Портативний перекладач-4
Номер патенту: 122888
Опубліковано: 25.01.2018
Автори: Ніколаєвський Олександр Юрійович, Пампуха Ігор Володимирович, Нікіфорова Олена Миколаївна, Замаруєва Ірина Вікторівна, Аронов Андрій Олексійович, Литвиненко Леонід Олександрович




Формула / Реферат
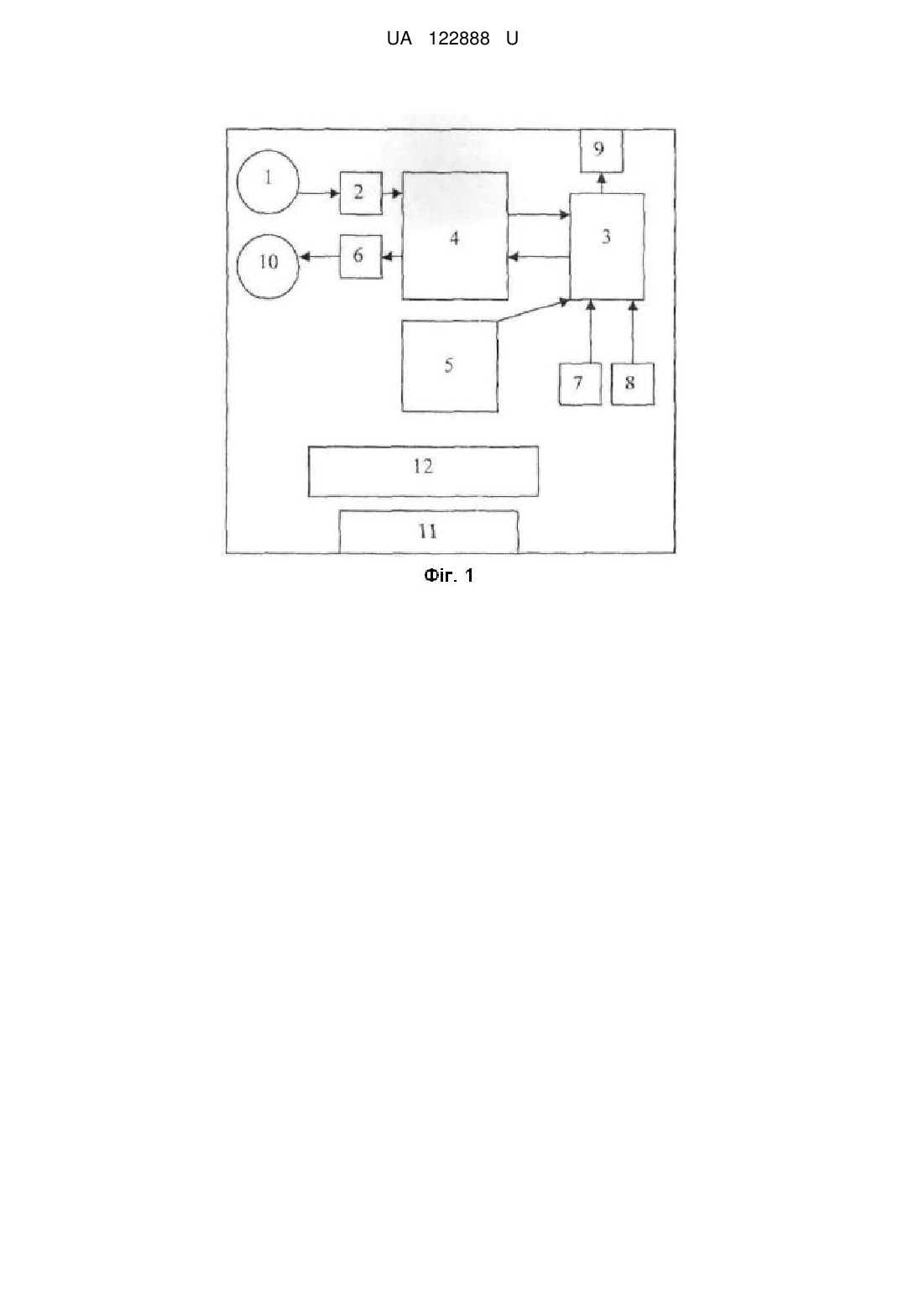
Портативний переклад, який відрізняється тим, що містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце (АРМ) "Синтаксис".
