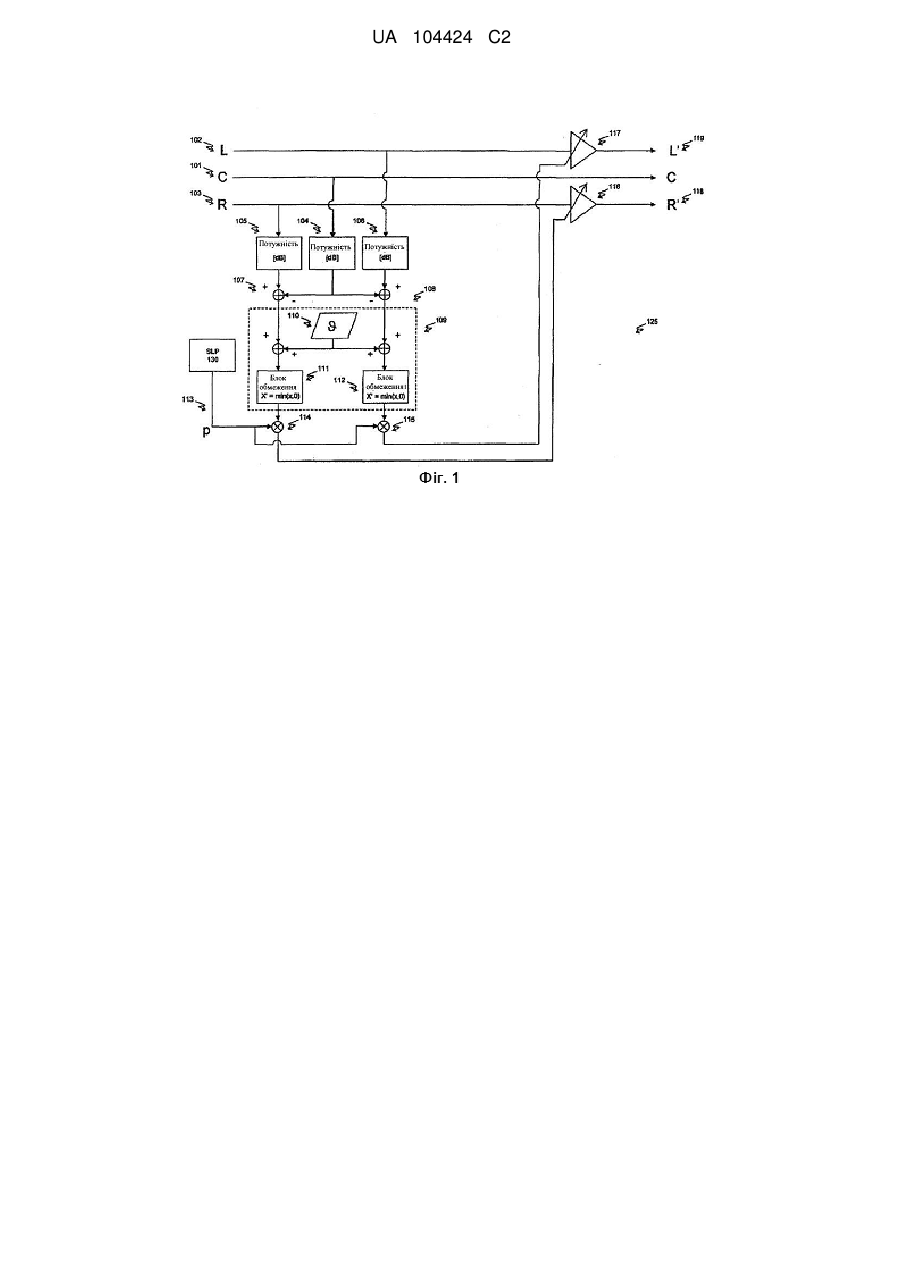
Спосіб та пристрій для підтримки чутності мови у багатоканальному аудіосигналі з мінімальним впливом на систему об’ємного звучання











Формула / Реферат
1. Спосіб покращення чутності мови в багатоканальному звуковому сигналі, при цьому згаданий спосіб включає наступні етапи:
порівнюють першу характеристику і другу характеристику багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому порівняння першої характеристики і другої характеристики включає наступні операції:
виконують прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови;
коректують коефіцієнт підсилення, який застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і
використовують скоригований коефіцієнт підсилення як коефіцієнт ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій.
коректують коефіцієнт ослаблення відповідно до значення імовірності мови для формування скоригованого коефіцієнта ослаблення; і
ослабляють другий канал з використанням скоригованого коефіцієнта ослаблення.
2. Спосіб за п. 1, який додатково включає наступний етап:
обробляють багатоканальний звуковий сигнал для формування першої характеристики і другої характеристики.
3. Спосіб за п. 1, який додатково включає наступний етап: обробляють перший канал для формування значення імовірності мови.
4. Спосіб за п. 1, в якому другий канал є одним з множини других каналів, при цьому друга характеристика є однією з множини других характеристик, причому коефіцієнт ослаблення є одним з множини коефіцієнтів ослаблення, і
причому скоригований коефіцієнт ослаблення є одним з множини скоригованих коефіцієнтів ослаблення, причому спосіб додатково включає наступні етапи:
порівнюють першу характеристику і множину других характеристик для формування множини коефіцієнтів ослаблення;
коректують множину коефіцієнтів ослаблення відповідно до значення імовірності мови для формування множини скоригованих коефіцієнтів ослаблення; і
ослаблюють множину других каналів з використанням множини скоригованих коефіцієнтів ослаблення.
5. Спосіб за п. 1, в якому багатоканальний звуковий сигнал містить третій канал, який містить, переважно, немовний звук, при цьому спосіб додатково включає наступні етапи:
порівнюють першу характеристику і третю характеристику для формування додаткового коефіцієнта ослаблення, причому третя характеристика відповідає третьому каналу;
коректують додатковий коефіцієнт ослаблення відповідно до значення імовірності мови для формування скоригованого додаткового коефіцієнта ослаблення; і
ослаблюють третій канал з використанням скоригованого коефіцієнта ослаблення.
6. Спосіб за п. 1, в якому другий спектр потужності містить множину частотних смуг, при цьому етап порівняння першої характеристики і другої характеристики додатково містить виконання обчислення рівня гучності на основі другого спектра потужності для формування обчисленого рівня гучності; причому етап корекції коефіцієнта підсилення додатково містить корекцію множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності; і причому етап використання коефіцієнта підсилення включає використання множини скоригованих коефіцієнтів підсилення як коефіцієнта ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності.
7. Пристрій для покращення чутності мови в багатоканальному звуковому сигналі, який містить схему для покращення чутності мови в багатоканальному звуковому сигналі, при цьому пристрій містить:
схему порівняння, яка виконана з можливістю порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому схема порівняння містить:
схему прогнозування розбірливості мови, яка виконана з можливістю прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови;
схему корекції коефіцієнта підсилення, яка виконана з можливістю корекції коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і
схему вибору коефіцієнта підсилення, яка виконана з можливістю вибору скоригованого коефіцієнта підсилення як коефіцієнт ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій;
помножувач, який виконаний з можливістю корекції коефіцієнта ослаблення відповідно до значення імовірності мови, для формування скоригованого коефіцієнта ослаблення; і
підсилювач, який виконаний з можливістю ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення.
8. Пристрій за п. 7, в якому другий спектр потужності містить множину частотних смуг, і при цьому схема порівняння додатково містить:
схему обчислення рівня гучності, яка виконана з можливістю виконання обчислення рівня гучності на основі другого спектра потужності, для формування обчисленого рівня гучності; і
схему оптимізації, яка виконана з можливістю корекції множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності, і, яка використовує множину скоригованих коефіцієнтів підсилення як коефіцієнт ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності.
