» або «LD50»). При цьому важливо, щоб стручки відкривались головним чином в зоні розкривання, а не просто подрібнювались, як може трапитись зі стручками, що не розкриваються. Вираз «агрономічно релевантне підвищення резистентності до розкривання стручків», як він 9 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 тут використовується, стосується підвищення резистентності до розкривання стручків у рослини, яке має своїм результатом зменшення втрати врожаю внаслідок розкривання стручків у полі (до збирання врожаю), у порівнянні з тим, що звичайно спостерігається з цією рослиною у полі. Для олійного рапсу втрата врожаю через розкривання стручків у полі становить біля 11% для сезону з середніми гарними умовами для росту і біля 25% для сезону з середніми поганими умовами для росту. Була встановлена позитивна кореляція між цими рівнями втрати насіння і рівнем втрати насіння після 9,7 с і 17 с обробки, відповідно, в рандомізованому ударному тесті, як описали Bruce et al., 2002 (Biosystems Eng 81(2): 179-184). Альтернативно, для визначення того, або є рівень резистентності до розкривання стручків агрономічно релевантним, період напівжиття зразку стручків («LD50», дивись вище) рослини можна порівняти з періодом напівжиттям зразку стручків рослини з відомим середнім рівнем резистентності до розкривання стручків, такої як, у випадку олійного рапсу, всі сучасні промислові сорти олійного рапсу. Вирази «осипання насіння або стручка» або «розкриття плоду або стручка» стосуються процесу, який відбувається у плоді після дозрівання насіння і при якому стулки від’єднуються від центральної перегородки, вивільнюючи насіння. Ділянка, що розривається (тобто, «зона розкривання»), проходить по всій довжині плоду між стулками стручка і зовнішньою перегородкою. При досягненні зрілості «зона розкривання» являє собою суттєво нелігніфікований шар клітин між ділянкою лігніфікованих клітин в стулці і перегородкою. Розкривання стручка відбувається завдяки комбінації ослаблення стінок клітин в зоні розкривання і напруження внаслідок різних механічних властивостей клітин стручка, що висихають. «Плід» Brassica, як він тут використовується, стосується органу рослини Brassica, який розвивається з гінекею, що складається зі зрощених плодолистиків, який після запліднення виростає, щоб стати «(сім’яним) стручком», що містить насіння, яке розвивається. «(Сім’яний) стручок» Brassica складається зі стінки плоду (плодолистика), яка охоплює два гнізда, розділені перегородкою. «Зони розкривання» розвиваються по краях плодолистика, суміжних з перегородкою, і простягаються на всю довжину стручка. Клітини зони розкривання в кінці кінців починають розкладатись, і це ослаблює контакт між стінками плодолистика або стулками і перегородкою. Втрата клітинного зчеплення обмежується клітинами зони розкривання і є результатом руйнування середньої ламели (Meakin and Roberts, 1990, J Exp Bot 41, 995-1011). Термін «зони розкривання», як він тут використовується, стосується шарів простих, паренхіматозних клітин, що містяться по обидва боки двохстулкового стручка рослин, зокрема рослин Brassica. Зони розкривання розміщуються між краєм стулки стручка і центрального перегородкою, яка містить головний судинний пучок до стеблинки або плодоніжки. Дисоціація клітин в зоні розкривання відбувається під час старіння стручка і завершується до моменту, коли стручки досягають повної зрілості (Meakin & Roberts, 1990, supra). Тоді може трапитись розділення стулок. Зона розкривання містить судинні сліди, які проходять від стінки стручка до плодоніжки і перегородки. Процес розкривання стручка відбувається тільки після того, як зовнішня сила зруйнує делікатні судинні жилки, дозволяючи стулкам розділитись, а насінню впасти на землю. Це трапляється під час порушення пологу, наприклад внаслідок контакту з комбайном при збиранні врожаю. Судинна тканина містить потовщені, лігніфіковані клітини, що утворюють коленхіматозні групи клітин, які знаходять суміжними з провідними клітинами (Meakin and Roberts, 1990, supra). Це забезпечує цій тканині жорсткість і, можливо, певну резистентність до ламання. Вираз «агрономічно релевантне змолочування», як він тут використовується, стосується резистентності стручка, зокрема стручка олійного рапсу, до розкривання в зоні розкривання стручка з одночасним вивільненням насіння після прикладання фізичної сили, яка забезпечує повне розкривання стручків без нанесення ушкоджень насінню, наприклад у збиральному комбайні. Була встановлена позитивна кореляція між періодом півжиття зразка стручків («LD50») в рандомізованому ударному тесті та їх змолочуванням. Період напівжиття зразка стручків олійного рапсу, визначений з використанням RIT, як описано в Прикладах, який відповідає агрономічно релевантному змолочуванню, не повинний перевищувати 80 секунд. Типові значення періоду напівжиття для контрольних ліній промислових сортів олійного рапсу становлять близько 10 секунд. Отже, лінії з суттєво підвищеною резистентністю до розкривання стручків і з агрономічно релевантним змолочуванням мають період напівжиття зразку стручків в RIT від приблизно 10 до приблизно 80 секунд, від приблизно 10 до приблизно 60 секунд, від приблизно 10 до приблизно 50 секунд, від приблизно 20 до приблизно 60 секунд, від приблизно 20 до приблизно 50 секунд, від приблизно 40 до приблизно 60 секунд, приблизно 57 секунд. «Насінна рослина, плоди якої розкриваються розтріскуванням» означає рослину, яка продукує сухий плід, що розкривається розтріскуванням, який має стінки плоду, розкривання 10 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 яких дозволяє насінню, що міститься у плоді, вийти назовні. Плоди, які розкриваються розтріскуванням, звичайно містять кілька насінин і включають плоди, відомі, наприклад, як плоди бобових, насінні коробочки і стручки. «Сільськогосподарська культура» стосується видів рослин, що культивуються як культура, таких як Brassica napus (AACC, 2n=38), Brassica juncea (AABB, 2n=36), Brassica carinata (BBCC, 2n=34), Brassica rapa (syn. B. campestris) (AA, 2n=20), Brassica oleracea (CC, 2n=18) or Brassica nigra (BB, 2n=16). Це визначення не поширюється на бур’яни, такі як Arabidopsis thaliana. Термін «послідовність нуклеїнових кислот» (або молекула нуклеїнової кислоти) стосується молекули ДНК або РНК в одно- або двонитчастій формі, зокрема ДНК, що кодує білок або фрагмент білку за цим винаходом. «Ендогенна послідовність нуклеїнових кислот» стосується послідовності нуклеїнових кислот в рослинній клітині, наприклад ендогенному алелі гену IND, присутньому в ядерному геномі клітини Brassica. Вираз «виділена послідовність нуклеїнових кислот» використовується по відношенню до послідовності нуклеїнових кислот, яка вже не знаходиться в своєму природному оточенні, наприклад in vitro або в рекомбінантній бактеріальній або рослинній клітині-хазяїні. Термін «ген» означає послідовність ДНК, що містить ділянку (транскрибовану ділянку), яка транскрибується в молекулу РНК (наприклад, в пре-мРНК, що містить послідовності інтрону, яка потім перетворюється на зрілу мРНК або безпосередньо на мРНК без послідовностей інтрону) в клітині, функціонально зв’язану з регуляторними ділянками (наприклад, промотором). Отже, ген може включати кілька функціонально зв’язаних послідовностей, таких як промотор, 5’ лідерна послідовність, що містить, наприклад, послідовності, задіяні в запуску трансляції, кодуюча (білок) ділянка (кДНК або геномна ДНК) і 3’ нетрансльована послідовність, що містить, наприклад, сайти закінчення транскрипції. Термін «ендогенний ген» використовується для диференціації від «чужорідного гену», «трансгену» або «химерного гену» і стосується гену від рослини певного роду, виду або сорту, який не був введений в цю рослину шляхом трансформації (тобто, не є «трансгеном»), але який є нормально присутнім в рослинах цього роду, виду або сорту або який є введеним в цю рослину з рослин іншого роду, виду або сорту, в яких він звичайно є присутнім, за допомогою звичайних методів виведення сорту або шляхом соматичної гібридизації, наприклад з використанням злиття протопластів. Подібно до цього, «ендогенний алель» не вводиться в рослину або рослинну тканину шляхом трансформації рослини, а, наприклад, створюється шляхом мутагенезу рослини та/або селекції або отримується шляхом скринінгу природних популяцій рослин. «Експресія гену» стосується процесу, в якому ділянка ДНК, яка функціонально зв’язана з відповідними регуляторними ділянками, зокрема промотором, транскрибується в молекулу РНК. Молекула РНК потім піддається подальшій обробці (в пост-транскрипційних процесах) в клітині, наприклад шляхом сплайсингу РНК, запуску трансляції, трансляції в амінокислотний ланцюг (поліпептид) і закінчення трансляції стоп-кодонами трансляції. Термін «функціонально експресований» використовується тут, щоб показати, що продукується функціональний білок; термін «експресований не функціонально» показує, що продукується білок з суттєво зниженою або відсутньою функціональністю (біологічною активністю) або що не продукується жодного білку (докладніше дивись далі). Терміни «білок» стосується молекули, яка містять ланцюг з амінокислот, без посилання на конкретний спосіб дії, розмір, тривимірну структуру або походження. Отже, «фрагмент» або «частина» білку IND все ще може називатись «білком». Термін «виділений білок» стосується білку, який вже не знаходиться в своєму природному оточенні, наприклад in vitro або в рекомбінантній бактеріальній або рослинній клітині-хазяїні. «Амінокислоти» є основними будівельними блоками білків і ферментів. Вони включаються в білки шляхом перенесення РНК згідно генетичному коду, тоді як інформаційна РНК декодується рибосомами. Під час і після остаточного складання білку його амінокислотний склад диктує просторові і біохімічні властивості білку або ферменту. Амінокислотний каркас визначає первинну послідовність білку, але природа бокових ланцюгів визначає його властивості. Вираз «подібні амінокислоти», як він тут використовується, стосується амінокислот, які мають подібні амінокислотні бокові ланцюги, тобто амінокислот, що мають полярні, неполярні або практично нейтральні бокові ланцюги. «Неподібні амінокислоти» - це амінокислоти, які мають різні амінокислотні бокові ланцюги. Наприклад, амінокислота з полярним боковим ланцюгом є неподібною до амінокислоти з неполярним боковим ланцюгом. Полярні бокові ланцюги звичайно мають тенденцію бути присутніми на поверхні білку, де вони можуть взаємодіяти з водним середовищем у клітинах («гідрофільні» амінокислоти). З іншого боку, «неполярні» амінокислоти мають тенденцію знаходитись у центрі білку, де вони можуть взаємодіяти з подібними неполярними сусідами («гідрофобні» амінокислоти). Прикладами амінокислот, що мають полярні бокові ланцюги, є 11 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 аргінін, аспарагін, аспартат, цистеїн, глютамін, глутамат, гістидин, лізин, серин і треонін (всі з яких є гідрофільними, крім цистеїну, що є гідрофобним). Прикладами амінокислот, що мають неполярні бокові ланцюги, є аланін, гліцин, ізолейцин, лейцин, метіонін, фенілаланін, пролін і триптофан (всі з яких є гідрофобними, крім гліцину, що є нейтральним). Термін «фактор транскрипції» стосується білку, який