Спосіб семантичної компресії тексту із заданим рівнем стислості
Номер патенту: 82942
Опубліковано: 27.08.2013
Автори: Єгоров Станіслав Вячеславович, Єгорова Ірина Миколаївна





Формула / Реферат
Спосіб семантичної компресії тексту із заданим рівнем стислості, що полягає в тому, що отримують речення, які належать до вихідного тексту, з яких видаляються стоп-слова, вираховують вагові коефіцієнти, вибирають речення із найвищими ваговими коефіцієнтами за для формування частини фінального узагальнення, речення розташовують у порядку, в якому вони йшли у вихідному тексті, який відрізняється тим, що здійснюють компресію із заданим рівнем стислості, визначають поняття рівня стислості, ключового слова, рангу слова, рангу речення, модифікованого інвертованого індексу, інвертованого індексу анотації, встановлюють функціональну залежність між кількістю ключових слів у анотації та рівнем стислості, що задає користувач, що дозволяє створити анотацію визначеного об'єму, яка повністю відображує сенс вихідного тексту.
Текст
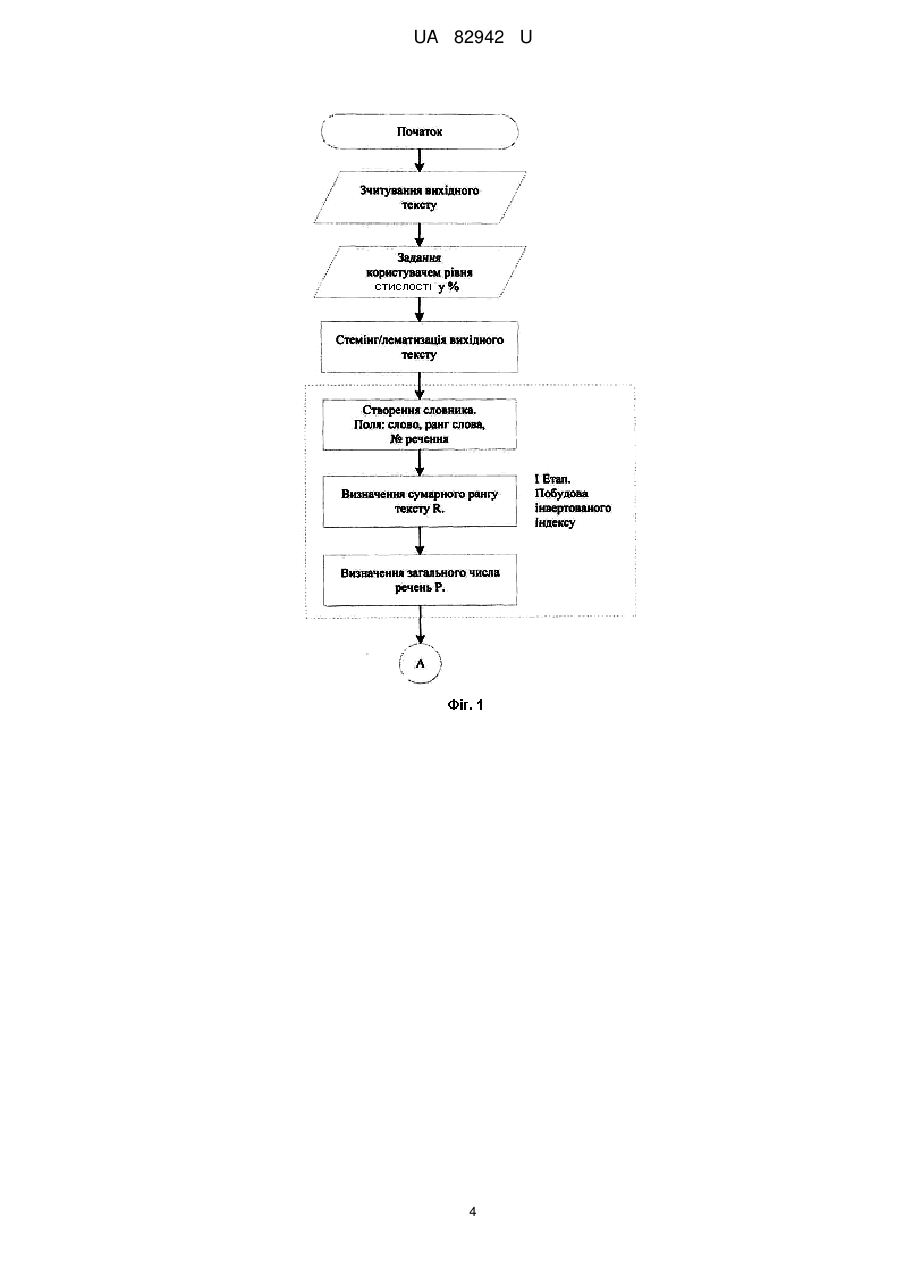
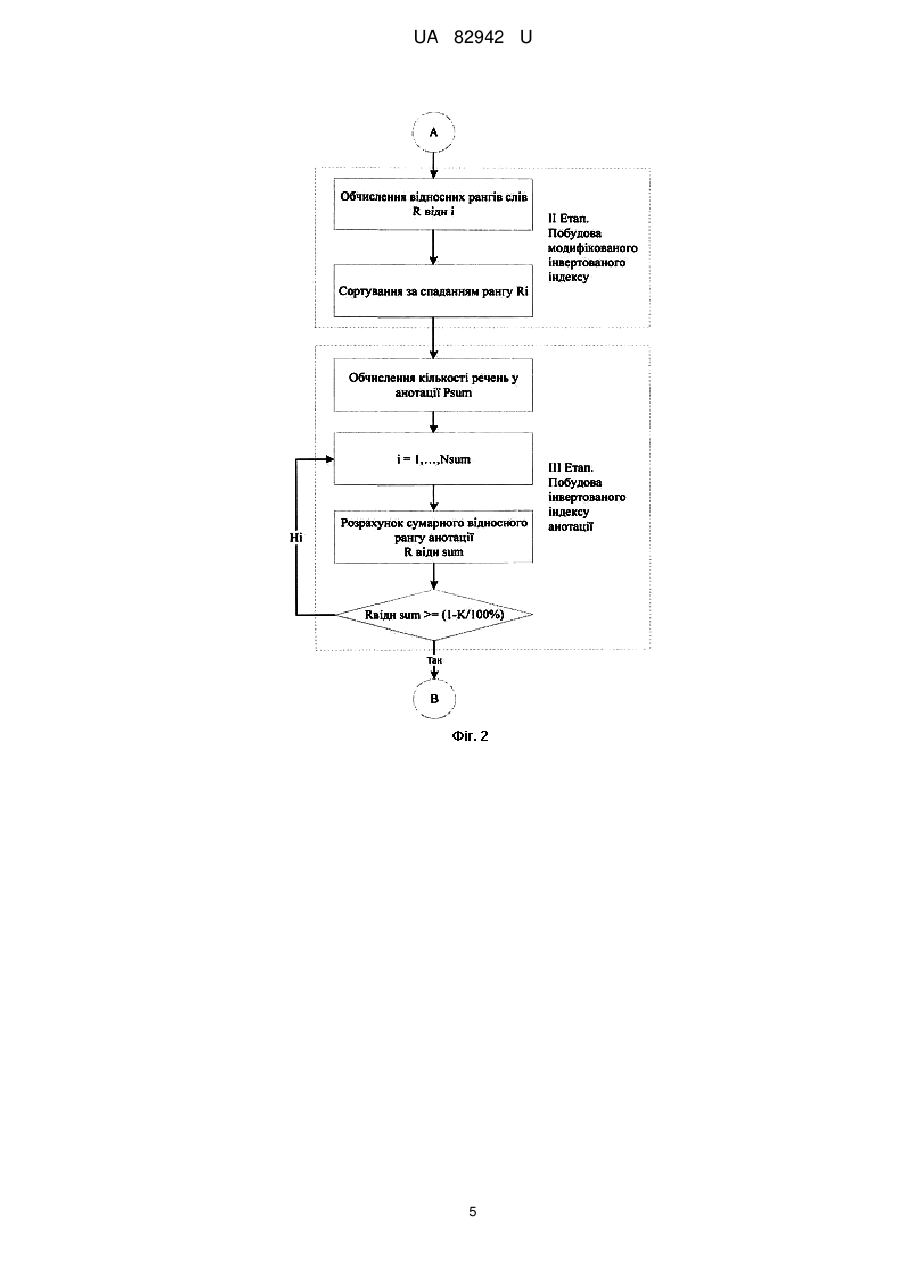
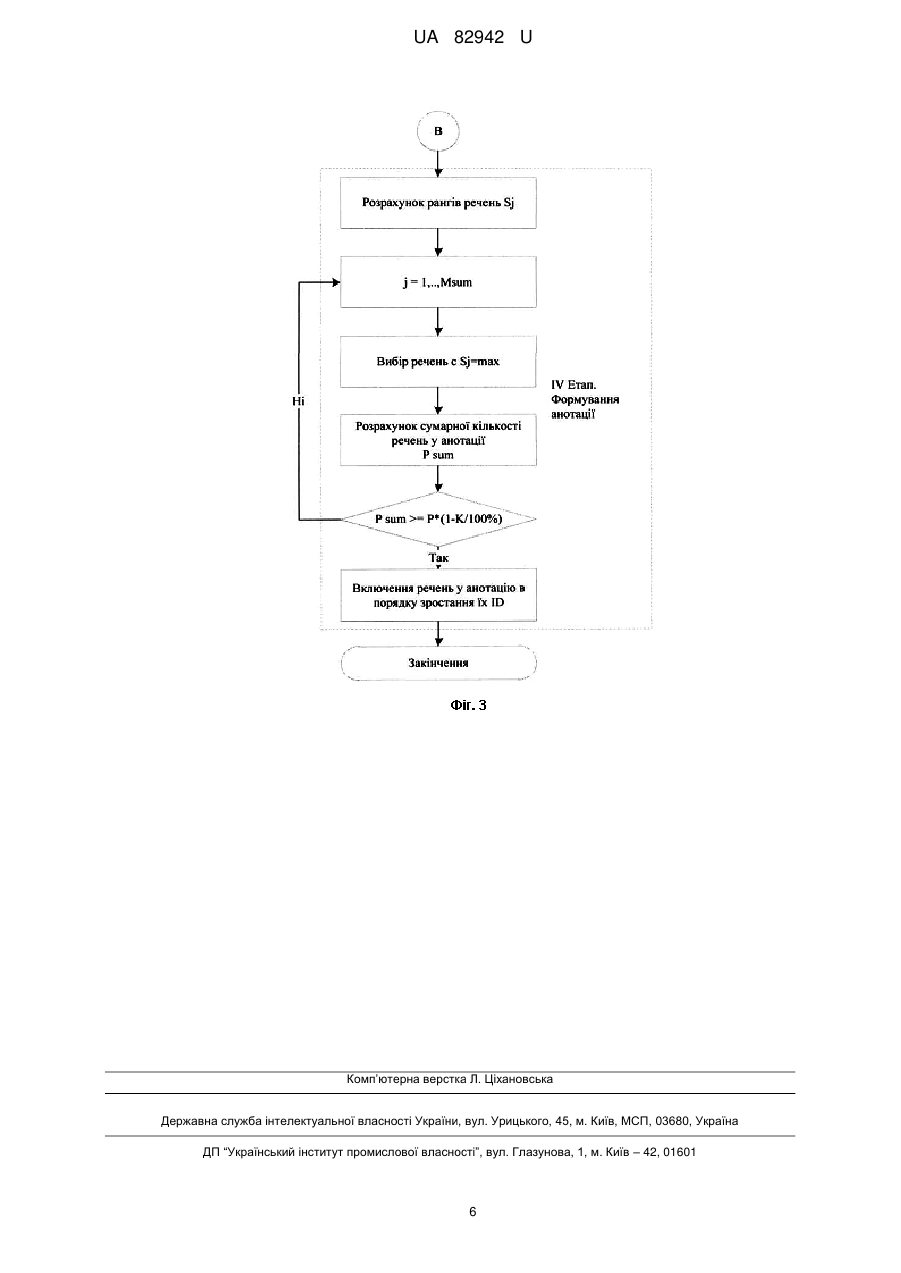
Реферат: UA 82942 U UA 82942 U 5 10 15 20 25 30 35 40 45 50 Корисна модель належить до галузі обробки даних комп'ютерними системами, зокрема обробки текстів. Відомий спосіб семантичної стислості тексту, що базується на спрощенні речень вихідного тексту [1]. Відомий спосіб аналізує структуру синтаксично складних речень, наприклад таких, що містять дієприслівникові звороти, та замінює їх низкою синтаксично простих речень. Однак, цей спосіб не дозволяє досягти суттєвого коефіцієнта стислості, а також не передбачає можливості завдання бажаного рівня стислості тексту. Відомий також, вибраний як прототип, спосіб автоматичного узагальнення тексту [2], що базується на принципі кількості коду. Відомий спосіб передбачає, що отримують речення, що належать до вихідного тексту, з яких видаляються стоп-слова, вираховують вагові коефіцієнти, вибирають речення із найвищими ваговими коефіцієнтами за для формування частини фінального