9. Пристрій за п. 7, який додатково містить:
перший обчислювач спектральної густини потужності, який виконаний з можливістю обчислення першого спектра потужності першого каналу; і
другий обчислювач спектральної густини потужності, який виконаний з можливістю обчислення другого спектра потужності другого каналу.
10. Пристрій за п. 7, який додатково містить:
перший набір фільтрів, який виконаний з можливістю розбиття першого каналу на першу множину спектральних складових;
перший набір блоків оцінювання потужності, який виконаний з можливістю обчислення першого спектра потужності по першій множині спектральних складових;
другий набір фільтрів, який виконаний з можливістю розбиття другого каналу на другу множину спектральних складових; і
другий набір блоків оцінювання потужності, який виконаний з можливістю обчислення другого спектра потужності по другій множині спектральних складових.
11. Пристрій за п. 7, який додатково містить:
процесор визначення мови, який виконаний з можливістю обробки першого каналу, для формування значення імовірності мови.
12. Машиночитаний носій інформації для покращення чутності мови в багатоканальному звуковому сигналі, який містить збережену на ньому комп'ютерну програму, яка керує пристроєм для виконання обробки, який містить:
порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому порівняння містить:
виконання прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови;
корекцію коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і
використання скоригованого коефіцієнта підсилення як коефіцієнта ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій;
корекцію коефіцієнта ослаблення відповідно до значення імовірності мови для формування скоригованого коефіцієнта ослаблення; і
ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення.
13. Пристрій для покращення чутності мови в багатоканальному звуковому сигналі, який містить схему для покращення чутності мови в багатоканальному звуковому сигналі, при цьому пристрій містить:
засіб для порівняння першої характеристики і другої характеристики багатоканального звукового сигналу, для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому засіб для порівняння містить:
засіб для виконання прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови;
засіб для корекції коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і
засіб для використання скоригованого коефіцієнта підсилення як коефіцієнта ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій;
засіб для корекції коефіцієнта ослаблення відповідно до значення імовірності мови, для формування скоригованого коефіцієнта ослаблення; і
засіб для ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення.
14. Пристрій за п. 13, в якому другий спектр потужності містить множину частотних смуг, при цьому засіб для порівняння додатково містить засіб для виконання обчислення рівня гучності на основі другого спектра потужності, для формування обчисленого рівня гучності; причому засіб для корекції коефіцієнта підсилення відповідає засобу для корекції множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності; і засіб для використання коефіцієнта підсилення відповідає засобу для використання множини скоригованих коефіцієнтів підсилення як коефіцієнта ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності.
Текст
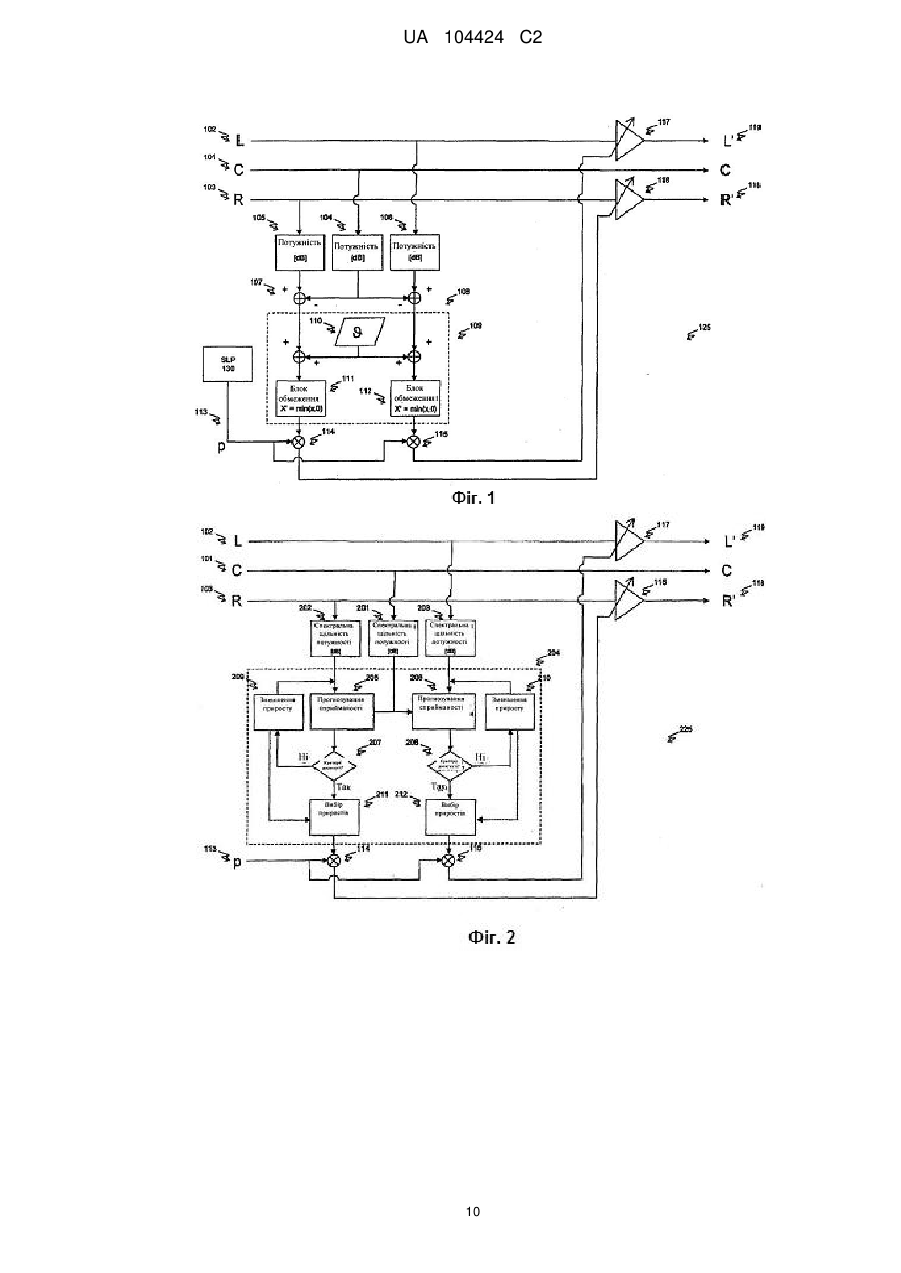
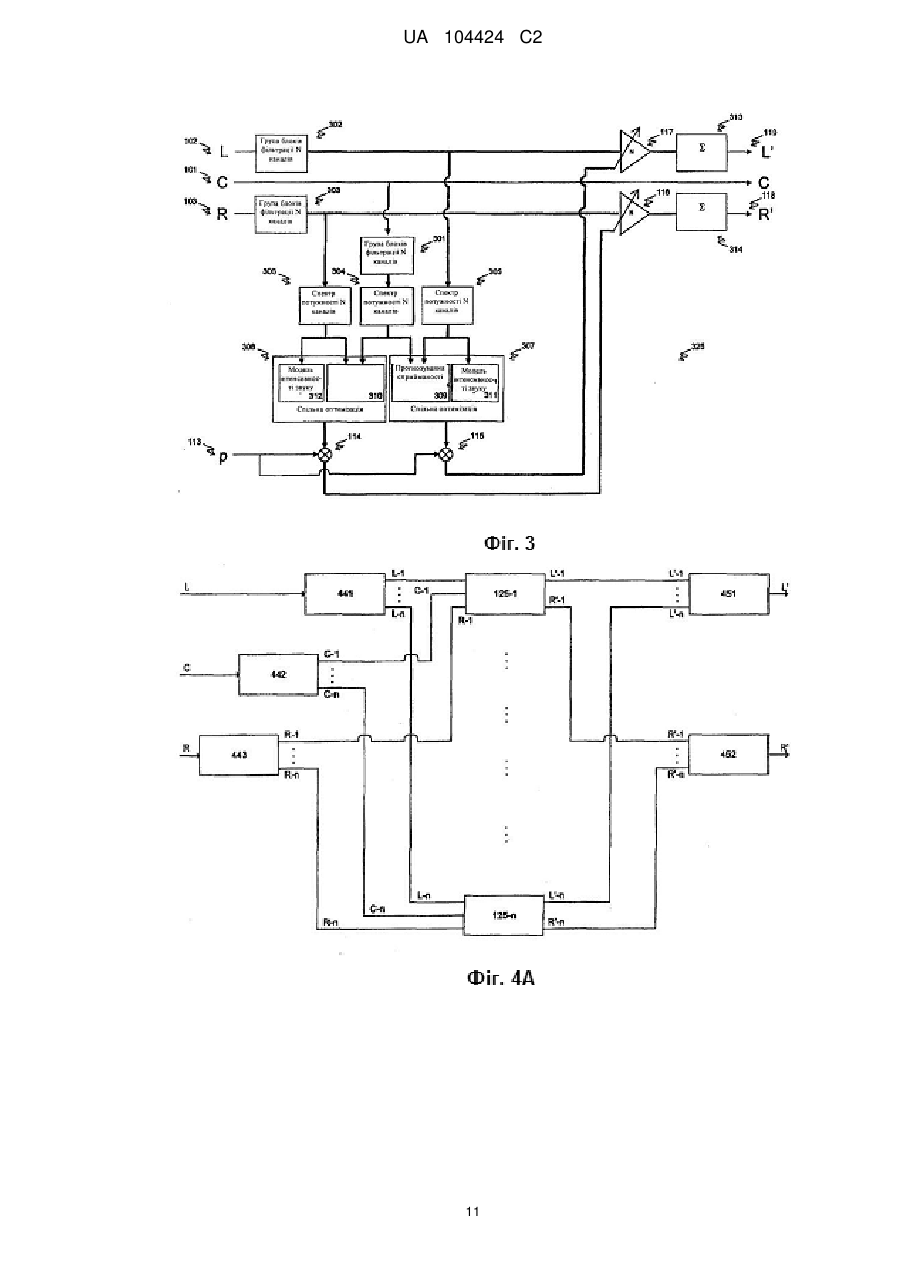
Реферат: Винахід належить до обробки звукових сигналів, до поліпшення сприйманості мови в багатоканальному звуковому сигналі. Спосіб включає в себе порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для генерації коефіцієнта ослаблення, при цьому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовні і немовні звукові сигнали, а друга характеристика відповідає другому каналу багатоканального звукового сигналу, який, переважно, містить немовні звукові сигнали. Спосіб додатково включає в себе коректування послаблюючого коефіцієнта, згідно з оцінкою імовірності мови, для генерації скоректованого послаблюючого коефіцієнта та включає в себе ослаблення другого каналу з використанням скоректованого послаблюючого коефіцієнта. UA 104424 C2 (12) UA 104424 C2 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 60 Дана заявка на винахід заявляє пріоритет попередньої заявки на патент США № 61/046,271, поданої 18 квітня 2008 року, яка шляхом посилання включається в даний документ у всій своїй повноті. РІВЕНЬ ТЕХНІКИ Даний винахід, загалом, належить до обробки звукових сигналів, а більш конкретно, до поліпшення чіткості діалогу і усного мовлення, зокрема, в об'ємному розважальному звуковому супроводі. Підходи, описані в даному розділі документа, не являють собою попередній рівень техніки по відношенню до формули винаходу в даній заявці і не можуть бути визнані як попередній рівень техніки через включення в даний розділ, якщо тільки не вказане зворотне. Сучасний розважальний звуковий супровід з численними одночасними звуковими каналами (система об'ємного звуку) надає слухачам реалістичні звукові оточення з ефектом занурення, що мають колосальне розважальне значення. У таких оточеннях багато які звукові елементи, такі як діалог, музика і звукові ефекти, представлені одночасно і конкурують, відволікаючи увагу слухача. Для деяких членів аудиторії - особливо зі зниженими слуховими рецепторами або з уповільненим когнітивним сприйняттям - діалог і усне мовлення можуть бути важкі для розуміння протягом деяких частин програми, в яких представлені гучні конкуруючі звукові елементи. Протягом таких епізодів для цих слухачів було б корисно, якби рівень конкуруючих звуків знизився. Усвідомлення того, що музика і ефекти можуть придушувати діалог, не нове, і було запропоновано декілька способів для виправлення цієї ситуації. Однак, як буде стисло викладено далі, ці запропоновані способи або несумісні з сучасною практикою широкомовних передач, накладають зайво високу плату на всю індустрію розваг, або і те, і інше. У виробництві об'ємного звукового супроводу в кіно і на телебаченні загальноприйнятою практикою є розміщення більшої частини діалогу і усного мовлення тільки в один канал (центральний канал, його називають також мовним каналом). Звичайно, музика, звуки навколишнього середовища і звукові ефекти мікшуються, як в мовному, так і у всіх інших каналах (наприклад, в Лівому [L], Правому [R], Лівому об'ємному [Is] і в Правому об'ємному [rs] каналах, їх називають також немовними каналами). В результаті цього, мовний канал переносить велику частину мовного і значну кількість немовного звукового супроводу, що міститься в звуковій програмі, тоді як немовні канали переносять, переважно, немовний звуковий супровід, але також можуть переносити невелику кількість мови. Один простий підхід до полегшення сприйманості діалогу або усного мовлення в цих уживаних музичних