Портативний перекладач-3
Номер патенту: 122887
Опубліковано: 25.01.2018
Автори: Ільїн Олег Олександрович, Литвиненко Леонід Олександрович, Нікіфорова Олена Миколаївна, Ніколаєвський Олександр Юрійович, Пампуха Ігор Володимирович, Замаруєва Ірина Вікторівна




Формула / Реферат
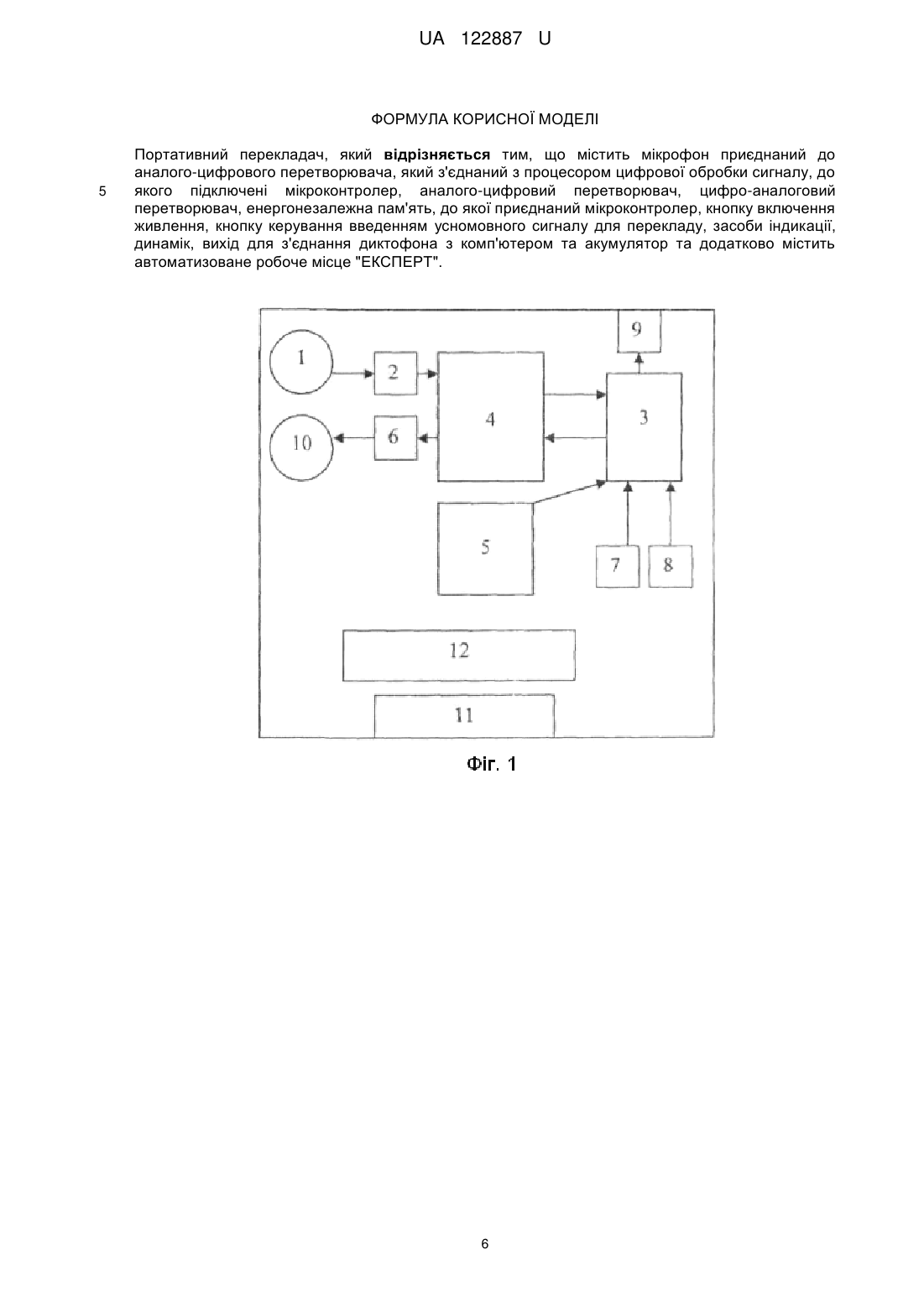
Портативний перекладач, який відрізняється тим, що містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце "ЕКСПЕРТ".