Текст
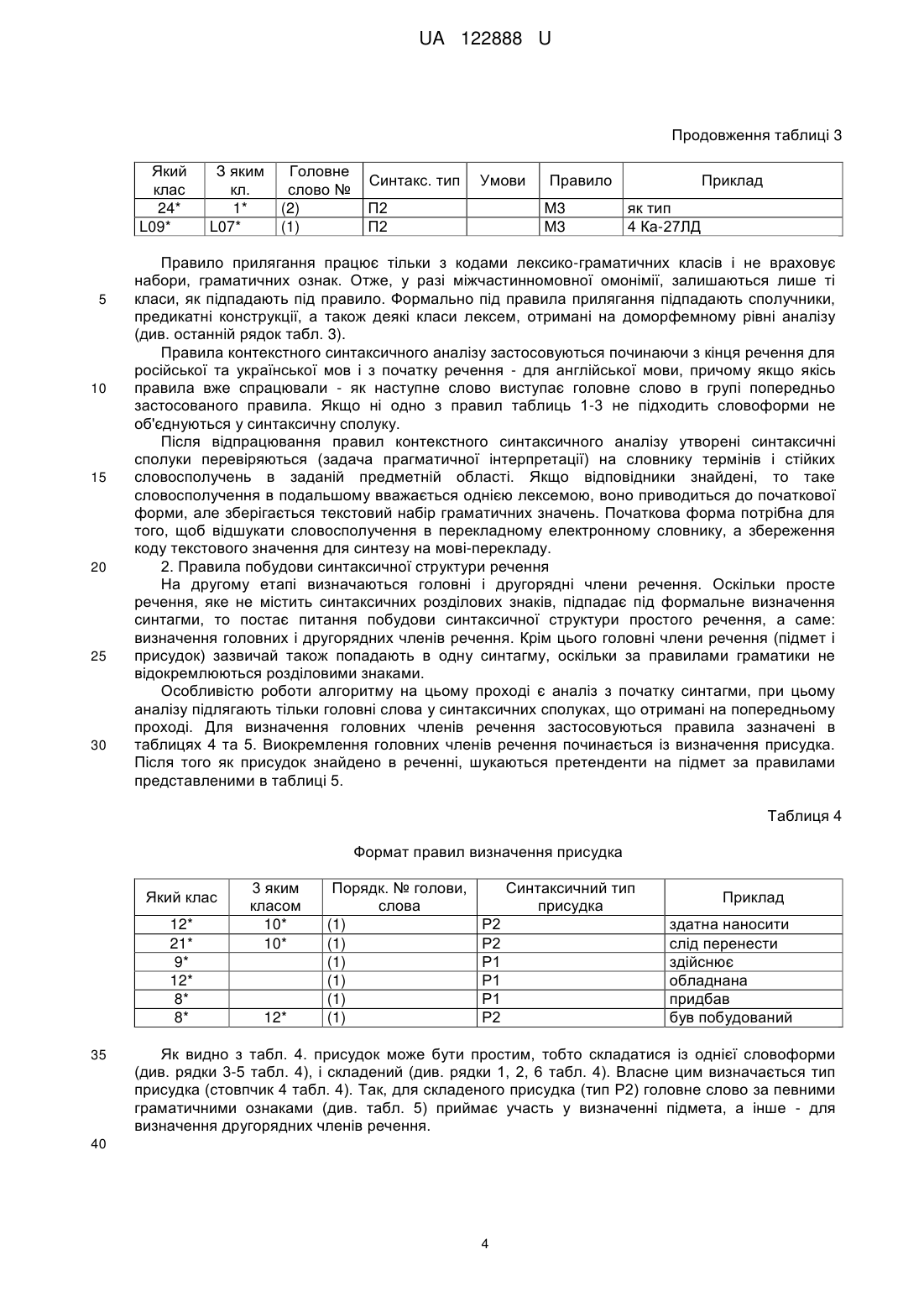
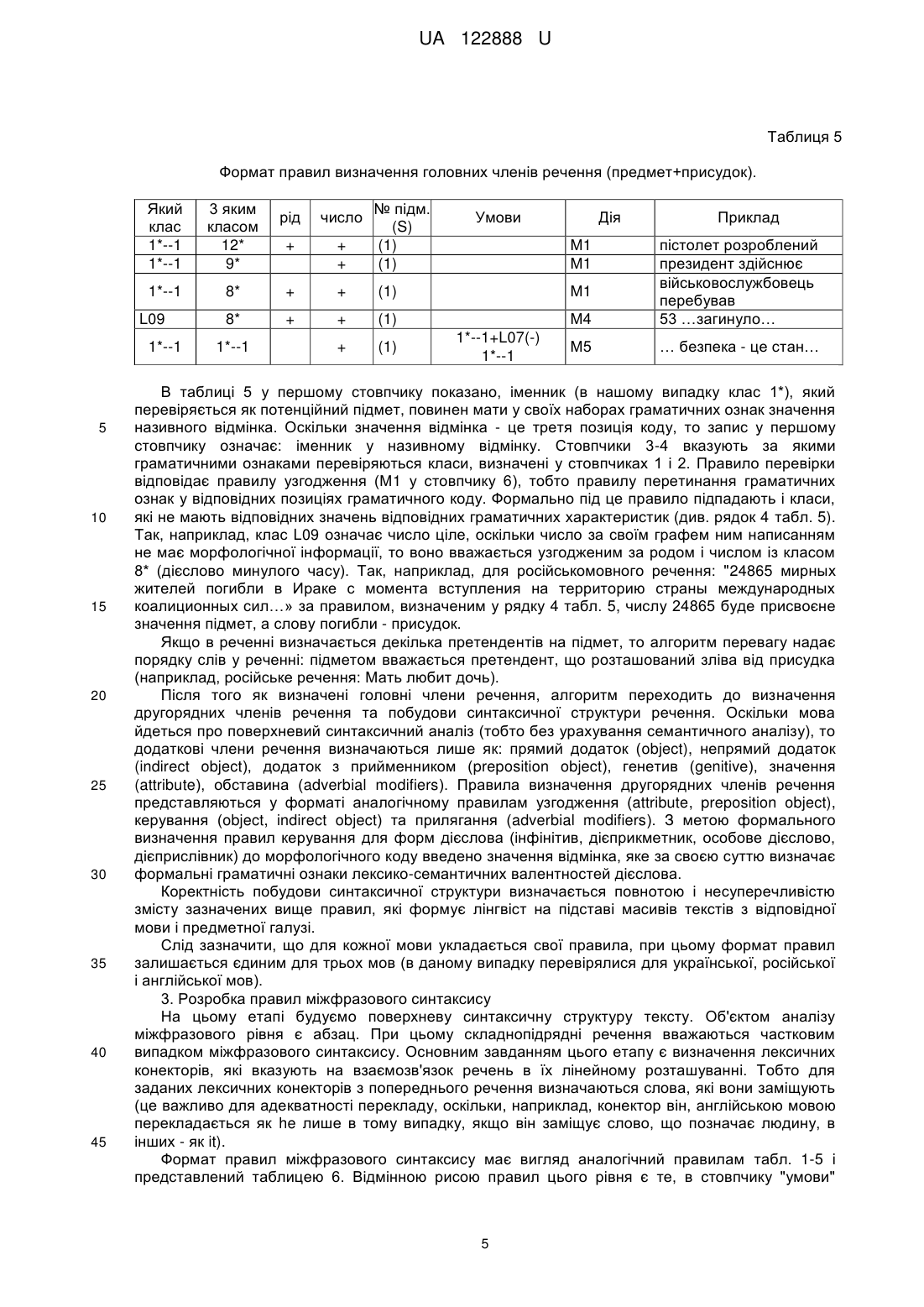
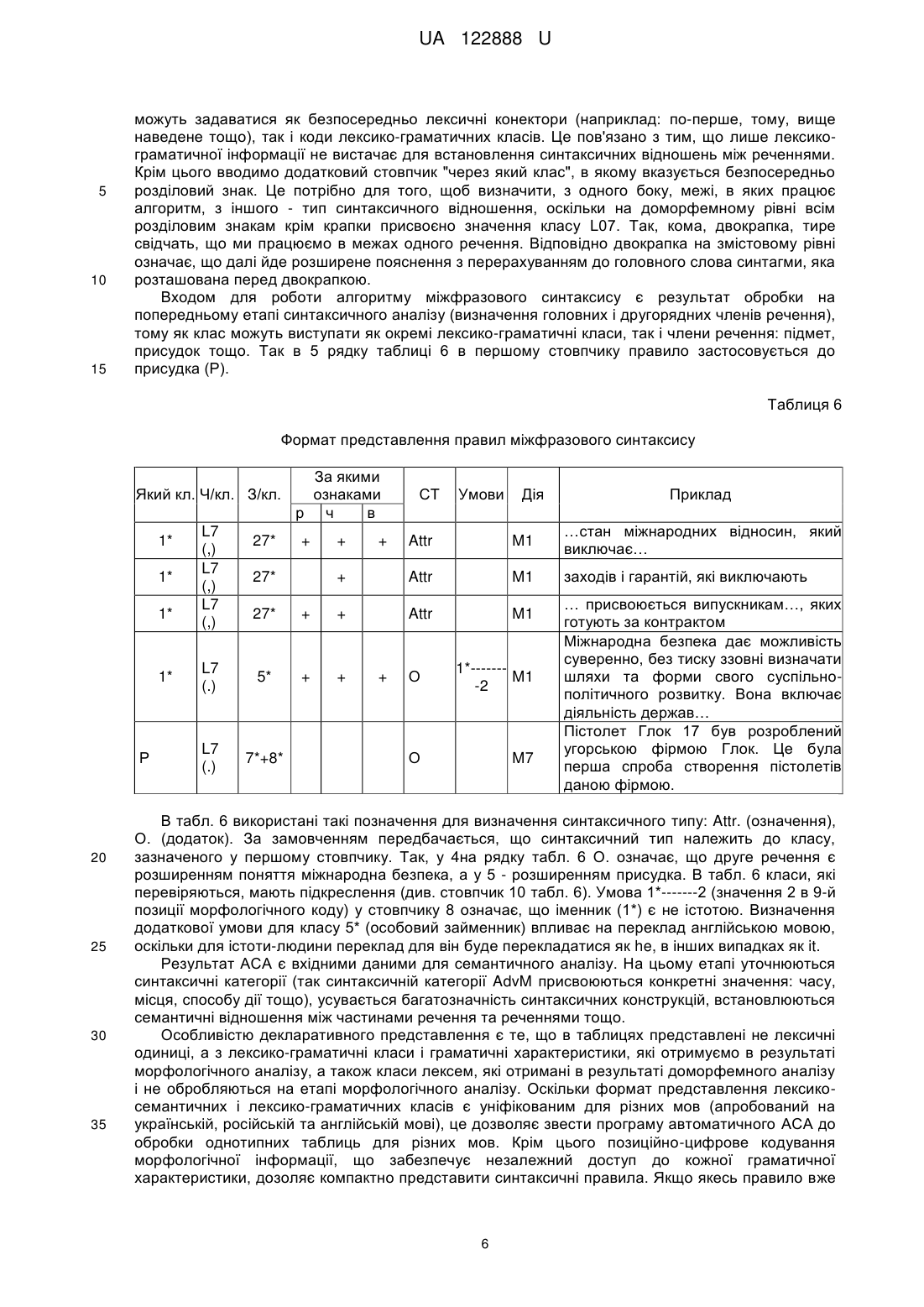
Реферат: Портативний переклад - 4 містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце (АРМ) "Синтаксис". UA 122888 U (12) UA 122888 U UA 122888 U 5 10 15 20 25 30 35 40 45 50 55 60 Корисна модель належить до портативних перекладачів. Корисна модель належить до способу табличного представлення декларативних правил на основі формальних характеристик для забезпечення автоматичного синтаксичного аналізу тексту, який представляє собою формування таблиць правил синтаксису у вигляді логічної структури алгоритму (ЛСА). Можна виділити два підходи до автоматичної обробки тексту. Перший підхід включає послідовну обробку всього тексту спочатку на граматичному рівні (морфологічному), потім реалізується етап синтаксичного аналізу, потім - семантичного [Кобзарева Т.Ю. Иерархия задач поверхностно-синтаксического анализа русского предложения / Т.Ю. Кобзарева // НТИ. - Сер. 2, № 1, 2007. - С. 23-35.]. Такий підхід вимагає розподіленого подання всіх видів інформації (морфологічної, синтаксичної, семантичної) до текстових одиниць в базі даних. Принципи реалізації першого підходу покладені в розробку більшості лінгвістичних процесорів (ЛП). Основою другого підходу є гіпотеза, вперше сформульована Р. Шенком та Л. Бірнаумом [Шенк Р. Обработка концептуальной информации. - Μ., 1980. - 360 с.], суть якої можна висловити наступним чином: синтаксичні й семантичні структури обробляються одночасно; синтаксис і семантика реалізуються в ході одного процесу; обробка мовних повідомлень за своєю природою тотожна обробці в пам'яті. Другий підхід потребує сумісного подання всієї інформації до текстової одиниці, обробка тексту при цьому підході здійснюється по реченнях. Слід зазначити, що перевагою першого підходу є: можливість зупинитися на будь якому етапі обробки, що сприяє більш ефективній "відладці" програмних модулів; окреме подання даних робить систему в технологічному плані більш гнучкою до прикладних задач. Недоліком таких систем є те, що виникнення відмов в роботі лінгвістичного процесора (ЛП) на будь-якому етапі призводить до невиконання задачі в цілому. Цікаво, що другий підхід є дзеркальним відображенням першого, тобто недоліки першого підходу є перевагою другого, переваги першого - недоліками другого. За найближчий аналог вибрано ЕСТАСО Partner UT-203 [www.ectaco.com]. Partner UT-203 є портативним пристроєм, що містить процесор цифрової обробки сигналів й має апаратну систему розпізнавання усномовних фраз. Пристрій призначений для перекладу усномовних фраз з російської та англійської мови на одну з трьох мов: англійську, російську або німецьку. Результат перекладу фрази виводиться на екран й може бути озвучений російською, німецькою, або англійською мовами. Partner UT-203 заявлений як багатодикторна система, тобто така, що не потребує попереднього настроювання на голос диктора. Розпізнавання на пристрої обмежується 3000 фразами, які розбито на 16 підкатегорій. Загальним недоліком розглянутих способів представлення декларативних правил і портативного пристрою ЕСТАСО Partner UT-203 для забезпечення автоматичного синтаксичного аналізу тексту, в якому застосовуються відповідні словники є вузько спеціалізована сфера їх використання, не адаптованість для різноманітних задач автоматичної обробки природно-мовних текстів. Задачею корисної моделі є створення портативного перекладача-4 з меншими габаритами та з автоматичним синтаксичним аналізом тексту, як елемента лінгвістичного забезпечення, при цьому точність перекладу підвищується на 20-30 % у порівнянні з відомими аналогами. На кресленні зображено структурну схему портативного перекладача-4, в якому реалізований спосіб усномовного перекладу з автоматичним синтаксичним