узагальнення, речення розташовують у порядку, в якому вони йшли у вихідному тексті. Однак, цей спосіб не передбачає можливості завдання рівня стислості тексту, таким чином користувачеві невідомо, якого розміру анотацію він отримає. В основу корисної моделі поставлена задача створити спосіб семантичної компресії тексту із заданим рівнем стислості, що дозволяє отримати анотацію визначеного розміру, яка повністю відображує сенс початкового тексту, та надати користувачеві можливість власноруч задавати рівень стислості. Поставлена задача вирішується тим, що в способі семантичної компресії тексту із заданим рівнем стислості отримують речення, які належать до вихідного тексту, з яких видаляються стоп-слова, вираховують вагові коефіцієнти, вибирають речення із найвищими ваговими коефіцієнтами за для формування частини фінального узагальнення, речення розташовують у порядку, в якому вони йшли у вихідному тексті, згідно з корисною моделлю, здійснюють компресію із заданим рівнем стислості, визначають поняття рівня стислості, ключового слова, рангу слова, рангу речення, модифікованого інвертованого індексу, інвертованого індексу анотації, встановлюють функціональну залежність між кількістю ключових слів у анотації та рівнем стислості, що задає користувач, що дозволяє створити анотацію визначеного об'єму, яка повністю відображує сенс вихідного тексту. Тут і далі терміном "рівень стислості" позначено величину, що визначена у відсотках, на яку потрібно стиснути вихідний текст; терміном "ключове слово" позначено слово, що увійде до анотації та має високе значення рангу; терміном "ранг слова" позначено кількість повторень слова у початковому тексті; терміном "модифікований інвертований індекс" позначено інвертований індекс, що побудовано в порядку зменшення рангів слів та містить посилання не на номер документу, а на номер речення; терміном "інвертований індекс анотації" позначено скорочений модифікований інвертований індекс, що містить ключові слова; терміном "ранг речення" позначено число повторень номеру речення у інвертованому індексі анотації. Отримання анотації заданого