сумішах полягає в постійному зниженні рівня гучності всіх немовних каналів, відносно рівня гучності мовного каналу, наприклад, на 6 dB. Цей підхід простий і ефективний, і він практикується в наші дні (наприклад, система відновлення звуку SRS [Sound Retrieval System] для чистоти діалогу (Dialog Clarity) або модифіковані рівняння понижувального мікшування в об'ємних декодерах). Однак він страждає щонайменше на один недолік: постійне ослаблення немовних каналів може до такої міри знизити рівень гучності спокійних звуків навколишнього середовища, які не заважають сприйняттю мови, що їх неможливо буде почути. При ослабленні не заважаючих звуків навколишнього середовища порушується естетичний баланс передачі без якої-небудь користі для розуміння мови слухачами. Альтернативне рішення описане в серії патентів авторів Vaudrey і Saunders (U.S. Patent No. 7,266,501, U.S. Patent No. 6,772,127, U.S. Patent No. 6,912,501, і U.S. Patent No. 6,650,755). Наскільки зрозуміло, їх підхід має на увазі модифікацію змісту і розподілу продукції. Згідно з цією конфігурацією, споживач отримує два різних звукових сигнали. Перший з цих сигналів містить "Головний зміст" звукового супроводу. У багатьох випадках цей сигнал повністю поглинається мовою, але, за бажанням продюсера продукції, він може містити також і інші типи сигналів. Другий сигнал містить "Повторний зміст" звукового супроводу, який складений з всіх звукових елементів, що залишилися. Користувачеві надане керування відносними рівнями гучності цих двох сигналів або за допомогою ручного настроювання рівня гучності кожного з сигналів або за допомогою автоматичної підтримки відношення потужностей, вибраного користувачем. Хоч ця конфігурація допомагає обмежити зайве ослаблення не заважаючих звуків навколишнього середовища, її широкому поширенню заважає несумісність з усталеними способами виробництва і розподілу продукції. Інший приклад способу керування відносними рівнями гучності мовного і немовного звукового супроводу був запропонований автором Bennett в U.S. Application Publication No. 20070027682. Всі приклади на попередньому рівні техніки розділяють один спільний недолік: вони не надають ніяких технічних засобів мінімізації впливу, який надає підвищення чіткості діалогу на 1 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 систему звучання, що мається на увазі творцем програми, крім інших вад. Отже, об'єктом даного винаходу є надання технічних засобів для обмеження рівня гучності немовних каналів в традиційно мікшованій багатоканальній розважальній програмі таким чином, щоб мова залишалася зрозумілою, в той час як підтримувалася б також сприйманість немовних звукових компонентів. Таким чином, є потреба в поліпшених методиках підтримки сприйманості мови. Даний винахід вирішує ці та інші проблеми за допомогою надання пристрою і способу поліпшення сприйманості мови в багатоканальному звуковому сигналі. СУТЬ ВИНАХОДУ Втілення даного винаходу поліпшують сприйманість мови. У одному втіленні даний винахід включає в себе спосіб поліпшення сприйманості мови в багатоканальному звуковому сигналі. Цей спосіб включає в себе порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для генерації коефіцієнта ослаблення. Ця перша характеристика відповідає першому каналу цього багатоканального звукового сигналу, який містить мовні і немовні звукові сигнали, а друга характеристика відповідає другому каналу цього багатоканального звукового сигналу, який, переважно, містить немовні звукові сигнали. Цей спосіб додатково включає в себе коректування цього послаблюючого коефіцієнта, згідно з оцінкою імовірності мови, для генерації скоректованого послаблюючого коефіцієнта. Цей спосіб додатково включає в себе ослаблення другого каналу з використанням цього скоректованого послаблюючого коефіцієнта. Перший аспект цього винаходу оснований на спостереженні, що мовний канал типової розважальної програми протягом значної частини цієї програми переносить немовний сигнал. Тому, згідно з цим першим аспектом винаходу, маскування мовного звукового супроводу немовним звуковим супроводом може керуватися за допомогою: (а) визначення ослаблення сигналу в немовному каналі, необхідного для того, щоб межа відношення потужності сигналу в немовному каналі до потужності сигналу в мовному каналі не перевершувала заздалегідь визначеної порогової величини, і (b) градуювання цього ослаблення за допомогою коефіцієнта, який монотонно пов'язаний з оцінкою імовірності того, що сигнал в мовному каналі є мовою, і (с) застосування цього градуйованого ослаблення. Другий аспект цього винаходу оснований на спостереженні, що відношення потужності мовного сигналу до потужності маскуючого сигналу є поганим показником для прогнозу сприйманості мови. Тому, згідно з цим другим аспектом винаходу, ослаблення сигналу в немовному каналі, яке необхідне для підтримки заздалегідь визначеного рівня сприйманості мови, обчислюється за допомогою прогнозування сприйманості мовного сигналу в присутності немовних сигналів за допомогою прогнозуючої моделі сприйманості мови, основаної на психоакуетиці. Третій аспект цього винаходу оснований на спостереженнях, що, якщо ослабленню дозволити змінюватися в залежності від частоти, то (а) заданий рівень сприйманості мови може бути досягнутий за допомогою багатьох схем ослаблення, і (b) різні схеми ослаблення можуть виробляти різні рівні інтенсивності або виразності немовного звукового супроводу. Тому, згідно з цим третім аспектом винаходу, маскування мовного звукового супроводу немовним звуковим супроводом керує за допомогою знаходження схеми ослаблення, яка максимізує інтенсивність або деякі інші показники виразності немовного звукового супроводу при обмеженні, що досягається заздалегідь визначеним рівнем прогнозної сприйманості мови. Втілення даного винаходу можуть бути здійснені як способи або технологічний процес. Ці способи можуть бути реалізовані як електронна схема, як обладнання або програмне забезпечення супроводу або як комбінація вищезазначеного. Електронна схема, що звичайно використовується для реалізації цього технологічного процесу, може являти собою спеціалізовану електронну схему (що виконує тільки специфічні завдання) або загальну електронну схему (запрограмовану для здійснення одного або декількох конкретних завдань). Наступний докладний опис і супутні креслення забезпечують краще розуміння суті і переваг даного винаходу. КОРОТКИЙ ОПИС КРЕСЛЕНЬ Фіг. 1 демонструє процесор сигналів, згідно з одним втіленням даного винаходу. Фіг. 2 демонструє процесор сигналів, згідно з іншим втіленням даного винаходу. Фіг. 3 демонструє процесор сигналів, згідно з іншим втіленням даного винаходу. Фіг. 4А і Фіг. 4В являють собою структурні діаграми, які демонструють додаткові варіації втілень по кресленнях 1-3. ДОКЛАДНИЙ ОПИС СУТІ ВИНАХОДУ 2 