Текст
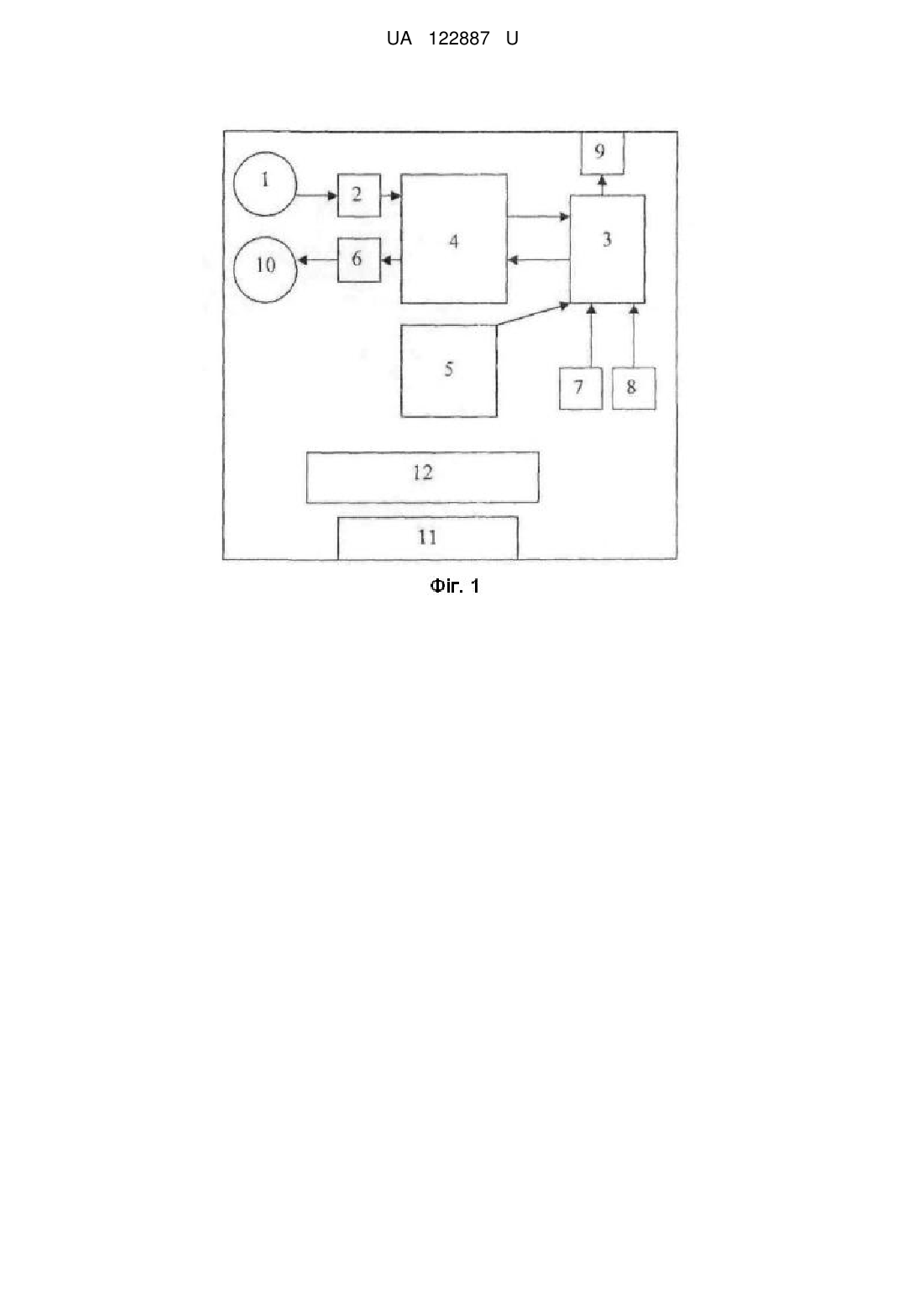
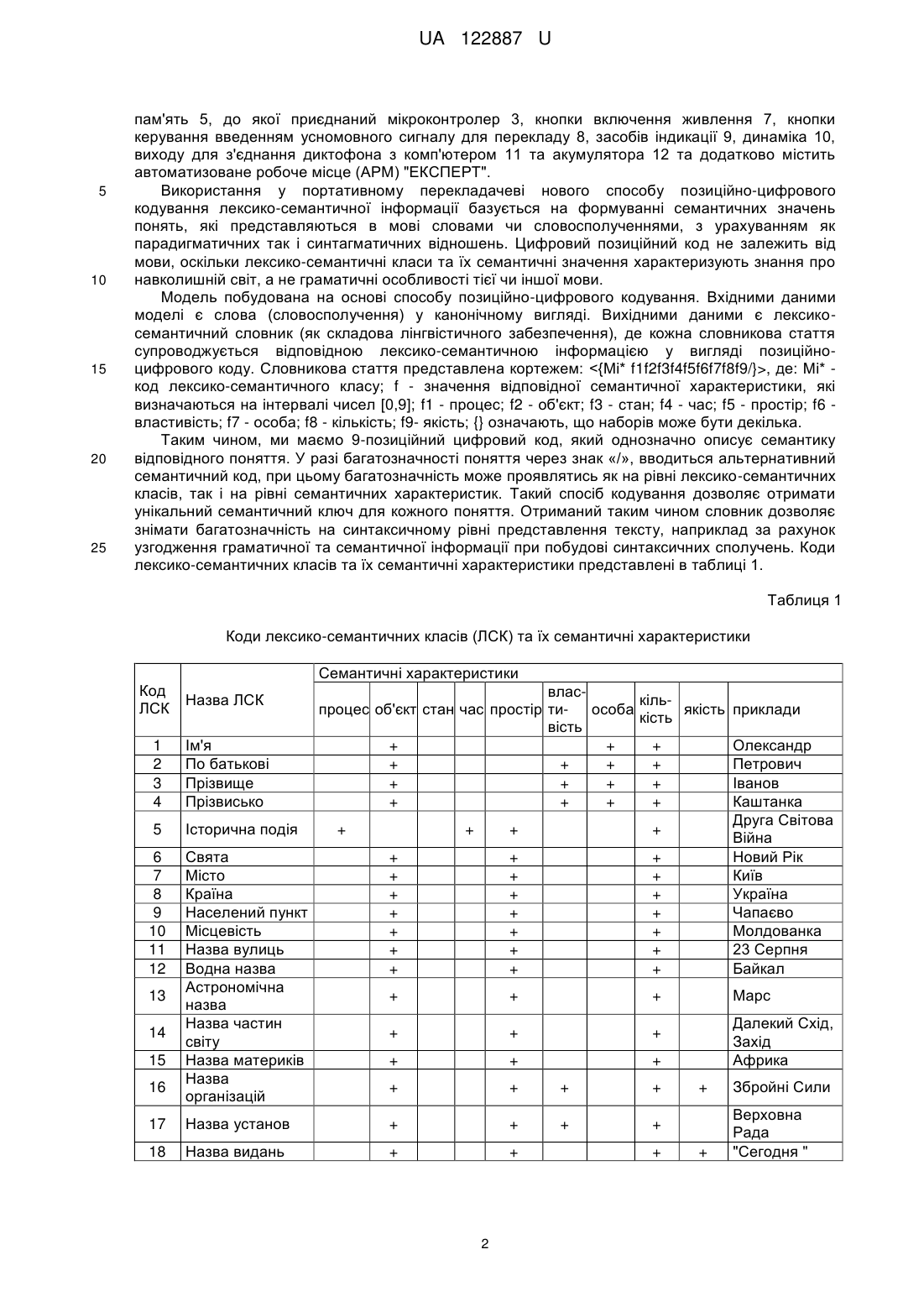
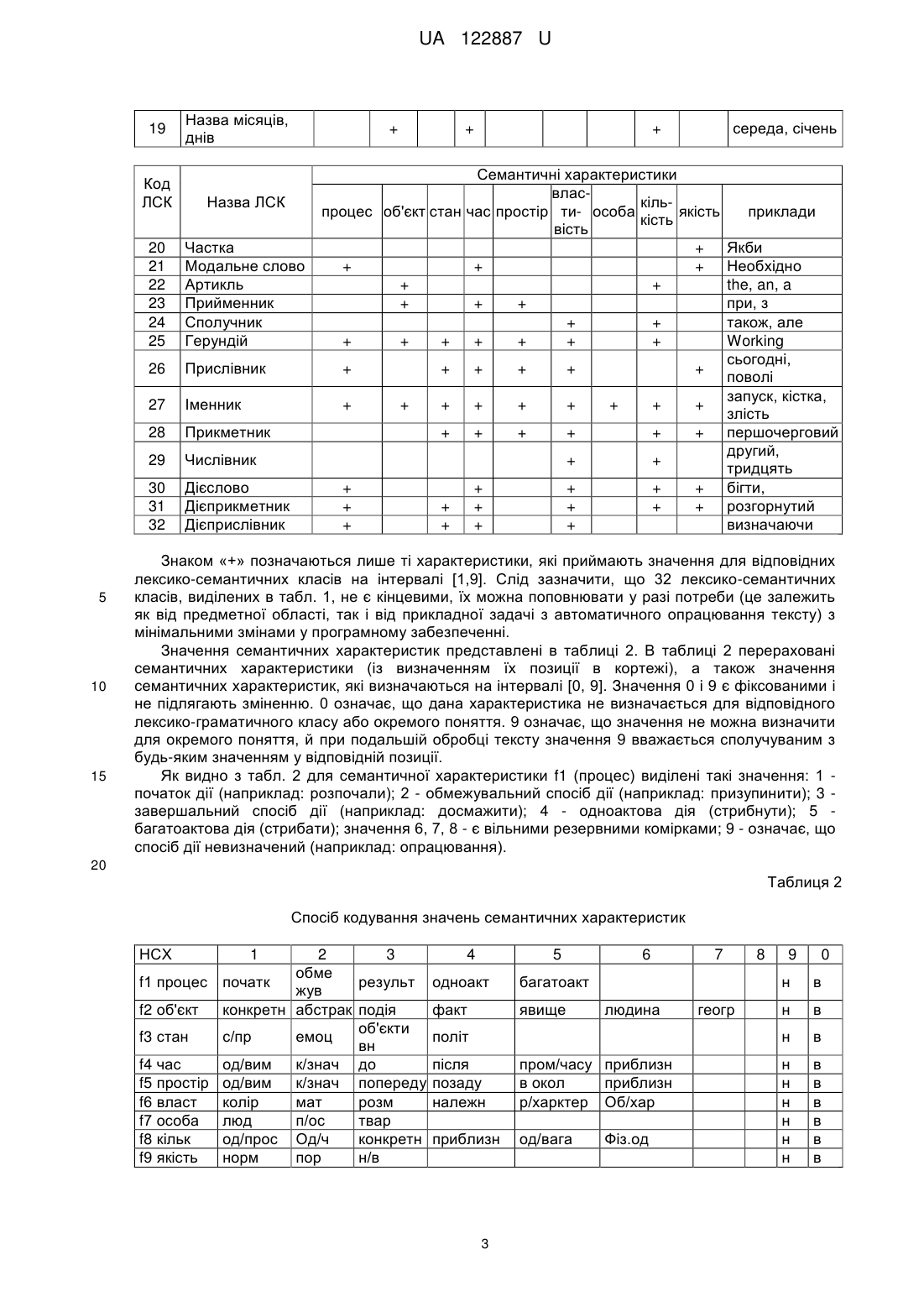
Реферат: Портативний перекладач-3 містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце "ЕКСПЕРТ". UA 122887 U (12) UA 122887 U UA 122887 U 5 10 15 20 25 30 35 40 45 50 55 60 Корисна модель належить до портативних перекладачів. Відомі способи кодування лексико-семантичної інформації орієнтовані на представлення парадигматичних відношень (тобто відношень в предметній області) або синтагматичних відношень (тобто відношень між словоформами. що реалізуються в тексті. При цьому позиційно-цифрове кодування лексико-семантичної інформації лексем, який представляє собою формування семантичного значення лексеми у вигляді фіксованої послідовності цифр, кожна позиція з яких визначається на інтервалі [0, 9], і може знайти широке використання в задачах автоматичного опрацювання природно-мовних текстів в портативних перекладачах. Спосіб кодування парадигматичних відношень лексичних одиниць, представлений Поспеловим [Поспелов Д.А. Логико-лингвистические модели в системах управления. - Μ., 1981. -232 с.], призначений для автоматичної обробки речень вузької предметної області на базі реляційних моделей. Відомі способи кодування лексико-семантичної інформації орієнтовані на представлення парадигматичних відношень (тобто відношень в предметній області) або синтагматичних відношень (тобто відношень між словоформами, що реалізуються в тексті). Мова формалізованого подання знань має загальні закономірності для всього класу реляційних моделей. Для моделювання знань про навколишній світ (ПрО) виділяють декілька класів елементів, які подаються через лінгвістичні (слова та словосполучення) одиниці, які виступають як базові поняття і відношення опису певної ПрО. Так виділяють імена, відношення, поняття. Поняття поділяються на поняття-класи, поняття-процеси і поняття-стани. Поняття-клас - це сукупність конкретних об'єктів та предметів, які мають визначені властивості (генератор шуму, стіл тощо). Поняття-процеси описують групу однорідних процесів (навантаження, ушкодження тощо). Поняття-стан визначає стан об'єкта (нормальний режим, лінія ввімкнена тощо). Імена слугують для ідентифікації екстралінгвістичних понять (літак АН-64А, фірма "Макдоннел гелекоптер" тощо). Відношення слугують для встановлення зв'язків на множині понять. Виділяється до 200 простих (базових) відношень. Так, наприклад: часові (бути одночасно - R11, бути одночасно - R12 тощо), просторові (знаходитись в оточенні - R21, знаходитись позаду - R12 тощо), динамічні (рухатися до - R31 тощо), класифікаційні (належати до класу - R41 тощо), ідентифікуючі (мати ім'я - ρ), прагматичні (слугувати для - R51 тощо), Так, наприклад, в наступних різних фразах: "Деталь переміщується по конвеєру до кінцевого бункера", "Робот йде до складу № 4", "Автомобіль наближається до перехрестя" - реалізується одне відношення R31. Для виводу правильно побудованих формул (ППФ) вводиться сукупність синтаксичних правил. Недоліком наведеного способу кодування є його орієнтація на вузьку предметну область і обмеженість синтаксичної структури речення, що не дає можливості його застосовувати для автоматичного аналізу довільних природно мовних текстів. Це пов'язане з тим, що відношення в тексті може представляться не тільки через широкий спектр лексичних одиниць, але й через складні синтагматичні відношення (які в мові можуть представлятися навіть цілим реченням). А синтагматичні відношення при даному способі кодування не передбачаються. Інший спосіб кодування орієнтований на представлення синтагматичних зв'язків в реченні. Універсальний семантичний код розроблений Мартиновим [Мартынов В.