об'єму, що повністю відображує сенс початкового тексту, досягається за рахунок здійснення відбору слів, що несуть найбільше смислове навантаження на основі встановленої функціональної залежності між кількістю ключових слів в анотації та рівнем стислості, що задав користувач. У свою чергу, прив'язка таких слів до речень, у яких вони зустрічаються, дозволяє здійснювати відбір речень для анотації, що повністю відображують сенс початкового тексту. Заявлений спосіб здійснюється таким чином. Користувач задає потрібний рівень стислості у процентах. Вихідний текст піддається стандартній процедурі видалення стоп-слів, а також приведення слів до їх словарної форми за допомогою стемінгу/лематизації (фіг. 1). На основі упорядкованого тексту, що не містить стоп-слів, будується інвертований індекс, що включає словник словопозицій, ранг слів та номери речень, у яких ці слова зустрічаються. У той же час розраховуються загальне число речень P та сумарний ранг тексту R N R Ri , i 1 55 де R i - ранг і-го слова, N - кількість слів, приведених до словарної форми, що містяться у вихідному тексті. На основі інвертованого індексу будується модифікований інвертований індекс (МІІ), у якому слова упорядковані за спаданням їх рангів із прив'язкою до номеру речення (фіг. 2). МІІ також містить значення відносних рангів слів як відношення рангу слова до сумарного рангу тексту R R в ідн i i R 1 UA 82942 U МІІ є базою для побудови інвертованого індексу анотації (ІІА). Формування ІІА відбувається покроково, починаючи з ключового слова, що має найвищі показники рангу та відносного рангу. На кожному кроці слід розраховувати відносний ранг анотації R в ідн sum як суму відносних рангів ключових слів 5 10 15 20 25 Rв ідн sum Nsum Rв ідн i , i 1 де Nsum - кількість ключових слів у анотації, що залежить від рівня стислості, заданого користувачем, визначеного у способі як коефіцієнт стиснення K . Коефіцієнт приймає значення K 0; 0.1 ;1 100 % та визначений як відношення кількості речень, виключених з анотації у ; результаті стислості, до загальної кількості речень у тексті P Psum K 100 % , P