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 60 Тут описані технічні прийоми для підтримки сприйманості мови. У подальшому описі, з метою пояснення, приведені численні приклади і конкретні технічні подробиці для надання повного розуміння даного винаходу. Однак фахівцям в даній галузі техніки буде зрозуміло, що даний винахід, як це визначено в формулі винаходу, може включати в себе деякі або всі ознаки тільки цих прикладів або в комбінації з іншими ознаками, описаними нижче, і може додатково включати в себе модифікації або еквіваленти ознак і концепцій, описаних в даному документі. Різні способи і технологічні процеси описуються нижче. Те, що вони описуються в певному порядку, зроблено в основному для полегшення викладу. Потрібно розуміти, що конкретні етапи при бажанні можуть бути здійснені в іншому порядку або паралельно, в залежності від різних реалізацій. Якщо деякий конкретний етап повинен передувати або слідувати за іншим етапом, це буде точно вказано, якщо тільки це не зрозуміло з контексту. Принцип першого втілення винаходу демонструє Фіг. 1. Посилаючись тепер на Фіг. 1, приймається багатоканальний сигнал, що складається з мовного каналу (101) і двох немовних каналів (102 і 103). Потужності сигналів в кожному з цих каналів вимірюються групою блоків оцінки потужності (104, 105 і 106) і виражаються в логарифмічній шкалі [dB]. Ці блоки оцінки потужності можуть мати механізм згладжування, такий як інтегратор витоків, з тим, щоб результат вимірювання рівня потужності відображав рівень потужності, усереднений по тривалості пропозиції або усього мовного епізоду. Цей рівень потужності в мовному каналі віднімається з рівня потужності в кожному з немовних каналів (за допомогою блоків підсумовування 107 і 108), щоб отримати показник різниці рівнів потужності між цими двома типами сигналів. Контур порівняння 109 визначає для кожного немовного каналу кількість dB, на яку цей немовний канал повинен бути ослаблений для того, щоб його рівень потужності залишався щонайменше на dB нижче за рівень потужності сигналу в мовному каналі. (Символ " " означає змінну і на нього також можна посилатися як на букву тета рукописного шрифту). Згідно з одним втіленням, однією з реалізацій цього є додавання цієї порогової величини (яка зберігається в електронному контурі 110) до різниці рівнів потужності (цей проміжний результат називають допуском) з обмеженням, щоб цей результат дорівнював або був меншим ніж нуль (за допомогою блоків обмеження 111 і 112). Цей результат є приростом (або інвертованим ослабленням) в dB, який повинен бути застосований до немовних каналів для того, щоб підтримувати рівень їх потужності на dB нижче рівня потужності мовного каналу. Прийнятне значення величини становить 15 dB.T. Це значення величини 0 при бажанні може бути скоректоване в інших втіленнях. Оскільки має місце однозначна відповідність між показником, вираженим в логарифмічній шкалі (dB), і тим же самим показником, вираженим в лінійній шкалі, може бути виготовлений електронний контур, який еквівалентний Фіг. 1, в якому потужність, приріст і порогова величина виражаються в лінійній шкалі. У цій реалізації всі різниці рівнів замінюються відношеннями лінійних оцінок. У альтернативній реалізації можна замінити цей показник потужності показником, який пов'язаний з силою сигналу, таким як абсолютна величина сигналу. Потрібно згадати, що однією з важливих ознак цього першого аспекту винаходу є градуювання отриманим таким чином приросту за допомогою оцінки, монотонно пов'язаної з імовірністю того, що сигнал в мовному каналі дійсно є мовою. Все ще посилаючись на Фіг. 1, приймається керуючий сигнал (113) і множиться з приростами (за допомогою блоків множення 114 і 115). Ці градуйовані прирости потім застосовуються до відповідних немовних каналів (за допомогою підсилювачів 116 і 117) для вироблення модифікованих сигналів L' і R' (118 і 119). Керуючий сигнал (113) звичайно є автоматично отриманим показником імовірності того, що сигнал в мовному каналі є мовою. Можуть використовуватися різні способи автоматичного визначення імовірності того, що сигнал є мовою. Згідно з одним втіленням, процесор 130 імовірності мови генерує значення імовірності мови р (113) з інформації в С каналі 101. Один з прикладів такого механізму описується авторами Robinson і Vinton в "Automated Speech/Other Discrimination for Loudness Monitoring" (Audio Engineering Society, Preprint number 6437 of Convention 118, May 2005). Як альтернатива, цей керуючий сигнал (113) може бути створений вручну, наприклад, творцем програми, і переданий разом із звуковим сигналом кінцевому користувачеві. Фахівці в даній галузі техніки без великих зусиль зрозуміють, як ця конфігурація може бути поширена на будь-яку кількість вхідних каналів. Фіг. 2 демонструє принцип другого аспекту винаходу. Посилаючись тепер на Фіг. 2, приймається багатоканальний сигнал, що складається з мовного каналу (101) і двох немовних каналів (102 і 103). Потужності сигналів в кожному з цих каналів вимірюються групою блоків оцінки потужності (201, 202 і 203). На відміну від відповідної групи блоків на Фіг. 1, ці блоки оцінки потужності вимірюють розподіл потужності сигналу відносно частоти, що в результаті дає 3 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 60 спектр потужності, а не єдине число. Цей спектральний дозвіл спектра потужності ідеально відповідає спектральному дозволу моделі прогнозування сприйманості мови (205 і 206, це поки ще не обговорювалося). Ці два спектри потужності завантажуються в контур 204 порівняння. Цей блок призначений для визначення ослаблення, яке потрібно застосувати до кожного з немовних каналів для забезпечення того, щоб немовний канал не зменшив сприйманість мови сигналу в мовному каналі до величини, яка менша ніж заздалегідь визначений критерій. Цей функціональний засіб здійснюється за допомогою використання контурів прогнозування сприйманості мови (205 і 206), які прогнозують сприйманість мови на основі спектрів потужності мовного сигналу (201) і немовних сигналів (202 і 203). Контури 205 і 206 прогнозуючі сприйманості мови можуть реалізувати відповідну модель прогнозування сприйманості мови, в залежності від вибраної архітектури і вибору оптимальних співвідношень. Прикладом цього є індекс сприйманості мови (Speech Intelligibility Index), детально описаний в ANSI S3.5-1997 ("Methods for Calculation of the Speech Intelligibility Index"), і модель чутливості розпізнавання мови (Speech Recognition Sensitivity model) авторів Muesch і "Buus (Using statistical decision theory to predict speech intelligibility. I. Model structure" Journal of the Acoustical Society of America, 2001, Vol 109, p 28962909). Зрозуміло, що вихідні дані моделі прогнозування сприйманості мови не мають ніякого значення у випадку, коли сигнал в мовних каналах