аналізом тексту. Поставлена задача вирішується тим, що портативний перекладач-4, згідно з корисною моделлю, містить мікрофон 1 приєднаний до аналого-цифрового перетворювача 2, який з'єднаний з процесором цифрової обробки сигналу 4, до якого підключені мікроконтролер 3, аналого-цифровий перетворювач 2, цифро-аналоговий перетворювач 6, енергонезалежну пам'ять 5, до якої приєднаний мікроконтролер 3, кнопки включення живлення 7, кнопки керування введенням усномовного сигналу для перекладу 8, засобів індикації 9, динаміка 10, виходу для з'єднання диктофона з комп'ютером 11 та акумулятора 12 та додатково містить автоматизоване робоче місце (АРМ) "Синтаксис". В основу пропонованого лінгвістичного процесора покладена гіпотеза скачкової обробки тексту, її суть зводиться до наступних положень: текст являє собою єдність трьох різних систем: семіотичної системи, лінгвістичної системи та системи знань про світ; процес обробки природно-мовних текстів, (людиною) проходить в трьох системах одночасно; в рамках кожної системи обробка здійснюється по спіралі. "Скачковість" обробки полягає в тому, що на кожному з етапів обробки текстової інформації здійснюється "занурення" отриманих результатів обробки в знання про світ. Такий підхід дозволяє обернути на переваги недоліки в рамках перших двох підходів. Це проявляється в 1 UA 122888 U 5 10 15 20 25 тому, що кожний етап обробки моделюється як незалежний модуль, який дозволяє отримати точнішу інформацію. Так, на етапі морфологічної обробки занурення в базу знань про світ дозволяє точніше визначити граматичні характеристики таких лексичних одиниць, як ім'я, назва тощо. Наприклад, в англійській мові для повного ім'я: Martha Browner визначити категорію роду можливо лише за рахунок інтерпретації цієї лексеми на базі знань з предметної галузі, де для першої словоформи Martha буде визначено: жіночий рід, істота (людина). За рахунок роботи інтерпретатора зменшується кількість помилок як в процесі аналізу вхідного тексту, так і в процесі синтезу. Крім цього імітація об'ємної (тобто в трьох вимірах) обробки інформації дозволяє значно скоротити час обробки тексту. Вхідними даними автоматичного синтаксичного аналізу (АСА) є текст як результат обробки на доморфемному і морфологічному рівнях обробки. Процедура аналізу включає три етапи: Перший етап. Контекстний синтаксичний аналіз - його призначення встановлення синтаксичних сполук в межах синтагми. Другий етап. Побудова дерева синтаксичного підпорядкування для речення. Третій етап. Міжфразовий синтаксичний аналіз - його призначення побудова синтактикосемантичної структури тексту. До задач першого етапу відносимо: виокремлення синтаксичних сполук за граматичними ознаками, отриманими на етапі морфологічного аналізу; усунення морфологічної омонімії, отриманої на етапі морфологічного аналізу; визначення словосполучень, що є термінами і усталеними поняттями в заданій предметній області. Одиницею контекстного аналізу виступає синтагма, яка в даній роботі формально визначається як послідовність лексем, обмежених синтаксичними розділовими знаками. Як синтагма також може виступати просте речення, яке містить розділових синтаксичних знаків. В межах синтагми формуються синтаксично-поєднані сполуки, на підставі синтаксичних правил узгодження, керування, прилягання. Формально сутність правила граматичного узгодження полягає у здійсненні операції перетинання множин граматичних характеристик словоформ A і B . У формалізованому вигляді правило граматичного узгодження можна представити формулою: УЗГ : N A N B G1 , r (1) 30 де N A - код лексико-граматичного класу словоформи A , NB - код лексико-граматичного r 1 35 класу словоформи B , G - множина граматичних ознак, які є результатом здійснення операції узгодження граматичних характеристик для двох словоформ. Результатом операції