складається з щонайменше двох окремих доменів - домену зв’язування ДНК і домену активації або репресії, які працюють разом, модулюючи швидкість ініціювання транскрипції з промоторів цільового гену (Ptashne, 1988, Nature 335, 683-689). Термін «основний фактор транскрипції домену спіраль-петля-спіраль (bHLH)» стосується фактору транскрипції, який містить, крім домену зв’язування ДНК bHLH (Heim et al., 2003, Mol Biol Evol 20, 735-747; Toledo-Ortiz et al., 2003, Plant Cell 15, 1749-1770), домени, що є важливими для регуляції експресії гену, яка може бути збереженою на амінокислотному рівні в споріднених білках від різних видів (Quong et al., 1993, Mol Cell Biol 13, 792-800). Регулятори транскрипції, що містять домен bHLH, зв’язують ДНК через залишки на основній ділянці, тоді як домен спіраль-петля-спіраль сприяє димеризації, дозволяючи представникам родини утворювати гетеро- або гомодимери (Murre et al., 1989, Cell 56, 777-783). Термін «ген IND» стосується тут послідовності нуклеїнових кислот, кодуючої білок INDEHISCENT (IND) (білок нерозкривання), що є основним фактором транскрипції домену bHLH, необхідним для розкидання насіння (Liljegren et al., 2004, Cell 116: 843-853). Термін «алель», як він тут використовується, означає будь-яку з однієї або більше альтернативних форм гену в конкретному локусі. В диплоїдній (чи амфідиплоїдній) клітині організму алелі даного гену розміщуються в конкретному місці або локусі на хромосомі. Один алель є присутнім на кожній хромосомі пари гомологічних хромосом. Термін «гомологічні хромосоми», як він тут використовується, означає хромосоми, які містять інформацію для тих самих біологічних ознак і містять ті самі гени в тих самих локусах, але можливо різні алелі цих генів. Гомологічні хромосоми є хромосомами, які паруються під час мейозу. «Негомологічні хромосоми», які представляють всі біологічні ознаки організму, утворюють комплект, і кількість комплектів в клітині називається плоїдністю. Диплоїдні організми містять два комплекти негомологічних хромосом, в яких кожна гомологічна хромосома є успадкованою від іншого батька. У амфідиплоїдних видів існує по суті два комплекти диплоїдних геномів, завдяки чому хромосоми цих двох геномів називаються «гомеологічними хромосомами» (і, подібним чином, локуси або гени цих двох геномів називаються гомеологічними локусами або генами). Диплоїдний або амфідиплоїдний вид рослини може містити велику кількість різних алелів в одному конкретному локусі. Термін «гетерозиготний», як він тут використовується, означає генетичний стан, коли два різних алеля знаходяться в одному конкретному локусі, але позиціонуються індивідуально на відповідних парах гомологічних хромосом в клітині. З іншого боку, термін «гомозиготний», як він тут використовується, означає генетичний стан, який існує тоді, коли два ідентичні алелі знаходяться в одному конкретному локусі, але позиціонуються індивідуально на відповідних парах гомологічних хромосом в клітині. Термін «локус», як він тут використовується, означає специфічне місце або сайт на хромосомі, де знаходиться, наприклад, ген або генетичний маркер. Наприклад, «локус IND-A1» стосується позиції на хромосомі геному А, де можуть знаходитись ген IND-A1 (і два алелі INDA1), тоді як «локус IND-С1» стосується позиції на хромосомі геному С, де можуть знаходитись ген IND-С1 (і два алелі IND-С1). При посиланні на «рослину» або «рослини» за цим винаходом слід розуміти, що маються на увазі також частини рослини (клітини, тканини або органи, сім’яні стручки, насіння, корінці, листя, квіти, пилок і т.п.), потомство рослин, яке зберігає відмінні ознаки батьків (зокрема, властивості щодо розкривання плодів), таке як насіння, отримане самозапиленням або перехресним запиленням, наприклад гібридне насіння (отримане схрещуванням двох інбредних батьківських ліній), гібридні рослини і частини рослин, отримані з них, які охоплюються цим винаходом, якщо немає вказівки на інше. «Молекулярна проба» (чи тест) стосується тут проби, яка показує (прямо або непрямо) присутність або відсутність одного або більше конкретних алелів IND в одному або обох локусах IND (наприклад, в одному або обох локусах IND-A1 або IND-C1). В одному варіанті здійснення вона дозволяє визначати, або є даний (дикого типу або мутантний) алель гомозиготним або гетерозиготним в конкретному локусі будь-якої окремої рослини. Термін «дикий тип», як він тут використовується, стосується типової форми рослини або гену, в якій вони найчастіше зустрічаються в природі. «Рослина дикого типу» стосується рослини з найпоширенішим фенотипом такої рослини в природній популяції. «Алель дикого типу» стосується алелю гену, необхідного для отримання фенотипу дикого типу. З іншого боку, 12 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 «мутантна рослина» стосується рослини з відмінним рідкісним фенотипом такої рослини в природній популяції або отриманим завдяки втручанню людини, наприклад шляхом мутагенезу, а «мутантний алель» стосується алелю гену, необхідного для отримання мутантного фенотипу. Термін «IND дикого типу» (наприклад, IND-A1 або IND-C1 дикого типу), як він тут використовується, означає алель IND природного походження, знайдений в рослинах, зокрема в рослинах Brassicacea, таких як рослини Brassica, який кодує функціональний білок IND (наприклад, функціональний IND-A1 або IND-C1, відповідно). З іншого боку, термін «мутантний IND» (наприклад, мутантний IND-A1 або IND-C1), як він тут використовується, стосується алелю IND, який не кодує функціональний білок IND, тобто алеля IND, кодуючого нефункціональний білок IND (наприклад, нефункціональний IND-A1 або IND-C1, відповідно). Нефункціональний білок стосується тут білку IND, який не має біологічної активності або має суттєво знижену біологічну активність у порівнянні з відповідним функціональним білком IND дикого типу, або зовсім не кодує жодного білку. «Повний нокаутний» або «нульовий» мутантний алель IND, як цей термін тут використовується, стосується мутантного алелю IND, який кодує білок IND, що не має біологічної активності або має суттєво знижену біологічну активність у порівнянні з відповідним функціональним білком IND дикого типу, або зовсім не кодує жодного білку. Такий «повний нокаутний мутантний алель IND» є, наприклад, алелем IND дикого типу, який містить одну або більше мутацій в своїй послідовності нуклеїнових кислот, наприклад одну або більше не смислових або міссенс мутацій. Зокрема, такий повний нокаутний мутантний алель IND є алелем IND дикого типу, який містить мутацію, що переважно має своїм результатом продукцію білку IND, якому бракує щонайменше одного функціонального домену, такого як домен активації, домен зв’язування ДНК та/або домен димеризації, або щонайменше однієї амінокислоти, вирішальної для його функції, такої як амінокислота, вирішальна для зв’язування ДНК, наприклад аргінін в позиції 127 в послідовності SEQ ID №: 2 або в позиції 140 в послідовності SEQ ID №: 4 і т.п., або глютамін в позиції 122 в послідовності SEQ ID №: 2 або в позиції 135 в послідовності SEQ ID №: 4 і т.п., так що біологічна активність білку IND повністю анулюється або така мутація переважно має своїм результатом відсутність продукції білку IND. «Частковий нокаутний» мутантний алель IND, як цей термін тут використовується, стосується мутантного алелю IND, який кодує білок IND, що має суттєво знижену біологічну активність у порівнянні з відповідним функціональним білком IND дикого типу. Таким «частковим нокаутним мутантним алелем IND» є, наприклад, алель IND дикого типу, який містить одну або більше мутацій в своїй послідовності нуклеїнових кислот, наприклад одну або більше міссенс мутацій. Зокрема, такий частковий нокаутний мутантний алель IND є алелем IND дикого типу, який містить мутацію, що переважно призводить до продукції білку IND, в якому щонайменше одна збережена та/або функціональна амінокислота є заміщеною на іншу амінокислоту, так що біологічна активність є суттєво зниженою, але не усунутою повністю. Такий повний або частковий нокаутний мутантний алель IND може також кодувати домінантний негативний білок IND, який здатний ушкоджувати біологічну активність інших білків IND в межах тієї самої клітини. Такий домінантний негативний білок IND може бути білком IND, який все ще здатний взаємодіяти з тими ж елементами, що й білок IND дикого типу, але який блокує певний аспект своєї функції. Прикладами домінантних негативних білків IND є білки IND, яким бракує домену активації та/або домену димеризації або специфічних амінокислотних залишків, вирішальних для активації та/або димеризації, але які все ще містять домен зв’язування ДНК, так що не тільки їх власна біологічна активність знижується або усувається, але вони також знижують загальну активність IND в клітині через конкуренцію з білками IND дикого типу та/або частковими нокаутними білками IND, присутніми в клітині для сайтів зв’язування ДНК. Іншими прикладами домінантних негативних білків IND є білки IND, яким бракує домену активації та/або домену димеризації або специфічних амінокислотних залишків, вирішальних для активації та/або димеризації, так що не тільки їх власна біологічна активність знижується або усувається, але вони також знижують загальну активність IND в клітині внаслідок продукції білкових димерів, яким бракує щонайменше одного функціонального домену. Мутантні алелі послідовностей нуклеїнових кислот, кодуючих білок IND, позначаються тут як «ind» (наприклад, ind-a1 або ind-c1, відповідно). Мутантні алелі можуть бути або «природними мутантними» алелями, які є мутантними алелями, віднайденими у природі (наприклад, такими, що з’явились спонтанно, без застосування людиною мутагенів), або «індукованими мутантними» алелями, які з’явились внаслідок втручання людини, наприклад з використанням мутагенезу. «Суттєво зменшена кількість функціонального білку IND» (наприклад, функціонального білку IND-A1 або IND-C1) стосується зменшення кількості функціонального білку IND, продукованого клітиною, що містить мутантний алель IND, щонайменше на 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95% або 100% (тобто, клітина не виробляє функціонального білку IND) у порівнянні з 13 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 кількістю функціонального білку IND, продукованого клітиною, що не містить мутантного алелю IND. Це визначення охоплює продукцію «нефункціонального» білку IND (наприклад, усіченого білку IND), який не володіє біологічною активністю in vivo, зменшення абсолютної кількості функціонального білку IND (наприклад, функціональний білок IND не виробляється через мутацію гену IND) та/або продукцію білку IND з суттєво зниженою біологічною активністю порівняно з активністю функціонального» білку IND дикого типу (такого як білок IND, в якому один або більше амінокислотних залишків, що є вирішальними для біологічної активності закодованого білку IND, як буде показано на прикладах далі, заміщені іншим амінокислотним залишком), та/або ушкоджуючий вплив домінантних негативних білків IND на інші функціональні та/або частково функціональні білки IND. Термін «мутантний білок IND», як він тут використовується, стосується білку IND, кодованого мутантною послідовністю нуклеїнових кислот IND («алель ind»), де ця мутація призводить до суттєво зниженої або відсутньої активності IND in vivo, порівняно з активністю білку IND, кодованого не мутантною послідовністю IND дикого типу («алель IND»). «Мутагенез», як цей термін тут використовується, стосується процесу, в якому рослинні клітини (наприклад, певна кількість насіння Brassica або інших частин, таких як пилок і т.