де Psum - кількість речень у анотації. Включення до розглядання нового слова на кожному кроці слід здійснювати з урахуванням перевірки умови: відносний ранг анотації повинен бути більшим або рівним різниці між одиницею (найвище значення коефіцієнта стислості) та коефіцієнтом стислості, що виражений у відносних одиницях K . R в ідн sum 1 100 % Таким чином, формуємо ІІА, у якому кількість ключових слів буде змінюватись у залежності від заданого коефіцієнта стислості. Тобто, встановлена залежність між кількістю ключових слів у анотації Nsum та рівнем стислості із заданим коефіцієнтом K Nsum f K Отриманий ІІА є основою для формування анотації, до якої включені речення, що містять ключові слова, які мають найвищий ранг, тобто ті, що несуть найбільше смислове навантаження (фіг. 3). Кількість таких речень Psum залежить від загального числа речень P та коефіцієнта стислості K . Слід здійснити підбір речень, у яких найчастіше зустрічаються ключові слова. Розглядати слід тільки речення, що увійшли до ІІА, а не всі речення, що містяться у тексті. Розраховується ранг кожного j-гo речення, як S j , та здійснюється покроковий відбір речень, що мають максимальне значення рангу. При цьому на кожному кроці повинна перевірятися умова: кількість речень в анотації має бути більшою або дорівнювати результату множення загальної кількості речень у тексті на різницю одиниці (найвище значення коефіцієнта стислості) та коефіцієнта стислості, що виражений у відносних одиницях. 30 35 40 45 K Psum P 1 100 % Таким чином, до анотації увійдуть речення, які містять ключові слова, що несуть найбільше смислове навантаження. Кількість таких речень так саме, як і кількість ключових слів, що будуть включені до ІІА, залежать від заданого користувачем рівня стислості. Послідовність включення вибраних речень до анотації відповідає їх розташуванню у вихідному тексті, тобто за зростанням номера речення j. Таким чином, зберігається послідовність викладу. Приклад. Задано вихідний текст, що підлягає стислості. Користувачем визначено рівень стислості у 60 %. Після застосування стандартних процедур