узгодження є перетинання множин граматичних характеристик словоформ. Інші граматичні характеристики у словоформ убираються. Якщо операція перетинання дає пусту множину, то вважається що правило не спрацювало, словоформи в цьому випадку не об'єднуються у словосполучення, а лексико-граматична інформація залишається без змін. Формат правила узгодження представлений в таблиці 1. Таблиця 1 Формат представлення правил узгодження Який кл. 3 яким кл. 2* 1* 23* L09* 3* … 1* 1* 1* … За якими ознаками р ч в + + … Пор. № Синт. тип гол. сл. + + (2) С1 + … + + + … (1) (2) (2) … С2 C3 C3 … Умови Дія 2* : 12 * М1 1* : 2 * … М1 М4 М1 … Приклад національної безпеки від форми 1985 році два підйомники … 40 В табл. 1 використані такі позначення: 1*, 2*, 23*, 12* - коди лексико-граматичних класів, які отримані на етапі морфологічного аналізу і, відповідно означають - іменник, прикметник, прийменник, дієприкметник; знак «+» означає наявність однакових значень у відповідних 12 позиціях лексико-граматичних класів. В колонці "умови" запис “ 2* : * ” означає, що 2 UA 122888 U 5 10 правило можна застосовувати, якщо у словоформи 2* відсутні набори з лексико-граматичним класом 12*. Це потрібно для того, щоб уникнути хибних синтаксичних сполук, як наприклад, …присвоєному офіцеру. Колонка "правило" визначає, яку процедуру необхідно застосувати. Так, М1 означає, що для лексико-граматичних класів 1* і 2* застосовується процедура перетинання наборів їх граматичних кодів, зазначених в стовпчиках 3-5 табл. 1. Набори, які не відповідають умовам перетинання, видаляються як омонімічні. Формально до правила узгодження відносимо синтаксичні сполуки із прийменником (клас 23*), оскільки виконується таж сама операція перетинання за третьою позицією (відмінок). При цьому головним словом у синтаксичній сполуці визначаємо прийменник. Це потрібно для коректного визначення другорядних членів речення в подальшому. Клас L09* означає "число ціле" і визначається на етапі доморфемного аналізу. Вважається, що він підлягає під правило узгодження, якщо іменник, який слідує за ним не в родовому відмінку (див. табл. 1, рядок 3, стовпчик "умови"). Керування в природній мові формально визначається через певний відмінок підпорядкованої словоформи. Формально правило керування записується наступним чином: 15 i УПР : N A N B Gd , (2) i 1,2,...,9 , i де Gd визначає відмінок на лексико-граматичному класі словоформи B, якого вимагає словоформа A від B , - операція керування. При цьому, якщо правило спрацювало, то зайва граматична інформація видаляється тільки 20 з поля граматичної інформації словоформи представлений таблицею 2. B. Формат подання правил керування Таблиця 2 Формат представлення правил керування Який Головне 3 яким кл. клас слово № 1* 1*--2 (1) L09 1*--2 (1) 1* 1*--5 (1) … … … 25 Синт. тип У1 У2 У2 … Умови Правило … М2 М2 М2 … Приклад норма права, підтримання миру 17000 військовослужбовців керівництво країною … В табл. 2 у другій колонці запис "1*--2" означає, що у лексеми класу 1* у 3-ій позиції відмінок може приймати значення 2 або 5 (див. 1 і 3 рядок). Правило М2 визначає, що у другої лексеми залишається лише набір граматичної інформації з відповідним значенням відмінка, перша лексема зберігає всі свої набори значень. Правило прилягання має наступний вигляд: ПРИЛ : N A N B G fj (3) 30 Операція прилягання означає, що дві словоформи є словосполученням, якщо вони задовольняють умовам поєднання на рівні лексико-граматичних класів, граматичні характеристики цих словоформ не враховуємо. Таблиця 3 визначає формат правил прилягання, які діють тільки на синтаксичній сполучуваності лексико-граматичних класів. Таблиця 3 Формат представлення правил прилягання Який клас 9* 14* 14* 8* З яким кл. 10* 10* 12* 12* Головне слово № (1) (2) (2) (1) Синтакс. тип Умови П1 П2 П1 П1 Правило М3 