п.) піддаються обробці методами, які викликають мутації в ДНК цих клітин, такими як контакт з мутагенним агентом, таким як хімічна речовина (така як етилметилсульфонат (EMS), етилнітрозосечовина (ENU) і т.д.) або іонізуюча радіація (нейтрони в мутагенезі швидкими нейтронами і т.п.), альфа промені, гамма промені (такі як від джерела Кобальт 60), рентгенівські промені, УФ опромінення і т.п.), або комбінацією двох або більше з них. Отже, бажаний мутагенез одного або більше алелів IND можна здійснити за допомогою хімічних засобів, таких як контакт однієї або більше рослинних тканин з етилметилсульфонатом (EMS), етилнітрозосечовиною (ENU) і т.д., або за допомогою фізичних засобів, таких як рентгенівські промені або гамма опромінення (таке як від джерела Кобальт 60). Якщо мутації, створювані опроміненням, часто являють собою великі делеції або інші значні ураження, такі як транслокації або складні реаранжирування, то створювані хімічними мутагенами мутації часто є більш дискретними ураженнями, такими як точкові мутації. Наприклад, EMS алкілує гуанінові основи, що призводить до помилкового парування основ: алкілований гуанін буде паруватись з тиміновою основою, результатом чого будуть в основному переходи G/C до A/T. Після мутагенезу рослини Brassica регенеруються від оброблених клітин з використанням відомих методів. Наприклад, отримане насіння Brassica можна посіяти у відповідності до звичайної методики вирощування, і після самозапилення на цих рослинах розвивається насіння. Альтернативно, можна відділити подвійні гаплоїдні саджанці, щоб відразу сформувати гомозиготні рослини, наприклад як описано Coventry et al. (1988, Manual for Microspore Culture Technique for Brassica napus. Dep. Crop Sci. Techn. Bull. OAC Publication 0489. Univ. of Guelph, Guelph, Ontario, Канада). Додаткове насіння, отримане після такого самозапилення в теперішньому або в наступному поколінні, можна зібрати і піддати скринінгу на присутність мутантних алелів IND. Відомо кілька методів для скринінгу на конкретні мутантні алелі, TM наприклад Deleteagene (Delete-a-gene; Li et al., 2001, Plant J 27: 235-242) використовує тести з полімеразною ланцюговою реакцією (ПЛР) для скринінгу на делеційні мутанти, створені шляхом мутагенезу під дією швидких нейтронів; TILLING (цільові індуковані локальні ураження в геномах; McCallum et al., 2000, Nat Biotechnol 18:455-457) ідентифікує викликані EMS точкові мутації і т.д. Додаткові методики скринінгу на присутність конкретних мутантних алелів IND будуть описані в Прикладах далі. Термін «неприродного походження» або «культивовані», коли він використовується по відношенню до рослин, означає рослину з геномом, який було модифіковано людиною. Трансгенна рослина, наприклад, є рослиною неприродного походження, що містить екзогенну молекулу нуклеїнової кислоти, наприклад химерний ген з транскрибованою ділянкою, яка після транскрипції дає біологічно активну молекулу РНК, здатну зменшити експресію ендогенного гену, такого як ген IND, і, відповідно, була генетично модифікована людиною. Крім того, рослина, яка містить мутацію в ендогенному гені, наприклад мутацію в ендогенному гені IND (наприклад, в регуляторному елементі або в кодуючій послідовності), як результат піддавання дії мутагенного агенту, також вважається неприродною рослиною, оскільки її було генетично модифіковано людиною. Більш того, рослина конкретного виду, така як Brassica napus, яка містить мутацію в ендогенному гені, наприклад в ендогенному гені IND, якої не трапляється в природі у даного конкретного виду рослини, як результат, наприклад, процесів спрямованого схрещування, таких як схрещування з використанням маркеру, і селекції або інтрогресії, з рослиною того самого або іншого виду, такого як Brassica juncea або rapa, також вважається рослиною неприродного походження. З іншого боку, рослина, яка містить тільки спонтанні 14 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 мутації або мутації природного походження, тобто рослина, яка не була генетично модифікована людиною, не є «рослиною неприродного походження», як її тут визначено, і, відповідно, не охоплюється даним винаходом. Для спеціалістів в цій галузі має бути зрозумілим, що, хоча рослина неприродного походження типово має нуклеотидну послідовність, яка є зміненою у порівнянні з рослиною природного походження, рослина неприродного походження також може бути генетично модифікованою людиною без зміни її нуклеотидної послідовності, наприклад шляхом модифікації характеру її метилювання. Термін «ортолог» гену або білку стосується тут гомологічного гену або білку, віднайденого у іншого виду, який має ту саму функцію, що й даний ген або білок, але (звичайно) відхиляється в послідовності від того моменту часу, коли відхилився вид, що містить ці гени (тобто, ці гени еволюціонували від спільного предка шляхом видоутворення). Отже, ортологи генів IND Brassica napus можуть бути ідентифіковані в інших рослинах (наприклад, Brassica juncea, etc.) на основі порівняння двох послідовностей (наприклад, на основі відсотку ідентичності послідовностей по всій їх довжині або на ділянці специфічних доменів) та/або функціонального аналізу. «Сорт» використовується тут у відповідності з конвенцією UPOV і стосується угрупування рослин в межах одного ботанічного таксону найнижчого відомого рангу, яке можна визначити за вираженням ознак, що є результатом даного генотипу або комбінації генотипів, яке можна відрізними від інших угрупувань рослин за вираженням щонайменше однієї з вказаних ознак і яке розглядається як одиниця стосовно його придатності для розповсюдження в незмінному (стабільному) стані. Термін «що містить» має інтерпретуватись як такий, що вказує на присутність встановлених частин, етапів або компонентів, але не виключає присутності однієї або більше додаткових частин, етапів або компонентів. Отже, рослина, що містить певну ознаку може містити додаткові ознаки. Зрозуміло, що, коли якесь слово вжито в однині (наприклад, рослина або корінь), припускається також множина (наприклад, певна кількість рослин, певна кількість коренів). Отже, якщо вказівка на якийсь елемент супроводжується невизначеним артиклем, це не виключає тієї можливості, що присутнім є більше ніж один елемент, коли контекст чітко не вимагає, щоб тут був один і тільки один з елементів. Таким чином, невизначений артикль звичайно означає «щонайменше один». Для цілей цього винаходу «ідентичність послідовностей» двох споріднених нуклеотидних або амінокислотних послідовностей, виражена як відсоток, стосується кількості позицій в двох оптимально зіставлених послідовностях, які мають ідентичні залишки (х 100), поділеної на кількість порівнюваних позицій. Пропуск, тобто позиція при зіставленні, де залишок є присутнім в одній послідовності, але відсутнім в іншій, розглядається як позиція з неідентичними залишками. «Оптимальне зіставлення» двох послідовностей досягається зіставленням двох послідовностей по всій їх довжині у відповідності до алгоритму глобального зіставлення Needleman і Wunsch (Needleman and Wunsch, 1970, J Mol Biol 48(3):443-53) у відкритому пакеті програмного забезпечення The European Molecular Biology Open Software Suite (EMBOSS, Rice et al., 2000, Trends in Genetics 16(6): 276-277; дивись, наприклад, http://www.ebi.ac.uk/emboss/align/index.html) з використанням установок за умовчанням (штраф за відкриття пропуску в послідовності = 10 (для нуклеотидів) / 10 (для білків); штраф за протяжність пропуску в послідовності = 0,5 (для нуклеотидів) / 0,5 (для білків)). Для нуклеотидів матрицею замін за умовчанням є EDNAFULL, а для білків матрицею замін за умовчанням є EBLOSUM62. Терміни «суттєво ідентичні» або «суттєво подібні», як вони тут використовуються, стосуються послідовностей, які при оптимальному зіставленні, як описано вище, поділяють щонайменше певний мінімальний відсоток тотожності послідовностей (як буде визначено далі). «Суворі умови гібридизації» можуть бути використані для ідентифікації нуклеотидних послідовностей, що є суттєво ідентичними з даною нуклеотидною послідовністю. Суворі умови залежать від послідовності і будуть різними за різних обставин. Загалом, суворі умови вибираються такими, щоб бути приблизно на 5°С нижчими, ніж температура плавлення (Tm) для конкретних послідовностей при визначених іонній силі і рН. Tm є температурою (при визначених іонній силі і рН), при якій 50% цільової послідовності гібридизуються до бездоганно підібраного зонду. Типово, будуть вибиратись такі суворі умови, при яких концентрація солі становить біля 0,02 моля при рН 7 і температура є щонайменше 60°С. Зниження концентрації солі та/або підвищення температури збільшують суворість. Суворі умови для гібридизацій РНК-ДНК (Нозерн блотинг з використанням зонду, наприклад 100nt) є, наприклад, такими, що включають щонайменше одну промивку в 0,2X SSC при 63°С впродовж 20 хвилин, або еквівалентними 15 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 умовами. «Умови високої суворості» можуть бути забезпечені, наприклад, гібридизацією при 65°С у водному розчині, що містить 6x SSC (20x SSC містить 3,0 M NaCl, 0,3 M Na-цитрату, pH 7,0), 5x Denhardt's (100X Denhardt’s містить 2% Ficoll, 2% полівініл пиролідону, 2% альбуміну бичачої сироватки), 0,5% натрію додецил сульфату (SDS) і 20 мкг/мл денатурованого носія ДНК (однонитчаста ДНК сперми риби, з середньою довжиною 120-3000 нуклеотидів) в якості неспецифічного конкурента. Після гібридизації промивання високої суворості може здійснюватись в кілька етапів, з останнім промиванням (біля 30 хвилин) при температурі гібридизації в 0,2-0,1× SSC, 0,1% SDS. «Умови помірної суворості» стосуються умов, еквівалентних гібридизації у вищеописаному 0 розчині, але при температурі біля 60-62 С. Промивання помірної суворості може здійснюватись при температурі гібридизації в 1x SSC, 0,1% SDS. «Низька суворість» стосується умов, еквівалентних гібридизації у вищеописаному розчині при температурі біля 50-52°С. Промивання низької суворості може здійснюватись при температурі гібридизації в 2x SSC, 0,1% SDS. Дивись також Sambrook et al. (1989) та Sambrook & Russell (2001). «Підвищений зібраний врожай» або «підвищений врожай насіння або зерна» стосується більшої кількості насіння або зерна, зібраної з певної кількості рослин, кожна з яких містить мутантні алелі IND за цим винаходом, у порівнянні з кількістю насіння або зерна, зібраною з подібної кількості ізогенних рослин без мутантних алелів IND. Врожай типово виражається в одиницях об’єму зібраного насіння на одиницю площі, наприклад в бушелях/акр або кг/га. Зростання врожаю типово виражається у відсотках; при цьому врожай з еталонних або контрольних рослин береться за 100%, а врожай з рослин за цим винаходом виражається як відсоток відносно врожаю з контрольних рослин. Спостережувані підвищення врожаю з рослин Brassica за цим винаходом були в межах від щонайменше 101% до щонайменше 