В. Универсальный семантический код. - Минск, 1977. - 190 с.]. Елементарна структура умовного скорочення (УСК) представляється трійкою: (S A 0), де S - підмет в реченні, А - присудок, О - пряме доповнення. Правила перетворення природно-мовного речення до УСК полягають у виділенні елементарних конструкцій на реченні. Над елементарними структурами вводиться алгебра (складання синтагм, інтегрування, розкладання). Недоліком наведеного способу кодування є його орієнтація лише на синтагматичні відношення в тексті, що не дає змогу автоматично семантично правильно виділяти синтаксичні ланцюги в тексті, оскільки за граматичними ознаками може підходити декілька варіантів синтаксичних ланцюгів і тільки один відповідає семантиці тексту. Задачею корисної моделі є створення портативного перекладача - 3 з меншими габаритами та автоматично семантично правильно виділяти синтаксичні ланцюги в тексті, оскільки за граматичними ознаками може підходити декілька варіантів синтаксичних ланцюгів і тільки один відповідає семантиці тексту, як елемент лінгвістичного забезпечення дозволяє підвищити якість перекладу на 30 відсотків у порівнянні з відомими аналогами, при цьому об'єм словника не збільшується. Поставлена задача вирішується тим, що портативний перекладач - 3, згідно з корисною моделлю, містить мікрофон 1 приєднаний до аналого-цифрового перетворювача 2, який з'єднаний з процесором цифрової обробки сигналу 4, до якого підключені мікроконтролер 3, аналого-цифровий перетворювач 2, цифро-аналоговий перетворювач 6, енергонезалежну 1 UA 122887 U 5 10 15 20 25 пам'ять 5, до якої приєднаний мікроконтролер 3, кнопки включення живлення 7, кнопки керування введенням усномовного сигналу для перекладу 8, засобів індикації 9, динаміка 10, виходу для з'єднання диктофона з комп'ютером 11 та акумулятора 12 та додатково містить автоматизоване робоче місце (АРМ) "ЕКСПЕРТ". Використання у портативному перекладачеві нового способу позиційно-цифрового кодування лексико-семантичної інформації базується на формуванні семантичних значень понять, які представляються в мові словами чи словосполученнями, з урахуванням як парадигматичних так і синтагматичних відношень. Цифровий позиційний код не залежить від мови, оскільки лексико-семантичні класи та їх семантичні значення характеризують знання про навколишній світ, а не граматичні особливості тієї чи іншої мови. Модель побудована на основі способу позиційно-цифрового кодування. Вхідними даними моделі є слова (словосполучення) у канонічному вигляді. Вихідними даними є лексикосемантичний словник (як складова лінгвістичного забезпечення), де кожна словникова стаття супроводжується відповідною лексико-семантичною інформацією у вигляді позиційноцифрового коду. Словникова стаття представлена кортежем: , де: Мі* код лексико-семантичного класу; f - значення відповідної семантичної характеристики, які визначаються на інтервалі чисел [0,9]; f1 - процес; f2 - об'єкт; f3 - стан; f4 - час; f5 - простір; f6 властивість; f7 - особа; f8 - кількість; f9- якість; {} означають, що наборів може бути декілька. Таким чином, ми маємо 9-позиційний цифровий код, який однозначно описує семантику відповідного поняття. У разі багатозначності