є чимось іншим, відмінним від мови. Незважаючи на це, в подальшому цей вихідний результат моделі прогнозування сприйманості мови буде називатися як прогнозна сприйманість мови. Відмічена помилка буде врахована в подальшій обробці за допомогою градуювання оцінок приросту на виході з контуру 204 порівняння з параметром, який пов'язаний з імовірністю того, сигнал є мовою (113, це поки ще не обговорювалося). Спільна риса моделей прогнозування сприйманості мови полягає в тому, що вони дають прогноз або на поліпшення, або на незмінність сприйманості мови в результаті зниження рівня гучності немовного сигналу. Просуваючись по структурній схемі етапів технологічного процесу по Фіг. 2, контури 207 і 208 порівняння порівнюють прогнозну сприйманість мови з оцінкою критерію. Якщо оцінка рівня немовного сигналу низька, так що прогнозна сприйманість мови перевершує критерій, параметр приросту, який початково встановлений на 0 dB, витягується з контурів 209 або 210 і надається на контури 211 і 212 як вихідний результат контуру 204 порівняння. Якщо критерій не досягнутий, параметр приросту меншає на фіксовану величину і прогнозування сприйманості мови повторюється. Прийнятний розмір кроку для зменшення приросту дорівнює 1 dB. Описаний тут ітеративний процес продовжується доти, доки прогнозна сприйманість мови не досягне або перевершить величину критерію. Звичайно, можливо таке, що сигнал в мовному каналі такий, що критерій сприйманості мови не може бути досягнутий навіть при відсутності сигналу в немовному каналі. Прикладом такої ситуації служить мовний сигнал дуже низького рівня або з надзвичайно обмеженою смугою частот. Якщо таке трапилося, наступить момент, коли ніяке додаткове скорочення приросту, що застосовується до немовного каналу, не надає ефекту на прогнозну сприйманість мови, і критерій ніколи не може бути досягнутий. У таких умовах, петля, утворена з (205, 206), (207, 208) і (209, 210), продовжується нескінченно, і може бути застосований додатковий логічний блок для розриву цієї петлі. Одним з особливо простих прикладів такого логічного блоку може служити підрахунок числа інтерацій і вихід з петлі, як тільки буде перевершено заздалегідь визначена кількість інтерацій. Просуваючись по структурній схемі етапів технологічного процесу по Фіг. 2, керуючий сигнал р (113) приймається і множиться на приріст (за допомогою блоків множення 114 і 115). Керуючий сигнал (113) звичайно буде являти собою автоматично зроблений показник імовірності того, що сигнал в мовному каналі є мовою. Способи автоматичного визначення імовірності того, що сигнал є мовою, відомі per se і обговорювалися в контексті Фіг. 1 (див. процесор 130 імовірності мови). Ці скоректовані прирости потім застосовуються до своїх відповідних немовних каналів (за допомогою блоків посилення 116 і 117) для вироблення 1 1 модифікованих сигналів R і L (118 і 119). Фіг. 3 демонструє принцип третього аспекту винаходу. З посиланням тепер на Фіг. 3, приймається багатоканальний сигнал, що складається з мовного каналу (101) і двох немовних каналів (102 і 103). Кожен з цих трьох немовних каналів розбивається на свої спектральні компоненти (за допомогою групи блоків 301, 302 і 303 фільтрації). Цей спектральний аналіз може бути отриманий за допомогою N-канальної групи блоків фільтрації у часовій області. Згідно з одним втіленням, це розбиття діапазону частот групою блоків фільтрації на смуги частот в 1/3 октави нагадує фільтрацію, яка, як передбачають, здійснюється всередині людського вуха. Той факт, що тепер сигнал складається з N підсигналів, продемонстрований за допомогою використання жирних ліній. Процес по Фіг. 3 може бути ідентифікований як 4 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 60 розгалужений процес (sidebranch process). Слідуючи по шляху сигналу, кожен з цих N підсигналів, які утворюють немовні канали, градуюється за допомогою одного з членів множини з N оцінок приростів (блоками посилення 116 і 117). Виробництво цих оцінок приростів буде описане пізніше. Далі, ці градуйовані підсигнали возз'єднуються в єдиний звуковий канал, це може бути зроблено через просте підсумовування (за допомогою контурів 313 і 314 підсумовуючі). Як альтернатива, може бути використана група фільтруючих блоків синтезу, яка сполучена з групою фільтруючих блоків аналізу. Результатом цього процесу є модифіковані сигнали R' і L' (118 і 119). Описуючи тепер шлях розгалуженого процесу по Фіг. 3, кожне з вихідних даних групи фільтруючих блоків віддається в розпорядження відповідної групи з N блоків оцінки (304, 305 і 306) потужності. Отримані в результаті цього спектри служать як вхідні дані для контурів (307 і 308) оптимізації, які видають як вихідні дані N-вимірний вектор приростів. Ця оптимізація використовує як контур (309 і 310) прогнозу сприйманості мови, так і контур (311 і 312) обчислення інтенсивності звуку для знаходження вектора приростів, який максимізує інтенсивність звуку в немовному каналі, при цьому підтримує заздалегідь визначену оцінку прогнозної сприйманості мови мовного сигналу. Відповідні моделі для прогнозування сприйманості мови обговорювалися в зв'язку з Фіг. 2. Контури 311 і 312 обчислення інтенсивності звуку можуть реалізувати відповідну модель прогнозування інтенсивності звуку, в залежності від вибраної архітектури і вибору оптимальних співвідношень. Прикладами відповідних моделей є американський національний стандарт (American National Standard) "ANSI S3.4-2007 Procedure for the Computation of Loudness of Steady Sounds" і німецький стандарт (German standard) "DIN 45631 Berechnung des Lautstarkepegels und der Lautheit aus dem Gerauschspektrum". У залежності від обчислювальних ресурсів і накладених обмежень, вид і складність цих контурів (307, 308) оптимізації можуть надзвичайно сильно відрізнятися. Згідно з одним втіленням використовується ітераційна багатомірна оптимізація з обмеженнями N вільних параметрів. Кожен параметр представляє приріст, що застосовується до кожної з смуг частот в немовному каналі. Для знаходження максимуму можуть бути застосовані стандартні технічні засоби, такі як рух по шляху найбільшого градієнта в N-вимірному просторі. У іншому втіленні, обчислювально менш вимогливий підхід обмежує функціональні засоби прирости-частота, як ті, що лежать в малій множині можливих функціональних засобів прирости-частота, такій як множина різних спектральних градієнтів або shelf-фільтрів (super-hard extremely-low frequency). 