124%. І очікується, що можна досягти більшого підвищення врожаю. Підвищення врожаю може бути також в межах від 104% до 108% або від 105% до 110%. Докладний опис винаходу Як описано в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), раніше було встановлено, що рослини Brassica napus, що є гомозиготними щодо повного нокаутного алелю ind тільки в одному з їх двох генів IND, тобто в IND-A1 або IND-C1, не демонструють значного підвищення резистентності до розкривання стручків, у порівнянні з рослинами Brassica napus, які не містять мутантних алелів IND, тоді як у рослин Brassica napus, що є гомозиготними щодо повного нокаутного алелю ind в обох генах IND, резистентність до розкривання стручків була значно підвищеною, але рівень резистентності до розкривання стручків був надто високим для забезпечення агрономічно релевантної змолочуваності стручків. З іншого боку, резистентність до розкривання стручків була значно підвищеною у рослин , які містять три повні нокаутні алелі ind з двох генів IND Brassica napus, до рівня, що дозволяє цим рослинам підтримувати агрономічно релевантну змолочуваність стручків. Винахідниками неочікувано було встановлено, що рослини Brassica napus з фенотипом розкривання стручків, подібним до рослин Brassica, описаних в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), тобто рослин, які поєднують підвищену резистентність до розкривання стручків з агрономічно релевантною змолочуваністю стручків, можуть бути отримані також шляхом комбінування двох часткових нокаутних мутантних алелів IND з двома повними нокаутними мутантними алелями IND, замість комбінування трьох повних нокаутних мутантних алелів IND. Було також встановлено, що мутації в гені IND-C1 приводять до більш значного підвищення резистентності до розкривання стручків, ніж мутації в гені IND-A1. Більш значне підвищення резистентності до розкривання стручків у рослин Brassica napus, наприклад, спостерігалось тоді, коли два повні нокаутні мутантні алелі IND були повними нокаутними мутантними алелями IND від гену IND-C1, а два часткові нокаутні мутантні алелі IND були частковими нокаутними мутантними алелями IND від гену IND-A1, ніж коли два повні нокаутні мутантні алелі IND були повними нокаутними мутантними алелями IND від гену IND-C1, а два часткові нокаутні мутантні алелі IND були частковими нокаутними мутантними алелями IND від гену IND-A1. Неочікувано, рослини Brassica napus, які поєднують підвищену резистентність до розкривання стручків з агрономічно релевантною змолочуваністю стручків, можуть бути отримані також шляхом введення тільки двох часткових нокаутних мутантних алелів IND, зокрема з гену IND-C1. Відповідно, в одному варіанті здійснення цього винаходу, пропонується рослина Brassica, яка містить щонайменше два гени IND, зокрема рослина Brassica napus, що містить ген IND-A1 і ген IND-C1, яка характеризується тим, що вона включає в своєму геномі два часткові нокаутні 16 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 мутантні алелі IND, зокрема з гену IND-A1 та/або IND-C1, переважно з гену IND-C1, і, як результат, алелі ind приводять до значно зменшеної кількості функціонального білку IND того типу, який кодується еквівалентом дикого типу цих мутантних алелів, і, відповідно, до загальної значно зменшеної кількості функціональних білків IND, що продукуються в рослинних клітинах, зокрема в сім’яних стручках, які розвиваються, in vivo. В іншому варіанті здійснення рослина Brassica додатково містить в своєму геномі два повні нокаутні мутантні алелі IND, зокрема з гену IND-A1 та/або IND-C1, відповідно, переважно з гену IND-C1, як рослини, описані в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), наприклад ind-a1-ems01, ind-a1-ems05, ind-c1-ems01 або ind-c1ems03 і т.п. Вважається також, що, комбінуючи достатню кількість копій специфічних часткових нокаутних мутантних алелів IND з достатньою кількістю копій специфічних повних нокаутних мутантних алелів IND та/або алелів IND дикого типу в одній рослині, зокрема в рослині Brassica, можливо тонко настроїти кількість та/або тип отримуваних функціональних білків IND, що, в свою чергу, впливає на пов’язані з розкриванням плоду властивості рослини. Абсолютна і відносна кількість білків IND може бути відрегульована таким чином, щоб створити рослини, які продукують достатньо білку (білків) IND, щоб забезпечити агрономічно релевантну змолочуваність сім’яних стручків при зменшенні осипання насіння до або під час збирання врожаю. Відповідно, в іншому варіанті здійснення цього винаходу, пропонується рослина, зокрема рослина Brassica, яка містить щонайменше один частковий нокаутний мутантний алель IND, що кодує частково функціональний білок IND, такий як ті, що описані далі, наприклад ind-a1-ems06, ind-a1-ems09, ind-a1-ems13, ind-c1-ems04, ind-c1-ems08 або ind-c1-ems09 і т.п., тоді як решта алелів можуть бути частковими нокаутними, повними нокаутними алелями IND та/або алелями IND дикого типу. У відповідності до одного аспекту даного винаходу, пропонується рослина Brassica, що містить щонайменше два гени IND, зокрема рослина Brassica napus, що містить два часткові нокаутні алелі ind і n-кратну кількість повних нокаутних алелів ind з щонайменше двох різних генів IND в цій рослині Brassica, зокрема генів IND-A1 та/або IND-C1, переважно гену IND-C1, де n ≤ 2 (наприклад, n = 0, 1 або 2), так щоб принаймні один алель продукував щонайменше частково функціональний білок IND. У відповідності до іншого аспекту даного винаходу, пропонується гомозиготна IND одинарно мутантна (n=2, тобто гомозиготна щодо часткового нокаутного мутантного алелю з одного гену IND) та/або гомозиготна IND подвійно мутантна (n=4, тобто гомозиготна щодо повного та/або часткового нокаутного мутантного алелю з двох генів IND) рослина виду Brassica, яка містить щонайменше два гени IND, зокрема Brassica napus, де ці мутантні алелі є мутантними алелями від двох різних генів IND в цій рослині Brassica, а саме генів IND-A1 та/або IND-C1. Такі мутантні рослини можуть, у відповідності до цього винаходу, використовуватись для цілей покращання сортів. Відповідно, в одному варіанті здійснення цього винаходу пропонується гомозиготна IND одинарно мутантна, частково нокаутна рослина Brassica napus, генотип якої можна описати як ind-a1/ind-a1, IND-C1/IND-C1 або IND-A1/IND-A1, ind-c1/ind-c1. В іншому варіанті здійснення цього винаходу пропонується гомозиготна IND подвійно частково мутантна рослина Brassica P P P P napus, генотип якої можна описати як ind-a1 /ind-a1 , ind-c1 /ind-c1 . В ще іншому варіанті здійснення цього винаходу пропонується гомозиготна IND подвійно частково і повністю F F P P мутантна рослина Brassica napus, генотип якої можна описати як ind-a1 /ind-a1 , ind-c1 /ind-c1 P P F F або ind-a1 /ind-a1 , ind-c1 /ind-c1 . Даний винахід пропонує також послідовності нуклеїнових кислот часткових нокаутних мутантних генів/алелів IND від видів Brassica, а також часткові нокаутні мутантні білки IND. Також пропонуються способи створення і комбінування часткових нокаутних мутантних алелів IND в рослинах Brassica, як і рослини Brassica і частини рослин, що містять в своєму геномі конкретні комбінації повних і часткових нокаутних мутантних алелів IND, завдяки чому в цих рослинах зменшується осипання насіння. Використання цих рослин для перенесення часткових нокаутних мутантних алелів IND в інші рослини також є одним з варіантів здійснення цього винаходу, як і рослинні продукти будь-якої з описаних тут рослин. Крім того, пропонуються набори і методи для відбору з допомогою маркеру (MAS) для комбінування або виявлення генів та/або алелів IND. Кожний з цих варіантів здійснення даного винаходу буде докладно описаний далі. Описані тут рослини Brassica, які демонструють зменшене або відстрочене осипання насіння, забезпечують зростання врожаю зібраного насіння. Однак спостерігалось, що не тільки 17 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 зібраний врожай насіння з рослин Brassica, що містять лише алель ind-c1-09 в гомозиготному стані (які демонструють спостережуваний фенотип зменшеного або відстроченого осипання насіння), але також зібраний врожай насіння з інших рослин Brassica, які містять лише два мутантні алелі IND в гомозиготному стані, тобто генотип цих рослин можна описати як indP P P P a1 /ind-a1 , IND-C1/ IND-C1 або IND-A1/ IND-A1, ind-c1 /ind-c1 , також був значно підвищеним у порівнянні з ізогенними рослинами Brassica, які не містять мутантних алелів IND, не дивлячись на відсутність спостережуваного фенотипу зменшеного або відстроченого осипання насіння в рослинах Brassica, що містять ці мутантні алелі IND. Даний винахід пропонує також рослини Brassica, що містять щонайменше два гени IND, в яких принаймні два алелі продукують функціональний білок IND, і забезпечують підвищений врожай насіння. Має бути ясно, що ці два мутантні алелі в локусі IND-A або в локусі IND-С можуть бути тим самим мутантним алелем або різними мутантними алелями. Послідовності нуклеїнових кислот згідно з цим винаходом Пропонуються часткові нокаутні мутантні послідовності нуклеїнових кислот ind, кодуючі частково функціональні білки IND, тобто білки IND з суттєво зниженою біологічною активністю (такі послідовності нуклеїнових кислот містять одну або більше мутацій, що призводять до значно зниженої біологічної активності кодованого білку IND) генів IND від Brassicaceae, зокрема від видів Brassica, таких як Brassica napus, але також від інших культурних видів Brassica. Наприклад, види Brassica, що містять геном А та/або геном С, можуть включати різні алелі генів IND-A1 або IND-C1, які є суттєво подібними до часткових нокаутних мутантних алелів IND за цим винаходом і які можуть ідентифікуватись і комбінуватись в одній рослині у відповідності до даного винаходу. Крім того, для створення мутацій в алелях IND дикого типу можуть бути використані методи мутагенезу з отриманням мутантних алелів ind, суттєво подібних до часткових нокаутних мутантних алелів IND за цим винаходом, для застосування за даним винаходом. Оскільки конкретні алелі IND переважно комбінуються в рослині шляхом схрещування і відбору, в одному варіанті здійснення пропонуються послідовності нуклеїнових кислот ind в одній рослині (тобто, ендогенно), наприклад рослині Brassica, переважно рослині Brassica, яка може бути схрещеною з Brassica napus або яка може бути використана для створення «синтетичної» рослини Brassica napus. Гібридизація між різними видами Brassica є описаною в літературі, наприклад як показано у Snowdon (2007, Chromosome research 15: 8595). Міжвидова гібридизація може, наприклад, бути використаною для перенесення генів з, наприклад, геному С в B. napus (AACC) в геном С в B. carinata (BBCC), або навіть з, наприклад, геному С в B. napus (AACC) в геном В у B. juncea (AABB) (шляхом використання спорадичного випадку неправильної рекомбінації між геномами С і В). «Ресинтезовані» або «синтетичні» лінії Brassica napus можуть бути отримані шляхом схрещування початкових предків B. oleracea (CC) і B. rapa (AA). Міжвидові, а також міжродові, бар’єри несумісності можна успішно подолати в кросах між культурними видами Brassica і їх родичами, наприклад за допомогою методики ембріонального спасіння або злиття протопластів (дивись, наприклад, Snowdon, вище). Однак виділені послідовності нуклеїнових кислот ind (наприклад, виділені з рослини шляхом клонування або отримані синтетично шляхом синтезу ДНК), а також варіанти і фрагменти будьякої з них також пропонуються в цьому винаході, оскільки вони можуть бути використані для визначення того, яка послідовність є присутньою в рослині або частині рослини ендогенно, або кодує ця послідовність функціональний, нефункціональний білок або не кодує жодного білку (наприклад, шляхом експресії в рекомбінантній клітині-хазяїні, як буде описано далі), і для відбору і перенесення конкретних алелів з однієї рослини в іншу з метою створення рослини з бажаною комбінацією часткових та/або повних нокаутних мутантних алелів IND. Нові часткові нокаутні мутантні послідовності нуклеїнових кислот IND-A1 і IND-C1 були виділені з Brassica napus. Послідовності IND дикого типу, описані в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), відображені в послідовностях SEQ ID №: 1, SEQ ID №: 3, SEQ ID №: 5 і SEQ ID №: 7 переліку послідовностей, тоді як нові часткові нокаутні мутантні варіанти ind цих послідовностей і послідовності, суттєво подібні до них, описані далі і в Прикладах з посиланням на послідовності IND дикого типу. Геномна IND білок-кодуюча ДНК від Brassica napus не містить жодних інтронів. «Послідовності нуклеїнових кислот IND-A1» або «варіантні послідовності нуклеїнових кислот IND-A1» за цим винаходом є послідовностями нуклеїнових кислот, кодуючими амінокислотну послідовність, що має щонайменше 75%, щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 96%, 97%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 2, або послідовностями нуклеїнових кислот, що мають щонайменше 75%, щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 96%, 97%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 5. Ці послідовності нуклеїнових кислот можуть 18 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 вважатись також «суттєво подібними» або «суттєво ідентичними» з послідовностями IND, наведеними в переліку послідовностей. «Послідовності нуклеїнових кислот IND-С1» або «варіантні послідовності нуклеїнових кислот IND-С1» за цим винаходом є послідовностями нуклеїнових кислот, кодуючими амінокислотну послідовність, що має щонайменше 75%, щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 96%, 97%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 4 (IND-C1-довга) або з SEQ ID №: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 210 (IND-C1-коротка), або послідовностями нуклеїнових кислот, що мають щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 96%, 97%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 3 (IND-C1-довга), з SEQ ID №: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633 (IND-C1-коротка) або з SEQ ID №: 7. Ці послідовності нуклеїнових кислот можуть вважатись також «суттєво подібними» або «суттєво ідентичними» з послідовностями IND, наведеними в переліку послідовностей. Отже, даний винахід пропонує нові часткові нокаутні мутантні послідовності нуклеїнових кислот з тих послідовностей нуклеїнових кислот, які кодують білки дикого типу і функціональні білки IND-A1 та IND-C1, включаючи їх варіанти і фрагменти (як докладніше буде визначено далі), де мутації в послідовності нуклеїнових кислот переважно мають своїм результатом введення, делецію або заміщення однієї або більше амінокислот у порівнянні з білком IND дикого типу, зокрема заміщення однієї або більше амінокислот, внаслідок чого біологічна активність білку IND значно знижується. Суттєве зниження біологічної активності білку IND означає тут зниження або усунення активності зв’язування ДНК, здатності до димеризації та/або активності щодо регуляції транскрипції білку IND, в результаті чого резистентність до розкривання стручків рослини, що експресує мутантний білок IND, підвищується у порівнянні з рослиною, яка експресує відповідний білок IND дикого типу. Для оцінки функціональності конкретного алеля/білку IND в рослинах, зокрема в рослинах Brassica, можна визначити рівень резистентності до розкривання стручків в рослинах шляхом проведення макроскопічного, мікроскопічного та гістологічного тестів на плодах і квітах рослин, що містять цей алель/білок IND, і відповідних рослин дикого типу, аналогічних тестам, які виконуються на плодах і квітах Arabidopsis, як описано Liljegren et al. (2004, supra) або як описано в наведених далі Прикладах. В короткому викладі: зміни резистентності до розкривання стручків можна оцінити та/або виміряти, наприклад, за допомогою макроскопічних тестів, таких як огляд сім’яних стручків неозброєним оком для оцінки, наприклад, присутності або відсутності країв стулок, довжини носику стручків і т.п.; ручний динамічний тест (МІТ) для порівняння рівня резистентності до розкривання стручків між різними мутантними IND лініями і відповідними лініями дикого типу шляхом оцінки легкості розкривання стручків при їх легкому скручуванні; рандомізований ударний тест (RIT) для порівняння обмолочування сім’яних стручків від рослин з різних мутантних IND ліній і з відповідних ліній дикого типу шляхом визначення періоду півжиття зразків стручків з цих ліній; та/або за допомогою мікроскопічних тестів для визначення того, або впливають і як впливають мутації в IND на клітини на краю стулок і в зоні розкривання сім’яних стручків. Коли партнер по димеризації білку IND (наприклад, сам білок IND у випадку, коли його функціонування залежить від утворення гомодимеру, або інший білок у випадку, коли його функціональність залежить від утворення гетеродимеру) та/або ген (гени), транскрипція яких регулюється цим білком IND, ідентифікуються і характеризуються, функціональність конкретного алеля/білку IND може альтернативно оцінюватись за допомогою методів рекомбінантної ДНК, відомих в цій галузі, наприклад шляхом ко-експресії обох партнерів димеру в клітині-хазяїні (наприклад, бактерії, такій як E. coli) і оцінки того, або димери все ще можуть утворюватись, або ці димери все ще можуть зв’язуватись з сайтом зв’язування bHLH цього регульованого гену (генів) та/або або транскрипція цього гену (генів) все ще регулюється цим зв’язуванням. Цей винахід пропонує як ендогенні, так і виділені послідовності нуклеїнових кислот. Також пропонуються фрагменти мутантних послідовностей IND і мутантні варіантні послідовності нуклеїнових кислот IND, визначені вище, для використання в якості праймерів або зондів і в якості компонентів комплектів за одним з аспектів даного винаходу (докладніше дивись далі). «Фрагмент» послідовності нуклеїнових кислот ind або її варіант (як визначено) можуть бути різної довжини, такої як щонайменше 10, 12, 15, 18, 20, 50, 100, 200, 500, 600 суміжних нуклеотидів послідовності IND або ind (або варіантної послідовності). Послідовності нуклеїнових кислот, кодуючі функціональні білки IND Послідовності нуклеїнових кислот, наведені в переліку послідовностей, кодують функціональні білки IND дикого типу від Brassica napus. Отже, ці послідовності є ендогенними для рослин Brassica napus, з яких вони були виділені. Інші культурні види Brassica, сорти, 19 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 виведені лінії або дикі поповнення можуть бути піддані скринінгу на інші алелі IND, кодуючі ті самі білки IND або їх варіанти. Наприклад, методи гібридизації нуклеїнових кислот (такі як Саузерн блотинг з використанням, наприклад, суворих умов гібридизації) або методи на основі ПЛР можуть бути використані для ідентифікації алелів IND, ендогенних для інших рослин Brassica, таких як різні сорти, лінії або поповнення Brassica napus, але також Brassica juncea (особливо алелі IND на A-геномі), Brassica carinata (особливо алелі IND на C-геномі) та рослини, органи і тканини Brassica rapa (A-геном) і Brassica oleracea (C-геном) можуть бути піддані скринінгу на інші алелі IND дикого типу. Для здійснення скринінгу таких рослин, рослинних органів або тканин на присутність алелів IND можуть бути використані послідовності нуклеїнових кислот IND, наведені в переліку послідовностей, або варіанти або фрагменти будьякої з них. Наприклад, повні послідовності або фрагменти можуть бути використані як зонди або праймери. Так, специфічні або вироджені праймери можуть бути використані для ампліфікації послідовностей нуклеїнових кислот, кодуючих білки IND з геномної ДНК рослини, її органу або тканини. Ці послідовності нуклеїнових кислот IND можуть бути виділені і секвеновані з використанням стандартних методів молекулярної біології. Потім можна скористатись біоінформаційним аналізом, щоб охарактеризувати алель (алелі), наприклад для того, щоб визначити, якому алелю IND відповідає дана послідовність і який білок IND або білковий варіант кодується цією послідовністю. Чи кодує послідовність нуклеїнових кислот функціональний білок IND, можна проаналізувати методами рекомбінантної ДНК, як відомо в цій галузі, наприклад за допомогою генетичного комплементаційного тесту з використанням, наприклад, рослини Arabidopsis, що є гомозиготною щодо повного нокаутного мутантного алелю ind, або рослини Brassica napus, що є гомозиготною щодо повного нокаутного мутантного алелю ind обох генів IND-A1 і IND-C1. Крім того, зрозуміло, що послідовності нуклеїнових кислот IND і їх варіанти (чи фрагменти будь-якої з них) можуть бути ідентифіковані in silico, шляхом скринінгу баз даних нуклеїнових кислот на суттєво подібні послідовності. Більш того, послідовність нуклеїнових кислот можна синтезувати хімічним шляхом. Пропонуються також фрагменти молекул нуклеїнових кислот за цим винаходом, які докладніше будуть описані далі. Фрагменти включають послідовності нуклеїнових кислот, кодуючі тільки домен bHLH, або менші фрагменти, що містять частину домену bHLH, таку як базовий домен або домен HLH, і т.