поняття через знак «/», вводиться альтернативний семантичний код, при цьому багатозначність може проявлятись як на рівні лексико-семантичних класів, так і на рівні семантичних характеристик. Такий спосіб кодування дозволяє отримати унікальний семантичний ключ для кожного поняття. Отриманий таким чином словник дозволяє знімати багатозначність на синтаксичному рівні представлення тексту, наприклад за рахунок узгодження граматичної та семантичної інформації при побудові синтаксичних сполучень. Коди лексико-семантичних класів та їх семантичні характеристики представлені в таблиці 1. Таблиця 1 Коди лексико-семантичних класів (ЛСК) та їх семантичні характеристики Семантичні характеристики Код ЛСК 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 власкільпроцес об'єкт стан час простір ти- особа якість приклади кість вість Ім'я + + + Олександр По батькові + + + + Петрович Прізвище + + + + Іванов Прізвисько + + + + Каштанка Друга Світова Історична подія + + + + Війна Свята + + + Новий Рік Місто + + + Київ Країна + + + Україна Населений пункт + + + Чапаєво Місцевість + + + Молдованка Назва вулиць + + + 23 Серпня Водна назва + + + Байкал Астрономічна + + + Марс назва Назва частин Далекий Схід, + + + світу Захід Назва материків + + + Африка Назва + + + + + Збройні Сили організацій Верховна Назва установ + + + + Рада Назва видань + + + + "Сегодня " Назва ЛСК 2 UA 122887 U 19 Назва місяців, днів + Частка Модальне слово Артикль Прийменник Сполучник Герундій 26 Прислівник + 27 Іменник + 28 Прикметник 29 Числівник 30 31 32 15 Назва ЛСК 20 21 22 23 24 25 10 середа, січень + Семантичні характеристики власкільпроцес об'єкт стан час простір ти- особа якість кість вість + + + + + + + + + + + + + + + + + + Код ЛСК 5 + Дієслово Дієприкметник Дієприслівник + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + приклади Якби Необхідно the, an, a при, з також, але Working сьогодні, поволі запуск, кістка, злість першочерговий другий, тридцять бігти, розгорнутий визначаючи Знаком «+» позначаються лише ті характеристики, які приймають значення для відповідних лексико-семантичних класів на інтервалі [1,9]. Слід зазначити, що 32 лексико-семантичних класів, виділених в табл. 1, не є кінцевими, їх можна поповнювати у разі потреби (це залежить як від предметної області, так і від прикладної задачі з автоматичного опрацювання тексту) з мінімальними змінами у програмному забезпеченні. Значення семантичних характеристик представлені в таблиці 2. В таблиці 2 перераховані семантичних характеристики (із визначенням їх позиції в кортежі), а також значення семантичних характеристик, які визначаються на інтервалі [0, 9]. Значення 0 і 9 є фіксованими і не підлягають зміненню. 0 означає, що дана характеристика не визначається для відповідного лексико-граматичного класу або окремого поняття. 9 означає, що значення не можна визначити для окремого поняття, й при подальшій обробці тексту значення 9 вважається сполучуваним з будь-яким значенням у відповідній позиції. Як видно з табл. 2 для семантичної характеристики f1 (процес) виділені такі значення: 1 початок дії (наприклад: розпочали); 2 - обмежувальний спосіб дії (наприклад: призупинити); 3 завершальний спосіб дії (наприклад: досмажити); 4 - одноактова дія (стрибнути); 5 багатоактова дія (стрибати); значення 6, 7, 8 - є вільними резервними комірками; 9 - означає, що спосіб дії невизначений (наприклад: опрацювання). 