видалення стоп-слів, а також стемінгу/лематизації, отримано набір з 543 слів, розраховані ранги слів R i . Створено словник словопозицій, що містить слова з їх рангами та номерами речень, у яких вони зустрічаються. Розраховано сумарний ранг тексту R (як сума рангів усіх слів словника), що дорівнює 1320 та визначено загальну кількість речень у вихідному тексті - 300. Таким чином, побудовано інвертований індекс. Побудова МІІ базується на використанні інформації інвертованого індексу. Додатково розраховуються відносні ранги слів R в ідн i , здійснюється сортування слів за спаданням їх рангів. Формування ІІА здійснюємо послідовно, починаючи з першого слова, яке має найвищі показники рангу R i та відносного рангу R в ідн i . Покроково додаємо ключові слова та розраховуємо значення відносного рангу анотації R в ідн sum . Здійснюємо перевірку умови 2 UA 82942 U 5 10 15 K . У прикладі це значення складає 0,4. Таким чином, у ІІА увійде 81 R в ідн sum 1 100 % ключове слово, яке задовільняє умові, та несуть найбільше смислове навантаження. У отриманому ІІА розраховуємо ранги речень S j , що можуть увійти до анотації. Спосіб передбачає прив'язку номерів речень до ключових слів, що мають найвищі значення рангів. У ІІА містяться ключові слова із прив'язкою до номерів речень, у яких вони зустрічаються. Таких речень у тексті 246. Формування анотації здійснюється покроково шляхом відбору речень, що мають найвище значення рангу S j . У прикладі кількість речень анотації розраховується виходячи з умови Psum P 1 K , та складає 120 речень. Відібравши речення з 100 % найвищими значеннями рангів, упорядковуємо їх за зростанням номерів речень. Сформована анотація, що задовольняє вимогам заданого користувачем рівня стислості, та повністю відображує сенс вихідного тексту. Наведений приклад підтверджує досягнення технічного результату при здійсненні заявленого способу. Джерела інформації: 1. Klebanov В. В., Knight K., Marcu D. Text Simplification for Information-Seeking Applications. Springer Verlag, 2004. - 13 p. 2. Lloret E., Palomar M. Challenging Issues of Automatic