д. Послідовності нуклеїнових кислот, кодуючі мутантні білки IND Даний винахід пропонує послідовності нуклеїнових кислот, що містять одну або більше нуклеотидних делецій, вставок або заміщень, по відношенню до послідовностей нуклеїнових кислот IND дикого типу, які представлені в переліку послідовностей послідовностями SEQ ID №: 1, 3, 5 і 7, де мутація (мутації) в послідовності нуклеїнових кислот має своїм результатом суттєво знижену біологічну активність, тобто частковий нокаут біологічної активності, кодованих білків IND по відношенню до білку дикого типу, а також фрагменти таких мутантних молекул нуклеїнової кислоти. Такі мутантні послідовності нуклеїнової кислоти (які називаються тут P послідовностями ind ) можуть бути створені та/або ідентифіковані за допомогою різних відомих методів, як докладніше буде описано далі. І цього разу, такі молекули нуклеїнових кислот пропонуються як в ендогенній формі, так і у виділеній формі. В основному, будь-яка мутація в послідовностях нуклеїнових кислот IND дикого типу, що має своїм результатом білок IND, який містить щонайменше одну амінокислотну вставку, делецію та/або заміщення по відношенню до білку IND дикого типу, може призвести до суттєво зниженої або повністю усунутої біологічної активності. Однак зрозуміло, що певні мутації в білку IND з більшою ймовірністю призводять до повного усунення біологічної активності білку IND, так як мутації, внаслідок яких випадають значні частини функціональних доменів, таких як домен зв’язування ДНК («b»), домен димеризації («HLH») та/або домени регуляції транскрипції, або певні важливі амінокислотні залишки в межах цих доменів, такі як амінокислоти Gln (Q), Ala (A) і Arg (R) в позиціях 5, 9 і 13, або основні амінокислотні залишки (зокрема, залишки Arg (R)) в позиціях 10 і 12 консенсусної послідовності домену bHLH, визначених Heim et al. (2003, Mol Biol Evol 20, 735-747; вони відповідають позиціям 123, 127 і 131, а також 128 і 130, відповідно, в послідовності SEQ ID №: 10, дивись Таблицю 1), є відсутніми або заміщеними, переважно неподібними або не збереженими амінокислотами. В той самий час, інші мутації в білку IND з більшою ймовірністю призводять до суттєвого зниження біологічної активності білку IND, такі як мутації, що призводять до заміщень конкретних амінокислот, наприклад збережених амінокислот, наведених в Таблиці 1, викликаючи менш ефективне зв’язування ДНК, менш ефективну димеризацію та/або менш ефективну регуляцію транскрипції без повного усунення біологічної активності закодованого білку IND. В публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052) описані, наприклад, повні нокаутні мутантні алелі 20 UA 106725 C2 5 10 15 20 25 30 35 IND, зокрема ind-a1-ems01, ind-c1-ems01 і ind-c1-ems03, які містять «нонсенс» мутацію, що призводить до продукції усічених білків IND, яким бракує домену bHLH, і повні нокаутні мутантні алелі IND, зокрема ind-a1-ems05, кодуючого мутантний білок IND, в якому збережений Arg в позиції 10 консенсусного домену bHLH заміщений на ароматичний His, тоді як даний винахід описує часткові нокаутні мутантні алелі IND, зокрема, наприклад, ind-c1-ems09, кодуючий мутантний білок IND, в якому збережений Ala в позиції 9 консенсусного домену bHLH заміщений на Thr, і ind-c1-ems04, кодуючий мутантний білок IND, в якому збережений Arg в позиції 12 консенсусного домену bHLH заміщений на Cys. Молекули нуклеїнових кислот можуть включати одну або більше мутацій, таких як: (а) «міссенс-мутація», що є такою зміною в послідовності нуклеїнових кислот, яка має своїм результатом заміщення однієї амінокислоти іншою амінокислотою; (b) «нонсенс-мутація» або «мутація стоп-кодону» що є такою зміною в послідовності нуклеїнових кислот, яка має своїм результатом введення передчасного стоп-кодону, а, отже, і зупинку трансляції (що призводить до усіченого білку); рослинні гени містять стоп-кодони трансляції «TGA» (UGA в РНК), «TAA» (UAA в РНК) і «TAG» (UAG в РНК); отже, будь-яка нуклеотидна вставка, заміщення, делеція, яка приводить до того, що один з цих кодонів попадає в зрілу мРНК, що транслюється (в рамці зчитування), буде зупиняти трансляцію; (с) «мутація зі вставкою» однієї або більше амінокислот, внаслідок додавання до кодуючої послідовності нуклеїнових кислот одного або більше кодонів; (d) «мутація з делецією» однієї або більше амінокислот, внаслідок делеції з кодуючої послідовності нуклеїнових кислот одного або більше кодонів; (е) «мутація зі зміщенням рамки зчитування», яка приводить до того, що після мутації послідовність нуклеїнових кислот транслюється в іншій рамці зчитування. Мутація зі зміщенням рамки може мати різні причини, такі як вставка, делеція або дуплікація одного або більше нуклеотидів. В Таблиці 1 наведені довжина білку IND Arabidopsis в послідовності SEQ ID №: 10, INDкодуючої ДНК Arabidopsis в послідовності SEQ ID №: 9 і білків IND-A1 і IND-C1 Brassica napus в послідовностях SEQ ID №№: 2 і 6 та SEQ ID №№: 4 і 8, відповідно; позиція доменів bHLH в білках IND-A1 і IND-C1 Brassica napus на основі вказаної позиції домену pfam PF00010, домену smart SM00353, домену prosite PS50888 і домену superfam G3D.4.10.280.10 або SSF47459 білку IND Arabidopsis згідно бази даних The Arabidopsis Information Resource (TAIR) database (http://www.arabidopsis.org/; locus At4g00120.1, включеної в даний опис за посиланням; SEQ ID №: 10); позиція доменів bHLH і збережених амінокислот в білках IND-A1 і IND-C1 Brassica napus на основі вказаної позиції домену bHLH і збережених амінокислот в білку IND Arabidopsis згідно Heim et al. (2003, Mol Biol Evol 20, 735-747), згідно Toledo-Ortiz et al. (2003, Plant Cell 15: 17491770), і згідно Liljegren et al. (2004, Cell, 116, 843-853), включених в даний опис за посиланням; як докладніше описано в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), включеної в даний опис за посиланням. Таблиця 1 Білки IND - амінокислоти (АА), ділянки і позиції AtIND1 (SEQ ID №: 10) Кодуюча ділянка TAIR: PF00010 SM00353 PS50888 G3D.4.10.280.10 SSF47459 Liljegren et al. bHLH: Heim et al. Toledo-Ortiz et al. Liljegren et al. 1-198 (198 AA) 121-168 124-173 112-168 114-196 114-198 30-198 (169 AA) 119-174 115-167 119-167 AtIND1 (SEQ ID №: 9) 1-594 361-504 370-519 334-504 340-588 340-594 BnIND-A1 (SEQ ID №: 2/6) BnIND-C1a/b (SEQ ID 4/8 від 16-210 / SEQ ID 4/8) 1-185 (185 AA) 120-167 123-172 111-167 16-210 / 1-210 (195 / 210 AA) 133-180 136-185 124-180 127-208 127-210 118-173 114-166 118-166 131-186 127-179 131-179 88-594 355-523 343-501 355-501 21 UA 106725 C2 Таблиця 1 Білки IND - амінокислоти (АА), ділянки і позиції AtIND1 (SEQ ID №: 10) b Heim et al. Toledo-Ortiz et al. Liljegren et al. H1 Heim et al. Toledo-Ortiz et al. Liljegren et al. L Heim et al. Toledo-Ortiz et al. Liljegren et al. H2 Heim et al. Toledo-Ortiz et al. Liljegren et al. T N (1 ) Збережені AA T V (2 ) H Q (5 ) H T A (9 - 13 ) H T R (10 - 14 ) H T R (12 - 16 ) H R (13 ) H T I (16 - 20 ) T S ( 21 ) H T I (20 - 24 ) H T L (23 - 27 ) T K ( 28 ) H V (27 ) T K (39 ) T T (42 ) H A (36 ) T M (45 ) H T L (39 -46 ) T A (49 ) H T I (43 - 50 ) T Y (52 ) T T (53 ) H T L (49 -56 ) H V (53 ) H L (56 ) ind-5 (W13>STOP) На ind L ind-2 (A26>FS) ind-6 L W ind-4 (Q63>STOP) L ind-3 (R99>H) L ind-1 (L112>F) L AtIND1 (SEQ ID №: 9) BnIND-A1 (SEQ ID №: 2/6) BnIND-C1a/b (SEQ ID 4/8 від 16-210 / SEQ ID 4/8) 119-131 115-131 119-131 132-146 132-146 132-145 147-152 147-152 146-152 153-174 153-167 153-167 115 116 123 127 128 130 131 134 135 138 141 142 145 150 153 154 156 157 160 161 163 164 167 171 174 355-393 343-393 355-393 394-438 394-438 394-435 439-456 439-456 436-456 457-523 457-501 457-501 343-345 346-348 367-379 379-381 382-384 388-390 391-393 400-403 404-406 412-414 421-423 424-426 433-435 448-450 460-463 460-462 466-468 469-471 478-480 481-483 487-489 490-492 499-501 511-513 580-582 118-132 114-132 118-132 133-145 133-145 133-144 146-151 146-151 145-151 152-173 152-166 152-166 114 115 122 126 127 129 130 133 134 137 140 141 144 149 152 153 155 156 159 160 162 163 166 170 173 (A) 131-145 127-145 131-145 146-158 146-158 146-157 159-164 159-164 158-164 165-186 165-179 165-179 127 128 135 139 140 142 143 146 147 150 153 154 157 162 165 166 168 169 172 173 175 176 179 183 186 42 124-126 25 41 55 Вставка після 61 92 128 141 163-165 Вставка після 185 274-276 382-384 421-423 91 127 140 104 140 153 H T Heim et al., : Heim et al., 2003, Mol Biol Evol 20, 735-747; Toledo-Ortiz et al., : Toledo-Ortiz et L W al., 2003, Plant Cell 15: 1749-1770; Liljegren et al., : Liljegren et al., 2004, Cell, 116, 843-853; : Wu 22 UA 106725 C2 5 10 15 20 25 30 35 40 45 et al., 2006, Planta 224, 971-979. Оптимальне зіставлення послідовності нуклеїнових кислот IND Arabidopsis (SEQ ID №: 9) та амінокислотної послідовності (SEQ ID №: 10) з послідовностями нуклеїнових кислот IND, зокрема з послідовностями нуклеїнових кислот IND Brassica (SEQ ID №№: 1 і 3) і амінокислотними послідовностями (SEQ ID №№: 2 і 4) за цим винаходом, дозволяє визначити позиції відповідних збережених доменів і амінокислот в цих послідовностях Brassica (дивись Таблицю 1 у відношенні послідовностей IND Brassica SEQ ID №№: 1 і 4). Відповідно, в одному варіанті здійснення пропонуються часткові нокаутні мутантні послідовності нуклеїнових кислот IND, що містять одну або більше з мутацій будь-якого описаного тут типу. В іншому варіанті здійснення пропонуються часткові нокаутні послідовності ind, що містять одну або більше мутацій стоп-кодону (нонсенс-мутацій), одну або більше міссенс-мутацій та/або одну або більше мутацій зміщення рамки зчитування. Будь-яка з вищенаведених мутантних послідовностей нуклеїнових кислот пропонується per se (у виділеній формі), як пропонуються рослини і частини рослин, що містять такі послідовності ендогенно. В таблицях, що наведені далі, перелічені алелі ind, яким віддається перевага, і вказані депоновані сорти насіння Brassica napus, що містять один або більше алелів ind. Нонсенс-мутація в алелі IND, як тут використовується, - це мутація в алелі IND, завдяки якій один або більше стоп-кодонів трансляції вводяться в кодуючу ДНК і відповідну послідовність мРНК відповідного алеля IND дикого типу. Стоп-кодонами трансляції є TGA (UGA в mRNA), TAA (UAA) і TAG (UAG). Отже, будь-яка мутація (делеція, вставка або заміщення), яка приводить до створення стоп-кодону всередині рамки зчитування в кодуючій послідовності, буде мати своїм результатом закінчення трансляції та усічення амінокислотного ланцюга. В одному варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить нонсенсмутацію, де стоп-кодон в рамці є введеним в послідовність кодону IND шляхом заміщення єдиного нуклеотиду, таку як мутації CAG до TAG, TGG до TAG, TGG до TGA або CAA до TAA. В іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить нонсенс-мутацію, де стоп-кодон в рамці є введеним в послідовність кодону IND шляхом подвійних заміщень нуклеотидів, таку як мутації CAG до TAA, TGG до TAA або CGG до TAG або TGA. В ще іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить нонсенс-мутацію, де стоп-кодон в рамці є введеним в послідовність кодону IND шляхом потрійного заміщення нуклеотидів, таку як мутація CGG до TAA. Такий усічений білок є позбавленим амінокислот, кодованих кодуючою ДНК далі від мутації (тобто, С-термінальною частиною білку IND), і зберігає амінокислоти, кодовані кодуючою ДНК перед мутацією (тобто, Nтермінальною частиною білку IND). В одному варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить нонсенс-мутацію, де ця нонсенс-мутація присутня десь перед збереженим залишком Leu домену Н2 (в позиції 56 консенсусної послідовності домену bHLH, як описано Heim et al., 2003, дивись Таблицю 1), так що принаймні збережений залишок Leu є виключеним. Чим більше усіченим є мутантний білок IND у порівнянні з білком IND дикого типу, тим більше це усічення може призводити до суттєво зниженої або відсутньої активності білку IND. Відповідно, в іншому варіанті здійснення, пропонується мутантний алель IND, що містить нонсенс-мутацію, яка призводить до усіченого білку з менше ніж приблизно 170 амінокислот (відсутній збережений залишок Leu), з менше ніж приблизно 145 амінокислот (відсутні домени L і Н2) або з менше ніж приблизно 130 амінокислот (відсутній домен HLH) (дивись Таблицю 1). Наведені далі таблиці описують низку можливих нонсенс-мутацій в послідовностях IND Brassica napus, запропонованих тут: Таблиця 2a Потенційні мутації СТОП-кодону в IND-A1 (SEQ ID №: 1) Позиція амінокислоти Позиція нуклеотиду 25 74 75 74+75 169 169+171 271 292 57 91 98 23 Дикий тип мутантний кодон tgg tag tgg tga tgg taa cag tag cag taa caa taa cag tag Дикий тип мутантна амінокислота TRP STOP TRP STOP TRP STOP GLN STOP GLN STOP GLN STOP GLN