М3 М3 М3 35 3 Приклад продовжують виконувати суттєво впливати вже націлені був закладений UA 122888 U Продовження таблиці 3 Який клас 24* L09* 5 10 15 20 25 30 З яким кл. 1* L07* Головне слово № (2) (1) Синтакс. тип Умови П2 П2 Правило М3 М3 Приклад як тип 4 Ка-27ЛД Правило прилягання працює тільки з кодами лексико-граматичних класів і не враховує набори, граматичних ознак. Отже, у разі міжчастинномовної омонімії, залишаються лише ті класи, як підпадають під правило. Формально під правила прилягання підпадають сполучники, предикатні конструкції, а також деякі класи лексем, отримані на доморфемному рівні аналізу (див. останній рядок табл. 3). Правила контекстного синтаксичного аналізу застосовуються починаючи з кінця речення для російської та української мов і з початку речення - для англійської мови, причому якщо якісь правила вже спрацювали - як наступне слово виступає головне слово в групі попередньо застосованого правила. Якщо ні одно з правил таблиць 1-3 не підходить словоформи не об'єднуються у синтаксичну сполуку. Після відпрацювання правил контекстного синтаксичного аналізу утворені синтаксичні сполуки перевіряються (задача прагматичної інтерпретації) на словнику термінів і стійких словосполучень в заданій предметній області. Якщо відповідники знайдені, то таке словосполучення в подальшому вважається однією лексемою, воно приводиться до початкової форми, але зберігається текстовий набір граматичних значень. Початкова форма потрібна для того, щоб відшукати словосполучення в перекладному електронному словнику, а збереження коду текстового значення для синтезу на мові-перекладу. 2. Правила побудови синтаксичної структури речення На другому етапі визначаються головні і другорядні члени речення. Оскільки просте речення, яке не містить синтаксичних розділових знаків, підпадає під формальне визначення синтагми, то постає питання побудови синтаксичної структури простого речення, а саме: визначення головних і другорядних членів речення. Крім цього головні члени речення (підмет і присудок) зазвичай також попадають в одну синтагму, оскільки за правилами граматики не відокремлюються розділовими знаками. Особливістю роботи алгоритму на цьому проході є аналіз з початку синтагми, при цьому аналізу підлягають тільки головні слова у синтаксичних сполуках, що отримані на попередньому проході. Для визначення головних членів речення застосовуються правила зазначені в таблицях 4 та 5. Виокремлення головних членів речення починається із визначення присудка. Після того як присудок знайдено в реченні, шукаються претенденти на підмет за правилами представленими в таблиці 5. Таблиця 4 Формат правил визначення присудка Який клас 12* 21* 9* 12* 8* 8* 35 3 яким класом 10* 10* 12* Порядк. № голови, слова (1) (1) (1) (1) (1) (1) Синтаксичний тип присудка Р2 Р2 Р1 Р1 Р1 Р2 Приклад здатна наносити слід перенести здійснює обладнана придбав був побудований Як видно з табл. 4. присудок може бути простим, тобто складатися із однієї словоформи (див. рядки 3-5 табл. 4), і складений (див. рядки 1, 2, 6 табл. 4). Власне цим визначається тип присудка (стовпчик 4 табл. 4). Так, для складеного присудка (тип Р2) головне слово за певними граматичними ознаками (див. табл. 5) приймає участь у визначенні підмета, а інше - для визначення другорядних членів речення. 