3 такими додатковими обмеженнями задача оптимізації може бути зведена до малої кількості одномірних оптимізацій. Ще в одному втіленні здійснюється вичерпний пошук в дуже малій множині можливих функцій приросту. Цей останній підхід може виявитися особливо бажаним в додатках в реальному часі, в яких потребується постійне завантаження і швидкість пошуку. Фахівці в даній галузі техніки легко розпізнають додаткові обмеження, які можуть бути накладені на оптимізацію, відповідно до додаткових втілень даного винаходу. Одним з прикладів є обмеження, щоб інтенсивність звуку модифікованого немовного каналу була не більшою, ніж інтенсивність звуку до модифікації. Інший приклад являє собою обмеження на різниці приростів між прилягаючими смугами частот для того, щоб обмежити можливості для часового спотворення реконструюючою групою фільтруючих блоків (313, 314) або скоротити можливості для небажаних модифікацій тембру. Бажані обмеження залежать як від технічної реалізації групи блоків фільтрації, так і від вибору оптимальних співвідношень між поліпшенням сприйманості мови і модифікацією тембру. Для зрозумілості демонстрації на Фіг. 3 ці обмеження опущені. Просуваючись по структурній схемі технологічного процесу по Фіг. 3, приймається керуючий сигнал р (113) і множиться на прирости (за допомогою блоків множення 114 і 115). Керуючий сигнал (113) звичайно буде являти собою автоматично зроблений показник імовірності того, що сигнал в мовному каналі є мовою. Способи автоматичного визначення імовірності того, що сигнал є мовою, обговорювалися в зв'язку з Фіг. 1 (див. процесор 130 імовірності мови). Ці скоректовані прирости потім застосовуються до своїх відповідних немовних каналів (за допомогою блоків посилення 116 і 117), як це описано раніше. Фіг. 4А і Фіг. 4В являють собою структурні діаграми, що демонструють варіації аспектів, показаних на Фіг. 1-3. Додатково, фахівці в даній галузі техніки розпізнають декілька шляхів комбінування елементів винаходу, описаних на кресленнях 1-3. Фіг. 4А показує, що конфігурація на Фіг. 1 також може бути застосована до однієї або декількох підсмуг частот сигналів L, С, і R. Більш конкретно, кожен з цих сигналів L, С і R може бути пропущений через групу фільтруючих блоків (441, 442 і 443) для вироблення трьох множин з п підсмуг смуги частот: {L1, L2,…, Ln}, {С1, C2,…, Сn} і {R1, R2,…, Rn}. Підсмуги, які підходять в 5 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 пару, пропускаються в n екземплярів контуру 125, продемонстрованого на Фіг. 1, і оброблені під сигнали рекомбінуються (за допомогою контурів підсумовування 451 і 452). Для кожної із субсмуг можуть бути вибрані окремі порогові величини n. Гарним вибором є множина, в якій n пропорційні середньому числу мовних тональних міток, які переносяться у відповідній області частот; тобто смугам на краях спектра частот приписуються менші порогові величини, ніж смугам, відповідним домінуючим частотам мови. Ця реалізація винаходу пропонує дуже хороший вибір оптимальних співвідношень між складністю обчислень і продуктивністю системи. Фіг. 4В показує інший варіант. Наприклад, для зниження обчислювального навантаження може бути поліпшений типовий об'ємний звуковий сигнал з п'ятьма каналами (С, L, R, Is і rs) за допомогою обробки сигналів L і R відповідно до контуру 325, показаного на Фіг. 3, і сигналів Is і rs, які звичайно менш потужні, ніж сигнали L і R, відповідно до контуру 125, показаного на Фіг. 1. У описах, приведених вище, використовуються терміни "мова" (або мовний звуковий супровід або мовний канал або мовний сигнал) і "не мова" (або немовний звуковий супровід або немовний канал або немовний сигнал). Кваліфікований фахівець в даній галузі техніки зрозуміє, що ці терміни в більшій мірі використовуються для того, щоб встановити відмінність, а в меншій мірі для того, щоб абсолютно описати зміст цих каналів. Наприклад, в сцені фільму в ресторані, мовний канал переважно може нести в собі діалог за одним столом, а немовні канали можуть нести в собі діалоги за іншими столами (таким чином, обидва канали несуть "мову", як використав би цей термін не професіонал). Проте, визначені втілення даного винаходу направлені на ослаблення саме діалогів за іншими столами. РЕАЛІЗАЦІЇ ВИНАХОДУ Цей винахід може бути реалізований у вигляді обладнання або програмного забезпечення супроводу, або у вигляді комбінації і того, і іншого (наприклад, матриці програмованих логічних елементів). Якщо точно не вказано, алгоритми, включені до складу винаходу, по суті не належать до якого-небудь конкретного комп'ютера або іншого пристрою. Зокрема, можуть бути використані різні комп'ютери загального користування з програмами, написаними відповідно до того, що пояснено в даному документі, або може виявитися більш зручним сконструювати спеціалізований пристрій (наприклад інтегральну схему) для здійснення необхідних етапів способу. Отже, цей винахід може бути реалізований у вигляді однієї або декількох комп'ютерних програм, що виконуються на одній або декількох комп'ютерних системах, що програмуються, кожна з яких містить щонайменше один процесор, щонайменше одну систему зберігання даних (включаючи довготривалу і недовготривалу пам'ять і/або елементи зберігання даних), щонайменше один пристрій введення або порт введення і щонайменше один пристрій виведення або порт виведення. Програмний код застосовує вхідні дані для здійснення функціональних засобів, описаних тут, і генерує вихідну інформацію. Ця вихідна інформація, відомим чином, прямує до одного або декількох пристроїв виходу. Кожна така програма може бути реалізована на будь-якій бажаній комп'ютерній мові (включаючи машинні, асемблерні або процедурні, логічні або об'єктно-орієнтовані мови програмування) для роботи з комп'ютерною системою. У будь-якому випадку, мова може бути мовою програмування, що інтерпретується або транслюється. Кожна така комп'ютерна програма переважно зберігається в середовищі або пристрої зберігання інформації або завантажується туди (наприклад, твердотільна пам'ять або середовище, або магнітне або оптичне середовище), зчитувана програмованим комп'ютером (спеціалізованим або загального користування), для настроювання і функціонування цього комп'ютера після того, як комп'ютерна програма звернеться до середовища або пристрою зберігання інформації для здійснення описаних тут процедур. Може також бути розглянута реалізація цієї системи винаходу як середовище зберігання зчитуваної комп'ютером інформації, оснащена комп'ютерною програмою, при цьому середовище зберігання інформації, настроєне таким чином, примушує цю комп'ютерну систему функціонувати спеціальним і заздалегідь визначеним чином для здійснення функціональних засобів, описаних тут. Опис, приведений вище, демонструє різні втілення даного винаходу разом з прикладами того, як може бути реалізовано даний винахід. Приклади і втілення, приведені вище, не треба сприймати як єдино можливі втілення, і вони представлені для демонстрації гнучкості і переваги даного винаходу, як це визначено в подальшій формулі винаходу. На основі розкриття суті винаходу, приведеного вище, і наступної формули винаходу, фахівцям в даній галузі техніки будуть зрозумілі інші конфігурації, втілення, реалізації винаходу і їх еквіваленти, які можуть бути використані без відходу від духу і букви цього винаходу, як це визначено в формулі винаходу. 