STOP UA 106725 C2 Таблиця 2a Потенційні мутації СТОП-кодону в IND-A1 (SEQ ID №: 1) Позиція амінокислоти Позиція нуклеотиду 292+294 364 364+366 382+383 382+384 382+383+384 412+413 412+414 412+413+414 502+503 502+504 502+503+504 505 505+507 542 543 542+543 122 128 138 168 169 181 Дикий тип мутантний кодон cag taa cag tag cag taa cgg tag cgg tga cgg taa cgg tag cgg tga cgg taa cgg tag cgg tga cgg taa cag tag cag taa tgg tag tgg tga tgg taa Дикий тип мутантна амінокислота GLN STOP GLN STOP GLN STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP GLN STOP GLN STOP TRP STOP TRP STOP TRP STOP Таблиця 2b Потенційні мутації СТОП-кодону в IND-C1 (SEQ ID №: 3) Позиція амінокислоти Позиція нуклеотиду 41 122 123 122+123 148 271 271+272 310 331 331+333 403 403+405 421+422 421+423 421+422+423 451+452 451+453 451+452+453 541+542 541+543 541+542+543 544 544+546 559 559+561 571 571+573 50 73 104 111 135 141 151 181 182 187 191 24 Дикий тип мутантний кодон tgg tag tgg tga tgg taa caa taa cag tag cag taa caa taa cag tag cag taa cag tag cag taa cgg tag cgg tga cgg taa cgg tag cgg tga cgg taa cgg tag cgg tga cgg taa cag tag cag taa cag tag cag taa cag tag cag taa Дикий тип мутантна амінокислота TRP STOP TRP STOP TRP STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP ARG STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP GLN STOP UA 106725 C2 5 10 15 20 25 30 35 Очевидно, мутації не обмежуються тими, що наведені в Таблицях вище, і зрозуміло, що аналогічні СТОП мутації можуть бути присутніми в інших алелях ind, ніж ті, що попали в перелік послідовностей і в ці Таблиці. Міссенс-мутація в алелі IND, як цей термін тут використовується, - це будь-яка мутація (делеція, вставка або заміщення) в алелі IND, коли один або більше кодонів змінюються в кодуючій ДНК і відповідній послідовності мРНК відповідного алеля IND дикого типу, результатом чого є заміщення однієї або більше амінокислоти в білку IND дикого типу на одну або більше інших амінокислот в мутантному білку IND. В одному варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, що призводить до заміщення валінового залишку (Val) в позиції 124 білку IND в послідовності SEQ ID №: 2 або в послідовності, суттєво подібній до неї, зокрема метіоніновим залишком (Met), такий як алель ind-a1-EMS06 (Таблиця 3а). В іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, що призводить до заміщення гліцинового залишку (Gly) в позиції 146 білку IND в послідовності SEQ ID №: 2 або в послідовності, суттєво подібній до неї, зокрема сериновим залишком (Ser), такий як алель ind-a1-EMS09 (Таблиця 3а). В ще іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, що призводить до заміщення аланінового залишку (Ala) в позиції 159 білку IND в послідовності SEQ ID №: 2 або в послідовності, суттєво подібній до неї, зокрема валіновим залишком (Val), такий як алель ind-a1-EMS13 (Таблиця 3а). В ще іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенсмутацію, що призводить до заміщення треонінового залишку (Thr) в позиції 136 білку IND в послідовності SEQ ID №: 4 або в послідовності, суттєво подібній до неї, зокрема метіоніновим залишком (Met), такий як алель ind-c1-EMS08 (Таблиця 3b). В подальшому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, що призводить до заміщення аланінового залишку (Ala) в позиції 139 білку IND в послідовності SEQ ID №: 4 або в послідовності, суттєво подібній до неї, зокрема треоніновим залишком (Thr), такий як алель ind-c1-EMS09 (Таблиця 3b). В ще іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, що призводить до заміщення аргінінового залишку (Arg) в позиції 142 білку IND в послідовності SEQ ID №: 4 або в послідовності, суттєво подібній до неї, зокрема цистеїновим залишком (Cys), такий як алель indc1-EMS04 (Таблиця 3b). Еталонне насіння, яке містить алелі ind-a1-EMS06, ind-a1-EMS09, inda1-EMS13, ind-c1-EMS08, ind-c1-EMS09 та ind-c1-EMS04 в гомозиготному стані було депоноване в NCIMB Limited (Ferguson Building, Craibstone Estate, Bucksburn, Aberdeen, Scotland, AB21 9YA, Велика Британія) 7 липня 2008 року під номерами доступу NCIMB 41570, NCIMB 41571, NCIMB 41572, NCIMB 41573, NCIMB 41574 та NCIMB 41575, відповідно. Таблиця 3a Міссенс-мутації в IND-A1 Позиція амінокислоти Позиція нуклеотиду Дикий тип мутантний кодон Дикий тип мутантна амінокислота SEQ ID: 2/6 SEQ ID: 1 370 930 gtg atg VAL MET 146 436 996 ggc agc GLY SER 159* 476 1036 gcc gtc ALA VAL Номер депонування SEQ ID: 5 124 Назва алеля 25 ind-a1EMS06 ind-a1EMS09 ind-a1EMS13 NCIMB 41570 NCIMB 41571 NCIMB 41572 UA 106725 C2 Таблиця 3b Міссенс-мутації в IND-C1 Позиція амінокислоти Позиція нуклеотиду Дикий тип мутантний кодон Дикий тип мутантна амінокислота Назва алеля SEQ ID: 4/8 20 25 30 35 40 45 903 acg atg THR MET ind-c1-EMS08 415 911 gct act ALA THR ind-c1-EMS09 142* 15 407 139* 10 SEQ ID: 7 136 5 SEQ ID: 3 424 920 cgt tgt ARG CYS ind-c1-EMS04 Номер депонуван ня NCIMB 41573 NCIMB 41574 NCIMB 41575 В іншому варіанті здійснення пропонується частковий нокаутний мутантний алель IND, що містить міссенс-мутацію, кодуючий білок IND, в якому одна або більше збережених амінокислот, наведених вище або в Таблиці 1, є заміщеними, такий як часткові нокаутні мутантні алелі IND ind-a1-EMS13, ind-c1-EMS04 та ind-c1-EMS09 (позначені * в Таблиці 3). Як описано у Heim et al. (2003, Mol Biol Evol 20, 735-747), Toledo-Ortiz et al. (2003, Plant Cell 15: 1749-1770), Liljegren et al. (2004, Cell, 116, 843-853) і в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), певні зі збережених амінокислот є більш важливими для біологічної активності білку IND, ніж інші. Так, наприклад, міссенс-мутації, які приводять до заміщення, наприклад, амінокислот в позиціях 5, 9 (наприклад, ind-c1-EMS09) і 13 або в позиціях 10 (наприклад, ind-a1-EMS05) і 12 (наприклад, ind-c1-EMS04) консенсусної послідовності домену bHLH, визначених Heim et al. (supra), з більшою ймовірністю забезпечують суттєве зменшення або відсутність активності через знижену здатність білку IND зв’язуватись з цільовою ДНК білку IND. Подібно до цього, міссенс-мутації, які приводять до заміщення, наприклад, амінокислот в позиціях 16, 20, 23, 27 в спіралі 1 або в позиціях 36, 39, 43, 49 (наприклад, ind-a1-EMS13), 53 і 56 в спіралі 2 консенсусної послідовності домену bHLH, визначених Heim et al. (supra), з більшою ймовірністю забезпечують суттєве зменшення активності через знижену здатність білку IND до димеризації. В ще іншому варіанті здійснення частковим нокаутним мутантним алелем IND, що містить міссенс-мутацію, який може бути використаним за цим винаходом, є алель IND, що містить міссенс-мутацію, яка відповідає міссенс-мутації в часткових нокаутних алелях ind-1 Arabidopsis (Liljegren et al., 2004, supra) (дивись Таблицю 1). Мутація зміщення рамки зчитування в алелі IND, як цей термін тут використовується, є мутацією (делецією, вставкою, дуплікацією і т.п.) в алелі IND, який приводить до того, що дана послідовність нуклеїнових кислот транслюється в іншу рамку далі від місця мутації. Амінокислотні послідовності за цим винаходом Пропонуються часткові нокаутні мутантні амінокислотні послідовності IND (тобто, амінокислотні послідовності IND, що містять одну або більше мутацій, які приводять до суттєво зменшеної біологічної активності білку IND) від Brassicaceae, зокрема від видів Brassica, а точніше від Brassica napus, але також від інших агрокультур Brassica. Наприклад, види Brassica, що містять геном А та/або геном С, можуть кодувати різні IND-A або IND-C амінокислоти, які є суттєво подібними до нових часткових нокаутних мутантних білків IND за цим винаходом. Крім того, методи мутагенезу можуть бути використані для створення мутацій в алелях IND дикого типу з отриманням мутантних алелів, які можуть кодувати інші мутантні білки IND, які є суттєво подібними до нових часткових нокаутних мутантних білків IND за цим винаходом. В одному варіанті здійснення пропонуються мутантні амінокислотні послідовності IND в рослині Brassica (тобто, ендогенно). Однак пропонуються також і виділені амінокислотні послідовності IND (наприклад, виділені з рослини або отримані синтетично), а також їх варіанти і фрагменти будьякої з них. Амінокислотні послідовності, які є суттєво подібними до нових часткових нокаутних мутантних білків IND за цим винаходом, можуть бути отримані шляхом заміни амінокислот в часткових нокаутних амінокислотних послідовностях IND за цим винаходом іншими амінокислотами, що мають подібні властивості (такі як подібні гідрофобність, гідрофільність, антигенність, схильність утворювати або руйнувати -спіральні структури або -листкові 26 UA 106725 C2 структури). Таблиці консервативних заміщень є добре відомими в цій галузі (дивись, наприклад, Creighton (1984) Proteins. W.H. Freeman and Company і Таблицю 4 даної патентної заявки). Таблиця 4 Приклади консервативних амінокислотних заміщень Залишок Ala Arg Asn Asp Gln Cys Glu Gly His Ile 5 10 15 20 25 30 35 40 45 Консервативні заміщення Ser Lys Gln, His Glu Asn Ser Asp Pro Asn, Gln Leu, Val Залишок Leu Lys Met Phe Ser Thr Trp Tyr Val Консервативні заміщення Ile, Val Arg, Gln Leu, Ile Met, Leu, Tyr Thr, Gly Ser, Val Tyr Trp, Phe Ile, Leu Нові часткові нокаутні мутантні амінокислотні послідовності IND білків IND-A1 і IND-C1 дикого типу були виділені з Brassica napus. Послідовності IND дикого типу, як описано в публікації WO09/068313 (заявлений пріоритет Європейської патентної заявки EP 07023052), є відображеними в послідовностях SEQ ID №: 2 і SEQ ID №: 4, тоді як нові часткові нокаутні мутантні варіанти цих послідовностей і послідовностей, суттєво подібних до них, описані далі і в Прикладах з посиланням на послідовності IND дикого типу. Як вже зазначалось, білки IND дикого типу Brassica napus, описані тут, мають приблизно 185-210 амінокислот в довжину і містять низку структурних і функціональних доменів. «Амінокислотні послідовності IND-A1» або «варіантні амінокислотні послідовності IND-А1» за цим винаходом є амінокислотними послідовностями, що мають щонайменше 75%, щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 2. Ці амінокислотні послідовності можуть називатись також «суттєво подібними» або «суттєво ідентичними» з послідовностями IND, наведеними в переліку послідовностей. «Амінокислотні послідовності IND-С1» або «варіантні амінокислотні послідовності IND-С1» за цим винаходом є амінокислотними послідовностями, що мають щонайменше 75%, щонайменше 80%, щонайменше 85%, щонайменше 90%, щонайменше 95%, 98%, 99% або 100% ідентичність послідовностей з SEQ ID №: 4 (IND-С1-довга) або з SEQ ID №: 4 від амінокислоти в позиції 16 до амінокислоти в позиції 210 (IND-С1-коротка). Ці амінокислотні послідовності можуть називатись також «суттєво подібними» або «суттєво ідентичними» з послідовностями IND, наведеними в переліку послідовностей. Отже, даний винахід пропонує нові часткові нокаутні мутантні послідовності амінокислотних послідовностей дикого типу, функціональні білки IND-A1 і IND-C1, включаючи їх варіанти і фрагменти (як буде визначено далі), де мутація в амінокислотній послідовності переважно має своїм результатом суттєве зниження біологічної активності білку IND у порівнянні з біологічною активністю відповідного білку IND дикого типу. Суттєве зниження біологічної активності