Summarization: Relevance Detection and Quality-based Evaluation. - Department of Software and Computing Systems, University of Alicante, Spain, 2009. - 8 p. 20 ФОРМУЛА КОРИСНОЇ МОДЕЛІ 25 30 Спосіб семантичної компресії тексту із заданим рівнем стислості, що полягає в тому, що отримують речення, які належать до вихідного тексту, з яких видаляються стоп-слова, вираховують вагові коефіцієнти, вибирають речення із найвищими ваговими коефіцієнтами за для формування частини фінального узагальнення, речення розташовують у порядку, в якому вони йшли у вихідному тексті, який відрізняється тим, що здійснюють компресію із заданим рівнем стислості, визначають поняття рівня стислості, ключового слова, рангу слова, рангу речення, модифікованого інвертованого індексу, інвертованого індексу анотації, встановлюють функціональну залежність між кількістю ключових слів у анотації та рівнем стислості, що задає користувач, що дозволяє створити анотацію визначеного об'єму, яка повністю відображує сенс вихідного тексту. 3 UA 82942 U 4 UA 82942 U 5 UA 82942 U Комп’ютерна верстка Л. Ціхановська Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 6
ДивитисяДодаткова інформація
Назва патенту англійськоюMethod of text semantic compression with prescribed compaction degree
Автори англійськоюYehorov Stanislav Viacheslavovych, Yehorova Iryna Mykolaivna
Назва патенту російськоюСпособ семантической компрессии текста с заданным уровнем сжатости
Автори російськоюЕгоров Станислав Вячеславович, Егорова Ирина Николаевна
МПК / Мітки
МПК: G06F 17/21
Мітки: заданим, семантичної, компресії, тексту, рівнем, спосіб, стислості
Код посилання
<a href="https://ua.patents.su/8-82942-sposib-semantichno-kompresi-tekstu-iz-zadanim-rivnem-stislosti.html" target="_blank" rel="follow" title="База патентів України">Спосіб семантичної компресії тексту із заданим рівнем стислості</a>
Спосіб представлення документа для відкритої обробки (варіанти), спосіб відображення тексту (варіанти) та спосіб відображення множини текстових ієрархій (варіанти)

Номер патенту: 66835
Опубліковано: 15.06.2004
Автор: Уолкер Рендл К.