40 4 UA 122888 U Таблиця 5 Формат правил визначення головних членів речення (предмет+присудок). Який клас 1*--1 1*--1 3 яким класом 12* 9* 1*--1 L09 1*--1 5 10 15 20 25 30 35 40 45 рід число + + + № підм. (S) (1) (1) 8* + + (1) 8* + + (1) 1*--1 + (1) Умови Дія М1 М1 Приклад М4 пістолет розроблений президент здійснює військовослужбовець перебував 53 …загинуло… М5 … безпека - це стан… М1 1*--1+L07(-) 1*--1 В таблиці 5 у першому стовпчику показано, іменник (в нашому випадку клас 1*), який перевіряється як потенційний підмет, повинен мати у своїх наборах граматичних ознак значення називного відмінка. Оскільки значення відмінка - це третя позиція коду, то запис у першому стовпчику означає: іменник у називному відмінку. Стовпчики 3-4 вказують за якими граматичними ознаками перевіряються класи, визначені у стовпчиках 1 і 2. Правило перевірки відповідає правилу узгодження (М1 у стовпчику 6), тобто правилу перетинання граматичних ознак у відповідних позиціях граматичного коду. Формально під це правило підпадають і класи, які не мають відповідних значень відповідних граматичних характеристик (див. рядок 4 табл. 5). Так, наприклад, клас L09 означає число ціле, оскільки число за своїм графем ним написанням не має морфологічної інформації, то воно вважається узгодженим за родом і числом із класом 8* (дієслово минулого часу). Так, наприклад, для російськомовного речення: "24865 мирных жителей погибли в Ираке с момента вступления на территорию страны международных коалиционных сил…» за правилом, визначеним у рядку 4 табл. 5, числу 24865 буде присвоєне значення підмет, а слову погибли - присудок. Якщо в реченні визначається декілька претендентів на підмет, то алгоритм перевагу надає порядку слів у реченні: підметом вважається претендент, що розташований зліва від присудка (наприклад, російське речення: Мать любит дочь). Після того як визначені головні члени речення, алгоритм переходить до визначення другорядних членів речення та побудови синтаксичної структури речення. Оскільки мова йдеться про поверхневий синтаксичний аналіз (тобто без урахування семантичного аналізу), то додаткові члени речення визначаються лише як: прямий додаток (object), непрямий додаток (indirect object), додаток з прийменником (preposition object), генетив (genitive), значення (attribute), обставина (adverbial modifiers). Правила визначення другорядних членів речення представляються у форматі аналогічному правилам узгодження (attribute, preposition object), керування (object, indirect object) та прилягання (adverbial modifiers). З метою формального визначення правил керування для форм дієслова (інфінітив, дієприкметник, особове дієслово, дієприслівник) до морфологічного коду введено значення відмінка, яке за своєю суттю визначає формальні граматичні ознаки лексико-семантичних валентностей дієслова. Коректність побудови синтаксичної структури визначається повнотою і несуперечливістю змісту зазначених вище правил, які формує лінгвіст на підставі масивів текстів з відповідної мови і предметної галузі. Слід зазначити, що для кожної мови укладається свої правила, при цьому формат правил залишається єдиним для трьох мов (в даному випадку перевірялися для української, російської і англійської мов). 3. Розробка правил міжфразового синтаксису На цьому етапі будуємо поверхневу синтаксичну структуру тексту. Об'єктом аналізу міжфразового рівня є абзац. При цьому складнопідрядні речення вважаються частковим випадком міжфразового синтаксису. Основним завданням цього етапу є визначення лексичних конекторів, які вказують на взаємозв'язок речень в їх лінейному розташуванні. Тобто для заданих лексичних конекторів з попереднього речення визначаються слова, які вони заміщують (це важливо для адекватності перекладу, оскільки, наприклад, конектор він, англійською мовою перекладається як he лише в тому випадку, якщо він заміщує слово, що позначає людину, в інших - як it). Формат правил міжфразового синтаксису має вигляд аналогічний правилам табл. 1-5 і представлений таблицею 6. Відмінною рисою правил цього рівня є те, в стовпчику "умови" 5 UA 122888 U 5 10 15 можуть задаватися як безпосередньо лексичні конектори (наприклад: по-перше, тому, вище наведене тощо), так і коди лексико-граматичних класів. Це пов'язано з тим, що лише лексикограматичної інформації не вистачає для встановлення