20 Таблиця 2 Спосіб кодування значень семантичних характеристик НСХ 1 2 3 обме f1 процес початк результ жув f2 об'єкт конкретн абстрак подія об'єкти f3 стан с/пр емоц вн f4 час од/вим к/знач до f5 простір од/вим к/знач попереду f6 власт колір мат розм f7 особа люд п/ос твар f8 кільк од/прос Од/ч конкретн f9 якість норм пор н/в 4 5 одноакт явище 7 багатоакт факт 6 8 9 0 н політ після позаду належн пром/часу приблизн в окол приблизн р/харктер Об/хар приблизн од/вага 3 Фіз.од геогр н в н людина в в н н н н н н в в в в в в UA 122887 U 5 10 15 20 25 30 35 40 45 50 55 60 Семантична характеристика f2 (об'єкт) має такі значення: 1 - обчислювальний (наприклад: стіл); 2 - не обчислювальний (борошно); 3 - конкретний (дім, стіл, борошно); 4 - абстрактний (філософія); 5 - подія (війна, день народження); 6 - географічна назва (Київ); 7 - явище (сонячне затемнення). Семантична характеристика f3 (стан) має такі значення: 1 - стан-процес (наприклад: заморожений); 2 - емоційний (радість, хвилювання); 3 - об'єктивний (здоровий); 4 - політичний (банкрутство, занепад). Семантична характеристика f4 (час) має такі значення: 1 - одиниця вимірювання (наприклад: місяць, рік, доба, хвилина); 2 - конкретне значення (5 година ранку); 3 - до конкретного значення (до вечора); 4 - після конкретного значення (після обіду); 5 - проміжок часу (з понеділку по п'ятницю); 6 - приблизне значення (близько о півночі). Семантична характеристика f5 (простір) має такі значення: 1 - одиниця вимірювання (наприклад: метр, кілометр); 2 - конкретне значення (у парку, під деревом); 3 - попереду (перед будинком); 4 - позаду (за будинком); 5 - в околиці (в районі вокзалу); 6 - приблизне розташування (біля церкви). Семантична характеристика f6 (властивість) має такі значення: 1 - колір (наприклад: зелений); 2 - матеріал (залізний, дерев'яний); 3 - розмір (маленький); 4 - приналежність (мамин); 5 - риси характеру (стійкий, врівноважений); 6 - об'єктивна характеристика (вологостійкий). Семантична характеристика f7 (особа) має такі значення: 1 - людина (наприклад: мати, дитина); 2 - посадова особа (державний службовець, президент, прокурор); 3 - тварина (корова, собака). Семантична характеристика f8 (кількість) має такі значення: 1 - одиниця простору (км, с); 2 одиниця часу (хв, г); 3 - конкретний (двадцять, сто); 4 - приблизно (мало, багато); 5 - одиниця ваги (кілограм); 6 - інші одиниці (ампер). Семантична характеристика f9 (якість) має такі значення: 1 - норма (наприклад: гарний); 2 порівняльний ступінь (гарніший); 3 - найвищий ступінь (найкращий). Значення семантичних характеристик з табл. 2 також не є усталеним, і дозволяє досліднику або доповнювати резервні комірки (оскільки не всі комірки заповнені значеннями на інтервалі [1,8], або формувати замінювати назву семантичної характеристики під власні прикладні задачі аналізу тексту. Це дозволяє налаштовувати дані в системі як на нову предметну область, так і на нові завдання аналізу природно-мовний текст (ПМТ) без змін програмного забезпечення. Запропонований 9-позиційний цифровий код, який однозначно описує семантику відповідного поняття. У разі багатозначності поняття через знак «/», вводиться альтернативний семантичний код, при цьому багатозначність може проявлятися як на рівні лексико-семантичних класів так і на рівні семантичних характеристик. Такий спосіб кодування дозволяє отримати унікальний семантичний ключ для кожного поняття. В процесі автоматичної обробки семантична багатозначність усувається як за рахунок