6 UA 104424 C2 ФОРМУЛА ВИНАХОДУ 5 10 15 20 25 30 35 40 45 50 55 1. Спосіб покращення чутності мови в багатоканальному звуковому сигналі, при цьому згаданий спосіб включає наступні етапи: порівнюють першу характеристику і другу характеристику багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому порівняння першої характеристики і другої характеристики включає наступні операції: виконують прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови; коректують коефіцієнт підсилення, який застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і використовують скоригований коефіцієнт підсилення як коефіцієнт ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій; коректують коефіцієнт ослаблення відповідно до значення імовірності мови для формування скоригованого коефіцієнта ослаблення; і ослабляють другий канал з використанням скоригованого коефіцієнта ослаблення. 2. Спосіб за п. 1, який додатково включає наступний етап: обробляють багатоканальний звуковий сигнал для формування першої характеристики і другої характеристики. 3. Спосіб за п. 1, який додатково включає наступний етап: обробляють перший канал для формування значення імовірності мови. 4. Спосіб за п. 1, в якому другий канал є одним з множини других каналів, при цьому друга характеристика є однією з множини других характеристик, причому коефіцієнт ослаблення є одним з множини коефіцієнтів ослаблення, і причому скоригований коефіцієнт ослаблення є одним з множини скоригованих коефіцієнтів ослаблення, причому спосіб додатково включає наступні етапи: порівнюють першу характеристику і множину других характеристик для формування множини коефіцієнтів ослаблення; коректують множину коефіцієнтів ослаблення відповідно до значення імовірності мови для формування множини скоригованих коефіцієнтів ослаблення; і ослаблюють множину других каналів з використанням множини скоригованих коефіцієнтів ослаблення. 5. Спосіб за п. 1, в якому багатоканальний звуковий сигнал містить третій канал, який містить, переважно, немовний звук, при цьому спосіб додатково включає наступні етапи: порівнюють першу характеристику і третю характеристику для формування додаткового коефіцієнта ослаблення, причому третя характеристика відповідає третьому каналу; коректують додатковий коефіцієнт ослаблення відповідно до значення імовірності мови для формування скоригованого додаткового коефіцієнта ослаблення; і ослаблюють третій канал з використанням скоригованого коефіцієнта ослаблення. 6. Спосіб за п. 1, в якому другий спектр потужності містить множину частотних смуг, при цьому етап порівняння першої характеристики і другої характеристики додатково містить виконання обчислення рівня гучності на основі другого спектра потужності для формування обчисленого рівня гучності; причому етап корекції коефіцієнта підсилення додатково містить корекцію множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності; і причому етап використання коефіцієнта підсилення включає використання множини скоригованих коефіцієнтів підсилення як коефіцієнта ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності. 7. Пристрій для покращення чутності мови в багатоканальному звуковому сигналі, який містить схему для покращення чутності мови в багатоканальному звуковому сигналі, при цьому пристрій містить: 7 UA 104424 C2 5 10 15 20 25 30 35 40 45 50 55 схему порівняння, яка виконана з можливістю порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому схема порівняння містить: схему прогнозування розбірливості мови, яка виконана з можливістю прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови; схему корекції коефіцієнта підсилення, яка виконана з можливістю корекції коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і схему вибору коефіцієнта підсилення, яка виконана з можливістю вибору скоригованого коефіцієнта підсилення як коефіцієнт ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій; помножувач, який виконаний з можливістю корекції коефіцієнта ослаблення відповідно до значення імовірності мови, для формування скоригованого коефіцієнта ослаблення; і підсилювач, який виконаний з можливістю ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення. 8. Пристрій за п. 7, в якому другий спектр потужності містить множину частотних смуг, і при цьому схема порівняння додатково містить: схему обчислення рівня гучності, яка виконана з можливістю виконання обчислення рівня гучності на основі другого спектра потужності, для формування обчисленого рівня гучності; і схему оптимізації, яка виконана з можливістю корекції множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності, і, яка використовує множину скоригованих коефіцієнтів підсилення як коефіцієнт ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності. 9. Пристрій за п. 7, який додатково містить: перший обчислювач спектральної густини потужності, який виконаний з можливістю обчислення першого спектра потужності першого каналу; і другий обчислювач спектральної густини потужності, який виконаний з можливістю обчислення другого спектра потужності другого каналу. 10. Пристрій за п. 7, який додатково містить: перший набір фільтрів, який виконаний з можливістю розбиття першого каналу на першу множину спектральних складових; перший набір блоків оцінювання потужності, який виконаний з можливістю обчислення першого спектра потужності по першій множині спектральних складових; другий набір фільтрів, який виконаний з можливістю розбиття другого каналу на другу множину спектральних складових; і другий набір блоків оцінювання потужності, який виконаний з можливістю обчислення другого спектра потужності по другій множині спектральних складових. 