синтаксичних відношень між реченнями. Крім цього вводимо додатковий стовпчик "через який клас", в якому вказується безпосередньо розділовий знак. Це потрібно для того, щоб визначити, з одного боку, межі, в яких працює алгоритм, з іншого - тип синтаксичного відношення, оскільки на доморфемному рівні всім розділовим знакам крім крапки присвоєно значення класу L07. Так, кома, двокрапка, тире свідчать, що ми працюємо в межах одного речення. Відповідно двокрапка на змістовому рівні означає, що далі йде розширене пояснення з перерахуванням до головного слова синтагми, яка розташована перед двокрапкою. Входом для роботи алгоритму міжфразового синтаксису є результат обробки на попередньому етапі синтаксичного аналізу (визначення головних і другорядних членів речення), тому як клас можуть виступати як окремі лексико-граматичні класи, так і члени речення: підмет, присудок тощо. Так в 5 рядку таблиці 6 в першому стовпчику правило застосовується до присудка (Р). Таблиця 6 Формат представлення правил міжфразового синтаксису Який кл. Ч/кл. З/кл. 1* 1* 1* 1* Ρ 20 25 30 35 L7 (,) L7 (,) L7 (,) 27* За якими ознаками р ч в СТ Умови Дія Приклад 27* Attr M1 …стан міжнародних відносин, який виключає… + + Attr M1 заходів і гарантій, які виключають Attr M1 + 27* + + L7 (.) 5* + + L7 (.) 7*+8* + + О 1*------M1 -2 О M7 … присвоюється випускникам…, яких готують за контрактом Міжнародна безпека дає можливість суверенно, без тиску ззовні визначати шляхи та форми свого суспільнополітичного розвитку. Вона включає діяльність держав… Пістолет Глок 17 був розроблений угорською фірмою Глок. Це була перша спроба створення пістолетів даною фірмою. В табл. 6 використані такі позначення для визначення синтаксичного типу: Attr. (означення), О. (додаток). За замовченням передбачається, що синтаксичний тип належить до класу, зазначеного у першому стовпчику. Так, у 4на рядку табл. 6 О. означає, що друге речення є розширенням поняття міжнародна безпека, а у 5 - розширенням присудка. В табл. 6 класи, які перевіряються, мають підкреслення (див. стовпчик 10 табл. 6). Умова 1*-------2 (значення 2 в 9-й позиції морфологічного коду) у стовпчику 8 означає, що іменник (1*) є не істотою. Визначення додаткової умови для класу 5* (особовий займенник) впливає на переклад англійською мовою, оскільки для істоти-людини переклад для він буде перекладатися як he, в інших випадках як it. Результат АСА є вхідними даними для семантичного аналізу. На цьому етапі уточнюються синтаксичні категорії (так синтаксичній категорії AdvM присвоюються конкретні значення: часу, місця, способу дії тощо), усувається багатозначність синтаксичних конструкцій, встановлюються семантичні відношення між частинами речення та реченнями тощо. Особливістю декларативного представлення є те, що в таблицях представлені не лексичні одиниці, а з лексико-граматичні класи і граматичні характеристики, які отримуємо в результаті морфологічного аналізу, а також класи лексем, які отримані в результаті доморфемного аналізу і не обробляються на етапі морфологічного аналізу. Оскільки формат представлення лексикосемантичних і лексико-граматичних класів є уніфікованим для різних мов (апробований на українській, російській та англійській мові), це дозволяє звести програму автоматичного АСА до обробки однотипних таблиць для різних мов. Крім цього позиційно-цифрове кодування морфологічної інформації, що забезпечує незалежний доступ до кожної граматичної характеристики, дозоляє компактно представити синтаксичні правила. Якщо якесь правило вже 6 UA 122888 U 5 спрацювало - як наступне слово для перевірки правила виступає головне слово в групі попередньо застосованого правила. Коректність АСА залежить від повноти правил. Зміст таблиць для кожної мови формує лінгвіст. Представлені етапи на доморфемному і морфологічному рівнях обробки текстової інформації суттєво впливають на обсяг використаних словників та достовірність перекладу. ФОРМУЛА КОРИСНОЇ МОДЕЛІ 10 15 Портативний переклад, який відрізняється тим, що містить мікрофон приєднаний до аналогоцифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце (АРМ) "Синтаксис". Комп’ютерна верстка А. Крижанівський Міністерство економічного розвитку і торгівлі України, вул. М. Грушевського, 12/2, м. Київ, 01008, Україна ДП “Український інститут інтелектуальної власності”, вул. Глазунова, 1, м. Київ – 42, 01601 7