граматичного розбору речень (за рахунок узгодження лексико-граматичних і лексико-семантичних класів), так і на етапі прагматичного аналізу тексту. Для автоматизованого формування семантичних характеристик призначено АРМ "ЕКСПЕРТ", який в автоматизованому режимі здійснює побудову словників як компонента лінгвістичного забезпечення автоматичного опрацювання ПМТ. Система АРМ "ЕКСПЕРТ" дозволяє вводити та зберігати семантичну інформацію, що призначена для автоматизованого формування енциклопедичних знань про навколишній світ. Як видно з наведених прикладів застосування у портативному перекладачеві нового словника, сформованого на способі позиційно-цифрового кодування лексико-семантичної інформації, який базується на формуванні семантичних значень понять, які представляються в мові словами чи словосполученнями, з урахуванням як парадигматичних так і синтагматичних відношень є універсальним відносно мови і дозволяє в єдиній системі кодування представляти словоформи, що відносяться до різних мов. Надлишковість запропонованого цифрового семантичного коду надає змогу експерту додавати специфічні семантичні характеристики, притаманні певній предметній області; універсальними семантичними характеристиками (час, простір, якість, кількість, обчислювальність тощо), що дозволяє визначати семантичну сполучуваність слів в реченні; незалежним доступом до кожної семантичної характеристики (забезпечується позиційно-цифровим кодуванням семантичної інформації); можливістю в межах єдиної системи кодування враховувати як семантику слова, так і екстралінгвістичні знання, і надає можливість практично застосовувати в системах автоматичної обробки природно-мовних письмових текстів. На Фіг. 1 зображено структурну схему портативного перекладача-3, в якому реалізований спосіб усномовного перекладу; 4 UA 122887 U 5 10 15 20 25 30 35 40 45 50 55 Фіг. 2 автоматизоване робоче місце (АРМ) "ЕКСПЕРТ". Приклад реалізації Портативний перекладач-3 складається з наступних частин: 1 - мікрофона; 2 - аналогоцифрового перетворювача; 3 - мікроконтролера; 4 - процесора цифрової обробки сигналів; 5 енергонезалежної пам'яті; 6 - цифро-аналогового перетворювача; 7 - кнопки включення живлення; 8 - кнопки керування введенням усномовного сигналу для перекладу; 9 - двох світлових індикаторів; 10 - динаміка; 11 - виходу для з'єднання диктофона з комп'ютером; 12 акумулятору. Мікрофон 1 приєднаний до аналого-цифрового перетворювача 2, який з'єднаний з процесором 4 цифрової обробки сигналу. До процесора 4 підключені мікроконтролер 3, аналого-цифровий 2 та цифро-аналоговий 6 перетворювачі. Мікроконтролер 3 приєднаний до енергонезалежної пам'яті 5, клавіатури 7, 8, та засобів індикації 9. Живлення пристрою виконується за допомогою акумулятора 12. Для зв'язку з комп'ютером призначений USB-πορτ 11. Введення усномовних слів та словосполучень активується натисненням кнопки керування введенням усномовного сигналу. Введення усномовного сигналу полягає в тому, що звуковий сигнал, який з мікрофона 1 надходить в аналого-цифровий перетворювач 2, оцифровується і подається в процесор 4 цифрової обробки сигналу, починає сприйматися ним як послідовність звукових відліків, які починають поділятися на блоки даних, оброблятися, перетворюватися на вектори параметрів та розпізнаватися. Результатом розпізнавання можуть бути переклад або відмова від розпізнавання (наприклад, якщо слово або словосполучення відсутнє в словнику транскрипцій). В залежності від