МПК: G06F 3/048, G06F 17/21
Мітки: ієрархій, відкритої, відображення, тексту, представлення, обробки, документа, множині, спосіб, варіанти, текстових
Формула / Реферат:
1. Спосіб представлення документа для відкритої обробки з встановленим автором порядком слів, який відрізняється тим, що включає виділення конкретних атрибутів тексту з вказаного тексту і зміну вказаного представлення тексту відповідно до вказаних атрибутів при збереженні встановленого автором порядку слів.2. Спосіб за п. 1, який відрізняється тим, що вказані атрибути тексту включають позицію конкретного тексту в загальній текстовій...
Контекстно-орієнтований словник, пристрій для читання розміченого тексту і спосіб його використання, пристрій для розмітки тексту і спосіб його використання

Номер патенту: 62070
Опубліковано: 15.12.2003
Автор: Соловйов Валентин Вячеславович
МПК: G06F 17/27
Мітки: тексту, спосіб, контекстно-орієнтований, використання, розміченого, розмітки, словник, пристрій, читання
Формула / Реферат:
1. Контекстно-орієнтований словник, призначений для однозначної ідентифікації усіх варіантів уживання лексичних одиниць, що належать визначеному набору текстів, що можуть викликати утруднення в читачів, що представляє собою розміщений на електронному носії набір записів, кожен з яких включає принаймні унікальний код, що однозначно ідентифікує конкретне значення згаданої лексичної одиниці у визначеному контексті й один чи кілька визначених...
Система обробки тексту природної мови

Номер патенту: 19513
Опубліковано: 15.12.2006
Автори: Бандура Іван Миколайович, Токар Дмитро Сергійович, Гавриленко Олег Іванович, Спасьонов Сергій Миколайович
МПК: G06F 15/00
Мітки: обробки, мови, система, тексту, природної
Формула / Реферат:
Система обробки тексту природної мови, що містить послідовно з'єднані рецептори, блок морфологічного розбору тексту, блок синтаксичного розбору тексту, експертну систему, шар синтезу символьних послідовностей і шар ефекторів, яка відрізняється тим, що додатково введено семантичний зворотний зв'язок шляхом включення комутатора між входом рецепторів і виходом шару ефекторів, регістратор зовнішнього середовища, підключений до другого входу...
Реактивний двигун з збільшеним рівнем реактивної тяги та зменшеним рівнем акустичних шумів

Номер патенту: 15477
Опубліковано: 17.07.2006
Автори: Гріцун Сергій Миколайович, Федосенко Володимир Олегович, Тарасова Галіна Борісовна, Фєдосєнко Олєг Фьодоровіч, Павлов Сергій Петрович
МПК: F02K 9/84
Мітки: збільшеним, рівнем, реактивної, тяги, реактивний, зменшеним, шумів, двигун, акустичних
Формула / Реферат:
1. Реактивний двигун з збільшеним рівнем реактивної тяги та зменшеним рівнем акустичних шумів, що містить газогенератор із соплом для формування діаграми витікаючого газового потоку, який відрізняється тим, що співвісно з соплом реактивного двигуна додатково установлено об'ємний резонатор з реактивним соплом, герметично з'єднаним з корпусом газогенератора.2. Реактивний двигун з збільшеним рівнем реактивної тяги та зменшеним рівнем...
Спосіб введення тексту і команд в портативний цифровий пристрій

Номер патенту: 24237
Опубліковано: 25.06.2007
Автор: Романько Вадим Анатолійович
МПК: G06F 3/023, H03M 11/04
Мітки: цифровий, спосіб, портативний, пристрій, команд, введення, тексту
Формула / Реферат:
1. Спосіб введення тексту і команд в портативний цифровий пристрій, при якому введення здійснюють пальцями рук шляхом натиснення прямо на елементи керування, який відрізняється тим, що портативний цифровий пристрій прикріплюють до однієї з рук із забезпеченням можливості дії кожним з пальців на відповідні йому елементи керування, а введення здійснюють з використанням додаткових видів натиснень на елемент керування кожним з пальців: вліво,...
Попередній патент: Пристрій для видалення водню із свинцево-кислотних акумуляторів
Наступний патент: Фільтр аквакор-117
Випадковий патент: Соус емульсійного типу