ДивитисяДодаткова інформація
МПК / Мітки
МПК: G06F 17/28
Мітки: портативний, перекладач-4
Код посилання
<a href="https://ua.patents.su/9-122888-portativnijj-perekladach-4.html" target="_blank" rel="follow" title="База патентів України">Портативний перекладач-4</a>
Портативний перекладач

Номер патенту: 107669
Опубліковано: 24.06.2016
Автори: Литвиненко Леонід Олександрович, Лісовський Володимир Миколайович, Балабін Віктор Володимирович, Пампуха Ігор Володимирович, Ніколаєвський Олександр Юрійович, Замаруєва Ірина Вікторівна
МПК: G06F 17/28
Мітки: перекладач, портативний
Формула / Реферат:
Портативний перекладач, який відрізняється тим, що містить мікрофон, приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік,...
Портативний перекладач-3

Номер патенту: 122887
Опубліковано: 25.01.2018
Автори: Замаруєва Ірина Вікторівна, Ніколаєвський Олександр Юрійович, Литвиненко Леонід Олександрович, Пампуха Ігор Володимирович, Ільїн Олег Олександрович, Нікіфорова Олена Миколаївна
МПК: G06F 17/28
Мітки: перекладач-3, портативний
Формула / Реферат:
Портативний перекладач, який відрізняється тим, що містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік,...
Портативний перекладач

Номер патенту: 107670
Опубліковано: 24.06.2016
Автори: Пампуха Ігор Володимирович, Лісовський Володимир Миколайович, Балабін Віктор Володимирович, Замаруєва Ірина Вікторівна, Литвиненко Леонід Олександрович, Ніколаєвський Олександр Юрійович
МПК: G06F 17/28
Мітки: портативний, перекладач
Формула / Реферат:
Портативний перекладач, який відрізняється тим, що містить мікрофон, приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік,...
Голосовий портативний словник-перекладач

Номер патенту: 48218
Опубліковано: 10.03.2010
Автори: Стасевич Петро Анатолійович, Тертичний Григорій Миколайович, Гриценко Володимир Ілліч, Павлов Олег Ігоревич, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: словник-перекладач, портативний, голосовий
Формула / Реферат:
Голосовий портативний словник-перекладач, що містить мікрофон, з'єднаний з аналого-цифровим перетворювачем, динамік, з'єднаний з цифро-аналоговим перетворювачем, процесор цифрової обробки сигналів, виходами підключений до динаміка через цифро-аналоговий перетворювач та до входу мікроконтролера, на входи якого підключені кнопка включення живлення такнопка керування процесами введення усномовного сигналу, його подальшого розпізнавання і...
Голосовий фразник-перекладач

Номер патенту: 52350
Опубліковано: 25.08.2010
Автори: Вінцюк Тарас Климович, Гриценко Володимир Ілліч
МПК: G01L 15/00
Мітки: голосовий, фразник-перекладач
Формула / Реферат:
Голосовий фразник-перекладач, що містить мікрофон, цифро-аналоговий та аналого-цифровий перетворювачі, динамік, процесор цифрової обробки сигналів, кнопки керування, індикатор та акумулятор, при цьому мікрофон з'єднаний через аналого-цифровий перетворювач з процесором цифрової обробки сигналу, який через цифро-аналоговий перетворювач з'єднаний з динаміком, мікроконтролер приєднаний до процесора цифрової обробки сигналу, індикатора, кнопок...
Попередній патент: Портативний перекладач-3
Наступний патент: Відеоелектронний комплекс для високошвидкісної зйомки балістичних процесів
Випадковий патент: Біологічно активна добавка для зміцнення захисних сил організму