результату розпізнавання, процесор 4 генерує сигнал мікроконтролеру 3, який вибирає за заданим алгоритмом слово або словосполучення для озвучення та викликає його із енергонезалежної пам'яті 5. Слово або словосполучення для озвучення подається в процесор 4, декодується в прийнятну для озвучення форму, надходить в цифро-аналоговий перетворювач 6 та озвучується в динаміку 10. Світлові індикатори 9 індексують режими, в яких працює пристрій: очікування, перекладу, озвучення, з'єднання з персональним комп'ютером тощо. Для розширення або зміни набору фраз для розпізнавання семантичних характеристик автоматично включається режим граматичного розбору речень (за рахунок узгодження лексикограматичних і лексико-семантичних класів), який міститься в пам'яті портативного перекладача для автоматизації побудови словників як компонента лінгвістичного забезпечення автоматичного опрацювання природно-мовних текстів. В нашому випадку словники формуються: 1. Укладання лінгвістичної бази даних Лінгвістична база даних (ЛБД) є невід'ємним етапом побудови лінгвістичного забезпечення і самим трудомістким. Для автоматизованого формування наборів кодів розроблено автоматизоване робоче місце (АРМ) "ЕКСПЕРТ" (див. фіг. 2). АРМ який призначений для автоматизації побудови словників як компонента лінгвістичного забезпечення автоматичного опрацювання природно-мовних текстів. Інтерфейс системи АРМ "ЕКСПЕРТ" представлений на фіг. 2. Система АРМ "ЕКСПЕРТ" дозволяє вводити та зберігати семантичну інформацію, що призначена для автоматизованого формування енциклопедичних знань про навколишній світ. 1.1. Оптимізація лексико-граматичного коду під задачу В залежності від прикладної задачі на інтервалі [0,9] однозначно описується семантика відповідного поняття. У разі багатозначності поняття через знак «/», вводиться альтернативний семантичний код, при цьому багатозначність може проявлятись як на рівні лексико-семантичних класів, так і на рівні семантичних характеристик. Такий спосіб кодування дозволяє отримати унікальний семантичний ключ для кожного поняття. Отриманий таким чином словник в АРМ "ЕКСПЕРТ" дозволяє знімати багатозначність на синтаксичному рівні представлення тексту, наприклад, за рахунок узгодження граматичної та семантичної інформації при побудові синтаксичних сполучень. Крім цього задача машинного перекладу передбачає всі етапи аналізу тексту, включаючи морфологічний, синтаксичний і семантичний аналіз тексту. Тому значення 0 і 9 семантичних характеристик представлені в таблиці 2 є фіксованими і не підлягають зміненню. Перераховані особливості суттєво впливають на якість перекладу і обсяги словників. 5 UA 122887 U ФОРМУЛА КОРИСНОЇ МОДЕЛІ 5 Портативний перекладач, який відрізняється тим, що містить мікрофон приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік, вихід для з'єднання диктофона з комп'ютером та акумулятор та додатково містить автоматизоване робоче місце "ЕКСПЕРТ". 6 UA 122887 U Комп’ютерна верстка Л. Литвиненко Міністерство економічного розвитку і торгівлі України, вул. М. Грушевського, 12/2, м. Київ, 01008, Україна ДП “Український інститут інтелектуальної власності”, вул. Глазунова, 1, м. Київ – 42, 01601 7
ДивитисяДодаткова інформація
МПК / Мітки
МПК: G06F 17/28
Мітки: портативний, перекладач-3
Код посилання
<a href="https://ua.patents.su/9-122887-portativnijj-perekladach-3.html" target="_blank" rel="follow" title="База патентів України">Портативний перекладач-3</a>
Портативний перекладач