білку IND стосується тут зниження активності зв’язування ДНК, здатності до димеризації та/або активності щодо регуляції транскрипції білку IND, так що резистентність до розкриття стручків у рослин, що експресують мутантний білок IND, була підвищеною, порівняно з резистентністю до розкриття стручків відповідної рослини дикого типу. Даний винахід пропонує як ендогенні, так і виділені амінокислотні послідовності. Також пропонуються фрагменти амінокислотних послідовностей IND і варіантних амінокислотних послідовностей IND, як їх було визначено вище. «Фрагмент» амінокислотної послідовності IND або її варіант (як визначено) може мати різну довжину, таку як щонайменше 10, 12, 15, 18, 20, 50, 100, 150, 175, 180 суміжних амінокислот послідовності IND (або варіантної послідовності). Амінокислотні послідовності функціональних білків IND Амінокислотні послідовності, наведені в переліку послідовностей, є дикого типу, функціональними білками IND від Brassica napus. Отже, ці послідовності є ендогенними для рослин Brassica napus, з яких їх було виділено. Інші культурні види Brassica, сорти, лінії розведення або дикі поповнення можуть бути піддані скринінгу на інші функціональні білки IND з тими самими амінокислотними послідовностями або їх варіантами, що й описані вище. 27 UA 106725 C2 5 10 15 20 25 30 35 40 45 50 55 60 До того ж, зрозуміло, що амінокислотні послідовності IND і їх варіанти (чи фрагменти будьякої з них) можуть бути ідентифіковані in silico, шляхом скринінгу баз даних амінокислот щодо суттєво подібних послідовностей. Пропонуються також фрагменти амінокислотних молекул за цим винаходом. Фрагменти включають амінокислотні послідовності домену bHLH, або менші фрагменти, які містять частину домену bHLH, таку як основний домен або домен HLH і т.д. Амінокислотні послідовності мутантних білків IND Даний винахід пропонує амінокислотні послідовності, що містять делеції, вставки або заміщення однієї або більше амінокислот по відношенню до амінокислотних послідовностей IND дикого типу, відображених в послідовностях SEQ ID №№: 2 і 4 переліку послідовностей, де мутація (мутації) в амінокислотній послідовності має своїм результатом значно знижену біологічну активність, тобто частковий нокаут біологічної активності, кодованого білку IND по відношенню до білку дикого типу, а також фрагменти таких мутантних амінокислотних молекул. Такі мутантні амінокислотні послідовності можуть бути створені та/або ідентифіковані за допомогою різних відомих методів, як вже описувалось. І цього разу, молекули амінокислот пропонуються як в ендогенній, так і у виділеній формах. Як вже зазначалось, в основному, будь-яка мутація в амінокислотних послідовностях IND дикого типу, що приводить до білку, який містить щонайменше одну амінокислотну делецію, вставку або заміщення по відношенню до білку IND дикого типу, може обумовлювати суттєво знижену біологічну активність або відсутність такої активності. Однак має бути зрозумілим, що певні мутації в білку IND з більшою ймовірністю призводять до повного усунення біологічної активності білку IND зниженої функції мутантного білку IND, такі як мутації, що викликають утворення усічених білків, внаслідок чого відсутніми або заміщеними стають суттєві частини функціональних доменів, таких як домен зв’язування ДНК («b»), домен димеризації («HLH») та/або амінокислоти, що є важливими для регуляції транскрипції (дивись Таблицю 1). Це стосується і мутацій, внаслідок яких стають відсутніми або заміщеними певні важливі амінокислотні залишки в цих доменах, такі як амінокислоти Gln (Q), Ala (A) і Arg (R) в позиціях 5, 9 і 13 або основні амінокислотні залишки (зокрема, залишки Arg (R)) в позиціях 10 і 12 консенсусної послідовності домену bHLH, визначених Heim et al. (supra; відповідають позиціям 123, 127 і 131, а також 128 і 130, відповідно, в послідовності SEQ ID №: 10, дивись Таблицю 1), переважно неподібними або неконсервативними амінокислотами, тоді як інші мутації цього білку з більшою ймовірністю приводять до значного зниження біологічної активності білку IND, такі як мутації, що мають своїм результатом заміщення специфічних амінокислот, наприклад наведених в Таблиці 1 консервативних амінокислот, які призводять до менш ефективного зв’язування ДНК, менш ефективної димеризації та/або менш ефективної регуляції транскрипції без повного усунення біологічної активності кодованого білку IND. Відповідно, в одному варіанті здійснення пропонуються часткові нокаутні мутантні білки IND, що містять одну або більше мутацій-делецій або мутацій-вставок, де ці делеції або вставки мають своїм результатом мутантний білок з суттєво зниженою активністю in vivo. Такі мутантні білки IND є білками IND, в яких щонайменше 1, щонайменше 2, 3, 4, 5, 10, 20, 30, 50, 100, 100, 150, 175, 180 або більше амінокислот є вилученими або вставленими у порівнянні з білком IND дикого типу, причому ці делеції або вставки мають своїм результатом мутантний білок, що має суттєво знижену активність in vivo. В іншому варіанті здійснення пропонуються часткові нокаутні мутантні білки IND, що є усіченими, де це усічення має своїм результатом мутантний білок, який має суттєво знижену активність in vivo. Такі усічені білки IND є білками IND, в яких відсутні функціональні домени в Стермінальній частині відповідного білку IND дикого типу і які зберігають N-термінальну частину відповідного білку IND дикого типу. Відповідно, в одному варіанті здійснення пропонується частковий нокаутний мутантний білок IND, що містить N-термінальну частину відповідного білку IND дикого типу аж до збереженого залишку Leu домену Н2, але не включаючи його (в позиції 56 в консенсусній послідовності домену bHLH, як описано Heim et al., 2003, дивись вище). Чим більше усіченим є мутантним білок у порівнянні з білком дикого типу, тим з більшою ймовірністю це усічення може мати своїм результатом суттєво знижену активність білку IND. Отже, в іншому варіанті здійснення пропонується частковий нокаутний мутантний білок IND, що містить Nтермінальну частину відповідного білку IND дикого типу без частини або всього другого домену Н, та/або без частини або всього домену L, та/або без частини або всього першого домену Н (дивись Таблицю 1). В ще іншому варіанті здійснення пропонуються часткові нокаутні мутантні білки IND, що містять одну або більше мутацій заміщення, де ці заміщення мають своїм результатом мутантний білок, який має суттєво знижену активність in vivo. Відповідно, в одному варіанті здійснення пропонується частковий нокаутний мутантний білок IND, що містить мутацію 28
ДивитисяДодаткова інформація
Назва патенту англійськоюBrassica plant comprising a mutant indehiscent allelle
Автори російськоюLaga, Benjamin, Den Boer, Bart, Lambert, Bart
МПК / Мітки
МПК: A01H 5/00, C12N 15/82, C07K 14/415
Мітки: мутантний, містить, яка, рослина, brassica, алель, нерозкривання, стручків
Код посилання
<a href="https://ua.patents.su/75-106725-roslina-brassica-yaka-mistit-mutantnijj-alel-nerozkrivannya-struchkiv.html" target="_blank" rel="follow" title="База патентів України">Рослина brassica, яка містить мутантний алель нерозкривання стручків</a>
Рослина brassica, яка містить мутантний алель нерозкривання

Номер патенту: 99636
Опубліковано: 10.09.2012
Автори: Ден Боер Барт, Ламберт Барт, Лага Бенджамін
МПК: A01H 5/00, C12N 15/82
Мітки: рослина, brassica, алель, нерозкривання, мутантний, містить, яка
Формула / Реферат:
1. Рослина Brassica, або її клітина, частина, насіння або потомство, яка містить в своєму геномі принаймні один мутантний алель IND, вибраний з групи, яка включає: (а) молекулу нуклеїнової кислоти, що має щонайменше 90 % ідентичність послідовності з SEQ ID №: 1, SEQ ID №: 3 від нуклеотиду в позиції 46 до нуклеотиду в позиції 633, SEQ ID №: 3, SEQ ID №: 5 або SEQ ID №: 7; (b) молекулу нуклеїнової кислоти,...
Рослина brassica, яка містить мутантні алелі з комплексом жирний ацил-білок, що переносить ацил (ацил-acp), тіоестерази

Номер патенту: 99471
Опубліковано: 27.08.2012
Автори: Лага Бенджамін, Ден Боер Барт, Ламберт Барт
МПК: C12N 15/82, C12N 9/16, A01H 5/00
Мітки: мутантні, комплексом, ацил, яка, ацил-acp, тіоестерази, переносить, містить, жирний, ацил-білок, рослина, brassica, алелі
Формула / Реферат:
1. Мутантний алель гена, що кодує функціональний FATB білок, в якому функціональний FATB ген містить молекулу нуклеїнової кислоти, вибрану з групи, що включає:- молекулу нуклеїнової кислоти, яка має щонайменше 90 % тотожності послідовності з SEQ ID №: 1, SEQ ID №: 3, SEQ ID №: 5, SEQ ID №: 7, SEQ ID №: 9 або SEQ ID №: 11; і- молекулу нуклеїнової кислоти, що кодує амінокислотну послідовність, яка має щонайменше 90 % тотожність...
Рослина капусти качанної (brassica oleracea), стійка до albugo candida

Номер патенту: 100121
Опубліковано: 26.11.2012
Автори: Постма-Хаарсма Адріана Дорін, Схрейвер Альбертус Йоханесс Марія, Гес де Ян, Хоогланд Йоханесс Герардус Марія
МПК: C12N 15/82, C12Q 1/68, A01H 5/00
Мітки: candida, стійка, капусти, рослина, качанної, brassica, albugo, oleracea
Формула / Реферат:
1. Рослина Brassica oleracea, що містить домінантний ген стійкості до Albugo Candida, який викликає білу іржу хрестоцвітих, де ген стійкості одержують з рослини B. oleracea, насіння якої депоновано 1 березня 2006 р. до Американської колекції типових культур (ATCC) під номером PTA-7412, де наявність інтрогресії гену стійкості може бути показана за допомогою принаймні двох специфічних маркерів ДНК вибраних з...
Рослина капусти brassica oleracea, стійка до захворювання килою

Номер патенту: 84548
Опубліковано: 10.11.2008
Автори: Ліндерс Енріо Герардус Альбертус, Тжертес Петер, Хуанг Ціа-Ченг, де Хаас Йоханнес Марія
МПК: A01H 5/00, C12N 15/09, A01H 1/00, A01H 5/10, C12Q 1/68
Мітки: рослина, захворювання, стійка, килою, oleracea, brassica, капусти
Формула / Реферат:
1. Рослина B. oleracea, стійка до захворювання килою, де ознаку стійкості одержують зі стійких до кили рослин B. rapa і де ознака стійкості до кили є моногенною та домінантною. 2. Рослина за п. 1, де ураження захворюванням цієї рослини B. oleracea відповідає балу 2 або нижче при оцінці ураження, яке викликається захворюванням, за 1-9-бальною шкалою, або балу 1 або нижче при оцінці ураження, що викликається...
Рослина виду brassica oleracea з чоловічою стерильністю і спосіб її отримання

Номер патенту: 72420
Опубліковано: 15.03.2005
Автор: Бартен Пітер
МПК: A01H 4/00, A01H 1/06, C12N 5/14, C12N 15/05
Мітки: виду, чоловічою, oleracea, стерильністю, brassica, рослина, отримання, спосіб
Формула / Реферат:
1. Рослина виду Brassica oleracea з чоловічою стерильністю, клітинна цитоплазма якої утворена соматичною гібридизацією через злиття протопластів і має отриману від фертильної рослини Brassica napus мітохондріальну ДНК, яка у комбінації зі специфічною ядерною ДНК Brassica oleracea спричиняє цитоплазматичну чоловічу стерильність у рослини виду Brassica oleracea.2. Рослина за п. 1, яка відрізняється тим, що її вибрано з групи, яка...
Попередній патент: Спосіб отримання заміщених піримідинових похідних
Наступний патент: Композиції для профілактики та лікування дерматологічних захворювань/захворювань слизової та їх застосування
Випадковий патент: Пристрій для укладання пляшок в тару в горизонтальному положенні