11. Пристрій за п. 7, який додатково містить: процесор визначення мови, який виконаний з можливістю обробки першого каналу, для формування значення імовірності мови. 12. Машиночитаний носій інформації для покращення чутності мови в багатоканальному звуковому сигналі, який містить збережену на ньому комп'ютерну програму, яка керує пристроєм для виконання обробки, який містить: порівняння першої характеристики і другої характеристики багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому порівняння містить: 8 UA 104424 C2 5 10 15 20 25 30 35 40 виконання прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови; корекцію коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і використання скоригованого коефіцієнта підсилення як коефіцієнта ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій; корекцію коефіцієнта ослаблення відповідно до значення імовірності мови для формування скоригованого коефіцієнта ослаблення; і ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення. 13. Пристрій для покращення чутності мови в багатоканальному звуковому сигналі, який містить схему для покращення чутності мови в багатоканальному звуковому сигналі, при цьому пристрій містить: засіб для порівняння першої характеристики і другої характеристики багатоканального звукового сигналу, для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому спектру потужності сигналу в першому каналі, причому друга характеристика відповідає другому каналу багатоканального звукового сигналу, який містить, переважно, немовний звук, і причому друга характеристика відповідає другому спектру потужності сигналу у другому каналі, причому засіб для порівняння містить: засіб для виконання прогнозування розбірливості мови на основі першого спектра потужності і другого спектра потужності для формування прогнозованої розбірливості мови; засіб для корекції коефіцієнта підсилення, що застосовується до другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій; і засіб для використання скоригованого коефіцієнта підсилення як коефіцієнта ослаблення, як тільки прогнозована розбірливість мови задовольнить критерій; засіб для корекції коефіцієнта ослаблення відповідно до значення імовірності мови, для формування скоригованого коефіцієнта ослаблення; і засіб для ослаблення другого каналу з використанням скоригованого коефіцієнта ослаблення. 14. Пристрій за п. 13, в якому другий спектр потужності містить множину частотних смуг, при цьому засіб для порівняння додатково містить засіб для виконання обчислення рівня гучності на основі другого спектра потужності, для формування обчисленого рівня гучності; причому засіб для корекції коефіцієнта підсилення відповідає засобу для корекції множини коефіцієнтів підсилення, що застосовуються, відповідно, до кожної частотної смуги другого спектра потужності, поки прогнозована розбірливість мови не задовольнить критерій розбірливості мови, і обчислений рівень гучності не задовольнить критерій рівня гучності; і засіб для використання коефіцієнта підсилення відповідає засобу для використання множини скоригованих коефіцієнтів підсилення як коефіцієнта ослаблення для кожної частотної смуги, відповідно, як тільки прогнозована розбірливість мови задовольнить критерій розбірливості мови, і обчислений рівень гучності задовольнить критерій рівня гучності. 9 UA 104424 C2 10 UA 104424 C2 11 UA 104424 C2 Комп’ютерна верстка С. Чулій Державна служба інтелектуальної власності України, вул. Урицького, 45, м. Київ, МСП, 03680, Україна ДП “Український інститут промислової власності”, вул. Глазунова, 1, м. Київ – 42, 01601 12
ДивитисяДодаткова інформація
Автори російськоюMuesch, Hannes
МПК / Мітки
МПК: H04S 5/00, H04S 3/00, G10L 19/00, G10L 21/00
Мітки: систему, впливом, мінімальним, підтримки, спосіб, чутності, аудіосигналі, пристрій, багатоканальному, об`ємного, звучання, мови
Код посилання
<a href="https://ua.patents.su/14-104424-sposib-ta-pristrijj-dlya-pidtrimki-chutnosti-movi-u-bagatokanalnomu-audiosignali-z-minimalnim-vplivom-na-sistemu-obehmnogo-zvuchannya.html" target="_blank" rel="follow" title="База патентів України">Спосіб та пристрій для підтримки чутності мови у багатоканальному аудіосигналі з мінімальним впливом на систему об’ємного звучання</a>
Спосіб і пристрій для підтримки сприйманості мови в багатоканальному звуковому супроводі з мінімальним впливом на систему об’ємного звучання

Номер патенту: 101974
Опубліковано: 27.05.2013
Автор: Мюш Ханнес
МПК: G10L 21/00
Мітки: впливом, мови, багатоканальному, підтримки, сприйманості, спосіб, мінімальним, пристрій, звучання, систему, об`ємного, звуковому, супроводі
Формула / Реферат:
1. Спосіб поліпшення чутності мови в багатоканальному звуковому сигналі, який включає етапи, на яких:порівнюють першу характеристику i другу характеристику багатоканального звукового сигналу для формування коефіцієнта ослаблення, причому перша характеристика відповідає першому каналу багатоканального звукового сигналу, який містить мовний звук і немовний звук, причому перша характеристика відповідає першому виміряному показнику, який...
Пристрій для навчання правильної вимови слів при вивченні іноземної мови

Номер патенту: 61956
Опубліковано: 15.12.2003
Автор: Кубай Роман Іванович
МПК: G11B 13/00, G09B 19/06, G09B 5/00
Мітки: вимови, навчання, правильної, іноземної, мови, пристрій, вивченні, слів
Формула / Реферат:
Пристрій для навчання правильної вимови слів при вивченні іноземної мови, що містить джерело зразкової інформації і мікрофон, який відрізняється тим, що додатково містить навушники та блок звукової обробки, в якому є генератор інфразвукової частоти, звуковий змішувач і канал звукової затримки, причому вихід генератора інфразвукової частоти з’єднаний з першим входом звукового змішувача, третій вхід якого з'єднаний з виходом каналу звукової...
Спосіб побудови словника для перекладу з іноземної мови

Номер патенту: 60217
Опубліковано: 15.09.2003
Автор: Карпусь Ігор Васильович
МПК: G09B 19/06
Мітки: словника, іноземної, мови, спосіб, побудови, перекладу
Формула / Реферат:
Спосіб побудови словника для перекладу з іноземної мови, який полягає в тому, що слова іноземної мови, які відібрані зі словникового запасу, розташовують на носії інформації послідовно, починаючи з початку слова, який відрізняється тим, що перед кожним написом слова розташовують його семантичний код та після кожного напису групують семантичні коди слів, близьких за змістом, при цьому при слові, яке є перекладом, також розташовують його...
Спосіб підвищення розбірливості мови у хворих на нейросенсорну туговухість

Номер патенту: 88559
Опубліковано: 26.10.2009
Автори: Прасол Ігор Вікторович, Нечипоренко Аліна Сергіївна
МПК: G10L 21/00, G10L 15/00
Мітки: підвищення, хворих, спосіб, туговухість, мови, розбірливості, нейросенсорну
Формула / Реферат:
Спосіб підвищення розбірливості мови у хворих на нейросенсорну туговухість за допомогою смугової фільтрації мовного сигналу та ділення спектра на частотні смуги, який відрізняється тим, що у спектрі мовного сигналу виділяють форманти, після чого здійснюють фільтрацію двох перших формант звуків, які належать до мовної послідовності, з подальшим видаленням частотних смуг, що знаходяться на межі з областю формантного піка, а також накладенням...
Спосіб виявлення порушення розбірливості мови

Номер патенту: 7393
Опубліковано: 15.06.2005
Автори: Римар Наталія Валеріївна, Розкладка Анатолій Іванович
МПК: A61B 5/12
Мітки: порушення, розбірливості, спосіб, мови, виявлення
Формула / Реферат:
Спосіб виявлення порушення розбірливості мови шляхом подачі заздалегідь записаних фонограм мовних тестів, який відрізняється тим, що тести подаються з прискореним темпом мови без зміни її частотних характеристик.
Наступний патент: Піноутворювальна композиція
Випадковий патент: Торцевий асинхронний електродвигун з вільним ротором