Номер патенту: 107669
Опубліковано: 24.06.2016
Автори: Литвиненко Леонід Олександрович, Ніколаєвський Олександр Юрійович, Замаруєва Ірина Вікторівна, Лісовський Володимир Миколайович, Балабін Віктор Володимирович, Пампуха Ігор Володимирович
МПК: G06F 17/28
Мітки: перекладач, портативний
Формула / Реферат:
Портативний перекладач, який відрізняється тим, що містить мікрофон, приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік,...
Портативний перекладач

Номер патенту: 107670
Опубліковано: 24.06.2016
Автори: Замаруєва Ірина Вікторівна, Ніколаєвський Олександр Юрійович, Лісовський Володимир Миколайович, Пампуха Ігор Володимирович, Балабін Віктор Володимирович, Литвиненко Леонід Олександрович
МПК: G06F 17/28
Мітки: перекладач, портативний
Формула / Реферат:
Портативний перекладач, який відрізняється тим, що містить мікрофон, приєднаний до аналого-цифрового перетворювача, який з'єднаний з процесором цифрової обробки сигналу, до якого підключені мікроконтролер, аналого-цифровий перетворювач, цифро-аналоговий перетворювач, енергонезалежна пам'ять, до якої приєднаний мікроконтролер, кнопку включення живлення, кнопку керування введенням усномовного сигналу для перекладу, засоби індикації, динамік,...
Голосовий портативний словник-перекладач

Номер патенту: 48218
Опубліковано: 10.03.2010
Автори: Тертичний Григорій Миколайович, Гриценко Володимир Ілліч, Павлов Олег Ігоревич, Стасевич Петро Анатолійович, Вінцюк Тарас Климович
МПК: G10L 15/00
Мітки: портативний, словник-перекладач, голосовий
Формула / Реферат:
Голосовий портативний словник-перекладач, що містить мікрофон, з'єднаний з аналого-цифровим перетворювачем, динамік, з'єднаний з цифро-аналоговим перетворювачем, процесор цифрової обробки сигналів, виходами підключений до динаміка через цифро-аналоговий перетворювач та до входу мікроконтролера, на входи якого підключені кнопка включення живлення такнопка керування процесами введення усномовного сигналу, його подальшого розпізнавання і...
Голосовий фразник-перекладач

Номер патенту: 52350
Опубліковано: 25.08.2010
Автори: Гриценко Володимир Ілліч, Вінцюк Тарас Климович
МПК: G01L 15/00
Мітки: голосовий, фразник-перекладач
Формула / Реферат:
Голосовий фразник-перекладач, що містить мікрофон, цифро-аналоговий та аналого-цифровий перетворювачі, динамік, процесор цифрової обробки сигналів, кнопки керування, індикатор та акумулятор, при цьому мікрофон з'єднаний через аналого-цифровий перетворювач з процесором цифрової обробки сигналу, який через цифро-аналоговий перетворювач з'єднаний з динаміком, мікроконтролер приєднаний до процесора цифрової обробки сигналу, індикатора, кнопок...
Спосіб усномовного перекладу фраз та голосовий фразник-перекладач на його основі

Номер патенту: 67700
Опубліковано: 25.04.2007
Автори: Гриценко Володимир Ільїч, Вінцюк Тарас Климович, Ситніков Даніїл Анатолійович, Федорин Ярослав Володимирович
МПК: G10L 15/00
Мітки: спосіб, фразник-перекладач, голосовий, усномовного, фраз, основі, перекладу
Формула / Реферат:
1. Спосіб усномовного перекладу фраз, який заснований на перетворенні звукового сигналу, що несе інформацію про відповідну фразу, в електричний аналоговий сигнал, підсилюванні його та перетворенні у цифровий сигнал, розпізнаванні останнього та лінгвістичному аналізі результату розпізнавання, генеруванні цифрового сигналу, що несе інформацію про переклад відповідної фрази, перетворенні його в електричний аналоговий сигнал, підсилюванні...